")
Estadística
Estadística
María Eugenia Ángel
Mario Enrique Borgna
Graciela Fernández
Carpeta de trabajo
Diseño original de maqueta: Hernán Morfese
Procesamiento didáctico: Marina Gergich / Bruno De Angelis
Primera edición: Septiembre de 2009
ISBN: 978-987-1782-07-9
© Universidad Virtual de Quilmes, 2009
Roque Sáenz Peña 352, (B1876BXD) Bernal, Buenos Aires
Teléfono: (5411) 4365 7100 | http://www.virtual.unq.edu.ar
La Universidad Virtual de Quilmes de la Universidad Nacional de
Quilmes se reserva la facultad de dis- poner de esta obra, publicarla,
traducirla, adaptarla o autorizar su traducción y reproducción en
cualquier forma, total o parcialmente, por medios electrónicos o
mecánicos, incluyendo fotocopias, grabación magnetofónica y
cualquier sistema de almacenamiento de información. Por consiguiente, nadie tiene facultad de ejercitar los derechos precitados sin
permiso escrito del editor.
Queda hecho el depósito que establece la ley 11.723
Impreso en Argentina
Íconos
Lectura obligatoria
Es la bibliografía imprescindible que acompaña el desarrollo de los contenidos. Se trata tanto de textos completos como de capítulos de libros, artículos y "papers" que los estudiantes deben leer, en lo posible, en el momento
en que se indica en la Carpeta.
Actividades
Se trata de una amplia gama de propuestas de producción de diferentes tipos. Incluye ejercicios, estudios de caso, investigaciones, encuestas, elaboración de cuadros, gráficos, resolución de guías de estudio, etcétera.
Leer con atención
Son afirmaciones, conceptos o definiciones destacadas y sustanciales que
aportan claves para la comprensión del tema que se desarrolla.
Para reflexionar
Es una herramienta que propone al estudiante un diálogo con el material, a través de preguntas, planteamiento de problemas, confrontaciones del tema con la
realidad, ejemplos o cuestionamientos que alienten la autorreflexión, etcétera.
Lectura recomendada
Es la bibliografía que no se considera obligatoria, pero a la cual el estudiante puede recurrir para ampliar o profundizar algún tema o contenido.
Pastilla
Se utiliza como reemplazo de la nota al pie, para incorporar informaciones
breves, complementarias o aclaratorias de algún término o frase del texto
principal. El subrayado indica los términos a propósito de los cuales se incluye esa información asociada en el margen.
nd
Índice
Introducción...........................................................................................9
Mapa conceptual ..................................................................................10
Problemática del campo ........................................................................10
Objetivos del curso ...............................................................................11
1. Estadística descriptiva .....................................................................13
1.1. Los datos y su organización ...........................................................13
1.1.1. Variables estadísticas y su clasificación ................................13
1.1.2. Ordenamiento y tabulación de los datos................................15
1.1.3. Representaciones gráficas ...................................................23
1.2. Medidas estadísticas .....................................................................28
1.2.1. Medidas de posición............................................................28
1.2.2. Medidas de dispersión.........................................................39
1.2.3. Medidas de intensidad.........................................................43
1.3. Matrices ejemplos .........................................................................51
2. Probabilidad.....................................................................................55
2.1. Elementos de la teoría de probabilidad ...........................................55
2.1.1. Experimento aleatorio .................................................................55
2.1.2. Definiciones de probabilidad........................................................62
2.1.3. Axiomatización de la probabilidad ................................................63
2.1.4. Tipos de probabilidad..................................................................64
2.2. Variable aleatoria...........................................................................69
2.2.1. Variable aleatoria discreta ...........................................................69
2.2.2. Modelos especiales de variables aleatorias discretas ...................71
2.2.3. Variable aleatoria continua ..........................................................76
2.2.4. Modelos especiales de variables aleatorias continuas ..................77
3. Inferencia estadística.......................................................................87
3.1. Distribución de estadísticos muestrales ..........................................87
3.1.1. Distribución del estadístico media muestral .................................88
3.1.2. Distribución del estadístico proporción muestral ...........................90
3.1.3. Teorema central del límite ...........................................................91
3.2. Problemas fundamentales de la inferencia estadística .....................94
3.2.1. Estimación por intervalo de confianza ..........................................94
3.2.2. Pruebas de hipótesis ................................................................105
4. Elementos básicos de econometría.................................................113
4.1. Introducción ................................................................................113
4.2. Análisis de regresión y de correlación ...........................................114
4.3. Series de tiempo .........................................................................120
Referencia bibliográfica ......................................................................125
7
Universidad Virtual de Quilmes
Anexo ................................................................................................127
Tabla 1: Percentiles de la distribución normal estándar .........................127
Tabla 2: Percentiles de la distribución t de Student...............................129
8
Introducción
El material de esta carpeta contiene, en su inicio –Unidad 1–, diversas formas
de organización de los conjuntos de datos (apartado 1.1.). En algunos casos
datos de campo y en otros compilados, como preparación del material de base
para elaborar las medidas estadísticas (apartado 1.2.) también denominadas
indicadores estadísticos, y producir información útil.
La importancia de la organización de los datos, en vistas del tratamiento
posterior, reside en que permite establecer distintas líneas de trabajo en pos
de la calidad de la información que se busca. Una información estadística de
calidad es primordial para la comprensión de las cualidades o características
del mundo real con perspectiva de su modelización.
A comienzos del siglo XIX el astrónomo Adolfo Quetelet –considerado el fundador de la estadística moderna– aplicó a las ciencias sociales los métodos
estadísticos hasta entonces utilizados en las ciencias naturales, contribuyendo a la ampliación del campo de la estadística. Sin embargo, fue a partir
de mediados de la década de 1960 con el Análisis Exploratorio de Datos (EDA)
– desarrollado por J. Tukey y otros– que surgió un enfoque más amplio en el
tratamiento de datos, cimentado en el uso de la informática, donde el soporte tecnológico permitió sostener una gran masa de datos y procesarlos en
tiempo real, contribuyendo así al mejoramiento de la calidad de la información
resultante.
Luego del tratamiento descriptivo de los datos desarrollado en la Unidad
1, se incorporan nociones sobre la teoría de la probabilidad –Unidad 2–.
A partir del siglo XVII comenzó a evolucionar el Cálculo de probabilidad
como disciplina científica introduciéndose el uso sistemático de los conceptos de azar, indeterminismo y aleatoriedad. La Estadística, que a la sazón ya
tenía un desarrollo de varios milenios donde el campo de trabajo era exclusivamente las poblaciones o universos, es decir la totalidad de los individuos o
elementos involucrados en el estudio de un problema, se vio enriquecida por
el desarrollo de la teoría de la probabilidad la cual le permitió extender su
alcance hacia el interior de dichas poblaciones y ampliar su metodología al
tratamiento de los subconjuntos de ellas, las muestras.
Los trabajos de Bernoulli, Laplace, Gauss y Galton entre otros, proveyeron
al cálculo de probabilidades de recursos matemáticos que permitieron diseñar modelos probabilísticos aplicables a diversos campos de la ciencia. Los
modelos probabilísticos, cuyo núcleo son las distribuciones de probabilidad
de las variables involucradas en los problemas de estudio (apartado 2.2.),
son la base de la inferencia estadística.
La inferencia estadística –Unidad 3– es el procedimiento por el cual se
extrapolan o extienden a la población en estudio los resultados de una muestra representativa. A partir de los indicadores o estadísticos muestrales se
estiman (apartado 3.2.) o se someten a prueba (apartado 3.3.) los indicadores poblacionales también denominados parámetros.
9
Universidad Virtual de Quilmes
Por último, se tratan algunos elementos de econometría –Unidad 4–, nociones sobre la relación entre variables como el análisis de regresión lineal, el
análisis de correlación y un breve estudio sobre las series de tiempo.
El orden y sentido en que se desarrollan los distintos conceptos en el transcurso del presente material se sintetiza en el diagrama siguiente.
Mapa conceptual
Problemática del campo
La estadística se compone de dos grandes áreas, la descriptiva y la inferencial.
Por medio de la estadística descriptiva se analizan propiedades de un conjunto de datos referidas al contexto en el que ellos se encuentran inmersos y
no como entidades aisladas. Por ese motivo es muy importante antes del análisis descriptivo, conocer y clarificar el entorno del que provienen los datos.
Cuando hablamos del entorno estamos haciendo referencia a la población en
estudio (o a una parte de ella) y a sus unidades de análisis, a los atributos
que interesa estudiar y a la calidad del dato que se puede extraer.
Por otro lado, en los estudios de campo se da con frecuencia y por distintas causas la imposibilidad de acceder a toda la población y es en esos casos
donde los datos tienen que extraerse de un subconjunto de ella al que denominamos muestra. Si el objetivo del análisis de la muestra es realizar inferencias respecto a la población, necesariamente debe ser una muestra representativa que comportándose como una imagen reducida de esa población
de estudio refleje sus características. Estas muestras son obtenidas por
métodos de muestreo aleatorio.
La estadística inferencial tiene como objetivo realizar inferencias sobre la
población en un ambiente de incertidumbre producto del azar y la aleatoriedad.
En síntesis, hay dos grandes problemas con los que se encuentra este
campo del saber el conocimiento del contexto de estudio y el tratamiento de
la incertidumbre.
10
Objetivos del curso
• Aprehender técnicas y métodos estadísticos tanto de la Estadística descriptiva como de la Estadística inferencial.
• Emplear esas técnicas y métodos en la formalización de modelos estadísticos en el ámbito de las ciencias económicas.
• Aplicar el conocimiento estadístico adquirido a la vida cotidiana como parte
de una cultura general.
11
1
Estadística descriptiva
Objetivos
• Determinar y analizar distintos indicadores socioeconómicos.
• Construir e interpretar gráficos estadísticos diversos.
1.1. Los datos y su organización
En este apartado se tratarán algunas de las formas de organizar los datos
recolectados o recopilados y se preparará el material de base para que en los
apartados siguientes puedan elaborarse medidas estadísticas, comúnmente
denominadas indicadores estadísticos.
Los datos son tomados de una cierta población o universo objeto de estudio: la población objetivo.
Por ejemplo, todos los empleados de una determinada pyme constituyen
una población objetivo. Y en ese caso, cada individuo de ese universo –cada
empleado– es lo que se denomina una unidad de observación.
En el estudio de la población nos pueden interesar determinados atributos comunes a los individuos como la edad, el salario, la antigüedad, etc. Los
archivos de la empresa combinados con entrevistas personales pueden haber
sido los instrumentos con que se relevó la información.
El paso inicial para organizar toda la información primaria obtenida del
grupo de empleados de la pyme y que la presente en su totalidad, es elaborar una tabla denominada matriz de datos. Una matriz de datos es un arreglo
de filas y columnas donde cada fila representa un individuo o unidad de observación y cada columna un atributo variable (en el apartado 1.3. figuran cuatro
matrices de datos llamadas a partir de ahora matrices ejemplo –ME– cada
vez que se haga referencia a ellas).
Cada uno de los atributos variables que se observan en la matriz son pasibles de convertirse en lo que llamamos variables estadísticas.
En el apartado 1.6. figuran varios ejemplos de
población objetivo y de unidad de
observación.
Otros instrumentos de
recolección de datos son:
documentos, encuestas o simple
observación.
Puede haber atributos
que no varíen de un individuo a otro, como la pertenencia a la empresa, ya que todos
son empleados.
1.1.1. Variables estadísticas y su clasificación
Las variables estadísticas se obtienen a partir de los atributos. Por ejemplo,
si el atributo primario hubiese sido la fecha de nacimiento de cada empleado,
para su tratamiento estadístico se diseña la variable edad en años. Por otro
lado, contando con la fecha de nacimiento y la fecha de ingreso podría dise13
Universidad Virtual de Quilmes
ñarse la variable “edad que tenía cuando ingresó a la empresa” (en este caso
la variable surge de una combinación de atributos).
Para un primer tratamiento se convertirá cada atributo de las matrices ejemplo ME en una variable estadística.
Si se observan detenidamente cada una de las variables se puede notar
que algunas asumen valores numéricos y otras valores no numéricos.
A las que asumen valores numéricos las denominaremos variables cuantitativas y a las que asumen valores no numéricos, es decir cualidades, variables cualitativas.
Son ejemplos de variables cuantitativas la antigüedad, el salario quincenal, la cantidad de personal, la longitud de las piezas de plástico, etc. Son
ejemplos de variables cualitativas el sexo, el tipo de posesión de la vivienda,
el rubro de las pymes, el tipo de materia prima, etcétera.
1.
Clasificar como cuantitativas o cualitativas cada una de las variables de
las ME del apartado 1.3.
Si se observan más detenidamente las variables de las matrices ejemplo se
puede notar que hay variables cuantitativas que asumen valores dentro del
conjunto de los números reales y hay otras cuyos valores son números enteros. A las que asumen valores reales las denominamos cuantitativas continuas y a las otras cuantitativas discretas. Por ejemplo: la “edad civil” es por
naturaleza una variable discreta pero eventualmente si se tratara la “edad biológica” ésta sería por naturaleza una variable cuantitativa continua.
Con respecto a las variables cualitativas se puede notar que en algunas de
ellas sus valores pueden ordenarse y en otras no. Esto justifica también subclasificarla en cualitativas ordenables y cualitativas no ordenables. Un ejemplo de variable cualitativa ordenable es el “nivel de detalle de terminación de
las piezas plásticas” y un ejemplo de no ordenable es el “rubro de las pymes”.
$ISCRETAS
#UANTITATIVAS
#ONTINUAS
6ARIABLES
/RDENABLES
#UALITATIVAS
.O ORDENABLES
),1'(/((5$7(172
2.
Completar la actividad 1 con la clasificación de las variables.
&20,(1=2'($&7,9,'$'
&RPSOHWDUODDFWLYLGDGFRQODFODVLILFDFLyQGHODVYDULDEOHV
¿Por qué motivo
cree que es necesaria la clasificación realizada para las
variables y cuál),1'($&7,9,'$'
será su utilidad?
14
&20,(1=2'(3$5$5()/(;,21$5
¢3RU TXp PRWLYR FUHH TXH HV QHFHVDULD OD FODVLILFDFLyQ UHDOL]DGD
SDUDODVYDULDEOHV\FXiOVHUiVXXWLOLGDG"
),1'(3$5$5()/(;,21$5
Completar la actividad 1 con la clasificación de las variables.
FIN DE ACTIVIDAD
COMIENZO DE PARA REFLEXIONAR
Estadistica
¿Por qué motivo cree que es necesaria la clasificación realizada para las variables y cuál será su utilidad?
FIN DE PARAyREFLEXIONAR
1.1.2. Ordenamiento
tabulación de los datos
A partir de aquí se seguirá la organización de los datos centrando la atención
1.1.2.
Ordenamiento
y tabulación
decuenta
los datos
en
cada una
de las variables
y teniendo en
su complejidad.
A partir de
aquí se seguirá
la organización de los datos centrando la atención en cada una de las variables y tenie
Variable
cualitativa
no ordenable
en cuenta su complejidad.
Elegimos para esta categoría la variable “Rubro de la pyme” de la matriz de
Variable
no ordenable
ejemplo
MEcualitativa
3.
Los rubros relevados en la muestra son: servicios (S), industrial (I), agríElegimos
para esta categoría
variable “Rubro
de la empresas
pyme” de la
matriz
de ejemplo ME 3.
cola (A) y comercial
(C). Podríala interesarnos
cuántas
hay
de cada
Los
rubros relevados
muestratabla
son: servicios
(S), tabla
industrial
(I), agrícola (A) y comercial (C). Podría interesa
rubro,
entonces
armamosen
la la
siguiente
denominada
de distribución
cuántas
empresas
hay
de
cada
rubro,
entonces
armamos
la
siguiente
tabla denominada tabla de distribución
de frecuencias.
frecuencias.
Rubro
A
C
I
S
Total
Cantidad de Pymes
6
5
9
4
24
El conteo realizado para la segunda columna de la tabla constituye lo que llamaremos de aquí en más frecue
Elabsoluta
conteo .realizado para la segunda columna de la tabla constituye lo que llamaremos de aquí en más frecuencia absoluta.
La notación usual para la frecuencia absoluta es f y para la
cantidad total de datos
cada valor
de la nvariable
en
muestrales
.
COMIENZO DE LEER ATENTO
SeSedenomina
frecuencia
absoluta
a la acantidad
de veces
que aparece
cada
denomina
frecuencia
absoluta
la cantidad
de veces
que aparece
el grup
valor
de
la
variable
en
el
grupo
de
datos
estudiado.
datos estudiado.
Es importante
tener en
cuenta
la suma
todas las
absoEs importante
tener
en que
cuenta
que de
la suma
defrecuencias
todas las frecuencias
absolutas es igual a la cantidad
Si el grupo relevado es
lutas
es
igual
a
la
cantidad
total
de
datos.
de datos.
FIN DE LEER ATENTO
una población denotaremos con N a la cantidad total
de datos.
Ampliando
el PASTILLA
concepto
de frecuencia de tal manera de involucrar no sólo las
COMIENZO DE
ENIUHFXHQFLDDEVROXWD
cantidades
cadaabsoluta
rubro sino
su incidencia
respecto
La notacióncon
usualque
paraaparece
la frecuencia
es f ytambién
para la cantidad
total de datos
muestrales n.
FINtotal,
DE PASTILLA
del
surgen las denominadas frecuencias porcentuales y relativas.
COMIENZO DE PASTILLA ENFDQWLGDGWRWDOGHGDWRV
La frecuencia relativa se calcula dividiendo cada frecuencia absoluta por
el total de datos.
La frecuencia porcentual se calcula multiplicando por 100 la respectiva
frecuencia relativa.
La frecuencia relativa se abrevia
con fr y el total es 1.
La frecuencia porcentual
se abrevia con f% y el total
es 100.
La tabla que sigue, que llamaremos de aquí en adelante tabla de distribución
de frecuencias o distribución de frecuencias a secas, incluye a los tres tipos
de frecuencias definidas anteriormente.
15
/DIUHFXHQFLDSRUFHQWXDOVHDEUHYLDFRQf%\HOWRWDOHV
FIN DE PASTILLA
Universidad Virtual de Quilmes
La tabla que sigue, que llamaremos de aquí en adelante tabla de distribución de frecuencias o
a secas, incluye a los tres tipos de frecuencias definidas anteriormente.
Tabla 1.1.
Tabla 1.1.
Rubro
Rubro
A
A
C
C
I
I
S
S
Total
Total
f
frr
0,25
0,21
0,37
0,17
1,00
1,00
f
f
6
6
5
5
9
9
4
4
24
24
f
f%%
25
25
21
21
37
17
100
100
Donde: Rubro Agrícola: A; Comercial: C; Industrial: I y Servicios: S.
'RQGH5XEUR$JUtFROD$&RPHUFLDO&,QGXVWULDO,\6HUYLFLRV6
Variable
Variable cualitativa
cualitativa ordenable
ordenable
Como ejemplo para este tipo de variables tomaremos el “nivel de detalles de
Como ejemplo para este tipo de variables tomaremos el “nivel de detalles de terminación de
terminación de las piezas plásticas” de la ME 4.
ME 4.
Tabla 1.2.
1.2.
Tabla
Tabla 1.2.
Detalle de
Detalle de
terminación
terminación
Regular
5HJXODU
Bueno
%XHQR
Muy bueno
0X\EXHQR
Excelente
Excelente
Total
Total
f
f
5
5
5
5
5
5
5
5
20
f
f%%
25
25
25
25
25
25
25
25
100
f
frr
0,25
0,25
0,25
0,25
1
1
Como puede apreciarse, en la tabla de distribución de frecuencias se consignaron los
sentido creciente, acorde con la naturaleza ordenable de la variable. En la tabla podemos l
Como
apreciarse,
la tabla de
de frecuencias
se consig-nivel de detalle d
piezaspuede
de plástico
(o quéen
porcentaje
de distribución
ellas) cumplen
con un determinado
naron los valores –o categorías– en sentido creciente, acorde con la naturaleza
ordenable
de la variable.
la tabla podemos
leer, nos
por ejemplo,
El carácter
de ordenables
queEn
adquieren
las categorías
habilita acuántas
crear lo que denomina
piezas
de
plástico
(o
qué
porcentaje
de
ellas)
cumplen
con
un
determinado
ordenados:
nivel de detalle de terminación.
El carácter de ordenables que adquieren las categorías nos habilita a crear lo
que denominaremos un arreglo de datos ordenados:
5
5
5
5
5
B
B
B
B
B
MB
MB
MB
MB
MB
E
E
E
E
E
'RQGH'HWDOOHGHWHUPLQDFLyQ5HJXODU5%XHQR%0X\EXHQR0%\([FHOHQWH(
Donde: Detalle de terminación Regular: R; Bueno: B; Muy bueno: MB y Exce-
Por una cuestión de economía de espacio hemos elegido representar el arreglo mediante una ma
lente: E.
usarse una matriz columna sin que ello altere la esencia del ordenamiento.
Por una cuestión de economía de espacio hemos elegido representar el arre-
Aprovechando la propiedad de ordenamiento de las categorías, someteremos las frecuencias de
glo mediante una matriz fila, pero puede usarse una matriz columna sin que
mecanismo de acumulación y definiremos las frecuencias acumuladas absoluta, relativa y porcent
ello altere la esencia del ordenamiento.
piezas de plástico (o qué porcentaje) cumplen con un nivel máximo de detalles de terminación.
Aprovechando la propiedad de ordenamiento de las categorías, someteremos las frecuencias de la tabla 1.2. a un mecanismo de acumulación y defiCOMIENZO DE LEER ATENTO
niremos las frecuencias acumuladas absoluta, relativa y porcentual, esto es
La frecuencia absoluta acumulada –que denotamos con F– hasta una determinada categoría
cuántas piezas de plástico (o qué porcentaje) cumplen con un nivel máximo
de sumarle a su frecuencia absoluta todas las frecuencias absolutas de los valores o catego
de detalles de terminación.
16
La frecuencia relativa acumulada Fr hasta una categoría se calcula sumándole a su fr
frecuencias relativas de las categorías anteriores.
La frecuencia porcentual acumulada F% hasta una determinada categoría o valor se c
su frecuencia porcentual las frecuencias porcentuales anteriores.
FIN DE LEER ATENTO
Por
hemos
representar
5 una
5 cuestión
5 5 Bde economía
B B B de
B espacio
MB MB
MB elegido
MB MB
E E elE arreglo
E E mediante una matriz fila, pero pu
una matriz columna sin que ello altere la esencia del ordenamiento.
usarse
'RQGH'HWDOOHGHWHUPLQDFLyQ5HJXODU5%XHQR%0X\EXHQR0%\([FHOHQWH(
5
Estadistica
Aprovechando
la propiedad
de ordenamiento
de las
categorías,
someteremos
frecuencias
de la fila,
tablapero
1.2.pua
Por una cuestión
de economía
de espacio hemos
elegido
representar
el arreglo las
mediante
una matriz
mecanismo
de
acumulación
y
definiremos
las
frecuencias
acumuladas
absoluta,
relativa
y
porcentual,
esto
es
cuán
frecuencia
absoluta
–que denotamos
hasta una deterusarse unaLamatriz
columna
sinacumulada
que ello altere
la esencia con
del F–
ordenamiento.
piezas deminada
plásticocategoría
(o qué porcentaje)
un nivel
detalles de terminación.
de la variablecumplen
resulta decon
sumarle
a su máximo
frecuenciadeabsoluta
todas
las
frecuencias
absolutas
de
los
valores
o
categorías
menores.
Aprovechando la propiedad de ordenamiento de las categorías, someteremos las frecuencias de la tabla 1.2. a
COMIENZO
DE LEER
ATENTO
La
frecuencia
relativa
Fr hasta
una categoría
se calcula sumánmecanismo
de
acumulación
yacumulada
definiremos
las frecuencias
acumuladas
absoluta, relativa y porcentual, esto es cuán
La
frecuencia
absoluta
acumulada
–que
denotamos
con
F–
hasta
una determinada
categoría de la variable res
dole
a
su
frecuencia
relativa
las
frecuencias
relativas
de
las
categorías
piezas de plástico (o qué porcentaje) cumplen con un nivel máximo de detalles
de terminación.
de sumarle a su frecuencia absoluta todas las frecuencias absolutas de los valores o categorías menores.
anteriores.
La frecuencia
acumuladaF%
Frhasta
hastauna
unadeterminada
categoría se catecalcula sumándole a su frecuencia relativa
La
frecuencia
porcentual
COMIENZO
DE relativa
LEER acumulada
ATENTO
frecuencias
deacumulada
las categorías
goría
o valorrelativas
se
calcula
sumándole
a suanteriores.
frecuencia porcentual
fre-determinada categoría de la variable resu
La
frecuencia
absoluta
–que
denotamos
con F– hastalasuna
La
frecuencia
porcentual
acumulada
F%
hasta
una
determinada
o valor
se calcula
sumándo
cuencias
porcentuales
anteriores.
de sumarle a su frecuencia absoluta todas las frecuencias absolutas decategoría
los valores
o categorías
menores.
su frecuencia
porcentual
frecuencias
anteriores.
La frecuencia
relativa las
acumulada
Fr porcentuales
hasta una categoría
se calcula sumándole a su frecuencia relativa
FIN
DE
LEER
ATENTO
frecuencias relativas de las categorías anteriores.
En la siguiente
se encuentran
ya consignadas
las frecuen- categoría o valor se calcula sumándo
Ladistribución
frecuencia porcentual
acumulada
F% hastatodas
una determinada
En
la
siguiente
distribución
se
encuentran
ya
consignadas
todas
las
frecuencias definidas anteriormente.
cias definidas
anteriormente.
su frecuencia
porcentual las frecuencias porcentuales anteriores.
FIN DE LEER ATENTO
Tabla 1.3.
1.3.
Tabla
En la siguiente distribución se encuentran ya consignadas todas las frecuencias definidas anteriormente.
Detalle de
f
terminación
Tabla5HJXODU
1.3.
5
%XHQR
5
Detalle
de
0X\EXHQR
f5
terminación
Excelente
5
5HJXODU
5
Total
%XHQR
5
0X\EXHQR
5
Excelente
5
Variable
Totalcuantitativa
fr
fr
1
discreta
1
f%
25
25
f%25
25
25
25
25
25
F
Fr
F%
5
15
F
5
15
Fr
25
F
%
25
Variable cuantitativa discreta
Caso 1. Edad de los trabajadores de una empresa cooperativa, (extraída de la EM 1).
Para
tratamiento
dediscreta
esta variable
procederemos
como se hizo
para la de
cualitativa ordenable.
Variable
cuantitativa
Caso
1. el
Edad
de los trabajadores
de una
empresa cooperativa,
(extraída
la EM 1).
Arreglo
datos
Caso
1. de
Edad
de ordenados
los trabajadores
de una
empresa cooperativa,
(extraída
la EM 1).
Para
el
tratamiento
de esta variable
procederemos
como se hizo
para lade
cuaParaordenable.
el tratamiento de esta variable procederemos como se hizo para la cualitativa ordenable.
litativa
21 25 28 42 48 51 Arreglo de datos
datos ordenados
ordenados
Distribución de frecuencias
21 25 28 42 48 51 Distribución
Distribución de
de frecuencias
frecuencias
17
Universidad Virtual de Quilmes
Tabla 1.4.
1.4.
Tabla
Tabla 1.4.
Edad
Tabla 1.4.
f
1
1
1
1
1
2
1
2
2
1
1
1
1
1
20
fr
f%
Fi
Fr
F%
5
1
5
21
Edad
f
fr
f%
Fi
Fr
F%
5
2
25
1
21
Edad
f
fr f5% 5
F1i Fr F5% 15
28
1
5
2
25
1
5 5
1 4 21 30
5 1
5
15
28
1
5 5
2 5 25 34
25
5
4
1
30
1
5
28 36
15 1
5
5
25
34
1
5 15
4 30 37
2
36
1
5
5
34
5
11
25 55
38
15
37
2
36 39
65
1
5
11
55
38
15 15 37 40
2
65
39
5
11
1
38
5
16
55 42
2
15
40
2
5
39 48
65 85
1
5
16
42
2
15
40
5
18
51
1
5
85
48
1
5 5
16 19 42 57
95
1
5
18
51
1
5
48
5
85
63
1
5
19
95
57
1
1
5 18
51
Total
1
5
63
1
5
19
95
57
1
Total
20
1
5
63
1
Total2. Edad20
Caso
de los
los empleados
empleados
deuna
unafábrica
fábricaautomotriz.
automotriz.
Caso 2.
Edad de
de
A continuación se transcriben las edades de una muestra de 80 empleados
se transcriben
las fábrica
edades automotriz.
de una muestra de 80 empleados de una fábrica
Caso A
2. continuación
Edad de los empleados
de una
de una fábrica automotriz.
A continuación
transcriben
edades
deautomotriz.
una muestra de 80 empleados de una fábrica au
Caso
2. Edad de losseempleados
delas
una
fábrica
18 54 42 24 42 64 48 58 29 49
A continuación se transcriben las edades de una muestra de 80 empleados de una fábrica au
18 41 54 1842 42 46 24 42 64 4448 58 21 5529 49 15
29
18
41 62
54
25
18 42
42 22
46 49
24
2142
41
44 2548
58
21 55 29
49
15 44
64
45
46
48
49
51
54
19
56
28
59
29 41
62 25 18
42
22 46
49 21 41 44
25 21
55
15
44 45 62
46 25
48 22
49 49
21
51 41
54 19 25
56 28 59 44
29
Arreglo de datos ordenados
45 46 48 49 51 54 19 56 28 59 Arreglo de datos ordenados
Arreglo
ordenados
15 de
18datos
18 19
21 21 22 24 25 25 28 29 29 Arreglo de datos ordenados
15 18 18 19 21 21 22 24 25 25 28 29 29 15
18
18
19
21
21
22
24
25
4125
41
42
42
4228
29
29
44
44
45
46
46
48
48
49
49
49
51
41 41 54
42 54
42 55
42 56
58
59
44 62
44 64
45 46 46 48 48 49 49 49 51 41
41
54 42
54 42
55 42
56 58 59 44
62 44
64
Si intentáramos listar en una tabla de frecuencias los 80 datos nos encontraríamos con una
sus correspondientes
frecuencias
son similares.
Antenos
esteencontraríamos
panorama el sentido
comú
Si Además,
intentáramos
listar en una tabla
de frecuencias
los 80 datos
con una
gra
datos
por
franjas
de
edad.
Además,
sus
correspondientes
frecuencias
son
similares.
Ante
este
panorama
el
sentido
común
Si intentáramos listar en una tabla de frecuencias los 80 datos nos encontraríamos con una gra
Tabla
1.5.
Si
intentáramos
tabla de frecuencias
losAnte
80 datos
nos encondatos
por
franjas
delistar
edad.en una
Además,
sus
correspondientes
frecuencias
son similares.
este panorama
el sentido común
traríamos
con
una
gran
variedad
de
valores.
Además,
sus
correspondientes
freTabla
1.5.
datos por franjas de edad.
45 46 46 48 48 49 49 49 51 54 54 55 56 58 59 62 64
Franja de edad
f
cuencias
Tabla
1.5. son similares. Ante este panorama el sentido común aconseja orga15
a
19
5
nizar
de edad.
Franjalos
de datos
edad por franjas
f
D
15 a
Franja
de19
25
aedad
29
D
15 D
a 19
25 a 29
D
D
D
25
a 29
D
D
D
45 a 49
D
D
D
45 a 49
D
55 a 59
D
45
a 49
D
55 a 59
D
Total
D
55
a 59
Total
D
18
Total
6
5
f 8
6
5
8
6
16
8 12
16
8
12
16 6
8
12
4
6
8
2
4
6
2
4
2
45 46 46 48 48 49 49 49 51 54 54 55 56 58 59 62 64
Si intentáramos listar en una tabla de frecuencias los 80 datos nos encontraríamos con una gran variedad de valor
Además, sus correspondientes frecuencias son similares. Ante este panorama el sentido común aconseja
Estadistica organizar
datos por franjas de edad.
Tabla
Tabla1.5.
1.5.
Franja de edad
15 a 19
D
25 a 29
D
D
D
45 a 49
D
55 a 59
D
Total
f
5
6
8
16
12
8
6
4
2
Para poder usar, más adelante, con comodidad este material llamamos a esas
franjas intervalos de clase y los describimos agregando para el conteo alguPara
poder usar, más adelante, con comodidad este material llamamos a esas franjas intervalos de clase y los describim
na convención.
agregando para el conteo alguna convención.
Tabla 1.6.
Tabla 1.6.
Edad
F
fr
f%
Fi
Fr
F%
>²
>²
>²
>²
>²
>²
>²
>²
>²
>²
Total
5
6
8
16
12
8
6
4
2
5
11
19
48
68
La convención que se usó para ajustar los intervalos de clase y hacerlos adyacentes, fue cerrarlos a izquierda y abrir
El conjunto
de intervaa derecha. Podría haber sido al revés, abiertos a izquierda y cerrados a derecha, pero una
vez elegida
una de las d
La convención que se usó para ajustar los intervalos de clase y hacerlos adyalos
debe
ser
exhaustivo
convenciones debe mantenérsela para toda la distribución.
centes, fue cerrarlos a izquierda y abrirlos a derecha. Podría haber sido al
–es decir, ningún dato puede quedar excluido– y los intervalos son
revés,
abiertos
a
izquierda
y
cerrados
a
derecha,
pero
una
vez
elegida
una
de
COMIENZO DE PASTILLA EN LQWHUYDORVGHFODVH
excluyentes entre sí por eso deben
las dos convenciones debe mantenérsela para toda la distribución.
(OFRQMXQWRGHLQWHUYDORVGHEHVHUH[KDXVWLYR²HVGHFLUQLQJ~QGDWRSXHGHTXHGDUH[FOXLGR²\ORVLQWHUYDORVVRQH[FOX\HQWHVHQWUHVtSRU
ser semiabiertos.
GHEHQVHUVHPLDELHUWRV
FIN DE PASTILLA
¿Por qué es necesario mantener la convención elegida en toda la distriCOMIENZO DE PARA REFLEXIONAR
bución? ¿Qué problemas acarrearía utilizar las dos convenciones en una
¿Por qué es necesario mantener la convención elegida en toda la distribución? ¿Qué problemas acarrearía utiliz
misma tabla?
Caso 3. En la siguiente tabla elaborada por los editores de una revista estudiantil universitaria con base en informaci
del
Nunca Más (Informe de la CONADEP, Eudeba, 1984), se presenta la edad de las personas desaparecidas en
Caso 3. En la siguiente tabla elaborada por los editores de una revista estuArgentina
por la última dictadura militar (1976-1983).
diantil universitaria con base en información del Nunca Más (Informe de la
CONADEP, Eudeba, 1984), se presenta la edad de las personas desaparecidas
Tabla 1.7.
en la Argentina por la última dictadura militar (1976-1983).
Edad al momento de la
desaparición forzada
D
D
11 a 15
D
f%
19
¿Por qué es necesario mantener la convención elegida en toda la distribución? ¿Qué pro
Universidad Virtual de Quilmes
Caso 3. En la siguiente tabla elaborada por los editores de una revista estudiantil universitaria
del Nunca Más (Informe de la CONADEP, Eudeba, 1984), se presenta la edad de las perso
Argentina por la última dictadura militar (1976-1983).
Tabla 1.7.
Tabla 1.7.
Edad al momento de la
desaparición forzada
D
D
11 a 15
D
21 a 25
D
D
D
41 a 45
D
51 a 55
D
61 a 65
D
GH
Total
f%
Notemos que en este caso no disponemos de los datos de campo y que en consecuencia no necesitamos adoptar convención alguna para el conteo. Para futuNotemos
que en estealgunos
caso nolímites
disponemos
de los datos
de forma
campoque
y que
en consecuencia
ros usos retocamos
de los intervalos
de tal
sean
convención
alguna
para el conteo.
rigurosamente
adyacentes
en el dominio de los números reales y tengan la
Para
futuros
usos
retocamos
algunos
límites
los intervalos
de tal forma que sean riguros
misma amplitud, y agregamos una
columna
con de
frecuencias
acumuladas:
dominio de los números reales y tengan la misma amplitud, y agregamos una columna con fr
Tabla 1.8.
Tabla 1.8.
Edad al momento de la
desaparición forzada
²
²
²
²
²
²
²
²
²
²
²
²
²
²
²
Total
f%
F%
Variable cuantitativa continua
familia, de 96 familias escogidas al azar de cierta localidad.
20
²
²
²
Total
Estadistica
Variable
Variable cuantitativa
cuantitativa continua
continua
Consideremos el siguiente conjunto de datos correspondiente a gastos por
familia,
demedio
96 familias
al azar
cierta localidad.
consumo
diario escogidas
de alimentos
pordefamilia,
de 96 familias escogidas al
azar de cierta localidad.
Arreglo de
Arreglo
dedatos
datosordenados
ordenados
Como se puede apreciar se optó por organizar el arreglo con forma de matriz columna, la que además se partió en cin
tramos para economizar espacio.
Como
puede
apreciar
optó
el arreglo
forma dediscreta
matriz del Caso 2, y por idénticos motivos
De se
forma
similar
a lose
que
se por
hizoorganizar
anteriormente
concon
la variable
columna, la que
además se partió
en cinco tramos
para economizar
espacio.
confecciona
a continuación
una distribución
de frecuencias
agrupando
los datos en intervalos de clase:
De forma similar a lo que se hizo anteriormente con la variable discreta del
Tabla 1.9.
21
Gasto medio
diario
f
f%
F
F%
Universidad Virtual de Quilmes
Como se puede apreciar se optó por organizar el arreglo con forma de matriz columna, la que a
tramos para economizar espacio.
De 2,
forma
a lomotivos,
que se hizo
anteriormente
con la variable
Caso
y porsimilar
idénticos
se confecciona
a continuación
una discreta
distribu- del Caso 2, y p
confecciona
a
continuación
una
distribución
de
frecuencias
agrupando
los datos en intervalo
ción de frecuencias agrupando los datos en intervalos de clase:
Tabla
Tabla 1.9.
1.9.
Gasto medio
diario
(15 – 25]
²@
²@
(45 – 55]
(55 – 65]
²@
@
@
Total
f
f%
F
F%
11
15
11
1
2
96
11
82
94
96
Tabla de distribución conjunta
Tabla de distribución conjunta
Para
Para armar
armar la
la siguiente
siguiente tabla
tabla de
de doble
doble entrada
entrada se
seconsideraron
consideraronlas
lasvariables
variables“Puesto de traba
“Rubro”,
ambas
de la
ME2001
3. y 2003” y “Rubro”, ambas de la ME 3.
“Puesto de
trabajo
entre
Tabla
Tabla 1.10.
1.10.
Tabla
1.10.
Puestos
de trabajo
Rubro
&RPHUFLDO ,QGXVWULDO 6HUYLFLRV
'LVPLQX\y
1
1 Rubro 2
Puestos
de trabajo
2001-2003
$JUtFROD
&RPHUFLDO
,QGXVWULDO
6HUYLFLRV
0DQWXYR
2
1
$XPHQWy
2
1
4
12
'LVPLQX\y
1
1
0DQWXYR
2
1
Cada uno
de los números que
en la tabla 4resultó del1conteo
$XPHQWy
2 figuran 1
2001-2003
$JUtFROD
simultáneo o conjunto
cada
categoría
pertenece
a
una
variable
distinta.
Cada uno de los números que figuran en la tabla resultó del conteo simultáhay
pymes
la muestra
queconteo
sona del
rubro
y que
Cada
uno
deobservar
los
quecuatro
figuran
en
la en
tabla
resultó
del
simultáneo
o conjunto
neoSeo puede
conjunto
denúmeros
dosque
categorías,
donde
cada
categoría
pertenece
una
varia- industrial
de
trabajo
entre
2001
y
2003.
cada
categoría pertenece a una variable distinta.
ble distinta.
Se
Se puede
puede observar
observarque
quehay
hay cuatro
cuatro pymes
pymes en
en la
la muestra
muestra que
que son
sondel
del rubro
rubro industrial y que
Tabla
1.11.
de
trabajoyentre
2001 y 2003.
industrial
que aumentaron
los puestos de trabajo entre 2001 y 2003.
Tabla
1.11.
1.11.
Puestos
de trabajo
22
Rubro
'LVPLQX\y
Puestos
de trabajo
0DQWXYR
2001-2003
$XPHQWy
'LVPLQX\y
Total
0DQWXYR
$JUtFROD
1
2
$JUtFROD
21
52
&RPHUFLDO
1
&RPHUFLDO
11
5
,QGXVWULDO
Rubro
,QGXVWULDO
4
6HUYLFLRV
2
1
6HUYLFLRV
12
41
Total
9
Total
8
24
9
$XPHQWy
2
1
4
1
8
2001-2003
Las frecuencias
que figuran
denominan4 frecuencias
Total
5 en la tabla
5 1.10. se 24 absolutas conjuntas y
tabla 1.11. En esta última se incorporaron además los totales por filas y columnas que son la
totales.
Las
frecuencias que
figuranen
enlalatabla
tabla1.10.
1.10.sesedenominan
denominanfrecuencias
frecuenciasabsoabsolutas conjuntas y
Las frecuencias
que figuran
tabla
1.11.
En
esta
última
se
incorporaron
además
los
totales
por
filas
y
columnas
que son la
lutas conjuntas y están sombreadas en la tabla 1.11. En esta última se incorCOMIENZO
DE
LEER
ATENTO
totales.
poraron además los totales por filas y columnas que son las frecuencias marSi
bien olastotales
palabras
ginales
. valor, categoría y clase pueden usarse como sinónimos, en lo sucesivo
respecto
del
significado
cada una. En ese sentido diremos que las variables cualitativas
COMIENZO DE LEER de
ATENTO
cuantitativas
toman valores
o se agrupan
en clases
(de usarse
valores).
Si bien las palabras
valor, categoría
y clase
pueden
como sinónimos, en lo sucesivo
FIN
DE
LEER
ATENTO
respecto del significado de cada una. En ese sentido diremos que las variables cualitativas
cuantitativas toman valores o se agrupan en clases (de valores).
FIN DE LEER ATENTO
Estadistica
Si bien las palabras valor, categoría y clase pueden usarse como sinónimos, en lo sucesivo seremos más rigurosos respecto del significado de
cada una. En ese sentido diremos que las variables cualitativas asumen
categorías y las cuantitativas toman valores o se agrupan en clases (de
valores).
1.1.3. Representaciones gráficas
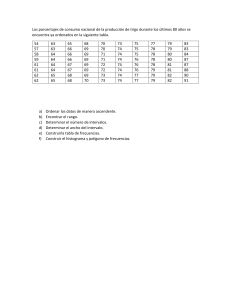
Para visualizar las distribuciones de frecuencias realizadas previamente recurriremos a distintos gráficos. Como el mundo de los gráficos es muy amplio y
sólo limitado por la imaginación, seleccionaremos aquellos que consideramos
más convenientes según su adecuación con el tipo de variable analizada.
Variables cualitativas
Para la confección de los siguientes gráficos se utilizó la información de las
tablas 1.1. y 1.2.
Gráfico circular o de torta
G.1.2.
G.1.2.
Rubro de la PyME
Rubro de la PyME
Tabla 1.1.
Tabla 1.1.
Servicios 17%
Servicios 17%
Industrial 37%
Industrial 37%
G.1.3.
G.1.3.
Detalle de terminación
Detalle de terminación
Tabla 1.2.
Tabla 1.2.
Agrícola 25%
Agrícola 25%
Comercial 21%
Comercial 21%
Regular
Bueno
Regular
Bueno
Muy bueno
Excelente
Muy bueno
Excelente
Gráfico de barras
Gráfico de barras
Gráfico de barras
G.1.4. Rubro de la PyME
Rubro de la PyME
G.1.4. Tabla
1.1.
Tabla 1.1.
f
6
5
4
3
2
1
0
Servicios
Servicios
Industrial
Industrial
Agrícola
Agrícola
Comercial
Comercial
0
G.1.5.
G.1.5.
0
0,1 0,2 0,3 0,4 fr
0,1 0,2 0,3 0,4 fr
Detalle de terminación
Detalle de terminación
Tabla 1.2.
Tabla 1.2.
f
6
5
4
3
2
1
0 Regular
Bueno Muy bueno Excelente
Regular
Bueno Muy bueno Excelente
23
Universidad Virtual de Quilmes
El ojo humano es más eficiente para reconocer
pequeñas diferencias lineales que
para advertir diferencias angulares
o de áreas, por lo que un gráfico
lineal como el de barras no necesita especificación adicional.
En el gráfico circular es necesario explicitar la frecuencia de cada valor
de la variable porque no es un gráfico lineal como el de barras.
Variables cuantitativas
Para representar gráficamente las variables cuantitativas se utilizó la información de las tablas 1.4. a 1.9.
Gráfico de bastones
FR
%DAD DE LOS EMPLEADOS DE LA EMPRESA COOPERATIVA
4ABLA ,QVHUWDU,PDJHQ1*
*UiILFRGHHVFDORQHV
%DAD DE LOS EMPLEADOS DE LA EMPRESA COOPERATIVA
)
4ABLA Desde la Biometría las contribuciones de Karl Pearson a la teoría estadística son importantes
y numerosas. Fue cofundador en
1901 de la revista Biometrika que
se convirtió en el receptáculo de
todos los aportes a la estadística provenientes de distintas ciencias y que se sigue publicando hasta ho y.
Gráfico de escalones
Histogramas de Pearson y polígonos de frecuencias
24
Estadistica
Gráfico 1.8.
f
20
Gráfico 1.9.
Edad de los empleados
Tabla 1.6.
f
20
15
15
10
10
5
5
0
Edad de los empleados
Tabla 1.6.
0
15 20 25 30 35 40 45 50 55 60 65
Gráfico 1.11.
Gráfico 1.10.
Edad al momento de la desaparición
Tabla 1.8.
Edad al momento de la desaparición
Tabla 1.8.
35
30
25
20
15
10
5
0
5 10 15 20 25 30 35 40 45 50 55 60 65 70 75
Gráfico 1.12.
Gráfico 1.13.
Gasto medio diario
Tabla 1.9.
Gasto medio diario
Tabla 1.9.
35
30
25
20
15
10
5
0
35
30
25
20
15
10
5
0
15 25 35 45 55 65 75 85 95
15 25 35 45 55 65 75 85 95
Los gráficos 1.8., 1.10. y 1.12. son histogramas, los 1.9. y 1.11. son polígonos de frecuencias y en el 1.13. se combinan ambos.
