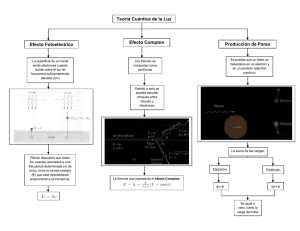
Visualización de Escenas 3D Fotorealistas mediante Hardware
Anuncio

Visualización de escenas 3D fotorrealistas mediante hardware gráfico programable (GPU) Federico Jorge Marino [email protected] Tesis de Grado en Ingeniería Informática Director: Ing. Horacio Abbate Facultad de Ingeniería, Universidad de Buenos Aires Resumen El trabajo comienza exponiendo los fundamentos de las técnicas de iluminación global para la síntesis de imágenes partir de un modelo 3D y su base físico-matemática. Se reseñan los diferentes algoritmos entre los que se encuentran: Ray Tracing, Path Tracing, Radiosity y Photon Mapping. Luego se analizan las plataformas disponibles para implementar sistemas de rendering en tiempo real como ser clusters de PCs o GPUs (Graphics Processing Unit). Se analiza en detalle la arquitectura de las GPU y las técnicas para computar algoritmos de propósito general en ellas (GPGPU). A continuación se propone un caso de estudio que consiste en implementar el algoritmo de Photon Mapping sobre una GPU utilizando OpenGL y el lenguaje Cg. Para ello, se diseño una capa de software orientada a objetos basada en los conceptos del paradigma Streaming Programming Model y la extensión de OpenGL, Framebuffer Object para implementar kernels y streams utilizando los mecanismos de cómputo del hardware gráfico. Sobre esa base se construyo un motor de Photon Mapping adaptando una estructura de aceleración de trazado de rayos denominada BVH (Bounding Volumen Hierarchy) y la técnica de Photon Splatting para computar la iluminación indirecta. Finalmente se evalúa el desempeño, escalabilidad de la implementación en relación a varios parámetros, y se analizan diferentes imágenes generadas a partir de un modelo de caja de Cornell (Cornell Box). I Agradecimientos Debo comenzar agradeciendo especialmente a Horacio, por sus consejos, su dedicación y su paciencia durante el extenso desarrollo de este proyecto. Siguiendo por los docentes de la Facultad de Ingeniería que me orientaron en mi búsqueda de un proyecto interesante para investigar. También tengo que agradecer a mi familia, por su colaboración en la redacción y revisión de varios puntos que integran este trabajo. Siguiendo por mi madre, sin cuya asistencia logística/gastronómica no hubiera podido dedicar el tiempo suficiente a esta tarea. Por último, a mis amigos y conocidos que creyeron que algún día este proyecto estaría concluido. Federico J. Marino Octubre de 2007 II Índice General Resumen I Agradecimientos II 1. Introducción 1 2. Fundamentos de la iluminación global 2 2.1. La física de la luz 2 2.2. Terminología de iluminación 2 2.3. Técnicas 6 2.4. La ecuación del Rendering 6 2.5. Interacción luz-superficie 7 2.5.1. La función BSSRDF 7 2.5.2. La función BRDF 8 2.5.3. Reflectancia 9 2.5.4. Reflectancia difusa 9 2.5.5. Reflexión especular 10 2.5.6. Refracción 11 3. Algoritmos de iluminación global 12 3.1. Ray Tracing clásico 12 3.1.1. Estructuras de aceleración 14 3.1.2. Ventajas 14 3.1.3. Desventajas 14 3.2. Path Tracing 14 3.2.1. Ventajas 16 3.2.2. Desventajas 17 3.3. Bidirectional Path Tracing 17 3.3.1. Ventajas 18 3.3.2. Desventajas 18 3.4. Metropolis Light Transport 18 3.4.1. Ventajas 18 I 3.4.2. Desventajas 19 3.5. Radiosity 19 3.5.1. Etapa 1, determinación de los factores de forma 20 3.5.2. Etapa 2, resolución del sistema de ecuaciones 21 3.5.3. Etapa 3, sntesis de la imagen 22 3.5.4. Ventajas 22 3.5.5. Desventajas 22 3.7. Photon Mapping 22 3.7.1. Motivación y antecedentes 22 3.7.2. El método 23 3.7.3. Fase 1, trazado de fotones 23 3.7.4. Fase 2, rendering 26 3.7.5. Desempeño y mejoras 27 4. Plataformas de Rendering de alto desempeño 29 4.1. Clusters de PCs 29 4.2. Hardware gráfico programable 30 5. GPU (Graphics Processing Unit) 32 5.1. El pipeline gráfico 33 5.2. El pipeline gráfico programable 35 5.3. Modelo de memoria de la GPU 37 5.4. El procesador de vértices 38 5.5. El rasterizador 38 5.6. El procesador de fragmentos programable 39 5.7. Stream Programming Model 39 5.8. GPGPU 40 5.9. Computando con un programa de fragmentos 41 6. Implementación de un caso de estudio 45 6.1. Proyección perspectiva de la escena 45 6.2. Fuente de luz 46 6.3. Geometría de la escena 46 6.4. Modelo de iluminación 47 II 6.5. Marco de trabajo basado en Kernels y Streams 48 6.5.1. Clase FpKernel 48 6.5.2. Clase FpStream 49 6.5.3. Ejemplo de uso 51 6.6. Trazador de fotones y rayos en la GPU 51 6.6.1. La estructura de aceleración BVH 52 6.6.2. Clase Tracer 54 6.6.3. El trazado de fotones 55 6.7. Photon Splatting 56 6.8. Motor de Rendering basado en Photon Mapping 59 6.8.1. La clase SceneLoader 60 6.8.2. La clase PhotonMapper 60 6.8.3. La clase Raytracer 62 7. Evaluación de la implementación 64 7.1. Entorno de hardware y software 64 7.2. Mediciones del desempeño 64 7.3. Imágenes 70 8. Conclusiones 74 8.1. Trabajos Futuros 74 A Publicaciones 76 B Código Fuente 77 Referencias 94 III Capítulo 1 - Introducción Los gráficos generados por computadora son cada vez una parte más fundamental de la vida cotidiana. Desde ámbitos como el cine en donde mediante técnicas sofisticadass casi cualquier producción con un presupuesto mediano, puede realizan complejas simulaciones que derivan en la creación de personajes o escenarios virtuales de extremo realismo. Pasando por la industria de los videojuegos, en donde una audiencia cada vez más exigente y demandante de efectos y simulaciones más reales, impulsan el desarrollo de la tecnología de semiconductores, dotando a los dispositivos de juego de un poder de cómputo extraordinario. Llegando a aplicaciones de CAD y animación 3D para computadores personales que permiten diseñar y modelar objetos o escenas que pueden ser navegadas virtualmente en tiempo real. La creación o síntesis de imágenes fotorrealistas se refiere al proceso de generar imágenes artificiales capaces de engañar al ojo humano al tal punto que resulten casi indistinguibles de fotografías tomadas del mundo real. Hace más de dos décadas surgieron las primeras técnicas, como Ray Tracing (1980) y Radiosity (1984), que utilizaron por primera vez simulaciones basadas en principios físicos. Dichos métodos tienen su origen en otros campos anteriores a la computación gráfica como la óptica y los problemas de transferencia de calor. Tras años de evolución, se han logrado modelar muchos de los efectos de la interacción entre la luz y las superficies. Sin embargo para lograr altos niveles de realismo aún se requieren recursos computacionales importantes. En el caso de la industria cinematográfica los tiempos que demanda la generación de un cuadro de animación no son un factor fundamental (aunque puedan demandar horas o días). Si, en cambio, lo es la calidad del resultado obtenido. Cuando se trata de emplear estos algoritmos de síntesis de imágenes realistas en aplicaciones de tiempo real generalmente se llega a una solución de compromiso entre una menor calidad a cambio de una mayor velocidad de generación. La rápida evolución en el hardware de procesamiento gráfico disponible para PCs, ha renovado el interés en investigar nuevas formas de utilizarlo ya sea para implementar algoritmos de iluminación mas complejos o para el cómputo de otros tipos de aplicaciones no gráficas que impliquen procesar grandes volúmenes de datos. En este trabajo se busca conocer el estado de arte en cuanto a las técnicas de iluminación fotorrealistas, analizar que plataformas están disponibles para construir aplicaciones de tiempo real que implementen ese tipo de métodos y diseñar una solución que reuna aspectos de los últimos trabajos en la materia. 1 Capítulo 2 - Fundamentos de la iluminación global 2.1 La física de la luz La luz tiene una naturaleza dual ya que posee las propiedades de una onda y de una partícula. La luz visible es radiación electromagnética con longitudes de onda en el rango de los 380 a los 780 nanómetros. A lo largo de la historia, la luz intentó ser explicada mediante diversos modelos: • • • • Óptica de rayos: explica efectos como reflexión y refracción. Óptica de ondas: explica todos los fenómenos de la óptica de rayos y además explica el efecto de interferencia y de difracción. Óptica electromagnética: incluye a la óptica de ondas y agrega explicaciones a los fenómenos de dispersión y polarización. Óptica de partículas: explica la interacción entre luz y materia. En computación gráfica se usa casi exclusivamente la óptica de rayos, o también llamada óptica geométrica. El proceso que determina el color que tendrá la luz que entra al ojo proveniente de una superficie, es dinámico y complejo. Este proceso está regido por las propiedades físicas de la luz y de los materiales que componen las superficies. Si se observa la luz, desde su aspecto corpuscular, se la puede considerar como una serie de paquetes de energía que viajan a la velocidad de la luz, denominados fotones. Cuando un fotón interactúa con una superficie pueden suceder tres casos: • • • Reflexión: si el fotón rebota en una superficie perfectamente suave, el ángulo es determinado por la ley de reflexión, la cual especifica que el mismo, es igual y opuesto al ángulo de incidencia respecto de la normal (reflexión especular). En el caso de superficies irregulares o rugosas, el ángulo de reflexión es mas difícil de predecir ya que la normal en el punto de impacto solo puede determinarse en forma probabilística (reflexión difusa). Refracción (o también conocido como transición): el fotón viaja a través de una superficie. La dirección se determina según la ley de refracción o ley de Snell que tiene en cuenta los índices de refracción de los dos medios que comparten la superficie. Absorción: el fotón genera la excitación de los átomos de la superficie convirtiendo la energía lumínica en calor o reemitiéndola. La intensidad o brillo de la luz es proporcional al número de fotones y su color depende de la energía contenida en el fotón. 2.2 Terminología de iluminación La energía de un fotón eλ varía de acuerdo a su longitud de onda λ y está definida por: 2 eλ = hc (2.1) λ Donde h ≈ 6,63 ⋅ 10−34 J ⋅ s es la constante de Planck y c es la velocidad de la luz. La energía radiante espectral Qλ, en nλ fotones con longitud de onda λ se define como: Qλ = nλ ⋅ eλ = nλ ⋅ hc (2.2) λ La energía radiante Q es la energía de un conjunto de fotones que se calcula integrando la energía espectral sobre un espectro de longitudes de onda, dada por: ∞ Q = ∫ Q λ dλ (2.3) 0 El flujo radiante Ф, es la cantidad de energía irradiada por diferencial de tiempo definido como: Φ= dQ dt (2.4) La densidad de flujo radiante por unidad de área, se define como el diferencial de flujo dФ por diferencial de área dA , sobre una superficie determinada y su expresión es: dΦ d 2Q = dA dt ⋅ dA (2.5) La exitancia radiante M o radiosidad B, se refieren a la densidad de flujo radiante por unidad de área, saliendo de una superficie en un punto x y está definida por: M ( x) = B( x) = dΦ dA (2.6) La irradiancia E es la densidad de flujo radiante por unidad de área, llegando o incidiendo en el punto x de una superficie es: E ( x) = dΦ dA (2.7) r La intensidad radiante, es el flujo radiante por unidad de ángulo sólido dw , definida por: r dΦ I ( w) = r dw (2.8) 3 r La radiancia, es el flujo radiante por unidad de ángulo sólido dw por unidad de área proyectada dA (ver figura 2.1): r L( x, w) = ∞ d 2Φ d 4 nλ hc dλ r = ∫0 r cos θ ⋅ dA ⋅ dw cos θ ⋅ dw ⋅ dA ⋅ dt ⋅ dλ λ (2.9) Representa la radiancia expresada como la integral sobre las longitudes de onda del flujo de energía en nλ fotones por diferencial de área dA por diferencial de ángulo r r sólido dw por unidad de tiempo, donde θ es el ángulo entre la dirección dw y la r normal n de la superficie. Esta cantidad es la que representa de modo más cercano el color de un objeto. Puede pensarse como el número de fotones llegando por unidad de tiempo a un área pequeña desde una dirección determinada y puede usarse para describir la intensidad de luz en un punto dado y una dirección determinada. Figura 2.1: La radiancia, L, r definida como el flujo radiante por unidad de ángulo sólido dw , por unidad de área proyectada dA. Cuando se trabaja con iluminación que proviene de cierta dirección no tiene sentido tener en cuenta un solo rayo que sería infinitamente delgado porque virtualmente ningún fotón viajaría en él. En cambio tiene mas sentido hablar del área que rodea a cierta dirección. También conocido como ángulo cónico, el ángulo sólido, es la “porción de cielo” que abarca un objeto visto desde un punto dado. Se puede decir que representa simultáneamente el tamaño angular y la dirección (expresada en coordenadas esféricas) de un haz. Su unidad es el estereoradián (sr) y es equivalente a un radián al cuadrado. r El tamaño de un diferencial de ángulo sólido, dw (ver figura 2.2) en coordenadas esféricas es: r dw = (dθ ) * (sin θ ⋅ dφ ) = sin θ ⋅ dθ ⋅ dφ (2.10) Donde, θ es el ángulo entre la dirección y la normal de la superficie S1 y φ es el ángulo entre la dirección proyectada sobre el plano tangente a la superficie y el eje x. El lado derecho de la ecuación (2.10) expresa el área infinitesimal en la esfera unitaria como un producto del largo del arco de longitud dθ y la longitud del arco de latitud sin θdφ . 4 Figura 2.2: El ángulo sólido. r La dirección w del ángulo sólido se puede calcular como: x = sin θ * cos φ y = sin θ * sin φ (2.11) z = cos θ 5 2.3 Técnicas Las técnicas de iluminación pretenden simular o aproximar los fenómenos físicos de distribución de la luz (reflexión, refracción, absorción, etc.) sobre una escena 3D, con el objetivo de calcular la intensidad lumínica en cualquier punto del modelo. Las técnicas de iluminación directa son aquellas que tienen en cuenta solamente la luz que llega a las superficies en forma directa, desde las fuentes. En cambio, las de iluminación global, permiten capturar la iluminación indirecta (la que proviene de reflexiones y refracciones en otras superficies), lo cual aporta una gran cuota de realismo a las imágenes generadas aunque a un costo de cómputo mayor. Sin ella, las imágenes obtenidas tienen un aspecto plano y sintético. Estos algoritmos se alimentan de datos como: • • • Descripción geométrica de la escena (vértices, caras, normales, etc.). Descripción de materiales de las superficies (coeficientes de brillo, transparencia, color, rugosidad, etc.). Descripción de fuentes de luz (color, dirección, potencia, etc.). Existen numerosas técnicas de iluminación global, pero sin duda las más famosas son Ray Tracing y Radiosity. Analizándolas en detalle la mayoría se pueden incluir en uno de estos dos grupos: • • Métodos de muestreo de puntos: por ejemplo Ray Tracing, donde se toman gran cantidad de muestras de la iluminación en diferentes puntos de la escena. Métodos de elementos finitos: por ejemplo Radiosity. La distribución de luz se calcula resolviendo un sistema de ecuaciones lineales que representa el intercambio de luz entre parches de las superficies. Además hay técnicas híbridas que combinan aspectos de ambos métodos. 2.4 La ecuación del Rendering La ecuación, que fue presentada por Kajiya [1], surgió como una forma abstracción o generalización de los distintos algoritmos de iluminación global. Provee un contexto unificado para analizar cada método particular y describe matemáticamente el transporte de luz en cada punto de una escena. Los distintos algoritmos de iluminación global producen resultados que definen flujos de energía mediante la aproximación numérica de esta ecuación, que se basa en la ley de conservación de energía. r Básicamente dice que toda la luz emitida en la dirección w por el punto x, Lo, es la r suma de la luz reflejada por el punto, Lr y dispersada en la dirección w mas la luz emitida por el punto Le (es no nula solo si el punto es emisor de luz). r r r Lo( x, w) = Le ( x, w) + Lr ( x, w) (2.12) Desarrollando el término de la radiancia reflejada (Lr) obtenemos: 6 r r Lo ( x, w) = Le( x, w) + r r r r r r ∫ f ( x, w' , w) L ( x, w)(w'⋅n )dw' r i r w '∈Ω (2.13) r Donde Ω es el conjunto de todas las direcciones posibles, n es la normal de la superficie, Li es la radiancia incidente para cada dirección y fr es la denominada función BRDF (Bidirectional Reflectance Distribution Function) que para un punto x, da la r fracción de la luz total proveniente de la dirección w' que es reflejada en la dirección r saliente w . El valor de la función BRDF varía entre 0 (no hay reflexión) y 1 (reflexión especular r perfecta) y además para cada par x, w' se cumple que: r r ∫ fr ( x, w' , w) ≤ 1 (Cada punto no refleja más que la luz que recibe) (2.14) r w '∈Ω Algunas características a destacar de la ecuación son: • • • Es lineal (solo está compuesta por sumas y multiplicaciones). Homogeneidad espacial (es la misma para todas las posiciones y orientaciones). Depende de la longitud de onda λ de la luz, por lo tanto la ecuación debería ser resuelta para cada λ posible. En la práctica se resuelve para un solo valor (obteniendo la luminancia) o para las tres componentes RGB. Debido a que, la radiancia incidente Li en un punto, es la radiancia saliente Lo de r otro punto x’ en la dirección – w' , la integral se convierte en recursiva; lo cual la hace imposible de resolver por métodos analíticos, excepto para casos muy simples. Es por ello, que los métodos disponibles llevan a una solución aproximada. Existen algunos fenómenos naturales que no pueden ser modelados por esta ecuación como ser: • • • • La fluorescencia (la luz es reflejada con una longitud de onda diferente). La fosforescencia (la luz es reflejada un instante mas tarde). La polarización. La interferencia. 2.5 Interacción luz-superficie El fenómeno de dispersión es aquel donde algunas formas de radiación como en este caso la luz se desvían de su trayectoria original ya sea porque encuentran un obstáculo o cambios en el medio que atraviesan. 2.5.1 La función BSSRDF Esta función, presentada por Nicodemus et al. [2], según sus siglas en inglés Bidirectional Scattering Surface Reflectance Distribution Function, describe el proceso por el cual un haz de luz que ingresa en un material, se dispersa en su interior para luego abandonar la superficie en una ubicación diferente (ver figura 2.3). Esto es común especialmente en materiales traslucidos como la piel, el mármol o la cera, donde solo un bajo porcentaje se refleja directamente desde el punto de impacto en la superficie. Este comportamiento ocurre en cierta medida, en la mayoría los materiales no metálicos. 7 Figura 2.3: Funciones BRDF y BSSRDF. La función BSSRDF (ecuación 2.15) [2], S, relaciona un diferencial de radiancia r reflejada, dLr, en x en la dirección w , con el diferencial de flujo incidente dΦi , en x’ en r la dirección w' . Dado que tiene de ocho dimensiones, es muy costosa su evaluación. r r r dLr ( x, w) S ( x, w, x' , w' ) = r dΦi ( x' , w' ) (2.15) 2.5.2 La función BRDF La función BRDF (Bidirectional Reflectance Distribution Function), fue presentada por Nicodemus et al. [2] y describe las características reflectivas de las superficies o también se dice que describe un modelo local de iluminación. Surge de simplificar la BSSRDF, condicionando a que el punto en el que la luz impacta y en el que se refleja sea el mismo (x=x’), reduciendo así la dimensionalidad de la función a seis. r r r r dLr ( x, w) dLr ( x, w) fr ( x, w' , w) = r = r r r r dEi ( x, w' ) Li ( x, w' )( w'⋅n )dw' (2.16) Esta función fr, define que porcentaje de la irradiancia se convierte en radiancia r reflejada y donde n es la normal en x. Partiendo del conocimiento del campo de radiancia incidente en un punto de la superficie, es posible calcular la radiancia reflejada (ecuación 2.17) en todas las direcciones, integrando la radiancia incidente Li: r r r r r r r r r r Lr ( x, w) = ∫ fr ( x, w' , w)dE ( x, w' ) = ∫ fr ( x, w' , w) Li ( x, w' )( w'⋅n )dw' Ω (2.17) Ω r Aquí n es la normal en el punto x de la superficie, y Ω es el hemisferio de r r direcciones incidentes en x (cabe notar que w ⋅ n = cos θ donde θ es el ángulo entre la r r normal n y la dirección w ). La función BRDF posee las siguientes propiedades: 8 • • • Invariancia posicional: en general la función es invariante respecto de la posición si se trata de superficies homogéneas. Por el contrario, no es invariante en superficies rugosas o heterogéneas. Reciprocidad: que establece que la función es independiente de la dirección en la que fluye la luz, por lo tanto es posible trazar los recorridos de la luz en ambas direcciones. Conservación de energía: una superficie no puede reflejar más luz de la que recibe. Existen dos clases de funciones BRDF: • • Isotrópicas: se refiere a aquellas en donde propiedades de reflectancia no varían según la dirección. Ocurre en superficies muy suaves. Anisotrópicas: por el contrario, se refiere a esos casos en donde las propiedades son diferentes o dependen de la dirección. La mayoría de los materiales tienen principalmente un comportamiento isotrópico, y exhiben en un grado menor comportamiento anisotrópico. 2.5.3 Reflectancia Esta cantidad representa la relación entre el flujo de luz incidente y reflejado en un punto x. La reflectancia ρ , es un valor entre 0 y 1. La fracción de luz que no es reflejada es absorbida o refractada. ρ ( x) = dΦ r ( x ) dΦ i ( x ) (2.18) En la práctica, para la mayoría de los materiales, la distribución de la energía reflejada en las diferentes direcciones, puede modelarse como la suma de dos componentes: • • Reflexión difusa. Reflexión especular. 2.5.4 Reflectancia difusa Típicamente ocurre en superficies rugosas o materiales que dispersan la luz dentro de sus superficies como por ejemplo tierra, piedra o tela. Las pinturas del tipo “mate” tienen una alta proporción de reflexión difusa. También se conoce con el nombre de superficies lambertianas a aquellas que exhiben este comportamiento. La luz incidente es reflejada en todas las direcciones del hemisferio de manera uniforme (ver figura 2.4). La dirección de reflexión es perfectamente aleatoria, por lo r tanto la función BRDF, fr,d, es constante respecto de la dirección saliente w y se define como: r r Lr ( x, w) = fr , d ( x) ∫ dEi ( x, w' ) = fr , d ( x) Ei ( x) (2.19) Ω 9 Luego término, ρd , conocido como reflectancia difusa, se define como: ρd ( x ) = dΦ r ( x ) = dΦ i ( x ) r Lr ( x)dA∫ dw Ω Ei ( x)dA r fr , d ( x) Ei ( x)dA∫ dw Ω = Ei ( x)dA Dado que = π ⋅ fr , d ( x ) r ∫ dw = π (2.20) (2.21) Ω Figura 2.4: Reflexión difusa ideal o lambertiana (izquierda), reflexión difusa (derecha). 