Teoremas Límite
Anuncio

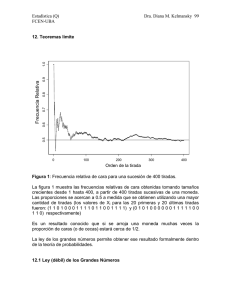
95 Teoremas límite Consideremos el experimento aleatorio que consiste en arrojar una moneda equilibrada n veces. Supongamos que se registra la proporción de caras. Un resultado conocido es que esta proporción estará cerca de 1/2. Formalizando un poco tenemos: ε: ‘se arroja una moneda equilibrada n veces’ A = salió cara X: no de caras que se observan, X ~ Bi (n, 1/2) 0 Xi = 1 si sale ceca si sale cara 1 ≤ i ≤ n, luego X / n = 1 n ∑ Xi = X n n i =1 X / n : proporción de caras ( = frecuencia relativa del suceso A = fA = nA / n ) Se espera que a medida que n crece la frecuencia relativa de cara 0.5 = E ( X i ) (media poblacional) 0.9 0.8 0.7 0.6 0.5 Frecuencia Relativa 1.0 -----se acerque a------> 1 n ∑ Xi = X / n n i =1 0 100 200 300 Orden de la tirada Figura 2: Frecuencia relativa de cara para una sucesión de 400 tiradas 400 96 La figura 2 muestra que las frecuencias relativas de cara obtenidas en 400 tiradas sucesivas de una moneda se acercan a 0.5 a medida que aumenta la cantidad de tiradas (los valores de Xi para las 20 primeras y 20 últimas tiradas fueron: 1 1 0 1 0 0 0 1 1 1 1 0 1 1 0 0 1 1 1 1 y 0 1 0 1 0 0 0 0 0 0 1 1 1 1 1 0 0 1 1 0 respectivamente) Veremos a continuación la ley de los grandes números. Establece que la probabilidad de que la media muestral (calculada a partir de una muestra aleatoria de una distribución) difiera de la media poblacional en más de un valor fijo (que puede ser arbitrariamente pequeño) tiende a cero a medida que el tamaño de la muestra tiende a infinito. Por eso promediamos!! Ley (débil) de los Grandes Números Sea X1, X2, ...., Xn, una sucesión de v.a. independientes tales que E(Xi) = µ y Var(Xi) = σ2 < ∞, entonces ∀ ε > 0 P ( X n − µ > ε ) → 0 (1) n → ∞ n siendo X n = ∑X i =1 n i . E( X n ) = µ y Dem: Sabemos que Var ( X n ) = σ2 , entonces aplicando la n desigualdad de Chebishev a X n , P( X n − µ > ε ) ≤ Var ( X n ) ε2 = σ2 nε 2 ∀ε > 0 y, por lo tanto ( ) σ2 =0 n →∞ n ε 2 lim P X n − µ > ε ≤ lim n →∞ ∀ε > 0 cqd. Cuando vale (1) decimos que la media muestral converge en probabilidad a µ, lo indicamos por p X n → µ También decimos que X n es un estimador consistente de µ Observación 1: La frecuencia relativa de un suceso A tiende a su probabilidad. Consideremos n repeticiones independientes de un experimento aleatorio y sea A un suceso con probabilidad P(A) = p, constante en las n repeticiones. Si llamamos nA a la frecuencia absoluta de A (número de veces que ocurre A en las n repeticiones) y fA = nA / n a la frecuencia relativa, entonces p fA → p 97 Esto resulta de la ley de los grandes números con Xi ~ Bi(1,p), p = P(A) n fA = nA / n = ∑ X i / n i =1 E(fA) = p y Var(fA) = p (1-p) / n. Observación 2 La desigualdad de Chebishev también nos permite acotar la cantidad de repeticiones necesarias para que la frecuencia relativa del suceso A difiera de