DEL SISTEMA Pb (II) / Tl (I)
Anuncio
 / Tl (I)")
UNIVERSIDAD DE CÁDIZ
FACULTAD DE CIENCIAS
DEPARTAMENTO DE QUÍMICA ANALÍTICA
TÉCNICAS MATEMÁTICAS
APLICADAS A LA RESOLUCIÓN
DE SEÑALES ELECTROQUÍMICAS
DEL SISTEMA Pb (II) / Tl (I)
JOSÉ MARÍA PALACIOS SANTANDER
CÁDIZ 2000
TÉCNICAS MATEMÁTICAS APLICADAS A LA RESOLUCIÓN DE SEÑALES
ELECTROQUÍMICAS DEL SISTEMA Pb (II) / Tl (I).
El Director:
El Director:
José Luis Hidalgo Hidalgo de
Ignacio Naranjo Rodríguez,
Cisneros, Profesor Titular del
Profesor
Departamento
Departamento
de
Química
Titular
de
del
Química
Analítica de la Universidad de
Analítica de la Universidad de
Cádiz.
Cádiz.
Memoria presentada por José María Palacios Santander para
optar al Grado de Licenciatura en Ciencias Químicas.
Fdo.: José María Palacios Santander
D. JOSÉ LUIS HIDALGO HIDALGO DE CISNEROS, PROFESOR DEL
DEPARTAMENTO DE QUÍMICA ANALÍTICA, Y D. IGNACIO NARANJO
RODRÍGUEZ, PROFESOR TITULAR DEL DEPARTAMENTO DE QUÍMICA
ANALÍTICA DE LA UNIVERSIDAD DE CÁDIZ,
CERTIFICAN: Que el presente trabajo de investigación, realizado
íntegramente en los laboratorios de este Departamento bajo nuestra
dirección, reúne las condiciones exigidas para optar al Grado de
Licenciatura en Ciencias Químicas.
Y para que conste, expedimos y firmamos el presente certificado, en
Cádiz, a 6 de Junio de 2000.
Fdo.: J.L. Hidalgo Hidalgo de Cisneros
Fdo.: I. Naranjo Rodríguez
D. MANUEL GARCÍA VARGAS, CATEDRÁTICO DE UNIVERSIDAD Y
DIRECTOR DEL DEPARTAMENTO DE QUÍMICA ANALÍTICA DE LA
UNIVERSIDAD DE CÁDIZ,
CERTIFICA: Que el presente trabajo, realizado íntegramente en los
laboratorios de este Departamento, bajo la dirección conjunta de los
Profesores D. José Luis Hidalgo Hidalgo de Cisneros y D. Ignacio Naranjo
Rodríguez, reúne las condiciones exigidas para optar al Grado de
Licenciatura en Ciencias Químicas.
Y para que conste, expido y firmo el presente certificado, en Cádiz,
a 6 de Junio de 2000.
Fdo.: Manuel García Vargas.
Pedir perdón y dar las gracias son dos cosas superdifíciles para
cualquier persona. En cuanto a la primera situación, porque a nadie
le gusta reconocer que ha fallado en algo. Con respecto a la segunda,
porque en ese acto nos sentimos vulnerables. Y no me refiero a dar
las gracias cuando te pasan el tarro del azúcar o te devuelven un
libro, sino a cosas más grandes, como la ayuda que me han prestado
durante la realización de este trabajo.
Yo ya he pedido perdón a quien correspondía, pero por si acaso,
de nuevo ruego disculpas a todas aquellas personas que han estado
a mi lado en todo este tiempo y que han sabido aguantarme, porque,
he de reconocer, que soy insufrible y “más pesao que un collá de
melones”.
En cuanto a los agradecimientos, si me sintiese vulnerable en
estos momentos, no haría justicia alguna a la labor que han llevado
a cabo las personas que nombro a continuación:
w En primer lugar (aunque aquí no hay lugares, pero por
alguien he de empezar), doy las gracias de todo corazón a mis
compañeros del Grupo de Instrumentación y Ciencias
Ambientales, que son los mejores (no os lo creáis, ¿eh?):
& A Laura, porque es la que más me ha soportado de todos,
por su comprensión y dulzura en los momentos difíciles.
& A Mª del Mar y Esther que me han aguantado durante todo
el santo y bendito día y además ¡desde las 8:00 de la
mañana! y que han sufrido mis canciones, mis rabietas y
mi vocabulario soez contra el electrodo de mercurio y todo
lo que se ponía a tiro.
% A Carlos (que es un tío estupendo y por el cual todos
suspiramos), por saber alegrarme en las malas situaciones
que hemos vivido en la “cueva” gracias a su humor y
simpatía.
& A Puri y Loli por sus consejos y esas comidas tan
estupendas que hemos pasado juntos.
%, & A Sergio y Juana Mari, que siempre han sabido
perdonarme (eso espero) el que les arrebatase o no les
dejase el ordenador. El pobre ya echa humo y se queda
colgado cada dos por tres, pero es que las redes
neuronales son la caña.
%, & A Jesús y Mª Eli, por su tranquila tranquilidad e inquieta
inquietud, respectivamente.
% A José Luis porque no puede estar en el tribunal y darme
una lección magistral de uso y desuso del castellano
echando mano de su querido D.R.A.E (“Diccionario de la
Real Academia Española”, para los no iniciados).
% A Ignacio, por las apariciones tan oportunas de las que ha
hecho gala cuando el puñe... electrodo de mercurio no
funcionaba ni siquiera a martillazos.
w A mis padres y a mi familia, por su amor y cariño, que han
sabido inculcar en mí cosas verdaderamente buenas, aunque
yo sea un cascarrabias (no sé que voy a dejar para cuando
tenga 50 años). En especial a mi madre, que un día de estos
me “esloma” por darle un susto.
w A mi amada Laura, por ser quien eres, el pilar que sostiene
mi vida.
w A mis directores de Tesis: José Luis e Ignacio, por la acertada
orientación que me han prestado y los esfuerzos que han
realizado para comprender todo lo que aquí se detalla.
Muchas veces he pensado que esto era mucho pedir para un
químico, pero como a José Luis se le antojaron las redes
neuronales, aquí puede recoger su primera cosecha.
w Por último, he querido dejar para el final a la persona que
más me ha ayudado literalmente con la realización de esta
memoria. Con él verdaderamente se ha hecho la luz en este
maremágnum de números, ecuaciones, hiperplanos, nodos,
modelos matemáticos, etc. Él también ha soportado mis
cabreos, aunque también mis momentos de humor, que son
más numerosos, ¡gracias a Dios! Andrés Jiménez2, muchas
gracias por todo. ¡Eres un tío Kohonudo!
A mi amada Laura, lo más hermoso
que me ha sucedido en este mundo.
A mis padres y a mi hermano.
ÍNDICE
Pág.
i
ÍNDICE
OBJETO DEL TRABAJO
1
CAPÍTULO 1: INTRODUCCIÓN
1) Introducción a las técnicas voltamperométricas
2) La voltamperometría
3) Aplicaciones de la voltamperometría
4) Ventajas e inconvenientes
5) Sensibilidad
6) El problema de la superposición de ondas y su resolución
7) Métodos de resolución de mezclas
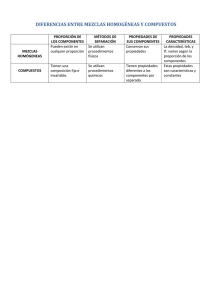
A) Métodos físico-químicos
Métodos basados en técnicas de separación
Métodos químicos: formación de complejos y ácido-base
Métodos instrumentales
a) Separaciones electrolíticas
b) Actuación o modificación por ordenador en tiempo real
c) Sustracción de datos almacenados
B) Métodos basados en modelización matemática
Método de los espectros cocientes o de división de la señal
Métodos de ajuste
a) Métodos referidos al tratamiento de la muestra
1) Regresión lineal múltiple
2) Regresión por mínimos cuadrados clásica
3) Regresión por mínimos cuadrados inversa
4) Regresión por mínimos cuadrados parciales
5) Regresión por búsqueda de proyecciones
6) Métodos discontinuos para regresión no lineal
7) Estimación de parámetros por calibración para datos
característicos
8) Métodos globales de estimación de parámetros
b) Métodos referidos al tratamiento de las señales
1) Métodos recursivos para regresión no lineal
2) Estimación de parámetros en el dominio de Fourier
Reconocimiento de patrones
a) Métodos supervisados
1) Análisis discriminante
b) Métodos no supervisados (Técnicas de reducción de
dimensiones)
1) Análisis de componentes principales
2) Escalado multidimensional
3) Análisis de clusters
3
4
5
5
7
8
8
10
11
11
12
12
12
13
14
14
14
16
16
16
18
19
21
24
28
-i-
30
31
31
31
32
33
33
34
35
35
38
41
ÍNDICE
c) Técnicas de reconocimiento de señales
1) Derivación o diferenciación de señales
2) Ajuste de curvas (Deconvolución numérica)
3) Aplicación de transformadas de funciones
Redes neuronales artificiales
a) Conceptos y estructura de la red neuronal
b) Mecanismo de aprendizaje de las redes neuronales
c) Aprendizaje supervisado
d) Aprendizaje no supervisado
e) Entrenamiento de la red neuronal
f) Tipos de redes neuronales
1) Perceptrones
2) Red neuronal de Hopfield
3) Memoria asociativa bidireccional adaptativa
4) Red neuronal de Kohonen
5) Red neuronal de retropropagación
g) Algoritmo de retropropagación
h) Red neuronal y clasificación
i) Relación con modelos polinomiales
j) Algunas aplicaciones de las redes neuronales
Sistemas expertos y modelos borrosos
a) Aplicaciones de los sistemas expertos
b) Modelos borrosos
Bibliografía
CAPÍTULO 2:
1)
2)
3)
4)
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y
REACTIVOS
Aparatos y material utilizado
A) Aparatos
B) Material utilizado
Productos y reactivos empleados
Preparación de disoluciones
Descripción del método experimental
A) Aspectos generales de la técnica utilizada
B) Método experimental
C) Parámetros del programa
D) Procedimiento de actuación
Bibliografía
46
46
46
51
59
61
64
65
66
67
69
69
69
71
72
73
74
76
77
77
81
81
82
85
CAPÍTULO 3: RESULTADOS OBTENIDOS
1) Patrones puros de talio
2) Patrones puros de plomo
3) Mezclas de los patrones de talio y plomo
A) Grupo A de mezclas (Diagonal superior)
B) Grupo B de mezclas (Diagonal principal)
-ii-
90
91
91
93
93
94
95
95
96
98
99
100
101
102
105
108
113
114
ÍNDICE
C) Grupo C de mezclas (Diagonal inferior)
CAPÍTULO 4: TRATAMIENTO ESTADÍSTICO DE DATOS
1) Descripción de los datos empleados en el tratamiento estadístico
A) Reducción de dimensiones
2) Etapas del tratamiento estadístico de datos
A) Exploración de las señales de los patrones
Análisis lineal discriminante (ALD)
Escalado multidimensional
B) Aplicación de modelos analíticos
C) Métodos de predicción o de separación de señales
Estimación por interpolación
a) Verificación del método de estimación por interpolación
1) Prueba de validación
2) Modelo mejorado I
3) Modelo mejorado II
Redes neuronales artificiales
a) Redes neuronales discretas
b) Redes neuronales continuas
1) Afinamiento del modelo
Bibliografía
116
119
120
120
123
124
124
131
132
138
138
157
160
164
167
170
170
179
203
218
CONCLUSIONES
219
ANEXO I
ANEXO II
ANEXO III
ANEXO IV
ANEXO V
ANEXO VI
ANEXO VII
ANEXO VIII
ANEXO IX
ANEXO X
ANEXO XI
ANEXO XII
223
232
236
239
241
244
246
255
257
259
261
263
-iii-
Objeto del Trabajo
“...cuando miras a un abismo, el abismo también te
mira.”
Friedrich Nietzsche
OBJETO DEL TRABAJO
Con este trabajo el grupo de Instrumentación y Ciencias Ambientales da un paso más en
el campo de la quimiometría (utilización de las técnicas estadísticas en el diseño e interpretación
de experimentos), en el que ya se había iniciado con éxito en el campo de las técnicas
espectroscópicas, extendiéndolo ahora al campo electroquímico.
La selectividad es uno de los problemas más importantes a resolver en los métodos
voltamperométricos, puesto que muchas especies químicas ofrecen señales electroquímicas a
potenciales muy parecidos, provocando el solapamiento de los picos y haciendo muy difícil su
separación. Hoy por hoy, las técnicas instrumentales permiten solventar estas cuestiones en
algunos casos, siendo totalmente inútiles en otros. Es en éste punto donde las técnicas estadísticas
alcanzan un gran protagonismo, permitiendo separar señales incluso en los casos de solapamiento
más severo.
Tomando como modelo la mezcla de Tl (I) y Pb (II) que representa un caso de solapamiento
bastante severo ya que la diferencia entre los potenciales de pico de ambas especies es tan sólo
de 25 mV, en esta memoria se aborda el estudio y aplicación de técnicas estadísticas todavía muy
novedosas en electroanálisis, algunas relacionadas con la inteligencia artificial, como las redes
neuronales, y la comparación de los resultados obtenidos en este caso con otras técnicas
estadísticas más establecidas.
La metodología establecida en esta Tesis de Licenciatura constituirá la base sobre la que
desarrollar una Tesis Doctoral, con la finalidad de aplicar estos conocimientos en los distintos
campos de actividad de nuestro grupo: técnicas espectroscópicas, sensores electroquímicos y
sensores piezoeléctricos.
-2-
Capítulo 1:
Introducción.
/±0%DF
0%DF×314JISULMVd‹Š†”
314JISULMVd‹Š†”0
0¥½
ei
INTRODUCCIÓN
1. INTRODUCCIÓN A LAS TÉCNICAS VOLTAMPEROMÉTRICAS.
Los métodos electroquímicos de análisis se han convertido en una herramienta de gran
interés y utilidad en los laboratorios químicos a la hora de detectar y determinar sustancias de
origen muy diverso.
No obstante, el problema principal hoy día no se encuentra relacionado con la detección de
sustancias de manera simple y aislada como sucedía anteriormente, puesto que existen una gran
cantidad de técnicas que, según sus características, pueden servirnos en mayor o menor medida
para tal propósito. La cuestión fundamental a la que nos enfrentamos y para la que no tenemos
respuesta en la mayoría de los casos, radica en la detección de sustancias en muestras de
diferentes tipos, por ejemplo: aguas residuales, alimentos, etc.
En el mundo en el que vivimos las exigencias de pureza y, sobre todo, de calidad, se
encuentran a la orden del día. Ello implica la necesidad imperiosa de desarrollar métodos de
análisis y control para medios complejos, que nos facilite la solución a estos problemas. En este
punto es donde los métodos electroquímicos pueden desempeñar un papel muy importante, de
acuerdo con sus características.
Entre los más importantes, cabe destacar aquellos que se engloban dentro del marco de la
voltamperometría. Todos ellos se basan en la medida de la intensidad de corriente que se
desarrolla en una celda electroquímica en condiciones de polarización total de la concentración.1
En voltamperometría, se aplica una señal de excitación (potencial variable) a una celda
electroquímica, que provoca una respuesta de intensidad de corriente característica en la que se
basa el método.2 La celda contiene: un electrodo de trabajo (cuyo potencial varía con el tiempo
linealmente), un electrodo auxiliar o contraelectrodo (conduce la electricidad desde la fuente
hasta el electrodo de trabajo, a través de la disolución), un electrodo de referencia (su potencial
permanece constante durante la medida), el analito (en pequeña concentración) y el electrolito
soporte no electroactivo (en concentración elevada).3
Se genera una diferencia de potencial entre el electrodo de trabajo y el auxiliar y ésta se
mide entre el electrodo de trabajo y el de referencia.
En los últimos tiempos, la voltamperometría ha alcanzado un gran desarrollo, constituyendo
una técnica de análisis de trazas con grandes posibilidades de aplicación.
A continuación, se describirá brevemente el fundamento de la voltamperometría.
-4-
INTRODUCCIÓN
2. LA VOLTAMPEROMETRÍA.
La voltamperometría, históricamente desarrollada a partir de la polarografía, es un método
electroquímico que estudia curvas de despolarización electródica, intensidad-potencial,
conseguidas por electrólisis, usando generalmente electrodos sólidos o renovables de mercurio
estacionario, en condiciones tales que la reacción electródica total está controlada por la
velocidad de transferencia electrónica, de modo que el tiempo de electrólisis no interviene en
dicho fenómeno y requiriendo, además, un alto nivel de agitación. Al alcanzar la situación en que
dicha reacción se controla por la difusión de la sustancia reaccionante, se alcanza una meseta o
valor límite proporcional a la concentración de la disolución, que se considera constante.4, 5
La diferencia, por tanto, entre ambas técnicas radica en el tipo de electrodo de trabajo que
emplean y en el factor controlante de la reacción electródica, así como por la necesidad de
agitación en este último caso. La polarografía es, por tanto, un caso particular de la
voltamperometría.1, 6
La característica principal, en todos estos casos, es que la concentración del electrolito
inerte es muchísimo mayor que la del analito y el consumo de éste es mínimo.7
3. APLICACIONES DE LA VOLTAMPEROMETRÍA.
La voltamperometría es utilizada ampliamente por los químicos inorgánicos, los químicofísicos y los bioquímicos con objetivos no analíticos que incluyen estudios fundamentales de
procesos de oxidación y reducción en diversos medios, procesos de adsorción sobre superficies
y mecanismos de transferencia de electrones en superficies de electrodos químicamente
modificados.1
Hace algunos años, la voltamperometría (en particular la polarografía clásica) fue utilizada
con frecuencia por los químicos para la determinación de iones inorgánicos y ciertas especies
orgánicas en disoluciones acuosas. A finales de los años cincuenta y principio de los años
sesenta, sin embargo, estas aplicaciones analíticas fueron ampliamente sustituidas por diversos
métodos espectroscópicos y la voltamperometría dejó de ser importante en análisis excepto para
ciertas aplicaciones especiales, tales como la determinación de oxígeno molecular en
disoluciones.
A mediados de los años sesenta, se desarrollaron varias modificaciones importantes de las
técnicas voltamperométricas clásicas para exaltar significativamente la sensibilidad y la
selectividad del método. Al mismo tiempo, el advenimiento de los amplificadores operacionales
de bajo coste hizo posible el desarrollo comercial de instrumentos relativamente baratos que
-5-
INTRODUCCIÓN
incorporaban muchas de estas modificaciones y los hacían asequibles a todos los químicos. El
resultado ha sido el resurgimiento del interés en la aplicación de los métodos voltamperométricos
para la determinación de una multitud de especies. Además, la voltamperometría acoplada con
la cromatografía líquida (HPLC) se ha convertido en una herramienta poderosa para el análisis
de mezclas complejas de diferentes tipos. La voltamperometría moderna continúa siendo también
una herramienta útil para algunos químicos interesados en el estudio de mecanismos y cinética
de reacciones de oxidación y reducción, al igual que de procesos de adsorción.2
El método voltamperométrico se emplea para la determinación analítica de: sustancias
solubles electroactivas y sustancias solubles o elementos no electroactivos pero que participan
químicamente en una reacción electroquímica, como son los indicadores electroquímicos.8
Se aplica principalmente en análisis químico cuantitativo, basado en la proporcionalidad
entre la corriente de difusión y la concentración de las sustancias electrorreducibles que la
motivan. Rara vez se usa para la caracterización química cualitativa, o en todo caso, con fines
de comprobación.9
La voltamperometría se utiliza mucho en el análisis de sustancias inorgánicas y orgánicas,10
aunque estas últimas son mucho más difíciles de determinar, debido a su tendencia a interferir
unas con otras y a la irreversibilidad de la mayoría de sus reacciones.11 Se ha aplicado con éxito
a prácticamente todos los iones inorgánicos, en una gran variedad de medios y de disolventes
(acuosos, orgánicos, sales fundidas, fase gaseosa) y también a muchas sustancias orgánicas
(operando en medios debidamente tamponados, ya que el ion hidrógeno interviene en todas la
oxidaciones y reducciones de dichas sustancias orgánicas). Su contribución ha sido decisiva en
la determinación de zinc, cadmio, plomo y oxígeno en disolución.9
La polarografía y la voltamperometría tienen su aplicación en multitud de campos. A modo
de ejemplos se puede citar la determinación de formaldehído en productos farmacéuticos;
manganeso en materiales biológicos, cereales o en atmósfera industrial; plomo en bebidas
carbónicas, compuestos orgánicos y alimentos envasados; paladio y sus aplicaciones a la
determinación de dióxido de carbono en sangre; ácido nicotínico y vitamina B en presencia de
ácido fólico; riboflavina en extractos hepáticos y vitamina K en productos farmacéuticos; acetona
en orina; cistina en ovoalbúmina; determinación de hidracida del ácido nicotínico, vitamina C
y K en productos farmacéuticos y sangre en orina.12
En química nuclear se ha empleado para determinar uranio e impurezas y también torio en
arenas.13 En la industria química se han realizado determinaciones de plomo tetraetilo en
gasolinas y análisis de aguas, atmósferas y gases.14
En la industria agrícola y edafología para el análisis de alimentos, plantas y suelos.15
Además, posee un gran número de aplicaciones en Química Física y Electroquímica: cinética
-6-
INTRODUCCIÓN
electroquímica;16 reversibilidad e irreversibilidad;17 determinación de potenciales de equilibrio
en procesos irreversibles;18 proceso electródicos controlados por una reacción química previa;19
detección de corrientes catalíticas;20 estudio de fenómenos de adsorción en electrodos;21 cinética
de reacciones electródicas; estudios de la naturaleza de iones complejos;22 cinética de reacciones
químicas;23 estructura electrónica de iones y comportamiento polarográfico;24 cálculo del número
de electrones implicados en la reacción electródica;25 cálculo del coeficiente de difusión;26
determinación del radio del capilar del electrodo de mercurio y cálculo de la tensión interfacial.27
También posee importantes aplicaciones en metalurgia: la polarografía se ha aplicado para
la determinación de diversos metales en aceros (cobre, plomo, níquel, cobalto, molibdeno,
vanadio, cromo y arsénico, entre otros), solos o en mezclas y en la determinación de distintos
elementos metálicos en materiales magnéticos, aleaciones, rocas y minerales.28
4. VENTAJAS E INCONVENIENTES.
Los métodos electroanalíticos y, entre ellos, la voltamperometría presentan ciertas ventajas
sobre otros tipos de procedimientos. Estas ventajas son las que se enumeran a continuación:
w las medidas electroanalíticas son a menudo específicas para un estado de oxidación
particular de un elemento;29
w se pueden aplicar señales de excitación diferentes al electrodo, permitiendo una
mejora significativa en la sensibilidad y selectividad por medio de la selección de las
señales de excitación/respuesta;30
w son de muy fácil puesta a punto, prestándose a las determinaciones en serie e incluso
automáticas;
w es posible repetir cuantas veces se desee la determinación sobre la misma muestra,
ya que ésta, prácticamente, no se consume y sólo se precisa una pequeña cantidad;
w se pueden determinar simultáneamente varios elementos, si las condiciones exigibles
de sensibilidad lo permiten;
w las determinaciones pueden realizarse a distancia o en recintos herméticamente
cerrados, como ocurre con muestras radioactivas;
w el equipo instrumental es bastante sencillo y económico comparado con otros
métodos instrumentales;31
w son métodos muy veloces, con un fundamento teórico bien desarrollado y aplicables
a una amplia variedad de sistemas.32
w son muy versátiles para el análisis cuantitativo y poseen cierta utilidad en el ámbito
-7-
INTRODUCCIÓN
cualitativo.33
Entre los inconvenientes podríamos destacar su poca selectividad, así como la necesidad
de eliminar el oxígeno en los procesos de reducción, mediante el paso de una corriente de
nitrógeno a través de la disolución de la celda.
En la actualidad, los métodos de impulso han sustituido casi completamente al método de
la polarografía clásica, ya que aumentan significativamente la sensibilidad del método
polarográfico y por su conveniencia y selectividad;10 además, en el caso de la onda cuadrada,
posee una gran velocidad y sensibilidad.34
5. SENSIBILIDAD.
La precisión de la determinación electroquímica depende de numerosos factores,
principalmente de la selectividad y reproducibilidad de la llamada corriente residual.35
Con respecto a la sensibilidad de los métodos electroanalíticos, en polarografía clásica, el
intervalo óptimo de concentración de la sustancia en estudio es del orden de 10-2 - 10-4 M ,
lográndose la determinación analítica con un error no superior al ± 1%; no obstante, se pueden
realizar medidas entre 10-4 - 10-5 M (límite de detección), con un error del ± 5%.9 Se trata, por
tanto, de un método de sensibilidad media, útil para analizar mezclas.36
Con las técnicas de voltamperometría de onda cuadrada y de pulso diferencial, se pueden
alcanzar sensibilidades del orden de 10-8 M, con errores no superiores al 1%, según la
concentración investigada y la naturaleza del método analítico. Por último, la voltamperometría
de redisolución anódica lleva la sensibilidad a un límite extraordinario, alrededor de 10-9 M.9
6. EL PROBLEMA DE LA SUPERPOSICIÓN DE ONDAS Y SU RESOLUCIÓN.
Como se ha comentado anteriormente, a la hora de analizar muestras reales en el
laboratorio, el principal problema con el que nos encontramos es que la disolución o sustancia
problema no contiene una única especie que haya que detectar y determinar. Al contrario, posee
en su seno diferentes elementos o compuestos químicos, cuyo número y abundancia de cada uno
depende de la complejidad de la mezcla.
Dos son los factores que van a influir en este punto: la selectividad y la sensibilidad, los
cuales constituyen uno de los mayores problemas a resolver en el análisis electroquímico, al igual
que en otros campos analíticos. La selectividad en los sensores voltamperométricos se obtiene
para diferentes especies electroactivas que sufren reducción (u oxidación) a diferentes potenciales
de electrodo; no obstante, muchos analitos pueden interferirse mutuamente si poseen potenciales
-8-
INTRODUCCIÓN
de pico muy próximos o si se encuentran en un exceso de concentraciones elevado sobre el otro
componente presente en la muestra.30 Esto provoca la superposición de señales de dos o más
especies existentes en la disolución, haciendo mucho más difícil la determinación
voltamperométrica.37 El grado de solapamiento puede ser tal que la existencia de dos procesos
en paralelo no puede distinguirse visualmente. En estos casos, pueden producirse malas
interpretaciones y resultados erróneos.38
Este problema de determinación de dos o más especies con potenciales de pico similares
ha suscitado gran interés en voltamperometría desde el comienzo de la técnica polarográfica
como método analítico.39
La resolución en técnicas electroquímicas voltamperométricas depende fundamentalmente
de la diferencia de los potenciales de pico de dos o más especies electroactivas presentes en la
disolución a analizar,37 de la altura de onda relativas (afectadas por las concentraciones relativas
y el número de electrones requeridos para cada reducción, si éstas son reversibles), del grado de
irreversibilidad del proceso redox40 y de la forma de la curva intensidad-potencial obtenida
usando una técnica particular.37
Para las técnicas electroanalíticas, Bond definió la resolución cuantitativa en términos de
diferencia entre los potenciales medios de onda de dos especies electroactivas que permitan que
el proceso de electrodo que está siendo medido pueda determinarse con una exactitud del 99%.
En este contexto, por ejemplo, para dos reducciones reversibles con valores iguales de
concentración y de n, número de electrones transferidos, la separación entre los potenciales
medios de onda, (ÄE½)·n requerida en onda cuadrada es de 155 mV.41 Según Sánchez Batanero,
la diferencia entre los potenciales de onda media de dos ondas polarográficas debe ser de 250
mV; de este modo, pueden ser consideradas como diferentes y apropiadas para llevar a cabo
determinaciones analíticas simultáneas.8
Para las técnicas que ofrecen señales en forma de pico, como la voltamperometría de onda
cuadrada, pulso diferencial y de redisolución, se producen serios solapamientos cuando la
diferencia en los potenciales de onda media es menor de 100/n mV (siendo n el número de
electrones envueltos en la reducción u oxidación electroquímica), especialmente cuando la
relación de concentraciones de las especies es mayor de 3:1.37
La selectividad de la voltamperometría de pulso diferencial no es suficiente para resolver
mezclas de metales tales como In(III) y Cd(II) o Pb(II) y Tl(I), porque los potenciales de pico de
esos metales son muy similares y, consecuentemente, los voltamperogramas se consideran
solapados. Por esta razón, se han usado las técnicas derivadas voltamperométricas. Sin embargo,
éstas introducen artefactos instrumentales indeseables que las hacen poco útiles a la hora de dar
una respuesta teórica.42
-9-
INTRODUCCIÓN
Como la anchura de un pico voltamperométrico (típicamente de 100 mV a la altura media)
es una fracción apreciable del rango de potencial accesible (normalmente 1500 mV), el
solapamiento de los picos se produce más comúnmente en voltamperometría que en
cromatografía o la mayoría de métodos espectrales.43
El éxito del método cuantitativo en la mayoría de los casos, puede atribuirse directamente
a que se encuentren condiciones de disoluciones particulares, que proporcionen una resolución
sobre ondas superpuestas. Es precisamente este factor, operando a la inversa, el que dificulta la
posibilidad de realizar análisis cualitativos mediante la voltamperometría. Cuando se conocen
las especies presentes, pueden tomarse medidas para eliminar interferencias; de otra manera, es
casi segura la superposición de ondas de electrólisis si se está estudiando una mezcla.44
7. MÉTODOS DE RESOLUCIÓN DE MEZCLAS.
El problema de la resolución de mezclas de especies electroanalíticas lleva mucho tiempo
estudiándose. Se han ideado gran cantidad de métodos de separación de ondas polarográficas y
voltamperométricas para lograr una correcta y adecuada detección y determinación de sustancias.
Y la investigación continúa.
A continuación se propone una clasificación de los distintos métodos de resolución de
mezclas. Estos se pueden dividir en dos tipos:
w métodos físico-químicos
w métodos basados en la modelización matemática
La última aproximación es mucho más sencilla y se prefiere cuando se usa el electrodo de
trabajo como un sensor electroquímico global o multianalito. No obstante, los métodos de
modelización matemática sufren muchas interferencias debidas al ruido introducido por la
manipulación matemática de la señal de la mezcla o global, denominado ruido de resolución.45
Dentro de los métodos físico-químicos podemos encontrar los siguientes:
# métodos basados en técnicas de separación
# métodos químicos: formación de complejos y ácido-base
# métodos instrumentales
Con referencia a los métodos basados en la modelización, tenemos:
-10-
INTRODUCCIÓN
# método de los espectros cocientes o de división de la señal
# métodos de ajuste
# reconocimiento de patrones
# redes neuronales artificiales
# sistemas expertos y modelos borrosos
Seguidamente, se comentarán cada uno de ellos: metodología, ventajas, aplicaciones, etc.
A) MÉTODOS FÍSICO-QUÍMICOS.
MÉTODOS BASADOS EN TÉCNICAS DE SEPARACIÓN.
Este tipo de métodos , junto con el de formación de complejos y reacciones ácido-base, es
quizás uno de los métodos de resolución de mezclas más antiguos que se han utilizado y, por
tanto, de los primeros en emplearse para tal fin.
Consiste, fundamentalmente, en la separación de las especies que componen la mezcla
mediante varias técnicas, como son el cambio de disolvente o el empleo de resinas de
intercambio iónico.
La aplicación del cambio de disolvente se refiere a la extracción del ion o iones que nos
interesan entre sí y de una mezcla de otros iones interferentes; o bien a eliminar, de una
disolución que se va a investigar, un ion que interfiere con otro u otros que se van a determinar
electroquímicamente. Un ejemplo de éste último caso lo constituye el trabajo realizado por
Almagro Huertas, utilizando polarografía clásica, destinado a la determinación de trazas de
algunos elementos: cobre, cadmio, níquel, cobalto, plomo y zinc en el uranio y sus compuestos.
El uranio (VI), presente en una concentración elevada en toda disolución de ataque de los
materiales que lo contienen, posee una onda a -0,4 V aproximadamente. Al encontrarse en gran
proporción, impide prácticamente la determinación polarográfica directa de cualquier otro
elemento que le acompañe como impureza o como componente de sus aleaciones. Por tanto, es
necesario separar el uranio de los restantes componentes de la disolución de ataque. El uranio
se extrae como un complejo de uranio-fosfato de tributilo a un disolvente orgánico,
especialmente ciclohexano, en presencia de nitrato amónico como agente salino desplazante.46
De este modo, una vez realizada la separación, el resto de las especies presentes en la muestra
pueden determinarse fácilmente por el método polarográfico.
Con respecto a las resinas de intercambio iónico, constituyen un magnífico instrumento para
la separación de iones que se interfieren mutuamente. Éstas pueden ser aniónicas o catiónicas,
-11-
INTRODUCCIÓN
según el tipo de ion que se desea retener, aunque también existen resinas capaces de retener
aniones complejos de los metales. Las resinas de intercambio aniónico han sido estudiadas
detalladamente por varios autores, lo que ha posibilitado el establecimiento de curvas de
absorción de gran número de iones en diferentes condiciones. Así, podría elaborarse un esquema
de separación mediante el cual, los diversos grupos formados por diferentes eluciones permitirían
el análisis de un material en principio complejo.
Varios autores han ideado diversos sistemas para el análisis de mezclas complejas, que
resultan especialmente útiles en la determinación de los microconstituyentes en diferentes
sustancias. Cabe citar la separación y determinación del zinc, cobalto, hierro y cobre, o la del
cadmio, cobre, manganeo, níquel y zinc.
Del mismo modo, también se han llevado a cabo aplicaciones de resinas líquidas a las
separaciones previas en polarografía.47
MÉTODOS QUÍMICOS: FORMACIÓN DE COMPLEJOS Y ÁCIDO-BASE.
Del mismo modo, los métodos químicos de formación de complejos o de reacciones ácidobase48 permiten enmascarar dos o más sustancias presentes en la mezcla, separándolas de la
misma y posibilitando una correcta detección e identificación de la especie de interés, o ampliar
la diferencia existente entre los potenciales de onda media de cada una de las mismas,
impidiendo, de este modo, el solapamiento de las ondas voltamperométricas y alcanzando una
buena separación de la mezcla.37, 39, 45
Generalmente, una combinación del método físico-químico junto con el de complejación,
resultaría más factible que la aplicación individual de los mismos. Como ejemplo, podemos citar,
de nuevo, el trabajo de Almagro Huertas sobre la determinación de trazas de elementos en uranio,
detallado en el apartado anterior, en el cual, el uranio se extrae en forma de complejo y por un
cambio de disolvente, separándolo del resto de las especies.46
MÉTODOS INSTRUMENTALES.
a) Separaciones Electrolíticas.
Las separaciones electrolíticas, especialmente a potencial controlado, son de una gran
utilidad como técnica auxiliar en voltamperometría. Se pueden aplicar a la purificación de
reactivos, a la eliminación de interferencias por cambio de valencia, al aislamiento de elementos
a investigar o a la separación de grupos de elementos compatibles en el análisis polarográfico.
-12-
INTRODUCCIÓN
Todo ello se basa en que cada elemento tiene un potencial de deposición característico,
relacionado con su potencial redox, con el que coincide prácticamente si sus concentraciones no
son muy elevadas. Mediante un potenciostato capaz de controlar intervalos muy estrechos de
potencial pueden separarse elementos cuyos potenciales redox estén muy próximos, incluso en
0,2 V, en determinadas condiciones.
Generalmente, se utiliza un cátodo de mercurio, y los elementos que nos interesan pueden
quedar en disolución o disueltos en el mercurio del electrodo. Cuando ocurre esto último se
pueden recuperar estos elementos destilando el mercurio y recogiendo el residuo, y en otros casos
por maceración de dicho mercurio con ácido clorhídrico o ácido nítrico diluidos.
En otros casos, el cambio de valencia producido en el ion interferente puede eliminar la
onda que produce la perturbación. Un caso típico es la interferencia del ion hierro (III) con un
gran número de especies reducibles, ya que produce una onda a 0,00 V aproximadamente. Si se
produce una reducción prolongada a este potencial, se elimina esta causa de interferencia, ya que
el ion hierro (II) no produce onda hasta -1,5 V aproximadamente.
También adquieren gran importancia la separación de grupos de iones que luego se
determinan simultáneamente. Así, por ejemplo, si durante un cierto tiempo aplicamos a la celda,
con el potenciostato, una diferencia de potencial de -1,0 V, todos los elementos que se reducen
a potenciales menos negativos, como el cobre (II), plomo (II) o cadmio (II), pueden quedar
separados de aquellos que se reducen a potenciales superiores como el zinc (II), manganeso (II)
o aluminio (III).
También, hay que citar el método propuesto por Lingane para la determinación sucesiva de
cobre, plomo, estaño, níquel y cinc. Se electroliza la muestra a -0,35 V en un medio de cloruro
para depositar el cobre después de haber sido determinado inicialmente. A continuación, pueden
determinarse el plomo y el estaño en los medios apropiados, apareciendo sus ondas a un potencial
aproximado de -0,76 V. Después se electroliza la disolución a -0,70 V para depositar todo el
estaño y el plomo, y la disolución que queda sirve para determinar el níquel y el zinc.49
b) Actuación O Modificación Por Ordenador En Tiempo Real.
El método de actuación o modificación por ordenador en tiempo real no es muy conocido.
Consiste en provocar interrupciones en el potencial durante el proceso de medida, de modo que,
al continuar el barrido se alcanza una mejora en la señal, eliminando el solapamiento de los
picos, si no totalmente, por lo menos en gran medida. La interrupción se aplica después de cada
paso de reducción; es decir, cuando se ha detectado el primer componente y comienza la
detección del siguiente, siendo la separación entre ambos menor de 155/n mV.
-13-
INTRODUCCIÓN
Dos de las técnicas voltamperométricas en las que se ha empleado este método son la
voltamperometría en escalera y la onda cuadrada. No obstante, en este último caso, no se
obtienen resultados tan satisfactorios como en la anterior.41, 50
c) Sustracción De Datos Almacenados.
La resolución de mezclas con el método de sustracción de datos almacenados tampoco se
conoce ampliamente. La única limitación que presenta radica en la reproducibilidad de las curvas
intensidad-potencial grabadas.
El proceso de determinación de los componentes en una mezcla binaria A-B es el siguiente:
una vez obtenido el voltamperograma de la mezcla A-B en el potenciostato, se almacena en
memoria. Se prepara un blanco de B y también se almacena. A continuación, se sustrae éste del
polarograma mezcla y se examina visualmente el resultado: si la cantidad de B añadida es la
correcta (extremos de la curva a la misma altura), el paso siguiente consiste en determinar A con
una curva de calibrado; si se ha añadido demasiado B (extremos con valores negativos), se diluye
el blanco y se repite el proceso y si se ha añadido B por defecto (aparece un hombro), habrá que
añadir más cantidad de B y repetir el proceso de nuevo.
Este método no requiere formulación matemática alguna, ni ajustes de curvas, y es aplicable
para cualquier técnica voltamperométrica y para todo tipo de procesos: reversible, irreversible
o controlado cinéticamente. La altura de los picos de la mezcla, unas vez determinados sus
componentes, es idéntica a la de las muestras por separado, dentro del error experimental del ±
1%.
La determinación de la onda correcta debe hacerse de acuerdo con la comparación de
potenciales de pico y la forma de la onda (anchura media) con respecto a las curvas de
calibración.
Un problema que presenta es que conforme se aproximen más los potenciales medios de
onda de las especies de la mezcla, mejor hay que afinar en el análisis, hasta el punto de alcanzar
una completa anulación en el procedimiento de sustracción cuando se desean determinar especies
con el mismo valor de potencial medio de onda.39
B) MÉTODOS BASADOS EN MODELIZACIÓN MATEMÁTICA.
MÉTODO DE LOS ESPECTROS COCIENTES O DE DIVISIÓN DE LA SEÑAL.
Éste método se aplica fundamentalmente al estudio de señales completas, las cuales pueden
-14-
INTRODUCCIÓN
tratarse también como un conjunto de muestras.
El método de los espectros cocientes o de división de la señal trata situaciones extremas de
solapamiento de ondas que son imposibles de resolver adecuadamente mediante el uso de otros
métodos. En este caso, se dispone de una mezcla de analitos con un exceso muy grande de uno
de ellos (concentración muy alta, de varios órdenes de magnitud con respecto a los otros) en las
que se pretende determinar el o los componentes minoritarios.
El proceso se lleva a cabo del siguiente modo: la señal global, correspondiente a una mezcla
de tres iones, se divide por la señal individual del componente mayoritario multiplicada por un
factor f. De este modo, se pretende eliminar lo más posible la contribución a la señal global del
componente en exceso, demostrando así la existencia de los componentes minoritarios.
La expresión aplicada para la resolución de los picos es la siguiente:
I global =
I global + I k
f ⋅ I indiv + I k
donde: Iglobal representa la intensidad de la señal global (mezcla de todos los componentes); Iindiv
es la intensidad de la señal del componente individual (el que se encuentra en exceso, a la misma
concentración que en la mezcla); Ik es un factor empleado para evitar divisiones por cero o entre
valores muy pequeños (varía entre un 1 y un 30% de la señal global) y f es el factor de
multiplicación.
La señal del compuesto en mayor concentración no se emplea tal cual, sino que se utiliza
parte de ella, ya que el componente individual no contribuye sólo a la señal global (se emplea un
90 - 95% de la señal individual, mediante un valor de f de 0,90 ó 0,95). Hay que aproximarse lo
más posible a esta contribución para que, al dividir, aparezcan los otros dos iones, que
contribuyen en menor proporción, pero lo suficiente para no poder usar la señal individual total.
De este modo, se pueden separar analitos, cuyos potenciales de onda media difieren menos
de 80 mV. El error relativo cuantificado es inferior al 10%, si se emplea éste sistema.45
Otra posibilidad es la de dividir la señal global por una señal exponencial del componente
en exceso, es decir, elevada a un exponente. De este modo, conforme aumenta ese exponente,
más aguda se hace la función del denominador y mejor resolución aporta. No obstante, esto
introduce un nuevo problema: el fenómeno de sobreagudización, que consiste en la aparición de
picos “fantasmas” o “artefactos” que no pertenecen a ninguna especie presente en disolución y
que impiden una correcta identificación de los picos correspondientes a cada sustancia. Aún así,
la distorsión introducida es menor que cuando se emplean algunos métodos de tipo matemático,
como por ejemplo, la transformada de Fourier. En este caso, se llegan a determinar especies
-15-
INTRODUCCIÓN
cuyos potenciales de onda media están separados unos 70 mV, lográndose una reproducibilidad
inferior al 5%. No obstante, el método de división de la señal es aplicable si los componentes de
la muestra son conocidos y si su potencial de pico es independiente de la concentración, dentro
de los límites del error experimental. La mezcla se resuelve finalmente con diagramas de
calibración.30
Una variante del método de los espectros cocientes es el de los espectros cocientes
derivados, que consiste en la unión de dos técnicas: la de derivación (“zero-crossing”) y la
comentada en este apartado. Éste método ha sido aplicado también con éxito en
espectrofotometría, para la resolución de mezclas binarias por medidas de áreas de sus espectros
cocientes51.
MÉTODOS DE AJUSTE.
Los métodos de estimación de parámetros constituyen una disciplina relacionada con el
ajuste de los datos a modelos matemáticos. Es útil cuando se desea establecer relaciones directas
entre la respuesta y la concentración diferentes a la forma lineal o no lineal.
Los modelos usados en rutinas de estimación de parámetros pueden ser analíticos,
expresables en forma ajustada o generados numéricamente. Los de forma ajustada pueden
proceder a su vez de relaciones teóricas para el sistema en estudio o derivados empíricamente.
Por otro lado, los numéricos requieren cálculos extensos para generar la función de respuesta
apropiada.
Debido a que estos modelos son con frecuencia más complejos que los de calibración
multivariante, algunas variantes de regresiones no lineales son utilizadas para ajustar el modelo
a los datos.
A continuación, se comentarán algunos de estos métodos de ajuste, según si se encuentran
referidos a una muestra o a una señal completa.
a) Métodos Referidos Al Tratamiento De La Muestra.
1) Regresión Lineal Múltiple.
El método de regresión lineal múltiple o MLR se emplea cuando muchas variables
independientes están relacionadas linealmente con un conjunto de variables dependientes. Cada
variable dependiente r se expresa como combinación lineal de un conjunto de variables
independientes (el conjunto de n concentraciones ci):
-16-
INTRODUCCIÓN
r=
n
∑b
i= 0
i
⋅ ci + f
donde, para el caso de una voltamperometría, r representa la intensidad de corriente, bi y ci son
respectivamente el coeficiente de regresión y la concentración de la especie i, n es el número total
de analitos en la mezcla y f el término de error. (Ejemplo: una muestra de agua donde se mide
la concentración de Fe3+, Cu2+ y Zn2+.)
La ecuación anterior describe la dependencia multilineal para una única muestra. Si existen
respuestas múltiples de cada medida, es decir, varias muestras, la ecuación anterior se transforma
en la siguiente expresión:
r = C⋅ b + f
Ahora todos los parámetros representan matrices, donde r, b y f son vectores o matrices columna.
(Ejemplo: tres muestras distintas de agua donde se mide la concentración de las tres especies
anteriores.)
Si existe más de una variable dependiente, en notación matricial, la ecuación toma la forma
del modelo clásico:
R = C⋅ B+ F
(Ejemplo: un conjunto de n muestras de agua donde se mide la concentración de m variables en
p condiciones de pH.)
Para un conjunto de variables dependientes e independientes el fin de la calibración consiste
en estimar la matriz de los coeficientes de regresión B, que define el modelo MLR. No obstante,
se pueden distinguir tres situaciones:
w m > n; hay más variables que muestras. En este caso hay un número infinito de
soluciones para B, que ajustan la ecuación.
w m = n; el número de muestras es igual al de variables. Ofrece una única solución para
B. Esto nos permite escribir: F = Y ! XB = 0, donde F es la matriz de residuos, la cual
es nula.
w m < n; hay más muestras que variables. Esto no proporciona una solución exacta para
B; sin embargo, se puede conseguir una solución minimizando la matriz de los residuos
en la siguiente ecuación: F = Y ! XB.
El método más popular para hacer esto se denomina el método de mínimos cuadrados, cuya
-17-
INTRODUCCIÓN
solución es la siguiente:
B = ( C t C) ⋅ C t R
−1
La regresión por mínimos cuadrados ajusta bien los coeficientes cuando las variables
independientes son casi o totalmente ortogonales. Si existe cierta correlación entre las variables
independientes se producen problemas en la estimación de la matriz de los coeficientes B. Esto
se evita prestando especial atención a la hora de realizar las medidas de las mezclas, haciendo
uso de un buen diseño experimental.52, 53
Las aplicaciones del modelo MLR han sido muy diversas: se ha empleado para el estudio
de electrodos selectivos de iones, así como para aspectos de calibración no lineal de los mismos
y también para el análisis de datos voltamperométricos.
2) Regresión Por Mínimos Cuadrados Clásica.
Denominado también por los espectroscopistas método de matriz K y según los autores:
calibración total o directa. Constituye el primer método de regresión aplicado en el análisis
multivariante y está basado en el modelo de la ley de Beer que, para datos espectrales, es el
siguiente: la absorbancia a cada frecuencia es proporcional a la concentración, tal que se asume
que el error se centra en dicha respuesta. El modelo de la ley de Beer para m estándares de
calibración que contienen l componentes químicos con espectros de n respuestas digitalizadas
viene dado por:
A = C ⋅ K + EA
donde A es la matriz de orden m×n de los espectros de calibración; C es la matriz m×l de las
concentraciones de los componentes; K es la matriz l×n de los productos de longitud de pasoabsortividad y EA es la matriz m×n de los errores espectrales o residuos no ajustados por el
modelo. K representa, por tanto, la matriz de concentración de los espectros de los componentes
puros y longitud de paso unidad.
La solución de la ecuación durante la calibración es:
$ = ( C t C) −1 ⋅ C t A
K
$ son las estimaciones por mínimos cuadrados de la matriz K con la suma de los errores
donde K
espectrales al cuadrado que están siendo minimizados.
Durante la predicción, la solución de mínimos cuadrados para el vector de las
concentraciones de los componentes desconocidos, c, es:
-18-
INTRODUCCIÓN
$ ⋅K
$ t)⋅ K
$ ⋅a
c$ = ( K
donde a es el espectro de la muestra desconocida. El espectro de componentes puros (filas de K)
son los factores o vectores de carga y las concentraciones químicas (elementos en C) son los
puntos.
El modelo transforma la representación del espectro de calibración en un nuevo sistema de
coordenadas, siendo las nuevas coordenadas los l espectros de los componentes puros. Las l
intensidades espectrales para cada mezcla en el nuevo sistema de coordenadas de espectros de
componentes puros son los elementos de C; esto es, las intensidades en el nuevo sistema son las
concentraciones de los componentes.
Al tratarse de un método de espectro completo ofrece cierta mejora en la precisión con
respecto a los métodos que están restringidos a un número de frecuencias pequeño; además,
permite el ajuste simultáneo de las líneas base espectrales y es muy útil para el examen e
interpretación de los residuos del espectro completo y del espectro de componentes puros
estimado por mínimos cuadrados.
No obstante, esta técnica requiere conocer todos los componentes químicos interferentes
e introducirlos en la calibración.
Cuando el solapamiento abarca todo el espectro de señales, se debe poseer información
sobre todos los componentes de la muestra para un análisis espectral cuantitativo seguro.
Por último, el tipo de información que puede extraerse de un CLS es la siguiente: existencia
de interacciones moleculares y qué parte de las mismas presente en la muestra interactúan;
existencia de no linealidad espectrométrica; presencia e identificación de componentes no
esperados en muestras desconocidas; presencia de interferentes; determinación de los
componentes que reaccionan en la mezcla reactiva y aquellos que constituyen los productos de
la reacción e información que permite una asignación estructural y química rápida de las bandas
espectrales.54
3) Regresión Por Mínimos Cuadrados Inversa.
El método ILS o de matriz P, para los espectroscopistas, recibe muchos nombres en la
literatura: MLR, calibración indirecta o parcial. Difiere del anterior en que la concentración es
función de la absorbancia, todo lo contrario que ocurría con el CLS. El modelo de la ley de Beer
inversa para m estándares de calibración con un espectro de n absorbancias digitalizadas viene
dado por:
C = A ⋅ P + EC
-19-
INTRODUCCIÓN
donde C y A poseen el mismo significado que en el apartado anterior; P es la matriz n×l de los
coeficientes de calibración desconocidos que relacionan las l concentraciones de los componentes
con las intensidades espectrales y EC es el vector m×l de los errores de concentración al azar o
los residuos que no ajusta el modelo.
Si se asume que el error del modelo radica en el error de la concentración de los
componentes, el método minimiza los errores al cuadrado en las concentraciones durante la
calibración.
El uso de la ley de Beer inversa presenta la ventaja de que el análisis es univariante con
respecto al número de componentes químicos l, incluidos en el mismo.
Al considerar que los elementos en las distintas columnas de EC son independientes, un
análisis idéntico para cada analito individual puede obtenerse considerando el modelo reducido
para un componente:
c = A ⋅ p + ec
donde c es el vector m×1 de las concentraciones del analito de interés en m muestras de
calibración; p es el vector n×1 de los coeficientes de calibración y ec el vector m×1 de los
residuos de la concentración no ajustados por el modelo.
Durante la calibración, la solución de mínimos cuadrados para p en la ecuación anterior
viene dada por:
p$ = ( A t A ) ⋅ A t c
−1
En el proceso de predicción, la solución para la concentración del analito en una muestra
desconocida es:
c$ = a t ⋅ p$
Esto implica que el análisis espectral cuantitativo puede hacerse si sólo se conoce la
concentración de un componente en la mezcla de calibración. Los componentes no incluidos en
el análisis deben estar presentes y modelados implícitamente durante la calibración.
Las desventajas del ILS se enumeran a continuación: el análisis está restringido a un
$
número pequeño de frecuencias, debido a que la matriz que hay que invertir en la ecuación de p
tiene una dimensión igual al número de frecuencias y este número no puede exceder el número
de mezclas de calibración empleadas en el análisis; además, un número de frecuencias elevado
en el análisis origina problemas de relaciones lineales, lo que provoca cierta degradación en los
resultados.
La mejora en la precisión y las ventajas del CLS no son posibles con el ILS. La
-20-
INTRODUCCIÓN
determinación del número de frecuencias a incluir en el análisis no es trivial para mezclas
complejas; una mala elección dará lugar a problemas de modelización de la línea base, a una
inflación del ruido debido a la colinealidad y a un sobreajuste.54
Como se ha podido comprobar, tanto el ILS como el CLS utilizan técnicas similares a las
de MLR, pero con distintas propiedades, ventajas y desventajas.
4) Regresión Por Mínimos Cuadrados Parciales.
El modelo PLS está construido sobre las propiedades del algoritmo NIPLS. La regresión
por mínimos cuadrados parciales extiende la idea de usar el modelo inverso y reemplazar las
variables con un conjunto truncado de sus componentes principales. Según algunos autores,53 es
un método mucho más robusto que el PCA y el MLR, ya que los parámetros del modelo no
varían mucho cuando se toman nuevas muestras de calibración del total de la población. Además,
se trata de un método de análisis de varios factores, al igual que el PCR y el CLS, aunque éste
último no se presenta normalmente como tal.
En el PLS, las variables independientes X y las dependientes Y se autodescomponen
simultáneamente. Las ecuaciones del PLS, que representan las relaciones externas, son:
∑t ⋅p
+ F = ∑ u ⋅q
X = T ⋅ Pt + Ω =
Y = U ⋅ Qt
h
h
t
h
+Ω
t
h
+F
donde T y U son los puntos para cada bloque, X e Y; P y Q son las cargas respectivas y Ù y F
son las matrices de los residuos, construidas a partir de los puntos y cargas de los componentes
principales descartados.
La descomposición simultánea de X e Y viene controlada por la relación interna:
u$ h = b h ⋅ t h
donde bh es el vector de los coeficientes de regresión para el componente principal h-ésimo en
los bloques X e Y. Juega el mismo papel que los coeficientes de regresión bi en los modelos PCR
(regresión de componentes principales) y MLR.
Si en la relación externa para la variable Y, el factor uh es reemplazado por su valor
estimado ûh, se obtiene una relación mezclada que posee la siguiente expresión:
Y = T ⋅ B⋅ Qt + F
la cual, asegura la posibilidad de usar los parámetros del modelo a partir de un conjunto de
-21-
INTRODUCCIÓN
prueba.
Una forma de mejorar la relación interna es mediante el intercambio de puntos entre ambos
bloques de variables, X e Y. Además, para obtener puntos del bloque X que sean ortogonales,
como en PCA (análisis de componentes principales), es necesario introducir pesos.
La parte más importante de cualquier regresión es su utilización en la predicción del bloque
dependiente a partir del independiente. Esto se lleva a cabo por la descomposición del bloque X
y la construcción del Y. Para ello se requiere un número de componentes adecuado. Si el modelo
fundamental que relaciona ambas variables es un modelo lineal, el número de componentes
necesarios para describir este modelo es igual a la dimensionalidad del mismo. Modelos no
lineales exigen componentes extra que describan la no linealidad. El número de componentes que
se van a utilizar es una propiedad muy importante del modelo PLS.52, 53
Uno de los métodos mayormente empleados para la determinación del número de
componentes se denomina método de validación cruzada, basado en el cálculo del estadístico
PRESS o suma de los cuadrados de los residuos de predicción. Dado un conjunto de m muestras
de calibración se lleva a cabo la calibración a partir de m-1 muestras y, a través de ella, se predice
la concentración de la muestra suprimida durante el proceso de calibración. El esquema se repite
un total de m veces hasta que cada muestra haya sido suprimida una vez del conjunto. La
concentración predicha para cada muestra se compara luego con la concentración conocida en
la de referencia. El PRESS para todas las muestras de calibración es una medida de la bondad
del ajuste de un modelo PLS particular para una serie de datos de concentración. El PRESS se
calcula del mismo modo cada vez que un nuevo factor es añadido al modelo, tal que el número
de componentes cuyo PRESS sea mínimo será el que ofrezca una predicción óptima del mismo.
Pero éste mínimo no se encuentra bien definido la mayoría de las veces, ya que la medida de la
bondad del modelo a través de este método está basado en un número finito de muestras y, por
tanto, sujeto a error. Esto es, si se utiliza un número de factores h* que logran el PRESS mínimo,
se suelen producir sobreajustes.
Un mejor criterio para seleccionar el modelo óptimo implica la comparación del PRESS
a partir de modelos con un menor número de factores que h*. El modelo seleccionado es aquel
con el menor número de factores, tal que el PRESS para ese modelo no es significativamente
mejor que el PRESS para el modelo con h* factores. Se emplea el estadístico F para establecer
el límite de significación, de modo que el número de factores para el primer valor de PRESS
cuya relación de probabilidad de F cae por debajo de 0,75 es el que se selecciona como óptimo,
según Haaland y Thomas.
Otro posible criterio para seleccionar el modelo óptimo, el cual puede no ser tan sensible
a la existencia de interferencias, implica la estimación del error en el PRESS. El modelo
-22-
INTRODUCCIÓN
seleccionado sería aquel que posee el número más reducido de vectores de carga que alcanza un
PRESS dentro de un error estándar del PRESS obtenido a partir del modelo que alcanza el
PRESS mínimo. Tan sólo ocasionalmente se alcanza un número diferente de factores por ambos
métodos.54
Una vez obtenido el número óptimo de factores PLS, se necesita desarrollar la calibración
final, usando todas las m muestras de calibración con esos factores.
PCR y PLS se basan en la regresión de las concentraciones químicas sobre variables
latentes o factores, difiriendo uno de otro en que el segundo utiliza datos de concentración a
partir del conjunto de entrenamiento y de los datos del espectro en la modelización. Un gran
número de experimentos electroquímicos generan datos cuantitativos útiles que pueden ser
tratados con ambos métodos. Por ejemplo, algunos autores usaron el PLS para resolver
cuantitativamente respuestas solapadas obtenidas de voltamperometría de redisolución anódica
de pulso diferencial. Demostraron que calibrando con PLS un conjunto de datos pequeño, para
un problema de dos componentes, se obtuvo un resultado superior que cuando se aplicó un
análisis mucho más sencillo, que empleó tan sólo la corriente medida a dos potenciales para
resolver las ecuaciones simultáneas para las concentraciones.
Todo aquel conjunto de datos que no pueda usarse directamente para modelización por
software o métodos de calibración, puede ser transformado previamente al análisis. En esto se
basan ciertas investigaciones en las que se desarrolla un modelo de calibración para una serie de
electrodos selectivos de iones empleados en la determinación simultánea de Ca, Mg, K y Na. Los
errores de predicción obtenidos fueron inferiores a los del modelo MLR. La disparidad
aumentaba conforme al número de sensores en la serie. A mayor número de electrodos, más
información redundante en el conjunto de respuestas de los sensores para cada muestra. Esta
correlación es la responsable de la degradación de los resultados observados en MLR, de ahí que
el error fuese mayor en este modelo que con el PLS. En éste último, la colinealidad o
dependencia en las respuestas de los sensores no afecta al resultado, ya que la regresión está
mejor condicionada gracias al intercambio de puntos entre los bloques X e Y.
En resumen, cuando existen un gran número de variables en la calibración, PLS da un
resultado significativamente mejor que el modelo MLR.52, 53
Recientemente, se ha publicado un trabajo en el que se comparan dos métodos de PLS:
PLS-1 o normal y PLS-2; en el primero, los análisis de calibración y predicción se realizan para
un sólo componente y en el segundo para dos o más componentes simultáneamente. Ambos se
emplearon en la resolución de mezclas de tres componentes en dos tipos de diseños: triangular
y ortogonal, en técnicas espectroscópicas de absorción y de primera derivada. El número de
factores se determinó mediante validación cruzada. Las conclusiones obtenidas fueron que no
-23-
INTRODUCCIÓN
existía diferencia alguna entre los modelos de PLS empleados y que el diseño del conjunto de
calibración es muy importante para la habilidad predictiva del método de calibración
multivariante, siendo conveniente en algunos casos derivar antes la señal.
Posteriormente, Haaland y Thomas encontraron que en muestras reales, el modelo PLS-1
alcanzaba una mejor predicción que el PLS-2, aplicándose éste último para reconocimiento de
patrones más que para predicción de especies individuales. También explicaron el método PLS
y la base para cada paso de ejecución del algoritmo en cada una de las etapas: calibración y
predicción.54
También es de especial interés la aplicación del método PLS llevada a cabo por EspinosaMansilla et al., dirigida a la determinación simultánea del 2-furfuraldehido, 5hidroximetilfurfuraldehido y malonaldehido en mezclas, mediante técnicas de espectrofotometría
derivada.55
Otros campos de aplicación del PLS son la espectrofotometría UV, de IR próximo y la
cromatografía.
5) Regresión Por Búsqueda De Proyecciones.
En ocasiones, una relación entre variables dependientes e independientes no puede forzarse.
Para estos casos, existe un método de calibración no lineal denominado regresión por búsqueda
de proyecciones. La matriz de las variables de respuesta R es modelada como una función de
combinaciones lineales de variables independientes, por ejemplo, concentraciones. La función
usada es un atenuador de ruido determinado empíricamente:
K
r j = G j ⋅ ∑ θ kj ⋅ c k + f j
k =1
donde rj es el vector del bloque de respuestas; Gj es la función de atenuación univariante; è kj el
coeficiente de regresión; ck el vector de concentración para la especie k-ésima y fj el error
asociado con el ajuste de la respuesta para el sensor j-ésimo.
La función de eliminación de ruido puede usarse directamente o reemplazándolo por una
función analítica apropiada. La regresión por búsqueda de proyecciones es útil cuando no se
requieren conocimientos previos de datos o del modelo físico fundamental; no obstante, se puede
usar la expresión analítica para el modelo físico si ésta es conocida o puede estimarse.
El algoritmo comienza seleccionando un conjunto inicial de coeficientes indicadores è;
luego, para la respuesta, se genera un atenuador o eliminador de ruido G como una función de
combinaciones lineales seleccionada. A partir de la función de respuesta atenuada, se determina
-24-
INTRODUCCIÓN
la fracción de la variación no implicada en los datos y se utiliza para evaluar el ajuste. Si el valor
de la variación no explicada contenida en el ajuste cae por debajo de un umbral definido por el
usuario, el algoritmo de regresión culmina en este punto. Alternativamente, el proceso anterior
puede repetirse hasta obtener la tolerancia deseada.
Aunque se puede linealizar cualquier respuesta no lineal (algoritmo de LevenbergMarquardt) existe un límite de exactitud para cualquier método de linealización.
Con electrodos selectivos de iones es donde más comúnmente se producen relaciones de
no linealidad entre la respuesta y la concentración. Una de las aplicaciones de la regresión por
búsqueda de proyecciones ha ido por este camino y más concretamente a la calibración
multivariante de una serie de electrodos de este tipo. La respuesta de los electrodos constituyó
la matriz de respuestas, R y las concentraciones fueron las variables indicadoras, C. En este caso,
la función de eliminación de ruido fue sustituida por una expresión logarítmica empírica, que
modelaba la respuesta teórica de los electrodos selectivos de iones.
Cuando existen datos de calibración limitados es preferible utilizar la calibración con MLR
o PLS antes que este otro método.52
Existe mucha bibliografía que trata sobre comparación de distintos métodos de análisis y
calibración multivariante con respecto a una técnica en particular.
Un ejemplo lo constituye el trabajo de McClaurin et al. aplicado a la espectrofotometría UV
/ visible. En este caso, se contrastan tres métodos diferentes: PCR, PLS y análisis
multicomponente directo o DMA. PCR y PLS son métodos de calibración indirectos, que no
requieren las señales individuales de cada analito, ni necesitan conocer con antelación las
interferencias presentes en la disolución; sin embargo, requieren por otro lado un conjunto
adecuado de muestras de calibración que representen todos los fenómenos físico-químicos
esperados que puedan influir en la señal de las muestras para la predicción. En este conjunto se
debe conocer la concentración de cada analito y no así las interferencias. En contraste con ambos,
DMA sí necesita conocer ambos parámetros para calibrar con éxito. Para sistemas de 3 y 4
componentes resulta mejor el DMA, aunque la diferencia con respecto a los otros es mínimo.
Mientras que para sistemas de 5 componentes, aquel no es aplicable, siendo mejor PLS o PCR,
sin discrepancia entre ambos.56
Entre los trabajos más importantes que reflejan la diferente utilidad de los distintos métodos
de análisis y calibración multivariante se encuentran los dirigidos por Haaland y Thomas.
En el primero de ellos,54 se lleva a cabo un estudio teórico comparativo de diversos
métodos: regresión por mínimos cuadrados clásica o CLS, regresión por mínimos cuadrados
inversa o ILS, PLS y PCR, los cuales son empleados en investigaciones posteriores en el análisis
cuantitativo de datos espectrales. Tras dar una serie de explicaciones breves acerca del
-25-
INTRODUCCIÓN
fundamento de cada uno de ellos, haciendo especial hincapié en el PLS, demuestran que la
calibración PLS está compuesta por una serie de pasos CLS e ILS simplificados: etapa de
calibración CLS, seguida de una predicción y calibración ILS. Por medio de esto, han podido
identificar información espectral cualitativa interpretable químicamente, a través de los pasos
intermedios del algoritmo, afirmando que esta información es superior a la obtenida del método
PCR, pero no tan completa como la que se genera durante un análisis CLS. Descubren que el PLS
tiene propiedades que combinan ventajas separadas de los otros dos métodos de regresión,
mejorando las del PCR y establecen el método de obtención del número de factores a incluir en
el análisis a través del cálculo del PRESS y su relación con el estadístico F, proceso que se ha
comentado con anterioridad. De la información que puede obtenerse a partir del PLS hay que
destacar lo siguiente: el primer vector de carga con peso, ë1, aproximación de primer orden al
espectro del componente puro del analito, puede usarse para asignar bandas y determinar qué
regiones del espectro son más relevantes para un analito en particular; y el vector bf, vector de
los coeficientes de regresión de la calibración final, indica qué región es importante para la
predicción y está relacionado con el espectro del componente puro, teniendo en cuenta todos los
efectos producidos por las interferencias y algunos provocados por las interacciones moleculares,
componentes no esperados y variaciones de la línea base. No obstante, es incapaz de detectar
desviaciones de la linealidad, ya que es capaz de modelar algunos de estas situaciones. Como
conclusión final a esta investigación, los autores afirman que a menos que uno de los vectores
de carga mayoritarios del PCR se encuentre directamente relacionado con el componente de
interés, éste método será generalmente menos útil para obtener información que el PLS y el CLS,
descartándose totalmente el ILS.
En un trabajo posterior,57 vuelven a compararse de nuevo los métodos PLS, CLS y PCR,
pero esta vez para datos de espectros de IR de cristales basados en silicatos. Mediante el análisis
de un conjunto de datos espectrales simulados, observaron que el PLS se aproxima al modelo de
predicción óptimo mucho más rápidamente que el PCR, siendo además computacionalmente más
eficaz. Sin embargo, no existe ninguna diferencia significativa entre sus errores de predicción.
Ambos modelos son muy superiores al CLS, ya que en éste sólo se conoce la concentración de
un analito en las muestras de calibración y los componentes desconocidos solapan todas las
características espectrales de los analitos. Su precisión mejora considerablemente cuando se
conoce la concentración de tres componentes en la calibración, sin que varíe en ningún momento
la de los otros dos.
Para terminar, a través de una última investigación,58 Haaland y Thomas contrastaron la
habilidad de predicción cuantitativa de cuatro métodos de calibración multivariante: PLS, CLS,
ILS y PCR, para el análisis de datos simulados bajo un amplio conjunto de condiciones
-26-
INTRODUCCIÓN
experimentales: de referencia; ruido espectral; ruido de concentración; solapamiento espectral;
linea base al azar; número de puntos de datos espectrales; diseño de calibración y número de
muestras de calibración, con el fin de estudiar cómo afecta cada uno de esos factores sobre los
distintos métodos. El resultado fue que los métodos de espectro completo (CLS, PLS y PCR)
superaban al ILS en un amplio rango de condiciones experimentales, de tal modo que, éste pasa
a ser competitivo cuando el conjunto de calibración está contaminado con errores razonablemente
grandes. Por otro lado, PCR y PLS resultaron muy parecidos, destacando éste en varias
situaciones: cuando se adiciona una línea base al azar y si existen componentes espectrales
mayoritarios que varían independientemente y que solapan con las características espectrales del
analito. Por tanto, la elección óptima del método de calibración depende de las condiciones
experimentales particulares. No obstante, según los autores, el PLS parece ser la elección más
razonable para un amplio rango de condiciones. El único peligro inherente que conlleva la
elección de éste o del PCR radica en los ajustes por exceso o por defecto que resultan de un
número inapropiado de factores. Por último, consideran que en el caso de que el modelo de la ley
de Beer sólo fuese válido para unas cuantas intensidades espectrales, el método ILS superaría con
creces a los de espectro completo, ya que estos contendrían intensidades espectrales fuera del
rango de aceptación del modelo.
Un último ejemplo, pero dedicado esta vez a la espectroscopía de absorción es el llevado
a cabo por Navarro-Villoslada et al.,59 los cuales han realizado un estudio comparativo para
seleccionar mezclas de calibración y longitudes de onda en métodos de calibración multivariante.
Los métodos estudiados fueron CLS, ILS, PLS, PCR y filtrado Kalman.
La elección del método de calibración depende de las condiciones del sistema particular.
Cuando se emplean datos experimentales, en vez de simulados, el conocimiento de su
comportamiento puede no sea predicho debido a una variedad de parámetros, principalmente:
ruido espectral y de concentración, número de longitudes de onda, así como las muestras
utilizadas en el conjunto de calibración, grado de solapamiento espectral, presencia de un pulso
de línea base y el error del modelo. Por otro lado, una aproximación muy común es la de usar un
diseño de mezclas para muestras sintéticas asegurando que se incluyen todas las variaciones
importantes. No obstante, existen limitaciones prácticas y económicas acerca del número de
muestras de calibración que van a usarse.
Para cada método, las muestras de calibración fueron seleccionadas al azar a partir de una
población total de 37 estándares de calibración, teniendo en cuenta el error estándar de predicción
o SEP:
-27-
INTRODUCCIÓN
p
SEP =
∑
(c
$
ij − c ij
i =1
)
2
p
donde ‡ij es la concentración estimada del componente j-ésimo para la muestra desconocida iésima, cij es la concentración real del componente j-ésimo y p es el número de muestras
desconocidas. De este modo, para CLS y filtro Kalman se eligieron 20 mezclas de calibración,
15 para PLS y PCR y, por último, 20 para ILS.
La selección las longitudes de onda analíticas para cada método se realizó utilizando
diferentes criterios: el número de condiciones para CLS y filtro Kalman, la relación señal/ruido
y el número de condiciones para el método ILS, y todos los criterios previos y el espectro
completo para PCR y PLS.
Los mejores resultados se obtuvieron empleando el número de condiciones como criterio
para seleccionar las longitudes de onda analíticas; es decir, el rango de 280 - 300 nm para CLS
y filtro Kalman, entre 10 - 15 longitudes de onda para el ILS y para PLS y PCR también 15
longitudes de onda, en cuyo caso se corresponden con 5 factores, ya que el uso del espectro
completo requería 6.
Todos los métodos se aplicaron para evaluar la habilidad predictiva de cada método en la
determinación de la concentración de clorofenol en mezclas binarias, ternarias y cuaternarias,
mediante espectroscopía de absorción. Las mezclas empleadas fueron 14, elegidas al azar. Los
resultados fueron similares en todos los casos.
6) Métodos Discontinuos Para Regresión No Lineal.
En la regresión no lineal, la respuesta medida, y, es modelizada como una función no lineal
ö de un conjunto de parámetros que van a ser estimados, è i. Las funciones objeto Î que son
minimizadas en la regresión no lineal consisten normalmente en una suma pesada de los errores
al cuadrado entre la respuesta medida y la predicha:
Ξ=
m
∑
j= 1
(
)
w j ⋅ y j − θ j ⋅ (θ 1 , θ 2 , θ 3 ,..., θ N )
2
donde wj son los coeficientes de peso. En el caso más simple, todos los pesos son iguales entre
sí y toman el valor 1.
Minimizando esta función objeto con respecto a los parámetros è i, resulta en un ajuste por
-28-
INTRODUCCIÓN
mínimos cuadrados no lineales del modelo h y el conjunto de parámetros è i a los datos. El
proceso se realiza iterativamente, en una búsqueda directa o por gradientes descendentes, según
el tipo de mínimo que exista en el área de estudio. El método del gradiente requiere información
derivada, la cual puede proporcionarse numérica o analíticamente.
