ECONOMETRÍA PRÁCTICA
CON EXCEL
SERGIO ZÚÑIGA
Universidad Católica del Norte
Julio, 2004
PRESENTACION
Es sabido que el estudio de la econometría requiere, en apoyo al estudio de los aspectos
conceptuales, la estimación empírica de los modelos econométricos para análisis, contrastación
y predicción. Para esto el estudiante debe estar familiarizado con un buen programa de
ordenador, de los cuales existen en el mercado muchas alternativas, como por ejemplo RATS,
E-Views, Limdep, Gauss, Stata o SAS, cada uno de ellos con características especiales. Este
libro se ocupa de introducir al lector en el programa Excel.
Si bien Excel no es el programa preferido por los econometristas, a través de este libro
mostramos la forma en que éste puede ayudar a alcanzar la mayor parte de los objetivos
planteados para una asignatura de econometría de pregrado.
Como se verá, este libro es un texto de apoyo en los laboratorios computacionales de
econometría, es decir tiene un objetivo netamente práctico, por lo cual hemos intentado
presentar y resolver gran número de ejemplos numéricos, a costa de centrarnos solo en los
aspectos fundamentales de la teoría subyacente, la que asumimos será estudiada en alguno de
los númerosos libros de texto introductorio existentes, tales como “Introducción a la
Econometría” de Maddala, “Análisis Econométrico” de Green, “Introduction to the Theory and
Practice of Econometrics” de Judge et al., y “Econometría” de Gujarati.
INDICE
PRESENTACION ............................................................................................................................................................. 1
CAPÍTULO 1..................................................................................................................................................................... 1
EL PROGRAMA EXCEL ................................................................................................................................................ 1
1.1.
ESTADISTICA DESCRIPTIVA CON EXCEL ................................................................................................ 1
1.2.
SESGO, CURTOSIS Y NORMALIDAD.......................................................................................................... 4
1.3.
GRAFICOS DE PROBABILIDAD NORMAL................................................................................................. 6
1.4.
HISTOGRAMA ................................................................................................................................................ 9
1.5.
OPERACIONES CON ESCALARES Y MATRICES .................................................................................... 11
a) Crear una fórmula matricial.................................................................................................................................. 11
b) Calcular un único resultado .................................................................................................................................. 11
c) Calcular varios resultados ..................................................................................................................................... 11
d) Operaciones Matriciales........................................................................................................................................ 12
1.6.
DISTRIBUCIONES DE PROBABILIDAD.................................................................................................... 13
1.7.
POTENCIA DE UN TEST .............................................................................................................................. 15
1.7.1. APLICACIÓN: SELECCIÓN ENTRE TESTS ALTERNATIVOS ................................................................. 16
1.8.
NIVEL DE SIGNIFICANCIA MARGINAL: CDF O P-VALUE.................................................................... 17
1.8.1. Distribución Normal......................................................................................................................................... 17
1.8.2. Distribución t.................................................................................................................................................... 18
1.8.3. Distribución F .................................................................................................................................................. 19
1.8.4. Distribución Chi cuadrado............................................................................................................................... 20
1.9. PRUEBAS SOBRE LA MEDIA EN EXCEL ......................................................................................................... 21
1.9.1. Inferencia respecto a una Media...................................................................................................................... 21
1.9.2. Diferencia de dos Medias (Univariado)........................................................................................................... 22
1.9.3. Inferencia En Excel .......................................................................................................................................... 23
1.10.
SERIES DE DATOS........................................................................................................................................ 26
CAPÍTULO 2................................................................................................................................................................... 28
EL MODELO DE REGRESIÓN LINEAL................................................................................................................... 28
2.1.
INTRODUCCIÓN: ¿QUE ES LA ECONOMETRÍA? .................................................................................... 28
2.2.
ESTIMACIÓN DE MODELOS DE REGRESIÓN ......................................................................................... 28
2.2.1. EL MÉTODO DE MÍNIMOS CUADRADOS ................................................................................................... 29
2.2.2. IMPLEMENTACIÓN DE MCO ....................................................................................................................... 31
2.3.
PRUEBA DE HIPÓTESIS............................................................................................................................... 33
2.3.2. LA DISTRIBUCIÓN DE b Y SUS PROPIEDADES ..................................................................................... 33
2.3.3. LA MATRIZ DE COVARIANZAS DE LOS ERRORES ................................................................................ 34
2.3.4. UNA MEDIDA DEL ÉXITO DE AJUSTE.................................................................................................... 36
2.4. CASO DE ESTUDIO .............................................................................................................................................. 38
2.4.1. Describiendo los Datos .................................................................................................................................... 38
2.4.2. Calculando Estadísticas ................................................................................................................................... 39
2.4.3. Transformación de datos y creación de nuevas series ..................................................................................... 39
2.4.5. Gráficos de Series de Tiempo........................................................................................................................... 40
2.4.6. Gráficos X-Y (Scatter) ...................................................................................................................................... 40
2.4.7. CASO DE ESTUDIO: Corriendo la Regresión 1 ............................................................................................. 42
2.4.8. CASO DE ESTUDIO: Corriendo la Regresión 2 ............................................................................................. 43
2.5.
INTERPRETACION DE LOS COEFICIENTES DE REGRESIÓN............................................................... 45
i
2.5.1. INTRODUCCIÓN ........................................................................................................................................ 45
2.5.2. FORMA DOBLE LOGARÍTMICA ............................................................................................................... 46
2.5.3
MODELO LOGARÍTMICO LINEAL (DE CRECIMIENTO CONSTANTE) ................................................ 46
2.5.4. OTRA VISIÓN DE LOS COEFICIENTES DE PENDIENTE....................................................................... 47
2.6 RESUMEN: UNA CRÍTICA AL MODELO....................................................................................................... 50
CAPÍTULO 3................................................................................................................................................................... 51
MÍNIMOS CUADRADOS RESTRINGIDOS (INFERENCIA) ................................................................................. 51
3.1.
MCO CON ERRORES NORMALES ............................................................................................................. 51
3.2.
PRUEBAS SOBRE UN COEFICIENTE......................................................................................................... 53
3.3.
TRES TESTS EQUIVALENTES .................................................................................................................... 54
3.4.
TEST DE RAZON DE VEROSIMILITUD (LR) ............................................................................................ 54
3.4.1. LR BAJO ESPECIFICACION LINEAL-LINEAL ............................................................................................. 55
3.5. TEST DE WALD .................................................................................................................................................... 57
3.5.1. WALD BAJO ESPECIFICACION LINEAL-LINEAL ....................................................................................... 57
3.5.2. EJEMPLO NUMERICO DEL TEST DE WALD .............................................................................................. 58
3.6. TEST DEL MULTIPLICADOR DE LAGRANGE................................................................................................. 59
3.7.
PRUEBA DE SIGNIFICANCIA GLOBAL .................................................................................................... 60
3.8.
PRUEBA DE EXCLUSION DE VARIABLES............................................................................................... 61
3.9.
PRUEBA DE CAUSALIDAD (GRANGER, 1969) ........................................................................................ 62
3.10.
TEST DE ESTABILIDAD (CAMBIO ESTRUCTURAL).............................................................................. 65
3.11.
ESTIMANDO REGRESIÓNES RESTRINGIDAS ........................................................................................ 66
CAPÍTULO 4................................................................................................................................................................... 67
VIOLACIÓN DE ALGUNOS SUPUESTOS ................................................................................................................ 67
4.1.
MÍNIMOS CUADRADOS GENERALIZADOS............................................................................................ 68
4.2.
HETEROCEDASTICIDAD............................................................................................................................ 69
4.2.1. CORRECCIÓN CON MCG (ϕ CONOCIDA) ............................................................................................. 70
4.2.2. DETECCION DE LA HETEROCEDASTICIDAD ....................................................................................... 72
1.- Test de Goldfeld y Quandt (1972) ........................................................................................................................................ 72
2.- Arch Test de White (1980): .................................................................................................................................................. 73
3.- Arch Test de Engle (1982):................................................................................................................................................... 74
4.2.3. CORRIGIENDO POR HETEROCEDASTICIDAD: MC PONDERADOS................................................... 75
4.3.
CORRELACIÓN SERIAL .............................................................................................................................. 77
4.3.1. CORRECCIÓN CON MCG (ϕ CONOCIDA) ............................................................................................. 78
4.3.2. DETECCION DE AR(1): DURBIN-WATSON (1951) ................................................................................. 80
4.3.3. DETECCION EN MODELOS CON Y REZAGADA: Test h de Durbin ....................................................... 83
4.3.4. DETECCIÓN DE LA AUTOCORRELACIÓN DE ORDEN SUPERIOR..................................................... 84
a) Test de BREUSCH (1978) Y GODFREY (1978) .................................................................................................................. 84
b) Test Q de Ljung y Box (1978) (Box-Jenkins model identification) ....................................................................................... 85
4.3.4.
CORRIGIENDO LA AUTOCORRELACION EN EXCEL............................................................................ 87
4.3.4.1. Primeras Diferencias ..................................................................................................................................................... 87
4.3.4.2. PDG: Métodos Alternativos .......................................................................................................................................... 89
4.4.
ESTIMACION ROBUSTA ............................................................................................................................ 91
4.4.1. CORRECCION DE WHITE (1980) ............................................................................................................. 92
4.4.2. CORRECCION DE NEWEY Y WEST (1987) .............................................................................................. 93
4.4.
MULTICOLINEALIDAD............................................................................................................................... 95
4.4.1. MULTICOLINEALIDAD PERFECTA......................................................................................................... 95
4.4.2. MULTICOLINEALIDAD MUY ALTA.......................................................................................................... 95
4.5.3. SOLUCIONES A LA MULTICOLINEALIDAD ........................................................................................... 96
CAPÍTULO 5................................................................................................................................................................... 97
ESTACIONARIEDAD Y COINTEGRACIÓN............................................................................................................ 97
ii
5.1.
REGRESIONES ESPUREAS ......................................................................................................................... 97
5.2.
ESTACIONARIEDAD ................................................................................................................................... 99
5.2.1. DEFINICIÓN ................................................................................................................................................... 99
5.2.2. SERIE ESTACIONARIA ................................................................................................................................... 99
5.2.3. SERIE NO ESTACIONARIA .......................................................................................................................... 101
5.3. PRUEBAS DE ESTACIONARIEDAD ................................................................................................................ 103
5.3.1. CORRELOGRAMA Y TEST Q ....................................................................................................................... 103
5.3.2. PRUEBAS DE RAICES UNITARIAS: Dickey y Fuller .............................................................................. 105
5.3.3. PRUEBAS DE RAICES UNITARIAS: Augmented Dickey Fuller (ADF) Test ........................................... 106
5.3.
DIFERENCIACION DE SERIES I(1)........................................................................................................... 108
5.4.
COINTEGRACIÓN: PRUEBA DE ENGLE-GRANGER ............................................................................ 110
5.4.1. INTRODUCCIÓN ...................................................................................................................................... 110
5.4.2. DEFINICIÓN FORMAL DE COINTEGRACION...................................................................................... 111
5.4.3. PRUEBA DE ENGLE-GRANGER (1987).................................................................................................. 113
5.4.4. TEOREMA DE REPRESENTACION DE GRANGER.................................................................................... 114
5.5. COMENTAROS FINALES .................................................................................................................................. 116
CAPÍTULO 6................................................................................................................................................................. 117
INTRODUCCIÓN A LA PREDICCIÓN EN EXCEL............................................................................................... 117
6.1.
EL ERROR DE PREDICCIÓN ..................................................................................................................... 119
6.2.
PREDICCIÓN ESTATICA ........................................................................................................................... 119
6.3.
CASO PRÁCTICO........................................................................................................................................ 122
a) Tasa de Ocupación (OCCUP) ............................................................................................................................. 123
b) Ingreso por Habitación (Room Rate)................................................................................................................... 125
c) Número de Habitaciones (ROOMS)..................................................................................................................... 126
d) Predicción Final .................................................................................................................................................. 127
6.4. MEDIDAS DE ERROR DE PREDICCION.......................................................................................................... 128
6.4.1. Error Cuadrático Medio (Mean Squared Error, MSE).................................................................................. 128
6.4.2. Promedio del Error Absoluto (Mean Absolute Error, MAE) ......................................................................... 128
6.4.3. Promedio del Porcentaje de Error Absoluto (Mean Absolute Percentage Error, MAPE)............................. 128
6.4.4. Ejemplo de Cálculo ........................................................................................................................................ 129
CAPÍTULO 7................................................................................................................................................................. 130
MODELOS ARIMA...................................................................................................................................................... 130
7.1.
9.2.
9.2.1.
9.2.2.
9.3.
9.3.1.
9.3.2.
9.3.
7.4.
9.4.1.
9.4.2.
9.4.3.
9.4.4.
AUTOCORRELACIONES SIMPLES Y PARCIALES................................................................................ 130
PROCESOS AUTORREGRESIVOS (AR) ................................................................................................... 131
SIMULACION DE PROCESOS AR(1) ...................................................................................................... 132
ESTIMACION DE UN PROCESO AUTOREGRESIVO ............................................................................ 133
PROCESOS DE MEDIAS MOVILES .......................................................................................................... 134
SIMULACION DE PROCESOS MA(1) ..................................................................................................... 134
ESTIMACION DE UN PROCESO DE MEDIAS MOVILES...................................................................... 134
PROCESOS ARIMA..................................................................................................................................... 136
EL ENFOQUE DE BOX Y JENKINS ........................................................................................................... 138
PASO 1: IDENTIFICACIÓN ..................................................................................................................... 139
PASO 2: ESTIMACIÓN ............................................................................................................................. 140
PASO 3: VERIFICACIÓN / DIAGNÓSTICO ............................................................................................ 143
PASO 4: PREDICCIÓN............................................................................................................................. 144
CAPÍTULO 8................................................................................................................................................................. 147
ERROR EN LAS VARIABLES: INSTRUMENTOS................................................................................................. 147
8.1. VARIABLES INSTRUMENTALES.................................................................................................................... 147
8.2.
ESTIMACIÓN CON INSTRUMENTOS EN SPSS ...................................................................................... 148
8.3.
EL ESTIMADOR DE VARIABLES INSTRUMENTALES......................................................................... 150
iii
REFERENCIAS ............................................................................................................................................................ 151
ANEXO: DATOS UTILIZADOS EN EL LIBRO ....................................................................................................... 153
iv
CAPÍTULO 1
EL PROGRAMA EXCEL
1.1. ESTADISTICA DESCRIPTIVA CON EXCEL
Microsoft Excel ofrece un conjunto de herramientas para el análisis de los datos (Herramientas
para Análisis) lo que permite efectuar análisis estadístico de una manera simple. Algunas herramientas
generan gráficos además de tablas de resultados.
Para ver una lista de las herramientas de análisis disponibles, elija 'Análisis de Datos' en el menú
Herramientas. Si este comando no está en el menú, en el menú Herramientas, elija Complementos, y allí
seleccione Herramientas para Análisis. Si no aparece la opción Herramientas para Análisis, necesita el CD
de instalación de Excel.
Para usar el análisis de datos, vaya ahora a Herramientas, y allí seleccione 'Análisis de Datos'
(Herramientas / Análisis de datos). Aparecerá la lista de opciones en donde seleccionamos Estadística
Descriptiva:
En el cuadro de diálogo de Estadística descriptiva, lo único que és "obligatorio" suministrar son los
datos a analizar (Rango de entrada) y el lugar en donde se desea escribir los resultados (Rango de
salida).
1
Ejemplo. Se tienen datos de la cantidad de producción (kg), capital ($)y de trabajo (horas) de 10
empresas:
Comenzaremos calculando estadística de la serie 'capital'. El "Rango de entrada" es $B$1:$B$11, es decir
seleccionando los títulos como promera observación, de modo que se debe activar la opción 'Rótulos en la
primera fila'. A continuación debemos activar la selección del rango de salida, por ejemplo la celda $A$13,
como se muestra acontinuación:
El resultado es el siguiente:
CAPITAL
Media
Error típico
Mediana
Moda
Desviación estándar
Varianza de la muestra
Curtosis
Coeficiente de asimetría
Rango
Mínimo
Máximo
Suma
Cuenta
Mayor (2)
Menor(2)
Nivel de confianza(95,0%)
5,6
0,733333333
6
6
2,319003617
5,377777778
-1,11811742
-0,058802684
7
2
9
56
10
8
3
1,658915249
Nota: Muchos de estos resultados anteriores pueden obtenerse individualmente a través del menú
Insertar/Función, y allí ir dentro de las funciones estadísticas.
2
Media: Devuelve el promedio (media aritmética) de los argumentos. PROMEDIO(número1;número2;...)
Error típico (de la media): (Desviación estándar)/raiz(T)
Mediana: Devuelve la mediana de los números. La mediana es el número que se encuentra en medio de
un conjunto de números, es decir, la mitad de los números es mayor que la mediana y la otra mitad
es menor. MEDIANA(número1;número2; ...)
Moda: Devuelve el valor que se repite con más frecuencia en una matriz o rango de datos. Al igual que
MEDIANA, MODA es una medida de posición.
Desviación estándar: Calcula la desviación estándar en función de un ejemplo. La desviación estándar es
la medida de la dispersión de los valores respecto a la media (valor promedio). DESVEST(número1;
número2; ...)
Varianza de la muestra: Calcula la varianza en función de una muestra (con n-1 g.l.).
VAR(número1;número2; ...)
Curtosis: Devuelve la curtosis de un conjunto de datos. La curtosis caracteriza la elevación o el
achatamiento relativos de una distribución, comparada con la distribución normal. Una curtosis
positiva indica una distribución relativamente elevada, mientras que una curtosis negativa indica
una distribución relativamente plana. CURTOSIS(número1;número2; ...)
Coeficiente de asimetría: Devuelve la asimetría de una distribución. Esta función caracteriza el grado de
asimetría de una distribución con respecto a su media. La asimetría positiva indica una distribución
unilateral que se extiende hacia valores más positivos. La asimetría negativa indica una distribución
unilateral que se extiende hacia valores más negativos.
COEFICIENTE.ASIMETRIA(número1;número2; ...)
Rango: MAX(Rango) – MIN(Rango).
Mínimo: Devuelve el valor mínimo de un conjunto de valores. MIN(número1;número2; ...)
Máximo: Devuelve el valor máximo de un conjunto de valores. MAX(número1;número2; ...)
Suma: La sumatora de las observaciones
Cuenta: El número de observaciones (T)
Mayor (2): Késimo mayor. Devuelve el valor késimo mayor de cada rango de datos en la tabla de
resultados. En el cuadro, escriba el número que va a utilizarse para k. Si escribe 1, esta fila
contendrá el máximo del conjunto de datos.
Menor (2): Késimo menor. Devuelve el valor késimo menor de cada rango de datos en la tabla de
resultados. En el cuadro, escriba el número que va a utilizarse para k. Si escribe 1, esta fila
contendrá el mínimo del conjunto de datos.
Nivel de confianza (95,0%): Nivel de confianza para la media. Devuelve el nivel de confianza de la media
en la tabla de resultados. En el cuadro, escriba el nivel de confianza que desee utilizar. Por ejemplo,
un valor de 95 % calculará el nivel de confianza de la media con un nivel de importancia del 5 %.
3
1.2. SESGO, CURTOSIS Y NORMALIDAD
Existen 4 formas comunes de estimar la normalidad:
1.2.3.4.-
Histograma de residuos
Normal Probability Plot
Anderson-Darling normality test (A2 stat)
Jarque-Bera (JB) test of Normality (asintótico)
Por ahora estamos interesados en la prueba de Jarque Bera, la que tiene la siguiente
specificación:
⎡ S2 K2 ⎤
⎥ ≈a
JB = T ⎢
+
24 ⎥
⎢⎣ 6
⎦
χ 2 ( 2)
donde S es el coeficiente de Sesgo y K es el coeficiente de curtosis. Para una variable distribuída
normalmente, S=0 y K=3. Luego, el test JB de normalidad es una prueba conjunta de si S=0 y K=3. Si el
valor p es suficientemente bajo, se puede rechazar la hipótesis que la variable está normalmente
distribuída.
Ejemplo: Chi-Squared(2)= 1.061172 with Significance Level 0.58826017, donde Ho: Normalidad. Luego,
no podemos rechazar en este caso la hipótesis de normalidad (la conclusión es no rechazar normalidad).
Las definiciones y pruebas estadísticas para el sesgo y la curtosis son las siguientes:
a) Sesgo:
En Excel: =coeficiente.asimetria( )
La prueba estadística de que el sesgo es cero se basa en una Normal, y es:
b) Curtosis:
En Excel: =curtosis( )
La prueba estadística de que la curtosis es cero se basa en una Normal, y es:
4
Ejemplo: Siguiendo el ejemplo de la serie CAPITAL anterior mostramos el cálculo de éstas. Los
resultados a obtener son los siguientes:
Observaciones
Media Muestral
Desv estandar
Varianza
Error est de la media
Estadistico t
Sesgo
Curtosis
Jarque Bera
10
5,6
2,319003617
5,377777778
0,733333333
7,636363636 Pruebas de Hipotesis Significancia a 1 cola
-0,058802684
-0,064415113
0,948639697
-1,11811742
-0,488540664
0,62516693
0,526673995
0,526673995
0,768482877
Las fórmulas usadas en cada caso se muestran a continuación:
5
1.3. GRAFICOS DE PROBABILIDAD NORMAL
Los gráficos de probabilidad normal (normal probability plot) son una técnica gráfica para valorar
si los datos son o no aproximadamente normalmente distribuñidos. Los datos son graficados contra una
distrinución normal teórica de tal forma que los puntos deben formar aproximadamente una línea recta.
Las desviaciones de la línea recta indican desviaciones de la normalidad. El gráfico de probabilidad normal
es un caso especial de los gráficos de probabilidad.
Existen varios tipos de gráficos de probabilidad normal 1. Aquí nos referimos solamente al tipo más
simple de ellos: Percentiles vs Datos.
Los pasos para construir un gráfico de probabilidad normal son:
1
1.
Las observaciones son rankeadas (ordenadas) de la menor a la mayor, x(1), x(2), . . ., x(n).
2.
Las observaciones ordenadas x(j) son graficadas contra su frecuencia acumulativa observada,
tipicamente; j/(n + 1)) sobre un gráfico con el eje Y apropiadamente escalado para la distribución
hipotetizada.
3.
Si la distribución hipotetizada describe adecuadamente los datos, los puntos graficados se ubican
aproximadamente sobre una línea recta. Si los puntos se desvían significativamente de la
lñinearecta, especialmente en las puntas, entonces la distribución hipotetizada no es apropiada.
Vease por ejemplo www.itl.nist.gov/div898/handbook/eda/section3/probplot.htm.
6
4.
Para valorar la cercanía de los ountos a la línea recta, la prueba del grosor de un lápiz se usa
comunmente. Si todos los puntos se encuentran dentro del lapis imaginario, entonces la
distribución hipotetizada es probablemente la apropiada.
Ejemplo: Los siguientes datos representan el grosor de una hoja plástica, en micrones: 43, 52, 55, 47,
47, 49, 53, 56, 48, 48
Ordered data Rank order Cumulative Frequency
(j)
( j/(n + 1))
43
1
1/11 = .0909
47
2
2/11 = .1818
47
3
3/11 = .2727
48
4
4/11 = .3636
48
5
5/11 = .4545
49
6
6/11 = .5454
52
7
7/11 = .6363
53
8
8/11 = .7272
55
9
9/11 = .8181
56
10
10/11 = .9090
Los datos ordebados son graficados contra su respectiva frecuencia acumulada. Note como el eje Y es
escalado tal que una línea recta resultará para datos normales.
Basados en el gráfico, parece que los datos se encuentran normalmente distribuídos. Sin embargo
se requieren otras pruebas estadísticas para concluir que el supuesto de normlidad es apropiado.
7
En Excel puede obtenerse este gráfico en Herramientas / Analisis de Datos / Regresion / y allí
seleccionando la opcion Grafico de probabilidad normal.
Para el caso de la serie 'Capital' del ejemplo que se ha estado analizando, se tiene el siguiente
resutado a partir de Excel.
8
1.4. HISTOGRAMA
Un histograma es un gráfico para la distribución de una variable cuantitativa continua que
representa frecuencias mediante el volumen de las áreas. Un histograma consiste en un conjunto de
rectángulos con (a): bases en el eje horizontal, centros en las marcas de clase y longitudes iguales a los
tamaños de los intervalos de clase y (b): áreas proporcionales a las frecuencias de clase.
Si en la distribución se toman clases de la misma longitud, las frecuencias son proporcionales a las
alturas de los rectángulos del histograma ya que el área se obtiene multiplicando la base por la altura por
lo que queda similar a un diagrama de barras, solo que ahora las barras van una junto a otra por tratarse
de una variable continua.
En Excel, la herramienta para histogramas se encuentra en Herramientas / Análisis de Datos /
Histograma. Antes de ejecutarla se puede (es opcional) definir el 'Rango de Clases', a fin de definir las
divisiones para cada rango del histograma. El 'Rango de Clases' son valores límite que definen rangos de
clase, los que deberán estar en orden ascendente. Si se omite el rango de clase, Excel creará un conjunto
de clases distribuidas uniformemente entre los valores mínimo y máximo de los datos.
Ejemplo: En el ejemplo de la serie 'Capital' un histograma es obtenido de la siguiente forma:
9
Histograma
120,00%
3,5
3
100,00%
2,5
Frecuencia
80,00%
2
60,00%
Frecuencia
% acumulado
1,5
40,00%
1
20,00%
0,5
0
0,00%
2
4,333333333
6,666666667
y mayor...
Clase
10
1.5. OPERACIONES CON ESCALARES Y MATRICES
Excel permite realizar operaciones matriciales con facilidad. En Excel, las fórmulas que hacen
referencia a matrices se encierran entre corchetes {}. Al trabajar con matrices en Excel hay que tener en
cuenta lo siguiente:
•
•
•
No se puede cambiar el contenido de las celdas que componen la matriz
No se puede eliminar o mover celdas que componen la matriz
No se puede insertar nuevas celdas en el rango que compone la matriz
a) Crear una fórmula matricial
Una fórmula matricial es una fórmula que lleva a cabo varios cálculos en uno o más conjuntos de
valores y devuelve un único resultado o varios resultados. Las fórmulas matriciales se encierran entre
llaves { } y se especifican presionando CTRL+MAYÚS+ENTRAR. Cuando se introduce una fórmula
matricial Microsoft Excel inserta de forma automática la fórmula entre llaves ({}).
b) Calcular un único resultado
Puede utilizar una fórmula matricial para realizar varios cálculos que generen un único resultado.
Este tipo de fórmula matricial permite simplificar un modelo de hoja de cálculo sustituyendo varias
fórmulas distintas por una sola fórmula matricial.
Por ejemplo, la siguiente calcula el valor total de una matriz de precios de cotización y acciones, sin
utilizar una fila de celdas para calcular y mostrar los valores individuales de cada cotización.
- Haga clic en la celda en que desee introducir la fórmula matricial (en B5).
- Escriba la fórmula matricial. Cuando se escribe la fórmula ={SUMA(B2:C2*B3:C3)} como fórmula
matricial, se multiplica las acciones y el precio correspondiente a cada cotización, y luego se suma los
resultados de estos cálculos.
- Presione CTRL+MAYÚS+ENTRAR.
c) Calcular varios resultados
- Seleccione el rango de celdas en que desee introducir la fórmula matricial.
- Escriba la fórmula matricial. Por ejemplo, dada un serie de tres cifras de ventas (columna B) para una
serie de tres meses (columna A), la función TENDENCIA determinará los valores de la línea recta para las
cifras de ventas. Para mostrar todos los resultados de la fórmula, se escribe en tres celdas en la columna
C (C1:C3). Al introducir la fórmula =TENDENCIA(B1:B3,A1:A3) como fórmula matricial, generará tres
resultados separados (22196, 17079 y 11962) basados en las tres cifras de ventas y en los tres meses.
11
Presione CTRL+MAYÚS+ENTRAR.
d) Operaciones Matriciales
Existen una serie de operaciones matriciales en Excel, siendo las más usadas las siguientes:
MDETERM Devuelve la matriz determinante de una matriz
MINVERSA Devuelve la matriz inversa de una matriz
MMULT Devuelve la matriz producto de dos matrices
Veámos un ejemplo para el caso de una multiplicación.
- Seleccione el rango de celdas en que desee introducir la fórmula matricial. Para esto debe calcularse la
dimensión resultante de la operación matricial. Por ejemplo, si se multiplican dos matrices de dimensiones
2x3, y 3x4 respectivamente, las celdas de la formula matricial que deben seleccionarse es de dimensión
2x4.
Presione CTRL+MAYÚS+ENTRAR. Con esto se tiene la matriz resultante, dada por:
19
29
28
42
44
66
46
69
12
1.6. DISTRIBUCIONES DE PROBABILIDAD
En econometría, para efectos de inferencia acerca de los coeficientes estimados, es necesario
trabajar con un número de distribuciones de probabilidad. A continuación recordamos las más
importantes: la distribución Normal, Chi-cuadrado, t y F.
La siguiente es la función de densidad normal para una variable aleatoria X con una distribución
normal con media μ y varianzas σ2:
f (x / μ,σ 2 ) =
1
⎧ 1 SCErrt ⎫
EXP ⎨−
⎬
2
σ 2π
⎩ 2 σ
⎭
donde SCErr representa la suma cuadrada de errores, es decir de desviaciones respecto a la media.
Cuando se tienen n variables aleatorias normales Z distribuidas independiente e idénticamente,
entonces la distribución conjunta multivariada con media μ y matriz de covarianza 2 ∑ es:
g ( x) = 2π − n / 2 Σ
1/ 2
⎧ 1
⎫
EXP ⎨− ( x − μ )' Σ −1 ( x − μ )⎬
⎩ 2
⎭
Si Z es una variable aleatoria normal estándar ( Z
1)
≈ N (0,1) ), entonces puede mostrarse que:
Z
t (r ) =
χ 2 (r )
r
Es decir, una variable aleatoria normal estándar dividida por la raíz cuadrada de una variable
aleatoria chi cuadrada con r grados de libertad dividida por r, se distribuye como una t con r grados de
libertad (gl).
χ 2 (r1)
2)
F (r1, r 2) =
r1
χ ( r 2)
2
r2
Es decir, una variable F con r1 gl en el numerador y r2 gl en el denominador corresponde a una
chi-cuadrada con r1 gl dividida por r1, dividida por otra chi-cuadrada con r2 gl dividida por r2.
3)
Z2 ≈
χ
2
(1)
Es decir, una variable aleatoria normal estándar al cuadrado se distribuye chi-cuadrado con 1
grado de libertad.
4)
2
Z 12 + Z 22 + ... + Z n2 ≈
χ
2
( n)
No confundir el símbolo de la matriz de covarianza ∑, con el operador de sumatorias.
13
Es decir, la suma de n variables aleatorias normales estándar al cuadrado se distribuye chicuadrado con n grados de libertad. Este resultado puede generalizarse cuando se trata de variables
normales no estandarizadas
X ≈ N ( μ , Σ) :
( X − μ )' Σ −1 ( X − μ ) ≈ χ 2 (n)
14
1.7. POTENCIA DE UN TEST
Hay dos formas en que un test nos puede llevar a cometer un error:
-
Error del tipo I: Rechazar Ho cuando es verdadera, y
Error del tipo II: No rechazar Ho cuando es Falsa.
El punto es que en la práctica no es posible hacer ambos errores arbitrariamente pequeños, pues
reduciendo la probabilidad de cometer un error aumenta la probabilidad de cometer el otro error. Sin
embargo es más grave el Error del tipo I que el Error del tipo II: es peor condenar a una persona inocente
que dejar libre a un culpable, y por este motivo se trata que la magnitud del error del tipo I sea fijado
usualmente a un valor pequeño, es decir queda bajo control del analista:
Error tipo I :
Rechazar Ho cuando es verdadera (gravísimo)
Error tipo II:
No rechazar Ho cuando es Falsa (grave)
P(Error tipo I) = α = Tamaño del test (size) o nivel de
significancia.
P(Error tipo II) = β
La forma de medir la calidad de un test estadístico es a través de su potencia.
La Potencia de un test es la probabilidad de que correctamente rechacemos Ho cuando es falsa (la
probabilidad de detectar que Ho es falsa).
Potencia = 1 − β = 1 − P ( Error tipo II )
Un test “perfecto” tendrá una potencia de 1.0, pues siempre llevará a una decisión correcta. Esto
puede lograrse, para un nivel dado de significancia, cuando el tamaño de la muestra aumenta (a infinito).
Así, la evaluación de un buen test debe hacerse en base a su función de potencia. En general el
procedimiento óptimo es seleccionar con anticipación el tamaño máximo del error del tipo I que podemos
aceptar, y después se intenta construir una prueba que minimice el tamaño del error del tipo II. Cuando
Ho es falsa, la potencia puede ser calculada asumiendo varios valores críticos para el parámetro
desconocido.
15
1.7.1. APLICACIÓN: SELECCIÓN ENTRE TESTS ALTERNATIVOS
En el siguiente ejemplo σ=1.4 (desviación estándar), T=25 (número de observaciones); y se
desea probar la hipótesis Ho:μ=10 versus H1:μ>10.
Asumiendo que se desea un tamaño de error (α) de hasta 0.06, escogeremos entre 3 distintas
regiones críticas a una cola, sabiendo que las medias muestrales son: Prueba A: 10.65, Prueba B: 10.45 y
Prueba C: 10.25.
Para las diferentes medias muestrales verificamos el cumplimiento del tamaño del test requerido:
A
B
C
P(Error Tipo I)=α=Tamaño del test
P[z> (10.65-10)/0.28 3]=P[z>2.32]=0.0102
P[z> (10.45-10)/0.28]=P[z>1.61]=0.0537
P[z> (10.25-10)/0.28]=P[z>0.89]=0.1867 (no cumple)
Repitiendo para diferentes valores supuestos de μ calculamos la potencia del test:
A
B
P(Error Tipo II) con μ=10.4
P[z> (10.65-10.4)/0.28]=P[z≤0.89]=0.8133
P[z> (10.45-10.4)/0.28]=P[z≤0.18]=0.5714
μ=10.4
μ=10.2
μ=11.0
Potencia Potencia Potencia
0.19
0.05
0.89
0.43
0.98
0.19
Luego:
Al aumentar el tamaño del error del tipo I de 0.0102 a 0.0537, el error del tipo II disminuye de
0.8133 a 0.5714, y viceversa (no es posible eliminar ambos errores).
Puesto que puede tolerarse un error del tipo I de 0.06, entonces la prueba B es mejor que la A,
debido a que su potencia es mayor para distintos valores de μ.
El análisis de potencia permite determinar el tamaño muestral apropiado para cumplir ciertos
niveles predefinidos de α y β.
3
Recuerde que el error estándar para la media en este caso seá 1.4/(25)**0.5=0.28
16
1.8. NIVEL DE SIGNIFICANCIA MARGINAL: CDF O P-VALUE
Hemos dicho anteriormente que la magnitud del error del tipo I queda bajo el control del analista,
quien lo fija en un valor relativamente pequeño, usualmente 5%. Así, la probabilidad de cometer un error
del tipo I es justamente el Nivel de Significancia Marginal (NSM).
Decimos que un resultado es estadísticamente significativo cuando el NSM es menor que el nivel
deseado (generalmente 5%), es decir se tiene suficiente evidencia para rechazar Ho. Si es mayor,
entonces es estadísticamente no significativo (no podemos rechazar Ho). Es decir, bajos niveles de P
llevan a rechazar Ho.
1.8.1. Distribución Normal
Excel entrega los valores críticos de la normal acumulando la probabilidad de izquierda a derecha y
a 1 cola (ej. si decimos al 5%, asignará 5% en 1 cola, la cola izquerda).
Ejemplo: El valor crítico a 2 colas al 95% es:
=DISTR.NORM.ESTAND.INV(0,975) = 1,95996
Ejemplo (significancia): Si el valor Z calculado es 2,0, entonces la significancia (p-value) es:
=DISTR.NORM.ESTAND(2) = 0,97724987
Sin embargo en este caso es más conveniente leer la significancia como
=1-DISTR.NORM.ESTAND(2) = DISTR.NORM.ESTAND(-2) = 0,0228. Puesto que 0,0228 es < que 5%, se
rechaza Ho a 2 colas y también a 1 cola.
17
1.8.2. Distribución t
Excel solo puede entregar los valores críticos de la t de la derecha (los positivos), y lo hace
acumulando la probabilidad de derecha a izquierda a 2 colas (ej. si decimos al 5%, distribuirá 2,5% en cada
cola).
