Semana 1: Características de los lenguajes de marcas
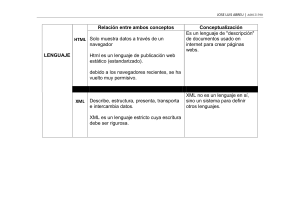
Concepto de lenguaje de marcas
La palabra marcado se originó en la industria de la publicación electrónica. En la
publicación tradicional, el manuscrito se anota con instrucciones de diseño para el
tipógrafo. Estas anotaciones se conocen como marcado.
Un lenguaje de marcado o lenguaje de marcas es una forma de codificar un
documento que, junto con el texto, incorpora etiquetas o marcas que contienen
información adicional acerca de la estructura del texto o su presentación. Las marcas
también están formadas de texto pero que es interpretado cuando se muestra el
documento, estas marcas se suelen llamar también etiquetas. El lenguaje de marcas
más extendido es el HTML, fundamento del World Wide Web. Los lenguajes de
marcado suelen confundirse con lenguajes de programación. Sin embargo, no son lo
mismo, ya que el lenguaje de marcado no tiene funciones aritméticas o variables,
como sí poseen los lenguajes de programación.
Tipos de Lenguajes de Marcas
Se suele diferenciar entre dos clases de lenguajes de marcas: el marcado de
procedimientos y el marcado descriptivo aunque en la práctica pueden combinarse
varias clases en un mismo documento. Por ejemplo, el HTML contiene etiquetas
puramente procedimentales, como la <b> de bold (negrita), junto con otras puramente
descriptivas (p.e. el atributo href de <a>). El HTML también incluye el elemento <pre>,
que indica que el texto debe representarse tal y como está escrito.
El marcado de procedimientos
Está enfocado hacia la presentación del texto, sin embargo, también es visible para el
usuario que edita el texto. El programa que representa el documento debe interpretar
1
Semana 1: Características de los lenguajes de marcas
el código en el mismo orden en que aparece. Por ejemplo, para formatear un título,
debe haber una serie de directivas inmediatamente antes del texto en cuestión,
indicándole al software instrucciones tales como centrar, aumentar el tamaño de la
fuente, o cambiar a negrita. Inmediatamente después del título deberá haber
etiquetas inversas que reviertan estos efectos. En sistemas más avanzados se utilizan
macros que facilitan el trabajo.
<i><b><big> TITULO </big></b></i>
La etiqueta <i> indica que se escribirá el texto en cursiva
La etiqueta <b> indica que se escribirá el texto en negrita
La etiqueta <big> indica que se escribirá el texto con un tamaño mayor
El resultado será el siguiente:
TITULO
Algunos ejemplos de lenguajes de marcas de procedimientos son nroff, troff, TeX. Este
tipo de marcado se ha usado extensivamente en aplicaciones de edición profesional,
manipulados por tipógrafos calificados, ya que puede llegar a ser extremadamente
complejo.
Un documento en Tex podemos verlo a continuación:
La f\'ormula cuadr\'atica es $x_{1,2}={-b\pm\sqrt{b^2-4\cdot a\cdot c} \over {2 \cdot a}}$
\bye
Con el texto de arriba deberías obtener algo que se viese como esto:
La fórmula cuadrática es
El marcado descriptivo o semántico
Utiliza etiquetas para describir los fragmentos de
texto, pero sin especificar cómo deben ser
representados, o en qué orden, es decir sirve
para describir la estructura del documento,
separando un texto en los elementos que lo
componen como título, párrafos, pie, etc. Los
lenguajes expresamente diseñados para generar
marcado descriptivo son el SGML y el XML.
En los lenguajes de marcas descriptivos el
formato está separado del contenido,
permitiendo flexibilidad a la hora de reformatear
el texto.
2
Semana 1: Características de los lenguajes de marcas
Una de las virtudes del marcado descriptivo es su flexibilidad: los fragmentos de texto
se etiquetan tal como son, y no tal como deben aparecer. Estos fragmentos pueden
utilizarse para más usos de los previstos inicialmente. Por ejemplo, los hiperenlaces
fueron diseñados en un principio para que un usuario que lee el texto los pulse. Sin
embargo, los buscadores los emplean para localizar nuevas páginas con información
relacionada, o para evaluar la popularidad de determinado sitio web.
El marcado descriptivo está evolucionando hacia lo que se denomina el marcado
genérico. Los nuevos sistemas de marcado descriptivo estructuran los documentos en
árbol, con la posibilidad de añadir referencias cruzadas. Esto permite tratarlos como
bases de datos, en las que el propio almacenamiento tiene en cuenta la estructura.
