modulo estadistica ciclo v grado decimo
Anuncio

1
I.E.
CÁRDENAS CENTRO
MÓDULO DE ESTADÍSTICA
CICLO V
GRADO DÉCIMO
2
TABLA DE CONTENIDO
pág.
UNIDAD 1
1.
1.1.
1.2.
1.3.
1.4.
2.
3.
3.1.
3.2.
3.3.
POBLACIÓN, MUESTRA, VARIABLE ESTADÍSTICA: CUALITATIVA Y CUANTITATIVA
POBLACIÓN
LA MUESTRA
VARIABLE CUALITATIVA
VARIABLE CUANTITATIVA
ELABORACIÓN DE TABLAS DE DISTRIBUCIÓN DE FRECUENCIA CON DATOS AGRUPADOS
GRÁFICOS ESTADÍSTICOS: HISTOGRAMA, POLÍGONO DE FRECUENCIAS, OJIVA
HISTOGRAMA
POLÍGONO DE FRECUENCIAS
OJIVA
4
4
4
4
4
4
5
5
5
5
UNIDAD 2
1.
1.1.
1.2.
1.3.
2.
2.1.
2.1.1.
2.1.2.
2.1.3.
2.2.
2.2.1.
2.3.
2.3.1.
2.3.2.
2.3.3.
2.4.
2.4.1.
2.4.2.
2.4.3.
3.
4.
4.1.
4.2.
MEDIDAS DE TENDENCIA CENTRAL CON DATOS AGRUPADOS: MEDIA ARITMÉTICA,
MEDIANA Y MODA
MEDIA PARA DATOS AGRUPADOS
MEDIANA PARA DATOS AGRUPADOS
LA MODA PARA DATOS AGRUPADOS
MEDIDAS DE DISPERSIÓN: RANGO, DESVIACIÓN MEDIA, VARIANZA, DESVIACIÓN TÍPICA
O ESTANDAR
RANGO
Rango para datos no agrupados
Rango para datos agrupados
Propiedades del Rango o Recorrido
DESVIACIÓN MEDIA
Propiedades
DESVIACIÓN TÍPICA
Cálculo de la desviación típica para datos no agrupados en clases
Cálculo de la desviación típica para datos agrupados en clases y agrupados por frecuencias
Propiedades
VARIANZA
Varianza para datos agrupados
Varianza para datos NO agrupados
Propiedades
ANÁLISIS DE RESULTADOS DE ENCUESTAS
NÚMERO ÍNDICE
APLICACIONES DE LOS NÚMEROS ÍNDICES
VENTAJAS DE LOS NÚMEROS ÍNDICES
EVALUACIÓN DE COMPETENCIAS
7
7
7
8
8
8
8
8
9
9
10
10
11
11
11
11
12
12
13
14
14
15
15
16
UNIDAD 3
1.
1.1.
TÉNICAS DE CONTEO
DIAGRAMA DE ÁRBOL
17
17
3
1.2.
1.3.
1.3.1.
1.3.2.
PRINCIPIO DE MULTIPLICACIÓN
COMBINACIONES Y PERMUTACIONES
Combinaciones
Permutaciones
17
18
18
18
EVALUACIÓN DE COMPETENCIAS
19
UNIDAD 4
1.
2.
3.
3.1.
3.1.1.
3.1.2.
3.1.3.
CONCEPTO DE PROBABILIDAD
ESPACIOS MUESTRALES
CÁLCULO DE PROBABILIDADES
INDEPENDENCIA DE EVENTOS
Sucesos Excluyentes
Sucesos Independientes
Sucesos Dependientes
20
20
20
21
21
21
21
EVALUACIÓN DE COMPETENCIAS
22
BIBLIOGRAFÍA
24
4
UNIDAD 1
1. POBLACIÓN, MUESTRA, VARIABLE ESTADÍSTICA: CUALITATIVA Y CUANTITATIVA
1.1. POBLACIÓN
número de hermanos, número de discos vendidos,
número de pulsaciones.
Ess
el
conjunto
de
individuos, con alguna
característica común, sobre el que se hace un
estudio estadístico.
Una variable estadística cuantitativa es continua
cuando puede tomar todos los valores posibles de un
intervalo (es decir, se puede medir). Por ejemplo:
peso, talla, medida del salto de longitud.
1.2. LA MUESTRA
Ess un subconjunto de la población, seleccionada de
modo que ponga de manifiesto las carac
características de
la misma, de ahí que la propiedad más importante de
las muestras es su representatividad.
El proceso seguido en la extracción de la muestra se
llama muestreo.
Cada uno de los aspectos que se desea conocer
acerca de la población se denomina
variable
estadística. Las variables estadísticas pueden ser:
2. ELABORACIÓN DE TABLAS DE DISTRIBUCIÓN
DE FRECUENCIA CON DATOS AGRUPADOS
Es aquella distribución en la que la disposición
tabular de los datos estadísticos se encuentran
ordenadoss en clases y con la frecuencia de cada
clase; es decir, los datos originales de varios valores
adyacentes del conjunto se combinan para formar un
intervalo de clase. No existen normas establecidas
para determinar cuándo es apropiado utilizar datos
agrupados
os o datos no agrupados; sin embargo, se
sugiere que cuando el número total de datos (N) es
igual o superior a 50 y además el rango o recorrido
de la serie de datos es mayor de 20, entonces, se
utilizará la distribución de frecuencia para datos
agrupados, también se utilizará este tipo de
distribución cuando se requiera elaborar gráficos
lineales como el histograma, el polígono de
frecuencia o la ojiva.
1.3. VARIABLE CUALITATIVA
Sii se pueden observar o leer, pero no se pueden
contar o medir. Por ejemplo: color de pelo, lugar de
nacimiento, profesión.
1.4. VARIABLE CUANTITATIVA
Si se pueden
eden contar o medir. Por ejemplo: número de
hermanos, peso, número de discos vendidos, talla.
