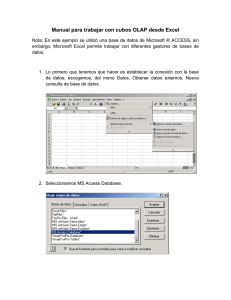
Almacenes de datos
Anuncio

Grandes de Bases de Datos
Almacenes de Datos (DW) e
Inteligencia de negocios
IN (BI)
¿Qué es Inteligencia de Negocios?
• Las TI permiten la toma de decisiones basadas
en procesos de análisis sobre datos simples o
complejos
– Administración de BD
– Consultas y reportes
– Análisis de datos y simulaciones
– Paneles
– Minería de datos
¿Por qué IN (BI)?
• Proyectar la dirección de las organizaciones a
un nivel de administración superior
– Toma de decisiones con mejor información
– Análisis competitivos
– Estrategias de publicidad enfocadas
– Escenarios y predicciones de negocios
– Optimización en operación
– Cumplimiento con regulaciones
¿Se usa la BI realmente?
– Desde 2009
• Existen sistemas que integran procesos de toma de
decisiones de manera colaborativa dentro de
plataformas BI
– Desde el 2010
• El 20% de las organizaciones contaba con una
aplicación analítica específica de la industria, entregada
a través de software como servicio (SaaS) como un
componente estándar de su cartera de BI
¿Se usa la BI realmente?
– Para 2012
• Más del 35% de las empresas globales no toman
decisiones adecuadas sobre cambios significativos en
sus negocios y mercados (o hacen decisiones no
adecuadas).
• Las unidades de negocio controlarán al menos el 40%
del presupuesto total de BI
• Una tercera parte de aplicaciones analíticas aplicadas a
procesos de negocio se entregarán mediante
aplicaciones genéricas (no desarrollos específicos)
Conocimientos y habilidades
– Conocimiento de BD y almacenes de datos (DWH)
– Administrar, integrar y probar sistemas de BD
– Administrar sistemas de reportes
– Implementar políticas, requerimientos de
seguridad y regulaciones
Elementos de BI
– Almacenamiento
• Almacenes de datos
– Análisis
• Estadística
• Minería de datos
– Presentación
• Visualización
Almacenes de datos
– Conceptos básicos
– Arquitecturas
– Data Marts
– Estructuras de datos y flujo de datos
– Modelado dimensional
– Extracción, limpieza, congregación y entrega de
datos
– Generación y entrega de reportes
– Monitoreo y verificación de desempeño
Almacenes de datos
Un Data Warehouse (DW - almacén de datos),
generaliza y consolida datos en espacios de múltiples
dimensiones.
Almacenes de datos
La construcción de un DW incluye limpieza,
transformación e integración de los datos
Almacenes de datos
Proveen herramientas de proceso analítico en línea
(OLAP) para el análisis interactivo de datos de múltiples
dimensiones en varias granularidades.
Facilita la generalización efectiva de los datos y la
minería de datos.
En conjunto con operaciones OLAP, tenemos funciones
de minería de datos como clasificación, predicción,
asociación y cúmulos.
Almacenes de datos
Uso de datos
concentrados
según área
Definición
El término de Data Warehouse se dio a conocer en el
artículo "An architecture for a business and information
system" en 1988.
El término que se empleo en tal artículo fue "Business
Data Warehouse" el cuál propone un repositorio de
datos y herramientas para su uso.
Definición
Base de datos de soporte de decisiones que se mantiene separada de las bases
de datos operacionales de la organización en cuestión.
“Un almacén de datos es una colección de datos
Orientada a un objetivo
Integrada
Variante en el tiempo
No volátil
utilizada principalmente en la organización para la toma de decisiones”[1]
[1] William H. Inmon
Orientado a Objetivo
• Organización de los datos en objetos mejor definidos.
• Exclusión de los datos que no son útiles en el proceso.
• Enfoque en el modelado y análisis de datos para los
encargados de decisiones.
$
Integrados
• Múltiples fuentes de datos heterogéneas.
• Pre-procesamiento de datos
Variante en tiempo
• El horizonte de datos es mayor que una BD operacional
• Cada elemento contiene una referencia al tiempo,
explicita o implícitamente. (aunque no necesariamente
el elemento principal)
No volátil
• Almacenamiento físico distinto del ambiente
operacional
• Actualizaciones operacionales no se reflejan en el
ambiente del DW
• ¿Procesamiento de transacciones? ¿Recuperación?
