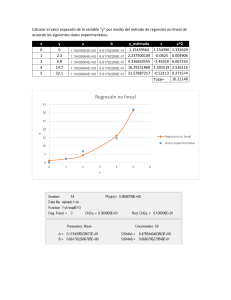
UNIVERSIDAD DE LAS FUERZAS ARMADAS ESPE SEDE SANTO DOMINGO DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN CARRERA DE INGENIERÍA EN TECNOLOGÍAS DE LA INFORMACIÓN PERIODO : Noviembre 2020 – Abril 2021 ASIGNATURA : Inteligencia artificial TEMA : Ejercicio de Machine Learning NOMBRES : Kevin Joel Monteros González NIVEL-PARALELO : Sexto “A” DOCENTE : Ing. Luis Chica FECHA DE ENTREGA : 18/03/2021 SANTO DOMINGO - ECUADOR 2021 Índice 1. Introducción 3 2. 3 3. Sistemas de Objetivos 2.1. Objetivo General: 3 2.2. Objetivos Específicos: 3 2.2.1. Objetivo específico 1 3 2.2.2. Objetivo específico 2 3 2.2.3. Objetivo específico 3 3 2.2.4. Objetivo específico 4 3 Desarrollo 4 3.1. Conceptualización del tema 4 3.1.1. Regresión lineal 4 3.1.2. Relación con Machine Learning 4 3.2. Ejercicio de regresión lineal múltiple 4 3.2.1. Puntos a tener en cuenta 4 3.2.2. Paso 1: Optimizaciones al modelo 5 3.2.3. Paso 2: Creación del modelo de regresión lineal 6 3.2.4. Paso 3: Creación de gráficas 6 3.2.5. Paso 4: Solución a reto planteado 7 3.2.6. Ejecuciones en distintos resultados 8 4. Conclusiones 9 5. Recomendaciones 9 Listado de figuras Figura 1. Variables en un ejercicio de regresión lineal. ........................................................ 4 Figura 2. Variables en un ejercicio de regresión lineal múltiple. .......................................... 5 Figura 3. Paso 1: optimizaciones al modelo. ......................................................................... 5 Figura 4. Paso 2: Creación del modelo de regresión lineal. .................................................. 6 Figura 5. Paso 3: Creación de gráficas. ................................................................................. 7 Figura 6. Paso 4: Solución a reto planteado. ......................................................................... 7 Figura 7. Ejecución gráfica. .................................................................................................. 8 Figura 8. Ejecución viendo el explorador de variables. ........................................................ 8 Figura 9. Ejecución y resultado en consola. .......................................................................... 8 1. Introducción En el presente documento se detalla el procedimiento paso a paso sobre la resolución de un ejercicio de regresión lineal múltiple. Para dicho ejercicio utilizaremos tres herramientas: anaconda, python y Spider. Cada una de estas herramientas juega un rol específico y conjuntamente nos ayudarán a resolver este ejercicio e incluso para obtener una aproximación al funcionamiento de Machine Learning. La regresión lineal es un algoritmo de aprendizaje supervisado que se utiliza en Machine Learning y en estadística. En su versión más sencilla, lo que haremos es “dibujar una recta” que nos indicará la tendencia de un conjunto de datos continuos (si fueran discretos, utilizaríamos Regresión Logística). 2. Sistemas de Objetivos 2.1. Objetivo General: Resolver el ejercicio planteado en clase sobre regresión lineal múltiple, mediante el uso de python, anaconda y otras herramientas, para comprender el funcionamiento de un ejercicio asociado con Machine Learning. 2.2. Objetivos Específicos: 2.2.1. Objetivo específico 1 Comprender la lógica y los conceptos asociados con Machine Learning, Data Mining y Regresión Lineal. 2.2.2. Objetivo específico 2 Resolver el ejercicio propuesto en clases sobre regresión lineal múltiple. 2.2.3. Objetivo específico 3 Detallar el paso a paso de la resolución del ejercicio, evidenciándolo con capturas de pantalla. 2.2.4. Objetivo específico 4 Comprender el ejercicio realizado y su relación con Machine Learning. 3. Desarrollo 3.1. Conceptualización del tema 3.1.1. Regresión lineal En estadísticas, regresión lineal es una aproximación para modelar la relación entre una variable escalar dependiente “y” y una o más variables explicativas nombradas con “X”. Figura 1. Variables en un ejercicio de regresión lineal. En este contexto Y es el resultado, X es la variable, a la pendiente (o coeficiente) de la recta y b la constante o también conocida como el “punto de corte con el eje Y” en la gráfica (cuando X=0). 3.1.2. Relación con Machine Learning Los algoritmos de Machine Learning Supervisados, aprenden por sí mismos y -en este casoa obtener automáticamente esa “recta” que buscamos con la tendencia de predicción. Para hacerlo se mide el error con respecto a los puntos de entrada y el valor “Y” de salida real. El algoritmo deberá minimizar el coste de una función de error cuadrático y esos coeficientes corresponderán con la recta óptima. Hay diversos métodos para conseguir minimizar el coste. Lo más común es utilizar una versión vectorial y la llamada Ecuación Normal que nos dará un resultado directo. 3.2. Ejercicio de regresión lineal múltiple 3.2.1. Puntos a tener en cuenta Para este ejercicio: Utilizaré la estructura base para el ejercicio de regresión lineal simple (ya realizado durante clases). Se utilizará 2 “variables predictivas” para poder graficar en 3D, pero recordar que para mejores predicciones podemos utilizar más de 2 entradas y prescindir del gráfico. Nuestra primera variable seguirá siendo la cantidad de palabras y la segunda variable será la suma de 3 columnas de entrada: la cantidad de enlaces, comentarios y cantidad de imágenes. Figura 2. Variables en un ejercicio de regresión lineal múltiple. 