II. Paradigmas de Programación Paralela
Anuncio

Paralelización
Paralelización en la Supercomputadora
“Cray Origin 2000”
Oscar Rafael García Regis
Enrique Cruz Martínez
2003-III
Paralelización
Oscar Rafael García Regis
Laboratorio de Dinámica No Lineal
Facultad de Ciencias, UNAM
Enrique Cruz Martínez
Dirección General de Servicios de Cómputo Académico. (DGSCA)
UNAM. Cómputo Aplicado
Paralelización
Paralelización en la Supercomputadora “Cray Origin 2000”
Resumen
Se describe el cómputo paralelo a través de conceptos básicos, arquitecturas de máquinas paralelas
y técnicas de programación paralela que se implementa en máquinas de tipo Memoria Compartida
Distribuida como la Cray Origin 2000.
Desde un principio se debe justificar el paralelizar un código y posteriormente elegir la mejor opción
para paralelizarlo. Para ello se debe reconocer y dividir el código en pedazos “independientes”, y
ejecutarse en múltiples procesadores. Este procedimiento se ejemplifica usando varios paradigmas
de programación paralela.
Se analiza un caso de estudio en varios modelos de programación, mostrando las ventajas y
desventajas de las diversas técnicas de programación paralela.
Paralelización
Indice
Introducción
Razón de ser de la paralelización.
Sistemas de Alto Rendimiento.
3
3
3
P a r t e I: Conceptos
I. Fundamentos de paralelización.
I.1 ¿Qué es paralelismo y qué es cómputo paralelo?
I.2 ¿Qué es computación Paralela y que aspectos involucra?
I.3 ¿Qué es una computadora paralela?
I.4 ¿Cuándo paralelizar?
I.5 ¿Qué se necesita para paralelizar?
5
5
5
5
5
7
II. Etapas en la creación de programas paralelos
II.1 Particionamiento
II.1.1. Descomposición
II.1.2. Aglomeración (Asignación)
II.2 Orquestación
II.2.1. Sincronización
II.2.2. Comunicación
II.3 Mapeo
7
7
8
8
10
10
11
12
III. Paradigmas de Programación Paralela
III.1 Basado en Arquitecturas de computadoras
III.1.1 SISD
III.1.2 SIMD
III.1.3 MIMD
III.1.3.1 Sistemas de Memoria Compartida
III.1.3.2 Sistemas de Memoria Distribuida
III.1.3.3 Sistemas de Memoria Compartida Distribuida
III.1.4 MISD
III.2 Basado en la Naturaleza del Algoritmo
III.2.1 Teoría de la Paralelización Homogénea (Homoparalelismo)
III.2.2 Teoría de la Paralelización Heterogénea (Hetereoparalelismo)
14
14
14
15
15
16
17
17
18
18
19
19
IV. Niveles de paralelismo
IV.1 Programación Paralela
IV.2 Granularidad
IV.2.1 Teoría de la Paralelización de Grano Fino
IV.2.2 Teoría de la Paralelización de Grano Grueso
20
20
20
20
20
P a r t e II: Paradigmas de Programación Paralela
I. ¿Que hacer ante un problema a paralelizar?
22
II. Paradigmas de Programación Paralela
II.1 Código C, Fortran y C++ usando procesos UNIX. (Nivel proceso)
II.2 Código fuente C con hebras POSIX. (Nivel hilo)
22
22
24
1
Paralelización
II.3 Código fuente en C o Fortran usando envío de Mensajes (Nivel proceso)
25
II.4 Código fuente en FORTRAN, C o C++ usando directivas o pragmas
respectivamente. (Nivel Sentencia)
26
II.4.1 OpenMP
26
III. Compiladores Paralelizadores
III.1 Dependencia de datos
III.2 Bases Teóricas de la Paralelización Automática y Técnicas de Paralelización de
Programas Secuenciales
III.2.1 Casos de Estudio de No Paralelización
III.2.2 Analizadores PCA y PFA
III.3 Paralelización Manual
III.3.1 Sintaxis de las directivas de paralelización
III.3.2 Creando bloques independientes
III.3.3 Ejemplo de paralelización automática
29
29
33
36
37
38
39
IV. Análisis de Rendimiento
IV.1 Modelación de Rendimiento
IV.1.1 Ley de Amdhal
IV.1.2 Extrapolación a partir de observaciones
IV.1.3 Análisis Asintótico
IV.1.4 Basado en modelos idealizados
IV.2 Tiempo de Ejecución
IV.2.1 Tiempo de Cómputo
IV.2.2 Tiempo de Comunicación
IV.2.3 Tiempo de Espera
IV.3 Modelo de Comunicación
IV.4 Eficiencia y Aceleración
IV.4.1 Eficiencia y Aceleración Absolutas
IV.5 Análisis de Escalabilidad
IV.5.1 Escalabilidad de un algoritmo
IV.5.2 Escalabilidad con problema variable
IV.6 Perfiles de Ejecución
IV.7 Estudios Experimentales
IV.7.1 Diseño Experimental
IV.7.2 Obteniendo y validando datos experimentales
IV.7.3 Ajuste de datos
43
43
43
44
44
45
45
45
45
46
46
46
47
47
47
48
49
49
49
50
50
V. Estudio Comparativo
IV.1 Programa Secuencial
IV.2 Empleando Procesos Unix
IV.3 Empleando Hilos Posix
IV.4 Comunicación con MPI
IV.5 Comunicación con PVM
IV.6 Comunicación con SHMEM
IV.7 Empleando directivas de PCA
IV.8 Comparación de los modelos anteriores
51
51
52
56
57
60
65
66
69
Glosario
Referencias
72
75
2
28
28
Paralelización
I. Introducción
Intuitivamente paralelismo esta relacionado con la simultaneidad, por ejemplo: el cuerpo
humano realiza actividades paralelas a cada instante, el medio ambiente que nos rodea esta
basado en este tipo de actividad. Cualquier partícula esta sometida bajo la influencia de todo el
universo, y esa interacción es simultánea, cada planeta y estrella están movimiento de manera
permanente y realizando complejas trayectorias debido a la influencia de los demás objetos
estelares.
Dentro del cerebro humano se llevan a cabo simultáneamente una cantidad increíblemente
grande de fenómenos eléctricos, las neuronas son las responsables de estos eventos, muchas
de ellas recogen señales eléctricas de sus vecinas, muchas otras disparan potenciales de
acción, todo esto ocurre de manera simultánea. En fin, cualquier escenario de nuestro universo
manifiesta un perfecto paradigma paralelo.
Razón de ser de la paralelización
Desde el modelo propuesto por Von Neuman, la computación secuencial ha sido el modo
habitual de computación. Sin embargo, existe una demanda permanente de mayor rendimiento
computacional, por ende se recurre al cómputo paralelo, pues la solución en máquinas
secuénciales no sería óptimo o posible en tiempos razonables. El uso del cómputo paralelo
comprende una amplia gama de aplicaciones, tales como: la predicción del clima, modelado de
la biosfera, exploración petrolera, procesamiento de imágenes, fusión nuclear, modelado de
océanos, sincronización de osciladores entre otras.
Este modelo de programación ofrece:
•
•
•
•
•
•
•
•
Alternativas a los relojes rápidos de mejorar el rendimiento.
Aplicación a todos los niveles del diseño de un sistema de cómputo.
Mayor importancia en aplicaciones que demandan alto rendimiento.
Una insaciable necesidad de computadoras rápidas.
Tendencias en la Tecnología, en la arquitectura y en la economía.
Apoyo para el Cómputo Científico: Física, Química, Biología, Oceanografía,
Astronomía, etc., y para el aceleramiento del cómputo de propósito general:
video, CAD, Bases de Datos, Procesamiento de Transacciones, etc.
Una forma natural de mejorar el rendimiento.
Explotación a muchos niveles.
- A nivel de instrucciones.
- Servidores multiprocesadores.
- Computadoras paralelas masivas.
Sistemas de Alto Rendimiento
Procesadores superescalares (1992)
Relojes de alta velocidad.
Paralelismo a nivel de instrucciones.
Varios niveles de memoria cache.
Procesadores para Vectores (1970´s)
Supercomputadoras (1980)
3
Paralelización
Arreglos de procesadores VLSI (1985)
Custom Computing (1992)
Computadoras Paralelas (1986)
La evolución de los sistemas de alto rendimiento ha sido consecuencia de:
El rendimiento de los procesadores se incrementa entre 50% y 100% cada año.
La densidad de transistores en Circuitos Integrados se duplica cada 3 años.
La capacidad de la DRAM se cuadruplica cada 3 años.
4
Paralelización
P a r t e I: Conceptos
I. Fundamentos de paralelización
I.1 ¿Qué es Paralelismo y qué es Cómputo Paralelo?
El paralelismo es la realización de varias actividades al mismo tiempo que tienen una
interrelación.
El cómputo paralelo es la ejecución de más de un cómputo (cálculo) al mismo tiempo usando
más de un procesador.
Se trata de reducir al mínimo el tiempo total de cómputo, distribuyendo la carga de trabajo entre
los procesadores disponibles. Obtener un alto rendimiento o mayor velocidad al ejecutar un
programa es una de las razones principales para utilizar el paralelismo en el diseño de
hardware o software.
I.2 ¿Qué es Computación Paralela y que aspectos involucra?
Es el proceso de información que enfatiza la manipulación concurrente de elementos de datos
pertenecientes a uno o más procesos resolviendo un problema común (Quinn 1994).
Entre los aspectos más importantes relacionados con la computación paralela están:
Diseño de Computadoras Paralelas.
Diseño de Algoritmos Eficientes.
Métodos para Evaluar Algoritmos Paralelos.
Programación Automática de Computadoras Paralelas.
Lenguajes de Programación Paralela.
Herramientas para Programación Paralela.
Portabilidad de Programas Paralelos.
I.3 ¿Qué es una computadora paralela?
Una computadora paralela es un conjunto de procesadores capaces de trabajar
cooperativamente para resolver un problema computacional. (Quinn 1994)
Esta definición es suficientemente amplia para incluir supercomputadoras paralelas que tienen
cientos o miles de procesadores, redes de estaciones de trabajo, etc. Las computadoras
paralelas son interesantes porque ofrecen recursos computacionales potenciales.
Otra definición: (Culler 1994) “Una colección de elementos de procesamiento que se comunican
y cooperan entre sí para resolver problemas grandes de manera rápida”.
I.4 ¿Cuando Paralelizar?
La respuesta a esta pregunta no es sencilla, dado que debe analizarse si se cuenta con el
hardware y software necesario, para determinar si vale la pena paralelizar el programa o
viceversa.
5
Paralelización
En términos del hardware, paralelizar código involucra conocer la arquitectura de la
supercomputadora o "cluster" donde se pretende paralelizar, conocer el número de
procesadores con los que cuenta, la cantidad de memoria, espacio en disco, los niveles de
memoria disponible, el medio de interconexión, etc.
En términos de software, se debe conocer qué sistema operativo esta manejando, si los
compiladores instalados permiten realizar aplicaciones con paralelismo, si se cuenta con
herramientas como PVM o MPI (en sistemas distribuidos), PCA, PFA u OpenMP (en sistemas
de memoria compartida), etc.
Para decidir si es conveniente paralelizar un código, podemos ubicar el problema considerando
los siguientes puntos:
1. Necesidad de respuesta inmediata de resultados
Al ejecutar varias veces un programa en una máquina secuencial con diferentes datos
de entrada, donde cada tiempo de ejecución es considerable (horas o días), es
inapropiado o costoso esperar tanto tiempo para volver a realizar otra ejecución,
afectando notablemente el desempeño de su máquina. Esto, sin considerar las
modificaciones al código o fallas en la ejecución del modelo. La paralelización y la
ejecución del programa en una máquina paralela permiten realizar más análisis en
menos tiempo.
2. Problema de Gran Reto
Cuando un problema se tiene que resolver mediante algoritmos de cálculo científico
intensivo que demandan grandes recursos de cómputo (CPU, memoria, disco), la frase
"divide y vencerás" tiene un significado más amplio. Las tareas se dividen entre varios
procesadores, se ejecutan en paralelo y se obtiene una mejora en la relación costo desempeño. Actualmente las arquitecturas de cómputo incorporan paralelismo en los
más altos niveles de sus sistemas, satisfaciendo las exigencias de los problemas de
gran reto.
3. Elegancia de programación
Es decisión del programador escribir un algoritmo paralelo aunque no se justifique ni por
tiempo ni por uso intensivo de otros recursos.
Para paralelizar un programa es importante identificar en el código:
Tareas independientes, por ejemplo, que existan ciclos for o do independientes, y
rutinas o módulos independientes. De tal forma que no existan dependencias de datos
que dificulten la paralelización.
Zonas donde se efectúa la mayor carga de trabajo y que por lo tanto consumen la mayor
parte de tiempo de ejecución. Para detectar dichas zonas existen herramientas que
permiten obtener una perspectiva o perfil del programa. Por ejemplo en Origin 2000
existen una amplia variedad de herramientas para llevar a cabo estas tareas, tanto
herramientas que ofrece el mismo sistema de Origin 2000: SpeedShop, Perfex, etc como
herramientas de dominio público que se pueden descargar e instalar: JumpShot,
UpShot, Vampir, Paradyn, PAPI, etc
6
Paralelización
I.5 ¿Qué se necesita para paralelizar?
Es necesario disponer de un ambiente paralelo, constituido de:
•
•
•
Hardware de Multiprocesamiento.
Soporte del sistema operativo para paralelizar.
Herramientas de desarrollo de software paralelizable.
II. Etapas en la creación de programas paralelos
II.1 Particionamiento
Esta etapa consiste en resaltar las posibilidades de ejecución paralela.
Se concentra en la definición de un gran número de pequeñas tareas a fin de producir lo
que se conoce como la descomposición de un problema en grano fino.
Esta etapa se subdivide en 2 partes:
Descomposición, y
Aglomeración (Asignación).
7
Paralelización
Un buen particionamiento divide tanto los cálculos asociados con el problema como los datos
sobre los cuales opera.
II.1.1. Descomposición
Hay alternativas en esta sub-etapa:
a) Descomposición del dominio: Se concentra en el particionamiento de los datos.
Primero, se busca descomponer los datos asociados al problema.
Se trata de dividir los datos en piezas del mismo tamaño.
Después, se dividen los cálculos que serán realizados.
Asociando cada operación con los datos sobre los cuales opera.
Los datos a ser descompuestos pueden ser:
La entrada del programa
La salida computada por el programa.
Los valores intermedios mantenidos por el programa.
Regla
Concentrarse en la estructura de datos más grandes o la que se accede con mayor frecuencia.
b) Descomposición funcional: Se concentra en la descomposición de funciones o tareas.
Primero, se concentra en los cálculos que serán realizados.
Se divide el procesamiento en tareas disjuntas.
Después, se procede a examinar los datos que serán utilizados por esas tareas.
Si los datos son disjuntos, el particionamiento es completo.
Si los datos no son disjuntos, se requiere replicar los datos o comunicarlos entre tareas
diferentes.
Objetivos de la Descomposición
Definir al menos un orden de magnitud de más tareas que procesadores en la computadora
paralela., Pues en caso contrario, se tendrá poca flexibilidad en las etapas siguientes.