2.5.5 Reflexión especular Sucede cuando un haz de luz choca con una superficie suave, típicamente metálica o de un material dieléctrico (vidrio o agua). En el caso ideal (reflexión especular perfecta o reflexión tipo espejo) de una superficie perfectamente suave, toda la luz incidente se reflejaría en una dirección que forma un ángulo igual y opuesto al ángulo de incidencia respecto de la normal de la superficie (según la ley de reflexión), también conocida como dirección de reflexión del espejo (ver figura 2.5). Pero la mayoría de las superficies son imperfectas, por lo tanto en estos casos, la luz es reflejada alrededor de un pequeño cono centrado en la dirección de reflexión del espejo. Este tipo de materiales se denominan “glossy” (ver figura 2.5). El grado de imperfección es un parámetro habitual del material llamado comunmente rugosidad usado en los modelos de reflexión. La radiancia debido a la reflexión especular está definida como: r r Lr ( x, ws ) = ρs ( x) Li ( x, w' ) (2.22) r r Donde w , es la dirección incidente, ws es la dirección de reflexión del espejo, ρs , es la reflectancia especular y Li la radiancia incidente. r En el caso de una reflexión especular perfecta, ws es: 10 r r r r r w s = 2( w ⋅ n ) n − w (2.23) r r Donde ws = 1 y w = 1 Figura 2.5. Reflexión especular perfecta o tipo espejo (izquierda), reflexión especular tipo “glossy” (derecha). 2.5.6 Refracción Es el efecto de cambio en la dirección de una onda debido a un cambio en su velocidad. Sucede cuando una onda pasa de un medio a otro. En óptica ocurre cuando un haz de luz pasa de un medio con un cierto índice de refracción a otro con un índice diferente. Figura 2.6: Refracción de un haz de luz. La ley de Snell o ley de refracción se utiliza para calcular la dirección del rayo r refractado wr , en función de los índices de refracción de los dos medios η1 y η2, la r r dirección incidente w y la normal de la superficie n (ver figura 2.6). La relación entre los ángulos está dada por: η 1 sin θ 1 = η 2 cos θ 2 (2.24) Y la dirección del rayo refractado se define como: r r r r η1 r r r r η1 wr = − ( w − ( w ⋅ n )n ) − ( 1 − ( ) 2 (1 − ( w ⋅ n ) 2 ) )n η2 η2 (2.25) 11 Capítulo 3 - Algoritmos de iluminación global 3.1 Ray Tracing clásico Fue una de las primeras técnicas que propuso una solución de iluminación global, ya que mediante un algoritmo recursivo incorpora efectos de reflexión, refracción y sombras. Fue presentada por Whitted en 1980 [3]. Se basa en la observación que los rayos de luz que importan son solo aquellos que llegan al ojo del observador. En la naturaleza las fuentes de luz emiten fotones que se dispersan por la escena y solo una pequeña fracción de ellos alcanza al ojo, pero simular el proceso de esa manera, no es práctico. La idea principal es trazar el camino recorrido por la luz en sentido inverso, desde el ojo hacia las fuentes de luz, utilizando el hecho de que los fotones se mueven en línea recta a través del espacio vacío y que la dispersión de la luz en las superficies es simétrica. Los parámetros de entrada del algoritmo de Ray Tracing son: • • • • La posición del observador. Un plano de vista (dirección y campo de visión). La descripción de la geometría y los materiales de la escena. Las características de las fuentes de luz. Un rayo r se define por un origen x y una distancia d que es la recorrida en la r dirección w , y se resume en la siguiente fórmula: r r r ( x, w) = x + d ⋅ w (3.1) El algoritmo pretende calcular el color (la radiancia promedio) de cada uno de los píxeles que conforman el plano de vista. Esto se logra trazando uno o más rayos por cada píxel (ver figura 3.1) y promediando los valores obtenidos. Figura 3.1: Trazado inverso del recorrido de un haz de luz. 12 El recorrido completo de un haz de luz se conforma de varios segmentos. Cada vértice del recorrido representa una interacción con las superficies que hace cambiar su dirección. En la figura 3.1 se observa que el primer segmento o rayo del recorrido (ojo del observador a x1) se denomina rayo primario y es aquel que atraviesa el plano de proyección. Luego en los puntos x1, x2 y x3 se generan rayos secundarios producto de la reflexión especular y refracción en las respectivas superficies. Para calcular la radiancia del rayo primario debemos hallar la menor distancia (el menor valor de d) a la cual el rayo interseca un objeto, dicho de otro modo, hay que encontrar el objeto visto a través del píxel. Hallado el punto de intersección x, debemos calcular la radiancia saliente en la dirección del rayo. Para tal fin, debemos conocer la normal de la superficie y la función BRDF, fr en x. Con esos datos podemos computar la iluminación aportada por cada fuente de luz estimando la irradiancia en x. Por ejemplo, la radiancia reflejada, Lr, debido a una fuente puntual con potencia Φl en el punto p se puede calcular como: r r r r r w⋅ n Φl Lr ( x, w) = fr ( x, w, w' ) V ( x, p ) 2 4π p−x (3.2) r Donde w = ( p − x) / p − x es el vector unitario en la dirección de la fuente de luz. La función de visibilidad, V, se evalúa trazando un rayo de sombra desde el punto x hacia la luz. Si el rayo de sombra interseca un objeto entre x y la luz entonces V=0, de lo contrario V=1. Para superficies especulares o traslúcidas el algoritmo debe evaluar la reflexión especular o refracción trazando rayos secundarios y sumar su aporte a la radiancia total del recorrido, utilizando el mismo procedimiento usado para el rayo primario. A continuación se detalla una versión simplificada del algoritmo: Para cada píxel de la imagen crear un rayo desde el ojo a través de un píxel Color de píxel=trazar(rayo) trazar(rayo) encontrar intersección mas cercana con la escena computar punto de intersección y normal color = sombrear(punto, normal) return color sombrear(punto,normal) color=0 para cada fuente de luz trazar rayo de sombra hacia la luz si rayo de sombra interseca luz color=color + iluminación directa si es especular color = color+ trazar(rayo reflejado/refractado) return color Dada la naturaleza recursiva de método, la complejidad computacional crece rápidamente a medida que el árbol de recorridos y rayos aumenta en su profundidad. Es 13 por ello que se han propuesto numerosas estrategias para mejorar el desempeño de Ray Tracing, como por ejemplo la del control adaptativo del nivel máximo de recursión a alcanzar en el trazado según las características de la escena. Otras estrategias, buscan aprovechar la coherencia existente entre rayos paralelos, cercanos en el plano de vista, que probablemente tendrán interacciones similares con las superficies, para ahorrar u optimizar las ciclos de trazado. 3.1.1 Estructuras de aceleración En las primeras implementaciones de Ray Tracing se iteraba sobre todos los objetos para verificar su intersección con cada rayo. Esto genera un problema de búsqueda lineal de orden O(N) en una escena con N objetos, lo cual resultaba muy ineficiente. En cambio, es conveniente subdividir el modelo en regiones más pequeñas y solo verificar la intersección de cada rayo con los objetos de las regiones que este atraviesa. De este modo se logran tiempos de búsqueda sub-lineales. Este concepto se materializa en lo que se conoce como estructura de aceleración, que es una estructura de datos ordenada y construida mediante un preproceso, a fin de reducir la cantidad de verificaciones de intersección entre rayos y objetos. Estás estructuras pueden clasificarse en dos grandes grupos: • • De subdivisión espacial: el espacio de la escena se particiona en regiones. Luego conociendo que regiones atraviesa el rayo, se prueba la intersección únicamente con los objetos que estén contenidos en ellas. Algunos ejemplos son las grillas uniformes (regiones de igual tamaño)[4], grillas jerárquicas [5], los KD-trees o la BSP (Binary Space partition) [7]. De agrupamiento de objetos: los elementos de geometría forman grupos que a su vez conforman una jerarquía de volúmenes simples. Entonces, si no hay intersección entre un volumen y el rayo, se evita probar la intersección con todos los objetos incluidos en dicho volumen. Un ejemplo de esta estructura es BVH (Bounding Volumen Hierachy) que se detalla en el punto 6.6.1. Además, existen numerosas estructuras híbridas que combinan aspectos de las principales. 3.1.2 Ventajas • Simplicidad de implementación. 3.1.3 Desventajas • • • • • No puede calcular la iluminación indirecta en superficies difusas. No permite computar sombras suaves. No permite computar efectos de enfoque debido a los lentes de cámara. Es dependiente del punto de vista de la escena. No puede simular inter-reflexión difusa entre superficies. 3.2 Path Tracing Es una técnica que extiende el método de Ray Tracing, como una solución a la ecuación del rendering y fue presentada por Kajiya en 1986 [1]. Incorporó conceptos 14 propuestos por Cook et al. en 1984 [9] en su algoritmo conocido como Distribution Ray Tracing. Esté último utiliza el muestreo estocástico para computar efectos como “motion blur”, profundidad de campo y sombras suaves. Path Tracing hace posible calcular los efectos que requieren evaluar los problemas de integración recursiva trazando rayos en forma aleatoria en el dominio de integración para calcular el valor de la integral, método al cual se lo conoce como Monte Carlo. El concepto principal de la teoría de Monte Carlo es que la integral i puede ser aproximada evaluando la función f sobre un número de muestras xi (i=1..N). Obteniendo un valor estimado para I expresado como I : i = ∫ f ( x)dx I = 1 N N f ( xi ) ∑ p( x ) i =1 (3.3) i Donde p(xi) es la probabilidad de elegir xi . Lo general del método lo hace aplicable a integrales de varias dimensiones o a funciones arbitrarias. Sin embargo, aunque el estimador de I converge a I cuando N → ∞ , la convergencia es lenta. El error estándar es proporcional a 1 N por lo tanto para reducir el error a la mitad se necesitan cuatro veces mas muestras. Aplicándolo a Path Tracing, la función desconocida es la distribución de luz. Aquí el método de Monte Carlo busca resolver la ecuación del rendering completa, por medio de la generación de todos los posibles recorridos de los rayos comenzando en el ojo y terminando en las fuentes de luz (ver figura 3.2). Figura 3.2: Trazado de múltiples recorridos de rayos por cada píxel. Con cada impacto sobre una superficie, se suma la radiancia emitida desde el punto y se envía un nuevo rayo en una dirección aleatoria seleccionada de un hemisferio alrededor del punto, de acuerdo con la BRDF de la superficie. Si el rayo impacta en otra superficie, el algoritmo se hace recursivo, el resultado es multiplicado por la probabilidad de elegir esa dirección y agregado al estimador actual. 15 Para estimar con precisión la radiancia en un punto, se debe muestrear y promediar un gran número (varios miles) de recorridos de rayos por cada píxel. Un detalle importante de Path Tracing es que utiliza un solo rayo reflejado/refractado para estimar la iluminación indirecta. Si utilizara varios rayos en cada evento de dispersión de luz, provocaría un crecimiento exponencial en el número total de rayos requeridos, dada su naturaleza recursiva. Además, el autor señaló que era conveniente concentrar esfuerzos en los eventos que son resultado de pocas reflexiones. Al trazar un solo rayo por evento (reflexión, refracción, etc.) se asegura que el mismo esfuerzo es invertido en todas las superficies que son vistas directamente por el observador. Para evitar que el algoritmo genere recorridos de rayos de longitud infinita hay que fijar un criterio de terminación. Una opción sería trazar todos los recorridos hasta una longitud máxima fija, lo cual resulta ineficiente y generaría errores considerables en el resultado de la estimación al truncar recorridos que podrían aportar a la radiancia del píxel en cuestión. La solución alternativa y elegante es incorporar la idea del muestreo probabilístico al problema de determinar la longitud del recorrido, sin agregar un sesgo al resultado de la estimación. Esta técnica conocida como Ruleta Rusa, introducida al área de computación grafica por Arvo et al. [26], es una forma de muestreo que tiene en cuenta la distribución probabilística de la función a estimar para eliminar partes no importantes del dominio. En este hace posible trazar un haz a través de un número finito de rebotes y aún así obtener un resultado comparable al que se hubiera logrado trazándolo un número infinito de rebotes. Dado que el proceso de generación de cada recorrido depende de variables aleatorias (la dirección de reflexión al intersecar una superficie difusa es escogida al azar) y que en píxeles cercanos el valor de iluminación estimado puede variar considerablemente, es común que se produzca un efecto de ruido (varianza del estimador) en la imagen final. Para reducir dicho efecto es necesario trazar muchos recorridos por píxel y promediar su valor. Hay métodos para reducir la varianza de los métodos de Monte Carlo. Uno de ellos es conocido como muestreo por importancia, se fundamenta en tratar de tomar las muestras en aquellas zonas en donde la función desconocida tiene valores elevados (usando algún conocimiento a priori de la función) para lograr así que el método converja más rápido. Por ejemplo, una forma de lograr esto es concentrar las muestras en zonas más iluminadas, las cuales probablemente estén cerca de las fuentes de luz. Aplicando esta idea a Path Tracing, se suelen trazar recorridos secundarios desde cada nodo de un recorrido principal hacia las zonas brillantes. Otro método que funciona muy bien especialmente en escenas de exteriores que incluyen luz de cielo (la cual varía suavemente) es el método de muestreo estratificado. La idea es dividir el espacio de muestreo en celdas, de manera de tratar de cubrir de manera uniforme dicho espacio. 3.2.1 Ventajas • • • No requiere etapas de preprocesamiento. Maneja cualquier tipo de función BRDF. Maneja cualquier tipo de geometría. 16 • No requiere demasiado espacio de memoria. 3.2.2 Desventajas • • La varianza del estimador de radiancia (el ruido que resulta de usar pocos recorridos por píxel y por lo tanto pocas muestras para estimar la iluminación). Convergencia lenta (sobre todo en escenas complejas en donde la probabilidad de que un recorrido alcance una zona de alta iluminación, es muy baja). 3.3 Bidirectional Path Tracing El término bidireccional, se refiere a que los recorridos de los rayos se originan desde dos puntos: el ojo del observador y la fuente de luz. Este cambio logra captar mas fácilmente los efectos de refracción (vaso de vidrio o una lupa) o de reflexión que producen concentraciones de luz sobre superficies difusas. Este efecto tiene una baja probabilidad de ser captado por el Path Tracing tradicional, ya que implicaría que el rayo pasara por una serie de reflexiones que terminen en la fuente de luz. La técnica fue presentada por Lafortune y Willems [10] en 1993 e independientemente por Veach y Guibas [11] en 1994 como una extensión del algoritmo de Path Tracing. La idea del método es comenzar trazando dos recorridos parciales iniciados respectivamente en la fuente de luz y el ojo del observador. Luego se intenta conectarlos mediante segmentos para los cuales se evalúa una función de visibilidad V. Dicha función define si los segmentos o caminos aportan o no iluminación según estén o no obstruidos por alguna superficie de la escena. La figura 3.3 ilustra un ejemplo en donde cada nodo Ei (vértices del recorrido originado en el ojo) se intenta conectar con todos los Li (vértices del recorrido originado en la fuente de luz). Del resultado de estas combinaciones surgirán una serie de recorridos válidos que capturarán de forma mas eficiente efectos de inter-reflexión o iluminación indirecta. Figura 3.3: Combinación de recorridos parciales en Bidirectional Path Tracing. 17 3.3.1 Ventajas • Se requieren evaluar menos recorridos por píxel. 3.3.2 Desventajas • • La varianza o el ruido de la imagen final es un problema al igual que en el método tradicional. Cada recorrido de luz implica mayor trabajo ya que hay que evaluar las conexiones entre ambos recorridos parciales E y L. 3.4 Metropolis Light Transport Fue presentado por Veach y Guibas [28] en 1997. En realidad, el método tiene sus orígenes en la década de 1950 para la resolución de problemas de física computacional. La estrategia que utiliza es concentrar el trabajo de muestreo en las zonas que más aportan a la imagen ideal final o en regiones de alta radiancia. En lugar de hacer un muestreo aleatorio de la función a integrar, a medida que se generan recorridos (se crean de modo similar que en Bidirectional Path Tracing), estos son clasificados según su aporte. Luego a partir de los recorridos que más contribuyen, se aplican mutaciones de segmentos o de pequeños conjuntos de vértices, para generar nuevos recorridos. Luego del proceso de mutación, se analiza si el nuevo recorrido es aceptado o descartado dependiendo de si está obstruido por alguna superficie y según una función de aceptación cuidadosamente definida. Si no se cumplen las condiciones, el recorrido es descartado como inválido. La función de aceptación permite que los cambios a un recorrido sean aceptados siempre en una dirección, mientras que algunas veces son rechazados en la dirección opuesta. Para las mutaciones se usan dos diferentes estrategias: • • Permutaciones: la idea es que produciendo cambios pequeños (corrimiento de los vértices) a un recorrido con alta contribución a la iluminación, se producirá un nuevo recorrido con alta probabilidad de aceptación. Estas estrategias de mutación se enfocan a capturar efectos específicos como el efecto “caustics” (concentración de luz debido a la reflexión o refracción en superficies curvas, como el que produce una lupa o un vaso de vidrio). Se dividen en permutaciones de lentes, permutaciones de caustics y permutaciones de cadenas múltiples. Mutaciones bidireccionales: consisten en reemplazar aleatoriamente tramos del recorrido por nuevos segmentos, pudiendo modificar su longitud total. 3.4.1 Ventajas • • Muy efectivo en escenas “difíciles”. Esto es en aquellas donde el aporte a la iluminación viene de un área reducida (como por ejemplo un agujero en la pared) que conduce a un área muy iluminada. Una vez que logra encontrar un camino a través del agujero, generará mediante mutaciones nuevos recorridos que capturarán la iluminación de esa zona. No es sesgado. 18 3.4.2 Desventajas • • • No es eficiente en escenas simples (aquellas escenas donde la luz se encuentra distribuida de manera uniforme). No es aplicable a fuentes de luz puntuales. El nivel de ruido generado en la imagen final es afectado por numerosos parámetros del algoritmo y escoger los valores óptimos a fin de reducirlo no resulta trivial y es altamente dependiente de la escena particular. 3.5 Radiosity Fue presentado por Goral et al. [12] en 1984 y luego mejorado por Cohen et al. [13,14]. Tiene su origen en los principios físicos de transferencia de radiación térmica. La técnica solo es capaz de computar la iluminación global de escenas con superficies difusas y que puedan ser subdivididas en pequeñas superficies planas (denominadas parches, ver figura 3.4) sobre las cuales la radiancia reflejada y emitida se considera constante. Típicamente, solo tiene en cuenta aquellos recorridos de luz que salen de la fuente y se reflejan en forma difusa un cierto número de veces hasta alcanzar el ojo del observador. Incluyendo estás restricciones se logra simplificar la ecuación del rendering y la función BRDF ya no depende de la dirección incidente, quedando de la siguiente forma. Lo = Le + fr ∫ Li cos θdwi (3.4) Ω Donde Lo la radiancia reflejada es la suma de la radiancia emitida Le más la BRDF por la integral sobre el hemisferio, de la radiancia incidente Li por el coseno del ángulo de incidencia θ. Figura 3.4. Escena subdividida en parches. 19 La radiosidad Bi para cada parche se define como la suma de la luz auto-emitida Ei (no nulo solo para fuentes de luz) más la luz reflejada, donde ρi es la constante de reflectancia del parche (es parte de la descripción de la escena) y Fij el denominado factor de forma. N Bi = Ei + ρi ∑ BjFij ρi ∈ 0..1 (3.5) j =1 El factor de forma es una cantidad sin unidad, que representa la fracción de la energía total saliendo del parche i que alcanza al parche j. Su cómputo se realiza a partir del tamaño, la orientación y posición de ambos parches. Dado que depende solo de las características geométricas, el factor es válido para cualquier longitud de onda. Si aplicamos la última ecuación (ecuación 3.5) sobre todos los parches de la escena, obtenemos un sistema de N ecuaciones con N términos (B1...BN), el cual puede ser resuelto numéricamente por el método de Gauss-Seidel. 1 − ρ 1F 11 − ρ 1F 12 ... − ρ 1F 1N B1 E1 − ρ 2 F 21 1 − ρ 22 F 22 ... − ρ 2 F 2 N B 2 E 2 ⋅ = ... ... ... ... ... − ρNFN 2 ... 1 − ρNFNN BN EN − ρ NFN 1 El algoritmo consta de tres etapas: determinación de factores de forma, calculo de radiosidad (resolución del sistema de ecuaciones) y rendering de la imagen final. 3.5.1 Etapa 1, determinación de los factores de forma Para que el cálculo de factores de forma sea preciso es necesaria una subdivisión en parches suficientemente fina como para obtener sombras de buena resolución. Figura 3.5: Factor de forma. Su expresión matemática es la siguiente (ver figura 3.5): Fij = 1 Ai V (i, j ) cos(θi ) cos(θj )dAidAj πr 2 Ai Aj ∫∫ (3.6) Donde Ai es el área del parche i, θi es el ángulo entre su normal y el diferencial de área del parche j, pur útlimo, la función V(i,j) determina la visibilidad entre ambos puntos y puede valer 0 o 1. 