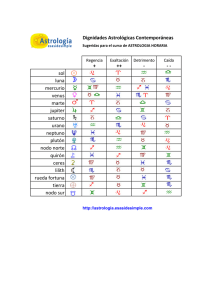
Clementine 9.0 - Facultad de Ciencias Económicas
Anuncio

CLEMENTINE 9.0 Autores: Sandra Milena Gómez Sandoval Oscar Ricardo Castillo Blanco Director Unidad Informática: Henry Martínez Sarmiento Tutor Investigación: Álvaro Enrique Palacios Coordinadores: Leydi Diana Rincón Luis Alfonso Nieto Coordinador Servicios Web: Miguel Ibañez Analista de Infraestructura y Comunicaciones: Adelaida Amaya Analista de Sistemas de Información: Álvaro Enrique Palacios Villamil UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES BOGOTÁ D.C. DICIEMBRE DE 2006 CLEMENTINE 9.0 Director Unidad Informática: Tutor Investigación: Henry Martínez Sarmiento Álvaro Enrique Palacios Auxiliares de Investigación: ANDREA PATRICIA GARZON ANGELA ARAUJO FANDIÑO DIANA CAROLINA ROA PAULA ALEJANDRA RODRÍGUEZ ROBERTO MAURICIO SÁNCHEZ ALEJANDRA TELLEZ LEIDI CAROLINA RINCON JAVIER MAURICIO NIÑO ANGÉLICA RODRÍGUEZ CRISTIAN CAMILO IBAÑEZ DANIEL HERNÁN SANTIAGO CRISTIAN GERARDO GIL JOHN FREDY ARIAS SIDNEY MAGNOLIA CUBIDES SANDRA MILENA GOMEZ NATALIA CUESTAS MONDRAGÓN DIANA KATHERINE SANCHEZ VIVIANA BERNAL LOPEZ DANIEL ERNESTO CABEZAS SANDRA PAOLA RAMIREZ DANIEL QUINTERO JORGE ELIECER ROJAS DIEGO FELIPE CORTES CAMILO ERNESTO LOPEZ ELKIN GIOVANNI CALDERÓN JEISON OSWALDO BERNAL HENRY ALEXANDER RINCON HOOVER QUITIAN REYES SERGIO ALEJANDRO PIÑEROS PAULA CATALINA PARRA BRAYAN RICARDO ROJAS SANDRA LILIANA BARRIOS OSCAR RICARDO CASTILLO ALVARO ESNEYDER RONCANCIO EDSSON DIRCEU RODRIGUEZU Este trabajo es resultado del esfuerzo de todo equipo perteneciente a la Unidad de Informática. el Esta obra esta bajo una licencia de reconocimiento-no comercial 2.5 Colombia de creativecommons. Para ver una copia de esta licencia, visite http://creativecommons.org/licenses/by/2.5/co/ o envié una carta a creative commons, 171second street, suite 30 San Francisco, California 94105, USAPlataformas colaborativas. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES BOGOTÁ D.C. DICIEMBRE DE 2006 CLEMENTINE 9.0 TABLA DE CONTENIDO TABLA DE CONTENIDO ................................................................................................................... 3 INTRODUCCION ................................................................................................................................. 5 OBJETIVO GENERAL ........................................................................................................................... 5 OBJETIVOS ESPECIFICOS ................................................................................................................... 6 RESUMEN ................................................................................................................................................ 7 ABSTRACT .............................................................................................................................................. 8 PARA QUE CLEMENTINE Y QUIEN LO USA .............................................................................. 9 INSTALACION CLEMENTINE 9.0 .................................................................................................... 9 ENTORNO CLEMENTINE ............................................................................................................... 20 COMO INGRESAR A CLEMENTINE ............................................................................................ 22 VENTANAS DE CLEMENTINE ....................................................................................................... 22 1. Lienzo de rutas ....................................................................................................................... 23 2. Paletas ....................................................................................................................................... 23 a) Favoritos .............................................................................................................................. 23 b) Orígenes .............................................................................................................................. 24 c) Gráficos ............................................................................................................................... 24 d) Operaciones con registros .............................................................................................. 25 e) Operaciones con campos ................................................................................................ 26 f) Modelado............................................................................................................................. 26 g) Resultado ............................................................................................................................. 27 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 3 CLEMENTINE 9.0 3. Administradores ..................................................................................................................... 27 4. Proyectos ................................................................................................................................. 28 5. Informe y Estado .................................................................................................................... 28 6. Barras de Herramientas ....................................................................................................... 29 7. Barra De Menús ..................................................................................................................... 31 a) Menú Archivo ..................................................................................................................... 31 b) Edicion.................................................................................................................................. 32 c) Insertar................................................................................................................................. 32 d) Ver ........................................................................................................................................ 33 e) Herramientas ...................................................................................................................... 33 f) Supernodo ........................................................................................................................... 33 g) Ventana ................................................................................................................................ 34 h) Ayuda ................................................................................................................................... 34 USO DE TECLAS DEL TECLADO ABREVIADO ....................................................................... 35 IMPORTACION DE DATOS EN CLEMENTINE ........................................................................ 36 LA MINERIA DE DATOS CON CLEMENTINE .......................................................................... 55 TECNICAS DE MODELADO EN CLEMENTINE ....................................................................... 88 EJERCICIO PRÁCTICO ..................................................................................................................... 97 CONCLUSIONES ............................................................................................................................. 119 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 4 CLEMENTINE 9.0 INTRODUCCION Clementine es un programa de minería de datos de SPSS, este programa permite realizar modelos predictivos para ayudar a la toma de decisiones de las empresas. Utiliza técnicas analíticas que ayudan a conseguir resultados medibles y tangibles, aportando una comprensión más clara de los datos. Lo que se busca con la implementación de este software es utilizar los datos que manejan las empresas como consecuencia de sus operaciones y combinarlos con los conocimientos empresariales, en este caso se quiere aprovechar los datos de la UIFCE para descubrir nuevas maneras de enfocar los problemas e identificar nuevas o mejores oportunidades para optimizar los servicios ofrecidos por la Unidad. Su aplicación en la facultad se puede dar para las tres carreras puesto que en todas manejamos diferentes volúmenes de datos con diferentes variables que nos podrían dar mayor flujo de información como herramientas de análisis. OBJETIVO GENERAL UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 5 CLEMENTINE 9.0 Descubrir las principales ventajas y aplicaciones que Clementine brinda para implementarlo en la facultad. Clementine es un programa de minería de datos de SPSS, este programa permite realizar modelos predictivos para ayudar a la toma de decisiones de las empresas. Utiliza técnicas analíticas que ayudan a conseguir resultados medibles y tangibles, aportando una comprensión más clara de los datos. Lo que se busca con la implementación de este software es utilizar los datos que manejan las empresas como consecuencia de sus operaciones y combinarlos con los conocimientos empresariales, en este caso se quiere aprovechar los datos de la UIFCE para descubrir nuevas maneras de enfocar los problemas e identificar nuevas o mejores oportunidades para optimizar los servicios ofrecidos por la Unidad. Dentro de las cualidades más importantes del programa se pueden resaltar la ejecutabilidad de procesos para descubrir patrones y tendencias ocultas en grandes conjuntos de datos con el fin de proporcionarnos el conocimiento necesario para la toma correcta de decisiones. Su aplicación en la facultad se puede dar para las tres carreras puesto que en todas manejamos diferentes volúmenes de datos con diferentes variables que nos podrían dar mayor flujo de información como herramientas de análisis. OBJETIVOS ESPECIFICOS Analizar el software para encontrar ventajas y aplicaciones Evaluar la aplicabilidad que tiene a las distintas materias que se dictan en la facultad. Los campos de desarrollo en las carreras serian los siguientes: Administración de Empresas: En donde más se podría dar el desarrollo del programa, puesto que se puede utilizar en diferentes áreas de conocimiento UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 6 CLEMENTINE 9.0 de la carrera, se pueden procesar datos para inducir a nuevas o mejoras en la utilización de los recursos para las actividades económicas, orientadas siempre a crear una mejor estructura para la producción, transformación, circulación, administración o custodia de bienes o para la prestación de servicios. Contaduría Publica: Se puede llevar un registro con mejor información de los procesos contables y de La información financiera, además de que se podrían comparar la información de la empresas frente a su sector industrial, o en bases de datos en la cámara de comercio, la DIAN o el DANE Economía: La medición de datos se hace para saber los comportamientos de los agentes en el mercado, su influencia en la economía y la relación que puede existir entre sí, ya sea a nivel micro y/o macroeconómico, modelos econométricos, entre otros. Realizar un ejercicio de análisis de datos, tomando como base los datos que nos ofrece el WebSiui, ya sea en cuanto a turnos de usuarios, cursos libres, etc. Determinar la pertinencia de adquirirlo para que sea utilizado como una herramienta en algunas asignaturas ofrecidas por la facultad de ciencias económicas y para ajustarlo a un curso libre. RESUMEN Este manual contiene las principales características de Clementine. Como aplicación de minería de datos, Clementine ofrece un método estratégico para encontrar relaciones útiles entre grandes conjuntos de datos. Al contrario que los métodos estadísticos más tradicionales, no es necesario saber lo que se está buscando al comenzar. Puede explorar los datos, mediante el ajuste de diferentes modelos y la investigación de diferentes relaciones, hasta que encuentre la información que resulte útil. Clementine ofrece plantillas para muchas de estas aplicaciones de minería de datos. Las plantillas de aplicaciones de Clementine, también denominadas CAT, están disponibles para los siguientes