Es posible modificar la función Î , tal que se lleve a cabo una búsqueda condicionada del
óptimo.
Una regresión no lineal, basada en la optimización simplex, se ha empleado con éxito para
una búsqueda directa en conjunción con un modelo de simulación de las diferentes finitas
explícitas o EFD.
En la literatura se ha propuesto un método de estimación de parámetros basado en el
simplex, que luego ha sido refinado para dar lugar al algoritmo COOL. Éste permite la
estimación de parámetros cinéticos y termodinámicos a partir de voltamperogramas de impulso
de sistemas que siguen un mecanismo E con cinética cuasireversible. Algunas aplicaciones del
método incorporan correcciones al efecto de la doble capa eléctrica sobre la cinética de la
reacción observada.
Este algoritmo posee varias ventajas: el escalado automático de las dimensiones del
modelo, eliminando la necesidad de exactitud en las medidas del área del electrodo y las
concentraciones de la disolución; la compensación mediante el instrumento a través de la
estimación de los parámetros de intersección de la regresión y que los intervalos de confianza son
calculados a través de la probabilidad máxima para cada uno de los parámetros estimados.
En principio, este método se ha aplicado al ajuste de series de voltamperogramas de onda
cuadrada a distintas frecuencias, aunque también se ha utilizado en impulso.
La regresión no lineal también se ha utilizado para los siguientes casos: el ajuste de datos
polarográficos, la resolución de voltamperogramas solapados, el análisis de áreas de respuesta
producidas por ondas polarográficas, la extracción de información cinética a partir de
polarografía de pulso diferencial mediante regresión no lineal basada en el simplex, análisis de
procesos EC de primer orden por el ajuste de polarogramas de corriente directa y derivativos, y
para análisis de datos de admitancia e impedancia, entre otros.
Como ejemplo de los métodos de regresión no lineal, podría destacarse el ajuste de datos
de voltamperometría de paso de potencial y semiderivativa, llevado a cabo por Boudreau y
Perone, a funciones gaussianas y de Cauchy asimétricas, aplicado todo ello a la resolución de
espectros solapados, aplicación que podrá constatarse cuando estudiemos la deconvolución
numérica en apartados posteriores.41
En otros trabajos, se ha llegado a resolver picos de componentes con una separación del
orden de 40 mV, empleando técnicas de voltamperometría de barrido lineal diferencial y de
-29-
INTRODUCCIÓN
redisolución anódica semidiferencial.
La estimación de parámetros cinéticos electroquímicos desde datos de cronoamperometría
y cronocoulometría empleando regresión no lineal y búsqueda simplex está bien establecida. Hay
que señalar algunas investigaciones en las que se empleó una linealización que transformó la
estimación no lineal en una regresión lineal. Esta aproximación hace uso de la misma estrategia
básica que sustenta el algoritmo COOL.
En la mayoría de estudios de regresión no lineal apenas se ha aplicado el problema del error
en la estimación de los parámetros obtenidos en el ajuste. Además, tampoco se han elegido
apropiadamente un conjunto de coeficientes de paso para la regresión, otra etapa crítica a la que
se ha prestado muy poca atención.
Para minimizar la elevada carga computacional, principal desventaja de este conjunto de
métodos, algunos autores, junto con la simulación por diferencias finitas explícita, emplearon el
algoritmo de Levenberg-Marquardt, un método de ajuste y estimación mucho más eficiente. Pero
incluso en este caso, hay que ejecutar la simulación completa para cada iteración en la regresión,
lo que supone un respetable cálculo computacional.52
7)
Estimación De Parámetros Por Calibración Para Datos
Característicos.
Se ha propuesto un método alternativo de estimación de parámetros voltamperométricos
basado en el desarrollo de correlaciones empíricas entre parámetros de sistemas relevantes, tales
como constantes de velocidad homogénea y heterogénea y las características de respuestas
voltamperométricas producidas por estos sistemas.
Estos autores desarrollaron un paquete de simulaciones para generar voltamperogramas que
modelizaran un amplio rango de cinética de sistemas, dando lugar a curvas de trabajo para cada
mecanismo en estudio. Características clave, como la posición del pico, se pueden extraer de la
serie de voltamperogramas. Después se utiliza el análisis de regresión para correlacionar esas
características extraídas de las respuestas voltamperométricas a partir de los parámetros cinéticos
de los sistemas. Una vez generado el modelo adecuado, por distintos métodos, se emplea para
el análisis de los voltamperogramas de las muestras. Las características extraídas de estos se
utilizan para predecir parámetros de sistemas apropiados para el mecanismo en estudio. Los
parámetros obtenidos se usan luego en la simulación correspondiente para generar
voltamperogramas sintéticos, que son comparados posteriormente con los experimentales. Si el
ajuste observado es bueno, el procedimiento se acaba en este punto y se dan por buenos los
parámetros obtenidos. Si ocurre lo contrario, hay que repetir todo el proceso con un modelo
-30-
INTRODUCCIÓN
diferente.
Reduciendo los datos de una respuesta voltamperométrica completa a un conjunto de
parámetros descriptivo mediante el uso de una correlación empírica simple, se disminuyen
mucho los requerimientos computacionales y de almacenamiento.52
8) Métodos Globales De Estimación De Parámetros.
Se han propuesto análisis de datos voltamperométricos para estimar parámetros de cinética
heterogénea a partir de sistemas que muestran un mecanismo E. No se emplea ninguna técnica
quimiométrica sofisticada, constituyendo así una nueva forma de transformar y analizar los datos.
El principio base consiste en que los parámetros cinéticos para la reacción del electrodo
serán descritos especialmente en un espacio tridimensional, que se define por el potencial
aplicado, la corriente y la semiintegral de la corriente. El análisis resultante es reducido a una
simple representación gráfica. Una vez se ha llevado a cabo esta reducción, una regresión lineal
pesada es aplicada para obtener la estimación de los parámetros.52
b) Métodos Referidos Al Tratamiento De Las Señales.
1) Métodos Recursivos Para Regresión No Lineal.
El filtro Kalman fue el primer filtro digital lineal recursivo en el dominio temporal,
utilizado hoy día en un gran número de campos. Su habilidad para extraer parámetros a partir de
datos ruidosos y modelar sistemas complejos es bien conocida.
Consiste en un método de estimación donde se aplica una regresión lineal multivariante a
cada variable de forma individual (cuando se obtiene una se pasa a otra y así sucesivamente) y
no a todas al mismo tiempo. No requiere que todos los datos estén disponibles para el análisis,
con lo cual se puede realizar una calibración en tiempo real; además, puede aplicarse también al
análisis de datos obtenidos de manera discontinua e intermitente.
Su uso puede proporcionar una separación rápida de respuestas solapadas, ayuda a decidir
cómo y cuándo medir una respuesta y permite eliminar componentes extraños de respuestas
instrumentales. Con este método de filtrado, además, se puede evaluar la calidad de los modelos
que describen los procesos químicos.52, 60
Existen varias modificaciones al filtro Kalman básico para su uso en problemas de
optimización no lineales, ya que el filtro básico no es útil en casos de no linealidad. Estas
modificaciones incluyen el filtro Kalman extendido, el extendido iterativo, el de segundo orden
-31-
INTRODUCCIÓN
y otros órdenes superiores y el filtro Kalman linealizado. Aunque sólo los dos primeros se han
aplicado en electroquímica.
El filtro Kalman extendido se ha utilizado en problemas con modelos de medida no lineales,
sistemas no lineales dinámicos o ambos. Consiste en representar ambos modelos en series de
Taylor sobre la trayectoria actual del vector de estado. Las funciones se linealizan luego
truncando las series después de los términos lineales que definen la dinámica de sistemas
linealizados y matrices de medida. El resto del algoritmo es igual al filtro Kalman discreto lineal.
Sus aplicaciones más interesantes se basan en el empleo de su naturaleza recursiva para
optimizar de forma eficiente una simulación, mientras se ajusta el modelo de simulación a un
conjunto de datos.
Brown et al. fueron los primeros en acoplar una simulación por voltamperometría de
barrido lineal a un filtro Kalman extendido para desarrollar la optimización de forma recursiva.
De este modo, estimaron constantes de velocidad estándar y coeficientes de transferencia de
carga para reacciones de transferencia de electrones heterogéneas simples.61
Otros autores lo aplicaron para optimizar una simulación por voltamperometría cíclica.
Además, emplearon un filtro Kalman extendido iterativo y optimización simplex y de Marquardt.
Este procedimiento de optimización recursivo incrementa en muy poco tiempo el cálculo
computacional como consecuencia de la ejecución de la simulación individual.52
2) Estimación De Parámetros En El Dominio De Fourier.
Este método fue introducido por Binkley y Dessy, los cuales utilizaron regresión por
mínimos cuadrados lineales en el dominio de Fourier para resolver voltamperogramas de onda
cuadrada solapados.
Posee la ventaja de la naturaleza lineal de la transformada de Fourier: la FT de una
respuesta conjunta es igual a la suma de las FT de las respuestas individuales. De este modo,
como las respuestas son aditivas en ambos dominios, la estimación de parámetros puede
desarrollarse en cada uno de ellos. Además, se reduce la dimensionalidad del problema. La
información de la señal está contenida en la zona de baja frecuencia del espectro, lo que permite
que el tamaño del conjunto de datos sea reducido a partir del número original de puntos de datos,
en el voltamperograma muestra, hasta unos pocos coeficientes de frecuencia (los primeros) que
contienen información relevante de la señal.
Esta reducción en la dimensión de la matriz de datos resulta en un problema mejor
condicionado para el uso del modelo MLR.62
-32-
INTRODUCCIÓN
RECONOCIMIENTO DE PATRONES.
Estos métodos se encuentran muy relacionados con la clasificación e identificación de
muestras. Se pueden dividir en dos grandes conjuntos:
w métodos supervisados
w métodos no supervisados
a) Métodos Supervisados.
Los métodos de reconocimiento de patrones supervisados se basan en el desarrollo de reglas
o modelos de carácter semicuantitativo para la clasificación de muestras de origen desconocido,
sobre la base de un grupo de muestras con clasificación desconocida que se han caracterizado
previamente mediante una serie de medidas. Cada patrón de muestra u objeto contiene N
variables de respuesta, las cuales pueden ser escaladas o no, centradas con respecto a una media
o transformadas de otra manera para mejorar el posterior análisis de datos. Tanto las variables
transformadas como las que no han sufrido ningún tipo de cambio se denominan “caracteres”.
Con N caracteres, cada objeto en los datos es descrito por un vector en un espacio N-dimensional.
Cada uno de los métodos de reconocimiento de patrones pretende describir cómo cada una de las
muestras pertenecientes a una clase conocida están orientadas con respecto a las demás y con
respecto a las de otras clases en el espacio multidimensional. Mediante el establecimiento de
similitudes entre datos para muestras de clase desconocida y explotando este carácter, se puede
establecer una clasificación de las mismas.
El éxito de la clasificación depende de si las reglas de clasificación son óptimas para el
problema en estudio. En el análisis de datos multivariante, cada objeto representa un punto en
el espacio de patrones multidimensional, coincidiendo los ejes con las diferentes variables. Si las
variables usadas en el problema de clasificación se eligen de forma apropiada, entonces, los
objetos pertenecientes a las distintas clases se sitúan en subespacios separados del espacio de
patrones. Las reglas de clasificación desarrolladas por los métodos supervisados equivalen al
establecimiento de una serie de límites que dividen el espacio de patrones en varios subespacios.
Derde y Massart han establecido perfectamente los diferentes criterios, tanto en sus aspectos
técnicos (matemáticos) como prácticos, que deberían considerarse a la hora de seleccionar una
técnica de reconocimiento de patrones supervisada para una aplicación particular.63
Las aplicaciones de los métodos de reconocimiento de patrones son muy variadas. Por
ejemplo, Sybrandt y Perone fueron los primeros en aplicarlos al análisis cualitativo de mezclas
-33-
INTRODUCCIÓN
en polarografía de electrodo estacionario.64 En otros casos, se ha llegado más lejos y se han
conseguido cuantificar analitos en muestras complejas con un error inferior al 10 %.
Algunos autores han comparado varios métodos de reconocimiento de patrones en la
identificación de respuestas voltamperométricas, recomendando el uso del método de
clasificación por el vecino más próximo frente a la máquina de aprendizaje lineal.
También se han aplicado al estudio de cinéticas electroquímicas y a la identificación de
mecanismos, más concretamente a la extracción de información cualitativa sobre los procesos
de electrodo en experimentos voltamperométricos.52
A continuación, veremos una de las técnicas supervisadas más utilizadas en el
reconocimiento de patrones, así como otras relacionadas con los procesos de reducción de
dimensiones y de reconocimiento a partir de señales.
1) Análisis Discriminante.
El análisis discriminante, tanto el lineal o ALD como el cuadrático o AQD, es una técnica
discriminante, probabilística y paramétrica. Esta última característica se debe a que asume
cuestiones sobre la distribución de la población en estudio, como por ejemplo: en el ALD, las
clases se distribuyen normalmente de forma multivariante y su dispersión interna es la misma.
Aquí, las reglas de decisión se definen en un espacio reducido, cuyos ejes se obtienen
optimizando los criterios, tal que en este espacio se preserva la mayoría de las discriminaciones
entre clases. Esto se corresponde con la optimización de la relación dispersión-entreclases/dispersión-dentro-de-las-clases, observada en este espacio reducido. En el cálculo de las
variables canónicas, el criterio de selección de paso puede usarse para incluir aquellas variables
que son relevantes para la discriminación. El análisis discriminante ofrece de este modo la
posibilidad de eliminar parámetros redundantes. En ALD, los límites entre las diferentes clases
se sitúan a mitad de camino entre los centroides (punto central) de las clases.
ALD y AQD son técnicas probabilísticas, ya que mediante el uso del teorema de Bayes la
probabilidad posterior puede usarse para estimar el grado de exactitud de la clasificación. Como
estas técnicas son de tipo discriminatorio, la detección de objetos extraños es directamente
imposible.
Como las reglas de decisión están basadas sobre todas las clases del conjunto de
entrenamiento, la actualización con nuevos objetos y/o nuevas clases requiere la redeterminación
completa de las reglas de clasificación. Al asumir cuestiones sobre distribución de la población,
sólo variables medidas en un intervalo pueden utilizarse en el problema de clasificación.63
-34-
INTRODUCCIÓN
b) Métodos No Supervisados (Técnicas De Reducción De Dimensiones).
A continuación, veremos un conjunto de técnicas empleadas para la reducción de
dimensiones, las cuales se incluyen dentro del grupo de los métodos no supervisados, puesto que
no necesitan reglas o modelos de carácter semicuantitativo para la clasificación de las muestras.
1) Análisis De Componentes Principales.
Uno de los métodos de modelización más utilizado como técnica de reducción de
dimensiones en quimiometría es el análisis de componentes principales o PCA. Consiste en una
familia de técnicas computacionales relacionadas con el aislamiento de las fuentes de variación
en un conjunto de datos. Dichas fuentes se aíslan descomponiendo la serie de datos en sus
autovectores y autovalores (vectores y valores propios).
El primer paso en el PCA es la formación de la matriz de covarianzas, Z:
Z = Dt D
(1)
a partir de la matriz de datos originales, D. La matriz de covarianzas se diagonaliza a través de
la siguiente transformación unitaria:
Λ = V −1 ⋅ Z ⋅ V
(2)
donde Ë es la matriz diagonal cuyos elementos son los autovalores de Z y V es la matriz de
autovectores, referida con frecuencia a valores abstractos o cargas. Los datos en D se reproducen
a partir de las cargas y los puntos (componentes o factores principales de los datos) por medio
de la relación:
D = T ⋅ Vt
(3)
Las cargas son los cosenos de los ángulos de los vectores directores o las proyecciones de los
datos sobre un conjunto de bases ortonormales que abarcan los datos D y los puntos son las
proyecciones de los datos o puntos de muestra sobre la dirección de los componentes principales.
El conjunto de bases se define por los puntos de datos T. Los vectores y las cargas pueden
calcularse por parejas mediante un procedimiento iterativo: NIPLS o regresión por mínimos
cuadrados parciales no lineal iterativo. Esta regresión extrae los vectores de carga del espectro
completo (vectores propios de Dt·D) en el orden de su contribución a la varianza en el espectro
de calibración. Tras la determinación del primer vector de carga, éste es eliminado del espectro
de calibración y el proceso se repite hasta que se ha calculado el número deseado de vectores de
-35-
INTRODUCCIÓN
carga.
Un método para la realización de autoanálisis en la ecuación (2) es por medio de la
descomposición de los valores individuales. En la descomposición de dichos valores, la matriz
de datos es dividida en el producto de tres matrices:
D = U ⋅ S ⋅ Vt
(4)
donde U es una matriz de autovectores fila (vectores propios de D·Dt), S es la matriz diagonal
de los valores individuales (raíces cuadradas de los autovalores) y V es la matriz de los
autovectores columna (vectores propios de Dt·D). La matriz V obtenida por descomposición de
los valores individuales es equivalente a la matriz V de la ecuación (2). La matriz producto de
la matriz de autovectores fila y la matriz de valores individuales es equivalente a la matriz de
puntos T en la ecuación (3).
Como consecuencia del proceso de descomposición se obtiene una reducción de ruido en
los datos.
Si existen n medidas, se obtienen n vectores propios en la diagonalización. No todos los
autovectores transportan información útil; algunos representan a los componentes de mayor ruido
del conjunto de datos. Al reunir los datos con una gran relación señal/ruido, el ruido dominará
en aquellos autovectores con autovalores pequeños, ya que aquel contribuye sólo en pequeña
cantidad a la variación de los datos. La eliminación de las cargas asociadas a autovalores propios
pequeños impide la reconstrucción de la información presente en la matriz de datos originales
y la reducción de ruido resulta de usar cargas y puntos truncados en la ecuación (3).
Si el ruido es una parte significativa de los datos, el número correcto de factores a retener
no se pone fácilmente de manifiesto. Cuidando la selección de un subconjunto de autovectores,
manteniendo aquellos que contienen mayormente la señal y eliminando los que contienen ruido
en mayor grado, es posible reducir el ruido en una serie de datos.
Otro beneficio de la descomposición consiste en la determinación de la verdadera
dimensionalidad del problema. Es posible disminuir un conjunto de datos expresado mediante
cientos de variables independientes en sólo unos cuantos vectores propios por medio del PCA.
El PCA se ha empleado para estudiar potenciales de onda media polarográficos de iones
metálicos alcalinos y alcalinotérreos. Se consiguió determinar el número apropiado de factores
requeridos para describir la variación causada por el disolvente. Con tres componentes
principales, los potenciales de onda medios en cada sistema de disolvente fueron modelados
adecuadamente.
Este modelo también puede usarse para estimar el número de componentes presentes en un
sistema cuando el número de componentes físicos que varían sistemáticamente es desconocido.
-36-
INTRODUCCIÓN
Si los vectores de datos que representan las respuestas de la muestra son grabados a intervalos
regulares y discretos de tiempo, potencial o cualquier otra variable indexable, la evolución del
número de componentes presente en la mezcla puede asegurarse como una función de esa
variable indexable. Existen varias técnicas capaces de desarrollar esta estimación. Podemos
destacar el EFA o análisis de factores evolutivos, el EFA diferencial y la matriz de proyección.
Jones et al. emplearon mínimos cuadrados y análisis de factores (basado en PCA) para
resolver solapamientos en mezclas binarias utilizando técnicas de luminiscencia. En este caso,
el PCA incluye análisis de factores de aniquilación de rangos, que requiere mucho tiempo. No
obstante, una alternativa es el análisis de factores de transformación de objetos, el cual exige una
calibración elevada.65
Otra aplicación del PCA en el análisis cuantitativo de datos consiste en representar un
conjunto de datos por un número reducido de variables ortogonales, obteniéndose un gran
número de ventajas a la hora de realizar la regresión. El truncaje cuidadoso de los puntos y cargas
de un conjunto de datos con un bajo contenido en ruido permite modelizar únicamente la
variación sistemática y no así el ruido. Esta combinación de MLR y PCA se conoce como
regresión de componentes principales o PCR.
El paso clave para llevar a cabo una regresión útil, usando los componentes principales
como el conjunto de variables independientes, implica la eliminación (por truncaje) de los puntos
y cargas no significativos de los datos.
Cuando un conjunto incompleto de puntos y cargas son utilizados para representar una
$ de datos estimados:
matriz de datos D, resulta una matriz D
$ = U ⋅ Vt
D
donde â y V t son los puntos y cargas truncados, respectivamente.
Como se emplea un número reducido de componentes principales en la reconstrucción, la
información presente en los datos originales ha sido comprimida en una dimensión espacial más
pequeña. Además, las nuevas variables usadas para representar los datos son ortogonales, puesto
que son puntos. En resumen, la PCR relaciona variables dependientes Y con un conjunto de
variables independientes en D, empleando para ello una matriz de puntos truncada obtenida a
partir de D en lugar de las variables independientes en D:
Y = U⋅ B
La estimación de los coeficientes se realiza por regresión de mínimos cuadrados, igual que
en MLR, pero con la ventaja importante de que la inversión ât·â
â puede hacerse sin dificultad.
Además, la PCR permite incluir variables independientes altamente correlacionadas tales como,
-37-
INTRODUCCIÓN
espectros o voltamperogramas, sin problema de que la ecuación:
B = ( C t C) ⋅ C t R
−1
pueda fallar, debido al alto grado de similitud entre las variables independientes.
De igual modo, se puede incluir el uso de un modelo inverso donde la matriz de respuestas
R es modelada como la variable independiente y la matriz de concentraciones como la variable
dependiente:
C = R⋅ B+ F
Así, se asume que el error está incluido en la concentración. Esta aproximación es extraña, pero
puede satisfacerse si se realiza el truncaje apropiado de los puntos de R, â, y si estos se incluyen
en el modelo de regresión mediante la ecuación:
C = U⋅ B
El ajuste de los puntos de datos por esta ecuación posee una doble ventaja: requiere menos
variables independientes y emplea datos con menos ruido, como consecuencia de la compresión
de datos y la reducción de ruido, generada en la descomposición propia, y el truncaje de los datos
de respuesta en R. Éste último debe elegirse bien, sino se producen errores en la modelización
por la introducción de tendencias.52, 53
2) Escalado Multidimensional
El escalado multidimensional puede considerarse como una alternativa al análisis factorial
y se utiliza típicamente como método exploratorio. En general, la finalidad de este análisis
consiste en detectar dimensiones subyacentes significativas que permitan al investigador dar
explicaciones sobre semejanzas o diferencias (distancias) entre los objetos que forman parte del
estudio. Mientras que en el análisis factorial, las similitudes entre objetos (variables) se expresan
en una matriz de correlación, con el escalado multidimensional, no sólo se pueden analizar dichas
matrices de correlación, sino también cualquier clase de matriz de similitudes o disimilitudes
(incluyendo conjuntos de medidas que no son consistentes internamente).
El siguiente ejemplo permite demostrar la lógica del análisis muldimensional. Supongamos
que construimos una matriz con las distancias entre las ciudades más grandes de España y,
posteriormente, analizamos dicha matriz especificando que se desea reproducir dichas distancias
en dos dimensiones. Como resultado del escalado multidimensional, probablemente
obtendríamos una representación bidimensional de las localizaciones de las ciudades; esto es,
-38-
INTRODUCCIÓN
básicamente resultaría un mapa bidimensional.
Por tanto, en general, este tipo de análisis intenta agrupar “objetos” (ciudades, en el ejemplo
anterior) en un espacio con un número particular de dimensiones (2, en nuestro caso), tal que se
reproduzcan las distancias observadas. Como resultado, podremos explicar las distancias en
términos de dimensiones subyacentes; en el ejemplo, las distancias tendrían sentido en términos
de dos dimensiones geográficas: norte/sur y este/oeste.
El escalado multidimensional no es tanto un procedimiento exacto como una forma de
“reagrupar” objetos de forma eficiente, tal que se alcance una configuración que aproxima mejor
las distancias observadas. Normalmente, este análisis hace uso de algoritmos de minimización
de funciones para evaluar diferentes configuraciones con la meta de maximizar la bondad del
ajuste. Para ello, mueve los objetos alrededor del espacio definido por un número de dimensiones
determinado y comprueba con que fiabilidad pueden reproducirse las distancias entre objetos con
cada nueva configuración.
La forma más común de determinar la bondad con la que una configuración particular
reproduce la matriz de distancias observada es mediante la medida del STRESS, Ö. Este se
define como:
Φ =
∑ [d
( )]
ij − f d ij
i, j
2
donde dij son las distancias de los datos de entrada y f(dij) son los valores predichos para las
distancias, de acuerdo con el número de dimensiones especificado. Cuanto más pequeño sea el
valor del STRESS, mejor será el ajuste de la matriz de distancias reproducidas con respecto a
la matriz observada.
Normalmente, las distancias reproducidas para un número particular de dimensiones se
representan mediante un diagrama de Shepard.
Hay que resaltar que, en general, cuantas más dimensiones se empleen para reproducir la
matriz de distancias, mejor será el ajuste de la matriz reproducida frente a la observada (esto es,
un valor más pequeño del STRESS). Si se emplean tantas dimensiones como variables, se podrá
reproducir perfectamente la matriz de distancias observada. No obstante, el fin perseguido
consiste en reducir lo más posible la complejidad del sistema, es decir, explicar la matriz de
distancias mediante el menor número posible de dimensiones ocultas. Volviendo al ejemplo de
las ciudades, es más sencillo visualizar el conjunto en el mapa bidimensional que extraer
conclusiones directamente desde la matriz de distancias.
Para establecer el número de dimensiones más apropiado a nuestro sistema, lo más normal
es representar los valores de STRESS frente al número de dimensiones. Esta prueba fue
-39-
INTRODUCCIÓN
propuesta por Cattell en 1966 refiriéndose al problema del número de factores en el análisis
factorial. Un segundo criterio para decidir el número de dimensiones se basa en la claridad de la
configuración final. Algunas veces, como ocurre en nuestro ejemplo, las dimensiones resultantes
se pueden interpretar fácilmente. Sin embargo, en otras ocasiones, los objetos representan una
nube de puntos y no existe una forma fácil o directa de interpretar las dimensiones obtenidas.
Ante esta situación, lo más conveniente sería introducir dimensiones por exceso o por defecto
y comprobar la configuración final resultante. Con frecuencia se obtienen resultados bastante
buenos. Si, por el contrario, los datos no siguen ningún patrón o el gráfico del STRESS no
muestra un punto crítico claro, los datos son, probablemente, ruido aleatorio.
La interpretación de las dimensiones representa normalmente el paso final del análisis. Éste
puede realizarse gráficamente produciendo representaciones de los objetos en diferentes planos
bidimensionales. Soluciones en tres dimensiones pueden ser más complejas de interpretar. Lo
más sensato a la hora de buscar dimensiones significativas sería investigar la presencia de grupos
de puntos o patrones y configuraciones particulares. Por otro lado, una forma analítica de
interpretar dimensiones sería emplear técnicas de regresión múltiple que permitan hacer
corresponder algunas variables con las coordenadas de cada dimensión.
La principal característica del escalado multidimensional radica en que podemos analizar
cualquier clase de matriz de distancias o de similitudes. Estas similitudes pueden representar
cualquier cosa: desde el porcentaje de acuerdo entre jueces hasta el número de veces que un
sujeto falla para discriminar entre estímulos. Por ejemplo, en investigación psicológica se ha
aplicado muy comúnmente un método de escalado multidimensional relacionado con la
percepción de las personas, donde se analizaron las similitudes existentes entre rasgos descritos
para descubrir la dimensionalidad oculta de las percepciones de los rasgos de las personas.
También se ha aplicado para detectar el número y naturaleza de las dimensiones que subyacen
a la percepción de marcas o productos.
En general, el método de escalado multidimensional permite al investigador responder a
preguntas del tipo “¿cuánto se asemeja la marca A a la B?” y derivar, a partir de ellas, las
dimensiones ocultas sin que aquellos que responden conozcan siquiera cuál es el interés real del
investigador.
Aunque existe un cierto parecido en el tipo de preguntas a la cuales pueden aplicarse el
escalado multidimensional y el análisis de factores, ambos son fundamentalmente métodos
diferentes. El análisis de factores requiere que los datos subyacentes se encuentren distribuidos
de un modo normal multivariante, y que las relaciones sean lineales. El escalado
multidimensional no implica tales restricciones. Por otro lado, el análisis factorial tiende a extraer
un mayor número de factores (dimensiones) que el escalado. Como consecuencia de ello, este
-40-
INTRODUCCIÓN
último método suele presentar soluciones más interpretables. Más importante, sin embargo, es
que el escalado puede aplicarse a cualquier clase de matriz de distancias o de similitudes,
mientras que el análisis factorial requiere primeramente que el investigador calcule una matriz
de correlaciones. Por último, el escalado puede basarse en la asignación directa de similitudes
de objetos entre estímulos, mientras que el análisis de factores requiere objetos para clasificar
dichos estímulos en alguna lista de atributos (meta perseguida con el análisis de factores).
En resumen, los métodos de escalado multidimensional son aplicables a una amplia
variedad de diseños de investigación, puesto que las distancias medidas pueden obtenerse de
cualquier forma.66
3) Análisis De Clusters
El término análisis de clusters, acuñado por Tryon (1939) engloba un gran número de
algoritmos de clasificación diferentes, los cuales se utilizan para desarrollar taxonomías que
forman parte del análisis de datos exploratorios. Por ejemplo, los biólogos han de organizar las
diferentes especies de animales antes de que sea posible una descripción significativa de las
diferencias existentes entre ellos. De acuerdo con el sistema de clasificación empleado en
biología el hombre es un primate, un mamífero, un amniota, un vertebrado y un animal. En esta
clasificación, cuanto más alto es el nivel de agregación, menos similares son los miembros en la
clase respectiva. El hombre posee más en común con todos los otros primates que con los
miembros más “distantes” de los mamíferos (por ejemplo, los perros).
El método de análisis de clusters suele desarrollarse en base a variables y casos. Otro
ejemplo: imaginemos un estudio donde el investigador médico ha reunido datos sobre diferentes
medidas de salud física (variables) para una muestra de pacientes del corazón (casos). El
investigador desea agrupar los casos para detectar conjuntos de pacientes con síntomas similares.
Al mismo tiempo, el investigador puede querer agrupar variables (medidas de salud) para
detectar conjuntos de pacientes que presenten habilidades físicas similares.
Existen varios tipos de algoritmos empleados en el análisis de clusters:
w Algoritmo de agrupamiento en árbol (Joining-Tree Clustering): su propósito consiste en
reunir o agrupar los objetos en clusters sucesivamente más grandes, utilizando alguna
medida de la similitud o distancia. Un resultado típico de este método es el árbol
jerárquico, del cual se hablará posteriormente.
w Algoritmo de agrupamiento de dos vías (Two-way Joining): este algoritmo permite
agrupar simultáneamente variables y casos. Es útil en circunstancias en las que uno
-41-
INTRODUCCIÓN
espera que tanto unas como otros contribuyan simultáneamente al descubrimiento de
patrones significativos de agrupamiento. Por ejemplo, el investigador médico puede
querer identificar a los pacientes que son semejantes con respecto a grupos particulares
de medidas similares de bondad física. No obstante, la dificultad en la interpretación de
los resultados se desprende del hecho de que las similitudes entre diferentes clusters
pueden ser causadas por algún otro subconjunto de variables. De este modo, la
estructura resultante (clusters) no es homogénea por naturaleza. Probablemente, es el
método de agrupamiento menos usado de todos.
w Algoritmo de agrupamiento por las medias de K (K-means Clustering): es muy diferente
de los otros dos. Supongamos que se posee alguna hipótesis que relaciona el número de
clusters con nuestros casos o variables; entonces, lo más lógico sería especificar en el
ordenador que forme exactamente tres clusters que sean tan distintos como sea posible.
De este modo, el algoritmo obtendrá exactamente K grupos con las mayores diferencias
entre ellos. En el ejemplo de la salud física, el investigador médico, de acuerdo con su
experiencia clínica, puede decidir que sus pacientes pueden agruparse de acuerdo con
tres categorías clínicas diferentes de salud física. Esto llevaría a la pregunta de si su
intuición puede cuantificarse; esto es, si un análisis de cluster por las medias de K de la
medida de la salud física resultaría, en efecto, en tres grupos de pacientes, como se
esperaba. Si ocurre así, las medias de las diferentes medidas de salud física para cada
cluster representarían una forma cuantitativa de expresar la hipótesis o intuición de los
investigadores.
Computacionalmente, podría compararse este método con el análisis de la varianza a la
inversa. Éste comienza con un conjunto de K clusters elegidos al azar para luego mover
los objetos entre aquellos clusters con la finalidad de minimizar la variabilidad dentro
de los clusters y maximizarla entre ellos. Esto es análogo al ANOVA inverso en el
sentido de que el test de significancia en el ANOVA evalúa la variabilidad entre grupos
frente a la variabilidad entre clusters cuando se calcula dicho test para la hipótesis de
que las medias en los grupos son diferentes unas de otras. En este método de
agrupamiento, el programa intenta mover los objetos (casos) dentro y fuera de los
grupos (clusters) para conseguir los resultados más significativos del ANOVA.
Para interpretar los resultados del análisis de agrupamiento por las medias de K, se
examinarían las medias de cada cluster sobre cada dimensión, para asegurar cuán
diferentes son los K clusters. Idealmente, obtendríamos medias muy diferentes para la
mayoría de las dimensiones, si no todas, utilizadas en el análisis. La magnitud de los
valores de F del análisis de la varianza desarrollado sobre cada una de las dimensiones
-42-
INTRODUCCIÓN
es otro indicativo de lo bien que discriminan las respectivas dimensiones entre los
clusters.
El análisis de clusters se encuentra muy ligado con los árboles de clasificación. Es por esto,
que dedicamos aquí algunas palabras al respecto.
Los árboles de clasificación se utilizan para predecir la pertenencia de casos u objetos a las
clases de una variable de categoría dependiente a partir de sus medidas sobre una o más variables
de predicción.
Consiste en una técnica muy empleada cuya finalidad es la de predecir o explicar respuestas
en base a variables categóricas dependientes. Su flexibilidad los convierte en una opción para el
análisis muy atractiva, pero esto no conlleva que se haga uso de ella en detrimento de los
métodos más tradicionales. Sin embargo, como técnica exploratoria o como técnica de último
recurso, cuando los métodos tradicionales fallan, posee una importancia indiscutible, en opinión
de muchos investigadores.
Un árbol de clasificación podría asemejarse a los procesos de separación de la materia
particulada de acuerdo con el tamaño (diámetro) de los granos que la componen. En este caso,
el material granulado se hace pasar por tamices con tamaño de poro diferente ordenados de
menor a mayor diámetro. De este modo, primero se separan los granos más finos para terminar
con los más grandes. Este conjunto de tamices constituiría un árbol de clasificación. El proceso
de decisión utilizado aquí (tamaño del grano) proporciona un método eficiente para desarrollar
la clasificación.
La aplicabilidad de este tipo de estudio no es muy amplia en el campo de la probabilidad
ni en el de reconocimiento de patrones estadísticos. Sin embargo, se utilizan mucho en medicina
(diagnosis), ciencia computacional (estructura de datos), botánica (clasificación) y psicología
(teoría de decisiones).
Por otro lado, los árboles de clasificación permiten su representación gráfica. Esto da lugar
a una interpretación de los resultados más sencilla de lo que sería posible con una interpretación
estrictamente numérica. Por ejemplo, si se está interesado en las condiciones que provocan una
clase partircular de respuesta, un gráfico de tres dimensiones sería muy útil en este sentido para
determinar el nodo terminal del árbol que contiene un mayor número de respuestas del tipo
deseado.
Las dos características sobresalientes de este método son su naturaleza jerárquica y su
flexibilidad. La primera se relaciona con el hecho de que el procedimiento se desarrolla
estableciendo una serie de cuestiones, las cuales siguen una jerarquía determinada, y la decisión
final depende de las respuestas a todas las preguntas anteriores (el ejemplo más típico es el de
-43-
INTRODUCCIÓN
la clasificación de especies botánicas siguiendo una serie de tablas: éstas contienen un conjunto
de preguntas, las cuales siguen un orden, y las respuestas a ellas conducen a otras, y así
sucesivamente). Con respecto a la segunda, ésta radica en la habilidad para examinar los efectos
de todas las variables de predicción al mismo tiempo y no de forma individual. Si embargo, hay
otro medio por el cual los árboles de clasificación son más flexibles que los métodos
tradicionales, que consiste en la habilidad de este método para desarrollar divisores (splits)
univariantes (individuales o como combinaciones lineales), examinando los efectos de todos los
predictores a la vez. Además, los niveles de medida de las variables predictoras son mucho
menos exigentes que para el caso del análisis lineal discriminante.
El algoritmo QUEST (Quick, Unbiased, Efficient, Statistical Trees) es un programa de árbol
de clasificación desarrollado por Loh y Shih que emplea una modificación del análisis cuadrático
discriminante recursivo e incluye una serie de características innovadoras para la mejora de la
exactitud y eficacia del árbol de clasificación que se calcula. Esta aplicación es muy usada para
seleccionar los divisores univariantes antes mencionados. Existe otro programa de árbol de
clasificación denominado CART, descrito por Breiman en 1984, que utiliza una búsqueda
exhaustiva, en forma de malla, de todos los posibles divisores para un árbol de clasificación.
QUEST es mucho más veloz que CART cuando las variables predictoras poseen una docena de
niveles; además, no presenta sesgos. La utilización conjunta de ambos programas explota al
máximo la flexibilidad del árbol de clasificación. Otros programas son FACT y THAID, este
último relacionado con el programa AID (Automatic Interaction Detection) y CHAID (ChiSquare Automatic Interaction Detection).
Una ventajas que presenta este método sobre los tradicionales, como el análisis lineal
discriminante, consiste en que el gráfico del árbol presenta toda la información posible de una
forma muy simple y directa, tal que se tarda muy poco tiempo en interpretar los resultados.
Como desventaja cabría citar que en ocasiones se obtienen un número superior de divisores
comparado con el análisis lineal discriminante. Sin embargo, gracias a la flexibilidad del método,
esto puede subsanarse aplicando el algoritmo QUEST que permite calcular combinaciones
lineales de divisores en vez de divisores individuales
En resumen, las ventajas y desventajas de los árboles de clasificación radica en que estos
son tan buenos como la elección de la opción de análisis utilizada para producirlos. Para
encontrar modelos que predigan bien, no hay ningún sustituto para una comprensión minuciosa
de la naturaleza de las relaciones entre las variables dependientes y las de predicción.
El proceso de cálculo computacional de los árboles de clasificación sigue cuatro etapas:
1) Especificar el criterio de exactitud en la predicción: la predicción de mayor exactitud se
-44-
INTRODUCCIÓN
define operacionalmente como la predicción con el mínimo coste, lo que equivale a
minimizar la proporción de clases mal clasificadas cuando las prioridades elegidas son
proporcionales al tamaño de las clases y cuando el coste de una mala clasificación es
igual para cada clase. En algunos casos se habla de pesos para las variables a la hora de
minimizar el coste.
2) Seleccionar los divisores para las variables predictoras: estas variables se utilizan para
predecir la pertenencia a las clases de las variables dependientes para los casos u objetos
en el análisis. A pesar de la naturaleza jerárquica del método, son elegidos todos al
mismo tiempo
3) Determinar cuándo parar el proceso de división: si no se coloca ningún límite al número
de divisiones que han de llevarse a cabo, se logrará eventualmente una clasificación
"pura", donde cada nodo terminal contendrá una única clase de casos u objetos.
Normalmente, una clasificación de este tipo es utópica, pero el resultado obtenido podría
asemejarse bastante a este caso. Otra opción para cesar las divisiones consiste en
permitir que éstas continúen hasta que todos los nodos terminales sean puros o no
contengan más casos que una fracción mínima especificada del tamaño de una o más
clases.
4) Seleccionar el tamaño correcto del árbol: se prefiere emplear un árbol de clasificación
que clasifique perfectamente tanto las muestras de prueba como de entrenamiento frente
a uno que clasifique bien únicamente las últimas (algo parecido a lo que ocurre con las
redes neuronales, las cuales estudiaremos posteriormente). Algunas estrategias para
lograr el tamaño correcto son: dejar crecer el árbol hasta un tamaño adecuado
determinado por el usuario a partir del conocimiento obtenido por investigaciones
previas, información de diagnóstico o incluso la intuición; otra estrategia consiste en
hacer uso de un procedimiento bien documentado y estructurado desarrollado por
Breiman para seleccionar el tamaño del árbol.
En definitiva, los métodos tradicionales y el árbol de clasificación emplean técnicas
diferentes para predecir la pertenencia a una clase en base a una variable categórica dependiente.
Él árbol de clasificación utiliza una jerarquía de predicciones, de elevado número en algunas
situaciones, para clasificar los casos en las clases predichas. Los métodos tradicionales utilizan
técnicas simultáneas para hacer una y sólo una predicción de pertenencia a una clase para cada
uno de los casos. Con respecto a otras situaciones, como obtener una predicción con una
determinada exactitud, el análisis de árbol de clasificación es más bien mediocre frente a los
métodos tradicionales.66
-45-
INTRODUCCIÓN
c) Técnicas De Reconocimiento De Señales.
Dentro de los métodos de reconocimiento de patrones se engloban las técnicas de
reconocimiento de señales, de especial relevancia a la hora de llevar a cabo el tratamiento
estadístico de los datos obtenidos en el análisis.
1) Derivación O Diferenciación De Señales.
Con respecto a las técnicas de reconocimiento de señales, la primera que nos encontramos
es la de derivación o diferenciación de señales (en el dominio de Fourier).
Hay que decir que no es útil cuando nos enfrentamos con solapamientos severos, puesto que
se alcanza poca resolución para el elevado coste de relación señal/ruido que implica. Esto se debe
a que se acentúan las frecuencias altas, relativas al ruido, en detrimento de las frecuencias bajas,
relacionadas con la señal, en el dominio de Fourier.41 No obstante, en otros casos, nos
proporciona gran cantidad de información y permite resolver las mezclas. En esta última
situación, las técnicas derivativas se aplican con éxito para la resolución de mezclas binarias,
mientras que mezclas más complejas no pueden ser resueltas normalmente por diferenciación.
En primer lugar, la primera derivada de una señal en forma de pico, que represente, por
ejemplo, intensidad-potencial, nos permite localizar el pico de la especie y determinar el
potencial de reducción u oxidación de cada componente. Esto se debe a que la señal corta el eje
de abcisas precisamente en ese punto, lo que muchos autores denominan "zero-crossing".
Las siguientes derivadas se emplean para agudizar más los picos obtenidos en el
voltamperograma original, que una vez diferenciados poseen componentes de frecuencias más
altas que afectan a la relación señal/ruido, como se ha comentado anteriormente. Además,
permiten calcular su anchura e intensidad.67 Por último, mediante el uso de curvas de calibrado,
se determina la concentración de cada componente.42, 68
Este método se ha empleado no sólo en voltamperometría, sino que también se ha aplicado
con éxito en espectrofotometría.
2) Ajuste De Curvas (Deconvolución Numérica).
El método de ajuste de curvas, también llamado deconvolución numérica, se ha convertido
en uno de los más empleados en investigación. Y no sólo se ha aplicado a la voltamperometría,
sino a otras muchas técnicas de análisis, como por ejemplo, la cromatografía,
El ajuste de curvas consiste en lo que su nombre indica: se intenta hacer coincidir lo mejor
-46-
INTRODUCCIÓN
posible las señales obtenidas en el aparato de medición con curvas de origen muy diverso, con
el fin de detectar e identificar las sustancias que componen la mezcla. Las curvas de ajuste
pueden obtenerse de varias formas: a partir de bases de datos o librerías, que se construyen desde
señales de componentes individuales a diferentes concentraciones; de expresiones matemáticas
cuya formulación está perfectamente conocida en la literatura, tales como la función lorentziana,
gaussiana o de Cauchy; y también empíricamente, mediante el método de prueba y error.
A continuación, veremos algunos ejemplos basados en el ajuste de curvas o deconvolución
numérica y no todos ellos aplicados a la voltamperometría.
Boudreau y Perone ajustaron picos estándares e individuales de especies diferentes
empleando combinaciones lineales de funciones gaussianas y de Cauchy, ambas asimétricas,
estimando sus parámetros de ajuste. La elección de estas funciones fue completamente arbitraria.
Luego, las aplicaron a la mejora de la resolución cuantitativa de datos voltamperométricos
solapados, para casos donde los potenciales medios de onda diferían en menos de 155/n mV.
Para ello utilizaron técnicas de voltamperometría de onda cuadrada y en escalera, comparando
posteriormente los resultados obtenidos.
La forma de la función es la siguiente:
(
)
2
ln 1 + 2 b ⋅ ( X − X ) / ∆ X
/
i
0
1
2
+
y( X i ) = f ⋅ Y0 ⋅ exp − ln 2
b
(
(1 − f ) ⋅ Y0
)
ln 1 + 2 b ⋅ ( X − X ) / ∆ X
i
0
1/ 2
1+
b
2
donde Y0 (A1) es la altura del pico; X0 (A2) su localización; ÄX½ (A3) la anchura de altura media;
b (A4) el factor de asimetría y f (A5) el factor de forma.
Primero se simularon voltamperogramas de especies individuales y sus parámetros fueron
ajustados a la expresión anterior, empleándose posteriormente dichos ajustes para simular
mezclas binarias de analitos y llevar a cabo la correspondiente separación o deconvolución de
los mismos. La deconvolución numérica implica la regresión de la ecuación, utilizando para ello
sólo 4 parámetros: altura (A1) y localización del pico (A2) de cada especie, permaneciendo el
resto como constantes conocidas. Se alcanza, de este modo, una cuantificación con un error
relativo inferior al 3 %, siendo el método válido para separaciones de 30/n mV y altura de pico
similar y, si ésta no lo es, para relaciones inferiores a 5:1.41
Otro ejemplo de deconvolución de picos muy solapados mediante ajuste de curvas es el
llevado a cabo por Huang et al. El método consiste en emplear una relación de corriente-voltaje
sintetizada previamente, la cual se intenta ajustar en lo posible al voltamperograma experimental
de la mezcla.
-47-
INTRODUCCIÓN
Para ello, se construye una curva teórica: Ith = IA + IB, cuya intensidad es la suma de las
intensidades individuales de los dos analitos que constituyen la muestra. A continuación, se
corrige progresivamente IA e IB por variación de una serie de parámetros, tales como el potencial
y la intensidad del pico, el índice de reversibilidad y el factor de asimetría, con el fin de
minimizar la discrepancia entre Ith e Iexp - Ifondo. Los parámetros correctos de A serán aquellos
cuya curva se ajuste lo más posible a la de IA + Iblanco, sin el analito B, e igual para éste. Se aplicó
a diversos sistemas binarios: In (III) / Cd (II), Tl (I) / Pb (II) y Cr (III) / Zn(II), empleando
diferentes técnicas voltamperométricas en cada caso.69
Otra combinación lineal de funciones, pero esta vez de funciones lorentziana y gaussiana,
ha sido aplicada a la espectrofotometría infrarroja, ajustándola a los espectros en un
procedimiento basado en el método de mínimos cuadrados.70
En cromatografía, se han analizado picos cromatográficos solapados de forma cuantitativa
construyendo cromatogramas sintéticos, los cuales se ajustan a los experimentales por análisis
de regresión no lineal iterativo.71
Westerberg ha ideado un método de resolución de picos que utiliza un modelo de ajuste de
curvas que cubre los detalles para un modelo gaussiano, de gauss modificado y para modelos de
datos tabulares generales, ajustando los parámetros por el método de mínimos cuadrados
estándar.72
Las curvas de ajuste podían tener también un origen totalmente empírico o proceder de una
librería o base de datos creada para tal efecto. Este es el caso en el trabajo de Gutknecht y Perone,
en el que llevan a cabo deconvoluciones numéricas de curvas polarográficas de electrodo
estacionario. Por medio de una ecuación empírica que describe este tipo de ondas para una gran
cantidad de especies electroactivas, en la primera parte del proceso de análisis, las señales de las
especies estándares son ajustadas a la misma y las constantes de esta ecuación determinadas
específicamente para cada especie, almacenándolas en una librería.
A la hora de analizar una mezcla, estas constantes estándares son usadas para generar una
serie de curvas que luego son ajustadas a los componentes de la señal desconocida. El método
fue aplicado a dos tipos de mezclas: una, cuyos analitos se encontraban bien separados, y otra,
en las que la diferencia entre los potenciales de onda media era de 40 mV. Los errores relativos
obtenidos oscilaron entre el 1 y el 2 %.
La función descriptora de las curvas polarográficas de electrodo estacionario se obtuvo por
una combinación de términos geométricos y algebraicos, mediante el sistema de tanteo y error.
La función responde a la siguiente expresión:
[
Y = A ⋅ F ⋅ P1 + (1,0 − F) ⋅ P2
-48-
]
INTRODUCCIÓN
donde A determina la altura del pico; F es la función que une P1 y P2; P1 es la función, de tipo
gaussiano asimétrica, que representa el extremo de entrada de la señal; 1.0 es el término de
decaimiento del extremo de salida y P2 es la función que representa el decaimiento (exponencial),
en función del tiempo, del extremo de salida.
A la hora de llevar a cabo la deconvolución numérica, pueden emplearse dos
procedimientos: el primero consiste en ajustar una curva estándar almacenada en la librería a la
señal desconocida; en el segundo caso, se ajusta a la señal desconocida una curva calculada, la
cual es derivada desde una sumatoria de funciones individuales que describen las contribuciones
de los componentes individuales de la señal de la mezcla.32
En cromatografía, también se ha logrado aplicar con éxito el ajuste de curvas. Fellinger
utilizó un modelo EMG (gaussiano modificado exponencialmente), para describir los picos
cromatográficos asimétricos. La deconvolución de estos picos, que solapan entre sí, se lleva a
cabo mediante su división por una función de agudización, de tipo EMG, cuya parte gaussiana
y exponencial tienen área unidad y la primera se encuentra centrada en el origen de coordenadas,
lo que permite que se conserve el área y la localización del pico original durante la resolución del
sistema.
Este modelo permite explicar qué clase de señales pueden esperarse tras la deconvolución
y prueba la imposibilidad de conservar la forma del pico y el perfil de asimetría durante el
proceso. Del mismo modo, también explica por qué surgen lóbulos laterales y picos falsos
durante el procedimiento, lo que se encuentra directamente relacionado con los parámetros de
forma del pico agudizado.
La validez del modelo se comprobó mediante métodos numéricos de deconvolución:
método de relajación iterativa forzado (o condicionado), también llamado método de Janson, una
de las herramientas más útiles y poderosa hasta finales de los 80, y la deconvolución directa de
Fourier. Esta última es la responsable de la aparición de lóbulos laterales como consecuencia de
la introducción de ruido matemático.
El modelo EMG procede de considerar a un pico gaussiano como distorsionado por un
decaimiento de primer orden, debido a volúmenes muertos en el inyector o el detector de
volumen. La función que describe un pico EMG agudizado (convolución de una función de
densidad de distribución normal h(t) y una función de decaimiento exponencial f(t)) es:
A
Y( t ) =
2τ
⋅ 1 − erf ⋅
σ2
σ
t− m
t − m
−
⋅ exp
2 −
τ
2⋅ τ
2⋅τ
2⋅σ
donde Y(t) es el pico EMG original; A es el área del pico; ô es una constante de tiempo de la
función de decaimiento exponencial; erf es la función de error; ó es la contribución gaussiana
-49-
INTRODUCCIÓN
a la anchura del pico; t es el tiempo y m es la localización del máximo del pico gaussiano.
El resultado de la deconvolución es una combinación lineal de un pico gaussiano de
anchura ó´ y una función EMG de parámetros ó´ y ô:
x( t ) =
τd
τ
⋅ h( t , σ ′ ) + 1 − d ⋅ y( t , σ ′ )
τ
τ
donde ô y t poseen el mismo significado de la ecuación anterior; d es la constante de tiempo de
la función de decaimiento exponencial de área unidad; h(t,ó´) es la función gaussiana; ó´ es la
contribución gaussiana a la anchura del pico agudizado e y(t,ó´) es el pico EMG original.73
Goodman y Brenna realizaron deconvolución de señales mediante ajuste de curvas
empleando también funciones del tipo EMG. Pero, en este caso, fue aplicada a la técnica híbrida
cromatografía gaseosa/espectrometría de masas de relación de isótopos de combustión.
A la hora de ajustar los picos solapados se utilizaron combinaciones lineales de funciones
matemáticas de varios tipos: EMG, GID (funciones de Giddings), NLC (cromatográficas no
lineales) y HVL (Haarhoff-VanderLinde), para modelarlos satisfactoriamente.
Para resolver cuantitativamente solapamientos elevados, el mejor resultado se obtuvo con
la combinación Haarhoff-VanderLinde-EMG, estimando en buena medida las áreas de los
picos.74
Otro modelo propuesto para describir picos cromatográficos asimétricos, se basa en la
modificación de la desviación estándar de un pico gaussiano puro con la distancia al máximo del
pico, mediante el uso de una función polinomial:
h( t ) = H ⋅ exp −
1
2
t − tR
⋅
S + S ( t − t ) + S ( t − t ) 2 + ...
0
1
R
2
R
2
donde H es la altura y t la posición en el máximo del pico; S0 es la desviación estándar de un pico
gaussiano simétrico y S1 y S2 son los coeficientes que cuantifican la asimetría del pico.
Este modelo se denomina PMG (gaussiano modificado polinomialmente) y muestra una
amplia flexibilidad con picos de amplio rango de asimetría y puede usarse para predecir con
seguridad los perfiles de los picos asimétricos.
Para ajustar los picos asimétricos se emplearon funciones polinómicas de hasta segundo o
tercer grado. De estos estudios se deducen que polinomios de primer grado son adecuados para
picos con bajo grado de asimetría y polinomios de mayor grado lo son cuando se trata de picos
de asimetría mayor.
Se aplicó al estudio y deconvolución de mezclas binarias y ternarias de componentes y los
-50-
INTRODUCCIÓN
resultados fueron comparables o incluso superiores a los alcanzados con el modelo EMG, con
errores menores y no superiores al 10 %.
El modelo, además, sirve para predecir o simular picos cromatográficos, mediante el cálculo
de los parámetros del pico (altura, posición, eficacia y factor de asimetría), cuyo número es
coincidente con los de la función h(t): H, tR, S0 y S1.75
Otros métodos de deconvolución numérica están basados en la aplicación de ecuaciones
empíricas, que permiten calcular el área de los picos solapados. Un ejemplo, lo constituye la
ecuación diseñada por Foley:
A = 1,64 ⋅ h p ⋅ W
0 , 75
⋅
b
a
0 , 717
donde A es el área del pico; hp y W son la altura y la anchura del pico, respectivamente, y b/a es
la simetría medida al 75 % de la altura del pico.76
Algunos autores emplean, para el ajuste de picos solapados, funciones matemáticas
diferentes a las vistas hasta ahora. Es el caso de Le-Vent, que compara el modelo Bigaussiano
(también utilizado por otros grupos de investigación)77 y el Gaussiano-Lorentziano, con el
EMG.78
Por último, otros modelos aplicados para la deconvolución numérica son la distribución
binomial y de Poisson79 y el EMS (función cuadrática modificada exponencialmente), esta última
dirigida para picos de FIA.80 Algunos de estos métodos son llevados a cabo, no de forma
numérica, sino gráficamente.
3) Aplicación De Transformadas De Funciones.
Entre los métodos más importantes de transformadas de funciones caben destacar la
transformada de Fourier y las “wavelet”. En este apartado se comentará tan sólo la primera de
ellas.
Hasta ahora, se ha hablado de métodos de derivación y de ajuste de curvas para resolver
mezclas de señales, en las que aparecen picos solapados correspondientes a más de un analito.
La transformada de Fourier es más sencilla y rápida de aplicar que cualquier otro método
matemático, algunos de los cuales requieren algoritmos mucho más complejos que éste, puesto
que trabaja en el dominio de las frecuencias.37 Sin embargo, suele perderse en un exceso de
ecuaciones matemáticas y en la aplicación de funciones o formas de onda arbitrarias68, tal como
ocurría con el ajuste de curvas, aunque en menor medida que éstas.
No obstante, este método de modelización presenta una clara desventaja con respecto a los
-51-
INTRODUCCIÓN
demás. Ésta radica en la introducción de cierto ruido matemático, denominado ruido de
resolución que, a veces, en determinadas situaciones, hacen imposible su aplicación para alcanzar
una correcta resolución del sistema multianalito. Uno de esos casos es el comentado
anteriormente en el apartado sobre el método de los espectros cocientes o de división de la señal:
la transformada de Fourier no es útil cuando uno de los analitos de la mezcla se encuentra en
concentración muy elevada con respecto a los restantes.
El ruido de resolución tiene su origen en varios factores: por un lado, el número final de
puntos que, a veces, es modificado mediante la adición de ceros, puesto que muchos programas,
para realizar la deconvolución por transformada de Fourier precisan de un número concreto de
datos: 2N, (siendo N un número entero positivo); y, por otro lado, los errores de redondeo,
inherentes a las matemáticas. Como veremos posteriormente, algunos autores relacionan
directamente el fenómeno de sobreagudización o la formación de picos laterales o “spikes” con
estos errores37, 45, lo que induce a equivocaciones a la hora de determinar y diferenciar las señales
de los analitos procedentes de la mezcla.
Como consecuencia de todo esto algunos autores aconsejan el uso de la transformada de
Fourier única y exclusivamente en aquellos análisis que no requieran una exactitud elevada.81
Con respecto a los campos de aplicación de la transformada de Fourier, algunos de los
cuales se comentarán en detalle con posterioridad, hay que decir que estos son muy amplios. Se
ha empleado para la deconvolución de picos en cromatografía73, 75, 82, 83 y espectroscopía68, en la
eliminación de ruido84 e interpolación de datos de señales,85 en estudios sobre efectos de
adsorción y sobre circuitos analógicos86, en investigaciones de efectos cinéticos de
transformación de carga heterogénea que monitorizan el estado de reacción del electrodo87 y, por
último, a medidas de admitancia faradaica88, 89.
Principalmente se ha usado para representar señales en el espacio de Fourier. Por ejemplo,
en la Figura 1, se recoge la representación gráfica en el dominio del tiempo (izquierda) y en el
de la frecuencia (derecha) del sonido que se obtiene al puntear una cuerda de guitarra en su punto
medio. Se obtiene entonces un sonido fundamental (frecuencia fundamental o dominante) que
se ha supuesto de 440 Hz, superpuesto a otros de frecuencias múltiplos impares de la
fundamental (1320, 2200, ... Hz) La amplitud de estos armónicos es inversamente proporcional
al cuadrado de su orden.
-52-
INTRODUCCIÓN
Figura 1: Espectro de Fourier para una señal de sonido.
Como puede observarse, la señal en el tiempo se ha logrado descomponer en unas pocas
frecuencias y amplitudes dominantes en el espacio de Fourier, lo que supone una gran ventaja
si se combina con una técnica de reducción de dimensiones.90
Por otro lado, Grabariƒ et al. han llevado a cabo deconvolución de señales
voltamperométricas en mezclas de dos analitos, donde la diferencia entre los potenciales de onda
media de cada uno de ellos es menor de 100/n mV. Este método agudiza y estrecha los picos del
voltamperograma, eliminando el solapamiento en función de la magnitud de éste. La posición
del pico y la proporcionalidad lineal entre la altura del pico y la concentración de la especie
siguen manteniéndose.
El procedimiento es el siguiente: se divide la transformada de Fourier de la función a
deconvolucionar por la transformada de Fourier de la función deconvolución. Al resultado se le
aplica la transformada de Fourier inversa y se obtiene la función deconvolucionada.
La expresión de la función deconvolución que emplean estos autores es:
f ( x) =
K
cosh ( n d ⋅ x)
2
donde K es una constante arbitraria y nd es el número de electrones de la función deconvolución,
el cual no tiene que ser necesariamente un entero. El margen de reproducibilidad del pico se
encuentra dentro del intervalo de ±1 mV, con un grado de error del ±2 % en la altura.37 Se eligió
-53-
INTRODUCCIÓN
esta función deconvolución para minimizar o eliminar en lo posible los efectos de la cinética de
transferencia de carga heterogénea. En otras ocasiones, la elección es fundamentalmente
empírica: mediante el uso de una función modelo que describe con exactitud la forma de la
señales de la muestra. Tales funciones son determinadas con frecuencia por la aplicación de un
análisis de regresión. Sin embargo, otros autores han propuesto la señal individual de uno de los
componentes de la mezcla como función deconvolución.41, 91
El grado de agudización de los picos es función de la amplitud media de la función
deconvolución (esto es, aparece reflejada en el valor de nd). Si éste valor se aproxima a la
amplitud media del componente más estrecho en la señal solapada de la mezcla que se va a
deconvolucionar, se obtienen picos sobreagudizados, es decir, aparecen otros picos más pequeños
a ambos lados de los picos principales. El efecto de sobreagudización no influye en la posición
del pico, a menos que se produzca en tal extensión que el resultado de la deconvolución sea una
función oscilante a lo largo de todo el rango de potenciales aplicado.
La sobreagudización, aunque sea moderada, impide un buen reconocimiento de los picos
del voltamperograma. El grado de resolución del solapamiento es función de nd, cuyo valor
óptimo debe determinarse inspeccionando los picos resultantes de la deconvolución. Valores de
nd pequeños permiten deconvoluciones más agudas y estrechas. Sin embargo, cuanto menor sea
este valor, mayor grado de sobreagudización se producirá.
La deconvolución por transformada de Fourier es menos efectiva cuando los componentes
de la mezcla poseen diferentes valores de n.
Por último, hay que comentar que éste es uno de los casos en los que se utiliza el relleno
con ceros hasta obtener un número de puntos igual a 2N, como se ha apuntado con anterioridad;
además, se da el valor de cero a aquellos componentes que poseen frecuencias más altas y que
contribuyen a aumentar el ruido del voltamperograma. La unión de estos dos factores, en
conjunción con la aplicación de un método matemático, como es la transformada de Fourier,
explica la aparición de los picos “fantasma” englobados bajo el fenómeno de sobreagudización.37
Kirmse y Westerberg han establecido la base teórica de la agudización de picos simétricos
en el campo de las frecuencias, aplicándola fundamentalmente a la cromatografía de gases.
Asumiendo la forma gaussiana de los picos se hace la transformada de Fourier de la señal
mezcla y se divide por la transformada de Fourier de la función deconvolución, cuya expresión
es:
y = exp( − 2 ⋅ π 2 ⋅ f 2 ⋅ σ 2 )
donde f es la frecuencia y ó la varianza. Al resultado se le aplica la transformada de Fourier
inversa y se obtiene un pico más estrecho y agudo, con un área proporcional a la concentración
-54-
INTRODUCCIÓN
del componente y reteniendo su posición.
En este caso, el fenómeno de sobreagudización está controlado por la relación existente
entre ó 2l y ó 2, varianza del pico l y varianza de la función de agudización, respectivamente. De
tal modo que, ó debe ser lo más cercana posible a ó l, si se desea obtener una agudización
significativa; además, debe cumplirse ó 2 < ó 2l, si no, se produce una sobreagudización semejante
a como ocurría con el parámetro nd de Grabariƒ et al., dando lugar a una onda oscilante sin
sentido.
La aplicación del método provoca un aumento del ruido (ruido de digitalización), tal que,
tras la deconvolución se obtiene una función de onda que oscila bastante y carece de utilidad.
Para poder entresacar alguna información de ellas, se elimina de la función la zona de frecuencias
más altas, a partir de un punto denominado frecuencia de corte, fc y, a continuación, se aplica un
filtro o ventana denominada: ventana de Hamming, cuya forma es la siguiente:
π ⋅f
→ f < fc
0,54 + 0,46 cos
fc
W( f ) =
0
→ Cualquier otra
El valor de fc se conoce a partir del espectro obtenido multiplicando la transformada de
Fourier de la mezcla por su complejo conjugado. Si se aplicase una ventana de tipo rectangular,
la agudización del pico sería mayor, pero el fenómeno de sobreagudización también se
acrecentaría, originando una confusión aún mayor.82
Debido a la gran sensibilidad de la transformada de Fourier al ruido, se encuentran muchas
dificultades a la hora de elegir la frecuencia de corte y la ventana de alisamiento.81
Este sistema es mejor que las técnicas de diferenciación: filtrado analógico y digital, que
aumentan la resolución a costa de la relación señal-ruido.67
Küllik et al. utilizaron también la transformada de Fourier para resolver mezclas en
cromatografía gaseosa. No obstante, emplearon funciones lineales como funciones de
deconvolución y, en vez de aplicar una ventana de Hamming, multiplicaron el resultado por una
función apodizada. Aunque se puede mejorar la resolución mediante la aplicación de filtros, estos
provocan la aparición de lóbulos en ambos laterales de los picos principales. Como única
condición es necesario conocer la amplitud media del pico más estrecho de los componentes de
la mezcla, cuestión que debe estar relacionada con los problemas de sobreagudización
anteriormente mencionados.81
En principio, la deconvolución por transformada de Fourier provoca la conversión de los
picos voltamperométricos en una función ä de Dirac, que permite la separación de dos procesos
-55-
INTRODUCCIÓN
energéticamente iguales.
Basándose en esta premisa, Piz•ta empleó el siguiente procedimiento: un primer paso
consiste en aplicar una ventana digital al conjunto de datos (se considera la señal como un
periodo de una función periódica y el filtrado evita discontinuidades entre esos periodos haciendo
que la señal comience y finalice en el mismo valor: cero) o, también puede sustraerse una recta
a la función mezcla. Seguidamente se adicionan ceros hasta duplicar la longitud de los datos, tal
que existan 2N puntos (debido a que el algoritmo asume deconvolución circular y se debe aplicar
linealmente) y se emplea la transformada de Fourier para llevarla al dominio de las frecuencias.
Por otro lado, previa elección de la amplitud de la función deconvolución, se sigue con ella un
proceso paralelo al anterior, empleándose el relleno con ceros para alcanzar la misma longitud
de datos que en el caso anterior; además, antes de pasarla al dominio de Fourier, hay que
“desenvolverla” o “desplegarla”. Una vez que ambas funciones se encuentran en el campo de las
frecuencias, se divide la señal mezcla por la de deconvolución; al resultado se aplica un filtro
adecuado de paso bajo para eliminar el ruido (frecuencias elevadas) producido por el tratamiento
matemático (división de números muy pequeños) y, posteriormente, la transformada de Fourier
inversa. Por último, si se sustrajo una recta al principio, ahora es el momento de añadirla, pero
dividida por un factor de proporcionalidad. Hay que resaltar que el proceso puede repetirse de
forma iterativa.
Este autor emplea la siguiente función de deconvolución:
n⋅ E
exp
E − E 0 )
(
R⋅T
I( E ) =
2
n⋅ E
1 + exp R ⋅ T ( E − E 0 )
donde n indica la amplitud de la función deconvolución y no tiene que ser un número entero.
Hay que elegir la función deconvolución y n de tal forma que aquella ha de tener una
amplitud menor o igual que la del pico más estrecho de la señal mezcla, como ocurría con
Grabariƒ et al. Si n es más pequeño, se produce sobreagudización y aparecen picos laterales; si
es mayor, se obtiene una oscilación sin sentido. Por tanto, la función deconvolución debe elegirse
con el fin de alcanzar un compromiso entre la oscilación lateral (sobreagudización) y la
resolución de los picos.
La determinación de la concentración de los componentes se lleva a cabo mediante el uso
de rectas de calibrado. La exactitud de dicha determinación depende de la distancia de los picos
solapados, de la relación de sus amplitudes (#20) y de sus amplitudes medias.91
Raspor, Piz•ta y Branica utilizaron el procedimiento antes comentado y lo compararon con
-56-
INTRODUCCIÓN
el método de evaluación del propio aparato de medida y con el ajuste de tangentes manual. El
objetivo era obtener una correspondencia óptima con la recta de calibrado elaborada
previamente.83
Horlick también ha empleado la transformada de Fourier para resolver señales, pero en
espectroscopía.
Su método se basa fundamentalmente en lo siguiente: se aplica la transformada de Fourier
a la señal de la muestra; una vez en el dominio de las frecuencias, se separan la parte real y la
parte imaginaria; y, por último, se toma la parte real y se multiplica por una función de
deconvolución adecuada. Normalmente, se emplea la función de resolución del espectrómetro
(la amplitud, que es función de la rendija), con lo cual, se pierden las frecuencias más elevadas
(ruido) y se disminuye la amplitud de las frecuencias más bajas (señales de picos).
Este mismo procedimiento puede emplearse para mejorar la resolución de un espectro de
baja resolución. Para ello hay que utilizar una función de deconvolución apropiada, obtenida a
partir del cociente entre el espectro de frecuencias de alta resolución y el espectro de frecuencias
de baja resolución.
Otra aplicación de la transformada de Fourier empleada por Horlick ha sido la corrección
y eliminación de ruido de las señales, mediante el uso de filtros digitales de paso bajo, que
controla la frecuencia de corte y elimina los cambios de fase, o de igualación; éste último para
los casos en los que el ruido sea uniforme.68 Normalmente, la función se elige empíricamente.
La base de este fundamento estriba en que el ruido se produce en una zona diferente de la
que aparece la señal y, por tanto, puede ser eliminado. En la mayoría de los datos analíticos
sucede que los componentes de la señal poseen amplitud elevada y su respuesta varía lentamente,
mientras que el ruido es una fluctuación de amplitud pequeña que varía muy rápidamente. En casi
todos los sistemas el ruido es al azar o uniforme en el carácter, pero en el campo de las
frecuencias, la situación es diferente: la información que describe los componentes de la señal
está contenida en la zona de baja frecuencia del espectro, mientras que el ruido uniforme se
distribuye a lo largo de todo el rango del mismo.
La transformada de Fourier contiene componentes de frecuencias reales e imaginarios.
Como los datos son números reales, la parte imaginaria del espectro contiene la imagen espejo
del espectro real. Aunque la parte imaginaria, que contiene información redundante, no es
utilizada en la mayoría de las aplicaciones, debería incluirse en los cálculos para prevenir
violaciones del teorema de Parseval. Sin embargo, si sólo se usan componentes reales, los
resultados deben ajustarse por un factor de 2 para retener el mismo poder integrado total.
Determinando la frecuencia de corte más allá de la cual no existe información de la señal, es
posible eliminar de manera efectiva la mayoría del ruido de los datos.
-57-
INTRODUCCIÓN
Actualmente, se ha desarrollado un nuevo algoritmo que presenta una ventaja sobre el
método anterior: elimina la parte compleja de la transformación. No obstante, los resultados son
similares al empleo de la FT estándar o de la transformada de Hartley, versión real de la FT.
Asimismo, se han propuesto nuevas funciones de paso que reducen considerablemente la
resonancia asociada comúnmente a este tipo de funciones.52
En el trabajo de Horlick, éste multiplicó el filtro por la parte real de la señal en el dominio
de Fourier (convolución), eliminando así las frecuencias más altas que corresponden al ruido. Si
el filtro o la función no es la apropiada, se obtienen picos laterales falsos a ambos lados de la
señal original.68
Del mismo modo, Hayes et al. han utilizado la transformada de Fourier para llevar a cabo
una corrección de ruido en las señales. Esta operación implica los siguientes pasos: transformar
el espectro original a un espectro de Fourier, multiplicar éste por una función de filtro y hacerle
al resultado la transformada de Fourier inversa.
Las funciones de filtro rectangulares pueden ser aplicables cuando los datos originales
comienzan y acaban en valores próximos o iguales a cero. Si no es así, se introducen una serie
de picos laterales falsos tras el tratamiento. Esto sucede como consecuencia de que el algoritmo
matemático detecta la no iniciación o terminación en cero como un tránsito discontinuo, al igual
que le ocurría a Piz•ta. En algunos casos, estas oscilaciones pueden abordar todo el
voltamperograma. No obstante, mediante ciertas modificaciones en la función del filtro se puede
minimizar este problema. A pesar de todo, esto provoca distorsiones en la respuesta final.
Una solución a esta cuestión sería la empleada por Hayes et al.: la aplicación de una
rotación-traslación a los datos originales, tal que los puntos iniciales y finales acaben en cero,
eliminando así el tránsito abrupto. Es lo que ellos denominan: “corrección de datos por
transformada de Fourier modificada”.
