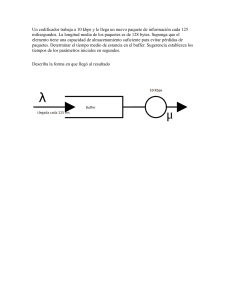
")
1. ¿Qué es la Comunicación? Es principalmente transmitir información desde un punto a otro a través de una sucesión de procesos. Los diferentes medios de comunicación tienen algo en común: transmiten información. 2. ¿Qué es la telecomunicación? Las telecomunicaciones es la comunicación a distancia, técnica que consiste en transmitir un mensaje desde un punto a otro, normalmente con una comunicación de tipo bidireccional. Las telecomunicaciones abarcan varias formas de comunicación a distancia, la radio, telegrafía, televisión, transmisión de datos e interconexión de PCs a nivel de enlace. 3. ¿Cómo es el proceso de un Sistema de Comunicaciones? Dentro del *procesamiento de comunicaciones digitales* se trabaja con: El formato: este transforma la información de la fuente a una simbología digital. La codificación de la fuente: produce conversión A/D si se trata de fuente análogas y elimina la información redundante o innecesaria. El cifrado: evita que el mensaje sea entendido por usuarios no autorizados y previene que se introduzcan falsos mensajes. La codificación del canal: donde se puede reducir la probabilidad de error o los requerimientos de SNR a expensas del ancho de banda o complejidad en el decodificador. Dentro de los procesos de un Sistemas Digital de Comunicaciones se trabaja con: Generación (Abstracta): Es la generación de señal mensaje en la fuente de información. La descripción (Símbolos): Generación de señal mensaje en la fuente de información. La codificación (la adecuación al medio): Codificación de Fuente: elimina información redundante. Codificación de Canal: Adiciona información adecuada. Modulación: adaptación al canal de transmisión. La transmisión, decodificación y Regeneración de Información: Transmisión a través de un canal. Demodulación: recuperación de versión ruidos de la señal original. Decodificación de Canal: eliminar perturbaciones y estimar (recuperar) la señal original. Decodificación de Fuente: añadir información redundante necesaria para su reinterpretación por el nuevo dispositivo de recepción. Entrega de la señal mensaje estimada al usuario destino. 4. Tareas de un Sistema de Comunicaciones: Uso de un Sistema de Transmisión: Que tiene una necesidad de uso eficaz de los recursos. Intervienen técnicas de multiplexación y control de flujo. Generación de señal: Generar señales electromagnéticas para que la misma se propague por el medio de transmisión hasta el receptor. Sincronismo: Sincronismo entre el transmisor y el receptor. Sincronismo en la interfaz. Gestión del intercambio: Reglas y requisitos a cumplir por ambas partes para que la comunicación tenga efecto. Detección y corrección de errores: Para el caso que sea necesario se aplican una o ambas tareas. Control de flujo: La forma de regular el flujo de información para que no se reproduzca perdida de información por congestión. Direccionamiento: La manera de identificar las fuentes y destinos. Enrutamiento: El camino que se decide por el que los datos son enviados por la fuente hacia un destino específico. Recuperación: Recupero ante una falla. Formato de mensajes: Acuerdo entre fuente y destino. Seguridad y gestión de red: Se asegura que la información enviada por la fuente la recibe sólo el receptor. Y en gestión monitorea y configuración de los recursos que hacen al sistema. 5. Networking El objetivo básico de una red es permitir que la información se pueda compartir entre personas y/o máquinas. Uno de los tipos más comunes de redes es la Red de Área Local o LAN. Una red de computadoras puede definirse como "dos o más computadoras conectadas de alguna manera por la cual son capaces de intercambiar información." según Gary A. Donahue, de Network Warrior, 2007. A través del networking, es posible que diferentes tipos de computadoras se comuniquen. Dentro del networking, lo más importante es que todos los dispositivos hablen el mismo idioma o protocolo. Las LANS lograron reducir costos al permitir la utilización compartida entre periféricos, archivos y demás dispositivos de forma más eficiente. Con el aumento de su popularidad y uso, se hizo necesario la vinculación de distintas LAN's para poder transferir información. La solución fue la creación de las Redes de Área amplia, las WAN. LAs WAN hicieron posible que las empresas se comunicaran entre ellas, aún estando geográficamente alejadas entre sí. Central de Conmutación (Def): Una central de conmutación dentro de las telecomunicaciones, es una dispositivo clave pata poder permitir la comunicación fluida entre diferentes dispositivos redes. Su función principal es permitir que los usuarios se conecten entre si a través de diferentes medios de comunicación. En otras palabras, en un "puente" entre diferentes sistemas de comunicación. Puede ser sistemas telefónicos, plataformas de comunicaciones más complejas. Actualmente, se usan varios tipos de centrales de conmutación dentro de las telecomunicaciones: Centrales telefónicas analógicas: Estas son las que se consideran más antiguas. Centrales telefónicas digitales: usan señales digitales para transmitir la voz y otros datos. Centrales híbridas: Combinan las características de las centrales analógicas y digitales. Centrales telefónicas basadas en tecnología IP: Usan el protocolo de Internet para transmitir la voz como los datos a través de la red. Centrales virtuales: Son sistemas basados en la nube que proporcionan servicios de centralita sin necesidad de una hardware físico. 6. Redes de Datos: La comunicación se realiza por la transmisión de datos a través de nodos de conmutación. A los nodos de conmutación no les importa el contenido. Los dispositivos extremos se denominan estaciones (las computadoras, las terminales, los teléfonos, etc). Los nodos se conectan con cierta topología a través de enlaces de transmisión. Las estaciones se conectan a un nodo. El conjunto de nodos es una red de comunicaciones. 7. Evolución cronológica de las distintas redes: El primer avance que se hace en la red de transmisión entre las centrales de un aérea múltiple comienza con la posibilidad de transmitir sobre los pares de cobre señales digitales. 7.1 TDM (Time Division Multiplexing): TDM (Time Division Multiplexing): Esta tecnología consiste en la intercalación en el tiempo de nuestras de diferentes fuentes de tal manera que la información de toda ellas sea transmitida en serie sobre un mismo canal de transmisión. Es el método de combinar diversas señales muestreadas en una secuencia previamente definida. Existe dos normas fundamentales para esta multicanalización: La norma americana que contempla el envío de 24 señales simultaneas de 64 Kbits/s con una capacidad final de 1.536 Mbits/s. Su denominación es T1. La norma europea en la que envían 30 señales con carga de datos mas dos de control (30 + 2). 30 canales x 64 Kbits/s = 2.048 Mbits/s. Su denominación es E1. 7.2 PCM (Pulse Code Modulation): Después del PCM que utilizaba como medio físico los cables multipares de cobre, se logra otro salto cuantitativo con el advenimiento de la Fibra Óptica como medio superior de transmisión. Esto permitió un crecimiento en las posibilidades que ofrecía este método de multicanalización. El último paso hasta el presente proceso evolutivo de los sistemas de transmisión lo constituye la Tecnología IP. IP es un protocolo no orientado conexión, división en caso de ser necesario en paquetes, direccionamiento con direcciones internet de 32 Bits. Tamaño máximo de los paquetes: 65535 bytes. Tiempo de vida finito de los paquetes. Entrega de acuerdo al "mejor esfuerzo". 8. Central de conmutación Digital: Las evoluciones posteriores de este tipo de Centrales de Conmutación se presentan solo con modificaciones de software: La última evolución de esta tecnología es el salto cualitativo desde el concepto de la conmutación de circuitos a la de paquetes IP. Estas funciones, es decir la comunicación de clientes entre sí, ya no son efectuadas principalmente por hardware sino que en una red totalmente IP, lo que en realidad se "conmuta" son paquetes y acá juegan roles especiales los routers distribuidos en toda la red. El equipo final o de conmutación propiamente dicho lo constituye el softswitch. 9. ¿Qué es Internet? El Internet es una red de redes. Es una red conectada a otra de manera continua y simultanea. Internet es una plataforma mundial de comunicaciones multimedia, basada en el en muchos protocolos y el direccionamiento de objetos de información, servicios e individuos basado en el DNS (Domain Name System) que es el vehículo para todas las actividades que se relacionen en cualquier grado con el intercambio de información humana y de contenido en tiempo real o diferido (voz, datos, videos) y de información de comunicaciones y control entre sistemas (multimedia), utilizando diferentes sistemas informáticos y terminales de usuarios fijas y/o móviles. 9.1 Organismos de Estandarización: En las redes de datos, intervienen principalmente los siguientes organismos de estandarización: ISOC - Internal Society (1992) Miembros de la comunidad de Internet. IAB - Internet Activity Board (1993) Diseño, Ingeniería y Administración de Internet. IETF - Internet Engineering Task Force. IRTF - Internet Research Task Force (Grupo de trabajo de investigación para internet. IEEE - Institute of Electrical and Electronics Engineers. ISO - International Organization of Standardization. FNC - Federal Networking Council (Consejo federal de Redes). La IETF es una gran comunidad internacional abierta de diseñadores, operadores, proveedores e investigadores de redes preocupados por la evolución de la arquitectura y el buen funcionamiento de Internet. El trabajo se organiza en grupos por tema y cubre varias áreas (enrutamiento, transporte, seguridad, etc.). La ISO es una organización internacional no gubernamental independiente con 164 organismo nacionales de normalización como miembros. ISO llegó a publicar 22784 normas internacionales y documentos relacionados, que cubren casi todas las industrias, desde la tecnología hasta la seguridad alimentaria, la agricultura y la atención médica. Las normas internacionales ISO impactan a todos, en todas partes. el Sus inicios se dan el 23 de febrero de 1947. La IEEE es una asociación dedicada a promover la innovación y la excelencia tecnológica en beneficio de la humanidad, es la sociedad profesional técnica más grande del mundo. Se diseño para servir a profesionales involucrados en todos los aspectos de los campos eléctricos, electrónicos e informáticos y áreas relacionadas de ciencia y tecnología que subyacen a la civilización moderna. La IEEE es un desarrollador líder de estándares de la industria en una amplia gama de tecnologías que impulsan la funcionalidad, capacidades e interoperabilidad de productos y servicios, por ejemplo: IEEE 802 - Redes LAN/MAN, IEEE 802.3 - Ethernet, IEEE 802.11 - Wi-Fi, IEEE 802.15 - Wireless PAN. 1. Clasificación según área de cobertura: 1.1 WAN - Wide Area Networks: Cubren una extensa área geográfica. Se construyen usando circuitos/servicios provistos por carriers. Dentro de las telecomunicaciones un carrier es un operador de telefonía que proporciona conexión a Internet a alto nivel. Son empresas de telecomunicaciones que ofrecen servicio de conexión para empresas y usuarios particulares. Estas empresas manejan grandes redes y sistemas de comunicación para proveer servicios de alta calidad. Son vínculos o redes de largo alcance. Tradicionalmente son comunicaciones punto a punto. Cubre los requerimientos de unir diversas LANs y MANs. Puede tener limitaciones de velocidad y retardo. Sus tecnologías por lo general son: X.25 Frame relay ATM (Asynchronous Transfer Mode) 1.2 MAN - Metropolitan Area Networks: Cobertura circunscripta a una ciudad o área de la misma. Puede ser pública o privada: Entre LANs y WANs. El formato tradicional de las WANs (punto a punto conmutado) resulta inadecuado para el crecimiento de las organizaciones. Requerimientos de altas velocidades a costos menores, en áreas grandes. Tecnologías: Wireless Networks Metropolitan Ethernet (MetroEthernet) 1.3 LAN - Local Area Networks Geográficamente restringidas a oficinas, edificios, campus o casas. Normalmente los dispositivos conectados, así como su infraestructura pertenecen a una única organización. Altas velocidades. Corto alcance. Típicamente un solo edificio o un grupo de ellos. Apunta a diferentes soluciones técnicas. Usualmente una LAN es de una misma organización. La responsabilidad de la gestión queda en el dueño, Las velocidades de datos de las redes LAN suele ser alto, Tecnologías: Ethernet Token Ring FDDI ATM WIFI 1.4 PAN - Personal Area Network PAN es una red informática para interconectar dispositivos centrados en el espacio de trabajo de una persona. Una PAN proporciona transmisión de datos entre dispositivos como PC, teléfonos, tablets y wearebles, etc. Posicionamiento: No compite con WIFI porque los alcances y velocidades no son comparables. El target son los dispositivos que no requieren grandes volúmenes de datos a transferir. Características: El alcance de la PAN se extiende a 10 metros. WPAN: Red PAN inalámbrica. Se apoya en protocolos definidos en IEEE 802.15. Redes PAN inalámbricas. Protocolos cableados (USB, FireWire, etc.). Bajo costo y bajo consumo. Hasta 8 dispositivos por red. Data rates menores a 1Mbps. Tecnologías: Bluetooth IEEE 802.15.1 2. Tipos de redes: 2.1 Point-to-Point: El canal de datos es usado para la comunicación entre dos nodos. En este escenario ambos dispositivos se consideran iguales en el proceso de comunicación. Puede ser: Simplex, Half duplex y Full duplex. 2.2 Multipoint: Acá varios elementos están conectados en un mismo medio, se pueden ver entre sí, si lo requieren. Cada nodo puede transmitir y recibir. 2.3 Switched Networks: Contiene nodos de conmutación. Estos nodos no tienen injerencia en el contenido de los transmitido. La información atraviesa la red pasando a través de los nodos. Clasificación: conmutación de circuitos, conmutación de paquetes. 