- Ninguna Categoria
Sistemas de representación de mapas de posicionamiento
Anuncio
Sistemas de representación de mapas de posicionamiento bursátiles. Aplicaciones a empresas del IBEX 35. MAPIBEX Autor: ROBERTO ALONSO LUNA MADRID, JUNIO DE 2007 Autorizada la entrega del proyecto del alumno: Roberto Alonso Luna 20 de junio de 2007 EL DIRECTOR DEL PROYECTO Fdo.: Carlos Maté Jiménez Vº Bº del Coordinador de Proyectos Fdo.: Claudia Meseguer Velasco Fecha: 20/ 06 / 07 Agradecimientos A Jacobo, Oliver y don Eugenio que con su colaboración desinteresada han colaborado a elaborar este proyecto, y especialmente a mi madre. Resumen del Proyecto Actualmente los mercados bursátiles han cobrado especial importancia, debido al aumento del número de inversores. Estos inversores ya no sólo son los broker y las compañías financieras, sino también familias y pequeños inversores. Según las teorías tradicionales de inversión, las habilidades necesarias para obtener beneficios de una inversión son psicología, manejo del dinero y método. Y la mayoría de los métodos coinciden en la necesidad de manejar una información adecuada. Sin embargo, la información que habitualmente se ofrece requiere un gran nivel de conocimiento de los mercados financieros y no es muy intuitiva, por lo que muchos pequeños inversores tendrán problemas para el análisis de dicha información. MAPIBEX pretende simplificar dicho análisis y hacerlo accesible a un mayor número de usuarios. Los antecedentes son los mapas preceptuales usados en Marketing, obtenidos mediante análisis de correspondencias, cuyas principales cualidades son su claridad y ser muy intuitivos. Partiendo de la realidad anterior, y la investigación desarrollada hasta la fecha por el equipo del Profesor Carlos Maté en el área de investigación de mercados, el proyecto consiste en el desarrollo de un sistema informático para tratar adecuadamente la información disponible de las cotizaciones en Yahoo Finanzas. El desarrollo del sistema se ha realizado utilizando para ello la plataforma estadística Xlstat y el programa Matlab, ambos muy extendidos entre investigadores de ámbito tanto profesional como académico. Aprovechando las posibilidades de este entorno, el sistema proporciona mapas del mercado financiero español que permite evaluar el posicionamiento de las empresas, e índices respecto a sus variaciones, y la influencia en el mercado de su volumen monetario negociado y del reparto de dividendos. Todo este sistema está acompañado de una propuesta de interfaz de usuario realizada con Matlab, una plataforma y lenguaje de programación que permitirá una extensión del producto a ámbitos más generales. El proyecto actual continúa un trabajo de investigación y desarrollo iniciado cuatro años antes del inicio del mismo. Surge como idea a partir de una herramienta ya existente en el mercado, que incorpora alguna de las características desarrolladas a lo largo del proyecto, sin embargo su aplicación al análisis de los mercados financieros resulta completamente novedosa y permite obtener unos resultados muy satisfactorios. Abstract Nowadays financial markets are becoming very important, due to the increase of the number of investors. These investors are not only brokers and large investment banks, there also many families and small investors. According to traditional investment theories, the requested skills to obtain benefits of an invest, are mind, money management and method. And the most of these methods agree that is extremely necessary managing appropriate information. However the information that is usually given requires a large knowledge about financial markets, in fact it is a hard work to analyze financial news. Therefore many small investors will have a problem in order to analyze this information. MAPIBEX tries to simplify this analysis and to make it accessible to a large number of investors. The antecedents of this project are perceptual maps used in Marketing. These maps are designed applying correspondence analysis and some main characteristics of perceptual maps are polyvalency and also to be very intuitive. Taking into consideration the already described situation, and the research undertaken up to date by Prof. Carlos Maté in the marketing research area, the current project consists on development of a new software to adequately treat the financial market information available in Yahoo Finanzas. The development of the system has been done making an intensive use of Xlstat and Matlab, which are widely used both in corporative and educational environments. Taking advantage of this environment, the developed software offers Spanish financial markets maps that allow investors to evaluate the company and index positioning, with regard to variation, and the influence in the equity´s prize of the dealt volume and giving dividends. A graphical user interface prototype for the system has been designed using the Matlab environment. This platform permits an easy portability of the current system to other operating systems or hardware settings. The following project continues the investigative and developing work started four years before. An existing product in the market with some of the features developed in the current system gave the idea for this project. However applying in financial markets in analysis is absolutely new and obtains very satisfactory results. Índice 1 Motivación y Objetivos del proyecto 1 1.1 Motivación 1 1.2 Objetivos 2 2 Las bolsas de valores 4 2.1) La bolsa en España 4 2.1.1) Historia de la bolsa en España 4 2.1.2) Funcionamiento de la bolsa en España 6 2.1.3) El sistema SIBE 9 2.2) El IBEX-35 11 2.3) Otros índices 14 2.3.1) Índices nacionales 14 2.3.2) Índices internacionales 15 3 Técnicas gráficas de inversión bursátil 21 3.1 Tendencia 21 3.2 Tipos de gráficos 21 3.2.1 Gráficos lineales 23 3.2.2 Gráficos de barra 24 3.2.3 Gráfico de punto y cifra 35 3.2.4 Gráficos de subida bajada 37 3.3 Indicadores técnicos 38 3.3.1 Medias móviles 39 3.3.2 Osciladores 41 4 Parámetros bursátiles 45 4.1 Volatilidad 45 4.1.1) Técnicas para predecir la volatilidad 46 4.2) Correlación 49 4.3) Riesgo y estrategias de gestión de carteras 50 4.3.1) Riesgo de una cartera 50 4.3.2) Estrategias de gestión de carteras 51 4.4) Creación de valor 53 4.5) Volumen bursátil 55 5 Métodos de análisis multivariante usados en el análisis de mercados 57 5.1 Análisis de Correspondencias 57 5.1.1) Matriz de correspondencias y filas y columnas marginales 60 5.1.2) Perfiles marginales y condicionales 62 5.1.3) Dependencia e interdependencia mediante Pearson Chi-Cuadrado 64 5.1.4) Inercia total 65 5.1.5) Coordenadas de los perfiles fila y columna 66 5.1.6) Contribuciones parciales a la Inercia Total 67 5.1.7) Cosenos al cuadrado 68 5.1.8) Principio de la distribución equivalente 69 5.1.9) Aproximación generalizada de los menores cuadrados 69 5.1.10) Filas y columnas de desviaciones y autovectores 70 5.2) Escalado Multidimensional 70 5.2.1) Proceso del escalado multidimensional 72 5.2.2) Interpretación de los resultados del escalado multidimensional 77 5.3 Análisis de Componentes principales 5.3.1) Proceso del análisis de Componentes Principales 78 80 5.3.2) Representación gráfica del análisis de componentes principales 81 5.4 Análisis Factorial 82 5.4.1) El Análisis Factorial frente a otros métodos de análisis 83 5.4.2) Formulación del problema de Análisis Factorial 84 5.4.3) Proceso del Análisis Factorial 85 5.4.4) Rotación de factores 86 5.4.5) Representación gráfica del análisis factorial 88 5.5 Análisis Cluster 89 5.5.1) Proceso del análisis Cluster 90 5.5.3) Métodos jerárquicos frente no jerárquicos 95 5.6) Mapas Perceptuales 5.6.1) Interpretación de los mapas perceptuales 96 96 6 Desarrollo de la herramienta y caso práctico 99 6.1) Software empleado 99 6.1.1) Excel 99 6.1.2) Matlab 100 6.1.3) Xlstat 101 6.2) Técnicas empleadas 102 6.2.1) Análisis de Correspondencias 102 6.2.2) Técnicas de Interdependencia 103 6.2.3) Coeficiente de variación 105 6.3) Niveles de la herramienta 106 6.4) Caso práctico 108 7 Manual del Usuario 117 7.1) Pasos previos al uso de MAPIBEX 117 7.2) Captura y transformación de los datos 118 7.3) Obtención de la tabla de contingencia. Niveles de uso. 121 7.4) Obtención del mapa de representación y análisis de dependencia 125 8) Conclusiones 129 8.1) Conclusiones generales derivadas del uso de MAPIBEX 129 8.2) Conclusiones particulares derivadas del uso de MAPIBEX 130 9) Bibliografía 131 10) Anexos 133 Índice de figuras 2.1) Organización del mercado español 8 3.1) Gráfico lineal de nivel del IBEX-35 24 3.2) Construcción de un gráfico de barras 25 3.3) Gráfico de barras con información del volumen negociado 26 3.4) Dos candlestick de cierre mayor que apertura y de apertura mayor que cierre 26 3.5) Martillo (hammer) 28 3.6) Martillo invertido (invertid hammer) 28 3.7) Hombre colgado (hanging man) 29 3.8) Estrella fugaz seguida de martillo 29 3.9) Envolvente alcista 30 3.10) Envolvente bajista 31 3.11) Nube oscura (dark cloud cover) 32 3.12) Harami 33 3.13) Estrella 34 3.14) Lucero del alba (morning star) 34 3.15) Estrellas Doji 35 3.16) Mañana Doji Star 35 3.17) Estrella vespertina ( evening star) 36 3.18) Estrella Doji de por la tarde 36 3.19) Gráfico de punto y cifra 37 4.1) Diagrama de dispersión: indica una posible relación lineal 50 5.1) Gráfico de los factores en el espacio factorial rotado 88 5.2) Dendograma 89 5.3) Mapa perceptual 82 6.1) Mapa perceptual 115 7.1) Descarga de copia de evaluación Xlstat 117 7.2) Se han de rellenar varios datos para descargar el Xlstat 117 7.3) Instalación del Xlstat, se deberá especificar la localización 118 7.4) Captura de datos de Yahoo Finanzas 118 7.5) Inicio de MAPIBEX 121 7.6) Pantalla de inicio de MAPIBEX 122 7.7) Selección de número de empresas y resultados a obtener 122 7.8) Selección de empresas y semanas límites de estudio 123 7.9) Fecha límite, si la fecha de origen del estudio es 07/05/2007 se deberá introducir como origen en Acerinox el número de fila, esto es,2. 123 7.10) Error causado por un error en la introducción de fechas 124 7.11) En caso de que aparezca este símbolo en Matlab tras una lectura de datos o al obtener resultados se deberá esperar unos segundos para continuar. 124 7.12) Resultados obtenidos en Excel. 126 7.13) Análisis Factorial de Correspondencias 126 7.14) Representación gráfica 127 7.15) Pruebas de independencia sobre tabla de contingencia 127 Índice de tablas 2.1) Componentes del IBEX-35 13 2.2) Componentes del Dow-Jones Industrial 17 5.1) Tabla de correspondencias 60 5.2) Resumen de términos 61 5.3) Matriz R para los perfiles fila 62 5.4) Matiz C para los perfiles columna 63 5.5) Coordenadas para los perfiles fila en ejes principales fila 67 5.6) Coordenadas para los perfiles columna en ejes principales columna 67 5.7) Medidas de distancias 93 5.8) Comparación de métodos en análisis Cluster 95 6.1) Tabla de contingencia 108 6.2) Medidas de independencia 109 6.3) Medidas sobre tabla de contingencia 109 6.4) Valores propios y porcentaje de varianza 110 6.5) Pesos, distancias al origen e inercias de los puntos fila 111 6.6) Coordenadas de los puntos fila 111 6.7) Medidas de los puntos fila 112 6.8) Medidas de los puntos columna 114 6.9) Coeficientes de variación 115 7.1) Correspondencias entre acrónimos de las empresas y sus respectivos nombres para ser guardadas. 120 7.2) Macros para el cálculo y transformación de datos 120 Capítulo 1 Motivación y objetivos del proyecto En una sociedad como la nuestra, en la que se han de tomar decisiones muy relevantes, para lo cual gozamos de amplia y renovada información, pero eso sí, en un muy corto espacio de tiempo, los gráficos cobran una gran importancia. Éstos tienen la ventaja de ofrecernos bastante información resumida de modo que el usuario podrá interpretarlos en un breve periodo y por tanto tomar decisiones. Además suelen presentar la ventaja de ser bastante intuitivos, por lo que no es estrictamente necesario que un usuario sea un experto para obtener unos resultados satisfactorios. Con todo esto vemos que el campo de acción de los gráficos es inmenso, pero si en un área resultan especialmente críticos es en la representación de los diferentes movimientos que se producen en los mercados bursátiles, pues cumplen todas las condiciones antes citadas. 1.1) Motivación Teniendo en cuenta lo anterior, este proyecto pretende desarrollar una aplicación en MATLAB con el fin de generar y analizar datos sobre los movimientos de las cotizaciones de las empresas del IBEX-35, aunque la intención es que sea lo suficientemente polivalente como para que fuera usado con otros índices, tales como el Dow Jones o el Nasdaq. Los resultados obtenidos nos deberán informar sobre la rentabilidad presente, e incluso, sobre la tendencia futura de las diferentes empresas analizadas. Este proyecto se enmarca dentro del trabajo de investigación que el profesor Carlos Maté lleva desarrollando varios años, aunque hasta ahora el enfoque de estas investigaciones iba encaminado hacia el Marketing. Los factores que llevaron al autor a realizar este proyecto fueron: 1 El centro: el IIT – Instituto de Investigación tecnológica es un reconocido centro que destaca por la calidad, innovación y trascendencia de sus trabajos El director: goza entre el alumnado de fama de eficiente y de poseer elevados conocimientos en el campo de la estadística y el análisis de datos El software: MATLAB es sin duda uno de los programas más extendidos y valorados internacionalmente gracias a su potencia, versatilidad y posibilidades gráficas. Además se ofrece la posibilidad de trabajar con un programa como el R que aunque se encuentra en sus primeros pasos de desarrollo, no sería extraño que dentro de no muchos años sea uno de los lenguajes de programación dominantes en el campo de la estadística. El objeto de estudio: los mercados bursátiles, debido a su importancia, dinamismo, y al amplio despliegue tecnológico que últimamente su estudio requiere, resultan un campo de lo más interesante. La originalidad: si bien precisamente por la tecnología usada en su estudio hacen que sea un campo donde un ingeniero pueda trabajar satisfactoriamente, se aleja bastante de las tareas más usuales de un ingeniero. El aprendizaje: este proyecto supone un reto diferente, y además ofrece la posibilidad de aprender bastante acerca del mundo de las finanzas. El futuro: sin duda la tendencia es que cada vez cobrará más valor el análisis de datos, ya que a medida que las tecnologías avancen y se hagan más accesibles al gran público, tendremos un mayor y más reciente número de datos, por lo que serán necesarias aplicaciones que nos ayuden a sacar las conclusiones adecuadas de éstos. 1.2) Objetivos 1. Desarrollar un sistema de captura automática de información bursátil y posterior almacenamiento de ésta, de forma que definiéndole unos parámetros de búsqueda, y aprovechando las posibilidades que Internet ofrece nos provea de los datos deseados. 2. Desarrollar una aplicación fiable y potente para realizar mapas de posicionamiento bursátiles, y que sea lo suficientemente polivalente como para 2 poder analizar varias características diferentes y en diversos periodos de tiempo. Se ofrecerá la posibilidad de varios niveles de uso (nivel pequeño usuario, nivel broker) para hacer que la herramienta se adapte mejor a los potenciales clientes. También con objeto a la posterior distribución de la herramienta se cuidará especialmente el interfaz para hacer atractivo el producto. Una vez desarrollada la herramienta, se determinará la estrategia de comercialización con el objeto de llegar a un mayor y más diversificado número de clientes 3 Capítulo 2 Las bolsas de valores Conocidas como bolsa, su origen se remonta a la edad media con la aparición de las lonjas en las principales europeas. Su nombre [LAROU97] rememora a la familia de banqueros Van der Bursen que en el siglo XIII realizaba reuniones de carácter mercantil, siendo el escudo de armas de dicha familia tres bolsas de plata. Así entre los ss. XV y XVIII se fueron formando las principales bolsas europeas y americanas: Amberes (1847), Amsterdam (1561), Lyon (1595), Berlín (1685), París (1724), Nueva York (1792) o Madrid (1831) que permitieron financiar los grandes proyectos industriales tales como los ferrocarriles, siderúrgicas, metalúrgicas o textiles canalizando el ahorro hacia estas inversiones. En las bolsas de valores tiene lugar el intercambio de ofertas y demandas de valores mobiliarios por mediación de los agentes de cambio. Las sociedades anónimas han acudido al ahorro para financiar sus inversiones, a través de la colocación de acciones y obligaciones e incluso también el estado puede acudir. 2.1) La bolsa en España 2.1.1) Historia de la bolsa en España En 1809 José Bonaparte decide crear la primera bolsa de España en Madrid en el convento iglesia de San Felipe el Real, en la Puerta del Sol. Sin embargo hasta 1831 y con Fernando VII no se constituiría el mercado bursátil. Así la primera jornada de cotización se produce el 20 de Octubre de dicho año, siendo la cotización en reales. En este periodo la bolsa estuvo lastrada por el intervencionismo estatal, la debilidad y el atraso de la economía española, las continuas crisis, el excesivo peso de la deuda. Al igual que en ferrocarriles y minería, y gracias a las ayudas y ventajas fiscales empezó la inversión extranjera con ejemplos tales como Rothschild y Péreire. Sin embargo la 4 resistencia a adoptar el patrón oro (frente al patrón oro-plata) y el poco interés por parte de las autoridades poco contribuyeron a modernizar la institución y sí a su aislamiento. En 1845 con la reforma de Mon-Santillán se trató de que en la anárquica economía española se impusiesen algunos atributos que hoy se consideran fundamentales tales como: equidad, generalidad, legalidad, simplicidad, suficiencia y flexibilidad. Los resultados no fueron espectaculares, pero se empezó con una buena práctica: desde 1854 se emite el Boletín Oficial de Contratación. Uno de los problemas más acuciantes de la segunda mitad del XIX fue la deuda pública. La emisión de deuda pública para cubrir gastos no fue una solución, pues a un incremento de déficit, se emitía más deuda pública, por la que había que pagar elevados intereses. Tanto es así, que los valores más negociados, con un 90% eran los estatales, desplazando a los industriales y agrícolas. Otros hechos destacados de este periodo son el nacimiento de la peseta o la construcción del actual Palacio de la Bolsa de Madrid. Sin embargo este siglo se despedirá con una nueva crisis provocada por la pérdida de Cuba, Puerto Rico y Filipinas, cayendo la contratación y el precio de las acciones. Sin embargo en 1900 la repatriación de los capitales de dichas colonias supuso un espaldarazo. Durante la Primera Guerra Mundial continuó abierta y con un ritmo de ligero crecimiento. El crack de la bolsa de Nueva York del 29 no supuso una caída inmediata de la bolsa, sin embargo, el periodo republicano fue muy negativo para los cotizaciones. Desde 1936 hasta 1940 la bolsa permanece cerrada debido a la Guerra Civil. El 5 de Marzo de 1940 la bolsa abre las puertas a un periodo marcado por la autarquía que impuso el régimen, aunque desde 1953 se produce una paulatina apertura al exterior que va incrementando su volumen de contratación. Entre 1959 y 1970 como consecuencia del Plan de Estabilización la bolsa sube apoyada por la inversión extranjera. Desde 1974 se comienza con el nuevo sistema de liquidación de operaciones, base del actual sistema de anotación en cuenta. 1975 es un año negro para la bolsa con grandes pérdidas debidas a la muerte de Franco, la crisis del petróleo y el inicio de la transición democrática. Esta tendencia se invierte a partir de 1978 gracias a las mejoras técnicas introducidas que alientan a la inversión extranjera. Por su parte el periodo comprendido entre la superación del golpe de estado (1982) y la adhesión a la 5 Comunidad Económica Europea (1987) es el de mayor y más rápido crecimiento, con fuertes revalorizaciones de las acciones. En 1988 se crea la Ley del Mercado de Valores que transforma la Bolsa española. Los Agentes de Cambio y Bolsa son sustituidos por Sociedades y Agencias de Valores. Se crea la Sociedad Rectora de la Bolsa y la Comisión Nacional del Mercado de Valores (CNMV). En 1989 comienza a funcionar el mercado continuo para acciones CATS (computer assisted trading sistem) con 7 valores, que se convierten en 51 a final de dicho año, con lo que poco a poco se van relegando los tradicionales corros del parquet por la contratación electrónica hasta que en 1993 todas las operaciones se hacen de forma electrónica. Sin embargo este sistema se sustituye en 1995 por el SIBE (sistema de interconexión bursátil español). Esta mejora, junto con la rebaja de los tipos de interés, la inversión colectiva, la privatización de grandes empresas y el auge de la inversión colectiva se tradujeron en un gran aumento de la contratación y de la cotización. Desde el 1 de Enero de 1999 la moneda de cotización es el euro, poniéndose en marcha el Latibex, Mercado de Valores Latinoamericanos. El siglo XXI se inicia con fuertes incrementos debidos al mercado tecnológico, sin embargo el descubrimiento de grandes escándalos financieros, sobre todo en Estados Unidos, junto a las pérdidas de las sobrevaloradas empresas tecnológicas condujo a un proceso de pérdidas. En 2002 se constituye Bolsas y Mercados Españoles (BME) que aglutina el 100% de las Bolsas de Madrid, Barcelona, Valencia y Bilbao. A día de hoy los mercados españoles se encuentran en máximos de actividad y capitalización. 2.1.2) Organización de la bolsa en España En España existen cuatro bolsas de valores [INFOBOLSA]: la de Madrid (65% del total de la cotización bursátil), Barcelona (20%), Bilbao(10%) y Valencia (5%) que están reguladas por la ley del mercado de valores de 1988, cuyos objetivos fueron permitir una mayor transparencia en las operaciones e implantar una reforma en la organización de los profesionales que participan en la bolsa. Dicha ley es complementada en 2003 con la “Ley de Transparencia”, que establece nuevos requisitos de información y la obligación 6 de dotarse de un conjunto de mecanismos en materia de gobierno corporativo. El organismo que fija las reglas de mercado es la CNMV (Comisión Nacional del Mercado de Valores). Por su parte la sociedad que integra las diferentes empresas que dirigen y gestionan los mercados de valores y sistemas financieros en España BME (Bolsas y Mercados Españoles), agrupa bajo la misma unidad de acción, decisión y coordinación, los mercados de renta variable, de renta fija derivados y sistemas de compensación y liquidación españoles. La figura 2.1 es representativa de la organización del mercado español. Figura 2.1 Organización del mercado español 7 Para la admisión de valores a cotización oficial, las sociedades, personas jurídicas, fondos de inversión y demás personas físicas emisoras de títulos dirigen su solicitud a la junta sindical de la bolsa, concretando las distintas características de los títulos y aportando diversa documentación esencial sobre la personalidad del solicitante. Las juntas sindicales pueden establecer las condiciones mínimas para la admisión a cotización oficial. Una vez admitidos los valores a cotización éstos podrán ser de cotización calificada si cotizan como mínimo en un 60% de las sesiones o en más de 100 sesiones al año, registrando un volumen de contratación del 1,5% del capital social en las acciones y un 0,5% en las obligaciones. Si no cumplen los requisitos citados serán valores de cotización simple, salvo en valores emitidos o avalados por el estado. Sea cual sea la naturaleza de la cotización, las sociedades están obligadas a remitir a la junta sindical información económica y contable de la empresa, como estados financieros, pago de dividendos, aumentos y disminuciones de capital. Las bolsas españolas se limitan a negociar con títulos de renta fija y variable, y en mucha menor medida con metales preciosos, divisas, mercancías y efectos comerciales. Las operaciones se realizan a partir del último cambio cotizado las juntas sindicales pueden proponer unos intervalos de variaciones en las cotizaciones a partir de los cuales puede suspenderse la sesión bursátil. Acaba la sesión la junta publica en boletín de cotización oficial. La persona o grupo que desea realizar una operación debe transmitir una orden al intermediario precisando los detalles de la operación: número y naturaleza de los títulos, precio, validez temporal, al contado o a plazo. Dichas órdenes pueden ser al primer precio, al más favorable de la sesión, a un precio fijo o dejando cierto margen. El agente deberá responder a su cliente en el mismo día si son operaciones al contado, o enviando una cuenta de liquidación en las operaciones a plazo. Estas operaciones implican un gasto en concepto de aranceles o comisiones de el 1,25 por mil en valores del estado y del 1,75 8 por mil en el resto, estando también sujetos al pago del impuesto sobre transmisiones patrimoniales 2.1.3) Sistema SIBE Es donde se concentra la negociación de las acciones de las empresas más representativas de la economía española y con mayor volumen de contratación. Se trata de un sistema de interconexión bursátil [BORSABCN] de ámbito estatal integrado por una red informática que conecta las bolsas de Madrid, Barcelona, Bilbao y Valencia para la negociación de aquellos valores que acuerde la CNMV. En este sistema electrónico de negociación multilateral y automático la prioridad del cierre de operaciones viene dada en primer lugar por el precio, y en caso de igualdad de este por el orden temporal en que se dieron las órdenes, siendo la unidad de estas operaciones la acción, el derecho de suscripción o el warrant. Las sesiones se celebrarán días hábiles de lunes a viernes y el horario en que se podrán desarrollar las operaciones serán: Subasta de apertura: entre las 8:30 y las 9, será cuando se introduzcan, modifiquen y cancelen propuestas. No se cruzarán operaciones Sesión abierta: entre las 9 y las 17:30 se efectuar la contratación continuada Subastas de volatilidad: duran unos 5 minutos más un final aleatorio de un máximo de 30 segundos y se realizan antes de que se registren operaciones cuyos precios pudieran alcanzar o sobrepasar los límites máximos de variación estipulados (rangos estático y dinámico). Subasta de cierre: Entre las 17.30 y las 17.35 horas, destinada a la introducción, modificación y cancelación de órdenes. No se cruzan operaciones. Las variaciones de precios en cada sesión vendrán dadas por unas mínimas de 0,01 o 0,05 euros según el precio alcance o supere los 50 euros. Las 9 máximas vendrán dadas por el precio y rango estático (durante toda la sesión) y por el precio y el rango dinámico (en sesión abierta y en subasta de cierre). Así el precio estático es el precio dominante de la última subasta y su rango es la máxima variación permitida respecto a este precio calculándose esta en función de la volatilidad histórica de cada valor. Análogamente el precio dinámico es el último precio negociado de un valor, por lo que se actualiza continuamente durante la sesión. Su rango se calcula en función de la serie histórica de variaciones de precios durante la sesión. La fijación de precios y asignación de unidades de contratación será diferente durante la sesión de apertura que durante la sesión abierta. En la primera a la vista de los precios introducidos durante el periodo de ajuste , el primer precio será aquel que permita negociar un mayor número de unidades de contratación; si dos o más precios permiten negociar el mismo número, el primer precio será el que produzca el menor desequilibrio, entendiéndose por desequilibrio la diferencia entre el volumen ofrecido y el volumen demandado a un mismo precio. Si no hay desequilibrio o si los desequilibrios son iguales, se escogerá el precio del lado que tenga mayor volumen. Si las tres condiciones anteriores coinciden, será precio de la subasta, de las dos posibles, el más cercano al último negociado con las excepciones de que el último precio negociado esté dentro de la horquilla de los dos posibles precios de la subasta, el precio de la subasta será ese último precio negociado. La otra excepción se dará en el caso de que no haya último precio negociado o que se encuentre fuera de la horquilla de precios del rango estático, en cuyo caso el precio de la subasta será el más cercano al precio estático. Una vez fijado el primer precio, se cumplimentarán, en primer lugar, las órdenes de mercado y por lo mejor, a continuación las limitadas con precios mejores que el de subasta y, finalmente, el resto de órdenes limitadas al precio de subasta, en la medida que sea posible, según el orden temporal en el que se introdujeron en el sistema. 