Tesis - Dirección General de Servicios Telemáticos
Anuncio

Sistema Administrador de
números de guía de paquetería
en forma distribuida
Ing. Mario Eduardo Figueroa Verduzco
Agradecimientos
Agradezco a Dios, a mis padres y a mis hermanos porque de no ser por
ellos no seria hoy lo que soy
A mis maestros por sus enseñanzas
A mis compañeros por su amistad
A Carlos Ulibarri que de no ser por su apoyo no hubiera podido concluir
este trabajo
Resumen
Con esta tesis se presenta un prototipo capaz de automatizar eficientemente
los números de guía de la paquetería que se envía por medio de la empresa
Estafeta, manejando el concepto de bases de datos distribuidas.
En un sistema de Bases de Datos Distribuido, los datos se encuentran en
diferentes máquinas, generalmente situados en localizaciones geográficas
diferentes. Dichas máquinas pueden ser de distinto tipo atendiendo a su
tamaño, prestaciones y Sistema Operativo.
Con este prototipo se pretende: mejorar los procesos actuales de la empresa,
en cuanto al manejo de la información que se genera con los diferentes
registros de los números de guía en cada plaza del país, reducir tiempos de
espera en la actualización de la información generada por cada plaza así como
también de disponer de los registros de los números de guía de los paquetes
enviados y recibidos en las diferentes plazas al momento que se generen.
En cada plaza existirán tres programas individuales los cuales serán:
-
Programa para controlar los números de guía.
-
Programa que recibirá las solicitudes de información de las demás
plazas.
-
Programa por medio del cual se podrá hacer consultas y/o
modificaciones de las bases de datos que están almacenadas
localmente o en forma distribuida.
La implementación de éste prototipo permitiría a los administradores y
personas encargadas de atender a los clientes, saber en cualquier momento y
en cualquier plaza, donde está un paquete en especial, lo cual dará lugar a que
la información que soliciten los clientes sea la más precisa referente a la
ubicación de su paquete.
El prototipo reduciría tiempos de espera en la actualización de la información,
los encargados de los departamentos de sistemas de las diferentes plazas ya
no tendrían que esperar a que la central les envié la información actualizada de
la ubicación de los paquetes.
Abstract
This thesis presents a prototype whose purpose is to automate the
assigning and tracking of reference numbers of packages that are sent by means
of a package express company, efficiently managing the concept of distributed
databases.
In a Distributed Database System, the data are generally located in different
machines in different geographical locations. These machines can be of different
types according to their specifications and operating systems.
The purpose of this prototype is to improve the current processes of the
company with respect to handling the information that is generated by the different
reference and tracking numbers that are assigned in each company office, in order
to reduce waiting times and facilitate the actualization of information generated by
each office..
Each office requires 3 programs that will work jointly that include:
-
a program to control reference and tracking numbers
-
a program to receive information requests from other offices
-
a program to permit consultations and/or modifications of the databases that
may be stored either locally or in distributed form
The implementation of this prototype will allow to the administrators and
persons responsible for assisting clients to know at any time in any office where a
package is, particularly information the client request with respect to the specific
location of his package.
This prototype will also reduce the time needed to update information. Persons
in charge of the computer systems at the different offices would no longer have to
wait for the main office to send them up-to-date information about the location of
packages.
CONTENIDO
Pagina
Resumen
Abstract
Agradecimientos
Presentación
Objetivo General
Objetivos Particulares
Justificación
Planteamiento
Metodología
i
i
ii
iii
1. Introducción
1.1 Redes de comunicación de datos
1.2.1 LANs
1.2.2 WANs
1.2.3 Internet
1.2.4 Intranet
1.2 Bases de Datos
1.1.1 ¿ Qué es un sistema de base de datos?
1.1.2 ¿ Por qué utilizar bases de datos?
1.3 Sistemas de Bases de Datos Distribuidas
1.3.1 ¿Que es un sistema de Bases de Datos Distribuidas?
1.3.2 Ventajas de los sistemas de Bases de Datos Distribuidas
1.3.3 Desventajas de los sistemas de Bases de Datos Distribuidas
1.3.4 Objetivos de una Base de Datos Distribuida
1.3.5 Objetivos de los sistemas de Bases de Datos Distribuidas
1.3.6 Problemáticas en los sistemas administradores de Bases de
Datos Distribuidas
1.3.7 Arquitectura cliente/servidor
1.3.8 Sistema Distribuido
1.4 Visual Basic
1.4.1 Tecnología de Acceso a datos
1.4.1.1 DAO
1.4.1.2 RDO
1.4.1.3 ADO
1.4.2 Winsock de Visual Basic
2. Conceptos de diseño enfocados al desarrollo de aplicaciones distribuidas
2.1 Aspectos de diseño de programas
2.1.1 Transparencia
2.1.2 Confiabilidad
2.1.3 Escalabilidad
v
2
3
3
4
4
5
6
7
9
9
10
11
11
12
15
19
19
20
20
24
24
25
2.1.4 Flexibilidad
2.2 El Diseño de la distribución
2.2.1 Tipos de Fragmentación
2.2.1.1 Reglas de corrección de la fragmentación
2.2.1.2 Alternativas de Asignación
2.2.1.3 Información Necesaria
26
26
31
33
34
36
2.3 El diseño de distribución Bottom-Up (Ascendente)
2.3.1 Problemas de diseño en la construcción de un sistema global
2.3.2 Trabajando con los datos inconsistentes durante la operación
36
37
38
3. Contexto de la Empresa (Estafeta S.A. de C.V.)
3.1 Historia
3.2 Infraestructura
3.3 Logros
3.4 Estafeta en números
41
42
42
45
4. Análisis del funcionamiento de envíos y entregas de paquetes (situación antes
de la implementación del sistema)
4.1 Equipo con que se cuenta actualmente
47
4.2 Flujo de Información
48
4.3 Información que se obtiene por cada paquete que se envía o se entrega 52
4.4 Lista de plazas a cargo de Colima
54
4.5 Descripción de los números de guía
54
4.6 Tipos de movimientos de los paquetes
55
5. Implementación
5.1 Aspectos de diseño a considerar en la implementación del sistema
5.2 Elementos que forman el prototipo
5.2.1 Control de Números de guía (en los servidores)
5.2.2 Servidor
5.2.3 Cliente
5.3 Seguridad
5.3.1 Algoritmo UU-Encoding
5.4 Otras características del sistema
5.4.1 Replicas
5.4.2 Bloqueos
Conclusiones
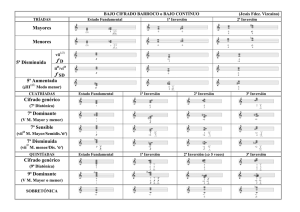
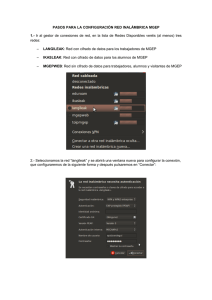
Anexo 1.- Seguridad y Cifrado de la información
Anexo 2.- Diagramas del Flujo de Información por Usuario
Bibliografía
57
59
60
63
66
79
80
84
85
87
90
105
108
Sistema administrador de números de guía
de paquetería en forma distribuida
Objetivo General
Desarrollar un prototipo capaz de automatizar eficientemente los números
de guía de la paquetería que se envía por medio de la empresa Estafeta,
manejando el concepto de bases de datos distribuidas.
Objetivos Particulares
Mejorar los procesos actuales de la empresa, en cuanto al manejo de la
información que se genera con los diferentes registros de los números de guía en
cada plaza del país.
Reducir tiempos de espera en la actualización de la información generada
por cada plaza
Disponer de los registros de los números de guía de los paquetes enviados
y recibidos en las diferentes plazas al momento en que se generen.
Justificación
La necesidad de tener la información disponible para el personal operativo de
la empresa Estafeta al momento en que se genera es de suma importancia
para una compañía con enlaces mundiales, particularmente si la información se
genera desde diferentes puntos del país.
Este prototipo evitará que se realicen procesos innecesarios (separación de
información, envió por parte de los encargados a la central, formateo de
información, etc.), lo cual reducirá tiempos en la disponibilidad de la misma
para una mejor atención hacia los clientes de la empresa, así como también
para una mejor administración por parte de los coordinadores de los diferentes
departamentos de sistemas en las diferentes regiones del país.
También permitirá que cada plaza sea la encargada de administrar la
información que se genera, evitando que se centralice el control y
administración de los procesos para el manejo de la misma.
Planteamiento
El sistema pretende tener toda la información de los números de guía
disponible al momento en que son capturados en las diferentes plazas para su
consulta. Para hacer esto, utiliza el concepto de bases de datos distribuidas.
También permite a los encargados de los diferentes departamentos de
sistemas hacer actualizaciones a la información si es necesario.
Características generales del sistema
-
El prototipo trabaja bajo el concepto de bases de datos distribuidas.
-
Existen al menos tres programas en cada plaza: un servidor, un programa
por medio del cual se van a capturar los números de guía de los paquetes,
y uno o varios clientes los cuales van a acceder a la información
almacenada y administrada por los servidores.
-
La comunicación entre los clientes y los servidores es a través de sockets.
-
Se trabaja bajo la plataforma de Windows, en cualquiera de sus versiones.
-
Se utiliza Visual Basic 6 como herramienta de desarrollo, utilizando el
control winsock para la comunicación.
-
Se manejan dos tipos de usuarios, el administrador o supervisor, el cual
puede hacer actualizaciones sobre la información ya almacenada, y los
usuarios que solo pueden hacer consultas o rastreos de los números de
guía.
-
Se maneja lo que se llama bloqueos de registros, esto evita la
inconsistencia de la información.
Metodología
I.
Investigación
bibliográfica
y
recopilación
de
información
disponible en Internet.
II.
Descripción de la tecnología de software para el desarrollo de
sistemas de bases de datos distribuidas.
III.
Seleccionar las herramientas de desarrollo de software para la
elaboración de los programas que conformaran el sistema de
bases de datos distribuidas.
IV.
Descripción de los procesos actuales que realiza la empresa
Estafeta, y en base a ellos, diseñar la base de datos, identificar
los procesos que se modifican, seleccionar un método para el
diseño del sistema de base de datos distribuidas.
V.
Elaboración del prototipo.
VI.
Conclusión y presentación de resultados.
VII.
Elaboración de material para presentación de los resultados de la
investigación.
CAPÍTULO 1
INTRODUCCIÓN
-
Redes de Computadoras
Bases de Datos
Sistemas de Bases de Datos Distribuidas
Herramientas de Desarrollo de Aplicaciones
En este capítulo se hace una revisión de los conceptos que
abarcan algunos conceptos fundamentales referentes con las
bases de datos distribuidas y con las tecnologías que se utilizan
para desarrollar el sistema que se pretende implementar.
Algunos conceptos abarcan redes de computadoras, bases
de datos, conceptos del Visual Basic como herramienta de
desarrollo seleccionada, así como también el tema principal de la
tesis que son las bases de datos distribuidas.
REDES DE COMPUTADORAS
Las redes en general, consisten en "compartir recursos", y uno de sus
objetivos es hacer que todos los programas, datos y equipo estén disponibles para
cualquiera de la red que así lo solicite, sin importar la localización física del
recurso y del usuario. En otras palabras, el hecho de que el usuario se encuentre
a 1000 kms de distancia de los datos, no debe evitar que este los pueda utilizar
como si fueran originados localmente.
Un segundo objetivo consiste en proporcionar una alta fiabilidad, al contar
con fuentes alternativas de suministro. Por ejemplo todos los archivos podrían
duplicarse en dos o tres máquinas, de tal manera que si una de ellas no se
encuentra disponible, podría utilizarse una de las otras copias. Además, la
presencia de múltiples CPU significa que si una de ellas deja de funcionar, las
otras pueden ser capaces de encargarse de su trabajo, aunque se tenga un
rendimiento global menor.
Otro objetivo es el ahorro económico. Los ordenadores pequeños tienen
una mejor relación costo / rendimiento, comparada con la ofrecida por las
máquinas grandes. Estas son, a grandes rasgos, diez veces más rápidas que el
más rápido de los microprocesadores, pero su costo es miles de veces mayor.
Este desequilibrio ha ocasionado que muchos diseñadores de sistemas
construyan sistemas constituidos por poderosos ordenadores personales, uno por
usuario, con los datos guardados una o mas máquinas que funcionan como
servidor de archivo compartido (Vela, 1999).
Local Area Networks (LANs)
Las redes de computadoras son conjuntos de maquinas independientes que
se comunican una con otra sobre un medio de red.
Redes de Area Local (Local Area Networks o LANs) son aquellas redes
usualmente confinadas a un área geográfica, tal como un edificio individual o el
Campus de una Universidad.
LANs, sin embargo, no son necesariamente simples en diseño, en la
medida que ellas pueden conectar muchos cientos de computadoras y ser
utilizadas por miles de usuarios.
El desarrollo de varios protocolos de interconexión estándar y medios de
transmisión han hecho posible la proliferación de LANs en organizaciones a nivel
mundial para aplicaciones de negocios y aplicaciones educacionales (Ender,
2001).
Wide Area Networks (WANs)
Las WANs son Redes Remotas, lo cual quiere decir que están lejos los
recursos a compartir, generalmente en otra ciudad, en otro estado o bien, en otro
país. Estas pueden ser de dos tipos. A través de una red pública como Internet,
Frame Relay o X.25 o bien a través de una red privada con enlaces telefónicos,
analógicos o digitales punto a punto. Dependiendo del ancho de banda de las
conexiones a través de estas redes puede haber transmisión de datos, voz y hasta
video (Ulternet, 1997).
Internet
Es una red de computadoras interconectadas entre si que ofrecen acceso y
comparten información a través de un lenguaje común. En la actualidad es la red
de computadoras más grandes que existe en el mundo; se conecta por teléfono (a
través de un módem) o por fibra óptica y transmite toda clase de información.
La palabra Internet es el resultado de la unión de dos términos: Inter, que
hace referencia a enlace o conexión y Net (Network) que significa interconexión de
redes. Es decir, Internet no es otra cosa que una conexión integrada de redes de
computadores o redes interconectadas.
Por medio de todo este conjunto de componentes de hardware y software.
Se crearon y continúan desarrollándose numerosos servicios, aplicaciones y usos
de toda índole que son aprovechados para diferentes fines, los que conforman el
infinito mundo Internet (Poleo, 2000).
Intranet
Es una red privada de ordenadores desarrollada con tecnologías de Internet
tales como el navegador que le permite ahora consultar esta misma página Web o
el programa gestor de correo electrónico a la vez que utiliza los mismos protocolos
y
estándares abiertos que permiten que ordenadores de diferentes tipos y
fabricantes se puedan comunicar entre ellos. Así como Internet es una gran plaza
pública donde todo el mundo participa en la Web a través de conferencias, grupos
de noticias o simplemente teniendo acceso a la información editada en formato
HTML (lenguaje que se utiliza para publicar páginas Web en Internet), la Internet
es un club privado al que acceden tan solo los miembros de la compañía. Más allá
del concepto Intranet existe el concepto Extranet el cual permite extender los
privilegios de una Intranet a otras Intranets dispuestas en puntos geográficos
distintos aprovisionando a éstas de aquellos recursos que hasta el momento tan
solo se utilizaban en la propia red local creando de este modo una red privada de
trabajo dentro de la red de redes (Serrano, 2001).