Tanto el histograma como el polígono de frecuencias encierran la misma
área, el área es igual al total de los datos si se grafican las frecuencias
absolutas, uno si se trata de las frecuencias relativas y cien si es la f% la
representada.
Ojiva de Galton
El gráfico de frecuencias acumuladas Ojiva se debe a Francis Galton,
también biómetra y maestro de K.
Pearson; cofundador con
él de Biometrika.
25
Edad acumulativa
Tabla 1.6.
f%
f%
120
100
100
Universidad Virtual de Quilmes
80
80
60
40
Edad acumulativa
Tabla 1.8.
60
Gráfico 1.14.
40 Gráfico
1.15.
20
20
0
0
Edad acumulativa
f%
15 20 Tabla
25 301.6.
35 40 45 50 55 60 65 70
Edad acumulativa
Tabla20
1.8.30 40 50 60 70
0 10
f%
120
100
100
80
Gráfico 1.16.80
60
60
40
20
f%
0
120
acumulativo
Gasto medio diario 40
20
Tabla 1.9.
0
15 20 25 30 35 40 45 50 55 60 65 70
0 10 20 30 40 50 60 70
100
80
60
Gráfico 1.16.
40
20
0f %
Gasto medio diario acumulativo
Tabla 1.9.
120 15 25 35 45 55 65 75 85 95 105
100
80
60
40
20
0
15 25 35 45 55 65 75 85 95 105
Gráficos para representar tablas de distribución conjunta
Los siguientes gráficos sirven para representar tablas del tipo de la tabla 1.11
en la que intervienen dos variables.
Gráfico de barras adyacentes y gráfico de barras segmentadas
Gráfico
Gráfico
1.17. 1.17.
Gráfico
Gráfico
1.18.
Rubro y puestos de trabajo de las PyMEs
Tabla 1.11.
Rubro y puestos de trabajo de las PyMEs
Tabla 1.11.
5
4
3
2
1
5
4
3
2
1
26
1.18.
Gráfico 1.17.
Gráfico 1.18.
Rubro y puestos de trabajo de las PyMEs
Tabla 1.11.
Rubro y puestos de trabajo de las PyMEs
Tabla 1.11.
Puede observarse que en el gráfico de barras segmentadas se incluyó
información sobre la frecuencia de cada segmento. Esto se debe a que
las comparaciones entre distintos segmentos son areales, no lineales, lo
mismo que ocurre con el gráfico circular.
COMIENZO DE LEER ATENTO
Puede observarse que en el gráfico de barras segmentadas se incluyó información sobre la frecuencia de ca
segmento. Esto se debe a que las comparaciones entre distintos segmentos son areales, no lineales, lo mis
que ocurre con el gráfico circular.
Estadistica
FIN DE LEER ATENTO
Pirámides deDE
población
COMIENZO
TEXTO APARTE
Pirámides
de población
población es un gráfico que se aplica a distribuciones bivariadas donde las
Una pirámidede
Una
pirámide
de
es un
gráfico
que segeneralmente
aplica a distribuciones
variables son “sexo” población
y “edad”, esta
última
organizada
en intervalos.bivariadas donde las variables son “sexo” y “edad”, e
La siguiente
distribución
de frecuencias
conjuntas corresponde a un grupo de 1000
organizada
generalmente
en intervalos.
última
personas,
La siguiente distribución de frecuencias conjuntas corresponde a un grupo de 1000 personas
Tabla
1.12.
Tabla
1.12.
Sexo
Edades
>²
>²
>²
>²
>²
>²
>²
>²
>²
>²
F
M
'RQGH)HPHQLQR)\0DVFXOLQR0
La correspondiente pirámide de población es
Gráfico 1.19.
%$!$
F
MUJERES
HOMBRES
),1'(7(;72$3$57(
3.
Representar gráficamente las variables de la ME 2.
&20,(1=2'($&7,9,'$'
5HSUHVHQWDUJUiILFDPHQWHODVYDULDEOHVGHOD0(
),1'($&7,9,'$'
/DV FRQVWUXFFLRQHV TXH DFDEDPRV GH UHDOL]DU ±GLVWULEXFLyQ GH
27
Universidad Virtual de Quilmes
Las construcciones que acabamos de realizar –distribución de frecuencias,
arreglo de datos ordenados y gráficos sobre el eje numérico– involucran cuatro espacios abstractos bien diferenciados, el espacio de los valores (primera columna de la tabla de frecuencias), el espacio de las frecuencias (las
columnas de frecuencias de la distribución), el espacio de los datos ordenados (el arreglo) y el espacio de los números reales (el eje horizontal de los gráficos hechos). Ellos son los espacios de definición de las medidas estadísticas, también denominados indicadores estadísticos, y a las cuales nos
dedicaremos en el próximo apartado.
Los gráficos elaborados permiten tener una idea de conjunto del grupo
de datos relevados complementando la lectura de la información que
hacen los indicadores estadísticos. Su objetivo principal es maximizar
la extracción de la información contenida en los datos empíricos.
1.2. Medidas estadísticas
Las medidas estadísticas son resúmenes o indicadores que permiten caracterizar el comportamiento del grupo de datos en estudio. Según el criterio de
diseño existen distintos tipos de medidas, las de posición, las de dispersión
y las de intensidad.
1.2.1. Medidas de posición
Las medidas de posición determinan, con distintos criterios, ubicaciones unívocas en el conjunto de datos.
Moda o modo
Observando las distribuciones tratadas anteriormente notamos que sobresale –que predomina– algún valor o categoría o clase.
La moda o modo –que denotaremos como Mo– es el valor, categoría o
clase que registra la frecuencia mayor en la distribución de la variable.
En la variable “rubro de las pymes” (tabla 1.1. y gráficos G.1.2. y G.1.4.) observamos que predomina la categoría industrial.
En el “nivel de terminación de las piezas de plástico” (tabla 1.2. y gráfico
G.1.5.) no predomina ninguna categoría de datos, no hay moda.
La edad de los empleados (tabla 1.4 y gráfico G.1.7) más frecuente es 37
años.
En la tabla 1.6. y en el gráfico G.1.8. –empleados de una fábrica– notamos que la clase de edad –franja etaria– que tiene mayor frecuencia es [35 –
40] y repasando los datos sobre el arreglo concluimos que entre los empleados de la fábrica predominan las edades que van de 35 a 39 años.
En la distribución de la tabla 1.10. y en el gráfico 1.12. se aprecian dos inter28
Estadistica
valos modales –[25-35] y [35-45]–, que interpretamos volviendo nuevamente
a los datos de la siguiente manera: en la muestra predominan las familias
que tienen un gasto medio diario en alimentos de entre $26,80 y $34,65 y
entre $37,20 y $43,90. Como en esta distribución los intervalos modales
resultaron ser adyacentes, con un criterio práctico puede también interpretarse que en la muestra predominan las familias que tienen un gasto diario
medio en alimentos de entre $26,80 y $43,90.
En el caso de la tabla 1.8., la interpretación del intervalo modal 20-25 no
puede hacerse sobre los datos originales porque no contamos con ellos (desde
la publicación estudiantil, se entiende). Y decimos entonces que en el universo de las personas desaparecidas por la dictadura militar 1976-1983 en
la Argentina, la edad predominante al momento de la desaparición forzada es
de entre 21 y 25 años (aprovechando la información de la tabla 1.7. y los gráficos 1.10. y 1.11.)
¿Es factible concluir que la moda es aplicable a cualquier tipo de variable?
Tanto en la tabla conjunta 1.11. como en el gráfico G.1.17 se ve que en la
muestra de 24 pymes predominan las del rubro industrial que aumentaron los
puestos de trabajo entre 2001 y 2003.
Finalmente, en el caso de la tabla 1.12. predominan las mujeres que tienen hasta 10 años de edad. Además, se observa que hay predominio de población joven y eso queda reflejado en el gráfico G.1.19. (en las poblaciones
donde predominan las edades mayores la pirámide se vería invertida).
4.
a. Determinar la moda de las variables de la ME 2.
b. Determinar la moda de la distribución conjunta de edad y sexo de
la tabla 1.12.
Media aritmética o promedio
La media aritmética, comúnmente conocida como promedio, es una medida
que incumbe sólo a las variables cuantitativas.
El promedio se denota
con X si el grupo de datos
es una muestra y con µ si es toda
la población.
La media aritmética representa, en el dominio de los números reales, el
punto de equilibrio del conjunto de datos.
Vemos entonces que la edad promedio de los empleados de una cooperativa
que integran la muestra del caso 1, es de 38,9 años. O que los 80 empleados seleccionados al azar entre todos los de una fábrica automotriz (caso 2)
tienen, en promedio, una edad de 37,4 años.
También, en la muestra de las 96 familias, el gasto medio diario en alimentos es, en promedio, de $44,27 por familia.
29
Vemos entonces que la edad promedio de los empleados de una
cooperativa que integran la muestra del caso 1, es de 38,9 años. O que
los 80 empleados seleccionados al azar entre todos los de una fábrica
automotriz (caso 2) tienen, en promedio, una edad de 37,4 años.
Universidad Virtual de Quilmes
También, en la muestra de las 96 familias, el gasto medio diario en
alimentos es, en promedio, de $44,27 por familia.
Además, de la forma más popular de calcular la media –sumando los valoAdemás, de la forma más popular de calcular la media –sumando los
res de todos los datos y dividiendo por el total– surgen otras formas de cálvalores de todos los datos y dividiendo por el total– surgen otras formas
culo ligadas al empleo de las tablas de frecuencias.
de cálculo ligadas al empleo de las tablas de frecuencias.
(1.1.)
COMIENZO DE TEXTO APARTE
A modo de ejemplificación se explicitan a continuación dos formas de
calcular
unodede
los resultados
expuestos
anteriormente
(edad
promedio
A modo
ejemplificación
se explicitan
a continuación
dos formas
de calcular
uno de los
resultados
expuestos
anteriormente
(edad que
promedio
de los la
empleados
de una cooperativa que
de los
empleados
de una
cooperativa
integran
muestra):
integran la muestra):
Si estuviéramos en una situación similar al caso 3, donde no se cuenta con
los datos, se podría calcular igualmente un promedio aproximado aplicando la
misma fórmula 1.1. pero considerando como valores de la variable xi los puntos medios de cada intervalo denominados a partir de aquí marca de clase.
Si se hace el cálculo se tiene que la edad promedio de los desaparecidos
en Argentina por la última dictadura militar es de 28,09 años aproximadamente.
5.
Determinar la media aritmética de las variables cuantitativas de la ME 2.
¿Cuál es la diferencia de calidad entre una media aritmética calculada con
los datos y la calculada a partir del agrupamiento en intervalos de clase?
Mediana
Mediana es el lugar geométrico del arreglo de datos ordenado que lo divide
en dos partes iguales.
30
COMIENZO DE PARA REFLEXIONAR
FIN DE
PARA
REFLEXIONAR
es la
diferencia
de calidad entre una media aritmética calculada con los datos y la calculada a partir
¿Cuál
agrupamiento en intervalos de clase?
MedianaFIN DE PARA REFLEXIONAR
Estadistica
Mediana es el lugar geométrico del arreglo de datos ordenado que lo divide en dos partes iguales.
Mediana
En En
el arreglo
ordenado
de la
“nivel
de detalles
de de
terminación
de las
el arreglo
ordenado
devariable
la variable
“nivel
de detalles
terminación
de las piezas plásticas” ubicamos la posic
piezas
plásticas”
ubicamos
la
posición
de
la
mediana,
de la mediana,
Mediana
es el lugar geométrico del arreglo de datos ordenado que lo divide en dos partes iguales.
En el arreglo ordenado de la variable “nivel de detalles de terminación de las piezas plásticas” ubicamos la posic
R R R B B B B B MB MB MB MB MB E E E E E
deR la Rmediana,
10 datos
Me
10 datos
Si
R ahora
R Rdeterminamos
R R B B laBmediana
B B sobre
MB el
MBarreglo
MB de
MB datos
MB ordenado
E E E E E
Si
ahora
determinamos
la
mediana
sobre
el
arreglo
de
datos
ordenado
la información
queempleados”
ella nos
da
la
siguiente
manera:
la mitad (inferior) de las piezas de plástico co
deylaleemos
variable
“ edad
de
la
muestra
de
la
empresa
10
datos de los
10
datos
y la
leemos
la información
ella
nos Me
de de
la siguiente
manera:
laempresa
mitad (infedemáximo
variable
“ edad
de que
los
empleados”
la muestra
de
tienen
un nivel
de detalle
dedaterminación
Bueno
y lalaotra
mitad (superior) tiene como mínimo un nivel
cooperativa,
rior) de las piezas de plástico como máximo tienen un nivel de detalle de tercooperativa,
de laterminación
Muy
ydetalle
leemos
información
queBueno.
ella
nos datiene
de lacomo
siguiente
manera:
la de
mitad
minación
Bueno
y la otra mitad
(superior)
mínimo
un nivel
deta-(inferior) de las piezas de plástico co
ahora
determinamos
ladetalle
mediana
sobre
datos
ordenado
de
la variable
“edad
de los
empleados”
d
21máximo
25Si 28
30
34
36
36
37
37
37de38terminación
39 el
39arreglo
40 Bueno
40de42
48otra
51 mitad
57 63
tienen
un
nivel
de
y
la
(superior)
tiene
como
mínimo
un nivel
lle25de 28
terminación
Muy36Bueno.
21muestra
30
34
36
37
37
37
38
39
39
40
40
42
48
51
57
63
la empresa cooperativa,
detalle
dedeterminación
MuylaBueno.
Me sobre el arreglo de datos ordenado de
Si ahora
determinamos
mediana
Me
Si
ahora
determinamos
la
mediana
el arreglo
datos ordenado
de la variable “edad de los empleados” d
la variable “edad de los empleados” desobre
la muestra
de lade
empresa
cooperativa,
21
25
28
30
34
36
36
37
37
37
38
39
39
40
40
42
48
51
57
63
muestra
la empresa
leemos
lo de
siguiente:
lacooperativa,
mitad de los empleados de la muestra tienen
leemos
siguiente:
mitad
de los
empleados de la muestra tienen
Me
hasta
37lo
años
y la otrala
mitad
desde
38 años.
hasta
37
años
y
la
otra
mitad
desde
38
años.
21 25 28 30 34 36 36 37 37 37 38 39 39 40 40 42 48 51 57 63
leemos lo siguiente: la mitad de los empleados de la muestra tienen hasta 37 años y la otra mitad desde 38 años.
COMIENZO DE ACTIVIDADMe
COMIENZO DE ACTIVIDAD
6.
COMIENZO
DE ACTIVIDAD
6.
leemos
lo
siguiente: la mitad
de los
empleados
la
muestra
tienen
hasta
años y la otra mitad desde 38 años.
la mediana
dede
todas
las variables
de la37
leemosDeterminar
lo6.siguiente:elainterpretar
mitad de los
empleados
de
la muestra
tienen hasta
37
Determinar
e
interpretar
la
mediana
de
todas
las
variables
de
la
2 que
lo permitan.
años y ME
la Determinar
otra
mitad
desde
38 años.
e interpretar
la mediana de todas las variables de la ME 2 que lo permitan.
COMIENZO
DE ACTIVIDAD
ME
2
que
lo permitan.
FIN
DE
ACTIVIDAD
FIN
DE
ACTIVIDAD
FIN
6. DE ACTIVIDAD
Determinar
e interpretar
la mediana
todas las variables
de la ME 2 que lo permitan.
EnEnelel caso
caso
la variable
de lasde
personas
desaparecidas,
6.dede
la
variable
edad deedad
las personas
desaparecidas,
recordemos que no se cuenta con los datos originales.
FIN
DE
ACTIVIDAD
En
el
caso
de
la
variable
edad
de
las
personas
desaparecidas,
recordemosDeterminar
que no se cuenta
con los
datos originales.
Sinvariables
embargo,
si ME
es 2
e interpretar
la mediana
de todas las
de la
embargo, sique
es necesario
contar
con
tentativo
que
la aproxime
recordemos
no
se cuenta
con
losalgún
datosvalor
originales.
Sin
embargo,
esy que permita extraer información de for
necesario
contar
con
algún
valor
tentativo
que la
aproxime
y sique
queyalorealizado,
permitan.
similar
a
lo
debe
elegirse
algún
criterio
para
determinarla.
En el caso
de lainformación
variable
edadde
de forma
las personas
desaparecidas,
recordemos
que no se cuenta con los datos originales.
necesario
contar
con algún
valor
tentativo
que
aproxime
y debe
que
permita
extraer
similar
acon
lolaya
realizado,
Para
obtener
la
mediana
si
se
cuenta
solamente
un
agrupamiento
de
en intervalos,
debe localiza
embargo,
si escriterio
necesario
contar
algún
valor tentativo
la aproxime
que permita
extraerprimero
información
de for
permita
extraer
información
decon
forma
similar
a lo ya que
realizado,
debeydatos
elegirse
algún
para
determinarla.
el
intervalo
mediano
–el
intervalo
donde
caería
la
mediana—
y
luego
para
ese
intervalo
se
aplica
como
criterio algu
elegirse
algún
criterio
para
determinarla.
similar
a
lo
ya
realizado,
debe
elegirse
algún
criterio
para
determinarla.
En
el caso de lalavariable
edad se
de cuenta
las personas
desaparecidas,
recordemos que
Para
mediana
solamente
con un agrupamiento
de
las obtener
fórmulas
que
siguen.si
Para
obtener
la
mediana
se
cuenta
solamente
con
un
agrupamiento
de datos en intervalos, primero debe localiza
Para
obtener
la
mediana
si
se
cuenta
solamente
con
un
agrupamiento
se cuenta
con losprimero
datos originales.
Sin embargo,
si es necesario
contar
deno
datos
en intervalos,
debe localizarse
el intervalo
mediano –el
el
intervalo
mediano
–el
intervalo
donde
caería
la
mediana—
y
luego
para
ese intervalo se aplica como criterio algu
de
datos
en
intervalos,
primero
debe
localizarse
el
intervalo
mediano
–el
con algún
valor
tentativo
que la aproxime
y quepara
permita
extraer información
COMIENZO
DE
PASTILLA
EN
intervalo
donde
caería
lafórmulas
mediana—
y luego
ese intervalo
se aplica de
intervalo
donde
lalas
mediana—
ysencillamente
luego
paramediante
ese
intervalo
se aplica
de
las
fórmulas
queyade
siguen.
Estas
fórmulas
pueden
obtenerse
rápida
interpolación
lineal.
forma
similar
acaería
lo
realizado,
debeyque
elegirse
algún
criterio
para determinarla.
como
criterio
alguna
fórmulas
siguen.
FIN DE
PASTILLA
como
criterio
alguna
de
las
fórmulas
que
siguen.
Para obtener la mediana si se cuenta solamente con un agrupamiento de
COMIENZO DE PASTILLA ENfórmulas
COMIENZO DE PASTILLA EN fórmulas
datosfórmulas
enDE
intervalos,
primero
debe
el intervalo
mediano –el
interEstas
pueden obtenerse
rápida localizarse
y sencillamente
mediante interpolación
lineal.
COMIENZO
PASTILLA
EN fórmulas
Estas
fórmulas
pueden
obtenerse
rápida y sencillamente mediante interpolación lineal.
FIN
DE
PASTILLA
valo
donde
caería
la
mediana—
y
luego
para
ese
intervalo
se
aplica
como
Estas
pueden obtenerse rápida y sencillamente mediante interpolación lineal. criFIN
DEfórmulas
PASTILLA
FINterio
DE PASTILLA
alguna de las fórmulas que siguen.
Estas fórmulas pueden
obtenerse rápida y sencillamente mediante interpolación
mediano,
el subíndice i de las
lineal.
Donde: a es la amplitud de los intervalos, li es el límite inferior del intervalo
frecuenc
n
F(i1)
simples se refierenalintervalo
mediano0,5
y el (i-1)
hace referencia al intervalo anterior.
50 acumuladas
F%(i1)
Fr(i1) de las frecuencias
2 F(i1)
M eEl=intervalo
l i + a mediano
=las edades
l i + a 0,5
=
l
+
a
50
F%
Fr
i
de
de
los
desaparecidos
es
[25;
30]
y
reemplazando
(i1)
Donde:
de los
li ies(i1)
el límite
intervalo
mediano, elvalores:
subíndice i de las frecuenc
fr
M e = a es
l i +laaamplitud
2 fi
= intervalos,
li + a = inferior
l i + a delf%
i
f
fr
f%
i
i
i
simples se refiere al intervalo
mediano y el (i-1)
de las frecuencias acumuladas
hace referencia al intervalo anterior.
El
intervalo
mediano
de
las
edades
de
los
desaparecidos
es
[25;
30]
y
reemplazando
valores:
Donde: a es la amplitud
los intervalos, l i es el límite inferior del
Donde:
a
es
la
amplitud
de
los
intervalos,
l
es
el
límite
inferior
del
i
intervalo
el subíndice
de las frecuencias
simples
se refiere
al
Donde: mediano,
a es la amplitud
de los i intervalos,
li es el límite
inferior
del intervalo
intervalo
mediano,
el
subíndice
i
de
las
frecuencias
simples
se
refiere
alde la desaparición forzada de la mitad de
El
valor
obtenido
significa
que
la
edad
máxima
aproximada
al
momento
intervalo
mediano
y
el
(i-1)
de
las
frecuencias
acumuladas
hace
mediano, el subíndice i de las frecuencias simples se refiere al intervalo mediaintervalo
mediano
y anterior.
elera(i-1)
de las
acumuladas hace
personas
desaparecidas
de acumuladas
25,99
años.frecuencias
referencia
al
intervalo
no y el (i-1)
de las frecuencias
hace referencia al intervalo anterior.
referencia
al
intervalo
anterior.
ElElvalor
obtenido
significa
edad máxima
aproximada ales
momento
de yla desaparición forzada de la mitad de
mediano
de
las
edades
de
Elintervalo
intervalo
mediano
deque
lasla
edades
delos
losdesaparecidos
desaparecidos
es[25;
[25;30]
30]
El
intervalo
mediano
de
las
edades
de
los
desaparecidos
es
[25;
30]
y reemplazando
valores: era de 25,99 años.
personas
desaparecidas
reemplazando
valores:
y reemplazando valores:
EstadisticasU1.indd 22
8/2
EstadisticasU1.indd 22
8/2
El valor obtenido significa que la edad máxima aproximada al momento
El la
valor
obtenido significa
que
edadde
máxima
aproximada
al momento
de
desaparición
forzada de
lala
mitad
las personas
desaparecidas
era
de 25,99
la desaparición
forzada de la mitad de las personas desaparecidas era
de
años.
de 25,99 años.
COMIENZO DE PARA REFLEXIONAR
31
Universidad Virtual de Quilmes
El valor obtenido significa que la edad máxima aproximada al momento de
la desaparición forzada de la mitad de las personas desaparecidas era de
25,99 años.
),1'(3$5$5()/(;,21$5
&20,(1=2'(/((5$7(172
¿Es
posible determinar la mediana en cualquier tipo de variable?
(Q ODV YDULDEOHV FXDQWLWDWLYDV ODV WUHV PHGLGDV GH SRVLFLyQ
YLVWDV KDVWD DKRUD ±PRGR PHGLD DULWPpWLFD \ PHGLDQD±
WDPELpQ VH GHQRPLQDQ PHGLGDV GH WHQGHQFLD FHQWUDO SRU VX
FRPSRUWDPLHQWR
HQ UHODFLyQ
OD de
]RQD
FHQWUDO
OD
En
las variables cuantitativas,
las tresFRQ
medidas
posición
vistasGH
hasta
GLVWULEXFLyQ
6L ODaritmética
GLVWULEXFLyQ
GH ORV
GDWRV se
HVdenominan
VLPpWULFDmediHVWDV
ahora
–modo, media
y mediana–
también
WUHV
PHGLGDV
VH
SRVLFLRQDQ
JHRPpWULFDPHQWH
HQ
HO
PLVPR
das de tendencia central por su comportamiento en relación con la zona
SXQWRde la distribución. Si la distribución de los datos es simétrica estas
central
),1'(/((5$7(172
tres medidas se posicionan geométricamente en el mismo punto.
$QiOLVLVGHODDVLPHWUtDHVWDGtVWLFDGHXQDGLVWULEXFLyQ
Análisis de la asimetría estadística de una distribución
/RV JUiILFRV TXH VLJXHQ SHUPLWHQ YL]XDOL]DU ORV WLSRV GH DVLPHWUtDV
HVWDGtVWLFDV\VXVGHQRPLQDFLRQHV
Los
gráficos que siguen permiten vizualizar los tipos de asimetrías estadísticas y sus denominaciones.
,QVHUWDU,PDJHQ1*
Gráfico 1.20.
!SIM£TRICA A IZQUIERDA
3IM£TRICA
!SIM£TRICA A DERECHA
Observando la “forma” que adoptan los gráficos G.1.6.; G.1.8.; G.1.10. y
G.1.12.
de las distribuciones de las variables cuantitativas analizadas, se
2EVHUYDQGROD³IRUPD´TXHDGRSWDQORVJUiILFRV***
puede
notar tanto en el G.1.10. como en el G.1.12. que hay una clara asi\*GHODVGLVWULEXFLRQHVGHODVYDULDEOHVFXDQWLWDWLYDVDQDOL]DGDV
metría
–en ambos casos– hacia la derecha, porque en esa dirección es donde
VHSXHGHQRWDUWDQWRHQHO*FRPRHQHO*TXHKD\XQDFODUD
se
registran los valores más alejados de la región con mayor densidad de
DVLPHWUtD±HQDPERVFDVRV±KDFLDODGHUHFKDSRUTXHHQHVDGLUHFFLyQHV
datos.
Sin
noORV
queda
muy claro
existen asimetrías
en G.1.6
G.1.8.
GRQGH
VHembargo,
UHJLVWUDQ
YDORUHV
PiVsiDOHMDGRV
GH OD UHJLyQ
FRQy PD\RU
Las evidentes
limitaciones
del análisis
obligan
encontrar
alguna
GHQVLGDG
GH GDWRV
6LQ HPEDUJR
QRgráfico
TXHGD
PX\aFODUR
VL H[LVWHQ
forma
analítica para el estudio de la asimetría de una distribución, como la
DVLPHWUtDVHQ*\*
de comparar
las tres
medidas deGHO
tendencia
aprovechando
de ellas
/DV HYLGHQWHV
OLPLWDFLRQHV
DQiOLVLVcentral
JUiILFR
REOLJDQ D HQFRQWUDU
su
distintoIRUPD
comportamiento
dinámico
éste,
se aclarará
DOJXQD
DQDOtWLFD SDUD
HO (concepto
HVWXGLR GH
ODque
DVLPHWUtD
GH más
XQD
adelante).
GLVWULEXFLyQFRPRODGHFRPSDUDUODVWUHVPHGLGDVGHWHQGHQFLDFHQWUDO
DSURYHFKDQGR GH HOODV VX GLVWLQWR FRPSRUWDPLHQWR GLQiPLFR FRQFHSWR
pVWHTXHVHDFODUDUiPiVDGHODQWH ,QVHUWDU,PDJHQ1*
$VLPpWULFDDL]TXLHUGD
32
6LPpWULFD
$VLPpWULFDDGHUHFKD
Estadistica
Gráfico 1.21.
!SIM£TRICA A IZQUIERDA
-E -O
-E
-O
3IM£TRICA
-E -O
-O -E
!SIM£TRICA A DERECHA
-O-E
-O
-E
Como el análisis de asimetría se realiza en el dominio de los números
&20,(1=2'(/((5$7(172
reales HODQiOLVLVGHDVLPHWUtDVHUHDOL]DHQHOGRPLQLRGHORV
se necesita contar con un número real para cada una de las tres
&RPR
medidas
de tendencia central.
Q~PHURVUHDOHVVHQHFHVLWDFRQWDUFRQXQQ~PHURUHDOSDUDFDGD
La media –por definición– es un número real, pero no así la moda
XQDGHODVWUHVPHGLGDVGHWHQGHQFLDFHQWUDO
ni /DPHGLD±SRUGHILQLFLyQ±HVXQQ~PHURUHDOSHURQRDVtOD
la mediana para las cuales hay que emplear alguna convención que
permita
un número
real.
PRGD
QLasignarles
OD PHGLDQD
SDUD ODV
FXDOHV KD\ TXH HPSOHDU DOJXQD
FRQYHQFLyQTXHSHUPLWDDVLJQDUOHVXQQ~PHURUHDO
),1'(/((5$7(172
Estudiaremos analíticamente la asimetría de la “Edad de los empleados de la
empresa cooperativa” (gráfico G.1.6.).
(VWXGLDUHPRVDQDOtWLFDPHQWHODDVLPHWUtDGHOD³(GDGGHORVHPSOHDGRV
Al modo puede asignársele
el número real
GHODHPSUHVDFRRSHUDWLYD´
JUiILFR*
37 directamente porque, para
la$O
variable
tratamiento,
su valor
es un número.
PRGRenSXHGH
DVLJQiUVHOH
HO Q~PHUR
UHDO GLUHFWDPHQWH SRUTXH
La
marca
de
la
mediana
quedó
posicionada
entre dos datos cuyos valores
SDUDODYDULDEOHHQWUDWDPLHQWRVXYDORUHVXQQ~PHUR
son
y 38 GH
y, siODbien
cualquier
número
real entreHQWUH
esosGRV
dos GDWRV
valores
podría
/D37
PDUFD
PHGLDQD
TXHGy
SRVLFLRQDGD
FX\RV
representarla
en
el
dominio
de
los
números
reales,
convenimos
en
usar
YDORUHV VRQ \ \ VL ELHQ FXDOTXLHU Q~PHUR UHDO HQWUH HVRV GRVde
aquí en SRGUtD
más el promedio
entre HQ
ambos
valores, en
37,5. UHDOHV
YDORUHV
UHSUHVHQWDUOD
HO GRPLQLR
GHeste
ORVcaso
Q~PHURV
Como
la
media
aritmética
es
un
número
real
–tal
cual
se
la
determinó– no
FRQYHQLPRVHQXVDUGHDTXtHQPiVHOSURPHGLRHQWUHDPERVYDORUHVHQ
necesitamos aplicarle ninguna convención para volcarla en el dominio de los
HVWHFDVR
números
&RPR reales.
OD PHGLD DULWPpWLFD HV XQ Q~PHUR UHDO ±WDO FXDO VH OD
Entonces
tenemos:
GHWHUPLQy±QRQHFHVLWDPRVDSOLFDUOHQLQJXQDFRQYHQFLyQSDUDYROFDUOD
M
=
37
años
Me = 37,5 años
x = 38,9 años
o
HQHOGRPLQLRGHORVQ~PHURVUHDOHV
(QWRQFHVWHQHPRV
Resultando:
Mo ≤ Me ≤ X
0R DxRV0H
DxRV
DxRV
Como el valor del promedio es el más alto, concluimos que hay una asimetría
5HVXOWDQGR
hacia
la derecha.
Las tres medidas de tendencia central tienen –en el dominio de los
&RPR HO YDORU
GHOreales–
SURPHGLR
HV HO PiV DOWR
FRQFOXLPRV
TXH KD\ XQD
números
comportamientos
dinámicos
diferenciados.
DVLPHWUtDKDFLDODGHUHFKD
El promedio es, de las tres, la medida más sensible ante la presencia de valores muy alejados de la zona de mayor densidad, los cuales
&20,(1=2'(/((5$7(172
la atraen rápidamente hacia ellos. Por esta particularidad la media es
/DVWUHVPHGLGDVGHWHQGHQFLDFHQWUDOWLHQHQ±HQHOGRPLQLRGH
determinante en el análisis de la asimetría de una distribución; si hay
ORVQ~PHURVUHDOHV±FRPSRUWDPLHQWRVGLQiPLFRVGLIHUHQFLDGRV
asimetría hacia un lado (derecho o izquierdo), la media –consecuente(OSURPHGLRHVGHODVWUHVODPHGLGDPiVVHQVLEOHDQWHOD
mente–
se desplaza en esa dirección.
SUHVHQFLD
GH YDORUHV
PX\
DOHMDGRV
GH OD natural
]RQD GH
PD\RUde
La mediana,
a la sazón
sacada
de su dominio
–el arreglo
GHQVLGDGORVFXDOHVODDWUDHQUiSLGDPHQWHKDFLDHOORV3RUHVWD
SDUWLFXODULGDG OD PHGLD HV GHWHUPLQDQWH HQ HO DQiOLVLV GH OD
DVLPHWUtD GH XQD GLVWULEXFLyQ VL KD\ DVLPHWUtD KDFLD XQ ODGR
33
desplaza en esa dirección.
La mediana, a la sazón sacada de su dominio natural –el
arreglo de datos ordenados– y transferida –convención
mediante– al de los números reales, obviamente no tiene la
misma sensibilidad que la media. Una situación parecida se da
ordenados–
y transferida
–convención
mediante–
al de los númecondatos
la moda,
quien es
aún más insensible
que
la mediana.
ros
reales,
obviamente
no
tiene
la
misma
sensibilidad
que
la media. Una
En análisis de asimetría que presenten situaciones ambiguas
situacióndonde
parecida
da con la relativa
moda, quien
es aún
más insensible
o confusas
la se
ubicación
de estas
medidas
no se que
la
mediana.
encuadre en algunos de los tres casos prescritos anteriormente,
En análisis
de asimetría
presenten
situaciones
ambiguas
o conconviene
descartar
la moda que
y sólo
comparar
la mediana
y la
fusas
donde
la
ubicación
relativa
de
estas
medidas
no
se
encuadre
en
media aritmética.
de los
tres casos prescritos anteriormente, conviene descartar la
FINalgunos
DE LEER
ATENTO
moda y sólo comparar la mediana y la media aritmética.
Universidad Virtual de Quilmes
COMIENZO DE ACTIVIDAD
7. 7.
a. Verificar
analíticamentelala asimetría
asimetría de
distribuciones
corresa. Verificar
analíticamente
delaslas
distribuciones
pondientes
a
los
gráficos
G.1.8.;
G.1.10.
y
G.1.12.
correspondientes a los gráficos G.1.8.; G.1.10. y G.1.12.
b. Analizarqué
qué tipo
presentan
las variables
cuantitativas
b. Analizar
tipo dedeasimetría
asimetría
presentan
las variables
de
la
ME
2.
cuantitativas de la ME 2.
FIN DE ACTIVIDAD
Cuartiles
Cuartiles
cuartiles
lugares
geométricos
arreglode
dedatos
datosordenado
ordenado que
LosLos
cuartiles
sonson
trestres
lugares
geométricos
deldelarreglo
quelo
lodividen
dividenenencuatro
cuatropartes
partesiguales
iguales
Extendiendo el concepto aplicado para el posicionamiento de la mediana,
Extendiendo el concepto aplicado para el posicionamiento de la
en el arreglo ordenado de la variable “nivel de detalles de terminación de las
mediana,
en el arreglo ordenado de la variable “ nivel de detalles de
piezas plásticas” ubicamos los tres cuartiles,
terminación de las piezas plásticas” ubicamos los tres cuartiles,
R
R
R
R
5 datos
1/4
R
B
Q1
B
B
B
B
MB
5 datos Q2 = M e
1/4
MB
MB
5 datos
1/4
MB
MB
Q3
E
E
E
E
E
5 datos
1/4
y leemos la información que nos brindan de la siguiente manera: el
y leemos
información
que nosnivel
brindan
la siguiente
manera: elcomo
cuarto de
cuarto
de laslapiezas
con menor
de de
detalle
de terminación
las
piezas
con
menor
nivel
de
detalle
de
terminación
como
máximo
presenta
máximo presenta un nivel Regular, la mitad de las piezas de plástico
a
un nivel
Regular,
mitad
las piezas
de plástico a Bueno
lo sumoyposee
un nivel
lo sumo
posee
un la
nivel
dededetalle
de terminación
las tres
de detalle
Bueno
y lastienen
tres cuartas
partes
piezas de
cuartas
partesde
determinación
las piezas de
plástico
hasta un
niveldedelasdetalle
plástico tienen
hasta
un nivel de detalle de terminación Muy Bueno.
de terminación
Muy
Bueno.
La
mitad
central
de
los
de de
detalle
de terminación
de lasdepiezas
La mitad central de losniveles
niveles
detalle
de terminación
las se
encuentra
entre Bueno
Muy Bueno.
EstaBueno.
información
extrae combinando
piezas
se encuentra
entrey Bueno
y Muy
Estase
información
se
Q
y
Q
.
extrae1 combinando
Q1 y Q3.
3
COMIENZO DE ACTIVIDAD
8. 8.
Determinar
e interpretar
cuartilesde
de la
la variable
de de
trabajo
Determinar
e interpretar
losloscuartiles
variable“Puestos
“ Puestos
2001-2003”,
de ,ladematriz
EM EM
3. 3.
trabajo
2001-2003”
la matriz
28
Para la variable “edad de los empleados” de la muestra de la empresa cooperativa la posición de los cuartiles es:
34
FIN DE ACTIVIDAD
FIN DE ACTIVIDAD
Para la variable “ edad de los empleados” de la muestra de la empresa
cooperativa
la posición
delos
los empleados”
cuartiles es: de la muestra de la empresa
Para
la variable
“ edad de
21 25 28 30 34 36 36 37 37
37
38
cooperativa la posición de los cuartiles es:
21 25 28 30 34 Q36
36 37 37
1
Q1
Estadistica
39 39 40 40 42 48 51 57 63
372 = Me
38 39 39 40 40 Q42
48 51 57 63
Q
3
Q2 = Me
Q3
Interpretando la información se tiene que el primer cuarto de los
Interpretando
la información
que
primer cuartas
cuarto de
los empleados
empleados tiene
a lo sumose34tiene
y el
las
restantes
Interpretando
la
información
seaños
tiene
quetres
elrestantes
primer partes
cuartomínimo
de los
tiene
a
lo
sumo
34
años
y
las
tres
cuartas
partes
como
36
como
mínimo
36
años.
La
mitad
de
los
empleados
de
la
muestra
detenta
empleados
tiene
a
lo
sumo
34
años
y
las
tres
cuartas
partes
restantes
años.
La
los
empleados
de la
detenta
hasta
37 años
y la
hasta mínimo
37 mitad
años 36
ydelaaños.
otra
mitad
desde
38muestra
años y que
lasla
tres
cuartas
partes
como
La
mitad
de los
empleados
de
muestra
detenta
otra
mitad
desde
38
años
y
que
las
tres
cuartas
partes
de
los
empleados
de los37empleados
jóvenes
como
máximo
tienen
40
años
y el partes
cuarto
hasta
añoscomo
y la más
otra
mitad
desde
38
años
y que
lasde
tres
cuartas
más
jóvenes
máximo
tienen
40
años
y
el
cuarto
mayor
edad
como
delos
mayor
edad como
mínimo
cuenta
con 42 años
de edad.
de
empleados
más
jóvenes
como máximo
tienen
40 años y el cuarto
mínimo
cuenta
con
42
años
de
edad.
En el edad
caso como
3, “ Edad
promedio
de los
desaparecidos
en Argentina
de mayor
mínimo
cuenta
con
42 años
de edad.
En
el
caso
3,
“Edad
promedio
de
los
desaparecidos
en
Argentina
durante
durante
última
, se procede
dedesaparecidos
la misma manera
para
el
En el la
caso
3, dictadura”
“ Edad
promedio
de
los
enelque
Argentina
la
última
dictadura”,
se
procede
de
la
misma
manera
que
para
cálculo
de
cálculo
de
la
mediana,
con
las
siguientes
fórmulas
de
interpolación:
durante la última dictadura” , se procede de la misma manera que para el
la mediana, con las siguientes fórmulas de interpolación:
cálculo de la mediana, con las siguientes fórmulas de interpolación:
Q2 = Me
Q2 = Me
Donde: a es la amplitud de los intervalos, l i es el límite inferior del
Donde: a es la amplitud de los intervalos, li es el límite inferior del intervalo
intervalo
donde
se encuentra
el cuartil,l es
el elsubíndice
i de del
las
Donde:
a es
la amplitud
deellos
intervalos,
límite inferior
donde
se encuentra
el cuartil,
subíndice
i de ilas frecuencias
simples
se
frecuencias
simples
se
refiere
al
intervalo
del
cuartil
y
el
(i-1)
de
las
intervalo
dondedelsecuartil
encuentra
el subíndice
i de hace
las
refiere
al intervalo
y el (i-1)eldecuartil,
las frecuencias
acumuladas
frecuenciassimples
acumuladas
hace referencia
al del
intervalo
frecuencias
se refiere
al intervalo
cuartilanterior.
y el (i-1) de las
referencia
al intervalo anterior.
frecuencias acumuladas hace referencia al intervalo anterior.
COMIENZO DE ACTIVIDAD
9.
COMIENZO
DE ACTIVIDAD
9.
Calcular
e
interpretar los cuartiles de la “ Edad de los
9.
Calcular
e interpretar
los cuartiles
de la “Edad
de los desaparecidos
en
desaparecidos
en Argentina
la última de
dictadura”
.
Calcular
e interpretar
losporcuartiles
la “ Edad
de los
Argentina por
la última dictadura”.
FIN DE ACTIVIDAD
desaparecidos
en Argentina por la última dictadura” .
Fractiles y percentiles
Fractiles y percentiles
Fractiles y percentiles
Continuando con la idea de subdividir a la masa de datos en distintas
Continuando con la idea de subdividir a la masa de datos en distintas partes
partes o fracciones
iguales
tienen losafractiles,
que
puedenenexpresarse
Continuando
con lase
idea
deselos
subdividir
la masa
deexpresarse
datos
distintas
o fracciones iguales
tienen
fractiles, que
pueden
como percomo
percentiles
–usando
un
lenguaje
de
porcentajes–
en
los
casos
que
partes
o –usando
fracciones
sede
tienen
los fractiles,
que
pueden
centiles
uniguales
lenguaje
porcentajes–
en los
casos
que expresarse
sea necesasea
necesario
hacer
más
comprensible
la
información
que
suministran.
como
percentiles
–usando un
lenguaje deque
porcentajes–
en los casos que
rio hacer
más comprensible
la información
suministran.
Fractiles
son
las
m-1
marcas
del
arreglo
de
datos
ordenado
que lo
seaFractiles
necesario
hacer
másmarcas
comprensible
la información
que
suministran.
son
las m-1
del arreglo
de datos ordenado
que lo dividen
dividen
en
m
partes
iguales.
Fractiles son las m-1 marcas del arreglo de datos ordenado que lo
FIN DE ACTIVIDAD
en m partes iguales.
dividen
en mdetermina
partes iguales.
Un fractil
el máximo de una cierta fracción del conjunto de los
29
datos y consecuentemente, el mínimo de la fracción restante.
Percentiles son los fractiles mismos, pero expresados en un lenguaje más
amigable como es el de los porcentajes.
29
35
Universidad Virtual de Quilmes
Un fractil determina el máximo de una cierta fracción del conjunto
de los datos y consecuentemente, el mínimo de la fracción restante.
Percentiles son los fractiles mismos, pero expresados en un lenguaje
más amigable como es el de los porcentajes.
Retomando la variable edad de los trabajadores de la empresa
Retomando la variable edad de los trabajadores de la empresa cooperativa:
cooperativa,
21 25 28 30 34 36 36 37 37
37
38
39 39 40 40 42 48 51 57 63
Explorando los datos observamos que el salto más grande de edades se da
Explorando
que
el saltopodemos
más grande
de edades
se 20
entre 42 ylos
48 datos
años, observamos
marcando esa
posición
ver que
16 de los
daempleados
entre 42 ytienen
48 años,
esadeposición
ver quecomo
16 de
una marcando
edad máxima
42 añospodemos
y los 4 restantes
mínilosmo
2048
empleados
tienen
una
edad
máxima
de
42
años
y
los
4
restantes
años.
comoEsa
mínimo
48–que
años.es el fractil 16/20 y se lee: la dieciseis veinteava parte
marca
Esa
marca
–que
el fractil
16/20
se lee:
la dieciseis
veinteava
de los trabajadoreses
tienen
a lo sumo
42yaños–
conviene
expresarla
como perparte
de
los
trabajadores
tienen
a
lo
sumo
42
años–
conviene
expresarla
centil 80 (P80) y decir que el 80% de los trabajadores tienen hasta 42 años.
como
percentil
(P80trabajadores
) y decir que
el 80%
los trabajadores
tienen
O, que
el 20% 80
de los
tiene
comode
mínimo
48 años.
hasta Para
42 años.
O,
que
el
20%
de
los
trabajadores
tiene
como
mínimo
48la
el mismo caso también podríamos habernos preguntado cuál es
años.
edad máxima del 80% de los empleados y la respuesta es 42 años.
Para el mismo caso también podríamos habernos preguntado cuál es
la edad máxima del 80% de los empleados y la respuesta es 42 años.
El uso de porcentajes, que es el lenguaje de los percentiles, puede introducir algunas
al momento de producir información,
COMIENZO
DEinconsistencias
LEER ATENTO
todoporcentajes,
cuando el conjunto
es pequeño.
El sobre
uso de
que esdeel datos
lenguaje
de los percentiles,
puede introducir algunas inconsistencias al momento de
producir información, sobre todo cuando el conjunto de datos
es 10.
pequeño.
Determinar
interpretar algunos percentiles de la variable “Puestos de
FIN DE LEEReATENTO
trabajo 2001-2003”, de la matriz EM 3.
COMIENZO DE ACTIVIDAD
10.
Si no se
contara conelosinterpretar
datos originales,
como
es el caso de
“edad
Determinar
algunos
percentiles
de lalavariable
variable
de las “personas
al
momento
de
la
desaparición
forzada”
y
se
quisiera
calcuPuestos de trabajo 2001-2003” , de la matriz EM 3.
lar algún
percentil,
en forma análoga a lo hecho con la mediana, se puede utiFIN
DE ACTIVIDAD
lizar la siguiente fórmula de interpolación:
Si no se contara con los datos originales, como es el caso de la variable
“ edad de las personas al momento de la desaparición forzada” y se
quisiera calcular algún percentil, en forma análoga a lo hecho con la
mediana, se puede utilizar la siguiente fórmula de interpolación:
Donde: k es el % de datos que el percentil deja hacia atrás (valores menores
a él), a es la amplitud de los intervalos, li es el límite inferior del intervalo
donde se encuentra el percentil, el subíndice i de las frecuencias simples se
Donde: kdel
espercentil
el % deydatos
el percentil
deja
hacia atrás
refiere al intervalo
el (i-1)que
de las
frecuencias
acumuladas
hace
(valores
menores
a
él),
a
es
la
amplitud
de
los
intervalos,
li
referencia al intervalo anterior.
es el límite inferior del intervalo donde se encuentra el
percentil, el subíndice i de las frecuencias simples se refiere
al intervalo del percentil y el (i-1) de las frecuencias
11.
acumuladas
hacemáxima
referencia
al intervalo
anterior. en Argentina.
a.