DISTR.T.INV(probabilidad de 2 colas;grados_de_libertad)
Ejemplo: los valores críticos de la t con 4 gl, y al 95% a 2 colas son: -2,776 y 2,776
=DISTR.T.INV(0,05;4) = 2,776
Nota: Puede obtenerse un valor t crítico de 1 cola reemplazando p por 2*probabilidad.
Ejemplo (significancia): Si el valor t calculado es 3,69, con 4 gl, y al 95% a 2 colas, entonces la
significancia (p-value) es:
=DISTR.T(3,69;4;2) = 0,02101873
lo que implica que Ho es rechazado al 2,1% (a 2 colas), y también al 5%.
Es importante notar que la función =DISTR.T(.) no acepta argumentos negativos, es decir, solamente puede
buscarse la significancia en el lado derecho de la distribución.
18
1.8.3. Distribución F
Excel entrega los valores críticos de la F acumulando la probabilidad de derecha a izquierda y a 1
cola.
DISTR.F.INV(probabilidad de 1 cola;gl Num;gl Denom)
Ejemplo: El valor crítico de una F(1,4) a 1 cola al 95% es:
=DISTR.F.INV(0,05;1;4) = 7,70864742
Ejemplo (significancia): Si el valor F(3,30) calculado es 3,0, entonces la significancia (p-value) a 1 cola es:
=DISTR.F(3;3;30) = 0,04606
lo que implica que Ho es rechazado al 5% a 1 cola.
19
1.8.4. Distribución Chi cuadrado
Excel entrega los valores críticos de la Chi acumulando la probabilidad de derecha a izquierda y a 1
cola.
PRUEBA.CHI.INV(probabilidad;grados_de_libertad)
Ejemplo: El valor crítico de la Chi cuadrado con 10 grados de libertad a 1 cola, al 95% es:
=PRUEBA.CHI.INV(0,05; 10) = 18,307
20
1.9. PRUEBAS SOBRE LA MEDIA EN EXCEL
1.9.1. Inferencia respecto a una Media
Ejemplo: Se tiene información de producción de 10 empresas. Un intervalo de confianza al 95% para la
media de la producción en Excel se desarrolla como sigue:
Sabemos que se trata de 9 grados de libertad, por lo que:
a) el estadístico t es = DISTR.T.INV(0,05;9) = 2,262
b) el error típico de la media es = desvest(…)/Raiz(10) = 20,29477/Raiz(10) = 6,41777
Y el intervalo viene dado por = (Media +/- 2,262*6,41777) = (88,9 +/- 14,518). Es decir, (74,382 ;
103,418).
En Excel, aparece en la última fila:
PRODUCCION
Media
Error típico
Mediana
Moda
Desviación estándar
Varianza de la muestra
Curtosis
Coeficiente de asimetría
Rango
Mínimo
Máximo
Suma
Cuenta
Nivel de confianza(95,0%)
88,9
6,417770468
90
#N/A
20,29477218
411,8777778
-1,230556217
-0,154506756
61
57
118
889
10
14,5180054
Note que al aumentar la confianza, se amplía el Intervalo de Confianza (verifíquelo).
21
1.9.2. Diferencia de dos Medias (Univariado)
Para comparar 2 grupos de datos, se tienen básicamente dos enfoques:
- Datos son Normales: Test t
- Datos solo tienen una distribución ordinal (no paramétrica): Test U y Test de Wilcoxon)
A continuación nos referiremos solamente a las comparaciones del primer tipo.
El estadístico:
Z =
X − Y − (μ 1 −μ 2 )
σ
2
1
m
+
σ
2
≈ N (0,1)
2
n
Ejemplo: El análisis de una muestra de m = 20 personas arrojó una edad media de 29.8 años. Una
segunda muestra de n = 25 tuvo un promedio de 34.7 años. Las distribuciones de la edad son normales
con
σ 1 = 4.0 y σ 2 = 5.0. ¿Son las edades diferentes: Ho:μ1=μ2? Realice el test con un α = 0.01
Solución: Ho: μ1 - μ2, test de dos colas: Zona de rechazo: +/- 2.58
Z =
29.8 − 34.7
− 4.9
=
− 3.65
16 25 1.3416
+
20 25
se rechaza Ho ⇒ las edades son diferentes.
IC es (-4.9 +/- 2.58*1.3416) = (-4.9 - 3.46 , -4.9 + 3.46) = (-8.36 , -1.43)
puesto que 0 se ubica fuera del IC, la diferencia de edades es significativamente diferente de cero (los
promedios de cada grupo son diferentes).
Ejemplo: Se realizaron test de resistencia en dos tipos de alambres:
Tamaño de la muestra
Media
M = 129
X = 107.6
Y = 123.6
N = 129
μ1 - μ2 = 107.6 – 123.6 ± 1.96
Conclusiones:
Kg mm 2
(1.3)2
129
+
(2.0)2
129
Desviación Estándar
S1 = 1.3
S2 = 2.0
= -16 ± 0.4116 = (-16.4116; -15.5884)
μ2 > μ1. μ2 es aproximadamente 16
⎡ Kg ⎤
⎢⎣ mm 2 ⎥⎦
más grande que μ1
22
“Problema de Behrens-Fisher”
La solución más simple al caso de varianzas desiguales es llamada “la aproximación a la t de
Welch”, la que corrige los grados de libertad de la t como sigue:
2
⎛ s12 s 22 ⎞
⎜⎜ + ⎟⎟
n n
gl = ⎝ 12 2 ⎠ 2
⎛ s 22 ⎞
⎛ s12 ⎞
⎜⎜ ⎟⎟
⎜⎜ ⎟⎟
n
⎝ 1 ⎠ + ⎝ n2 ⎠
n1 − 1 n2 − 1
El resultado puede ser no entero, y entonces se lo aproxima al entero más cercano.
1.9.3. Inferencia En Excel
Ejemplo: Supóngase que se desea comparar las medias de salario inicial de los dos grupos de
trabajadores (474 observaciones) definidos por la variable sexo (h=hombres y m=mujeres). “Employee
data.xls”
a) Varianzas Conocidas: Prueba Z para medias de dos muestras.
Debe ingresarse las varianzas conocidas.
b) Varianzas Desconocidas. Prueba t para dos muestras suponiendo varianzas iguales.
(Muestras Independientes)
Prueba t para dos muestras suponiendo varianzas iguales
Media
Varianza
Observaciones
Varianza agrupada
Diferencia hipotética de las medias
Grados de libertad
Estadístico t
P(T<=t) una cola
Valor crítico de t (una cola)
P(T<=t) dos colas
Valor crítico de t (dos colas)
Variable 1
13091,9676
8617742,74
216
49131619
0
472
-11,1523866
4,2491E-26
1,64808834
8,4981E-26
1,96500259
Variable 2
20301,3953
83024550,6
258
La prueba t arroja un valor de 11,152 para 472 grados de libertad. La significancia estadística a
dos colas es prácticamente cero, y se rechaza la igualdad de medias de salarios.
La diferencia de las medias es 7.209,43 y el error estandar de la diferencia es 646,45. Un
intervalo de confianza para la diferencia de media es (5.939,16 ; 8.479,70).
23
c) Varianzas Desconocidas. Prueba t para dos muestras suponiendo varianzas desiguales.
(Muestras Independientes)
Prueba t para dos muestras suponiendo varianzas desiguales
Media
Varianza
Observaciones
Diferencia hipotética de las medias
Grados de libertad
Estadístico t
P(T<=t) una cola
Valor crítico de t (una cola)
P(T<=t) dos colas
Valor crítico de t (dos colas)
Variable 1
13091,9676
8617742,74
216
0
319
-11,9874833
6,9028E-28
1,64964432
1,3806E-27
1,96742832
Variable 2
20301,3953
83024550,6
258
La prueba t arroja un valor de 11,987 para 318,818 grados de libertad. La significancia estadística
a dos colas es prácticamente cero.
La diferencia de las medias es 7.209,43 y el error estandar de la diferencia es 601,41. Un
intervalo de confianza para la diferencia de media es (6.026,19 ; 8.392,67).
t=
20301,4 − 13091,97
2
9111 2935
+
258
216
2
=
7209.4
= 11.987
601.4
vs =distr.t.inv(0,05;319)=1.967, se rechaza la igualdad de
medias de salarios.
El IC es: 7209,43 +/- 1.96*601,412
24
d) Varianzas Desconocidas. Prueba t para medias de dos muestras emparejadas (relacionadas
o pareadas). En este caso los rangos de las variables deben contener el mismo número de
observaciones.
Cuando no hay completa independencia entre los pares de las muestras, posiblemente debido a
un origen común, por ejemplo el caso de el ingreso y el tamaño de las casa de las familias.
Lo que se hace es trabajar con las diferencias entre cada par de observaciones, de modo que el
procedimiento puede ser llamado una prueba t de una sola muestra como vimos anteriormente.
Ejemplo: Comparar las medias de las series Salario Actual y Salario Inicial.
Prueba t para medias de dos muestras emparejadas
Media
Varianza
Observaciones
Coeficiente de correlación de Pearson
Diferencia hipotética de las medias
Grados de libertad
Estadístico t
P(T<=t) una cola
Valor crítico de t (una cola)
P(T<=t) dos colas
Valor crítico de t (dos colas)
Variable 1
34419,5675
291578214
474
0,88011747
0
473
35,0359608
8,051E-134
1,64808148
1,61E-133
1,96499192
Variable 2
17016,0865
61946945
474
La media es 17.403,48, la desviación estándar es 10.814,62, y el error estándar de la media es
496,73. El intervalo de confianza es (16.427,41 ; 18.379,56). El estadístico t es de 35,036 para 473
grados de libertad, lo que arroja una significancia a dos colas cercana a cero.
25
1.10. SERIES DE DATOS
Las Series son los datos más importantes en cualquier investigación, pues contienen la
información que ha sido recopilada acerca de las variables de interés. Son esencialmente arreglos de
elementos de una dimensión, como los vectores, pero tienen una estructura mucho más compleja, puesto
que, por ejemplo, pueden tener elementos definidos y no definidos. Por ejemplo, en una serie “Consumo
Nacional Anual” es posible que no dispongamos del dato de un año en particular, pero aún así podemos
construir la serie.
Operacionalmente las series siempre tienen la estructura de una matriz rectangular, en que las
columnas contienen las variables, y las filas representan los casos o sujetos, y además no hay elementos
vacíos.
En econometría las series de datos pueden ser de 3 tipos: corte transversal (cross section), series
de tiempo (time series) y del tipo panel o combinadas (panel data).
tiempo.
Las series de corte transversal son observaciones de determinadas variables en un momento del
Ejemplo: Las series Capital y Reservas (en millones de pesos) de los bancos nacionales,
en enero de 1990, constituyen una serie de corte transversal.
Banco
1
2
3
4
5
6
7
Capital y Reservas
3.661
5.590
3.047
9.296
6.604
6.908
8.122
Las series de tiempo están constituidas por observaciones de un número de variables a través del
tiempo (diarias, mensuales, anuales, etc.).
Ejemplo: La serie Producto Interno Bruto anual de Chile en $ reales de 1986 entre 1972 y
1976 es una serie de tiempo.
AÑO
1972
1973
1974
1975
1976
PIB ($ reales 1986)
2.659.800
2.544.814
1.864.085
2.341.477
2.329.343
Los datos de panel están constituidos por combinaciones de datos de corte transversal y series de
tiempo.
26
Ejemplo: La siguiente tabla muestra 3 series de colocaciones de 3 bancos entre enero y
julio de 1990, por lo que se trata de un panel de datos.
Fecha
90.01
90.02
90.03
90.04
90.05
90.06
90.07
Colocaciones Colocaciones Colocaciones
Banco 1
Banco 2
Banco 3
5132
2525
507
4704
3223
518
4941
2200
517
4806
3012
527
4943
2553
535
4566
3101
541
4167
3176
550
Hemos señalado que los datos econométricos pueden ser de 3 tipos: corte transversal, series de
tiempo y datos de panel. Excel no está diseñado especialmente para trabajar con datos de panel.
27
CAPÍTULO 2
EL MODELO DE REGRESIÓN LINEAL
2.1. INTRODUCCIÓN: ¿QUE ES LA ECONOMETRÍA?
Diccionarios especializados definen econometría como “la aplicación de técnicas matemáticas y
estadísticas a la economía en el estudio de problemas, análisis de datos, el desarrollo y la prueba de
teorías y modelos."
En efecto, cuando un economista plantea un determinado modelo en el cual existe una variable
dependiente de otras variables explicativas a través de una determinada especificación funcional, esta es
susceptible de ser estimada con datos de la realidad. En casos simples, el modelo no requiere estar
especificado demasiado formalmente, pues en muchos casos es aceptada cierta relación ente variables,
por ejemplo Ventas-Publicidad, Ingreso-Consumo, Nivel de tasas de interés-Inversión, etcétera. Esto es
en breve lo que se entiende por econometría.
Así como iremos viendo a través de este libro, los tres principales usos de la econometría
incluyen:
1)
2)
3)
Medición de Parámetros (estimación de modelos)
Prueba de Hipótesis
Predicción
2.2. ESTIMACIÓN DE MODELOS DE REGRESIÓN
El análisis de regresión estudia la relación de dependencia de una variable dependiente en una o
más variables explicativas, con el objetivo de estimar y/o predecir resultados promedio o poblacionales de
la primera, en términos de valores conocidos o fijos (en muestras repetidas) de las últimas. El aspecto
común de todos los modelos de regresión es entonces la existencia de variables dependientes (Y) que son
explicadas por una serie de variables independientes (X’s). De todos los modelos de regresión el más
común es del tipo lineal múltple (uniecuacional), en el cual Y es función lineal de las diferentes X’s. Como
veremos, esta especificación posee una serie de ventajas respecto, por ejemplo, a los modelos no
lineales. Nótese también que existen diferencias entre el análisis de regresión y el de correlación, pues la
primera de ellas asume un tratamiento asimétrico de las variables (separándolas en dependientes e
independientes) y asumiendo un comportamiento aleatorio (estocástico) de la variable dependiente. En el
análisis de correlación las variables tienen un tratamiento simétrico (no existe distinción entre variables
dependientes e independientes).
28
Los modelos econométricos pueden ser lineales o no lineales en los parámetros 4. Son lineales
cuando la variable explicada (dependiente) puede ser escrita como una combinación lineal de las variables
explicativas (independientes). Por ahora trabajaremos solamente con modelos lineales.
Ejemplo: Modelo Lineal:
Yt = β 0 + β 1Yt −1 + β 2 X t + ε t
;* es un modelo lineal en los parámetros. Los
parámetros a estimar o incógnitas son los coeficientes β, mientras que las
variables explicativas son X e Y rezagada. La variable explicada o endógena es Y.
Ejemplo: Modelo no Lineal:
Yt = β 0 + β 1Yt −1 + β 22 X t + ε t
;* es un modelo no lineal en los parámetros, pues
hay un coeficiente β que se encuentra al cuadrado, y no hay forma de eliminar ese
exponente sin afectar la linealidad de los restantes parámetros.
La segunda clasificación importante es la de modelos de regresión simples o múltiples, de acuerdo
al número de variables que explican a la variable dependiente. Cuando solamente existe una variable
explicativa se llama a éste un modelo de regresión simple y cuando son varias se le llama modelo de
regresión múltiple.
Ejemplo:
VENTAS t = β 0 + β 1 PUBLICIDADt + ε t
;* es un modelo de regresión simple:
La relación lineal entre las ventas (y) y los gastos en publicidad (x)
Ejemplo:
CONSUMOt = β 0 + β 1 INGRESOS t + β 2 ACTIVOS t + β 3TAMAÑOt + ε t
;* es
un modelo de Regresión Múltiple. La relación lineal entre el gasto en consumo de las
familias (y) en función del ingreso (x1), los activos financieros de la familia (x2) y
del tamaño de la familia (x3).
2.2.1. EL MÉTODO DE MÍNIMOS CUADRADOS
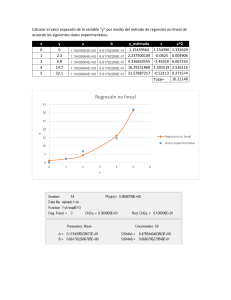
Supongamos que disponemos de información de Ingreso (variable exógena) y de Consumo
(variable endógena) de 20 familias en un determinado periodo (ver datos en archivo 'Tabla 04.xls'). Esta
información es mostrada en el siguiente gráfico (scatter).
4
La no linealidad se refiere a los parámetros, puesto que la no linealidad de las variables consiste simplemente en una
transformación de éstas.
29
Consumo
Relacion Ingreso-Consumo
45,0
40,0
35,0
30,0
25,0
20,0
15,0
10,0
5,0
0,0
0,0
10,0
20,0
30,0
40,0
50,0
Ingreso
Al obtener la información real, esta no se ajustará exactamente al modelo (que suponemos en
este caso es lineal), pues algunos puntos se ubican sobre y otros por debajo de la recta. Las
observaciones parecen una nube de puntos, y nuestro objetivo es determinar el mejor ajuste a la línea, lo
que implica estimar el intercepto y la pendiente de la recta de mejor ajuste a la nube de puntos. Puesto
que existe una desviación o error entre cada valor observado de Y y cada valor predicho por la recta
( Yˆ ), entonces el mejor ajuste será el que minimice tales errores 5.
Puesto que habrá errores positivos y negativos, una posibilidad es encontrar la recta óptima (es
decir el parámetro de intercepto y pendiente) minimizando la suma cuadrara de los errores (SCErr),
procedimiento llamado Mínimos Cuadrados Ordinarios. Estos parámetros de intercepto y pendiente son
llamados también parámetros de posición.
Variable endógena Y
Es conveniente suponer que Y es una variable aleatoria, es decir las observaciones de Y son
sucesos observados en un experimento, y que éstos tienen alguna distribución como se muestra a
continuación:
Valores posibles de Y
dado un valor de X
Y=a+bX
Variable Exogena X
5
Se agrega un término de Error (e) pues la relación entre X e Y es estocástica, lo que se puede deber a:
- Elementos impredecibles (aleatorios) del comportamiento humano.
- Gran número de variables omitidas, algunas no cuantificables.
- Errores de medición en y.
30
Así, si efectivamente la relación subyacente es lineal, uno esperaría que a través de repeticiones
sucesivas de Y (experimentos repetidos) se obtendría observaciones con frecuencias como las descritas
en cada distribución de la ilustración, de modo que el error esperado de cada observación sea cero.
Un supuesto importante en esta parte es que si bien Y y X son observables, X está fijo es decir es
una variable completamente definida por el investigador. Por el contrario Y es estocástico, producto que
existe el error en el modelo, y este error es estocástico, efecto que se transmite a Y.
2.2.2. IMPLEMENTACIÓN DE MCO
Hemos dicho que un modelo del tipo lineal simple contiene una sola variable explicativa (X). La
especificación general es un modelo lineal múltiple con muchas variables explicativas. Considerando todas
las observaciones (supongamos que se trata de T observaciones disponibles), esta relación puede
escribirse entonces de un modo matricial como sigue:
YTx1 = X TxK β Kx1 + ε Tx1
es decir:
⎡ Y1 ⎤
⎢Y ⎥
⎢ 2⎥
Y =⎢ . ⎥
⎢ ⎥
⎢ . ⎥
⎢⎣YT ⎥⎦
⎡1
⎢
⎢1
X =⎢ .
⎢
⎢.
⎢
⎣1
X X
X X
11
12
21
.
.
22
.
.
X X
T1
T2
.
.
.
.
.
.
.
.
.
.
X ⎤⎥
X⎥
ik
2k
. ⎥
⎥
. ⎥
XTk⎥⎦
⎡β 0 ⎤
⎢β ⎥
⎢ 1⎥
β =⎢ . ⎥
⎢ ⎥
⎢ . ⎥
⎢⎣ β k ⎥⎦
⎡ε1 ⎤
⎢ε ⎥
⎢ 2⎥
ε =⎢ . ⎥
⎢ ⎥
⎢ . ⎥
⎢⎣ε T ⎥⎦
donde Y es el vector de variables explicadas por el modelo, X es una matriz de valores conocidos de
variables explicatorias fijas o no estocásticas 6, ε es un vector tal que (X,ε) es una secuencia de vectores
aleatorios independientes 7, y β es un vector de K parámetros desconocidos. Para efectos de notación
matricial, el primer subíndice de X indica el número de la observación y el segundo identifica la variable.
El método de mínimos cuadrados (MCO) para encontrar los coeficientes β que proporcionan el
mejor ajuste consiste en minimizar la suma cuadrada de errores, S. Esta suma cuadrada de errores
resulta más sencilla de expresar en términos matriciales como sigue:
Expresemos el vector de errores como la siguiente diferencia:
ε = ( y − Xβ )
luego, la suma cuadrada de errores es:
6
Más adelante veremos que este supuesto de X fijas puede ser levantado.
El caso en que X contiene algún tipo de información acerca del valor esperado en el error, se produce sesgo e
inconsistencia. Otros supuestos relevantes se relacionan con la necesidad de que las varianzas de los errores estén
uniformemente acotadas y que la matriz promedio de covarianza de los regresores sea no singular.
7
31
S = ( y − Xβ )' ( y − Xβ )
= ( y '− β ' X ' )( y − Xβ )
= y ' y − β ' X ' y − y ' Xβ + β ' X ' Xβ
= y ' y − 2 β ' X ' y + β ' X ' Xβ
El objetivo de MCO es encontrar el valor del vector de coeficientes que minimice S, para lo cual
debe derivarse S respecto a b (el estimador de MCO), es decir:
∂S
= −2 X ' y + 2 X ' Xβ = 0
∂β
⇒ X ' Xb = X ' y
⇒ b = ( X ' X ) −1 X ' y
Luego, el estimador de MCO de β es b y viene dado por:
b = ( X ' X ) −1 X ' y
que es un vector aleatorio puesto que, como se ve, es una función lineal de Y. Nótese que b tiene
dimensión Kx1, de modo que para el caso de un modelo lineal simple, K=2, y el elemento (1,1) de b será
el intercepto, y el elemento (2,1) será la pendiente.
Así hemos mostrado que el estimador de MCO de los coeficientes de regresión (b) viene dado por
el producto de la matriz X y del vector Y. Luego, el procedimiento para calcular b es meramente
matemático.
32
2.3. PRUEBA DE HIPÓTESIS
2.3.2. LA DISTRIBUCIÓN DE b Y SUS PROPIEDADES
Hemos señalado que b (el estimador de β) es también una variable aleatoria, de modo que si se
conoce su distribución seremos capaces de hacer inferencias de éstos, tales como intervalos de confianza
y pruebas de hipótesis. Veamos entonces la distribución del estimador b, en cuanto a su valor esperado y
su varianza.
Puede mostrarse que el valor esperado y la varianza de b vienen dadas respectivamente por 8:
E (b) = β + ( X ' X ) −1 X ' E (ε )
V (b) = E [(b − β )(b − β )'] = ( X ' X ) −1 X ' E (εε ' ) X ( X ' X ) −1
donde E(εε’) corresponde a la matriz de varianzas y covarianzas de los errores.
La matriz de varianzas y covarianzas de los coeficientes es cuadrada y simétrica de dimensiones
KxK, es decir:
Cov (b1 , b2 )
⎡ Var (b1 )
⎢Cov (b , b )
Var (b2 )
2
1
E [(b − β )(b − β )'] = ⎢
⎢
⎢
⎣
⎤
⎥
⎥
⎥
⎥
Var (bk )⎦
donde los elementos de la diagonal son las varianzas de cada coeficiente, los que se encuentran fuera de
la diagonal son las covarianzas.
Así, b tiene la siguiente distribución general 9:
[
b ≈ β + ( X ' X ) −1 X ' E (ε ) , ( X ' X ) −1 X ' E (εε ' ) X ( X ' X ) −1
]
Nótese también que el comportamiento de los errores (ε), es decir la matriz de varianzas y
covarianzas de los errores, E(εε’), tiene gran importancia en la esperanza y la varianza de b. En efecto,
para que b sea un estimador insesgado de β (es decir E(b)=β) se requiere que X’E(ε)=0, es decir que los
errores sean independientes de las variables explicativas X, lo que se lograría siempre en el caso que X
fuera fija, y también en algunos casos cuando X es estocástica (véase regresores estocásticos).
Respecto a la varianza de b, cuando E(εε’)=σ2I, lo que significa que los errores están distribuidos
independiente y constantemente, V(b) es mínima, es decir, el estimador b es eficiente (de varianza
mínima), y en este caso la varianza de b viene dada por:
V (b) = ( X ' X ) −1 X 'σ 2 X ( X ' X ) −1 = σ 2 ( X ' X ) −1
Es decir:
8
Véase ecuación 5.6.8.a) en página 201 de Judge et al. (1988).
Note que no especificamos aún, pues no lo requerimos, la distribución específica de b, es decir si por ejemplo se trata
de una distribución Normal o no.
9
33
[
b ≈ β , σ 2 ( X ' X ) −1
]
Donde la matriz X' tiene dimensión KxT, X tiene dimensión TxK, (X'X)-1 es una matriz inversa simétrica de
dimensión KxK y σ2 es un escalar.
Teorema de Gauss-Markov
Así, bajo condiciones ideales (errores bien comportados) el estimador lineal de MCO es insesgado
y eficiente. Esto es resumido por el Teorema de Gauss-Markov, en cuanto a que puede mostrarse10 que b
es MELI, es decir, es el mejor estimador insesgado de entre la clase de los estimadores lineales de β.
Para entender la importancia del Teorema de Gauss-Markov debemos notar primero que b es un
estimador lineal, en vista que puede escribirse como una combinación lineal de la variable dependiente Y,
y que no se requiere normalidad de los errores (más adelante tomaremos este supuesto, y como
resultado, la variable Y transmite sus propiedades aleatorias (estocásticas) al estimador b). Nótese que
este teorema no dice que b son los mehjores de todos los posibles estimadores. Esto pues existen varias
clases de estimadores lineales que podrían usarse para estimar los parámetros de intercepto y pendiente
del modelo, y una porción de estos incluso será insesgados. Sin embargo, b tiene la propiedad adicional
que tiene una varianza menor que todos los estimadores lineales que sean insesgados, lo que lo convierte
en MELI, es decir el mejor estimador lineal insesgado de entre todas las clases de estimadores lineales
(estimador de varianza mínima).
Para que el teorema sea verdadero deben cumplirse los primeros 5 supuestos que siguen:
1.
2.
3.
4.
5.
6.
Modelo de Regresión Lineal
Error tiene media cero (el método de MCO asegura este resultado)
El término de error tiene varianza constante para todas las observaciones (homocedasticidad)
Los términos de error son estadísticamente independientes entre sí (no autocorrelación serial)
Las X son variables no estocásticas, o alternativamente las X no están correlacionadas con el
término de error (ambas son ortogonales): Cov(X,e) = E(Xe) = 0
(Optional) Error tiene una distribución normal: E~N(0, σ2)
Errores bien comportados en un modelo de regresión lineal se refiere a los supuestos 3), 4) y 5).
A continuación explicams esto con mayor detalle.
2.3.3. LA MATRIZ DE COVARIANZAS DE LOS ERRORES
La matriz de varianzas y covarianzas de los errores tiene la siguiente forma:
⎡ ε 1ε 1 ε 1ε 2
⎢ε ε
E [εε '] = E ⎢ 2 1
⎢
⎢
...
⎣
Cov(ε 1ε 2 )
⎤
⎤ ⎡ V (ε 1 )
⎥
⎥ ⎢Cov(ε ε )
2 1
⎥
⎥=⎢
...
... ⎥
... ... ⎥ ⎢
⎥
⎥ ⎢
εTεT ⎦ ⎣
V (ε T )⎦
...
donde los elementos de la diagonal representan la varianza de cada error, y los elementos fuera de la
diagonal son las covarianzas respectivas entre errores. Puesto que la covarianza entre el error 4 y el error
6 es la misma que la covarianza entre el error 6 y el error 4, entonces ésta matriz es simétrica y cuadrada
de dimensión TxT.
Esta matriz no es posible de observar ni estimar completamente con los datos, por la sencilla
razón de que existen solamente T observaciones o grados de libertad inicialmente, y E(εε’) contiene
10
Véase sección 5.7 en Judge et al.
34
T(T+1)/2 incógnitas 11. Por este motivo deben hacerse supuestos simples acerca de su comportamiento, y
el más sencillo es asumir que los errores están idealmente bien comportados, lo que quiere decir que
éstos errores se distribuyen independiente e idénticamente.
Veamos esto con algún detalle.
Cuando los errores se distribuyen idénticamente significa que tienen igual varianza (sabemos que
tienen media cero). En econometría a esta propiedad se le llama homocedasticidad, o inexistencia de
heterocedasticidad. Esto significa que la matriz de varianzas y covarianzas de los errores debe tener a lo
largo de toda su diagonal el mismo elemento, es decir una constante, reflejando que la varianza del error
de cada observación es el mismo para las T observaciones.
Cuando los errores se distribuyen independientemente quiere decir que éstos no están
correlacionados entre sí. En econometría a esta propiedad se le llama no-autocorrelación serial, o errores
no correlacionados serialmente. En este caso la matriz de varianzas y covarianzas de los errores debe
presentar que todos los elementos fuera de la diagonal (es decir las covarianzas) sean cero.
Así, en el caso de errores bien comportados, esto se traduce en homocedasticidad y no
autocorrelación, lo que significa que la matriz de varianzas y covarianzas de los errores debe ser igual a:
⎡σ 2
⎢
0
E [εε '] = ⎢
⎢ ...
⎢
⎣⎢ 0
0
σ
2
0⎤
⎡ 1 0 ... 0⎤
⎥
⎢
⎥
⎥ = σ 2 ⎢0 1
⎥ =σ 2I
⎥
⎢...
...
... ⎥
⎢
⎥
2⎥
σ ⎦⎥
1⎦
⎣0
...
es decir σ2 veces la matriz identidad. De este modo, en adelante, cuando nos referimos a errores bien
comportados queremos decir errores con varianzas del tipo escalar-identidad o σ2I, donde I es la matriz
identidad. Por el contrario, cuando los errores están mal comportados se dice que su matriz de varianzas
y covarianzas tiene la forma de σ2ψ, donde ψ es una matriz cuadrada simétrica TxT pero distinta de la
matriz identidad.
En cualquier caso, si bien ψ no puede estimarse a partir de los datos, sí puede obtenerse un
estimador de σ2, la varianza de los errores (σ es conocida el error estándar de la estimación) que
denominamos s2, el que puede mostrarse, viene dado por:
t =T
s2 =
∑ε
2
t
SCErr t =1
ε 'ε
=
=
T −K T −K T −K
Puede apreciarse que s2 proviene de la fórmula tradicional de varianza de una serie, es decir la
suma cuadrada de las desviaciones de cada observación respecto a la media (la media de los errores es
cero) dividido por el número de grados de libertad, en este caso T menos el número de parámetros
estimados en la regresión previa a la estimación de s2.
La forma de efectuar pruebas de hipótesis sobre coeficientes se mostrará en el capítulo siguiente.
Por ahora solo hemos mostrado dos resultados importantes para hacer esto: la distribución de b y la
varianza de los errores.
11
Por ejemplo, se tienen 3 observaciones, E(εε’) tiene por incógnitas los 3 elementos de la diagonal de ésta matriz más
los 3 elementos debajo de la diagonal (pues es una matriz simétrica, los elementos de arriba de la diagonal son
iguales), es decir un total de 3+3 = 3*4/2 = 6 incógnitas.
35
2.3.4. UNA MEDIDA DEL ÉXITO DE AJUSTE
Una vez que hemos conocido la forma de estimar los coeficientes de regresión (estimador b) y sus
propiedades más importantes, debemos proceder a establecer alguna medida que determine el grado de
ajuste de la línea de regresión a los datos. La medida usual para evaluar el grado de éxito de ajuste de los
estimadores (del método de MCO en este caso) es el coeficiente R- cuadrado. Un buen modelo de
regresión es aquel que ayuda a explicar una proporción grande de la varianza de Y. Recordemos que
existen desviaciones positivas y negativas, por lo que el tamaño de los errores constituye una útil medida
para determinar el ajuste entre la línea de regresión y los datos.
La derivación del R-cuadrado se obtiene descomponiendo la suma cuadrada total en suma de
cuadrados explicada y suma de cuadrados no explicada por la regresión (SCErrores):
SCT = SCExpl + SCErr
∑(y
t
− y ) 2 = ∑ ( yˆ t − y ) 2 + ∑ ( y t − yˆ t ) 2
donde
y i son los valores observados de Y, y es el valor promedio de los y observados, lo que sirve para
reescalar apropiadamente los cálculos, y por último ŷ i corresponde a los valores de Y predichos por la
regresión ajustada. Un mejor ajuste implicará que la SCExplicada es mayor que la SCErrores. Así,
dividiendo ambos lados de la igualdad por el término de la izquierda se tiene que:
∑ ( yˆ
1=
∑(y
R
2
∑ ( yˆ
=
∑(y
t
− y) 2
t
− y)
2
t
− y) 2
t
− y) 2
∑(y
+
∑(y
, o escrito de otro modo,
− yˆ t ) 2
t
t
− y) 2
R2 =
suma cuadrada explicada
suma cuadrada total
Este coeficiente tiene un rango de valores posible entre 0 y 1. Mientras más cercano a cero
indicará un mal ajuste y mientras más cercano a 1 indicará un mejor ajuste. Esto es fácil de observar a
través del siguiente ejemplo: si todas las observaciones de una muestra cayeran sobre la línea de
regresión, el ajuste sería perfecto (R-cuadrado = 1).
ˆ
y = b1 + b2x
et=yt-yt
yt
ŷt
•
yt − y
ˆt − y
y
y
xt
36
Lamentablemente el R-cuadrado está afectado por el número de parámetros usados en el modelo,
de modo que en general, siempre se obtendrá un R-cuadrado más alto cuanto mayor sea el número de
variables explicativas, lo que dificulta las comparaciones. De otro modo, se esperan bajos R-cuadrados
para modelos relativamente simples. Sin embargo la regla de la parsimonia indica que los modelos con
demasiados parámetros hacen perder grados de libertad y confianza en las estimaciónes, aspecto que el
R-cuadrado no considera.
Debido a este problema fue desarrollado el coeficiente R-cuadrado ajustado de la siguiente forma:
⎛ T −1 ⎞
2
R 2 =1− ⎜
⎟(1 − R )
T
−
K
⎝
⎠
el cual presenta una especie de corrección / castigo para los modelos con muchos parámetros, puesto que
al aumentar K caerá el valor de esta medida. Como desventaja, el R-cuadrado ajustado puede ser
negativo.
37
2.4. CASO DE ESTUDIO
El siguiente ejemplo es obtenido de Pindyck y Rubinfeld (Econometrics Models and Economic
Forecast), el que trabaja con la siguiente información (más de 400 observaciones a partir de enero de
1959). El archivo de datos en formato Excel de este (“Pindyck.xls”) y otros ejemplos se encuentra en el
SID de la UCN, y también con acceso libre en www.finanzascl.cl/econometria/data_excel.htm.
Rate
IP
M1
M2
PPI
:
:
:
:
:
Tasa de interés de los T-Bill de los EEUU de 3 meses.
Indice de producción industrial del FED, ajustado estacionalmente (1987=100).
Cantidad de dinero M1, en billones de US dollars, ajustados estacionalmente.
Cantidad de dinero M2, en billones de US dollars, ajustados estacionalmente.
Indice de precios al productor, todas las mercancías (1982=100), no ajustado estacionalmente.
Se tienen dos modelos de regresión como sigue:
Rt = α + β1IPt + β2(M1t − M1t −3) + β3PSUMt + ut
donde
PSUM
=
Δ PPI t
Δ PPI t − 1
Δ PPI t − 2
+
+
PPI t
PPI t − 1
PPI t − 2
Rt = α + β1IPt + β 2GRM2t + β3GRPPIt −1 + ut
donde
GRM 2 t =
(1)
(2)
( M 2 t − M 2 t −1 )
( PPI t − PPI t −1 )
, GRPPIt = 100
M 2 t −1
PPI t −1
2.4.1. Describiendo los Datos
Sabemos que el archivo cuenta con 446 observaciones en la forma de una serie de tiempo. Luego
es importante que al momento de estimar los modelos o al obtener estadísticas parciales de datos lo
podamos hacer refiriéndonos a fechas en lugar de la posición de cada observación. Para esto, es
conveniente que la primera columna contenga las fechas en el formato deseado, por ejemplo, año, mes.
Esto además permitirá hacer gráficos de series de tiempo con los datos.
38
2.4.2. Calculando Estadísticas
Luego de ingresados los datos a Excel, es recomendable chequear si el ingreso de los mismos se
ha hecho de manera adecuada. La forma de efectuar este chequeo es consultando algunos estadísticos
básicos para verificar por ejemplo el número de observaciones (N) y los valores máximos y mínimos.
