I. Variables
Anuncio

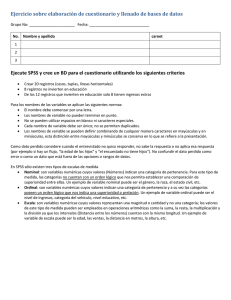
A. Importancia de la estadística para los estudiantes 1. Todo ciudadano está en continuo contacto con las estadísticas en todos los medios de comunicación. Debe poder comprender la información que se le ofrece para detectar mentiras y tomar decisiones informadas. 2. Como lector de artículos de investigación debe poder comprender la información cuantitativa que se le ofrece en los artículos que lee 3. Como productor de investigaciones, debe poder utilizar las estadísticas en sus propias investigaciones. B. Múltiples significados dependiendo del contexto Meteorología En este contexto, en la televisión, por estadísticas se refieren a la cantidad de lluvia en el año; la temperatura promedio del mes; la temperatura máxima y mínima del día, etc. Matemáticas En este contexto la estadística es el área de aplicación de modelos probabilísticos. Ciencias sociales El significado de la estadística en el contexto de la investigación social se enfoca más en los métodos o procedimientos utilizados por los investigadores para comprender e interpretar datos. Es parte integral del proceso de investigación y en la mayoría de las tesis y disertaciones ocupa una posición central. II. El proceso investigativo A. Etapas del proceso investigativo El proceso investigativo tradicional con el que se genera una disertación o tesis consiste de varias etapas o momentos entre los que se distinguen como esenciales 1. el planteamiento del objetivo de la investigación o creación de la pregunta de investigación 2. el planteamiento de las hipótesis de investigación 3. la recolección de datos para someter a prueba la hipótesis de investigación 4. el análisis de los datos recogidos 5. la evaluación de las hipótesis a la luz de estos análisis B. La función de la estadística dentro del proceso de investigación empírica Dentro del proceso de investigación se puede llamar estadística a todos y cada uno de los siguientes procesos 1. la recolección de datos a través de cuestionarios y observaciones 2. la presentación de los datos en tablas y gráficas 3. la transcripción de datos por medio de medidas de tendencia central y dispersión 4. el análisis e interpretación de resultados 5. la presentación de conclusiones (donde se interpretan cualitativamente los resultados cuantitativos) 6. el proceso (puntos 1-5) en su totalidad como la justificación para la toma de decisiones. III. Tipos de estadísticas A. Estadística descriptiva (Descriptive statistics) Se origina con la recolección de datos poblacionales para censos. En la estadística descriptiva, el investigador debe preocuparse por organizar y presentar los datos de una forma comprensible y sobre todo honesta. Definición: Métodos utilizados para organizar, presentar y describir datos de manera adecuada. Una definición más general es la disciplina que estudia la variabilidad B. Estadística inferencial (Inferential statistics) Se origina en el Renacimiento con el desarrollo de la probabilidad matemática, que a su vez se basa en el estudio de los juegos de azar. Comienza a desarrollarse plenamente con Karl Pearson (1857-1936) y Ronald Fisher (1890-1962) a principios del siglo XX. Está íntimamente relacionada con los conceptos de población, muestra, parámetro y estadísticas. Población (Population) Es el total de objetos bajo consideración Es el grupo o conjunto sobre el cual el investigador quiere hacer una inferencia La mayor parte de las veces es muy grande Algunas veces es hipotética Si, por ejemplo, si se quiere demostrar que la semejanza entre personas afecta el nivel de atracción, la población de "personas semejantes" es hipotética pues se hace imposible encontrar una población de personas semejantes en todos los aspectos. Muestra (sample) Aunque el investigador se interesa, la mayor parte de las veces en la población, muy pocas veces puede llegar a toda ella. Para hacer cualquier estudio se ve obligado a seleccionar parte de la población. La muestra es la porción de la población seleccionada para la investigación La selección se hace porque generalmente el costo, el tiempo y los recursos son limitados para hacer la investigación con toda la población. Partiendo de los resultados del estudio con la