BASES DE DATOS
¿Qué es un sistema de base de datos?
La tecnología de las bases de datos se ha descrito como “una de las áreas
de la ciencia de la computación y la informática de más rápido desarrollo”. Como
campo comercial, aun es relativamente nueva. Pese a su calidad de innovación,
sin embargo, el campo rápidamente ha cobrado importancia práctica y teórica. La
cantidad total de datos encomendados a las bases de datos se mide, sin exagerar,
en varios miles de millones de bytes; la inversión financiera al respecto alcanza
una cifra igualmente enorme; y no es exagerado afirmar que muchos miles de
organizaciones dependen de la operación continua y eficaz de un sistema de
bases de datos (Hernández, 1996).
¿Qué es exactamente un sistema de bases de datos? En esencia, no es
mas que un sistema de mantenimiento de registros basados en computadoras, es
decir, un sistema cuyo propósito general es registrar y mantener información. Tal
información puede estar relacionada con cualquier cosa que sea significativa para
la organización donde el sistema opera - en otras palabras, cualquier dato
necesario para los procesos de tomas de decisiones inherentes a la
administración de esa organización. Un sistema de bases de datos incluye cuatro
componentes principales: datos, hardware, software y usuarios.
Hay quienes conciben la base de datos como un enorme receptáculo en el
que un organismo guarda todos los datos procesables que reúne y al cual acuden
muy diversos usuarios a “pescar”. Éste gran almacén puede estar concentrado en
una localidad determinada o distribuida en varias, todas ellas posiblemente
interconectadas mediante un sistema de telecomunicación. Tienen acceso a la
base de datos programas de la más diversa índole.
En la mayoría de los sistemas, la expresión base de datos no se refiere a
todos los tipos de registro, sino a una colección limitada y especifica de estos.
Dentro de un sistema, coexisten, por lo general varias bases de datos. No
obstante, se supone que los contenidos de estas bases son independientes y
disjuntos. Las colecciones de bases de datos de esta clase se denominan
sistemas de bases de datos (Hernández, 1996).
¿Por qué utilizar bases de datos?
La respuesta general a esta pregunta es que un sistema de bases de datos
proporciona a la empresa un control centralizado de sus datos de operación que
constituyen uno de sus activos más valiosos. Esto contrasta de manera aguda con
la situación que prevalece actualmente en muchas empresas, donde a menudo
cada aplicación tiene sus propios archivos - y muchas veces sus propias cintas o
paquetes de discos particulares -, de modo que los datos de operación se hallan
muy dispersos y, por tanto, es probable que sean difíciles de controlar
(Hernández, 1996).
SISTEMAS DE BASES DE DATOS DISTRIBUIDAS
¿Qué es un sistema de Base de Datos Distribuida?
En un sistema de Bases de Datos Distribuido, los datos se encuentran en
diferentes máquinas, generalmente situados en localizaciones geográficas
diferentes. Dichas máquinas pueden ser de distinto tipo atendiendo a su tamaño,
prestaciones y Sistema Operativo. A cada uno de los ordenadores que integran el
sistema de Bases de Datos distribuido se le conoce como nodo o emplazamiento
del sistema y pueden ser administrados de forma diferente (De Miguel, 1999).
Una característica importante de las Bases de Datos Distribuidas es que
realizan dos tipos de transacciones bien diferenciados:
Transacciones Locales: cuando se accede a los datos del único
emplazamiento donde se inició la transacción.
Transacciones Globales: Cuando se accede a datos de emplazamientos
distintos al emplazamiento donde se inició la transacción.
Un sistema será distribuido si cumple con lo siguiente:
•
Los distintos nodos están informados sobre los demás.
•
Aunque algunas tablas estén almacenadas sólo algunos nodos, éstos
comparten un esquema global común.
•
Cada nodo proporciona un entorno de ejecución de transacciones tanto
local como global.
•
Generalmente, los nodos ejecutan el mismo software de gestión distribuida.
En caso contrario, aumenta en gran medida la dificultad de implementación
del sistema de Bases de Datos Distribuidas. En este caso se dice que el
sistema es heterogéneo.
Los sistemas de Bases de Datos Distribuidas son el resultado de la unión
de dos tecnologías, como se aprecia en la siguiente figura:
* Tecnología de
Bases de Datos
* Redes de
Computadoras
* Sistema de Bases de
Datos Distribuidas
Un sistema administrador de Bases de Datos Distribuidas es el software
que administra la Base de Datos Distribuida y proporciona un mecanismo de
acceso que hace transparente esta distribución a los usuarios (De Miguel, 1999).
Ventajas de los sistemas de Bases de Datos Distribuidas
•
Compartimiento de datos. Los usuarios de un nodo son capaces de acceder
a los datos de otro nodo. Por ejemplo, desde el Rectorado, se puede
consultar los datos de los alumnos de Informática.
•
Autonomía. Cada nodo tiene cierto grado de control sobre sus datos, en un
sistema centralizado, hay un administrador del sistema responsable de los
datos a nivel global. Cada administrador local puede tener un nivel de
autonomía local diferente.
•
Disponibilidad. Si en un sistema distribuido falla un nodo, los nodos
restantes pueden seguir funcionando. Si se duplican los datos en varios
nodos, la transacción que necesite un determinado dato puede encontrarlo
en cualquiera de los diferentes nodos (De Miguel, 1999).
Desventajas de los sistemas de Bases de Datos Distribuidas
•
Coste de desarrollo del software. La complejidad añadida que es necesaria
para mantener la coordinación entre nodos hace que el desarrollo de
software sea más costoso.
•
Mayor probabilidad de errores. Como los nodos que constituyen el sistema
funcionan en paralelo, es más difícil asegurar el funcionamiento correcto de
los algoritmos, así como de los procedimientos de recuperación de fallos
del sistema.
•
Mayor sobrecarga de procesamiento. El intercambio de mensajes y
ejecución de algoritmos para el mantenimiento de la coordinación entre
nodos supone una sobrecarga que no se da en los sistemas centralizados
(De Miguel, 1999).
Objetivos de una Base de Datos Distribuida
-
Tener autonomía local.
-
No depender de un sitio central.
-
Ofrecer operación continua.
-
Transparencia de localización.
-
Transparencia de fragmentación.
-
Transparencia de réplica.
-
Procesamiento distribuido de consultas.
-
Procesamiento de transacciones distribuidas.
-
Transparencia de hardware.
-
Transparencia de sistema operativo.
-
Transparencia de red.
-
Transparencia de sistema administrador de Bases de Datos (Hernández,
1996).
Objetivos de los sistemas de Bases de Datos Distribuidas
Elaborar informes corporativos que involucren el acceso a datos que se
encuentran repartidos en varias computadoras remotas (procesamiento global).
Procesar informes que solo involucren los datos que residen en la misma
computadora (procesamiento local).
Compartir los datos que residan en cada máquina con las otras
computadoras que están interconectadas en la red de acuerdo a las políticas de
la organización (Ibidem, Hernández).
Problemáticas en los sistemas administradores de Bases de
Datos Distribuidas
•
Diseño de la Base de Datos.
-
¿Cómo distribuir la Base de Datos?
-
Distribución de la Base de Datos replicada o no replicada.
-
Problema relacionado con la administración del directorio (Ibidem,
Hernández).
•
Procesamiento de consultas.
-
Problema de optimización.
-
Convertir transacciones de usuario a instrucciones de manipulación de
datos.
-
Minimizar costos (transmisión de datos + procesamiento local)
(Hernández, 1996).
El proceso de optimización de consultas necesita ser distribuido y consta de
dos fases:
-
Optimización global. Medio de transmisión, distribución de subconsultas.
-
Optimización local. Accesos a disco, manipulación de memoria, índices
(Ibidem, Hernández).
Arquitectura Cliente/Servidor
El modelo Cliente/Servidor divide la funcionalidad de la aplicación en torno
a dos roles muy bien definidos: “cliente” y “servidor”. De modo abstracto, el
servidor ofrece una serie de servicios que pueden ser utilizados por los clientes
para completar la funcionalidad de la aplicación.
Una interacción básica Cliente/Servidor implica a un cliente que inicie una
petición de algún servicio a un servidor, posiblemente incluyendo algunos
parámetros que modifiquen el comportamiento del servidor. El servidor entonces
realiza la función especificada por el cliente, devolviendo los posibles resultados
que el servicio genera.
Esta abstracción permite desarrollar la aplicación en torno a las
abstracciones de descomposición modular que proporcionan los servicios.
En la práctica, los clientes y servidores se implementan como procesos que
se están ejecutando en maquinas conectadas a una red.
Tomando como base la manera en que la funcionalidad se divide entre
cliente y servidor, las aplicaciones Cliente/Servidor se dividen en dos grupos:
aplicaciones de dos niveles y aplicaciones de tres o n niveles.
Las aplicaciones de dos niveles fueron el primer paso en el desarrollo de
aplicaciones Cliente/Servidor. Típicamente, la lógica de presentación, la de
negocio y la de datos quedaban en la parte del cliente, dejando a los servidores
encargados de solo guardar los datos, es decir, como servidores de Bases de
Datos. Esta organización es sin duda un paso adelante con respecto a las
soluciones basadas en mainframes, ya que permite una cierta escalabilidad y que
varios clientes se puedan beneficiar de los datos residentes en los servidores. Sin
embargo, no esta libre de inconvenientes. Aunque es verdad que a lo largo del
ciclo de vida de una aplicación los datos son más estables que los procedimientos,
con esta configuración, un cambio en las bases de datos requerirá la
programación de una nueva aplicación cliente y la distribución a todos los
usuarios. Esta configuración se muestra en la siguiente figura:
Cliente
Servidor
Presentación
Lógica del negocio
Acceso a datos
Servidores BD
Sistemas Legacy
Etc.
Nivel 1
Nivel 2
Nivel 1
Nivel 2
Arquitectura de dos niveles Cliente/Servidor
Además, esta solución también presenta una baja escalabilidad, ya que a
medida que el número de clientes aumenta, el servidor de bases de datos se ve
cargado de forma proporcional al número de clientes. Las aplicaciones son
específicas para realizar cierta función y solo comparten los datos. No se pueden
reutilizar partes de aplicaciones ya creadas y se queda ligado al producto utilizado
como servidor de base de datos.
Un refinamiento de la arquitectura anterior es la arquitectura de 3 ó n
niveles. Aquí, el cliente se encarga de mantener interfaz gráfico de usuario,
mientras que existen una serie de componentes intermedios en el sistema que se
encargan de implementar la lógica de la aplicación. Por ultimo, hay un nivel que se
encarga de la lógica de datos, típicamente SGDBx o aplicaciones legacy. En el
momento en el que los componentes de este último nivel se conviertan en clientes
de otros componentes, se convierte en una estructura multinivel. De forma
esquemática, esta arquitectura se muestra a continuación.
Lógica del negocio
Acceso a datos
Cliente
Presentación
Servidor
Servidores BD
Sistemas Legacy
etc.
Nivel 2
Nivel 1
Nivel 3
Arquitectura de tres niveles Cliente/Servidor
Esta configuración permite que los clientes se construyan en base a unos
servicios encapsulados en los procesos que implementan la lógica de la
aplicación, y por lo tanto son más inmunes a cambios tanto en la lógica como
en los datos. Aun así, la funcionalidad que los clientes implementan es tan
sencilla que los cambios son muy superficiales. Varios clientes pueden
reutilizar servicios estándar definidos en el nivel intermedio. La aplicación, al
estar dividida en partes pequeñas, hace que el proceso de distribución de
funcionalidad en los procesadores mas adecuados sea mas flexible (Bohnhoff,
1994).
Sistema Distribuido
Los sistemas distribuidos representan el último paso en la computación
Cliente/Servidor. En vez de diferenciar entre las distintas partes de la
aplicación, los sistemas distribuidos ofrecen toda la funcionalidad en forma de
"objetos", con un significado muy en la línea del termino " objeto" de la
programación orientada a objetos. No existen los roles específicos de "cliente"
y "servidor", sino que toda la funcionalidad están ahí para ser utilizada. Los
procesos que componen la aplicación y que se están ejecutando en las
distintas máquinas de la red con clientes y servidores y cooperan para seguir la
funcionalidad total de la aplicación. Esto da máxima flexibilidad.
Los sistemas distribuidos son un mundo de “entidades pares” (peer-to-peer),
esto es, elementos de procesamiento o “nodos” con distintas disponibilidades
de recursos, distinta capacidad de almacenamiento, distintos requerimientos,
etc., que cooperan ofreciendo servicios en forma de objetos y requiriendo otros
servicios de otros objetos implementados en otros nodos de la red.
En general, un sistema distribuido es un sistema Cliente/Servidor multinivel con
un número potencialmente grande de entidades que pueden desempeñar roles
de clientes y servidores según sus necesidades. El hecho de ofrecer una serie
de servicios en forma de objetos hace que el diseño y desarrollo se haga en
base a interfaces bien definidos que facilitan y apoyan la modularidad y
reutilización, a la vez que permiten un diseño mucho más flexible.
En comparación con un sistema centralizado existe:
•
Mejor aprovechamiento de los recursos.
•
Mayor poder de cómputo a más bajo costo (procesamiento paralelo).
•
En teoría, mayor confiabilidad, si se maneja suficiente redundancia. (Si se
cae una máquina, no se cae todo el sistema).
•
Crecimiento incremental.
•
El software es mucho más complejo (de hecho, todavía no está muy claro
como hacerlo).
•
Es complejo mantener un nivel de seguridad debido al múltiple acceso de
usuarios de diferentes localidades (Lewis, 1995).
HERRAMIENTAS DE DESARROLLO DE APLICACIONES
Existen una gran variedad de herramientas para el desarrollo de
aplicaciones, Visual Basic, Visual Fox Pro, Delphi, etc., a continuación se describe
la herramienta utilizada en el desarrollo de este prototipo.
Visual Basic
Visual-Basic (VB) es una herramienta de diseño de aplicaciones para
Windows, en la que estas se desarrollan en una gran parte a partir del diseño de
una interface gráfica. En una aplicación Visual - Basic, el programa está formado
por una parte de código puro, y otras partes asociadas a los objetos que forman la
interface gráfica.
Es por tanto un término medio entre la programación tradicional, formada
por una sucesión lineal de código estructurado, y la programación orientada a
objetos. Combina ambas tendencias. Ya que no podemos decir que VB
pertenezca por completo a uno de esos dos tipos de programación, debemos
inventar una palabra que la defina: PROGRAMACION VISUAL (Gurowich, 1999).
La creación de un programa bajo Visual Basic lleva los siguientes pasos:
- Creación de una interface de usuario. Esta interface será la principal
vía de comunicación hombre máquina, tanto para salida de datos como
para entrada. Será necesario partir de una ventana - Formulario - a la
que se le añaden los controles necesarios.