3. Clasificación según la forma de transmisión: Conmutación de paquetes: Es no orientado a la conexión. La información (datos) se transfieren a la red divididos en pequeñas unidades que se las llama paquetes, que contienen la información que permite al hardware de la red saber a donde y cómo enviar un paquete de una máquina a otra. La principales ventajas son que pueden procesarse múltiples comunicaciones entre múltiples máquinas, su costo y su desempeño. La conmutación de paquetes es más adecuada para la transmisión de datos comparada con la conmutación de circuitos. 3.1 Tipos de transmisión: Simplex: Es unidireccional, es la transmisión que ocurre en una sola dirección, deshabilitando al receptor de responder al transmisor. Half Duplex: Permite transmitir en ambas direcciones, sin embargo, la transmisión puede ocurrir solamente en una dirección a la vez. Full Duplex: describe a la transmisión y recepción de datos simultáneas a través de un canal. Un dispositivo que opera en modo full duplex es capaz de realizar transmisiones de datos de red bidireccionales al mismo tiempo. Puede enviar y recibir datos al mismo tiempo, lo que mejora el rendimiento al duplicar el uso del ancho de banda. 4. Topologías de la red: Topología física de red: es una representación gráfica o mapa de cómo de unen en red las estaciones de trabajo de la red y sus dispositivos. Tipos: Topología de malla: Todas las estaciones de la red se conectan entre sí. Topología de anillo: Consta de varios nodos unidos formando un círculo lógico. Los mensajes se mueven de nodo en una sola dirección. El cable forma un bucle cerrado formando un anillo. Topología estrella: Todas las estaciones de la red tienen que pasar a través de un dispositivo conocido como concentrador (HUB). Topología bus: Consta de un único cable (BUS) al que se conecta cada dispositivo de la red. 5. Medios de Networking: Para que los dispositivos transmitan entre ellos esta información codificada, tienen que estar conectados físicamente entre sí. Entonces, se usa cableado de distintos tipos: Cable coaxial. Par trenzado. Fibra óptica. A estos materiales se los denomina medios de transmisión. El tipo de medio a utilizar se va a determinar en base a: La velocidad que se desea que los datos se envíen por la red. El costo. La ubicación física y geográfica del cableado. 5.1 Cable Coaxial: El cable coaxial consiste en dos elementos de conducción. 1) Uno está ubicado en el centro del cable y es un conductor de cobre. 2) El conductor de cobre está rodeado por un cable de aislación flexible. 3) Sobre este material aislante hay un blindaje compuesto de un trenzado de cobre tramado o una malla metálica que actúa como segundo cable del circuito. 4) El trenzado exterior actúa como blindaje del conductor interno. 5) De este modo ayuda a reducir la cantidad de interferencia. Existen dos tipos de cable coaxial: THICK (Grueso): Más conocido como cable amarillo. Fue el que más se utilizaba en la mayoría de la redes por su velocidad y distancia mayores, pero son de costo alto y con poca flexibilidad. THIN (Delgado): Se utilizó para reducir costos en el cableado. Limitación en su distancia, esto llevaba a la no regeneración de la señal. 5.2 Cable de par trenzado: Se tiene que tomar en cuenta: El máximo que se puede separar los pares son de ½ pulgadas. El máximo de tensión que se puede aplicar es de 11.34 Kg. Tipos de cable de par trenzado: UTP (Unshielded Twisted Pair): Es un cable de par trenzado normal. No tiene blindaje. Bajo costo y su facilidad de manejo. Su mayor desventaja es su alta tasa de error, limitaciones para trabajar a grandes distancias. Con el tiempo se convirtió en el sistema de cableado más ampliamente usado en el mercado. Los pares trenzados minimizan los efectos electromagnéticos causados por el cable, así como también la interferencia de campos externos. STP (Shielded Twisted Pair): Los pares trenzados están protegidos por una malla metálica, y cada par por una lamina blindada. La malla evita las interferencias (menor tasa de error). Alto costo de fabricación. 6. Atenuación: 6.1 ¿Qué es? La atenuación representa la perdida de potencia de señal a medida que esta se propaga desde el transmisor hacia el receptor. Se mide en decibeles. Atenuación = 20 Log10 (V. Trans/V. Rec.) Se puede medir en una vía (round trip). Una atenuación pequeña es buena y es lo que busca ya que significa que es la correcta combinación entre la atenuación del cable y los conectores adecuados con su longitud correcta y su correcto crimpeamiento. Near End CrossTalk (NEXT); Es la interferencia electromagnética causada por una señal generada por un par sobre otro par resultando en ruido. *NEXT = 20Log10 (V. Trans./V. Acoplado) (V. Acoplado es el "ruido" en el segundo par.) Se mide en el extremo del transmisor (donde la señal es más fuerte). Un NEXT grande es bueno y es lo buscado ya que cuanto mayor es este valor, menor es el ruido que es producido por el segundo par. Cuando un sistema de cableado tiene problemas con el NEXT pueden ocurrir errores en la red. Para evitar el NEXT se usa el cable y los conectores adecuados ponchados de manera correcta. 6.2 ACR (Attenuation-to-crosstal ratio) Tambien conocido como headroom, es la diferencia en decibeles (dB), entre la atenuación de la señal producida por un cable y el NEXT. Para que una señal sea recibida con una tasa de errores de bit aceptable, la atenuación y el NEXT tiene que estar optimizados. En la práctica, la atenuación depende de la longitud y el diámetro del cable y es una cantidad fija. Sin embargo, el NEXT puede reducirse asegurando que el cable esté bien trenzado, no aplastado, y asegurando que los conectores estén instalados correctamente. El NEXT también puede ser reducido cambiando el cable UTP por STP. El ACR tiene que estar de varios dB para que el cable funcione adecuadamente. Si el ACR no es lo suficientemente grande, los errores se presentan con más frecuencia. Una pequeña mejora en el ACR reduce dramáticamente la tasa de errores a nivel de bit. 7. Fibra Óptica: Constituido por uno o más hilos hechos de cuarzo fundido o plástico especialmente tratado. Cada uno de estos consta de: Núcleo central. Cubierta del núcleo. Aislante entre fibras. Tienen un gran anchoo de banda. Baja atenuación de la señal. Integridad. Inmunidad a interferencias. Alta seguridad. Larga duración. Alto costo en fabricación e instalación. ¿Cómo funciona? ¿Por qué no se sale la luz de la fibra óptica? La luz no se escapa del núcleo porque la cubierta y el núcleo están hechos de diferentes tipos de vidrio (y por lo tanto tienen diferentes índices de refracción). Esta diferencia en los índices obliga a que la luz sea reflejada cuando toca la frontera entre el núcleo y la cubierta. El cable de la fibra óptica: Revestimiento: Capa de protección puesta sobre la cubierta. Se hace con un material termoplástico si se requiere rígido o con un material tipo gel si necesita que sea suelto. Material de refuerzo: Sirve para proteger la fibra de esfuerzos a los que sea sometida durante la instalación, de contradicciones y expansiones debidos a cambios de temperatura, etc. Se hacen de varios materiales, desde acero (en algunos cables con varios hilos de fibra) hasta Kevlar. Envoltura: Es el elemento del cable. Es el que protege al cable del ambiente donde esté instalado. De acuerdo a la envoltura que se use el cabe es para interiores, exteriores, aéreo o para ser enterrado. 7.1 Tipos de Cable de fibra óptica: Cable aéreo (de 12 a 96 hilos): Es cable para exteriores, ideal para aplicaciones de CATV. 1. Alambre mensajero. 2. Envoltura de polietileno. 3. Refuerzo, 4. Tubo de protección, 5. Refuerzo central, 6. Gel resistente al agua, 7. Fibras ópticas, 8. Cinta de Mylar. 9. Cordón para romper la envoltura de instalación. Cable de alta densidad de hilos (de 96 a 256 hilos): Cable para exteriores para troncales de redes de telecomunicaciones. 1. Polietileno, 2. Acero corrugado, 3. Cinta impermeable, 4. Polietileno, 5. Refuerzo, 6. Refuerzo central, 7. Tubo de protección, 8. Fibras ópticas, 9. Gel resistente al agua, 10. Cinta de Mylar, 11. Cordón para romper la envoltura. 7.2 Clases de fibras ópticas: Multimodo: Usada generalmente para comunicación de datos. Tiene un núcleo grande (más fácil de acoplar). En este tipo de fibra muchos rayos de luz (o modos) se pueden propagar simultáneamente. Cada modo sigue su propio camino. La máxima longitud recomendada del cable es de 3 Km. I = 850 nm. Monomodo: Tiene un núcleo más pequeño que la fibra multimodo. En este tipo de fibra sólo un rayo de luz (o modo) puede propagarse a la vez. Es utilizada especialmente para telefonía y televisión por cable. Permite transmitir a altas velocidades y a grandes distancias (40 km). I = 1300 nm. 8. Ancho de banda de la fibra óptica: Los fabricantes de fibra multimodo especifican cuánto afecta la dispersión modal a la señal estableciendo un producto ancho de banda-longitud (o ancho de banda). Una fibra de 200Mhz-km puede llevar una señal de 200 MHz un Km de distancia o 100 MHz en 2km. La dispersión modal varía de acuerdo con la frecuencia de la luz utilizada. Se deben revisar las especificaciones del fabricante. Un rango de ancho de banda muy utilizado en fibra multimodo para datos es 62.5/125 con 160 MHz-km en una longitud de onda de 850 nm. La fibra monomodo no tiene dispersión modal, por eso no se especifica el producto ancho banda-longitud. Cuanto más conectores tenés, o más largo sea el cabe de fibra, mayor perdida de potencia va a haber. Si los conectores están mal empatados, o si están sucios, va a haber más perdida de potencia (por eso se tienen que usar protectores en las puntas de fibra no utilizadas). Un certificador con una fuente de a luz incoherente (un LED) muestra un valor de atenuación mayor que uno con luz de LASER (Gigabit usa LASER, por eso la F.A para gigabit debe certificarse con este tipo de fuente de luz). 9. Subcapa MAC y LCC Todos los medios de transmisión y las topologías comprende una capa física del modelo de capas de una red. La capa superior es la capa de enlace de datos, la cual comprende dos subcapas: MAC (Control de accedo al medio): Acceso a la Capa Física, Protocolos MAC asociado a la topología, y considerando la Tecnología. LLC (Control de enlace lógico): Entramado, Control de flujo, Control de Errores, Independiente de la tecnología. La Subcapa LCC maneja la comunicación de enlace de datos y define el uso de puntos de interfaz lógica, llamados SAPs (Service Access Points) o puntos de acceso al servicio. Estos estándar están definidos por Norma IEEE 802.2. Servicios que proporciona la Capa de Red: Entramado de la información: Encapsulado de la información en trama. Delimitación del principio y fin de la trama (conteo de caracteres, entre otros). Control de errores: División del flujo de información. Suma de comprobación de trama (Checksum). Códigos de paridad o redundancia. Recuperación entre Fallos: Detectar y asegurar que todas las tramas sean entregadas, en el orden correcto, a la capa de red del host destino. Control de flujos: que un emisor no sature a un receptor lento (Técnicas de retroalimentación). La Subcapa MAC es la más baja de las dos subcapas, proporciona el acceso compartido para las NIC de los host conectados. Trabaja en medio compartidos (LANs). Esta capa se comunica directamente con la NIC y es responsable de difundir tramas libres de colisiones entre dos o más dispositivos de subred. Métodos de Acceso al Medio: Es el procedimiento que regulo la compartición del medio físico de todos los equipos y maquinas conectadas a la subred: Estático: Métodos de acceso estático: FDM (Multiplexación por división de frecuencia): para X usuarios el ancho de banda se divide en X partes iguales (esto origina en algunos casos bajo rendimiento). TDM (Multiplexación por división de tiempo): cada usuario tiene asignado un slot o intervalo temporal (esto origina en algunos casos perdida de ancho de banda). Dinámico: acá el aprovechamiento del canal es mayor, y se tiene que tener en cuenta lo siguiente: Métodos de enviar tramas. Medio compartido. Colisión. Tiempo. Portadora. Subcapa MAC - Métodos de Acceso Dinámico: Método de enviar tramas: si se tiene X host con un programa de usuarios que genere tramas, no se transmite nada hasta que la trama anterior no se haya transmitido con éxito. Medio compartido: existe un único canal para todos los equipos, todos pueden enviar y recibir. Las prioridades serán determinadas por los protocolos. Colisión: si dos o más tramas se transmiten simultáneamente se superpondrán en el tiempo (dañando la señal) dando lugar a una retransmisión de tramas. Tiempo: Continuo: La transmisión es el cualquier instante. Ranurado: El tiempo se divide en intervalos discretos. Portadora: este método puede seguir dos políticas: Detección de portadora: los equipos pueden ver si el canal esta siendo utilizado antes de intentar usarlo. Sin detección de portadora: los equipos transmiten según el protocolo en cuestión sin comprobar antes el estado del canal. 10. Modelo Jerárquico de tres capas: ![[Pasted image 20240409174339.png]] 1. Protocolos de red: Los protocolos son conjuntos de reglas que gobiernan el intercambio de datos entre dos entidades. Son las normas que se acuerdan para poder producir la unificación de criterios entre los fabricantes de redes de comunicaciones y telemáticas. La unificación o estandarización de criterios tiene como fin la interconexión de dichas redes. 1.1 Definiciones básicas: Sintaxis: es el formato del mensaje, acuerdo o procedimiento que se usa para la transmisión de información (son los procedimientos normalizados). Las acciones que tienen que realizar al transmitir o recibir mensajes por parte de los nodos o equipos terminales de datos. Semántica: es la información de control (coordinación, manejo de errores). Tiempos: ajuste de velocidad, armado de secuencias. 1.2 ¿Por qué se usan protocolos? Las comunicaciones de datos requieren procesos complejos: El que envía identifica el camino de datos y el receptor. Los sistemas negocian estados. Las aplicaciones negocian estados. Se produce traducción de formatos de archivos. Para que todo esto pase, se requiere de altos niveles de cooperación. 