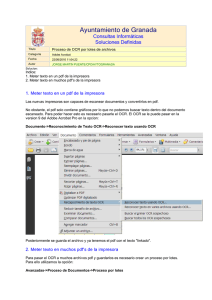
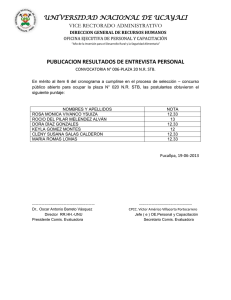
desarrollo de un analizador de imágenes basado en el
Anuncio

UNIVERSIDAD SIMÓN BOLÍVAR Decanato de Estudios Profesionales Coordinación de Ingeniería Electrónica DESARROLLO DE UN ANALIZADOR DE IMÁGENES BASADO EN EL RECONOCIMIENTO ÓPTICO DE CARACTERES Por JOYNER ALBERTO CADORE CHACÓN INFORME DE PASANTÍA Presentado ante la Ilustre Universidad Simón Bolívar como requisito parcial para optar al título de Ingeniero Electrónico. Sartenejas, Febrero de 2009 UNIVERSIDAD SIMÓN BOLÍVAR Decanato de Estudios Profesionales Coordinación de Ingeniería Electrónica DESARROLLO DE UN ANALIZADOR DE IMÁGENES BASADO EN EL RECONOCIMIENTO ÓPTICO DE CARACTERES Por: JOYNER ALBERTO CADORE CHACÓN Realizado con la Asesoría de: Prof. Trina Adrián de Pérez (Tutor Académico en Venezuela) Prof. Narciso García Santos (Tutor Académico en España) INFORME DE PASANTÍA Presentado ante la Ilustre Universidad Simón Bolívar como requisito parcial para optar al título de Ingeniero Electrónico. Sartenejas, Febrero de 2009 iii UNIVERSIDAD SIMÓN BOLÍVAR Decanato de Estudios Profesionales Coordinación de Ingeniería Electrónica DESARROLLO DE UN ANALIZADOR DE IMÁGENES BASADO EN EL RECONOCIMIENTO ÓPTICO DE CARACTERES. Por JOYNER ALBERTO CADORE CHACÓN RESUMEN Para garantizar la alta calidad del Servicio de Televisión sobre IP (IPTV) Imagenio, la empresa Telefónica S.A. debe asegurarse de que los Descodificadores de dicho servicio funcionen correctamente antes de distribuirlos entre los usuarios El presente Proyecto de Grado, llamado “Desarrollo de un Analizador de Imágenes Basado en el Reconocimiento Óptico de Caracteres”, se desarrolló durante el período de Pasantía Larga en la empresa Telefónica I+D (Madrid, España). Consistió, básicamente, en la extracción de información de imágenes de los Descodificadores del Servicio Imagenio de Telefónica S.A., contenedoras de la configuración (de red, de emisión de audio y video, etc.) de los mismos, para su posterior comprobación. Para ello, fue necesario aplicar técnicas de tratamiento digital de imágenes, reconocimiento óptico de caracteres (OCR) y un algoritmo (llamado de Semejanza de Texto) que permitiese corroborar la veracidad de la información obtenida mediante OCR. Las pruebas realizadas fueron completamente satisfactorias. PALABRAS CLAVES IPTV, STB, Reconocimiento Óptico de Caracteres (OCR), Tesseract, Algoritmo de Levenshtein, Algoritmo de Brew, Segmentación, OTSU, Algoritmo de Canny, Dilatación, Interpolación. iv AGRADECIMIENTOS A la empresa Telefónica I+D, en particular a la División de Video Bajo Demanda y Servicios a Terceros, por haberme brindado la oportunidad de hacer mi Pasantía Larga y con ella, mi Proyecto de Grado. A mis tutores académicos en España y Venezuela, Prof. Narciso García Santos y Prof. Trina Adrián de Pérez, respectivamente, por apoyarme desde el comienzo en la realización de este proyecto. Gracias por haber estado a mi lado y por haberme guiado con tanta dedicación y paciencia. A mi familia, por respaldarme incondicionalmente, por creer en mí siempre a pesar de mis errores. Un millón de gracias. A mis amigos, por estar allí en todo momento, por estar presentes tanto en los momentos dulces como en los agrios. v A Mis Padres. vi ÍNDICE GENERAL ACTA DE EVALUACIÓN .......................................................................................................iii RESUMEN ......................................................................................................................... iv PALABRAS CLAVES ............................................................................................................ iv AGRADECIMIENTOS ........................................................................................................... v ÍNDICE GENERAL .............................................................................................................. vii ÍNDICE DE FIGURAS........................................................................................................... x ÍNDICE DE TABLAS .......................................................................................................... xiii LISTA DE ABREVIATURAS ................................................................................................. xiv INTRODUCCIÓN ................................................................................................................. 1 CARACTERÍSTICAS PRINCIPALES ........................................................................................ 2 OBJETIVOS DEL PROYECTO ................................................................................................ 4 ORGANIZACIÓN DEL INFORME ........................................................................................... 5 CAPÍTULO I ...................................................................................................................... 6 CAPÍTULO I - LA EMPRESA: TELEFÓNICA I+D ...................................................................... 6 CAPÍTULO II ..................................................................................................................... 9 CAPÍTULO II - MARCO TEÓRICO ......................................................................................... 9 2.1 RECONOCIMIENTO ÓPTICO DE CARACTERES ................................................................. 9 2.2 DISTANCIA ENTRE CADENAS DE TEXTO....................................................................... 14 2.2.1 DISTANCIA DE EDICIÓN DE LEVENSHTEIN ................................................................. 