Max
Min
Media
Desv St
Num Obs
16,2950
2,2680
6,0590
2,7752
446,0000
1151,4000
138,9000
448,0933
312,0299
446,0000
3690,2000
286,7000
1579,5439
1144,2819
446,0000
123,7000
36,0000
77,4686
24,1488
446,0000
126,1000
31,3000
71,5206
34,8445
446,0000
También es posible obtener importantes estadísticos que nos indican como se distribuyen los datos, para
cada una de las variables a considerar. En el siguiente cuadro podemos apreciar la información obtenida
de la variable RATE.
Valores
Observaciones
446
Media Muestral
6,0590
Desv estándar
2,7752
Varianza
Error est. de la media
7,70182173
0,13141027
Estadístico t
46,1073203 Hipótesis
Sesgo
1,18620737
10,19269
2
Curtosis
Jarque Bera
1,58711239
151,403572
6,788193
151,4035
2
1,3278E-33
Significancia a 1 cola
2.4.3. Transformación de datos y creación de nuevas series
En la realización de cualquier trabajo se requerirá algunas transformaciones de datos, o bien la
creación de nuevas series. En el caso del ejemplo deben realizarse varias transformacionesque se
muestran a continuación en un segmento de los datos:
M1t-M1t-3
0,8000
1,3000
1,5000
2,0000
1,2000
-0,2000
-1,2000
-1,5000
-1,0000
-0,5000
-0,5000
dPPIt/PPIt
0,0000
0,0000
0,0031
0,0000
-0,0032
0,0000
-0,0032
0,0032
-0,0032
-0,0032
0,0000
0,0032
0,0000
dPPIt-1/PPIt-1 dPPIt-2/PPIt-2
0,0000
0,0000
0,0031
0,0000
-0,0032
0,0000
-0,0032
0,0032
-0,0032
-0,0032
0,0000
0,0032
0,0000
0,0000
0,0031
0,0000
-0,0032
0,0000
-0,0032
0,0032
-0,0032
-0,0032
0,0000
PSUM
0,0031
0,0031
0,0000
-0,0032
-0,0063
0,0000
-0,0032
-0,0032
-0,0063
0,0000
0,0032
GRM2t
GRPPIt
0,00348797
0
0,00521376
0
0,00311201 0,31545259
0,0072389
0
0,00650237 -0,31446062
0,00374025
0
0,00406498 -0,31545861
0,00101221
0,3164569
-0,00067412 -0,31545861
0,00202363 -0,3164569
0,00235605
0
0,00134322 0,31746032
0,00067069
0
39
2.4.5. Gráficos de Series de Tiempo
En el menú de Excel, encontramos el asistente de gráficos, la cual nos permite acceder a una gran
variedad de gráficos. Dentro de los tipos de gráficos que más utilizaremos se encuentran los gráficos de
Lineas, Scatter y Secuencias. A continuación se presenta un ejemplo del trazado de gráfico de secuencia
de las series “rate”, “ip” y “ppi”.
Se indica que en el eje de las X's se rotule la fecha correspondiente para cada observación. La salida de
Excel nos mostrará el siguiente gráfico:
2.4.6. Gráficos X-Y (Scatter)
También es posible graficar una serie contra otra a partir de la opción SCATTER ( dispersión). Para
esto se debe hacer clic en esta opción y se despliega el siguiente cuadro:
Hemos definido un Scatterplot Simple. Luego se deben definir las series de acuerdo a como
queramos que se ubiquen en los ejes. Para este ejemplo definiremos en el eje de las X a la serie “grppi”y
en el eje de las Y a la serie “rate”, y obtenemos la siguiente gráfica:
40
RATE VS GRPPI
18
16
14
12
RATE
10
8
6
4
2
0
-0,03
-0,02
-0,01
0
0,01
0,02
0,03
0,04
0,05
0,06
0,07
GRPPI
Al seleccionar la opción agregar línea de tendencia, logramos obtener la regresión lineal simple
correspondiente para estas dos variables, la cual se puede apreciar en el grafico subsiguiente.
RATE VS GRPPI
18
16
14
12
y = 97,252x + 5,7621
2
R = 0,0569
RATE
10
8
6
4
2
0
-0,03
-0,02
-0,01
0
0,01
0,02
0,03
0,04
0,05
0,06
0,07
GRPPI
41
2.4.7. CASO DE ESTUDIO: Corriendo la Regresión 1
Retomando el caso de estudio anterior, debemos hacer un número de transformaciones previas
para correr las dos ecuaciones de regresión:
Rt = α + β1IPt + β2 (M1t − M1t−3 ) + β3 PSUMt + ut
donde
PSUM
=
(1)
Δ PPI t
Δ PPI t − 1
Δ PPI t − 2
+
+
PPI t
PPI t − 1
PPI t − 2
El objetivo es obtener la regresión de (1) desde febrero de 1960 hasta diciembre de 1980 (1960:2
1980:12). Luego, escogiendo a la opción Análisis de datos, y luego la opción regresión, se deben ingresar
los datos correspondientes. Así obtendremos la siguiente tabla adjunta:
Resumen
Estadísticas de la regresión
Coeficiente de correlación múltiple
0,825962178
Coeficiente de determinación R^2
0,68221352
R^2 ajustado
0,678353765
Error típico
1,395907712
Observaciones
251
ANÁLISIS DE VARIANZA
Regresión
Residuos
Total
Intercepción
IP
M1t-M1t-3
PSUM
Grados de libertad Suma de cuadrados Promedio de los cuadrados
3
1033,22587
344,4086233
247
481,2939099
1,94855834
250
1514,51978
Coeficientes
-2,490797219
0,125778816
-0,082500634
30,23544113
Error típico
0,488327556
0,009459776
0,039357017
7,170339111
F
Valor crítico de F
176,7504807
3,39702E-61
Estadístico t
Probabilidad
-5,100668986 6,74644E-07
13,2961728 8,66531E-31
-2,096211583 0,037081155
4,216737962 3,48055E-05
Hemos solicitado estimar una regresión donde la variable dependiente “rate” se explica por las
variables “ip”, “M1diff” y “ppisum”, y se incluye automáticamente el intercepto de la recta de regresión.
El primer cuadro muestra los coeficientes de determinación R2 y R2 ajustado, además del coeficiente de
correlación múltiple y el error estándar de la regresión.
En segundo lugar, encontramos la información contenida en la tabla “ANOVA”, donde se muestra
la descomposición de la suma cuadrada de errores, y los grados de libertad correspondientes. Además,
esta tabla contiene el estadístico F, y el valor P correspondiente a la 'prueba F de significancia global' de
los parámetros de regresión.
En el cuadro “coeficientes”, se entrega los valores de los estimadores de los parámetros de
regresión. La columna Error Típico que entrega el error estándar de cada coeficiente. Finalmente, las
últimas 2 columnas entregan el estadístico t y el valor P (a 2 colas) de la 'prueba de significancia
individual' de los parámetros.
El análisis de las salidas anteriores en cuanto a pruebas de hipótesis se muestra en el capítulo
siguiente.
42
2.4.8. CASO DE ESTUDIO: Corriendo la Regresión 2
La segunda regresión es:
Rt = α + β1IPt + β 2GRM2t + β3GRPPIt −1 + ut
donde
GRM 2 t =
(2)
( PPI t − PPI t −1 )
( M 2 t − M 2 t −1 )
, GRPPIt = 100
PPI t −1
M 2 t −1
Haciendo las transformaciones correspondientes:
Fecha
RATE
IP
GRM2t
GRPPIt-1
1959,01 2,83699989
36
1959,02 2,71199989 36,7000008 0,00348797
1959,03
2,852 37,2000008 0,00521376
0
1959,04 2,96000004
38 0,00311201
0
1959,05 2,85100007 38,5999985
0,0072389 0,00315453
1959,06 3,24699998 38,5999985 0,00650237
0
1959,07 3,24300003 37,7000008 0,00374025 -0,00314461
1959,08 3,35800004 36,4000015 0,00406498
0
1959,09 3,99799991 36,4000015 0,00101221 -0,00315459
1959,1
4,1170001 36,0999985 -0,00067412 0,00316457
1959,11 4,20900011 36,2999992 0,00202363 -0,00315459
1959,12 4,57200003 38,5999985 0,00235605 -0,00316457
1960,01 4,43599987
39,6 0,00134322
0
1960,02
3,954
39,2 0,00067069
0,0031746
1960,03 3,43899989
38,9 0,00335121
0
1960,04 3,24399996
38,6 0,00200401 0,00632911
1960,05 3,39199996
38,5
0,003
0
1960,06 2,64100003
38,1 0,00465271 -0,00314465
1960,07 2,39599991
37,9 0,00595435
0
1960,08 2,28600001
37,9
0,0092075
0
1960,09 2,48900008
37,5 0,00488759 -0,00315457
y corriendo el modelo para el periodo enero 1960 a agosto 1995, se tiene que:
Resumen
Estadísticas de la regresión
Coeficiente de
0,46514599
Coeficiente de
0,21636079
R^2 ajustado
0,21081617
Error típico
2,48102561
Observaciones
428
VARIANZA
Promedio de
los
Suma de
cuadrados
cuadrados
3 720,594185 240,198062
424 2609,92694 6,15548806
427 3330,52112
Grados de
libertad
Regresión
Residuos
Total
Intercepción
Variable X 1
Variable X 2
Variable X 3
F
39,0217736
Valor crítico
de F
2,7558E-22
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%
1,21407799 0,55169206
2,2006443 0,02829968 0,12968608
0,04835294 0,00550301 8,78663601 3,8642E-17 0,03753637
140,326144 36,0385012 3,89378414 0,00011462 69,4897811
104,588446 17,4421792 5,99629467
4,325E-09 70,3045416
Superior
95%
2,2984699
0,05916952
211,162508
138,872351
Inferior
95,0%
0,12968608
0,03753637
69,4897811
70,3045416
Superior
95,0%
2,2984699
0,05916952
211,162508
138,872351
43
44
2.5. INTERPRETACION DE LOS COEFICIENTES DE
REGRESIÓN
2.5.1. INTRODUCCIÓN
Cuando se plantea un modelo de regresión lineal, como por ejemplo:
Yt = β 0 + β1 X 1,t + β 2 X 2,t + et
los coeficientes de pendientes de ésta regresión miden el efecto parcial de X1 sobre Y y de X2 sobre Y, es
decir las derivadas parciales de Y respecto a X1 y X2 respectivamente.
Así, la interpretación de los coeficientes es a veces confusa, puesto que se debe tener muy claro
como son medidas las variables. Veámoslo a través de un ejemplo:
Ejemplo: Se dispone de la información de la producción mensual (en kilogramos) de 10
empresas durante el mes pasado, y se cree que la producción depende del capital utilizado
(monto de deuda de la empresa, en millones de pesos) y del trabajo usado (en número de
personas contratadas), según la siguiente tabla de datos:
Empresa
1
2
3
4
5
6
7
8
9
10
Capital
8
9
4
2
6
6
3
6
8
4
Coeficientes
Intercepción 56,20094158
Capital
4,873711127
Trabajo
0,120945774
Trabajo
23
14
38
97
11
43
93
49
36
43
Producción
106
81
72
57
66
98
82
99
110
118
Error típico Estadístico t
43,70386574 1,28594898
4,974703122 0,97969889
0,392826007 0,307886372
Aquí la interpretación de los coeficientes es:
- Constante: si no se utiliza capital ni trabajo, la producción será de 56.20 Kg. Mensuales.
- Capital: por cada millón de pesos adicional de deuda, se espera producir 4.87 Kg. Mensuales.
- Trabajo: por cada persona contratada adicionalmente, se espera que la producción aumente en 0.12 Kg.
Mensuales.
Existen otras especificaciones similares a la lineal anterior, pero que llevan a una interpretación
distinta de los coeficientes, tal como veremos a continuación.
45
2.5.2. FORMA DOBLE LOGARÍTMICA
Corresponde a una especificación (lineal) en que tanto la variable dependiente como las variables
independientes están expresadas como logaritmos naturales.
Ejemplo:
LN (Yt ) = β 0 + β1 LN ( X 1 ) + β 2 LN ( X t ) + et
;* es una especificación doble log
La propiedad más importante de esta especificación es que los coeficientes pueden interpretarse
como elasticidades. En efecto, la interpretación de los coeficientes β1 es:
β1 =
d ln Y
d ln X 1
puesto que, por ejemplo, la elasticidad precio de la demanda puede escribirse como:
dQ
Elasticidad =
Q
dP
=
P
d ln Q
d ln P
donde Q es la función de demanda Q(P), y P el precio.
Esta especificación es entonces útil para calcular elasticidades precio, elasticidades ingreso,
elasticidades cruzadas, etcétera, de acuerdo a las variables involucradas en el modelo.
2.5.3 MODELO LOGARÍTMICO LINEAL (DE CRECIMIENTO CONSTANTE)
Cuando se tiene una especificación Log-Lineal, la interpretación del coeficiente relevante es la de
la tasa de crecimiento constante de la variable asociada.
Ejemplo:
ln Y = β 0 + β1 X
;* un modelo lineal simple en forma log-lin.
La interpretación del coeficiente β en este caso es:
dY
d ln Y
β1 =
= Y
dX
dX
El numerador corresponde al cambio porcentual de Y (dado por dY/Y), mientras que el
denominador es el cambio (muy pequeño) en X. Si por simplicidad X es una medida de tiempo o
tendencia, entonces la interpretación de β es el cambio porcentual en Y ante un pequeño periodo de
tiempo. Note que si β<0, se tratará de la tasa de disminución en Y.
46
2.5.4. OTRA VISIÓN DE LOS COEFICIENTES DE PENDIENTE
Puede mostrarse que cada coeficiente en una regresión lineal puede calcularse como:
βi =
Cov( X i , Y ) ρ ( X i , Y ) ⋅ σ ( X i ) ⋅ σ (Y ) ρ ( X i , Y ) ⋅ σ (Y )
=
=
Var ( X i )
Var ( X i )
σ (Xi )
es decir la covarianza entre Xi e Y dividido por la varianza de la variable Xi, o alternativamente, el
coeficiente de correlación entre Xi e Y, multiplicado por la desviación estándar de Y y dividido por la
desviación estándar de Xi.
La interpretación de este resultado es que la covarianza (o el coeficiente de correlación)
justamente intentan obtener el efecto neto entre Xi e Y, eliminando el efecto de otras variables sobre Y,
puesto que esta efecto será obtenido en el beta correspondiente a esa variable. El otro aspecto
importante es que si la correlación entre Xi e Y fuera cercana a 1.0, y las desviaciones estándar de Xi y de
Y son similares, entonces esperamos una pendiente cercana a 1.0 (βi=1.0). Por último, puede notarse que
el valor de este coeficiente βi estará afectado por las unidades de medida de Xi e Y, lo que se reflejará en
sus respectivas desviaciones estándar.
Ahora mostraremos a través de un ejemplo que los coeficientes de una regresión múltiple pueden
escribirse como la covarianza dividida por la varianza, en el caso que las variables X1 y X2 no estén
correlacionadas, es decir:
Y = β0 +
Cov( X 1 , Y )
Cov( X 2 , Y )
X1 +
X2 +ε
Var ( X 1 )
Var ( X 2 )
Ejemplo: Supongamos que tenemos 3 series de 10 observaciones.
y
x1
30
27
29
39
35
38
37
40
48
55
x2
5,912195122
6,365853659
8,365853659
11,91219512
12,8195122
8,087804878
11,72682927
16,27317073
8,995121951
9,541463415
8
9
9
8
10
15
12
11
17
16
Verificamos que para este ejemplo las correlaciones y covarianzas entre X1 y X2 son cero.
y
y
x1
x2
66,96
20,9
7,38146341
x1
10,25
2,51266E-13
=COEF.DE.CORREL(B2:B11;C2:C11)
x2
9,1404878
2,5959E-14
47
Calculamos los coeficientes de pendientes (Cov/var) por separado como sigue:
= 20.9/10.2500000 = 2.03902 para el primer coeficiente de pendiente
= 7.3814634/9.1404878 = 0.80756 para el segundo coeficiente de pendiente
Y verificamos a través de una regresión múltiple el valor de los coeficientes de pendientes estimados
anteriormente.
Coeficientes
6,275651148
2,03902439
0,807556836
Intercepción
x1
x2
Error típico
8,077266366
0,506177022
0,536018368
Estadístico t
0,776952358
4,028283192
1,506584259
Note que esto es posible debido a que en las covarianzas anteriores no hay 'contaminación' de
información de X1 en X2 y viceversa.
Otro aspecto importante referido a la interpretación de los coeficientes de pendientes, y
relacionado con lo anterior, es que éstos corresponden a la relación entre cada variable Xi con Y, una vez
que se ha eliminado el efecto de las demás series X sobre Xi. Veamos esto a través de un ejemplo:
Ejemplo: Se tiene información de 30 empresas respecto a una función de producción COBB-DOUGLAS
simple, en que el producto (Q) es explicado por el capital (K) y el trabajo (L):
... Ver datos en Tabla 2 del Anexo al final del libro.
Intercepción
Ln(L)
Ln(K)
Coeficientes Error típico Estadístico t
0,424867718 0,137798197 3,083260349
0,735825294 0,065790541 11,18436308
0,949011153 0,062901265 15,08731428
El coeficiente de Ln(L) (Beta1) es 0.7358252943. Verifiquemos que éste coeficiente puede
obtenerse con regresiones separadas como sigue:
a) regresionando Ln(L) versus Ln(K) y guardando los residuos en una nueva serie llamada Error, que
corresponden a la información que queda en Ln(L) después de eliminar lo explicado por Ln(K). De otro
modo, Error es la parte de Ln(L) que está libre del efecto de Ln(K), es decir el contenido de información
neto de Ln(L).
Empresa
1
2
3
4
5
6
7
8
Trabajo (L) Capital (K)
Producto (Q)
0,228
0,802
0,256918
0,258
0,249
0,183599
0,821
0,771
1,212883
0,767
0,511
0,522568
0,495
0,758
0,847894
0,487
0,425
0,763379
0,678
0,452
0,623130
0,748
0,817
1,031485
Ln(Q)
-1,35899831
-1,69500125
0,19300017
-0,64900016
-0,16499965
-0,27000065
-0,47300011
0,03099951
Ln(L)
-1,47840965
-1,35479569
-0,19723217
-0,26526848
-0,70319752
-0,71949116
-0,38860799
-0,2903523
Ln(K)
Error
-0,22064667 -0,25733826
-1,39030238 -0,32590464
-0,26006691 1,01736228
-0,67138569 0,88174421
-0,27707189 0,50860292
-0,85566611 0,39724333
-0,7940731 0,73824654
-0,20211618 0,93376374
b) Regresionando Ln(Q) versus los errores:
Intercepción
Error
Coeficientes Error típico Estadístico t
-1,53267649 0,21299129 -7,19595845
0,73582529 0,17827666 4,12743473
48
Obtenemos el mismo coeficiente Beta1=0.735825294, con lo cual verificamos que basta solo 1
regresión múltiple para esto, y no es necesario efectuar varias estimaciones para eliminar el ruido, o
contenido de Ln(K) en Ln(L).
49
2.6 RESUMEN: UNA CRÍTICA AL MODELO
Para terminar este capítulo recordemos que en la implementación del método de los MCO se ha
supuesto:
a) Que se trata de un modelo lineal en los parámetros: Este supuesto puede no ser aplicable en
muchos modelos, sin embargo en muchos otros es válido, por lo tanto es una misión del analista
determinar si el supuesto es aplicable o no. Cuando no es posible trabajar bajo este supuesto (cuando
tampoco es posible linealizar el modelo), entonces seguramente se requerirán métodos de regresión no
lineales, los que veremos más adelante.
b) Que las X son fijas o no estocásticas: El cumplimiento de este supuesto es de importancia extrema
en el análisis de regresión, por cuanto de no cumplirse, y exista relación entre las series X y los errores,
se tendrán estimadores sesgados de los verdaderos coeficientes, lo que es extremadamente grave. Sin
embargo en muchos casos es posible que los X no sean fijos (es decir sean estocásticos) y aún estén no
correlacionados con los errores. Este aspecto lo veremos más adelante en el tópico regresores
estocásticos (variables instrumentales).
c) Que X contiene el conjunto correcto de variables explicatorias: En efecto, se supone que el
modelo está bien especificado, es decir no faltan ni sobran variables explicativas. En general es más grave
omitir variables que incluir variables en exceso, puesto que si la variable omitida está correlacionada con
la variable presente en el modelo, la variable omitida estará reflejada en el error (ε), de modo que existirá
correlación entre el error y la variable presente, implicando sesgo. Esto no ocurrirá en el caso de
sobreespecificación, aunque los coeficientes serán en general ineficientes respecto de aquellos estimados
bajo una correcta especificación.
d) Que ε es bien comportado: En efecto, suponemos que éstos están libres de autocorrelación y
heterocedasticidad, lo que asegura estimadores MELI, o MEI en el caso del modelo bajo el supuesto de
normalidad. Este supuesto es levantado más adelante.
e) Que Y es medido sin error: Puesto que en general Y es la variable estocástica del modelo de
regresión (además del error, ε), se espera que éste sea una realización insesgada de un correcto
procedimiento de muestreo, cuestión que debe ser considerada por el analista. No mencionamos
preocupación respecto a las series X, pues se suponen fijas, o controladas por el investigador.
f) Que los parámetros β son fijos (estables): Cuando estimamos un modelo de regresión para un
determinado periodo, implícitamente se asumen que los verdaderos parámetros son constantes para todo
el periodo, es decir, si se subdivide el periodo total en 2 subperiodos y se efectúa nuevamente la
estimación en cada subperiodo, esperamos que los coeficientes de pendientes de ambas regresiónes sean
básicamente los mismos, lo que en la práctica puede no ser verdadero. Las pruebas para la estabilidad de
los parámetros es mostrada en el siguiente capítulo.
50
CAPÍTULO 3
MÍNIMOS CUADRADOS RESTRINGIDOS
(INFERENCIA)
3.1. MCO CON ERRORES NORMALES
Recordemos que en el capítulo anterior señalamos que las condiciones ideales para la
implementación de los estimadores MCO incluyen:
las perturbaciones son esféricas, es decir, errores independientes e idénticamente distribuidos con
media 0 y varianza σ2, de modo que E[εε'] = σ2I, lo que implica homocedasticidad y ausencia de
autocorrelación serial,
los regresores son fijos (las variables X son no estocásticas),
los errores tienen una distribución desconocida.
Cumpliéndose estas condiciones, puede mostrarse por el teorema de Gauss-Markov que el
estimador de MCO, b es MELI (es decir, el mejor estimador insesgado de entre la clase de los
estimadores lineales de β), y que tenía una distribución no precisada (hasta ahora) con una media y
varianza que incluía, entre sus componentes, el comportamiento de los errores (ε).
Para efectos de implementar procedimientos de inferencia estadística acerca de los coeficientes es
necesario conocer la distribución de éstos. El caso más simple es asumir que los errores se comportan de
acuerdo a una distribución normal. En este caso los coeficientes b se distribuirán también normalmente,
puesto que éstos son una combinación lineal de un error distribuido normalmente (puesto que las
variables X están fijas). Es decir:
[
b ≈ Normal β + ( X ' X ) −1 X ' E (ε ) , ( X ' X ) −1 X ' E (εε ' ) X ( X ' X ) −1
]
Si en adición, los errores están bien comportados, los coeficientes b se distribuyen normalmente:
[
b ≈ Normal β , σ 2 ( X ' X ) −1
]
Así, bajo este resultado es posible implementar un número de pruebas de inferencia estadística,
incluyendo pruebas F, y además se justifica la aplicación del método de máxima verosimilitud, aunque en
este caso si bien b es insesgado, s2 no lo es en pequeñas muestras.
Como resultado adicional puede mostrarse 12 que al incorporar el supuesto de errores normales el
estimador b es el óptimo (suficiente), es decir el mejor estimador insesgado (MEI) incluyendo la clase de
los estimadores no lineales, de modo que no existe un mejor estimador posible que el de MCO. Este es un
12
Véase sección 6.1.3e en Judge et al.
51
resultado más poderoso que el obtenido bajo ausencia de normalidad (estimadores MELI). Respecto a s2,
en este caso también es óptimo.
En resumen, puede decirse que existen 2 principales implicancias de asumir errores normales:
- Los estimadores MCO pasan a ser MEI
- Los estimadores MCO tienen ahora una distribución normal, lo que implica que puede hacerse inferencia
estadística de los verdaderos parémetros de regresión.
52
3.2. PRUEBAS SOBRE UN COEFICIENTE
Cuando los errores están bien comportados la prueba de hipótesis para un coeficiente b en un
modelo de regresión lineal involucra la prueba t, es decir:
t=
b−β
σ ( X ' X ) −1
2
≈ t (T − K )
donde Ho: la restricción es verdadera. Nótese que el denominador corresponde a la desviación estándar
(error estándar) del coeficiente sobre el cual se está haciendo la prueba. La hipótesis será rechazada
cuando t calculado sea mayor, en valor absoluto, que el t de tabla.
Por ejemplo, si el t de tabla es t(9) al 0.05 = 2.262. Puesto que para un número de grados de
libertad mayor a 30 el valor t de tabla al 5% es cercano a 2.0 ó 1.96 para T-K muy grande, en muchos
por simplicidad casos se acepta 1.96 como t crítico.
Veamos que para el caso en que Ho: βi=0, esta prueba es reportada automáticamente en Excel.
Ejemplo:
A modo de ilustración, asumamos que se dispone de información mensual de
actividad económica en Chile (IMACEC), de desempleo en miles de personas
desocupadas, y del índice de precios al consumidor (Base: Diciembre 1998=100).
Ver Tabla 1 en el Anexo al final del libro. La salida de la regresión es:
Resumen
Estadísticas de la regresión
Coeficiente de
correlación múltiple
0,61777745
Coeficiente de
determinación R^2
0,38164898
R^2 ajustado
0,24423764
Error típico
47,4030464
Observaciones
12
ANÁLISIS DE
VARIANZA
Promedio de
Suma de
los
cuadrados
cuadrados
2
12481,996
6240,998
9 20223,4393 2247,04881
11 32705,4353
Grados de
libertad
Regresión
Residuos
Total
Intercepción
imacec
ipc
F
2,77741986
Valor crítico
de F
0,11496294
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%
-139,008756 1162,56508 -0,11957073 0,90744975 -2768,91368
-3,11131208
1,722777 -1,80598654 0,10439648 -7,0085044
13,8423467 10,0214799 1,38126772 0,20052202 -8,82781574
Superior
Inferior
95%
95,0%
2490,89617 -2768,91368
0,78588024 -7,0085044
36,5125091 -8,82781574
Superior
95,0%
2490,89617
0,78588024
36,5125091
;* Si se desea probar las siguientes hipótesis:
a) Ho: el intercepto (constante) = 0
La prueba estadística respectiva es una t:
t = Abs((–139,0-0)/1162,565)=-0,11957 < 2.262,
y no se rechaza Ho (no hay evidencia suficiente para rechazar Ho).
El resultado de esta prueba es mostrado en la salida de la regresión de Excel.
La conclusión también puede obtenerse con la significancia reportada, pues esta
es mayor que 0.05 (es 0.907).
53
b) Ho: El coeficiente de IMACEC = 0
t = Abs((–3,111-0)/1,723)=1.8059 < 2.262, no se rechaza Ho.
c) Ho: El coeficiente de IPC = 0
t = Abs((13,84-0)/10,02)=1,38 < 2.262, no se rechaza Ho.
3.3. TRES TESTS EQUIVALENTES
Cuando se hacen pruebas que involucran a 2 o más coeficientes simultáneamente, entonces debe
usarse otro tipo de pruebas. Los 3 tests que veremos son el test de razón de verosimilitud (Likelihood
ratio, LR por Neyman y Pearson en 1928), el test de WALD (W, por A. Wald en 1943) y el test de los
multiplicadores de Lagrange (LM, por C. Rao en 1948).
Para desarrollarlos en forma simple, a continuación supongamos que se desea probar un número
de hipótesis lineales referidas a los coeficientes de un modelo de regresión lineal múltiple. Puede
mostrarse que en este caso los 3 tests entregarán un resultado idéntico, todos en términos de una
distribución del tipo F conocida.
Cuando se trabaja con modelos no lineales, o con sistemas de ecuaciones, solamente pueden
obtenerse resultados asintóticos, de modo que los tres tests generalmente entregan resultados diferentes,
y en estos casos la distribución general es una del tipo Chi-cuadrado. En cualquier caso se cumplirá que:
W ≥ LR ≥ LM
Cuando se trabaja evaluando hipótesis lineales sobre el modelo lineal general, entonces puede
mostrarse que los tres son idénticos, es decir:
W = LR = LM
3.4. TEST DE RAZON DE VEROSIMILITUD (LR)
13
Esta prueba de hipótesis compara el valor de la función de verosimilitud del modelo no restringido
con el valor de la función del modelo restringido, pues Ho puede ser vista como restringiendo el conjunto
de posibles valores de los parámetros, lo que a su vez restringe el valor máximo de la función de
verosimilitud. Al comparar las estimaciónes restringida y sin restringir, y si las dos fueran cercanas, se
apoya Ho, es decir Ho es verdadera, con lo cual λ debe ser cercano a 1, es decir:
λ=
Max L restringido
Max L no restringido
donde “Max L restringido” es la función máxima verosimilitud del modelo restringido, y “Max L no
restringido” es la función de máxima verosimilitud del modelo no restringido.
A efectos de implementación de la prueba estadística, puede mostrarse que:
LR = −2 ln λ ≈ χ 2 ( J )
13
Es decir, Likelihood Ratio Test.
54
donde J es el número de hipótesis o restricciones.
Nótese que para implementar esta prueba se requiere estimar tanto el modelo sin restringir como
el modelo restringido. Esto puede ser difícil de hacer por ejemplo en sistemas ecuaciones, a partir de lo
cual surgen las alternativas del test de Wald y del Multiplicador de Lagrange.
3.4.1. LR BAJO ESPECIFICACION LINEAL-LINEAL
Cuando tanto las restricciones como el modelo de regresión son lineales (lineal-lineal), entonces la
maximización de la función de verosimilitud entrega los mismos estimadores que la minimización de la
suma cuadrada de errores, de modo que puede rescribirse como:
λ=
SCErr Restringidos
SCErr No Restringidos
sin embargo ésta no tiene una distribución exacta conocida, aunque con una modificación leve se puede
llegar a una distribución que se sabe es F:
(SCErr Restr − SCErr no Restr )
F=
SCErr no Restr
m ≈ F(m,T − K)
T −K
donde Rrss es la suma cuadrada de errores restringida
Urss es la suma cuadrada de errores no restringida
m es el número de restricciones
Ejemplo: Si en el ejemplo del IMACEC, desempleo e IPC queremos probar la hipótesis
conjunta que:
Ho : β1 + β 2 = 10,0
Entonces:
a) Modelo no restringido:
y
β0 = 0
;* se trata de 2 restricciones conjuntas
Yt = β 0 + β 1 X 1 + β 2 X t + ε t , correr este modelo y guardar la SCErrores
(no restringido) con los grados de libertad (ver salida de tabla ANOVA)
b) Modelo Restringido: Implica reescribir el modelo asumiendo que la hipótesis se cumple, es decir:
Y = 0 + (10 − β 2 ) X 1 + β 2 X 2
Y = 10 X 1 − β 2 X 1 + β 2 X 2
Y − 10 X 1 = β 2 ( X 2 − X 1 )
Luego, se debe correr este modelo (en este caso el modelo restringido resulta ser uno sin
intercepto) y guardar la SCErrores (restringido) con sus grados de libertad. Con esto se tiene la siguiente
información;
55
Estadísticas de la regresión
Coeficiente de correlación
múltiple
0,99977636
Coeficiente de
determinación R^2
0,99955276
R^2 ajustado
0,90864367
Error típico
43,028741
Observaciones
12
ANÁLISIS DE VARIANZA
Promedio de
Suma de
los
cuadrados
cuadrados
1 45517219,5 45517219,5
11
20366,198 1851,47255
12 45537585,7
Grados de
libertad
Regresión
Residuos
Total
Intercepción
X2-X1
F
24584,334
Valor crítico
de F
2,7353E-18
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%
0
#N/A
#N/A
#N/A
#N/A
13,5444251 0,08638361 156,793922
8,901E-20
13,354296
Superior
95%
#N/A
13,7345541
Inferior
95,0%
#N/A
13,354296
Superior
95,0%
#N/A
13,7345541
Luego se construye la prueba F, con la información de las ANOVAS, tanto del modelo no restringido como
el restringido.
F=
( SRC R − SRC NR ) / m
( SRC NR /( n − k ))
Finalmente buscamos el nivel de significancia marginal para el estadístico F calculado;
=DISTR.F(0,03177;2;9) = 0,9688
LR test.
En conclusión la hipótesis claramente no puede ser rechazada a los niveles usuales, a través del
56
3.5. TEST DE WALD
Este es el test más popular, pues según el caso, puede ser el más simple de calcular. Excel no
tiene implementado automáticamente un procedimiento para este cálculo, si bien la mayoría de los
programas econométricos lo hacen.
El test de Wald se basa en una de las relaciones entre variables normales y la Chi cuadrado vista
anteriormente, es decir:
(b − β )' Σ −1 (b − β ) ≈ χ 2 (n)
Mientras mayor sea la diferencia entre el valor de los coeficientes estimados b y el valor de los
coeficientes poblacionales hipotetizados (β), mayor será el valor calculado de la prueba, lo que incidirá en
que puede ser rechazada la hipótesis de igualdad con más fuerza.
Para el caso de que las restricciones (hipótesis) sean combinaciones lineales de los coeficientes
(sin importar el tipo de modelo subyacente), siempre podrán escribirse como:
Rβ = r
donde R es una matriz mxk con m el número de restricciones y k el número de parámetros del modelo, β
es un vector de Kx1, y r es un vector de Qx1 conteniendo los coeficientes de la derecha de las hipótesis.
Ejemplo:
Las hipótesis
como:
Ho : β1 − β 2 = 1.0
⎡1 − 1⎤ ⎡ β1 ⎤ ⎡1.0 ⎤
⎢0 1 ⎥ ⎢ β ⎥ = ⎢0.0⎥ ,
⎣
⎦⎣ 2 ⎦ ⎣ ⎦
β2 = 0
y
es decir
pueden escribirse matricialmente
⎡1 − 1⎤
R=⎢
⎥
⎣0 1 ⎦
y
⎡1.0 ⎤
r=⎢ ⎥
⎣0.0⎦
Así, la expresión general para restricciones lineales del test de Wald es:
(r − Rβ )' [RΣ X R'](r − Rβ ) ≈
χ 2 ( n)
donde ∑X es la matriz de varianzas y covarianzas de los coeficientes que ha sido estimada.
Nótese que en el caso del test de Wald solo se requiere estimar el modelo no restringido, es decir
solamente conocer los coeficientes b. Este aspecto es de gran utilidad práctica por lo que la mayoría del
los programas computacionales especializados automáticamente implementarán un test de Wald para el
caso lineal-lineal.
3.5.1. WALD BAJO ESPECIFICACION LINEAL-LINEAL
En el caso particular que tanto el modelo como las restricciones sean lineales, puede mostrarse
que el test de Wald se comporta con una distribución F del siguiente modo:
[
( Rβ − r )' R ( X ' X ) −1 R '
m⋅s
2
]
−1
( Rβ − r )
≈ F (m, T − K )
57
3.5.2. EJEMPLO NUMERICO DEL TEST DE WALD
Veamos el siguiente ejemplo numérico a fin de verificar distintos cálculos del test de Wald, lo que
será ilustrativo:
Ejemplo:
y
100
106
107
120
110
116
123
133
137
x2
100
104
106
111
111
115
120
124
126
x3
100
99
110
126
113
103
102
103
98
Si se desea probar ahora 2 hipótesis lineales simultáneas, por ejemplo:
Ejemplo:
Ho : β1 − β 2 = 1.0
⎫
⎧
⎡− 49,34⎤
⎪⎡0 1 − 1⎤ ⎢
⎥ ⎡0 ⎤ ⎪
⎨⎢
⎥ ⎢ 1,3642 ⎥ − ⎢ ⎥ ⎬
⎪⎣0 0 1 ⎦ ⎢ 0,1138 ⎥ ⎣1⎦ ⎪
⎣
⎦
⎭
⎩
'
y
β 2 = 0.0
'⎤
⎡ ⎡0 1 − 1⎤
−1 ⎡0 1 − 1⎤ ⎥
⎢⎢
(X ' X ) ⎢
⎥
⎢ ⎣0 0 1 ⎥⎦
0 0 1⎦⎥
⎣
⎦
⎣
2⋅ s2
⎧⎪⎡0,2504 ⎤ ⎫⎪
⎨⎢
⎥⎬
⎪⎩⎣ 0,1139 ⎦ ⎪⎭
'⎡
'⎤
⎢ ⎡⎢0 1 − 1⎤⎥ ( X ' X ) −1 ⎡⎢0 1 − 1⎤⎥ ⎥
⎢ ⎣0 0 1 ⎦
⎣0 0 1 ⎦ ⎥⎦
⎣
2⋅s
2
−1
−1 ⎧
⎫
⎡− 49,34⎤
⎪⎡0 1 − 1⎤ ⎢
⎥ ⎡0 ⎤ ⎪
⎨⎢
⎥ ⎢ 1,3642 ⎥ − ⎢ ⎥ ⎬
⎪⎣0 0 1 ⎦ ⎢ 0,1138 ⎥ ⎣1 ⎦ ⎪
⎣
⎦
⎭ ≈ F ( m, T − K )
⎩
⎡0,2504 ⎤
⎢
⎥
⎣ 0,1139 ⎦
=
85,3473
2 ⋅ s2
= 3,3020 ≈ F ( 2,6)
y este es el resultado del test a través de la formulación de Wald.
