Web Semántica
Anuncio

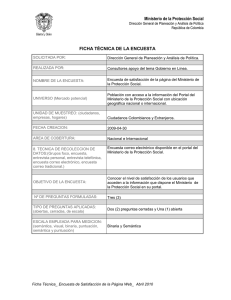
Web Semántica Raquel Arenas Prieto Marta García González I.T.T. Telemática Universidad Carlos III Leganés, Madrid I.T.T. Telemática Universidad Carlos III Leganés, Madrid [email protected] [email protected] RESUMEN En este trabajo abordaremos el tema de la Web Semántica, que es una extensión de la Web actual en la que la información tiene un significado bien definido no sólo para los seres humanos, sino también para las máquinas y los agentes inteligentes. La principal ventaja que puede surgir de este descubrimiento es la de facilitarnos las tareas de búsqueda a los internautas y hacernos más sencillo encontrar la información que deseamos, quitándonos gran parte del trabajo manual que estas búsquedas requieren. Términos Generales Web, Semántica, buscadores, agentes, lógica. Figura 1: Resultados con un buscador normal. Palabras Clave 1.2 ¿Qué es la Web Semántica? Agentes Inteligentes, ontologías, OWL, RDF, XML, XML Schema, DTD, metadatos, Web Services. 1. INTRODUCCIÓN 1.1 ¿Cómo funciona Internet hoy? En la actualidad, todos los usuarios de Internet hemos podido comprobar por nuestra propia experiencia diaria, que la Web de hoy en día, está constituida por una cantidad inmensa de información poco estructurada y escasamente definida. Una de las causas que explican este problema, es que la Web actual se basa principalmente en documentos escritos en lenguaje HTML. Este lenguaje tan extendido, nos permite codificar hipertextualmente imágenes, textos, sonidos y multimedia, pero su problema radica en que está orientado a la presentación de datos y la información que ofrece es muy limitada, por lo que se puede decir que no permite describir datos y no es extensible. Por ejemplo, si un usuario desea buscar todos los vuelos a Praga para mañana por la mañana, con un buscador normal y corriente, no obtendrá los resultados que realmente desea y tendrá que ir descartando la información que no le interese, de un modo bastante laborioso y pesado que requiere perder bastante tiempo. Le aparecerán todo tipo de resultados que contengan información sobre Praga pero que nada tienen que ver con lo que realmente solicita. La Web Semántica es una Web extendida y dotada de mayor significado, en la que los internautas podrán encontrar respuestas a sus preguntas de forma rápida y sencilla gracias a una información mejor definida. Para conseguirlo, se propone describir los recursos de la web con representaciones procesables y entendibles no sólo por las personas, sino también por programas que puedan reemplazar a los seres humanos en tareas rutinarias de búsqueda que requieren gran cantidad de tiempo y esfuerzo por nuestra parte. La semántica de los elementos webs, se deberá codificar mediante lenguajes de metadatos y ontologías. La Web Semántica, por tanto, se apoya en lenguajes universales y en agentes inteligentes que resuelven los problemas ocasionados por una web carente de significado. Estos agentes, recorrerán la Web a través de los enlaces entre recursos (hiperdocumentos, ontologías,...) en busca de aquella información que les sea solicitada, pudiendo además interactuar con el entorno para el cumplimiento de estas tareas. Por ejemplo, un agente inteligente, ante una consulta dada, podría consultar autónomamente un buscador, y a partir de sus resultados, explorar la Web hasta encontrar la información solicitada, pudiendo finalmente llevar a cabo una acción sobre dicho recurso. Siguiendo con el ejemplo que habíamos puesto anteriormente para explicar el funcionamiento de Internet hoy en día, vamos a ejemplificar ahora como quedaría la misma búsqueda si el usuario hubiera escrito esa misma información en un buscador semántico. En este caso, los resultados serían muy distintos ya que la Web Semántica nos ofrece una búsqueda exacta. Si el usuario, por ejemplo, buscase desde España o desde cualquier otro país, su ubicación geográfica sería detectada automáticamente sin necesidad de especificarla. Elementos de la oración como "mañana" adquirirían significado, convirtiéndose en un día concreto calculado en función de un "hoy". Algo semejante ocurriría con el segundo "mañana", que sería interpretado como un momento determinado del día. Todo ello a través de una Web en la que los datos pasan a ser información llena de significado. El resultado final sería la obtención de forma rápida y sencilla de todos los vuelos a Praga para mañana por la mañana. Figura 2: Resultados con un buscador semántico. o o o Para obtener esa adecuada definición de los datos, la Web Semántica utiliza esencialmente herramientas como RDF, SPARQL, y OWL, mecanismos que ayudan a convertir la Web en una infraestructura global en la