tipos de actividades: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 7 CLEMENTINE 9.0 Minería Web Detección de fraude CRM analítico CRM analítico de telecomunicaciones Análisis de micromatriz Detección y prevención de delitos Clementine es un conjunto de técnicas avanzadas para la extracción de información escondida en grandes bases de datos. Esta precisamente es la finalidad de la minería de datos, ya que las bases de datos actuales han acumulado una gran variedad y cantidad de datos, estadísticas, índices, etc. en los cuales la información útil no es fácil de encontrar o inferir a simple vista. ABSTRACT This manual contains Clementine's principal characteristics. As application of data mining, Clementine offers a strategic method to find useful relations between(among) big sets of information. Unlike the most traditional statistical methods, it is not necessary to know what is looked on having begun. It(he,she) can explore the information, by means of the adjustment of different models and the investigation(research) of different relations, until he(she) finds the information that turns out to be useful. Clementine offers insoles(staff) for many of these applications of data mining. The insoles(staff) of Clementine's applications, also named CAT, are available for the following types of activities: · Mining industry Web · Detection of fraud · analytical CRM · analytical CRM of telecommunications · Analysis of microcounterfoil · Detection and prevention of crimes Clementine is a set of technologies(skills) advanced for the extraction of information hidden in big databases. This one precisely is the purpose of the data mining, since the current databases have accumulated a great variety and quantity of information, statistics, indexes, etc. In which the useful information is not easy to find or infer to simple sight. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 8 CLEMENTINE 9.0 PARA QUE CLEMENTINE Y QUIEN LO USA Este programa busca convertir los datos sin procesar que maneja una empresa en información estratégica para la compañía. Al evaluar correctamente los datos y cuantificarlos se puede establecer patrones y tendencias dándole un mejor uso a la información sin procesar. La información de los datos es tomada como punto de referencia para mejorar el desempeño de corto y largo plazo de una empresa, al identificar patrones dentro de la organización se puede dar mejor uso a la información y de esta manera optimizar los procesos. Dentro de las técnicas analíticas que le permiten transformar datos sin procesar en herramientas para la toma de decisiones encontramos la correlación entre variables, las reglas de asociación (a priori), la segmentación, los patrones secuenciales. INSTALACION CLEMENTINE 9.0 Al insertar el respectivo CD de instalación de Clementine 9.0 nos encontramos con la siguiente ventana: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 9 CLEMENTINE 9.0 En donde escogemos la opción Instalar Clementine 9.0 y nos lleva a la siguiente ventana: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 10 CLEMENTINE 9.0 Seleccionamos Licencia personal, y aceptamos los términos del contrato: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 11 CLEMENTINE 9.0 Damos clic en siguiente y nos aparece el siguiente cuadro de dialogo: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 12 CLEMENTINE 9.0 Al dar clic en siguiente nos pregunta la ubicación en la cual queremos que queden almacenados los archivos del programa, escogemos la ubicación y damos clic en Siguiente: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 13 CLEMENTINE 9.0 Al dar clic en siguiente nos pregunta en que idioma queremos que aparezca la documentación del programa, seleccionamos español y damos clic en siguiente: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 14 CLEMENTINE 9.0 Antes de la instalacion nos aparece la siguiente ventana: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 15 CLEMENTINE 9.0 Damos clic en Instalar y comienza la instalación del programa en nuestro equipo, así : UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 16 CLEMENTINE 9.0 Una vez terminado este proceso aparecerá: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 17 CLEMENTINE 9.0 Una vez aparezca esta ventana damos clic en finalizar y hemos terminado el respectivo proceso de instalacion. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 18 CLEMENTINE 9.0 Para ingresar al programa vamos al menú Inicio – Todos los programas – Clementine Y ya ingresamos a nuestro programa para comenzar a trabajar. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 19 CLEMENTINE 9.0 ENTORNO CLEMENTINE Dentro de las cualidades más importantes del programa se pueden resaltar la ejecutabilidad de procesos para descubrir patrones y tendencias ocultas en grandes conjuntos de datos con el fin de proporcionarnos el conocimiento necesario para la toma correcta de decisiones. El entorno Clementine está basado en nodos que se van disponiendo y conectando para formar una ruta, estas rutas se pueden organizar en proyectos que se pueden abrir y modificar. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 20 CLEMENTINE 9.0 Una ruta es la ejecución de algunos nodos que se encuentran interconectados. Los enlaces entre nodos que se observan en la grafica indican la dirección del flujo de los datos, las series de nodos representan las operaciones que van a realizarse con los mismos. Para crear una ruta lo primero que se debe hacer es añadir los nodos a utilizar en el lienzo de rutas, conectar los nodos para formar una ruta, especificar cualquier opción del nodo o de la ruta y por ultimo ejecutar la ruta. Podemos decir entonces que para trabajar con Clementine hay que seguir tres pasos, primero leer los datos en Clementine, segundo realizar una serie de manipulaciones con ellos y el tercero, enviar los datos a un destino o salida. Precisamente esta secuencia que siguen los datos es a lo que se le denomina Ruta de datos y cada operación que se realiza con los datos se representa con un nodo. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 21 CLEMENTINE 9.0 COMO INGRESAR A CLEMENTINE Para ingresar al programa Clementine vamos al menú Inicio – Programas – Clementine. Otra forma de ingresar al programa es dando doble clic en el icono de acceso directo que aparece en el escritorio. VENTANAS DE CLEMENTINE UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 22 CLEMENTINE 9.0 La ventana de Clementine consta de varias partes: 1. Lienzo de rutas El lienzo de ruta es el área de trabajo de Clementine, donde se generan los nodos y rutas de datos. 2. Paletas En la parte inferior de la ventana de Clementine encontramos las Paletas. Cada una de estas paletas contiene un grupo de nodos. Las paletas disponibles en el programa son: a) Favoritos UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 23 CLEMENTINE 9.0 En esta paleta de favoritos se encuentran los nodos que son mas utilizados por los usuarios. Base de datos: Esta opción nos permite obtener datos a través de una base de datos ODBC. Archivo Var: Permite importar datos que tienen un tamaño de caracteres variable por registro. Seleccionar: Permite seleccionar filas imponiéndoles condiciones de inclusión o exclusión. b) Orígenes En la paleta orígenes se encuentran los nodos utilizados para introducir los datos a Clementine, estos nodos son: Base de datos: Esta opción nos permite obtener datos a través de una base de datos ODBC. Archivo Var: Permite importar datos que tienen un tamaño de caracteres variable por registro. Archivo Fijo: Este nodo nos permite importar datos que tienen un tamaño fijo de caracteres por campo. Archivo SPSS: Permite importar datos desde un archivo SPSS. Archivo SAS: Este nodo permite la importación de datos desde un archivo SAS. Datos Usuario: Este nodo permite acceder los datos manualmente. Se usa en casos en los cuales no se tenga un archivo de datos ya creado. c) Gráficos UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 24 CLEMENTINE 9.0 Esta paleta contiene los nodos relacionados con la creación de gráficos en Clementine, estos son: Grafico: Representa las relaciones entre variables. Histograma: Permite representar un histograma de la distribución de los datos numéricos. Distribución: Representa un histograma de la distribución de los datos no numéricos. Malla: Este nodo nos permite apreciar las asociaciones entre los campos y hacia que dirección se dirigen. Graficas Múltiples: Este nodo permite definir varios campos Y respecto a unos campos X. Es decir variables endógenas y exógenas. Evaluación: Permite realizar la evaluación de los posibles comportamientos del modelo. d) Operaciones con registros Esta paleta llamada operaciones con registros contiene los siguientes módulos: Seleccionar: Permite seleccionar filas imponiéndoles condiciones de inclusión o exclusión. Muestrear: Permite realizar una muestra de los datos, ya sea aleatoreamente o tomándolos salteados. Equilibrar: El nodo equilibrar permite realizar una especie de sobre muestreo, para aumentar o disminuir la proporción de registros. Agregar: El nodo agregar permite usar algunas funciones de agregación a los datos, por ejemplo sumar, contar, etc. Ordenar: Este nodo permite ordenar los registros de una tabla. Fundir: Este nodo permite combinar dos tablas, o si se prefiere crear una tabla nueva seleccionando un conjunto de campos a unir en una sola tabla. Añadir: El nodo añadir permite realizar la unión de dos o mas fuentes de datos. Distinguir: Este nodo verifica que los registros no estén repetidos y si encuentra repeticiones las elimina. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 25 CLEMENTINE 9.0 e) Operaciones con campos En la paleta operaciones con campos se encuentran los siguientes nodos: Tipo: El nodo tipo permite asignar el tipo a los campos. Filtro: El nodo filtro permite identificar algunos grupos de datos Derivar: Este nodo permite derivar nuevos campos a partir de la combinación de otros. Rellenar: Permite rellenar o sustituir campos faltantes siguiendo determinados parámetros. Marcas: El nodo marcas permite generar nuevos campos de un valor discreto a nuevos campos boléanos. Histórico: El nodo histórico permite generar campos acumulados, parciales, en general campos con memoria. f) Modelado En la paleta modelado podemos encontrar los siguientes módulos: Red Neural: El nodo red neural permite clasificar e interpolar datos. C.S.G: El nodo C.S.G permite realizar árboles de decisión. Árbol C & R: Este nodo permite realizar regresión y clasificación en árboles. Quest: El nodo Quest es un nodo que permite realizar un analisis mas afondo de lo que lo permite el Arbol C & R. Chaid: El nodo Chaid es un nodo basado en la chi-cuadrado, es muy similar al nodo C & R. Kohonen: El nodo Kohonen es un algoritmo, que agrupa los datos y distribuye las caracterisiticas de una forma gradual. Regresión: El nodo regresión arroja la regresión lineal de los datos introducidos. Secuencia: Este nodo permite realizar reglas de asociación secuenciales. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 26 CLEMENTINE 9.0 g) Resultado En la paleta resultados se encuentran los siguientes módulos: Tabla: Este nodo es muy útil en clementine ya que permite visualizar los datos de una ruta en forma de tabla. Matriz: El nodo matriz genera una matriz de ocurrencias para los valores de dos campos. Analisis: Este nodo permite analizar la valides de los datos. Auditar datos: Este nodo se utiliza para generar estadísticos y gráficos, generalmente en la fase inicial de exploración de los datos para dar una mirada general al comportamiento de los datos. Estadísticos: Genera los principales estadísticos de los atributos de los datos. Calidad: Este nodo nos permite generar un informe de los datos faltantes por cada campo. Informes: El nodo informes genera informes combinando los diferentes resultados de una ruta. Bases de datos: El nodo bases de datos permite exportar datos con el ODBC. Archivo plano: Este nodo permite exportar datos a un archivo plano. 