Este nuevo método fue comparado con la corrección por mínimos cuadrados, como la
realizada por Bond y Grabariƒ,92 siendo muy pequeña la diferencia significativa entre ambas
aproximaciones. Sin embargo, la balanza se equilibró a favor del método por transformada de
Fourier debido a su velocidad e interpretación.
Si el ruido y la señal solapan entre sí en el espectro, el método anteriormente comentado
no es factible, al producirse errores en la aplicación de la rotación-traslación.84
Por otro lado, O´Halloran y Smith han utilizado el espectro de las frecuencias para llevar
a cabo interpolaciones de datos electroquímicos no continuos, definiendo mejor la localización
del pico en el conjunto de datos.
El procedimiento es el siguiente: al conjunto de datos se le aplica la transformada de
Fourier; se rellena con ceros hasta obtener un número de datos de 2N y, por último, se hace la
-58-
INTRODUCCIÓN
transformada de Fourier inversa. El resultado es una red interpolada que contiene 2N veces el
número de puntos que los datos originales.
Antes o después de la interpolación se emplea un filtro digital para hacer una corrección de
ruido. Además, se ajusta un polinomio a varios puntos en cada extremo de la red de datos
originales y se resta de los mismos antes de la interpolación y/o filtrado. Esta modificación
asegura que los datos comiencen y acaben en cero, suprimiendo así el error de truncamiento.
Como paso final, se añade a la red de datos interpolados una versión convenientemente
interpolada del polinomio, provocando un aumento de la red de datos originales. Mientras el
llenado de ceros vaya precedido de la resta polinomial, éste no causa errores.
El número mínimo de datos necesarios para asegurar una buena definición del espectro en
el dominio de Fourier es de diez, lográndose de este modo unos parámetros de pico satisfactorios.
El fin de la interpolación de datos es el de evaluar distintos parámetros, tales como la
posición y magnitud del pico, su amplitud de área a la altura media, potenciales de onda media
y la separación de los picos, entre otros.85
Además, la transformada de Fourier permite llevar a cabo gran cantidad de estudios, tales
como el procesamiento de datos a partir del espectro de admitancia faradaica para estudios
cinético-mecanísticos en electroquímica, la obtención de espectros de respuesta de medidas de
relajación electroquímica de pequeña amplitud y características de no linealidad faradaica.
También se emplea para el cálculo de admitancias y para procesos de correlación y
decorrelación, siendo los dos últimos muy útiles en ensayos cualitativos y cuantitativos.86, 89
Por último, la transformada de Fourier se ha aplicado con éxito a gran número de técnicas
diferentes a las comentadas en los ejemplos anteriores. Entre ellas podemos destacar la
espectroscopía de absorción74 y la espectroscopía de resonancia de ion-ciclotrón.93
REDES NEURONALES ARTIFICIALES.
Este método de modelización matemática se ha empleado muy poco en electroquímica. Su
utilidad radica en el trazado de mapas no lineales, calibración multivariante no lineal y en
clasificación o reconocimiento de patrones lineal y no lineal.52
Existen numerosas formas de definir las redes neuronales. Algunas de estas definiciones
son las siguientes:
2. Una nueva forma de computación, inspirada en modelos biológicos.
3. Un modelo matemático compuesto por un gran número de elementos procesales
organizados en niveles.
-59-
INTRODUCCIÓN
4. “... un sistema de computación hecho por un gran número de elementos simples,
elementos de proceso muy interconectados, los cuales procesan información por medio
de su estado dinámico como respuesta a entradas externas.” [Hecht-Niesen].
5. “Redes neuronales artificiales son redes interconectadas masivamente en paralelo de
elementos simples (usualmente adaptativos) y con organización jerárquica, las cuales
intentan interactuar con los objetos el mundo real del mismo modo que lo hace el
sistema nervioso biológico.” [Kohonen].94
En relación con las redes neuronales, se habla muy frecuentemente de paradigmas. En este
contexto, un paradigma comprende normalmente la descripción de la forma de una unidad de
procesamiento y su función, una topología de red que describe los patrones por la cual una serie
de interconexiones pesadas transportan las señales de salida de unas unidades hasta la entrada
de otras, y una regla de aprendizaje para establecer los valores de los pesos. Las unidades de
procesamiento (neuronas) y las redes empleadas en estos paradigmas artificiales son la esencia
enormemente simplificada de las dendritas (ramas de entrada), axones (ramas de salida), sinapsis
(conexiones) e interconexiones encontradas en los sistemas vivos que poseen neuronas
biológicas. Se ha encontrado que esta esencia dispone del potencial para capturar una porción
significativa de las funciones de un sistema vivo. Aunque los paradigmas difieren en detalle unos
de otros, cada uno extrae su poder a partir de una serie de atributos.95
Los atributos de una red neuronal típica son: elementos de procesamiento simples; alta
conectividad; procesamiento en paralelo; transferencia no lineal; vías de retroalimentación;
procesamiento no algorítmico; adaptación (aprendizaje); autoorganización; tolerancia a fallos;
obtención de salidas útiles a partir de entradas borrosas; generalización; posee el potencial de
ejecutarse a altas velocidades; operación en tiempo real; y, por último, fácil inserción dentro de
la tecnología existente.95, 96
De entre todas las características anteriores, podríamos destacar las siguientes:
w aprendizaje adaptativo: capacidad de aprender a realizar tareas basadas en un
entrenamiento o una experiencia inicial
w autoorganización: una red neuronal puede crear su propia organización o
representación de la información que recibe mediante una etapa de aprendizaje
w tolerancia a fallos: la destrucción parcial de una red conduce a una degradación de
su estructura; sin embargo, algunas capacidades de la red se pueden retener, incluso
sufriendo un gran daño
w operación en tiempo real: los computadores neuronales pueden ser realizados en
-60-
INTRODUCCIÓN
paralelo, y se diseñan y fabrican máquinas con hardware especial para obtener esta
capacidad
w fácil inserción dentro de la tecnología existente: se pueden obtener chips
especializados para redes neuronales que mejoran su capacidad en ciertas tareas; ello
facilitará la integración modular en los sistemas existentes.96
a) Conceptos Y Estructura De La Red Neuronal.
A continuación, veremos algunos conceptos y una breve descripción de la estructura y el
funcionamiento de las redes neuronales, según Zupan y Gasteiger.97
Las redes neuronales surgieron a partir de un intento por modelar el funcionamiento del
cerebro humano.
Figura 2: Esquema comparativo entre una neurona biológica y una neurona
artificial.
En una neurona típica del córtex humano, las señales procedentes de otras neuronas entran en ella
a través de las dendritas (canales de entrada de la neurona). Si la suma de las señales recibidas
en un momento dado excede un cierto valor umbral, el cuerpo de la célula genera una señal de
salida la cual viaja luego a lo largo del axón (el canal de salida) y es transportada (corriente
abajo) a otras neuronas. El proceso mediante el cual la señal es transmitida de una neurona a la
siguiente se denomina sinapsis. La magnitud de la influencia de esta señal sobre la próxima
neurona está modulada por la eficacia de la intervención sináptica, denominada fortaleza
-61-
INTRODUCCIÓN
sináptica.
De este modo, la neurona artificial o simulada por ordenador se ha diseñado para imitar la
función de una neurona biológica. La entrada a esta nueva neurona es la señal que llega a ella
procedente de una o más neuronas y la salida significa la señal emitida por ella a la próxima
neurona corriente abajo. La sinapsis es representada aquí por las conexiones entre dos o más
neuronas artificiales y la fortaleza sináptica viene simbolizada por los pesos asociados con cada
conexión.
Un peso consiste simplemente en un número real. Si el peso es positivo, tiende a estimular
a la neurona siguiente para que transmita su propia señal corriente abajo; si el peso es negativo
no provoca esa estimulación. El conjunto de los valores de los pesos asociados con las neuronas
en una red determina las propiedades computacionales de la red y el entrenamiento de la misma
consiste en alcanzar unos valores adecuados de los pesos por modificación de los mismos.
Junto a los pesos, existe un parámetro adicional, è j, denominado sesgo, que es necesario
para determinar el funcionamiento propio de cada neurona j. Cada neurona necesita del sesgo
para ajustar todas sus entradas Netj tal que caigan dentro de la región donde pueden ser utilizadas
por la función de transferencia para obtener el mayor beneficio posible del desarrollo completo
de la red. Este parámetro, que siempre recibe el valor de 1, es tratado igual que cualquier otro
peso y debido a su valor puede considerarse como la línea base de toda la red.
La estructura de una red neuronal podría ser la que aparece representada en la Figura 3:
Figura 3: Esquema de una red neuronal artificial.
Dentro de cada neurona, tienen lugar dos procesos:
-62-
INTRODUCCIÓN
1) Todas las entradas pesadas a la neurona j son combinadas para producir una entrada
de red Netj, a partir de la matriz de multiplicación:
Net j =
∑ (Inp ⋅ w ) + θ
i
ij
j
i
donde Inpi son las entradas a la neurona j que proceden de las i neuronas anteriores
y wij son los pesos asociados a cada una de las conexiones de las i neuronas
anteriores con la neurona j.
2) Netj se utiliza para determinar qué salida Outj se va a generar. La función por la cual
se calcula Outj a partir de Netj se denomina función de transferencia sigmoidal,
llamada también en otros casos función de apilamiento. Su forma es bastante
arbitraria y se haya limitada únicamente por dos condiciones, que deben mantenerse
para todos los valores de Netj: en primer lugar, sus valores deben pertenecer al
intervalo [0, 1]; en segundo lugar, debe ascender de forma monotónica.
Normalmente, esta función es no lineal, ya que es necesario mantener una relación
de este tipo entre la entrada Netj y la salida Outj; sin embargo, algunos autores han
utilizado funciones lineales.98 La forma de la función de transferencia más
comúnmente empleada es la función logística:
(
)
f Net j =
1
1 + exp⋅ −
∑(
i
Inp i ⋅ w ij + θ j
)
No obstante, existe otra función mucho más rápida computacionalmente denominada
límite o umbral lógico:
(
)
[
(
)]
f Net j = max 0, min Net j , 1
Desde el punto de vista de su utilización en hardware, el límite lógico es
considerablemente más sencillo y barato de usar que la función de transferencia
sigmoidal. Además, es muy útil en situaciones donde se realizan clasificaciones
alternativas de entradas individuales. Sin embargo, desde el punto de vista teórico no
es conveniente emplearla ya que su derivada no está definida en dos puntos.
La arquitectura o estructura de una red neuronal está determinada por la forma en como las
-63-
INTRODUCCIÓN
salidas de las neuronas están conectadas a otras neuronas. En el caso estándar, las neuronas o
unidades de procesamiento de la red se dividen en varios grupos denominados capas o estratos,
donde cada neurona de una capa está conectada a todas las neuronas presentes en la siguiente
(mediante esta topología de interconexión se pueden obtener modelos no lineales muy
complejos). Básicamente, son posibles arquitecturas mono- o multicapa. El primer estrato
consiste en un conjunto de entrada, donde cada neurona está conectada a una entrada individual.
Las siguientes capas se denominan capas ocultas. Y la última, capa de salida.
Todas las n neuronas de una capa poseen el mismo número de entradas, esto es, el mismo
número de pesos wij (i = 1, ..., m; j = 1, ..., n), los cuales serán modificados durante el proceso
de entrenamiento. Esas m entradas proceden de otras tantas neuronas situadas en la capa
inmediatamente anterior (capa oculta) o bien de un dispositivo de entrada externo (capa de
entrada). De este modo, todas las neuronas situadas en la misma capa reciben simultáneamente
una señal de entrada con m variables: X (x1, x2, ..., xj, ..., xm).
Por otro lado, cada neurona origina una única salida. Así, en el caso de una arquitectura
monocapa, las n salidas Outj de la capa actual, obtenidas por aplicación de una de las dos
ecuaciones anteriores, representarán la salida de la red. Si la estructura es multicapa, constituirán
las entradas del siguiente estrato, formado ahora por p neuronas. Esta nueva capa, posee ahora
n × p pesos y originará p salidas, las cuales serán propagadas hacia capas más profundas. La
salida final de la red completa está formada simplemente por las salidas colectivas de la capa
final de neuronas. El número de neuronas de una capa y el número de capas depende
considerablemente de la aplicación particular que se dé a la red, es decir, según el número de
variables para los objetos, el número de objetos implicados en el estudio o el número y calidad
de las respuestas.97
b) Mecanismo De Aprendizaje De Las Redes Neuronales.
El aprendizaje es el proceso por el cual una red neuronal modifica sus pesos en respuesta
a una información de entrada. Los cambios que se producen durante el proceso de aprendizaje
se reducen a la destrucción, modificación y creación de conexiones entre las neuronas. En los
modelos de redes neuronales artificiales, la creación de una nueva conexión implica que el peso
de la misma pasa a tener un valor distinto de cero. De la misma forma, una conexión se destruye
cuando su peso pasa a ser cero.
Durante el proceso de aprendizaje, los pesos de las conexiones de la red sufren
modificaciones, por tanto se puede afirmar que este proceso ha terminado (la red ha aprendido)
cuando los valores de los pesos permanecen estables (su variación en el tiempo es cero).
-64-
INTRODUCCIÓN
Un aspecto importante respecto al aprendizaje en las redes neuronales es el conocer cómo
se modifican los valores de los pesos; es decir, cuáles son los criterios que se siguen para cambiar
el valor asignado a las conexiones cuando se pretende que la red aprenda una nueva información.
Estos criterios determinan lo que se conoce como la regla de aprendizaje de la red. Existen
dos tipos de reglas que, posteriormente, van a permitir clasificar las redes en base a ellas. Esas
reglas son las siguientes:
w Aprendizaje supervisado
w Aprendizaje no supervisado
La diferencia entre ellas estriba en la existencia o no de un agente externo (supervisor) que
controle el proceso de aprendizaje de la red.
Otro criterio que se puede utilizar para diferenciar las reglas de aprendizaje se basa en
considerar si la red puede aprender durante su funcionamiento habitual o si el aprendizaje supone
la desconexión de la red; es decir, su inhabilitación hasta que el proceso termine. En el primer
caso se trataría de un aprendizaje ON LINE, mientras que el segundo es lo que se conoce como
aprendizaje OFF LINE.
c) Aprendizaje Supervisado.
Este tipo se caracteriza porque el proceso de aprendizaje se realiza mediante un
entrenamiento controlado por un agente externo (supervisor, maestro) que determina la respuesta
que debería generar la red a partir de una entrada determinada. El supervisor comprueba la salida
de la red y en el caso de que ésta no coincida con la deseada, se procederá a modificar los pesos
de las conexiones, con el fin de conseguir que la salida obtenida se aproxime a la deseada.
Existen tres formas de llevar a cabo esta clase de aprendizaje:
w Aprendizaje por corrección de error: consiste en ajustar los pesos de las conexiones
de la red en función de la diferencia entre los valores deseados y los obtenidos en la
salida de la red; es decir, en función del error cometido en la salida.
w Aprendizaje por refuerzo: en este caso, la función del supervisor se reduce a indicar
mediante una señal de refuerzo si la salida obtenida en la red se ajusta a la deseada
(éxito = +1, fracaso = -1), y en función de ello se ajustan los pesos basándose en un
mecanismo de probabilidades. Se podría decir que en este tipo de aprendizaje la
función del supervisor se asemeja más a la de un crítico (que opina sobre la respuesta
-65-
INTRODUCCIÓN
de la red) que a la de un maestro (que indica a la red la respuesta concreta que debe
generar), como ocurría en el caso anterior.
w Aprendizaje estocástico: consiste básicamente en realizar cambios aleatorios en los
valores de los pesos de las conexiones de la red y evaluar su efecto a partir del
objetivo deseado y de distribuciones de probabilidad. En este caso, se suele hacer la
siguiente analogía: se asocia la red neuronal con un sólido físico que posee cierto
estado energético. En el caso de la red, la energía de la misma representaría el grado
de estabilidad de la red, de tal forma que el estado de mínima energía correspondería
a una situación en la que los pesos de las conexiones consiguen que su
funcionamiento sea el que más se ajusta al objetivo deseado. Según lo anterior, el
aprendizaje consistiría en realizar un cambio aleatorio en los valores de los pesos y
determinar la energía de la red. Si la energía es menor después del cambio, es decir,
si el comportamiento de la red se acerca al deseado, se acepta el cambio. Si, por el
contrario, la energía no es menor, se aceptaría el cambio en función de una
determinada y preestablecida distribución de probabilidades.
d) Aprendizaje No Supervisado.
Las redes con aprendizaje no supervisado (también conocido como autosupervisado) no
requieren influencia externa para ajustar los pesos de las conexiones entre sus neuronas. La red
no recibe ninguna información por parte del entorno que le indique si la salida generada en
respuesta a una determina entrada es o no correcta. Por ello, suele decirse que estas redes son
capaces de autoorganizarse.
Estas redes deben encontrar las características, regularidades, correlaciones o categorías que
se puedan establecer entre los datos que se representen en su entrada. Al no existir ningún
supervisor que indique a la red la respuesta que debe generar ante una entrada concreta, hay
varias posibilidades en cuanto a la interpretación de la salida de estas redes, que depende de su
estructura y del algoritmo de aprendizaje empleado.
En algunos casos, la salida representa el grado de familiaridad o similitud entre la
información que se le presenta a la entrada y la mostrada hasta entonces (en el pasado). En otro
caso, podría realizar un agrupamiento o establecimiento de categorías, indicando la red a la salida
a qué categoría pertenece la información presentada a la entrada, siendo la propia red quien debe
encontrar las categorías apropiadas a partir de correlaciones entre las informaciones presentadas.
El aprendizaje sin supervisión permite realizar una codificación de los datos de entrada,
generando a la salida una versión codificada de la entrada, pero manteniendo la información
-66-
INTRODUCCIÓN
relevante de los datos.
Existen dos formas de aprendizaje no supervisado:
w Aprendizaje hebbiano: es una regla de aprendizaje no supervisado, puesto que la
modificación de los pesos se realiza en función de los estados (salidas) de las
neuronas obtenidos tras la presentación de cierto estímulo (información de entrada
a la red), sin tener en cuenta si se deseaba obtener o no esos estados de activación.
Consiste básicamente en el ajuste de los pesos de las conexiones de acuerdo con la
correlación (multiplicación en el caso de valores binarios +1 y -1) de los valores de
activación (salidas) de las dos neuronas conectadas. En este sentido, si las dos
unidades son activas (positivas), se produce un reforzamiento de la conexión; por el
contrario, cuando una es activa y la otra pasiva (negativa), se produce un
debilitamiento de la conexión.
w Aprendizaje competitivo y cooperativo: en este aprendizaje, suele decirse que las
neuronas compiten (y cooperan) unas con otras con el fin de llevar a cabo una tarea
dada. Con esto se pretende que cuando se presente a la red cierta información de
entrada, sólo una de las neuronas de salida de la red, o una por cierto grupo de
neuronas, se active (alcance su valor de respuesta máximo). Por tanto, las neuronas
compiten por activarse, quedando finalmente una, o una por grupo, como neurona
vencedora, anulándose el resto, que son forzadas a sus valores de respuesta mínimos.
La competición entre neuronas se realiza en todas las capas de la red, existiendo en
estas neuronas conexiones recurrentes de autoexcitación y conexiones de inhibición
(signo negativo) por parte de neuronas vecinas. Si el aprendizaje es cooperativo, estas
conexiones con las vecinas serán de excitación (signo positivo). El objetivo de este
aprendizaje es categorizar los datos de entrada a la red. De este modo, informaciones
similares que son clasificadas dentro de una misma categoría deben activar la misma
neurona de salida. Las clases o categorías son creadas por la propia red a partir de las
correlaciones entre los datos de entrada, al tratarse de un aprendizaje no
supervisado.99
e) Entrenamiento De La Red Neuronal.
Una vez elegida una arquitectura adecuada a nuestro problema, el siguiente paso consiste
en obtener los valores de los pesos a partir de patrones conocidos que nos permitan utilizar la red
para predecir muestras desconocidas. Es la fase de entrenamiento de la red neuronal. No obstante,
-67-
INTRODUCCIÓN
existen dos tipos de entrenamiento de acuerdo con la meta perseguida: obtener un vector de
salida predefinido Yk para cualquier señal de entrada Xk o activar, para cualquier objeto de
entrada Xk perteneciente a una clase p, una neurona dentro del segmento p-ésimo de las neuronas
de salida de la red.
En el primer caso, la red debe ser entrenada de manera supervisada a partir de un conjunto
de pares entrada/salida (Xk, Yk), denominado “conjunto de entrenamiento”. Xk es el vector de
entrada de m componentes (espectro, secuencia de proteínas, etc.) mientras que Yk es la salida
deseada o conjunto de respuestas para este vector de entrada particular. El entrenamiento
supervisado se inicia con unos valores de pesos al azar, que junto con la entrada individual Xk,
permite calcular el vector de salida. Este vector es comparado con el vector Yk conocido y que
se desea obtener. A continuación, se aplica una medida correctiva para cambiar los pesos de la
red (incluyendo los sesgos) en base a los errores observados en los patrones de salida, de tal
forma, que los pesos corregidos darán una mejor aproximación a Yk. El procedimiento de
corrección usado varía de una red a otra. La presentación de los pares de entrenamiento (Xk, Yk)
junto con los correspondientes pesos corregidos se considera un ciclo del procedimiento de
aprendizaje. El proceso se repite muchas veces hasta que se alcance un acuerdo aceptable entre
todos los pares (Xk, Yk) y la salida producida Y´k, o hasta que se exceda el número de ciclos
permitido. La ventaja de este proceso es que luego, a partir de estos patrones, se puede
generalizar (dentro de unos límites) para obtener resultados correspondientes a otras entradas que
no se hayan estudiado aún. Aunque el entrenamiento es bastante largo (según la estructura de la
red), una vez realizado, la red ofrece respuestas o predicciones casi instantáneamente. De este
modo, se sacrifica el tiempo de entrenamiento para alcanzar procesamientos posteriores
extremadamente rápidos.
En el segundo caso, la activación de una neurona específica o grupo de ellas, se logra
mediante un entrenamiento no supervisado, que únicamente requiere conocer el vector de entrada
Xk y la categoría asociada (o región) a la que pertenece. Esta categoría no se usa de manera
explícita, sino que aparece implicada por la posición del vector Xk en el espacio de medida de
sus variables. En este tipo de entrenamiento, se desea encontrar un mapa entre dos grupos de
objetos Xk y las regiones que están integradas finalmente en el plano (o matriz) de las neuronas
de salida de la red. En este caso, no se utiliza ninguna información acerca de los grupos a los que
pertenece el objeto Xk para la corrección de los pesos después de obtener la salida Y´k. De este
modo, la única posibilidad consiste en adjudicar las neuronas más activas (o posiblemente, la
región vecina completa). Después de evaluar la salida Y´k, a la neurona que ha provocado la salida
más grande se le asigna el valor 0 y sus correspondientes pesos wi0 son aumentados para que la
próxima vez ofrezca una respuesta todavía mayor. Algunas veces, no sólo se estimula la neurona
-68-
INTRODUCCIÓN
0, sino también sus vecinos superiores hasta el r-ésimo. El entrenamiento continúa hasta que el
vector de entrada Xk es trazado dentro del mapa de las regiones que estaban integradas en el
dominio completo de las neuronas de salida.97
f) Tipos De Redes Neuronales.
1) Perceptrones.
Este fue el primer modelo de red neuronal artificial desarrollado por Rosenblatt en 1958.
Despertó un enorme interés en los años 60, debido a su capacidad para aprender a reconocer
patrones sencillos: un perceptrón, formado por varias neuronas lineales para recibir las entradas
a la red y una neurona de salida, es capaz de decidir cuándo una entrada presentada a la red
pertenece a una de las dos clases que es capaz de reconocer.
La única neurona de salida del perceptrón realiza la suma ponderada de las entradas, resta
el umbral y pasa el resultado a una función de transferencia de tipo escalón. La regla de decisión
es responder +1 si el patrón presentado pertenece a la clase A, o -1 si el patrón pertenece a la
clase B. La salida dependerá de la entrada neta (suma de las entradas xi ponderada) y del valor
umbral è.
Una técnica utilizada para analizar el comportamiento de redes como el perceptrón es
representar en un mapa las regiones de decisión creadas en el espacio multidimensional de
entradas a la red. En estas regiones se visualiza qué patrones pertenecen a una clase y cuáles a
otra. El perceptrón separa las regiones por un hiperplano cuya ecuación queda determinada por
los pesos de las conexiones y el valor umbral de la función de activación de la neurona. En este
caso, los valores de los pesos pueden fijarse o adaptarse utilizando diferentes algoritmos de
entrenamiento de la red.
Sin embargo, el perceptrón, al constar sólo de una capa de entrada y otra de salida con una
única neurona tiene una capacidad de representación bastante limitada. Este modelo sólo es capaz
de discriminar patrones muy sencillos, linealmente separables.100
2) Red Neuronal De Hopfield.
En 1982, J.J. Hopfield demostró las propiedades tan interesantes y útiles que podían
encontrarse cuando se conectaban elementos de procesamiento simple en una estructura de
retroalimentación con conexiones de pesos especificadas de cierta forma. Además, supuso el
detonante de la explosión actual de interés por las redes neuronales.
-69-
INTRODUCCIÓN
La memoria de los ordenadores digitales tradicionales deben buscar byte a byte para
recuperar una parte específica de información cuya dirección en el ordenador se desconoce.
Dicha búsqueda es eliminada si se emplea una memoria cuya información puede obtenerse en
un sólo paso, sin importar cuál sea su ubicación: memoria de contenido direccionable o CAM.
Hopfield describió una CAM que recuperaba correctamente una memoria completa, dada
cualquier subparte de tamaño suficiente. Que esta subparte contenga más o menos errores es
irrelevante; estos se corrigen automáticamente. Es decir, la idea de fondo de la red de Hopfield
es que sirve para reproducir cualquier patrón usado para el entrenamiento cuando se introduce
de nuevo en la red, incluso si el patrón presentado es defectuoso en mayor o menor medida.
Para ver cómo funciona la memoria de Hopfield, considérense un conjunto de cuatro
neuronas artificiales elementales o unidades de procesamiento. Cada unidad recibe unas entradas
pesadas procedentes de otras unidades y construye una suma. Los pesos son calculados a partir
de la memoria deseada, empleando los componentes xis de todos los p patrones Xs en el conjunto
de entrenamiento (pero no en el sentido iterativo como el descrito anteriormente), mediante la
fórmula:
p
x si ⋅ x sj
w ij = s= 1
0
∑
( para i ≠ j)
( para i = j)
Si la suma excede un valor límite prefijado, tomado como 0, se elige su estado de salida
como 1; de otro modo, la salida es 0 (representación binaria). Esta operación la realizan
continuamente todas las unidades. Para obtener la salida Outj para un objeto desconocido, la
función sigmoidal o el límite lógico se reemplazan por una función de paso simple:
Out j = signo
∑
i
+1
w ij ⋅ x i =
−1
para
para
∑
w ij ⋅ x i ≥ 0
∑
w ij ⋅ x i < 0
i
i
Tan pronto como se alcanzan las condiciones establecidas para cada unidad, se actualiza la salida
de la red de manera rápida, según las condiciones de hardware. Las unidades funcionan, por
tanto, asincrónicamente.
Una vez obtenida la salida de la red, ésta se introduce (retroalimentación) como una nueva
-70-
INTRODUCCIÓN
entrada y se repite el proceso anterior hasta que dos salidas sucesivas no difieran
significativamente.
El algoritmo de Hopfield es rico en su analogía con respecto a los sistemas físicos y
biológicos. Se ha generalizado para sistemas continuos (no binarios) en los cuales las unidades
de procesamiento han clasificado las respuestas a las entradas.
La red de Hopfield es muy útil en aplicaciones químicas (por ejemplo, para la clasificación
de formas de líneas base espectrales), especialmente porque su entrenamiento es muy rápido
comparado con los de otros diseños de redes neuronales, y también se ha empleado para resolver
problemas de optimización combinatoria.95, 97
3) Memoria Asociativa Bidireccional Adaptativa.
La memoria asociativa bidireccional adaptativa o ABAM, la cual adapta su matriz de pesos
a los objetos que van a aprenderse, es una red neuronal monocapa que es similar, en algunos
aspectos, a la red de Hopfield.
ABAM hace uso de un entrenamiento supervisado y, de este modo, requiere pares de
objetos (Xk, Yk) para ejecutarlo. No existe ninguna condición que requiera que los objetos Xk
(xk1, xk2, ..., xkm) e Yk (yk1, yk2, ..., ykn) sean representados en un espacio con la misma dimensión,
esto es, que n sea igual a m. Como el ABAM es una red monocapa, los pesos wij se almacenan
en una matriz W de dimensiones m × n.
La idea básica del ABAM procede del hecho de que esa matriz m × n puede multiplicarse
desde dos direcciones diferentes: en la forma estándar, por un vector m-dimensional, o en la
forma traspuesta, vector n-dimensional. En el lenguaje de las redes neuronales, esto quiere decir
que o bien un objeto de entrada X produce la salida Y´, o bien la entrada Y en el lado de las
salidas produce un vector de salida X´, en el lado de las entradas a la matriz de pesos. De este
modo, para cualquier par de objetos (X, Y), se construye otro par (X´, Y´).
La matriz de pesos del ABAM se construye a partir de los pares de entrada del siguiente
modo:
p
w ij =
∑ f (x ) ⋅ f (x )
s
i
s
j
s= 1
donde f(u) es la función sigmoidal. El proceso de entrenamiento del ABAM comienza con el par
(X, Y) para el cual se calcula la matriz de pesos W; multiplicando dicha matriz por los vectores
X e Y, se obtiene el siguiente par (X´, Y´), y se repite el proceso desde el principio. El
-71-
INTRODUCCIÓN
entrenamiento acaba cuando en la iteración i-ésima ocurre lo siguiente: Xi·Wi ÷ Yi; Yi·Wi T ÷
Xi, es decir, cuando se produce un par de objetos idénticos al par de entrada.
En resumen, podría decirse que en el ABAM las señales oscilan, mientras que en la red de
Hopfield circulan. Además, en contraste con la red de Hopfield, la entrada en el ABAM puede
ser de diferente dimensión que la salida, y en el caso extremo, incluso más pequeña. Una
dimensión pequeña de la capa de salida se traduce en una reducción del tamaño de la matriz de
pesos. Desafortunadamente, esto conlleva un efecto negativo sobre el número de pares que
pueden ser almacenados en el ABAM. Por tanto, hay que llegar a un acuerdo entre el tamaño de
la matriz y el número de pares que son aprendidos.97
4) Red Neuronal De Kohonen.
La arquitectura de red que semeja más ajustadamente las conexiones y el proceso de
aprendizaje de las neuronas biológicas es probablemente la descrita por Kohonen.
La red de Kohonen está basada en una capa individual bidimensional. Sin embargo, la red
de Kohonen puede incluirse dentro de una red mucho más compleja como una de sus capas
constituyentes o empleada en combinación con otras técnicas.
La característica más importante de la red de Kohonen es que obliga a las neuronas a
competir entre ellas para decidir cuál será estimulada. La competición puede decidirse en base
a la salida más grande obtenida para una entrada determinada, o comparando y encontrando la
neurona j que tiene todos los pesos wij (i = 1, m), es decir, el vector de pesos Wj (w1j, w2j, ..., wmj)
más parecido al vector de entrada Xs (xs1, xs2, ..., xms):
(
) ∑ (x − w )
d X , Wj =
s
m
s
i
2
ij
i
El sumatorio en esta ecuación se corresponde con todos los m pesos en la neurona j. Después de
que todas las neuronas se hayan comprobado, la neurona j que alcanza el valor más pequeño de
d(Xs, Wj) para un vector de entrada dado Xs se selecciona para la estimulación, junto con su
sector. El sector se define como el conjunto de células más próximas a la seleccionada por uno
de los posibles criterios aplicados a la red de Kohonen. Esta neurona central denominada 0 puede
seleccionarse como la que posee la respuesta más grande Y0 o el vector de pesos W0 más
parecido al vector de entrada Xs. Para estimular la neurona j y su sector ha de emplearse una
función dependiente de la topología: a = a·(r0 - rj), que puede poseer un perfil lineal o en forma
de sombrero mexicano. Una vez se ha encontrado esta neurona, la corrección de todos los pesos
wij (i = 1, 2) de la neurona j-ésima que cae dentro de la región definida por la topología anterior
-72-
INTRODUCCIÓN
se hace aplicando la siguiente ecuación:
(
)(
w (ijnuevo ) = w (ijviejo ) + a ⋅ r0 − rj ⋅ x si − w (ijviejo )
)
No hay ningún problema si la diferencia entre xsi y el peso antiguo es positiva o negativa, ya que
si el primero es más grande o más pequeño que el segundo, el peso nuevo estará más cercano a
xsi que el viejo.
Una vez que el entrenamiento se ha completado, la red exhibe una estructura topológica
homomórfica con la forma del patrón de entrenamiento.
Existe un pequeño problema computacional inherente a la red de Kohonen, que
afortunadamente no da problemas si la red está aplicada sobre un ordenador en serie, pero que
puede afectar seriamente el desarrollo de aplicaciones a gran escala ejecutadas en ordenadores
en paralelo. Para establecer qué neurona (y sector) va a estimularse hay que llevar a cabo una
comprobación de todas las neuronas. Esto supone una seria restricción cuando se entrenan redes
extensas. Incluso para un ordenador en paralelo se requieren como mínimo log2 N pasos con N/2
comparaciones paralelas, siendo N el número de neuronas.97
5) Red Neuronal De Retropropagación.
Constituye el paradigma más popular y ampliamente utilizado en la literatura a causa de su
enorme aplicabilidad.
Supone una generalización del algoritmo de Widrow-Hoff, empleado de manera efectiva
durante años en el campo del procesamiento de señales adaptativas. Se demostró, además, que
podía servir para entrenar estructuras en forma de capas semejantes a los perceptrones,
incluyendo unidades no lineales capaces de desarrollar funciones del tipo OR exclusiva. Incluso
solventó cuestiones difíciles, tales como la conversión de un texto escrito a un idioma
comprensible, por medio del entrenamiento de un conjunto de patrones, y el reconocimiento de
dígitos de código postal ZIP escritos a mano.
Aunque el término de retropropagación se refiere a la propia regla de aprendizaje de los
valores de pesos de una red, en el contexto actual se empleará dicho término para hacer referencia
a las redes neuronales entrenadas por el citado algoritmo.
La red de retropropagación, al contrario que la de Hopfield, no emplea retroalimentación.
En su versión más simple, utiliza una estructura en forma de capas de alimentación directa, cuya
estructura fue descrita en el apartado de arquitectura de la red.
Supóngase una red neuronal con tres capas, las unidades de la capa de entrada no llevan a
-73-
INTRODUCCIÓN
cabo ningún procesamiento especial, simplemente amortiguan los valores de entrada y lo
transportan a la capa oculta por medio de un conjunto de conexiones pesadas. Seguidamente,
cada unidad de procesamiento en la capa intermedia calcula una suma pesada de sus entradas.
Los pesos pueden ser positivos (excitadores) o negativos (inhibidores). Después, la unidad de
procesamiento aplica una función de apilamiento sigmoidal (descrita con anterioridad) a dicha
suma, la cual transforma un amplio dominio de entrada en un rango limitado de salidas. La salida
de cada unidad en la capa oculta pasa a las correspondientes neuronas de la capa de salida, las
cuales, suman y apilan sus entradas pesadas para ofrecer, finalmente, una salida adecuada.
El entrenamiento de la red, se lleva a cabo de acuerdo a lo anteriormente explicado en el
apartado de entrenamiento de la red. Existe cierto número de algoritmos destinados a tal fin, entre
los cuales, podemos destacar el algoritmo del error de predicción recursivo98 y el algoritmo de
retropropagación, el cual trataremos a continuación.95
g) Algoritmo De Retropropagación.
El algoritmo más utilizado para ajustar los pesos en el entrenamiento de redes de
alimentación directa es la regla de la retropropagación del error, conocida en la literatura como
“backprop”. Este algoritmo de aprendizaje no refleja similitud particular alguna con los procesos
reales del cerebro. Consiste básicamente en un procedimiento multicapa y como tal requiere una
cantidad considerable de espacio en el ordenador y de tiempo de cálculo, incluso para redes de
tamaño medio. Se aplica especialmente en casos donde la ausencia de soluciones teóricas,
analíticas e incluso numéricas requieren una buena modelización con predicciones exactas.
El hecho de ser el algoritmo más empleado por los científicos que trabajan con redes
neuronales radica en su habilidad para ajustar todos y cada uno de los pesos de las conexiones
de la red, de modo que al introducir cualquier patrón de entrada en el interior de la misma ésta
sea capaz de ofrecer una salida adecuada al problema que se está tratando. Para llevar a cabo el
ajuste de los pesos, primero hay que considerar una medida del error en la salida que viene dado
por la suma de los cuadrados de los errores de las unidades de salida individuales:
(
1 M
Y = ∑ t j − zj
2 j= 1
)
2
donde tj es el valor buscado de la salida j-ésima de la última capa; zj es la salida calculada de la
última capa de la red y M es el número de unidades de salida.
Esta función de coste puede visualizarse como una superficie que representa el error como
la variable dependiente en un hiperespacio de N + 1 dimensiones, donde N es el número de pesos
-74-
INTRODUCCIÓN
en la red. Un estado instantáneo de la red aparece como un punto individual en la superficie. El
efecto de un cambio pequeño en cualquier peso puede observarse como un pequeño movimiento
de ese punto sobre la superficie, mientras que el resto de los pesos permanecen constantes. Un
cambio de peso pequeño puede provocar o un incremento o una disminución del error o ningún
cambio en absoluto. Como se desea hacer actuar a la red de acuerdo a un conjunto determinado
de patrones hay que ajustar los pesos para que el error alcance el valor más bajo posible.
Una observación crucial a tener en cuenta en este punto es que la dependencia por parte del
error de un pequeño cambio en cualquier peso puede determinarse adecuadamente por aplicación
directa de la regla de la cadena mediante diferenciación a partir del cálculo elemental. Para
aplicar la regla de la cadena, hay que obtener primero la contribución de cada unidad de salida
al error Y. Diferenciando la función de apilamiento sigmoidal, el error correspondiente en la
suma interna de cada una de las unidades se determina y se propaga hacia atrás en la red, estrato
a estrato, usando sucesivas aplicaciones de la regla de la cadena para derivadas parciales hasta
alcanzar la capa de entrada. De este modo, se logra obtener el error correspondiente a las salidas
de las unidades de las capas inmediatamente anteriores que alimentan los sucesivos estratos. Este
procedimiento puede extenderse para determinar la sensibilidad del error Y a cualquier peso en
la red neuronal.
Las sensibilidades representadas por el conjunto de tales derivadas, una por cada peso en
la red, define un vector gradiente en el hiperespacio de N + 1 dimensiones. El valor negativo de
este gradiente define la dirección del descenso más profundo hasta alcanzar el valor más bajo del
error Y. El entrenamiento de la red se lleva a cabo realizando pequeños pasos en la dirección del
descenso más profundo para cada ejemplar presentado. Para redes grandes, especialmente
aquellas que poseen una estructura formada por un gran número de estratos, cada contribución
de los pesos al error total es relativamente pequeña. Más aún, la superficie que define Y puede
ser muy compleja y tener múltiples mínimos. El punto del hiperespacio que representa el estado
de la red puede describir una trayectoria tortuosa conforme se ejecuta el entrenamiento.
Típicamente, la red debe procesar el entrenamiento de los patrones muchas veces antes de
obtener valores útiles de los pesos.95
Este método de ajuste de pesos se denomina método del gradiente descendente y, como se
ha podido comprobar, resulta bastante lento en la mayoría de los casos. Zupan y Gasteiger han
elaborado una amplia descripción matemática acerca del mismo. La expresión del algoritmo es
la siguiente:
∂E
w ij ( t + 1) = w ij ( t ) + η
∂ w ij
-75-
INTRODUCCIÓN
y la función que realiza consiste en la actualización del peso wij de la capa t+1 empleando para
ello el peso de la capa t inmediatamente anterior. Uno de los parámetros que interviene en dicha
ecuación es la velocidad de aprendizaje ç . La actualización se realiza en base al error obtenido
E.101
h) Redes Neuronales Y Clasificación.
Una red neuronal de retropropagación puede emplearse para clasificar grupos de medidas.
Sea un conjunto de M medidas que representan un objeto o estado de un sistema, un miembro
de un conjunto de tales objetos o estado. Cada grupo puede agruparse como un vector
característico en el hiperespacio definido por las variables de medida. Para clasificar los objetos
o estados en dos categorías y poder separarlas por un hiperplano, puede utilizarse una función
lineal discriminante o perceptrón; no es necesaria una red neuronal más compleja.
La red puede desempeñar dicha tarea gracias a una función de apilamiento no lineal. En el
caso general de dos clases, si la red posee M entradas, una por cada una de las variables de
medida, y se proporciona una única salida, ésta puede emplearse para clasificar las medidas. Un
conjunto de entrenamiento de vectores característicos cuya clasificación se conoce a priori se
presentan una y otra vez a la entrada de la red. El error en el desarrollo de la red se utiliza para
ajustar los pesos, haciendo uso del algoritmo de retropropagación y el método del gradiente
descendente.
Al igual que ocurre con otros métodos de construcción de modelos matemáticos, es típico
alterar el modelo hasta lograr el mejor resultado. Si no se ha dotado a la red de un número
adecuado de grados de libertad mediante un número suficiente de unidades ocultas y pesos, la
clasificación de todos los vectores característicos puede resultar imposible. El error de la medida
puede ser, además, responsable de clasificaciones erróneas. Si se han empleado demasiadas
unidades ocultas y se ha entrenado muy exhaustivamente la red, ésta puede clasificar
correctamente los patrones o el conjunto de entrenamiento y, sin embargo, ejecutar un desarrollo
peor sobre nuevos vectores presentados para la clasificación. Este problema equivale al
sobreajuste de los datos.
Al igual que ocurre con la regresión polinomial, un ajuste exacto de los datos a un modelo
incorrecto o el ajuste de datos ruidosos puede resultar en una variabilidad de la función ajustada
o en el desarrollo de la red. Si los datos poseen algo de ruido y se ha elegido el número correcto
de unidades ocultas, la red proporciona un desarrollo sin ruido y responde correctamente a
entradas nuevas. Esto es lo que se conoce como capacidad de generalización de la red. La
generalización correcta de un número elevado de variables de entrada confusas y relacionadas
-76-
INTRODUCCIÓN
de forma no lineal es uno de los atributos más poderosos de la red de retropropagación.102
i) Relación Con Modelos Polinomiales.
Un modelo polinomial que exhibe el desarrollo del modelo de retropropagación requiere
numerosos términos cruzados de orden elevado. Estos términos surgen como consecuencia de
la necesidad de simular las ausencias de linealidad de las funciones de apilamiento que han de
emplearse. Hay que recordar, que capa por capa, la red suministra combinaciones no lineales en
otras combinaciones del mismo tipo. Una función polinomial equivalente sería virtualmente
imposible de ajustar por el método estándar de los mínimos cuadrados lineales, el cual
proporciona un conjunto de ecuaciones normales. El número de términos y ecuaciones sería
increíblemente grande, y los puntos de datos (vectores característicos) insuficientes para
establecer valores de los coeficientes. En cambio, la red de retropropagación es capaz de
desarrollar este problema como si sólo hubiese dado importancia a los términos de orden más
alto, eliminando a los otros. Esto no implica que la red neuronal sea un modelo polinomial, sino
que se pueden establecer ciertas similitudes entre ambos casos.102
j) Algunas Aplicaciones De Las Redes Neuronales.
El cálculo con redes neuronales ha suscitado un enorme interés no sólo en el campo de la
Química, sino en multitud de disciplinas relacionadas con aquella, como por ejemplo,
Bioquímica, Farmacia, Medicina e Ingeniería Química, entre otras.
En la literatura se dan cita gran número de artículos que cubren un amplio espectro acerca
del uso de las redes neuronales en química: problemas espectroscópicos (IR, masas, 1H-RMN,
13
C-RMN, XPS, AES, etc.) que incluyen calibración; estudios sobre aplicación de electrodos
selectivos de iones; estudios de relación cuantitativa estructura/actividad o QSAR; predicción
de la estructura secundaria de las proteínas; predicción de fallos y diagnóstico de sus posibles
causas durante el control de procesos químicos; en tecnología de microsensores metalocerámicos
gaseosos; determinación de parámetros cinéticos y clasificación de niveles de energía atómica.
Además, se han empleado muchas técnicas analíticas en combinación con redes neuronales:
voltamperometría de redisolución anódica, cíclica y de pulso diferencial, casi todas las
espectroscopías, análisis térmico, cromatografía, etc.
Se han publicado gran cantidad de artículos teóricos que discuten las propiedades,
algoritmos mayoritarios, ventajas y limitaciones de las redes neuronales, junto con algunas de sus
aplicaciones. En uno de ellos, se presentan cuatro problemas en el uso de dichos métodos para
-77-
INTRODUCCIÓN
la modelización de datos: sobreajuste, efectos de cambio, sobreentrenamiento e interpretación.97
Otros autores emplearon redes neuronales artificiales para la deconvolución cuantitativa de
espectros de masas de pirólisis de Staphylococcus aureus mezclado con Escherechia coli.
No obstante, hay todavía muy poco escrito sobre redes neuronales y electroquímica. A
continuación, se comentarán algunas de las aplicaciones más importantes en este campo de la
Química.
Bos et al. han aplicado redes neuronales artificiales de alimentación directa para calibración
no lineal de series de electrodos selectivos de iones. Analizaron sistemas de 4 componentes: Ca2+,
K+, Cl- y NO-3. Además, incluyeron un electrodo de pH. El error medio obtenido fue de ± 6 %.
Del mismo modo, hicieron uso de una red recurrente con topología en malla que proporciona un
camino de retroalimentación para la calibración no lineal multivariante de un sistema de dos
componentes: Ca2+ y Cu2+. No obstante, esta aplicación presenta un problema: el entrenamiento
de la red para electrodos selectivos de iones es muy lento.103, 104
Cladera et al. han empleado también redes neuronales, junto con métodos de análisis
multicomponente basados en regresión lineal múltiple, para la resolución de señales muy
solapadas obtenidas por voltamperometría de redisolución anódica de pulso diferencial. Dichos
procedimientos fueron aplicados al muy conocido modelo químico compuesto por Pb(II), Tl (I),
In (III) y Cd (II) en mezclas binarias, ternarias y cuaternarias. Posteriormente, la metodología
propuesta por los autores fue utilizada en la determinación de esos cuatro metales en agua del
grifo.
En este trabajo, se hace uso de diferentes arquitecturas de redes neuronales multicapa, cuyas
unidades de procesamiento aplican funciones de activación sigmoidales, y en la fase de
entrenamiento se utiliza el algoritmo de retropropagación, el cual ajusta los pesos minimizando
el error a través del método del gradiente descendente. Los vectores de entrada estaban
constituidos por 30 valores de intensidad correspondientes a potenciales igualmente espaciados,
procedentes de los voltamperogramas de redisolución anódica. Las salidas de la red fueron las
4 concentraciones de cada uno de los componentes presentes en las distintas muestras. A partir
de 61 mezclas sintéticas, 48 fueron elegidas al azar como conjunto de entrenamiento y las 13
restantes formaron el conjunto de predicción.
Con idea de estudiar la capacidad de la red para resolver el sistema estudiado, se probaron
diferentes estructuras neuronales, todas ellas compuestas por tres capas: una capa de entrada, otra
oculta y una tercera de salida. El mejor resultado lo alcanzó la arquitectura 15 × 7 × 4.
En la comparación de los métodos de análisis multicomponente con las redes, se alcanzó
un 30 % menos de error en el segundo caso. En la regresión, los errores eran inferiores para
plomo y talio, mientras que las redes proporcionaban mejores resultados para indio y cadmio.105
-78-
INTRODUCCIÓN
Otra aplicación de redes neuronales, pero esta vez en la deconvolución de picos solapados
en cromatografía, es la llevada a cabo por Miao et al. La idea básica de este método consistía en
encontrar un conjunto de parámetros que caracterizaran la forma de los picos solapados y emplear
una red de perceptrones multicapa para correlacionar los parámetros con el porcentaje de área
de cada pico individual.
La ventaja de esta técnica es que se desarrolla muy bien, alcanzando una gran exactitud en
las determinaciones y requiriendo menos tiempo de cálculo computacional que otros métodos
convencionales.
La red neuronal empleada fue una red de alimentación directa multicapa entrenada por
medio del algoritmo de retropropagación. La arquitectura era 5 × 10 × 1.Cada patrón de entrada
estaba compuesto por un vector de cinco componentes (5 parámetros adimensionales que
relacionaban la anchura y altura relativa de los picos solapados); por otra parte, el porcentaje de
área de cada pico constituía el vector de salida (el número de componentes era variable en
relación con el número de patrones de la mezcla analizada).
500 patrones fueron seleccionados al azar, a partir de un conjunto de 630, para el
entrenamiento de la red. Los restantes se emplearon para estudiar el desarrollo de la red y su
habilidad de predicción. Además, la robustez de la estructura fue probada mediante la adición
de un 10 % de error relativo a las entradas de la misma, de tal modo, que el error en las salidas
no excedió del 6 %. Incluso cuando se tomaron cinco parámetros característicos, procedentes de
varios picos solapados sintetizados a partir de un modelo Gaussiano modificado
exponencialmente (EMG), el error relativo de la salida en la red rara vez superó el 4 %.
Comparando la exactitud de la red con otros métodos de resolución, tales como el método
de división por línea vertical y el de ajuste de curvas, resultó que la red neuronal era mucho
mejor, sin importar la severidad del solapamiento entre los picos cromatográficos. Como la red
entrenada sólo necesita un tiempo de cálculo pequeño para procesar los patrones de entrada, el
método de deconvolución por redes neuronales artificiales supone un sistema útil para su
aplicación en tiempo real.106
Las redes neuronales no se emplean solo para resolver especies en mezclas, sino también
para casos donde se desea extender el rango de respuesta de un sensor de pH de fibra óptica. Tal
es el caso del artículo escrito por Taib et al.
Gracias a su capacidad para modelizar sistemas complejos no lineales y proporcionar datos
precisos mediante su extracción desde las señal medida con una muy baja relación señal/ruido,
los autores decidieron emplear las redes neuronales para procesar la respuesta de un sensor de
pH de fibra óptica. La arquitectura utilizada fue la de una red de alimentación directa con una
única capa oculta: 8 × 20 × 1. En este caso, a diferencia de los anteriores, el algoritmo para el
-79-
INTRODUCCIÓN
entrenamiento de la red fue el algoritmo del error de predicción recursivo. El principal objetivo
era extender la linealidad de la respuesta del sensor mientras que, al mismo tiempo, el error de
predicción se mantenía en un nivel aceptable. Otra variación con respecto a los trabajos anteriores
es que las neuronas emplean una función de apilamiento sigmoidal lineal, con vistas a alcanzar
un rango dinámico más amplio para la salida de la red.
Los vectores de entrada estaban compuestos por ocho puntos procedentes de espectros de
reflectancia del sensor de pH óptico. Se obtuvieron 30 espectros distintos, formando 4 de ellos
el conjunto de predicción y los restantes el de entrenamiento. La salida obtenida poseía una única
componente: el pH.
El entrenamiento de la red se ejecutó mediante 20000 ciclos, haciendo uso de varias
estructuras de red que variaban en el número de neuronas de la capa oculta: de 1 a 20; se obtuvo
la convergencia más rápida para 17 neuronas en la capa oculta. Para evaluar el efecto de
aumentar los ciclos de entrenamiento se eligieron varias arquitecturas de red, sometiéndolas a
otros 20000 ciclos, sin que por ello se alcanzara mejora alguna en la exactitud de la predicción.
En el estudio de robustez de las redes, se aplicó ruido blanco a las entradas en el intervalo de ±
0,03 %, identificándose el tipo de red que proporcionaba un menor error (0,01 pH) y que, por
tanto, era más robusta. La peor dio un error de 0,07 - 0,08 pH..
Las conclusiones fueron que una red con arquitectura 8 × 13 × 1 resultó la más útil para el
propósito perseguido.98
Una última aplicación, también muy alejada de la resolución de mezclas, es la de Yatsenko.
En su trabajo, investiga la influencia de contaminantes en objetos biológicos, tales como sistemas
fotosintetizadores, en orden a revelar las capacidades y características de sus aplicaciones como
sensores controlantes en microsistemas de monitorización ecológica integral. Este autor propuso
la elaboración de sensores inteligentes en base a tres aspectos: la tecnología de redes neuronales;
la posibilidad de separar las características de las sustancias disueltas en agua por medio de
métodos de reconocimiento de patrones en el espacio funcional de las curvas de fluorescencia
y los resultados del análisis cromatográfico de muestras de agua estándar. Este sensor permite
predecir el estado del agua (desde muy contaminada a muy pura) y toma las decisiones óptimas
para corregir las condiciones del ecosistema. La eficacia de tal sistema para análisis de agua
puede mejorarse utilizando el principio de medida dual, el cual sugiere la identificación de un
modelo de biosensor que esté de acuerdo con los datos experimentales.
Los objetos de estudio fueron: plantas, algas, centros de reacción extraídos, bacterias
fotosintéticas y películas de Langmuir-Blodgett-Shefer tomadas a partir de centros de reacción
de la bacteria púrpura Rh. Sphaeroides. Las muestras de agua examinadas procedían de diferentes
estanques artificiales. Se estudió la influencia ejercida por diversos contaminantes (herbicidas,
-80-
INTRODUCCIÓN
metales pesados, etc.) sobre las características funcionales de los objetos fotosintéticos. Las
curvas de fluorescencia retardada y de inducción de fluorescencia fueron examinadas para este
propósito, ya que reflejan respuestas frente a condiciones desfavorables en el ambiente.
Mediante el uso de un chip neuronal basado en neuronas probabilísticas se reconocieron
las características de los contaminantes del agua: una vez acabado el entrenamiento, el sistema
de reconocimiento de patrones efectúa un diagnóstico con respecto a la calidad del agua en
función del grado de pertenencia del objeto a la noción “agua pura” o “agua contaminada”.
Este artículo junto con otros constituye un primer paso hacia la construcción de una teoría
matemática de sensores.107
SISTEMAS EXPERTOS Y MODELOS BORROSOS.
Los sistemas expertos son productos de software que incorporan el conocimiento de un
experto e intentan hacer consistentes las decisiones sobre la base de este conocimiento. Consiste
fundamentalmente de dos partes: el conocimiento base y la deducción de una máquina que toma
decisiones basándose en el contenido de la base de conocimiento.
En general, esta técnica traslada un método heurístico a un árbol de decisión que puede
implementarse para automatizar el análisis de los datos para un problema particular. No obstante,
posee un inconveniente: la exactitud de la clasificación se basa únicamente en la comprensión
del problema por parte del programador y en su habilidad para prever el flujo de muestras de
difícil clasificación a través del árbol de decisión.
Por contra, presenta una ventaja: no requiere el tradicional conjunto de entrenamiento para
establecer las reglas de clasificación. No obstante, aunque parezca paradójico, a la hora de
establecer esas reglas, lo cual debe hacerse de alguna forma, se necesita una serie de datos de
entrenamiento.52
En los denominados sistemas expertos de construcción de reglas, el conocimiento puede
introducirse a modo de ejemplos, es decir, como una base de datos que contiene un conjunto de
observaciones hechas sobre varios objetos con una clasificación conocida.63
a) Aplicaciones De Los Sistemas Expertos.
Por citar algunas aplicaciones de los sistemas expertos, Rusling desarrolló una nueva
técnica denominada reconocimiento de patrones de desviación, una clasificación llevada a cabo
sobre los residuos producidos por el ajuste mediante regresión lineal a un voltamperograma
experimental. Está basado en un sistema experto que conduce el proceso de desarrollo de una
-81-
INTRODUCCIÓN
regresión no lineal analizando el gráfico de dispersión de las desviaciones y seleccionando el
mecanismo apropiado.
Inicialmente, todo el conjunto de datos se ajustan con una regresión no lineal al mismo
mecanismo. El análisis de los residuos determina luego el camino a tomar a través del árbol de
decisión. La clasificación continúa automáticamente hasta que se identifica el mecanismo
correcto, indicado por una distribución de los residuos de regresión, o hasta que el sistema
experto sea incapaz de igualar el voltamperograma con cualquiera de los mecanismos presentes
en el árbol de decisión.101, 102
Una versión simplificada se utilizó luego en otras investigaciones para distinguir
voltamperogramas catalíticos solapados de los correspondientes a sistemas no catalíticos.
En resumen, los sistemas expertos constructores de reglas están disponibles comercialmente
a nivel de usuario y poseen una importante desventaja: los algoritmos empleados en ellos para
derivar las reglas de decisión no son óptimos para todas las aplicaciones. Además, las técnicas
supervisadas son bastante poderosas, sobre todo las técnicas de modelización probabilística. De
este modo, una combinación de ambas, denominada “incorporación de los algoritmos de
modelización a la trama de un sistema experto”, podría suponer una herramienta muy atractiva
y útil para la mayoría de las aplicaciones supervisadas.
b) Modelos Borrosos.
Aproximaciones estadísticas del tipo del análisis de componentes principales, análisis de
clusters y redes neuronales no supervidadas, al igual que sistemas basados en el conocimiento,
como las máquinas de aprendizaje, presentan una serie de problemas generales a la hora de
interpretar las señales. Estos problemas pueden ser de tres tipos:
w Problema de discretización: aquellos parámetros que un hombre colocaría dentro de
un intervalo determinado, aunque no pertenezca específicamente a él, no son vistos
de la misma manera por cualquiera de los métodos enumerados anteriormente, ya que
estos son mucho más rígidos y taxativos en este sentido, pudiendo dar lugar a errores
de interpretación.
w Problema de decisión: las decisiones han de basarse siempre en un criterio exacto y
han de ser lo más generales posibles.
w Problema de la representación del conocimiento: sobre todo cuando se emplean
sistemas simbólicos, como por ejemplo, haciendo uso de colores. El color verde y el
azul son suministrados al sistema y cuando se presenta el elemento verdoso o
-82-
INTRODUCCIÓN
azulado, el sistema no será capaz de igualarlo a ninguno de los existentes en su
memoria.
w Problema de adquisición del conocimiento: una máquina de aprendizaje puede
desarrollarse tanto por métodos numéricos y estadísticos como por procesamiento del
conocimiento simbólico. Hasta ahora, sin embargo, estas dos aproximaciones no se
han empleado conjuntamente. Por ello, son necesarios métodos que sean capaces de
adquirir conocimiento numérico y simbólico con la misma aproximación general.
La aproximación que permitirá resolver los problemas antes comentados se basa en
sistemas borrosos. La idea básica de la lógica borrosa fue introducida por Zadeh en 1965. Desde
entonces, esta teoría se ha empleado principalmente en control industrial, pero otras áreas tales
como sistemas expertos y análisis de datos borrosos se han hecho muy importantes. En Química,
la primera aplicación estuvo relacionada con la búsqueda en librerías en el intervalo espectral del
IR.
La teoría del conjunto borroso se desarrolló con vistas a representar el conocimiento
incierto. En general, hay varios tipos de incertidumbre. Si se caracteriza la selectividad de un
sistema espectroscópico como “que apenas es selectivo”, entonces esta clase de incertidumbre
se denomina ausencia de especificidad. No somos capaces de caracterizar la selectividad, sino
sólo de catalogarla como una amplia categoría que es miembro de algún conjunto. La
incertidumbre sobre los resultados de un experimento analítico es una clase de variabilidad que
se interpreta normalmente como aleatoriedad. Una tercera y última clase es la borrosidad, que
se adscribe a situaciones donde no se puede establecer ninguna distinción rigurosa entre un
concepto y su negación.
Mediante los modelos borrosos no se pretende estabilizar o eliminar esa incertidumbre, sea
de la naturaleza que sea, sino que se intenta describirla lo más acertadamente posible mediante
una función matemática, la denominada función de pertenencia.
En la teoría clásica, la función de pertenencia se define única y exclusivamente para dos
valores, esto es, 1 y 0. Se asigna el valor de pertenencia de 1 para todos los elementos que están
contenidos en el subconjunto considerado, A, del universo X. El valor de 0 es para aquellos
elementos que no forman parte de A:
1
m( x) =
0
si x ∈ A ⊆ X
si x ∉ A ⊆ X
Los modelos borrosos comprenden el concepto de pertenencia gradual a un conjunto. De
este modo, la función de pertenencia, m(x), puede representar cualquier función de crecimiento
-83-
INTRODUCCIÓN
o decrecimiento monótono.
La información obtenida a partir de las señales puede utilizarse tanto en forma continua
(todos los puntos de la señal al completo) como en forma discreta (tablas con parámetros
característicos de la señal). Para describir la incertidumbre de la señal al completo, las
intensidades medidas (eje Y) se consideran como números borrosos para cada valor frente al cual
se representa dicha señal (eje X). El grado de incertidumbre puede variar de un valor xi a otro
(realmente, se producen variaciones de la distribución de la función de pertenencia). Además, no
existe ninguna restricción con respecto a la simetría de la función de pertenencia sobre la variable
intensidad. Si la señal se representa mediante una tabla de parámetros (intensidad, posición y
anchura de pico en voltamperometría) la incertidumbre se representa mediante un conjunto
borroso.
Aparte de la información primaria, comentada anteriormente, que puede extraerse de
cualquier señal, un conocimiento experimental incierto ha de tratarse en conexión con un sistema
de interpretación. Por ejemplo, en espectroscopía de emisión atómica acoplada con plasma
inductivamente o ICP-AES, un hecho típico podría ser el siguiente: “han de encontrarse la
mayoría de líneas importantes de un elemento”. Esto implica que se deben encontrar tantas líneas
como puedan ser detectadas. Una función de pertenencia útil para la “mayoría” aumenta
conforme se incrementa el número de líneas detectadas.
Algunas veces la importancia de este hecho borroso se expresa por medio de un valor de
pertenencia en el sentido de un valor de incertidumbre o de Bayes. Por ejemplo, si un pico a 0,520 V indica la presencia de Pb (II) y la muestra posee un pico a -0,520 V para un valor de
pertenencia de 0,80, entonces la muestra posee indicaciones de la presencia de Pb (II) hasta un
valor verdadero de 0,75.
Esta teoría es descrita por Otto para la interpretación de espectros. Como paso preliminar
a dicha interpretación, se emplea la búsqueda en librerías espectrales para estrechar cuanto sea
posible el rango de moléculas o elementos candidatos. Esta búsqueda se realiza teniendo en
cuenta las dos formas en las que se puede presentar la incertidumbre de una señal: en forma
continua, usando el espectro completo (funciones borrosas), o mediante tablas de parámetros
(conjuntos de datos borrosos). La comparación entre los espectros de las librerías y el de la
muestra se lleva a cabo mediante sustracciones borrosas, generándose un índice de similitud
deducido a partir de la integración sobre la función de diferencia borrosa y normalizando el
número resultante en el intervalo [0, 1].
El modelo borroso que representa la posición, intensidad o anchura de la banda se halla
también de forma similar.
Según Otto, la interpretación de los espectros mediante razonamiento borroso se realiza en
-84-
INTRODUCCIÓN
base a una serie de aproximaciones. La formulación de un conjunto apropiado de reglas
constituye la base para los diferente métodos de inferencia empleados. Para ello se puede emplear
la regla composicional de inferencia introducida por Zadeh, cuya aplicación al razonamiento
espectral es directa. Por otro lado, existe el esquema de razonamiento de Yager. La ventaja de
éste radica en su viabilidad de aplicación para razonamientos por defecto y su flexibilidad para
elegir los conectivos AND y OR, convencionalmente mínimo y máximo, respectivamente, así
como el operador de agregación.
El autor explica que los primeros pasos en la implementación de un razonamiento borroso
se llevaron a cabo para la interpretación de espectros obtenidos mediante la técnica ICP-AES,
en XRF y en sistemas de interpretación de IR. Sin embargo, hasta ahora, sólo se han aplicado
inferencias simples tal que el procesamiento del conocimiento borroso constituye un reto a la
hora de implementarlo en sistemas de interpretación de espectros.
En los comienzos del desarrollo de los sistemas de interpretación de espectros, las reglas
fueron derivadas únicamente a partir del conocimiento del experto. Esto mismo es aplicable para
especificar las funciones de pertenencia en sistemas expertos borrosos que tengan en cuenta la
incertidumbre en el sentido de la borrosidad. Las fuentes para especificar los conjuntos borrosos
fueron, por tanto, la experiencia, aspectos subjetivos y la orientación sobre material estadístico.
Esta estrategia se puede aplicar con éxito si se consideran una o dos variables, con una
función de pertenencia uni- o bidimensional, respectivamente, y si el sistema en estudio se
encuentra bien definido. Sin embargo, con funciones de pertenencia multidimensionales la
especificación de dicha función es muy difícil.
Como consecuencia de esto, las investigaciones llevadas a cabo recientemente han ido
dirigidas hacia la aplicación e implementación de los modelos borrosos en redes neuronales
artificiales.108
BIBLIOGRAFÍA.
1.-
Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 624.
2.-
Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 625.
3.-
Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 626.
4.-
Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 63.
5.-
Almagro, V. Teoría y Práctica de Electroanálisis (1969) 1ª Ed. Ed Alhambra, S.A. pág. 173.
6.-
Sánchez Batanero, P. Química Electroanalítica: Fundamentos y Aplicaciones (1981) Alhambra
Universidad. pág. 248.
7.-
Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. págs. 2 y 64.
-85-
INTRODUCCIÓN
8.-
Sánchez Batanero, P. Química Electroanalítica: Fundamentos y Aplicaciones (1981) Alhambra
Universidad. págs. 252 y 253.
9.-
Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. págs. 4, 5 y 146.
10.- Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 651.
11.- Strobel, H.A.; Instrumentación Química (1982) 1ª Ed. Ed Limusa. pág. 585.
12.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. págs. 12 y 13.
13.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 178.
14.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 181.
15.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 192.
16.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 204.
17.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 212.
18.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 216.
19.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 218.
20.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 219.
21.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 221.
22.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 226.
23.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 231.
24.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 232.
25.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 236.
26.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 234.
27.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 241.
28.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 158.
29.- Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 539.
30.- Grabariƒ, Z.; Grabariƒ. B.S.; Esteban, M. y Cassasas, E.; Anal. Chim. Acta. 312, 27 (1995).
31.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 157.
32.- Gutknecht, W,F. y Perone, S.P.; Anal. Chem. 42, 906 (1970).
33.- Strobel, H.A.; Instrumentación Química (1982) 1ª Ed. Ed Limusa. pág. 547.
34.- Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 650.
35.- Sánchez Batanero, P. Química Electroanalítica: Fundamentos y Aplicaciones (1981) Alhambra
Universidad. pág. 254.
36.- Strobel, H.A.; Instrumentación Química (1982) 1ª Ed. Ed Limusa. pág. 545.
37.- Grabariƒ, B.S.; O´Halloran, R.J. y Smith, D.E.; Anal. Chim. Acta. 133, 349 (1981).
38.- Raspor, B.; Piz•ta, I. y Branica, M.; Anal. Chim. Acta. 285, 103 (1994).
39.- Bond, A.M. y Grabariƒ, B.S.; Anal. Chem. 48, 1624 (1976).
40.- Strobel, H.A.; Instrumentación Química (1982) 1ª Ed. Ed Limusa. pág. 575.
-86-
INTRODUCCIÓN
41.- Boudreau, P.A. y Perone, S.P.; Anal. Chem. 51, 811 (1979).
42.- Berzas Nevado, J.J. y Rodríguez Flores, J.; Fresenius J. Anal. Chem. 342, 273 (1992).
43.- Huang, W.; Henderson, T.L.; Bond, A.M. y Oldham, K.B.; Anal. Chim. Acta. 304, 1 (1995).
44.- Strobel, H.A.; Instrumentación Química (1982) 1ª Ed. Ed Limusa. pág. 574.
45.- Grabariƒ, Z.; Grabariƒ. B.S.; Esteban, M. y Cassasas, E.; Analyst. 121, 1845 (1996).
46.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 134.
47.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 135.
48.- Sánchez Batanero, P. Química Electroanalítica: Fundamentos y Aplicaciones (1981) Alhambra
Universidad. pág. 273.
49.- Almagro Huertas, V. Polarografía (1971) 1ª Ed. Ed. Alhambra, S.A. pág. 132 y 133.
50.- Perone, S.P.; Jones, D.O. y Gutknecht, W. F. Anal. Chem. 41, 1154 (1969).
51.- Berzas Nevado, J.J.; Lemus Gallego, J.M. y Castañeda Peñalvo, G.; Anal. Quim. 89, 223
(1993).
52.- Brown, S.D. y Bear, R.S. Jr.; Crit. Rev. Anal. Chem. 24 (2), 99 (1993).
53.- Geladi, P. y Kowalsky, B.R.; Anal. Chim. Acta. 185, 1 (1986).
54.- Haaland, D.M. y Thomas, E.V.; Anal. Chem. 60, 1193 (1988).
55.- Espinosa-Mansilla, A.; Muñoz de la Peña, A. y Salinas, F.; Anal. Chim. Acta. 276, 141 (1993).
56.- McClaurin, P.; Worsfold, P.J.; Crane, M. y Norman, P.; Anal. Proc. 29, 65 (1992).
57.- Haaland, D.M. y Thomas, E.V.; Anal. Chem. 60, 1202 (1988).
58.- Haaland, D.M. y Thomas, E.V.; Anal. Chem. 62, 1098 (1990).
59.- Navarro-Villoslada, F.; Pérez-Arribas, L.V.; León-González, M.E. y Polo-Díez, L.M.; Anal.
Chim. Acta. 313, 93 (1995).
60.- Brown, S.D.; Anal. Chim. Acta. 181, 1 (1986).
61.- Brown, T.F.; Caster, D.M. y Brown, S.D.; Anal. Chem. 56, 1214 (1984).
62.- Binkley, D.P. y Dessy, R.E.; Anal. Chem. 52, 1335 (1980).
63.- Derde, M.P. y Massart, D.L.; Anal. Chim. Acta. 191, 1 (1986).
64.- Sybrandt, L.B. y Perone, S.P. Anal. Chem. 43, 382 (1971).
65.- Jones, R.; Coomber, T.J.; McCormick, J.P.; Fell, A.F. y Clark, B.J.; Anal. Proc. 25, 381 (1988).
66.- Ayuda del programa informático Statistica 5.1.
67.- Morrey, J.R.; Anal. Chem. 40, 905 (1968).
68.- Horlick, G.; Anal. Chem. 44, 943 (1972).
69.- Huang, W.; Henderson, T.L.E.; Bond, A.M. y Oldham, K.B.; Anal. Chim. Acta. 304, 1 (1995).
70.- Vandeginste, B.G.M. y De Galan, L. Anal. Chem. 47, 2124 (1975).
71.- Anderson, A.H.; Gibb, T.C. y Littlewood, A.B.; Anal. Chem. 42, 434 (1970).
72.- Westerberg, A.W.; Anal. Chem. 4, 1770 (1969).
-87-
INTRODUCCIÓN
73.- Fellinger, A.; Anal. Chem. 66, 3066 (1994).
74.- Goodman, K.J. y Thomas Brenna, J.; Anal. Chem. 66, 1294 (1994).
75.- Torres Lapasió, J.R.; Baeza-Baeza, J.J. y García-Álvarez-Coque, M.C.; Anal. Chem. 69, 3822
(1997).
76.- Foley, J.P; J. Chromatogr. 384, 301 (1987).
77.- Torres Lapasió, J.R.; Villanueva Camañas, R.M.; Sanchís Mallols, J.M.; Medina Hernández,
M.J. y García-Álvarez-Coque, M.C.; J. Chromatogr. 677, 239 (1994).
78.- Le-Vent, S.; Anal. Chim. Acta. 312, 263 (1995).
79.- Grushka, E.; Myers, N.M.; Schettler, P.D. y Giddings, J.C.; Anal. Chem. 41, 889 (1969).
80.- Berthod, A.; Anal. Chem. 63, 1879 (1991).
81.- Küllik, E.; Kaljurand, M. y Ess, L.; J. Chromatogr. 118, 313 (1976).
82.- Kirmse, D.W. y Westerberg, A.W.; Anal. Chem. 43, 811 (1979).
83.- Raspor, B.; Piz•ta, I. y Branica, M.; Anal. Chim. Acta. 285, 103 (1994).
84.- Hayes, J.W.; Glover, D.E.; Smith, D.E. y Overton, M.W.; Anal. Chem. 45, 277 (1973).
85.- O´Halloran, R.J. y Smith, D.E.; Anal. Chem. 50, 1391 (1978).