10 Durante la sesión abierta se negociará si finalizada la subasta de apertura no coincidieron la oferta y la demanda. Aquí el cierre de operaciones se deberá al rango de precios, y en caso de igualdad, a la prioridad temporal 2.2) El IBEX-35 Un índice es un concepto estadístico, que agrupa en un solo dato numérico resultados de caracteres diferentes que se refieren a un mismo fenómeno. Un índice puede ser simple, en cuyo caso se podría asimilar a la media aritmética o ponderado, cuando se da más peso a unos caracteres que a otros en función se su importancia. Es evidente que es un concepto de gran utilidad y con grandes aplicaciones, sobre todo en el ámbito de la economía como podría ser el IPC (índice de precios al consumo). En la bolsa se llevan usando índices desde hace más de un siglo, pues es una forma simple y clara de reflejar las variaciones de valor o de rentabilidades promedio de las acciones que lo componen. Las acciones que compondrán un índice deberán cumplir unos requisitos tales como: pertenecer a una misma bolsa de valores, tener una capitalización bursátil similar o pertenecer a un mismo sector, por ejemplo, al tecnológico. Gran parte de su importancia es que suelen ser tomados como referencias para carteras y fondos. Este proyecto se centrará especialmente en las empresas que componen el IBEX-35, que son empresas que cotizan a través del sistema SIBE anteriormente citado. Este índice es ponderado de capitalización bursátil, es decir, no todas las empresas que lo forman tienen el mismo peso. Se puso en marcha el 29 de diciembre de 1989 [BOLSAMADRID] con una base de 3000 puntos. Como se dijo antes, su cálculo atiende a la capitalización bursátil, que es el precio por el número de acciones de las empresas 11 consideradas, pero con un coeficiente de ajuste para que operaciones financieras excepcionales no alteren el valor del índice. La expresión que nos dará el valor exacto será: IBEX 35(t ) IBEX 35(t 1) Capitalización(t ) Capitalización(t 1) J Siendo J la cantidad utilizada para ajustar el valor del índice por ampliaciones de capital o otras contingencias extraordinarias. El criterio que marca para una empresa la entrada en el IBEX-35 atiende a la liquidez, entendiendo ésta por el volumen de contratación, tanto en cantidad de euros como de órdenes, lo que se podría resumir en que Para que un valor forme parte del Ibex 35 es necesario que su capitalización media supere el 0,3% de la del Ibex 35 en el período analizado y que dicho valor haya sido contratado por lo menos en la tercera parte de las sesiones de ése período. Así la formación del IBEX-35 se revisa cada seis meses, a 1 de enero y 1 de julio no ajustándose necesariamente por dividendos, aunque sí lo hará por ciertas operaciones financieras de los valores que lo componen: ampliaciones de capital, reducciones de capital por amortización de acciones, variaciones de valor nominal, fusiones y absorciones. A 18 de Septiembre del año 2006 los valores que lo componen, el número de acciones y su cotización se muestran en la siguiente tabla [BOLSAMADRID]: 12 VALOR ABERTIS INFRAESTRUCTURAS, SERIE A ACCIONA ACERINOX ACS ACTIVIDADES CONST.Y SERVICIOS ALTADIS ANTENA 3 DE TELEVISION BANCO BILBAO VIZCAYA ARGENTARIA BANCO DE SABADELL BANCO ESPAñOL DE CREDITO BANCO POPULAR ESPAñOL BANCO SANTANDER CENTRAL HISPANO BANKINTER CINTRA CONC.INFRA.DE TRANSPORTE CORPORACION MAPFRE ENAGAS ENDESA FADESA INMOBILIARIA FERROVIAL FOMENTO CONSTR.Y CONTRATAS(FCC) GAMESA CORPORACION TECNOLOGICA GAS NATURAL SDG GESTEVISION TELECINCO IBERDROLA IBERIA IND. DE DISEÑO TEXTIL (INDITEX) INDRA, SERIE A METROVACESA NH HOTELES PROMOTORA DE INFORMACIONES RED ELECTRICA DE ESPAÑA REPSOL YPF SACYR VALLEHERMOSO SOGECABLE TELEFONICA UNION FENOSA TÍTULOS COTIZACIÓN 456.777.479 19,85 50.840.000 114,35 259.500.000 14,49 352.873.134 36,10 256.121.426 37,35 133.334.400 16,50 3.390.852.043 17,77 306.003.420 28,55 138.866.020 14,56 1.215.432.540 12,51 6.254.296.579 12,22 78.585.044 54,20 294.669.676 10,64 191.120.565 15,46 238.734.260 18,34 1.058.752.117 28,32 90.650.239 25,24 112.211.794 57,50 78.340.490 60,20 243.299.904 16,36 268.665.617 27,45 147.985.114 20,32 901.549.181 31,50 947.893.931 2,07 373.998.240 34,67 145.652.313 16,74 81.429.740 78,30 123.782.898 16,56 131.287.500 12,56 135.270.000 29,94 1.220.863.463 21,65 170.781.727 30,82 82.303.082 26,75 4.921.130.397 13,01 243.743.461 38,50 Tabla 2.1 Composición del IBEX-35 13 2.3) Otros Índices 2.3.1) Índices nacionales Ibex Médium Cap: El Índice IBEX MEDIUM CAP se compone de los 20 valores cotizados en los Segmentos de Contratación General y Nuevo Mercado del Sistema de Interconexión Bursátil de las cuatro Bolsas Españolas que, excluidos los 35 valores componentes del índice IBEX 35, tengan la mayor capitalización ajustada por capital flotante y cumplan los siguientes requisitos de liquidez: rotación anualizada sobre capital flotante superior al 15% y porcentaje de capital flotante superior al 15% rotación. Por rotación se entiende la relación entre el volumen de contratación en Euros en el mercado de órdenes (Segmentos de Contratación del Sistema de Interconexión Bursátil denominados Contratación General y Nuevo Mercado) y la capitalización ajustada por flotante. El cálculo del índice y las reglas que lo rigen son similares a las del IBEX 35 Ibex Small Cap: El Índice IBEX SMALL CAP se compone de los 30 valores cotizados en los Segmentos de Contratación General y Nuevo Mercado del Sistema de Interconexión Bursátil de las cuatro Bolsas Españolas que, excluidos los 35 valores componentes del índice IBEX 35 y los 20 valores componentes del índice IBEX MEDIUM CAP, tengan la mayor capitalización ajustada por capital fl otante y cumplan en el periodo de control, los mismos requisitos de liquidez que el IBEX MEDIUM CAP. El cálculo del índice las reglas que lo rigen son similares a las del IBEX 35. Ibex Nuevo Mercado: El Indice IBEX NUEVO MERCADO se compone de los valores incluidos en el segmento de contratación del Sistema de Interconexión Bursátil español denominado Nuevo Mercado. El Comité Asesor Técnico elegirá como componentes del mismo aquellos valores más representativos atendiendo a la liquidez y considerando que el Indice no tiene un número limitado de valores. La normativa aplicable al IBEX NUEVO MERCADO para su cálculo y organización es igual que la del IBEX 35 14 Latibex: se trata del único mercado internacional para valores latinoamericanos. Nace en Diciembre de 1999 siendo aprobado por el Gobierno español y regulado bajo la vigente Ley del Mercado de Valores española. Actualmente está integrado en la oferta de servicios y productos de Bolsas y Mercados Españoles. Latibex trata de canalizar de manera eficaz las inversiones europeas hacia Latinoamérica, pues permite a los inversores europeos comprar y vender las principales empresas latinoamericanas a través de un único mercado, con un único sistema operativo de contratación y liquidación, con gran transparencia y seguridad y en una sola divisa: el euro. Se apoya en la plataforma de negociación (SIBE) y liquidación de valores de BME, de tal forma que los valores de América Latina cotizados en él, se contratan y liquidan como cualquier valor español. Por otro lado, permite a las principales empresas de América Latina un acceso sencillo y eficiente al mercado de capitales europeo. 2.3.2) Índices internacionales Dow Jones: se trata del padre del resto de los índices, y sin duda del de mayor importancia. El nacimiento del Dow Jones Industrial Average, se debió a la iniciativa de Charles Henry Dow y de Edward D. Jones. Ambos periodistas, junto con Charles Bergstresser, fundaron en 1882 Dow Jones & Company, un servicio de noticias financieras que, dos años mas tarde, lanzó el primer índice de cotizaciones en la Bolsa de New York, siendo publicado por el prestigioso diario financiero “The Wall Street Journal” , del cual Charles Dow era editor, siendo su objetivo original el establecimiento de un barómetro medidor de la actividad económica, y no el análisis de la tendencia de los valores, aplicación por la que ha ganado merecida reputación con el paso de los años. En 1902 muere Dow y William P. Hamilton que fuera su socio y posterior sucesor al frente del Wall Street Journal y, despúes, Robert Rhea recopilaron, sistematizaron y desarrollaron los hallazgos de Charles Dow creando la conocida como Teoría de Dow, extendiendo su campo de acción a la identificación de tendencias y a la prognosis de los mercados de valores. El índice Dow comprende apenas 30 acciones, sobre el total de unas 10,000 empresas que cotizan. Dow estableció dos medias o índices sectoriales: un 15 índice industrial (Dow Jones Industrial Average) y un índice de transportes (Dow Jones Transportation Average). Esta división se entiende observando la teoría desarrollada por Dow, según la cual cuando la actividad económica atraviesa un período de auge. las empresas industriales experimentan un aumento de producción y incrementando sus beneficios. Por esto adquieren un mayor atractivo para los inversores, aumentando la demanda de sus acciones, y el precio de sus acciones comienza a progresar. A medida que el sector industrial avanza en su expansión, la demanda de servicios de transporte aumenta y con ello los beneficios de las empresas transportistas. Como en el caso de las sociedades industriales, esta evolución positiva habría de atraer inversores que con su actividad compradora incidirían en la recuperación del precio de las acciones del sector transporte. Posteriormente se incluiría el Promedio de Utilidades Dow Jones (DJUA). Originalmente Dow incluyó en el índice industrial (DJIA) 12 valores representativos de distintas industrias. Este número se incremento en 1916 a 20, para quedar fijado finalmente en 30 a partir de 1928. A diferencia del IBEX-35 los promedios del Dow se calculan sobre la base del precio y no de la capitalización. Por tanto, el peso de los componentes varía de acuerdo al precio de las acciones, sin tener en cuenta el número de acciones en circulación. En principio, su valor era calculado simplemente por la suma del precio de todos los componentes de cada índice y dividiéndolo por el número de componentes del mismo. Luego, se inició la práctica de utilizar un divisor para suavizar los efectos de la división de acciones (stock split) y otras estrategias corporativas. 16 Ticker Nombre Última transacción Variación Volumen AA ALCOA INC 27,49 $ 22:01 0,03 (0,11%) 6.504.400 AIGAMER INTL GROUP INC 66,84 $ 22:01 0,36 (0,54%) 5.539.400 AXP AMER EXPRESS INC 56,65 $ 22:01 1,39 (2,39%) 19.254.700 BA BOEING CO 82,80 $ 22:02 1,06 (1,30%) 2.796.200 C 50,62 $ 22:02 0,71 (1,42%) 20.70 CAT CATERPILLAR INC 60,42 $ 22:01 1,42 (2,41%) 21.272.300 DD DU PONT E I DE NEM 45,45 $ 22:01 0,48 (1,07%) 3.709.500 DISWALT DISNEY-DISNEY C 31,28 $ 22:01 0,17 (0,54%) 8.290.900 GE GEN ELECTRIC CO 35,53 $ 22:01 0,06 (0,17%) 26.070.000 GMGEN MOTORS 35,19 $ 22:03 1,85 (5,55%) 17.704.100 HD HOME DEPOT INC 36,24 $ 22:02 0,25 (0,69%) 11.491.100 42,09 $ 22:01 0,39 (0,94%) 3.512.800 HPQ HEWLETT PACKARD CO 39,87 $ 22:01 0,49 (1,24%) 14.709.000 IBMINTL BUSINESS MACH 91,56 $ 22:00 1,08 (1,19%) 8.830.700 INTC INTEL CP 21,45 $ 22:01 0,12 (0,56%) 53.069.819 JNJJOHNSON AND JOHNS DC 69,10 $ 22:01 0,48 (0,70%) 8.879.00 JPM JP MORGAN CHASE CO 47,39 $ 22:03 0,27 (0,57%) 8.732.500 KO COCA COLA CO THE 47,28 $ 22:00 0,53 (1,13%) 15.032.700 MCD MCDONALDS CP 42,14 $ 22:01 0,67 (1,62%) 12.573.600 MMM 3M COMPANY 80,09 $ 22:02 1,62 (2,06%) 5.274.900 MOALTRIA GROUP INC 80,16 $ 22:00 0,49 (0,62%) 12.798.900 MRK MERCK CO INC 45,70 $ 22:00 0,06 (0,13%) 11.977.500 MSFT MICROSOFT CP 28,45 $ 22:01 0,02 (0,07%) 48.438.046 PFEPFIZER INC 27,73 $ 22:00 0,05 (0,18%) 30.796.500 PG PROCTER GAMBLE CO 63,28 $ 22:00 0,60 (0,96%) 7.295.900 T AT&T INC. 34,71 $ 22:01 0,27 (0,78%) 29.911.800 UTXUNITED TECH 64,98 $ 22:02 0,04 (0,06%) 2.529.800 VZ VERIZON COMMUN 38,02 $ 22:00 0,22 (0,58%) 9.716.900 WMT WAL MART STORES 51,28 $ 22:00 1,91 (3,87%) 52.321.600 XOM EXXON MOBIL CP 69,92 $ 22:01 0,37 (0,53%) 16.991.000 CITIGROUP INC HON HONEYWELL INTL INC Tabla 2.3 Componentes del Dow Jones Industrial 17 Nasdaq: el Nasdaq propiamente dicho no es un índice, sino el mercado electrónico más grande del mundo, también el primero. Sus negociaciones se realizan a través de un sofisticado sistema de computadoras y canales de telecomunicación. Por medio de esta tecnología se trasmiten cotizaciones en tiempo real y datos de transacción a más de 1,3 millones de usuarios en 83 países. El carecer de limitaciones geográficas hace que millones de participantes tengan acceso a negociar las acciones de una empresa. El Nasdaq Stock Market cubre dos tipos de mercado: El Nasdaq National Market, en el cual cotizan acciones de empresas con una mayor capitalización, y el Nasdaq Smallcap Market, en el cual cotizan los títulos de pequeñas empresas con capacidad de crecimiento. En la actualidad el Nasdaq cubre los títulos de alrededor de 4.100 empresas. La mayoría de estos títulos pertenecen al sector tecnológico, de las telecomunicaciones, banca, minoristas y otras industrias en crecimiento. Las negociaciones del Nasdaq no se limitan a un número específico de participantes lo que facilita la accesibilidad a las empresas de inversión conectarse a la red y competir. Otra característica peculiar es que no se obliga a los inversores a utilizar una sola entidad financiera para comprar y vender acciones, el Nasdaq conecta a una variedad de negociadores y deja que los participantes elijan con cual de ellos van a negociar. Para ello, estos negociadores deben tener una certificación de la Comisión de Valores de los Estados Unidos (SEC) y deben estar registradas de acuerdo a las regulaciones del Nasdaq y el NASD. En este existen varios índices que agrupa un número de empresas de ese mercado: El Nasdaq Composite en un índice de capitalización bursátil de funcionamiento similar al IBEX-35 , a diferencia del Dow Jones, que es un promedio de precios El Composite también representa una proporción, basada en la relación que existe entre el valor total de mercado de todas las acciones que conforman el índice hoy, y el valor total de las mismas el día que el índice empezó a funcionar. Para calcular el valor del índice, se divide el valor de mercado actual, esto es la suma de los precios por el total de acciones en circulación de cada 18 valor que cotiza en el índice y se divide entre el valor de mercado el primer día del índice. Nasdaq 100 Index Este índice incluye 100 de las empresas más grandes, locales e internacionales, que cotizan en el Nasdaq y que no pertenecen al sector financiero. Este índice refleja la evolución de empresas pertenecientes al sector de la informática, telecomunicaciones, minoristas / mayoristas y biotecnología. Las compañías pertenecientes al sector financiero, incluyendo las de inversión, no son consideradas en este índice. El Nasdaq 100 se calcula por medio de una metodología basada en el peso por capitalización. Nasdaq Financial-100 Index El Nasdaq Financial-100 mide la actividad de 100 de las mayores organizaciones financieras, tanto nacionales como internacionales, que cotizan en el Nasdaq. Al igual que los anteriores, este índice representa el peso de las empresas sobre la base de su capitalización e incluye instituciones pertenecientes al sector de banca, ahorros y casas matrices relacionadas, compañías de seguros, compañías de inversión y servicios financieros. Nikkei 225: índice que refleja desde el 16 de Mayo de 1949 y por iniciativa del periódico económico japonés Nihon Keizai Shinbun de cuyas iniciales toma el nombre, la evolución de los 225 principales valores que cotizan en la bolsa de Tokio. Su cálculo se basa en la suma de las cotizaciones de sus 225 compañías. La evolución del índice refleja la diferencia en porcentaje de la suma de las cotizaciones de un día frente a la del día anterior. No considera, por tanto, la capitalización de cada uno de los valores, como suele ser habitual en los índices de Bolsa. El hecho de que no se tenga en cuenta la capitalización y de que sea un índice apenas renovado (aunque la lista se renueva cada año) hizo que se lanzase el Nikkei 300, que ponderaba la capitalización bursátil y, por tanto, era más representativo. Sin embargo, este 19 nuevo índice, en el que tienen una mayor representación los bancos, no ha logrado el éxito esperado. Eurostoxx 50: se trata del índice más importante de las compañías de la zona euro. Los encargados de calcularlo son por la compañía Stoxx Limited, de la que son parte el grupo Deutsche Boerse (bolsa alemana), el grupo SWX (bolsa suiza) y Dow Jones & Company. Se trata de un índice ponderado por capitalización bursátil, pues las compañías con mayor capitalización tienen mas peso en el mismo. Se crea en febrero de 1998, partiendo de una base de 1000 puntos a 31 de diciembre de 1991. Para calcular el Eurostoxx 50 se utiliza una formula en la que se incluyen las 50 compañías que lo componen, se opera su capitalización bursátil, precio por numero de acciones, y se aplica un coeficiente de ajuste divisor, para asegurar que ciertas operaciones corporativas que se produzcan, no alteraran el valor del índice. Su composición se revisa una vez al año, en septiembre. Se ajusta por dividendos y por ciertas operaciones financieras en las compañías del índice, como ampliaciones de capital o escisiones. 20 Capítulo 3 Técnicas gráficas de inversión bursátil Se trata de uno de los instrumentos más útiles para determinar y predecir las oscilaciones de los precios bursátiles. Los gráficos tratan de adivinar cambios de tendencia y de anticiparse a esos cambios y se representan en un sistema de abcisas y ordenadas en donde aparecen la contratación y cotización de un valor durante períodos de tiempo, que el usuario con la aplicación de indicadores numéricos, que tratan de predecir la tendencia futura en función de lo ocurrido antes en el mercado, tales como: medias móviles, osciladores, indicadores de tendencia y otros. Así, puesto que el fin último de los gráficos es sacar conclusiones para poder anticiparnos a la tendencia futura, y por tanto, poder obrar correctamente, será interesante definir el más detalladamente el concepto de tendencia antes de entrar en los tipos de gráficos. 3.1) Tendencia La tendencia [ELACCIONISTA] es la dirección en la que se mueven los activos estudiados. La causa por la que existe la tendencia es el equilibrio entre la oferta y la demanda. Los activos nunca se moverán en línea recta, sino en zigzag, pudiendo moverse estos zigzags en tres direcciones distintas: alcista, bajista y horizontal. Tendencia alcista: Gráficamente una tendencia alcista se caracteriza porque los niveles máximos y los niveles mínimos formados por el movimiento zigzag, se superan unos a otros sucesivamente. Es síntoma de exceso de inversores comprando en el mercado Tendencia bajísta: Gráficamente una tendencia bajista se caracteriza porque los niveles máximos y los niveles mínimos formados en el movimiento zigzag, van descendiendo. Es síntoma de exceso de inversores vendiendo en el mercado. 21 Tendencia horizontal: Gráficamente una tendencia horizontal se caracteriza porque todos sus máximos se encuentran a los mismos niveles y lo mismo sucede con todos sus mínimos. Es síntoma de equilibrio entre los inversores que compran y los inversores que venden. Las tendencias pueden ser clasificadas en a largo plazo, a medio plazo y a corto plazo, siendo esta clasificación muy subjetiva. Normalmente se considera que una tendencia es a largo plazo si dura más de un año. Una tendencia es a medio plazo cuando dura más de un mes, pero menos de un año. Por úlitmo una tendencia a corto plazo va de una semana a un mes. Cada gráfica podrá tener unos puntos característicos. Así a los puntos máximos del zigzag estudiado se les da el nombre de resistencia y a los puntos mínimos se les da el nombre de soporte. Análogamente un soporte se forma cuando, a un nivel, existen en el mercado los suficientes compradores como para que la tendencia bajista del activo haga una pausa. Una resistencia se producirá cuando, a un nivel, existen en el mercado los suficientes vendedores como para que la tendencia alcista del activo haga una pausa. Las principales propiedades de los soportes y de las resistencias son: Los soportes y resistencias son señales de posibles cambios de tendencia. Si en la tendencia alcista o bajista de un activo, existe una resistencia o soporte que no se consigue superar, es factible un cambio de tendencia. Los soportes y resistencias pueden invertir sus funciones, cuando una resistencia es superada se convierte en un nivel de soporte y cuando un soporte es roto, se convierte en un nivel de resistencia. Los números redondos suelen actuar como soportes y resistencias siendo bastante común que números redondos como los terminados en 50 y 00 actúen como soportes y resistencias. Una formación asociada a las resistencias y a los soportes son los canales. Se dan cuando se pueden trazar líneas de soporte y resistencia que son paralelas o que estén muy cerca de serlo. Las formaciones de canal se pueden traducir tanto en tendencia alcista, como en una bajista y horizontal. Cuando en un 22 activo hay un canal, éste tiende a moverse dentro de él, tocando sucesivamente la línea de soporte y de resistencia. Su importancia radica en que dan señales claras de cuando hay posibilidad de entrar a comprar activos y cuando hay que vender los activos. 3.2) Tipos de gráficos [MILLARD91] 3.2.1) Gráficos lineales Se representa en el eje horizontal la escala de tiempos, y en el vertical la escala de precios, equivaliendo las divisiones de ambas escalas al mismo número de días o de variación de precio respectivamente. Luego se une el valor de cierre de las acciones mediante una línea continua. Su principal ventaja es su sencillez. Sin embargo no refleja la evolución de la acción durante la sesión, permite comparar cambios porcentuales fácilmente. Aunque para solucionar este problema se puede utilizar una escala semilogarítmica (esta solución también se podrá adoptar en los gráficos de barras que luego se mostrarán). Para la escala del tiempo se seguirá empleando una escala lineal, utilizando una logarítmica para lo de precios. De este modo la distancia que separa por ejemplo 100 y 200 puntos en el eje de precios es la misma que hay entre 200 y 400 puntos, por lo que el cambio porcentual permanece constante al subir por la escala vertical. Esto será muy ventajoso en el análisis de tendencias en los gráficos a largo plazo y principalmente para comparar dos inversiones. Sin embargo presenta el inconveniente de que el cero y los valores negativos carecen de significado. 23 Figura 3.1: Gráfico lineal del nivel del IBEX35 3.2.2) Gráficos de barra: Son lo más extendidos actualmente. Distinguiremos entre dos tipos, los tradicionales y una variación de estos que cobra fuerza como son los candlestick (gráficos de velas japonesas). En los tradicionales la evolución diaria de los precios de una acción se representa mediante una barra vertical que refleja la cotización máxima, mínima y el precio de cierre y el precio de apertura que ha registrado un determinado valor a lo largo de cada jornada bursátil. Para su construcción de este tipo se trazan dos ejes, en el eje de ordenadas se refleja la escala de precios del valor, y en el de abscisas las unidades de tiempo o fechas correspondientes. Una vez trazados estos ejes de coordenadas, se marcará el máximo y mínimo precios de un día determinado y unirlos mediante un trazo de barra vertical. El precio de cierre mediante un pequeño trazo horizontal hacia la derecha de la barra y análogamente el de apertura con un trazo a la izquierda. Para continuar la gráfica en el tiempo, basta con desplazarse una división en la escala horizontal de tiempos y repetir el proceso anterior. 