14 2.2.2 DISTANCIA DE EDICIÓN DE BREW............................................................................. 17 2.3 TÉCNICAS DE SEGMENTACIÓN DE IMÁGENES .............................................................. 20 2.3.1 UMBRALIZACIÓN ...................................................................................................... 20 2.3.2 ALGORITMOS DE DETECCIÓN DE BORDES: CANNY ..................................................... 20 vii 2.3.3 CONVERSIÓN A ESCALA DE GRISES ........................................................................... 23 2.3.4 CONVERSIÓN A BLANCO Y NEGRO – MÉTODO DE OTSU ............................................. 23 CAPÍTULO III .................................................................................................................. 25 CAPÍTULO III - DISEÑO DEL ANALIZADOR DE IMÁGENES ................................................... 25 3.1 SELECCIÓN DEL LENGUAJE DE PROGRAMACIÓN Y DEL ENTORNO DE DESARROLLO ....... 25 3.2 SELECCIÓN DEL OCR .................................................................................................. 25 3.3 TESSERACT - OCR ...................................................................................................... 28 3.4 ALGORITMO DE SEMEJANZA DE TEXTO ....................................................................... 28 3.5 SELECCIÓN DE LA HERRAMIENTA DE TRATAMIENTO DE IMÁGENES .............................. 33 3.6 TRATAMIENTO DE IMÁGENES ..................................................................................... 33 3.7 PREPARACIÓN DE LAS IMÁGENES PARA EL OCR ........................................................... 39 3.8 LOCALIZACIÓN DE LAS CADENAS DE TEXTO EN LA IMAGEN.......................................... 39 3.8.1 LOCALIZACIÓN DE LAS CADENAS DE TEXTO MEDIANTE EL EMPLEO DE UMBRALIZACIÓN. ....................................................................................................................................... 40 3.8.2 LOCALIZACIÓN DE LAS CADENAS DE TEXTO MEDIANTE EL EMPLEO DE ALGORITMOS DE DETECCIÓN DE BORDE...................................................................................................... 45 3.9 OBTENCIÓN DE LAS CADENAS DE TEXTO EN IMÁGENES INDIVIDUALES ........................ 46 3.10 MEJORAS DE LAS IMÁGENES CONTENEDORAS DE LAS CADENAS DE TEXTO PARA EL TESSERACT – OCR. .......................................................................................................... 49 3.11 PROCESAMIENTO DE LA INFORMACIÓN CONTENIDA EN LAS IMÁGENES ...................... 50 3.11.1 CLASIFICACIÓN DE LAS DE CADENAS DE TEXTO....................................................... 51 3.11.2 ALMACENAMIENTO DE LA INFORMACIÓN ................................................................. 52 3.11.3 EXTRACCIÓN Y VALIDACIÓN DE LA INFORMACIÓN ................................................... 53 3.12 CONSULTA DE LA INFORMACIÓN ............................................................................... 57 3.13 IMPLEMENTACIÓN DEL ANALIZADOR DE IMÁGENES ................................................... 57 CAPÍTULO IV .................................................................................................................. 59 viii CAPÍTULO IV - PRUEBAS REALIZADAS Y ANÁLISIS DE LOS RESULTADOS............................. 59 4.1 PRIMERA PRUEBA: PARA LAS CUATRO PANTALLAS DE CONFIGURACIÓN, EMITIDAS POR UN STB. .......................................................................................................................... 59 4.2. SEGUNDA PRUEBA: SOBRE UNA MISMA PANTALLA DE CONFIGURACIÓN, EMITIDA POR DIFERENTES STB. ............................................................................................................ 62 4.3. CONCLUSIONES SOBRE LAS PRUEBAS ........................................................................ 64 CONCLUSIONES Y RECOMENDACIONES ............................................................................. 65 REFERENCIAS BIBLIOGRÁFICAS ........................................................................................ 67 APÉNDICES...................................................................................................................... 69 APÉNDICE A: SONDA ROBOT WITBE ................................................................................. 69 APÉNDICE B: STB............................................................................................................. 70 APÉNDICE C: CONFUSIONES MÁS COMUNES EN OCR. ........................................................ 71 APÉNDICE D: TAREA DE PÁGINAS LOCALES. ...................................................................... 73 ix ÍNDICE DE FIGURAS Figura 1.1: Logo de Imagenio. ............................................................................................. 1 Figura 1.2: Diagrama de Distribución de Señales IPTV. ........................................................... 3 Figura 1.3: Arquitectura del Sistema de Automatización de Pruebas......................................... 4 Figura 1.4: Logo de la Empresa. ........................................................................................... 6 Figura 2.1: Imagen original I. ............................................................................................. 21 Figuras 2.2 y 2.3: Imágenes IX e IY. .................................................................................... 22 Figuras 2.4 y 2.5: Imagen N, antes y después de suprimir los píxeles que no son máximos. .... 22 Figuras 2.6: Imagen final, luego de aplicar histéresis. ........................................................... 