Calcular la edad
del 90%
de los desaparecidos
30
36
b. ¿Qué porcentaje de personas tenía hasta 32 años al momento de desaparecer?
Estadistica
El gráfico de caja y bigotes (box-and-whisker plots)
Este gráfico suele llamarse usualmente box-plot, y es aplicable con exclusividad a los casos de variables cuantitativas en los que se cuenta con los datos.
El box-plot es un gráfico delineado en el dominio de los números reales y
que se basa en una caja –construida con Q1 y Q3 como límites– que contiene nominalmente al 50% central de los datos. El 50% nominal restante se
encuentra distribuido en partes iguales a ambos lados de la caja y los valores comprendidos en él se representan con distintas simbologías.
El siguiente gráfico, que corresponde a la edad de los empleados de la cooperativa, presenta todos los elementos (algunos auxiliares y otros definitivos)
con los que se construye un box-plot.
El box-and-whisker plot
fue diseñado por John W.
Tukey y presentado en su libro
Exploratory data analysis de 1977,
aunque ya lo había usado en papers
anteriores a esa fecha.
Cuando ambos cuartiles
quedan ubicados sobre
datos, no entre dos datos, los porcentajes no llegan al 50%.
Gráfico 1.22.
Las líneas continuas (horizontales) que se extienden a partir de Q1 y Q3 (convertidos a números reales mediante el mismo procedimiento que se usó para
la mediana) son los bigotes y su finalidad es describir al conjunto de valores
llamados adyacentes, sin identificarlos individualmente. Por afuera de ellos
se ubican los valores externos (que aquí los representamos con un círculo) y
los lejanos (cuyo símbolo es un asterisco) ambos denominados también valores raros (“outliers”) o atípicos para el grupo.
Las líneas auxiliares identificadas al pie como Vi y Ve se llaman vallas –interiores y exteriores–, se encuentran respectivamente a una distancia de la caja
de una vez y media la medida de su base y de tres veces dicha medida, y se
usan como referencia para delimitar las zonas donde se encuentran los valores atípicos.
A continuación, se presentan los cálculos ligados a la construcción del box-plot
de “edad” de los trabajadores de una cooperativa que integran una muestra.
Q3 – Q1 = 41 – 35 = 6
Q1 – 1,5(Q3 – Q1) = 35 – 9 = 26 y
Q1 – 3(Q3 – Q1) = 35 – 18 = 17 y
Q3 + 1,5(Q3 – Q1) = 41 + 9 = 50
Q3 + 3(Q3 – Q1) = 41 + 18 = 59
Existen otros criterios –para establecer las distancias de las vallas
a la caja– distintos al de Tukey, pero
éste es el más usado.
Base:
Q3 – Q1
Vallas interiores:
Q1 – 1,5 . (Q3 – Q1) y
Q3 + 1,5. (Q3 – Q1)
Vallas exteriores:
Q1 – 3 . (Q3 – Q1) y
Q3 + 3. (Q3 – Q1)
El box-plot definitivo, libre de líneas auxiliares, queda como sigue
Gráfico 1.23.
37
Universidad Virtual de Quilmes
En el gráfico G.1.23. puede observarse que en la cooperativa las edades de
21, 25, 51, 57 y, sobre todo, 63 años son atípicas o raras para el grupo. Si
una distribución de datos no tuviera valores atípicos entonces todos los que
están fuera de la caja serían adyacentes por lo que los bigotes llegarían hasta
el máximo y el mínimo y se vería de la siguiente forma.
Gráfico 1.24.
El box-plot precedente es el caso de la muestra de empleados de la fábrica
automotriz, en la cual no se detectan edades atípicas.
12.
Confeccionar y analizar los box-plot de las variables cuantitativas de la
EM 2.
En el siguiente gráfico se presentan conjuntamente los dos box-plots realizados anteriormente para ejemplificar la comparación de dos distribuciones de
datos bajo una misma variable.
Gráfico 1.25.
Las siguientes son algunas lecturas que surgen de la comparación.
En ambas distribuciones la mitad de los empleados tienen como mínimo
prácticamente la misma edad.
El 50% central de las edades de los empleados de la cooperativa es más
concentrado que el 50% central de las edades de la fábrica automotriz.
Si bien una edad de 63 años es rara en la muestra de la cooperativa, no
ocurre lo mismo en la muestra de la fábrica automotriz.
13.
Confeccionar en un mismo gráfico, analizar y comparar los box-plots de
las variables “participación quincenal actual” y “participación quincenal anterior” de la ME 1.
38
Estadistica
El box-plot, en complemento con los demás gráficos vistos, conforma
una herramienta visual que se puede utilizar para ilustrar la distribución, estudiar asimetrías y sus colas, bosquejar supuestos sobre la distribución y comparar distintas distribuciones.
1.2.2. Medidas de dispersión
Para describir completamente una distribución de datos no basta con los indicadores elaborados hasta el momento a través de las medidas de posición,
sino que además es necesario tener una idea del grado de variabilidad de los
valores que esos datos toman.
Ese grado de variabilidad hablará de la “variedad”, de la “diversidad” de
valores en el conjunto de datos y para cuantificarlo surgen las medidas de
dispersión que se definen –al igual que la media– en el dominio de los números reales, por lo que se aplican sólo a las variables cuantitativas.
Las medidas de dispersión que se tratarán en este curso son el rango o
amplitud total, el rango intercuartílico, la varianza, el desvío estándar y, como
un caso de medida de dispersión relativa, el coeficiente de variación.
Rango o amplitud total
El rango indica la longitud o extensión total de una distribución de datos y se
calcula de la siguiente manera:
Rg = AT = xmáx – xmín
Constituye una forma simple de determinar la dispersión de los datos de una
distribución. Es una medida limitada porque explica la variabilidad a partir de
sólo dos valores, sin tener en cuenta todos los valores intermedios entre los
extremos.
En la variable edad de los trabajadores de la muestra de la empresa cooperativa, el rango es:
Rg = 63 – 21 = 42 años
Quiere decir que en una franja o amplitud de 42 años se encuentra toda la
“diversidad” –en cuanto a la edad de los trabajadores– de la muestra de la cooperativa.
Rango intercuartílico
Esta medida expresa algo parecido a lo que representa el rango de toda la
distribución –con sus mismas limitaciones– pero se refiere únicamente a los
datos centrales que, como ya se vio, quedan encerrados entre el primero y el
tercer cuartil.
d = Q3 – Q1
39
YDULDQ]D
HV XQD
PHGLGD
TXHTXH
IXHIXH
SURSXHVWD
SRUSRU
*DXVV
\ WLHQH
HQ HQ
/D /D
YDULDQ]D
HV XQD
PHGLGD
SURSXHVWD
*DXVV
\ WLHQH
WRGRV
ORV
YDORUHV
GH
ORV
GDWRV
GH
OD
GLVWULEXFLyQ
3DUD
VX VX
FXHQWD
FXHQWD WRGRV ORV YDORUHV GH ORV GDWRV GH OD GLVWULEXFLyQ 3DUD
Universidad Virtual de Quilmes
FRQVWUXFFLyQVHXWLOL]DODPHGLDDULWPpWLFDFRPRUHIHUHQFLDSDUDFDOFXODU
FRQVWUXFFLyQVHXWLOL]DODPHGLDDULWPpWLFDFRPRUHIHUHQFLDSDUDFDOFXODU
;L±
ODVGHVYLDFLRQHV
;L±GHOYDORUGHFDGDXQRGHORVGDWRVUHVSHFWRD
ODVGHVYLDFLRQHV
GHOYDORUGHFDGDXQRGHORVGDWRVUHVSHFWRD
Varianza
y
desvío
estándar
HOODHOOD
*DXVV
&20,(1=2'(3$67,//$(1
Karl Friedrich Gauss en
*DXVV
&20,(1=2'(3$67,//$(1
La varianza es una medida
que fue propuesta por Gauss y tiene en cuenta
.DUO)ULHGULFK*DXVVHQ7KHRUtDPRWXVFRUSRUXPF
OHVWLXP+DPJXUJR
Theoría motus corporum
.DUO)ULHGULFK*DXVVHQ7KHRUtDPRWXVFRUSRUXPF
OHVWLXP+DPJXUJR
todos los valores de los datos de la distribución.
Para su construcción
se uticælestium, Hamgurgo (1809). ),1'(3$67,//$
),1'(3$67,//$
liza la media aritmética como referencia para calcular las desviaciones (Xi – )
delJUiILFR
valor de*
cada uno
los datosDOJXQDV
respectoPDJQLWXGHV
a ella.
(Q (Q
HO
VHde
REVHUYDQ
\ VHQWLGRV
GH GH
HO JUiILFR
*
VH REVHUYDQ
DOJXQDV PDJQLWXGHV
\ VHQWLGRV
En
el
gráfico
G.1.26.
se
observan
algunas
magnitudes y sentidos de estos
HVWRVGHVYtRVUHVSHFWRGHODPHGLD
HVWRVGHVYtRVUHVSHFWRGHODPHGLD
desvíos respecto de la media:
,QVHUWDU,PDJHQ1*
,QVHUWDU,PDJHQ1*
Gráfico 1.26.
El objetivo es elaborar una medida que sintetice al conjunto de todos los des(OREMHWLYRHVHODERUDUXQDPHGLGDTXHVLQWHWLFHDOFRQMXQWRGHWRGRVORV
(OREMHWLYRHVHODERUDUXQDPHGLGDTXHVLQWHWLFHDOFRQMXQWRGHWRGRVORV
víos\y SDUD
para FDOFXODUOD
calcularla SRGUtDPRV
podríamos promediarlos
contando
así
unXQ
desvío
GHVYtRV
SURPHGLDUORV
FRQWDQGR
DVtcon
FRQ
GHVYtRV
\ SDUD FDOFXODUOD
SRGUtDPRV
SURPHGLDUORV
FRQWDQGR
DVt FRQ
XQ
promedio.
GHVYtRSURPHGLR
GHVYtRSURPHGLR
Pero al momento de realizar ese promedio nos encontraríamos con la dificul3HURDOPRPHQWRGHUHDOL]DUHVHSURPHGLRQRVHQFRQWUDUtDPRVFRQOD
3HURDOPRPHQWRGHUHDOL]DUHVHSURPHGLRQRVHQFRQWUDUtDPRVFRQOD
tad
deGH
que
la suma
de las
siempre
da cero,
obvia
conseGLILFXOWDG
TXH
OD VXPD
GH desviaciones
ODV
GHVYLDFLRQHV
VLHPSUH
GDcomo
FHUR
FRPR
GLILFXOWDG
GH TXH
OD VXPD
GH ODV
GHVYLDFLRQHV
VLHPSUH
GD FHUR
FRPR
cuencia de que la media es el centro de equilibrio de todos los desvíos, es decir:
REYLDFRQVHFXHQFLDGHTXHODPHGLDHVHOFHQWURGHHTXLOLEULRGHWRGRV
REYLDFRQVHFXHQFLDGHTXHODPHGLDHVHOFHQWURGHHTXLOLEULRGHWRGRV
ORVGHVYtRVHVGHFLUTXH
ORVGHVYtRVHVGHFLUTXH
X I XX X I
3DUDVDOYDUHVWHHVFROORHOFULWHULRTXHXWLOL]y*DXVV\TXHORKDFHPRV
3DUDVDOYDUHVWHHVFROORHOFULWHULRTXHXWLOL]y*DXVV\TXHORKDFHPRV
Para salvar este escollo el criterio que utilizó Gauss, y que lo hacemos nuesQXHVWURHVSURPHGLDUORVFXDGUDGRVGHODVGHVYLDFLRQHV/DPHGLGDDVt
QXHVWURHVSURPHGLDUORVFXDGUDGRVGHODVGHVYLDFLRQHV/DPHGLGDDVt
tro, es promediar los cuadrados de las desviaciones. La medida así determiGHWHUPLQDGDVHGHQRPLQDYDULDQ]D
GHWHUPLQDGDVHGHQRPLQDYDULDQ]D
nada se denomina varianza.
La media poblacional es una sola,
como también lo es la varianza
poblacional. En cambio hay tantas
medias muestrales como muestras
distintas se puedan extraer de la
población; y también hay tantas
varianzas muestrales como medias
muestrales puedan obtenerse. Por
lo que una varianza muestral está
atada a una determinada media,
tiene un (1) condicionamiento que
no tenía la poblacional. Ese condicionamiento le resta (1)
un grado de libertad.
40
)RUPDOPHQWHODYDULDQ]DVHH[SUHVDFRPR
)RUPDOPHQWHODYDULDQ]DVHH[SUHVDFRPR
Formalmente la varianza se expresa como
[ L [X XIL IL si el grupo de datos es una población o
L
VLHOJUXSRGHGDWRVHVXQDSREODFLyQR
VLHOJUXSRGHGDWRVHVXQDSREODFLyQR
1 1
[ L [X XIL IL
L
3 3 si el grupo de datos es una muestra.
VLHOJUXSRGHGDWRVHVXQDPXHVWUD
VLHOJUXSRGHGDWRVHVXQDPXHVWUD
Q Q El divisor N o el n-1, según el caso, se llama grados de libertad. A este tópico nos arrimaremos con más detalle en estadística inferencial.
Para la distribución del “gasto medio mensual en alimentos” de la matriz
ME 2, la varianza muestral (recordemos que esas 32 viviendas son una muestra extraída de un universo más grande de viviendas del barrio) es:
S² = 195.607,537 $²
Recordando que la media es X= 1.227,25$, se aprecia que la magnitud
de la varianza es el cuadrado de la magnitud de la variable y esto complica las
matriz ME 2, la varianza muestral (recordemos que esas 32 viviendas
son una muestra extraída de un universo más grande de viviendas del
barrio) es:
S = 195.607,537 $
, se aprecia que la
Recordando que la media es
cosasde
al la
momento
dees
interpretar
estade
medida
de variabilidad.
Para poder
magnitud
varianza
el cuadrado
la magnitud
de la variable
y comla dispersión
la magnitud
la variable,
esto patibilizar
complica lalasmagnitud
cosas alde momento
de con
interpretar
estademedida
de simplemente
le
sacamos
la
raíz
cuadrada
a
la
varianza,
resultando
una
variabilidad. Para poder compatibilizar la magnitud de la dispersión con nueva
medida de
llamada
desvíosimplemente
estándar.
la magnitud
la variable,
le sacamos la raíz cuadrada a la
varianza, resultando una nueva medida llamada desvío estándar.
Estadistica
Formalmente, el desvío se expresa como
Formalmente, el desvío se expresa como
=
S=
(x
x )2 f i si el grupo de datos es una población o
i
N
(x
si el grupo de datos es una población o
x )2 f i si el grupo de datos es una muestra.
i
n -1
si el grupo de datos es una muestra.
Para el gasto mensual de los hogares encuestados el desvío estándar
Para el gasto mensual de los hogares encuestados el desvío estándar muesmuestral es: S = $422,28. Esta lectura absoluta, aisladamente no
tral es: S = $422,28. Esta lectura absoluta aisladamente no suministra una
suministra una información muy clara sobre los alcances de la
información muy clara sobre los alcances de la dispersión.
dispersión.
COMIENZO DE LEER ATENTO
En una distribución simétrica el desvío estándar describe un entorno
En una distribución simétrica el desvío estándar describe un
alrededor de la media que contiene aproximadamente las 2/3 partes (~
entorno alrededor de la media que contiene aproximadamente las
68%) de los datos.
2/3 partes (~ 68%) de los datos.
FIN DE LEER ATENTO
Si se tuviera que el gasto mensual está distribuído simétricamente, sólo podrí-
Si se amos
tuviera
queuna
el gasto
mensualen
está
distribuído
hacer
interpretación
el sentido
de losimétricamente,
expuesto diciendosólo
que apropodríamos
hacer
una
interpretación
en
el
sentido
de
lo
expuesto
ximadamente las dos terceras partes de las viviendas de la muestra tienen un
diciendo
que
aproximadamente
lasentre
dos terceras
partes
de las viviendas
gasto
mensual
comprendido
$804,97
y $1649,53
($1227,25 ±
de la$422,28).
muestra tienen un gasto mensual comprendido entre $804,97 y
$1649,53Para
($1227,25
± $422,28).
ampliar el
concepto anterior rescatamos los indicadores de los casos
1 y 2 de variables cuantitativas discretas donde, en ambos, la variable es
“edad”.
donde, en ambos, la variable es “edad”.
0HGLGDV
&DVR´(GDGGHORV
WUDEDMDGRUHVGHXQD
HPSUHVDFRRSHUDWLYDµ
&DVR´(GDGGHORVHPSOHDGRVGHXQDIiEULFD
DXWRPRWUL]µ
X
DxRV
DxRV
DxRV
DxRV
Mo
DxRV
DxRV PDUFDGHFODVHGHOLQWHUYDORPRGDO
5
S2
S
DxRV
DxRV2
DxRV
DxRV
DxRV2
DxRV
$VLPHWUtDDGHUHFKD
&DVLVLPpWULFD
Me
GHORVFDVRV
DSUR[LPDGDPHQWH
1RVHSXHGH
&RPSUHQGHODVHGDGHVGHDxRVDDxRV
YDORUHVTXHFDHQGHQWURGHOLQWHUYDOR
COMIENZO DE LEER ATENTO
La utilidad de las medidas de dispersión aparece claramente cuando se comparan distintas distribuciones de da
referidas a la misma variable.
FIN DE LEER ATENTO
41
Utilizando la información del cuadro anterior para comparar las distribuciones de edades de los grupos analizad
Universidad Virtual de Quilmes
La utilidad de las medidas de dispersión aparece claramente cuando se
donde, en ambos,comparan
la variable
es “edad”.
distintas
distribuciones de datos referidas a la misma variable.
&DVR´(GDGGHORV
&DVR´(GDGGHORVHPSOHDGRVGHXQDIiEULFD
0HGLGDV
WUDEDMDGRUHVGHXQD
Utilizando la información
del cuadro anterior, para comparar
las distribuciones
DXWRPRWUL]µ
HPSUHVDFRRSHUDWLYDµ
de edades de los grupos analizados, notamos que todas las medidas de disson mayores en el caso 2 respecto delDxRV
caso 1. Esto estapersión calculadas DxRV
Me
DxRV
DxRV
ría indicando que las edades de los empleados de la muestra de la fábrica autoMo
DxRV que las edades
DxRV
PDUFDGHFODVHGHOLQWHUYDORPRGDO
motriz
están más dispersas
de los trabajadores
de la muestra
5
DxRV
DxRV
de la cooperativa.
2
2
S2 Es importante DxRV
señalar que las edades promedio deDxRV
los dos grupos son
S
DxRV
DxRV
similares,
característica
que permitió comparar sin problemas
las medidas de
$VLPHWUtDDGHUHFKD
&DVLVLPpWULFD
dispersión. Si los grupos analizados no tuvieren similar promedio entonces la
comparación de la dispersión de las distribuciones
debería intentarse por otro
&RPSUHQGHODVHGDGHVGHDxRVDDxRV
GHORVFDVRV
1RVHSXHGH
DSUR[LPDGDPHQWH
camino.
YDORUHVTXHFDHQGHQWURGHOLQWHUYDOR
Otro problema se presenta cuando se quieren comparar las dispersiones
de variables distintas surgidas de un mismo grupo de estudio.
COMIENZO DE LEER ATENTO
La utilidad de las medidas de dispersión aparece claramente cuando se comparan distintas distri
Coeficiente
variación
referidas a la de
misma
variable.
FIN DE LEER ATENTO
Se debe a K. Pearson y soluciona el problema de comparar la dispersión de
las distribuciones de variables que tienen distinta magnitud.
Utilizando
la información del cuadro anterior para comparar las distribuciones de edades de los g
Este coeficiente puede utilizarse también para comparar variables de igual
notamos que todas las medidas de dispersión calculadas son mayores en el caso 2 respecto del ca
magnitud pero con promedios significativamente distintos.
indicando
que las edades de los empleados de la muestra de la fábrica automotriz están más dispersas
Es en realidad una dispersión relativa –no absoluta como el desvío estánlos trabajadores de la muestra de la cooperativa.
dar– y se calcula como el cociente entre el desvío estándar y la media.
Es importante señalar que las edades promedio de los dos grupos son similares, característica que p
sin problemas las medidas de dispersión. Si los grupos analizados no tuvieren similar promedio entonc
de la dispersión de las distribuciones debería intentarse por otro camino.
Otro problema se presenta cuando se quieren comparar las dispersiones de variables distintas surgi
grupo de estudio.
También se puede expresar en porcentajes
Coeficiente de variación
Se debe a K. Pearson y soluciona el problema de comparar la dispersión de las distribuciones de var
distinta magnitud.
Este coeficiente puede utilizarse también para comparar variables de igual magnitud pero
Compararemos todas las variables cuantitativas de la ME 2 calculando todos
significativamente
distintos.
los CV.
Medidas
Cantidad de
ambientes
Cantidad de personas
ocupantes
Gasto medio
mensual
Cantidad de personas
mayores con trabajo
S
DPE
SHUV
SHUV
X
DPE
SHUV
SHUV
CV
&9
De la comparación de los CV se concluye que el grupo de viviendas relevadas es más compacto,
De la comparación
CV se concluye
que el
grupo de porque
viviendas
relevadas
menos disperso,
en cuantode
a laloscantidad
de personas
ocupantes,
tiene
el menor de los coefic
es
más
compacto,
más
homogéneo,
menos
disperso,
en
cuanto
a
la
cantidad
También puede concluirse que el grupo de viviendas de la muestra es más heterogéneo, más disperso, m
de apersonas
ocupantes,
porque
tiene el
menor
de los coeficientes calculados.
en cuanto
la cantidad
de personas
mayores
con
trabajo.
42
Estadistica
También puede concluirse que el grupo de viviendas de la muestra es más
heterogéneo, más disperso, menos compacto, en cuanto a la cantidad de personas mayores con trabajo.
14.
Calcular las medidas de dispersión para todas las variables cuantitativas
de la ME 1 y hacer todas las comparaciones posibles.
1.2.3. Medidas de intensidad
Cotidianamente se utilizan indicadores socio-económicos denominados tasas
para mostrar la incidencia relativa de algún valor de la variable o sus cambios
espacio-temporales. Esos indicadores son las medidas estadísticas de intensidad y se expresan como coeficientes o como porcentajes.
Previo al tratamiento de estas medidas leemos el artículo periodístico que
sigue.
04 de Junio de 2005
NO CEDE EL DESEMPLEO DEL CONURBANO
Cordones sin reacción
La cantidad de desocupados en los 28 centros urbanos encuestados por el Indec resultó de
1.369.000 personas durante el primer trimestre, de los cuales 677 mil estaban localizados en
los partidos del Gran Buenos Aires. Los datos surgen de la Encuesta Permanente de Hogares
del Indec publicados ayer, dos semanas después de conocerse la tasa de desocupación para el
período, del 13 por ciento. Los subocupados demandantes, es decir aquellos que no llegan a
completar la jornada laboral y están buscando otro trabajo, suman otras 948 mil personas con
problemas de empleo. Las zonas urbanas del país más afectadas por el problema global de desocupación y subocupación demandante resultaron, en el primer trimestre, el conurbano bonaerense y el núcleo Gran Tucumán (ciudad capital y sus alrededores) –Tafí Viejo. El primero
sumaba 15,5 por ciento de desocupados más 10,4 por ciento de subocupados demandantes;
el segundo, 14,2, más 16,5 por ciento. La desocupación, en los partidos del Gran Buenos Aires
fue superior a la del cuarto trimestre de 2004 en siete décimas e idéntica a la registrada en el
primer trimestre de ese mismo año. Es decir que la región muestra un estancamiento en la
recuperación del empleo. En tanto, en el Gran Tucumán-Tafí Viejo el dato más preocupante
es el aumento de la subocupación demandante, del 15,5 por ciento en el primer trimestre, con
un salto de 1,4 punto en la última medición con respecto a la inmediata anterior y 2,3 puntos
cuando se la compara con la de un año antes. Los otros grandes distritos urbanos (con más de
500 mil habitantes) que registraron tasas de desocupación por encima del promedio del país
fueron el Gran Rosario, 14 por ciento, y el Gran La Plata, con el 13,5 por ciento. Entre los grandes aglomerados, la tasa más baja de desocupación corresponde al Gran Mendoza, con el 8 por
ciento, y entre las regiones a la Patagonia, con el 7,6 por ciento. Además, en esta última región,
la tasa de subocupación demandante reflejada por el Indec es prácticamente insignificante, del
3,4 por ciento, en tanto en el Noroeste se eleva al 11,2 por ciento.
© 2000-2002 Pagina12/WEB República Argentina
43
Universidad Virtual de Quilmes
Del artículo anterior rescatamos la siguiente información referida al 2005:
• la tasa de desocupación para el Gran Rosario es del 14%;
• hay 1,44 desocupados por cada subocupado demandante;
• la desocupación en los partidos del Gran Buenos Aires creció un 0,7% entre
el 4to. trimestre del 2004 y el 1er. trimestre de 2005.
Recrearemos las lecturas anteriores de la siguiente manera:
• la proporción de desocupados en el Gran Rosario es del 14%;
• la relación entre desocupación y subocupación es a razón de 1,44 desocupados por cada subocupado demandante;
• tomando como base de referencia (100%) el 4to. trimestre de 2004, el
índice de desocupación para el 1er. trimestre del 2005 es del 100,7%.
Proporción
De las variables ya tratadas podemos decir, por ejemplo, que la proporción de
pymes del rubro industrial es del 37,5%, o también que la proporción de piezas de plástico con un nivel de terminación bueno o muy bueno es del 50%.
La proporción mide el peso –incidencia– que tiene una o varias categorías/valores de la variable en el conjunto total de datos.
La proporción se calcula haciendo el cociente entre la frecuencia correspondiente a una categoría –o valor– de la variable y el total de los datos.
En símbolos:
Si bien el resultado es un coeficiente comprendido entre 0 y 1, la proporción
también se expresa en porcentajes (multiplicándola por 100).
Los cálculos implícitos en el párrafo inicial son:
El primer ejemplo tiene en cuenta sólo una categoría de la variable por eso se
lo considera una proporción simple y el segundo es una proporción compuesta
porque interviene más de una categoría.
15.
a. Determinar e interpretar la proporción de viviendas de 4 ambientes
de la ME 2.
b. ¿Qué porcentaje de empleados están al menos conformes con el fun44
Estadistica
cionamiento de la empresa cooperativa (ME 1)?
c. ¿Cuál es la proporción de desaparecidos con una edad de entre 30 y
35 años?
d. Identificar qué tipo de proporción (simple o compuesta) es cada una
de las calculadas en los ítems anteriores.
Razón
La razón, a diferencia de la proporción, es un indicador que se obtiene calculando el cociente entre las frecuencias de valores distintos de una variable.
La razón mide el peso –incidencia– que tiene una o varias categorías/valores de la variable con respecto a otra u otras categorías/valores.
La razón entre A y B se calcula haciendo el cociente entre sus respectivas frecuencias, siendo A y B valores/categorías o grupos de valores/categorías.
Como en el caso de las
proporciones, las razones pueden ser simples o compuestas.
En símbolos:
Ejemplos
Por cada 1 vivienda de dos ambientes hay 1,6 viviendas de tres ambientes (o
también, en la muestra hay un 60% más de viviendas con 3 ambientes que con
2 ambientes).
Por cada pieza que se fabrica con un nivel de terminación regular hay dos piezas con nivel bueno o muy bueno.
El primer ejemplo tiene en cuenta sólo una categoría de la variable en
ambos factores del cociente, por ello es una razón simple y el segundo es una
razón compuesta porque interviene más de una categoría en por lo menos
uno de los dos factores.
16.
a. ¿Cuál es la razón entre los empleados que están conformes y los que
están muy conformes con el funcionamiento de la empresa cooperativa? (ME 1).
b. Por cada trabajador mayor a 40 años, ¿cuántos hay de entre 30 y 40
años? (ME 1).
c. Identificar qué tipo de razón (simple o compuesta) es cada una de las
calculadas en los ítems anteriores.
45
Universidad Virtual de Quilmes
En las distribuciones bivariadas (tablas de doble entrada), son compuestas todas las tasas calculadas a partir de las frecuencias conjuntas.
Por ejemplo, en la distribución conjunta entre rubro y puestos de trabajo
Por ejemplo, en la distribución conjunta entre rubro y puestos de trabajo de las pymes
de(ver
las
pymes
(ver puede
tabla
1.10) seque
puede
observar
que
elde16,67%
(4/24100)
deson
Por
ejemplo,
distribución
entre
rubro
y ypuestos
trabajo
tabla
1.10.) seen
observar
elconjunta
16,67%
(4/24´100)
las
pymes
dede
lade
muestra
Por
ejemplo,
enlala
distribución
conjunta
entre
rubro
puestos
trabajo
las
pymes
de
la
muestra
son
del
rubro
industrial
y
aumentaron
los
puestos
de
rubro
industrial
ytabla
aumentaron
los
puestos
de trabajo
entre
2001
y 2003,
o que porde
cada
del
dede
laslas
pymes
(ver
tabla
1.10)
sese
puede
observar
que
el el16,67%
(4/24100)
pymes
(ver
1.10)
puede
observar
que
16,67%
(4/24100)
de
trabajo
entre
2001
y 2003,
que
por
cada
pymes
del rubro
comercial
que
pymes
del
rubro
comercial
que o
mantuvo
hay
1,33 (4/3)
industrial
que aumentó
sus puestos
las
pymes
de
la
muestra
son
del
rubro
industrial
y
aumentaron
los
puestos
de
las
pymes
de
la
muestra
son
del
rubro
industrial
y
aumentaron
los
puestos
de
mantuvo
hay 1,33
industrial
sus puestos
de trabajo.
de trabajo.
trabajo
entre
2001(4/3)
y 2003,
o queque
poraumentó
cada pymes
del rubro
comercial que
trabajo
entre 2001
y 2003, o que por cada pymes del rubro comercial que
FIN
DE hay
TEXTO
APARTE
mantuvo
1,33
(4/3)
aumentó
sus
puestos
dede
trabajo.
mantuvo
hay
1,33
(4/3)industrial
industrialque
que
aumentó
sus
puestos
trabajo.
FIN
DE
TEXTO
APARTE
FIN DE TEXTO APARTE
Números
Números índice
índice
Números
índice
Números
índice
Un
las variaciones
variacionesrelativas
relativasdedelala
ocurrencia
Unnúmero
número índice
índice mide
mide las
ocurrencia
de de
loslos
valovalores/categorías
de
una
variable
a
través
de
distintas
situaciones
res/categorías
de una variable
a través de distintas
situaciones
espaciales
o
Un
índice
las
ocurrencia
los
Unnúmero
número
índicemide
mide
lasvariaciones
variacionesrelativas
relativasdedelala
ocurrenciadede
los
espaciales
o
temporales.
temporales.
valores/categorías
valores/categoríasdedeuna
unavariable
variablea através
travésdededistintas
distintassituaciones
situaciones
En
símbolos:
espaciales
o
temporales.
En
símbolos:
espaciales o temporales.
EnEnsímbolos:
ó
símbolos:
óó
Donde “ i” indica una situación espacial
o temporal cualquiera y “ o”
indica
de referencia
llamada
Dondela
indica una
situación espacial
obase.
temporal
cualquiera
y “o” yindica
la
Donde
“ “i”
i”“situación
una
espacial
o otemporal
cualquiera
Donde
i”indica
indica
unasituación
situación
espacial
temporal
cualquiera
y“ o”
“ o”
Para
estudiar
si
hubo
algún
cambio
en
la
cantidad
de
trabajadores
situación
de referencia
llamada llamada
base. base.
indica
lala
situación
dede
referencia
indica
situación
referencia
llamada
base.
(ME
1)
que
cobran
actualmente
más
de
$750
respecto
de los (ME
que 1)
Para
estudiar
si
hubo
algún
cambio
enen
la la
cantidad
de trabajadores
Para
estudiar
si
hubo
algún
cambio
dedetrabajadores
Para también
estudiar más
si hubo
algún
cambio
en anterior,
lacantidad
cantidad
trabajadores
cobraban
de
$750
en
el
período
calculamos
que cobran actualmente
más de $750 respecto
de los que cobraban
también
(ME
(ME1)1)que
quecobran
cobranactualmente
actualmentemás
másdede$750
$750respecto
respectodedelos
losque
que
más
de
$750
en
el
período
anterior,
calculamos
cobraban
también
más
de
$750
en
el
período
anterior,
calculamos
cobraban también más de $750 en elf período
anterior,
(> 750)
13 calculamos
Iactual/anterior(másde750) = actual
= = 2,60
(>750)
750) 5
f anterior
(>
actual
f actual
(> 750)= 1313= 2,60
Iactual/anterior
(másde750)
=
Iactual/anterior(másde750) =f
= = 2,60
(>(>750)
anterior
750) 5 5
f anterior
El grupo de trabajadores que hoy tienen un salario quincenal superior a
Elgrupo
grupoes
deel
trabajadores
quehoy
hoy
tienen un
un salario
salario
quincenal
superior
aalos
los
$750
260% del grupo
de trabajadores
que en
el período
anterior
El
de
trabajadores
que
tienen
quincenal
superior
El
grupo
de
trabajadores
que
hoy
tienen
un
salario
quincenal
superior
$750
eseselel260%
del
grupo
dede
trabajadores
queque
en en
el período
anterior
tenían
también
más
de
$750
detrabajadores
salario quincenal.
decir,
quetenían
laa
los
$750
260%
del
grupo
elEs
período
anterior
los
$750
es
el
260%
del
grupo
de
trabajadores
que
en
el
período
anterior
también
más
demás
$750
deque
salario
quincenal.
Es
ladecir,
cantidad
delatracantidad
de
trabajadores
hoy
ganan
más
dedecir,
$750que
aumentó
unque
160%
tenían
también
dede
$750
dede
salario
quincenal.
EsEs
tenían
también
más
$750
salario
quincenal.
decir,
que
bajadores
que
gananque
más
de ganan
$750 aumentó
un 160%
con respecto
alala
con
respecto
a lahoy
situación
anterior.
cantidad
dede
trabajadores
hoy
más
dede
$750
aumentó
unun160%
cantidad
trabajadores
que
hoy
ganan
más
$750
aumentó
160%
situación
anterior.
En
el caso
los trabajadores
de la cooperativa y de la fábrica
con
respecto
aa
lade
situación
anterior.
con
respecto
la
situación
anterior.
Enelel caso
caso
de los trabajadores
de de
ladeterminada
cooperativa
yfranja
de la
automotriz
automotriz
podemos
comparar
una
de la
edad,
por
EnEn
trabajadores
cooperativa
y yfábrica
de
fábrica
el
casodedelos
los
trabajadores
delala
cooperativa
de la
fábrica
podemos
comparar
una
determinada
franja
de
edad,
por
ejemplo
empleados
ejemplo
empleados
de
entre
20
y
30
años,
haciendo
automotriz
podemos comparar
una
automotriz
comparar
unadeterminada
determinadafranja
franjadedeedad,
edad,por
por
de entre
20 podemos
y 30 años,
haciendo
ejemplo
empleados
de
entre
20
y
30
años,
haciendo
ejemplo empleados de entre 20 yf30 años,
haciendo
4
cooperativa (20 edad 30)
Icooperativa/fábrica (entre20y30años) =
= = 0,25
fffábrica (20
f cooperativa
(20edad
edad30)
30) 16
4
cooperativa (20 edad 30)
Icooperativa/fábrica
(entre20y30años)
=
= = 4= =0,25
Icooperativa/fábrica (entre20y30años) = f
0,25
(20
fábrica
(20 edad
edad 30)
30) 1616
f fábrica
El grupo de empleados de la cooperativa de 20 a 30 años es el 25% de
El grupo
de empleados
de la cooperativa
20 hay
a 30 un
años
es elmenos
25% de
los
trabajadores
de la de
fábrica.
Es decirde
que
75%
delos
El
grupo
dedeempleados
lalacooperativa
de
20
aa
3030años
es
elel25%
de
trabajadores
de
la
fábrica.
Es
decir
que
hay
un
75%
menos
de
personas
de
20
El
grupo
empleados
de
cooperativa
de
20
años
es
25%
de
personas
de 20 ade
30 la
años
trabajando
en laque
cooperativa
que
enmenos
la fábrica
los
trabajadores
fábrica.
Es
decir
hay
un
75%
de
a 30trabajadores
años. trabajando
en fábrica.
la cooperativa
que en
la hay
fábrica
los
de la
Es decir
que
unautomotriz.
75% menos de
automotriz
personas
personasdede2020a a3030años
añostrabajando
trabajandoenenlalacooperativa
cooperativaque
queenenlalafábrica
fábrica
automotriz
.
automotriz
Índices de. precios
Índices de precios
46
42
Veremosde
a continuación
Índices
Índices
deprecios
precios cómo se construyen y cómo se usan los índices generales de precios.
Veremos a continuación cómo se construyen y cómo se usan los índices
generalesade
precios.
Veremos
continuación
construyen
usan
índices
Veremos a
continuacióncómo
cómosese
construyeny ycómo
cómosese
usanlos
los
índices
generales
de
precios.
generales de precios.
Índices de precios
Producto Precio 2003 Cantidad 2003
Precio 2004
Cantidad 2004
A
$13
500
$15
550
Veremos
cómo 280
se construyen y cómo
índices generales de precios.
B a continuación
$25
$21 se usan los 250
C
$5
990
$6
1200
Estadistica
Construcción de índices de precios
Construcción de índices de precios
En realidad la canasta
Convengamos que todos los productos de la canasta familiar se puedan redufamiliar está integrada por
COMIENZO
DE PASTILLA
Convengamos
que
todos
productos
la años
canasta
familiarseserelevaron
puedan reducir
tres (A,EnB este
y C)caso,
y que en dos
cir a, digamos,
tres
(A,EN
Blos
ycanasta
C)
y que familiar
ende
dos
distintos
los pre-a, digamos,
muchos productos.
En
realidad
la canasta
familiarlos
está
integrada
por
muchos
productos.
En este caso,
años
distintos
se
relevaron
precios
(p)
y
las
cantidades
(q)
consumidas
de
cada
uno
de
ellos:
como recurso didáctico, usamos
cios (p) y las cantidades (q) consumidas de cada uno de ellos:
como recurso didáctico, usamos tres productos como representativos de todos sólo
para reducir la cantidad de cálculos.
FIN DE
PASTILLA
Producto
Precio 2003
Cantidad 2003
Precio 2004
Cantidad 2004
A
$15
tres productos como representativos de todos sólo para reducir la
cantidad de cálculos.
B
los
Podemos
analizar$25cómo evolucionó
el precio$21
de cada uno de
C
$5 tres índices $6
productos,
haciendo
simples de precios.
I 2004/2003
= 15 / 13elprecio
100 =de
115,38%
Podemos analizar
cómo(A)
evolucionó
cada uno de los productos,
COMIENZO DE PASTILLA EN FDQDVWDIDPLOLDU
haciendo
tres
índices
de 15,38%
precios.
El(Q
precio
del
producto
Asimples
subió
un
entre SURGXFWRV
el 2003 y(Q
elHVWH
2004.
UHDOLGDG
OD FDQDVWD
IDPLOLDU
HVWi LQWHJUDGD
SRU PXFKRV
FDVR FRPR UHFXUVR GLGiFWLFR XVDPRV WUHV SURGXFWRV FRPR
UHSUHVHQWDWLYRVGHWRGRVVyORSDUDUHGXFLUODFDQWLGDGGHFiOFXORV
FIN DE PASTILLA I
(B) = 21 / 25 100 = 84,00%
2004/2003
I2004/2003
(A) = 15 / 13 × 100 = 115,38%
El El
precio
preciodel
delproducto
productoBA bajó
subióun
un16,00%
15,38%entre
entreelel2003
2003yyelel2004.
2004.
Podemos analizar cómo evolucionó el precio de cada uno de los productos, haciendo tres índices simples de precios.
I2004/2003 (B) = 21 / 25 × 100 = 84,00%
I 2004/2003 (C) = 6 / 5 100 = 120,00%
El precio del producto B bajó un 16,00% entre el 2003 y el 2004.
I2004/2003
(A) el
= 15
/ 13y =el 100
= 115,38%
El precio del producto A subió un 20,00%
entre
2003
2004.
I2004/2003 (C) = 6 / 5 × 100 = 120,00%
El precio del producto A subió un 15,38% entre el 2003 y el 2004.
El precio del producto C subió un 20,00% entre el 2003 y el 2004.
(B) = 21
25 tres
= 100
= 84,00%
Para medir la evolución del conjuntoI2004/2003
de precios
de /los
productos
medir
la
evolución
del conjunto
de precios
los ytres
productos necesinecesitamos
conBíndices
ElPara
precio
delcontar
producto
bajó
uncompuestos.
16,00%
entre el de
2003
el 2004.
tamos contar con índices compuestos.
Media de relativos simples (o media de índices simples)
dedel
relativos
simples
(o media
de índices
ElMedia
precio
producto
A subió
un 20,00%
entre simples)
el 2003
y el de
2004.
Es
la media
aritmética
de todos
los índices
simples
todos los
Es la media aritmética de todos los índices simples de todos los productos.
productos. Para el ejemplo que estamos viendo, el cálculo sería.
Para el ejemplo que estamos viendo, el cálculo sería.
I2004/2003 (C) = 6 / 5 = 100 = 120,00%
Para medir la evolución del conjunto de precios de los tres productos necesitamos contar con índices compuestos.
I2004 ( A) + I2004 (B) + I2004 (C)
2003
2003
2003
I2004 ( A,B,C) =
= 106, 46%
Media de
simples)
2003relativos simples (o media de índices
3
EsLos
la media
aritmética
de
todos losA,
índices
de todos los
productos.
Para el ejemplo que estamos viendo, el
precios
productos
B y simples
C en
subieron
un los
Los precios
de de
los los
productos
A, B y C subieron
conjuntoen
unconjunto
6,46% entre
cálculo
sería.
6,46% entre los años 2003 y 2004.
años 2003 y 2004.
Relativo de agregados no ponderados (o índice de agregados no ponderados)
Relativo
de agregados
no entre
ponderados
(o (agregación)
índice de agregados
Se construye
como cociente
la sumatoria
de los preciosnopara
ponderados)
el año 2004 y la sumatoria (agregación) de los precios para el año base 2003.
Los precios de los productos A, B y C bajaron en conjunto un 2,33% entre los
43
años 2003 y 2004.
Relativo de agregados ponderados (o índice de agregados ponderados)
Se construyen no solamente con los precios sino con algún otro elemento de ponderación que permita darle un “peso” distinto a cada producto. Ese elemento
de ponderación generalmente es la cantidad consumida de cada producto.
47
Universidad Virtual de Quilmes
La cuestión que aparece a continuación es decidir con qué cantidades
ponderar, las del año tomado como base o las del año para el que se hace
el estudio que convenimos en llamar año dado.
Fue publicado en 1870
por el economista y estadístico alemán Ernst Louis Etienne
Laspeyres.
Entre los criterios existentes, el de Laspeyres adopta, para ponderar las cantidades consumidas en el año base, la siguiente manera:
Este es el criterio que utiliza el Sistema Estadístico Nacional (INDEC y Direcciones Provinciales de Estadísticas) para la construcción de todos los índices
generales de precios: Índice de Precios al consumidor (IPC), Sistema de Índices de precios mayoristas (SIPM) e Índice de costos de la construcción (ICC).
Para el ejemplo que estamos desarrollando, el cálculo del índice de precios según el criterio de Laspeyres para el conjunto de los productos A, B,
C es:
Los precios de los productos A, B, C subieron en conjunto un 4,72% entre los
años 2003 y 2004. Es decir que en 2004 esos productos fueron en conjunto
un 4,72% más caros respecto del año 2003.
Si esos tres productos fueran todos los de la canasta familiar, como estamos simulando, las cantidades consumidas podrían entrar en la fórmula de Laspeyres como porcentajes del total:
La estructura de ponderación actual del IPC asigna para Alimentos y bebidas: 31,29%,
Indumentaria: 5,18%, Vivienda:
12,68%, Equipamiento y mantenimiento del hogar: 6,55%, Atención
médica y gastos para la salud:
10,04%, Transporte y comunicaciones: 16,96%, Esparcimiento:
8,67%, Educación: 4,20%, Bienes
y servicios varios: 4,43%.
48
Esta estructura de ponderación es la que usa el INDEC para publicar los Índices Generales de precios. El criterio de Paasche usa para ponderar las cantidades del año dado.
Para los mismos productos y el mismo período, un índice de precios elaborado con este criterio es:
(GXFDFLyQ%LHQHV\VHUYLFLRVYDULRV
FIN DE PASTILLA
Estadistica
El caso
criterio
Paasche
para
ponderar lasde
cantidades
del añoconsumidado.
En este
haydeque
contarusa
con
la información
las cantidades
das en el año dado y para la elaboración de índices generales eso implica un
serio Para
problema
operativo.
Este criterio
puede usarse
enun
trabajos
donde
los mismos
productos
y el mismo
período,
índicelocales,
de precios
elaborado con este criterio es:
se tengan planificados y asegurados los recursos y se pueda encarar la modalidad operativa que requiere ese índice.
Un tercer criterio, el de Fisher, combina las virtudes de los dos anteriores
mediante el empleo de la media geométrica entre IL y IP, pero también carga
con las mismas limitaciones operativas de P.
En este caso hay que contar con la información de las cantidades consumidas en el año dado y para la elabor
de índices generales eso implica un serio problema operativo. Este criterio puede usarse en trabajos locales, don
tengan planificados y asegurados los recursos y se pueda encarar la modalidad operativa que requiere ese índice.
Un tercer criterio, el de Fisher, combina las virtudes de los dos anteriores mediante el empleo de la media geom
y IPproductos
, pero también
carga con las mismas limitaciones operativas de P.
entre
Para
losILtres
del ejemplo:
Para los tres productos del ejemplo:
Uso de los números índices
Llamemos i, j a dos años dados cualesquiera y o al año base.
