actividad 06 - WordPress.com
Anuncio

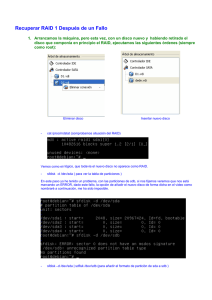
ACTIVIDAD 06 TALLER CONOCIMIENTOS PREVIOS APLICACIONES WEB BRIGITTE NATASHA VARGAS IBARRA Ficha: 259747 Instructor Mauricio Ortiz CENTRO DE SERVICIOS Y GESTION EMPRESARIAL MEDELLIN SENA 2912 1. Defina claramente qué es RAID Es un método de almacenamiento el cual usa múltiples discos duros entre los cuales se reparte los datos dependiendo de su configuración, llamada nivel en los cuales puede combinar varios discos duros en una sola unidad lógica o volumen. 2. ¿Por qué es útil RAID en servidores? Porque protege los datos contra el fallo de una unidad de disco duro. Si se produce un fallo, RAID mantiene el servidor activo y en funcionamiento hasta que se sustituya la unidad defectuosa. También se utiliza con mucha frecuencia para mejorar el rendimiento de servidores y estaciones de trabajo. Estos dos objetivos, protección de datos y mejora del rendimiento, no se excluyen entre sí 3. ¿Cuál es la diferencia de implementar RAID por hardware o por software? En el RAID por software: se pueden ver dos o más discos y se puede hacer un RAID tomando partición a partición, uniéndolas en un solo RAID y el procesador del equipo se encarga de realizar todos los cálculos tomar todas las decisiones y especificar todo lo relacionado con el RAID. El RAID por hardware en el sistema operativo se puede ver un solo disco que es la controladora del RAID que se hace pasar por un disco por lo que el sistema operativo no se entera que tiene un RAID debajo y solamente leerá y escribirá en el disco. 4. ¿Cuál es la función de una controladora RAID? El RAID permite mayor velocidad de escritura en los discos, backup de datos, seguridad. Es posible implementar varias de estas funciones de acuerdo con la cantidad de discos que tengas. 5. Explique los principales niveles de RAID. Utilice imágenes. RAID 0 (Data Striping) Distribuye los datos equitativamente entre dos o más discos sin información de paridad que proporcione redundancia. Es importante señalar que RAID 0 no era uno de los niveles de RAID originales y que no es redundante. El RAID 0 se usa normalmente para incrementar el rendimiento, aunque también puede utilizarse como forma de crear un pequeño número de grandes discos virtuales a partir de un gran número de pequeños discos físicos. RAID 1 Crea una copia exacta de un conjunto de datos en dos o más discos. Esto resulta útil cuando el rendimiento en lectura es más importante que la capacidad. Un conjunto RAID 1 solo puede ser tan grande como el más pequeño de sus discos. Un RAID 1 clásico consiste en dos discos en espejo, lo que incremente exponencialmente la fiabilidad respecto a un solo disco; es decir, la posibilidad de fallo del conjunto es igual al producto de las probabilidades de fallo de cada uno de los disco (pues para que el conjunto falle es necesario que lo hagan todos sus discos). RAID 2 Divide los datos a nivel de bits en lugar de a nivel de bloques y usa un código de Hamming para la corrección de errores. Los discos son sincronizados por la controladora para funcionar al unísono. Éste es el único nivel RAID original que actualmente no se usa. Permite tasas de trasferencias extremadamente altas. Teóricamente, un RAID 2 necesitaría 39 discos en un sistema informático moderno: 32 se usarían para almacenar los bits individuales que forman cada palabra y 7 se usarían para la corrección de errores. RAID 3 Usa división a nivel de bytes con un disco de paridad dedicado. El RAID 3 se usa rara vez en la práctica. Uno de sus efectos secundarios es que normalmente no puede atender varias peticiones simultáneas, debido a que por definición cualquier simple bloque de datos se dividirá por todos los miembros del conjunto, residiendo la misma dirección dentro de cada uno de ellos. Así, cualquier operación de lectura o escritura exige activar todos los discos del conjunto, suele ser un poco lento porque se producen cuellos de botella. Son discos paralelos pero no son independientes (no se puede leer y escribir al mismo tiempo). RAID 4 También conocido como IDA (acceso independiente con discos dedicados a la paridad) usa división a nivel de bloques con un disco de paridad dedicado. Necesita un mínimo de 3 discos físicos. El RAID 4 es parecido al RAID 3 excepto porque divide a nivel de bloques en lugar de a nivel de bytes. Esto permite que cada miembro del conjunto funcione independientemente cuando se solicita un único bloque. Si la controladora de disco lo permite, un conjunto RAID 4 puede servir varias peticiones de lectura simultáneamente. En principio también sería posible servir varias peticiones de escritura simultáneamente, pero al estar toda la información de paridad en un solo disco, éste se convertiría en el cuello de botella del conjunto. RAID 5 Es una división de datos a nivel de bloques distribuyendo la información de paridad entre todos los discos miembros del conjunto. El RAID 5 ha logrado popularidad gracias a su bajo coste de redundancia. Generalmente, el RAID 5 se implementa con soporte hardware