Las variables estadísticas cuantitativas pueden ser
discretas o continuas:
Una variable estadística cuantitativa es discreta
cuando sólo toma un número finito de valores
aislados (es decir, se puede contar). Por ejemplo:
5
La razón fundamental para utilizar la distribución de
frecuencia de clases es proporcionar mejor
comunicación
cación acerca del patrón establecido en los
datos y facilitar la manipulación de los mismos. Los
datos se agrupan en clases con el fin de sintetizar,
resumir, condensar o hacer que la información
obtenida de una investigación sea manejable con
mayor facilidad.
sobre el eje OX, este será la base del rectángulo que
se dibuja sobre él con altura igual o proporcional a su
frecuencia absoluta. Como los intervalos son
consecutivos, los rectángulos quedan adosados. Si
se utilizaran rectángulos de amplitud diferente,
dif
el
área del rectángulo es la que tendría que ser
proporcional
a
la
frecuencia
absoluta
correspondiente a ese intervalo. Se utiliza el
histograma acumulativo, si se utiliza la frecuencia
absoluta acumulativa.
Ejemplo: Ejemplo, la siguiente tabla muestra las
notas que se sacaron 45 alumnos de un curso en su
última prueba:
Observa que en este caso las clases son las notas y
las frecuencias de clase son la cantidad de alumnos.
3.2. POLÍGONO DE FRECUENCIAS
Se utilizan para variables estadísticas cuantitativas,
discretas o continuas. Para una variable discreta,
el polígono de frecuencias se obtiene uniendo por
una poligonal, los extremos superiores de las barras.
Para una variable continua,
continua el polígono de
frecuencias
uencias se obtiene uniendo por una poligonal los
puntos medios de la base superior de los polígonos
del histograma. Las escalas utilizadas para
representar los polígonos de frecuencias influyen
mucho por el impacto visual de los mismos.
3. GRÁFICOS ESTADÍSTICOS:
S: HISTOGRAMA,
POLÍGONO DE FRECUENCIAS, OJIVA
Representación gráfica de datos estadísticos. Las
tablas estadísticas representan toda la información
de modo esquemático y están preparadas para los
cálculos posteriores. Los gráficos estadísticos nos
transmiten
en esa información de modo más expresivo,
nos van a permitir, con un sólo golpe de vista,
entender de que se nos habla, observar sus
características más importantes, incluso sacar
alguna conclusión sobre el comportamiento de la
muestra donde se está realizando
ando el estudio.
Los gráficos estadísticos son muy útiles para
comparar distintas tablas de frecuencia. Los gráficos
estadísticos más usuales son:
3.1. HISTOGRAMA
3.3. OJIVA
Se utiliza para la representación de variables
cuantitativas continuas, cada intervalo se representa
r
Su objetivo,
jetivo, al igual que el histograma y el polígono
de frecuencias es representar distribuciones de
6
frecuencias de variables cuantitativas continuas, pero
sólo para frecuencias acumuladas.
La diferencia con el polígono de frecuencia es que la
frecuencia acumulada no se plotea sobre el punto
medio de la clase, sino al final de la misma, ya que
representa el número de individuos acumulados
hasta esa clase. Como el valor de la frecuencia
acumulada es mayor a medida que avanzamos en la
distribución, la poligonal que se obtiene siempre va a
ser creciente y esa forma particular de la misma es la
que ha hecho que se le dé también el nombre de
ojiva.
No se utilizan barras en su confección, sino
segmentos de recta, por ello no sólo es útil para
representar una distribución de frecuencias sino
también cuando se quiere mostrar más de una
distribución o una clasificación cruzada de una
variable cuantitativa continua con una cualitativa o
cuantitativa discreta.
ACTIVIDAD
Se ha realizado una encuesta a 20 personas sobre el número de veces, que en la semana, van al cine y se han
obtenido las siguientes respuestas:
Nº días (xi)
fr. absoluta (ni)
0
1
1
2
2
4
3
7
4
1
5
1
6
3
7
1
Total
20
Realiza el diagrama de barras, el polígono de frecuencias y el diagrama de sectores correspondiente.
7
UNIDAD 2
1. MEDIDAS DE TENDENCIA CENTRAL CON
DATOS AGRUPADOS: MEDIA ARITMÉTICA,
MEDIANA Y MODA
dato. Por lo que se utilizan métodos alternos para
aproximar los valores de las medidas descriptivas.
1.1. MEDIA PARA DATOS AGRUPADOS
Cuando se trabaja con datos que han sido
agrupados en una distribución de frecuencias, no se
sabe con certeza los valores individuales de cada
Al calcular la media para datos agrupados, se
supone que las observaciones en cada clase son
iguales al punto medio de la clase:
1.2. MEDIANA PARA DATOS AGRUPADOS
Primero se encuentra la clase mediana, la cual es la clase cuya frecuencia acumulada es mayor o igual a n/2 y
puede determinarse mediante la siguiente fórmula:
8
1.3. LA MODA PARA DATOS AGRUPADOS
Es la observación que ocurre con mayor frecuencia, por lo que es necesario identificar la clase modal, esta se
localiza encontrando la clase que tenga más frecuencia.
2.
MEDIDAS
DE
DISPERSIÓN:
RANGO,
DESVIACIÓN MEDIA, VARIANZA, DESVIACIÓN
TÍPICA O ESTANDAR
2.1. RANGO
Es la medida de variabilidad más fácil de calcular.
Para datos finitos o sin agrupar, el rango se define
como la diferencia entre el valor más alto (Xn ó
Xmax.) y el más bajo (X1 ó Xmin) en un conjunto de
datos.
Con las medidas de centralización y posición
podemos conocer los valores centrales de un
conjunto de datos y la distribución de éstos. Uno de
los objetivos de las medidas de tendencia central es
la de sintetizar la información de los datos, pero
estas medidas por sí solas no bastan para ver su
grado de significación, veámoslo con un ejemplo.
2.1.1. Rango para datos no agrupados
R = Xmáx.-Xmín = Xn-X1
Ejemplo:
Consideremos las notas de dos grupos de 50
alumnos, en el primero 25 alumnos obtienen un 10 y
25 un 4, en el segundo los 50 alumnos obtienen un
7. Si calculamos la media en ambos conjuntos es la
misma (7), si sólo nos fijamos en la media podemos
afirmar que los dos grupos de alumnos son
bastantes buenos, pero lo cierto es que en el primer
grupo hay 25 alumnos que han obtenido una nota
excelente y 25 con mala nota, mientras que en el
segundo todos los alumnos han sacado una buena
nota.