Debe evitar cálculos y almacenamientos redundantes. En caso contrario, difícilmente se logrará
un algoritmo escalable.
Debe generar tareas de tamaño comparable. En caso contrario, puede ser difícil asignar a cada
procesador cantidades de trabajo similares.
Debe generar tareas escalables con el tamaño del problema.
Un incremento en el tamaño del problema debe incrementar el número de tareas en
lugar del tamaño de las tareas individuales.
Es recomendable considerar varias alternativas de descomposición.
En las etapas siguientes se puede obtener mayor flexibilidad teniendo varias
alternativas.
II.1.2 Aglomeración (Asignación)
Para reducir comunicaciones y explorar la vecindad de los cálculos es conveniente considerar si
es útil aglomerar o combinar las tareas identificadas en la fase de descomposición.
Puede ser útil también replicar datos para evitar comunicaciones.
8
Paralelización
El número de procesos producidos en la fase de aglomeración, aunque reducido, aún
puede ser mayor que el número de procesadores.
Por tal razón, el diseño de un programa paralelo en la fase de aglomeración aún
permanece abstracto.
En la fase de aglomeración se persiguen los siguientes objetivos:
Balancear la carga de trabajo.
Limite de la aceleración
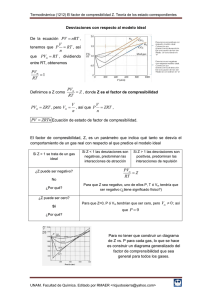
Speedup ≤
TrabajoSecuencial
MaxTrabajoenCualquier Pr ocesador
El trabajo incluye acceso a datos y otros costos.
El trabajo no solo debe ser repartido equitativamente sino también debe de
realizarse al mismo tiempo.
Actividades para lograr un buen balance de carga
Identificar suficiente paralelismo.
Decidir como manejar la aglomeración.
Determinar la granularidad del paralelismo.
Reducir las tareas seriales y los costos de sincronización.
Incrementar la granularidad del cómputo y de la comunicación.
Retener flexibilidad con respecto a las decisiones de escalabilidad y mapeo.
Reducir los costos de desarrollo.
¿Cómo manejar la aglomeración?
Puede manejarse de manera:
• Estática
• Dinámica
a) Aglomeración Estática
La aglomeración se basa en la entrada y en el problema, no cambia.
Los requerimientos de cómputo deben ser predecibles.
Es preferible a otros enfoques.
No aplicable en ambientes heterogéneos.
b) Aglomeración Dinámica
Para casos en donde la distribución de trabajo o el medio ambiente es impredecible.
Se adapta en tiempo de ejecución para balancear la carga de trabajo.
Puede incrementar las necesidades de comunicación y reducir la localidad.
Puede incurrir en un trabajo adicional para manejar a las tareas.
Basada en perfiles (semi-estática)
Se obtiene el perfil de una distribución de un trabajo en tiempo de ejecución.
Se hace particionamiento de manera dinámica.
Tareas Dinámicas.
Permite abordar programas y medio ambientes impredecibles.
Alta interacción entre cómputo, comunicaciones y sistema de memoria.
Aplicable a multiprogramación y heterogeneidad.
Se utiliza por los sistemas operativos.
Modelo de programación
“pool” de tareas
Granja de procesos
9
Paralelización
Maestro-Esclavo
Colas de Entrada
Centralizada vs Distribuida
II.2 Orquestación
En la fase de orquestación se establecen los patrones de:
•
•
Comunicación y
Sincronización del programa paralelo.
La arquitectura, el modelo de programación y el lenguaje de programación juegan un papel
importante.
Se requieren mecanismos para:
Nombrar (identificar) datos.
Intercambiar datos con otros procesadores (comunicación).
Sincronización entre todos los procesadores.
Decisiones acerca de la organización de estructuras de datos, la calendarización de
tareas, mezclar o dividir mensajes, traslapar cómputo con comunicación.
Objetivos de la Orquestación
Reducción de costos de comunicación y sincronización.
Promover la localidad de referencias a datos.
Facilitar la calendarización de tareas para evitar tiempos latentes.
Reducción del trabajo adicional para controlar el paralelismo.
II.2.1 Sincronización
Una buena sincronización de actividades paralelas se logra mediante las actividades de
calendarización y mapeo.
•
•
Calendarización: Determinar el momento en que se realiza cada una de las
actividades.
Mapeo: Determinar quien ejecutará el trabajo a realizar.
La calendarización y el mapeo en la fase de orquestación trabajan a nivel de procesos.
La calendarización y el mapeo de procesadores se realizan en la fase final del diseño de
un programa paralelo.
Sin embargo, durante la orquestación se deben determinar actividades seriales
provocadas en la fase de particionamiento.
Dos aspectos fundamentales se deben de considerar:
•
Reducir el uso de sincronización conservadora.
Ej. Punto a punto en lugar de barreras, cuidar la granularidad de comunicaciones punto
a punto.
Sincronización en grano fino es más difícil de programar y requiere más operaciones.
•
Exclusión Mutua
10
Paralelización
Usar candados diferentes para datos diferentes.
Candados por tarea en una cola de tareas, no por la cola total.
Grano fino implica menor contención y serialización, más espacio y menos
reusabilidad.
Reducir el tamaño de las secciones críticas de código.
No haber pruebas por condiciones dentro de una sección crítica.
II.2.2 Comunicación
La comunicación se establece en dos fases:
a) Canales de comunicación entre emisores y receptores
Lógicos o físicos
b) Estructura de los mensajes entre emisores y receptores
Patrones de comunicación.
Dependiendo de la tecnología de programación, puede no ser necesario crear lógica y
explícitamente esos canales de comunicación.
Definir un canal de comunicación involucra un costo intelectual.
Transmitir un mensaje por un canal de comunicación implica un costo físico.
¿Cómo se establecen los mecanismos de comunicación de acuerdo a la estrategia de
particionamiento?
Descomposición de dominio
Difícil de determinar los requerimientos de comunicación.
Para hacer un cálculo se pueden requerir datos de varias tareas.
Análisis de dependencia de datos.
Descomposición funcional
Los requerimientos de comunicación corresponden al flujo de datos entre tareas.
Clasificación de la Comunicación
Local vs. Global:
En comunicación local cada tarea se comunica con un pequeño conjunto de tareas
vecinas.
En comunicación global se requiere que cada tarea se comunique con muchas tareas.
Estructurada vs. No Estructurada
En comunicación estructurada se establecen patrones regulares de comunicación.
En comunicación no estructurada no existen patrones definidos.
Estática vs. Dinámica
En comunicación estática los participantes no cambian con el tiempo.
En comunicación dinámica los patrones de comunicación se determinan en tiempo de
ejecución.
Síncrona vs. Asíncrona
Los participantes de una comunicación síncrona lo hacen de manera coordinada.
11
Paralelización
En comunicación asíncrona es posible solicitar datos sin el acuerdo de un emisor o
productor de datos.
Objetivos de la Comunicación
Se debe balancear las comunicaciones entre todas las tareas.
Un desbalance en las comunicaciones conduce a un programa no escalable.
Distribuir estructuras de datos frecuentemente accedidas entre las tareas.
Siempre que se pueda, se debe tratar de tener comunicaciones locales.
Las operaciones de comunicación deben promover el paralelismo, esto es, se deben ejecutar
en forma paralela.
Utilice divide y vencerás para descubrir concurrencia.
Las operaciones de comunicación deben permitir que las tareas del cómputo se realicen en
forma concurrente.
Si esto no sucede, el algoritmo seguramente será ineficiente y no escalable.
Estructurando la Comunicación
Dada una cantidad de comunicaciones (inherente o artificial) el objetivo es reducir su costo.
El objetivo es reducir los términos del tiempo de espera e incrementar el traslape entre cómputo
y comunicación.
II.3. Mapeo
En la fase de mapeo se hace una asignación de procesos a procesadores físicos.
El objetivo es minimizar el tiempo de ejecución de un programa paralelo.
Las estrategias son:
Colocar procesos que son capaces de ejecutarse concurrentemente en procesadores
diferentes.
Colocar procesos que se comunican frecuentemente en el mismo procesador para
fomentar la vecindad (espacial y temporal).
El problema del mapeo no aparece en computadoras con un solo procesador o en
computadoras con memoria compartida.
En multiprocesadores, mecanismos de hardware o del sistema operativo hace una
calendarización de procesos automática.
No existen, hasta el momento, mecanismos de mapeo de propósito general.
Mapeo es un problema difícil (NP-completo) que tiene que ser abordado de manera explícita
cuando se diseñan algoritmos y programas paralelos.
Se tienen distintos enfoques:
Mapeo Estático
Descomposición del dominio, número fijo de procesos del mismo tamaño, comunicación
estructurada local y global.
Modelos de programación para Mapeo
Las interacciones entre procesos puede expresarse por tres modelos diferentes:
12
Paralelización
13
Paralelización
III. Paradigmas de Programación Paralela
III.1 Basado en Arquitecturas de computadoras
En 1966, Michael Flynn propuso un mecanismo clásico de clasificación de las computadoras, y
aunque no cubre todas las posibles arquitecturas, sí proporciona una importante penetración en
varias arquitecturas de computadoras modernas. Esta clasificación esta basada en el número
de instrucciones y secuencia de datos que la computadora utiliza para procesar la información.
Puede haber secuencias de instrucciones sencillas o múltiples y secuencias de datos sencillas
o múltiples. Dando lugar a 4 tipos de computadoras, de las cuales sólo dos son aplicables a las
computadoras paralelas.
Clasificación de Flynn:
III.1.1 SISD (Single Instruction Single Data)
Modelo tradicional de computación secuencial, donde una unidad de procesamiento recibe sólo
una secuencia de instrucciones que opera en una secuencia de datos.
Modelo SISD (Single Instruction Single Data)
Ejemplo: Para realizar la suma de N números a1, a2, ..., aN, el procesador necesita acceder a
memoria N veces consecutivas (para recibir un número). Ejecutando en secuencia N-1
adiciones. Es decir, los algoritmos para las computadoras SISD no contienen ningún
paralelismo, éstas están constituidas de un procesador.
14
Paralelización
III.1.2 SIMD (Single Instruction Multiple Data)
A diferencia del SISD, aquí existen múltiples procesadores que sincronizadamente ejecutan la
misma secuencia de instrucciones, pero en diferentes datos. La memoria es distribuida.
Modelo SIMD(Single Instruction Multiple Data)
Hay N secuencias de datos, una por procesador: Cada procesador ejecuta la misma instrucción
con diferentes datos. Los procesadores operan sincronizadamente y un reloj global se utiliza
para asegurar esta operación.
A este tipo de máquinas corresponden: ICL DAP (Distributed Array Processor) y computadoras
vectoriales como CRAY 1 & 2 y CIBER 205.
Ejemplo: Sumar las matrices A, B, con A y B de orden 2, si la suma se realiza con 4
procesadores, entonces se pueden ejecutar simultáneamente las siguientes instrucciones:
A11 + B11 = C11
A21 + B21 = C21
A12 + B12 = C12
A22 + B22 = C22
De esta forma la suma de dos matrices se realiza en un paso, en comparación con cuatro pasos
en una máquina secuencial.
III.1.3 MIMD (Multiple Instruction Multiple Data)
Esta computadora también es paralela como la SIMD, pero MIMD es asíncrono. No tiene un
reloj central. Cada procesador en un sistema MIMD puede ejecutar su propia secuencia de
instrucciones y tener sus propios datos. Esta característica es la más general y poderosa de
esta clasificación.
Modelo MIMD(Single Instruction Multiple Data)
15
Paralelización
Se tienen N procesadores, N secuencias de instrucciones y N secuencias de datos. Cada
procesador ejecuta su propia secuencia de instrucciones con diferentes datos. Los
procesadores operan asincrónicamente; pueden estar haciendo diferentes cosas en diferentes
datos al mismo tiempo. Los sistemas MIMD se clasifican en:
Sistemas de Memoria Compartida
Sistemas de Memoria Distribuida
Sistemas de Memoria Compartida Distribuida
III.1.3.1. Sistemas de Memoria Compartida
En este sistema cada procesador tiene acceso a toda la memoria, es decir, hay un espacio de
direccionamiento compartido. Los tiempos de acceso a memoria son uniformes, pues todos los
procesadores se encuentran igualmente comunicados con la memoria principal, sus lecturas y
escrituras tienen las mismas latencias, y el acceso a memoria es por medio de un canal común.
En esta configuración, debe asegurarse que los procesadores no tengan acceso simultáneo a
regiones de memoria que provoquen algún error. Actualmente los sistemas operativos de estos
equipos controlan todo esto mediante mecanismos tipo semáforos.
Ventaja:
Más fácil programar que en sistemas de memoria distribuida.
Desventajas:
El acceso simultáneo a memoria es un problema.
En PCs y estaciones de trabajo:
Todos los CPUs comparten el camino a memoria.
Un CPU que acceda la memoria, bloquea el acceso de todos los otros CPUs
En computadoras vectoriales como Cray, etc.
Todos los CPUs tienen un camino libre a la memoria.
No hay interferencia entre CPUs.
La razón principal por el alto precio de Cray es la memoria.
Sistemas de Memoria Compartida
Las computadoras MIMD con memoria compartida son conocidas como sistemas de
multiprocesamiento simétrico (SMP), donde múltiples procesadores comparten un mismo
sistema operativo y memoria. Otro término con que se le conoce es máquinas firmemente
acopladas o de multiprocesadores. Ejemplos son: SGI Power Challenge, SGI/Cray C90,
SGI/Onyx, ENCORE, MULTIMAX, SEQUENT y BALANCE, entre otras.
16
Paralelización
III.1.3.2. Sistemas de Memoria Distribuida
Estos sistemas tienen su propia memoria local. Se comparte información sólo a través de
mensajes, es decir, si un procesador requiere datos contenidos en la memoria de otro, deberá
enviar un mensaje solicitándolos. Esta comunicación se le conoce como Paso de Mensajes.
Ventajas:
Los equipos son más económicos que los de memoria compartida.
Escalabilidad: Las computadoras con sistemas de memoria distribuida son fáciles de
escalar, pues cuando la demanda de los recursos crece, se puede agregar más memoria
y procesadores.
Desventajas:
El acceso remoto a memoria es lento conforme crece la máquina.
La programación puede ser complicada porque requiere de programación paralela
explícita.
Sistemas de Memoria Distribuida
Las computadoras MIMD de memoria distribuida son conocidas como sistemas de
procesamiento masivamente paralelas (MPP), donde múltiples procesadores trabajan en
diferentes partes de un programa, usando su propio sistema operativo y memoria. También se
les conoce como multicomputadoras, máquinas libremente juntas o cluster. Algunos
ejemplos de este tipo de máquinas son IBM SP2 y SGI/Cray T3D/T3E.
III.1.3.3 Sistemas de Memoria Compartida - Distribuida
Es un conjunto de procesadores que tienen acceso a una memoria compartida pero sin un
canal compartido. Esto es, físicamente cada procesador posee su memoria local y se
interconecta con otros procesadores por medio de un dispositivo de alta velocidad, y todos ven
las memorias de cada uno como un espacio de direcciones globales.
El acceso a memoria se realiza bajo el esquema de Acceso a Memoria No Uniforme (NUMA), la
cual toma menos tiempo en acceder a la memoria local de un procesador que acceder a
memoria remota de otro procesador.
