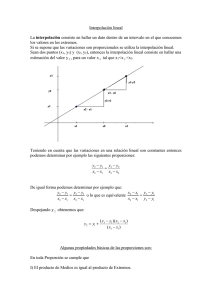
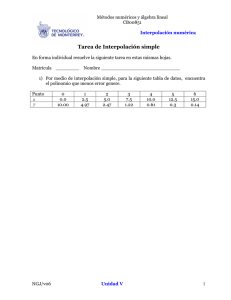
Métodos de Interpolación … Kriging
Anuncio

Proyección Regional de Escenarios de Cambio
Climático. Técnicas y Proyectos en Curso.
Homogeneización e Interpolación de
Observaciones de Alta Resolución
Sixto Herrera García
Instituto Nacional de Meteorología
Universidad de Cantabria
Santander, España
http://www.meteo.unican.es
Introducción
2
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos.
3. Métodos de Interpolación.
4. Aplicaciones. Test de Tendencias.
5. Bases de Datos.
6. Referencias.
3
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos.
3. Métodos de Interpolación.
4. Aplicaciones. Test de Tendencias.
5. Bases de Datos.
6. Referencias.
4
Contraste de Hipótesis
• Establecemos la hipótesis nula, H0.
• La hipótesis contraria se denota por H1 y se denomina hipótesis
alternativa.
• Establecemos el nivel de significación, α. Éste nos define la
probabilidad de error con la que aceptamos la hipótesis nula.
• Elegir un estadístico asociado al test con distribución
conocida o tabulada.
• Comparar el estadístico obtenido a partir de los datos de la
muestra con la distribución teórica del estadístico.
5
Ejemplo
Por ejemplo, a partir de la muestra de alturas de los n=30 individuos
del curso se quiere contrastar la hipótesis de que la altura media en
Suances es 1.80.
1.80
Estadístico:
Nivel de Confianza: α=5%
Cálculo:
6
Contraste de Hipótesis
En los contrastes tenemos varias cantidades importantes:
• Error de Tipo I o de primera especie: Es aquel que cometemos
rechazando la hipótesis nula siendo cierta.
• Error de Tipo II o de segunda especie: Es el error que cometemos
cuando aceptamos la hipótesis nula siendo falsa.
• Nivel de significación: Es la probabilidad máxima de cometer un error
de primera especie.
Una vez hemos definido un nivel de significación, la hipótesis
nula será rechazada para aquellos valores del estadístico para
los cuales se supere el valor del nivel de significación
establecido. Los niveles de significación típicos son: 0.05, 0.01,
o 0.001.
7
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos.
3. Métodos de Interpolación.
4. Aplicaciones. Test de Tendencias.
5. Bases de Datos.
6. Referencias.
8
Homogeneización de Datos
Una serie climática es homogénea cuando sus variaciones responden
exclusivamente a las variaciones de la atmósfera (Conrad y Pollack. 1950)
En la práctica es difícil encontrar series climáticas homogéneas ya que
existen multitud de factores externos que las alteran:
• Cambios en la localización y el entorno del observatorio.
• Cambios en la instrumentación.
• Cambios en al forma de tomar las mediciones (fórmulas, etc…).
• Errores de codificación.
Estos factores pueden provocar cambios en el nivel medio de las
observaciones, en la tendencia, discontinuidades en los datos, etc…
Los métodos de homogeneización tratan de detectar estas
discontinuidades en los datos y, si es posible, corregirlas para obtener
una serie de datos que refleje únicamente la señal climática.
9
Métodos Directos
Análisis de Metadatas: Los archivos metadata de las
estaciones recogen los cambios más relevantes de la
estación. De este modo quedan registrados los cambios
de localización, de instrumentación, etc… El estudio
directo de estos archivos nos dan una referencia de las
posibles discontinuidades de la serie.
Este es un metadata
indicando los obstáculos
que podrían afectar a las
mediciones de
precipitación de la
estación.
No hay metodología
estándar para su
tratamiento
(subjetividad).
10
Métodos Indirectos (opción A)
Análisis de la Serie Aislada:
Estos métodos no son muy utilizados ya que se confunden
discontinuidades debidas a cambios bruscos en la climatología de la
zona con aquellas provocadas por factores externos.