para el cálculo de la paridad. RAID 5 necesitará un mínimo de 3 discos para ser implementado. En el gráfico de ejemplo anterior, una petición de lectura del bloque «A1» sería servida por el disco 0. Una petición de lectura simultánea del bloque «B1» tendría que esperar, pero una petición de lectura de «B2» podría atenderse concurrentemente ya que sería servida por el disco 1. RAID 6 Amplía el nivel RAID 5 añadiendo otro bloque de paridad, por lo que divide los datos a nivel de bloques y distribuye los dos bloques de paridad entre todos los miembros del conjunto. El RAID 6 no era uno de los niveles RAID originales. El RAID 6 puede ser considerado un caso especial de código Reed-Solomon. El RAID 6, siendo un caso degenerado, exige sólo sumas en el Campo de galois. Dado que se está operando sobre bits, lo que se usa es un campo binario de Galois de galois (GF (2m)). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR. 6. Describa cómo se realiza una implementación de RAID por software en los sistemas operativos Windows y Linux. Implementación de RAID 5 en Windows server 2008 1. nos vamos a configuración – almacenamiento – controlador sata – agregar discos duros, y agregamos 3 y al terminar le damos aceptar. 2. Después iniciamos Windows server 2008, y nos vamos al administrador del servidor Luego En la opción de almacenamiento, elegimos administrador de discos, y nos aparecerá una opción para inicializar los discos. Elegimos los 3 y le Damos aceptar. 3. para a crear el volumen raid 5, nos podemos ubicar en sobre cualquiera de los discos nuevos, le damos clic en el botón derecho y escogemos la opción raid 5. 4. nos aparece lo siguiente y debemos agregar los otros discos faltantes, hasta que queden agregados. 5. luego elegimos la letra que asignaremos para la unidad. En este caso la F. 6. después nos aparecerá una ventana de formateo, en este caso se le a agregado por etiqueta “mona” y se a elegido “NTFS” y formato rápido. 7. aparecerá una ventana con un mensaje, debemos de dar Sí. 8. como se puede observar en el pantallazo, las unidades del disco aparecen como dinámicas de color verde claro. En la parte de arriba aparece la letra “F”, y con la etiqueta “mona”. 9. verificamos en mi pc, en nuestro caso encontraremos la unidad c, d , e y F que es la RAID 5. Implementación de RAID 5 en Centos Creamos una máquina virtual con este sistema operativo de centos y le agregamos 3 discos duros más. Luego vamos a device y seleccionamos la opción create partition table. nos aparecera esta ventana y para crear la particion nueva y escoger el formato que le vamos a dar, y se deja el tamaño total y damos clic en add. luego de debemos de dar aplicar. despues debemos de ir a la pestaña que dice partition y escogemos la opcion Manage flags. nos aparacera el siguiente cuadro y escogemos donde dice raid. Luego debemos de ingresar al modo root con el comando su – Despues usamos el comando fdisk –l listaremos las particiones contenidas en nuestro disco duro. Para editar los discos duros lo hacemos con el comando “fdisk” seguido por el disco duro a editar, los siguientes pasos de edición de discos los debemos hacer con todos y cada uno de los discos mencionados anteriormente. Iniciaremos entonces editando el primer disco duro “/dev/sdb” esto lo haremos de la siguiente manera. “fdisk /dev/sdb”. Luego de esto, procederemos a instalar la herramienta llamada mdadm, la cual sirve paraimplementar raid. Miramos si quedo instalado el paquete con rpm –q Ahora lo que vamos a hacer es particionar los dos discos vacios, con la herramienta fdisk,damos m para ver la ayuda. Damos n para una nueva partición y la hacemos primaria con la letra p. Le damos t, y le decimos que la partición 1 estará del tipo fd; luego daremos p para escribir loscambios. Por último damos w, para que guarde y cierre. Damos fdisk –l y vemos que las dos particiones quedaron en un modo raid autodetectect, yque tienen una partición 1 la cual es primaria (sdd1 – sde1). Como el punto de montaje md0 en este caso ya estaba ocupado, procederemos a crear unnuevo punto de montaje con el nombre de md1, con el comando mknod. Usaremos entonces el siguiente comando “mdadm –create /dev/md1 –level=raid5 –raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1 mdadm: es el gestor de dispositivos RAID de Linux create /dev/md1: estamos creando la partición de RAID la cual sera /dev/md1 level: estamos definiendo el nivel de RAID, aunque RAID tiene muchos niveles usaremos el 5 ya que es el que tiene mejor rendimiento. raid-devices: la cantidad de dispositivos a usar, en este caso son 4 discos duros y declaramos cada uno de estos. Le damos formato al punto de montaje con el comando mkfs, en este caso un formato ext3 Procedemos a montar el punto md1 en /mnt Luego de esto miramos si el arreglo fue creado y está funcionando con cat /proc/mdstat Podemos ver que está activo, en el punto de montaje md1 7. Diseñe uno o varios gráficos en los que se muestre todo el proceso de comunicación usando el modelo OSI, de la interacción cliente servidor de una