Ventajas:
Escalable como en los sistemas de memoria distribuida.
17
Paralelización
Fácil de programar como en los sistemas de memoria compartida.
No existe el cuello de botella, como en máquinas de sólo memoria compartida.
Sistemas de Memoria Compartida Distribuida
Algunos ejemplos de este tipo de sistemas son HP/Convex SPP-2000 y SGI Origin2000.
III.1.4 MISD (Multiple Instruction Single Data)
En este modelo, secuencias de instrucciones pasan a través de múltiples procesadores.
Diferentes operaciones son realizadas en diversos procesadores. N procesadores, cada uno
con su propia unidad de control comparten una memoria común.
MISD (Multiple instruction Single Data)
Existen N secuencias de instrucciones (algoritmos/programas) y una secuencia de datos. Cada
procesador ejecuta diferentes secuencias de instrucción, al mismo tiempo, con el mismo dato.
Las máquinas MISD son útiles donde la misma entrada esta sujeta a diferentes operaciones. No
existe ningún equipo comercial basado en este tipo de arquitectura.
III.2 Basado en la Naturaleza del Algoritmo
La naturaleza del algoritmo determina el modelo apropiado para su paralelización.
Tenemos dos tipos de algoritmos:
Homogéneos: Aplican el mismo código a múltiples elementos de datos.
Heterogéneos: Aplican múltiples códigos a múltiples elementos de datos.
18
Paralelización
Estas dos alternativas describen diferentes formas de generar pedazos que pueden ser
ejecutados en paralelo.
La independencia entre los pedazos asegura que un pedazo no modificará una variable que
otro (pedazo) pueda estar leyendo o modificando simultáneamente.
III.2.1 Teoría de la Paralelización Homogénea (Homoparalelismo)
Se lleva a cabo este tipo de paralelismo cuando el trabajo realizado por el algoritmo puede ser
descompuesto en tareas idénticas (homogéneas), cada una es una porción del trabajo total. Por
ejemplo, los lazos o ciclos compuestos de un número finito de iteraciones. En este caso todos
los pedazos se ejecutaran y terminaran al mismo tiempo y solo tendrán dos puntos de
sincronización, al inicio y al final.
III.2.2 Teoría de la Paralelización Heterogénea (Hetereoparalelismo)
Es posible cuando el trabajo realizado por el algoritmo puede ser distribuido en tareas
diferentes, siendo cada tarea una porción del algoritmo total. Por ejemplo, cualquier algoritmo
con múltiples componentes independientes. En este caso solo tendrán un punto de
sincronización al inicio de las tareas y posteriormente terminaran a diferentes tiempos
dependiendo del tamaño de los pedazos.
19
Paralelización
IV. Niveles de paralelismo
Normalmente la computadora se concibe como una máquina secuencial, donde el CPU lee la
instrucción de la memoria y la ejecuta una por una. De la misma manera, al especificar
algoritmos se concibe una secuencia de instrucciones a ser ejecutadas una a una.
Aunque internamente, las computadoras secuénciales presentan un paralelismo en diversas
funciones (paralelismo a nivel de instrucciones), por mencionar algunas: el traslape de algunas
operaciones, mientras un proceso esta escribiendo a disco, otro proceso esta ejecutándose en
el CPU; a nivel de micro operación, señales de control se generan y viajan al mismo tiempo a
través de canales paralelos, como el caso de la comunicación a una impresora conectada al
puerto paralelo.
En computadoras modernas de tipo SISD el paralelismo viene implementado en la arquitectura
del procesador, conocido como paralelismo a nivel instrucción, por ejemplo: Pipeline o
procesamiento en línea de instrucciones. Este consiste en ejecutar al mismo tiempo diversas
etapas de instrucciones del programa; mientras en una etapa se hace la ejecución de una
instrucción, simultáneamente en otra etapa se está realizando una lectura de la siguiente
instrucción.
Una característica de procesadores recientes es que poseen varias ALUs (Unidad Aritmética
Lógica) para realizar operaciones de suma, resta, multiplicación y división en forma paralela. El
paralelismo a nivel de programación puede ser complicado o sencillo, depende de la
arquitectura, del modelo para programar en paralelo e inclusive del programa en sí.
IV.1 Programación Paralela
Para paralelizar una aplicación, es necesario contar con un lenguaje o biblioteca que brinde los
mecanismos necesarios para ello. Dependiendo de la herramienta y limitantes del equipo
disponible que se tenga, se particionará el código en piezas para que se ejecute en paralelo en
varios procesadores, originando el término “granularidad”.
IV.2 Granularidad
Granularidad es el tamaño de las piezas en que se divide una aplicación. Dichas piezas pueden
ser desde una sentencia de código, una función hasta un proceso en sí que se ejecutarán en
paralelo.
IV.2.1 Teoría de la Paralización de Grano Fino
Se presenta cuando el código se divide en una gran cantidad de piezas pequeñas. A nivel de
sentencia, o en un ciclo cuando se divide en varios subciclos que se ejecutan en paralelo.
También se le conoce como Paralelismo de Instrucción.
IV.2.1 Teoría de la Paralización de Grano Grueso
Se realiza a nivel de subrutinas o segmentos de código, donde las piezas son pocas y de
cómputo más intensivo que las de grano fino. También se le conoce como Paralelismo de
Tareas.
20
Paralelización
El nivel más alto de paralelismo de grano grueso se presenta cuando se detectan tareas
independientes y estas se ejecutan como procesos independientes en más de un procesador.
Este esquema es común en las aplicaciones de Productor/Consumidor, Lector/Escritor,
Maestro/Esclavo y Cliente/Servidor. En los modelos de Memoria Distribuida (paso de mensajes)
solo se implementa paralelismo de grano grueso.
El paralelismo de grano fino y grueso se puede presentar en sistemas de memoria compartida
sólo que el de grano grueso es más complicado de programar que el de grano fino.
21
Paralelización
P a r t e II: Paradigmas de Programación Paralela
I. ¿Que hacer ante un problema a paralelizar?
Es una pregunta abierta, para la cual no existe una única respuesta, pues depende de la
naturaleza del problema. Solo se podrán paralelizar aquellos problemas cuya estructura lógica
subyacente sea de naturaleza paralela; es decir que nuestro problema pueda ser analizado a
partir de la descomposición de sus partes, y estas partes tengan cierto grado de independencia.
Aunque no hay una receta para paralelizar, en la Origin 2000 se aconseja:
•
•
•
•
•
Primero debemos considerar el código serial y optimizado.
Aplicarle paralelización automática.
Revisar el código paralelizado, para mejorar y afinas zonas en las que todavía no han
sido explotado su paralelismo.
Compilar y ejecutar el programa.
Revisar y comparan los resultados, con los resultados que se pretenden obtener. Si los
resultados son alentadores entonces restaría afinar aún más las partes de código, como
ciclos y estructuras. En caso contrario, se buscaría algún otro paradigma de
paralelización y realizar estudios comparativos de los resultados.
En general quizá sea más conveniente:
Iniciar el diseño de códigos paralelos desde cero.
II. Paradigmas de Programación Paralela
Se pueden desarrollar aplicaciones en paralelo mediante el uso de los siguientes paradigmas:
Lenguaje C, Fortran y C++ usando procesos UNIX (Nivel Proceso).
Lenguaje C con hebras POSIX (Nivel hilo).
Código fuente en FORTRAN, C o C++ usando directivas o pragmas respectivamente
(Nivel Sentencia).
Lenguaje C o Fortran usando envío de Mensajes (Nivel Proceso).
II.1 Código C, Fortran y C++ usando procesos UNIX (Nivel proceso)
Un proceso UNIX es una instancia de un programa en ejecución. Consta de un espacio de
direcciones, atributos del proceso y un hilo de ejecución. El kernel o núcleo es el encargado de
crear procesos y distribuirlos a diferentes CPUs, así como de maximizar la utilización del
sistema.
Los procesos UNIX se clasifican en:
Procesos pesados.
Procesos ligeros.
Tienen su propia pila, registros, datos y texto.
Toman un largo tiempo para crearse y destruirse. Se crean mediante el
uso de fork().
Comparten atributos con sus procesos padres.
Se crean y destruyen rápidamente.
22
Paralelización
Se conocen también como hilos.
Se crean mediante el uso de sproc().
La función fork() crea un nuevo proceso (hijo). El proceso hijo es una copia exacta del proceso
padre, el hijo corre en un espacio duplicado de direcciones del padre.
Ejemplo de fork en C:
/* fork.c: Función fork, se genera un proceso hijo que se ejecuta en paralelo con el padre */
#include <stdio.h>
#include <unistd.h>
main( )
{
}
printf("Inicio del proceso padre. PID = %d\n", getpid() );
if ( fork() == 0 ) { /* Proceso hijo con su propio codigo*/
printf ("Inicio proceso hijo. PID = %d, PPID = %d\n", getpid(), getppid());
/* codigo que se ejecutara en paralelo con el código del padre */
...
sleep(1); }
else
{
/* Proceso padre */
printf ("Continuación del padre. PID=%d\n", getpid ());
/* codigo que se ejecutara en paralelo con el hijo */
.
sleep (1);
}
printf ("Fin del proceso %d\n", getpid ());
exit (0);
sproc() es una llamada al sistema que permite crear un proceso que comparte algunos de los
atributos (espacio de direcciones virtuales, uid, descriptor de archivo, etc.) del proceso padre. El
padre y el hijo tienen su propio contador de programa, registros, apuntador a la pila, pero todo el
texto y datos que esta en el espacio compartido de direcciones (memoria) es visible a ambos
procesos. Por lo tanto, un proceso creado con sproc() no tiene su propio espacio de
direcciones, este continúa ejecutándose en el espacio de direcciones del proceso original. En
este sentido, cuando se paraleliza un programa se generan varios hilos de ejecución donde
cada hilo es una secuencia de instrucciones que corre en cada procesador. Existe un tipo de
hilos ligeros llamados hilos POSIX que ofrecen ciertas ventajas sobre los hilos convencionales.
Cuando usar sproc()
Cuando el espacio de direcciones es
compartido. Se pueden usar variables globales
para compartir datos.
Cuando el desempeño es crítico.
Cuando la portabilidad no es importante. No es
disponible en otros UNIX.
En IRIS, es el método más rápido y eficiente.
Cuando usar fork()
Cuando los procesos no puedan compartir
recursos.
fork() crea una copia exacta del padre.
El hijo obtiene su propia copia de espacio de
direcciones.
23
Paralelización
II.2 Código fuente C con hebras POSIX. (Nivel hilo)
En este método es necesario que el sistema operativo de la máquina paralela soporte hilos
POSIX. Por ejemplo IRIX, que es el sistema operativo de la Origin 2000 soporta hilos POSIX.
Cuando el sistema operativo crea un proceso, el proceso en sí es un hilo de ejecución. Un
programa puede crear muchos hilos que se ejecutan en el mismo espacio de memoria en forma
paralela.
Hilos POSIX (pthreads) son similares a los procesos ligeros de IRIX que se generan con
sproc(). Los hilos POSIX son los más recomendables a emplear, dado que son portables y
tienen mejor desempeño que los procesos ligeros de UNIX.
La portabilidad de código permite compilar y ejecutar el programa en otra plataforma que
soporte hilos POSIX. Se paraleliza el código insertando funciones de hilos POSIX, lo compila y
lo ejecuta en una plataforma de un procesador o de múltiples procesadores (IRIX) y el mismo
código lo puede compilar y ejecutar en otra plataforma (por ejemplo en Solaris).
Hilos POSIX pueden paralelizar:
Algunas dependencias de datos, usando
herramientas de sincronización.
E/S en C.
Llamadas a subrutinas o funciones.
Hilos POSIX no pueden paralelizar:
Ciclos individuales dentro de un programa
(deben ser reescritos como funciones).
Pipas gráficas.
Ejemplo de uso de hilos POSIX:
/* hola.c: Se generan 2 hilos POXIS para imprimir a pantalla "hola mundo". compilar:
cc hola.c -o hola -lpthread */
#include <pthread.h>
#include <stdio.h>
void* imprime_mensaje( void *ptr ); /*Prototipo de Función*/
main()
{
}
pthread_t hilo1, hilo2;
char *mensaje1 = "hola";
char *mensaje2 = "mundo";
/* se generan 2 hilos que se ejecutaran en paralelo con el padre */
pthread_create(&hilo1, NULL, imprime_mensaje, (void*) mensaje1);
/* El hilo padre puede estar haciendo otra cosa en paralelo con los 2 hilos POSIX hijos. Por ejemplo: */
printf("A lo mejor esto se imprime primero... \n");
pthread_create(&hilo2, NULL, imprime_mensaje, (void*) mensaje2);
sleep(1);
exit(0);
void* imprime_mensaje( void *ptr )
{
char *mensaje;
mensaje = (char *) ptr;
24
Paralelización
}
printf("%s \n", mensaje);
pthread_exit(0);
II.3 Código fuente en C o Fortran usando envío de Mensajes (Nivel
proceso)
En sistemas de memoria distribuida donde cada procesador tiene su propia memoria, el
programa a ejecutarse en paralelo debe hacer uso del modelo de “Envío de Mensajes”. Este
modelo es apropiado para la comunicación y sincronización entre procesos que se ejecutan de
manera independiente (con su propio espacio de direcciones) en diferentes computadoras. La
programación consiste en enlazar y hacer llamadas dentro del programa por medio de
bibliotecas que manejarán el intercambio de datos entre los procesadores.
Existen principalmente tres bibliotecas para programar bajo este esquema:
Message Passing Interface (MPI)
Parallel Virtual Machine (PVM)
Shared Memory (SHMEM)
En la Cray Origin 2000 la memoria esta físicamente distribuida entre todos los nodos y
lógicamente es compartida, por lo tanto los modelos que se hacen mención son aplicables.
Este esquema de implementación de paralelismo mediante el envío de mensajes es a nivel de
grano grueso, dada la generación de procesos o tareas independientes que se ejecutan en
varios procesadores. En MPI, PVM y SHMEM uno de los principales esquemas que se emplean
en la comunicación y generación de los procesos es el modelo de Maestro - Esclavo. Un
proceso maestro divide y distribuye el trabajo en sub-tareas, que las asigna a cada nodo
conocido como "trabajador" o "esclavo". Terminando cada "trabajador" su parte, envían los
resultados al maestro para que este recopile la información y la presente.
El siguiente ejemplo con MPI, no emplea el modelo de “Maestro-Esclavo” sino de "Todos
Trabajadores" que se ejecutan independientemente sin notificar a un maestro sus resultados.
Ejemplo:
/* MPIHola.c: Genera procesos independientes que imprimen a pantalla la cadena "Hola Mundo" */
#include <stdio.h>
#include "mpi.h"
main(int argc, char **argv)
{
int node, size;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size );
MPI_Comm_rank(MPI_COMM_WORLD, &node);
printf("Hola Mundo del proceso %d de %d procesos \n",node, size);
MPI_Finalize();
}
Compilación en Origin:
Ejecución:
% cc -o MPIHola MPIHola.c -lmpi
% mpirun -np 4 MPIHola
25
Paralelización
II.4 Código fuente en FORTRAN, C o C++ usando directivas o pragmas
respectivamente. (Nivel Sentencia)
El paralelismo a nivel sentencia da la facilidad de que un programa escrito en forma serial
pueda re-escribirse manual o automáticamente en forma paralela, mediante el uso de algunas
herramientas (PCA, PFA, OpenMP) de los sistemas de memoria compartida.