3. Administradores UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 27 CLEMENTINE 9.0 Estas fichas de administradores se utilizan para mostrar y administrar los diferentes tipos de objetos correspondientes. En la ficha rutas se almacenan las diferentes rutas con las que se este trabajando. En la ficha Resultados estarán los resultados obtenidos durante los procesos ejecutados y por ultimo en la ficha Modelos se encontraran los distintos modelos elaborados. 4. Proyectos En esta ventana se encuentra información útil para organizar el proceso de minería de datos en Clementine. 5. Informe y Estado Estas ventanas muestran algunos comentarios sobre el progreso de las distintas UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 28 CLEMENTINE 9.0 operaciones que esta ejecutando el programa e indican cuando son necesarios los comentarios del usuario. 6. Barras de Herramientas Crear una nueva ruta Guardar la ruta actual Abrir plantillas de aplicaciones Copiar la selección al portapapeles Abrir una ruta existente Imprimir una ruta actual Cortar y mover una selección al portapapeles Pegar el contenido del portapapeles en la selección UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 29 CLEMENTINE 9.0 Deshacer la última acción Editar las propiedades de la ruta Ejecutar selección Añadir supernodo Alejar supernodo Rehacer la última acción Ejecutar la ruta actual Detener la ejecución de la ruta actual Acercar supernodo UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 30 CLEMENTINE 9.0 7. Barra De Menús a) Menú Archivo El menú archivo contiene las siguientes opciones: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 31 CLEMENTINE 9.0 b) Edicion c) Insertar UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 32 CLEMENTINE 9.0 d) Ver e) Herramientas f) Supernodo UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 33 CLEMENTINE 9.0 g) Ventana h) Ayuda UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 34 CLEMENTINE 9.0 USO DE TECLAS DEL TECLADO ABREVIADO UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 35 CLEMENTINE 9.0 IMPORTACION DE DATOS EN CLEMENTINE Para comenzar a trabajar con Clementine es necesario ingresar los datos con los cuales vamos a trabajar. Clementine cuenta con un sistema que le permite importar datos de distintas bases de datos (mediante el ODBC) o de archivos. Las clases de archivos que nos permite importar Clementine son: 1. Bases de datos Para importar una base de datos vamos al menú insertar – orígenes – bases de datos. También podemos ir a la paleta orígenes y damos clic en bases de datos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 36 CLEMENTINE 9.0 Nos aparece el siguiente grafico: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 37 CLEMENTINE 9.0 Damos doble clic sobre el cuadro que aparece en la ventana Bases de datos, y obtenemos este cuadro de dialogo: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 38 CLEMENTINE 9.0 Desplegamos la pestaña de origen de datos Aparece este nuevo cuadro de dialogo en donde seleccionamos el origen de los datos, luego le decimos conectar y por ultimo aceptar. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 39 CLEMENTINE 9.0 Volvemos al primer cuadro de dialogo en donde vamos a la opción seleccionar y aparece: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 40 CLEMENTINE 9.0 Aquí seleccionamos la tabla a utilizar y le damos clic en aceptar, retornamos de nuevo al primer cuadro de dialogo donde podemos observar las pestañas Datos, Filtro, Tipos y Anotaciones: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 41 CLEMENTINE 9.0 Por ultimo damos clic en aplicar y luego en aceptar. Y así hemos concluido la importación de nuestra base de datos. Para visualizar los datos que acabamos de importar, vamos a el menú insertar – resultado – tabla: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 42 CLEMENTINE 9.0 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 43 CLEMENTINE 9.0 Cuando aparece el grafico de tabla en nuestra ventana de trabajo, vamos al grafico región (que es el titulo de nuestra base de datos) y utilizamos el botón central de Mouse para hacer clic sostenido sobre ella y así lo arrastramos hacia el grafico tabla. Si lo realizamos correctamente nos aparece una flecha que comunica los dos gráficos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 44 CLEMENTINE 9.0 Por ultimo vamos hacemos clic sobre el icono Ejecutar de la barra de herramientas y nos aparece la tabla de datos que importamos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 45 CLEMENTINE 9.0 2. Archivo SPSS Para importar una base de datos vamos al menú insertar – orígenes – Archivo SPSS. También podemos ir a la paleta orígenes y damos clic en Archivo SPSS. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 46 CLEMENTINE 9.0 Hacemos doble clic sobre el grafico Archivo SPSS y nos aparece el siguiente cuadro de dialogo: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 47 CLEMENTINE 9.0 Damos clic en la opción importar archivo y seleccionamos la ubicación del archivo de SPSS que vamos a importar: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 48 CLEMENTINE 9.0 Volvemos al primer cuadro de dialogo, y observamos el contenido de las pestañas filtro, tipos y anotaciones: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 49 CLEMENTINE 9.0 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 50 CLEMENTINE 9.0 Damos clic entonces en aplicar, y luego en aceptar. Ahora para visualizar los datos en forma de tabla, vamos al menú Insertar – Resultado – Tabla: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 51 CLEMENTINE 9.0 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 52 CLEMENTINE 9.0 Cuando aparece el grafico de tabla en nuestra ventana de trabajo, vamos al grafico región (que es el titulo de nuestro archivo de SPSS) y utilizamos el botón central de Mouse para hacer clic sostenido sobre ella y así lo arrastramos hacia el grafico tabla. Si lo realizamos correctamente nos aparece una flecha que comunica los dos gráficos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 53 CLEMENTINE 9.0 Por ultimo vamos hacemos clic sobre el icono Ejecutar de la barra de herramientas y nos aparece la tabla de datos que importamos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 54 CLEMENTINE 9.0 LA MINERIA DE DATOS CON CLEMENTINE Data Mining es el proceso para descubrir patrones y tendencias ocultas en grandes conjuntos de datos con el fin de proporcionarnos el conocimiento necesario para la toma de decisiones en la organización. La transformación de una organización mediante la información es un proceso, y cada paso del mismo proporciona mayor valor a la toma de decisiones. A medida que se han ido implantando las distintas fases del proceso de Business Intelligence las empresas se han dado cuenta que los sistemas ERP mejoran la eficiencia de las operaciones pero no proporcionan información estratégica para el crecimiento de la empresa. Los Data Warehouse almacenan datos pero carecen de las herramientas para analizarlos. Reporting y los productos OLAP responden a cuestiones del tipo ¿Qué?, como por ejemplo, qué región vende más, qué clientes son los más rentables, etc. Mientras que las técnicas de Data Mining responden a cuestiones estratégicas como ¿por qué las ventas están bajando?, ¿por qué los clientes se van a otras compañías?, es decir, nos proporcionan UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 55 CLEMENTINE 9.0 información, conocimiento valioso con el que poder diseñar nuestra política de ventas, marketing, etc. Entre las técnicas más utilizadas en el proceso de Data Mining podemos destacar las técnicas exploratorias de análisis gráfico, árboles de decisión y redes neuronales. Como complemento a las técnicas de Data Mining antes comentadas, SPSS también proporciona otras técnicas llamadas confirmatorias como Regresión, Modelos ARIMA, ANOVA, etc., las cuales entran dentro de la categoría de Análisis de datos y están incluidas en módulos como SPSS Base, Modelos de Regresión, Modelos Avanzados, Tendencias, etc1 Como aplicación de minería de datos, Clementine ofrece un método estratégico para encontrar relaciones útiles entre grandes conjuntos de datos. Al contrario que los métodos estadísticos más tradicionales, no es necesario saber lo que se está buscando al comenzar. Puede explorar los datos, mediante el ajuste de diferentes modelos y la investigación de diferentes relaciones, hasta que encuentre la información que resulte útil. Clementine ofrece plantillas para muchas de estas aplicaciones de minería de datos. Las plantillas de aplicaciones de Clementine, también denominadas CAT, están disponibles para los siguientes tipos de actividades: Minería Web Detección de fraude CRM analítico CRM analítico de telecomunicaciones Análisis de micromatriz Detección y prevención de delitos Clementine es un conjunto de técnicas avanzadas para la extracción de información escondida en grandes bases de datos. Esta precisamente es la finalidad de la minería de datos, ya que las bases de datos actuales han acumulado una gran variedad y cantidad de datos, estadísticas, índices, etc. en 1 http://www.spss.com/la/soluciones/data-mining2.htm UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 56 CLEMENTINE 9.0 los cuales la información útil no es fácil de encontrar o inferir a simple vista. La Minería de Datos en Clementine es una combinación de procesos como: Visualización, que permite obtener una visión general de los datos. Puede crear gráficos para explorar las relaciones entre los campos del conjunto de datos y generar hipótesis para explorarlas durante el modelado. Manipulación, que permite limpiar y preparar los datos para el modelado. Puede ordenar datos o añadirlos, filtrar campos, descartar valores que falten o sustituirlos, y derivar nuevos campos. Modelado, que ofrece la visión más amplia de las relaciones entre campos de datos. Los modelos realizan una serie de tareas, como pronosticar resultados, detectar secuencias y agrupar similitudes. Estos ayudan al crecimiento de la organización, simplifican procesos, detectan fraudes y retiene a los clientes más valiosos. Para comenzar a observar las bondades que nos brinda clementine, vamos a trabajar con el archivo DATOS de Excel. Para comenzar hagamos la respectiva importación de los datos a clementine, así como lo explicamos anteriormente. Este archivo contiene los siguientes campos: Id turno: Este campo contiene un número consecutivo de los turnos que se asignan en las salas Id persona: Documento de Identificación del usuario, puede ser tarjeta de Identidad o Cedula de Ciudadanía. Fecha: Corresponde a la fecha en que fue asignado el turno Hora: Corresponde a la hora en la que se pide el turno de sala. Duración: El tiempo en que el usuario utilizo el servicio de la sala. Id salón : Sala de la Unidad en la cual fue asignado el turno UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 57 CLEMENTINE 9.0 Id equipo: Computador en el cual el usuario utiliza el servicio en la sala Estado: Esta categorizado de la siguiente manera: 1. Programado 2. Entrado 3. Salido 4. Cancelado H_entrada: Hora en la que el usuario hace efectiva su reservación de equipo H_salida: Hora en la que termina de utilizar el servicio el usuario Cancelación: si una reserva se cancela antes de que comience la hora solicitada Tmod: Es la fecha y hora de creación del registro. 1. Nodo seleccionar Este nodo selecciona registros del nodo actual. Este nos permite seleccionar filas imponiéndoles condiciones de inclusión o exclusión. Por ejemplo: Vamos a la paleta de Operaciones con registros y buscamos el nodo seleccionar, lo conectamos con la base de datos y lo conectamos de una vez con un nodo tabla. Ahora resulta que nosotros necesitamos únicamente la información de sala 3, entonces, damos clic en el nodo seleccionar y damos clic en el generador de expresiones. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 58 CLEMENTINE 9.0 Estando en el generador de expresiones seleccionamos el campo idsalon y escribimos que queremos que sea igual a ‘SALA3’. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 59 CLEMENTINE 9.0 Damos clic en comprobar para verificar que la expresión introducida no contenga errores y luego damos clic en aceptar. El resultado nos arroja la siguiente tabla, en donde están consignados los turnos que fueron asignados en sala 3. 