23 Figura 3.1: Resumen del Tratamiento de Imágenes. ............................................................. 34 Figura 3.2: Páginas Locales del STB de Imagenio – Pantalla de Configuración de los Parámetros de Red. ............................................................................................................................ 35 Figura 3.3: Páginas Locales del STB de Imagenio – Pantalla de Configuración de los Parámetros de Emisión de Video. ......................................................................................................... 36 Figura 3.4: Páginas Locales del STB de Imagenio – Pantalla de Configuración de los Parámetros de Emisión de Audio. ......................................................................................................... 37 Figura 3.5: Páginas Locales del STB de Imagenio – Pantalla con Información acerca del STB. .. 38 Figuras 3.6a, 3.6b, 3.6c y 3.6d: Imágenes con pedazos de las cadenas de texto de interés, para calcular los histogramas de los modelos de color HSV y RGB. ................................................ 40 Figura 3.7a: Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6a para obtener el histograma. ............................................................ 41 Figura 3.8a: Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6a para obtener el histograma ............................................................. 41 Figura 3.7b: Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6b para obtener el histograma. ............................................................ 42 Figura 3.8b.- Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6b para obtener el histograma ............................................................. 42 Figura 3.7c.- Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6c para obtener el histograma.............................................................. 43 Figura 3.8c: Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6c para obtener el histograma.............................................................. 43 x Figura 3.7d.- Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6d para obtener el histograma. ............................................................ 44 Figura 3.8d.- Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6d para obtener el histograma. ............................................................ 44 Figura 3.9: Pantalla de Configuración de los Parámetros de Emisión de Audio, luego de la aplicación del Algoritmo de Canny....................................................................................... 45 Figura 3.10: Imagen resultante luego de dilatar los bordes conseguidos con el Algoritmo de Canny. ............................................................................................................................. 46 Figura 3.11: Pantalla de Configuración de los Parámetros de Emisión de Audio, en escala de grises. .............................................................................................................................. 47 Figura 3.12: Pantalla de Configuración de los Parámetros de Emisión de Audio, en blanco y negro. .............................................................................................................................. 48 Figura 3.13: Cadenas de texto individualizadas. ................................................................... 48 Figura 3.14: Ejemplos de cadenas de texto individualizadas, aumentadas por un factor de 4 utilizando interpolación vecino más próximo. ....................................................................... 49 Figura 3.15: Ejemplos de cadenas de texto individualizadas, aumentadas por un factor de 4 utilizando interpolación bilineal. .......................................................................................... 50 Figura 3.16: Ejemplos de cadenas de texto individualizadas, aumentadas por un factor de 4 utilizando interpolación bicúbica. ........................................................................................ 50 Figura 3.17: Identificación de las Cadenas de Texto en la Pantalla de Configuración de los Parámetros de Emisión de Audio......................................................................................... 52 Figura 3.18: Resultado de la lectura de un Campo Estático con Tesseract – OCR. ................... 53 Figura 3.19: Campo Estático obtenido. ................................................................................ 54 Figura 3.20: Comprobación de Título / Campo Estático. ........................................................ 55 Figura 3.21: Resultado de la lectura de un Campo Variable con Tesseract – OCR. ................... 55 Figura 3.22: Comprobación de Campo Variable. ................................................................... 57 Figura 3.23: Esquema de la implementación del Analizador de Imágenes en la sonda robot WITBE.............................................................................................................................. 58 Figura A.1: Sonda Video Robot WITBE S4000 (imagen referencial). ....................................... 69 Figura C.1: Tablas de confusiones más comunes, pertenecientes al primer estudio. ................ 71 Figura C.2: Tablas de confusiones más comunes, pertenecientes al segundo estudio. ............. 72 Figura D.1: Tarea de Páginas Locales – Paso 1. ................................................................... 73 Figura D.2: Tarea de Páginas Locales – Paso 2. ................................................................... 