3.2.2. Paso 1: Optimizaciones al modelo Lo primero que se debe hacer, será optimizar el modelo original de regresión lineal, con una dimensión más. Para poder graficar en 3D, haremos una variable nueva que será la suma de los enlaces, comentarios e imágenes. Previamente se tenía 2 variables de entrada en XY_train y nuestra variable de salida pasa de ser “Y” a ser el eje “Z” (como podemos ver en la figura 2). Figura 3. Paso 1: optimizaciones al modelo. 3.2.3. Paso 2: Creación del modelo de regresión lineal Para esto, será necesario crear un nuevo objeto de Regresión Lineal. Entrenamos el modelo, esta vez, con 2 dimensiones obtendremos 2 coeficientes, para graficar un plano. Hacemos la predicción con la que tendremos puntos sobre el plano hallado. Imprimimos los coeficientes en consola. Imprimimos el valor del error cuadrático medio. Imprimimos el valor de la evaluación del puntaje de varianza (siendo 1.0 el mejor posible). Figura 4. Paso 2: Creación del modelo de regresión lineal. Hasta aquí, en resumen: Se crea un nuevo objeto de Regresión lineal con SKLearn pero esta vez tendrá las dos dimensiones que entrenar: las que contiene XY_train. Al igual que antes, imprimimos los coeficientes y puntajes obtenidos Se obtiene 2 coeficientes (cada uno correspondiente a nuestras 2 variables predictivas), pues ahora lo que graficamos no será una línea si no, un plano en 3 Dimensiones. El error obtenido sigue siendo grande, aunque algo mejor que el anterior y el puntaje de Varianza mejora casi el doble del anterior (aunque sigue siendo muy malo, muy lejos del 1). 3.2.4. Paso 3: Creación de gráficas En esta sección generamos todos los parámetros gráficos de nuestro plot. Además, realizamos algunos otros cálculos que nos ayudarán a comprender de mejor manera el resultado graficado. Se Grafica los puntos de las características de entrada en color azul y los puntos proyectados en el plano en rojo. Recordemos que, en esta gráfica, el eje Z corresponde a la “altura” y representa la cantidad de Shares que obtendremos. Creamos una malla, sobre la cual graficaremos el plano Calculamos los valores del plano para los puntos x e y Calculamos los correspondientes valores para z. Debemos sumar el punto de intercepción. Graficamos el plano. Graficamos en azul los puntos en 3D del entrenamiento. Graficamos en rojo, los puntos en 3D de la predicción. Con “view_init” situamos la "camara" con la que visualizamos. Figura 5. Paso 3: Creación de gráficas. 3.2.5. Paso 4: Solución a reto planteado Como punto final del ejercicio se nos plasma la siguiente incógnita: ¿Que predicción se obtendrá para un artículo de 2000 palabras, con 10 enlaces, 4 comentarios y 6 imágenes? Para dar resolución a este requerimiento con nuestro modelo, utilizamos el código mostrado a continuación. Figura 6. Paso 4: Solución a reto planteado. 3.2.6. Ejecuciones en distintos resultados A continuación, adjunto capturas de pantalla de los distintos tipos de resultados que ofrece esta herramienta: plots (gráfica), variable explorer (explorador de variables con el contenido de cada una) y consola (con los datos impresos en el código). Figura 7. Ejecución gráfica. Figura 8. Ejecución viendo el explorador de variables. Figura 9. Ejecución y resultado en consola. 4. Conclusiones La mayoría de los algoritmos de aprendizaje automático se incluyen en la categoría de aprendizaje supervisado. Es el proceso donde se usa un algoritmo para predecir un resultado basado en los valores ingresados previamente y los resultados generados a partir de ellos. En contexto, el aprendizaje supervisado lee el valor de la variable ingresada 'x' y la variable resultante 'y' para que pueda usar esos resultados para predecir posteriormente un dato de salida altamente preciso de 'y' a partir del valor ingresado de 'x'. Un problema de regresión es cuando la variable resultante contiene un valor real o continuo. En la regresión lineal simple utilizamos una única variable independiente para predecir el valor de una variable dependiente, mientras que en la regresión lineal múltiple se utilizan dos o más variables independientes para predecir el valor de una variable dependiente. La diferencia entre los dos es el número de variables independientes. En ambos casos existe una única variable dependiente. Finalmente, puedo concluir que, la regresión lineal es un algoritmo de aprendizaje automático basado en el aprendizaje supervisado ya que realiza una tarea de regresión. La regresión modela un valor de predicción objetivo basado en variables independientes. Se utiliza principalmente para conocer la relación entre las variables y la previsión (tal como pudimos ver en esta práctica). 5. Recomendaciones Para el ejercicio de regresión lineal múltiple, debemos tomar muy en cuenta la diferencia que tiene con la regresión lineal normal. La diferencia principal radica en que la regresión lineal múltiple utiliza 2 o más variables independientes para predecir el valor de la variable dependiente, mientras que la regresión lineal simple, utiliza una única variable dependiente e independiente. Cuando trabajamos con regresión lineal, nuestro objetivo principal es encontrar la línea de mejor ajuste que signifique que el error entre los valores predichos y los valores reales debe minimizarse. La línea de mejor ajuste tendrá el menor error.