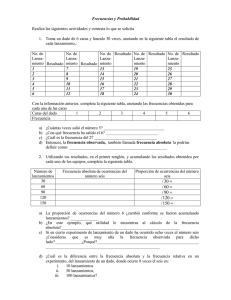
Conceptos de estadística inferencial
Anuncio

Estadística
Conceptos de
Estadística inferencial
Estadística inferencial
Es la rama de la Estadística que, basada en la descriptiva,
estudia el comportamiento y propiedades de las muestras,
y la posibilidad y los límites de la generalización de los
resultados obtenidos a partir de ellas a las poblaciones que
representan.
Esta generalización permite hacer estimaciones o inferencias
de tipo inductivo basadas en la probabilidad, como medio de
probar hipótesis o tomar decisiones.
Para empezar vamos a realizar un experimento sencillo:
Lanzamiento de una moneda ( no trucada )
¿ Qué resultados podemos obtener ?
Es lógico que si la lanzamos una vez, los posibles
resultados sean :
1) que salga cara
2) que salga número
de modo que el número de resultados posibles es 2.
Lanzamiento de una moneda ( no trucada )
Veamos el experimento con variables :
Si definimos a nuestra variable como
X = número de veces que sale cara,
los valores que puede tomar X son : {0, 1} ,
presentándose cada uno de ellos una sola
vez en el experimento.
Vemos que hay que “traducir” primero las situaciones a un lenguaje
matemático para luego utilizar los términos y cálculos estadísticos.
Traducción y Análisis de los posibles resultados
Recordando que la frecuencia absoluta es el número de veces que
aparece un cierto valor de la variable en el experimento, mientras que la
relativa es el cociente entre aquélla y el número de datos, resulta :
z am
1 lan
ien to
Resultados posibles
Nº caras
Nº caras
frec.abs.
frec.rel.
N=Nº datos
número
cara
0
1
0
1
1
1
0,5
0,5
2
Resultados posibles
Nº caras
Nº caras
frec.abs.
frec.rel.
N=Nº datos
número
número
cara
cara
número
cara
número
cara
0
1
1
2
0
1
2
1
2
1
0,25
0,5
0,25
3
Nº resultados
4
Nº resultados
s
ien to
m
a
z
2 lan
2
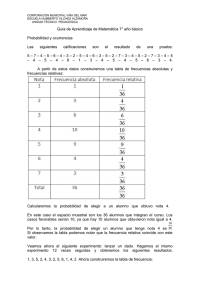
Ver que se siguió un razonamiento similar para calcular qué sucedería si
hacemos dos lanzamientos de la moneda.
Experimentos con una moneda / ruleta de colores :
Otra interpretación de los resultados obtenidos
Observemos que los datos obtenidos se pueden interpretar en términos de
porcentaje, diciendo que en el caso de un lanzamiento tenemos un 50% de
posibilidades de obtener cara, o bien interpretando la posibilidad de obtención
de un valor de una variable como la probabilidad de que ocurra un suceso:
Probabilidad de obtener el suceso “una vez cara en 1 lanzamiento” es 0,5
O simbólicamente ( asociando el suceso al valor 1 de la variable ) :
Pr(x=1) = 0,5
En este sentido la frecuencia relativa da la probabilidad correspondiente.
Resultados posibles
número
cara
Nº resultados
2
Nº caras
frec.abs.
frec.rel.
0
1
1
1
0,5
0,5
Probabilidad de un suceso :
En Estadística la probabilidad de que ocurra un suceso es el cociente entre
el número de posibilidades de que ocurra y el número total de posibilidades.
Ejemplo : Probabilidad de que al lanzar una moneda salga cara =
Número de veces que puede salir cara
Número de resultados posibles
Si hago un experimento concreto obtengo la llamada probabilidad empírica, que
es el cociente entre el número de veces que salió cara y el número de veces
que lanzé la moneda ( así que coincide con la frecuencia relativa ).
Estrictamente, esta probabilidad empírica tiende a la probabilidad
cuando el número de lanzamientos es muy grande ( infinito ).