que es posible compartir, y reutilizar documentos entre diferentes tipos de usuarios. En los siguientes apartados, hablaremos de todos estos mecanismos en detalle. Este proyecto tan sumamente interesante, fue impulsado por el World Wide Wide Consortium (W3C) dentro de uno de sus dominios de actividades, el denominado Technology & Society. El fundador y director del W3C, Tim Berners Lee, es el principal artífice. Según palabras textuales de Berners Lee, la definición de Web Semántica es la siguiente: “Una web semántica es una red de datos que pueden ser procesados directa o indirectamente por máquinas. Es una web extendida que permitirá a humanos y máquinas trabajar en cooperación mutua.” o 2. CAPAS DE LA WEB SEMÁNTICA Berners Lee propuso que la infraestructura de lenguajes y tecnologías que posibilitan la implementación de la Web Semántica se dividiese en distintas capas o niveles. o o o o o Unicode: Es el alfabeto, la codificación de texto que permite utilizar caracteres y alfabetos internacionales para que así no aparezca ningún símbolo extraño que pueda ser ininteligible. De este modo, podemos tener información expresada en cualquier idioma en la Web Semántica. URI (Uniform Resource Identifier): Son cadenas que permiten que podamos acceder de forma inequívoca a cualquier recurso de la Web. Se trata de la URL y el URN. En la Web Semántica, las URIs, funcionarán como identificadores de objetos del mundo real. Todos los objetos se podrán identificar mediante estas URIs. Esta forma de identificar a los objetos puede acarrear el problema de que varios usen la misma URI como identificador, tema que está intentando resolver el W3C. XML+NS+xmlschema: Es la capa más técnica de la Web Semántica. En esta capa se agrupan tecnologías diferentes que posibilitan la comunicación entre agentes. XML (Extensible Markup Language) es el lenguaje que se utiliza actualmente para intercambiar datos en la red. NS (namespaces) proporciona un método para cualificar elementos y atributos de nombres usados en documentos XML asociándolos con espacios de nombres identificados por referencias URIs. XML Schema es un lenguaje para describir la estructura y restringir el contenido de documentos XML. La relación entre XML y XML Schema es una relación de control sintáctico. RDF+rdfschema: Define un lenguaje universal con el que podemos expresar diferentes ideas en la Web Semántica. RDF es un lenguaje que define un modelo de datos para describir recursos mediante tripletas sujeto-predicado-objeto. Los dos primeros serán URIs y el tercero puede ser URI o un valor literal. RDF Schema es un vocabulario RDF que nos permite describir recursos mediante una orientación a objetos. Esta capa no sólo ofrece una descripción de los datos, sino también cierta información semántica. Lenguaje de ontologías: Son conceptualizaciones que definen el significado de un conjunto de conceptos para un determinado dominio. Las ontologías se expresan en lenguajes formales como OWL. Lógica: Permite determinar si los datos son correctos e inferir conclusiones a partir de ellos. Pruebas: Las pruebas verifican y explican los pasos de los razonamientos lógicos. Confianza: Hasta que no se haya comprobado de forma exhaustiva las fuentes de información, los agentes deberían ser muy escépticos acerca de lo que leen en la Web Semántica. Firma digital: Concepto de comercio seguro. Es empleada por los ordenadores y agentes para verificar que la información ha sido ofrecida por una fuente de confianza. 3. PRINCIPALES COMPONENTES y TECNOLOGÍAS EMPLEADAS Figura 3: Capas en las que se divide la Web Semántica Entre los principales componentes de la Web Semántica podemos encontrar XML, RDF y OWL. Así como el uso de taxonomías, ontologías y metadatos para categorizar los elementos de forma jerárquica y que la web adquiera mayor significado semántico. 3.2 XML Mientras que HTML es un lenguaje de marcado para documentos de hipertexto, XML es un lenguaje de marcado para documentos de todas las clases. Se dice que XML es extensible porque permite al programador asociar sus propias etiquetas (metadatos) a los datos. XML representa una primera aproximación a la web semántica, y aunque no está expresamente pensado para dar significado semántico, es el estándar más extendido hoy día en las aplicaciones que se están acercando a esta Web. Este lenguaje permite estructurar datos y documentos en forma de árboles de etiquetas con atributos. Los documentos XML, están formados por unidades de almacenamiento llamadas entidades que contienen datos procesados o sin procesar. Los datos procesados están formados por caracteres, algunos de los cuales forman datos de carácter y otros de marcas. Las marcas codifican la descripción del