su probabilidad (P(A) = p ) como máximo en 0.01 con probabilidad mayor o igual que 0.90. En efecto, queremos encontrar n tal que P ( f A − p ≤ 0.01) ≥ 0.90 , (1) por Chebishev con ε = 0.01 tenemos que P( f A − p ≤ 0.01) ≥ 1 − p(1 − p) n (0.01) 2 Luego la desigualdad (1) se cumplirá siempre que 1− p(1 − p) p(1 − p) p(1 − p) ≥ 0.90 ⇔ ≤ 0.10 ⇔ n ≥ 2 2 n (0.01) n (0.01) (0.01) 2 (0.10) El valor mínimo de n depende de p. Es máximo cuando p = 0.50. Por ejemplo, p = 0.50 ⇒ n ≥ 25000 p = 0.10 ⇒ n ≥ 9250 p = 0.01 ⇒ n ≥ 990 Observación 3: La existencia de la varianza no es necesaria para la validez de la ley de los grandes números, mientras que la de la esperanza es indispensable. Figura 3: comportamiento de la media muestral para una sucesión de observaciones de una variable aleatoria N(0,1) y una variable aleatoria Cauchy 98 La figura 3 muestra que la sucesión correspondiente a la N(0,1) se acerca a cero, mientras que la sucesión correspondiente a la distribución Cauchy muestra un comportamiento errático. ¿Cómo es la distribución Cauchy? La función de densidad de probabilidad de una variable aleatoria Z llamada Cauchy es 1 f Z ( z) = −∞ < z < ∞ π (1 + z 2 ) y su función de distribución acumulada 1 1 FZ ( z ) = + arctan( z ) − ∞ < z < ∞ 2 π ¿Qué forma tiene la función de densidad de la distribución Cauchy? 0.5 - Es simétrica con respecto al cero - Tiene forma de campana - Las colas tienden a cero más lentamente que la Normal 0.3 0.4 N(0,1) 0.0 0.1 0.2 Cauchy -4 -2 0 2 4 z Figura 4: funciones de densidad de probabilidad N(0,1) y Cauchy Debido a la simetría alrededor de cero de la función de densidad la esperanza de una variable Cauchy debería ser cero. Sin embargo 99 ∞ E(|Z|) = ∫ |z| 2 −∞ π (1 + z ) dz = 2∞ z 2 dz = lim log(1 + a 2 ) = ∞ ∫ 2 π 0 (1 + z ) π a →∞ La razón por la cual falla la existencia de la esperanza es debido a que la densidad decrece tan lentamente que valores grandes de la variable pueden ocurrir con una probabilidad sustancial ¿ Cómo surge la distribución Cauchy? Se puede demostrar ( vea por ejemplo John Rice “Mathematical Statistics and Data Analysis” 1988-1995) que el cociente de dos variables aleatorias N(0,1) independientes tiene distribución Cauchy. Corolario de la Ley de los Grandes Números una muestra aleatoria de una distribución con E(X i ) = µ Var(X i ) = σ 2 < ∞ entonces Sea X1, ...,Xn p a) X → µ poblacional y La media muestral converge en probabilidad a la media p b) S X2 → σ 2 poblacional La varianza muestral converge en probabilidad a la varianza Dem. a) Por la Ley de los Grandes Números. b) Demostraremos que la varianza muestral S X2 es un estimador consistente de la varianza poblacional. n n 2 2 ( ) X − X ∑ Xi ∑ i n 1 n i =1 2 2 2 2 i =1 = −X SX = ∑ X i − nX = n −1 n − 1 i =1 n −1 n p Por la Ley de los Grandes Números X → µ , entonces p X2 → µ2. Por otra parte, aplicando nuevamente la Ley de los Grandes Números a X i2 n ∑X i =1 n 2 i p → E ( X 2 ) = V ( X ) + [E ( X )] = σ 2 + µ 2 2 100 Como además n → 1 , se obtiene n −1 n 2 ∑ Xi n i =1 p 2 2 SX = −X → σ 2 + µ2 − µ2 =σ 2 n −1 n y por lo tanto la varianza muestral es un estimador consistente de σ 2 . Teorema Central del Límite: Sean X 1 , X 2 ,.... v.a. i.i.d con E ( X i ) = µ y Var ( X i ) = σ 2 < ∞ , entonces si n es suficientemente grande, T − nµ ( a ) ~ N (0,1) nσ n ( X − µ ) (a) ~ N (0,1) σ con T = ∑ X i Dicho de otro modo, T − nµ nσ D → Z ~ N (0,1) n (X − µ) D → Z ~ N (0,1) σ D donde la convergencia en distribución ( → ) se interpreta en el siguiente sentido: T − nµ ≤ a ≅ Φ (a ) P nσ n (X − µ) ≤ a ≅ Φ (a ) P σ es decir, que las funciones de distribución convergen a la función de distribución normal standard. Observación: ¿Qué significa n suficientemente grande? ¿Cómo sabemos si la aproximación es buena? El tamaño de muestra requerido para que la aproximación sea razonable depende de la forma de la distribución de las Xi . Mientras más simétrica y acampanada sea, más rápidamente se obtiene una buena aproximación. 1.0 2.0 n=2 3.0 1.0 2500 1000 0 2.0 n=5 3.0 1.4 2.0 n=30 2.6 3.0 3.0 0 2000 0 2000 0 2.0 n=1 2.0 0.0 0.4 0.8 n=2 0.0 0.5 n=30 0.7 2.0 0.3 1.0 0.0 0.0 0.2 1.0 n=1 0.4 0.8 n=5 0.4 0.6 0.2 0.0 0.0 0 0.0 0.6 n=2 0.6 0.0 0.8 0.4 0.8 n=1 1.0 0.0 0.0 0.8 2 4 1.5 1.0 1.0 6 1.2 1.0 1000 2000 101 0.2 n=5 0.4 0.0 0.04 n=30 Figura 5: Distribución de X para distintas distribuciones: a) discreta, b) Uniforme, c) Exponencial Ejemplo: Al sumar números, una calculadora aproxima cada número al entero más próximo. Los errores de aproximación se suponen independientes y con distribución U(-0.5,0.5). a) Si se suman 1500 números, ¿cuál es la probabilidad de que el valor absoluto del error total exceda 15? Sea Xi el error correspondiente al i-ésimo sumando, E ( X i ) = 0 y Var ( X i ) = 1500 El error total es T1500 = ∑ X i y por lo tanto E (T1500 ) = 0 y Var (T1500 ) = i =1 P (T1500 > 15) = 1 − P( T1500 ≤ 15) = 1 − P(−15 ≤ T1500 ≤ 15) = 1500 . 12 1 12 . 102 T1500 − 15 − 15 15 15 = 1 − P ≤ ≤ ≅ 1 − Φ + Φ = 1500 / 12 1500 / 12 1500 / 12 1500 / 12 1500 / 12 = 1 − Φ (1.34) + Φ (−1.34) = 0.18 b) ¿Cuántos números pueden sumarse a fin de que el valor absoluto del error total sea menor o igual que 10 con probabilidad mayor o igual que 0.90? Buscamos el valor de n tal que P( Tn ≤ 10) ≥ 0.90 − 10 P (Tn ≤ 10 ) ≥ 0.90 ⇔ P(− 10 ≤ Tn ≤ 10) ≥ 0.90 ⇔ P ≤ Tn ≤ n / 12 ≥ 0.90 n / 12 10 Aplicando la aproximación normal, debemos hallar n tal que 10 − 10 10 10 − Φ ≥ 0.90 ⇔ 2Φ − 1 ≥ 0.90 ⇔ Φ ≥ 0.95 Φ n / 12 n / 12 n / 12 n / 12 ⇔ 10 n / 12 ≥ 1.64 ⇔ n ≤ 21.12 ⇔ n ≤ 446 es decir, que se pueden sumar a lo sumo 446 números para que el valor absoluto del error total sea menor o igual que 10 con probabilidad mayor o igual que 0.90. Aproximación de la distribución binomial por la normal: Sea X ~ Bi (n,p), entonces X es el número de éxitos en n repeticiones