petición Web. Comience desde que el usuario ingresa la URL en el navegador Web y tenga en cuenta las consultas a los servidores DNS. Suponga dirección IP privada para el cliente (Dentro de una LAN) y dirección IP pública para el servidor Web. Puede usar Packet Tracer como ayuda y analizar la PDU de cada capa del modelo OSI. 8. ¿Cuáles son los puertos bien conocidos del modelo TCP/IP? Numero de Descripción Puerto •0 Reservado •1 TCP Servicio de multiplexado de puertos (TCPMUX) •4 No asignado •5 RJE (“Remote Job Entry”) •6 No asignado •7 ECHO • 18 MSP (“Message Send Protocol”) • 20 FTP (“File Transfer Protocol” Datos • 21 FTP (“File Transfer Protocol”) Control • 22 SSH Secure Shell Remote Login Protocol • 23 Telnet (acceso a terminal remoto • 25 SMTP (“Simple Mail Transfer Protocol”) • 29 MSG ICP • 37 Time • 42 Host Name Server (Nameserv) • 43 Whois • 49 Login Host Protocol (Login) • 53 DNS (“Domain Name System”) • 59 IDENT • 69 TFTP (“Trivial File Transfer Protocol”) • 70 Servicio Gopher • 79 Servicio Finger • 80 WWW-HTTP (“Hyper Text Transfer Protocol” • 103 X.400 Standard • 108 SNA Gateway Access Server • 109 POP2 (“Post Office Protocol”) • 110 POP3 (“Post Office Protocol”) • 111 SUN-RPC. (“Remote Procedure Call”) • 113 UDP (“User Datagram Protocol” • 115 SFTP (“Simple File Transfer Protocol”) • 118 Servicios SQL • 119 NNTP (“Network News Transfer Protocol” • 137 NetBIOS-ns NETBIOS Name Service • 138 • 139 • 143 • 156 • 161 • 162 • 179 • 190 • 194 • 197 • 210 • 389 • 396 • 443 • 444 • 445 • 458 • 513 • 546 • 547 • 563 • 569 • 631 • 1080 netbios-dgm NetBIOS Datagram Service netbios-ssn NetBIOS Session Service IMAP (“Interim Mail Access Protocol”) SQL Server SNMP (“Simple Network Management Protocol”) SNMP trap BGP (“Border Gateway Patrol”) GACP (“Gateway Access Control Protocol”) IRC (“Internet Relay Chat”) DLS (“Directory Location Service”) wais (servicio de búsquedas LDAP (“Lightweight Directory Access Protocol”) Novell Netware sobre IP HTTPS (“HyperText Transfer Protocol” SNNP (“Simple Network Paging Protocol”) Microsoft-DS Apple QuickTime rlogin Acceso remoto DHCP (“Dynamic Host Configuration Protocol” Cliente DHCP Servidor SNEWS MSN UDP (“User Datagram Protocol”) Socks Proxy Otros puertos no estándar • 1503T.120 Utilizado por aplicaciones que comparten aplicaciones • 1720H.323 Utilizado para escuchar llamadas entrantes por aplicaciones como VideoLink_Pro de • Smith Micro y Microsoft NetMeeting. • 1723PPTP (“Point-to-Point Tunneling Protocol”) • 2049NFS. • 6660-6669TCP (“Transmission Control Protocol”) • 8080Web proxy caching service 9. ¿Cuáles son los puertos registrados del modelo TCP/IP? Puerto Protocolo Servicio 1080 TCP 1337 TCP 1352 1433 1434 1434 1984 1494 1863 2427 TCP TCP TCP UDP TCP TCP TCP UDP 3128 TCP 3306 3389 3396 TCP TCP TCP 3689 TCP 3690 4899 5190 5222 5269 5432 6000 6346 6347 6667 TCP TCP TCP TCP TCP TCP TCP TCP UDP TCP SOCKS proxy menandmice.com DNS. Often used on compromised/infected computers - "1337" a "Leet speak" version of "Elite". See unregistered use below. IBM Lotus Notes/Domino RCP Microsoft SQL database system Microsoft SQL Monitor Microsoft SQL Monitor Big Brother Citrix MetaFrame ICA Client MSN Messenger Cisco MGCP HTTP used by web caches and the default port for the Squid cache MySQL Database system Microsoft Terminal Server Novell NDPS Printer Agent DAAP Digital Audio Access Protocol used by Apple's ITunes Subversion version control system RAdmin remote administration tool AOL and AOL Instant Messenger XMPP/Jabber XMPP/Jabber PostgreSQL database system X11 Gnutella Filesharing Gnutella IRC 8000 TCP iRDMI 8080 TCP HTTP Alternate (http-alt) 8118 TCP Privoxy web proxy Observaciones not to be confused with standard DNS port network monitoring tool RDP often Trojan horse client connection server connection used for X-windows Bearshare, Limewire etc. Internet Relay Chat often mistakenly used instead of port 8080 used when running a second web server on the same machine (the other is in port 80), for web proxy and caching server, or for running a web server as a non-root user. Default port for Jakarta Tomcat. advertisements- filtering web proxy 10. Defina HTTP HTTP es un protocolo sin estado, es decir, que no guarda ninguna información sobre conexiones anteriores. El desarrollo de aplicaciones web necesita frecuentemente mantener estado. Para esto se usan las cookies, que es información que un servidor puede almacenar en el sistema cliente. Esto le permite a las aplicaciones web instituir la noción de "sesión", y también permite rastrear usuarios ya que las cookies pueden guardarse en el cliente por tiempo indeterminado. 11. Dé un ejemplo real de un diálogo HTTP, mostrando los encabezados de la solicitud y la respuesta. Utilice Wireshark u otro software capturador de tráfico. 12. ¿Cuáles son los códigos de estado HTTP? 1xx: Respuestas informativas 100 Continúa: Esta respuesta significa que el servidor ha recibido los encabezados de la petición, y que el cliente debería proceder a enviar el cuerpo de la misma. 