- Definición de las propiedades de los controles - Objetos - que se
hayan colocado en ese formulario. Estas propiedades determinarán la
forma estática de los controles, es decir, como son los controles y para
qué sirven.
- Generación del código asociado a los eventos que ocurran a estos
objetos. A la respuesta a estos eventos (click, doble click, una tecla
pulsada, etc.) se le llama “procedimiento”, y deberá generarse de
acuerdo a las necesidades del programa.
- Generación del código del programa. Un programa puede hacerse
solamente con la programación de los distintos procedimientos que
acompañan a cada objeto. Sin embargo, VB ofrece la posibilidad de
establecer un código de programa separado de estos eventos. Este
código puede introducirse en unos bloques llamados Módulos, en otros
bloques llamados Funciones, y otros llamados Procedimientos. Estos
Procedimientos no responden a un evento acaecido a un objeto, sino
que responden a un evento producido durante la ejecución del
programa (Gurowich, 1999).
Tecnologías de acceso a datos
Data Access Object (DAO)
El modelo DAO ha sido programado en especial para acceder a
bases de datos tipo ISAM, muy propias de Access en redes de área local, Visual
Basic 6 incluye dos bibliotecas DAO para sus programas
-
La biblioteca de objetos DAO 3.51 (la versión actual)
- La biblioteca de compatibilidad DAO 2.5/3.51, que permite el uso de los
objetos ya obsoletos de DAO 2.5 en sus programas de Visual Basic 6 (Gurowich,
1999).
Remote Data Object (RDO)
Una de las diferencias mas obvias entre DAO y RDO es el tamaño de
ambos modelos. El DAO tiene 21 objetos principales y el RDO tiene poco menos
de 15. Esto refleja las principales diferencias de ambos modelos. El modelo DAO
se ha diseñado para dar a los programadores un acceso completo tanto a los
datos como el manejo de su esquema (estructura de tablas), y el RDO se ha
diseñado tan solo para permitir el acceso a datos. Dado que la interfaz RDO se ha
diseñado para utilizarse al hacer una conexión con grandes sistemas de bases de
datos multiusuario (SQL Server, Oracle, etc.), los detalles para la creación y
modificación de tablas no son tareas estratégicas del RDO (Ibidem, Gurowich).
ActiveX Data Object (ADO)
El modelo de objetos ActiveX de acceso, podría interpretarse como el
eslabón perdido entre DAO y RDO, Aunque no se relacionan de alguna manera en
especial, todos estos modelos se enfocan en dar servicios de datos a las
aplicaciones sin la sobrecarga del modelo DAO y con algunas adiciones al RDO.
En sí, una de las mayores diferencias con DAO y RDO es que ADO se ha creado
para utilizar la interfaz OLEDB como el proveedor de datos subyacente en lugar de
ODBC. Con OLEDB "bajo cubierta", ADO también puede acceder a conjuntos de
datos que no provengan de bases de datos SQL, como correo electrónico, A/400,
hasta servicios de directorios en red (Gurowich. 1999).
Winsock de Visual Basic
El control WinSock permite conectarse a un equipo remoto e intercambiar datos
con el Protocolo de datagramas de usuario (UDP) o con el Protocolo de control de
transmisión (TCP). Ambos protocolos se pueden usar para crear aplicaciones
cliente-servidor.
Aplicaciones posibles
•
Crear una aplicación cliente que recopile información del usuario antes de
enviarla a un servidor central.
•
Crear una aplicación servidora que funcione como un punto central de
recopilación de datos procedentes de varios usuarios.
•
Crear una aplicación de "conversación".
Seleccionar un protocolo
Cuando se utilice el control WinSock, primero se debe tener en cuenta si se va
a usar el protocolo TCP o el protocolo UDP. La principal diferencia entre los dos
radica en su estado de conexión:
•
TCP es un protocolo basado en la conexión y es análogo a un teléfono: el
usuario debe establecer una conexión antes de continuar.
•
UDP es un protocolo sin conexión y la transacción entre los dos equipos es
como pasar una nota: se envía un mensaje desde un equipo a otro, pero no
existe una conexión explícita entre ambos. Además, el tamaño máximo de
los datos en envíos individuales está determinado por la red.
La naturaleza de la aplicación que se esté creando determinará generalmente qué
protocolo se debe seleccionar. He aquí varias cuestiones que pueden ayudar a
seleccionar el protocolo adecuado:
1.
¿Necesitará la aplicación la confirmación por parte del cliente o el
servidor cuando se envíen o reciban datos? Si es así, el protocolo TCP
requiere una conexión explícita antes de enviar o recibir datos.
2.
¿Será muy grande el tamaño de los datos (como en el caso de los
archivos de imágenes o sonidos)? Una vez establecida la conexión, el
protocolo TCP mantiene la conexión y asegura la integridad de los datos.
3.
¿Se enviarán los datos de forma intermitente o en una sesión? Por
ejemplo, si está creando una aplicación que avisa a equipos específicos
cuando se han completado ciertas tareas, el protocolo UDP puede ser el
más apropiado. Este protocolo es también el más adecuado para enviar
pequeñas cantidades de datos (Gurowich, 1999).
CAPÍTULO 2
CONCEPTOS DE DISEÑO
ENFOCADOS AL DESARROLLO DE
APLICACIONES DISTRIBUIDAS
- Aspectos de Diseño de Programas
- El Diseño de la Distribución
- El Diseño de Distribución Bottom-Up (Ascendente)
ASPECTOS DE DISEÑO DE PROGRAMAS
Un sistema distribuido debe hacer que los usuarios (procesos) perciban el
sistema como un monoprocesador virtual. No es necesario que los usuarios estén
al tanto de la existencia de múltiples máquinas y múltiples procesadores en el
sistema. En la actualidad no hay ningún sistema que cumpla cabalmente con esta
definición, pero se están haciendo avances.
Los aspectos que hay tener en cuenta en el diseño de un sistema
distribuido se describen a continuación.
Transparencia
Los usuarios deben poder accesar los objetos remotos de la misma forma
que los locales. Es responsabilidad del sistema operativo distribuido localizar el
recurso y obtener la interacción adecuada.
La transparencia también tiene que ver con la forma de nombrar los objetos:
el nombre de un objeto no debe depender del lugar en que se almacena. Un
recurso debe poder migrar de un lugar a otro, sin que esto signifique que haya que
cambiar su nombre. Los usuarios, además, deben tener la misma vista del
sistema, independientemente del lugar en que el usuario haga login (Navarro,
1998).
Confiabilidad
Si tenemos un sistema con 5 máquinas, cada una con una probabilidad del
95% de estar funcionando normalmente en cualquier instante, el hecho de que
una máquina se caiga, hace que deje de funcionar todo el sistema, entonces la
probabilidad de que el sistema esté funcionando en un instante dado es del 77%.
Si en cambio el sistema está hecho de manera tal que cualquier máquina puede
asumir el trabajo de una máquina que se cae, entonces el sistema estará
funcionando un 99.9994% del tiempo. La primera opción es definitivamente mala
(mucho peor que en un sistema centralizado); la segunda, es poco realista (muy
difícil de implementar). Además, la tolerancia a fallas es un tema particularmente
complejo, debido a que, en general, no es posible diferenciar entre un enlace de
comunicaciones caído, una máquina caída, una máquina sobrecargada, y pérdida
de mensajes.
La confiabilidad tiene que ver con la consistencia de los datos. Si un archivo
importante se replica, hay que asegurarse que las réplicas se mantengan
consistentes; mientras más haya, más caro es mantenerlas, y más probable es
que haya inconsistencias.
La seguridad es también un aspecto fundamental de la confiabilidad
(Navarro, 1998).
Escalabilidad
La escalabilidad de un sistema es la capacidad para responder a cargas de
trabajo crecientes. En particular un sistema distribuido escalable debe diseñarse
de manera que opere correcta y eficientemente con diez o con millones de
máquinas (Ibidem, Navarro).
Flexibilidad
Los sistemas distribuidos son nuevos. Es importante, por ende, que
se puedan adaptar a nuevas tecnologías y a nuevos avances en el tema (Navarro,
1998).
EL DISEÑO DE LA DISTRIBUCION
El diseño de un sistema de base de datos distribuido implica la toma de
decisiones sobre la ubicación de los programas que accederán a la base de datos
y sobre los propios datos que constituyen esta última, a lo largo de los diferentes
puestos que configuren una red de ordenadores. La ubicación de los programas,
a priori, no debería suponer un excesivo problema dado que se puede tener una
copia de ellos en cada máquina de la red. Sin embargo, ¿cuál es la mejor opción
para colocar los datos? en una gran máquina que albergue a todos ellos,
encargada de responder a todas las peticiones del resto de las estaciones –
sistema de base de datos centralizado –, o se podría pensar en repartir las
relaciones, las tablas, por toda la red. En el supuesto de que se seleccionara esta
segunda opción, ¿qué criterios se deberían seguir para llevar a cabo tal
distribución? ¿Realmente este enfoque ofrecerá un mayor rendimiento que el
caso centralizado? ¿Podría optarse por alguna otra alternativa? (Rodríguez,
1999).
Tradicionalmente se ha clasificado la organización de los sistemas de
bases de datos distribuidos sobre tres dimensiones: el nivel de compartición, las
características de acceso a los datos y el nivel de conocimiento de esas
características de acceso (vea la figura 1). El nivel de compartición presenta tres
alternativas: inexistencia, es decir, cada aplicación y sus datos se ejecutan en un
ordenador con ausencia total de comunicación con otros programas u otros datos;
se comparten sólo los datos y no los programas, en tal caso existe una réplica de
las aplicaciones en cada máquina y los datos viajan por la red; y, se reparten
datos y programas, dado un programa ubicado en un determinado sitio, éste
puede solicitar un servicio a otro programa localizado en un segundo lugar, el cual
podrá acceder a los datos situados en un tercer emplazamiento.
Figura 1. Enfoque de la distribución (Rodríguez, 1999).
Existen dos alternativa respecto a las características de acceso a los datos:
el modo de acceso a los datos que solicitan los usuarios puede ser estático, es
decir, no cambiará a lo largo del tiempo, o bien, dinámico. Sin embargo, lo
realmente importante radica, estableciendo el dinamismo como base, que tan
dinámico es y cuántas variaciones sufre a lo largo del tiempo.
Esta dimensión establece la relación entre el diseño de bases de datos
distribuidas y el procesamiento de consultas.
La tercera clasificación es el nivel de conocimiento de las características de
acceso. Una posibilidad es, evidentemente, que los diseñadores carezcan de
información alguna sobre cómo los usuarios acceden a la base de datos. Es una
posibilidad teórica, pero sería muy laborioso abordar el diseño de la base de datos
con tal ausencia de información. Lo más práctico sería conocer con detenimiento
la forma de acceso de los usuarios o, en el caso de su imposibilidad, conformarse
con una información parcial de ésta.
El problema del diseño de bases de datos distribuidas podría enfocarse a
través de esta trama de opciones. En todos los casos, excepto aquel en el que no
existe compartición, aparecerán una serie de nuevos problemas que son
irrelevantes en el caso centralizado (Rodríguez, 1999).
A la hora de abordar el diseño de una base de datos distribuida se puede
optar principalmente por dos tipos de estrategias: la estrategia ascendente y la
estrategia descendente. Ambos tipos no son excluyentes, y no resultaría extraño
a la hora de abordar un trabajo real de diseño de una base de datos que se
pudiesen emplear en diferentes etapas del proyecto una u otra estrategia. La
estrategia ascendente podría aplicarse en aquel caso donde haya que proceder a
un diseño a partir de un número de pequeñas bases de datos existentes, con el
fin de integrarlas en una sola.
En este caso se partiría de los esquemas conceptuales locales y se
trabajaría para llegar a conseguir el esquema conceptual global. Aunque este
caso se pueda presentar con facilidad en la vida real, se prefiere pensar en el
caso donde se parte de cero y se avanza en el desarrollo del trabajo siguiendo la
estrategia descendente (Ibidem, Rodríguez).
Existen diversas formas de afrontar el problema del diseño de la
distribución. Las más usuales se muestran en la figura 2. En el primer caso, caso
A, los dos procesos fundamentales, la fragmentación y la asignación, se abordan
de forma simultánea. Esta metodología se encuentra en desuso, sustituida por el
enfoque en dos fases, caso B: la realización primeramente de la partición para
luego asignar los fragmentos generados. El resto de los casos se comentan en la
sección referente a los distintos tipos de la fragmentación.
Figura 2. Enfoques para realizar el diseño distributivo (Rodríguez, 1999).
El principal problema de la fragmentación radica en encontrar la unidad
apropiada de distribución.
Una relación no es una buena unidad por muchas razones. Primero, las
vistas de la aplicación normalmente son subconjuntos de relaciones. Además, la
localidad de los accesos de las aplicaciones no está definida sobre relaciones
enteras pero sí sobre subconjuntos de las mismas.
Por ello, sería normal considerar como unidad de distribución a estos
subconjuntos de relaciones (Rodríguez, 1999).
Segundo, si las aplicaciones tienen vistas definidas sobre una determinada
relación (considerándola ahora una unidad de distribución) que reside en varios
sitios de la red, se puede optar por dos alternativas. Por un lado, la relación no
estará replicada y se almacena en un único sitio, o existe réplica en todos o
algunos de los sitios en los cuales reside la aplicación. Las consecuencias de esta
estrategia son la generación de un volumen de accesos remotos innecesario.
Además, se pueden realizar réplicas innecesarias que causen problemas en la
ejecución de las actualizaciones y puede no ser deseable si el espacio de
almacenamiento está limitado.
Tercero, la descomposición de una relación en fragmentos, tratados cada
uno de ellos como una unidad de distribución, permite el proceso concurrente de
las transacciones. También la relación de estas relaciones, normalmente,
provocará la ejecución paralela de una consulta al dividirla en una serie de
subconsultas que operará sobre los fragmentos (Ibidem, Rodríguez).
Pero la fragmentación también acarrea inconvenientes. Si las aplicaciones
tienen requisitos tales que prevengan la descomposición de la relación en
fragmentos mutuamente exclusivos, estas aplicaciones cuyas vistas estén
definidas sobre más de un fragmento pueden sufrir una degradación en el
rendimiento. Por tanto, puede ser necesario recuperar los datos de dos
fragmentos y llevar a cabo sobre ellos operación de unión y yunto , lo cual es
costoso.
Un segundo problema se refiere al control semántico. Como resultado de la
fragmentación los atributos implicados en una dependencia se descomponen en
diferentes fragmentos los cuales pueden destinarse a sitios diferentes. En este
caso, la sencilla tarea de verificar las dependencias puede resultar una tarea de
búsqueda de los datos implicados en un gran número de sitios (Rodríguez, 1999).