Se tienen las edades de cinco estudiantes
universitarios de Ier año, a saber: 18,23, 27,34 y 25.,
para calcular la media aritmética (promedio de las
edades, se tiene que:
R = Xn-X1 ) = 34-18 = 16 años
Con datos agrupados no se saben los valores
máximos y mínimos. Si no hay intervalos de clases
abiertos podemos aproximar el rango mediante el
uso de los límites de clases. Se aproxima el rango
tomando el límite superior de la última clase menos
el límite inferior de la primera clase.
La media para el primer grupo es menos
representativa que para el segundo. Hemos visto un
ejemplo, bastante exagerado para comprobar que las
medidas de tendencia central necesitan un
complemento, una medida que nos permita otorgar
mayor o menor representatividad estas medidas.
2.1.2. Rango para datos agrupados
R= (lim. Sup. de la clase n – lim. Inf. De la clase 1)
Ejemplo:
Si se toman los datos del ejemplo resuelto al
construir la tabla de distribución de frecuencia de
9
las cuentas por
cobrar
de Cabrera’s
Asociados que fueron los siguientes:
Clases
P.M.
fi
fr
fa↓
fa↑
y
fra↓ fra↑
•
Xi
7.420
21.835
– 14.628
10
0.33 10
30
0.3 1.00
3
21.835
36.250
– 29.043
4
0.13 14
20
0.4 0.67
6
36.250
50.665
– 43.458
50.665
65.080
– 57.873
3
0.10 22
11
0.7 0.37
3
65.080
79.495
– 72.288
3
0.10 25
8
0.8 0.27
3
79.495
93.910
– 86.703
5
0.17 30
XXX
30
1.00 XXX XX
X
Total
5
0.17 19
16
5
2.2. DESVIACIÓN MEDIA
0.6 0.54
3
En teoría, la desviación puede referirse a cada una
de las medidas de tendencia central: media, mediana
o moda; pero el interés se suele centrar en la medida
de la desviación con respecto a la media, que
llamaremos desviación media.
Puede definirse como la media aritmética de las
desviaciones de cada uno de los valores con
respecto a la media aritmética de la distribución, y de
indica así:
1.0 0.17
0
XX
X
XXX
Nótese que se toman las desviaciones en valor
absoluto, es decir, que la fórmula no distingue si la
diferencia de cada valor de la variable con la media
es en más o en menos.
El rango de la distribución de frecuencias se calcula
así:
Ya se habrá advertido que esta expresión sirve para
calcular la desviación media en el caso de datos sin
agrupar.
R= (lim. Sup. de la clase n – lim. Inf. De la clase 1)
= (93.910 – 7.420) = 86.49
Veamos un ejemplo: Se tiene los valores 2, 2, 4, 4,
5, 6, 7, 8, 8. Averiguar la desviación media de estos
valores.
2.1.3. Propiedades del Rango o Recorrido:
•
•
•
puesto que no cuenta con los demás valores de
la variable. Por tal razón, siempre existe el peligro
de
que
el
recorrido
ofrezca
una descripción distorsionada de la dispersión.
En el control de la calidad se hace un uso
extenso del recorrido cuando la distribución a
utilizarse no la distorsionan y cuando
el ahorro del tiempo al hacer los cálculos es un
factor de importancia.
El recorrido es la medida de dispersión más
sencilla de calcular e interpretar puesto que
simplemente
es
la
distancia
entre los
valores extremos (máximo y mínimo) en una
distribución
Puesto que el recorrido se basa en
los valores extremos éste tiende s ser errático. No
es
extraño
que
en
una
distribución
de datos económicos o comerciales incluya a
unos pocos valores en extremo pequeños o
grandes. Cuando tal cosa sucede, entonces el
recorrido solamente mide la dispersión con
respecto a esos valores anormales, ignorando a
los demás valores de la variable.
La principal desventaja del recorrido es que sólo
está influenciado por los valores extremos,,
10
x
x−x
x
2
2
4
4
4
5
6
7
8
8
-3
3
-1
-1
-1
0
1
2
3
3
DM = 1,8
3
3
1
1
1
0
1
2
3
3
Veamos ahora cómo se calcula la desviación media
en el caso de datos agrupados en intervalos.
La desviación media viene a indicar el grado de
concentración o de dispersión de los valores de la
variable. Si es muy alta, indica gran dispersión; si es
muy baja refleja un buen agrupamiento y que los
valores son parecidos entre sí.
La desviación media se puede utilizar como medida
de dispersión en todas aquellas distribuciones en las
que la medida de tendencia central
más
significativas haya sido la media.
Donde observamos que ahora las desviaciones van
multiplicadas por las frecuencias de los intervalos
correspondientes. Además, las desviaciones son de
cada centro, o marca de clase, a la media aritmética.
Es decir,
2.2.1. Propiedades
Nos da la media de la dispersión de los
datos.
Intervienen para su cálculo todos los datos.
Cada vez que insertemos un dato nuevo se
modificará.
Al intervenir un valor absoluto los cálculos
son complicados.
A mayor concentración de los datos entorno
a la media menor será su valor.
DM es no negativa
DM=0 si y sólo si todos los valores son
coincidentes.
Ejemplo:
Para hallar la desviación media de la siguiente tabla
referida a las edades de los 100 empleados de una
cierta empresa:
Clase
ni
16-20
2
20-24
8
24-28
8
28-32
18
32-36
20
36-40
18
40-44
15
44-48
8
48-52
3
Veamos cómo se procede:
Clase
ni
xm
ni ⋅ xm
16-20
20-24
24-28
28-32
32-36
36-40
40-44
44-48
48-52
2
8
8
18
20
18
18
8
3
100
18
22
36
176
2.3. DESVIACIÓN TÍPICA
Con la varianza se elevan al cuadrado las unidades
de medida, sería interesante tener una medida de
dispersión con las mismas unidades de la media y
los datos, esto lo podemos conseguir haciendo la
raíz cuadrada positiva de la varianza, a la que
llamaremos desviación típica.
x−x
16,72
ni ⋅ x − x
Es sin duda la medida de dispersión más importante,
ya que además sirve como medida previa al cálculo
de otros valores estadísticos.
33,44
La desviación típica se define como la raíz cuadrada
de la media de los cuadrados de las desviaciones
con respecto a la media de la distribución. Es decir,
Para datos sin agrupar
DM = 6,09
11
Donde:
I: amplitud de la clase
Para datos agrupados
D: distancia en clases desde cada una en concreto a
la clase que contiene a la media supuesta A.
