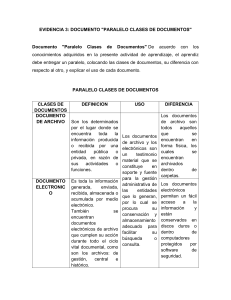
")
Procesamiento de datos masivos También llamado macrodatos o datos masivos, Big data es un término que hace referencia al proceso que abarca la recolección de grandes cantidades de datos y su inmediato análisis. se refiere a grandes cantidades de datos o información digital tales que, por su volumen, velocidad y variedad, requieren de tecnología especializada para su aprovechamiento. Esta tecnología comprende tanto equipo de cómputo de alto rendimiento como programas o técnicas de análisis apropiadas ¿Qué es? El procesamiento de datos es la acción de acumular y manipular elementos y datos para así elaborar información importante. Consiste básicamente en la recolección de diversos datos, para luego transformarlos en información que sea funciona ¿Dónde se lleva a cabo el procesamiento de los datos? Resumiéndolo, podemos decir que un centro de procesamiento de datos (o CPD) es la instalación que centraliza las operaciones y la infraestructura de TI de una organización, en la que se almacenan, procesan, tratan y difunden datos y aplicaciones. ¿El uso correcto? El uso correcto de los datos masivos promete grandes beneficios a diferentes sectores de la sociedad, desde el aumento del margen de operación de una empresa, hasta mejoras en el sistema de salud pública. Por lo tanto, la toma de decisiones guiadas por datos se ha vuelto una herramienta fundamental para los tomadores de decisiones de la actualidad. ¿El uso incorrecto? Un uso incorrecto de los datos puede acarrear problemas tanto éticos como socioeconómicos, por lo que es de suma importancia contar con personal calificado y tener un marco regulatorio claro y preciso que promueva su buen uso. EJEMPLO DE DATOS MASIVOS: Un ejemplo de datos masivos es la información producida por los dispositivos con acceso a internet, que pueden comunicarse entre sí y generar aún más información, en una gran variedad de formatos (audio, fotos, videos, texto, coordenadas). PROCESAMIENTO PARALELO MASIVO El procesamiento masivamente paralelo (MPP) es un paradigma de procesamiento en el que cientos o miles de nodos de procesamiento trabajan en partes de una tarea informática en paralelo. Cada uno de estos nodos ejecuta instancias individuales de un sistema operativo. ¿Cuáles son los principales componentes de hardware del procesamiento masivamente paralelo? Es esencial comprender los componentes de hardware de un sistema de procesamiento masivamente paralelo para comprender varias arquitecturas. Nodos de procesamiento: Los nodos de procesamiento son los componentes básicos del procesamiento masivamente paralelo. Estos nodos son núcleos de procesamiento simples y homogéneos con una o más unidades centrales de procesamiento Interconexión de alta velocidad: Los nodos en un sistema de procesamiento masivamente paralelo trabajan en forma paralela en partes de un solo problema de computación. Aunque su procesamiento es independiente entre sí, necesitan comunicarse regularmente entre sí mientras intentan resolver un problema común. Se requiere una conexión de baja latencia y alto ancho de banda entre los nodos, lo cual se denomina interconexión de alta velocidad o bus Administrador de bloqueo distribuido (DLM): En aquellas arquitecturas de procesamiento masivamente paralelo donde la memoria externa o el espacio en disco se comparte entre los nodos, un administrador de bloqueo distribuido (DLM) coordina este intercambio de recursos. Sistemas de disco compartido: Cada nodo de procesamiento en el sistema de disco compartido tendrá una o más unidades centrales de procesamiento (CPU) y una memoria de acceso aleatorio (RAM) independiente. Estos nodos, sin embargo, comparten un espacio de disco externo para el almacenamiento de archivos. ¿Cómo se relaciona Big Data con el procesamiento paralelo y Data Science? Big Data se relaciona más con la tecnología de la computación distribuida y las herramientas y el software de análisis (Hadoop, Java, Hive, etc.). Esto se opone al de Data Science que se enfoca en estrategias para decisiones de negocios, diseminación de datos utilizando matemáticas, estadísticas, etc