A pesar de sus defectos, este tipo de métodos es útil para redes con
estaciones aisladas en las cuales otro tipo de análisis puede darnos
resultados engañosos.
11
Métodos Indirectos (opción B)
Comparación con Series de Referencia:
Una series de referencia para una serie base (objeto de estudio) es
una serie definida en el mismo periodo temporal y que no presenta
inhomogeneidades. Así, por comparación se pueden descubrir
discontinuidades en la serie base.
Las series de referencia puede ser creadas de forma artificial o
pueden elegirse a partir de las series de las estaciones vecinas a la
estación de la serie base (por ejemplo un promedio areal).
En el caso de usar series artificiales debemos tener en cuenta que el
método de construcción puede ser importante y suele ser específico
del problema que queremos estudiar.
12
Tests de Homogeneidad
En esta sección aplicaremos el contraste de hipótesis a la detección
de discontinuidades. Los tests que definiremos son los siguientes:
• Test SNHT (Standar Normal Homogeneity Test).
• Test de Alexandersson para precipitación y temperatura.
• Test de Buishand.
• Test de Pettitt.
• Test de von Neumann.
13
Tests de Homogeneidad … SNHT
SNHT (serie aislada): Este es un test muy difundido y del cual se
han desarrollado versiones para analizar cambios en la media, la
varianza y la tendencia de la serie. Además es un test aplicado a una
gran variedad de variables.
• La hipótesis nula será la homogeneidad de la serie.
• El método trabaja con la serie normalizada:
yi =
yi − μ
σ
• Consideramos como estadístico el máximo ,T*, de la serie T definida
2
2
por: T ( k ) = k z + ( n − k ) z , k = 1,..., n
1
2
n
1 k
1
z1 = ∑ yi , z 2 =
yi
∑
( n − k ) i = k +1
k i =1
14
Tests de Homogeneidad … SNHT
• Localizamos el valor de T* en la siguiente tabla, dependiente del
tamaño de la muestra y del nivel de significación:
• La hipótesis nula será aceptada si para el valor T* y para el tamaño
de la muestra se supera el nivel de significación impuesto. Por ejemplo
para una muestra de 20 miembros y un valor de T* superior a 6.95 se
obtiene una confianza del 95%, es decir de cada 100 casos en estas
condiciones que consideremos homogéneos, sólo 5 serán realmente
inhomogéneos.
15
Tests de Homogeneidad … Alexandersson
Test de Alexandersson (serie de referencia): Este test está basado
en el anterior ya que aplica el SNHT para una serie auxiliar construida
a partir de la serie base y series de referencia.
Aplicaremos este test a series de precipitación y temperatura
únicamente ya que la serie auxiliar definida en cada caso es diferente.
• La hipótesis nula es la homogeneidad de la serie base.
• Generamos K series de referencia.
• Calculamos los coeficientes de correlación entre las series de
referencia y la serie base: n
ρj =
∑ (x
i =1
ji
− x )( yi − y )
n
∑ ( x ji − x )
i =1
n
2
2
(
y
−
y
)
∑ i
i =1
16
Tests de Homogeneidad … Alexandersson
• Calculamos la serie auxiliar Q, que cambia en función de la variable:
•Precipitación:
k
Qi = yi /{[∑ ρ x ji y / x j ]
j =1
2
j
k
2
ρ
∑ j}
j =1
• Temperatura:
k
k
Qi = yi − {∑ ρ [ x ji − x j + y ] / ∑ ρ 2j }
j =1
2
j
j =1
• Una vez calculada la serie auxiliar, se aplica el test SNHT.
• Al igual que en el caso anterior la hipótesis nula se rechaza si el valor
del estadístico no alcanza el nivel de significación para el tamaño de
muestra considerado.
17
Tests de Homogeneidad ... observaciones
• La longitud mínima de las series para asegurar la siginificación del
método está entre 10 y 15 datos.
• La hipótesis de homogeneidad limita nuestro estudio a variables
gaussianas o promedios mensuales o anuales de variables con peor
comportamiento. En este sentido, el dato diario no cumple esta
hipótesis en general y por ello la mayoría de los estudios realizados se
refieren a medias mensuales y anuales.
• Si queremos buscar más de una discontinuidad podemos aplicar este
algoritmo iterativamente sin más que dividir la serie inicial en las
subseries posterior y anterior al punto de discontinuidad, mientras las
longitudes de nuestras series sean suficientemente grandes.