2.3.1. Cálculo de la desviación típica para datos
no agrupados en clases. Veamos la fórmula
anterior aplicada a un caso concreto.
Ejemplo:
Las alturas en cm de un grupo de 103 personas se
distribuyen así:
Hallar la desviación típica de la serie: 5, 8, 10, 12, 16.
x−x
x
5
8
10
12
16
x−x
-5,2
-2,2
-0,2
1,8
5,8
2
Clases
150 – 155
155 – 160
160 – 165
165 – 170
170 – 175
175 – 180
180 – 185
185 – 190
190 – 195
195 – 200
27,04
4,84
0,04
3,24
33,64
Primero hallamos x = 10,2
Luego S =
13,76 = 3,71
Resp: S = 9,56
2.3.2. Cálculo de la desviación típica para datos
agrupados en clases y agrupados por
frecuencias. Método largo: Se aplica la siguiente
fórmula
S=
Donde
∑ fx
2.3.3. Propiedades
Tiene la misma unidad que los datos y que la
media.
Siempre es positiva, será cero si y sólo si
todos los datos son coincidentes.
Es la medida de dispersión más usada.
Es invariante ante cambios de origen.
Si se produce un cambio de escala la nueva
desviación típica es igual a la anterior
multiplicada por el cambio.
Si se produce simultáneamente un cambio de
origen y escala en los datos, sólo el cambio de
escala afectará a la desviación típica.
2
N
x = x m − x y f es la frecuencia absoluta de
cada intervalo.
Método abreviado o corto: La fórmula a utilizar es:
S=I
∑ fd
N
2
∑ fd
−
N
f
3
6
12
18
25
17
10
7
4
1
103
2
2.4. VARIANZA
La desviación media es una medida de dispersión de
datos correcta pero presenta un inconveniente y es
la complejidad de manipulación al intervenir valores
absolutos. Sería conveniente encontrar otra medida
que no presente el problema inicial (que no se
compensen las dispersiones negativas con las
positivas) y cuyo manejo se hace más sencillo. Otra
forma de evitar la compensación de dispersiones es
elevar al cuadrado la diferencia y es más sencillo
trabajar con cuadrados que con valores absolutos,
12
La varianza es
la media
aritmética
del
cuadrado de las des
desviaciones
viaciones respecto a la
media de una distribución estadística.
teniendo
en
cuenta
esta
consideración
introduciremos el concepto de varianza.
La varianza se representa
presenta por
.
2.4.1. Varianza para datos agrupados
Para simplificar el cálculo de la varianza vamos o utilizar las siguientes expresiones que son
equivalentes a las anteriores.
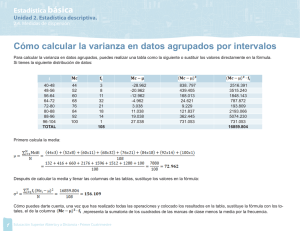
2.4.2. Varianza para datos NO agrupados
Ejemplo:
Calcular la varianza de la distribución:
9, 3, 8, 8, 9, 8, 9, 18
13
2.4.3. Propiedades
Como sumamos cuadrados la varianza siempre es positiva y será nula cuando todos los valores de la
variable sean coincidentes y por tanto iguales a la varianza.
Al elevar al cuadrado elevamos la unidad de medida de las observaciones al cuadrado.
Al elevarse al cuadrado las desviaciones aquellos valores más alejados de la media afectarán mucho a la
varianza.
Es invariante ante cambios de origen.
Si se produce un cambio de escala la nueva varianza es igual a la anterior multiplicada por el cuadrado
del cambio.
Si se produce simultáneamente un cambio de origen y escala en los datos, sólo el cambio de escala
afectará a la varianza.
EJERCICIOS
1) Sumando 5 a cada número del conjunto 3, 6, 2, 1, 7, 5, obtenemos 8, 11, 7, 6, 12, 10. Probar que ambos
conjuntos de números tienen la misma desviación típica pero diferentes medias ¿cómo están relacionadas las
medias?.
2) Multiplicando cada número 3, 6, 2, 1, 7 y 5 por 2 y sumando entonces 5, obtenemos el conjunto 11, 17, 9 7, 19
15. ¿Cuál es la relación entre la desviación típica de ambos conjuntos? ¿Y entre las medias?
3) Tenemos una variable X de la que sabemos que: CV = 0,5 y que Sx = 3. ¿Cuál es el valor de la media de X?.
4) Tenemos dos variables X e Y con el mismo recorrido y media, siendo sus varianzas 4 y 9 respectivamente.
¿Para cual de las dos variables el valor de la media es más representativo?
5) La distribución de edades del Censo Electoral de Residentes a 1 de enero de 1.999 para 2 comunidades
autónomas X y Y, en tantos por cien es la siguiente:
Edades
16–18
18–30
30–50
50–70
70–90
X
Y
3.54
21.56
31.63
28.14
15.12
4.35
29.99
35.21
21.97
8.48
a) Representa sobre los mismos ejes de coordenadas los histogramas de la distribución de la edad para
las dos CC.AA. (emplea distinto trazo o distintos colores). ¿Qué conclusiones obtienes a la vista de los
histogramas?
b) Calcula la edad mediana para las dos comunidades. Compáralas. ¿Qué indican estos resultados?
c) Qué comunidad tiene mayor variabilidad en la distribución de su edad?
14
3. ANÁLISIS DE RESULTADOS DE ENCUESTAS
implica la capacidad de generalización de los
resultados obtenidos.
“Analizar significa establecer categorías, ordenar,
manipular y resumir los datos,” (Kerlinger, 1982, p.
96). En esta etapa del proceso de investigación se
procede a racionalizar los datos colectados a fin de
explicar e interpretar las posibles relaciones que
expresan las variables estudiadas.
Una vez concluidas las etapas de colección y
procesamiento de datos se inicia con una de las más
importantes fases de una investigación: el análisis de
datos. En esta etapa se determina como analizar los
datos y que herramientas de análisis estadístico son
adecuadas para éste propósito. El tipo de análisis de
los datos depende al menos de los siguientes
factores.