20 Hay que destacar que el factor de forma Fij tiene carácter recíproco, o sea que Fij=Fji. Por lo tanto basta con calcular la mitad de los factores y además Fii es obviamente nulo. Existen dos maneras de calcularlo: con el método del hemicubo y con el método de trazado de rayos. El método del hemicubo fue propuesto por Cohen et al. en 1985 [14]. La idea es que el área de la proyección del parche sobre un hemisferio que envuelve al parche receptor dividida por el área total del hemisferio da el factor de forma (ver figura 3.6). Figura 3.6: cómputo de factor de forma por el método del hemicubo. En la práctica se utiliza un hemicubo en lugar de un hemisferio, ya que aunque es posible proyectar los parches analíticamente sobre el hemisferio, esto es mucho más complejo. El hemicubo y sus 5 caras está subdividido en píxeles, para los cuales se precalcula un factor de forma delta. Luego, el algoritmo consiste en proyectar todos los parches de la escena sobre el hemicubo. En caso de encontrar que dos o mas parches se proyectan sobre el mismo píxel se almacena la información del mas cercano. Para finalizar, el factor de forma de un parche i se obtiene sumando todos los factores delta de los píxeles asociados al parche i. Este proceso es fácilmente implementable por hardware. La precisión del cálculo se puede ajustar modificando la cantidad de píxeles del hemicubo. El resultado también depende de la distancia entre los parches y el tamaño de estos.Si el parche es muy pequeño respecto de la distancia puede directamente desaparecer del cálculo. Por otra parte, el método de trazado de rayos, consiste en aplicar el método de Monte Carlo, trazando estocásticamente rayos desde el parche i y contabilizando cuantos de ellos alcanzan el parche j. Entonces, el factor de forma se aproxima mediante el cociente entre la cantidad de los rayos que llegaron a j y el número total de rayos trazados N. Cuando N tiene infinito el valor del conciente converge al de la integral que se pretende estimar. 3.5.2 Etapa 2, resolución del sistema de ecuaciones El sistema de ecuaciones puede ser resuelto en forma completa o iterativa. El primer modo requiere que la matriz principal permanezca en memoria, lo cual no es práctico en escenas con miles de parches (una escena con N parches genera un sistema de N2 términos) y además puede llevar mucho tiempo. 21 El otro modo es utlizando el algoritmo denominado Progressive Radiosity, que consiste en calcular una solución inicial gruesa o aproximada (que puede ser visualizada) la cual luego será refinada hasta alcanzar un criterio de convergencia establecido. Este método solo requiere la presencia en memoria de una sola fila o columna de la matriz principal. 3.5.3 Etapa 3, síntesis de la imagen La información de iluminación indirecta obtenida en la etapa 2, puede ser utilizada por un Ray Tracer estándar o un algoritmo de Scan-Line para computar la imagen final. Típicamente, los valores de radiosidad aplicados a los vértices, pueden ser interpolados usando sombreado de Gouraud [31] y ser visualizados interactivamente. 3.5.4 Ventajas • • Información de iluminación indirecta puede ser precalculada y reutilizada mientras no cambie la información geométrica. Solución de iluminación global independiente de la vista (no depende de la posición del observador). 3.5.5 Desventajas • • • • Solo resuelve iluminación para superficies difusas. Obliga a subdividir la geometría en pequeños elementos (parches) y la calidad de la solución depende de esta subdivisión. Requerimientos de memoria se incrementan con parques mas chicos. No captura efectos de iluminación de alta frecuencia (de rápida variación sobre un área reducida), como ser sombras con bordes bien definidos (hard shadows). 3.6 Photon Mapping 3.6.1 Motivación y antecedentes Existen métodos híbridos de varias pasadas que combinan las técnicas de elementos finitos con las basadas en Monte Carlo, utilizando una fase inicial de preprocesamiento donde se computa una solución preliminar gruesa de la iluminación indirecta por el método de Radiosity y luego una segunda fase que calcula la imagen final usando métodos de Monte Carlo Ray Tracing como Path Tracing. Estas combinaciones son más rápidas y de mejor calidad que los dos métodos en su variante más pura, pero sufren de las limitaciones de los métodos de elementos finitos, que no pueden manejar geometría compleja. Otra alternativa son los mapas de iluminación (illumination maps), donde un mapa de texturas (mapas de bits) se utiliza para representar la irradiancia del modelo. Aquí el problema es determinar la resolución adecuada de estas texturas y cómo mapearlas en superficies complejas. Los únicos métodos que pueden lidiar con la simulación de iluminación global completa en modelos complejos y funciones BRDF arbitrarias son los métodos basados en Monte Carlo Ray Tracing. Sus ventajas son que no requieren convertir la geometría en un mallado de parches, consumen poca memoria, y dan un resultado correcto excepto por la varianza o ruido, lo cual constituye su mayor problema. 22 Un defecto común de los algoritmos de estimación de densidad es que su representación de los impactos de las partículas de luz está directamente acoplada a la descripción geométrica de la escena, condicionando el nivel de detalle de la iluminación a la definición del modelo. En casos extremos puede ocurrir que algunos elementos geométricos no reciban ningún impacto y por ende sean visualizados en negro. Está claro a partir de análisis de ventajas y desventajas de métodos mencionados previamente, que un buen algoritmo de iluminación global debe realizar el muestreo desde ambos puntos de vista, las fuentes de luz y desde el observador para captar todos los efectos. Otra observación importante es que la iluminación en general varía suavemente en grandes áreas y tiene variaciones grandes en otras áreas más pequeñas. 3.6.2 El método De todas las consideraciones anteriores surge el método de Photon Mapping desarrollado por Jensen [15]. El término fotón en este contexto se utiliza para denominar una partícula que transporta una cantidad discreta de energía lumínica en una dirección específica. El método se clasifica como un algoritmo de estimación de densidad (de fotones por unidad de área) de dos fases: distribución de fotones y recopilación de estadísticas de iluminación (síntesis de la imagen). La característica principal de la técnica es que la estructura de datos que almacena la distribución de fotones está desvinculada de la representación geométrica de la escena y se denomina mapa de fotones (Photon Map). Este mapa es una versión multidimensional de un árbol de búsqueda binaria llamado árbol KD, donde todos los nodos son fotones. Es similar a los árboles BSP, donde cada nodo subdivide el espacio en dos sub-espacios (dos nodos hijos) excepto por las hojas. Photon Mapping consiste de dos fases: • • Trazado de fotones: construcción del mapa de fotones trazándolos desde las fuentes de luz. Rendering: utilizando la información del mapa de fotones se sintetiza la imagen final. La estimación de densidad usando el mapa de fotones presenta errores de baja frecuencia a diferencia del Monte Carlo Ray Tracing tradicional, lo cual es una gran ventaja desde el punto de vista perceptivo ya que este ruido de baja frecuencia es mucho menos notorio que el de alta frecuencia. El precio que se paga es que el método es sesgado (no converge al valor de la integral que se pretende aproximar). 3.6.3 Fase 1, trazado de fotones Es el proceso que construye el mapa de fotones (Photon Map). Estos se crean en las fuentes de luz que pueden tener una diversidad de formas o distribuciones particulares (ver figura 3.7). Cada fuente posee una potencia que es repartida en sus fotones (cada uno transporta una cantidad fija de energía). 23 Figura. 3.7: Emisión de fotones desde distintas fuentes de luz. En una fuente de luz puntual, los fotones son emitidos uniformemente en todas las direcciones. La emisión se puede realizar de dos maneras: por muestreo explícito, que consiste en mapear variables aleatorias en coordenadas esféricas para cubrir la superficie de una esfera ó muestreo por rechazo que consiste en generar puntos al azar en un cubo unitario y descartar aquellos que no estén incluidos en la esfera de diámetro unitario. En una fuente esférica, primero se escoge un punto de origen en la superficie de la esfera y luego se escoge una dirección al azar (siempre que apunte hacia el exterior de la misma). En el caso de una fuente cuadrada, el proceso es similar al de una fuente esférica. En una fuente direccional, que se caracteriza por emitir rayos de luz paralelos, se debe generar primero un volumen que envuelva a todo el modelo, luego proyectarlo en la dirección de la fuente de luz y escoger un punto sobre esa superficie para determinar el origen de cada rayo (ver figura 3.8). Para las fuentes de luz complejas con formas arbitrarias, se deben generar los fotones con una densidad acorde al perfil de la fuente. Cuando hay más de una fuente en una escena, la cantidad de fotones emitidos por cada fuente debe ser proporcional a la potencia de la misma (todos los fotones transportan la misma cantidad de energía lumínica). Fig. 3.8. Fuentes de luz direccionales. 24 Es importante diferenciar un aspecto del proceso de trazar fotones del de trazar rayos. Mientras que los rayos pretenden capturar radiancia, los fotones propagan flujo lumínico, es por ello que la interacción de los rayos con las superficies es diferente a la de los fotones. Cuando un fotón impacta sobre una superficie, puede ser absorbido, reflejado o refractado. En el caso de la reflexión, si el fotón impactó una superficie especular, se reflejará en la dirección de reflexión del espejo. En cambio si impactó una superficie difusa, se reflejara en una dirección aleatoria escogida de un hemisferio ubicado por encima el punto de impacto con una probabilidad proporcional a la BRDF. Cabe aclarar que usualmente los materiales de las superficies se modelan como la suma de una componentes: difusa o especular y ante el impacto de un fotón, se tiene en cuenta uno de los dos comportamientos de acuerdo a su respectiva probabilidad En el caso de la refracción, la nueva dirección será determinada por las leyes de refracción. Finalmente en el caso de la absorción, si la superficie es no-especular, la información del fotón es almacenada en el Photon Map (posición, dirección, etc.). Dado que los fotones almacenados en superficies especulares no aportan información útil porque la probabilidad de encontrar uno que coincida en forma exacta con cierta dirección de reflexión especular es muy pequeña. La decisión sobre cual de los eventos debe suceder, es determinado mediante la técnica de Ruleta Rusa y el material de la superficie. Utilizando una variable aleatoria uniforme ξ ∈ [0..1] y comparando su valor contra las probabilidades de que suceda cada evento: ξ ∈ [0..ρd ] → Reflexión especular ξ ∈ [ ρd ..ρd + ρs ] → Reflexión difusa ξ ∈ [ ρd + ρs..ρd + ρs + ρr ] → Refracción ξ ∈ [ ρd + ρs + ρr ..1] → Absorción (3.7) Donde ρd , ρs , ρr representan la probabilidad de reflexión difusa, especular y de refracción respectivamente. El Photon Map es una estructura de datos estática, utilizada para computar densidades de fotones en puntos del modelo 3D. Concretamente es una estructura de árbol KD diseñada con el fin de resolver búsquedas de fotones cercanos a determinado punto del espacio 3D de una manera rápida y a la vez eficiente. Debe ser capaz de almacenar millones de fotones que se distribuyen en forma no uniforme por la escena. Cada nodo del árbol particiona una de las dimensiones (X, Y o Z) en dos sub-árboles que contienen los fotones a un lado y otro del plano divisorio. La estructura permite encontrar los k fotones mas cercanos de un conjunto de N para una posición dada del espacio, en un tiempo promedio del orden de O(k + log N). Del proceso de construcción puede resultar un árbol de fotones desbalanceado. Por eso usualmente se agrega un paso adicional de balanceo que permite luego representar el árbol por un arreglo plano evitando así el almacenamiento de dos punteros a los nodos hijos. El paso de balanceo toma un tiempo adicional del orden de O(N log N) donde N es el número de fotones del árbol. Algunos trabajos recientes como el de Wald et al. [16] muestran que un árbol cuidadosamente desbalanceado puede superar en desempeño a uno balanceado, con un costo en tiempo de precómputo mayor y con requerimientos de almacenamiento adicionales. 25 El algoritmo de búsqueda es una directa extensión del de búsqueda en un árbol binario estándar. Se establece un rango máximo de búsqueda (un radio alrededor de un punto), de lo contrario el método se haría muy lento obligando a recorrer zonas con escasos fotones. Se mantiene una lista ordenada de los fotones que van siendo hallados según su cercanía al centro del volumen de búsqueda, de modo que si hay n fotones encontrados y se encuentra uno nuevo, se puede eliminar el último de la lista que es el que estaba más lejos. 3.6.4 Fase 2, rendering Durante esta fase, se pretende aproximar la ecuación del rendering para computar la radiancia reflejada en posiciones de las superficies. La imagen final se obtiene promediando un número de estimaciones por cada píxel, trazando rayos desde el ojo del observador hacia la escena. Si consideramos que la BRDF fr es usualmente la combinación de dos componentes: especular fr,S y difusa fr,D y que la radiancia incidente es en realidad la suma de tres componentes: iluminación directa Li,l, iluminación indirecta por reflexión especular o refracción Li,c, e iluminación indirecta por reflexión difusa (al menos una vez) Li,d, podemos descomponer la radiancia reflejada de la siguiente manera: r r r r r r r Lr ( x, w) = ∫ fr ( x, w' , w) Li ( x, w' )( w'⋅n )dw' Ω r Lr ( x, w) = D + E + C + I r r r r r r D = ∫ fr ( x, w' , w) Li , l ( x, w' )( w'⋅n )dw' Ω r r r r r r r E = ∫ fr , S ( x, w' , w)( Li , c ( x, w' ) + Li , d ( x, w' ))( w'⋅n )dw' (3.8) Ω r r r r r r C = ∫ fr , D ( x, w' , w) Li , c ( x, w' )( w'⋅n )dw' Ω r r r r r r I = ∫ fr , D( x, w' , w) Li , d ( x, w' )( w'⋅n )dw' Ω El término de la iluminación directa D, corresponde al cálculo de la radiancia reflejada debido a la luz que proviene directamente de la fuente y se calcula de manera precisa del mismo modo que en el Ray Tracing tradicional, ya que es uno de los términos más importantes porque genera por ejemplo el efecto de sombra. En el caso de fuentes de luz no puntuales, se utilizan varios rayos de sombra para estimar apropiadamente las zonas de penumbra. Para el término de reflexiones especulares E, no se utiliza el Photon Map, en cambio, se utiliza la técnica de Monte Carlo Ray Tracing. El término C se puede calcular de manera aproximada evaluando el estimador de radiancia a partir del Photon Map, o de manera mas precisa usando uno especial denominado Caustics Photon Map, que almacena solo los fotones que generan el efecto de caustics (luces enfocadas por reflexión o refracción). Este último se construye trazando fotones solo hacia objetos del tipo especular. Por último el término que representa la luz proveniente de reflexiones sobre superficies difusas I, se calcula también evaluando el estimador de radiancia pero a partir del Photon Map principal. 26 El cómputo del denominado estimador de radiancia, se basa en que la radiancia r reflejada Lr, de la ecuación del rendering en el punto x y la dirección w , puede ser estimada con los k fotones más cercanos del Photon Map: r 1 Lr ( x, w) ≈ 2 πr k r r r p , w) ∆Φp ( x, wp ) ∑ f ( x, w r (3.9) p =1 r Donde wp es la dirección incidente, y ∆Φp es la potencia del fotón p, r es la distancia máxima hasta cada fotón y π ⋅ r 2 es el área del círculo conteniendo los fotones. Dado que la búsqueda de los fotones se realiza en una esfera, es probable que se introduzcan errores en la estimación, al incluir fotones que llegan a la superficie por detrás, en una esquina o atravesando un objeto delgado y que no deberían contribuir a la iluminación del punto x. Estos efectos pueden reducirse, comparando la dirección incidente y la normal de la superficie y descartando mediante un producto escalar a aquellos que llegan por detrás. Aunque los fotones están contenidos en una esfera, la densidad se mide sobre el área de la esfera proyectada sobre la superficie (ver figura 3.9) la cual que tiene forma de disco. El uso de una distancia máxima r es para evitar que la búsqueda de fotones abarque áreas excesivamente grandes. Fig. 3.9: estimador de radiancia El ruido en la imagen final se reduce a medida que se aumenta la cantidad de fotones usados en el estimador de radiancia. Está demostrado que se puede obtener un estimador arbitrariamente bueno incluyendo una cantidad suficiente de fotones. 3.6.5 Desempeño y mejoras El algoritmo genera soluciones de iluminación global completas, de mayor calidad y en menor tiempo que otros métodos como Path-Tracing. Dada la popularidad de esta técnica, su robustez y su sencilla implementación, se presentaron muchas mejoras y extensiones. Entre ellas, se presentó una extensión para computar efectos de dispersión dentro de superficies traslucidas (sub-surface scattering) que simulan materiales como la piel o el mármol. También se desarrollaron extensiones para computar efectos atmosféricos tales como niebla o humos. Entre las mejoras propuestas se encuentra el algoritmo propuesto por Ward [17] denominado Irradiance Caching, que permite reducir el número de búsquedas de fotones cercanos para 27 computar los estimadores de radiancia interpolando los valores de otros estimadores calculados para puntos cercanos del espacio. 28 Capítulo 4 - Plataformas de Rendering de alto desempeño Estas plataformas comprenden aquellas comúnmente utilizadas para implementar sistemas de visualización que requieren el procesamiento de grandes volúmenes de datos en tiempos relativamente breves con el objetivo de sintetizar imágenes a partir de un modelo o escena. Tal es el caso de sistemas que requieren generar secuencias de imágenes para componer una animación, en donde es deseable una tasa de generación de cuadros cercana a los 15 cuadros por segundo para lograr una sensación de fluidez de movimiento propia de las secuencias cinematográficas. También es el caso de los sistemas de visualización interactivos (por ejemplo sistemas de realidad virtual), en donde la intervención del usuario mediante algún dispositivo de entrada modifica las variables del modelo (por ejemplo el cambio de posición o dirección observación de la escena), a partir de las cuales el sistema debe generar una nueva respuesta en forma de imagen. Las estrategias generalmente aplicadas en estos sistemas, apuntan a subdividir las tareas de cómputo en bloques independientes que puedan ser resueltos en forma simultánea o paralela por varias unidades de procesamiento. Los algoritmos de síntesis de imágenes suelen ser altamente paralelizables, lo cual significa que existe un alto de grado de independencia entre los datos a procesar y los resultados que estos generan, permitiendo su cómputo simultáneo en unidades separadas. Esta es una característica deseable ya que reduce la necesidad de comunicación o sincronización entre nodos y logra un máximo aprovechamiento del tiempo de procesamiento de cada unidad. En el caso de los algoritmos de iluminación global mencionados en el capítulo 3, la gran cantidad de cálculos y la complejidad de la escena a sintetizar, hacen que una CPU estándar (Intel Pentium IV 3.0 GHz) demore varios minutos y hasta incluso horas en generar una imagen. Dos caminos para encarar el problema planteado son: • • Implementación sobre clusters de PCs. Implementación sobre hardware gráfico programable (GPUs). A continuación se analizarán más en detalles ambas alternativas. 4.1 Clusters de PCs Son sistemas conformados por un conjunto de hosts o PCs interconectados mediante una red local (ver figura 4.1) de alta velocidad (Fast o Giga Ethernet) entre los cuales se distribuyen las tareas de cómputo para ser procesadas en forma simultanea por todos los nodos. Respecto al modo de subdividir las tareas de cómputo, algunos sistemas definen como unidad básica de trabajo un cuadro o imagen completa. Otros en cambio, explotan al paralelismo inter-cuadro, subdividiendo la ventana de visualización en porciones o fragmentos independientes. Estos son alimentados a cada nodo para luego ser integrados nuevamente en una sola imagen o ser provistos directamente a dispositivos de visualización conformados por múltiples pantallas en configuración de matriz. 29 Cada nodo de la red posee una memoria propia, debiendo intercambiar información o sincronizar su estado con el resto de la red mediante el pasaje de mensajes. Estos sistemas explotan el paralelismo de “grano grueso”, lo cual significa que las tareas a realizar por cada procesador, deben insumir un tiempo relativamente largo en comparación a los tiempos de comunicación entre nodos (latencia de la red y overhead de los mensajes). De otro modo, la eficiencia del sistema se vería reducida, ya que se desperdiciaría un alto porcentaje de tiempo en la comunicación. Figura 4.1. Cluster de PCs. Existen ejemplos como el caso del sistema Chromium [23], que provee un mecanismo genérico para manipular y procesar secuencias de comandos de una API grafica estándar. El sistema virtualiza los recursos disponibles en la red, permitiendo ejecutar por ejemplo una aplicación OpenGL (Open Graphics Library) estándar incluso sin necesidad de recompilarla. Otro caso es el de WireGL [24], un sistema de rendering distribuido, escalable, que permite a una aplicación realizar el proceso de rendering sobre una matriz de múltiples pantallas. No requiere el uso de una API específica y puede funcionar sobre hardware estándar de bajo costo. 