7. Descripciyn de las matrices del LDD
Anuncio

CAPÍTULO 7. Descripción de las matrices del LDD
'HVFULSFLyQGHODVPDWULFHVGHO/''
Como vimos en el capítulo anterior, durante el desarrollo de este proyecto surgió la
necesidad de ampliar la funcionalidad de los arrays del LDD. Estos arrays eran
exclusivamente unidimensionales, podían almacenar datos alfanuméricos, y el acceso a los
elementos individuales era exclusivamente por índice. Los nuevos arrays son
multidimensionales y el acceso a los elementos se puede efectuar por índice y por clave.
Para la implementación de esta nueva funcionalidad podíamos bien reutilizar el
código existente, o reescribirlo ex-profeso. Se optó por la segunda opción debido a las
siguientes razones:
Reescribir el código permite hacer un diseño a medida de la funcionalidad
requerida, por lo que el código final resulta más limpio y estructurado.
Al no heredar código antiguo, podemos realizar una implementación puramente
orientada a objetos y utilizar las librerías estándar de C++.
Como la nueva funcionalidad difiere sensiblemente de la anterior, la reestructuración
del viejo código no iba a ahorrarnos un tiempo significativo.
En definitiva, se optó por rediseñar de nuevo este módulo y hacer una
implementación con objetos, aprovechando además los contenedores y algoritmos
proporcionados por la librería estándar de C++.
/DOLEUHUtDHVWiQGDUGH&
Cuando se escribe un programa nuevo, es importante no “reinventar la rueda”. Es
decir, hay que tratar de evitar en lo posible programar estructuras de datos y algoritmos
básicos que hayan sido ya implementados por otros profesionales especialistas en ello. Estas
estructuras y algoritmos suelen ofrecerse al programador recopiladas en forma de librerías,
cuya utilización ahorra tiempo al programador de aplicaciones, al tiempo que le proporciona
herramientas más optimizadas que las que él mismo pudiera programar.
Para el correcto uso de esta biblioteca, nos hemos basado en la descripción que se
hace de ella en la referencia [Stroustrup-98]. También se puede encontrar en esta fuente una
justificación de las decisiones de diseño adoptadas. A continuación resumimos en este
apartado los elementos y características de esta biblioteca.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
La librería estándar de C++ proporciona:
Soporte para características del lenguaje tales como la gestión de memoria (funciones
new y delete) y la información de tipos en tiempo de ejecución.
Información sobre aspectos del lenguaje definidos por la implementación, tales como
el valor del float más grande.
Funciones que no se pueden implementar de manera óptima en el propio lenguaje
para todos los sistemas, como sqrt() y memmove().
Componentes no primitivos en cuya portabilidad puede confiar el programador, como
listas, mapas, funciones de clasificación y flujos de E/S. La portabilidad está
asegurada al formar la librería parte del más moderno estándar de C++.
Una estructura que permite al usuario proporcionar E/S para un tipo definido por él
según el estilo de E/S para los tipos predefinidos. Es decir, los operadores insertores y
extractores.
Una base común para otras bibliotecas.
El diseño de la biblioteca está determinado fundamentalmente por los tres últimos
puntos, que están estrechamente relacionados entre sí. Por ejemplo, la portabilidad es
habitualmente un criterio de diseño importante para una biblioteca especializada, y los tipos
de contenedores habituales, como listas y mapas, son esenciales para una comunicación
cómoda entre bibliotecas desarrolladas por separado.
El último punto es especialmente importante desde una perspectiva de diseño porque
ayuda a limitar el ámbito de la biblioteca estándar y pone limitaciones a sus componentes.
Así, por ejemplo, la biblioteca estándar proporciona recursos de cadena y de lista. Si no lo
hiciera, las bibliotecas desarrolladas sólo podrían comunicarse utilizando los tipos
predefinidos. Por ejemplo, no se incluyen facilidades de gráficos, porque estos no
intervienen en la comunicación de bibliotecas desarrolladas por separado.
Los recursos que ofrece la librería estándar están diseñados para que:
Sean útiles y asequibles para prácticamente todos los programadores de aplicaciones
y de otras librerías.
Las usen directa o indirectamente todos los programadores para todo lo que está
dentro del ámbito de la biblioteca.
Sean suficientemente eficientes como para proporcionar auténticas alternativas a las
funciones, clases y plantillas codificadas a mano en la implementación de nuevas
bibliotecas.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
Están libres de criterios, o den al usuario la opción de proporcionar criterios como
argumentos.
Sean primitivas en sentido matemático. Es decir, un componente que desempeñe dos
papeles débilmente relacionados entre sí soportará casi con toda seguridad costes
extra, en comparación con componentes individuales diseñados para desempeñar un
único papel.