86.- Smith, D.E.; Anal. Chem. 48, 517A (1976).
87.- Schwall, R.J.; Bond, A.M. y Smith, D.E.; Anal. Chem. 49, 1805 (1977).
88.- Schwall, R.J.; Bond, A.M., Loyd, R.J.; Larsen, J.G. y Smith, D.E.; Anal. Chem. 49, 1797
(1977).
89.- Smith, D.E.; Anal. Chem. 48, 221A (1976).
90.- Jáñez Escalado, L.; Fundamentos de Psicología Matemática (1989) Ed. Pirámide.
91.- Piz•ta, I.; Anal. Chim. Acta. 285, 95 (1994).
92.- Bond, A.M. y Grabariƒ, B.S.; Anal. Chem. 51, 337 (1979).
93.- Marshall, A.G. y Comisarow, M.B.; Anal. Chem. 47, 491A (1975).
94.- Hilera, J.R. y Martínez, V.J.; Redes Neuronales Artificiales. Fundamentos, Modelos y
Aplicaciones (1995) Ed. RA-MA. pág. 9.
95.- Janson, P.A.; Anal. Chem. 63, 357A (1991).
96.- Hilera, J.R. y Martínez, V.J.; Redes Neuronales Artificiales. Fundamentos, Modelos y
Aplicaciones (1995) Ed. RA-MA. pág. 12.
97.- Zupan, J. y Gasteiger, J.A.; Anal. Chim. Acta. 248, 1 (1991).
98.- Taib, M.N.; Andrés, R. y Narayanaswamy, R.; Anal. Chim. Acta. 330, 31 (1996).
99.- Hilera, J.R. y Martínez, V.J.; Redes Neuronales Artificiales. Fundamentos, Modelos y
Aplicaciones (1995) Ed. RA-MA. pág. 75 - 89.
100.- Hilera, J.R. y Martínez, V.J.; Redes Neuronales Artificiales. Fundamentos, Modelos y
Aplicaciones (1995) Ed. RA-MA. pág. 101 - 103.
-88-
INTRODUCCIÓN
101.- Rusling, J.F.; Anal. Chem. 55, 1719 (1983).
102.- Rusling, J.F.; Anal. Chem. 55, 1713 (1983).
103.- Bos, M.; Bos, A. y Van der Linden, W.E.; Anal. Chim. Acta. 233, 31 (1990).
104.- Van der Linden, W.E.; Bos, M. y Bos, A.; Anal. Proc. 26, 329 (1989).
105.- Cladera, A.; Alpízar, J.; Estela, J.M.; Cerdà, V.; Catasús, M.; Lastres, E. y García, L.; Anal.
Chim. Acta. 350, 163 (1997).
106.- Miao, H.; Yu, M. y Hu, S.; J. Chromatogr. A. 749, 5 (1996).
107.- Yatsenko, V.; J. Chromatogr. A. 722, 233 (1996).
108.- Otto, M.; Anal. Chim. Acta. 283, 500 (1993).
-89-
Capítulo 2:
Parte experimental:
Instrumentación y
reactivos.
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
1. APARATOS Y MATERIAL UTILIZADO.
A) APARATOS.
Para la realización del trabajo experimental, se emplearon los aparatos que a continuación
se describen:
1) Las medidas voltamperométricas de las dos especies catiónicas, así como también las
de las mezclas, se realizaron en un sistema Autolab®/PGSTAT20 y Stand VA 663 de
Metrohm, compuesto por un electrodo de trabajo MME, un electrodo de referencia
Ag/AgCl/KCl (3M) y un electrodo auxiliar de platino.
El electrodo de trabajo MME (Multi Mode Electrode) es una combinación de tres tipos
de electrodos de mercurio: electrodo de gota colgante de mercurio (HMDE), electrodo
de gotas de mercurio (DME) y electrodo de gota estacionaria de mercurio (SMDE). La
modalidad en la que se ha utilizado en el presente trabajo es la de gota colgante o
suspendida (HMDE), seleccionándose su tamaño manualmente.
Autolab®/PGSTAT20 es un sistema de medida electroquímico controlado por ordenador
que, combinado además con un paquete de software denominado GPES (General
Purpose Electrochemical System), consiste en un sistema de adquisición de datos y un
potenciostato.
En un esquema de bloques puede representarse del siguiente modo:
-91-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
IMPRESORA
ORDENADOR
AUTOLAB
DIO
POTENCIOSTATO
STAND CON CELDA
ELECTROQUÍMICA
IME
Cuadro1: Diagrama de bloques de la instrumentación empleada.
donde las diferentes partes del sistema Autolab® se manejan mediante el ordenador.
El módulo DIO permite controlar el sistema de electrodos, de tal modo que, conectado
al Stand VA 663 Metrohm, se puede influir en el proceso de purga con nitrógeno, así
como en la agitación, y activar también el tiempo de goteo.
La interfaz para el electrodo de mercurio se denomina IME y proporciona todas las
órdenes y conexiones necesarias para los mismos, así como un sistema de martilleo para
generar las gotas en los DME; controla, además, la salida de mercurio por el capilar
mediante la presión de nitrógeno.
El potenciostato ofrece la posibilidad de aplicar un barrido de potenciales controlado y
medir intensidades (o la opción inversa cuando actúa como galvanostato). Los rangos
de corriente, así como el resto de los parámetros y condiciones de medida, se introducen
por medio del software incluido en el ordenador.1
El Stand VA 663 de Metrohm permite seleccionar la modalidad de electrodo de
mercurio a utilizar y el tamaño de gota, sirviendo también como soporte a la celda
electroquímica y a los tres electrodos.
2) Otros aparatos empleados fueron los siguientes:
-92-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
w Las medidas de pH se efectuaron en un pH-metro digital MicropH-2002 Crison.
w La agitación de algunas disoluciones se llevó a cabo en un agitador magnético
Agimatic-P de Selecta.
w Las sustancias fueron pesadas en una balanza analítica Mettler AE 240 de dos
campos: uno de 40 mg con detección hasta 0,01 mg y otro de 200 g con detección
hasta 0,1 mg. Uno u otro campo se empleó según la precisión requerida.
w Como fuente de nitrógeno se dispuso de una botella AIR-LIQUIDE tipo N-55 con
válvula Alphagaz.
B) MATERIAL UTILIZADO.
Para las medidas voltamperométricas se emplearon celdas de 50 ml y las adiciones estándar
se realizaron con una pipeta de vidrio de 1 ml.
El material de vidrio habitual incluyó: pipetas, matraces aforados, vasos de precipitado, etc.
2. PRODUCTOS Y REACTIVOS EMPLEADOS.
Los reactivos se distribuyen en los siguientes grupos:
w Especies Catiónicas:
Tl+
TlNO3
MERCK p.a.
Pb2+
Pb(NO3)2
MERCK p.a.
w Especies del Medio Voltamperométrico:
Mercurio
MERCK p.a.
Cloruro de potasio
MERCK p.a.
Ácido acético glacial
MERCK p.a.
Acetato amónico
PANREAC p.a.
-93-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
3. PREPARACIÓN DE DISOLUCIONES.
El procedimiento experimental llevó consigo la preparación y utilización de cierto número
de disoluciones. Mencionaremos en este apartado las más importantes o que sirvieron de base
para otras posteriores.
w Disoluciones de muestras patrones:
Para el talio (I) y el plomo (II) se prepararon disoluciones madre de 250 mg·l-1,
disolviendo las cantidades que se expresan en 50 ml de agua destilada:
Tl+
0,0168 g de TlNO3
Pb2+
0,0199 g de Pb(NO3)2
A partir de ellas se obtuvieron sendas disoluciones de los dos cationes metálicos con
una concentración final de 25 mg·l-1.
w Disolución de cloruro de potasio (3M):
Empleada como electrolito de relleno en el electrodo de referencia de Ag/AgCl/KCl.
w Reguladora:
La reguladora utilizada fue 2 M de AcOH + 2 M AcONH4. Se tomaron 154,164 g de
AcONH4 y 114,61 ml de AcOH y se llevaron a un matraz aforado de 1 litro de
capacidad, enrasando con agua destilada. El pH final fue de 4,8 - 5,00.
La elección del medio indicado se llevó a cabo con vistas a obtener una señal lo más
definida y con la mayor intensidad posible, de acuerdo con la concentración existente
en la disolución para cada una de las especies por separado.
Así, en este medio y según la bibliografía consultada, el Tl+ debe presentar un
potencial de semionda situado a -0,43 V y el Pb2+ a -0,46 V aproximadamente, ambos
bastante bien definidos.2
-94-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
4. DESCRIPCIÓN DEL MÉTODO EXPERIMENTAL.
A) ASPECTOS GENERALES DE LA TÉCNICA UTILIZADA.
La técnica voltamperométrica empleada para obtener los datos de medida de cada una de
los patrones y las mezclas fue la voltamperometría de redisolución.
En este procedimiento electroquímico, el analito se deposita primero sobre un
microelectrodo, normalmente desde una disolución agitada. Después de un tiempo perfectamente
medido, se detiene la electrólisis y la agitación y el analito depositado se determina mediante otro
procedimiento voltamperométrico. Durante esta segunda etapa del análisis, el analito del
microelectrodo se redisuelve, lo que da nombre al método.
En los métodos de redisolución anódica, el microelectrodo se comporta como un cátodo
durante la etapa de deposición y como un ánodo durante la etapa de redisolución, en la que el
analito es reoxidado a su forma original. En un método de redisolución catódica, el
microelectrodo se comporta como un ánodo durante la etapa de deposición y como un cátodo
durante la redisolución. La etapa de deposición equivale a una preconcentración electroquímica
del analito; esto es, la concentración del analito en la superficie del microelectrodo es mucho
mayor que en el seno de la disolución.
Los métodos de redisolución son de gran importancia en análisis de trazas, ya que el efecto
de concentración de la electrólisis permite la determinación en pocos minutos de un analito con
una exactitud razonable. De modo que es factible el análisis de disoluciones en el intervalo entre
10-6 y 10-9 M, por métodos que son a la vez sencillos y rápidos.
Veamos ahora cada una de las etapas del procedimiento por separado:
w Etapa de electrodeposición:
Normalmente, durante esta etapa sólo se deposita una fracción del analito y, por
tanto, los resultados cuantitativos dependen no sólo del control del potencial del
electrodo, sino también de factores tales como el tamaño del electrodo, la duración
de la deposición y de la velocidad de agitación, tanto de las disoluciones de la
muestra como de los estándares utilizados en el calibrado.
El electrodo más popular es el electrodo de gota colgante de mercurio (HMDE), que
consiste en una única gota de mercurio en contacto con un hilo de platino; no
obstante, existen otros tipos de electrodos: de oro, plata, platino y el carbono en
formas diversas. Sin embargo, el electrodo de mercurio parece dar resultados más
reproducibles, especialmente a concentraciones elevadas del analito. Por tanto, en la
-95-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
mayoría de las aplicaciones se utiliza el HMDE.
Para llevar a cabo la determinación de un ión metálico por redisolución anódica, se
forma una nueva gota de mercurio, se empieza la agitación y se aplica un potencial
que es unas cuantas décimas de voltio más negativo que el potencial de pico del ión
que interesa. La deposición tiene lugar mediante un tiempo cuidadosamente medido.
Hay que resaltar que estos tiempos rara vez dan lugar a una eliminación completa del
ión. El periodo de electrólisis se determina en función de la sensibilidad del método
utilizado posteriormente para la realización del análisis.
w Etapa del análisis voltamperométrico:
El analito recogido en el electrodo de gota colgante puede determinarse por
cualquiera de los distintos procedimientos voltamperométricos existentes, siendo el
más ampliamente utilizado el método anódico de impulso diferencial. Por medio de
él, se obtienen a menudo picos estrechos que son especialmente adecuados cuando
se han de analizar mezclas.3
B) MÉTODO EXPERIMENTAL.
En el presente trabajo se ha hecho uso de un método de redisolución para la determinación
acuosa de iones Tl (I) y Pb (II) por separado, así como también de mezclas constituidas por
ambos cationes. El rango de concentraciones utilizado para ambos ha sido de 0,1 a 1,0 mg·l-1, con
una variación de 0,1 mg·l-1 entre un patrón y otro. Para completar el análisis se empleó el método
voltamperométrico de impulso diferencial. Es decir, la técnica que comúnmente se conoce por
el nombre de voltamperometría de redisolución anódica de impulso diferencial o DPASV.
Inicialmente, en todos los casos, se aplicó al microelectrodo un potencial catódico constante
de aproximadamente - 1,3 V, el cual provocó que tanto los iones Tl (I) como los iones Pb (II) se
redujeran y se depositasen como metales, formando una amalgama con el mercurio del electrodo.
Los procesos catódicos serían los siguientes:
Pb2+ + 2 e- ÷ Pb - Hg
Tl+ + e- ÷ Tl - Hg
El electrodo se mantiene a este potencial durante varios minutos hasta que una cantidad
significativa de los dos metales se haya depositado sobre la superficie de la gota de mercurio del
electrodo. Se detiene, entonces, la agitación durante unos 20 s, tiempo empleado para equilibrar
-96-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
y estabilizar el electrodo y la disolución. Finalmente, el potencial del electrodo se hace variar
linealmente hacia potenciales cada vez menos negativos, mientras que la intensidad de la celda
se registra en función del potencial; dicho registro también podría haberse hecho en función del
tiempo.
Paralelamente a la disminución lineal del potencial, se superponen una serie de escalones
o de pulsos de potencial, expresado en mV, de determinado valor, que constituyen la base de la
técnica de impulso diferencial.
La Figura 1 muestra el voltamperograma resultante para la determinación del ion Pb (II).
A un potencial algo menos negativo de -0,7 V el plomo comienza a oxidarse, causando un
aumento brusco de la intensidad hasta alcanzar un máximo a aproximadamente -0,52 V,
proporcional a la cantidad de Pb presente en la gota, disminuyendo posteriormente a su nivel
original.
3,50E-07
3,00E-07
2,50E-07
I (A)
2,00E-07
Pb (II)
1,50E-07
1,00E-07
5,00E-08
0,00E+00
-0,90
-0,70
-0,50
-0,30
-0,10
E (V)
Figura 1: Voltamperograma del patrón de Pb (II) a 1,0 mg·l-1.
Lo mismo sucede con el Tl (I) y con las mezclas de ambos cationes, excepto por un
desplazamiento del máximo de intensidad del pico, los cuales se obtienen a aproximadamente
a -0,50 y -0,51 V, respectivamente.
Si superponemos los voltamperogramas de ambos metales y el de la mezcla
correspondiente (Figura 2), puede observarse la diferencia tan pequeña que existe entre la
-97-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
posición de los picos de los dos analitos. Como consecuencia de esto, si analizamos mediante
voltamperometría una disolución que contiene las dos especies, ambas se manifiestan como un
único pico cuya intensidad máxima es la suma de las intensidades de los picos que se obtienen
al determinar cada una de ellas individualmente. Por ello, se hace necesaria la separación de los
metales a la hora de analizar la concentración de dichos cationes en la disolución que se está
tratando.
6,93E-07
5,93E-07
4,93E-07
I (A)
3,93E-07
Tl (I)
Pb (II)
2,93E-07
M e zcla
1,93E-07
9,30E-08
-7,00E-09
-0,90
-0,70
-0,50
-0,30
-0,10
E (V)
Figura 2: Superposición de los voltamperogramas del Tl (I) a 1,0 mg·l-1, Pb (II) a 1,0 mg·l-1 y la
mezcla de ambos.
Por último, las reacciones que se producen en la etapa de redisolución son las siguientes:
Pb - Hg ÷ Pb2+ + 2 eTl - Hg ÷ Tl+ + eC) PARÁMETROS DEL PROGRAMA.
La voltamperometría de redisolución anódica fue desarrollada por el Autolab®/PGSTAT20,
anteriormente descrito. Los parámetros principales del programa empleado fueron los siguientes:
-98-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
w Etapa de Purga:
! Tiempo de purga (con N2) = 300 s.
w Etapa de Deposición:
! Potencial de deposición = -1,3 V.
! Tiempo de deposición = 120 s.
! Tiempo de equilibrio = 20 s.
w Etapa de Redisolución y Medida:
! Potencial inicial = -1,3 V.
! Potencial final = 0 V.
! Potencial de “Stand by” = 0 V.
! Incremento de potencial = 0,0051 V.
! Amplitud de impulso = 0,10005 V.
! Tiempo de impulso = 0,07 s.
! Tiempo de repetición del impulso = 0,6 s.
w Otros Parámetros:
! Tamaño de gota = posición 3 (máximo) del Stand VA 663 de Metrohm, que
equivale a un área de 0,52 mm2 ± 10 %.
D) PROCEDIMIENTO DE ACTUACIÓN.
El procedimiento de actuación fue el que aparece descrito a continuación:
1. Una vez elegido y determinado el programa de aplicación de la técnica de DPASV,
se coloca la celda electroquímica en el Stand VA 663 de Metrohm con 25 ml de
reguladora 2 M de AcOH + 2 M AcONH4 y se procede a ejecutar el programa.
2. Primero se hace pasar un flujo de N2 a través de la misma durante 300 segundos, para
eliminar el oxígeno disuelto en la disolución (cuando sea necesario).
3. Seguidamente, se lleva a cabo la etapa de electrodeposición anteriormente descrita.
4. Después y, tras un tiempo de estabilización de unos 20 segundos, se continua el
proceso con la etapa de medida, que culmina con la obtención de una gráfica de
intensidad-potencial para el fondo de la reguladora, la cual es salvada en un archivo
con formato ASCII. Al mismo tiempo, el ordenador suministra la información
-99-
PARTE EXPERIMENTAL: INSTRUMENTACIÓN Y REACTIVOS
relacionada con los parámetros de la señal obtenida: EP, Ip, anchura de pico y su área,
así como también su derivada.
5. A continuación se añade el patrón a medir o las sustancias que componen la mezcla
y se comienza el programa de nuevo en el punto 2.
6. El resultado consiste también en un archivo que contiene pares de valores intensidadpotencial, correspondientes a un patrón de Tl (I), Pb (II) o bien a una mezcla de
ambas especies.
7. Posteriormente, estos archivos reciben un formato más adecuado para su posterior
tratamiento matemático.
BIBLIOGRAFÍA.
1.-
Eco Chemie; Manual de Autolab®. (1995).
2.-
Metrohm; Polarografía, Voltamperometría de Redisolución, Fundamentos y Aplicaciones.
(1991).
3.-
Skoog, D.A. y Leary, J.J.; Análisis Instrumental (1996) 4ª Ed. Ed. McGraw-Hill. pág. 653.
-100-
Capítulo 3:
Resultados obtenidos.
RESULTADOS OBTENIDOS
Todos los voltamperogramas obtenidos, tanto de las muestras puras como de las mezclas,
poseían inicialmente 259 puntos. Para su posterior tratamiento matemático, fueron recortados
hasta 80 puntos, en el intervalo de potenciales desde -0,70 hasta -0.30 V.
1. PATRONES PUROS DE TALIO.
Los resultados obtenidos en la determinación de los patrones puros de Tl (I) son los que
aparecen en la Tabla 1. En ella se recogen los valores para los distintos parámetros de pico de
todas y cada una de las muestras de talio (patrón 1), por triplicado (réplica), dentro del rango de
concentraciones de 0,1 a 1,0 mg·l-1. Dichos parámetros son los siguientes: volumen añadido
(Vol.) en ml, potencial (Pot.) en V, intensidad (Int.) en nA, área, anchura de pico en V, derivada,
desviación estándar de las réplicas de los patrones (Desv. Est.), intensidad media de las mismas
en nA (Int. Media) y concentración ([mg/l]).
En la Figura 1, aparecen superpuestos todos los gráficos de los patrones de talio en el rango
investigado. Son diez voltamperogramas que difieren unos de otros en una concentración de 0,1
mg·l-1.
Por último, se recogen los datos de la calibración efectuada en base a los 10 patrones de
talio analizados. En la Figura 2, aparece representada la recta de calibrado correspondiente, junto
con los datos relacionados con el ajuste.
-102-
RESULTADOS OBTENIDOS
Tabla 1: Parámetros de pico de todos los voltamperogramas analizados de Tl (I) de 0,1 a 1,0 mg·l-1 .
Talio Patrón
Tl 0,1
1
Tl 0,1
1
Tl 0,1
1
Tl 0,2
1
Tl 0,2
1
Tl 0,2
1
Tl 0,3
1
Tl 0,3
1
Tl 0,3
1
Tl 0,4
1
Tl 0,4
1
Tl 0,4
1
Tl 0,5
1
Tl 0,5
1
Tl 0,5
1
Tl 0,6
1
Tl 0,6
1
Tl 0,6
1
Tl 0,7
1
Tl 0,7
1
Tl 0,7
1
Tl 0,8
1
Tl 0,8
1
Tl 0,8
1
Tl 0,9
1
Tl 0,9
1
Tl 0,9
1
Tl 1,0
1
Tl 1,0
1
Tl 1,0
1
Réplica
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
1
2
3
Vol. (ml) Pot. (V) Int. (nA) Área (10-8) Anchura (V) Derivada (10-7 ) Desv. Est. Int.Media (nA) [mg/l]
0,1
-0,494
22,98
0,2768
0,111
5,767
0,04509
22,845
0,1
0,1
-0,494
22,94
0,2755
0,111
5,715
0,04509
22,845
0,1
0,1
-0,494
22,89
0,2743
0,111
5,744
0,04509
22,845
0,1
0,2
-0,494
51,80
0,6315
0,111
13,060
0,59969
51,194
0,2
0,2
-0,494
50,93
0,6161
0,111
12,670
0,59969
51,194
0,2
0,2
-0,494
52,08
0,6302
0,111
13,020
0,59969
51,194
0,2
0,3
-0,499
81,37
0,9888
0,116
20,410
1,78998
78,366
0,3
0,3
-0,499
78,38
0,9549
0,116
19,650
1,78998
78,366
0,3
0,3
-0,494
78,17
0,9543
0,111
19,600
1,78998
78,366
0,3
0,4
-0,484
108,10
1,2790
0,111
26,500
1,18462
105,774
0,4
0,4
-0,489
106,10
1,2750
0,111
27,120
1,18462
105,774
0,4
0,4
-0,489
108,20
1,2930
0,111
27,150
1,18462
105,774
0,4
0,5
-0,494
137,70
1,6670
0,116
34,070
2,60576
136,275
0,5
0,5
-0,494
137,30
1,6710
0,116
34,160
2,60576
136,275
0,5
0,5
-0,494
142,00
1,7010
0,116
34,790
2,60576
136,275
0,5
0,6
-0,499
175,00
2,1320
0,116
43,630
2,91605
167,611
0,6
0,6
-0,479
170,00
2,0290
0,111
41,280
2,91605
167,611
0,6
0,6
-0,494
169,90
2,0630
0,116
42,280
2,91605
167,611
0,6
0,7
-0,494
201,70
2,4650
0,116
50,480
1,15326
195,136
0,7
0,7
-0,494
200,70
2,4160
0,111
50,180
1,15326
195,136
0,7
0,7
-0,489
199,40
2,3900
0,111
49,230
1,15326
195,136
0,7
0,8
-0,489
228,50
2,7720
0,111
56,200
2,86182
224,612
0,8
0,8
-0,484
233,30
2,8070
0,111
56,410
2,86182
224,612
0,8
0,8
-0,484
233,60
2,7900
0,111
56,480
2,86182
224,612
0,8
0,9
-0,494
251,80
3,0330
0,111
61,130
2,89194
246,075
0,9
0,9
-0,489
257,50
3,0890
0,111
62,640
2,89194
246,075
0,9
0,9
-0,484
255,50
3,0720
0,111
65,060
2,89194
246,075
0,9
1,0
-0,489
286,80
3,5070
0,116
72,100
3,98790
280,128
1,0
1,0
-0,494
292,90
3,5700
0,116
73,090
3,98790
280,128
1,0
1,0
-0,494
294,30
3,5770
0,116
74,120
3,98790
280,128
1,0
-103-
I (A)
RESULTADOS OBTENIDOS
3.00E-07
Tl01
2.50E-07
Tl02
2.00E-07
Tl03
Tl04
1.50E-07
Tl05
1.00E-07
-0.70
-0.60
-0.50
-0.40
Tl06
5.00E-08
Tl07
0.00E+00
-0.30
Tl08
Tl09
E (V)
Tl10
Figura 2: Superposición de los voltamperogramas de los patrones de Tl (I) de 0,1 a 1,0 mg·l-1.
La tabla empleada para la calibración fue la siguiente:
I (nA)
22,845
51,194
78,366
105,774
136,275
[mg·l-1]
0,1
0,2
0,3
0,4
0,5
I (nA)
167,611
195,136
224,612
246,075
280,128
[mg·l-1]
0,6
0,7
0,8
0,9
1,0
El ajuste lineal de los datos dio como resultado la gráfica que se recoge a continuación:
-104-
RESULTADOS OBTENIDOS
1.2
y = 0.0035x + 0.0221
1
2
R = 0.9994
[mg/l]
0.8
Tl (I)
0.6
Lineal (Tl (I))
0.4
0.2
0
0
50
100
150
200
250
300
I (nA)
Figura 3: Recta de calibrado de los patrones de Tl (I) de 0,1 a 1,0 mg·l-1.
Como puede observarse, el ajuste de la recta de calibrado es bastante bueno.
2. PATRONES PUROS DE PLOMO.
Los resultados obtenidos en la determinación de los patrones puros de Pb (II) aparecen en
la Tabla 2. En ella se recogen los valores para los distintos parámetros de pico de todas y cada
una de las muestras de plomo (patrón 2), también por triplicado, y dentro del mismo rango de
concentraciones que el Tl (I): de 0,1 a 1,0 mg·l-1. Los parámetros representados son los mismos.
En la Figura 3, se representa una superposición de todos los gráficos de los patrones de
plomo en el rango analizado. Del mismo modo que con el talio, se trata de diez
voltamperogramas que difieren unos de otros en una concentración de 0,1 mg·l-1.
En última instancia, se recogen los datos de la calibración efectuada en base a los 10
patrones de plomo. En la Figura 4, aparece representada la recta de calibrado correspondiente,
y, a continuación, los datos relacionados con el ajuste.
-105-
RESULTADOS OBTENIDOS
Tabla 2: Parámetros de pico de todos los voltamperogramas analizados de Pb (II) de 0,1 a 1,0 mg·l-1 .
Plomo Patrón Réplica Vol. (ml) Pot. (V) Int. (nA) Área (10-8) Anchura (V) Derivada (10-7 ) Desv. Est. Int.Media (nA) [mg/l]
Pb 0,1
2
1
0,1
-0,530
40,65
0,4072
0,096
15,480
0,28361
40,810
0,1
Pb 0,1
2
2
0,1
-0,525
41,09
0,4112
0,096
15,710
0,28361
40,810
0,1
Pb 0,1
2
3
0,1
-0,520
41,18
0,4127
0,096
15,730
0,28361
40,810
0,1
Pb 0,2
2
1
0,2
-0,525
74,87
0,7542
0,096
28,610
0,44859
73,962
0,2
Pb 0,2
2
2
0,2
-0,525
74,75
0,7511
0,096
28,560
0,44859
73,962
0,2
Pb 0,2
2
3
0,2
-0,520
74,04
0,7450
0,096
28,320
0,44859
73,962
0,2
Pb 0,3
2
1
0,3
-0,520
106,40
1,0680
0,096
40,660
1,25831
104,974
0,3
Pb 0,3
2
2
0,3
-0,525
104,90
1,0490
0,096
39,720
1,25831
104,974
0,3
Pb 0,3
2
3
0,3
-0,520
107,40
1,0740
0,096
41,010
1,25831
104,974
0,3
Pb 0,4
2
1
0,4
-0,525
140,00
1,4030
0,096
53,400
1,32288
137,303
0,4
Pb 0,4
2
2
0,4
-0,525
140,50
1,4100
0,096
53,620
1,32288
137,303
0,4
Pb 0,4
2
3
0,4
-0,525
138,00
1,3800
0,096
52,590
1,32288
137,303
0,4
Pb 0,5
2
1
0,5
-0,520
178,90
1,7920
0,101
68,370
0,98658
174,935
0,5
Pb 0,5
2
2
0,5
-0,520
179,10
1,7970
0,096
68,330
0,98658
174,935
0,5
Pb 0,5
2
3
0,5
-0,520
177,30
1,7810
0,096
67,970
0,98658
174,935
0,5
Pb 0,6
2
1
0,6
-0,520
212,40
2,1320
0,096
81,420
3,15331
204,427
0,6
Pb 0,6
2
2
0,6
-0,520
209,50
2,1030
0,096
80,230
3,15331
204,427
0,6
Pb 0,6
2
3
0,6
-0,520
206,10
2,0700
0,096
78,850
3,15331
204,427
0,6
Pb 0,7
2
1
0,7
-0,520
246,60
2,4760
0,096
94,390
3,10000
236,479
0,7
Pb 0,7
2
2
0,7
-0,520
240,70
2,4170
0,096
92,210
3,10000
236,479
0,7
Pb 0,7
2
3
0,7
-0,520
242,00
2,4290
0,096
92,670
3,10000
236,479
0,7
Pb 0,8
2
1
0,8
-0,525
282,80
2,8380
0,101
107,900
3,06649
272,125
0,8
Pb 0,8
2
2
0,8
-0,525
282,40
2,8350
0,096
108,000
3,06649
272,125
0,8
Pb 0,8
2
3
0,8
-0,520
277,30
2,7860
0,096
105,900
3,06649
272,125
0,8
Pb 0,9
2
1
0,9
-0,520
309,20
3,0920
0,096
118,600
2,81484
300,997
0,9
Pb 0,9
2
2
0,9
-0,520
314,80
3,1580
0,096
120,600
2,81484
300,997
0,9
Pb 0,9
2
3
0,9
-0,520
311,50
3,1260
0,096
119,300
2,81484
300,997
0,9
Pb 1,0
2
1
1,0
-0,520
337,20
3,3810
0,096
129,700
7,15984
328,109
1,0
Pb 1,0
2
2
1,0
-0,520
349,50
3,5050
0,096
134,200
7,15984
328,109
1,0
Pb 1,0
2
3
1,0
-0,520
337,00
3,3820
0,096
129,300
7,15984
328,109
1,0
-106-
RESULTADOS OBTENIDOS
Pb01
3.00E-07
Pb02
2.50E-07
Pb03
2.00E-07
Pb04
1.50E-07
Pb05
1.00E-07
Pb06
5.00E-08
Pb07
0.00E+00
-0.30
Pb08
I (A)
3.50E-07
-0.70
-0.60
-0.50
-0.40
Pb09
E (V)
Pb10
Figura 5: Superposición de los voltamperogramas de los patrones de Pb (II) de 0,1 a 1,0 mg·l-1.
La tabla empleada para la calibración fue la siguiente:
I (nA)
40,810
73,962
104,974
137,303
174,935
[mg·l-1]
0,1
0,2
0,3
0,4
0,5
I (nA)
204,427
236,479
272,125
300,997
328,109
[mg·l-1]
0,6
0,7
0,8
0,9
1,0
El ajuste lineal de los datos dio como resultado la gráfica que se recoge a continuación:
-107-
RESULTADOS OBTENIDOS
1.2
y = 0.0031x - 0.0289
1
2
R = 0.9993
[mg/l]
0.8
Pb (II)
0.6
Lineal (Pb (II))
0.4
0.2
0
0
100
200
300
400
I (nA)
Figura 6: Recta de calibrado de los patrones de Pb (II) de 0,1 a 1,0 mg·l-1.
En este caso, el ajuste también es muy bueno.
3. MEZCLAS DE LOS PATRONES DE TALIO Y PLOMO.
Una vez analizados los patrones de plomo y talio por separado, se llevó a cabo su
determinación conjunta en mezclas con diferentes concentraciones de ambas especies.
Las mezclas estudiadas son las que aparecen reflejadas en la Tabla 3. Como puede
observarse, éstas se distribuyen en tres diagonales: una principal y dos secundarias.
Este tipo de muestreo se realizó con la intención de que todas las líneas de la tabla
contuviesen dos mezclas analizadas y, además, para que la distancia entre una y otra fuesen
idénticas en todos los casos.
-108-
RESULTADOS OBTENIDOS
T1
P1
T2
T3
T4
T5
T1P1
P2
T6
T7
T8
T9
T6P1
T2P2
P3
T7P2
T3P3
P4
T8P3
T4P4
P5
T9P4
T5P5
P6
T1P6
P7
T7P7
T3P8
P9
T8P8
T4P9
P10
T10P5
T6P6
T2P7
P8
T10
T9P9
T5P10
T10P10
Tabla 3: Mezclas de los patrones de Tl (I) y Pb (II) analizadas.
La nomenclatura empleada en la tabla es la siguiente: T = Tl (I), P = Pb (II) y los números
indican la concentración de cada uno de los patrones: 1 / 0,1 mg·l-1, 2 / 0,2 mg·l-1, ..., 10 / 1,0
mg·l-1.
En adelante, a la hora de presentar los datos, nos referiremos a tres grupos de mezclas en
función de su pertenencia a una u otra diagonal. De este modo, las mezclas T6P1 a T10P5 (color
azul), de la diagonal superior, serán el grupo A; desde T1P1 hasta T10P10 (color rojo), de la
diagonal principal, constituyen el grupo B y, por último, las de la diagonal inferior, T1P6 a
T5P10 (color verde), formarán parte del grupo C.
Los resultados obtenidos en la determinación de las mezclas de los patrones de Tl (I) y Pb
(II) aparecen reflejados en la Tabla 4. En ella se recogen los valores para los distintos parámetros
de pico de todas y cada una de las mezclas de talio y plomo analizadas (patrón 3), por triplicado
(réplica), dentro del rango de concentraciones de 0,1 a 1,0 mg·l-1. Dichos parámetros son los
siguientes: volumen añadido (Vol.) en ml, potencial (Pot.) en V, intensidad (Int.) en nA, área,
-109-
RESULTADOS OBTENIDOS
anchura de pico en V, derivada, desviación estándar de las réplicas de las mezclas (Desv.Est),
intensidad media de las mismas en nA (Int. Media), concentración de Tl (I) y Pb (II) en la mezcla
([Tl+] y [Pb2+]) en mg·l-1, intensidad esperada en nA (Int. Esperada) considerando los valores de
altura de pico de los patrones individuales y, finalmente, el error (%) entre la intensidad final y
la esperada.
-110-
RESULTADOS OBTENIDOS
Tabla 4: Parámetros de pico de todos los voltamperogramas analizados de las mezclas de patrones de Tl (I) y Pb (II).
Mezclas
Patrón Réplica Vol. (ml) Pot. (V) Int. (nA) Área (10-8 ) Anchura (V) Derivada (10-7) Desv. Est. Int.Media (nA) [Tl+] [Pb2+ ] Int. Esperada (nA) Error (%)
Tl 0,1 y Pb 0,1
3
1
0,2
-0,509
65,28
0,7323
0,106
20,59
0,20809
65,00
0,1
0,1
63,65
2,121
Tl 0,1 y Pb 0,1
3
2
0,2
-0,509
65,63
0,7390
0,106
20,68
0,20809
65,00
0,1
0,1
63,65
2,121
Tl 0,1 y Pb 0,1
3
3
0,2
-0,509
65,65
0,7376
0,106
20,73
0,20809
65,00
0,1
0,1
63,65
2,121
Tl 0,6 y Pb 0,1
3
1
0,7
-0,494
214,00
2,5290
0,111
54,42
1,99750
209,44
0,6
0,1
208,42
0,487
Tl 0,6 y Pb 0,1
3
2
0,7
-0,499
217,60
2,5380
0,111
54,38
1,99750
209,44
0,6
0,1
208,42
0,487
Tl 0,6 y Pb 0,1
3
3
0,7
-0,494
214,30
2,5340
0,111
55,91
1,99750
209,44
0,6
0,1
208,42
0,487
Tl 0,2 y Pb 0,2
3
1
0,4
-0,509
129,90
1,4500
0,106
41,01
2,28692
125,30
0,2
0,2
125,17
0,100
Tl 0,2 y Pb 0,2
3
2
0,4
-0,504
125,60
1,4060
0,106
39,73
2,28692
125,30
0,2
0,2
125,17
0,100
Tl 0,2 y Pb 0,2
3
3
0,4
-0,504
126,40
1,4250
0,106
39,59
2,28692
125,30
0,2
0,2
125,17
0,100
Tl 0,7 y Pb 0,2
3
1
0,9
-0,504
276,70
3,2490
0,111
75,91
1,85203
265,35
0,7
0,2
269,11
-1,398
Tl 0,7 y Pb 0,2
3
2
0,9
-0,504
273,00
3,2000
0,111
75,67
1,85203
265,35
0,7
0,2
269,11
-1,398
Tl 0,7 y Pb 0,2
3
3
0,9
-0,499
275,00
3,2260
0,111
76,23
1,85203
265,35
0,7
0,2
269,11
-1,398
Tl 0,3 y Pb 0,3
3
1
0,6
-0,509
189,60
2,1360
0,106
59,95
1,36504
184,93
0,3
0,3
183,34
0,866
Tl 0,3 y Pb 0,3
3
2
0,6
-0,504
187,90
2,1170
0,106
59,33
1,36504
184,93
0,3
0,3
183,34
0,866
Tl 0,3 y Pb 0,3
3
3
0,6
-0,504
190,60
2,1460
0,106
60,34
1,36504
184,93
0,3
0,3
183,34
0,866
Tl 0,8 y Pb 0,3
3
1
1,1
-0,499
340,60
3,9670
0,111
96,90
4,42380
328,45
0,8
0,3
329,58
-0,343
Tl 0,8 y Pb 0,3
3
2
1,1
-0,499
340,10
3,9580
0,111
96,87
4,42380
328,45
0,8
0,3
329,58
-0,343
Tl 0,8 y Pb 0,3
3
3
1,1
-0,499
348,00
4,0510
0,111
99,11
4,42380
328,45
0,8
0,3
329,58
-0,343
Tl 0,4 y Pb 0,4
3
1
0,8
-0,509
246,80
2,7650
0,106
78,90
2,12211
240,08
0,4
0,4
243,07
-1,228
Tl 0,4 y Pb 0,4
3
2
0,8
-0,509
246,30
2,7570
0,106
78,82
2,12211
240,08
0,4
0,4
243,07
-1,228
Tl 0,4 y Pb 0,4
3
3
0,8
-0,509
250,20
2,8030
0,106
80,00
2,12211
240,08
0,4
0,4
243,07
-1,228
Tl 0,9 y Pb 0,4
3
1
1,3
-0,504
390,90
4,5300
0,111
112,70
5,10327
377,06
0,9
0,4
383,37
-1,646
Tl 0,9 y Pb 0,4
3
2
1,3
-0,504
398,50
4,6100
0,111
115,50
5,10327
377,06
0,9
0,4
383,37
-1,646
Tl 0,9 y Pb 0,4
3
3
1,3
-0,504
400,60
4,6380
0,111
116,10
5,10327
377,06
0,9
0,4
383,37
-1,646
Tl 0,5 y Pb 0,5
3
1
1,0
-0,504
322,80
3,6350
0,106
101,60
5,42801
316,41
0,5
0,5
311,23
1,664
Tl 0,5 y Pb 0,5
3
2
1,0
-0,504
332,10
3,7420
0,106
104,50
5,42801
316,41
0,5
0,5
311,23
1,664
Tl 0,5 y Pb 0,5
3
3
1,0
-0,504
332,30
3,7420
0,106
104,60
5,42801
316,41
0,5
0,5
311,23
1,664
Tl 1,0 y Pb 0,5
3
1
1,5
-0,504
472,90
5,4520
0,111
139,10
2,24796
447,96
1,0
0,5
455,06
-1,561
Tl 1,0 y Pb 0,5
3
2
1,5
-0,504
474,30
5,4660
0,111
139,50
2,24796
447,96
1,0
0,5
455,06
-1,561
Tl 1,0 y Pb 0,5
3
3
1,5
-0,504
477,30
5,5020
0,111
140,30
2,24796
447,96
1,0
0,5
455,06
-1,561
-111-
RESULTADOS OBTENIDOS
Tabla 4: Parámetros de pico de todos los voltamperogramas analizados de las mezclas de patrones de Tl (I) y Pb (II) (continuación).
Mezclas
Patrón Réplica Vol. (ml) Pot. (V) Int. (nA) Área (10-8 ) Anchura (V) Derivada (10-7) Desv. Est. Int.Media (nA) [Tl+] [Pb2+ ] Int. Esperada (nA) Error (%)
Tl 0,1 y Pb 0,6
3
1
1,6
-0,525
230,60
2,4100
0,101
84,30
4,15812
228,70
0,1
0,6
227,27
0,628
Tl 0,1 y Pb 0,6
3
2
1,6
-0,520
235,90
2,4670
0,101
86,13
4,15812
228,70
0,1
0,6
227,27
0,628
Tl 0,1 y Pb 0,6
3
3
1,6
-0,520
238,80
2,4980
0,101
87,21
4,15812
228,70
0,1
0,6
227,27
0,628
Tl 0,6 y Pb 0,6
3
1
1,2
-0,504
387,00
4,3640
0,106
121,10
2,72213
366,32
0,6
0,6
372,04
-1,538
Tl 0,6 y Pb 0,6
3
2
1,2
-0,504
381,90
4,3050
0,106
119,50
2,72213
366,32
0,6
0,6
372,04
-1,538
Tl 0,6 y Pb 0,6
3
3
1,2
-0,504
382,80
4,3180
0,106
119,80
2,72213
366,32
0,6
0,6
372,04
-1,538
Tl 0,2 y Pb 0,7
3
1
0,9
-0,515
295,00
3,1410
0,101
105,00
4,45421
288,61
0,2
0,7
287,67
0,327
Tl 0,2 y Pb 0,7
3
2
0,9
-0,515
303,80
3,2350
0,101
102,90
4,45421
288,61
0,2
0,7
287,67
0,327
Tl 0,2 y Pb 0,7
3
3
0,9
-0,515
298,20
3,1760
0,101
108,10
4,45421
288,61
0,2
0,7
287,67
0,327
Tl 0,7 y Pb 0,7
3
1
1,4
-0,504
451,70
5,0680
0,106
143,80
7,75048
435,13
0,7
0,7
431,61
0,816
Tl 0,7 y Pb 0,7
3
2
1,4
-0,504
459,60
5,1520
0,106
146,30
7,75048
435,13
0,7
0,7
431,61
0,816
Tl 0,7 y Pb 0,7
3
3
1,4
-0,504
467,20
5,2400
0,106
148,80
7,75048
435,13
0,7
0,7
431,61
0,816
Tl 0,3 y Pb 0,8
3
1
1,1
-0,515
369,50
3,9390
0,101
131,00
5,76223
347,57
0,3
0,8
350,49
-0,832
Tl 0,3 y Pb 0,8
3
2
1,1
-0,515
359,10
3,8290
0,101
127,10
5,76223
347,57
0,3
0,8
350,49
-0,832
Tl 0,3 y Pb 0,8
3
3
1,1
-0,515
360,00
3,8370
0,101
127,50
5,76223
347,57
0,3
0,8
350,49
-0,832
Tl 0,8 y Pb 0,8
3
1
1,6
-0,509
518,10
5,6580
0,101
156,20
11,37995
494,42
0,8
0,8
496,73
-0,464
Tl 0,8 y Pb 0,8
3
2
1,6
-0,499
539,10
5,8150
0,101
157,20
11,37995
494,42
0,8
0,8
496,73
-0,464
Tl 0,8 y Pb 0,8
3
3
1,6
-0,509
521,00
5,6000
0,101
154,60
11,37995
494,42
0,8
0,8
496,73
-0,464
Tl 0,4 y Pb 0,9
3
1
1,3
-0,509
421,00
4,5420
0,106
146,30
4,78435
405,42
0,4
0,9
405,87
-0,111
Tl 0,4 y Pb 0,9
3
2
1,3
-0,509
429,70
4,6360
0,106
149,40
4,78435
405,42
0,4
0,9
405,87
-0,111
Tl 0,4 y Pb 0,9
3
3
1,3
-0,509
428,80
4,6230
0,106
149,00
4,78435
405,42
0,4
0,9
405,87
-0,111
Tl 0,9 y Pb 0,9
3
1
1,8
-0,504
578,20
6,4920
0,106
182,80
2,55408
542,04
0,9
0,9
546,17
-0,756
Tl 0,9 y Pb 0,9
3
2
1,8
-0,504
583,10
6,5460
0,106
184,40
2,55408
542,04
0,9
0,9
546,17
-0,756
Tl 0,9 y Pb 0,9
3
3
1,8
-0,504
581,90
6,5390
0,106
184,00
2,55408
542,04
0,9
0,9
546,17
-0,756
Tl 0,5 y Pb 1,0
3
1
1,5
-0,509
485,40
5,2780
0,106
165,90
8,19532
461,76
0,5
1,0
464,41
-0,570
Tl 0,5 y Pb 1,0
3
2
1,5
-0,509
498,90
5,4210
0,106
171,00
8,19532
461,76
0,5
1,0
464,41
-0,570
Tl 0,5 y Pb 1,0
3
3
1,5
-0,509
484,10
5,2650
0,106
165,70
8,19532
461,76
0,5
1,0
464,41
-0,570
Tl 1,0 y Pb 1,0
3
1
2,0
-0,494
664,90
7,0160
0,101
190,00
4,62853
610,71
1,0
1,0
608,24
0,406
Tl 1,0 y Pb 1,0
3
2
2,0
-0,499
656,60
6,9560
0,101
192,00
4,62853
610,71
1,0
1,0
608,24
0,406
Tl 1,0 y Pb 1,0
3
3
2,0
-0,509
657,20
6,9490
0,101
195,10
4,62853
610,71
1,0
1,0
608,24
0,406
-112-
RESULTADOS OBTENIDOS
A) GRUPO A DE MEZCLAS (DIAGONAL SUPERIOR).
En la Figura 5, se representa una superposición de todos los gráficos de las mezclas que
constituyen la diagonal superior de la Tabla 3. Son cinco voltamperogramas que se corresponden
con sendas mezclas.
Para comprobar que existe linealidad entre las mezclas, se procedió a realizar un ajuste
lineal de las mismas. Los resultados pueden comprobarse viendo la Figura 6, así como los datos
del ajuste.
5.00E-07
4.50E-07
E (V)
4.00E-07
3.50E-07
T6P1
3.00E-07
T7P2
2.50E-07
T8P3
2.00E-07
T9P4
1.50E-07
T10P5
1.00E-07
5.00E-08
-0.70
-0.60
-0.50
0.00E+00
-0.30
-0.40
I (A)
Figura 9: Superposición de los voltamperogramas de las mezclas del grupo A.
La tabla empleada para el ajuste lineal es la siguiente:
T6P1
T7P2
T8P3
T9P4
T10P5
I (nA)
209,436
265,347
328,448
377,060
447,956
[mg·l-1]
0,7
0,9
1,1
1,3
1,5
Como puede observarse, la concentración utilizada es la suma de las concentraciones de
-113-
RESULTADOS OBTENIDOS
los patrones que componen cada mezcla.
El ajuste lineal de los datos dio como resultado la gráfica que se recoge a continuación:
1.6
1.5
y = 0.0034x - 0.0034
1.4
R = 0.9974
2
[mg/l]
1.3
1.2
Mezcla Tl / Pb
1.1
Lineal (Mezcla Tl / Pb)
1
0.9
0.8
0.7
0.6
200
300
400
500
I (nA)
Figura 10: Ajuste lineal de las mezclas pertenecientes al grupo A.
B) GRUPO B DE MEZCLAS (DIAGONAL PRINCIPAL).
En la Figura 7, se representa una superposición de todos los gráficos de las mezclas que
constituyen la diagonal principal de la Tabla 3. Son diez voltamperogramas que se corresponden
con sendas mezclas.
En este caso, al igual que antes, también se realizó un ajuste lineal de las mezclas. En la
Figura 8 se recoge la recta resultante del ajuste.
-114-
RESULTADOS OBTENIDOS
7.00E-07
T1P1
6.00E-07
5.00E-07
T2P2
T3P3
T4P4
I (A)
4.00E-07
3.00E-07
T5P5
T6P6
T7P7
2.00E-07
T8P8
1.00E-07
T9P9
T10P10
-0.70
-0.60
-0.50
0.00E+00
-0.30
-0.40
E (V)
Figura 11: Superposición de los voltamperogramas de las mezclas del grupo B.
La tabla empleada para el ajuste lineal es la siguiente:
T1P1
T2P2
T3P3
T4P4
T5P5
I (nA)
65,000
125,295
184,928
240,084
316,410
[mg·l-1]
0,1
0,2
0,3
0,4
0,5
T6P6
T7P7
T8P8
T9P9
T10P10
I (nA)
366,317
435,133
494,424
542,040
610,710
[mg·l-1]
0,6
0,7
0,8
0,9
1,0
Como las mezclas contenían la misma proporción de talio que de plomo, para el ajuste
lineal se ha utilizado únicamente la concentración de una de las especies.
El ajuste lineal de los datos dio como resultado la gráfica que se recoge a continuación:
-115-
RESULTADOS OBTENIDOS
1.2
y = 0.0016x - 0.0067
1
2
R = 0.9991
[mg/l]
0.8
Mezcla Tl / Pb
0.6
Lineal (Mezcla Tl / Pb)
0.4
0.2
0
0
200
400
600
I (nA)
Figura 12: Ajuste lineal de las mezclas del grupo B.
C) GRUPO C DE MEZCLAS (DIAGONAL INFERIOR).
En la Figura 9, se representa una superposición de todos los gráficos de las mezclas que
constituyen la diagonal inferior de la Tabla 3. Son cinco voltamperogramas que se corresponden
con sendas mezclas.
Al igual que antes, se hizo el ajuste lineal de las mezclas, que aparece en la Figura 10.
-116-
RESULTADOS OBTENIDOS
5.00E-07
4.50E-07
I (A)
4.00E-07
3.50E-07
T1P6
3.00E-07
T2P7
2.50E-07
T3P8
2.00E-07
T4P9
1.50E-07
T5P10
1.00E-07
5.00E-08
-0.70
-0.60
-0.50
0.00E+00
-0.30
-0.40
E (V)
Figura 13: Superposición de los voltamperogramas de las mezclas del grupo C.
La tabla empleada para el ajuste lineal es la siguiente:
T1P6
T2P7
T3P8
T4P9
T5P10
I (nA)
228,696
288,610
347,573
405,418
461,761
[mg·l-1]
0,7
0,9
1,1
1,3
1,5
Del mismo modo que con la diagonal superior, la concentración utilizada es la suma de las
concentraciones de los patrones que componen cada mezcla.
-117-
RESULTADOS OBTENIDOS
1.6
1.5
y = 0.0034x - 0.0883
1.4
R = 0.9999
2
[mg/l]
1.3
1.2
Mezcla Tl / Pb
1.1
Lineal (Mezcla Tl / Pb)
1
0.9
0.8
0.7
0.6
200
300
400
500
I (nA)
Figura 14: Ajuste lineal de las mezclas del grupo C.
-118-
Capítulo 4:
Tratamiento
estadístico de datos.
TRATAMIENTO ESTADÍSTICO DE DATOS
1. DESCRIPCIÓN DE LOS DATOS EMPLEADOS EN EL TRATAMIENTO
ESTADÍSTICO.
El tratamiento estadístico se ha llevado a cabo mediante los paquetes de software MATLAB
4.0, STATISTICA 5.1, QWIKNET 3.2 y QNET 2000, así como diversas herramientas ofimáticas
del entorno OFFICE´97. La información considerada fue dividida en dos conjuntos diferentes
de datos:
w Conjunto de datos discretos: constituido por los parámetros de intensidad, potencial
y anchura de pico de cada una de las señales voltamperométricas de las muestras
analizadas (Tablas 1, 2 y 4 del capítulo anterior). Estos valores coinciden con los
resultados del análisis de pico facilitado por el aparato de medida Autolab®
PGSTAT20.
w Conjunto de datos continuo: formado por las señales de los voltamperogramas
completos de las muestras obtenidas de Autolab®, constituidas por 80 datos de
intensidad (en el intervalo de potenciales de -0,7 a -0,3 V, con un incremento de
potencial de 0,0051 V) correspondientes a cada una de las 40 muestras analizadas.
Este conjunto se recoge en el Anexo I, presentando una estructura matricial de
dimensiones 80 × 40.
A) REDUCCIÓN DE DIMENSIONES.
Uno de los objetivos del tratamiento de la información continua consiste en su reducción
de dimensiones de forma que se conserve la mayor cantidad de información posible y se eliminen
los efectos del ruido aleatorio u otras posibles perturbaciones.
A tal efecto, se utilizó una aplicación informática (ver Anexo II), programada para llevar
a cabo el proceso de filtrado y reducción de dimensiones que a continuación se detalla:
1. En primer lugar, se lee la información suministrada, en formato de texto, referente a
todos los vectores columna de 80 datos correspondientes a las 40 muestras analizadas.
2. Se inserta el número de frecuencias de Fourier del espectro resultante, en el cual se van
a descomponer cada una de las señales que componen los distintos voltamperogramas.
Los espectros de Fourier podrán ser de 128 ó 256 frecuencias, aunque también puede
-120-
TRATAMIENTO ESTADÍSTICO DE DATOS
utilizarse cualquier otro valor múltiplo de 2N, donde N es un entero positivo.
3. A continuación, la aplicación calcula la transformada de Fourier de cada señal
presentada, transformándola en un espectro de Fourier cuyo número de frecuencias que
lo componen irá en función del valor que se haya elegido anteriormente.
4. Después, se realizó el filtrado definiendo para ello la frecuencia de corte; de este modo,
se eliminan todas aquellas frecuencias que se encuentren por encima de la elegida. Esto
equivale a la aplicación de un filtro de paso bajo, el cual desestima las frecuencias más
altas, correspondientes normalmente a ruido y se queda exclusivamente con las
frecuencias bajas o de amplitud máxima, que contienen la mayor parte de la información
útil. En estos momentos, el vector columna con 80 valores para cada muestra, se ha
transformado en un vector columna de tan sólo 10 valores o menos, según la frecuencia
de corte definida.
5. Por último, la señal de cada voltamperograma se recompone mediante la transformada
de Fourier inversa y se calcula el error de recomposición mediante la expresión:
ε=
80
∑
(e
i
i =1
− e*i )
e2i
2
donde ei y e*i son los valores de la señal inicial y de la recompuesta, respectivamente.
Según la frecuencia de corte que se haya elegido, se obtendrán unas dimensiones más
o menos pequeñas para cada vector columna; no obstante, cuanto más pequeña sea la
frecuencia de corte, más se reduce el número de dimensiones, pero a costa de obtener
un error de recomposición más elevado.
6. Gráficamente todo el proceso anterior se resume del siguiente modo (Figura 1):
-121-
TRATAMIENTO ESTADÍSTICO DE DATOS
-7
x 10-7
8
Señal original s(t)
Modulo (FFT)
4
-6
s(t)
3
2
1
0
0
-6
FFT(Original)
6
4
2
0
1
4
0
x 10
40
3
4
2
0
-7
20
Frec Hz.
S(t) Recompuesta
FFT Filtrada
6
s(t) y S(t)
Modulo (FFT)
8
x 10
0.5
t
x 10 -6
0
20
Frec Hz.
2
1
0
40
0
0.5
t
1
Figura 1: Etapas llevadas a cabo por el programa de MATLAB para cada señal de los
voltamperogramas de las muestras.
Se parte de la señal original, se calcula su transformada de Fourier, se filtra y, mediante
la transformada de Fourier inversa, se recompone de nuevo la señal de partida,
calculándose el error de recomposición. En este caso, el proceso se corresponde con la
reducción de dimensiones para la señal voltamperométrica de la mezcla T5P5 (Tl (I) a
0,5 y Pb (II) a 0,5 mg·l-1), con un error de recomposición del 1,50 %.
En base a todo lo anterior y para alcanzar un adecuada reducción de dimensiones del
conjunto de datos continuo, se realizó una serie de pruebas para cada muestra, utilizando
espectros de Fourier de 128 y 256 frecuencias y variando la frecuencia de corte entre valores que
oscilaron entre 6 y 2 (ver Anexo III). Con todo esto se pretendía reducir al máximo la
información y obtener una dimensión mínima e idéntica para todas las señales, de tal modo que
el error de recomposición no superase en ningún momento el valor fijado del 3 %.
Este porcentaje de error máximo admisible no fue determinado arbitrariamente, sino con
vistas a la posterior aplicación de redes neuronales a este conjunto de datos. Se consideró que el
-122-
TRATAMIENTO ESTADÍSTICO DE DATOS
número de neuronas de entrada a la red, definido por la dimensión de los vectores columna que
componen el conjunto de datos continuo, no debía ser muy elevado, pues esto implicaba
topologías de redes con un elevado número de parámetros a ser estimados. Por tanto, había que
llegar a un compromiso entre el error y el número de dimensiones obtenidas con el proceso de
reducción.
La frecuencia de corte idónea se eligió a partir de los datos obtenidos en las pruebas
anteriores.
A continuación, se presenta una tabla resumen con los resultados de dichas pruebas:
Frecuencias del espectro
128
256
Frecuencia de corte (ù )
6
5
4
3
2
6
5
4
3
2
Dimensiones (N)
10
9
7
5
4
20
17
13
10
7
Error (%)
<1,5
<1,5
<2,2
<3 <5
>8
<2 <3
<6 >6
Como puede observarse, el valor de frecuencia de corte idóneo resultó ser ù = 4 con el
espectro de 128 frecuencias. El número mínimo de dimensiones correspondiente a esta frecuencia
fue de N = 7, es decir, 7 datos de amplitud por cada señal de voltamperograma.
De este modo, cada uno de los vectores columna de dimensiones 80 × 1 (valores de
intensidad) se transformaron en vectores columna de 7 × 1 dimensiones (valores de amplitud).
La matriz del conjunto de datos continuo resultó por consiguiente de 7 × 40 (ver Anexo IV),
mucho más manejable para el posterior tratamiento estadístico, a diferencia de la inicial, de
tamaño 80 × 40. Otra diferencia interesante entre la matriz de partida y la resultante, tras aplicar
la reducción, radica en que mientras la primera se expresa en el dominio temporal, la segunda lo
hace en el espacio de las frecuencias. En resumidas cuentas, se ha logrado reducir el tamaño de
la matriz inicial en un 91,25 %, conservando, al menos, el 97 % de la información.
2. ETAPAS DEL TRATAMIENTO ESTADÍSTICO DE DATOS.
El tratamiento estadístico de datos se dividió en varias etapas:
w Exploración de las señales de los patrones.
w Aplicación de modelos analíticos.
w Métodos de predicción o de separación de señales.
-123-
TRATAMIENTO ESTADÍSTICO DE DATOS
A continuación, describiremos con detalle cada una de estas etapas.
A) EXPLORACIÓN DE LAS SEÑALES DE LOS PATRONES.
Una apreciación global de la totalidad de las muestras pudo realizarse empleando los
métodos estadísticos multivariantes que se recogen a continuación:
w análisis lineal discriminante
w escalado multidimensional
Dichos métodos se emplean comúnmente para el análisis estadístico de la información
química, sea cual sea su procedencia.
ANÁLISIS LINEAL DISCRIMINANTE (ALD).
Para desarrollar éste método, se hizo uso del conjunto de datos discretos. Los valores que
forman parte de este conjunto no aparecen estandarizados, sino que se encuentran dispuestos
simplemente tal como fueron presentados por el aparato de medida Autolab® PGSTAT20.
El análisis lineal discriminante fue aplicado para visualizar las muestras en un plano y para
determinar si, tanto patrones puros (10 de talio y 10 de plomo) como mezclas (20 en total), eran
susceptibles de ser agrupados por su contenido en Tl (I) y Pb (II).
El conjunto de datos discretos (intensidad, potencial y anchura de pico) fue utilizado como
variable independiente y como variable de clasificación las siguientes: Tl (I) = 0, Pb (II) = 1 y
Mezclas = 2. El método utilizado para efectuar el análisis fue un método catalogado como
estándar, el cual se caracteriza porque todas las variables seleccionadas son introducidas
simultáneamente en el modelo. El valor de tolerancia empleado en el análisis fue el que aparecía
por defecto en el programa y era igual a 0,01. Este valor normalmente se calcula como 1-R2 de
cada una de las variables, estando el resto incluidas en el modelo, e indica la proporción de
varianza que es única para la variable seleccionada. Por último, la distancia utilizada para
calcular la pertenencia de cada muestra a un grupo u otro fue la distancia de Mahalanobis.
A continuación se presenta la matriz de clasificación asociada al modelo de ALD, en donde
las filas son las clasificaciones observadas y las columnas las clasificaciones predichas:
-124-
TRATAMIENTO ESTADÍSTICO DE DATOS
Grupo
% Clasificación
Tl (I)
Pb (II)
Mezclas
Tl (I)
100,0000
10
0
0
Pb (II)
100,0000
0
10
0
Mezclas
90,0000
1
1
18
Total
95,0000
11
11
18
Estos resultados corroboran el diagrama de puntos presentado anteriormente. Como puede
observarse, las muestras puras de talio y plomo son clasificadas al 100 %. Sin embargo, en el
caso de las mezclas, aparecen dos errores de clasificación, lo que disminuye el porcentaje
correcto hasta el 90 %. Una de las mezclas es catalogada en el grupo de los patrones de Tl (I) y
otra en el de los patrones de Pb (II). La clasificación total de las 40 muestras resultó ser del 95
%.
El gráfico de puntos del análisis lineal discriminante es el siguiente (Figura 2):
Clasificación discriminante según el contenido de Tl (I) y/o Pb (II)
Plano Factorial
3.0
2.5
1.5
P6
P7
T8
P9
P10 T1P6
0.0
P8
-0.5
T3
T3P3
P5
0.5
T4
T1P1
T2P2
P4
1.0
Dimensión 2
T1
T2
P1
P2
P3
2.0
T6P1
T2P7
T9
T5 T6
T7
T4P4
T5P5
T3P8
-1.0
T7P2
T6P6
T8P8
T4P9 T7P7
-1.5
T8P3
T10
T9P4
T10P10
T5P10
-2.0
T9P9 T10P5
-2.5
-3.0
-6
-4
-2
0
2
4
Dimensión 1
Figura 2: Análisis lineal discriminante de las muestras analizadas.
-125-
6
Tl (I)
Pb (II)
Mezclas
TRATAMIENTO ESTADÍSTICO DE DATOS
Del gráfico se desprende que las dos muestras que no se clasifican bien son la T1P6 y la
T6P1, correspondientes a la mezclas Tl 0,1 y Pb 0,6 mg·l-1 y Tl 0,6 y Pb 0,1 mg·l-1,
respectivamente. Como puede observarse en la Tabla 3 del capítulo anterior, las citadas muestras
se localizan en zonas próximas a los extremos de dicha tabla, lo que implica confusión, puesto
que constituyen puntos críticos a la hora de clasificarlas: elevada concentración de un ión
metálico y baja concentración del otro.
El resumen de las inferencias asociadas al análisis de la función discriminante se recoge a
continuación:
w nº de variables en el modelo: 3
w nº de variables de agrupamiento: 3
w Lambda de Wilks: 0,0755
w p < 10-5
Tolerancia 1-Tol. (R2)
N = 40
ë de Wilks
ë Parcial
F (2,35)
p
Intensidad
0,128115
0,589416
12,19042
0,000096
0,881873
0,118127
Anchura
0,090160
0,837545
3,39440
0,044941
0,784489
0,215511
Potencial
0,132642
0,569300
13,23949
0,000052
0,725504
0,274496
Las muestras mal agrupadas fueron identificadas a partir de la matriz de clasificación de
casos, que aparece a continuación:
-126-
TRATAMIENTO ESTADÍSTICO DE DATOS
Muestras
Clasificación
Observada
Predicción
Muestras
Clasificación
Observada
Predicción
T1
Tl (I)
Tl (I)
T1P1
Mezcla
Mezcla
T2
Tl (I)
Tl (I)
T6P1*
Mezcla
Tl (I)
T3
Tl (I)
Tl (I)
T2P2
Mezcla
Mezcla
T4
Tl (I)
Tl (I)
T7P2
Mezcla
Mezcla
T5
Tl (I)
Tl (I)
T3P3
Mezcla
Mezcla
T6
Tl (I)
Tl (I)
T8P3
Mezcla
Mezcla
T7
Tl (I)
Tl (I)
T4P4
Mezcla
Mezcla
T8
Tl (I)
Tl (I)
T9P4
Mezcla
Mezcla
T9
Tl (I)
Tl (I)
T5P5
Mezcla
Mezcla
T10
Tl (I)
Tl (I)
T10P5
Mezcla
Mezcla
P1
Pb (II)
Pb (II)
T1P6*
Mezcla
Pb (II)
P2
Pb (II)
Pb (II)
T6P6
Mezcla
Mezcla
P3
Pb (II)
Pb (II)
T2P7
Mezcla
Mezcla
P4
Pb (II)
Pb (II)
T7P7
Mezcla
Mezcla
P5
Pb (II)
Pb (II)
T3P8
Mezcla
Mezcla
P6
Pb (II)
Pb (II)
T8P8
Mezcla
Mezcla
P7
Pb (II)
Pb (II)
T4P9
Mezcla
Mezcla
P8
Pb (II)
Pb (II)
T9P9
Mezcla
Mezcla
P9
Pb (II)
Pb (II)
T5P10
Mezcla
Mezcla
P10
Pb (II)
Pb (II)
T10P10
Mezcla
Mezcla
* Indica las clasificaciones incorrectas.
Como puede verse, la mezcla T6P1 se clasifica en el grupo del Tl (I) y la T1P6 en el del Pb
(II). El grupo elegido para esta catalogación se corresponde con el del ión metálico de mayor
concentración en la mezcla, lo cual corrobora nuestra conclusión anterior: son muestras que
constituyen puntos críticos a la hora de clasificarlas, debido a la elevada concentración de uno
de los cationes con respecto del otro.
Por último, los coeficientes estandarizados para las variables canónicas fueron los
siguientes:
-127-
TRATAMIENTO ESTADÍSTICO DE DATOS
Variables
Dimensión 1
Dimensión 2
Intensidad
-0,253221
-1,02686
Anchura
0,381436
-0,45266
Potencial
0,796084
0,31341
Valores propios
7,101360
0,63463
Proporción acumulativa
0,917964
1,00000
Sobre el conjunto de datos continuo, constituido por las 7 amplitudes dominantes obtenidas
del espectro de Fourier, no pudo realizarse el análisis lineal discriminante, al encontrarse mal
condicionada la matriz resultante de dicha información.
Esto se pudo probar, posteriormente, estableciendo la matriz de correlación de dicha
información continua, que como puede apreciarse en la tabla siguiente, refleja una gran linealidad
entre todas las amplitudes consideradas:
Variable
A1
A2
A3
A4
A5
A6
A7
A1
1,00
1,00*
0,99*
0,97*
0,93*
0,88*
0,82*
A2
1,00*
1,00
1,00*
0,98*
0,94*
0,89*
0,84*
A3
0,99*
1,00*
1,00
0,99*
0,97*
0,93*
0,87*
A4
0,97*
0,98*
0,99*
1,00
0,99*
0,97*
0,91*
A5
0,93*
0,94*
0,97*
0,99*
1,00
0,99*
0,93*
A6
0,88*
0,89*
0,93*
0,97*
0,99*
1,00
0,96*
A7
0,82*
0,84*
0,87*
0,91*
0,93*
0,96*
1,00
* Las correlaciones marcadas son significativas a p < 0,05000 (N = 40).
Como puede observarse, la correlación entre las variables (amplitudes) del conjunto de
datos continuo es muy elevada, lo cual confirma la dependencia lineal.
Una posibilidad que evitase esto hubiera sido el elegir una frecuencia de corte más alta
durante la reducción de dimensiones, aún a costa de aumentar el error de reconstrucción de la
señal de cada muestra. Pero esto no era factible, ya que suponía introducir un error mucho mayor
a la hora de aplicar las redes neuronales como método de predicción y clasificación.
-128-
TRATAMIENTO ESTADÍSTICO DE DATOS
Como consecuencia de lo anterior, pudo establecerse un modelo de ajuste con una elevada
capacidad predictiva entre dos amplitudes cualesquiera (Figura 3):
Correlación A1 vs. A2
A2 = 0,0000 + 0,9119 * A1
Correlación: r = 0,9994
1.4e-5
1.2e-5
1e-5
A2
8e-6
6e-6
4e-6
2e-6
0
-2e-6
-2e-6
0
2e-6
4e-6
6e-6
8e-6
1e-5
1.2e-5
1.4e-5
Regresión
95% confianza
A1
Figura 3: Gráfico de correlación entre dos amplitudes, A1 y A2, del conjunto continuo
de datos.
Como puede verse, la relación entre las dos variables es clara, sobre todo si se tiene en
cuenta la expresión matemática que ofrece la correlación: A2 = 0,9119 × A1.
A través de la matriz de correlaciones, se puede observar también la clara dependencia de
una amplitud con respecto de otra (Figura 4):
-129-
TRATAMIENTO ESTADÍSTICO DE DATOS
Matriz de correlaciones
A1
A2
Figura 4: Matriz de correlaciones para las amplitudes A1 y A2 del conjunto continuo
de datos.
Estas conclusiones demuestran que todas las señales completas de los voltamperogramas
podrían definirse casi en su totalidad conociendo únicamente el valor de una de las amplitudes
que la componen. Por ejemplo, la mezcla T5P5 podría describirse por un único punto P en el
dominio de Fourier, correspondiente a una amplitud y a su frecuencia relacionada, que es la que
nos da la posición del pico: P (ù ; A) = (0,625; 6,496×10-6). Si en el dominio de las frecuencias
cada señal de un voltamperograma se ha reducido a 7 conjuntos de valores frecuencia-amplitud,
el punto arriba indicado se corresponde con la segunda pareja que describe la señal de la mezcla
indicada. No obstante, podría haberse escogido cualquier otra pareja de datos, puesto que, como
hemos demostrado, los valores de amplitud son proporcionales entre sí.
Por consiguiente, a la vista de estos resultados, se empleó otra forma de proyectar el
conjunto de datos continuo.
-130-
TRATAMIENTO ESTADÍSTICO DE DATOS
ESCALADO MULTIDIMENSIONAL.
El escalado multidimensional se basa en el hecho de que conocida una matriz de distancias
entre puntos (muestras) es posible conocer la geometría del conjunto formado por dichos puntos,
salvo un movimiento rígido.
Empleado como proceso de reducción de dimensiones sobre los datos continuos en el
espacio de Fourier, permitió obtener una visión exploratoria en un plano de la información
continua.
Para lograr el escalado multidimensional hubo que tener en cuenta las siguientes
consideraciones:
1. Para realizar el escalado, se obtuvo la matriz de distancias euclídeas asociada al
conjunto de amplitudes considerado.
2. La matriz de distancias se utilizó como entrada al algoritmo de escalado
multidimensional, en donde la configuración inicial por defecto para el conjunto de
datos fue la estándar de Guttman-Lingoes. Este procedimiento equivale a un análisis de
componentes principales y en la mayoría de los casos sirve para proporcionar una
configuración de inicio para los procedimientos de ajuste mediante iteraciones
sucesivas.
3. Partiendo de esta solución inicial, el algoritmo realiza las iteraciones necesarias para
alcanzar un valor óptimo entre las distancias reales y las distancias de la proyección
plana.
4. Los parámetros de interés en este modelo son el número de iteraciones (entre 6 y 50) y
el valor de epsilon, a partir del cual las distancias son significativas.
A la vista de todo lo anterior, la representación del escalado multidimensional resultó así
(Figura5):
-131-
TRATAMIENTO ESTADÍSTICO DE DATOS
Representación del conjunto de voltamperogramas
Escalado multidimensional sobre el espectro de Fourier
0.25
T8
T6
0.15
T10
T9
T7
T6P1
T8P3
T7P2
T9P4
T10P5
T5
Dimension 2
T4
T3
0.05
T5P5
T2
T1
T2P2
T1P1
T3P3
T6P6
T7P7
T9P9
T4P4
T8P8
P1
P2
-0.05
P3
T2P7
T1P6
P4
T3P8
T4P9
T10P10
T5P10
P5
P6
P7
P8
-0.15
P9
P10
-0.25
-2
-1
0
1
2
3
Dimension 1
Figura 5: Escalado multidimensional para el conjunto continuo de datos.
A partir de la representación anterior puede concluirse la disposición casi geométricamente
perfecta, en términos de alineación, de los grupos de muestras (como información continua)
considerados en la Tabla 3 del capítulo anterior. Puede observarse que mediante el trazado de dos
rectas que se cortan en un punto interno de la representación, se consiguen separar los tres grupos
de muestras, siendo posible la clasificación de todas las muestras analizadas, a diferencia del
análisis lineal discriminante, en el cual no se podían establecer dos superficies de corte que
aislasen completamente a los clusters unos de otros.