2. Nodo tipo El nodo tipo permite asignar el tipo a los campos. El tipo de datos se usa para describir características de los datos en un campo determinado. Si se conocen todos los detalles de un campo, éste se denomina completamente instanciado. El tipo de un campo difiere del almacenamiento de un campo, lo cual indica si los datos están almacenados como cadenas, números enteros, números reales, fechas, horas o marcas de tiempo. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 60 CLEMENTINE 9.0 Clementine maneja los siguientes tipos de datos: Rango. Se usa para describir valores numéricos, como el rango de 0 a 100 o de 0,75 a 1,25. Los números de los rangos pueden ser un número entero, un número real o la fecha/hora. Discreto. Se utiliza en el caso de los valores de cadena, cuando se desconoce un número exacto de valores distintos. Se trata de un tipo de datos sin instanciar, lo que significa que toda la información posible acerca del almacenamiento y utilización de los datos aún no se conoce. Una vez leídos los datos, el tipo será una marca o un conjunto, o no tendrá tipo, dependiendo del tamaño del conjunto máximo especificado en el cuadro de diálogo de propiedades de la ruta. Marca. Se usa para datos con dos valores distintos, como Sí y No o 1 y 2. Los números pueden representarse como texto, número entero, número real o fecha/hora. Nota: la fecha/hora hace referencia a tres tipos de almacenamiento: hora, fecha o marca de tiempo. Conjunto. Se usa para describir datos con varios valores distintos, cada uno tratado como un miembro de un conjun a de). En esta versión de Clementine los conjuntos pueden tener cualquier almacenamiento: numérico, de cadena o de fecha/hora. Tenga en cuenta que, al definir un tipo en Conjunto, no se cambian automáticamente los valores a valores de cadena. Conjunto ordenado. Se usa para describir datos con múltiples valores distintos que tienen un orden inherente. Por ejemplo, las categorías salariales o los rangos de satisfacción pueden escribirse como un conjunto ordenado. El orden de un conjunto ordenado en Clementine viene definido por el orden de clasificación natural o por sus elementos. Por ejemplo, 1, 3, 5 es el orden de clasificación por defecto de un conjunto de números enteros, mientras que ALTO, BAJO, NORMAL (orden alfabético ascendente) es el orden de un conjunto de cadenas. El tipo de conjunto ordenado permite definir un conjunto de datos categóricos como datos ordinales para la visualización, generación de modelos (C5.0, Árbol C&R, Bietápico), y la exportación a otras aplicaciones como SPSS, que reconoce los datos ordinales como un tipo distinto. Puede utilizar un campo de conjunto ordenado en cualquier lugar donde se pueda utilizar un campo de este tipo. Además, los campos de cualquier tipo de almacenamiento (real, entero, cadena, fecha, hora, etc.) pueden definirse como un conjunto ordenado. Nota: al trabajar con datos de SPSS, las variables definidas como ordinales en la versión 8.0 o posterior de SPSS se escribirán como un conjunto ordenado en UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 61 CLEMENTINE 9.0 Clementine. De igual manera, al exportar datos a SPSS, los conjuntos ordenados se volverán a escribir como ordinales en el archivo .sav exportado. Sin tipo. Se usa en el caso de los datos que no se ajustan a ninguno de los tipos anteriores o con los tipos de conjuntos con demasiados miembros. Resulta útil con los casos en los que, de lo contrario, el tipo sería un conjunto con demasiados miembros (como un número de cuenta). Cuando se selecciona Sin tipo para un campo, el papel se define directamente en Ninguno. El tamaño máximo por defecto de los conjuntos es de 250 valores únicos. Este número puede ajustarse o desactivarse en el cuadro de diálogo de propiedades de la ruta. Para nuestro ejercicio, ingresemos un nodo tipo a nuestro lienzo de rutas, de la siguiente forma: Ahora demos doble clic en el nodo tipo y asegurémonos por favor que los campos que contiene la tabla tengan el siguiente el tipo de dato al que corresponde, de la siguiente manera: Id turno: Rango Id persona: Rango Fecha: Rango Hora: Rango Duración: Rango Id salón: Conjunto Id equipo: Conjunto Estado: Rango H_entrada: Marcas UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 62 CLEMENTINE 9.0 H_salida: Marcas Cancelación: Marcas Tmod: Rango Ahora decimos aplicar y aceptar. 3. Nodo tabla UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 63 CLEMENTINE 9.0 El nodo Tabla permite crear una tabla a partir de los datos, que se puede mostrar en la pantalla o escribir en un archivo. Esto es útil en cualquier momento en que necesite inspeccionar sus valores de datos o exportarlos en un formato fácilmente legible. El nodo tabla nos permite apreciar en forma de tabla los resultados que nos ofrece clementine. Con este nodo ya estamos mas familiarizados ya que en los dos anteriores ejemplos lo hemos utilizado. El nodo tabla se encuentra en la paleta de resultados. Conectemos a nuestros nodos base de datos y tipo el nodo tabla, de esta forma: Luego vamos al menú herramientas – ejecutar. utilizando el botón O si no lo podemos hacer . UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 64 CLEMENTINE 9.0 El resultado es el siguiente: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 65 CLEMENTINE 9.0 4. Nodo ordenar Los nodos Ordenar se pueden usar para organizar registros en orden ascendente o descendente atendiendo a los valores de uno o varios campos. Por ejemplo, los nodos Ordenar se usan con frecuencia para ver y seleccionar registros con los valores de datos más comunes. Generalmente, primero se añaden los datos usando el nodo Agregar y, a continuación se usa el nodo Ordenar para organizar los datos añadidos en el orden descendente del recuento de registros. Si se muestran estos resultados en una tabla, se facilita la exploración de los datos y la toma de decisiones, como la selección de registros de los 10 mejores clientes. Ordenar por. Todos los campos seleccionados como claves de ordenación se muestran en una tabla. Un campo clave funciona mejor en la ordenación si es numérico. Para añadir campos a esta lista, utilice el botón de selección de campos de la parte derecha. Seleccione un orden pulsando en las flechas Ascendente o Descendente de la columna Orden de la tabla. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 66 CLEMENTINE 9.0 Elimine campos usando el botón de eliminación rojo. Ordene directivas usando los botones de flecha arriba y abajo. Orden de clasificación por defecto. Seleccione Ascendente o Descendente para determinar el orden de clasificación por defecto cuando se añadan nuevos campos a la tabla. Ingresemos un nodo ordenar a nuestra ruta, de la siguiente manera: Demos doble clic sobre dicho nodo y aparece la siguiente ventana: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 67 CLEMENTINE 9.0 Demos clic en el botón Seleccionar del conjunto de campos disponibles y seleccionamos el campo fecha de la siguiente forma: Por ultimo damos clic en aceptar y el resultado lo podemos ver al generar la ruta, en la tabla ya nos muestran los datos organizados por fecha: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 68 CLEMENTINE 9.0 5. Nodo filtro Los nodos Filtro tienen tres funciones: Filtrar o descartar campos de registros que pasan por ellos. Por ejemplo, como investigador médico, es posible que no esté interesado en el nivel de potasio (datos de nivel de campo) de los pacientes (datos de nivel de registro); por ello, puede filtrar el campo K (potasio). Cambiar el nombre de los campos. Establecer correspondencias de campos entre un nodo de origen y otro. Consulte Correspondencia de rutas de datos si desea obtener más información. El nodo filtro permite identificar algunos grupos de datos, o también nos da la posibilidad de importar ciertos campos de una base de datos sin necesidad de importar todos los campos de la base. Insertemos en nuestro lienzo de rutas el nodo filtro, de la siguiente forma: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 69 CLEMENTINE 9.0 Ahora demos doble clic en el nodo filtro, nos aparece la siguiente ventana: Ahora demos clic sobre los campos idequipo e idsalon, ya que estos campos no estamos interesados en visualizarlos. Al dar clic sobre la flecha que se encuentra al frente de estos campos aparece una cruz roja tachando dicha flecha. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 70 CLEMENTINE 9.0 Por ultimo damos clic en aplicar y en aceptar. El resultado podemos visualizarlo si generamos la ruta y en la tabla nos muestra todos los campos a excepcion de idsalon e idequipo. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 71 CLEMENTINE 9.0 6. Nodo Añadir Los nodos Añadir se pueden usar para concatenar conjuntos de registros. A diferencia con los nodos Fundir, que une registros de diferentes orígenes, los nodos Añadir leen y pasan a la parte de abajo todos los registros de un único origen hasta que no quede ninguno. A continuación, los registros procedentes del siguiente origen se leen usando la misma estructura de datos (número de registros, número de campos, etc.) que la entrada primera (o primaria). Cuando el origen primario contiene más campos que otro registro de entrada, se usa la cadena de valor nulo del sistema ($null$) para los valores incompletos. Los nodos Añadir son útiles para combinar conjuntos de datos con estructuras similares pero datos diferentes. por ejemplo, podría tener datos de transacción almacenados en diferentes archivos para diferentes períodos (un archivo de datos de venta para el mes de marzo y otro para el mes de abril, por ejemplo). Suponiendo que tengan la misma estructura (los mismos campos en el mismo orden), el nodo Añadir los une en un archivo de gran tamaño que se puede analizar. Este nodo nos permite añadir dos tablas de datos. Por ejemplo queremos unir la tabla de turnos con la tabla personas. Esta tabla contiene la identificación de la UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 72 CLEMENTINE 9.0 persona y su respectivo código. Para ello vamos a ingresar la tabla turnos y la tabla persona_estudiante, tambien vamos a insertar el nodo añadir y el nodo tabla de la siguiente manera. Ahora damos doble clic en el nodo añadir y aparece el siguiente cuadro en el que seleccionamos la casilla etiquetar registros incluyendo el conjunto de datos de origen del campo, de la siguiente forma: Ahora damos clic en aceptar. Y ejecutamos la ruta para ver los resultados. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 73 CLEMENTINE 9.0 El resultado que obtenemos es la unión de las dos tablas pero de forma que una se encuentra encima de la otra, es decir, la tabla turnos quedo en la parte de arriba y la tabla personas quedo en la parte de abajo. 7. Nodo Fundir La función de un nodo Fundir es tomar varios registros de entrada para crear un registro de salida que contenga todos o algunos de los campos de entrada. Se trata de una operación útil cuando se desean fusionar datos de diferentes orígenes, como datos de clientes internos y datos demográficos adquiridos. Existen dos modos de fusionar datos en Clementine: Fusionar por orden: concatena registros correspondientes procedentes de todos los orígenes en el orden de entrada hasta vaciar el origen de datos más pequeño. Si se usa esta opción, es importante haber ordenado previamente los datos con un nodo Ordenar. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 74 CLEMENTINE 9.0 Fusionar usando un campo clave, como el ID de cliente, para especificar cómo relacionar los registros procedentes de un origen de datos con los procedentes de otros. Clementine ofrece varias posibilidades de unión, incluidas la unión interior, la exterior, la exterior parcial y la anti-unión. Consulte Tipos de uniones si desea obtener más información. Este nodo nos permite unir dos tablas, pero a diferencia del nodo añadir, este nos permite agregar los campos de las dos tablas en una sola. Veamos el siguiente ejemplo: Insertemos las tablas turnos y personas, al igual que el nodo Fundir y el nodo tabla de la siguiente forma: Ahora damos doble clic sobre el nodo fundir y tenemos este cuadro de dialogo: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 75 CLEMENTINE 9.0 Ahora le damos aplicar, luego aceptar. Y por ultimo le damos ejecutar a nuestra ruta, el resultado que obtenemos es el siguiente: 8. Nodo Agregar El nodo Agregar se puede usar para reemplazar una secuencia de registros de entrada con registros de salida agregados de resumen. Este nodo nos permite realizar un conteo de los registros, para ello vamos a insertar el nodo en nuestra ruta de datos de la siguiente forma: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 76 CLEMENTINE 9.0 Ahora vamos a darle doble clic al nodo agregar y seleccionamos como campo clave idpersona, en la parte de agregar campos selecciono éxito, selecciono la casilla suma y también la casilla incluir recuento de registros en campo. Ahora le damos aplicar, aceptar. Y generamos nuestra ruta, el resultado que nos arroja es el siguiente: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 77 CLEMENTINE 9.0 Esta tabla nos indica que la persona identificada como 53105017 solicito turno en total 53 veces y solamente obtuvo el turno respectivo 25 veces. Es decir que de 53 veces que solicito turno solamente 25 veces lo consiguió. 9. Nodo Distinguir Los nodos Distinguir se pueden usar para eliminar registros duplicados pasando el primero de los registros distintos a la ruta de datos o descartando el primer registro y pasando cualquier duplicado a la ruta de datos en su lugar. Esta operación resulta útil si se desea tener un único registro para cada elemento de los datos, como clientes, cuentas o productos. Por ejemplo, los nodos Distinguir pueden ser útiles para buscar registros duplicados en una base de datos de clientes o para obtener un índice de todos los ID de producto de la base de datos. Modo. Especifique si desea incluir o excluir (descartar) el primer registro. Incluir. Seleccione esta opción para incluir el primer registro distinto en la ruta de datos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 78 CLEMENTINE 9.0 Descartar. Seleccione esta opción para descartar el primer registro distinto detectado y pasar cualquier duplicado a la ruta de datos en su lugar. Esta opción resulta útil para buscar duplicados en los datos con el fin de examinarlos posteriormente en la ruta. Campos. Enumera los campos utilizados para determinar si los registros son idénticos. Para añadir campos a esta lista, utilice el botón de selección de campos de la parte derecha. Elimine campos usando el botón de eliminación rojo. 10. Nodo derivar Una de las funciones más eficaces de Clementine es la capacidad de modificar valores de datos y derivar campos nuevos a partir de datos existentes. Durante proyectos minería de datos de larga duración, es común realizar varias derivaciones, como extraer un ID de cliente a partir de una cadena de datos del registro Web o crear un valor de por vida de clientes basado en los datos demográficos y de transacción. Todas estas transformaciones pueden realizarse en Clementine, utilizando diversos nodos de operaciones con campos. Al utilizar el nodo Derivar, puede crear seis tipos de campos nuevos desde uno o más campos existentes: Fórmula. El campo nuevo es el resultado de una expresión CLEM arbitraria. Marca. El campo nuevo es una marca que representa una condición especificada. Conjunto. El campo nuevo es un conjunto, lo cual supone que sus miembros conforman un grupo de valores especificados. Estado. El campo nuevo es uno de dos estados. El cambio entre estos estados los desencadena una condición especificada. Recuento. El campo nuevo está basado en el número de veces que una condición es verdadera. Condicional. El campo nuevo es el valor de una de las dos expresiones, dependiendo del valor de una condición. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 79 CLEMENTINE 9.0 Cada uno de estos nodos contiene un conjunto de opciones especiales en el cuadro de diálogo del nodo Derivar. Estas opciones se describen en los siguientes temas. 11. Nodo reclasificar El nodo Reclasificar permite la transformación desde un conjunto de valores discretos a otro. La reclasificación es útil para contraer categorías o reagrupar datos para su análisis. Por ejemplo, se pueden reclasificar los valores Producto en tres grupos, como por ejemplo Utensilios de cocina, Baño y ropa de cama y Electrodomésticos. A menudo, esta operación se realiza directamente desde un nodo de distribución agrupando valores y generando un nodo Reclasificar. Consulte Utilización de un gráfico de distribución si desea obtener más información. La reclasificación puede realizarse mediante uno o varios campos simbólicos. También puede sustituir los nuevos valores por el campo existente o generar un campo nuevo. 12. Nodo Intervalos El nodo Intervalos permite crear automáticamente conjuntos de campos nuevos basándose en los valores de uno o varios campos de rangos numéricos existentes. Por ejemplo, puede transformar un campo de ingresos de escala en un campo categórico nuevo que contenga grupos de ingresos como desviaciones desde la media. Una vez creados los intervalos para el campo nuevo, puede generar un nodo Derivar basado en los puntos de corte. 13. Nodo de partición Los nodos de partición se utilizan para generar un campo de partición que divide los datos en subconjuntos o muestras independientes para las fases de UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 80 CLEMENTINE 9.0 entrenamiento, comprobación y validación en la generación del modelo. Al usar una muestra para generar el modelo y otra muestra independiente para comprobarla, puede obtener una buena indicación de lo bien que generará el modelo conjuntos de datos de mayor tamaño similares a los datos actuales. El nodo de partición genera un campo de conjunto con la dirección establecida en Partición. Si lo prefiere, en el caso de que un campo adecuado ya exista en los datos, puede designarse como una partición utilizando un nodo Tipo. En este caso no se requiere ningún nodo de partición independiente. Se puede utilizar cualquier campo de conjunto instanciado con dos o tres valores. Consulte Configuración de la dirección del campo si desea obtener más información. En una ruta se pueden definir múltiples campos de partición pero, de hacerlo, será necesario seleccionar un campo de partición simple en la ficha Campos de cada nodo de modulado que utilice la partición. (Si sólo hay una partición, se usará automáticamente siempre que se active la partición.) Activación de la partición. Para utilizar la partición en un análisis, ésta debe estar activada en la ficha Opciones de modelo en el nodo Análisis o la generación de modelos adecuada. Si se anula esta opción, se posibilita la desactivación de la partición sin eliminar el campo. 14. Nodo Marcas El nodo Marcas se utiliza para derivar varios campos de marcas basándose en los valores simbólicos definidos para uno o más campos de conjuntos. Por ejemplo, puede haber adquirido datos de varios productos que se pueden comprar en distintos departamentos de una tienda. Actualmente, los datos constan de un producto por compra e incluyen el código de producto y el código del departamento (un conjunto) como dos atributos. Para manejar los datos de una forma más sencilla, puede crear un campo de marcas para cada departamento, que indicará si el producto se compró en ese departamento. 15. Nodo Histórico UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 81 CLEMENTINE 9.0 Los nodos Histórico se suelen utilizar para los datos secuenciales, como los datos de series temporales. Se utilizan para crear campos nuevos que contienen datos de los campos de registros anteriores. Al utilizar un nodo Histórico, es posible que desee tener los datos ordenados previamente por un campo determinado. Puede utilizar un nodo Ordenar para hacerlo. 16. Nodo Reorg. campos El nodo Reorg. campos permite definir el orden natural utilizado para mostrar campos en la parte posterior de la ruta. Este orden afecta a la visualización de campos en diversas ubicaciones, como las tablas, las listas y el selector campos. Esta operación resulta útil, por ejemplo, al trabajar con conjuntos datos amplios que hacen más visibles los campos de interés. los los de de 17. Nodo Equilibrar Los nodos Equilibrar se pueden usar para corregir los desequilibrios de los conjuntos de datos de modo que cumplan determinados criterios de comprobación. Por ejemplo, imagine que un conjunto de datos contiene sólo dos valores, bajo o alto, y que el 90% de los casos es bajo y sólo el 10% de ellos es alto. Muchas técnicas de modelado presentan problemas con estos datos sesgados, puesto que tenderán a aprender sólo el resultado bajo y omitirán el valor alto, puesto que es más inusual. Si los datos están bien balanceados con aproximadamente el mismo número de resultados de bajo y alto, los modelos tendrán más posibilidades de encontrar patrones que hagan la distinción entre los dos grupos. En este caso, un nodo Equilibrar resulta útil para la creación de una directiva de equilibrado que reduzca los casos con un resultado bajo. El equilibrado se lleva a cabo mediante el duplicado y posterior descarte de registros basándose en las condiciones que se especifiquen. Los registros para los que no se establece ninguna condición siempre se pasan. Como este proceso funciona duplicando y descartando registros, la secuencia original de los datos se pierde en las operaciones efectuadas más abajo. Asegúrese de derivar cualquier valor relacionado con la secuencia antes de añadir un nodo Equilibrar a la ruta de datos. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 82 CLEMENTINE 9.0 Nota: los nodos Equilibrar se pueden generar de forma automática desde histogramas y gráficos de distribución. 18. Nodo Gráfico Los nodos Gráfico muestran la relación entre los campos numéricos. Puede crear un gráfico con puntos (también denominado diagrama de dispersión) o puede utilizar líneas. Puede crear tres tipos de gráficos de líneas especificando un valor de Modo para X en el cuadro de diálogo. Modo para X = Ordenar Al establecer el Modo para X en Ordenar, los datos se clasifican por valores en el campo representado por el eje x. Así se ejecuta una sola línea de izquierda a derecha en el gráfico. Al utilizar una variable de conjunto como una superposición, se producen varias líneas de diferentes tonos que se ejecutan de izquierda a derecha en el gráfico. Modo para X = Superponer Al establecer el Modo para X en Superponer, se crean varios gráficos de línea en el mismo gráfico. Los datos no se ordenan en el caso de un gráfico de superposición; siempre que los valores del eje x aumenten, los datos se representarán en una sola línea. Si los valores disminuyen, comienza una línea nueva. Por ejemplo, si x se mueve de 0 a 100, los valores de y se representarán en una sola línea. Cuando x cae por debajo de 100, se representa una línea nueva además de la primera. El gráfico terminado puede tener numerosos gráficos que resultan útiles para comparar varias series de valores de y. El tipo de gráfico es útil para los datos con un componente temporal periódico, como una demanda de electricidad en períodos sucesivos de 24 horas. Modo para X = Como se lee Al establecer el Modo para X en Como se lee, los valores de x e y se representan como se leen desde el origen de datos. Esta opción es útil para los datos con un componente de serie temporal donde el interés recae sobre tendencias o patrones que dependen del orden de los datos. Puede que sea necesario ordenar los datos antes de crear este tipo de gráfico. También puede ser útil comparar dos gráficos similares con el Modo para X establecido en Ordenar y Como se lee para determinar hasta qué punto el patrón depende del orden. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 83 CLEMENTINE 9.0 19. Nodo G. múltiple Un gráfico múltiple es un tipo especial de gráfico que muestra varios campos Y sobre un sólo campo X. Los campos Y están trazados como líneas coloreadas y cada uno equivale a un nodo Gráfico con el estilo establecido en Línea y Modo para X establecido en Ordenar. Los gráficos múltiples son útiles cuando se tienen datos de una secuencia temporal y se desea explorar la fluctuación de diversas variables durante un período de tiempo. 