¿Concurrencia?
• Dos actividades:
• Carga inicial
• Acceso a datos
Diferencias entre Sistemas Operacionales de
Bases de Datos y Data Warehouse
• Transacción y procesamiento de consultas.
• Esos sistemas son conocidos como sistemas de
procesamiento de transacciones en línea (OLTP).
• Cubren la mayor parte de las operaciones diarias de
una organización, tales como venta, inventario, etc.
Diferencias entre Sistemas Operacionales de
Bases de Datos y Data Warehouse
• Sirven a los usuarios o trabajadores del conocimiento
en el papel de análisis de datos y toma de decisiones.
• Pueden organizar y presentar los datos en varios
formatos de tal forma que se acomoden a las
necesidades de los diferentes usuarios.
• Estos sistemas son conocidos como sistemas de
procesamiento analítico en línea (OLAP).
OLTP vs OLAP
Característica OLTP
OLAP
Funcionalidad Operación diaria
Soporte de Decisiones
Diseño
Datos
Vista
Uso
Unidad
Acceso
Registros
Tamaño BD
Métrica
Orientado a la aplicación Relacional
Actualizados, aislados, no
repetidos
Detallada, plana relacional
Estructurado, repetitivo
Transacciones simples
Lectura/Escritura
Millones
100GB/1000GB
"Throughput" de transacciones
Orientado a objetivos - Estrella,
copo de nieve
Históricos, consolidados
Resumida, múltiples dimensiones
Ad Hoc
Consultas complejas
Lectura
Billones
1TB/1000TB
"Response" de consultas
¿Dónde debe encontrarse?
¿Dónde debe encontrarse?
¿Dónde debe encontrarse?
¿Dónde debe encontrarse?
• Desempeño
– BD operaciones diseñadas y optimizadas para
cargas de trabajo distintas
– Consultas OLAP complejas degradan el desempeño
(bloqueos, etcétera)
– Organización de datos especial que permite:
•
•
Métodos de acceso y de implementación para datos de
múltiples dimensiones
Vistas y consultas de datos de múltiples dimensiones
¿Dónde debe encontrarse?
• Funcionalidad
• Datos faltantes:
– Requieren datos históricos, que generalmente no mantienen las BD
operacionales
• Consolidación de datos:
– Requieren consolidación (agregación, resúmenes) de datos múltiples fuentes de datos externas
• Calidad de Datos:
– Necesidad de procesamiento previo a los datos
Modelo de datos de múltiples
dimensiones
• DW y herramientas OLAP están basadas en un modelo
de datos multidimensional
• tiendaWeb:
– Se han vendido $120,000
– Se han vendido $120,000 durante el último trimestre
– Se han vendido $120,000 en DVD’s durante el último
trimestre
– Se han vendido $120,000 en DVD’s durante el último
trimestre en la ciudad de Monterrey
Cada elemento, agrega valor al contexto de
enunciado inicial
Modelo de datos de múltiples
dimensiones
• DW y herramientas OLAP están basadas en un modelo
de datos multidimensional
– TABLA DE HECHOS
• Nombres de hechos, medidas, llaves a otras
tablas de dimensión
• Medidas numéricas: Unidades vendidas, dinero,
etcétera.
– Modelo más común en DW
Modelo de datos de múltiples
dimensiones
• DW y herramientas OLAP están basadas en un modelo
de datos multidimensional
– TABLA DE DIMENSION
• Representa información contextual al hecho y
agrega significado
• Ayuda al análisis desde distintos puntos de vista
sobre los hechos
• Se organiza en forma de atributos y jerarquías
Modelo de datos de múltiples
dimensiones
• Los datos se encuentran organizados en múltiples
dimensiones y cada dimensión contiene múltiples
niveles de abstracción definidos por jerarquías de
conceptos.
¿Ejemplo?
Modelo de datos de múltiples
dimensiones
• Los datos se encuentran organizados en múltiples
dimensiones y cada dimensión contiene múltiples
niveles de abstracción definidos por jerarquías de
conceptos.
¿Ejemplo?
Modelo de datos de múltiples
dimensiones
• Los datos se encuentran organizados en múltiples
dimensiones y cada dimensión contiene múltiples
niveles de abstracción definidos por jerarquías de
conceptos.
• Esta organización provee a los usuarios de la
flexibilidad de analizar los datos desde distintas
perspectivas.
• Existen un número de operaciones de cubo OLAP
para materializar esas diferentes vistas, permitiendo
consultas interactivas y análisis de los datos.