Sean cómodas, eficientes y razonablemente seguras para los usos habituales.
Sean completas en lo que hacen. La biblioteca estándar puede dejar funciones
importantes a otras bibliotecas, pero, si asume una tarea, debe proporcionar la
funcionalidad suficiente para que los usuarios o implementadores individuales no
tengan que sustituirlas para conseguir que se haga el servicio básico.
Armonicen bien y aumenten los tipos y operaciones predefinidos.
Sean, por defecto, seguras con respecto al tipo.
Soporten los estilos de programación comúnmente aceptados.
Sean extensibles de modo que puedan ocuparse de los tipos definidos por el usuario
de forma similar a como se manejan los tipos predefinidos y los tipos de la biblioteca
estándar.
Para ver cómo se reflejan estos objetivos en el diseño de la biblioteca tomemos un
ejemplo, la típica función de ordenación qsort. Evidentemente, no es aceptable incorporar el
criterio de clasificación a la propia función de ordenación, puesto que una lista de elementos
se puede ordenar de acuerdo con múltiples criterios. Por esa razón la función qsort de la
biblioteca estándar de C toma una función de comparación como argumento, en lugar de
basarse en algo fijado, como el operador <. Sin embargo esta solución no es la mejor de las
posibles, puesto que el coste extra que impone una llamada a función para cada comparación
compromete a qsort como bloque constructivo para la ulterior construcción de bibliotecas.
Para casi todos los tipos de datos es fácil hacer una comparación sin imponer el coste extra
de una llamada de función. Para evitar esta ineficiencia, la biblioteca estándar proporciona a
la función de ordenación el criterio de comparación mediante un argumento de plantilla, que
se resuelve en tiempo de compilación y no genera ineficiencias en la ejecución.
Los componentes de la biblioteca estándar se definen en el espacio de nombres std, y
se presentan como un conjunto de cabeceras. Veamos a continuación algunos de sus
elementos, centrando la atención en los usados en el módulo matrices.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
&RQWHQHGRUHVGHODELEOLRWHFDHVWiQGDU
Un contenedor es un objeto que contiene otros objetos, como las listas, vectores y
arrays asociativos. La función primordial de un contenedor es almacenar una serie de datos,
organizándolos de una manera particular que optimice determinadas manipulaciones sobre
ellos; por ello las operaciones esenciales y comunes a todos los contenedores son las de
añadir, borrar y acceder a sus elementos.
Naturalmente, esta idea se puede presentar a los usuarios de muchas formas
diferentes. Los contenedores de la biblioteca estándar de C++ se han diseñado para satisfacer
dos criterios: proporcionar la máxima libertad en el diseño de un contenedor individual,
permitiendo al mismo tiempo que los contenedores presenten una interfaz común a los
usuarios. Esto posibilita una eficiencia óptima en la implementación de los contenedores, y
permite a los usuarios escribir código que es independiente del contenedor concreto
utilizado.
Los diseños de contenedores satisfacen habitualmente sólo uno de los dos criterios
anteriores de diseño. Los contenedores y algoritmos que forman parte de la biblioteca
estándar (denominada a menudo, STL, por STandard Library) se pueden considerar una
solución al problema de proporcionar simultáneamente funcionalidad y eficiencia.
El objetivo de eficiencia descarta las funciones virtuales, difíciles de insertar para
funciones de acceso pequeñas y de uso frecuente. Por tanto, no podemos presentar una
interfaz estándar para los contenedores o una interfaz de iterador estándar como clase
abstracta. Por el contrario, cada modalidad de contenedor soporta un conjunto estándar de
operaciones básicas. Para evitar tener que definir unas interfaces demasiado gruesas no se
incluyen en el conjunto de operaciones comunes las operaciones que no se pueden
implementar eficientemente para todos los contenedores. Por ejemplo, se proporciona
subindexación para el tipo vector, pero no para list. Además, cada modalidad proporciona
iteradores propios que soportan un conjunto estándar de operaciones de iterador.