El diseño de tablas estadísticas permite aplicar
técnicas de análisis complejas facilitando este
proceso. El análisis debe expresarse de manera
clara y simple utilizando lógica tanto inductiva como
deductiva.
Los resultados de una investigación basados en
datos muestrales requieren de una aproximación al
verdadero valor de la población (Zorrilla, 1994). Para
lograr lo anterior se requiere de una serie de técnicas
estadísticas. Estas técnicas se derivan tanto de la
estadística paramétrica como de la estadística no
paramétrica. La primera tiene como supuestos que la
población estudiada posee una distribución normal y
que los datos obtenidos se midieron en una escala
de intervalo y de razón. La segunda no establece
supuestos acerca de la distribución de la población
sin embargo requiere que las variables estudiadas se
midan a nivel nominal u ordinal (ver Weiers, 1993).
a) El nivel de medición de las variables (los niveles
de medición fueron explicados en la sección 2.4 del
capítulo II).
b) El tipo de hipótesis formulada (ver sección 2.2,
capítulo II).
c) El diseño de investigación utilizado indica el tipo
de análisis requerido para la comprobación de
hipótesis.
El análisis de datos es el precedente para la
actividad de interpretación. La interpretación se
realiza en términos de los resultados de la
investigación. Esta actividad consiste en establecer
inferencias sobre las relaciones entre las variables
estudiadas
para
extraer
conclusiones
y
recomendaciones (Kerlinger, 1982). La interpretación
se realiza en dos etapas:
Las tablas diseñadas para el análisis de datos se
incluyen en el reporte final y pueden ser útiles para
analizar una o más variables. En virtud de éste último
criterio el análisis de datos puede ser univariado,
bivariado o trivariado dependiendo de la cantidad de
variables que se analizan.
4. NÚMERO ÍNDICE
a) Interpretación de las relaciones entre las variables
y los datos que las sustentan con fundamento en
algún nivel de significancia estadística.
Un número índice es una medida estadística que
permite caracterizar la evolución de una magnitud
(simple, como el precio del pan, o compuesta, como
el PIB) en dos instantes o períodos de tiempo
distintos “0” y “t”. Se suelen representar mediante
una letra afectada por un subíndice (que indica el
instante o período que se toma como base o
referencia) y un superíndice (que indica el otro
b) Establecer un significado más amplio de la
investigación, es decir, determinar el grado de
generalización de los resultados de la investigación.
Las dos anteriores etapas se sustentan en el grado
de validez y confiabilidad de la investigación. Ello
15
Ejemplo: un comerciante ha registrado las
siguientes ventas anuales. Tomando como base el
año 1980
instante o período de tiempo al que se refiere el
número índice).
Un Número índice es un valor representativo que
indica las variaciones de una o más variables en un
periodo dado con respecto a un periodo base.
Año
1980
Ventas ($) 200.000
1981
1982
1983
1984
250.000
200.000
190.000
220.000
Cálculo de un índice de ventas
Año
Razón
Cambio de un decimal
Índice multiplicado x 100
1980
200.000/200.000
1.00
100
1981
250.000/200.000
1.25
125
1982
200.000/200.000
1.00
100
1983
190.000/200.000
0.95
95
1984
220.000/200.000
1.10
110
4.1. APLICACIONES DE LOS NÚMEROS ÍNDICES
Los gerentes se valen de los números índices como
parte de un cálculo intermedio para entender mejor
otra información.
Los números índices
son muy versátiles, lo
que los hace aplicable
a cualquier ciencia o
campo de estudio.
Esencialmente
se
usan
para
hacer
comparaciones.
En educación se pueden usar los números índices
para comparar la inteligencia relativa de estudiantes
en sitios diferentes o en años diferentes.
Los índices estaciónales sirven para modificar o
mejorar las estimaciones del futuro.
En el campo donde los números índices son de
mayor utilidad es, en la economía, ya que esta se
vale de indicadores económicos, para estudiar las
situaciones presentes y tratar de predecir las futuras,
dichos indicadores económicos en esencia son
números índices, ejemplo de ello son IPC, PNI,
deflactor implícito del PNI, entre muchos otros.
4.2. VENTAJAS DE LOS NÚMEROS ÍNDICES
Un número índice facilita comparar los cambios en
diferentes tipos de información.
Un índice muestra el cambio en porcentajes del año
base.
Si no existiera cambio alguno, el numerador y el
denominador serian iguales.
Como los números índices muestran cambios en
porcentaje, más bien que cambios aritméticos, el
tamaño de la información y las unidades de medición
no son importantes.
Un número índice puede representar cambios en
muchas cantidades.
ANALIZA
2 situaciones en las que pueden ser útil el número
índice. Relaciona los ejemplos.
16
EVALUACIÓN DE COMPETENCIAS
1. Qué son los fenómenos aleatorios
a) Los que no sabemos lo que va a resultar
b) Un conjunto de posibles resultados.
c) Los que sabemos lo que va a resultar a priori
d) Un conjunto total de fenómenos
c) Los cuartiles.
d) El 2º coeficiente de Ficher
8. En las medidas de dispersión si la variabilidad
es muy grande:
a) La media no tiene trascendencia
b) Los datos están ordenados de forma
creciente
c) La media es siempre cero
d) El espacio muestral es infinito no numerable.
2. Qué es probabilidad
a) Es el resultado de un suceso aleatorio
b) Es dar la medida al resultado de un suceso
aleatorio
c) Es la medida del resultado de un suceso
simple
d) Es el resultado de un suceso simple.
9. Qué otro nombre recibe la curva normal de
media?:
a) Curva de Laplace
b) Curva Normal
c) Curva de Gauss
d) Curva de Tipificación.
3. Una permutación es:
a) La cuasi varianza de un suceso normal y
creciente.
b) Un elemento cuya varianza es infinito
c) Un conjunto de n elementos que se pueden
ordenar
d) La cuasi varianza de un suceso aleatorio
10. En una variable tipificada:
a) La media es la mitad de la varianza.
b) La media es cero
c) La varianza es cero
d) La media es la unidad
4. La varianza nos mide:
a) Alrededor de la cuasi varianza
b) Nos mide la exactitud de la muestra
c) La variabilidad de la variable alrededor de la
media
d) Nos mide la linealidad del espacio muestral.
