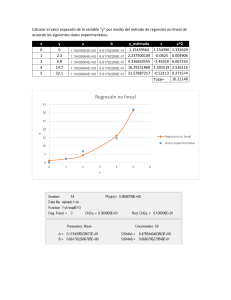
Machine learning Supervised Este el tipo de aprendizaje que predice o clasifica información nueva a partir del análisis de información. Problema de regresión La variable Y es cuantitativa Este modelo predice a partir de datos o valores conocidos de X para obtener una salida Y Problema de clasificación La variable Y es cuantitativa Este modelo categoriza como resultado las variables X No supervised Es el tipo de aprendizaje que busca una estructura en la información, la cual no tiene etiqueta. Machine Learning Resuelve problemas de tipo Supervisado No supervisado Regresión agrupamiento Clasificación Orden de aplicación Asigna una tarea a la computadora Repite y adquiere experiencia Mide el desempeño de la computadora en la tarea Mejora hasta un nivel optimo Mejoras en la aplicación del Machine Learning Precisión Eficiencia Aprovechamiento de recursos Velocidad de ejecución Regresión lineal Función de Hipótesis 𝐻 = 𝑎0 + 𝑎1 ∗ 𝑥1 Función de perdida 𝑚 1 𝐸= ∑(ℎ𝑖 − 𝑦𝑖 )2 2𝑚 𝑖=1 Descenso de gradiente 𝛿𝐸 𝑎𝑗 = 𝑎𝑗 − 𝑎 𝛿𝑎𝑗 i = ejemplo del entrenamiento ℎ𝑖 = el valor de la hipótesis para un valor de entrada determinada 𝑦𝑖 = el valor real de salida para el valor de entrada m = cantidad de ejemplos en el conjunto de entrenamiento 𝑎𝑗 = parámetros de la hipótesis 𝑑𝐸 𝛿𝑎𝑗 = la rapidez de cambio con respecto a 𝑎𝑗 𝑎 = tasa de aprendizaje Ej. 1.- asigna valores iniciales a la función de hipótesis 2.- recalcula los parámetros (𝑎0 , 𝑎1 ) 3.- sustituye los valores nuevamente en la hipótesis (Función de hipótesis) 4.- Repetir hasta que los valores no varíen (2, 3) Regresión Logística Límite de decisión 1 ℎ= −(𝑎 +𝑎 1 + 𝑒 0 1 𝑥1 +𝑎2 𝑥2 ) Separa los datos en dos etiquetas a partir de características numéricas Formula de optimización de parámetros 𝑚 𝑎𝑗= 𝑎𝑗− 𝛼 ∑(ℎ𝑖 − 𝑦𝑖 ) ∗ 𝑥𝑗 𝑖=1 Árboles de decisiones Cart Calcula la impureza del producto 1.- Calcula la impureza 2.- Formula una pregunta 3.- Obtener la ganancia 4.- Repetir 2 y 3 5.- repetir a partir del paso 2 y 𝑥1 𝑥2 Color Diámetro Verde 3 Estrella Amarillo 3 Estrella Amarillo 3 Planeta Rojo 1 Meteorito Rojo 1 Meteorito Para calcular la impureza de un conjunto 𝑘 𝐼 = 1 − ∑ 𝑃(𝑖)2 𝑖=1 2 5 2 5 1 5 I = 1 – ( )2 - ( )2 - ( )2 = 0.64 K = Números de clases P(i) Probabilidad de escoger al azar un elemento de la clase ‘i’ (Probabilidad a priori) Para formar un nuevo árbol, se realiza un a nueva pregunta a partir de los atributos *Separando y formando dos nuevos nodos La ganancia de información para la pregunta se obtiene con la formula G = 𝐼𝐽−1 − 𝐼𝐽 𝐼𝐽−1 = La impureza del nodo padre 𝐼𝐽 = La impureza promedio de los nodos hijos Finalmente se debe probar con diferentes preguntas y elegir la que tenga una mayor ganancia Así se deberá repetir hasta que todos los nodos hijo Clustering Jerárquico Es una técnica para agrupar datos al encontrar similitudes entre ellos cuando no se conoce el número de categorías en que se dividen. El Agrupamiento jerárquico cuenta con dos enfoques: Divisivo Al inicio considera todo como un solo grupo, para luego separar los elementos semejantes en otros grupos. Aglomerativo Al inicio considera cada elemento como un grupo distinto, así se encarga de unir los elementos mas parecidos. Para el enfoque de aglomeración se utiliza el algoritmo AGNES: Distancia entre grupos Una manera para calcular la distancia en un plano cartesiano es mediante la “distancia Manhattan” 𝑑𝑚 (𝐴, 𝐵) = |𝑥1 − 𝑥2 | + | 𝑦1 − 𝑦2 | La distancia entre grupos se puede calcular con enfoques: Single Linkage Se obtiene la distancia entre los dos elementos mas cercanos del grupo Complete Linkage Se obtiene la distancia entre los dos elementos más lejanos de cada grupo Las distancias de los grupos se almacenan en la matriz de proximidad A partir de una tabla y utilizando el enfoque single Linkage en conjunto con la formula Manhattan se obtendrá la distancia de punto a punto de todos los elementos, la cual se llama matriz de proximidad. (Tal matriz de proximidad queda pendiente por motivos de que no cache como mierda resolver la tabla) K means Es un algoritmo de agrupamiento por particiones utilizando para separar un conjunto de entrenamiento en una cantidad conocidas de grupos. Se vale de los conceptos de media y distancia euclidiana Media: es el resultado de la suma de todos los elementos dividido en el total de elementos. 𝑚 1 𝐶 = ∑ 𝑦𝑖 𝑚 𝑖=1 Distancia euclidiana: es la distancia mas corta entre dos puntos del plano 𝐷𝑒 (𝑎, 𝑏) = √(𝑥1 − 𝑥2 )2 + (𝑦1 − 𝑦2 )2 Calculo media mas cercana 𝑛 𝐶 − min = ∑ 𝑑(𝐶𝑘 , 𝑦𝐽 ) 𝑖=1 𝐶𝐾 = Representa cada una de las medias 𝑌𝐽 = Representa cada uno de los puntos del conjunto Mezclas gaussianas Es un modelo que separa un conjunto de datos en una cantidad conocida de grupos cuyos elementos se mezclan. 𝑁( 𝑥| 𝜇, 𝜎) = 1 𝜎√2𝜋 𝑒 −(𝑥−𝜇)2 2𝜎 2 N = Distribución Normal x = Valores de eje horizontal 𝜇 = El valor medio de los valores x 𝜎 = Es la desviación estándar Campana de gauss. Los valores en el eje vertical representan la probabilidad de encontrar el dato x en el conjunto. Desviación estándar 𝑛 1 𝜎 = √ ∑(𝑥𝑖 − 𝜇)2 𝑛 𝑖=1 n = El número de elementos en el conjunto de datos 𝑥𝑖 = cada uno de los datos Se asigna valores para 𝜇, 𝜎 y dependiendo de la cantidad de grupos que haya, se calcula la distribución normal para cada grupo. Para comparar los valores de W y dependiendo cual tenga el valor mayor se asignará su respectivo grupo. 𝑊1 = 𝐴 𝐴+𝐵 𝐵 𝐴+𝐵 Asumiendo que haya 2 grupos A, B. 𝑊2 =