Puesto que F(2,6)= 3.30200 con Significancia 0.10787701, la hipótesis no es
rechazada.
58
3.6. TEST DEL MULTIPLICADOR DE LAGRANGE
Este test, a diferencia de los anteriores, solamente requiere conocer la estimación del modelo
restringido, por lo que es útil cuando el modelo original es relativamente complejo y la hipótesis nula es
por ejemplo que todos los coeficientes son simultáneamente iguales a cero, pues el modelo restringido es
sencillo de calcular.
El test del multiplicador de Lagrange es útil bajo el resultado de Engle (1982) quien muestra que
para un tamaño de muestra grande, entonces asintóticamente:
T ⋅ R2
≈
χ 2 ( m)
donde m es el número de restricciones.
Este resultado será particularmente útil más adelante en varias pruebas de detección de
heterocedasticidad y autocorrelación (véase capítulo 4).
59
3.7. PRUEBA DE SIGNIFICANCIA GLOBAL
¿Qué ocurre si deseamos probar la hipótesis que todos los coeficientes de pendientes son cero
(sin considerar el intercepto)? Este es justamente el llamado test de significancia global, por cuanto
permitirá saber si conjuntamente las variables X tienen poder explicativo en conjunto por sobre Y.
Es decir:
Y = β 0 + β1 X 1 + β 2 X 2 + ε
Ho : β1 = β 2 = .... = 0
Claramente se trata de una prueba F, donde el número de grados de libertad en el numerador es
m=número de coeficientes (sin considerar intercepto), y el número de grados de libertad en el
denominador es T-K.
Ejemplo: Para el ejemplo desempleo, la regresión restringida es:
Y = β0
Lamentablemente, esto modelo no puede correrse en Excel. Sin embargo, puesto que
consiste en una línea de regresión horizontal (las pendiente son cero), entonces la SCErr
= SCT del modelo no restringido.
Así, SCErr(NR)=20223,4393 con 9 gl, y SCErr(R)=32705,4353 con 11 gl, y en
consecuencia:
(132705,4 − 20223,4)
F=
2 = 2,777
(20223,4)
9
Finalmente, se calcula el NSM para el estadístico F:
=DISTR.F(2,7774;2;9) = 0,11496
por lo tanto no existe evidencia significativa para rechazar H0, de modo que se entiende
que hay una baja explicación del IMACEC y del IPC respecto al desempleo.
60
3.8. PRUEBA DE EXCLUSION DE VARIABLES
Una prueba típica de MCR es verificar si una de las variables explicativa es estadísticamente
importante en el modelo, es decir, si existe diferencia significativa entre la restricción no restringida (con
todas las variables) y la regresión restringida (eliminando la variable en cuestión).
Esta prueba es especialmente útil cuando se trabaja con modelos que tienen variables explicativas
con diferentes rezagos (modelos de series de tiempo) y se desea saber si algunos de estos rezagos
pueden ser excluídos del modelo.
Note que cuando se trata de excluir solamente 1 variable, esto puede ser hecho simplemente con
la prueba t de significancia individual.
Ejemplo: Para el ejemplo del desempleo, se desea verificar si puede excluirse el índice
de precios al consumidor, sin costo para el modelo. La hipótesis es
Bajo Ho el modelo restringido es:
es:
Ho : β 2 = 0 .
Y = β 0 + β1 X 1 y el resultado de la estimación
Estadísticas de la regresión
Coeficiente de correlación
múltiple
0,50056508
Coeficiente de
determinación R^2
0,2505654
R^2 ajustado
0,17562194
Error típico
49,5081659
Observaciones
12
ANÁLISIS DE VARIANZA
Promedio de
Suma de
los
cuadrados
cuadrados
1 8194,85039 8194,85039
10 24510,5849 2451,05849
11 32705,4353
Grados de
libertad
Regresión
Residuos
Total
Intercepción
imacec
F
3,34339242
Valor crítico
de F
0,09741527
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%
1354,53348 446,028899
3,0368738 0,01252925 360,719164
-3,28155063 1,79467342 -1,82849458 0,09741527 -7,28033219
Superior
Inferior
95%
95,0%
2348,34779 360,719164
0,71723094 -7,28033219
Superior
95,0%
2348,34779
0,71723094
Sabemos que la SCErr(NR)=20223,4393 con 9 gl, y ahora, que SCErr(R)=24510,58.
Implementamos una prueba F, para probar la hipótesis nula:
(24510,58 − 20223,4)
F=
1 = 1,9079
(20223,4)
9
donde m=1 es el número de restricciones y T-k=9 representa los grados de libertad del
modelo no restringido.
Finalmente, calculamos el NSM:
=DISTR.F(1,9079;1;9)= 0,200522
por lo tanto no existe suficiente evidencia para rechazar la hipótesis nula, es decir, no
se rechaza que β2=0, y en consecuencia, el IPC puede ser excluído del modelo sin costo
(al 5%).
61
3.9. PRUEBA DE CAUSALIDAD (GRANGER, 1969)
Se dice que X causa en el sentido de Granger a Y, si Y puede ser predicho mejor usando
información pasada de Y y de X, que usando solamente información pasada de Y.
Veamos el concepto con un ejemplo 14: el retorno accionario de la bolsa de valores de Brasil causa
al retorno de Chile (Rbrt→Rcht), por ejemplo, si el retorno de Chile se puede predecir mejor utilizando
valores pasados del retorno de Brasil (Rbrt-i) y del retorno de Chile (Rcht-j), que usando solamente valores
pasados del retorno de Chile.
Formalmente, se dice que Brasil (Rbrt) causa a Chile (Rcht), si existe una diferencia significativa
entre las ecuaciones (1) y (2), notando que en esta última ecuación el término rezagado del retorno de
Brasil no está presente:
n
n
i =1
j =1
Rcht = δ 0 + ∑α i Rbrt − i + ∑ β j Rcht − j + μ1t
(1)
n
Rcht = δ 0 + ∑ β j Rcht − j + μ1t
(2)
j =1
Aquí δ0, αi, βj, son los coeficientes de la regresión, y μ1t son las perturbaciones que se suponen
bien comportadas. La ecuación (1) constituye la regresión no restringida, a partir de la cual puede
obtenerse la suma cuadrada de errores no restringidos (SRCnr), y la ecuación (2) es la regresión
restringida (es decir αi = 0), de la cual se obtiene la suma de los residuos al cuadrado restringidos (SRCR).
Para verificar la significancia que tiene el retorno de Brasil en la regresión usamos la prueba F
comparando la suma de los residuos al cuadrado restringidos y no restringidos de las regresiónes (1) y
(2), es decir una prueba de mínimos cuadrados restringidos para la exclusión de variables (ecuación 3):
F=
( SRC R − SRC NR ) / m
( SRC NR /(n − k ))
(3)
donde, m es igual al número de términos rezagados de Rbr (el número de restricciones lineales), k es el
número de parámetros estimados en la regresión no restringida, n el número de observaciones, y F sigue
una distribución con m y (n–k) grados de libertad. La hipótesis nula es que los términos rezagados de Rbr
no pertenecen a la regresión (H0: Σαi=0). Si el valor F calculado no excede al valor F crítico, no existirán
argumentos para rechazar la hipótesis nula (Ho: no existe causalidad), con lo cual los términos
rezagados del retorno de Brasil no ayudan a explicar al retorno de Chile.
14
Véase a Aedo y Zúñiga (2001) “Análisis de Causalidad entre Bolsas Latinoamericanas”, Documento de Trabajo,
Escuela de Ingeniería Comercial, U.C.N.
62
Ejemplo: Un test de causalidad de R2 hacia R1, donde R representa rentabilidad mensual,
es el siguiente: Tenemos las series temporales de precios de mercado de las las acciones
1, 2 y 3.
P1
p2
100
100
106
104
107
106
120
111
110
111
116
115
123
120
133
124
137
126
100
100
106
104
107
106
120
111
Obtenemos los rendimientos contínuos de cada acción aplicando logaritmos naturales a las
razones de precios:
LN(P1(t)/P1(t-1)) ; cambiando por p2 y p3 cuando corresponda.
Para probar la hipótesis de si existe causalidad a lo Granger de R2 a R1, corremos una regresión
en donde el rendimiento del activo 1 (R1) es explicado por los rendimientos de los activos 2 y 3, cada uno
con 1 y 2 rezagos, bajo la siguiente hipótesis nula:
R1,t = β 0 + β1R1,t −1 + β 2 R1,t − 2 + β 3 R2,t −1 + β 4 R2,t − 2 + ε
Ho : β 3 = β 4 = 0
Las series transformadas y reordenadas en Excel son:
R1
R1-1
R1-2
R2-1
R2-2
0,05826891
0,00938974 0,05826891
0,03922071
0,11466291 0,00938974 0,05826891 0,01904819 0,03922071
-0,08701138 0,11466291 0,00938974 0,04609111 0,01904819
0,05310983 -0,08701138 0,11466291
0 0,04609111
0,05859416 0,05310983 -0,08701138 0,03540193
0
0,07816477 0,05859416 0,05310983 0,04255961 0,03540193
0,0296318 0,07816477 0,05859416 0,03278982 0,04255961
-0,31481074
0,0296318 0,07816477 0,01600034 0,03278982
0,05826891 -0,31481074
0,0296318 -0,23111172 0,01600034
0,00938974 0,05826891 -0,31481074 0,03922071 -0,23111172
0,11466291 0,00938974 0,05826891 0,01904819 0,03922071
0,11466291 0,00938974 0,04609111 0,01904819
0,11466291
0,04609111
El modelo No restringido estimado es:
63
Resumen
Estadísticas de la regresión
Coeficiente de correlación
múltiple
0,56343587
Coeficiente de
determinación R^2
0,31745998
R^2 ajustado
-0,22857204
Error típico
0,14232138
Observaciones
10
ANÁLISIS DE VARIANZA
Grados de
libertad
F
0,58139443
Valor crítico
de F
0,69033198
Coeficientes Error típico Estadístico t Probabilidad
0,00952583 0,04512862
0,2110818 0,84115682
-1,95451248 1,48187744 -1,31894341 0,24436243
-1,83643976 1,50804878 -1,21775886 0,27764342
2,44345398 2,12411549 1,15033951 0,30203135
2,50431257
2,1759706 1,15089449
0,3018231
Inferior 95%
-0,10648098
-5,7637997
-5,71300255
-3,01675871
-3,08919792
Regresión
Residuos
Total
Intercepción
Variable X 1
Variable X 2
Variable X 3
Variable X 4
Promedio de
Suma de
los
cuadrados
cuadrados
4 0,04710545 0,01177636
5 0,10127688 0,02025538
9 0,14838233
Superior
95%
0,12553264
1,85477473
2,04012302
7,90366668
8,09782306
Inferior
95,0%
-0,10648098
-5,7637997
-5,71300255
-3,01675871
-3,08919792
Superior
95,0%
0,12553264
1,85477473
2,04012302
7,90366668
8,09782306
Luego se corre una segunda regresión, donde se excluye los rendimientos rezagados del activo 2;
Resumen
Estadísticas de la regresión
Coeficiente de correlación
múltiple
0,22985245
Coeficiente de
determinación R^2
0,05283215
R^2 ajustado
-0,21778723
Error típico
0,14169533
Observaciones
10
ANÁLISIS DE VARIANZA
Grados de
libertad
Regresión
Residuos
Total
Intercepción
Variable X 1
Variable X 2
Promedio de
Suma de
los
cuadrados
cuadrados
2 0,00783936 0,00391968
7 0,14054297 0,02007757
9 0,14838233
F
0,19522678
Valor crítico
de F
0,82697869
Coeficientes Error típico Estadístico t Probabilidad
0,01228862 0,04487075 0,27386707 0,79209195
-0,23976642 0,39281205 -0,61038459
0,5608931
-0,1024898
0,3886021 -0,26373968 0,79957601
Inferior 95%
-0,09381385
-1,16861931
-1,02138775
Superior
Inferior
95%
95,0%
0,1183911 -0,09381385
0,68908647 -1,16861931
0,81640816 -1,02138775
Superior
95,0%
0,1183911
0,68908647
0,81640816
Entonces con la información de las tablas ANOVA construimos la prueba F;
F=
(0,14054 − 0,1012769 ) / 2
= 0,96989
(0,1012769 / 5)
Finalmente, realizamos el test F (para F=0.96989 con 2 y 5 grados de libertad), donde el
resultado obtenido es de 0.4406. Puesto que el nivel de significancia de F(2,5)=0.96928 es 0.44081152,
no se puede rechazar H0.
64
3.10. TEST DE ESTABILIDAD (CAMBIO ESTRUCTURAL)
Al estimar una regresión se asume que los coeficientes son estables a través del tiempo, sin
embargo esto puede ser falso. La prueba para cambio estructural es una F implementada por Chow
(1960), tal como veremos.
Si el periodo total, que contiene T observaciones, puede ser descompuesto en 2 conjuntos
independientes de datos con tamaños T1 y T2 (que no tienen por qué sumar T), la ecuación de regresión
es:
Para el 1º grupo:
y1 = β10 + β11x1 + β12 x2 + ... + β1k xk + e1
Para el 2º grupo:
y2 = β20 + β21x1 + β22x2 + ... + β2k xk + e2
Una prueba de estabilidad de los parámetros entre las poblaciones es la siguiente hipótesis
simultánea:
Ho : β10 = β 20 ; β11 = β 21; β12 = β 22 ;...; β1k = β 2k
(inexistencia de cambio estructural)
Para esto usamos el test de razón de verosimilitud:
(SCErr Restr − SCErr no Restr )
F=
SCErr no Restr
m ≈ F(m,T − K)
T −K
haciendo :
SCErr Restr
: calculando el modelo para el periodo total
SCErr No Restr : calculando por separado el modelo en cada uno de las submuestras y luego sumándolas.
m
: el número de restricciones, es decir el número de parámetros (incluyendo el intercepto)
T-k
: los grados de libertad del denominador son la suma de los grados de libertad de cada
una de las regresiónes de las submuestras.
Para la implementación de dicho test se requiere que se corra una regresión para el periodo total
(modelo restringido) y dos regresiónes para cada periodo (modelo no restringido). El primero es un
modelo restringido pues asume que los coeficientes a través del tiempo son estables, es decir, no tienen
un cambio significativo en el valor de los coeficientes a través del tiempo. En cambio el otro modelo
acepta la posibilidad de cambios en la magnitud de los coeficientes. Nótese que puesto que se estimarán
3 regresiones se requiere una cantidad suficiente de observaciones en cada submuestra.
Ejemplo: Se tiene la siguiente información sobre ahorro e ingreso del Reino Unido 19461963 (millones de libras), y se desea determinar si existe un cambio estructural del
período 1946-1954 versus 1955-1963 ('Tabla 3').
a) Primero corremos una regresión para el modelo restringido (todo el periodo),
fijando la atención en los resultados de la tabla ANOVA.
Residuos
16
0,57222646
b) Luego descomponemos las observaciones en dos submuestras (la primera desde
1946 a 1954 y la segunda de 1955 a 1963) y se corren regresiónes separadas de las
submuestras. Los resultados son:
65
Residuos
Residuos
7
7
0,13965034
0,19312074
c) Para la prueba F, tanto la SCErrNR como los grados de libertad del
denominador, serán la suma de los valores respectivos entregados para ambas
submuestras.
(0,572 − (0,13965 + 0,193))
F=
2 = 5,03706
(0,13965 + 0.193)
14
d) Finalmente;
=DISTR.F(5,03706;2;14) = 0,02249279
Puesto que el nivel de significancia es menor a 5%, rechazamos la hipótesis
nula, lo que implica que nos inclinamos a favor de la existencia de cambio
estructural.
Nótese que en esta prueba también puede ser implementada a través de variables dummies,
llegando a conclusiones equivalentes.
3.11. ESTIMANDO REGRESIÓNES RESTRINGIDAS
En muchas ocasiones se requiere efectuar estimaciónes de modelos en que deben imponerse
restricciones sobre los coeficientes. El ejemplo típico de estimaciones restringidas ocurre en la estimación
de funciones de costo translogaritmicas, la que se puede transcribir de la siguiente manera:
ln C =
αo +
m
∑
n
αi ln Qi +
i =1
∑
βjln Wj +
j =1
1 m m
∑ ∑ γik ln Qi ln Qk +
2 i =1 k =1
1 n n
∑ ∑ λjs lnWj ln Ws +
2 j =1 s=1
m
n
∑∑
θij ln Qi ln Wj
i =1 j =1
donde:
α0 = intercepto
C = costos totales
Qi = productos que fabrican las empresas
Wj = insumos requeridos para producir los productos
La función de costos tiene que ser linealmente homogénea y cóncava en Wj, y creciente en Qi y
Wj, por lo tanto, esta ecuación debe estar sujeta a las siguientes restricciones:
n
∑
j =1
βj = 1 ;
n
∑
j =1
λjs = 0 ;
n
∑
θij = 0 ; γik = γki ; λjs = λsj
j =1
En programas como RATS, esto puede hacerse fácilmente. Lamentablemente Excel no tiene
implementada esta característica.
66
CAPÍTULO 4
VIOLACIÓN DE ALGUNOS SUPUESTOS
Ahora nos concentraremos en el caso en que los errores están mal comportados, es decir, cuando
la matriz de covarianzas de los errores V=E[εε'] ya no es escalar Identidad 15, sino que E[εε']=σ2ψ, con ψ
una matriz definida positiva, de modo que pueden ocurrir dos casos simples:
- V diagonal, pero con elementos distintos (heterocedasticidad).
- V no diagonal (autocorrelación).
Anteriormente mostramos que en cualquiera de estas condiciones el estimador b de MCO es
insesgado 16, y que para calcular la matriz de varianzas de los coeficientes a través de MCO ya no puede
hacerse la siguiente simplificación:
E [(b − β )(b − β )'] = ( X ' X ) −1 X ' E (εε ' ) X ( X ' X ) −1
= ( X ' X ) −1 X '⋅σ 2 I ⋅ X ( X ' X ) −1 = σ 2 ( X ' X ) −1
sino que tendremos:
E [(b − β )(b − β )' X ] = σ 2 ( X ' X ) −1 X '⋅ Ψ ⋅ X ( X ' X ) −1
de tal modo que si se usa erróneamente σ2(X'X)-1 se sobrestimará o subestimará la verdadera matriz de
varianzas. Aún así, MCO es útil en la mayoría de las situaciones, y aun cuando se violen algunos de éstos
supuestos, la estimación de los parámetros por este método sigue siendo consistente aunque ya no
eficiente, es decir no con el menor error.
15
Equivale a decir que los errores ya no son IID.
Suponiendo que se mantiene la independencia de los regresores con el término de error, pues si esto no ocurriera, a
través de MCO se generan estimadores inconsistentes. Este problema será dejado para un análisis posterior.
16
67
4.1. MÍNIMOS CUADRADOS GENERALIZADOS
En este capítulo mostraremos que si se usa el procedimiento de Mínimos Cuadrados Generalizados
(MCG) 17 se tendrán estimadores que superan el problema de errores mal comportados, los que como
sabemos, tienen la propiedad de ser MEI.
El procedimiento de Mínimos Cuadrados Generalizados consistente en transformar la ecuación de
regresión con errores mal comportados (E[εε']=σ2ψ, conocida) multiplicándola por una determinada matriz
P (TxT) a fin de obtener errores con media cero y matriz de covarianzas escalar identidad (errores bien
comportados). En este caso el estimador de los coeficientes de regresión es:
b = ( X 'ψ −1 X ) −1 X 'ψ −1Y
con
E [(b − β )(b − β )' X ] = σ 2 ( X '⋅ ψ −1 ⋅ X ) −1
de modo que b de MCG es MELI para el caso de E[εε'] no esférica (es decir mal comportada) pero
conocida.
En caso de usar MCO bajo E[εε'] no esférica, la verdadera matriz de varianzas y covarianzas,
cuando conocemos la naturaleza de E[εε'] debería ser la siguiente:
E [(b − β )(b − β )'] = σ 2 ( X ' X ) −1 X '⋅ψ ⋅ X ( X ' X ) −1
Sin embargo, usar MCO entregará erróneamente la siguiente matriz:
E [(b − β )(b − β )'] = σ 2 ( X ' X ) −1
que es menor a la anterior, de modo que la existencia de heterocedasticidad / autocorrelación lleva
siempre a una sobreestimación de los valores t (es decir errores menores a los verdaderos). Entonces se
genera un estimador sesgado de la matriz de covarianzas de los coeficientes. Además se tienen sólo
resultados asintóticos 18.
17
Puesto que es asumido que la forma de la matriz de covarianza de las perturbaciones es conocida, entonces el
procedimiento de solución consiste en aplicar MCGeneralizados.
18
Puesto que el estadístico t ya no es una variable normal dividido por su desviación estándar aproximada (el
estimador b de MCO es ineficiente), y además el test F tampoco será válido (véase Judge 342).
68
4.2. HETEROCEDASTICIDAD
La heterocedasticidad o varianzas de los errores no constantes no suele presentarse en series de
tiempo, sino que en datos de corte transversal. En el modelo lineal general, hemos dicho que la
heterocedasticidad ocurre cuando los elementos de la diagonal de la matriz ψ no son todos idénticos:
y = Xβ + e
E ( e) = 0
(1)
E (ee' ) = σ Ψ = Φ
2
donde ϕ es una matriz cuadrada semidefinida positiva distinta a σ2I.
En la práctica esto puede ocurrir, por ejemplo, debido a que ingresos familiares menores tienden a
gastar a un ritmo más constante (en primera necesidad), mientras que las rentas más altas tienden a
gastar más erráticamente.
Ejemplo: Supongamos que tenemos información sobre de consumo e ingreso de 20 familias
(Tabla 4 del Anexo al final del libro).
Ordenamos las series en forma ascendente, en base al ingreso. Luego graficamos (scatter).
Ingreso - Consumo
50,0
Ingreso
40,0
30,0
20,0
10,0
0,0
0,0
10,0
20,0
30,0
40,0
50,0
Consumo
; notamos que efectivamente a mayores niveles de rentas existe una mayor volatilidad, es decir evidencia
de heterocedasticidad. Lamentable cuando se trata de modelos múltiples este tipo de gráfico no tendrá
sentido, aunque un gráfico de los residuos de la regresión respecto a la serie de variable dependiente
entregará alguna evidencia.
Luego graficamos el consumo versus los errores (click en Gráfico de Residuales);
69
Ingreso Gráfico de los residuales
Residuos
2,5
2
1,5
1
0,5
0
-0,5 0,0
-1
-1,5
-2
10,0
20,0
30,0
40,0
50,0
-2,5
-3
Ingreso
Ahora se ve más claramente la existencia de heterocedasticidad.
4.2.1. CORRECCIÓN CON MCG (ϕ CONOCIDA)
Supongamos que la matriz de covarianzas de los errores tiene la siguiente forma:
⎡σ 12 0
0
⎢
2
⎢ 0 σ2 0
E (ee' ) = Φ = ⎢ 0
0 σ 32
⎢
⎢ ... ... ...
⎢0
0
0
⎣
0⎤
⎥
0⎥
2
2
2
2
... 0 ⎥ = diag (σ 1 , σ 2 ,σ 3 ,...σ T )
⎥
... ⎥
... σ T2 ⎥⎦
...
...
Puede verificarse que la transformación de MCG apropiada es:
⎡1 / σ 1
⎢
⎢ 0
P=⎢ 0
⎢
⎢ ...
⎢ 0
⎣
0
1/ σ 2
0
...
0
0
0
1/ σ 3
...
0
0 ⎤
⎥
0 ⎥
−1
−1
−1
−1
0 ⎥ = diag (σ 1 ,σ 2 ,σ 3 ,...σ T )
⎥
... ⎥
... 1 / σ T ⎥⎦
...
...
...
puesto al multiplicar el modelo heterocedástico en (1), se tiene que así la varianza de los errores
resultante es homocedástica (una constante igual a 1).
En efecto:
Y = Xβ + e
/P
PY = PXβ + Pe
70
Y* = X*β* + e*
La varianza de los errores del modelo anterior es:
V(e*) = P2V(e) = I = una constante (homocedaticidad)
es decir:
⎡⎛ ε
var(ε *) = E (ε ) = E ⎢⎜⎜ t
⎢⎣⎝ σ t
*2
t
⎞
⎟⎟
⎠
2
⎤
⎥ =1
⎥⎦
El procedimiento de MCG es entonces es dividir cada observación por la desviación estándar del
error correspondiente a esa observación, procedimiento que se llama Mínimos Cuadrados Ponderados.
71
4.2.2. DETECCION DE LA HETEROCEDASTICIDAD
El procedimiento inicial de detección es el gráfico, pero muchas veces el patrón de la
heterocedasticidad no puede ser apreciado gráficamente, de modo que existe una batería de tests para la
hipótesis:
Ho: Homocedasticidad
entre los cuales destacamos, para el ejemplo anterior, los siguientes:
1.- Test de Goldfeld y Quandt (1972)
Es un test F, en que se comparan los residuos de regresiónes corridas a dos partes distintas de la
muestra, de modo que se requiere un número relativamente alto de observaciones.
a) Primero ordenamos por X (ó por Y sin son varias X). Dividimos T en 2 grupos (a veces se sugiere dejar
libre en el medio algunas).
b) Se corren regresiónes separadas para cada una y se guarda la Suma Cuadrada de Errores y los grados
de libertad.
En la prueba F se sugiere dejar la mayor varianza en el numerados, y la menor varianza en el
denominador.
Ejemplo: Tomemos el caso del consumo explicado por el ingreso 'Tabla 04.xls',
descomponiendo las observaciones en 2 submuestras de 10 observaciones cada una. La salida
para la primera regresión es;
Solución:
Para la 1º regresión
Regresión
Residuos
Total
Grados de libertad Suma de cuadrados
1
1449,390497
8
20,649503
9
1470,04
Para la 2º regresión:
Regresión
Residuos
Total
Grados de libertad Suma de cuadrados
1
654,8411093
8
10,24789069
9
665,089
c) Se calcula el test F y su significancia
SCErr2
gl 2
10,25 / 8
=
= 0,49
F=
SCErr1 20,65 / 8
gl1
F tabulado =Distr.F.inv(0,05;8;8)=3,43
NSM =Distr.F(0,49;8;8)=0,82
72
;* concluimos que en este ejemplo no tenemos evidencia suficiente para rechazar
homocedasticidad.
2.- Arch Test de White (1980):
Es una prueba Chi Cuadrado que es una variación del test de Breush y Pagan (1979), donde se
corren los residuos cuadrados contra los regresores, sus cuadrados y en algunos casos sus productos.
Ejemplo : y = B0
ERR2 =
X2X2 =
X2X3 =
X3X3 =
+ B1 x2 + B2 x3; los errores son almacenados en la serie ERR
ERR^2
X2^2
X2^3
X3^2
err2 = b0 + b1 X2 + b2 X3 + b3 X2X2 + b4 X3X3
T ⋅ R 2 ≈ χ 2 (k )
El número de grados de libertad en el test chi es aquí el número de variables explicativas, es decir el
número de parámetros menos 1 (menos el intercepto).
Ejemplo: En nuestro caso, 'Tabla 04.xls', luego de corrida la regresión original,
guardamos los errores y transformamos la series ingreso y de residuos, elevándolas al
cuadrado. Obtenemos;
consumo = b0 + b1 ingreso
err2 = ERR^2
X2X2 = ingreso^2
Corremos ahora una regresión de los residuos cuadrados contra ingreso e ingreso
al cuadrado.
err2 = b0 + b1 ingreso + b2 X2X2
chistat = 0,8781*20 = 17,6
Chi tabulado = Pruebachi.inv(0,05;2) = 5,99
NSM = distr.chi(17,6;2) = 0.00015360
* y hay evidencia para rechazar homocedasticidad.
Centramos la atención en el resultado de R-Cuadrado, ya que éste multiplicado por el número de
observaciones nos permitirá obtener el estadístico Chi-2 para la obtener el nivel de significancia. En este
caso; Chistat = 0.878*120 = 17.56. Finalmente, realizamos el test Chi; 1-CDF.CHISQ(17.56,2) =
0.000154; el número de grados de libertad en el test chi es aquí el número de variables explicativas, es
decir el número de parámetros menos el intercepto.
73
3.- Arch Test de Engle (1982):
Para el caso de error del tipo ARCH(1), es decir:
u t ≈ N (0, σ 2 (1 + α ⋅ u 2 t −1 ))
el test consiste en regresionar los residuos al cuadrado sobre su 1º rezago. Para el caso de error del tipo
ARCH(2), se regresionan los residuos al cuadrado sobre su 1º rezago y 2º rezago. Así sucesivamente.
Ejemplo: Para el ejemplo anterior, los residuos al cuadrado se rezagan 1, 2 y 3
observaciones, es decir se hace una especificación ARCH(3). Los resultados relevantes de
la regresión son;
consumo = b0 + b1 ingreso
err2 = err^2
err2 = b0 + b1 err2{1} + b1 err2{1} + b1 err2{1} ;especificación ARCH(3)
chistat = 0,2257*17 = 3,83
Chi Tabulado = pruebachi.inv(0,05;3)=7,814
NSM=distr.chi(3,83;3)=0,27
Y no se rechaza Ho.
Nuevamente para obtener el estadístico Chi se multiplica el R-Cuadrado por el número de observaciones.
74
4.2.3. CORRIGIENDO POR HETEROCEDASTICIDAD: MC PONDERADOS
Los modelos de regresión típicos asumen que la varianza es constante en la población. Si las
diferencias de variabilidad se pueden estimar a través de otra variable, es posible calcular los coeficientes
mediante mínimos cuadrados ponderados (MCP), de manera que se les de mayor ponderación a las
estimaciónes mas precisas (es decir, aquellas con menos variabilidad) al determinar los coeficientes de
regresión. Algunos programas de computación calculan el procedimiento 'Weight Estimation', que
contrasta varios tipos de transformaciones de ponderación, e indica cual se ajustará mejor a los datos.
Puesto que en general no se conoce exactamente la forma de la heterocedasticidad, lo más común
para intentar reducirla es deflactar/ponderar a partir de alguna medida de tamaño. Una alternativa similar
es transformar los datos a través de logaritmos.
Para explicar el método de MC Ponderados, supongamos que se tiene el siguiente modelo de
regresión lineal simple:
yt = β1 + β 2 xt + et
En el caso más simple, se desea corregir por heterocedastididad usando la misma variable xt. Para
esto debe multiplicarse el modelo original como sigue:
yt
xt
=
β1
xt
xt
+ β2
xt
yt* =
yt
x1*t =
1
xt
x 2*t =
xt
+
et
xt
xt
xt
De este modo, el modelo a estimar (corregido) es el siguiente:
y t* = β 1 x1*t + β 2 x 2*t + et*
Nótese que para estimarlo debe correrse una regresión con 2 variables explicativas y sin
intercepto.
Ejemplo: Una empresa aérea desea calcular el consumo de combustible por viaje de sus
aviones (C, en miles de litros de kerosene), en función de la distancia recorrida por los
mismos (D en miles de kilómetros). Se tiene tambien el número de pasajeros que
transportan (P) (ver tabla de datos abajo). Para ello usa el siguiente modelo:
C j = α 0 + α1 D j + e j
Se desea correr mínimos cuadrados ponderando por P.
Haciendo las transformaciones paso a paso, debemos generar nuevas series multiplicando las
originales por en inverso de la raiz cuadrada de la serie Pasajeros.
75
y* = Kerosene / (pasajero) ^0.5
x2* = Kilometro / (pasajero) ^0.5
La segunda variable del modelo (que corresponde al intercepto) es:
x1* = 1 / (pasajero) ^0.5
Kerosene
kilometros
11
14
10
13
16
13
13
18
9
10
pasajeros
23
29
21
27
30
29
25
35
20
22
93
91
105
90
99
80
100
100
96
92
K*
x1*
x2*
1,14064686 0,10369517
2,3849889
1,46759877 0,10482848 3,04002603
0,97590007 0,09759001 2,04939015
1,37032032 0,10540926 2,84604989
1,6080605 0,10050378 3,01511345
1,45344419
0,1118034 3,24229857
1,3
0,1
2,5
1,8
0,1
3,5
0,91855865 0,10206207 2,04124145
1,04257207 0,10425721 2,29365855
La regresión debe correrse sin intercepto:
Estadísticas de la regresión
Coeficiente de correlación
múltiple
0,9986603
Coeficiente de
determinación R^2
0,9973224
R^2 ajustado
0,8719877
Error típico
0,0772815
Observaciones
10
ANÁLISIS DE VARIANZA
Promedio de
Suma de
los
cuadrados
cuadrados
2 17,7963658 8,89818291
8 0,04777944 0,00597243
10 17,8441453
Grados de
libertad
Regresión
Residuos
Total
Intercepción
x1*
x2*
F
1489,87641
Valor crítico
de F
6,2323E-10
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%
0
#N/A
#N/A
#N/A
#N/A
-2,32157884 1,41944525 -1,63555364 0,14057161 -5,59482547
0,5739753 0,05351484 10,7255345 5,0199E-06 0,45056985
Superior
Inferior
95%
95,0%
#N/A
#N/A
0,95166778 -5,59482547
0,69738074 0,45056985
Superior
95,0%
#N/A
0,95166778
0,69738074
Los resultados de esta regresión se asume entonces que están libres del problema de la
heterocedasticidad (habría que verificarlo). Lamentablemente el procedimiento de MCPonderados afecta la
interpretación de los coeficientes de la regresión.
76
4.3. CORRELACIÓN SERIAL
La correlación serial ocurre cuando el término de error de un periodo está correlacionado con el de
otro periodo. Ocurre principalmente en series de tiempo. Posibles motivos para la aparición de correlación
serial son el sesgo de especificación (una forma funcional incorrecta o variables excluidas) y los modelos
autorregresivos (donde los errores son intrínsecamente correlacionados), es decir aquellos modelos en
que aparece como variable explicativa la variable explicada rezagada (Yt-1).
La especificación siguiente define un modelo lineal general con errores auto correlacionados de 1º
orden, AR(1):
y = Xβ + ε
ε t = ρ ⋅ ε t −1 + v t
E (v ) = 0
E (vv' ) = σ v ⋅ I
2
donde ρ es el coeficiente de correlación entre los errores sucesivos, e es el error auto correlacionado, y v
es un error bien comportado.
Al igual que en el caso de la heterocedasticidad, en los casos simples es posible detectar esta
anomalía graficando los residuos, como veremos en el siguiente ejemplo:
Ejemplo: Supongamos que disponemos de información anual de inventarios (Y) y de ventas
(X) en una determinada región (‘Inventarios_Ventas.xls’). Luego graficamos inventarios
versus los errores.
15
10
Errores
5
0
0
50
100
150
200
250
-5
-10
-15
Inventario
El gráfico muestra que efectivamente los errores poseen un patrón cíclico, lo que en este caso se
traduciría en errores auto correlacionados positivamente.