El paralelismo a nivel sentencia consiste en paralelizar declaraciones de ciclos DO o for en el
código fuente de un programa, mediante la implementación de directivas, además de rutinas o
procedimientos más complejos.
Una vez que al código fuente se le han insertado las directivas o pragmas, el programa puede
compilarse y ejecutarse en un ambiente serial o paralelo. Serial en el sentido de que si no se
cuenta con un compilador paralelizador que soporte el uso de directivas o que la plataforma no
sea de multiprocesamiento, las directivas se ignoran totalmente y se ejecuta en forma
secuencial.
La concurrencia generada con las directivas o pragmas del compilador son del tipo de hilos
(procesos ligeros de sproc() ).
Dos de las herramientas más conocidas en los sistemas de memoria compartida como Origin
2000 son:
IRIS Power C (PCA)
IRIS Power Fortran (PFA)
Estas herramientas son propias de SGI, cuyas directivas y pragmas son exclusivas de esta
arquitectura.
II.4.1 OpenMP
OpenMP es un API estándar para programar en paralelo en sistemas de memoria compartida,
las funciones se pueden llamar desde C/C++ o fortran. Consta de directivas estándares, que
permiten la portabilidad y la escalabilidad, presenta además una interfase simple y flexible para
desarrollar aplicaciones en paralelo desde una PC hasta una supercomputadora paralela o
masivamente paralela.
El paralelismo de grano fino y grueso se implementa usando directivas o pragmas. Por ejemplo:
#define MAX 1000000
#include <stdio.h>
double a[MAX], b[MAX], c[MAX];
void diddle(double [], double [], double [], long);
void initialize()
{
26
Paralelización
}
int i;
for (i = 0; i < MAX; i++)
a[i] = b[i] = c[i] = 100.0;
main()
{
}
initialize();
diddle(a, b, c, MAX);
printf("a[0] = %g, b[3] = %g, c[0] = %g\n", a[0], b[3], c[0]);
void diddle(double a[], double b[], double c[], long max)
{
long i;
#pragma parallel local(i) shared(a, b, c) byvalue(max)
#pragma pfor iterate(i=0; max; 1)
for (i=0; i<max; i++)
a[i] = b[i] + c[i];
#pragma parallel local(i) shared(a, b, c) byvalue(max)
#pragma pfor iterate(i=0; max; 1)
for (i=0; i<max; i++)
b[i] = a[i] + c[i];
if (b[3] > 0.01)
b[3] = 0.01;
#pragma parallel local(i) shared(a, b, c) byvalue(max)
#pragma pfor iterate(i=0; max; 1)
for (i=0; <max; i++)
c[i] = a[i] + b[i];
}
27
Paralelización
III. Compiladores Paralelizadores
En cada arquitectura de multiprocesamiento, existen compiladores que aprovechan al máximo
las capacidades implícitas del microprocesador y manejo de la memoria. Tal es el caso de los
MIPSpro Compilers y el High Perfomance Fortran (HPF) de la Origin 2000 de SGI.
Estos compiladores soportan el uso de directivas de multiprocesamiento que se pueden
implementar de dos maneras:
Implementación Explícita (Paralelización Manual): La inserción de directivas lo realiza
el programador y aplica otras técnicas de programación dentro de código fuente.
Implementación Implícita (Paralelización Automática): El compilador analiza y reestructura el programa con una pequeña o ninguna intervención del programador.
En la paralelización automática se utilizan los analizadores para C o Fortran, cuya función es
detectar e incluir paralelismo de grano fino en el código, es decir, solo en los ciclos en donde no
exista dependencia de datos.
El uso del paralelismo explícito requiere de conocer las directivas y su colocación dentro del
código fuente. Después, mediante el compilador paralelizador como PFA o PCA, se genera el
código objeto con las transformaciones necesarias para que el programa se ejecute en paralelo
en un ambiente de multiprocesadores.
III.1 Dependencia de Datos
En la programación paralela es importante identificar que parte del código se puede dividir en
piezas para su ejecución independiente. Idealmente al tomar un código serial, se distribuyen las
operaciones en números iguales entre la cantidad de procesadores, de esta forma los
procesadores ejecutarían la misma cantidad de instrucciones en paralelo. Sin embargo,
usualmente los códigos tienen algunas operaciones que se deben ejecutar serialmente. Si estas
operaciones son forzadas para ejecutarse en paralelo, producirán resultados incorrectos, puesto
que las variables serán utilizadas antes de que su valor sea calculado o actualizado. Esta
condición es llamada dependencia de datos.
La condición esencial requerida para paralelizar correctamente un ciclo es que cada iteración
debe ser independiente del resto de las iteraciones. Si un ciclo cumple con esta condición,
entonces el orden de ejecución de las iteraciones no importa. Pueden ser ejecutadas al revés o
al mismo tiempo, y la respuesta sigue siendo la misma. Es decir hay independencia de datos.
En un programa, las posiciones de memoria son representadas por nombres de variables. Así
pues, determinar si un ciclo en particular puede ejecutarse en paralelo, consiste en examinar la
manera en que las variables son utilizadas en los ciclos. Es necesario poner particular atención
en las variables que aparecen en el lado izquierdo de las asignaciones, porque la dependencia
de datos ocurre solamente cuando las posiciones de memoria son modificadas. Si una variable
no se modifica, no hay dependencia de datos asociada a ella.
Ejemplo: Hay un ciclo en el cual cada elemento de un arreglo es multiplicado por 2. Si el ciclo se
ejecuta en 2 procesadores, a cada procesador se le asignará un grupo de índices del ciclo. En
el ejemplo, al procesador 1 se le asigna i = 1, 50, y al procesador 2 se le asigna i = 51, 100.
28
Paralelización
En este ejemplo no hay dependencia de datos. Pero si el ciclo lo escribimos diferente:
Si las dimensiones del ciclo son de 0 a 100, y a(0) = 1, el ciclo serial generará resultados para la
variable a = 1, 2, 4, 8,... En cambio, si el ciclo se distribuye en dos procesadores, se presenta
un problema, pues el procesador 2 inicia el cómputo con a(51) = a(50)*2.0, pero a(50) todavía
no ha encontrado su valor inicial, así que el resultado a(51)=2.0, no es el resultado que se
espera. Este es un ejemplo de dependencia de datos.
III.2 Bases Teóricas de la Paralelización Automática y Técnicas de Paralelización
de Programas Secuenciales
Las opciones de paralelización automática del compilador analizan y reestructuran el programa
con poco o nada de intervención del programador. Esta paralelización ayuda a tomar ventaja
del paralelismo en programas para proveer un mejor rendimiento en sistemas de
multiprocesamiento. Es una extensión del compilador controlada con banderas en la línea de
instrucciones que invoca la paralelización automática de algunos compiladores.
La paralelización automática inicia con la determinación de la dependencia de datos de
variables y arreglos en ciclos. La dependencia de datos puede evitar que los ciclos sean
ejecutados en paralelo, pues el resultado final puede variar dependiendo del orden de acceso
de los procesadores a las variables y arreglos.
III.2.1 Casos de Estudio de No Paralelización
Hay situaciones donde no se puede paralelizar los ciclos con la opción automática:
a. Llamada a funciones en ciclos.
b. Declaraciones GO TO en ciclos.
29
Paralelización
c. Subíndices complicados en arreglos.
d. Referencia indirecta a un arreglo.
e. Índices imposibles de analizar
f. Conocimiento oculto.
g. Variables condicionales temporales asignadas en un ciclo.
h. Uso de punteros en C/C++ imposibles de analizar.
i. Arreglos de Arreglos
j. Ciclos limitados por comparaciones de punteros
k. Parámetros "aliados"
l. Ciclos anidados paralelizados incorrectamente
a. Llamada a funciones en ciclos
Por defecto, el paralelizador automático no paraleliza un ciclo que contiene una llamada a
función, pues la función en una iteración puede modificar o depender de datos de otras
iteraciones del ciclo.
b. Declaraciones GO TO en ciclos
Su uso puede causar dos problemas:
No es posible paralelizar ciclos con salidas tempranas, ni automática o manualmente.
Flujos de control no estructurados.
c. Subíndices complicados en arreglos
Casos donde los índices del arreglo son muy complicados para permitir la paralelización.
d. Referencia indirecta a un arreglo
El paralelizador automático no puede analizar referencias indirectas del arreglo. Por ejemplo:
for (i = 1; i < n; i++)
a[b[i]]...
Este ciclo no puede ser ejecutado en paralelo si la referencia indirecta a b[i] tiene el mismo valor
para diferentes iteraciones de i. Si cada elemento del arreglo b es único, el ciclo se puede
ejecutar en paralelo. En tales casos, es posible utilizar los métodos manuales o las directivas
para permitir la paralelización.
e. Índices imposibles de analizar
El analizador automático no puede paralelizar ciclos que contienen arreglos con índices
imposibles de analizar. En el siguiente caso, el paralelizador automático no puede analizar el
símbolo "/" en el subíndice del arreglo y no puede reordenar el ciclo.
for (i = 1; i < u; i+=2)
a(i/2) = ...; /* No se puede paralelizar ni reordenar*/
f. Conocimiento oculto
Puede haber conocimiento oculto en la relación entre las variables. m y n en este ejemplo:
for (i = 1; i < n; i++) a[i] = a[i+m]; /* Error */
El ciclo puede ser ejecutado en paralelo si n > m, porque los arreglos no se traslaparán. Sin
embargo, el paralelizador automático no conoce el valor de las variables, este no puede
paralelizar el ciclo.
30
Paralelización
g. Variables condicionales temporales asignadas en un ciclo
Cuando se paraleliza un ciclo, el paralelizador automático localiza (privatiza) variables
temporales escalares y arreglos. Por ejemplo:
for (i = 1; i < n; i++) {
for (j = 1; j < n; j++)
for (j = 1; j < n; j++)
tmp[j] = …
a[j][i] = a[j][i] + tmp[j]
}
El arreglo tmp es utilizado para "guardar" espacio local. Para paralelizar adecuadamente el
ciclo externo “for (i)”, cada procesador se debe dar una parte distinta del arreglo tmp. En este
ejemplo, el paralelizador automático puede localizar el tmp y paralelizar el ciclo. El paralelizador
automático se ejecuta con problemas cuando una variable condicional asignada temporalmente
puede ser utilizada fuera del ciclo, como en el ejemplo siguiente:
function s1(a, b)
{
real t;
for (j = 1; j < n; j++) if (b[j])
}
{
t = ...
a(i) = a(i) + t;
}
s2(); /* Llamada a la función s2*/
Si el ciclo se ejecutara en paralelo, habría un problema si el valor de t fuera utilizado dentro de
la subrutina s2(). ¿Cuál copia de t utilizaría la subrutina s2()? Si t no fuera asignada
condicionalmente, la respuesta sería que el procesador ejecute la iteración n. Pero t es
condicionalmente asignada y el paralelizador automático no puede determinar cual copia debe
utilizar.
El ciclo es paralelo si la variable t asignada condicionalmente es localizada. Si el valor de t no
es utilizado fuera del ciclo, se podría reemplazar a t con una variable local. A menos que t sea
una variable local, el paralelizador automático debe asumir que s2() pudo ser utilizada.
h. Uso de punteros imposibles de analizar en C/C++
C y C++ tienen características que dificultan paralelizar automáticamente. Muchas de estas
características se relacionan con la utilización de punteros. En Fortran es más fácil paralelizar
ya que los punteros tienen un uso muy restringido.
i. Arreglos de Arreglos
Los arreglos multidimensionales son algunas veces implementados como arreglos de arreglos.
double **p;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
p[i][j] = ...
Si p es un arreglo multidimensional, el ciclo externo puede ejecutarse en paralelo. Si dos de los
punteros del arreglo, por ejemplo p[2] y p[3], se refieren al mismo arreglo, el ciclo no debe
ejecutarse en paralelo. Aunque esta referencia duplicada es inverosímil, el paralelizador
31
Paralelización
automático no puede probar que no existe. Se puede evitar este problema utilizando siempre
arreglos verdaderos. La forma adecuada de paralelizar el fragmento de código anterior será:
double p[n][n];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
p[i][j] = ...
j. Ciclos limitados por comparaciones de punteros
El paralelizador automático reordena sólo ciclos donde el número de iteraciones pueda ser
determinado exactamente. En Fortran es raro que esto sea un problema, pero en C y C++
pueden surgir problemas referentes a sobreflujo y aritmética sin signo. En consecuencia los
ciclos no se deben limitar por comparaciones de punteros tales como:
int* pl, pu;
f
or (int *p = pl; p != pu; p++)
Este ciclo no puede ser paralelizado, y la compilación dará un archivo de resultados *.l que
indica que el límite no puede ser evaluado. Para evitarlo, se debe reestructurar el ciclo así:
int lb, ub;
for (int i = lb; i <= ub; i++)
k. Parámetros "aliados"
Los alias ocurren cuando existen múltiples maneras de referirse al mismo dato. Por ejemplo,
cuando el direccionamiento de una variable global se pasa como argumento a una subrutina,
puede ser referenciado con su nombre global o vía puntero. Quizás el impedimento más
frecuente para paralelizar en C y C++ es la información "aliada". Aunque Fortran garantiza que
los múltiples parámetros para una subrutina no son aliados unos a otros, C y C++ no lo hacen.
Ejemplo:
void sub(double *a, double *b, n) {
for (int i = 0; i < n; i++) a[i] = b[i];
Este ciclo puede ser paralelizado solamente si los arreglos a y b no poseen el mismo espacio
en memoria.
l. Ciclos anidados paralelizados incorrectamente
El paralelizador automático paraleliza un ciclo distribuyendo sus iteraciones entre los
procesadores disponibles, normalmente intenta paralelizar el ciclo exterior, pues el resultado del
rendimiento es usualmente mejor. Si no puede hacerlo, probablemente es por una de las
razones que se mencionaron, entonces intenta hacer un intercambio del ciclo externo por el
interno que si puede ser paralelizado. Ejemplo de ciclos anidados.
for (i = 1; i < n; i++)
for (j = 1; j < n; j++)
...
Sin embargo, es posible que un ciclo este paralelizado incorrectamente. Dada una jerarquía de
ciclos, el paralelizador automático sólo paralelizará uno de los ciclos en la anidación. En
32
Paralelización
general, es mejor paralelizar ciclos externos que internos. Intentará paralelizar el ciclo externo o
intercambiar el ciclo paralelizado de modo que sea externo, pero esto a veces no es posible.
Es mejor paralelizar ciclos que tienen gran número de iteraciones. Ejemplo:
for (i = 1; i < m; i++)
for (j = 1; j < n; j++)
El paralelizador automático puede decidir paralelizar el ciclo de i, pero si m es muy pequeña,
sería mejor intercambiar el ciclo de j para que sea exterior y después paralelizarlo. El
paralelizador automático no tiene manera de saber si m es pequeña. En tales casos, se debe
utilizar cualquier directiva insertada manualmente para decirle al paralelizador automático que
paralelize el ciclo.
Debido a la jerarquía de la memoria, el rendimiento puede ser mejorado si los procesadores
tienen acceso a los mismos datos en todos los ciclos anidados paralelos.