esquema de almacenamiento y la estructura lógica del documento, y pueden establecer mecanismos de restricción tanto al esquema de almacenamiento como a la estructura lógica. Se separan los datos de la representación y del procesamiento, así permite mostrar y procesar los datos como se desee, dependiendo de las diferentes aplicaciones u hojas de estilo empleadas. Figura 4: Mapa Conceptual de la Web Semántica 3.1 Metadatos y Lógica Uno de los aspectos más importantes del XML es que es un conjunto de tecnologías basadas en otros estándares abiertos, que forman módulos opcionales y que amplían sus posibilidades. Algunos de estos módulos son: Dos de los principales factores a los que debemos la construcción de la Web Semántica son a los metadatos y a la lógica proposicional aplicada sobre dichos metadatos. o Los metadatos, son datos altamente estructurados que describen información. Pueden detallar colecciones de objetos y también los procesos en los que están involucrados, describiendo cada uno de los eventos, sus componentes y cada una de las restricciones que se les aplican. Definen las relaciones entre objetos generando estructuras y permiten una serie de ventajas a la hora de la búsqueda y recuperación del texto. o Al aportar valor semántico a los datos incluidos dentro de una página web, los buscadores pueden encontrar información asociada al código de dichas páginas. Como ejemplo podemos hablar de las etiquetas meta de las páginas, que proporcionan información sobre el contenido de una página sin necesidad de que el texto sea analizado. o El mayor problema que puede derivarse del uso de los metadatos es que éstos no se gestionan de una manera automática, lo que obliga a que el propio creador de la web sea el que se tiene que preocupar de crear y gestionar las etiquetas meta, algo problemático si los contenidos cambian o si son muy grandes. Todo esto supone que el futuro de la Web Semántica se vea retrasado hasta que no se generalicen los sistemas automáticos para la recuperación y organización de la información. En cuanto a la lógica, hay que decir que es otro de los puntos clave en el desarrollo de la web del futuro. Gracias a ella, podemos analizar los conceptos utilizados para la elaboración de conclusiones a partir de una información dada. Estas conclusiones son importantísimas, ya que son las que utilizarán los agentes inteligentes para tomar decisiones, ejecutar acciones y colaborar entre ellos. o o o o o DTD (Document Type Definition): Es un conjunto de declaraciones de elementos, atributos y entidades que le indican a un sistema exactamente el tipo de etiquetado que se utiliza en dicho documento. XML Schema: Es similar a un DTD pero más estricto. Un esquema permitiría a un procesador validar el documento por inconsistencias de una forma más apropiada. XML Namespaces: Es una especificación que describe como asociar una URI con cada etiqueta y atributo en un documento XML. CSS: Es el lenguaje de hojas de estilo, básicamente presentacional. XSL : Es un lenguaje avanzado para expresar hojas de estilo, que se basa en XSLT (eXtensible Stylesheet Language Transformation) para la transformación de documentos desde el punto de vista del contenido. DOM: es un conjunto estándar de funciones para realizar llamadas, desde un lenguaje de programación, para manipular ficheros XML. Xlink : Describe como añadir hiperenlaces a un fichero XML. XPointer y Xfragments : Son sintaxis que indican la forma de apuntar a una parte, dentro de un documento XML. El aspecto de un documento XML es similar al mostrado en el ejemplo de la figura. <?xml version="1.0" encoding="ISO-8859-1" ?> <!DOCTYPE Edit_Mensaje SYSTEM "Lista_datos_mensaje.dtd" [<!ELEMENT Edit_Mensaje (Mensaje)*>]> <Edit_Mensaje> <Mensaje> procese documentos o un agente inteligente, las etiquetas carecen de significado. <Remitente> <Nombre>Nombre del remitente</Nombre> <Mail> Correo del remitente </Mail> </Remitente> <Destinatario> <Nombre>Nombre del destinatario</Nombre> <Mail>Correo del destinatario</Mail> </Destinatario> <Texto> <Asunto>Este es mi documento</Asunto> <Parrafo>Este es mi documento</Parrafo> </Texto> </Mensaje> </Edit_Mensaje> Figura 4: Ejemplo de documento XML Como hemos podido observar en el ejemplo, un documento XML consiste en una serie anidada de etiquetas abiertas y cerradas, donde cada etiqueta tiene ciertos valores. Es asunto del programador definir los nombres de las etiquetas y sus combinaciones permitidas. Para ello es para lo que se usan los documentos DTD que mencionábamos o los XML Schemas. Los DTD y los Schemas son usados por los analizadores sintácticos para comprobar si un documento XML es válido, o lo que es lo mismo, para comprobar si cumple con su gramática. <?xml version="1.0" encoding="ISO-8859-1" ?