2. ¿Cuáles son las tareas de los protocolos? 1. Establecer el canal de comunicaciones en caso de ser conmutado. 2. Establecer la transmisión. 3. Efectuar la Transmisión. 4. Verificar las transmisiones. 5. Fin de la transmisión. 6. Corte del canal. 3. ¿Qué función tienen que cumplir? 1. Segmentación y ensamblado. 2. Encapsulamiento. 3. Control de conexión. 4. Entrega de orden. 5. Control de flujo. 6. Control y detección de errores. 7. Direccionamiento. 4. Búsqueda de estandarización: #Data-and-computer-comunications8thEdition Cuando las computadoras, terminales y otros tipos de dispositivos que procesan información entre ellos, el procedimiento involucrado en el medio puede ser bastante complejo, tiene que existir un camino de datos entre ambos dispositivos. 4.1 ¿Cuáles son las tareas de los protocolos? #Data-and-computer-comunications8thEdition 1. El sistema del dispositivo tiene que activar el procedimiento que usa para crear el camino de datos que se va usar o informar al dispositivo de red el destino al que quiere llegar. 2. El sistema encargado de este proceso tiene que chequear que el destino está preparado para poder recibir datos. 3. El software/hardware/programa que se use para transferir estos datos tiene que certificar que el dispositivo de destino está preparado para aceptar y guardar los archivos en el correcto formato. 4. Si el formato que usan estos dos sistemas que se quieren comunicar son distintos, el emisor o el receptor tiene que ser el encargado de transformar los datos al correcto formato para hacer la transmisión. Claramente entre ambas partes se necesita un nivel alto de cooperación para lograr esta conexión exitosamente. En vez de emplear todo este proceso dentro de un solo módulo, se divide en subtareas que se implementan de manera separadas. Cada capa del proceso trabaja con una única parte del proceso de comunicación entre dos partes. Dentro del Modelo OSI (que se introduce abajo) cada capa depende exactamente de la capa que se encuentra justo abajo para poder llevar a cabo funciones más básicas o primitivas. Por ejemplo, la capa de Transporte depende de la Capa de Red para enviar y recibir paquetes. Además, cada capa del Modelo OSI oculta los detalles de cómo realizar sus funciones a las otras capas. Esto significa que cada capa no necesita saber exactamente cómo exactamente las otras capas están haciendo sus tareas, siempre y cuando cada una realice de manera correcta su parte del proceso. Finamente, cada capa del Modelo OSI proporciona servicios a la capa que está justo encima de ella. Por ejemplo, la Capa de Red proporciona servicios de envío y recepción de paquetes a la capa de transporte. 4.2 Compatibilidad e interoperabilidad: La estandarización posibilitó a los equipos informáticos de diferentes fabricantes poder comunicarse entre sí con éxito en una misma red. O 5. Modelo OSI: #Data-and-computer-comunications8thEdition El Open Systems Interconnections (OSI) hace referencia al modelo desarrollado por la International Organization for Standardization (ISO), modelo para cada arquitectura de una computadora como infraestructura para desarrollar estándares de protocolos. Las capas más bajas están encargadas de la transmisión en la red, las más altas de la transmisión entre los host. El modelo OSI consiste en 7 CAPAS: APLICATION (Capa de aplicación): Es la única capa que interactúa directamente con los datos del usuario. Las aplicaciones de software, como navegadores web y clientes de correo electrónico, dependen de la capa de aplicación para iniciar comunicaciones. Sin embargo, hay que recordar que las aplicaciones de software del cliente no forman parte de la capa de aplicación, más bien, la capa de aplicación es responsable de los protocolos y la manipulación de datos de los que depende el software para presentar datos significativos al usuario. Los protocolos de la capa de aplicación incluyen HTTP, como también SMTP. PRESENTATION (Capa de presentación): Esta es la capa principalmente responsable de preparar los datos para que los pueda usar la capa de aplicación, en otras palabras, la capa 6 hace que lo datos se preparen para su consumo por las aplicaciones. La capa de presentación es responsable de la traducción, el cifrado y la compresión de los datos. Dos dispositivos de comunicación que se conectan entre sí podrían estar usando distintos métodos de codificación, por lo que la capa 6 es la responsable de traducir los datos entrantes en una sintaxis que la capa de aplicación del dispositivo receptor pueda entender. Si los dispositivos se comunican a través de una conexión cifrada, esta misma capa es responsable de añadir el cifrado en el extremo del emisor, así como de codificar el cifrado en el extremo del receptor, para poder presentar a la capa de aplicación de datos descifrados y legibles. Además, la capa de presentación también es la encargada de comprimir los datos que recibe de la capa de aplicación antes de ser enviados a la capa de sesión. SESSION (Capa de sesión): La capa de sesión es la responsable de la apertura y cierre de comunicaciones entre dos dispositivos. Este tiempo que transcurre entre la apertura de la comunicación y el cierre de esta se conoce como sesión. La capa de sesión garantiza que la sesión permanezca abierta el tiempo suficiente para transferir todos los datos que se está intercambiando, después de esto, se cierra sin demora la sesión para evitar desperdicios de recursos. Esta capa también sincroniza la transferencia de datos utilizando puntos de control. Por ejemplo, si un archivo de 100 MB se está transfiriendo, a capa de sesión podría fijar un punto de control cada 5 MB. En caso de desconexión o caída tras haberse transferido, por ejemplo, 52 MB, la sesión podría reiniciarse a partir del último punto de control, con lo cual solo quedarían unos 50 MB pendientes de transmisión. Sin esos puntos de control, la transferencia en u totalidad tendría que reiniciarse desde cero. TRANSPORT (Capa de Transporte): La capa 4 o de transporte es la responsable de la comunciaciones de extremo a extremo ntre dos dispositivos. Esto implica, antes de proceder a ejecutar el envío a la capa 3, tomar datos de la capa de sesión y fragmentarlos seguidamente en trozo más pequeños que se los llama segmentos. La capa de transporte del dispositivo receptor es responsable de rearmar estos segmentos y construir los datos que la capa de sesión pueda o tenga que procesar. La capa de transporte también es responsable del control de flujo y el control de errores. El control de flujo determina una velocidad óptima de transmisión para garantizar que un emisor con una conexión rápida no abrume a un receptor con una conexión lenta. La capa de transporte realiza un control de errores en el extremo receptor al garantizar que los datos recibidos estén completos y solicitar una retransmisión si no lo están. Los protocolos más comunes de esta capa incluyen el TCP y el UDP. NETWORK (Capa de Red): La capa de red es responsable de facilitar la transferencia de datos entre dos redes diferentes. Si los dispositivos que se comunican se encuentran en la misma red, entonces la capa de red no es necesaria. Esta capa divide los segmentos de la capa de transporte en unidades más pequeñas que se llaman paquetes, en los dispositivos del emisor, y se vuelven a juntar estos paquetes en el dispositivo del receptor. La capa de red también busca la mejor ruta física para que los datos lleguen a su destino, esto se conoce como enrutamiento. Los protocolos de la capa de red incluyen IP, ICMP, IGMP y el paquete IPsec. DATA LINK (Capa de enlace): La capa de enlace de dtos es muy similar a la capa de red, a diferencia que la capa de enlace de datos facilita la transferencia de datos entre dos dispositivos dentro la misma red. La capa de enlace de datos toma los paquetes de la capa de red y los divide en partes todavía más pequeñas que se llaman tramas. Al igual que la capa de red, también es responsable del flujo y el control de errores en las comunicaciones dentro de la red (la capa de transporte solo realiza tareas de control de flujo y de control de errores para las comunicaciones dentro de la red). PHYSICAL (Capa Física): Esta capa incluye el equipo físico implicado en la transferencia de datos, tal como los cables y los conmutadores de red. Esta también es la capa donde los datos se convierten en una sencuencia de bits. La capa física de ambos dispositivos tienen que estar de acuerdo en cuanto a una convención de señal para que los 1 puedan distinguirse de los 0 en ambas partes. Ejemplos de algunos protocolos: - Capa Física: (Estándares) DSL, IEEE 802. - Capa de enlace de Datos: ARP, HDCL, IEEE 802.3, PPP, ATM. - Capa de Red: IPv4, IPv6, IPX, Apple Talk, IPsec, ICMP, IGMP. - Capa de Transporte: TCP, UDP, SPX. - Capa de Sesión: NetBIOS. L2TP. SAP. - Capa de Presentación: SSL, TLS. - Capa de Aplicación: HTTP, POP3, STMP, IMAP, FTP. Originalmente los diseñadores del Modelo OSI asumieron que este modelo y los protocolos desarrollados dentro de este modelo llegarían a dominar las comunicaciones informáticas, remplazando eventualmente las implementaciones de protocolos propietarios y modelos multivendedor rivales como TCP/IP. En el momento que se estaba desarrollando el Modelo OSI, los protocolos TCP/IP ya existían. Estos fueron creados en 1974 como un solución práctica par un problema del ejercito: transmitir información de forma segura entre una red de computadoras distribuidas capaces de sobrevivir a un ataque nuclear (ARPANET). A pesar de las expectativas iniciales, el Modelo OSI no logró remplazar a TCP/Ip. Mientras que muchos usuarios estaban esperando que OSU sea la solución al problema de interconexión a nivel global que tenían, creció el uso de TCP/IP para satisfacer las presiones concretas a corto plazo para la interoperabilidad. La burocracia y lentitud en la creación de las normas, junto con las divisiones entre los ingenieros informáticos de OSI y los de telecomunicaciones, terminaron matando a OSI. En cuanto a si TCP/IP respeta el modelo OSI, la respuesta es que sí y no (Se va a desarrollar más a fondo después). Existen varias razones de por qué TCP/IP creció más que OSI. Una podría ser que TCP/IP era un protocolo maduro y bien testeado, mientras que los protocolos que se estaban desarrollando para OSI todavía estaban en esta misma etapa. Cuando los negocios se dieron cuenta de esta necesidad de interoperabilidad, el protocolo más acertado en ese momento para usar era claramente TCP/IP. Otra razón podría ser que el Modelo OSI es según muchos expertos, innecesariamente complejo, con 7 capas para realizar tareas que TCP/IP hace con menos. 5.1 Estandarización con OSI: El objetivo principal de OSI era brindar esta infraestructura para poder estandarizar las comunicaciones entre sistemas informáticos. Con este modelo, uno o más protocolos estándar pueden ser desarrollados en cada capa. El modelo define en términos generales que funciones se tienen que cumplir en cada capa y esto se podía lograr gracias a que: Las funciones que tenían que cumplir cada capa esta bien definidas, los estándares pueden ser desarrollados de manera independiente y simultáneamente para cada capa. Esto facilitaba y aceleraba el proceso. Los límites entre cada capa estaban también bien marcados, cambiar algo en una capa no podría afectar al software que corre sobre otra capa. Esto facilita que se pueden agregar nuevos estándares. La siguiente imagen muestra el uso de OSI como infraestructura. Todo el proceso está dividido en 7 Capas: La siguiente figura muestra específicamente la naturales de por qué se necesita esta estandarización en cada capa. Hay 3 elementos que son clave: La especificación del protocolo: Dos entidades en la misma capa pero de diferentes sistemas cooperan y interactúan entre sí mediante el protocolo. Como dos distintos sistemas abiertos están involucrados, se tiene que especificar exactamente que protocolo se va a usar. Esto incluye el formato de la información que se va a intercambiar, la semántica que se va a usar y la secuencia disponible de PDUs. Las siglas PDU corresponden a "Protocols Data Units" o "Unidades de Datos de Protocolo", un PDU en un bloque de información que se transmite como una unidad única entre nodos de una red. En cada capa de OSI, los PDUs tienen distintos nombres y estructuras. Por ejemplo, en la Capa de Transporte, un PDU se llama "segmento" o "datagrama", mientras que en la Capa de Red, se llama "Paquete". Definición de Servicio: Para que el protocolo/s opere en la capa que le asigne, se necesita estandarizar lo que este vaya a enviar a la capa que le sigue, a la capa de arriba. Direccionamiento: Cada capa brinda servicios a entidades que se encuentran después de ellos, a la que le sigue. Cada capa proporciona servicios a la capa superior, servicios que pueden incluir cosas como el envío de datos, la detección y correción de errores, el control de flujo de datos, etc. Las entidades que usan estos servicios se las denomina Entidades de Servicio y se accede a ellas a través de lo que se conoce como *Service access point (SAP) o Punto de acceso al servicio. Un SAP es esencialmente una dirección o identificador que se usa para acceder a una entidad de servicio en una capa específica. Por lo tanto, un Network Service Access Point (NSAP), es un tipo de de SAP que se utiliza para acceder a una entidad en la capa de Transporte. En otras palabras, un NSAP indica una entidad de transporte que se un usuario del servicio de red. 5.2 Servicios primitivos y parámetros: Los servicios entre las capas dentro de la arquitectura del Modelo OSU son expresados dentro de los términos primitivos y parámetros. Uno primitivo es una operación o función que se realiza en una capa. Por ejemplo, los primitivos pueden incluir acciones como "Conectar", "Desconectar", "Envair datos", etc. Cada primitivo específica la acción a realizar o informa sobre el resultado de una acción previamente solicitada. Los parámetros se usan para pasar datos e información de control cuando se realiza un servicio primitivo. Por ejemplo, un parámetro podría ser el paquete de datos que se va a enviar o recibir, o la dirección del SAP de la capa inferior. Existen 4 tipos básicos de primitivos que se usan para definir la interacción entre dos capas: Request (Solicitud): Un primitivo enviado por la capa (N + 1) a la capa N para solicitar un nuevo servicio. Indication (Indicación): Un primitivo devuelto a la capa (N + 1) desde la capa N para informar la activación de un servicio solicitado o de una acción iniciada por el servicio de la capa N. Response (Respuesta): Un primitivo proporcionado por la capa (N + 1) en respuesta a un primitivo de indicación. Puede reconocer o completar una acción previamente invocada por un primitivo de indicación. Confirm (Confirmación): Un primitivo devuelto a la capa solicitante (N + 1) por la capa N para reconocer o completar una acción previamente invocada por un primitivo de solicitud. Un ejemplo podría ser la transferencia de datos entre dos entidades en la misma capa (N) en diferentes sistemas, usando el modelo OSI: 1. Solicitud de la entidad fuente: La entidad en la capa (N) en el sistema fuente (el que envía los datos) solicita a su entidad en la capa (N + 1) que envíe datos. Esta solicitud se realiza mediante un un "servicio primitivo de solicitud", que es una operación o función que se realiza en una capa. Los parámetros asociados con esta primitiva incluyen los datos que se van a transmitir y dirección del destino. 