Ejemplo: Ciclo ineficiente
for (i = 1; j < n; j++)
for (i = n; i > 1; j--)
a[j]…
a[i]...
Asumiendo que existen p procesadores. En el primer ciclo, el primer procesador tendrá acceso
a los primeros n/p elementos de a, el segundo procesador tendrá acceso a los siguientes n/p y
así sucesivamente. En el segundo ciclo el primer procesador tendrá acceso a los últimos n/p
elementos de a. Asumiendo que n no es muy grande, esos elementos estarán en el caché de
los procesadores. Acceder a datos que están en el caché de algún otro procesador puede ser
muy costoso. El ejemplo mencionado, puede ser más eficientemente si se invierte la dirección
de uno de los ciclos.
Ejemplo: Ciclo Eficiente
for (i = 1; i < n; i++)
for (j = 1; j < n; j++)
for (i = 1; i < n; i++)
for (j = 1; j < n; j++)
a[i][j] = b[j][i] + ...
b[i][j] = a[j][i] + ...
Aquí, el paralelizador automático puede elegir paralelizar el ciclo externo en ambas anidaciones.
Esto significa que en el primer ciclo el primer procesador esta accesando los primeros n/p
renglones de a y las primeras n/p columnas de b, mientras que en el segundo ciclo el primer
procesador esta accesando las primeras n/p columnas de a y los primeros n/p renglones de b.
Este ejemplo será más eficiente si se paraleliza el ciclo i en una anidación y el ciclo j en la otra.
Alternativamente puede preferir agregar directivas para resolver este problema.
III.2.2 Analizadores PCA y PFA
Cuando una aplicación se ejecuta en una plataforma de multiprocesadores y el rendimiento es
crítico, se puede hacer que algunas partes se ejecuten en paralelo. Los compiladores de SGI, C
y Fortran, tienen pre-procesadores que analizan el código fuente y donde es posible, producen
el código objeto que utiliza un ambiente de multiprocesadores.
Los analizadores PCA y PFA son pre-procesadores que asisten en la optimización y
paralelización de programas en C o Fortran.
33
Paralelización
PCA:
Permite hacer uso eficiente de las plataformas de multiprocesamiento de SGI,
generando segmentos de código que se ejecuten en paralelo.
Consta del compilador estándar de C y un pre-procesador que automáticamente analiza
el código secuencial para determinar qué ciclos pueden ser ejecutados en paralelo. El
pre-procesador genera una versión modificada del código fuente con las directivas de
multiprocesamiento agregadas.
El compilador de C, cuando compila el código fuente modificado, interpreta las directivas y
produce un código objeto que utiliza múltiples procesadores. Una ventaja de PCA es que se
puede usar para recompilar programas seriales existentes de modo que se ejecuten
eficientemente en computadoras de multiprocesamiento sin tener que volver a codificar.
PCA es un pre-procesador de optimización de código en C que detecta el paralelismo.
El analizador PCA tiene las siguientes funciones:
•
•
•
•
Generar código en C para ejecutarse en paralelo.
Determinar dependencia de datos, pues evitan que el código se ejecute en paralelo.
Distribuir los ciclos "bien portados" a través de multiprocesadores.
Optimizar el código fuente.
Se puede utilizar PCA como herramienta independiente o como una fase del compilador de C.
También se pueden incorporar directivas directamente en el programa que producen código
concurrente, mejor que utilizando PCA. La siguiente figura ilustra el papel de PCA en producir
un módulo ejecutable que pueda utilizar más de un procesador en un sistema de
multiprocesamiento.
Utilizando PCA para producir un programa paralelizado
PCA produce un listado que contiene información acerca de los ciclos que pueden o no pueden
ser paralelizados. Utilizando esta información, se puede modificar el código fuente de modo que
una compilación subsecuente de PCA produzca un código más eficiente. Se puede seleccionar
una compilación de PCA para el código fuente especificando la opción del compilador PCA
donde se compila el programa.
PFA:
Es un pre-procesador de Fortran, que permite ejecutar eficientemente programas de
Fortran en sistemas de multiprocesamiento.
PFA analiza un programa e identifica ciclos independientes de datos. Cuando determina que un
ciclo no contiene dependencia de datos, automáticamente inserta directivas especiales del
34
Paralelización
compilador en el programa para producir una copia modificada del código fuente. El compilador
Fortran 77 de SGI puede entonces interpretar estas directivas para generar código que puede
ejecutarse a través de todos los procesadores disponibles.
Como las directivas insertadas por PFA parecen declaraciones estándares de comentarios de
Fortran 77, PFA no afecta la portabiblidad del código a los sistemas que no son de SGI. Si PFA
no puede determinar que ciclo es independiente, produce un archivo de listado detallando
donde existe el problema. La siguiente figura ilustra el papel de PFA en producir un módulo que
puede utilizar más de un procesador en un sistema de multiprocesadores.
Utilizando PFA para producir un programa paralelizado
Si se requiere PFA puede producir un archivo de listado, que explica qué ciclos fueron
paralelizados y cuales no, explicando ¿por qué?. Podemos utilizar esta información para
modificar la aplicación para un uso eficiente en múltiples procesadores.
Compilando con PCA/PFA
Los compiladores MIPSpro invocan la paralelización automática utilizando las banderas: -pfa o pca en la línea de instrucciones. La sintaxis para compilar con paralelización automática es:
Para Fortran 77 y Fortran 90 se usa -pfa:
Para C y C++ se usa -pca:
% f77 -pfa [{ list | keep }] [ -mplist ] archivo.f
% f90 -pfa [{ list | keep }] [ -mplist ] archivo.f
% cc -pca [{ list | keep }] [ -mplist ] archivo.c
% CC -pca [{ list | keep }] [ -mplist ] archivo.cc
Donde:
Opciones
-pfa y –pca
list
keep
-mplist
Descripción
Invocan la paralelización automática y habilitan las directivas de
multiprocesamiento.
Produce un listado de las partes del programa que pueden (o no) ser ejecutadas
en paralelo en múltiples procesadores. El archivo de listado tiene la extensión *.l.
o *.list. En al Origin 2000 de la DGSCA (UNAM) la extensión es *.list.
Genera el archivo de listado (*.list), el programa equivalente transformado (*.m), y
crea un archivo de salida para ser utilizado con WorkShop MPF (*.anl).
Genera un programa equivalente transformado en un archivo a.w2f.f para Fortran
77 o a.w2c.c para C.
La paralelización automática presenta las siguientes desventajas
Inserta directivas de paralelización en regiones que no tienen gran peso en el cómputo.
Todos los ciclos for o do que encuentre intentara paralelizarlos.
Asume que hay dependencias de datos donde con la intervención del programador se
puede eliminar esa dependencia.
35
Paralelización
Por tal razón, es recomendable recurrir a la paralelización manual después de haber analizado
el código con los analizadores PCA o PFA.
Limitantes de los Analizadores:
PCA
Solo puede analizar “ciclos for”.
No puede paralelizar “ciclos for” con apuntadores
de notación aritmética.
No puede analizar “ciclos while o do”.
No busca paralelizar bloques de código.
PFA
Sólo puede analizar “ciclos do”.
III.3 Paralelización Manual
La paralelización manual se realiza mediante el uso de directivas del compilador y otras
técnicas de programación dentro del código. Antes de proceder con esta técnica de
paralelización, el programador debe conocer la respuesta a las cuestiones como:
¿Cuales ciclos se pueden paralelizar?,
¿Qué variables son locales para cada hilo?,
¿Qué variables son compartidas?,
¿Cómo se distribuyen los datos?, etc.
Con la inserción de directivas en el código, se especifica al compilador lo que debe realizar.
Se emplea la paralelización manual cuando:
El paralelizador automático no paraleliza suficientemente el código y se recurre a
insertar directivas manualmente.
El paralelizador automático detecta que hay casos en que la paralelización es imposible,
como por ejemplo: una lectura/escritura, llamadas a subrutinas, y dependencias de datos
en el ciclo.
Región paralela:
Es una sección de código con ciclos o bloques ejecutados independientemente.
Una región paralela de código puede contener secciones que se ejecutan secuencialmente, así
como otras secciones que se ejecutan concurrentemente (ver figura).
Esquema de un programa con partes ejecutándose en modo secuencial y paralelo
Regiones paralelas dentro del código fuente usando directivas o pragmas
36
Paralelización
PCA:
#pragma parallel [modificador (lista) ...] ...
{
/* codigo "local" ejecutado por todos los hilos (threads) */
}
Las demás directivas de paralelización deben estar dentro de una región paralela.
PFA:
C$DOACROSS [modificador (lista), ...] ...
DO I = 1, N
C
Cuerpo del ciclo
END DO
III.3.1 Sintaxis de las directivas de paralelización
El uso de directivas para paralelizar código ya escrito previamente resulta ventajoso.
Mencionamos las directivas más importantes para llevarlo a cabo la paralelización de códigos:
En Fortran:
Directiva C$DOACROSS
Es una directiva de PFA para crear una región paralela, por ejemplo:
c$doacross share(a), local(x),
c$& lastlocal(j)
do j =1, n
x = a(j) ** j
enddo
Modificadores para C$DOACROSS
Los modificadores se escriben como una lista separada por comas sobre la misma línea
o una línea separada usando C$&
shared (variables): Variables compartidas entre los hilos.
reduction (variables): Variables involucradas en una reducción.
local (variables): Variables locales a cada hilo.
lastlocal (variables): Variables locales en el ciclo; el valor de la ultima iteración
del ciclo original es guardado.
En C:
Directiva “#pragma parallel”
Esta directiva de PCA es usada para crear una región paralela, por ejemplo:
main()
{
int cuenta;
....
#pragma parallel shared(a,b,c) local(i) byvalue(max)
#pragma if (cuenta > 5)
{
/* Codigo del bloque A */
}
37
Paralelización
...
}
Modificadores para “#pragma parallel”
Los modificadores pueden ser colocados en la misma línea, o como una sentencia
pragma por separado después de “#pragma parallel”. Los más comunes son:
shared (nombres de variables): Variables compartidas entre los hilos.
byvalue (nombres de variables): Variables compartidas de solo lectura.
local (nombres de variables): Variables locales a cada hilo.
Directiva #pragma pfor
#pragma parallel ...
{
#pragma pfor iterate (i = 0; 1000; 1)
#pragma schedtype(dynamic) chunksize(10)
}
for(i=0; i<1000; i++) {
/* Bloque de codigo B */ }
Modificadores:
iterate (index = start; num_iters; incr): Significa que inicializa un valor, el número
total de iteraciones y los brincos.
La variable index debe ser inicializada antes del ciclo.
schedtype(arg): Especifica que tipo de calendarización se aplicará al ciclo.
chunksize(arg): Número de iteraciones por hilo cuando la calendarización es
dinámica (dynamic) o intercalada (interleave).
III.3.2 Creando bloques independientes
No solo los ciclos pueden paralelizarse, sino también el código delimitado con la directiva
“#pragma independent” llamado código independiente dentro de una región paralela (esto solo
es valido para PCA). Su ejecución en paralelo es una tarea que se ejecuta en un hilo. Este tipo
de paralelismo es de grano grueso o "paralelismo heterogéneo", ya que el código de cada hilo
de ejecución es diferente, en comparación al de grano fino o "paralelismo homogéneo", en la
que todos los hilos ejecutan el mismo código sobre diferentes datos.
PCA:
Cada bloque de código independiente es calendarizado en su propio hilo.
Cuando finaliza un hilo, la ejecución de un bloque independiente, empieza a trabajar sobre otro.
#pragma parallel ....
{
#pragma independent
{
/* tarea 1, corre en paralelo pero independiente*/
#pragma independent
{
/* tarea 2, corre en paralelo pero independiente*/
<código local es ejecutado por todos los hilos>
}
38
}
}
Paralelización
PFA:
c$doacross local(i)
do i=1, 2
if (i .eq. 1) then
else
enddo
endif
call tarea1
call tarea2
III.3.3 Ejemplo de paralelización automática
//Archivo de nombre: Par_aut.c de Paralelización Automática
#define MAX 1000000
#include <stdio.h>
double a[MAX], b[MAX], c[MAX];
void diddle(double [], double [], double [], long);
void initialize();
main()
{
}
initialize();
diddle(a, b, c, MAX);
printf("a[0] = %g, b[3] = %g, c[0] = %g\n", a[0], b[3], c[0]);
void initialize()
{
int i;
for (i = 0; i < MAX; i++)
}
a[i] = b[i] = c[i] = 100.0;
void diddle(double a[], double b[], double c[], long max)
{
long i;
for (i=0; i<max; i++)
a[i] = b[i] + c[i];
for (i=0; i<max; i++)
b[i] = a[i] + c[i];
if (b[3] > 0.01) b[3] = 0.01;
for (i=0; i<max; i++)
c[i] = a[i] + b[i];
39
Paralelización
}
Compilando este programa con la opción de paralelización automática:
% cc -pca list Par_aut.c
El archivo de listado (Par_aut.list) muestra que los ciclos no han sido paralelizados debido a la
dependencia de datos detectada, y muestra el estado de paralelización de cada lazo:
Si se sabe que un ciclo se puede paralelizar, aunque en la forma automática no lo haya
realizado, entonces se procede a eliminar esa dependencia insertando directivas manualmente.
#define MAX 1000000
#include <stdio.h>
double a[MAX], b[MAX], c[MAX];
void diddle(double [], double [], double [], long);
void initialize()
{
int i;
for (i = 0; i < MAX; i++)
}
main()
{
a[i] = b[i] = c[i] = 100.0;
initialize();
diddle(a, b, c,MAX);
40
Paralelización
printf("a[0] = %g, b[3] = %g, c[0] = %g\n", a[0], b[3], c[0]);
}
void diddle(double a[], double b[], double c[], long max)
{
long i;
#pragma parallel local(i) shared(a, b, c) byvalue(max)
#pragma pfor iterate(i=0; max; 1)
for (i=0; i<max; i++)
a[i] = b[i] + c[i];
#pragma parallel local(i) shared(a, b, c) byvalue(max)
#pragma pfor iterate(i=0; max; 1)
for (i=0; i<max; i++)
b[i] = a[i] + c[i];
if (b[3] > 0.01)
b[3] = 0.01;
#pragma parallel local(i) shared(a,b,c) byvalue(max)
#pragma pfor iterate( i = 0; max; 1)
for (i=0; i<max; i++)
c[i] = a[i] + b[i];
}
Al compilar el programa con las directivas insertadas se genera el ejecutable para un sistema
de multiprocesamiento, de la siguiente manera:
%cc -mp -o salida ParautDi.c
la opción –mp genera código de multiprocesamiento para los archivos a ser compilados. Esta
opción origina que el compilador reorganice todas las directivas de multiprocesamiento. La
opción –apo contiene esta opción.
Se define la variable de ambiente MP_SET_NUMTHREADS para indicar con cuantos hilos
(usualmente se ejecuta uno por procesador) se ejecutará el programa:
%setenv MP_SET_NUMTHREADS 4
Al final, se ejecuta el programa salida monitoreándolo con la instrucción top.
41
Paralelización
42
Paralelización
IV. Análisis de Rendimiento
El rendimiento de un programa paralelo es una cuestión compleja que depende de muchos
factores:
Tiempo de ejecución, escalabilidad, generación, almacenamiento y comunicación de
datos.