18
Tests de Homogeneidad … Homogeneización
Alexandersson señala un modo de corregir la serie alrededor del punto
de discontinuidad. Sea k la posición de la inhomogeneidad, entonces
tendremos dos niveles diferentes antes y después de la ruptura:
q1 = σ Q z1 + Q ,
q2 = σ Q z 2 + Q .
Por lo tanto, basta corregir con la razón (precipitación) o la diferencia
(temperatura) entre ambos niveles.
Este proceso podemos repetirlo en cada subserie en la que hayamos
encontrado una discontinuidad.
Normalmente se corrige homogeneizando con la subserie más reciente.
Veamos un ejemplo sobre Italia. Las estaciones pertenecen todas a las
fuerzas aéreas italianas (UGM/AMI):
19
Ejemplo ... España
Red secundaria (11660)
Temperatura
Precipitación
1360 estaciones
4139 estaciones
865 estaciones
3491 estaciones
20
Tests de Homogeneidad … Buishand
• Consideramos como hipótesis nula la homogeneidad de la serie.
• Definimos el estadístico S:
k
S 0 = 0, S k = ∑ ( yi − y ), k = 1,..., n
i =1
• En caso de homogeneidad, los valores de S deben ser próximos a 0.
• Si existe una discontinuidad en la posición K, entonces S tendrá un
máximo o un mínimo alrededor de esa posición.
• Los valores críticos del test vienen tabulados respecto al valor:
R = (max S k − min S k ) / s
0≤ k ≤ n
0≤ k ≤ n
21
Tests de Homogeneidad … Pettitt
Este es un test no paramétrico (no asume ninguna distribución)
basado en la serie de los rangos {ri :i=1,…,n}.
El rango se define como la posición del dato en la serie ordenada de
menor a mayor. En caso de que haya observaciones con el mismo
valor se les asigna a todas el mismo rango, correspondiente a la
media aritmética de los rangos que corresponderían a los elementos.
• Consideramos como hipótesis nula la homogeneidad de la serie.
• Calculamos el siguiente estadístico:
k
X k = 2 ∑ ri − k ( n + 1), k = 1,..., n
i =1
• En caso de existir una discontinuidad en la posición K-ésima, el
estadístico presentará un extremo cerca de esa posición.
22
Tests de Homogeneidad … Pettitt
El nivel de significación y los valores críticos viene tabulado en función
del tamaño de la muestra y del valor: X = max X
K
( )
1≤ i ≤ n
i
23
Tests de Homogeneidad … von Neumann
El test de von Neumann se basa en el valor conocido como la razón de
von Neumann, que está definido por el valor N:
n −1
N = ∑ ( yi − yi +1 )
i =1
n
2
2
(
y
−
y
)
∑ i
i =1
• En caso de homogeneidad el valor esperado de N es 2.
• En caso de existir alguna inhomogeneidad el valor es menor del
esperado.
• Notar que este test no aporta información acerca de la localización de
la discontinuidad.
• Los valores críticos vienen dados en la siguiente tabla:
24
Ejemplo … ENSEMBLES
Red de Estaciones ENSEMBLES
Variables
Nubosidad
Humedad
Precipitación
Presión
Nieve
Insolación
Temperatura media
Temperatura mínima
Temperatura máxima
Este proyecto quiere generar un grid de 25 km de resolución.
25
Ejemplo … ENSEMBLES
26
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos:
- Tests de Homogeneidad.
- Multiple Linear Regression.
- Otros métodos.
3. Métodos de Interpolación.
4. Aplicaciones. Test de Tendencias.
5. Bases de Datos.
6. Referencias
27
Tests de Homogeneidad … MLR
Este método analiza cuatro posibles comportamientos de la serie
base:
• Serie homogénea.
• Serie con una tendencia global.
• Serie con un salto o cambio brusco de nivel en un punto.
• Serie con un cambio de pendiente brusco.