En las publicaciones, todos los índices generales aparecen referidos a un
año base por lo que se cuenta entonces con los índices Ii/o y Ij/o.
Para algún uso específico en el que necesitáramos un índice Ij/o que describa
entre
los años i y j, utilizaremos las llamadas cadenas o
Uso la
deevolución
los números
índices
enlaces relativos.
Llamemos i, j a dos años dados cualesquiera y o al año base.
En las publicaciones, todos los índices generales aparecen
referidos a un año base por lo que se cuenta entonce
Ij
y
.I
los índices
Ij =Ij
Ij = o
i
o
Ii
i
que describa la evolución entre los años
Para algún uso específicoi en elo que necesitáramos
un
o índice
utilizaremos las llamadas cadenas o enlaces relativos.
Supongamos que el índice compuesto de precios de varios productos fue de
120 en 2000 y de 129 en 2001, calculados ambos con base 1999, y querePor
ejemplo:
representa
el
del
año 1988
mos
saber cuánto
el nivel de de
precios
entre
2000productos
y 2001. La
Supongamos
que aumentó
el índice compuesto
precios
desalario
varios
fueresde 120 en 2000 y de 129 en 2001, calcu
puesta
quebase
el nivel
deyprecios
aumentó
un 7,50aumentó
% (se calcula:
/ 120 entre 2000 y 2001. La respuesta es q
ambosescon
1999,
queremos
saber cuánto
el nivel129
de precios
x 100
%).aumentó un 7,50 % (se calcula: 129 / 120 x 100 =107,50 %).
nivel=107,50
de precios
índice de
de precios
precios al
al consumidor
consumidor yyelelpromedio
ElElíndice
promediodedesalarios
salariospor
porhora
horaenencierciertas industrias seleccionadas se encue
tas
seleccionadas se encuentran en la tabla siguiente.
enindustrias
la tabla siguiente.
Año
IPC
Servicios
1988
1989
1991
Salarios por hora (en $)
Comercio al menudeo
Manufactura
Analizaremos cómo evolucionó el salario real de un empleado tipo en cada una de las tres industrias seleccion
Analizaremos
cómo1988
evolucionó
salario real de un empleado tipo en cada
entre el año base
y el añoel1991.
una de
laseste
tresanálisis
industrias
seleccionadas,
entre
año
1988eny el
el tiempo
año una magnitud económica –en este
rol el
será
el base
de mover
Para
utilizaremos
el IPC cuyo
1991.
Para este análisis utilizaremos el IPC cuyo rol será el de mover en el tiempo una magnitud económica –en este caso el salario– y hacer comparaciones.
49
Universidad Virtual de Quilmes
Ii
o
Ij =Ij
i
o
Ij =
i
Ij
o
Ii
Cualquier índice general utilizado con esta finalidad orecibe el nombre de índice deflactor.
Porejemplo:
ejemplo:
Por
representaelelsalario
salariodel
delaño
año1988
1988
representa
trasladado al año 1991, para un empleado del sector servicios. Este es el
valor del salario del año 1988 corregido por el costo de la vida en el lapso
1988-1991.
Si comparamos el valor obtenido ($8,40) con el que realmente recibe en 1991
($9,49), vemos que su salario real aumentó un 12,98% (=9,49/8,40 x 100).
17.
Usando la información de la tabla anterior describir la evolución del
salario del sector servicios entre 1989 y 1990.
¿Es posible concluir que las medidas de intensidad son aplicables a cualquier tipo de variable?
Se puede ver el artículo completo en
w w w . p a g i n a 1 2 . c o m . a r,
Suplemento Radar libros del
diario Página 12, con fecha
22/03/2009.
50
18.
Extraer todas las conclusiones posibles a partir de la lectura del texto
que se transcribe a continuación y que es parte de un artículo publicado en el diario Página 12.
Todos los libros el libro
Por Gabriel D. Lerman
“[…] Según estimaciones publicadas por el SINCA (Sistema de Información Cultural de la Argentina), la cultura argentina constituye un
3% del PBI nacional, cifra que supera, por ejemplo, al sector de la minería. Más 9100 millones de pesos producidos y más 200 mil puestos de
trabajo generados componen un sector diverso, heterogéneo, que sin
embargo se caracteriza por una alta concentración económica y geográfica, que reproduce el más feroz centralismo porteño.
La industria editorial ha sido por décadas uno de los puntales de la cultura argentina, punto de referencia para toda América latina y el mundo
hispanoparlante. Hacia mediados de la década del setenta, el país producía unos 50 millones de ejemplares al año, cifra que diez años más
tarde había caído a 17. En 1996 se produjeron 42 millones de libros, en
el 2000 se llegó a 74 millones y en el 2002, tras la crisis, la producción
cayó a la mitad. A partir de la devaluación, Argentina recuperó condiciones favorables e inició una franca recuperación: de 38 millones de
libros en 2003 se pasó a 56 en 2004. En 2007, la industria editorial
argentina tuvo el record histórico de 93 millones de ejemplares impresos […]
[…] Cerca del 75% de las editoriales se encuentra emplazada en la región
metropolitana, mientras que el resto se ubica en los principales centros
urbanos. Si bien esto responde a la concentración de la población, hay
provincias que sólo poseen una o dos editoriales que apenas sobreviven
con ayuda oficial.
Estadistica
[...] Tres de cada cuatro libros les corresponden a las grandes editoriales
[...]
[...] Argentina y Colombia lideran el comercio exterior de libros en América del Sur.
[...] Según la publicación Nosotros y los otros, del Mercosur Cultural,
un 77% de los libros exportados por la región sudamericana quedan en
el continente. Esto muestra una baja capacidad de penetración en mercados internacionales más vigorosos, incluso España, que adquiere sólo
el 1,6% del total exportado. Por el contrario, si se miden las importaciones se comprueba que sólo el 41% proviene de los mismos países,
mientras que las compras a España trepan al 29% [...]”
1.3. Matrices ejemplos
Las siguientes matrices corresponden a muestras representativas seleccionadas de diferentes poblaciones objetivo de estudio, con distintos tipos de
unidades de observación.
1.3. 1.
Matrices
ejemplos de una empresa cooperativa donde cada traMatriz
Población: trabajadores
Matriz
1.
Población:
de una empresa cooperativa donde cada trabajador es una unidad de observació
bajador es una unidadtrabajadores
de observación.
ME 1Empleado
edad
sexo
Antigüedad
Especialización
Conformidad
Quincena$
actual
Quincena$
anterior
1
2
4
5
6
8
9
51
21
25
28
48
42
M
F
M
F
F
M
F
F
M
F
F
M
F
M
F
F
M
F
M
F
1
5
4
9
4
5
5
8
2
1
1
B
A
M
M
M
B
B
M
M
M
A
A
B
A
A
M
B
M
A
M
C
M
P
C
M
P
C
M
P
P
M
M
C
M
M
M
C
M
P
M
1145
452
965
698
11
12
14
15
16
18
19
Referencias:
Gasto
Personas
Cant. de
Personas
Nivel
de especialización:
B: bajo, M:
mediano,medio
A: alto. mayores con ¿Hay niños
Vivienda
ambientes Mantenimiento ocupantes mensual
que trabajan?
trabajo P:
Conformidad con el funcionamiento de la empresa cooperativa:
poco con1
B
1
N
forme,
C:
conforme,
M:
muy
conforme.
2
2
M
1
N
5 salario quincenal
B
2
N
Quincena
actual:
de4los trabajadores
(participación
quince4
1
N
nal en
las ganancias
de la 5Bcooperativa)2 en el mes
en curso después
de haber5
4
2
S
se producido
un
6
1 incremento
B en las ventas.
1
N
2
los trabajadores
N
Quincena
anterior:
salarioMquincenal de
previo
al incremento
8
4
E
2
2
N
de las
9 ventas.5
B
5
2
N
11
12
14
4
4
2
5
B
M
B
B
2
2
1
2
N
N
N
S
N
51
M
5
A
M
F
B
C
M
8
A
M
F
A
M
F
2
M
M
28
M
B
C
48
F
1
M
M
Matriz 2. Población: viviendas de un determinado barrio
19
M
A
P
42
es launidad de análisis.
F
1
M
M
12
Universidad Virtual de Quilmes
14
15
16
18
Cant. de Mantenimiento Personas
Vivienda ambientes
ocupantes
1
2
4
5
6
8
9
11
12
14
15
16
18
19
21
22
24
25
26
28
29
2
5
4
1
2
4
5
4
4
2
4
2
4
1
2
4
5
4
4
5
6
4
1
4
B
M
B
B
5
B
M
E
B
5
B
M
B
B
M
B
5
B
M
E
B
5
B
5
B
B
5
B
M
E
B
5
4
2
2
5
2
2
5
2
5
2
5
2
5
Gasto
medio
mensual
452
965
donde cada vivienda
1145
698
Personas
¿Hay niños
mayores con que
trabajan?
trabajo
1
N
1
N
2
N
1
N
2
S
1
N
N
2
N
2
N
N
2
N
N
1
S
2
N
N
2
N
N
N
N
2
S
N
2
N
4
N
N
1
S
1
N
N
2
N
5
N
1
S
2
N
N
Referencias
Referencias:
Mantenimiento o estado de mantenimiento: M: malo, R: regular, B: bueno, E:
excelente.
Gasto medio mensual en alimentos del grupo que vive en la vivienda en $.
¿Hay niños que trabajan?: S: sí, N: no.
52
Mantenimiento o estado de mantenimiento: M: malo, R: regular, B: bueno, E: excelente
Estadistica
Gasto medio mensual en alimentos del grupo que vive em la vivienda em $
¿Hay niños que trabajan?: S: sí, N: no
Matriz 3. Población: pymes de la República Argentina año 2004/2005 donde
cada pyme
es la unidad
de estudio.
Matriz
3. Población:
pymes
de la República Argentina año 2004/2005 donde cada pyme es la unidad de estudio.
ME 3PyME
Tipo
Rubro
Antigüedad
Endeudamiento
Cantidad de
Personal
Puestos de trabajo
2001-2003
1
P
S
1
M
128
M
D
2
P
I
6
M
5
A
8
N
19
A
4
5
6
5
P
P
C
I
A
4
8
M
MA
A
112
M
M
D
8
9
5
P
P
I
S
C
8
4
B
MA
M
114
A
D
M
11
12
P
5
P
A
A
I
2
4
MA
M
B
148
154
A
A
D
14
15
16
18
P
5
P
5
p
5
C
I
A
I
C
I
5
6
2
9
MA
A
MA
A
M
B
142
22
5
D
A
M
M
M
M
D
19
P
S
11
M
5
I
6
N
A
21
P
I
M
D
22
P
A
4
A
M
P
C
25
MA
A
24
5
S
11
B
144
A
Referencias:
Tipo de pyme: R: recuperada, P: privada.
Referencias:
Tipo de pyme: R: recuperada, P: privada.
Antigüedad, en años, al 2005.
Rubro: A: agrícola, C: comercial, I: industrial, S: servicios.
Nivel de endeudamiento: N: ninguno, B: bajo, M: medio, A: alto, MA: muy alto.
Antigüedad, en años, al 2005.
Puestos de trabajo durante 2001-2003: D: disminuyó, M: mantuvo, A: aumentó.
Nivel de endeudamiento: N: ninguno, B: bajo, M: medio, A: alto, MA: muy alto.
Puestos de trabajo durante 2001-2003: D: disminuyó, M: mantuvo, A: aumentó.
Rubro: A: agrícola, C: comercial, I: industrial, S: servicios.
53
Universidad Virtual de Quilmes
Matriz 4. Población: todas las piezas plásticas especiales fabricadas por una
determinada empresa, donde cada pieza es la unidad que se observa para su
Matriz 4. Población: todas las piezas plásticas especiales fabricadas por una determinada emp
estudio y análisis.
la unidad que se observa para su estudio y análisis.
ME 4
Pieza
Longitud
[cm]
Materia
prima
Tiempo de
Detalles
de
Peso
[gr]
Característica
señalable
1
2
4
5
6
8
9
11
12
14
15
16
18
19
N
I
N
N
I
N
I
N
N
I
N
N
I
N
N
I
N
I
N
N
261
145
168
194
59
65
128
22
81
11
5
E
B
MB
MB
5
5
MB
B
MB
E
B
5
E
E
MB
5
B
E
B
N
N
N
S
N
N
S
N
S
N
S
N
S
N
S
N
S
S
N
N
Referencias
Referencias:
Materia
prima: N: nacional, I: importada.
Materia
N: tiempo,
nacional,
I: importada.
Tiempo
de prima:
fabricación:
en días,
que lleva de fabricada la pieza.
Tiempo
de fabricación:
tiempo,
enB:días,
de fabricada
la pieza.
Nivel
de detalles
de terminación:
R: regular,
bueno,que
MB:lleva
muy bueno,
E: excelente.
Nivel alguna
de detalles
de terminación:
B: bueno, MB: muy bueno, E: exce¿Tiene
característica
señalable?: S: sí,R:
N: regular,
no.
lente.
¿Tiene alguna característica señalable?: S: sí, N: no.
54
2
Probabilidad
Objetivos
• Desarrollar algunas herramientas básicas para poder abordar con fundamento los problemas de la inferencia estadística.
• Sistematizar, organizar y cimentar los conceptos probabilísticos presentes
en la cultura cotidiana.
2.1. Elementos de la teoría de probabilidad
En la presente Unidad trataremos conceptos de la teoría de probabilidad por
ser ésta la herramienta conceptual necesaria para abordar con fundamento los
problemas de la estadística inferencial.
2.1.1. Experimento aleatorio
Comenzaremos leyendo el siguiente texto que fue extraído de la novela El jugador
de Fedor Dostoievsky.
Párrafo del capítulo IV de
El jugador (1866), una de
las más célebres y populares novelas de Fedor Dostoievsky, en gran
parte un relato autobiográfico.
“[...] Las salas de juego estaban repletas de público. ¡Cuánta insolencia y cuánta avidez! Me
abrí paso entre la muchedumbre y me coloqué frente al propio croupier. Empecé a jugar tímidamente, arriesgando cada vez dos, tres monedas. Entretanto, observaba. Tengo la impresión
de que el cálculo previo vale para poco y, desde luego no tiene la importancia que le atribuyen
muchos jugadores: llevan papel rayado, anotan las jugadas, hacen cuentas, deducen las probabilidades, calculan; por fin, apuestan y pierden. Igual que nosotros simples mortales, que jugamos sin cálculo alguno. He llegado, sin embargo, a una conclusión, al parecer, justa: existe, en
efecto, si no un sistema, por lo menos cierto orden en la sucesión de probabilidades casuales, lo
cual es muy extraño. Suele ocurrir, por ejemplo, que tras las doce cifras centrales salgan las doce
últimas. Cae, por ejemplo, dos veces en las doce últimas y pasa a las doce primeras. De las doce
primeras, vuelve a las centrales: sale tres o cuatro veces seguidas y de nuevo pasa a las doce últimas. Tras dos vueltas, cae sobre las primeras, que no salen más de una vez, y las cifras centrales
salen sucesivamente tres veces. Esto se repite durante hora y media o dos horas. Uno, tres y dos;
uno, tres y dos. Resulta muy divertido. Hay días, mañanas, en que el negro alterna con el rojo,
casi en constante desorden, de modo que ni el rojo ni el negro salen más de dos o tres veces
seguidas. Al día siguiente, o a la misma tarde, sale el rojo hasta veinticinco veces sucesivas, y continúa así durante algún tiempo, a veces, durante todo el día [...]”.
55
Universidad Virtual de Quilmes
Experimento aleatorio,
probabilístico o estocástico: es aquel donde no se puede
determinar a priori cuál va a ser su
resultado.
La búsqueda de las leyes que, supuestamente, gobiernan el azar no solo atrae
la concentración de algún jugador empedernido, sino que domina permanentemente los cálculos de casi todo el espectro científico desde –en un rango
cronológico– la astronomía hasta la economía.
Lo que aparece claramente en el párrafo seleccionado es la observación
del fenómeno que interesa estudiar –la ruleta– mediante series de frecuencias.
Cada vez que se realiza una jugada se está llevando a cabo un experimento
aleatorio o azaroso, ¿por qué aleatorio? Porque no se puede predecir de antemano el resultado que se va a obtener en esa jugada.
Existen muchos experimentos aleatorios fuera del juego, por ejemplo, podríamos anotar la edad de cada una de las personas que lee esta carpeta, cada
edad del conjunto de todas las edades anotadas puede ser un resultado del
experimento.
Podemos citar también como experimento aleatorio la observación de la
ocurrencia del robo de un auto realizada por un actuario de seguros. Este
actuario podría anotar en función de resultados previos cuántos autos de una
determinada marca y modelo fueron robados entre todos los que existen en
el mercado y a partir de ello inducir si un nuevo auto cualquiera, elegido al
azar de ese modelo y marca, tiene alguna posibilidad de ser robado.
Tanto la jugada única del jugador, como el aseguramiento de un auto cualquiera tomado al azar, constituyen experimentos aleatorios simples porque
involucran tomar un solo elemento al azar de una población.
Tanto la avidez del jugador como la de la compañía de seguros nos llevan
a los experimentos aleatorios compuestos –tomar más de un elemento al
azar– donde el jugador haría varias jugadas o la compañía aseguraría varios
autos.
El proceso de tomar al azar uno o más elementos de una determinada
población es un experimento aleatorio.
Si se selecciona un solo elemento, referido a una variable, el experimento es simple y si se seleccionan dos o más elementos, referidos a esa
variable, el experimento aleatorio es compuesto porque es el resultado
de la repetición de uno simple.
Por otro lado, si se selecciona un elemento al azar pero referido a dos
o más variables conjuntamente resulta también un experimento aleatorio compuesto.
Cuando se seleccionan muestras aleatorias de tamaño n de una población se
están realizando n experimentos aleatorios simples.
Espacio muestral
Denominamos espacio muestral (E) al conjunto de todos los resultados posibles de un experimento aleatorio.
En el ejemplo del actuario nos interesa si al seleccionar un auto de esa
marca y modelo éste puede ser robado o no, entonces los resultados posibles son: será robado o no será robado:
56
Estadistica
E = {robado, no robado}
En una jugada de la ruleta los resultados posibles son:
E = {todos los números de la ruleta} = {0, 1, 2, 3, ......... , 34, 35, 36}
En la siguiente tabla figuran distintos tipos de experimentos aleatorios y espacios muestrales asociados a ellos.
Experimento aleatorio
Si se tomara/n al azar:
Espacio muestral
Se obtendrían los siguientes resultados
1- Una pyme del grupo que figura en la matriz
ME 3 de la Unidad anterior y se examinara el E ={ A, C, I, S}
rubro al que pertenece.
2- Dos empleados de la empresa cooperativa E={FF, FM, MF, MM}
de la matriz ME 1 y se observara el sexo al
que pertenece cada uno.
3- Una vivienda entre las de la ME 2 y
se reflexionara acerca de la cantidad de
ambientes que tiene.
E ={ 1, 2, 3, 4, 5}
Como puede apreciarse, los experimentos 1 y 3 son simples y el 2 es un experimento compuesto por repetición de uno simple.
Para describir los elementos de un espacio muestral de un experimento
compuesto se puede recurrir a un diagrama denominado diagrama de árbol
donde cada una de las ramas representa a cada uno de los elementos compuestos del espacio muestral.
El diagrama de árbol (G.2.1.) correspondiente al segundo experimento es
Gráfico 2.1. Diagrama de árbol
Suceso o evento aleatorio
Un suceso o evento aleatorio es cualquier subconjunto de un espacio
muestral.
57
Universidad Virtual de Quilmes
Son ejemplos de sucesos aleatorios del Espacio muestral del experimento 3,
que la vivienda seleccionada tenga:
S1 = {hasta 3 ambientes}
S1 = {1, 2, 3}
S2 = {1 ambiente}
S2 = {1}
S3 = {8 ambientes}
S3 = { } = Φ
S4 = {hasta 5 ambientes}
S4 = {1, 2, 3, 4, 5} = E
S5 = {3 o 4 ambientes}
S5 = {3, 4}
S6 = {menos de 4 ambientes}
S6 = {1, 2, 3}
S7 = {más de 3 ambientes}
S7 = {4, 5}
Un suceso ocurrirá si el resultado del experimento aleatorio es un elemento de dicho suceso.
Si un suceso tiene un solo elemento (por ejemplo S2) se dice que es un suceso elemental.
Si los elementos de un suceso son todos los del espacio muestral (el suceso coincide con E como el S4) al suceso se lo denomina suceso cierto y ocurre siempre al realizar el experimento.
Si un suceso no tiene elementos, es un conjunto vacío como el S3 y se llama
suceso imposible. Este suceso no podría ocurrir al realizar el experimento.
Relaciones entre sucesos
Las relaciones más destacables que se pueden establecer entre dos o más
sucesos son: identidad, exclusión e independencia. Para ejemplificarlas usaremos los sucesos S1 a S7.
Identidad
Dos o más sucesos son idénticos cuando tienen los mismos elementos.
Considerando el suceso S6 podemos notar claramente que es idéntico al suceso S1.
58
Estadistica
Exclusión
Dos sucesos son mutuamente excluyentes cuando la ocurrencia de uno
excluye la ocurrencia del otro. Es decir, que no tienen elementos en
común.
Por ejemplo, los sucesos S2 y S5 porque si ocurre S2 no puede ocurrir S5 y
viceversa, por lo tanto son mutuamente excluyentes.
Dos sucesos aleatorios son no excluyentes, caso S5 y S7, cuando tienen
elementos en común.
Un suceso está incluido en otro cuando todos sus elementos son parte de los
elementos del otro como en el caso del suceso S2 que está contenido en S1.
El espacio muestral y los sucesos aleatorios pueden representarse mediante un diagrama de Venn.
En los siguientes diagramas se visualizan las tres formas que puede adoptar la relación de exclusión entre dos sucesos aleatorios.
Juan Venn (1834-1923).
Filósofo e historiador inglés.
Su obra de lógica más original es
la Lógica del azar.
Gráfico 2.2.
Independencia
Dos sucesos son independientes cuando la ocurrencia de uno no condiciona
la ocurrencia del otro.
Observando el primer caso del gráfico 2.2. –donde los sucesos son mutuamente excluyentes– si uno ocurriera, el otro nunca podría ocurrir. Eso implica
la total dependencia del segundo suceso respecto del primero, y viceversa.
Si dos sucesos son mutuamente excluyentes entonces son fuertemente
dependientes.
En el tercer diagrama, del mismo gráfico, si ocurriese el suceso incluido necesariamente el suceso incluyente ocurrirá, por lo que éste también es fuertemente dependiente de aquél.
59
Universidad Virtual de Quilmes
Si un suceso incluye a otro entonces es fuertemente dependiente del
suceso incluido.
En el caso de los sucesos no excluyentes, segunda forma del gráfico, el análisis de la independencia requiere de otras consideraciones que se irán incorporando paulatinamente. Pero sí se puede afirmar que:
Si dos sucesos son independientes no son mutuamente excluyentes.
Operaciones entre sucesos
Estudiadas sistemáticamente por el lógico irlandés J. Boole (1815-1864) y aplicadas al diseño de circuitos electrónicos
a partir de 1939 y a la telefonía,
control automático y computadoras en general hasta hoy.
Las operaciones entre sucesos son las tres operaciones de Boole (unión, intersección y complemento) del álgebra de conjuntos más la operación diferencia.
Estas operaciones aplicadas a dos o más sucesos aleatorios devuelven
siempre un nuevo suceso aleatorio.
Unión
La unión de dos sucesos Si y Sj es un nuevo suceso (Si U Sj) cuyos elementos pertenecen a alguno de los dos sucesos (a Si o a Sj o a ambos).
Gráfico 2.3.
Consideremos las siguientes uniones de sucesos aleatorios:
S2 U S5 = {1} U {3, 4} = {1, 3, 4}
S7 U S5 = {4, 5} U {3, 4} = {3, 4, 5}
S1 U S2 = {1, 2, 3} U {1} = {1, 2, 3}
60
Estadistica
Intersección
La intersección de dos sucesos Si y Sj es un nuevo suceso (Si Sj) cuyos
elementos pertenecen conjuntamente a ambos sucesos.
Gráfico 2.4.
La intersección de los sucesos S7 y S5, con los que ya operamos, es:
S7 I S5 = {4, 5} I {3, 4} = {4}
El suceso S7 I S5 ocurrirá sí y solo sí ocurrieran simultáneamente los sucesos S7 y S5.
1.
a. Realizar la intersección entre los sucesos S2 y S5.
b. Indicar qué tipo particular de suceso es la intersección entre dos sucesos mutuamente excluyentes.
Complemento
El complemento de un suceso S es otro suceso cuyos elementos son todos
los elementos del espacio muestral que no pertenecen al suceso S.
Gráfico 2.5.
El complemento del suceso S1 es:
S {todos los elementos de E que no están en S1} = {4, 5}
61
Universidad Virtual de Quilmes
Diferencia
La diferencia entre dos sucesos Si y Sj es un nuevo suceso (Si –Sj) cuyos
elementos pertenecen sólo a Si.
Gráfico 2.6.
Las siguientes diferencias entre sucesos son:
S7 – S5 = {4, 5} – {3, 4} = {5}
S1 – S2 = {1, 2, 3} – {1} = {2, 3}
2.
a. Determinar la diferencia entre los sucesos S2 y S5.
b. Determinar el suceso resultante de la diferencia entre dos sucesos
mutuamente excluyentes.
2.1.2. Definiciones de probabilidad
Enunciaremos las definiciones de probabilidad teniendo en cuenta su formulación histórica.
Definición clásica
Essai philosophique sur
les probabilités (1814).
Pierre Simón de Laplace (17491827), astrónomo y matemático
francés. Otras obras: Mecánica
Celeste y El sistema del mundo.
La definición clásica de probabilidad se debe a Pierre Simón de Laplace para
quien la teoría del azar consiste en determinar el número de casos favorables
al acontecimiento cuya probabilidad se indaga. La razón de este número con
la de todos los casos posibles es la medida de la probabilidad, que no es más
que una fracción cuyo numerador es el número de casos favorables y cuyo
denominador es el número total de casos posibles.
Es decir:
p=
cantidad de casos favorables
cantidad de casos posibles
Apliquemos esta definición a algún suceso en la jugada de la ruleta, por ejemplo, si nos interesa que en la próxima tirada de la ruleta salga par.
62
Estadistica
El espacio muestral es:
E = {todos los números de la ruleta}
E = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31. 32, 33, 34, 35, 36}
y el suceso o evento de interés es:
S = {que salga par}
S = {2, 4, 6, 8, 10, 12, 14, 16, 18 , 20, 22, 24, 26, 28, 30, 32, 34, 36}
P(S) = P(par) = 18 / 37 = 0,4865
Definición frecuencial
Richard E. von Mises propuso la siguiente definición de probabilidad frecuencial en 1919.
La probabilidad de un suceso cualquiera es “[...] el Valor Límite de la
Frecuencia Relativa... Esta es la razón del número de casos en que el atributo a
sido hallado al número total de observaciones [...]” Matemático y filósofo austríaco (1883-1953).
Tomado de su libro
Probabilidad, Estadística
y Verdad (1928).
Supongamos que el actuario ha recabado información sobre una cantidad grande de autos asegurados y que de ello
el 15% sufrió algún robo. El actuario con ese dato puede calcular la probabilidad del suceso S: “el auto asegurado no
sería
robado”.
Es decir:
p =P(S)
f r = P( no robado) = 85/100 = 0,85
Supongamos que el actuario ha recabado información sobre una cantidad
grande Axiomatización
de autos asegurados
y que
de ellos el 15% sufrió algún robo. El actua2.1.3.
de la
probabilidad
rio con ese dato puede calcular la probabilidad del suceso S: “el auto asegu-
rado
no sería
La
Teoría
de larobado”.
Probabilidad fue estructurada algebraicamente a partir de 1930 por matemáticos de la escuela ruso
francesa, dentro de una teoría especial de la medida de conjuntos. Esa teoría de la medida nos permitiría hablar de l
= P(
no robado)
= la
85/100
probabilidad de un P(S)
suceso
aleatorio,
como
medida=de0,85
su ocurrencia.
COMIENZO DE PASTILLA EN escuela ruso-francesa
Los referentes más importantes de esta escuela son: A. N. Kolmogoroff, F. Cantelli, E. Borel y otros.
2.1.3.
Axiomatización de la probabilidad
FIN
DE PASTILLA
LaSu
Teoría
de la reside
Probabilidad
fue estructurada
algebraicamente
partir
de 1930 algebraica, es decir, un conjunto d
utilidad
en entregar
al cálculo de
probabilidadesauna
herramienta
Los referentes más
por matemáticos
de ladeescuela
ruso-francesa,
dentro de una teoría especial
operaciones
y maneras
operar con
probabilidades.
importantes de esta
deSu
la cuerpo
medidaprincipal
de conjuntos.
Esaenteoría
de la medida
nos permitiría
hablar (teoremas).
de
consiste
tres axiomas
y un grupo
de propiedades
escuela son: A. N. Kolmogoroff, F.
Cantelli, E. Borel y otros.
la probabilidad de un suceso aleatorio, como la medida de su ocurrencia.
Su utilidad
en entregar
al cálculo de probabilidades una herramienCOMIENZO
DEreside
PASTILLA
EN axiomas
ta algebraica,
es decir,
conjunto de
operaciones
y maneras
de operar
Recordar
que los axiomas
sonun
proposiciones
intuitivas
aceptadas
sin demostración
y que acon
partir de ellos pueden deducirse las propiedade
probabilidades.
(teoremas).
Recordar que los axiomas
principal consiste en tres axiomas y un grupo de propiedades
FIN Su
DEcuerpo
PASTILLA
son proposiciones intui(teoremas).
tivas aceptadas sin demostración
y que a partir de ellos pueden deducirse las propiedades (teoremas).
Axiomas
A.1. P (S) * 0
la probabilidad de un suceso aleatorio S es un
número no negativo.
A.2. P(E) = 1
la probabilidad del espacio muestral E es 1.
A.3. Si ! Sj = entonces
P(Si , Sj) = P (Si) + P(Sj)
la probabilidad de la unión de dos sucesos
aleatorios Si y Sj mutuamente excluyentes es la
suma de sus respectivas probabilidades.
Propiedades
P.1. 0 ) P(S) ) 1
Se deduce combinando A.1. y A.2.
63
A.2. P(E) = 1
A.3. Si ! Sj = entonces
Universidad Virtual de Quilmes
P(Si , Sj) = P (Si) + P(Sj)
la probabilidad del espacio muestral E es 1.
la probabilidad de la unión de dos sucesos
aleatorios Si y Sj mutuamente excluyentes es la
suma de sus respectivas probabilidades.
Propiedades
P.1. 0 ) P(S) ) 1
Se deduce combinando A.1. y A.2.
P.2. P( S ) = 1 – P(S)
Se deduce combinando A.2. y A.3.
P.3. P() = 0
Se deduce de A.3. y considerando que es el complemento de E
P.4. P(Si , Sj) = P (Si) + P(Sj) – P(Si ! Sj)
Se deduce de A.3. y de considerar a cada uno de los sucesos como unión de partes
mutuamente excluyentes.
COMIENZO
DE ACTIVIDAD
3.
3.
Demostrar la P.4. utilizando la sugerencia dada.
Demostrar la P.4. utilizando la sugerencia dada.
FIN DE ACTIVIDAD
2.1.4. Tipos de probabilidad
Hay tres tipos de probabilidad de que ocurra un suceso aleatorio, a saber: probabilidad total, probabilidad conjunta o compuesta y probabilidad condicional
Probabilidad total
Se denomina probabilidad total a la probabilidad del suceso resultante de la
unión de dos o más sucesos cualesquiera.
Las probabilidades de los sucesos vistos en el subapartado 2.1.2. “que el
auto asegurado no sea robado” y “que salga un número par en la jugada de
la ruleta” son ejemplos de probabilidad total.
El suceso “que el auto asegurado no sea robado” es un suceso elemental, en cambio el suceso “que salga un número par en la jugada de la ruleta”
resulta de la unión de los sucesos elementales {2}, {4}, {6}, {8},......, {30},
{32},{34},{36} o sea,
P(sea par) = P({2}U{4}U {6}U{8}U......U{30}U{32}U{34}U{36})
P(sea par) = P(2) + P(4) + P(6) + P(8) +...+ P(30) + P(32) + P(34) + P(36) =
1/37 + 1/37 + 1/37 +…….+ 1/37 + 1/37 = 18 .1/ 37 = 18/37
Se entiende por equiprobabilidad, en el sentido
expresado por Laplace, a la igualdad de oportunidad que tiene cada
uno de los resultados elementales
de una población para ser seleccionado durante la realización de
un experimento aleatorio.
64
El cálculo realizado se basa en el tercer axioma y supone la equiprobabilidad
de cada uno de los resultados de la jugada de la ruleta.
Probabilidad condicional
Supongamos que un estudio contable que recién se inicia debe presentar ante
un organismo oficial dos declaraciones juradas (DDJJ) tomadas al azar entre
sus 10 clientes. Entre ellos, tres son grandes contribuyentes (G) y el resto
monotributistas (M).
El espacio muestral E = {GG, GM, MG, MM} puede obtenerse a partir del
diagrama de árbol del gráfico 2.7. en el que se incluyen las probabilidades
totales correspondientes a la primera selección
Estadistica
Gráfico 2.7. Diagrama de árbol
Es decir, por ejemplo, que hay una probabilidad de 0,3 –probabilidad total–
de que la primera declaración jurada seleccionada corresponda a un gran
contribuyente.
A continuación, completaremos el diagrama agregando las probabilidades
de los resultados de la segunda selección de una declaración teniendo en
cuenta que en la segunda instancia el conjunto de DDJJ va a contar con un elemento menos cambiando también su composición.
Gráfico 2.8. Diagrama de árbol
Si nos interesara, por ejemplo, la probabilidad de que la segunda declaración
jurada extraída sea de un monotributista tendríamos dos respuestas posibles
(7/9 y 6/9) dependiendo de cuál haya sido el resultado de la primera selección. Es decir, que la segunda selección está sujeta o condicionada a lo que
ocurrió en la primera. Las probabilidades consignadas al lado de cada resultado de la segunda extracción son probabilidades condicionales.
La probabilidad condicional mide la ocurrencia de un suceso B si hubiera ocurrido el suceso A y se expresa P(B/A), donde A es el suceso condición y el símbolo “/” es una notación (no una operación).
Las probabilidades condicionales consignadas en el árbol son:
P(G/G) = 2/9 = 0,2222
P(G/M) = 7/9 = 0,7778
P(M/G) = 3/9 = 0,3333
P(M/M) = 6/9 = 0,6667
La notación P(B/A) se
debe al economista inglés
J. M. Keynes (1883 – 1946) en su
Tratado sobre las probabilidades
(1933).
65
Universidad Virtual de Quilmes
La primera se lee: 0,2222 es la probabilidad de que en la segunda selección
la Declaración Jurada sea de un gran contribuyente si (dado que, tal que,
sabiendo que) la primera hubiera sido también de un gran contribuyente.
Probabilidad conjunta o compuesta
Las probabilidades de cada uno de los sucesos del espacio muestral se denominan probabilidades compuestas y miden la probabilidad de ocurrencia conjunta o simultánea de dos resultados particulares en ambas selecciones.
Convenimos en:
P(GG) = P(primero G y segundo G) = P(G1 I G2) = P(G I G)
La probabilidad compuesta o conjunta es la probabilidad de que ocurran simultáneamente dos o más sucesos.
Utilizando la definición de Laplace (casos favorables/casos posibles) la probabilidad del suceso GG resulta :
donde la cantidad de casos posibles resulta de contar todas las combinaciones de diez DDJJ (al momento de la primera selección) por nueve DDJJ (en la
segunda instancia), y la cantidad de casos favorables también resulta de la
combinación de 3 G (primera vez) por 2 G (segunda vez).
Relacionando con las probabilidades del árbol resulta finalmente:
Generalizando para dos sucesos cualesquiera A y B:
P(A I B) = P(A). P(B/A)
La probabilidad compuesta entre dos sucesos A y B resulta de la multiplicación de la probabilidad total del suceso condición A por la probabilidad condicional de B tal que A.
Conclusiones
Dados dos sucesos A y B de un espacio muestral de un experimento aleatorio con probabilidades no nulas, a partir de lo visto, se pueden deducir las
siguientes proposiciones:
66
Estadistica
Los experimentos aleatorios compuestos por repetición de uno simple son el
mecanismo básico para la confección de muestras en una población.
Otro tipo de experimentos compuestos sirven al estudio de la asociación
y/o relación causa efecto entre variables y son los experimentos compuestos
bivariados.
Experimento bivariado
Como ejemplo para el tratamiento de la probabilidad en experimentos bivariados analizaremos un caso particular como medio para la generalización.
Con la finalidad de pronosticar el estado del tránsito en función de la ocurrencia de embotellamiento a partir de la existencia de un accidente en una
autopista en determinada franja horaria, se relevaron datos históricos obteniéndose la siguiente información: el 20% de los automóviles que circulan por
esa autopista en el horario estudiado tuvieron algún tipo de accidente; el 95%
de las veces en que ocurrió un accidente se produjo un embotellamiento y
cuando no hubo accidente ocurrió un embotellamiento el 15% de las veces.
Notamos que podríamos identificar la ocurrencia de un accidente como
causa y el embotellamiento como un efecto.
En el diagrama de árbol del gráfico 2.9. se ilustra la información:
Gráfico 2.9. Diagrama de árbol
67
Insertar Imagen Nº G.2.9.
Insertar Imagen Nº G.2.9.
0,85
0,85
Donde las probabilidades que se tienen son:
Universidad Virtual de Quilmes
Donde las probabilidades que se tienen son:
Donde las probabilidades que se tienen son:
total de Accidente
P(A) = 0,20
total de Accidente total de No accidente
P(A) = 0,20
total de No accidente
P( A ) = 0,80
condicional de Embotellamiento tal que Accidente
P( ) = 0,80
P(E/A) = 0,95
condicional de Embotellamiento
Accidente
P(E/A) = 0,95
condicional detal
Noque
embotellamiento
tal que Accidente
P(
condicional de No condicional
embotellamiento
tal que Accidente
P( E /A) = 0,05
de Embotellamiento
tal que No accidente
condicional de Embotellamiento
No accidente tal que No
P(E/
A ) = 0,15
condicional detal
Noque
embotellamiento
accidente
condicional de No embotellamiento tal que No accidente
/A) = 0,0
P(E/
P(
) = 0,1
/
) = 0,
P( E / A ) = 0,85
A partir de estas probabilidades pueden calcularse las probabilidades conjuntas
A partir de estas probabilidades pueden calcularse las probabilidades conjuntas
A partir de estas probabilidades pueden calcularse las probabilidades conjuntas:
de Accidente y Embotellamiento
de Accidente y Embotellamiento
P(AEE) = 0,19
de Accidente y No embotellamiento
P(AEE) = 0,19
de Accidente y No de
embotellamiento
P(AE ) = 0,01
No accidente y Embotellamiento
P( A EE) = 0,12
de No accidente y de
Embotellamiento
P( EE) = 0,12
No accidente y No embotellamiento
P( A E E ) = 0,68
de No accidente y No embotellamiento
P(
E
P(AE E ) = 0,01
) = 0,68
Con las probabilidades
totales detotales
las causas
y lascausas
conjuntas
tabla conjunta
de probabili
Con las probabilidades
de las
y lasarmamos
conjuntasuna
armamos
una
Con las probabilidades totales de las causas y las conjuntas armamos una tabla conjunta de pr
contingencias.
tabla conjunta de probabilidades o tabla de contingencias.
contingencias.
E
A
Total
A
A
Total
0,19
0,12
0,31
E
0,19
0,12
0,31
0,01
0,68
0,69
E
0,01
0,68
0,69
Total
0,20
0,80
1
Total
0,20
0,80
1
En la que además aparecen calculadas las probabilidades totales de los efectos Embotell
EnEn la
queademás
ademásaparecen
aparecen
calculadas
las probabilidades
de los efectos Em
la que
calculadas
las probabilidades
totalestotales
de los efecembotellamiento.
Embotellamiento
y No
embotellamiento.
Por embotellamiento.
sutos
ubicación
en la tabla de
contingencia,
a las probabilidades totales se las suele denominar tambié
Por
su
ubicación
en
la
tabla
de contingencia,
a las aprobabilidades
totalestotales
se las suele denominar
de contingencia,
las probabilidades
marginales. Por su ubicación en la tabla
marginales.
se las
tambiénpueden
probabilidades
marginales
.
A partir
de lasuele
tabladenominar
de contingencias
calcularse
las siguientes
probabilidades condicionale
A
partir
de
la
tabla
de
contingencias
pueden
calcularse
las
condi
partir de la tabla de contingencias pueden calcularse lassiguientes
siguientesprobabilidades
propartir de losAefectos
partir
de los efectos
babilidades
condicionales de las causas a partir de los efectos:
Accidente tal que Embotellamiento
P(A/E) = 0,19/0,31 = 0,6129
Accidente tal que Embotellamiento
P(A/E) = 0,19/0,31 = 0,6129
Accidente tal que No embotellamiento
P(A/ E ) = 0,01/0,69 = 0,0145
Accidente tal que No embotellamiento
P(A/ ) = 0,01/0,69 = 0,0145
No accidente tal que Embotellamiento
P( A /E) = 0,12/0,31 = 0,0039
No accidente tal que Embotellamiento
P( /E) = 0,12/0,31 = 0,0039
No accidente tal que No embotellamiento P( A / E ) = 0,68/0,69 = 0,9855
No accidente tal que No embotellamiento P( / ) = 0,68/0,69 = 0,9855
Las probabilidades calculadas se denominan probabilidades bayesianas o probabilidades condicionales
Las probabilidades
calculadas
se denominan probabilidades bayesianas o probabilidades condic
formalizan
mediante el teorema
de Bayes
formalizan mediante el teorema de Bayes
68
COMIENZO DE PASTILLA EN Bayes
DElaPASTILLA
En 1764,COMIENZO
después de
muerte EN
de Bayes
Thomas Bayes (1702-1761), se publicó An essay formars solving a problem in the d
En 1764,
de la muerte
de Thomas
Bayes (1702-1761),
se publicó An
formars
solving
una memoria
en ladespués
que aparece,
por vez primera,
la determinación
de la probabilidad
deessay
las causas
a partir
de alosproblem
efectos
una memoria en la que aparece, por vez primera, la determinación de la probabilidad de las causas a partir de los
observados.
observados.
FIN DE PASTILLA
FIN DE PASTILLA
Estadistica
Las probabilidades calculadas se denominan probabilidades bayesianas o probabilidades condicionales de la causas y se formalizan mediante el teorema
de Bayes.
Dado el suceso B (efecto) de un espacio muestral E y una partición de n
sucesos Ai (causas) de dicho espacio, la probabilidad de que ocurra el suceso Ai si ocurriera el suceso B es:
donde P(B) es la probabilidad total del suceso condición y P(B) ≠ 0.
En 1764, después de la
muerte de Thomas Bayes
(1702-1761), se publicó An essay
formars solving a problem in the
doctrine of chances, una memoria en la que aparece, por vez primera, la determinación de la probabilidad de las causas a partir
de los efectos que han podido ser
observados.
Para Aj cualquier suceso del conjunto de los Ai con i = 1, 2…n
4.
Considerando la tabla conjunta 1.11. del subapartado 1.1.2. de la Unidad anterior referida al rubro y evolución de los puestos de trabajo de
las pymes, calcular una probabilidad de cada uno de los tipos vistos e
interpretarla.
2.2. Variable aleatoria
Una variable aleatoria asigna valores numéricos, del conjunto de los números
reales, a los sucesos definidos en el espacio muestral asociado a un experimento aleatorio.
En caso de que el espacio muestral de un experimento aleatorio tenga una
cantidad finita o infinita numerable de elementos, es decir, que permite algún
mecanismo de conteo, la variable aleatoria diseñada será una variable aleatoria discreta.
En caso de que el experimento aleatorio involucre algún tipo de medición,
–cuyos resultados pertenecen a regiones del conjunto de los números reales–
donde es clara la imposibilidad de conteo, la variable aleatoria es de naturaleza continua y por ello se la denomina variable aleatoria continua.
Se denomina variable aleatoria a una función del espacio muestral sobre
el espacio de los números reales.
2.2.1. Variable aleatoria discreta
Las variables aleatorias discretas son funciones del espacio muestral sobre
el subconjunto de los enteros.
Diseñaremos una variable aleatoria discreta para el ejemplo del estudio
contable utilizado en el subapartado 2.1.4. (probabilidad condicional).
69
Recordemos que el espacio muestral es: E = {GG, GM, MG, MM}
Universidad Virtual de Quilmes
La variable aleatoria de diseño que elegimos es:
de clientes
monotributistas
las dos
seleccionadas”
X: “cantidadque
de DDJJ
Recordemos
el espacio
muestral
es: E = {GG,entre
GM, MG,
MM}
COMIENZO
DE PASTILLA
La variable
aleatoria
de diseño EN
quemonotributistas
elegimos es:
Al momento de diseñar
una variable aleatoria discreta debe optarse por alguna de
las categorías involucradas en el
problema para la cual la variable
hará el conteo. En nuestro caso,
podría haberse optado por otra variable que contara la cantidad de ddjj
de grandes clientes entre las dos
seleccionadas.
Al momento de diseñar una variable aleatoria discreta debe optarse por alguna de las categorías involucradas
variable hará el conteo. En nuestro caso, podría haberse optado por otra variable que contara la cantidad de DD
X:dos
“cantidad
de DDJJ de clientes monotributistas entre las dos seleccionadas”
seleccionadas.
FIN DE PASTILLA
La variable aleatoria X recorrerá los valores enteros entre 0 y 2, donde 0 significa
ninguna
de las dos
DDJJ corresponderían
a monotributistas
2 que 0 significa que
Laque
variable
aleatoria
X recorrerá
los valores enteros
entre 0 y 2,y donde
ambas
declaraciones
sean
de
monotributistas.
corresponderían a monotributistas y 2 que ambas declaraciones sean de monotributistas.