4.2 Hardware gráfico programable Esté tipo de hardware también conocido como GPU (Graphics Processing Unit), comprende unidades dedicadas exclusivamente al procesamiento de gráficos 3D. A diferencia de las CPU, su diseño especializado permite procesar tareas gráficas en tiempos más breves. Aunque, las GPUs más recientes son capaces de procesar cientos de millones de vértices y miles de millones de fragmentos (estructura de datos que actualiza el color de cada píxel) por segundo, no están preparadas para computar algoritmos de propósito general, Es decir no es sencillo portar código de una aplicación escrito originalmente para una CPU. A pesar de ello, hoy en día, representan la mejor relación entre poder computacional por dólar. Además su desempeño crece a ritmos mayores que las CPU, dado que se duplica aproximadamente cada 12 meses. El crecimiento e innovación en este campo es impulsado principalmente por la industria de los video-juegos. A continuación se comparan las características de ambas unidades de procesamiento: 30 CPU GPU • Utiliza la memoria principal (RAM) del sistema. • Utiliza una memoria dedicada contenida en la placa gráfica de la PC (memoria de texturas). • Arquitectura SISD (single instruction single data). • Arquitectura SIMD (single instruction multiple data). • Optimizada para alto desempeño de código genérico secuencial (caches y predicción de bifurcación). • Optimizada para procesamiento paralelo de código con alta proporción de operaciones aritméticas. • Su desempeño se duplicada cada 18 meses. • Su desempeño se duplica cada 12 meses • Intel Pentium 4 3.0 GHz Desempeño: 6 Gigaflops (teóricos) Memoria: 6 GB/seg (pico). • Nvidia GeforceFX 5900 Desempeño: 20 Gigaflops Memoria: 20 GB/seg (pico). • Aptos para algoritmos de propósito general. • Diseñadas para implementar algoritmos gráficos específicos • Accesible en forma directa. • Accesible mediante una API (Aplication Programming Interfase). • Paradigmas de programación convencionales como: Programación Orientada a Objetos, Procedural, etc. • Requiere el uso de nuevos paradigmas no convencionales, como Stream Programming. 31 Capítulo 5 - GPU (Graphics Processing Unit) El término fue acuñado por NVIDIA a finales de la década de los 90, cuando el término Video Graphics Array (VGA) Controller ya no definía de forma precisa las funciones del hardware gráfico en una PC. Se trata de un dispositivo capaz de manipular, procesar y mostrar gráficos de manera eficiente. Su arquitectura altamente paralela, conformada por múltiples unidades de ejecución, es capaz de realizar operaciones de punto flotante con 32 bits de precisión y trabajar simultáneamente sobre múltiples conjuntos de datos. Hoy en día, es un componente estándar del subsistema de video en la mayoría de las PC. En el siguiente cuadro se detalla su evolución: 1998 3DFX Voodoo, NVIDIA TNT y ATI Rage. Realizan proceso de rasterización (conversión de forma vectorial a píxeles) de triángulos y mapeo de hasta 2 texturas. Menos de 10 millones de transistores por GPU. No son capaces de aplicar transformaciones a los vértices. Operaciones aritméticas muy limitadas. Implementan funciones de DirectX 6.0. 2000 NVIDIA GeForce serie 2 y ATI Radeon. 25 millones de transistores por GPU. Incorporan capacidad de transformar vértices. Son configurables, pero aún no programables. Implementan funciones de DirectX 7.0. 2001 NVIDIA GeForce series 3 / 4 y ATI Radeon serie R200. Incorporan programabilidad en el procesador de vértices. 60 millones de transistores por GPU. Poseen más opciones de configuración que las series anteriores, para procesar vértices, pero aún no son programables. Implementan funciones de DirectX 8.0. 2003 NVIDIA GeForce serie FX y ATI Radeon serie R300. 120 millones de transistores por GPU. Programabilidad a nivel vértices y fragmentos. Soporte completo de DirectX 9.0. 2004 NVIDIA GeForce serie 6 y ATI Radeon serie R420. 220 millones de transistores por GPU. Introducción de sistema SLI (Scalable Link Interface). Introducción de modo MRT (Múltiple Render Targets). 2005 NVIDIA GeForce serie 7 y ATI Radeon serie R520. 300 millones de transistores por GPU. Mayor velocidad de reloj y ensanchamiento del pipeline (más unidades de procesamiento en paralelo). 32 2006 NVIDIA GeForce serie 8 y ATI Radeon serie R600. Arquitectura de unidades de procesamiento unificada (procesan vértices y fragmentos). 700 millones de transistores por GPU. Soporte completo para DirectX 10.0. En futuras generaciones se espera que los recursos de la GPU se generalicen cada vez más permitiendo aún mayor grado de programabilidad. 5.1 El pipeline gráfico Un pipeline consta de una secuencia de etapas que operan en un orden determinado (similar a una línea de montaje industrial). Cada etapa recibe en su entrada el resultado del proceso de la etapa anterior y todas las etapas en conjunto pueden operar simultáneamente sobre distintos elementos. El pipeline gráfico puede ser pensado como una caja negra por donde fluyen conjuntos de datos que sufren transformaciones para generar como resultado final una imagen 2D o un mapa de bits. Aunque en realidad no se trata de una caja negra ya que uno puede controlar la forma en que los datos son transformados. Este pipeline recibe en su entrada los vértices correspondientes a la geometría de la escena 3D. Cada vértice es una estructura de datos que contiene las coordenadas homogéneas de un punto en el espacio 3D y otros atributos opcionales que pueden ser escalares o vectoriales (de 2, 3 o 4 componentes) que se definen en función de la aplicación que se quiera implementar. Los principales son: • • • • Posición: coordenadas homogéneas del vértice. Normal: vector que indica la dirección en que apunta la superficie, en el punto definido por la posición. Este dato es útil para cálculos de iluminación. Color: este dato luego será utilizado para sombrear el área de pantalla que cubra la primitiva geométrica según el tipo de algoritmo de sombreado que se use. Puede haber más de un color definido por cada vértice. Coordenadas de textura: un par de coordenadas reales mapean un punto sobre una textura 2D, que se utilizará luego para el sombreado de la primitiva geométrica. Pueden utilizarse varios pares de coordenadas de vértice para indexar diferentes texturas. Además, el usuario puede definir otros atributos de utilidad para modelar características de los materiales de las superficies representadas. Sobre los vértices se aplican una serie de operaciones matemáticas denominadas transformaciones de vértices que incluyen traslaciones, rotaciones, cambios de escala y proyecciones. Al utilizar un sistema de coordenadas homogéneas, todas las transformaciones pueden representarse por matrices (de 4 x 4) que al multiplicarlas por los vectores de coordenadas de los vértices dan como resultado el vector transformado. Otra ventaja de las coordenadas homogéneas, es la posibilidad de encadenar varias transformaciones multiplicando sus matrices asociadas. El objetivo de las transformaciones es traducir las coordenadas de la escena 3D del espacio de coordenadas abstracto de cada objeto (modelo o patrón de un objeto 3D) a las coordenadas 2D en el denominado plano de vista o plano de visualización. 33 Esta conversión de coordenadas se subdivide en varias fases: • • • Transformación de modelado: implica posicionar, rotar y escalar el objeto respecto del resto de la escena (traducir coordenadas del modelo a coordenadas del mundo). Transformación de vista: implica convertir las coordenadas de toda la escena a un sistema con origen en el punto de vista y la dirección de la “cámara” o el “ojo” que observa la escena. Transformación de proyección: implica convertir coordenadas del espacio tridimensional de las coordenadas de vista a coordenadas en un plano de proyección bidimensional. Existen varios tipos de proyección como ser la perspectiva o la ortográfica. La matriz de proyección se define a partir de un denominado volumen de vista (view frustum) que establece como mapear una porción de espacio sobre el plano de proyección. Las 3 transformaciones se aplican en orden a cada vértice de la escena. Luego, los vértices transformados son combinados en la etapa de ensamblado, para formar las que se conocen como primitivas geométricas (ver figura 5.1) que comprenden: puntos, líneas, triángulos, etc. Figura 5.1: Primitivas geométricas. Para continuar, el proceso de rasterización descompone las primitivas en elementos del tamaño de píxeles, llamados fragmentos que intervienen en la definición del color de los píxeles de la imagen 2D generada a la salida del pipeline. Figura 5.2: Representación del pipeline gráfico. 34 Un fragmento es una estructura de datos asociada a la ubicación de un píxel de la imagen de salida. También se puede pensar al fragmento como un “píxel potencial” ya que algunos son descartados. En la figura 5.2, se detalla la evolución de los datos a lo largo de las etapas. En la industria, OpenGL y Direct3D son los dos modelos de pipelines gráficos ampliamente aceptados como estándares. 5.2 El pipeline gráfico programable En la actualidad la mayoría de las etapas del pipeline gráfico son implementadas directamente en el hardware, exhibiendo un alto grado de programabilidad. Esto significa que los algoritmos que implantan son modificables y son suministrados por la aplicación de alto nivel como parte del flujo de datos de entrada del pipeline. Incluso es posible ingresar secuencias que intercalan datos geométricos y los programas que deban procesarlos, permitiendo el uso de diferentes algoritmos para distintos objetos de la escena. En las primeras generaciones de GPUs dichos programas estaban grabados en el hardware (no eran modificables) y eran solo configurables en forma limitada. Los programas suministrados al pipeline programable son de dos tipos: los programas de vértices (aplican las transformaciones a los vértices) y los programas de fragmentos (computan los datos que definirán los colores de los píxeles). Ambos tipos de programas pueden ser escritos en diversos lenguajes como: • • • Cg (C for Graphics): es un lenguaje [29] de sombreado (shading language) de alto nivel desarrollado por NVIDIA y Microsoft. Está basado en el lenguaje C y tiene algunos tipos de datos agregados, adecuados para programar en la GPU. Es un lenguaje especializado. Un compilador lo traduce al assembler o código de máquina. HLSL (High Level Shading Language): desarrollado por Microsoft para utilizarse con Direct3D, es muy similar a Cg. GLSL (OpenGL Shading Language): fue creado por OpenGL Architecture Review Board y tiene características muy similares a los dos anteriores. La figura 5.3 ilustra la estructura del pipeline gráfico programable. El proceso comienza cuando la aplicación de alto nivel envía a la GPU un conjunto de vértices. En la primera etapa el procesador de vértices los trasforma de acuerdo a un programa de vértices y define el valor del resto de sus atributos. Las transformaciones tienen como objetivo traducir la posición de cada vértice, del sistema de coordenadas del objeto modelado (tridimensional) al sistema de coordenadas de la pantalla (bidimensional) aplicando un conjunto de operaciones aritméticas representadas por productos de matrices (de traslación, escalado, rotación y proyección). 35 Figura 5.3: El pipeline gráfico programable. En la segunda etapa (ensamblado y rasterización) se ensamblan los vértices transformados (vértices con coordenadas en el espacio de pantalla) para formar la primitiva geométrica. A la primitiva ensamblada se le aplican los procesos de Clipping y Culling. El proceso de Clipping, se encarga de recortar la primitiva geométrica, para remover las porciones que quedan fuera del área que se pretende visualizar (denominada ventana del mundo). El proceso de Culling se encarga de descartar aquellas primitivas que no deben dibujarse ya que se encuentran de espaldas al observador de la escena. Las primitivas geométricas que no son descartadas, pasan al proceso de rasterización. Este consiste en determinar qué píxeles del dispositivo de salida son cubiertos por la primitiva geométrica y generar los correspondientes fragmentos. Los fragmentos son estructuras de datos transitorias que almacenan atributos como: • • • • Posición: ubicación del píxel al que está asociado. Son un par de coordenadas enteras. Profundidad: es la distancia en el eje Z (eje perpendicular al plano de vista) al origen del punto de observación. Color: surge de la interpolación lineal de los atributos de color de los vértices que dieron origen al fragmento. Coordenadas de texturas: del mismo modo que el color, su valor es interpolado linealmente. Además un fragmento puede poseer otros atributos especialmente definidos por la aplicación como por ejemplo varios colores y pares de coordenadas de texturas adicionales. La tercera etapa, habitualmente llamada de sombreado (porque tradicionalmente define el color de los píxeles según algún modelo de iluminación) es implementada por el procesador de fragmentos según un programa, que da como resultado el color del píxel asociado. El programa resuelve el color a partir de los atributos del fragmento y otros datos disponibles en la memoria de la GPU, como texturas y parámetros globales definidos por la aplicación. La información almacenada en texturas se accede mediante 36 índices computados por el programa a partir, por ejemplo, de las coordenadas de texturas. Para finalizar, los fragmentos pasan por una serie de pruebas (Scissor Test, Alpha Test, Stencil Test y Depth Test) y procesos (Blending y Dithering) que son parte estándar de OpenGL y Direct3D para evaluar cuales producirán una actualización del píxel correspondiente en el buffer de salida y cuales deben ser descartados. 5.3 Modelo de memoria de la GPU Existen tres áreas de almacenamiento de datos en una GPU: • • • Memoria para datos de vértices: este espacio es esencialmente utilizado para leer los atributos de los vértices desde el procesador de vértices. Estos son cargados desde la aplicación ejecutada en la CPU. En las GPUs más recientes es posible escribir o copiar datos en esta memoria, a partir de un programa de fragmentos (modo copy-to-vertex-array). Framebuffers: se utilizan principalmente para escribir los resultados generados por el procesador de fragmentos (hasta 16 valores de punto flotante de 32 bits, utilizando el modo MRT) y luego ser visualizados en el dispositivo de salida. Memoria de texturas: su nombre se debe a que surgió como un espacio para almacenar información de imágenes 2D que representan muestras de colores y atributos de superficies. Está optimizada para acceso mediante coordenadas 2D. Es la que se utiliza como memoria de trabajo en programas de fragmentos que implican múltiples pasadas permitiendo hacer ciclos de lectura y escritura de datos. Hoy en día es posible utilizarla para otros datos, que no necesariamente están relacionados con imágenes o colores. Por ejemplo, es posible almacenar estructuras de datos más complejas, como listas, arreglos 1D y 3D, etc. Estas estructuras requieren implementar mecanismos de traducción de direcciones y conversión de tipos de datos, ya que la forma primitiva de organizar los datos es en arreglos bidimensionales de valores de punto flotante con tamaño fijo. La siguiente figura 5.4 ilustra la relación entre las 3 áreas de memoria, los procesadores de vértices, fragmentos y la CPU. Figura 5.4: Áreas de memoria en la GPU. 37 Se espera que este modelo de memoria siga evolucionando hacia un modelo más general que permita una mayor flexibilidad en las operaciones de lectura y escritura. 5.4 El procesador de vértices Es el encargado de ejecutar los programas de vértices (vertex programs). El proceso comienza con la carga de los atributos de los vértices en registros de entrada. A medida que se ejecutan las instrucciones del programa de vértices, los resultados intermedios son almacenados en registros temporales. Además el programa tiene acceso a registros de solo lectura en donde se almacenan constantes globales de la aplicación (existe una sola instancia para todos los programas de vértices). Las instrucciones disponibles incluyen operaciones matemáticas sobre vectores de punto flotante de hasta 4 componentes (X, Y, Z, W), instrucciones de control de flujo, de salto y lazos. Las últimas generaciones de GPUs permiten el acceso aleatorio a memoria de texturas desde el programa de vértices. La salida del programa son las coordenadas transformadas del vértice y el resto de sus atributos que son almacenados en registros de sólo-escritura para luego ser provistos al rasterizador. Existe un límite en la cantidad total de instrucciones, por ejemplo, para las GPUs NVIDIA de la serie GeForce 6 es de 512 instrucciones estáticas (las del programa compilado) y 65535 dinámicas (son las que realmente se ejecutan al multiplicar los bloques que incluyen ciclos por la cantidad total de ciclos especificados). Es importante destacar que por cada vértice de la escena se ejecuta una instancia independiente del programa de vértices, pudiéndose así procesar varios vértices en paralelo dependiendo de la cantidad de unidades de procesamiento de vértices que posea la GPU. 5.5 El rasterizador Primero el rasterizador ensambla los vértices transformados por la etapa anterior para conformar la primitiva geométrica de acuerdo a un comando suministrado por la aplicación que indica como deben vincularse los vértices, para formar un polígono determinado. Figura 5.5: Proceso Clipping, Culling y Rasterización. Sobre el plano de vista, se define un área rectangular denominada ventana del mundo, que representa la zona de interés que se pretende visualizar. 38 Luego el proceso de Clipping se encarga de determinar que partes de la primitiva están dentro de la ventana de visualización o ventana del mundo y generar, de ser necesario, una versión recortada de las mismas. En la figura 5.5, el triángulo nro. 1 es recortado para remover las porciones que están fuera del área de interés. El proceso de Culling determina si las primitivas están de frente o de espaldas al observador de la escena, evitando así dibujar elementos no visibles (por ejemplo en la figura 5.5, el triángulo nro. 4 es descartado por este proceso). Por último, el proceso de rasterización proyecta la primitiva recortada sobre el plano de visualización, convirtiendo el elemento geométrico vectorial 2D en su representación en forma de fragmentos (ver figura 5.5). Los fragmentos generados son suministrados a la etapa siguiente junto con las coordenadas del píxel al que están asociados. Es importante señalar que la cantidad de fragmentos no tiene relación con la cantidad de vértices de una primitiva (un polígono de 3 vértices puede generar millones de fragmentos, si la primitiva cubre toda ventana del mundo). 5.6 El procesador de fragmentos programable Este procesador ejecuta programas de fragmentos. En una GPU existen más de una unidad de procesamiento de fragmentos, cada una capaz de procesar un fragmento a la vez. Las entradas del programa de fragmentos son los atributos que surgen de hacer una interpolación lineal de los atributos de los vértices que le dieron origen al fragmento. Además de las instrucciones típicas disponibles en los programas de vértices, los de fragmentos agregan instrucciones para acceder a una textura mediante un par de coordenadas reales. Este mecanismo utiliza lo que se denominan “sampler objects”, que toman una muestra de la textura en base a la interpolación de los valores de los píxeles cercanos. El procesador de fragmentos cuenta también con un conjunto de registros de lectura/escritura para almacenar valores intermedios. Como salida, el procesador de fragmentos genera una serie de valores que representan atributos de un píxel de la imagen final como ser color, transparencia, etc. En el caso de los programas de fragmentos el límite en la cantidad de instrucciones es de 65535, tanto dinámicas como estáticas. Aunque los programas de fragmentos y vértices permiten el uso de instrucciones de bifurcación (If / Else), es importante saber que a diferencia de un programa ejecutado en una CPU, ambas ramas de la condición son evaluadas. Y el costo en tiempo computacional es el de la suma de ambas. 5.7 Stream Programming Model Este paradigma o modelo de programación nació con el surgimiento de los procesadores de streams y un cambio de tendencia en el desarrollo de la tecnología de semiconductores, en donde el costo de cómputo es proporcionalmente cada vez más barato que el costo del acceso a la memoria. En este tipo de procesadores se trata de reutilizar al máximo los registros internos del chip para entrada/salida de datos y así minimizar el acceso al sistema de memoria externa para poder mejorar el desempeño de los programas. Se pretende explotar la localidad y el paralelismo existente en los programas empleando centenares de unidades trabajando simultáneamente sobre distintas partes o tareas independientes que componen un mismo programa. 39 El modelo impone restricciones sobre la forma en que deben ser escritos los programas a fin de que el compilador logre optimizar el código y mapearlo de modo directo al hardware. El paralelismo y la localidad del código están explícitamente definidos en el modelo. Uno de los componentes de este modelo son los kernels, que básicamente son llamadas a funciones que realizan un número considerable de cómputos sobre un conjunto de datos de entrada y escribe los resultados sobre otro conjunto de datos de salida. Estos conjuntos de datos sobre los que opera se denominan streams. Los kernels no pueden poseer un estado, esto significa que sus resultados no deben depender de los resultados de una invocación anterior. Figura 5.6: Stream Programming Model En resumen, la figura 5.6 ilustra los conceptos esenciales del modelo, donde un kernel (programa) procesa streams (datos de entrada) y genera streams (datos de salida). Además un kernel puede tener acceso a parámetros globales almacenados en un área de memoria de sólo-lectura. Los streams son los elementos que conectan los kernels entre sí. Relacionando los conceptos del modelo con el modelo de programación en una GPU, se pueden observar analogías en la forma en que los kernels operan sobre los streams y el modo en el que los programas de fragmentos operan sobre los datos almacenados en la memoria de texturas. Por lo tanto, el procesador de fragmentos puede ser interpretado como un procesador de streams que implementa un subconjunto de funciones de las que tendría un procesador de streams ideal. Esto se debe a ciertas limitaciones de las GPUs actuales, entre las que se encuentran la imposibilidad de escribir un dato en una dirección computada dinámicamente desde un programa de fragmentos, o el límite en la cantidad de streams de salida por programa (4 streams). Existen varios trabajos recientes, orientados en este sentido, como los Purcell [6,8] en donde propone la implementación de un motor de Ray Tracing o un motor de Photon Mapping sobre hardware gráfico programable, utilizando el paradigma de Stream Programming. 