> <!-- Este es el DTD de Edit_Mensaje --> <!ELEMENT Texto)*> Mensaje (Remitente, Destinatario, <!ELEMENT Remitente (Nombre, Mail)> <!ELEMENT Nombre (#PCDATA)> <!ELEMENT Mail (#PCDATA)> <!ELEMENT Destinatario (Nombre, Mail)> <!ELEMENT Nombre (#PCDATA)> <!ELEMENT Mail (#PCDATA)> <!ELEMENT Texto (Parrafo)> <!ELEMENT Asunto (#PCDATA)> <!ELEMENT Parrafo (#PCDATA)> Figura 5: Ejemplo de DTD para el XML de la figura 4 Pese a las ventajas que se le atribuyen a este lenguaje, por sí solo no proporciona una interoperabilidad completa, ya que no incorpora mecanismos para garantizar la interoperabilidad semántica. XML sirve para especificar el formato y la estructura de cualquier documento, pero no impone ninguna interpretación común de los datos del documento. Dado un documento XML, no se pueden reconocer en él los objetos y relaciones del dominio de interés. Cuando una persona lee un DTD asociado a un determinado XML, puede extraer la semántica de sus elementos prestando atención a las etiquetas que lo componen y puede interpretar la información semánticamente. En cambio, para un programa que 3.3 RDF RDF es una base para procesar metadatos que proporciona interoperabilidad entre aplicaciones que intercambian información legible por máquina en la Web. Destaca por la facilidad para habilitar el procesamiento automatizado de los recursos Web. Puede utilizarse en distintas áreas de aplicación; por ejemplo: en recuperación de recursos para proporcionar mejores prestaciones a los motores de búsqueda, en catalogación para describir el contenido y las relaciones de contenido disponibles en un sitio Web, una página Web, o una biblioteca digital particular, por los agentes inteligentes para facilitar el intercambio y para compartir conocimiento; en la calificación de contenido, en la descripción de colecciones de páginas que representan un documento lógico individual, para describir los derechos de propiedad intelectual de las páginas web, y para expresar las preferencias de privacidad de un usuario, así como las políticas de privacidad de un sitio Web. RDF junto con las firmas digitales será la clave para construir una Web de confianza para el comercio electrónico, la cooperación y otras aplicaciones. Uno de los objetivos de RDF es hacer posible especificar la semántica para las bases de datos en XML de una forma normalizada e interoperable. RDF y XML son complementarios: RDF es un modelo de metadatos y sólo dirige por referencia muchos de los aspectos de codificación que requiere el almacenamiento y transferencia de archivos. Para estos aspectos, RDF cuenta con el soporte de XML. Para describir los recursos se recurre a RDF en lugar de a XML porque XML no es apropiado para incluir semántica. El modelo de un dominio puede representarse con varias DTDs o varios XML Schemas, y una DTD o un Schema pueden corresponder a muchos modelos distintos. Suele decirse que RDF es un lenguaje, pero en realidad es un modelo de metadatos. La construcción básica es una sentencia formada por un sujeto, un predicado y un objeto. El sujeto, identifica a qué se refiere la sentencia. El predicado es la parte que identifica la característica del sujeto a la que se refiere la sentencia. Y la parte que identifica el valor de la propiedad es el objeto. Los sujetos, los predicados y los objetos son recursos. Los recursos con que trabaja RDF no son necesariamente recursos presentes en la Web: pueden ser personas, animales, números de teléfono, etc. En general, un recurso RDF es cualquier cosa con identidad. Para identificarlos se recurre a los URI, que como hemos mencionado ya en apartados anteriores, son como unos URL universales. Cualquier organización o persona puede crear URIs y usarlos para trabajar con sus dominios de interés. Los URIs pretenden referirse a un mismo recurso ubicado en distintas localizaciones. Además de en forma de sentencias de sujeto, predicado y objeto, las sentencias RDF pueden representarse también en XML. La ventaja de utilizar la representación de XML en RDF consiste en que podemos utilizar todas las herramientas existentes para XML. Se pueden aprovechar los analizadores sintácticos, las transformaciones XSLT, la representación en memoria de los objetos XML (DOM, SAX), etc. RDF no se asocia a ningún dominio en particular, lo podemos emplear en cualquier campo. Cada persona puede definir su propia terminología mediante lo que se conoce como RDF Schema, que está definido en función de sentencias RDF. Por ejemplo, en el dominio de una biblioteca, podríamos definir mediante el esquema de RDF un vocabulario concreto que podría estar formado por las palabras autorDe, tieneCarnetDeSocio, etc. Resulta necesario definir este esquema ya que permite comprobar si un conjunto de metadatos resulta válido o no para ese esquema. Al disponer de este esquema nos aseguramos de que las propiedades aplicadas a los recursos sean correctas y si los valores vinculados a las propiedades tienen sentido. Estos esquemas, al contrario que los de XML o los DTD que sólo se limitan a especificar el orden y las combinaciones de etiquetas que son aceptadas, especifican que interpretación hay que dar a las etiquetas de un modelo de datos RDF. RDF Schema es similar a los lenguajes de orientación a objetos. 