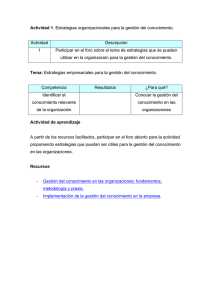
Ubicación de Actividades - Universidad Veracruzana
Anuncio

Ubicación de Actividades Cursos Preforo: Contribuciones Libres: CR1: Galindo CR2: Osuna CR3: Nelson CR1: 1, 3, 5, 7, 9, 11 y 13 (CR 1) (CR 2) (CR 3) Un solo salón (CR 4) Cursos Foro: CR1: Lebart CR3: 2, 4, 6, 8, 10, 12 y 14 Inauguración, Magistrales y Clausura: CR4 Asamblea General de la AME: CR2 CR2: Barrios Brindis de Bienvenida: Jardín Sur CR3: Multion y SAS e s t ro ó n i g Re ripci c ins Carteles y Stands: Foyer XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ PROGRAMA PREFORO _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística ________________________________________________________________________________________________________________ PROGRAMA PREFORO (Cursos Cortos) HORA DOMINGO 7 9:00 – 11:00 LUNES 8 Dra. Galindo 11:00 – 11:30 Dra. Osuna MARTES 9 Dr. Nelson Descanso para café 11:30 – 13:30 Dra. Galindo 13:30 – 16:00 Dra. Osuna Dra. Galindo Dra. Osuna Dra. Osuna Dr. Nelson Descanso para café Dr. Nelson Receso para Comida 16:00 – 17:00 Dra. Galindo HORA Dr. Nelson Dra. Galindo Dra. Osuna 11:00 – 11:30 Dr. Nelson Receso para Comida Dra. Galindo Dra. Osuna 9:00 – 11:00 11:30 – 13:30 13:30 – 16:00 Dr. Nelson 16:00 – 17:00 Registro 17:00 – 17:30 17:30 – 18:30 Cursos Cortos (Hotel Sede) 18:30 – 20:30 Descanso para café Dra. Galindo Dra. Osuna Descanso para café Dr. Nelson Dra. Galindo Dra. Osuna 17:00 – 17:30 Dr. Nelson 17:30 – 18:30 Junta Mesa Directiva de la AME Registro XXIII Foro Nacional de Estadística (Hotel Sede) 18:30 – 20:30 ________________________________________________________________________________________________________________ 4 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CURSOS PREFORO _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística ____________________________________________________________________________________________________________ AVANCES EN ANÁLISIS DE DATOS MULTIVARIANTES Dra. Purificación Galindo Departamento de Estadística Universidad de Salamanca, España Descripción: Se expondrán los avances que se tienen en Análisis de Datos Multivariantes, partiendo desde cuando se trata de analizar una sola matriz de datos, cuando se trata de analizar la relación que existe entre dos matrices de datos y análisis de k matrices de datos. Programa: 1. Análisis de una matriz de datos: Análisis de Componentes Principales, GH-Biplot, JK-Biplot, HJ-Biplot, Análisis de Correspondencias, Modelo de Respuesta Gaussiana y Análisis Indirecto del Gradiente. 2. Análisis de las relaciones entre dos matrices de datos: Análisis Canónico de Correspondencias, Análisis de la Co-Inercia y CoCorrespondence Analysis. 3. Análisis de k matrices de datos: STATIS DUAL, STATIS CANÓNICO, CCA Asimétrico y AFM Asimétrico. ____________________________________________________________________________________________________________ 5 XXIII Foro Nacional de Estadística ____________________________________________________________________________________________________________ ANÁLISIS ESTADÍSTICO DE DATOS TEXTUALES Dra. Zulaima Osuna Departamento de Estadística Consejo Nacional de Universidades Caracas, Venezuela Descripción: Se expondrán las diferentes metodologías para el Análisis de Datos Textuales desde la perspectiva estadística, bajo los enfoque lexicométricos o de la estadística textual, apoyados en las técnicas estadísticas desarrolladas por la Escuela Francesa de Análisis de Datos (Analyse des Données) y el modelo vectorial propuesto por Salton y McGill. Los participantes al final del curso podrán sintetizar la información latente contenida en un corpus. Programa: 4. Introducción al Análisis de Datos Textuales. Abordaremos su definición, el concepto de estadística textual, unidades tratables, protocolos lexicométricos, corpus, y lematización. 5. Metodología general del análisis de datos textuales. Tablas Léxicas y/o matriz de co-ocurrencia, Análisis Factorial de Correspondencia, ponderación de unidades tratables y reglas de interpretación. 6. Los Métodos Biplots como herramienta alternativa del análisis de datos textuales. Fundamentos teóricos de los Biplots, AC como solución particular de los Métodos Biplots. 7. Identificación de palabras características mediante un Biplot Robusto. 8. Aplicación práctica. ____________________________________________________________________________________________________________ 6 XXIII Foro Nacional de Estadística ____________________________________________________________________________________________________________ ANÁLISIS DE DATOS DE CONFIABILIDAD Y SUPERVIVENCIA Dr. Wayne Nelson Consultor Internacional (USA) Descripción Se describirán diferentes métodos para recolectar y analizar datos de confiabilidad y supervivencia, hacia la mejora del diseño, desarrollo, ensayo, fabricación y gestión de productos para hacerlos más confiables y de menor costo. Los participantes aprenderán cómo recolectar y analizar eficientemente datos de ensayo y de servicio, que permitan obtener información para la gestión y mejora de la confiabilidad de productos. Programa 1.- Introducción al análisis de datos de supervivencia y reparación de productos. Se expondrán los métodos básicos para el Análisis de Datos de Supervivencia y Reparación de productos. 2.- Distribuciones para confiabilidad y supervivencia. Conceptos básicos: distribución acumulada, gráficos de probabilidad, función de confiabilidad, percentiles y tasa de falla. Propiedades de las distribuciones exponenciales, de Weibul, logarítmico-normal, etc. 3.- Análisis gráfico para datos de confiabilidad y supervivencia. Poblaciones y muestras, datos válidos, falla y uso, los tipos de datos (completos, censurados, intervalos) y la información deseada. 4.- Análisis por computadora y de datos con modos de falla. Cómo utilizar software para obtener estimadores, límites de confianza, y verificar los modelos aplicados. Reseña sobre diferentes opciones de software. 5.- Análisis de datos de reparación y de eventos recurrentes. Conceptos básicos para eventos recurrentes: función acumulada de historia de cada unidad, modelo de la población, función acumulada promedio (FAP), y la tasa de recurrencias. ____________________________________________________________________________________________________________ 7 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ PROGRAMA FORO _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística ________________________________________________________________________________________________________________ PROGRAMA GENERAL (Sesión matutina) HORA MIERCOLES 10 8:30-9:55 Cursos Barrios y Lebart col. JUEVES 11 SAS Contribuciones libres Lebart Curso Barrios y col. VIERNES 12 Multion Consulting Contribuciones libres Lebart Cursos Barrios y col. HORA SAS 8:30-9:55 Contribuciones libres Sesión 11 10:00 – 11:35 Sesión 2 Sesión 1 Estadística Bayesiana I 11:35 – 12:00 Diseños Factoriales y Confiabilidad Sesión 5 Análisis Multivariado I Sesión 6 Modelos de Regresión Descanso para café Descanso para café Contribuciones libres Contribuciones libres Modelos Lineales y Modelos Lineales Generalizados Sesión 12 Descanso para café 13:35 – 16:00 Series de Tiempo, Estadística Espacial y Estadística EspacioTemporal 11:35 – 12:00 Contribuciones libres Sesión 3 12:00 – 13:35 10:00 – 11:35 Estadística Bayesiana II Sesión 14 Sesión 7 Sesión 4 Prueba de Hipótesis Comida Teoría y Aplicaciones de Valores Extremos Sesión 8 Sesión 13 Análisis Multivariado II Estadística Comida Multivariada III Tesis ganadoras del Premio FAO 12:00 – 13:35 y Muestreo Comida 13:35 – 16:00 ________________________________________________________________________________________________________________ 8 XXIII Foro Nacional de Estadística ________________________________________________________________________________________________________________ PROGRAMA GENERAL (Sesión vespertina) HORA MIERCOLES 10 JUEVES 11 Conferencia Magistral II 16:00 – 17:00 Ceremonia de Inauguración 17:00 – 18:00 18:00 – 18:30 VIERNES 12 HORA Conferencia Magistral IV 16:00 – 17:00 Conferencia Magistral I Purificación Galindo Villardón Conferencia Magistral III Rubén Hernández Cid Ludovic Lebart Javier Rojo Descanso para café Descanso para café Descanso para café 18:00 – 18:30 Ceremonia de Clausura 18:30-19:40 José M. González-Barrios Conferencia Magistral V 17:00 – 18:00 Contribuciones libres 18:30 – 19:40 Carteles Sesión 9 Sesión 10 Datos Censurados Divulgación 19:40 – 20:00 Receso 20:00 Brindis de Bienvenida Asamblea General de la AME Registro al Foro y entrega de material en el Hotel Sede: • Martes 9 de septiembre de 18:30 a 20:30 hrs. • Miércoles y Jueves de 8:30 a 10:00 hrs. ________________________________________________________________________________________________________________ 9 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CURSOS FORO _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística ____________________________________________________________________________________________________________ ESTADÍSTICA TEXTUAL: VISUALIZACIÓN Y VALIDACIÓN Ludovic Lebart Télécom-ParisTech Centre National de la Recherche Scientifique, Paris Para describir y comparar textos, la estadística textual incorpora métodos procedentes de la estadística exploratoria multidimensional, esencialmente los métodos de clasificación automática, los mapas autoorganizativos de Kohonen y el análisis de correspondencias. Dichas herramientas operan a partir del recuento sistemático de las distintas palabras del corpus de textos de partida. Las respuestas a preguntas abiertas en las encuestas constituyen un campo de aplicación privilegiado. El curso insistira sobre los métodos de visualización grafica y sobre la validación de ellos mediante varias formas de bootstrap. Programa 1. Introducción: El marco de la estadística textual. Elección de las unidades. 2. Los datos estructurados. El caso de las respuestas a preguntas abiertas. 3. Las herramientas básicas: análisis de correspondencias, clasificación jerárquica, mapas de Kohonen, métodos de seriación. Complementaridad de los diversos enfoques. 4. Palabras y respuestas características. 5. Estabilidad de los resultados. Aplicación del bootstrap (bootstrap parcial, total, específico). Validación de los mapas obtenidos. Regiones de confianza. 6. Una herramienta relacionada: La semiometria. 7. Aplicaciones prácticas con los softwares DTM y Lexico3. ____________________________________________________________________________________________________________ 10 XXIII Foro Nacional de Estadística ____________________________________________________________________________________________________________ PROGRAMACIÓN EN “R PARA ESTADÍSTICA Ernesto Barrios, Elías y Luís Felipe González Investigadores del Instituto Tecnológico Autónomo de México (ITAM) R es un sistema para análisis estadísticos y gráficos creado por Ross Ihaka y Robert Gentleman. R tiene una naturaleza doble de programa y lenguaje de programación y es considerado como un dialecto del lenguaje S creado por los Laboratorios AT&T Bell. S está disponible como el programa S-PLUS comercializado por Insightful. R se distribuye gratuitamente bajo los términos de la GNU (General Public Licence); su desarrollo y distribución son llevados a cabo por varios estadísticos conocidos como el Grupo Nuclear de Desarrollo de R. R posee muchas funciones para análisis estadísticos y gráficos; estos últimos pueden ser visualizados de manera inmediata en su propia ventana y ser guardados en varios formatos (jpg, png, bmp, ps, pdf, emf, pictex, xfig; los formatos disponibles dependen del sistema operativo). Los resultados de análisis estadísticos se muestran en la pantalla, y algunos resultados intermedios (como valores P-, coeficientes de regresión, residuales, etc.) se pueden guardar, exportar a un archivo, o ser utilizados en análisis posteriores. Programa 1. Introducción y manipulación de datos. 2. Graficación y muestreo. 3. Simulación y paquetes. ____________________________________________________________________________________________________________ 11 XXIII Foro Nacional de Estadística ____________________________________________________________________________________________________________ ANALISIS MULTIVARIADO CON STATA 10 Jesús Pérez Multion Consulting Se expondrá brevemente las capacidades y ventajas de Stata para el manejo y depuración de bases de datos, la aplicación de técnicas del análisis multivariado como son el análisis de componentes principales, el análisis de factores, análisis discriminante y análisis cluster enfatizando la rapidez y eficiencia de los algoritmos propios de Stata al momento de obtener los resultados y su interpretación, con lo cuales el usuario optimiza el tiempo en la obtención de resultados. Usando datos del Índice de Desarrollo Humano (IDH) de la República Mexicana. ____________________________________________________________________________________________________________ 12 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONFERENCIAS MAGISTRALES _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONFERENCIA MAGISTRAL I Miércoles 10 de Septiembre, 2008 17:00-18:00 ESTADÍSTICA MULTIVARIADA EN LA INVESTIGACIÓN EN CIENCIAS SOCIALES Rubén Hernández Cid ITAM, México. Resumen Como cualquier disciplina científica, la Estadística tiene orígenes muy diversos, en ocasiones un tanto desconocidos o francamente olvidados. Esta charla, principalmente dirigida a los estudiantes de nivel licenciatura, tiene como objetivo mostrar algunas de las relaciones entre la Estadística Multivariada y algunas áreas de las Ciencias Sociales (principalmente la Sociología). De manera particular se analiza el estudio de fenómenos complejos por medio del análisis de matrices de datos censales tomando como ejemplo el fenómeno de la marginación en México durante los últimos veinte años. _______________________________________________________________________________________________________ 13 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONFERENCIA MAGISTRAL II Jueves 11 de Septiembre, 2008 16:00-17:00 STATIS y AFM, ante cambios Alfa, Beta y Gamma Ma. Purificación Galindo Villardón Universidad de Salamanca, España. Resumen En este trabajo se analiza el comportamiento de los métodos STATIS y AFM ante la presencia de cambios Alfa, Beta y Gamma y se pone de manifiesto que ni el RV utilizado en el método STATIS, ni el Lg utilizado en el AFM, son útiles a la hora de definir qué tipo de cambio se produce entre una estructura y otra. _______________________________________________________________________________________________________ 14 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONFERENCIA MAGISTRAL III Jueves 11 de Septiembre, 2008 17:00-18:00 RESAMPLING TECHNIQUES FOR ASSESSING THE VISUALISATIONS OF MULTIVARIATE DATA Ludovic Lebart Telecom-Paris Tech, Paris. Abstract Multivariate descriptive techniques involving singular values decomposition (such as Principal Components Analysis, Simple and Multiple Correspondence analysis) may provide misleading visualisations of the data. We briefly show that several types of resampling techniques could be carried out to assess the quality of the obtained visualisations: a) Partial bootstrap, that considers the replications as supplementary variables, without diagonalization of the replicated moment-product matrices. b) Total bootstrap type 1, that performs a new diagonalization for each replicate, with corrections limited to possible changes of signs of the axes. c) Total bootstrap type 2, which adds to the preceding one a correction for the possible exchanges of axes. d) Total bootstrap type 3, that implies procrustean transformations of all the replicates striving to take into account both rotations and exchanges of axes. e) Specific bootstrap, implying a resampling at different levels (case of a hierarchy of statistical units). Examples are presented and discussed for each technique. _______________________________________________________________________________________________________ 15 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONFERENCIA MAGISTRAL IV Viernes 12 de Septiembre, 2008 16:00-17:00 UNA PRUEBA DE ASOCIATIVIDAD PARA CÓPULAS José M. González-Barrios y Arturo Erdely IIMAS UNAM, México. Resumen En esta plática se presentará una nueva estadística pareja de variables aleatorias continuas con cópula para probar si unos datos aleatorios de tamaño , provenientes de una , satisfacen la condición de asociatividad, es decir si la cópula satisface la condición para todas Esta condición es básica para que la cópula . pertenezca a la familia de cópulas arquimedeanas. También se incluirán algunos ejemplos para checar la potencia de la prueba. Finalmente se harán algunos comentarios acerca del comportamiento asintótico de la estadística . _______________________________________________________________________________________________________ 16 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONFERENCIA MAGISTRAL V Viernes 12 de Septiembre, 2008 17:00-18:00 INFERENCIA SOBRE LA COLA DE DISTRIBUCIONES DE PROBABILIDAD Javier Rojo Universidad de Rice, Houston, TX, EU. Resumen Se presentará un resumen de conceptos acerca de la pesadez de las colas de las distribuciones de probabilidad, se incluirán conceptos para categorizar distribuciones. Se presentará una nueva metodología para probar hipótesis sobre la pesadez de la cola junto con resultados sobre la potencia de esta prueba. _______________________________________________________________________________________________________ 17 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CONTRIBUCIONES LIBRES _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 1: ESTADÍSTICA BAYESIANA I Miércoles 10 de septiembre 10:00-11:35 1. 10:00-10:20 Curvas Bayesianas de Mortalidad Primer autor (Ponente): Manuel Mendoza Segundo: Daniel Straulino Resumen: La tabla que actualmente se utiliza para el cálculo de las llamadas reservas legales para el seguro de vida en México se produjo en el año 2000 a partir de un modelo de regresión Bayesiano. Recientemente se ha planteado la actualización de esa tabla y con ese motivo se han considerado algunas ideas que parten de la misma base pero producen resultados más robustos. En esta plática se examina el proceso que se ha seguido hasta ahora. 2. 