Se puede concluir pues, sobre nuestra información, que éste método de visualización hace
posible una visión exploratoria que mejora a la aportada por el ADL, utilizado en el conjunto de
datos discretos.
B) APLICACIÓN DE MODELOS ANALÍTICOS.
Una vez explorada la disposición de los dos conjuntos de datos, ya fuese mediante análisis
lineal discriminante o a través de un escalado multidimensional, el siguiente paso fue encontrar
una función matemática que se ajustase a las señales de los voltamperogramas de las muestras
-132-
TRATAMIENTO ESTADÍSTICO DE DATOS
analizadas.
Como consecuencia de la observación directa de los voltamperogramas, se llegó a la
conclusión de que un modelo de tipo gaussiano podría ser capaz de ajustarse con bastante
exactitud a las diferentes señales.
La estructura elegida para esta función matemática fue la siguiente:
[
Modelo = C × exp P × ( E( V) − E( V) max )
2
]
la cual se corresponde claramente con una función gaussiana, donde: E(V) son los valores de
potencial; E(V)max es el potencial al que aparece el máximo de intensidad; y, por último, C y P
son dos constantes, definidas como “constante” y “parámetro”, respectivamente.
Estos dos coeficientes se han de determinar mediante un proceso de estimación por el
método de mínimos cuadrados para cada señal. Como estadístico de la bondad del ajuste
empleamos el valor del coeficiente de determinación (R).
Por tanto el problema queda definido como sigue:
Min f ( V) − y( V)
s. a.:
y = C ⋅ e P⋅( V− Vmax )
2
A continuación se describen las etapas efectuadas para llevar a cabo el proceso de ajuste:
1. El conjunto de datos continuo, con los datos de intensidad-potencial en su formato
nativo, es decir, sin verse sometido al proceso de reducción de dimensiones, fue el
empleado (ver Anexo I).
2. A este conjunto, con las intensidades expresadas en nA para facilitar los cálculos, se le
aplicó un ajuste mínimo cuadrático para cada señal que lo componía.
3. La estimación se realizó en base al modelo anterior. La función de pérdida utilizada, L,
también fue definida, adquiriendo la forma que a continuación se presenta:
L(C, P) =
∑ (obs
80
i =1
i
− pred i )
2
4. Otros parámetros del modelo fueron los siguientes: el máximo número de iteraciones
fue de 50 y el criterio de convergencia igual a 0,001. Por último, el método de
estimación elegido fue el cuasi-Newton, que es el método más rápido para lograr la
convergencia. Consiste en un método iterativo, por medio del cual, las derivadas
-133-
TRATAMIENTO ESTADÍSTICO DE DATOS
(parciales) de segundo orden de la función de pérdida fueron estimadas asintóticamente
y utilizadas para determinar los cambios de los parámetros de una iteración a otra. Este
procedimiento es mucho más eficaz que cualquier otro en el caso en que las derivadas
de segundo orden de la función de pérdida sean significativas (y normalmente lo son).
La desventaja que presenta con respecto a otros métodos de estimación, tales como el
simplex, el de Rosenbrock o el de Hooke-Jeeves, radica en que es menos robusto que
estos, en el sentido en que posee una mayor eficacia en la convergencia hacia mínimos
locales y es más sensible a valores iniciales inadecuados.
Una vez definido el procedimiento a seguir, todas las señales de los voltamperogramas
fueron ajustadas al modelo analítico, obteniéndose resultados satisfactorios, como puede
observarse en la Tabla 1:
-134-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 1: Parámetros y coeficientes de ajuste para la aproximación gaussiana de las señales de los voltamperogramas.
PLOMO
P1
P2
P3
P4
P5
P6
P7
P8
P9
P10
TALIO
R=0.9906
C=43.7876
P= -325.981
R=0.9901
C=78.9196
P= -329.7137
R=0.9895
C=119.9772
P= -330.737
R=0.9907
C=146.0105
P= -334.350
R=0.9957
C=187.0196
P= -337.429
R=0.9960
C=218.6532
P= -338.508
R=0.9959
C=252.8242
P= -338.480
R=0.9909
C=289.2859
P= -335.233
R=0.9960
C=321.8346
P= -339.094
R=0.9960
C=350.9841
P= -339.743
T1
R=0.9941
C=23.798
P= -184.939
R=0.9971
C=67.47893
P= -254.843
T2
R=0.9979
C=52.26244
P= -200.477
T3
R=0.9991
C=79.6575
P= -203.5324
T4
R=0.9973
C=106.175
P= -207.6287
T5
R=0.9995
C=136.844
P= -207.832
T6
R=0.9960
C=170.0394
P= -193.721
R=0.9963
C=242.6326
P= -311.027
R=0.9979
C=129.7817
P= -258.727
T7
R=0.9956
C=195.149
P= -208.161
T8
R=0.9979
C=224.993
P= -207.0365
T9
R=0.9871
C=241.904
P= -204.5816
T10
R=0.9949
C=280.7367
P= -209.96
R=0.9972
C=304.9605
P= -301.046
R=0.9915
C=189.5485
P= -254.073
R=0.9976
C=366.9298
P= -300.548
R=0.9981
C=248.9773
P= -264.234
R=0.9933
C=424.0794
P= -288.695
R=0.9933
C=324.4907
P= -256.063
R=0.9995
C=209.5356
P= -221.756
R=0.9941
C=481.5672
P= -283.958
R=0.9941
C=375.7182
P= -255.796
R=0.9990
C=269.5875
P= -231.543
R=0.9927
C=446.9373
P= -259.346
R=0.9936
C=332.1701
P= -233.570
R=0.9971
C=500.7769
P= -275.668
R=0.9987
C=385.0555
P= -242.054
R=0.9946
C=557.0440
P= -260.004
R=0.9984
C=458.0142
P= -245.251
-135-
R=0.9938
C=606.6414
P= -279.075
TRATAMIENTO ESTADÍSTICO DE DATOS
Para el caso de la mezcla T5P5 (Tl (I) 0,5 y Pb (II) 0,5 mg·l-1), el gráfico de estimación fue
el siguiente (Figura 6):
Modelo: T5P5=constante*exp(parámetro*(V+0.504)**2)
y=(324.4907)*exp((-256.0627)*(x+0.504)**2)
350
300
250
I (nA)
200
150
100
50
0
-50
-0.7
-0.6
-0.5
-0.4
E (V)
Figura 7: Superposición de la señal de la mezcla T5P5 (Tl (I) a 0,5 y Pb (II) a 0,5 mg·l-1)
junto con el modelo gaussiano que mejor se le ajusta (línea roja).
Los puntos azules se corresponden con los valores de intensidad observados y la línea roja
con la predicción efectuada a través del modelo. Como se desprende de la función de estimación
representada en la parte superior del gráfico, el valor de la constante es 324,4907 y el del
parámetro es -256,0627. El coeficiente de determinación en este caso es 0,9933, que equivale a
un ajuste del 98,67 %, el cual podemos considerar que es bastante bueno.
A continuación, aparece una tabla donde se refleja el porcentaje de ajuste para cada señal:
-136-
TRATAMIENTO ESTADÍSTICO DE DATOS
Muestras
Ajuste
(%)
Error (%)
Muestras
Ajuste
(%)
Error (%)
T1
98,820
1,180
T1P1
99,424
0,576
T2
99,582
0,418
T1P6
99,905
0,095
T3
99,828
0,172
T2P2
99,573
0,427
T4
99,467
0,533
T2P7
99,797
0,203
T5
99,908
0,092
T3P3
98,310
1,690
T6
99,196
0,804
T3P8
98,722
1,278
T7
99,115
0,885
T4P4
99,628
0,372
T8
99,575
0,425
T4P9
99,772
0,228
T9
97,437
2,563
T5P5
98,667
1,333
T10
98,979
1,021
T5P10
99,690
0,310
P1
98,128
1,872
T6P1
99,252
0,748
P2
98,026
1,974
T6P6
98,820
1,180
P3
97,915
2,085
T7P2
99,442
0,558
P4
98,147
1,853
T7P7
98,547
1,453
P5
99,146
0,854
T8P3
99,513
0,487
P6
99,204
0,796
T8P8
99,427
0,573
P7
99,187
0,813
T9P4
98,662
1,338
P8
98,182
1,818
T9P9
98,933
1,067
P9
99,202
0,798
T10P5
98,815
1,185
P10
99,195
0,805
T10P10
98,762
1,238
En la mayoría de los casos, el error es inferior al 2 %, lo que indica un grado de ajuste a la
función gaussiana casi perfecto.
De igual modo, puede afirmarse que los errores más elevados se producen en el ajuste de
los patrones de Pb (II), puesto que si se observan los gráficos correspondientes a los mismos
(Figura 3 del capítulo anterior) se comprueba que las señales de los voltamperogramas son más
anchas y menos puntiagudas, difiriendo así un poco de una curva gaussiana.
En el resto de las muestras analizadas, se mantiene en mayor medida el carácter gaussiano,
aunque las mezclas de ambos elementos, también suelen dar un error más elevado.
-137-
TRATAMIENTO ESTADÍSTICO DE DATOS
C) MÉTODOS DE PREDICCIÓN O DE SEPARACIÓN DE SEÑALES.
Dos son los métodos de predicción utilizados para lograr la separación de las señales en
cada una de las mezclas analizadas de Tl (I) y Pb (II), de acuerdo con la Tabla 3 del capítulo
anterior.
Estos métodos son los siguientes:
w Estimación por interpolación.
w Redes neuronales artificiales.
A continuación describiremos el procedimiento seguido con cada uno de ellos.
ESTIMACIÓN POR INTERPOLACIÓN.
A partir de las rectas de calibrado de los dos cationes y de las rectas de ajuste que pueden
establecerse en las diagonales formadas por las mezclas analizadas, recogidas en el capítulo
anterior (ver Figuras 2, 4, 6, 8 y 10), se desprende que existe linealidad entre las señales de las
distintas mezclas y las de los patrones puros de Tl (I) y Pb (II) que las componen.
Por consiguiente, en un principio, cada una de las mezclas obtenidas puede expresarse
como combinación lineal de los patrones puros. El problema queda definido entonces de la
siguiente manera (Modelo 1):
( )
( )
f Ti Pj = α ⋅ f (Ti ) + β ⋅ f Pj
donde f(TiPj) son los datos de intensidad que conforman la señal de la mezcla TiPj; Ti y Pj
representan las señales correspondientes a los patrones puros de Tl (I) y Pb (II), respectivamente;
y á y â son las contribuciones de cada uno de los patrones a la señal total de la mezcla. Los
subíndices i y j toman valores enteros de 1 a 10, cada uno de los cuales equivale a un valor de
concentración en el intervalo estudiado, que va desde 0,1 a 1,0 mg·l-1.
En el siguiente gráfico (Figura 7), se superponen las señales de los voltamperogramas para
la mezcla T7P7: Tl (I) a 0,7 y Pb (II) a 0,7 mg·l-1 y para los patrones puros T7: Tl (I) a 0,7 mg·l-1
y P7: Pb (II) a 0,7 mg·l-1:
-138-
TRATAMIENTO ESTADÍSTICO DE DATOS
5.00E-07
4.50E-07
4.00E-07
I (A)
3.50E-07
3.00E-07
T7
2.50E-07
P7
2.00E-07
T7P7
1.50E-07
1.00E-07
5.00E-08
-0.70
-0.60
-0.50
-0.40
0.00E+00
-0.30
E (V)
Figura 8: Superposición de las señales de los voltamperogramas de Tl (I) a 0,7 mg·l-1, Pb (II) a
0,7 mg·l-1 y de la mezcla de ambos.
Como puede observarse, la señal de la mezcla T7P7 es una combinación lineal de dos
señales individuales, cada una de las cuales contribuye de forma diferente a la señal global. Dicha
contribución se explica por el valor de los parámetros á y â.
En general, la forma de la señal resultante es acampanada y, por tanto, susceptible de ser
aproximada muy bien por una distribución normal. Pero esto ocurre solo cuando las posiciones
de los picos están suficientemente próximas, como puede comprobarse en la Figura 7. Una
situación extrema sería la que aparece reflejada en la Figura 8; sin embargo, esta anomalía no
sucede en nuestro caso, aunque en los límites del intervalo considerado contribuye ligeramente
a empeorar la aproximación por una gaussiana:
-139-
TRATAMIENTO ESTADÍSTICO DE DATOS
7,00E-07
6,00E-07
5,00E-07
I (A)
4,00E-07
No normal
Normal
3,00E-07
2,00E-07
1,00E-07
-0,70
-0,60
-0,50
0,00E+00
-0,30
-0,40
E (V)
Figura 9: Superposición de dos mezclas con diferente distribución.
No obstante, existen otros muchos modelos matemáticos que podrían definir también el
problema en cuestión. Un nuevo ejemplo podría ser el que considera la interferencia (Modelo 2):
( )
( )
f Ti Pj = α ⋅ f (Ti ) + β ⋅ f Pj + γ ⋅ f ( Ti × Pj )
donde f(Ti × Pj) representa aquí la posible interacción existente entre los dos iones presentes en
la mezcla y ã su correspondiente contribución.
Este modelo sería más completo que el precedente; no obstante, en el caso que nos ocupa,
donde se mezclan dos iones metálicos, como son Pb2+ y Tl+, esta interacción puede considerarse
como nula (ã = 0). Por tanto, no se utilizará esta formulación para resolver las mezclas.
Por último, podría haber un tercer modelo, representado del siguiente modo (Modelo 3):
( ) ∑ α ⋅ f (T ) + ∑ β ⋅ f ( P ) + ∑ γ ⋅ f ( T × P )
f Ti Pj =
n = 10
i =1
n = 10
i
i
j= 1
n = 10
j
j
ij
i
j
i, j
En esta situación, la señal de la mezcla se considera como una combinación lineal de todos
y cada uno de los patrones puros analizados, tanto de Tl (I) como de Pb (II), teniendo cada uno
de ellos una contribución diferente a la señal global.
Este modelo sería aplicable únicamente en aquellos casos donde se desconozca la
-140-
TRATAMIENTO ESTADÍSTICO DE DATOS
composición de la mezcla de partida. Por tanto, habría que suponer una contribución de todos
los patrones de cada uno de los iones allí presentes y no solamente la de un único y determinado
patrón (ver Modelo 1), siempre dentro del intervalo de concentraciones establecido.
El Modelo 3 nos sirve, en cierto modo, para predecir las posibles concentraciones de cada
uno de los elementos existentes en la mezcla desconocida. Y escribimos “posibles” porque la
solución obtenida a partir de la aplicación del mismo no es única: existen infinitas soluciones,
es decir, podemos encontrar infinitas combinaciones lineales de todo el conjunto de patrones
cuyo resultado sea la señal global de la mezcla TiPj que se desea resolver.
Una vez vistos todos los posibles modelos a aplicar en la resolución del problema se
escogió el Modelo 1, puesto que los resultados obtenidos con éste fueron muy aceptables. A
partir de aquí, el problema queda establecido en notación matricial como sigue:
[T P ] = α ⋅ [T ] + β ⋅ [ P ]
i
j
i
j
donde ahora, [TiPj], [Ti] y [Pj] son vectores-columna.
Finalmente, el problema sería el que se presenta a continuación:
Ti (1)
Ti Pj (1)
(
)
T
P
2
i j
Ti ( 2)
=
f
f
M
M
(
)
T
P
80
Ti ( 80)
i j
80 × 1
Pj (1)
Pj ( 2) α
⋅
M β
Pj ( 80)
80 × 2
2× 1
que equivale a un sistema de ecuaciones del tipo Y = A·X, de dimensiones 80×2, es decir, 80
ecuaciones y 2 incógnitas. A la vista de lo anterior, el sistema tendría de ecuaciones resultante
estaría sobredeterminado, pudiendo no tener solución.
La forma general de actuar sería hallar la pseudosolución del sistema; ello supondría
transformar el sistema anterior hasta llegar a una solución del tipo B ·Y = X, donde X es la
matriz-columna formada por los parámetros á y â.
Sin embargo, para que actuando de esta forma la solución fuese única, correspondiente a
los valores para dichos parámetros en cada mezcla, tendría que ocurrir lo siguiente:
w El sistema Y = A·X debería ser 2×2, para cada problema o mezcla, es decir, que fuese
un sistema compatible determinado.
w La matriz A del sistema debería ser cuadrada, regular y su determinante distinto de
-141-
TRATAMIENTO ESTADÍSTICO DE DATOS
cero, es decir, tendría que ser invertible. Su inversa, de este modo, sería A-1 y se
obtendría del siguiente modo:
A −1 =
A adj
A
Pero como se ha comentado antes, el sistema de ecuaciones está sobredeterminado, puesto
que hay más ecuaciones que incógnitas. Además, la matriz A, de dimensiones 80×2, no es
invertible, al incumplir las condiciones exigidas.
Para transformar el sistema de ecuaciones de dimensiones 80×2, en un sistema compatible
determinado, de dimensiones 2×2, cuya matriz A sea invertible, hay que recurrir al concepto de
“matriz inversa generalizada”. La inversa generalizada se halla del siguiente modo:
A →
m× n
A − 1 = (A t ⋅ A )
-1
→
n × m m× n
A −1
n× n
En nuestro caso, quedaría:
A →
80 × 2
A − 1 = (A t ⋅ A )
-1
→
2 × 80 80 × 2
A −1
2× 2
Es decir, la inversa generalizada de una matriz A de orden n×m (no cuadrada) se obtiene hallando
la inversa de la matriz formada por el producto de la matriz traspuesta de A (At) y la matriz A
del sistema.
Por tanto, la solución del sistema, para el problema planteado por el Modelo 1, sería:
(A t ⋅ A)−1 ⋅ A t ⋅ Y = X
De este modo, obtenemos las contribuciones de cada uno de los patrones de Tl (I) y Pb (II)
presentes en la mezcla. El problema se repite para todas y cada una de las 20 mezclas analizadas.
Así, conseguiremos expresar las mezclas como combinaciones lineales de los iones que las
componen.
Esta sería la forma general de resolver el problema planteado por el Modelo 1, es decir, la
solución es independiente del método de resolución que se aplique. La única diferencia entre un
método y otro radica en las operaciones o transformaciones intermedias que empleen.
El método de mínimos cuadrados que a continuación se presenta es equivalente al proceso
descrito anteriormente, en el sentido en que la solución del problema, Y =A·X, es la misma que
-142-
TRATAMIENTO ESTADÍSTICO DE DATOS
la del problema Prij:
[( )
( ) ]
Prij (α , β ) ≡ Min∑ f Ti Pj ( k ) − α ⋅ f (Ti )( k ) − β ⋅ Pj ( k )
80
k =1
2
El procedimiento aquí empleado ha sido un ajuste mínimo cuadrático. Con vistas a hacer
de este método una buena herramienta predictiva, las etapas que lo constituyen son:
1. Se emplearon como datos de partida las señales de los voltamperogramas
correspondientes a cada muestra analizada, compuestas por 80 valores de intensidad.
2. El ajuste se realizó para las 20 mezclas, en base al modelo elegido: Modelo 1.
3. No se consideraron modelos con términos independientes, al suponerse la inexistencia
de señal en el blanco y se eligió como límite de tolerancia el valor de 0,00010.
4. Los coeficientes del ajuste á y â (solución del sistema para cada problema), así como
la bondad del ajuste en cada caso, se recogen en la siguiente tabla (Tabla 2):
-143-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 2: Tabla de resultados para el método de ajuste de las señales.
P1
T1
" = 1.137
ß = 0.958
R=0.9993
P2
T2
" = 1.059
ß = 0.987
R = 0.9998
P3
T3
" = 1.154
ß = 0.919
R = 0.9997
P4
T4
" = 0.956
ß = 1.072
R = 0.9998
P5
P6
P7
P8
P9
P10
" = 6.961
ß = 0.193
R = 0.9979
" = 3.319
ß = 0.412
R = 0.9998
" = 3.009
ß = 0.340
R = 0.9995
" = 2.078
ß = 0.561
R = 0.9999
T5
" = 1.035
ß = 1.052
R=0.9999
T6
" = -0.053
ß = 5.783
R = 0.9983
" = 0.932
ß = 1.064
R = 0.9996
" = 1.951
ß = 0.589
R = 0.9998
-144-
T7
" = 0.263
ß = 3.269
R=0.9999
" = 0.969
ß = 1.096
R = 0.9999
T8
" = 0.319
ß = 2.686
R = 0.9998
" = 1.129
ß = 0.877
R = 0.9980
T9
" = 0.449
ß = 2.238
R = 0.9996
" = 0.987
ß = 1.059
R = 0.9997
T10
" = 0.441
ß = 1.998
R=0.9999
" = 1.267
ß = 0.714
R = 0.9974
TRATAMIENTO ESTADÍSTICO DE DATOS
Como puede observarse, todos los valores de R son superiores a 0,9974.
Para establecer si los modelos anteriores son robustos o no a la presencia de ruido se
utilizaron señales construidas artificialmente, contaminando cada señal original con un cierto
porcentaje de ruido. Este nuevo conjunto se obtuvo del siguiente modo:
1. Se procedió a la generación de números aleatorios que variasen entre 0 y el 5 % del
máximo de la señal.
2. Después, estos valores se añadieron al conjunto de datos formado por los valores de
intensidad de las señales de los voltamperogramas de las muestras.
3. El resultado fue un nuevo conjunto de datos afectado por un ruido aleatorio, cuya
amplitud máxima era del 5 %. Esto es, la relación señal / ruido para el conjunto obtenido
era inferior o igual a un 5 %.
Por ejemplo, en la Figura 9, se compara la señal del patrón Tl (I) a 0,7 mg·l-1 original con
su correspondiente señal afectada de ruido al 5 %:
2.50E-07
2.00E-07
I (A)
1.50E-07
1.00E-07
5.00E-08
-0.70
-0.60
-0.50
-0.40
E (V)
0.00E+00
-0.30
T l 0,7 mg/l
T l 0,7 mg/l + ruido
Figura 11: Superposición de las señales del patrón Tl (I) a 0,7 mg·l-1 y su correspondiente señal
afectada de ruido al 5 %.
Los 80 datos de intensidad para cada señal, que componen el nuevo conjunto generado,
fueron formateados adecuadamente y trasladados al software Autolab®, donde se procedió a la
medida de los parámetros de pico para todas las muestras con ruido. Los resultados se recogen
en la Tabla 3:
-145-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 3: Valores de los parámetros de pico para las señales
afectadas por ruido.
Muestras
Potencial (V) Intensidad (nA) Anchura (V)
Tl 0,1
-0,504
23,24
0,111
Tl 0,2
-0,494
53,19
0,111
Tl 0,3
-0,494
80,07
0,116
Tl 0,4
-0,494
107,40
0,111
Tl 0,5
-0,489
136,80
0,116
Tl 0,6
-0,489
173,00
0,116
Tl 0,7
-0,499
199,20
0,111
Tl 0,8
-0,484
231,90
0,111
Tl 0,9
-0,484
248,80
0,111
Tl 1,0
-0,489
289,70
0,116
Pb 0,1
-0,520
41,67
0,096
Pb 0,2
-0,515
75,83
0,101
Pb 0,3
-0,520
108,20
0,106
Pb 0,4
-0,520
142,50
0,096
Pb 0,5
-0,515
181,30
0,101
Pb 0,6
-0,530
209,70
0,096
Pb 0,7
-0,520
241,80
0,101
Pb 0,8
-0,520
280,20
0,101
Pb 0,9
-0,520
312,50
0,101
Pb 1,0
-0,515
340,70
0,101
Tl 0,1 y Pb 0,1
-0,504
66,22
0,106
Tl 0,6 y Pb 0,1
-0,499
213,80
0,111
Tl 0,2 y Pb 0,2
-0,499
127,60
0,106
Tl 0,7 y Pb 0,2
-0,504
268,50
0,111
Tl 0,3 y Pb 0,3
-0,504
191,80
0,106
Tl 0,8 y Pb 0,3
-0,499
340,90
0,111
Tl 0,4 y Pb 0,4
-0,504
248,70
0,106
Tl 0,9 y Pb 0,4
-0,499
386,60
0,111
Tl 0,5 y Pb 0,5
-0,499
325,40
0,106
Tl 1,0 y Pb 0,5
-0,499
462,50
0,106
Tl 0,1 y Pb 0,6
-0,520
233,40
0,106
Tl 0,6 y Pb 0,6
-0,509
375,10
0,106
Tl 0,2 y Pb 0,7
-0,515
296,00
0,101
Tl 0,7 y Pb 0,7
-0,509
450,10
0,101
Tl 0,3 y Pb 0,8
-0,520
356,80
0,101
Tl 0,8 y Pb 0,8
-0,504
507,90
0,101
Tl 0,4 y Pb 0,9
-0,509
418,10
0,106
Tl 0,9 y Pb 0,9
-0,504
548,50
0,106
Tl 0,5 y Pb 1,0
-0,504
474,60
0,106
Tl 1,0 y Pb 1,0
-0,509
615,40
0,096
-146-
TRATAMIENTO ESTADÍSTICO DE DATOS
Posteriormente, y antes de llevar a cabo la comprobación de robustez, se visualizaron las
muestras con ruido mediante un análisis lineal discriminante, en idénticas condiciones a las
empleadas con las señales originales. El objetivo perseguido consistía en verificar si el método
del ALD seguía siendo eficaz en la tarea de clasificar y diferenciar el conjunto de datos
contaminado. Los resultados se muestran en la Figura 10:
Clasificación discriminante según el contenido de Tl (I) y/o Pb (II)
Muestras afectadas por un 5 % de ruido (Plano Factorial)
4
3
P3
T2
T3
T4
1
Dimension 2
P1
T1
2
T5
T6
P4
T2P2
T10
P5
T3P3
T7
T1P6
T8
T9
0
P2
T1P1
T4P4
T2P7
T5P5
T3P8
T4P9
-1
P6
T6P1
P7
P8
T7P2
P9
P10
T8P3
T6P6
T9P4
T7P7
T5P10 T10P5
T8P8
T9P9
-2
T10P10
-3
-4
-5
-4
-3
-2
-1
0
1
2
3
4
5
Tl (I)
Pb (II)
Mezclas
Dimension 1
Figura 13: Análisis lineal discriminante del conjunto de datos afectado de un 5 % de ruido.
La matriz de clasificación para este caso es la siguiente:
-147-
TRATAMIENTO ESTADÍSTICO DE DATOS
Grupo
% Clasificación
Tl (I)
Pb (II)
Mezclas
Tl (I)
90,0000
9
0
1
Pb (II)
90,0000
0
9
1
Mezclas
80,0000
2
2
16
Total
85,0000
11
11
18
Estos resultados corroboran el diagrama de puntos presentado anteriormente. Como puede
observarse, las muestras puras de talio y plomo son clasificadas al 90 %. Ya aquí, se ha perdido
un 10 % de clasificación con respecto al análisis lineal discriminante aplicado a las muestras
originales. Del mismo modo, en el caso de las mezclas, aparecen dos errores más de
clasificación, lo que disminuye el porcentaje correcto hasta el 80 %. La clasificación total de las
40 muestras resultó ser del 85 %, un 10 % menor que con las señales originales.
En este caso, los errores cometidos en la clasificación se corresponden con las muestras
recogidas en la tabla que a continuación se presenta:
Muestras
Clasificación observada
Predicción
T1
Tl (I)
Mezcla
P10
Pb (II)
Mezcla
T1P1
Mezcla
Tl (I)
T2P2
Mezcla
Tl (I)
T6P1
Mezcla
Pb (II)
T8P3
Mezcla
Pb (II)
Como conclusión a todo lo anterior, podemos afirmar que el análisis lineal discriminante
empeora un 10 % la clasificación y diferenciación de las muestras cuando éstas se encuentran
afectadas por ruido, que en este caso alcanza un 5 % de amplitud máxima.
Para obtener la mejor aproximación a cualquiera de las señales contaminadas con ruido,
se llevó a cabo el siguiente proceso:
1. Se tomaron dos tablas: la primera, constituida por el conjunto de datos de intensidad de
-148-
TRATAMIENTO ESTADÍSTICO DE DATOS
las señales originales y, la segunda, formada por los valores de sus correspondientes
señales afectadas de ruido.
2. Se escogieron doce señales originales al azar, pero con la condición de que incluyeran
las que fuesen críticas: T6P1 y T1P6, que fueron las que el ALD no clasificó bien (ver
Figura 2).
3. A continuación, se compararon cada una de ellas con las 40 señales afectadas de ruido,
de tal modo, que el resultado que mostrase el error más pequeño nos daría la
correspondencia entre la señal original y la ruidosa. Si dicho resultado hacía coincidir
la muestra original con su respectiva, pero afectada de ruido, se demostraría así la
robustez del método.
4. El error utilizado en este caso fue el error cuadrático:
ε=
∑ (x
80
i =1
i
− x *i )
2
donde xi y x*i son los valores de intensidad de la señal original y ruidosa,
respectivamente.
5. En la Tabla 4, se recogen los resultados obtenidos para cada una de las pruebas
efectuadas:
-149-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 4: Resultados de la comprobación de robustez del método analítico de ajuste de las señales.
T1
P1
T10
P10
T1P6
T4P4
T4P9
T5P5
T5P10
T6P1
T6P6
T7P2
T1error
3,85E-17
6,59E-15
1,13E-12
1,44E-12
5,65E-13
7,63E-13
2,07E-12
1,40E-12
2,97E-12
6,72E-13
1,92E-12
1,12E-12
T2error
1,57E-14
1,08E-14
8,84E-13
1,19E-12
3,98E-13
5,73E-13
1,74E-12
1,13E-12
2,57E-12
5,13E-13
1,61E-12
8,97E-13
T3error
5,88E-14
4,19E-14
6,79E-13
9,74E-13
2,65E-13
4,15E-13
1,44E-12
9,04E-13
2,22E-12
3,81E-13
1,33E-12
7,04E-13
T4error
1,26E-13
1,03E-13
5,07E-13
8,34E-13
1,67E-13
3,07E-13
1,21E-12
7,31E-13
1,92E-12
3,12E-13
1,11E-12
5,75E-13
T5error
2,38E-13
2,01E-13
3,35E-13
6,48E-13
7,69E-14
1,88E-13
9,36E-13
5,30E-13
1,57E-12
2,23E-13
8,58E-13
4,16E-13
T6error
4,23E-13
3,76E-13
1,80E-13
5,25E-13
2,64E-14
1,19E-13
6,83E-13
3,67E-13
1,24E-12
2,04E-13
6,33E-13
3,12E-13
T7error
5,51E-13
4,92E-13
1,07E-13
4,31E-13
9,53E-15
7,84E-14
5,34E-13
2,67E-13
1,03E-12
1,82E-13
4,94E-13
2,40E-13
T8error
7,61E-13
6,94E-13
4,24E-14
3,96E-13
2,93E-14
8,39E-14
3,92E-13
1,97E-13
8,21E-13
2,30E-13
3,75E-13
2,20E-13
T9error
9,17E-13
8,44E-13
1,82E-14
3,81E-13
5,96E-14
1,02E-13
3,13E-13
1,64E-13
6,95E-13
2,73E-13
3,10E-13
2,17E-13
T10error
1,24E-12
1,14E-12
6,01E-15
3,26E-13
1,39E-13
1,40E-13
1,71E-13
1,03E-13
4,62E-13
3,38E-13
1,84E-13
2,00E-13
T1
P1
T10
P10
T1P6
T4P4
T4P9
T5P5
T5P10
T6P1
T6P6
T7P2
P1error
7,14E-15
1,20E-16
1,03E-12
1,27E-12
4,91E-13
6,57E-13
1,90E-12
1,26E-12
2,77E-12
5,57E-13
1,75E-12
9,80E-13
P2error
4,62E-14
2,00E-14
8,11E-13
9,79E-13
3,37E-13
4,61E-13
1,56E-12
9,78E-13
2,36E-12
3,73E-13
1,42E-12
7,29E-13
P3error
1,17E-13
7,30E-14
6,31E-13
7,42E-13
2,23E-13
3,08E-13
1,27E-12
7,47E-13
1,99E-12
2,33E-13
1,14E-12
5,27E-13
P4error
2,20E-13
1,58E-13
4,95E-13
5,39E-13
1,49E-13
1,93E-13
1,03E-12
5,57E-13
1,68E-12
1,27E-13
8,98E-13
3,61E-13
P5error
3,93E-13
3,10E-13
3,44E-13
3,32E-13
8,54E-14
8,47E-14
7,43E-13
3,50E-13
1,30E-12
4,38E-14
6,27E-13
1,95E-13
P6error
5,54E-13
4,54E-13
2,88E-13
2,12E-13
8,43E-14
4,59E-14
5,85E-13
2,42E-13
1,08E-12
1,21E-14
4,74E-13
1,08E-13
P7error
7,55E-13
6,38E-13
2,45E-13
1,14E-13
1,06E-13
3,00E-14
4,35E-13
1,51E-13
8,59E-13
9,52E-15
3,33E-13
4,44E-14
P8error
1,03E-12
8,93E-13
2,66E-13
3,83E-14
1,90E-13
6,24E-14
3,26E-13
9,93E-14
6,71E-13
4,15E-14
2,27E-13
1,38E-14
P9error
1,28E-12
1,13E-12
2,66E-13
1,02E-14
2,60E-13
1,02E-13
2,30E-13
6,43E-14
5,05E-13
1,06E-13
1,43E-13
1,34E-14
P10error
1,56E-12
1,39E-12
3,13E-13
7,58E-15
3,68E-13
1,76E-13
1,78E-13
6,68E-14
3,87E-13
1,93E-13
9,89E-14
4,22E-14
-150-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 4: Resultados de la comprobación de robustez del método analítico de ajuste de las señales.
T1
P1
T10
P10
T1P6
T4P4
T4P9
T5P5
T5P10
T6P1
T6P6
T7P2
T1P1error T1P6error T2P2error T2P7error T3P3error T3P8error T4P4error T4P9error T5P5error
3,17E-14
6,20E-13
1,87E-13
1,07E-12
4,66E-13
1,66E-12
8,38E-13
2,26E-12
1,51E-12
1,45E-14
5,47E-13
1,39E-13
9,55E-13
3,88E-13
1,52E-12
7,31E-13
2,10E-12
1,37E-12
8,16E-13
8,57E-14
4,44E-13
3,90E-14
2,03E-13
9,17E-14
9,78E-14
2,43E-13
1,09E-13
1,05E-12
3,21E-13
6,11E-13
1,49E-13
3,08E-13
1,67E-13
1,34E-13
2,75E-13
8,79E-14
2,75E-15
3,45E-13
1,19E-13
8,40E-14
2,26E-14
2,92E-13
4,88E-14
5,68E-13
2,46E-13
4,91E-13
3,66E-14
1,99E-13
3,78E-14
3,96E-14
1,89E-13
4,06E-15
4,14E-13
1,28E-13
1,61E-12
4,40E-13
1,03E-12
1,72E-13
5,85E-13
2,88E-14
2,90E-13
1,21E-14
5,75E-14
6,21E-15
1,02E-12
1,89E-13
5,71E-13
3,67E-14
2,56E-13
2,85E-14
7,66E-14
1,22E-13
2,41E-12
9,02E-13
1,69E-12
4,91E-13
1,10E-12
2,00E-13
6,74E-13
6,13E-14
2,62E-13
4,19E-13
1,26E-13
1,73E-13
1,49E-13
5,88E-14
3,59E-13
6,07E-14
6,25E-13
2,49E-13
1,47E-12
3,94E-13
9,18E-13
1,40E-13
5,01E-13
2,80E-14
2,28E-13
3,49E-14
3,07E-14
7,82E-13
1,60E-13
4,03E-13
5,97E-14
1,58E-13
1,31E-13
4,00E-14
2,86E-13
6,25E-14
T1
P1
T10
P10
T1P6
T4P4
T4P9
T5P5
T5P10
T6P1
T6P6
T7P2
T6P1error T6P6error T7P2error T7P7error T8P3error T8P8error T9P4error T9P9error T10P5error T10P10error
7,29E-13
2,06E-12
1,21E-12
2,98E-12
1,79E-12
3,66E-12
2,51E-12
4,68E-12
3,37E-12
5,45E-12
6,12E-13
1,89E-12
1,07E-12
2,77E-12
1,62E-12
3,45E-12
2,32E-12
4,43E-12
3,14E-12
5,19E-12
2,83E-13
2,25E-13
1,80E-13
5,54E-13
2,58E-13
8,08E-13
4,53E-13
1,34E-12
8,02E-13
1,70E-12
1,35E-13
1,66E-13
2,84E-14
3,95E-13
4,93E-14
7,06E-13
2,02E-13
1,09E-12
4,70E-13
1,56E-12
1,23E-13
4,84E-13
1,92E-13
9,73E-13
4,08E-13
1,36E-12
7,54E-13
2,02E-12
1,24E-12
2,51E-12
4,80E-14
3,17E-13
6,52E-14
7,26E-13
2,22E-13
1,09E-12
5,09E-13
1,67E-12
9,29E-13
2,16E-12
4,89E-13
1,26E-14
1,88E-13
9,87E-14
7,44E-14
2,34E-13
7,39E-14
5,40E-13
2,16E-13
8,14E-13
1,86E-13
6,82E-14
3,42E-14
2,97E-13
4,25E-14
5,47E-13
1,74E-13
9,65E-13
4,39E-13
1,35E-12
9,28E-13
9,90E-14
4,72E-13
1,80E-14
2,21E-13
4,64E-14
7,63E-14
2,08E-13
7,47E-14
3,88E-13
3,04E-15
4,80E-13
1,01E-13
9,32E-13
3,04E-13
1,38E-12
6,43E-13
1,96E-12
1,10E-12
2,55E-12
9,31E-15
3,79E-13
1,17E-13
1,20E-13
2,88E-14
2,93E-13
5,78E-14
6,11E-13
2,22E-13
9,28E-13
6,35E-14
1,85E-13
6,17E-15 4,88E-13
8,24E-14
8,20E-13
2,89E-13
1,28E-12
6,19E-13
1,76E-12
-151-
T5P10error
3,21E-12
3,01E-12
5,97E-13
5,48E-13
1,09E-12
8,58E-13
1,31E-13
3,86E-13
1,34E-14
1,12E-12
1,81E-13
6,29E-13
TRATAMIENTO ESTADÍSTICO DE DATOS
De ella se desprende que el método analítico de ajuste es capaz de tratar señales que se
encuentran afectadas por un 5 % de ruido, al haberse alcanzado durante las pruebas un 100 % de
correspondencias entre las señales originales y las ruidosas, incluyendo los casos críticos.
En la Figura 11, pueden observarse los errores obtenidos tras la comparación de la mezcla
T5P5 con las señales ruidosas, estableciéndose el error mínimo en la señal ruidosa T5P5.
1,60E-12
1,40E-12
1,20E-12
Error
1,00E-12
8,00E-13
Error
6,00E-13
4,00E-13
2,00E-13
0,00E+00
1
6
11
16
21
26
31
36
nº de muestras
Figura 16: Error obtenido en la comparación de la mezcla T5P5 (Tl (I) a 0,5 y Pb (II) a
0,5 mg·l-1) con todas las señales afectadas por un 5 % de ruido.
Se podía haber aumentado el porcentaje de ruido que afecta a las señales originales, para
ver, posteriormente, cuán robusto llega a ser el método. Sin embargo, no se han efectuado más
pruebas de este tipo, puesto que nos basta con el grado de robustez alcanzado.
Retomando, de nuevo, la Tabla 2, donde se recogían los valores de los coeficientes de
ajuste, á y â, así como la bondad del mismo para cada mezcla, podemos observar que ésta
representa una matriz “sparse” (o casi vacía) 10×10, la cual será completada por medio de la
aplicación del método de estimación por interpolación. Para ello, en base a las señales de los
patrones puros y los valores de á y â obtenidos, se construye un conjunto de modelos
matemáticos que nos sirve para obtener las señales de cualquier mezcla de dicha tabla. Esto,
finalmente, nos permitirá también predecir la concentración de los iones que componen la mezcla
en cuestión. Además, estos modelos matemáticos no sólo son válidos para los casos
representados en la matriz, sino también para cualquier valor intermedio de concentración, puesto
que sólo habría que variar de forma continua, en cada modelo, el valor del parámetro ë.
-152-
TRATAMIENTO ESTADÍSTICO DE DATOS
Estos modelos matemáticos predictivos se construirán en base a la suposición de que entre
dos señales conocidas cualesquiera, próximas entre sí, la evolución desde la primera hasta la
segunda es aproximadamente lineal, como se refleja en la Figura 12:
2.50E-07
2.00E-07
T1P1
1.50E-07
T6P1
1.00E-07
T3P1
5.00E-08
0.00E+00
1
12 23 34 45 56 67 78 89 100
Figura 17: Evolución lineal de las señales entre dos mezclas conocidas.
Estos modelos matemáticos adoptan la siguiente expresión:
( )
[
( )]
f Ti Pj + λ ⋅ f (Tk Pl ) − f Ti Pj
donde ë toma valores continuos desde 0 hasta 1, aunque en la práctica, para completar la tabla,
se emplearon valores fraccionarios. Para cada fila o columna, las fracciones de ë se definen en
función del número de mezclas entre dos conocidas de la tabla. Así, cuando haya cuatro espacios
vacíos (cuatro mezclas no analizadas), los valores de son submúltiplos de 1/5; si hay tres
espacios, múltiplos de 1/4, y así sucesivamente.
Veamos la construcción de uno de estos modelos con la ayuda de un ejemplo. Para las
mezclas situadas en la primera fila de la tabla (desde T1P1 hasta T6P1), el modelo matemático
predictivo sería el siguiente:
[
]
f (T1P1 ) + λ ⋅ f (T6 P1 ) − f (T1P1 )
donde λ = 0,
1
, .. . , 1
5
Si sustituimos f(T1P1) y f(T6P1) por sus combinaciones lineales en función de los patrones puros
-153-
TRATAMIENTO ESTADÍSTICO DE DATOS
y los valores de á y â correspondientes a las contribuciones de cada uno a la señal global de la
mezcla, la ecuación resultante es:
[
]
1137
.
⋅ f (T1 ) + 0.958 ⋅ f ( P1 ) + λ ⋅ ( − 0.053) ⋅ f (T6 ) + 5.783 ⋅ f ( P1 ) − 1137
.
⋅ f (T1 ) − 0.958 ⋅ f ( P1 )
donde λ = 0,
1
, . .. , 1
5
cuya expresión, simplificando y agrupando términos, queda reflejada en la primera fila de la
Tabla 5.
Además, hay casos donde las mezclas pueden predecirse tanto horizontal como
verticalmente, mientras que en otros tan solo puede hacerse de una de las dos formas. En base
a todo lo anterior, hemos establecido dos tablas de modelos matemáticos: una correspondiente
a modelos horizontales (Tabla 5) y otra a modelos verticales (Tabla 6), presentada esta última de
forma traspuesta:
-154-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 5: Tabla de modelos matemáticos predictivos para las mezclas susceptibles de ser explicadas mediante modelos horizontales.
P1
P2
P3
P4
P5
T1
" = 1.137
ß = 0.958
R=0.9993
(1-0.0138)f(P2)+1.0598f(T2); 8 = 0, 1/2, 1
T4
(1-0.5888)f(P7)+3.3198f(T2); 8 = 0, 1/2, 1
T5
" = 1.154
ß = 0.919
R = 0.9997
(1-0.6608)f(P8)+3.0098f(T3); 8 = 0, 1/3, ..., 1
" = 0.956
ß = 1.072
R = 0.9998
-155-
" = 0.319
ß = 2.686
R = 0.9999
" = 0.449
ß = 2.238
R = 0.9996
" = 0.441
ß = 1.998
R=0.9999
" = 0.932
ß = 1.064
R = 0.9996
" = 0.969
ß = 1.096
R = 0.9999
" = 1.129
ß = 0.877
R = 0.9980
2.078(1-8)f(T4)+[0.561(1-8)+1.0598]f(P9)+
0.9878f(T9); 8 = 0, 1/5, ..., 1
" = 1.951
ß = 0.589
R = 0.9998
(1-0.4118)f(P10)+1.9518f(T5); 8 = 0, 1/5, ..., 1
T10
" = 0.263
ß = 3.269
R=0.9999
3.009(1-8)f(T3)+[0.340(1-8)+0.8778]f(P8)+
1.1298f(T8); 8 = 0, 1/5, ..., 1
" = 2.078
ß = 0.561
R = 0.9999
T9
1.035(1-8)f(T5)+[1.052(1-8)+1.9988]f(P5)+
0.4418f(T10); 8 = 0, 1/5, ..., 1
3.319(1-8)f(T2)+[0.412(1-8)+1.0968]f(P7)+
0.9698f(T7); 8 = 0, 1/5, ..., 1
(1-0.4398)f(P9)+2.0788f(T4); 8 = 0, 1/4, ..., 1
T8
0.956(1-8)f(T4)+[1.072(1-8)+2.2388]f(P4)+
0.4498f(T9); 8 = 0, 1/5, ..., 1
" = 1.035
ß = 1.052
R=0.9999
" = 3.009
ß = 0.340
R = 0.9995
T7
1.154(1-8)f(T3)+[0.919(1-8)+2.6868]f(P3)+
0.3198f(T8); 8 = 0, 1/5, ..., 1
6.961(1-8)f(T1)+[0.193(1-8)+1.0648]f(P6)+
0.9328f(T6); 8 = 0, 1/5, ..., 1
" = 3.319
ß = 0.412
R = 0.9998
T6
" = -0.053
ß = 5.783
R = 0.9983
1.059(1-8)f(T2)+[0.987(18)+3.2698]f(P2)+0.2638f(T7); 8 = 0, 1/5, ..., 1
(1+0.0528)f(P5)+1.0358f(T5); 8 = 0, 1/5, ..., 1
P7
P10
T3
(1+0.0728)f(P4)+0.9568f(T4); 8 = 0, 1/4, ..., 1
" = 6.961
ß = 0.193
R = 0.9979
P9
" = 1.059
ß = 0.987
R = 0.9998
(1-0.0818)f(P3)+1.1548f(T3); 8 = 0, 1/3, ..., 1
P6
P8
T2
1.137(1-8)f(T1)+[0.958(1-8)+5.7838]f(P1)+(0.053)8f(T6); 8 = 0, 1/5, ..., 1
" = 0.987
ß = 1.059
R = 0.9997
1.951(1-8)f(T5)+[0.589(1-8)+0.7148]f(P10)+
1.2678f(T10); 8 = 0, 1/5, ..., 1
" = 1.267
ß = 0.714
R = 0.9974
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 6: Tabla de modelos matemáticos predictivos para las mezclas susceptibles de ser explicadas mediante modelos verticales.
T1
T2
T3
T4
T5
P1
" = 1.137
ß = 0.958
R=0.9993
(1+0.0598)f(T2)+0.9878f(P2); 8 = 0, 1/2, 1
P4
(1-0.7378)f(T7)+3.2698f(P2); 8 = 0, 1/2, 1
P5
" = 1.154
ß = 0.919
R = 0.9997
(1-0.6818)f(T8)+2.6868f(P3); 8 = 0, 1/3, ..., 1
" = 0.956
ß = 1.072
R = 0.9998
(1-0.5518)f(T9)+2.2388f(P4); 8 = 0, 1/4, ..., 1
" = 1.035
ß = 1.052
R=0.9999
-156-
P10
" = 3.009
ß = 0.340
R = 0.9995
" = 2.078
ß = 0.561
R = 0.9999
[1.035(1-8)+1.9518]f(T5)+1.052(1-8)f(P5)+
0.5898f(P10); 8 = 0, 1/5, ..., 1
" = 1.951
ß = 0.589
R = 0.9998
" = 0.932
ß = 1.064
R = 0.9996
" = 0.969
ß = 1.096
R = 0.9999
" = 1.129
ß = 0.877
R = 0.9980
[0.449(1-8)+0.9878]f(T9)+2.238(1-8)f(P4)+
1.0598f(P9); 8 = 0, 1/5, ..., 1
" = 0.441
ß = 1.998
R=0.9999
(1-0.5598)f(T10)+1.9988f(P5); 8 = 0, 1/5, ..., 1
P9
" = 3.319
ß = 0.412
R = 0.9998
[0.319(1-8)+1.1298]f(T8)+2.686(1-8)f(P3)+
0.8778f(P8); 8 = 0, 1/5, ..., 1
" = 0.449
ß = 2.238
R = 0.9996
P8
[0.956(1-8)+2.0788]f(T4)+1.072(1-8)f(P4)+
0.5618f(P9); 8 = 0, 1/5, ..., 1
[0.263(1-8)+0.9698]f(T7)+3.269(1-8)f(P2)+
1.0968f(P7); 8 = 0, 1/5, ..., 1
" = 0.319
ß = 2.686
R = 0.9999
P7
[1.154(1-8)+3.0098]f(T3)+0.919(1-8)f(P3)+
0.3408f(P8); 8 = 0, 1/5, ..., 1
[(-0.053(1-8)+0.9328]f(T6)+5.783(1-8)f(P1)+
1.0648f(P6); 8 = 0, 1/5, ..., 1
" = 0.263
ß = 3.269
R=0.9999
P6
" = 6.961
ß = 0.193
R = 0.9979
[1.059(1-8)+3.3198]f(T2)+0.987(1-8)f(P2)+
0.4128f(P7); 8 = 0, 1/5, ..., 1
(1+0.0358)f(T5)+1.0528f(P5); 8 = 0, 1/5, ..., 1
T7
T10
P3
(1-0.0448)f(T4)+1.0728f(P4); 8 = 0, 1/4, ..., 1
" = -0.053
ß = 5.783
R = 0.9983
T9
" = 1.059
ß = 0.987
R = 0.9998
(1+0.1548)f(T3)+0.9198f(P3); 8 = 0, 1/3, ..., 1
T6
T8
P2
[1.137(1-8)+6.9618]f(T1)+0.958(1-8)f(P1)+
0.1938f(P6); 8 = 0, 1/5, ..., 1
" = 0.987
ß = 1.059
R = 0.9997
[0.441(1-8)+1.2678]f(T10)+1.998(1-8)f(P5)+
0.7148f(P10); 8 = 0, 1/5, ..., 1
" = 1.267
ß = 0.714
R = 0.9974
TRATAMIENTO ESTADÍSTICO DE DATOS
A partir de estas tablas, empleando el modelo adecuado junto con el correspondiente valor
para ë, puede obtenerse cualquier mezcla que se desee, ya sean valores de concentración
intermedios o especificados en la Tabla 2.
A continuación, se comprobará la eficacia de este método, haciendo uso de 8 nuevas
mezclas analizadas y, supuestamente, desconocidas.
a) Verificación Del Método De Estimación Por Interpolación.
Se realizaron nuevas experiencias con el aparato Autolab®/PGSTAT20, hasta conseguir un
total de 8 voltamperogramas que fueron utilizados como conjunto de prueba. En la Tabla 7, se
recogen dichas mezclas con las 20 de partida:
T1
P1
T2
T3
T2P2
T7
T8
T3P3
T5P3
T3P5
T10P2
T8P3
T9P4
T5P5
T1P6
P7
T10P5
T6P6
T2P7
P8
T8P6
T7P7
T3P8
T1P9
T6P8
T8P8
T4P9
T2P10
T10
T9P1
T4P4
P5
T9
T7P2
P4
P10
T6
T6P1
P3
P9
T5
T1P1
P2
P6
T4
T9P9
T5P10
T10P10
Tabla 7: Tabla de las mezclas originales (azules) y las mezclas de comprobación (rojas).
Los parámetros de pico para estas muestras se reflejan en la Tabla 8:
-157-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 8: Parámetros de pico de los voltamperogramas de comprobación para mezclas de patrones de Tl (I) y Pb (II).
Pruebas
Patrón Réplica Vol. (ml) Pot. (V) Int. (nA) Área (10-8) Anchura (V) Derivada (10-7) Desv. Est. Int.Media [Tl+] [Pb2+] Int. Esperada Error (%)
Tl 0,1 y Pb 0,9
4
1
1,0
-0,540
340,1
3,5400
0,101
123,20
1,95021
328,878
0,1
0,9
322,94
1,839
Tl 0,1 y Pb 0,9
4
2
1,0
-0,540
344,0
3,5870
0,101
124,80
1,95021
328,878
0,1
0,9
322,94
1,839
Tl 0,1 y Pb 0,9
4
3
1,0
-0,540
342,0
3,5650
0,101
124,10
1,95021
328,878
0,1
0,9
322,94
1,839
Tl 0,2 y Pb 1,0
4
1
1,2
-0,540
391,3
4,0850
0,101
139,60
2,66333
374,014
0,2
1,0
379,30
-1,394
Tl 0,2 y Pb 1,0
4
2
1,2
-0,540
394,9
4,1250
0,101
141,20
2,66333
374,014
0,2
1,0
379,30
-1,394
Tl 0,2 y Pb 1,0
4
3
1,2
-0,540
389,7
4,0720
0,101
139,60
2,66333
374,014
0,2
1,0
379,30
-1,394
Tl 0,9 y Pb 0,1
4
1
1,0
-0,525
299,6
3,5520
0,111
80,25
1,80831
287,885
0,9
0,1
286,88
0,350
Tl 0,9 y Pb 0,1
4
2
1,0
-0,525
301,1
3,5710
0,111
80,59
1,80831
287,885
0,9
0,1
286,88
0,350
Tl 0,9 y Pb 0,1
4
3
1,0
-0,525
297,5
3,5310
0,111
79,54
1,80831
287,885
0,9
0,1
286,88
0,350
Tl 1,0 y Pb 0,2
4
1
1,2
-0,525
362,2
4,2740
0,111
99,51
1,98578
343,543
1,0
0,2
354,11
-2,984
Tl 1,0 y Pb 0,2
4
2
1,2
-0,525
359,6
4,2490
0,111
98,33
1,98578
343,543
1,0
0,2
354,11
-2,984
Tl 1,0 y Pb 0,2
4
3
1,2
-0,525
358,3
4,2390
0,111
97,88
1,98578
343,543
1,0
0,2
354,11
-2,984
Tl 0,3 y Pb 0,5
4
1
0,8
-0,535
264,3
2,8630
0,101
88,58
1,83576
255,329
0,3
0,5
253,30
0,801
Tl 0,3 y Pb 0,5
4
2
0,8
-0,535
261,4
2,8350
0,101
87,76
1,83576
255,329
0,3
0,5
253,30
0,801
Tl 0,3 y Pb 0,5
4
3
0,8
-0,535
264,8
2,8710
0,101
88,89
1,83576
255,329
0,3
0,5
253,30
0,801
Tl 0,5 y Pb 0,3
4
1
0,8
-0,530
253,3
2,8940
0,111
75,74
1,35277
244,186
0,5
0,3
241,27
1,209
Tl 0,5 y Pb 0,3
4
2
0,8
-0,530
250,6
2,8580
0,111
75,06
1,35277
244,186
0,5
0,3
241,27
1,209
Tl 0,5 y Pb 0,3
4
3
0,8
-0,530
252,1
2,8740
0,111
75,56
1,35277
244,186
0,5
0,3
241,27
1,209
Tl 0,6 y Pb 0,8
4
1
1,4
-0,535
468,9
5,1580
0,106
152,20
2,11266
443,024
0,6
0,8
439,73
0,749
Tl 0,6 y Pb 0,8
4
2
1,4
-0,540
469,2
5,1460
0,106
151,90
2,11266
443,024
0,6
0,8
439,73
0,749
Tl 0,6 y Pb 0,8
4
3
1,4
-0,540
465,4
5,1290
0,106
151,50
2,11266
443,024
0,6
0,8
439,73
0,749
Tl 0,8 y Pb 0,6
4
1
1,4
-0,530
450,3
4,8890
0,101
128,20
7,92654
422,917
0,8
0,6
429,04
-1,427
Tl 0,8 y Pb 0,6
4
2
1,4
-0,530
452,0
4,9140
0,101
131,10
7,92654
422,917
0,8
0,6
429,04
-1,427
Tl 0,8 y Pb 0,6
4
3
1,4
-0,535
437,5
4,9450
0,106
135,30
7,92654
422,917
0,8
0,6
429,04
-1,427
-158-
TRATAMIENTO ESTADÍSTICO DE DATOS
Antes de verificar la validez del método, los datos de comprobación fueron formateados
en dos conjuntos, con características similares a las del conjunto discreto y continuo de las
muestras de partida, presentados al principio de este capítulo.
De igual modo que con las 40 señales iniciales, en los Anexos V y VI se incluyen los
valores de intensidad-potencial y frecuencia-amplitud, respectivamente, pertenecientes al
conjunto de datos de comprobación.
Hay que señalar que en el proceso de reducción de dimensiones para las mezclas nuevas
se empleó la misma frecuencia de corte que con el resto de muestras, obteniéndose un error de
recomposición del 2 % como máximo, tal como aparece recogido en el Anexo VI.
Como cabía esperar, las visiones exploratorias de las nuevas muestras de prueba, junto con
las originales, suministradas por el análisis lineal discriminante (ver Figura 13) sobres los datos
discretos y el escalado multidimensional (ver Figura 12) sobre los datos continuos, corroboran
los resultados establecidos en su momento, obteniéndose un 95,85 % de clasificación para el
ALD y un 100 % para el escalado.
El gráfico de puntos del análisis lineal discriminante es el siguiente:
Clasificación discriminante según el contenido de Tl (I) y/o Pb(II)
Plano Factorial conteniendo las 8 muestras de comprobación
5
4
T6P8
3
T2P10
T1P9
Dimensión 2
2
T8P6
T10P10
T8P8
1
T3P5
-1
P7
P6
P4
-2
P3
P2
P1
T10P2
T9P1
T5P3
T4P4
T7P7
P5
T10P5
T9P4
T8P3
T7P2
T6P6
T5P5
T4P4
T3P8
P8
T2P7
T1P6
P10
P9
0
T9P9
T5P10
T10
T6P1T9
T8
T3P3
T2P2
T1P1
T7
T5T6
T3
T2 T4
T1
-3
-4
-3
-2
-1
0
1
2
3
4
Tl (I)
Pb (II)
Mezclas
Dimensión 1
Figura 21: Análisis lineal discriminante del conjunto de muestras originales y de comprobación.
Con el escalado multidimensional, se obtuvo lo siguiente:
-159-
TRATAMIENTO ESTADÍSTICO DE DATOS
Representación del conjunto de voltamperogramas más 8 muestras de comprobación
Escalado multidimensional sobre el espectro de Fourier
0,25
T8
T6
0,15
T10
T9
T10P2
T9P1
T7
T6P1
T7P2
T8P3
T10P5
T9P4
T5
Dimension 2
T4
T5P3
T3
0,05
T2
T1
T2P2
T1P1
T5P5
T6P6
T8P6
T7P7
T9P9
T4P4
T3P3
T6P8
T8P8
T3P5
P1
P2
-0,05
P3
T2P7
T1P6
P4
T3P8
T4P9
T5P10
T10P10
P5
P6
T1P9 T2P10
P7
-0,15
P8
P9
P10
-0,25
-2,5
-1,5
-0,5
0,5
1,5
2,5
3,5
Dimension 1
Figura 22: Escalado multidimensional de las muestras originales y las de comprobación.
Una vez visualizada la posición de las 8 nuevas muestras respecto de la totalidad del
conjunto inicial, se procedió a la comprobación de la validez del método de estimación por
interpolación. Para ello, se llevó a cabo la prueba que a continuación se detalla.
1) Prueba de validación.
Se obtuvo la expresión numérica de todos los modelos a partir de las funciones analíticas
que figuran en las Tablas 9 y 10, resultando una serie de 100 señales (predicciones) con 80 datos
de intensidad para cada valor del parámetro ë.
-160-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 9: Tabla de numeración de los modelos matemáticos predictivos horizontales.
P1
P2
T1
" = 1.137
ß = 0.958
R=0.9993
T3
T4
P5
P7
18
P8
" = 0.932
ß = 1.064
R = 0.9996
" = 0.969
ß = 1.096
R = 0.9999
8
" = 3.009
ß = 0.340
R = 0.9995
P10
" = 0.441
ß = 1.998
R=0.9999
6
7
" = 1.129
ß = 0.877
R = 0.9980
9
" = 2.078
ß = 0.561
R = 0.9999
14
T10
" = 0.449
ß = 2.238
R = 0.9996
4
" = 1.035
ß = 1.052
R=0.9999
" = 3.319
ß = 0.412
R = 0.9998
P9
T9
" = 0.319
ß = 2.686
R = 0.9999
" = 0.956
ß = 1.072
R = 0.9998
16
T8
3
5
" = 6.961
ß = 0.193
R = 0.9979
T7
" = 0.263
ß = 3.269
R=0.9999
" = 1.154
ß = 0.919
R = 0.9997
13
P6
T6
" = -0.053
ß = 5.783
R = 0.9983
2
15
P4
T5
1
" = 1.059
ß = 0.987
R = 0.9998
17
P3
T2
" = 0.987
ß = 1.059
R = 0.9997
10
" = 1.951
ß = 0.589
R = 0.9998
11
" = 1.267
ß = 0.714
R = 0.9974
12
Tabla 10: Tabla de numeración de los modelos matemáticos predictivos verticales.
P1
" = 1.137
T1 ß = 0.958
R = 0.9993
T2
P5
T7
18
P10
" = 2.078
ß = 0.561
R = 0.9999
" = 1.035
ß = 1.052
R=0.9999
" = 1.951
ß = 0.589
R = 0.9998
6
" = 0.932
ß = 1.064
R = 0.9996
" = 0.263
ß = 3.269
R = 0.9999
" = 0.969
ß = 1.096
R = 0.9999
8
" = 0.319
ß = 2.686
R = 0.9998
14
P9
" = 3.009
ß = 0.340
R = 0.9995
4
7
16
P8
" = 3.319
ß = 0.412
R = 0.9998
" = 0.956
ß = 1.072
R = 0.9998
5
" = -0.053
ß = 5.783
R = 0.9983
P7
3
13
T6
P6
" = 6.961
ß = 0.193
R = 0.9979
2
" = 1.154
ß = 0.919
R = 0.9997
T5
T9
P4
1
15
T4
T8
P3
" = 1.059
ß = 0.987
R = 0.9998
17
T3
P2
" = 1.129
ß = 0.877
R = 0.9980
9
" = 0.449
ß = 2.238
R = 0.9996
10
" = 0.441
-161-
" = 0.987
ß = 1.059
R = 0.9997
" = 1.267
TRATAMIENTO ESTADÍSTICO DE DATOS
Cada muestra de prueba se trabajó suponiendo sus contribuciones desconocidas. Para cada
una de estas muestras, se calculó el error cuadrático, g, existente entre ella y las predicciones
analíticas mencionadas anteriormente. El error mínimo obtenido define la mejor aproximación
entre los modelos de predicción y la muestra de prueba considerada, como puede observarse en
la Figura 15:
Muestra de prueba
Min g
g1
g2
F(TIPJ)
Hiperplano de las muestras reales conocidas
Figura 24: Esquema de aproximaciones entre una muestra de prueba y las muestras reales conocidas.
Esta mejor aproximación es la estimación de la señal de prueba e informa, por tanto, de las
contribuciones de los iones Tl (I) y Pb (II) existentes. La validez del modelo se pone de
manifiesto cuando predice con suficiente aproximación las concentraciones de ambos cationes
presentes en todas las muestras de prueba. Así, por ejemplo, para la mezcla T9P1, el error
mínimo obtenido debe producirse cuando se aplica el modelo vertical 14, para ë = 1 (ver Tabla
10). Y del mismo modo con las restantes señales de comprobación.
Sin embargo, en la práctica nos encontramos con una situación diferente, como puede
observarse por los resultados que aparecen en la tabla que se presenta a continuación (ver
también Anexo VII):
-162-
TRATAMIENTO ESTADÍSTICO DE DATOS
Modelos
Muestras
Teórico
Error Mínimo
Clasificación
T1P9
H14ë11
H14ë0
P9
T2P10
H11ë2
H11ë0
P10
T3P5
H5ë3 / V3ë22
H1ë5 / V7ë0
T6P1
T5P3
H3ë2 / V5ë3
H1ë5 / V7ë0
T6P1
T6P8
H9ë3
H4ë5 / V10ë0
T9P4
T896
V9ë3
H11ë1
T1P10
T9P1
V14ë1
H2ë5 / V8ë0 / V18ë2
T7P2
T10P2
V11ë2
H11ë1
T1P10
1
H14ë1: modelo predictivo horizontal 14, con ë = 1 (ver Tabla 9).
2
V3ë2: modelo predictivo vertical 3, con ë = 2 (ver Tabla 10).
Como puede observarse, hay algunas situaciones, como la T1P9 y la T2P10, donde la
aproximación es bastante buena, puesto que sólo existen diferencias entre los valores de ë de los
modelos. Pero el dato de mayor interés consiste en que existen mezclas, como T3P5 y T5P3, que
poseen contribuciones diferentes y ofrecen idéntica señal. Esto se debe a que cualquier campana
de gauss puede expresarse de forma no única como suma de contribuciones de dos patrones
puros. Como consecuencia de lo anterior, aunque el modelo descrito anteriormente aproxima
bien algunas señales, tiende a confundir otras, lo cual sucede en el caso de las seis muestras
restantes.
La aplicación que podría darse a los resultados aquí obtenidos podría ser la que se describe
en el ejemplo siguiente:
“Imaginemos una industria en la que se hace uso del sistema Tl (I) y Pb (II) en el
proceso de fabricación de sus productos y supongamos que se encuentran con el
problema de decidir entre dos mezclas de ambos iones. Además, se sabe que una de
-163-
TRATAMIENTO ESTADÍSTICO DE DATOS
ellas posee un mayor coste que la otra. Por tanto, mediante el uso del modelo que
hemos propuesto, puede averiguarse si ambas mezclas, que poseen contribuciones
químicas diferentes, dan idéntica señal y sirven por igual a la hora de aplicar un
tratamiento químico. Si tal es el caso, el problema se resuelve inmediatamente,
eligiéndose la configuración más barata, lo que implica una disminución en el coste del
proceso.”
2) Modelo mejorado I.
Con la mejora que aquí se presenta, se pretenden reducir las condiciones en las que se han
llevado a cabo las pruebas anteriores. Hemos podido comprobar que si se desconocen las
concentraciones de los dos iones que componen la mezcla, el método se confunde.
En una segunda comprobación, se estudió si, conociendo la cantidad de uno de los cationes
metálicos, era posible la correcta clasificación del ion desconocido, lo que indicaría que el
método serviría bien para establecer predicciones de mezclas.
De acuerdo con lo anterior, en la Tabla 9 se fijó un Pj y en la 10 un Ti, para cada una de las
mezclas de comprobación, y se aplicaron los modelos correspondientes en cada caso. El objetivo
fue averiguar si reduciendo ahora el número de modelos aplicar, aquel que daba el mínimo error
se correspondía o aproximaba con el modelo teórico que explicaba las nuevas muestras. Por
ejemplo, para el caso de la mezcla T3P5, se probaron los modelos 5 y 6 de la Tabla 9 (para P5
= constante) y los modelos 15 y 3 de la Tabla 10 (para T3 = constante). En la mayoría de los
casos, sólo hubo que aplicar modelos pertenecientes a una única tabla, pero para T3P5 y T5P3
hubo que hacer uso de las dos, ya que podían ser explicados tanto por modelos horizontales como
verticales.
Los resultados obtenidos se recogen en la siguiente tabla:
-164-
TRATAMIENTO ESTADÍSTICO DE DATOS
Muestras
Ti y Pj = cte.
Mod. Error Mín. Mod. Teórico Clasificación
T1P9
P9
H14ë0
H14ë1
P9
T9P1
T9
V14ë2
V14ë1
T9P2
T2P10
P10
H11ë0
H11ë2
P10
T10P2
T10
V11ë3
V11ë2
T10P3
P3
H3ë2
H3ë2
T5P3
T5P3
T5
V5ë3
V5ë3
P5
H5ë2
H5ë3
T2P5
T3
V3ë1
V3ë2
T3P4
T6P8
P8
H16ë1
H9ë3
T1P8
T8P6
T8
V16ë3 / V9ë0
V9ë3
T8P3
T3P5
Como se muestra en la tabla, las aproximaciones del modelo de estimación por
interpolación son bastante buenas, obteniéndose un error del orden de 0,1 mg·l-1 para la
concentración desconocida, en la mayoría de los casos.
A partir de la tabla puede observarse que las clasificaciones son mucho más próximas a las
reales que con la prueba de validación, incluso existe un caso en el que es completa (T5P3). Los
errores obtenidos son consecuencia de que al no considerarse como parámetro la posición del
pico, el método de ajuste por mínimos cuadrados escogido para llevar a cabo las interpolaciones
toma como modelo de error mínimo el que se encuentra más centrado con respecto a la muestra
que se pretende clasificar.
Veamos esto último gráficamente (Figura 16 y Anexo VIII):
-165-
TRATAMIENTO ESTADÍSTICO DE DATOS
Predicciones para el T2P10 con P10 = cte
4,50E-07
4,00E-07
3,50E-07
I (A)
3,00E-07
2,50E-07
2,00E-07
1,50E-07
1,00E-07
5,00E-08
0,00E+00
Figura 25: Ejemplo de mal funcionamiento del Modelo mejorado I.
En la figura aparecen representadas las siguientes señales:
w Mezcla real de comprobación T2P10 (roja).
w Modelo de error mínimo, H11ë0, que establece una de las predicciones, colocando
a la muestra real en la posición correspondiente a la P10 (ambos de color azul).
w Modelo predictivo H12ë0, que es el otro modelo aplicado para P10 = cte y que
clasifica la mezcla T2P10 en el lugar de la T5P10 (ambos de color verde).
w Modelo teórico H11ë2 (negro), que sería el que debiera poseer un error mínimo,
según el Modelo mejorado I.
Como puede observarse, el pico que más se asemeja a la muestra real es el perteneciente
al modelo teórico, tanto en altura como en anchura. No obstante, el Modelo mejorado I nos
acerca más la mezcla T2P10 a la P10, que se corresponde con el modelo de mínimo error. Esto
es debido a que la mezcla P10 se encuentra más centrada con respecto a la T2P10, que es la que
se está intentando clasificar. Con respecto al otro modelo, puede descartarse con sólo echar un
vistazo a la figura.
Por tanto, tras estudiar los resultados, podemos concluir que la posición del pico vuelve a
ser un factor muy importante a la hora de clasificar correctamente las muestras, al igual que
determina una buena o mala predicción por parte del método de estimación por interpolación
mediante mínimos cuadrados.
-166-
TRATAMIENTO ESTADÍSTICO DE DATOS
Esto da lugar a la consideración del siguiente modelo mejorado.
3) Modelo mejorado II.
Del estudio de los resultados anteriores se desprendió la posibilidad de una segunda mejora
(y su comprobación). Ésta consiste en llevar a cabo un procedimiento basado en el Modelo
mejorado I, pero con la siguiente modificación: antes de establecer comparaciones con la muestra
real de prueba que se desea clasificar, se realiza un centrado de las predicciones de cada modelo
aplicado con respecto a la mezcla de comprobación. De este modo, la estimación por
interpolación mediante el método de mínimos cuadrados debería clasificar mejor y predecir bien
todas las muestras.
En esta prueba, los errores de comparación se obtuvieron de dos formas diferentes: como
suma de errores cuadráticos y como el máximo de dichos errores.
Los resultados obtenidos se recogen en la tabla que a continuación se presenta:
Muestras
Ti y Pj = cte.
Mod. Error Mín. Mod. Teórico Clasificación
T1P9
P9
H14ë1
H14ë1
T1P9
T9P1
T9
V14ë1
V14ë1
T9P1
T2P10
P10
H11ë1
H11ë2
T1P10
T10P2
T10
V11ë2
V11ë2
T10P2
P3
H3ë2
H3ë2
T5P3
T5P3
T5
V5ë3
V5ë3
P5
H5ë3
H5ë3
T3P5
T3P5
T3
V3ë2
V3ë2
T6P8
P8
H9ë3
H9ë3
T6P8
T8P6
T8
V9ë3
V9ë3
T8P6
-167-
TRATAMIENTO ESTADÍSTICO DE DATOS
Salvo para la mezcla T2P10, que fue clasificada con un error de 0,1 mg·l-1 para el catión
desconocido, los resultados fueron muy satisfactorios.
Veámoslo gráficamente (Figura 17 y Anexo VIII):
Predicción del T10P2 cuando T10 = cte (centrado).