101 Conmutando protocolos 102 Procesando 2xx: Peticiones correctas 2xx: Peticiones correctas 200 OK Respuesta estándar para peticiones correctas. 201 Creado La petición ha sido completada y ha resultado en la creación de un nuevo recurso. 202 Aceptada La petición ha sido aceptada para procesamiento, pero este no ha sido completado 203 Información no autoritativa (desde HTTP/1.1) 204 Sin contenido 205 Recargar contenido 206 Contenido parcial La petición servirá parcialmente el contenido solicitado 207 Estado múltiple (Multi-Status, WebDAV) El cuerpo del mensaje que sigue es un mensaje XML y puede contener algún número de códigos de respuesta separados, dependiendo de cuántas sub-peticiones sean hechas. 3xx: Redirecciones 300 Múltiples opciones Indica opciones múltiples para el URI que el cliente podría seguir 301 Movido permanentemente Esta y todas las peticiones futuras deberían ser dirigidas a la URI dada. 302 Movido temporalmente código de redirección. la redirección debió ser hecha con otra URI, pero de igual manera es procesada con la URI dada. 303 Vea otra (desde HTTP/1.1) La respuesta a la petición puede ser encontrada bajo otra URI utilizando el método GET. 304 No modificado Indica que la petición a la URL no ha sido modificada desde que fue requerida por última vez 305 Utilice un proxy (desde HTTP/1.1) Muchos clientes HTTP 306 Cambie de proxy Esta respuesta está descontinuada. 307 Redirección temporal (desde HTTP/1.1) Se trata de una redirección que debería haber sido hecha con otra URI, sin embargo aún puede ser procesada con la URI proporcionada. 4xx Errores del cliente 400 Solicitud incorrecta La solicitud contiene sintaxis errónea y no debería repetirse. 401 No autorizado 402 Pago requerido 403 Prohibido 404 No encontrado Recurso no encontrado 405 Método no permitido Una petición fue hecha a una URI utilizando un método de solicitud no soportado por dicha URl 406 No aceptable El servidor no es capaz de devolver los datos en ninguno de los formatos aceptados por el cliente 407 Autenticación Proxy requerida 408 Tiempo de espera agotado El cliente falló al continuar la petición 409 Conflicto 410 Ya no disponible Indica que el recurso solicitado ya no está disponible y no lo estará de Nuevo. 411 Requiere longitud 412 Falló precondición 413 Solicitud demasiado larga 414 URI demasiado larga 415 Tipo de medio no soportado 416 Rango solicitado no disponible El cliente ha preguntado por una parte de un archivo, pero el servidor no puede proporcionar esa parte 417 Falló expectativa 421 Hay muchas conexiones desde esta dirección de internet 422 Entidad no procesable La solicitud está bien formada pero fue imposible seguirla debido a errores semánticos 423 Bloqueado El recurso al que se está teniendo acceso está bloqueado. 424 Falló dependencia La solicitud falló debido a una falla en la solicitud previa. 425 Colección sin ordenar 426 Actualización requerida El cliente debería cambiarse a TLS/1.0. 449 Reintente con Una extensión de Microsoft: La petición debería ser reintentada después de hacer la acción apropiada. 5xx Errores de servidor 500 Error interno error mostrado generalmente por aplicaciones montadas en ISS otomcat, cuando hay un error ajeno a la naturaleza del servidor 501 No implementado 502 Pasarela incorrecta 503 Servicio no disponible 504 Tiempo de espera de la pasarela agotado 505 Versión de HTTP no soportada 506 Variante también negocia 507 Almacenamiento insuficiente 509 Límite de ancho de banda excedido Este código de estatus, mientras que es utilizado por muchos servidores, no es oficial. 510 No extendido 13. ¿Qué son las cookies? Las cookies son una pequeña pieza de información enviada por un sitio web, las cuales son almacenadas en el navegador del usuario del sitio, de esta manera el sitio web puede consultar dicha información para notificar al sitio de la actividad previa del usuario. 14. ¿Cuál es la diferencia entre una aplicación en el lado del cliente una aplicación en el lado del servidor? Dé ejemplos. Aplicaciones en el lado del cliente: El cliente web es el encargado de ejecutarlas en la máquina del usuario. Son las aplicaciones tipo Java "applets" o JavaScript: el servidor proporciona el código de las aplicaciones al cliente y éste, mediante el navegador, las ejecuta. Es necesario, por tanto, que el cliente disponga de un navegador con capacidad para ejecutar aplicaciones (también llamadas scripts).Comúnmente, los navegadores permiten ejecutar aplicaciones escritas en lenguaje JavaScript y java, aunque pueden añadirse más lenguajes mediante el uso de plugins. Un "plug-in" es un adaptador que permite al "Navegador" ejecutar y desplegar apropiadamente la información que usted está bajando de Internet. Las aplicaciones del lado del cliente se ejecutan directamente en el browser sin necesidad de realizar ninguna solicitud al servidor. Por ejemplo: Para usar JavaScript en una página web sólo es necesario tener un bloc de notas dónde codificar y luego llamar ese documento desde una página HTML. Esto es porque todo el código JavaScript se ejecuta del lado del