Métricas diversas.
Tiempo de ejecución, eficiencia, requerimientos de memoria, throughput, latencia,
rango de entrada/salida, uso de la red, costos de implementación, requerimientos
de hardware, portabilidad, escalabilidad, etc.
Las métricas pueden ser dependientes de la aplicación.
Predicción de tiempo: tiempo de ejecución, costos de hardware, costos de
implementación, exactitud, confiabilidad y escalabilidad.
Bases de datos paralelas: throghput, costos de implementación y mantenibilidad.
Sistemas de visión: cantidad de imágenes procesadas por segundos (throughput) y el
tiempo de espera (latencia).
Aplicaciones bancarias: rango de tiempo de ejecución/costo.
Puntos a revisar:
•
•
Tiempo de Ejecución.
Escalabilidad
IV. 1 Modelación del Rendimiento
Enfoques usuales:
•
•
•
Ley de Amdahl
Extrapolación de Observaciones
Análisis Asintótico.
IV.1.1 Ley de Amdahl
Si la fracción s del tiempo es inherentemente secuencial, entonces, la aceleración es ≤
T p = st s +
S ( P) =
(1 − s )t s
p
ts
p
=
st s + (1 − s )t s / p 1 + ( p − 1)s
¿Qué representa la “inherentemente secuencial”?
Es relevante en la paralelización gradual y parcial de programas secuénciales.
¿Se puede aplicar a una solución paralela nueva?
43
1
.
s
Paralelización
IV.1.2 Extrapolación a partir de observaciones
Ejemplo:
T1 = n +
n2
,
p
(
)
(
T2 = n + n 2 / p + 100 ,
)
T3 = n + n 2 / p + 0.6 p 2
Aceleración de 10.8 con 12 procesadores para n = 100
IV.1.3 Análisis Asintótico
“Un algoritmo requiere O(n log n ) tiempo en O(n ) procesadores”
Existen constantes c y n 0 , tal que, para todo n > n 0 , cos to( n) ≤ cn log n en n
procesadores.
Si el costo actual del algoritmo es 10n + n log n el termino 10n es mayor para n < 1024 .
Costo asintótico, no absoluto.
Ejemplo: 100n log n > 10n 2 , n < 996
44
Paralelización
IV.1.4 Basado en modelos idealizados
Ejemplo: PRAM (Parallel Random Access Machine)
Un buen modelo de rendimiento
Deber ser capaz de explicar observaciones.
Debe predecir circunstancias futuras.
Debe abstraer detelles no relevantes.
Técnicas para modelado de rendimiento a un nivel de detalle intermedio
Adecuadas para multicomputadoras: T = f (n, p, u ,...)
El objetivo es desarrollar expresiones matemáticas que especifiquen el tiempo de
ejecución como funciones de n, p,...
Los modelos deben ser suficientemente simples pero con un nivel de exactitud
aceptable.
IV. 2 Tiempo de Ejecución
El tiempo de ejecución de un programa paralelo es el tiempo que transcurre desde que el primer
procesador inicia su ejecución hasta que el último procesador termina su ejecución.
T = Tcomp + Tcomm + Tidle
Tcomp = Tiempo de cómputo
Tcomm = Tiempo de comunicación
Tidle = Tiempo de espera
IV.2.1 Tiempo de Cómputo
Tiempo invertido en procesamiento (no en comunicación ni en espera)
Depende normalmente del tamaño del problema, n .
Replicación: depende también de la cantidad de tareas.
Heterogeneidad: varía de procesador a procesador.
IV.2.2 Tiempo de Comunicación
45
Paralelización
Tiempo invertido en comunicar información de un procesador a otro.
Comunicación entre procesadores, es distinto a la comunicación dentro de un procesador.
IV.2.3 Tiempo de espera
Tiempo perdido en espera de la ocurrencia de eventos, tiempos de sincronización, tiempos de
trabajo adicional.
IV. 3 Modelo de Comunicación
Modelo de Comunicación Simple
Tmsg = t s + t w L
t s = Tiempo de arranque (latencia)
t w = Tiempo de transferencia por palabra
L = Longitud del mensaje en palabras
IV. 4. Eficiencia y aceleración
Eficiencia Relativa: la fracción del tiempo que los procesadores se mantienen haciendo trabajo
útil.
E relativa =
T1
pT p
Dado que los tiempos de ejecución varían con el tamaño del problema, los tiempos de ejecución
deben ser normalizados cuando se compara el rendimiento de un algoritmo para problemas de
diferente tamaño.
Aceleración Relativa: el factor por el cual el tiempo de ejecución se reduce en p procesadores.
S relativa = pE relativa
Las métricas son relativas ya que se calculan con respecto al algoritmo paralelo ejecutado en
un solo procesador.
Las métricas relativas son útiles para explorar la escalabilidad de un algoritmo pero no
constituyen una figura de mérito absoluta.
T1 = 10,000 seg , T1000 = 20seg , E relativa = 0.5 , S relativa = 500
46
Paralelización
T1 = 1,000seg , T1000 = 5seg , E relativa = 0.2 , S relativa = 200
IV.4.1 Eficiencia y Aceleración Absoluta
*
T1 el mejor algoritmo secuencial conocido
*
E absoluta =
T1
pT p
S absoluta = pE absoluta
IV. 5. Análisis de Escalabilidad
IV.5.1 Escalabilidad de un algoritmo
Que tan efectivamente se puede usar con un número creciente de procesadores.
¿Cómo varía el rendimiento del algoritmo con varios parámetros como el tamaño del problema,
el número de procesadores y el costo de arranque de mensajes?
Problema Fijo:
La variación del tiempo de ejecución, T , y eficiencia, E , con un número creciente de
procesadores para el mismo tamaño del problema.
¿Que tan rápido se puede resolver un problema en una computadora?
¿Cuál es el máximo número de procesadores que se pueden utilizar para mantener la
eficiencia arriba de un cierto nivel?
Problema: Revolvedor de Ecuaciones
Tcomp = t c n 2 / p
(
Tcomm = 2 p(t s + t w 2 * n )
E = t c n 2 / t c n 2 + t s 2 p + t w 4np
T = t c n 2 / p + 2 pt s + 4npt w
)
47
Paralelización
IV.5.2. Escalabilidad con problema variable
Problema Escalado:
Función de Isoeficiencia
Considera cómo la cantidad de cómputo realizado se debe escalar con el número
de procesadores para mantener la eficiencia constante.
O ( p ) es altamente escalable, pues la cantidad de cómputo que se
requiere incrementar crece únicamente en forma lineal para mantener la
eficiencia constante.
O( p 2 ) u O(2 p ) indicarían algoritmos no escalables.
E=
Tcomp
T1
+ Tcomm + Tidle
El tiempo de ejecución en un solo procesador se debe incrementar al mismo rango en que se
incrementa el tiempo paralelo total.
La cantidad de cómputo esencial se debe incrementar al mismo rango que el trabajo
adicional debido a replicación, comunicación y tiempos de espera.
El análisis de escalabilidad no se aplica a cualquier problema.
En algunas aplicaciones, como predicción de tiempo, es más importante terminar
una actividad dentro de ciertos límites de tiempo.
Ejemplo: Revolvedor de Ecuaciones
Para eficiencia constante, una función de p , cuando se sustituye por n , debe satisfacer la
siguiente relación para cuando p crece y E permanece constante.
(
t c n 2 ≈ E t c n 2 + t s 2 p + t w 4np
)
La función n = p , satisface este requerimiento y produce la siguiente relación la cual es válida
excepto cuando p es pequeña,
2
t c ≈ E t c + t s + t w 4
p
48
Paralelización
Escalando n con p provoca que el número de puntos de la malla y la cantidad de cómputo se
( )
escale con p 2 . La función de isoeficiencia es O p 2 .
IV. 6. Perfiles de Ejecución
Si el análisis de escalabilidad sugiere que el rendimiento es bajo en problemas de cierto tamaño
o con cierta cantidad de procesadores, entonces, se pueden usar modelos para identificar
ineficiencias y aspectos en los cuales un algoritmo puede ser mejorado.
Cómputo redundante, tiempos de espera, tiempo de inicio de mensajes, costos de
transferencia de datos, etc.
El perfil de ejecución de un algoritmo indica las contribuciones de estos factores diversos a los
tiempos de ejecución como factores de n y de p .
IV. 7. Estudios Experimentales
Los estudios experimentales se pueden usar para medir el valor de los parámetros de un
modelo (t c , t s , t w ,...) o para validar al modelo.
•
•
•
Diseño Experimental
Obteniendo y validando datos experimentales
Ajuste de datos
IV.7.1 Diseño Experimental
Identificación de datos:
Tiempo de cómputo para un problema unitario,
49
Paralelización
Tiempo de transferencia,
Tiempo de espera,
Promedio de búsqueda en un árbol, etc.
Diseño de experimentos
IV.7.2 Obteniedno y validando datos experimentales
Medición repetitiva de tiempos de ejecución.
Obtención de datos exactos y reproducibles.
Algoritmos no deterministas
Uso de relojes inexactos
Costos de inicio y terminación variables con el resto del sistema
Interferencia con otros programas.
Contención (varias computadoras comunicándose al mismo tiempo)
Asignación aleatoria de recursos.
IV.7.3 Ajuste de Datos
Cuando los estudios experimentales se realizan con el propósito de calibrar parámetros, se
ajustan los resultados observados a la función de interés para obtener los valores de los
parámetros conocidos.
Ajuste por mínimos cuadrados.
Ajuste por mínimos cuadrados escalados.
∑ (obs(i) − f (i) )
obs (i ) − f (i )
∑i obs(i)
2
i
50
2
Paralelización
V. Estudio Comparativo
En esta sección se analiza el rendimiento del programa que calcula el valor de pi por
aproximaciones rectangulares, aplicándole los diferentes modelos de programación paralela
mencionados. Para conocer cual es el modelo recomendable a emplearse en un sistema Cray
Origin 2000 de memoria distribuida - compartida, en base a los criterios de:
•
•
Tiempo de ejecución, y
Facilidad en la programación
De inicio se debe obtener un perfil del programa ejecutado en forma secuencial y después
compararlo con los otros perfiles obtenidos en cada paradigma aplicado, finalmente se debe ir
midiendo el rendimiento del programa conforme se aumenta el número de procesadores, este
proceso es conocido como “aceleración” o “SpeedUp”.
Nota: Un buen perfil del programa, implicó ejecutarlo con 1 millon (10 6 ) de intervalos.
IV.1 Programa Secuencial (pi.c)
/*pi.c : Calcula el valor de pi, usando una aproximación rectangular a la integral de la función f(x) = 4/(1+x*x) */
#define MAXRECT 100000000 /* Número de intervalos */
#include <stdio.h>
void pieza_de_pi(int);
double total_pi = 0.0;
/* variable global */
main(int argc, char *argv[])
{
int nrects = MAXRECT; /* Número de rectangulos*/
pieza_de_pi(nrects);
printf("El valor de pi es = %f \n", total_pi);
}
void pieza_de_pi (int nrects)
{
double ancho; /* ancho del rectangulo de aproximación */
double x;
/* valor de x */
int i;
/* contador */
ancho = 1.0 / nrects;
/* peso de cada iteración */
for ( i = 0; i < nrects; i++ )
{
x = ((i - 0.5) * ancho); /* calcula x */
total_pi = total_pi + (4.0/(1.0 + x*x)); /* suma los valores de f(x) */
}
total_pi = total_pi * ancho; /* integra la curva */
}
Compilación:
%cc -o pi pi.c
Ssusage pone en ejecución un programa ejecutable e imprime los recursos utilizados.
51
Paralelización
Es una instrucción de SpeedShop. Se utiliza exactamente en la misma forma que time, pero
ssusage imprime información adicional. Aquí lo usamos para obtener el tiempo de ejecución
Salida: % ssusage pi y time pi (Observe las diferencias de información reportada)
Comparación al ejecutar el programa pi con las instrucciones ssusage y time
Al emplear diversos modelos de programación paralela, se encontrarán distintos tiempos de
ejecución. En consecuencia podremos determinar cual es el modelo más apropiado en términos
de tiempo y aceleración para esta máquina.
IV.2 Empleando Procesos Unix (SGI_pi.c)
Se anexan las funciones correspondientes de Irix para la generación de procesos ligeros, como
la función sproc().