Los iteradores son un concepto general y útil para tratar con secuencias de elementos
en contenedores. Cualquier iterador concreto es un objeto de algún tipo. Hay, sin embargo,
muchos tipos diferentes de iteradores, porque un iterador tiene que contener la información
necesaria para hacer su trabajo para un tipo de contenedor determinado. Estos tipos de
iteradores pueden ser tan diferentes como los contenedores y las necesidades especializadas
que atienden. Así, por ejemplo, un iterador de vector es con toda probabilidad un puntero
ordinario, porque un puntero es una forma bastante razonable de referirse a un elemento de
un vector. Alternativamente, un iterador vector podría implementarse como un puntero al
vector más un índice; esto tendría la ventaja de permitir la comprobación de rango. En el
caso de una lista un iterador no puede ser simplemente un puntero a un elemento, porque los
elementos de una lista no suelen estar en posiciones de memoria consecutivas, y el iterador
debe saber cuál es la siguiente posición de la lista. Una manera lógica de implementar un
iterador de lista es mediante un objeto que contenga una referencia o puntero al nodo de la
lista, de modo que pueda devolver el valor contenido en dicho nodo, y conozca la posición
del nodo siguiente.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
Lo que sí es común a los iteradores es su semántica y el nombre de sus operaciones.
Así, por ejemplo, al aplicar ++ a cualquier iterador se obtiene un iterador que hace referencia
al elemento siguiente. De forma similar, * da el elemento al que se refiere el iterador. Un
iterador se puede ver como una generalización del concepto de puntero, pues básicamente
dispone de las operaciones de estos (incremento, decremento, desreferenciación, distancia),
pero eliminando la restricción de que los elementos referenciados tengan que residir en
posiciones consecutivas de memoria, aunque deben estar ligados a un tipo específico de
contenedor para que sean operativos. Además los usuarios de los contenedores rara vez
necesitan conocer el tipo exacto de un iterador; cada contenedor “conoce” sus tipos de
iterador y los hace accesibles bajo los nombres convencionales iterator y const_iterator.
Los contenedores estándar no se derivan de una base común. En lugar de ello, todos
los contenedores implementan todas las interfaces estándar del contenedor. De forma
semejante, no hay una clase base de iterador común. En el uso de contenedores e iteradores
estándar no interviene comprobación alguna de tipo en tiempo de ejecución, explícita o
implícita. La cuestión, difícil e importante, de proporcionar servicios comunes para todos los
contenedores se maneja por medio de “asignadores” que se pasan como argumentos de
plantilla, y no por medio de una base común.
Antes de entrar en detalle en los contenedores concretos usados en el módulo
matrices, resumiremos las ventajas e inconvenientes de los contenedores STL. Las ventajas
son:
Los contenedores individuales son simples y eficientes (no tan simples como los
contenedores verdaderamente independientes, pero igual de eficientes).
Cada contenedor proporciona un conjunto de operaciones estándar con nombres y
semántica estándar. Se proporcionan operaciones adicionales para un tipo concreto de
contenedor a medida de las necesidades. Por ejemplo, todos los contenedores tienen la
misma estructura de constructores y las operaciones push_back, size, pop_back, etc.
Por medio de los iteradores estándar se proporcionan aspectos comunes de uso
adicionales. Cada contenedor proporciona iteradores que soportan un conjunto de
operaciones estándar con nombres y semántica estándar. Para cada tipo concreto de
contenedor se define un tipo de iterador, de modo que los iteradores sean lo más
simples y eficientes que sea posible.
Para atender necesidades diferentes en relación con los contenedores, se pueden
definir iteradores y otras interfaces generalizadas diferentes, además de los iteradores
estándar.
Los contenedores son, por defecto, seguros en cuanto a tipo y homogéneos (es decir,
todos los elementos de un contenedor son del mismo tipo). Se puede proporcionar un
contenedor heterogéneo como contenedor homogéneo de punteros a una clase base
común o por medio de un contenedor de void *.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
Los contenedores no son intrusivos (es decir, no es necesario que un objeto tenga una
clase base o campo de enlace especial para que sea miembro de un contenedor). Los
contenedores no intrusivos funcionan bien con los tipos predefinidos y con los structs
de disposición impuesta externamente.
Los contenedores intrusivos se pueden encajar en la estructura general. Naturalmente,
un contenedor intrusivo impondrá limitaciones a sus tipos de elementos.
Cada contenedor toma un argumento, denominado allocator, que se puede usar como
manejador para implementar servicios para todos los contenedores. Esto facilita
considerablemente la provisión de servicios universales, tales como la persistencia y
la E/S de objetos. Normalmente se trabaja con un allocator estándar por defecto para
aquellos usuarios de la librería que no quieran meterse en complicaciones de gestión
de memoria.
La desventaja de los contenedores STL es que no tienen representación estándar en
tiempo de ejecución, que se pueda pasar como argumento de función, aunque es fácil definir
tales representaciones para los contenedores e iteradores estándar cuando es necesario para
una aplicación concreta. Por ejemplo, no podemos definir una función que mezcle dos
vectores tomando el primer elemento del primero, el segundo del segundo, el tercero del
primero, y así sucesivamente. Es decir, no podemos definir una función así:
vector<T> Mezcla (vector<T> a, vector<T> b);
ya que vector<T> no es un tipo concreto. Tenemos dos opciones: particularizarla para una
instancia específica de vector (vector<int>, por ejemplo) o bien definirla como plantilla,
precediéndola de template<class T>.