Un ejemplo de marcado descriptivo en XML podemos verlo a continuación:
<?xml version="1.0" ?>
<!doctype email system "http://www.sitio.es/DTDs/email.dtd">
<email id="E1X108">
<head>
<from>
<name>Jesús Vegas</name>
<address>[email protected]</address>
</from>
<to>
<name>Fulanito</name>
<address>[email protected]</address>
</to>
<subject>Introducción a XML</subject>
</head>
<body>
<p>Este es el guión de la conferencia sobre XML.
Mira a ver qué te parece. Saludos, jvegas.</p>
<attach encoding="mime" name="ixml.html" />
</body>
</email>
3
Semana 1: Características de los lenguajes de marcas
XML
Introducción
XML, el lenguaje de marcas extensible (Extensible Markup Language), es un estándar
avalado por el W3C (Consorcio World Wide Web) para marcar documentos. Permite
que los diseñadores creen sus propias etiquetas, permitiendo la definición,
transmisión, validación e interpretación de datos entre aplicaciones y entre
organizaciones. Define una sintaxis genérica utilizada para marcar datos con etiquetas
sencillas y de fácil lectura.
XML no es realmente un lenguaje en particular, sino una manera de definir lenguajes
para diferentes necesidades. METALENGUAJE
XML está diseñado para trasladar datos de una forma eficiente e independiente del
sistema o plataforma, no para visualizar los datos. Se propone un estándar para el
intercambio de información estructurada entre diferentes plataformas. Se puede usar
en bases de datos, editores de texto, hojas de cálculo y casi cualquier cosa imaginable.
XML por sí sólo no hace nada, sólo describe información.
Por ejemplo:
<nota>
<para>Raquel</para>
<de>Javier</de>
<cabecera>Recordatorio</cabecera>
<mensaje>No te olvides que quedamos para este fin de semana.</mensaje>
</nota>
En XML las etiquetas definen la estructura y el significado de los datos: qué son los
datos.
Se utiliza un sistema para generar los datos y marcarlos con etiquetas XML, y después
procesar esos datos en otros muchos sistemas, independientemente de la plataforma
de hardware y del sistema operativo. Esta portabilidad es la razón por la que XML se
ha convertido en una de las tecnologías más populares para el intercambio de datos.
XML no es sólo una herramienta de uso en sistemas de Web, se utiliza como método
de intercambio y traspaso de información entre múltiples aplicaciones.
XML no sustituye a HTML (no sirven para lo mismo):
‐ XML se encarga de trasladar los datos y su formato.
‐ HTML se encarga de visualizar los datos.
En XML no dependemos de un formato ya predefinido de etiquetas, como en HTML.
Nos podemos inventar las etiquetas que necesitemos para definir nuestros datos, es
por esto por lo que XML es un lenguaje de meta‐marcas. XML permite a
4
Semana 1: Características de los lenguajes de marcas
desarrolladores y escritores inventar los elementos que necesitan, cuando los
necesitan. Los químicos pueden usar elementos que describen moléculas y átomos y
los agentes inmobiliarios elementos que describen apartamentos, pisos, alquileres y
ubicaciones. La X de XML proviene de extensible lo que significa que el lenguaje se
puede ampliar y adaptar para ajustarse a las distintas necesidades.
El ejemplo siguiente muestra un documento XML sencillo. Este documento se puede
encontrar en un sistema de control de inventario o en una base de datos de existencias
y marca los datos con etiquetas y atributos que describen el color, el tamaño, etc.
Este documento es texto y se puede guardar en un archivo de texto. Podemos editar
este archivo con cualquier editor de textos como Notepad o vi.
Los programas que realmente intentan interpretar el contenido del documento XML
(es decir, hacen algo más que simplemente tratarlo como texto) van a usar un
analizador sintáctico XML. Este analizador es el responsable de dividir el documento
en elementos, atributos y otras piezas individuales. Si en cualquier momento el
analizador detecta una infracción de las reglas de una estructura bien formada de XML,
informa del error a la aplicación y detiene el análisis sintáctico. A veces, el analizador
puede seguir leyendo el documento, pasado el error original, para detectar e informar
de otros errores.
5
Semana 1: Características de los lenguajes de marcas
Para preparar el manual hemos usado EditiX 2010. Tiene una versión free que puedes
bajar desde http://free.editix.com/download.html
Evolución de XML
XML es un descendiente de SGML, el Lenguaje estándar de marcas generalizadas
(Standard Generalized Markup Language).El lenguaje que finalmente se convertiría en
SGML, fue creado por un equipo de IBM dirigido por Charles F. Goldfarb a finales de
1970 y fue desarrollado por cientos de personas hasta su adopción final como estándar
ISO en 1986. Es un lenguaje de marcas estructurado para documentos de texto. Es muy
eficaz y cosechó gran éxito en los sectores militares y gubernamentales de USA y en
otros sectores que necesitaban formas de administrar documentos técnicos con miles
de páginas de contenido.