X
E A½
GG
0
GM
MG
1
MM
2
El recorrido de X es R(X) = {0, 1, 2}
El recorrido de X es R(X) = {0, 1, 2}
Calculamos la probabilidad para cada valor r del recorrido de X obteniendo así los valores
Calculamos la probabilidad para cada valor r del recorrido de X obteniendo así
de probabilidad h(r). Siendo h(r) = P(X = r)
los valores de la denominada función de probabilidad h(r). Siendo h(r) = P(X = r)
h (0)
= P(= X=
0 M)0 =M)
P(GG)
= 6/90
h (0)
P( X=
= P(GG)
= 6/90
h (1)
=
P(
X=
1
M)
=
P(G,
M)
P(MG)
= 21/90
+ 21/90
= 42/= 90
h (1) = P( X= 1 M) = P(G,+ M)
+ P(MG)
= 21/90
+ 21/90
42/ 90
h (2)
=
P(
X=
2
M)
=
P(MM)
=
42/90
h (2) = P( X= 2 M) = P(MM) = 42/90
Confeccionamos aacontinuación
la tabla
(T.2.1.)
de distribución
de probabilidades.
Confeccionamos
continuación
la tabla
(T.2.1.)
de distribución
de probabilidades.
T.2.1.
T.2.1.
r
0
1
2
h(r)
6/90
42/90
42/90
F(r)
6/90
48/90
1
Donde F(r) es la función de distribución acumulativa o simplemente función de distribución.
Donde F(r) es la función de distribución acumulativa o simplemente función de
COMIENZO
LEER
≤ r). ATENTO
distribución
. Siendo F(r) DE
= P(x
h(r) es una función de probabilidad de una variable aleatoria discreta X si y sólo si
R(X) se cumplen las siguientes propiedades que se desprenden de los dos primeros a
0
h(r)1)esh(r)
una*función
de probabilidad de una variable aleatoria discre
h(r)
=
1
ta X sí y sólo si para todo elemento r del R(X) se cumplen las siguienFIN
DE LEER ATENTO
tes propiedades
que se desprenden de los dos primeros axiomas de
probabilidad.
Un gráficoh(r)
adecuado
para la función de probabilidad h(r) es el de bastones y para la función
≥0
escalones,∑ambos
en el subapartado 1.1.3. de la Unidad 1.
h(r) = vistos
1
El carácter numérico de la variable aleatoria permite calcular algunas de las medidas –m
estándar– de las aplicadas anteriormente a las variables estadísticas, con la siguiente salvedad: e
Unmedia
gráficocorresponde
adecuado para
función de
probabilidad
h(r) es
de una
bastones
y aleatoria la m
la
a unlapromedio
observado
mientras
queel en
variable
para la función
distribución
es el de escalones,
esperado,
o valorde
esperado,
y se denomina
esperanza.ambos vistos en el subapartado 1.1.3. de la Unidad 1.
La esperanza E(X), la varianza V(X) y el desvío estándar DS(X) se expresan
70
E(X) =
para todo r del R(X)
Estadistica
El carácter numérico de la variable aleatoria permite calcular algunas de las
medidas –media, varianza y desvío estándar– de las aplicadas anteriormente
a las variables estadísticas, con la siguiente salvedad: en una variable estadística la media corresponde a un promedio observado mientras que en una
variable aleatoria la media indica un promedio esperado, o valor esperado, y
se denomina esperanza.
La esperanza E(X), la varianza V(X) y el desvío estándar DS(X) se expresan
La esperanza de la variable del problema es:
E (X) = 0.6/90 +1.42/90 + 2. 42/90 = 1,4 DDJJ de monotributistas
Es decir, que si se seleccionan al azar dos DDJJ se espera que entre ellas haya
1,4 de clientes monotributistas.
La varianza y el desvío estándar son: V(X) = 0,3733 y DS(X) = 0,611
Propiedades de la esperanza y de la varianza
P.1. E(C) = C
La esperanza de una constante es ella misma.
Las propiedades que se
enuncian son válidas en
cualquier experimento aleatorio,
sea este simple o compuesto.
P.2. E(C + n . X) = C + n . E(X)
C + n.X es una nueva variable aleatoria resultante de una transformación
lineal de X.
P.3. E(n . X) = n . E(X)
Caso particular que se desprende de la propiedad anterior
P.4. E(X + Y) = E(X) + E(Y)
X + Y es una nueva variable aleatoria, resultante de sumar las variables
X e Y.
P.5. V(X + Y) = V(X) + V(Y)
Sólo si X e Y son independientes.
2
P.6. V(n . X) = n . V(x)
Se deduce de la definición de varianza
2.2.2. Modelos especiales de variables aleatorias discretas
Existen problemas de distinta índole originados en ramas diversas de la ciencia, que al ser vinculados con experimentos aleatorios presentan caracterís71
Universidad Virtual de Quilmes
ticas similares; esas características comunes son las que permiten modelarlos unívocamente.
Para la construcción de un modelo probabilístico, primero deben identificarse exhaustivamente cada una de las características específicas del experimento y seguidamente asociarle una variable aleatoria apropiada.
Experimento binomial
El experimento binomial es un experimento compuesto que consiste en n repeticiones independientes de un experimento simple dicotómico.
Por lo tanto las características que lo identifican son:
Si el experimento tiene
más de dos resultados
posibles hay que dicotomizarlo.
Si las repeticiones del
experimento simple no
fueran independientes, el modelo que se generaría se denomina
modelo hipergeométrico.
• El experimento simple tiene sólo dos resultados posibles, denominados
éxito –suceso que interesa seguir– y fracaso – suceso complementario.
• Se repite n veces el experimento simple.
• Las repeticiones del experimento simple son independientes entre sí.
Vinculadas al experimento binomial pueden definirse más de una variable aleatoria, con sus correspondientes distribuciones de probabilidad, cumpliendo
distintos roles dentro del mismo experimento. Ellas son las variables aleatorias binomial, geométrica y de Pascal (o binomial negativa).
Variable aleatoria binomial
En este experimento, la variable
aleatoria x asociada toma valores 0 y 1. La esperanza de esta
variable resulta ser la probabilidad de éxito. P. Santiago Jacobo
Bernouilli o Bernoulli (1654-1705)
fue un matemático suizo de origen belga. Entre otras cosas fue
quien usó por primera vez la palabra “integral” y escribió el “Ars
conjectandi” sobre el cálculo de probabilidades.
En símbolos X ~ B(n,P)
Es una variable discreta que cuenta la cantidad r de éxitos en un experimento binomial.
Llamaremos P a la probabilidad de éxito y en consecuencia 1-P a la probabilidad de fracaso.
El modelo binomial queda caracterizado por n (número de repeticiones
del experimento simple o de Bernoulli) y P (probabilidad de éxito en cada
repetición) que son sus parámetros. Entonces decimos que la variable aleatoria X asociada tiene distribución binomial con parámetros n y P.
El modelo matemático para la distribución binomial permite calcular los valores de la función de probabilidad h(r).
h (r) = P(X = r) = nCr . Pr . (1-P) n-r
nCr combinatorio
es un número combinatorio que cuenta la cantidad de combinaCOMIENZO DE PASTILLA Donde
EN número
n
n!
nCr = =
r r!(n r)!
FIN DE PASTILLA
ciones de n elementos tomados de a r, es decir la cantidad de grupos de r elementos que pueden formarse a partir de los n.
Ejemplo
De la revisión de los archivos de una empresa de larga trayectoria en un deterEjemplo
minado rubro
surge
que en
70% trayectoria
de sus balances
De la revisión de los archivos
de una
empresa
deellarga
en unsemanales se registraron
superávit.
auditoría
propusosemanales
realizar unase
muestra con los balances
determinado rubro surge
que enEnel una
70%
de susse
balances
de 10
al azar
en forma
registraron superávit. En
unasemanas
auditoríatomadas
se propuso
realizar
unaindependiente.
muestra
con los balances de 10 semanas tomadas al azar en forma independiente.
Conceptualizando que esa muestra es un experimento aleatorio y
7
2
pasando revista a sus características comprobamos que responden a un
modelo binomial a saber: hay dos resultados posibles (superávit o no
h (r) = P(X = r) = nCr . Pr . (1-P) n-r
Donde nCr es un número combinatorio que cuenta la cantidad de combinaciones de n elementos tomados de a r,
Estadistica
es decir la cantidad de grupos de r elementos que pueden formarse a partir de los n.
COMIENZO
DE PASTILLA EN número
combinatorio
Conceptualizando
que esa
muestra
es un experimento aleatorio y pasando revista a sus características comprobamos que responden a un modelo
binomial a saber: hay dos resultados posibles (superávit o no superávit) cada
FIN
PASTILLA
vezDEque
se seleccione un balance semanal y se toman n (10) balances en
forma independiente.
Ejemplo
Ante la futura auditoría nos podemos preguntar acerca de la probabilidad
De
revisión
de los archivos
empresa
de sumo
larga trayectoria
en un
determinado
surge que en el 70% de sus
de laque
se encuentren
en de
la una
muestra
a lo
5 balances
con
superávit rubro
o
balances
semanales
se
registraron
superávit.
En
una
auditoría
se
propuso
realizar
una
muestra
con los balances de 10
entre 3 y 6 balances con superávit o al menos 6 balances con superávit.
semanas tomadas al azar en forma independiente.
La variable aleatoria asociada al experimento, para responder los interroConceptualizando que esa muestra es un experimento aleatorio y pasando revista a sus características comprobamos
gantes del auditor, podría ser:
que responden a un modelo binomial a saber: hay dos resultados posibles (superávit o no superávit) cada vez que se
seleccione un balance semanal y se toman n (10) balances en forma independiente.
X: “cantidad de balances con superávit entre los 10 seleccionados al azar en
forma
independiente”.
X:
“cantidad
de balances con superávit entre los 10 seleccionados al azar en forma independiente”.
Losparámetros
parámetros
la distribución
resultan
entonces,
Los
de de
la distribución
resultan
entonces,
n = 10
Pn
= =0,70
10
P = 0,70
losvalores
valores
la función
de probabilidad
de la función
de distribuyy los
dede
la función
de probabilidad
h(r) yh(r)
los ydelos
la función
de distribución
F(r) = P(X ) r) se encuentran en la
ción T.2.2.
F(r) = P(X £ r) se encuentran en la tabla T.2.2.
tabla
T.2.2.
T.2.2.
0
1
2
3
4
5
6
7
8
9
10
h(r)
ri
0,000006
0,000138
0,001447
0,009002
0,036757
0,102919
0,200121
0,266828
0,233474
0,121061
0,028248
F(r)
0,000006
0,000144
0,001591
0,010593
0,047350
0,150268
0,350389
0,617217
0,850691
0,971752
1
La probabilidad de que en la muestra se encuentren a lo sumo 5 balances con superávit será:
La probabilidad de que en la muestra se encuentren a lo sumo 5 balances
con superávit será:
o también
La probabilidad de que en la muestra haya entre 3 y 6 balances con superávit
o también
Al menos 6 balances con superávit
73
Universidad Virtual de Quilmes
o también
Esperanza y varianza de una distribución binomial
Como el experimento binomial consiste en n repeticiones independientes de
un ensayo Bernoulli, la variable aleatoria binomial X es una transformación
lineal de la variable aleatoria Bernoulli x, es decir,
Luego,, aplicando las propiedades de la esperanza y varianza P.4. y P.5. enunciadas anteriormente en el presente apartado calculamos la esperanza y la
varianza de una variable aleatoria binomial X..
La esperanza es:
y la varianza resulta:
Volviendo al ejemplo de los balances, la cantidad de balances que se espera
encontrar con superávit entre los 10 seleccionados será
E(X) = n . p = 10 . 0,70 = 7 balances con superávit
Con una desviación estándar de
Proceso de Poisson
Un proceso de Poisson es un experimento de naturaleza binomial donde
los éxitos ocurren o no a lo largo de un intervalo continuo (el cual puede
estar dado en tiempo, longitud, superficie, volumen, etcétera).
La intensidad media es la cantidad de éxitos esperada por unidad del continuo, mientras el proceso sea el mismo.
74
Es un proceso donde los “éxitos” ocurren en el transcurso del continuo y a diferencia de un experimento binomial puro los “fracasos” no pueden ocurrir porque representan la ausencia de éxito.
Lo que caracteriza unívocamente a un determinado proceso de Poisson es
la intensidad media (a) de ocurrencias de éxito en la unidad del continuo.
Estadistica
Por ejemplo, una distribuidora mayorista comprobó que, en las primeras
semanas de cada mes, la cantidad media demandada de un determinado producto es de 3 toneladas diarias. El fenómeno descrito involucra un proceso
de Poisson donde a = 3 tn/día para esa época del mes.
También, que en las últimas semanas de cada mes la demanda media diaria baja a 2 toneladas. En este caso el proceso de Poisson sería otro porque
presenta una intensidad media a = 2 tn/día, diferente a la anterior.
Diferentes a indican procesos poissonianos distintos.
En un proceso aleatorio poissoniano es posible definir variables aleatorias
de distinto tipo. Para procesos de este tipo, en esta carpeta, presentaremos
una variable aleatoria discreta llamada de Poisson (que cuente la cantidad de
éxitos en un intervalo continuo) y una variable aleatoria continua denominada
exponencial que veremos en 2.2.4.
Variable aleatoria de Poisson
Es una variable discreta que cuenta la cantidad de “éxitos” que podrían ocurrir en un cierto intervalo continuo, durante un proceso de Poisson.
Establecido un intervalo de longitud t en el continuo, la cantidad media esperada de ocurrencia de éxitos en ese intervalo es E(X) = α . t,, donde α es la ya
vista intensidad media de ocurrencias de éxito en la unidad del continuo.
La esperanza E(x), que simbolizamos con la letra griega λ es el parámetro
de esta distribución.
Si una variable aleatoria discreta X sigue una distribución de Poisson de
parámetro λ podemos expresarla en símbolos como X ~ P(l) y la probabilidad
P(X= r) de que sucedan r éxitos en un intervalo t dado se calcula mediante la
siguiente fórmula:
La probabilidad de una variable aleatoria X que se distribuye en forma de
Poisson:
• depende únicamente de la longitud (t) del intervalo considerado,
• es independiente de lo ocurrido en alguno de los intervalos precedentes.
Para intervalos de diferente longitud t habrá distintas distribuciones de probabilidad, cada una con su propio λ todas dentro de un mismo proceso caracterizado por α.
Lo particular de esta variable aleatoria es que su varianza también es λ .
Volviendo al ejemplo de la distribuidora mayorista nos planteamos las siguientes inquietudes.
• ¿Cuál es la probabilidad de que en dos días de la primera semana de un
mes cualquiera se produzca una demanda de 5 toneladas?
Determinamos primero el valor del parámetro λ para un t = 2 días:
75
Universidad Virtual de Quilmes
La probabilidad de que en esos dos días la demanda sea de 5 toneladas es
de 0,1606.
Con base al λ calculado podemos decir que en esos dos días se espera que
haya una demanda de 6 toneladas del producto.
• ¿Cuál es la probabilidad de que en un día y medio de la última semana de
un mes cualquiera la demanda sea superior a 2 toneladas.
En este caso, λ = tn/día . 1,5 días = 3 tn
Luego:
La probabilidad de que en ese día y medio la demanda supere las 2 tn es
0,8009.
Con base al λ calculado podemos decir que en esos dos días se espera que
haya una demanda de 3 toneladas del producto.
5.
Buscar tres ejemplos de la vida real que pudieran constituir un proceso
de Poisson y para cada uno describir la variable involucrada.
2.2.3. Variable aleatoria continua
Existen fenómenos que no permiten ser tratados con modelos de variables
aleatorias discretas debido a que los resultados del experimento aleatorio
asociado a él sólo son medibles en el conjunto de los números reales. En
este caso la variable aleatoria asociada debe ser una variable continua para
la cual no se pueden listar puntualmente cada uno de sus valores pero sí considerar su recorrido mediante intervalos.
Al ser las variables aleatorias continuas funciones del espacio muestral
sobre el espacio de los números reales, el tratamiento de la misma deberá realizarse mediante intervalos, los problemas de probabilidad que las involucran
son del tipo P(x ≤ a), P(x ≥ b) o P(a ≤ x ≤ b).
En una variable aleatoria continua, el correlato de la función h(r) de las
variables aleatorias discretas es la función f(x) denominada función de densidad
de probabilidad que a diferencia de la h(r) no asigna probabilidades sino que
permite calcularlas en intervalos de números reales.
La función de densidad de probabilidad cumple con las siguientes propiedades:
76
Estadistica
Los valores de la función f(x) deben ser siempre positivos o 0 para cualquier
valor de la variable X.
El área encerrada entre la función –en todo su dominio– y el eje de las abscisas es 1.
La probabilidad de que la variable aleatoria se encuentre entre dos valores a
y b resulta de integrar la función de densidad f(x) entre esos dos límites.
Gráfico 2.10.
En el caso que a coincida con b el área de la región sombreada en el G.2.10.
tendría base igual a 0 y el área es 0, lo que también se desprende de la P.3.
cuando a y b coinciden en un mismo punto. Es decir, que en una variable aleatoria continua las probabilidades puntuales son cero.
Una función de densidad de probabilidad es un modelo teórico probabilístico sustentado, en general, por la distribución de una población.
Como consecuencia de
que las probabilidades
puntuales son cero los sucesos
“x < a” y “x ≤ a” son idénticos y
por lo tanto sus probabilidades son
iguales.
2.2.4. Modelos especiales de variables aleatorias continuas
Como se hiciera mención en el subapartado 2.2.2. las características comunes
de algunos fenómenos aleatorios son las que permiten elaborar modelos.
En el caso de las variables aleatorias continuas desarrollaremos dos modelos especiales de distribución.
77
Universidad Virtual de Quilmes
Distribución normal
Un fenómeno que genera típicamente una población con distribución normal
es la medición del tiempo requerido para efectuar una misma operación por
todos los clientes de una determinada entidad bancaria, bajo el supuesto de
que todos deberían tardar el mismo tiempo para realizar dicha operación.
A la hora de medir efectivamente el fenómeno podemos observar que predominan los clientes que emplearían para hacer la operación un tiempo cercano al promedio, sin embargo, algunos son más rápidos y otros más lentos
generando una distribución del tiempo como la siguiente.
Gráfico 2.11.
El modelo teórico de la distribución normal de una variable continua x se formaliza matemáticamente mediante la función f(x) cuya expresión
representada gráficamente es
Gráfico 2.12.
donde µ –la media– y σ –el desvío estándar– son los parámetros de la distribución y para cada par de valores de µ y σ se tendrá una curva diferente.
Características de la curva normal
La curva que es la representación gráfica de la distribución normal tiene las
siguientes características:
78
Estadistica
• Es perfectamente simétrica alrededor de µ.
• Es asintótica con el eje de la variable x hacia ±∞, es decir que el 100% de
la población queda encerrado entre esos dos límites.
• Como consecuencia de las dos características anteriores la mitad de la
población se encuentra entre –∞ y µ y la otra mitad entre µ y +∞ .
Gráfico 2.13.
• Presenta dos puntos de inflexión a una distancia de un desvío estándar a
ambos lados de la media.
• Las proporciones de población que quedan comprendidos en secciones de
un desvío estándar de amplitud a ambos lados de la media aparecen asentadas en el gráfico G.2.14.
Gráfico 2.14.
El siguiente ejemplo, se refiere a un experimento aleatorio sobre una población con distribución normal, donde la función f(x) que describe esa distribución poblacional es la función de densidad de probabilidad de la variable aleatoria involucrada en el experimento.
Ejemplo
Retomando el caso de los clientes de una entidad bancaria que efectúan una
operación determinada, se ha encontrado que el tiempo medio requerido para
realizarla es de 130 segundos con un desvío estándar de 43 segundos.
Si se tomara un cliente al azar –experimento aleatorio– se podrían plantear las siguientes preguntas: a) ¿cuál es la probabilidad de que esa persona
emplee menos de 100 seg. para realizar la operación? o b) ¿cuál es la probabilidad de que tarde entre 2 y 3 minutos en realizar la transacción?
Esquematizamos las dos situaciones planteadas en los gráficos 2.15. y
2.16. respectivamente.
79
Universidad Virtual de Quilmes
Gráfico 2.15.
Gráfico 2.16.
Y las sendas respuestas son:
a. P( x < 100s) = F(100) = 0,2427
b. P(2min< x <3 min) = P(120 s < x < 180 s) = P( x < 180s) – P( x < 120s) =
= F(180) – F(120) = 0,8775 – 0,4081 = 0,4694
A los resultados obtenidos puede arribarse por integración analítica de la función de densidad normal entre los extremos que correspondan o bien utilizando un programa estadístico (por ejemplo el módulo estadístico de Excel, o
los programas SPSS, InfoStat u otro).
Si no se contara con las mencionadas herramientas de cálculo puede utilizarse como recurso la tabla de probabilidades acumuladas de la denominada distribución normal estándar que figura en el Anexo I y cuyas características, además de las generales descritas anteriormente para cualquier
distribución normal, son:
• nombre de la variable normal estándar : Z
• parámetros: mz = 0 y sz = 1
• función de densidad normal estándar:
Para convertir un valor cualquiera x correspondiente al problema real (con distribución normal) a un valor estandarizado z (con el fin de aprovechar la tabla
del Anexo I) se utiliza la siguiente fórmula de estandarización:
80
Estadistica
Aplicando la distribución normal estándar a la resolución de los ítems anteriores, resulta
Las diferencias que se detectan al realizar los cálculos con la tabla se deben
al redondeo a dos decimales de z que tiene dicha tabla.
6.
a. Calcular el tiempo máximo que, con una probabilidad de 0,90, tardaría en hacer dicha operación un cliente de la entidad bancaria
tomado al azar.
b. En relación con la población de clientes observada, si se consideraran sólo los clientes que tardaron menos de 130 segundos ¿qué porcentaje de ellos tardó más de 100 segundos?
Experimento exponencial
El experimento exponencial se define dentro de un proceso de Poisson y en
consecuencia la variable continua exponencial está íntimamente relacionada
con la variable discreta de Poisson.
Mientras el rol de la variable aleatoria de Poisson es contar la cantidad de
éxitos a lo largo de un intervalo continuo, la variable aleatoria exponencial
mide, a partir del último éxito ocurrido, la longitud del continuo hasta la ocurrencia del siguiente éxito.
Con el último éxito concluye el experimento exponencial lo que determina
su carácter de efímero (se desarrolla sólo entre dos éxitos), por lo que fijado
un cierto intervalo t del continuo a partir del último éxito sólo podrían ocurrir
dos sucesos aleatorios:
• que la variable exponencial mida la ocurrencia del siguiente éxito antes de
transcurrido t es decir x < t, o
• que la variable exponencial mida la ocurrencia del siguiente éxito después
de transcurrido t es decir x > t.
Los sucesos x < t y x > t son los dos únicos sucesos aleatorios que pueden imaginarse dentro de un experimento exponencial y por lo tanto son
complementarios y como tales, mutuamente excluyentes.
81
Universidad Virtual de Quilmes
La primera consecuencia de lo expresado anteriormente es que no hay sucesos compuestos en un experimento exponencial porque el único suceso concebible {x < t} I {x > t}
es un suceso imposible {x < t} I {x > t} = Ø
y por lo tanto su probabilidad es nula
P({x < t} I {x > t}) = P( Ø ) = 0
La segunda consecuencia es que no hay probabilidades condicionales puesto que no hay posibilidad de particionar la población para definir un suceso aleatorio que represente la condición porque, como razonamos anteriormente, el
experimento es efímero y no hay una colección de datos que permita describir una población, por lo tanto no existen poblaciones exponenciales.
Formalmente, y asignando arbitrariamente a uno de los dos sucesos posibles el rol de condición, se tiene:
Al no haber población, no podemos contar inicialmente con una función de
densidad exponencial procediendo de forma similar a como se obtuvo, por
ejemplo, la función de densidad normal.
Usaremos un camino distinto aprovechando el vínculo entre las distribuciones de Poisson y exponencial dentro de un mismo proceso de Poisson
caracterizado por α.
Para ello, definiremos un suceso aleatorio S: que transcurra todo un cierto
intervalo t sin que ocurra éxito, cuya probabilidad pueda calcularse tanto utilizando la variable aleatoria de Poisson como la variable aleatoria exponencial.
P(que no ocurra éxito a lo largo de t) = P(XPoisson = 0) = P(xexponencial > t)
Donde:
P(XPoisson = 0) = e-a.t = P(xexponencial > t)
Luego, las probabilidades de los únicos sucesos posibles de un experimento
exponencial resultan:
-α.t
P(x > t) = e
y aplicando la propiedad de la probabilidad de sucesos complementarios
-α.t
P(x < t) = 1 - P(x > t) = 1 - e
se observa que esta expresión corresponde a la función de distribución acumulada, luego se tiene que
-α.t
F(t) = 1 - e
82
Estadistica
y derivándola se obtiene la función de densidad de probabilidad f(x)
F´ (x) = f(x)
La función de densidad que sintetiza al modelo es entonces
Cuya representación gráfica es G.2.17.
Gráfico 2.17.
El parámetro de la distribución exponencial es el mismo a que caracteriza al proceso de Poisson.
La esperanza de esta variables es:
y la varianza
Aplicaciones de la distribución exponencial
Caso A. Como distribución de los tiempos de espera, la exponencial puede
aplicarse a problemas de rotación de inventario donde el experimento comienza a partir de un pedido (éxito) y luego la variable recorre los valores aleatorios del tiempo en que puede ocurrir el siguiente (éxito) pedido. A continuación
se desarrolla un ejemplo.
Una distribuidora mayorista comprobó que cada 5 días hábiles recibe en promedio 3 pedidos de embarque de cierto artículo (a = 3 pedidos/5 días = 0,6
pedidos/día).
83
Universidad Virtual de Quilmes
1- Teniendo en cuenta que el tiempo para reponer un embarque en depósito
es de 1 día, despachado un pedido ¿con qué probabilidad el siguiente llegará después de ese lapso?
2- Siendo el tiempo medio esperado entre pedidos: E(X) = 1/a = 1,67 días,
¿con qué probabilidad el siguiente pedido será antes de lo esperado?
3- Con una probabilidad de 0,90 ¿de cuánto tiempo se dispone entre dos
pedidos?
despejando t se tiene t = ln 0,90 / -0,6 = 0,18 días
4- Habiendo despachado un pedido, ¿con qué probabilidad el siguiente llegará entre 1 y 2 días después?
Caso B. La distribución exponencial también puede aplicarse a problemas de
fiabilidad o plazo de servicio de los artículos en circulación, vida útil de materiales o de mercancías perecederas, donde la variable recorre los valores aleatorios de vida útil de los mismos hasta quedar fuera de servicio. Aquí no hay
dos éxitos pues el experimento comienza con el inicio del servicio y termina
en la falla, que es el único éxito. A continuación se analiza un ejemplo.
Para ciertas lámparas de bajo consumo, su fabricante midió que la vida
media de funcionamiento sin fallo es de 8.000 horas. Si se instalara una cualquiera de esas lámparas.
1- ¿Cuánto tiempo se espera que dure?
Dentro del experimento aleatorio, que consiste en tomar al azar una de las
lámparas e instalarla, la media observada con anterioridad se convierte en
un media esperada E(X) = 8.000 h.
2- ¿Con qué probabilidad durará más de 8.000 h?
α = 1/E(X) = 1/8000 = 0,000125
84
Estadistica
3- ¿Cuántas horas de funcionamiento sin falla se puede garantizar, con una
probabilidad de 0,90?
7.
Tomando el ejemplo ya trabajado en la distribución Poisson, una distribuidora mayorista comprobó que, en las primeras semanas de cada
mes, la cantidad media demandada de un determinado producto es de
3 toneladas diarias. Luego de la última tonelada demandada, para la
misma época del mes
a. ¿Cuántos días se espera que transcurran hasta el siguiente pedido de
una tonelada?
b. Calcular la probabilidad de que el siguiente pedido de una tonelada
ingrese luego de transcurridos 2 días.
c. Calcular la probabilidad de que el pedido se realice antes de que pase
un día y medio.
85
3
Inferencia estadística
Objetivos
• Estudiar las relaciones entre los estadísticos muestrales y los parámetros
poblacionales.
• Desarrollar procedimientos relativos a dos de los problemas fundamentales de la inferencia estadística: estimación de parámetros y prueba de
hipótesis.
3.1. Distribución de estadísticos muestrales
En el estudio de una población es factible observar que los individuos que la
conforman presentan diferencias entre sí y como reflejo de ello todas las muestras posibles de cierto tamaño n, seleccionadas al azar de esa población, también presentarán variaciones entre ellas en su conformación. Tales variaciones se transmiten al compotamiento de las medidas muestrales también
denominadas estadísticos muestrales calculados a partir de cada una de las
muestras, dando origen a nuevas poblaciones de naturaleza teórica, las poblaciones de los estadísticos muestrales.
La importancia del estudio de la distribución de los estadísticos muestrales radica en el hecho de que ellos son los estimadores de los parámetros
poblacionales.
Dada una población conocida de tamaño N con media poblacional µ y proporción poblacional P(e) = P de algún valor e elegido como éxito, si de ella se
seleccionan aleatoriamente todas las muestras posibles de tamaño n y para
cada una de ellas se calcula la media aritmética Xi y la proporción de éxito
pi(e)= pi, se tendrán m muestras y consecuentemente la misma cantidad m de
medias aritméticas y de proporciones muestrales.
87
Universidad Virtual de Quilmes
El mejor estimador de un
parámetro poblacional
es aquel que cumple con ciertas
cualidades (insesgabilidad, consistencia, eficiencia y suficiencia)
que aquí no se analizarán.
Las dos últimas columnas constituyen las poblaciones de las variables aleatorias media muestral y proporción muestral. Por su importancia conceptual,
seguidamente trataremos las distribuciones teóricas de las poblaciones de
los estadísticos media muestral (como mejor estimador de µ) y proporción
muestral (como mejor estimador de P).
3.1.1. Distribución del estadístico media muestral
Los gráficos que se presentan a continuación se refieren a la distribución de
dos poblaciones, la primera corresponde a una población original conformada
por las edades de los 497 empleados de una empresa –gráfico.3.1– mientras que la segunda –gráfico 3.2– representa a la distribución de la población
teórica de las edades medias de todas las muestras de tamaño 2 que se
extrajeron de la población original.
Gráfico.3.1
Gráfico
3.1.
Gráfico.3.1
Distribución de la población original
Distribución de la población original
frecuencia
frecuenciarelativa
relativa
0,17
0,17
0,14
0,14
0,11
0,11
0,08
0,08
0,06
0,06
0,03
0,03
0,00
0,00
22
22
35
35
48
48
62
62
X
X
Los parámetros de la población original (de edades) son:
µ = 35 años y σ = 82,90 años
2
2
Gráfico 3.2.
Gráfico.3.2
Gráfico.3.2
Distribución de la población de las medias
Distribución de la población de las medias
muestrales (muestras de tamaño 2)
muestrales (muestras de tamaño 2)
frecuencia
frecuenciarelativa
relativa
0,20
0,20
0,10
0,10
0,10
0,10
0,05
0,05
0,00
0,00
88
22
22
35
35
48
48
62
62
Medias muestrales
Medias muestrales
Estadistica
Los parámetros de la población teórica de las medias muestrales de todas
las muestras de tamaño 2 son:
x = 35 años y
2x = 41,45 años2
x = 35 años y 2x = 41,45 años2
2
2
Si se
tomaran
tamañoaños
n=1
el gráfico resultante para la
2 xde
2
añosmuestras
41,45
x= =
3535años
y y = =41,45
años
Si
se
tomaran
muestras
de
tamaño
n=1
el gráfico
resultantede
para la poblax
x
población
teórica
de
las
medias
muestrales
de todas
las muestras
Si se tomaran
muestras
de
tamaño
n=1
el
gráfico
resultante
para
la
ción teórica
de las igual
medias
de todas cada
las muestras
tamaño
1 sería
exactamente
quemuestrales
elresultante
G.3.1.
media dede tamaño 1
maran
muestras
detamaño
tamaño
n=1
elgráfico
gráfico
paralalas
la muestras
teórica
de las
medias
muestrales
de (porque
todas
aran población
muestras
de
n=1
el
resultante
para
sería
exactamente
igual
que
el
Gráfico.3.1.
(porque
cada
media es el elees el de
elemento
que muestrales
conformaigual
lademuestra)
sus
parámetros
nteórica
teórica
medias
todas
lasymuestras
muestras
decada serían
tamaño
1lassería
exactamente
que
ellas
G.3.1.
(porque
media los
de
las
medias
muestrales
de
todas
de
conforma laoriginal.
muestra) y sus parámetros serían los mismos que los
mismos
quemento
losigual
deque
laconforma
población
seríaes
exactamente
que
G.3.1.
(porquecada
cada
media
el elemento
que
la (porque
muestra)
y sus
parámetros serían los
ería
exactamente
que
elel
G.3.1.
media
de igual
la población
original.
mento
que
conforma
la
muestra)
y
sus
parámetros
serían
los
mismos
que
los
de
la
población
original.
ento que conforma la muestra) y sus parámetros
serían 2los
2
original.
=
35
años
y
=
82,90
años
ue
los
de
la
población
x
x
e los de la población original.
2
x = 35 años y x = 82,90 años2
2
2
Como
se35
puede
lasaños
medias
de las poblaciones teóricas,
2 x todas
años observar,
82,90
x= =
35 años
y y = =82,90
años2
x
x
aún variando
n, coincidentodas
con la
de lalas
población
de donde
se
Como
se puede
lasmedia
medias
poblaciones
teóricas,
Como observar,
se puede observar,
todas
lasde
medias
de las poblaciones
teóricas, aún
extrajeron
las
muestras.
puede
observar,
todas
medias
poblaciones
teóricas, de
aún
variando
n, coinciden
con
lalas
media
población
dedonde
dondeseseextrajeron las
variando
n,medias
coinciden
con
la
mediadedelalateóricas,
población
uede
observar,
todas
laslas
dede
las
poblaciones
ndon,extrajeron
n,coinciden
coinciden
conlalamedia
mediadedelalapoblación
poblacióndededonde
dondesese
las
muestras.
do
con
muestras.
Conclusión:
nlaslasmuestras.
muestras.
x = Conclusión:Conclusión:
ón:
x = n:
Y las varianzas disminuyen
proporcionalmente al tamaño n de la
=
x x= muestra.
Y las varianzas disminuyen proporcionalmente
al tamaño n de la
2
2
arianzas
disminuyen
proporcionalmente
altamaño
tamañon ndedela
muestra.
ianzas
disminuyen
proporcionalmente
Y las varianzas
disminuyen
allatamaño n de la muestra.
x =alproporcionalmente
2
n
2x =
2
2
2 n
2 x =
Además, si las muestras
extraídas
de la población son de tamaño grande
x =
n
(usualmente
n >muestras
30), elngráfico
dede
la la
distribución
de las
Además,
si las
extraídas
población de
sonladepoblación
tamaño grande
medias
muestrales
resulta
–G.3.3.–
aproximadamente
normal.
silaslasmuestras
muestras
extraídas
población
son
tamañogrande
(usualmente
n > 30),
el
de son
la
distribución
degrande
la
población de las
extraídas
dede
lalagráfico
población
dedetamaño
nte
n
>
30),
el
gráfico
de
la
distribución
de
la
población
de
las
medias
muestrales
resulta
–G.3.3.–
aproximadamente
normal.
Además,
si distribución
las muestrasde
extraídas
de la de
población
son de tamaño grande
e n >Insertar
30), elImagen
gráfico
la
la población
las
Nº de
G.3.3.
uestrales
resulta
–G.3.3.–
aproximadamente
normal.
(usualmente
n
>
30),
el
gráfico
de
la
distribución
de
la
población
de las medias
estrales resulta –G.3.3.– aproximadamente
normal.
G.3.3.
Insertar Imagen Nº G.3.3.
G.3.3.
muestrales resulta –Gráfico.3.3.– aproximadamente normal.
agenNºNºG.3.3.
G.3.3.
gen
G.3.3.
G.3.3.
Gráfico 3.3.
Gráfico.3.3
Distribución de la población de las medias muestras (n>30)
35
Propiedades de la variable aleatoria media muestral
Medias muestrales
Propiedades de la variable aleatoria media muestral
Gráfico.3.4
en la
unavariable
determinada
población
se define
una variable aleatoria X: {x1,
adesSi
de
aleatoria
media
muestral
2
des
de
la
variable
aleatoria
media
muestral
x
,
x
x
}
con
esperanza
E(X)
=
<
y las
varianza
V(X)
= X:
y{xse
,…, .determinada
m,…….
Distribución de
poblaciónuna
de
proporciones
muestras
(n>100)
Si2 en3una
población
seladefine
variable
aleatoria
1,
2
selecciona
sólo
una
muestra
aleatoria
de
tamaño
n
de
dicha
población
determinada
población
sedefine
define
unavariable
variable
aleatoria
x2, x3 ,…,población
con
esperanza
E(X) =aleatoria
< y varianza
V(X)
= y se
1,
.xm,…….} se
eterminada
una
X:X:{x{x
1,
} con esperanza
= <aleatoria
y varianza
V(X) = n22dey dicha
se
.xm,…….
selecciona
sólo una E(X)
muestra
de tamaño
población
89
Universidad Virtual de Quilmes
Propiedades de la variable aleatoria media muestral
Si para
en una
población
se define
variable aleatoria
X: {x1, x2, x3teórica
la determinada
cual su media
muestral
es una
un elemento
de la población
2 la población teórica
para
la
cual
su
media
muestral
es
un
elemento
de
,…,de
.xm,……. se verifican las siguientes propiedades. y se selecciona sólo
de muestra
se verifican
propiedades.
una
aleatoria las
de siguientes
tamaño n de
dicha población para la cual su media
muestral
X essuunmedia
teórica de
de la
X’spoblación
se verifican
las
para
es un elemento
teórica
P.1 la cual
E( ) =) =elemento
=X =muestral
de la población
P.1
E(
siguientes
propiedades:
X
de
se verifican
las siguientes propiedades.
Esta propiedad está relacionada con la cualidad
de insesgabilidad del estimador X.
COMIENZO
PASTILLA
COMIENZO
DEDE
PASTILLA
EN EN
P.1P.1
P.1
E(
)
=
=
Esta
propiedad
está
relacionada
la cualidad
de insesgabilidad
del estimador
Esta propiedad está X
relacionada con con
la cualidad
de insesgabilidad
del estimador
.
FINDE
DEPASTILLA
PASTILLA
FIN
COMIENZO DE PASTILLA EN P.1
Esta propiedad está relacionada
con la cualidad de insesgabilidad del estimador .
2 2
FIN DE PASTILLA
DS( ) = =
P.2
V( ) = 2 =2
P.2
V( ) = X X =
.
DS( ) = =
X
X
n n
n n
2
DS(
) = X =error estándar de la media
P.2desvío
V(estándar
) = 2X = también
El
se
denomina
n también
desvío
estándar
se denomina
error
la media
n deestándar
El El
desvío
estándar
σx también
error estándar
se denomina
la media de
muesmuestral
respecto
de
la
media
poblacional.
de poblacional.
la media poblacional.
tralmuestral
respectorespecto
de la media
Estas
propiedades
setambién
desprenden
inmediatamente
de las propiedades
ElEstas
desvío
estándar
se denomina
error estándar
delasla propiedades
media
Estas
propiedades
se
desprenden
inmediatamente
propiedades se desprenden
inmediatamente
de lasde
propiedades
enunciadas
anteriormente
en
el
apartado
2.2.1.
de
la
Unidad
2
para
la
muestral
respecto
de la media
poblacional.
enunciadas
anteriormente
en
el apartado
2.2.1.
de la2 para
Unidad
2 para la
enunciadas
anteriormente
en el apartado
2.2.1. de
la Unidad
la espeesperanza
y varianza de
una
variable inmediatamente
aleatoria cualquiera
como
se puede
Estas
propiedades
sede
desprenden
deselas
propiedades
ranza
y varianza
de una variable
cualquiera
puede
verificar
esperanza
y varianza
unaaleatoria
variable
aleatoriacomo
cualquiera
como
se puede
verificar
a
continuación.
enunciadas anteriormente en el apartado 2.2.1. de la Unidad 2 para la
a continuación.
verificar a continuación.
esperanza y varianza de una variable aleatoria cualquiera como se puede
COMIENZO
DE TEXTO APARTE
verificar a continuación.
TEXTO APARTE
n DE
COMIENZO
n
P.1
Xn i n 1
1=1 X= E 1 . X = 1 .
E( X
E(
X
)=
E
)= . n . =
COMIENZO
DE
TEXTO
APARTE
i
i
n i
n
P.1
Gráfico.3.3
n
n
n
n
1 1
1
E( X )=En 1=1 = Ei=1 . X i = i=1. E( X i ) = . n . = X
n
n
n
n
i 1 n i=1 1 n i=1 1
P.1
de
=E . X = .
n
X i ) = .(n>30)
E( X )= E1=1
n . =
E(muestras
Distribución
la población
dei las medias
n X
i n n i=1 n
n
i=1 n P.2
n 1
1
1
2
V( X )= V 1=1 X= V . X i = 2 . V( X i ) = 2 . n . 2 =
n i n i=1 n n
n
n
P.2
n 1=1 1
1i=1 n
1
2
2
=
V
=
.
X
.
V(
X
)
=
.
n
.
=
V( X )= V
X
i
i
2
P.2
ni 1 nn i=1 1 n n2 i=1
n
1 n
2
=V . X = .
V( X i ) = 2 . n . 2 =
V( XTEXTO
)= V 1=1
i
FIN DE
APARTE
2
n n i=1 n
n
n
i=1
APARTE
FIN DE TEXTO
3.1.2. Distribución del estadístico proporción muestral
FIN DE TEXTO APARTE
3.1.2.
Distribución
del estadístico
proporción
muestral
En
el gráfico
G.3.4. se
representa
la distribución
de
la muestral
población
teórica
3.1.2.
Distribución
estadístico
proporción
3.1.2.
Distribución
deldel
estadístico
proporción
muestral
de las proporciones de empleados mayores a 45 años de todas las
En el gráfico
G.3.4.tamaño
se representa
la adistribución
la población teórica
muestras
de unG.3.4.
cierto
n superior
100. de lade
En el gráfico
se representa
la distribución
población teórica
En el gráfico 3.4. se representa la distribución de la población teórica de las
35 de empleadosMedias
de las
lasproporciones
proporcionesde
mayores
45 años
de todas
muestrales
de
mayores
45a años
de todas
proporciones
de empleados empleados
mayores a 45
años de atodas
las muestras
de las
un
Insertar
Imagen
Nº
G.3.4.
muestras
de
un
cierto
tamaño
n
superior
a
100.
muestras
de un
cierto tamaño
n superior a 100.
cierto
tamaño
n
superior
a
100.
G.3.4.
G.3.4.
G.3.4.
Distribución de la población de las proporciones muestras (n>100)
InsertarImagen
Imagen
G.3.4.
Gráfico.3.4
Insertar
NºNº
G.3.4.
Gráfico
3.4.
0
90
4
Gráfico.3.5
0,11
1
Proporciones muestrales
las
Estadistica
la población
original,
la proporción
de empleados
los empleados
mayores
En laEnpoblación
original,
la proporción
de los
mayores
a 45a 45
Enaños
la población
original,
la
proporción
de
los
empleados
mayores
a
45
años
es:
años es: es:
P(>45)
= 0,11
P(>45)
= 0,11
P(>45) = 0,11
y los
parámetros
de distribución
la distribución
–G.3.4.–
de proporciones
las proporciones
y los
parámetros
de la
–G.3.4.–
de las
y los
parámetros
de
la
distribución
–gráfico
3.4.–
de
las
proporciones
muesmuestrales
muestrales
son: son:
2
trales son:
p = 0,11
p = 0,0002
p =0,11
y y2p =0,0002
Conclusión:
Conclusión:
Conclusión:
µp=0,11
y
2
σp =0,0002
p =Pp = P
µp=P
Y varianzas
las varianzas
disminuyen
proporcionalmente
al tamaño
Y las
disminuyen
proporcionalmente
al tamaño
n den lade la
muestra.
muestra.
Y las varianzas disminuyen proporcionalmente al tamaño n de la muestra.
P.(12
P.(1P) P)
2p = p =
n n
Además,
si muestras
las
muestras
extraídas
la población
fueran
Además,
las
muestras
de
población
fueran
chicas,
lachicas,
distribuAdemás,
sisilas
extraídas
delalade
población
fueran
chicas,
la la
distribución
de
la
población
de
las
proporciones
muestrales
no
ción de la población
de las proporciones
no necesariamente
resuldistribución
de la población
de las muestrales
proporciones
muestrales no
necesariamente
resultaría
aproximadamente
normal.
taría
aproximadamente
normal.
necesariamente
resultaría
aproximadamente
normal.
Propiedades
de
la variable
aleatoria
proporción
muestral
Propiedades
de
aleatoria
proporción
muestral
Propiedades
dela
lavariable
variable
aleatoria
proporción
muestral
Si
en una
determinada
población
caracterizada
por
una
variable
Si Sien
determinada
población
caracterizada
unaaleatoria
variable
en una determinada
población
caracterizada
por unapor
variable
X, se
aleatoria
X,efectúa
se efectúa
un experimento
binomial
con
parámetros
n yycon
Py
aleatoria
unbinomial
experimento
binomial
con
n
y
P
efectúaX,
unse
experimento
con parámetros
n y Pparámetros
y en consecuencia
2
2 = n.P.(1-P), se
en
consecuencia
con
esperanza
<
=
n.P
y
varianza
2
n.P.(1-P),
se
en esperanza
consecuencia
cony varianza
esperanza
< n=. Pn.P
y ) ,varianza
= sólo
µ = n.P
σ =
.(1-P
se selecciona
una muestra
selecciona
sólo
aleatoria
de tamaño
ndicha
de dicha
población
aleatoria
de tamaño
n demuestra
dicha
población
la cual
su
proporción
muestral
selecciona
sólo
una una
muestra
aleatoria
de para
tamaño
n de
población
lap cual
su las
proporción
muestral
de éxito
p verifica
las siguientes
para
la
cual
su proporción
muestral
de éxito
p verifica
las siguientes
depara
éxito
verifica
siguientes
propiedades:
propiedades.
propiedades.
P.1 P.1E(p)E(p)
= <P==<PP = P
P.(1- P)
P.(12
P.(1P) P) DS(x) = P P.(1= P)
DS(x)
=
=
P.2 P.2V(p)V(p)
= =2p = p =
P
n n
n n
El desvío
estándar también
también
se denomina
estándar
El desvío
estándar
se denomina
errorerror
estándar
de lade la
El desvío estándar σp también se denomina error estándar de la proporción
proporción muestral
respecto
la proporción
poblacional.
proporción
respecto
de lade
proporción
poblacional.
muestral muestral
respecto de
la proporción
poblacional.