2. Preparación de la PDU por la entidad fuente: La entidad en la capa (N + 1) en el sistema fuente prepara un PDU para ser enviado a su entidad homóloga en la capa (N + 1) en el sistema de destino. 3. Entrega de los datos por la entidad de destino: La entidad en la capa (N + 1) en el sistema de destino entrega los datos a la entidad apropiada en la capa (N) mediante un "servicio primitivo de indicación", que incluye los datos y la dirección de origen como parámetros. 4. Respuesta de la entidad de destino: Si se requiere un reconocimiento, la entidad en la capa (N) en el sistema de destino emite un "servicio primitivo de respuesta" a su entidad en la capa (N + 1). 5. Trasporte del reconocimiento por la entidad (N + 1): La entidad en la capa (N + 1) en el sistema de destino transmite el reconocimiento en un PDU de la capa (N + 1). 6. Entrega del reconocimiento a la entidad fuente: El reconocimiento se entrega a la entidad en la capa (N) en el sistema fuente como un "servicio primitivo de confirmación". 5.2 Protocolos que funcionen sobre TCP: Existen un gran número de aplicaciones que se configuraron para usarse con TCP y sus protocolos. Lo 3 más comunes son: El Simple Mail Transfer Protocol (SMTP) que brinda una servicio básico para enviar mensajes de correo electrónico a través de Internet o mediante una red informática. Brinda mecanismos para transferir mensajes entre distintas servidores. Algunas de las funcionalidades de SMTP son las listas de correo, entre otras. Este protocolo no específica la forma en que los mensajes tienen que ser creados, se necesita algo en el medio de la comunicación para que se encuentre todo en el mismo formato. Una vez que un mensaje es creado, SMTP acepta el mensaje y hace uso de TCP para enviarlo al módulo SMTP de otro servidor. El File Transfer Protocol (FTP) se usa para enviar archivos de un sistema a otro. Se pueden enviar tanto archivos de teto como binarios, y el protocolo brinda características para controlar el acceso a usuarios. Cuando se quiere enviar un archivo, FTP prepara una conexión TCP al sistema que haga de destino, con el objetivo de controlar mensajes. Esta conexión habilita al usuario un ID y una contraseña para especificar el archivo y las acciones sobre el mismo. Una vez que la transferencia se aprueba, un segunda conexión por TCP se prepara para hacer la transferencia. Cuando esta se completa el "control de conexión" se usa para la espera de nuevas accione a arealizar sobre el archivo enviado. 6. TCP/IP: IP o Internet Protocol es el sistema de direcciones de Internet y tiene la función principal de entregar paquetes de información desde un dispositivo de origen a uno de destino. Es la forma principal en la que se realizan las conexiones de red y establece la base de Internet, pero NO gestiona el orden de los paquetes ni la verificación de errores. Esta funcionalidad requiere de otro protocolo encargado de esto, normalmente el TCP o Transmission Control Protocol. La relación entre los protocolos TCP e IP es similar a enviar alguien un mensaje escrito en un rompecabezas por correo postal. El protocolo IP garantiza que las piezas lleguen a su dirección de destino. Por la otra parte, TCP sería como la persona que ordena las piezas del rompecabezas en el otro lado. Reúnes las piezas en el orden correcto, solicita el reenvío de las piezas que faltan e informa al remitente de que se recibió todo con éxito. Además, mantiene la conexión con el remitente antes del envío de la primera pieza del rompecabezas hasta después del envío de la última pieza. IP es un protocolo sin conexión, lo que significa que cada unidad de datos se aborda individualmente y se enruta desde el dispositivo de origen al dispositivo de destino, que no envía una confirmación de vuelta al origen. Ahí es donde entran en juego protocolos como el TCP. Este último se uso con IP para mantener una conexión entre el remitente y el destino y para garantizar el orden de los paquetes. La versión primaria de IP que se utiliza en Internet hoy en día es versión 4 (IPv4). Las limitaciones de tamaño en el número total de direcciones posibles en IPv4 incentivó el desarrollo de un protocolo más nuevo. Este se llama IPv6, que permite que haya muchas direcciones más disponibles y su adopción es cada vez más frecuente. Características de TCP: Orientado a la conexión, al flujo de datos. Utiliza el three-way handshake para establecer la conexión. Protocolo seguro (asegura la entrega). Usa números de secuencia para controlar el envío y la recepción. Tiene control de errores. Utiliza retransmisiones (ACK, NACK).. Tiene control de flujo (reacción ante redes congestionadas). Tiene 20 bytes de encabezado. 7. User Datagram Protocol (UDP/IP): El User Datagram Protocol (UDP) es un protocolo de comunicación que se usa en Internet para transmisiones sujetas a limitaciones temporales, como la reproducción de video o las busquedas en DNS. Acelera las comunicaciones al no establecer formalmente una conexión antes de transferir los datos. Esto permite que los datos se transfieran muy rápido, pero también puede hacer que los paquetes se pierdan en tránsito y crear oportunidades para vulnerabilidades en forma de ataques DDos. Es un método estandarizado para transferir datos entre dos dispositivos en una red. Comparado con otros protocolos, el UDP realiza este proceso de forma sencilla: envía paquetes directamente a un ordenador destino, sin establecer primero una conexión, ni indicar el orden de los paquetes, ni comprobar si llegaron como estaba previsto. Los paquetes de UDP se llaman Datagramas. UDP es más rápido pero menos seguro que TCP. 7.1 ¿Para qué sirve el UDP? El UDP se suele usar en las comunicaciones sujetas a limitación temporal, en las que ocasionalmente es mejor dejar caer los paquetes que esperar. El tráfico de voz y de video se envía mediante este protocolo, porque ambos están sujetos a limitación temporal y están diseñados para soportar cierto nivel de pérdida. Por ejemplo, VOIP (Voz sobre IP), que usan muchos servicios telefónicos basados en Internet, funciona sobre UDP. Esto es así porque es preferible una conversación telefónica estática a una muy clara, pero con mucho retraso. Esto también hace que el UDP sea el protocolo ideal para los videojuegos en línea. De forma similar, como los servidores DNS tienen que ser rápidos y eficientes, funcionan también mediante UDP. 7.2 ¿Cómo funciona UDP? Los "riesgos" de UDP, como la pérdida de paquetes, no son un problema grave en la mayoría de los casos de uso. Sin embargo, se puede aprovechar el UDP con fines maliciosos. Ya que UDP no necesita un protocolo de enlace, los atacantes pueden "inundar" un servidor objetivo con tráfico UDP sin obtener primero el permiso de este servidor víctima para iniciar la comunicación. Este tipo de ataques envía un gran número de datagramas UDP a puertos aleatorios del dispositivo objetivo. Esto obliga al objetivo a responder con un número igualmente grande de paquetes ICMP, que indican que esos puertos eran inalcanzables. Los recursos informáticos necesarios para responder a cada datagrama fraudulento pueden abrumar al objetivo, provocando una denegación de servicio al tráfico legítimo. Normalmente los métodos que hay en contra de esto son limitar la tasa de respuestas de los paquetes ICMP, como también en recibir y responder el tráfico UDP a través de una red intermediaria de muchos centros de datos distribuidos, evitando que un servidor origen único se va desbordado por solicitudes fraudulentas. 1. LA CAPA DE ENLACE DE DATOS: En este capítulo se ven los algoritmos de la segunda capa que logran una comunicación confiable y eficiente de unidades completas de información llamadas TRAMAS (en vez de bits individuales, como en la capa física) entre dos máquinas adyacentes. Los protocolos que se usan para comunicaciones tienen que considerar todos los factores a la hora de comunicar. 1.1 Cuestiones de diseño de la capa de enlace de datos: La capa de enlace de datos usa los servicios de la capa física para enviar y recibir bits a través de los canales de comunicación. Tiene varias funciones específicas, entre las que se incluyen: Proporcionar a la capa de red una interfaz de servicio bien definida. Manejar los errores de transmisión. Regular el flujo de datos para que los emisores rápidos no puedan saturar a los receptores lentos. Para poder cumplir con esas funciones, la capa de enlace de datos toma los paquetes que obtiene de la capa de red y los divide en partes más chicas que se llaman tramas para poder transmitirlas. Cada TRAMA tiene: un encabezado, un campo de carga útil (payload) para almacenar el paquete y un terminador. El manejo de las tramas es la tarea más importante en la capa de enlace de datos. SI bien la capa de enlace de datos usa distintos métodos para poder controlar el fuljo y los errores, estos mismos se presentan también en la capa de transporte y en otros protocolos, ya que la confiabilidad es una meta general que se logra cuando todas las capa trabajan en conjunto. De hecho, en muchas redes estas funciones se encuentran casi siempre en las capas superiores y la capa de enlace de datos sólo se encarga de la tarea mínima que es "suficiente". 1.1.1 Servicios proporcionados a la capa de red: La función de la capa de enlace de datos es proveer servicios a la capa de red. El servicio principal es la transferencia de datos de la capa de red en la máquina de origen, a la capa de red en la máquina destino. En la capa de red de la máquina origen está una entidad, una entidad llamada proceso, que entrega algunos bits de la capa de enlace de datos para que los transmita al destino. La tarea de la capa de enlace de datos es transmitir los bits a la máquina destino, de modo que se pueden entregar a la capa de red de esa máquina (a). La transmisión real sigue la trayectoria de la figura (b), pero es más fácil pensar en términos de dos procesos de la capa de enlace de datos que se comunican mediante un protocolo de enlace de datos. La capa de enlace de datos puede diseñarse para ofrecer varios servicios. Los servicios reales ofrecidos varían de un protocolo a otro. 3 posibilidades razonables que normalmente proporcionan son: Servicio sin conexión ni confirmación de recepción: consiste en hacer que la máquina de origen envíe tramas independientes a la máquina de destino sin que esté confirmando la recepción. Ethernet es un ejemplo de una capa de enlace de datos que provee esta clase de servicios. No se establece una conexión lógica de antemano ni se librea después. Si se pierde una trama debido al ruido en la línea, en la capa de enlace de datos no se realiza ningún intento por detectar la pérdida o recuperarse de ella. Esta clase de servicios es apropiada cuando la tasa de error es muy baja, de modo que la recuperación se deja a las capas superiores, también es apropiada para el tráfico en tiempo real, como el de voz, en donde es peor tener retraso en los datos que errores en ellos. Servicio sin conexión con confirmación de recepción: El siguiente paso en términos de confiabilidad es este servicio sin con conexión con confirmación de recepción. Cuando se ofrece este servicio tampoco se usan conexiones lógicas, pero se confirma de manera individual la recepción de cada trama enviada. Entonces, el emisor sabe si la trama llegó bien o se perdió. Si no llegó en un intervalo especificado, se puede enviar de nuevo. Este servicio es útil en canales no confiables, como los de los sistemas inalámbricas 802.11 (Wifi) es un bueno ejemplo de esta clase de servicios. -El hecho de proporcionar confirmaciones de recepción en la capa de enlace de datos es más una cuestión de optimización, más que un requerimiento. La capa de red siempre que puede enviar un paquete y esperar a que si igual en la máquina remota confirme u recepción. Si la confirmación no llega antes de que expire e temporizador, el emisor puede volver a enviar el mensaje completo. El problema con esta estrategia es puede llegar a ser ineficiente. Por lo general los enlaces tienen una estricta longitud máxima para la trama, que esta impuesta por el hardware, además de retrasos en el medio. La capa de red no conoce estos parámetros. Servicio orientado a conexión con confirmación de recepción: el servicio más sofisticado que puede proveer la capa de enlace de datos a la capa de red es el servicio oriantado a la conexión. Con este servicio, las máquinas de origen y de destino establecen una conexión antes de transferir datos. Cada trama enviada a través de la conexión está numerada, y la capa de enlace de datos garantiza que cada trama enviado llegue a su destino, garantiza que cada trama se reciba una sola vez y que todas las tramas se reciban en el orden correcto. Así el servicio orientado a conexión ofrece a los procesos de la capa de red el equivalente a un flujo de bits confiable. Es apropiado usarlo en enlaces largos y no confiables, como un canal satélite o un circuito telefónico de larga distancia. Si se usa un servicio no orientado a conexión con confirmación de recepción, es posible que las confirmaciones de recepción perdidas ocasionen que una trama se envíe y se reciba varias veces, desperdiciando ancho de banda. Cuando se usan servicios orientado a conexión, las transferencias pasan por tres fases distintas. 