cliente (en el browser). Sin embargo, si JavaScript se ejecutara del lado del servidor como: asp.net o php sería indispensable que primero se instale una aplicación servidor como: IIS, Apache, etc. Aplicaciones en el lado del servidor: El servidor web ejecuta la aplicación; ésta, una vez ejecutada, genera cierto código HTML; el servidor toma este código recién creado y lo envía al cliente por medio del protocolo HTTP. Las aplicaciones de servidor muchas veces suelen ser la mejor opción para realizar aplicaciones web. La razón es que, al ejecutarse ésta en el servidor y no en la máquina del cliente, éste no necesita ninguna capacidad añadida, como sí ocurre en el caso de querer ejecutar aplicaciones JavaScript o java. Así pues, cualquier cliente dotado de un navegador web básico puede utilizar este tipo de aplicaciones. Un lenguaje de lado servidor es independiente del cliente por lo que es mucho menos rígido respecto al cambio de un navegador a otro o respecto a las versiones del mismo 15. Explique la diferencia entre una página Web dinámica y una página Web estática. Paginas dinámicas: Las páginas estáticas son páginas con poco contenido y desarrolladas con HTML y CSS. En los últimos tiempos también se utiliza en este tipo de páginas tecnologías que nos ofrecen algunos efectos más llamativos como Jquery y Ajax. Este tipo de páginas está recomendado para mostrar contenidos que no van a necesitar modificarse en el tiempo. Para una empresa, es como su tarjeta de presentación, donde solo le va a interesar ofrecer unos contenidos fijos. Presentación de la empresa, Servicios Ofrecidos, Situación geográfica, Datos de contacto y formulario de Contacto. Muchos son los casos, en los que ofrecer esa información puede ser suficiente. Paginas estáticas: Las páginas dinámicas son páginas en las que hay una mayor complejidad en su programación y en la utilización de bases de datos que son los que cargan algunos de los datos en la web según lo que el usuario que entre en nuestra página nos solicite. Por lo tanto este tipo de páginas se diferencia en que los contenidos pueden ir variando dependiendo de la interacción del usuario en la web. Como ejemplo nos puede servir el caso de la página web de una inmobiliaria, donde además de la parte corporativa y de contenidos estáticos de la web, también contamos con un buscador de pisos donde es el usuario el que solicita la información que precisa utilizando los filtros que desde la interfaz de la página web puede seleccionar, como por ejemplo pueden ser, la ciudad, metros cuadrados, habitaciones, etc....que busca como características de su vivienda. Cuando el usuario seleccione estas características y pulse el botón de buscar, en la página web solo se mostrarán las viviendas que se encuentren en nuestra base de datos y que cumplan los requisitos elegidos por el cliente. 16. ¿Cuáles son los elementos y atributos de una estructura HTML? Elementos Los elementos son la estructura básica de HTML. Los elementos tienen dos propiedades básicas: atributos y contenido. Cada atributo y contenido tiene ciertas restricciones para que se considere válido al documento HTML. Un elemento generalmente tiene una etiqueta de inicio (por ejemplo, <nombre-de-elemento>) y una etiqueta de cierre (por ejemplo, </nombre-de-elemento>). Los atributos del elemento están contenidos en la etiqueta de inicio y el contenido está ubicado entre las dos etiquetas (por ejemplo, <nombre-de-elemento atributo="valor">Contenido</nombre-de-elemento>). Algunos elementos, tales como <br>, no tienen contenido ni llevan una etiqueta de cierre. Debajo se listan varios tipos de elementos de marcado usados en HTML. Atributos La mayoría de los atributos de un elemento son pares nombre-valor, separados por un signo de igual «=» y escritos en la etiqueta de comienzo de un elemento, después del nombre de éste. El valor puede estar rodeado por comillas dobles o simples, aunque ciertos tipos de valores pueden estar sin comillas en HTML (pero no en XHTML). De todas maneras, dejar los valores sin comillas es considerado poco seguro. En contraste con los pares nombre-elemento, hay algunos atributos que afectan al elemento simplemente por su presencia Estructura básica de html: <! DOCTYPE> <html> <head> </head> <body> </body> </html> 17. Cree una tabla en la que muestre las etiquetas y atributos correspondientes a los siguientes elementos de un documento HTML (Dé ejemplos): ELEMENTO Inicio final de un documento HTML Cabecera de un documento HTM Título de la página Web Cuerpo de la página Web APERTURA ATRIBUTO ETIQUETA <html> Head y body <head> <title> <body> CIERRE ETIQUETA </html> Base, title, isindex,nextid, meta No </head> Bgcolor, backgroud,text, link, vlink, alink Border,cellpaddding ,cellspacing,heingth, width Align, valign </body> </title> Tabla <table> Fila <tr> Columna <td> Hipervínculo <a> División de la página Texto en negrita Texto en cursiva Texto subrayado Formulario y elementos del formulario <strong> <em> <u> <form> No No No Código de un script <script> Insertar una imagen <img> Fuentes <font> Var, if, for, </script> funtion,lenth, retung, new Alt, align, ismap,src, vspace, hspace,windth, height Size, color </font> Align, valign,nowrap, colspan,rowspan, heigth,width Href, name, rel, rev,title <table> </tr> </td> </a> </strong> </em> </u> </form> Salto de línea Marcos <br /> <noframe> </noframe> 18. Ingrese al sitio Web http://www.ayddiseno.com/web.html, obtenga el código fuente de la página Web e identifique todas las etiquetas del documento HTML. <html> Define el inicio del documento HTML, le indica al navegador que lo que viene a continuación debe ser interpretado como código HTML. <head> Define la cabecera del documento HTML, esta cabecera suele contener información sobre el documento que no se muestra directamente al usuario. <title> Desarrollo web</title>define el título de la página. Por lo general, el título aparece en la barra de título encima de la ventana <style type="text/css"> <body> define el contenido principal o cuerpo del documento. Esta es la parte del documento html que se muestra en el navegador; dentro de esta etiqueta pueden definirse propiedades comunes a toda la página, como color de fondo y márgenes. </style> Para colocar el estilo interno de la página; ya sea usando CSS, u otros lenguajes similares. <Script> Incrusta un script en una web. </script> </head> <table <tr> <td> </table> </body> </html> 19. Consulte la tabla de colores RGB con su correspondiente código hexadecimal 20. ¿Qué son las hojas de estilo (CSS)? Las hojas de estilo representan un avance importante para los diseñadores de páginas web, al darles un mayor rango de posibilidades para mejorar la apariencia de sus páginas. En los entornos científicos en que la Web fue concebida, la gente estaba más preocupada por el contenido de sus páginas que por su presentación. A medida que la Web era descubierta por un espectro mayor de personas de distintas procedencias, las limitaciones del HTML se convirtieron en fuente de continua frustración, y los autores se vieron forzados a superar las limitaciones estilísticas del HTML. Aunque las intenciones han sido buenas -- mejorar la presentación de las páginas web --, las técnicas para conseguirlo han tenido efectos secundarios negativos. Entre estas técnicas, que dan buenos resultados para algunas personas, algunas veces, pero no siempre ni para todas las personas, se incluyen: -La utilización de extensiones propietarias del HTML -Conversión del texto en imágenes -Utilización de imágenes para controlar el espacio en blanco -La utilización de tablas para la organización de las páginas -Escribir programas en lugar de usar HTML Estas técnicas incrementan considerablemente la complejidad de las páginas web, ofrecen una flexibilidad limitada, sufren de problemas de interoperabilidad, y crean dificultades para las personas con discapacidades. 21. ¿Qué es una aplicación Web? Realice una lista de 20 aplicaciones Web. Las aplicaciones web son populares debido a lo práctico del navegador web como cliente ligero, a la independencia del sistema operativo, así como a la facilidad para actualizar y mantener aplicaciones web sin distribuir e instalar software a miles de usuarios potenciales. Existen aplicaciones como los webmails, wikis, weblogs, tiendas en línea y la propia Wikipedia que son ejemplos bien conocidos de aplicaciones web. Audio y podcasting Odeo: http://www.odeo.com vimeo: http://www.vimeo.com Caspost: http://www.castpost.com Internet Archive: http://www.archive.org CastingWords: http://castingwords.com/ Feed 2 Podcast: http://www.feed2podcast.com liveplasma: http://www.liveplasma.com/ Fluctu8: http://www.fluctu8.com folcast: http://www.folcast.com PodOmatic: http://www.podomatic.com Podtranscript: http://www.podtranscript.com Blogs: creación La Coctelera : http://www.lacoctelera.com Blogger : http://www.blogger.com Blogsome : http://www.blogsome.com Zoomblog : http://www.zoomblog.com Blogalia : http://www.blogalia.com Blogspirit : http://www.blogspirit.com Blogs: utilidades FEEDblitz: http://www.feedblitz.com FeedBurner: http://feedburner.com Calendarios Google Calendar: http://calendar.google.com kiko: http://www.kiko.com 30boxes: http://30boxes.com CalendarHub: http://calendarhub.com/ Chat e IM chatCREATOR: http://www.chatcreator.com ajchat: http://www.ajchat.com Gabbly: http://gabbly.com chatsum: http://www.chatsum.com 3bubbles: http://www.3bubbles.com Campfire: http://www.campfirenow.com Correo electrónico Gmail: http://gmail.google.com Laszlo Mail: http://www.laszlomail.com Zimbra: http://www.zimbra.com goowy: http://www.goowy.com PookMail.com: http://www.pookmail.com Editores de fotos PHIXR: http://www.phixr.com/ Preloadr: http://www.preloadr.com/ PXN8: http://pxn8.com/ Snipshot: http://snipshot.com/ Feeds: buscadores Technorati: http://www.technorati.com Feedster: http://www.feedster.com Plazzo: http://www.plazoo.com Blogz: http://www.sarthak.net/blogz/index.php Blogwise: http://www.blogwise.com Feeds: lectores Bloglines: http://www.bloglines.com alesti: http://www.alesti.org BloxOr: http://www.bloxor.com