Para cada uno de estos comportamientos define un modelo de
regresión lineal:
yi = a1 + c1 x1i + d1 x2i + f1 x3i + ei , i = 1,..., n
yi = a2 + b2i + c2 x1i + d 2 x2i + f 2 x3i + ei , i = 1,..., n
yi = a3 + b3 I + c3 x1i + d 3 x2 i + f 3 x3i + ei , i = 1,..., n
yi = a4 + b4iI1 + a5 I 2 + b5iI 2 + c4 x1i + d 4 x2i + f 4 x3i + ei , i = 1,..., n
I = 0, i = 1,..., p − 1
I 1 = 1, I 2 = 0, i = 1,..., p − 1
I = 1, i = p ,..., n
I 1 = 0, I 2 = 1, i = p ,..., n
28
Tests de Homogeneidad … MLR
Para testear cada modelo se aplica el test de Durbin – Watson a la
serie de errores obtenida. En caso de que el modelo ajuste
correctamente la serie, se detiene el proceso, se subdivide la serie
respecto al punto encontrado y se reinicia el proceso en las subseries
generadas.
Tras la aplicación del primer modelo, en caso de que no ajuste bien la
serie, se puede observar la serie de errores:
En el tercer caso la magnitud del cambio viene dada por la expresión:
m = ( a 4 + a5 + b5 p ) − ( a 4 + b4 ( p − 1))
29
Durbin - Watson
Como hemos usado este test de forma continua a lo largo de este último
test, vamos a definir el test de Durbin – Watson. Es un test para
contrastar la independencia de los errores de un modelo de regresión
lineal o múltiple.
La hipótesis nula considerada el que no existe correlación en la serie,
mientras que la alternativa es que ésta sí existe.
El estadístico del test viene dado por:
n
En función del tamaño de la muestra, el
2
(ei − ei −1 )
número de regresores del modelo y el
D = i=2 n
nivel de significación buscado, existen
2
ei
una cota inferior y una superior para el
i =1
test. Por encima de la cota superior el
test acepta la hipótesis nula, por debajo de la cota inferior el test rechaza
la hipótesis nula y entre ambas cotas el test no es concluyente.
∑
∑
30
Otros Métodos
• Aproximación Bayesiana: Ouarda et al.1999; Perreault et al. 1999 and
2000.
• Método WRS: Karl and Williams. 1987
• Método ST: Gullet et al. 1990
• Método t-Student: Panofsky and Bries. 1968.
• M.A.S.H: Szentimrey. 1994, 1995, 1996.
• Método de Caussinus-Mestre: Caussianus and Lyazrhi, 1997.
Caussinus and Mestre, 1996.
• Método TPS: Andrew R. Solow, 1987.
• Método TPS: D.R.Easterling and T.C.Peterson, 1995.
31
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos.
3. Métodos de Interpolación.
4. Aplicaciones. Test de Tendencias.
5. Bases de Datos.
6. Referencias.
32
Métodos de Interpolación
El objetivo de los métodos de interpolación es pasar de una red de
observaciones irregularmente distribuida a un grid regular de forma que
éste mantenga las características climáticas de las observaciones:
Red de Precipitación
Grid Regular
33
Métodos de Interpolación
Los métodos que describiremos serán los siguientes:
• Nearest Neighbour.
• Natural Neighbour Interpolation.
• Angular Distance Weighting.
• Kriging.
• Splines.
• Conditional Interpolation.
• Reduced Space Optimal Interpolation.
• Inverse Distance Weighting.
• Cressman o método de las correcciones.
• ….
34
Métodos de Interpolación … NN y NNI
Estos métodos estás basado en una partición de Voronoi del plano.
Una vez realizada la partición, en el primer caso a cada celda de la
partición se le asigna el valor de la estación contenida en ella mientras
que en el segundo caso el valor interpolado es combinación lineal del
valor de las estaciones vecinas cuyas celdas intersecten con la del
nuevo punto.
Nearest Neighbour
Natural Neighbour
35
Métodos de Interpolación … ADW
El angular distance weighting es una modificación del IDW en la cual se
incorpora una componente angular a los pesos para tener en cuenta la
distribución irregular de las observaciones.
Para evitar asignar más peso a sectores con mayor densidad de
observaciones se introduce una componente angular en los pesos que
‘premia’ las observaciones bien distribuidas en el espacio.