/* SGI_pi.c: Calcula el valor de pi, usando una aproximación rectangular a la integral de la función f(x) = 4/(1+x*x)
usando llamadas de SGI [sproc()] y una arena. Usando distinta cantidades de procesadores: 1, 2, 4, 6, 8, 10*/
#include <stdio.h>
#include <ulocks.h>
#include <task.h>
#define MAXRECT 100000000 /* Número de intervalos */
#define MAX_PROCS 10;
void pieza_de_pi(void *); /* Prototipo de funcion*/
usptr_t *arena;
barrier_t *barr;
double cada_pi[MAX_PROCS];
int nrects = MAXRECT;
int nprocs;
/* variable global */
/* Número de rectangulos*/
main(int argc, char *argv[])
{
int i;
double total_pi = 0.0;
nprocs = prctl(PR_MAXPPROCS);
arena = usinit("/usr/tmp/theArena");
barr = new_barrier(arena);
for (i=0; i< nprocs -1; i++)
sproc(pieza_de_pi, PR_SALL, (void *)i);
pieza_de_pi((void *)(nprocs - 1));
/* sumando todas las piezas de pi */
for (i = 0; i < nprocs; i = i+1)
total_pi = total_pi + cada_pi[i];
printf("El valor de pi es = %f \n", total_pi);
}
52
Paralelización
void pieza_de_pi (void *arg)
{
double total_pi = 0.0;
double ancho;
/* ancho del rectangulo de aproximación */
double x;
/* valor de x */
int i;
/* contador */
int mi_id = (int) arg, inicio, fin, pedazo;
}
/* Esperar hasta que todos estén listos */
barrier(barr, nprocs);
pedazo = nrects/nprocs;
inicio = mi_id * pedazo;
fin = inicio + pedazo;
if (mi_id == (nprocs - 1)) fin = nrects;
ancho = 1.0 / nrects;
/* peso de cada iteración */
for ( i = inicio; i < fin; i++ )
{
x = ((i - 0.5) * ancho);
/* calcula x */
total_pi = total_pi + (4.0/(1.0 + x*x));
/* suma los valores de f(x) */
}
total_pi = total_pi * ancho; /* integra la curva */
cada_pi[mi_id] = total_pi;
/* espera hasta que todos hayan terminado */
barrier(barr, nprocs);
Compilación: % cc -o SGI_pi SGI_pi.c
Salida (Utilizando distintas cantidades de procesadores):
% ssusage ./SGI_pi
Prueba de SGI_pi sometido a miser con un procesador
53
Paralelización
Prueba de SGI_pi sometido a miser con 2 procesadores
Prueba de SGI_pi sometido a miser con 4 procesadores
Prueba de SGI_pi sometido a miser con 6 procesadores
54
Paralelización
Prueba de SGI_pi sometido a miser con 8 procesadores
Prueba de SGI_pi sometido a miser con 10 procesadores
55
Paralelización
Prueba de SGI_pi sometido a ssusage (arriba) y ejecución del "top" (abajo)
IV.3. Empleando Hilos Posix (POSIX_pi.c)
/* POSIX_pi.c: Calcula el valor de pi, usando una aproximación rectangular a la integral de la función f(x) = 4/(1+x*x)
usando hilos POSIX. Usando distinta cantidades de hilos POSIX : 1, 2, 4, 6, 8, 10 */
#include <pthread.h>
#include <stdio.h>
#include <math.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define MAXRECT 100000000
#define NUMTHREADS 8
/* Numero de intervalos */
/* Numero de hilos */
double total_pi = 0.0;
pthread_mutex_t mi_mutex;
int nrects = MAXRECT; /* Numero de rectangulos*/
void* pieza_de_pi(void*);
main()
{
pthread_t mis_hilos[NUMTHREADS], temp;
int i, retval;
retval = pthread_mutex_init(&mi_mutex, NULL); /* Inicializa un mutex, para la sincronizacion de los hilos */
for ( i = 0; i < NUMTHREADS; i++)
{
retval = pthread_create(&temp, NULL, pieza_de_pi, (void*) i);
mis_hilos[i] = temp;
if (retval !=0 )
{
puts(strerror(retval));
exit(1);
}
56
Paralelización
}
}
for (i = 0; i < NUMTHREADS; i++ )
printf("valor de pi = %f \n", total_pi);
pthread_join(mis_hilos[i],0);
void* pieza_de_pi(void* arg)
{
double mi_pieza = 0.0;
double ancho; /* anchura del rectangulo */
double x;
int i;
int mi_id = (int) arg,inicio,fin,pedazo;
int retval;
pedazo = nrects/NUMTHREADS;
inicio = mi_id * pedazo;
fin = inicio + pedazo;
if (mi_id == (NUMTHREADS-1)) fin = nrects; /*Ult. proceso toma el resto de los intervalos */
ancho = 1.0 / nrects; /* peso de cada iteracion */
for (i=inicio; i<fin; i=i+1 ) {
x = ((i - 0.5) * ancho); /* calcula x */
mi_pieza = mi_pieza + (4.0/(1.0 + x*x)); } /* suma de f(x) */
mi_pieza = mi_pieza * ancho; /* integra la curva */
retval = pthread_mutex_lock(&mi_mutex);
total_pi = total_pi + mi_pieza;
retval = pthread_mutex_unlock(&mi_mutex);
pthread_exit(0);
}
Compilación:
% cc -o POSIX_pi POSIX_pi.c -lpthread
Salida (con varios hilos): % ssusage ./POSIX_pi
IV.4 Comunicación con MPI (MPI_pi.c)
/* MPI_pi.c: Calcula pi, usando una aproximación rectangular a la integral de la funcion f(x) = 4/(1+x*x) usando MPI.*/
#include <stdio.h>
#include "mpi.h"
double pieza_de_pi(int, int, long);
void main(int argc, char ** argv)
{
long intervalos = 100000000;
int miproc, numproc;
double pi, di;
int i;
MPI_Status status;
double t3, t4;
t3 = MPI_Wtime(); /* tiempo de inicio */
57
Paralelización
MPI_Init (&argc, &argv); /* Inicializar MPI */
MPI_Comm_rank(MPI_COMM_WORLD,&miproc); /* Determinar posición de procesos*/
MPI_Comm_size(MPI_COMM_WORLD,&numproc); /* Numero de procesadores */
MPI_Barrier(MPI_COMM_WORLD); /* sincronizar la distribución y cálculos */
if (miproc == 0) /* Si el maestro distribuye los intervalos */
{
for (i = 1; i < numproc; i++)
MPI_Send(&intervalos, 1, MPI_LONG, i, 98, MPI_COMM_WORLD);
}
else /* es un esclavo, recibe la seccion de intervalos */
MPI_Recv(&intervalos, 1, MPI_LONG, 0, 98, MPI_COMM_WORLD, &status);
/* cada proceso ejecuta pieza_de_pi */
pi = pieza_de_pi(miproc, numproc, intervalos);
MPI_Barrier (MPI_COMM_WORLD); /* sección de sincronización */
if (miproc == 0) /* maestro recoge los resultados, suma y los imprime */
{
for ( i = 1; i < numproc; i++)
{
MPI_Recv (&di, 1, MPI_DOUBLE, i, 99, MPI_COMM_WORLD, &status);
pi += di;
}
MPI_Barrier(MPI_COMM_WORLD);
t4 = MPI_Wtime(); /* tiempo final */
printf("Valor de pi: %lf \n",pi);
printf("Tiempo de ejecucion: %.3lf seg\n",t4-t3);
}
else
{ /* el esclavo envia los resultados al maestro */
MPI_Send(&pi, 1, MPI_DOUBLE, 0, 99, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
}
MPI_Finalize ();
}
double pieza_de_pi(int idproc, int nproc, long intervalos)
{
double ancho, x, localsum;
long j;
}
ancho = 1.0 / intervalos; /* peso de la muestra */
localsum = 0.0;
for (j = idproc; j < intervalos; j += nproc)
{
x = (j + 0.5) * ancho;
localsum += 4 / (1 + x * x);
}
return(localsum * ancho);
Compilación:
Salida(con varios hilos):
% cc -o MPI_pi MPI_pi.c -lmpi
% ssusage mpirun -np 8 ./MPI_pi
58
Paralelización
Con 1 solo procesador:
Tiempo consumido (Arriba). Se ejecuta un solo proceso (Abajo con el comando “top”)
Con 2 procesadores:
Tiempo consumido (Arriba). Se ejecutan 2 procesos (Abajo con el comando “top”)
Con 4 procesadores:
Tiempo consumido (Arriba). Se ejecutan 4 procesos (Abajo con el comando “top”)
Con 6 procesadores:
59
Paralelización
Tiempo consumido (Arriba). Se ejecutan 4 procesos (Abajo con el comando “top”)
IV.5 Comunicación con PVM (PVM_Masterpi.c)
¿Qué es PVM (Parallel Virtual Machine)?
Es un paquete de software (conjunto de bibliotecas) para crear y ejecutar aplicaciones
concurrentes o paralelas, basado en el Modelo de paso de mensajes.
Funciona sobre un conjunto heterogéneo de ordenadores con sistema operativo UNIX
conectados por una o mas redes.
Permite:
- Arquitecturas de ordenadores diferentes.
- Redes de varios tipos.
Tiene dos componentes básicos:
A). El proceso daemon (pvmd3)
• Proceso Unix encargado de controlar el funcionamiento de los procesos de usuario
en la aplicación PVM y de coordinar las comunicaciones.
• Un daemon se ejecuta en cada máquina configurada en la máquina virtual paralela.
• Cada daemon mantiene una tabla de configuración e información de los procesos
relativa a su máquina virtual.(/tmp/pvmd.uid).
• Los procesos de usuario se comunican unos con otros a través de los daemons.
• Primero se comunican con el daemon local vía la librería de funciones de interfase.
• Luego el daemon local manda/recibe mensajes de/a daemons de los hots remotos.
• Cada máquina debe tener su propia versión de pvmd3 instalada y construida de
acuerdo con su arquitectura y además accesible con $PVM_ROOT.
B). La librería de rutinas de interface(libpvm3.a, libfpvm3.a & libgpvm3.a)
• libpvm3.a - Librería en lenguaje C de rutinas de interfase: Son simples llamadas a
Funciones que el programador puede incluir en la aplicación paralela.
Proporciona capacidad de:
60
Paralelización
•
•
•
•
- iniciar y terminar procesos.
pack, send, and receive mensajes.
sincronizar mediante barreras.
conocer y dinámicamente cambiar la configuración de la máquina virtual
paralela.
Las rutinas de la librería no se conectan directamente con otros procesos, si no que
mandan y reciben la configuración de la máquina virtual paralela.
libgpvm3.a- Se requiere para usar grupos dinámicos.
libfpvm3.a- Para programas en Fortran
Es un software de dominio Público desarrollado por el Oak Ridge National
Laboratory
¿Por qué usar PVM
Promete cumplir los requerimientos que necesita la computación distribuída del futuro,
permitiéndo escribir programas que utilicen una serie de recursos capaces de operar
independientemente y que son coordinados para obtener un resultado global que depende de
los cálculos realizados en todos ellos.
Reduce el "wall clock execution time"
Fácil instalación y uso. Con una interface de programación simple y completa.
Es un software de dominio público con creciente aceptación y uso.
Flexibilidad:
- Se adapta a diversas arquitecturas.
- Permite combinaciones de redes locales con las de área extendida.
- Cada aplicación "decide" donde y cuando sus componentes son ejecutados y
determina su propio control y dependencia.
- Se pueden programar diferentes componentes en diferentes lenguajes.
- Es fácil la definición y la posterior modificación de la propia Máquina Virtual Paralela.
Permite aprovechar el hardware existente, asignando cada tarea a la arquitectura más
adecuada.
Se puede implementar aplicaciones tolerantes a fallos.
Configuración de PVM
Hay dos formas de iniciar PVM:
A). Con la consola, llamada pvm.
Este programa inicia pvmd3 si no está ya corriendo y puede ser invocado un número
arbitrario de veces en cualquiera de los ordenadores que forman la máquina virtual. Este
programa permite añadir y quitar ordenadores de la máquina virtual, así como el inicio y
terminación de procesos PVM con los comandos:
add: Añade uno o más hosts.
conf:Muestra la configuración de la máquina virtual( hostnames, task ,ID, ....).
halt: Para la ejecución de todos los procesos y sale de PVM.
spawn: Inicia un proceso PVM.
help: Ayuda para los comandos interactivos.
delete: Elimina uno o más hosts.
61
Paralelización
ps: Muestra el estado de la aplicación; con el flag -a , muestra todas las
aplicaciones.
quit: Sale de la consola sin terminar el proceso pvmd3.
kill: Termina el proceso PVM especificado.
B). Mediante pvmd3.
Acepta como argumento opcional un fichero de configuración en el que se describen las
características que PVM necesita conocer de cada sistema que vaya a formar parte de
la máquina virtual. El formato del fichero de configuración, que puede tener cualquier
nombre, son líneas de texto con el nombre del computador y tras él las siguientes
opciones:
lo=userid Permite especificar un login alternativo para este ordenador. Si no se
usa esta opción, se utilizará el login empleado en la máquina donde se inició la
ejecución de PVM.
dx= localización_de_pvmd Permite al usuario especificar para este computador
una ruta distinta de la establecida por defecto para encontrar pvmd3. (Esta ruta
debe incluir el nombre del programa pvmd3).
ep= path_a_los_ ejecutables. Con esta opción se puede indicar una serie de
paths para buscar los ficheros que se requieran ejecutar en este sistema.
Distintos paths están separados por un punto y coma. Si no se especifica ep,
PVM busca las tareas de aplicación en el directorio $HOME/pvm3/bin/ARCH,
siendo ARCH el nombre de la arquitectura considerada.
Las líneas en blanco se ignoran, y aquellas que comiences con # son líneas de
comentarios. Un & antes del nombre de un host indica que no se añadirá inicalmente
pero que se podrá añadir desde consola con las opciones especificadas en el fichero.
NOTA: La consola PVM también admite un hostfile como argumento opcional
Cuando usamos PVM es necesario codificar un programa maestro y otro esclavo.
Programa Maestro:
/* PVM_Masterpi.c : Programa PVM maestro que distribuye los intervalos entre los esclavos y recolecta los
resultados enviados por los esclavos y los suma para obtener el valor de pi. Se hace uso de una cantidad variable de
procesadores: 1, 2, 4, 6, 8, 10*/
#include <stdio.h>
#include "/usr/array/PVM/include/pvm3.h”
#define NPROC 10
/* son 10 procesadores disponibles */
#define NDATOS 1000000
/* numero de intervalos */
void main(int argc, char **argv)
{
int *a;
/* variable que toma los intervalos del 1 al 1000 000 */
double *cada_pi; /* variable que toma el valor calculado de pi de cada tarea*/
int mitid, tid, i, j, tids[NPROC];
int pedazo;
double total_pi = 0.0;
mitid = pvm_mytid();
pedazo = NDATOS/NPROC;
a = (int *)malloc(NDATOS*sizeof(int));
62
Paralelización
cada_pi = (double *)malloc(NPROC*sizeof(double));
if (a == NULL || cada_pi == NULL) {
printf("Error al abrir memoria");
pvm_exit();
exit(0);
}
for ( i = 0; i < NDATOS; i++) /* se llena el arrreglo con valores del 1 a X cantidad.. */
a[i] = i;
/* Se crean N tareas esclavas */
i=pvm_spawn("/usr/inv/orgr/parall",(char**)0,0,"",NPROC,tids);
if(i!= NPROC) {
printf("Error al crear tareas \n");
pvm_exit();
exit(0);
}
/* Se envían los datos a cada proceso esclavo */
for (i=0; i<NPROC; i++)
{
pvm_initsend(PvmDataRaw); /* Enviar sin codificar */
pvm_pkint(&pedazo,1,1); /* Tamaño del intervalo */
pvm_pkint(&a[i*pedazo],pedazo,1); /* Envió del arreglo */
pvm_send(tids[i],tids[i]);
}
/* Recibe los resultados de todos los procesos esclavos */
for ( i = 0; i < NPROC; i++)
{
pvm_recv(-1,1); /* Recibe de quien sea con tag 1 */
pvm_upkint(&tid,1,1); /* Desempaca que proceso lo envia*/
for(j=0; j<NPROC; j++) /* Busca el renglon segun el */
if(tids[j]==tid) /* proceso que lo envia */
break;
/* Desempaca el valor calculado de cada proceso */
pvm_upkdouble(&cada_pi[j],1,1);
}
}
/*Obtiene el valor de pi sumando todos los intervalos calculados */
for(i=0; i<NPROC; i++) total_pi = total_pi + cada_pi[i];
printf("\nEl valor de pi = %lf \n",total_pi);
Programa esclavo:
/* PVM_Esclavopi.c: Programa PVM esclavo que calcula el valor de pi usando aproximaciones rectangulares de la
función * f(x) = 4/(1+x*x) */
#include <stdio.h>
#include "/usr/array/PVM/include/pvm3.h"
#define NDATOS 1000000 /* Numero de intervalos */
main()
{
int *a, inicio, fin;
double total_pi = 0.0;
63
Paralelización
}
double ancho, x;
int i, maestro;
int mitid, datos;
mitid = pvm_mytid(); /* Obtener el ID de esta tarea */
maestro = pvm_parent(); /* Encuentra el id del proceso maestro */
pvm_recv(maestro, mitid); /* Recibe del maestro con tag = mi tid */
pvm_upkint(&datos,1,1); /* Desempaca el Tamanio del arreglo */
a=(int *)malloc(datos*sizeof(int)); /* abre memoria para datos */
if(a == NULL)
{
printf("Error al abrir memoria");
pvm_exit();
exit(0);
}
pvm_upkint(a, datos, 1); /* Desempaca el pedazo de datos en el arreglo a */
inicio = a[0]; /* Numero inicial del intervalo o pedazo */
fin = a[datos-1]; /* Numero final del pedazo */
ancho = 1.0 / NDATOS; /* peso de cada iteracion */
for ( i = inicio; i < fin; i++ )
{
x = ((i - 0.5) * ancho); /* calcula x */
total_pi = total_pi + (4.0/(1.0 + x*x)); /* suma los valores de f(x) */
}
total_pi = total_pi * ancho; /* integra la curva */
/* Envia el resultado al proceso maestro */
pvm_initsend(PvmDataRaw); /* Envio sin codificar */
pvm_pkint(&mitid,1,1); /* Empaca el identificador del esclavo */
pvm_pkdouble(&total_pi,1,1); /* Empaca el resultado */
pvm_send(maestro,1); /* Envia al maestro con tag = 1 */
pvm_exit(); /* Salir de PVM */
Compilación:
Para llevar a cabo una correcta compilación en PVM, son necesarias variables de ambiente.
a) Definir la arquitectura del procesador. % setenv PVM_ARCH SGIMP64
b) Definir la trayectoria de las bibliotecas de PVM. % setenv PVM_ROOT /usr/array/PVM
c) Actualizar la variable PATH.