Resumiendo, los contenedores y los iteradores no tienen representaciones estándar
fijas. En lugar de ello, cada contenedor proporciona una interfaz estándar en forma de
conjunto de operaciones, de modo que los contenedores se puedan usar de manera
intercambiable. Los iteradores se manejan de una manera similar. Esto permite al
programador aprovechar los aspectos comunes de los contenedores e iteradores. El
planteamiento STL hace un uso intensivo de las plantillas; para evitar la excesiva replicación
de código, habitualmente se necesita especialización parcial que proporcione
implementaciones compartidas para los contenedores.
$OJRULWPRVGHODELEOLRWHFDHVWiQGDU
Un contenedor no es en sí mismo demasiado interesante. Para que sea realmente útil
debe estar soportado por operaciones básicas tales como encontrar su tamaño, iterar, copiar,
clasificar y buscar elementos. Afortunadamente, la biblioteca estándar proporciona
algoritmos para atender las necesidades habituales y básicas que tienen los usuarios de
contenedores.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
Cada algoritmo se expresa como una función de plantilla o un conjunto de funciones
de plantilla. De esa forma, un algoritmo puede operar sobre muchas modalidades de
secuencias con elementos de diversos tipos. La biblioteca estándar ofrece una provisión
abundante de algoritmos, unos sesenta en total. Tomemos como ejemplo la función find_if
que encuentra un valor en una secuencia que verifica un predicado, y estudiemos a través de
ella las propiedades comunes de estos algoritmos genéricos:
template <class InputIterator, class Predicate>
InputIterator find_if (InputIterator first, InputIterator last,
Predicate pred)
{
while (first != last && !pred(*first)) ++first;
return first;
}
Los algoritmos trabajan sobre una secuencia de elementos comprendidos entre un
iterador de inicio de secuencia y un iterador de fin de secuencia. Ello permite aplicar
un mismo algoritmo a diversos tipos de contenedores, según el tipo de iteradores que
se les pase como argumento de plantilla. Como se puede ver, el algoritmo recorre la
secuencia basándose sólo en el incremento del iterador hasta alcanzar el fin de esta.
Esta propiedad de incremento del iterador es común a todos los tipos de iteradores,
con lo que el algoritmo funciona para cualquier tipo de secuencia.
Las secuencias son semiabiertas, es decir, su iterador de comienzo se refiere al primer
elemento, y el de fin, al elemento que debiera estar después del último. Esto hace que
las secuencias vacías se puedan expresar fácilmente mediante un par de iteradores con
el mismo valor. Nótese como el bucle se recorre sólo mientras first!=last.
Los algoritmos que devuelven un iterador como resultado usan generalmente el final
de una secuencia de entrada para indicar un fallo. Véase cómo find_if devuelve first.
Los algoritmos no realizan comprobación de rango con su entrada ni con su salida.
Los criterios para realizar comparaciones (predicados) se proporcionan mediante
objetos de función que son argumentos de plantilla. El especificar de este modo los
predicados tiene una ventaja sobre los punteros de función y la ligadura tardía: que se
pueden insertar en línea sin pagar el precio de una llamada a función.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
'LVHxRGHFODVHVGHOPyGXOR´PDWULFHVµ
A continuación mostramos el diagrama de clases del módulo “matrices”:
• Ilustración 7-1: Diagrama de clases de matrices.
A continuación explicamos detalladamente cada una de las clases mediante la
descripción precisa de su interfaz.
&ODVH7YHFW1'LP
Implementa un vector n-dimensional accesible exclusivamente por índice. El índice
es en realidad un vector de índices, uno por cada dimensión. El acceso se realiza en tiempo
constante, 0(1), para un número de dimensiones fijo. La interfaz es la siguiente:
Página
CAPÍTULO 7. Descripción de las matrices del LDD
class TvectNDim {
public:
// Tipos
typedef std::string Tvalor;
typedef vector<unsigned> TvIndices;
typedef bool (* TfuncCmpValores) (const Tvalor &, const Tvalor &);
// Constructores y asignación
TvectNDim (): vDim(0), vElem(0) {}
TvectNDim (const TvIndices v): vDim(v), vElem( CumMult(v) ) {}
TvectNDim (const TvectNDim &vect):
vDim(vect.vDim),vElem(vect.vElem){}
TvectNDim &operator = (const TvectNDim &vect);
// Operaciones Get
unsigned GetNumDim () const { return vDim.size(); }
const TvIndices &GetDim () const { return vDim; }
// Acceso (por índice)
Tvalor &operator () (const TvIndices &v);
// Búsqueda de un valor
bool BuscarPosConValor (TvIndices &vPos, const Tvalor &valor,
TfuncCmpValores cmp);
private:
TvIndices vDim;
vector<Tvalor> vElem;
static unsigned CumMult (const TvIndices &v);
};
En primer lugar se definen unos tipos. Estos tipos se deben entender como aliases
que hacen más fácil la notación del programa y permiten cambiar fácilmente los tipos
utilizados. El tipo más importante es el Tvalor que representa el tipo de los valores
contenidos en el array multidimensional, que como se puede ver son strings. El hecho de
que los datos se almacenen como strings permite almacenar, en la misma estructura de datos,
contenidos numéricos y textuales.