Estas
propiedades,
al
igual
que
las
de
la media
muestral,
Estas
propiedades,
igualque
que
la media
muestral,
se se
Estas
propiedades, al
al igual
las las
de lademedia
muestral,
se desprenden
desprenden
inmediatamente
de enunciadas
las enunciadas
anteriormente
en el
desprenden
inmediatamente
de las
anteriormente
en el
inmediatamente
de las enunciadas
anteriormente en
el apartado 2.2.1.
de la
apartado
2.2.1.
de
la
Unidad
2
para
la
esperanza
y
varianza
de
apartado
la Unidady varianza
2 para la
varianzacualquiera.
de una una
Unidad 2.2.1.
2 para de
la esperanza
de esperanza
una variabley aleatoria
variable
aleatoria
cualquiera.
variable
aleatoria
cualquiera.
3.1.3.
Teorema
central
deldel
límite
3.1.3.
Teorema
central
límite
3.1.3.
Teorema
central
del límite
El teorema
central central
del límite formaliza
el comportamiento
asintóticamente
norteorema
límite
formaliza
comportamiento
El El
teorema
central del del
límite
formaliza
el el
comportamiento
mal,
bajo determinadas
condiciones,
dedeterminadas
la distribución de
una variable aleatoasintóticamente
normal,
condiciones,
asintóticamente
normal,
bajo bajo
determinadas
condiciones,
de de
la la
ria, en particular el de las variables aleatorias media y proporción muestrales.
También denominado teorema del límite central, el Teorema central del límite
–TCL– como resultante de una construcción colectiva es factible de enunciarse, siguiendo a Meyer (1986) de la siguiente manera.
Teorema Central del
Límite o Teorema del
Límite Central de De Moivre (1733)
5
–Laplace (~1810) y otros.5
91
COMIENZO DE PASTILLA EN Teorema central del límite
Laplace (~1810) y otros.
Teorema Central del Límite o Teorema del Límite Central de De Moivre (1733) –
Laplace (~1810) y otros. FIN DE PASTILLA
FIN DE PASTILLA
Sean X1, X2,…Xn... una sucesión de variables aleatorias independientes
Sean X1, X2,…Xn... una sucesión de variables aleatorias independientes
con E(Xi) = Fi y V(Xi) = , i = 1, 2, …
Sean Xi1=
, X1,
2,…X
n... una sucesión de variables aleatorias independientes con
con E(Xi) = Fi y V(Xi) =
2, …
,
2
Universidad Virtual de Quilmes
E(Xi) = µi y V(Xi) = σi , i = 1, 2, …
Sea X = X1 + X2 + …+ Xn.
Sea X = X1 + X2 + …+ Xn.
Xn.
Sea X = X1 + X2 + …+ Luego,
para
n tendiendo
a lainfinito,
la X tiene
distribución
Luego, para
n tendiendo
a infinito,
X tiene distribución
asintóticamente
norLuego, para n tendiendo
distribución
mal con a infinito, la X tiene
n
n
asintóticamente normal con = µ y 2 = 2
n
n
i
i
asintóticamente normal con = µ y 2 = 2
i=1
i=1
i
i
i=1
i=1
Este teorema nos está diciendo que si una variable aleatoria es la suma
de n variables
independientes
Este teorema nos está diciendo
que sialeatorias
una variable
aleatoria es entonces
la suma esa variable aleatoria
Este
teorema
nos
está
diciendo
que
si
una
variable aleatoria es la suma de
suma
tendrá distribución
normal,
para n grande.
de n variables aleatorias
independientes
entonces
esa variable
aleatoria
n
variables
aleatorias
independientes
entonces
esa variable
aleatoria suma
tenEn particular
si tales n variables aleatorias
independientes
tienen
suma tendrá distribución normal,
para n grande.
drá ndistribución
normal,
paraindependientes
nentonces
grande. se verifica
todas
distribución
normal
En particular si tales
variables
aleatorias
tienen que su suma tiene
En
particular
si
tales
n
variables
aleatorias
independientes tienen todas
distribución
normal,
para cualquier
de n.
todas distribución normal
entonces
se verifica
que suvalor
suma
tiene
distribución
entonces
se verifica que su suma tiene distribución nordistribución normal, para
cualquier normal
valor de
n.
mal, para cualquier valor de n.
COMIENZO DE LEER ATENTO
corolario, se concluye que bajo determinadas condiciones,
COMIENZO DE LEERComo
ATENTO
las
distribuciones
de la media
y determinadas
proporción condiciones,
muestral sonlas
Comoque
corolario,
se concluye
que
bajo
Como corolario, se concluye
bajo determinadas
condiciones,
normales.
las distribuciones de distribuciones
la media y deproporción
muestral son
la media y proporción
muestral son normales.
normales.
EjemplosFIN DE LEER ATENTO
FIN DE LEER Teniendo
ATENTOen cuenta la información poblacional de las edades de los 497 empleEjemplos
ados de una empresa (ver apartados 3.1.1. y 3.1.2.) a saber: la edad media
Teniendo en cuenta la información poblacional de las edades de los 497
Ejemplos
poblacional es de 35 años con un desvío estándar de 9,105 años y una proempleados de
una empresa
(ver
apartados
Teniendo en cuenta la información
poblacional
de las
edades
de los3.1.1.
497 y 3.1.2.) a saber: la
porción de empleados mayores a 45 años del 11%, si se proyectara abrir un
edad
media
poblacional
es
de
35
años
con
un
estándar de 9,105
empleados de una empresa
(ver apartados 3.1.1. y 3.1.2.) a saber: desvío
la
anexo cercano a la empresa con parte del personal y para ello se van a eley una
proporción
empleados
mayores
a 45 años del 11%, si se
edad media poblacionalaños
es de
35 años
con un de
desvío
estándar
de 9,105
gir al azar 119 empleados, podemos formularnos las siguientes preguntas:
abrirmayores
un anexo
cercano
la 11%,
empresa
años y una proporción proyectara
de empleados
a 45
años adel
si secon parte del personal y
ello se avan
a elegir con
al azar
proyectara abrir un anexo
cercano
la empresa
parte119
delempleados,
personal y podemos formularnos
1)para
1) siguientes preguntas:
las
para ello se van a elegir
al azar
119 empleados, podemos
formularnos
a.a.¿Cuál
¿Cuálserá
serálalaprobabilidad
probabilidadde
deque
quelalaedad
edadmedia
mediadedelalamuestra
muestradede119
119
las siguientes preguntas:1)empleados que trabajarán en el nuevo anexo sea inferior a los 34
empleados
queprobabilidad
trabajarán endeelque
nuevo
anexomedia
sea inferior
a los 34 de
años?
a.años?
¿Cuál
será la
la edad
de la muestra
119
6
empleados que trabajarán en el nuevo anexo sea
inferior
a
los
34
9,105 Como
n
=
119
es
una
muestra
grande
entonces
Como
n = 119 es una muestra grande entonces N 35,
años?
119
9,105 Como
n = 119 es una muestra grande entonces N 35,
Por
lo tanto
119 Por lo tanto
Por lo tanto
34 - 35 = P(z < 1,198 ) = F (1,20 ) = 0,1151
P(X < 34 años) = P z <
9,105 34 - 35
P(X < 34 años) =P z < 119 = P(z < 1,198 ) = F (1,20 ) = 0,1151
9,105 La probabilidad de que
de edad de los empleados que
la media
119inferior
trabajarían en el nuevo anexo
sea
a 34 años es 0,1151.
La probabilidad de que la media de edad de los empleados que
el nuevo anexo
34 años
b.trabajarían
¿Cuál será en
la probabilidad
de sea
queinferior
la edad amedia
de es
los0,1151.
119 empleados
supere los 37 años?
b. ¿Cuál será la probabilidad
92
de que la edad media de los 119 empleados
supere los 37 años?
37 - 35 = P(z > 2,40) = 1 F (2, 40 ) = 1 0,9918 = 0,0082
P(X > 37 años) = P z >
Por lo tanto
Por lo tanto
119 34 - 35 P(X < 34 años) = P z < 34 - 35 = P(z < 1,198 ) = F (1,20 ) = 0,1151
P(X < 34 años) = P z < 9,105 = P(z < 1,198 ) = F (1,20 ) = 0,1151
9,105 119 La probabilidad de que la media
de edad de los empleados que trabajarían en
La probabilidad de que la 119
media
de edad de los empleados que
el
nuevo
anexo seade
inferior
ala34media
años esde0,1151.
La
probabilidad
que
de es
los0,1151.
empleados que
trabajarían en el nuevo anexo sea inferior aedad
34 años
trabajarían en el nuevo anexo sea inferior a 34 años es 0,1151.
b. ¿Cuál será la probabilidad de que la edad media de los 119 empleados
b. ¿Cuál será la probabilidad de que la edad media de los 119 empleados
supereserá
los 37
años?
b. ¿Cuál
la probabilidad
de que la edad media de los 119 empleados
supere
los 37 años?
supere los 37 años?
37 - 35 P(X > 37 años) = P z > 37 - 35 = P(z > 2,40) = 1 F (2, 40 ) = 1 0,9918 = 0,0082
P(X > 37 años) = P z > 9,105 = P(z > 2,40) = 1 F (2, 40 ) = 1 0,9918 = 0,0082
9,105 119 119edad
media de los empleados supere los 37
La probabilidad de que la
La
la edad
media
de los
supere
los 37
La probabilidad
probabilidad
que
la edad
media
de empleados
los empleados
supere
losaños
37
años
es 0,0082. dedeque
años
es 0,0082.
es
0,0082.
2)
2)
2)
¿Cuál
será la probabilidad de que la proporción de los empleados
¿Cuál
serálaala
deanexo
la
de los empleados
¿Cuál
será
probabilidad
de que
laque
proporción
de losalempleados
mayores a
mayores
45probabilidad
años del nuevo
seaproporción
inferior
10%.
a 45 años
delsea
nuevo
anexo
sea inferior al 10%.
45 mayores
años del nuevo
anexo
inferior
al 10%?
0,10 - 0,11 P(p < 0,10) = P z < 0,10 - 0,11 = P(z < -0,35) = F(-0,35 ) = 0,3632
P(p < 0,10) = P z < 0,11.0,89 = P(z < -0,35) = F(-0,35 ) = 0,3632
0,11.0,89
119 119 Estadistica
La probabilidad de que la proporción de los empleados mayores a 45
La probabilidad
probabilidad
que
proporción
deesempleados
los
empleados
mayores
45
años
del nuevo anexo
sea
inferior
al 10%
0,3632.
La
dedeque
la la
proporción
de los
mayores
a 45 aaños
años
del
nuevo
anexo
sea
inferior
al
10%
es
0,3632.
del nuevo anexo sea inferior al 10% es 0,3632.
COMIENZO DE ACTIVIDAD
COMIENZO DE ACTIVIDAD
1.
1.
1. Una
a.
carpinteríarecibe
recibe
periódicamente
grandes
a.
Una carpintería
periódicamente
grandes
partidaspartidas
de postesdede
a.
Una
carpintería
recibe
periódicamente
grandes
partidas
de
madera
de longitud
media demedia
4 metros
de un aserradepostes
de madera
de longitud
de procedentes
4 metros procedentes
de
postes
de
madera
de
longitud
media
de
4
metros
procedentes
de
SabiendoSabiendo
que la precisión
procesodel
de proceso
cortado de
postes
un ro.
aserradero.
que la del
precisión
de los
cortado
un
aserradero.
Sabiendo
que
la
precisión
del
proceso
de
cortado
está
dada
por
un
desvío
estándar
de
3,5
cm.
de los postes está dada por un desvío estándar de 3,5 cm.
postes
está
dada por un
de 3,5
cm.
ilos
. ¿Cuál
probabilidad
de desvío
que
poste
al azar
midamida
entre
i.de¿Cuál
es eslala
probabilidad
de
que un
unestándar
posteelegido
elegido
al azar
i.
¿Cuál
es
la
probabilidad
de
que
un
poste
elegido
al
azar
mida
3,98
y
4,03
metros?
entre 3,98 y 4,03 metros?
entre
yelige
4,03una
metros?
ii . 3,98
Si
una
muestra
de ladeúltima
partidapartida
recibiii.
Si
se seelige
muestradede8080postes
postes
la última
ii.
Si
se
elige
una
muestra
de
80
postes
de
la
última
partida
da,
¿cuál
es
la
probabilidad
de
que
la
longitud
media
de
la
muestra
recibida, ¿cuál es la probabilidad de que la longitud media de la
recibida,
¿cuál
es laentre
probabilidad
deymetros?
que
longitud media de la
esté comprendida
3,98
4,03
muestra
esté
comprendida
entrey3,98
4,03lametros?
muestra
esté
entre
metros?
ii i. ¿Cuál
escomprendida
la diferencia
entre
i)y yii)ii)y? ?4,03
Justifique.
iii.
¿Cuál
es la
diferencia
entre
i) 3,98
Justifique.
iii. ¿Cuál es la diferencia entre i) y ii) ? Justifique.
b. Una inmobiliaria de Quilmes ha cambiado su política de alquileres
introduciendo una opción de alquiler a sola firma. Actualmente el
55% de los departamentos que ofrece son con esta modalidad. Del
archivo de alquileres de la inmobiliaria se tomó una muestra aleatoria de 180 fichas. ¿Cuál es la probabilidad de que la proporción de
inquilinos sin garante esté comprendida entre el 48% y el 60%?
7
7
93
Universidad Virtual de Quilmes
3.2. Problemas fundamentales de la inferencia
estadística
En la vida cotidiana, como en el campo científico o profesional, surgen situaciones caracterizadas por la incertidumbre pese a lo cual deben tomarse decisiones sustentadas usualmente en los modelos teóricos elaborados con base
en observaciones previas de fenómenos similares.
Los dos problemas fundamentales que atañen a la inferencia estadística
son la estimación de un parámetro desconocido y las pruebas de hipótesis
cuyas soluciones se basan necesariamente en la evidencia muestral.
3.2.1. Estimación por intervalo de confianza
La estimación por intervalo de confianza de un parámetro desconocido consiste en construir –a partir de la evidencia muestral– un intervalo o rango continuo de valores que contendría, con una cierta probabilidad asociada, el verdadero valor del parámetro poblacional.
Por ejemplo, toda persona que realiza una rutina diaria de su casa al trabajo
de hecho está colectando evidencia muestral sobre el tiempo que le insume
el viaje. A partir de las veces que anteriormente hizo el recorrido casa-trabajo (lo que constituye un muestreo) estima un cierto intervalo de tiempo que
emplearía un día cualquiera en llegar a su trabajo (se entiende, siguiendo la
rutina cotidiana), con una cierta probabilidad.
En el relato anterior se pueden identificar casi completamente todos los elementos necesarios para la construcción de un intervalo de confianza, a saber:
la evidencia muestral, el nivel de confianza –la probabilidad– de la estimación
y el parámetro –tiempo esperado– a estimar.
La construcción de intervalos de confianza se basa en las distribuciones
que tienen los estadísticos muestrales, o estimadores de los parámetros
poblacionales, ya vistas en el apartado 3.1.
Intervalos de confianza para la media poblacional
Antes de abocarnos al cálculo de intervalos desarrollaremos los fundamentos de su construcción. Mantengamos por el momento la pauta del apartado
anterior de contar con una población cuyos µ y σ son conocidos y que de ella
se extraerá una muestra de tamaño n.
La distribución de los X alrededor de µ bajo las condiciones generales
expuestas en 3.1.3., se representa de la siguiente forma:
94
Gráfico.3.4
Distribución de la población de las proporciones muestras (n>100)
Estadistica
0
0,11
1
Proporciones muestrales
Gráfico 3.5.
Gráfico.3.5
0
0,11
1
Proporciones muestrales
Gráfico.3.5
X
µ
Gráfico.3.6
Si en vez de interesarnos en preguntas como P(X>a) ó P(X<b) nos planteáramos una del tipo P(a<x<b) con a y b equidistantes de µ., el área sombreada
(denominada 1–α ) será la respuesta.
X
µ
Gráfico.3.6
Gráfico
3.6.
1-α
a
b
µ
X
1-α
a
µ
b
X
Si 1–α es la probabilidad de que x caiga dentro del intervalo [a,b] entonces α
será la probabilidad de que x caiga fuera de él. Como se puede advertir α quedará partido en dos, porque estamos considerando un intervalo simétrico alrededor de µ. Y estandarizando según Z se tiene lo siguiente.
G.3.7
Gráfico 3.7.
1-α
α/2
a
Z α/2
µ
α/2
b
Z 1−α/2
X
Z
G.3.8
95
Universidad Virtual de Quilmes
1-α
Los subíndices
α/2 con el criterio de acumulación de la
α/2 de los Z están en relación
tabla de la distribución normal estándar. Como el punto “a” acumula α/2 de
b
a
µ Z será
X “b” acumula 1–α/2
probabilidad su estandarizado
Zα/2 y como el punto
1−α/2 Z1–α/2. En rigor
de probabilidadZsuα/2estandarizadoZserá
y Z1-α/2 son iguaZ Zα/2
Los subíndices de los Z están en relación con el criterio
de acumulación
les en valor absoluto pero tienen signo contrario.
de
tabla de de
la los
distribución
Comodeelacumulación
punto “a”
Loslasubíndices
Z están ennormal
relaciónestándar.
con el criterio
acumula
/2 de
de probabilidad su estandarizado Z será Z/2 y como el
deG.3.8
la tabla
Gráfico
3.8. la distribución normal estándar. Como el punto “a”
punto
“b”
acumula
1–/2 de probabilidad
su estandarizado
Z1–/2el.
acumula /2 de probabilidad
su estandarizado
Z será Z/2 será
y como
En
rigor
Z
y
Z
son
iguales
en
valor
absoluto
pero
tienen
signo
1-/2
punto “b” /2
acumula
1–/2 de probabilidad su estandarizado será Z
1–/2.
contrario.
En rigor Z/2 y Z1-/2 son iguales en valor absoluto pero tienen signo
contrario.
G.3.8.
G.3.8.
Insertar Imagen Nº G.3.8.
Insertar Imagen Nº G.3.8.
1-α
α/2
α/2
-Z α/2
0
Z 1−α/2
Z
Entonces estandarizando la variable X
Entonces estandarizando la variable
x Entonces estandarizando la
variable
G.3.9.
Z=
x Z=
n
n
el cálculo de la probabilidad
planteada será:
X
Límite inferior el cálculo de la probabilidad planteada será:
planteada será:
del intervalo el cálculo de la probabilidad
a - x ε b ε máx
< máx = 1 <
P(a < x < b) = P
Límite superior
del intervalo
a- x b = 1 P(a < x < b) = P
<
<
n
n n
n n
n
x P(a < x < b) = PZ <
< Z = 1 1
2 x 2
P(a < x < b) = P Z <
< Z = 1 n
1
2
2
n
G.3.10
x P(a < x < b) = PZ < gl grande
< Z = 1 1
1
x 2
2
P(a < x < b) = P Z <
< Z = 1 1
n
1 2
2
n gl mediano
Luego, despejando de
10
Luego, despejando
despejando dede
Luego,
10
96
gl chico
x P Z <
< Z = 1 1
1
2
2
n
se tiene
= 1 P Z .
< x < Z .
1
n
1 2 n
2
x
x
Z
< Z< Z = 1
PP
Z
< < x = 1
1
=
1 x
<1Z2=
PZ
1 < <
1 21
1
P Z
<
Z
1 22 1 1 22
2
n n 2 n n
Estadistica
se
setiene
tiene
se tiene
tiene
se
se tiene
P
Z
.
<
x
<
Z
.
PPZ
1
Z .
< x <<1Z
Z.. = 1
==1
1. 2112 .n< xn <x<Z
1 n=
21
1
P Z
.
n
2
n
n
2
2
1
1
n
n
2
2
Como
es esla ladiferencia
Como+ ++eses
esconocido,
conocido,
diferenciaque
quepodría
podríahaber
haberentre
entrela la
la
Como
conocido,
esdiferencia
la diferencia
que
podría
haber
entre
Como
+
es
conocido,
es
la
que
podría
haber
entre
media
de
la
muestra
que
se
seleccionará
y
la
media
conocida
deladela la
media
de
la
muestra
que
se
seleccionará
y
la
media
conocida
media
dePor
la muestra
que
sea seleccionará
y media
lala media
conocida
de la
media
de µla
muestra
que
seesseleccionará
y lapodría
conocida
demedia
la
población.
susunaturaleza,
esta
diferencia
consideramos
como
población.
Por
naturaleza,
a
esta
diferencia
la
consideramos
como
Como
es
conocido,
X–µ
la
diferencia
que
haber
entre
la
de
población.
Por
su naturaleza,
a esta
diferencia
la consideramos
como
población.
Porque
su se
naturaleza,
a esta
diferencia
la consideramos
como
error.
error.
la
muestra
seleccionará
y
la
media
conocida
de
la
población.
Por
su
error. es el error de la media muestral respecto de la media
error.
naturaleza,es
diferencia
consideramos
error.de
esa esta
el error
error
de la
lala media
media
muestralcomo
respecto
de la
la media
media
el
de
muestral
respecto
eseselely error
error
de
la
media
muestral
respecto
de valor
lavalor
media
poblacional
1- 1dees
su
probabilidad.
El
máximo
que
poblacional
y
es
su
probabilidad.
El
máximo
quepuede
puede
la
media
muestral
respecto
de
la
media
poblacional
y 1–α
X–µ
poblacional
y
1
es
su
probabilidad.
El
máximo
valor
que
puede
poblacional
y
1
es
su
probabilidad.
El
máximo
valor
que
puede
tomar
ese
error
o
error
máximo
,
en
valor
absoluto
es
tomar
ese error
error oo error
error
máximovalor
, en
en que
valor
absoluto
esese error o error máxies
su ese
probabilidad.
El máximo
puede
tomares
tomar
máximo
valor
absoluto
tomar
error máximo
, en ,valor
absoluto
es
moese
, enerror
valoroabsoluto
es
máx
==
z1z . . máx
máx =máxz1= z112. 22 . n nn
2
n
Puede
observarse
que
cuando
se
agranda
Puede observarse
observarse que
que cuando
cuando se
se agranda
agrandael el
eltamaño
tamañodede
dela la
lamuestra
muestrael el
el
Puede
tamaño
muestra
Puede
observarse
que
cuando
se
agranda
el
tamaño
de
la
muestra
el
error
máximo
se
achica
y
lo
mismo
ocurre
cuando
disminuye
el
nivel
de
error máximo
máximo se
se achica
achica yy lo
lo mismo
mismo ocurre
ocurre cuando
cuando disminuye
disminuye el
el nivel de
de
error
error
máximo
seComo
achica
yambos
lo
mismo
cuando
disminuye
el nivelnivel
de
Puede
observarse
que
cuando
seocurre
agranda
el
tamaño
de
la muestra
el se
error
confianza.
Como
ambos
casos
tienen
distintas
connotaciones
confianza.
casos
tienen
distintas
connotaciones
se
confianza.
Como
ambos
casos
tienen
distintas
connotaciones
se
confianza.
Como
ambos
casos
tienen
distintas
connotaciones
se
máximo
se
achica
y
lo
mismo
ocurre
cuando
disminuye
el
nivel
de
confianza.
analizarán
con
más
detalle
al
abordar
la
construcción
de
los
intervalos.
analizarán con
con más
más detalle
detalle al
al abordar
abordar la
la construcción
construcción de
de los
los intervalos.
intervalos.
analizarán
analizarán
con
más
detalle
al de
abordar
laproblemas
construcción
deselosanalizarán
intervalos.
EnEn
laambos
realidad
concreta
loslos
problemas
estadísticos,
enen
general
Como
casos
tienen
distintas
connotaciones
conno
más
la
realidad
concreta
de
estadísticos,
general
no
En
la
realidad
concreta
de
los
problemas
estadísticos,
en
general
no
la
realidad
concreta
de
los
problemas
estadísticos,
en
general
no
seEn
conoce
el
valor
de
la
media
poblacional
+
de
ahí
la
necesidad
de
su
detalle
al
abordar
la
construcción
de
los
intervalos.
se conoce
conoce el
el valor
valor de
de la
la media
media poblacional
poblacional ++ de
de ahí
ahí la
la necesidad
necesidad de
de su
se
seestimación
conoce
valor
deello
la
media
poblacional
+ de
ahí
la necesidad
de suno su
y para
se se
utiliza
evidencia
muestral
y la
información
En laelrealidad
concreta
de
loslaproblemas
estadísticos,
enla
general,
se
estimación
y
para
ello
utiliza
la
evidencia
muestral
y
información
estimación
y
para
ello
se
utiliza
la
evidencia
muestral
y
la
información
estimación
y para
ello
utiliza
la evidencia
muestral
y la información
poblacional
que
sela
posea
como
el eltipo
de
distribución
poblacional
conoce
el
valor
de
media
poblacional
µ.
De
ahí
la
necesidad
de
su estimapoblacional
que
sese
posea
como
tipo
de
distribución
poblacional
poblacional
que
se
posea
como
el tipo
de
distribución
poblacional
poblacional
que
se
posea
como
el
tipo
de
distribución
poblacional
(normal
o
no)
y
el
conocimiento
de
otros
parámetros
(varianza
o
ción
y
para
ello
se
utiliza
la
evidencia
muestral
y
la
información
poblacional
que
(normal oo no)
no) yy el
el conocimiento
conocimiento de
de otros
otros parámetros
parámetros (varianza
(varianza desvío
desvío
(normal
oo desvío
(normal
o
no)
y
el
conocimiento
de
otros
parámetros
(varianza
o
desvío
estándar).
se
posea como el tipo de distribución poblacional (normal o no) y el conociestándar).
estándar).
estándar).
ElElcálculo
dede
la laestimación
porpor
dedeconfianza
miento
de otros
parámetros
(varianza
ointervalos
desvío
estándar).
cálculo
estimación
intervalos
confianzapara
para+ ++
El cálculo
de
la estimación
por
intervalos
de confianza
para
Elpresenta
cálculo
de
la
estimación
por
intervalos
de
confianza
para
+ con
presenta
distintos
casos
dependiendo
de
la
información
poblacional
con
El cálculo
de la estimación
por intervalos
confianza para
µ presenta
disdistintos
casos dependiendo
dependiendo
de la
ladeinformación
información
poblacional
presenta
distintos
casos
de
poblacional
con
presenta
distintos
casos
dependiendo
de
la
información
poblacional
con
que
se
cuente.
tintos
casos
dependiendo
de
la
información
poblacional
con
que
se
cuente.
que se
se cuente.
cuente.
que que
se cuente.
2
Población
normal
o oaproximadamente
normal
yyyσ22conocido
2conocido
Población
normal
normal
Población
normal
aproximadamente
normal
conocido
Población
normal
ooaproximadamente
aproximadamente
normal
2 y conocido
Población
normal
o
aproximadamente
normal
y
conocido
EnEn
este
caso
particular,
para
la
construcción
del
intervalo
confianza
deldel
intervalo
dedeconfianza
para
En este
este caso
caso particular,
particular,para
paralalaconstrucción
construcción
intervalo
de
confianza
En +,
este
caso
particular,
para
ladel
construcción
del intervalo
de respecto
confianza
Enpara
este
caso
particular,
para
la del
construcción
del
intervalo
de confianza
se
parte
de
la
expresión
error
de
la la
media
muestral
µ
,
se
parte
de
la
expresión
error
de
la
media
muestral
respecto
de la
para
+,
se
parte
de
la
expresión
del
error
de
media
muestral
respecto
se poblacional
parte
la expresión
del error
la media
muestral
respecto
para
+,la
se+,
parte
de ladeaexpresión
delarribamos
error
de anteriormente:
ladeanteriormente:
media
muestral
respecto
depara
la
media
a la
que
de
media
poblacional
a
la
que
arribamos
media
poblacional
la
que
arribamos
anteriormente:
la media
poblacional
la que
arribamos
anteriormente:
de lademedia
poblacional
a la aque
arribamos
anteriormente:
P(Z
x< Z< Z . . ) =)1
. . < x
<
P(Z
1
1 .n
<x<Z
<1Z
) ==1
1 < x
1 .)n=n
21
21
P(ZP(Z
.
.
1
n
2
2
n
n
2
2
1
1
n
n
2
2
y yyteniendo
enen
cuenta
que
la laincógnita
teniendo
cuenta
que
ahora
la incógnita
es µ laes
despejamos
obteniendo:
teniendoen
cuenta
queahora
ahora
incógnita
es+ ++la la
ladespejamos
despejamos
y
teniendo
en
cuenta
que
ahora
la
incógnita
es
despejamos
y obteniendo:
teniendo
en
cuenta
que
ahora
la
incógnita
es
+
la
despejamos
obteniendo:
obteniendo:
obteniendo:
P
x
z
<
<
x
+
z
P x za a 1
<< xx ++1zz = 1
==1
<< n
1 a n
1
2
=
1
P xPzx a1z21
<
<
x
+
z
n n
1 2
2
n
n
1
1
2n
2n
2
2
Donde ahora 1- α es la probabilidad, la confianza que tenemos de que el
intervalo
1111
11
11
97
Z α/2
Z 1−α/2
Z
G.3.8
Universidad Virtual de Quilmes
contenga al verdadero valor de µ.
El mismo intervalo (con una probabilidad 1–α asociada) que anteriormente se ubicaba alrededor del µ, ahora se ubica alrededor del X para poder estimar (con una confianza 1–α) el µ desconocido.
1-α
α/2
α/2
Nótese además que, en rigor, lo único que se trajo del estudio previo es el
Z
-Z α/2
Z 1−α/2
segmento que se colocó
sobre0 X y su probabilidad
asociada. No hay una distribución sobre él (la distribución de la muestra, en todo caso, no forma parte
de la construcción que hicimos).
En resumen, los límites del intervalo se obtienen sumando y restando el
error máximo a la media muestral ya que ésta es el centro del intervalo.
G.3.9.
Gráfico 3.9.
X
Límite inferior
del intervalo
ε máx
ε máx
Límite superior
del intervalo
Por lo tanto, al intervalo también se lo puede expresar del siguiente modo:
G.3.10
Como el error máximo
gl grande
disminuye cuando aumenta el
gl mediano
tamaño de la muestra o cuando es menor el nivel de confianza, entonces:
• Si aumenta el tamaño de la muestra, para un mismo nivel de confianza –
gl chico
el valor de z se mantiene constante– se obtiene un intervalo de menor
amplitud que implica mayor precisión en la estimación.
• Si disminuye el nivel de confianza (manteniendo el tamaño de la muestra) se
obtiene un intervalo de menor amplitud pero eso no implica mejorar la precisión ya que el intervalo tendrá menor probabilidad de contener al parámetro.
Ejemplo
Con el fin de controlar el proceso de llenado de paquetes de galletitas de
medio kilo, se seleccionaron al azar 16 de esos paquetes y el peso en gramos
de cada uno de ellos fue el siguiente: 505; 510; 495; 508; 504; 512; 496;
512; 514; 505; 493; 496; 506; 502; 509; 497.
Como información adicional se conoce por catálogo de compra de la máquina que la precisión de ella al envasar está dada por un desvío estándar de
σ = 5 gramos.
98
unlos
intervalo
un nivel envasados
de confianza
de todos
paquetescon
de galletitas
por de
esa0,95.
máquina, mediante
un intervalo con un nivel de confianza de 0,95.
COMIENZO DE PASTILLA EN nivel de confianza
En la elección de un nivel de confianza, son estándares los valores 0,90; 0,95 o
COMIENZO DE PASTILLA EN nivel de confianza
0,99. de un nivel de confianza, son estándares los valores 0,90; 0,95 o
En la elección
Estadistica
FIN DE PASTILLA
0,99.
Con base en la muestra de los 16 paquetes estimaremos el peso medio de
FIN DE PASTILLA
todos los paquetes de galletitas envasados por esa máquina, mediante un
Lacon
información
que se
intervalo
un nivel de con
confianza
decuenta
0,95. es la siguiente.
La información con que se cuenta es la siguiente.
La información con que se cuenta es la siguiente.
Sobre la población:
En la elección de un nivel
de confianza, son estándares los valores 0,90; 0,95 o 0,99.
Sobre la población:
Sobre la población:
la distribución
de los
pesoslos
depaquetes
todos los
paquetes
la•distribución
de los pesos
de todos
llenados
por llenados por
• La distribución
de los pesos
de todos(olos
paquetes llenados por
la máquiaproximadamente
normal)
la máquina
la máquina
es
normales(onormal
aproximadamente
normal) porque
los porque los
na es normal
(o
aproximadamente
normal)
porque
los
procesos
de
medi- (medir
de medición
de unvalor
mismo
valor
nominal
procesosprocesos
de medición
de un mismo
nominal
(medir
ción de un longitudes,
mismo valor nominal
(medir
longitudes,
etc.) entregan
pesar,
etc.) naturalmente
entregan pesar,
naturalmente
poblaciones
longitudes,
pesar, etc.)
entregan
poblaciones
naturalmente
poblaciones
normales.
normales.
normales.
estándar
σ =5g.
•• El desvío
el•desvío
= 5g. = 5g.
elestándar
desvío
estándar
•
Sobre la muestra:
Sobre
laSobre
muestra:
la muestra:
de la muestra seleccionada es n = 16.
•• El tamaño
el tamaño
de la muestra seleccionada es n = 16.
• medio
el tamaño
de la muestra
seleccionada es n = 16.
• El peso
de los paquetes
X = 504g.
•
el peso medio
de los paquetes
= 504g.
elestándar
peso Smedio
de los paquetes = 504g.
estándar
= 6,802g.
•• El desvío
el•desvío
S = 6,802g.
•
el desvío estándar S = 6,802g.
Se obtiene
el intervalo
confianza
para
peso
medio m
llenadodede los
Se obtiene
el intervalo
de de
confianza
para
el elpeso
medio
dedellenado
paquetes,
utilizando
la
expresión:
Se obtiene el intervalo de confianza para el peso medio de llenado
los paquetes, utilizando la expresión:
la expresión:
los paquetes, utilizando
I = x z ,x + z 1
1 z
I =2 x n z 2 , xn +
1
2
n
1
2
de
n
Sabiendo que el nivel de confianza establecido es 1- = 0,95
calculamos
valor
de 1-/2
y a continuación
buscamos
en lacalculamos
tabla
Sabiendoelque
el nivel
de confianza
es 1-α = 0,95
Sabiendo
que
el
nivel
deestablecido
confianza
establecido
es el1-el = 0,95
de 1-α/2
continuación buscamos en la tabla el z1-α/2. Luego z0,975 =
. Luego
z0,975 =y a1,96.
z1-/2valor
calculamos el valor de 1-/2 y a continuación buscamos en la tabla el
z1-/2. Luego
z0,975 = 1,96.
Reemplazando
se obtiene:
1,96.
Reemplazando
se
5 obtiene:
5 I = Reemplazando
,504
+ 1,96 504 1,96 = [501,55; 506, 45]
se
obtiene:
16
16 5
5 I = 504 1,96 ,504 + 1,96 = [501,55; 506, 45]
Concluimos que, con base en una
paque
tes y con una
16 muestra de 1616
confianza del 95%, se estima que el peso medio de todos los paquetes
fabricados
seencueos
ntra
entre
501,55g
Concluim
que
, con
base eyn506,45g.
una muestra de 16 paquetes y con una
Concluimos que, con base en una muestra de 16 paquetes y con una conconfianza del 95%, se estima que el peso medio de todos los paquetes
fianza del 95%, se estima que el peso medio de todos los paquetes fabricafabricadosseencuentra entre501,55g y 506,45g.
dos se encuentra entre 501,55g y 506,45g.
13
Supongamos que el error máximo (2,45g) de la estimación fuera grande para
cumplir con determinadas exigencias del control de calidad. En ese caso sería
necesario mejorar la estimación achicando el error máximo tomando una muestra de mayor tamaño.
La pregunta que surge es ¿de qué tamaño deberá ser la nueva muestra
para que el error máximo asociado de la futura estimación sea, por ejemplo
de 1g, obviamente con el mismo nivel de confianza?
99
Universidad Virtual de Quilmes
De la fórmula del εmáx. se despeja n.
Para poder estimar la media de todos los paquetes envasados por esa máquina con un error máximo de 1g y con una confianza del 95% deberán seleccionarse como mínimo 97 paquetes.
2.
Con base en la muestra de 20 piezas plásticas de la matriz ME4 consignada en el apartado 1.3. de la Unidad 1 y sabiendo que la precisión
de la balanza está definida por un desvío estándar de 1g.
a. Estimar, con un nivel de confianza del 95%, el peso medio de todas
las piezas plásticas fabricadas por esa empresa.
b. ¿En qué se fundamenta la normalidad de la distribución de todos
los pesos de las piezas plásticas?
La distribución t de
Student fue publicada en
1908 por W. S. Gosset bajo el seudónimo de Student.
Población normal o aproximadamente normal y σ2 desconocido
Consideremos ahora que la especificación de la desviación estándar poblacional dada en el problema anterior no se conoce, porque se perdió el catálogo o porque el fabricante de la máquina no lo proveyó, o por otras razones.
¿Podemos realizar igualmente la estimación de la media poblacional?
Si la población es normal, y estamos en ese caso, es posible calcular el
error máximo reemplazando el s desconocido por su mejor estimador que es
el desvío muestral S. Pero en lugar de la distribución normal estándar se deberá utilizar la distribución t de Student la cual fue diseñada especialmente para
el muestreo en poblaciones normales.
Sean X1, X2, . . . , Xn variables aleatorias independientes que son todas normales con media
y desviación estándar
s. Entonces la variable aleatoria
tiene una distribución t
x
x
con n-1 grados de libertad.
Características de la distribución t de Student
1- Al igual que en la distribución Normal:
a) El rango de valores de la t de Student varía de -∞ a +∞
b) Es simétrica respecto de su media.
V(t) siempre mayor a 1 pero si crece el tamaño de la muestra, n → ∞ el desvío tiende a 1 y
la distribución t es asintóticamente normal de parámetros (0, 1)
100
G.3.9.
X
Límite inferior
del intervalo
Límite superior
del intervalo
Estadistica
3- Es más aplanada
ε que la Normal por tener
ε mayor dispersión.
máx
máx
4- Hay una familia de curvas de la distribución t de Student dependiendo de los grados de
libertad que para una variable es n–1 como se muestra en el gráfico G.3.10.
Gráfico 3.10.
G.3.10
gl grande
gl mediano
gl chico
5- Las curvas dependen de los grados de libertad, a mayor grado de libertad corresponde
menor dispersión.
Entonces, en este caso el error máximo es
Y el intervalo de confianza para la media poblacional es:
Volviendo al problema:
La información con la que contamos es la siguiente.
Sobre la población:
• La distribución de los pesos de todos los paquetes llenados por la máquina es normal (o aproximadamente normal) porque los procesos de medición de un mismo valor nominal (medir longitudes, pesar, etc.) entregan
naturalmente poblaciones normales.
Sobre la muestra:
• El tamaño de la muestra seleccionada n = 16.
• El peso medio de los paquetes de la muestra X=504g.
• El desvío de la muestra S = 6,802g.
Utilizando el mismo nivel de confianza 1–α = 0,95 y sabiendo que los grados
de libertad son 15, buscamos en la tabla de la t del Anexo el valor correspondiente a tn-1;1-α/2. Luego t15;0,975 = 2,131.
Reemplazando los datos construimos el intervalo de confianza para la media:
101
Universidad Virtual de Quilmes
Finalmente, con base en una muestra de 16 paquetes y con una confianza del
95%, se estima que el peso medio de todos los paquetes fabricados se encuentra entre 500,38g y 507,63g.
Notamos que el intervalo obtenido es menos preciso que el hallado en el
ejemplo anterior, donde se conocía el desvío poblacional, y esto se debe a que
en este segundo caso sólo se cuenta con las medidas muestrales. Como
era de esperar al contar con menor información se obtuvo menor precisión
en la estimación.
3.
Con base en la muestra de 20 piezas plásticas de la matriz ME4 consignada en el apartado 1.3 de la Unidad 1;
a . Estimar, con un nivel de confianza del 95%, la longitud media de
todas las piezas plásticas fabricadas por esa empresa.
b. ¿Qué supuesto tuvo en cuenta acerca de la distribución de todas las
longitudes de las piezas de plástico para realizar la estimación?
Población no normal y σ2 conocido
Cuando la población no es normal o se desconoce el tipo de distribución que
posee y se conoce la varianza poblacional, para poder estimar la media poblacional es necesario que la muestra sea grande para que –en virtud del Teorema
central del límite– dicha estimación pueda realizarse utilizando la misma expresión de la primera situación tratada.
Por otro lado, si la muestra es chica no se puede llevar a cabo la estimación
por intervalo de confianza de la media poblacional.
Ejemplo
Consideremos la población de los tiempos empleados para realizar todas las
transacciones bancarias posibles por la totalidad de los clientes de un determinado banco.
En este problema la distribución de los tiempos empleados para realizar
todas las transacciones bancarias no necesariamente es normal.
Repasar las características de la población definida en este ejemplo con
la tratada en la Unidad 2, apartado 2.2.4. para reconocer la distinta naturaleza de cada una.
102
s características de la ejemplo
poblacióncondefinida
en este
la tratada
en la Unidad 2, apartado 2.2.4. para
n la tratada en la Unidad
2, apartado
2.2.4.
para de cada una.
reconocer
la distinta
naturaleza
a distinta naturaleza de cada
FINuna.
DE PARA REFLEXIONAR
RA REFLEXIONAR
Estadistica
Convengamos que la desviación estándar de todas las operaciones es
ue la desviaciónConvengamos
estándar ydeestodas
las
operaciones
es de todas las operaciones es conoconocida
= la
1,5
minutos.
que
desviación
estándar
,5 minutos.
cidaSiy se
esdeseara
σ = 1,5estimar
minutos.
el tiempo medio que tardan los clientes en realizar todas
ar el tiempo medio
tardan
los clientes
enelrealizar
Sioperaciones
se
deseara
tiempotodas
medio
que tardan
los de
clientes
en realizar
lasque
y estimar
se seleccionara
una
muestra
aleatoria
60 clientes
que
seleccionara unatodas
muestra
aleatoria
de
60
clientes
que
las operaciones
se seleccionara
unadesvío
muestra
aleatoria
de minutos,
60 clientes
emplearon
en promedioy 3,7
minutos con un
estándar
de 2,1
la
io 3,7 minutos con
unemplearon
desvíocon
estándar
de
2,1 3,7
minutos,
que
en
promedio
minutos
con un desvío estándar de 2,1 minuinformación
la que
contaríamos
seríalala siguiente:
contaríamos seríatos,
la siguiente:
la información con la que contaríamos sería la siguiente:
Sobre la población:
Sobre• la población:
el desvío = 1,5 min
= 1,5 min •Sobre
El desvío
σ = 1,5 min.
la muestra:
Sobre• la muestra:
el tamaños de la muestra seleccionada n = 60
s de la muestra •seleccionada
ntiempo
=la60
El•tamaño
muestra
seleccionada
= 60.
el de
medio
de las ntransacciones
de la muestra
o medio de •lasEl tiempo
transacciones
de
la
muestra
medio de las transacciones de la muestra X=3,7min.
• El•desvíoelde
la muestra
S = 2,1 min.
desvío
de la muestra
S = 2,1 min
de la muestra S = 2,1 min
Calcularemos
confianza
deldel
95%.
Calcularemosun
unintervalo
intervalopara
paraμ ?con
conuna
una
confianza
95%.
ervalo para ? con una confianza del 95%.
1,5
1,5 I
=
3,7
1,96
,3,7
+
1,96
= (3,31 , 4,08)
1,5
1,5
= (3,31 , 4,08
60)
60 1,96 ,3,7 + 1,96 60
60 Luego, con base en una muestra de 60 transacciones y con una
Luego, con base en una muestra de 60 transacciones y con una confianza del
una muestra deconfianza
60 transacciones
una que el tiempo medio de todas las
del 95%,y seconestima
95%, se estima que el tiempo medio de todas las operaciones del banco se
se estima que operaciones
el tiempo medio
de
todas
las entre 3,31 min y 4,08 min.
del banco se encuentra
encuentra entre 3,31 min y 4,08 min.
o se encuentra entre 3,31 min y 4,08 min.
Intervalo de confianza para la proporción poblacional
Intervalo
de confianza
para la proporción poblacional
nfianza para la
proporción
poblacional
Toda la lógica empleada para fundamentar la construcción de intervalos
Toda la lógica
empleada para
fundamentar la construcción de intervalos de
eada para fundamentar
la construcción
intervalos
de confianza
para la demedia
poblacional puede extenderse a la
confianza para
la media
poblacional
extenderse a la fundamentala media poblacional
puede
a lapuede
fundamentación
deextenderse
la construcción
de intervalos de confianza para
ción
de
la
construcción
de
intervalos
de
confianza
para estimar la proporción
la construcción
de intervalos
de confianza
estimar
la proporción
poblacionalpara
P debido a que, en virtud al Teorema
P debido
a que,alen
virtud al Teorema central del límite, la variaón poblacional Ppoblacional
debidodel
a que,
en virtud
Teorema
central
límite,
la variable
aleatoria proporción muestral tiene
ble
aleatoria
proporción
muestral
tiene distribución normal de parámetros
la variable aleatoria proporción muestral tiene
P.(1 P)
si el tamaño
distribución normal
P.(1deP)parámetros ?p= P y p =
n
si el tamaño
de parámetros ?p= P y p =
n intervalo de confianza para la proporción
nPara
de laconstruir
muestra esun
grande.
rande.
siPara
el tamaño
de laun
muestra
escasos
grande.
poblacional,
alnigual
que
en los
para lapara
media,
intervalo
construir
intervalo
de vistos
confianza
la elproporción
Para construir
un intervalo
de casos
confianza
para
la proporción
al
sepoblacional,
centrará
en al
el igual
estadístico
muestral
y será
simétrico
él.
que en
los
vistos
para
laalrededor
media, poblacional,
elde
intervalo
igual
que
en
los
casos
vistos
para
la
media,
el
intervalo
se
centrará
en
el
estase centrará en el estadístico muestral y será simétrico alrededor de él.
dístico muestral y seráI simétrico
= p alrededor
;p +deél.
