junio-04
Anuncio

Universidad del País Vasco
Facultad de Informática
Dpto. de Arquitectura y Tecnología
de Computadores
Arquitecturas Paralelas
Examen de Junio
16 – Junio – 2004
Apellidos:
Grupo:
Nombre:
Firma:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
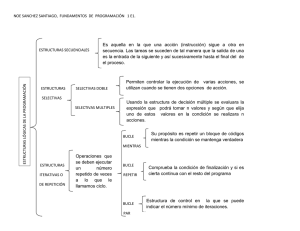
Ejercicio B
El examen consta de dos partes, A y B. En la primera se trabajan conceptos básicos de la asignatura, y en la segunda se
plantea un problema más largo. Evaluada cada parte en 10 puntos, la nota del examen será la mejor de:
- considerando todo el examen
0,7 A + 0,3 B
- considerando sólo la primera parte
0,8 A
En todo caso, es necesario sacar más de 3 puntos de 10 en la parte A para aprobar la asignatura.
Parte A
22 cuestiones — 2,5 horas — 7 puntos (u 8)
Se trata de resolver las cuestiones que se plantean y, en su caso, escoger la respuesta adecuada de entre las que se ofrecen
(rodear con un círculo). Utiliza para la respuesta el espacio asignado a cada pregunta; aunque no es necesario, si necesitas
más, utiliza la parte trasera de la hoja. En todo caso, las respuestas deben ser precisas.
Las preguntas valen 1 (cursiva) o 2 (negrita) puntos. En total, son 29 puntos. Las respuestas equivocadas no quitan puntos,
pero sólo se tomarán en consideración las que provengan de una determinado cálculo o razonamiento. En general,
las respuestas se considerarán sólo como bien o mal.
1. La siguiente tabla muestra un resumen de la ejecución de un programa en un procesador vectorial. Completa
la tabla teniendo en cuenta las siguientes características de la máquina: las instrucciones se encadenan;
existen 2 buses a memoria; no hay conflictos en el acceso a los módulos de memoria; el paso (stride) de los
vectores es 1; y la frecuencia del reloj es 0,8 GHz.
Calcula el rendimiento (MF/s) que se obtendrá con vectores de 128 elementos.
LV
SV
SUBVI
SV
V1, A(R1)
B(R1), V1
V2, V1, #5
C(R1), V2
t inicio
lat. UF.
3
6
1. dat
N. dat
2
2. Un procesador vectorial utiliza una memoria entrelazada en 32 módulos y con una latencia de 10 ciclos.
Podríamos esperar que el procesador dispusiera del siguiente número de buses para acceder a memoria:
a. en el mejor de los casos, 10, uno por cada ciclo de latencia
b. 1, 2 o 3
c. al menos 2: uno para lecturas (LV) y otro para escrituras (SV)
d. si las instrucciones no se encadenan, bastaría con 1 bus; si se encadenan, al menos 2
e. ninguna de las respuestas anteriores es correcta
3. De acuerdo a los datos del gráfico, que representa el rendimiento obtenido en la ejecución de un programa
en una máquina vectorial en función de la longitud de los vectores, ¿cuál es el valor de N3/4 para ese
programa?
a. sólo se puede decir que N3/4 es mayor que 200
b. N3/4 no se puede obtener de la gráfica; el valor más
pequeño que se puede obtener es N5
c. 150
d. 30
e. ninguna de las respuestas anteriores es correcta
200
150
100
50
0
0
50
100
150
Longitud de los vectores
200
4. En un determinado bucle escalar, cuyos límites son i = 0 e i = 127, la instrucción j lee en A(100+20i), y la
instrucción j+2 escribe A(6i+4). Por ello, tras aplicar el test de dependencias, se puede decir que:
a. existe una dependencia de datos (RD) de la instrucción j a la j+2
b. existe una dependencia de datos (RD) de la instrucción j a la j+2, pero fuera de los límites del bucle
c. existe una antidependencia (DR) de la instrucción j a la j+2
d. existe una antidependencia (DR) de la instrucción j+2 a la j
e. no hay dependencia entre las dos instrucciones
5. El grafo de la figura representa las dependencias de un
determinado bucle. Escribe un bucle escalar, lo más sencillo
posible, que sea compatible con dicho grafo.