Los pesos tienen por tanto una componente radial y otra angular:
Punto del grid
j
Punto de observación
dist
l
θ
k
36
Métodos de Interpolación … ADW
El método se formula del siguiente modo:
Z ( x0 ) = ∑k =1Wk Z ( xk )
N
Wk = wk ∗ (1 + ak )
∑l =1,l ≠k wl (1−cos(θ j ( k ,l )))
ak =
nj
∑l =1,l ≠k wl
nj
wk = r , r = e
m
−x
dc
Donde m y dc son el exponente del método y el radio de decaimiento.
Estos serán los únicos parámetros del método y definen la componente
radial.
37
Métodos de Interpolación … Kriging
El kriging es un método geoestadístico muy difundido y del cual existen
un gran número de modificaciones.
El método de interpolación está basado en la descripción de la variación
espacial de los datos que se modelan mediante el variograma.
Éste se calcula ajustando una función al variograma experimental que
2
1
viene dado por la expresión: γ ( h) =
z −z
2 N (h)
∑
i
( i , j )∈N ( h )
j
Los modelos utilizados habitualmente en el ajuste del variograma son:
Gaussiano, Exponencial, Esférico, Polinomial, etc…
38
Métodos de Interpolación … Kriging
Gaussiano:
γ (h) = C0 + A ∗ (1 − e
Exponencial: γ ( h) = C0 + A ∗ (1 − e
− ( hr ) 2
( hr )
), h > 0
), h > 0
3 h
1 h 3
γ
(
h
)
=
C
+
A
∗
(
(
−
Esférico:
0
2 r
2 ( r ) )), h ≤ r
γ ( h ) = C 0 + A, h > r
Lineal: γ ( h ) = C 0 + A ∗ r , h > 0
Como vemos todos los modelos dependen de tres parámetros (C0, A, r),
nugget, sill y range respectivamente.
h
39
Métodos de Interpolación … Kriging
El valor interpolado en el punto ‘x’ del grid viene dado por la combinación
lineal:
N
Z ( x ) = ∑ λi Z ( x i )
i =1
Los pesos de la combinación lineal minimizan la varianza del error de la
estimación y son solución del siguiente sistema (Biau, G. et al. 1999):
N
N
i =1
i =1
− ∑ λiγ ( x j − xi ) + μ = −γ ( x − x j ), ∑ λi = 1.
40
Métodos de Interpolación … TPS
Al igual que el kriging, el thin plate splines es un método tipo BLUE
(best linear unbiased estimation).
Mientras el kriging minimiza la varianza del error de la estimación, el
TPS minimiza la rugosidad de la superficie interpolada.
Este método depende del parámetro de alisamiento, λ, (smoothing
parameter) que es hallado minimizando la GCV.
En el caso más simple el modelo supone que los datos pueden
representarse por una función ‘suave’ a la que se suma una variable
aleatoria: Z i = f ( xi , yi ) + ε i
Esta función se calcula minimizando el funcional:
n
2
[(
Z
−
f
(
x
,
y
))
/
d
]
+ λJ m ( f )
∑ i
i
i
i
i =1
El valor m define la clase de la función. Por ejemplo, si m=2 la
segunda derivada ha de ser continua en todo punto.
41
Métodos de Interpolación ... Ejemplo
Veamos un ejemplo con datos de precipitación sobre la isla de Mallorca
Red secundaria INM
Estaciones Homogéneas
Para calcular la homogeneidad de las series hemos empleado el test de
Alexandersson con 5 series de referencia y un mínimo de 20 años en el
periodo 1950-2003 con un porcentaje máximo de ‘missing data’ en cada
año del 10%.
42
Métodos de Interpolación ... Ejemplo
El primer problema que encontramos es la densidad de estaciones, la
cual limita la resolución del grid:
Grid 0.05º
Grid 0.1º
Grid 0.2º
43
Métodos de Interpolación ... Ejemplo
Una vez elegida una resolución, aplicamos los diferentes métodos y
observamos como reproducen la climatología de la zona:
Análisis de las medias
Observaciones
ADW
Kriging
TPS
44
Métodos de Interpolación ... Ejemplo
Análisis de las Desviaciones Típicas
Observaciones
ADW
Kriging
TPS
45
Métodos de Interpolación ... Ejemplo
Pasemos ahora a analizar la validación de los métodos. La validación
está hecha con validación cruzada ‘leave one out’.
El bias representa la diferencia media entre los datos observados y los
interpolados y el RMSE es la raíz del error cuadrático medio.