74 xi Figura D.3: Pantalla de Configuración de los Parámetros de Video, correspondiente al STB Motorola 1720. .................................................................................................................. 74 Figura D.4: Tarea de Páginas Locales – Paso 3. ................................................................... 75 Figura D.5: Tarea de Páginas Locales – Paso 4. ................................................................... 75 Figura D.6: Tarea de Páginas Locales – Paso 5. ................................................................... 76 Figura D.7: Tarea de Páginas Locales – Paso 6 (y último) ..................................................... 76 Figura D.8: Tarea de Páginas Locales – Resultados. ............................................................. 77 xii ÍNDICE DE TABLAS Tabla 2.1: Comparación de Cadenas de Texto usando el Algoritmo de Levenshtein. ............... 16 Tabla 2.2: Comparación de Cadenas de Texto usando el Algoritmo de Brew. ......................... 19 Tabla 3.1: Comparativas de Motores y Software OCR. ......................................................... 26 Tabla 3.2: Tabla de Confusiones más Comunes................................................................... 30 Tabla 3.3: Resultados del AST, en modalidad # 1. .............................................................. 54 Tabla 3.4: Resultados del AST, en modalidad # 1. .............................................................. 56 Tabla 4.1: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Red....................................................................................... 60 Tabla 4.2: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Video. ................................................................................... 60 Tabla 4.3: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Audio. ................................................................................... 61 Tabla 4.4: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Otros Parámetros. .................................................................. 61 Tabla 4.5: Resultados obtenidos para las imágenes emitidas por el STB Philips 5750. ............ 62 Tabla 4.6: Resultados obtenidos para las imágenes emitidas por el STB ADB 5810. ............... 63 Tabla 4.7: Resultados obtenidos para las imágenes emitidas por el STB Motorola 1920. ......... 63 Tabla 4.8: Resultados obtenidos para las imágenes emitidas por los 3 STB. .......................... 64 xiii LISTA DE ABREVIATURAS ADSL: Asymmetric Digital Subscriber Line - Línea Analogica-Digital Asimétrica. AST: Algoritmo de Semejanza de Texto. BMP: Bitmap – Mapa de Bits CF – CO: Cadena Fuente, Cadena Objetivo. LD: Levenshtein Distance – Distancia de Levenshtein HD: High Definition – Alta Definición. HDMI: High Definition Multimedia Interface – Interfaz Multimedia de Alta Definición. HSV: Hue, Saturation, Value – Tonalidad, Saturación, Valor (Modelo de Color). IP: Internet Protocol - Protocolo de Internet. IPTV: Internet Protocol Television – Televisión sobre IP. OCR: Optical Character Recognition - Reconocimiento Óptico de Caracteres. RGB: Red, Green, Blue - Rojo, Verde, Azul (Modelo de Color). SD: Standard Definition – Definición Estándar. STB: Set Top Box – Descodificador de Televisión Digital. VOD: Video on Demand – Video Bajo Demanda. xiv 1 INTRODUCCIÓN Imagenio[1] (ver figura 1.1) es un servicio de televisión digital interactiva del grupo Telefónica S.A. Es suministrado conjuntamente con el servicio de ADSL, sobre una misma infraestructura, pero con un ancho de banda reservado. En otras palabras, la señal de televisión se transporta utilizando conexiones de banda ancha sobre el protocolo IP. Este servicio es denominado IPTV. Figura 1.1: Logo de Imagenio. La señal de televisión llega codificada al router ADSL del usuario final, y para obtenerla, se conecta a este último un dispositivo descodificador denominado Set Top Box (STB). Desde el STB se puede obtener la señal de televisión en formato tradicional (SD, a través del Euroconector) o en formato de alta definición ((HD, HD, a través de un conector HDMI). El proceso de certificación de los terminales de usuario, los STB, de la Plataforma IPTV Imagenio, requiere un elevado uso de recursos de laboratorio y de personal cualificado por varios motivos. Primero, por la existencia de un catálogo técnico de descodificadores heterogéneo, y segundo, por la gran cantidad de entregas software (Kernels) de cada uno de los modelos para la resolución de incidencias o incorporación de nuevas funcionalidades o servicios. Adicionalmente, la cada vez mayor complejidad de los servicios ofertados por Imagenio conlleva a que el proceso de certificación certificación de terminales de usuario sea más complejo y más extenso. Telefónica S.A., a través del Departamento Conectividad y Redes del Hogar, otorgó a Telefónica I+D (TID) el Proyecto “Sistema para la Validación Automática de Descodificadores y Aplicaciones Imagenio”, con el fin de de mejorar el proceso de 2 certificación actual de los descodificadores de Imagenio, y conseguir reducir significativamente el tiempo necesario y los costes. Para ello se propuso una solución integral para la automatización del proceso de pruebas de certificación de los STB, basada en herramientas comerciales y desarrollos adaptados a las necesidades específicas del cliente (Telefónica S.A.). Características Principales El sistema de validación automática de los STB está basado en las sondas robot Witbe (ver Apéndice A), adaptadas por TID para completar la funcionalidad requerida por el cliente. Estas sondas interactúan con los STB mediante un emisor de infrarrojos (figura 1.2), que emula el comportamiento del mando a distancia que poseen los usuarios de Imagenio, y que permite ejecutar casos de prueba durante el proceso de certificación de los descodificadores. Estas sondas, además, permiten medir la disponibilidad y la calidad de los servicios de vídeo, tanto de TV como de Video on Demand (VoD), conectándose a las salidas ofrecidas por los STB: Euroconector y/o HDMI. La funcionalidad soportada por las sondas debe incluir: 1. Medición de la disponibilidad de los servicios TV y VoD. 2. Medición de la calidad de los servicios (tanto en TV como en VoD), basada en criterios de Quality of Experience (QoE), con un Mean Opinion Score (MOS) de 1 a 5. 