5.8 GPGPU La posibilidad de utilizar la GPU como un procesador de streams ha generado todo una tendencia que se conoce como GPGPU (General Purpose Computation on a GPU) que implica la utilización de la unidad de procesamiento gráfico para computar 40 algoritmos de propósito general que incluso no relacionados a la computación gráfica como por ejemplo: • • • • Procesamiento de señales de audio y video. Simulaciones físicas. Procesamiento de bases de datos. Simulaciones científicas. En la práctica sólo se hace uso del procesador de fragmentos, ya que las GPUs actuales poseen mayor cantidad de unidades de procesamiento de fragmentos que de vértices. Entre las dificultades se encuentran las limitaciones inherentes al hardware gráfico sobre el que se trabaja, la casi nula existencia de herramientas de depuración. 5.9 Computando con un programa de fragmentos Bajo el esquema GPGPU, los programas de fragmentos escriben sus datos de salida en la memoria de texturas, en lugar del framebuffer (buffer utilizado para mostrar la salida por el dispositivo de pantalla), para que luego puedan ser utilizados como entrada en fases de cómputo subsiguientes. Este modo de trabajo se conoce como rendering a texturas (Render-to-Texture). La extensión de OpenGL llamada Framebuffer Object [19] permite gestionar y vincular las texturas OpenGL con buffers lógicos especiales asociados a las salidas del procesador de fragmentos. Un programa de fragmentos puede escribir hasta en 4 texturas simultáneamente utilizando el mecanismo MRT (Multiple Render Targets). Respecto de las entradas de un programa de fragmentos, existen 2 tipos: • • Parámetros uniformes: son suministrados directamente por la aplicación ejecutada en la CPU. Pueden ser valores escalares, vectores o manejadores de texturas (un puntero a un arreglo de valores de punto flotante). Su valor es constante e idéntico para todos los fragmentos asociados al programa. Parámetros variables: llegan al programa de fragmentos luego de la etapa de rasterización (color, coordenadas de texturas, normales, etc.) y cada fragmento recibe un valor diferente que surge de la interpolación lineal de los correspondientes atributos de los vértices. Hay casos en que se desea definir valores de entrada específicos para cada fragmento, que no sean el resultado de la interpolación lineal de atributos de los vértices de la primitiva geométrica. En estos casos se utiliza un mecanismo de direccionamiento de memoria en base a coordenadas de textura. Dichas coordenadas se definen para los vértices de una primitiva geométrica que al ser rasterizada genera los pares de coordenadas intermedias mediante interpolación lineal. En el programa de fragmentos, se hace una lectura de la textura 2D que contiene los valores de entrada, utilizando como índice el par de coordenadas de textura. Este mecanismo es aplicable a múltiples streams de entrada. La figura 5.7 ilustra un caso donde el programa de fragmentos utiliza tres parámetros de entrada in1, in2 e in3. El par de coordenadas coord lo genera el rasterizador, interpolando el atributo del mismo nombre, definido en los 4 vértices del rectángulo. 41 Figura. 5.7: Acceso indirecto a la memoria de texturas. El cómputo de propósito general en la GPU tiene algunas limitaciones que impiden implementar cierto tipo de algoritmos que requieren operaciones de escritura a memoria de acceso aleatorio, también conocidas como operaciones de dispersión (scattering operations). En este esquema, cada programa de fragmentos puede guardar información persistente solo en el píxel del buffer de salida (utilizando MRT se puede extender esta cantidad a 4 píxeles, cada uno con 4 componentes de 32 bits, correspondientes al formato de color RGBA), pero no puede escribir en una dirección de memoria aleatoria. Por el contrario, las operaciones de reunido (gathering operations) son sencillas de implementar, como se observó en el ejemplo de la figura 5.7. Para ejecutar los cómputos especificados en el kernel, bajo la plataforma OpenGL, se deben efectuar los siguientes pasos (ver figura 5.8): • • • • • • • Configurar la matriz de proyección: definir la matriz de proyección (GL_PROJECTION) para obtener proyección ortográfica de la escena. Configurar la matriz de transformación: cargar la matriz identidad como matriz de transformación (GL_MODELVIEW) . Configurar la ventana en el dispositivo de salida: establecer el área de pantalla (en píxeles) sobre la cual se computará la salida del pipeline. Está área debe coincidir con las dimensiones exactas del o los streams de salida (en definitiva una textura 2D). Cargar el programa de fragmentos: se carga y compila el programa a partir del archivo de texto con extensión “.cg”. Establecer parámetros: Se establecen los valores parámetros uniformes y variables requeridos por el programa Cg, desde la aplicación de alto nivel. Configurar de buffers de salida: Se vinculan las texturas de los streams de salida con los 4 buffers lógicos disponibles mediante la extensión FBO. Dibujo de la primitiva: se dibuja una primitiva geométrica del tipo rectángulo (GL_QUADS) que cubra todo el plano de vista y se definen las coordenadas de textura de sus vértices, de modo que coincidan con las coordenadas de sus píxeles asociados (ver ejemplo en figura 575). 42 • Actualizar buffers de salida: mediante el comando glFlush() se inicia el proceso de rasterización del rectángulo y se inicia el cómputo del programa de fragmentos. Figura 5.8: Cómputo de un kernel usando el procesador de fragmentos en el modo render-to-texture. Es importante notar que para cada fragmento se ejecuta una instancia independiente del programa Cg. Estas instancias se ejecutan en paralelo por múltiples unidades (en GPUs como las NVIDIA GeForce de la serie 6 oscilan entre 16 y 32 unidades). Por lo tanto no es posible referirse, en una instancia, a los valores de salida generados por otra. En esta limitación yace la eficiencia del procesamiento paralelo del sistema. Muchos algoritmos requieren múltiples ejecuciones de un mismo kernel en ciclos que implican leer y escribir sobre un mismo conjunto de datos (streams de entrada y salida). En estos casos se maneja la estrategia de “ping-pong”, que consiste en alternar 43 en sucesivas iteraciones el rol de 2 streams, uno de entrada y otro de salida (ver figura 5.9). Figura 5.9: Estrategia de Ping Pong. Esta estrategia se utiliza debido a que la especificación de la extensión Framebuffer Object no garantiza un correcto funcionamiento al leer y escribir una misma textura dentro de un mismo programa. Sin embargo, en este trabajo, no se observaron inconvenientes con este modo de utilización, por lo tanto se descartó el uso de pingpong a pesar de la falta de garantías. Cuando se implementan kernels de múltiples pasadas (múltiples iteraciones de un mismo kernel sobre un conjunto de streams) es necesario poder detectar cuales elementos del stream no requieren más procesamiento (porque alcanzaron cierto estado final definido según el algoritmo implementado). Esto puede ocurrir en diferentes momentos para diferentes elementos del stream, dependiendo de las condiciones particulares y los valores de las variables involucradas. En un programa de fragmentos, es posible indicar esta condición o estado de finalización mediante una instrucción Cg, denominada “discard”. Esta instrucción evita que el resultado del programa de fragmentos sea escrito en el buffer de salida, aunque no ahorra en ciclos de cómputo, activa un bit especial asociado al píxel. La extensión de OpenGL, OCCLUSION_QUERY, permite saber cuantos fragmentos alcanzaron dicha condición contabilizando la cantidad de esos bits que están activos. La forma de utilizar este mecanismo sería la siguiente: mientras (fragmentos_activos>0){ kernel.ejecutar(); fragmentos_activos=obtenerOcclusionQuery() } 44 Capítulo 6 - Implementación de un caso de estudio En este capítulo, se propone el desarrollo de una aplicación que implemente el algoritmo de Photon Mapping sobre una plataforma basada en hardware gráfico programable, con el fin de analizar cuales fases de esta técnica son factibles de computar en la GPU, evaluar el desempeño y las limitaciones existentes. Se diseño una capa de software de base o un marco de trabajo que provee los mecanismos básicos del Stream Programming Model, esto es, un conjunto de clases que encapsulan los conceptos de los kernels y los streams. Luego a partir de esas clases se construyó un motor de rendering, que combina una estructura de aceleración de trazado denominada BVH (Bounding Volumes Hierachy) y la técnica de Photon Splatting para reconstruir la iluminación indirecta. Ambas técnicas ya fueron implementadas individualmente en una GPU, en el caso de BVH, se generalizó la implementación original, para trazar tanto rayos como fotones. A continuación se establecen los parámetros que describirán el observador de la escena (ubicación, dirección y campo de visión, resolución de imagen de salida, etc.), la fuente de luz, la geometría 3D y las propiedades de sus materiales en la aplicación. Además se definen las características del modelo de iluminación implementado. 6.1 Proyección perspectiva de la escena A continuación se definen los parámetros de la aplicación, que definen las dimensiones del volumen de visualización (o “view frustum”, ver figura 6.1), que es la porción de espacio 3D a ser proyectada sobre el plano de proyección para representar la vista de la escena. Figura 6.1: Volumen de visualización. • • • • • wsize y hsize: resolución horizontal y vertical (píxeles) de la imagen de salida (también denominada resolución del viewport). width y height: ancho y alto del área de proyección de la escena en el plano cercano. pos: vector posición de ojo del observador o punto de vista. normal: vector perpendicular al plano de proyección. up: vector que señala el lado superior del plano de proyección. 45 • • near: distancia al plano de proyección cercano desde el ojo del observador. far: distancia a plano lejano. 6.2 La fuente de luz La fuente de luz fue modelada como una fuente tipo spotlight, donde los rayos son emitidos dentro de la zona delimitada por un cono orientado (ver figura 6.2). Los parámetros que la definen son los siguientes: • • • • • • • pos: vector origen de la fuente lumínica. normal: vector que indica dirección de emisión. up: vector que indica lado superior del plano de emisión. maxAngle: es el ángulo respecto de la normal que indica el punto en el que la potencia lumínica decae a cero. minAngleRatio: indica el ángulo mínimo como una fracción del ángulo máximo, a partir del cual la potencia comienza a decaer linealmente hasta cero. splatRadius: es el radio del splat, utilizado en la etapa de Photon Splatting. power: indica la potencia lumínica total de la fuente. Figura 6.2: Fuente de luz tipo spotlight. Como se observa en la figura 6.2, la intensidad lumínica de la fuente se mantiene en su valor máximo entre la dirección normal y el ángulo mínimo. Luego decae linealmente hasta cero en el ángulo máximo (maxAngle). En la aplicación implementada sólo está prevista la definición de una única fuente. 6.3 La geometría de la escena Los modelos geométricos utilizados en este caso de estudio, fueron generados con 3D Studio Max y exportados en el formato 3DS. Luego, en la aplicación, este archivo es interpretado por una librería que devuelve las coordenadas de los vértices y las normales de los triángulos junto con el nombre del material y su color. Utilizando el nombre del material como clave de búsqueda, se accede a una librería de atributos de materiales definida en el archivo de parámetros general (.INI). Para cada material se definen: • • color: en formato RGB. diffuseK: índice de reflexión difusa, es un número real entre 0 y 1. 46 • • • • specularK: índice de reflexión especular, es un número real entre 0 y 1. reflectK: índice de reflectividad del material, define la intensidad con que se refleja el entorno. Es un número real entre 0 y 1. Un valor mayor a 0 implica trazar un rayo secundario para calcular el color la inter-reflexión especular o reflexión tipo espejo. smoothing: indica si las normales deben ser o no interpoladas sobre la superficie de cada triángulo para lograr un efecto de superficie suave. Admite dos valores posibles: 0 o 1. selfIlum: indica si el material emite luz propia. Admite dos valores: 0 ó 1. se utiliza sólo para destacar claramente un objeto rectangular que representa la fuente de luz, pero no altera ni genera iluminación sobre su entorno. Para evaluar el desempeño de la implementación, se generaron variantes del modelo conocido como Cornell Box (ver figura 6.3), utilizando diferentes tipos de materiales y objetos ubicados en el interior de la caja. Figura 6.3: Modelo Cornell Box. 6.4 El modelo de iluminación Mediante Ray Tracing, luego de trazar los rayos primarios desde el ojo del observador (ver figura 6.4), se calcula la iluminación en las superficies intersecadas combinando las siguientes componentes: • • Ambiente: se define como el producto del color del material y el coeficiente de luz ambiental (ambientK), que es un parámetro global de la aplicación. Directa: utilizando modelo de Phong [30], se computa en base a los coeficientes de reflexión difusa y especular asociados al material de la superficie (diffuseK y specularK respectivamente) y se multiplica por un factor de visibilidad que puede valer 0 ó 1. Dicho factor, se obtiene trazando un rayo de sombra para determinar la visibilidad de la fuente de luz. Es la iluminación que proviene directamente de la fuente. 47 • • Indirecta: se computa utilizando la técnica de Photon Splatting (ver punto 6.7 para más detalles). Es la iluminación que llega al punto tras, al menos, una reflexión difusa. Inter-reflexión especular perfecta: se obtiene trazando un rayo secundario en la dirección de reflexión del espejo. Sólo en los casos en que el material de la superficie en cuestión posea un índice de reflectividad (reflectK) mayor a cero. Figura 6.4: Componentes de iluminación. A, B y C son tres fotones que aportan iluminación indirecta al punto P. 6.5 Marco de trabajo basado en Kernels y Streams En base a los conceptos presentados en el capitulo 5, se construyó una capa de software de base que provee los elementos básicos del Stream Programming Model implementado sobre el hardware gráfico, utilizando el mecanismo de rendering a texturas y el procesador de fragmentos de la GPU. Para ello, se definieron dos clases C++ denominadas FpKernel y FpStream. 6.5.1 La clase FpKernel Está asociada a un programa de fragmentos Cg y sirve para implementar kernels de una o de múltiples pasadas. Utiliza los servicios de clase FBO [22], que presenta una mínima abstracción de la extensión OpenGL Framebuffer Object, para la gestión y vinculación de texturas y buffers de salida. La figura 6.5 muestra mediante un diagrama UML los métodos y atributos principales de la clase. El método constructor recibe como parámetros las dimensiones del o los streams de salida, el nombre archivo Cg y el nombre de la función Cg a invocar dentro de ese archivo (entryPoint). El procedimiento de uso de la clase es el siguiente en: • • • Inicializar la clase: mediante el método init. Establecer parámetros uniformes: mediante los métodos setParamater. Vincular streams: mediante el método setStream. 48 • Ejecutar el kernel: mediante el método run. Figura 6.5: Clase FpKernel. El método setParameter1f admite un parámetro real escalar y el método setParameter3fv admite un vector de 3 componentes reales, además en ambos casos en necesario suministrar el nombre del parámetro asociado al valor, en el programa Cg. El método setStream, vincula los streams al kernel, esto es, conecta el identificador de la textura 2D OpenGL con el parámetro asociado en el programa Cg Finalmente el método run, inicializa, vincula la instancia del Framebuffer Object y realiza el cómputo utilizando el modo de render a texturas. El método devuelve la cantidad de fragmentos activos en la corrida del programa (OCCLUSION_QUERY). 6.5.2 La clase FpStream Su atributo principal es una textura rectangular OpenGL con un formato de 1,3 o 4 canales float de 32 bits de precisión que representa el stream (de tipo GL_TEXTURE_RECTANGLE_ARB). Existen tres clases descendientes asociadas a los modos de uso de los streams (entrada, salida o entrada/salida). A continuación, la figura 6.6 detalla los métodos y atributos principales de la clase y sus tres clases descendientes: 49 Figura 6.6: Clase FpStream y sus clases descendientes. El método constructor de un stream de entrada (FpStreamInputOnly) admite como parámetro un stream de salida (FpStreamOutputOnly), permitiendo vincular la salida de un kernel con la entrada de otro. Este vínculo se establece a nivel lógico (ver figura 6.7), ya que en realidad existe una sola instancia de los datos, representada por un mismo identificador de textura OpenGL (texture id). Nivel lógico (Instancias de FpKernel y FpStream) Vínculo lógico FpKernel 1 Output FpStream 1 Input FpStream 2 FpKernel 2 Nivel físico (Programas Cg y texturas 2D) Entrada Salida Programa de fragmentos Cg 1 Textura OpenGL 2D Programa de fragmentos Cg 2 Figura 6.7. Esquema lógico y físico de Kernels y Streams 50 Es posible también crear múltiples streams de entrada por referencia, esto es, varios streams que comparten el mismo espacio de almacenamiento bajo diferentes denominaciones. 6.5.3 Un ejemplo de uso El siguiente ejemplo ilustra la forma en que se combinan ambas clases para crear un programa sencillo que implementa un kernel de múltiples pasadas. int w = 64; h = 64; // Resolución horizontal y vertical // Declaración de kernels FpKernel k; FpStreamInput sIn1,sIn2; FpStreamInputOutput sInOut; // instanciación de los kernels // inN son los identificadores en el programa CG // *dataN poseen datos para inicializar los streams k = new FpKernel (w,h,”krn1.cg”); sIn1=new FpStreamInput(w,h,”in1”,*data1); sIn2=new FpStreamInput(w,h,”in2”,*data2); sInOut = new FpStreamInputOutput (w,h,0,”in3”,*data3); // fija el valor de un parámetro uniforme k->setParameter1f(“sampleparam”,1.75); k->setStream(sIn1); //vincula stream de entrada 1 k->setStream(sIn2); //vincula stream de entrada 2 k->setStream(sInOut);//vincula stream de entrada/salida int occlusion_query=0; do { occlusion_query=k->run(); // ejecuta el kernel } while (occlusion_query>0); // iterar La figura 6.8 muestra la relación entre los distintos objetos del ejemplo anterior. Figura 6.8: Diagrama de Kernels y Streams para el ejemplo de uso. 6.6 Trazador de fotones y rayos en la GPU Dadas las similitudes entre el proceso de trazado de rayos y fotones, se decidió diseñar una clase C++ capaz de resolver el trazado de ambos casos mediante un 51 mecanismo unificado. Se utilizó la estructura de aceleración BVH (Bounding Volumes Hierachy) y los ejemplos provistos en el trabajo de Thrane et al. [18] como base para la implementación del caso de estudio. En dicho trabajo se presenta a esta estructura como la más eficiente y sencilla desde el punto de vista de la programación, para implementar en la GPU. 6.6.1 La estructura de aceleración BVH Es una estructura que subdivide la escena en una jerarquía conformada por dos tipos de nodos: triángulos y volúmenes envolventes (ver figura 6.9). La estructura tiene la forma de un árbol binario. Los nodos internos corresponden a los volúmenes envolventes que contienen a todos los elementos de su rama. Los volúmenes, en este caso, son cajas alineadas con los ejes coordenados. Las hojas del árbol corresponden a los elementos geométricos de la escena (en este caso los triángulos). La idea detrás de esta estructura es ahorrar un gran número de verificaciones de intersección entre triángulos y rayos. Para ello se envuelve un conjunto de elementos geométricos cercanos con una caja (alineada a los ejes coordenados) y se evalúa la intersección del rayo con la caja (lo cual, tiene de hecho, un costo menor que evaluar la intersección de un rayo y un triángulo). En caso de no existir intersección con la caja, tampoco existirá con los elementos geométricos contenidos en ella. El proceso para verificar la intersección de un rayo con toda la escena implica recorrer el árbol haciendo un descenso recursivo comenzando por la raíz. Figura 6.9: Ejemplo de la estructura BVH aplicada a un conjunto de 5 triángulos. No existe hasta el momento un algoritmo óptimo de construcción del árbol, pero existen diferentes heurísticas. El algoritmo que se utilizó en esta implementación esta basado en el presentado por Thrane et al. [18]. La idea general es tomar el conjunto de triángulos que conforman la escena, calcular las dimensiones de una caja alineada a los ejes coordenados que envuelva a todo el conjunto (Bounding Box) y luego calcular la media aritmética de las coordenadas de los vértices de todos los triángulos. A continuación se debe dividir el conjunto de triángulos en 2 mitades, según un plano cuya normal coincida con el lado más largo de la caja, que pase por la media aritmética del conjunto de vértices (ver figura 6.9). Cada subconjunto de triángulos pasa a formar parte de los dos nodos hijos según el centro de cada triángulo se encuentre de uno u otro lado del plano de corte. Luego el proceso se repite para cada nodo hasta que quede un solo triángulo por nodo. 52 A continuación se delinea el algoritmo de construcción: BVHNode construirArbol (triángulos) if (triángulos es solo 1 triángulo){ return hoja del árbol con un triángulo }else { Calcular punto de corte (media arit. de coord. de los vértices) Calcular mejor plano de corte (cuya normal = al lado mas largo) BVHNode res res.leftChild = construirArbol (triángulos a la izq. del corte) res.rightChild = construirArbol (triángulos a la der. del corte) res.boundingBox = caja que envuelva a todos los triángulos return res } El proceso de construcción lo realiza la CPU como un preproceso junto con la carga del modelo 3D. El resultado es un conjunto de arreglos (ver fig. 6.10) que indican como recorrer el árbol para hacer la verificación de intersecciones (no se almacena la estructura completa, sino sólo los datos necesarios para recorrerlo en forma descendente). 