46
Métodos de Interpolación ... Ejemplo
En este caso, comparamos los errores obtenidos con los diferentes
métodos:
47
Métodos de Interpolación ... Ejemplo
Comparamos los errores cometidos al realizar la interpolación semanal
siguiendo dos filosofías:
• Interpolar el dato diario agrupado en medias semanales.
• Interpolar el dato diario y agruparlos a posteriori en medias semanales.
48
Métodos de Interpolación ... Ejemplo
Comparamos los errores cometidos al realizar la interpolación mensual
siguiendo dos filosofías:
• Interpolar el dato diario agrupado en medias mensuales.
• Interpolar el dato diario y agruparlos a posteriori en medias mensuales.
49
Métodos de Interpolación … RSOI
La interpolación óptima es un método estocástico que ha sido usado
principalmente para datos oceánicos (SST y SLP) a escala mensual y
anual.
En el caso del RSOI se combina el método de interpolación óptima
con una reducción del espacio de variables a EOFs.
Al igual que el kriging y el TPS, la superficie interpolada por este
método es la solución por mínimos cuadrado con suma de pesos igual
a 1.
Si definimos xb, y0, como la raíz y las observaciones en los puntos del
grid podemos formular el método como:
Donde la matriz W se calcula de forma estadística. Al igual que el
método de Cressman se pueden aplicar correcciones sucesivas.
50
Métodos de Interpolación … CI
Este método sólo se ha aplicado a datos de precipitación. Lo más
novedoso del método es el uso de SOMs para clasificar el estado de la
atmósfera y modificar los pesos de la interpolación en función de ese
estado. En la interpolación podemos distinguir dos fases:
• Se identifica la fase del punto del grid según el estado de la
atmósfera.
• En las zonas en las que se considere que va a llover se realiza la
interpolación dando una magnitud de la precipitación media en esa
zona del grid.
Entenderemos por fase de un estación a la dualidad llueve/no llueve.
Los pesos de la interpolación son inicialmente calculados del mismo
modo que en el caso del ADW. Posteriormente se corrigen teniendo en
cuenta las relaciones obtenidas por la SOM.
51
Métodos de Interpolación … IDW
En el Inverse Distance Weighting método los pesos son asignados
únicamente en función de la distancia. Los pesos decrecen con la
distancia (Ponderación con el inverso de la distancia).
Si denotamos por Z(xi) a la observación en la i-ésima estación y por di0 a
la distancia entre la estación y el punto x0, el valor interpolado en ese
punto viene dado por la combinación expresión:
m
Z ( x 0 ) = ∑ λi Z ( x i )
i =1
λi =
d i−0 p
m
−p
d
∑ i0
i =1
Notar que la suma de los pesos es igual a 1.
52
Métodos de Interpolación … Cressman
Sean Z0(x0), Z0(xi) y O(xi) la raíz considerada en el punto de grid y en la
estación y el dato observado en la estación.
Definimos el error cometido en la estimación de la observación :
E0i = Z 0 ( xi ) − O( xi )
Aplicamos la corrección del método:
C 0 = −W ∗ E0 , Z1 ( x0 ) = Z 0 ( x0 ) + C 0
El vector W está definido por:
W =
D2 −d 2
D2 +d 2
Estación i
d
D
,d < D
El método se aplica sucesivamente partiendo de un valor de D alto y
reduciéndolo posteriormente.
En cada paso se corrige el valor de la aproximación con el error
cometido por el método en los valores observados.
53
Métodos de Interpolación ... validación
Para validar los métodos de interpolación se suele utilizar la validación
cruzada.
• Estos métodos dividen la muestra en dos conjuntos: uno de
entrenamiento y otro de test.
• El método se calibra en el conjunto de entrenamiento.
• Se aplica el método al conjunto de test y se estudian los errores.
En nuestro caso usaremos el método “leave one out” que consiste en
escoger como conjunto de entrenamiento todas las estaciones menos
una, estudiar el error cometido en la estación restante y repetir el proceso
con todas las estaciones de la red.
54
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos.
3. Métodos de Interpolación.
4. Aplicaciones. Estudio de Tendencias.
5. Bases de Datos.
6. Referencias.
55
Aplicaciones. Estudio de Tendencias
Una de las aplicaciones habituales de los grids es el cálculo de
tendencias. Uno de los contrastes de hipótesis más utilizados para el
cálculo de tendencias es el test de Mann-Kendall (Kendall,M.G.1975).