muestra (si ésta es verdaderamente representativa de la población), el investigador puede hacer inferencias sobre la población. Parámetro (parameter) Es la medida de una característica numérica de la población. (Media, mediana, varianza, etc.) . Es un elemento descriptivo de la población. Estadísticas (statistics) Es una medida que se utiliza para describir una característica numérica de la muestra, no de la población como en el caso del parámetro. La estadística inferencial sirve para determinar cómo una estadística y un parámetro se relacionan. Actividad: (Se organizan grupos de 3 o cuatro estudiantes y se les pide que definan la estadística inferencial utilizando las palabras muestra, población, parámetro, estadística, método. Deben reducir la definición a un mínimo de palabras.) C. Definiciones posibles de la estadística inferencial 1. Métodos o procedimientos que hacen posible la estimación de una característica de la población basándose exclusivamente en los resultados obtenidos en la muestra. 2. Métodos que hacen posible la estimación de un parámetro basándose exclusivamente en la estadística correspondiente. 3. Generalizaciones sobre la población basadas exclusivamente en los resultados de la muestra. Variables y datos I. Variables En un proceso de observación o en un cuestionario se observan o se hacen preguntas sobre ciertas características de los sujetos o sobre ciertos fenómenos. Estas características que se tratan de medir en la investigación se llaman variables. Cuando en una investigación cuantitativa se pasa de la pregunta o preguntas de investigación a las hipótesis es necesario expresar las hipótesis en términos de variables. Una hipótesis de investigación, por lo general, se expresa como una relación entre dos variables, la variable independiente y la variable dependiente. Éstas se pueden visualizar a veces como la causa y el efecto en la relación. (Aunque pocas veces las relaciones que se establecen en las investigaciones educacionales corresponden a causas y efectos). Definición Una variable es una característica de los sujetos que puede asumir más de un valor. Los valores que asumen las variables en cada uno de los sujetos son los datos. Ejemplo: En un estudio en que se trata de determinar el aprovechamiento de los estudiantes en una escuela, una de las variables puede ser la nota obtenida en el curso de estadísticas. Los datos son, en este caso, las notas obtenidas en estadísticas por cada uno de los estudiantes que han tomado el curso. II. Datos 1. Datos publicados Se pueden utilizar datos publicados previamente que el investigador no tiene que recoger. Estamos en la época de la tecnología y la información. Las bibliotecas están equipadas con computadoras y a través de éstas se pueden localizar bancos de datos que otras personas o instituciones han recogido y almacenado. Estas fuentes de datos para las investigaciones pueden ser: Fuentes primarias. Estas son las personas u organizaciones que recogen los datos directamente. Fuentes secundarias. Son las personas u organizaciones que han compilado los datos en tablas y gráficas. Por lo general, tanto el gobierno como las universidades son fuentes primarias y secundarias. 2. Datos obtenidos en la experimentación En la investigación a menudo se utilizan datos obtenidos a través de la experimentación. Esto ocurre principalmente en las investigaciones de medicina y de ciencias naturales. La investigación consiste en el montaje de un experimento en que se controlan todas las variables que pueden influir en los resultados y entonces se maneja la variable independiente y se observan los cambios en la variable dependiente. Cuando esto ocurre se puede hablar de una relación de "causa y efecto". La investigación es un verdadero experimento. En las ciencias sociales es más difícil puesto que se dificulta imponer controles sobre el medio social. En el momento de la recolección de datos debe haber control sobre todas las variables que pueden afectar variaciones en el experimento. Para hablar de un "experimento" y de una relación de causa y efecto es necesario que se den tres condiciones: a. la variable dependiente es el objetivo de la investigación. Se trata de determinar cómo se modifica esta variable dependiente cuando se ha modificado la variable independiente. b. la modificación en la variable independiente ocurre antes que la modificación en la variable dependiente c. la variable independiente ejerce una influencia directa o indirecta en la variable dependiente. 