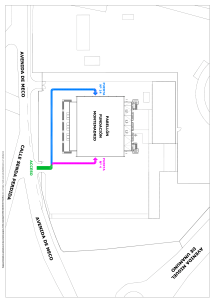
USO DE LIBRERÍA PANDAS >>> Parte 1: Ciencia de Datos y Caracterización Data Frames Recordemos Revisamos todas las herramientas básicas en Python para el procesamiento de datos de forma masiva. Son muy poderosas y tienen un gran potencial. Reflexionemos No obstante, siempre quedan las dudas. ¿Hasta dónde podemos llegar con Python? ¿Cuál es el estado del arte? La disciplina que está a la vanguardia hoy en día en cuanto a procesamiento de datos es la ciencia de datos. >>> Ciencia de Datos ¿Qué es la ciencia de datos? Revisemos algunas definiciones: Es la disciplina que permite encontrar patrones predecibles en sets de datos estructurados, y no estructurados. (Dhar, 2013). Es un concepto que busca unificar estadísticas, análisis de datos, inteligencia artificial y cualquier otro método similar para poder entender y analizar fenómenos con los datos. (Hayashi, 1996). ¿Qué es la ciencia de datos? Ejemplo: La astronomía Con la tecnología que existe hoy en día y los instrumentos de observación que se están creando actualmente, diariamente se genera un exabyte de datos. Para ejemplificar, es el doble de la información que se genera en todo internet en un día. ¿Qué es la ciencia de datos? Científico de datos Lo importante son las herramientas que los científicos ocupan para poder trabajar. Python es un buen ejemplo, ocupan este lenguaje para poder hacer análisis e identificar patrones. Además, generan paquetes (como el paquete random, que vimos anteriormente), para facilitar esta labor. A estos paquetes también podemos llamarlos librerías. Librería pandas Es una librería de código abierto, que provee estructuras de datos de alto rendimiento y fáciles de usar. Además, provee herramientas para el análisis de datos en Python. >>> Caracterización Data Frames ¿Cómo usar pandas? Para comenzar a usar pandas, debemos tener claro dos conceptos claves: series Data frames Estructura de Datos La serie es la estructura de datos básica en la librería pandas. Es una lista de datos con un largo fijo, aquí no podemos agregar o quitar elementos, solo modificarlos. Además, los datos de una serie son del mismo tipo. Por ejemplo: “Roberto” “Andrea” “Felipe” “Pamela” “Daniela” “Vicente” La serie tiene 6 elementos de tipo texto. Específicamente, son los nombres de distintas personas. Data frames Son la estructura más usada en la librería pandas y podemos imaginarlos como una matriz de datos, donde podemos agregar filas y columnas a nuestro antojo. - - - - - - - - - - - - - - - - - - - - - - - - Cada columna, representa datos para una variable específica Las columnas de un data frame son series, y por eso es importante manejarlas. Data frames Son la estructura más usada en la librería pandas y podemos imaginarlos como una matriz de datos, donde podemos agregar filas y columnas a nuestro antojo. - - - - - - - - - - - - - - - - - - - - - - - - Cada fila corresponde a medidas o valores de cada instancia y podrá tener valores de distintos tipo Data frames Veamos un ejemplo de un data frame, con las calificaciones de ciertas personas en una asignatura de una universidad: Nombre Edad Género Calificación Felipe 24 Masculino 4,5 Andrea 21 Femenino 7,0 Tomás 22 Masculino 6,1 Roberto 20 Masculino 5,5 Data frames Analicemos el ejemplo anterior: Nombre Edad Género Calificación Felipe 24 Masculino 4,5 Andrea 21 Femenino 7,0 Tomás 22 Masculino 6,1 Roberto 20 Masculino 5,5 La columna “Nombre” es de tipo texto (o string). Data frames Analicemos el ejemplo anterior: Nombre Edad Género Calificación Felipe 24 Masculino 4,5 Andrea 21 Femenino 7,0 Tomás 22 Masculino 6,1 Roberto 20 Masculino 5,5 La columna “Edad” es de tipo entero (o int). Data frames Analicemos el ejemplo anterior: Nombre Edad Género Calificación Felipe 24 Masculino 4,5 Andrea 21 Femenino 7,0 Tomás 22 Masculino 6,1 Roberto 20 Masculino 5,5 La columna “Género” es de tipo texto (o string). Data frames Analicemos el ejemplo anterior: Nombre Edad Género Calificación Felipe 24 Masculino 4,5 Andrea 21 Femenino 7,0 Tomás 22 Masculino 6,1 Roberto 20 Masculino 5,5 La columna “Calificación” es de tipo decimal (o float). Data frames Nombre Edad Género Calificación Felipe 24 Masculino 4,5 Andrea 21 Femenino 7,0 Tomás 22 Masculino 6,1 Roberto 20 Masculino 5,5 Para resolver el ejercicio, es necesario ocupar Python IDLE Data frames La mayor ventaja de la librería pandas es poder procesar grandes volúmenes de datos. Definir Data frames de forma manual nunca nos permitirá manejar Data frames con