3. Medición de tiempos entre cambios de canal (contenidos TV) y Trick Modes (contenidos VoD). 4. Detección de artefactos, congelaciones, pixelaciones y pérdidas de audio en el video. 5. Detección de pérdidas de sincronismo entre el audio y el vídeo de un contenido. 6. Análisis del tráfico de red. 7. Detección de retardos en la navegación por los menús de la aplicación Imagenio. 8. Reconocimiento óptico de caracteres para la comprobación de configuraciones. 3 Figura 1.2: Diagrama de Distribución de Señales IPTV. Por otra parte, el sistema de validación automática de los STB permite a los usuarios del sistema, mediante una herramienta gráfica (llamada Gestor de Pruebas), la definición y planificación de casos de prueba que serán ejecutados por las sondas. El Gestor de Pruebas es el encargado de generar y enviar ficheros con órdenes que serán ejecutados por las sondas. Tras ejecutar los casos de prueba, las sondas generan unos resultados que serán visibles y gestionables por los usuarios desde dicho Gestor de Pruebas. En la figura 1.3 se presenta la arquitectura de dicho sistema. En base a las funcionalidades mencionadas anteriormente, las sondas son capaces de realizar pruebas sobre: 1. Calidad de audio/video Unicast y Multicast. 2. Trick Modes sobre VoD. 3. Cambios de canal sobre TV. 4. Audio: control de volumen, mute, idiomas. 5. Configuración de Páginas Locales de los STB. 6. Navegación por las Aplicaciones Imagenio. 4 Figura 1.3: Arquitectura del Sistema de Automatización de Pruebas. Objetivos del Proyecto Sobre la prueba “Configuración de Páginas Locales de los STB”, mencionada en el apartado anterior, se desarrolló el Proyecto que se presenta a continuación. Esta prueba requiere de la funcionalidad de “Reconocimiento Óptico de Caracteres para la comprobación de configuraciones”, que necesitó ser desarrollada antes de su implementación en las sondas robot WITBE. Esta funcionalidad lo que permite es comprobar la correcta configuración de Red, Video, Audio y demás de los STB. Los Objetivos del Proyecto son los siguientes: 1. Diseño de un analizador de imágenes para el ordenador, que permita: a. Tomar una imagen (capturada con la sonda robot WITBE), que contenga texto, como parámetro de entrada y devolver las cadenas de caracteres presentes en ella. 5 b. Verificar la validez de las cadenas de texto obtenidas de la imagen, mediante la comparación con las cadenas de texto buscadas. 2. Diseño de un algoritmo de toma de decisiones, que permita determinar la validez de los resultados. Para ello será necesario: a. Definir los criterios de validez para las cadenas de texto obtenidas de las imágenes, mediante la comparación de las mismas con las cadenas de texto buscadas. Se utilizaran criterios como números de caracteres, distancia y semejanza entre los mismos, etc. Organización del Informe Después de la Introducción, se presenta el Capítulo Primero con información sobre la empresa donde se realizó la Pasantía Larga. Seguidamente, se presenta el Capítulo Segundo con el Marco Teórico; en el mismo se explican todas las herramientas utilizadas para el desarrollo del Analizador de Imágenes. El Capítulo Tercero contiene, en detalle, el diseño del analizador de imágenes, que consiste de 2 grandes partes: selección y/o creación de las herramientas apropiadas e implementación de las mismas, mediante el uso de algoritmos especiales. En el Capítulo Cuarto se detallan las diferentes pruebas realizadas para demostrar la fiabilidad del Analizador de Imágenes. Finalmente, se presentan las conclusiones y recomendaciones del Proyecto en general. 6 CAPÍTULO I LA EMPRESA: TELEFÓNICA I+D Telefónica I+D (TID)[2] (ver figura 1.4) perteneciente al Grupo Telefónica S.A., es la empresa más importante de España en el área de investigación y desarrollo. Desarrolla actividades a nivel nacional e internacional, dirigidas principalmente a la innovación tecnológica. Figura 1.4: Logo de la Empresa. Desde su creación en Marzo de 1988, se dedica al desarrollo de numerosos productos y servicios para telefonía (fija y móvil), internet y televisión (IMAGENIO), destinados a resolver las necesidades presentes, a la vez que crea soluciones innovadoras para anticiparse a los retos futuros. Actualmente existen cinco sedes de TID en España, localizadas en Barcelona, Granada, Huesca, Madrid y Valladolid. Fuera de España hay sedes 2 sedes, una en São Paulo, Brasil y la otra en Ciudad de México, México. Sus actividades han estado ligadas principalmente a la evolución de las telecomunicaciones y a las demandas sociales en esas áreas. 