24 Figura 3.2: Construcción de un gráfico de barras Se podrán añadir informaciones adicionales como el volumen y el interés abierto (no lo desarrollamos porque se utiliza sobre todo para la negociación de contratos de futuro de materias primas, divisas, productos energéticos). El volumen representa la actividad total desarrollada en cada sesión en torno a un valor, esto es el total negociado cada jornada. Puede expresarse en términos de número de acciones que cambian de mano, o en términos de volumen monetario negociado. En ambos casos la representación gráfica de este dato se realiza trazando una línea vertical debajo de la barra diaria de precios. La dimensión de la barra de volumen es proporcional a al cantidad de acciones negociadas. Así, una barra más larga representa una mayor actividad negociadora. 25 Figura 3.3: Gráfico de barras con información del volumen negociado Por su parte los candlestick o gráficos de velas japonesas están en pleno auge desde que se empezaron a usar para gráficos bursátiles hace unas dos décadas. Sin embargo se llevan empleando desde antes del año 1700 en Japón para predecir el precio del arroz [ELACCIONISTA]. Para su construcción al igual que para los gráficos de barras se necesitarán el precio de apertura, el de cierre, el valor máximo alcanzado y el mínimo. Sin embargo los candlestick presentan un cuerpo entre el rango de apertura y de cierre. Si el cuerpo es negro representa que el cierre fue más bajo que la apertura, (normalmente tendencia bajista) y si el cuerpo es blanco significa que el cierre fue más alto que la apertura (normalmente tendencia alcista). Las líneas verticales delgadas por encima y por debajo del cuerpo se denominan sombras y representa el precio máximo alcanzado y el mínimo respectivamente. 26 (a) (b) Figura 3.4: Dos “candlestick” de cierre mayor que apertura (a) y de cierre menor que apertura (b) Se puede dar el caso que un gráfico no presente cuerpo en el caso de que el valor de apertura y de cierre sea el mismo o muy parecido, en cuyo caso la longitud de la línea vertical determinará la diferencia de valores alcanzados por la acción. Los modelos de reversión de velas dentro del contexto del mercado anterior nos pueden ayudar a identificar un cambio en la tendencia, aunque también es posible que el mercado decida flotar lateralmente. Es importante remarcar que una vela por si misma carece de significado se deben estudiar siempre con relación a una tendencia definida, de forma que una misma vela puede tener significado diferente dependiendo del contexto. Las formaciones más habituales son: Martillo (hammer): vela con una sombra más baja larga y el cuerpo real pequeño. El cuerpo puede ser negro o blanco, pero la condición fundamental es que esta vela aparezca en una tendencia a la baja o en un mercado sobrevendido. No será muy significativo si aparece en ligera bajada o en una bajada de dos o tres días. Se puede dar una venta en la subida desde el martillo, entonces el mercado irá a probar el soporte realizado por el martillo. Cuanto más larga la sombra más fiabilidad tendrá la figura. 27 Figura 3.5: Martillo (hammer) Martillo invertido (invertded hammer): se asemeja a una estrella fugaz. En Una tendencia bajista puede ser una reversión señalada no siendo dominante el color crítico Figura 3.6: Martillo invertido (invertid hammer) Hombre colgado (hanging man): aparentemente igual al martillo, pero se da en el contexto de una tendencia alcista. Cuerpo real pequeño, blanco o negro y sombra inferior muy larga. Para confirmar la reversión bajista observaremos el cierre de la sesión siguiente, si éste está por debajo del cuerpo real del hombre colgado significa que todo aquel que compró en la apertura o el cierre del hombre colgado está ahora perdiendo dinero. Con este panorama los compradores lo normal es que decidan liquidar, arrastrando así al mercado a la baja 28 Figura 3.7. Hombre colgado (hanging man) Estrella fugaz: se caracteriza por un cuerpo real pequeño cerca del extremo más bajo del rango, con una sombra superior larga. El color del cuerpo no es crítico. No es tanto una señal de la reversión mayor, sino una advertencia. Tiene una sombra superior larga y un cuerpo real pequeño y situado cerca del extremo inferior de la banda de fluctuación Figura 3.8. Estrella fugaz seguida de martillo Envolvente alcista (Engulfing Patterns): constará de dos velas y se forma cuando, durante una tendencia bajista, un cuerpo real blanco envuelve a uno 29 negro. La definición básica de una pauta envolvente es que el segundo cuerpo real debe envolver un cuerpo real de distinto color. Su efecto es mayor si la primera vela es más pequeña y el cuerpo de la segunda vela es mayor y envuelve por completo a la anterior incluyendo las sombras o lo que es lo mismo tiene un mínimo por debajo y un máximo por encima de la vela anterior. Figura 3.9. Envolvente alcista Envolvente bajista (Bearish): constará de dos velas. La alcista se forma cuando, durante una tendencia alcista, un cuerpo real negro envuelve a uno blanco. 30 Figura 3.10. Envolvente bajista Nube oscura (Dark Cloud Cover) es síntoma de que el mercado tiene pocas oportunidades de subir. La primera vela de la cubierta de nube oscura es una sesión blanca fuerte. En la siguiente sesión el mercado abre por encima pero cae, cerrando por debajo del centro de la sesión anterior. Cuanto más abajo cierre mayor será la tendencia bajista y si cierra por encima de la mitad muchos operadores esperarán a la siguiente sesión, donde si los precios cierran por debajo, entonces se confirmará la tendencia bajista. Sin embargo esta tendencia será menor que en la envolvente bajista. 31 Figura 3.11. Nube Oscura (Dark Cloud Cover) Pauta penetrante (Piercing pattern): es el fenómeno opuesto a la cubierta de nube oscura. Se da en una tendencia bajista, cuando la primera vela tiene un cuerpo negro y la segunda tiene un cuerpo largo y blanco. Este último día abre con bajadas pronunciadas, por debajo del mínimo del día negro anterior. Sin embargo el precio de cierre estará sobre el 50% del cuerpo negro del día anterior. Es menos alcista que la envolvente alcista (Ver figura 3.10 donde se aprecia una pauta penetrante) Harami: el harami está formado por un cuerpo real largo y otro corto dentro de su banda. El harami es el fenómeno opuesto a la pauta envolvente. El harami es un cuerpo muy largo seguido de un cuerpo real pequeño. El color no es crítico, sin embargo tras una tendencia bajista, un harami negro-blanco o blanco-blanco se considerará más alcista que uno negro-blanco o negro-negro. Esto se debe a que una vela blanca larga se considera alcista por si misma, con lo que tiende a contrarrestar la tendencia bajista del mercado. Para comprobar la fiabilidad de la figura se comprobará: a) Si el segundo cuerpo real se encuentra hacia el medio de la banda de fluctuación del primer cuerpo real. Si después de una subida, el segundo 32 cuerpo real del harami está cerca del extremo superior del primer cuerpo real, lo más probable es que el mercado fluctúe de forma lateral . Si está abajo es más probable que gire. b) Si la banda completa del cuerpo real y sombras están dentro del cuerpo real previo, es más probable que el mercado gire. c) Cuanto más corto sea el cuerpo real y las sombras de las egunda vela más nos acercamos al caso óptimo, esto es, un doji. Figura 3.12. Harami Estrellas: consisten en un cuerpo real pequeño que abre con gap del cuerpo real que lo precede. El cuerpo real de la estrella no solapará el cuerpo real anterior estrella no siendo crítico el color. Se suelen dar en cimas y fondos. 33 Figura 3.13. Estrella Lucero del Alba (morning star): nos indica una reversión de la tendencia alcistas . La formación estará formada de 3 velas. La primera vela es negra con el cuerpo real alto, la segunda, con un cuerpo real pequeño que abre en gap. La tercera vela es un cuerpo real blanco que pasa al cuerpo de la primera vela negra de la formación. Figura 3.14. Lucero del alba (morning star) Estrellas Doji (Doji Stars): Si un doji abre con gap sobre un cuerpo real en una tendencia al alza, o con gap bajo un cuerpo real en un mercado bajista, ese doji en particular se llama una estrella doji. Dos estrellas doji populares son la estrella de la tarde y la mañana.. 34 Figura 3.15 Estrellas Doji Estrella Doji de la mañana (Morning doji star): se trata de una estrella del tipo doji en una tendencia bajista seguida por un cuerpo real largo, blanco que cierra en el cuerpo negro anterior. Si la vela después de la estrella del doji es negra y con gaps a la baja entonces el doji no es válido Figura 3.16. Mañana doji star 35 Estrella vespertina (Evening Star): Se compone de tres velas, la primera vela es blanca y larga, la segunda tiene un cuerpo real pequeño de cualquier color, donde el primer cuerpo y el segundo no se tocan, la tercera vela es un cuerpo real negro que normalmente no toca al segundo cuerpo y además cierra dentro de la linea de la vela blanca que constituye la primera vela de esta pauta. Si la segunda vela en vez de ser un cuerpo real pequeño es un doji, esta formación será una doji vespertina . Figura 3.17. Estrella vespertina (Evening Star) Estrella doji de la tarde (Doji Star Evening) Se da cuando aparece una estrella doji en una tendencia alcista, seguida por un cuerpo real largo, negro que cierra el cuerpo real blanco precedente . Si la vela después de la estrella doji es blanca y presenta un gap más alto, la reversión a la baja del doji no es válida. 36 Figura 3.18. Estrella Doji de la tarde 3.2.3) Gráficos de punto y cifra: Populares sobre todo en Estados Unidos. Se caracterizan porque si el precio no cambia no se registra ningún punto en el gráfico, por lo que son una buena medida de la volatilidad de un valor. Tienen una escala vertical lineal, pero en lugar de que una línea horizontal corresponda al precio, éste será el hueco entre las líneas. Se caracterizan además por tener otro valor cuantitativo, la inversión de recuadro. El valor más habitual es la inversión de tres recuadros, pero el valor puede ser cualquiera desde un recuadro para arriba. Cuanto mayor sea el número de recuadros menos sensible será el gráfico a la variación en el precio. Por convenio se suelen usar “X” para precio al alza y “O” para un precio a la baja 37 Figura 3.19. Gráfico de punto y cifra 3.2.4) Gráficos de subida-bajada Tienen un eje temporal pero carecen de eje precio. El eje vertical es un indicador del sentido y sus divisiones son una medida de cuanto tiempo ha continuado la evolución del precio de la acción en un sentido. No tiene en cuenta la cuantía de la subida o bajada, sólo el mero hecho de la subida o bajada. Es por esto que es un gráfico muy útil para determinar los cambios de sentido del precio de la acción. 3.3) Indicadores técnicos Se trata de un conjunto de técnicas complementarias a las gráficas presentadas en apartados anteriores. Suelen ser cantidades numéricas calculadas a partir del precio de la acción o de otros datos como el número de acciones que suben o bajan en el periodo de tiempo estudiado y otros incluso no requieren cálculo alguno. El objetivo de este conjunto de técnicas será poner de manifiesto la tendencia real de la acción, eliminando en la medida de lo posible aquellos fenómenos que podrían dificultar la interpretación de la evolución de la acción, y además poder hacer predicciones acerca del comportamiento futuro de dicha acción y del mercado. Se pueden distinguir 38 básicamente dos tipos de indicadores técnicos, los promedios móviles y los osciladores. 3.3.1) Medias móviles Media móvil simple: se trata de una técnica básica de análisis bursátil y de ella se derivan otros indicadores y conceptos de uso frecuente. Es una media de los precios de cierre de n días, que se va recalculando a medida que se van incorporando nuevas cotizaciones manteniendo para el cálculo de forma constante el mismo número de cierres que indica el periodo. Así las expresiones que se tienen para su cálculo son: MediaMóvil p1 p 2 ..... p n n MediaMóvil hoy MediaMóvil ayer p1 p n1 n n Hay varios valores tradicionalmente extendidos para n, tales como 10, 40 o 200 días dependiendo si queremos analizar a corto, a medio o a largo plazo, aunque en cualquier caso esto es muy subjetivo. En cualquier caso los valores obtenidos se interpretarán como un soporte en un mercado alcista, y como una resistencia en un mercado bajista. Con todo esto se interpreta que la función de dicha media es suavizar la serie de datos sobre la que se calcula, permitiendo observar de forma más clara la dirección actual, esto es, la tendencia. Una interesante propiedad de la media móvil simple será, que en el caso que la acción estudiada tenga una fluctuación periódica, si tomamos un n suficientemente grande, dicha variación será eliminada. Sin embargo este método presenta la desventaja de que su valor puede depender demasiado de antiguos valores, siendo en este caso más adecuado el uso de las medias ponderadas o exponenciales. Este método nos permite crear sistemas automáticos de gestión de acciones, así se generarán señales de compra si los precios cortan al alza el valor de la 39 media móvil. Sin embargo si cortan a la baja dicha media se generarán señales de venta. Media móvil ponderada: se trata de una técnica que deriva de la media móvil simple, sin embargo se da progresivamente más importancia a los últimos datos obtenidos frente a los primeros. Así se multiplica cada cierre por un peso que desciende de manera progresiva, aplicándose el mayor peso al cierre más próximo. Tiene propiedades similares a la media móvil simple, sin embargo se ajusta más a la serie de precios al otorgar más importancia a los cierres más recientes y por tanto es más sensible a los movimientos en sus cercanías. Se deberá tener cuidado al aplicarse en mercados planos o sin tendencia pues generará una gran cantidad de señales falsas. Las expresiones con las que se obtiene son: MediaMóvilPonderada n p1 n 1 p 2 ...... 2 p n 1 p n n (n 1) ........ 2 1 Para ir calculándola en días sucesivos: Total hoy Total ayer p1 p n 1 Numeradorhoy Numeradorayer np1 Total ayer MediaMóvilPonderada hoy Numeradorhoy n (n 1) .... 2 1 Media móvil exponencial: se trata de un indicador que se deriva de la media móvil simple en un intento de otorgar importancia progresiva a las cotizaciones más recientes utilizando un sistema de ponderación o suavizado exponencial, y que tiene en cuenta todos los datos de la serie. El periodo se utilizar para calcular el factor de suavizado, de forma que si el periodo es P, el factor de suavizado será demás tiene características similares a las 2 . Por lo P 1 medias móviles anteriormente presentadas. Las expresiones son: 40 MediaMóvil exp onencial p1 (1 ) p 2 (1 ) 2 p3 .... 1 (1 ) (1 ) 2 .... MediaMóvil exp onencial hoy p (1 ) MediaMóvil exp onencial ayer Bandas de Bollinger: es un indicador inventado por John Bollinger en los años 80. A partir de una de las medias móviles anteriormente explicadas sobre el precio de cierre se trazan dos bandas que se obtienen de sumar y restar a la media un numero n de desviaciones estándar. Los valores que se suelen usar habitualmente son 21 para la media y dos n=2 para las desviaciones estándar, y aunque estos valores no son fijos, si debemos guardar una proporción entre los valores de la media y de las desviaciones. Así para una media de 50 valores (largo plazo) tomaremos n=2.5, mientras que para 10 valores (corto plazo) n=1.5. Con dichas bandas conseguimos ubicar el precio de la acción en relación a sus valores pasados, determinar la volatilidad de una acción y establecer niveles de precios, identificando cuando nos podemos encontrar en una resistencia y cuando en un soporte. Así un valor que se encuentra por encima de la media y próximo a la banda superior es muy posible que se encuentre sobrecomprado y si llega a superar dicha banda es síntoma de fortaleza, y por el contrario si esta por debajo de la media y próximo a la banda inferior se encontrará sobrevendido, siendo síntoma de debilidad que baje por debajo de dicha banda. Por su parte la amplitud de las bandas nos informará de la volatilidad de la acción. 3.3.2) Osciladores Los osciladores son modelos matemáticos aplicados a la acción del precio, basados en alguna observación específica sobre el comportamiento del mercado. Normalmente se grafican por debajo de la gráfica de cotizaciones, ya sea como líneas o histogramas, y miden la fortaleza de las tendencias o movimientos en el precio. Cuando se detecta debilidad en la tendencia, se sospecha que podría estar cerca de revertirse. Así los osciladores cobran 41 especial importancia cuando las medias móviles más problemas tienen, esto es, en mercados planos o sin una tendencia clara aparente. Momento: es un oscilador que estudia la variación absoluta entre dos cierres en un periodo determinado. Por su construcción lleva implícito el concepto de velocidad de aceleración, por lo que trata de adelantarse a los giros que se producirán. Con esto conseguimos saber con que fuerza sube o baja la cotización de un valor, que puede ser ascendente o descendente y acelerando o desacelerando respectivamente. Se trata de un valor no normalizado, por lo que lo importante no es su valor, si no su dirección y sentido. Viene dado por las expresiones: Momento Cierre hoy Cierre n diasantes También se define el índice de cambio como: Indicedecambio Cierrehoy Cierren diasantes Cierren diasantes Índice de Fuerza Relativa (RSI): Se trata del indicador técnico más extendido creado por Welles Wilder y publicado por primera vez en 1978. Su nombre no es del todo apropiado, pues dicha fuerza relativa no se calcula respecto a otros valores o índices, sino respecto a sí mismo. Tiene una presentación lineal y normalizada, independiente de la acción o índice que se utilice. Este indicador agrupa los precios en precios ascendentes y precios descendentes, soliendo elegirse periodos de 14 días. Para obtener la cantidad que llamaremos arriba se suman todas las subidas de precio. Para la cantidad abajo sumamos toas las bajadas de precio durante el mismo periodo y operamos: Welles Wilder 100 100 arriba 1 abajo 42 Su valor estará siempre entre 0 y 100. Es resistente a las fluctuaciones a corto plazo pues los términos arriba y abajo ya van promediados. Así si el valor sube por encima de 70 se considera que se está sobrecomprando mientras que por debajo de 30 se esta sobrevendiendo. Es además un indicador anticipado, da la señal antes de que el precio de la acción cambie de sentido, en contraposición a la media móvil que da la señal cuando la acción ya ha cambiado de sentido Oscilador Estocástico: es un indicador desarrollado por George Lane en los años 50 compuesto por dos líneas que se conocen como %K y %D. Esta basado en la observación de que cuando los precios suben el pecio de cierre se aproxima más a los máximos del día, y cuando los precios bajan el precio de cierre se encuentra más cercano a los mínimos de la sesión. Así trata de establecer en % como está el precio de cierre de la sesión respecto al rango de precios del periodo de cálculo. El indicador tiene funcionalidad cuando los valores no se encuentran en tendencias fuertes y se emplea para determinar los distintos zig-zags en los que se van moviendo los precios, y proporcionar señales de compra y venta. Es un indicador normalizado que se mueve dentro de una escala de 0 a 100 y presenta dos áreas o niveles que adquieren especial importancia cuando son alcanzadas por el indicador. Estas áreas o niveles son entre 0 y 20 y entre 80 y 100. A veces según preferencias se amplían estos límites hasta 30 y hasta 70, siendo estas las áreas de sobreventa y sobrecompra respectivamente. Los parámetros por defecto que se utilizan son 14 para %K y 7 para %D, en donde 14 es el periodo en días que se toma de referencia para los cálculos y 7 para calcular la versión allanada de %K. El indicador proporciona señal de compra cuando se produce un corte de la línea %K por encima de %D en la zona de sobreventa 0-20(30). El indicador activa una señal de venta cuando se produce un corte de la línea %K por debajo de %D en la zona de sobrecompra (70) 80-100. También se utiliza mucho para el análisis de 43 divergencias. Sus cortes de líneas siempre marcan un cambio de dirección en los precios, el problema estrjoiba en que no es posible cuantificar la amplitud del movimiento. Se obtiene con las expresiones: %K Cierrehoy Cierremasbajo n dias Cierremasalto n dias Cierremasbajo n dias Por su parte %D es la media móvil simple de 3 días de K MACD: Convergencia/Divergencia de medias móviles, Se trata de un indicador basado en la diferencia de amplitud de dos medias exponenciales de diferente periodo a la que se aplica una nueva media exponencial creado por Gerard Appel y que posteriormente fue desarrollado por Tomas Aspray. Se componen de dos líneas que oscilan alrededor de la línea de 0, la primera de ellas es la diferencia entre las dos medias móviles y la segunda es la media móvil exponencial de la diferencia. A la media móvil exponencial de la diferencia se la conoce como línea de señal. A veces se grafica también la diferencia entre estas dos líneas en el mismo gráfico en forma de histograma. Como otros indicadores basados en las medias móviles su utilidad es la de proporcionar señales de compra y venta cuando el mercado está en tendencia. Permite encontrar divergencias entre el oscilador y el gráfico de precios y también marcar momentos o niveles de sobrecompra o sobreventa. Los valores por defecto de los periodos de las medias que se utilizan para el cálculo son 12 para la media exponencial rápida, 26 para la media exponencial lenta y 9 para la media exponencial de la diferencia. Los cruces de las dos líneas son las que marcan las compras y las ventas. Si el MACD cruza a la línea de señal al alza, es posible el inicio de un movimiento al alza y se activa una compra. Si el MACD cruza la línea de señal a la baja, se incrementa la posibilidad del inicio de un movimiento a la baja y se activa una venta. 44 Capítulo 4 Parámetros bursátiles 4.1) Volatilidad La volatilidad [MERCADOS04] se puede definir como la desviación estándar del cambio en el valor de un instrumento financiero con un horizonte temporal determinado. Se usa con frecuencia para cuantificar el riesgo del instrumento a lo largo de dicho período temporal. La volatilidad se expresa típicamente en términos anualizados. Así la volatilidad se incrementa según la raíz cuadrada del tiempo conforme aumenta el tiempo. Esto se debe a que existe una probabilidad creciente de que el precio del instrumento esté más alejado del precio inicial conforme el tiempo aumenta. Matemáticamente se podrá expresar como: (R n 1 i R) 2 n Donde: Ri es el rendimiento activo R es el promedio de rendimientos n es el número de datos o observaciones Para evitar errores derivados de una tasa de variación constante, y para simplificar los cálculos se suele usar la expresión, que asume que el rendimiento medio es cero, por lo que la medida de la volatilidad vendrá dada por la distancia de cada uno de los rendimientos hasta cero: Ri2 n Por su parte para convertir en anual obtenida a partir de datos diarios multiplicaremos la desviación típica por la raíz cuadrada del número de observaciones 45 AÑO DIA 252 (Teniendo en cuenta 252 sesiones anuales) AÑO SEMANA 52 4.1.1) Técnicas para predecir la volatilidad Tenemos dos grandes familias de métodos [MEDIDAS 93], por un lado están las técnicas fundamentales y por otro aquellas basadas en comportamientos históricos. a) Técnicas fundamentales También denominadas volatilidad implícita se basan en descubrir y analizar de dónde proviene en términos económicos la volatilidad. Así el valor de las acciones viene determinado por el valor actual de los flujos de caja que esperamos recibir en un futuro: V CFn Vn CF1 ......... 1 r (1 r ) n Siendo CFn la caja que genera la empresa cada año n y Vn el valor residual de la empresa en el año n. A su vez r, esto es, la tasa de descuento, dependerá de: Los tipos de interés al plazo adecuado La estructura financiera del balance de la empresa (a mayor apalancamiento, mayor tasa de descuento) Riesgo del negocio: a mayor incertidumbre, mayor tasa de descuento En resumen la incertidumbre en el precio de las acciones vendrá de: La percepción del riesgo del negocio La evolución de la estructura financiera de la empresa La estimación de los flujos de caja La tasa de descuento Por tanto inferir valores de la volatilidad, será estimar como van a evolucionar los cambios de todas estas variables. 46 B) Técnicas basadas en comportamientos pasados b1) Volatilidad histórica Se trata de una de las técnicas más usadas en los mercados, y consiste en tomar una muestra de datos (20, 60, 120 sesiones) e inferir como volatilidad futura, la de la ventana elegida. Esta técnica toma la hipótesis de que la varianza del rendimiento de las acciones no depende del tiempo, si no que se mantiene constante. Sin embargo frente a su sencillez presenta inconvenientes tales como la distorsión producida por construir la volatilidad como un promedio de distancias o también la cantidad de observaciones a tomar. En el caso concreto del IBEX-35 parece que lo más adecuado es tomar una muestra de 365 días, teniendo en cuenta también los días festivos, pues según el estudio de Fernández e Yzaguirre, los cambios que se producen el lunes reflejan el cambio de tres días, y no sólo de uno. Otro de los problemas que presenta esta técnica es que da el mismo valor a las últimas observaciones tomadas que a las primeras, pudiendo solucionar esto mediante la volatilidad histórica ponderada. b2) Volatilidad histórica ponderada Con esta técnica conseguimos dar más peso a las observaciones más recientes en detrimento de las observaciones más anticuadas. La expresión matemática de esta técnica será: n t t 1 n t 1 Rt2 t El valor de λ debe ser inferior a uno, y en el caso que n sea muy grande se puede aproximar por: n t 1 t ( 2 ........ n ) 1 1 b3) Volatilidades históricas ponderadas por los precios de cierre, los precios máximos y los mínimos diarios 47 La principal ventaja que presentan estas técnicas es que las anteriores sólo tienen en consideración los precios de cierre de los activos, sin embargo, los precios máximos y mínimos alcanzados durante la sesión nos darán pistas sobre el futuro de la volatilidad. La utilidad de este tipo de volatilidad reside en que permite captar los momentos puntuales de mayor movimiento en precio, que suelen venir reflejados en cambios bruscos en las volatilidades implícitas negociadas dentro del mismo día. Las diferentes expresiones con las que calcular dichas volatilidades son: n 1 n t 1 Alto t ln Bajo t 4 ln 2 2 1 n Altot ln n t 1 Bajot Cierret ln Bajot 2 ln 2 1 Alto 1 2 ln Bajot t Cierret (2 ln 2 1) ln Apertura t n 2 b4) Volatilidades ARCH Y GARCH ARCH Y GARCH son acrónimos respectivamente de heterocedasticidad condicional autoregresiva y heterocedasticidad condicional autoregresiva generalizada. Estos modelos consisten en asumir que los rendimientos de los activos financieros oscilan alrededor de una media según una distribución de probabilidad Normal con media cero, y varianza la volatilidad de dichos rendimientos, por lo que se toma la hipótesis de que el rendimiento futuro de un activo es puramente aleatorio. Esto se expresa mediante las expresiones: Rt R t donde t N (0, t ) 48 Recurriendo a la definición primera de volatilidad la distancia de cada punto a la media será la perturbación ε por lo que se podrá definir la varianza histórica como: t2 1 t21 t2 2 ........ t2 n n Por su parte el modelo GARCH hará depender la varianza en un instante dado de un término constante 0 , de la distancia del último rendimiento a la media t21 y de la varianza histórica de los periodos anteriores t21 según la expresión: t2 0 1 t21 2 t21 Los coeficientes se obtendrán mediante técnicas econométricas tales como la de Máxima Verosimilitud a partir de datos históricos, por lo que podremos cuantificar en que medida la varianza futura depende de la pasada. 4.2) La correlación. Aplicación a los mercados financieros. Se expresa numéricamente mediante el coeficiente ρ y es una medida de la intensidad de la asociación de dos variables, en este caso entre dos acciones o índices bursátiles. La asociación que mostrará entre las dos variables será la relación lineal existente entre ellas. El valor obtenido del análisis deberá estar comprendido entre [-1,1], de forma que cuanto más próximo este dicho coeficiente a -1 ó 1 se explicará en mayor medida el movimiento de una acción por el movimiento de la otra. Sin embargo si dicho valor es cero o un valor muy próximo podremos concluir que apenas si hay relación lineal entre las variables estudiadas. Por su parte el signo de dicho coeficiente nos indica el sentido de la relación, esto es, será de signo positivo si el valor de ambas variables crece a la vez, y de signo negativo si cuando una variable crece la otra decrece. Para el cálculo matemático de dicho coeficiente es muy recomendable partir de un diagrama de dispersión que represente las variables en un mapa cartesiano, y que indicará a simple vista si tiene sentido el cálculo de dicho coeficiente o si por el contrario los valores no parecen presentar ningún orden definido. 49 Figura 4.1: Diagrama de dispersión. Indica una posible relación lineal La fórmula que relacionará las dos series financieras será: ( x, y ) cov( x, y ) donde cov( x, y ) E x E ( x) y E ( y ) x y 4.3) Riesgo de una cartera y estrategias de gestión. 4.3.1) Riesgo Se trata de uno de los campos donde más útil resulta el estudio de las correlaciones entre varias acciones. Por cartera entendemos el conjunto de acciones de diferentes títulos que posee un sujeto. Así mientras el riesgo de un solo título viene dado por la varianza de sus rendimientos, de forma análoga, el riesgo de una cartera será la varianza de los rendimientos de dicha cartera, viniendo dado el peso que representa cada título sobre el total de la cartera por wi : c2 E Rc Rc E wi ri wi ri E wi (ri ri ) 2 2 2 Y generalizando para una cartera de n acciones: 50 n n c2 wi w j ij i 1 j 1 Los diferentes casos que se nos presentarán en función del valor del coeficiente de correlación: Correlación perfecta y positiva entre los activos (ρ=1): el riesgo de la cartera es una media ponderada del riesgo de los dos activos y por tanto es imposible reducir el riesgo por debajo de aquel que lo tenga menor Correlación perfecta y negativa entre los activos (ρ=-1): en este caso podremos encontrar incluso una cartera con riesgo nulo jugando con los pesos de cada acción. Correlación no perfecta entre los activos (ρ≠1,-1): oscilaremos entre el máximo riesgo obtenido en caso de correlación perfecta y el nulo. 4.3.2) Estrategias de gestión de carteras Existen dos estrategias contrapuestas de gestión de carteras [JOURFIN93]: Las estrategias contrarias de gestión de carteras Las estrategias basadas en los beneficios pasados o en índices de fuerza relativa. Ambas estrategias son contrapuestas, pero ambas se pueden aplicar con resultados beneficiosos, dependiendo del periodo de tiempo pasado en el que analicemos el comportamiento de la acción, y del tiempo durante el que mantengamos la estrategia desde la formación de la cartera. Por un lado las estrategias contrarias se basan en comprar acciones “perdedoras” o cuyo comportamiento no ha sido bueno en el pasado y vender títulos “ganadores” que han tenido unos buenos rendimientos en el pasado”. Los periodos adecuados para la aplicación de dicha estrategia parecen ser o a muy largo plazo, comprando acciones con rendimientos pobres en los últimos 3-5 años que se comportarán favorablemente en los siguientes 3-5 años, o por el contrario a corto plazo, con acciones cuyo comportamiento no haya sido satisfactorio en la última semana o mes, y manteniéndolas durante un mes o una semana. 51 La otra familia de tácticas son aquellas basadas en la inercia o en la fuerza relativa, con ejemplos tales como los dados en los rankings elaborados por Value Line o por los fondos de inversión de Grinblatt y Titman. Estas estrategias basadas en comprar acciones que en pasado tuvieron beneficios o “ganadores” o como sostiene Levy, aquellas acciones cuyos precios actuales sean sustancialmente más altos que la media de las últimas 27 semanas, vendiendo aquellas que menos beneficios han producido. Éstas técnicas producen beneficios especialmente en periodos que van de 3 a 12 meses desde la creación de la cartera. Sin embargo dichos beneficios se desvanecen en los siguientes dos años. Un punto importante para unos resultados precisos es dejar una semana entre la formación de la cartera y el comienzo del estudio de la misma, para evitar el efecto de la oferta-demanda, la presión del precio y reacciones retrasadas del precio de la acción a algunos factores. El por qué dos estrategias antagónicas pueden producir igualmente beneficios se explica por: Los beneficios actuales no se deben a los beneficios obtenidos en el pasado o que estos tienden al engaño. Diferencia que se da en las estrategias contrarias entre los periodos de tiempo recomendados en la teoría y los que se usan en la práctica. Tienen rangos de aplicación muy diferentes, mientras que aquellas estrategias basadas en beneficios pasados son principalmente aplicadas en periodos de 3-12 meses, las estrategias contrarias se usan en rangos tan dispares Un aspecto importante es la influencia de la información sobre el precio de las acciones. Si dichos precios tienden a reaccionar en demasía o si por el contrario no reaccionan, en ese caso las técnicas basadas en las ganancias pasadas tendrán sentido. Una aplicación de esta técnica se presenta en este artículo, ordenando las acciones que componen la cartera cada principio de mes en orden ascendente, de manera que cada principio de mes variamos la composición de nuestra cartera comprando aquellas acciones que se consideran “ganadoras” y vendiendo aquellas de resultados más pobres. 52 A pesar de que el propósito fundamental del proyecto no es la elaboración de estrategias futuras de gestión de carteras, sino la representación simplificada de las acciones en base a unos atributos determinados, si nos puede servir como apoyo para trazar dichas estrategias gracias a la representación de la rentabilidad de las acciones en los mapas teniendo en cuenta el periodo de análisis. En primer lugar deberemos elegir la técnica con la que trabajar, o bien una basada en la fuerza relativa o una estrategia contraria. Si nos decantamos por la de fuerza relativa deberemos representar los datos de rentabilidad de las últimas 27 semanas, resultando interesantes aquellas acciones cuya rentabilidad haya sido mayor en dicho periodo, y vendiendo las que peores resultados obtengan. Si por el contrario elegimos una estrategia contraria, deberemos decidir también si queremos resultados a muy corto, corto o largo plazo, para representar los datos de una semana, un mes o 3-5 años respectivamente, resultando interesantes aquellas acciones que hayan tenido peor comportamiento, y desprendiéndonos de aquellas que mayor crecimiento hayan tenido. 4.4) Creación de valor La creación de valor vendrá dada por la diferencia entre aquellos factores que suponen un beneficio para el accionista, menos aquellos asociados al riesgo asumido y a la oportunidad perdida, siendo estos: Rentabilidad de los activos de renta fija. Prima de riesgo del mercado. La beta: coeficiente que compara el riesgo sistemático de un valor, medido por su volatilidad, frente al mercado. Por su parte aquellos factores que suponen un beneficio para el accionista serán principalmente: Revalorización bursátil Los dividendos pagados Las ampliaciones y amortizaciones de capital. 53 Sin embargo hay que matizar varios aspectos. Uno de ellos es que en muchas ocasiones, y con más incidencia en los últimos tiempos, la creación de valor se origina a partir de la existencia de una OPA. Sin embargo es dudoso que este modelo sea sostenible. Las soluciones para cuantificar este hecho serían por un lado un estudio en el que lo más importante fuera la tendencia, frente a un valor puntual y por otro establecer algún tipo de coeficiente que penalizase el crecimiento mediante este procedimiento. Otros hechos muy a tener en cuenta son el reparto de dividendos. Frente a otros factores tales como el atractivo de los negocios, el éxito de las operaciones de expansión, la fortaleza de las cuentas de resultados o una saneada estructura de balance, se aprecia en mayor medida el reparto de dividendos. Esto se debe a que: Se suele relacionar con la capacidad de la empresa de obtener beneficios estables y sostenibles. Supone un retorno seguro de la inversión. Sirve para alimentar el interés del mercado, lo que favorece su revalorización y por tanto la creación de riqueza, independientemente de que el ciclo bursátil sea bueno o malo. Por todo esto puede ser interesante, que en el caso de aquellas empresas en las que se compruebe que habitualmente suelen repartir dividendos bonificarlas mediante un coeficiente. Además es interesante comparar el ciclo bursátil de referencia con el tipo de valor estudiado. Así se denominarán blue chips a los valores estrella de cualquier mercado, siendo grandes empresas con balances saneados y que al margen de sus beneficios puedan fluctuar con el ciclo económico, sin riesgo financiero. Por el contrario los “chicharros” son valores de baja calidad, los pequeños muy manipulados e incluso empresas con situaciones financieras muy delicadas, con los que se especula ferozmente. Según varios estudios, los blue chips en periodos bajistas destruyen mucho valor para el accionista, puesto que suelen recortar el reparto de dividendos y se vuelven más volátiles. Sin embargo en periodos alcistas su comportamiento es muy potente creando riqueza. Otro tipo de compañías son aquellas que son muy constantes creando 54 valor para el accionista. Se comportan mejor en periodos irregulares, pero no se puede esperar de ellas repuntes de rentabilidad. 4.5) Volumen bursátil Se puede definir el volumen como el número de contratos casados, durante una sesión o una semana. Dado que para que se efectúe una compra, es necesario que alguien venda, al final de cada sesión el número de contratos comprados tiene que ser igual al de contratos vendidos. Por su parte se puede definir el volumen monetario negociado, como el número de contratos de compra venta, por el precio al que se han firmado. La importancia del volumen, además de por ser un indicador del grado de actividad bursátil, viene dada porque puede ser utilizado como un elemento de análisis para definir el grado de fortaleza de las tendencias que siguen los precios de las acciones. Así por ejemplo se dan los siguientes casos según tendencia: Tendencia alcista sólida: el volumen sube mientras la cotización sigue subiendo. Tendencia alcista débil: la cotización sube pero el volumen va disminuyendo Tendencia bajista fuerte: el volumen sube mientras la cotización sigue bajando. Tendencia bajista débil: la cotización baja pero el volumen se va reduciendo De este análisis se pueden extraer conclusiones de gestión de carteras, resumidas en indicadores de volúmenes de forma que cada día se suma el volumen de acciones negociadas si el precio cierra al alza, y se resta si el 55 precio baja. Si el balance de volumen va subiendo es debido a que la tendencia alcista es predominante, por lo que conviene comprar. Si por el contrario el balance del volumen va bajando es porque predomina la tendencia descendente, por lo que es el momento de vender. 56 Capítulo 5 Métodos de Análisis Multivariante usados en el estudio de mercados El análisis Multivariante es el conjunto de métodos estadísticos y matemáticos para analizar, describir e interpretar las medidas múltiples de cada individuo o objeto sometido a investigación, pudiendo ser estas medidas de tipo cuantitativo, cualitativo o una mezcla de ambas [CUADRAS96]. En este capítulo se describen las principales técnicas que abarca el Análisis Multivariante, incidiendo más en el Análisis de Correspondencias que se presentará en primer lugar. Por último se abordará la representación gráfica de los resultados obtenidos, esto es, los mapas perceptuales. 5.1) Análisis de Correspondencias El Análisis de correspondencias (CA) es una técnica estadística de interdependencia. Se trata de una técnica de composición pues obtendrá una representación gráfica, llamada mapa perceptual, que se basa en la asociación entre objetos y un conjunto de características descriptivas o atributos especificados por el investigador, todo esto partir de tablas de contingencia. Las variables se representan como puntos en el mapa. Lo que determina el grado de relación entre las variables es la proximidad entre puntos, de forma que a mayor cercanía, más relacionadas están las variables. Las principales aplicaciones del análisis de correspondencias se centrarán en por un lado establecer las ventajas o desventajas competitivas de una empresa respecto a otras, encontrando sus puntos débiles y sus fortalezas, y por otro lado el posicionamiento ideal del mercado, y por tanto poder, establecer que empresas se encuentran más cercanas a dicha área ideal. Se trata de un tipo de análisis [PEDRET00] que en origen es un caso particular del análisis factorial de componentes principales (que posteriormente será estudiado), del que se diferencia en: 57 Frente al análisis de componentes principales trata de simplificar las variables del análisis mediante la construcción de nuevas variables más sintéticas, el análisis de correspondencias trata de analizar las formas que adoptan las relaciones entre las variables, esto es, descubrir las dimensiones estructurales que revelan un conjunto de datos. Se puede analizar cualquier matriz de números no negativos, independientemente de su escala de medida, por lo que es especialmente apropiado para tratar variables cualitativas. Su objetivo básico es analizar las relaciones entre dos conjuntos de variables (generalmente a partir de matrices), donde un grupo en nuestro caso serán las empresas del IBEX-35 y por otro lado los atributos analizados. Representa simultáneamente dos conjuntos de variables en un mismo espacio. Esta representación se basa no en los valores absolutos, sino en las correspondencias entre las características, esto es, en valores relativos. . Realiza la reducción dimensional de la misma forma que el análisis multidimensional o el análisis factorial, representando el resultado obtenido en un mapa perceptual en los que las categorías se encuentran representadas en espacio multidimensional. Como paso previo al análisis se deberá efectuar el siguiente tratamiento previo de los datos: Los valores calculados en porcentajes según filas Los valores calculados en porcentajes según columnas El peso de cada fila y de cada columna La reducción del número de atributos intercorrelacionados a un número más pequeño de dimensiones independientes. Una vez realizado el tratamiento previo de los datos, los pasos básicos que deberemos seguir para utilizar esta técnica son [HAIR99]: 1) Determinación del objetivo básico, pudiendo darse dos casos: Asociación entre categorías de columna o fila: el CA puede utilizarse para examinar la asociación entre las categorías de sólo una fila o columna. Las categorías pueden compararse para ver si dos de ellas 58 pueden ser combinadas, es decir, están muy próximas en el mapa, o si por el contrario ofrecen discriminación, con lo que estarán muy alejadas en el mapa perceptual. Asociación entre categorías de filas y columnas: es el objetivo más usual y su fin es representar la asociación entre categorías de filas y columnas, como por ejemplo sería tratar de averiguar la relación entre las subidas de una empresa, y que esta pertenezca al sector de la construcción. 2) Diseño de la investigación mediante análisis de correspondencias: este análisis requerirá una matriz de datos rectangular de tabulación cruzada y entradas no negativas, llamada matriz de correspondencias. Este concepto se explica más detalladamente en el apartado 4.1.1. 3) Supuestos del análisis de correspondencias: goza de una relativa libertad respecto a sus supuestos básicos. El uso de datos estrictamente no métricos puede representar relaciones lineales y no lineales. Sin embargo la falta de supuestos no exime de buscar la comparabilidad de objetos y a considerar la generalidad de los atributos utilizados. 4) Obtención de resultados con análisis de correspondencias y valoración del ajuste conjunto: con la tabulación cruzada, las frecuencias para cualquier combinación de filas y columnas de las categorías están relacionadas con otras combinaciones basadas en frecuencias marginales. Con este método obtendremos una expectativa condicionada, esto es, un valor chi-cuadrado. Obtenidos dichos valores, se estandarizan y se convierten en una distancia métrica y a continuación se definen soluciones de dimensiones reducidas. Estos factores relacionan simultáneamente filas y columnas en un mismo gráfico. Para evaluar el ajuste conjunto, se identificará el número óptimo de dimensiones y su importancia, siendo el máximo número de estas uno menos el número más pequeño de filas y de columnas (si por ejemplo tenemos 4 filas y 3 columnas tendremos como máximo dos dimensiones). Para obtener la contribución relativa de cada dimensión a la variación de las categorías obtendremos los autovalores o valores singulares. Otra medida de la variación explicada es la inercia. 59 5) Interpretación de los resultados: se podrá identificar una asociación de categorías con otras categorías por su proximidad, tras hacer la normalización adecuada. 6) Validación de los resultados: se tratará de asegurar la generalización mediante el análisis split o multimuestra. La generalidad de los objetos individuales y como conjunto la evaluaremos mediante la sensibilidad de los resultados a la adición o sustracción de un objeto o atributo. Con este método sabremos si el análisis es dependiente de unos pocos objetos o atributos 5.1.1) Matriz de correspondencias y filas y columnas marginales Como se expuso antes se trata de una matriz de datos rectangular (tabulación cruzada) de entradas no negativas. Las filas y las columnas no tienen significados predefinidos, esto es, los atributos no tienen que ser siempre filas, pero si representan las respuestas de una o más variables categóricas. El análisis comienza con la tabla de correspondencias que nos informa de la frecuencia de cada suceso observado, que se denominará O. 1 2 ........... c Marginal Fila 1 o 11 o 12 2 o 11 o 11 . . . . . . . . . ........... o 1C o 1 ........... o 11 o 2 . . . . . . . . . r o R1 Marginal o .1 o R2 o .2 o 11 ........... o RC ........... o .c o R 1 Columna Tabla 5.1. Tabla de correspondencias 60 En esta tabla observamos oij = nij/n representa la frecuencia relativa del caso ij, donde n es el numero total de casos estudiados y nij la frecuencia del caso ij. Las filas de densidad marginal vendrán representadas por oi· = ni·/n siendo las columnas de densidad marginal referidas por o·j = n·j/n. En ambos casos ni· y n·j son la fila y columna de frecuencias absolutas marginales, n n c Estas expresiones se obtendrán respectivamente de: 1,2,…..r y n respectivamente. i. j 1 ij , siendo i= i 1 nij siendo j=1,2,….c. Por su parte designaremos como r al r j. vector fila marginal (r x 1) que se obtienen de oi·, i = 1, 2, . . . , r, y de forma análoga como c al vector columna marginal. La forma de obtener c y r es respectivamente: r O ec y c O´ er siendo eye c r son la columna y la fila unidad respectivamente. La fila y la columna marginal se podrán usar para construir matrices diagonales Dr(r x r) y Dc(c x c) respectivamente. Las nomenclaturas usadas para cada elemento se resumen en la tabla 5.2 Elemento Nomenclatura Tamaño Matriz de O (r xc) Comentarios correspondencias Vector fila unitario e e (r x 1) Formado por 1s (c x 1) Formado por 1s r (r x 1) Columna de densidad c (c x 1) r Columna fila unitario c Fila de densidad marginal marginal Matriz diagonal de filasDr (r x r) marginales Matriz diagonal por los términos de r de D c (c x c) columnas marginales Matriz transpuesta La diagonal formada La diagonal formada por los términos de c X´ Cualquiera La transpuesta de X se notará como X´ Tabla 5.2. Resumen de términos 61 5.1.2) Perfiles marginales y condicionales Los perfiles marginales describen la distribución marginal de las variables fila (r) y columna (c). Con ambas distribuciones podremos obtener las matrices R y C que agrupan los perfiles condicionales. Estos describen las distribuciones condicionadas asociadas a la tabla de correspondencias, Los perfiles fila describen las distribuciones condicionadas de las variables j=1,2,…..c, condicionadas por i=1,2,….r. Por su parte los perfiles columna describen las distribuciones de las variables i=1,2,……r condicionadas por j=1,2,….c 1 1 2 . . . n 2 11 n n 21 n 12 1. n n 22 2. . . . n ........... c ........... n Total 1c n 1. n n ........... 2c 2. . . . 1 1. n 1 2. . . . . . . . . . r Total n r1 n .1 n n n r2 n r. n .2 ........... n rc r. ........... n n .c n 1 r. 1 n Tabla 5.3. Matriz R para los perfiles fila 62 1 n 1 n 2 . . . 2 11 21 n n 12 .1 n n 22 .1 . . . n ........... c ........... n Total 1c .2 n n ........... 2c .2 . . . n n 1. .c n n . . . . . 2. .c n n . . . . n r Total r1 n n r2 .1 1 n 1 n ........... .2 ........... rc n n .c 1 r. n 1 Tabla 5.4. Matriz C para los perfiles columna Con estas dos matrices y la matriz de correspondencia podremos obtener una medida de la desviación de la independencia de los factores. Bajo la hipótesis de dependencia el producto de las matrices fila y columna de densidades marginales deberá ser aproximadamente igual a la matriz de correspondencias. Por lo tanto la expresión (O − rc′) nos dará una medida de la desviación de la independencia. Se puede obtener un perfil fila medio, usando una media ponderada de los r perfiles dados por ri, i = 1, 2, . . . , r. Este perfil fila medio se obtiene de r i 1 ri ( ni . n ) =c, que es el (c x 1) vector marginal columna. Este perfil fila medio se muestra en la tabla 4.3. Análogamente se podrá definir un perfil columna medio, que se representa en la tabla 4.4, que es la media ponderada de los c perfiles columna, obtenidos con la expresión c j 1 cj( n. j n ) =r Al igual que obtuvimos antes una medida de la independencia, la resta de matrices (R − erc′) y (C − ecr′) representan la desviación de los perfiles de la media de los perfiles. Estas matrices también son medida de la independencia. 