Éste se define por:
•La hipótesis nula es la independencia de la serie.
• Calculamos el estadístico T dado por: T =
n −1
n
∑ ∑ signo( y
i =1 j =i +1
j
− yi )
• Bajo la hipótesis nula, el estadístico sigue un distribución normal de
parámetros: E (T ) = 0
var(T ) = 181 [n(n − 1)(2n + 5) −
∑ r (r − 1)(2r + 1)]
r = val .rep
Comparamos el valor del estadístico con la distribución para
determinar la significación del test.
56
Estudio de Tendencias … España
En España hemos realizado un estudio de las tendencias en la
precipitación y la temperatura máxima en un grid de resolución 0.2º. Si
bien el grid es de dato diaro, el análisis de la tendencia está realizado con
medias anuales.
57
Estudio de Tendencias … India
Veamos un ejemplo sobre el estudio de tendencias en la India. El IMD
(India Meteorological Department) ha creado un grid de precipitación
sobre la India de resolución 1ºx1º para el periodo 1951-2003.
Sobre este grid se ha realizado un estudio sobre las tendencias en este
periodo y en la zona enmarcada.
Media Estacional
Varianza de las anomalías
58
Estudio de Tendencias … Europa
El JRC (Joint Research Centre) ha desarrollado un grid de 50 km de
resolución sobre Europa con datos de precipitación, temperatura
(Tx,Tn,Tg), presión, evapotranspiración (E0,ES0,ET0), nieve y viento
desde 1975.
Missing Data
Grid
59
Estudio de Tendencias … Europa
Hemos repetido el estudio de tendencias realizado sobre España
en el grid del JRC. De nuevo, el test aplicado ha sido el MannKendall. Los resultados para precipitación y temperatura máxima
han sido:
Precipitación
TempMax
60
Resumen
1. Contrastes de Hipótesis. Tests Estadísticos.
2. Métodos de Homogeneización de Observaciones:
• Métodos Directos.
• Métodos Indirectos.
3. Métodos de Interpolación.
4. Aplicaciones. Test de Tendencias.
5. Bases de Datos.
6. Referencias
61
Bases de Datos
• European Climate Assesment & Dataset (ECA&D): http://eca.knmi.nl/
• Joint Research Center: http://agrifish.jrc.it/marsstat/datadistribution
• Deutscher Wetterdienst (DWD): http://www.dwd.de/en/en.htm
• CISL Research Data Archive: http://dss.ucar.edu
• Joint Institute for the Study of Atmosphere and Ocean (JISAO):
http://www.jisao.washington.edu
• Earth System Research Laboratory (ESRL): http://www.cdc.noaa.gov
• Climatic Research Unit (CRU): http://www.cru.uea.ac.uk.
• Global Historical Climatology Network (GHCN):
http://lwf.ncdc.noaa.gov/oa/climate/research/ghcn/ghcngrid_prcp.html.
• Global Precipitation Climatology Project (GPCP):
http://cics.umd.edu/~yin/GPCP/main.html.
• KNMI, Climate Explorer: http://climexp.knmi.nl.
• Climate Prediction Center (CPC):
http://www.cdc.noaa.gov/cdc/data.unified.html.
• International Water Management Institute: http://www.iwmi.org.
62
Bases de Datos … CRU
El CRU (Climate Research Center) es un centro dedicado al estudio del
cambio climático.
Este centro ha desarrollado una base de datos de precipitación mensual
del periodo 1900-1998 con una resolución de 5ºx5º o de 2.5ºx3.75º
sobre todo el globo y de anomalías de temperatura de 5ºx5º.
El método de interpolación utilizado es un Natural Neighbour
Interpolation. Si no existe dato en alguna estación, éste se aproxima
aplicando un ADW a las vecinas siempre que existan al menos 2
vecinas en un radio de 600 km (para el periodo 1997-1998 este radio se
redujo a 400 km). En la interpolación se usan un máximo de 50
estaciones.
Estos datos pueden conseguirse en la página web del CRU asi como la
documentación de la metodología.