77
4.3.1. CORRECCIÓN CON MCG (ϕ CONOCIDA)
Puede mostrarse que en el caso de un proceso AR(1) 19 de los errores la esperanza y covarianza
de éstos es respectivamente como sigue:
E (ε ) = 0
Var (ε ) =
σ v2
1− ρ 2
⎛ σ v2
E (ε t ε t −1 ) = ρE (ε t2−1 ) + E (ε t −1 v t ) = ρσ e2 = ρ ⎜⎜
2
⎝1 − ρ
⎛ σ v2
E (ε t ε t − s ) = ρ σ = ρ ⎜⎜
2
⎝1 − ρ
s
2
e
s
⎞
⎟
⎟
⎠
⎞
⎟
⎟
⎠
donde la correlación entre cualquier par de errores es ρs, y entre errores consecutivos es ρ. Haciendo
sustitución recursiva puede también mostrarse que el error auto correlacionado puede escribirse como un
proceso autorregresivo:
∞
ε t = vt + ρ ⋅ vt −1 + ρ 2 ⋅ vt − 2 + ... = ∑ ρ i ⋅ v t −i
i =0
y cuando |ρ|<1 se dice que el proceso autorregresivo es estacionario, es decir la media y varianza de e no
cambian a través del tiempo. En este caso puede mostrase que la matriz de covarianzas de los errores
tiene la siguiente forma:
⎡ 1
⎢
2
σv ⎢ ρ
2
Φ =σv Ψ =
1− ρ2 ⎢
⎢ T −1
⎢⎣ ρ
ρ
1
ρ T −1 ⎤
⎥
ρ T −2 ⎥
⎥
⎥
1 ⎥⎦
ρ T −2
y que la matriz P apropiada para efectos de corrección por MCG es:
⎡ 1− ρ2
⎢
⎢ −ρ
P=⎢ 0
⎢
⎢ ...
⎢ 0
⎣
0
1
0
...
0
...
...
−ρ 1
... ... ...
0 ... − ρ
0⎤
⎥
0⎥
0⎥
⎥
...⎥
1 ⎥⎦
En efecto, al multiplicar la matriz Y y la matriz X por P (es decir implementar MCG) se generan las
siguientes series nuevas para Y y para ε (no incluimos la transformación de X pues es trivial):
19
El concepto de procesos autorregresivo (AR) y procesos ARIMA son desarrollados en el capítulo 8 y 9.
78
⎡ 1− ρ 2
⎢
⎢ −ρ
P ⋅Y = ⎢ 0
⎢
⎢
⎢ 0
⎣
⎡ 1− ρ 2
⎢
⎢ −ρ
P ⋅ε = ⎢ 0
⎢
⎢
⎢ 0
⎣
0
0
1
0
1
−ρ
−ρ
0⎤ ⎡ Y1 ⎤ ⎡Y1 1 − ρ 2 ⎤
⎥
⎥ ⎢ ⎥ ⎢
0⎥ ⎢Y2 ⎥ ⎢ Y2 − ρY1 ⎥
⎥
.
0⎥ ⋅ ⎢ . ⎥ = ⎢
⎥
⎥ ⎢ ⎥ ⎢
.
⎥
⎥ ⎢.⎥ ⎢
⎢
⎥
⎥
⎢
1⎦ ⎣YT ⎦ ⎣YT − ρYT −1 ⎥⎦
−ρ
0⎤ ⎡ ε 1 ⎤ ⎡ ε 1 1 − ρ 2 ⎤
⎥
⎥ ⎢ ⎥ ⎢
0⎥ ⎢ε 2 ⎥ ⎢ ε 2 − ρε 1 ⎥
⎥
.
0⎥ ⋅ ⎢ . ⎥ = ⎢
⎥
⎥ ⎢ ⎥ ⎢
.
⎥
⎥ ⎢. ⎥ ⎢
⎢
⎥
⎥
⎢
1⎦ ⎣ε T ⎦ ⎣ε T − ρε T −1 ⎥⎦
0
0
0
1
0
1
−ρ
0
Puesto que anteriormente especificamos que
ε t = ρε t −1 + vt , tal que V estaba bien comportado,
entonces el nuevo error en el modelo transformado (Pε=ε*) está efectivamente bien comportado, con lo
cual se corrige el problema de errores autocorrelacionados.
Nótese que la solución de la correlación de 1º orden consiste en calcular primeras diferencias a las
series, es decir restar a cada valor de Y su valor anterior, multiplicado por ρ, es decir Yt*=Yt-ρYt-1. Este
procedimiento particular de MCG es llamado Primeras Diferencias Generalizadas. Note que si ρ=1, se
tienen primeras diferencias simples.
79
4.3.2. DETECCION DE AR(1): DURBIN-WATSON (1951)
Si bien el procedimiento inicial de detección es normalmente el gráfico (errores versus X, ó Y 20), el
procedimiento de Durbin-Watson (DW) es el estándar.
El test de DW mide solamente la asociación entre residuos adyacentes (correlación serial de 1º
orden) y requiere un intercepto en la regresión. El test de DW es el siguiente:
∑
d=
T
t =2
(e t − e t −1 ) 2
∑
T
t =1
et2
el que puede mostrarse se encuentra entre 0 y 4, tal que:
Si d cercano a 0, existe correlación de 1º orden en los residuos positiva.
Si d cercano a 2, no hay correlación de 1º orden
Si d cercano a 4, la correlación es perfecta negativa.
Para probar ‘Ho: no existe correlación’, Durbin-Watson tabularon las zonas de indecisión buscadas
en la tabla de DW para T observaciones y K parámetros y un error de α% es como sigue:
dl y du
= son los límites inferior y superior de la zona de indecisión para el caso de sospecha de
autocorrelación positiva. Deben buscarse en una tabla.
4-du y 4-dl
= son los límites inferior y superior de la zona de indecisión para el caso de sospecha de
autocorrelación negativa.
En términos gráficos:
Z o n a s d e in d e c is ió n
0
dl
du
A R p o s itiv a
2
4 -d u
4 -d l
4
A R N e g a tiv a
No AR
Note que cuando T es grande, al resolver la suma del binomio al cuadrado en el numerador, el
primer término al cuadrado es igual al segundo término al cuadrado, entonces:
⎛
⎜
d ≈ 2⎜ 1 −
⎜
⎝
∑ ee
∑e
t
t −1
2
t
⎞
⎟
~
⎟ = 2(1 − ρ )
⎟
⎠
20
A diferencia de la detección gráfica de la heterocedasticidad, aquí los errores al cuadrado normalmente no son de
utilidad.
80
donde ρ es el coeficiente de correlación estimado entre et y et-1. Luego, conocido el valor del test de
Durbin-Watson, d, podemos despejar un estimador de ρ, puesto que ρ=1-d/2.
Ejemplo: En el ejemplo anterior de inventario y ventas (‘Inventarios_Ventas.xls’),
corremos la regresión como de costumbre, y calculamos paso a paso el test Durbin-Watson:
Et
-3,14065594
-3,21951873
-2,11951873
-2,89811373
-3,87155832
-4,06072192
-5,2970425
-1,85965069
2,23004851
1,93058412
4,30998253
8,95198913
4,89453134
-1,08867844
-1,00305841
12,9459732
10,3093848
2,40584127
-7,3714147
-12,0484029
Et-1
-3,14065594
-3,21951873
-2,11951873
-2,89811373
-3,87155832
-4,06072192
-5,2970425
-1,85965069
2,23004851
1,93058412
4,30998253
8,95198913
4,89453134
-1,08867844
-1,00305841
12,9459732
10,3093848
2,40584127
-7,3714147
(Et-Et-1)^2
0,00621934
1,21
0,60621016
0,94759438
0,03578287
1,5284886
11,8156625
16,7256396
0,08967892
5,66153679
21,5482253
16,4629637
35,7987993
0,00733079
194,575484
6,95159836
62,4660009
95,5947342
21,8742182
493,906167
Et^2
9,86371971
10,3653009
4,49235967
8,39906318
14,9889638
16,4894625
28,0586593
3,4583007
4,97311637
3,72715506
18,5759494
80,1381094
23,956437
1,18522074
1,00612617
167,598223
106,283416
5,78807221
54,3377546
145,164011
708,849421
Luego d = 493,9 / 708,849 = 0,6967. Puesto que T=20, y K=2, buscamos en la tabla de DW al 5%, y
dl=1.201 y du=1.411 que constituye el rango de indecisión. Puesto que 0.69677 < 1.201 tenemos
evidencia suficiente para rechazar la hipótesis nula a cambio de AR positiva.
81
82
4.3.3. DETECCION EN MODELOS CON Y REZAGADA: Test h de Durbin
El test de DW es sesgado cuando existen variables dependientes rezagadas (yt-1) y en los modelos
de tiempo del tipo ARMA. En el primer caso debe usarse el test h de Durbin (1970), que es más simple y
robusto en este tipo de situaciones.
En efecto, cuando se tiene un modelo con variables explicativas rezagadas (un modelo AR),
entonces esa variable se relaciona con el término de error, lo que viola gravemente un supuesto del
sistema lineal, entregando estimaciones sesgadas e inconsistentes del coeficiente de yt-1. También el
estadístico DW estaría sesgado hacia 2, de modo que en muchos casos no detectaríamos correlación
aunque existiera.
El test h de Durbin para detectar AR (Ho: no autocorrelación), es el siguiente:
h = ρˆ
T
≈ N (0,1)
1 − T ⋅ V (b1 )
Como se ve, este test es de carácter asintótico (válido en grandes muestras) y se distribuye
normal estándar, de modo que lamentablemente tiene bajo poder para muestras pequeñas.
Aquí V(b1) es la varianza del coeficiente que contiene la serie Y rezagada. ρ puede ser obtenido a
partir del test DW anterior. Note que no está definido para T*V(b1)>0, de modo que en este caso h=0.
Ejemplo:
Una estimación de demanda por alimentos, con T=50 entrega el siguiente
resultado:
Log Qt = 0.65 - 0.31 log Pt + 0.45 log Yt + 0.65 log Qt-1
Err st
(0.14) (0.05)
(0.20)
(0.14)
R2 = 0.90 y
DW = 1.8
La varianza del coeficiente de Qt-1 es 0.14**2 = 0.0196.
H = 0.1 * (50/(1-50*0.0196))**0.5 = 5.0 (vs. 2.575) que es significativo al 1%
y rechazamos ρ=0.
Ejemplo:
Un cálculo más general para el test es el siguiente:
LINREG Y
# CONSTANT Y{1} X1 X2
COM DENOM=1-%NOBS*%SEESQ*%XX(2,2)
IF DENOM>0
COM H=%RHO*SQRT(%NOBS/DENOM)
ELSE
COM H=0.0
END IF
CDF NORMAL H
Esto es, usando un ciclo que determinará automáticamente si el denominador es cero o no, y
aplicando en cada caso el test que corresponda.
83
4.3.4. DETECCIÓN DE LA AUTOCORRELACIÓN DE ORDEN SUPERIOR
a) Test de BREUSCH (1978) Y GODFREY (1978)
Es una generalización Chi cuadrada en base al test LM del test h de Durbin, y permite probar Ho:
inexistencia de correlación de orden N. Generalmente se prueba para 3º orden:
H 0 : ρ1 = ρ 2 = ρ 3 = 0
Ejemplo: En el ejemplo anterior de inventario y ventas (‘Inventarios_Ventas.xls’),
corremos una regresión guardando los errores. Luego, regresionamos el inventario (Y)
contra las ventas y los errores rezagados desde 1 a 3.
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Inventario
58,2
60
63,4
68,2
78
84,7
90,6
98,2
101,7
102,7
108,3
124,7
157,9
158,2
170,2
180
198
Ventas
33,4
35,1
37,3
41
44,9
46,5
50,3
53,5
52,8
55,9
63
73
84,8
86,6
98,8
110,8
124,7
Et-1
-2,11951873
-2,89811373
-3,87155832
-4,06072192
-5,2970425
-1,85965069
2,23004851
1,93058412
4,30998253
8,95198913
4,89453134
-1,08867844
-1,00305841
12,9459732
10,3093848
2,40584127
-7,3714147
Et-2
-3,21951873
-2,11951873
-2,89811373
-3,87155832
-4,06072192
-5,2970425
-1,85965069
2,23004851
1,93058412
4,30998253
8,95198913
4,89453134
-1,08867844
-1,00305841
12,9459732
10,3093848
2,40584127
Et-3
-3,14065594
-3,21951873
-2,11951873
-2,89811373
-3,87155832
-4,06072192
-5,2970425
-1,85965069
2,23004851
1,93058412
4,30998253
8,95198913
4,89453134
-1,08867844
-1,00305841
12,9459732
10,3093848
Calculamos el estadístico Chi-2 multiplicando el R2 por T (0,991*17=16,84).
Chi Tabulado = prueba.chi.inv(0,05;3)=7,81
NSM = distr.chi(7,81;3)=0,000759. Es decir existe AR hasta 3º orden.
84
b) Test Q de Ljung y Box (1978) (Box-Jenkins model identification) 21
En un test muy popular para detectar correlación serial de altos órdenes, aunque sus resultados
son también asintóticos, es decir tiene baja potencia para correlaciones de bajos órdenes.
M
Q( M ) = T (T + 2)∑
i =1
ri 2
(T − i )
χ 2 (M )
≈
donde ri es el coeficiente de autocorrelación de los residuos al i-ésimo rezago. M es el número de
autocorrelaciones usadas, es decir M=1; M=2; etc, y la hipótesis es:
Ho: los coeficientes de correlación son cero, ρ1, ρ2, ρ3.....ρM=0
Se sugiere que la hipótesis se establezca de ρ1 = 0 hasta ρM, donde M es dado por:
⎞
⎛T
M = min⎜ , 3 T ⎟
⎠
⎝4
excepto para modelos ARIMA, en que el número de grados de libertad es M-(número de parámetros
ARMA).
Nota: Cuando se calculan autocorrelaciones para pruebas de correlación serial y evaluación de modelos
de autocorrelación, es deseable usar el mismo divisor a cualquier rezago, lo que preserva varias
propiedades deseables para varias consideraciones relacionadas con series de tiempo. Es decir, se
recomienda:
T
rt ,t −i =
∑e e
t =2
T
t −i
t
∑e
t =1
T
en lugar de rt ,t −i =
2
t
∑e e
t =2
t −i
t
T
T
t =2
t =2
∑ et2 ∑ et2−i
En consecuencia, por este motivo los resultados de esta prueba pueden variar levemente.
Ejemplo: En el ejemplo anterior (‘Inventarios_Ventas.xls’) se desea calcular el test Q
para diferente número de rezagos, desde 1 a 5. Los resultados usando la fórmula de
cálculo anterior es:
⎡ 0,6136 2 ⎤
2
Q(1) = 20(22) ⎢
⎥ = 8,71 ≈ χ (1) = 3,84
20
1
−
⎣
⎦
2
⎡ 0,6136
0,040 2 ⎤
2
Q(2) = 20(22) ⎢
+
⎥ = 8,75 ≈ χ (2) = 5,99
20 − 2 ⎦
⎣ 20 − 1
⎡ 0,6136 2 0,040 2 − 0,232 ⎤
+
+
Q(3) = 20(22) ⎢
⎥ = 10,23 ≈
20 − 2
20 − 3 ⎦
⎣ 20 − 1
χ 2 (3) = 7,81
k
21
Un test previo (ya obsoleto) fue el de Box-Pierce(1970):
Q * (k ) = T ∑ ri 2 ≈ χ 2 (k )
i =1
85
Ljung-Box Q-Statistics
Q(1) =
8,71. NSM= 0,003149
Q(2) =
8,75. NSM= 0,01258
Q(3) =
10,23. NSM= 0,01670
Luego, hay evidencia de autocorrelación hasta el 3º orden al 1% pero no al 5%.
86
4.3.4. CORRIGIENDO LA AUTOCORRELACION EN EXCEL
4.3.4.1. Primeras Diferencias
Hemos dicho que la forma de corregir la autocorrelación de errores de primer orden en RATS es a
través de primeras diferencias generalizadas (PDG), para lo cual es requerido una estimación del
coeficiente de correlación de los errores (ρ). La forma más simple es obtener una estimación de ρ a partir
del estadístico DW, sin embargo veremos métodos más precisos de estimación a través de la instrucción
AR1.
Veamos la implementación de PDG a través de un ejemplo:
Ejemplo:
En el ejemplo de inventarios y ventas (Tabla 5):
el modelo sin corregir:
Intercepción
Ventas
Coeficientes Error típico Estadístico t
6,60808463 3,32914979 1,98491659
1,631438 0,05097468 32,0048706
Durbin Watson: 493,906/798,848=0.69677. Puesto que dl=1,2 y du=1,41, hay evidencia de
autocorrelación de 1º orden positiva.
a) Aplicando Primeras Diferencias:
Intercepción
dX
Coeficientes Error típico Estadístico t
0,98563788 1,76329147 0,55897615
1,33869576 0,26216392 5,10633114
Durbin Watson: 782,18/456,26=1,71. Puesto que dl=1,18 y du=1,40, no hay evidencia de
autocorrelación de 1º orden positiva.
87
b) Aplicando Primeras Diferencias Generalizadas:
ρ = 1-%DURBIN/2 = 0.65161 es la estimación de ρ basada en DW
T
1
2
...
T
Y(*)
(1-ρ^2)^0,5 * Y
Yt-ρYt-1
...
Yt-ρYt-1
Y(*)
40,1275
19,3298
19,8434
22,4266
22,0763
24,3034
26,8879
33,5602
33,8744
35,4086
39,1641
37,7119
36,4313
41,3797
54,1306
76,6442
55,3108
67,1153
69,0960
80,7102
Intercepto
(1-ρ^2)^0.5
1-ρ
...
1-ρ
intercepto
0,7586
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
0,3484
X(*)
(1-ρ^2)^0,5 * X
Xt-ρXt-1
...
Xt-ρXt-1
X(*)
22,9842
11,1562
10,7653
13,2653
13,3362
14,4285
16,6949
18,1840
17,2427
20,0001
20,7240
17,9389
21,4950
26,5750
31,9486
37,2325
31,3435
42,3706
46,4209
52,5016
La regresión a correr (sin intercepto) es Y(*) = B1*Intercepto + B2*X(*)
Estadísticas de la regresión
Coeficiente de correlación múltiple
0,99495861
Coeficiente de determinación R^2
0,98994264
R^2 ajustado
0,93382834
Error típico
4,83628351
Observaciones
20
Intercepción
intercepto
X(*)
Coeficientes Error típico Estadístico t
0
#N/A
#N/A
9,83147214 5,79735915 1,69585356
1,56026736 0,08129833 19,1918757
Puesto que el nuevo Durbin-Watson = 1.259994 y dl=1.201 y du=1.411, se está ahora en la
zona de indecisión.
88
4.3.4.2. PDG: Métodos Alternativos
Existen varias opciones para la estimación del coeficiente ρ.
a) Método iterativos:
El principal método es el de Cochrane-Orcutt (1949), que corresponde a la opción CORC en RATS.
Consiste en correr el modelo original y guardar los residuos. Luego correr los residuos contra los residuos
rezagados (sin intercepto). Implementar PDG, calcular los residuos sobre el modelo original pero con los
nuevos coeficientes estimados y estimar nuevos residuos. Correr nuevamente PDG usando la ultima
estimación de ρ. Así sucesivamente hasta converger en la estimación de ρ. Estos métodos iterativos son
más rápidos, sin embargo no garantizan que se encuentre el óptimo. Si hay variables dependientes
rezagadas CORC entrega un resultado sesgado, y debe usarse HILU.
b) Método no iterativos:
El principal es el de Hidreth-Lu (1960), que corresponde a la opción HILU en RATS. Consiste en
calcular PDG usando diferentes valores de ρ entre -1 y 1. Se escoge aquel ρ que entregue la menor Suma
Cuadrada de Residuos. En muestras grandes entrega el mismo resultado de Máxima Verosimilitud.
Otros métodos basados en el criterio de máxima verosimilitud se implementan en RATS con la
opción SEARCH y con MAXL.
Podemos verificar estos resultados usando la instrucción AR1 con la opción CORC y MAXL de
RATS siguiendo el ejemplo anterior.
Ejemplo:
La corrección de Cochrane-Orcutt:
AR1(METHOD=corc) inventario
# CONSTANT ventas
Dependent Variable INVENTARIO - Estimation by Cochrane-Orcutt
Annual Data From 1980:01 To 1998:01
Usable Observations
19
Degrees of Freedom
16
Centered R**2
0.989581
R Bar **2
0.988278
Uncentered R**2
0.998409
T x R**2
18.970
Mean of Dependent Variable
105.87894737
Std Error of Dependent Variable 46.17620333
Standard Error of Estimate
4.99934157
Sum of Squared Residuals
399.89465850
Durbin-Watson Statistic
1.443620
Q(4-1)
6.140217
Significance Level of Q
0.10498413
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
15.871887522 9.651170285
1.64456 0.11956256
2. VENTAS
1.492261658 0.113915934
13.09967 0.00000000
*******************************************************************************
3. RHO
0.743057461 0.197925645
3.75423 0.00173224
;* el coeficiente ρ estimado es 0.743057461
89
Ejemplo:
La corrección de Hidreth-Lu
AR1(METHOD=hilu) inventario
# CONSTANT ventas
Dependent Variable INVENTARIO - Estimation by Hildreth-Lu
Annual Data From 1980:01 To 1998:01
Usable Observations
19
Degrees of Freedom
16
Centered R**2
0.989581
R Bar **2
0.988278
Uncentered R**2
0.998409
T x R**2
18.970
Mean of Dependent Variable
105.87894737
Std Error of Dependent Variable 46.17620333
Standard Error of Estimate
4.99934157
Sum of Squared Residuals
399.89465850
Durbin-Watson Statistic
1.443629
Q(4-1)
6.140247
Significance Level of Q
0.10498272
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
15.872102891 9.651368445
1.64454 0.11956494
2. VENTAS
1.492259063 0.113917491
13.09947 0.00000000
*******************************************************************************
3. RHO
0.743063504 0.197924711
3.75427 0.00173206
;* el coeficiente ρ estimado es 0.743063504
Al implementar la corrección AR1 en RATS, por simplicidad no se considera que la primera
observación tiene un tratamiento diferente de las demás, de modo que en realidad lo que se hace es
aplicar el procedimiento de PDG a las T observaciones. Verifiquemos entonces a través del siguiente
ejemplo como se implementa el procedimiento de Cochrane-Orcutt.
Ejemplo:
Para los datos del ejemplo de inventario y ventas, nótese que es posible
verificar paso a paso el resultado de la estimación de Cochrane-Orcutt anterior
como sigue:
COM RO = 0.743057461
;* definimos ρ como el obtenido en CORC
SET YP = inventario-RO*inventario{1}
SET X2P = ventas-RO*ventas{1}
SET X1P = 1-RO*1
LINREG YP
# X1P X2P
...
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. X1P
15.871887527 9.363010474
1.69517 0.10828013
2. X2P
1.492261658 0.110514689
13.50284 0.00000000
;* que corresponde al mismo resultado de CORC.
90
4.4.
ESTIMACION ROBUSTA
Si la forma de la varianza de los errores, E(εε'), es conocida, puede ser posible obtener
estimadores eficientes usando alguna forma de Mínimos Cuadrados Generalizados, tal como MCP (con
opción SPREAD en RATS) o a través de PDG (con la instrucción AR1 en RATS).
Sin embargo, si esto no ocurre, es decir, si no se tiene información acerca de la forma de E(εε'),
White(1980) y Newey y West (1987) mostraron que es posible obtener estimaciones robustas de los
coeficientes de regresión ante autocorrelación y heterocedasticidad, es decir resultados válidos para
grandes muestras (propiedades asintóticas). Veamos la mecánica de este procedimiento, llamado
estimación robusta.
Sabemos que la varianza de los coeficientes es:
cov( β ) = ( X ' X ) −1 X ' E (εε ' ) X ( X ' X ) −1
o alternativamente:
cov( β ) = ( X ' X ) −1 ⋅ m cov( X , ε ) ⋅ ( X ' X ) −1
donde
ε = son los errores del modelo de regresión
X = es la matriz de variables explicatorias
El procedimiento de estimación robusta define la matriz mcov de diferentes modos, como veremos
a continuación, a efectos de corregir la varianza de los errores y por este intermedio la matriz de
covarianzas de los coeficientes.
Ejemplo:
Si se tiene un modelo lineal del tipo
Yt = β 0 + β 1 X 1 + β 2 X 2 + ε t
y T=9
observaciones como sigue.
ALL 9
DATA(UNIT=INPUT,ORG=OBS) / y x1 x2
100
100
100
106
104
99
107
106
110
120
111
126
110
111
113
116
115
103
123
120
102
133
124
103
137
126
98
linreg y
# constant x1 x2
Dependent Variable Y - Estimation by Least Squares
Usable Observations
9
Degrees of Freedom
Centered R**2
0.938502
R Bar **2
0.918003
Uncentered R**2
0.999376
T x R**2
8.994
Mean of Dependent Variable
116.88888889
Std Error of Dependent Variable 12.55432639
Standard Error of Estimate
3.59493951
Sum of Squared Residuals
77.541540508
Regression F(2,6)
45.7825
Significance Level of F
0.00023258
Durbin-Watson Statistic
1.635298
6
91
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
-49.34133898 24.06088696
-2.05069 0.08616009
2. X1
1.36423789
0.14315290
9.52994 0.00007617
3. X2
0.11388062
0.14337364
0.79429 0.45728186
;* construimos la variable sigmaid conteniendo el error estándar de la
estimación (E(εε’)), y X la matriz conteniendo las variables explicativas (y un
vector de unos como intercepto). Podemos calcular la matriz de covarianzas de
los coeficientes como sigue:
com var =inv((tr(X)*X))*(tr(X)*X *sigmaid)*inv((tr(X)*X))
WRI VAR
578.9263
-2.6911
-2.5792
-2.6911
0.0205
3.5420e-003
-2.5792
3.5420e-003
0.0206
do II=1,3
wri (var(II,II))**0.5
end do
;* las desviaciones estándar de los coeficientes son
24.0609
0.1432
0.1434
;* que corresponde al resultado del modelo sin corregir.
4.4.1. CORRECCION DE WHITE (1980)
Intenta corregir solamente por heterocedasticidad reemplazando σ2 en σ2(X’X) por una matriz TxT
que contiene en su diagonal cada error al cuadrado, es decir pre y postmultiplicar X’X por el vector de
errores.
m cov = ∑t ε t X t ' X t − k ε t − k
y hacemos ddiag es la matriz diagonal que contiene los errores al cuadrado en la diagonal.
Ejemplo:
En el ejemplo anterior, obtenemos la matriz mcov corregida:
com var =inv((tr(X)*X))
WRI VAR
283.2035
-0.8457
-1.8279
*(tr(X)*ddiag*X)
-0.8457
7.7754e-003
-8.9365e-005
*inv((tr(X)*X))
-1.8279
-8.9365e-005
0.0177
do II=1,3
wri (var(II,II))**0.5
end do
16.8287
0.0882
0.1332
;* son los errores estándar de los coeficientes bajo la corrección de White.
92
En RATS la corrección anterior (solamente por heterocedasticidad) implica usar la opción
ROBUSTERRORS (sin LAGS).
Ejemplo:
linreg(robusterrors) y
# constant x1 x2
Dependent Variable Y - Estimation by Least Squares
Usable Observations
9
Degrees of Freedom
Centered R**2
0.938502
R Bar **2
0.918003
Uncentered R**2
0.999376
T x R**2
8.994
Mean of Dependent Variable
116.88888889
Std Error of Dependent Variable 12.55432639
Standard Error of Estimate
3.59493951
Sum of Squared Residuals
77.541540508
Durbin-Watson Statistic
1.635298
6
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
-49.34133898 16.82865139
-2.93198 0.00336804
2. X1
1.36423789
0.08817821
15.47137 0.00000000
3. X2
0.11388062
0.13317015
0.85515 0.39246742
;* lo que verifica la corrección (reducción) en el error estándar de los
coeficientes. Nótese que los coeficientes propiamente tales no se ven
alterados.
4.4.2. CORRECCION DE NEWEY Y WEST (1987)
Sugieren reemplazar σ2 por una suma de matrices TxT, las que son ponderadas de acuerdo a cada
rezago (k) considerando que el rezago máximo es L (note que en caso de White la ponderación es 1).
⎧
k ⎫
L
m cov = ∑k =− L ∑t et X t ' X t −k et −k ⋅ ⎨1 −
⎬
⎩ L + 1⎭
donde L indica el grado del error de medias móviles que se desea corregir por autocorrelación de acuerdo
al horizonte de predicción (por ejemplo si se trata de una predicción de k=3 periodos, entonces L=3-1=2,
y existirán 5 sumandos en mcov).
Ejemplo:
En el ejemplo anterior con T=9, si L=2, existirán 5 sumandos en mcov, y cada
una de ellos será ponderado por (1-2/3), (1-1/3), (1), (1+1/3), (1+2/3)
respectivamente.
Definamos x1 a la 1º fila de la matriz X; x2 la 2º fila, etc. y definamos u1 el
1º residuo; u2 el 2º residuo; etc.
La matriz mcov será la suma de:
com mcov = xx1+xx2+xx3+xx4+xx5
donde:
com xx1 = (u1*tr(x1)*x3*u3 + u2*tr(x2)*x4*u4 + u3*tr(x3)*x5*u5 + $
u4*tr(x4)*x6*u6 + u5*tr(x5)*x7*u7 + u6*tr(x6)*x8*u8 + u7*tr(x7)*x9*u9)*(1-2/3)
com xx2 = (u1*tr(x1)*x2*u2 + u2*tr(x2)*x3*u3 + u3*tr(x3)*x4*u4 + $
u4*tr(x4)*x5*u5 + u5*tr(x5)*x6*u6 + u6*tr(x6)*x7*u7 + u7*tr(x7)*x8*u8 + $
93
u8*tr(x8)*x9*u9 )*(1-1/3)
com xx3 = (u1*tr(x1)*x1*u1 + u2*tr(x2)*x2*u2 + u3*tr(x3)*x3*u3 + $
u4*tr(x4)*x4*u4 + u5*tr(x5)*x5*u5 + u6*tr(x6)*x6*u6 + u7*tr(x7)*x7*u7 + $
u8*tr(x8)*x8*u8 + u9*tr(x9)*x9*u9)*(1-0/3)
com xx4 = (u2*tr(x2)*x1*u1 + u3*tr(x3)*x2*u2 + u4*tr(x4)*x3*u3 + $
u5*tr(x5)*x4*u4 + u6*tr(x6)*x5*u5 + u7*tr(x7)*x6*u6 + u8*tr(x8)*x7*u7 + $
u9*tr(x9)*x8*u8 )*(1-1/3)
com xx5 = (u3*tr(x3)*x1*u1 + u4*tr(x4)*x2*u2 + u5*tr(x5)*x3*u3 + $
u6*tr(x6)*x4*u4 + u7*tr(x7)*x5*u5 + u8*tr(x8)*x6*u6 + u9*tr(x9)*x7*u7)*(1-2/3)
com mcov = xx1+xx2+xx3+xx4+xx5
com var = inv((tr(X)*X)) * (mcov) * inv((tr(X)*X))
;* la matriz de
covarianzas corregida de los coeficientes
do II=1,3
wri (var(II,II))**0.5
end do
;* son los errores estándar corregidos
En RATS este ajuste es ofrecido por la instrucción ROBUSTERRORS pero agregando la opción
LAGS=L (para corregir por autocorrelación hasta un proceso de medias móviles del grado L) y DAMP=1.0
(para el estimador de Newey-West, aunque pueden obtenerse otros ajustes con otro valor de DAMP, pero
son poco usados).
Ejemplo:
linreg(robusterrors, lags=2, damp=1) y
# constant x1 x2
Dependent Variable Y - Estimation by Least Squares
Usable Observations
9
Degrees of Freedom
Centered R**2
0.938502
R Bar **2
0.918003
Uncentered R**2
0.999376
T x R**2
8.994
Mean of Dependent Variable
116.88888889
Std Error of Dependent Variable 12.55432639
Standard Error of Estimate
3.59493951
Sum of Squared Residuals
77.541540508
Durbin-Watson Statistic
1.635298
6
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
-49.34133898 14.82204895
-3.32891 0.00087185
2. X1
1.36423789
0.09248540
14.75085 0.00000000
3. X2
0.11388062
0.08901050
1.27941 0.20075389
Una de las dificultades para implementar la estimación robusta puede ser determinar el valor
apropiado de L, aunque en muchos casos, éste proviene de la teoría, y el conocimiento que la sobre
posición de horizontes de predicción (overlapping) genera un termino de error tipo MA de orden k-1
(donde k es el horizonte de predicción). Así, por ejemplo errores en predicciones de 6 periodos tendrán un
proceso MA de orden 5 (L=5), con lo cual se captura la mayoría de la correlación serial
En resumen, en RATS la opción ROBUSTERRORS calcula los errores estándar de la regresión y la
matriz de covarianzas permitiendo heterocedasticidad y correlación serial de los residuos, y funciona junto
a LAGS y DAMP en las instrucciones LINREG, NLLS, NLSYSTEM, y MAXIMIZE. Pueden definirse
estructuras más complicadas usando la instrucción WMATRIX, que es la matriz de ponderaciones usada
junto a INSTRUMENTS.
94
4.4. MULTICOLINEALIDAD
En el modelo
Yt = β 0 + β 1 X 1 + β 2 X 2 + ε t
la multicolinealidad (o colinealidad) se presenta
cuando hay correlación lineal entre las variables explicativas X1 y X2, de modo que ambas variables, en el
fondo, están midiendo el mismo fenómeno.
La presencia de alta colinealidad entre las variables explicativas X1 y X2 impide que se pueda
estimar con precisión los coeficientes de la regresión, es decir el efecto de cada una de estas variables
sobre Y, debido a que MCO no puede "separar" el efecto de X1 sobre Y, y el efecto de X2 sobre Y. Así, se
esperan relativamente altos errores estándar para los coeficientes.
Ejemplo: Usando el archivo ‘multicolinealidad.xls’.
y
100
106
107
120
110
116
123
133
137
x1
100
104
106
111
111
115
120
124
126
a) Creamos la serie X2a, tal que X2a = 2*X1-4, donde X2a presenta multicolinealidad perfecta con X1, es
decir es una combinación lineal de X1. La correlación entre X1 y X2a es +1,0 en este caso.
b) Creamos la serie X2b, que es igual a X2a, con la única diferencia que la 1º observación es 200 en lugar
de 196. La correlación entre X1 y X2b es 0,9970693 en este caso, es decir extremadamente alta, pero no
perfecta.
4.4.1. MULTICOLINEALIDAD PERFECTA
En este caso MCO simplemente no puede estimar el coeficiente de X2 (no es posible invertir la
matriz (X’X) para calcular β). Contradictoriamente el estadístico R2 puede ser bastante alto, y el test F de
significancia global indicar que ambos coeficientes de pendientes son estadísticamente distintos de cero,
es decir en conjunto X1 y X2 explican Y, pero no individualmente. Verifiquemos esto con el ejemplo
anterior:
Ejemplo: En ‘multicolinealidad.xls’ corremos una regresión donde Y se explica por X1 y
X2. Pero puesto que están perfectamente correlacionadas, no es posible efectuar la
estimación en Excel.
4.4.2. MULTICOLINEALIDAD MUY ALTA
En este caso será posible obtener la estimación de los coeficientes, pero ésta será muy ruidosa. A
pesar de no existir pruebas estadísticas formales, para la detección de multicolinealidad, es posible
calcular ciertos estadísticos que pueden ayudar a diagnosticar la presencia de multicolinealidad, se trata
de estadísticos orientativos, que si bien pueden ayudarnos a determinar si existe mayor o menor grado de
multicolinealidad, no permiten tomar una decisión clara sobre la presencia o no de ésta.
El nivel de tolerancia: Este valor se obtiene de la diferencia 1-R2, aunque el R2 se obtiene de regresar esa
variable sobre el resto de las variables independientes. Valores de tolerancia muy pequeños indican que la
95
respectiva variable puede ser explicada por una combinación lineal del resto de variables independientes,
lo cual significa que existe multicolinealidad.
Factores de inflación de la varianza (VIF): Estos valores corresponden a los inversos de los niveles de
tolerancia. Reciben este nombre porque son utilizados en el cálculo de las varianzas de los coeficientes de
regresión. Cuanta mayor es el VIF de una variable, mayor es la varianza del correspondiente coeficiente
de regresión. De ahí que uno de los problemas de la existencia de multicolinealidad (tolerancias pequeñas
y VIF’s grandes) se la inestabilidad de las estimaciónes de los coeficientes de regresión.
Podemos concluir que la multicolinealidad aumenta el error en la estimación de los coeficientes
individuales, disminuyendo los test t. Luego, que sospechamos existencia de multicolinealidad cuando los
coeficientes individuales tienen bajas significancias, pero el estadístico R2 es alto. También, dado el alto
error, los coeficientes estimados son altamente sensibles a cambios en las observaciones, de modo que
por ejemplo eliminando un dato, los coeficientes cambiarán importantemente. El último aspecto es las
predicciónes del modelo con multicolinealidad serán peores (alto error) que aquellas obtenidas
considerando solo un pequeño grupo de variables explicativas que no son colineales.