muchas líneas. Por lo tanto, y como vimos anteriormente, la mejor forma de cargar información es mediante archivos. Importante Al cargar un archivo CSV, es posible que te encuentres con varios errores. Como un comentario general, es difícil poder anticiparnos a qué errores te saldrán, así que recomendamos fuertemente que seas autónomo al momento que aparezcan errores. Esto significa copiar el error que te sale en la consola, y buscar en internet alguna solución. Esto además te permitirá poder aprender más de esta grandiosa librería por tu cuenta. error Algunos errores comunes Puedes observar que el segundo parámetro usado al crear el Data frame es: encoding="latin-1" De forma general, si tus datos tienen algún tipo de carácter que se use solo en el español (por ejemplo, tildes, ñ o ¡), debes ocupar este parámetro para evitar errores. Algunos errores comunes Fíjate que el separador de columnas dentro del archivo CSV sea “;” ó “,”. El tercer parámetro utilizado: sep=";" Nos asegura que la librería pandas sepa cómo separar las columnas en cada fila. Fíjate que el separador decimal para números decimales sea un punto. Verifica que el archivo que estás cargando esté en la misma carpeta que el archivo tipo Python. USO DE LIBRERÍA PANDAS >>> Parte 2: Operaciones básicas con Data Frames Data frames Sabemos cómo crear un Data frame. Ahora veremos sus características básicas y cómo poder trabajar con él. Esto es muy importante, antes de ver algunas herramientas más avanzadas de la librería pandas. Data frames También podemos filtrar nuestros datos según los valores de ciertas columnas. De forma general: df.loc[df['Nombre columna'] (operación lógica)] A continuación, veamos algunos ejemplos para que quede más claro. Data frames df.loc[df['Nombre columna'] (operación lógica)] CÓDIGO RESULTADO import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") print(df.loc[9999]["FECHA_NAC"]) ID RUT ... MONTO PUNTAJE_CREDITICIO 1 21.930.631-4 ... 8153651 2.37 12 13.674.785-2 ... 469341 2.81 19 15.452.563-10 ... 1836607 0.33 21 7.699.998-8 ... 5766978 7.70 Aquí filtramos solo a los clientes que son de tipo A. Data frames df.loc[df['Nombre columna'] (operación lógica)] CÓDIGO RESULTADO ID RUT ... MONTO PUNTAJE_CREDITICIO import pandas as pd 442 13.393.426-9 ... 54358 3.35 df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") 526 7.345.656-5 ... 42298 3.70 537 20.081.815-9 ... 72235 2.89 573 17.796.256-1 ... 27274 7.90 print(df.loc[df['MONTO'] < 100000]) Aquí filtramos solo a los clientes que tienen menos de $100.000 en su cuenta corriente (lo que se ve reflejado en la columna Monto). Data frames df.loc[df['Nombre columna'] (operación lógica)] CÓDIGO RESULTADO ID RUT ... MONTO PUNTAJE_CREDITICIO import pandas as pd 2 9.655.791-3 ... 9509104 9.91 df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") 8 20.749.832-5 ... 4441737 8.18 11 7.271.618-0 ... 5832527 8.08 15 6.355.671-0 ... 668186 9.84 print(df.loc[df['PUNTAJE_CREDITICIO'] >= 8.0]) Aquí filtramos solo a los clientes que tienen un score crediticio mayor o igual a 8.0. Data frames Observemos que no solo nos sirve para poder filtrar columnas según cierta información, sino que también para crear tablas filtradas. Podemos asignar la tabla filtrada a una variable para luego seguir trabajando con ella: CÓDIGO import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin-1",sep=";") df_final = df.loc[df['PUNTAJE_CREDITICIO'] >= 8.0] Data frames Crear columnas: También podemos agregar nuevas columnas a los Data frames. Digamos que queremos agregar la nacionalidad de los clientes a nuestra base de datos. En este caso, son todos chilenos. CÓDIGO import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") df["NACIONALIDAD"] = "CHILE" print(df) RESULTADO ID RUT ... PUNTAJE_CREDITICIO NACIONALIDAD 0 21.930.631-4 ... 1.17 CHILE 1 11.269.366-8 ... 2.37 CHILE 2 9.655.791-3 ... 9.91 CHILE 3 16.644.711-4 ... 2.86 CHILE Data frames Las columnas creadas también pueden ser el resultado de un cálculo. En este caso, crearemos una nueva columna con el monto en dólares en la cuenta corriente de cada cliente (que estaba en la columna original “Monto”). CÓDIGO import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") df["MONTO_DOLAR"] = df["MONTO"]/700 print(df) RESULTADO ID RUT ... PUNTAJE_CREDITICIO MONTO_DOLAR 0 21.930.631-4 ... 1.17 7725.641429 1 11.269.366-8 ... 2.37 11648.072857 2 9.655.791-3 ... 9.91 13584.434286 3 16.644.711-4 ... 