11. Cómo definirías la mediana:
a) El valor cuadrado de la moda
b) El valor de la variable que hace que la
frecuencia condicionada sea 0.5
c) Ajustar la moda al valor 0.5.
d) Tipificar una variable aleatoria
5. En un espacio muestral la moda será:
a) El valor medio de todos los datos
b) El valor que más veces se repita
c) El valor situado en la mitad de la muestra
d) La media entre el primer y el último valor.
12. Qué es lo que mide la relación entre las
variables?:
a) Coeficiente de determinación
b) Correlación
c) Coeficiente de correlación lineal.
d) Regresión
6. Las medidas de posición son:
a) Varianza, moda y cuasi varianza
b) Moda, varianza y mediana
c) Moda, media y mediana
d) Media, mediana y desviación típica.
7. Quién nos medirá la simetría
distribución?
a) El 1er coeficiente de Ficher
b) Las medidas de dispersión
de
13. Qué estudia la correlación?:
a) La dependencia al exponencial de las
variables.
b) La relación lineal de las variables
c) La interdependencia de las variables
d) La recta de regresión de las variables
una
17
UNIDAD 3
1. TÉNICAS DE CONTEO. Si el número de posibles
resultados de un experimento es pequeño, es
relativamente fácil listar y contar todos los posibles
resultados. Al tirar un dado, por ejemplo, hay seis
posibles resultados. Si, sin embargo, hay un gran
número de posibles resultados tales como el número
de niños y niñas por familias con cinco hijos, sería
tedioso listar y contar todas las posibilidades.
EJERCICIO
Un hombre tiene tiempo de jugar ruleta cinco veces
como máximo, él empieza a jugar con un dólar,
d
apuesta cada vez un dólar y puede ganar o perder
en cada juego un dólar, él se va a retirar de jugar si
pierde todo su dinero, si gana tres dólares (esto es si
completa un total de cuatro dólares) o si completa los
cinco juegos.
Las posibilidades serían, 5 niños, 4 niños y 1 niña, 3
niños y 2 niñas, 2 niños y 3 niñas, etc. Para facilitar
esta tarea existen las técnicas de conteo
1.1. DIAGRAMA DE ÁRBOL
ULTIPLICACIÓN
1.2. PRINCIPIO DE MULTIPLICACIÓN
Un diagrama de árbol es una representación gráfica
de un experimento que consta de r pasos, donde
cada uno de los pasos tiene un número
núme finito de
maneras de ser llevado a cabo.
Si hay m formas de hacer una cosa y hay n formas
de hacer otra cosa, hay m x n formas da hacer
ambas cosas.
Ejemplo:
En términos de fórmula.
fórmula Número total de arreglos =
mxn
Se lanza una moneda, si sale águila se lanza un
dado y si sale sol se lanza la moneda de nuevo.
Esto puede ser extendido a más de dos eventos.
Para tres eventos, m, n, y o:
o
Número total de arreglos = m x n x o
Ejemplo:
Un vendedor de autos quiere presentar a sus clientes
todas las diferentes opciones con que cuenta: auto
convertible, auto de 2 puertas y auto de 4 puertas,
cualquiera de ellos con rines deportivos o estándar.
estándar
¿Cuántos diferentes arreglos de autos y rines puede
ofrecer el vendedor?
Para solucionar el problema podemos emplear la
técnica de la multiplicación, (donde m es número de
modelos y n es el número de tipos de rin).
Número total de arreglos = 3 x 2
No fue
e difícil de listar y contar todos los posibles
arreglos de modelos de autos y rines en este
ejemplo. Suponga, sin embargo, que el vendedor
tiene para ofrecer ocho modelos de auto y seis tipos
de rines. Sería tedioso hacer un dibujo con todas las
posibilidades.
ades.
Aplicando la técnica
de la
multiplicación fácilmente realizamos el cálculo:
Número total de arreglos = m x n = 8 x 6 = 48
18
1.3. COMBINACIONES Y PERMUTACIONES
Ejemplo:
1.3.1. Combinaciones. Las combinaciones son muy
parecidas a los arreglos, con la diferencia de que en
los conjuntos que se forman no importa el orden de
manera que { , , } y { , , }. El número de
combinaciones de an elementos que puedo hacer de
un total de m elementos será:
Tres componentes electrónicos - un transistor, un
capacitor, y un diodo - serán ensamblados en una
tablilla de una televisión. Los componentes pueden
ser ensamblados en cualquier orden. ¿De cuantas
diferentes maneras pueden ser ensamblados los tres
componentes?
Las diferentes maneras de ensamblar los
componentes son llamadas permutaciones, y son las
siguientes:
TDC DTC CDT
TCD DCT CTD
Cnm =
m!
n !i( m − n ) !
Ejemplo:
Permutación: Todos los arreglos de r objetos
seleccionados de n objetos posibles
Si se quiere formar un equipo de trabajo formado por
2 personas seleccionadas de un grupo de tres (A, B
y C). Si en el equipo hay dos funciones diferentes,
entonces si importa el orden, los resultados serán
permutaciones. Por el contrario si en el equipo no
hay funciones definidas, entonces no importa el
orden y los resultados serán combinaciones. Los
resultados en ambos casos son los siguientes:
La fórmula empleada para contar el número total de
diferentes permutaciones es:
n P r = n!
(n – r )!
Donde:
Permutaciones: AB, AC, BA, CA, BC, CB
nPr es el número de permutaciones posible
n es el número total de objetos
r es el número de objetos utilizados en un mismo
momento
Combinaciones: AB, AC, BC
1.3.2. Permutaciones. La técnica de la permutación
es aplicada para encontrar el número posible de
arreglos donde hay solo un grupo de objetos.
n P r = n! = 3! = 3 x 2 = 6
(n – r )!
( 3 – 3 )!
RESUELVE
Juanita invito a sus amigos a cenar. Juanita tiene 10 amigos, pero solo tiene 6 lugares en la mesa.
a) ¿De cuantas maneras los puede sentar a la mesa?, si no le importa como queden acomodados.
b) ¿De cuantas maneras los puede sentar a la mesa?, si le importa como queden acomodados.
c) Dos de sus amigos son un feliz matrimonio, Juanita decidió sentarlos a la mesa juntos. ¿De cuantas maneras
los puede sentar a la mesa?, si no le importa como queden acomodados los demás.
d) ¿De cuantas maneras los puede sentar a la mesa?, si le importa como queden acomodados los demás.
e) Dos de sus amigos son enemigos, Juanita no los quiere sentar juntos a la mesa. ¿De cuantas maneras los
puede sentar a la mesa?, si no le importa como queden acomodados los demás.
f) ¿De cuantas maneras los puede sentar a la mesa?, si le importa como queden acomodados los demás.
