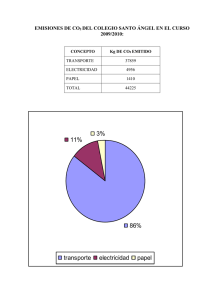
TRABAJO PRACTICO COMPETENCIAS DISCURSIVAS PROF.: ROJAS, NATALY ALUMNO: VALENZUELA, MAURICIO En el siguiente trabajo vamos a realizar el análisis de un set de datos, utilizando los distintos cálculos que nos proporciona la estadística descriptiva, como ser: definir población, muestra, cálculo de cuartiles, moda, media, tabla de frecuencias, etc. Set de datos proporcionados: Nation CO2 Albania 2.0 Austria 6.9 Belgium 8.3 Bosnia 6.2 Bulgaria 5.9 Croatia 4.0 Cyprus 5.3 Czech 9.2 Denmark 5.9 Finland 8.7 France 4.6 Germany 8.9 Greece 6.2 Hungary 4.3 Ireland 7.3 Italy 5.3 Latvia 3.5 Lithuania 4.4 Malta 5.4 Montenegro 3.6 Netherlands 9.9 Norway 9.3 Portugal 4.3 Romania 3.5 Serbia 5.3 Slovak 5.7 Slovenia 6.2 Spain 5.0 Sweden 4.5 Switzerland 4.3 UK 6.5 En base a este set de datos analizaremos los siguientes puntos: ¿Cuál serıa la variable aleatoria que se quiere estudiar? ¿Cuál serıa la población y cual serıa la muestra? Haciendo una vista general de los datos ¿Cuál es el valor máximo y cuál es el valor mínimo? ¿Nota alguna tendencia central de los valores? ¿Nota algún/os valor/es atípico/s en los datos? Realice un histograma de los datos. Interprete la forma que tiene el histograma ¿Nota alguna simetría? Realice un diagrama de cajas y responda la pregunta del inciso anterior. Estime a partir de este grafico cual serıa la mediana y los cuartiles. Calcule numéricamente la media, la moda, la mediana, los cuartiles y el desvío estándar. Compare estos resultados con los estimados anteriormente. Realice una conclusión de lo descrito. Para empezar, podemos definirá a la variable aleatoria como “las cantidades de CO2 emitidas por diferentes países europeos en millones de toneladas al año”. Con esto queremos analizar cuánto CO2 están liberando estos países y cómo eso puede afectar el medio ambiente. Observando los datos a primera vista, se puede decir que la población de interés es el conjunto de países europeos y sus niveles de emisión de CO2. La muestra, en este caso, es una selección específica de países y sus respectivas emisiones. Al analizar los datos de emisión de CO2 en países europeos, podemos observar que estos números representan la huella ambiental de cada nación. Es como medir el tamaño del impacto que tienen en nuestro planeta. Al examinar los datos, puedo ver que la emisión más baja registrada es por Albania con un Xmin= 2.0 millones de toneladas anuales, mientras que la más alta es para Netherlands con un Xmax= 9.9 millones de toneladas anuales. Parece que hay una variabilidad considerable entre los países en términos de su huella de CO2. En cuanto a la tendencia central, no parece haber una concentración clara alrededor de un valor específico. Algunos países tienen niveles de emisión relativamente bajos, mientras que otros tienen niveles más altos. No se observan valores atípicos evidentes que se alejen significativamente de la mayoría de los países. Analizando a simple vista, observamos que hay una concentración de países con emisiones alrededor de 4 a 6 millones de toneladas anuales. A medida que nos alejamos de este rango, la frecuencia de países disminuye. Esto indica que la mayoría de los países europeos tienen emisiones moderadas, mientras que hay pocos países con emisiones extremadamente altas. En cuanto a la simetría, el histograma no muestra una distribución perfectamente simétrica. Hay una ligera asimetría hacia la derecha, lo que indica que hay algunos países con emisiones más altas que la mayoría. Esto puede deberse a factores como la industrialización, el tamaño del país y sus políticas ambientales. El diagrama de cajas nos proporciona a simple vista un análisis de los valores representados en el diagrama: Observamos que el diagrama de cajas no muestra una distribución simétrica, ya que el tamaño de los bigotes (las líneas que se extienden desde el rectángulo) es casi similar en ambos extremos. Esto sugiere una distribución equilibrada de las emisiones de CO2 entre los países. Ahora, vamos a ver cómo encontrar los distintos valores que se desprenden en el análisis de datos y que la estadística descriptiva puede proporcionarnos: Mediana: Para calcular la mediana, primero ordenaremos los datos de menor a mayor y luego utilizaremos la siguiente fórmula: Si el número de datos es impar: Mediana = valor central Si el número de datos es par: Mediana = (valor central izquierdo + valor central derecho) / 2 La línea central dentro del rectángulo se encuentra alrededor de 5.4 millones de toneladas anuales. Primer Cuartil (Q1) = valor que acumula los primeros el 25% de los datos Segundo Cuartil (Q2) = valor que acumula el 50% de los datos por debajo (mediana) Tercer Cuartil (Q3) = valor que deja el 75% de los datos por debajo Q1 = 4.3 Q2 = 5.7 Q3 = 6.9 Media: La fórmula para calcular la media es: Moda: La moda se refiere al valor o valores que aparecen con mayor frecuencia en el conjunto de datos. Observamos que varios valores de CO2 tienen la misma frecuencia, por lo que hay múltiples modas en este conjunto de datos. En este caso, los valores de CO2 con mayor frecuencia son 5.3 y 6.2, cada uno con una frecuencia de 3. Por lo tanto, podemos decir que la moda está comprendida por los valores 5.3 y 6.2. Desviación estándar: La fórmula para calcular la desviación estándar es: Desviación estándar = [(∑(xi - Media)^2) / n] Desviación estándar = [(∑(xi - 5.506)^2) / 31] Desviación estándar = 1.918 Conclusión: En resumen, este análisis de los niveles de emisión de CO2 en países europeos nos permite comprender mejor la diversidad y la distribución de las emisiones. Usando los cuartiles Q1, Q3 y viendo el valor de la media trazada en el gráfico, podemos ver como que la gran mayoría de los países europeos con medianas emisiones de CO2 se concentran dentro de estos umbrales. Es importante tener en cuenta que estos valores son referenciales, aunque los mismos podrían usarse para implementar políticas ambientales efectivas y trabajar hacia un futuro más sostenible.