Otra forma de detectar la colinealidad (alta) es considerar la Regla de Klein (1962) que afirma que
"la multicolinealidad es un problema sólo si la correlación simple entre dos variables es mayor que la
correlación entre alguna éstas con la variable explicada (Y)".
4.5.3. SOLUCIONES A LA MULTICOLINEALIDAD
Existen varios métodos, algunos relativamente complejos, que intentan solucionar la
multicolinealidad, sin embargo la multicolinealidad es un problema de la muestra (de los datos) y poco
puede hacerse, a no ser que se disponga de más información del proceso en estudio, de modo que la
solución básica se encuentra en encontrar más información.
Caminos de solución alternativos son eliminar del modelo una de las series que presentan
colinealidad. Sin embargo debe considerarse que esto puede introducir error de especificación.
96
CAPÍTULO 5
ESTACIONARIEDAD Y COINTEGRACIÓN
5.1. REGRESIONES ESPUREAS
En muchas ocasiones se estiman modelos de regresión de series de tiempo, en los que tanto X
como Y están afectos a fuertes tendencias temporales.
Ejemplo: Sean los siguientes datos los Precios Accionario de Endesa (Y) y el valor del Indice General de
precios accionarios (IGPA) (X):
600
500
400
300
T
t
t+1
t+2
t+3
t+4
t+5
t+6
P_Endesa
67
170
220
175
280
350
300
Igpa
150
200
220
350
400
410
500
200
100
0
t
t+1
t+2
t+3
P_Endesa
t+4
t+5
t+6
IGPA
Si corremos una regresión entre el precio accionario de Endesa (Y) y el Indice de Precios Accionarios (X)
se tiene que:
Intercepción
Variable X 1
Coeficientes Error típico Estadístico t
29,0375919 62,8781058 0,46180768
0,60929904 0,18467334 3,29933402
Y los resultados aparecen satisfactorios (para la pendiente) a la luz del estadístico t. Sin embargo
analizando el gráfico, ambas series X e Y muestran una fuerte tendencia.
97
Una forma de eliminar la tendencia temporal es calcular las primeras diferencias de X e Y. Para esto
calculamos las rentabilidades, que son:
T
t
t+1
t+2
t+3
t+4
t+5
t+6
P_Endesa
67
170
220
175
280
350
300
Igpa
150
200
220
350
400
410
500
Rent_Endesa Rent_IGPA
1,537
0,294
-0,205
0,600
0,250
-0,143
0,333
0,100
0,591
0,143
0,025
0,220
1,800
1,600
1,400
1,200
1,000
0,800
0,600
0,400
0,200
0,000
-0,200
-0,400
t+1
t+2
t+3
Rent_Endesa
t+4
t+5
t+6
Rent_Igpa
En efecto, en el gáfico parece desaperecer la tendencia. Los resultados de la regresión entre la
rentabilidad de Endesa y la variación porcentual del IGPA es ahora:
Intercepción
Variable X 1
Coeficientes Error típico Estadístico t
0,46561786 0,46613367 0,99889342
-0,325641 1,55449381 -0,20948363
Con esto se aprecia que la calidad de los resultados cae fuertemente, entregando evidencia que la
1º regresión (con tendencia) arrojó resultados satisfactorio solamente debido a la existencia de una
tendencia, pero no debido a que existiera una relación verdadera entre ellas.
Así, se entiende que un supuesto clave para la consistencia del modelo de regresión es, aparte de
la linealidad, la Dependencia Débil.
Para analizar este punto con mayor detalle, pasamos a continuación a definir el concepto de
Estacionariedad.
98
5.2. ESTACIONARIEDAD
5.2.1. DEFINICIÓN
La principal definición de estacionariedad (estacionariedad débil) implica que la media (μ) y la
varianza (σ2) del proceso son constantes, y las autocovarianzas (γk) y autocorrelaciones (ρk) dependen
sólo del rezago k (γ0=V(xt)) 22.
Las principales implicancias de la estacionariedad para nuestros fines son dos:
a)
La existencia de estacionariedad asegura que la varianza del proceso es finita y que una
innovación en el proceso tiene solamente un efecto temporal sobre éste.
b)
Cuando no exista estacionariedad para dos series X e Y, una regresión entre éstas será espuria,
en el sentido que existirá un alto R2 debido a la existencia de una tendencia y no debido a una fuerte
relación entre las variables.
Respecto al concepto de Integración, se dice que una serie yt no estacionaria es integrada de
orden “d”, y se representa como yt~I(d), cuando puede ser transformada en una serie estacionaria
diferenciándola “d” veces.
Una caracterización típica de las series I(0) e I(1) es la siguiente:
5.2.2. SERIE ESTACIONARIA
Un buen ejemplo de serie estacionaria es el llamado Ruido Blanco (White noise). Un Ruido blanco
es un proceso estocástico donde los Xt son todos identica e independientemente distribuídos (Cov=0). Por
definición un ruido blanco es estacionario.
22
La Estacionariedad Estricta implica que, además de lo anterior, el proceso no es afectado por un cambio de origen de
tiempo. Bajo normalidad conjunta el set de momentos caracterizan completamente las propiedades del proceso, es
decir ambas estacionariedades son equivalentes.
99
Ejemplo: Un proceso ruido blanco puede ser simulado en Excel a través de: =Aleatorio().
Realizamos un gráfico y obtenemos 100 valores simulados;
1,2
1
0,8
0,6
0,4
0,2
0
1
7
13 19 25 31 37 43 49 55 61 67 73 79 85 91 97
Nótese que la media parece ser constante (igual a 0,5) y que la volatilidad parece también
constante, por lo que esta serie parece ser estacionaria.
Una mejor forma de realizar una simulación en Excel es a través de:
Herramientas-> Analisis de Datos -> Generación de Numeros Aleatorios ->
Otro ejemplo de proceso estacionario es un de medias móviles (moving average process) de
orden 1 [MA(1)] que puede ser caracterizado por xt = et + a1et-1, t = 1, 2, … siendo et una una secuencia
iid con media 0 y varianza
σ e2 .
Esta es una secuencia estacionaria debilmente dependiente, con variables
correlacionadas en 1 periodo, pero no para 2 periodos.
Ejemplo: Procesos Estacionarios:
a)
b)
X t = β 2 X t −1 + ε t
X t = β1 + β 2 X t −1 + ε t
−1 < β2 < 1
−1 < β2 < 1
100
5.2.3. SERIE NO ESTACIONARIA
Una serie es no estacionaria cuando presenta alguna tendencia, sea ésta determinística o
estocástica. Ejemplos típicos de series no estacionarias son los índices de precios accionarios, o los índices
de precios o de actividad económica. En economía los Random Walk 23 son usados para modelar esto.
El siguiente gráfico muestra 8 random walks comenzando en 0.
Un random walk pueder ser representado por un proceso autoregresivo de orden 1. Un proceso
autoregresivo de orden 1 [AR(1)] puede ser caracterizado por yt = r yt-1 + et , t = 1, 2,… con et una
secuencia iid con media 0 and variance
σ e2 .
Para que este proceso sea débilmente dependiente |r| < 1.
Corr(yt ,yt+h) = Cov(yt ,yt+h)/(sysy) = r1h , el que disminuye al aumentar h.
A random walk is integrated of order one, [I(1)], meaning a first difference will be I(0)
Ejemplo: Procesos no estacionarios:
a) Random Walk:
X t = X t −1 + ε t , es decir un proceso AR(1) con coeficiente 1, meaning the series is not
weakly dependent.
b)
X t = β1 + X t −1 + ε t
c)
X t = β1 + β 2 t + ε t
(Random walk with drift)
(Deterministic trend)
23
Los random walks tienen dos propiedades importantes: la propiedad de Markov (la única información relevante para
el valor futuro de la variable es su valor actual), y la propiedad de martingala (la expectativa condicional de un valor
futuro de la variable es su valor actual). En el caso de una martingala, si bien los cambios en la variable deben ser
siempre cero, no necesitan tener varianza constante, ni las innovaciones ser independientes. En el caso de una
tendencia positiva se llaman sub-martingalas, y en el caso de tendencias negativas supramartingalas.
101
Ejemplo: Consideremos el Índice General de Precios de las Acciones (IGPA) de la Bolsa de
Comercio de Santiago (Valor Nominal mensual) ‘Tabla 14.xls’:
IGPA mensual
1990.01 - 2001.03
2000,09
2000,01
1999,05
1998,09
1998,01
1997,05
1996,09
1996,01
1995,05
1994,09
1994,01
1993,05
1992,09
1992,01
1991,05
1990,09
1990,01
7000,00
6000,00
5000,00
4000,00
3000,00
2000,00
1000,00
0,00
Así, puesto que la serie IGPA parece tener una tendencia, creemos que no es estacionaria. Sin
embargo existen pruebas formales de estacionariedad, como veremos a continuación.
102
5.3. PRUEBAS DE ESTACIONARIEDAD
5.3.1. CORRELOGRAMA Y TEST Q 24
Una característica de las series no estacionarias es que las autocorrelaciones de las realizaciones
comienzan en un valor muy alto (cercano a 1.0) y disminuyen lentamente para grandes rezagos. En
cambio para series estacionarias se esperaría que la caída de las correlaciones sea muy fuerte, y no
gradual.
Ejemplo: Para la serie IGPA calcular valor del estadístico Q de Ljung-Box hasta 3
rezagos:
⎡ 0,990 2 ⎤
2
Q(1) = 135(137) ⎢
⎥ = 135,27 ≈ χ (1) = 3,84
134
⎣
⎦
⎡ 0,990 2 0,974 2 ⎤
2
Q(2) = 135(137) ⎢
+
⎥ = 267,19 ≈ χ (2) = 5,99
133 ⎦
⎣ 134
⎡ 0,990 2 0,974 2 0,959 2 ⎤
2
Q(3) = 135(137) ⎢
+
+
⎥ = 396,34 ≈ χ (3) = 7,81
134
133
132
⎣
⎦
Se aprecia que las autocorrelaciones descienden en forma gradual a medida que aumenta el
número de rezagos. Fijándonos en el último rezago (3), el valor del estadístico Q es 390,77 con un nivel
de significancia de 0.000; por lo tanto, rechazamos la hipótesis que las correlaciones sean cero.
A su vez, el gráfico de las autocorrelaciones luestra que éstas en efecto disminuyen gradualmente,
como se esperaría en el caso de una serie no estacionaria.
1.0
ACF
0.9
0.8
0.7
0.6
0.5
0.4
0.3
J
F
M
A
M
J
J
1990
A
S
O
N
D
J
F
M
A
M
J
J
1991
A
S
24
Recordemos que el correlograma, al igual que la prueba de Ljung-Box han sido utilizados anteriormente para
detectar la autocorrelación de los residuos.
103
A efectos de comparación podemos calcular las correlaciones de un ruido blanco.
Ejemplo: Generando una serie de números aleatorios provenientes de una distribución
Normal con media 0 y desviación estándar 1, calculamos los estadísticos Q(1), Q(2) y
Q(3). Puesto que se trata de números aleatorios, los resultados no serán identicos, sin
embargo se obtendrá que Q(1)≈0,9, Q(2)≈1,6 y Q(3)≈2,7; por lo que ahora la hipótesis que
las correlaciones son cero (estacionariedad) no es rechazada, implicando que no se
encuentra evidencia de que la serie sea no estacionaria.
A continuación veremos otro tipo de pruebas formales, llamadas de raíces unitarias, que han sido
muy populares (y también criticadas) en los años recientes.
104
5.3.2. PRUEBAS DE RAICES UNITARIAS: Dickey y Fuller 25
Subyacente en el concepto de una prueba de raíz unitaria se encuentra la existencia de una fuerte
relación entre la realización de una serie en el momento t y la realización de esta misma serie en el
momento t-1. Esto es medido a través de la siguiente regresión:
Yt = β ⋅ Yt −1 + ε t
donde ε en un error bien comportado. Si β es igual a 1.0 (Ho:ρ=1.0), es decir un proceso AR(1), entonces
la serie no es estacionaria, y además se dice que tiene una “raíz unitaria”. La serie con esta característica
es llamada un Random-Walk. Luego, la hipótesis de raíz unitaria es Ho: β=1.0.
Sin embargo Dickey y Fuller (1979, 1981) mostraron que, para la hipótesis anterior, la tradicional
prueba t no puede se aplicada, pues existe sesgo. En cambio mostraron que los valores correctos son, en
el caso de correr la regresión con intercepto:
-
al 90% el coeficiente β estimado es menor que 2.58 errores estándar de la unidad
al 95% el coeficiente β estimado es menor que 2.89 errores estándar de la unidad
al 99% el coeficiente β estimado es menor que 3.51 errores estándar de la unidad
En la práctica es más simple escribir el modelo anterior como sigue:
Yt − Yt −1 = ( β − 1)Yt −1 + ε t
ΔYt = ( β − 1)Yt −1 + ε t
ΔYt = ρ ⋅ Yt −1 + ε t
de modo que la hipótesis cambia ahora a Ho: ρ=0.0, haciendo más simple de estimar la hipótesis.
Ejemplo: Correremos una regresión de la serie IGPA (135 observaciones) contra la misma
serie rezagada en un período (‘Tabla 14.xls’).
a)
Yt = β ⋅ Yt −1 + ε t
Intercepción
Variable X 1
b)
Coeficientes Error típico Estadístico t
0
#N/A
#N/A
1,0036686 0,00430903 232,922307
tau =
(β
− 1)
σβ
=
(1,0036686
0 , 004309
− 1)
= 0 ,8513
ΔYt = ρ ⋅ Yt −1 + ε t
Intercepción
Variable X 1
Coeficientes Error típico Estadístico t
0
#N/A
#N/A
0,0036686 0,00430903
0,8513744
tau =
β
0 , 0036686
=
= 0 ,8513
0 , 004309
σρ
Puesto que 0,8513 < 2,89 no podemos rechazar que la serie IGPA es no estacionaria
(Ho: Existe raiz unitaria).
25
El conjunto de pruebas anteriores son llamadas de Dickey y Fuller. Existe un número importante de otras pruebas de
raíces unitarias especializadas, entre las cuales es usual la de Phillips–Perron.
105
5.3.3. PRUEBAS DE RAICES UNITARIAS: Augmented Dickey Fuller (ADF) Test
Dickey y Fuller proponen una serie de regresiónes más generales para verificar la existencia de
raíces unitarias, las que son conocidas como pruebas de Dickey y Fuller Aumentadas (ADF):
p
Modelo 1:
ΔYt = ρYt −1 + ∑ β i ΔYt −i +1 + ε t
(modelo básico + DY rezagados)
i=2
p
Modelo 2:
ΔYt = α + ρYt −1 + ∑ β i ΔYt −i +1 + ε t
(modelo 1 + intercepto)
i =2
p
Modelo 3:
ΔYt = α + ρYt −1 + δt + ∑ β i ΔYt −i +1 + ε t
(modelo 2 + tendencia)
i =2
En estas pruebas deben agregarse rezagos de dY hasta que et son ruido blanco, lo que es una
condición necesaria para que este test sea válido. El número apropiado de rezagos puede encontrarse por
el criterio BIC, aunque pueden plantearse otros criterios alternativos 26.
Los valores críticos usuales son 1%, 5%, y 10% los que dependen del tamaño de la muestra. Los
valores críticos pueden obtenerse de Hamilton (1994, Tabla B.6).
26
(1) AIC criterion, (2) BIC criterion (el más usado), (3) agregando rezagos (lags) hasta que el test de Ljung-Box test
no rechace no correlación serial a un nivel de significancia, (4) idem con el Lagrange Multiplier test, o (5) partiendo con
un número máximo de diferencias rezagadas, si la última es significativa, elija ese número de rezagos, si no se reduce
en uno hasta que el último rezago inluido es ignificativo.
106
Ejemplo: En el ejemplo del IGPA (Tabla 14.xls), implementar Augmented Dickey-Fuller ttest para los modelos 1, 2 y 3:
Modelo 1: Minimum AIC at lag: 2; Minimum BIC at lag: 2.
ΔYt = ρYt −1 + [β 2 ΔYt −1 + β 3 ΔYt −2 ] + ε t
linreg digpa
# igpa{1} digpa{1} digpa{2}
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. IGPA{1}
0.002606237 0.004043451
0.64456 0.52035847
2. DIGPA{1}
0.429916390 0.085891215
5.00536 0.00000179
3. DIGPA{2}
-0.228846913 0.086136727
-2.65679 0.00888546
* Augmented Dickey-Fuller t-test with 2 lags:
*
1%
5%
10%
*
-2.58
-1.95
-1.62
0.6446
*
*
*
Modelo 2: Minimum AIC at lag: 2; Minimum BIC at lag: 2.
ΔYt = α + ρYt −1 + [β 2 ΔYt −1 + β 3 ΔYt −2 ] + ε t
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
115.4506088
48.6524791
2.37296 0.01913416
2. IGPA{1}
-0.0225541
0.0113227
-1.99193 0.04850725
3. DIGPA{1}
0.4141438
0.0846512
4.89236 0.00000294
4. DIGPA{2}
-0.2312968
0.0846373
-2.73280 0.00716841
* Augmented Dickey-Fuller t-test with 2 lags:
*
1%
5%
10%
*
-3.46
-2.88
-2.57
-1.9919
*
*
*
Modelo 3: Minimum AIC at lag: 2; Minimum BIC at lag: 2.
ΔYt = α + ρYt −1 + δt + [β 2 ΔYt −1 + β 3 ΔYt −2 ] + ε t ,
t=1,2, ...
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
115.7046426
48.9172119
2.36532 0.01952855
2. TREND
0.0617520
0.6593128
0.09366 0.92552598
3. IGPA{1}
-0.0237014
0.0167111
-1.41830 0.15855218
4. DIGPA{1}
0.4149103
0.0853740
4.85991 0.00000340
5. DIGPA{2}
-0.2299966
0.0860934
-2.67148 0.00854127
* Augmented Dickey-Fuller t-test with 2 lags:
*
1%
5%
10%
*
-3.99
-3.43
-3.13
-1.4183
*
*
*
En los tres casos nos lleva a concluir que no se rechaza Ho, es decir existe raíz
unitaria en el IGPA.
107
5.3. DIFERENCIACION DE SERIES I(1)
Un proceso que contiene una raíz unitaria es denotado I(1). En estos casos es posible eliminar la
raíz unitaria diferenciando las series, esto es, calculando la primera diferencia. En series que contienen
dos raíces unitarias, I(2), se debe diferenciar dos veces para obtener una serie estacionaria, y así
sucesivamente.
El problema es que en muchas ocasiones la serie resultante de la diferenciación no es de interés,
por lo que debe buscarse un camino de solución alternativo. Afortunadamente en el caso del IGPA, la
diferenciación nos lleva a obtener una serie de rendimientos, de modo que la recomendación para los
estudios financieros-bursátiles es usar las series de rendimientos del IGPA en lugar del GPA propiamente
tal.
Verifiquemos ahora que la serie diferenciada del IGPA, es decir los rendimientos accionarios, es
estacionaria.
Ejemplo: Calculamos la 1º diferencia y los rendimientos mensuales del IGPA; y graficamos
la nueva serie:
Diferenciacion del IGPA vs Rentabilidad del IGPA
800,00
25,00%
20,00%
600,00
15,00%
400,00
10,00%
200,00
5,00%
19
9
19 0,02
90
19 ,06
90
19 ,10
91
19 ,02
91
19 ,06
91
19 ,10
9
19 2,02
9
19 2,06
9
19 2,10
93
19 ,02
93
19 ,06
93
19 ,10
94
19 ,02
94
19 ,06
9
19 4,10
95
19 ,02
95
19 ,06
95
19 ,10
96
19 ,02
96
19 ,06
9
19 6,10
97
19 ,02
9
19 7,06
97
19 ,10
98
19 ,02
98
19 ,06
98
19 ,10
9
19 9,02
9
19 9,06
9
20 9,10
00
20 ,02
00
20 ,06
00
20 ,10
01
,0
2
0,00
0,00%
-200,00
-5,00%
-400,00
-10,00%
-600,00
-15,00%
-800,00
-20,00%
D_IGPA
R_IGPA
El gráfico de la serie muestra que esta parece ahora ser estacionaria. Veamos lo que nos dice el
test de Dickey-Fuller. Corremos la regresión de los rendimientos del IGPA contra la misma serie rezagada
en 1 periodo. Omitiendo parte de la salida, los resultados son:
t=
− 0 ,5783
= − 7 . 36
0,07852
Así, con una significancia del 5% y valor critico –2,88, se rechaza la existencia de raíz unitaria. Esta
prueba no encuentra una raíz unitaria y afirma que la serie diferenciada es estacionaria. El econometrista
108
experimentado notará del gráfico de la serie IGPA, que existe la posibilidad de un quiebre significativo en
1995, de modo que sugerirá otras pruebas de raíces unitarias que mejor se ajusten a este caso.
Cuando la serie diferenciada no sea de interés, puede seguirse el camino tradicional de incorporar
una variable de tendencia a la regresión, la que tiene por objeto justamente capturar la tendencia
dejando que el coeficiente estimado de la serie I(1) libre del efectos de la tendencia, de modo que la
regresión es válida.
Otras formas de eliminar raíces unitarias, consiste en aplicar logaritmos naturales para calcular
rendimientos contínuos, y la deflactación a moneda real.
set lrrate = Log(rrate)
set lpgnp = log(pgnp)
;* el deflactor del Producto
linreg lrrate
# constant lrrate{1} lpgnp{1}
set lrooms = log(rooms)
set lrgnp = log(gnp/pgnp)
linreg lrooms
# constant lrooms{1} lrgnp{1}
Sin embargo actualmente se distingue entre tendencias determinísticas y estocásticas,
afirmándose que este último procedimiento (incorporar una tendencia) solo es posible en el caso de una
tendencia determinística. En caso contrario, la única posibilidad es verificar la existencia de cointegración,
lo que justificaría correr regresiónes entre variables I(1), sin que el resultado de ésta sea espurio. Este
tópico (cointegración) será tratado a continuación.
109
5.4. COINTEGRACIÓN: PRUEBA DE ENGLE-GRANGER
5.4.1. INTRODUCCIÓN
Si se tiene un modelo de regresión en que tanto la variable dependiente como la independiente
son I(1), entonces se tendrá una regresión espuria, puesto que la presencia de las tendencias
contaminará los resultados. Esto, a menos que ambas series tengan una relación de equilibrio de largo
plazo, es decir, que estén COINTEGRADAS.
Se dice que dos series (o más) están cointegradas si una combinación lineal de éstas es
estacionaria, es decir:
X es I (1)⎫
⎬ si aX + bY es I (0) ⇒ X e Y están cointegradas
Y es I (1) ⎭
Entonces, es posible estimar regresiones con variables X e Y conteniendo una raiz unitaria,
siempre y cuando ambas estén cointegradas, pues de lo contrario surgirá el problema de Regresión
Espúrea.
Para analizar el caso de la Regresión Espúrea, consideremos dos series X1t, x2t y zt, tales que:
x1t ≈ I (1)
x2t ≈ I (1)
zt = α 0 + α 1 x1t + α 2 x2t ;
z t ≈ I (1)
Reordenando esta combinación lineal se tiene que:
con
Las implicancias son, por un lado los residuos son I(1), es decir
ε t ≈ I (1) , por lo que no se
cumplen las condiciones subyacentes del modelo de regresión lineal. En efecto:
Puesto que OLS ya no son consistentes, implicando que los resultados de la regresión (pruebas t y
F) están erradas. En particular, los resultados de una regresión que incluye variables no estacionaras
independientes están caracterizadas por:
110
- Muy altos R cuadrados
- Muy altos valores t
- Bajos Durbin Watson d
Lo anterior es lo que se conoce como el famoso ‘Problema de la Regresión Espúrea’: cuando
regresionamos variables no estacionarias, los resultados de la estimación no deben ser tomados
seriamente.
5.4.2. DEFINICIÓN FORMAL DE COINTEGRACION
Las variables de kx1 vextores
(d,b), denotado por
xt ≈ CI (d , b) , si:
se dice que están cointegradas de grado
a) todas las variables xt son I(d)
b) existe al menos un vector de coeficientes
tal que la combinación lineal
es integrada de un orden menor, es decir:
β ⋅ xt ≈ I (d − b) . Beta es
conocido como el vector cointegrante (cointegrating vector).
Ejemplo: Si
x1t ≈ I (1)
y
x2t ≈ I (1)
y los residuos de la regresión
son I(0),
entonces x1 y x2 se dice que están cointegradas de orden CI(1,1), con vector cointegrante
La Interpretación Económica es que si dos o más series están unidas por una relación de
equilibrio, entonces aún cuando las series en sí mismas son no estacionarias, ellas sin embargo se
moverán casi juntas a través del tiempo, y la diferencia entre ellas será estacionaria. El concepto de
cointegración indica la existencia de un equilibrio de largo plazo al cual el sistema económico converge a
través del tiempo, y et puede ser interpretado como el error de desequilibrio, es decir la distancia a que el
sistema se encuentra alejado del equlibrio en el momento t.
Desde el punto de vista econométrico, si dos variables están cointegradas, el análisis de regresión
entrega información importante acerca de la relación de largo plazo entre las variables. Si dos variables
no estacionarias no están cointegradas, los resultados de la regresión no son útiles, es decir se se tiene
una regresión espúrea.
111
Por Ejemplo, las siguientes series xit y x2t están cointegradas, con vector cointegrante (1,-1).
25
20
15
10
6
5
4
0
2
-5
0
-2
-4
-6
50
100
Residual
150
Actual
200
250
Fitted
Puesto que los errores son I(0), ambas series están cointegradas.
112
5.4.3. PRUEBA DE ENGLE-GRANGER (1987)
El procedimiento de Engle-Granger para detectar cointegración es muy simple e intuitivo.
Paso 1: Verificar el orden de integración de las variables. Verificar que ambas son I(1). Por ejemplo,
suponemos que tanto el ingreso como el consumo son I(1):
CONSUMOt = β 0 + β 1 INGRESO + ε t
Paso 2: Para que exista cointegración, el error, que es una combinación lineal de las series, debe ser
estacionario, I(0):
ε t = CONSUMOt − β 0 − β 1 INGRESO
Si los errores son I(1) concluimos que las variables no están cointegradas. Si los residuos son I(0)
decimos que las variables son cointegradas de orden (1,1). Lamentablemente aquí tampoco pueden
usarse los valores críticos de Dickey-Fuller, sino que por ejemplo los de Engle y Yoo (1987) o de acuerdo
a MacKinnon (1991), como se muestra en la siguiente tabla.
113
5.4.4. TEOREMA DE REPRESENTACION DE GRANGER
El concepto de cointegración se refiere a un equilibrio, en el cual las variables convergen en el
largo plazo. Este equilibrio de largo plazo puede ser observado raramente, por lo que es interesante
considerar la evolución de corto plazo de las variables, es decir la dinámica del ajuste.
Un enfoque simple para esto es el llamado Modelo de Correccion de Errores (ECM), que proviene
del Teorema de Representación de Granger, el que establece que si un conjunto de variables están
cointegradas, entones existe una representación de los datos del tipo error-corrección.
Si x1t y x2t son CI(1,1), con vector cointegrante
corrección de errores (ECM) de forma general dada por:
, entonces existe un modelo de
donde:
Son polinomios quepermiten una estructura más rica al proceso.
Este modelo incorpora los efectos de corto y de largo plazo. En efecto:
a) El efecto de largo plazo está dado por el vector cointegrante:
b) Cuando el sistema está en equilibrio:
, puesto que e mide la distancia del
sistema del equilibrio en el momento t.
c) El parámetro alfa mide la velocidad de ajuste, es decir cómo x1t-1 cambia en respuesta al desequilibrio
et en el momento t. (Si x1t y x2t son cointegradas, alfa es distinto de cero).
d) El parámetro delta captura un posible cambio (drift) en las series.
Ejemplo: Para estimar el modelo de corrección de errores. Esto es, si las series son cointegradas (1,1), a
corto plazo puede haber desequilibrios, que son capturados por el término de error. Luego, la regresión
es:
ΔCONSUMOt = β 0 + β 1ΔINGRESO + β 2 et −1 + ut
donde se espera que el nuevo error, u, esté bien comportado.
En esta especificación de corrección de errores el coeficiente β1 captura las perturbaciones de
corto plazo la variable INGRESO, mientras que β2 captura las perturbaciones de largo plazo, o el ajuste de
largo plazo, indicando qué proporción del desequilibro en el CONSUMO en un periodo es corregida en el
periodo siguiente.
114
Ejemplo: A modo de ilustración, considere la tabla en el archivo ‘Pindyck - EX164.xls’ que precios del
petrólero y del cobre desde 1870 a 1987.
En primer lugar verificamos si el petroleo es estacionario:
* Augmented Dickey-Fuller t-test with 5 lags:
*
1%
5%
10%
*
-2.58
-1.95
-1.62
0.2295
*
*
*
Como conclusión, contiene una raiz unitaria.
Calculamos la primera diferencia del petróleo y obtenemos:
* Augmented Dickey-Fuller t-test with 4 lags:
*
1%
5%
10%
*
-2.58
-1.95
-1.62
-6.5234
*
*
*
-1.1085
*
*
*
-11.2136
*
*
*
Como conclusión, solo posee 1 raíz unitaria.
Repetimos para el cobre:
* Augmented Dickey-Fuller t-test with 0 lags:
*
1%
5%
10%
*
-2.58
-1.95
-1.62
Para la primera diferencia se tiene que:
* Augmented Dickey-Fuller t-test with 0 lags:
*
1%
5%
10%
*
-2.58
-1.95
-1.62
Como conclusión, solo posee 1 raíz unitaria.
Corremos ahora la regression:
oil = alfa + beta copper
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
5.053783705 0.666379893
7.58394 0.00000000
2. COPPER
-0.022111545 0.017261735
-1.28096 0.20276371
Y analizamos si los residuos tienen una raiz unitaria:
* Augmented Dickey-Fuller t-test with 0 lags:
*
1%
5%
10%
*
-2.58
-1.95
-1.62
-3.1511
*
*
*
De modo que las series están cointegradas.
115
Ahora podemos estimar el modelo de corrección de errors:
Doil = alfa + beta*dcopper + gama*err{1}
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. Constant
-0.019713655 0.095227174
-0.20702 0.83636581
2. DCOPPER
0.003278421 0.014628690
0.22411 0.82307364
3. ERR{1}
-0.138753133 0.044560449
-3.11382 0.00233565
Y concluímos que los ajustes de largo plazo aparecen como los más importantes y significativos.
5.5. COMENTAROS FINALES
Por último debemos notar que aún existen importantes problemas en la aplicación de las técnicas
de regresión requeridas para implementar la prueba de cointegración de Engle y Granger, especialmente
las referidas a los valores críticos de las pruebas para pequeñas muestras.
También debemos comentar que existe otra técnica de detección de la cointegración entre series y
es la de Johansen (1988) basada en el principio de máxima verosimilitud, la que supera una de las críticas
al esquema de Engle-Granger, el que requiere definir a priori cual de las variables será la dependiente y
cual la independiente en la regresión (cuando existen muchas variables es posible que exista
cointegración bajo una especificación y no en otra) y que éste procedimiento sea un estimador de dos
pasos (se requieren dos regresiónes).
116
CAPÍTULO 6
INTRODUCCIÓN A LA PREDICCIÓN EN
EXCEL
En este capítulo desarrollaremos la predicción (estática). Más adelante, en siguientes capítulos se
tratará la predicción dinámica (modelos ARIMA). También es importante notar que existen muchas formas
de efectuar predicciónes, incluyendo modelos de Vectores Autorregresivos, Sistemas de Ecuaciones
Simultáneas y Análisis Espectral. Sin embargo, por ahora analizaremos la técnica tradicional para la
predicción estática en un contexto de mínimos cuadrados ordinarios.
El siguiente esquema ilustra simplificadamente las diferentes técnicas de predicción, diferenciando
entre métodos objetivos y métodos subjetivos.
Tipos de
Técnicas de Predicción
Métodos Subjetivos
Métodos Objetivos
causal
extrapolación
Modelos Econométricos
(Modelos de Regresión
simple o múltiple)
(requiere variable dependiente
y una o varias variables explicativas)
Box-Jenkins
(ARIMA)
Modelos a-teóricos
- Opinión de Ejecutivos
- Técnica Delphi (consenso de
expertos)
- Basadas en Fuerza Ventas
- Encuestas de intenciones de
compra
Métodos de
Series de Tiempo
Suavizamiento
Exponencial
Predicción
Espectral
117
Un enfoque alternativo para la selección de un modelo de Predicción es el siguiente:
Si
Pocos datos disponibles?
Métodos
Subjetivos
No
Objective Methods
1.
2.
3.
4.
Data disponible sobre variables causales
Existe un buen conocimiento a priori de las relaciones
Se esperan importantes cambios a futuro
Se requieren predicciones a muy largo plazo
Si
Métodos
Causales
No
Métodos de Extrapolación
118
6.1. EL ERROR DE PREDICCIÓN
Antes de comentar la predicción propiamente tal, es necesario que consideremos que la
desviación estándar del error de la predicción individual de Y en MCO viene dada por27:
σ (eo ) = σ (Yo − Yˆo ) = σ (1 + X o ' ( X ' X ) −1 X o )
donde σ es el error estándar de la regresión, Ŷ es la estimación de Y, Xo son valores proyectados de X, y
X son los valores originales. El intervalo de confianza para las predicciónes en el caso de un gran número
de observaciones es entonces (usando una distribución t):
[Yˆ − 2.0 ⋅ σ (e ) , Yˆ + 2.0 ⋅ σ (e )]
0
0
Para el caso de un modelo de regresión simple, la expresión anterior se reduce a:
1
( Xo − X ) 2
ˆ
σ (eo ) = σ (Yo − Yo ) = σ (1 + + i =T
T ∑ ( X i − X )2
i =1
Esta es una expresión sencilla de interpretar:
Puesto que el error estándar de predicción crece proporcionalmente con cuadrado de la diferencia
entre el valor de la variable explicativa deseado y la media observada de ésta, mientras más alejada del
valor medio sea la predicción, ésta será más que proporcionalmente riesgosa. Por ejemplo, en un caso
simple, si se tiene una muestra de 10 años (la media es 5 años) la varianza de la estimación del año 10 al
año 11 aumenta un 44% (desde 25=(10-5)^2 hasta 36=(11-5)^2), pero con una muestra de 3 años
como en nuestro caso, la varianza de la predicción anual desde el año 3 al año 4 aumenta un 178%
(desde 82.25=(3-1.5)^2 hasta 6.25=(4-1.5)^2).
El error de estimación se reduce al aumentar el número de observaciones (T), y al aumentar la
dispersión de la variable X, medida por la suma cuadrada de la diferencia de X respecto a su media.
6.2. PREDICCIÓN ESTATICA
En el caso más simple, se quiere proyectar una sola serie (Y) a través del tiempo, y no se tiene un
modelo explicativo. En este caso debe generarse una serie de tendencia como se explica a continuación.
Ejemplo: Supongamos que deseamos obtener una predicción individual de Y a través del
tiempo (‘prediccion.xls’). Los datos corresponden a los años 1991 al 2000, y se desea una
predicción para los años 2001, 2002, 2003, 2004 y 2005.
Primero debemos generar una serie de tendencia, por ejemplo 1, 2, … como se muestra abajo, la
que será una serie índice para el tiempo (eje X). Luego debemos correr la regresión de Y contra la serie
de tendencia generada. La predicción en Excel puede obtenerse seleccionando la casilla “Curva de
Regresión Ajustada”.
Intercepción
Tendencia
27
Coeficientes Error típico Estadístico t
55 4,43556563 12,3997714
10,1818182 0,71485613 14,2431712
Véase un aspecto simplificado de la demostración en Judge et al., sección 5.3.3.
119
Para obtener la predicción, seleccione las celdas del ponóstico, como se muestra abajo, y arrastre
(con la cruz de la derecha abajo) 5 celdas hacia abajo:
Para construir un intervalo de confianza, note que puesto que T=10, se tienen 8 grados de
libertad para la distribución t, de modo que t(8)=2,306.
Lim_sup = Y_PREDICC + 2.306*ERST
Lim_inf = Y_PREDICC - 2.306*ERST
120
son:
El error estándar de predicción y los límites inferiores y superiores de los intervalos de confianza
Para apreciar el ajuste del modelo, veamos que sucede a través de gráficos de series de tiempo.