7 El número de proyectos anuales desarrollados en la empresa es de 1500 aproximadamente, que generalmente potencian los servicios telefónicos fijos, móviles, multimedia e interactivos, los sistemas de gestión de redes y servicios, los sistemas de soporte a operaciones y de apoyo al negocio, y a la innovación. Asimismo, las investigaciones de TID han contribuido notablemente en el desarrollo de la banda ancha/ADSL y de los servicios de internet de Telefónica (como la televisión digital interactiva, mejor conocida como Imagenio), a mejorar los servicios móviles y a lanzar nuevos servicios al mercado, así como también a mejorar la atención al cliente y a contribuir a hacer realidad el hogar digital (o vivienda virtual). Las actividades de TID han generado un sin fin número de patentes y registros, que han contribuido significativamente a incrementar la Propiedad Intelectual e Industrial del Grupo Telefónica S.A. TID colabora estrechamente con las Universidades, las Comunidades Autónomas y la Administración Central del Estado Español, y tiene una importante presencia en los principales foros, congresos y publicaciones, nacionales e internacionales, sobre telecomunicaciones. También se ha caracterizado por participar, desde su creación, en programas y proyectos cofinanciados por la Unión Europea (UE), junto a otras empresas e instituciones del continente. Actualmente, es conocida como el primer centro de investigación y desarrollo de telecomunicaciones por participación en proyectos del Programa Marco de la UE. Innovación Tecnológica Una de las cosas más importantes en el Grupo Telefónica S.A. es la innovación, pues contribuye al negocio de las telecomunicaciones, mejorando lo ya existente y abriendo continuamente nuevos espacios. La idea de innovación va más allá de la tecnología, llegando a los ámbitos comerciales y de procesos, con el objetivo de transformar las ideas en productos y servicios rentables y/o mejores. Esta filosofía ha logrado que TID sea la acreedora de numerosos premios y distinciones a la innovación y a la excelencia. 8 Su estrategia en el proceso de generación de nuevas ideas se basa en la incorporación de conocimientos multidisciplinares y en la apertura a numerosas fuentes generadoras de propuestas. En este sentido, ha incrementado su presencia en los foros y programas de investigación nacionales y europeos, así como en eventos dedicados a presentar los últimos avances tecnológicos, donde se suelen llevar a cabo concursos para la búsqueda de nuevos talentos. Campos de Investigación Telefónica I+D tiene participación en muchos de los proyectos de investigación más prometedores de la actualidad: nuevo protocolo para internet (IPv6); técnicas biométricas más avanzadas para la identificación y autentificación segura de las personas; aplicaciones de vanguardia para la gestión del conocimiento; servicios y aplicaciones móviles del futuro independientes de la tecnología de acceso; plataformas abiertas para servicios controlados por voz; sistemas domóticos avanzados dirigidos al hogar digital; aplicaciones para la seguridad informática, etc. No obstante, el área donde posee más participación es la dedicada a las comunicaciones móviles (análisis espectral, infraestructura e interfaz radio, gestión de la movilidad en los servicios móviles de banda ancha, etc.). También trabaja activamente en las áreas de creación de nuevos servicios y contenidos para banda ancha, siendo uno de los principales el servicio de IPTV Imagenio. En TID también existen áreas de investigación orientadas hacia aplicaciones sociales. Algunas de las actividades que se están desarrollando en la actualidad son: el nuevo servicio de seguridad estructural para edificios mediante redes ópticas; sistemas de atención médica para el tratamiento de la diabetes; aplicaciones de tele-enseñanza y educación virtual adaptadas a la realidad de los países iberoamericanos; entre otros. 9 CAPÍTULO II MARCO TEÓRICO 2.1 RECONOCIMIENTO ÓPTICO DE CARACTERES Un software de reconocimiento óptico de caracteres (OCR, por sus siglas en inglés, Optical Character Recognition) permite extraer los caracteres presentes en una imagen y almacenarlos en un formato manejable por un editor de texto en un ordenador. Antecedentes del OCR[3] En 1929, Gustav Tauschek patentó en Alemania un método para hacer OCR. Poco después, en 1933, Handel obtuvo una patente en Estados Unidos para patentar otro método para hacer OCR. En 1935, Tauschek patento su método en Estados Unidos. La máquina (mecánica) creada por Tauschek, que usaba plantillas, consistía en un fotodetector y funcionaba de la siguiente manera: las plantillas de caracteres eran colocadas sobre cada caracter del texto, el cual era irradiado con luz. Al haber una coincidencia, toda la luz era absorbida (por el caracter que en principio era negro o algún otro color oscuro). En el caso de no coincidir plantilla y caracter, se reflejaba una porción de luz al fotoreceptor, que lo detectaba y reportaba el fallo. Este es uno de los primeros intentos de hacer un sistema de OCR, antes de la Segunda Guerra Mundial. El desarrollo de los sistemas OCR continuó pasada la Segunda Guerra Mundial. Los sistemas OCR utilizados durante los años 50 (primera generación) seguían estando basados, en su mayoría, en el sistema de Tauschek. El sistema de ausencia / presencia de luz y su traducción a lógica binaria de 0’s y 1’s, para conformar bytes de información, era muy 10 limitada, pues requería el uso de fuentes muy específicas. Quienes trabajaban con el sistema de Tauschek de base, pronto se darían cuenta de esta limitante y comenzarían a desarrollar alternativas. En 1950 el criptólogo/criptoanalista David Shepard, de la Agencia de Seguridad de las Fuerzas Armadas de los Estados Unidos, trabajó con el Dr. Louis Tordella en procesos de automatización de datos, para dicha Agencia. Trabajaron sobre el problema de cómo convertir mensajes impresos en algún formato manejable por el ordenador para su posterior procesamiento. Shepard consideró la posibilidad de construir una máquina para ésta tarea, y lo hace: con la