3.4 Ontologías RDF no es la mejor solución para describir recursos de una manera compatible con los objetivos de la Web Semántica. Para conseguir esto, hay que recurrir a lenguajes de descripción del conocimiento más avanzados, a lenguajes formales de ontologías que dan significado semántico a los archivos y documentos que nos podemos encontrar en la Red. Las ontologías son una tecnología imprescindible para conseguir la Web Semántica. Con ellas, los usuarios organizarán la información de tal manera que los agentes inteligentes puedan interpretar el significado. Gracias al conocimiento almacenado en las ontologías, las aplicaciones podrán extraer automáticamente datos de las páginas webs, procesarlos y sacar conclusiones de ellos, así como tomar decisiones y negociar con otros agentes o personas. Las ontologías proceden del campo de la Inteligencia Artificial. Son vocablos comunes para las personas y aplicaciones que trabajan en un dominio. La descripción de un modelo de interés se llama modelo conceptual del dominio. Los modelos conceptuales deben transformarse en una forma que pueda almacenarse en la memoria de los ordenadores y que permita aplicar algoritmos. semántica formal. OWL tiene tres sublenguajes, con un nivel de expresividad creciente: OWL Lite, OWL DL, y OWL Full. Como ya hemos mencionado anteriormente, la Web semántica se basará en la capacidad de XML para definir esquemas de etiquetas a medida y en la aproximación de RDF para representar datos. El primer nivel requerido por encima de RDF para la Web semántica es un lenguaje de ontologías que pueda describir formalmente el significado de la terminología usada en los documentos Web. Si se espera que las máquinas hagan tareas útiles de razonamiento sobre estos documentos, el lenguaje debe ir más allá de las semánticas básicas del RDF Schema. OWL ha sido diseñado para cubrir esta necesidad de un lenguaje de ontologías Web y forma parte de un conjunto creciente de recomendaciones del W3C relacionadas con la Web Semántica Recapitulando, XML proporciona una sintaxis superficial para documentos estructurados, pero no impone restricciones semánticas en el significado de estos documentos. XML Schema, se utiliza para restringir la estructura de los documentos XML, además de para ampliar XML con tipos de datos. RDF, es un modelo de datos para objetos y relaciones entre ellos. Este tipo de modelo de datos puede ser representado en una sintaxis XML. Por último, RDF Schema es un vocabulario utilizado para describir propiedades y clases de recursos RDF, con una semántica para la generalización y jerarquización tanto de propiedades como de clases. OWL, añade más vocabulario para describir propiedades y clases: entre otros, relaciones entre clases, cardinalidad, igualdad, características de propiedades y clases enumeradas. OWL proporciona tres lenguajes, cada uno con nivel de expresividad mayor que el anterior, diseñados para ser usados por comunidades específicas de desarrolladores y usuarios. OWL Lite está diseñado para aquellos usuarios que necesitan principalmente una clasificación jerárquica y restricciones simples. Por ejemplo, a la vez que admite restricciones de cardinalidad, sólo permite establecer valores cardinales de 0 ó 1. OWL DL está diseñado para aquellos usuarios que quieren la máxima expresividad conservando completitud computacional (se garantiza que todas las conclusiones sean computables), y resolubilidad (todos los cálculos se resolverán en un tiempo finito). OWL DL incluye todas las construcciones del lenguaje de OWL, pero sólo pueden ser usados bajo ciertas restricciones (por ejemplo, mientras una clase puede ser una subclase de otras muchas clases, una clase no puede ser una instancia de otra). OWL Full está dirigido a usuarios que quieren máxima expresividad y libertad sintáctica de RDF sin garantías computacionales. Por ejemplo, en OWL Full una clase puede ser considerada simultáneamente como una colección de clases individuales y como una clase individual propiamente dicha. OWL Full permite una ontología para aumentar el significado del vocabulario preestablecido (RDF ó OWL). Es poco probable que cualquier software de razonamiento sea capaz de obtener un razonamiento completo para cada característica de OWL Full. Toda ontología modela, mediante conceptos y relaciones, lo que se conoce sobre un dominio o un área de conocimiento. Se suelen representar mediante clases y restricciones sobre los atributos y propiedades de las clases. Son una herramienta para compartir información y conocimiento y para conseguir la interoperabilidad. Cuando definimos un nuevo vocabulario formal de los conceptos del dominio y un conjunto de relaciones entre ellos, esto permite que las aplicaciones „comprendan‟ la información. 