Un documento SGML se compone de tres partes o archivos:
• Declaración SGML
• Declaración de tipo de documento (DTD)
• Instancia de Documento
La declaración SGML caracteriza la DTD y, por tanto, las instancias de documento (que
incluyen el contenido propiamente dicho) que se generen a partir de ella, en términos
de conjunto de caracteres usados y otros puntos opcionales de SGML. Esta
declaración puede ser omitida, en cuyo caso se asumen unos grupos de caracteres por
defecto y ninguna característica opcional.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2//EN">
6
Semana 1: Características de los lenguajes de marcas
Esta cabecera indica que el DTD, desarrollada por W3C es la versión 3.2 para HTML y
está escrito en inglés.
Una clase de documentos tiene en común una gramática que define el marcado
permitido en esa clase, el marcado requerido, y cómo debe ser utilizado dicho
marcado en la instancia de documento. El estándar define esta gramática mediante la
DTD. SGML no especifica ningún conjunto particular de elementos; el conjunto de
elementos que pueden utilizarse se define en la DTD.
<!ELEMENT DOCUMENTO - - (titulo, contenido, autor?) >
<!ELEMENT CONTENIDO - - (capitulo+) >
<!ELEMENT CAPITULO - (subtitulo, parrafo?) >
La instancia de documento lleva, pues, el contenido estructurado según el marco
definido en la DTD y con las características fijadas por la declaración SGML.
<documento>
<titulo>HIPERTEXTO</titulo>
<autor> MARIA JESUS LAMARCA </autor>
<contenido>
<capitulo>
<subtitulo>EL NUEVO CONCEPTO DE DOCUMENTO EN LA
CULTURA DE LA IMAGEN
</subtitulo>
<parrafo> Doctorado: Fundamentos, Metodología y Aplicaciones de las
Tecnologías Documentales y Procesamiento de la Información.
</parrafo>
</capitulo>
</contenido>
</documento>
El mayor éxito de SGML fue HTML, que es una aplicación SGML. Sin embargo HTML no
permite su uso más allá de la propia aplicación de diseño de páginas web. No podemos
utilizar HTML para intercambiar datos entre bases de datos incompatibles ni para
enviar catálogos de productos actualizados a los sitios de venta. HTML crea páginas
web y lo hace muy bien, pero solo crea páginas web.
SGML fue la opción evidente para otras aplicaciones que aprovechaban Internet. El
problema residía en que SGML era complicado (muy, muy complicado). La
especificación oficial SGML tiene aproximadamente 150 páginas muy técnicas y analiza
muchos casos especiales y escenarios poco probables. Es tan complejo que ningún
software lo ha implementado completamente.
En 1996 Jon Bosak, Tim Bray y otros empezaron a trabajar en una versión “liviana” de
SGML que conservaba la mayor parte de la eficacia de SGML, a la vez que recortaba
muchas opciones que habían demostrado ser redundantes, demasiado complicadas
para su implementación, confusas para los usuarios finales o, simplemente inútiles a lo
largo de los 20 años de experiencia con SGML. El resultado, en febrero de 1998, fue
XML y obtuvo un éxito inmediato. Muchos desarrolladores que sabían que necesitaban
7
Semana 1: Características de los lenguajes de marcas
un lenguaje de marcas estructural pero que no podían aceptar la complejidad de SGML
adoptaron XML con confianza. Se comenzó a usar en sectores tan variados como los
tribunales o los criaderos de cerdos.
Sin embargo, XML 1.0 fue tan solo el principio. El siguiente estándar fueron los
espacios de nombres (Namespaces), un esfuerzo para permitir que marcas de distintas
aplicaciones con el mismo nombre se pudieran usar en el mismo documento sin
conflicto. Así, un documento sobre libros podía tener un elemento titulo que hacía
referencia al título del libro y elementos titulo para los títulos de los capítulos y ambos
sin presentar conflicto alguno.
A continuación apareció el Lenguaje de hojas de estilo extensible (XSL, Extensible
Stylesheet Language), una aplicación para transformar documentos XML en un
formulario que podía visualizarse en una página web. Pronto aparecieron las
transformaciones XSL (XSLT, Transformations XSL)y los objetos de formato XSL (XSL‐FO,
XSL Formatting Objects). XSLT se ha convertido en un lenguaje de propósito general
para transformar un documento XML en otro, ya sea para una presentación web o
para cualquier otro propósito y XSL‐FO sirve para dar formato PostScript a un
documento XML.
Para el direccionamiento de partes individuales del documento surge XPath y otra
pieza del rompecabezas fue una interfaz para el direccionamiento desde un programa
java, javascript o C++. La API más simple solamente trataba el documento como un
objeto que contenía a otros objetos. Se inició una labor dentro y fuera del W3C para
definirlo como modelo de objeto de documento (DOM Document Object Model) para
HTML. Ampliar este esfuerzo a XML no resultó difícil.