de un experimento binomial con probabilidad de éxito igual a p, y X / n es la proporción muestral de éxitos. Definamos las siguientes variables aleatorias 1 Xi = 0 si se obtuvo Éxito en la repetición i si se obtuvo Fracaso en la repetición i n para i = 1, ..., n. Estas v.a. son independientes, Xi ~ Bi (1, p) ∀ i y X = ∑ X i . i =1 Aplicando el Teorema Central del Límite, si n es suficientemente grande, 103 X ( a ) p (1 − p ) ~ N p, n n (a) X ~ N (np, np (1 − p ) ) La aproximación es buena si n p ≥ 5 y n (1-p) ≥ 5. Si p = 1/2 la aproximación es buena aún para n pequeño pues en ese caso la distribución binomial es simétrica. 0.2 0.4 0.6 0.4 0.8 1.0 0.0 0.2 0.0 0.0 Bi(10,0.10) 0.2 0.4 0.6 Bi(5,0.10) 0.0 0.2 0.2 0.3 0.4 0.5 0.0 0.1 0.0 0.1 0.2 0.3 0.4 0.15 0.20 0.08 0.05 0.10 0.15 0.20 0.25 0.0 0.04 0.06 0.0 1.0 Bi(200,0.10) 0.12 Bi(100,0.10) 0.0 0.8 Bi(50,0.10) 0.15 0.0 0.0 0.6 0.10 Bi(20,0.10) 0.4 0.0 0.05 0.10 Figura 6: Distribución probabilidades de X n Corrección por continuidad Cuando se aproxima una distribución discreta por una continua, como es el caso de la aproximación de la distribución binomial por la normal, es necesario efectuar una corrección. Consideremos el siguiente ejemplo: Sea X ~ Bi (100, 0.6) y calculemos en forma aproximada P(X ≤ 50) y P(X ≥ 51). Si aplicamos directamente el TCL, obtenemos: 104 X − 60 50 − 60 P ( X ≤ 50) = P ≤ ≅ Φ (− 2.04) = 0.021 24 24 X − 60 51 − 60 P ( X ≥ 51) = P ≥ ≅ 1 − Φ (−1.84) = 0.967 24 24 Si bien, P(X ≤ 50) + P(X ≥ 51) = 1, los valores aproximados no satisfacen esta restricción. Para evitar este problema, se efectúa la siguiente corrección, denominada corrección por continuidad, X − 60 50.5 − 60 P ( X ≤ 50) = P( X ≤ 50.5) = P ≤ ≅ Φ(− 1.94) = 0.026 24 24 X − 60 50.5 − 60 P ( X ≥ 51) = P( X ≥ 50.5) = P ≥ ≅ 1 − Φ (−1.94) = 0.974 24 24 En general, cuando la v.a. es discreta y xi – xi-1 = 1, la corrección se realiza en la forma: P ( X ≤ a) = P( X ≤ a + 0.5) P ( X ≥ a ) = P( X ≥ a − 0.5) Si la distancia entre dos valores sucesivos de X es k > 1, ¿cómo aplicaría la corrección por continuidad? Ejemplo: Sea X ~ Bi(60,1/3). Calcular en forma aproximada la probabilidad de que X sea mayor o igual que 25. X − 60 ⋅ 1 24.5 − 60 ⋅ 1 3 ≥ 3 ≅ 1 − Φ (1.23) = 0.11 P ( X ≥ 25) = P( X ≥ 24.5) = P 1 2 1 2 60 ⋅ ⋅ 60 ⋅ ⋅ 3 3 3 3 Otras aplicaciones del Teorema Central del Límite: a) Sean X 1 , X 2 ,..., X n v.a. i.i.d. con distribución Poisson de parámetro λ, entonces n ∑X i =1 i ~ P(nλ ) Por lo tanto, cualquier v.a. con distribución de Poisson con parámetro suficientemente grande puede ser aproximada por la distribución normal. 105 b) Sean X 1 , X 2 ,..., X n v.a. independientes con distribución Gamma de parámetros ni y λ, o sea X i ~ Γ(ni , λ ) entonces n X ~ Γ ∑ ni , λ ∑ i i =1 i =1 n Por lo tanto, cualquier v.a. con distribución Γ(m, λ) con parámetro m suficientemente grande puede ser aproximada por la distribución normal.