1. la conexión se establece haciendo que ambos lados inicialicen variables y los contadores necesarios para seguir la posta de las tramas que se recibieron y las que no. 2. se transmiten una o más tramas. 3. la conexión se libera al igual que las variables, los búferes y otros recursos utilizados para mantener la conexión. 1.1.2 Entramado o Networking: Para proveer servicios a la capa de red, la capa de enlace de datos tiene que usar el servicio que la capa física le proporciona. Lo que hace la capa física es aceptar un flujo de bits puros y tratar de entregarlo al destino. Si el canal es ruidoso, como en la mayoría de los enlaces inalámbricos y en algunos alámbricos, la capa física agrega cierta redundancia a sus señales para reducir la tasa de error de bits a un nivel tolerable. Sin embargo, no se garantiza que el flujo de bits que se recorra por la capa de enlace de datos esté libre de errores. Algunos bits pueden tener distintos valores y la cantidad de bits recibidos puede ser menor, igual o mayor que la cantidad de bits transmitidos. Es responsabilidad de la capa de enlace de datos detectar y, de ser necesario, corregir los errores. El método más común para hacer esto que la capa de enlace divida el flujo de bits en tramas discretas, calcule un token corto conocido como suma de verificación para cada trama, e incluya a esa suma de verificación en la trama al momento de transmitirla. Cuando una trama llega al destino, se recalcula la suma de verificación. Si la nueva suma de verificación calculada es distinta de la contenida en la trama, la capa de enlace de dato sabe que hubo un problema en el medio y toma las medidas necesarias para manejarlo. Igualmente, es más difícil dividir el flujo de bits en tramas de lo que parece a simple vista. Un buen diseño debe facilitar a un receptor el proceso de encontrar el inicio de las nuevas tramas al tiempo que usa una pequeña parte del ancho de banda del canal. Los 4 métodos de ENTRAMADO más conocidos son: Conteo de bytes: En este método se vale de un campo en el encabezado para especificar el número de bytes en la trama. Cuando la capa de enlace del destino ve el conteo de bytes, sabes cuántos bytes siguen y, por lo tanto, dónde concluye la trama. El problema con este algoritmo es que el conteo se puede alterar por un error de transmisión. Bytes bandera con relleno de bytes: En este método de entramada se evita el problema de volver a sincronizar nuevamente después de un error al hacer que cada trama inicie y termine con bytes especiales. Con frecuencia se usa el mismo byte, denominado bytes bandera, como delimitador inicial y final. Este byte se muestra como FLAG. Dos bytes banderas consecutivos señalan el final de una trama y el inicio de la siguiente. De esta forma, si el receptor pierde alguna vez la sincronización, todo lo que tiene que hacer es buscar los bytes bandera para encontrar el fin de la trama actual y el inicio de la siguiente. Sin embargo, todavía existen problemas sin resolver. Se puede dar el caso de que el byte bandera aparezca en los datos, en especial cuando se transmiten datos binarios como fotografías o canciones. Esta situación interferiría con el entramado. Una forma de resolver este problema es hacer que la capa de enlace de datos del emisor inserte un byte de escape especial (ESC) justo antes de cada byte bandera "accidental" en los datos. De esta forma es posible diferenciar un byte bandera del entramado de uno en los datos mediante la ausencia o presencia de un byte de escape antes del byte bandera. La capa de enlace de datos del lado receptor saca el byte de escape antes de entregar los datos a la capa de red. Esta técnica se llama relleno de bytes. ¿Qué pasa si aparece un byte de escape en medio de los datos? Se rellena también con un byte de escape. En el receptor se saca el primer bytes de escape y se deja el byte de datos que le sigue (el cual podría ser otro byte de escape, o incluso el byte bandera). En la figura (b) se muestran ejemplos. En todos los casos la secuencia de bytes que se entrega después de borrar los bytes de relleno es exactamente la misma que la secuencia de bytes original. Así todavía podemos encontrar un límite de trama si buscamos dos bytes bandera seguidos, sin molestarnos por eliminar los escapes. El esquema de relleno de bytes que se muestra en la figura es una simplificación del esquema que usa el protocolo PPP (Protocolo Punto a Punto), que se usa para transmitir paquetes a través de los enlaces de comunicación. Bits bandera con relleno de bits: el tercer método de eliminar el flujo de bits resuelve una desventaja del relleno de bytes: que está obligado a usar bytes de 8 bits. También se puede realizar el entramado a nivel de bit, de modo que las tramas puede contener un número arbitrario de bits compuestos por unidades de cualquier tamaño. Esto se desarrolló para el protocolo HDLC (High-Level Data Link Control o Control de Enlace de Datos de Alto Nivel), que tuvo un momento en el que era popular. Cada trama empieza y termina con un patrón de bits especial, 01111110 o 0x7E en hexadecimal. Este patrón en un byte bandera. Cada vez que la capa de enlace de datos del emisor encuentra cinco bits 1 consecutivos en los datos, inserta automáticamente un 0 como relleno en el flujo de bits de salida. Este relleno de bits es análogo al relleno de bytes, en el cual se asegura una densidad mínima de transiciones que ayudan a la capa física a mantener la sincronización. La tecnología USB usa relleno ode bits por esta razón. Cuando el receptor ve cinco bits 1 de entrada consecutivos, seguidos de un bit 0, extrae (o sea, borra) de manera automática el bit 0 de relleno. Así como el relleno de bytes es completamente transparente para la capa de red en ambas computadoras, también los es el relleno de bits. Si los datos del usuario contienen el patrón bandera 01111110, éste se transmite como 011111010, pero se almacena en la memoria del receptor como 011111010. La siguiente figura es un ejemplo de relleno de bits. Con el relleno de bits, e límite entre las dos tramas puede ser reconocido sin ambigüedades mediante el patrón bandera. De esta forma, si el receptor pierde la pista de dónde está, lo único que tiene que hacer es explorar la entrada en busca de secuencias de banderas, ya que sólo pueden ocurrir en los limites de las tramas y nunca dentro de los datos. Un efecto secundario del relleno de bits y de bytes es que la longitud de una trama depende ahora del contenido de los datos que lleva. Por ejemplo, su no hay bytes bandera en los datos, se podrían llevar 100 bytes en una trama aproximadamente 100 bytes. Ahora, si los datos consisten sólo de bytes banderas, habría que incluir un byte escape para cada uno de estos bytes y la trama va a ser de 200 byres de longitud más o menos. Con el relleno de bits, el aumento sería cerca del 12,5% ya que se entrega 1 bit a cada byte. Violaciones de codificación de la capa física: Este último método de entramado es usar un atajo desde la capa física. La codificación de bits como señales incluye normalmente redundancia para ayudar al receptor. Por ejemplo, en el código de línea 4B/5B se asignan 4 bits de señal para asegurar suficientes transiciones de bits. Esto significa que no se usan 16 de las 32 posibles señales. Podemos usar algunas señales reservadas para indicar el inicio y el fin de las tramas. Estamos usando "violaciones de código" para delimitar tramas. La ventaja de este esquema es que, como hay señales reservadas, es fácil encontrar el inicio y el final de las tramas y no hay necesidad de rellenar los datos. Muchos protocolos de enlace de datos usan una combinación de estos métodos por seguridad. Un patrón común usado para Ethernet y 802.11 es hacer que una trama inicie con un patrón bien definido, conocido como preámbulo. Este patrón puede llegar a ser bastante largo de forma que el receptor se pueda preparar para un paquete entrante. El preámbulo va seguido de un campo de longitud en el encabezado, que se usa para localizar el final de la trama. 1.1.3 Control de Errores: Ya resuelto el problema de poder marcar el inicio y el fin de cada trama, se presenta un nuevo problema: cómo asegurar que todas las tramas realmente se entregan en el orden apropiado a la capa de red del destino. La manera normal de asegurar la entrega confiable de datos es proporcionar retroalientación al emisor sobre lo que está pasando del otro lado de la línea. Por lo general, el protocolo exige que el receptor devuelva tramas de control especiales que tengan confirmaciones de recepción positivas o negativas de las tramas que van llegando. Si el emisor recibe una confirmación de recepción positiva de una trama, sabe que llegó de forma correcta. Si se presenta el caso contrario, sabe que algo falló y que tiene que volver a transmitir la trama. Una complicación adicional sale de la posibilidad de que los problemas de este hardware causen la desaparición de una trama completa. En este caso, el receptor no reaccionaría en absoluta, porque en ningún momento le llegó nada. Lo mismo ocurriría si se pierde la trama de confirmación de recepción, el emisor no tendría porque responder. Para lidiar con este problema se introducen los temporizadores en la capa de enlaces de datos. Cuando el emisor envía tramas, por lo general también inicia el temporizador. Éste se ajusta de modo que expire cuando haya transcurrido un intervalo suficiente para que la trama llegue a su destino, se procese ahí y la confirmación de recepción llegue devuelta al emisor. En el caso de que la trama de confirmación se pierda, el temporizado expira, alertando al emisor sobre un potencial problema. La solución obvia es simplemente transmitir de nuevo la trama. Sin embargo, aunque éstas se pueden volver a transmitir muchas veces, existe el peligro del otro lado de que al receptor acepta la misma trama en dos o más ocasiones y que la pase a la capa de red más de una vez. 1.1.4 Control de flujo: Otro tema de diseño muy importante que se presenta en la capa de enlace de datos es qué hacer con un emisor que quiere transmitir tramas de manera sistemática y a mayor velocidad que aquella con que puede aceptarlos el receptor. En esa situación puede pasar cuando el emisor opera una computadora más rápida que la del receptor. Por lo general, se usan dos métodos, el control de flujo basado en retroalimentación, que es cuando el receptor regresa información al emisor para autorizarle que envíe más datos o por lo menos indicarle su estado. Y el segundo, el control de flujo basado en tasa, donde el protocolo tiene un mecanismo integrado que limita la tasa en la que el emisor puede transmitir los datos, sin tener que usar la retroalimentación por parte del receptor. Los esquemas basados en la retroalimentación se ven tanto en la capa de enlace como en las capas superiores. En realidad, es más común esto último, en cuyo caso el hardware de la capa de enlace se diseña para operar con rapidez suficiente como para no producir pérdidas. Por ejemplo, se dice alguna veces que las implementaciones de hardware de la capa de enlace como NIC (Tarjetas de Interfaz de Red), operan a "velocidad de alambre", que significa que pueden manejar las tramas con las misma rapidez con la que pueden llegar al enlace. De esta forma, los excesos no son un problema del enlace, por lo que lo esto lo manejan las capas superiores. Dentro de los esquemas de control de flujo basados en retroalimentación, el protocolo tiene reglas bien definidas respecto al momento en que un emisor puede transmitir la siguiente trama. Normalmente estas reglas prohíben el envío de tramas hasta que el receptor lo autorice. 1.2 Detección y corrección de errores: Los canales de comunicación tienen muchas características. Algunos como los que usan la fibra óptica en las redes de telecomunicaciones, tienen tasas de error pequeñas de modo que los errores de transmisión son una muy rara ocurrencia. Por otros canales, en especial los enlaces inalámbricos y los viejos lazos locales, tienen tasas de error más grandes. Para estos enlaces, los errores de transmisión son la norma. No se pueden evitar a un costo razonable en términos de rendimiento. La conclusión es que los errores de transmisión van a existir. Las personas que diseñan redes trabajaron con dos estrategias básicas para mejorar los errores. Ambas añaden información redundante a los que se envían. Una es incluir suficiente información redundante para que el receptor pueda deducir cuáles debieron ser los datos transmitidos. La otra estrategia es incluir sólo suficiente redundancia para permitir que el receptor sepa que hubo un error (pero no cuál) y entonces solicite una retransmisión. La primer estrategia códigos de corrección de errores; la segunda usa códigos de detección de errores.. El uso de códigos de corrección de errores se conoce normalmente como FEC (Forward Error Correction o corrección de errores hacia adelante). En canales confiables (como los de fibra), es más económico usar un código de detección de errores y sólo retransmitir los bloques que llegaron mal. En canales propensos a causar errores (enlaces inalámbricos) la mejor opción es agregar redundancia suficiente a cada bloque para que el receptor pueda descubrir cuál era el bloque original que se transmitió. FEC se usa en canales ruidosos ya que las retransmisiones tienen la misma probabilidad de ser tan erróneas como la primera transmisión. Una consideración clave para estos códigos es el tipo de de errores que pueden llegar a presentarse. Ni los códigos de corrección de errores ni los de detección de errores pueden manejar todos los posibles errores, ya que los bits que son redundantes tienen la misma probabilidad de ser recibidos con errores que los bits de datos. Los más ideal sería que el canal tratara a los bits redundantes de una manera distinta a los bits de datos. 