10:25-10:45 Métodos Variacionales como una Alternativa para los MCMC Primer autor (Ponente): Guadalupe Eunice Campiran García Segundo: Eduardo Gutiérrez Peña Resumen: Para aproximar la distribución a posteriori en estadística bayesiana se utilizan los métodos de simulación MCMC, desafortunadamente en problemas con muchas variables, resultan sumamente lentos. En esta plática se presentara otro enfoque diferente, en donde la distribución a posteriori será aproximada por métodos variacionales que son más rápidos ya que no involucran simulaciones. _______________________________________________________________________________________________________ 18 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. 10:50-11:10 Estimación de Toxicidades en un Ensayo Clínico Fase III: Inferencia Bayesiana para Respuestas Ordinales Anidadas en Respuestas Categóricas Primer autor (Ponente): Luis G León-Novelo Segundo: Xian Zhou Tercero: B. Nebiyou Bekele Cuarto: Peter Muller Resumen: Consideramos el modelaje de respuestas ordinales anidadas en respuestas categóricas. Extendemos el modelo Bayesiano Probit multinominal (MNP por sus siglas en inglés) tomando en cuenta la posible dependencia entre las respuestas en las diferentes categorías. Introducimos una mezcla de distribuciones normales para las variables latentes asociadas con los datos ordinales esta mezcla en el modelo permite fijar los parámetros de puntos de corte que ligan la variable latente con la respuesta ordinal observada. Además, esta mezcla hace más flexible la estimación de la probabilidad de que una observación pertenezca a cierto nivel dentro de cierta categoría que la tradicional regresión ordinal probit Bayesiana con puntos de corte aleatorios. Aplicamos este modelo a un ensayo clínico aleatorio fase III para comparar tratamientos en base a las toxicidades registradas por efecto tóxico y grado dentro de cada tipo de efecto. Los datos incluyen el nivel de toxicidad de cada tipo de efecto tóxico para cada paciente. El hecho de que algunos pacientes presenten más de un efecto tóxico incluye una fuente adicional de dependencia más que modelamos con un efecto aleatorio específico para cada paciente. 4. 11:15-11:35 Un Modelo Bayesiano para Regresión Circular-Lineal Primer autor (Ponente): Gabriel Núñez Antonio Segundo: Eduardo Gutiérrez Peña Tercero: Gabriel Escarela Resumen: Los datos direccionales se encuentran de manera natural en muchas áreas y son especialmente comunes en las ciencias biológicas y geofísicas. Particularmente, Arnold y SenGupta (2006) presentan un panorama general de la aplicación de datos direccionales en las ciencias ecológicas y del medio ambiente. Por otro lado, este tipo de observaciones aparece a menudo _______________________________________________________________________________________________________ 19 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ en modelos de regresión como la variable de respuesta. El análisis de datos direccionales requiere de técnicas estadísticas especiales, dada la periodicidad inherente de este tipo de observaciones. Más aún, la aplicación de técnicas convencionales puede conducir a resultados no adecuados si no se toma en cuenta la diferencia entre la topología del círculo y la de la línea recta. Los modelos de regresión propuestos en la literatura que tratan las respuestas circulares como escalares sufren de varias dificultades que los hacen poco prácticos para el análisis de tales datos (ver por ejemplo, Downs y Mardia, 2002, y Presnell et al. 1998). En este trabajo se presenta una propuesta de análisis, desde el punto de vista Bayesiano, vía la introducción de variables latentes y el uso de métodos MCMC, de un modelo de regresión lineal bivariado para datos circulares con covariables lineales. Este modelo considera las respuestas circulares como proyecciones, sobre el círculo unitario, de vectores parcialmente observables. Se discute el problema de datos faltantes en la variable respuesta y el uso de un criterio predictivo para la selección de covariables. _______________________________________________________________________________________________________ 20 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 2: DISEÑOS FACTORIALES Y CONFIABILIDAD Miércoles 10 de septiembre 10:00-11:35 1. 10:00-10:20 Análisis Robusto de Factoriales Fraccionales no Replicados Primer autor (Ponente): Víctor Aguirre Segundo: Román de la Vara Resumen: Los métodos de análisis para experimentos factoriales fraccionales que no contemplan la posibilidad de datos atípicos tienen un desempeño pobre cuando esta posibilidad se convierte en realidad. Mostramos un método basado en regresión robusta que tiene una buena habilidad aun en presencia de datos contaminados. 2. 10:25-10:45 Fractional Factorial Designs in the Analysis of Categorical Data Primer autor (Ponente): Alexander Von Eye Resumen: In this contribution, first, fractional factorial designs are reviewed, with an emphasis on Box-Hunter designs. Based on the Sparsity of Effects Principle, it is argued that, when higher order effects are indeed unimportant in most hypotheses, fractional designs can be used without loss of information. Fractional factorial designs can be specified such that the desired level of interactions can be interpreted. Given a fixed amount of time and money, these designs allow one to include more factors in a study than completely crossed designs, or to increase the sample. It is then shown that, when the outcome variables are categorical, the same principles apply. It is also shown that, to obtain the same resolution, higher order effects need to be specified when the outcome variables are categorical. Parameter interpretation is illustrated for a selection of fractional factorial designs. The application of fractional factorial designs is illustrated in both explanatory and exploratory contexts. An empirical data set is analyzed using the fractional and the complete information. It is illustrated that distortion from only using the fractional information can be minimal. _______________________________________________________________________________________________________ 21 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. 10:50-11:10 Comparación de Errores de Medida de dos Instrumentos ¿cómo Estudiar una Desviación Estándar con una sola Medida? Primer autor (Ponente): Wayne Nelson Resumen: This talk presents a comparison of two measuring instruments for statistically significant differences between their sample means and standard deviations of measurement error. In application, a number of specimens were each measured twice with one instrument and just once with the other. The pairs of measurements with the firs instrument readily yield an estimate of the standard deviation of its measurements error. This talk shows to estimate the standard deviation of measurement error of the second instrument when there is just one measurement on each specimen. The estimate is illustrated with measurements (below) of the depth of craters produced in metal specimens by impact of steel balls. 4. 11:15-11:35 Análisis de Tiempos entre Fallas considerando Riesgos en Competencias Primer autor (Ponente): Julio César Villegas Segundo: Raúl Villa Diharce Resumen: Considere un componente o equipo que presenta interrupciones en su funcionamiento en los tiempos t1, t2,…,tn . Suponga que los paros del equipo son provocados por dos causas: 1. Reparación motivada por falla 2. Ejecución de mantenimiento preventivo o predictivo Del esquema anterior se tiene que, además de contar con los tiempos de paro ti, también se cuenta con una “etiqueta” o “identificador” ci que señala la causa por la cual el equipo dejó de operar, esto es, los datos con los que se cuenta, son de la siguiente forma: (t1,c1) (t2,c2),…, (tn,cn) con ti 0 y ci= 1,2 para i= 1,2,…,n . a este tipo de datos se les conoce como datos de riesgos en competencia. Un problema interesante que surge en este contexto es el de valorar la calidad del mantenimiento que se da al equipo, para lo cual se podría estar interesado, por ejemplo, en las distribuciones de probabilidad marginales de los tiempos de falla y tiempos de mantenimiento. Se presentan algunos modelos para datos de riesgos en competencia y se ejemplifica la inferencia con datos provenientes de una bomba centrífuga utilizada en una refinería. _______________________________________________________________________________________________________ 22 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 3: SERIES DE TIEMPO, ESTADÍSTICA ESPACIAL Y ESTADÍSTICA ESPACIO-TEMPORAL Miércoles 10 de septiembre 12:00-13:35 1. 12:00-12:20 Métodos Multivariados en la Determinación de Puntos de Corte Dinámicos Primer autor (Ponente): Belem Trejo Valdivia Segundo: Ximena Duque López Tercero: Sergio Flores Hernández Resumen: En la población general las deficiencias de micronutrientes son un problema de salud pública y en particular, la deficiencia de hierro durante el primer año de vida es un problema importante. Tradicionalmente se ha asociado a la anemia con deficiencia de hierro pero se puede tener deficiencia de hierro sin anemia y anemia por otras causas. Los marcadores biológicos más usados para diagnosticar deficiencia de hierro y anemia son la concentración de ferritina sérica y de hemoglobina, respectivamente. Cuando la ferritina sérica es menor que 10 ng/ml se habla de deficiencia de hierro, mientras que si la hemoglobina es menor que los valores normales para la edad, se habla de anemia. Por otro lado, los niños nacidos a términos tienen concentraciones altas de ferritina pero ésta va disminuyendo rápidamente en sus primeros meses de vida. Debido al rápido crecimiento de los niños durante el primer año de vida y a la necesidad de un aporte externo de hierro a partir de los 6 meses de edad, se considera que durante el primer año de vida los niños están en mayor riesgo de presentar deficiencia de hierro. De lo anterior, surge la siguiente pregunta: ¿Es adecuado el uso de un solo punto de corte para identificar deficiencia de hierro a través de la concentración de en niños menores de 1 año? Un solo punto de corte no parece tomar en cuenta el proceso natural de disminución de las reservas corporales de hierro durante el primer año de vida, ni otras características como sexo o la concentración de hemoglobina. En esta plática se discute el uso de métodos multivariados de agrupamiento para determinar puntos de corte de ferritina sérica a lo largo del primer año y para evaluar los patrones de asociación entre los niveles de ferritina sérica y hemoglobina durante la misma etapa. Se utiliza información proveniente de un ensayo clínico aleatorizado cuyo objetivo es el de evaluar el efecto de una suplementación profiláctica con hierro para prevenir la deficiencia de hierro en niños durante el primer año de vida. _______________________________________________________________________________________________________ 23 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 2. 12:25-12:45 Diseño en Procesos Gaussianos Primer autor (Ponente): J. Andrés Christen Resumen: Presentamos algunos avances en el diseño de experimentos computacionales usando Procesos Gaussianos (GP) como modelos sustitutos. Un GP es ajustado a datos provenientes de un “experimento computacional” (modelo matemático “resuelto” numéricamente, con diversos niveles de aproximación, usualmente siendo un procedimiento computacionalmente extremadamente demandante). Este modelo de GP se le llama sustituto (surrogate, en inglés). Es muy importante el diseño experimental para minimizar y optimizar la cantidad de evaluaciones que se hacen del experimento computacional. Nosotros ensayamos con la estrategia de “Active Learning” (AL), proveniente del área de robótica, que trata de maximizar la reducción en varianza predictiva para encontrar puntos de diseño. Usando una serie de aproximaciones considerando resultados conocidos de álgebra lineal (desigualdades de Weyl) establecemos un score para maximizar y encontrar diseños adecuados, que es muchísimo más fácil y rápido de calcular diseños AL. Se presenta un ejemplo simulado, con una rejilla de 10,200 puntos, y otro real de un experimento computacional (de clima global) desarrollado en el MIT, con una rejilla de 426 puntos. 3. 12:50-13:10 Modelos Espaciales de Regresión Primer autor (Ponente): Alejandro Alegría Resumen: Hace poco más de cien años Galton (1889) hizo notar que las inferencias obtenidas al realizar comparaciones, con observaciones supuestamente independientes, pueden ser equivocadas si la variable de interés se ve afectada no solo por los atributos que se comparan, sino también por un efecto de difusión entre las unidades de observación, el cual produce cierto tipo de dependencia entre las observaciones. Por ejemplo, la respuesta de las personas ante un incentivo o un tratamiento no depende solamente de los atributos individuales de las personas, sino de la estructura del sistema al que pertenecen, su posición dentro del mismo y de las interacciones con otros individuos. En este caso, una forma de modelar la dependencia entre observaciones es por medio de los modelos espaciales de regresión. El propósito de esta plática es mostrar la forma de este modelo así como algunas de sus propiedades, y ejemplificar su uso. Es conveniente mencionar que en estos modelos se puede usar una noción de distancia diferente a la usual distancia euclidiana. _______________________________________________________________________________________________________ 24 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 4. 13:15 – 13:35 Procesos Puntuales tipo Shot-Noise y su Aplicación al Modelado Espacial y Temporal de Incendios Forestales Primer autor (Ponente): Carlos Díaz Ávalos Resumen: Los procesos puntuales espaciales constituyen una herramienta que ha sido utilizada con éxito en el modelado de fenómenos que se presentan de manera localizada (eventos), tales como epicentros de terremotos, brotes de enfermedades, ocurrencia de actos delictivos y distribución de mamíferos marinos, entre muchos otros. En la mayoría de los casos, estos fenómenos pueden definirse en el espacio tridimensional compuesto por el espacio y el tiempo. Dado que la presencia del fenómeno bajo estudio raramente es homogénea, es necesario utilizar modelos que sean capaces de modelar el agregamiento de eventos que usualmente se observa en la naturaleza. En este trabajo se presenta una descripción de los procesos puntuales tipo shot-noise y se presenta un ejemplo de aplicación al modelado de incendios forestales. _______________________________________________________________________________________________________ 25 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 4: PRUEBA DE HIPÓTESIS Miércoles 10 de septiembre 12:00-13:35 1. 12:00-12:20 Prueba de White modificada para Heterogeneidad de Varianza Primer autor (Ponente): Araceli Martínez-Franco Segundo: Gustavo Ramírez-Valverde Tercero: Benito Ramírez-Valverde Resumen: La prueba de White (1980) para detectar heterogeneidad de varianzas es una prueba que no requiere que se especifique estructura alguna a las varianzas, motivo que la hizo popular, al grado de ser la prueba que en forma automática realizan algunos paquetes estadístico (SAS, E-Views y Stata, etc.); sin embargo, algunos estudios sugieren que esta prueba no debería ser empleada por su baja potencia (Lyon-Tsai, 1996 y Dios-Rodríguez, 1999). En este trabajo se propone una modificación a la prueba de White para mejorar su potencia. Mediante un estudio de simulación, la potencia y el tamaño de la prueba propuesta son evaluados y comparados con algunas pruebas alternativas. 2. 12:25-12:45 Una Estrategia para el Cálculo del Nivel de Significancia Real de las Pruebas de no-Inferioridad para dos Proporciones Primer autor (Ponente): David Sotres Ramos Segundo: Félix Almendra Arao Tercero: Cecilia Ramírez Figueroa Resumen: Las pruebas de no-inferioridad son frecuentemente utilizadas en la investigación clínica para demostrar que un tratamiento nuevo (con mínimos efectos secundarios o bajo costo) no es sustancialmente inferior en eficacia que el tratamiento estándar. Un problema práctico importante que presentan las pruebas de no-inferioridad es el cálculo del nivel de significancia real de la prueba. Este problema se presenta debido a que por la mera formulación de las hipótesis de no-inferioridad el espacio _______________________________________________________________________________________________________ 26 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ nulo de parámetros es una región contenida en el plano. En este trabajo se presenta una prueba un resultado que facilita de manera muy importante el cálculo de dicho nivel de significancia real. Se presentan varias aplicaciones de este resultado, entre ellas se explica cómo fue posible construir tablas para el uso de la prueba exacta de Farrington-Manning. 3. 12:50-13:10 Pruebas de Bondad de Ajuste para la Distribución Normal Asimétrica Primer autor (Ponente): Paulino Pérez Rodríguez Segundo: José A. Villaseñor Alva Resumen: En este trabajo se proponen dos pruebas de bondad de ajuste para la distribución normal asimétrica, basadas en propiedades de esta familia de distribuciones y el coeficiente de correlación. Los valores críticos para las pruebas son obtenidos utilizando simulación Monte Carlo. La potencia de las pruebas propuestas es comparada con las estudiadas por Mateu et al. (2007) usando simulación Monte Carlo y la estudiada por Meintanis (2007) utilizando Bootstrap paramétrico. Los resultados muestran que las pruebas propuestas son más potentes que las estudiadas por Mateu et al. y Meintainis varias de las alternativas consideradas. 4. 13:15-13:35 Comparación de dos Enfoques para el Contraste de Hipótesis Estadísticas en un Modelo Lineal Funcional Primer autor (Ponente): María Guzmán Segundo: Eduardo Castaño Resumen: Este trabajo compara por vía de un ejemplo con datos reales de un experimento en tecnología de alimentos, a dos enfoques para contrastar hipótesis estadísticas relevantes cuando en el experimento la variable de respuesta puede pensarse como funcional y los factores toman valores reales; los procedimientos corresponden a los desarrollados por Ramsay y Silverman (2005) y por Abramovich et al (2004), respectivamente. Las diferencias de los enfoques se comentan en los siguientes aspectos: en la base utilizada para la representación funcional de los datos y correspondiente grado de suavizamiento en tal representación, en la estructura del error en los modelos estadísticos supuestos, y en el criterio de optimalidad utilizado para desarrollar el _______________________________________________________________________________________________________ 27 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ procedimiento de contraste respectivo. El objetivo de esta comparación es esclarecer desde el punto de vista práctico la facilidad de uso de los procedimientos comparados. _______________________________________________________________________________________________________ 28 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 5: ANÁLISIS MULTIVARIADO I Jueves 11 de septiembre 10:00-11:35 1. 