0 1 2 3 4 5 6 7 8 Traversal Array type index escape code 0 0 INF 0 1 6 0 2 5 1 0 -1 1 1 -1 1 2 -1 0 3 INF 1 3 -1 1 4 -1 type: 0 = bounding box 1 = triangle 0 1 2 3 0 1 2 3 4 bbox_min (x,y,z) … … … V0 (x,y,z) … … … … V1 … … … … … bbox_max … … … … V2 … … … … … N0 … … … … … N1 … … … … … N2 … … … … … Figura 6.10: Estructuras de datos del algoritmo BVH. 53 El algoritmo de detección de intersecciones rayo-triángulo usando la estructura BVH, comienza recorriendo el arreglo Traversal Array en orden secuencial, evaluando en cada posición si hay intersección entre el rayo y el nodo. Si el valor del campo type es 0, se debe acceder a los parámetros de la caja envolvente en los arreglos bbox_min y bbox_max, que definen las coordenadas de sus extremos usando el valor del campo index. Si el valor del campo type es 1, se debe acceder a los arreglos V0, V1, V2, que definen los vértices del triángulo. En caso de no verificarse intersección,con un nodo, esto significa que tampoco ocurrirá con ningún elemento de la rama. El código de escape (escape code) indica a qué registro del arreglo hay que saltar para evitar toda la rama. Los arreglos N0, N1 y N2 son las normales en cada uno de los vértices de los triángulos. 6.6.2 Clase Tracer Esta clase se ocupa de trazar rayos o fotones, a partir de dos streams que indican los orígenes y las direcciones. La clase utiliza los servicios de la clase SceneLoader (ver punto 6.8.1), encargada de cargar la geometría de la escena desde un archivo y generar las estructuras de datos para el algoritmo BVH. La figura 6.11 detalla los métodos y atributos principales de la clase. Figura 6.11: Clase Tracer. El método init, que inicializa los atributos internos, acepta como parámetros: los streams de orígenes, direcciones y de estado inicial (indica si algún rayo o fotón no debe ser trazado). El método trace realiza el trazado utilizando la estructura de aceleración detallada en el punto 6.6.1. Por último, los métodos getTraverserStates y getIntersectorNormals devuelven en forma de streams el resultado del trazado que incluye por cada rayo o fotón: • Estado: indica si el rayo o fotón impactó alguna superficie o salió fuera de los límites de la escena. 54 • • • Coordenadas de impacto: define el punto exacto de impacto sobre el triángulo, en coordenadas locales del plano del triángulo. Identificador del triángulo impactado: el índice del triángulo dentro de la escena. Distancia Z: la distancia al punto de impacto desde el origen del rayo o fotón hasta alcanzar el punto de impacto en la superficie. 6.6.3 El trazado de fotones Para el caso de estudio se estableció un máximo de 4 etapas de trazado de fotones. En la figura 6.12 se observa un ejemplo en donde se emiten 1000 fotones desde la fuente de luz. En la primera etapa los fotones son trazados hasta interactuar la primera superficie S1. Dichos fotones representan iluminación directa, por lo tanto, no es útil almacenarlos, ya que la iluminación directa se resuelve mediante Ray Tracing. Por lo tanto Ab1 es 0 y todos los fotones incidentes en S1 son reflejados. diffuseK = 0,3 specularK = 0,1 absorbK = 0,6 S2 Fuente de Luz Nf=1000 Ab2=600 Pm2=600 Re1=1000 Rd1=750 Rs1=250 S4 Re3=160 Rd3=120 Rs3=40 Ab4=96 Pm4=96 Re4=64 Re2=400 Rd2=300 Rs2=100 S1 Ab1=0 Pm1=0 S3 Ab3=240 Pm3=240 Nf = número de fotones emitidos Rei = fotones reflejados por la superficie i Rsi = fotones reflejados en forma difusa por la superficie i Rdi = fotones reflejados en forma especular por la superficie i Abi = fotones absorbidos por la superficie i Pmi= fotones almacenados en la superficie i Figura 6.12: Fases de trazado de fotones. Luego, en las superficies S2, S3 y S4 una fracción de los fotones incidentes son absorbidos. Aquellos fotones que son reflejados desde la última superficie S4, son descartados. Rdi y Rsi corresponden a la cantidad de fotones reflejados en forma difusa o especular de acuerdo a los coeficientes diffuseK y specularK en la superficie i. 55 En el método aplicado, en el caso de estudio, los fotones absorbidos por cada superficie Si, son los almacenados para luego ser utilizados en la fase de Photon Splatting (ver detalles en el punto 6.7). 6.7 Photon Splatting Esta técnica fue presentada por primera vez por Stürzlinger y Bastos [19] en 1997. Permite hacer una reconstrucción de la iluminación indirecta a partir de la información generada por el trazado de fotones, usando un método basado en imágenes. Luego Paulin et al. [21] presento algunas mejoras al método original utilizando hardware gráfico. El objetivo es reconstruir la irradiancia en cada píxel del plano de vista estimando el aporte de cada fotón. Esto se puede lograr de 2 maneras: • • Para cada píxel, buscar los fotones que impactan dentro de cierto radio del punto visible a través del píxel y sumar su contribución al estimador. Para cada fotón, agregar su aporte al estimador de cada píxel cercano (a una distancia menor a cierto radio del punto visible este a través del píxel). Esta segunda forma es la que aplica la técnica de Photon Splatting. Un splat tiene la forma de un disco, que representa la contribución del fotón a la iluminación indirecta en las cercanías del punto de impacto. Dicha contribución se computa y acumula sobre cada píxel del plano de vista, cubierto por la proyección del splat, sólo si dicho píxel pertenece a la misma superficie en la que impactó el fotón. Esto es importante, ya que la cercanía en el plano de proyección no implica una cercanía en el espacio tridimensional. De hecho, para 2 píxeles contiguos, su distancia en la coordenada Z (normal al plano de proyección) puede ser considerable (mayor al radio del splat). El algoritmo consiste en iterar sobre la lista de fotones de la escena y generar por cada uno, un disco centrado en el punto donde impactó el fotón y orientado según la normal de la superficie, que luego es proyectado sobre el plano de vista. La suma de todas las proyecciones se acumulará en el buffer de salida, utilizando el modo de OpenGL de fundido aditivo (additive blending). Antes de comenzar el proceso, se establece la matriz de vista y proyección según los parámetros de la escena. Luego se procede a dibujar cada disco o splat ejecutando un comando OpenGL que dibuja un triángulo (GL_TRIANGLE). Un programa de fragmentos que resuelve el sombreado del triángulo muestrea la función de distribución de energía del fotón a partir de una textura 2D. La forma de esta distribución responde a una función patrón (o kernel function) también conocida como filtro, que depende de la distancia al centro del splat. Existen tres tipos de funciones patrón usadas habitualmente (ver figura 6.13): • • • Constante: La intensidad es constante dentro del disco, y nula fuera de este. Cónica: La intensidad decae linealmente desde el centro hasta el radio del disco. Gaussiana: La intensidad decae desde el centro hacia afuera según la forma de una campana gaussiana. Luego del proceso de rasterización del splat, se debe analizar para cada fragmento (o “píxel potencial”) si el aporte definido por el muestreo de la función patrón debe ser agregado o no al buffer de salida. Para sumarlo deben cumplirse dos condiciones: 56 • r r Las normales n x y n f en los puntos X y F respectivamente, deben ser similares Esta similitud se define en términos un producto escalar entre ambos vectores (ver figura 6.14). r r n x • n f > umbral Donde 0 < umbral < 1. Esto evita que en zonas como esquinas, el fotón aporte iluminación a una superficie cercana, pero que está orientada en una dirección muy diferente. • Los identificadores de superficie en los píxeles X’ y F’ deben ser coincidentes. Estos identificadores son valores enteros asignados a todos los triángulos de cada objeto de la escena (un objeto puede estar compuesto por varios triángulos). Figura 6.13: Funciones patrón. Figura 6.14: Condiciones de aceptación/rechazo de fragmentos del splat. 57 En el ejemplo de la figura 6.15 se ilustran diferentes casos. Dado el punto F correspondiente al punto de impacto del fotón, analizando el punto X1 (asociado al píxel r r X1’) se ve que las normales n x1 y n f son similares y sus identificadores de superficie también ya que ambos puntos pertenecen al mismo objeto, por lo tanto el aporte del r píxel X1’ es agregado al buffer de salida. Para el punto X2, las normales n x 2 y r n f difieren considerablemente, por lo tanto, se descarta el aporte del píxel X2’del splat. Por último para el punto X2, las normales son similares pero difieren en los identificadores de superficies por ende su aporte tampoco es tenido en cuenta. Figura 6.15: Distribución de aporte de un fotón sobre los píxeles del plano de vista. La calidad de la solución obtenida mediante el método de Photon Splatting, es proporcional al número de fotones utilizados en el proceso. A mayor cantidad de splats sumados, más suave (con menor ruido) es la iluminación de la imagen obtenida. A su vez, un radio de splat más grande también contribuye a reducir el ruido, pero elimina detalles locales de la iluminación, ya que cada splat afecta un área demasiado grande. En la figura 6.16, se ilustran 4 casos en donde se aplica el método sobre una escena conformada por una caja y una fuente de luz direccional ubicada en el plano superior apuntando hacia abajo. En cada caso se utilizó una cantidad diferente de fotones. La figura 6.16a exhibe una calidad insuficiente, mientras que la figura 6.16d logra una calidad aceptable con un nivel de ruido casi imperceptible. Además, la calidad depende del tipo de función patrón que se utiliza. El filtro gaussiano generalmente genera mejores resultados. La imagen resultante del proceso de splatting se denomina textura de irradiancia y sirve de entrada a la fase de rendering. Provee el valor de la irradiancia sobre los puntos de las superficies vistos desde el ojo del observador (por lo tanto es dependiente del punto de vista de la escena). 58 Figura 6.16: Photon Splatting con una función patrón constante (radio del splat=1,5 unidades, las paredes de la escena miden 10x10 unidades). 6.8 Motor de Rendering basado en Photon Mapping Sobre la base del marco de trabajo presentado en 6.5 se diseñó un motor de rendering capaz de sintetizar una vista de una escena 3D a partir de dos archivos de entrada que contienen la descripción de la escena. El motor se compone de 3 clases principales: • • SceneLoader: carga y conversión a streams de los datos de entrada y generación de estructura de aceleración de trazado. PhotonMapper: Resuelve el trazado de fotones. 59 • RayTracer: integra los resultados generados por la clase PhotonMapper con el trazado de rayos desde el ojo del observador para sintetizar la imagen de salida. En la figura 6.17 se detalla la relación entre estas clases y el flujo de datos entre ellas. Figura 6.17: Arquitectura del motor de Rendering. 6.8.1 La clase SceneLoader Se ocupa de cargar en memoria la información de la escena desde archivos, construir la estructura de aceleración para el trazado de rayos o fotones (detallada en 6.6.1) y convertir esos datos a streams. La información de la geometría de la escena, es leída desde un archivo en formato 3DS. Este formato es un estándar para el intercambio de modelos 3D que nació como parte del software de edición 3D Studio. Además carga los parámetros que describen la fuente de luz, el punto de vista, las propiedades de los materiales y las características de la imagen a sintetizar, desde un archivo de texto plano denominado “param.ini”. La clase implementa un singleton que provee los streams de entrada requeridos por las clases RayTracer y PhotonMapper. 6.8.2 La clase PhotonMapper Esta clase se encarga de trazar los fotones emitidos por la fuente de luz a través de la escena. El proceso se realiza por medio de cuatro kernels (ver figura 6.18). Primero, el kernel Photons Generator, muestrea el espacio de emisión de fotones de la fuente de luz mediante la generación de pares de coordenadas polares aleatorias dentro de los límites del cono de luz (ver figura 6.2) definido para la escena. Este kernel 60 genera como salida los streams que representan origen, dirección, estado y color de los fotones. El proceso de muestreo requiere la generación de números al azar desde el programa Cg con el que se implementa el kernel. Debido a que en la plataforma de software utilizada, la instrucción Cg para generar números aleatorios no está implementada, fue necesario generar dichas secuencias de números en la CPU y cargarlas en texturas para ser utilizadas por el kernel. Parámetros de la fuente de luz Photons Generator Streams de geometría 3D + estructura. BVH 1 Parámetros de la vista Tracer 4 2 PhotonMapper Photons Reflector 3 Photons Projector Streams 1. Fotones (origen, dirección y estado) 2. Fotones (datos de intersección) 3. Fotones reflejados (origen y dirección), son la entrada de una nueva fase de trazado. 4. Fotones absorbidos(origen, dirección y datos de intersección) 5. Splats (posición, id de objeto, color y normal) 5 Datos de los Splats Figura 6.18: Diseño interno de la clases PhotonMapper (flujo de datos entre los kernels) El proceso continúa con una fase de trazado derivada a una instancia de la clase Tracer (detallada en el punto 6.6.2). Los fotones trazados pasan luego al kernel Photons Reflector, que se encarga de simular la interacción con las superficies, determinando cuales deben ser absorbidos, reflejados de forma difusa o especular. Los fotones reflejados sirven de entrada para una nueva etapa de trazado. Este proceso se repite hasta completar un número máximo de fases de trazado definido en el archivo “param.ini”. Aquellos fotones que son reflejados luego de la última fase trazado junto con aquellos que escapan fuera de los límites de la escena, son descartados. Al concluir las N fases de trazado, se tiene un conjunto de datos que especifica los fotones absorbidos por las superficies (incluyendo el color que es modificado de acuerdo al color de las superficies en las que impacto el fotón). Para finalizar, el kernel Photons Projector traduce los fotones absorbidos en una lista de atributos que especifican la forma y ubicación de los splats en el sistema de coordenadas de la escena, que servirán de entrada a la fase de Photon Splatting. Concretamente: • • Las coordenadas X, Y, Z de vértices del triangulo que representa al splat. Las coordenadas X, Y, Z de la normal del splat. 61 • El identificador de la superficie impactada. 6.8.3 La clase Raytracer Se encarga de trazar los rayos desde el ojo del observador, realizar el proceso de Photon Splatting usando los datos generados por la clase PhotonMapper, para luego sintetizar la imagen final. En la figura 6.19 se observan los kernels involucrados en el proceso. Parámetros del punto de vista Raytracer Datos de los Splats Surface-Data Generator Eye Rays Generator 2 1 Tracer 9 2 10 Shader (primarios) Proceso de Photon Splatting 8 2 Specular Reflections Generator 9 2 Shadows Generator 4 3 Integrator Clase Tracer 5 7 Clase Tracer 6 Shader (secund.) 11 Streams Imagen Rayos primarios (origen y dirección). sintetizada Rayos primarios (datos de intersecciones). Rayos de sombra (origen y dirección). Rayos de sombra (datos de intersecciones). Rayos secundarios por inter-reflexiones especulares (origen y dirección). Rayos secundarios por inter-reflexiones especulares (datos de intersección). Colores en puntos de impacto de rayos secundarios. Colores en puntos de impacto de rayos primarios. Normales e identificadores de superficies en los puntos de impacto de los rayos primarios. 10. Irradiancia en puntos de impacto de los rayos primarios. 11. Píxeles de la imagen sintetizada. 1. 2. 3. 4. 5. 6. 7. 8. 9. Figura 6.19: Diseño interno de la clase RayTracer (flujo de datos entre sus kernels). 62 Primero, el kernel Eye Ray Generator muestrea los píxeles sobre el plano de proyección y genera los rayos primarios, con su origen en el ojo del observador. Una instancia de la clase Tracer traza los rayos primarios y determina los puntos de intersección con las superficies. A partir de los resultados del trazado, el kernel Surface-Data Generator determina los atributos de las superficies impactadas por cada rayo (normal e identificador de superficie). El kernel Specular Reflections Generador, genera los rayos secundarios que corresponden a las inter-reflexiones especulares en los puntos impactados por los rayos primarios. El kernel Shadows Generator genera los rayos de sombra que determinarán la visibilidad de la fuente de luz desde los puntos de impacto de los rayos primarios. Tanto los rayos de sombra como los rayos secundarios, son trazados utilizando los servicios de una instancia de la clase Tracer. El kernel Shader calcula el sombreado local usando el modelo de Phong incorporando la irradiancia computada en la fase de Photon Splatting y la información capturada por los rayos de sombra para determinar la intensidad de iluminación directa que llega al punto. Para finalizar, el kernel Integrator, agrega el aporte de iluminación por interreflexión especular (color capturado por los rayos secundarios) a la imagen generada por el kernel Shader. 63 Capítulo 7 - Evaluación de la implementación En este capítulo se presentan una serie de mediciones realizadas sobre la aplicación implementada en el caso de estudio definido en el capítulo anterior, con el fin de evaluar el tiempo requerido para sintetizar una imagen de una escena de prueba, bajo diferentes parámetros. Además se describe la plataforma de hardware y software utilizada. Por último se hace un análisis cualitativo de las imágenes generadas. 7.1 Entorno de hardware y software La plataforma utilizada para la implementación posee las siguientes características: Software: • Sistema operativo: Microsoft Windows XP SP2. • Lenguaje de programación: Microsoft Visual C++ 7.0. • OpenGL 2.0. y NVIDIA Cg Toolkit 1.5. • Controlador de video NVIDIA versión 91.45. Hardware: • CPU: AMD Athlon 64 3000+ (1.8 GHz). • GPU: MSI NVIDIA GeForce 6600 GTS 128 MB DDR. • RAM: 1024 MBytes DDR400 MHz. 7.2 Mediciones del desempeño Se diseñó un modelo de una “caja de Cornell” (Cornell Box) para evaluar el funcionamiento de la implementación. En la figura 7.1 se observan los ángulos que definen al cono de emisión de la fuente de luz. El modelo está delimitado por las paredes que forman un cubo de 10x10x10 unidades, excepto la pared cercana al ojo del observador que fue removida, por lo tanto, los fotones emitidos hacia dicha superficie saldrán fuera de los límites de la escena y por lo tanto serás descartados. Todas las superficies del modelo poseen un coeficiente de reflexión difusa de 0,2 y un coeficiente de reflexión especular de 0,1. Por lo tanto, si 100 fotones intersecan una de estas superficies, el 70% será absorbido y el 30% restante es reflejado, parte en forma especular (10%) y el resto en forma difusa (20%). Se estableció un máximo de 4 fases, para el proceso de trazado de fotones (por lo tanto un fotón puede ser reflejado como máximo en 3 veces). Además, para todas las superficies se definió, un coeficiente de inter-reflexión especular perfecta con valor nulo, por lo tanto no se computaron rayos secundarios en la etapa de Ray Tracing. Bajo estas restricciones se evaluaron las 27 combinaciones de los siguientes parámetros: • • • Resolución de imagen de salida: 128x128, 256x256 y 512x512 píxeles. Radio del splat: 0,5; 1,0 y 1,5 unidades. Número de fotones generados: 16384, 65535 y 262144. 64 Figura 7.1: Modelo “Cornell Box” utilizado en las mediciones. Estos 3 parámetros fueron seleccionados ya que afectan en forma más directa la calidad de la solución obtenida. En el caso de los parámetros de resolución de imagen y la cantidad de fotones un incremento suele producir una mejor solución o estimación de la iluminación de la escena. Tabla 1. Medición de tiempos de generación de un cuadro. Tiempo de generación (seg.) según la resolución de imagen (píxeles) Radio del splat 0,5 1,0 1,5 Tiempo de fase de splatting (seg.) según resolución de imagen (píxeles) Fotones generados 128 x 128 256 x 256 512 x 512 128 x 128 256 x 256 512 x 512 16384 4,87 5,09 6,17 0,20 0,22 0,33 65535 5,87 6,56 7,37 0,50 0,52 0,73 262144 10,67 11,43 12,33 1,48 1,51 1,92 16384 5,47 5,11 6,78 0,22 0,25 0,53 65535 5,89 6,25 8,22 0,51 0,64 1,59 262144 10,69 11,22 15,89 1,51 1,72 5,23 16384 4,86 5,19 6,65 0,23 0,33 0,84 65535 6,00 6,53 9,48 0,61 0,95 2,84 262144 10,7 12,34 20,43 1,48 2,84 10,01 65 Sin embargo, en el caso del radio de splat, un valor muy grande genera una solución incorrecta por afectar la iluminación de puntos demasiado distantes al punto de impacto del fotón. Es importante mencionar que debido a limitaciones del controlador de video y el kit de desarrollo de software Cg utilizado, no fue posible utilizar en las mediciones, streams de salida con resoluciones de textura mayores a 512x512 píxeles. De ahí surge el valor máximo de resolución de la imagen de salida y el número de fotones utilizados en las mediciones. Cabe aclarar que no todos los fotones generados se traducen en un splat, dado que algunos se reflejan fuera de la escena y otros se descartan luego de ser reflejados pasado el número máximo de reflexiones de los fotones. Empíricamente, en esta escena, la cantidad de splats resultó ser equivalente a 75 ± 3% de los fotones generados. Por lo tanto si se generan 262144 fotones, se producen aproximadamente 196000 splats. Este valor es aproximado, ya que incluso en corridas sucesivas bajo parámetros idénticos, el número de splats es variable debido a que los eventos que determinan el camino recorrido por un fotón dependen de variables aleatorias. En la tabla 1 se presentan los tiempos totales de generación de un cuadro (sin incluir los tiempos de preprocesamiento iniciales requeridos para leer los archivos de la escena y generar la estructura BVH). Tabla 2. Incremento de tiempo de generación vs. Incremento en la cantidad de fotones generados. Factor de incremento del tiempo de generación (seg.) según la resol. de imagen (píxeles) Radio del splat 0,5 1,0 1,5 Definición del factor Factor de incremento en la cantidad de fotones generados 128 x 128 256 x 256 512 x 512 1 (16384 fotones) 1,00 1,00 1,00 t1/t1 4 veces 1,21 1,29 1,19 t2/t1 16 veces 2,19 2,25 2,00 t3/t1 1 (16384 fotones) 1,00 1,00 1,00 t1/t1 4 veces 1,10 1,28 1,40 t2/t1 16 veces 1,95 2,20 2,34 t3/t1 1 (16384 fotones) 1,00 1,00 1,00 t1/t1 4 veces 1,23 1,26 1,43 t2/t1 16 veces 2,20 2,38 3,07 t3/t1 * t1 = tiempo de generación para 16384 fotones * t2 = tiempo de generación para 65535 fotones * t3 = tiempo de generación para 262144 fotones 66 En la tabla 2, se analiza el incremento en el tiempo de generación de un cuadro al aumentar la cantidad de fotones. Se puede observar en todos los casos que el tiempo crece sublinealmente respecto de la cantidad de fotones. En la tabla 3, se comparan