63 5.1.3) Dependencia e interdependencia mediante Pearson Chi-Cuadrado La existencia de relación de algún tipo entre las variables fila y columna se analiza mediante contrastes de hipótesis sobre la independencia de dichas variables. El test de hipótesis habitualmente utilizado es el de la Chi-Cuadrado de Pearson. En dicho test la hipótesis nula es H0: las variables fila y las variables columna son independientes y la alternativa es H1: las variables son dependientes. El test se basa en comparar los perfiles fila y columna con los perfiles marginales correspondientes, teniendo en cuenta que si H0 es cierta todos los perfiles fila (resp. columna) son iguales entre sí e iguales al perfil marginal de fila (resp. columna). El estadístico del test viene dado por la expresión: Donde: A simple vista se intuye que valores del estadístico pequeños significarán valores de n ij y e ij son de magnitud parecida, con lo que aceptamos la hipótesis nula, mientras que en caso de valores grandes aceptaremos la hipótesis alternativa. Bajo la hipótesis nula el estadístico se distribuye según una distribución: viniendo el p-valor del test dado por: donde es el valor observado en la muestra del estadístico. Para un nivel de significación 0< α <1 la hipótesis nula se rechaza si dicho p valor es menor o igual que α. De esta forma si rechazamos la hipótesis nula las variables de las filas y las columnas son dependientes. En este caso conviene analizar los perfiles condicionales fila y columna así como los residuos del modelo para estudiar qué tipo de dependencia existe entre 64 ellas. Los residuos más utilizados son los llamados residuos tipificados corregidos que vienen dados por la expresión: n Si toman valores grandes en valor absoluto se deberá a que los valores e ij ij y son muy diferentes. Los residuos se distribuyen asintóticamente según una N(0,1) la hipótesis nula y a un nivel de confianza del 95% residuos con un valor absoluto mayor que dos se consideran como valores anormalmente altos 5.1.4) Inercia total Es una medida del grado total de dependencia entre variables y se expresa y se obtiene de G 2 n . También se puede interpretar como una medida de la desviación media total de la columna o de la fila. La forma matricial de expresar la inercia total es: . La teoría de la descomposición del valor singular generalizado se puede obtener para obtener una relación entre la inercia total y una aproximación a la matriz de desviaciones (O − rc′). Para la matriz (O − rc′) la descomposición del valor singular generalizado sujeto a las condiciones y viene dado por: Donde las columnas de A (r x K) y B (c x K) se designan ak y bk, donde μ1, μ2,……….., μk son los elementos de la diagonal de la matriz Dμ (K x K) siendo K el rango de la matriz descompuesta, que será el mínimo de (r-1) ó (c-1). Los vectores ak siendo k=1,2,……,K son denominados ejes principales de las 65 columnas de (O − rc′) y análogamente los vectores bk siendo k=1,2…..K los ejes principales de las filas de (O − rc′). Los elementos diagonales μ1, μ2,……….., μk de Dμ son llamados los valores singulares de (O − rc′). Con todo esto podremos expresar la inercia total como la suma de las medias de los valores singulares: 5.1.5) Coordenadas de los perfiles fila y columna Para la descomposición del valor singular generalizado de (O − rc′) dada por ADµB′ las columnas de las matrices A y B proporcionan los ejes principales para las filas y columnas de (O − rc′) respectivamente. Cada fila de (O − rc′) se podrá expresar como una combinación lineal de filas de columnas de B (filas de B transpuesta) y por consiguiente las coordenadas de las filas de (O − rc′) en el espacio que generan las filas de B transpuesta vienen dadas por ADµ. Las coordenadas de la i-ésima fila de (O − rc′) vienen dadas por la i-ésima columna de ADµ. Análogamente las coordenadas de las columnas de (O − rc′) con respecto al espacio generado por las columnas de A se obtiene de DµB′. Con las expresiones: y se obtendrán las coordenadas para las desviaciones del perfil fila y del perfil columna. Otras expresiones análogas son: A partir de r´V=0 y c´V=0, las coordenadas de las desviaciones del perfil fila y del perfil columna se relacionan mediante las ecuaciones: y 66 Las coordenadas para las r desviaciones del perfil fila vienen dadas por los elementos de Vik, i = 1, 2, . . . , r, k = 1, 2, . . . , k de V que se resumen en la tabla 4.5 Tabla 5.5. Coordenadas para los perfiles fila en ejes principales fila Análogamente procederemos para las c desviaciones del perfil columna que vienen dada por los elementos wjk, j = 1, 2, . . . , c, k = 1, 2, . . . , k, de W que se resumen en la tabla 4.6 Tabla 5.6. Coordenadas para los perfiles columna en ejes principales columna Cada fila de V de la tabla 4.5 proporciona las coordenadas para una desviación del perfil fila con respecto a los K ejes principales dados por las columnas de B. Cada columna de V proporciona las coordenadas de las r desviaciones perfil respecto a un eje principal particular o columna de B. Esto será aplicable de modo análogo a las coordenadas halladas en la tabla 4.6. Las coordenadas para los dos primeros ejes principales (vi1, vi2), i = 1, 2, . . . , r se podrán usar para localizar las r desviaciones perfil en un espacio bidimensional definido por los dos ejes principales. Para las desviaciones de los perfiles columna, las coordenadas de los primero ejes principales vienen dadas por (wj1,wj2), j = 1, 2, . . . , c. 67 5.1.6) Contribuciones parciales a la Inercia Total Una media ponderada de las coordenadas en una columna de V dada por r´V produce el vector cero, y por consiguiente la media de cada columna de V es cero. La media del cuadrado de los elementos en una columna de V es dada por la expresión: Por consiguiente usando las filas marginales como términos, las coordenadas con respecto a cada eje principal tienen de media cero y de varianza μ 2K , k = 1, 2, . . . ,K. A partir de que los cuadrados de los valores singulares vienen dados por μ 2K y de que K k 1 μ 2K representa la inercia total, se puede concluir que las varianzas ponderadas de las columnas de V muestran la contribución de cada eje principal a la inercia total. La inercia total se podrá representar: Por consiguiente oi. i 1Vik2 nos da la contribución de la i-ésima desviación del perfil fila a la inercia total. De la misma forma, los elementos de W relacionarán la inercia total de las desviaciones de los perfiles columna y sus ejes principales. 5.1.7) Cosenos al cuadrado Para cada desviación del perfil fila la inercia oi. i 1Vik2 puede ser asignada a las K dimensiones como oi21 , oi22 ,…….., oik2 . Las proporciones muestran la asignación de la desviación del perfil fila a la k-ésima división. Esta proporción representa el cuadrado del coseno del ángulo entre la dimensión k 68 y una linea que une el origen con el punto que representa el perfil fila. La expresión que permitirá hallar dicho ángulo será: La interpretación de este resultado es que cuanto más cercano sea su valor a 1, más próximo esta el i-ésimo punto fila a el k-ésimo eje, y por consiguiente más importante es este eje para esa dimensión. Si efectuamos este proceso con todos los puntos fila podremos representar estos puntos en un gráfico llamado mapa perceptual. 5.1.8) Principio de la distribución equivalente Esta propiedad de la Chi-Cuadrado muy usada en CA dice que si dos perfiles fila son idénticos, se podrán remplazar por un solo perfil fila que será la suma de los perfiles, no afectando esto a los perfiles columna. De la misma forma, un perfil fila se podrá dividir en dos o más filas. Si dos perfiles son idénticos, estarán situados en el mismo lugar del espacio fila. Con esto se asegura la independencia de la solución con respecto a la codificación inicial de las variables. 5.1.9) Aproximación generalizada de los menores cuadrados El objetivo del CA es sustituir la matriz de desviaciones (O − rc′) por una aproximación más simple que dicha matriz, de forma que tenga un menor numero de ejes principales de la descomposición generalizada de valores singulares, siendo el resultado una matriz X (r x C). Normalmente, X vendrá dada por los dos primeros términos de K k 1 a k bk´ k con lo que será una aproximación de segundo orden de (O − rc′). Minimizando: entre todas las matrices X de segundo orden o menores se consigue la ecuación: 69 Por consiguiente, la descomposición generalizada de valores singulares ofrece una aproximación a las desviaciones de (O − rc′). Esta aproximación maximiza la proporción de la inercia total que puede ser asignada a las dos dimensiones. Por tanto sólo necesitaremos las dos primeras columnas de las tablas 4.5 y 4.6 para obtener la representación. La primera columna de la tabla 4.5 dará los lugares en los primeros ejes principales fila, mientras que la segunda columna dará lo mismo a lo largo de los segundos ejes principales. Para la tabla 5.6 se procederá igual, pero esta vez para las columnas. 5.1.10) Filas y columnas de desviaciones y autovectores Las expresiones: y junto con las coordenadas de los vectores para las desviaciones de las filas y columnas proporcionan las ecuaciones de los autovalores. Estos autovalores reflejan la relación entre el vector de coordenadas y los autovalores y autovectores de las dos matrices simétricas: y 5.2) Escalado Multidimensional El escalado multidimensional son un conjunto de técnicas estadísticas cuyo fin suele ser la representación gráfica de un conjunto de datos. Se basa en las comparaciones entre objetos. Estos objetos tendrán varias dimensiones, debiendo diferenciar entre dimensiones objetivas y subjetivas. Así por ejemplo la cotización de una acción en un periodo de tiempo será una acción será una dimensión objetiva, mientras que la confianza de los inversores en que esta acción tenga un comportamiento alcista será una dimensión subjetiva. Las dos diferencias principales entre estas dimensiones son [HAIR99]: Diferencias individuales: las dimensiones percibidas por el individuo, en este caso los inversores, pueden no coincidir con las dimensiones objetivas supuestas. Así los individuos pueden considerar diferentes conjuntos de características objetivas y variar la importancia dada a 70 cada dimensión. Así en nuestro ejemplo, puede que una acción haya sufrido pérdidas en la última semana. Sin embargo un inversor basándose en la impresión personal que le transmite la empresa y en experiencias pasadas considera que lo más probable es que dicha acción entre en un ciclo alcista. Interdependencia: las evaluaciones de las dimensiones pueden no ser independientes y pueden no concordar. Las dimensiones objetivas como las percibidas pueden interactuar con el resto creando evaluaciones inesperadas. Por ejemplo una acción puede considerarse un mejor “valor refugio” que otra, a pesar de que está probado que tiene una mayor volatilidad y es más sensible a los cambios del mercado. Los objetivos del escalado multidimensional serán: Construir un espacio métrico Conseguir el menor número de dimensiones posibles Conseguir el mayor grado posible de fidelidad Dicho de otra forma, el análisis de escalas multidimensionales estudiará como de similares (próximos) están las empresas cotizadas. Otro de los principales fines es el posicionamiento de las empresas, esto es, establecer aquellas características que diferencian a unas empresas de otras El escalado multidimensional [PEÑA02] arranca cuando tenemos una matriz cuadrada (n x n) de distancias o disimilitudes entre los n elementos de un conjunto. Estas distancias pueden haberse obtenido a partir de ciertas variables, o pueden ser el resultado de una estimación directa, por ejemplo haciendo un sondeo a varios inversores. El objetivo que se pretende es representar esta matriz mediante un conjunto de variables ortogonales, y1 ,..,y p llamadas coordenadas principales donde p <n, de manera que las distancias euclídeas entre las coordenadas de los elementos respecto a estas variables sean iguales (o los más próximas posibles) a las distancias o disimilaridades de la matriz original. Es decir, a partir de la matriz D se pretende obtener una matriz X, de dimensiones n × p, que pueda interpretarse como la matriz de p variables en los n individuos, y donde la distancia euclídea entre los elementos reproduzca, aproximada-mente, la matriz de distancias D inicial. Cuando p >2, 71 las variables pueden ordenarse en importancia y suelen hacerse representaciones gráficas en dos y tres dimensiones para entender la estructura existente. Podemos comparar el escalado multidimensional con otras técnicas de interdependencia como el análisis factorial o el análisis de componentes principales. El análisis factorial agrupa variables en valores teóricos que definen las dimensiones subyacentes del conjunto original de variables, agrupando conjuntamente aquellas variables que estén muy correlacionadas. Por su parte el estudio de componentes principales considera la matriz (p x p) de correlaciones o covarianzas entre variables e investiga su estructura y el análisis cluster agrupa observaciones de acuerdo con su perfil sobre un conjunto de variables (valor teórico cluster) en la cual las observaciones muy cercanas se agrupan juntas. Frente a estos métodos el escalado multidimensional, a diferencia del análisis cluster puede obtener una solución para cada individuo y no utiliza el valor teórico, con lo que se reduce la influencia del investigador al no exigir la especificación de las variables que se utilizan la comparación de objetos. Por su parte frente al análisis de componentes principales se puede decir que tienen enfoques complementarios pues mientras que con componentes principales se considera la matriz ( p x p) de correlaciones o covarianzas entre variables e investiga su estructura, el escalado dimensional estudia la estructura de la matriz (n x n) de distancias entre individuos 5.2.1) Proceso del escalado multidimensional Las técnicas de análisis multivariante se agrupan en dos conjuntos principales: análisis de proximidades y análisis de preferencias. Si partimos de similitudes o diferencias entre las empresas se aplicará el análisis de proximidades, para evaluar dichas similitudes. Por el contrario, si el dato de partida es una clasificación de las empresas, ordenadas según algún factor, se utilizará el análisis de preferencias. Los datos de entrada pueden ser métricos o no métricos, en cuyo caso se asumirá que los datos son cuantitativos o cualitativos (ordinales), respectivamente. 72 a) Análisis de proximidades. Las etapas de las que consta el análisis de proximidades son [PEDRET00]: 1) Diseño del análisis: los datos sobre los que se efectúa este análisis se expresan mediante una matriz de similitudes o de disimilitudes entre objetos. A partir de las similitudes entre n objetos pertenecientes a un conjunto E E 1,......, j , k ,......n . A cada par de objetos está asociada una semejanza S jk que aumenta cuando la semejanza entre j y k aumenta. Este índice de similitud cumplirá las siguientes propiedades: 0 S jk S max siendo S max el valor máximo de similitud fijado por el investigador. S jj S max j E S jk S kj j , k E De forma análoga se podrá asociar a cada par de objetos un índice de disimilitud DS jk que aumenta a medida que los objetos j y k son menos parecidos. Las propiedades de los índices de disimilitud son: 0 DS jk DS max siendo S max el valor máximo de similitud fijado por el investigador. DS jj 0j E DS jk DS kj j , k E 2) Procedimiento de resolución: dada una medida de disimilitud entre los n elementos de un conjunto finito de objetos (empresas) se trata de buscar una configuración de los n objetos en un espacio, que tenga el menor número posible de dimensiones, de forma que las distancias entre los puntos calculados en este espacio sean lo más parecidas posible a las medidas de disimilitudes iniciales. Así se parte de la matriz de disimilitudes DS ds jk para determinar: Las dimensiones r, r <n, siendo n el número de objetos inicial La configuración de n vectores X 1 ,....., X j , X k ,.... X n R r , donde cada vector representa las coordenadas de cada empresa en las r 73 dimensiones, tales que si las distancia entre dos objetos X j y X k R r viene dada por d 2jk ( X j X k )´( X j X k ) la ordenación dada por los s jk sea idéntica a la dada por los d jk debiéndose cumplir: - ( j , k ) y ( j´, k´) E - ds jk ds j´k ´ d jk d j´k ´ (condición de monotonía) - (ds jk d jk ) 2 sea una cantidad mínima j k Para analizar si la configuración de los n objetos en las r dimensiones respeta la configuración de los índices disimilitud iniciales, se dispone del índice de llamado stress que indica el grado de monotonía en la relación entre la ordenación engendrada por las disimilitudes ds jk y la ordenación dada por las distancias d jk 1 (ds jk d jk ) 2 2 jk St estando dicho valor comprendido entre 0 y 1, siendo 2 ds jk jk mejor el ajuste cuanto más próximo a 0, debiendo ser siempre menor para considerarse aceptable que 0,2 3) Selección del número de dimensiones: se asocia al número de ejes a conservar, siendo esta decisión más subjetiva que estadística, siendo determinante el conocimiento previo del estudio. Criterios: Criterio estadístico: se basa en la medida del stress, eligiéndose aquella dimensionalidad para la que se obtenga el menor valor de stress, aunque ya que este decrece a medida que se aumentan las dimensiones, será necesario buscar un equilibrio entre el valor de dicho índice y las dimensiones a incluir. Facilidad de interpretación: generalmente bastará con dos dimensiones, pero puede darse el caso de que sea fácilmente interpretable con 3 pero no con 2 Facilidad de uso: suele ser más fácil trabajar con 2 dimensiones 74 4) Interpretación de las dimensiones: esta interpretación puede partir de la posición de los objetos en el espacio resultante (aproximación subjetiva) o por métodos estadísticos (aproximación objetiva): Aproximación subjetiva: se establece que una dimensión no existe si no se puede interpretar, basándose la interpretación en la posición de los objetos en el espacio resultante, identificando que empresas ocupan los extremos del espacio, y posteriormente identificando un atributo o propiedad que explique las posiciones relativas del objeto en el espacio. Aproximación objetiva: si se identifica alguna variable que guarda una relación sistemática con la posición de las empresas, será razonable tratar de utilizar esta variable para explicar la configuración. En el caso de que no sirva sólo con interpretar las dimensiones, sino que también sea necesario saber cómo se posicionan las empresas respecto a los atributos se procederá de la siguiente forma: 1) Obtener la puntuación media de cada objeto en los atributos investigados. 2) Efectuar una regresión múltiple del tipo: ai 0 1 X i1 .... r X ir 3) Analizar el coeficiente de correlación múltiple de la ecuación anterior, si el valor es alto se determinará que se usó el atributo al hallar las matrices de similitud. 4) Obtención de los cosenos directores de los vectores atributo con mayores coeficientes de correlación simple: i i 2 i siendo i=1,2,…,r. Por su parte R 2 indica el porcentaje de variación de la puntuación de cada tipo de programación es explicado por la posición de la cadena en la configuración de dos dimensiones 75 b) Análisis de preferencias Se basa en que para cada sujeto existe por lo menos una combinación perfecta de las características de un objeto. Se pueden interpretar dichas combinaciones como que reflejan la mayor o menor proximidad de los objetos al punto ideal. Desde el punto de vista de la representación geométrica, cada individuo está representado en un punto, de forma que los objetos más próximos son los preferidos. También se puede representar al sujeto en forma de vector de forma que ahora el orden de preferencias se determina por el orden de las proyecciones. Las etapas del análisis de preferencias son: 1) Diseño del análisis: sea E 1,...., j , k ,.......n un conjunto de empresas e I 1,...., i,.......m un conjunto de individuos. La obtención de información sobre las preferencias de los individuos suele efectuarse mediante los siguientes métodos: a) Ranking de preferencias: cada individuo asignará un ranking de preferencia de 1 a n a cada objeto, siendo n el número total de objetos. Dicho ranking se representa por: Pmn pij donde pij es el ranking dado por el individuo i al objeto j b) Comparaciones por pares: los datos toman la forma de una relación binaria, la cual representa la relación de preferencias del individuo. Se representa para un individuo i por Am,n ai , jk en donde ai , jk =1 j preferido a k si j>k ai , jk =0 k preferido a j si k > j ai , jk =1/2 k y j son diferentes si k = j a i , jj =1 A su vez en el análisis de preferencias podrá distinguirse ente el análisis interno, que trata de estimar las similitudes entre objetos y puntos ideales, partiendo de las preferencias expresadas por los individuos. Por el contrario en el análisis externo las similitudes de los objetos han sido obtenidas anteriormente, tratándose únicamente de estimar los puntos ideales 76 2) Procedimiento de resolución: dada una configuración de n objetos en un espacio R r se deberán determinar la posición de los m individuos en este espacio, de forma que las posiciones relativas de los objetos y de los individuos en el espacio de representación se correspondan con las preferencias expresadas previamente. Sea X= ( X 1 ,....., X j ,.... X n ) , siendo Xj un vector que representa las coordenadas del punto-objeto j en las r dimensiones seleccionadas. Se tratará de encontrar en R r la configuración de los puntos individuo o puntosY ( y1 ,.........., y i ,...... y m ) e yi un vector de R r que ideales Y, siendo representa las coordenadas del punto-individuo i. Se pretende asociar a cada individuo I un punto, tal que el orden de las distancias entre x j e y i sea lo más parecida posible al orden inicial de preferencias del individuo i. Siendo: Pi ,n pij el orden de preferencias del individuo i sobre los n objetos Di , n d ij el orden de las distancias en el espacio R r entre el punto ideal y i del individuo i y cada uno de los n objetos, siendo la representación de las preferencias del individuo i en las r dimensiones: 1 r 2 d ij ( y it x jt ) 2 siendo adecuada esta representación si Pi ,n Di ,n t 1 3) Interpretación de resultados: el principal objetivo es hallar la vulnerabilidad de las diferentes empresas analizadas. Dicho grado de vulnerabilidad se puede medir por la distancia entre los puntos ideales y las empresas 5.2.2) Interpretación de los resultados del escalado multidimensional Al igual que en otros métodos, la relación de los objetos representados en el mapa perceptual vendrá dada por la proximidad de estos objetos en dicho mapa. Del mismo modo cuanto más alejados se encuentren, menor es la relación entre dichos objetos. 77 Una vez tenemos todas las distancias entre todos los objetos del mapa, deberemos determinar cuantas dimensiones son necesarias para explicar el modelo. Deberemos añadir dimensiones hasta que no se produzcan mejoras sustanciales, En esta interpretación deberemos tener en cuenta las limitaciones del método. Una es que no está garantizado que logremos un conjunto de dimensiones significativas. Además factores psicológicos pueden falsear los resultados si no son manejados convenientemente 5.3 Análisis de Componentes principales El Análisis de Componentes Principales (ACP) es una técnica estadística de síntesis de la información, o reducción de la dimensión (número de variables). Es decir, ante un banco de datos con muchas variables (p), el objetivo será reducirlas a un menor número perdiendo la menor cantidad de información posible. Los nuevos componentes principales o factores serán una combinación lineal de las variables originales, y además serán independientes entre sí. Un aspecto clave en ACP es la interpretación de los factores, ya que ésta no viene dada a priori, sino que será deducida tras observar la relación de los factores con las variables iniciales (habrá, pues, que estudiar tanto el signo como la magnitud de las correlaciones). Esto no siempre es fácil, y será de vital importancia el conocimiento que el experto tenga sobre la materia de investigación. Una propiedad interesante es que los primeros componentes explican la mayor parte de la variación de las variables originales. Normalmente los componentes se disponen en orden descendente, de forma que cada componente explica la mayor parte que puede de la variable original, siendo esta información cada vez menor según vamos avanzando componentes. Por tanto se decidirá cual 78 es número apropiado de componentes para representar la información que originalmente se tenían. El análisis de componentes principales se puede interpretar como una rotación de los ejes existentes a una nueva posición. En esta nueva rotación no habrá correlación entre las nuevas variables definidas por la rotación. El requisito que se debe cumplir es que todos los componentes deben ser ortogonales, por lo que no habrá relación entre ellos. Esto significa que cada componente cuantifica diferentes dimensiones de los datos dados. Por otro lado las variables deben estar relacionadas entre ellas para que se puedan resumir en un número reducido de componentes. Cada componente principal puede ser expresada en función de las p variables observadas que están correlacionadas entre ellas usando las ecuaciones: Para evitar la influencia de la escala de medida original, es normal normalizar los valores originales antes de extraer los componentes principales. La versión normalizada de las anteriores ecuaciones es: En ambos casos los coeficientes λ representan los pesos o coeficientes de saturación de las diferentes variables observadas en cada componente principal. 79 Los coeficientes e λ k1, λ k2, . . . , λ deberán cumplir las siguientes kp condiciones: Primer componente principal: combinación lineal de PC1 que maximiza Var(PC1) y || λ 1||=1 Segundo componente principal: combinación lineal de PC2 que maximiza Var(PC2 ) y || λ 2||=1 y Cov (PC1, PC2)=0 j-ésimo componente principal: combinación lineal de PCj que maximiza Var(PCj) y || λ j||=1 y Cov (PCk, PCj)=0 para todo k<j Esto significa que los componentes principales de estas combinaciones lineales que maximizan la varianza de la combinación lineal y que tienen una covarianza nula con el componente anterior. El porcentaje de la variación total de cada uno de los componentes es dado por la expresión: %Variación j j 100 p i 1 i Existen muchos algoritmos de calculo para hallar los Componentes Principales. Dado el mismo punto inicial producirán los mismos resultados salvo en un caso: cuando en un punto halla dos o mas rotaciones posibles que contienen la misma variación máxima, está indeterminado cual usar. En dos dimensiones la nube de dispersión de los datos parecerá un círculo en lugar de una elipse. En un círculo cualquier rotación será equivalente. Mientras en una nube de dispersión de datos elíptica el primer componente será paralelo al eje principal de la elipse. Por consiguiente la mayoría de los mapas obtenidos con esta técnica ofrecen un gráfico elíptico de los diferentes elementos representados, permitiendo una optima interpretación del mapa. Para una mayor seguridad en los coeficientes de correlación, es importante que la muestra tenga al menos cinco casos para cada variable observada 5.3.1) Proceso del análisis de Componentes Principales Los pasos a dar serán: 1) Conseguir los datos necesarios 80 2) Restar la media: para un proceso correcto es necesario restar la media de cada una de las dimensiones de datos, siendo esta media la media de cada dimensión. Con esto se consigue un conjunto de datos cuya media es cero 3) Calcular la matriz de covarianzas: para un conjunto de datos de n dimensiones se obtiene a partir de la expresión: Donde C nxn es una matriz de n filas y n columnas, y Dim x es la x-ésima dimensión. Para n=3 la matriz tendrá el siguiente aspecto: Esta matriz será simétrica, mientras que en la diagonal principal se encuentran los valores de la varianza de cada dimensión. 