10:00-10:20 Biplot versus Coordenadas Paralelas Primer autor (Ponente): Purificación Galindo Villardón Segundo: Purificación Vicente Villardón Tercero: Carlomagno Araya Alpízar Resumen: En este trabajo realizaremos un estudio comparativo de dos técnicas de representación de datos multivariantes: los Métodos BIPLOT (Gabriel, 1971; Galindo, 1986) y las Coordenadas Paralelas (Inselberg, 1992). Presentaremos la interpretación en coordenadas paralelas de los conceptos variabilidad, correlación, contribuciones, perfiles multivariantes, etc., los cuales son clave en los análisis Biplot. Aplicaremos ambos métodos al estudio de la caracterización multivariante de las preferencias de los sociólogos de finales del siglo XX, para poner de manifiesto las similitudes y diferencias entre ambos métodos, así como sus ventajas e inconvenientes. 2. 10:25-10:45 Cuantificación de Variables Categóricas Mediante Análisis Multivariante no Lineal: una Aplicación al Estudio del Perfil de Mujeres Inmigrantes en Situación Laboral Irregular, en España Primer autor (Ponente): Mª Carmen Patino Alonso Segundo: Mª Purificación Vicente Galindo Tercero: Mª Elena Vicente Galindo Cuarto: Purificación Galindo Villardón Resumen: Es muy frecuente encontrar publicaciones en las cuales intervienen variables expresadas en escala tipo Licker las cuales son analizadas estadísticamente como si fueran variables cuantitativas. Sin embargo, es bien conocido que esa forma de _______________________________________________________________________________________________________ 29 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ análisis no captura la información contenida en los datos de manera óptima. Tomando como escenario de referencia el Sistema Gifi, es posible obtener el mejor conjunto de cuantificaciones simples de un sistema multivariante, de forma que se minimice la pérdida de información inherente a la reducción de la dimensionalidad del sistema original. En este trabajo utilizamos el método HOMALS para cuantificar las categorías de las variables nominales y/o ordinales y para describir las relaciones entre esas variables en un subespacio de baja dimensión, de tal forma que la homogeneidad sea máxima. El procedimiento se aplica a la búsqueda del perfil multivariante de mujeres inmigrantes que se encuentran en situación laboral irregular en España, entendiendo por tal, que no cumplen con las cotizaciones a la seguridad Social, Para llevar a cabo la investigación, se ha elaborado un cuestionario específico basado en la información recogida en 50 entrevistas en profundidad y 2 grupos de discusión que recoge información sobre características sociodemográficas, formación y cualificación, situación laboral y trabajo, estado de opinión sobre diversos aspectos relacionados con las consecuencias de la situación de irregularidad, demandas y medidas. El estudio se ha realizado sobre la información recogida en 3100 encuestas, realizadas en 144 municipios de la provincia de Salamanca (Castilla y León, España), utilizando un muestreo multietápico en el cual la etapa final fue un muestreo en bola de nieve, proporcional. Los estratos se han elegido utilizando un HJ-BIPLOT (Galindo, 1985), sobre los datos tomadas del Anuario Social de España. Realizando un análisis de conglomerados de k-medias sobre las variables categóricas cuantificadas, ha sido posible describir 2 clusters de mujeres inmigrantes y diferenciarlos de las mujeres en situación laboral regular: uno constituido por mujeres jóvenes inmigrantes que buscan un complemento monetario para sus gastos personales, pero dependen económicamente de sus padres y viven con ellos, desempeñando su actividad en el sector de la hostelería; y el grupo de mujeres inmigrantes, dedicadas al servicio doméstico. Las mujeres manifiestan su deseo de pasar a una situación regular de forma unánime, solicitan una flexibilización en los horarios y ayuda de la Administración en la atención de niños y ancianos, que les permita conciliar su vida familiar y su vida laboral. 3. 10:50-11:10 Segmentación Estadística Basada en Análisis No Simétrico de Correspondencia Primer autor (Ponente): Claudio Rafael Castro López Segundo: Purificación Galindo Villardón Resumen: En el marco de los métodos de segmentación estadística, se presenta una propuesta de algoritmo de segmentación de muestras y/o poblaciones, en base a la creación de árboles ternarios con variable respuesta latente. Se abordan los Modelos de _______________________________________________________________________________________________________ 30 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ Clases Latentes y la descomposición factorial de la predictividad mediante el Análisis No Simétrico de Correspondencias (ACNS). Se presenta una aplicación del Algoritmo propuesto. Contexto El Análisis de Correspondencia No Simétrico (ACNS), es un método, basado en la idea de analizar la dependencia en una tabla de dos dimensiones, y puede ser considerado como una alternativa al análisis de correspondencia, en donde se sabe que la hipótesis de independencia es reformulada, en base al concepto de probabilidad condicional, estamos interesados en considerar la información a priori, dada por las categorías de la variable explicativa columna, sobre las categorías de la variable fila. Se presenta una propuesta para segmentar basada en estas ideas. 4. 11:15-11:35 Análisis de Componentes Principales para el Modelo Poblacional “Spiked” cuando la Dimensión de los Datos es mayor que el Tamaño de la Muestra Primer autor (Ponente): Addy Margarita Bolivar Segundo: Víctor Manuel Pérez Abreu Carrión Resumen: El análisis de componentes principales a menudo falla en estimar correctamente los valores y vectores propios poblacionales cuando la dimensión de los datos es mayor que el tamaño de la muestra. Esto se debe a que la matriz de covarianza muestral no es una buena aproximación a la matriz de covarianza poblacional. En esta plática daré una introducción al modelo poblacional “spiked”, que es utilizado para modelar datos normales multivariados de dimensión n mayor al tamaño de la muestra. Se mostrara algunos casos en los cuales es posible estimar correctamente los valores propios poblacionales más importantes del modelo poblacional “spiked” utilizando un análisis de componentes principales cuando la dimensión de los datos es mayor que el tamaño de muestra y ambos tienden al infinito. _______________________________________________________________________________________________________ 31 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 6: MODELOS DE REGRESIÓN Jueves 11 de septiembre 10:00-11:35 1. 10:00-10:20 Construcción de Tablas Antropométricas mediante un nuevo Algoritmo de Regresión por Cuantiles Primer autor (Ponente): Roberto Jasso Fuentes Segundo: Carlos Cuevas Covarrubias Tercero: Nelly Altamirano Resumen: Las tablas de crecimiento son una herramienta fundamental en la evaluación médica del desarrollo infantil. En México son pocos los estudios que se han hecho con este objetivo. Presentamos un nuevo algoritmo de regresión por cuantiles basado en kérneles de suavizamiento y su aplicación en la construcción de tablas antropométricas basadas en experiencia de niños mexicanos. Comentamos además algunos aspectos relacionados con su implementación computacional. 2. 10:25-10:45 El Problema de Programación Cuadrática mediante la Técnica de Ramificación y Acotamiento Primer autor (Ponente): Blanca Rosa Pérez Salvador Resumen: El análisis de regresión lineal con restricciones lineales sobre los parámetros del modelo, así como la tecnología de superficies de respuestas con restricciones lineales sobre los factores da origen a un problema de programación cuadrática. En este trabajo se presentan los resultados del estudio del problema de programación cuadrática utilizando la técnica de ramificación y acontecimiento como una alternativa del método de Kunh-Tuker o el algoritmo del cono. _______________________________________________________________________________________________________ 32 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. 10:50-11:10 Punto de Cambio Estructural en Modelos de Regresión Lineal Primer autor (Ponente): María Guadalupe Salazar Segundo: Blanca Rosa Pérez Salvador Resumen: El problema de cambio estructural en modelos lineales, viene a modelar problemas en los cuales la variable respuesta Y, la cual depende de dos o más variables explicativas X1,… ,Xn, representa un cambio en la tendencia de Y dentro de la región de observación. El cambio se puede deber a fenómenos naturales, si Y indica una respuesta geográfica, a cambios en los modelos económicos y sociales, si Y indica una variable económica; o un cambio en la edad, si Y indica mediciones clínicas del organismo humano, entre otros casos. Este problema ha sido abordado por diferentes autores, los que han publicado diferentes estadísticas de prueba, pero los trabajos realizados no consideran la función de verosimilitud para obtener resultados, puesto que considera que la técnica de verosimilitud es inaplicable por el hecho de que el logaritmo de la función de verosimilitud no es diferenciable en el punto de cambio. En el presente trabajo se estudiará el modelo del cambio de estructural para el caso multivariado aplicando el método de máxima verosimilitud para la estimación del punto de cambio y el cociente de verosimilitud para encontrar la región crítica uniformemente más potente. 4. 11:15-11:35 Mínimos Cuadrados Ortogonales Primer autor (Ponente): Edilberto Nájera Rangel Segundo: Jorge Alejandro Bernal Arroyo Resumen: Si se tiene un conjunto de datos en el plano cartesiano que exhibe una tendencia lineal, de modo tal que tanto la abscisa como la ordenada de los puntos son valores de variables aleatorias, o representan mediciones hechas con algún grado de error, no hay razón para ajustarles a los puntos una línea recta por el método de mínimos cuadrados ordinarios. En este trabajo se prueba que una mejor alternativa es ajustarles la línea recta para que la suma de los cuadrados de las distancias de los puntos a ella es mínima, es decir, ajustarles a los puntos una línea recta por el método de mínimos cuadrados ortogonales. También se demuestra que este procedimiento se reduce al método usual cuando únicamente minimiza la dispersión de las ordenadas con la recta ajustada, o bien cuando esto se hacía con las abscisas. _______________________________________________________________________________________________________ 33 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 7: TEORÍA Y APLICACIONES DE VALORES EXTREMOS Jueves 11 de septiembre 12:00-13:35 1. 12:00-12:20 Regular Variation and Related Properties for the Multivariate GARCH Process with Constant Conditional Correlations Primer autor (Ponente): Nelson Muriel Segundo: Begoña Fernández Resumen: We focus on the multivariate GARCH i.i.d. nois e sequence process with constant conditional correlation matrix , and given by generated by the , , , We establish the multivariate regular variation of its finite dimensional distributions under mild assumptions on the distribution of the noise variables , namely the sequence has a density strictly positive on and is such that for there exists for which Using this result, we derive the distributional limit and rates of convergence for the any given autocovariance function of the process which agree with those given by Basrak, Davis and Mikosch for the real case. We further provide a general formula for the multivariate extreme value distribution associated to the process . 2. 12:25-12:45 Un Modelo para Máximos de Conjuntos de Observaciones Dependientes Primer autor (Ponente): Elizabeth González Estrada Segundo: José A. Villaseñor Alva Resumen: En esta plática se propone un modelo distribucional paramétrico para los máximos de conjuntos de concentraciones que exceden un umbral tomando en consideración la dependencia entre las concentraciones del conjunto. Este modelo proporciona una familia de distribuciones conjuntas para el máximo y el número de observaciones en el conjunto, el cual permite _______________________________________________________________________________________________________ 34 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ estudiar el valor medio del tamaño del conjunto condicionado a que el máximo del conjunto no excede a un valor dado. Se discute el problema de la estimación de los parámetros y se aplica el modelo a un conjunto de datos de ozono de la ciudad de México. 3. 12:50-13:10 Modelación Espacio-Temporal de la Temperatura Máxima Anual en el Estado de Veracruz Primer autor (Ponente): Luis Hernández Rivera Segundo: Sergio Francisco Juárez Cerrillo Resumen: Presentamos un modelo semiparamétrico para extremos espacio-temporales. Este modelo lo aplicamos para detectar la presencia de tendencias en las temperaturas máximas en el estado de Veracruz. Los datos analizados consisten de temperaturas máximas anuales registradas en 22 estaciones climatológicas del estado de Veracruz de 1960 al 2002. Además de describir la temperatura máxima anual en espacio-tiempo, el modelo permite interpolar espacio-temporalmente en puntos en donde no se tienen estaciones. El modelo nos da evidencia de presencia de calentamiento en el estado de Veracruz. 4. 13:15-13:35 Una Prueba de Bootstrap para la Distribución Pareto Generalizada Primer autor (Ponente): José A. Villaseñor Alva Segundo: Elizabeth González Estrada Resumen: En esta plática se discute una prueba de bondad de ajuste para la familia de distribuciones Pareto generalizada (PG) con parámetro de forma que toma los valores en R. La que se propone es del tipo intersección –unión la cual prueba separadamente los casos Ύ ≥0 y Ύ 0, rechazando la hipótesis de PG cuando ambos casos son rechazados. Con base en un estimador de Ύ se construye una prueba de bootstrap paramétrico para cada uno de los casos anteriores, usando como estadística de prueba al coeficiente de correlación muestral. Mediante un estudio de simulación Monte Carlo es posible establecer el desempeño de esta prueba en términos de su función de potencia con respecto a algunas distribuciones alternativas. _______________________________________________________________________________________________________ 35 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 8: ANÁLISIS MULTIVARIADO II Jueves 11 de septiembre 12:00-13:35 1. 12:00-12:20 Mapeos Autoorganizados para el Análisis de Datos Multivariados. Una Introducción Primer autor (Ponente): Antonio Neme Segundo: Armando Esquivel Resumen: El mapeo autoorganizado es un modelo de red neuronal no supervisada inspirado en un mecanismo relativamente simple de organización en la corteza cerebral. La idea que subyace al modelo es que un mundo multidimensional es inteligible en un mapa bidimensional, como lo es la superficie de la corteza cerebral, pues existe un mapeo no lineal que va del espacio de alta dimensión (el mundo)al espacio discreto de baja dimensión constituido por la red de neuronas (la corteza).Una de las propiedades interesantes de este mapeo no lineal es que los estímulos del ambiente, esto es, los vectores de entrada, que son semejantes entre sí son mapeados a neuronas próximas entre sí en tanto que estímulos diferentes son mapeados a neuronas alejadas. Esta propiedad, la de la preservación de la topología definida por los vectores de entrada, se conoce como mapa topográfico. Los mapeos autoorganizados han mostrado ventajas sobre otros métodos de análisis de datos multivariados como lo son el análisis de componentes principales, escalamiento multidimensional y el análisis de componentes independientes, sobre todo en espacios multidimensionales no convexos, pues la red neuronales capaz de aproximar con más detalle las variaciones en la distribución de los datos. Los mapas autoorganizados se han aplicado con gran éxito en el análisis de datos multivariados en diversos contextos, como la biología molecular, el análisis de biodiversidad, el flujo vehicular, entre otros. En esta plática se detalla algoritmo del mapeo autoorganizado. Además, se muestran algunas de sus aplicaciones en diversos contextos y se compara con el desempeño mostrado por otros métodos de análisis de datos multivariados. _______________________________________________________________________________________________________ 36 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 2. 12:25-12:45 Un Enfoque Diferente para Clasificación Primer autor (Ponente): Ruth Fuentes García Segundo: Stephen Walker Resumen: En muchas aplicaciones resulta de interés el problema de clasificación. En este trabajo, primero buscamos obtener un modelo de clasificación, construyendo después un modelo de mezclas al rededor de éste. Esto permite asignar las observaciones a los diferentes grupos de manera sencilla. 3. 12:50-13:10 Estudio sobre la Concepción de Ciencia, Tecnología e Innovación en las Empresas Venezolanas Primer autor (Ponente): Zulaima Osuna Segundo: María Purificación Galindo Resumen: El propósito fundamental de este trabajo es analizar las declaraciones de las empresas venezolanas sobre las concepciones conceptuales sobre ciencia, tecnología e innovación. El enfoque metodológico empleado es el ‘Análisis Estadístico de Datos Textuales’ apoyado en las técnicas estadísticas desarrollado por la escuela Francesas de Análisis de Datos (Analyses des Donnèes) (BENZÈCRI, 1973, 1976), sustentado en la estadística textual o lexicometría, con el objeto de obtener datos relevantes (palabras) del corpus, las cuales nos proporcionaran una simplificación de la información que permita analizar las principales características léxicas e intentar descubrir las concepciones. Palabras Claves: HJ-Biplot, protocolos lexicométricos, ciencia-tecnología-innovación. _______________________________________________________________________________________________________ 37 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 4. 