IPP = [ p máx
máx ;p + máx
máx ]
I P = [ p máx ;p + máx ]
17
17
En este caso el cálculo del error máximo debería ser:
este
caso
cálculodel
delerror
errormáximo
máximo debería
debería ser:
EnEneste
caso
el el
cálculo
P.(1 P)
máx = z P.(1 P)
máx = z1 2 P.(1
n P)
n
máx = z1 2 pero al desconocer P se utiliza su1mejor estimador
p, quedando
n
2
pero al desconocer P se utiliza su mejor
estimador
p, quedando
pero
desconocerPPseseutiliza
pero
alaldesconocer
quedando
utilizasu
sumejor
mejor estimador
estimador p,
p, quedando
p.(1 p)
máx
z
p.(1 p)
1
n
1
máx
máx z 22 1
n
2
Por tal motivo, el intervalo de confianza para la proporción poblacional
Por tal motivo, el intervalo de confianza
P resulta para la proporción poblacional
P resulta
p.(1 p)
p.(1 p) 103
máx z z p.(1 p)
máx
máx12 z1 2 n n
1
n
2
Por talPor
motivo,
el intervalo
de confianza
para la
proporción
poblacional
tal motivo,
el intervalo
de confianza
para
la proporción
poblacional
P
resulta
Por tal motivo, el intervalo de confianza
P resulta para la proporción poblacional
P resulta
Por tal motivo, el intervalo de confianza
para la proporción poblacional P resulta
Universidad Virtual de Quilmes
p.(1 p)
p.(1 p) I P = Ip =z p z p.(1, p)p +, z p + z p.(1 p) I PP = 1p 2 z1 2 n p.(1
n p) , 1p 2+ z1 2 n p.(1
n p) 1
1
n
n
2
2
Ejemplo
Ejemplo
Ejemplo
Para estimar
la proporción
de familias
que ven
por
TV
determinado
Ejemplo
Para
estimar
lalaproporción
de
familias
que
ven
porun
TV
un determinadoproPara
estimar
proporción
de
familias
que
ven
por
TV
un determinado
programa,
se
seleccionó
una
muestra
de
2200
familias
que
poseen
uno ouno o
Para
estimar
la
proporción
de
familias
que
ven
por
TV
un
determinado
programa,
seseleccionó
seleccionóuna
unamuestra
muestradede2200
2200familias
familias
que poseen
grama, seen
que poseen
uno o más
más televisores
una
determinada
ciudad,
y
de
la
muestra
se
obtuvo
programa,
se seleccionó
una muestra ciudad,
de 2200 yfamilias
que poseen
uno o
más
televisores
en
una
determinada
de
la
muestra
se
obtuvo
televisores
en
una
determinada
ciudad,
y deutilizando
la muestraunsenivel
obtuvo
que 871
que 871
familias
ven
ese
programa.
Estimar,
de
más
televisores
en
una
determinada
ciudad,
y
de
la
muestra
se
obtuvo
que
871 familias
ven ese programa.
Estimar,
utilizando
un nivel
de
familias
ven
ese
programa.
Estimar,
utilizando
un
nivel
de
confianza
de 0,95,
confianza
de 0,95,
un intervalo
la
proporción
deutilizando
familias
que
que
871
familias
ven
ese para
programa.
un ven
nivel
de
confianza
de 0,95,
un intervalo
para
laEstimar,
proporción
de familias
que ven
un intervalo para la proporción de familias que ven ese programa.
ese programa.
confianza
de 0,95, un intervalo para la proporción de familias que ven
ese programa.
ese programa.
La información
la que
contamos
la siguiente.
La información
concon
lacon
que
es es
la siguiente.
La información
lacontamos
que contamos
es la siguiente.
•
El
tamaño
de
la
muestra
seleccionada
=siguiente.
2200.
• La
tamaño
de lacon
muestra
queseleccionada
contamos
esnnla=2200
•el información
el tamaño
de la muestra
seleccionada
n =2200
Laproporción
proporción
muestral
de
que
el programa
dede
TV.TV
• • •la
muestral
de familias
familias
queven
ven
programa
el
de lamuestral
muestra
seleccionada
la tamaño
proporción
de
familias
quenel=2200
ven
el programa
de TV
871
•
la
proporción
muestral
de
familias
que
ven
el
programa
de
TV
0,396
p = p = =871
=
0,396
871 2200
p = 2200 = 0,396
2200
la tabla
es es
1,96.
ParaPara
una
confianza
del
95%,
el
valor
z0,975
Parauna
unaconfianza
confianza
95%,
el valor
zde
detabla
la tabla
es 1,96.
0,975
deldel
95%,
el valor
z0,975
de la
1,96.
Para una confianza del 95%, el valor z0,975 de la tabla es 1,96.
Reemplazando
se tiene
que elque
intervalo
para Ppara
es: P es:
Reemplazando
tiene
intervalo
Reemplazando
sesetiene
que el el
intervalo
para P es:
Reemplazando se tiene que el intervalo para P es:
p.(1 p)
p.(1 p) IP = pI z= p z p.(1
, p + p)
z ,p+ z p.(1 p)
P 1
1
I = 2p z 1 2 n p.(1
n p) n p) , 2p + z 1 2 n p.(1
P
1
1
n
n 2
2
0,396.0,604
0,396.0,604
0,396.0,604
0,396.0,604 1,96.
,
0,396
+
1,96.
IP 0,396
, 0,396 + 1,96.
I 0,396 1,96.
0,396.0,604
0,396.0,604
I P0,396 1,96.2200
2200 , 0,396 + 1,96.2200
2200
P
2200
2200
IP= [0,386;
0,406]
IP= [0,386; 0,406]
IP= [0,386; 0,406]
18
18
18
Con base en una muestra de 2200 familias con el 95% de confianza la verdaCon
base en una muestra de 2200 familias con el 95% de confianza la
dera proporción de familias que ven ese programa de TV está comprendida entre
verdadera proporción de familias que ven ese programa de TV está
el 38,6% y el 40,6%.
comprendida
entre el 38,6% y el 40,6%.
COMIENZO DE ACTIVIDAD
4.
4.
Con base en la muestra de las 96 familias escogidas al azar de cierta locaCon base en la muestra de las 96 familias escogidas al azar de
lidadlocalidad
(apartado 1.1.2.
de la 1.1.2.
Unidadde1) la
conUnidad
1 – α =1)
0,95
estimar
cierta
(apartado
con
1 – la =proporción de familias en toda la población cuyo gasto medio en alimen0,95
estimar la proporción de familias en toda la población
tos supere los $46.
cuyo gasto medio en alimentos supere los $46.
FIN DE ACTIVIDAD
Determinación del tamaño de una muestra
Determinación del tamaño de una muestra
Comose
se hizo
hizo para
media,
se despeja
n de la
del error máximo,
Como
parala la
media,
se despeja
n fórmula
de la fórmula
del errorque
en
su
forma
original
y
en
su
forma
aproximada
es:
máximo, que en su forma original y en su forma aproximada es:
máx = z
1
2
104
P.(1 P)
p.(1 p)
z 1
n
n
2
Al no conocer P porque es lo que se quiere estimar y al no conocer p
porque aún no se tomó la muestra (justamente necesitamos calcular de
qué tamaño mínimo deberá ser), se presenta un problema que debemos
sortear. Para hacerlo se parte de la suposición teórica de que P = 0,50 ,
máximo, que en su forma original y en su forma aproximada es:
máx = z
1
2
P.(1 P)
p.(1 p)
z 1
n
n
2
Estadistica
Al no
eses
lo lo
queque
se se
quiere
estimar
y al ynoalconocer
p porque
Al
no conocer
conocerPPporque
porque
quiere
estimar
no conocer
p
aún
no
se
tomó
la
muestra
(justamente
necesitamos
calcular
de
qué
tamaño
porque aún no se tomó la muestra (justamente necesitamos calcular de
mínimo
deberá
ser), deberá
se presenta
un presenta
problemaunque
debemos
sortear.
Para
qué
tamaño
mínimo
ser), se
problema
que
debemos
hacerlo Para
se parte
de la se
suposición
de que Pteórica
= 0,50, de
lo que
sortear.
hacerlo
parte deteórica
la suposición
quees
P lógico
= 0,50por,
que
es
el
sustento
teórico
de
la
curva
de
distribución
de
las
proporciones
lo que es lógico porque es el sustento teórico de la curva de distribución
muestrales;
aunque luego
–como es
esperable–
realidad
del modede
las proporciones
muestrales;
aunque
luego la–como
esdifiera
esperable–
la
lo
teórico.
realidad difiera del modelo teórico.
Reemplazando y
y despejando
Reemplazando
despejando nn se
se tiene:
tiene:
máx
2
z .0,50 0,50.0,50
0,50
= z .
n = 1
=z 1
1
n
máx
n
2
2
3.2.2. Pruebas de hip ótes is
3.2.2. Pruebas de hipótesis
COMIENZO DE LEER ATENTO
Una
prueba–test
–test
o contraste–
de hipótesis
en un
Una prueba
o contraste–
de hipótesis
consiste enconsiste
un procedimiento
procedimiento
cualunse
somete(uaotra
prueba
un
mediante el cual mediante
se somete a el
prueba
parámetro
característiparámetro
(u otra
característica)
sobre
ca) poblacional
desconocido
sobre poblacional
el que se tienedesconocido
alguna suposición.
elComo
que se
tiene
alguna de
suposición.
todo
problema
inferencia estadística la prueba de hipótesis
Como
todo
inferencia estadística la prueba de
debe
basarse
en problema
la evidenciademuestral.
hipótesis debe basarse en la evidencia muestral.
FIN DE LEER ATENTO
Cuando el objetivo de una prueba de hipótesis es testear el valor de un pará-
metro θ el
(desconocido)
partir
de undevalor
hipotético
θo de dicho
parámetro,
Cuando
objetivo de auna
prueba
hipótesis
es testear
el valor
de un
surge una primera
hipótesis aestadística
hipótesisnula
dicho
parámetro
(desconocido)
partir de denominada
un valor hipotético
o) que
o de (H
presupone
que
no
habría
una
diferencia
significativa
entre
θ
y
θ
y
que
se
o
parámetro, surge una primera hipótesis estadística denominada hipótesis
expresa
nula
(Ho) que presupone que no habría una diferencia significativa entre
Ho : θ = θo
y o y que se expresa
El valor hipotético de un
parámetro es una presunción o una suposición que se
realiza sobre él, como por ejemplo una especificación para el control de calidad, un valor histórico,
un valor de comparación o un valor
que se elige arbitrariamente.
19
Si la evidencia muestral contradijera la afirmación de H0 y existiera sospecha
de que la diferencia pudiera ser significativa, surge por oposición una segunda hipótesis estadística que llamamos hipótesis alternativa (HA) la cual sostiene, en contraste con H0, que el valor del parámetro θ diferiría significativamente del hipotético θ0.
HA puede asumir alguna de las siguientes formas:
HA : θ < θ0
ó
HA : θ > θ0
En una prueba de hipótesis (PPHH) la hipótesis nula H0 es en rigor la que se
somete a prueba, y como resultante H0 puede ser aceptada o rechazada. Si
H0 resulta ser rechazada la conclusión final de la prueba se inclinaría a favor
de HA.
Debido al ambiente de incertidumbre en el que se realiza una PPHH, dado
que se basa en la evidencia proporcionada por una muestra, en la decisión final
se pueden cometer dos tipos de errores: rechazar H0 si en realidad fuere verdadera y aceptar H0 si en realidad fuere falsa. El primero de ellos se denomina
error de tipo I y tiene asociada una probabilidad α, llamada nivel de significación de la prueba.
105
Universidad Virtual de Quilmes
P(error de tipo I) = P(rechazar H0 / H0 verdadera) = a
El segundo error (aceptar H0 si en realidad fuere falsa) se llama error de tipo
II y su probabilidad asociada es β.
P(error de tipo II) = P(aceptar H0 / H0 falsa) = β
En esta carpeta se trabajará sólo con la probabilidad a de cometer un error de
tipo I.
Prueba de hipótesis para la media poblacional
La PPHH para la media µ presenta distintos casos, dependiendo de la información poblacional con que se cuente, tal como ocurre en la estimación por
intervalos de confianza.
Población normal o aproximadamente normal y σ2 conocido
Volviendo al ejemplo de controlar el proceso de llenado de paquetes de galletitas de medio kilo, abordado en estimación de la media poblacional por intervalo de confianza, cabe preguntarnos si se podría imprimir en todos los paquetes el valor nominal de 500g. Para responder a la pregunta debemos realizar
un contraste de hipótesis donde, el parámetro desconocido (que genéricamente llamábamos θ) es el promedio µ del peso de todos los paquetes envasados, cuyo valor hipotético µ0 = 500g es el valor nominal que se quiere imprimir. Luego, la hipótesis nula será H0: µ = µ0 , es decir:
H0: µ = 500g
A partir de la evidencia de la muestra de los 16 paquetes donde el peso medio
resultó X= 504g, se puede plantear la siguiente hipótesis alternativa,
HA: µ > 500g
dado que la evidencia muestral arrojó un peso medio (estadístico muestral)
superior al valor nominal (parámetro hipotético).
Entonces el juego de hipótesis para esta PPHH es:
H0: µ = 500g
HA: µ > 500g
Estableceremos ahora un criterio que permita discriminar cuándo la diferencia entre el estadístico muestral y el parámetro hipotético no es significativa
(y por extensión no sería significativa la diferencia entre µ y µ0 por lo que se
acepta la H0) y cuándo esa diferencia sí es significativa (y en consecuencia se
rechaza H0 a favor de HA).
Ese criterio está sustentado por el nivel de significación de la prueba que
determina un valor denominado punto crítico, el cual establece dos regiones:
106
Estadistica
Gráfico 3.11.
G.3.11
Zona de Aceptación de HO
Zona de Rechazo de HO
1-α
G.3.11
µO
Zona de Aceptación de HO
Pto.
crítico
X
Zona de Rechazo de HO
1-α
En particular esta prueba se denomina unilateral derecha porque la zona de
rechazo se encuentra a la derecha µdel
O punto
Pto.crítico.
X
G.3.12
críticode las hipótesis se realiza en
El desarrollo de la prueba o la contrastación
el dominio de la normal estándar, por lo que habrá que estandarizar tanto µ0
y el punto crítico.
Zona de Aceptación de HO
Zona de Rechazo de HO
1-α
Si el juego de hipótesis
fuera H0: µ = 500g y HA:
µ < 500g, la zona de rechazo del
gráfico estaría a la izquierda y la
prueba se denominaría unilateral
izquierda.
Gráfico 3.12.
G.3.12
0
Zona de Aceptación de HO
G.3.11
G.3.13
Zona de Aceptación de HO
Z∗1−α
Z
Zona de Rechazo de HO
1-α
1-α
0
Zona de Rechazo de HO
Z
Z∗1−α
Zona de Aceptación de HO
Zona de Rechazo de HO
µO
Pto.
crítico
0,05
0
1,64
G.3.13
X
Z
3,2
Zona de Aceptación de HO
Zona de Rechazo de HO
El X estandarizado se denomina estadístico de prueba.
G.3.12
0,05
Para el problema que estamos desarrollando, fijaremos
un nivel de significación
o probabilidad de cometer error tipo I 0de α = 0,05.
Z
1,64
El punto
crítico en
Z Oy el estadístico de prueba resultan:
Zona
de Aceptación
de H
3,2Zona de Rechazo de HO
1-α
0
Z∗1−α
En la elección de un nivel
de significación son
estándares los valores 0,10; 0,05
o 0,01, pero puede optarse por
cualquier otro valor intermedio
entre ellos.
Z
Gráfico 3.13.
G.3.13
Zona de Aceptación de HO
Zona de Rechazo de HO
0,05
0
Z
1,64
3,2
107
Universidad Virtual de Quilmes
Finalmente, comparando el estadístico de prueba calculado Z=3,2 con el punto
*
crítico Z 0,95=1,64, observamos que aquél cae en la zona de rechazo de la H0
por lo que, con base en la muestra de 16 paquetes y con un nivel de significación del 5%, rechazamos H0 a favor de HA.
Conclusión estadística, con base en la muestra de 16 paquetes y con una
probabilidad de cometer error de tipo I de 0,05; habría una diferencia significativa entre la media de todos los paquetes envasados y el valor nominal de
500g. O también, el peso medio de todos los paquetes envasados podría ser
significativamente superior a 500g, en consecuencia, no estaríamos en condiciones de imprimir 500g en los paquetes.
Comentario
Comentarioadicional
adicional
La La
conclusión
estadística
a la que
arribó
está indicando
que habría
desa-un
conclusión
estadística
a lase
que
se arribó
está indicando
que un
habría
juste
en el proceso
de llenado
los paquetes
por lo cual
desajuste
en el proceso
de de
llenado
de los paquetes
porselodebería
cual seinspecdebería
cionar
el
proceso
de
envasado.
Realizar
un
ajuste,
si
fuere
necesario,
inspeccionar el proceso de envasado. Realizar un ajuste, ysidesarfuere
mar
los
paquetes
ya
hechos
para
volver
a
llenarlos
con
la
máquina
corregida.
necesario, y desarmar los paquetes ya hechos para volver a llenarlos con
Como
esta decisión
implicaComo
costos
adicionales
la fabricación
conviene, enen
la máquina
corregida.
esta
decisión en
implica
costos adicionales
primer
lugar, agrandar
la muestra
y luego,
de acuerdo
nuevos
resulta-de
la fabricación
conviene,
en primer
lugar,
agrandarcon
la los
muestra
y luego,
dosacuerdo
del test,con
tomar
la
decisión.
los nuevos resultados del test, tomar la decisión.
5. 5.
UnUn
fraccionador
de soda
envasa paquetes
utilizandoutilizando
una máquifraccionador
de cáustica
soda cáustica
envasa paquetes
una
na máquina
que tieneque
unatiene
precisión
de
σ=8
gramos.
Sobre
una
partida
lista
para
una precisión de =8 gramos. Sobre una partida lista
su distribución,
compuesta
de paquetes
cuyo valor
nominal
es de 250g,
para su distribución,
compuesta
de paquetes
cuyo
valor nominal
es de
seleccionó
una
muestra
de
45
bolsas
la
cual
arrojó
una
media
de
245
250g, seleccionó una muestra de 45 bolsas la cual arrojó una media de
gramos
con un con
desvío
10 gramos.
¿La evidencia
muestralmuestral
estaría indi245 gramos
un de
desvío
de 10 gramos.
¿La evidencia
estaría
cando
que
la
media
de
toda
la
partida
no
tendría
una
diferencia
signiindicando que la media de toda la partida no tendría una diferencia
ficativa
con el valor
impreso
en los en
envases?
significativa
con elnominal
valor nominal
impreso
los envases?
COMIENZO DE ACTIVIDAD
FIN DE ACTIVIDAD
Población
normal
o aproximadamente
normal
y σ2ydesconocido
Población
normal
o aproximadamente
normal
2 desconocido
Si Si
en en
el el
proceso
dede
llenado
dede
paquetes
nono
sese
proceso
llenado
paquetesdedegalletitas
galletitasdedemedio
mediokilo
kilo
conoce
la
precisión
de
la
máquina,
la
prueba
se
realiza
utilizando
el
desvío
de
conoce la precisión de la máquina, la prueba se realiza utilizando el
la muestra
s=la6,802g.
caso,En
se este
usa la
t dese
Student
consecuendesvío de
muestraEns=este
6,802g.
caso,
usa la yt en
de Student
y en
ciaconsecuencia
las expresiones
del
punto
crítico
y
del
estadístico
de
prueba
son
respec-de
las expresiones del punto crítico y del estadístico
tivamente:
prueba son respectivamente:
t *n1,1
*
Entonces t *n1,1 = t15;0,95
= 1,75
y
y
t=
x 0
S
n
x 0 504 500
t=
=
= 2,35
6,802
S
n
108
16
Nuevamente el valor calculado del estadístico de prueba es mayor al
Nuevamente
el valor
calculado
del estadístico
prueba
mayor al se
punto
crí, entonces
rechaza
punto crítico
y cae
en la zona
de rechazodede
la H0es
B =en500g
y sede
llega
a la siguiente
conclusión
ticoque
y cae
la zona
rechazo
de la H0, entonces
seestadística.
rechaza que µ = 500g
Conabase
en una muestra
de estadística.
16 paquetes, desconociendo la precisión
y se llega
la siguiente
conclusión
de
máquina
y con
un nivel
significación
del 5%, ellapeso
mediodede
Conlabase
en una
muestra
de 16depaquetes,
desconociendo
precisión
todos losy con
paquetes
envasados
podríadel
ser5%,
significativamente
superior
la máquina
un nivel
de significación
el peso medio de todos
los a
500g, en consecuencia, no estaríamos en condiciones de imprimir 500g
en los paquetes.
Estadistica
paquetes envasados podría ser significativamente superior a 500g, en consecuencia, no estaríamos en condiciones de imprimir 500g en los paquetes.
Pruebas de hipótesis bilaterales o a dos colas
Estas pruebas se generan en ciertos problemas donde previamente a la realización de la muestra, es decir antes de contar con la evidencia muestral, es necesario tener definida la región
de rechazo.
Son ejemplos de estas pruebas algunas rutinas de control de calidad, en las que entra en consideración que se estaría en situación crítica si X cayera tanto a la derecha como a la izquierda
de µ0. En este caso la región de rechazo está definida en dos tramos y hay dos puntos críticos.
Gráfico 3.14.
G.3.14
Zona de Aceptación de HO
Zona de Rechazo de HO
Zona de Rechazo de HO
1-α
α/2
α/2
–Z*
0
Z*
Z
G.3.14
G.3.14
Consecuentemente,
el juego de hipótesis es:
¿La población
SI
tiene distribución
Zona normal?
de Rechazo de HO
H0: µ=µ0
Usar Z para estimar µ por
Zona de H
Aceptación
A: µ≠µ0 de
SI HO
intervalo de confiannza o
¿σ conocido?
para realizar un test de
Zona
de Rechazo de HO
El desarrollo de la prueba de hipótesis es similar a la anterior, hipótesis
teniendo en cuenta que: si el
1-α
estadístico de prueba Z cayera en la zona de aceptación,
se acepta H0; si Z cayera dentro de
NO
α/2
α/2
NO
la región crítica (zona de rechazo de H0) se rechaza H0 y si estuviera muy próximo a Z* ó Usar
–Z*
0 t para estimar
Z* µ por intervalo deZconfianza
o para realizar un test de hipótesis.
Z* es conveniente agrandar la muestra.
Usar Z (en virtud del teorema central
del límite) para estimar µ por intervalo
Gráfico 3.15. Cuadro guía en inferencia estadística
media
poblacional
de confianzapara
o parala
realizar
un test
de
hipótesis.
NO
NO
G.3.14
¿σ conocido?
SI
¿n>30?
SI
Estas situaciones no se tratan en este curso
¿La población
SI
¿σ conocido?
tiene distribución
normal?
Usar Z para estimar µ por
intervalo de confiannza o
para realizar un test de
hipótesis
SI
NO
NO
Usar t para estimar µ por intervalo de confianza
o para realizar un test de hipótesis.
G.3.15
SIO
Zona de¿σRechazo
conocido?de H
NO
0,05
Usarde
Z (en
Zona deSI
Aceptación
H virtud del teorema central
¿n>30?
del límite)Opara estimar µ por intervalo
de confianza o para realizar un test de
hipótesis.
NO
0
1,64
Estas situaciones no se tratan
en este curso
Z
−0,38
109
Universidad Virtual de Quilmes
G.3.14
Prueba de hipótesis para la proporción poblacional
de Aceptación
de Hutilizado
En la muestra de 2200 Zona
familias
del ejemplo
en intervalos de conO
fianzadepara
la proporción
poblacional, las que venZona
un determinado
Rechazo
de HO
de Rechazo deprograma
HO
Zona
de TV representan el 39,6%.
1-α
Los productores delα/2programa, para decidir
α/2los costos de los espacios
comerciales cuentan con
un
raiting
histórico
del
muestral
–Z*
0
Z* 40%. La evidencia
Z
¿estaría indicando una disminución significativa de la posición del programa
en el raiting?
G.3.14
Para responder a la pregunta se realizará una PPHH con un nivel de significación del 5%.
Entonces, el par de hipótesis para esta PPHH es:
¿La población
tiene distribución
normal?
SI
¿σ
: P = 0,40
H0conocido?
HA: P < 0,40
SI
Usar Z para estimar µ por
intervalo de confiannza o
para realizar un test de
hipótesis
NO
Dado que elNO
tamaño de la muestra es grande, el estadístico proporción muesUsar t para estimar µ por intervalo de confianza
tral tiene distribución normal. El punto
crítico
eltest
estadístico
o para
realizaryun
de hipótesis. de prueba son,
¿σ conocido?
SI
Y
SI
¿n>30?
:
NO
NO
P 0
0 N
Usar Z (en virtud del teorema central
del límite)
para estimar
µ por intervalo
un
deconfianza o para realizar
test de
0 hipótesis. Estas situaciones no se tratan en este curso
respectivamente. Resultando,
Gráfico.3.16.
G.3.15
Zona de Aceptación de HO
Zona de Rechazo de HO
0,05
0
1,64
Z
−0,38
que el estadístico de prueba cae en la zona de aceptación de la H0 (ya que 1,64 < -0,38).
Conclusión: con base en una muestra de 2200 familias y con un nivel de significación de 0,05, la proporción de familias que ven ese programa de TV en
toda la población no habría cambiado significativamente.
6.
Un método de lectura veloz es efectivo en el 70% de los casos. Un nuevo
método intenta mejorar la efectividad y para comprobarlo se toma una
muestra de 205 estudiantes de los cuales 155 mejoraron su lectura. ¿Se puede
concluir que el nuevo método es significativamente mejor que el anterior?
110
Estadistica
Procedimiento para realizar una prueba de hipótesis
Cualquiera sea el parámetro que se someta a una PPHH, el procedimiento involucra los siguientes pasos:
• Formular las hipótesis a contrastar a partir de la comparación de la
evidencia muestral –o del planteo previo a la evidencia (prueba bilateral)– con el valor hipotético del parámetro.
• Elegir el nivel de significación.
• Designar el tipo de distribución de probabilidades del estimador alrededor del parámetro a probar.
• Calcular el o los puntos críticos.
• Estandarizar el estadístico muestral para producir el estadístico de
prueba.
• Observar la zona en la que se ubica el estadístico de prueba respecto del o de los puntos críticos.
• Decidir la aceptación o el rechazo de la hipótesis nula, o –si el estadístico de prueba se encuentra en un entorno muy próximo al punto
crítico– la realización de una nueva prueba seleccionando una muestra más grande.
• Concluir en el marco del problema.
7.
Al aumentar el nivel de significación en una PPHH, la probabilidad de
rechazar una hipótesis nula que en realidad fuera verdadera: ¿aumenta,
disminuye o permanece inalterada?
111
4
Elementos básicos de econometría
Objetivos
• Especificar algunos modelos de relación entre variables económicas.
• Predecir el comportamiento de determinados agentes económicos con base
en los modelos de relación elaborados.
4.1. Introducción
No hay error más común que el de suponer que, porque se hicieron prolongados y exactos cálculos matemáticos, la aplicación del resultado a algún hecho de
la naturaleza conduce a la certeza absoluta.
A.A. Whitehead
(citado por M. J. Moreney en Hechos y Estadísticas)
Un fenómeno económico cualquiera puede entenderse como el resultado de
la acción de múltiples variables que inciden sobre él en distinto grado y que
pueden utilizarse como variables potencialmente explicativas del comportamiento de dicho fenómeno.
En su forma general, el análisis econométrico consiste en estudiar un modelo que relacione la variable Y representativa del fenómeno económico con las
posibles variables explicativas X1, X2,.....,Xk. Tal modelo de relación puede
representarse matemáticamente como
Y = f (X1, X2,.....,Xk)
Donde la función f puede asumir distintas expresiones matemáticas a saber:
lineal, logarítmica, exponencial, potencial, etcétera.
Particularmente un modelo lineal de relación expresa el comportamiento
medio de la variable Y en función del conjunto de variables explicativas Xi y
tiene la siguiente expresión general,
=
Y = α + β1.X1 + β2.X2 +...+ βk.Xk
en la cual α, β1,... βk son los parámetros del modelo.
El análisis de la relación funcional entre la variable a explicar y las variables explicativas se denomina análisis de regresión.
113
Universidad Virtual de Quilmes
El modelo se completa con el análisis de correlación que consiste en estudiar el grado o fuerza de la relación existente entre ambas variables.
Los análisis de regresión y correlación lineales (apartado 4.2.) más simples
corresponden al modelo lineal bivariado en el cual sólo interviene una variable explicativa y cuya expresión matemática es:
Y = α + β.X con parámetros α y β
y es el que desarrollaremos en esta carpeta.
En el caso particular en que la variable explicativa es el tiempo, el modelo corresponde a las denominadas series cronológicas o series de tiempo
(apartado 4.3).
4.2. Análisis de regresión y de correlación
El diagrama de puntos 4.1. es la representación gráfica conjunta de las variables salario quincenal actual y edad de la población de todos los trabajadores
de la empresa cooperativa, de la cual se extrajo la muestra de 20 empleados
de la ME1 de la Unidad I. Sobre dicho gráfico puede observarse también la
recta de regresión poblacional que resume el comportamiento medio de la
nube de puntos.
G.4.1.
Gráfico 4.1.
Salario quincenal actual y edad
1600
Quincena actual
1400
1200
1000
800
600
400
200
0
18 22 26 30 34 38 42 46 50 54 58 62 66
Edad
En este problema partimos de una supuesta población conocida. Sin embargo, en la realidad de los trabajos estadísticos suelen desconocerse los datos
de la totalidad de la población y se trabaja con los datos de una muestra representativa extraída de aquella.
En el diagrama 4.2. se indentifican los datos que conforman la muestra
G.4.2.
ME1 extraídos aleatoriamente de la población, que en lo sucesivo consideraremos desconocida.
Salario quincenal actual y edad
1600
114
ncena actual
1400
1200
1000
800
600
Estadistica
G.4.2.
Gráfico 4.2.
Salario quincenal actual y edad
1600
Quincena actual
1400
1200
1000
800
600
400
200
0
18 22 26 30 34 38 42 46 50 54 58 62 66
ŷ = a + b.x
Edad
A partir de los datos de la muestra se construye la recta de regresión muesY = estimador
+ .X desconocida.
regresión
poblacional
tral ŷ =a-b.x
la cual
será el mejor
de la recta de regresión poblacional Y = α + β.X desconocida.
G.4.3.
Gráfico 4.3.
Salario quincenal actual y edad –muestra–
1600
Quincena actual
1400
1200
1000
800
600
400
ŷ =208,8 + 15,89 x
200
0
18 22 26 30 34 38 42 46 50 54 58 62 66
Edad
Esta recta representa el comportamiento medio de los datos muestrales y es
la que hace mínimo el conjunto de los desvíos entre los valores y de los datos
observados y los valores ŷ de sus correspondientes proyecciones en la recta.
Observando el gráfico 4.4. se pueden notar tales desvíos d = y –ŷ, también
G.4.4.
llamados residuos.
Salario quincenal actual y edad –muestra–
1600
cena actual
1400
1200
1000
800
a
115
Universidad Virtual de Quilmes
Gráfico 4.4.G.4.4.
Salario quincenal actual y edad –muestra–
1600
Quincena actual
1400
1200
1000
a
800
600
400
ŷ =208,8 + 15,89 x
200
0
18 22 26 30 34 38 42 46 50 54 58 62 66
Edad
En el marco del modelo lineal, un valor ŷ obtenido mediante la ecuación de
regresión representa una estimación del comportamiento de la variable Y (salario quincenal actual) para un cierto xi (una determinada edad del trabajador).
La formalización matemática del concepto de que el conjunto de los desvíos es mínimo puede hacerse a través de distintos criterios. Uno de ellos,
que visualiza mejor el problema, es el que considera que la sumatoria de los
valores absolutos de los desvíos debe ser mínima y se expresa:
El criterio de cuadrados
mínimos fue desarrollado por K. F. Gauss en Theoria
motus corporum coelestium, 1809.
Otro es el criterio de cuadrados mínimos, el cual impone como condición que
la suma de los cuadrados de los desvíos debe ser mínima, es decir:
Ecuación de la regresión lineal
A partir del criterio de los cuadrados mínimos se encuentran las expresiones de “a” y “b” con los que se construye la ecuación de regresión muestral ŷ = a-b.x que es la que mejor estima la ecuación de regresión poblacional
Y =α+β.x , cuyos parámetros son α y β.
Los valores de “a” y “b” están dados por
116
Obtención de las expresiones de a y b
Estadistica
Obtención de las expresiones de a y b
Obtención
expresiones
ay ybaby b
Obtención
delaslas
expresiones
Obtención
dedelas
expresiones
dedeade
Obtención de las expresiones de a y b
A partirdebe
de la idea
de que
debe ser míni
partirdede lalaidea
ideadedeque
que
mínima
AApartir
debe serser mínima
yy
A partir
de de
la laidea
debe
ser,mínima
mínima
y quesu expresión
A partir
ideade
de que
que
debe ser
reemplareemplazando
, resulta
reemplazando
por susuexpresión
expresión
resultaypor
reemplazando
por
, resulta
que
zando
ŷ
por
su
expresión
ŷ
=
a-b.x
,
resulta
que
reemplazando
por su expresión
, resulta que debe ser mínima por lo que sus prim
debe serser mínima
mínima por
por lolo que
quesus
susprimeras
primeras
debe
debe
ser
mínima
por
lo
que
sus
primeras
debe ser parciales
mínima por
lo quedesus
primeras
derivadas
parciales
respecto
de a yde
deaby de b deben ser cero, es decir,
parciales
respecto
derivadas
respecto
ay yde
deb bdeben
deben
serderivadas
cero,
esdecir,
decir,
derivadas
parciales
respecto
de
a
ser
cero,
es
debenparciales
ser cero,respecto
es decir,de a y de b deben ser cero, es decir,
derivadas
llegandoaadeterminarse
determinarse el siguiente
sistema
dedellegando
ecuaciones
a normales
determinarse
llegando
siguientesistema
sistemade
ecuaciones
normales el siguiente sistema de ecuaciones normales
llegando
a determinarse elelsiguiente
ecuaciones
normales
llegando a determinarse el siguiente sistema de ecuaciones normales
cuya resolución culmina con las expresiones
En la muestra de los 20 trabajadores, los estadísticos muestrales a y b son,
a = 208,8
y
b = 15,89
y la ecuación de la recta de regresión muestral resulta
La información útil que puede extraerse de la expresión de la ecuación obtenida es la relacionada con la pendiente b=+$15,89/año. Ésta indica que en
la muestra por cada año de diferencia en la edad de los trabajadores hay una
diferencia de $15,89 en el salario. Más precisamente, teniendo en cuenta el
signo de la pendiente, cuando se incrementa en un año la edad de los trabajadores, el salario quincenal actual aumenta $15,89.
Por otro lado, la recta de regresión nos permitirá estimar el salario quincenal
actual de un trabajador de la población que no estuviese en la muestra y cuya
edad fuera, por ejemplo, 48 años.
117
Universidad Virtual de Quilmes
Entonces, el salario quincenal actual estimado para un trabajador de 48 años
será aproximadamente de $971,52.
Coeficiente de correlación lineal
Para estudiar el grado o fuerza de la relación lineal que existe entre dos variables se utiliza como medida el denominado coeficiente de correlación.
El coeficiente de correlación poblacional se denomina ρ y su mejor estimador es el coeficiente de correlación muestral r que se determina como,
Se debe al biómetra inglés
Karl Pearson y es aplicable a variables cuantitativas.
donde SXY es la covarianza o varianza conjunta o variación conjunta entre las
variables aleatorias X e Y, y SX y SY son los desvíos estándar de X e Y respectivamente.
• Cuando la covarianza entre X e Y es nula el coeficiente de correlación es r = 0.
• Cuando hay covariabilidad perfecta entre X e Y y ambas varían en el mismo
sentido, el coeficiente de correlación es r = +1.
• Cuando hay covariabilidad perfecta entre X e Y y ambas varían con sentido
contrario, la correlación es r = -1.
• En cualquier otra situación, el coeficiente de correlación puede ser
-1< r <0 ó 0< r <+1.
G.4.5.
Gráfico 4.5.
G.4.5.
Y
Y
Correlación lineal directa, r entre 0 y+1
Correlación lineal directa, r entre 0 y+1
Y
Y
Correlación lineal directa, r entre 0 y+1
Correlación lineal directa, r entre 0 y+1
X
X
No hay correlación, r muy próximo a 0
Y
X
X
No hay correlación, r muy próximo a 0
Y
X
Para calcular el coeficiente de correlación del ejemplo del salario quincenal
X
actual y la edad de los trabajadores de la empresa cooperativa se puede utilizar la siguiente expresión:
118
Estadistica
resultando r = +0,557. Esto estaría indicando que ambas variables tienen un
mediano grado de correlación directa.
Coeficiente de determinación
Complementariamente a los coeficientes de regresión y de correlación, se presenta una medida denominada coeficiente de determinación r2 que indica
cuánto del comportamiento de Y es explicado o puede entenderse por el modelo de regresión.
Su expresión de cálculo es:
El coeficiente de determinación toma valores entre 0 y 1, y se interpreta como
porcentaje.
En el ejemplo que estamos desarrollando, se tiene un r2 = 0,31. Este resultado indica que en la muestra, el 31% de la variación de los salarios quincenales actuales quedan explicados por las variaciones de las edades de los
trabajadores de la empresa cooperativa.
El análisis de regresión lineal permite hallar la recta que mejor se ajusta
a los datos muestrales.
• La pendiente de la recta b, llamada también coeficiente de regresión,
suministra información sobre la variación de y por cada cambio unitario de x y su signo indica el sentido de la relación.
• La estimación del comportamiento en la población de la variable
explicada Y queda circunscripta a valores de la variable explicativa X
que no estén muy alejados de su rango.
El coeficiente de correlación r y el coeficiente de regresión b comparten la
misma información respecto de si la relación entre las variables es directa o inversa (consecuentemente los numeradores de sus respectivas expresiones son iguales).
• Si la relación entre las variables es directa, la recta será creciente, la
pendiente positiva y el coeficiente de regresión también positivo
variará entre 0 y +1.
• Si la relación entre las variables es inversa, la recta será decreciente,
la pendiente negativa y el coeficiente de regresión también negativo
variará entre -1 y 0.
El coeficiente de determinación r2 es el cuadrado del coeficiente de correlación r y se interpreta en una escala del 0 al 100.
119
Universidad Virtual de Quilmes
Los coeficientes de regresión, de correlación y el de determinación dados son las
herramientas necesarias para estudiar la relación lineal entre dos variables.
1.
Efectuar un análisis de regresión y correlación para las variables:
a. Longitud y peso de la ME4 correspondiente a una muestra de 20
piezas de plástico especiales fabricadas por una determinada empresa.
b. Antigüedad y cantidad de empleados de las pymes de la República
Argentina año 2004/2005.
4.3. Series de tiempo
En el análisis estadístico de un fenómeno económico, social, etc. en el que
cada valor de la variable en estudio esté vinculado a un momento de tiempo,
el enfoque es el de una serie cronológica o serie de tiempo.
En una serie de tiempo, la variable estadística a estudiar es dependiente
de la variable matemática tiempo, es decir que sus valores varían en el transcurso del tiempo.
Son objeto de estudio econométrico, en el marco de una serie cronológica, la
evolución en el tiempo del salario de los trabajadores de un determinado rubro,
de las ventas de los negocios de un centro comercial, de la tasa de desempleo en una región, etcétera.
Modelo matemático de una serie de tiempo
Al estudiar una variable estadística a través del tiempo, cada uno de los valores que ella asume es la resultante de los efectos producidos por distintas causas y esos efectos intervienen en el modelo como componentes del mismo.
Las componentes del modelo son: la tendencia (T) general, las distintas
variaciones cíclicas (C) alrededor de la tendencia y el ruido (R) estadístico.
El modelo matemático genérico usualmente aceptado para las series económicas es,
X=T.C.R
En las series de tiempo
económicas, una componente cíclica periódica importante es la llamada variación estacional (E), para la cual el ciclo dura
un año.
120
Las componentes cíclicas pueden presentarse como periódicas (Cp) y como
no periódicas (Cnp), entonces el modelo matemático finalmente resulta,
X = T . Cp. Cnp . R
Estadistica
donde Cp y Cnp representan, en rigor, familias de componentes con distintas
longitudes de tiempo.
De las componentes señaladas, la única que aquí veremos será la tendencia T, que se expresa como una ecuación lineal obtenida a partir del método de los cuadrados mínimos.
Ejemplo
La siguiente información se extrajo del Anuario Estadístico de la República
Argentina 2000, sección Economía, del diario Clarín y fue elaborada con base
en datos del INDEC.
G.4.6.
Gráfico
4.6.
Balanza comercial argentina en U$S
Año
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
Exportaciones
8.107
8.396
6.852
6.360
9.135
9.579
12.353
11.978
12.235
13.118
15.839
20.963
23.811
26.432
26.441
23.333
Importaciones
4.585
3.814
4.724
5.818
5.322
4.203
4.077
8.275
14.672
16.784
21.590
20.122
23.762
30.450
31.404
25.508
35
30
25
20
15
Exportaciones
10
5
Importaciones
0
84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
A partir de la tabla se puede analizar por separado la evolución en el tiempo
Millones
de u$s
de las variables
Exportaciones
e Importaciones. En el gráfico que acompaña
Año
Exportaciones
la tabla,1 los puntos
que
representan
los datos colectados a lo largo del tiem8.107
po se unen
para expresar
la cronología.
2
8.396
3
6.852
Procesaremos
la variable Exportaciones analizando su evolución a lo largo
4
6.360
del tiempo,
destacando
que dicha variable es la única variable estadística en
5
9.135
juego ya6 que el tiempo
es
una variable matemática.
9.579
7
12.353
Si bien este es un caso de estadística univariada, se puede utilizar per8
11.978
fectamente
el recurso
de ajustar por cuadrados mínimos ya empleado ante9
12.235
riormente
la recta de la regresión lineal. En una serie de tiem10 para determinar
13.118
11
15.839será la tendencia.
po, la recta
de ajuste
20.963
Para12calcular la
recta que describa la tendencia T de las exportaciones,
13
23.811
codificaremos
la
variable
14
26.431 independiente tiempo considerando: t = 1 para 1984,
15 1985 y26.441
t = 2 para
así sucesivamente.
16
23.333
121
1996
1997
1998
1999
23.811
26.432
26.441
23.333
23.762
30.450
31.404
25.508
Universidad Virtual de Quilmes
Año
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Millones de u$s
Exportaciones
8.107
8.396
6.852
6.360
9.135
9.579
12.353
11.978
12.235
13.118
15.839
20.963
23.811
26.431
26.441
23.333
Entonces
T = 2782,55 + 1400,075. t
Una predicción realizada en el marco de una
serie cronológica se denomina
pronóstico y se realiza en cualquier sentido, hacia atrás o hacia
adelante, en el tiempo.
La pendiente b=1400,075 de la tendencia indica que por cada año transcurrido (en el período tomado), las exportaciones aumentaron en promedio 1400,
075 millones de dólares por año.
Usando la recta de tendencia calculada se pueden pronosticar las exportaciones para:
a) El año 2000.
2782,55 + 1400,075 . 17 = 26.583,825 (17 es el código para el año 2000).
Se estima que en el año 2000 las exportaciones fueron del orden de los
26.583,825 millones de dólares.
b) El año 1982.
2782,55 + 1400,075 . (-1) = 1.382,475 (-1 es el código para el año 1982).
Se estima que en el año 1982 las exportaciones fueron del orden de los
1.382,475 millones de dólares.
c) El año 2020.
2782,55 + 1400,075 . 37 = 54.585,325 (37 es el código para el año 2020).
El año para el que se quiere pronosticar está muy alejado del rango
observado; no es conveniente usar el valor calculado como pronóstico
o estimación.
d) El año 2007.
2782,55 + 1400,075 . 24 = 36.384,350 (24 es el código para el año 2007).
Se estima que en el año 2000 las exportaciones fueron del orden de los
36.384,350 millones de dólares.
2.
Realizar las siguientes actividades:
Para la variable Importaciones: calcular la recta de tendencia, interpretar su pendiente y realizar pronósticos.
122
Estadistica
A partir de la información de la siguiente tabla, calcular la recta de tendencia, interpretar su pendiente y realizar pronósticos.
Año
1980
1985
1986
1987
1988
1989
1990
1993
1994
Tasa de desempleo
2,6
6,1
5,6
5,9
6,3
7,8
7,4
9,6
10,8*
Fuente: INDEC , Encuesta Permanente de Hogares.
Fuente: INDEC, Encuesta Permanente de Hogares.
123
Referencias Bibliográficas
CHOU, Ya-Lun (1992), Análisis estadístico, McGraw-Hill, México.
MAYER, P. (1986), Probabilidad y aplicaciones estadísticas, Addison Wesley,
México.
MORONEY, M. J. (1965), Hechos y estdísticas, EUDEBA, Buenos Aires.
SPIEGEL, M.R. (2002), Estadística, McGraw-Hill, México.
TORANZOS, I. F. (1997), Teoría Estadística y Aplicaciones, Macchi, Buenos
Aires.
TUKEY, J. W. (1977), Exploratory Data Analysis, Addison Wesley, U.S.A.