Para ello, al marcar la casilla “Curva de Regresión Ajustada” Excel entregó un gráfico que compara las
observaciones actuales con las observaciones ajustadas por la regresión. A este gráfico es posible agregar
una línea de tendencia (lineal) seleccionando con el botón derecho del Mouse uno de los puntos
ajustados, y en opciones Extrapolar hacia delante 5 unidades (años). También es posible agragar las
series de los limites inferior y superior del Intervalo de confianza, obteniendo lo que se muestra a
continuación:
Tendencia Curva de regresión ajustada
250
y = 10,182x + 55
200
Ventas
150
100
50
0
0
2
4
6
8
10
12
14
16
Tendencia
Ventas
Pronóstico Ventas
Lim Inferior
Lim Superior
Lineal (Pronóstico Ventas)
121
6.3. CASO PRÁCTICO
Comenzaremos analizando el caso desarrollado por Hall, R., J. Johnston y D. Lilien (1990). Ver
datos en ‘Tabla 06.xls’.
Se trata de efectuar una predicción del ingreso del año 2001 de una cadena de hoteles, a partir de
información de los años 1990 al 2000. El ingreso total viene dado por:
INGRESO TOTAL = NÚMERO DE HABITACIONES * INGRESO POR HABITACION * OCUPACION
La información disponible corresponde a datos anuales del periodo 1990:1 2000:1.
CPR = Tasa de interés de los papeles comerciales,
GNP = Producto nacional bruto,
OCCUP = Tasa de Ocupación (%),
PGNP = deflactor del producto,
ROOMS = número de habitaciones disponibles en la cadena de hoteles,
RRATE = ingreso promedio por habitación diaria,
UNEMP = tasa de desempleo.
Las ventas históricas de la cadena de hoteles viene dada por el siguiente gráfico:
Ingresos Anuales (millones de $)
3500,0
3000,0
2915,5
2605,5
2500,0
2161,0
2000,0
1780,5
1539,1
1500,0
1369,2
1223,6
1121,7
1000,0
962,6
813,7
697,3
500,0
0,0
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
Intentamos proyectar separadamente la tasa de ocupación (OCCUP, porcentaje de habitaciones
usadas por noche), el ingreso por habitación (RRATE, ingreso promedio por habitación usada por noche) y
el número de habitaciones (ROOMS, número de habitaciones en la cadena de hoteles).
122
a) Tasa de Ocupación (OCCUP)
Probablemente la tasa de ocupación esté relacionada con medidas generales de la economía, tal
como la tasa de desempleo o las tasas de interés. Puesto que la ocupación parece mostrar una tendencia
creciente, puede ser necesario considerar una variable de tendencia en el modelo.
OCCUP
76,00
74,00
72,00
70,00
68,00
66,00
64,00
62,00
60,00
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000
Entonces creamos una serie de tendencia que comienza en T=10 (a efectos que los resultados
intermedios coincidan con los reportados por los autores originales del ejemplo). Aquí esta serie debe
llegar hasta 21, partiendo desde la observación 11.
tend = T+10
;*creamos la variable de tendencia que comienza en T=10
occup = beta0 + beta1*unemp + beta2*tend
Intercepción
UNEMP
Tend
Coeficientes Error típico Estadístico t
69,0928581 2,38288717 28,9954384
-1,85418239 0,38522873 -4,81319859
0,78418836
0,1340615 5,84946753
Se aprecia una relación inversa entre desempleo y ocupación de habitaciones (como se esperaría),
y la relación positiva entre la tendencia y la ocupación.
A efectos de poder predecir la ocupación se otra ecuación para predecir el desempleo para el año
2001. De modo que el enfoque de la ecuación anteriormente estimada tiene algunas limitaciones28.
El enfoque sugerido es utilizar una especificación que incluya información rezagada de las
variables para efectos de predicción (esto es, una especificación AR). Siguiendo a los autores del ejemplo,
esto es lo que hacemos ahora, de modo que eliminamos la tendencia, pues ahora se tiene la variable
dependiente rezagada como regresor.
Incorporamos también la tasa de interés de corto plazo (Commercial Paper Rate) en la
estimación. Luego corremos la regresión con variable dependiente OCCUP y variables independientes el
intercepto, OCCU, UNEMP y CPR rezagadas todas un periodo.
28
Se puede hacer una predicción separada para el desempleo, y después usar la regresión anterior para predecir la
ocupación de habitaciones. Esto sería un error, ya que se estará usando un coeficiente de 1.85 inapropiado. Otra
alternativa es hacer una predicción separada para el desempleo, y regresionar éste contra la ocupación. En este caso el
coeficiente de pendiente debe ser menor a 1.85 anterior, lo que sería más correcto.
123
El resultado de la regresión es el siguiente:
Occup = beta0 + beta1*occup{1} +beta2*unemp{1} + beta3*CPR{1}
Intercepción
Variable X 1
Variable X 2
Variable X 3
Coeficientes Error típico Estadístico t
-0,50976699 11,3977026 -0,04472542
0,99298019 0,15414898 6,44169159
1,04981138 0,36578966 2,86998647
-0,72478546 0,20525279 -3,53118445
Con esto, los valores observados y ajustados (predichos) son:
Prediccion
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
gráfico.
Occup
67,058108
68,9073325
72,1736289
68,8317072
66,0360939
68,7666435
71,6160245
73,4803004
73,7764965
70,9536707
68,50
67,40
70,70
70,60
68,30
65,40
68,40
71,20
74,30
73,80
71,50
Así, la predicción de la ocupación para el año 2001 es de 69,034. Podemos también hacer un
Tasa de Ocupación Observada y Ajustada
76
74
72
70
68
66
64
62
60
1991
1992
1993
1994
1995
pronostico
1996
1997
1998
1999
2000
Observado
124
b) Ingreso por Habitación (Room Rate)
Puesto que la variable está medida en dólares, existirá un impacto por la inflación, de modo que
se requiere el uso de logaritmos. Crearemos las series de logaritmos para Ingreso por Habitación (RRATE)
y Producto nacional (PGNP), el deflactor del producto:
lrrate = ln(rrate)
lpgnp = lln(pgnp)
;* el deflactor del Producto
lrrate = beta0 + beta1*lrrate{1} + beta2*lpgnp{1}
Intercepción
Variable X 1
Variable X 2
Coeficientes Error típico Estadístico t
-1,19183414 0,62933529 -1,89379834
0,86463788 0,20740382 4,16886176
0,35280069 0,25769805 1,36904681
El coeficiente de la serie LPGNP es muy bajo y tiene un alto error, sin embargo tiene sentido que
puesto que los ingresos se mueven con la inflación, el valor rezagado de ésta sea un buen predictor de de
los ingresos futuros, de modo que aceptamos esta especificación.
Pronostico
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2,7739593
2,84239938
2,87593936
2,93356366
2,999124
3,13980119
3,21040364
3,31896088
3,45130208
3,61873983
Log(RRATE)
2,74
2,80
2,83
2,87
2,91
3,04
3,10
3,20
3,33
3,49
3,61
La predicción para 2001 es 42,63. Luego, para poder graficar, se transforma la predicción de la
última regresión (el Log natural del ingreso por Habitación) aplicando la Exponencial.
Ingreso por Habitación vs Predicción
40,0
35,0
30,0
25,0
20,0
15,0
10,0
5,0
0,0
1990
1991
1992
1993
1994
1995
Pronostico
1996
1997
1998
1999
2000
RRATE
125
c) Número de Habitaciones (ROOMS)
El número de habitaciones parece tener una tendencia, por lo que se requiere de una
transformción. Crearemos las series de logaritmos para número de habitaciones (ROOMS).
Se supone que l número de habitaciones disponibles depende de la actividad económica real. Par
esto se deflacta el GNP, calculando el cuociente entre GPN y PGNP, y luego aplicando logaritmos, lrgnp =
log(gnp/pgnp).
lrooms = ln(rooms)
lrgnp = ln(gnp/pgnp)
lrooms = beta0 + beta1*lrooms{1} + beta2*lrgnp{1}
Intercepción
Variable X 1
Variable X 2
Coeficientes Error típico Estadístico t
3,66544384 0,72033996 5,08849164
0,66808868 0,08184847 8,16250657
0,20183368 0,13747966 1,46809845
Luego se transforma la predicción de la última regresión, para representar la predicción realizada
para el número de habitaciones.
Pronostico
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
12,23
12,31
12,39
12,47
12,52
12,54
12,56
12,57
12,60
12,63
Ln(ROOMS)
12,10
12,21
12,31
12,42
12,50
12,52
12,54
12,54
12,57
12,60
12,62
Pronostico
204582,74
221853,54
239517,58
260808,82
274511,45
279291,79
284389,72
288083,79
296048,95
304657,94
ROOMS
179364
200464
221113
246913
267032
274969
278064
278957
286529
296251
303578
Número de Habitaciones vs. Predicción
350000
300000
250000
200000
150000
100000
50000
0
1991
1992
1993
1994
1995
1996
Pronostico
1997
1998
1999
2000
2001
ROOMS
126
d) Predicción Final
Ahora, obtenemos la predicción final para el año 2001:
Ingresos anuales = (occup/100)*(365*rrate/1000000)* rooms
= 69,034/100 * 365*42,63/1000000 * 309572
= 3325,67 millones de dólares por año
De este modo, la predicción para las ventas de la cadena de hoteles del año 2001 es de
US$3325.67 millones.
Note que a través de este enfoque no es posible obtener una predicción para el año 2002, a
menos que se cuente con nueva información del año 2001 para las diferentes variables explicativas. Este
problema es salvado en cierta medida por los modelos ateóricos del siguiente capítulo. Sin embargo, a
modo de ilustración, nótese que una especificación AR(2) para el ingreso de la cadena de hoteles puede
ser estimado como:
Ingreso = beta0 + beta1*Ingreso{1} + beta2*Ingreso{2}
Se obtiene:
Beta0=11,68
Beta1=1,39
Beta2=-0,29
Y una predicción para 2001 de 3326,67 millones de dólares por año, lo que es bastante similar a
lo obtenido anteriormente. Nótese que ahora puede estimarse ahora una predicción para 2002 usando la
misma ecuación anterior, lo que arroja: de 3811,03 millones de dólares por año
127
6.4. MEDIDAS DE ERROR DE PREDICCION
En ciertos casos se enfrentan varios modelos alternativos de predicción, y debe buscarse el mejor
de ellos. Para esto, es conveniente separar la muestra de observaciones disponibles en dos tipos:
a) Muestra de Calibración: Usada para calcular los prámetros del modelo
b) Muestra de Validación: Usada solo para estimar la precisión de la medición. Entrega una evaluación
ucho más precisa (realistica) que la muestra de calibración.
En el proceso de Validación, existen varias medidas que ayudan a seleccionar el modelo de
predicción que se ajusta mejor a los datos. Las medidas más usadas son:
6.4.1. Error Cuadrático Medio (Mean Squared Error, MSE)
Es la medida de precisión más usada en estadística:
n
MSE = ∑
1
et2
n
La mayoría de los errors caen dentro de 2*RMSE de los errores, por lo que su interpretación
esclara. Como característica adicional, penaliza los errores grandes más que los errores pequeños.
A veces se usa la raiz cuadrada (Root Mean Squared Error, RMSE).
6.4.2. Promedio del Error Absoluto (Mean Absolute Error, MAE)
n
et
1
n
MAE = ∑
Tiene por característica penalizar de igual modo todos los errores. Como ventaja ofrece una
interpretación atractiva: expresa el error promedio por perido, conservando las unidades originales de
medición.
6.4.3. Promedio del Porcentaje de Error Absoluto (Mean Absolute Percentage Error, MAPE)
et
n
MAPE = ∑
1
Yt
n
donde yt = y observado
128
Como ventaja presenta una interpretación atractiva, pues se expresa como porcentaje promedio
de error por periodo, lo que permite la comparación entre series diferentes (por ejemplo diferentes
productos).
6.4.4. Ejemplo de Cálculo
Evalúe el ajuste predictivo de (A) un modelo lineal y (B) un modelo AR(1) para las ventas de los
años 2000, 2001 y 2002.
Año
1.990 1.991 1.992 1.993 1.994 1.995 1.996 1.997 1.998 1.999 2.000 2.001 2.002
Ventas ($)
200
220
250
270
300
280
290
320
350
300
310
340
345
Para esto se estiman ambos modelos para los años 1990 - 1999. Los resultados de la estimación
son:
(A): Vt = -26315,33 + 13,33 Añot
(B): Vt = 107,83 + 0,649*Vt-1
Las predicciones con cada modelo se presentan a continuación en las columnas Ventas (A) y
Ventas (B):
1
2
3
4
5
6
7
8
9
10
11
12
13
Año
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
Ventas
200
220
250
270
300
280
290
320
350
300
310
340
345
Ventas (A)
218,00
231,33
244,67
258,00
271,33
284,67
298,00
311,33
324,67
338,00
351,33
364,67
378,00
Intercepto
Pendiente
-26.315,33
13,3333
Ventas (B)
237,63
250,61
270,08
283,06
302,53
289,55
296,04
315,51
334,98
325,23
318,91
314,80
Error 2 (A)
1.708,44
608,44
1.089,00
1.135,30
MSE
Error 2 (B)
232,08
444,86
911,88
529,61
MSE
Abs E (A)
41,33
24,67
33,00
33,00
MAD
Abs E (B)
15,23
21,09
30,20
22,17
MAD
% E (A)
13,33%
7,25%
9,57%
10,05%
MAPE
% E (B)
4,91%
6,20%
8,75%
6,62%
MAPE
107,83
0,6490
Nótese que a través del modelo B, para predecir los años 2000, 2001 y 2002 debe usarse los datos
anteriores de Ventas(B), y no los datos conocidos de Ventas. Por ejemplo 325,23=107,83 +
0,6490*334,98.
Luego, se prefiere el modelo de regresión AR(1).
129
CAPÍTULO 7
MODELOS ARIMA
Box y Jenkins (1976) propusieron la que hoy en día es una muy popular métodología para la
identificación, estimación y predicción de series de tiempo univariadas estacionarias. Esta métodología se
basa en los llamados modelos ARIMA, es decir modelos que poseen componentes autorregresivos (AR) y
de medias móviles (MA), los que nos avocaremos a estimar ahora. La generalización de los modelos
ARIMA al caso multivariado corresponde a los modelos de vectores autorregresivos (VAR).
Los modelos ARIMA y los modelos VAR son a veces llamados a-teóricos, en el sentido que una
determinada serie es explicada básicamente por información pasada de la misma serie, sin que
necesariamente exista un modelo teórico-económico detrás. A pesar de esto, cuando el objetivo es
predictivo se ha encontrado que tales modelos resultan ser exitosos en muchos casos. Puesto que éste es
un tema extenso y con un gran desarrollo, especialmente teórico, estamos aquí especialmente
interesados en los aspectos estimaciónales de los mismos.
7.1. AUTOCORRELACIONES SIMPLES Y PARCIALES
Anteriormente hemos calculado las autocorrelaciones simples de una serie usando la instrucción
CORRELATE. Sin embargo en el análisis de los modelos ARIMA es de interés estimar también las
autocorrelaciones parciales, por lo que comentaremos esta instrucción con mayor detalle.
Las autocorrelaciones parciales corresponden a las correlaciones entre observaciones que están
separadas k periodos de tiempo, manteniendo constantes las correlaciones de los rezagos intermedios. En
otras palabras, es la correlación entre Yt y Yt-k después de eliminar el efecto de todas las observaciones
intermedias de Y.
En una versión posterior de este manual se analizarán las Autocorrelaciones Parciales en Excel.
Por ahora nos limitamos a las autocorrelaciones simples.
130
9.2. PROCESOS AUTORREGRESIVOS (AR)
Un proceso autorregresivo de orden p, AR(p), es uno que tiene la siguiente forma:
Yt = θ 1Yt −1 + θ 2Yt − 2 + ... + θ pYt − p + et
es decir, el valor actual de Y es explicado por una serie de p rezagos de ésta serie, más un error que se
asume bien comportado.
131
9.2.1. SIMULACION DE PROCESOS AR(1)
A modo de ilustración, analicemos dos procesos AR(1):
Yt = 0.8Yt −1 + et
y
Yt = 1.05Yt −1 + et
donde et es N(0,1)
La simulación de estos procesos en Excel puede ser como sigue:
Simulación de modelos AR(1)
350
300
250
200
150
100
50
97
10
0
91
94
85
88
79
82
73
76
67
70
61
64
55
58
49
52
43
46
37
40
31
34
28
22
25
16
19
7
10
13
4
1
0
-50
0,85
1,05
Con esto concluimos que en un proceso autorregresivo puro, como los graficados, cuando el valor
del coeficiente de Yt-1 es menor que 1 se tiene un proceso estable (estacionario), mientras que cuando
este coeficiente es mayor a uno (por ejemplo 1.05 como en este último caso), el proceso no es estable (a
veces es llamado explosivo) 29, de modo que ésta es entonces una condición para la estabilidad del
proceso (parte de este resultado ya fue analizado en el capítulo anterior de raíces unitarias).
29
En realidad estas condiciones pueden mostrarse formalmente, para lo cual remitimos al lector a un libro de texto,
por ejemplo Hamilton (1994).
132
9.2.2. ESTIMACION DE UN PROCESO AUTOREGRESIVO
Un proceso AR puro es sencillo de estimar pues es lineal, de modo que en Excel puede hacerse a
través de MCO.
Veamos su funcionamiento a través de un ejemplo:
Ejemplo: Ver datos en Tabla 1 del Anexo al final del libro
Un modelo AR=||1,3|| para el DESEMPLEO, es decir donde Y depende de Y{1} y de
Y{3}, es:
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. AR{1}
1.531501948 0.194296334
7.88230 0.00010018
2. AR{3}
-0.551202184 0.200659270
-2.74696 0.02862940
133
9.3. PROCESOS DE MEDIAS MOVILES
Un proceso de medias móviles de orden q es uno de la siguiente forma:
Yt = φ 0 et + φ1et −1 + φ 2 et −2 + ... + φ q et −q
es decir, el valor actual de Y es explicado por una serie de q rezagos de los errores de estimación. El
procedimiento de estimación pasa por la implementación del algoritmo de Gauss-Newton con derivadas
numéricas, el que puede ser aplicado en Excel a través de Solver.
9.3.1. SIMULACION DE PROCESOS MA(1)
Podemos simular un proceso MA(q) haciendo que Y dependa de errores (0,1) rezagados.
9.3.2. ESTIMACION DE UN PROCESO DE MEDIAS MOVILES
Para el caso del desempleo, la estimación de un proceso MA(2) con constante, requiere un ajuste
o estimación en función de los dos parámetros buscados (beta0 y beta1), con la característica que el
ajuste depende de los errores, es decir de la diferencia entre las series Desempleo y Ajuste.
Desempleot = beta0 + beta1* et-2
Luego se calculan los errores al cuadrado y se suman, lo que constituye la suma cuadrada de
errores, que es lo que se quiere minimizar para lograr el mejor ajuste posible del modelo a los datos.
En los casos de los meses enero y febrero, el ajuste corresponde exactamente al coeficiente
beta0, que es la esperanza del proceso, lo que permite calcular todos los errores.
Los resultados del ejemplo se muestran a continuación:
fecha
desempleo
2000,01
497,40
2000,02
473,53
2000,03
479,93
2000,04
494,66
2000,05
521,18
2000,06
546,79
2000,07
592,45
2000,08
613,53
2000,09
626,59
2000,10
585,37
2000,11
551,84
2000,12
489,42
Ajuste
521,67
521,67
499,34
477,37
503,82
537,58
537,65
530,15
572,10
598,40
571,82
509,68
Error
-24,27
-48,14
-19,41
17,29
17,36
9,21
54,80
83,38
54,49
-13,03
-19,98
-20,26
SCErr=
Error_2
589,20
2317,79
376,62
298,90
301,54
84,77
3002,73
6952,89
2969,32
169,90
399,09
410,43
17873,17
beta0
beta1
521,67
0,92
Con esto, una predicción para enero y febrero de 2001 son respectivamente 503,29 y 503,03.
134
Dos observaciones on importantes en este punto:
a) La anterior es claramente una estimacion no lineal, es decir de tipo iterativo. En consecuencia, al no
tratarse de MCO, algunas de las propiedades de éstos no se cumplen ahora.
b) La herramienta SOLVER de Excel es de gran valor en esta parte. Sin embargo será presentada aquí de
un modo introductoria.
Un último ejemplo servirá para clarificar la estimación de este tipo de proceso:
Desempleot = beta0 + beta1* et-1 + beta2* et-3
es decir un proceso MA(1,3) con constante. Para esto, solo es posible calcular los errores correctamente
entre abril y diciembre. En marzo (celda B4) se escribe un modelo MA(1), aligual que en febrero. Enero se
plantea con beta0. Los resultados son los siguientes:
135
9.3. PROCESOS ARIMA
Un proceso ARIMA(p,q) tiene la siguiente forma:
Yt = θ 1Yt −1 + θ 2Yt −2 + ... + θ pYt − p + θ 0 et + φ1et −1 + φ 2 et −2 + ... + φ q et −q + et
es decir la unión de procesos AR(p) y MA(q).
La siguiente tabla ilustra la especificación para diferentes modelos ARIMA simples:
La estimación de un modelo ARIMA en Exel es como sigue:
Ejemplo:
BOXJENK(AR=||3||,MA=||2||) desempleo
Dependent Variable DESEMPLEO - Estimation by Box-Jenkins
Iterations Taken
10
Monthly Data From 2000:04 To 2000:12
Usable Observations
9
Degrees of Freedom
7
Centered R**2
-0.572325
R Bar **2 -0.796943
Uncentered R**2
0.988880
T x R**2
8.900
Mean of Dependent Variable
557.98888889
Std Error of Dependent Variable 49.94770877
Standard Error of Estimate
66.95495087
Sum of Squared Residuals
31380.758118
Durbin-Watson Statistic
0.387783
Q(2-2)
5.424152
Significance Level of Q
0.00000000
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. AR{3}
0.9825785293 0.0578230093
16.99286 0.00000060
2. MA{2}
1.0416452807 0.6656597453
1.56483 0.16160111
El mismo proceso con una constante será:
136
Ejemplo:
BOXJENK(constant, AR=||3||,MA=||2||) desempleo
Dependent Variable DESEMPLEO - Estimation by Box-Jenkins
NO CONVERGENCE IN 20 ITERATIONS
LAST CRITERION WAS 0.1534669
Monthly Data From 2000:04 To 2000:12
Usable Observations
9
Degrees of Freedom
6
Centered R**2
0.748319
R Bar **2
0.664425
Uncentered R**2
0.998220
T x R**2
8.984
Mean of Dependent Variable
557.98888889
Std Error of Dependent Variable 49.94770877
Standard Error of Estimate
28.93412632
Sum of Squared Residuals
5023.1019945
Durbin-Watson Statistic
0.314025
Q(2-2)
0.012288
Significance Level of Q
0.00000000
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. CONSTANT
492.9924859
1.5429219
319.51875 0.00000000
2. AR{3}
-0.6715100
0.2070111
-3.24384 0.01760192
3. MA{2}
4.5048722
2.3014910
1.95737 0.09805183
Nótese que el algoritmo no ha alcanzado la convergencia para este ejemplo, probablemente
debido al bajo número de observaciones. En cualquier caso el resultado obtenido anteriormente no puede
considerarse como admisible. Puede intentarse aumentando el numero de iteraciones con
ITERATIONS=100. Sin embargo esto tampoco asegura la convergencia.
137
7.4. EL ENFOQUE DE BOX Y JENKINS
Box y Jenkins han propuesto un procedimiento de 4 pasos que involucra la identificación,
estimación, diagnóstico y predicción de modelos ARIMA.
138
Veamos a continuación estos pasos para el ejemplo desarrollado por Enders (1996), pagina 47,
para el índice de precios al consumidor de los Estados Unidos.
9.4.1. PASO 1: IDENTIFICACIÓN
El objetivo aquí es identificar el tipo de modelo ARIMA apropiado a la serie que se está analizando.
Ejemplo:
;* la información es trimestral partiendo
en el 1º trimestre de 1960.
cal 1960 1 4
all 0 1992:2
data(unit=input,org=obs) / WPI
... Ver datos en la Tabla 15
table
Series
WPI
Obs
130
Mean
65.090000000
Std Error
31.366183959
Minimum
Maximum
30.500000000 116.200000000
source(noecho) c:\winrats\bjident.src
@bjident wpi
0 Regular 0 Seasonal
1.00
0.75
0.50
0.25
0.00
-0.25
-0.50
-0.75
CORRS
PARTIALS
-1.00
0
5
10
15
20
;* puesto que las correlaciones simples decrecen muy lentamente, asumimos que
la serie contiene una raíz unitaria, por lo que debe ser diferenciada.
set dlwpi = log(wpi) - log(wpi{1}) ;* es la diferenciación basada en logaritmos
@bjident dlwpi
;* calculamos nuevamente las autocorrelaciones
139
0 Regular 0 Seasonal
1.00
0.75
0.50
0.25
0.00
-0.25
-0.50
-0.75
CORRS
PARTIALS
-1.00
0
5
10
15
20
;* el gráfico no es claro en sugerir una determinada estructura, por lo que se
comienza intentando un ajuste ARMA(1,1):
9.4.2. PASO 2: ESTIMACIÓN
Una vez decidida una especificación para la serie, procedemos a estimarla verificando si el número
de rezagos es el apropiado.
140
boxjenk(constant,ar=1,ma=1) dlwpi / resids
;* un modelo ARMA(1,1) con
intercepto
...
Variable
Coeff
Std Error
T-Stat
Signif
*******************************************************************************
1. CONSTANT
0.010484902 0.004405769
2.37981 0.01883337
2. AR{1}
0.889069641 0.059263358
15.00201 0.00000000
3. MA{1}
-0.514522826 0.111683147
-4.60699 0.00000992
cor(partial=pacf,qstats,span=8,dfc=%nreg) resids
Correlations of Series RESIDS
Quarterly Data From 1960:03 To 1992:02
Autocorrelations
1: 0.0074000 -0.0485621 -0.0120277
7: -0.0709830 -0.0954604 -0.1005335
13: 0.0116557 0.0424470 -0.0253348
19: 0.0445649 0.1333987 0.0265432
25: -0.1075636 0.1326487 0.0098318
31: -0.0902157 0.1551906
;* la corrección por grados
de libertad es el número de
regresores en BOXJENK
0.1585506
0.0133654
0.0147031
0.0350266
0.0454919
-0.0483299 0.1502811
-0.1225670 -0.0374033
-0.0119804 -0.0822551
-0.0012545 0.0750815
-0.0901244 -0.0275496
Partial Autocorrelations
1: 0.0074000 -0.0486195 -0.0113184 0.1567634 -0.0534576 0.1706623
7: -0.0832060 -0.1059913 -0.0898829 -0.0540433 -0.1009550 -0.0392973
13: 0.0487349 0.0667988 0.0340725 0.0104601 -0.0115962 -0.1276234
19: 0.0045915 0.0816563 0.0384150 0.0976347 -0.0005648 0.1000586
25: -0.1483901 0.0856106 -0.0279169 0.0449157 -0.0325792 -0.0695697
31: 0.0058260 0.1388075
Ljung-Box Q-Statistics
Q(8)
=
9.0642.
Q(16) =
13.2492.
Q(24) =
18.5435.
Q(32) =
30.7083.
Significance
Significance
Significance
Significance
Level
Level
Level
Level
0.10653191
0.42875481
0.61439740
0.37930107
;* para efectos de comparación posterior, se calculan las medidas de bondad de
ajuste de Schwartz y Akaike respectivamente 30:
compute sbc = %nobs*log(%rss) + %nreg*log(%nobs)
compute aic = %nobs*log(%rss) + 2*%nreg
display 'AIC' aic 'SBC' sbc
AIC
-523.39339 SBC
-514.83730
;* analizamos los residuos, esperando que se comporten como ruido blanco, lo
que implicaría que el modelo ha sido bien ajustado.
30
Anteriormente vimos estas pruebas de parsimonia. El objetivo es minimizar ambos criterios, los que pueden ser
negativos.
141
@bjident resids
0 Regular 0 Seasonal
1.00
0.75
0.50
0.25
0.00
-0.25
-0.50
-0.75
CORRS
PARTIALS
-1.00
0
5
10
15
20
;* aparentemente las correlaciones del 4º residuo son altas en términos
relativos, por lo que puede sospecharse la existencia de un MA(4), debido
posiblemente a la estacionalidad. Enders intenta entonces una especificación
ARMA(1,||1,4||):
boxjenk(constant,ar=1,ma=||1,4||) dlwpi / resids
;* estimamos el modelo
ARMA(1,||1,4||)
...
cor(partial=pacf,qstats,span=8,dfc=%nreg) resids
Correlations of Series RESIDS
Quarterly Data From 1960:03 To 1992:02
Autocorrelations
1: 0.0089624 -0.0328139 0.0703164 -0.0371207 -0.1003303 0.1643790
7: -0.0416431 -0.0704238 -0.0637490 0.0023137 -0.0800136 0.0130417
13: 0.0672441 0.0760727 -0.0200882 -0.0009854 -0.0204687 -0.1018997
19: 0.0413006 0.1192971 0.0407567 0.0259783 0.0031011 0.0614874
25: -0.1015937 0.1397403 0.0185355 -0.0080937 -0.0413297 -0.0409861
31: -0.1119197 0.1516016
Partial
1:
7:
13:
19:
25:
31:
Autocorrelations
0.0089624 -0.0328968 0.0709975 -0.0399206 -0.0953807 0.1619230
-0.0503915 -0.0497286 -0.0944232 0.0118146 -0.0505699 -0.0143084
0.0645411 0.0882197 -0.0048105 -0.0319778 -0.0138617 -0.1005960
0.0351777 0.0883233 0.0754616 0.0357150 -0.0111996 0.1115583
-0.1192968 0.1231648 -0.0347506 0.0352566 -0.0425849 -0.0582155
-0.0172188 0.1442226
Ljung-Box Q-Statistics
Q(8)
=
6.9692.
Q(16) =
10.0318.
Q(24) =
15.0892.
Q(32) =
26.7146.
Significance
Significance
Significance
Significance
Level
Level
Level
Level
0.13752250
0.61317493
0.77128316
0.53382615
;* se calculan nuevamente las medidas de bondad de ajuste de Schwartz y Akaike:
142
compute sbc = %nobs*log(%rss) + %nreg*log(%nobs)
compute aic = %nobs*log(%rss) + 2*%nreg
display 'AIC' aic 'SBC' sbc
AIC
-527.39070 SBC
-515.98258
;* ambos criterios sugieren que esta última especificación es más apropiada.
Las autocorrelaciones son:
@bjident resids
0 Regular 0 Seasonal
1.00
0.75
0.50
0.25
0.00
-0.25
-0.50
-0.75
CORRS
PARTIALS
-1.00
0
5
10
15
20
;* en efecto, los residuos parecen ruido blanco, por lo que aceptamos esta
última especificación.
9.4.3. PASO 3: VERIFICACIÓN / DIAGNÓSTICO
Enders propone efectuar una prueba F de cambio estructural 31.
compute rssall = %rss
compute nobs = %nobs
boxjenk(noprint,constant,ar=1,ma=||1,4||) dlwpi 1960:3 1971:4 resid
compute rss1 = %rss
boxjenk(noprint,constant,ar=1,ma=||1,4||) dlwpi 1972:1 1992:2 resid
compute rss2 = %rss
compute F = ((rssall-rss1-rss2)/%nreg)/((rss1+rss2)/(nobs-2*%nreg))
display F
0.53825
cdf ftest F %nreg nobs-2*%nreg
F(4,120)=
31
0.53825 with Significance Level 0.70789873
Véase la sección 3.9.
143
Puesto que la hipótesis nula es inexistencia de cambio estructural, no podemos rechazarla a los
niveles usuales de confianza. Este resultado nos permitiría usar el modelo anterior para fines predictivos.
9.4.4. PASO 4: PREDICCIÓN
Se obtienen 8 predicciones para cada modelo, limitando ahora el periodo de estimación hasta
1990:4 solamente, en lugar de 1992:02 como antes, a fin de dejar un número de observaciones finales
para una comparación exsample, es decir con datos reales no usados en la estimación.
smpl 1960:1 1990:4
;* se efectuarán estimaciones solamente para este
subperiodo
boxjenk(noprint,define=eq1,constant,ar=1,ma=||1,4||) dlwpi 60:3 90:4 resids
forecast 32(print) 1 8 1991:1
# eq1 fore1
;* las predicciones son almacenadas en la serie fore1 y
pueden obtenerse con print 91:01 92:04 fore1
Entry
1991:01
1991:02
1991:03
1991:04
1992:01
1992:02
1992:03
1992:04
DLWPI
0.0188847938078
0.0125375481179
0.0174885621621
0.0225979697375
0.0202683832419
0.0184263689693
0.0169698801945
0.0158182281240
boxjenk(noprint,define=eq2,constant,ar=1,ma=1) dlwpi 60:3 90:4 resids
forecast(print) 1 8 1991:1
# eq2 fore2
;* las predicciones son almacenadas en la serie fore2
Entry
1991:01
1991:02
1991:03
1991:04
1992:01
1992:02
1992:03
1992:04
DLWPI
0.0188094779880
0.0180561216985
0.0173876265082
0.0167944333198
0.0162680598113
0.0158009791435
0.0153865123313
0.0150187327370
Ahora mostramos un resumen de las series originales y de las predicciones de cada
modelo.
32
Véase la predicción de sistemas VAR en la sección 9.5.3. para una descripción de esta instrucción.
144
print
1990:01
ENTRY
1990:01
1990:02
1990:03
1990:04
1991:01
1991:02
1991:03
1991:04
1992:01
1992:02
1992:03
1992:04
1992:04 wpi dlwpi fore1 fore2
WPI
111.00000000000
110.80000000000
112.80000000000
116.20000000000
113.80000000000
112.70000000000
112.50000000000
112.70000000000
112.40000000000
113.60000000000
NA
NA
DLWPI
0.014519311324
-0.001803426999
0.017889564751
0.029696505354
-0.020870322726
-0.009713100646
-0.001776199401
0.001776199401
-0.002665483586
0.010619568827
NA
NA
FORE1
NA
NA
NA
NA
0.0188847938078
0.0125375481179
0.0174885621621
0.0225979697375
0.0202683832419
0.0184263689693
0.0169698801945
0.0158182281240
FORE2
NA
NA
NA
NA
0.0188094779880
0.0180561216985
0.0173876265082
0.0167944333198
0.0162680598113
0.0158009791435
0.0153865123313
0.0150187327370
;* a fin de determinar cual modelo habría tenido más éxito en predecir los
valores futuros de la serie DLWPI puede calcularse ahora la media de la suma
cuadrada de los errores de predicción (mean squared forecast errors, MSE), y
también la suma cuadrada de los errores de predicción. La comparación será
hecha para el periodo 1991:01 a 1992:02.
smpl 91:1 92:2
set error1 91:1 92:2 = (dlwpi - fore1)**2
set error2 91:1 92:2 = (dlwpi - fore2)**2
table / error1 error2
Series
ERROR1
ERROR2
Obs
Mean
Std Error
Minimum
Maximum
6 0.00057785770 0.00051875480 0.00006094613 0.00158046929
6 0.00055395699 0.00055631156 0.00002684701 0.00157448658
;* el criterio de la MSE muestra que el modelo ARMA(1,1) lo habría hecho un
poco mejor que el modelo ARMA(1,||1,4||).
set error3 91:1 92:2 = (dlwpi - fore1)
set error4 91:1 92:2 = (dlwpi - fore2)
table / error3 error4
Series
ERROR3
ERROR4
Obs
Mean
6 -0.0221388274
6 -0.0209576728
Std Error
Minimum
Maximum
0.0102604107 -0.0397551165 -0.0078068001
0.0117336922 -0.0396798007 -0.0051814103
;* finalmente el último criterio llega a una conclusión similar.
145
METODOS DE SUAVIZAMIENTO
S = nivel de suavizamiento de las series
T = tasa de Tendencia
I = Indice estacional (factor)
e = error de predicción
P = span estacional
146
CAPÍTULO 8
ERROR EN LAS VARIABLES:
INSTRUMENTOS
Existen muchos casos en que alguna de las variables independientes X no puede ser observada
directamente, para lo cual puede asumirse que existe a su vez un modelo que explica X en función de un
número de otras variables. Si este es el caso, se generan dos tipos de problemas: en primer lugar X ya no
es fija, sino que es estocástica (regresores estocásticos), y segundo, X es medida con error (existe error
de medición o error en las variables).
Hemos dicho anteriormente que cuando los regresores son estocásticos o existe error de
medición, generalmente se viola el supuesto de independencia de los errores con los regresores del
modelo de regresión, lo que genera estimadores sesgados inconsistentes a través de MCO, por lo que éste
no es el método apropiado. Nótese que este problema también ocurre en los modelos de series de tiempo
tipo AR en que existe como variable explicativa una variable dependiente rezagada (Yt-1).