los tiempos de generación en relación al incremento en la resolución de la imagen de salida. Nuevamente se observa que el tiempo crece sublinealmente respecto de la resolución. En el peor caso (correspondiente a un radio de splat = 1,5; fotones generados = 262144 y una resolución de 512x512 píxeles) el tiempo de generación prácticamente se duplicó, para una imagen sintetizada con cuatros veces más de pixeles. Tabla 3. Incremento de tiempo de generación vs. Incremento en la resolución de imagen. Factor de incremento del tiempo de generación (seg.) según incremento en la resol. de imagen (píxeles) Radio del splat 0,5 1,0 1,5 Fotones generados 1 (128 x 128) 2 veces 4 veces 16384 1,00 1,05 1,27 65535 1,00 1,12 1,26 262144 1,00 1,07 1,16 16384 1,00 0,93 1,12 65535 1,00 1,09 1,58 262144 1,00 1,05 1,49 16384 1,00 1,07 1,37 65535 1,00 1,09 1,58 262144 1,00 1,15 1,91 t1/t1 t1/t2 t1/t3 Definición del factor * t1 = tiempo de generación para una imagen de 128x128 píxeles * t2 = tiempo de generación para una imagen de 256x256 píxeles * t3 = tiempo de generación para una imagen de 512x512 píxeles En la tabla 4, se analiza el incremento en el tiempo de rendering respecto del incremento en el radio del splat. Aquí se observa una variación mínima de tiempo (menor a un 15%) para la resolución de 256x256 respecto del caso patrón (128x128 píxeles), esto se debe a que los splats en estos casos cubren muy pocos píxeles, entonces el incremento en el radio no hace variar sustancialmente la cantidad de fragmentos que deben ser computados en la fase de Photon Splatting. Luego, igual que en las tablas 2 y 67 3, se observa que el tiempo de generación de un cuadro crece sublinealmente respecto del radio del splat. Tabla 4. Incremento de tiempo de generación vs. Incremento en la resolución de imagen. Factor de incremento del tiempo de generación (seg.) según la resol. de imagen (píxeles) Fotones generados 16384 65535 262144 Definición del factor Radio del splat 128 x 128 256 x 256 512 x 512 1 (0.5 unidades) 1,00 1,00 1,00 t1/t1 2 veces 1,12 1,00 1,10 t2/t1 3 veces 1,00 1,02 1,08 t3/t1 1 (0.5 unidades) 1,00 1,00 1,00 t1/t1 2 veces 1,02 1,00 1,29 t2/t1 3 veces 1,02 1,00 1,29 t3/t1 1 (0.5 unidades) 1,00 1,00 1,00 t1/t1 2 veces 1,00 0,98 1,29 t2/t1 3 veces 1,00 1,08 1,66 t3/t1 * t1 = tiempo de generación para un radio de splat de 0,5 unidades * t2 = tiempo de generación para un radio de splat de 1,0 unidades * t3 = tiempo de generación para un radio de splat de 1,5 unidades Tabla 5. Incidencia del trazado de fotones y fase de Photon Splatting (radio del splat = 1,25). Fotones generados Tiempo total de generación de un cuadro (seg.) % de tiempo consumido por la fase de trazado de fotones % del tiempo consumido por la fase de Photon Splatting 1024 6.81 40,82 2,90 4096 6.89 40,07 3,92 16384 7.42 40,16 8,33 65535 9.42 39,28 17,72 262144 16.92 42,90 32,56 68 En la tabla 5 se puede observar que las de fases de trazado de fotones y de Photon Splatting tienen una incidencia importante en el proceso de generación. Especialmente para el caso correspondiente a 262144 fotones generados (ver figura 7.2) donde la calidad de la imagen obtenida comienza a ser aceptable y ambas fases consumen casi del 75% del tiempo. Figura 7.2: Imagen generada con 512x512 píxeles, radio del splat =1,25 y 262144 fotones generados. Tabla 6. Porcentaje del tiempo utilizado por la GPU. Fotones generados Tiempo total de generación de un cuadro (seg.) % de tiempo de utilización de la GPU 1024 5,56 29,94 4096 5,62 30,70 16384 6,48 36,72 65535 9,59 48,42 262144 20,32 62,89 69 En la tabla 6 se puede observar cuál es el porcentaje del tiempo utilizado por la GPU durante el proceso de generación de la imagen en función de la cantidad de fotones generados. Estas mediciones fueron realizadas sobre la misma escena de las pruebas anteriores, utilizando una resolución de imagen de salida de 512x512 píxeles y un radio de splat de 1,5. Se podría decir que el tiempo de uso de la GPU crece en proporción al tamaño del problema a resolver ya que es dependiente de las dimensiones de los streams a procesar. En cambio, el rol de la CPU está mas relacionado a tareas de gestión de los recursos como: la transferencia de datos entre la memoria principal y la GPU, la compilación de los programas Cg, la gestión de los buffers, la ejecución de la API OpenGL y la administración de los recursos del hardware gráfico. Al incrementar la cantidad de fotones el tiempo de uso de la GPU adquiere mayor protagonismo. Es por esto que casos de mayor complejidad (más resolución de la imagen de salida, más cantidad de fotones, o mayor radio de splat) se resuelven de modo mas eficiente al consumir proporcionalmente menos tiempo en preparación y mas tiempo en la ejecución de los kernels en el procesador de fragmentos. 7.3 Imágenes A continuación se presentan diversas imágenes generadas con la aplicación implementada para evaluar el aspecto cualitativo de los resultados obtenidos. En la figura 7.3 se presenta dos ejemplos que incorporan materiales reflectivos. En 7.3a se puede notar el efecto de enfoque de fotones producido por la superficie espejada sobre el piso de la escena. En 7.3b se puede observar el efecto de sombra producido sobre el rincón trasero derecho, que es la suma las sombras “duras” generadas en la fase de Ray Tracing (por rayos de sombras) y las sombras suaves producto de la iluminación indirecta. (a) (b) Figura 7.3: Modelo “Cornell Box” con objetos reflectivos. 70 En la figura 7.4 se presentan imágenes de la misma escena utiliza en el punto 7.2 con sus componentes de iluminación separadas (7.4a y 7.4b). En la figura 7.4c se observan los puntos sobre las superficies en donde los fotones fueron absorbidos. Figura 7.4: (a) Componentes de iluminación ambiente + directa + sombras. (b) Componente de iluminación indirecta. (c) Distribución de los fotones. (d) Solución completa. En la figura 7.5a se puede apreciar el modo en que es afectada la iluminación en el piso de caja debido a los 2 tabiques verticales. Dichos tabiques tienen asociados materiales puramente difusos que desvían gran parte de los fotones de la fuente hacia el piso, excepto en la separación central en donde los fotones pasan al otro lado. En la figura 7.5b se observa un defecto en la iluminación indirecta propio de la técnica de Photon Mapping. En el borde inferior de la superficie rectangular ubicada en 71 el centro, algunos splats atraviesan la superficie filtrando luz por debajo e iluminando una zona del piso que debería estar oscura. (a) (b) Figura 7.5: Efectos de la iluminación indirecta. La figura 7.6 corresponde a una escena que incluye una esfera espejada con un índice de reflectividad (reflectK) de 0,3. Las tres imágenes corresponden a tres orientaciones diferentes de la fuente de luz (señalada con el vector en color verde). En esta figura se observa claramente el efecto conocido como “color bleeding” en donde los fotones “capturan” el color de las superficies sobre las que se reflejan. En la figura 7.6a es notorio el cambio de coloración de la escena hacia los rojos debido a que la mayoría de los fotones impactan en la pared izquierda. Por el contrario en la figura 7.6c la escena se tiñe de tonos azules. (a) (b) (c) Figura 7.6: Escena generada con 262144 fotones y un radio de splat = 1,0. (a) Fuente de luz orientada 45º a izquierda de la normal. (b) Fuente de luz orientada hacia abajo (c) Fuente de luz o orientada 45º a derecha de la normal 72 En la figura 7.7 se pueden comparar los resultados obtenidos al utilizar una función patrón gaussiana o una función constante, utilizando 65536 fotones. (a) (b) Figura 7.7: Comparación de tipos de funciones patrón. (a) Imagen generada con un filtro gaussiano. (b) Imagen generada con un filtro constante. En la figura 7.8, se observan dos imágenes sintetizadas a partir de la misma escena. En 7.8a se desactivó el cómputo de rayos secundarios, por lo tanto el material reflectivo se observa opaco. En 7.8b se ve el cómputo de la solución incluyendo rayos secundarios. (a) (b) Figura 7.8: Componente de inter-reflexión especular. (a) Imagen sin computar rayos secundarios. (b) Imagen con rayos secundarios. 73 Capítulo 8 - Conclusiones En este trabajo de tesis se presentaron diferentes técnicas de iluminación global para la síntesis de imágenes a partir de una escena 3D. Se definió un caso de estudio en base al método de Photon Mapping y el uso de los recursos de cómputo de una GPU. Con la aplicación desarrollada, se han logrado tiempos de rendering aptos para implementar aplicaciones interactivas. Es esperable que al ejecutar la misma aplicación, sobre hardware gráfico más moderno, sea capaz de sintetizar imágenes en tiempos aptos para aplicaciones de tiempo real, o que también sea capaz de obtener soluciones más precisas (mayor resolución de imagen o mayor cantidad de fotones) en igual tiempo de cómputo que en la plataforma utilizada en este proyecto. A partir de las mediciones realizadas en el punto 7.2 se puede concluir que la aplicación implementada resulta escalable respecto de los tres parámetros evaluados. La rápida evolución tecnológica de las GPUs, impone cambios en la forma de programar aplicaciones gráficas, que muchas veces obligan a rediseñarlas en forma completa para aprovechar al máximo el potencial de las nuevas generaciones. Al momento de concluir este proyecto (segundo semestre de 2007), NVIDIA presentó una nueva arquitectura de cómputo denominada CUDA (Compute Unified Device Architecture) que permitiría reescribir la implementación aquí presentada de manera mucho mas sencilla. Está nueva arquitectura permite aprovechar el poder de cómputo de la GPU para aplicaciones de propósito general mediante mecanismos mas simples. Es posible escribir los programas (los kernels del modelo de Stream Programming) directamente en lenguaje C estándar sin necesidad de utilizar la API gráfica como OpenGL o DirectX, evitando así definir explícitamente mecanismos de traducción de las estructuras de datos en texturas y las dificultades que se presentan a la hora de depurar el código. 8.1 Trabajos Futuros Respecto de las líneas de trabajo a seguir, sería recomendable comenzar por optimizar la fase de Photon Splatting. Ya que de las mediciones presentadas en la tabla 5, surge que dicha etapa tiene una incidencia importante en el costo total de cómputo. A tal fin, un camino sería evaluar el uso de otras primitivas geométricas para proyectar los splats sobre la textura de irradiancia. Concretamente, se plantea analizar si el uso de primitivas como puntos (GL_POINT) o rectángulos (GL_RECTANGLE) producen un ahorro en la cantidad de fragmentos evaluados en el proceso. Esto se sustenta en el hecho de que la forma circular de las funciones patrón se adapta de manera mas ajustada al contorno de la primitiva, generando una menor área donde la función filtro es nula (los puntos ubicados a una distancia mayor al radio del filtro). Otro punto a explorar sería la posibilidad de implementar los preprocesos que generan la estructura de aceleración BVH en la GPU. Dado que en este proyecto se trabajó sobre escenas estáticas, el costo computacional de esta etapa en la CPU no fue relevante. Pero ante la necesidad de diseñar un motor mas general, en donde las escenas se modifican a lo largo del tiempo, sería necesario reconstruir la estructura múltiples veces y allí es donde la incidencia de esta etapa cobraría mayor relevancia. Respecto de la API 3D en la que se basa la aplicación desarrollada (en este caso fue OpenGL), resultaría importante analizar las ventajas de utilizar la API de DirectX, para mejorar el desempeño. Específicamente, existe una funcionalidad de la GPU que podría resultar útil para optimizar el proceso de Photon Splatting, denominada “instanciación 74 de geometría” (geometry instancing). Esta funcionalidad, que no está disponible actualmente en la API de OpenGL, permite clonar elementos geométricos ya cargados a la memoria de la GPU. Para este proyecto podría ser utilizado para generar las múltiples instancias de los splats, en lugar de hacerlo desde la aplicación corriendo en la CPU. Otro aspecto a mejorar, está relacionado al aprovechamiento de los tiempos de cómputo ociosos de la CPU y la GPU respectivamente. Sería conveniente estudiar si es posible aprovechar el tiempo de cómputo de la CPU mientras la GPU está computando kernels. Quizás esto se pueda lograr mediante el uso de múltiples hilos (multi-threads) de ejecución en la aplicación C++ que se corran en forma asincrónica respecto de los procesos de la GPU. Un próximo paso a desarrollar a partir de este proyecto sería el diseño de un motor de Photon Mapping de tiempo real capaz de generar de secuencias de imágenes que conformen una animación. En ese caso habría que incorporar las ideas presentadas por Jozwowski [27], que plantea formas de reutilizar cómputos entre cuadros sucesivos aprovechando similitudes en las condiciones de iluminación. Concretamente platea que los fotones trazados pueden ser almacenados y reutilizados en cuadros sucesivos y asignándoles un atributo que mide su edad, conservarlos hasta que el cambio en las condiciones de iluminación justifique reemitirlos. De esta manera se reduce la cantidad total de fotones a trazar en cada cuadro, haciendo factible la generación de cuadros en fracciones de segundos. Otro tema central a indagar, es la posibilidad de realizar el proceso completo de Photon Splatting en la GPU. Como se mencionó en el capítulo 6 debido a la imposibilidad de direccionar aleatoriamente la memoria de la GPU para escritura desde un programa de fragmentos, es necesario transferir los datos de los splats a la CPU para luego proyectarlos sobre el plano de vista. Es esperable que futuras generaciones de GPUs provean mecanismos mas generales de direccionamiento y así evitar el costo innecesario de transferencia de datos entre la CPU y la GPU, el cual resulto ser particularmente alto debido al bajo ancho de banda de bus de datos AGP utilizado en este proyecto. Desde el punto de vista de la plataforma, existen actualmente tecnologías que permiten instalar multiples GPUs en una misma PC , mediante la tecnología de NVIDIA denominada SLI (Scalable Link Interface), sería interesante analizar que modificaciones serían necesarias realizar sobre la implementación para aprovechar la capacidad de este tipo de arquitecturas. Respecto del método de Photon Mapping aquí implementado existen muchos aspectos a ser mejorados a fin de implementar tipos de efectos de iluminación más complejos como los de refracción, caustics o el cómputo de la iluminación indirecta producto de inter-reflexiones en superficies del tipo “glossy” donde la dirección en la que impacta el fotón debe ser tenida en cuenta, a diferencia de las superficies difusas donde la radiancia reflejada se distribuye en forma uniforme en todas las direcciones. 75 A Publicaciones • Federico Marino y Horacio Abbate, “Implementación de Photon Mapping en hardware gráfico programable”. En AST (Simposio Argentino de Informática), como parte de las 36º Jornadas Argentinas de Informática. Agosto de 2007. • Federico Marino y Horacio Abbate, “Stream Programming Framework for Global Illumination Techniques Using a GPU”. En CACIC 2007 (Congreso Argentino de Ciencias de la Computación). Octubre de 2007. 76 B Código Fuente A continuación se incluye el código fuente de los kernels principales utilizados en la implementación, escritos en lenguaje Cg. Ray.cg #ifndef RAY_CG #define RAY_CG struct ray { float3 o; float3 d; }; float3 evaluate(in ray r, in float module) { return r.o + module*r.d; } #endif Photon.cg #ifndef PHOTON_CG #define PHOTON_CG struct photon { float3 o; float3 d; float power; }; #endif Common.cg #ifndef COMMON_CG #define COMMON_CG #define #define #define #define #define STATE_ABSORBED (-3) STATE_DONT_TRACE (-2) STATE_TRAV_SETUP (-1) STATE_SHADE (3) STATE_BACKGROUND (5) #define INF (999999999) const float infinity=9999999.9f; int index3dto1d(in float3 voxel_idx_3d) { int r=(floor(voxel_idx_3d.z)*gridCount*gridCount)+ (floor(voxel_idx_3d.y)*gridCount)+ floor(voxel_idx_3d.x); return r; } int3 index1d3d(in int voxel_idx_1d) { 77 int3 result; result.z = voxel_idx_1d/(gridCount*gridCount); voxel_idx_1d-=result.z * gridCount*gridCount; result.y = voxel_idx_1d/gridCount; voxel_idx_1d-=result.y*gridCount; result.x = voxel_idx_1d; return result; } float2 getAddress( in int idx, in int width) { return float2(0.25+fmod(float(idx),float(width)), idx/width); } void copyState(in float2 idx : TEXCOORD0, uniform samplerRECT states,out float4 state : COLOR0) { state = texRECT(states,idx); } #endif Random.cg uniform samplerRECT random; uniform float randomTex_width; uniform float global_rnd_seed; float2 randomgen(float2 seed){ float2 OUT=texRECT(random, seed*randomTex_width).xy; return OUT; } Generator.cg #include "photon.cg" #include "common.cg" #include "random.cg" // frustum atributes uniform int frustumSize; uniform float3 frustumOrigin; uniform float frustumLeft,frustumRight,frustumTop, frustumBottom,frustumNear; uniform float maxAngle; uniform float3 frustumUpVec,frustumNormalVec; //up and normal vector void generateEyeRay(in float2 photonIndex:TEXCOORD0, out float3 origin:COLOR0, out float3 direction:COLOR1, out float4 state:COLOR2) { const float scale=10; float3 frustumRightVec = cross(frustumUpVec,frustumNormalVec); float2 uv0 = float2(scale*frustumLeft,scale*frustumBottom); float2 uv1 = float2(scale*frustumRight,scale*frustumTop); float near = scale*frustumNear; //Vectors along the U and V axis of the cone, float3 a = (uv1.x - uv0.x)*frustumRightVec; 78 float3 b = (uv1.y - uv0.y)*frustumUpVec; //Vector from the frustum to the lower left point float3 c = frustumOrigin+uv0.x*frustumRightVec + uv0.y*frustumUpVec + near*frustumNormalVec; float2 hituv = float2(photonIndex.x/frustumSize, photonIndex.y/frustumSize); float3 hit = hituv.x * a + hituv.y * b + c; origin = frustumOrigin; // Photon origin direction = normalize(hit - frustumOrigin); // Photon direction // Photon state.x = state.y = state.z = state.w = state vector STATE_TRAV_SETUP; infinity; 0; 0; //state //last isect value //current voxel //current triangle } float3 generateRandomDirection(float3 normal,float3 u, float2 random){ float3 OUT; float3 v=cross(normal,u); float alfa=acos(sqrt(random.x))*(maxAngle/90.0f); float beta=random.y*radians(360.0); OUT=(normal*cos(alfa))+(u*sin(alfa)*sin(beta))+(v*sin(alfa)*cos(beta)); return OUT; } void generatePhoton(in float2 photonIndex:TEXCOORD0, out float3 origin:COLOR0, out float3 direction:COLOR1, out float4 state:COLOR2, out float3 color:COLOR3) { origin = frustumOrigin; // Photon origin float2 seed=float2(photonIndex.x/frustumSize,photonIndex.y/frustumSize); direction = normalize(generateRandomDirection(frustumNormalVec, frustumUpVec,randomgen(seed))); // Photon state vector state.x = STATE_TRAV_SETUP; //state state.y = infinity; //last isect value state.z = 0; //current voxel state.w = 0; //current triangle color=float3(1,1,1); } Bvh.cg #define #define #define #define #define #define STATE_ABSORBED (-3) STATE_DONT_TRACE (-2) STATE_TRAV_SETUP (-1) STATE_TRAV (0) STATE_SHADE (3) STATE_BACKGROUND (5) const float infinity=9999999.9f ; float4 ReadIndex(samplerRECT data, float index, float width) { 79 float2 index2D=float2(0.25+fmod(float(index),float(width)),index/width); return texRECT(data,index2D); } // Used for ray/triangle intersection testing. float4 Intersects(float3 a, float3 b, float3 c, float3 o, float3 d,float minT, float vertexIndex, float4 lasthit) { float3 e1 = b - a; float3 e2 = c - a; float3 p = cross(d, e2); float det = dot(p, e1); bool isHit = det > 0.00001f; //the triangle is nearly edge-on float invdet = 1.0f / det; float3 tvec = o - a; float u = dot(p, tvec) * invdet; float3 q = cross(tvec, e1); float v = dot(q, d) * invdet; float t = dot(q, e2) * invdet; isHit = (u >= 0.0f) && (v >= 0.0f) && (u + v <= 1.0f) && t >= 0.0f)&& (t < lasthit.z) && (t > minT); float4 retVal; if (isHit) retVal= float4(u, v, t, vertexIndex); else retVal=lasthit; return retVal; } // Checks for intersection between a ray and a box. bool BoxIntersects(float3 box_min, float3 box_max, float3 o,float3 d, float4 bestHit, float tMin) { float3 tmin, tmax; tmin = (box_min - o) / d; tmax = (box_max - o) / d; float3 real_min = min(tmin, tmax); float3 real_max = max(tmin, tmax); float minmax = min(min(real_max.x, real_max.y), real_max.z); float maxmin = max(max(real_min.x, real_min.y), real_min.z); bool res = minmax >= maxmin; return res && bestHit.z >= maxmin && tMin < minmax; } //this is the type for the output of the main program struct fragment_out { half4 bestHit : COLOR0; //best hit so far half4 renderState : COLOR1; //records how far we are }; // the main ray/scene intersection/traversal program (kernel). // returns the best hit so far and the index to the next element fragment_out multipass_main ( float2 streampos : TEXCOORD0,//texcoord to ray and best hit uniform samplerRECT bvhArray, uniform samplerRECT v0, uniform samplerRECT v1, uniform samplerRECT v2, uniform float vertexListTexWidth, uniform samplerRECT bboxMin, uniform samplerRECT bboxMax, uniform float bboxTexWidth, uniform samplerRECT origins, //a list of ray origins uniform samplerRECT directions, //a list of ray directions 80 uniform uniform uniform uniform uniform samplerRECT bestHits, //the best hits found so far samplerRECT renderStates, //records how far in the traversal float bvhArrayTexWidth, //the width of the geometry texture float maxIndex, //maximum legal index in geometry texture float looplimit //maximum number of allowed loops) { float4 renderState = texRECT(renderStates, streampos); float datapos = renderState.x; if (datapos > maxIndex) discard; //find the ray and the previously best hit float3 origin = texRECT(origins, streampos).xyz; float3 direction = texRECT(directions, streampos).xyz; float4 bestHit = texRECT(bestHits, streampos); int loopcount = looplimit; while (loopcount > 0 && renderState.x <= maxIndex) { half3 bvhData=ReadIndex(bvhArray,datapos,bvhArrayTexWidth); if (bvhData.x == 0) // current element is a bbox { half3 boxMinData=ReadIndex(bboxMin,bvhData.y,bboxTexWidth); half3 boxMaxData=ReadIndex(bboxMax,bvhData.y,bboxTexWidth); if (BoxIntersects(bboxMinData, bboxMaxData, origin, direction, bestHit, 0.0f)){ // advance to next record in BVH traversal Array renderState.x += 1; } else { // no bbox intersection use escape_code renderState.x =bvhData.z; } } else //current element is a triangle { half3 v0Data=ReadIndex(v0,bvhData.y,vertexListTexWidth); half3 v1Data=ReadIndex(v1,bvhData.y,vertexListTexWidth); half3 v2Data=ReadIndex(v2,bvhData.y,vertexListTexWidth); bestHit = Intersects(v0Data,v1Data,v2Data, origin.xyz, direction.xyz, 0.0,bvhData.y, bestHit); // advance to next record in BVH traversal Array renderState.x += 1; } datapos = renderState.x; loopcount--; } fragment_out result; result.bestHit = bestHit; result.renderState = renderState; return result; } void getStatesAndIsectData(in float2 pos : TEXCOORD0, uniform samplerRECT bestHits, uniform samplerRECT renderStates, uniform float vertexListTexWidth, out float4 outStates:COLOR0, out float4 outIsectData:COLOR1 ) { half4 renderState = texRECT(renderStates, pos); half4 bestHit = texRECT(bestHits, pos); 81 float4 states=float4(0,0,0,0); if ((renderState.x<0) || (renderState.x==(half)infinity)){ states.x=STATE_DONT_TRACE;// DON'T TRACE } else if (bestHit.w<0) { states.x=STATE_BACKGROUND; // Background states.y=infinity; } else { states.x=STATE_SHADE; // SHADE states.y=bestHit.z; } float4 isectData=float4(0,0,0,0); isectData.xy=bestHit.xy; float2 index2D=float2(0.25+fmod(float(bestHit.w), float(vertexListTexWidth)),bestHit.w/vertexListTexWidth); isectData.zw=index2D; outIsectData=isectData; outStates=states; } // is used as output by the initialization kernel. struct setup_out { half4 bestHit : COLOR0; half4 renderState : COLOR1; }; // Initialization kernel. Sets up empty intersection records and // traversal positions start at index 0. setup_out setup(in float2 tc : TEXCOORD0, uniform samplerRECT initialRenderStates) { setup_out result; half initialState = (half)texRECT(initialRenderStates, tc).x; result.bestHit = half4(0, 0, infinity, -1); //"no hit" half x=0.0; if ((initialState!