1
A,2
2
A,2
C,3
3
6. Indica si es posible vectorizar el bucle anterior y por qué. En su caso, escribe el código vectorial
correspondiente, completo.
7. Explica brevemente en qué consiste el problema conocido como “falsa compartición” y qué efectos puede
tener, positivos o negativos, en un sistema paralelo de memoria compartida.
8. Debido a una operación de escritura en cache, va a ser necesario remplazar un bloque en estado O. Por
tanto:
a. hay que invalidar el resto de copias del bloque que se va a reemplazar, que estarían en estado S
b. el caso que se plantea no es posible, ya que, si ha sido un acierto en la cache, se escribe sin remplazar
c. se remplaza sin más el bloque, ya que quedarán más copias del mismo en otras caches
d. se remplaza el bloque, pero sólo si estamos seguros de que quedan más copias en otras caches
e. ninguna de las respuestas anteriores es correcta
9. Un bloque de datos pasa por los siguientes estados en una cache de un multiprocesador SMP: (-) → E → S
→ O → S → (-). Indica las acciones que se van produciendo para que se efectúe esa secuencia de estados
(p.e. P1-wr-X). ¿Qué tipo de protocolo de coherencia se está utilizando, invalidación o actualización? ¿Por
qué?
10. La entrada a una sección crítica está controlada por una función de lock que utiliza el método de los
tickets/turno. Un proceso ejecuta dicha función y obtiene un ticket de valor 35. El valor del turno
en ese momento es 30. Mientras espera su turno de entrada a la sección crítica, ¿cuántas veces necesitará ese
proceso que se le transfiera a la cache el bloque de datos que contiene la variable turno?
a. sólo una, la última vez antes de entrar
b. antes de entrar, ninguna; sólo cuando abandone la sección crítica, para incrementar la variable turno
c. 5 veces, el número de incrementos que hay que hacer en la variable turno hasta que le llegue su turno
d. sólo una, la primera vez que intenta acceder a la sección crítica
e. las respuestas anteriores son falsas; turno es una variable compartida, y por tanto “visible” para todos
11. ¿Qué elementos forman, básicamente, una barrera de sincronización? ¿Para qué se utilizan?
12. Brevemente ¿Cuál es la diferencia básica entre los modelos de consistencia SC (consistencia secuencial) y
TSO (total store ordering)?
13. Un patrón de comunicación tipo perfect shuffle comunica el nodo 24 de una red Omega de 32 procesadores
con el nodo:
a. 3 (00011)
b. 17 (10001)
c. 7 (00111)
d. 28 (11100)
e. ninguno de ellas
14. La distancia entre los nodos 13 y 44 de un hipercubo de 6 dimensiones es:
≤
a. 1
b. 2
c. 4
d. 6
e. ninguna de ellas
15. ¿Cuántos nodos tiene el nodo 13 del hipercubo anterior a esa misma distancia?
≤
a. 6
b. 1
c. 12
d. 15
e. ninguna de ellas
16. ¿Verdadero o falso? ¿Por qué?
a. con tráfico aleatorio, el nivel de tráfico con el que se satura la red de comunicación de un
multicomputador es mayor si el encaminamiento es CT que si es WH
b. incluir canales virtuales en un encaminador significa repartir en diferentes colas los búferes de paquetes,
una cola por canal virtual (y tal vez añadir más)
c. usar canales virtuales hace que el tiempo de routing de los paquetes sea menor, al evitarse que éstos se
paren
d. turn model es un tipo de encaminamiento que permite encaminamiento adaptativo libre de deadlocks en
una malla (pero no en un toro)
e. el número de paquetes que puede gestionar la red sin saturarse es directamente proporcional a la
distancia media que recorren (crece con la distancia)
17. El sistema de comunicación de un multicomputador emplea los siguientes tiempos (en ns) para enviar un
paquete de L = 128 bytes, a distancia d = 10, siendo el ancho de banda de los enlaces B = 1 Gbit/s:
generación del paquete →
200 + 10×L
/* L en bytes */
transmisión del paquete →
5×d + L/B
recepción del paquete →
200 + 10×L
Si mejoramos la velocidad de transmisión de los enlaces hasta 4 Gbit/s, ¿cuántas veces más rápida será la
comunicación emisor/receptor? Analiza el porqué del resultado que obtengas.
a. 4×L
b. 1,24
c. 3,5
d. 0,7
e. ninguna de ellas
18. Un sistema MPP de 64 nodos utiliza un protocolo de coherencia tipo NUMA-Q, con listas encadenadas de
las copias en las caches y 4 bits de estado. ¿Cuánta información hay que añadir por cada bloque de cache en
cada procesador para mantener la coherencia?
