Practica Nº1 - Plan de Estudio de la Especialización
Anuncio

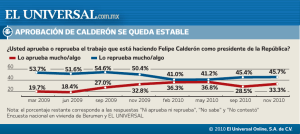
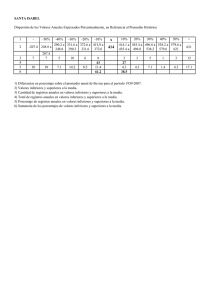
CARRERA DE POSGRADO ESPECIALIZACIÓN EN TECNOLOGÍAS DE LA INFORMACIÓN GEOGRÁFICA (TIG) ------------------------------------------------------------------------------------------------------------------------MODULO 3 – TEMA 2 ESTADÍSTICA ESPACIAL Y GEOESTADÍSTICA ------------------------------------------------------------------------------------------------------------------------- PRACTICA Nº 1 ------------------------------------------------------------------------------------------------------------------------- MEDIDAS DE CENTRALIDAD Y DISPERSIÓN ESPACIAL Ejercicio 1: Conocer las medidas de centralidad y de dispersión espacial. A.) Ejecutar el software Quantum Gis B.) Instalar el complemento > STATIST. Una vez instalado el complemento, no se requiere hacerlo otra vez. C.) Añadir capa vectorial > G:\MODULO III\TEMA 2\GEODATOS >RMS_CHILE_2014.shp D.) Ejecutar Menu Vectorial > Statist E.) Interfaz de usuario complemento Statist. Observar que el nombre de los campos (columnas) está ordenando en forma alfabética, no en el orden cómo está estructurada la BBDD. F.) Seleccionar campo POBREZA. Pulsar OK. Activar Show grid (mostrar grilla, para orientar decisiones) Se calculan automáticamente las siguientes medidas: Centralidad: Mean value (Promedio). También llamada media aritmética, corresponde a la suma de las medidas (Sum) dividida por la cantidad de mediciones (Count). Es el cálculo más utilizado para sintetizar la información correspondiente a un conjunto de mediciones para una variable. Median value (Mediana). Es un valor de la variable que tiene la propiedad de dejar por arriba y por debajo la misma cantidad de mediciones (la misma cantidad de unidades espaciales). Si Count es impar se utiliza el valor que está exactamente en medio de la serie. Si Count es par se debe sacar el promedio entre los dos valores centrales. Dispersión: Range (Rango). Es el intervalo entre el valor máximo (Máximun value) y el valor mínimo (Minimun value); por ello, comparte unidades con los datos. Permite obtener una idea de la dispersión de los datos, cuanto mayor es el rango, más dispersos están los datos de un conjunto. Standard deviation (Desviación estándar). Esta es una unidad de medida absoluta de dispersión que utiliza todas las observaciones de la variable atribuyéndole la misma importancia a cada una de ellas (con independencia del tamaño de cada unidad de análisis). A mayor desviación típica mayor desigualdad. Mayor “variabilidad” de la variable. Coefficient of Variation (Coeficiente de Variación). Es una medida relativa de dispersión y, por tanto, no sujeta a los problemas de unidad de medida. En este caso se relativiza por la media de la variable para contextualizar las desigualdades según los niveles medios de cada año. A mayor coeficiente de variación mayor desigualdad. Para responder a la pregunta de hasta qué valor de coeficiente de variación se puede considerar una distribución como suficientemente concentrada o dispersa, aplicaremos el siguiente criterio: Situación 1: Si no excede una cuarta parte se considerará pequeña, es decir, de notable homogeneidad territorial. Situación 2: Entre un cuarto y la mitad se considerará dispersión grande. Situación 3: Si excede la mitad será considerada como dispersión excesiva, esto es, indeseable desigualdad territorial. Preguntas: Dados los valores de centralidad y de dispersión de la variable POBREZA. ¿Cuán grande es la desigualdad en el área de estudio? ¿Qué método de clasificación para resumir los datos estadísticos en grupos/clases utilizaría? Natural Breaks. Maximiza las diferencias entre clases (que los grupos sean distintos), mientras minimiza las diferencias dentro de cada clase (que los elementos de cada clase se parezcan). Desviación estándar: Distancia de un valor en relación al valor central o la media. Útil para reconocer los valores sobre y bajo la desviación estándar. Quantile. Este método definirá las clases de tal manera que el número de valores en cada una son los mismos. Si tiene 100 valores y queremos 4 clases, el método cuantil definirá las clases de tal manera que cada clase tendrá 25 valores. Intervalo Igual: Como su nombre lo sugiere este método crea clases con el mismo tamaño. Si nuestros datos varían de 0-100 y queremos 10 clases, este método sería crear una clase de 0-10, 1020, 20-30 y así sucesivamente, manteniendo cada clase el mismo tamaño de 10 unidades. Tarea en clases: Realice el mismo procedimiento para las variables: INGRESO (Ingreso Monetario del Hogar). REPRUEBA (% de estudiantes que reprueba en la educación obligatoria). EMZADO (% de Embarazo Adolescente). SUICID (% de Suicidios en el total de defunciones) Ejercicio 2: Estandarizar (calcular el Puntaje Omega) para una variable. A.) Ejecutar el software Quantum Gis B.) Añadir capa vectorial > G:\MODULO III\TEMA 2\GEODATOS >RMS_CHILE_2014.shp C.) Abrir tabla de atributos. Botón derecho del mouse sobre la capa temática. D.) Conocer las variables alojadas en la Matriz de Datos Geográfica N Nombre Abreviatura Máx Valor 1 % de hogares pobres POBREZA Costo 2 Ingreso Monetario del Hogar INGRESO Beneficio 3 % de estudiantes que reprueba en la educación obligatoria REPRUEBA Costo 4 % de Embarazo Adolescente EMZADO Costo 5 % de Suicidios en el total de defunciones SUICID Costo E.) Estandarizar las variables según puntaje omega xi m EVi M m Dónde: EVi = Estandarización de la variable i Xi = Valor del indicador analizado para la unidad espacial M = Valor más negativo. De acuerdo al indicador estudiado, puede ser el valor más alto o más bajo m = Valor más positivo. De acuerdo al indicador estudiado, puede ser el valor más alto o más bajo Los valores resultantes oscilan entre 0 y 1, los cuales mientras más cercanos a 0 sean: más favorable y, en el sentido inverso, mientras más cercanos a 1: más desfavorable. F.) Ejecutar Menu Vectorial > Statist Sirve para conocer el valor mínimo, el valor máximo y calcular el rago (máximo-mínimo). G.) Conmutar el modo edición (editar la BBDD) H.) Agregar una columna nueva. Introducir Nombre: O_POBRE, Tipo: Número decimal (real) Double, Precision: 3 (e.g. 0,12) > OK. I.) Abrir calculadora de campos. J.) Introducir la siguiente sintaxis: (“POBREZA”-0.1)/26.8; Donde 0.1 corresponde al valor más positivo (Providencia) y 26.8 corresponde al rango. Los valores resultantes oscilan entre 0 y 1 K) Resultado de la estandarización de variables. Tarea en clases: Realice el mismo procedimiento para las variables: INGRESO (Ingreso Monetario del Hogar). REPRUEBA (% de estudiantes que reprueba en la educación obligatoria). EMZADO (% de Embarazo Adolescente). SUICID (% de Suicidios en el total de defunciones)