De tablas a cubos
• tiendaWeb
– Venta de varios productos
• Según clasificación de producto
• Según el color, tamaño o el peso del producto.
– Venta durante varios años
• Por años, meses, días
– Venta hacia clientes en distintos lugares
• Por Zona, País, Ciudad, Localidad.
– Venta mediante varios tipos de formas de pago
– Venta por detalles del cliente
• Según su grado escolar, numero de hijos, etcétera.
De tablas a cubos
Dimensiones: Tiempo, Producto
Cubos de datos en 3D
Mexico
Italia
China
Francia
Dimensiones: Tiempo, Producto, Localidad
Cubos de datos en 3D
Mexico
Italia
China
Francia
Dimensiones: Tiempo, Producto, Localidad
Cubos de datos en 3D
Dimensiones: Tiempo, Producto, Localidad
Cubos de datos en 4D
Forma de Pago
Visa
MasterCard
American Express
Dimensiones: Tiempo, Producto, Localidad, Forma de Pago
Modelo multidimensional
• Conjunto de HECHOS en un espacio de
múltiples dimensiones.
• Un hecho, contiene:
– Una dimensión de métrica
• Un conjunto de dimensiones en las cuales se
analizan los datos.
– Conforman un sistema de coordenadas y cada
dimensión tiene un conjunto de atributos.
– Los atributos de una dimensión se encuentran
relacionados por un orden parcial
• Jerárquico.
Modelo multidimensional
• Un modelo relacional no-normalizado
• Compuesto de tablas con atributos.
• Relaciones definidas por llaves foráneas.
• Organizado para su comprensión y facilidad
para hacer análisis, en lugar de actualizaciones.
• Consultado y mantenido por SQL o
herramientas administrativas de propósito
especial
ER vs Modelo multidimensional
• Una tabla por entidad
• Minimizar redundancia de
datos
• Optimizado para la
actualización
• Modelo de procesamiento
de transacciones
• Una tabla de hechos para
organizar los datos
• Maximizar comprensión
• Optimizado para acceso
• Modelo de almacenes de datos
Tabla de hechos
•
•
•
•
Contiene varias llaves foráneas
Tiende a contener bastantes registros
Hechos útiles tienden a ser numéricos y aditivos
Atributos No-llave (Los atributos en las tablas de
dimensión son constantes. Los hechos varían con la
granularidad de la tabla de hechos).
Lo que se mide
Tablas de dimensión
• Contienen texto e información descriptiva
• Una tabla (o jerarquía de tablas) conectada(s) con una
tabla de hechos mediante llaves y llaves foráneas.
• Valores univaluados para cada registro de la tabla de
hechos (1 en una relación 1-M).
• Generalmente, la fuente de restricciones de interés.
Las características
Medida
• La información contenida en la tabla de hechos, debe
ser ponderada
• Una medida es cualquier valor o cantidad que
representa un métrica alienada a la organización
• Se utilizan intercambiablemente “hecho”, “medida” o
“métrica”
• Un grupo de medidas es una colección de medidas
asociadas a una tabla de hechos
Medida
• Los tipos básicos son:
• Hechos totalmente aditivos
– Se pueden calcular para todas las dimensiones asociadas
– Ejemplo: Total de ventas para clientes, localidades y fechas
• Hechos semi – aditivos
– Se pueden calcular para algunas de las dimensiones
asociadas.
– Ejemplo: El balance bancario de un cliente NO se puede
calcular en la dimensión de fecha de manera aditiva
Medida
• Los tipos básicos son:
• Hechos no aditivos
– No se pueden calcular para ninguna de las dimensiones
asociadas (se carece de sentido)
– Ejemplo: Ganancia porcentual del producto no se puede
adicionar en la dimensión de tiempo
• Hechos derivados
– Se calculan a base de otros hechos
– Generalmente no se almacenan en el cubo, se calculan al
vuelo
– Ejemplo: Impuestos sobre ventas para dimensión de tiempo
Medida
• Los tipos básicos son:
• Hechos sin métrica
– No infieren información que modificar en la tabla de hechos,
pero se requieren para su análisis
– Ejemplo: Solicitar un balance de cuenta en cajero
automático
• Hechos textuales
– Es información no numérica que no es medible pero se
requiere para el análisis
– Ejemplo: Códigos de productos, banderas de estatus, etc.
¿Qué hacer desde el modelo
Relacional?