Esta rica colección de especificaciones solo dirige tecnologías que son principales para
XML. Se han desarrollado muchas más, y continúan haciéndolo a un ritmo acelerado.
Aplicaciones XML como SOAP utilizado en el intercambio de datos en los servicios web,
SVG para describir gráficos vectoriales, MathML para el uso en matemáticas, Atom
para la sindicación, XForms para definir interfaces de usuario a base de formularios
web, WordprocessingML para el trabajo con procesadores de texto y miles de ellas
más. XML ha demostrado por sí mismo ser una base sólida para muchas y variadas
tecnologías.
Componentes de XML
Elementos XML
Un elemento XML es cualquier cosa que incluya una marca de inicio, una marca de fin
y la información o no que se encuentra entre ambas marcas.
<pelicula>La Red Social</pelicula>
Atributos
Modificador de una etiqueta XML. Da una característica ampliada de la etiqueta
definida. Pueden utilizarse comillas dobles y simples indistintamente, pero se debe
abrir y cerrar con el mismo símbolo.
8
Semana 1: Características de los lenguajes de marcas
<pelicula categoria="Drama">La Red Social</pelicula>
<pelicula categoria='Comedia'>
2 tontos muy tontos</pelicula>
Sintaxis XML
•
•
•
•
•
•
•
DOCUMENTO BIEN FORMADO
Todas las marcas utilizadas en XML deben tener un inicio y un final, no como
sucede en HTML.
Las marcas de XML tienen en cuenta que sean mayúsculas y minúsculas (las
marcas deben colocarse de forma exacta).
Las marcas se deben cerrar en el mismo orden en que se abrieron.
Un documento XML debe tener un elemento raíz de partida.
Todos los atributos de XML deben colocarse entre comillas dobles.
Para colocar determinados caracteres reservados en XML, se deben utilizar
cadenas de identificación.
Se pueden colocar comentarios en XML.
Documento XML
Aunque a primera vista, un documento XML puede parecer similar a HTML, hay una
diferencia principal. Un documento XML contiene datos que se autodefinen,
exclusivamente. Un documento HTML contiene datos mal definidos, mezclados con
elementos de formato. En XML se separa el contenido de la presentación de forma
total.
Una forma de entender rápidamente la estructura de un documento XML, es viendo
un pequeño ejemplo:
<?xml version="1.0"?>
<!DOCTYPE MENSAJE SYSTEM "mensaje.dtd">
<mensaje>
<remite>
<nombre>Alfredo Reino</nombre>
<email>[email protected]</email>
</remite>
<destinatario>
<nombre>Bill Clinton</nombre>
<email>[email protected]</email>
</destinatario>
<asunto>Hola Bill</asunto>
<texto>
<parrafo>¿Hola qué tal? Hace
<enfasis>mucho</enfasis> que no escribes. A ver si llamas
y quedamos para tomar algo.</parrafo>
</texto>
</mensaje>
9
Semana 1: Características de los lenguajes de marcas
Este mismo documento puede ser visto de forma gráfica, para comprender mejor la
estructura de un documento XML.
¾ Realiza las Actividades 1 y 2.
Estructura de un documento XML
Un documento XML tiene dos estructuras, una lógica y otra física.
Físicamente, el documento está compuesto por unidades llamadas entidades. Una
entidad puede hacer referencia a otra entidad, causando que esta se incluya en el
documento. Cada documento comienza con una entidad documento, también llamada
raíz.
Lógicamente, el documento está compuesto de declaraciones, elementos,
comentarios, referencias a caracteres e instrucciones de procesamiento, todos los
cuales están indicados por una marca explícita. Las estructuras lógica y física deben
encajar de manera adecuada:
Los documentos XML se dividen en dos grupos, documentos bien formados y
documentos válidos.
•
Bien formados: Son todos los que cumplen las especificaciones del lenguaje
respecto a las reglas sintácticas sin estar sujetos a unos elementos fijados en un
DTD. De hecho los documentos XML deben tener una estructura jerárquica
muy estricta y los documentos bien formados deben cumplirla. El documento
debe de contener una sóla raíz y todas las etiquetas estar correctamente
anidadas.
10
Semana 1: Características de los lenguajes de marcas
•
Válidos: Además de estar bien formados, siguen una estructura y una
semántica determinada por un DTD: sus elementos y sobre todo la estructura
jerárquica que define el DTD, además de los atributos, deben ajustarse a lo que
el DTD dicte. Veremos más adelante más detalladamente lo que es un DTD,
pero podemos ir adelantando que un DTD permite especificar la estructura del
documento, y que el DTD puede estar separado del documento.