=STATE_TRAV_SETUP)) x=(half)infinity; result.renderState = half4(x, 1.0f, 1.0f, 1.0f); return result; } PhotonSplatVp.cg struct appdata { float4 position : POSITION; float4 coord0 : TEXCOORD0; }; struct vfconn { float4 pos : POSITION; float2 coord0 : TEXCOORD0; }; 82 vfconn photonSplat(appdata IN, uniform float4x4 ModelViewProjMatrix) { vfconn OUT; OUT.pos = mul(ModelViewProjMatrix, IN.position); OUT.coord0=IN.coord0; return OUT; } PhotonSplatFp.cg uniform uniform uniform uniform uniform uniform uniform float photonObjectId; float3 photonNormal; float3 photonIrradiance; sampler2D splat; samplerRECT irradiances; samplerRECT surfNormals; samplerRECT surfDatas; void photonSplat(in float2 pos:TEXCOORD0, in float2 uv0:WPOS, out half4 color:COLOR0 ) { color = texRECT(irradiances, uv0.xy); float4 surfdata = texRECT(surfDatas, uv0.xy); float3 surfnormal = texRECT(surfNormals, uv0.xy).xyz; half3 splatColor; if ((surfdata.x==photonObjectId) && (dot(surfnormal,photonNormal)>0.75)){ splatColor=photonIrradiance*tex2D(splat, pos).x; } else { discard; } color=color+half4(splatColor.r,splatColor.g,splatColor.b,1); } PhotonsReflector.cg uniform samplerRECT uniform samplerRECT uniform samplerRECT uniform samplerRECT uniform samplerRECT // geometry data origins; directions; colors; states; isectdatas; //ray origins //ray directions uniform samplerRECT v0; uniform samplerRECT v1; uniform samplerRECT v2; uniform samplerRECT n0; uniform samplerRECT n1; uniform samplerRECT n2; uniform samplerRECT matColors; uniform samplerRECT matAttribs; 83 uniform float bouncenum; #include "ray.cg" #include "common.cg" #include "random.cg" float3 lert(float3 a, float3 b, float3 c, float u, float v) { return a + u*(b - a) + v*(c-a); } float3 diffuseReflection(float3 normal,float3 u, float2 random){ float3 OUT; float3 v=cross(normal,u); float alfa=acos(sqrt(random.x)); float beta=random.y*radians(360.0); OUT=(normal*cos(alfa))+(u*sin(alfa)*sin(beta))+(v*sin(alfa)*cos(beta)); return OUT; } void photonsReflector(in float2 rayIndex:TEXCOORD0, out float3 outrayOrig:COLOR0, out float3 outrayDirec:COLOR1, out float4 outrayState:COLOR2, out float3 outrayColor:COLOR3) { float3 float3 float4 float3 float4 inrayOrig= texRECT(origins, rayIndex).xyz; inrayDirec= texRECT(directions, rayIndex).xyz; inrayState= texRECT(states, rayIndex).xyzw; inrayColor= texRECT(colors, rayIndex).xyz; inrayIsectData= texRECT(isectdatas, rayIndex); outrayOrig=float3(0,0,0); outrayDirec=float3(0,0,0); outrayState=float4(0,0,0,0); outrayColor=float3(0,0,0); float2 triangleIndex = inrayIsectData.zw; float4 matattribs = texRECT(matAttribs, triangleIndex); float3 matColor = texRECT(matColors, triangleIndex).xyz; if (inrayState.x == STATE_SHADE) { float float float float float diffuseK=matattribs.x; specularK=matattribs.y; reflectK=matattribs.z; smoothing=matattribs.w; rangoRandomMax; outrayColor=float3(inrayColor.x*(matColor.x/255.0), inrayColor.y*(matColor.y/255.0), inrayColor.z*(matColor.z/255.0)); if (bouncenum==0) rangoRandomMax=diffuseK+specularK; else rangoRandomMax=1; float event=randomgen(inrayIsectData.yx).y*rangoRandomMax; if (event<(diffuseK+specularK)){// reflexión difusa o especular 84 // Photon should float3 vertex0 = float3 vertex1 = float3 vertex2 = be reflected texRECT(v0, triangleIndex).xyz; texRECT(v1, triangleIndex).xyz; texRECT(v2, triangleIndex).xyz; //Fetch normal float3 normal0 = texRECT(n0, triangleIndex).xyz; float3 normal1 = texRECT(n1, triangleIndex).xyz; float3 normal2 = texRECT(n2, triangleIndex).xyz; //calculate hit point ray r; r.o = inrayOrig; r.d = inrayDirec; float3 hitpoint = evaluate(r,inrayState.y); //Calculate normal float ucoord=inrayIsectData.x; float vcoord=inrayIsectData.y; if (smoothing<1.0) { ucoord=0.5; vcoord=0.5; } float3 normal = normalize(lert(normal0, normal1, normal2,ucoord,vcoord));// surface normal float3 u=normalize(vertex0-vertex2); if (event<specularK) // Photon is speculary reflected outrayDirec=reflect(inrayDirec,normal); else // Photon is diffusely reflected outrayDirec=diffuseReflection(normal,u, randomgen(inrayIsectData.xy)); // sumo para evitar auto intersección outrayOrig=hitpoint+normalize(outrayDirec)*0.01f; outrayState.x=STATE_TRAV_SETUP; outrayState.y=INF; } else {// Photon is absorbed outrayState=inrayState; outrayState.x=STATE_ABSORBED; } } else if (inrayState.x == STATE_BACKGROUND || inrayState.x == STATE_DONT_TRACE || inrayState.x == STATE_ABSORBED ) { outrayState=inrayState; } else { outrayState.x=-99; // error } } 85 PhotonsProjector.cg uniform uniform uniform uniform samplerRECT samplerRECT samplerRECT samplerRECT origins; directions; states; colors; uniform samplerRECT isectdatas; uniform samplerRECT n0; uniform samplerRECT n1; uniform samplerRECT n2; uniform samplerRECT matColors; uniform samplerRECT matAttribs; uniform float3 frustumOrigin; float photonPower; uniform float hParam; uniform float iParam; uniform float splatArea; #include "ray.cg" #include "common.cg" float3 lert(float3 a, float3 b, float3 c, float u, float v) { return a + u*(b - a) + v*(c-a); } void projector(in float2 rayIndex:TEXCOORD0, out float4 data1:COLOR0, out float4 data2:COLOR1, out float4 data3:COLOR2, out float4 data4:COLOR3) { const float3 zAxis=float3(0,0,1); float4 state = texRECT(states, rayIndex).xyzw; float3 photonColor = texRECT(colors, rayIndex); data1=float4(0,0,0,-1); data2=float4(0,0,0,0); data3=float4(0,0,0,0); data4=float4(0,0,0,0); if (state.x == STATE_ABSORBED) { float4 isectdata = texRECT(isectdatas, rayIndex); float2 triangleIndex =isectdata.zw; float4 matAttrib = texRECT(matAttribs, triangleIndex); float4 matColor = texRECT(matColors, triangleIndex); // Hit Point POSITION ray r; r.o = texRECT(origins, rayIndex).xyz; r.d = texRECT(directions, rayIndex).xyz; // get a vector with "r" direction , "o" origin and state.y float3 hitPosition = evaluate(r,state.y); // Hit Point SURFACE NORMAL float3 normal0 = texRECT(n0, triangleIndex).xyz; float3 normal1 = texRECT(n1, triangleIndex).xyz; float3 normal2 = texRECT(n2, triangleIndex).xyz; 86 float3 normal = normalize(lert(normal0, normal1, normal2,isectdata.x,isectdata.y)); // Irradiance float3 irradiance=photonColor*max(dot(normal, -normalize(r.d))*(photonPower/splatArea),0); // Splat Triangle Vertex float3 u,v; if (abs(dot(normal,zAxis))<1.0) u=cross(zAxis,normal); else u=float3(1,0,0); v=normalize(cross(normal,u)); float4 vertexA; float4 vertexB; float4 vertexC; vertexA.xyz=hitPosition-hParam*(u+v); vertexB.xyz=hitPosition+iParam*u-hParam*v; vertexC.xyz=hitPosition+iParam*v-hParam*u; data1.xyz=vertexA.xyz; data2.xyz=vertexB.xyz; data3.xyz=vertexC.xyz; data4.xyz=normal; data1.w=matColor.w; // OBJECT ID data2.w=irradiance.r; // irradiance RED data3.w=irradiance.g; data4.w=irradiance.b; //data1.w=-1; } else { data1=float4(0,0,0,0); data2=float4(0,0,0,0); data3=float4(0,0,0,0); data4=float4(0,0,0,0); } } Shader.cg uniform int viewSize; uniform float colorscale; uniform int specularBounce; uniform uniform uniform uniform float3 lightOrigin; float3 lightUpVec,lightNormalVec; float maxAngle; float minAngleRatio; uniform uniform uniform uniform uniform samplerRECT samplerRECT samplerRECT samplerRECT samplerRECT uniform uniform uniform uniform samplerRECT v0; samplerRECT v1; samplerRECT v2; int vertexListSize; origins; directions; states; isectdatas; photonhits; uniform samplerRECT n0; 87 uniform uniform uniform uniform samplerRECT samplerRECT samplerRECT samplerRECT n1; n2; matColors; matAttribs; uniform samplerRECT photonmapNormals; uniform samplerRECT irradiance; uniform samplerRECT shadows; uniform uniform uniform uniform float float float float addAmbientIlum; addDirectIlum; addIndirectIlum; addShadows; #include "ray.cg" #include "common.cg" float3 lert(float3 a, float3 b, float3 c, float u, float v) { return a + u*(b - a) + v*(c-a); } const float ambientK=0.15; const float glossiness=15.0; void shader(in float2 rayIndex:TEXCOORD0, out float4 color:COLOR0) { const float minLightLevel=0; float3 origin = texRECT(origins, rayIndex).xyz; float3 direction = texRECT(directions, rayIndex).xyz; float4 state = texRECT(states, rayIndex).xyzw; float4 isectdata = texRECT(isectdatas, rayIndex); float4 photonhit = texRECT(photonhits, rayIndex); float4 shadow = texRECT(shadows, rayIndex); half3 irrad = texRECT(irradiance, rayIndex).xyz; color = float4(0,0,0,1); float3 lightLeftVec = cross(lightUpVec,lightNormalVec); if (state.x == STATE_SHADE) { float2 triangleIndex = isectdata.zw; //Fetch normal half3 normal0 = texRECT(n0, triangleIndex).xyz; half3 normal1 = texRECT(n1, triangleIndex).xyz; half3 normal2 = texRECT(n2, triangleIndex).xyz; //Fetch material color half3 matColor = texRECT(matColors, triangleIndex).xyz; half4 matAttrib = texRECT(matAttribs, triangleIndex); half half half half bool diffuseK=matAttrib.x; // prob. of diffuse reflection specularK=matAttrib.y; // prob. of specular reflection reflectK=matAttrib.z; smoothing=fmod(matAttrib.w,128); selfilum=(matAttrib.w>=128); //calculate hit point ray r; r.o = texRECT(origins, rayIndex).xyz; r.d = texRECT(directions, rayIndex).xyz; float3 hit = evaluate(r,state.y); float3 lightVec = lightOrigin-hit; 88 float3 lightVecN = normalize(lightVec); // project light-hitpoint vector into light coordinates system float lx=dot(lightLeftVec,lightVecN); float ly=dot(lightUpVec,lightVecN); float lz=dot(lightNormalVec,lightVecN); float lightDistance=length(lightVec); float alfa=degrees(atan2(sqrt(lx*lx+ly*ly),-lz)); float lightPower=minLightLevel; if ((alfa<maxAngle) && (lz<0)) lightPower=(minLightLevel+smoothstep(maxAngle, maxAngle*0.8,alfa)*(1-inLightLevel)); float attenuation=1/(1+0.01*lightDistance*lightDistance); lightPower=lightPower*min(1,attenuation); //Calculate normal float ucoord=isectdata.x; float vcoord=isectdata.y; if (smoothing<1.0) {ucoord=0.5; vcoord=0.5;} // surface normal float3 normal = normalize(lert(normal0, normal1, normal2,ucoord,vcoord)); float3 halfVec = normalize(lightVecN - direction); float3 ambient=ambientK*matColor/255; // Ambient component // Diffuse component float noshadow=1; if ((addShadows==1.0) && (shadow.y+0.1<lightDistance)) noshadow=0; float d=dot(normal,lightVecN); float3 directDiffuse=noshadow*diffuseK*max(d,0)*(matColor/255)* lightPower*attenuation; //Specular component float3 directSpecular=float3(0,0,0); float s=dot(normal, halfVec); if ((s>0.0001) && (d>0)) directSpecular=noshadow*specularK*(max(0,pow(s,glossiness)) * lightPower*attenuation)*float3(1,1,1); // Indirect component float3 indirect=(matColor/255)*(irrad*0.1); if (selfilum){ color.xyz=matColor/255;color.w=1; } else{ color.xyz=colorscale*(addAmbientIlum*ambient+ addDirectIlum*(directDiffuse+directSpecular) +addIndirectIlum*(indirect)); color.w=max(0,1-reflectK); } } else if (state.x == STATE_BACKGROUND) { color = float4(0,0,0,1); } else if (state.x == STATE_DONT_TRACE) { color = float4(0,0,0,0); } else 89 { discard; } } ShadowsGenerator.cg uniform samplerRECT origins; //Texture of ray origins uniform samplerRECT directions; //Texture of ray directions uniform samplerRECT states; //State vector uniform float3 lightOrigin; #include "ray.cg" #include "common.cg" void shadowsGenerator(in float2 rayIndex:TEXCOORD0, out float3 outrayOrig:COLOR0, out float3 outrayDirec:COLOR1, out float4 outrayState:COLOR2) { float3 inrayOrig= texRECT(origins, rayIndex).xyz; float3 inrayDirec= texRECT(directions, rayIndex).xyz; float4 inrayState= texRECT(states, rayIndex).xyzw; outrayOrig=float3(0,0,0); outrayDirec=float3(0,0,0); outrayState=float4(0,0,0,0); if (inrayState.x == STATE_SHADE) { //calculate hit point ray r; r.o = inrayOrig; r.d = inrayDirec; float3 hitpoint = evaluate(r,inrayState.y); outrayDirec=normalize(lightOrigin-hitpoint); outrayOrig=hitpoint+normalize(outrayDirec)*0.01f; outrayState.x=STATE_TRAV_SETUP; outrayState.y=INF; } else //if (inrayState.x == STATE_BACKGROUND) { outrayState.x=STATE_DONT_TRACE; } } SpecularReflectionsGenerator.cg uniform uniform uniform uniform samplerRECT samplerRECT samplerRECT samplerRECT origins; directions; states; isectdatas; uniform samplerRECT n0; uniform samplerRECT n1; 90 uniform samplerRECT n2; uniform samplerRECT matAttribs; #include "ray.cg" #include "common.cg" float3 lert(float3 a, float3 b, float3 c, float u, float v) { return a + u*(b - a) + v*(c-a); } void specularReflector(in float2 rayIndex:TEXCOORD0, out float3 outrayOrig:COLOR0, out float3 outrayDirec:COLOR1, out float4 outrayState:COLOR2) { float3 float3 float4 float4 inrayOrig= texRECT(origins, rayIndex).xyz; inrayDirec= texRECT(directions, rayIndex).xyz; inrayState= texRECT(states, rayIndex).xyzw; inrayIsectData= texRECT(isectdatas, rayIndex); outrayOrig=float3(0,0,0); outrayDirec=float3(0,0,0); outrayState=float4(0,0,0,0); if (inrayState.x == STATE_SHADE) { float2 triangleIndex = inrayIsectData.zw; float4 matattribs = texRECT(matAttribs, triangleIndex); float specularity=matattribs.y; float reflectivity=matattribs.z; float smoothing=matattribs.w; if (reflectivity>0.0){ //Fetch normal float3 normal0 = texRECT(n0, triangleIndex).xyz; float3 normal1 = texRECT(n1, triangleIndex).xyz; float3 normal2 = texRECT(n2, triangleIndex).xyz; //calculate hit point ray r; r.o = inrayOrig; r.d = inrayDirec; float3 hitpoint = evaluate(r,inrayState.y); float u=0.5; float v=0.5; if (smoothing==1.0) { u=inrayIsectData.x; v=inrayIsectData.y; } float3 normal = normalize(lert(normal0, normal1, normal2,u,v));// surface normal outrayDirec=reflect(inrayDirec,normal); // specular outrayOrig=hitpoint+normalize(outrayDirec)*0.001f; outrayState.x=STATE_TRAV_SETUP; outrayState.y=INF; outrayState.z=0; outrayState.w=0; } else { outrayState.x=STATE_DONT_TRACE; } 91 } else //if (inrayState.x == STATE_BACKGROUND) { outrayState.x=STATE_DONT_TRACE; } } SurfaceDataGenerator.cg uniform samplerRECT states; uniform samplerRECT isectdatas; uniform uniform uniform uniform uniform samplerRECT samplerRECT samplerRECT samplerRECT samplerRECT n0; n1; n2; matAttribs; matColors; #include "common.cg" float3 lert(float3 a, float3 b, float3 c, float u, float v) { return a + u*(b - a) + v*(c-a); } void surfData(in float2 rayIndex:TEXCOORD0, out half3 surfnormal:COLOR0, out half4 surfdata:COLOR1) { float4 state = texRECT(states, rayIndex).xyzw; float4 isectdata = texRECT(isectdatas, rayIndex); surfnormal=half3(0,0,0); surfdata=half4(0,0,0,0); if (state.x == STATE_SHADE) { float2 triangleIndex = isectdata.zw; //Fetch normal half3 normal0 = texRECT(n0, triangleIndex).xyz; half3 normal1 = texRECT(n1, triangleIndex).xyz; half3 normal2 = texRECT(n2, triangleIndex).xyz; //Fetch material color half4 matAttrib = texRECT(matAttribs, triangleIndex); half4 matColor = texRECT(matColors, triangleIndex); half smoothing=matAttrib.w; float u=isectdata.x; float v=isectdata.y; if (smoothing<1.0) { u=0.5; v=0.5; } half3 normal = normalize(lert(normal0, normal1, normal2,u,v)); surfnormal=normal; surfdata.x=matColor.w;// Object ID } } 92 Integrator.cg uniform samplerRECT directIlumination; uniform samplerRECT indirectIlumination; uniform samplerRECT specularReflections; uniform int addReflections; void integrator(in float2 rayIndex:TEXCOORD0,out float3 color:COLOR0) { float4 eyerays = texRECT(directIlumination, rayIndex); float4 reflections = texRECT(specularReflections, rayIndex); color=(eyerays.w)*(eyerays.xyz)+(reflections.xyz)*addReflections; } 93 Bibliografía [1] J.T. Kajiya, “The rendering equation”. In Proceedings of the 13th annual conference on Computer graphics and interactive techniques (1986), ACM Press, pp. 143–150. [2] F. E. Nicodemus, J. C. Richmond, J. J. Hsia, I.W. Ginsberg, and T. Limperis, “Geometric considerations and nomenclature for reflectance”. Monograpgh 161, National Bureau of Standards (US), October 1977. [3] Tuner Whitted. “An improved illumination for shaded display”. Communications of the ACM 23(6): 343 - 349 (June 1980). [4] John M. Snyder and Alan H. Barr, “Ray Tracing complex models containing surface tessellations”. Computer Graphics (Proc. Siggraph ’87) 21 (4): 119-128 (July 1987). [5] Kryzsztof S. Ckilmansezewski and Thomas W. Sederberg. “Faster Ray Tracing using adaptive grids”. IEEE Computer Graphics & Applications 17(1): 42-51 (January-February 1997). [6] T. J. Purcell. “Ray Tracing on a Stream Processor” PhD thesis, Stanford University, 2004. [7] Frederik W. Jansen. “Data structures for Ray Tracing”. In Data structures for Raster Graphics, edited by L.R.A. Kessener, F.J. Peters, y m. L. P. van Lierop, pp. 57-73, Berlin: Springer-Verlag, 1985. [8] T. J. Purcell, C. Donner, M. Cammarano, H. W. Jensen, and P. Hanrahan. “Photon mapping on programmable graphics hardware”. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Graphics Hardware. [9] Robert L. Cook, Thomas Porter, and Loren Carpenter. “Distributed Ray Tracing”. Computer Graphics (Proc. SIGGRAPH ’84) 18(3): 137-45 (July 1984). [10] Eric. P. Lafortune and Yves D. Willems. “Bidirectional Path Tracing”. In Compugraphics’93, pp. 95-104, 1993. [11] Eric Veach and Leonidas Guibas. “Bidirectional estimators for light transport”. In Fifth Eurographics Workshop on Rendering, pp. 147-162, Eurographics, 1994. [12] C. M. Goral, K. E. Torrance, D. P. Greenberg, and B. Battaile, “Modeling the interaction of light between diffuse surfaces”. In Proceedings of the 11th annual conference on Computer Graphics and Interactive Techniques (1984), pp. 213 – 222. 94 [13] M. F. Cohen, S. E. Chen, J. R. Wallace, and D. P. Greenberg, “A progressive refinement approach to fast Radiosity image generation”. In proceedings of the 15th annual conference on Computer graphics and interactive techniques (1988), ACM Press, pp. 75–84. [14] M. F. Cohen, and D. P. Greenberg, “The hemi-cube: a Radiosity solution for complex environments”. In Proceedings of the 12th annual conference on Computer graphics and interactive techniques (1985), ACM Press, pp. 31 – 40. [15] H. W. Jensen, “Realistic Image Synthesis using Photon Mapping”. A K Peters. ISBN 1568811470 (2001) [16] I. Wald, J. G¨unther, and P. Slusallek, “Balancing Considered Harmful – Faster Photon Mapping using the Voxel Volume Heuristic”. Computer Graphics Forum 22, 3 (2004), 595–603. (Proceedings of Eurographics). [17] G. J. Ward, F. M. Rubinstein, and R. D. Clear, “A Ray Tracing solution for diffuse interreflection”. In SIGGRAPH ’88: Proceedings of the 15th annual conference on Computer graphics and interactive techniques (New York, NY, USA, 1988), ACM Press, pp. 85–92. [18] Niels Thrane, Lars Ole Simonsen. “A Comparison of Acceleration Structures for GPU Assisted Ray Tracing”. Master’s thesis, University of Aarhus, August, 2005. [19] Framebuffer Object Extension. http://oss.sgi.com/projects/ogl-sample/registry/EXT/framebuffer_object.txt [20] W. Stürzlinger, R. Bastos, “Interactive Rendering of Globally Illuminated Glossy Scenes”. Eurographics Rendering Workshop ’97. ISBN 3-211-83001-4. (June 1997) 93-102. [21] F. Lavignotte, M. Paulin, “Scalable Photon Splatting for Global illumination”. Graphite 2003 (International Conference on Computer Graphics and Interactive Techniques in Australasia and South East Asia). Melbourne, Australia. ACM SIGGRAPH. 1-11 [22] Framebuffer Object Class http://www.gpgpu.org/developer/ [23] G. Humphreys, M. Houston, Y.-R. Ng, R. Frank, S. Ahern, P. Kirchner, and J. T. Klosowski, "Chromium: A Stream Processing Framework for Interactive Graphics on Clusters," presented at SIGGRAPH, San Antonio, Texas, 2002 [24] Greg Humphreys, Ian Buck, Matthew Eldridge, and Pat Hanrahan, “Distributed rendering for scalable displays”. In Supercomputing, 2000. 95 [25] F. Randima and Mark J. Kilgard, “The Cg Tutorial: The Definitive Guide to Programmable Real-Time Graphics”.Addison-Wesley, 1996. ISBN 0-321-19496-9 [26] James Arvo, David B. Kirk “Particle transport and image synthesis”. Computer Graphics (Proc. SIGGRAPH ’90) 24(4): 63-66 (August 1990). [27] T. R. Jozwowski, “Real Time Photon Mapping”. Master's thesis, Michigan Technological University, 2002. [28] Eric Veach and Leonidas J. Guibas, “Metropolis Light Transport”. In Proceedings of SIGGRAPH 97, Computer Graphics Proceedings, Annual Conference Series, edited by Turner Whitted, pp. 65-76, Reading, Ma: Addison Wesley, August 1997. [29] The NVIDIA Cg Toolkit. http://developer.nvidia.com/page/cg_main.html [30] Bui-Tuong Phong, “Illumination for Computer Generated Pictures”. Comm. ACM 18(6), 311-317. [31] H. Gouraud, "Continuous shading of curved surfaces". IEEE Transactions on Computers, 20(6):623–628, 1971. 96