• En la mayoría de los casos, se crean múltiples índices y
tablas de resumen para evitar recorridos constantes
(el costo de E/S) sobre grandes tablas.
• La proliferación de estos elementos para mejorar el
desempeño de consultas y agregaciones que los
usuarios realizan, no hace sino incrementar el tiempo
de creación y espacio en disco utilizado para ello.
• Generalmente requiriendo más tiempo y espacio que
los datos originales.
Modelo de negocio
• Identificar la estructura de los datos, atributos y restricciones
para el ambiente que manejaran los clientes dentro del almacén
de datos
• Estable
• Optimizado para consultar
• Flexible
• Desventajas
• Desempeño
• Complejo
• Inflexible
Proceso de diseño
Elección del "Data Mart“.
Definición de la granularidad.
Elección de las dimensiones.
Elección de los hechos.
Proceso de diseño
• Enfoque de arriba – abajo
– Los problemas a ser resueltos están claros y bien
entendidos, tecnología disponible
• Enfoque de abajo – arriba
– El desarrollo de la tecnología en curso con uso de
prototipos
• Combinación de ambos
– Utiliza el enfoque de arriba – abajo y el uso oportunista
de abajo - arriba
Proceso de diseño
• En un inicio:
– Instalación
– Despliegue
– Entrenamiento
– Orientación
Proceso de diseño
• En la administración
– Refresco
– Sincronización
– Recuperación de desastres
– Control de acceso y seguridad
– Crecimiento
– Mejoramiento
Construir un DW a partir de un BD
• Desarrollar un modelo E/R del DW.
• Trasladarlo a un modelo de múltiples dimensiones.
(Este paso refleja las características analíticas y la
información del DW.
• Trasladar a un modelo físico (Esto refleja los cambios
necesarios para alcanzar los objetivos de
desempeño)
Modelado multidimensional
• Seleccionar una entidad asociativa como tabla de
hechos.
• Determinar la granularidad.
• Remplazar llaves con llaves generadas.
• Promover las llaves de todas las jerarquías hacia la
tabla de hechos.
Modelado multidimensional
• Tomar la intersección de las entidades como tablas de
hechos y construir las relaciones llaves foráneas
llaves primarias, como dimensiones.
• Agregar datos de dimensión.
• Dividir todos los atributos compuestos.
• Agregar dimensiones categóricas necesarias
• Hechos (Varían con el tiempo) / Atributos (Constante)
Granularidad
• La granularidad <- -> nivel de detalle.
Por ejemplo:
– Transacciones individuales.
– Instantáneas (puntos en el tiempo).
– Elementos en un documento
• Generalmente mejor enfocar en granularidad
pequeña.
Ejemplo
Ejemplo
Esquema en estrella
• Estrella
– Tabla central llamada tabla de hechos, sin
redundancias
– Un juego de tablas mas pequeñas llamadas tablas
de dimensión
– Cada dimensión esta representada por una sola
tabla con atributos propios
Esquema en estrella
Esquema en copo de nieve
• Copo de nieve
– Algunas tablas de dimensión están normalizadas,
permitiendo la división en tablas adicionales
– Tablas de dimensión normalizadas que evitan
redundancia y ahorran espacio
– Más reuniones (JOIN) para encontrar los datos
Esquema en copo de nieve
Detalles del diseño
• ¿Llaves primarias y subrogadas?
Detalles del diseño
• Primaria:
– Identifica un registro y tiene un significado dentro
del contexto del negocio
– Ejemplo: Número de incidente, número de
seguridad social, correo electrónico, etcétera.
• Puede ser numérica, cadena o combinación,
pero las reuniones son más lentas
Detalles del diseño
• Primaria:
• Ocupa más espacio
• No permite el mantenimiento de un historial
– ¿Qué sucede si un cambio en los datos del cliente
se realiza?
• La fusión de varias fuentes es más compleja
Detalles del diseño
• Subrogada:
– Identifica un registro y NO tiene un significado
dentro del contexto del negocio
– Ejemplo: nIdAlgo, Unique identifier, secAlgo,
etcétera.