13:15-13:35 Optimización de Modelos Discriminantes para Tres Grupos Mediante Algoritmos Genéticos Primer autor (Ponente): Carlos Alberto Gómez Grajales Segundo: Julia Aurora Montano Rivas Resumen: El término clasificación implica el procedimiento realizado para tomar una decisión o realizar una predicción en base a la información disponible en el momento, así que el proceso de clasificación se define como un procedimiento formal para poder repetir el razonamiento desarrollado en caso de presentarse situaciones nuevas. Este tipo de problemas se presentan de forma natural en numerosas situaciones en la vida real. Aplicaciones cada vez más recurrentes se están suscitando en áreas como la mercadotecnia, las finanzas, la medicina, la economía y la industria. Dentro del análisis lineal discriminante, una de las herramientas más útiles son los modelos de clasificación, los que permiten de forma sencilla catalogar individuos en base a sus características. Más aun al trabajar con más de dos grupos, caso en el que los modelos canónicos pueden llegar a resultar procesos de clasificación confusos y complicados. Sin embargo, el rendimiento de este tipo de modelos suele ser muy pobre, resultando en ocasiones un error de clasificación más alto de lo aceptable. Precisamente, estas limitantes hacen necesario la búsqueda de nuevas alternativas que permitan optimizar el ajuste alcanzado. Una posible solución podemos encontrarla mediante un proceso de optimización a través de algoritmos genéticos, una herramienta informática de reciente desarrollo. Incorporando en el desarrollo de un análisis discriminante para tres grupos un algoritmo genético es posible tener mejores modelos de clasificación que contribuyan al perfeccionamiento de la clasificación, mediante un proceso que fácilmente podrá generalizarse a más poblaciones. _______________________________________________________________________________________________________ 38 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 9: DATOS CENSURADOS Jueves 11 de septiembre 18:30-19:40 1. 18:30-18:50 Estimación de Parámetros de Modelos de Espacio de Estados Lineal Gaussiano con Observaciones Censuradas Primer autor (Ponente): Francisco J. Ariza Hernández Segundo: Gabriel A. Rodríguez Yam Resumen: La función de verosimilitud de modelos de espacios de estados (SSM, por sus siglas en inglés) lineal Gaussiano se puede obtener fácilmente con las recursiones de Kalman. Sin embargo, cuando se tienen observaciones censuradas, aun para este modelo simple, la función de verosimilitud no se puede obtener explícitamente. En esta plática la función de verosimilitud de un SSM lineal Gaussiano con observaciones censuradas por la izquierda se obtiene usando integración Monte Carlo. Los estimadores que se obtienen al maximizar esta aproximación de la función de verosimilitud son comparados con los estimadores obtenidos con el algoritmo EM Estocástico. 2. 18:55-19:15 Análisis de Modelos de Regresión con Datos Censurados Usando R Primer autor (Ponente): Carlos Abraham Carballo Monsiváis Segundo: Jorge Domínguez Domínguez Resumen: Los modelos de regresión generados a partir de los datos experimentales permiten caracterizar la confiabilidad de un producto. Los datos se obtienen mediante una estrategia experimental con el fin de caracterizar la confiabilidad en un producto. En este tipo de situaciones los datos tienen propiedades específicas tales como la censura o distribuciones no normales. En la literatura estadística existen el método clásico de Máxima verosimilitud para resolver estos problemas, lo comparemos con los métodos de Hamada-Wu y Hahn, Morgan-Schmee para modelar ese tipo de datos. El primero es un algoritmo generado por máxima verosimilitud, el segundo consiste del método de mínimos cuadrados clásico con ponderación iterada para tomar en _______________________________________________________________________________________________________ 39 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ cuenta la censura y la distribución. En la actualidad R desempeña un papel importante en el cómputo estadístico. En este trabajo se ilustra la implementación de R en estos dos métodos estadísticos que permiten modelar datos en confiabilidad y se evalúa la utilidad del lenguaje R. También se compara y discuten las ventajas y desventajas de ambos procedimientos con diversos casos de la literatura. Los resultados de estas comparaciones son la pauta para análisis de la confiabilidad de muchos productos que se manufacturan en el sector industrial. 3. 19:20-19:40 Una Propuesta Alternativa al Algoritmo EM para la estimación Máximo Verosímil con Datos Incompletos Primer autor (Ponente): Ernesto Menéndez Segundo: Ernestina Castells Resumen: En este trabajo se propone un algoritmo alternativo al algoritmo EM para la estimación máximo verosímil con datos incompletos. Este algoritmo EM alternativo (EMA) ha sido aplicado en el caso de una muestra aleatoria de la cual solamente se conoce su tamaño y el máximo de las observaciones, bajo la suposición de dos modelos de probabilidad: Exponencial con media ; y Normal con varianza conocida. Además, se resuelven otros dos ejemplos. El primero de ellos esta basado en el conocido ejemplo genético de Rao y el segundo es el ejemplo de un modelo de mezcla de dos distribuciones, considerado por Pawitan. El algoritmo EMA consiste en sustituir el paso E del algoritmo EM por el completamiento de la muestra mediante la generación de números aleatorios, y una vez que la muestra está completa, se obtiene con ella la estimación máximo verosímil. Este último paso sustituye al paso M del algoritmo EM. También es realizado un estudio por simulación para estudiar el desempeño del algoritmo EMA. Por los resultados obtenidos el nuevo procedimiento de estimación muestra resultados alentadores. _______________________________________________________________________________________________________ 40 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 10: DIVULGACIÓN Jueves 11 de septiembre 18:30-19:40 1. 18:30-18:50 Un Modelo para Cursos de Probabilidad y Estadística en Línea de acuerdo con las Preferencias en cuanto a los Estilos de Aprendizaje de los Docentes Primer autor (Ponente): José Luis García Cue Segundo: José Antonio Santizo Rincón Tercero: María José Marques Dos Santos Resumen: El presente trabajo comienza con una breve descripción de los proyectos de investigación donde se han incorporado las TIC en cursos de Probabilidad y Estadística tanto en el Colegio de Postgraduados como en la Facultad de Estudios Superiores Zaragoza de la UNAM. Más adelante se hace una revisión de conceptos sobre Estilo y Estilos de Aprendizaje. Después se hace la propuesta de cada uno de los elementos que integra el modelo diseñado para cursos de Estadística vía Internet de acuerdo a los Estilos de Aprendizaje. Al final se muestran los resultados, la discusión, las conclusiones y las fuentes documentales. 2. 18:55-19:15 Vale más Prevenir que Lamentar: Pronóstico de Contingencias Ambientales Primer autor (Ponente): José Elías Rodríguez Muñoz Resumen: El problema de contaminación atmosférica por emisiones de SO2 y PM10 sigue siendo común en ciertas ciudades con actividad industrial. El monitoreo de los niveles de concentración de estos contaminantes y la aplicación de medidas preventivas para no permitir niveles altos de éstos son actividades cotidianas que realizan los organismos gubernamentales de ecología. Para lograr que dichas medidas preventivas sean pertinentes, es necesario contar con un modelo que estime la probabilidad de que se presenten futuras contingencias ambientales por altas concentraciones de SO2 y PM10. Esta presentación mostrará cómo se construyó un modelo que genera dichas estimaciones para la ciudad de Salamanca. _______________________________________________________________________________________________________ 41 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. 19:20-19:40 Método para Estimar el Tiempo en Circulación de los Billetes a partir de su Serie y Folio Primer autor (Ponente): Joaquín Vargas Resumen: Se propone un método para estimar el tiempo en circulación de los billetes a partir de dos elementos únicos de fabricación: folio y serie. Mediante la liga entre estos dos datos es posible es posible rastrear la fecha y el lugar en que fue puesto a circular un billete, puede medirse el efecto del tiempo sobre el deterioro paulatino de los billetes y así planear su reposición. En este trabajo se aplica dicho método a una muestra de billetes depositados en instituciones bancarias. Se estima el tiempo que estuvieron en circulación, el tiempo en circulación que presentan billetes con distinto grado de deterioro y se exploran algunos hechos estilizados de su patrón migratorio. _______________________________________________________________________________________________________ 42 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 11: MODELOS LINEALES Y MODELOS LINEALES GENERALIZADOS Viernes 12 de septiembre 10:00-11:35 1. 10:00-10:20 Operador Proyector en el Modelo Lineal General Mixto considerando la Estimación de Efectos Fijos, Aleatorios y Mixtos Primer autor (Ponente): Fernando Velasco Luna Segundo: Mario Miguel Ojeda Ramírez Resumen: El modelo lineal general mixto es un modelo que permite analizar datos con estructura jerárquica. En este trabajo se presenta la manera en que el operador proyector interviene en la estimación en el modelo lineal general mixto. En particular en la estimación de los parámetros fijos, en la predicción de los efectos aleatorios y en la predicción de efectos mixtos. 2. 10:25-10:45 Modelos Lineales Generalizados con Restricciones Lineales de Desigualdad en los Parámetros Primer autor (Ponente): Silvia Ruíz Velasco A. Segundo: Federico O’Reilly Resumen: En este trabajo se presenta una propuesta para obtener los estimadores de los parámetros en Modelos Lineales Generalizado sujetos a restricciones lineales de desigualdad en los parámetros utilizando el algoritmo del cono. Los resultados obtenidos son comparados con los resultados de McDonald y Diamond (1990) a través del ejemplo ahí presentado y de simulaciones. _______________________________________________________________________________________________________ 43 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. 10:50-11:10 Modelamiento de Datos Poisson Longitudinales con Exceso de Ceros Primer autor (Ponente): Yaneth Cecilia Pérez Fonseca Segundo: Luis Guillermo Díaz Monroy Resumen: Los datos con exceso de ceros se presentan en industria, agricultura, medicina, entre otros campos, y ha sido ampliamente discutido por varios autores como Lambert (1992); Heibron (1989); Mullahy (1997); Ridout, Hinde y Demetrio (1998); Viera, Hindey Demetrio (2000); Hall (2000); quienes en sus diferentes propuestas no modelan la sobredispersión causada por el exceso de ceros; además, si los datos son tomados a través del tiempo se presenta un problema adicional, ya que se presenta una, tienen un tratamiento especial ya que se presenta una correlación entre las observaciones. Teniendo en cuenta lo anterior proponemos un modelo para datos Poisson longitudinales con exceso de ceros, en el cual se modela la sobredispersión en dos etapas bajo un modelo binomial negativo aumentado BNA (Haab & McConnell 1996). Se presentan los cálculos de los dos primeros momentos de orden central para construir las GEE bajo el modelo BNA y se muestran las ventajas obtenidas al considerar la estructura de dependencia y el exceso de ceros en el modelamiento. 4. 11:15-11:35 Modelamiento Univariado de datos Longitudinales Binarios en Presencia de Sobredispersión 'una Aplicación en Medicina' Primer autor (Ponente): Leidy Rocío León Dávila Segundo: Luis Guillermo Díaz Monroy Resumen: En muchas áreas tales como la agronomía, ingeniería, medicina, economía, entre otros, se registra si una unidad experimental presenta o no, una determinada característica durante varios intervalos de tiempo; esta estructura de datos corresponde a datos longitudinales binarios. El tratamiento de los datos longitudinales binarios a través de los modelos lineales clásicos resulta inapropiado, pues las mediciones son desarrolladas en el tiempo sobre un mismo individuo, las cuales son correlacionadas, las observaciones no se ajustan a una distribución normal, y, además, se puede encontrar que la varianza de los datos es mayor que la varianza esperada bajo el modelo probabilístico asumido, esto se conoce como sobredispersión (Kachman 2004).El objetivo de este artículo es proponer un modelo estadístico y desarrollar una metodología que considere la _______________________________________________________________________________________________________ 44 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ sobredispersión en datos binarios longitudinales, teniendo en cuenta la detección y caracterización de la sobredispersión en estos, luego la estimación de los parámetros para modelar estos datos y finalmente verificar la metodología propuesta a través de datos reales de tipo biológico específicamente en parasitología. Los datos longitudinales han sido estudiados por Potthoff y Roy (1964). Singer y Andrade (1986) presentan una revisión de los métodos más comunes usados en el análisis de datos longitudinales. Liang y Zeger (1986), proponen ecuaciones de estimación generalizadas (EEG),. Verbeke y Molenberghs (2005) proponen modelos para datos longitudinales discretos. Para el cálculo del parámetro de sobredispersión hay soluciones propuestas por Jorgensen (1989) y Collet (1991). Se encontró una metodología apropiada para modelar datos binario longitudinales en presencia de sobredispersión; el modelamiento se hace con el modelo de dos etapas, específicamente, el modelo tipo II de Williams expuestos por Hinde y Demétrio (1998). Como instrumento básico de estimación se emplean las ecuaciones de estimación generalizadas (EEG) en las cuales se incluyen el parámetro de sobredipersión y la naturaleza longitudinal de los datos, además se realiza una aplicación en la medicina. _______________________________________________________________________________________________________ 45 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 12: ESTADÍSTICA BAYESIANA II Viernes 12 de septiembre 10:00-11:35 1. 10:00-10:20 Bayesian Generalized Method of Moments Primer autor (Ponente): Guosheng Yin Resumen: We propose the Bayesian generalized method of moments (GMM) and a new sampling algorithm, which are particularly useful when likelihood-based methods are difficult. We can easily derive the moments and concatenate them together, which often converges to a zero-mean normal distribution asymptotically. We build up a weighted quadratic objective function in the GMM framework. As in a normal density function, we take the negative GMM quadratic function divided by two and then exponentiate it to substitute for the likelihood. After specifying the prior distributions, we apply the Markov chain Monte Carlo procedure to sample from the posterior distribution. We carry out simulation studies to examine the finite sample properties of the proposed Bayesian GMM procedure, and, as illustration, apply our method to real data. 2. 10:25-10:45 El twalk: Un Método de MCMC Genérico y Autoajustable Primer autor (Ponente): J Andrés Christen Segundo: Colin Fox Resumen: En aplicaciones donde se usa simulación de una distribución objetivo compleja (eg. estadística Bayesiana) es común el uso de métodos de MCMC. Normalmente las distribuciones de propuesta tienen que ser calibradas con mucho cuidado y en general el MCMC resultante es muy difícil de poner a punto para que se simule razonablemente bien de la distribución posterior en cuestión. En Christen y Fox (2007) presentamos un MCMC Cautoajustable (llamado t-walk) que, siendo un algoritmo de Metropolis-Hastings en el espacio producto de la distribución original, presenta de adaptabilidad para obtener eficientemente muestras de la distribución objetivo en cuestión, aun para distribuciones altamente correlacionadas, multimodales, con secciones _______________________________________________________________________________________________________ 46 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ planas, y en dimensiones de hasta 200 parámetros etc. Presentaremos varios ejemplos de cómo el t-walk puede resolver problemas en la aplicación y varios avances recientes. 3. 10:50-11:10 Estimación de la Distribución de las Características de Pacientes con Cáncer de Mama Primer autor (Ponente): Luis E. Nieto Barajas Segundo: Nebiyou Bekele Tercero: Mark Munsell Resumen: En este trabajo estimamos la distribución de varias características clínicas y patológicas conocidas como predictoras en el desarrollo de la enfermedad en pacientes con cáncer de mama. Estas características incluyen Receptores de estrógeno, involucramiento nodal, HER-2 y etapa de la enfermedad. En particular estimamos la distribución conjunta de las primeras 3 características condicional en la cuarta característica. Esto nos permite explotar la asociación Markoviana entre las probabilities de distintas etapas de la enfermedad. Es decir, las probabilidades condicionales en la etapa actual se consideran función de las probabilidades en la etapa anterior. Proponemos entonces un proceso de Markov con marginales Dirichlet que nos permite usar información de distintas etapas para estimar la distribución de las características de los pacientes en una determinada etapa de la enfermedad. 4. 