Veamos ahora los resultados que obtuvimos anteriormente, más otros con
la ayuda de una hoja de cálculo :
Comportamiento de las frecuencias relativas ( probabilidades ) (1)
4 lanzam ientos
Frecuencia
relativa
0,600
0,400
0,200
0,000
0
0,400
0,300
0,200
0,100
0,000
Serie1
0
1
1
2
3
4
Nº de caras
Nº caras
10 lanzamientos
2 lanzamientos
Frecuencia relativa
0,300
0,6
0,5
0,4
0,3
0,2
0,1
0
0,250
0,200
0,150
0,100
0,050
0,000
0
1
0
2
1
2
3
4
5
6
7
8
9
10
Nº caras
Nº de caras
30 lanzamientos
Nº de caras
30
26
28
24
22
20
18
16
14
12
8
10
Nº de caras
3
6
2
4
1
2
0
0,16
0,14
0,12
0,1
0,08
0,06
0,04
0,02
0
0
0,400
0,300
0,200
0,100
0,000
Fre cue nc ia re lativ a
3 lanzam ientos
Frecuencia
relativa
Frecuencia relativa
Frecuencia relativa
1 lanzamiento
Comportamiento de las frecuencias relativas ( probabilidades ) (2)
Vemos que a medida que
aumenta el número de
lanzamientos, las diferencias
entre frecuencias relativas
contiguas se van haciendo más
pequeñas y el polígono de
frecuencias se va aproximando
a una curva, a grandes rasgos
continua.
x = 5,00
Frecuencia relativa
10 lanzamientos
σ = 1,12
0,300
0,250
0,200
0,150
0,100
0,050
0,000
0
1
2
3
4
5
6
7
8
9
Nº de caras
Nº de caras
30
28
24
22
20
18
16
14
12
10
8
6
4
2
0
Frecuencia relativa
0,16
0,14
0,12
0,1
0,08
0,06
0,04
0,02
0
26
x = 15,00
σ = 2,74
30 lanzamientos
También se observa que hay un
cierto valor de la variable que
tiene probabilidad máxima de
aparición : es la moda y por la
simetría observada, es también
la media y la mediana de los
datos.
10
Pasaje al límite ( extrapolación )
Con los resultados anteriores, es bastante razonable pensar que, al pasar al
límite de “infinitos” lanzamientos, el polígono de frecuencias quede bastante
parecido al siguiente
Esta es la famosa Distribución Normal o de Gauss o “campana” de Gauss,
cuya variable es x, con media m y desviación típica s
Comentarios y conclusiones
En la extrapolación vista se ha usado un argumento intuitivo ( de pasaje al
límite de lanzamientos ), el cual no es estrictamente matemático, aunque el
resultado final sí es correcto matemáticamente.
También se ha pasado rápidamente de una variable discreta ( número de
caras ) a una variable continua como es la utilizada en la definición de la
distribución normal. Esto no es muy grave si se tiene en cuenta que se trata
de una aproximación en los cálculos.
Sin embargo hay un concepto que debemos adecuar a esta situación.
Vimos anteriormente que en el caso discreto la suma de las frecuencias
relativas ( o probabilidades ) de todos los valores de la variable da 1.
Para lograr un acuerdo, se define que en el caso continuo el área total bajo la
curva vale 1. Entonces el área se convierte en una probabilidad.
Veremos a continuación la importancia de esta definición y conceptos.
* Propiedades de la Distribución de Gauss normalizada:
Es una distribución de la variable
z ≡
DN(0,1)
s=1
x−µ
σ
( de valor medio 0 y s= 1) :
1) El área marcada bajo la curva
es la probabilidad de que z tome
valores mayores que zc
2) La curva es simétrica respecto
a la media (que vale 0), así que:
Pr( z < 0 ) = Pr( z > 0 ) = 0,5
2’) Pr ( z < -a ) = Pr ( z > a)
z =µ =0
3) Pr ( -1<z<1) = 0,683 ó
3’) Pr ( z > 1) = 0,1587
* Intervalo de confianza para la media de una DN(0,1)
s=1
x =µ =0
Definición :
Es el intervalo de valores de
la variable z para los cuales la
probabilidad de que la media
de los datos se encuentre en
dicho intervalo, es un valor
determinado ( llamado nivel
de confianza : NC).