• Es numérica y las reuniones son más rápidas
Detalles del diseño
•
•
•
•
Subrogada :
Ocupa menos espacio
Permite el mantenimiento de un historial
La fusión de varias fuentes es más sencilla
Ejemplos
Almacenamiento OLAP
A. OLAP Relacional (ROLAP)
– SMBDR especializado para almacenar y administrar
datos de DW
B. OLAP Multidimensional (MOLAP)
– Estructuras basadas en arreglos y cubos
C. OLAP Hibrido (HOLAP)
– Almacenamiento detallado en SMBDR
– Almacenamiento de agregaciones en SMBDM
– Acceso vía herramientas MOLAP
ROLAP: Modelado multidimensional usando
un SMBDR
• Esquemas especiales: star, snowflake
• Índices especiales: bitmap, columnas
• Tecnología probada, supera en rendimiento a
sistemas especializados con grandes conjuntos de
datos
Puntos sobre ROLAP
• Define modelado complejo usando conceptos
sencillos
• Reduce el numero de reuniones necesarias
• Permite evolucionar al DW con poco
mantenimiento
• Contiene datos de resumen y detallados.
• ROLAP se basa en tecnologías probadas y con
una fuerte base.
Puntos sobre ROLAP
Pero!!!
• Usa SQL para manipulaciones de múltiples
dimensiones.
– GROUP BY
– WITH CUBE, WITH ROLLUP
– GROUPING SETS
MOLAP: Modelo multidimensional puro
• Modelo de datos especifico
• Los hechos se almacenan en arreglos
multidimensionales
• Dimensiones usadas en índices
• Generalmente sobre BD relacionales
Puntos sobre MOLAP
• Consolidar los datos de transacciones mejora
la velocidad.
PERO
– Requiere una sobrecarga enorme la consolidación
de todos los datos entrantes. En procesamiento
como en almacenamiento
• Si los datos son menores a 50GB, es buen
modelo de datos.
• Rolling up y Drilling down se realiza sobre los
datos agregados.
OLAP Hibrido (HOLAP)
• Almacenamiento detallado en SMBDR
• Almacenamiento de agregaciones en SMBDM
• Acceso vía herramientas MOLAP
Flujo de datos en HOLAP
SMBDR
SMBDM
Meta datos
Datos
calculados
SQL
Clientes
Elementos a considerar para elegir
• Desempeño:
• ¿Qué tan rápido es necesario?
– MOLAP se desempeña mejor.
• Volumen de datos y escalabilidad:
– MOLAP manejan fácilmente 50GB, pero los
SMBDR van hacia 100 – 1000 gigabytes.
Métricas, categorización y computo
• Es una función que puede ser evaluada en cada
punto del espacio del cubo.
– Distributivas:
count()
– Algebraicas:
avg()
– Estadísticas:
median()
mode()
Operaciones multidimensionales
• ¿Para qué son útiles las Jerarquías de Concepto
en OLAP?
– Drill-Down
– Roll-Up
– Slice & Dice
– Pivot
Operaciones multidimensionales
• Drill-Down
Forma de Pago
Visa
MasterCard
American Express
Dimensiones: Tiempo, Producto, Localidad , Forma de Pago
Operaciones multidimensionales
• Roll-Up
Forma de Pago
Visa
MasterCard
American Express
Dimensiones: Tiempo, Producto, Localidad , Forma de Pago
Operaciones multidimensionales
• Slice & Dice
Dimensiones: Tiempo, Producto, Localidad
Operaciones multidimensionales
• Slice & Dice
Dimensiones: Tiempo, Producto, Localidad : Localidad = {Verde}
Operaciones multidimensionales
• Slice & Dice
Dimensiones: Tiempo, Producto, Localidad : Producto = {BR}
Operaciones multidimensionales
• Slice & Dice
Dimensiones: Tiempo, Producto, Localidad : Tiempo = {2000}
Operaciones multidimensionales
• Pivot
Dimensiones: Tiempo, Producto, Localidad
Arquitectura de un DW
• Enfoques en la elaboración de DW
– Top-down
– Data source
– Data warehouse
– Business
Arquitectura de un DW
• A tomar en consideración:
– Extractores
– Software de actualización
– Transformación de datos para la Toma de
decisiones
– Capacidad de búsqueda de patrones y anomalías
Arquitectura de un DW
Arquitectura de un DW
Arquitectura de un DW
Ambientes
transaccionales que
alimentan los
repositorios
Arquitectura de un DW
Servidores
intermedios que
procesan los datos y
posiblemente los
limpian
Arquitectura de un DW
Servidores OLAP
a)OLAP Relacional
(ROLAP)
b) Multidimensional
(MOLAP)
c) Híbrido
Arquitectura de un DW
Herramientas de
consulta y de reporte
además de
herramientas de
análisis y/o de
minería de datos.