Las estructuras de datos (privadas) que componen esta clase son dos:
TvIndices vDim: Contiene la “dimensión” (máximo número de índice más uno) para
cada dimensión. El número de componentes de este vector es, por tanto, el número de
dimensiones del array multidimensional.
vector<Tvalor> vElem: es el verdadero contenedor de los valores del array. Las
posiciones de los elementos del vector se referencian externamente mediante una ntupla con un índice por dimensión, pero internamente estos índices se mapean en una
sola dimensión.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
Los métodos que componen la clase son los siguientes:
Constructores:
TvectNDim (const TvIndices v): inicializa las estructuras privadas a partir
del vector de índices que se le pasa como parámetro. Nótese como la
dimensión asignada al verdadero contenedor es el producto de los
valores del vector de índices.
TvectNDim (): es el constructor por defecto. Es útil para poder definir
fácilmente vectores de TvectNDim.
TvectNDim (const TvectNDim &vect): es el constructor de copia, que
crea una matriz a partir de otra.
Asignación: TvectNDim &operator = (const TvectNDim &vect)
Operaciones de consulta (tipo “get”):
GetNumDim: devuelve el número de dimensiones del array.
GetDim: devuelve el array de tamaños para cada dimensión.
Acceso por índice ( Tvalor &operator () (const TvIndices &v) ): devuelve una
referencia al valor que ocupa la posición indicada por el vector de índices para cada
dimensión. Por supuesto, la dimensión del vector de índices debe ser igual al número
de dimensiones del array. Además, el valor de cada índice (cada elemento del vector
de índices) debe ser inferior al tamaño reservado para esa dimensión. De no ser así, se
genera la excepción TvectNDim::Error. Básicamente, esta función implementa un
mapeo de cada n-tupla de índices al índice del vector vElem.
Búsqueda de un valor (bool BuscarPosConValor (TvIndices &vPos, const Tvalor
&valor, TfuncCmpValores cmp): devuelve en vPos la posición en que se encuentra el
valor usando como criterio de comparación la función cmp (en caso de que se
encuentre). Si dicho valor se encuentra, devuelve como resultado true, y si no
devuelve false. El criterio de comparación es necesario proporcionarlo para poder
comparar cadenas alfanuméricas, discriminando o no mayúsculas y minúsculas.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
&ODVH7YHFW1'LP1&ODYH
Esta clase deriva de la anterior, añadiéndole la funcionalidad del acceso por clave. Su
interfaz se representa en el siguiente cuadro:
De nuevo, se definen unos tipos que ayudan a simplificar la notación del lenguaje:
Tclave (typedef std::string Tclave): es el tipo que designa las claves que se utilizan,
que no son otra cosa que cadenas de texto (strings).
TvClaves ( typedef vector<Tclave> TvClaves ): es el equivalente a TvIndices de la
clase base; identifica una posición del array mediante la clave asociada a cada
dimensión.
El único atributo, privado, que añade es la tabla de claves (tablaClaves). Esta es un
vector que contiene para cada dimensión del array un map<Tclave, unsigned>, el cual
refleja el índice asignado a cada clave definida para dicha dimensión.
class TvectNDimNClave: public TvectNDim
public:
// Tipos
typedef std::string Tclave;
typedef vector<Tclave> TvClaves;
{
// Constructores y asignación
TvectNDimNClave () {}
TvectNDimNClave (const TvIndices &v): TvectNDim(v),
tablaClaves(v.size()) {}
TvectNDimNClave (const TvectNDimNClave &vect): TvectNDim(vect),
tablaClaves (vect.tablaClaves) {}
TvectNDimNClave &operator = (const TvectNDimNClave &vect)
// Acceso (por clave)
Tvalor &operator () (const TvClaves &clave);
// Búsqueda de un elemento
bool BuscarClaveConValor (TvClaves &claves, const Tvalor &valor,
TfuncCmpValores cmp);
private:
vector< map<Tclave,unsigned, std::less<Tclave> > > tablaClaves;
};
Página
CAPÍTULO 7. Descripción de las matrices del LDD
A continuación vemos los métodos que manejan estos atributos:
Constructores y asignación: son exactamente los mismos que los definidos en la
clase base. Se redefinen para inicializar adecuadamente el nuevo método:
tablaClaves.