Ejemplo : Para la DN(0,1)
al 68,3% de NC,
la media de z está en el
intervalo: [-1,1] con una
probabilidad del 0,683
( ver tabla y propiedades)
* Intervalo de confianza para la media de una DN (m,s)
-s
+s
Para una DN(m,s), cuya
variable es x, la media está
en el intervalo centrado en
m:
[m
m - s, m +s ] con
una probabilidad del 0,683
[m
m - 2s,
s, m +2s ] con una
probabilidad del 0,955
[m
m - 3s,
s, m +3s ] con una
probabilidad del 0,997
x=µ
* Prueba de hipótesis / toma de decisiones
Aunque no lo parezca, la importancia de los conceptos y propiedades
vistas está en que sirven para aceptar o no una hipótesis y por ende,
para tomar decisiones:
s
s
Ejemplo :
Si la media de la muestra
está en la región marcada,
aceptamos la hipótesis de
que esta media coincide
con la media de la
población con un nivel de
confianza del 68,3 %.
De lo contrario,
rechazamos tal hipótesis.
xP
* Correlación entre variables
Retomemos el caso de una muestra de una población, en la cual
medimos dos variables y queremos averiguar si están o no
relacionadas entre sí ( distribución bidimensional )
Ejemplo : Si sobre una población de niños
estudiamos las variables peso y estatura,
esperamos que a mayor estatura también
encontremos mayor peso, aunque es posible
que en algunos pocos casos no ocurra así.
Vemos que parece existir una relación entre las
dos variables, aunque no conocemos cual es la
función, o sea, no podemos determinar con
exactitud el peso que corresponderá a cada
estatura.
* Dependencia entre variables
• Traduciendo a términos estadísticos, supongamos que estamos
buscando una relación entre dos variables distintas
( ejemplo : X e Y), que corresponden a una misma muestra o población.
xi
1
2
3
4
5
yi
1,3
1,5
1,5
2
2,1
Frec. Abs.
yi
2
1
3
5
4
N=15
1,3
2
1
2
3
4
5
ny
xi
1,5
5
2
4
2
1,5
y
1
0,5
0
1
2
3
x
2,1
1
3
2,5
0
2
4
5
6
5
4
4
nx
2
1
3
5
4
N=15
* Dependencia entre variables
• Lógicamente se pueden dar dos resultados según exista o no
relación entre ambas :
(1) X e Y dependientes :
¿?
existe relación entre ambas, aunque
su expresión funcional es desconocida.
Si ocurre esto decimos que las
variables están correlacionadas o bien
que hay correlación entre ellas.
(2) X e Y independientes :
no existe relación entre ambas,
o una no proporciona información
sobre la otra
* Dependencia entre variables
Ejemplo numérico:
Se tienen dos conjuntos de datos numéricos (X,Y) y cada uno de ellos
aparece una vez :
¿?
x
1
2
3
4
y
1.0
1.5
1.7
2.0
Sospechamos que existe una
relación entre ellos, pero
¿podremos encontrar alguna
función que los relacione?
* Dependencia entre variables : ajuste lineal
La primera aproximación es ver si la dependencia es lineal :
x
1
2
3
4
y
1.0
1.5
1.7
2.0
Vemos que hay bastante diferencia entre
algunos datos y la recta hallada.
* Dependencia entre variables : ajuste cuadrático
La segunda aproximación es ver si la dependencia es cuadrática :
x
1
2
3
4
y
1.0
1.5
1.7
2.0
Nuevamente hay diferencias, pero
vemos que nos vamos aproximando
a un ajuste razonable.
Resumen y casi el final
Hemos visto :
• Utilización básica de una hoja de cálculo
• Nociones de probabilidad
• Distribución normal
• Nociones de prueba de hipótesis
• Nociones de correlación y ajuste
Terminado este “viaje panorámico“ por el país de la Estadística,
sólo me resta desearles ánimo para aplicar estos procedimientos
y herramientas, a los que se deben incorporar fuertes dosis de
interpretación conceptual.
Supongo que ahora sólo resta plasmar vuestras conclusiones o
impresiones de tal viaje, aunque imagino formarán un conjunto
más o menos parecido al siguiente :
* Conclusiones Fin de curso (¿?)
Muchas gracias por su atención.
Adolfo Fajardo