11:15-11:35 Una Estrategia para el Cálculo del Nivel de Significancia de las Pruebas de No-Inferioridad para dos Proporciones Primer autor (Ponente): David Sotres Ramos Segundo: Félix Almendra Arao Tercero: Cecilia Ramírez Figueroa Resumen: Las pruebas de no-inferioridad son frecuentemente utilizadas en la investigación clínica para demostrar que un tratamiento nuevo (con mínimos efectos secundarios o bajo costo) no es sustancialmente inferior en eficacia que el tratamiento estándar. Un problema práctico importante que presentan las pruebas de no-inferioridad es el cálculo del nivel de significancia _______________________________________________________________________________________________________ 47 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ real de la prueba. Este problema se presenta debido a que por la mera formulación de las hipótesis de no-inferioridad el espacio nulo de parámetros es una región contenida en el plano. En este trabajo se presenta una prueba un resultado que facilita de manera muy importante el cálculo de dicho nivel de significancia real. Se presentan varias aplicaciones de este resultado, entre ellas se explica como fue posible construir tablas para el uso de la prueba exacta de Farrington-Manning. _______________________________________________________________________________________________________ 48 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN 13: ESTADÍSTICA MULTIVARIADA III Y MUESTREO Viernes 12 de septiembre 12:00-13:35 1. 12:00-12:20 Estadística con Senderos Primer autor (Ponente): Ignacio Méndez Ramírez Resumen: Se tiene una mejor visión de la estadística si se contemplan las principales ideas de la estadística a la luz del análisis de senderos. En virtud de esto, se presentan en esta ponencia, los siguientes aspectos: 1.- Análisis de senderos, 2.- Estadística Básica con senderos, 2.1 Prueba de t, 2.2 Análisis de Varianza y Covarianza, 2.3 regresión múltiple, 2.4 Análisis de Varianza multivariado, 2.5 Paradoja de Simpson, 2.6 Análisis de factores Confirmatorio y 2.7 Sistemas de Ecuaciones Estructurales. Al usar los senderos se tiene más control e información sobre algunos de los supuestos básicos y ayuda a explicar algunos aspectos como la multicolinealidad. Todas las ideas se presentan con ejemplos que se que se corren con el paquete EQS y con este se producen las graficas. 2. 12:25-12:45 Análisis Multivariado con Kernels Primer autor (Ponente): Julia Aurora Montano Rivas Segundo: Sergio Francisco Juárez Cerrillo Resumen: En esta plática revisamos lo aspectos teóricos y metodológicos de las técnicas kernel aplicados al análisis de componentes principales (ACPK), análisis de correlación canónica (ACCK) y análisis discriminante (ADK). Presentamos como realizar ACPK, ACCK y ADK con algunos ejemplos tomados de problemas reales. Finalmente, discutiremos algunos problemas abiertos a la investigación sobre estas técnicas, en particular revisaremos el problema de selección óptima de kernels. _______________________________________________________________________________________________________ 49 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. 12:50-13:10 Comparación en Muestras Complejas de Estimadores de Regresión del Total bajo tres Especificaciones de la Matriz de Varianzas y Covarianzas Primer autor (Ponente): Flaviano Godínez Jaimes Segundo: Ignacio Méndez Ramírez Tercero: Ma. Natividad Nava Hernández Resumen: Los estimadores de regresión del total usan el modelo E(Y)=Xβ, V(Y)=V. Esto supone que la matriz de varianzas y covarianzas V es conocida, lo cual no es cierto en muestreo de conglomerados y tampoco en muestras complejas que involucren conglomerados. Para resolver este problema se puede considerar que V=I, es decir que se tiene una muestra aleatoria simple, que V es una función de las probabilidades de inclusión o bien V se puede estimar mediante las ecuaciones de estimación generalizadas. En este trabajo se hace una comparación empírica de los estimadores de regresión del total en muestras complejas considerando las tres propuestas de la matriz V. 4. 13:15-13:35 Funciones en R para el Análisis de Encuestas Primer autor (Ponente): Alberto Manuel Padilla Terán Resumen: Actualmente, una gran parte de encuestas o muestras se extraen mediante diseños complejos. El análisis de las muestras así obtenidas requiere el uso de los pesos muestrales en el cálculo de las estimaciones. En el mercado existen paquetes comerciales que cuentan con módulos que permiten realizar este tipo de análisis; empero, una opción atractiva la constituye el paquete R, en particular con el programa survey desarrollado por Thomas Lumley. En esta plática se mencionan las funciones principales de dicho programa, así como ejemplos de gráficas ponderadas con los pesos muestrales, estimaciones puntuales de totales, razón y de regresión, así como sus varianzas estimadas, tablas de contingencia, modelos lineales generalizados, métodos de remuestreo, entre otros. _______________________________________________________________________________________________________ 50 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ CARTELES _______________________________________________________________________________________________________ XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ SESIÓN DE CARTELES Miércoles 10 de septiembre, 18:00-20:00 1. Análisis de la Capacidad de Proceso en la producción de Miel Zayoli en la región de Coatepec, Veracruz Primer autor (Ponente): Atzín García Flores Segundo: Carlos Rodrigo Meza Zamora Resumen: Cualquiera que ha trabajado en una planta ó laboratorio, entiende que no siempre dos unidades ó partes son exactamente iguales. Este concepto se llama variación. La variabilidad es un acontecimiento natural y puede ser medida. Las empresas necesitan poseer una herramienta que le permita de forma rápida la cuantificación de la calidad con que se está produciendo en cada proceso. El control estadístico no tiene nada que ver con límites de especificación. Si un proceso despliega un control estadístico, entonces, el promedio y la variabilidad del proceso son consistentes a través del tiempo. Esto no significa que todo el proceso sea aceptable. Significa únicamente que el proceso es consistente. Si el promedio y la variabilidad son consistentes, entonces podemos realizar predicciones acerca del desempeño de un proceso. En este documento, discutiremos la capacidad del proceso. La capacidad del proceso analiza la habilidad del mismo de producir dentro de especificaciones. Un prerrequisito para el análisis de la capacidad de proceso es que debe presentar algún grado de control estadístico. 2. Construcción de un Índice de Desempeño de Tutores de la UV mediante Componentes Principales No Lineales Primer autor (Ponente): Guadalupe García Flores Segundo: Sergio Francisco Juárez Cerrillo Resumen: El Sistema Institucional de Tutorías (SIT) de la Universidad Veracruzana tiene como tarea diseñar estrategias de atención individualizada y/o grupal que desarrollan los tutores para los estudiantes con el fin de ofrecerles a estos un servicio de apoyo académico para ayudarlos a que logren una formación integral. En este trabajo construimos un índice para evaluar el desempeño de los tutores (IDT), el cual, a partir de la opinión de los estudiantes, toma en cuenta las funciones básicas que realiza el tutor periodo a periodo. En este cartel presentamos la metodología, basada en Cuantificación Óptima (CO) y Componentes Principales Cualitativos, para construir el IDT y presentamos resultados preliminares basados en un estudio piloto. _______________________________________________________________________________________________________ 51 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 3. Uso del Modelo Hurdle en dos partes (Two-part Hurdle Model) para analizar el efecto del Seguro Popular sobre la utilización de los servicios de salud Primer autor (Ponente): Aaron Salinas-Rodríguez Segundo: Sandra Sosa-Rubí Tercero: Betty Manrique-Espinoza Resumen: El uso de modelos de regresión para datos de conteo ha tenido, en fechas recientes, un importante incremento, entre otros motivos, por el desarrollo de algoritmos que forman parte de la mayoría de los paquetes informáticos especializados en estadística. Entre otros, han sido particularmente utilizados el modelo Poisson, el Quasi-Poisson, y el modelo Binomial Negativo. Mientras que si se tiene una variable de conteo sin ceros, se utilizan modelos de regresión truncados (Poisson o Binomial Negativo). En otras ocasiones se puede tener una variable de conteo con un número excesivo de ceros, para lo cual se ha propuesto el uso de algún modelo de regresión cero-inflado (Zero-inflated Counts). Un ejemplo clásico de esta situación es cuando se trata de analizar el número de visitas al médico o a los servicios de salud en un periodo de tiempo determinado, donde una gran proporción de personas reportan no utilizar dichos servicios. Un problema con el modelo de regresión cero-inflado es que se debe especificar con detalle el mecanismo probabilístico que determina el exceso de ceros, en términos, sobre todo, de las variables que explican dicho exceso.Un enfoque alternativo ha sido propuesto por Mullahy (1986) y es conocido como el modelo de regresión hurdle en dos partes. La idea básica es que la distribución binomial puede ser utilizada para determinar si la variable de conteo es cero o si asume un valor de 1 si el conteo es positivo, mientras que alguna distribución para datos de conteo truncados (Poisson o Binomial Negativa) es utilizada para explicar la distribución condicional de los valores positivos. Este modelo ha sido utilizado en este trabajo para evaluar el efecto del Seguro Popular sobre la probabilidad de uso de los servicios de salud (consulta externa) y sobre la intensidad de uso de dichos servicios (número de consultas). Los resultados muestran, en general, que el Seguro Popular ha aumentado dicha probabilidad así como la intensidad de uso. _______________________________________________________________________________________________________ 52 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 4. La Varianza como Biomarcador en Estudios Toxicológicos Primer autor (Ponente): José J. H. Herrera-Bazan Segundo: Patricia Ramos-Morales Resumen: La Toxicología estudia el daño real y potencial de agentes tóxicos físicos, químicos y biológicos a los seres vivos y ecosistemas. Una de sus tareas es la obtención de la información necesaria para definir los límites de seguridad de la exposición humana a diversos agentes. A menudo, el establecimiento de Riesgo Toxicológico involucra la extrapolación de datos epidemiológicos y experimentales limitados, a situaciones más amplias como el medioambiente o poblaciones humanas. Los estudios experimentales en toxicología están obligados al uso de otros organismos ante la obvia imposibilidad de utilizar organismos de la especie (humana) hacia la cual se desea calcular el Riesgo. La mosca de fruta Drosophila melanogaster es uno de los organismos modelo más utilizado en Toxicología. Las variables de respuesta utilizadas en estudios toxicológicos con Drosophila son cuantitativas, y como cualquier otro protocolo experimental, el efecto sobre la variable de respuesta involucrada se evalúa comparando mediante métodos paramétricos la media de la variable de un grupo experimental y la media de la variable un grupo control de moscas. Las medidas de dispersión como la varianza generalmente no forman parte del análisis, y se calculan sólo para buscar la homoscedasticidad necesaria en pruebas de hipótesis o ANOVA. En diversos trabajos de nuestro laboratorio al evaluar distintas variables de respuesta en moscas Drosophila tratadas con diferentes tóxicos y contaminantes (NitroDiMetilAmina, Talidomida, Cromo, Glifosato) hemos observado un patrón en la varianza dependiente de la concentración en el que; 1) en concentraciones sumamente bajas donde no se altera el equilibrio fisiológico, bioquímico, y genético funcional de un organismo, la media y la varianza son similares a la de organismos control; 2) conforme aumenta la concentración, el estímulo comienza a ser detectado y aunque daña al organismo no lo afecta de manera vital y los organismos responden a él en distinto grado según su variabilidad individual aumentando la varianza sin alterar la media; 3) en concentraciones donde el estímulo interfiere significativamente con el metabolismo de las moscas dejando como opciones de sobrevivencia pocas vías de desintoxicación, se unifica la respuesta individual disminuyendo la varianza, mientras la media es evidentemente significativa y los análisis estadísticos determina diferencias significativas; 4) en concentraciones muy altas que alteran el equilibrio de los organismos y comprometen su sobrevivencia la respuesta poblacional tiende a homogenizarse, en el punto donde todos los organismos mueren la varianza es cero. La varianza es otra opción de variable de respuesta a considerar en estudios toxicológicos ya que refleja cambios en la respuesta individual ante un efecto tóxico y hace urgente reconsiderar su observación y el uso de análisis estadísticos que la involucren como una variable de respuesta para el establecimiento de Riesgo Toxicológico. _______________________________________________________________________________________________________ 53 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 5. Escenarios de Temperatura Máxima Diaria en Veracruz con Análisis Espectral Singular para Series de Tiempo Multivariadas Primer autor (Ponente): Alejandro Ramírez Núñez Segundo: Sergio Francisco Juárez Cerrillo Resumen: El Análisis Espectral Singular Multicanal (AESM) es una técnica de desarrollo reciente usado para extraer información de la dinámica de un conjunto de p series de tiempo. El AESM se ha aplicado ampliamente en geofísica, climatología, meteorología y recientemente en econometría y finanzas. En este trabajo utilizamos AESM para estudiar la variación espacio-temporal de la temperatura máxima diaria registrada de 1960 a 2002 en 25 estaciones climatológicas localizadas en el estado de Veracruz, una vez que hemos caracterizado esta variación usamos el AESM para hacer pronósticos de la temperatura máxima diaria en el Estado de Veracruz. 6. Modelación de precios de gas. En un Horizonte a Corto Plazo, ¿Presentan Reversión a la Media? Primer autor (Ponente): Víctor Hugo Ibarra Mercado Segundo: Patricia Saavedra Barrera Resumen: En los mercados de energéticos, a partir de 1995, con la aparición del artículo de Litzberger y Rabinowitz, es muy común encontrar que las dinámicas para los modelos de precios sean con reversión a la media, por ejemplo modelos de Schwartz (1997), Pilipovic (1995) y Miltersen (2003). Por otro lado, en el estudio realizado por Bessembinder (Bessembinder et al., 1995), se da evidencia de que en 11 mercados diferentes, sobre todo de energéticos, se presenta en mayor o menor grado la reversión a la media. Pero, debido a que tanto el gas como el petróleo son recursos no renovables y tienden a agotarse, en los últimos años los precios de estos energéticos han mostrado un comportamiento consistentemente a la alza, por lo que se puede cuestionar la validez de los modelos de reversión a la media, véase Geman (Geman, 2007 y Geman, 2005). Con base en lo anterior, se plantea el problema de determinar si el modelo browniano geométrico puede ser adecuado, para modelar precios de gas, y por tanto ser utilizado para la valuación de opciones asiáticas en un horizonte a corto plazo. Con base en los precios diarios de cierre del gas Henry-Hub, cotizados en NYMEX (New York Mercantile Exchange), se realizarán pruebas estadísticas para determinar si el proceso de precios presenta reversión a la media. Una forma de determinar si una serie de precios presenta reversión a la media es probar la ausencia de una raíz unitaria en el modelo autorregresivos. Se aplicarán dos pruebas para la detección de raíces _______________________________________________________________________________________________________ 54 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ unitarias, comúnmente utilizadas para este fin. La prueba aumentada de Dickey-Fuller (ADF) (Dickey-Fuller) y la prueba de Phillips-Perron (PP) (Phillips-Perron}. Para realizar estas pruebas se hará uso de los datos de gas tomados de 1994 a la fecha. 7. Cuantificación del Efecto del Error de Medición sobre los Estimadores de Interacción: Aplicación en un Estudio sobre los Efectos del Plomo en la Salud Humana Primer autor (Ponente): Héctor Lamadrid-Figueroa Segundo: Martha M. Téllez-Rojo Tercero: Gustavo Ángeles Cuarto: Mauricio Hernández-Ávila Resumen: Estudios previos han buscado estimar el grado en el cual la movilización del plomo en el hueso, medida por la interacción entre los N-telopétidos de colágena tipo I (NTX) y las concentraciones de plomo en el hueso medidas por fluorescencia de rayos X (XRF), influyen sobre las concentraciones de plomo en sangre. No obstante, intentos previos han ignorado el error de medición introducido por la estimación XRF, lo cuál muy probablemente ha resultado en la subestimación del impacto de la movilización ósea en las concentraciones sanguíneas de plomo. Presentamos aquí resultados obtenidos por una estrategia alternativa de medición que toma en cuenta la medición de la imprecisión que se obtiene del XRF y que provee de estimadores insesgados del efecto de variables predictoras medidas con error. Un total de 193 mujeres mexicanas se evaluaron (1997-1999) en el primero, segundo y tercer trimestres de embarazo. Las concentraciones de plomo en sangre y en plasma, y la concentración urinaria del biomarcador de resorción ósea NTX se midieron en cada trimestre. Se midieron las concentraciones de plomo en el hueso 4 semanas después del parto por medio de XRF. La relación entre el plomo en sangre/plasma (variable respuesta) plomo en hueso y el NTX se estimó en cada etapa del estudio usando regresión de Errores-en-Variables (EIV) así como Mínimos Cuadrados Ordinarios (MCO) con mediciones de plomo en hueso ponderadas por la imprecisión (el tratamiento estándar de los datos). Encontramos que aunque las pruebas de hipótesis arrojaron los mismos resultados con los dos métodos, los estimadores de efecto obtenidos por MCO fueron entre 20 y 22% menores que los estimadores obtenidos por EIV. Estos resultados confirman consideraciones teóricas previas acerca de la importancia de tomar en cuenta el error en la medición de plomo en hueso por XRF cuando esta variable es un predictor en un modelo de regresión. _______________________________________________________________________________________________________ 55 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 8. Modelo Lineal Jerárquico en Tres Niveles: Una Aplicación Primer autor (Ponente): María Nayeli Hernández Carmona Segundo: Mario Miguel Ojeda Ramírez Tercero: Fernando Velasco Luna Resumen: Los modelos lineales jerárquicos forman una clase general de modelos que permiten la modelación en una gran variedad de situaciones en las cuales se tienen datos que presentan una estructura jerárquica, son también conocidos en la literatura bajo una gran variedad de nombres, tales como modelos multinivel (Goldstein, 1986, 1995), modelos de coeficientes aleatorios (Longford, 1995), modelos de componentes de la varianza y covarianza (Searle et al., 1992), o como modelos de efectos mixtos (Laird y Ware, 1982). Estos modelos tienen una gran variedad de aplicaciones en diversa áreas, una de ellas es en la investigación educativa, biología, investigación social, psicología, medicina, entre otras. En un sistema con estructura jerárquica puede ser de interés estudiar la relación existente entre una variable respuesta, la cual se mide en las unidades de nivel 1, y variables explicatorias las cuales se pueden medir en cada uno de los niveles de la estructura jerárquica, en el presente trabajo se aplicara un modelo lineal jerárquico en tres niveles, en el área de la investigación educativa. 