Un fichero puede estar bien escrito según las reglas de XML (bien formado), pero
no “tener ni pies ni cabeza” ( no válido)
Aquí podemos ver otro ejemplo muy sencillo de documento XML:
<?xml version=" 1.0 " encoding=" UTF-8 " standalone= " yes "?>
<ficha>
<nombre> Angel </nombre>
<apellido> Barbero </apellido>
<direccion> c/Ulises, 36 </direccion>
</ficha>
La estructura básica de un bloque XML, se muestra en la siguiente figura:
11
Semana 1: Características de los lenguajes de marcas
Lo primero que tenemos que observar es la primera línea. Con ella deben empezar
todos los documentos XML, ya que en ella se indica que el documento es XML. Aunque
es opcional, es recomendable incluirla. Puede tener varios atributos, algunos
obligatorios y otros no:
•
•
•
version: Indica la versión de XML usada en el documento. Es obligatorio
ponerlo, a no ser que sea un documento externo a otro que ya lo incluía.
encoding: La forma en que se ha codificado el documento. Se puede poner
cualquiera, y depende del parser el poder entender o no la codificación. Por
defecto es UTF‐8, aunque podrían ponerse otras, como UTF‐16, US‐ASCII, ISO‐
8859‐1, etc. No es obligatorio salvo que sea un documento externo a otro
principal.
standalone: Indica si el documento va acompañado de un DTD ("no"), o no lo
necesita ("yes"); en principio no hay porqué ponerlo, porque luego se indica el
DTD si se necesita. Veremos los DTD más adelante.
¾ Realiza la Actividad 3.
Características de los documentos XML bien formados
Un documento XML se dice que está bien formado si encaja con las especificaciones
XML de producción, lo que implica:
Estructura jerárquica de elementos
Los documentos XML deben seguir una estructura estrictamente jerárquica con lo que
respecta a las etiquetas que delimitan sus elementos. Una etiqueta debe estar
correctamente "incluída" en otra. Asímismo, los elementos con contenido, deben
estar correctamente "cerrados". A continuación se muestra un ejemplo incorrecto y
posteriormente otro ejemplo escrito correctamente.
<li>HTML <b> permite <i> esto </b> </i>. Æ Ejemplo incorrecto
<li>En XML la <b> estructura <i> es </i> jerárquica </b>.</li> Æ Ejemplo correcto
¾ Realiza la Actividad 4
12
Semana 1: Características de los lenguajes de marcas
Etiquetas vacías
HTML permite elementos sin contenido. XML también, pero la etiqueta debe ser de la
siguiente forma <elemento sin contenido />. A continuación se muestra un ejemplo
incorrecto y posteriormente otro correcto.
<li>Esto es HTML <br> en el que casi todo está permitido </li>
Hay que tener en cuenta que el símbolo "<" siempre se interpreta como inicio de una
etiqueta XML. Si no es el caso, el documento no estará bien formado. Para usar ciertos
símbolos se usan las entidades predefinidas, que se explican más adelante.
Un elemento vacío, es el que no tiene contenido. Por ejemplo;
<identificador DNI="23123244" />
<linea-horizontal />
Al no tener una etiqueta de cierre que delimite un contenido, se utiliza la forma
<etiqueta />, que puede contener atributos o no. La sintaxis de HTML permite
etiquetas vacías tipo <hr> o <img src="..."> En HTML reformulado para que sea un
documento XML bien formado, se debería usar <hr /> o <img src="..."
Atributos
Como se ha mencionado antes, los elementos pueden tener atributos, que son una
manera de incorporar características o propiedades a los elementos de un documento.
Por ejemplo, un elemento "chiste" puede tener un atributo "tipo" y un atributo
"calidad", con valores "vascos" y "bueno" respectivamente.
<chiste tipo="vascos" calidad="bueno">
Esto es un día que Patxi y Josu van paseando...
</chiste>
En una Definición de Tipo de Documento (DTD), se especifican los atributos que
pueden tener cada tipo de elemento, así como sus valores y tipos de valor posible.
Al igual que en otras cadenas literales de XML, los atributos pueden estar marcados
entre comillas simples (') o doble ("). Cuando se usa uno para delimitar el valor del
atributo, el otro tipo se puede usar dentro.
<verdura clase="zanahoria" longitud='15" y media'>
<cita texto="'Hola buenos dias', dijo él">
13
Semana 1: Características de los lenguajes de marcas
A veces, un elemento con contenido, puede modelarse como un elemento vacío con
atributos. Un concepto se puede representar de muy diversas formas, pero una vez
elegida una, es aconsejable fijarla en el DTD, y usar siempre la misma
consistentemente dentro de un documento XML.