¿Cuál es el máximo número de copias de un bloque que se admite en el sistema?
¿En cuánto se reduciría la información de control de coherencia por cada bloque de cache si redujéramos el
número de copias admitidas a la mitad?
19. Indica breve y esquemáticamente las acciones a realizar para mantener la coherencia en una máquina tipo
Origin 2000 cuando un procesador escribe en un bloque que está en su cache en estado (a) E; (b) S; y (c) M.
20. Una determinada aplicación ejecuta el siguiente bucle, en el que el tiempo de ejecución de cada función
viene a ser de 1 segundo:
do i = 1, 200
(1) A(i) = FUNC1(i)
(2) B(i) = FUNC2(A(i-1))
enddo
Se quiere ejecutar el bucle en un sistema paralelo SMP de 8 procesadores. ¿Es posible hacerlo de manera
eficiente? Si no lo es, explica por qué. Si es posible, escribe el correspondiente código (si hay que
sincronizar, utiliza vectores de eventos).
Caso de que pueda ejecutarse en paralelo, haz una estimación del speed-up que se conseguirá.
21. Un determinado bucle de 3 dimensiones puede paralelizarse en cualquiera de ellas sin necesidad de
sincronización, y se va a ejecutar en una máquina SMP de 8 procesadores. Lo más adecuado sería:
a. paralelizar el bucle interno, para que el tamaño de grano sea grande
b. paralelizar el bucle externo, para que las tareas que ejecute cada procesador sean grandes
c. paralelizar los tres bucles, para tener muchas tareas independientes que asignar a cada procesador
d. ejecutar en serie, porque son pocos procesadores para un bucle de 3 dimensiones
e. las respuestas anteriores son correctas, y la solución más adecuada va a depender del protocolo de
coherencia de cache que utilice el multiprocesador: invalidación o actualización.
22. Existen dos tipos de estrategias de scheduling dinámico. ¿En qué se diferencian entre sí? ¿Qué busca cada una
de ellas?
Parte B
1 h — 3 puntos
Un computador paralelo de memoria distribuida privada está compuesto por 64 procesadores conectados
mediante una red en forma de toro de 2 dimensiones, con enlaces de 4 Gbit/s. El tiempo de procesado de los
paquetes en los encaminadores de la red es de 5 ns. Los paquetes son de 1+31 bytes (=flits).
1. (a) Se envía un paquete a un nodo a distancia máxima en la red. Calcula el tiempo de transmisión del
paquete si la comunicación se efectúa en modo cut-through.
(b) Una determinada aplicación que se está ejecutando en esta máquina sólo efectúa comunicación con los
nodos vecinos, con probabilidad P = 0,7, y con los nodos a distancia máxima, con probabilidad P = 0,3.
Calcula la distancia media recorrida por los paquetes de dicha aplicación.
2.
(c) Finalmente, calcula el máximo número de paquetes por segundo que es capaz de absorber la red de esta
máquina en condiciones de tráfico aleatorio (en espacio y tiempo).