TIPOS DE FRAGMENTACION
Dado que una relación se corresponde esencialmente con una tabla y la
cuestión consiste en dividirla en fragmentos menores, inmediatamente surgen dos
alternativas lógicas para llevar a cabo el proceso: la división horizontal y la
división vertical. La división o fragmentación horizontal trabaja sobre las tuplas,
dividiendo la relación en subrelaciones que contienen un subconjunto de las
tuplas que alberga la primera. La fragmentación vertical, en cambio, se basa en
los atributos de la relación para efectuar la división. Estos dos tipos de partición
podrían considerarse los fundamentales y básicos. Sin embargo, existen otras
alternativas. Fundamentalmente, se habla de fragmentación mixta o híbrida
cuando el proceso de partición hace uso de los dos tipos anteriores.
La fragmentación mixta puede llevarse a cabo de tres formas diferentes:
desarrollando primero la fragmentación vertical y, posteriormente, aplicando la
partición horizontal sobre los fragmentos verticales (denominada partición VH), o
aplicando primero una división horizontal para luego, sobre los fragmentos
generados, desarrollar una fragmentación vertical (llamada partición HV), o bien,
de forma directa considerando la semántica de las transacciones. Otro enfoque
distinto y relativamente nuevo, consiste en aplicar sobre una relación, de forma
simultánea y no secuencial, la fragmentación horizontal y la fragmentación
vertical; en este caso, se generara una rejilla y los fragmentos formaran las celdas
de esa rejilla, cada celda será exactamente un fragmento vertical y un fragmento
horizontal (nótese que en este caso el grado de fragmentación alcanzado es
máximo, y no por ello la descomposición resultará más eficiente).
Grado de fragmentación. Cuando se va a fragmentar una base de datos se debe
sopesar qué grado de fragmentación va a alcanzar, ya que éste será un factor
que influirá notablemente en el desarrollo de la ejecución de las consultas. El
grado de fragmentación puede variar desde una ausencia de la división,
considerando a las relaciones unidades de fragmentación; o bien, fragmentar a un
grado en el cada tupla o atributo forme un fragmento. Ante estos dos casos
extremos, evidentemente se ha de buscar un compromiso intermedio, el cual
debería establecerse sobre las características de las aplicaciones que hacen uso
de la base de datos. Dichas características se podrán formalizar en una serie de
parámetros. De acuerdo con sus valores, se podrá establecer el grado de
fragmentación del banco de datos (Rodríguez, 1999).
Figura 3. Distintos tipos de fragmentación (Rodríguez, 1999).
Reglas de correción de la fragmentación
A continuación se enuncian las tres reglas que se han de cumplir durante el
proceso de fragmentación, las cuales asegurarán la ausencia de cambios
semánticos en la base de datos durante el proceso.
1.
Compleción. Si una relación R se descompone en una serie de fragmentos
R1, R2, ..., Rn, cada elemento de datos que pueda encontrarse en R deberá
poder encontrarse en uno o varios fragmentos Ri. Esta propiedad
extremadamente importante asegura que los datos de la relación global se
proyectan sobre los fragmentos sin pérdida alguna. Tenga en cuenta que en
el caso horizontal el elemento de datos, normalmente, es una tupla, mientras
que en el caso vertical es un atributo.
2.
Reconstrucción. Si una relación R se descompone en una serie de
fragmentos R1, R2, ..., Rn, puede definirse una operador relacional
El operador
tal que
será diferente dependiendo de las diferentes formas de
fragmentación. La reconstrucción de la relación a partir de sus fragmentos
asegura la preservación de las restricciones definidas sobre los datos en
forma de dependencias.
3.
Disyunción. Si una relación R se descompone horizontalmente en una serie
de fragmentos R1, R2, ..., Rn, y un elemento de datos di se encuentra en
algún fragmento Rj, entonces no se encuentra en otro fragmento Rk (k
j).
Esta regla asegura que los fragmentos horizontales sean disjuntos. Si una
relación R se descompone verticalmente, sus atributos primarios clave
normalmente se repiten en todos sus fragmentos (Rodríguez, 1999).
Alternativas de asignación
Partiendo del supuesto que el banco de datos se haya fragmentado
correctamente, habrá que decidir sobre la manera de asignar los fragmentos a los
distintos sitios de la red. Cuando una serie de datos se asignan, éstos pueden
replicarse para mantener una copia. Las razones para la réplica giran en torno a
la seguridad y a la eficiencia de las consultas de lectura. Si existen muchas
reproducciones de un elemento de datos, en caso de fallo en el sistema se podría
acceder a esos datos ubicados en sitios distintos. Además, las consultas que
acceden a los mismos datos pueden ejecutarse en paralelo, ya que habrá copias
en diferentes sitios. Por otra parte, la ejecución de consultas de actualización, de
escritura, implicaría la actualización de todas las copias que existan en la red,
cuyo proceso puede resultar problemático y complicado. Por tanto, un buen
parámetro para afrontar el grado de réplica consistiría en sopesar la cantidad de
consultas de lectura que se efectuarán, así como el número de consultas de
escritura que se llevarán a cabo. En una red donde las consultas que se procesen
sean mayoritariamente de lectura, se podría alcanzar un alto grado de réplica, no
así en el caso contrario. Una base de datos fragmentada es aquella donde no
existe réplica alguna. Los fragmentos se alojan en sitios donde únicamente existe
una copia de cada uno de ellos a lo largo de toda la red. En caso de réplica, se
puede considerar una base de datos totalmente replicada, donde existe una copia
de todo el banco de datos en cada sitio, o considerar una base de datos
parcialmente replicada donde existan copias de los fragmentos ubicados en
diferentes sitios. El número de copias de un fragmento será una de las posibles
entradas a los algoritmos de asignación, o una variable de decisión cuyo valor lo
determine el algoritmo. La figura 4 compara las tres alternativas de réplica con
respecto a distintas funciones de un sistema de base de datos distribuido (Alberto,
1999).
Procesamiento de
consultas
Gestión del directorio
Réplica total
Réplica
parcial
Partición
fácil
dificultad
Similar
fácil o
inexistente
dificultad
Similar
Control de
concurrencia
Seguridad
Realidad
moderado
difícil
muy alta
posible
aplicación
alta
realista
Fácil
Baja
posible
aplicación
Figura 4. Comparación de las alternativas de réplica
Información necesaria
Un aspecto importante en el diseño de la distribución es la cantidad de
factores que contribuyen a un diseño óptimo. La organización lógica de la base de
datos, la localización de las aplicaciones, las características de acceso de las
aplicaciones a la base de datos y las características del sistema en cada sitio,
tienen una decisiva influencia sobre la distribución. La información necesaria para
el diseño de la distribución puede dividirse en cuatro categorías: la información del
banco de datos, la información de la aplicación, la información sobre la red de
ordenadores y la información sobre los ordenadores en sí. Las dos últimas son de
carácter cuantitativo y servirán, principalmente, para desarrollar el proceso de
asignación (Alberto, 1999).
EL DISEÑO DE DISTRIBUCIÓN BOTTOM-UP
(ASCENDENTE)
En este enfoque, el esquema representando la porción de los datos
almacenados en cada sitio individual constituye el punto de partida en el diseño, y
la distribución del diseño consiste en la identificación de los datos que son
comunes a ellos, así como sus diferencias.
Durante la operación, los sistemas de bases múltiples proveen sólo
capacidad de consulta global y capacidad de actualización local (update), de modo
que cada sistema local puede estar actualizado por transacciones realizadas en
ese lugar. Si el diseñador no puede modificar las bases de datos locales de un
sistema de base de datos múltiple, entonces la resolución del conflicto tiene que
ser incorporada en el procesamiento de la capacidad del programa de consulta del
sistema.
El apoyo de la multi-base provee un señalamiento automático de las
consultas señaladas de acuerdo con el panorama global, aplicables al esquema
local y coordina la ejecución de las consultas y la recolección de los resultados
(Besso, 1999).
Problemas de diseño en la construcción de un sistema global
Los problemas en el diseño bottom-up de un sistema de bases múltiples se
debe a la necesidad de construcción de un esquema global (llamado Superview).
El proceso de integración reconoce entidades relacionadoras y sus atributos.
Para integrar las bases de datos necesitamos seleccionar un tipo adecuado
de modelos de datos para el esquema global. Una generalización jerárquica
permite la definición de una relación subtipo-tipo entre dos entidades; esto puede
ser útil cuando dos vistas dan una descripción que se superponen parcialmente de
la misma identidad. Entonces, la solución clásica del panorama de integración
consiste en la generación de tres entidades, una con los atributos comunes y otras
dos con atributos que no se interpongan entre sí.
La necesidad de las jerarquías de generalización indica que los modelos
conceptuales como el ER (extendido por la generalización), el modelo estructural,
o el modelo funcional son buenos candidatos para el proceso de integración.
Otra cuestión general es el orden de integración de los panoramas. Cuando
hay varias vistas presentes, la generalización típicamente se lleva a cabo al unir
una vista al mismo tiempo con el esquema global, lo que a su vez se construye
gradualmente. Así el problema general que consideramos es el de cómo construir
la super vista de dos panoramas. En general, es mejor integrar primero la más
grande o la más importante de las vistas, seguida de la más pequeña o la menos
importante (Alberto,1999).
Trabajando con los datos inconsistentes durante la operación
En la práctica, las bases de datos múltiples tienen errores. Esos pueden ser
debidos a la transcripción de las entradas, omisión o fallo en la sincronización de
las actualizaciones, y de la recuperación inadecuada desde los errores del
sistema. El diseñador de la base de datos debe decidir las políticas para
sobrellevar las inconsistencias que surgen durante la operación de la base de
datos global.
El diseñador de la base de datos tiene varias opciones sobre cómo manejar
las inconsistencias. Mientras que las inconsistencias serán detectadas en el
momento de la ejecución, la determinación de las políticas para resolver las
inconsistencias es un problema de diseño, estas políticas incluyen:
Presentar cualquiera de los valores inconsistentes sin notificárselo al
usuario: la solución más directa pero al mismo tiempo más peligrosa.
Presentar todos los valores inconsistentes y mostrar al usuario las fuentes
de la información. En este caso, el usuario debería ser capaz de evaluar los casos
de inconsistencias.
Evaluar alguna función agregada a los valores de inconsistencia y presentar
el resultado a la función del usuario. Las funciones agregadas posibles incluyen
promedio, máximo y minino. Esta técnica fue utilizada cuando se esperó que las
observaciones fueran diferentes ya que ocurrieron en tiempos diferentes.
Presentar el valor más reciente. Esta política requiere la misma elaboración
de las operaciones actualizaciones o updates (que son caras) basada en el
supuesto de que las inconsistencias se deban a las actualizaciones retrasadas, y
de este modo el último valor es el que más se necesita.
Presentar el valor desde el sistema más confiable. Esta política está basada
en la suposición que el diseñador es capaz de evaluar la confiabilidad de los sitios
en la base de datos distribuida (Alberto, 1999).
CAPÍTULO 3
CONTEXTO DE LA EMPRESA
ESTAFETA
- Historia
- Infraestructura
- Logros
- Estafeta en Números
ESTAFETA S.A. DE C.V.
Estafeta ocupa el primer lugar nacional en número de clientes, ventas y
cantidad de envíos transportados. También ofrece a sus clientes los servicios de
mensajería y paquetería a 200 países del mundo.
En los últimos doce años, la empresa ha logrado un crecimiento significativo
al acercarse a 50 millones de recolecciones y entregas en 1997, cifra que
representó una participación superior al 35% del mercado doméstico.
El crecimiento constante que han experimentado desde sus inicios los llevó
en 1997 a una facturación por arriba de los 100 millones de dólares.
Estafeta garantiza la entrega puntual de sus envíos en los destinos donde
presta el servicio.
Las cifras avalan su entrega y compromiso: 50 millones de entregas y
recolecciones realizadas durante 1997.
Estafeta ofrece productos y servicios diseñados para responder a las
necesidades de comunicación y distribución, así como soluciones integrales de
logística.
Historia
Estafeta Mexicana, S.A. de C.V., surge en agosto de 1979 en el estado de
Querétaro como una empresa mexicana pionera en el servicio de mensajería
acelerada. La empresa fue fundada por sus socios actuales (2 socios alemanes y
2 socios mexicanos). La empresa comenzó a ofrecer sus servicios con una PC
286 y una camioneta Ford modelo 1974 para sus entregas. Después abren una
oficina en el DF y a partir de eso empiezan a establecer sucursales en todo
México. Desde sus inicios ha venido ofreciendo servicios de mensajería y
paquetería con un nivel de calidad competitivo a nivel mundial (Estafeta, 2000).
Infraestructura
Actualmente Estafeta posee una flotilla de distribución de más de 1,500
vehículos de carga, incluyendo aviones propios, cuenta con 30 Centros
Operativos, además a lo largo y ancho del territorio nacional tiene 325 oficinas
propias totalmente automatizadas y conectadas a una red privada de
telecomunicaciones.
Logros
Apoyan a fabricantes y comercializadores con servicios adecuados de
distribución que les permiten colocar y resurtir sus productos en los mercados de
casi cualquier parte de la República Mexicana.
El servicio a sus clientes, les ha permitido atender las características
particulares del mercado nacional y así responder a la demanda de la población
con un servicio confiable, rápido y económico.
Su misión
Ofrecer el servicio líder en mensajería y Paquitería en el Mercado
nacional (Ibidem, Estafeta).
El objetivo de la empresa es:
La satisfacción total del cliente (Estafeta, 2000).
Cobertura Amplia
Estafeta está presente en la gran mayoría de las ciudades de la República
Mexicana, al igual que en más de 180 países en los cinco continentes.
Servicios Electrónicos
Es posible saber en todo momento el lugar en el que se encuentran los
envíos, así como
cualquier información detallada sobre los mismos, solo es
cuestión de realizar una llamada a Estafeta y por medio de un sistema de rastreo
electrónico es posible obtener la ubicación y en su caso, la confirmación de la
entrega.
Además
Estafeta
cuenta
con
una
dirección
de
internet
www.estafeta.com.mx en la cual ponen a disposición de los usuarios las
herramientas electrónicas para poder consultar en forma remota, la ubicación de
los envíos y demás información de la empresa.
Comando Estafeta
Estafeta cuenta con un software para la administración y gestión de envíos,
el cual pone a trabajar la información en beneficio de los clientes de manera
inteligente. Sistema Comando asegura el control sobre los envíos, permitiendo
automatizar la mensajería y paquetería, mientras reduce los costos y aumenta las
ventas. Este software está disponible en versiones para Windows 3.X y Windows
95.
Comando Estafeta permite:
-
Automatizar la impresión de las guías.
-
Rastrear y confirmar los envíos en forma remota (vía modem o
disquete).
-
Obtener reportes pormenorizados de todas las operaciones.
Descripción
Empresa de mensajería y paquetería
Fundación
Agosto de 1979
Numero de empleados
3,000
Clientes
50,000 regulares
Ventas Anuales
100 millones de dólares
Posición en el mercado
domestico
Participación del mercado
1er. Lugar
34% aproximadamente
Cobertura
100% del mercado nacional
Oficinas
325 propias
Centros operativos y de
intercambio
Vehículos terrestres
40 a nivel nacional
Vehículos aéreos
11 jets de carga
Conexiones aéreas propias
59 a nivel nacional
Volumen diario de operaciones
200,000 entregas y recolecciones
Volumen diario de carga
1,200,000 kilos a nivel nacional
Kilómetros recorridos
diariamente
240,000 a nivel nacional
1,500 unidades
Estafeta en números (Estafeta, 2000).