<gato>
<nombre>Micifú</nombre>
<raza>Persa</raza>
</gato>
<gato raza="Persa">
Micifú
</gato>
<gato raza="Persa" nombre="Micifú"/>
Entidades Predefinidas
En XML 1.0, se definen cinco entidades para representar caracteres especiales y que
no se interpreten como marcado en el procesador XML. Es decir, que así podemos usar
el carácter "<" sin que se interprete como el comienzo de una etiqueta XML, por
ejemplo Entidad
Carácter
&amp;
&lt;
&gt
&apos;
&quot;
&
<
>
‘
“
Secciones CDATA
Existe otra construcción en XML que permite especificar datos, utilizando cualquier
carácter, especial o no, sin que se interprete como marcado XML. La razón de esta
construcción llamada CDATA (Character DATA) es que a veces es necesario para los
autores de documentos XML, poder leerlo fácilmente sin tener que descifrar los
códigos de entidades. Especialmente cuando son muchos.
Como ejemplo, el siguiente (primero usando entidades predefinidas y luego con un
bloque CDATA). Podemos comprobar su uso en el siguiente ejemplo:
<ejemplo>
&lt;html&gt;
&lt;head&gt;&lt;title>Rock &amp; Roll&lt;/title&gt;&lt;/head&gt;
</ejemplo>
<ejemplo>
<![CDATA[
<html>
<head><title>Rock & Roll</title></head>
]]>
</ejemplo>
14
Semana 1: Características de los lenguajes de marcas
Como hemos visto dentro de una sección CDATA podemos poner cualquier cosa, que
no será interpretada como algo que no es así. Existe una excepción y es la cadena "]]>"
con el que termina el bloque CDATA. Esta cadena no puede utilizarse dentro de una
sección CDATA.
Comentarios
A veces es conveniente insertar comentarios en el documento XML, que son ignorados
por el procesado de la información y las reproducciones del documento. Los
comentarios tienen el mismo formato que los comentarios de HTML. Es decir,
comienza por la cadena "<!‐‐" y termina con "‐‐>".
<!‐‐ Esto es un comentario ‐‐>
Se pueden introducir comentarios en cualquier parte del documento salvo dentro de
las declaraciones, etiquetas, u otros comentarios.
¾ Realiza la actividad 5 y 6
Espacios de nombre (NameSpaces)
En XML, los espacios de nombre (namespace) tienen dos propósitos:
1. Distinguir entre elementos y atributos de distintos vocabularios con distintos
significados que puedan compartir el mismo nombre.
2. Agrupar todos los elementos y atributos relacionados de una sola aplicación
XML para que el software pueda reconocerlos con facilidad.
El primer propósito es más fácil de explicar y entender, pero el segundo es más
importante en la práctica.
La extensibilidad es una facultad que no es gratuita. En un entorno distribuido, esta
facultad deberá ser administrada para evitar conflictos. Los espacios de nombre son
una solución para ayudar a administrar la extensibilidad de XML.
Un espacio de nombres puede ser definido como un mecanismo para identificar
elementos XML. Establece los nombres de los elementos en un contexto global.
Supongamos que decide publicar sus marcadores como muestra el siguiente
documento:
15
Semana 1: Características de los lenguajes de marcas
<?xml version="1.0" encoding="UTF-8"?>
<!-- New document created with EditiX at Sat Sep 18 16:55:14
CEST 2010 -->
<referencias>
<nombre>Pearson Education</nombre>
<link href="http://www.pearson.com.mx" />
<categoría>5 estrellas</categoría>
<nombre>Pineapplesoft</nombre>
<link href="http://www.pineapplesoft.com/newsletter" />
<categoría>5 estrellas</categoría>
<nombre>XML</nombre>
<link href="http://www.xml.com" />
<categoría>4 estrellas</categoría>
<nombre>Cómics</nombre>
<link href="http://www.comics.com" />
<categoría>5 estrellas</categoría>
<nombre>Fatbrain</nombre>
<link href="http://www.fatbrain.com" />
<categoría>4 estrellas</categoría>
<nombre>Noticias ABC</nombre>
<link href="http://www.abcnews.com" />
<categoría>3 estrellas</categoría>
</referencias>
Con frecuencia es necesario extender un documento existente para transmitirle nueva
información. No obstante, hay problemas si la extensión no se administra. Suponga
que alguien más decide clasificar la lista anterior con asesoría para padres. El listado
siguiente muestra el resultado (Noticias ABC y Cómics podrían contener violencia o
escenas de sexo, por esto tienen un nivel de Guía paterna).