9. Concentración de Precipitación en el Estado de Veracruz con Entropía Primer autor (Ponente): Enrique Del Callejo Canal Segundo: Sergio Francisco Juárez Cerrillo Resumen: En este trabajo caracterizamos la variabilidad espacio-temporal de la concentración de la precipitación en el estado de Veracruz mediante entropía. Comparamos los resultados con el índice de concentración de precipitación (Índice de Gini) y comentamos ventajas y desventajas de ambas medidas. _______________________________________________________________________________________________________ 56 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 10. Estudios de Caso de Estadística: La Experiencia de 12 años en la Especialización en Métodos Estadísticos Primer autor (Ponente): Regino Fernández Cabrera Segundo: Juan Manuel Lara Chávez Tercero: Anahí Solano Portilla Cuarto: Sergio Francisco Juárez Cerrillo Resumen: La especialización en Métodos Estadísticos (EME) es un programa dirigido a profesionistas sin la formación de un estadístico profesional pero que requieren de un conocimiento básico en métodos estadísticos para responder a las necesidades de sus trabajos. Esto ha originado que en la EME se realice un trabajo importante de vinculación con la problemática local, regional y estatal ya que bajo la dirección de los académicos de la EME los estudiantes presentan las soluciones a sus problemas como proyectos de titulación. En este trabajo hacemos una recopilación de algunos de estos proyectos con el objetivo es desarrollar un material didáctico que sirva de apoyo en el proceso de enseñanza-aprendizaje en cursos de estadística con ejemplos de basados en problemas reales surgidos en disciplinas como economía, biología, sicología, agronomía, educación, climatología, por mencionar algunas y que se han solucionado con la aplicación de estadística exploratoria, modelos de regresión, diseño experimental, análisis de datos de encuestas, estadística multivariante, métodos no paramétricos, y modelos para series de tiempo. Partimos de la premisa de que el aprendizaje basado en casos reales y no de libro de texto, proporciona una mayor motivación en el aprendizaje de cualquier disciplina, incluida la estadística. Debemos mencionar que varios de los proyectos que presentamos motivan además investigación en el desarrollo de metodología estadística ya sea a través aplicaciones innovadoras o bien mediante la adecuación de metodología ya desarrollada. 11. Modelos de Transición para Series de Tiempo Ambientales Primer autor (Ponente): Lorelie Hernández Segundo: Gabriel Escarela Resumen: Este estudio considera el problema de extender series de tiempo Gaussianas autorregresivas a un marco de respuestas de valor extremo, la metodología propuesta consiste en especificar el modelo autorregresivo en forma de distribución condicional cuya parametrización pertenece a la familia exponencial de distribuciones; para ello, se analizan niveles máximos diarios de ozono de la Ciudad de Guadalajara. _______________________________________________________________________________________________________ 57 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 12. Estimación Robusta en Fechamientos con Radiocarbono Primer autor (Ponente): Sergio Pérez Elizalde Segundo: Andrés Christen Resumen: El método general presentado por Christen (1994) para analizar fechamientos con radiocarbono está condicionado a que la desviación estándar reportada por los laboratorios, refleja la incertidumbre del proceso. Sin embargo, esta incertidumbre esta medida dentro de cada laboratorio por lo que ignora la incertidumbre extra debida a la variabilidad de los procesos entre laboratorios. En este trabajo se propone un método para el análisis de fechamientos con radiocarbono en el que se considera que la varianza está dada por el producto de una constante desconocida y la varianza reportada por el laboratorio. Con este enfoque, asumiendo que proviene de una población normal y que a priori tiene una distribución Gamma, el modelo para los fechamientos es una distribución t. Así, la introducción del parámetro permite hacer un análisis robusto en presencia de datos atípicos a la vez que incorpora la incertidumbre asociada a los procesos de determinación en cada laboratorio. Para la inferencia sobre los parámetros del modelo se utiliza el enfoque bayesiano por medio de métodos de simulación MCMC. 13. Reconocimiento de Patrones basado en el Color para la Clasificación de Frutas Primer autor (Ponente): Ana María Vázquez Vargas Segundo: Noemí Ortiz-Suárez Tercero: Everardo Lozada-Martínez Cuarto: Patricia Balderas-Cañas Resumen: Dada una partición en clases de un universo, tratamos de determinar a qué clase pertenece cualquier elemento de ese universo. Por ejemplo, en una imagen satelital sería identificar bosques de rocas, o áreas de cultivo de áreas urbanas, entre otras. Generalmente, no conocemos las variables discriminantes de nuestros objetos de estudio, entonces tratamos de estudiar nuestros objetos, a fin de identificar la clase a la cual pertenecen. Supongamos un universo de estudio U particionado en M clases y tomemos un elemento X de U. El problema se convierte en definir un sistema reconocedor de patrones que permita tomar la decisión de la clase a la cual pertenece U. En este trabajo, nuestro universo consiste en frutas que pueden ser de tres clases: manzanas rojas (clase 1), naranjas (clase 2) y manzanas amarillas (clase 3) y tratamos de diferenciarlas por su color. Siempre que se toma una decisión es necesario considerar el riesgo de error que hicimos al tomar esa decisión. Para minimizar el riesgo de _______________________________________________________________________________________________________ 58 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ error, utilizamos la Regla de Bayes para tener el mínimo riesgo. En un estudio anterior (Ortiz y Lozada, 2008), realizamos un experimento que consistió en seleccionar las frutas (30 manzanas rojas, 30 manzanas amarillas y 30 naranjas), tomar una fotografía digital de cada una de ellas. Aprovechamos el conocimiento que se tiene sobre la descomposición cromática básica (rojo, verde y azul), en los rangos de 0 a 255 y seleccionamos un píxel de cada fruta y anotamos los valores de los 3 colores, eliminando el azul ya que tuvimos la experiencia de que el azul sesga los resultados, nos quedamos entonces, para “medir el color” por medio de los colores rojo y verde los cuales quedaron representados por la proporción del rojo y verde, denominando a esta variable discriminatoria tasa de rojez. Los datos correspondientes a cada clase fueron las medias aritméticas: (0.525880241, 0.76908766, 0.91210009), y sus desviaciones estándares (0.036181704, 0.04204817, 0.027016). De esta manera la Regla de Bayes obtuvo los puntos frontera entre las clases, siendo estas dos intersecciones los valores: en donde los subíndices indican las clases involucradas. La discriminación entre manzanas rojas y naranjas no mostró ningún error y la discriminación entre manzanas amarillas y naranjas y manzanas amarillas tuvieron un error asociado de 0.03732838496, que consideramos como aceptable. Concluimos que fuimos capaces de determinar la validez del sistema reconocedor de frutas, basado en una selección de colores mencionada (Marques de Sá, 2001). 14. Análisis de Confiabilidad para la Predicción de Vida Útil de Alimentos Primer autor (Ponente): Fidel Ulín-Montejo Segundo: Rosa Ma. Salinas-Hernández Resumen: En este trabajo se presentan conceptos y métodos de análisis de confiabilidad usados en estudios sensoriales y fisicoquímicos para la predicción de vida útil de frutos frescos cortados. Las funciones de confiabilidad se definen como la probabilidad de aceptación de los consumidores a un fruto fresco almacenado a lo largo de ciertos tiempos establecidos. El fenómeno de censura, se ha definido y demostrado que ocurre en datos sensoriales y fisicoquímicos de vida útil de alimentos. Métodos estadísticos para datos de confiabilidad fueron aplicados a un conjunto de datos obtenidos de consumidores quienes probaron muestras del fruto fresco cortado con diferentes tiempos de almacenamiento, respondiendo 'si' o 'no' a las muestra que consumirían. De este conjunto de datos censurados, algunos modelos fueron obtenidos permitiendo las estimaciones de vida útil. También se presenta un modelo de Arrhenius para analizar los datos basados en la aceptación o rechazo de muestras conservadas a diferentes tiempos y diferentes temperaturas. La inferencia estadística para la estimación y predicción de vida útil fueron realizadas a través de rutinas de cómputo y graficación en R. _______________________________________________________________________________________________________ 59 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 15. Análisis Post-Cosecha en la Calidad del Café Pergamino Primer autor (Ponente): Consuelo Amador Valencia Segundo: Oscar González Ríos Tercero: Mario Miguel Ojeda Ramírez Resumen: Se presenta un análisis estadístico de cuatro tratamientos post-cosecha en la calidad del café pergamino, utilizando datos obtenidos en un invernadero en la ciudad de Coatepec, Veracruz, México. Se realizó un diseño experimental, donde intervinieron cuatro tratamientos diferentes. Se hicieron análisis preliminares tanto físicos como químicos, se obtuvo en cada etapa un análisis exploratorio, tanto univariado como multivariado y tablas de análisis de varianza, mismo que permitió verificar los datos y detectar cuál era el mejor tratamiento para la calidad en el café pergamino. La técnica estadística utilizada para trabajar conjuntamente las variables de calidad es la de Análisis de Componentes Principales (ACP). 16. Análisis Factorial de Correspondencias Múltiples en un Estudio de Satisfacción de Usuarios sobre Servicios de Personal Bibliotecario Primer autor (Ponente): Gladys Linares Fleites Segundo: María de Lourdes Sandoval Solís Tercero: Minerva Haideé Díaz Romero Cuarto: María Guadalupe Romero Vázquez Resumen: La Dirección General de Bibliotecas de la Benemérita Universidad Autónoma de Puebla está empeñada en alcanzar niveles de excelencia en los servicios que brinda a la comunidad universitaria. En este trabajo se reportan los resultados de una encuesta llevada a cabo con 100 usuarios en la Biblioteca del área de las carreras de ingeniería, Biblioteca Ing. L. Barragán, a través de la técnica de Análisis Factorial de Correspondencias Múltiples. Se analizaron los aspectos de la encuesta referidos al personal bibliotecario que atiende esta biblioteca destacándose dos dimensiones importantes: una, que denominamos Capacitación y Eficiencia del Personal con 74.34% de inercia y, otra, que nombramos Trato y Amabilidad del Personal, con 12.45% de inercia. El análisis de estas dimensiones en conjunción con otras opiniones y características de los usuarios permite arribar a recomendaciones para elevar la calidad de los servicios bibliotecarios. _______________________________________________________________________________________________________ 60 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 17. Métodos Multivariados en la Búsqueda de Indicadores de Degradación Ambiental en la Sierra Norte de Puebla Primer autor (Ponente): Gladys Linares Fleites Segundo: Miguel Ángel Valera Pérez Tercero: María Guadalupe Tenorio Arvide Resumen: Para el diagnóstico de procesos de degradación ambiental es necesario utilizar múltiples indicadores, fundamentalmente, indicadores de degradación de suelos, ya que el proceso de degradación de este recurso natural está estrechamente relacionado al primero. La evaluación de los suelos se realiza a través de diferentes parámetros físicos, químicos, mineralógicos y biológicos, por lo que la utilización de métodos estadísticos multivariados se torna imprescindible. Con el objetivo de contar con indicadores de degradación de suelos que permitan evaluar los suelos de la Sierra Norte de Puebla se han aplicado diversas técnicas exploratorias de datos, tales como, Componentes Principales, Conglomerados Jerárquicos y Escalamiento Multidimensional, que han permitido obtener algunos indicadores de la degradación de suelos de la Sierra Norte de Puebla. El propósito del presente trabajo ha sido realizar un análisis confirmatorio a través de los métodos de Discriminación Lineal y Regresión Logística para corroborar que los indicadores obtenidos permiten diagnosticar la degradación de estos suelos y, por ende, la degradación ambiental. 18. El Análisis Multivariado Aplicado al Cultivo del Cirián Primer autor (Ponente): Emilio Padrón Corral Segundo: Ignacio Méndez Ramírez Tercero: Armando Muñoz Urbina Cuarto: Haydée de la Garza Rodríguez Resumen: Usando el análisis multivariado es posible examinar en forma simultánea la estructura de los datos así como los valores de las variables y la relación que existe entre ellas. En este trabajo se desarrolló un análisis de correlación canónica y un análisis de coeficientes de sendero, utilizando datos de la especie árborea Cirián (crescentia alata H.B.K.) donde las variables a medir fueron: altura del árbol, número de ramas, diámetro de ramas, cobertura, diámetro ecuatorial, diámetro polar, número de frutos, peso de frutos y rendimiento; con el fin de determinar los siguientes objetivos: 1.- Analizar datos del árbol y del fruto mediante correlación canónica, a fin de determinar aquellas variables que mas influyen sobre la producción. 2.- Efectuar un _______________________________________________________________________________________________________ 61 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ análisis de coeficientes de sendero para estudiar las relaciones de causa y efecto entre las componentes del rendimiento. La metodología usada en el análisis de la dasometría del árbol fue el muestreo probabilístico por conglomerados en dos etapas, para el caso del fruto se utili\-z ó el mismo tipo de muestreo pero en tres etapas. Para el análisis de correlación canónica la matriz de datos originales se particionó de acuerdo la naturaleza de sus variables en dos submatrices, cada una correspondiente a dos grupos de variables. En el análisis de sendero las características fueron tratadas como variables de primero y segundo orden, los efectos directos e indirectos del análisis de sendero fueron estimados utilizando el paquete computacional MatLab. En los resultados obtenidos del análisis de correlación canónica se observó una correlación altamente significativa entre el primer par de variables canónicas. El segundo par de variables canónicas presentaron una correlación significativa. En el análisis de sendero se detectó que de los efectos directos sobre número de frutos; cobertura fue la más sobresaliente. Las conclusiones indican que en el análisis de correlación canónica los dos grupos de variables (árbol y fruto) se encuentran relacionados. Estimándose una correlación altamente significativa entre el primer par de variables canónicas y una correlación significativa entre el segundo par de variables canónicas. El análisis de sendero mostró que la cobertura fue un factor importante para determinar el número de frutos. Los efectos directos de diámetro ecuatorial y diámetro polar sobre peso de fruto fueron de aproximada magnitud y explicaron en un 69% la variación en el peso de fruto. En el análisis de sendero para rendimiento de fruto, se observó que el coeficiente de determinación explicó el 97% de la variación en el rendimiento de fruto. 