feedness: http://www.feedness.com Pageflakes: http://www.pageflakes.com newsgator: http://www.newsgator.com Fotografía Flickr: http://www.flickr.com 23hq: http://www.23hq.com Zoto: http://www.zoto.com Navegadores Mozilla Firefox: http://www.mozilla.com/firefox/ Flock: http://www.flock.com/ Tiras cómicas StripGenerator: http://www.stripgenerator.com Comics: http://www.mainada.net/comics/ 22. Explique los siguientes lenguajes de programación y conceptos relacionados con las aplicaciones Web: PHP Es un lenguaje de programación interpretado, diseñado originalmente para la creación de páginas web dinámicas. Se usa principalmente para la interpretación del lado del servidor (server-side scripting) pero actualmente puede ser utilizado desde una interfaz de línea de comandos o en la creación de otros tipos de programas incluyendo aplicaciones con interfaz gráfica usando las bibliotecas Qt o GTK+. ASP Es un framework para aplicaciones web desarrollado y comercializado por Microsoft. Es usado por programadores para construir sitios web dinámicos, aplicaciones web y servicios web XML. Apareció en enero de 2002 con la versión 1.0 del .NET Framework, y es la tecnología sucesora de la tecnología Active Server Pages (ASP). ASP.NET está construido sobre el Common Language Runtime, permitiendo a los programadores escribir código ASP.NET usando cualquier lenguaje admitido por el .NET Framework. Perl Es un lenguaje de programación diseñado por Larry Wall en 1987. Perl toma características del lenguaje C, del lenguaje interpretado bourne shell (sh), AWK, sed, Lisp y, en un grado inferior, de muchos otros lenguajes de programación. Estructuralmente, Perl está basado en un estilo de bloques como los del C o AWK, y fue ampliamente adoptado por su destreza en el procesado de texto y no tener ninguna de las limitaciones de los otros lenguajes de script. Python Es un Lenguaje de programación interpretado cuya filosofía hace hincapié en una sintaxis muy limpia y que favorezca un código legible. Se trata de un lenguaje de programación multiparadigma ya que soporta orientación a objetos, programación imperativa y, en menor medida, programación funcional. Es un lenguaje interpretado, usa tipado dinámico, es fuertemente tipado y multiplataforma. CGI Es el sistema más antiguo que existe para la programación de las páginas dinámicas de servidor. Actualmente se encuentra un poco desfasado por diversas razones entre las que destaca la dificultad con la que se desarrollan los programas y lapesada carga que supone para el servidor que los ejecuta. .NET .net (network, internet)es un dominio de Internet genérico que forma parte del sistema de dominios de Internet. El domino .net es manejado por la compañía VeriSign. .net fue uno de los dominios originales (si bien no se menciona en el RFC 920), fue creado en enero de 1985. Originalmente se orientó su uso a entidades de manejo de redes, tales como proveedores de Internet. Actualmente no existen requisitos particulares para registrar un dominio .net. Por lo tanto, aún cuando es popular entre operadores de redes, normalmente es tratado como un "segundo" .com JSP Es un acrónimo de Java Server Pages, que en castellano vendría a decir algo como Páginas de Servidor Java. Es, pues, una tecnología orientada a crear páginas web con programación en Java. 23. Defina WAMP, LAMP y XAMPP WAMP: es el acrónimo usado para describir un sistema de infraestructura de internet que usa las siguientes herramientas: * Windows, como sistema operativo; * Apache, como servidor web; * MySQL, como gestor de bases de datos; * PHP (generalmente), Perl, o Python, como lenguajes de programación. LAMP: el acrónimo 'LAMP' se refiere a un conjunto de subsistemas de software necesarios para alcanzar una solución global, en este caso configurar sitios web o Servidores dinámicos con un esfuerzo reducido. XAMPP: es un servidor independiente de plataforma, software libre, que consiste principalmente en la base de datos MySQL, el servidor web Apache y los intérpretes para lenguajes de script: PHP y Perl. El nombre proviene del acrónimo de X (para cualquiera de los diferentes sistemas operativos), Apache, MySQL, PHP, Perl. 24. ¿Qué es una base de datos? Es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido, una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. 25. ¿Cuáles son las principales características de SQL? La característica más distintiva de SQL sobre otros lenguajes de programación es que es declarativo, en lugar de imperativo o procedural como la mayoría de los lenguajes corrientes (C, Perl, Java, PHP, etc). Esto significa que el programador debe indicarle (declarar) al sistema lo que desea obtener, en lugar de enumerar los pasos que deben efectuarse para obtenerlo. En SQL no existen constructos típicos de otros lenguajes como IF, FOR, WHILE, GOTO, etc. Las cuatro sentencias principales de SQL son SELECT, INSERT, UPDATE y DELETE, que permiten respectivamente obtener, ingresar, actualizar y eliminar datos de la base de datos. 