4) Calcular los autovalores y autovectores de la matriz de covarianzas: se pueden interpretar como las direcciones fundamentales de un conjunto de datos, ofreciendo una valiosa información sobre el modelo de los datos. El primer autovector muestra como dos conjuntos de datos están relacionados a lo largo de una línea. El segundo da otro modelo que siguen los datos, siendo menos importante que el primero. En este segundo modelo todos los puntos siguen la misma línea principal pero algunos están a un lado de la línea principal. Por su parte los autovalores pueden ser considerados como una evaluación de cuan representativo es un componente los datos. El mayor autovalor de un componente será el más representativo. También ofrecen una medida del porcentaje de la varianza total explicada. Sin embargo esto depende de lo adecuados que sean los componentes para resumir los datos. En teoría la suma de todos los componentes debería explicar el 100% de la variabilidad de los datos, sin embargo esto raramente se consigue. 81 Por consiguiente con los autovalores de la matriz de covarianzas se consiguen líneas que caracterizan los datos, con lo que el resto del proceso perseguirá transformar los datos en términos de las líneas. 5) Elección de los componentes y formación del vector característico: obtenidos los autovalores, se procederá a ordenar de mayor a menor, con lo que los componentes se ordenan en orden de importancia, lo que simplifica la elección de los componentes, pues aquellos cuyos autovalores sean menores aportarán menos información, con lo que se podrán despreciar, con lo que el conjunto final de datos será de una dimensión menor a la dimensión p inicial. 5.3.2) Representación gráfica del análisis de componentes principales La interpretación gráfica habitual de este análisis son los planos compuestos generalmente por dos dimensiones por motivos de simplicidad. En ellos se representan tanto los puntos fila, como los puntos columna, con respecto a las dos dimensiones elegidas de que aquellas que hayan resultado del análisis. Y aunque el criterio para interpretar dichos mapas es la proximidad de los puntos, no se deberá comparar directamente la proximidad entre puntos fila y puntos columna. El método correcto para comparar puntos de diferente naturaleza es observar los cosenos de los ángulos que forman los vectores de dirección de los puntos, pudiendo concluir que aquellos puntos fila y columna que presenten cosenos de valor parecido se encuentran próximos o aparecerán con frecuencia juntos. Para determinar la validez de la representación gráfica se puede calcular las varianzas de los puntos filas y columnas con respecto a las dimensiones halladas y la correlación entre las mismas para cada punto fila o columna. Así una varianza elevada supone una mayor incertidumbre sobre la posición de los puntos de una población. Por otro lado, valores elevados de las correlaciones entre dimensiones respecto a un punto determinado indican que dicho punto puede asociarse a más de una dimensión. 82 5.4 Análisis Factorial El Análisis Factorial [HAIR99] es el nombre genérico que se da a una serie de métodos estadísticos multivariantes cuyo propósito principal es obtener la estructura subyacente en una matriz de datos. Analiza la estructura de las interrelaciones entre un gran número de variables no exigiendo ninguna distinción entre variables dependientes e independientes. Utilizando esta información calcula un conjunto de dimensiones latentes, conocidas como factores, que buscan explicar dichas interrelaciones. Es, por lo tanto, una técnica de reducción de datos dado que si se cumplen sus hipótesis la información contenida en la matriz de datos puede expresarse, sin mucha distorsión, en un número menor de dimensiones representadas por dichos factores. Un Análisis Factorial tiene sentido si se cumplen dos condiciones: Parsimonia e Interpretabilidad. 5.4.1) El Análisis Factorial frente a otros métodos de análisis El Análisis Factorial (AF) difiere de las técnicas de dependencia anteriormente expuestas, en que se consideran una o más variables explícitamente como las variables de criterio o dependientes, siendo las demás variables de predicción o independientes. En el AF los valores teóricos (los factores) se forman para maximizar la explicación la serie de variables entera, y no para predecir una variable dependiente. Así en el resto de técnicas de dependencia, cada una de las variables observadas sería una variable dependiente que es una función de una serie de funciones (dimensiones) subyacentes que están compuestas por todas las otras variables, por lo que cada variable es predicha por todas las demás. Por el contrario en el AF se puede considerar cada factor (valor teórico) como una variable dependiente que es función del conjunto entero de las variables observadas. Como resumen se podría decir que mientras que las técnicas de dependencia tienen como objetivo la predicción, las técnicas de interdependencia buscarán la identificación de la estructura 83 El AF también se diferencia bastante de técnicas como el Escalado Multidimensional o el análisis Cluster. Así mientras el AF se suele aplicar a la matriz de correlaciones, los otros métodos son más generales y se pueden aplicar a cualquier matriz de medidas similares. Sin embargo estos métodos no pueden enfrentarse a propiedades de la matriz de correlaciones tales como la proyección de variables. Además el AF puede reconocer ciertas propiedades de las correlaciones, pues estas se consideran simplemente medidas similares. 5.4.2) Formulación del problema de Análisis Factorial Se seleccionan [GORSUCH83] las variables a analizar así como los elementos de la población en las que dichas variables van a ser observadas. Aunque pueden realizarse análisis factoriales con variables discretas y/o ordinales lo habitual será que las variables sean cuantitativas continuas. Es importante que dichas variables recojan los aspectos más esenciales de la temática de estudio y su selección deberá estar marcada por la teoría subyacente al problema. No tiene sentido incluir variables que no vengan fundamentadas por los aspectos teóricos del problema porque se corre el riesgo de que los resultados obtenidos tengan una estructura muy complicada con la consiguiente dificultad de interpretación. Por eso es importante tener una idea previa al análisis de los factores a medir, y las variables que mejor los van a reflejar y no al revés pues puede suceder que los factores queden mal estimados por una mala selección de las variables. Así mismo, la muestra debe ser representativa de la población objeto de estudio y del mayor tamaño posible. Como regla general deberán existir por lo menos cuatro o cinco veces más observaciones (tamaño de la muestra) que variables. Si el tamaño de la muestra es pequeño y esta relación es menor, los resultados deben interpretarse con precaución. Conviene hacer notar, finalmente, que los resultados del análisis no tienen por qué ser invariantes a cambios de origen y escala por lo que se deberá normalizar los datos antes de realizar el análisis, especialmente cuando las unidades de medida de las variables no son comparables. 84 5.4.3) Proceso del Análisis Factorial Los pasos a seguir para la realización de un análisis factorial son: 1) Definir los objetivos deseados: básicamente son la identificación de la estructura mediante un resumen de datos o bien la reducción de datos. En el primer caso podremos distinguir entre: a) Análisis factorial R: es el más usual y se aplica a la matriz de correlación de las variables. En él se analiza una serie de variables para identificar las dimensiones que no son fácilmente observadas b) Análisis factorial Q: se aplica a la matriz de correlación de las observaciones individuales, y es un método que persigue combinar o condensar grandes grupos de individuos en grupos claramente diferenciados dentro de una población mayor. Este método presenta bastantes dificultades operativas, por lo que será más recomendable realizar un análisis Cluster. En cuanto a la reducción de datos podremos con el análisis factorial podremos tanto identificar las variables suplentes de una serie de variables más grande para su utilización en análisis multivariantes posteriores o crear una serie de variables completamente nueva más pequeña en número para reemplazar parcial o completamente la serie original de variables para su inclusión en técnicas posteriores. 2) Diseño de un análisis factorial: implicará el cálculo de los datos de entrada, esto es, una matriz de correlación. Deberemos determinar también el número de variables, las propiedades de medición de dichas variables y los tipos de variables permisibles y por último el tamaño muestral necesario. En cuanto a esto último, además de lo expuesto anteriormente, no se tomará una muestra inferior a 50 observaciones, y preferiblemente debería ser mayor de 100 observaciones. Supuestos en el análisis factorial: será deseable que haya un cierto grado de multicolinealidad pues el objetivo es identificar series de variables interrelacionadas. Se deberá determinar la justificación del uso del AF: 85 Test de esfericidad de Barlett [INVESTIGACION96]: comprueba si la matriz de correlaciones es una matriz identidad. Serán validos aquellos resultados que arrojen un valor elevado del test y cuya fiabilidad sea menor que 0,05. Coeficiente de correlación parcial: es una medida de la intensidad de la relación entre dos variables, eliminando la influencia de otras variables. Si las variables tienen factores comunes, el coeficiente de correlación parcial entre estas variables deberá ser muy bajo, pues se eliminan los efectos lineales de otras variables, siendo recomendable observar el número de celdas no pertenecientes a la matriz diagonal cuyo valor es superior a 0,05 ó 0,1 Índice de Kaiser-Meyer-Olkin (KMO): compara los coeficientes de correlación simple con los coeficientes de correlación parcial, cuyos valores oscilan entre 0 y 1. La interpretación de dicho índice se efectuará según estos parámetros: 1≥ KMO ≥ 0,9: Muy Bueno 0,9 ≥ KMO ≥ 0,8: Meritorio 0,8 ≥ KMO ≥ 0,7: Mediano 0,7 ≥ KMO ≥ 0,6: Mediocre 0,6 ≥ KMO ≥ 0,5: Bajo 0,5 ≥ KMO: Inaceptable 3) Estimación de los factores y valoración del ajuste general: el número de factores a extraer es crítico, pues deben ser suficientes para explicar la estructura, pero si son demasiados o insuficientes harán más oscura la estructura. Los criterios que se suelen aplicar son: Criterio de raíz latente: es la más frecuente y sencilla de aplicar. Dice que cualquier factor individual debería justificar la varianza de por lo 86 menos una única variable. Cada variable contribuye con un valor de 1 para el autovalor total. Por eso sólo se considerarán autovalores mayores que 1, desestimando los menores. Criterio de a priori: se establece un número factores a extraer y se para el análisis cuando se alcanza dicho número. Criterio de porcentaje de la varianza: se basa en obtener un porcentaje acumulado especificado de la varianza total extraída. No se debería detener hasta alcanzar al menos un 95% de la varianza. 4) Interpretación de los factores: se calculará la matriz inicial de factores no rotados para obtener una indicación preliminar de los factores a obtener. Sin embargo no suele suministrar un patrón significativo por lo que será aconsejable rotar los factores pues disminuye la ambigüedad. Finalmente se evaluará si hay que especificar un nuevo modelo o el existente es válido. 5.4.4) Rotación de factores La matriz de factores que muestra la relación entre las variables y los factores suele ser de difícil interpretación, pues suele haber muchas variables que tienen un valor alto de coeficiente en más de un factor. Sin embargo para comprender todos los datos de la matriz de factores el objetivo será que casi toda la varianza de una variable sea explicada por un único factor. Por consiguiente un coeficiente cuyo valor sea próximo a 0 significará que no hay relación entre una variables y un factor, mientras que si el coeficiente tiene un valor absoluto próximo a 1, supondrá la existencia de relación. Uno de los métodos que nos permite identificar estas situaciones es la rotación de factores. La rotación es una forma de girar los ejes principales para aproximar las variables empíricas y simplificar la interpretación. El objetivo será que cada variable quede mejor definida por una de las dimensiones que por el resto. Por tanto, como el número de componentes permanece constante, sólo varía la composición de los diferentes factores. Con esta operación no afectamos a los autovalores, pero si alterará los autovalores de los factores y la carga de los factorial (correlaciones entre cada 87 variable y el factor), y por tanto el porcentaje de variación explicada. Los tipos de rotación son: a) Rotación ortogonal: parte de que cada factor es independiente de los otros, por tanto, mantiene los ejes de los factores perpendiculares entre ellos. Algunos de los métodos de este tipo son: Varimax: es el método más usado. Trata de simplificar la estructura de los factores maximizando la varianza de los coeficientes de los factores al cuadrado en cada uno de los factores ( ij2 ). Normalmente estos factores suelen usarse normalizados. Quartimax: es similar al anterior, pero aplica el procedimiento entre variables representadas en las filas de la matriz en oposición de las columnas, que son usadas en el método anterior. Es más simple que el anterior, pero muestra la separación entre los diferentes factores de una forma menos clara. Equimax: es una mezcla de los anteriores, trata de simplificar tanto las filas como las columnas de la matriz, sin embargo no es muy usado b) Rotación oblicua: es aplicado cuando toda la información ha sido normalizada, siendo el resultado de la combinación de dos criterios, Quartimin, que es similar a Quartimax pero minimizando y Covarimin, que minimiza las covarianza de los coeficientes de los factores al cuadrado. Hay dos procesos de este tipo: Oblimax que trata de maximizar el numero de grandes y pequeños coeficientes, reduciendo el rango medio Promax, que es un método nuevo que aplica métodos ortogonales para encontrar la matriz deseada. 5.4.5) Representación gráfica del Análisis Factorial La representación más habitual es la representación de los factores en el espacio factorial rotado, que consiste en un mapa en que se exponen las 88 cargas factoriales de cada atributo, lo que puede ayudar a la interpretación del análisis. Para simplificar dicho gráfico normalmente no se representan más de dos factores. En nuestro ejemplo representamos los atributos P17 respecto a los factores resultantes de la aplicación de un análisis factorial, esto es, el Factor 1 y el Factor 2. Factor 1 P17_09 P17_13 P17_06 P17_08 P17_12 Factor 2 0,8426 0,103 0,133 1,107 -0,215 Gráfico de los factores en el espacio factorial rotado Factor 2 1,2 1 0,8 P17_09 0,6 P17_13 0,4 0,2 P17_06 0 -0,2 0 P17_08 P17_12 0,5 1 -0,4 Factor 1 Figura 5.1: Gráfico de los factores en el espacio factorial rotado 5.5 Análisis Cluster Por análisis Cluster se conoce al grupo de técnicas multivariantes cuyo objetivo es agrupar objetos basándose en las características que poseen. Por tanto este análisis clasifica los objetos en conglomerados, dentro de los cuales cada objeto es muy parecido al resto de componentes respecto a algún criterio de selección predeterminado. Por tanto los conglomerados de objetos resultantes 89 deben mostrar un alto grado de homogeneidad interna (dentro del conglomerado) y un alto grado de heterogeneidad externa (entre conglomerados). Si esto se cumple, en la representación gráfica los objetos de un mismo conglomerado se encontrarán muy próximos, mientras que los diferentes conglomerados se encontrarán muy alejados. Una de las formas típicas de representación son los dendogramas, siendo un ejemplo el de la figura 5.5 Figura 5.2. Dendograma La principal ventaja que ofrece este análisis es su facilidad para clasificar y agrupar toda clase de objetos o individuos. Sin embargo el análisis Cluster puede definirse como descriptivo, ateórico y no inferencial. Este análisis no tiene bases estadísticas sobre las que deducir inferencias estadísticas para una población a partir de una muestra, por lo que se utiliza fundamentalmente como una técnica exploratoria. El análisis Cluster siempre creará conglomerados, 90 independientemente de la existencia de una estructura real de datos. Además es totalmente dependiente de las variables utilizadas como base para la medición de similitud, lo que añade un alto grado de subjetividad al análisis. 5.5.1) Proceso del análisis Cluster Los pasos a seguir para la realización de un análisis cluster adecuado serán: 1) Elección de las variables: la selección de las variables a incluir en el valor teórico del análisis cluster debe hacerse con relación a consideraciones teóricas, conceptuales y prácticas. Así se deberán incluir aquellas variables que caracterizan los objetos que se están agrupando, y que se refieren más específicamente a los objetivos que buscamos con el análisis, esto es, diferenciar claramente unos conglomerados de otros. Esto se debe a que el análisis cluster es muy sensible a la inclusión de una o mas variables inapropiadas o escasamente diferenciadas. Otro problema que plantea el análisis cluster es la existencia de valores atípicos o “outliers”. Estos valores pueden observaciones que o bien no son representativas de la población en general o una muestra reducida del grupo de la población que provoca una representación de los grupos de la muestra. En ambos casos el análisis se presentará distorsionado y de difícil interpretación. La mejor forma de detección de estos valores atípicos es una representación preliminar. Una vez detectados se presenta la incógnita de qué hacer con ellos. Si gozamos de una muestra lo suficientemente amplia, y estos valores están arbitrariamente distribuidos lo mejor será su eliminación. En caso contrario, los valores se incluirán en el análisis, pues su eliminación podría suponer una reducción drástica de la muestra y producir resultados falseados. Otra disyuntiva que se presenta en este análisis es la de normalizar las variables. Normalmente se mantendrán en su estado original si son del mismo rango y no hay grandes diferencias entre los valores. Sin embargo si procederemos a su normalización en caso contrario y si se usa el método K 91 2)Elección de métodos de análisis: se podrá distinguir entre procedimientos jerárquicos y no jerárquicos, que se aplicarán a una matriz de distancias. Los métodos jerárquicos consisten en la construcción de una estructura en forma de árbol. Dentro de estos métodos se puede diferenciar entre: Métodos de aglomeración: el conglomerado por aglomeración empieza con cada objeto en un grupo separado. Los conglomerados se forman al agrupar los objetos en conjuntos cada vez más grandes. Este proceso continúa hasta que todos los objetos formen parte de un solo grupo Métodos de división: todos los objetos agrupados en un solo conjunto. Los conglomerados se dividen hasta que cada objeto sea un grupo independiente. Puesto que el método más extendido es el aglomerativo, nos centraremos en él, siendo sus algoritmos más usuales [HAIR99]: Encadenamiento simple: se basa en la distancia mínima, encuentra los dos objetos separados por la distancia más corta y los coloca en el primer conglomerado. A continuación encuentra la distancia más corta o une un tercer elemento al conglomerado y así sucesivamente. La distancia entre dos conglomerados cualquiera será la distancia más corta desde cualquier punto de un conglomerado a cualquier punto en el otro. Encadenamiento completo: análogo al anterior salvo que se basa en la distancia máxima. Encadenamiento medio: también es similar a los anteriores, pero esta vez el criterio es la distancia media de todos los individuos de un conglomerado con los individuos de otro. Método de Ward: en él la distancia entre conglomerados es la suma de los cuadrados entre dos conglomerados sumados para todas las variables. En cada paso se 92 minimiza la suma de los cuadrados dentro del conglomerado. Método del centroide: la distancia entre los dos conglomerados es la distancia entre sus centroides. Los centroides de los grupos son los valores medios de las observaciones de las variables en el valor teórico del conglomerado. Cada vez que se agrupa a los individuos se calculará un nuevo centroide. La ventaja de este método es su resistencia a valores atípicos. En cuanto a los métodos no jerárquicos no implican la construcción de árboles, sino que se asignan los objetos a conglomerados una vez que el número de conglomerados a formar está identificado. El primer paso será seleccionar una semilla de conglomerado como centro del conglomerado inicial y todos los objetos se situarán dentro de una distancia umbral especificada. Luego se designa otra semilla y se siguen situando objetos y así sucesivamente hasta que todos los objetos queden clasificados. Estos métodos se suelen denominar de la K-media. Estos procesos [MATE03] se caracterizan por que no requiere una relación inicial entre los casos. La “K” se refiere a un cierto número elegido por el analista para desarrollar el proceso, mientras que la media se refiere a que la media de las observaciones o centroide reprensentan un conglomerado particular. Los métodos que se suelen usar son: Umbral secuencial: se empieza seleccionando una semilla e incluye a todos los objetos que caen dentro de una distancia previamente especificada. A continuación se define una nueva semilla y se procede de la misma forma que antes, y así sucesivamente. Umbral paralelo: se seleccionan varias semillas de conglomerado simultáneamente al principio y se asigna objetos dentro de la distancia umbral hasta la semilla más cercana. A medida que el proceso avanza se puede ajustar las distancias umbral para incluir más o menos objetos en los conglomerados. 93 Optimización: es análogo a los anteriores, salvo que permite la reubicación de los objetos. Si en el curso de la asignación de los objetos, un objeto se acerca más a otro conglomerado que no es el que tiene asignado en este momento, entonces se cambia el objeto al conglomerado más cercano 3)Elección de las medidas de distancia y proximidad: se podrá trabajar con dos posibles matrices: Una matriz de casos y variables (n x p), cuando los caso están representados por sus atributos en las variables. Una matriz de proximidad para cada par de objetos, tanto de casos (n x n) como de variables (p x p). Esta matriz también podrá ser una matriz de distancias si mide la distancia entre dos objetos, o una matriz de similitudes cuando las similitudes o diferencias entre objetos están clasificadas. A mayores valores, mayores similitudes. Las diferentes medidas de distancia que se podrán usar para construir la matriz de distancia o similitudes será vendrán dadas en la tabla 4.7 Medida de distancia Expresión Distancia Euclídea Cudrado de la distancia Euclídea Mahalanobis D 2 Distancia Manhattan Distancia Chebychev Distancia Minkowsky Potencia métrica absoluta Tabla 5.7 Medidas de distancias 94 4)Decisión del número de conglomerados: hay varios métodos para efectuar esta operación: Criterio teórico: este método basa su fortaleza en un criterio teórico usado para determinar la decisión de un número específico de conjuntos. Se recomienda no quedarse con los primeros resultados obtenidos, sino evaluar los diferentes resultados obtenidos y quedarse con aquella de mayor significado teórico y estadístico. Coeficientes de conglomeración: se trata de buscar variaciones significativas en los valores de los coeficientes que indiquen el número apropiado de conjuntos. El número de conjuntos vendrá dado por el numero de conjuntos anteriores a un gran salto en el valor de los coeficientes de conglomeración. Mediante un gráfico “scree”: el criterio para determinar el número de conjuntos está dado por una nivelación en la pendiente de los datos mostrados en el gráfico, siendo este número el de los conjuntos que se representan antes de dicha nivelación Mediante dendogramas: uno de los gráficos más gráficos del análisis jerárquico. Usando programas específicos, tales como CLUSTAN 5)Presentación e Interpretación de los resultados: se hará tanto gráficamente como con tablas de resultados, difiriendo éstas según se haya usado el método jerárquico o el no jerárquico. Así en el método jerárquico se podrá elegir entre tablas de pertenencia de conglomerados y tablas históricas de conglomerados. Mientras, los métodos no jerárquicos incluyen tablas de centroides, tablas ANOVA y tablas resumen. Por su parte la representación gráfica ofrece una forma clara y fácil de interpretar los resultados, y de la misma forma que con las tablas, habrá diferentes posibilidades según el método elegido. Los dendogramas y los gráficos de carámbanos son los más 95 útiles para métodos jerárquicos, mientras que en los no jerárquicos se mostrarán los resultados en un gráfico de pertenencia de conjuntos. 6)Validación de los resultados: se debe asegurar que la solución es representativa de la población en general. La forma más directa es realizar un análisis cluster para varias muestras, siendo esto costoso en tiempo y medios. Algo más simple es dividir la media en dos grupos, analizando cada conglomerado por separado y comparando después los resultados. También se puede establecer una validez predictiva, seleccionando una variable no utilizada para formar los conglomerados pero que se sabe que cambia a lo largo del conglomerado. 