% setenv PATH ${PATH}:${PVM_ROOT}/lib/$PVM_ARCH
Nota: Para establecer estas variables de ambiente en cada nueva sesión, es recomendable
modificar el archivo:
.cshrc si se utiliza csh o cts., o
el archivo de configuración .login si se usa sh o bash
O bien, Adicionar el siguiente script para la “Configuración del ambiente de PVM”
# Para PVM
if ( ! $?MANPATH ) then
setenv MANPATH /usr/share/catman
endif
setenv PVM_ROOT /usr/array/PVM
setenv PVM_ARCH `$PVM_ROOT/lib/pvmgetarch`
setenv MANPATH $PVM_ROOT/man:$MANPATH
setenv XPVM_ROOT $PVM_ROOT/xpvm
set path=( $PVM_ROOT/lib $PVM_ROOT/lib/$PVM_ARCH
64
Paralelización
$PVM_ROOT/bin/$PVM_ARCH $XPVM_ROOT $path )
if ( ! $?PVM_ROOT ) then
setenv PVM_ROOT /usr/array/PVM
# setenv PVM_ROOT /usr/array/PVM.290999
setenv PVM_ARCH `$PVM_ROOT/lib/pvmgetarch`
# setenv PVM_ARCH SGIMP64
setenv MANPATH $PVM_ROOT/man:$MANPATH
setenv XPVM_ROOT $PVM_ROOT/xpvm
set path=( $PVM_ROOT/lib $PVM_ROOT/lib/$PVM_ARCH
$PVM_ROOT/bin/$PVM_ARCH $XPVM_ROOT $path )
endif
d) Compilar el programa esclavo:
% cc -o PVM_Esclavopi PVM_Esclavopi.c -64 -lpvm3
e) Compilar el programa maestro:
% cc -o PVM_Masterpi PVM_Masterpi.c -64 -lpvm3
f) Activar el demonio de PVM.
% pvmd3 &
Ejecución (con 10 procesos esclavos). Solo ejecutar el maestro:
% PVM_Masterpi
IV.6 Comunicación con SHMEM (shmem_pi.c)
Shmem es un conjunto de rutinas de envío de datos similar a las rutinas de envío de mensajes
de MPI o PVM. Así como las rutinas de envío de mensajes, las rutinas de shmem envían datos
entre procesos paralelos.
Las rutinas de shmem se usan en programas que realizan cálculos en espacios de direcciones
separadas y que explícitamente envían datos a y desde diferentes procesos en el programa.
Dichos procesos son llamados elementos de procesamiento (denotados como PEs).
Shmem minimiza el overhead asociado con los requerimientos de envío de datos, maximiza el
ancho de banda y minimiza la latencia de los datos. Por latencia de los datos debemos entender
el periodo de tiempo que inicia cuando un PE inicia una transferencia de datos y termina cuando
un PE puede usar el dato.
Soporta transferencia remota de datos a través de operaciones put, las cuales transfieren datos
a distintos PEs, y operaciones get, que transfieren datos desde un PE. Algunas otras
operaciones soportadas son: trabajo compartido, difusión y reducción, sincronización de
barreras y operaciones atómicas de memoria. Una operación atómica de memoria es una
operación atómica de lectura y actualización, tal como un fetch e incremento, sobre un dato
local o remoto. El valor leído garantiza ser el valor del dato previo a la actualización.
Rutinas de SHMEM pueden ser usadas junto con rutinas de MPI en el mismo programa. Estos
programas deben llamar MPI_Init y MPI_Finalize pero omitir la llamada a la rutina start_pes,
pues el número de PEs será igual a la cantidad de procesos indicados en MPI.
Compilación de programas en Shmem
Las rutinas de Shmem residen en libsma.so.
Sistemas IRIX:
cc -64 c_program.c -lsma
65
Paralelización
CC -64 cplusplus_program.c -lsma
f90 -64 -LANG:recursive=on fortran_program.f -lsma
f77 -64 -LANG:recursive=on fortran_program.f -lsma
Sistemas IRIX con Fortran 90 version 7.2.1:
f90 -64 -LANG:recursive=on -auto_use shmem_interface fortran_program.f -lsma
Nota: El software Shmem esta empaquetado con el “Message Passing Toolkit”.
Ejemplos:
El siguiente programa en C corre en IRIX:
#include <mpp/shmem.h>
main()
{
}
long source[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
static long target[10];
start_pes(0);
if ( _my_pe() == 0 )
{
/* coloca 10 palabras en el “target” sobre el PE 1 */
shmem_long_put(target, source, 10, 1);
}
shmem_barrier_all(); /* sincroniza emisor y receptor */
if ( _my_pe() == 1 )
shmem_udcflush();
/* necesario en T90 */
printf("target[0] on PE %d is %d\n", _my_pe(), target[0]);
Este programa en C, realiza lo siguiente:
El PE 0 envía 10 enteros al arreglo “target” del PE 1.
Para ejecutar el programa bastará con 2 PEs y usamos la siguiente variable:
env NPES=2 a.out
IV.7 Empleando directivas de PCA (Power_pi.c)
El uso de directivas del compilador de multiprocesamiento ofrece dos formas de emplearlas,
manual o automática. Usando el analizador automático de PCA se genera un archivo *.list que
proporciona la paralelización para cada ciclo, mediante la instrucción:
Compilación:
% cc -o pi -pca list pi.c
El archivo pi.list contiene la información siguiente:
66
Paralelización
Al compilarlo del modo % cc -o pi -pca -mplist pi.c, se generan dos archivos transformados,
nombrados: pi.w2c.c y pi.w2c.h. Cada uno de ellos contiene la información siguiente:
pi.w2c.c
pi.w2c.h
67
Paralelización
/* POWER_pi.c : Calcula el valor de pi, usando una aproximación rectangular a la integral de la funcion f(x) =
4/(1+x*x) */
#include <stdio.h>
#define MAXRECT 100000000
double pieza_de_pi(int);
/* Numero de intervalos */
main(int argc, char *argv[])
{
double pi_valor; int nrects = MAXRECT; /* Numero de rectangulos*/
pi_valor = pieza_de_pi(nrects);
printf("El valor de pi es = %f \n", pi_valor);
}
double pieza_de_pi (int nrects)
{
double ancho; /* ancho del rectangulo de aproximación*/
double x;
/* valor de x */
int i;
/* contador */
double parte_pi, total_pi = 0.0;
ancho = 1.0 / nrects; /* peso de cada iteracion */
parte_pi = 0.0;
#pragma parallel local(i, x, parte_pi) shared(total_pi) byvalue(nrects)
{
#pragma pfor iterate(i=0; nrects; 1)
for ( i = 0; i < nrects; i++ )
{
x = ((i - 0.5) * ancho);
/* calcula x */
parte_pi = parte_pi + (4.0/(1.0 + x*x));
/* suma los valores de f(x) */
}
#pragma critical
68
Paralelización
}
total_pi = total_pi + parte_pi;
}
total_pi = total_pi * ancho;
/* integra la curva */
return(total_pi);
Compilación:
% cc –o Power_pi Power_pi.c -mp
Salida (con varios procesadores) % ssusage ./Power_pi
IV.7 Comparativo de los modelos de programación paralela
Realizamos un comparativo de resultados para el cálculo del valor de pi, para tener una mejor
perspectiva del desempeño del programa con cada paradigma empleado. (Resultados en
segundos). Se utilizó una aproximación rectangular a la integral de la función f(x) = 4/(1+x*x)
con 100000000 intervalos en dicha aproximación.
Usando ./ssusage y se considero el tiempo real, pues según el manual de este comando el
tiempo real corresponde al tiempo de pared del sistema. La información obtenida esta en
segundos.
Estas pruebas se realizaron varias veces para cada uno de los casos mostrados, y se considero
el promedio de cada uno de ellos.
Paradigma /
#Procesadores
1
2
4
6
8
10
Secuencial
Procesos Unix
Hilos POSIX
MPI
PVM
PCA
26.26
38.31
26.24
27.46
20.15
18.11
14.44
8.6
10.10
8.00
5.28
6.88
5.87
5.65
4.70
32.46
19.7
10.69
7.00
7.7
Comportamiento del rendimiento del programa de acuerdo a los paradigmas mostrados:
69
Paralelización
Tabla de SpeedUp para cada paradigma de programación paralela mostrado
SpeedUp /
#Procesadores
Secuencial
Procesos Unix
Hilos POSIX
MPI
PVM
PCA
1
2
4
6
8
10
1
1
1
1
1.9012
1.448
1.902
4.4546
2.5980
3.4325
7.255
3.8139
4.678
4.644
5.5829
1
1.647
3.0364
4.637
4.2155
70
Paralelización
71
Paralelización
Glosario
Algoritmo
Conjunto de sentencias / instrucciones en lenguaje nativo, los cuales expresan la lógica
de un programa.
Algoritmo cualitativo, Son aquellos que resolver un problema no ejecuta operaciones
matemática en el desarrollo de algoritmo.
Algoritmo cuantitativo, Son aquellos algoritmos que ejecutan operaciones numéricas
durante su jecución.
Archivo
Conjunto de datos relacionados entre sí que se tratan como una unidad.
Arena
Archivo de intercambio de memoria propio de SGI, usado para compartir memoria y
herramientas de sincronización entre procesos.
Barrera
Herramienta de sincronización. Todos los procesos esperaran hasta que el ultimo
proceso llegue, y proceder a continuar simultáneamente.
Biblioteca de Programas
Conjunto de programas y rutinas ampliamente usados en diversa aplicaciones y
compactados para su fácil uso.
Buffer
Memoria intermedia, una porción reservada de la memoria, que se utiliza para
almacenar datos mientras son procesados.
C
Lenguaje de programación de alto nivel, de aplicación general que además permite a los
usuarios escribir instrucciones de máquina de bajo nivel que se acercan en densidad y
eficiencia a las que se codifican en lenguaje de máquina.
Cluster
Conjunto de PC's (granja), interconectadas por un dispositivo de red de alta velocidad
para efectuar procesamiento en paralelo.
Código fuente
Programa en su forma original, tal y como fue escrito por el programador, el código
fuente no es ejecutable directamente por el computador, debe convertirse en lenguaje de
maquina mediante compiladores, ensambladores o interpretes.
Compilador
Programa de computadora que produce un programa en lenguaje de maquina, desde un
programa fuente.
Concurrente
Código corriendo en paralelo.
Dependencia de datos
72
Paralelización
Es un constructor en el programa el cual hace que el resultado dependa del orden de
ejecución de un ciclo o hilo, esto se refleja en los índices de los contadores de ciclos.
Directiva
Comentario especial que se inserta en el código fuente, para dar información al
compilador o al analizador y así poder explotar otras características del equipo.
Granularidad
Es el tamaño de la pieza de código que se ejecuta en un procesador y es la unidad de
ejecución de un código paralelo.
Interfaz
Una conexión e interacción entre hardware, software y usuario, es decir como la
plataforma o medio de comunicación entre usuario o programa.
IRIX
Sistema operativo de multiprocesamiento y multiusuario basado en UNIX System V
Release 4 propio de SGI.
Kernel
Núcleo del sistema operativo, encargado de administrar los recursos de la máquina.
Lógica
Es una secuencia de operaciones realizadas por el hardware o por el software.
Lógica del hardware: Circuitos y Chips que realizan las operaciones de control de la
computadora.
Lógica del software o lógica del programa: Secuencia de instrucciones en un programa.
MPI (Message Passing Interface)
Conjunto de rutinas estándares para la comunicación entre procesadores de
multicomputadoras o "clusters" usando el modelo de envío de mensajes, también se le
conoce como Interface de Envío de Mensajes.
Llamada
Transferencia del control de un programa principal, rutina o función a una función o
rutina.
NUMA (Non-Uniform Memory Access)
Diseño de memoria de una computadora, la cual se encuentra distribuida en varios
nodos, cuyos accesos son no uniformes, varían de acuerdo a la ubicación de la memoria
respecto al CPU, por cuántos hubs y/o enrutadores deben pasar los datos. Esta
arquitectura puede tener diferentes topologías de interconexión, por ejemplo Hipercubo
como en el caso del sistema Origin 2000, también se le conoce como sistemas de
Acceso No-Unifome a la Memoria.
POSIX (Portable Operating System Interface)
Conjunto de interfaces estándares del sistema operativo basado en UNIX. Con la
finalidad de lograr la portabilidad del código sobre diversas arquitecturas sin la
necesidad de ser re-codificado.
73
Paralelización
PCA
Producto de SGI que incluye el Analizador de C, el compilador de multiprocesamiento en
C y las rutinas de multiprocesamiento.
Procesamiento Paralelo
Es una forma eficiente de procesar la información con énfasis en la explotación de
eventos concurrentes en el proceso de cómputo. Este concepto implica: paralelismo,
simultaneidad y pipelining.
PVM (Parallel Virtual Machine)
Es un conjunto de bibliotecas que permiten realizar cómputo paralelo en una red de
computadoras de la misma o diferente arquitectura basado en el modelo de envío de
mensajes, también se le conoce como Máquina Virtual Paralela.
Programa
1) Plan para obtener la solución a un problema;
2) Conjunto de instrucciones en secuencia que hacen que la computadora lleve a cabo
determinadas acciones.
Programa Fuente: Programa escrito en algún lenguaje de alto nivel como C, Fortran, etc.
Programa Objeto: Programa completamente compilado o ensamblado que está listo para
cargarse en la computadora.
Solaris
Sistema operativo UNIX basado en el System V Release 4 y del BSD 4.2 de SUN
Corporation.
74
Paralelización
Bibliografia
IRIS Power C User's Guide. SGI.
Parallel Programming Student Handbook. SGI. September 1996.
Parallel Programming for Everyone
http://csdocs.cs.nyu.edu:80/Dienst/UI/2.0/Describe/ncstrl.nyu_cs/TR1999779?abstract=Parallel+Programming
Introduction to Parallel Processing on SGI Shared Memory Computers
http://scv.bu.edu/SCV/Tutorials/SMP/smp.html
Designing and Building Parallel Programs
http://www-unix.mcs.anl.gov/dbpp/text/book.html
SGI TechPubs Library Display (auto_p.z)
http://techpubs.sgi.com/library
Distributed and Parallel Computing
http://www.manning.com/El-Rewini/Intro.html
Parallel Computing CSCI 6356
http://www.cs.panam.edu/~meng/Course/CS6356/Notes/master/master.html
Parallel Programming with the Origin2000: Introduction
http://www-jics.cs.utk.edu/origin2000/labO2K/
75