CAPÍTULO 4
ANÁLISIS DEL FUNCIONAMIENTO
DE ENVIOS Y ENTREGAS DE
PAQUETES (Situación antes de la
implementación del sistema)
− Equipo con que se cuenta actualmente
− Flujo de Información
− Información que se obtiene por cada paquete que se envía o se
entrega
− Lista de plazas a cargo de Colima
− Descripción de los números de guía
− Tipos de movimientos de los paquetes
La empresa Estafeta en su sucursal Colima cuenta con un departamento de
sistemas el cual es el encargado de la zona occidente, la cual consta de tres
estados (Colima, Jalisco, Tepic), en el se lleva todo el control sobre los números
de guía de los paquetes que se envían y se reciben en las diferentes plazas de la
zona occidente. Toda la información se concentra en la plaza para después ser
enviada a la central para que sea procesada y separada por plazas.
Para poder llevar este control, Estafeta de México cuenta con una red
privada, la cual conecta las diferentes plazas en toda la república. Esta red consta
de líneas privadas DS0, servidores Uníx, Terminales con Windows 95-98 y
conexiones vía modem.
Equipo con que se cuenta actualmente
El departamento de sistemas cuenta con un servidor UNIX, en el cual se
conectan varias terminales tontas (solo monitor y teclado) y varias computadoras
con Windows 95 o 98. También es posible accesar al servidor UNIX por medio de
modem.
Colima es la primera plaza en la que se implementaron los lectores ópticos
portátiles para entregas y recolecciones de paquetes, lo cual significa que si se
trabaja mejor con estos lectores, después se implementarán en las demás plazas
de la república. Estos lectores permiten a los que entregan los paquetes llevar un
mejor control sobre estos.
También se cuenta con lectores de código de barra para obtener los
números de guía de los paquetes que entran y salen de Estafeta. Para los lectores
de código de barra se cuenta con una computadora, la cual es la que recaba la
información de los diferentes números de guía de los paquetes. Existe un
programa por medio del cual se leen los códigos de barra y se procesan de
acuerdo a la acción que se está haciendo con el paquete.
Flujo de Información
Después de recabar la información por medio de los lectores de código de
barras y de los lectores ópticos portátiles, la información se lleva al servidor UNIX
en el cual la información se formatea para enviarla a la oficina central de Estafeta,
Cuando la información llega a la oficina central, esta se separa y se envía a cada
plaza para llevar un control sobre los paquetes que se enviaron o se recibirán.
También esta información se almacena en el servidor Web para que los clientes
puedan consultar por medio de un navegador la localización actual de su paquete
y poder darse una idea de cuando o a que hora aproximadamente llegará el
paquete a su destino.
Se realiza esta operación por lo menos tres veces al día.
Recopilación de Información
Traslado al servidor
Formateo de Información
Envío de información
Separación de información
Actualización de la información en el
servidor Web
Envío de la información a las diferentes
plazas
Disponibilidad de
la información
Diagrama del Flujo de Información actual
Descripción del diagrama de flujo
Recopilación de información: Esta parte genera la información de los
números de guía de los paquetes, y la información se recopila mediante lectores
de código de barras portátiles y no portátiles. Además, se capturan los números de
guía de los paquetes en forma manual cuando los códigos de barra no pueden ser
leídos por el lector.
Traslado al servidor: Como la información es generada en un sistema que
trabaja bajo Windows y el servidor trabaja Bajo UNIX, es necesario que se haga
una transformación de formatos de archivos, Esta transformación se realiza en
este punto.
Formateo de información: Aquí se verifica que toda la información tenga el
formato necesario para enviarla a la central en México.
Envío de información: Hasta este punto, la información se envía a la central.
El envío se hace mediante comandos de UNIX y a través de la red privada de la
empresa.
Separación de información: A cada plaza, se le envía la información
referente a los paquetes que han sido enviados por ellos, así como los números
de los paquetes que se van a recibir para entregarlos a los distintos destinos en el
estado.
Actualización de la información en el servidor Web: Se actualiza la
información del servidor Web para que esté disponible para las consultas por
medio de su sitio web.
Envío de la información a las diferentes plazas: La información que ha sido
separada se regresa a cada plaza que corresponde para que tengan actualizada
su información.
Disponibilidad de la información: Hasta este momento la información que
fue generada en cada plaza está disponible para consultas o, en ciertos casos,
para ser actualizada.
Recopilación de
información
Envío de la
Disponibilidad
de la información
información a la
central
ibilidad
Actualización del
servidor web
ación
Disponibilidad
de la
información
Diagrama del flujo de información que se obtendrá
Información que se obtiene por cada paquete que se envía o se
entrega
ENTREGAS
Al momento de que se va a entregar un paquete es necesario que se
genere la siguiente información para el control de Estafeta:
-
Número de guía (cadena de 22 caracteres).
-
Clave del lector óptico portátil o del lector de código de barras (cadena
de 4 caracteres).
-
Destino (cadena de 3 caracteres).
-
Origen (cadena de 3 caracteres).
-
Nombre de la persona que recibe el paquete (cadena de 50 caracteres).
Esta información se obtiene al momento de entregar un paquete y es
almacenada en el lector óptico portátil para después descargar toda la información
en una computadora, la cual almacena toda la información del día referente a las
entregas de paquetes.
Para cuando se utilizan los lectores de código de barras, existe un software
especial para recabar la información del número de guía, Este software se ejecuta
bajo el entorno de Windows 95 0 98.
Para pasar los archivos generados bajo Windows al servidor UNIX primero
se copian los archivos al servidor por medio de comandos de UNIX. A
continuación, por medio de otro software el cual se ejecuta en entorno UNIX, los
archivos generados en Windows se incorporan al sistema en UNIX para llenar los
datos que hicieron falta, cabe señalar que cuando se utilizan los lectores de código
de barras, estos solamente obtienen el número de guía y, en algunas ocasiones,
el origen del paquete. Por lo tanto los datos que hacen falta deben de capturarse
manualmente.
ENVIOS
Al momento de que se va a enviar un paquete es necesario que se genere
la siguiente información para el control de Estafeta:
-
Número de guía.
-
Destino.
-
Origen.
-
Nombre de la persona que envía el paquete.
Esta información es obtenida en los puntos de venta de Estafeta. También
esta información debe transmitirse al servidor para ser tratada y enviada a la
central de Estafeta.
Lista de plazas a cargo de Colima
Colima
Tecomán
Puerto Vallarta Arandas
Ciudad
Guzmán
Tepatitlan
San Miguel del Manzanillo
Tepic
Alto
Autlan
San Juan de
los Lagos
La Barca
Ocotlan
Descripción de los números de guía
Cada número de guía consta de 22 dígitos, los cuales se dividen de la
siguiente forma:
No. de Dígitos
Descripción
10
Número de cliente
3
Número de plaza
2
Tipo de servicio
7
Número consecutivo
El número de cliente es único, Cada vez que llega un cliente nuevo, se le
asigna un número o se le asigna los números ya establecidos, los cuales tienen la
terminación 9999 o 0000.
Cada plaza tiene asignada un número único, algunos de los cuales son:
Colima
012
Tecomán
177
Manzanillo
183
Puerto Vallarta
072
Ciudad Guzmán
105
Tipos de movimientos de los paquetes
Cada vez que llega un paquete a una plaza, éste se da de alta. Una vez
dado de alta, el paquete se entrega en la oficina de la plaza o a domicilio, Para
estas acciones, también se le hace un registro que indica de que forma se va a
entregar el paquete. Si el paquete solo está de paso, también se registra su salida.
En algunas ocasiones, los paquetes se detienen en los retenes instalados en las
carreteras, donde se quedarán unos días, Por lo tanto, también se registran
paquetes que se detienen en los retenes por un tiempo.
−
CAPÍTULO 5
IMPLEMENTACIÓN
− Aspectos de diseño a considerar en la implementación del sistema
− Elementos que forman el prototipo
− Control de Números de guía (en los servidores)
− Servidor
− Cliente
− Seguridad
− Otras Características del Sistema
Aspectos de diseño a considerar en la implementación del sistema
-
Estructura de la Base de Datos
Cada plaza contará con una base de datos en donde se manejaran los
datos de los números de guía localmente. Esta base de datos será de la siguiente
forma:
Servidor
Tabla – Guías
Nombre
Tipo
Tamaño
NoGuia
Tipo
Subtipo
Fecha
Hora
Texto
Byte
Byte
Fecha/Hora
Fecha/Hora
22
Cliente
Tabla - DirIP
Nombre
Tipo
Tamaño
Plaza
IP
Posición
Texto
Texto
Autonumerico
30
15
Tabla - Usuarios
Nombre
Tipo
Tamaño
Usuario
Texto
10
Password
Texto
10
Nombre
Texto
50
TipoU
Byte
- Fragmentación de la Base de Datos
No será necesario fragmentar la base de datos que exista localmente en
cada plaza si no que se tendrá una ausencia de la división. Considerando a las
relaciones unidas de fragmentación, esto significa que la base de datos de cada
plaza quedará intacta y no será fragmentada.
- Replicas
En cada plaza se tendrá una réplica de cada base de datos que está
almacenada localmente, por si en algunas ocasiones la computadora que tiene
almacenada la base de datos falla o sucede algún contratiempo con ella. La
réplica permitirá al menos hacer consultas de la información. La base de datos que
servirá de réplica tendrá la misma estructura que la base de datos original, la cual
se mostró anteriormente.
- Método de distribución de la Base de Datos
Como ya existen en cada plaza todas las bases de datos, se implementará
el método Bottom-Up (ascendente). Este método ya fue explicado en el capítulo
anterior.
- Comunicación entre clientes y servidores
La comunicación entre las diferentes plazas se realizará a través de
sockets. En particular, se utilizará el control Winsock de Visual Basic, utilizando el
protocolo TCP. Se enviarán entre los clientes y los servidores cadenas, las cuales
tendrán una estructura específica para indicar el tipo de función que hará el cliente
o el servidor, así como también se enviarán los argumentos necesarios para
realizar la función que se está solicitando o realizando.
Para identificar los servidores, se utilizarán direcciones IP las cuales ya se
tienen asignadas en cada plaza existente.
CLIEN
SERVIDO
SERVIDO
Réplica
TCP/IP
Réplica
SERVIDO
SERVIDO
R
Réplica
CLIEN
Réplica
Esquema general del funcionamiento del sistema
Elementos que forman el Prototipo
En cada plaza existirán tres programas individuales los cuales serán:
-
Programa para controlar los números de guía.
-
Programa que recibirá las solicitudes de información de las demás
plazas.
-
Programa por medio del cual se podrán hacer consultas y/o
modificaciones de las bases de datos que están almacenadas
localmente o en forma distribuida.
A continuación se describe el funcionamiento de los tres programas.
Control de números de guía (en los servidores)
Existen 2 programas los cuales permiten llevar el control de los números de
de guía de los servidores
Un programa permite capturar los números de guía de los paquetes y
registrarlos de acuerdo a la acción de que se le hará al paquete. Por ejemplo.
-
Darle entrada a un paquete.
-
Indicarle al sistema que determinado paquete está detenido en un retén.
-
Registrar que un paquete será entregado en las oficinas de Estafeta.
-
Indicar que el paquete se entregará a domicilio.
-
Registrar la salida de un paquete.
Estas acciones se hacen por medio de la siguiente pantalla:
Consideraciones para registrar los números de guía.
"Registrar Entrada". Para registrar la entrada de un número de guía, éste no
debe de estar dado de alta con anterioridad.
"Detenido en reten". Para hacer este registro, no debe de estar registrado
de entrada el número de guía. Cuando un paquete ya salió de un reten y llega a
una plaza y está registrado que fue detenido en un reten, se presiona el botón
"Registrar Entrada" y este lo registrará de entrada y le quitará el registro de que
está en un retén.
"Entrega en oficina". Para poder registrar un número de guía de esta forma,
el número de guía debe de estar ya registrado de entrada.
"Entrega a domicilio". Para poder registrar un número de guía de esta
forma, el número de guía debe de estar ya registrado de entrada.
"Registrar Salida". Para poder registrar un número de guía de esta forma, el
número de guía debe de estar ya registrado de entrada.
A continuación se muestra un diagrama que explica el funcionamiento de
esta parte del sistema:
Captura del
número de
Error
Registrar
entrada
Detenido
en reten
Entrega
en oficina
Entrega a
domicilio
Ya
esta
regis
trado
Regi
stro
de
entra
Regi
stro
de
entra
Regi
stro
de
entra
No
Y
Si
Si
Registrar
salida
Regi
stro
de
entra
Error
SI
Si
No
No
Dete
nido
en
Error
Registra
No
Error
Registra
Error
Error
Registra
Registra
No
Sali
r
Si
Sali
r
Sali
r
Sali
r
Si
Cambiar
registro a
Sali
r
Diagrama general del funcionamiento de la
captura de los números de guía
Servidor
El segundo programa realiza las
solicitudes de los clientes que se conecten al
sistema.
Este programa se queda residente en
memoria y se puede controlar por medio de
un icono en la barra del sistema.
Las opciones que se tienen para el
servidor son las siguientes, las cuales son
muy descriptivas de lo que hacen.
Principales funciones del servidor.
- Agregar Registros a la base de datos.
- Modificar registros de la base de datos.
- Borrar registros de la base de datos.
- Buscar un determinado número de guía.
- Enviar los registros por una determinada fecha.
- Enviar los registros que se encuentran registrados en la fecha actual.
- Enviar todos los registros de la base de datos.
- Administrar la réplica de la base de datos.
- Controlar los bloqueos a los registros.
En el siguiente código se muestra como se realizan las funciones del
servidor dependiendo de las solicitudes de los clientes.