5.5.2) Análisis Cluster. Comparación de métodos jerárquicos frente a los no jerárquicos. Jerárquicos No jerárquicos No exigen la definición del número Exigen definir el número de clusters de cluster a priori que se desean Llevan a cabo un proceso iterativo de abPoseen algunos índices que indican abajo hacia arriba con n-1 pasos, el número de clusters optimo partiendo de n grupos para terminar en 1 Permite obtener resultados gráficos distintos y tipos numéricos Dan de los valores de los centroides de que los grupos lo que facilita la facilitan al interpretación de los clusters interpretación Requieren gran cantidad de cálculos, Dan lo soluciones de tipo óptimo que limita sus posibilidades a muestras no muy grandes Se pueden aplicar a las observaciones Sólo pueden aplicarse sobre las y a las variables Observaciones realizando grupos de individuos Tabla 5.8 Comparación de métodos en el análisis Cluster 96 5.6) Mapas Perceptuales Abarcan un conjunto de técnicas gráficas que surgen en el ámbito del marketing y cuyo objetivo es representar las percepciones de clientes o potenciales clientes, y donde se suelen representar un objeto frente a su competidores, con lo que podremos obtener una imagen clara de en que características se diferencian o se asemejan (dichas similitudes o divergencias no siempre son evidentes) y de su percepción general. Deberemos diferenciar entre las representaciones obtenidas a partir del análisis multidimensional y el análisis de correspondencias, ambos presentados en puntos anteriores. Así mientras el análisis de correspondencias presenta un medio de comparación directa de similitud y diferencia de objetos de estudio y de sus atributos asociados mientras que el análisis multidimensional se ciñe a la comparación entre objetos. Sin embargo el análisis de correspondencias presenta la desventaja que la solución está condicionada por los atributos incluidos por el investigador, con lo que se añade un cierto grado de subjetividad. En un principio se supone que todos los atributos son apropiados para todas los objetos y que se aplica la dimensión para cada objeto, y esto puede no ser del todo cierto. Por eso el resultado obtenido sólo deberá ser evaluado en el contexto de los objetos y los atributos incluidos en el análisis. 5.6.1) Interpretación de los mapas perceptuales En resumen un mapa perceptual es una forma de representar gráficamente un conjunto de objetos relacionando dos o más factores. Esta comparación se lleva a cabo mediante un mapa cartesiano. En el análisis de un mapa preceptual se distinguen dos objetos, el espacio perceptual y el propio mapa perceptual. El espacio perceptual es la representación gráfica de los factores más importantes que son de interés en el análisis. Estos factores son atributos que se asocian a los objetos, y son usados como el lugar donde los diferentes objetos serán situados luego, comparándose entre ellos. Esto hace que en un mapa perceptual no tenga de por sí zonas mejores o peores, sino puede que un lugar sea el adecuado que queríamos para un determinado objeto, o por el contrario, que no lo sea. 97 Por consiguiente el primer paso al desarrollar un mapa perceptual es definir el espacio perceptual. Se necesita definir un mapa cartesiano donde distribuir los atributos que modelarán posteriormente a los objetos, según los atributos que se les aplique a estos. El conjunto del espacio perceptual, a la situación de los objetos en él configurarán el mapa perceptual completo. La longitud de un vector atributo es igual a la raíz cuadrada de la suma de los cuadrados de las correlaciones con las dimensiones. Esta longitud no podrá ser nunca que uno, y la longitud relativa de vector atributo en dos dimensiones cualquiera es una medida de cuanto explican dichas dimensiones ese atributo. Una vez se ha determinado la aportación de cada atributo a las dimensiones, se podrá obtener el grado en el que cada objeto es explicado por cada atributo, lo que emplea para representar cada objeto en el mapa. La media de todos los objetos respecto a cada atributo y a cada dimensión son cero. Esto se traduce gráficamente en que el centro de gravedad de todos los productos es el centro del mapa perceptual. Finalmente podremos definir la similitud entre objetos y los atributos que se les suponen midiendo la proximidad (o en caso contrario lejanía) respecto a estos. Symmetric plot (axes F1 and F2: 93,39 %) Bankinter 0,2 0,1 Bajista Muy bajista F2 (31,54 %) Valencia Popular Sabadell BBVA Alcista Santander IBEX 0 Muy alcista -0,1 Estable -0,2 Banesto Guipuzcoano -0,3 -0,5 -0,4 -0,3 -0,2 -0,1 0 0,1 0,2 0,3 0,4 F1 (61,85 %) Columns Rows Figura 5.3: Mapa perceptual que representa el sector bancario español frente al IBEX35 98 Capítulo 6 Desarrollo de la herramienta y caso práctico 6.1) Software empleado Para el desarrollo de la herramienta se emplearon tres programas diferentes: Excel Matlab Xlstat La utilización de dicha cantidad podría suponer una desventaja, pues podría añadir restricciones y restar fiabilidad al sistema. Sin embargo, en este caso supone todo lo contrario. Además de emplear cada programa para aquello que es más potente, con lo que se ahorra tiempo en operaciones intermedias, dichos programas tienen la virtud de ser compatibles, contando con comandos que los comunican de una manera fácil y segura. 6.1.1) Excel El conocido programa de cálculo y manejo de datos disponible con el paquete de utilidades Microsoft Office será el soporte para la descarga de los datos necesarios, y tras varias operaciones, para la posterior muestra de resultados. En primer lugar las tablas correspondientes a cada empresa se descargarán de http://es.finance.yahoo.com/q/cp?s=%5EIBEX, obteniéndose una tabla en formato Excel, de la que los valores que se utilizarán serán la semana, la apertura y el cierre. Posteriormente dichos valores de apertura y cierre, mediante un función de Visual Basic para Excel se transformarán en una columna de variaciones semanales, datos que ya pueden ser exportados a Matlab para su tratamiento. De este proceso podemos extraer todas las ventajas que aporta trabajar con Excel: Fácil acceso a los datos. 99 Claro manejo de tablas de datos y posibilidad de actualizar dichas tablas de forma automática. Empleo de funciones de Visual Basic, y automatización de éstas y de otras labores mediante el empleo de Macros. Sobre todo serán útiles para el cálculo de las variaciones semanales y del volumen monetario de la semana, y posteriormente corregir dichas columnas y la columna de precio de cierre, pues en aquellas filas dónde se representan el reparto de dividendos se producirá un error, que de no ser corregido asignándole un número determinado, no podrá ser tratado por Matlab. 6.1.2) Matlab Una vez obtengamos las columnas de las variaciones semanales, de volumen monetario negociado en la semana y del precio de cierre semanal de cada valor, se procederá a formar la tabla de contingencia que permitirá analizar las relaciones entre los atributos de variación y volumen y las empresas seleccionadas por un lado, y la columna con los valores de los coeficientes de correlación por otro. Para importar los datos de Excel a Matlab se recurrirá al comando xlsread (muy importante que la carpeta de trabajo de Matlab esté en la carpeta que contenga los archivos de Excel a importar). Por ejemplo: Variacion1:xlsread(‘ACS’,’Hoja1’,’i2:i18’) Volumen1:xlsread(‘ACS’,’Hoja1’,’k2:k18’) Cierre1: xlsread(‘ACS’,’Hoja1’,’l2:l18’) Posteriormente para eliminar aquellos datos que representan dividendos, aplicaremos a cada columna una función de filtro, por ejemplo: Variacion1:filtrovar(Variacion1) Volumen1:filtrovolumen(Volumen1) Cierre1: filtrocotizacion(Cierre1) Procediendo de manera análoga para cada empresa a analizar (muy importante que los datos de todas las empresas estén referidos al mismo 100 periodo), se obtienen las diferentes columnas de las matrices de variaciones semanales, volúmenes medios negociados semanalmente y cierres semanales, ensamblándose dichas columnas de la siguiente forma: Variaciones=[Variacion1 Variacion2……VariaciónN] Volumenes=[Volumen1 Volumen2……..VolumenN] Cierres=[Cierre1 Cierre2……….CierreN] Para transformar la matriz de variaciones y de volúmenes en una sola tabla de contingencia se recurre a una función que tendrá como argumento dichas matrices: resultado=contingencia(Variaciones,Volúmenes) Por su parte, para obtener la columna con los coeficientes de correlación de las diferentes empresas, que pueden ser muy útiles en la interpretación del mapa de posicionamiento: Coeficientes=coefvariacion(Cierres) Por último, se debe exportar dicho resultado a Excel para su análisis final, lo que se efectuar mediante el comando xlswrite: xlswrite( ‘Resultadofinal’,resultado,’Hoja1’,’b2’). xlswrite(‘Resultadofinal’,Coeficientes,’Hoja2’,’b2’) Las ventajas que subyacen del empleo de Matlab son: Facilidad de trabajo con matrices. Empleo de funciones (M. files) que dotan al sistema de polivalencia y simplifican su uso. Interfaz gráfica (Ver apartado 7) 6.1.3) Xlstat Una vez se tiene la tabla de contingencia, en una hoja de Excel se procederá al Análisis de Correspondencias y a otros test de independencia como el de la 101 V de Cramer mediante el Xlstat. Dicha herramienta es una barra de herramientas que trabaja sobre archivos de Excel, dando de una manera sencilla un resultado completo. La elección del Xlstat se fundamenta en: La variedad de técnicas estadísticas disponibles y la comodidad de su realización. Se muestran los resultados de una manera clara y completa. La posibilidad de automatizar parcialmente alguno de los pasos a dar mediante la implementación con Macros de Excel. 6.2) Técnicas estadísticas empleadas Las principales técnicas estadísticas empleadas son el Análisis de Correspondencias y la V de Cramer, partiendo ambas de la tabla de contingencia obtenida. 6.2.1) Análisis de Correspondencias Como se expuso anteriormente en el capítulo 5 se trata de una técnica de interdependencia que a partir de una tabla de contingencia halla las relaciones entre los atributos definidos y las variables de estudio, en este caso las empresas del IBEX-35, y que valiéndose de varios tipos de test y de medidas como las de inercia o autovalores, halla unas nuevas variables sintéticas y representa en un mapa cartesiano tanto las atributos como las empresas estudiadas. Los principales resultados obtenidos del análisis son: Test de independencia: mediante un contraste de hipótesis donde la hipótesis nula (Ho) será la independencia entre atributos y empresas, y la hipótesis alternativa (Ha), la existencia de dicha relación. El valor de significación α será habitualmente del 5% (pero se puede modificar). Dicho valor se comparará con el P-value que es la probabilidad de obtener un resultado como el observado o mayor si la hipótesis nula es cierta, rechazándose la hipótesis nula si dicho valor es menor que α, siendo el riesgo de rechazar Ho siendo cierta menor que el del P-value 102 Inercia total: medida del grado de dependencia entre variables. Dicha inercia total se podrá desglosar en inercias parciales que representarán la contribución de cada eje principal a la inercia total. Autovalores: determinan la contribución relativa de cada nueva variable al mapa. Para simplificar se representarán las dos variables con mayor valor de autovalor. Cosenos al cuadrado: la interpretación de este resultado es que cuanto más cercano sea su valor a 1, más próximo esta el atributo o la empresa a la variable artificial, y por consiguiente más importante es este eje para este atributo o empresa. 6.2.2) Técnicas de independencia Su importancia nace de la conveniencia para dotar de sentido estadístico al estudio de la tabla de contingencia de que exista cierto grado de relación entre los atributos asignados referentes a la variación y al volumen y las empresas estudiadas. De hecho la inclusión en el estudio responde a dicha necesidad, habiéndose testado la posibilidad de añadir como atributo el reparto de dividendos con resultados insatisfactorios. a)V de Cramer Se trata de una medida estadística basada en la distribución Chi-Cuadrado, que nos determinará de manera muy adecuada para las tablas de contingencia un grado de independencia total (V=0) o absoluto (V=1). Se consideran aceptables valores por debajo de 0,3 para aceptar independencia entre variables, aceptándose dependencia a partir de dicho valor. Sin embargo, dicho valor deberá ser analizado desde la perspectiva del P-valor que es la práctica habitual en estadística aplicada. b) Chi-Cuadrado La existencia de relación de algún tipo entre las variables fila y columna se analiza mediante contrastes de hipótesis sobre la independencia de dichas variables. El test de hipótesis habitualmente utilizado es el de la Chi-Cuadrado de Pearson. En dicho test la hipótesis nula es H0: las variables fila y las variables columna son independientes y la alternativa es H1: las variables son dependientes. El test se basa en comparar los perfiles fila y columna con los 103 perfiles marginales correspondientes, teniendo en cuenta que si H0 es cierta todos los perfiles fila (resp. columna) son iguales entre sí e iguales al perfil marginal de fila (resp. columna). El estadístico del test viene dado por la expresión: Donde: A simple vista se intuye que valores del estadístico pequeños significarán valores de n ij y e ij de magnitud parecida, con lo que aceptamos la hipótesis nula, mientras que en caso de valores grandes aceptaremos la hipótesis alternativa. Bajo la hipótesis nula el estadístico se distribuye según una distribución: viniendo donde el p-valor del test dado por: es el valor observado en la muestra del estadístico. Para un nivel de significación 0< α <1 la hipótesis nula se rechaza si dicho p-valor es menor o igual que α. De esta forma si rechazamos la hipótesis nula las variables de las filas y las columnas son dependientes. En este caso conviene analizar los perfiles condicionales fila y columna, así como los residuos del modelo para estudiar qué tipo de dependencia existe entre ellas. Los residuos más utilizados son los llamados residuos tipificados corregidos que vienen dados por la expresión: 104 n Si toman valores grandes en valor absoluto se deberá a que los valores e ij ij y son muy diferentes. Los residuos se distribuyen asintóticamente según una N(0,1) la hipótesis nula y a un nivel de confianza del 95% residuos con un valor absoluto mayor que dos se consideran como valores anormalmente altos. En resumen, se rechazará la hipótesis nula Ho cuando el valor del coeficiente observado sea mayor que el crítico para el nivel de significación escogido. c) Tau de Goodman Kruskal La Tau de Goodman y Kruskal indica la reducción en el error de clasificación de los elementos para una de las variables (dependiente) cuando se tiene información sobre el comportamiento de la otra (independiente). d) Coeficiente de contingencia Se define como C 2 Esta medida de asociación no se ve afectada por 2 n el tamaño de la muestra y está acotada entre 0 y 1, de forma que si las variables son independientes se tiene C=0, pero en caso de asociación perfecta nunca alcanza el valor 1. En el caso de que la tabla sea cuadrada de dimensión R x R se puede calcular la cota superior que es R 1 R e) Phi de Pearson Se trata de una modificación de la Chi cuadrado de Pearson, y sus valores oscilan entre 0 para la inexistencia de relación y 1 para la relación total entre las variables estudidas. 6.2.3) Coeficiente de variación Habitualmente se denomina coeficiente de variación a la medida de variabilidad relativa g s x 100 donde el valor de la media no es nulo. Sin embargo en este caso se prescindirá del valor absoluto, empleando la media 105 con signo, pues así nos informará del sentido de cambio del valor de cierre de las cotizaciones. Típicamente deberá ser menor que 100. 6.3) Niveles de la herramienta La herramienta constará de varios niveles de uso para adaptarse a las diferentes necesidades del público a la que va enfocada: Nivel amateur: los niveles de variación para clasificar las acciones serán: -Muy alcista: variación ≥3 -Alcista: 1< variación ≤3 - Estable: -1< variación ≤1 -Bajista: variación -3< variación ≤-1 -Muy bajista: variación ≤-3 Nivel avanzado: se clasificarán las variaciones en 8 rangos de valores -Extremadamente alcista: variación > 4 -Muy alcista: 2.5< variación ≤4 -Alcista: -Ligeramente alcista: 1< variación ≤2.5 -Ligeramente alcista: 0< variación ≤1 -Ligeramente bajista: -1< variación ≤0 -Bajista: -2.5< variación ≤-1 -Muy bajista: -4< variación ≤-2.5 -Extremadamente bajista: variación ≤-4 Nivel Personalizado: el usuario podrá definir los límites de los ocho rangos presentados en el nivel avanzado. -Extremadamente alcista: variación > límite1 -Muy alcista: límite2< variación ≤límite1 -Alcista: -Ligeramente alcista: límite3< variación ≤límite2 -Ligeramente alcista: límite4< variación ≤límite3 -Ligeramente bajista: límite5< variación ≤límite4 106 -Bajista: límite6< variación ≤límite5 -Muy bajista: límite7< variación ≤límite6 -Extremadamente bajista: variación ≤límite7 Por su parte el volumen monetario negociado será clasificado según su pertenencia a las diferentes cuartilas definidas por dichas observaciones del volumen en el nivel avanzado: 0 < Volumen ≤ Q1 Q1 < Volumen ≤ Q2 Volumen=2 Q2< Volumen ≤ Q3 Volumen > Q3 Volumen=1 Volumen=3 Volumen=4 En el nivel amateur, la clasificación del volumen monetario negociado se hará mediante la medina: 0 < Volumen ≤ Mediana Volumen=1 Volumen > Mediana Volumen=2 La mediana [ESTADISTICA97] es una medida estadística de tendencia central, tal que, ordenados en magnitud los datos, el 50% es menor que ella y el 50% es mayor a ella, de forma que para n datos, la mediana será n impar y X n 1 2 2 X n 2 X n 1 2 para para n par. Una de las ventajas que nos ofrece es que no es excesivamente sensible a los valores atípicos. Análogamente se definen las cuartilas, sin embargo en lugar de quedar el 50% de las observaciones a cada lado de la medida como sucedía con la mediana, entre cada uno de los cuatro rangos de valores de definidos entre 0, Q1, Q2 y Q3 quedarán el 25% de las observaciones. La función de la herramienta es calcular para cada semana los valores de la mediana, o de Q1, Q2 y Q3 según el modo de uso, de los volúmenes monetarios totales negociados, para a continuación poder clasificar el volumen de cada empresa en el rango que le corresponda esa 107 semana. Una vez obtenida la tabla de observaciones, se lo podrá aplicar el análisis de correspondencias. *Observaciones respecto al volumen monetario 1) Por simplicidad de cálculos se ha utilizado una aproximación para el cálculo de dicho volumen: volumen _ monetario n º acciones _ negociadas Pr ecioapertura Pr eciocierre 2 2) No se recomienda el estudio conjunto de la evolución del IBEX-35 y del volumen monetario negociado de las empresas, pues el IBEX-35 es una índice estadístico en cuyo caso influye decisivamente el volumen de todas las empresas, lo que falsearía el estudio, y además su medida es un puntos, no en euros. 6.4) Caso práctico Para ilustrar este proceso, se visualizará el mapa perceptual obtenido mediante análisis de correspondencias y se comentarán las medidas asociadas, para los datos de variación semanal desde 02/01/2007 hasta el 19/03/2007 (13 semanas) para las siguientes 7 empresas: Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefónica La elección de dichas empresas no es casual, sino que responde a que a priori presentan comportamientos contrapuestos de volatilidad, porcentaje de variación o volumen. Para obtener una mayor claridad en los resultados dicho análisis se hará a nivel amateur. 108 Tras las operaciones oportunas descritas en epígrafes anteriores la tabla de contingencia obtenida es la siguiente: Muy bajista Bajista Estable Alcista Muy alcistaMuy poco volumenEscaso volumenBastante volumenMucho volumen Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica Tabla 6.1 Tabla de contingencia Aplicando a dicha tabla un análisis de interdependencia obtenemos el valor de la V de Cramer y otras medidas de interdependencia: Coeficiente Phi de Pearson V de Cramer T de Tschuprow Coeficiente de contingencia U de Theil (R|C) U de Theil (C|R) U de Theil medio Tau de Goodman & Kruskal (R|C) Tau de Goodman & Kruskal (C|R) Tau de Goodman & Kruskal medio Valor 0,773 0,316 0,294 0,612 0,100 0,103 0,101 Tabla 6.2 Medidas de independencia Dicho valor, que para 0 indicaría independencia absoluta entre las variables y para 1 un grado de relación total, al ser superior a 0,3, se puede considerar que existe un cierto grado de relación entre las empresas y los atributos asignados. Por su parte, el valor de Phi de Pearson (0,773) o el del coeficiente de contingencia (0,612) parecen confirmar la existencia de dependencia entre los atributos estudiados. A continuación se aplicará el análisis correspondencias a la tabla de contingencia. Pruebas de independencia entre las filas y columnas de la tabla de contingencia: Prueba del Chi-cuadrado: Chi-cuadrado (valor observado) Chi-cuadrado (valor crítico) GDL 108,845 65,171 109 de p-value unilateral Alpha < 0,0001 Conclusión: Al umbral de significación Alfa=0,050 se puede rechazar la hipótesis nula de independencia entre las filas y columnas. Dicho de otro modo, la dependencia entre las filas y columnas es significativa. Prueba de la razón de verosimilitud del Chi-cuadrado (G² de Wilks): G² de Wilks (valor observado) G² de Wilks (valor crítico) GDL p-value unilateral Alpha 130,822 65,171 < 0,0001 Conclusión: Al umbral de significación Alfa=0,050 se puede rechazar la hipótesis nula de independencia entre las filas y columnas. Dicho de otro modo, la dependencia entre las filas y columnas es significativa. Tabla de estadísticas que prueba la independencia filas/columnas: Valor GDL 108,845 130,822 Chi-cuadrado G² de Wilks p-value < 0,0001 < 0,0001 Tabla 6.3: Medidas de independencia Mediante los diferentes análisis de hipótesis se confirma la existencia de un cierto grado de dependencia entre atributos y empresas. Esta conclusión también la confirma el hecho de que el valor Chi-Cuadrado observado sea mayor que el del valor crítico para un alpha de 0,05. Posteriormente se muestran los autovalores, que nos informan sobre el grado de explicación obtenido con las variables artificiales obtenidas, lo que se visualiza mejor en el scree plot. En este caso tenemos un 83,68% de variación explicada con las nuevas variables artificiales F1 y F2, lo que se considera bastante bueno, pues se considerará aceptable a partir de un 60%. Valores propios y porcentaje de varianza: F1 Valor propio % varianza 0,409 68,326 F2 0,092 15,356 F3 F4 0,049 8,261 F5 0,033 5,540 F6 0,013 2,243 0,002 0,275 110 % acumulado 68,326 83,681 91,942 Número de valores propios triviales suprimidos: 2 97,482 99,725 100,000 Tabla 6.4: Valores propios y porcentaje de varianza Posteriormente se nos muestra la aportación individual de cada empresa e índice a la inercia total y su distancia al punto de origen, que tiene la propiedad de ser el centro de gravedad de todas las variables. Pesos, distancias al origen e inercias de los puntos-filas: Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica Peso Distancia d d² Inercia Inercia normalizada 0,143 0,744 0,553 0,079 0,132 0,143 0,751 0,564 0,081 0,135 0,143 0,870 0,758 0,108 0,181 0,143 0,512 0,262 0,037 0,063 0,143 0,842 0,709 0,101 0,169 0,143 0,941 0,885 0,126 0,211 0,143 0,674 0,455 0,065 0,109 Tabla 6.5: Pesos, distancias al origen e inercias de los puntos fila. A continuación, tras hallar las distancias Chi-cuadrado de las empresas e índices, nos presenta sus coordenadas definitivas respecto a las 4 variables artificiales construidas, aunque sólo se representarán en el mapa aquellas variables que aporten mayor grado de información: Coordenadas de los puntos-filas: 111 Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica F1 F2 -0,415 0 0,726 0,034 0,805 -0,160 -0,229 0,294 -0,689 -0,261 -0,794 -0,364 0,597 -0,106 F3 F4 -0,010 0,029 -0,193 -0,082 0,390 -0,331 0,197 F5 0,247 -0,135 0,049 -0,339 -0,056 0,068 0,166 F6 -0,031 0,111 -0,210 0,004 -0,101 0,092 0,134 -0,018 -0,073 0,007 0,047 -0,016 -0,006 0,058 Tabla 6.6: Coordenadas de los puntos fila También se ofrece el grado de contribución de cada variable a la construcción de dichas variables artificiales y su respectiva inercia, además de las coordenadas estandarizadas: Coordenadas estandarizadas de los puntos-filas: Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica F1 F2 F3 -0,650 1,860 -0,047 1,135 0,112 0,130 1,260 -0,529 -0,868 -0,359 0,969 -0,368 -1,078 -0,861 1,757 -1,241 -1,202 -1,490 0,933 -0,349 0,886 F4 F5 1,359 -0,741 0,266 -1,861 -0,310 0,374 0,912 F6 -0,265 0,960 -1,810 0,037 -0,873 0,796 1,155 -0,444 -1,792 0,1 1,154 -0,390 -0,141 1,434 Inercias de los puntos-filas: F1 Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica F2 0,025 0,075 0,093 0,008 0,068 0,090 0,051 F3 0,045 0,000 0,004 0,012 0,010 0,019 0,002 F4 0,000 0,000 0,005 0,001 0,022 0,016 0,006 F5 0,009 0,003 0,000 0,016 0,000 0,001 0,004 F6 0,000 0,002 0,006 0,000 0,001 0,001 0,003 0,000 0,001 0,000 0,000 0,000 0,000 0,000 Contribuciones de los puntos-filas (%): F1 Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica F2 F3 F4 49,43 18,41 22,66 16,60 22,02 12,44 F5 13,16 46,81 10,77 13,41 10,59 20,65 F6 26,40 49,49 44,08 31,72 11,22 45,88 19,02 10,89 11,89 19,07 29,36 112 Cosenos cuadrados de los puntos-filas: F1 Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica F2 0,312 0,933 0,856 0,200 0,670 0,711 0,783 F3 0,575 0,002 0,034 0,328 0 0,150 0,025 F4 0,000 0,001 0,049 0,026 0,215 0,124 0,085 F5 0,111 0,032 0,003 0,437 0,004 0,005 0,061 F6 0,002 0,022 0,058 0,000 0,014 0,010 0,039 0,001 0,009 0,000 0,008 0,000 0,000 0,007 Tabla 6.7: Medidas de los puntos fila En la tabla de cosenos al cuadrado observamos que, como cabía esperar para la variable F1 la mayoría de