Clasificación de tipos de DW
• Warehouse enterprise: Recolecta toda la
información sobre los temas de la organización.
Provee de integración de datos a lo largo de la
corporación. También incluye datos detallados, datos
resumidos y su alcance va de unos cuantos gigabytes
hasta terabytes o más.
Clasificación de tipos de DW
• Data mart: Contiene un subconjunto de datos
corporativos que es de valor a un grupo específico de
usuarios. El alcance es confinado a una selección
específica de temas. Los datos tienden a ser
resumidos.
– Dependientes
– Independientes
Clasificación de tipos de DW
• Virtual Warehouse: es un conjunto de vistas sobre
una base de datos operacional.
Implementación de un DW
Calculo eficiente de cubos
• Computo eficiente de agregaciones a través de
muchos conjuntos de dimensiones.
En términos SQL estas agregaciones se llaman
group-by’s.
• Cada group-by puede ser representado por un
cuboide, donde el conjunto de group-by’s forma
un enrejado de cuboides, definiendo un cubo de
datos.
• Un cubo de datos es un enrejado de cuboides.
La maldición de la dimensionalidad
Calcula agregados sobre todos los
subconjuntos de las dimensiones
especificadas en la operación.
Ejemplo:
Supongamos que queremos calcular un cubo para
tiendaWeb con las dimensiones: ciudad, producto, año
y el hecho: ventas.
Queremos analizar los datos con consultas como:
• Calcular la suma de ventas, agrupando por ciudad y
producto.
• Calcular la suma de ventas, agrupando por ciudad.
• Calcular la suma de ventas, agrupando por producto.
Ejemplo:
Tomamos ciudad, producto y año como dimensiones
del cubo de datos y ventas como la medida.
El total de group-by’s que podemos calcular es:
23=8
{(ciudad; producto; año), (ciudad; producto), (ciudad; año),
(producto; año), (ciudad), (producto), (año), ()}
El cuboide base contiene tres dimensiones.
Menos generalizado (más especifico)
El cuboide cima ó 0-D es el caso donde el group-by es vacío.
Mas generalizado (menos especifico)
(ciudad)
(producto)
(ciudad, producto)
(ciudad, año)
(año)
• Un
Para
operador
un cuboen
con
el ncubo
dimensiones,
en n dimensiones
hay un(producto,
total
es deaño)
2n
equivalente
a una colección
de group-by’s,
uno por
cuboides,
incluyendo
el cuboide
base
cada subconjunto de las n dimensiones. Por lo tanto, el
operador en el cubo es la generalización n-dimensional
(ciudad, producto, año)
del operador group-by.
La maldición de la dimensionalidad
• Si no hay jerarquías asociadas con cada dimensión,
entonces el numero total de cuboides para un cubo
de datos n-dimensional es 2n .
• Los requisitos de almacenamiento son excesivos
cuando muchas de las dimensiones han asociado
jerarquías de concepto, cada una con niveles
múltiples.
• Para un cubo de datos n-dimensional el numero total
de cuboides que puede ser generado (incluyendo los
cuboides generados por las jerarquías) es:
Calculo eficiente de cubos
n
Numero de cuboides ( Li 1)
i 1
Li es el numero de niveles asociado con una
dimensión i.
Esta formula se basa en el hecho de que a lo mas un
nivel de abstracción en cada dimensión aparecerá en
un cuboide.
Se suma 1 a la ecuación para incluir el nivel 0-D.
Calculo eficiente de cubos
• Si hay muchos cuboides y éstos son grandes en
tamaño, una opción mas razonable es la
materialización parcial, esto es, materializar solo
algunos de los posibles cuboides que pueden ser
generados.
Calculo eficiente de cubos
Hay tres opciones para la materialización de un cubo de
datos dado un cuboide base.
1. No materialización:
No pre-calcular los cuboides “no base”. Esto conduce a
calcular los agregados multidimensionales costosos lo cual
puede ser extremadamente lento.
(ciudad)
(producto)
(ciudad, producto)
(ciudad, año)
(ciudad, producto, año)
(año)
(producto, año)
Calculo eficiente de cubos
2. Materialización completa:
Pre-calculo de todos los cuboides. El enrejado resultante de
calcular los cuboides es llamado cubo completo. Esta opción
comúnmente requiere enormes cantidades de espacio en
memoria para almacenar todos los cuboide pre-calculados.