Private Sub Server_DataArrival(Index As Integer, ByVal bytesTotal As Long)
Dim Cadena, cad As String
Dim a, c As Integer
Dim b, d, e, f As String
Server(Index).GetData cad
Cadena = Decodificar(cad)
a = InStr(1, Cadena, ";", vbTextCompare)
If a Then
Else
Exit Sub
End If
b = Mid(Cadena, 1, a - 1)
If StrComp(b, "Agregar") Then 'Agregar nuevo registro
Else
c = InStr(a + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (a + 1), (c - a - 1))
a = InStr(c + 1, Cadena, ",", vbTextCompare)
d = Mid(Cadena, c + 1, a - c - 1)
c = InStr(a + 1, Cadena, ",", vbTextCompare)
f = Mid(Cadena, a + 1, c - a - 1) ''''
Call Registro(Trim(b), Val(d), Val(f))
cad = Codificar("Agregado;")
Server(Index).SendData cad
Exit Sub
End If
If StrComp(b, "Modificar") Then
'Modificar registro
Else
c = InStr(a + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (a + 1), (c - a - 1))
a = InStr(c + 1, Cadena, ",", vbTextCompare)
d = Mid(Cadena, c + 1, a - c - 1)
c = InStr(a + 1, Cadena, ",", vbTextCompare)
f = Mid(Cadena, a + 1, c - a - 1) ''''
Call MRegistro(Trim(b), Val(d), Val(f))
cad = Codificar("Modificado;")
Server(Index).SendData cad
Exit Sub
End If
If StrComp(b, "Borrar") Then 'Borrar Registro
Else
c = InStr(a + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (a + 1), c - a - 1) '''
Call BRegistro(Trim(b))
cad = Codificar("Borrado;")
Server(Index).SendData cad
Exit Sub
End If
If StrComp(b, "Busqueda") Then
'Busqueda de un numero de guía
Else
c = InStr(a + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (a + 1), c - a - 1) '''''
Call Busqueda(Trim(b), Index)
Exit Sub
End If
If StrComp(b, "PorFecha") Then
'Regresa los registros que se encuentran
en una fecha determinada
Else
c = InStr(a + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (a + 1), c - a - 1)
Call RegistrosF(Trim(b), Index)
Exit Sub
End If
If StrComp(b, "Registros") Then
actual
Else
If Bloqueado = 1 Then
Call Registros(Index)
cad = Codificar("Bloqueado;")
Server(Index).SendData cad
Else
Call Registros(Index)
Bloqueado = 1
IndiceB = Index
End If
Exit Sub
End If
If StrComp(b, "Todos") Then
Else
Call Todos(Index)
Exit Sub
End If
'Regresa los registros con fecha
'Regresa todos los registros
End Sub
Cliente
La primera acción que se hace al
momento de activar el cliente es introducir el
nombre de usuario, así como su contraseña
para saber que tipo de usuario está entrando
al sistema.
Existen dos tipos de usuario permitidos en el sistema:
-
Supervisor. Este usuario puede hacer uso de todas las opciones del
sistema.
-
Usuarios normales. Estos usuarios solo pueden hacer búsquedas de un
número de guía en específico.
Nota: En el anexo 2 se muestra por medio de un esquema las opciones
para cada usuario.
La verificación de los usuarios se hace mediante el siguiente código:
Adodc1.RecordSource = "select * from usuarios where usuario = '" &
txtUserName & "'"
Adodc1.Refresh
If Adodc1.Recordset.EOF Then
MsgBox "La contraseña no es válida. Vuelva a intentarlo", , "Inicio de
sesión"
txtPassword.SetFocus
SendKeys "{Home}+{End}"
Exit Sub
Else
If txtPassword = Adodc1.Recordset.Fields(1) Then
Menu.TipoU.Caption = Trim(Adodc1.Recordset.Fields(3))
Menu.Show
LoginSucceeded = True
Me.Hide
Else
MsgBox "La contraseña no es válida. Vuelva a intentarlo", , "Inicio
de sesión"
txtPassword.SetFocus
SendKeys "{Home}+{End}"
End If
End If
Al entrar al sistema se muestra la siguiente pantalla (para el usuario
“Supervisor”).
En caso de que fuera un usuario normal, no se mostraría el menú
“Administración” ni el icono de la barra de herramientas que permite ir a una plaza
en específico.
El menú “Buscar” cuenta con dos opciones como, se muestran en la siguente imagen.
En todas las plazas: Esta opción permite buscar un número de guía en específico
por medio de la siguiente pantalla.
Ya que se introdujo el número de guía que se quiere encontrar, se presiona
botón “Buscar” para que realice la búsqueda.
El procedimiento de búsqueda es el siguiente:
1. El cliente busca en su base de datos de servidores los números IP de
estos para comunicarse con ellos.
El código que lo hace es el siguiente:
Menu.DirIPB.RecordSource = "select * from dirip where posicion = " &
Posicion
Menu.DirIPB.Refresh
If Menu.DirIPB.Recordset.EOF Then
Else
NoGuia = Trim(Numero)
Menu.Winsock1.Connect
Menu.DirIPB.Recordset.Fields(1),
Menu.DirIPB.1000
End If
Menu.ListaB.ListItems.Clear
2. Toma el primer servidor y le pide que realice la búsqueda del numero de
guía.
cad = Codificar("Busqueda;" & NoGuia)
Winsock1.SendData (cad)
3. Si el servidor tiene almacenado el número de guía le regresa al cliente la
información almacenada referente al numero de guía.
4. El cliente revisa la información y si está registrado que el paquete se va
a entregar en la oficina, se va a entregar a domicilio, el paquete está en
un retén o al paquete se le registro entrada pero no salida, se detiene la
búsqueda y se le indica al usuario cualquiera de estas opciones que
tiene el paquete.
5. En caso de que se le registró al paquete entrada y salida de la plaza el
cliente le hace la misma solicitud de búsqueda al siguiente servidor.
6. Si ya se realizó en todos los servidores la búsqueda y todos tienen
registrado entrada y salida se le muestra al usuario un historial del
recorrido que ha hecho el paquete por las diferentes plazas.
El código que realiza todas las verificaciones mencionadas en los últimos
puntos se muestra a continuación:
If StrComp(b, "Busqueda") Then
Else
a = InStr(c + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (c + 1), (a - c - 1))
If StrComp(b, "NO") Then
Set mItem = ListaB.ListItems.Add(, , Text:=Trim(NoGuia))
c = InStr(a + 1, Cadena, ",", vbTextCompare)
d = Mid(Cadena, a + 1, c - a - 1)
a = InStr(c + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (c + 1), (a - c - 1))
If Val(d) = 2 Then
Buscando.Hide
MsgBox "El paquete esta en un reten cerca de " &
DirIPB.Recordset.Fields(0)
BusquedaN = 0
Winsock1.Close
ListaB.Visible = False
Exit Sub
Else
If Val(b) = 2 Or Val(b) = 3 Then
Buscando.Hide
MsgBox "El paquete se va a entregar en " &
DirIPB.Recordset.Fields(0)
BusquedaN = 0
Winsock1.Close
ListaB.Visible = False
Exit Sub
ElseIf Val(b) = 0 Then
Buscando.Hide
MsgBox "El paquete se encuentra en " &
DirIPB.Recordset.Fields(0)
BusquedaN = 0
Winsock1.Close
ListaB.Visible = False
Exit Sub
End If
End If
mItem.ListSubItems.Add , , Text:=DirIPB.Recordset.Fields(0)
c = InStr(a + 1, Cadena, ",", vbTextCompare)
d = Mid(Cadena, a + 1, c - a - 1)
mItem.ListSubItems.Add , , Text:=d
a = InStr(c + 1, Cadena, ",", vbTextCompare)
b = Mid(Cadena, (c + 1), a - c - 1) ''''
mItem.ListSubItems.Add , , Text:=b
BusquedaN = 0
Else
End If
Menu.DirIPB.RecordSource = "select * from dirip"
Menu.DirIPB.Refresh
If Posicion = DirIPB.Recordset.RecordCount Then
Buscando.Hide
BusquedaN = 0
Winsock1.Close
ListaB.SortKey = 2
ListaB.Sorted = True
Exit Sub
End If
Posicion = Posicion + 1
BusquedaN = 1
Menu.DirIPB.RecordSource = "select * from dirip where posicion = "
& Posicion
Menu.DirIPB.Refresh
If Menu.DirIPB.Recordset.EOF Then
Else
Menu.Winsock1.Close
Do While Menu.Winsock1.State <> sckClosed
DoEvents
Loop
Menu.Winsock1.Connect Menu.DirIPB.Recordset.Fields(1),
Menu.DirIPB.Recordset.Fields(2)
End If
Exit Sub
End If
Ir a una plaza en específico: Esta opción permite al usuario estar en una plaza en
específico para realizar actualizaciones en la base de datos de la plaza a la cual
se desplaza.
El sistema muestra un mapa con las diferentes zonas que existen e n el
país.
A través de este mapa se selecciona la zona en la cual está la plaza a la
cual el usuario se dirige. Para seleccionar la zona solo es cuestión de posicionar el
mouse sobre el nombre de la zona a la cual el usuario quiere ir y presionar el
botón izquierdo.
Después de seleccionar la zona, se muestran todas la plazas que existen
en la zona seleccionada.
Aquí se selecciona la plaza a la cual se quiere accesar. La plaza se selecciona
de la misma forma que con las zonas.
Ya que se selecciona la plaza, se muestra una lista con los registros de los
números de guía que pertenecen a la fecha actual, y se activan las opciones
restantes, las cuales permiten manipular la información de la plaza.
Al entrar a una plaza en específico el programa cliente mantiene una conexión
con el servidor por medio de sockets utilizando el protocolo TCP y utili zando el
puerto 1000, Esta conexión termina cuando el cliente se cambia de plaza,
cuando realiza una búsqueda en todas las plazas o cuando se sale del sistema.
Las operaciones que se pueden hacer después de seleccionar la zona y la
plaza son las siguientes:
-
Agregar un registro a la base de datos de la plaza seleccionada.
-
Borrar un registro de la base da datos.
-
Modificar un registro de la base da datos.
-
Pedir todos los registros de la base da datos
-
Pedir los registros que se encuentren en una determinada fecha.
El menú Comandos cuenta con las siguientes opciones
Agregar Registro: Permite introducir en la base de datos de la plaza un
nuevo registro. Esto se hacer por medio de la siguiente pantalla:
Borrar Registro: Borra el registro que esté seleccionado en la lista de registros. Al
entrar a esta opción el sistema pregunta al usuario si esta seguro de querer
borrarlo, solo borrará el registro si el usuario dice que si.
Modificar Registro: Permite hacerle cambios al registro que esté actualmente
seleccionado. Solo se pueden modificar los campos "Tipo" y "Subtipo", (no es
posible modificar el campo del número de guía).
NOTA: Los dos campos (Tipo, Subtipo) que aparecen en cada registro son los
que indican el estado actual del paquete en la plaza.
Tipo Subtipo
1
2
Explicación
0
El paquete esta en la plaza
1
El paquete entró y salió de la plaza
2
El paquete se entrega en la oficina de Estafeta
3
El paquete se entrega a domicilio
0
El paquete está en un reten
El menú Buscar cuenta con dos nuevas opciones:
Información por Fecha: Permite visualizar los registros que pertenezcan a una
determinada fecha, Se selecciona la fecha por medio de la siguiente pantalla.
Ya que el usuario selecciona la fecha y presiona el botón “Aceptar”, solo se
mostrarán en pantalla los registros que hayan sido registrados en la fecha que se
selecciono.
Todos los Registros: Muestra todos los registros que tenga la base de datos de la
plaza.
El menú administración cuenta con dos opciones:
Direcciones IP de las plazas: Aquí permite configurar los servidores que estarán
activos en el sistema.
Para Agregar un registro primero se presiona el botón "Agregar", después
de presionarlo debemos de llenar los campos y presionar el botón "Actualizar".
Para modificar un registro solo hacemos las modificaciones en los campos y
presionamos el botón "Actualizar".
Para borrar un registro nos posicionamos en el registro que queremos
borrar por medio de la barra de desplazamiento y presionamos el botón "Eliminar".
Usuarios: En este apartado se captura la información de los usuarios que tendrán
acceso al sistema.
Para Agregar un registro primero se presiona el botón "Agregar", después
de presionarlo debemos de llenar los campos y presionar el botón "Actualizar".
Para modificar un registro solo hacemos las modificaciones en los campos y
presionamos el botón "Actualizar".
Para borrar un registro nos posicionamos en el registro que queremos
borrar por medio de la barra de desplazamiento y presionamos el botón "Eliminar".
Para salir del sistema entramos al menú salir y seleccionamos la opción
"Abandonar el sistema".
Todas las solicitudes y respuestas por parte de los clientes y los servidores
se forman en una cadena que se envía por medio del socket. Esta cadena se
forma de la siguiente manera:
"operacion;argumento1,argumento2,argumento3,..."
Dependiendo de la operación, el cliente o el servidor sabrán cuantos
argumentos contiene la cadena.
SEGURIDAD
Cada usuario para entrar al sistema (en el cliente) debe de contar con un
nombre de usuario y un password, los cuales le indican al programa el tipo de
usuario que está entrando al sistema. Existen dos niveles de usuario: los que
pueden visualizar y hacer actualizaciones en las bases de datos de las plazas y
los usuarios que solo pueden hacer búsquedas de ciertos números de guía.
Por medio del siguiente código se verifica si el usuario esta registrado en el
sistema.
Adodc1.RecordSource = "select * from usuarios where usuario = '" &
txtUserName & "'"
Adodc1.Refresh
If Adodc1.Recordset.EOF Then
MsgBox "La contraseña no es válida. Vuelva a intentarlo", , "Inicio de sesión"
txtPassword.SetFocus
SendKeys "{Home}+{End}"
Exit Sub
Else
If txtPassword = Adodc1.Recordset.Fields(1) Then
Menu.TipoU.Caption = Trim(Adodc1.Recordset.Fields(3))
Menu.Show
LoginSucceeded = True
Me.Hide
Else
MsgBox "La contraseña no es válida. Vuelva a intentarlo", , "Inicio de
sesión"
txtPassword.SetFocus
SendKeys "{Home}+{End}"
End If
End If
Y por medio del siguiente se verifica el tipo de usuario que entro
Private Sub Form_Activate()
BusquedaN = 0
If Val(TipoU) = 2 Then
MIrenEspecifico.Visible = False
Madministracion.Visible = False
Toolbar1.Buttons.Item(5).Visible = False
End If
End Sub
Dentro del programa cliente existe un apartado para dar de alta los
diferentes usuarios que podrán accesar al sistema el cual ha sido explicado con
anterioridad.
Para la transferencia de información a través de los clientes y servidores se
implementa un algoritmo de codificación de información el cual es explicado a
continuación.
Algoritmo UU-encoding
- Permite la transformación de los datos binarios en una secuencia de caracteres
imprimibles.
- Toma los datos binarios y l o s s e p a r a e n b l o q u e s d e 3 b y t e s . C a d a b l o q u e
contiene
24(8*3)
bits.
De
estos
24
bits
se
extraen
6
bits.
Después
de
esto a cada byte se le suma 32 (valor ASCII del espacio). El byte, el cual
consiste de solo 6 bits puede mostrar solo 64 valores al contrario de lo 128 que se puede
mostrar con 8 bits.