Acceso por clave (Tvalor &operator () (const TvClaves &clave) ): devuelve una
referencia al elemento identificado por el vector de claves que se le pasa como
parámetro. El acceso a este elemento se produce en dos fases:
Se averigua, para cada clave, el número de índice que le corresponde; en
caso de que dicha clave tenga ya asociado un índice, por haber sido utilizada
con anterioridad. Si no es así, se le asigna el primer índice de dicha
dimensión que no tenga asignada clave. La consulta del índice asociado a
una clave se realiza utilizando la función de subindexación para el map
tablaClaves. El map mantiene las claves ordenadas alfabéticamente, por lo
que este acceso se resuelve en un tiempo O(log n).
Una vez se tiene una n-tupla de índices, se accede al elemento usando el
método de la clase base, que, recordemos, accedía a los elementos en un
tiempo O(1).
Lógicamente, el tiempo final de acceso está en O(log n).
Búsqueda de un elemento: es equivalente al método de la clase base, sólo que debe
traducir la posición numérica encontrada a un array del tipo TvClaves. Ello se
consigue traduciendo los números de los índices a cadenas de texto (strings).
Antes de continuar, veamos cómo se combinan las estructuras de datos de ambas
clases con un sencillo ejemplo. Supongamos que tenemos definida una matriz 2D de
dimensión 3x4, con las claves representadas en la figura adjunta. Podemos acceder al
elemento (1,2) bien directamente, o bien indicando las claves asignadas a cada posición:
(“B”,”γ”). Esto queda representado en la ilustración 7-1.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
tablaC laves[0 ]
(“B ”,”γ”)
“A ”
0
“B ”
1
“C ”
2
x4
(1,2)
+
tablaC laves[1 ]
“α ”
0
“β ”
1
“γ”
2
“δ”
3
0
8
4
11
vE lem
• Ilustración 7-1: Ejemplos de acceso por índices (1,2) y por claves (β,γ)
Como se puede ver, el acceso numérico es más rápido, pues nos ahorramos el buscar
la posición asignada a cada clave en las tablas de claves.
3ODQWLOODGHFODVH7PDSD(VWDWLFR7!
Esta clase implementa la estructura que sirve para almacenar el conjunto de arrays
pertenecientes a una línea. Básicamente es un contenedor de objetos del tipo T que se
referencian mediante un identificador entero o handle. La clase TmapaEstatico proporciona
los métodos necesarios para reservar y liberar memoria y handles, además del acceso a los
elementos referenciados por dicho identificador. Su interfaz se muestra en el cuadro de la
página siguiente.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
template <class T> class TmapaEstatico {
public:
class Error {};
explicit TmapaEstatico (unsigned n=0): dim(n), vElem(n),
ocupado(n,false) {};
TmapaEstatico (const TmapaEstatico &map): dim(map.dim),
vElem(map.vElem), ocupado(map.ocupado) {};
TmapaEstatico &operator= (const TmapaEstatico &map);
unsigned Insertar (const T &elem);
void Borrar (unsigned i);
T &operator [] (unsigned i);
bool Ocupado (unsigned i);
private:
unsigned dim;
vector<T> vElem;
vector<bool> ocupado;
};
Los atributos que define esta clase son los siguientes:
unsigned dim: es el máximo número de elementos T que puede almacenar el
contenedor.
vector<T> vElem: es el array que contiene los elementos de tipo T.
vector<bool> ocupado: es el array que marca cada posición del array anterior (y por
tanto cada índice) como libre u ocupado.
A continuación explicamos los métodos de la clase:
Constructores: se definen los siguientes:
explicit TmapaEstatico (unsigned n=0): fija la dimensión del contenedor
al valor del parámetro n. Se especifica un valor por defecto para el
parámetro, con el objeto de poder construir arrays estáticos de T . Esto es
necesario para poder definir un array de arrayPools estático con una
posición por cada línea. Se define como explicit por una cuestión técnica:
para evitar conversiones obscuras y no deseadas como, por ejemplo,
“TmapaEstatico<T> mapa= 5;”.