3. Datos obtenidos a través de cuestionarios La forma más común de llevar a cabo una investigación en las ciencias sociales es utilizando datos obtenidos a través de cuestionarios. En estos casos no se ejerce control sobre el comportamiento de las personas. Sólo se hacen preguntas y se observan las dos variables (independiente y dependiente) al mismo tiempo. En los cuestionarios no se busca una relación de causa y efecto, sino de correlación entre dos variables. Se busca determinar si la magnitud una variable se relaciona con la magnitud de la otra. Por lo general no se habla de variables independientes y dependientes, sino de predictores y criterios. El cambio en el predictor no es la causa del cambio en el criterio aunque un cambio implique el otro. Ejemplos: Causa y efecto: vacuna y prevención de la enfermedad. La vacuna es la causa de que la enfermedad no tenga lugar. Correlación: Se observa en la relación entre preparación académica y salario. Por lo general, mientras mayor es la preparación académica mayor es el salario. Pero esto no siempre ocurre y la causa del mayor salario puede muy bien ser otra diferente de la preparación académica. Una correlación que hace obvia esta situación es la alta relación que hay entre tamaño de pie y destrezas de lectura. Nadie en su sano juicio puede asegurar que el tamaño del pie es la causa de las destrezas, sin embargo mientras mayor es el tamaño de pie, mayor es la habilidad en la lectura. Hay una variable escondida que es la causa de ambas (el crecimiento). 4. Datos obtenidos de la observación Se utilizan mucho en antropología y en investigaciones sobre animales. Este método de recoger datos tiene problemas debido a la subjetividad del observador y al hecho de que la presencia del observador puede modificar la situación. III. Clasificación de datos y variables Datos o variables Preguntas Respuestas Categóricas o cualitativas Tienes pasaporte si / no (dicótoma) discretas ¿Cuántas camisas tienes? Número natural continuas ¿Cuánto pesas? Número real Numéricas o cuantitativas Esta clasificación se puede aplicar tanto a las variables como a los datos. A. Datos o variables categóricas / cualitativas Son características que se refieren a categorías como sexo, afiliación política, color de los ojos. Por lo general, estas características no se pueden describir por medio de números, pero se pueden contar. En los cuestionarios, por lo general, las preguntas sobre estas variables se pueden responder nombrandolas o eligiendo un nombre. El caso más simple es "si" o "no". Ejemplos: ¿De que color tiene los ojos? ¿Cuáles son las marcas de computadora que conoces? ¿ Cuáles de las siguientes actividades realiza durante su clase? ¿Posees un carro? ¿Vives en una casa? ¿Tienes los ojos azules? B. Datos o variables numéricas / cuantitativas Las preguntas que se hacen sobre estas variables se pueden responder con un número. ¿Cuánto pesas? ¿Cuánto mides? ¿Cuánto dinero ganas? ¿Cuántos hijos tienes? Las variables numéricas pueden ser : Discretas o Discontinuas Una variable es discreta si sus valores se pueden contar; si existe una relación biunívoca con el conjunto de los números naturales. Existe una unidad mínima que no puede subdividirse. Ejemplo: cantidad de carros, de hijos, ingreso anual, etc. No se puede tener medio hijo o un cuarto de carro. Continuas Los valores de estas variables no se pueden contar puesto que siempre existe un número entre dos de ellos. Generalmente se encuentran en los procesos de medición, como peso, altura, temperatura. Además en la realidad no hay dos sujetos con la misma medida. No existe una unidad indivisible para los datos continuos como ocurre con los datos discretos. Sin embargo, debido a que los instrumentos de medición generalmente no son muy sofisticados y precisos, en las investigaciones se encuentran sujetos con la misma medida (debido al redondeo) Por extensión las variables reciben el mismo nombre de los datos. Pueden ser categóricas y numéricas. Si