los valores están por encima de 0,5 y alguno próximo a uno. Sin embargo, para F2 el análisis empeora sensiblemente (mientras que F1 aporta un 68% de la información, F2 aporta el 15%). Todo el análisis anterior se repite de forma análoga para los atributos designados Pesos, distancias al origen e inercias de los puntos-columnas: Muy bajista Bajista Estable Alcista Muy alcista Muy poco volumen Escaso volumen Bastante volumen Mucho volumen Peso Distancia d d² Inercia Inercia normalizada 0,060 0,891 0,793 0,048 0,080 0,088 0,606 0,367 0,032 0,054 0,159 0,507 0,25 0,041 0,068 0,071 0,449 0,201 0,014 0,024 0,121 0,575 0,331 0,040 0,067 0,137 1,024 1,050 0,144 0,241 0,066 0,920 0,847 0,056 0,093 0,033 1,312 1,722 0,057 0,095 0,264 0,793 0,628 0,166 0,277 Coordenadas de los puntos-columnas: Muy bajista Bajista Estable Alcista Muy alcista Muy poco volumen Escaso volumen Bastante volumen F1 -0,640 0,001 0,429 -0,008 -0,241 -0,948 -0,856 -0,624 F2 -0,119 0,501 0,001 -0,359 -0,094 -0,305 0,266 1, F3 F4 0,221 0,554 -0,209 -0,087 -0,240 -0,042 -0,160 0,145 0,451 -0,244 -0,183 -0,146 -0,010 0,159 0,147 0,008 F5 F6 0,117 0,254 -0 -0,134 -0,017 0,049 -0,101 -0,266 -0,005 0,014 -0,038 0,086 -0,008 0,012 -0,089 0,097 113 Mucho volumen 0,786 -0,046 0,080 0,036 0,033 0,004 Coordenadas estandarizadas de los puntos-columnas: Muy bajista Bajista Estable Alcista Muy alcista Muy poco volumen Escaso volumen Bastante volumen Mucho volumen F1 F2 F3 -1,001 -0,392 0,995 0,001 1,654 -0,940 0,671 0,004 -1,078 -0,013 -1,186 -0,718 -0,377 -0,311 2,031 -1,483 -1,007 -0,825 -1,339 0,877 -0,046 -0,976 3,661 0,660 1,229 -0,153 0,359 F4 F5 3,044 -0,477 -0,231 0,796 -1,341 -0,804 0 0,041 0,195 F6 1,008 2,1 -0,962 -1,160 -0,144 0,427 -0,876 -2,293 0,283 -0,131 0,350 -0,943 2,128 -0,204 0,294 -2,182 2,400 0,092 Inercias de los puntos-columnas: Muy bajista Bajista Estable Alcista Muy alcista Muy poco volumen Escaso volumen Bastante volumen Mucho volumen F1 F2 F3 0,025 0,001 0,003 0,000 0,022 0,004 0,029 0,000 0,009 0,000 0,009 0,002 0,007 0,001 0,025 0,123 0,013 0,005 0,048 0,005 0,000 0,013 0,041 0,001 0,163 0,001 0,002 F4 F5 0,019 0,001 0,000 0,001 0,007 0,003 0,002 0,000 0,000 F6 0,001 0,006 0,002 0,001 0,000 0,000 0,001 0,002 0,000 0,0 0,000 0,000 0,001 0,000 0,000 0,001 0,000 0,000 Contribuciones de los puntos-columnas (%): F1 Muy bajista Bajista Estable Alcista Muy alcista Muy poco volumen Escaso volumen Bastante volumen Mucho volumen F2 F3 F4 F5 F6 55,99 24,06 42,22 14,76 18,50 14,15 32,35 10,05 49,86 30,22 11,83 21,73 13,92 44,19 31,40 18,99 17,34 39,86 Cosenos cuadrados de los puntos-columnas: Muy bajista Bajista Estable Alcista Muy alcista F1 F2 F3 0,516 0,018 0,062 0,000 0,684 0,119 0,716 0,000 0,223 0,000 0,642 0,126 0,175 0,027 0,616 F4 F5 0,38 0,021 0,007 0,104 0,180 F6 0,017 0,175 0,048 0,090 0,001 0,000 0,001 0,006 0,037 0,000 114 Muy poco volumen Escaso volumen Bastante volumen Mucho volumen 0,856 0,865 0,226 0,983 0,089 0,083 0,715 0,003 0,032 0,000 0,012 0,010 0,020 0,030 0,000 0,002 0,002 0,012 0,041 0,002 0,000 0,009 0,006 0,000 Tabla 6.8: Medidas de los puntos columna Por último y finalmente obtenemos el mapa perceptual que relaciona empresas, índices y atributos: Gráfico simétrico (ejes F1 y F2: 83,68 %) 1,5 B astante vo lumen 1 A cerino x 0,5 Escaso vo lumen B ajista Gas Natural Estable 0 M uy bajista M uy alcista Iberia M uy po co vo lumen M apfre A ltadis M ucho vo lumen Telefo nica Endesa Filas activas Co lumnas activas A lcista -0,5 -1 -1,5 -1,5 -1 -0,5 0 0,5 1 1,5 - - e je F 1 ( 6 8 ,3 3 %) - - > Figura 6.1: Mapa Perceptual De este mapa podremos extraer las siguientes conclusiones: El eje en el que se representa la variable artificial F1 parece representar la volatilidad. Se puede concluir que los valores menos volátiles tienen un mejor comportamiento que aquellos más proclives a grandes variaciones. De hecho, el atributo Muy alcista se encuentra próximo a Muy bajista y también a Bajista. Parecen comportarse mejor y tener menor volatilidad aquellas empresas de mayor volumen monetario negociado. La zona más favorable del mapa parece ser el cuadrante de F1 positivo y F2 negativo. 115 Por último, y como ayuda adicional para la interpretación del mapa, se incluyen los coeficientes de variación de las empresas: Acerinox Altadis Endesa Gas Natural Iberia Mapfre Telefonica Coef Variacion 4,333318008 7,882541649 3,137789131 5,517422991 9,585445284 2,72668864 2,818183262 Tabla 6.9: Coeficientes de variación Confirma las conclusiones del mapa, salvo por Altadis que tiene una variación excesiva, sobre todo comparada con las otras empresas y MAPFRE, que sin embargo presenta un coeficiente de variación más bajo de lo que cabría esperar. 116 Capítulo 7 Manual del Usuario 7.1) Pasos previos al uso de MAPIBEX MAPIBEX es una herramienta que combina aplicaciones tanto de Excel y de su herramienta estadística Xlstat, como de Matlab, por lo que se hace necesaria la instalación de dichos programas. Se podrá obtener una copia de evaluación de la herramienta Xlstat en la página web www.xlstat.com escogiendo la opción descargar versión de evaluación. MAPIBEX se entregará en forma de archivo en formato .zip, por lo que para empezar a trabajar se deberá descomprimir en la ubicación que elija el usuario la carpeta MAPIBEX, que contendrá todas las funciones de Matlab que realizan el análisis, la interfaz gráfica y las tablas de datos de las cotizaciones. Figura 7.1: Descarga de copia de evaluación Xlstat 117 Figura 7.2: Se han de rellenar varios datos para descargar el Xlstat Figura 7.3: Instalación del Xlstat, se deberá especificar la localización 7.2) Captura y transformación de los datos Las tablas de datos en formato Excel, que contienen la información acerca de las cotizaciones y el volumen de títulos negociados de las empresas del IBEX35 se pueden descargar http://es.finance.yahoo.com/q/cp?s=%5EIBEX, de la página seleccionando en web cada empresa cotizada, obtener los precios históricos y a su vez las variaciones semanales. 118 Figura 7.4: Captura de datos de Yahoo Finanzas Respecto a la selección de variaciones semanales, cabe destacar que si bien MAPIBEX en sus modos de uso Amateur y Avanzado ha sido programado para trabajar con datos semanales, dado que cuenta con una opción de uso Broker donde el usuario puede definir los límites de las variaciones, éste podrá definir dichas variaciones para trabajar con variaciones diarias. Las tablas que se obtendrán para cada empresa deberán ser nombradas de la siguiente forma para que MAPIBEX las reconozca y pueda leer sus datos: ANA Acciona FER ABE IBE Ferrovial Abertis Iberia ACX IBLA ACS ITX Acerinox Iberdrola ACS Inditex AGS AguasBarcelona ALT Altadis A3TV Antena3 SAB BancoSabadell BBVA BBVA BTO Banesto BKT Bankinter POP BancoPopular SAN BancoSantander CIN Cintra ENG Enagas ELE Endesa FAD Fadesa FCC FCC GAM Gamesa GAS GasNatural TL5 Telecinco 119 MAP Mapfre MCV Metrovacesa NHH NHH Hoteles REP Repsol YPF REE Red Eléctrica Española SYV Sacyr Vallehermoso SGC Sogecable TEF Telefónica UNF Unión Fenosa IBEX IBEX35 DJI Dow Jones Industrial Tabla 7.1: Correspondencias entre acrónimos de las empresas y sus respectivos nombres para ser guardadas. Una vez obtenidas las tablas, se deberán obtener la variación (en %), la variación corregida (en caso de reparto de dividendos se produce un mensaje de error que posteriormente no es reconocido por Matlab, por lo que es necesario tratarlo previamente), el volumen, el volumen corregido y el cierre corregido. Dichas operaciones se pueden realizar mediante las macros que ejecutan las funciones de Visual Basic para Excel variación y volumen, y a su vez en caso de error cambian dicho mensaje por un número previamente asignado. Calcula la variación y su columna Módulo1.Variación corregida Calcula el volumen y su columna Volumen corregida Calcula el cierre corregido Corrección cierre 120 Tabla 7.2: Macros para el cálculo y transformación de datos 7.3) Obtención de la matriz de contingencia. Niveles de uso. La obtención de mapas preceptúales se basa en la aplicación del análisis de correspondencias a una matriz de contingencia, por lo que dicha matriz es especialmente crítica. Para esto se ha desarrollado una interfaz que guiará y hará más cómoda la labor al usuario. El primer paso será abrir Matlab y teclear en la command window “principal”. Es muy importante que tanto los archivos de Excel que contienen los datos, como los m.files que soportan las funciones que efectuarán las operaciones y los archivos de Matlab de la interfaz se encuentren en una misma carpeta. Además, se deberá fijar dicha carpeta como directorio de trabajo en el Current Directory de la pantalla principal de Matlab. Figura 7.5: Inicio de MAPIBEX Una vez hemos tecleado principal nos aparecerá una pantalla que permitirá elegir el nivel de uso, y donde se adjuntan descripciones de dichos niveles. 121 Figura 7.6: Pantalla de inicio de MAPIBEX Una vez seleccionamos el nivel de uso deseado aparecerá una pantalla donde se debe seleccionar el número de empresas a estudiar (entre 4 y 8) y los resultados a lograr, esto es, estudiar sólo las variaciones semanales de el número de empresas elegidas, las variaciones y los volúmenes monetarios negociados o simultáneamente las variaciones, los volúmenes y el reparto de dividendos. 122 Figura 7.7 Selección de número de empresas y resultados a obtener En caso de analizar los volúmenes, no tiene sentido la inclusión de índices como el IBEX35 o el Dow Jones en el estudio. Por su parte en caso de analizar los dividendos se recomienda estudiar un periodo de al menos 2 ó 3 años para que exista un número significativo de dividendos. En la siguiente pantalla se seleccionarán las empresas a estudiar, de las que previamente se habrán introducido los números de las filas que corresponden con la semana de origen y de fin del estudio y una vez introducidas se podrá obtener la matriz de contingencia es la hoja de Excel llamada Resultado. 123 Figura 7.8 Selección de empresas y semanas límites de estudio Figura7.9 Fecha límite, si la fecha de origen del estudio es 07/05/2007 se deberá introducir como origen en Acerinox el número de fila, esto es, 2. Es extremadamente importante que tanto las semanas de origen como de fin de estudio de todas las empresas coincidan. De no hacerlo las dimensiones de las matrices no coincidirán y se producirá un mensaje de error en la pantalla de Matlab 124 Figura 7.10 Error causado por un error en la introducción de fechas La secuencia que se debe seguir para introducir los datos es en primer lugar definir el origen1 y el fin1 y posteriormente introducir la Empresa1 y así sucesivamente. Y una vez introducidas todas las empresas y sus límites se procederá a obtener los resultados en una hoja de Excel pulsando en Obtener Resultado en Hoja de Excel, denominada Resultado por defecto. A este respecto hacer dos observaciones: El proceso de introducir las empresas y de obtener los resultados en Excel, tarda unos segundos. Se aconseja paciencia al usuario y para comprobar que puede seguir operando con el programa, vigilar en la parte inferior izquierda de la pantalla de Matlab si aparece el símbolo “Busy” Figura 7.11 En caso de que aparezca este símbolo en Matlab tras una lectura de datos o al obtener resultados se deberá esperar unos segundos para continuar. Si se quieren hacer varios análisis se aconseja renombrar los archivos Resultados.xls para evitar que se sobrescriban, 125 En el caso que el nivel de usuario elegido sea el Personalizado, además del las fechas límites de estudio se deberán introducir los límites superiores e inferiores que delimitarán la franja de variación correspondiente a cada atributo, de forma que después cada variación estudiada sea asignada a su correspondiente zona y por tanto a su atributo correspondiente. Variación > Limite1 (Extremadamente Alcista) Limite2 < Variación <= Limite1 (Muy Alcista) Limite3 < Variación <= Limite2 (Alcista) Limite4 < Variación <= Limite3 (Ligeramente Alcista) Limite5 < Variación <= Limite4 (Ligeramente Bajista) Limite6 < Variación <= Limite5 (Bajista) Limite7 < Variación <= Limite6 (Muy Bajista) Variación<= Limite7 (Extremadamente Bajista) Además de aconsejar sentido común en la elección de los límites, es obvio que se deberá cumplir: Limite1 > Limite2 >………..> Limite7 7.4) Obtención del mapa de representación y análisis de dependencia Una vez se han dado todo los pasos anteriores se obtendrán por una parte en la Hoja1 la matriz de contingencia y en la Hoja2 una columna con los coeficientes de variación de las empresas analizadas. 126 Figura 7.12 Resultados obtenidos en Excel. El siguiente paso y último será efectuar el análisis de correspondencias, para ello se cargará la barra del Xlstat y posteriormente se seleccionará la opción de Análisis Factorial de Correspondencias y se seleccionará la matriz Figura 7.13 Símbolo para cargar Xlstat y Análisis Factorial de Correspondencias Finalmente se obtendrá el mapa y todas sus medidas asociadas. 127 Figura 7.14 Representación gráfica Por otra parte, para obtener las pruebas que ayudarán a validar la existencia de dependencia entre atributos elegimos la opción pruebas en las tablas de contingencia y seleccionamos la matriz, obteniendo una hoja con los principales test de independencia. Figura 7.15 Pruebas de independencia sobre tabla de contingencia 128 Capítulo 8 Conclusiones del proyecto Las conclusiones que a continuación se van a presentar se derivan de la realización de decenas de casos y de su posterior análisis. 8.1) Conclusiones generales derivadas del uso de MAPIBEX Dado que el análisis de correspondencias, técnica matemática en la que se basa MAPIBEX, trata de establecer relaciones entre las diferentes variables de estudio, es fundamental la existencia de cierto grado de relación entre las mismas. Sin embargo, cuando sólo se comparan variaciones entre las mismas, a menudo el análisis ofrece que dichas variables son independientes. Por el contrario si se incluye el volumen monetario negociado, si se obtendrá cierto grado de relación entre los atributos estudiados. Al respecto es importante señalar, que si bien el uso de MAPIBEX con volúmenes resulta matemáticamente más válido, esto puede ir en detrimento de la claridad del mapa, con el condicionante añadido de que no tiene sentido la representación conjunta de volúmenes y de índices como el IBEX35 o el Dow Jones, circunstancias que hacen que el análisis exclusivo no sea una opción desdeñable. La recomendación de elegir un periodo de representación de más de dos años, en el caso del análisis de dividendos, se justifica por la necesidad de que exista un número suficiente de observaciones de dividendos. Así además podrán establecerse más diferencias entre las empresas estudiadas. De elegir un periodo más corto, es posible, que el mapa resulte muy difuso, y que todos los valores se concentren en el centro del mismo. Para que un mapa sea considerado como aceptable en cuanto al nivel de información representada, dicho valor deberá ser superior al 60%, siendo considerada una buena representación por encima del 80%. La contribución que a dicho valor hacen las nuevas variables artificiales 129 producto del análisis de correspondencias vendrá representada por los ejes F1 (horizontal) y F2 (vertical). En la mayoría de los casos el eje F1 será el que aporte mayor información para establecer el análisis, con valores que suelen estar comprendidos entre 40% y 60%. Además dicho eje se suele poder identificar con la volatilidad de las empresas representadas. En la otra mano, el eje F2 suele aportar mucha menos información (20%, 30%), y si bien su interpretación no resulta tan clara como en el caso de F1, a menudo separa aquellas empresas con un comportamiento más positivo de manera continuada, de aquellas que acumulan más caídas. Aunque MAPIBEX tiene la capacidad de representar aquellas empresas que desee el usuario, resulta especialmente potente en la representación de análisis sectoriales, de forma que se representen conjuntamente los bancos o las constructoras por ejemplo. 8.2) Conclusiones particulares derivadas del uso de MAPIBEX Las conclusiones que a continuación se representan, surgen de la realización de decenas de casos, centrándose especialmente en algunos de los valores más importantes o más reveladores incluidos: Aquellos atributos que representan fuertes subidas, fuertes bajadas y bajadas, suelen quedar representados en el mapa muy próximos. De esto se concluye que aquellas empresas con mayor volatilidad por regla general tienden más perder valor que a ganarlo. Esto es especialmente cierto en aquellas empresas de menor volumen. Ejemplos al respecto pueden ser Bankinter, Sogecable o Ferrovial. En la otra mano, los atributos que representan tendencias alcistas, bastante alcistas y estables, suelen estar próximos, formando un triángulo cuyo vértice más cercano al origen es el atributo que representa a las tendencias estables. Además dichos valores suelen venir representados en el mismo cuadrante del mapa y suelen ser empresas de gran volumen. Valores que suelen venir asociados a esta zona suelen ser Banco Santander, Endesa o ACS. 130 La inclusión de índices resulta positiva para establecer puntos de referencia en el análisis, especialmente el IBEX35, pues suele representar la zona más estable del mapa, y de hecho a menudo suele estar situado próximo al origen. Sin embargo, el Dow Jones, aunque próximo al IBEX35 se suele representar más alejado del resto de los valores, y próximo a la tendencia estable. De esto se extrae, que existe cierto grado de relación de las empresas con el Dow Jones (especialmente de las empresas de gran volumen que a menudo tienen más intereses internacionales) pero menos del esperado. Resultan especialmente interesantes aquellas empresas que reparten dividendos entre sus accionistas, pues suelen ser aquellas empresas que presentan comportamientos alcistas, tales como de nuevo el Banco Santander, Acerinox o Sacyr Vallehermoso. 131 Bibliografía [ANALDATOS95] Uriel E. “Análisis de Datos: Series Temporales y Análisis Multivariante” Colección Plan Nuevo. Editorial AC 1995. [ANALISIS95] Fernández, P.; Yzaguirre, J.: “IBEX-35, Análisis e Investigaciones”. Ediciones Internacionales Universitarias. 1995 [CUADRAS96] Cuadras, Carles M. “Métodos de Análisis Multivariante” Ed. EUB, 1996 [ESTADISTICA97] Peña Sánchez de Rivera, “Estadística, modelos y métodos” Ed. Alianza 1997 [GORSUCH83] Gorsuch , R “Factor Analysis”. Second Edition. Ed. LEA, 1983 [HAIR99] Hair, Joseph F.; Anderson, Rolph E.; Tantham, Ronald L.; and Back, William C. “ Análisis Multivariante”. Ed. Prentice Hall, 1999 [JOURFIN93] N. Jegadeesh y S. Titman “Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency” The Journal of Finance 1993 [LAROU97] Enciclopedia “Larousse 2000” Ed. Planeta 1997 [MATE03] Maté, Carlos. “Análisis de Conglomerados” 2003 [MERCADOS04] “Los mercados financieros y sus matemáticas” Juan Pablo Jimeno Moreno Editorial Ariel 2004 [MEDIDAS93] Peña, I: "Medidas de Volatilidad en Mercados Financieros", Primer Foro de Finanzas 1993. [MILLARD95] Millard, Brian J. “Técnicas gráficas para rentabilizar inversiones en bolsa” Ed. Díaz de Santos, 1995 132 [MIQUEL96] Salvador Miquel, Enrique Bigné “Investigación de mercados” Salvador Miquel, Enrique Bigné… Ed. McGraw-Hill 1996 [PEDRET00] R. Pedret, L. Sagnier, F. Camp “Herramientas para segmentar mercados y posicionar productos” Ed. Deusto 2000 Páginas Web [BOLSAMADRID06] Bolsa de Madrid http://www.bolsamadrid.es [BOLSAVALENCIA06] Bolsa de Valencia http://www.bolsavalencia.es [BORSABCN06] Bolsa de Barcelona http://www.borsabcn.es [CIBER06] Lecciones de economía http://ciberconta.unizar.es [ElACCIONISTA06] El accionista http://elaccionista.com [ESTADISTICO06] El portal estadístico de habla hispana http://www.estadistico.com [WIKI06] Wikipedia: la enciclopedia libre http://www.wikipedia.org [YAHOO07] Yahoo finanzas http://es.finance.yahoo.com/ 133 Apéndice A Condiciones del proyecto Las condiciones y cláusulas fijadas en este documento tienen que ver con el préstamo de las aplicaciones desarrolladas en este proyecto a una persona física o legal. El cumplimiento de estas condiciones fuerza a las dos partes. Las condiciones son: 1) Ambas partes estas obligadas, desde la fecha de la firma del contrato, a cumplir todo lo próximo que está estipulado. 2) Cualquier queja, disputa o controversia que surja de o relativa a este acuerdo, su interpretación, o el incumplimiento, terminación, o validez deberá ser resuelto en el juzgado si no se alcanza otro acuerdo. 3) El vendedor debe facilitar a la otra parte cualquier información que pudiera contribuir a mejorar la instalación y ejecución del sistema, si así fuera requerido. 4) El cliente por el contrario debe explicar a los desarrolladores del sistema todas las características del sistema donde la aplicación será ejecutada, con el fin de facilitar su instalación. Ninguna responsabilidad se adquirirá por parte del proveedor si algún defecto resultase del incumplimiento de esta obligación. 5) Habrá un plazo de pago de dos meses desde la fecha de la firma del contrato. 6) Si la entrega se retrasase más de dos meses, el cliente puede cancelar el contrato, siendo indemnizado por todos los pagos hechos. 7) El sistema está garantizado por un año, desde la fecha de entrega del sistema. La garantía será cancelada tras dicho periodo o en caso de uso incorrecto, tales como instalación incorrecta o no usar el sistema para sus usos normales. 8) El periodo para empezar a usar el sistema no será superior a seis semanas desde la fecha de entrega. 134 9) La garantía sólo será válida si el sistema ha sido correctamente instalado, y a ha sido correctamente usado. La garantía termina si hay manipulaciones en el sistema por parte de personal no autorizado, siendo el personal autorizado explícitamente designado por el proveedor. 10) El proveedor no asumirá responsabilidad alguna sobre la compra de productos por ninguna cantidad de daños sobre la cantidad pagada por los productos bajo este acuerdo, no se pagarán indemnizaciones por otros daños directos o indirectos al personal o materiales. A2) Condiciones Económicas 1) El valor de la venta será acordado por las dos partes 2) Los plazos de pago serán los siguientes: 20% cuando el contrato esté firmado 60% cuando el sistema sea entregado 20% 45 días después de la entrega del sistema. 3) Cualquier retraso respecto a los pagos estipulados será penalizado con un 5% de interés anual. 4) Los gastos de envío y empaquetamiento serán responsabilidad del vendedor. 5) El vendedor asume cualquier responsabilidad sobre cualquier defecto o daño causado durante su transporte. 6) Hasta la expiración de la garantía, todos los gastos causados por reparaciones serán cubiertos por el vendedor. A3) Condiciones particulares y técnicas 1) El ordenador debe cumplir con todas las regulaciones efectivas en España en la fecha de entrega del presente proyecto. 2) El teclado del equipamiento estará en español. 3) La localización de la instalación debe cumplir las condiciones de humedad y temperatura recomendadas por el fabricante del ordenador. 4) La alimentación del sistema debe hacerse a 220V y 50 Hz, debiendo ajustarse a lo que está estipulado en el Reglamento de Baja Tensión. 5) El cliente necesita una licencia para el uso de las aplicaciones del sistema. 135 6) El cliente debe tener una licencia para todos los productos de software requeridos para la operación del sistema. Apéndice B Presupuesto del Proyecto El presupuesto del proyecto se desglosará en tres tipos de costes: Costes de ingeniería Inversión y costes de material Costes comerciales B1) Costes de ingeniería Un ingeniero suficientemente cualificado para el desarrollo del proyecto gana alrededor de 2500€/mes, más el 30% de de dicho sueldo destinado a pagar la seguridad social. Dicho ingeniero trabaja 8 horas/día y 22 días/mes, lo que hace un total de 176 horas/mes, con lo que si dividimos el coste total entre las horas se obtiene que el coste por hora es 18,48€/h. Por su parte el tiempo necesario para la realización del proyecto se divide en: Documentación previa: 50 horas. Entrevistas: 50 horas Programación: 500 horas Documentación: 200 horas Pruebas y mejoras: 200 horas Sumando todas las duraciones se obtienen 1000 horas, con lo que los gastos de ingeniería ascenderán a 18460 €. 136 B2) Inversión y costes de material Los útiles necesarios para el desarrollo de este proyecto serán un equipo informático y software: Elemento Precio PC 1200€ Software requerido 1890 € Otros gastos (conexión de Internet, materiales de oficina) 100€ Gastos materiales 3190€ Se considerará amortizada la herramienta tras un periodo de uso de 10.000 horas, con un porcentaje de uso del 85%, lo que da lugar a la siguiente tabla: Concepto Total Horas de uso del material 8500 horas Coste por hora 0,19 € Amortización total de los costes materiales 1615€ Si se asume que la inversión hecha ronda alrededor del 5% de los gastos de ingeniería, los gastos de la inversión suman 923€. Por tanto el coste total del proyecto, que es la suma de los gastos de ingeniería, de material y la inversión, se estima en 20998€ B3) Gastos comerciales Los gastos comerciales se dividen en gastos de administración, de ventas y costes de interés variable. Los gastos de administración se suponen alrededor del 6% del proyecto, siendo los gastos de ventas el doble de los de administración. Por último, se considerarán alrededor del 5% de los costes totales del proyecto Clase de coste Total Gastos de administración 1259,88€ Gastos de ventas 2519,76€ Gastos de interés variable 1049,5€ Total de gastos comerciales 4829,54€ 137 Por consiguiente, el coste total suma de los costes del proyecto y de los comerciales, asciende a 25827,54€ 138
 0
0
Anuncio

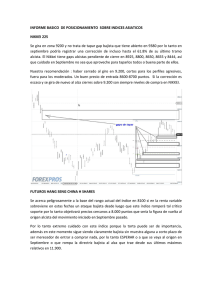


Descargar
Anuncio
Añadir este documento a la recogida (s)
Puede agregar este documento a su colección de estudio (s)
Iniciar sesión Disponible sólo para usuarios autorizadosAñadir a este documento guardado
Puede agregar este documento a su lista guardada
Iniciar sesión Disponible sólo para usuarios autorizados