5,00E-07
4,50E-07
4,00E-07
I (A)
3,50E-07
3,00E-07
2,50E-07
2,00E-07
1,50E-07
1,00E-07
5,00E-08
0,00E+00
Figura 26: Ejemplo del buen funcionamiento del Modelo mejorado II.
En la figura aparecen representadas las siguientes señales:
w Mezcla real de comprobación T10P2 (roja).
w Modelo de error mínimo, V11ë2 (azul).
w Modelo predictivo V12ë0, que es el otro modelo aplicado para T10 = cte (verde).
Como puede observarse, la aproximación para T10P2 es perfecta con el modelo V11ë2.
Esto indica que el modelo de error mínimo coincide con el modelo que teóricamente predeciría
dicha mezcla. A continuación, para demostrar esto, en la tabla siguiente se exponen los errores
de los modelos desde ë = 0 hasta ë = 5:
-168-
TRATAMIENTO ESTADÍSTICO DE DATOS
Sum
6,62×10-14
1,49×10-14
7,99×10-15
3,01×10-14
9,89×10-14
2,23×10-13
Máx
4,65×10-15
9,67×10-16
5,66×10-16
2,11×10-15
6,30×10-15
1,50×10-14
Sum
2,23×10-13
3,05×10-13
4,24×10-13
5,48×10-13
6,98×10-13
8,74×10-13
Máx
1,50×10-14
1,94×10-14
2,70×10-14
3,39×10-14
4,26×10-14
5,32×10-14
V11ë2
V12ë0
A partir de la tabla, puede verse que los valores de error mínimo se alcanzaron para el
modelo V11ë2.
Como en todas las mezclas de comprobación sucedió lo mismo, se puede concluir, por
tanto, que el procedimiento estimativo por interpolación mediante el método de aproximación
de mínimos cuadrados es una buena herramienta predictiva cuando:
T se conoce la concentración de uno de los iones de la mezcla,
T se realiza un centrado de las predicciones con respecto a la muestra real,
obteniéndose errores del orden de 0,1 mg·l-1 para el ion desconocido.
El modelo planteado podría mejorarse, dándole así una gran utilidad. La forma de actuación
podría ser alguna de las que se resumen a continuación:
w Construir una tabla corregida de clasificaciones de las mezclas tras la aplicación del
método de estimación mediante interpolación y colocar cada muestra de acuerdo con
el modelo de error mínimo obtenido en cada caso. Esto es, deshacer parte de la tabla
que da lugar a confusiones y rehacerla de acuerdo con los resultados obtenidos con
el modelo.
w Determinar la proporción Tl+ / Pb2+ que debe existir en una mezcla para que esta sea
bien clasificada; esto es, fijar una diagonal en la tabla.
w Por último, reconstruir las Tablas 5 y 6 de los modelos con expresiones matemáticas
que estén más de acuerdo con una correcta clasificación y predicción de las muestras,
es decir, aproximar mediante suma de dos campanas de gauss.
-169-
TRATAMIENTO ESTADÍSTICO DE DATOS
REDES NEURONALES ARTIFICIALES.
El segundo y último de los métodos predictivos que se van emplear para la separación de
señales de mezclas de Tl (I) y Pb (II) lo constituyen las redes neuronales artificiales.
En el capítulo primero de esta memoria se describe el fundamento teórico de esta poderosa
herramienta estadística, junto con muchas de sus funciones y aplicaciones: memorias asociativas
simuladas por ordenador, reconocimiento de patrones, control de procesos y muchas otras más.
En este trabajo, las redes neuronales se emplearon como método de reconocimiento de
patrones con el fin de resolver mezclas de dos iones y hallar de una manera lo más sencilla y
exacta posible sus correspondientes concentraciones.
Para ello se hizo uso de dos tipos de redes:
w Redes neuronales discretas: aquellas que utilizan la información clásica o habitual,
constituida por parámetros electroquímicos discretos.
w Redes neuronales continuas: aquellas que emplean la totalidad de la información
presente en las señales electroquímicas de cada muestra analizada.
A continuación, describiremos con detalle cada una de ellas junto con los resultados
obtenidos.
a) Redes Neuronales Discretas.
En la aplicación de estas redes, se utilizó el conjunto discreto de datos, es decir, el vector
formado por la intensidad, potencial y anchura de pico de todas las muestras analizadas, como
parámetros de entrada a la red neuronal. Esto equivale a tres neuronas de entrada a la red, una por
cada parámetro. Y como información de salida, las concentraciones de los iones presentes en las
mezclas, lo que hacen dos neuronas de salida. Los datos de entrada fueron estandarizados
previamente a su introducción en la red, tomando valores entre 0 y 1, puesto que esto optimiza
el funcionamiento del sistema (ver Anexo IX).
Estos datos, en un formato adecuado, se introdujeron como conjunto de entrenamiento en
el software de redes neuronales Qwiknet 3.2. Con esta herramienta se persiguió el siguiente
objetivo: entrenar y determinar cuáles eran las redes más sencillas para clasificar las muestras,
manteniendo al mismo tiempo una alta capacidad predictiva.
En la Figura 18, aparece la pantalla de trabajo de dicho programa, donde se pueden
modificar todos los parámetros de entrenamiento para la red neuronal:
-170-
TRATAMIENTO ESTADÍSTICO DE DATOS
Los parámetros de mayor interés empleados por el modelo neuronal son los siguientes:
Figura 27: Pantalla de configuración de las redes neuronales discretas en el software Qwiknet 3.2.
‘ Velocidad de aprendizaje (ç): controla la velocidad a la cual aprende la red. Cuanto
mayor sea el valor de ç, más rápido será el aprendizaje del sistema.
‘ Momentum (á): controla la influencia del cambio del último peso sobre la
actualización del peso que se esté tratando en ese momento.
‘ Tolerancia de convergencia: especifica el criterio de parada para el error de
entrenamiento RMS. El entrenamiento se detendrá cuando el error RMS alcance un
valor inferior al propuesto.
‘ Nº máximo de ciclos: controla el número máximo de ciclos utilizados para el
entrenamiento. Un ciclo equivale a un barrido completo del conjunto de
entrenamiento a través de la red.
‘ Margen de error: la red lo emplea para clasificar el número y el porcentaje de
patrones de entrenamiento que la red ha aprendido. Cualquier patrón con un error
RMS total inferior a este valor se considera aprendido.
‘ Recorte de patrones: indica el grado para el cual los patrones que ha aprendido la red
-171-
TRATAMIENTO ESTADÍSTICO DE DATOS
participan en el aprendizaje futuro.
‘ Entrenamiento por validación cruzada: divide el conjunto de entrenamiento en dos
subconjuntos: un 90% para el entrenamiento y un 10 % para la validación. El grupo
de prueba no se utiliza para actualizar los pesos, sino para comprobar la validez de
la red, al mismo tiempo que indica si existen o no problemas de memorización del
conjunto de entrenamiento.
‘ Método de entrenamiento: especifica el algoritmo empleado para optimizar la red
neuronal, esto es, para calcular los parámetros (pesos idóneos) capaces de establecer
el mayor porcentaje de clasificaciones correctas. Caben destacar los siguientes
algoritmos:
T Back-propagation: es el algoritmo de entrenamiento más comúnmente
empleado por las redes neuronales. Dentro de este grupo los más importantes
son back-propagation online, que actualiza los pesos después de que cada
patrón haya pasado por la red; back-propagation randomize, que es igual al
anterior, pero estableciendo un orden de entrada al azar de los patrones a la red
antes de cada ciclo, y back-propagation batch, que también es semejante al
primero, pero actualiza los pesos después de cada ciclo. (Permite un proceso
de aprendizaje estocástico).
T Delta-bar-Delta: es un método de velocidad de aprendizaje adaptativa en el
cual cada peso posee su propia velocidad de aprendizaje. La actualización de
los pesos se realiza en función del signo del gradiente.
T RPROP (Resilient Propagation): un método del mismo tipo que el anterior
donde la actualización de los pesos se basa únicamente en el signo del
gradiente local y no en sus magnitudes.
T QUICKPROP: está basado en dos postulados, 1) la función E(w) para cada
peso puede aproximarse por una parábola que se abre hacia arriba y, 2) el
cambio en la pendiente de E(w) para un peso determinado no se ve afectado
por todos los otros pesos que cambian al mismo tiempo.
‘ Número de capas ocultas: sirve para especificar el número total de capas ocultas en
la red neuronal.
‘ Ruido de entrada: especifica la cantidad de ruido gaussiano que se añade a los
patrones de entrenamiento de entrada. Una pequeña cantidad de ruido ayuda a
prevenir sobreajustes y mejora la generalización.
-172-
TRATAMIENTO ESTADÍSTICO DE DATOS
‘ Perturbación de pesos: consiste en el ajuste de los pesos a un porcentaje que no
exceda de un valor máximo fijado, lo que permite mover los pesos durante el
entrenamiento y que la red pueda escapar de un mínimo local.
‘ Saturación de neuronas: una neurona se encuentra saturada cuando un gran cambio
en la entrada tiene un pequeño efecto o ninguno sobre la salida. En este caso, su
contribución al aprendizaje de la red es despreciable. El límite de saturación indica
el porcentaje de patrones que deben saturar a la neurona antes de que se la considere
saturada. Si este porcentaje es superado, todos los pesos que introduzcan entradas en
dicha neurona se reducirán un 90% de magnitud.
‘ Función de activación: indica el tipo de función de activación que aplican las
neuronas de una capa determinada para generar sus correspondientes respuestas o
salidas. Pueden ser: sigmoidal, tangente hiperbólica, lineal y gaussiana.
Normalmente, se eligen funciones no lineales (cuando se quiere poner de manifiesto
alguna característica no lineal intrínseca del conjunto de datos), aunque los nodos de
la capa de entrada tienen asignados por defecto una función de activación lineal.1
En nuestro caso, las características especificadas para el entrenamiento y validación de las
redes han sido las siguientes:
w Topología de la red: 3-X-2, la cual se corresponde con una red neuronal constituida
por tres capas. En la primera capa (entrada) existen 3 neuronas, correspondientes a
los valores estandarizados de intensidad, anchura y potencial de pico de las señales
de los voltamperogramas de las muestras. En la segunda (oculta), el número de
neuronas oscila entre 2 y 4. Este valor no ha de diferenciarse mucho del de la capa
de entrada, ya que si es muy pequeño supondría reducir mucho la información desde
el comienzo del entrenamiento, lo que podría dar lugar a importantes pérdidas en la
misma; y si es muy elevado, implicaría un exceso de parámetros en el modelo, lo que
produciría pérdidas en su capacidad predictiva. Por último, la capa de salida posee
2 neuronas, cada una de las cuales ofrecerán como salida un valor de concentración
correspondiente a uno de los cationes que componen la mezcla. Véase la Figura 19
a modo de ejemplo:
-173-
TRATAMIENTO ESTADÍSTICO DE DATOS
Figura 28: Ejemplo de una red entrenada y validada con topología 3-4-2.
Los cuadrados representan las neuronas de entrada y los círculos las de la capa oculta
y las de salida. Por último, los triángulos son los sesgos para cada nodo. Las
conexiones o pesos entre neuronas poseen un valor indicado por la escala de colores.
w Algoritmos de entrenamiento: los algoritmos empleados para el entrenamiento de la
red fueron: Back-propagation Online, Back-propagation Randomize, Delta-barDelta y RPROP.
w Número máximo de ciclos: 100000.
w Funciones de activación: se emplearon las funciones lineales y sigmoidales
fundamentalmente, en todas sus combinaciones para las tres capas de la red (excepto
para la primera, que se encuentra definida por defecto como lineal): lineal-sigmoidalsigmoidal, lineal-sigmoidal-lineal, lineal-lineal-sigmoidal y lineal-lineal-lineal.
Los parámetros que se mantuvieron fijos durante todos los entrenamientos fueron los
siguientes:
-174-
TRATAMIENTO ESTADÍSTICO DE DATOS
Velocidad de aprendizaje
0,1
Momentum
0,0
Recorte de patrones
1
Tolerancia de convergencia
0,01
Margen de error
0,1
Máxima perturbación de pesos
20 %
Límite de saturación de neuronas
80 %
Además, se previno la saturación, fijando el límite de saturación en un 80 %, y el
entrenamiento se llevó a cabo por validación cruzada, es decir, las redes obtenidas con un 100
% de convergencia estaban entrenadas y validadas. Por último, el comienzo del entrenamiento
fue elegido aleatoriamente.
El proceso de entrenamiento y validación se puede describir del siguiente modo:
1. De los 40 patrones disponibles, el programa elige un conjunto aleatorio de 36 para el
entrenamiento, dejando el resto para la validación de la red.
2. Una vez hecho esto, los 36 patrones de entrenamiento se introducen en la red,
obteniéndose una serie de valores para los pesos o conexiones entre las neuronas.
3. Posteriormente, los 4 patrones de validación pasan a través de la red definida
previamente.
4. Si el error obtenido entre las concentraciones de salida de Tl (I) y Pb (II) y las
especificadas para dicho conjunto es menor que el valor de tolerancia fijado, la red se
encuentra entrenada y validada y no requiere de ningún ciclo más. Si, por el contrario,
el error es superior al valor de convergencia, la red repite todo el proceso desde el
principio, utilizando un nuevo conjunto de patrones de entrenamiento, elegido de
acuerdo al método de validación cruzada.
5. El proceso continúa hasta que se alcance un error RMS del conjunto de validación
inferior al valor establecido para la convergencia (100 % de clasificación de las
muestras) o se llegue al máximo número de ciclos fijado. Un ejemplo del primer caso
-175-
TRATAMIENTO ESTADÍSTICO DE DATOS
sería el siguiente: si para unos determinados valores de intensidad, potencial y anchura
de pico la concentración de Tl (I) equivale a 0,2 mg·l-1, la salida obtenida en la red debe
ser lo más parecida posible a ésta para que la red esté bien entrenada y validada.
Cuando se alcanza un 100 % de clasificación, las conexiones o pesos obtenidos son los
adecuados y el sistema se encuentra disponible para predecir nuevas mezclas con concentraciones
desconocidas de Tl (I) y Pb (II), obtenidas experimentalmente. De este modo, una red entrenada
y validada está perfectamente capacitada para resolverlas.
Como hemos comentado anteriormente, se probaron todas las combinaciones posibles de
funciones de activación lineales y sigmoidales para las topologías 3-2-2, 3-3-2 y 3-4-2, lo que
hicieron un total de 48 redes discretas (ver Anexo X). De entre todas ellas, tan sólo 16 redes
lograron un porcentaje de clasificación superior al 90 %, como se especifica en la siguiente tabla,
ordenada en orden creciente de número de ciclos:
Topología
Algoritmo1
% Clasificación
Nº de ciclos
Func. Activac.2
3-4-2
OB
100
5207
l-s-l
3-4-2
OR
100
5256
l-s-l
3-3-2
OR
100
5685
l-s-l
3-2-2
OR
100
6090
l-s-l
3-3-2
OB
100
10817
l-s-l
3-3-2
OR
100
20595
l-s-s
3-2-2
OR
100
22974
l-s-s
3-4-2
OR
100
26136
l-s-s
3-2-2
OB
100
29611
l-s-s
3-4-2
OB
100
39936
l-s-s
-176-
TRATAMIENTO ESTADÍSTICO DE DATOS
Topología
Algoritmo1
% Clasificación
Nº de ciclos
Func. Activac.2
3-2-2
OB
100
63330
l-s-l
3-3-2
OB
100
68603
l-s-s
3-3-2
RP
94,44
100000
l-s-l
3-4-2
RP
91,67
100000
l-s-l
3-4-2
DD
91,67
100000
l-s-s
3-2-2
RP
91,67
100000
l-s-l
1
OB: Back-propagation online; OR: Back-propagation online randomize;
DD: Delta-bar-Delta; RP: RPROP.
2
l-s-s: lineal-sigmoidal-sigmoidal; l-s-l: lineal-sigmoidal-lineal.
Como puede observarse, sólo existen dos combinaciones de funciones de activación
adecuadas, ofreciendo mejores resultados la lineal-sigmoidal-lineal, al converger a menor número
de ciclos. Los algoritmos de entrenamiento que mejor actúan son back-propagation online y
back-propagation online randomize, ambos en la misma proporción, aunque con el segundo se
alcanzan menos ciclos. Por último, los algoritmos RPROP y Delta-bar-Delta resultaron ser los
peores, alcanzándose porcentajes de clasificación del 90 % en el mejor de los casos.
Las redes propuestas poseen una topología muy sencilla y, en la mayoría de los casos, el
número de ciclos que logran clasificaciones del 100 % puede considerarse pequeño. Esto supone
una gran ventaja dado que el número de pesos a estimar es pequeño, lo que contribuye a mejorar
la capacidad predictiva de la red.
Como red óptima proponemos la red que posee el mínimo error RMS total, que se
corresponde con la topología 3-3-2 (intermedia en cuanto a la sencillez), algoritmo backpropagation online y funciones de activación lineal-sigmoidal-lineal. Además, esta configuración
ofrece un número muy pequeño de ciclos, tan sólo 10817.
En la Figura 20 se recoge la evolución del error RMS total para esta red neuronal:
-177-
TRATAMIENTO ESTADÍSTICO DE DATOS
Error RMS
Error RMS vs tiempo de entrenamiento
Nº de ciclos
Figura 29: Evolución del RMS error para la red óptima.
Como se desprende de la figura, el error de entrenamiento para la red óptima es siempre
descendente hasta alcanzar un valor mínimo (punto final) de 0,0384, momento en el cual la
clasificación de los patrones es del 100 %. A partir de este preciso instante, la red se encuentra
perfectamente entrenada y validada.
El gráfico anterior es representativo del proceso de convergencia de todas las redes. En
principio, existe una rápida convergencia de los pesos hasta alcanzar un valor de error
suficientemente pequeño, a partir del cual, comienza un proceso de afinamiento que culminará
con la clasificación que estabilice el error en las muestras.
A continuación, y para terminar con las redes neuronales discretas, presentamos la tabla de
pesos o conexiones entre las distintas neuronas de la red:
-178-
TRATAMIENTO ESTADÍSTICO DE DATOS
Pesos o conexiones entre:
Neuronas de la capa de entrada
Neuronas de la capa oculta
1
2
3
Sesgo
1
2,3845
0,4017
-0,3138
-0,9523
2
-6,5687
3,2123
-3,3093
3,6805
3
-5,3778
-3,3952
7,8116
-1,4749
Pesos o conexiones entre:
Neuronas de la capa oculta
Neuronas de la capa de salida
1
2
3
Sesgo
1
0,8143
2,0180
-2,8999
0,5955
2
2,2448
-1,9067
2,5279
-1,2013
Los pesos negativos indican una conexión que inhibe la respuesta del nodo, mientras que
los positivos, por el contrario, la estimulan. Puede comprobarse que la semejanza con el proceso
sináptico que ocurre en las neuronas biológicas es patente.
b) Redes Neuronales Continuas.
Habitualmente, las redes neuronales basadas en información continua (señales) han sido
aplicadas construyendo topologías cuyas capas de entrada llevan asociadas una neurona por cada
potencial recogido en el voltamperograma. La desventaja de este método es evidente, tanto desde
el punto de vista de la carga computacional como del de la complejidad del modelo.
A la hora de aplicar las redes continuas a nuestro caso se empleó el conjunto continuo de
datos, es decir, los valores de amplitudes dominantes correspondientes a cada una de las señales
de los voltamperogramas de las muestras, obtenidos a partir del proceso de reducción de
dimensiones (ver Anexo IV). Esta reducción simplificó notablemente el modelo y constituye un
aspecto novedoso en electroquímica, permitiendo soslayar las desventajas enunciadas
anteriormente.
-179-
TRATAMIENTO ESTADÍSTICO DE DATOS
Como vimos en su momento, dicho método se aplicó utilizando un filtrado previo,
definiendo una frecuencia de corte que proporcionase un número aceptable de dimensiones y un
error de recomposición para la señal lo más bajo posible (inferior al 3 %). La elección de dicha
frecuencia de corte era fundamental, puesto que el número de dimensiones (amplitudes que
representaban las señales) se asocia con las neuronas de entrada a la red. Por tanto, si cada señal
fue reducida a 7 amplitudes, esto significa que el número de neuronas de la capa de entrada debe
ser también 7. Esta es la razón por la cual hemos denominado a este tipo de redes como redes
continuas, ya que las entradas al sistema se corresponden con las señales completas de los
voltamperogramas de las muestras, pero con sus dimensiones reducidas (de 80 valores hasta 7).
El objetivo perseguido era el mismo que con las redes neuronales discretas: obtener redes
lo más sencillas posibles para predecir las aportaciones de Tl (I) y Pb (II) de las muestras.
Para ello, se optó por construir redes con 7 neuronas en la capa de entrada
(correspondientes a las 7 amplitudes de cada señal), un número de nodos próximo a siete en la
oculta y dos en la de salida, para obtener las concentraciones de Tl (I) y Pb (II) de cada mezcla.
Por tanto, las características especificadas para el entrenamiento y validación de las redes
fueron las siguientes:
w Topología de la red: 7-X-2, donde, de acuerdo con las recomendaciones
bibliográficas, X = 8, 7, 6 y 5 (capa oculta con un número de nodos parecido a la de
entrada).Véase la Figura 21 a modo de ejemplo:
Figura 30: Ejemplo de red continua con topología 7-7-2.
-180-
TRATAMIENTO ESTADÍSTICO DE DATOS
w Algoritmos de entrenamiento: fueron los mismos que para las redes discretas: Backpropagation Online, Back-propagation Randomize, Delta-bar-Delta y RPROP.
w Número máximo de ciclos: 100000.
w Funciones de activación: iguales a las de las redes discretas: lineal-sigmoidalsigmoidal, lineal-sigmoidal-lineal, lineal-lineal-sigmoidal y lineal-lineal-lineal.
Los valores para la velocidad de aprendizaje, momentum, tolerancia, margen de error, así
como la perturbación de los pesos y la saturación de la neuronas se mantuvieron fijos e iguales
a los empleados con las redes discretas. También se empleó el entrenamiento con validación
cruzada y los patrones fueron introducidos en la red de forma aleatoria.
Los resultados obtenidos aparecen en la Tabla 11:
-181-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 11: Tabla de resultados para las pruebas con redes neuronales continuas de topología 7-X-2.
Topología
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-8-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-7-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
7-6-2
Algoritmo
% Clasific. Nº de Ciclos
Online Backprop
66,67
100000
Online Backprop Rand
69,44
100000
Delta-bar-Delta
58,33
100000
RPROP
41,67
100000
Online Backprop
55,56
100000
Online Backprop Rand
61,11
100000
Delta-bar-Delta
0,00
100000
RPROP
38,89
100000
Online Backprop
58,33
100000
Online Backprop Rand
55,56
100000
Delta-bar-Delta
5,56
100000
RPROP
27,78
100000
Online Backprop
19,44
100000
Online Backprop Rand
22,22
100000
Delta-bar-Delta
0,00
100000
RPROP
27,78
100000
Online Backprop
77,78
100000
Online Backprop Rand
72,22
100000
Delta-bar-Delta
38,89
100000
RPROP
47,22
100000
Online Backprop
61,11
100000
Online Backprop Rand
58,33
100000
Delta-bar-Delta
0,00
100000
RPROP
52,78
100000
Online Backprop
61,11
100000
Online Backprop Rand
58,33
100000
Delta-bar-Delta
0,00
100000
RPROP
27,78
100000
Online Backprop
13,89
100000
Online Backprop Rand
22,22
100000
Delta-bar-Delta
0,00
100000
RPROP
27,78
100000
Online Backprop
75,00
100000
Online Backprop Rand
80,56
100000
Delta-bar-Delta
58,33
100000
RPROP
38,89
100000
Online Backprop
61,11
100000
Online Backprop Rand
58,33
100000
Delta-bar-Delta
0,00
100000
RPROP
38,89
100000
Online Backprop
55,56
100000
Online Backprop Rand
61,11
100000
Delta-bar-Delta
8,33
100000
RPROP
47,22
100000
Online Backprop
27,78
100000
Online Backprop Rand
19,44
100000
Delta-bar-Delta
0,00
100000
RPROP
25,00
100000
Func. Activac.
Total RMS Error
lineal-sigmoidal-sigmoidal
0,1003
lineal-sigmoidal-sigmoidal
0,0890
lineal-sigmoidal-sigmoidal
0,1117
lineal-sigmoidal-sigmoidal
0,1741
lineal-sigmoidal-lineal
0,1155
lineal-sigmoidal-lineal
0,0983
lineal-sigmoidal-lineal
599,1750
lineal-sigmoidal-lineal
0,1797
lineal-lineal-sigmoidal
0,1203
lineal-lineal-sigmoidal
0,1193
lineal-lineal-sigmoidal
0,5993
lineal-lineal-sigmoidal
0,1561
lineal-lineal-lineal
0,1900
lineal-lineal-lineal
0,1742
lineal-lineal-lineal
177286,0000
lineal-lineal-lineal
0,1768
lineal-sigmoidal-sigmoidal
0,0821
lineal-sigmoidal-sigmoidal
0,0877
lineal-sigmoidal-sigmoidal
0,1417
lineal-sigmoidal-sigmoidal
0,1393
lineal-sigmoidal-lineal
0,1018
lineal-sigmoidal-lineal
0,1049
lineal-sigmoidal-lineal
500,6840
lineal-sigmoidal-lineal
0,1401
lineal-lineal-sigmoidal
0,1175
lineal-lineal-sigmoidal
0,1183
lineal-lineal-sigmoidal
0,7116
lineal-lineal-sigmoidal
0,1472
lineal-lineal-lineal
0,1835
lineal-lineal-lineal
0,1708
lineal-lineal-lineal
44246,1000
lineal-lineal-lineal
0,1739
lineal-sigmoidal-sigmoidal
0,0928
lineal-sigmoidal-sigmoidal
0,0831
lineal-sigmoidal-sigmoidal
0,1133
lineal-sigmoidal-sigmoidal
0,1488
lineal-sigmoidal-lineal
0,1068
lineal-sigmoidal-lineal
0,1168
lineal-sigmoidal-lineal
499,5510
lineal-sigmoidal-lineal
0,1407
lineal-lineal-sigmoidal
0,1202
lineal-lineal-sigmoidal
0,1203
lineal-lineal-sigmoidal
0,4896
lineal-lineal-sigmoidal
0,1331
lineal-lineal-lineal
0,1805
lineal-lineal-lineal
0,1874
lineal-lineal-lineal
88592,3000
lineal-lineal-lineal
0,1738
.../...
-182-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 11: Tabla de resultados para las pruebas con redes neuronales continuas de topología 7-X-2.
(Continuación).
Topología
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
7-5-2
Algoritmo
% Clasific. Nº de Ciclos
Online Backprop
72,22
100000
Online Backprop Rand
75,00
100000
Delta-bar-Delta
69,44
100000
RPROP
38,89
100000
Online Backprop
55,56
100000
Online Backprop Rand
63,89
100000
Delta-bar-Delta
0,00
100000
RPROP
36,11
100000
Online Backprop
52,78
100000
Online Backprop Rand
58,33
100000
Delta-bar-Delta
5,56
100000
RPROP
55,56
100000
Online Backprop
30,56
100000
Online Backprop Rand
22,22
100000
Delta-bar-Delta
0,00
100000
RPROP
25,00
100000
-183-
Func. Activac.
Total RMS Error
lineal-sigmoidal-sigmoidal
0,0949
lineal-sigmoidal-sigmoidal
0,0857
lineal-sigmoidal-sigmoidal
0,1001
lineal-sigmoidal-sigmoidal
0,1748
lineal-sigmoidal-lineal
0,1131
lineal-sigmoidal-lineal
0,1031
lineal-sigmoidal-lineal
99,6339
lineal-sigmoidal-lineal
0,1683
lineal-lineal-sigmoidal
0,1206
lineal-lineal-sigmoidal
0,1198
lineal-lineal-sigmoidal
0,5993
lineal-lineal-sigmoidal
0,1225
lineal-lineal-lineal
0,1777
lineal-lineal-lineal
0,1934
lineal-lineal-lineal
132939,0000
lineal-lineal-lineal
0,1680
TRATAMIENTO ESTADÍSTICO DE DATOS
Como puede observarse en la Tabla 11, los resultados obtenidos distan mucho de ser los
esperados, tanto en el elevado número de ciclos de entrenamiento (100000) como en el
porcentaje de clasificación resultante. Éste fue tan sólo de un 80 % y se consiguió para una red
de topología 7-6-2, con el algoritmo Back-propagation Randomize y una combinación de
funciones de activación del tipo lineal-sigmoidal-sigmoidal.
Por consiguiente, las clasificaciones obtenidas con estas estructuras podemos considerarlas
como malas.
Para resolver todas estas dificultades y obtener redes entrenadas y validadas al 100 %, se
pensó en varias posibilidades:
w Aumentar el número de ciclos para lograr una convergencia del 100 %.
w Probar topologías más sencillas a base de simplificar la capa de entrada o la capa
oculta de las redes.
w Emplear una segunda capa oculta.
1) Aumentar el número de ciclos:
Con respecto a la primera actuación, se hicieron pruebas de convergencia a mayor número
de ciclos con varias redes, aquellas que en primera instancia ofrecían un porcentaje de
clasificación más elevado. Los resultados se muestran en la siguiente tabla:
Topología
Algoritmo1
% Clasificación
Nº de ciclos
Func. Activac.2
7-8-2
OB
100
3612460
l-s-s
7-8-2
OR
100
3411558
l-s-s
7-8-2
OR
100
2071290
l-s-l
1
OB: Back-propagation online; OR: Back-propagation online randomize;
2
l-s-s: lineal-sigmoidal-sigmoidal; l-s-l: lineal-sigmoidal-lineal.
De los resultados se desprende el elevado número de ciclos necesario para obtener un 100
% de clasificación. Esto es perjudicial, puesto que aparte del costo temporal, las clasificaciones
no serían fiables, ya que si el número de ciclos de ejecución de una red es muy elevado, ésta
alcanza un estado de sobreentrenamiento. Esto significa que la red no aprende de los patrones
suministrados, sino que los memoriza. Esta situación sería comparable a los procesos de
-184-
TRATAMIENTO ESTADÍSTICO DE DATOS
aprendizaje en la enseñanza de cualquier disciplina: la contraposición entre el aprendizaje
significativo y el puramente memorístico. El primero es más duradero y efectivo y permite
extrapolar los conocimientos obtenidos a situaciones nuevas (en nuestro caso, emplear las redes
entrenadas y validadas para la resolución de mezclas con concentraciones desconocidas de Tl+
y Pb2+); mientras que el segundo, es bastante más breve y no conlleva las aplicaciones que el otro
implica.
En general, es mejor una red neuronal entrenada y validada con pocos ciclos, pero que
clasifique tan sólo hasta el 90 %, que una red que alcance el 100 % de convergencia haciendo uso
de un número muy elevado de ciclos.
2) Probar topologías más sencillas simplificando la capa de entrada o la oculta:
w Con respecto a la capa de entrada:
Con idea de encontrar redes simples, a la vista de las correlaciones (dependencias lineales)
existentes entre los valores de amplitud de las señales, se estableció la siguiente hipótesis: si una
señal podía explicarse a partir de un único par de frecuencia/amplitud (debido a la
proporcionalidad, este valor de amplitud debía de contener información sobre las seis amplitudes
restantes en las que se dividía cada señal), no sería nada descabellado concebir la estructura de
una red neuronal con una única entrada. Esto ofrecería la oportunidad de trabajar con topologías
sencillísimas, tales como 1-2-2 ó 1-3-2, (siempre redes con tres capas de neuronas, ya que ésta
siempre ha sido una limitación del software).
En base a esto, se realizaron pruebas con el software de redes neuronales Qwiknet 3.2. Pero
los resultados obtenidos no fueron los que teóricamente se esperaban. Por consiguiente hubo que
rechazar la hipótesis de una sola entrada.
Sin embargo, el tema de las correlaciones entre amplitudes condujo a la puesta en práctica
de otra idea: si con una única entrada no se conseguía ningún logro, aumentando el número hasta
2, 3 ó 4 y continuando en la misma línea, el resultado podría perfilarse más. Y tampoco se
alcanzó este objetivo.
w Con respecto a la capa oculta:
En este caso, se simplificó el número de neuronas de la capa oculta. Para ello, se entrenaron
redes con secuencias de capas de neuronas tales como: 7-4-2, 7-3-2, 7-2-2 y 7-1-2. Los resultados
se recogen en la Tabla 12:
-185-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 12: Tabla de resultados de las pruebas con redes continuas de capa oculta pequeña.
Topología
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-4-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-3-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
7-2-2
Algoritmo
% Clasific. Nº de Ciclos
Online Backprop
75,00
100000
Online Backprop Rand
72,22
100000
Delta-bar-Delta
47,22
100000
RPROP
41,67
100000
Online Backprop
58,33
100000
Online Backprop Rand
55,56
100000
Delta-bar-Delta
0,00
100000
RPROP
41,67
100000
Online Backprop
52,78
100000
Online Backprop Rand
58,33
100000
Delta-bar-Delta
5,56
100000
RPROP
50,00
100000
Online Backprop
11,11
100000
Online Backprop Rand
22,22
100000
Delta-bar-Delta
0,00
100000
RPROP
30,56
100000
Online Backprop
72,22
100000
Online Backprop Rand
75,00
100000
Delta-bar-Delta
47,22
100000
RPROP
38,89
100000
Online Backprop
47,22
100000
Online Backprop Rand
55,56
100000
Delta-bar-Delta
0,00
100000
RPROP
27,78
100000
Online Backprop
52,78
100000
Online Backprop Rand
58,33
100000
Delta-bar-Delta
8,33
100000
RPROP
58,33
100000
Online Backprop
27,78
100000
Online Backprop Rand
19,44
100000
Delta-bar-Delta
0,00
100000
RPROP
27,78
100000
Online Backprop
44,44
100000
Online Backprop Rand
63,89
100000
Delta-bar-Delta
47,22
100000
RPROP
30,56
100000
Online Backprop
41,67
100000
Online Backprop Rand
36,11
100000
Delta-bar-Delta
0
100000
RPROP
30,56
100000
Online Backprop
58,33
100000
Online Backprop Rand
55,56
100000
Delta-bar-Delta
8,333
100000
RPROP
30,56
100000
Online Backprop
19,44
100000
Online Backprop Rand
22,22
100000
Delta-bar-Delta
0
100000
RPROP
27,78
100000
Func. Activac.
Total RMS Error
lineal-sigmoidal-sigmoidal
0,0857
lineal-sigmoidal-sigmoidal
0,0853
lineal-sigmoidal-sigmoidal
0,1377
lineal-sigmoidal-sigmoidal
0,1393
lineal-sigmoidal-lineal
0,1114
lineal-sigmoidal-lineal
0,1216
lineal-sigmoidal-lineal
488,8270
lineal-sigmoidal-lineal
0,1789
lineal-lineal-sigmoidal
0,1206
lineal-lineal-sigmoidal
0,1198
lineal-lineal-sigmoidal
0,5993
lineal-lineal-sigmoidal
0,1273
lineal-lineal-lineal
0,2936
lineal-lineal-lineal
0,1709
lineal-lineal-lineal
953,5730
lineal-lineal-lineal
0,1657
lineal-sigmoidal-sigmoidal
0,0908
lineal-sigmoidal-sigmoidal
0,0941
lineal-sigmoidal-sigmoidal
0,1394
lineal-sigmoidal-sigmoidal
0,1752
lineal-sigmoidal-lineal
0,1320
lineal-sigmoidal-lineal
0,1180
lineal-sigmoidal-lineal
102,0290
lineal-sigmoidal-lineal
0,1713
lineal-lineal-sigmoidal
0,1206
lineal-lineal-sigmoidal
0,1199
lineal-lineal-sigmoidal
0,4896
lineal-lineal-sigmoidal
0,1263
lineal-lineal-lineal
0,1778
lineal-lineal-lineal
0,1933
lineal-lineal-lineal
44031,7000
lineal-lineal-lineal
0,1711
lineal-sigmoidal-sigmoidal
0,1248
lineal-sigmoidal-sigmoidal
0,0989
lineal-sigmoidal-sigmoidal
0,1392
lineal-sigmoidal-sigmoidal
0,1585
lineal-sigmoidal-lineal
0,1408
lineal-sigmoidal-lineal
0,1461
lineal-sigmoidal-lineal
298,1690
lineal-sigmoidal-lineal
0,1713
lineal-lineal-sigmoidal
0,1204
lineal-lineal-sigmoidal
0,1193
lineal-lineal-sigmoidal
0,4896
lineal-lineal-sigmoidal
0,1433
lineal-lineal-lineal
0,1900
lineal-lineal-lineal
0,1742
lineal-lineal-lineal
7,7255
lineal-lineal-lineal
0,1729
.../...
-186-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 12: Tabla de resultados de las pruebas con redes continuas de capa oculta pequeña (Continuación).
Topología
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
7-1-2
Algoritmo
% Clasific. Nº de Ciclos
Online Backprop
19,44
100000
Online Backprop Rand
19,44
100000
Delta-bar-Delta
19,44
100000
RPROP
22,22
100000
Online Backprop
27,78
100000
Online Backprop Rand
30,56
100000
Delta-bar-Delta
0
100000
RPROP
27,78
100000
Online Backprop
19,44
100000
Online Backprop Rand
19,44
100000
Delta-bar-Delta
5,556
100000
RPROP
22,22
100000
Online Backprop
11,11
100000
Online Backprop Rand
19,44
100000
Delta-bar-Delta
0
100000
RPROP
30,56
100000
-187-
Func. Activac.
Total RMS Error
lineal-sigmoidal-sigmoidal
0,2315
lineal-sigmoidal-sigmoidal
0,2316
lineal-sigmoidal-sigmoidal
0,2295
lineal-sigmoidal-sigmoidal
0,2304
lineal-sigmoidal-lineal
0,2179
lineal-sigmoidal-lineal
0,2171
lineal-sigmoidal-lineal
157,7580
lineal-sigmoidal-lineal
0,2188
lineal-lineal-sigmoidal
0,2216
lineal-lineal-sigmoidal
0,2229
lineal-lineal-sigmoidal
0,5993
lineal-lineal-sigmoidal
0,2248
lineal-lineal-lineal
0,2950
lineal-lineal-lineal
0,2264
lineal-lineal-lineal
44141,0000
lineal-lineal-lineal
0,2174
TRATAMIENTO ESTADÍSTICO DE DATOS
Pero, tras una rápida inspección de la tabla, se puede comprobar que tampoco se obtuvo
ningún éxito, siendo el porcentaje máximo de clasificación del 75 % para una red 7-3-2 con las
mismas características que en las pruebas anteriores. Ni siquiera en aquellos casos donde las
transformaciones eran lineales, pudo obtenerse nada en claro, esperanza fundada a partir de la
existencia de correlaciones entre las amplitudes (ver tabla de correlaciones y Figura 3). Se supuso
que si éstas eran linealmente dependientes unas de otras, el uso de funciones de activación
lineales, para transferir los datos de una capa a otra, permitiría eliminar información redundante
contenida en las entradas a la red y podría establecerse una buena clasificación. Pero no fue así.
w Emplear una segunda capa oculta:
En cuanto a esta tercera y última posibilidad, emplear redes con un mayor número de capas
ocultas, resultó ser la opción acertada, como veremos a continuación.
Como el programa Qwiknet 3.2 posee la limitación de trabajar con una sola capa oculta,
hubo que utilizar otro software diferente denominado Qnet2000.
En la Figura 22, se representa la pantalla de trabajo de dicho programa:
Figura 35: Pantalla de control del programa de redes neuronales Qnet2000.
-188-
TRATAMIENTO ESTADÍSTICO DE DATOS
En ella se recogen las características que definen las redes empleadas. Pueden destacarse
el número de capas de la red, las neuronas de entrada y de salida, los nodos presentes en las capas
ocultas, las funciones de transferencia o de activación utilizadas, el número de conexiones entre
neuronas, los patrones de entrenamiento y los de validación, así como también, el modo de
entrenamiento.
Por otro lado, también aparecen reflejados los valores de cada uno de los parámetros de
entrenamiento. Estos se encuentran recogidos con más detalle en la Figura 23:
A continuación se da una breve descripción de los parámetros más importantes:
Figura 36: Pantalla de definición de los parámetros de entrenamiento para el
programa Qnet2000.
‘ Máximo número de iteraciones o ciclos: consiste en el máximo número de iteraciones
a realizar para llevar a cabo el entrenamiento. No hay ninguna forma de
predeterminar el número de ciclos que serán necesarios para alcanzar la convergencia
con una red (podría llevar unas pocos cientos de iteraciones o muchos miles).
‘ Iteración de comienzo del control de velocidad de aprendizaje: indica el ciclo en el
que se activa el control de velocidad de aprendizaje (LRC), el cual emplea un
algoritmo especial que se encarga de buscar un rango de velocidad óptimo durante
el entrenamiento en ejecución.
‘ Velocidad de aprendizaje: la velocidad de aprendizaje, ç (eta), controla la rapidez a
-189-
TRATAMIENTO ESTADÍSTICO DE DATOS
la que el algoritmo de entrenamiento del programa intenta aprender. Este factor
determina el tamaño del ajuste de los pesos de los nodos durante el proceso de
aprendizaje de la red. El rango de validez va desde 0,0 hasta 1,0. Un valor elevado
de ç conduce a un aprendizaje más rápido, pero implica inestabilidad y divergencia
en el entrenamiento; mientras que un valor pequeño da lugar a una mejora numérica
en la convergencia a costa de alargar considerablemente el tiempo de entrenamiento.
‘ Algoritmo de entrenamiento: el software emplea algoritmos de Back-propagation.
‘ Velocidad de aprendizaje máxima y mínima: marca los límites entre los que se
mueve la velocidad de aprendizaje. El sistema LRC puede modificar dichos límites
para evitar inestabilidades durante el entrenamiento.
‘ Momentum (á): es el coeficiente de aprendizaje empleado por los algoritmos de
entrenamiento del programa. Amortigua las variaciones que se producen en los pesos
y ayuda con la estabilidad de los algoritmos, proporcionando al mismo tiempo un
aprendizaje rápido.
‘ Patrones procesados por ciclo: permite establecer el número de patrones de
entrenamiento que se procesan antes de actualizar los pesos de la red. Este parámetro
puede provocar un gran efecto sobre todo el proceso de entrenamiento, así como
sobre la convergencia. El programa procesa por defecto todos los patrones antes de
actualizar los pesos de la red (valor igual a 0), calcula luego el vector de error global
y lo aplica a los algoritmos de ajuste de los pesos. Esto conduce generalmente a un
error bastante bueno tanto para el conjunto de entrenamiento como el de prueba, con
un costo considerable de tiempo. Se recomienda el uso de este método para conjuntos
de entrenamiento donde existan relaciones imprecisas entre las entradas y las salidas.
Cualquier modificación en este parámetro durante el entrenamiento puede provocar
grandes variaciones en las características del aprendizaje.
‘ Valor de tolerancia: durante el entrenamiento se calcula y muestra el porcentaje de
casos que caen dentro del valor de tolerancia especificado. Puede ser una herramienta
muy útil para medir la exactitud de un modelo.
‘ Error de entrenamiento RMS: permite elegir el error RMS del conjunto de prueba al
cual finalizará el entrenamiento.2
Las características de entrenamiento especificadas para las redes neuronales fueron las
siguientes:
w Topología de la red: 7-X-Y-2, la cual se corresponde con una red neuronal
-190-
TRATAMIENTO ESTADÍSTICO DE DATOS
constituida por cuatros capas. En la capa de entrada se dispusieron 7 neuronas,
correspondientes a los valores de amplitud de cada señal, los cuales constituyen el
conjunto continuo de datos. En la primera capa oculta, el número de neuronas (X)
osciló entre 6 y 5, valor próximo al estrato de entrada que evita pérdidas importantes
de información. Las opciones en la segunda capa oculta fueron más amplias,
empleándose en todos los casos de 2 a 5 nodos (Y). Por último, la capa de salida se
compuso de 2 neuronas, cada una de las cuales ofrecerían como salida un valor de
concentración correspondiente a uno de los cationes que componen la mezcla. Véase
la Figura 24 a modo de ejemplo:
Figura 37: Red neuronal entrenada y validada con topología 7-6-4-2.
En este caso, el número de nodos ocultos y de conexiones resultaron ser de 10 y 74,
respectivamente, variando ambos en cada caso según la estructura de la red.
w Algoritmos de entrenamiento: el algoritmo empleado para el entrenamiento de la red
fue el back-propagation estándar, puesto que el coeficiente de propagación rápida fue
fijado en cero.
w Número máximo de iteraciones: 50000.
w Funciones de activación: se emplearon los cuatro tipos posibles de funciones
aconsejadas en bibliografía: lineal, sigmoidal, gaussiana y tangente hiperbólica, en
todas sus combinaciones, para las cuatro capas de la red (excepto para la primera, que
-191-
TRATAMIENTO ESTADÍSTICO DE DATOS
se encuentra definida por defecto como lineal), lo que suponen 3×3×3 = 27
combinaciones.
El resto de los parámetros, cuyos valores aparecen en la Figura 23, se mantuvieron fijos
durante todos los entrenamientos. En todos los casos, el conjunto de entrenamiento estuvo
constituido por 32 patrones, mientras que los 8 restantes, elegidos aleatoriamente en cada red,
formaron parte del de prueba. Esto es equivalente al entrenamiento por validación cruzada
empleado en las redes discretas.
El proceso de entrenamiento y validación llevado a cabo por el programa Qnet2000 es
similar al ejecutado por Qwiknet 3.2, software utilizado para entrenar y validar las redes
neuronales discretas, descrito anteriormente.
Combinando los posibles valores de X e Y para las capas ocultas, así como las funciones
de activación, se entrenaron y validaron un total de 2×5×27 = 270 redes neuronales continuas.
Los entrenamientos finalizaron una vez alcanzado el máximo número de iteraciones dispuesto,
obteniéndose en cada caso el error RMS para el conjunto de prueba y el de entrenamiento, así
como la correlación alcanzada (en tanto por uno) para dichos conjuntos.
En las siguientes figuras, se representa la información gráfica obtenida a partir del
entrenamiento y validación de las redes continuas. En la Figura 25, aparece el error RMS para
el conjunto de entrenamiento; en la 26, el correspondiente a los patrones de prueba y, finalmente,
en la 27, se presenta la disposición de los patrones de entrenamiento y validación a la curva de
ajuste óptima que proporcionaría una red cualquiera, para cada muestra de entrada:
Figura 38: Error RMS para el conjunto de entrenamiento de una red neuronal
continua.
-192-
TRATAMIENTO ESTADÍSTICO DE DATOS
Figura 39: Error RMS para el conjunto de prueba de una red neuronal
continua.
En los dos casos, se observa una variación descendente a lo largo de todo el proceso,
aunque en el error del conjunto de prueba, se alcanza un mínimo a aproximadamente 25000
ciclos, ascendiendo de nuevo posteriormente. Y, por último, la Figura 27:
Figura 40: Gráfico de ajuste de los patrones de entrenamiento y de prueba a
una curva de correlación óptima.
-193-
TRATAMIENTO ESTADÍSTICO DE DATOS
El software también genera un archivo, después de cada prueba, con las columnas que
aparecen en la tabla siguiente:
Nº muestra Trn (1) o Tst (0) [Tl (I)] [Tl (I)]*
[Pb (II)]
[Pb (II)]*
donde se identifica cada patrón, sus concentraciones conocidas y las predichas por la red, tanto
si la muestra es de entrenamiento, como de prueba. Mediante una aplicación MATLAB (ver
Anexo XI), especialmente diseñada, se calculó el error total de la predicción como suma de
diferencias entre concentraciones de Tl (I) y Pb (II) reales y predichas, para cada uno de los
patrones pertenecientes a los dos subconjuntos, de entrenamiento y prueba.
El programa actúa de la siguiente manera:
1. Primero, realiza una lectura de los archivos de salidas de red suministrados.
2. Seguidamente, calcula las diferencias que existen entre los valores reales y los predichos
por las redes para las concentraciones de Tl (I) y Pb (II) en cada muestra.
3. Después, lleva a cabo la suma de dichas diferencias, distinguiendo si el patrón pertenece
al conjunto de entrenamiento o al de prueba (hay que recordar que Qnet2000 escogía
aleatoriamente si un patrón iba a pertenecer a un grupo o a otro).
4. Por último, presenta los errores totales de predicción para cada uno de los conjuntos y
realiza una representación gráfica de las diferencias individuales para cada ion. A
continuación, en la Figura 28, se muestra un ejemplo de dicha representación, donde los
errores de predicción de los patrones se han obtenido tras la aplicación de una red de
topología 7-6-4-2, cuyas funciones de activación son: lineal-sigmoidal-sigmoidalsigmoidal:
-194-
TRATAMIENTO ESTADÍSTICO DE DATOS
0.09
Tl (I)
0.08
Pb (II)
Errores de predicción
0.07
0.06
0.05
0.04
0.03
0.02
0.01
0
0
10
20
Nº de muestras
30
40
Figura 41: Errores de predicción para cada patrón de Tl (I) y Pb (II).
En el Anexo XII, se recogen los errores totales de predicción (E.Tot.Trn y E.Tot.Tst), junto
con los errores RMS y las correlaciones entre las predicciones y los valores reales para cada
conjunto en todas las redes.
Los errores totales de predicción para los conjuntos de entrenamiento y de prueba en cada
red constituyen un parámetro idóneo para encontrar la red neuronal continua óptima que permita
separar las mezclas de Tl (I) y Pb (II). Se pretende obtener una o varias redes que posean un error
de entrenamiento pequeño y, al mismo tiempo, conserven una alta capacidad predictiva (error de
prueba también pequeño).
En las Tablas 13 y 14 se reflejan dichos errores para los conjuntos de prueba y
entrenamiento, respectivamente:
-195-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 13: Errores totales de predicción para el conjunto de entrenamiento o training (trn)
Func.Activ.
lsss
lssg
lsst
lsgs
lsgg
lsgt
lsts
lstg
lstt
lgss
lgsg
lgst
lggs
lggg
lggt
lgts
lgtg
lgtt
ltss
ltsg
ltst
ltgs
ltgg
ltgt
ltts
lttg
lttt
7522
1,107675
1,103130
1,236687
1,466637
1,238456
1,345547
1,295759
1,157615
1,234528
0,664187
1,233113
1,084325
1,364768
0,949850
1,296610
1,274145
1,216044
0,969652
1,013286
1,025858
1,150707
1,228960
1,082578
1,208877
1,023026
1,068332
1,259062
7532
0,891009
1,073756
1,323953
1,323278
1,187585
1,522637
1,280227
1,043658
1,410022
0,843023
0,886216
1,185316
1,402001
1,103680
0,658661
0,985549
1,078193
1,106598
1,053669
1,020840
0,971144
1,257692
1,087142
1,017888
0,703059
1,067951
1,099244
7542
0,966013
1,094950
1,215681
1,465827
1,095600
0,964309
1,313773
1,072192
0,692974
0,913578
0,924507
1,359252
0,923932
1,165983
0,879829
0,519364
0,755272
0,838366
1,159274
1,033215
0,849688
1,222739
1,075201
1,011401
0,562666
0,958906
1,137773
7552
0,985124
1,309579
1,092167
1,161141
1,111367
1,164823
0,842564
1,011808
0,738703
1,070765
1,118903
1,309715
0,692331
0,897591
1,289685
0,621325
0,723344
0,643629
0,685969
1,038961
1,092438
1,039924
1,035533
1,267965
0,768675
0,985182
0,863865
7562
1,113920
1,124312
1,279944
1,261831
1,075662
1,235911
0,600305
0,972042
1,105449
0,672086
0,877401
0,998449
1,008617
0,736226
0,877507
0,596792
1,137754
0,678537
0,760383
0,977317
1,184173
0,568313
0,976369
0,771371
0,532917
0,998135
0,627645
-196-
7622
1,422057
1,225095
1,139438
1,423866
1,159591
1,260296
1,453952
1,103530
1,536911
1,201675
1,084615
1,039721
1,342304
1,215413
1,115462
1,485747
1,169399
1,293978
0,993969
1,062279
0,954735
1,385732
1,159479
1,307002
1,247130
1,269726
1,211851
7632
1,040311
1,205657
1,144597
1,328249
1,165931
1,415734
1,127116
1,090330
1,219166
0,956927
1,040397
0,722835
1,155184
1,010708
1,331204
0,469661
1,017174
1,303031
0,785962
1,030106
0,998677
1,288726
0,992554
1,315420
1,082926
1,045771
1,187998
7642
0,994338
0,960880
1,148853
1,371895
1,175392
1,326643
0,731624
1,111666
0,750222
0,881666
1,029328
1,063232
0,714783
0,713707
0,960136
0,561470
1,020878
0,666465
0,918282
0,996018
0,155535
1,061361
1,146994
1,109302
0,599717
0,778187
0,880180
7652
0,679934
0,973437
1,254039
0,959468
0,948965
1,433226
0,505727
1,210778
0,644802
0,573899
0,858952
1,011469
0,672774
1,070191
1,070191
0,668976
0,938349
0,542533
0,958034
0,890945
0,828915
0,557368
0,668878
0,621317
0,795324
0,995366
1,393730
7662
0,985389
1,114422
1,298055
1,038471
0,957491
1,163772
0,806963
1,086331
0,590225
0,838683
1,024802
1,166269
0,591929
0,990963
1,056977
0,649946
1,066177
0,596238
0,640654
1,116552
0,850613
0,536351
0,962403
1,395025
0,474249
0,961693
0,565859
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 14: Errores totales de predicción para el conjunto de prueba o test (tst)
Func.Activ.
lsss
lssg
lsst
lsgs
lsgg
lsgt
lsts
lstg
lstt
lgss
lgsg
lgst
lggs
lggg
lggt
lgts
lgtg
lgtt
ltss
ltsg
ltst
ltgs
ltgg
ltgt
ltts
lttg
lttt
7522
0,634440
0,465626
0,433174
0,486748
0,372620
0,556600
0,513401
0,492031
0,629679
0,422149
0,234641
0,416799
0,465816
0,574798
0,440270
0,529331
0,291606
0,421704
0,481144
0,335545
0,434616
0,457791
0,454682
0,528400
0,521848
0,345660
0,316526
7532
0,342098
0,383117
0,367839
0,525461
0,357595
0,375991
0,732084
0,385293
0,377587
0,466361
0,430798
0,553972
0,349048
0,274762
0,402771
0,496098
0,445201
0,555256
0,726547
0,442974
0,518527
0,532070
0,392861
0,407799
0,277255
0,384346
0,483252
7542
0,268429
0,305181
0,415611
0,361108
0,400773
0,451638
0,398854
0,358016
0,309079
0,487887
0,483707
0,431656
0,363480
0,339127
0,300346
0,314807
0,295162
0,399384
0,236657
0,327769
0,364763
0,442697
0,374843
0,402030
0,240280
0,555550
0,399221
7552
0,517881
0,311517
0,408062
0,541320
0,349470
0,775796
0,262355
0,331430
0,157635
0,415415
0,303329
0,339458
0,583042
0,437524
0,341114
1,080996
0,292933
0,274854
0,301206
0,317688
0,449873
0,335334
0,475322
0,381169
0,397319
0,455454
0,439046
7562
0,540992
0,404295
0,357621
0,460271
0,389139
0,537691
0,194300
0,348848
0,486119
0,488364
0,486805
0,366994
0,407777
0,185153
0,332484
0,338998
0,731018
0,482006
0,313453
0,453919
0,282727
0,418648
0,595426
0,463922
0,405767
0,365428
0,323627
-197-
7622
0,219749
0,394114
0,632003
0,690970
0,419568
0,620992
0,435717
0,499296
0,270376
0,449715
0,492202
0,210152
0,651372
0,951111
0,482952
0,408416
0,377347
0,516395
0,380197
0,385529
0,343924
0,482350
0,315946
0,516373
0,259481
0,516116
0,400319
7632
0,352828
0,294983
0,411270
0,596966
0,365350
0,434343
0,599043
0,414912
0,522454
0,490033
0,395214
0,253836
0,468150
0,410505
0,463714
0,432296
0,497043
0,335457
0,251718
0,375097
0,333186
0,400291
0,489027
0,362566
0,520921
0,330062
0,409564
7642
0,564377
0,556975
0,425015
0,378809
0,291869
0,435965
0,267675
0,279766
0,542392
0,295130
0,472643
0,262027
0,269104
0,431184
0,540470
0,464883
0,353292
0,436323
0,318188
0,311583
0,546659
0,370610
0,384312
0,593685
0,263039
0,255813
0,429364
7652
1,112983
0,560066
0,387469
0,382407
0,485152
0,421668
0,317489
0,510668
0,370716
0,281638
0,642981
0,591965
0,534323
0,354777
0,354777
0,307560
0,338116
0,396232
1,483472
0,404038
0,456573
0,415120
0,431105
0,239543
0,268123
0,343445
0,300453
7662
0,559776
1,046218
0,291142
0,496277
0,329979
0,519345
0,312822
0,402504
0,389026
0,335273
0,324864
0,469670
0,488836
0,370800
0,477086
0,268318
0,308595
0,314825
0,319667
0,252207
0,422688
0,351494
0,646243
0,345476
0,284622
0,356620
0,369139
TRATAMIENTO ESTADÍSTICO DE DATOS
En estas tablas, los valores en negrita indican los errores totales de predicción mínimos
obtenidos en cada una de las diez topologías investigadas.
Con vistas a obtener la red neuronal óptima, a partir de las tablas anteriores, se obtuvo la
Tabla 15, donde se recogen aquellas redes con los errores totales de predicción más pequeños
para los dos conjuntos:
-198-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 15: Redes neuronales continuas con valores de errores totales de predicción mínimos.
Topología de red
7-5-2-2
7-5-3-2
7-5-4-2
7-5-5-2
7-5-6-2
7-6-2-2
7-6-3-2
7-6-4-2
7-6-5-2
7-6-6-2
Topología de red
7-5-2-2
7-5-3-2
7-5-4-2
7-5-5-2
7-5-6-2
7-6-2-2
7-6-3-2
7-6-4-2
7-6-5-2
7-6-6-2
Conjunto de prueba
Error Min. Pred. Test
0,2346
0,2748
0,2367
0,1576
0,1852
0,2102
0,2517
0,2558
0,2395
0,2522
0,1576
Error Min.Trn Asociado
1,2331
1,1037
1,1593
0,7387
0,7362
1,0397
0,7860
0,7782
0,6213
1,1166
Conjunto de entrenamiento
Func.Activación. Error Min. Pred. Trn
lgss
0,6642
lggt
0,6587
lgts
0,5194
lgts
0,6213
ltts
0,5329
ltst
0,9547
ltss
0,4697
lttg
0,1555
lsts
0,5057
ltts
0,4742
Error mínimo
0,1555
Error Min. Test Asociado
0,4221
0,4028
0,3148
1,0810
0,4058
0,3429
0,4323
0,5467
0,3175
0,2846
Func.Activación.
lgsg
lggg
ltss
lstt
lggg
lgst
lgts
ltst
ltgt
ltsg
Error mínimo
Funciones de Activación:
l = lineal
s = sigmoidal
t = tangente hiperbólica
g = gaussiana
-199-
TRATAMIENTO ESTADÍSTICO DE DATOS
Gracias a ello, hemos reducido el conjunto de 270 redes iniciales hasta 20. Estudiando
detenidamente los resultados, puede llegarse a las siguientes conclusiones:
1. Los errores totales de predicción mínimos para el conjunto de validación (tst) y para
el de entrenamiento (trn) no coinciden en una misma red: 7-5-5-2 lstt para el tst y 76-4-2 lttg para el trn.
2. Se llevó a cabo un breve estudio para ver si se podía identificar algún tipo de analogía
y se observó que existían algunas combinaciones de funciones de activación que se
repetían bastante a la hora de poseer errores mínimos de predicción: en el tst, tan sólo
se repetía la combinación lggg, el resto aparecía una sola vez; no obstante, excepto
en dos de los casos, la función tangente hiperbólica formaba parte de todas ellas, lo
que ya era significativo; además, era la más abundante. Por otro lado, en el trn, se
repetían dos combinaciones: lgts y ltts, sucediendo igual que antes con respecto a la
tangente hiperbólica, aunque la función más abundante pasó a ser la gaussiana. Desde
un punto de vista global, topologías con combinaciones lgts (3), ltts (2), ltss (2), lggg
(2) y ltst (2), son las que más se repitieron (el número entre paréntesis indica el grado
de repetición).
3. A partir de todo lo anterior, parece ser que una combinación que posee una función
de activación del tipo tangente hiperbólica es muy probable que determine un error
total de predicción pequeño para el conjunto de validación, mientras que la presencia
de una gaussiana facilita el proceso para el de entrenamiento.
Obviamente, la bondad de una red no depende exclusivamente de uno sólo de los errores
totales , sino de la conjunción de ambos (prueba y entrenamiento). En base a esto, se descartaron
las redes que tuviesen un valor superior a 0,7 en al menos uno de sus errores totales de
predicción. De este modo, el conjunto quedó reducido a 9 redes.
En la siguiente tabla se representan las topologías seleccionadas, junto con los errores
correspondientes en cada caso:
-200-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tipo de Red
Error Pred. Mínimo
Tst o Trn asociado
Nº de red
7-5-2-2 lgss
0,6642
(tst) 0,4221
1
7-5-3-2 lggt
0,6587
(tst) 0,4028
2
7-5-4-2 lgts
0,5194
(tst) 0,3148
3
7-5-6-2 ltts
0,5329
(tst) 0,4058
4
7-6-3-2 ltss
0,4697
(tst) 0,4323
5
7-6-4-2 lttg
0,1555
(tst) 0,5467
6
7-6-5-2 ltgt
0,2395
(trn) 0,6213
7
7-6-5-2 lsts
0,5057
(tst) 0,3175
8
7-6-6-2 ltts
0,4742
(tst) 0,2846
9
A partir de la tabla, se desprende que ocho de las nueve topologías que presentaban un error
total de predicción mínimo inferior a 0,7 lo hacían para el conjunto de entrenamiento. Como
puede observarse, los valores de error asociado para el conjunto de test también son inferiores
a 0,7, a pesar de ser altos en algunos casos. Además, se encuentran presentes las dos redes con
combinación de funciones de activación ltts, señaladas anteriormente, lo que sigue siendo
bastante significativo.
Como se ha comentado y cabía esperar, a excepción de la red 7-6-4-2 lttg, cuyo error
mínimo de predicción es para el test, en todos los casos los errores del conjunto de entrenamiento
son inferiores a los asociados del conjunto de prueba.
Estos resultados son lógicos, puesto que, en general, si el error de un conjunto aumenta, el
del otro disminuye y a la inversa.
Observando la tabla anterior, se obtiene que existen dos redes para las cuales los errores
totales de predicción en los dos conjuntos son inferiores a 0,5. Estas redes se corresponden con
las topologías 7-6-3-2 ltss y 7-6-6-2 ltts. Sin embargo, esto no quiere decir que una de ellas o las
dos puedan considerarse como óptimas.
Para determinar finalmente cuál es la red neuronal óptima, es decir, la que posee un menor
-201-
TRATAMIENTO ESTADÍSTICO DE DATOS
error total de predicción para el conjunto de entrenamiento y de validación, nos basamos en una
tabla de decisiones. Esta se construyó mediante el siguiente procedimiento:
1. Se numeraron las redes del 1 al 9 (ver tabla anterior) y se ordenaron por orden
creciente de los errores totales de predicción para los dos conjuntos, tanto para el de
entrenamiento como el de prueba.
Orden según error del trn
6<5<9<8<3<4<7<2<1
Orden según error del tst
7<9<3<8<2<4<1<5<6
Posición
0
1
2
3
4
5
6
7
8
2. Se elaboró un “ranking” de clasificación para cada conjunto basado en los
estadísticos de rango, tomando como origen el valor del error mínimo en ambos
casos. El orden de preferencia obtenido fue el siguiente:
Red nº
1
2
3
4
5
6
7
8
9
Orden para el trn
8
7
4
5
1
0
6
3
2
Orden para el tst
6
4
2
5
7
8
0
3
1
“Ranking”
14
11
6
10
8
8
6
6
3
Esta tabla constituye un procedimiento de decisión basado en rangos, a partir de la
cual se obtendrá la red óptima.
Como se desprende del “ranking” obtenido, la red continua con menor puntuación fue la
red 9, de topología sencilla 7-6-6-2 y cuyas funciones de activación son lineal-tangencialtangencial-sigmoidal (la tangente hiperbólica aparece aquí por dos veces, aspecto que es bastante
significativo). Los errores totales de predicción correspondientes eran: 0,4742 para el trn y 0,2846
para el tst. De este modo, se obtuvo la red continua óptima.
Este resultado fue bastante bueno, puesto que la red elegida poseía el tercer error total de
predicción más pequeño para el trn y el segundo para el caso del conjunto de prueba. Además,
los errores totales de predicción para ambos conjuntos eran menores a 0,5, como se comentó
-202-
TRATAMIENTO ESTADÍSTICO DE DATOS
anteriormente.
Otras redes pseudoóptimas fueron las siguientes:
w 7-5-4-2 lineal-gaussiana-tangencial-sigmoidal.
w 7-6-5-2 lineal-tangencial-gaussiana-tangencial.
w 7-6-5-2 lineal-sigmoidal-tangencial-sigmodial.
En todos los casos, las topologías resultaron poseer una primera capa oculta con un número
de nodos próximo a los de la capa de entrada. Hay que resaltar también que entre las cuatro
mejores redes, la función de activación más abundante en todas las combinaciones fue la
tangencial.
1) Afinamiento del modelo.
Una vez elegida de este modo la red neuronal continua óptima, se puede afinar aún más a
la hora de clasificar y separar las mezclas. El proceso consistió en tomar la topología 7-6-6-2 con
la combinación de funciones de activación correspondiente: lineal-tangencial-tangencialsigmoidal, y entrenar redes con esta misma estructura, pero variando los parámetros de
aprendizaje principales, con vistas a obtener errores totales de predicción mucho más pequeños.
Los parámetros de aprendizaje que se utilizaron como variables en esta mejora de la
optimización fueron los siguientes:
w ç (eta): velocidad de aprendizaje de la red
w á (alfa): momentum
Los valores tomados por ç se obtuvieron del siguiente modo:
1. Se discretizó el intervalo cerrado [0,01; 0,3] en 6 partes iguales, tomando el
incremento:
∆ =
0,3 − 0,01
= 0,0483 ≅ 0,05
6
2. Por consiguiente, los siete valores para la velocidad de aprendizaje vienen dados por
la ecuación:
η i = 0,01 + (i − 1) ⋅ ∆
-203-
TRATAMIENTO ESTADÍSTICO DE DATOS
y fueron lo siguientes:
ç1
ç2
ç3
ç4
ç5
ç6
ç7
0,01
0,05
0,10
0,15
0,20
0,25
0,30
Los valores que tomó el momentum se escogieron del entorno (0,8 ± 0,4), que equivale al
intervalo abierto (0,4; 1,2). Sin embargo, como está acotado por el límite superior 1, se estimó
oportuno emplear los valores del intervalo [0,4; 1,0]:
á1
á2
á3
á4
á5
á6
á7
0,4
0,5
0,6
0,7
0,8
0,9
1,0
El número de redes entrenadas fueron, por tanto, 7×7 = 49, procedentes de todas las
combinaciones posibles entre ambos parámetros. Los resultados correspondientes a los errores
RMS para los conjuntos de entrenamiento y prueba, así como sus respectivas correlaciones y
errores totales de predicción se recogen en la Tabla 16:
-204-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 16: Búsqueda de la red óptima 7-6-6-2 ltts variando la velocidad de aprendizaje (eta) y
el momentum (alfa).
0
0,01
0,01
0,01
0,01
0,01
0,01
0,01
0,05
0,05
0,05
0,05
0,05
0,05
0,05
0,10
0,10
0,10
0,10
0,10
0,10
0,10
0,15
0,15
0,15
0,15
0,15
0,15
0,15
0,20
0,20
0,20
0,20
0,20
0,20
0,20
0,25
0,25
0,25
0,25
0,25
0,25
0,25
0,30
0,30
0,30
0,30
0,30
0,30
0,30
" Error RMS trn Error RMS tst Correlación trn Correlación tst
0,50
0,014125
0,013478
0,998366
0,998118
0,60
0,018404
0,016469
0,997192
0,997301
0,70
0,008228
0,013277
0,999412
0,998668
0,80
0,007033
0,014436
0,999580
0,998226
0,90
0,007730
0,015898
0,999475
0,998166
1,00
0,211263
0,195743
0,543846
0,401429
0,40
0,009548
0,021861
0,999218
0,996026
0,50
0,010642
0,020272
0,999019
0,996362
0,60
0,006861
0,014067
0,999616
0,997827
0,70
0,010051
0,019004
0,999167
0,996366
0,80
0,006532
0,014185
0,999655
0,998033
0,90
0,005759
0,019330
0,999714
0,997091
1,00
0,276962
0,426584
0,130159
-0,433963
0,40
0,009407
0,016023
0,999276
0,997841
0,50
0,007781
0,027198
0,999416
0,995156
0,60
0,007771
0,010847
0,999345
0,999261
0,70
0,006904
0,011066
0,999573
0,999119
0,80
0,004916
0,017961
0,999787
0,998067
0,90
0,005763
0,009394
0,999725
0,999055
1,00
0,610077
0,613830
0,000000
0,000000
0,40
0,006315
0,017228
0,999674
0,996762
0,50
0,006361
0,018784
0,999600
0,997940
0,60
0,007001
0,017082
0,999543
0,998372
0,70
0,006672
0,018685
0,999626
0,997526
0,80
0,003936
0,024784
0,999858
0,995778
0,90
0,006950
0,010048
0,999599
0,998991
1,00
0,551251
0,586345
0,035457
-0,176777
0,40
0,006401
0,020386
0,999632
0,997538
0,50
0,006422
0,017766
0,999624
0,998251
0,60
0,006144
0,016151
0,999675
0,997639
0,70
0,004287
0,016444
0,999857
0,996122
0,80
0,005614
0,026610
0,999732
0,993994
0,90
0,004472
0,023549
0,999822
0,995476
1,00
0,468002
0,366402
0,008898
-0,043193
0,40
0,006449
0,016448
0,999659
0,997355
0,008353
0,50
0,007194
0,999559
0,999323
0,60
0,004801
0,019040
0,999792
0,997519
0,70
0,004155
0,016945
0,999858
0,997307
0,80
0,003346
0,026553
0,999910
0,991806
0,90
0,004012
0,016775
0,999857
0,997827
1,00
0,432162
0,337564
0,000000
0,000000
0,40
0,004248
0,028271
0,999846
0,993092
0,50
0,005439
0,040025
0,999760
0,982086
0,60
0,004969
0,045753
0,999794
0,984788
0,70
0,006281
0,035299
0,999670
0,989710
0,80
0,004142
0,014141
0,999867
0,997635
0,002541
0,90
0,052944
0,999949
0,965726
1,00
0,416399
0,384000
-0,013608
0,055911
0,40
0,006222
0,018508
0,999639
0,997716
-205-
E. Tot. trn
0,990601
1,349316
0,616461
0,474249
0,539461
15,470532
0,708534
0,725008
0,509049
0,720988
0,459247
0,394738
19,933884
0,687587
0,542043
0,547551
0,461101
0,361856
0,362786
51,314304
0,464257
0,466800
0,500518
0,455366
0,269795
0,462602
44,914304
0,460175
0,422212
0,401102
0,302978
0,363111
0,305969
35,950784
0,428965
0,477832
0,336969
0,285854
0,217612
0,270972
32,859058
0,301951
0,357541
0,343280
0,469521
0,271212
0,149760
32,136580
0,380386
E. Tot. tst
0,263122
0,323781
0,255202
0,284622
0,317584
3,544809
0,382651
0,348311
0,266760
0,339220
0,264216
0,323054
8,452006
0,309355
0,432049
0,175538
0,202547
0,301582
0,167915
12,828576
0,314111
0,348649
0,366126
0,353706
0,410201
0,193871
12,228576
0,370007
0,234600
0,259875
0,296000
0,421949
0,421390
6,785152
0,284959
0,159464
0,347548
0,327764
0,443150
0,265172
6,114288
0,463519
0,673179
0,529636
0,529737
0,281200
0,813246
7,241520
0,253793
TRATAMIENTO ESTADÍSTICO DE DATOS
Los valores en negrita indican los errores mínimos, tanto para el error RMS como para los
de predicción totales (estos se calcularon de la misma forma que antes: utilizando la aplicación
de MATLAB que aparece descrita en el Anexo XI).
En la Tabla 17, se recoge la tabla de decisión que nos permite determinar cuál es la red
continua óptima dentro de la topología 7-6-6-2 ltts:
-206-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla17: Tabla de decisión para la red óptima 7-6-6-2 ltts.