Este algoritmo crece la infomación que se manda en un 33% (Chat,2002 Marks, 1992)
Ejemplo:
A continuación se muestran las funciones que realizan el proceso de codificar y
decodificar la información:
Public Function Codificar(Cadena As String) As String
Dim intFile
As Integer
Dim intTempFile
Dim lFileSize
As Integer
As Long
Dim strFileName
Dim strFileData
As String
As String
Dim lEncodedLines As Long
Dim strTempLine
As String
Dim i
As Long
Dim j
As Integer
Dim strResult
As String
strResult = "begin 664 " + vbLf
lFileSize = Len(Cadena)
lEncodedLines = lFileSize \ 45 + 1
strFileData = Space(45)
For i = 1 To lEncodedLines
If i = lEncodedLines Then
strFileData = Space(lFileSize Mod 45)
End If
strFileData = Mid(Cadena, (i - 1) * 45 + 1, 45)
strTempLine = Chr(Len(strFileData) + 32)
If i = lEncodedLines And (Len(strFileData) Mod 3) Then
strFileData = strFileData + Space(3 - (Len(strFileData) Mod 3))
End If
For j = 1 To Len(strFileData) Step 3
'1 byte
strTempLine = strTempLine + Chr(Asc(Mid(strFileData, j, 1)) \ 4 + 32)
'2 byte
strTempLine = strTempLine + Chr((Asc(Mid(strFileData, j, 1)) Mod 4) *
16 _
+ Asc(Mid(strFileData, j + 1, 1)) \ 16 + 32)
'3 byte
strTempLine = strTempLine + Chr((Asc(Mid(strFileData, j + 1, 1)) Mod
16) * 4 _
+ Asc(Mid(strFileData, j + 2, 1)) \ 64 + 32)
'4 byte
strTempLine = strTempLine + Chr(Asc(Mid(strFileData, j + 2, 1)) Mod 64
+ 32)
Next j
strTempLine = Replace(strTempLine, " ", "`")
strResult = strResult + strTempLine + vbLf
strTempLine = ""
Next i
strResult = strResult & "`" & vbLf + "end" + vbLf
Codificar = strResult
End Function
Public Function Decodificar(strUUCodeData As String) As String
Dim i As Integer
Dim vDataLine As Variant
Dim vDataLines As Variant
Dim strDataLine As String
Dim intSymbols As Integer
Dim intFile
As Integer
Dim strTemp
As String
Dim CadDecod As String
CadDecod = ""
strTemp = ""
If Left$(strUUCodeData, 6) = "begin " Then
strUUCodeData = Mid$(strUUCodeData, InStr(1, strUUCodeData, vbLf) + 1)
End If
If Right$(strUUCodeData, 5) = vbLf + "end" + vbLf Then
strUUCodeData = Left$(strUUCodeData, Len(strUUCodeData) - 10)
End If
vDataLines = Split(strUUCodeData, vbLf)
For Each vDataLine In vDataLines
strDataLine = CStr(vDataLine)
intSymbols = Asc(Left$(strDataLine, 1)) - 32
strDataLine = Mid$(strDataLine, 2)
strDataLine = Replace(strDataLine, "`", " ")
For i = 1 To Len(strDataLine) - 1 Step 4
'1 byte
strTemp = strTemp + Chr((Asc(Mid(strDataLine, i, 1)) - 32) * 4 + _
(Asc(Mid(strDataLine, i + 1, 1)) - 32) \ 16)
'2 byte
strTemp = strTemp + Chr((Asc(Mid(strDataLine, i + 1, 1)) Mod 16) * 16
+_
(Asc(Mid(strDataLine, i + 2, 1)) - 32) \ 4)
'3 byte
strTemp = strTemp + Chr((Asc(Mid(strDataLine, i + 2, 1)) Mod 4) * 64
+_
Asc(Mid(strDataLine, i + 3, 1)) - 32)
Next i
strTemp = Left(strTemp, intSymbols)
CadDecod = CadDecod + strTemp
strTemp = ""
Next
Decodificar = CadDecod
End Function
Otras Características del sistema
Réplicas
El sistema cuenta con un sistema de réplica el cual permite que exista la
disponibilidad del mismo.
Cada vez que se hacen actualizaciones en alguna base de datos también
se hacen en su réplica, esto permite que en caso de que algún servidor no esté
funcionando exista un respaldo de la información que permita al menos a los
usuarios consultar la información de las bases de datos. Cuando el cliente intenta
conectarse a un servidor y este no responde en un determinado tiempo, el cliente
se trata de conectar con el servidor que tiene la replica de la base de datos.
Bloqueos
Es necesario implementar bloqueos para evitar la inconsistencia de los
datos almacenados.
Cada vez que un usuario supervisor va a modificar un registro o a borrarlo
se bloquea el registro para que los demás usuarios no puedan hacerle
modificaciones al mismo registro, después de que se modificó el registro se les
manda a todos los usuario la información modificada.
ANEXO 1
Seguridad y Cifrado de la Información
Seguridad y Cifrado de la Información
Arquitectura de Redes
Estructura en niveles
El modelo OSI de ISO (International Standards Organization) surge, en el
año 1984, ante la necesidad imperante de interconectar sistemas de procedencia
diversa -diversos fabricantes-, cada uno de los cuales empleaba sus propios
protocolos para el intercambio de señales.
El modelo OSI está compuesto por una pila de 7 niveles o capas, cada uno
de ellos con una funcionalidad específica, para permitir la interconexión e
interoperatividad de sistemas heterogéneos. La utilidad radica en la separación
que en él se hace de las distintas tareas que son necesarias para comunicar datos
entre dos sistemas independientes.
Num. Nivel
Función
7
Aplicación
Datos normalizados
6
Presentación Interpretación de los datos
5
Sesión
Diálogos de control
4
Transporte
Integridad de los mensajes
3
Red
Encaminamiento
2
Enlace
Detección de errores
1
Físico
Conexión de equipos
Tabla 1 Niveles OSI de ISO
Los tres niveles inferiores están orientados al acceso del usuario - comunicaciones
de datos-; el cuarto nivel al transporte extremo a extremo de la información, y los tres
superiores a la aplicación.
Nivel de Presentación
El nivel de presentación se ocupa de la sintaxis de los datos, es decir la
representación de los datos extremo a extremo.
Así pues es responsable de alcanzar un acuerdo en los códigos y formatos que se
usarán en el intercambio de datos de aplicación durante una sesión. El nivel de presentación
puede ser responsable del formateo de chorros de datos para su correcta salida a una
impresora o a una determinada pantalla. También puede realizar compresión de datos y
descompresión.
Por lo tanto incluye los aspectos de:
•
Conversión
•
Cifrado
•
Compresión de datos
Cuando se establece comunicación entre dos entidades o capas de aplicación se
producen tres representaciones sintácticas de los datos transferidos entre dichas entidades
de aplicación:
•
La sintaxis usada por la entidad que origina los datos, entidad emisora.
•
La sintaxis usada por la entidad que los recibe los datos o entidad receptora
•
La sintaxis usada por el proceso de transferencia, es decir como son
representados en el cable (mientras viajan de una aplicación a otra).
Representación de datos
Los diferentes ordenadores tienen diferentes representaciones internas para los
datos. Estas representaciones son establecidas por los fabricantes en su momento y que
ahora les es muy difícil de cambiar, dado que tienen que mantener la compatibilidad con
sus antiguos sistemas.
Las redes informáticas permiten establecer comunicaciones entre los
distintos ordenadores sin tener en cuenta su arquitectura interna. Por ello el
modelo de referencia OSI de ISO establece que en la capa de presentación se
realice la conversión entre las representaciones internas de los equipos
conectados.
Para resolver este problema se han propuesto varias alternativas:
•
El extremo transmisor realiza la conversión.
•
El extremo receptor realiza la conversión.
•
Establecer un formato normalizado y que cada uno de los extremos realice
la conversión hacia y desde este formato normalizado de red.
Compresión de datos
El costo por utilizar una red depende, normalmente de la cantidad de datos
trasmitidos. Por lo tanto y a fin de rebajar la factura se utiliza la compresión de datos antes
de expedirlos al receptor para reducir la cantidad de datos a transmitir.
La compresión de datos está muy relacionada con la representación de los
datos, ya que, lo que intentamos es transmitir la misma información, con menor
número de bytes, representada mediante algún código especial pero con el mismo
significado.
Seguridad y Confidencialidad en las Redes
Con el desarrollo de las redes actuales las medidas de seguridad que se
tienen que aplicar, para evitar al máximo que los datos emitidos sean
interceptados por personas no autorizadas, se han disparado. Existe pues la
necesidad de establecer algún tipo de mecanismo de cifrado para conseguir que
los datos sean ininteligibles para aquellos que lo intercepten sin autorización.
La seguridad de los datos en la red debe contemplar los siguientes
aspectos:
•
Proteger los datos para que no puedan ser leídos por personas que no
tienen autorización para hacerlo.
•
Impedir que las personas sin autorización inserten o borren mensajes.
•
Verificar al emisor de cada uno de los mensajes.
•
Hacer posible que los usuarios transmitan electrónicamente documentos
firmados.
El cifrado es un método que permite llevar a cabo los objetivos descritos.
El cifrado, no obstante, no es un elemento que pertenece en exclusiva a la
capa de presentación sino que podemos encontrarlo en otras capas.
Cifrado de enlace
En este caso el cifrado se realiza en la capa física. La ventaja del cifrado de enlace
es que tanto las cabeceras como los datos se cifran.
Cifrado en transporte
Si introducimos el cifrado en la capa de transporte ocasionamos que el cifrado
se realice en la sesión completa.
Cifrado en presentación
Es quizás una solución más elaborada ya que el cifrado es sufrido sólo por aquellas
partes de los datos que sean consideradas necesarias, consiguiendo de este modo que la
sobrecarga del proceso de cifrado sea menor.
Análisis de tráfico
Otro aspecto relacionado con la seguridad en las redes es el conocimiento de los
patrones de tráfico, es decir, se estudia la longitud y frecuencia de los mensajes. Con este
análisis se consigue determinar los lugares donde se está produciendo un intenso
movimiento de datos.
De todas maneras es fácil engañar a este análisis introduciendo en el mensaje
grandes cantidades de datos de relleno o incluso enviando mensajes inútiles.
Seguridad en las redes
Cada vez es mayor el número de personas dotadas de los suficientes
conocimientos como parar causar daño al sistema informático de una
organización. Debido a esta tendencia, cada vez se establecen mayores medidas
preventivas y se dedica más atención a la seguridad en las redes.
Tipos de violación de los sistemas de seguridad
Una de las formas más usuales y sencillas de quebrantar la seguridad es el
falseamiento, es decir, la modificación previa a la introducción de los datos en el
sistema informático o en una red.
Otra forma de violación de la seguridad es el ataque ínfimo "salami attack",
que consiste en la realización de acciones repetitivas pero muy pequeñas, cada
una de las cuales es casi indetectable.
Una de las formas más eficaces de violación de la seguridad en una red, es
la suplantación de personalidad, que aparece cuando un individuo accede a una
red mediante el empleo de contraseñas o de códigos no autorizados. La
contraseña suele obtenerse directamente del usuario autorizado de la red, muchas
veces sin que éste se dé cuenta. Hay incluso algunos sistemas de acceso a la red
que pueden burlarse utilizando un ordenador para calcular todas las posibles
combinaciones de contraseñas.
Una forma de combatir el empleo no autorizado de contraseñas consiste en
instalar un sistema de palabras de acceso entre el canal de comunicaciones y el
ordenador. Este dispositivo, un vez que recibe la contraseña, desconecta
automáticamente la línea, consulta en una tabla cuál es el número de teléfono
asociado a ella, y vuelve a marcar para conectar con el usuario que posee el
número de teléfono designado.
Con este mecanismo, el intruso ha de disponer de la palabra de acceso o contraseña,
y ha de encontrarse físicamente en el lugar en el que se supone que debe estar el usuario
autorizado. No es una solución muy buena ya que hace verdaderos estragos en funciones
como la redirección de llamadas hacia otros números o contestación automática.
Las redes también pueden ser violadas mediante lo que se conoce como
"puertas traseras". Este problema se producirá cuando los dispositivos o los
programas de seguridad sean inadecuados o incluyan errores de programación, lo
que permitirá que alguien pueda encontrar el punto vulnerable del sistema.
Las redes también se ven comprometidas como consecuencia de la
intercepción y monitorización de los canales. Así, por ejemplo, las señales de
microondas o de satélites pueden interceptarse, si el intruso encuentra la
frecuencia adecuada.
Métodos de protección
Para garantizar la confidencialidad de la información se utilizan las técnicas de
cifrado de claves.
Una clave es un algoritmo software o un dispositivo hardware que codifica y
bloquea el acceso a la información. Sólo la misma clave o una clave asociada
puede descifrar la información.
Consideremos, por ejemplo, el envío de datos confidenciales a través de un
enlace telefónico. Se pueden utilizar técnicas de cifrado para que los datos sean
confidenciales, pero si se usa una clave para cifrar los datos, ¿cómo hacer que la
clave llegue al receptor para que así pueda descifrarlos?.
Si se envía la clave a través de la línea, entonces estaría a disposición de
cualquiera que estuviese conectado. Se podría enviar la clave a través de una
línea diferente o utilizar un servicio de distribución urgente, pero, ¿se puede estar
completamente seguro de que la clave llegó a su destino sin ser interceptada?.
Una solución consiste en intercambiar las claves antes de llevar a cabo las
transmisiones. Un banco podría hacerlo así para comunicarse con sus sucursales.
Pero ¿qué ocurre si lo que se quiere es enviar un mensaje confidencial aislado a
un receptor que no se conoce?. Las técnicas de cifrado de claves públicas
proporcionan una solución. Hay distintas técnicas que proporcionan seguridad en
entornos de informática distribuida, tales como:
•
Servicios de Autentificación.
•
Servicios de Autorización.
•
Servicios de Confidencialidad.
•
Servicios de Integridad.
•
No Repudiación.
Cifrado con claves privadas
Una técnica muy usada para aumentar la seguridad de las redes
informáticas es el cifrado. Esta técnica convierte el texto normal en algo
ininteligible, por medio de algún esquema reversible de codificación desarrollado
en torno a una clave privada que sólo conocen el emisor y el receptor. El proceso
inverso es el descifrado , mediante el cual el texto en clave vuelve a convertirse en
texto legible. El cifrado suele tener lugar en el emisor, mientras que el descifrado
suele realizarse en el receptor. El cifrado se clasifica en dos tipos: cifrado por
sustitución y cifrado por transposición.
* Sustitución : Es la forma más sencilla de cifrado. Consiste en reemplazar una
letra o un grupo de letras del original por otra letra o grupo de letras. Uno de los
esquemas más sencillos es el CIFRADO DE CÉSAR, en este mecanismo cada
letra del alfabeto es sustituida por otra.
Texto legible: ABCDEFGHIJKLMNOPQRSTUVWXYZ
Letras de sustitución: FGQRASEPTHUIBVJWKLXYZCONMD
Este tipo de cifrado se conoce como sustitución monoalfabética, ya que
cada una de las letras se sustituye por otra del mismo alfabeto.
El descifrado final del código se convierte en algo relativamente sencillo,
sobre todo si se utiliza un ordenador de alta velocidad. Hay otros métodos de
cifrado por sustitución más eficaces. Así, por ejemplo, algunos sistemas usan la
sustitución polialfabética, en la cual existen varios alfabetos de cifrado que se
emplean en rotación. Una variación del cifrado por sustitución consiste en utilizar
una clave más larga que el texto legible. Se usa como clave una secuencia
aleatoria de bits, que se cambia periódicamente.