1.2.1 Códigos de corrección de errores: Los códigos de corrección de errores más conocidos son: Códigos de Hamming. Códigos convolucionales binarios. Códigos de Reed-Solomon. Códigos de verificación de paridad de baja densidad. Todos estos códigos agregan redundancia a la información que se envía. Una trama consiste en m bits de datos (mensaje) y r bits redundantes (verificación). En código de bloque, los r bits de verificación se calculan en función de los m bit de datos con los que se asocian, como si los m bits se buscaran en una tabla para encontrar sus correspondientes r bits de verificación, en vez de que se codifiquen por si mismo antes de ser enviados. En un código lineal, los r bits de verificación se calculan como una función lineal de los m bits de datos. La tasa de códigos, es la fracción de tiempo de la palabra codificada que lleva información no redundante. Las tasas que se usan en la práctica puede variar mucho, normalmente depende del ruido que exista en el canal. Para entender la manera en que pueden manejarse los errores, es necesario estudiar lo que es en realidad un error. Dadas dos palabras codificadas que se puedan transmitir o recibir, por ejemplo 10001001 y 10110001, es posible determinar cuántos bits correspondientes difieren. En este caso, difieren solo 3 bits. Para determinar la cantidad de Bits diferentes, es suficiente con un aplicar un XOR a las dos palabras codificadas y la cantidad de bits 1 en el resultado. La cantidad de posiciones de bits en la que difieren dos palabras codificas se llama distancia de Hamming. Su significado es que, si dos palabras codificadas están separadas una distancia de Hamming "d", se va a requerir entonces de "d" errores de UN solo bit para convertir una en la otra. Las propiedades de detección y corrección de errores de un código de bloque dependen de su distancia de Hamming. Para detectar d errores de manera confiable se necesita de un código con distancia d + 1, ya que con ese código no hay forma de que d errores de un bit puedan cambiar una palabra codificada válida a otra. Cuando el receptor ve una palabra codificada inválida, sabe que ocurrió un error en la transmisión. 1.2.1.1 Códigos de Hamming: En los códigos de Hamming, los bits de la palabra codificada se numeran en forma consecutiva, comenzando por el bit 1 de la izquierda, el bit 2 de su derecha inmediata, etc. Los bits que son potencias de 2 son bits de verificación. El resto se rellenan con los bits de datos de la información que se quiere enviar. El patrón se muestra para un código de Hamming con 7 bits de datos y 4 de verificación. Cada bit de verificación obliga a que la suma módulo 2, o paridad de un grupo de bits, incluyendo a este mismo, sea par (o impar). Si no todos los resultados de verificación son cero, entonces se detectó un error. El conjunto de resultados de verificación forma el síndrome de error que se usa para señalarlo y corregirlo el error. Las distancias de Hamming son importantes para entender los códigos de bloque, y los códigos de bloque de Haming se usan en la memoria de corrección de errores. Sin embargo, la mayoría de redes usan códigos más robustos. 1.2.1.2 Código convolucional binario: Este código es el único que no es código de bloque. En un código convolucional, un codificador procesa una secuencia de bits de entrada y genera una secuencia de bits de salida. No hay un tamaño de mensaje natural, o límite de codificación, como en un código de bloque. La salida depende de los bits de entrada actual y previa Es decir, el codificador tiene memoria. El número de bits previos de los que depende la salida se denomina longitud de restricción del código. Los códigos convolucionales se usan much en ls redes implementadas, como el de la telefonía móvil GMS, en la comunicaciones de satélite y en 802.11. Existió un Código convolucional NASA de r = 1/2 y k = 7, ya que se usó por primera vez en las misiones espaciales del Voyager a partir de 1977. Desde entonces se reutilizó libremente, por ejemplo, como parte de las redes 802.11. En la figura cada bit de entrada del lado izquierda produce dos bits de salida al lado derecho, los cuales son las sumas XOR de la entrada y el estado interno. Ya que se trata con bits y se realizan operaciones lineales, es un código convolucional binario lineal. Un bit de entrada produce 2 bits de salida, la tasa de código es de 1/2. No es sistemático, ya que ninguno de los bits de salida es simplemente el bit de entrada. El estado interno se mantiene en seis registros de memoria. Cada vez que se introduce otro bit, los valores de los registros se van desplazando a la derecha. Se requiere siete desplazamientos para vaciar una entrada por completo, de forma que no afecte la salida. Por lo tanto, la longitud de restricción de este código es k = 7. Para decodificar un código convolucional es necesario buscar la secuencia de bits de entrada que tenga la mayor probabilidad de haber producido la secuencia de bits de salida (incluyendo también los errores). El algoritmo recorre la secuencia observada y guarda cada paso y cada posible estado interno la secuencia de entrada que hubiera producido la secuencia observada con la menor cantidad posible de errores. Al final, la secuencia de entrada que requiera la menor cantidad de errores es el mensaje más probable. Los códigos convolucionales fueron populares en la práctica, porque es fácil ignorar el hecho de que un bit sea 0 o 1 en la decodificación. Las extensiones del algoritmo de Viterbi pueden trabajar con esto mismo de un bit que se conoce como decodificació de decisión suave. Por el contrario, decidir si cada bit es un 0 o un 1 antes de la subsiguiente corrección de errores se conoce como decodificación de decisión dura. 1.2.1.3 Código de Reed-Solomon: Al igual que los código de Hamming, los códigos de Reed-Solomon son códigos de bloques lineales y con normalmente también sistemáticos. A diferencia de los códigos de Hamming, que operan sobre bits individuales, los códigos de Reed-Salomon operan sobre símbolos de m bits. Estos códigos se basan en el hecho de que todo polinomio de n grados se determina en forma única mediante n + 1 puntos. Por ejemplo, una línea con la forma ax + b se determina mediante dos puntos. Los puntos extra en la misma línea con redundantes, lo que es útil para la corrección de errores. Imaginemos que dos puntos de datos representan una línea y que enviamos esos dos puntos de datos con dos puntos de verificación seleccionados sobre la misma línea. Si uno de los puntos se recibe con error, de todas formas podemos recuperar los puntos de datos si ajustamos una línea a los puntos recibidos. Tres de los puntos van a estar sobre la línea y el otro punto (el error) no. Una vez que encuentra la línea, se sabe que se corrigió el error. Los códigos de Reed-Salomon se usan mucho más en la práctica por sus propiedades de corrección de errores, en especial para los errores de ráfagas. Se usan para DLS, datos sobre cable, comunicaciones de satélite y en los CD, DVD y discos Blu-ray. Ya que se basan en símbolos de m bits, tanto un error de un solo bit como un error de ráfaga de m bits se tratan simplemente como error de un símbolo. A veces los códigos de Reed-Solomon también se usan en combinación con otros códigos, como el convolucional. El razonamiento es el siguiente: Los códigos convolucionales son efectivos a la hora de manejar errores en bits aislados, pero pueden fallar con una ráfaga de errores, si hay demasiados en el flujo de bits recibidos, se agrega un código Reed-Solomon dentro del código convolucional, la decodificación de ReedSolomon puede limpiar las ráfagas de errores. 1.2.1.4 Código de Verificación de Paridad de Baja Densidad: 1. ¿Qué es la conmutación? La conmutación (switching) se considera como la acción de establecer una vía de extremo a extremo entre dos puntos, donde hay un emisor (Tx) y un receptor (Rx) a través de nodos o equipos de transmisión. Permite la entrega de la señal desde el origen hasta el destino requerido para lograr un camino apropiado de una red de telecomunicaciones. Permite la descongestión entre los usuarios de la red disminuyendo el tráfico y aumentando el ancho de banda. Representa una de las capas de los nuevos modelo de redes. La capa conmutación también conocida como Capa 2, permite a los nodos asignar direcciones y adjuntar datos a una señal. 2. Conmutación de Circuitos: Se denomina conmutación de circuitos (circuit switching) al establecimiento de una vía dedicada exclusiva y temporalmente a la transmisión de extremo a extremo entre dos puntos, un emisor y un receptor. En la conmutación de circuitos se busca y define una vía extremo-a-extremo con un ancho de banda fijo específico durante toda la sesión. La red recibe desde el extremo emisor una dirección que identifica al extremo destinatario y establece un "camino" hacia este destino. Cuando finaliza la sesión, la vía se libera y puede ser usada por un nuevo circuito. Su ventaja principal radica en que una vez establecido el circuito su disponibilidad es muy alta, ya que se garantiza este camino entre ambos extremos independientemente del flujo de información. Su principal inconveniente consiste en que se consumen muchos recursos del sistema mientras dura la comunicación independientemente de lo que en realidad pudiera requerir. La conexión se establece antes de que comience la transmisión de datos. La capacidad del canal debe estar disponible y reservada. Los nodos tienen que tener la capacidad para manejar la conexión. Los conmutadores tienen que tener la inteligencia para reservar recursos y ver la ruta. Camino dedicada entre dos estaciones. Secuencia conectada de enlaces entre nodos. La comunicación comprende 3 fases: Establecimiento del circuito. Transferencia de datos. Desconexión del circuito. Puede ser ineficiente: Capacidad dedicada durante la duración de la conexión, aún así los no están siendo transferidos. Para voz, la utilización es alta, pero igual así no llega al 100%. Para la conexión de terminales, debería estar disponible la mayor parte del tiempo. Retardo previo a las transferencias de datos para el establecimiento de llamadas. Una vez que el circuito esta establecido, la red es transparente a los usuarios. Transmisión de datos a velocidad fija. 2.1 Elementos de la Conmutación por Circuitos: Estaciones: Son los dispositivos finales que se desean comunicar. Puede ser teléfonos, computadoras, etc. Nodos: Son los dispositivos de conmutación que propagan la comunicación. Redes de comunicaciones: Es el conjunto de todos los nodos. 2.2 Establecimiento del circuito: 1. La estación A conectada al nodo 4 pide ser comunicada con la estación E. 2. El circuito desde A a 4 es usualmente una línea dedicada. 3. El nodo 4 busca la próxima pata al nodo 6. 4. Basada en la información de ruteo, disponibilidad, y costo, el nodo 4 selecciona el circuito al nodo 5. 5. Asigna un canal libre. 6. Nodo 4 requiere conexión a E. y así sigue... 7. Se cierra la conexión. Usualmente por un de las estaciones. 8. Se le avisa a los nodos que liberen recursos. 2.3 Enrutamiento de la redes de circuitos: Es una red de conmutación de circuitos muchas conexiones necesitan una ruta que pase a través de más de un conmutador. En una estrategia de enrutamiento hay dos requisitos fundamentales para la arquitectura de la red: eficiencia y flexibilidad: Eficiencia: Se desea minimizar la cantidad de equipos (conmutadores y enlaces) en la red, teniendo en cuenta que debe ser capaz de aceptar toda la carga esperada. Flexibilidad: Aunque se puede dimensionar la red teniendo en cuenta el tráfico en horas pico es posible que la carga supere temporalmente este nivel. La rede tiene que proporcionar un servicio razonable incluso bajo malas condiciones. El punto clave entre la eficiencia y flexibilidad es la estrategia de enrutamiento. 2.4 Señalización de control: En las redes de conmutación de circuitos, las señales de control constituyen el medio por el que se establecen, mantienen y finalizan las llamadas. La señalización puede clasificarse cuatro categorías: Supervisión: Se refiere a funciones de carácter binario. Direccionamiento: Enrutamiento que permite localizar el destino. Información sobre la llamada: Se refiere al estado de la llamada; establecimiento y cierre de la llamada. Gestión de red: Se usa para el mantenimiento, resolución de problemas y el funcionamiento general de la red. 2.5 Packet Switching - Circuit Switching Issues: Diseñados por voz: Los recursos están dedicados a una llamada en particular. Para voz, alta utilización: La mayor parte del tiempo, alguien está hablando. Para datos: Línea sin uso la mayor parte del tiempo. Velocidad de transmisión constante. Limita la interconexión de la variedad de computadoras, hosts y terminales. 3. Conmutación de Paquetes: Se denomina Conmutación de Paquetes o Packet Switching al intercambio de bloques de información (o "paquetes") con una tamaño específico entre dos puntos, un emisor y un receptor. En el origen, extremo emisor, la información se divide en "paquetes" a los cuales se les indica la dirección del destinatario. Cada paquete contiene, no solo los datos, sino que también un encabezado con información de control (prioridad y direcciones de origen y destino). Los paquetes se transmiten a través de la red y, después son reensamblados en el destino obteniendo así el mensaje original. En cada nodo de la red, un paquete puede ser almacenado temporalmente y encaminado dependiendo de la información de la cabecera. De esta forma, pueden existir varias vías o caminos de un punto a otro, siendo gestionado por la red el camino más óptimo. Las redes basadas en la conmutación de paquetes evitan que mensajes de gran longitud signifiquen grandes intervalos de espera ya que estos limitan el tamaño de los mensajes transmitidos. La red puede transmitir mensajes de longitud visible pero con una longitud máxima. La conmutación de paquetes es más adecuada para la transmisión de datos comparada con la conmutación de circuitos. Un paquete es un grupo de información que consta de dos partes, los datos y la información de control, en la que está especificado la ruta a seguir a lo largo de la red hasta el destino del paquete. Mil octetos es el límite de longitud superior de los paquetes, y si la longitud es mayor el mensaje se fragmenta en otros paquetes. 