19. Regresión Mínimo Cuadrática Parcial (PLS) Primer autor (Ponente): Marcela Rivera Martínez Segundo: Hortensia Reyes Cervantes Tercero: Luis René Marcial Castillo Cuarto: Gladys Linares Fleites Resumen: Resumen: En este trabajo se presenta un procedimiento de regresión por mínimos cuadrados parciales (PLS), para realizar predicciones, cuando las variables regresoras (X) son muchas y altamente colineales. A diferencia de otros métodos de regresión, la regresión PLS busca para un conjunto de componentes de X una descomposición simultánea de las variables regresoras (X) y las variables respuesta (Y), con la restricción de que éstas componentes expliquen tanto como sea posible la covarianza entre X e Y. En particular, se discute el algoritmo NIPALS (Nonlinear Iterative Partial Least Squares) por ser el de uso más frecuente y se muestra una aplicación del mismo. _______________________________________________________________________________________________________ 62 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 20. El Modelo de Zurek y su modificado aplicado a la Viscoelasticidad de Hilados de Poliester Primer autor (Ponente): Ana María Islas Cortés Segundo: Gabriel Guillén Buendía Tercero: Manuel Olvera Gracia Resumen: Los fundamentos matemáticos de la viscoelasticidad fueron establecidos por James C. Maxwell proponiendo el modelo que lleva su nombre. Considera dos elementos ideales, el primero explica la recuperación elástica de los cuerpos sometidos a tracción y está representado por un muelle; mientras que la segunda, la variación de las dimensiones que se producen en el material a lo largo del tiempo, ya sea durante la aplicación del esfuerzo o bien después de cesar el mismo, está relacionado con las tensiones internas acumuladas en el material que se liberan gradualmente y se representa por un émbolo. Uno de los modelos más trascendentes es el modelo de Zurek, en el cual el mecanismo de resistencia es remplazado por un sistema de fricción interna de masa M y fuerza de fricción T proporcional al alargamiento. La fricción interna esta incorporado a un sistema en paralelo compuesto por un muelle de Hooke con una constante k2 y un émbolo de Newton de viscosidad n. Todo conectado a un extremo de un muelle de Hooke de constante k1. Los parámetros del modelo de Zurek tienen significado físico, A es la rigidez; B esta determinado como la pendiente de la recta de la zona de refuerzo; C y D suelen estar relacionadas con propiedades mecánicas del material. Para el desarrollo de este trabajo se utilizo las curvas carga alargamiento promedio de hilos de poliéster de uso textil común, procesados en estiraje mecánico en una máquina Barmag a diferentes temperaturas y relaciones de estiraje. Se sometieron a ensayo de tracción en un dinamómetro universal bajo la normativa vigente. Las constantes numéricas del modelo de Zurek se determinan por los métodos gráfico, método iterativo Marquardt, y la técnica de mínimos cuadrados y los resultados obtenidos se comparan y son significativos al 1% de confianza. El modelo modificado también conduce a excelentes resultados. El presente estudio permite formular las siguientes conclusiones: La evaluación numérica de los parámetros del modelo de Zurek es resuelto por la técnica de mínimos cuadrados con excelentes resultados, el método iterativo de Newton-Raphson conduce con un mínimo de iteraciones a la solución óptima del modelo analógico, el modelo de Zurek modificado conduce a una bondad de ajuste del 5% de confianza estadística. _______________________________________________________________________________________________________ 63 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 21. El Modelo de Phillips como Función de Densidad de Muestra Primer autor (Ponente): Gabriel Guillén Buendía Segundo: Ana María Islas Cortés Resumen: En el ámbito de la ingeniería textil los modelos de peso estadístico de muestra son de gran interés, puesto que determinadas propiedades de las fibras textiles conducen a un histograma unimodal de moda centrada, por ejemplo las propiedades mecánicas de los hilos textiles, la finura de las fibras químicas; para la representación matemática de la campana envolvente de estos histogramas se usan modelos de peso estadístico de muestra que son tradicionales. En este documento se prueba el modelo de campana de Phillips como modelo de peso estadístico de muestra. El modelo de Phillips es un modelo de secante hiperbólica al cuadrado y tiene ventajas esenciales como ser directamente integrable, el modelo cumulativo de muestra se obtiene por una simple integración, el tamaño de un individuo “x” es despejable del modelo cumulativo ya citado, esto permite calcular el tamaño al cual son inferiores un cierto número de individuos acumulados de izquierda a derecha en el modelo de densidad de muestra, mediante un modelo numérico funcional muy sencillo. En el presente trabajo se ajusta el modelo de Phillips a un histograma de datos experimentales de alargamiento a la rotura de hilos de poliéster de 177 dtex (calibre), ensayados de acuerdo a norma técnica y utilizando un dinamómetro universal Instron de uso común en la industria textil. Del estudio se concluye que el modelo de Phillips es eficiente como función densidad de muestra para histogramas unimodales de moda centrada, asimismo se usaron tecnicas de ajuste a la distribución normal como la técnica del punto conocido, el algoritmo de Guggenheim, y el procedimiento Marquardt como métodos de comprobación, en todos los casos se lograron bondades de ajuste del 5% de confianza estadística. _______________________________________________________________________________________________________ 64 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 22. Estudio de la Validez del Constructo Inteligencia Emocional, en Estudiantes Universitarios, mediante un Modelo de Análisis Factorial Confirmatorio: Escala CASVI Primer autor (Ponente): Mª Elena Vicente Galindo Segundo: Juan Antonio Castro Posada Tercero: Mª Purificación Vicente Galindo Cuarto: Purificación Galindo Villardón Resumen: La Inteligencia Emocional es entendida como una metahabilidad cuya base es el autodominio de las competencias afectivas. A pesar de tratarse de una metahabilidad que incide en la totalidad del potencial del ser humano y que se encuentra implicada en una vida exitosa, ha recibido poca atención en la literatura científica. El constructo Inteligencia Emocional presenta gran dificultad para su evaluación. Hay diferentes tests en la literatura que evalúan las diferentes componentes de la inteligencia emocional y las diferencias individuales, desarrolladas, la mayoría, en Estados Unidos. (Davies, et al, 1990; Mayer y Salovey, 1993). La gran mayoría están dirigidos al medio laboral y las emplean los consultores en desarrollo organizacional, han sido traducidas y aplicadas directamente en nuestro país sin haber pasado por un proceso de adaptación, validación y estándarización, tienen baja validez de contenido, ya que no involucran ítems relacionados con el manejo de las emociones en otros escenarios, y generalmente todas las preguntas tienen la misma orientación semántica.Este trabajo se encuadra dentro de la perspectiva psicométrica de evaluación de la inteligencia emocional, que tiene por objetivo la validación y estudio de la fiabilidad de un instrumento para medir Inteligencia Emocional que evalúe metaconocimiento de los estados emocionales y nos permita detectar el perfil de inteligencia emocional de estudiantes universitarios: escala CASVI. La escala presenta un formato de inventario; es decir, está compuesta por 213 cuestiones. Cada ítem se corresponde con un enunciado que representa un rasgo de comportamiento paradigmático de la Inteligencia Emocional, expresado en escala tipo Licker, con 6 posibles respuestas. Tomamos como referente empírico una muestra no probabilística de 642 estudiantes universitarios, de las dos universidades de Salamanca, la USAL (pública) y la PONTIFICIA (privada), con edades comprendidas entre 18 y 35 años.El Análisis Factorial exploratorio (ACP, con rotación VARIMAX ) nos ha permitido simplificar la escala inicial y construir otra que contiene 43 ítems que configuran 4 dimensiones de la Inteligencia emocional: Autoestima (afectivo, cognitiva-comportamental), Autoconcepto (responsabilidad y empatía), Centración en si mismo y Dependencia Emocional, con alta consistencia interna, no sólo en las subescalas, sino también en su conjunto. Se ha desarrollado un modelo de Análisis Factorial Confirmatorio que ha permitido contrastar la configuración de la escala de Inteligencia Emocional de una manera científicamente válida: corrobora la estructura en cuatro dimensiones obtenida en el análisis exploratorio. El análisis Factorial Confirmatorio nos ha permitido, además, _______________________________________________________________________________________________________ 65 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ localizar los ítems para los cuales hay falta de ajuste, lo que nos lleva a pensar en profundizar en su estudio en investigaciones posteriores. 23. Ajuste del Modelo Exponencial y Gompertz usando la Técnica de los Tres Puntos de Apoyo de Lipka Primer autor (Ponente): Gabriel Guillén Buendía Segundo: Ana María Islas Cortés Resumen: Se estudia en el presente trabajo, la bondad de ajuste de la técnica de los tres puntos de apoyo de Lipka para la determinación numérica de los parámetros de los modelos exponencial y Gompetz, aplicados a datos experimentales obtenidos de la caracterización de materiales textiles. Para el caso del modelo exponencial se utilizaron datos del incremento de la tenacidad (resistencia específica) de hilos de algodón-Lyocell en función del contenido de ésta última fibra. En cuanto al modelo de Gompetz, se ajustó a datos experimentales del ensayo de sorción de iodo en fibras de poliéster en función de la temperatura del ensayo, útil para la caracterización indirecta de la microestructura. Asimismo, se compararon los resultados obtenidos de la técnica que da pie al presente documento con el algoritmo de Guggenheim y el método iterativo Marquardt. Este estudio formula las siguientes conclusiones: La técnica de los tres puntos de apoyo de Lipka aplicado a los modelos exponencial y Gompetz conduce a valores numéricos similares a los obtenidos por el método iterativo Marquardt. La transformación lineal de los modelos exponencial y Gompetz resulta una excelente herramienta para determinar los parámetros de dichos modelos, además de simplifica la compresión de los modelos haciendo uso de regresión simple. El valor didáctico de dichas técnicas se extiende a otros modelos no lineales. Los ajustes obtenidos fueron significativos al 5% de confianza estadística. _______________________________________________________________________________________________________ 66 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 24. Análisis de Supervivencia en un Contraste de los Atributos Defensivos de dos Especies de Hormigas Pseudomyrmex sobre Plantas Acacia Cornígera en una Selva Baja Caducifolia Primer autor (Ponente): Rosario Galván Martínez Segundo: Ingrid Rosario Sánchez Galván Tercero: Juan Carlos López Acosta Resumen: Una de las interacciones interespecificas defensivas más sobresalientes de la América neotropical son las relaciones mirmecofilas que se dan entre plantas de Acacia cornigera con hormigas del género Pseudomyrmex. En la cual las plantas ofrecen sitios de anidación por medio de espinas huecas de origen estipular (Domatios) y alimento mediante unos corpusculos amarillentos que crecen en el ápice de los foliolulos y nectarios extraflorales con glucosa y fructuosa. En una zona de selva baja caducifolia, nosotros encontramos la interacción entre plantas de A. cornigera con hormigas P. gracilis y P. ferrugineus con aparentes diferencias en su comportamiento defensivo. La herbivoría observada en las acacias nos indicaba que las hormigas P. ferrugineus eran más eficientes en términos de defensa antiherbivoro para las plantas que hormigas P. gracilis. Además experimentalmente ante la presencia de herbívoros simulados P. ferrugineus se recluto más rápido y con mayor número de hormigas ocurriendo ante el estímulo que P. gracilis. Nosotros intentamos inducir el reclutamiento de las hormigas P. gracilis ante señales químicas del post daño en un diseño pareado con extractos de Acacia, a los datos obtenidos se les aplico una metodología estadística con estudios de supervivencia, con la técnica no paramétrica de Kaplan- Meier con la cual se calcularon las curvas de supervivencia, también se utilizaron para comparar las distribuciones de supervivencia entre grupos (control vs. tratamiento) las pruebas de Log-Rank. Para los procesamiento necesarios se utilizó el paquete estadístico SPSS. En los tratamientos con extractos se observó mayor actividad defensiva de ambas hormigas, incrementando su tiempo y cantidad de patrullaje y velocidad de llegada al área de estímulo. Este estudio evidencia que el mantenimiento de las interacciones puede estar mediado por estímulos químicos, las cuales pueden ser interpretadas por las hormigas como señales fidedignas de daño. _______________________________________________________________________________________________________ 67 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 25. Modelos Lineales Aplicados a la Estimación de Demanda de Agua Primer autor (Ponente): Alejandro Salazar Adams Segundo: Nicolás Pineda Pablo Resumen: En este trabajo se utilizó un modelo de regresión lineal para estimar los parámetros de una función de demanda percápita de agua. La estimación se llevó a cabo con base en los datos de consumo de agua de una muestra de 57 ciudades con más de 50 mil habitantes en México. La función de demanda de agua está dada por: D = f(Y, P, TH, Temp, Precip), en donde: D es la demanda percápita de agua, Y es el ingreso percápita, P es el precio promedio por metro cúbico, TH es el tamaño del hogar, Temp es la temperatura, Precip es la precipitación. Se utilizó una forma funcional semi- logarítmica cuyos parámetros fueron estimados a través del método de mínimos cuadrados ordinarios. Con base en el modelo estimado se llevó a cabo la proyección de escenarios de demanda de agua en la ciudad de Hermosillo, Sonora hasta el año 2030 para determinar si es posible asegurar el abastecimiento de agua hasta dicho año. 26. Análisis Psicométrico del Funcionamiento Diferencial del Cuestionario QUALEFFO, para Evaluar Calidad de Vida en Pacientes Osteoporóticos, Ambulatorios, basado en el Modelo DFIT y en Regresión Logística Primer autor (Ponente): Mª Purificación Vicente Galindo Segundo: Mercedes Sánchez Barba Tercero: José Luis Vicente Villardón Cuarto: Purificación Galindo Villardón Resumen: A la mayoría de la gente le es familiar la expresión “calidad de vida” y tiene una idea intuitiva de lo que comprende. Sin embargo, es muy difícil dar una definición de Calidad de Vida, porque significa diferentes cosas para diferentes personas, para las mismas personas en diferentes momentos e, incluso, tiene diferentes significados dependiendo del área de aplicación. Una de las áreas en las que éste término ha adquirido una mayor importancia es en el ámbito de la salud. No hay, por el momento, una definición universalmente aceptada. En la mayoría de los trabajos se identifica el concepto con las dimensiones que evalúa el cuestionario que se utiliza. De ahí, la trascendencia de disponer de cuestionarios específicos con buenas propiedades psicométricas. Este trabajo se centra en el estudio del QUALEFFO, un cuestionario específico para evaluar Calidad de Vida en pacientes osteoporóticos, que fue diseñado para su uso en pacientes hospitalizados que habían sufrido fractura de _______________________________________________________________________________________________________ 68 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ cadera, mayoritariamente mujeres. Dada la trascendencia social y económica que tiene la osteoporosis, y su incidencia cada vez mayor, también en hombres, la Organización Mundial de la Salud ha recomendado su detección en el ámbito de Atención Primaria. El primer paso para evaluar el impacto en la Calidad de Vida del paciente es disponer de un cuestionario adecuado. SANCHEZ-BARBA, 2008, probó que el QUALEFFO sigue siendo válido el ser aplicado en screening en pacientes ambulatorios y demostró también que puede ser simplificado sin perder sus propiedades psicométricas. Este trabajo se centra en el estudio del funcionamiento diferencial, ya que de existir, no podría ser generalizado su uso a ambos géneros. Se ha evaluado el Funcionamiento Diferencial de los diferentes ítems del Qualeffo, con el modelo DFIT, para identificar si los hombres y las mujeres, con un mismo nivel de nivel de Calidad de Vida, tienen distinta probabilidad de elegir una determinada respuesta. Se han identificado cinco ítems con funcionamiento diferente en hombres y mujeres de los cuales, cuatro además no aportaban información relevante. El modelo de Regresión logística nos ha permitido identificar cinco ítems con funcionamiento diferencial no uniforme; es decir, cinco ítems para los cuales la probabilidad de responder una categoría concreta es distinta para el grupo de los hombres y para el grupo de las mujeres, en ciertos niveles de Calidad de Vida, mientras que en otros esto no sucede. 27. Modelación Factorial de la Estructura de Varianza-Covarianza de la Interacción Genotipo x Ambiente para el Agrupamiento de Genotipos y/o Ambientes sin Interacción de Entrecruzamiento Primer autor (Ponente): Juan Andrés Burgueño Segundo: José Crossa Tercero: Paul L. Cornelius Cuarto: Rong-Cai Yang Resumen: La variabilidad encontrada en la interacción genotipo x ambiente puede ser debida a interacción de entrecruzamiento o de no entrecruzamiento (heterogeneidad de varianza). Los métodos estadísticos para detectar y cuantificar la interacción de entrecruzamiento y formar grupos de ambientes y/o genotipos con interacción de entrecruzamiento despreciable han estado basados en modelos lineales bilineales de efectos fijos. El modelo lineal mixto y la modelación de la estructura de varianzacovarianza a través del análisis factorial, nos da una solución más realista y eficiente para cuantificar la interacción de entrecruzamiento y formar grupos de ambientes y genotipos sin interacción de entrecruzamiento. Los objetivos de este estudio son (i) presentar una metodología integrada para el agrupamiento de ambientes y genotipos sin interacción de entrecruzamiento, basada en el ajuste del modelo factorial de ensayos multiambiente, (ii) detectar interacción de entrecruzamiento, usando _______________________________________________________________________________________________________ 69 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ funciones predecibles basadas en el modelo lineal mixto con análisis factorial y en los mejores predictores lineales insesgados de genotipos. Los resultados de dos redes de ensayos internacionales de CIMMYT para la evaluación de maíz (Zea mays L.) fueron usados para ilustrar la metodología utilizada para la búsqueda de grupos de ambientes y genotipos sin interacción de entrecruzamiento. La metodología utilizada mostró, en ambos ensayos, que sí es posible formar grupos de ambientes y/o genotipos sin interacción de entrecruzamiento. El uso del modelo lineal mixto permite un mejor manejo del desbalance en la información, habitual en este tipo de ensayos. La principal ventaja de esta metodología integrada es que un único modelo lineal mixto, con modelación de la estructura de varianza-covarianza a través del análisis factorial, puede ser usada para (i) modelar la asociación entre ambientes, (ii) formar grupos de ambientes sin interacción de entrecruzamiento, (iii) formar grupos de genotipos sin interacción de entrecruzamiento, (iv) detectar interacción de entrecruzamiento usando las funciones predecibles apropiadas. 