125
Anexo
Anexo
Anexo
Anexo
Tabla 1:
1: Percentiles
Percentiles de
de lala distribución
distribución normal
normal estándar
estándar
Tabla
Tabla 1: Percentiles de la distribución normal estándar
PP
P
ZZ
Z
p
z
z
p
-4,00
z
p
0,00003
-4,00 0,00003
-3,99 0,00003
-4,00
-3,99 0,00003
0,00003
-3,98 0,00003
-3,99
-3,98 0,00003
0,00003
-3,97 0,00004
-3,98
-3,97 0,00003
0,00004
-3,96 0,00004
-3,97
-3,96 0,00004
0,00004
-3,95 0,00004
-3,96
-3,95 0,00004
0,00004
-3,94 0,00004
-3,95
-3,94 0,00004
0,00004
-3,93 0,00004
0,00004
-3,94
-3,93
0,00004
-3,92
0,00004
-3,93
-3,92 0,00004
0,00004
-3,91 0,00004
0,00005
-3,92
-3,91 0,00005
-3,90 0,00005
0,00005
-3,91
-3,90 0,00005
-3,89 0,00005
0,00005
-3,90
-3,89 0,00005
-3,88 0,00005
0,00005
-3,89
-3,88 0,00005
-3,87 0,00005
0,00005
-3,88
-3,87 0,00005
-3,86 0,00006
-3,87
-3,86 0,00005
0,00006
-3,85 0,00006
-3,86
-3,85 0,00006
0,00006
-3,84 0,00006
-3,85
-3,84 0,00006
0,00006
-3,83 0,00006
-3,84
-3,83 0,00006
0,00006
-3,82 0,00007
-3,83
-3,82 0,00006
0,00007
-3,81 0,00007
0,00007
-3,82
-3,81
0,00007
-3,80
0,00007
-3,81
-3,80 0,00007
0,00007
-3,79
0,00008
-3,80
-3,79 0,00007
0,00008
-3,78 0,00008
0,00008
-3,79
-3,78 0,00008
-3,77 0,00008
0,00008
-3,78
-3,77 0,00008
-3,76 0,00008
0,00008
-3,77
-3,76 0,00008
-3,75 0,00008
0,00009
-3,76
-3,75 0,00009
-3,74 0,00009
0,00009
-3,75
-3,74 0,00009
-3,73 0,00010
-3,74
-3,73 0,00009
0,00010
-3,72 0,00010
-3,73
-3,72 0,00010
0,00010
-3,71 0,00010
-3,72
-3,71 0,00010
0,00010
-3,70 0,00011
-3,71
-3,70 0,00010
0,00011
-3,69 0,00011
-3,70
-3,69 0,00011
0,00011
-3,68 0,00011
0,00012
-3,69
-3,68
0,00012
-3,67 0,00012
0,00012
-3,68
-3,67 0,00012
-3,66
0,00013
-3,67
-3,66 0,00012
0,00013
-3,65 0,00013
0,00013
-3,66
-3,65 0,00013
-3,64 0,00013
0,00014
-3,65
-3,64 0,00014
-3,63 0,00014
0,00014
-3,64
-3,63 0,00014
-3,62 0,00014
0,00015
-3,63
-3,62 0,00015
-3,61 0,00015
-3,62
-3,61 0,00015
0,00015
-3,60 0,00016
-3,61
-3,60 0,00015
0,00016
-3,59 0,00017
-3,60
-3,59 0,00016
0,00017
-3,58 0,00017
-3,59
-3,58 0,00017
0,00017
-3,57 0,00018
-3,58
-3,57 0,00017
0,00018
-3,56 0,00019
-3,57
-3,56 0,00018
0,00019
-3,55 0,00019
0,00019
-3,56
-3,55
0,00019
-3,54 0,00019
0,00020
-3,55
-3,54 0,00020
-3,53
0,00021
-3,54
-3,53 0,00020
0,00021
-3,52 0,00021
0,00022
-3,53
-3,52 0,00022
-3,51 0,00022
0,00022
-3,52
-3,51 0,00022
-3,51 0,00022
z
p
z
p
-3,50
z
p
0,00023
-3,50 0,00023
-3,49 0,00024
-3,50
-3,49 0,00023
0,00024
-3,48 0,00025
-3,49
-3,48 0,00024
0,00025
-3,47 0,00026
-3,48
-3,47 0,00025
0,00026
-3,46 0,00027
-3,47
-3,46 0,00026
0,00027
-3,45 0,00028
-3,46
-3,45 0,00027
0,00028
-3,44 0,00029
-3,45
-3,44 0,00028
0,00029
-3,43 0,00029
0,00030
-3,44
-3,43
0,00030
-3,42
0,00031
-3,43
-3,42 0,00030
0,00031
-3,41 0,00031
0,00032
-3,42
-3,41 0,00032
-3,40 0,00032
0,00034
-3,41
-3,40 0,00034
-3,39 0,00034
0,00035
-3,40
-3,39 0,00035
-3,38 0,00035
0,00036
-3,39
-3,38 0,00036
-3,37 0,00036
0,00038
-3,38
-3,37 0,00038
-3,36 0,00039
-3,37
-3,36 0,00038
0,00039
-3,35 0,00040
-3,36
-3,35 0,00039
0,00040
-3,34 0,00042
-3,35
-3,34 0,00040
0,00042
-3,33 0,00043
-3,34
-3,33 0,00042
0,00043
-3,32 0,00045
-3,33
-3,32 0,00043
0,00045
-3,31 0,00045
0,00047
-3,32
-3,31
0,00047
-3,30
0,00048
-3,31
-3,30 0,00047
0,00048
-3,29
0,00050
-3,30
-3,29 0,00048
0,00050
-3,28 0,00050
0,00052
-3,29
-3,28 0,00052
-3,27 0,00052
0,00054
-3,28
-3,27 0,00054
-3,26 0,00054
0,00056
-3,27
-3,26 0,00056
-3,25 0,00056
0,00058
-3,26
-3,25 0,00058
-3,24 0,00058
0,00060
-3,25
-3,24
0,00060
-3,23
0,00062
-3,24
-3,23 0,00060
0,00062
-3,22 0,00062
0,00064
-3,23
-3,22 0,00064
-3,21 0,00064
0,00066
-3,22
-3,21 0,00066
-3,20 0,00066
0,00069
-3,21
-3,20 0,00069
-3,19 0,00069
0,00071
-3,20
-3,19 0,00071
-3,18 0,00071
0,00074
-3,19
-3,18 0,00074
-3,17 0,00076
-3,18
-3,17 0,00074
0,00076
-3,16 0,00079
-3,17
-3,16 0,00076
0,00079
-3,15 0,00082
-3,16
-3,15 0,00079
0,00082
-3,14 0,00084
-3,15
-3,14 0,00082
0,00084
-3,13 0,00087
-3,14
-3,13 0,00084
0,00087
-3,12 0,00087
0,00090
-3,13
-3,12
0,00090
-3,11 0,00090
0,00094
-3,12
-3,11 0,00094
-3,10
0,00097
-3,11
-3,10 0,00094
0,00097
-3,09
0,00100
-3,10
-3,09 0,00097
0,00100
-3,08 0,00100
0,00104
-3,09
-3,08 0,00104
-3,07 0,00104
0,00107
-3,08
-3,07 0,00107
-3,06 0,00107
0,00111
-3,07
-3,06 0,00111
-3,05 0,00114
-3,06
-3,05 0,00111
0,00114
-3,04 0,00118
-3,05
-3,04 0,00114
0,00118
-3,03 0,00122
-3,04
-3,03 0,00118
0,00122
-3,02 0,00126
-3,03
-3,02 0,00122
0,00126
-3,01 0,00131
-3,02
-3,01 0,00126
0,00131
-3,01 0,00131
z
p
z
p
-3,00
z
p
0,00135
-3,00 0,00135
-2,99 0,00139
-3,00
-2,99 0,00135
0,00139
-2,98 0,00144
-2,99
-2,98 0,00139
0,00144
-2,97 0,00149
-2,98
-2,97 0,00144
0,00149
-2,96 0,00154
-2,97
-2,96 0,00149
0,00154
-2,95 0,00159
-2,96
-2,95 0,00154
0,00159
-2,94 0,00159
0,00164
-2,95
-2,94
0,00164
-2,93
0,00169
-2,94
-2,93 0,00164
0,00169
-2,92
0,00175
-2,93
-2,92 0,00169
0,00175
-2,91 0,00175
0,00181
-2,92
-2,91 0,00181
-2,90 0,00181
0,00187
-2,91
-2,90 0,00187
-2,89 0,00187
0,00193
-2,90
-2,89 0,00193
-2,88 0,00193
0,00199
-2,89
-2,88 0,00199
-2,87 0,00199
0,00205
-2,88
-2,87 0,00205
-2,86 0,00212
-2,87
-2,86 0,00205
0,00212
-2,85 0,00219
-2,86
-2,85 0,00212
0,00219
-2,84 0,00226
-2,85
-2,84 0,00219
0,00226
-2,83 0,00233
-2,84
-2,83 0,00226
0,00233
-2,82 0,00240
-2,83
-2,82 0,00233
0,00240
-2,81 0,00240
0,00248
-2,82
-2,81
0,00248
-2,80
0,00256
-2,81
-2,80 0,00248
0,00256
-2,79
0,00264
-2,80
-2,79 0,00256
0,00264
-2,78 0,00264
0,00272
-2,79
-2,78 0,00272
-2,77 0,00272
0,00280
-2,78
-2,77 0,00280
-2,76 0,00280
0,00289
-2,77
-2,76 0,00289
-2,75 0,00289
0,00298
-2,76
-2,75 0,00298
-2,74 0,00307
-2,75
-2,74 0,00298
0,00307
-2,73 0,00317
-2,74
-2,73 0,00307
0,00317
-2,72 0,00326
-2,73
-2,72 0,00317
0,00326
-2,71 0,00336
-2,72
-2,71 0,00326
0,00336
-2,70 0,00347
-2,71
-2,70 0,00336
0,00347
-2,69 0,00357
-2,70
-2,69 0,00347
0,00357
-2,68 0,00357
0,00368
-2,69
-2,68
0,00368
-2,67 0,00368
0,00379
-2,68
-2,67 0,00379
-2,66
0,00391
-2,67
-2,66 0,00379
0,00391
-2,65 0,00391
0,00402
-2,66
-2,65 0,00402
-2,64 0,00402
0,00415
-2,65
-2,64 0,00415
-2,63 0,00415
0,00427
-2,64
-2,63 0,00427
-2,62 0,00427
0,00440
-2,63
-2,62 0,00440
-2,61 0,00453
-2,62
-2,61 0,00440
0,00453
-2,60 0,00466
-2,61
-2,60 0,00453
0,00466
-2,59 0,00480
-2,60
-2,59 0,00466
0,00480
-2,58 0,00494
-2,59
-2,58 0,00480
0,00494
-2,57 0,00508
-2,58
-2,57 0,00494
0,00508
-2,56 0,00508
0,00523
-2,57
-2,56
0,00523
-2,55 0,00523
0,00539
-2,56
-2,55 0,00539
-2,54 0,00539
0,00554
-2,55
-2,54 0,00554
-2,53
0,00570
-2,54
-2,53 0,00554
0,00570
-2,52 0,00570
0,00587
-2,53
-2,52 0,00587
-2,51 0,00587
0,00604
-2,52
-2,51 0,00604
-2,51 0,00604
z
p
z
p
-2,50
z
p
0,00621
-2,50 0,00621
-2,49 0,00639
-2,50
-2,49 0,00621
0,00639
-2,48 0,00657
-2,49
-2,48 0,00639
0,00657
-2,47 0,00676
-2,48
-2,47 0,00657
0,00676
-2,46 0,00695
-2,47
-2,46 0,00676
0,00695
-2,45 0,00714
-2,46
-2,45 0,00695
0,00714
-2,44 0,00714
0,00734
-2,45
-2,44
0,00734
-2,43
0,00755
-2,44
-2,43 0,00734
0,00755
-2,42
0,00776
-2,43
-2,42 0,00755
0,00776
-2,41 0,00776
0,00798
-2,42
-2,41 0,00798
-2,40 0,00798
0,00820
-2,41
-2,40 0,00820
-2,39 0,00820
0,00842
-2,40
-2,39 0,00842
-2,38 0,00842
0,00866
-2,39
-2,38 0,00866
-2,37 0,00866
0,00889
-2,38
-2,37 0,00889
-2,36 0,00914
-2,37
-2,36 0,00889
0,00914
-2,35 0,00939
-2,36
-2,35 0,00914
0,00939
-2,34 0,00964
-2,35
-2,34 0,00939
0,00964
-2,33 0,00990
-2,34
-2,33 0,00964
0,00990
-2,32 0,01017
-2,33
-2,32 0,00990
0,01017
-2,31 0,01017
0,01044
-2,32
-2,31
0,01044
-2,30
0,01072
-2,31
-2,30 0,01044
0,01072
-2,29
0,01101
-2,30
-2,29 0,01072
0,01101
-2,28 0,01101
0,01130
-2,29
-2,28 0,01130
-2,27 0,01130
0,01160
-2,28
-2,27 0,01160
-2,26 0,01160
0,01191
-2,27
-2,26 0,01191
-2,25 0,01191
0,01222
-2,26
-2,25 0,01222
-2,24 0,01255
-2,25
-2,24 0,01222
0,01255
-2,23 0,01287
-2,24
-2,23 0,01255
0,01287
-2,22 0,01321
-2,23
-2,22 0,01287
0,01321
-2,21 0,01355
-2,22
-2,21 0,01321
0,01355
-2,20 0,01390
-2,21
-2,20 0,01355
0,01390
-2,19 0,01426
-2,20
-2,19 0,01390
0,01426
-2,18 0,01426
0,01463
-2,19
-2,18
0,01463
-2,17 0,01463
0,01500
-2,18
-2,17 0,01500
-2,16
0,01539
-2,17
-2,16 0,01500
0,01539
-2,15 0,01539
0,01578
-2,16
-2,15 0,01578
-2,14 0,01578
0,01618
-2,15
-2,14 0,01618
-2,13 0,01618
0,01659
-2,14
-2,13 0,01659
-2,12 0,01659
0,01700
-2,13
-2,12 0,01700
-2,11 0,01743
-2,12
-2,11 0,01700
0,01743
-2,10 0,01786
-2,11
-2,10 0,01743
0,01786
-2,09 0,01831
-2,10
-2,09 0,01786
0,01831
-2,08 0,01876
-2,09
-2,08 0,01831
0,01876
-2,07 0,01923
-2,08
-2,07 0,01876
0,01923
-2,06 0,01923
0,01970
-2,07
-2,06
0,01970
-2,05 0,01970
0,02018
-2,06
-2,05 0,02018
-2,04 0,02018
0,02068
-2,05
-2,04 0,02068
-2,03
0,02118
-2,04
-2,03 0,02068
0,02118
-2,02 0,02118
0,02169
-2,03
-2,02 0,02169
-2,01 0,02169
0,02222
-2,02
-2,01 0,02222
-2,01 0,02222
z
z
-2,00
z
-2,00
-1,99
-2,00
-1,99
-1,98
-1,99
-1,98
-1,97
-1,98
-1,97
-1,96
-1,97
-1,96
-1,95
-1,96
-1,95
-1,94
-1,95
-1,94
-1,93
-1,94
-1,93
-1,92
-1,93
-1,92
-1,91
-1,92
-1,91
-1,90
-1,91
-1,90
-1,89
-1,90
-1,89
-1,88
-1,89
-1,88
-1,87
-1,88
-1,87
-1,86
-1,87
-1,86
-1,85
-1,86
-1,85
-1,84
-1,85
-1,84
-1,83
-1,84
-1,83
-1,82
-1,83
-1,82
-1,81
-1,82
-1,81
-1,80
-1,81
-1,80
-1,79
-1,80
-1,79
-1,78
-1,79
-1,78
-1,77
-1,78
-1,77
-1,76
-1,77
-1,76
-1,75
-1,76
-1,75
-1,74
-1,75
-1,74
-1,73
-1,74
-1,73
-1,72
-1,73
-1,72
-1,71
-1,72
-1,71
-1,70
-1,71
-1,70
-1,69
-1,70
-1,69
-1,68
-1,69
-1,68
-1,67
-1,68
-1,67
-1,66
-1,67
-1,66
-1,65
-1,66
-1,65
-1,64
-1,65
-1,64
-1,63
-1,64
-1,63
-1,62
-1,63
-1,62
-1,61
-1,62
-1,61
-1,60
-1,61
-1,60
-1,59
-1,60
-1,59
-1,58
-1,59
-1,58
-1,57
-1,58
-1,57
-1,56
-1,57
-1,56
-1,55
-1,56
-1,55
-1,54
-1,55
-1,54
-1,53
-1,54
-1,53
-1,52
-1,53
-1,52
-1,51
-1,52
-1,51
-1,51
p
p
p
0,02275
0,02275
0,02330
0,02275
0,02330
0,02385
0,02330
0,02385
0,02442
0,02385
0,02442
0,02500
0,02442
0,02500
0,02559
0,02500
0,02559
0,02619
0,02559
0,02619
0,02680
0,02619
0,02680
0,02743
0,02680
0,02743
0,02807
0,02743
0,02807
0,02872
0,02807
0,02872
0,02938
0,02872
0,02938
0,03005
0,02938
0,03005
0,03074
0,03005
0,03074
0,03144
0,03074
0,03144
0,03216
0,03144
0,03216
0,03288
0,03216
0,03288
0,03362
0,03288
0,03362
0,03438
0,03362
0,03438
0,03515
0,03438
0,03515
0,03593
0,03515
0,03593
0,03673
0,03593
0,03673
0,03754
0,03673
0,03754
0,03836
0,03754
0,03836
0,03920
0,03836
0,03920
0,04006
0,03920
0,04006
0,04093
0,04006
0,04093
0,04182
0,04093
0,04182
0,04272
0,04182
0,04272
0,04363
0,04272
0,04363
0,04457
0,04363
0,04457
0,04551
0,04457
0,04551
0,04648
0,04551
0,04648
0,04746
0,04648
0,04746
0,04846
0,04746
0,04846
0,04947
0,04846
0,04947
0,05050
0,04947
0,05050
0,05155
0,05050
0,05155
0,05262
0,05155
0,05262
0,05370
0,05262
0,05370
0,05480
0,05370
0,05480
0,05592
0,05480
0,05592
0,05705
0,05592
0,05705
0,05821
0,05705
0,05821
0,05938
0,05821
0,05938
0,06057
0,05938
0,06057
0,06178
0,06057
0,06178
0,06301
0,06178
0,06301
0,06426
0,06301
0,06426
0,06552
0,06426
0,06552
0,06552
z
z
-1,50
z
-1,50
-1,49
-1,50
-1,49
-1,48
-1,49
-1,48
-1,47
-1,48
-1,47
-1,46
-1,47
-1,46
-1,45
-1,46
-1,45
-1,44
-1,45
-1,44
-1,43
-1,44
-1,43
-1,42
-1,43
-1,42
-1,41
-1,42
-1,41
-1,40
-1,41
-1,40
-1,39
-1,40
-1,39
-1,38
-1,39
-1,38
-1,37
-1,38
-1,37
-1,36
-1,37
-1,36
-1,35
-1,36
-1,35
-1,34
-1,35
-1,34
-1,33
-1,34
-1,33
-1,32
-1,33
-1,32
-1,31
-1,32
-1,31
-1,30
-1,31
-1,30
-1,29
-1,30
-1,29
-1,28
-1,29
-1,28
-1,27
-1,28
-1,27
-1,26
-1,27
-1,26
-1,25
-1,26
-1,25
-1,24
-1,25
-1,24
-1,23
-1,24
-1,23
-1,22
-1,23
-1,22
-1,21
-1,22
-1,21
-1,20
-1,21
-1,20
-1,19
-1,20
-1,19
-1,18
-1,19
-1,18
-1,17
-1,18
-1,17
-1,16
-1,17
-1,16
-1,15
-1,16
-1,15
-1,14
-1,15
-1,14
-1,13
-1,14
-1,13
-1,12
-1,13
-1,12
-1,11
-1,12
-1,11
-1,10
-1,11
-1,10
-1,09
-1,10
-1,09
-1,08
-1,09
-1,08
-1,07
-1,08
-1,07
-1,06
-1,07
-1,06
-1,05
-1,06
-1,05
-1,04
-1,05
-1,04
-1,03
-1,04
-1,03
-1,02
-1,03
-1,02
-1,01
-1,02
-1,01
-1,01
p
p
p
0,06681
0,06681
0,06811
0,06681
0,06811
0,06944
0,06811
0,06944
0,07078
0,06944
0,07078
0,07215
0,07078
0,07215
0,07353
0,07215
0,07353
0,07493
0,07353
0,07493
0,07636
0,07493
0,07636
0,07780
0,07636
0,07780
0,07927
0,07780
0,07927
0,08076
0,07927
0,08076
0,08226
0,08076
0,08226
0,08379
0,08226
0,08379
0,08534
0,08379
0,08534
0,08692
0,08534
0,08692
0,08851
0,08692
0,08851
0,09012
0,08851
0,09012
0,09176
0,09012
0,09176
0,09342
0,09176
0,09342
0,09510
0,09342
0,09510
0,09680
0,09510
0,09680
0,09853
0,09680
0,09853
0,10027
0,09853
0,10027
0,10204
0,10027
0,10204
0,10383
0,10204
0,10383
0,10565
0,10383
0,10565
0,10749
0,10565
0,10749
0,10935
0,10749
0,10935
0,11123
0,10935
0,11123
0,11314
0,11123
0,11314
0,11507
0,11314
0,11507
0,11702
0,11507
0,11702
0,11900
0,11702
0,11900
0,12100
0,11900
0,12100
0,12302
0,12100
0,12302
0,12507
0,12302
0,12507
0,12714
0,12507
0,12714
0,12924
0,12714
0,12924
0,13136
0,12924
0,13136
0,13350
0,13136
0,13350
0,13567
0,13350
0,13567
0,13786
0,13567
0,13786
0,14007
0,13786
0,14007
0,14231
0,14007
0,14231
0,14457
0,14231
0,14457
0,14686
0,14457
0,14686
0,14917
0,14686
0,14917
0,15151
0,14917
0,15151
0,15386
0,15151
0,15386
0,15625
0,15386
0,15625
0,15625
z
z
-1,00
z
-1,00
-0,99
-1,00
-0,99
-0,98
-0,99
-0,98
-0,97
-0,98
-0,97
-0,96
-0,97
-0,96
-0,95
-0,96
-0,95
-0,94
-0,95
-0,94
-0,93
-0,94
-0,93
-0,92
-0,93
-0,92
-0,91
-0,92
-0,91
-0,90
-0,91
-0,90
-0,89
-0,90
-0,89
-0,88
-0,89
-0,88
-0,87
-0,88
-0,87
-0,86
-0,87
-0,86
-0,85
-0,86
-0,85
-0,84
-0,85
-0,84
-0,83
-0,84
-0,83
-0,82
-0,83
-0,82
-0,81
-0,82
-0,81
-0,80
-0,81
-0,80
-0,79
-0,80
-0,79
-0,78
-0,79
-0,78
-0,77
-0,78
-0,77
-0,76
-0,77
-0,76
-0,75
-0,76
-0,75
-0,74
-0,75
-0,74
-0,73
-0,74
-0,73
-0,72
-0,73
-0,72
-0,71
-0,72
-0,71
-0,70
-0,71
-0,70
-0,69
-0,70
-0,69
-0,68
-0,69
-0,68
-0,67
-0,68
-0,67
-0,66
-0,67
-0,66
-0,65
-0,66
-0,65
-0,64
-0,65
-0,64
-0,63
-0,64
-0,63
-0,62
-0,63
-0,62
-0,61
-0,62
-0,61
-0,60
-0,61
-0,60
-0,59
-0,60
-0,59
-0,58
-0,59
-0,58
-0,57
-0,58
-0,57
-0,56
-0,57
-0,56
-0,55
-0,56
-0,55
-0,54
-0,55
-0,54
-0,53
-0,54
-0,53
-0,52
-0,53
-0,52
-0,51
-0,52
-0,51
-0,51
p
p
p
0,15866
0,15866
0,16109
0,15866
0,16109
0,16354
0,16109
0,16354
0,16602
0,16354
0,16602
0,16853
0,16602
0,16853
0,17106
0,16853
0,17106
0,17361
0,17106
0,17361
0,17619
0,17361
0,17619
0,17879
0,17619
0,17879
0,18141
0,17879
0,18141
0,18406
0,18141
0,18406
0,18673
0,18406
0,18673
0,18943
0,18673
0,18943
0,19215
0,18943
0,19215
0,19489
0,19215
0,19489
0,19766
0,19489
0,19766
0,20045
0,19766
0,20045
0,20327
0,20045
0,20327
0,20611
0,20327
0,20611
0,20897
0,20611
0,20897
0,21186
0,20897
0,21186
0,21476
0,21186
0,21476
0,21770
0,21476
0,21770
0,22065
0,21770
0,22065
0,22363
0,22065
0,22363
0,22663
0,22363
0,22663
0,22965
0,22663
0,22965
0,23270
0,22965
0,23270
0,23576
0,23270
0,23576
0,23885
0,23576
0,23885
0,24196
0,23885
0,24196
0,24510
0,24196
0,24510
0,24825
0,24510
0,24825
0,25143
0,24825
0,25143
0,25463
0,25143
0,25463
0,25785
0,25463
0,25785
0,26109
0,25785
0,26109
0,26435
0,26109
0,26435
0,26763
0,26435
0,26763
0,27093
0,26763
0,27093
0,27425
0,27093
0,27425
0,27760
0,27425
0,27760
0,28096
0,27760
0,28096
0,28434
0,28096
0,28434
0,28774
0,28434
0,28774
0,29116
0,28774
0,29116
0,29460
0,29116
0,29460
0,29806
0,29460
0,29806
0,30153
0,29806
0,30153
0,30503
0,30153
0,30503
0,30503
z
z
-0,50
z
-0,50
-0,49
-0,50
-0,49
-0,48
-0,49
-0,48
-0,47
-0,48
-0,47
-0,46
-0,47
-0,46
-0,45
-0,46
-0,45
-0,44
-0,45
-0,44
-0,43
-0,44
-0,43
-0,42
-0,43
-0,42
-0,41
-0,42
-0,41
-0,40
-0,41
-0,40
-0,39
-0,40
-0,39
-0,38
-0,39
-0,38
-0,37
-0,38
-0,37
-0,36
-0,37
-0,36
-0,35
-0,36
-0,35
-0,34
-0,35
-0,34
-0,33
-0,34
-0,33
-0,32
-0,33
-0,32
-0,31
-0,32
-0,31
-0,30
-0,31
-0,30
-0,29
-0,30
-0,29
-0,28
-0,29
-0,28
-0,27
-0,28
-0,27
-0,26
-0,27
-0,26
-0,25
-0,26
-0,25
-0,24
-0,25
-0,24
-0,23
-0,24
-0,23
-0,22
-0,23
-0,22
-0,21
-0,22
-0,21
-0,20
-0,21
-0,20
-0,19
-0,20
-0,19
-0,18
-0,19
-0,18
-0,17
-0,18
-0,17
-0,16
-0,17
-0,16
-0,15
-0,16
-0,15
-0,14
-0,15
-0,14
-0,13
-0,14
-0,13
-0,12
-0,13
-0,12
-0,11
-0,12
-0,11
-0,10
-0,11
-0,10
-0,09
-0,10
-0,09
-0,08
-0,09
-0,08
-0,07
-0,08
-0,07
-0,06
-0,07
-0,06
-0,05
-0,06
-0,05
-0,04
-0,05
-0,04
-0,03
-0,04
-0,03
-0,02
-0,03
-0,02
-0,01
-0,02
-0,01
-0,01
p
p
p
0,30854
0,30854
0,31207
0,30854
0,31207
0,31561
0,31207
0,31561
0,31918
0,31561
0,31918
0,32276
0,31918
0,32276
0,32636
0,32276
0,32636
0,32997
0,32636
0,32997
0,33360
0,32997
0,33360
0,33724
0,33360
0,33724
0,34090
0,33724
0,34090
0,34458
0,34090
0,34458
0,34827
0,34458
0,34827
0,35197
0,34827
0,35197
0,35569
0,35197
0,35569
0,35942
0,35569
0,35942
0,36317
0,35942
0,36317
0,36693
0,36317
0,36693
0,37070
0,36693
0,37070
0,37448
0,37070
0,37448
0,37828
0,37448
0,37828
0,38209
0,37828
0,38209
0,38591
0,38209
0,38591
0,38974
0,38591
0,38974
0,39358
0,38974
0,39358
0,39743
0,39358
0,39743
0,40129
0,39743
0,40129
0,40517
0,40129
0,40517
0,40905
0,40517
0,40905
0,41294
0,40905
0,41294
0,41683
0,41294
0,41683
0,42074
0,41683
0,42074
0,42465
0,42074
0,42465
0,42858
0,42465
0,42858
0,43251
0,42858
0,43251
0,43644
0,43251
0,43644
0,44038
0,43644
0,44038
0,44433
0,44038
0,44433
0,44828
0,44433
0,44828
0,45224
0,44828
0,45224
0,45620
0,45224
0,45620
0,46017
0,45620
0,46017
0,46414
0,46017
0,46414
0,46812
0,46414
0,46812
0,47210
0,46812
0,47210
0,47608
0,47210
0,47608
0,48006
0,47608
0,48006
0,48405
0,48006
0,48405
0,48803
0,48405
0,48803
0,49202
0,48803
0,49202
0,49601
0,49202
0,49601
0,49601
127
Universidad Virtual de Quilmes
z
p
z
p
0,00
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
0,09
0,10
0,11
0,12
0,13
0,14
0,15
0,16
0,17
0,18
0,19
0,20
0,21
0,22
0,23
0,24
0,25
0,26
0,27
0,28
0,29
0,30
0,31
0,32
0,33
0,34
0,35
0,36
0,37
0,38
0,39
0,40
0,41
0,42
0,43
0,44
0,45
0,46
0,47
0,48
0,49
0,50000
0,50399
0,50798
0,51197
0,51595
0,51994
0,52392
0,52790
0,53188
0,53586
0,53983
0,54380
0,54776
0,55172
0,55567
0,55962
0,56356
0,56749
0,57142
0,57535
0,57926
0,58317
0,58706
0,59095
0,59483
0,59871
0,60257
0,60642
0,61026
0,61409
0,61791
0,62172
0,62552
0,62930
0,63307
0,63683
0,64058
0,64431
0,64803
0,65173
0,65542
0,65910
0,66276
0,66640
0,67003
0,67364
0,67724
0,68082
0,68439
0,68793
0,50
0,51
0,52
0,53
0,54
0,55
0,56
0,57
0,58
0,59
0,60
0,61
0,62
0,63
0,64
0,65
0,66
0,67
0,68
0,69
0,70
0,71
0,72
0,73
0,74
0,75
0,76
0,77
0,78
0,79
0,80
0,81
0,82
0,83
0,84
0,85
0,86
0,87
0,88
0,89
0,90
0,91
0,92
0,93
0,94
0,95
0,96
0,97
0,98
0,99
0,69146
0,69497
0,69847
0,70194
0,70540
0,70884
0,71226
0,71566
0,71904
0,72240
0,72575
0,72907
0,73237
0,73565
0,73891
0,74215
0,74537
0,74857
0,75175
0,75490
0,75804
0,76115
0,76424
0,76730
0,77035
0,77337
0,77637
0,77935
0,78230
0,78524
0,78814
0,79103
0,79389
0,79673
0,79955
0,80234
0,80511
0,80785
0,81057
0,81327
0,81594
0,81859
0,82121
0,82381
0,82639
0,82894
0,83147
0,83398
0,83646
0,83891
z
1,00
1,01
1,02
1,03
1,04
1,05
1,06
1,07
1,08
1,09
1,10
1,11
1,12
1,13
1,14
1,15
1,16
1,17
1,18
1,19
1,20
1,21
1,22
1,23
1,24
1,25
1,26
1,27
1,28
1,29
1,30
1,31
1,32
1,33
1,34
1,35
1,36
1,37
1,38
1,39
1,40
1,41
1,42
1,43
1,44
1,45
1,46
1,47
1,48
1,49
p
0,84134
0,84375
0,84614
0,84849
0,85083
0,85314
0,85543
0,85769
0,85993
0,86214
0,86433
0,86650
0,86864
0,87076
0,87286
0,87493
0,87698
0,87900
0,88100
0,88298
0,88493
0,88686
0,88877
0,89065
0,89251
0,89435
0,89617
0,89796
0,89973
0,90147
0,90320
0,90490
0,90658
0,90824
0,90988
0,91149
0,91308
0,91466
0,91621
0,91774
0,91924
0,92073
0,92220
0,92364
0,92507
0,92647
0,92785
0,92922
0,93056
0,93189
z
1,50
1,51
1,52
1,53
1,54
1,55
1,56
1,57
1,58
1,59
1,60
1,61
1,62
1,63
1,64
1,65
1,66
1,67
1,68
1,69
1,70
1,71
1,72
1,73
1,74
1,75
1,76
1,77
1,78
1,79
1,80
1,81
1,82
1,83
1,84
1,85
1,86
1,87
1,88
1,89
1,90
1,91
1,92
1,93
1,94
1,95
1,96
1,97
1,98
1,99
p
0,93319
0,93448
0,93574
0,93699
0,93822
0,93943
0,94062
0,94179
0,94295
0,94408
0,94520
0,94630
0,94738
0,94845
0,94950
0,95053
0,95154
0,95254
0,95352
0,95449
0,95543
0,95637
0,95728
0,95818
0,95907
0,95994
0,96080
0,96164
0,96246
0,96327
0,96407
0,96485
0,96562
0,96638
0,96712
0,96784
0,96856
0,96926
0,96995
0,97062
0,97128
0,97193
0,97257
0,97320
0,97381
0,97441
0,97500
0,97558
0,97615
0,97670
z
2,00
2,01
2,02
2,03
2,04
2,05
2,06
2,07
2,08
2,09
2,10
2,11
2,12
2,13
2,14
2,15
2,16
2,17
2,18
2,19
2,20
2,21
2,22
2,23
2,24
2,25
2,26
2,27
2,28
2,29
2,30
2,31
2,32
2,33
2,34
2,35
2,36
2,37
2,38
2,39
2,40
2,41
2,42
2,43
2,44
2,45
2,46
2,47
2,48
2,49
p
0,97725
0,97778
0,97831
0,97882
0,97932
0,97982
0,98030
0,98077
0,98124
0,98169
0,98214
0,98257
0,98300
0,98341
0,98382
0,98422
0,98461
0,98500
0,98537
0,98574
0,98610
0,98645
0,98679
0,98713
0,98745
0,98778
0,98809
0,98840
0,98870
0,98899
0,98928
0,98956
0,98983
0,99010
0,99036
0,99061
0,99086
0,99111
0,99134
0,99158
0,99180
0,99202
0,99224
0,99245
0,99266
0,99286
0,99305
0,99324
0,99343
0,99361
z
2,50
2,51
2,52
2,53
2,54
2,55
2,56
2,57
2,58
2,59
2,60
2,61
2,62
2,63
2,64
2,65
2,66
2,67
2,68
2,69
2,70
2,71
2,72
2,73
2,74
2,75
2,76
2,77
2,78
2,79
2,80
2,81
2,82
2,83
2,84
2,85
2,86
2,87
2,88
2,89
2,90
2,91
2,92
2,93
2,94
2,95
2,96
2,97
2,98
2,99
p
0,99379
0,99396
0,99413
0,99430
0,99446
0,99461
0,99477
0,99492
0,99506
0,99520
0,99534
0,99547
0,99560
0,99573
0,99585
0,99598
0,99609
0,99621
0,99632
0,99643
0,99653
0,99664
0,99674
0,99683
0,99693
0,99702
0,99711
0,99720
0,99728
0,99736
0,99744
0,99752
0,99760
0,99767
0,99774
0,99781
0,99788
0,99795
0,99801
0,99807
0,99813
0,99819
0,99825
0,99831
0,99836
0,99841
0,99846
0,99851
0,99856
0,99861
z
3,00
3,01
3,02
3,03
3,04
3,05
3,06
3,07
3,08
3,09
3,10
3,11
3,12
3,13
3,14
3,15
3,16
3,17
3,18
3,19
3,20
3,21
3,22
3,23
3,24
3,25
3,26
3,27
3,28
3,29
3,30
3,31
3,32
3,33
3,34
3,35
3,36
3,37
3,38
3,39
3,40
3,41
3,42
3,43
3,44
3,45
3,46
3,47
3,48
3,49
p
0,99865
0,99869
0,99874
0,99878
0,99882
0,99886
0,99889
0,99893
0,99896
0,99900
0,99903
0,99906
0,99910
0,99913
0,99916
0,99918
0,99921
0,99924
0,99926
0,99929
0,99931
0,99934
0,99936
0,99938
0,99940
0,99942
0,99944
0,99946
0,99948
0,99950
0,99952
0,99953
0,99955
0,99957
0,99958
0,99960
0,99961
0,99962
0,99964
0,99965
0,99966
0,99968
0,99969
0,99970
0,99971
0,99972
0,99973
0,99974
0,99975
0,99976
Tabla 2: Percentiles de la distribución t de Student .
α
tα
128 gl
t0,001 t0,005 t0,01 t0,02 t0,025 t0,05 t0,10 t0,90 t0,975 t0,98 t0,99 t0,995 t0,999
1 -318,29 -63,66 -31,82 -15,89 -12,71 -6,31 -3,08 3,08
2 -22,33 -9,92 -6,96 -4,85 -4,30 -2,92 -1,89 1,89
12,71 15,89 31,82 63,66 318,29
4,30 4,85 6,96 9,92 22,33
z
3,50
3,51
3,52
3,53
3,54
3,55
3,56
3,57
3,58
3,59
3,60
3,61
3,62
3,63
3,64
3,65
3,66
3,67
3,68
3,69
3,70
3,71
3,72
3,73
3,74
3,75
3,76
3,77
3,78
3,79
3,80
3,81
3,82
3,83
3,84
3,85
3,86
3,87
3,88
3,89
3,90
3,91
3,92
3,93
3,94
3,95
3,96
3,97
3,98
3,99
p
0,99977
0,99978
0,99978
0,99979
0,99980
0,99981
0,99981
0,99982
0,99983
0,99983
0,99984
0,99985
0,99985
0,99986
0,99986
0,99987
0,99987
0,99988
0,99988
0,99989
0,99989
0,99990
0,99990
0,99990
0,99991
0,99991
0,99992
0,99992
0,99992
0,99992
0,99993
0,99993
0,99993
0,99994
0,99994
0,99994
0,99994
0,99995
0,99995
0,99995
0,99995
0,99995
0,99996
0,99996
0,99996
0,99996
0,99996
0,99996
0,99997
0,99997
α
Estadistica
tα
gl
t0,001 t0,005 t0,01 t0,02 t0,025 t0,05 t0,10 t0,90 t0,975 t0,98 t0,99 t0,995 t0,999
1 -318,29 -63,66 -31,82 -15,89 -12,71 -6,31 -3,08 3,08
2 -22,33 -9,92 -6,96 -4,85 -4,30 -2,92 -1,89 1,89
3 -10,21 -5,84 -4,54 -3,48 -3,18 -2,35 -1,64 1,64
4
-7,17 -4,60 -3,75 -3,00 -2,78 -2,13 -1,53 1,53
5
-5,89 -4,03 -3,36 -2,76 -2,57 -2,02 -1,48 1,48
6
-5,21 -3,71 -3,14 -2,61 -2,45 -1,94 -1,44 1,44
7
-4,79 -3,50 -3,00 -2,52 -2,36 -1,89 -1,41 1,41
8
-4,50 -3,36 -2,90 -2,45 -2,31 -1,86 -1,40 1,40
9
-4,30 -3,25 -2,82 -2,40 -2,26 -1,83 -1,38 1,38
10 -4,14 -3,17 -2,76 -2,36 -2,23 -1,81 -1,37 1,37
11 -4,02 -3,11 -2,72 -2,33 -2,20 -1,80 -1,36 1,36
12 -3,93 -3,05 -2,68 -2,30 -2,18 -1,78 -1,36 1,36
13 -3,85 -3,01 -2,65 -2,28 -2,16 -1,77 -1,35 1,35
14 -3,79 -2,98 -2,62 -2,26 -2,14 -1,76 -1,35 1,35
15 -3,73 -2,95 -2,60 -2,25 -2,13 -1,75 -1,34 1,34
16 -3,69 -2,92 -2,58 -2,24 -2,12 -1,75 -1,34 1,34
17 -3,65 -2,90 -2,57 -2,22 -2,11 -1,74 -1,33 1,33
18 -3,61 -2,88 -2,55 -2,21 -2,10 -1,73 -1,33 1,33
19 -3,58 -2,86 -2,54 -2,20 -2,09 -1,73 -1,33 1,33
20 -3,55 -2,85 -2,53 -2,20 -2,09 -1,72 -1,33 1,33
21 -3,53 -2,83 -2,52 -2,19 -2,08 -1,72 -1,32 1,32
22 -3,50 -2,82 -2,51 -2,18 -2,07 -1,72 -1,32 1,32
23 -3,48 -2,81 -2,50 -2,18 -2,07 -1,71 -1,32 1,32
24 -3,47 -2,80 -2,49 -2,17 -2,06 -1,71 -1,32 1,32
25 -3,45 -2,79 -2,49 -2,17 -2,06 -1,71 -1,32 1,32
26 -3,43 -2,78 -2,48 -2,16 -2,06 -1,71 -1,31 1,31
27 -3,42 -2,77 -2,47 -2,16 -2,05 -1,70 -1,31 1,31
28 -3,41 -2,76 -2,47 -2,15 -2,05 -1,70 -1,31 1,31
29 -3,40 -2,76 -2,46 -2,15 -2,05 -1,70 -1,31 1,31
30 -3,39 -2,75 -2,46 -2,15 -2,04 -1,70 -1,31 1,31
31 -3,37 -2,74 -2,45 -2,14 -2,04 -1,70 -1,31 1,31
32 -3,37 -2,74 -2,45 -2,14 -2,04 -1,69 -1,31 1,31
33 -3,36 -2,73 -2,44 -2,14 -2,03 -1,69 -1,31 1,31
34 -3,35 -2,73 -2,44 -2,14 -2,03 -1,69 -1,31 1,31
35 -3,34 -2,72 -2,44 -2,13 -2,03 -1,69 -1,31 1,31
36 -3,33 -2,72 -2,43 -2,13 -2,03 -1,69 -1,31 1,31
38 -3,32 -2,71 -2,43 -2,13 -2,02 -1,69 -1,30 1,30
40 -3,31 -2,70 -2,42 -2,12 -2,02 -1,68 -1,30 1,30
42 -3,30 -2,70 -2,42 -2,12 -2,02 -1,68 -1,30 1,30
44 -3,29 -2,69 -2,41 -2,12 -2,02 -1,68 -1,30 1,30
46 -3,28 -2,69 -2,41 -2,11 -2,01 -1,68 -1,30 1,30
48 -3,27 -2,68 -2,41 -2,11 -2,01 -1,68 -1,30 1,30
50 -3,26 -2,68 -2,40 -2,11 -2,01 -1,68 -1,30 1,30
55 -3,25 -2,67 -2,40 -2,10 -2,00 -1,67 -1,30 1,30
60 -3,23 -2,66 -2,39 -2,10 -2,00 -1,67 -1,30 1,30
65 -3,22 -2,65 -2,39 -2,10 -2,00 -1,67 -1,29 1,29
70 -3,21 -2,65 -2,38 -2,09 -1,99 -1,67 -1,29 1,29
80 -3,20 -2,64 -2,37 -2,09 -1,99 -1,66 -1,29 1,29
90 -3,18 -2,63 -2,37 -2,08 -1,99 -1,66 -1,29 1,29
100 -3,17 -2,63 -2,36 -2,08 -1,98 -1,66 -1,29 1,29
110 -3,17 -2,62 -2,36 -2,08 -1,98 -1,66 -1,29 1,29
120 -3,16 -2,62 -2,36 -2,08 -1,98 -1,66 -1,29 1,29
150 -3,15 -2,61 -2,35 -2,07 -1,98 -1,66 -1,29 1,29
200 -3,13 -2,60 -2,35 -2,07 -1,97 -1,65 -1,29 1,29
250 -3,12 -2,60 -2,34 -2,06 -1,97 -1,65 -1,28 1,28
350 -3,11 -2,59 -2,34 -2,06 -1,97 -1,65 -1,28 1,28
500 -3,11 -2,59 -2,33 -2,06 -1,96 -1,65 -1,28 1,28
3000 -3,09 -2,58 -2,33 -2,05 -1,96 -1,65 -1,28 1,28
12,71
4,30
3,18
2,78
2,57
2,45
2,36
2,31
2,26
2,23
2,20
2,18
2,16
2,14
2,13
2,12
2,11
2,10
2,09
2,09
2,08
2,07
2,07
2,06
2,06
2,06
2,05
2,05
2,05
2,04
2,04
2,04
2,03
2,03
2,03
2,03
2,02
2,02
2,02
2,02
2,01
2,01
2,01
2,00
2,00
2,00
1,99
1,99
1,99
1,98
1,98
1,98
1,98
1,97
1,97
1,97
1,96
1,96
15,89
4,85
3,48
3,00
2,76
2,61
2,52
2,45
2,40
2,36
2,33
2,30
2,28
2,26
2,25
2,24
2,22
2,21
2,20
2,20
2,19
2,18
2,18
2,17
2,17
2,16
2,16
2,15
2,15
2,15
2,14
2,14
2,14
2,14
2,13
2,13
2,13
2,12
2,12
2,12
2,11
2,11
2,11
2,10
2,10
2,10
2,09
2,09
2,08
2,08
2,08
2,08
2,07
2,07
2,06
2,06
2,06
2,05
31,82 63,66 318,29
6,96 9,92 22,33
4,54 5,84 10,21
3,75 4,60 7,17
3,36 4,03 5,89
3,14 3,71 5,21
3,00 3,50 4,79
2,90 3,36 4,50
2,82 3,25 4,30
2,76 3,17 4,14
2,72 3,11 4,02
2,68 3,05 3,93
2,65 3,01 3,85
2,62 2,98 3,79
2,60 2,95 3,73
2,58 2,92 3,69
2,57 2,90 3,65
2,55 2,88 3,61
2,54 2,86 3,58
2,53 2,85 3,55
2,52 2,83 3,53
2,51 2,82 3,50
2,50 2,81 3,48
2,49 2,80 3,47
2,49 2,79 3,45
2,48 2,78 3,43
2,47 2,77 3,42
2,47 2,76 3,41
2,46 2,76 3,40
2,46 2,75 3,39
2,45 2,74 3,37
2,45 2,74 3,37
2,44 2,73 3,36
2,44 2,73 3,35
2,44 2,72 3,34
2,43 2,72 3,33
2,43 2,71 3,32
2,42 2,70 3,31
2,42 2,70 3,30
2,41 2,69 3,29
2,41 2,69 3,28
2,41 2,68 3,27
2,40 2,68 3,26
2,40 2,67 3,25
2,39 2,66 3,23
2,39 2,65 3,22
2,38 2,65 3,21
2,37 2,64 3,20
2,37 2,63 3,18
2,36 2,63 3,17
2,36 2,62 3,17
2,36 2,62 3,16
2,35 2,61 3,15
2,35 2,60 3,13
2,34 2,60 3,12
2,34 2,59 3,11
2,33 2,59 3,11
2,33 2,58 3,09
129
Esta edición de 500 ejemplares
se terminó de imprimir en el mes de septiembre de 2009
en el Centro de impresiones de la Universidad Nacional de Quilmes,
Roque Sáenz Peña 352, Bernal, Argentina.