(ciudad)
(producto)
(ciudad)
(producto)
(año)
(ciudad, producto)
(ciudad, producto)
(ciudad, año)
(ciudad, año)
(producto, año)
(ciudad, producto, año)
(ciudad, producto, año)
(año)
(producto, año)
Calculo eficiente de cubos
3. Materialización parcial:
Calcular selectivamente un subconjunto propio de los
cuboides posibles. Calcular un subconjunto del cubo, el cual
contiene solo aquellas celdas que satisfacen algunos criterios
especificados por el usuario. Esta materialización representa
una compensación entre el espacio de almacén y el tiempo
de respuesta.
(ciudad)
(producto)
(ciudad)
(producto)
(año)
(ciudad, producto)
(ciudad, producto)
(ciudad, año)
(ciudad, año)
(producto, año)
(ciudad, producto, año)
(ciudad, producto, año)
(año)
(producto, año)
Calculo eficiente de cubos
La materialización parcial de cuboides o de sub-cubos
debe considerar tres factores:
1. Identificar el subconjunto de cuboides o sub-cubos para
materializar.
2. Aprovechar los cuboides o sub-cubos materializados
durante el proceso de consultas.
3. Actualizar eficientemente los cuboides o sub-cubos
materializados durante la carga y refresco
Índices en ambientes OLAP
El indexado en bitmap permite una búsqueda rápida en
cubos de datos.
Para un atributo dado, hay un vector de bits distinto, Bv,
para cada valor v en el dominio del atributo.
Si el dominio de un atributo dado consiste de n valores,
entonces son necesarios n bits para cada entrada en el
índice del bitmap (es decir, hay n vectores de bits).
Índices en ambientes OLAP
Cliente
ID
ColorFavorito
1 Rojo
2 Verde
3 Azul
4 Morado
5 Azul
6 Verde
7 Azul
8 Rojo
9 Verde
Pais
MX
UK
JP
MX
MX
US
US
UK
MX
IndiceBM1
ID
Rojo
1
2
3
4
5
6
7
8
9
IndiceBM2
ID
MX
1
2
3
4
5
6
7
8
9
Verde
1
0
0
0
0
0
0
1
0
Azul
0
1
0
0
0
1
0
0
1
US
1
0
0
1
1
0
0
0
1
Morado
0
0
1
0
1
0
1
0
0
UK
0
0
0
0
0
1
1
0
0
0
0
0
1
0
0
0
0
0
JP
0
1
0
0
0
0
0
1
0
0
0
1
0
0
0
0
0
0
Índices en ambientes OLAP
• Ventaja
– Útil para dominios de baja cardinalidad porque las
operaciones de comparación, unión y agregación son
reducidas a aritmética de bits, lo cual reduce
substancialmente el tiempo de procesamiento.
– Acelera operaciones de reunión y de unión
– Ideal para llaves foráneas y primarias entre tablas de
hechos y de dimensión
• Desventaja
– Para dominios de cardinalidad alta, el método puede ser
adaptado usando técnicas de compresión.
Índices en ambientes OLAP
El indexado por columna
• Considera un nuevo paradigma de almacenamiento
para los datos
• No es exclusivo de modelos de múltiples
dimensiones
• Permite una mejora tanto en velocidad como
almacenamiento
• No permite actualizaciones inmediatas
Índices en ambientes OLAP
Cliente
ID
1
2
3
4
5
6
7
8
9
Nombre
Hugo
Paco
Luis
Hugo
Ana
Silvia
Carmen
Ana
Hugo
ColorFavorito
Rojo
Verde
Azul
Morado
Azul
Verde
Azul
Rojo
Verde
Pais
MX
UK
JP
MX
MX
US
US
UK
MX
Ap_PaT
Abundes
Azul
Cruz
Bejenta
Berrulio
Cadiz
Santa
Villa
Perez
Encabezado
Encabezado
bytes)
Encabezado
Encabezado(96
(96
(96bytes)
bytes)
Nombr’1
Nombr’2
Nombr’3
Nombr’5
Nombr’6
Datos
1
Datos 2 Nombr’4 Datos
3
Nombr’7 Nombr’8 Nombr’9
Datos 4
Nombr’
ID
1
2
3
4
5
6
7
8
9
Nombre
Hugo
Paco
Luis
Hugo
Ana
Silvia
Carmen
Ana
Hugo
ColorFa’
ID
Nombre
1
Rojo
2
Verde
3
Azul
4
Morado
5
Azul
6
Verde
7
Azul
8
Rojo
9
Verde
Datos 5
Registro de
Datos 6
desplazamiento
Registro de8 7
desplazamiento
Cuerpo (8096 bytes)
Cuerpo (8096 bytes)
6
5
4
3
2
1
0
5
4
3
2
1
0
Índices en ambientes OLAP
• Ventaja
– Útil para consultas predefinidas de ambientes OLAP,
solamente se lee los atributos que se requieren lo cual
reduce substancialmente el tiempo de procesamiento.