26. Cuáles son los principales sistemas de gestión de bases de datos (Explique brevemente cada uno de ellos) Borland Paradox: Sistema de base de datos para entornos Windows, anteriormente estaba disponible para DOS y Linux. Fue desarrollada por Corel e incluida a WordPerfect (suite ofimática) Filemaker: Sistema de bases de más fácil de usar. Es compatible con Mac y Windows tanto para servidores equipos de escritorio y aplicaciones Web. Microsoft SQL server: Sistema de gestión de bases de datos y su propietario es Microsoft. Se basa en un lenguaje transact-SQL. Oracle: Sistema de gestión de bases de datos desarrollado por Oracle Corporation. Fue punto de crítica de expertos en cuanto a su seguridad, ya que se detectaron 22fallas que fueron corregidas con parches mejorando así el sistema MySQL: Sistema de gestión de base de datos desarrollada por Sun Microsystem y más usada en el mundo fuera de ser software libre con un licenciamiento de GNUGPL. Utilizado en plataformas Linux, Windows. Microsoft Access: Sistema de gestión de base de datos creado por Microsoft para pequeñas empresas; pertenece a la categoría de Gestión y no de la ofimática. Sybase ASE: Ase es un sistema de gestión de base de datos de la compañía Sybase. Es un motor de bases de datos de alto rendimiento, y puede manejar grandes volúmenes de información. 27. Instale un gestor de base de datos MYSQL en Windows y un gestor de base de datos MYSQL en Linux. Cree una base de datos y diferentes tablas y campos, mediante un software de administración gráfica y mediante línea de comandos. Use máquinas virtuales y evidencie el proceso. Instalación de gestor de base de datos MYSQL en Windows Server 2008 R2 Procedemos a instalar. 2. Le damos en aceptar Nos solicita el directorio en el queremos instalar la aplicación, por defecto nos marca c: \AppServ y le damos en next. le damos next luego debemos de llenar el campo del nombre del servidor y el email del administrador del servidor. En este caso el nombre del servidor es www.redes.local.com y el email es [email protected], el puerto 80. Y le damos en next. en esta parte debemos de darle una contraseña le damos en finalizar Para comprobar que todo quedo correctamente instalado probamos en el navegador web y escribimos http://localhost, y nos debe de aparecer lo siguiente, debemos de hacer clic en el link que dice phpMyAdmin Database Manager Versión 2.10.2 Nos aparece una ventana pidiendo el usuario y el password colocamos los usuarios por defecto Root. Y la de contraseña la que le colocamos y le damos en aceptar. Procedemos a crear nuestra base de datos. Vamos al campo crear una nueva base de datos le escribimos el nombre que le vayamos a la base de datos y le damos clic en crear. Luego le colocamos el nombre a la tabla y el número de campos que queremos que lleve, de ahí le damos clic en continuar. A continuación creamos los campos de la tabla y configuramos la longitud de valores y damos clic en grabar. Podemos observar la estructura de lo que sería nuestra tabla de base de datos redes1. Instalación de gestor de base de datos MYSQL en Centos 6.2 MYSQL en Centos 6.2Lo primero que debemos hacer es instalar los paquetes de mysql, con el comando “yum install mysql mysql-server” Para que mysql permanezca activo lo configuramos con chkconfig, y luego procedemos ainiciar el servicio mysql con el comando service mysqld Stara Agregamos la contraseña al root del mysql. Para crear bases de datos lo hacemos con create, y para eliminar bases de datos le damos la opción drop. Para entrar y utilizar mysql, basta con poner mysql en la terminal, pero si ya hemos creado una contraseña y un usuario debemos darle el comando mysql -u root -p Para listar las bases de datos existentes, damos “show databases;” Para usar la base de datos que queramos, damos USE”base_de_datos;” Podemos ver que la base de datos “basededatos” esta listada 28. Realice una lista de comandos para administrar una base de datos MYSQL Mysql> show databases; Mysql> show tables; Mysql> show columns from nombre_de_tabla; Mysql> show variables; Mysql> show grants for usuario@host; Mysql> show columns from base_de_datos.nombre_de_tabla; Mysql> show privileges; Mysql> show character set; Mysql> describe nombre_de_tabla Definición de datos: Mysql> drop database nombre_de_base_de_datos; Mysql> drop table nombre_de_tabla; Mysql> alter table nombre_de_tabla drop column nombre_de_columna; Mysql> alter table nombre_de_tabla add column nombre_de_columna tipo_de_dato; Mysql> alter table nombre_de_tabla change nombre_de_columna_originalnombre_de_columna_nuevotipo_de_dato; Mysql> alter table nombre_de_tabla add unique (nombre_de_columna); Mysql> alter table nombre_de_tabla modify nombre_de_columna tipo_de_dato; Administración $ Mysqladmin -u root -h host -p password “nuevo_password‟ $ Mysqladmin extended-status $ Mysqladmin status $ Mysqladmin variables $ Mysqladmin version $ Mysqladmin create base_de_datos $ Mysqladmin drop base_de_datos $ Mysqladmin flush-privileges $ Mysqladmin ping $ Mysqladmin reload $ Mysqladmin kill id_proceso, id_proceso… $ Mysqladmin shutdow