colaboración de Harvey Cook, construye “Gismo”. Shepard, posteriormente, funda la Intelligent Machines Research Corporation (IMR), donde se haría el primer sistema OCR comercial. Los sistemas OCR desarrollados por la IMR permitían, al igual que Gismo, tolerar cambios ligeros en el tipo de fuente, pero a diferencia de este último que requería cierta disposición en vertical de los caracteres, podían leer el texto sin restricciones de localización. Durante esta década, fueron varias las compañías que adquirieron sistemas comerciales a la IMR: Readers Digest, Standard Oil Company of California (interés en leer registros de tarjetas de crédito, para hacer los cobros), Ohio Bell Telephone Company, IBM; etc. Incluso la Fuerza Aérea de los Estados Unidos les adquirió un sistema OCR, para leer mensajes recibidos en forma impresa, siendo estos transmitidos a distancia. En la década de los 60, a mediados aproximadamente, se desarrolló una segunda generación de sistemas OCR. Usando tubos de rayos catódicos y lápices de luz en lugar de fotoreceptores, utilizaban la técnica de “Seguimiento de Curva”. Esto permitió que los sistemas OCR fueran más flexibles, a la hora de localizar el texto y de reconocer variados tipos de fuente. Esta tecnología introdujo el concepto de los caracteres escritos a mano, pudiendo ser leídos con ciertas restricciones. También introdujo el concepto de tintas no legibles, de color azul, que eran utilizadas por el sistema de lectura, altamente sensible al espectro ultravioleta. 11 En el año 1965, Readers Digest y la RCA colaboraron en la construcción de un lector de documentos basado en OCR, para digitalizar los seriales de los cupones utilizados que enviaban los consumidores. Dichos cupones eran elaborados con la fuente OCR-A, utilizando una impresora de RCA de nombre “Drum”. Los resultados de la lectura del OCR eran procesador directamente por un ordenador RCA 301 (de los primeros de estado sólido del mercado). Seguidamente, RCA le diseñó un lector OCR especializado a la Trans World Airlines, para el procesamiento de los billetes aéreos, con texto por ambas caras. Estos lectores OCR procesaban documentos a una tasa de 1500 por minuto, y descartaban aquellos que no podían ser correctamente leídos. En Europa, comenzaron a usarse sistemas OCR en el año 1965. La primera compañía en utilizarlos fue la Oficina Postal Británica. A ésta le siguió, entre otras, el banco británico National Giro, cuyo uso estaba destinado al procesamiento de recibos de pago; esto represento una revolución para la banca Británica de aquel momento. En los primeros años de la década de los 70, se introdujeron los dispositivos de tercera generación para los sistemas OCR: arrays de fotodiodos. El funcionamiento: los sensores eran alineados en arreglos, y la imagen reflejada de un documento con texto era procesada. Estos dispositivos tenían alta sensibilidad para el espectro infrarrojo por lo cual se comenzaron a utilizar tintas de color rojo ilegible. En 1974, Ray Kurzweil funda en los Estados Unidos la compañía Kurzweil Computer Products Inc., y desarrolla el primer sistema OCR capaz de leer cualquier tipo de texto impreso en fuente normal. En principio, él pensó que la mejor aplicación de esta tecnología sería la de crear una máquina que leyese para las personas con problemas severos en la visión y/o ciegas: Procesamiento del texto escrito y su posterior reproducción sonora. Esta idea requirió el desarrollo de dos tecnologías: Un escáner de texto y un sintetizador texto – voz. El producto fue terminado en enero de 1976. En 1978, la Kurzweil Computer Products pone a la venta una versión comercial de su motor OCR. Dos años más tarde, la compañía 12 es adquirida por Xerox, y se convierte en una filial; cambia su nombre a Nuance, compañía que continúa hoy en día trabajando en el área de reconocimiento óptico de caracteres y en el área de reconocimiento del habla. Las siguientes generaciones de sistemas OCR, a partir de la década de los 80, estaban basadas también en el escaneo con arrays. Esto, sumado a las cada vez más altas velocidades de procesamiento de los ordenadores, convergió en el concepto de Procesamiento de Imágenes. El Procesamiento de Imágenes requiere de arrays mucho más complejos que los arrays utilizados por la tercera generación de sistemas OCR. Cuando estas imágenes son procesadas con la lógica de un sistema OCR (esto es, con los códigos binarios adecuados) se pueden reconocer y/o interpretar los caracteres presentes en la imagen, almacenados en forma de matrices de puntos. Esto se traduce en sistemas flexibles frente a diferentes tipos de fuentes, y menos rigurosos en cuanto al posicionamiento de los caracteres. Estado Actual del OCR[4] Un software OCR, hoy en día, no tiene un acierto del 100 % para todos los casos. Suelen estar preparados para funcionar con algunos idiomas (uso de diccionarios), con ciertos tipos de caracteres (fuentes) y con imágenes de una calidad determinada. Modificaciones en algunos de estos tres parámetros pueden ocasionar que haya inserciones, pérdidas y/o sustituciones de caracteres. El desarrollo de los motores OCR ha mejorado con el paso del tiempo. Entre las cosas que continuamente se consiguen están: - Mayor exactitud en las lecturas de textos, disminuyendo el número de pérdidas y/o sustituciones de caracteres. - Menor dependencia del tipo de fuente. 