TmapaEstatico (const TmapaEstatico &map): es el constructor de copia.
unsigned Insertar (const T &elem): busca la primera posición marcada como libre en
el array ocupado, e inserta en dicha posición del array vElem el valor elem
proporcionado como parámetro. Devuelve como salida la posición del array asignada,
que servirá en adelante como identificador de dicho array.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
void Borrar (unsigned i): libera la memoria asociada al array de índice i, y marca la
posición como libre, permitiendo que se reutilice dicho identificador.
T &operator [] (unsigned i): devuelve una referencia al elemento de índice i.
bool Ocupado (unsigned i): indica si el índice i se corresponde con una posición
ocupada del array, o no.
7DUUD\3RRO
Es la clase que contiene todos los arrays de una línea, y sirve de interfaz a las
__funciones del módulo funcmatrices. Ofrece un método por cada __funcion, de modo que
aísla totalmente el módulo funcmatrices de la estructura de clases del módulo matrices. Su
interfaz es la siguiente:
class TarrayPool
public:
{
// Tipos
class Error {};
typedef TvectNDimNClave Ttabla;
typedef Ttabla::Tvalor Tvalor;
typedef Ttabla::Tclave Tclave;
typedef Ttabla::TvIndices TvIndices;
typedef Ttabla::TvClaves TvClaves;
class TidArray;
// Constructores y asignación
TarrayPool (unsigned n=0): mapTablas(n) {}
TarrayPool (const TarrayPool &arrayPool):
mapTablas(arrayPool.mapTablas) {}
TarrayPool &operator = (const TarrayPool &arrayPool)
/**************** Funciones interfaz ***************************/
TidArray CrearArray (const TvIndices &dim);
void LiberarArray (TidArray idArray);
const Tvalor &LeerValorDeArray (TidArray idArray, const TvClaves
&vClaves);
void EscribirValorEnArray (TidArray idArray, const TvClaves
&vClaves, Tvalor valor)
bool BuscarValorEnArray (TidArray idArray, Tvalor valor, bool
caseSensitive, TvClaves &claves)
private:
TmapaEstatico<Ttabla> mapTablas;
};
Página
CAPÍTULO 7. Descripción de las matrices del LDD
El único atributo es un TmapaEstatico<TvectNDimNClave> que contiene todos los
arrays de la línea. Se ofrecen unas definiciones de tipos para comodidad del usuario de la
clase.
Antes de continuar, merece la pena definir una clase auxiliar, la clase TidArray, cuya
definición es la siguiente:
class TidArray {
public:
TidArray (unsigned n=0): cadena(MiCnv::Int2String(n)) {}
TidArray (std::string cad): cadena(cad) {}
TidArray (const char *cad): cadena(cad) {}
operator unsigned () const
{ return MiCnv::String2Int(cadena); }
const char *c_str () { return cadena.c_str(); }
private:
std::string cadena;
};
La clase TidArray se compone básicamente de una cadena de texto que debe
contener un entero sin signo y proporciona conversiones automáticas string-entero y enterostring. Esta clase de define por comodidad, dado que las __funciones trabajan con índices de
array que son cadenas, mientras que el mapaEstatico trabaja con índices que son enteros.
La parte central de la clase TarrayPool son los métodos reflejo de las __funciones:
TidArray CrearArray (const TvIndices &dim): reserva memoria para un array de las
dimensiones especificadas por dim. Devuelve como resultado el identificador de array
asignado.
void LiberarArray (TidArray idArray): libera la memoria y el índice asignados al
array idArray.
const Tvalor &LeerValorDeArray (TidArray idArray, const TvClaves &vClaves):
devuelve el valor que contiene el array idArray en la posición identificada por la ntupla de claves vClaves.
void EscribirValorEnArray (TidArray idArray, const TvClaves &vClaves, Tvalor
valor): escribe el valor en la posición del array idArray identificada por la n-tupla de
claves vClaves.