2.86 8665.054286 Data frames Editar columnas: En este caso, le agregaremos un punto base a todos los puntajes crediticios. Lo importante es que podemos modificar el contenido de una columna en base al contenido original. Por ejemplo, aquí le sumamos 1. De forma general, lo podemos caracterizar de la siguiente manera: df['Nombre columna'] = df['Nombre columna'](operación matemática) Data frames CÓDIGO RESULTADO ID RUT ... MONTO PUNTAJE_CREDITICIO 0 21.930.631-4 ... 5407949 2.17 1 11.269.366-8 ... 8153651 3.37 df["PUNTAJE_CREDITICIO"] = df["PUNTAJE_CREDITICIO"]+1 2 9.655.791-3 ... 9509104 10.91 print(df) 3 16.644.711-4 ... 6065538 3.86 import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") Data frames RESULTADO Eliminar columnas: También podemos eliminar columnas a los Data frames. ID RUT ... PUNTAJE_CREDITICIO NACIONALIDAD 0 21.930.631-4 ... 1.17 CHILE 1 11.269.366-8 ... 2.37 CHILE 2 9.655.791-3 ... 9.91 CHILE 3 16.644.711-4 ... 2.86 CHILE CÓDIGO import pandas as pd RESULTADO df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") [100000 rows x 8 columns] ID RUT ... MONTO PUNTAJE_CREDITICIO 0 21.930.631-4 ... 5407949 1.17 print(df) 1 11.269.366-8 ... 8153651 2.37 del df["NACIONALIDAD"] 2 9.655.791-3 ... 9509104 9.91 3 16.644.711-4 ... 6065538 2.86 df["NACIONALIDAD"] = "CHILE" print(df) Data frames Para agregar o quitar filas, es mucho más fácil trabajar en el archivo CSV mismo (se puede trabajar en cualquier editor de texto plano, como Bloc de Notas en Windows). Simplemente se pueden borrar algunas o agregar al archivo mismo. - - - - - - - - - - - - - - - - Data frames En el caso de requerir unir dos Data frames distintos (con las mismas columnas, porque sino Python nos arrojará un error), lo podemos hacer con el siguiente código: CÓDIGO import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin-1",sep=";") df2 = pd.read_csv("clientes2.csv",encoding="latin-1",sep=";") df.append(df2) Estadísticos descriptivos Cuenta Promedio Desviación Estándar Mínimo Cuartiles Máximo Estadísticos descriptivos Podemos calcular rápidamente los estadísticos descriptivos de las variables numéricas de nuestra base de datos. En nuestro ejemplo, estas son Monto y Puntaje crediticio. CÓDIGO RESULTADO ID MONTO PUNTAJE_CREDITICIO 100000.000000 1.000000e+05 100000.000000 import pandas as pd count df = pd.read_csv("clientes.csv",encoding="latin1",sep=";") mean 49999.500000 5.001736e+06 5.001448 std 28867.657797 2.881127e+06 2.886175 min 0.000000 1.005600e+04 0.000000 print(df.describe()) En este ejemplo también calcula los estadísticos de la variable ID ya que también es numérica. Escribir archivo CSV Finalmente, podemos guardar lo que hicimos escribiendo el data frame en un nuevo archivo CSV. De forma general, lo podemos hacer de la siguiente manera: df.to_csv("(nombre archivo csv).csv",index=false) Por ejemplo CÓDIGO import pandas as pd df = pd.read_csv("clientes.csv",encoding="latin-1",sep=";") En este ejemplo guardamos nuestro nuevo Data frame con la columna df["NACIONALIDAD"] = "CHILE" “Nacionalidad” que no print(df) existía previamente. df.to_csv("clientes_mod.csv", index=False) Cierre El mayor potencial que tiene Python es la capacidad de trabajar con archivos de un tamaño considerable. Probablemente muchas cosas de las que vimos pueden hacerse con Excel, u otros softwares. No obstante, la mayoría de éstos no funciona bien con grandes volúmenes de datos. Cierre Con lo revisado, puedes editar datos de forma masiva y guardarlos en archivos. La librería pandas permite visualizar y sacar estadísticas básicas de una forma rápida, además de poder agregar, editar y eliminar columnas a tu antojo. Todo esto con volúmenes de datos que no serían bien soportados con otros softwares. Cierre Te invito a seguir explorando Python y las muchas funcionalidades de la librería pandas. En niveles más avanzados, esta permite identificar patrones y generar predicciones en bases a sets de datos, que son las necesidades que todas las empresas el día de hoy necesitan cubrir. Dhar, V. (2013). Data science and prediction. Communications of the ACM, 56(12), 64-73. Hayashi C. (1998) What is Data Science ? Fundamental Bibliografía Concepts and a Heuristic Example. In: Hayashi C., Yajima K., Bock HH., Ohsumi N., Tanaka Y., Baba Y. (eds) Data Science, Classification, and Related Methods. Studies in Classification, Data Analysis, and Knowledge Organization. Springer, Tokyo. >>> Cierre Has finalizado la revisión de los contenidos. A continuación, te invitamos a realizar las actividades y a revisar los recursos del módulo que encontrarás en plataforma.