<?xml version="1.0" encoding="UTF-8"?>
<!-- New document created with EditiX at Sat Sep 18 16:55:14
CEST 2010 -->
<referencias>
<nombre>Pearson Education</nombre>
<link href="http://www.pearson.com.mx" />
<categoría>G</categoría>
<nombre>Pineapplesoft</nombre>
<link href="http://www.pineapplesoft.com/newsletter" />
<categoría>G</categoría>
<nombre>XML</nombre>
<link href="http://www.xml.com" />
<categoría>G</categoría>
<nombre>Cómics</nombre>
<link href="http://www.comics.com" />
<categoría>Guía paterna</categoría>
<nombre>Fatbrain</nombre>
<link href="http://www.fatbrain.com" />
<categoría>G</categoría>
16
<nombre>Noticias ABC</nombre>
<link href="http://www.abcnews.com" />
<categoría>Guía paterna</categoría>
</referencias>
Semana 1: Características de los lenguajes de marcas
Esto es algo problemático. Supongamos que la extensión contempla ambos tipos de
categorías:
<?xml version="1.0" encoding="UTF‐8"?>
<!‐‐ New document created with EditiX at Sat Sep 18 16:55:14 CEST
2010 ‐‐>
<referencias>
<nombre>Pearson Education</nombre>
<link href="http://www.pearson.com.mx" />
<categoría>G</categoría>
<categoría>5 estrellas</categoría>
<nombre>Pineapplesoft</nombre>
<link href="http://www.pineapplesoft.com/newsletter" />
<categoría>G</categoría>
<categoría>5 estrellas</categoría>
<nombre>XML</nombre>
<link href="http://www.xml.com" />
<categoría>G</categoría>
<categoría>4 estrellas</categoría>
<nombre>Cómics</nombre>
<link href="http://www.comics.com" />
<categoría>Guía paterna</categoría>
<categoría>5 estrellas</categoría>
<nombre>Fatbrain</nombre>
<link href="http://www.fatbrain.com" />
<categoría>G</categoría>
<categoría>4 estrellas</categoría>
<nombre>Noticias ABC</nombre>
<link href="http://www.abcnews.com" />
<categoría>Guía paterna</categoría>
<categoría>3 estrellas</categoría>
</referencias>
El problema con el anterior listado es que un software diseñado para funcionar con el
anterior listado con el objetivo de listar vínculos ofensivos no sabría qué hacer con la
categoría 5 estrellas. El software tan sólo tiene que pasar por alto las etiquetas de
categoría de calidad pero ¿cómo podría hacerlo si no puede distinguir entre ambas
etiquetas de categoría?.
La solución es obvia: utilizar distintos nombres para ambas categorías, por ejemplo:
Para el control de calidad
<cld‐categoría>3 estrellas</categoría>
Y para el control parental
17
Semana 1: Características de los lenguajes de marcas
<pdr‐categoría>Guía paterna</categoría>
El problema del ejemplo anterior es … el carácter de extensibilidad de XML. Dado que
cualquiera puede generar etiquetas, hay un enorme riesgo de conflictos.
Una solución para evitarlo es establecer un registro global de etiquetas aceptadas y su
definición asociada. No obstante, podría limitar severamente la flexibilidad de XML.
Es lo que hace HTML
Nadie desea hacer esto. La flexibilidad fue una meta primordial en el diseño de XML. La
propuesta de los espacios de nombre corrige este problema con un método elegante:
no limita la extensibilidad sino que presenta mecanismos para administrarla.
El listado siguiente es similar al último pero utiliza espacios de nombre para evitar los
conflictos:
Xmlns Æ Xml Name Schema
<?xml version="1.0" encoding="UTF‐8"?>
<!‐‐ New document created with EditiX at Sat Sep 18 16:55:14 CEST
2010 ‐‐>
<referencias xmlns:cld="http://joker.playfield.com/star‐
categoria/1.0"
xmlns:pdr="http://penguin.xmli.com/review/1.0"
xmlns="http://catwoman.pineapplesoft.com/ref/1.5">
<nombre>Pearson Education</nombre>
<link href="http://www.pearson.com.mx" />
<pdr:categoría>G</categoría>
<cld:categoría>5 estrellas</categoría>
<nombre>Pineapplesoft</nombre>
<link href="http://www.pineapplesoft.com/newsletter" />
<pdr:categoría>G</categoría>
<cld:categoría>5 estrellas</categoría>
<nombre>XML</nombre>
<link href="http://www.xml.com" />
<pdr:categoría>G</categoría>
<cld:categoría>4 estrellas</categoría>
<nombre>Cómics</nombre>
<link href="http://www.comics.com" />
<pdr:categoría>Guía paterna</categoría>
<cld:categoría>5 estrellas</categoría>
<nombre>Fatbrain</nombre>
<link href="http://www.fatbrain.com" />
<pdr:categoría>G</categoría>
<cld:categoría>4 estrellas</categoría>
<nombre>Noticias ABC</nombre>
<link href="http://www.abcnews.com" />
<pdr:categoría>Guía paterna</categoría>
<cld:categoría>3 estrellas</categoría>
</referencias>
18
Semana 1: Características de los lenguajes de marcas
A primera vista todo parece similar pero la diferencia está en el formato de los
nombres. Ahora se agrega un prefijo a cada nombre de elemento. El prefijo y el
nombre están separados por dos puntos (:)
<cld:categoría>3 estrellas</categoría>
El prefijo identifica unívocamente el tipo de categoría en este documento. No
obstante, tales prefijos por sí solos no resuelven nada, dado que cualquier persona
puede generarlos. Así pues, distintas personas podrían generar prefijos incompatibles
y volvemos al primer paso. Para evitar tales conflictos, los prefijos deben estar
declarados:
<referencias xmlns:cld="http://joker.playfield.com/star-categoria/1.0"
xmlns:pdr="http://penguin.xmli.com/review/1.0"
xmlns="http://catwoman.pineapplesoft.com/ref/1.5">
La declaración asocia a un URI con un prefijo. Este es el punto crucial de la propuesta
de los espacios de nombre dado que los URIs, a diferencia de los nombres, son únicos.