20. Nodo Distribución Los gráficos de distribución muestran la ocurrencia de valores simbólicos (no numéricos), como un género o un tipo de hipoteca, en un conjunto de datos. El uso habitual del nodo de distribución consiste en mostrar los desequilibrios de los datos que pueden rectificarse mediante el nodo Equilibrar antes de crear un modelo. Puede generar automáticamente un nodo Equilibrar mediante el menú Generar en una ventana de gráfico de distribución. 21. Nodo Histograma Los nodos Histograma muestran ocurrencia de valores de los campos numéricos. Se suelen utilizar para explorar los datos antes de las manipulaciones y la generación de modelos. Al igual que con el nodo Distribución, con frecuencia los nodos de histogramas se utilizan para detectar desequilibrios en los datos. Nota: para mostrar la ocurrencia de valores para campos simbólicos, se debe utilizar un nodo Distribución. Campo. Permite seleccionar un campo numérico para el que se va a mostrar la distribución de los valores. Sólo aparecen en la lista los campos que no se han definido específicamente como simbólicos (categóricos). UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 84 CLEMENTINE 9.0 Superponer. Permite seleccionar un campo simbólico con objeto de mostrar categorías de valores para el campo seleccionado con anterioridad. Al seleccionar un campo de superposición, el histograma se convierte en un gráfico apilado donde los colores representan distintas categorías del campo de superposición. Existen tres tipos de superposiciones para los histogramas: Color. Permite seleccionar un campo para ilustrar las categorías de los valores de datos usando un color diferente para cada valor. Panel. Permite seleccionar un conjunto o campo de marcas para marcar un gráfico independiente para cada categoría. Los gráficos aparecerán "panelados" o juntos en una ventana de resultados. Animación. Permite seleccionar un conjunto o campo de marcas para ilustrar las categorías de los valores de datos creando una serie de gráficos secuenciados mediante la animación. 22. Nodo Colección Las colecciones son similares a los histogramas salvo por el hecho de que las colecciones muestran la distribución de los valores de un campo numérico relativo a los valores de otro, en lugar de la ocurrencia de los valores de un solo campo. Las colecciones son útiles para ilustrar una variable o un campo cuyos valores cambian con el tiempo. Con los gráficos 3D también puede incluir un eje simbólico que muestra las distribuciones por categoría. Recolectar. Permite seleccionar un campo cuyos valores se recopilarán y mostrarán en el rango de valores para el campo especificado a continuación en Sobre. Sólo se enumeran los campos definidos como simbólicos. Sobre. Permite seleccionar un campo cuyos valores se utilizan para mostrar el campo de colección especificado antes. Por. Activada al crear un gráfico 3D, esta opción permite seleccionar un conjunto o un campo de marcas utilizado para mostrar el campo de colección por categorías. Operación. Permite seleccionar lo que representa cada barra o bucket del gráfico de colección. Las opciones son Suma, Media, Máx, Mín y Desviación típica. Superponer. Permite seleccionar un campo simbólico con objeto de mostrar categorías de valores para el campo seleccionado con anterioridad. Al seleccionar UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 85 CLEMENTINE 9.0 un campo de superposición, la colección se convierte y se crean múltiples barras de distintos colores para cada categoría. Existen tres tipos de superposiciones para las colecciones: Color. Permite seleccionar un campo para ilustrar las categorías de los valores de datos usando un color diferente para cada valor. Panel. Permite seleccionar un conjunto o campo de marcas para marcar un gráfico independiente para cada categoría. Los gráficos aparecerán "panelados" o juntos en una ventana de resultados. Animación. Permite seleccionar un conjunto o campo de marcas para ilustrar las categorías de los valores de datos creando una serie de gráficos secuenciados mediante la animación. 23. Nodo Malla Los nodos Malla muestran la fuerza de las relaciones entre los valores de dos o más campos simbólicos. El gráfico muestra las conexiones usando varios tipos de líneas para indicar la fuerza de conexión. Puede utilizar un nodo Malla, por ejemplo, para explorar las relaciones existentes entre la compra de varios artículos en un sitio de comercio electrónico o un punto de venta al por menor tradicional. Mallas direccionales Los nodos de mallas direccionales son similares a los nodos Mallas en cuanto a que muestran la fuerza de las relaciones entre campos simbólicos. Sin embargo, los gráficos de mallas direccionales muestran sólo las conexiones de uno o más campos de origen (Desde) con un único campo de destino (Hacia). Las conexiones son unidireccionales en el sentido de que son conexiones de una sola dirección. A semejanza de los nodos Malla, el gráfico muestra las conexiones usando varios tipos de líneas para indicar la fuerza de conexión. Puede utilizar un nodo de malla direccional, por ejemplo, para explorar las relaciones entre el género y una propensión a ciertos artículos de compra. 24. Nodo de diagrama Evaluación UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 86 CLEMENTINE 9.0 El nodo de diagrama Evaluación ofrece una forma sencilla de evaluar y comparar modelos predictivos para elegir el mejor modelo para su aplicación. Los diagramas de evaluación muestran el comportamiento de los modelos pronosticando determinados resultados. Funcionan ordenando los registros basándose en el valor pronosticado y confianza del pronóstico, dividiendo los registros en grupos de igual tamaño (cuantiles), y a continuación, dibujando el valor del criterio de negocios de cada cuantil, del más alto al más bajo. El gráfico muestra múltiples modelos como líneas independientes. Los resultados se gestionan definiendo un valor o rango de valores específicos como un acierto. Los aciertos suelen indicar algún tipo de éxito (como una venta a un cliente) o un evento de interés (como un diagnóstico médico específico). Puede definir criterios de aciertos en la ficha Opciones del cuadro de diálogo. También puede utilizar los criterios de aciertos por defecto como se indica a continuación: Los campos de salida de marcas son directos; los aciertos corresponden a valores verdaderos. Par los campos de salida de conjuntos, el primer valor del conjunto define un acierto. Para los campos de salida de rango, los aciertos equivalen a valores mayores que el punto medio del rango del campo. Existen cinco tipos de diagramas de evaluación, cada uno de ellos con el énfasis puesto en un criterio de evaluación diferente. Ganancias Las ganancias se definen como la proporción de aciertos totales que se produce en cada cuantil. Las ganancias se calculan como el resultado de: (número de aciertos en cuantil / número total de aciertos) × 100%. Elevación La elevación compara el porcentaje de registros de cada cuantil que supone aciertos con el porcentaje global de aciertos de los datos de entrenamiento. Se calcula como el resultado de: (aciertos del cuantil / registros del cuantil) / (aciertos totales / registros totales). Respuesta UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 87 CLEMENTINE 9.0 La respuesta es sencillamente el porcentaje de registros del cuantil que son aciertos. La respuesta se calcula como el resultado de: (aciertos del cuantil / registros del cuantil) × 100%. Beneficio El beneficio es igual a los ingresos de cada registro menos el coste del registro. Los beneficios de un cuantil son la suma de los beneficios de todos los registros del cuantil. Se asume que los beneficios se aplican sólo a los aciertos, pero los costes se aplican a todos los registros. Los beneficios y los costes se pueden fijar o estar definidos por campos en los datos. Los beneficios se calculan como el resultado de: (suma de los ingresos de los registros del cuantil – suma de los costes de los registros del cuantil). Rentabilidad de la inversión La rentabilidad de la inversión (ROI, del inglés 'Return On Investment') es similar al beneficio en cuanto a que implica la definición de ingresos y costes. La rentabilidad de la inversión compara los beneficios con los costes del cuantil. La rentabilidad de la inversión se calcula como el resultado de: (beneficios del cuantil/costes del cuantil) × 100%. Los diagramas de evaluación también pueden ser acumulados, de forma que cada punto equivalga al valor del cuantil correspondiente más todos los cuantiles mayores. Los gráficos acumulados suelen mostrar mejor el rendimiento global de modelos, mientras que los gráficos no acumulados suelen ser mejores para indicar determinadas áreas de problemas para los modelos. TECNICAS DE MODELADO EN CLEMENTINE Clementine brinda varias técnicas de análisis de datos, estas están concentradas en los nodos ubicados en la paleta Modelado. Los nodos de modelado son las herramientas fundamentales del proceso de minería de datos. Los métodos disponibles en estos nodos permiten derivar nueva información procedente de los datos y desarrollar modelos predictivos. Cada método tiene ciertos puntos fuertes y es más adecuado para determinados tipos de problemas. Dentro de las aplicaciones más importantes de Clementine vamos a resaltar en el modelado del programa las siguientes: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 88 CLEMENTINE 9.0 Los métodos de modelado predictivo contienen: 1. Árboles de decisión Los árboles de decisiones permiten desarrollar sistemas de clasificación que pronostican o clasifican observaciones futuras basándose en un conjunto de reglas de decisión. Si dispone de datos divididos en clases que le interesan (por ejemplo, préstamos de alto riesgo frente a préstamos de bajo riesgo, suscriptores frente a no suscriptores, votantes frente a no votantes o tipos de bacterias), puede usar los datos para generar reglas que pueda usar para clasificar casos antiguos o recientes con la máxima precisión. Por ejemplo, podría generar un árbol que clasificara el riesgo de crédito o la intención de compra basándose en la edad y otros factores. En segundo lugar, el proceso incluirá automáticamente en su regla únicamente los atributos que realmente importan en la toma decisiones. Los atributos que no contribuyan a la precisión del árbol se omiten. La presentación del árbol de decisión resulta útil cuando se desea ver el modo en que los atributos de los datos pueden dividir o particionar la población en subconjuntos relevantes para el problema. La presentación del conjunto de reglas resulta de utilidad si se desea ver el modo en que determinados grupos de elementos se vinculan a una conclusión particular. Algoritmos de generación de árboles Existen cuatro algoritmos disponibles para realizar análisis de segmentación y clasificación. Todos estos algoritmos son básicamente similares: examinan todos los campos de la base de datos para detectar los que proporcionan la mejor clasificación o pronóstico dividiendo los datos en subgrupos. El proceso se aplica de forma recursiva, dividiendo los subgrupos en unidades cada vez más pequeñas hasta completar el árbol (según defina determinados criterios de parada). Los campos objetivo y de entrada utilizados en la generación del árbol pueden ser intervalos numéricos o categóricos, según el algoritmo que se utilice. Si se usa un objetivo de rango, se genera un árbol de regresión; si se usa un objetivo categórico, se genera un árbol de clasificación. El nodo de árbol de clasificación y regresión genera un árbol de decisión que permite pronosticar o clasificar observaciones futuras. El método utiliza la partición reiterada para dividir los registros de entrenamiento en segmentos minimizando las zas ca a as , s c s a“ ” si el 100% de los casos del nodo corresponden a una categoría específica del campo objetivo. Los campos objetivo UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 89 CLEMENTINE 9.0 y predictor pueden ser de rango o categóricos. Todas las divisiones son binarias (sólo se crean dos subgrupos). El nodo CHAID genera árboles de decisión utilizando estadísticos de de chi-cuadrado para identificar las divisiones óptimas. A diferencia de los nodos C&RT y QUEST, CHAID puede generar árboles no binarios, lo que significa que algunas divisiones tendrán más de dos ramas. Los campos objetivo y predictor pueden ser de rango o categóricos. CHAID exhaustivo es una modificación de CHAID que examina con mayor precisión todas las divisiones posibles, aunque necesita más tiempo para realizar los cálculos. El nodo QUEST proporciona un método de clasificación binario para generar árboles de decisión, diseñado para conseguir la reducción del tiempo de procesamiento necesario para los análisis de C&RT y reducir la tendencia de los métodos de clasificación de árboles para favorecer a los predictores que permiten realizar más divisiones. Los campos predictores pueden ser rangos numéricos, sin embargo el campo objetivo debe ser categórico. Todas las divisiones son binarias. El nodo C5.0 genera un árbol de decisión o un conjunto de reglas. El modelo divide la muestra basándose en el campo que ofrece la máxima ganancia de información en cada nivel. El campo objetivo debe ser categórico. Se permiten varias divisiones en más de dos subgrupos. Usos generales del análisis basado en árboles A continuación se detallan algunos usos generales del análisis basado en árboles: Segmentación. Identifica personas con probabilidad de pertenecer a una determinada clase. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 90 CLEMENTINE 9.0 Estratificación. Asigna casos en una o varias categorías, como grupos de alto, medio y bajo riesgo. Pronóstico. Crea reglas y las usa para pronosticar eventos futuros. Los pronósticos también pueden significar intentos de relacionar atributos predictivos con valores de una variable continua. Reducción de datos y filtrado de variables. Selecciona un subconjunto útil de predictores de un gran conjunto de variables para usarlo en la creación de un modelo paramétrico formal. Identificación de interacción. Identifica las relaciones que pertenecen sólo a subgrupos determinados y las especifica en un modelo paramétrico formal. Fusión de categorías y unión de variables continuas. Recodifica categorías de un predictor de grupos y variables continuas con una pérdida mínima de información. 2. Red Neuronal El nodo Red neuronal (anteriormente denominado "Entrenar red") se utiliza para crear y entrenar una red neuronal. Las redes neuronales son modelos simples que mulan el funcionamiento del sistema nervioso. Las unidades básicas son las neuronas, que generalmente se organizan en capas, como se muestra en la siguiente ilustración. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 91 CLEMENTINE 9.0 Una red neuronal, a menudo denominada perceptrón multicapa, es básicamente un modelo simplificado del modo en que el cerebro humano procesa la información. Funciona simultaneando un número elevado de unidades simples de procesamiento interconectadas que parecen versiones abstractas de neuronas. Las unidades de procesamiento se organizan en capas. Existen, generalmente, tres capas en una red neuronal: una capa de entrada, con unidades que representan los campos de entrada; una o varias capas ocultas; y una capa de salida, con unidades que representan los campos de salida. Las unidades se conectan con fuerzas de conexión variables, o ponderaciones. Los datos de entrada se presentan en la primera capa y los valores se propagan desde cada neurona hasta cada neurona de la capa siguiente. al final, se envía un resultado desde la capa de salida. La red aprende examinando los registros individuales, generando un pronóstico para cada registro y realizando ajustes a las ponderaciones cuando realiza un pronóstico incorrecto. Este proceso se repite muchas veces y la red sigue mejorando sus pronósticos hasta haber alcanzado uno o varios criterios de parada. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 92 CLEMENTINE 9.0 Al principio, todas las ponderaciones son aleatorias y las respuestas que resultan de la red son, posiblemente, disparatadas. La red aprende a través del entrenamiento. Continuamente se presentan a la red ejemplos para los que se conoce el resultado, y las respuestas que proporciona se comparan con los resultados conocidos. La información procedente de esta comparación se pasa hacia atrás a través de la red, cambiando las ponderaciones gradualmente. A medida que progresa el entrenamiento, la red se va haciendo cada vez más precisa en la replicación de resultados conocidos. Una vez entrenada, la red se puede aplicar a casos futuros en los que se desconoce el resultado. Requisitos: No se aplican restricciones a los tipos de campo. Los nodos Red neuronal pueden gestionar entradas y salidas numéricas, simbólicas o de marcas. El nodo Red neuronal espera uno o varios campos con dirección Entrada y uno o varios campos con dirección Salida. Se ignorarán los campos establecidos en Ambos o Ninguno. Los tipos de campo deben estar completamente instanciados al ejecutar el nodo. Puntos fuertes: Las redes neuronales son dispositivos eficaces de cálculo de funciones generales. Por lo general, realizan al menos las tareas de pronóstico y otras técnicas, y su rendimiento puede mejorar significativamente en determinadas ocasiones. También se precisa un conocimiento matemático o estadístico mínimo para entrenarlas o aplicarlas. Clementine incorpora varias funciones para evitar algunos problemas comunes de las redes neuronales. Entre ellas se incluyen el análisis de sensibilidad para facilitar la interpretación de la red, la poda y la validación para evitar el sobreentrenamiento, y las redes dinámicas para buscar automáticamente arquitecturas de red adecuadas2. 3. Modelos estadísticos. 2 Tomado de el tutorial Clementine. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 93 CLEMENTINE 9.0 Los modelos estadísticos utilizan ecuaciones matemáticas para codificar información extraída de los datos. Existen varios nodos de modelado estadístico. La regresión lineal es una técnica estadística común utilizada para resumir datos y realizar pronósticos ajustando una superficie o línea recta que minimice las discrepancias existentes entre los valores de salida reales y los pronosticados. En múltiples estudios estadísticos, aparece como una gran necesidad practica, el considerar simultáneamente dos o más variables, con el fin de analizar si entre ellas existe alguna relación, si se puede formalizar y que tan intensa es la misma. Los métodos estadísticos utilizados para estos análisis son conocidos como métodos de regresión. El objetivo de este tipo de procesos es tratar de estimar valores de las variables explicadas. Para poder alcanzar el objeto citado, es necesario darle alguna forma funcional a la relación, lo cual se logra mediante un ajuste de funciones estadístico – matemáticas, a tales funciones se les denomina Modelos de regresión. Estos modelos manejan una componente aleatoria que solo se puede manejar por medio de la probabilidad, por lo cual en la práctica no se puede incluir en el modelo, lo que imposibilita el poder determinar valores de las variables explicadas, limitándose el proceso a la estimación de las mismas. La natural diferencia entre los verdaderos valores de las variables explicadas y los que se estiman por medio del modelo, constituye la llamada variable aleatoria error y el principio fundamental para construir un modelo indica que este debe ser tal, que minimice la suma de los cuadrados de tal variable, principio que es entonces denominado como de mínimos cuadrados. El error del modelo son valores debidos a factores o condiciones externas que no controlamos. Hay que plantear UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 94 CLEMENTINE 9.0 modelos que garanticen que el error sea el mínimo. Volviendo a Clementine el nodo de regresión lineal genera un modelo de regresión lineal. Este modelo estima la ecuación lineal más adecuada para pronosticar el campo de salida, según los campos de entrada. La ecuación de regresión representa un plano o línea recta que minimiza las diferencias al cuadrado entre los valores de salida pronosticados y los reales. Ésta es una técnica estadística muy común para resumir los datos y realizar pronósticos. Requisitos: Sólo se pueden utilizar campos numéricos en un modelo de regresión. Debe tener exactamente un campo de Salida y uno o más de Entrada. Los campos que tengan dirección Ambas o Ninguna se ignoran, ya que no son campos numéricos. Puntos fuertes: Los modelos de regresión son relativamente simples y proporcionan una fórmula matemática fácil de interpretar para la creación de pronósticos. Debido a que el modelado de regresión es un procedimiento estadístico consolidado desde hace tiempo, las propiedades de estos modelos se conocen con mucho detalle. Normalmente, los modelos de regresión se entrenan muy rápidamente. El nodo Regresión lineal proporciona métodos para la selección automática de campos con el fin de eliminar de la ecuación los campos de entrada que no alcancen la significación3. La regresión logística es una técnica estadística para clasificar los registros en función los valores de los campos de entrada. Es análoga a la regresión lineal pero toma un campo 3 Tomado de el tutorial Clementine UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 95 CLEMENTINE 9.0 objetivo categórico en lugar de uno numérico. La regresión logística, también denominada regresión nominal, es una técnica estadística para clasificar los registros según los valores de los campos de entrada. Es análoga a la regresión lineal pero utiliza un campo objetivo simbólico en lugar de uno numérico. La regresión logística trabaja creando un conjunto de ecuaciones que relacionan los valores de los campos de entrada con las probabilidades asociadas a cada una de las categorías de los campos de salida. Una vez se ha generado el modelo, se puede utilizar para estimar las probabilidades de datos nuevos. Para cada registro, se calcula una probabilidad de pertenencia a cada categoría posible de salida. La categoría objetivo con la probabilidad más alta se asigna como el valor de salida pronosticado para cada registro. Requisitos: Para crear un modelo de regresión logística, se precisan uno o varios campos de Entrada y exactamente un campo simbólico de Salida. Se ignorarán los campos establecidos en Ambos o Ninguno. Los tipos de los campos utilizados en el modelo deben estar completamente instanciados. Puntos fuertes: Los modelos de regresión logística suelen ser bastante exactos. Pueden gestionar campos de entrada simbólicos y numéricos. Pueden proporcionar probabilidades pronosticadas para todas las categorías objetivo, de forma que el "segundo mejor pronóstico" sea fácil de identificar. También pueden realizar una selección automática de campos para el modelo logístico. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 96 CLEMENTINE 9.0 Al procesar conjuntos grandes de datos, puede mejorar sensiblemente el rendimiento desactivando el contraste sobre el cociente de verosimilitudes, una opción avanzada de los resultados. El nodo PCA/Factorial proporciona técnicas eficaces de reducción de datos para reducir la complejidad de los datos. Análisis de componentes principales (PCA) busca combinaciones lineales de los campos de entrada que realizan el mejor trabajo a la hora de capturar la varianza en todo el conjunto de campos, en el que los componentes son ortogonales (perpendiculares) entre ellos. Análisis factorial intenta identificar factores subyacentes que expliquen el patrón de correlaciones dentro de un conjunto de campos observados. Para los dos métodos, el objetivo es encontrar un número pequeño de campos derivados que resuman de forma eficaz la información del conjunto original de campos. Los modelos estadísticos llevan algún tiempo entre nosotros y se entienden relativamente bien, matemáticamente hablando. Representan modelos básicos que asumen tipos bastante simples de relaciones en los datos. En algunos casos pueden proporcionar modelos adecuados muy rápidamente. Incluso en el caso de problemas en los que técnicas más flexibles de aprendizaje de las máquinas (como redes neuronales) pueden ofrecer a la postre mejores resultados, es posible usar modelos estadísticos como modelos predictivos de línea base para juzgar el rendimiento de técnicas avanzadas. EJERCICIO PRÁCTICO4 Imagine que es un investigador médico que está recompilando datos para un estudio. Ha recopilado información sobre un conjunto de pacientes, de los cuales 4 Este ejercicio fue tomado del tutorial Clementine 9.0 UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 97 CLEMENTINE 9.0 todos sufrieron la misma enfermedad. Durante el curso del tratamiento, cada paciente respondió a un medicamento de un total de cinco. Parte de su trabajo consiste en utilizar la minería de datos para averiguar qué medicamento es el adecuado para un futuro paciente con la misma enfermedad. Los campos de datos que se utilizan en esta demostración son: Edad (número) Sexo MoF PS Presión sanguínea: ALTO, NORMAL o BAJO Colesterol Colesterol en sangre: NORMAL o ALTO Na Concentración de sodio en sangre K Concentración de potasio en sangre Droga Medicamento prescrito al que respondió un paciente 1. Etapa de exploración de los datos: El primer paso es agregar un nodo Archivo Var para ingresar los datos a Clementine. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 98 CLEMENTINE 9.0 Ahora damos doble clic sobre el nodo y aparece el siguiente cuadro de dialogo en donde vamos a especificar el archivo que vamos a importar, de la siguiente forma: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 99 CLEMENTINE 9.0 En la pestaña filtro observamos los campos del archivo que van a ser ingresados a Clementine, para nuestro caso vamos a dar clic sobre el campo sexo, esto quiere decir que no necesitamos importar dicho campo a nuestro trabajo. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 100 CLEMENTINE 9.0 Ahora observemos la pestaña Filtro, aquí podemos establecer el respectivo tipo de datos con los que vamos a trabajar: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 101 CLEMENTINE 9.0 Luego de haber configurado nuestros datos para ser importados a Clementine damos aplicar y por ultimo aceptar. Ahora agreguemos un nodo distribución a nuestro lienzo de rutas y conectémoslo con nuestro nodo de origen. En seguida damos doble clic sobre el nodo distribución y aparece el siguiente cuadro en el que vamos a establecer el campo droga por el cual vamos a realizar la distribución. En la pestaña resultados podemos seleccionar la forma en la cual queremos que aparezca el resultado, esta puede ser por pantalla, o archivo. Para nuestro ejemplo marquemos la salida por pantalla. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 102 CLEMENTINE 9.0 Ahora damos clic en aplicar y luego en ejecutar. Aparece el respectivo grafico de la distribución. Ahora vamos a adjuntar un nodo Auditar y lo conectamos con nuestro nodo origen, este nodo nos permitirá obtener una vista rápida de las distribuciones e histogramas de todos los campos a la vez. Igual que con el nodo anterior le damos clic en ejecutar y observamos el siguiente resultado. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 103 CLEMENTINE 9.0 Otra operación que se puede realizar con Clementine es crear un diagrama de dispersión de sodio frente a potasio utilizando las categorías de medicamento como una superposición de colores aprovechando que estos datos son numéricos. Entonces adjuntemos un nodo Grafico y conectarlo con el nodo de origen. Dar doble clic sobre el nodo para abrir el siguiente cuadro de dialogo donde seleccionamos Na como el campo X, K como el campo Y y Droga como el campo de superposición. Luego clic en ejecutar. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 104 CLEMENTINE 9.0 El resultado se puede observar de la siguiente forma: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 105 CLEMENTINE 9.0 Este grafico nos muestra un umbral sobre el cual el medicamento correcto siempre es el medicamento Y, y por debajo de el el medicamento correcto nunca es el medicamento Y. Este umbral es un cociente entre sodio (Na) y potasio (K). Para finalizar esta primera etapa eliminemos los nodos Grafico, distribución y tabla para limpiar un poco el espacio de trabajo. 2. Etapa de manipulación de los datos: Tenemos el nodo de origen de los datos y ahora insertemos un nodo Derivar para derivar un nuevo campo. Dar doble clic sobre el nodo y completar los campos, UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 106 CLEMENTINE 9.0 nombre: Na_K que es el nombre al nuevo campo que vamos a crear. Formula: Na/K. El resultado lo podemos observar con el nodo tabla. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 107 CLEMENTINE 9.0 Ahora conectemos al nodo derivar un nodo Histograma para revisar la distribución del campo resultante. Demos doble clic sobre dicho nodo y completemos los campos como se muestra a continuación: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 108 CLEMENTINE 9.0 El resultado lo podemos observar al dar clic en el botón ejecutar: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 109 CLEMENTINE 9.0 Entonces se puede concluir que cuando el valor Na_to_K es aproximadamente 15 o mayor, el medicamento Y es el que se debe elegir. Con el análisis que hemos realizado hasta el momento el cociente sodio-potasio en sangre parece que influye en la elección del medicamento. Sin embargo, aún no se pueden explicar todas las relaciones. Conectemos ahora un nodo de malla al origen para poder trabajar con los datos simbólicos. Demos doble clic sobre el y completemos los campos como se muestra a continuación: El resultado que obtenemos es: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 110 CLEMENTINE 9.0 Vemos ahora cómo afecta la presión sanguínea en la elección del medicamento. Con este grafico se puede ver claramente que sólo los medicamentos A y B están asociados a la presión sanguínea alta. Sólo los medicamentos C y X están asociados a la presión sanguínea baja. Y la presión sanguínea normal está asociada únicamente al medicamento X. 3. Etapa de Modelado Hasta el momento, hemos visto surgir algunos patrones al explorar y manipular los datos. El cociente sodio-potasio en sangre parece influir en la elección del medicamento, al igual que la presión sanguínea. Sin embargo, aún no se pueden explicar todas las relaciones. El siguiente paso consiste en intentar ajustar un modelo a los datos. En este caso, se utilizará un modelo que crea reglas, el C5.0. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 111 CLEMENTINE 9.0 Primero para preparar los datos insertemos un nodo filtro para filtrar la salida de los campos originales de la siguiente forma: Ahora insertemos un nodo tipo en donde establezcamos los siguientes valores: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 112 CLEMENTINE 9.0 Ahora insertemos un nodo C5 y conectémoslo al nodo tipo. Demos clic en el botón de ejecutar y enseguida aparece lo siguiente: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 113 CLEMENTINE 9.0 Como podemos observar se genera un modelo representado por un icono con forma de gema. Para examinar las reglas generadas por el modelo demos clic derecho sobre el icono de la gema y seleccione examinar en el menú desplegable que aparece. Aparece entonces la siguiente ventana: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 114 CLEMENTINE 9.0 Esta ventana se llama examinador de reglas, allí se encuentran consignadas las reglas generadas por el nodo en un árbol de decisión. Demos clic en la etiqueta todos para ver el árbol completo. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 115 CLEMENTINE 9.0 Ahora vamos a la pestaña visor para ver de forma grafica el arbol: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 116 CLEMENTINE 9.0 Aquí se puede observar más fácilmente el número de casos para cada categoría de presión sanguínea así como el porcentaje de casos. Para evaluar la precisión del modelo conectemos un nodo analisis a la gema C5. Por ultimo ejecute la ruta. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 117 CLEMENTINE 9.0 Al ejecutar la ruta el resultado es el siguiente: UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 118 CLEMENTINE 9.0 Este análisis nos dice que el modelo tiene una precisión del 99.5%. Esto nos indica que el modelo es casi 100% confiable para la elección del medicamento para cada registro del conjunto de datos. CONCLUSIONES Dentro de las cualidades más importantes del programa se pueden resaltar la ejecutabilidad de procesos para descubrir patrones y tendencias ocultas en grandes conjuntos de datos con el fin de proporcionarnos el conocimiento necesario para la toma correcta de decisiones. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 119 CLEMENTINE 9.0 Aplicaciones típicas: Éstas son algunas de las aplicaciones típicas de técnicas de minería de datos de Clementine: Correo directo. Determine qué grupos demográficos tienen una tasa de respuesta mayor. Utilice esta información para maximizar la respuesta a futuras campañas de correos. Puntuación del crédito. Utilice un historial de crédito individual para realizar las decisiones de crédito. Recursos humanos. Comprender los procedimientos de contratación anteriores y crear reglas de decisión a fin de hacer más eficiente el proceso de contratación. Investigación médica. Cree reglas de decisión que sugieran procedimientos adecuados basados en comprobaciones médicas. Análisis de mercado. Determine qué variables (como, por ejemplo, geografía, precio y características de los clientes) están asociadas con las ventas. Control de calidad. Analice los datos procedentes de la manufactura del producto e identifique las variables que determinan los defectos de éste. Estudio de la política. Utilice los datos de la encuesta para formular la política mediante las reglas de decisión a fin de seleccionar las variables más importantes. Atención médica. Puede combinar las encuestas al usuario con los datos clínicos a fin de descubrir las variables que contribuyen a la salud. La aplicación de Clementine en la facultad se puede dar para las tres carreras puesto que en todas manejamos diferentes volúmenes de datos con diferentes variables que nos podrían dar mayor flujo de información como herramientas de análisis. Los campos de desarrollo en las carreras serian los siguientes: Administración de Empresas: En donde más se podría dar el desarrollo del programa, puesto que se puede utilizar en diferentes áreas de conocimiento de la carrera, se pueden procesar datos para inducir a nuevas o mejoras en la utilización de los recursos para las actividades económicas, orientadas siempre a crear una mejor estructura para la producción, transformación, circulación, administración o custodia de bienes o para la prestación de UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 120 CLEMENTINE 9.0 servicios. Contaduría Publica: Se puede llevar un registro con mejor información de los procesos contables y de La información financiera, además de que se podrían comparar la información de la empresas frente a su sector industrial, o en bases de datos en la cámara de comercio, la DIAN o el DANE Economía: La medición de datos se hace para saber los comportamientos de los agentes en el mercado, su influencia en la economía y la relación que puede existir entre sí, ya sea a nivel micro y/o macroeconómico, modelos econométricos, entre otros. Con esta investigación se obtuvieron bastantes resultados positivos, ya que gracias a ella comprendimos la importancia que tiene difundir el manejo de esta herramienta tan útil, por eso hay que utilizar al máximo las ventajas que este software brinda, aplicándolo a las materias que tienen relación con el tema y que son dictadas en la facultad. En la facultad las materias de Producción, Mercados, Estadística, Econometria, Auditoria Financiera I, Auditoria Financiera II, Auditoria de sistemas, entre otras pueden utilizar este software. UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES 121