son numéricas pueden clasificarse en discretas y continuas. Cuando una variable numérica o categórica puede tener solamente dos valores se llama dicótoma, dicotómica, binomial, binominal.. IV. Escalas de medición Uno de los puntos más importantes de una investigación es determinar el tipo de análisis estadístico de los datos que se va a llevar a cabo. En estadísticas el tipo de análisis depende del nivel o escala de medición de las variables de la investigación. Los cursos de estadísticas en las ciencias de la educación y en las ciencias sociales están diseñados para que los estudiantes aprendan diversos métodos de análisis estadístico. Pero antes de aplicar cualquiera de ellos, el estudiante debe haber determinado el nivel de medición de sus variables de investigación. Cada nivel requiere un análisis diferente. La importancia de esta clasificación por niveles reside en el hecho de que mientras más complejo o alto es el nivel de medición, más efectivos son los métodos estadísticos que se pueden utilizar. Para hablar de niveles o escalas de medición es imprescindible primeramente clarificar que es "medir" en las ciencias sociales. Medir no es solamente determinar las dimensiones de un objeto. En las ciencias sociales la idea de medición se aplica en muchas otras ocasiones. Ejemplos: Se mide cuando determina: la religión de una persona el color de pelo el ingreso anual el género el peso el tamaño la puntuación en un examen la nota El tipo de medida que se obtiene en la investigación puede caer en una de las siguiente cuatro escalas o niveles de medición: nominal, ordinal, intervalar (o de intervalo) y de razón) Si las variables son categóricas entonces dependiendo del grado de precisión posible en la medición se utilizan la escalas Nominal y Ordinal: Escala nominal: La escala nominal se utiliza cuando los datos están clasificados en categorías en las que no hay ninguna idea de ordenamiento. No se puede decir que una categoría es mejor que otra. El propósito en este nivel es solamente clasificar, nombrar los datos. Se refiere a atributos de los sujetos, no a cantidades. En ningún momento se habla de números, aunque a la hora de entrar los datos a la computadora se puede asignar un número para hacer la entrada de datos más simple. A veces se ve asignar el #1 al género femenino y el #2 al masculino. En College Board se utilizan el #7 y el #8 para los dos géneros. Pero esta asignación de valores es arbitraria. Ejemplos: colores, religiones, partidos políticos, etc. Cuando se trabaja con correlaciones hay un tipo de escala nominal sumamente importante. Consta de sólo dos niveles. Las variables clasificadas en estas dos categorías se llaman dicótomas o dicotómicas. Algunas veces binominales Ejemplo: Sexo, fuma o no fuma, rico o pobre, etc. Generalmente cuando se codifica, para identificar la presencia del atributo se usa 1 y su ausencia 0. Escala ordinal: Hay orden en este nivel de medición. Se sugiere un rango en las categoría de forma que una categoría es mejor, más importante, mejor o mayor que otra. Sin embargo, no hay un sentido numérico para este orden. La diferencia entre dos rangos no es una cantidad exacta. Ejemplo: En una escala Likert los rangos pueden ser: Acuerdo total, acuerdo parcial, desacuerdo parcial y desacuerdo total. En este caso es posible que la diferencia entre acuerdo total y acuerdo parcial se pueda interpretar de formas diferentes por personas diferentes. Se hace imposible medir numéricamente la diferencia entre acuerdo total y acuerdo parcial, aunque es obvio que uno es mayor o mejor que otro. NO existen "unidades de acuerdo" que permitan decir que entre acuerdo parcial y acuerdo total hay " 5 unidades de acuerdo". En muchas ocasiones se usan números para codificar estas respuestas como: acuerdo total (5), acuerdo parcial (4), indeciso(3), desacuerdo parcial (2), desacuerdo total (1). Estos números sólo representan orden. En ningún momento se implica que la diferencia entre acuerdo total y acuerdo parcial es de una unidad. Hay orden en este nivel de medición. Se obtiene mayor información sobre la variable. Implica que una categoría es mejor que otra. También se usa mucho la clasificación en dos categorías aunque la variable en sí sea cuantitativa, continua