Existen casos en un modelo de regresión múltiple en que el coeficiente de la variable medida con
error no es de interés, por lo que uno podría plantearse simplemente el excluirla. Sin embargo es
recomendado el uso de variables proxies (aquellas medidas con error) para mantener la especificación del
modelo, pues la omisión de variables relevantes puede introducir sesgos en los estimadores restantes.
8.1. VARIABLES INSTRUMENTALES
La métodología estándar para trabajar con este problema es el uso de variables instrumentales,
es decir aquellas que explican a las variables medidas con error, las que deben cumplir con el requisito de
no estar correlacionadas con el error, pero estar altamente correlacionadas con las variable exógenas.
Bajo estas condiciones, el estimador de variables instrumentales es consistente en el límite, sin embargo
no necesariamente es el óptimo, pues pueden existir otros instrumentos con mejor comportamiento. Note
también que el uso de muchos instrumentos consume observaciones (grados de libertad).
Si el modelo que se desea estimar es
Y = β 0 + β1 X + ε
sin embargo X no es conocida, aunque puede estimarse con error usando las variables Z1 y Z2, es decir:
X * = α 0 + α 1 Z1 + α 2 Z 2 + ν
(1)
en que X* es una variable proxy de X, y Z es un instrumento. Ahora el modelo original puede ser reescrito
como:
147
Y = β + α1 β1 Z1 + α 2 β1 Z 2 + ε
(2)
Así, este problema puede ser reescrito como uno resolución de las dos ecuaciones (1) y (2)
simultáneamente. El procedimiento de resolución es llamado mínimos cuadrados en dos etapas (MC2E),
que consiste en:
Paso 1: estimar (1) y guardar la proyección de X.
Paso 2: estimar (2) usando la proyección de X anterior.
8.2. ESTIMACIÓN CON INSTRUMENTOS EN SPSS
Veamos la forma de implementar la estimación con instrumentos a través de un ejemplo:
Ejemplo: Se tiene Y que depende linealmente de X1 y X2 (“Instrumentos.sav”). Para la
estimación se dispone de los instrumentos Z2 y Z3.
Primero la estimación de X1 en función de los instrumentos, asegurando que los valores
predichos (ajustados) sean guardados:
Coefficientsa
Model
1
(Constant)
Z2
Z3
Unstandardized
Coefficients
B
Std. Error
16.325
10.187
.960
1.465
2.600
1.717
Standardi
zed
Coefficien
ts
Beta
.711
1.643
t
1.603
.655
1.514
Sig.
.135
.525
.156
a. Dependent Variable: X1
Luego la estimación de X2 en función de los instrumentos, asegurando que los valores
predichos (ajustados) sean guardados en otra serie nueva:
Coefficientsa
Model
1
(Constant)
Z2
Z3
Unstandardized
Coefficients
B
Std. Error
35.105
26.194
-.373
3.768
-4.737
4.414
Standardi
zed
Coefficien
ts
Beta
-.096
-1.046
t
1.340
-.099
-1.073
Sig.
.205
.923
.304
a. Dependent Variable: X2
Los resultados de las series son como sigue:
148
Finalmente, la estimación de Y en función de los valores predichos en las ecuaciones
anteriores, que corresponde a la estimación en dos etapas:
Coefficientsa
Model
1
(Constant)
Unstandardized
Predicted Value
Unstandardized
Predicted Value
Unstandardized
Coefficients
B
Std. Error
-.621
115.644
Standardi
zed
Coefficien
ts
Beta
t
-.005
Sig.
.996
1.122
3.384
1.017
.331
.746
9.696E-02
1.166
.255
.083
.935
a. Dependent Variable: Y
Este resultado es posible de obtener directamente a través de:
Analize > Regression > 2-Stage Least Squares…
y seleccionando z1 y z2 como instrumentos:
MODEL:
MOD_1.
. . .
------------------ Variables in the Equation -----------------Variable
X1
X2
(Constant)
B
SE B
Beta
T
Sig T
1.121658
.096963
-.621193
4.466377
1.539588
152.650768
1.084998
.268545
.251
.063
-.004
.8060
.9508
.9968
. . .
de modo que verificamos los resultados previos.
149
8.3. EL ESTIMADOR DE VARIABLES INSTRUMENTALES
a) En el modelo lineal:
Y = Xβ + e,
E [Z ' e] = 0
es decir con instrumentos independientes de los
errores, puede mostrarse que el estimador de V. Instrumentales es el de MC en 2 etapas dado por:
[(
b ≈ N X ' ZW −1 Z ' X
donde por default
) (X ' ZW
−1
−1
Z 'Y
)
(
, s 2 X ' ZW −1 Z ' X
)
−1
]
W −1 = ( Z ' Z ) −1 , aunque esta matriz puede modificarse con la opción WMATRIX para
generalizar y controlar el procedimiento.
Operacionalmente, debe existir a lo menos tantos instrumentos como parámetros a estimar, de lo
contrario el modelo puede resultar subidentificado (por ejemplo si se tienen que estimar 3 parámetros con
solamente 2 instrumentos).
b) En el caso de regresiónes no-lineales (por ejemplo modelos AR y Mínimos Cuadrados no lineales):
Y = f ( X , β ) + e, E [Z ' e] = 0
⎡
b ≈ N ⎢min e' ZW −1 Z ' e
⎢⎣ β
(
)
⎛ ⎛ ∂e ⎞
⎛ ∂e ⎞ ⎞
⎟⎟ ⎟⎟
⎟⎟' ZW −1 Z ' ⎜⎜
, s ⎜⎜ ⎜⎜
⎝ ∂β ⎠ ⎠
⎝ ⎝ ∂β ⎠
2
−1
⎤
⎥
⎥⎦
150
REFERENCIAS
Akaike, H. (1973). “Information Theory and the Extension of the Maximum Likelihood Principle”. En 2º
International Symposium on Information Theory. B. Petrov y F. Csaki eds., Budapest.
Bollerslev, T. (1986). “Generalized Autorregressive Conditional Heteroscedasticity”. Journal of
Econometrics, Vol. 31(1986), pp 307-327.
Box, G. y G. Jenkins (1976). Time Series Analysis, Forecasting and Control. Holden Day: San Francisco.
Breush, T. (1978). “Testing for Autocorrelation in Dynamic Linear Models”. Australian Economic Papers,
17, pp. 334-355.
Breusch, T. y A. Pagan (1979). “A Simple Test for Heteroscedaticity and Random Coefficient Variation”.
Econometrica, Vol. 47, pp. 1287-1294.
Chow, G. (1960). “Tests of Equality Between Sets of Coefficients in Two Linear Regressions”.
Econometrica 28, pp. 591-605.
Cochrane, D. y G. Orcutt (1949). “Application of Least Squares Regression to Relationships Containing
Autocorrelated Error Terms”. Journal of the American Statistical Association 44, pp. 32-61.
Doan, T. (1995). RATS-User’s Manual-versión 4.2. Estima: Evanston
Dickey, D. y W. Fuller (1979). "Distribution of the Estimates for Autoregressive Time Series with a Unit
Root", Journal of the American Statistical Association, 74, pp. 427-431.
Dickey, D. y W. Fuller (1981). "Likelihood ratio Statistics for Autoregressive Time Series with a Unit Root”.
Econometrica 49, pp. 1057-1072.
Durbin, J. y G. Watson (1951). “Testing for Serial Correlation in Least Squares Regression-II”. Biometrika
38, pp. 159-178.
Durbin, J. (1970). “Testing for Serial Correlation in Least Squares Regression When Some of the
Regressors are Lagged Dependent Variables”. Econometrica 38, pp. 410-421.
Engle, R. (1982).“Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United
Kingdom Inflation”. Econometrica (50): 987-1008.
Engle, R. y C. Granger (1987), "Cointegration and Error Correction: Representation, Estimation and
Testing", Econometrica, 55, 251-276.
Engle, R. y B. Yoo (1987). “Forecasting and Testing in Cointegrated Systems”. Journal of Econometrics
35. pp. 143-159.
Enders, W. (1995). Applied Econometric Time Series, New York. John Wiley and Sons.
Enders, W. (1996). Rats Handbook for Econometric Time Series. John Wiley and Sons.
Godfrey, L. (1978). “Testing AgainstGeneral Autorregresive and Moving Average Error Models When the
Regressors Include Lagged Dependent Variables”. Econometrica, 46. pp. 1293-1302.
Goldleld, S. y R. Quandt (1972). Nonlinear Methods in Econometrics. Amsterdam: North Holland, cap. 3.
Granger, C. (1969). “Investigating Causal Relations by Econometric Models and Cross Spectral Models”.
Econometrica, Vol. 37, pp. 424-438.
151
Greene, W. (1999). Análisis Econométrico, Prentice Hall Iberia S.R.L. 3a. Edición, Madrid, España.
Gujarati, D. (1997). Econometría. Mc Graw Hill. 3a. Edición, Santafé de Bogotá, Colombia.
Hall, R., J. Johnston y D. Lilien (1990). MicroTsp User’s Manual v. 7.0. Quantitative Micro Software, Irvine,
California.
Hamilton, J. (1994). Time Series Analysis. Princeton University Press.
Hidreth, C. y J. Lu (1960). “Demand Relations with Autocorrelated Disturbances”. Technical Bulletin
Nº276, Michigan State University. Agricultural Experiment Station.
Intriligator, M. (1991). Modelos Econométricos, Técnicas y Aplicaciones. Fondo de Cultura Económica.
México.
Johansen, S. (1988), "Statistical Analysis of Cointegrated Vectors", Journal of Economics Dynamics and
Control, 12, 231-254
Judge, G., Hill C. y Griffihs, W. (1988). Introduction to the theory and Practice of Econometrics. John
Wiley Sons. Second Edition.
Klein, L. (1950). Economic Fluctuations in the United States 1921-1941. New York: John Wiley and Sons.
Klein, L. (1962). An Introduction to Econometrics. Englewood Cliffs: Prentice Hall.
Ljung, G. Y G. Box (1978). “On a Measure of Lack of Fit in Time Series Models”. Biometrica 65, 297-303.
Maddala, G. S. (1996). Introducción a la Econometría. Segunda Edición. Prentice-Hall.
Mackinnon, J. (1991). “Critical Values of Cointegration Tests”, en Engle y Granger eds. Long Run
Economic Relationships: Readings in Cointegration, cap. 13. Oxford University Press. New York.
Mills, T. (1993). The Econometric Modelling of Financial Time Series. Cambridge University Press.
Newey, W. y K. West (1987). "A Simple Positive-Definite Heteroskedasticity and Autocorrelation
Consistent Covariance Matrix". Econometrica (55): 703–708.
Otero J. M. (1993). Econometría, Series Temporales y Predicción”. Editorial AC. Primera Edición.
Pindyck, R. y D. Rubinfeld (1998). Econometric Models and Economic Forecasts. 4º Edición. Irwin Mc Graw
Hill.
Schwartz, G. (1978). “Estimating the Dimension of a Model”. Annals of Statistics, Vol. 6, pp 461-464.
Sims, C. (1980). “Macroeconomics and Reality”. Econometrica, Vol. 48, pp 1-49.
White, H. (1980). “A Heteroskedasticity-Consistent Covariance Matrix Estimator and Direct Test for
Heteroskedasticity”. Econometrica, Vol. 48, pp. 817-838.
Zellner, A. (1962). “An Efficient Method of Estimating Seemingly Unrelated Regressions and Test of
Aggregation Bias”. Journal of the American Statistical Association 57, pp. 348-368.
152
ANEXO: DATOS UTILIZADOS EN EL LIBRO
TABLA 1
INFORMACIÓN MENSUAL DE ACTIVIDAD ECONÓMICA EN CHILE (IMACEC),
DESEMPLEO EN MILES DE PERSONAS DESOCUPADAS, E INDICE DE PRECIOS AL CONSUMIDOR
(BASE: DICIEMBRE 1998=100).
FECHA
IMACEC
DESEMPLEO
IPC
2000.01
254.40
497.40
102.49
2000.02
243.19
473.53
103.06
2000.03
267.40
479.93
103.81
2000.04
244.07
494.66
104.31
2000.05
248.97
521.18
104.53
2000.06
244.34
546.79
104.77
2000.07
242.02
592.45
104.91
2000.08
243.47
613.53
105.18
2000.09
235.21
626.59
105.82
2000.10
254.93
585.37
106.46
2000.11
252.29
551.84
106.82
2000.12
250.53
489.42
106.94
Fuente: Banco Central de Chile
153
TABLA 2
INFORMACIÓN DE 30 EMPRESAS RESPECTO A UNA FUNCIÓN DE PRODUCCIÓN COBB-DOUGLAS SIMPLE,
EN QUE EL PRODUCTO (Q) ES EXPLICADO POR EL CAPITAL (K) Y EL TRABAJO (L)
Empresa
Trabajo
(L)
Capital
(K)
Producto
(Q)
1
0.228
0.802
0.256918
2
0.258
0.249
0.183599
3
0.821
0.771
1.212883
4
0.767
0.511
0.522568
5
0.495
0.758
0.847894
6
0.487
0.425
0.763379
7
0.678
0.452
0.623130
8
0.748
0.817
1.031485
9
0.727
0.845
0.569948
10
0.695
0.958
0.882497
11
0.458
0.084
0.108827
12
0.981
0.021
0.026437
13
0.002
0.295
0.003750
14
0.429
0.277
0.461626
15
0.231
0.546
0.268474
16
0.664
0.129
0.186747
17
0.631
0.017
0.020671
18
0.059
0.906
0.100159
19
0.811
0.223
0.252334
20
0.758
0.145
0.103312
21
0.050
0.161
0.078945
22
0.823
0.006
0.005799
23
0.483
0.836
0.723250
24
0.682
0.521
0.776468
25
0.116
0.930
0.216536
26
0.440
0.495
0.541182
27
0.456
0.185
0.316320
28
0.342
0.092
0.123811
29
0.358
0.485
0.386354
30
0.162
0.934
0.279431
Fuente: Judge et al. Pág. 512
154
TABLA 3
AHORRO E INGRESO DEL REINO UNIDO 1946-1963
(MILLONES DE LIBRAS)
Año
Ahorro
Ingreso
1946
0.36
8.8
1947
0.21
9.4
1948
0.08
10.0
1949
0.20
10.6
1950
0.10
11.0
1951
0.12
11.9
1952
0.41
12.7
1953
0.50
13.5
1954
0.43
14.3
1955
0.59
15.5
1956
0.90
16.7
1957
0.95
17.7
1958
0.82
18.6
1959
1.04
19.7
1960
1.53
21.1
1961
1.94
22.8
1962
1.75
23.9
1963
1.99
25.2
Fuente: Gujarati, Pág. 258
155
TABLA 4
CONSUMO E INGRESO DE 20 FAMILIAS
(MILES DE DÓLARES)
Familia
Consumo
Ingreso
1
19.9
22.3
2
31.2
32.3
3
31.8
36.6
4
12.1
12.1
5
40.7
42.3
6
6.1
6.2
7
38.6
44.7
8
25.5
26.1
9
10.3
10.3
10
38.8
40.2
11
8.0
8.1
12
33.1
34.5
13
33.5
38.0
14
13.1
14.1
15
14.8
16.4
16
21.6
24.1
17
29.3
30.1
18
25.0
28.3
19
17.9
18.2
20
19.8
20.1
Fuente: Maddala, Pág. 231
156
TABLA 5
INFORMACIÓN ANUAL HIPOTETICA DE INVENTARIOS (Y)
Y DE VENTAS (X) EN UNA DETERMINADA REGIÓN.
Año
Inventario
Ventas
1979
52.9
30.3
1980
53.8
30.9
1981
54.9
30.9
1982
58.2
33.4
1983
60.0
35.1
1984
63.4
37.3
1985
68.2
41.0
1986
78.0
44.9
1987
84.7
46.5
1988
90.6
50.3
1989
98.2
53.5
1990
101.7
52.8
1991
102.7
55.9
1992
108.3
63.0
1993
124.7
73.0
1994
157.9
84.8
1995
158.2
86.6
1996
170.2
98.8
1997
180.0
110.8
1998
198.0
124.7
157
TABLA 6
INFORMACIÓN PARA LA PREDICCIÓN DE VENTAS DE UNA CADENA DE HOTELES.
TASA DE INTERÉS DE CORTO PLAZO (CPR, COMMERCIAL PAPER RATE)
PRODUCTO NACIONAL (GNP), OCUPACIÓN (OCCUP, PORCENTAJE DE HABITACIONES USADAS POR NOCHE),
DEFLACTOR DEL PRODUCTO (PGNP),
NUMERO DE HABITACIONES (ROOMS, NÚMERO DE HABITACIONES EN LA CADENA DE HOTELES).
INGRESO POR HABITACIÓN (RRATE, INGRESO PROMEDIO POR HABITACIÓN USADA POR NOCHE)
TASA DE DESEMPLEO (UNEMP)
Año
CPR
GNP
OCCUP
PGNP
ROOMS
RRATE
UNEMP
1990
7.72
992.70
68.50
91.45
179364
15.55
4.90
1991
5.11
1077.60
67.40
96.01
200464
16.50
5.90
1992
4.69
1185.90
70.70
100.00
221113
16.87
5.60
1993
8.15
1326.40
70.60
105.69
246913
17.63
4.90
1994
9.87
1434.20
68.30
114.92
267032
18.38
5.60
1995
6.33
1549.20
65.40
125.56
274969
20.86
8.50
1996
5.35
1718.00
68.40
132.11
278064
22.17
7.70
1997
5.60
1918.00
71.20
139.83
278957
24.56
7.00
1998
7.99
2156.10
74.30
150.05
286529
27.81
6.00
1999
10.91
2413.90
73.80
162.77
296251
32.65
5.80
2000
12.29
2627.40
71.50
177.45
303578
Fuente: Hall et al. (1990)
36.80
7.10
158
TABLA 7
DATOS HIPOTETICOS:
Y DEPENDE LINEALMENTE DE X1 Y X2.
LOS INSTRUMENTOS SON Z2 Y Z3
Z2
Z3
X1
Y
X2
1.1
5.0
30.4
34.8
10
1.5
4.7
29.8
35.6
12
1.7
4.6
29.1
34.1
15
1.8
4.4
29.5
33.2
13
2.0
4.2
29.8
33.8
12
2.3
4.0
29.6
32.1
16
2.4
3.7
28.0
32.0
18
2.7
3.6
29.1
32.9
19
3.0
3.5
28.3
31.9
17
3.1
3.2
26.7
33.7
18
3.4
3.0
27.3
31.9
20
3.6
2.9
27.4
31.0
19
3.9
2.6
27.0
32.3
21
4.0
2.5
26.6
30.3
22
4.5
2.2
26.3
32.4
Fuente: Judge et al. Pág. 589.
23
159
TABLA 8
UN MODELO DE PRODUCCIÓN Y DE OFERTA DE DINERO EN EEUU
(MILES DE MILLONES DE DÓLARES)
Año
PIB
OFMONET
INVERS
GASTO
1970
1010.7
628.1
150.3
208.5
1971
1097.2
717.2
175.5
224.3
1972
1207.0
805.2
205.6
249.3
1973
1349.6
861.0
243.1
270.3
1974
1458.6
908.6
245.8
305.6
1975
1585.9
1023.3
226.0
364.2
1976
1768.4
1163.7
286.4
392.7
1977
1974.1
1286.6
358.3
426.4
1978
2232.7
1388.7
434.0
469.3
1979
2488.6
1496.7
480.2
520.3
1980
2708.0
1629.5
467.6
613.1
1981
3030.6
1792.9
558.0
697.8
1982
3149.6
1951.9
503.4
770.9
1983
3405.0
2186.1
546.7
840.0
1984
3777.2
2374.3
718.9
892.7
1985
4038.7
2569.4
714.5
969.9
1986
4268.6
2811.1
717.6
1028.2
1987
4539.9
2910.8
749.3
1065.6
1988
4900.0
3071.1
793.6
1109.0
1989
5250.8
3227.3
832.3
1181.6
1990
5522.2
3339.0
799.5
1273.6
1991
5677.5
3439.8
721.1
Fuente: Gujarati Pág. 675
1332.7
160
TABLA 9
INFORMACIÓN DE 4 COSTOS Y PRODUCCION
DE 4 EMPRESAS DURANTE 10 MESES
Empresa Tiempo
Costo Producto
1
1
43.72
38.46
1
2
45.86
35.32
1
3
4.74
3.78
1
4
40.58
35.34
1
5
25.86
20.83
1
6
36.05
36.72
1
7
50.94
41.67
1
8
42.48
30.71
1
9
25.60
23.70
1
10
49.81
39.53
2
1
51.03
32.52
2
2
27.75
18.71
2
3
35.72
27.01
2
4
35.85
18.66
2
5
43.28
25.58
2
6
48.52
39.19
2
7
64.18
47.70
2
8
38.34
27.01
2
9
45.39
33.57
2
10
43.69
27.32
3
1
43.90
32.86
3
2
23.77
18.52
3
3
28.60
22.93
3
4
27.71
25.02
3
5
40.38
35.13
3
6
36.43
27.29
3
7
19.31
16.99
3
8
16.55
12.56
3
9
30.97
26.76
3
10
46.60
41.42
4
1
64.29
41.86
4
2
42.16
28.33
4
3
61.99
34.21
4
4
34.26
15.69
4
5
47.67
29.70
4
6
45.14
23.03
4
7
35.31
14.80
4
8
35.43
21.53
4
9
54.33
32.86
4
10
59.23
42.25
Fuente: Judge Pág. 477
161
TABLA 10
INFORMACIÓN SIMULADA DE Y(X1,X2)
OBS
Y
X1
X2
1
3.284
0.286
0.645
2
3.149
0.973
0.585
3
2.877
0.384
0.310
4
-0.467
0.276
0.058
5
1.211
0.973
0.455
6
1.389
0.543
0.779
7
1.145
0.957
0.259
8
2.321
0.948
0.202
9
0.998
0.543
0.028
10
0.379
0.797
0.099
11
1.106
0.936
0.142
12
0.428
0.889
0.296
13
0.011
0.006
0.175
14
1.179
0.828
0.180
15
1.858
0.399
0.842
16
0.388
0.617
0.039
17
0.651
0.939
0.103
18
0.593
0.784
0.620
19
0.046
0.072
0.158
20
1.152
0.889
0.704
Fuente: Judge et al. Pág. 500
162
TABLA 11
INFORMACIÓN SIMULADA DE Y(X1,X2)
OBS
Y
X1
X2
1
42.08376
14.53
16.74
2
41.48572
15.3
16.81
3
39.05569
15.92
19.5
4
45.08922
17.41
22.12
5
51.66982
18.37
22.34
6
51.18388
18.83
17.41
7
54.77771
18.84
20.24
8
60.33432
19.71
20.37
9
49.75518
20.01
12.71
10
55.45921
20.26
22.98
11
52.46684
20.77
19.33
12
50.67572
21.17
17.04
13
51.64282
21.34
16.74
14
56.18829
22.91
19.81
15
66.21643
22.96
31.92
16
63.22733
23.69
26.31
17
68.96477
24.82
25.93
18
64.25953
25.54
21.96
19
63.75415
25.63
24.05
20
69.68355
28.73
25.66
163
TABLA 12
INFORMACIÓN DE 3 ECUACIONES DE DEMANDA EN 30 PERIODOS:
CANTIDAD DEMANDADA (Q), PRECIO (P) E INGRESO (Y)
OBS
P1
P2
P3
Y
Q1
Q2
Q3
1
10.763
4.474
6.629
487.648
11.632
13.194
45.770
2
13.033
10.836
13.774
364.877
12.029
2.181
13.393
3
9.244
5.856
4.063
541.037
8.916
5.586
104.819
4
4.605
14.010
3.868
760.343
33.908
5.231
137.269
5
13.045
11.417
14.922
421.746
4.561
10.930
15.914
6
7.706
8.755
14.318
578.214
17.594
11.854
23.667
7
7.405
7.317
4.794
561.734
18.842
17.045
62.057
8
7.519
6.360
3.768
301.470
11.637
2.682
52.262
9
8.764
4.188
8.089
379.636
7.645
13.008
31.916
10
13.511
1.996
2.708
478.855
7.881
19.623
123.026
11
4.943
7.268
12.901
433.741
9.614
6.534
26.255
12
8.360
5.839
11.115
525.702
9.067
9.397
35.540
13
5.721
5.160
11.220
513.067
14.070
13.188
32.487
14
7.225
9.145
5.810
408.666
14.474
3.340
45.838
15
6.617
5.034
5.516
192.061
3.041
4.716
26.867
16
14.219
5.926
3.707
462.621
14.096
17.141
43.325
17
6.769
8.187
10.125
312.659
4.118
4.695
24.330
18
7.769
7.193
2.471
400.848
10.489
7.639
107.017
19
9.804
13.315
8.976
392.215
6.231
9.089
23.407
20
11.063
6.874
12.883
377.724
6.458
10.346
18.254
21
6.535
15.533
4.115
343.552
8.736
3.901
54.895
22
11.063
4.477
4.962
301.599
5.158
4.350
45.360
23
4.016
9.231
6.294
294.112
16.618
7.371
25.318
24
4.759
5.907
8.298
365.032
11.342
6.507
32.852
25
5.483
7.077
9.638
256.125
2.903
3.770
22.154
26
7.890
9.942
7.122
184.798
3.138
1.360
20.575
27
8.460
7.043
4.157
359.084
15.315
6.497
44.205
28
6.195
4.142
10.040
629.378
22.240
10.963
44.443
29
6.743
3.369
15.459
306.527
10.012
10.140
13.251
30
11.977
4.806
6.172
347.488
3.982
Fuente: Judge et al. Pág. 460
8.637
41.845
164
TABLA 13
INFORMACION DEL MODELO DE KLEIN
AÑO
1920
1921
1922
1923
1924
1925
1926
1927
1928
1929
1930
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
1941
NUM CONSUMPTION PROFIT PRIVWAGE INVEST KLAGGED PRODUCTION GOVTWAGE
1
39.8
12.7
28.8
2.7
180.1
44.9
2.2
1
41.9
12.4
25.5
-0.2
182.8
45.6
2.7
1
45.0
16.9
29.3
1.9
182.6
50.1
2.9
1
49.2
18.4
34.1
5.2
184.5
57.2
2.9
1
50.6
19.4
33.9
3.0
189.7
57.1
3.1
1
52.6
20.1
35.4
5.1
192.7
61.0
3.2
1
55.1
19.6
37.4
5.6
197.8
64.0
3.3
1
56.2
19.8
37.9
4.2
203.4
64.4
3.6
1
57.3
21.1
39.2
3.0
207.6
64.5
3.7
1
57.8
21.7
41.3
5.1
210.6
67.0
4.0
1
55.0
15.6
37.9
1.0
215.7
61.2
4.2
1
50.9
11.4
34.5
-3.4
216.7
53.4
4.8
1
45.6
7.0
29.0
-6.2
213.3
44.3
5.3
1
46.5
11.2
28.5
-5.1
207.1
45.1
5.6
1
48.7
12.3
30.6
-3.0
202.0
49.7
6.0
1
51.3
14.0
33.2
-1.3
199.0
54.4
6.1
1
57.7
17.6
36.8
2.1
197.7
62.7
7.4
1
58.7
17.3
41.0
2.0
199.8
65.0
6.7
1
57.5
15.3
38.2
-1.9
201.8
60.9
7.7
1
61.6
19.0
41.6
1.3
199.9
69.5
7.8
1
65.0
21.1
45.0
3.3
201.2
75.7
8.0
1
69.7
23.5
53.3
4.9
204.5
88.4
8.5
Fuente: Disponible en el archivo KLEIN.DAT de RATS
GOVTEXP TAXES
2.4
3.4
3.9
7.7
3.2
3.9
2.8
4.7
3.5
3.8
3.3
5.5
3.3
7.0
4.0
6.7
4.2
4.2
4.1
4.0
5.2
7.7
5.9
7.5
4.9
8.3
3.7
5.4
4.0
6.8
4.4
7.2
2.9
8.3
4.3
6.7
5.3
7.4
6.6
8.9
7.4
9.6
13.8
11.6
165
TABLA 14
INDICE GENERAL DE PRECIOS ACCIONARIOS (IGPA) DE LA BOLSA DE COMERCIO DE SANTIAGO
DATOS MENSUALES
FECHA
IGPA
1990.01
802.40
1993.01 2939.67
1996.01 5745.79
1999.01 3474.93
1990.02
829.68
1993.02 3127.27
1996.02 5625.93
1999.02 3739.60
1990.03
931.37
1993.03 2948.19
1996.03 5451.65
1999.03 3970.71
1990.04
901.06
1993.04 2787.76
1996.04 5378.07
1999.04 4412.83
1990.05
861.06
1993.05 2675.69
1996.05 5517.94
1999.05 4565.42
1990.06
891.60
1993.06 2826.93
1996.06 5453.43
1999.06 4648.06
1990.07
857.86
1993.07 2949.26
1996.07 5628.65
1999.07 4871.82
1990.08
888.76
1993.08 3040.29
1996.08 5407.54
1999.08 4657.97
1990.09
896.74
1993.09 3087.02
1996.09 5382.00
1999.09 4739.64
1990.10
858.42
1993.10 3208.54
1996.10 5488.50
1999.10 4548.55
1990.11
936.18
1993.11 3285.49
1996.11 5232.81
1999.11 4767.62
1990.12 1121.75
1993.12 3615.50
1996.12 4943.34
1999.12 5057.12
1991.01 1195.34
1994.01 4311.05
1997.01 5172.68
2000.01 5420.91
1991.02 1435.84
1994.02 4702.80
1997.02 5331.90
2000.02 5429.44
1991.03 1599.07
1994.03 4307.29
1997.03 5307.08
2000.03 5214.47
1991.04 1714.48
1994.04 4102.54
1997.04 5344.03
2000.04 5037.26
1991.05 1697.86
1994.05 4245.29
1997.05 5415.49
2000.05 4995.42
1991.06 1866.50
1994.06 4499.48
1997.06 5739.46
2000.06 4928.17
1991.07 2107.86
1994.07 4318.90
1997.07 5750.77
2000.07 4882.20
1991.08 2320.96
1994.08 4547.97
1997.08 5620.24
2000.08 4950.68
1991.09 2662.28
1994.09 4906.31
1997.09 5517.77
2000.09 4912.98
1991.10 2830.03
1994.10 5471.56
1997.10 5239.03
2000.10 4706.87
1991.11 2489.71
1994.11 5651.67
1997.11 4976.63
2000.11 4858.08
1991.12 2438.45
1994.12 5504.47
1997.12 4810.56
2000.12 4868.71
1992.01 2426.97
1995.01 5409.15
1998.01 4452.31
2001.01 5021.37
1992.02 2546.94
1995.02 5350.15
1998.02 4368.63
2001.02 4973.26
1992.03 2867.28
1995.03 5137.97
1998.03 4756.54
2001.03 4945.14
1992.04 2981.53
1995.04 5363.88
1998.04 4699.52
1992.05 3008.54
1995.05 5843.19
1998.05 4431.90
1992.06 2981.96
1995.06 6069.80
1998.06 4161.43
1992.07 3002.73
1995.07 6234.64
1998.07 4084.03
1992.08 2922.06
1995.08 6034.46
1998.08 3764.43
1992.09 2814.80
1995.09 5882.67
1998.09 3170.57
1992.10 2750.54
1995.10 5902.37
1998.10 3224.28
1992.11 2751.26
1995.11 5631.62
1998.11 3774.36
1992.12 2687.12
FECHA
IGPA
FECHA
IGPA
FECHA
IGPA
1995.12 5700.85
1998.12 3653.32
Fuente: Bolsa de Comercio de Santiago
166
TABLA 15
INDICE DE PRECIOS AL CONSUMIDOR DE LOS ESTADOS UNIDOS (WPI)
(TRIMESTRAL)
TRIM
WPI
TRIM
WPI
TRIM
WPI
TRIM
WPI
1960.1
30.7
1969.1
33.9
1978.1
65.4
1987.1
97.8
1960.2
30.8
1969.2
34.4
1978.2
67.4
1987.2
99.4
1960.3
30.7
1969.3
34.7
1978.3
68.4
1987.3
100.5
1960.4
30.7
1969.4
35.0
1978.4
70.0
1987.4
101.0
1961.1
30.8
1970.1
35.5
1979.1
72.5
1988.1
101.6
1961.2
30.5
1970.2
35.7
1979.2
75.1
1988.2
103.2
1961.3
30.5
1970.3
35.9
1979.3
77.4
1988.3
104.7
1961.4
30.6
1970.4
35.9
1979.4
80.2
1988.4
105.2
1962.1
30.7
1971.1
36.5
1980.1
83.9
1989.1
107.5
1962.2
30.6
1971.2
36.9
1980.2
85.6
1989.2
109.4
1962.3
30.7
1971.3
37.2
1980.3
88.4
1989.3
109.0
1962.4
30.7
1971.4
37.2
1980.4
90.4
1989.4
109.4
1963.1
30.6
1972.1
37.9
1981.1
93.1
1990.1
111.0
1963.2
30.5
1972.2
38.3
1981.2
95.2
1990.2
110.8
1963.3
30.6
1972.3
38.8
1981.3
95.9
1990.3
112.8
1963.4
30.7
1972.4
39.2
1981.4
95.8
1990.4
116.2
1964.1
30.7
1973.1
41.1
1982.1
96.6
1991.1
113.8
1964.2
30.6
1973.2
43.1
1982.2
96.7
1991.2
112.7
1964.3
30.7
1973.3
44.9
1982.3
97.1
1991.3
112.5
1964.4
30.7
1973.4
45.3
1982.4
97.2
1991.4
112.7
1965.1
30.9
1974.1
48.3
1983.1
97.3
1992.1
112.4
1965.2
31.2
1974.2
50.0
1983.2
97.6
1992.2
113.6
1965.3
31.4
1974.3
53.6
1983.3
98.6
1965.4
31.6
1974.4
55.4
1983.4
99.1
1966.1
32.1
1975.1
55.4
1984.1
100.2
1966.2
32.2
1975.2
56.0
1984.2
100.8
1966.3
32.6
1975.3
57.2
1984.3
100.6
1966.4
32.4
1975.4
57.8
1984.4
100.3
1967.1
32.3
1976.1
58.1
1985.1
100.1
1967.2
32.3
1976.2
59.0
1985.2
100.2
1967.3
32.4
1976.3
59.7
1985.3
99.5
1967.4
32.5
1976.4
60.2
1985.4
100.1
1968.1
32.9
1977.1
61.6
1986.1
98.6
1968.2
33.1
1977.2
63.0
1986.2
96.8
1968.3
33.3
1977.3
63.1
1986.3
96.3
1968.4
33.4
1977.4
63.9
1986.4
96.7
Fuente: Enders (1996), Pág. 47
167
TABLA 16
CAMBIOS TRIMESTRALES DESESTACIONALIZADOS
EN EL PRODUCTO PER CÁPITA (Y1)
Y EN EL INGRESO DISPONIBLE (Y2) DE LOS EEUU
TRIM
Y1
Y2
TRIM
Y1
Y2
1951.2
-61
42
1960.4
-9
-23
1951.3
8
-1
1961.1
-5
13
1951.4
-1
-11
1961.2
23
28
1952.1
-4
-12
1961.3
-3
17
1952.2
30
16
1961.4
37
38
1952.3
-1
41
1962.1
13
14
1952.4
45
14
1962.2
21
16
1953.1
17
17
1962.3
10
3
1953.2
2
26
1962.4
23
1
1953.3
-17
-20
1963.1
8
15
1953.4
-16
-10
1963.2
15
17
1954.1
-4
-11
1963.3
24
19
1954.2
8
-23
1963.4
8
30
1954.3
23
29
1964.1
39
47
1954.4
31
36
1964.2
38
75
1955.1
31
8
1964.3
35
27
1955.2
33
43
1964.4
-3
23
1955.3
14
31
1965.1
46
22
1955.4
26
29
1965.2
17
32
1956.1
-7
8
1965.3
35
76
1956.2
-6
9
1965.4
65
47
1956.3
-4
2
1966.1
29
17
1956.4
13
20
1966.2
-2
6
1957.1
4
-10
1966.3
22
27
1957.2
-6
5
1966.4
0
21
1957.3
5
1
1967.1
15
38
1957.4
-6
-20
1967.2
31
21
1958.1
-37
-35
1967.3
7
16
1958.2
12
6
1967.4
6
17
1958.3
25
45
1968.1
54
36
1958.4
16
25
1968.2
30
43
1959.1
39
6
1968.3
54
-7
1959.2
23
32
1968.4
8
9
1959.3
9
-30
1969.1
21
-2
1959.4
-5
10
1969.2
9
19
1960.1
1
6
1969.3
9
47
24
6
1969.4
16
10
1960.2
1960.3
-19
-12
Fuente: Judge et al. Pág. 760
168