63
Bases de Datos … CRU
64
Bases de Datos … IWMI and CRU
Ambos organismos han colaborado en la realización de un atlas climático
(World Water and Climate Atlas), en el cual crean un grid de alta resolución,
10’x10’, de medias mensuales. Las variables que consideran son:
• Precipitación.
• Frecuencia de días con precipitaciones.
• Temperatura.
• Rango diario de temperatura.
• Humedad relativa.
• Insolación.
• Velocidad del viento.
• Frecuencia de días con escarcha.
El método de interpolación que utilizaron fue el thin plate splines (ANUSPLIN)
y el periodo que abarca es 1961-1990.
65
Bases de Datos … DWD
El centro Deutscher Wetterdienst (DWD) ha desarrollado una
climatología de precipitación mensual de 50 años (1951-2000) en todo el
globo. El conjunto de datos mensuales ha sido interpolado en grids de
tres resoluciones diferentes (0.5° lat/lon, 1.0° lat/lon, 2.5° lat/lon). Las
estaciones utilizadas han sido y el método de interpolación el kriging:
66
Bases de Datos … DWD
Este grid ha sido usado para estudiar tendencias en la media anual de
precipitación mensual total promediada sobre todo el globo. El test
aplicado ha sido el test de Mann-Kendall.
67
Bases de Datos … DWD
Esta es la significación que han obtenido con el test.
68
Bases de Datos … KNMI.Climate Explorer
69
Bases de Datos … KNMI.Climate Explorer
70
Referencias
Proyecto ENSEMBLES: WP5.1 Development of daily high-resolution gridded
observational datasets for Europe. Hofstra, N. et al.
Hewitson, M.F., and R.G.Crane(2005), Gridded Area-Averaged Daily
Precipitation via Conditional Interpolation, Journal of Climate, 18, 41-57.
New, M. et al (2000), Representing twentieth-century space-time climate
variability. Part II: development of 1901-96 monthly grids of terrestrial surface
climate, Journal of Climate, 13, 2217-2238.
New, M. et al (2002), A high-resolution data set of surface climate over global
land areas, Climate Research, 21, 1-25.
Cressman, G.P. (1959), An Operational Objective Analysis System, Monthly
Weather Review, 87, 367-374.
Peterson, C.T., et al (1998), Homogeneity Adjustments of In Situ Atmospheric
Climate Data: A Review. Int.J.Climatol, 18, 1493-1517.
71
Referencias
Ducré-Robitaille, J.F., et al (2003), Comparison of Techniques for Detection of
Discontinuities in Temperature Series. Int.J.Climatol, 23, 1087-1101.
Wijngaard, J.B., et al (2003), Homogeneity of 20th Century European Daily
Temperature and Precipitation Series, Int.J.Climatol, 23, 679-692.
Zurbenko, I. et al (1996), Detecting Discontinuities in Time Series of Upper-Air
Data: Development and Demonstration of an Adaptive Filter Technique, Journal
of Climate, 9, 3548-3560.
Solow, A. (1987), Testing for Climate Change: An Application of the Two-Phase
Regression Model, Journal of Climate and Applied Meteorology, 26, 1401-1405.
Easterling and Peterson (1995), The effect of artificial discontinuities on recent
trends in minimun and maximun temperatures, Atmospheric Research, 37, 19-26.
Bartels, R, (1982), The Rank Version of von Neumann’s Ratio Test for
Randomness, Journal of the American Statistical Association, 77, 40-46.
72
Referencias
Alexandersson and Moberg (1997), Homogenizatoin of Swedish Temperature
Data. Part I: Homogeneity Test for Linear Trends, Int. J. Climatol., 17, 25-34.
Vincent, L.A. (1998), A Technique for the Identification of Inhomogeneities in
Canadian Temperature Series, Journal of Climate, 11, 1094-1104.
Biau, G. (1999), Estimation of Precipitation by Kriging in the EOF Space of the
Sea Level Pressure Field. Journal of Climate, 12, 1070-1085.
Sacks, Jerome. (1989), Design and Analysis of Computer Experiments, Statistical
Science, 4, 409-423.
Toolbox:
Vebyk: Toolbox de Matlab que realiza el kriging ordinario.
MATLAB Krigeage Toolbox Introduction for Version 3.
EasyKrig3.0.
ANUSPLIN: toolbox del CRU para la interpolación por splines.
73