– Acelera operaciones de reunión y de unión
• Desventaja
– Son estáticos entre carga y carga.
Procesamiento de consultas OLAP
El propósito de materializar cuboides y construir
estructuras de índices OLAP es acelerar el
procesamiento de consultas en cubos de datos. Dadas
vistas materializadas, el procesamiento de consultas
debe seguir la forma siguiente:
1. Determinar que operaciones se deben realizar en los
cuboides disponibles:
–
Esto implica transformar las operaciones de selección,
proyección , group-by y drill-down, especificadas en la
consulta a operaciones correspondientes en SQL y/o OLAP.
Procesamiento de consultas OLAP
El propósito de materializar cuboides y construir
estructuras de índices OLAP es acelerar el
procesamiento de consultas en cubos de datos. Dadas
vistas materializadas, el procesamiento de consultas
debe seguir la forma siguiente:
2. Determinar a cual cuboide materializado las operaciones
relevantes deben ser aplicas:
–
Esto implica identificar todos los cuboides materializados
que
pueden ser utilizados para responder la consulta, estimando el costo
de usar los cuboides materializados restantes y seleccionado el
cuboide con el menor costo.
Procesamiento de consultas OLAP
Supongamos que definimos un cubo de datos para tiendaWeb
de la forma: cubo ventas [fecha, producto, localidad]:
sum(total_venta), las jerarquías de dimensiones usadas
son:
día < mes < trimestre < año para fecha,
nombre < marca < tipo para producto y
calle < ciudad < estado < país para localidad.
Supongamos que la consulta que se procesará se encuentra en
{marca, estado}, con “año=2011” .
Procesamiento de consultas OLAP
También supongamos que hay cuatro cuboides materializados:
- cuboide 1: {año, nombre, ciudad}
- cuboide 2: {año, marca, país}
- cuboide 3: {año, marca, estado}
- cuboide 4: {nombre, estado}
Donde año = 2011
1. ¿Cuál de los cuboides debe ser seleccionado para procesar la consulta?
2. ¿Cómo se compararían los costos de cada cuboide si se utilizaron para
procesar la consulta?
Data Warehouse y Minería de datos
Uso de DW
Los DW y DM son utilizados en un rango muy amplio de
aplicaciones.
Evolución:
1. DW es utilizado principalmente para generar reportes y
contestar consultas predefinidas.
2. Progresivamente se utilizaron para analizar datos resumidos
y detallados, donde los resultados eran presentados en
forma de reportes o cartas.
Datamart
de Ventas
Datamart
Financiero
Datamart de
Recursos Humanos
Uso de DW
3. Después el DW se utilizo para propósitos estratégicos,
realizar análisis multidimensional y operaciones sofisticadas
de Slice & Dice.
4. Finalmente, ese emplea para descubrir conocimiento y
estrategias para tomar decisiones usando herramientas de
minería de datos. Las herramientas de DW pueden ser
categorizadas en herramientas de acceso y recuperación,
herramientas para reportar las base de datos, herramientas
de análisis de datos y herramientas de minería de datos.
Tipos de aplicaciones en DW
1.Procesamiento de información
Soporta consultas, análisis estadístico y divulgación utilizando
tablas cruzadas, tablas, cartas o graficas.
Una tendencia actual en el procesamiento de información de
DW es construir herramientas de acceso a la web de bajo
costo que son integradas con buscadores web.
Tipos de aplicaciones en DW
2. Procesamiento analítico
Soporta operaciones básicas OLAP incluyendo Slice & Dice,
Drill- Down, Roll-Up, y pivoteo, operando sobre datos
históricos en forma resumida y detallada.
El punto principal del procesamiento analítico en línea sobre
el manejo de información es el análisis de datos
multidimensional de los datos del DW.
Tipos de aplicaciones en DW
3. Minería de datos
Soporta el descubrimiento del conocimiento buscando
patrones y asociaciones ocultos, construyendo modelos
analíticos, realizando predicciones y clasificaciones y
presentando los resultados minados usando
herramientas de visualización.