19
EVALUACIÓN DE COMPETENCIAS
1. Suponga que hay ocho tipos de computadora pero solo tres espacios disponibles para exhibirlas en la tienda de
computadoras. ¿De cuantas maneras diferentes pueden ser arregladas las 8 máquinas en los tres espacios
disponibles?
2. El profesor quiere saber ¿cuántas series de 2 letras se pueden formar con las letras A, B, C, si se permite la
repetición?
3. En una compañía se quiere establecer un código de colores para identificar cada una de las 42 partes de un
producto. Se quiere marcar con 3 colores de un total de 7 cada una de las partes, de tal suerte que cada una
tenga una combinación de 3 colores diferentes. ¿Será adecuado este código de colores para identificar las 42
partes del producto?
4. En una escuela primaria de la ciudad, imparte clase la maestra Bety. Ella es feliz enseñando al grupo de tercer
grado, que está compuesto por 15 niñas y 12 niños. Bety propone a los niños formar una mesa directiva del grupo
formada por cinco de ellos. La mesa directiva estaría formada por un presidente, un secretario, un tesorero, y dos
vocales.
a) ¿De cuantas maneras puede formar la mesa directiva?, si no le importa como queden asignados los puestos.
b) Bety piensa que como hay más niñas que niños la mesa directiva debe integrarse por 3 niñas y 2 niños. ¿De
cuantas maneras puede formar la mesa directiva?, si no le importa como queden asignados los puestos.
c) La maestra Susana (la de cuarto) le sugiere que solo el puesto de presidente sea para niñas y los otros 4
puestos sean para niños. ¿De cuantas maneras puede formar la mesa directiva?, si no le importa como queden
asignados los otros puestos.
d) El profesor de educación física ( Ramón ) dice que todos los puestos deben de ser para niños, pero podría
dársele el puesto de secretaria a una niña. ¿De cuantas maneras puede formar la mesa directiva?, si le importa
como queden asignados los otros puestos.
e) En el grupo de tercer grado hay 4 reprobados (3 niños y una niña) y la maestra Bety decidió que ellos no
pueden formar parte de la mesa directiva. ¿De cuantas maneras puede formar la mesa directiva?, si no le importa
como queden asignados los puestos.
f) ¿Cuál es la probabilidad, si se selecciona la mesa directiva al azar entre todos los integrantes del grupo de
tercer grado, quede integrada por puras niñas? Sin importar como queden asignados los puestos.
g) ¿Cuál es la probabilidad, si se selecciona la mesa directiva al azar entre todos los integrantes del grupo de
tercer grado, quede integrada por puros niños? Sin importar como queden asignados los puestos.
h) ¿Cuál es la probabilidad, si se selecciona la mesa directiva al azar entre todos los integrantes del grupo de
tercer grado, el presidente, secretario y tesorero sean niños y las dos vocales niñas? Sin importar como queden
asignados los puestos.
20
UNIDAD 4
1. CONCEPTO DE PROBABILIDAD
espacio muestral en este caso es un conjunto de dos
elementos.
La probabilidad nos sirve para medir la frecuencia
con que ocurre un resultado de entre todos los
posibles en algún experimento.
Smoneda = {que salga cara, que salga sello}
Si en lugar de una moneda, lanzamos un dado
entonces el espacio muestral tendrá seis elementos,
uno correspondiente a cada cara del dado:
2. ESPACIOS MUESTRALES
Sdado = {1; 2; 3; 4; 5; 6}
El espacio muestral (lo abreviamos simplemente
como S) es un conjunto formado por todos los
resultados posibles de algún experimento, por
ejemplo, si lanzamos una moneda al aire (a esto
llamamos experimento), existen solo 2 posibilidades,
que salga cara o que salga sello. Por lo tanto el
Y si lanzamos el dado y la moneda al mismo tiempo
el espacio muestral estará conformado por pares
ordenados de la forma:
Smoneda+dado = (cara; 1); (cara; 2); (cara; 3); (cara; 4); (cara; 5); (cara; 6);
(sello; 1); (sello; 2); (sello; 3); (sello; 4); (sello; 5); (sello; 6)
3. CÁLCULO DE PROBABILIDADES
salga el dos), mientras que los casos posibles (n)
son seis (puede salir cualquier número del uno al
seis).
La probabilidad de ocurrencia de un determinado
suceso podría definirse como la proporción de veces
que ocurriría dicho suceso si se repitiese un
experimento o una observación en un número
grande de ocasiones bajo condiciones similares. Por
definición, entonces, la probabilidad se mide por un
número entre cero y uno: si un suceso no ocurre
nunca, su probabilidad asociada es cero, mientras
que si ocurriese siempre su probabilidad sería igual a
uno. Así, las probabilidades suelen venir expresadas
como decimales, fracciones o porcentajes.
Por lo tanto:
(o lo que es lo mismo, 16,6%)
b) Probabilidad de que al lanzar un dado salga un
número par: en este caso los casos favorables (f)
son tres (que salga el dos, el cuatro o el seis),
mientras que los casos posibles (n) siguen siendo
seis.
El método más utilizado en probabilidad es aplicando
la Regla de Laplace: define la probabilidad de un
suceso como el cociente entre casos favorables y
casos posibles.
Por lo tanto:
(o lo que es lo mismo, 50%)
Condiciones importantes
Ejemplos:
Para poder aplicar la Regla de Laplace el
experimento aleatorio tiene que cumplir dos
requisitos:
a) Probabilidad de que al lanzar un dado salga el
número 2: el caso favorable (f) es tan sólo uno (que
21
3.1. INDEPENDENCIA DE EVENTOS
a) El número de resultados posibles (sucesoso
eventos) tiene que ser finito. Si hubiera infinitos
resultados, al aplicar la regla "casos favorables
dividido por casos posibles" el cociente siempre sería
cero.