3.4.1 OWL El Lenguaje de OWL está diseñado para ser usado en aplicaciones que necesitan procesar el contenido de la información en lugar de únicamente representar información para los humanos. OWL facilita un mejor mecanismo de interpretabilidad de contenido Web que los mecanismos admitidos por XML, RDF, y RDF Schema, proporcionando vocabulario adicional junto con una 4. AGENTES INTELIGENTES Aplicaciones de integración de fuentes de datos heterogéneas: permitirán obtener, agrupar y correlacionar información dispersa en Internet sobre un dominio determinado. Ejemplo: deportes, noticias, cine, etc. Aplicaciones de anotación semántica de contenidos multimedia: estas aplicaciones permitirán catalogar los contenidos multimedia de forma semántica, pudiéndose realizar catálogos de contenidos personalizados para los usuarios, descubrimiento de nuevos recursos multimedia de interés para el usuario, etc. Aplicaciones de adaptación automática de contenidos en base a su anotación semántica: servirán para que los contenidos web sean adaptados dinámicamente teniendo en cuenta su semántica y la personalización asociada al usuario. Actualmente existen mecanismos automáticos de adaptación de contenidos, pero basados únicamente en aspectos sintácticos de las páginas. Aplicaciones para las empresas: son aplicaciones encaminadas a mejorar los mecanismos actuales de gestión de las empresas, explotando al máximo el nuevo abanico de posibilidades que ofrecen las tecnologías y plataformas de la Web Semántica. Para potenciar el uso de las ontologías en la Web, se necesitan aplicaciones específicas de búsqueda de ontologías que indiquen a los usuarios las ontologías existentes y sus características para utilizarlas en su sistema. En este sentido, se entiende por Agente Inteligente a una entidad de software que recoge, filtra y procesa la información contenida en la Web y realiza inferencias sobre dicha información interactuando con el entorno sin necesidad de supervisión constante por parte del usuario. Un agente inteligente debe ser: Comunicativo: debe entender las necesidades, objetivos y preferencias del usuario y debe poder comunicarse con el entorno mediante representaciones compartidas de conocimiento (ontologías). Capaz: no sólo debe proporcionar una información, sino también un servicio, es decir, debe tener capacidad para hacer cosas. Por ejemplo, si se precisa un artículo de revista y ésta es de pago, el agente debe ser capaz de encontrar el artículo, informar del precio, dar el número de tarjeta de crédito, etc. Autónomo: el agente debe poder interactuar también con el entorno, tomando decisiones y actuando por sí solo, limitando sus acciones según el nivel de autonomía permitida por el usuario. Adaptativo: debe ser capaz de aprender del entorno: preferencias de usuarios, fuentes de información y de otros agentes, etc. 5. APLICACIONES DE LA WEB SEMÁNTICA Existen multitud de campos donde son aplicables las tecnologías de la Web Semántica, a algunos de ellos no se les ha sacado partido aún. A continuación vamos a hacer una breve clasificación mencionando cuáles son estas aplicaciones: Aplicaciones de búsqueda: como hemos indicado ya a lo largo de todo nuestro trabajo, las tecnologías de la Web Semántica permiten desarrollar buscadores avanzados aplicados a distintos dominios. Los dominios con mayor potencial son la administración pública, la medicina, las búsquedas sociales, el empleo, las artes, la ciencia, la política, la economía, la gestión del conocimiento, etc. Los buscadores más avanzados disponibles en la actualidad, llevan a cabo el proceso de búsqueda utilizando técnicas clásicas de recuperación de información basadas en la ocurrencia de determinadas palabras clave en las páginas. Utilizan una búsqueda sintáctica, no semántica. Las tecnologías de web semántica van a permitir construir buscadores semánticos que complementarán a los tradicionales. Aplicaciones de asistencia al usuario: estas aplicaciones están relacionadas con los agentes personales de usuario que permiten realizar búsquedas avanzadas en Internet, descubrimiento de