Nº red
4
11
12
17
18
19
21
22
24
25
26
28
29
30
31
32
33
35
36
37
38
39
40
42
46
49
Red
Posición trn
Posición tst
"Ranking"
4
24
10
34
11
18
7
25
12
13
15
28
17
20
3
23
E. Tot. trn
0,474249
0,459247
0,394738
0,461101
0,361856
0,362786
0,464257
0,466800
0,455366
0,269795
0,462602
0,460175
0,422212
0,401102
0,302978
0,363111
0,305969
0,428965
0,477832
0,336969
0,285854
0,217612
0,270972
0,301951
0,271212
0,380386
18
9
13
22
19
10
1
11
21
22
14
36
22
23
18
41
Posición trn E. Tot. tst
24
0,284622
18
0,264216
13
0,323054
20
0,202547
9
0,301582
10
0,167915
22
0,314111
23
0,348649
17
0,353706
1
0,410201
21
0,193871
19
0,370007
15
0,234600
14
0,259875
7
0,296000
11
0,421949
6
0,421390
16
0,284959
25
0,159464
8
0,347548
4
0,327764
0
0,443150
2
0,265172
5
0,463519
3
0,281200
12
0,253793
24
17
19
36
25
1
21
22
26
21
2
23
28
19
20
39
-207-
29
15
4
19
30
14
6
20
31
7
12
19
32
11
23
34
Posición tst
10
7
15
3
13
1
14
18
19
21
2
20
4
6
12
23
22
11
0
17
16
24
8
25
9
5
33
6
22
28
35
16
11
27
36
25
0
25
37
8
17
25
38
4
16
20
39
0
24
24
40
2
8
10
42
5
25
30
46
3
9
12
49
12
5
17
TRATAMIENTO ESTADÍSTICO DE DATOS
Como puede observarse, la red continua que posee una menor puntuación es la
correspondiente a los valores ç = 0,25 para la velocidad de aprendizaje y á = 0,90 para el
momentum. Los errores RMS para esta red neuronal son: 0,004012 para el trn y 0,016775 para
el tst, perteneciendo ambos al grupo de los valores más pequeños, como se aprecia en la Tabla
17.
Las siguientes redes continuas en orden creciente de puntuación, de acuerdo con la tabla
de decisiones, son las que se recogen a continuación:
w 7-6-6-2 ltts, ç = 0,10 y á = 0,90
w 7-6-6-2 ltts, ç = 0,30 y á = 0,80
Hay que resaltar que los valores de momentum son elevados en todos los casos.
A continuación, en la Tabla 18, presentamos los resultados obtenidos para las
concentraciones de Tl (I) y Pb (II) en las mezclas analizadas haciendo uso de la red continua
establecida como óptima (7-6-6-2 ltts, ç = 0,25 y á = 0,90):
-208-
TRATAMIENTO ESTADÍSTICO DE DATOS
Tabla 18: Errores en las concentraciones de los iones Tl (I) y Pb (II) en las muestras analizadas
obtenidos por la aplicación de la red continua óptima de topología 7-6-6-2 ltts (0=0,25 y "=0,90).
Nº muestra Trn (1) Tst (0)
1
0
2
1
3
1
4
1
5
0
6
1
7
1
8
0
9
1
10
1
11
0
12
1
13
0
14
1
15
0
16
1
17
1
18
1
19
1
20
1
21
1
22
1
23
1
24
1
25
1
26
1
27
1
28
1
29
0
30
1
31
1
32
1
33
1
34
1
35
1
36
1
37
1
38
1
39
1
40
0
[Tl (I)] [Tl (I)]* [Pb (II)]
0,1000 0,0998
0,0000
0,2000 0,1958
0,0000
0,3000 0,3131
0,0000
0,4000 0,3877
0,0000
0,5000 0,5142
0,0000
0,6000 0,6066
0,0000
0,7000 0,6896
0,0000
0,8000 0,8369
0,0000
0,9000 0,9020
0,0000
1,0000 0,9966
0,0000
0,0000 0,0161
0,1000
0,0000 0,0007
0,2000
0,0000 0,0010
0,3000
0,0000 0,0029
0,4000
0,0000 0,0020
0,5000
0,0000 -0,0014
0,6000
0,0000 -0,0019
0,7000
0,0000 0,0011
0,8000
0,0000 0,0014
0,9000
0,0000 -0,0021
1,0000
0,1000 0,1011
0,1000
0,6000 0,6134
0,1000
0,2000 0,1908
0,2000
0,7000 0,6881
0,2000
0,3000 0,3109
0,3000
0,8000 0,8139
0,3000
0,4000 0,3917
0,4000
0,9000 0,8930
0,4000
0,5000 0,5096
0,5000
1,0000 1,0008
0,5000
0,1000 0,1008
0,6000
0,6000 0,5974
0,6000
0,2000 0,2030
0,7000
0,7000 0,7026
0,7000
0,3000 0,2953
0,8000
0,8000 0,8000
0,8000
0,4000 0,4070
0,9000
0,9000 0,9001
0,9000
0,5000 0,4968
1,0000
1,0000 0,9314
1,0000
-209-
[Pb (II)]*
0,0244
0,0083
-0,0069
0,0028
-0,0093
0,0050
0,0081
-0,0118
-0,0020
-0,0033
0,1105
0,2019
0,2985
0,4013
0,5144
0,5995
0,6935
0,8045
0,9013
0,9980
0,0938
0,0881
0,1999
0,2035
0,2949
0,3024
0,4061
0,4003
0,5368
0,4999
0,6047
0,5950
0,6969
0,7022
0,8006
0,7999
0,9004
0,8998
0,9997
0,9921
Error Tl (I) Error Pb (II)
-0,1510
0,0244
-2,0805
0,0083
4,3820
0,0069
-3,0865
0,0028
2,8372
0,0093
1,1023
0,0050
-1,4816
0,0081
4,6159
0,0118
0,2207
0,0020
-0,3400
0,0033
0,0161
10,5000
0,0007
0,9415
0,0010
-0,4970
0,0029
0,3155
0,0020
2,8844
0,0014
-0,0877
0,0019
-0,9293
0,0011
0,5656
0,0014
0,1429
0,0021
-0,1979
1,1060
-6,2340
2,2362
-11,8740
-4,5790
-0,0725
-1,7049
1,7720
3,6480
-1,6920
1,7330
0,8110
-2,0768
1,5298
-0,7800
0,0628
1,9268
7,3510
0,0812
-0,0274
0,8380
0,7840
-0,4363
-0,8288
1,5225
-0,4369
0,3703
0,3096
-1,5603
0,0786
-0,0021
-0,0165
1,7560
0,0421
0,0072
-0,0271
-0,6420
-0,0289
-6,8643
-0,7911
TRATAMIENTO ESTADÍSTICO DE DATOS
Con respecto a la tabla anterior cabe destacar los siguientes aspectos:
1. Los errores que aparecen para las concentraciones de Tl (I) y Pb (II) se encuentran
representados como errores relativos, excepto en los casos donde existe una
concentración real de 0,0 mg·l-1 para cualquiera de las especies, en los que se hace
uso del error absoluto.
2. Como puede observarse, los errores relativos son inferiores al 11,87 y 6,86 % (en
valor absoluto) para talio y plomo, respectivamente, lo que supone una mejora con
respecto a los valores encontrados en la bibliografía.
3. Sin embargo, dichos porcentajes son poco significativos si los comparamos con los
obtenidos para el resto de las predicciones de ambos iones, en las cuales no se supera
el 2 - 3 % de error en la mayoría de los casos.
4. Por último, los errores de predicción obtenidos para las concentraciones de los
cationes en las muestras en las que se hace uso del error absoluto, son inferiores a la
centésima de mg·l-1. Es más, puede observarse, que mayoritariamente estos errores
son 10 veces más pequeños, afectando a la milésima de mg·l-1.
A continuación, y para finalizar con la discusión del método de separación de mezclas
mediante redes neuronales artificiales, presentamos las superficies de error y de correlación para
los conjuntos de entrenamiento y de prueba de la red óptima 7-6-6-2 ltts (ver Figuras 29 a 36).
Estos gráficos se han obtenido mediante la representación de dichos parámetros con respecto a
los valores de ç y á investigados:
-210-
TRATAMIENTO ESTADÍSTICO DE DATOS
Figura 49: Superficie del error RMS correspondiente al conjunto de entrenamiento (trn).
A partir de la figura, y gracias a las curvas de nivel, podemos comprobar que el valor
mínimo para el error RMS del conjunto de entrenamiento se corresponde con los valores de ç =
0,30 y á = 0,90. En la Figura 30, se recoge la misma superficie anterior, pero haciendo uso
únicamente de dos dimensiones:
-211-
TRATAMIENTO ESTADÍSTICO DE DATOS
0.30
0.25
0.20
0.15
0.10
0.05
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
0.90
Figura 50: Curvas de nivel en dos dimensiones para el error RMS del conjunto de entrenamiento.
A mayor oscuridad en la superficie, más pequeño es el error RMS.
A continuación, en la Figura 31, se representa la superficie obtenida a partir de las
correlaciones para el conjunto de entrenamiento:
-212-
TRATAMIENTO ESTADÍSTICO DE DATOS
Figura 51: Superficie de correlación para el conjunto de entrenamiento.
Tras un detenido examen de las Figuras 29 y 31, se observa que ambas son
complementarias una con respecto a la otra, correspondiéndose los valores máximos en error con
los mínimos en correlación y viceversa. En este caso, la depresión que aparece en la parte anterior
de la Figura 31, se corresponde con el valor máximo en la Figura 29 (curvas de nivel de color
rojo). La esquina posterior izquierda indica la correlación máxima (correspondiente con el error
RMS mínimo).
-213-
TRATAMIENTO ESTADÍSTICO DE DATOS
0.90
0.85
0.80
0.75
0.70
0.65
0.60
0.55
0.50
0.45
0.40
0.05
0.10
0.15
0.20
0.25
0.30
Figura 52: Curvas de nivel en dos dimensiones para las correlaciones del conjunto de entrenamiento.
Los colores claros se corresponden con valores de correlación pequeños, y por tanto, no
aceptables. Por contra, el color oscuro de la esquina superior derecha indica el máximo de
correlación para el conjunto de entrenamiento.
La superficie de error para el conjunto de validación es la siguiente:
-214-
TRATAMIENTO ESTADÍSTICO DE DATOS
Figura 53: Superficie del error RMS correspondiente al conjunto de validación (tst).
Aquí se puede observar que el mínimo error RMS se encuentra en el pozo delimitado por
curvas de nivel de color verde (a la derecha de la figura). Éste se corresponde con unos valores
de ç = 0,25 y á = 0,50.
En la Figura 34 se representan las mismas curvas de nivel, pero en dos dimensiones:
-215-
TRATAMIENTO ESTADÍSTICO DE DATOS
0.90
0.85
0.80
0.75
0.70
0.65
0.60
0.55
0.50
0.45
0.40
0.05
0.10
0.15
0.20
0.25
0.30
Figura 54: Curvas de nivel en dos dimensiones para el error RMS del conjunto de validación.
Los colores claros hacen referencia a los valores más pequeños para el error RMS del
conjunto de prueba.
-216-
TRATAMIENTO ESTADÍSTICO DE DATOS
Figura 55: Superficie de correlación para el conjunto de validación.
Entre esta figura y la número 33, se puede observar también una complementariedad mucho
más clara que para el caso de las Figuras 29 y 31. La depresión presente en la esquina anterior
se corresponde con el máximo de la esquina posterior de la Figura 33. Además, el máximo
existente junto al valle de la izquierda de la representación, se corresponde con el mínimo error
RMS de la Figura 33.
Finalmente, en la Figura 36, se recogen las curvas de nivel en dos dimensiones para la
correlación presentada anteriormente:
-217-
TRATAMIENTO ESTADÍSTICO DE DATOS
0.30
0.25
0.20
0.15
0.10
0.05
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
0.90
Figura 56: Curvas de nivel en dos dimensiones para las correlaciones del conjunto de validación.
En este caso, el color blanco representa un mínimo en las correlaciones, esto es, valores no
aceptables.
Con este método de separación y predicción de señales, se ha conseguido obtener una red
neuronal artificial capaz de predecir las señales a nivel de las centésimas de mg·l-1. Esto significa
que, para cualquier mezcla de Tl (I) y Pb (II) de composición desconocida, el modelo presentado
permite conocer las concentraciones de los iones con una precisión de 0,01 mg·l-1.
BIBLIOGRAFÍA.
1.-
Ayuda del programa informático de redes neuronales: Qwiknet 3.2.
2.-
Ayuda del programa informático de redes neuronales: Qnet 2000.
-218-
Conclusiones.
“Aquello que no nos mata, nos hace más fuertes”.
Friedrich Nietzsche
CONCLUSIONES
A continuación, se exponen las conclusiones que pueden extraerse del análisis e
interpretación de los resultados obtenidos:
PRIMERA:
En este trabajo, se demuestra la utilidad de las técnicas estadísticas para la
interpretación de señales electroquímicas solapadas.
SEGUNDA:
Mediante un modelo de Análisis Lineal Discriminante basado en la
información discreta es posible clasificar un 95% de las muestras. Aparecen
errores de clasificación en aquellas muestras situadas en los extremos del
intervalo de concentración estudiado para ambos iones.
TERCERA:
Es posible emplear un modelo de aproximación gaussiano para representar las
señales de las muestras analizadas con un error inferior al 3 % .
CUARTA:
Haciendo uso de un modelo de interpolación por mínimos cuadrados, es
posible la predicción de una señal cualquiera TiPj desconocida a partir de las
dos señales puras que componen la mezcla, obteniéndose en este caso una
fiabilidad de R $ 0.997, mediante el siguiente modelo de aproximación:
( )
( )
f Ti Pj = α ⋅ f (Ti ) + β ⋅ f Pj + ε . Este modelo se muestra robusto al
contaminar la señal con un error gaussiano de hasta el 5 %.
QUINTA:
El modelo de interpolación también es capaz de resolver cualquier mezcla TiPj
desconocida si se conoce una de las concentraciones de los iones que la
componen, obteniéndose un error < 0.1 mg·l-1, con un 87,5 % de clasificaciones
correctas. Este método es válido para todo el intervalo de concentraciones
estudiado, pudiendo extenderse a valores intermedios del mismo con sólo
variar las fracciones del parámetro ë de los modelos matemáticos empleados.
SEXTA:
Se han hallado modelos neuronales de topologías sencillas, basados en los
parámetros característicos de las señales de los voltamperogramas (altura,
anchura y posición del pico), capaces no solo de clasificar bien el 100% de las
muestras, sino también de alcanzar un nivel de predicción con un error inferior
a 0.1 mg·l-1. Estos modelos fueron validados estadísticamente mediante
técnicas de validación cruzada.
-220-
CONCLUSIONES
SÉPTIMA:
La transformación de Fourier y su posterior filtrado, eliminando frecuencias
elevadas y conservando una información mínima del 97%, revelan altas
correlaciones entre los valores de amplitud y frecuencia que componen el
espectro de Fourier de la señal. Dicho modelo, combinado con el escalado
multidimensional, es capaz de clasificar el 100% de la información, pudiendo
utilizarse como modelo predictivo.
OCTAVA:
La aplicación de redes neuronales sobre las señales continuas expresadas en el
espacio de Fourier permite la predicción continua de cualquier señal TiPj
desconocida, permitiendo determinar las concentraciones de los iones que
constituyen las mezclas con un error entre las centésimas y milésimas de mg·l-1
en todos los casos.
NOVENA:
Aunque la aplicación de redes neuronales sobre datos continuos ya se ha
realizado en algunas ocasiones en el campo de la electroquímica, la innovación
que aquí se presenta radica en el empleo de un proceso previo de reducción de
dimensiones basado en la información de amplitud y frecuencia obtenida
mediante la transformada de Fourier.
DÉCIMA:
Los modelos neuronales aportan una gran capacidad predictiva y al mismo
tiempo una gran sencillez, iguálandolos operativamente a modelos ya
establecidos de tipo analítico y/o estadísticos. La bibliografía existente sobre
la aplicación de dichos modelos a problemas electroquímicos viene
representando tradicionalmente topologías más complejas y peores capacidades
predictivas que las aquí obtenidas, debido al grado de compresión de la
información que es necesario, dado que ninguna de ellas trabaja en el espacio
de Fourier.
UNDÉCIMA:
La aplicación de los modelos descritos ha puesto de manifiesto su utilidad
como métodos de reconocimiento de patrones en todos los casos, permitiendo
la predicción de mezclas mediante el modelo de interpolación y su resolución
por medio de redes neuronales artificiales.
-221-
CONCLUSIONES
DUODÉCIMA: Con estos métodos se han conseguido resolver mezclas de Tl (I) y Pb (II) en las
que la diferencia entre los potenciales de pico era del orden de 25 mV, lo que
originaba un fuerte solapamiento de las señales.
-222-
Anexo I.
ANEXO I
Datos de I/E de los voltamperogramas de las muestras desde -0,7 a -0,3 V:
Datos de I/E de los voltamperogramas de las muestras de Tl (I).
E (V)
-0,7008
-0,6958
-0,6908
-0,6857
-0,6807
-0,6757
-0,6706
-0,6656
-0,6606
-0,6555
-0,6505
-0,6454
-0,6404
-0,6354
-0,6303
-0,6253
-0,6203
-0,6152
-0,6102
-0,6052
-0,6001
-0,5951
-0,5901
-0,5850
-0,5800
-0,5750
-0,5699
-0,5649
-0,5598
-0,5548
-0,5498
-0,5447
-0,5397
-0,5347
-0,5296
-0,5246
-0,5196
-0,5145
-0,5095
-0,5045
T1
0,820
0,844
0,879
0,900
0,942
0,967
1,014
1,047
1,101
1,145
1,203
1,281
1,375
1,471
1,626
1,765
1,978
2,207
2,497
2,844
3,273
3,781
4,417
5,139
6,017
7,034
8,165
9,420
10,798
12,190
13,661
15,144
16,614
18,047
19,400
20,600
21,683
22,597
23,333
23,800
T2
0,785
0,843
0,878
0,943
0,984
1,049
1,123
1,214
1,314
1,419
1,563
1,742
1,960
2,213
2,529
2,917
3,360
3,926
4,580
5,393
6,348
7,505
8,902
10,474
12,430
14,506
16,996
19,664
22,654
25,627
28,971
32,188
35,570
38,854
41,879
44,426
47,071
49,042
50,796
51,692
T3
0,966
0,996
1,080
1,141
1,227
1,323
1,420
1,578
1,748
1,932
2,182
2,452
2,800
3,240
3,755
4,362
5,135
6,041
7,143
8,501
10,105
11,998
14,254
16,860
19,919
23,354
27,255
31,478
36,006
40,779
45,780
50,964
55,875
60,639
65,061
69,123
72,632
75,563
77,717
79,096
T4
0,800
0,857
0,939
1,002
1,089
1,194
1,293
1,448
1,599
1,805
2,041
2,334
2,711
3,180
3,692
4,358
5,179
6,162
7,373
8,728
10,450
12,486
14,983
17,989
21,810
25,428
29,835
34,675
40,266
46,417
52,604
59,371
66,077
72,772
78,691
85,967
91,010
95,998
100,845
103,450
T5
1,058
1,136
1,233
1,333
1,462
1,604
1,763
1,965
2,203
2,488
2,849
3,306
3,822
4,479
5,254
6,219
7,356
8,763
10,445
12,492
14,985
17,774
21,238
25,202
29,845
35,285
41,013
48,010
55,219
62,887
71,130
79,730
88,384
96,496
104,810
112,489
119,240
125,272
130,150
133,991
T6
2,525
2,510
2,550
2,579
2,916
3,202
3,349
3,616
3,872
4,133
4,640
5,300
6,018
6,816
7,679
9,024
10,828
12,225
14,522
17,270
20,318
23,708
28,193
33,168
39,076
45,361
52,633
60,631
69,038
78,357
87,805
97,389
108,469
117,923
128,280
137,397
145,420
154,148
160,339
165,098
T7
1,421
1,523
1,656
1,773
1,943
2,170
2,375
2,675
3,013
3,453
3,945
4,522
5,281
6,258
7,354
8,634
10,385
12,293
14,672
17,578
20,981
25,037
29,845
35,305
42,056
49,323
57,562
67,542
77,148
88,546
99,304
112,003
124,076
136,372
148,238
158,493
169,048
177,250
184,172
191,178
T8
1,278
1,380
1,528
1,692
1,873
2,129
2,350
2,682
3,079
3,579
4,090
4,790
5,660
6,738
8,011
9,593
11,519
13,865
16,555
19,788
23,701
28,164
33,762
40,133
47,449
55,846
65,053
75,580
87,249
99,016
111,112
123,733
137,415
150,362
163,129
176,093
188,348
197,897
206,486
217,056
T9
1,525
1,650
1,805
1,983
2,218
2,477
2,850
3,283
3,612
4,214
4,967
5,816
6,930
7,988
9,637
11,397
13,576
16,303
19,330
23,147
27,539
32,683
38,681
45,442
53,393
62,712
72,466
83,377
94,658
106,850
120,059
133,457
150,379
163,877
176,232
191,361
203,001
213,273
224,305
230,149
T10
1,294
1,418
1,604
1,814
2,060
2,325
2,676
3,079
3,578
4,166
4,906
5,812
6,872
8,195
9,783
11,741
14,124
16,927
20,380
24,550
29,400
35,202
42,189
50,397
59,896
70,558
82,990
96,376
111,480
127,780
145,070
162,436
180,053
198,042
214,647
230,576
246,121
257,595
267,853
275,348
.../...
-224-
ANEXO I
Datos de I/E de los voltamperogramas de las muestras de Tl (I) (continuación).
E (V)
-0,4994
-0,4944
-0,4893
-0,4843
-0,4793
-0,4742
-0,4692
-0,4642
-0,4591
-0,4541
-0,4491
-0,4440
-0,4390
-0,4340
-0,4289
-0,4239
-0,4189
-0,4138
-0,4088
-0,4037
-0,3987
-0,3937
-0,3886
-0,3836
-0,3786
-0,3735
-0,3685
-0,3635
-0,3584
-0,3534
-0,3484
-0,3433
-0,3383
-0,3333
-0,3282
-0,3232
-0,3181
-0,3131
-0,3081
-0,3030
T1
24,098
24,181
23,949
23,501
22,865
21,967
20,900
19,766
18,305
16,928
15,441
13,973
12,501
11,118
9,778
8,558
7,458
6,463
5,583
4,844
4,221
3,672
3,248
2,909
2,609
2,397
2,202
2,065
1,968
1,895
1,843
1,798
1,771
1,762
1,758
1,800
1,794
1,812
1,849
1,896
T2
52,480
52,533
52,003
51,044
49,822
47,834
45,407
42,698
39,708
36,564
33,264
30,010
26,669
23,511
20,508
17,729
15,190
12,932
10,962
9,261
7,803
6,597
5,595
4,762
4,094
3,568
3,119
2,795
2,533
2,318
2,164
2,037
1,973
1,897
1,871
1,863
1,875
1,905
1,918
1,961
T3
79,799
79,668
78,543
76,894
74,582
71,373
67,627
63,442
58,775
53,801
48,709
43,690
38,529
33,785
29,237
25,060
21,333
18,041
15,174
12,709
10,626
8,907
7,428
6,301
5,311
4,524
3,938
3,411
3,030
2,745
2,498
2,304
2,175
2,081
2,025
1,983
1,978
1,962
1,959
1,992
T4
104,912
105,804
106,826
106,370
102,763
99,824
95,671
91,133
84,553
79,588
71,874
65,192
58,433
50,895
45,104
39,165
33,595
28,431
24,149
20,017
16,997
13,970
11,746
9,797
8,111
6,874
5,910
5,099
4,409
3,946
3,441
3,225
3,052
2,875
2,822
2,889
2,758
2,905
2,941
2,878
T5
136,447
137,925
137,010
135,284
131,097
126,879
120,738
114,243
106,476
98,419
89,145
80,676
71,938
63,203
55,213
47,555
40,463
34,423
29,006
24,226
20,123
16,796
13,810
11,490
9,574
7,955
6,708
5,677
4,796
4,211
3,555
3,300
2,999
2,960
2,622
2,481
2,389
2,355
2,349
2,333
-225-
T6
168,707
170,485
171,658
170,726
168,446
162,962
156,162
148,559
139,598
129,573
118,716
107,340
96,190
85,316
74,751
65,398
55,939
48,288
40,768
34,319
29,651
24,779
21,248
18,280
16,538
13,927
12,681
12,200
10,458
10,805
9,598
8,664
9,246
8,872
8,490
9,114
8,637
8,669
8,646
9,911
T7
195,030
195,715
196,657
194,796
189,302
183,157
174,913
164,131
154,583
143,244
129,337
117,058
103,227
91,254
79,372
68,654
58,460
49,089
41,398
34,406
28,675
23,746
19,727
16,140
13,380
11,249
9,201
7,712
6,662
5,644
4,962
4,441
4,028
3,662
3,331
3,246
3,078
3,187
2,894
2,938
T8
222,351
225,545
227,079
226,747
222,303
215,762
207,325
196,973
183,921
168,786
154,791
140,339
125,058
110,493
96,648
83,030
71,023
60,412
50,753
42,055
35,434
29,460
24,287
20,284
16,881
14,016
11,983
10,072
8,560
7,578
6,770
6,152
5,904
5,300
5,158
5,206
5,049
5,049
4,956
4,962
T9
241,951
245,911
244,240
248,037
241,764
235,593
227,256
216,261
199,384
185,572
168,502
150,595
134,512
118,198
102,543
88,093
74,600
63,283
53,073
43,921
36,706
30,184
25,399
20,974
17,221
14,345
12,139
10,357
8,775
7,424
6,993
6,330
5,591
5,450
5,158
4,887
4,353
4,564
4,387
4,531
T10
280,498
281,334
281,360
276,552
271,080
261,734
249,338
235,399
219,702
203,215
184,791
165,855
147,503
129,580
112,722
96,774
82,451
69,388
57,904
48,078
39,491
32,596
26,440
21,600
17,557
14,396
11,724
9,645
7,894
6,513
5,493
4,681
4,030
3,548
3,125
2,844
2,611
2,450
2,357
2,277
ANEXO I
Datos de I/E de los voltamperogramas de las muestras de Pb (II).
E (V)
-0,7008
-0,6958
-0,6908
-0,6857
-0,6807
-0,6757
-0,6706
-0,6656
-0,6606
-0,6555
-0,6505
-0,6454
-0,6404
-0,6354
-0,6303
-0,6253
-0,6203
-0,6152
-0,6102
-0,6052
-0,6001
-0,5951
-0,5901
-0,5850
-0,5800
-0,5750
-0,5699
-0,5649
-0,5598
-0,5548
-0,5498
-0,5447
-0,5397
-0,5347
-0,5296
-0,5246
-0,5196
-0,5145
-0,5095
-0,5045
P1
0,340
0,364
0,374
0,406
0,024
0,445
0,439
0,465
0,477
0,489
0,510
0,526
0,574
0,636
0,728
0,828
1,081
1,387
1,841
2,540
3,498
4,869
6,749
9,350
12,415
16,248
20,578
24,916
29,146
32,820
35,734
38,062
39,632
40,571
41,311
41,412
41,332
41,026
40,321
39,497
P2
0,330
0,334
0,344
0,397
0,392
0,415
0,436
0,433
0,475
0,473
0,531
0,577
0,659
0,745
0,953
1,208
1,593
2,150
2,988
4,182
5,927
8,390
11,733
16,212
21,879
28,656
36,334
44,211
51,801
58,399
63,858
68,026
70,904
72,852
73,997
74,519
74,502
74,030
72,980
71,410
P3
0,416
0,445
0,454
0,449
0,521
0,531
0,517
0,562
0,561
0,600
0,722
0,719
0,842
0,964
1,223
1,584
2,083
2,887
4,034
5,736
8,166
11,571
16,309
22,632
30,606
40,235
50,999
62,244
72,797
82,324
90,151
96,045
100,316
103,154
104,898
106,031
105,781
105,127
103,773
101,621
P4
0,274
0,319
0,345
0,347
0,362
0,398
0,417
0,461
0,466
0,510
0,567
0,677
0,834
1,000
1,364
1,865
2,565
3,603
5,183
7,416
10,657
15,203
21,476
29,821
40,387
53,072
67,223
81,745
95,678
107,971
118,030
125,686
131,167
134,767
136,859
137,811
137,633
136,630
134,756
131,912
P5
0,343
0,370
0,387
0,407
0,419
0,442
0,479
0,525
0,544
0,579
0,654
0,772
0,932
1,173
1,525
2,064
2,873
4,020
5,769
8,321
11,986
17,166
24,408
34,097
46,629
61,868
79,168
97,710
115,948
132,508
146,250
157,014
164,849
170,184
173,491
175,097
175,516
174,701
172,657
169,395
P6
0,316
0,336
0,367
0,374
0,392
0,401
0,442
0,490
0,512
0,568
0,652
0,793
1,022
1,317
1,725
2,419
3,344
4,793
6,883
10,017
14,465
20,796
29,522
41,241
56,301
74,344
95,066
117,009
138,080
157,026
172,770
184,823
193,567
199,439
203,021
204,757
204,934
203,772
201,265
197,271
P7
0,318
0,364
0,343
0,367
0,397
0,435
0,471
0,487
0,545
0,612
0,729
0,872
1,086
1,411
1,924
2,674
3,783
5,460
7,854
11,406
16,517
23,771
33,731
47,189
64,470
85,297
109,120
134,382
158,970
180,868
199,153
213,236
223,530
230,403
234,641
236,691
236,978
235,711
232,879
228,314
P8
0,372
0,389
0,390
0,446
0,463
0,501
0,520
0,558
0,639
0,725
0,849
1,056
1,336
1,768
2,431
3,371
4,812
6,937
10,036
14,528
21,013
30,106
42,631
59,246
80,213
105,312
133,428
162,424
190,060
214,291
234,084
249,094
259,814
266,841
270,969
272,728
272,545
270,563
266,747
260,871
P9
0,340
0,353
0,370
0,395
0,422
0,463
0,504
0,538
0,584
0,659
0,822
0,995
1,306
1,725
2,390
3,355
4,784
6,927
10,041
14,616
21,201
30,487
43,358
60,632
82,738
109,499
139,969
172,198
203,467
231,340
254,466
272,249
285,130
293,678
298,898
301,346
301,547
299,815
296,033
290,038
P10
0,351
0,377
0,380
0,413
0,406
0,450
0,506
0,548
0,595
0,682
0,840
1,047
1,360
1,839
2,522
3,589
5,159
7,460
10,856
15,866
23,101
33,253
47,418
66,381
90,665
120,147
153,575
188,675
222,785
252,986
277,933
297,149
310,975
320,228
325,789
328,421
328,664
326,702
322,648
316,118
.../...
-226-
ANEXO I
Datos de I/E de los voltamperogramas de las muestras de Pb (II) (continuación).
E (V)
-0,4994
-0,4944
-0,4893
-0,4843
-0,4793
-0,4742
-0,4692
-0,4642
-0,4591
-0,4541
-0,4491
-0,4440
-0,4390
-0,4340
-0,4289
-0,4239
-0,4189
-0,4138
-0,4088
-0,4037
-0,3987
-0,3937
-0,3886
-0,3836
-0,3786
-0,3735
-0,3685
-0,3635
-0,3584
-0,3534
-0,3484
-0,3433
-0,3383
-0,3333
-0,3282
-0,3232
-0,3181
-0,3131
-0,3081
-0,3030
P1
38,149
36,515
34,154
31,274
27,760
23,853
19,678
15,603
11,938
8,881
6,522
4,699
3,415
2,525
1,921
1,535
1,268
1,106
0,972
0,911
0,888
0,836
0,859
0,846
0,863
0,885
0,899
0,932
0,965
0,973
0,993
1,020
1,049
1,090
1,126
1,143
1,173
1,250
1,300
1,726
P2
69,232
66,214
62,103
56,907
50,569
43,363
35,721
28,242
21,458
15,797
11,296
8,005
5,612
3,984
2,853
2,085
1,624
1,263
1,069
0,937
0,864
0,808
0,783
0,807
0,776
0,773
0,811
0,797
0,835
0,846
0,869
0,869
0,908
0,935
0,975
1,002
1,041
1,086
1,066
1,136
P3
98,489
94,215
88,478
81,069
72,064
62,045
51,093
40,345
30,622
22,436
15,989
11,234
7,831
5,577
3,848
2,807
2,082
1,624
1,354
1,149
1,034
0,955
0,966
0,939
0,925
0,950
0,943
0,979
0,999
1,016
1,029
1,059
1,085
1,109
1,128
1,409
1,225
1,245
1,299
1,375
P4
127,525
121,761
113,997
104,218
92,451
79,092
64,893
51,000
38,476
28,025
19,857
13,778
9,483
6,472
4,468
3,127
2,241
1,665
1,308
1,053
0,915
0,814
0,784
0,754
0,758
0,734
0,754
0,774
0,799
0,774
0,832
0,851
0,841
0,924
0,940
0,945
0,999
1,031
1,074
1,111
P5
164,607
157,883
148,943
137,440
123,233
106,741
88,847
70,939
54,254
39,996
28,609
19,967
13,713
9,394
6,398
4,394
3,079
2,233
1,695
1,341
1,120
0,973
0,881
0,868
0,825
0,836
0,821
0,835
0,868
0,856
0,873
0,890
0,914
0,931
0,950
1,003
1,035
1,065
1,093
1,159
-227-
P6
191,406
183,300
172,492
158,618
141,620
122,213
101,061
80,038
60,810
44,549
31,641
22,020
15,023
10,206
6,901
4,717
3,302
2,325
1,736
1,314
1,085
0,941
0,839
0,788
0,755
0,771
0,734
0,738
0,747
0,754
0,777
0,809
0,839
0,842
0,901
0,904
0,920
0,949
1,002
1,041
P7
221,634
212,355
200,008
184,091
164,566
142,082
117,754
93,393
71,070
52,083
37,015
25,717
17,569
11,902
8,023
5,433
3,775
2,644
1,938
1,479
1,167
0,982
0,890
0,826
0,793
0,772
0,748
0,752
0,764
0,795
0,800
0,828
0,870
0,833
0,910
0,938
0,935
0,952
1,039
1,070
P8
252,404
240,862
225,608
206,193
182,716
156,081
127,867
100,384
75,547
54,876
38,792
26,798
18,267
12,284
8,320
5,659
3,905
2,763
2,006
1,546
1,256
1,069
0,970
0,900
0,859
0,850
0,811
0,826
0,859
0,870
0,872
0,920
0,896
0,939
0,992
0,960
1,013
1,073
1,072
1,151
P9
281,395
269,463
253,583
233,212
208,192
179,363
148,413
117,501
89,208
65,253
46,295
32,034
21,825
14,701
9,900
6,663
4,535
3,152
2,250
1,669
1,298
1,077
0,963
0,862
0,825
0,802
0,780
0,791
0,802
0,815
0,828
0,861
0,845
0,911
0,918
0,933
0,960
1,005
1,031
1,109
P10
306,700
293,656
276,194
253,806
226,367
194,716
160,611
126,879
96,059
69,980
49,469
34,118
23,171
15,534
10,366
6,985
4,735
3,256
2,285
1,697
1,329
1,087
0,943
0,848
0,800
0,801
0,812
0,785
0,827
0,821
0,839
0,892
0,900
0,911
0,963
0,979
1,000
0,996
1,082
1,147
ANEXO I
Datos de I/E de los voltamperogramas de las mezclas de Tl (I) y Pb (II).
E (V)
-0,7008
-0,6958
-0,6908
-0,6857
-0,6807
-0,6757
-0,6706
-0,6656
-0,6606
-0,6555
-0,6505
-0,6454
-0,6404
-0,6354
-0,6303
-0,6253
-0,6203
-0,6152
-0,6102
-0,6052
-0,6001
-0,5951
-0,5901
-0,5850
-0,5800
-0,5750
-0,5699
-0,5649
-0,5598
-0,5548
-0,5498
-0,5447
-0,5397
-0,5347
-0,5296
-0,5246
-0,5196
-0,5145
-0,5095
-0,5045
T1P1
0,384
0,404
0,451
0,451
0,509
0,538
0,587
0,618
0,682
0,733
0,823
0,920
1,061
1,242
1,477
1,801
2,228
2,758
3,531
4,567
6,004
7,908
10,478
13,753
17,867
22,677
28,139
33,831
39,448
44,587
49,117
53,052
56,319
59,034
61,309
63,047
64,419
65,318
65,739
65,618
T1P6
0,724
0,810
0,919
1,028
1,166
1,343
1,521
1,760
2,061
2,392
2,834
3,350
4,039
4,849
5,834
7,111
8,701
10,684
13,127
16,246
19,982
24,777
31,082
38,499
47,466
57,212
69,235
82,188
96,021
109,576
122,834
137,132
149,442
160,861
171,621
181,700
191,196
197,791
203,249
208,085
T2P2
0,468
0,503
0,560
0,642
0,674
0,743
0,834
0,943
1,043
1,183
1,352
1,535
1,876
2,237
2,717
3,364
4,195
5,288
6,773
8,790
11,465
15,071
19,768
25,862
33,408
42,442
52,591
63,322
74,009
83,988
93,041
100,784
107,358
112,820
117,320
120,922
123,566
125,404
126,268
126,011
T2P7
0,693
0,792
0,916
1,048
1,177
1,348
1,579
1,810
2,125
2,538
3,008
3,645
4,386
5,346
6,530
8,069
10,056
12,553
15,817
20,027
25,505
32,539
41,551
52,895
66,732
83,004
101,311
120,828
140,564
159,778
177,764
194,324
209,293
222,704
234,598
244,793
253,264
259,874
264,381
266,574
T3P3
0,411
0,488
0,528
0,591
0,675
0,767
0,843
0,975
1,125
1,323
1,536
1,853
2,231
2,710
3,395
4,241
5,370
6,884
8,906
11,682
15,418
20,415
27,101
35,748
46,627
59,682
74,600
90,559
106,589
121,642
135,142
146,820
156,713
164,965
171,724
177,180
181,353
184,232
185,757
185,781
T3P8
0,741
0,808
0,931
1,077
1,246
1,430
1,657
1,925
2,256
2,679
3,247
3,884
4,720
5,776
7,089
8,754
10,934
13,709
17,292
21,986
28,079
35,981
46,307
59,346
75,630
95,136
117,720
142,251
167,644
192,526
215,967
237,386
256,602
273,584
288,489
301,362
312,002
320,399
326,308
329,486
T4P4
0,517
0,541
0,618
0,702
0,807
0,934
1,020
1,192
1,353
1,586
1,889
2,278
2,746
3,341
4,167
5,252
6,661
8,606
11,195
14,719
19,465
25,857
34,386
45,513
59,568
76,474
95,920
116,917
137,911
157,819
175,643
191,064
204,000
214,666
223,376
230,341
235,570
239,214
241,085
240,952
T4P9
0,785
0,904
1,032
1,171
1,354
1,558
1,798
2,103
2,510
2,965
3,583
4,301
5,223
6,408
7,887
9,746
12,204
15,340
19,461
24,775
31,748
40,796
52,623
67,727
86,534
109,272
135,456
164,200
193,959
223,030
250,284
275,067
297,186
316,564
333,385
347,732
359,518
368,686
375,015
378,225
T5P5
0,594
0,692
0,776
0,868
0,993
1,119
1,296
1,500
1,757
2,086
2,494
2,991
3,647
4,484
5,615
7,041
8,922
11,466
14,854
19,427
25,573
33,774
44,697
58,852
76,750
98,353
123,323
150,220
177,478
203,401
227,049
247,504
264,927
279,480
291,558
301,279
308,797
314,111
317,099
317,499
T5P10
0,819
0,917
1,047
1,196
1,396
1,635
1,947
2,296
2,737
3,255
3,946
4,807
5,851
7,196
8,909
11,140
13,978
17,617
22,419
28,681
36,964
47,774
61,867
79,976
102,676
130,078
161,874
196,799
232,810
267,959
300,904
330,577
356,824
379,638
399,233
415,029
428,455
438,820
445,758
449,098
.../...
-228-
ANEXO I
Datos de I/E de los voltamperogramas de las mezclas de Tl (I) y Pb (II) (continuación).
E (V)
-0,4994
-0,4944
-0,4893
-0,4843
-0,4793
-0,4742
-0,4692
-0,4642
-0,4591
-0,4541
-0,4491
-0,4440
-0,4390
-0,4340
-0,4289
-0,4239
-0,4189
-0,4138
-0,4088
-0,4037
-0,3987
-0,3937
-0,3886
-0,3836
-0,3786
-0,3735
-0,3685
-0,3635
-0,3584
-0,3534
-0,3484
-0,3433
-0,3383
-0,3333
-0,3282
-0,3232
-0,3181
-0,3131
-0,3081
-0,3030
T1P1
64,822
63,321
60,960
57,699
53,558
48,709
43,347
37,943
32,806
28,118
24,087
20,550
17,593
15,030
12,781
10,885
9,203
7,790
6,540
5,484
4,632
3,884
3,293
2,802
2,405
2,080
1,819
1,622
1,500
1,353
1,275
1,194
1,121
1,149
1,112
1,103
1,097
1,102
1,114
1,124
T1P6
210,721
209,123
205,456
200,556
192,592
182,618
170,617
157,228
143,468
128,916
115,385
102,659
91,142
79,202
68,701
59,020
49,925
41,837
34,987
29,083
24,179
19,829
16,374
13,320
11,002
8,969
7,392
6,201
5,167
4,446
3,766
3,317
2,970
2,679
2,469
2,348
2,255
2,180
2,144
2,170
T2P2
124,585
121,781
117,336
111,268
103,527
94,319
84,167
73,727
63,673
54,518
46,409
39,379
33,392
28,251
23,824
20,032
16,751
13,979
11,677
9,692
8,026
6,669
5,578
4,629
3,881
3,319
2,848
2,501
2,223
1,985
1,817
1,706
1,614
1,572
1,522
1,536
1,521
1,566
1,576
1,651
T2P7
266,144
262,886
256,453
246,715
233,743
217,926
200,092
181,144
162,189
144,066
127,012
111,335
96,916
83,718
71,825
61,087
51,646
43,279
36,010
29,802
24,521
20,142
16,463
13,469
11,019
9,022
7,423
6,150
5,128
4,318
3,716
3,200
2,783
2,514
2,299
2,141
2,045
1,956
1,899
1,901
T3P3
184,055
180,366
174,338
165,844
154,776
141,433
126,534
111,141
96,046
82,266
70,079
59,573
50,649
42,903
36,266
30,566
25,673
21,440
17,821
14,773
12,192
10,080
8,285
6,829
5,633
4,694
3,914
3,296
2,807
2,405
2,143
1,898
1,764
1,592
1,501
1,431
1,397
1,365
1,379
1,368
-229-
T3P8
329,604
326,329
319,244
308,063
292,679
273,511
251,258
227,228
202,829
179,274
157,285
137,171
119,005
102,655
87,846
74,674
63,074
52,910
44,023
36,439
29,998
24,558
20,059
16,330
13,288
10,809
8,837
7,216
5,984
4,948
4,148
3,581
3,036
2,664
2,373
2,173
2,012
1,900
1,850
1,768
T4P4
238,669
233,767
225,953
214,902
200,417
183,082
163,524
143,170
123,322
105,171
89,201
75,407
63,759
53,824
45,380
38,134
31,885
26,554
22,043
18,190
14,999
12,354
10,129
8,326
6,872
5,672
4,672
3,939
3,350
2,870
2,488
2,221
2,016
1,863
1,736
1,677
1,601
1,613
1,613
1,638
T4P9
377,916
373,780
365,221
351,977
333,892
311,421
285,246
257,031
228,421
201,008
175,509
152,408
131,672
113,119
96,601
81,910
69,047
57,756
48,008
39,653
32,613
26,666
21,733
17,661
14,367
11,668
9,474
7,765
6,389
5,285
4,400
3,764
3,256
2,818
2,518
2,295
2,130
1,990
1,899
1,842
T5P5
314,982
309,160
299,431
285,528
267,224
245,115
220,058
193,689
167,773
143,837
122,599
104,183
88,357
74,783
63,088
53,031
44,402
36,984
30,634
25,245
20,725
16,970
13,855
11,315
9,241
7,577
6,225
5,134
4,312
3,639
3,106
2,720
2,415
2,144
1,984
1,863
1,755
1,727
1,691
1,696
T5P10
448,311
442,870
432,275
416,095
394,013
366,739
334,974
300,809
266,251
233,229
202,712
175,246
150,918
129,229
110,074
93,203
78,367
65,469
54,394
44,903
36,909
30,191
24,520
19,971
16,180
13,109
10,681
8,731
7,120
5,861
4,900
4,118
3,497
3,017
2,677
2,408
2,210
2,074
1,961
1,924
ANEXO I
Datos de I/E de los voltamperogramas de las mezclas de Tl (I) y Pb (II) (continuación).
E (V)
-0,7008
-0,6958
-0,6908
-0,6857
-0,6807
-0,6757
-0,6706
-0,6656
-0,6606
-0,6555
-0,6505
-0,6454
-0,6404
-0,6354
-0,6303
-0,6253
-0,6203
-0,6152
-0,6102
-0,6052
-0,6001
-0,5951
-0,5901
-0,5850
-0,5800
-0,5750
-0,5699
-0,5649
-0,5598
-0,5548
-0,5498
-0,5447
-0,5397
-0,5347
-0,5296
-0,5246
-0,5196
-0,5145
-0,5095
-0,5045
T6P1
0,541
0,583
0,643
0,694
0,738
0,824
0,868
0,931
1,122
1,256
1,516
1,843
2,287
2,940
3,865
5,176
7,070
9,750
13,592
19,026
26,576
36,793
50,259
67,134
87,132
109,390
132,371
154,461
174,136
190,475
203,449
213,268
220,358
225,172
228,195
229,514
229,329
227,565
223,891
217,978
T6P6
0,790
0,866
0,967
0,790
1,192
1,394
1,560
1,816
2,118
2,512
2,994
3,605
4,358
5,340
6,635
8,307
10,537
13,449
17,380
22,627
29,719
39,055
51,519
67,642
87,982
112,607
141,020
171,906
203,338
233,399
260,782
284,758
305,168
322,299
336,535
347,995
356,842
363,239
366,844
367,545
T7P2
1,553
1,607
1,710
1,772
1,846
1,927
1,981
2,109
2,203
2,342
2,534
2,793
3,136
3,669
4,373
5,423
6,940
9,143
12,301
16,824
23,200
32,075
44,104
60,020
80,072
104,199
131,432
159,951
187,617
212,634
233,877
251,001
264,247
274,176
281,347
286,200
288,943
289,792
288,530
284,982
T7P7
0,852
0,939
1,054
1,193
1,342
1,481
1,720
1,991
2,356
2,772
3,315
3,984
4,871
6,021
7,492
9,445
12,011
15,436
20,031
26,254
34,553
45,727
60,560
79,841
104,388
134,046
168,517
205,875
243,927
280,204
313,203
341,801
366,065
386,183
402,694
415,147
425,223
432,265
436,128
436,436
T8P3
0,685
0,742
0,769
0,851
0,926
1,037
1,119
1,285
1,402
1,645
1,921
2,282
2,771
3,472
4,391
5,703
7,534
10,118
13,740
18,854
25,961
35,880
49,361
67,212
89,932
117,704
149,456
183,417
217,164
248,080
274,865
296,753
313,915
326,881
336,382
342,961
346,957
348,565
347,742
344,239
T8P8
0,739
0,826
0,962
1,081
1,243
1,452
1,685
1,975
2,329
2,796
3,318
4,050
4,959
6,167
7,743
9,791
12,573
15,977
21,024
27,255
35,977
47,135
61,471
80,028
102,700
129,449
158,545
190,780
227,243
263,206
308,248
335,847
371,136
401,239
432,648
455,307
467,955
484,122
495,213
493,865
T9P4
0,673
0,776
0,823
0,919
1,005
1,121
1,262
1,413
1,636
1,910
2,244
2,746
3,347
4,186
5,313
6,861
9,003
11,963
16,150
21,942
30,008
41,101
56,224
76,156
101,779
132,964
168,981
207,779
246,589
282,608
314,235
340,416
361,308
377,456
389,643
398,420
403,725
406,418
406,495
403,449
T9P9
0,886
0,987
1,113
1,261
1,459
1,665
1,949
2,310
2,725
3,251
3,914
4,766
5,841
7,221
9,054
11,411
14,518
18,629
24,151
31,504
41,462
54,685
72,252
95,261
124,621
160,335
202,112
247,919
295,202
340,770
382,554
419,070
449,356
475,290
496,622
513,826
527,045
536,534
542,086
543,272
T10P5
0,712
0,845
0,893
1,006
1,122
1,249
1,438
1,645
1,911
2,217
2,683
3,275
4,052
5,077
6,436
8,310
10,858
14,380
19,258
26,022
35,372
48,073
65,492
88,260
117,323
152,682
193,264
236,829
280,358
320,786
356,216
385,692
409,172
427,121
441,200
451,555
458,570
462,303
462,773
459,683
T10P10
0,879
1,005
1,137
1,295
1,520
1,761
2,068
2,416
2,909
3,494
4,193
5,163
6,377
7,912
9,970
12,572
16,141
20,589
26,618
34,855
45,242
58,458
75,729
96,680
122,473
151,594
186,466
219,677
256,415
298,460
342,776
382,218
419,944
463,773
507,703
519,289
560,987
576,923
601,893
608,091
.../...
-230-
ANEXO I
Datos de I/E de los voltamperogramas de las mezclas de Tl (I) y Pb (II) (continuación).
E (V)
-0,4994
-0,4944
-0,4893
-0,4843
-0,4793
-0,4742
-0,4692
-0,4642
-0,4591
-0,4541
-0,4491
-0,4440
-0,4390
-0,4340
-0,4289
-0,4239
-0,4189
-0,4138
-0,4088
-0,4037
-0,3987
-0,3937
-0,3886
-0,3836
-0,3786
-0,3735
-0,3685
-0,3635
-0,3584
-0,3534
-0,3484
-0,3433
-0,3383
-0,3333
-0,3282
-0,3232
-0,3181
-0,3131
-0,3081
-0,3030
T6P1
209,456
197,825
182,743
164,342
143,296
121,050
99,094
79,077
62,001
48,147
37,387
29,187
22,952
18,210
14,568
11,779
9,583
7,806
6,428
5,338
4,446
3,734
3,163
2,758
2,411
2,130
1,899
1,739
1,645
1,551
1,520
1,519
1,517
1,519
1,552
1,592
1,659
1,715
1,788
1,842
T6P6
364,811
358,279
347,350
331,553
310,782
285,558
256,822
226,558
196,592
168,799
143,968
122,437
103,888
87,895
74,132
62,305
52,086
43,409
35,939
29,635
24,336
19,905
16,260
13,256
10,807
8,824
7,238
6,000
4,992
4,213
3,558
3,052
2,689
2,418
2,202
2,053
1,978
1,861
1,836
1,844
T7P2
278,664
269,143
255,800
238,126
216,215
190,812
163,407
136,065
110,735
88,745
70,700
56,262
45,015
36,263
29,351
23,858
19,439
15,939
13,065
10,714
8,837
7,229
6,036
5,035
4,210
3,598
3,071
2,697
2,378
2,170
1,999
1,876
1,816
1,737
1,767
1,734
1,763
1,813
1,828
1,912
T7P7
432,824
424,636
411,149
391,960
366,693
336,059
301,149
264,399
228,381
194,973
165,255
139,699
117,909
99,404
83,451
69,821
58,184
48,300
39,891
32,695
26,809
21,877
17,734
14,411
11,748
9,618
7,846
6,453
5,341
4,466
3,787
3,238
2,826
2,532
2,320
2,130
2,031
1,950
1,923
1,911
T8P3
337,580
327,232
312,409
292,626
267,654
238,304
205,952
172,901
141,741
114,222
91,323
72,834
58,240
46,865
37,872
30,702
25,043
20,437
16,703
13,633
11,146
9,106
7,496
6,166
5,084
4,231
3,566
2,997
2,643
2,311
2,083
1,903
1,703
1,658
1,576
1,493
1,502
1,527
1,494
1,542
-231-
T8P8
492,928
483,472
473,682
448,729
420,162
388,917
348,208
307,967
268,692
230,870
197,054
166,298
140,312
118,074
99,268
83,302
69,745
57,794
47,832
39,390
32,449
26,196
21,483
17,448
14,150
11,433
9,327
7,687
6,399
5,333
4,502
3,877
3,333
3,006
2,659
2,478
2,328
2,241
2,174
2,138
T9P4
396,796
385,821
369,673
347,984
320,251
287,306
250,552
212,820
176,598
144,407
117,032
94,811
76,855
62,544
51,114
41,850
34,269
28,061
23,004
18,798
15,326
12,474
10,254
8,426
6,903
5,706
4,726
3,942
3,375
2,875
2,538
2,265
2,017
1,880
1,798
1,706
1,676
1,669
1,627
1,725
T9P9
539,637
530,452
514,804
492,219
462,129
425,196
382,732
337,591
292,650
250,565
212,987
180,221
152,227
128,314
107,779
90,338
75,317
62,478
51,565
42,379
34,693
28,278
22,907
18,627
15,097
12,222
9,954
8,122
6,648
5,506
4,597
3,859
3,347
2,890
2,594
2,341
2,148
2,034
1,954
1,917
T10P5
452,322
440,019
421,910
397,362
366,125
329,033
287,911
245,667
205,245
169,142
138,394
112,973
92,503
75,862
62,369
51,247
42,178
34,683
28,358
23,214
18,954
15,393
12,600
10,245
8,356
6,860
5,650
4,651
3,876
3,309
2,826
2,447
2,208
2,008
1,828
1,749
1,684
1,614
1,584
1,602
T10P10
610,370
605,586
586,606
565,875
528,340
491,088
442,599
388,769
337,276
287,044
243,378
204,835
172,142
142,481
120,290
100,717
83,142
68,561
56,580
46,417
37,949
31,007
25,073
20,411
16,530
13,620
11,010
9,043
7,395
6,167
5,211
4,456
3,876
3,445
3,138
2,840
2,679
2,574
2,484
2,434
Anexo II.
ANEXO II
Aplicación programada para llevar a cabo el proceso de filtrado y reducción de
dimensiones:
% -- ----------------------------------------------------------------------------------------------% -- ----------------------------------------------------------------------------------------------% -- Dada la señal espectral S(t) muestreada NPUNTOS veces durante un segundo.
% -* Se calcula su FFT en N=128, 256 ó 512 de sus frecuencias.
% -* Se filtran las frecuencias altas (eliminándolas).
% -* Se recompone la señal mediante la transformada inversa.
% -* Calcula el error de recomposición.
% -- ----------------------------------------------------------------------------------------------% -- ----------------------------------- Andrés Jiménez --------------------------------------freqmax = input('Frecuencia máxima admisible: ');
ampmin = 0;
N = input('Número de componentes máximo de frecuencia a considerar (128, 256, 512): ');
fichero = 'c:\matlab\bin\archivo.txt';
N2 = N/2;
NPUNTOS = 80;
% -- -------------------------------------------------% -- Número de muestras tomadas de la señal.
% -- --------------------------------------------------
% -- ------------------------------------------------------------% -- La señal original s(t) se lee de un fichero de texto.
% -- ------------------------------------------------------------Fs = NPUNTOS;
t = (1:Fs)/Fs;
% -- -----------------------------------------------------------% -- La señal se muestrea 100 veces el intervalo [0,1].
% -- -----------------------------------------------------------fid = fopen(fichero,'r');
for i = 1:NPUNTOS,
v = fscanf(fid,'%e', 1);
s(i) = v;
end;
fclose(fid);
% -- ----------------------------------------------% -- Transformadas de la señal original s(t).
% -- -----------------------------------------------233-
ANEXO II
subplot(2,2,1), hndl1 = plot( t, s);
title('Se±al original s(t) ')
set(hndl1, 'LineWidth', 1.25 );
xlabel('t')
ylabel('s(t)')
% -- --------------------------------------------------------Y = fft(s, N);
% -- fft discreta con N componentes de frecuencias.
% -- --------------------------------------------------------w = (0:N2-1)/N2*(Fs/2);
subplot(2,2,2), hndl2 = plot(w, abs(Y(1:N2)') );
title('FFT(Original)')
set(hndl2, 'LineWidth', 1.25 );
xlabel('Frec Hz.')
ylabel('Modulo (FFT)')
for i=1:N2
if( w(i) > freqmax )
Y(i) = 0;
end;
if( abs(Y(i)) < ampmin )
Y(i) = 0;
end;
fprintf(1, '\n %d \t %f \t %e ', i, w(i), abs(Y(i)) );
end;
subplot(2,2,3), hndl3 = plot(w, abs(Y(1:N2)') );
title('FFT Filtrada ')
set(hndl2, 'LineWidth', 1.25 );
xlabel('Frec Hz.')
ylabel('Módulo (FFT)')
% -- -------------------------------------------------------snew = ifft(Y); % -- snew(t) es la Transformada Inversa de Fourier.
% -- -------------------------------------------------------subplot(2,2,4), hndl4 = plot(t, s, t, real(snew(1:NPUNTOS)') );
title('S(t) Recompuesta de la filtrada')
set(hndl2, 'LineWidth', 1.0 );
xlabel('t')
ylabel('s(t) y Snew(t) ')
-234-
ANEXO II
% -- -------------------------------------------% -- Cálculo del error de recomposición.
% -- -------------------------------------------e1 = 0; e2 = 0;
for i=1:NPUNTOS
e1 = e1 + ( real(snew(i)) - s(i) )^2;
e2 = e2 + ( s(i)^2 );
end;
100 * sqrt(e1/e2)
-235-
Anexo III.
ANEXO III
Resultados de las pruebas de reducción de dimensiones de las muestras analizadas (en el
cuadro, los errores de recomposición aparecen en %):
N = 10; w =6
T1
T2
T3
T4
T5
T6
T7
T8
T9
T10
P1
P2
P3
P4
P5
P6
P7
P8
P9
P10
T1P1
T1P6
T2P2
T2P7
T3P3
T3P8
T4P4
T4P9
T5P5
T5P10
T6P1
T6P6
T7P2
T7P7
T8P3
T8P8
T9P4
T9P9
T10P5
T10P10
1,38
1,32
1,30
1,29
1,29
1,32
1,31
1,31
1,30
1,32
0,82
0,37
0,77
0,49
0,80
0,55
0,82
0,56
0,76
0,61
1,13
0,74
1,10
0,80
1,07
0,54
1,02
0,77
0,99
0,58
Espectro de Fourier de 128 frecuencias
N = 9; w = 5
N=7w=4
N = 5; w = 3
0,64
0,82
1,67
0,33
0,43
1,94
0,24
0,32
1,98
0,34
0,41
2,16
0,19
0,27
2,18
0,48
0,61
1,96
0,23
0,32
2,28
0,25
0,52
2,35
0,40
0,65
2,55
0,16
0,20
2,24
1,93
2,59
5,57
1,95
2,58
5,60
1,93
2,56
5,66
1,93
2,53
5,72
1,94
2,54
5,72
1,98
2,59
5,75
1,97
2,57
5,75
1,96
2,56
5,75
1,96
2,57
5,77
2,00
2,62
5,79
1,19
1,58
3,64
0,47
0,62
2,47
1,12
1,49
3,65
0,71
0,94
2,74
1,18
1,56
3,71
0,81
1,08
2,97
1,22
1,61
3,83
0,84
1,11
3,10
1,14
1,50
3,70
0,91
1,21
3,22
1,68
2,21
5,04
1,11
1,47
3,67
1,64
2,14
4,85
1,20
1,57
3,81
1,61
2,10
4,81
0,71
0,92
4,23
1,54
2,01
4,62
1,16
1,52
3,78
1,48
1,93
4,48
0,76
1,29
4,65
-237-
N = 4; w = 2
6,25
6,15
6,08
6,31
ANEXO III
N = 20; w =6
T1
T2
T3
T4
T5
T6
T7
T8
T9
T10
P1
P2
P3
P4
P5
P6
P7
P8
P9
P10
T1P1
T1P6
T2P2
T2P7
T3P3
T3P8
T4P4
T4P9
T5P5
T5P10
T6P1
T6P6
T7P2
T7P7
T8P3
T8P8
T9P4
T9P9
T10P5
T10P10
1,23
1,16
1,13
1,12
1,13
1,15
1,14
1,14
1,13
1,15
0,73
0,34
0,68
0,43
0,70
0,49
0,72
0,49
0,67
0,53
0,98
0,65
0,96
0,70
0,93
0,50
0,89
0,67
0,86
0,55
Espectro de Fourier de 256 frecuencias
N = 17; w = 5 N = 13; w = 4 N = 10; w = 3
0,69
0,83
1,22
0,36
0,46
1,40
0,26
0,35
1,43
0,36
0,45
1,59
0,20
0,32
1,62
0,50
0,62
1,45
0,24
0,37
1,71
0,28
0,57
1,81
0,42
0,71
2,02
0,17
0,25
1,67
2,06
2,59
4,62
2,08
2,58
4,63
2,06
2,55
4,64
2,06
2,53
4,68
2,06
2,54
4,68
2,11
2,58
4,72
2,09
2,57
4,71
2,08
2,55
4,71
2,09
2,56
4,72
2,13
2,61
4,74
1,27
1,57
2,93
0,50
0,64
1,88
1,19
1,49
2,91
0,76
0,94
2,12
1,26
1,56
2,97
0,87
1,08
2,31
1,30
1,60
3,07
0,89
1,10
2,42
1,21
1,50
2,95
0,97
1,21
2,53
1,79
2,20
4,11
1,18
1,47
2,92
1,71
2,13
3,94
1,27
1,66
3,05
1,71
2,10
3,90
0,75
1,01
3,37
1,63
2,01
3,74
1,23
1,52
3,01
1,57
1,92
3,63
0,80
1,42
3,81
-238-
N = 7; w = 2
7,89
7,76
7,68
7,89
7,76
7,68
7,84
7,82
7,91
7,78
8,28
Anexo IV.
ANEXO IV
Señales de los voltamperogramas de las muestras en el dominio de Fourier
(frecuencia/amplitud):
W (Hz)
A(T1)
A(T2)
A(T3)
A(T4)
A(T5)
A(T6)
A(T7)
A(T8)
A(T9)
A(T10)
A(P1)
A(P2)
A(P3)
A(P4)
A(P5)
A(P6)
A(P7)
A(P8)
A(P9)
A(P10)
A(T1P1)
A(T1P6)
A(T2P2)
A(T2P7)
A(T3P3)
A(T3P8)
A(T4P4)
A(T4P9)
A(T5P5)
A(T5P10)
A(T6P1)
A(T6P6)
A(T7P2)
A(T7P7)
A(T8P3)
A(T8P8)
A(T9P4)
A(T9P9)
A(T10P5)
A(T10P10)
1
0,0000
6,50E-07
1,34E-06
2,01E-06
2,65E-06
3,40E-06
4,45E-06
4,85E-06
5,61E-06
6,09E-06
6,91E-06
8,67E-07
1,53E-06
2,16E-06
2,78E-06
3,54E-06
4,12E-06
4,76E-06
5,48E-06
6,04E-06
6,59E-06
1,51E-06
5,01E-06
2,87E-06
6,28E-06
4,21E-06
7,69E-06
5,42E-06
8,76E-06
7,16E-06
1,03E-05
4,83E-06
8,30E-06
6,20E-06
9,79E-06
7,44E-06
1,07E-05
8,77E-06
1,22E-05
1,01E-05
1,29E-05
2
0,6250
5,39E-07
1,15E-06
1,75E-06
2,31E-06
2,98E-06
3,80E-06
4,25E-06
4,91E-06
5,33E-06
6,10E-06
7,86E-07
1,41E-06
2,00E-06
2,59E-06
3,30E-06
3,85E-06
4,46E-06
5,13E-06
5,66E-06
6,18E-06
1,35E-06
4,45E-06
2,59E-06
5,62E-06
3,81E-06
6,91E-06
4,92E-06
7,89E-06
6,50E-06
9,34E-06
4,46E-06
7,53E-06
5,69E-06
8,90E-06
6,85E-06
9,76E-06
8,06E-06
1,11E-05
9,22E-06
1,18E-05
3
1,2500
3,34E-07
7,70E-07
1,19E-06
1,59E-06
2,05E-06
2,49E-06
2,94E-06
3,37E-06
3,66E-06
4,27E-06
6,24E-07
1,15E-06
1,63E-06
2,13E-06
2,72E-06
3,18E-06
3,68E-06
4,24E-06
4,69E-06
5,11E-06
1,00E-06
3,17E-06
1,94E-06
4,09E-06
2,87E-06
5,07E-06
3,73E-06
5,83E-06
4,91E-06
6,93E-06
3,56E-06
5,68E-06
4,48E-06
6,76E-06
5,41E-06
7,43E-06
6,32E-06
8,41E-06
7,19E-06
8,99E-06
Dimensiones
4
1,8750
1,99E-07
4,49E-07
6,88E-07
9,28E-07
1,19E-06
1,44E-06
1,71E-06
1,95E-06
2,11E-06
2,47E-06
4,65E-07
8,42E-07
1,20E-06
1,56E-06
1,99E-06
2,32E-06
2,69E-06
3,09E-06
3,42E-06
3,74E-06
6,50E-07
1,89E-06
1,26E-06
2,49E-06
1,85E-06
3,12E-06
2,42E-06
3,62E-06
3,16E-06
4,33E-06
2,50E-06
3,65E-06
3,11E-06
4,38E-06
3,73E-06
4,86E-06
4,30E-06
5,44E-06
4,85E-06
5,91E-06
-240-
5
2,5000
1,11E-07
2,30E-07
3,43E-07
4,66E-07
5,86E-07
7,45E-07
8,45E-07
9,67E-07
1,05E-06
1,20E-06
2,93E-07
5,27E-07
7,50E-07
9,77E-07
1,24E-06
1,45E-06
1,68E-06
1,93E-06
2,14E-06
2,33E-06
3,62E-07
9,40E-07
6,95E-07
1,27E-06
1,02E-06
1,62E-06
1,34E-06
1,89E-06
1,74E-06
2,28E-06
1,51E-06
2,00E-06
1,86E-06
2,42E-06
2,21E-06
2,76E-06
2,51E-06
3,00E-06
2,81E-06
3,39E-06
6
3,1250
3,36E-08
7,91E-08
1,20E-07
1,72E-07
2,20E-07
2,65E-07
3,24E-07
3,78E-07
4,30E-07
4,59E-07
1,38E-07
2,54E-07
3,63E-07
4,80E-07
6,09E-07
7,14E-07
8,26E-07
9,52E-07
1,05E-06
1,15E-06
1,53E-07
3,60E-07
2,97E-07
4,98E-07
4,43E-07
6,53E-07
5,90E-07
7,81E-07
7,57E-07
9,52E-07
7,18E-07
8,71E-07
8,75E-07
1,07E-06
1,04E-06
1,32E-06
1,17E-06
1,32E-06
1,30E-06
1,67E-06
7
3,7500
2,32E-09
1,44E-08
2,42E-08
3,96E-08
5,69E-08
5,53E-08
9,01E-08
1,19E-07
1,54E-07
1,20E-07
4,42E-08
7,58E-08
1,08E-07
1,45E-07
1,81E-07
2,12E-07
2,45E-07
2,84E-07
3,14E-07
3,39E-07
4,12E-08
9,28E-08
7,94E-08
1,17E-07
1,17E-07
1,58E-07
1,58E-07
1,96E-07
2,01E-07
2,38E-07
2,12E-07
2,30E-07
2,48E-07
2,84E-07
2,98E-07
4,94E-07
3,29E-07
3,50E-07
3,64E-07
7,19E-07
Anexo V.
ANEXO V
Datos de I/E de los voltamperogramas de las muestras de comprobación desde -0,7 a -0,3
V:
E (V)
-0,7008
-0,6958
-0,6908
-0,6857
-0,6807
-0,6757
-0,6706
-0,6656
-0,6606
-0,6555
-0,6505
-0,6454
-0,6404
-0,6354
-0,6303
-0,6253
-0,6203
-0,6152
-0,6102
-0,6052
-0,6001
-0,5951
-0,5901
-0,5850
-0,5800
-0,5750
-0,5699
-0,5649
-0,5598
-0,5548
-0,5498
-0,5447
-0,5397
-0,5347
-0,5296
-0,5246
-0,5196
-0,5145
-0,5095
-0,5045
T1P9
4,728
4,785
4,871
4,918
5,007
5,108
5,244
5,440
5,745
6,164
6,830
7,868
9,515
11,995
15,685
21,027
28,621
39,179
53,502
72,327
95,983
124,244
156,044
189,251
221,546
250,460
274,837
294,219
308,659
318,859
325,566
329,294
330,463
329,316
325,718
319,446
310,046
297,035
279,726
257,724
T2P10
1,558
1,688
1,807
1,987
2,192
2,458
2,817
3,311
3,914
4,791
5,975
7,629
9,932
13,125
17,641
23,940
32,604
44,514
60,535
81,407
107,651
138,951
174,389
211,555
247,773
280,626
308,634
330,970
347,981
360,192
368,447
373,332
375,264
374,452
370,905
364,272
354,127
339,899
320,820
296,541
T3P5
1,567
1,684
1,830
2,044
2,283
2,590
2,973
3,446
4,065
4,904
6,000
7,438
9,398
12,035
15,568
20,345
26,831
35,459
46,781
61,267
78,961
99,727
122,680
146,326
169,336
190,070
207,941
222,587
234,155
242,970
249,451
253,750
256,197
256,640
255,052
251,248
244,841
235,550
222,953
206,947
T5P3
1,335
1,537
1,785
2,076
2,378
2,800
3,298
3,937
4,721
5,696
6,936
8,519
10,568
13,130
16,518
20,859
26,526
33,808
43,140
54,915
69,192
85,924
104,659
124,450
144,150
162,862
179,904
194,972
207,936
218,900
227,869
235,036
240,405
243,850
245,246
244,448
241,201
235,277
226,422
214,534
-242-
T6P8
1,983
2,297
2,648
3,085
3,633
4,341
5,218
6,368
7,852
9,801
12,354
15,717
20,246
26,272
34,395
45,229
59,632
78,222
101,981
131,054
164,994
202,866
242,258
281,001
317,245
349,053
376,200
397,808
414,222
427,082
436,465
442,698
444,239
443,468
437,717
428,084
413,066
392,432
366,192
334,576
T8P6
2,160
2,516
2,896
3,414
4,032
4,846
5,839
7,096
8,657
10,754
13,533
16,920
21,397
27,565
34,924
44,683
57,746
73,919
93,168
116,930
141,856
171,494
201,282
233,369
264,271
294,088
321,750
342,397
363,833
385,427
400,579
408,124
420,224
422,458
423,441
418,788
405,581
386,758
364,121
335,992
T9P1
2,625
2,911
3,239
3,608
4,051
4,617
5,284
6,062
7,088
8,291
9,837
11,737
14,128
17,095
20,870
25,586
31,514
38,927
48,141
59,457
73,033
88,910
106,911
126,403
146,624
166,799
186,368
204,851
222,038
237,573
251,490
263,507
273,458
281,253
286,500
289,133
288,869
285,647
279,138
269,358
T10P2
5,032
5,362
5,716
6,148
6,623
7,233
7,938
8,828
9,876
11,189
12,851
14,958
17,650
21,105
25,523
31,215
38,418
47,530
58,924
72,934
89,951
109,762
132,198
156,332
181,309
205,960
229,586
251,560
271,615
289,652
305,396
318,848
329,699
337,830
343,067
345,136
343,750
338,773
329,899
317,058
ANEXO V
E (V)
-0,4994
-0,4944
-0,4893
-0,4843
-0,4793
-0,4742
-0,4692
-0,4642
-0,4591
-0,4541
-0,4491
-0,4440
-0,4390
-0,4340
-0,4289
-0,4239
-0,4189
-0,4138
-0,4088
-0,4037
-0,3987
-0,3937
-0,3886
-0,3836
-0,3786
-0,3735
-0,3685
-0,3635
-0,3584
-0,3534
-0,3484
-0,3433
-0,3383
-0,3333
-0,3282
-0,3232
-0,3181
-0,3131
-0,3081
-0,3030
T1P9
231,249
201,176
169,291
137,860
109,158
84,558
64,636
49,191
37,444
28,705
22,184
17,293
13,652
9,741
8,750
7,107
5,833
4,840
4,087
3,496
3,021
2,666
2,454
2,267
2,145
2,042
1,989
1,988
1,963
2,025
2,038
2,059
2,115
2,180
2,231
2,281
2,345
2,406
2,502
2,583
T2P10
267,220
233,939
198,402
163,125
130,659
102,652
79,652
61,559
47,648
37,060
29,020
22,845
18,156
14,491
11,632
9,397
7,629
6,218
5,144
4,269
3,592
3,060
2,638
2,349
2,101
1,920
1,789
1,706
1,637
1,602
1,611
1,617
1,645
1,692
1,724
1,791
1,862
1,941
2,039
2,167
T3P5
187,744
166,197
143,468
121,113
100,412
82,376
67,179
54,786
44,634
36,479
29,848
24,403
19,996
16,359
13,405
10,975
9,014
7,412
6,112
5,102
4,287
3,642
3,114
2,739
2,412
2,191
2,000
1,880
1,789
1,751
1,711
1,737
1,742
1,789
1,822
1,875
1,947
2,067
2,134
2,234
T5P3
199,727
182,547
163,721
144,504
125,876
108,686
93,149
79,412
67,408
56,933
47,876
40,022
33,301
27,533
22,662
18,573
15,216
12,415
10,104
8,275
6,754
5,569
4,633
3,853
3,290
2,813
2,465
2,196
1,988
1,822
1,726
1,641
1,608
1,605
1,596
1,607
1,675
1,690
1,764
1,828
-243-
T6P8
298,645
260,970
223,738
188,827
158,021
131,520
109,268
90,657
75,119
62,153
51,209
42,058
34,448
28,100
22,859
18,553
15,066
12,229
9,954
8,087
6,648
5,487
4,580
3,836
3,330
2,894
2,577
2,323
2,140
2,024
1,944
1,891
1,873
1,892
1,916
1,973
2,035
2,115
2,203
2,290
T8P6
307,093
268,002
235,885
204,770
173,309
150,372
125,538
106,118
89,472
75,388
62,827
52,606
43,590
34,910
28,678
23,312
19,189
15,557
12,671
10,374
8,494
7,096
5,897
5,006
4,245
3,683
3,222
2,941
2,682
2,524
2,345
2,275
2,232
2,196
2,252
2,302
2,339
2,402
2,488
2,561
T9P1
256,412
240,668
222,578
203,103
183,091
163,310
144,318
126,396
109,793
94,433
80,522
68,095
57,104
47,558
39,292
32,287
26,421
21,526
17,485
14,172
11,535
9,375
7,661
6,277
5,214
4,363
3,712
3,187
2,811
2,538
2,298
2,149
2,012
1,956
1,932
1,909
1,909
1,959
1,988
2,048
T10P2
300,371
280,334
257,581
233,428
208,892
185,008
162,294
141,218
121,861
104,401
88,609
74,648
62,398
51,843
42,733
35,022
28,612
23,283
18,915
15,343
12,474
10,161
8,330
6,892
5,752
4,862
4,183
3,644
3,254
2,945
2,715
2,554
2,446
2,377
2,330
2,304
2,298
2,275
2,304
2,334
Anexo VI.