y tenga una distribución normal.Esto se debe, en la mayoría de los casos, a que no se recogieron los datos íntegros Ejemplo: Niños con IQ sobre 100 y bajo 100. Hay puntuación para cada niño, pero sólo se recogió si estaba sobre el promedio o no. Otros ejemplos de Variables categóricas son Variable categórica partido político Género Colores Satisfacción Nota Categorías PPD; PNP; PIP mujer, hombre negro, rojo,..... mucha, mediana, poca A, B, C, D, F Escala nominal nominal nominal ordinal ordinal Cuando las variables son cuantitativas entonces es posible usar una de las siguientes dos escalas: 3. Escala intervalar o de intervalo La escala intervalar se utiliza con datos numéricos. Cada sujeto recibe un número. En esta escala la diferencia entre dos medidas es significativa. Ejemplos: Puntuaciones en la Prueba de Razonamiento Verbal del College Board; IQ; temperatura del agua Estos datos se pueden sumar y restar. Es posible decir cuánto mejor salió un estudiante en la prueba que otro, o cuanto supera un sujeto a otro en IQ. La diferencia entre dos medidas es significativa Ejemplo: 79 grados es 2 más que 77 grados de temperatura. La diferencia entre 79 y 77 grados es la misma que entre 55 y 53 grados. Sin embargo no hay un cero verdadero. El cero en temperatura Fahrenheit es una temperatura seleccionada al azar. El cero en centígrados corresponde a otra temperatura muy diferente. El resultado es que, a pesar que 100 es el doble de 50, en una temperatura de 100 no hace el doble de calor que en una de 50. No se siente el doble de calor. Ejemplo: Un niño con un IQ de 150 no tiene el doble de inteligencia de uno con un IQ de 75. Esta es una de las razones por las que cuando se mide un atributo psicológico por medio de un instrumento, el cero no tiene sentido y en muchos de los instrumentos simplemente no existe. 4. Escala de razón Tiene un cero real. Tanto a - b (a menos b) como a/b (a dividido entre b) tienen significado. Ejemplo: peso, altura. Tiene sentido hablar de que una persona pesa el doble de otra. O que alguien tiene el doble de años que otro. Esta clasificación de las escalas para medir las variables es sumamente importante, pues dependiendo de la escala se van a seleccionar lo métodos estadísticos que se pueden emplear. Los métodos más precisos en términos de predicción son los métodos paramétricos, que son los que se estudian en este curso. Para poder usarlos, las variables tienen que medirse en escalas intervalares o de razón. Cuando las escalas son nominales u ordinales, no queda más remedio que utilizar métodos estadísticos no paramétricos, que no son tan precisos en su medición. En este curso nos limitaremos a hacer estudios descriptivos. Es siempre posible pasar de una escala a otra menos exigente. Ejemplo: Los estudiantes pueden medirse en metros (razón) o simplemente se pueden ordenar de mayor a menor (ordinal). Nota: A veces los investigadores convierten una variable cuantitativa a rangos o dicotomías, pero esto no lo hacen sin tener razones muy poderosas para ello, pues en realidad estarían perdiendo información muy valiosa. Generalmente cuando se hace es porque se trabaja con datos ya colectados en términos de rangos o dicotomías. Otros ejemplos de Variables numéricas Variable numérica Temperatura IQ peso altura edad Escala intervalar intervalar razón razón razón Si los datos son categóricos o cualitativos, entonces dependiendo del grado de precisión posible en la medición, se utilizan las siguientes dos escalas: V. Codificación y entrada de datos a la computadora Para codificar datos se crea un libro de código (codebook) o nomenclatura donde: 1. Se identifican las variables y se asignan las columnas requeridas para cada una de las variables 2. Se asignan códigos para cada valor de las variables no numéricas. 3. Se construye un archivo de datos (data file) en la computadora donde cada fila corresponde a un sujeto diferente. 4. Esta entrada de datos se puede hacer directamente usando un procesador de palabras cualquiera, pero se dificulta el proceso. 5. Generalmente se utiliza una hoja electrónica de datos (spreadsheet) de un programa estadístico como Excel o SPSS en los cuales se identifican mejor las columnas y es más fácil la entrada de datos.