3.1 Proceso: 1. Los datos se transmiten paquetes. 2. Los mensajes más largos se cortan en series de paquetes. 3. Cada paquete tiene parte o todos los datos, más la información de control. 4. La información de control incluye el ruteo de redes. 5. En cada nodo se reciben paquetes guardados por un tiempo corto y pasados al próximo nodo. 6. Las computadores que transmiten envían un mensaje como una secuencia de paquetes. 7. En el paquete se incluye información de la estación de destino. 8. Los nodos guardan por un instante los paquetes, determinan la próxima parada de la ruta, y encolan paquetes para que salgan por ese enlace. 9. Cuando el enlace (link) está disponible, el paquete es transmitido al próximo nodo. 10. Todos los paquetes siguen su camino por si mismos. Las ventajas podrían ser: Mayor eficiencia de línea: enlace de nodo a nodo compartido dinámicamente por muchos paquetes. Conversión de tasa de datos: Cada estación se conecta a su nodo a su velocidad de datos adecuada. Los nodos actúan como amortiguadores. Paquetes aceptados, incluso bajo tráfico pesado, pero el retraso en la entrega aumenta: las redes de conmutación de circuitos bloquearían directamente nuevos intentos de conexión. Las prioridades puede usadas. Las desventajas podrían ser: El retardo (Delay): el delay de la transmisión es igual al largo de los paquetes dividido por la velocidad del canal. Retardo variable debido al procesamiento y al encolado. Los paquetes pueden variar largo: puede tomar diferentes rutas. Puede estar sujeto a distintos retardos. El retardo de los paquetes varia sustancialmente. No es lo mejor para aplicaciones real-time. El "Overhead" incluye direcciones de destino, información de secuencia, etc: Reduce la capacidad disponible para los datos de usuario. Se requiere más procesamiento en cada nodo. 3.2 Técnicas de Conmutación: Para el uso de la conmutación de paquetes se definieron dos tipos de técnicas: los Datagramas y los Circuitos virtuales: 3.2.1 Datagrama: Los Datagramas son un fragmento de paquete que es enviado con la suficiente información para que la red pueda simplemente encaminarlo hacía el equipo terminal de datos "DTE" (Receptor), de manera independiente a los fragmentos restantes. Este puede provocar una recomposición desordenada o incompleta del paquete en el DTE destino. - No tiene fase de establecimiento de llamada. - El paso de datos es más seguro. - No todos los paquetes siguen una misma ruta. - Los paquetes pueden llegar al destino en desorden ya que se tratan de manera independiente. - Un paquete se puede destruir en el camino y su recuperación es responsabilidad de la estación de destino (esto da a entender que el resto de paquetes llegaron con éxito). Proceso de los Datagramas: Cada paquete es tratada de forma independiente, entonces: No hay referencia a los paquetes que pasaron anteriormente. Cada nodo elije cuál es el próximo en el camino. Paquetes con el mismo destino no necesariamente siguen el mismo camino. Pueden llegar fuera de secuencia. Los nodos finales o el destino rearma la información en orden. Los paquetes pueden perderse en el camino. Los nodos de salida o destino detectan las perdidas y solicitan la recuperación. Se evita el establecimiento de la llamada. Para mensajes cortos, el datagrama es más rápido, más flexible: Se puede evitar la congestión. La entrega es inherentemente más confiable. Si un nodo falla, los subsiguientes paquetes puede ser re-ruteados. 3.2.2 Circuitos virtuales: Un circuito virtual es un sistema de conmutación por el cual los datos de un usuario origen pueden ser transmitidos a otro usuario a través de más de un circuito de comunicaciones real durante un cierto periodo de tiempo, pero en el que la conmutación es transparente para el usuario. Un ejemplo de protocolo que usa circuitos virtuales es el ampliamente usado TCP: Su funcionamiento es similar al de conmutación de circuitos. Antes de la transmisión se establece la ruta por medio de paquetes de petición de llamda (pide conexión lógica al destino) y de llamada aceptada (en cado de que la estación destino esté apta para la transmisión envía este tipo de paquete); establecida la transmisión, se da el intercambio de datos, y una vez terminada, se presenta el paquete de petición de liberación (aviso de que la red está disponible, es decir que la transmisión llegó a su fin). Cada paquete tiene un identificador de circuito virtual en lugar de la dirección del destino. Los paquetes se reciben en el mismo orden en que fueron enviados. Proceso: Una ruta pre-planeada se establece antes de que los paquetes se envíen. Todos los paquetes siguen las misma rutas. Similar a la red de circuitos. Cada paquete tiene su identificador de circuito virtual. Los nodos en la ruta saben a donde direccionar los paquetes. No hay decisión de ruteo. NO es un camino dedicado. Los paquetes almacenan (buffered) en el nodo y se encolan para la salida. La decisión de ruteo se hace una vez para el circuito virtual. Las redes pueden proveer servicios relacionados con el circuito virtual: secuencia y control de error. Los paquetes transitan más rápidamente. Si el nodo falla todos los circuitos virtuales que pasan por el nodo fallan. Fases: En el circuito virtual se pueden diferenciar tres fases: 1. Apertura de la conexión: Se añade una entrada en la tabla de reenvío, se determina la ruta entre el emisor y el receptor, se reservan recursos (ancho de banda). Tenemos que tener en cuenta que esta conexión se hace de varios enlaces y routers por lo que todos los routers tienen que actualizar sus tablas de reenvío. 2. Transferencia de paquetes: en esta fase se transfieren los datos necesarios. 3. Cierre de la conexión: una vez terminada la fase de transferencia, se cierra la conexión avisando al otro nodo y se actualizan las tablas de reenvío de todos los routers. 3.3 Estrategias de enrutamiento: Estático: - Es la especificación para cada par de nodos origen-destino de la identidad del siguiente nodo en la ruta. - No se necesita saber la ruta completa sino sola la del siguiente nodo. - No existe diferenciación entre Datagrama y Circuitos virtuales ya que todos los paquetes van a seguir una misma ruta de manera secuencial. - Ventajas: Simplicidad y buen funcionamiento. - Desventaja: Falta de flexibilidad (no existe reacción a fallos ni congestionamiento). Inundaciones: Para mensajes de alta prioridad. No se precisa información sobre la red. El nodo origen envía una copia del paquete a los nodos vecinos y estos mediante enlaces van a enviar al resto de nodos hasta que una copia llegue al destino. Propiedades: a. Se prueban los posibles caminos entre los nodos y destinos. b. Una copia del paquete va a intentar usar el menor número de saltos. c. Se visitan todos los nodos que están directa o indirectamente conectados con el origen. d. Generación de demasiado tráfico. Aleatorio: Mayor control del congestionamiento. Selección de un único camino de salida para transmitir el paquete entrante. El enlace de salida se elije en forma aleatoria sin tomar en cuenta el enlace anterior. Adaptable: Las decisiones cambian a medida de las condiciones de la red (si la red tiene fallos el nodo o línea ya sabe que no puede ser parte de la ruta y en caso de congestionamiento se rodeo la zona gestionada). Los nodos intercambian información sobre el estado de la red. Esta técnica es más utilizada que la estática por: 1. Mejora en las prestaciones. 2. Retrasa el hecho de que aparezcan situaciones graves de congestionamiento. 3.4 Orientado o no a la conexión: Los protocolos de red y el tipo de tráfico de datos que soportan pueden ser caracterizados como orientados a conexión o sin conexión: 3.4.1 Orientado a la conexión: Implica el uso de un camino específico que se establezca durante una conexión. Los datos pasan a través de una conexión permanente establecida. Este tiene 3 Fases: 3 Fases: 1. Establecimiento de la conexión: Se determina un solo camino entre el origen y los sistemas destinatarios. Los recursos de la red generalmente son reservados en ese momento para asegurar una calidad constante del servicio. 2. Transferencia de datos: los datos se transmiten secuencialmente sobre el camino que se estableció. Llegan siempre el sistema destinatario en el orden en el cual fue enviado. 3. Fin de la conexión: una conexión establecida que no se necesita más se termina. La comunicación adicional entre el origen y los sistemas destinatarios requiere que sea establecida una nueva conexión. Ventajas: Son útiles para trasmitir datos que no toleran delay y el resencuenciamiento de paquetes. Las aplicaciones de voz y de vídeo se basa típicamente en servicios orientados a conexión. Desventajas: Reserva estática del camino: todo tráfico tiene que viajar a lo largo del mismo camino estático y un incidente en cualquier punto de ese camino va a hacer fallar la conexión. Reserva estática de recursos: todos los recursos quedan reservados para esa comunicación y no es posible compartirla con otros usuarios de la red. A menos que se utilice completo el rendimiento de procesamiento, de forma ininterrumpida, el ancho de banda no se usa de manera eficiente. 3.4.2 No orientado a la conexión: No implica la predeterminación del camino a seguir por lo paquetes. No garantiza: - La secuencia de paquetes. - La tasa de transferencia de datos. - Los recursos de la red. Cada paquete es transmitido independientemente por el sistema de origen y manejado independientemente por los dispositivos intermedios de la red. Ventajas: Selección dinámica del camino: permite al tráfico ser encaminado evitando fallas de la red porque los caminos se seleccionan paquete por paquete. Asignación dinámica del ancho de banda: permite hacer un uso más eficiente del ancho de banda, ya que no se afectan los recursos de red que no se utilizan. Son útiles para aplicaciones que toleran un cierto delay y resecuenciamiento de los paquetes. Típicamente usada por aplicaciones de datos (mail, web). Son descritos generalmente con sin estado: los puntos finales no guardan información para recordar una "conversación" de cambios de mensajes. Con los años la fusión de las computadoras y las comunicaciones tuvieron una profunda influencia en cuanto a la manera en que organizan los sistemas informáticos. El concepto que se conocía como "centro de cómputo" o "centro de informática", como un salón con una gran computadora a la que los usuarios llevaban su trabajo para procesarlo es ahora totalmente obsoleto. El viejo modelo de una sola computadora para entender todas las necesidades computacionales de la organización se remplazó por uno en el que un gran número de computadoras separadas pero interconectadas entre sí hacen el trabajo. A estos sistemas se los conoce como redes de computadoras. Una red de computadoras no es lo mismo que un sistema distribuido. La diferencia clave está en que un sistema distribuido, un conjunto de computadoras independientes aparece frente a sus usuarios como un solo sistema coherente. Por lo general, tiene modelo o paradigma único que se presenta a los usuarios. A veces se usa una capa de software encima del sistema operativo, conocido como middleware; esta capa es responsable de implementar este modelo. Un ejemplo muy conocido es la World Wide Web. Este sistema opera sobre Internet y presenta un modelo en el cual todo se ve como un documento (página web). En una red de computadoras no existe esta coherencia, modelo ni software. Los usuarios quedan expuestos a las máquinas real, sin que el sistema haga algún intento por hacer que éstas se vean y actúen de manera coherente. Si las máquinas tienen distinto hardware y distintos sistemas operativo, es algo que está a la vista de los usuarios. Si un usuario quiere ejecutar un programa en un equipo de manera remota, tiene que iniciar sesión en esa máquina y ejecutarlo ahí. Un sistema distribuido es un sistema de software construido sobre una red. El software le ofrece un alto nivel de cohesión y transparencia. Por ende, la distinción entre una red y un sistema distribuido recae en el software (en especial, en el sistema operativo) y no en el hardware. 1. Primer protocolo MAC, ALOHA (ALOHAnet): ALOHA, también llamado ALOHAnet, fue un sistema pionero de redes de computadoras desarrollado en la universidad de Hawái. Se lanzó por primera vez en 1970. Aunque la red ALOHA ya no se usa, uno de los conceptos esenciales de esta red es la base para la casi universal Ethernet. En ese momento en Hawái no podían cruzar el océano con cables de fibra óptica, así que encontraron un solución que implicaba radios de corto rango, en donde cada terminal de usuario compartía la misma frecuencia ascendente para enviar tramar a la computadora central. El sistema ALOHA usaba la radiodifusión basada en tierra, la idea básica es aplicable a cualquier sistema en el que usuarios no coordinados compiten por el uso de un solo canal compartido. Existen dos versiones de ALOHA, ALOHA puro y ranurado. El término ALOHA en la comunicación de datos se refiere a un tipo de protocolo que permite que los dispositivos se comuniquen entre sí sin necesidad de un control o coordinación centralizados. Este tipo de protocolos se usa o se usaba en redes inalámbricas o móviles, donde podría llegar a ser difícil mantener un control centralizado. En ALOHAnet, cada nodo escucha para saber si alguien está usando el canal, y si no escucha a nadie empieza a emitir. Este sistema se conoce como Acceso múltiple por detección de portadora. En resumen, ALOHA fue un sistema pionero que sirvió como la base para el desarrollo de redes Ethernet y Wi-Fi. 1.1 ALOHA PURO: La idea básica de ALOHA es la siguiente: permitir que los usuarios transmitan cuando tengan datos para enviar. Obvio pueden existir colisiones donde las tramas se ven afectadas. Los emisores necesitan alguna forma de saber si éste fue el caso. Después de cada estación envía su trama a la computadora central, ésta vuelve a difundir la trama a todas las estaciones. Así, una estación emisora puede escuchar la difusión de la estación terrena maestra (HUB) para ver si pasó su trama o no. En otros sistemas, como las LAN alámbricas, el emisor podría ser capaz de escucha si hay colisiones mientras transmite. Si la trama fue destruida, el emisor simplemente espera un tiempo aleatorio y la envía de nuevo. El tiempo de espera tiene que ser aleatorio o las misma tramar chocarían una y otra vez, en sincronía. Los sistemas en los cuales varios usuarios comparten un canal común de modo tal que puede dar pie a conflictos se conocen como sistemas de contención. 