ANEXO VI
Señales de los voltamperogramas de las muestras de comprobación en el dominio de
Fourier (frecuencia/amplitud):
1
W (HZ)
0,0000
A(T1P9) 6,91E-06
A(T2P10) 7,86E-06
A(T9P1) 6,88E-06
A(T10P2) 8,17E-06
A(T3P5) 5,61E-06
A(T5P3) 5,62E-06
A(T6P8) 9,78E-06
A(T8P6) 9,37E-06
2
0,6250
6,35E-06
7,26E-06
6,13E-06
7,27E-06
5,11E-06
5,06E-06
8,91E-06
8,47E-06
Dimensiones
3
4
5
1,2500
1,8750
2,5000
5,07E-06 3,60E-06 2,20E-06
5,80E-06 4,07E-06 2,44E-06
4,41E-06 2,66E-06 1,34E-06
5,25E-06 3,21E-06 1,66E-06
3,95E-06 2,67E-06 1,54E-06
3,77E-06 2,39E-06 1,28E-06
6,85E-06 4,54E-06 2,56E-06
6,37E-06 4,11E-06 2,26E-06
-245-
6
3,1250
1,09E-06
1,18E-06
5,30E-07
6,72E-07
7,19E-07
5,48E-07
1,19E-06
1,05E-06
7
3,7500
3,31E-07
3,61E-07
1,34E-07
1,67E-07
2,18E-07
1,53E-07
3,66E-07
3,76E-07
Error de recomposición (%)
2,16
2,08
0,63
0,73
1,17
1,71
1,47
1,03
Anexo VII.
ANEXO VII
Tablas de resultados de la prueba de validación para el método de estimación por
interpolación:
Modelo Horizontal
Muestra real T1P9
Error 82 Error 83
7,03E-13 5,28E-13
4,67E-13 3,63E-13
3,40E-13 2,97E-13
3,28E-13 3,45E-13
3,73E-13 3,54E-13
4,73E-13 5,47E-13
4,54E-13 4,34E-13
4,70E-13 5,29E-13
6,58E-13 7,71E-13
8,85E-13 1,05E-12
4,03E-13 5,50E-13
1,30E-12 1,51E-12
4,80E-13 4,27E-13
3,69E-13 4,95E-13
6,10E-13 5,28E-13
3,73E-13 5,18E-13
7,78E-13
4,64E-13
3,28E-13 2,97E-13
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
1,15E-12
7,78E-13
5,28E-13
3,99E-13
5,04E-13
4,08E-13
5,95E-13
4,64E-13
5,18E-13
6,54E-13
2,17E-13
9,53E-13
6,67E-13
2,15E-13
8,57E-13
2,16E-13
1,07E-12
3,01E-13
2,15E-13
Error 81
9,11E-13
6,05E-13
4,17E-13
3,46E-13
4,23E-13
4,27E-13
5,07E-13
4,48E-13
5,74E-13
7,52E-13
2,92E-13
1,12E-12
5,61E-13
2,76E-13
7,20E-13
2,72E-13
9,11E-13
3,57E-13
2,72E-13
Modelo Vertical
Error 80
Error 81 Error 82 Error 83 Error 84 Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
1,15E-12
7,78E-13
5,28E-13
3,99E-13
8,89E-13
4,08E-13
2,82E-13
2,56E-13
3,11E-13
4,84E-13
7,34E-13
7,76E-13
1,04E-12
7,34E-13
1,12E-12
7,59E-13
1,31E-12
7,50E-13
2,56E-13
9,85E-13
6,60E-13
4,69E-13
3,97E-13
7,05E-13
4,69E-13
2,61E-13
2,92E-13
4,07E-13
6,30E-13
6,31E-13
9,66E-13
8,17E-13
6,14E-13
8,82E-13
5,21E-13
1,02E-12
4,40E-13
2,61E-13
8,45E-13
5,70E-13
4,38E-13
4,21E-13
5,64E-13
5,54E-13
2,72E-13
3,61E-13
5,33E-13
8,05E-13
5,84E-13
1,18E-12
6,38E-13
5,81E-13
6,84E-13
3,71E-13
7,78E-13
2,56E-13
2,56E-13
7,34E-13
5,08E-13
4,36E-13
4,72E-13
4,68E-13
6,62E-13
3,15E-13
4,61E-13
6,87E-13
1,01E-12
5,92E-13
1,42E-12
4,98E-13
6,35E-13
5,28E-13
3,11E-13
Error 84
3,88E-13
2,92E-13
2,87E-13
3,97E-13
3,66E-13
6,48E-13
4,49E-13
6,25E-13
9,12E-13
1,26E-12
7,33E-13
1,74E-12
3,99E-13
6,54E-13
Error 85
2,82E-13
2,56E-13
3,11E-13
4,84E-13
4,08E-13
7,76E-13
4,98E-13
7,58E-13
1,08E-12
1,50E-12
9,53E-13
1,99E-12
2,87E-13 2,56E-13 2,15E-13
6,50E-13
4,72E-13
4,63E-13
5,50E-13
4,16E-13
7,95E-13
3,90E-13
5,94E-13
8,70E-13
1,24E-12
6,56E-13
1,69E-12
3,99E-13
7,76E-13
5,95E-13
4,64E-13
5,18E-13
6,54E-13
4,08E-13
9,53E-13
4,98E-13
7,58E-13
1,08E-12
1,50E-12
7,76E-13
1,99E-12
3,11E-13 3,90E-13 4,08E-13 2,56E-13
Mal clasificado; parece que un modelo vertical puede explicarlo cuando eso es imposible. Sólo puede ser
predicho mediante un modelo horizontal. En nuestro caso, éste coloca la señal en la correspondiente al
P9. El vertical clasifica en T7P2.
.../...
-247-
ANEXO VII
(continuación)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
1,57E-12
1,11E-12
7,75E-13
5,70E-13
7,65E-13
4,78E-13
8,24E-13
6,07E-13
5,78E-13
6,49E-13
2,65E-13
8,50E-13
9,79E-13
3,01E-13
1,21E-12
3,40E-13
1,47E-12
4,77E-13
2,65E-13
Error 81
1,28E-12
8,88E-13
6,19E-13
4,71E-13
6,46E-13
4,55E-13
6,90E-13
5,44E-13
5,93E-13
7,01E-13
3,10E-13
9,81E-13
8,37E-13
3,39E-13
1,04E-12
3,75E-13
1,28E-12
5,16E-13
3,10E-13
Muestra real T2P10
Error 82 Error 83
1,02E-12 8,01E-13
7,04E-13 5,54E-13
4,97E-13 4,07E-13
4,07E-13 3,78E-13
5,58E-13 5,00E-13
4,60E-13 4,92E-13
5,91E-13 5,26E-13
5,18E-13 5,30E-13
6,37E-13 7,09E-13
7,87E-13 9,09E-13
3,91E-13 5,08E-13
1,13E-12 1,31E-12
7,22E-13 6,33E-13
4,10E-13 5,13E-13
8,93E-13 7,75E-13
4,54E-13 5,78E-13
1,11E-12
6,07E-13
3,91E-13 3,78E-13
Error 84
6,15E-13
4,37E-13
3,52E-13
3,83E-13
4,74E-13
5,52E-13
4,95E-13
5,78E-13
8,09E-13
1,07E-12
6,61E-13
1,50E-12
5,70E-13
6,49E-13
Error 85
4,63E-13
3,55E-13
3,30E-13
4,23E-13
4,78E-13
6,39E-13
4,99E-13
6,65E-13
9,38E-13
1,26E-12
8,50E-13
1,72E-12
3,52E-13
3,30E-13
Modelo Vertical
Error 80
Error 81
Error 82
Error 83
Error 84
Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
1,57E-12
1,11E-12
7,75E-13
5,70E-13
1,22E-12
4,78E-13
4,63E-13
3,55E-13
3,30E-13
4,23E-13
8,83E-13
6,39E-13
1,41E-12
8,83E-13
1,52E-12
9,84E-13
1,74E-12
1,01E-12
3,30E-13
1,36E-12
9,52E-13
6,78E-13
5,33E-13
9,83E-13
5,04E-13
4,05E-13
3,53E-13
3,94E-13
5,34E-13
7,23E-13
8,03E-13
1,14E-12
6,92E-13
1,23E-12
6,77E-13
1,40E-12
6,18E-13
3,53E-13
1,18E-12
8,25E-13
6,10E-13
5,22E-13
7,90E-13
5,55E-13
3,80E-13
3,83E-13
4,87E-13
6,73E-13
6,19E-13
9,92E-13
9,09E-13
5,87E-13
9,82E-13
4,59E-13
1,11E-12
3,55E-13
3,55E-13
1,04E-12
7,25E-13
5,71E-13
5,38E-13
6,42E-13
6,29E-13
3,87E-13
4,45E-13
6,08E-13
8,41E-13
5,70E-13
1,21E-12
7,20E-13
5,70E-13
7,75E-13
3,30E-13
9,16E-13
6,52E-13
5,60E-13
5,80E-13
5,38E-13
7,28E-13
4,27E-13
5,39E-13
7,59E-13
1,04E-12
5,77E-13
1,45E-12
5,70E-13
6,39E-13
8,24E-13
6,07E-13
5,78E-13
6,49E-13
4,78E-13
8,50E-13
4,99E-13
6,65E-13
9,38E-13
1,26E-12
6,39E-13
1,72E-12
3,30E-13
4,27E-13
4,78E-13
Modelo Horizontal
2,65E-13
3,30E-13
Mal clasificado; parece que un modelo vertical puede explicarlo cuando eso es imposible. Sólo puede ser
predicho mediante un modelo horizontal. En nuestro caso, éste coloca la señal en la correspondiente al
P10. El vertical clasifica en T8P3.
.../...
-248-
ANEXO VII
(continuación)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
6,25E-13
3,60E-13
2,18E-13
1,89E-13
1,94E-13
3,31E-13
2,90E-13
2,78E-13
4,40E-13
6,59E-13
2,11E-13
1,09E-12
2,89E-13
1,55E-13
4,15E-13
1,06E-13
5,67E-13
1,13E-13
1,06E-13
Error 81
4,50E-13
2,53E-13
1,72E-13
2,03E-13
1,60E-13
4,09E-13
2,66E-13
3,28E-13
5,50E-13
8,21E-13
3,14E-13
1,29E-12
2,25E-13
2,32E-13
3,21E-13
1,72E-13
4,50E-13
1,71E-13
1,60E-13
Muestra real T3P5
Error 82 Error 83
3,10E-13 2,04E-13
1,80E-13 1,41E-13
1,60E-13 1,82E-13
2,51E-13 3,34E-13
1,56E-13 1,84E-13
5,14E-13 6,47E-13
2,77E-13 3,22E-13
4,15E-13 5,39E-13
6,89E-13 8,56E-13
1,02E-12 1,25E-12
4,53E-13 6,28E-13
1,52E-12 1,77E-12
1,87E-13 1,75E-13
3,41E-13 4,84E-13
2,56E-13 2,18E-13
2,84E-13 4,40E-13
3,60E-13
2,78E-13
1,56E-13 1,41E-13
Error 84
1,32E-13
1,36E-13
2,37E-13
4,52E-13
2,42E-13
8,07E-13
4,00E-13
7,01E-13
1,05E-12
1,52E-12
8,39E-13
2,04E-12
1,89E-13
6,59E-13
Error 85
9,44E-14
1,65E-13
3,26E-13
6,04E-13
3,31E-13
9,94E-13
5,13E-13
8,99E-13
1,28E-12
1,82E-12
1,09E-12
2,34E-12
1,32E-13
9,44E-14
Modelo Vertical
Error 80
Error 81
Error 82
Error 83
Error 84
Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
6,25E-13
3,60E-13
2,18E-13
1,89E-13
4,45E-13
3,31E-13
9,44E-14
1,65E-13
3,26E-13
6,04E-13
5,07E-13
9,94E-13
5,40E-13
5,07E-13
5,99E-13
4,35E-13
7,36E-13
3,92E-13
9,44E-14
5,01E-13
2,89E-13
2,05E-13
2,30E-13
3,34E-13
4,34E-13
1,14E-13
2,48E-13
4,58E-13
7,92E-13
4,93E-13
1,21E-12
3,93E-13
4,98E-13
4,30E-13
3,10E-13
5,25E-13
2,15E-13
1,14E-13
4,06E-13
2,45E-13
2,21E-13
2,98E-13
2,67E-13
5,61E-13
1,65E-13
3,63E-13
6,19E-13
1,01E-12
5,35E-13
1,45E-12
2,85E-13
5,77E-13
3,03E-13
2,74E-13
3,60E-13
1,65E-13
1,65E-13
3,39E-13
2,29E-13
2,65E-13
3,92E-13
2,44E-13
7,12E-13
2,49E-13
5,09E-13
8,09E-13
1,25E-12
6,32E-13
1,72E-12
2,17E-13
7,42E-13
2,18E-13
3,26E-13
3,01E-13
2,40E-13
3,38E-13
5,12E-13
2,66E-13
8,87E-13
3,65E-13
6,88E-13
1,03E-12
1,52E-12
7,85E-13
2,01E-12
1,89E-13
9,94E-13
2,90E-13
2,78E-13
4,40E-13
6,59E-13
3,31E-13
1,09E-12
5,13E-13
8,99E-13
1,28E-12
1,82E-12
9,94E-13
2,34E-12
2,17E-13
1,89E-13
2,78E-13
Modelo Horizontal
9,44E-14
9,44E-14
Mal clasificado; aunque puede explicarse por dos modelos: horizontal y vertical.
Modelo Horizontal: lo clasifica en el T6P1. Modelo Vertical: lo clasifica como T6P1.
De ahí el mismo error.
.../...
-249-
ANEXO VII
(continuación)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
5,55E-13
2,85E-13
1,38E-13
1,05E-13
1,36E-13
2,36E-13
1,86E-13
1,75E-13
3,28E-13
5,39E-13
1,64E-13
9,61E-13
2,32E-13
1,06E-13
3,55E-13
6,04E-14
5,06E-13
5,95E-14
5,95E-14
Error 81
3,85E-13
1,80E-13
9,46E-14
1,20E-13
9,40E-14
3,16E-13
1,64E-13
2,25E-13
4,36E-13
7,02E-13
2,51E-13
1,16E-12
1,61E-13
1,65E-13
2,55E-13
1,05E-13
3,82E-13
9,21E-14
9,21E-14
Muestra real T5P3
Error 82 Error 83
2,50E-13 1,49E-13
1,10E-13 7,31E-14
8,51E-14 1,09E-13
1,70E-13 2,55E-13
8,31E-14 1,03E-13
4,23E-13 5,58E-13
1,75E-13 2,21E-13
3,11E-13 4,35E-13
5,73E-13 7,38E-13
9,00E-13 1,13E-12
3,75E-13 5,34E-13
1,39E-12 1,63E-12
1,16E-13 9,75E-14
2,57E-13 3,82E-13
1,82E-13 1,38E-13
1,94E-13 3,28E-13
2,85E-13
1,75E-13
8,31E-14 7,31E-14
Error 84
8,15E-14
7,03E-14
1,67E-13
3,75E-13
1,54E-13
7,21E-13
3,01E-13
5,97E-13
9,31E-13
1,40E-12
7,30E-13
1,90E-12
1,05E-13
5,39E-13
Error 85
4,85E-14
1,01E-13
2,57E-13
5,29E-13
2,36E-13
9,11E-13
4,15E-13
7,95E-13
1,15E-12
1,71E-12
9,61E-13
2,19E-12
7,03E-14
4,85E-14
Modelo Vertical
Error 80
Error 81
Error 82
Error 83
Error 84
Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
5,55E-13
2,85E-13
1,38E-13
1,05E-13
3,43E-13
2,36E-13
4,85E-14
1,01E-13
2,57E-13
5,29E-13
3,65E-13
9,11E-13
4,43E-13
3,65E-13
5,15E-13
3,03E-13
6,57E-13
2,72E-13
4,85E-14
4,25E-13
2,08E-13
1,18E-13
1,39E-13
2,33E-13
3,33E-13
5,71E-14
1,76E-13
3,79E-13
7,08E-13
3,63E-13
1,11E-12
2,99E-13
3,71E-13
3,48E-13
1,99E-13
4,48E-13
1,24E-13
5,71E-14
3,23E-13
1,59E-13
1,28E-13
1,99E-13
1,67E-13
4,54E-13
9,80E-14
2,83E-13
5,29E-13
9,15E-13
4,16E-13
1,34E-12
1,95E-13
4,64E-13
2,22E-13
1,84E-13
2,85E-13
1,01E-13
9,80E-14
2,49E-13
1,37E-13
1,66E-13
2,86E-13
1,46E-13
5,99E-13
1,71E-13
4,22E-13
7,09E-13
1,15E-12
5,26E-13
1,60E-12
1,30E-13
6,44E-13
1,38E-13
2,57E-13
2,04E-13
1,42E-13
2,33E-13
3,99E-13
1,69E-13
7,68E-13
2,77E-13
5,93E-13
9,16E-13
1,41E-12
6,90E-13
1,88E-12
1,05E-13
9,11E-13
1,86E-13
1,75E-13
3,28E-13
5,39E-13
2,36E-13
9,61E-13
4,15E-13
7,95E-13
1,15E-12
1,71E-12
9,11E-13
2,19E-12
1,30E-13
1,05E-13
1,75E-13
Modelo Horizontal
4,85E-14
4,85E-14
Mal clasificado; aunque puede explicarse por dos modelos: horizontal y vertical.
Modelo Horizontal: lo clasifica en el T6P1. Modelo Vertical: lo clasifica como T6P1.
De ahí el mismo error.
.../...
-250-
ANEXO VII
(continuación)
Modelo Horizontal
Muestra real T6P8
Error 82 Error 83
1,71E-12 1,43E-12
1,28E-12 1,06E-12
9,49E-13 7,94E-13
7,46E-13 6,49E-13
1,06E-12 9,41E-13
6,68E-13 6,41E-13
1,01E-12 8,79E-13
8,10E-13 7,53E-13
8,21E-13 8,34E-13
8,65E-13 9,19E-13
6,01E-13 6,71E-13
1,10E-12 1,23E-12
1,30E-12 1,16E-12
6,96E-13 7,63E-13
1,53E-12 1,36E-12
7,92E-13 8,80E-13
1,81E-12
1,04E-12
6,01E-13 6,41E-13
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
2,39E-12
1,81E-12
1,36E-12
1,05E-12
1,38E-12
8,04E-13
1,37E-12
1,04E-12
8,80E-13
8,63E-13
5,68E-13
9,20E-13
1,66E-12
6,60E-13
1,96E-12
7,51E-13
2,28E-12
9,65E-13
5,68E-13
Error 81
2,04E-12
1,53E-12
1,14E-12
8,79E-13
1,20E-12
7,22E-13
1,17E-12
9,04E-13
8,36E-13
8,47E-13
5,67E-13
1,00E-12
1,47E-12
6,61E-13
1,73E-12
7,49E-13
2,03E-12
9,75E-13
5,67E-13
Modelo Vertical
Error 80
Error 81 Error 82 Error 83 Error 84
Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
2,39E-12
1,81E-12
1,36E-12
1,05E-12
1,92E-12
8,04E-13
9,53E-13
7,26E-13
5,84E-13
5,58E-13
1,32E-12
6,69E-13
2,17E-12
1,32E-12
2,33E-12
1,53E-12
2,60E-12
1,60E-12
5,58E-13
2,13E-12
1,60E-12
1,21E-12
9,56E-13
1,61E-12
7,79E-13
8,42E-13
6,67E-13
5,99E-13
6,17E-13
1,08E-12
7,91E-13
1,83E-12
1,02E-12
1,96E-12
1,13E-12
2,18E-12
1,10E-12
5,99E-13
1,37E-12
1,04E-12
8,80E-13
8,63E-13
8,04E-13
9,20E-13
7,21E-13
7,51E-13
9,46E-13
1,13E-12
6,69E-13
1,54E-12
1,90E-12
1,42E-12
1,08E-12
8,93E-13
1,34E-12
7,78E-13
7,63E-13
6,40E-13
6,43E-13
7,04E-13
8,91E-13
9,39E-13
1,53E-12
8,19E-13
1,64E-12
8,11E-13
1,81E-12
7,26E-13
6,40E-13
1,70E-12
1,26E-12
9,85E-13
8,57E-13
1,12E-12
8,01E-13
7,17E-13
6,45E-13
7,15E-13
8,18E-13
7,61E-13
1,11E-12
1,27E-12
7,01E-13
1,36E-12
5,84E-13
Error 84
1,17E-12
8,76E-13
6,72E-13
5,86E-13
8,57E-13
6,41E-13
7,83E-13
7,34E-13
8,75E-13
1,01E-12
7,78E-13
1,37E-12
1,05E-12
8,63E-13
Error 85
9,53E-13
7,26E-13
5,84E-13
5,58E-13
8,04E-13
6,69E-13
7,21E-13
7,51E-13
9,46E-13
1,13E-12
9,20E-13
1,54E-12
5,86E-13 5,58E-13 5,58E-13
1,52E-12
1,14E-12
9,18E-13
8,47E-13
9,40E-13
8,48E-13
7,02E-13
6,82E-13
8,16E-13
9,61E-13
6,87E-13
1,31E-12
1,05E-12
6,69E-13
5,84E-13 6,69E-13 6,69E-13
5,58E-13
Mal clasificado; parece que un modelo vertical puede explicarlo cuando eso es imposible. Sólo puede ser
predicho mediante un modelo horizontal. En nuestro caso, éste coloca la señal en la correspondiente al
T9P4. El vertical clasifica en T9P4.
.../...
-251-
ANEXO VII
(continuación)
Modelo Horizontal
Muestra real T8P6
Error 82 Error 83
1,41E-12 1,14E-12
9,86E-13 7,85E-13
6,79E-13 5,40E-13
4,95E-13 4,13E-13
7,77E-13 6,67E-13
4,33E-13 4,21E-13
7,21E-13 6,06E-13
5,46E-13 5,03E-13
5,68E-13 5,92E-13
6,31E-13 7,00E-13
3,78E-13 4,43E-13
8,77E-13 1,01E-12
1,01E-12 8,73E-13
4,51E-13 5,09E-13
1,23E-12 1,06E-12
5,32E-13 6,06E-13
1,81E-12
7,43E-13
3,78E-13 4,13E-13
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
2,05E-12
1,49E-12
1,06E-12
7,62E-13
1,09E-12
5,41E-13
1,06E-12
7,43E-13
6,06E-13
5,99E-13
3,56E-13
6,81E-13
1,36E-12
4,34E-13
1,64E-12
5,19E-13
2,28E-12
7,07E-13
3,56E-13
Error 81
1,71E-12
1,22E-12
8,51E-13
6,11E-13
9,18E-13
4,73E-13
8,72E-13
6,26E-13
5,73E-13
5,98E-13
3,49E-13
7,69E-13
1,17E-12
4,26E-13
1,42E-12
5,03E-13
2,03E-12
7,00E-13
3,49E-13
Modelo Vertical
Error 80
Error 81
Error 82 Error 83 Error 84 Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
2,05E-12
1,49E-12
1,06E-12
7,62E-13
1,57E-12
5,41E-13
7,04E-13
4,85E-13
3,63E-13
3,55E-13
9,87E-13
4,78E-13
1,82E-12
9,87E-13
1,97E-12
1,19E-12
2,24E-12
1,26E-12
3,55E-13
1,79E-12
1,29E-12
9,10E-13
6,77E-13
1,28E-12
5,21E-13
5,93E-13
4,30E-13
3,77E-13
4,17E-13
7,74E-13
5,96E-13
1,49E-12
7,29E-13
1,63E-12
8,23E-13
1,84E-12
8,10E-13
3,77E-13
1,57E-12
1,11E-12
7,91E-13
6,18E-13
1,03E-12
5,25E-13
5,16E-13
4,07E-13
4,21E-13
5,06E-13
6,16E-13
7,41E-13
1,21E-12
5,59E-13
1,32E-12
5,48E-13
1,49E-12
4,85E-13
4,07E-13
1,37E-12
9,60E-13
7,00E-13
5,85E-13
8,21E-13
5,53E-13
4,70E-13
4,16E-13
4,94E-13
6,24E-13
5,15E-13
9,12E-13
9,66E-13
4,75E-13
1,06E-12
3,63E-13
Error 84
9,04E-13
6,18E-13
4,35E-13
3,67E-13
5,89E-13
4,36E-13
5,24E-13
4,98E-13
6,44E-13
8,04E-13
5,44E-13
1,16E-12
7,62E-13
5,99E-13
Error 85
7,04E-13
4,85E-13
3,63E-13
3,55E-13
5,41E-13
4,78E-13
4,76E-13
5,30E-13
7,25E-13
9,43E-13
6,81E-13
1,33E-12
3,67E-13 3,55E-13 3,49E-13
1,20E-12
8,38E-13
6,39E-13
5,79E-13
6,59E-13
6,05E-13
4,57E-13
4,57E-13
5,95E-13
7,70E-13
4,69E-13
1,11E-12
7,62E-13
4,78E-13
1,06E-12
7,43E-13
6,06E-13
5,99E-13
5,41E-13
6,81E-13
4,76E-13
5,30E-13
7,25E-13
9,43E-13
4,78E-13
1,33E-12
3,63E-13 4,57E-13 4,76E-13 3,55E-13
Mal clasificado; parece que un modelo horizontal (error mínimo) puede explicarlo cuando eso es
imposible. Sólo puede ser predicho mediante un modelo vertical. En nuestro caso, éste coloca la
señal en la correspondiente al T9P4. El horizontal clasifica en T1P10.
.../...
-252-
ANEXO VII
(continuación)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
8,56E-13
4,82E-13
2,30E-13
1,02E-13
2,73E-13
9,73E-14
2,25E-13
1,13E-13
1,55E-13
2,80E-13
6,34E-14
5,79E-13
4,33E-13
4,74E-14
6,05E-13
5,14E-14
8,04E-13
1,01E-13
6,34E-14
Error 81
6,38E-13
3,25E-13
1,36E-13
6,41E-14
1,76E-13
1,31E-13
1,50E-13
1,06E-13
2,12E-13
3,88E-13
9,45E-14
7,35E-13
3,11E-13
5,64E-14
4,52E-13
4,09E-14
6,30E-13
8,22E-14
6,34E-14
Muestra real T9P1
Error 82 Error 83
4,54E-13 3,03E-13
2,03E-13 1,15E-13
7,51E-14 4,79E-14
6,11E-14 9,30E-14
1,10E-13 7,51E-14
1,93E-13 2,82E-13
1,08E-13 1,01E-13
1,37E-13 2,04E-13
2,98E-13 4,12E-13
5,31E-13 7,10E-13
1,62E-13 2,65E-13
9,13E-13 1,11E-12
2,15E-13 1,45E-13
9,81E-14 1,73E-13
3,27E-13 2,30E-13
7,54E-14 1,55E-13
4,82E-13
1,13E-13
6,11E-14 4,79E-14
Modelo Vertical
Error 80
Error 81
Error 82
Error 83 Error 84
Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
8,56E-13
4,82E-13
2,30E-13
1,02E-13
5,05E-13
9,73E-14
1,05E-13
3,96E-14
9,40E-14
2,61E-13
2,61E-13
5,43E-13
6,62E-13
2,61E-13
7,82E-13
3,02E-13
9,75E-13
3,25E-13
3,96E-14
6,74E-13
3,53E-13
1,58E-13
8,46E-14
3,35E-13
1,45E-13
5,75E-14
5,78E-14
1,63E-13
3,87E-13
2,06E-13
6,97E-13
4,62E-13
2,01E-13
5,57E-13
1,44E-13
7,05E-13
1,20E-13
5,75E-14
5,19E-13
2,52E-13
1,14E-13
9,37E-14
2,09E-13
2,18E-13
4,19E-14
1,08E-13
2,60E-13
5,42E-13
2,06E-13
8,77E-13
3,02E-13
2,28E-13
3,73E-13
7,47E-14
4,82E-13
3,96E-14
3,96E-14
3,93E-13
1,79E-13
9,89E-14
1,29E-13
1,27E-13
3,14E-13
5,87E-14
1,90E-13
3,87E-13
7,24E-13
2,63E-13
1,08E-12
1,82E-13
3,42E-13
2,30E-13
9,40E-14
2,25E-13
1,13E-13
1,55E-13
2,80E-13
9,73E-14
5,79E-13
1,89E-13
4,51E-13
7,26E-13
1,17E-12
5,43E-13
1,58E-12
Modelo Horizontal
Error 84
1,87E-13
6,02E-14
5,42E-14
1,60E-13
7,07E-14
3,98E-13
1,28E-13
3,09E-13
5,55E-13
9,24E-13
4,04E-13
1,33E-12
1,02E-13
2,80E-13
Error 85
1,05E-13
3,96E-14
9,40E-14
2,61E-13
9,73E-14
5,43E-13
1,89E-13
4,51E-13
7,26E-13
1,17E-12
5,79E-13
1,58E-12
5,42E-14 3,96E-14 3,96E-14
2,95E-13
1,32E-13
1,13E-13
1,91E-13
9,02E-14
4,34E-13
1,08E-13
3,05E-13
5,42E-13
9,34E-13
3,75E-13
1,32E-12
1,02E-13
5,43E-13
5,87E-14 9,02E-14 9,73E-14 3,96E-14
Mal clasificado; parece que un modelo horizontal (error mínimo) puede explicarlo cuando eso es
imposible. Sólo puede ser predicho mediante un modelo vertical (2). En nuestro caso, estos colocan la
señal en la correspondiente al T7P2. El horizontal clasifica en T7P2.
.../...
-253-
ANEXO VII
(continuación)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
Error 80
1,33E-12
8,49E-13
4,96E-13
2,75E-13
5,57E-13
1,43E-13
4,68E-13
2,50E-13
1,88E-13
2,34E-13
8,17E-14
4,12E-13
7,79E-13
1,13E-13
1,01E-12
1,64E-13
1,26E-12
2,78E-13
8,17E-14
Muestra real T10P2
Error 81 Error 82 Error 83
1,05E-12 8,09E-13 6,01E-13
6,36E-13 4,56E-13 3,11E-13
3,45E-13 2,28E-13 1,44E-13
1,79E-13 1,18E-13 9,17E-14
4,12E-13 2,99E-13 2,16E-13
1,26E-13 1,36E-13 1,74E-13
3,36E-13 2,38E-13 1,74E-13
1,84E-13 1,56E-13 1,65E-13
1,95E-13 2,30E-13 2,94E-13
2,84E-13 3,69E-13 4,90E-13
7,57E-14 1,06E-13 1,72E-13
5,27E-13 6,63E-13 8,21E-13
6,14E-13 4,75E-13 3,62E-13
9,38E-14 1,08E-13 1,54E-13
8,08E-13 6,38E-13 4,96E-13
1,27E-13 1,35E-13 1,88E-13
1,04E-12 8,49E-13
2,39E-13 2,50E-13
7,57E-14 1,06E-13 9,17E-14
Modelo Vertical
Error 80
Error 81
Error 82 Error 83 Error 84 Error 85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Error Mínimo
1,33E-12
8,49E-13
4,96E-13
2,75E-13
8,75E-13
1,43E-13
2,87E-13
1,21E-13
7,65E-14
1,44E-13
4,07E-13
3,32E-13
1,08E-12
4,07E-13
1,24E-12
5,42E-13
1,48E-12
6,06E-13
7,65E-14
1,10E-12
6,75E-13
3,77E-13
2,13E-13
6,40E-13
1,49E-13
1,95E-13
9,18E-14
1,05E-13
2,27E-13
2,80E-13
4,53E-13
8,21E-13
2,57E-13
9,49E-13
2,98E-13
1,14E-12
3,01E-13
9,18E-14
8,99E-13
5,28E-13
2,87E-13
1,79E-13
4,49E-13
1,78E-13
1,35E-13
9,44E-14
1,62E-13
3,37E-13
2,10E-13
6,01E-13
5,99E-13
1,95E-13
7,02E-13
1,43E-13
8,49E-13
1,21E-13
9,44E-14
Modelo Horizontal
7,27E-13
4,08E-13
2,25E-13
1,71E-13
3,03E-13
2,32E-13
1,07E-13
1,29E-13
2,49E-13
4,76E-13
1,95E-13
7,75E-13
4,17E-13
2,20E-13
4,96E-13
7,65E-14
Error 84
4,27E-13
1,99E-13
9,34E-14
1,01E-13
1,64E-13
2,39E-13
1,44E-13
2,11E-13
3,87E-13
6,46E-13
2,74E-13
1,00E-12
2,75E-13
2,34E-13
Error 85
2,87E-13
1,21E-13
7,65E-14
1,44E-13
1,43E-13
3,32E-13
1,49E-13
2,94E-13
5,07E-13
8,38E-13
4,12E-13
1,20E-12
9,34E-14 7,65E-14 7,57E-14
5,83E-13
3,15E-13
1,92E-13
1,89E-13
2,01E-13
3,10E-13
1,12E-13
1,95E-13
3,64E-13
6,43E-13
2,35E-13
9,75E-13
2,75E-13
3,32E-13
4,68E-13
2,50E-13
1,88E-13
2,34E-13
1,43E-13
4,12E-13
1,49E-13
2,94E-13
5,07E-13
8,38E-13
3,32E-13
1,20E-12
7,65E-14 1,12E-13 1,43E-13 7,65E-14
Mal clasificado; parece que un modelo horizontal (error mínimo) puede explicarlo cuando eso es
imposible. Sólo puede ser predicho mediante un modelo vertical. En nuestro caso, éste coloca la señal
en la correspondiente al T8P3. El horizontal clasifica en T1P10.
-254-
Anexo VIII.
ANEXO VIII
Resultados obtenidos al aplicar los modelos mejorados I y II para el método de estimación
por interpolación:
Modelo mejorado I
Muestra
T1P9
T9P1
T2P10
T10P2
T5P3
T3P5
T6P8
T8P6
Ti o Pj = cte Modelo Error Mínimo
H1480
2,15E-13
P9
H1481
6,54E-13
V1482
1,26E-13
T9
V1080
2,61E-13
H1180
2,65E-13
P10
H1280
8,50E-13
V1183
1,95E-13
T10
V1280
3,32E-13
H1583
1,38E-13
T3
H382
8,51E-14
V583
1,46E-13
P5
V680
2,36E-13
H582
1,56E-13
P5
3,31E-13
H680
V1583
2,18E-13
T3
2,05E-13
V381
7,49E-13
H1681
P8
H982
8,21E-13
V1683
3,63E-13
T8
V980
3,63E-13
Modelo Teórico
Clasificación
H1481
2,76E-13
P9
V1481
1,70E-13
T9P2
H1182
3,91E-13
P10
V1182
2,10E-13
T10P3
H382
8,51E-14
V583
1,46E-13
H583
1,84E-13
T2P5
V382
2,21E-13
T3P4
H983
8,34E-13
T1P8
V983
4,94E-13
T8P3
T5P3
Modelo mejorado II
Muestra
Ti o Pj = cte
T1P9
P9
T9P1
T9
T2P10
P10
T10P2
T10
P3
T5P3
P5
P5
T3P5
T3
T6P8
P8
T8P6
T8
Modelo Error Mínimo
Suma Error Máximo
H1481
5,45E-15
3,89E-16
H1080
8,65E-14
5,41E-15
V1481
1,42E-14
8,49E-16
2,22E-13
1,53E-14
V1080
H1181
1,88E-14
1,55E-15
H1280
1,59E-13
1,00E-14
V1182
7,99E-15
5,66E-16
V1280
2,23E-13
1,50E-14
H1583
5,88E-14
3,62E-15
H382
2,57E-15
1,87E-16
V583
4,39E-16
3,64E-17
V680
8,83E-14
5,33E-15
H583
6,11E-16
6,23E-17
H680
7,15E-14
3,63E-15
V1583
7,81E-14
5,29E-15
V382
8,06E-15
3,81E-16
H1683
2,08E-13
1,40E-14
H983
1,17E-15
V1683
1,08E-13
6,28E-15
V983
5,16E-15
2,44E-16
-256-
Modelo Teórico
Clasificación
H1481
2,76E-13
T1P9
V1481
1,70E-13
T9P1
H1182
3,91E-13
T1P10
V1182
2,10E-13
T10P2
H382
8,51E-14
V583
1,46E-13
H583
1,84E-13
V382
2,21E-13
H983
8,34E-13
T6P8
V983
4,94E-13
T8P6
T5P3
T3P5
Anexo IX.
ANEXO IX
Valores de los parámetros empleados en las redes neuronales artificiales basadas en la
información discreta (altura, anchura y posición del pico):
Valores reales.
I (n A) Anchura E (V) [Tl (I)] [Pb (II)]
22,845
0,111 -0,494 0,1
0,0
51,194
0,111 -0,494 0,2
0,0
78,366
0,116 -0,497 0,3
0,0
105,774 0,111 -0,487 0,4
0,0
136,275 0,116 -0,494 0,5
0,0
167,611 0,116 -0,491 0,6
0,0
195,136 0,116 -0,492 0,7
0,0
224,612 0,111 -0,486 0,8
0,0
246,075 0,111 -0,489 0,9
0,0
280,128 0,116 -0,492 1,0
0,0
40,810
0,096 -0,525 0,0
0,1
73,962
0,096 -0,523 0,0
0,2
104,974 0,096 -0,522 0,0
0,3
137,303 0,096 -0,525 0,0
0,4
174,935 0,101 -0,520 0,0
0,5
204,427 0,096 -0,520 0,0
0,6
236,479 0,096 -0,520 0,0
0,7
272,125 0,101 -0,523 0,0
0,8
300,997 0,096 -0,520 0,0
0,9
328,109 0,096 -0,520 0,0
1,0
65,000
0,106 -0,509 0,1
0,1
209,436 0,111 -0,496 0,6
0,1
125,295 0,106 -0,507 0,2
0,2
265,347 0,111 -0,502 0,7
0,2
184,928 0,106 -0,506 0,3
0,3
328,448 0,111 -0,499 0,8
0,3
240,084 0,106 -0,509 0,4
0,4
377,060 0,111 -0,504 0,9
0,4
316,410 0,106 -0,504 0,5
0,5
447,956 0,111 -0,504 1,0
0,5
228,696 0,101 -0,522 0,1
0,6
366,317 0,106 -0,504 0,6
0,6
288,610 0,101 -0,515 0,2
0,7
435,133 0,106 -0,504 0,7
0,7
347,573 0,101 -0,515 0,3
0,8
494,424 0,101 -0,506 0,8
0,8
405,418 0,106 -0,509 0,4
0,9
542,040 0,106 -0,504 0,9
0,9
461,761 0,106 -0,509 0,5
1,0
610,710 0,101 -0,501 1,0
1,0
Valores estandarizados.
I (nA) Anchura E (V) [Tl (I)] [Pb (II)]
0,037
0,957 0,941
0,1
0,0
0,084
0,957 0,941
0,2
0,0
0,128
1,000 0,947
0,3
0,0
0,173
0,957 0,928
0,4
0,0
0,223
1,000 0,941
0,5
0,0
0,274
1,000 0,934
0,6
0,0
0,320
1,000 0,938
0,7
0,0
0,368
0,957 0,925
0,8
0,0
0,403
0,957 0,931
0,9
0,0
0,459
1,000 0,938
1,0
0,0
0,067
0,828 1,000
0,0
0,1
0,121
0,828 0,996
0,0
0,2
0,172
0,828 0,994
0,0
0,3
0,225
0,828 1,000
0,0
0,4
0,286
0,871 0,990
0,0
0,5
0,335
0,828 0,990
0,0
0,6
0,387
0,828 0,990
0,0
0,7
0,446
0,871 0,996
0,0
0,8
0,493
0,828 0,990
0,0
0,9
0,537
0,828 0,990
0,0
1,0
0,106
0,914 0,970
0,1
0,1
0,343
0,957 0,944
0,6
0,1
0,205
0,914 0,966
0,2
0,2
0,434
0,957 0,957
0,7
0,2
0,303
0,914 0,963
0,3
0,3
0,538
0,957 0,950
0,8
0,3
0,393
0,914 0,970
0,4
0,4
0,617
0,957 0,960
0,9
0,4
0,518
0,914 0,960
0,5
0,5
0,734
0,957 0,960
1,0
0,5
0,374
0,871 0,994
0,1
0,6
0,600
0,914 0,960
0,6
0,6
0,473
0,871 0,981
0,2
0,7
0,713
0,914 0,960
0,7
0,7
0,569
0,871 0,981
0,3
0,8
0,810
0,871 0,963
0,8
0,8
0,664
0,914 0,970
0,4
0,9
0,888
0,914 0,960
0,9
0,9
0,756
0,914 0,970
0,5
1,0
1,000
0,871 0,954
1,0
1,0
-258-
Anexo X.
ANEXO X
Modelos neuronales de clasificación de las señales de los voltamperogramas obtenidos a
partir de la información discreta (altura, anchura y posición del pico):
Topología
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-2-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-3-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
3-4-2
Algoritmo
% Clasific. Nº de Ciclos
Online Backprop
100,00
29611
Online Backprop Rand
100,00
22974
Delta-bar-Delta
86,11
100000
RPROP
86,11
100000
Online Backprop
100,00
63330
Online Backprop Rand
100,00
6090
Delta-bar-Delta
25,00
100000
RPROP
91,67
100000
Online Backprop
77,78
100000
Online Backprop Rand
77,78
100000
Delta-bar-Delta
8,33
100000
RPROP
75,00
100000
Online Backprop
52,78
100000
Online Backprop Rand
41,67
100000
Delta-bar-Delta
2,78
100000
RPROP
58,33
100000
Online Backprop
100,00
68603
Online Backprop Rand
100,00
20595
Delta-bar-Delta
88,89
100000
RPROP
88,89
100000
Online Backprop
100,00
10817
Online Backprop Rand
100,00
5685
Delta-bar-Delta
0,00
100000
RPROP
94,44
100000
Online Backprop
80,56
100000
Online Backprop Rand
80,56
100000
Delta-bar-Delta
8,33
100000
RPROP
75,00
100000
Online Backprop
52,78
100000
Online Backprop Rand
55,56
100000
Delta-bar-Delta
0,00
100000
RPROP
52,78
100000
Online Backprop
100,00
39936
Online Backprop Rand
100,00
26136
Delta-bar-Delta
91,67
100000
RPROP
88,89
100000
Online Backprop
100,00
5207
Online Backprop Rand
100,00
5256
Delta-bar-Delta
0,00
100000
RPROP
91,67
100000
Online Backprop
80,55
100000
Online Backprop Rand
77,78
100000
Delta-bar-Delta
8,33
100000
RPROP
75,00
100000
Online Backprop
61,11
100000
Online Backprop Rand
55,56
100000
Delta-bar-Delta
0,00
100000
RPROP
52,78
100000
-260-
Func. Activac.
Total RMS Error
lineal-sigmoidal-sigmoidal
0,0608
lineal-sigmoidal-sigmoidal
0,0608
lineal-sigmoidal-sigmoidal
0,0685
lineal-sigmoidal-sigmoidal
0,0679
lineal-sigmoidal-lineal
0,0514
lineal-sigmoidal-lineal
0,0541
lineal-sigmoidal-lineal
0,2331
lineal-sigmoidal-lineal
0,0672
lineal-lineal-sigmoidal
0,0730
lineal-lineal-sigmoidal
0,0731
lineal-lineal-sigmoidal
0,4896
lineal-lineal-sigmoidal
0,0841
lineal-lineal-lineal
0,1189
lineal-lineal-lineal
0,1400
lineal-lineal-lineal
0,5111
lineal-lineal-lineal
0,1200
lineal-sigmoidal-sigmoidal
0,0536
lineal-sigmoidal-sigmoidal
0,0576
lineal-sigmoidal-sigmoidal
0,0644
lineal-sigmoidal-sigmoidal
0,0674
lineal-sigmoidal-lineal
0,0384
lineal-sigmoidal-lineal
0,0539
lineal-sigmoidal-lineal
102,3500
lineal-sigmoidal-lineal
0,0509
lineal-lineal-sigmoidal
0,0731
lineal-lineal-sigmoidal
0,0730
lineal-lineal-sigmoidal
0,4896
lineal-lineal-sigmoidal
0,0842
lineal-lineal-lineal
0,1195
lineal-lineal-lineal
0,1214
lineal-lineal-lineal
32409,7000
lineal-lineal-lineal
0,1262
lineal-sigmoidal-sigmoidal
0,0529
lineal-sigmoidal-sigmoidal
0,0539
lineal-sigmoidal-sigmoidal
0,0636
lineal-sigmoidal-sigmoidal
0,0682
lineal-sigmoidal-lineal
0,0419
lineal-sigmoidal-lineal
0,0403
lineal-sigmoidal-lineal
181,6240
lineal-sigmoidal-lineal
0,0605
lineal-lineal-sigmoidal
0,0732
lineal-lineal-sigmoidal
0,0728
lineal-lineal-sigmoidal
0,4896
lineal-lineal-sigmoidal
0,0801
lineal-lineal-lineal
0,1220
lineal-lineal-lineal
0,1209
lineal-lineal-lineal
129938,0000
lineal-lineal-lineal
0,1204
Anexo XI.
ANEXO XI
Aplicación programada para llevar a cabo el cálculo de los errores totales de predicción:
% -- --------------------------------------------------------------------------------------% -- --------------------------------------------------------------------------------------% -- Dadas las concentraciones reales y las predichas por la red neuronal:
% -* Se calcula el error en las concentraciones para el Tl (I) y el Pb (II).
% -* Se halla el error total de predicción para cada uno de los iones.
% -- --------------------------------------------------------------------------------------% -- ----------------------------------- Andrés Jiménez ------------------------------fichero = 'output.out';
fid = fopen(fichero,'r');
errortest= 0.0;
errortrn= 0.0;
for i = 1:40,
v1 = fscanf(fid,'%e', 1);
v2 = fscanf(fid,'%e', 1);
v3 = fscanf(fid,'%e', 1);
v4 = fscanf(fid,'%e', 1);
v5 = fscanf(fid,'%e', 1);
v6 = fscanf(fid,'%e', 1);
error1(i) = abs( v3-v4);
error2(i) = abs(v5-v6);
fprintf(1, '\n %f \t %f ' , error1(i), error2(i) );
if (v2 == 0)
errortest= errortest + error1(i)+ error2(i);
else
errortrn= errortrn + error1(i)+ error2(i);
end
end
fclose(fid);
fprintf(1, '\n\n\n Error Total trn = %f \n ' , errortrn );
fprintf(1, '\n\n\n Error Total test = %f \n ' , errortest );
% -- ----------------------------------------------% -- Transformadas de la señal original s(t).
% -- ----------------------------------------------i=1:40;
hndl1 = plot( i, error1(i), 'g', i, error2(i), 'r' );
title('Error talio y plomo ');
-262-
Anexo XII.
ANEXO XII
Tablas de resultados de las pruebas con redes neuronales artificiales basadas en la
información continua (señales completas de los voltamperogramas):
Topología 7-5-2-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
1,107675
0,634440
0,997750
0,015735
0,991841
0,035743
lssg
1,103130
0,465626
0,998045
0,014737
0,995037
0,027365
lsst
1,236687
0,433174
0,997681
0,016486
0,994874
0,025326
lsgs
1,466637
0,486748
0,996936
0,019087
0,994556
0,024103
lsgg
1,238456
0,372620
0,997624
0,016518
0,996255
0,021532
lsgt
1,345547
0,556600
0,997276
0,017995
0,994855
0,029511
lsts
1,295759
0,513401
0,997309
0,017759
0,994821
0,026684
lstg
1,157615
0,492031
0,998013
0,015890
0,991982
0,025049
lstt
1,234528
0,629679
0,997387
0,017274
0,989836
0,033974
lgss
0,664187
0,422149
0,999280
0,008905
0,995516
0,025123
lgsg
1,233113
0,234641
0,997777
0,016382
0,998367
0,012946
lgst
1,084325
0,416799
0,998188
0,014998
0,994021
0,023870
lggs
1,364768
0,465816
0,997018
0,018792
0,992988
0,027280
lggg
0,949850
0,574798
0,998552
0,012816
0,993901
0,032041
lggt
1,296610
0,440270
0,997556
0,017279
0,994028
0,027801
lgts
1,274145
0,529331
0,997539
0,017088
0,987384
0,035656
lgtg
1,216044
0,291606
0,997893
0,016258
0,997483
0,014971
lgtt
0,969652
0,421704
0,998336
0,014162
0,996420
0,022191
ltss
1,013286
0,481144
0,998345
0,014158
0,995925
0,025355
ltsg
1,025858
0,335545
0,998143
0,014719
0,997453
0,017424
ltst
1,150707
0,434616
0,997915
0,015574
0,993061
0,029777
ltgs
1,228960
0,457791
0,997347
0,017051
0,996743
0,024759
ltgg
1,082578
0,454682
0,997979
0,014885
0,995785
0,025581
ltgt
1,208877
0,528400
0,997607
0,016703
0,993523
0,028602
ltts
1,023026
0,521848
0,998220
0,015021
0,992673
0,028393
lttg
1,068332
0,345660
0,998266
0,014466
0,994054
0,018836
lttt
1,259062
0,316526
0,997529
0,017165
0,996536
0,018835
Topología 7-5-3-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
0,891009
0,342098
0,998520
0,013356
0,995192
0,022622
lssg
1,073756
0,383117
0,998066
0,014883
0,997514
0,020092
lsst
1,323953
0,367839
0,997211
0,018080
0,996807
0,021428
lsgs
1,323278
0,525461
0,997556
0,017298
0,991737
0,027363
lsgg
1,187585
0,357595
0,998085
0,015525
0,994936
0,020075
lsgt
1,522637
0,375991
0,996632
0,020171
0,996446
0,022122
lsts
1,280227
0,732084
0,997135
0,017218
0,990603
0,095557
lstg
1,043658
0,385293
0,998193
0,014488
0,997225
0,020551
lstt
1,410022
0,377587
0,997029
0,018615
0,997316
0,019324
lgss
0,843023
0,466361
0,998666
0,012317
0,995595
0,024302
lgsg
0,886216
0,430798
0,998569
0,012631
0,996752
0,022626
lgst
1,185316
0,553972
0,997693
0,016010
0,997693
0,030665
lggs
1,402001
0,349048
0,996899
0,019002
0,997475
0,020421
lggg
1,103680
0,274762
0,997979
0,015296
0,998413
0,013876
lggt
0,658661
0,402771
0,999336
0,008912
0,996006
0,021284
lgts
0,985549
0,496098
0,998194
0,014665
0,995173
0,030687
lgtg
1,078193
0,445201
0,998022
0,015255
0,995656
0,022012
lgtt
1,106598
0,555256
0,997817
0,015480
0,992729
0,034117
ltss
1,053669
0,726547
0,998058
0,014689
0,976585
0,058216
ltsg
1,020840
0,442974
0,998331
0,014063
0,995940
0,022124
ltst
0,971144
0,518527
0,998212
0,013996
0,995024
0,026832
ltgs
1,257692
0,532070
0,997098
0,017735
0,994628
0,030001
ltgg
1,087142
0,392861
0,998123
0,014690
0,997522
0,020883
ltgt
1,017888
0,407799
0,998000
0,014790
0,997093
0,022818
ltts
0,703059
0,277255
0,999172
0,009812
0,996273
0,019386
lttg
1,067951
0,384346
0,998263
0,014508
0,995216
0,023084
lttt
1,099244
0,483252
0,997943
0,016070
0,992370
0,026884
(.../...)
-264-
ANEXO XII
Topología 7-5-4-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
0,966013
0,268429
0,998400
0,014011
0,997893
0,013426
lssg
1,094950
0,305181
0,998227
0,014724
0,997294
0,016743
lsst
1,215681
0,415611
0,997626
0,016644
0,996337
0,021382
lsgs
1,465827
0,361108
0,996836
0,019474
0,996348
0,019848
lsgg
1,095600
0,400773
0,997971
0,015047
0,997669
0,020448
lsgt
0,964309
0,451638
0,998318
0,013787
0,995081
0,028223
lsts
1,313773
0,398854
0,997215
0,017767
0,995759
0,023922
lstg
1,072192
0,358016
0,998297
0,014195
0,995980
0,020810
lstt
0,692974
0,309079
0,999235
0,009424
0,997540
0,017177
lgss
0,913578
0,487887
0,998553
0,013088
0,992581
0,029062
lgsg
0,924507
0,483707
0,998410
0,012949
0,995600
0,029220
lgst
1,359252
0,431656
0,997102
0,018327
0,996163
0,025948
lggs
0,923932
0,363480
0,998486
0,013013
0,997302
0,019413
lggg
1,165983
0,339127
0,997684
0,015725
0,998331
0,020149
lggt
0,879829
0,300346
0,998775
0,011995
0,997070
0,017689
lgts
0,519364
0,314807
0,999545
0,007402
0,996833
0,018161
lgtg
0,755272
0,295162
0,998967
0,010812
0,997158
0,019623
lgtt
0,838366
0,399384
0,998864
0,011268
0,996461
0,023516
ltss
1,159274
0,236657
0,997973
0,015521
0,998596
0,013289
ltsg
1,033215
0,327769
0,998326
0,014029
0,997524
0,018110
ltst
0,849688
0,364763
0,998847
0,011666
0,996059
0,021539
ltgs
1,222739
0,442697
0,997437
0,016804
0,996686
0,022806
ltgg
1,075201
0,374843
0,998223
0,014614
0,996357
0,019618
ltgt
1,011401
0,402030
0,998220
0,014315
0,996652
0,021514
ltts
0,562666
0,240280
0,999398
0,008356
0,998916
0,012095
lttg
0,958906
0,555550
0,998540
0,013180
0,991651
0,031190
lttt
1,137773
0,399221
0,998106
0,015088
0,995410
0,022724
Topología 7-5-5-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
0,985124
0,517881
0,998284
0,014284
0,990296
0,029930
lssg
1,309579
0,311517
0,997687
0,016766
0,998362
0,015994
lsst
1,092167
0,408062
0,997878
0,015235
0,998253
0,024478
lsgs
1,161141
0,541320
0,997744
0,016142
0,993748
0,028300
lsgg
1,111367
0,349470
0,997830
0,015625
0,998178
0,017939
lsgt
1,164823
0,775796
0,997610
0,016173
0,992739
0,039712
lsts
0,842564
0,262355
0,998787
0,011786
0,998559
0,016102
lstg
1,011808
0,331430
0,998257
0,013723
0,997885
0,019480
lstt
0,738703
0,157635
0,999242
0,009595
0,999027
0,009787
lgss
1,070765
0,415415
0,998170
0,014910
0,990518
0,027561
lgsg
1,118903
0,303329
0,998115
0,015044
0,998660
0,016387
lgst
1,309715
0,339458
0,997404
0,017689
0,997222
0,017008
lggs
0,692331
0,583042
0,998893
0,011499
0,992026
0,029494
lggg
0,897591
0,437524
0,998691
0,012522
0,993656
0,026157
lggt
1,289685
0,341114
0,997115
0,017905
0,998306
0,018216
lgts
0,621325
1,080996
0,999314
0,008849
0,950090
0,081865
lgtg
0,723344
0,292933
0,999102
0,009874
0,997776
0,017630
lgtt
0,643629
0,274854
0,999296
0,009344
0,997415
0,015746
ltss
0,685969
0,301206
0,999270
0,009288
0,997114
0,017760
ltsg
1,038961
0,317688
0,998364
0,013685
0,996954
0,018496
ltst
1,092438
0,449873
0,997854
0,015569
0,996946
0,024324
ltgs
1,039924
0,335334
0,998257
0,014427
0,994898
0,023042
ltgg
1,035533
0,475322
0,998409
0,013725
0,994349
0,025281
ltgt
1,267965
0,381169
0,997527
0,017216
0,996291
0,020391
ltts
0,768675
0,397319
0,998933
0,010952
0,998108
0,020104
lttg
0,985182
0,455454
0,998230
0,013987
0,997594
0,024187
lttt
0,863865
0,439046
0,998631
0,012252
0,996553
0,024035
(.../...)
-265-
ANEXO XII
Topología 7-5-6-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
1,113920
0,540992
0,998051
0,015357
0,994687
0,028863
lssg
1,124312
0,404295
0,997920
0,015459
0,996539
0,021294
lsst
1,279944
0,357621
0,997373
0,017567
0,996938
0,018822
lsgs
1,261831
0,460271
0,997854
0,016362
0,994085
0,028108
lsgg
1,075662
0,389139
0,998341
0,014242
0,996240
0,022068
lsgt
1,235911
0,537691
0,997710
0,016725
0,992593
0,026169
lsts
0,600305
0,194300
0,999402
0,008441
0,997467
0,010480
lstg
0,972042
0,348848
0,998223
0,014030
0,997876
0,017372
lstt
1,105449
0,486119
0,997951
0,015324
0,993688
0,026285
lgss
0,672086
0,488364
0,999189
0,009400
0,992279
0,027897
lgsg
0,877401
0,486805
0,998684
0,012445
0,995615
0,023701
lgst
0,998449
0,366994
0,998842
0,014232
0,997522
0,023000
lggs
1,008617
0,407777
0,998037
0,015058
0,994897
0,026423
lggg
0,736226
0,185153
0,999139
0,009984
0,998960
0,010813
lggt
0,877507
0,332484
0,998793
0,012125
0,994961
0,022716
lgts
0,596792
0,338998
0,999418
0,008399
0,994972
0,020718
lgtg
1,137754
0,731018
0,997838
0,015288
0,986918
0,055513
lgtt
0,678537
0,482006
0,999161
0,009665
0,993336
0,025969
ltss
0,760383
0,313453
0,999027
0,010994
0,996476
0,018539
ltsg
0,977317
0,453919
0,998389
0,013363
0,995578
0,025521
ltst
1,184173
0,282727
0,997772
0,016387
0,998141
0,014136
ltgs
0,568313
0,418648
0,999335
0,008646
0,997470
0,025370
ltgg
0,976369
0,595426
0,998381
0,013337
0,993183
0,033302
ltgt
0,771371
0,463922
0,999016
0,010944
0,993694
0,024482
ltts
0,532917
0,405767
0,999508
0,007186
0,995888
0,025749
lttg
0,998135
0,365428
0,998475
0,013530
0,996407
0,019370
lttt
0,627645
0,323627
0,999394
0,008237
0,997959
0,016363
Topología 7-6-2-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
1,422057
0,219749
0,996970
0,018851
0,998405
0,012073
lssg
1,225095
0,394114
0,997684
0,016469
0,996714
0,019878
lsst
1,139438
0,632003
0,997600
0,015942
0,994368
0,031378
lsgs
1,423866
0,690970
0,996899
0,018603
0,989984
0,036174
lsgg
1,159591
0,419568
0,998075
0,015056
0,995910
0,021549
lsgt
1,260296
0,620992
0,997492
0,017643
0,994107
0,029977
lsts
1,453952
0,435717
0,997218
0,018740
0,992972
0,025091
lstg
1,103530
0,499296
0,997954
0,014890
0,996768
0,028602
lstt
1,536911
0,270376
0,996447
0,020022
0,998613
0,014202
lgss
1,201675
0,449715
0,997611
0,017089
0,994643
0,022905
lgsg
1,084615
0,492202
0,997996
0,014772
0,994954
0,027010
lgst
1,039721
0,210152
0,998097
0,014824
0,998553
0,013249
lggs
1,342304
0,651372
0,996916
0,018829
0,992396
0,034401
lggg
1,215413
0,951111
0,997643
0,016227
0,966266
0,078422
lggt
1,115462
0,482952
0,997931
0,015889
0,991276
0,027978
lgts
1,485747
0,408416
0,996689
0,019586
0,998047
0,022077
lgtg
1,169399
0,377347
0,998138
0,015305
0,997265
0,019718
lgtt
1,293978
0,516395
0,997314
0,017427
0,996578
0,027251
ltss
0,993969
0,380197
0,998387
0,013666
0,996269
0,021417
ltsg
1,062279
0,385529
0,998300
0,014317
0,996205
0,020140
ltst
0,954735
0,343924
0,998378
0,013795
0,995534
0,022765
ltgs
1,385732
0,482350
0,996833
0,019177
0,994550
0,025593
ltgg
1,159479
0,315946
0,997984
0,015520
0,997500
0,016504
ltgt
1,307002
0,516373
0,997006
0,017715
0,993170
0,034084
ltts
1,247130
0,259481
0,997542
0,017487
0,997812
0,013999
lttg
1,269726
0,516116
0,997442
0,016742
0,990550
0,042516
lttt
1,211851
0,400319
0,997527
0,016671
0,996359
0,023156
(.../...)
-266-
ANEXO XII
Topología 7-6-3-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
1,040311
0,352828
0,998167
0,014733
0,994064
0,019149
lssg
1,205657
0,294983
0,997797
0,016076
0,998148
0,015662
lsst
1,144597
0,411270
0,998080
0,015369
0,994746
0,021774
lsgs
1,328249
0,596966
0,996781
0,018241
0,995721
0,033639
lsgg
1,165931
0,365350
0,998097
0,015559
0,995584
0,019984
lsgt
1,415734
0,434343
0,996821
0,019194
0,996368
0,025145
lsts
1,127116
0,599043
0,998065
0,015272
0,991049
0,030909
lstg
1,090330
0,414912
0,998214
0,014697
0,993923
0,022677
lstt
1,219166
0,522454
0,997608
0,016273
0,996064
0,029965
lgss
0,956927
0,490033
0,998439
0,013810
0,994065
0,027676
lgsg
1,040397
0,395214
0,998326
0,013947
0,996624
0,020429
lgst
0,722835
0,253836
0,999192
0,009962
0,997819
0,013396
lggs
1,155184
0,468150
0,997781
0,015976
0,995521
0,029590
lggg
1,010708
0,410505
0,998346
0,013660
0,996098
0,024182
lggt
1,331204
0,463714
0,997333
0,017835
0,995157
0,023121
lgts
0,469661
0,432296
0,999561
0,007252
0,994805
0,023096
lgtg
1,017174
0,497043
0,998286
0,013875
0,994539
0,026240
lgtt
1,303031
0,335457
0,997303
0,017731
0,997819
0,017713
ltss
0,785962
0,251718
0,998909
0,010788
0,997538
0,020930
ltsg
1,030106
0,375097
0,998106
0,014475
0,996963
0,021145
ltst
0,998677
0,333186
0,998235
0,014807
0,996256
0,019359
ltgs
1,288726
0,400291
0,997299
0,017590
0,995747
0,025045
ltgg
0,992554
0,489027
0,998135
0,014153
0,996314
0,024805
ltgt
1,315420
0,362566
0,997495
0,017748
0,996058
0,018302
ltts
1,082926
0,520921
0,998039
0,015188
0,992154
0,030521
lttg
1,045771
0,330062
0,998131
0,014667
0,996154
0,022388
lttt
1,187998
0,409564
0,997741
0,016319
0,996216
0,020804
Topología 7-6-4-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
0,994338
0,564377
0,998258
0,014007
0,996915
0,029590
lssg
0,960880
0,556975
0,998768
0,012630
0,992154
0,028189
lsst
1,148853
0,425015
0,997824
0,016425
0,995510
0,022147
lsgs
1,371895
0,378809
0,997208
0,018330
0,996651
0,018852
lsgg
1,175392
0,291869
0,997854
0,015634
0,997977
0,018742
lsgt
1,326643
0,435965
0,997005
0,017743
0,996220
0,026290
lsts
0,731624
0,267675
0,999208
0,009706
0,997945
0,015302
lstg
1,111666
0,279766
0,998224
0,014796
0,997172
0,016768
lstt
0,750222
0,542392
0,998962
0,010960
0,991961
0,031970
lgss
0,881666
0,295130
0,998806
0,012151
0,997213
0,015593
lgsg
1,029328
0,472643
0,998397
0,014075
0,994633
0,023877
lgst
1,063232
0,262027
0,998196
0,014705
0,996982
0,016571
lggs
0,714783
0,269104
0,999053
0,010285
0,998405
0,016834
lggg
0,713707
0,431184
0,999053
0,010433
0,994286
0,026583
lggt
0,960136
0,540470
0,998343
0,013913
0,992993
0,031637
lgts
0,561470
0,464883
0,999472
0,007799
0,992418
0,030005
lgtg
1,020878
0,353292
0,998337
0,013682
0,996598
0,021475
lgtt
0,666465
0,436323
0,999176
0,009512
0,996920
0,023797
ltss
0,918282
0,318188
0,998561
0,013038
0,998242
0,019481
ltsg
0,996018
0,311583
0,998391
0,013964
0,996597
0,017854
ltst
0,155535
0,546659
0,997814
0,015880
0,995131
0,029031
ltgs
1,061361
0,370610
0,998224
0,014543
0,995767
0,021998
ltgg
1,146994
0,384312
0,997867
0,015527
0,996779
0,023652
ltgt
1,109302
0,593685
0,998180
0,014809
0,991756
0,029882
ltts
0,599717
0,263039
0,999338
0,008859
0,997662
0,015019
lttg
0,778187
0,255813
0,998944
0,011344
0,997679
0,016667
lttt
0,880180
0,429364
0,998677
0,012367
0,996415
0,021417
(.../...)
-267-
ANEXO XII
Topología 7-6-5-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
0,679934
1,112983
0,998284
0,014284
0,990296
0,029930
lssg
0,973437
0,560066
0,997687
0,016766
0,998362
0,015994
lsst
1,254039
0,387469
0,997878
0,015235
0,998253
0,024478
lsgs
0,959468
0,382407
0,997744
0,016142
0,993748
0,028300
lsgg
0,948965
0,485152
0,997830
0,015625
0,998178
0,017939
lsgt
1,433226
0,421668
0,997610
0,016173
0,992739
0,039712
lsts
0,505727
0,317489
0,998787
0,011786
0,998559
0,016102
lstg
1,210778
0,510668
0,998257
0,013723
0,997885
0,019480
lstt
0,644802
0,370716
0,999242
0,009595
0,999027
0,009787
lgss
0,573899
0,281638
0,998170
0,014910
0,990518
0,027561
lgsg
0,858952
0,642981
0,998115
0,015044
0,998660
0,016387
lgst
1,011469
0,591965
0,997404
0,017689
0,997222
0,017008
lggs
0,672774
0,534323
0,998893
0,011499
0,992026
0,029494
lggg
1,070191
0,354777
0,998691
0,012522
0,993656
0,026157
lggt
1,070191
0,354777
0,997115
0,017905
0,998306
0,018216
lgts
0,668976
0,307560
0,999314
0,008849
0,950090
0,081865
lgtg
0,938349
0,338116
0,999102
0,009874
0,997776
0,017630
lgtt
0,542533
0,396232
0,999296
0,009344
0,997415
0,015746
ltss
0,958034
1,483472
0,999270
0,009288
0,997114
0,017760
ltsg
0,890945
0,404038
0,998364
0,013685
0,996954
0,018496
ltst
0,828915
0,456573
0,997854
0,015569
0,996946
0,024324
ltgs
0,557368
0,415120
0,998257
0,014427
0,994898
0,023042
ltgg
0,668878
0,431105
0,998409
0,013725
0,994349
0,025281
ltgt
0,621317
0,239543
0,997527
0,017216
0,996291
0,020391
ltts
0,795324
0,268123
0,998933
0,010952
0,998108
0,020104
lttg
0,995366
0,343445
0,998230
0,013987
0,997594
0,024187
lttt
1,393730
0,300453
0,998631
0,012252
0,996553
0,024035
Topología 7-6-6-2
Func.Activ. E. Tot. Trn E.Tot.Test Corr. Trn. RMS E.Trn. Corr. Test RMS E.Test
lsss
0,985389
0,559776
0,998366
0,013607
0,994109
0,029991
lssg
1,114422
1,046218
0,997827
0,015161
0,951019
0,086089
lsst
1,298055
0,291142
0,997432
0,017251
0,997462
0,016516
lsgs
1,038471
0,496277
0,998153
0,014697
0,993725
0,027370
lsgg
0,957491
0,329979
0,998495
0,013538
0,996829
0,017664
lsgt
1,163772
0,519345
0,997780
0,015851
0,994342
0,028767
lsts
0,806963
0,312822
0,999067
0,010760
0,997920
0,017091
lstg
1,086331
0,402504
0,998066
0,014914
0,997358
0,021598
lstt
0,590225
0,389026
0,999337
0,008718
0,998097
0,023807
lgss
0,838683
0,335273
0,998826
0,012189
0,995859
0,017887
lgsg
1,024802
0,324864
0,998136
0,014252
0,998222
0,018805
lgst
1,166269
0,469670
0,997695
0,016021
0,994408
0,027026
lggs
0,591929
0,488836
0,999380
0,008429
0,995805
0,029918
lggg
0,990963
0,370800
0,998501
0,013472
0,996339
0,019750
lggt
1,056977
0,477086
0,998030
0,014747
0,996351
0,026394
lgts
0,649946
0,268318
0,999356
0,008554
0,998216
0,015241
lgtg
1,066177
0,308595
0,998010
0,015053
0,997970
0,016347
lgtt
0,596238
0,314825
0,999395
0,008330
0,997749
0,016403
ltss
0,640654
0,319667
0,999321
0,008768
0,997729
0,016907
ltsg
1,116552
0,252207
0,998069
0,014948
0,998645
0,013912
ltst
0,850613
0,422688
0,998615
0,012699
0,995441
0,023962
ltgs
0,536351
0,351494
0,999460
0,008008
0,996838
0,021389
ltgg
0,962403
0,646243
0,998448
0,013355
0,994995
0,031541
ltgt
1,395025
0,345476
0,997141
0,018401
0,996040
0,016757
ltts
0,474249
0,284622
0,999580
0,007033
0,998226
0,014436
lttg
0,961693
0,356620
0,998473
0,013190
0,997088
0,019134
lttt
0,565859
0,369139
0,999439
0,008013
0,996325
0,020480
-268-