bool BuscarValorEnArray (TidArray idArray, Tvalor valor, bool caseSensitive,
TvClaves &claves): busca el valor en todas las posiciones del array idArray. Devuelve
true si lo encuentra y la posición donde se halla en la n-tupla claves. La comparación
de las posiciones con el valor (recordemos que ambos son strings) se realiza teniendo
en cuenta las mayúsculas, o bien considerando mayúsculas y minúsculas como la
misma letra, dependiendo de que caseSensitive valga respectivamente 1 ó 0.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
(MHPSORGHXVRHQHO/''
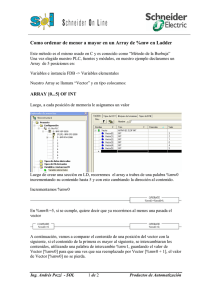
Veamos a continuación un ejemplo de uso de una matriz. Supongamos que
queremos almacenar en una tabla información relativa a productos para el baño. Cada fila
hace referencia a un producto y cada columna hace referencia a alguna propiedad de él tal
como su precio, olor, tamaño, etc. Veamos cómo podríamos rellenar y utilizar dicha tabla:
CREA_ARRAY (“10”,”5” ; n_array_productos);
ESCRIBE_ARRAY (n_array_productos, “jabón”, “precio”, “100” ;);
ESCRIBE_ARRAY (n_array_productos, “jabón”, “olor” , “limón” ;);
ESCRIBE_ARRAY (n_array_productos, “toalla”, “precio”, “1000” ;);
LEE_ARRAY
LEE_ARRAY
LEE_ARRAY
LEE_ARRAY
(n_array_productos,
(n_array_productos,
(n_array_productos,
(n_array_productos,
“jabón”,
“0”, “0”
“0”, “1”
“1”, “0”
“precio” ; n_a);
; n_b);
; n_c);
; n_d);
BUSCA_ARRAY (n_array_productos, 0, “limón” ; n_pos1, n_pos2);
LIBERA_ARRAY (n_array_productos);
Veamos a continuación el efecto de cada instrucción:
CREA_ARRAY (“10”,”5” ; n_array_productos): crea una tabla de 10x5 y asigna el
handle reservado a n_array_productos.
ESCRIBE_ARRAY (n_array_productos, “jabón”, “precio”, “100” ;): crea entradas
para las nuevas claves “jabón” y “precio”, asignándoles los primeros índices libres, es
decir, los índices 0 y 0. Escribe en la posición (0,0) de la tabla el valor “100”.
ESCRIBE_ARRAY (n_array_productos, “jabón”, “olor” , “limón” ;): crea una
entrada para la nueva clave “olor” y le asigna el primer índice de la segunda
dimensión que esté libre, esto es, el índice 1. Escribe en la posición (0,1) el valor
“limón”.
ESCRIBE_ARRAY (n_array_productos, “toalla”, “precio”, “1000” ;): sólo crea una
nueva entrada para la clave “toalla”. Escribe, por tanto, el valor “1000” en la posición
(1,0).
Una vez visto el mecanismo de escritura es fácil ver qué valores arrojarán las lecturas.
Estos serán: n_a=”100”, n_b=”100”, n_c=”limón”, n_d=”1000”. Obsérvese cómo se
mezclan libremente accesos por clave y directos.
BUSCA_ARRAY (n_array_productos, 0, “limón” ; n_pos1, n_pos2): lógicamente
asignará n-pos1=”0” y n_pos2=”1”.
Página
CAPÍTULO 7. Descripción de las matrices del LDD
(MHPSORGHXVRGHOPyGXORPDWULFHV
Veamos cómo se utilizaría el módulo matrices desde un programa en C++ que
incluyera el archivo de cabecera “matrices.h”, y que usara directamente la clase TarrayPro
Para ello haremos las acciones de crear un array, escribir en él, buscar un elemento y
liberarlo.
/* Crea espacio para 10 posibles vectores */
TarrayPool arrayPool(10);
/* Creación del array */
unsigned dim[]= {10,5};
vector<unsigned> vDim(&dim[0],&dim[2]);
TarrayPool::TidArray n_array_productos= arrayPool.CrearArray (vDim);
/* Escritura por clave */
string clave1[]= {"jabón", "precio"};
vector<string> vClave1(&clave1[0],&clave1[2]);
arrayPool.EscribirValorEnArray (n_array_productos, vClave1, "100");
/* Lectura por clave */
string n_a= arrayPool.LeerValorDeArray (n_array_productos, vClave1);
/* Lectura equivalente por índice */
string pos1[]= {"0", "0"};
vector<string> vPos1(&vPos1[0],&vPos1[2]);
string n_b= arrayPool.LeerValorDeArray (n_array_productos, vPos1);
/* Búsqueda de un elemento */
vector<string> vPos2;
arrayPool.BuscarValorEnArray (n_array_productos, "100", true, vPos2);
/* Liberación del array */
arrayPool.LiberarArray (n_array_productos);
Como se puede ver, se han escogido los mismos nombres que en el ejemplo anterior,
por lo que los resultados que se obtienen en la lecturas y las búsquedas deben ser idénticos.
Puede parecer incómoda la interfaz de TarrayPro, ya que antes de hacer lecturas y escrituras
hay que inicializar un vector. Esto es porque dicha interfaz no está preparada para usarse así,
sino que se supone que se dispone de los vectores de posición y claves rellenados al leer los
parámetros proporcionados por el usuario a las instrucciones del LDD.
Página