La principal desventaja de todas las estructuras basadas en una clave
privada es que todos los nodos de la red han de conocer cuál es la clave común.
La distribución y confidencialidad de las claves acarrea algunos problemas
administrativos y logísticos.
* Cifrado por transposición . Es un método criptográfico más sofisticado. En él las
claves de las letras se reordenan, pero no se disfrazan necesariamente.
La clave utilizada para el ejemplo es SEGURIDAD, que no es demasiado
buena para un sistema de seguridad. La clave se emplea para numerar las
columnas. La columna 1 se coloca bajo la letra de la clave más próxima al
comienzo del alfabeto, es decir, A, B, C,
Si la clave incluye alguna letra repetida, puede adoptarse el criterio de
numerar de izquierda a derecha.
A continuación se escribe el texto legible como una serie de renglones que
se colocan debajo de la clave. Después se lee el texto cifrado por columnas,
empezando por aquella columna cuya letra clave sea la más próxima al principio
del alfabeto. Así, la frase "compra barato vende caro y hazlo hoy" quedará como
sigue:
S
E
G
U
R
I
D
A
D
8
4
5
9
7
6
2
1
3
C
O
M
P
R
A
B
A
R
A
T
O
V
E
N
D
E
C
A
R
O
Y
H
A
Z
L
O
H
O
Y
A
B
C
D
E
F
Y el texto cifrado será el siguiente:
AELEBDZDRCOFOTROMOOYANACREHBCAAHPVYA
El Algoritmo DES
En 1977, el Departamento de Comercio y la Oficina Nacional de Estándares
de Estados Unidos publicaron la norma DES (estándar de cifrado de datos,
publicación 46 del FIPS ** ).
DES un esquema de cifrado de claves privadas. El algoritmo DES es un
sistema monoalfabético que fue desarrollado en colaboración con IBM y se
presentó al público con la intención de proporcionar un algoritmo de cifrado
normalizado para redes de ordenadores.
DES se basa en el desarrollo de un algoritmo de cifrado que modifica el
texto con tantas combinaciones que el criptoanalista no podría deducir el texto
original aunque dispusiese de numerosas copias.
La filosofía del algoritmo DES consiste en llevar a cabo varias etapas de
permutación y sustitución. DES utiliza una clave de 64 bits, de los cuales 56 son utilizados
directamente por el algoritmo DES y otros 8 se emplean para la detección de errores.
Existen unos setenta mil billones de claves posibles de 56 bits.
Evidentemente para romper una clave semejante sería necesaria una enorme
cantidad de potencia de cálculo. Sin embargo, no es una tarea imposible. Los ordenadores
de alta velocidad, mediante análisis estadísticos, no necesitan emplear todas las posibles
combinaciones para romper la clave. A pesar de ello, el objetivo de DES no es proporcionar
una seguridad absoluta, sino únicamente un nivel de seguridad razonable para las redes
orientadas a aplicaciones comerciales.
Este algoritmo ha sido motivo de gran controversia parte de ella se debe al
secreto que rodeó a su desarrollo. IBM trabajó en colaboración con la Agencia
Nacional de Seguridad de Estados Unidos y ambas guardaron el secreto de los
aspectos del diseño del algoritmo.
Cifrado con claves públicas
Muchos sistemas comerciales emplean métodos de cifrado / descifrado
basados en claves públicas. Este sistema está basado en el uso de claves
independientemente para el cifrado y para el descifrado de los datos. La
particularidad y enorme ventaja es que la clave y el algoritmo de cifrado pueden
ser de dominio público, siendo la clave de descifrado la que se mantiene en
secreto. Este método elimina los problemas logísticos y administrativos
relacionados con la distribución y gestión de las claves públicas.
Los sistemas basados en claves públicas no son tampoco infalibles ya que también
pueden romperse.
En cualquier caso, y para evitar que la clave pueda ser detectada, es
posible generar una clave distinta para cada transmisión, o de una forma más
realista, a intervalos periódicos o aleatorios. El cambio de clave frecuente aumenta
la seguridad de las transmisiones, ya que el posible intruso deberá intentar romper
la clave cada vez que ésta cambia.
Puede incluso añadirse otro nivel de seguridad, utilizando un sistema de claves
privadas para cifrar las claves públicas, es decir, pueden emplearse dos niveles de cifrado
para los datos más delicados.
Recomendaciones ISO relativas a la seguridad
El Organismo Internacional de Normalización (ISO) recomienda establecer
el cifrado en el nivel de presentación de la configuración según el modelo ISA.
Estas son las razones que aduce el ISO para ello:
1. Es importante colocar los servicios de cifrado en un nivel superior de red, para
poder simplificar el cifrado de extremo a extremo, y como el nivel más bajo donde
se dan los servicios extremo a extremo es en el nivel de transporte , es por ello,
que el cifrado se ha de realizar en un nivel superior a él.
2. Los servicios de cifrado han de estar en un nivel superior al de transporte si se
quiere minimizar la cantidad de programas a los que ha de confiarse el texto
legible. O sea, cuantos menos programas manejen el texto vulnerable mejor, lo
que nos lleva a deducir que el cifrado se debe realizar en el nivel superior al de
transporte.
3. El cifrado ha de establecerse por debajo del nivel de aplicación, ya que de lo
contrario las transformaciones sintácticas, sobre los datos cifrados serían
bastantes difíciles. Además, si el nivel de presentación se llevan a cabo
transformaciones sintácticas, éstas han de tener lugar antes de que se realice el
cifrado.
4. También se ha tenido en cuenta que el cifrado de datos se puede hacer de
forma selectiva, el organismo de ISO cree que donde mejor puede hacerse esta
selección es en el nivel de presentación o en uno superior, ya que por debajo de
este nivel no existe constancia de la división en campos de la corriente de datos.
5. Aunque el cifrado se puede realizar en cualquier nivel, la protección adicional
que obtienen los datos de usuario puede no compensar la sobrecarga de trabajo
que supone el cifrado.
Limitaciones de la Criptografía
Los algoritmos criptográficos tienden a degradarse en el tiempo. A medida
que pasa el tiempo los algoritmos de encriptación se van haciendo más fáciles de
quebrar debido al avance en la velocidad y potencia de los equipos de
computación. Todos los algoritmos criptográficos son vulnerables a los ataques de
fuerza bruta - tratar sistemáticamente con cada posible clave de encriptación,
buscando colisiones para funciones hash, factorizando grandes números, etc.- la
fuerza bruta se hace más fácil a medida que pasa el tiempo. En 1977 Martin
Gardner escribió que los números de 129 dígitos nunca serían factorizados, en
1994 se factorizó uno de esos números. Además de la fuerza bruta están los
avances en las matemáticas fundamentales que permiten nuevos métodos y
técnicas de criptoanálisis.
ANEXO 2
Diagramas del Flujo de
Información por Usuario
BIBLIOGRAFÍA
Aguirre Jorge Ramió (2000). Aplicaciones Criptográficas, Proyectos y Sistemas
Informáticos de la Universidad Politécnica de Madrid, España
Alberto C. (1999, 20 de Enero). Diseño Distribuido:
http://members.tripod.com/aguamar/dbinternet/dbdd.html
Besso Javier Alberto; Borghello Cristian Fabian (1999). El estado actual de la
tecnología de las Bases de Datos Distribuidas:
http://comunidad.ciudad.com.ar/argentina/entre_rios/dbinternet/sisdis5.htm
Besso Javier Alberto; Borghello Cristian Fabian (2000). Los Sistemas
Distribuidos: http://www.dbinternet.com.ar/sistdis.htm
Black Uyless (1998). Redes de Ordenadores. Protocolos, Normas e Interfases,
Rama
Bohnhoff P.; Janssen R.; Martin R. (1994). Fundamentos Cliente/Servidor. IBM.
Borghello Cristian Fabian, Besso Javier Alberto (1999). Los enfoques Top-Down
y Bottom-Up:
http://comunidad.ciudad.com.ar/argentina/entre_rios/dbinternet/metodo1.htm
Chat Forum (2002). How to UU-Encode a Large File and Send it in Parts:
http://email.about.com/library/weekly/aa112299-1.htm
De Miguel Tomas P. (1999, 18 de Enero). Bases de Datos Distribuidas:
http://greco.dit.upm.es/~tomas/cursos/bd/18dist/index.htm
Eddon Guy; Eddon Henry (1997). Active X Visual Basic 5.0, Mc Graw Hill
Ender (5 de Febrero de 2001). Lan´s y Ethernet:
http://www2.adi.uam.es/~ender/tecnico/tutorial.html
Estafeta (2000).http://www.estafeta.com.mx
GSC Grupo de Sistemas y Comunicaciones - Universidad Rey Juan Carlos (2001,
11 de Septiembre). Correo Electrónico:
http://gsyc.escet.urjc.es/docencia/cursos/fse-servidores/transpas/node7.html
Gurowich Nathan; Gurowich Orl (1999), Aprendiendo Visual Basic 5 en 21
Dias, Prentice Hall
Harry P. (1999, 29 de Julio). Bases de datos Distribuidas:
http://www.angelfire.com/ar/hary/bdistribuidas.html
Hernández Barbosa Oscar Daniel (1996). Apuntes de la materia, Bases de
Datos Distribuidas, Instituto Tecnológico de Colima
Huidobro José M. (1999). Comunicaciones, Paraninfo
Jiménez Raúl (2000, 19 de Marzo). Mandar E-mails con el winsock:
http://members.es.tripod.de/vbzone/docsmtp.htm
Lewis T. G. (1995) Where is client/server software headed? IEEE Computer,.
Marks Richard (1992). Documentation for UUEncode-Decode:
http://membrane.com/synapse/library/uuenc.html
Mowbray T. J.; Zahavi R. (1995). The Essential CORBA. John Wiley & Sons, Inc.
Navarro Juan E. (1998, 1 de Julio). Sistemas Distribuidos:
http://www2.ing.puc.cl/~jnavarro/iic2332/apuntes/apuntes_11.html
Orfali R.; Harkey D.; Edwards J. (1996). The Essential Distributed Objects
Survival Guide . John Wiley & Sons, Inc..
Poleo Carmelo (2000). Internet:
http://www.monografias.com/trabajos6/intert/intert.shtm
Pujolle Guy (1999). Telemática, Paraninfo
Purser Michael (1997). Redes de TeleComunicación y Ordenadores,
Díaz de Santos, S.A.
Ramos N. (1999). Comunicación y Redes:
http://anakena.diinf.usach.cl/~bibinfo/ramos/com_y_redes/cyr.html
Rodríguez J. (1999, 23 de Mayo). Diseño de Bases de Datos Distribuidas:
http://members.es.tripod.de/jrodr35/index.htm
Rossenberg J. (1997). Teach Yourself CORBA in 14 Days. Macmillan Computer
Publishing.
Rueda M (1999). Seminario de Bases de Datos Distribuidas:
http://www.fie.us.es/~mrueda/articulos/seminario-2.html
Serrano Adriana (2001). Intranets:
http://www.geocities.com/ahh_miedo/intranets.htm
Sheldom Tom (1995). Enciclopedia Lan Times De Redes (NetWorking),
McGraw-Hill
Tanenbaum Andrew S. (1995). Redes de Ordenadores, Prentice Hall
Tomas Jesús García (1998). Sistemas Y Redes Teleinformáticas, Sepa
UAEM Universidad Autónoma del Estado de México (2001). Panorama de los
Sistemas de Bases de Datos Distribuidos:
http://www.uaemex.mx/publica/informatica/boletin/panorama.htm
Ulternet (1997). Asesoria en Lan´s y Wan´s:
http://www.ulter.net/acerca/aseso.htm
UPM Universidad Politécnica de Madrid (1999). Sistemas Distribuidos:
http://jungla.dit.upm.es/~rdor/tema3/paq8.htm
UPM Universidad Politécnica de Madrid (2000). Bases de Datos Distribuidas:
http://www-oei.eui.upm.es/Asignaturas/BD/Distribuidas.htm
Vela Jose Emiro (1999). Introducción a Redes:
http://www.monografias.com/trabajos/introredes/introredes.shtml
Zaslavsky Arkady (2002, 22 de Febrero). Distributed Databases:
http://www.ct.monash.edu.au/~azaslavs/cot5200_link/ddb-l-03s/index.htm
CONCLUSIONES
CONCLUSIONES
El tema principal de esta tesis son los sistemas de bases de datos
distribuidas, y es satisfactorio mencionar que se lograron implementar los
siguientes objetivos de estos sistemas; tener autonomía local, no depender de un
sitio
central,
ofrecer
operación
continua,
transparencia
de
localización,
transparencia de fragmentación, transparencia de replica, transparencia de red;
así como también se logra hacer un trabajo en un tema de interés personal.
Los objetivos de la tesis se cumplieron,
ya que se logro desarrollar el
prototipo cumpliendo con los conceptos de los sistemas de bases de datos
distribuidas y se lograría mejorar los procesos de la empresa, dando así una mejor
respuesta en la actualización de la información y lo más importante, se lograría
tener la información disponible al momento en que está se genera, sin importar el
lugar en el que se esta generando.
Para que se llegara a instalar este sistema se tendría que proponer,
primero, al gerente general de la empresa en Colima para que éste lo propusiera
con sus superiores y después vendría una evaluación por parte del grupo de
desarrollo de la empresa, lo cual en mi particular punto de vista sería muy difícil
que se aprobara, por eso es que esta tesis propone el sistema como un prototipo,
aunque sería importante que lo tomaran en cuenta ya que les ofrece muchas
facilidades y muchas ventajas en comparación son su sistema actual.
Existe un pequeño inconveniente con este prototipo, trabaja bajo el sistema
operativo Windows, la empresa cuenta en cada plaza con servidores UNIX lo cual
tendría como consecuencia que se cambiara de sistema operativo, servidores
Windows NT y terminales con Windows 95, 98, 2000 o ME, aunque no sería
necesaria la adquisición de un servidor muy sofisticado ya que el equipo que
tienen, cuenta con la capacidad suficiente para que soporte este sistema.
Con este prototipo, se mejoraría el sistema actual y los procesos que están
implementados en la empresa Estafeta para el control de los números de guía de
paquetes. Así también se lograría optimizar su infraestructura ya establecida (red
privada), y no sería necesario implementar algún otro sistema de comunicación
entre las distintas plazas de la empresa.
La implementación de éste prototipo permitiría a los administradores y
personas encargadas de atender a los clientes, saber en cualquier momento y en
cualquier plaza, donde está un paquete en especial, lo cual dará lugar a que la
información que soliciten los clientes sea la más precisa referente a la ubicación
de su paquete.
El prototipo reduciría tiempos de espera en la actualización de la
información, los encargados de los departamentos de sistemas de las diferentes
plazas ya no tendrían que esperar a que la central les envié la información
actualizada de la ubicación de los paquetes.
El desarrollo de este prototipo dio lugar a que se aplicara un gran número
de los temas vistos en clase (redes, comunicaciones, programación, etc),
abarcando en un gran porcentaje el propósito de la maestría.