La siguiente función efectúa una determinada operación
con los elementos de un vector. Se trata de un cálculo que
es fácil de ejecutar en paralelo. En concreto, se va a
ejecutar en la máquina anterior, en la que la memoria de
cada nodo es privada, por lo que todas las variables son
privadas y la comunicación se debe efectuar mediante
operaciones explícitas de paso de mensajes. La
comunicación se efectúa cuando dos procesadores, emisor
y receptor, ejecutan las funciones ENVIAR(dir_dat,
num_elem, destino) y RECIBIR(dir_dat, num_elem,
origen).
double func_A ()
{ int
i, lvec;
double res, sum=0.0;
printf("\n long_vect? ");
scanf("%d", &lvec);
for (i=0; i<lvec; i++)
sum = sum + A[i]*A[i]/ (A[i]+2.5)
res = sqrt(sum) / lvec;
return res;
}
Los procesos se identifican mediante la variable pid. Uno de los procesos (p.e. pid=0) lee la longitud del
vector y reparte al resto de procesos, uno a uno, un trozo del vector A. A continuación, cada proceso ejecuta
localmente el correspondiente código, y, al finalizar, envía a pid=0 el resultado parcial obtenido, quien
efectuará el cálculo final. En resumen: un proceso se encarga de repartir datos y recoger y acumular
resultados parciales y el resto efectúa el cálculo.
El código paralelo podría ser el siguiente:
double func_A ()
{ int
i, lvec, nproc=64;
double res, sum=0.0, sum_aux=0.0;
// longitud del vector y num. de proc.
......................................................................................................
if (pid==0)
{ printf("\n long_vect? ");
scanf("%d", &lvec);
tam = lvec / (nproc – 1);
// el pr. 0
// lee el tamaño del vector
// tamaño de cada trozo de vector
for (i=1; i<nproc; i++) ENVIAR(&A[tam*(i-1)], tam, i); // envia trozos del vector, uno a uno
}
else RECIBIR(A, tam, 0);
// el resto espera recibir datos
......................................................................................................
BARRERA(nproc);
// sincronización global antes del cálculo
if (pid==0)
{ sum = sum_aux;
for (i=1; i<nproc; i++)
{ RECIBIR (&sum_aux, 1, i);
sum = sum + sum_aux;
}
res = sqrt(sum) / lvec;
return res;
}
else
{
for (i=0; i<tam; i++)
sum_aux = sum_aux + A[i]*A[i] / (A[i]+2.5);
ENVIAR(&sum_aux, 1, 0);
}
// pr. 0 recibe y acumula resultados parciales
......................................................................................................
// cálculo final
// cálculo local en el resto de procesadores
// se envian al pr. 0 los resultados parciales
......................................................................................................
}
(a) Se trata de obtener una estimación del speed-up que se puede conseguir al ejecutar este bucle en los 64
procesadores, para un vector de 63 × 105 elementos. Para simplificar el cálculo, vamos a efectuar las
siguientes hipótesis de tiempos (en ns):
- una iteración del bucle for de cálculo ...................................... 500
- una operación de comunicación <ENVIAR/RECIBIR> ....... 10.000 + 2 × L
- una operación de sincronización global..................................... 6.000
(b) ¿Es necesario utilizar en el código anterior la función de sincronización global BARRERA? ¿En qué
mejoraría o empeoraría el resultado si no se utilizara? Para razonar tus argumentos, representa en un
gráfico (similar a los que hemos utilizado para analizar el comportamiento de las instrucciones T&S,
LL/SC, ...) cómo se va efectuando la comunicación y el cálculo a lo largo del tiempo para el caso de 5
(1+4) procesadores.
(c) Durante el curso hemos visto cómo se implementa una barrera en un sistema de memoria compartida.
3.
¿Podrías esbozar cuál sería la implementación de una barrera de sincronización global en un sistema de
memoria privada?
Cambiamos ahora de máquina, ya que vamos a ejecutar el programa anterior en una máquina de memoria
compartida tipo SMP: 8 procesadores en un bus.
Escribe el código de los procesos que se ejecutarán en cada nodo para efectuar el cálculo en paralelo. Utiliza
las funciones de sincronización y las variables que consideres necesarias; en todo caso, indica claramente el
ámbito de las variables, global o local.
4. Para efectuar el cálculo en paralelo, se han repartido trozos de vector a cada procesador de a cuerdo a una
determinada política de scheduling. ¿Qué tipo de scheduling se ha utilizado en programa del apartado 2?
Retoma el código escrito para la maquina de memoria común del apartado 3 y rescribe la planificación del
bucle de cálculo utilizando el “otro” tipo de política, en la versión que prefieras.
¿Cuál consideras que es la estrategia de reparto más adecuada para este caso? ¿Por qué?