servicios, composición de servicios, etc. 6. INTEGRACIÓN: WEB SERVICES Un web service es un conjunto de aplicaciones o tecnologías con capacidad para interoperar en la Web. Estas aplicaciones o tecnologías intercambian datos entre sí con el objetivo de ofrecer servicios. Los proveedores ofrecen sus servicios como procedimientos remotos y los usuarios solicitan un servicio llamando a estos procedimientos a través de la Web. Se pueden reutilizar desarrollos empleados sin importar la plataforma en la que funcionan o el lenguaje en el que están escritos. Los Web Services se constituyen en una capa adicional a estas aplicaciones de forma que pueden interactuar entre ellas, a partir del uso de tecnologías estándares para comunicarse, desarrolladas en el contexto de Internet por organismos importantes de estandarización como: ANSI, IEEE, ISO y W3C. Actualmente, gran parte de los presupuestos destinados al diseño y mantenimiento de sistemas de información se dedican a resolver problemas de integración entre aplicaciones, de forma que puedan comunicarse independientemente de su plataforma operativa en tiempo real. Muchas de las compañías líderes del mercado de software han concebido un nuevo método mediante el cual solucionar el problema de la heterogeneidad e interoperabilidad entre aplicaciones web mediante el diseño y mantenimiento de los Web Services. El desarrollo de servicios web como aplicaciones en entornos distribuidos y descentralizados, básicamente utiliza las siguientes tecnologías: - Un formato que describa la interfaz del componente (sus métodos y atributos) basado en XML. Por lo general, este formato es el WSDL. - Un protocolo de aplicación basado en mensajes que permita que una aplicación interactúe con el Web Service. Por lo general, este protocolo es SOAP. La búsqueda que queremos realizar son los FOAF que contengan el nombre de Bill Clinton: Seleccionamos documentos FOAF: - Estructuras parecidas a las bases de datos que organizan los servicios web; así como especificaciones que definen un camino para publicar y descubrir información sobre los servicios Web mediante el estándar UDDI. - Un protocolo de transporte que se encargue de transportar los mensajes por Internet. Suele usarse HTTP. Los Web Services no son, por tanto, aplicaciones con una interfaz gráfica con los que las personas puedan interactuar, sino que son software accesible en Internet o en redes privadas que utilizan tecnologías de Internet en lugar de otras aplicaciones. De esta forma, pueden desarrollarse aplicaciones que hagan uso de otras, que estén disponibles en Internet e interactúen con ellas. En este sentido, un aspecto de suma importancia para la puesta en marcha y mejora de la web semántica es la existencia de herramientas de soporte y la re-utilización de ontologías que puedan utilizar los Web Services para recuperarlas, mediante una plataforma que una entornos de desarrollo de aplicaciones para la web semántica y un módulo de conexión a servicios web para la búsqueda y recuperación de ontologías. Empresas como Hewlet Packard y la National University of Ireland trabajan desde hace unos años en una plataforma orientada al descubrimiento, descripción y mediación entre Web Services en el marco de la web semántica conocida como Semantic Web Enabled Web Services. El Computer Science and Electrical Engineering Department de la Universidad de Maryland, desarrolló también un proyecto de investigación, iniciado en el año 2004 y finalizado en el 2006, que consiste en un buscador temático llamado Swoogle, con una interfaz de consulta muy sencilla que recupera ontologías codificadas en RDF, OWL y DAML+OIL mediante esta plataforma de intercambio de Web Services. Añadimos lo que buscamos: Y esto es lo que obtenemos: 7. EJEMPLOS WEB SEMÁNTICA Como ejemplos vamos a mostrar distintos “proyectos” de buscadores web que ya se encuentran activos. 7.1 Semantic Web Search Es un motor de búsqueda que localiza tanto vocabularios como recursos basados en vocabulario RDF, RSS, FOAF, DOAP, calendarios y otras aplicaciones RDF. Es un proyecto que se enfoca a visualizar la Web Semántica puesto que se basa en gráficos conceptuales. Su aspecto es el siguiente: 7.2 Swoogle Semantic Web Search http://swoogle.umbc.edu/ desarrollado por la Universidad de Maryland (Baltimore, USA). Se trata de un buscador que busca ontologías (tiene indizadas más de 10.000), documentos y términos escritos tanto en RDF como OWL, esto es, busca documentos de la Web Semántica o Semantic Web Documents (SWDs). Curiosamente, tanto su propio nombre como su interfaz de presentación son muy similares a los de Google. Pero éste no llega a mostrar páginas HTML que es lo que busca un usuario no especializado. Como