28. Análisis Multivariado de Covarianza para determinar la Influencia del Medio Ambiente sobre la Durabilidad del Concreto. Proyecto Duracon-Tampico Primer autor (Ponente): Haidie Lissete Hervert Zamora Segundo: Demetrio Nieves Mendoza Tercero: Miguel Ángel Baltazar Zamora Cuarto: Julio Cesar Barrientos Cisneros Resumen: La durabilidad de las estructuras de concreto esta generalmente asociada con las características mecánicas del mismo, tales como la resistencia a la compresión, la relación agua/cemento, la porosidad, etc. Sin embargo, es de vital importancia conocer el comportamiento del medio ambiente en el que están inmersas dichas estructuras, y de esta forma tomar medidas que optimicen la vida útil de las mismas. Para conocer la influencia que tienen las condiciones del medio ambiente al que están expuestas las estructuras de concreto reforzado en Ibero América, sobre su durabilidad se implementó el Proyecto IberoAmericano DURACON. Este proyecto se desarrolla mediante la exposición de vigas de concreto armado de dos relaciones agua/cemento (a/c, 0.45 y 0.65), con tres espesores de recubrimientos (15, 20 y 30 mm). El seguimiento del comportamiento electroquímico de las vigas fue mediante la técnica electroquímica de Resistencia a la polarización lineal (Rp), obteniéndose la medición del potencial de corrosión (Ecorr), y Velocidad de Corrosión (icor).En fenómenos como el descrito anteriormente, donde, aun bajo condiciones aparentemente idénticas, existe un alto grado de incertidumbre y variabilidad en los resultados, es difícil tomar decisiones; por lo que en el presente trabajo se muestra la aplicación de la técnica Estadística Análisis Multivariado _______________________________________________________________________________________________________ 70 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ de Covarianzas (MANCOVA) de los resultados de las técnicas electroquímicas del proyecto DURACON, en conjunto con las condiciones de experimentación (relación a/c, Recubrimiento, Cara Expuesta a los vientos predominantes o Resguardada) y las variables ambientales como son Temperatura y Humedad; con el objetivo de determinar estadísticamente el grado de influencia que tiene estas variables ambientales o en su caso de las condiciones de experimentación sobre la durabilidad del concreto. Los resultados muestran que las variables ambientales hasta el momento no presentan influencia alguna sobre la icor, y Ecorr, del mismo modo sobre las condiciones experimentales, excepto la condición Recubrimiento y Relación a/c que se muestran altamente significativas. 29. Modelos de Regresión Logística y Lineal para el Estudio de los Datos de los Pesos de los Recién Nacidos, en el Hospital Dr. Gustavo A. Rovirosa Pérez, de Villahermosa, Tabasco Primer autor (Ponente): Edilberto Nájera Rangel Segundo: José Juan Guzmán Hernández Tercero: Lucas López Segovia Resumen: A un conjunto de datos, en los que la variable de interés es el peso al nacer, se les ajustó un modelo de regresión logística y uno de regresión lineal. Las variables explicativas que se consideraron son las semanas de gestación, el sexo del recién nacido, el peso de la madre, la estatura de la madre, la edad de la madre y el número de visitas al ginecólogo. El objetivo es analizar el efecto que tiene el control del embarazo sobre el peso del producto al nacer. También se comparan los dos modelos ajustados. 30. Estimación del Tamaño de una Población de Difícil Detección en el Muestreo por Seguimiento de Nominaciones y Probabilidades de Nominación Heterogéneas Primer autor (Ponente): Martín H. Félix Medina Segundo: Pedro E. Monjardin Resumen: En este trabajo se presenta una generalización de un estimador del tamaño de una población de difícil detección (drogadictos, niños de la calle, sexo servidoras, etc.) propuesto por Félix Medina y Thompson (Jour. Official Stat., 2004) para el _______________________________________________________________________________________________________ 71 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ caso en el cual las probabilidades de nominación dependen de los individuos (probabilidades de nominación heterogéneas). El estimador propuesto es una adaptación del estimador que presentan Coull y Agresti (Biometrics, 1999) en el contexto de estudios de captura-recaptura múltiple. Mediante un estudio de simulación se analiza el desempeño del estimador propuesto y se compara con el del estimador que no toma en cuenta la heterogeneidad de las probabilidades de nominación presentado por Félix Medina y Thompson (2004). 31. Estudio Computacional sobre Aleatoriedad para Sucesiones Grandes en Desarrollo Decimal de Algunos Números Primer autor (Ponente): Agustín Jaime García Banda Segundo: Luis Cruz Kuri Tercero: Ismael Sosa Galindo Resumen: Es conocido que el número Pi, cociente del perímetro de un círculo y su diámetro, es trascendente, en el sentido de no ser raíz de algún polinomio con coeficientes enteros. Otro número que también es trascendente es e, la base de los logaritmos naturales; la raíz cuadrada de 2, por otra parte, es irracional pero no es trascendente. Con la introducción de programas de cómputo matemático, tales como Mathematica, es relativamente fácil obtener en computadoras personales expansiones decimales de tales números a millones de cifras. En el presente trabajo, se introduce un algoritmo computacional, desarrollado por nosotros, el cual permite hacer aplicación de algunas pruebas de aleatoriedad para las sucesiones correspondientes de los dígitos así generados; asimismo se discuten los hallazgos para algunos números selectos. 32. Estudio Computacional para Encontrar el Valor Óptimo de la Distancia Esperada entre un Punto y una Variable Aleatoria Real Primer autor (Ponente): Luis Cruz Kuri Segundo: Agustín Jaime García Banda Tercero: Ismael Sosa Galindo Resumen: Sea X una variable aleatoria fija con una distribución dada, discreta o absolutamente continua, y sea d una métrica sobre el espacio de los números reales. Para cada número real r se define la función f(r) =E(d(X,r)). El objetivo es encontrar el _______________________________________________________________________________________________________ 72 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ valor óptimo (máximo) de la función f. En el presente trabajo se describe como este problema se resuelve con el apoyo de un programa de cómputo matemático, ejecutado en una computadora personal, para algunas métricas y para algunas variables aleatorias. En particular, se ilustra lo que ya es conocido en dos situaciones especificas, a saber, que para la métrica euclidiana L2 el valor óptimo se obtiene con r=E(X) y, para la métrica L1, el valor óptimo se alcanza con r=Mediana(X). 33. Estudio de Algunas Distribuciones mediante el Apoyo de un Programa de Computo Matemático Primer autor (Ponente): Ismael Sosa Galindo Segundo: Luis Cruz Kuri Tercero: Agustín Jaime García Banda Resumen: Haciendo uso de un programa de cómputo matemático, se hace un estudio de algunas distribuciones, tanto discretas como absolutamente continuas, que aparecen en estadística y probabilidad multivariada. El programa que hemos utilizado para nuestras ilustraciones es Mathematica, el cual tiene capacidad de ejecución de procesamientos numéricos, simbólicos y gráficos. Con el propósito de poder visualizar algunas características gráficas en un espacio de tres o menos dimensiones, se seleccionan algunas distribuciones divariadas. Para dimensiones mayores, la visualización se consigue de manera parcial mediante proyecciones sobre subespacios de dimensiones uno y dos. Así, por ejemplo, para la distribución normal de tres dimensiones, se presentan, entre otros objetos geométricos, la colección de los así llamados “elipsoides de concentración”. Se hace un pequeño estudio de versiones multivariadas de distribuciones absolutamente continuas de algunos modelos clásicos, tales como el exponencial, etc. y, de manera análoga, para algunas distribuciones discretas, tales como las familias de la distribución binomial y la distribución hipergeométrica (con dos o más variables). 34. Análisis Descriptivo Multivariado de la contaminación en el corredor industrial del Estado de Guanajuato Primer autor (Ponente): Sergio Martín Nava Muñoz Segundo: Rafael Alberto Pérez Abreu Carrión Resumen: El monitoreo atmosférico es uno de los indicadores principales de la calidad del aire y representa una valiosa herramienta de gestión para instrumentar acciones de prevención y control de los contaminantes presentes en la atmósfera ante _______________________________________________________________________________________________________ 73 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ condiciones que ponen en riesgo la salud de los ciudadanos. Además, es una fuente de información para la ciudadanía sobre los niveles de contaminación. El presente trabajo ofrece una descripción del estado que guarda la Red de Monitoreo de la Calidad del Aire del Estado de Guanajuato para el año 2006. Esta descripción se da en términos de las variables ambientales y contaminantes medidos en las estaciones de monitoreo. Además se realiza un análisis de la situación de los contaminantes criterio respecto a los valores permisibles en la normatividad para la calidad del aire. Este estudio fue realizado con recursos del Fondo Mixtos del Estado de Guanajuato y en conjunto con el departamento de “coordinación de mejoramiento de la calidad del aire” del Instituto de Ecología del Gobierno de Guanajuato. 35. Regresión Lineal en Confiabilidad Usando el Lenguaje R Primer autor (Ponente): Carlos Abraham Carballo Monsiváis Segundo: Jorge Domínguez Domínguez Resumen: Los modelos de regresión generados a partir de los datos experimentales permiten caracterizar la confiabilidad de un producto. Los datos se obtienen mediante una estrategia experimental con el fin de caracterizar la confiabilidad de un producto. En este tipo de situaciones los datos tienen propiedades específicas tales como la censura o distribuciones no normales. En la literatura estadística existen el método clásico de Máxima verosimilitud para resolver estos problemas, lo compararemos con los métodos de Hamada – Wu y Hahn, Morgan – Schmee para modelar ese tipo de datos. El primero es un algoritmo generado por máxima verosimilitud, el segundo consiste del método de mínimos cuadrados clásico con ponderación iterada para tomar en cuenta la censura y la distribución. En la actualidad R desempeña un papel importante en el cómputo estadístico. En este trabajo se ilustra la implementación de R en estos dos métodos estadísticos que permiten modelar datos en confiabilidad y se evalúa la utilidad del lenguaje R. También se comparan y discuten ventajas y desventajas de ambos procedimientos con diversos casos de la literatura. Los resultados de estas comparaciones son la pauta para análisis de la confiabilidad de muchos productos que se manufacturan en el sector industrial. _______________________________________________________________________________________________________ 74 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 36. Aprendizaje de la Estadística con Base en Opciones Lúdicas: Proyecto Genios de la Estadística Primer autor (Ponente): Lorena López Lozada Segundo: Joaquín Díaz López Tercero: Víctor Manuel Méndez Sánchez Cuarto: Claudio Rafael Castro López Resumen: Sin duda, los programas académicos de estadística a nivel de licenciatura enfrentan la baja demanda en su matrícula y peor aún, la desorientación de los estudiantes que ingresan sobre que van a consistir sus estudios, ya que su pensamiento estadístico en los niveles de educación básica se desarrolla con algunas deficiencias graves. La carrera de Licenciado en Estadística que ofrece la Universidad Veracruzana en México es un caso que enfrenta problemas de baja demanda, desorientación y poca motivación del estudiante que ingresa en este programa académico. Esto último ha impactado en elevados índices de deserción escolar. En este contexto nace el proyecto Genios de la estadística, con el objetivo principal: motivar el aprendizaje y espíritu investigador que posee todo ser estadístico, a través de juegos populares, cuyos contenidos están orientados a conceptos y áreas relacionadas con la estadística con base a los contenidos temáticos que se abordan a nivel bachillerato. El proyecto se visualiza en tres grandes etapas: 1) Adaptación y prueba de los juegos, 2) Implementación informática de los juegos con tecnología Web para disponibilidad en línea y 3) Despliegue de los juegos a la comunidad usuaria para su evaluación y mejora, así como el seguimiento a usuarios interesados. Ésta información servirá para motivar entre otras cosas cambios en la educación estadística y la implantación de una campaña que promueva nuestro programa académico. Aquí se presenta la experiencia lograda de la adaptación y prueba (primera etapa) de los juegos denominados “La Oca estadística”, “ µparχ ” y “El Retador” llevados a cabo in situ con estudiantes de la Licenciatura de Estadística. El conocimiento incorporado en los juegos se basa en los contenidos temáticos que se abordan a nivel bachillerato. El contenido requirió la elaboración de un banco de 500 reactivos distribuidos en las temáticas: Algebra, Computación, Estadística Exploratoria, Probabilidad y Cultura General. Estos reactivos fueron planteados por los académicos que imparten dichas experiencias educativas. _______________________________________________________________________________________________________ 75 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 37. Calidad de vida de los habitantes de la ciudad de Xalapa, Ver.: Una perspectiva multivariante Primer autor (Ponente): Toshil Sarmiento Martínez Segundo: Claudio Rafael Castro López Resumen: La aceleración demográfica y la intensa migración regional bastan para que el problema de dimensión urbana versus calidad de vida sea argumento de apelación para reconsiderar la política de desconcentración de las ciudades grandes. La población de Xalapa ha crecido a un ritmo acelerado, lo cual implica una gran demanda de servicios e infraestructura local que no puede ser satisfecha a plenitud, ya que el gobierno municipal no posee la capacidad financiera necesaria y suficiente para proveer la cantidad y calidad de servicios, equipamiento e infraestructura para su población. Añádase además que en los últimos años, Xalapa ha experimentado un crecimiento explosivo, ante una planeación retardada por parte de sus gobiernos. Y que si bien, se tiene la presunción de que este aspecto ha impactado notablemente en la calidad de vida de sus habitantes, es conveniente plantearse la pregunta: ¿Cómo se mide y cuáles son las dimensiones de la calidad de vida de los habitantes de la ciudad de Xalapa? 38. Pruebas exactas incondicionales de no-inferioridad para la diferencia de probabilidades binomiales Primer autor (Ponente): Cecilia Ramírez Figueroa Segundo: David Sotres Ramos Tercero: Félix Almendra Arao Resumen: El objetivo de este trabajo es estudiar el comportamiento del nivel de significancia real de varias pruebas exactas que contrastan la no-inferioridad entre dos tratamientos; basada en la diferencia de dos proporciones binomiales así como su potencia. La investigación ha encontrado que la prueba de Blackwelder que se usa frecuentemente se debe aplicar con mucha precaución debido a su comportamiento excesivamente conservador, que repercute en una potencia baja. La prueba donde su estadística es la razón de verosimilitud es generalizada resulta mejor sólo para algunos valores del margen de no-inferioridad. Por último la prueba basada en una estadística tipo score (Farrington-Manning) se puede recomendar como la mejor porque mantienen los valores del nivel de significancia muy cercanos al nivel nominal y ligeramente supera a todas las pruebas estudiadas en cuanto ala potencia. Todos los estudios se realizan con cálculos detallados del nivel de significancia real, sin utilizar aproximaciones, para establecer conclusiones sólidas. _______________________________________________________________________________________________________ 76 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 39. Modelación de la Tendencia en Extremos no Estacionarios para Datos de Temperatura Obtenidos Alrededor de Citlaltépetl Primer autor (Ponente): Marisol López Cerino Segundo: Bulmaro Juárez Hernández Tercero: José del Carmen Jiménez Hernández Resumen: Los glaciares tropicales representan excelentes indicadores del cambio en el clima, están constituidos por reservas sólidas de agua dulce y son particularmente importantes, por los recursos hídricos que proporcionan. Los glaciares tropicales en México cubren una superficie aproximada de 11.4 km2. En este trabajo se presenta un análisis descriptivo de las temperaturas máximas y mínimas promedios mensuales. Se realizó un mapa de la región en la cual se pueden encontrar las estaciones meterelógicas de las cuales se obtuvieron los datos en un radio de 50 km. Parece ser un hecho la desaparición de los glaciares del volcán Citlaltéptl, a menos que las condiciones climáticas locales y globales cambien. Los patrones de temperatura de la región de estudio indican un incremento sistemático en la temperatura media anual. El ritmo de retroceso sostenido que se ha observado en el presente ocasionará sus desaparición en las próximas tres décadas. Los glaciares del volcán Citlaltépetl son fuente de recarga de los mantos acuíferos del valle de Puebla y la región del Estado de México, así como de municipios de Veracruz. La importancia del análisis de datos a través de series de tiempo, permite conocer la tendencia de temperatura, observándose del análisis de los datos una tendencia positiva para las temperaturas máximas y mínimas. Se necesita crear una conciencia sobre las preguntas que surgen naturalmente, ¿Desaparecerán los glaciares tropicales que se encuentran en el volcán Citlaltépetl? ( ¿En cuanto tiempo? ¿Qué se debe hacer para evitarlo? _______________________________________________________________________________________________________ 77 XXIII Foro Nacional de Estadística _______________________________________________________________________________________________________ 40. Distribución de Estimadores en Modelos de Regresión donde los Parámetros están Sujetos a Restricciones Lineales de Desigualdad Primer autor (Ponente): Leticia Gracia-Medrano V. Segundo: Federico O’Reilly Resumen: En este trabajo se muestra a través de re-muestreo paramétrico en distribuciones de los estimadores para modelos de regresión cuando se imponen restricciones lineales de desigualdad sobre los parámetros, se comparan estas simulaciones versus otro trabajo que utiliza muestreo de Gibbs. Las simulaciones son hechas utilizando un conjunto de datos conocido en la literatura. _______________________________________________________________________________________________________ 78