Existen relaciones entre los sucesos:
3.1.1. Sucesos Excluyentes. Dos o más sucesos
serán excluyentes si solo uno de ellos puede ocurrir
en un experimento, por ejemplo al lanzar una
moneda, si sale cara entonces no puede salir sello y
viceversa, por lo tanto estos sucesos son
excluyentes.
b) Todos los sucesos o eventos tienen que tener la
misma probabilidad. Si al lanzar un dado, algunas
caras tuvieran mayor probabilidad de salir que otras,
no podríamos aplicar esta regla.
A la regla de Laplace también se le denomina
"probabilidad a priori", ya que para aplicarla hay que
conocer antes de realizar el experimento cuales son
los posibles resultados y saber que todos tienen las
mismas probabilidades.
3.1.2. Sucesos Independientes. Dos o más
sucesos son independientes cuando la ocurrencia de
uno, no afecta la ocurrencia del o los otros. Por
ejemplo en el lanzamiento del dado y la moneda si
sale cara o sale sello, no afecta en ninguna medida
el número que salga en el dado, por lo tanto estos
sucesos son independientes.
Cuando se realiza un experimento aleatorio un
número muy elevado de veces, las probabilidades de
los diversos posibles sucesos empiezan a converger
hacia valores determinados, que son sus respectivas
probabilidades.
3.1.3. Sucesos Dependientes. Dos o más sucesos
son dependientes cuando la ocurrencia de alguno de
ellos sí afecta la ocurrencia de los otros. Por ejemplo
si tengo un saco con 2 bolas negras y una bola roja,
el suceso de sacar la bola roja me impedirá sacar
una bola roja en el siguiente intento pues en el saco
solo hay 2 bolas negras, en este caso esos sucesos
son dependientes.
22
EVALUACIÓN DE COMPETENCIAS
1. El siguiente gráfico circular muestra como
Jorge ganó $ 600.000 durante sus vacaciones:
Cuál es la medida del ángulo central de la
sección que lleva por nombre quehaceres?
a) 30º
b) 60º
c) 90º
4. Una familia necesitó $100.000 para hacer un
paseo. La mitad se gastó en carne y lo que
quedó se repartió de esta forma: a) la mitad en
vinos y bebidas, b) un cuarto en frutas y c) el
resto en verduras. ¿Cuál(es) de las siguientes
afirmaciones se desprende(n) de la información
dada?.
d) 120º
2. El diagrama de Venn muestra los resultados de
una encuesta en la que les preguntaron a 100
personas si se informan de las noticias leyendo
los periódicos o mirando televisión.
I)
El gasto de carne fue equivalente al doble
de lo ocupado en vinos y bebidas.
II) En frutas y verduras se gastó lo mismo
que para vinos y bebidas.
III) El 25% del total se ocupó en las frutas y
verduras.
a) Sólo II.
b) II y III
¿Cuál es la probabilidad de que una persona
seleccionada al azar de esta encuesta no elija a la
televisión como una fuente de información de las
noticias?
a) 15
100
c) I y II.
d) I, II y III.
e) I y III.
5. En un equipo de ″A″ jugadores (con pelo negro
y rubio) ″B″ de ellos son rubios. Entonces el
porcentaje que tiene pelo negro es:
c) 55
100
b) 35
d) 75
100
100
3. Los puntos del gráfico indican la cantidad de
cajas de cierto fármaco vendidas durante los seis
primeros meses de un año. ¿Cuál es la cantidad
promedio de cajas vendidas durante ese
período?
a)
b)
c) 100 (A + B) %
d)
e) Ninguna de las anteriores.
6. Una persona que participa en un concurso,
debe
responder Verdadero o Falso a
una
afirmación que se le hace en cada una de seis
etapas. Si la persona responde al azar, la
23
probabilidad de que acierte en las seis etapas es
de:
a)
1
2
1
b)
6
c)
d)
I) La probabilidad de que la flecha caiga en el
1
32
II) La probabilidad de que la flecha caiga en el
número 2 es
1
e)
64
número 2 ó en el 3 es
2
36
c)
5
36
b) Sólo II
c) Sólo III
d) Sólo I y II
1
d)
3
e)
2
3
a) Sólo I
7. Se lanzan dos dados, uno a continuación del
otro. Sabiendo que la suma de los puntos
obtenidos es 6, la probabilidad de que en un
dado aparezca un 2 es:
b)
1
.
4
III) La probabilidad de que la flecha caiga en el
1
12
2
a)
5
1
.
2
número 1 es
e) Sólo I y III
1
6
9. De una tómbola se saca una de 30 bolitas
numeradas de 1 a 30. ¿Cuál es la probabilidad de
que el número de la bolita extraída sea múltiplo
de 4?
a)
23
30
d)
30
7
b)
4
30
e)
30
23
c)
7
30
8. En la figura
se tiene una ruleta en que la flecha puede indicar
cualquiera de los 4 sectores y ella nunca cae en
los límites de dichos sectores. ¿Cuál(es) de las
siguientes proposiciones es(son) verdadera(s)?
24
BIBLIOGRAFÍA
http://html.rincondelvago.com/sistemas-digitales.html
http://es.wikipedia.org/wiki/Tridimensional
http://tdd.elisava.net/coleccion/12/cross-es
http://www.desarrolloweb.com/articulos/332.php
http://www.aulaclic.es/dreamweaver-cs5/t_2_2.htm#ap_02_02
http://web.educastur.princast.es/ies/aramo/departamentos/mate/complejos/complejos%20_1.htm
http://www.monografias.com/trabajos27/datos-agrupados/datos-agrupados.shtml#centiles
http://www.ematematicas.net/estadistica/medidas/index.php?tipo=ej_dispersion
http://www.ematematicas.net/parit.php
http://www.profesorenlinea.cl/matematica/ProbabilidadCalculo.htm
http://www.mitecnologico.com/Main/TecnicasDeConteo
http://tratamientodedatos.wordpress.com/2011/03/07/medidas-de-tendencia-central-para-datos-no-agrupados-yagrupados/
http://www.monografias.com/trabajos43/medidas-dispersion/medidas-dispersion2.shtml
http://www.eumed.net/libros/2006c/203/2n.htm
PAREDES NUÑEZ, Pamela; RAMÍREZ PANATT Manuel. Apuntes de Preparación para la Prueba de Selección
Universitaria Matemática.Chile. 2009.
25