ejemplo vamos a hacer una búsqueda: 7.3 The Semantic Web Search Engine SWSE Este buscador se define como uno de los motores de recuperación y búsqueda de datos de la Web Semántica, y presume de proporcionar resultados más acertados que los buscadores tradicionales. Se presenta a través de una interfaz HTML, aunque se advierte que no es operativo para el buscador Internet Explorer por problemas de compatibilidad de JavaScript. SWSE implementa las funcionalidades típicas de los motores de recuperación de documentos XML/RDF: búsqueda a través de semánticas RDF u OWL, cuyas ontologías y vocabularios permiten afinar las búsquedas. El contenido a indexar proviene de la exploración de la web mediante su framework MultiCrawler que le permite recopilar RDF, HTML y XML, convirtiendo estos dos últimos tipos en XML/RDF antes de añadirlos al índice. La recuperación de documentos XML/RDF se realiza de la siguiente forma: Se introduce la palabra de búsqueda. Se elige uno de los resultados obtenidos o bien permite refinar la búsqueda usando el filtro que ofrece el buscador: archivos de Wikipedia, FOAF Document, FOAF Person, RSS, etc. A continuación una muestra de una búsqueda con este buscador: [2] Web Semántica Hoy. http://www.wshoy.sidar.org/index.php?2005/12/09/30ontologias-que-son-y-para-que-sirven [3] Texto en la Wikipedia sobre la Web Semántica http://es.wikipedia.org/wiki/Web_sem%C3%A1ntica [4] Artículo sobre la Web Semántica http://web-semantica.org/advocacy/introduccion-websemantica [5] Web Semántica: Agentes Inteligentes http://personales.upv.es/ccarrasc/doc/20032004/websemag/agentes.htm 8. LAS BÚSQUEDAS EN EL FUTURO Lo que se espera para el futuro de las búsquedas es lo que nos muestra como publicidad “True Knowledge” en su página: http://www.trueknowledge.com/ en formato video. En el cual nos dice que no solo nos dará una lista de enlaces, sino que además podrá proporcionarnos respuesta a preguntas concretas. En el ejemplo del video nos dice que a la pregunta “¿está Jennifer López soltera?” el buscador devolverá además de los distintos enlaces relacionados con información sobre su matrimonio, nos responderá un “NO” por respuesta. 9. CONCLUSIONES [6] Pablo Castells, Universidad Autónoma de Madrid. La web semántica. http://arantxa.ii.uam.es/~castells/publications/castellsuclm03.pdf [7] Fundación Telefónica. Boletín de la Sociedad de la Información: Tecnología e Innovación. La Web Semántica, la Siguiente Generación de Webs (04-04-2007). http://sociedaddelainformacion.telefonica.es/jsp/articulos/det alle.jsp?elem=4299 [8] Web Semántica y Agentes. http://websemanticayagentes.blogspot.com/2007_05_01_arc hive.html La conclusión que podemos sacar al finalizar este trabajo, es que cuando se consiga llevar a cabo realmente la Web Semántica, el usuario final no tendrá problema alguno en adaptarse a ella, ya que claramente ayudará a las búsquedas que se realicen y facilitará nuestra labor, ahorrándonos gran cantidad de tiempo y trabajo. En cambio, para los programadores de páginas y los gestores de buscadores, supondrá un cambio muy grande de mentalidad y trabajo extra, puesto que ahora mismo se cuelgan y programan los documentos para Internet sin pensar en absoluto en las búsquedas ni en la capacidad metarrepresentacional de la información. Si queremos avanzar y llegar a ver cumplido este gran proyecto, habrá que programar los ficheros pertinentes para la Web en lenguajes propicios que sean capaces de representar el aspecto semántico de la información. De este modo, las máquinas serán capaces de „entender‟ el lenguaje humano, todo gracias a las ontologías y a que el lenguaje humano posee información de naturaleza metarrepresentacional que hará posible la creación de programas que simulen artificialmente la inteligencia. [9] Keylin Rodríguez Perojo, Rodrigo Ronda León. Web semántica: un nuevo enfoque para la organización y recuperación de información en el web. 10. REFERENCIAS [15] Luis Criado tiene un blog: [1] Maestros del Web http://www.maestrosdelweb.com/editorial/web-semantica-ysus-principales-caracteristicas/ http://bvs.sld.cu/revistas/aci/vol13_6_05/aci030605.htm [10] Lluis Codina, Cristofol Rovira. Recursos sobre la Web Semántica. Revista Española de Documentación Científica, vol. 29, n. 2, Abril-Junio 2006, p. 297-305. [11] Sebastián Bonilla. Web Semántica y Agentes Metarrepresentacionales basados en Marcadores Discursivos. [12] Miguel Ángel Abián. El futuro de la Web. [13] Web Motores Recuperación http://motoresrecuperacion.tripod.com/sws.html [14] María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen. http://www.hipertexto.info/documentos/web_semantica.htm http://lcriadof.blogspot.com/2008/06/situacin-de-losbuscadores-semnticos.html