1.2 ALOHA ranurado (Slotted ALOHA): Es una versión mejorada del protocolo ALOHA. Las diferencias clave entre ALOHA puro y ALOHA ranurado. Roberts (1972) publica un método para duplicarla capacidad de un sistema ALOHA. Su propuesta era dividir el tiempo en intervalos discretos llamados ranuras, cada una de estas ranuras correspondía una trama. Este método requiere que los usuarios acuerden límites de ranuras. Un manera de lograr la sincronización sería tener una estación especial que emitiera una señal al comienzo de cada intervalo, como un reloj. ALOHA ranurado a diferencia del ALOHA puro de Abramson, es que no permite que una estación envíe cada vez que el usuario escribe una línea. En cambio, se le obliga esperar el comienzo de la siguiente ranura. Por lo tanto, el ALOHA de tiempo continuo se convierte en uno de tiempo discreto. Esto reduce el periodo vulnerable a la mitad. El tiempo se organiza en ranuras uniformes de duración igual al tiempo de transmisión de una trama. Necesita un reloj central o otro mecanismo de sincronización. La transmisión se permite en los instantes de tiempo que coincidan con el comienzo de una ranura. Sino las tramas se pierden o se solapan completamente. La utilización máxima del sistema es del 37%. 2. Carrier Sense Multiple Access (CSMA): El protocolo de detección de portadora, también llamado CSMA, es un protocolo de control de acceso al medio (MAC) que se usa en las redes de computadoras para compartir canales de comunicación de manera eficiente. Este protocolos se basa en la detección de portadora, lo que significa que los dispositivos en la red tienen que escuchar y detectar si hay actividad en el canal antes de transmitir datos. La detección de portadora se refiere a la capacidad de un dispositivo de red para determinar si un canal de comunicación está actualmente en uso antes de intentar transmitir datos a través de la él. Si el canal está ocupad, el dispositivo va a esperar hasta que esté libre antes de comenzar a transmitir. El propósito de este protocolo es evitar colisiones de datos, que ocurren cuando dos o más dispositivos intentan transmitir datos al mismo tiempo en el mismo canal. Al evitar colisiones, el protocolo CSMA puede ayudar a mejorar la eficiencia de la red y garantizar una transmisión de datos más fluida y sin interrupciones. Existen varias variantes de CSMA, como CSMA/CD (Carrier Sense Multiple Access with Collision Detection) y CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance), que usan otros tipos de redes y tienen sus propios métodos para manejar y evitar colisiones. Cuando una estación tiene datos por enviar, primero escucha el canal para saber si alguien más está transmitiendo en ese momento. Si el canal está inactivo, la estación envía sus datos. En caso de estar ocupado, la estación espera hasta que se desocupa. Si ocurre una colisión, la estación espera una cantidad aleatoria de tiempo y comienza de nuevo. El protocolo se llama persistente-1 porque la estación transmite con una probabilidad de 1 cuando encuentra que el canal está inactivo. 2.1 CSMA No Persistente o Non-persistent CSMA: El CSMA no persistente es una variante del protocolo de Control de Acceso al Medio (MAC) CSMA. Cuando una estación tiene tramar por enviar, detecta el estado del canal. Si el canal está inactivo, la estación envía la trama inmediatamente. Si está ocupado, espera una cantidad de tiempo aleatoria para volver a detectar el estado del canal. Su propósito era abordar los problemas asociados con CSMA persistente, con las colisiones de datos. Sin embargo este método también tiene sus desventaja. Por ejemplo, puede resultar en un uso ineficiente del canal, ya que las estaciones no siempre transmiten inmediatamente cuando el canal está inactivo. 2.2 CSMA P-Persistente: Es otra variante de CSMA, que cuando una estación tiene tramas para enviar detecta el estado del cana. Si el canal está ocupado, la estación espera hasta el siguiente intervalo. Si el canal está inactivo, la estación transmite la trama con una probabilidad "p", y con una probabilidad "q" (donde q = 1 - p), la estación espera hasta el comienzo del siguiente intervalo de tiempo. Este proceso se repite hasta que la trama se transmite o hasta que otra estación comienza a transmitir. Se creó para abordar los problemas asociados con persistente-1. Si dos estaciones detectan que el canal está inactivo, ambas comenzarían a transmitir y terminaría en una colisión. Al agregar una probabilidad p de transmitir cuando el canal esta inactivo, este protocolo reduce la probabilidad de que dos estaciones intenten transmitir al mismo tiempo. 2,3 CSMA/CD o Carrier Sense Multiple Access with Collition Detection: Funcionamiento de los HUBs, bridge y switches. 1. ¿Cómo podemos extender las redes LAN? Breve historia: Los diseñadores especifican una distancia máxima para la extensión de una red LAN. Éste es el resultado del compromiso entre extensión de la red y la utilización del canal (mientras más abarca la red, los tiempos de propagación son mayores y la utilización de canal baja). También hay razones de tipo tecnológicas como la potencia requerida en los transmisores. Para extender las LAN se usan módems de fibra, repetidores, BRIDGES, SWITCHES, etc. Limitaciones de distancia: cuando el medio es compartido, las tecnologías LAN consideran un largo máximo para obtener retardos "moderados" y protocolos "eficientes". Las señales eléctricas se van debilitando con la distancia lo que limita su llegada a puntos que está lejos. Esta características limita el largo máximo de un segmento. Opciones para extender una red LAN: Extensión de fibra óptica. Repetidores. Bridges. Switches. 1.1 NIC (Network Interface Card): Provista para los host de acceso al medio. Los NICs operan en las capas 1 y 2. Se identifican por una dirección física llamada MAC (Media Access Control). MAC = OUI (24 Bits) + UAA (24 Bits) 1.2 Interconexión de dos PCs: Es la LAN más que chica que se puede hacer: Para conectar dos PCs se necesita: Que cada una tenga un NIC. Usar cables adecuados (cruzado o crossover). 1.3 Extensión vía fibra óptica: Un par de módems y fibra ópticas se usan para conectar una computadora a una LAN remota. El mecanismo es insertado entre la tarjeta de red y el transceiver remoto. 1.4 Repetidor: Los repetidores incrementan la distancia de un segmento: Para segmento de más de 100 metros o 300 pies es necesario el uso de un repetidor de señal. Este amplifica y regenera la señal (están obsoletos hoy en día). 1.5 Repetidores VS Hubs: Los repetidores conectan solo DOS PCs: Para interconectar MÁS de DOS dispositivos entre sí y que se puedan comunicar, es necesario que haya un REPETIDOR MULTI-PUERTO. 1.6 HUBs: Permiten conectar múltiples PCs. El repetidor multi-puerto se llama HUB. 1.6.1 HUBs: problemas: Las conexiones en cascada generan problemas. Los hubs comparten el ancho de banda entre todos los dispositivos conectados. Los hubs son dispositivos "tontos" de capa 1, por lo que no distinguen el tráfico. Constituyen una topología broadcast (difusión), que crea tormentas de tráfico reenviando la información a todos los dispositivos. Constituyen un problema de seguridad. 1.7 Bridges: Los puentes son dispositivos electrónicos que conectan dos segmentos en una LAN. Manejan la trama completa y usan la misma tarjeta interfaz que otras estaciones conectadas a la red. A diferencia del repetidor que trabaja en la capa física, el BRIDGE procesa la trama hasta la capa de enlace de datos. Los BRIDGES no retransmiten las colisiones ni tramas recibidas con error. Son transparentes para las PCs conectadas a la red. Los BRIDGES no retransmiten tramas a menos que sea necesario. Esto lo hacen observando las direcciones destino de las tramas y comparándolas con la información que manejan de la localización de las estaciones. La ubicación de las estaciones la aprenden en forma adaptativa observando la dirección origen en las tramas que se reciben. Si la dirección no está en la tabla, la trama es retransmitida. Las tramas broadcast son retransmitidas. Los BRIDGES permiten paralelismo en el uso de los segmentos. Ventajas: Fiabilidad. Rendimiento. Seguridad. Geografía. 1.7.1 Funciones de un BRIDGE: Lee todas las tramas transmitidas sobre la LAN y acepta las de direcciones de cualquier estación de otra LAN. Usan Protocolo MAC retransmite hacia otra LAN cada una de las tramas. Lo mismo en sentido contrario. 1.7.2 Aspectos de diseño: No se modifica contenido o formato de la trama. No encapsula. Copia exacta bit a bit de la trama. Mínimo almacenamiento en buffer para satisfacer demandas de pico. Capacidad de direccionamiento y enrutamiento: Tiene que ser capaz de decir que tramas pasar. Puede pasar más de un paquete. Poder conectar más de dos LANs. BRIDGING es transparente a las estaciones: estaciones en múltiples LAN parece como única LAN. 1.7.3 Arquitectura de protocolos: IEEE 802.1D. Nivel MAC: dirección de la estación, al mismo nivel. BRIDGE no necesita LLC: retransmisión de tramas MAC. Pueden pasar las tramas de sistemas de comunicación externa: Enlace WAN. Captura de trama. Encapsulamiento. Transmitirla hacia el otro lado del puente. Va a eliminar campos extra y va a transmitir la trama. 1.7.4 Árbol de expansión: LANs grandes requieren rutas alternativas: Balanceo de carga. Tolerancia a fallos. BRIDGE desarrollan automáticamente tablas de routing. Actualiza automáticamente en respuesta a cambios: Retransmisión de tramas. aprendizaje de direcciones. Resolución de bucles (loops). 1.7.4.1 Árbol de expansión - retransmisión de tramas: Mantiene una base de datos de retransmisión para cada puerto. Base indica lista de direcciones para cada puerto. Para cada trama que llega a un puerto X: Búsqueda de BD si dirección MAC asociado a puerto <> X. Si no encuentra dirección, se envía a todos excepto X. Si la dirección está en el puerto Y chequea si el puerto Y está bloqueado o disponible: el bloqueo impide al puerto recibir o transmitir. Si no está bloqueado, transmite. 1.7.4.2 Árbol de expansión - Aprendizaje de direcciones: Puede transmitir la base de datos precarhada. Puede aprenderla. Cuando la trama llega al puerto X, viene desde la dirección de la LAN entrante. Usa la dirección de origen para actualizar la base de datos de retransmisión de puerto X para incluir esa dirección. Temporizador en cada entrada de la base de datos. Cada vez que llega la trama, se comprueba su dirección de origen. Se actualiza. 1.7.4.3 Árbol de expansión - Algoritmo: Mecanismo de aprendizaje de direcciones. No cierra loops. Teoría de grafos. Mantiene conectividad pero no circuito cerrados. Cada bridge tiene asignado único identificador. Intercambio entre los puentes para establecer el árbol de expansión. 1.8 Diferencias entre un BRIDGE y un SWITCH: Los SWITCHES son más rápidos porque conmutan en hardware, los BRIDGES conmutan en software. Los SWITCHED pueden soportar altas densidades de puertos. Algunos SWITCHIES soportan conmutación cut-through que reduce retardos en la red, mientras que los BRIDGES solo soportan conmutación del tráfico store-andfordward. Los SWITCHIES proporcionan ancho de banda dedicado a cada segmento de red (menos colisiones). En el HUB todos los dispositivos comparten el mismo ancho de banda, mientras que el SWITCH el ancho de banda no se comparte. La información en enviada desde un dispositivo a otro, pero el HUB lo transmite a todos. Realizar broadcast de VLANs para la mejora de rendimiento y confidencialidad de información. 1.8 SWITCH: Un SWITCH se puede ver como un puente multipuertos, donde el tráfico se hace por dirección MAC en cada puerto del switch. Cada segmento tiene un ancho de banda dedicada, y se aumenta la seguridad. 1.8.1 SWITCHING (Conmutación): Físicamente un switch (conmutador) se parece a un HUB (concentrador). El HUB simula un único medio compartido mientras que el switch simula una LAN con bridges donde hay solo una PC por segmento. Como resultado, con un HUB solo una máquina puede acceder al medio pero con un SWITCH varias máquinas pueden enviar datos simultáneamente. Estas dos tecnologías se pueden combinar. Cada PC se conecta al HUB y estos se conectan a un SWITCH. Tipos de switches: Cut-through: alta velocidad, puede re-enviar frames malos. Store-and-forward: revisa el frame antes de enviarlo. FramengFree (Cut-through modificado): antes de enviar, espera a que lleguen 64 bytes. ATM (Asynchronous Transfer Mode): transfiere celdas fijas, soportan voz, video y datos. LAN: interconecta múltiples segmentos LAN, separa dominios de colisión. Switches nivel 3. 1.9 ROUTERS: La función del router es comunicar equipos de diferentes redes. Buscan la mejor ruta para enviar los paquetes. Realiza la siguientes tareas: Control de broadcast. Control de multicast. Determinación óptima de rutas. Administración del tráfico. Direccionamiento lógico. Conexiones a servicios WAN. 1.10 FIREWALL: Es un dispositivo de red que brinda principalmente seguridad perimetral. Algunos firewalls ofrecen protección contra negación de servicio. Se basa en: Routers. Equipos dedicados - PIX de Cisco. PC con Software - Linux. También en otros casos se usan para el filtrado de contenido y para la detección de intrusos.