Los espacios de nombre se fundamentan en los mecanismos de registro establecidos
para los URIs. Por tanto se garantiza que los URLs son únicos dado que están basados
en nombres de dominio registrados para garantizar la unicidad.
El nombre del espacio de nombre
El nombre del espacio de nombre es el URI, no el prefijo. Cuando una aplicación
compara a dos elementos, utiliza el URI, no el prefijo, para reconocer sus espacios de
nombre.
Así, en el listado siguiente rff:nombre y ref:nombre se consideran idénticos a pesar de
tener un prefijo distinto. Ambos están en el espacio de nombre
http://catwoman.pineapplesoft.com/ref/1.5
<?xml version="1.0" encoding="UTF-8"?>
<!-- New document created with EditiX at Sat Sep 18 17:50:12
CEST 2010 -->
<referencias>
<rff:nombre
xmlns:rff="http://catwoman.pineapplesoft.com/ref/1.5">
Pearson Educational
</rff:nombre>
<link href="http://www.pearson.com.mx" />
<ref:nombre
xmlns:ref="http://catwoman.pineapplesoft.com/ref/1.5">
Pineapplesoft
</ref:nombre>
<link href="http://www.pineapplesoft.com/newsletter" />
19
</referencias>
Semana 1: Características de los lenguajes de marcas
Espacio de nombre predeterminado
Todos los elementos sin prefijo, nombre y link en los ejemplos anteriores y todos sus
elementos descendientes pertenecen a un espacio de nombres predeterminado
añadiendo un atributo xmlns sin prefijo en el elemento de la parte superior. En nuestro
caso:
xmlns=http://catwoman.pineapplesoft.com/ref/1.5
Los atributos son diferentes. Los espacios de nombre predeterminados solo se aplican
a los elementos, no a los atributos. Por lo tanto en el espacio anterior el atributo sin
prefijo href no está en ningún espacio de nombre.
¾ Realiza la Actividad 7
Los URIs
Un URI (Uniform Resource Identifier) es una cadena corta de caracteres que identifica
inequívocamente un recurso (servicio, página, documento, dirección de correo
electrónico, enciclopedia, etc.). Normalmente estos recursos son accesibles en una red
o sistema.
En el caso que nos ocupa el URI solo se utiliza para asegurar la unicidad de los nombres
Podría (aunque no necesariamente) apuntar a una descripción del nombre. Por
ejemplo, podría haber un documento en http://penguin.xmli.com/review/1.0 que
describa la categoría o podría no haber nada.
No obstante, lo importante es que los URIs son únicos y deberíamos generarlos de
acuerdo con nuestros nombres de dominio.
Los nombres de dominio
Los URLs (Uniform Resource Locator) son direcciones para localizar recursos en
Internet, y actualmente han sido englobados por el concepto más general de URI.
Tienen el siguiente formato:
http://www.pearson.com.mx
http://www.pineapplesoft.com/newsletter
ftp://ftp.mcp.com
news://news.psol.com/comp.xml
mailto:[email protected]
El nombre del dominio es solo una parte del URL: “pearson.com.mx” y
“pineapplesoft.com” son dos de ellos.
20
Semana 1: Características de los lenguajes de marcas
El nombre del dominio está registrado por una autoridad global para asegurar que no
haya duplicados. Dada la globalidad del registro, uno no puede hacer lo que quiera con
los nombres de dominio. Por ejemplo, no es posible registrar nombres que ya estén en
uso.
La parte final del nombre de dominio (“.com”, por ejemplo) se conoce como Dominio
de nivel superior (TLD, Top Level Domain) identifica a la autoridad que asignó el
nombre de dominio.
InterNIC (www.internic.net) es la autoridad para la mayor parte de los llamados TLD
genéricos: “.com” (comercial), “.net” (proveedores de servicios de Internet), “.org”
(instituciones sin ánimo de lucro). Son genéricas puesto que están abiertas a empresas
u organizaciones con un ámbito mundial.
También hay TLDs específicos de un país: “.es” en España, “.uk” en el Reino Unido,
“.us” en Estados Unidos, etc.
Los nombres de dominio no son muy costosos (actualmente unos 15 € anuales) por lo
que es muy recomendable contratar uno.
21