13 - Mejoras en la capacidad de lectura de textos escritos a mano y de textos cursivos (estos últimos, son aquellos donde las letras están unidas, sin individualizar). - Admisión de imágenes de menor calidad para la extracción de texto (borrosas, con bajo contraste, etc.). Sin embargo, existen ciertas cosas que son difíciles de salvar: - La lectura de texto depende tanto del idioma como del alfabeto. Si se leen palabras de idiomas distintos, pero de alfabeto común (por ejemplo, inglés, italiano y español, todos basados en el alfabeto latino), se podrán reconocer muchos caracteres correctamente, e incluso palabras enteras. Pero, si se leen palabras de alfabetos distintos (latino, asiático, cirílicos, etc.) al que se ha utilizado en la configuración del motor OCR, difícilmente se podrá reconocer carácter alguno, y mucho menos una palabra. Especial es el caso de los números, que por ser de uso más universal, prácticamente cualquier motor OCR puede reconocerlos correctamente. - Similaridad entre letras y números. Por ejemplo, si a la hora de leer cadenas de texto aparecen la letra mayúscula “O” y/o el número “0”, es muy difícil discernir para el software OCR cuando es uno u otro, pues la diferencia es muy poca. Una persona puede determinar visualmente las diferencias existentes, e incluso si fuera necesario, por contexto. - Una persona puede ser capaz de leer un texto en una imagen con poco contraste, borrosa, o incluso leer texto sobre imágenes o texto sobre texto (superposición), pues posee la ventaja de conocer gran cantidad de palabras que permiten “adivinar” las que están en la imagen en el caso de que no se distingan claramente. Lograr que un software OCR tenga esta funcionalidad, de obtener sólo la información relevante de una imagen, es el mayor reto que existe hoy en día en esta área. 14 2.2 DISTANCIA ENTRE CADENAS DE TEXTO A pesar del buen funcionamiento que pudiese tener un software OCR, los resultados que arrojaría no serían 100% exactos para todas las imágenes. Esto hace que sea necesario comprobar de alguna manera que tan buenos son. Para tal tarea se pensó en la utilización de un algoritmo que determinase cuan parecida es una cadena de texto a otra. A continuación se presentan 2 algoritmos, Levenshtein y Brew, que permiten hallar cuántos caracteres diferentes hay en una cadena de texto respecto a otra, en el caso del primero; en el caso del segundo, permite hallar adicionalmente qué tipo de diferencia ha ocurrido (sustitución, supresión o adición de un carácter). 2.2.1 DISTANCIA DE EDICIÓN DE LEVENSHTEIN[5] La Distancia de Levenshtein (LD por sus siglas en inglés, Levenshtein Distance), también llamada Distancia de Edición, es una medida de semejanza entre dos cadenas de texto: una cadena fuente “CF” (lo que se tiene) y una cadena objetivo “CO” (lo que se desea obtener). El valor de la LD viene a ser el número de sustituciones, supresiones o adiciones necesarias para convertir a CF en CO. La Distancia de Levenshtein tiene las siguientes características: - LD = 0 sí y sólo sí las cadenas de texto comparadas son iguales. - Su valor mínimo será siempre, al menos, la diferencia de tamaño entre las dos cadenas de texto comparadas. - Su valor máximo será, en el peor caso, el tamaño de la cadena de texto más larga. A continuación presentamos de manera detallada los pasos del algoritmo, y un ejemplo de su aplicación: 15 1. Sean n y m los tamaños de las cadenas de texto CF y CO, respectivamente. Si n = 0, LD = m; si m = 0, LD = n; en otro caso, construimos una matriz D (de distancia) m x n. 2. Inicializamos la primera fila desde 0 hasta n; inicializamos la primera columna desde 0 hasta m. Ningún carácter es asociado con la posición (0,0) de la matriz. 3. Examinamos cada carácter de CF, con i entre 1 y n. Asimismo, examinamos cada carácter de CO, con j entre 1 y m. 4. Si CF[i] = CO[j], el costo es 0 (esto significa que ha ocurrido un acierto entre dos caracteres). Caso contrario, el costo es 1. 5. En la posición D[i,j] de la matriz, se coloca el valor mínimo de entre los siguientes: - D[i-1, j] + 1 - D[i, j-1] + 1 - D[i-1, j-1] + costo 6. Luego de que la iteración entre los pasos 3 y 5 finalice, el valor LD se obtendrá de la posición D[n,m] de la matriz. Ejemplo: Supongamos que tenemos dos cadenas de texto, una CF = ‘CAR4CE’ y otra CO = ‘CARACAS’. En este caso, tendríamos que LD = 3, puesto que necesitaríamos 3 cambios para convertir CF en CO: la sustitución de “4” por “A”, la sustitución de “E” por “A” y la adición de “S”. En el caso de no existir diferencia alguna entre CF y CO, LD = 0. La aplicación de los pasos del algoritmo se presenta en la tabla 2.1. La LD se encuentra en la posición n,m de la matriz D (tabla 2.1), es decir, D[n,m] = D[6,7] = 3 (esquina inferior derecha en la matriz de ejemplo). Esto concuerda con lo presentado anteriormente, que se necesitaban 3 cambios para CF = CO: la sustitución de “e” por “a” y la adición de una “s” al final de la cadena CF. 16 Tabla 2.1: Comparación de Cadenas de Texto usando el Algoritmo de Levenshtein. Pasos 1 y 2 C A R A C A S Pasos 3 al 5, con i = 1... C A R 4 C E Ammmaaaa C A R 4 C E 0 1 2 3 4 5 6 0 1 2 3 4 5 6 C 1 0 1 A 2 1 2 R 3 2 3 A 4 3 4 C 5 4 5 A 6 5 6 S 7 6 7 Pasos 3 al 5, con i = 2 C A R A C A S 0 1 2 3 4 5 6 7 Pasos 3 al 5, con i = 3oppp C A R 4 C E Ammmaaaa C A R 4 C E 1 2 3 4 5 6 0 1 2 3 4 5 6 C 1 0 1 2 0 1 A 2 1 0 1 1 0 R 2 1 3 2 1 0 A 4 3 2 1 3 2 C 5 4 3 2 4 3 A 6 5 4 3 5 4 S 7 6 5 4 6 5 Pasos 3 al 5, con i = 5 p C A R 4 C E Ammmaaaa 0 1 2 3 4 5 6 C 1 0 1 2 3 4 A 2 1 0 1 2 3 R 3 2 1 0 1 2 A 4 3 2 1 1 2 C 5 4 3 2 2 1 A 6 5 4 3 3 2 S 7 6 5 4 4 3 Pasos 3 al 5, con i = 6oppp C A R A C A S 0 1 2 3 4 5 6 7 C A R 4 C E 1 2 3 4 5 6 0 1 2 3 4 5 1 0 1 2 3 4 2 1 0 1 2 3 3 2 1 1 2 3 4 3 2 2 1 2 5 4 3 3 2 2 6 5 4 4 3 3 17 Las aplicaciones de la LD son varias: correctores ortográficos, detección de plagio, análisis de ADN, etc. Sin embargo, el conocer la LD no brinda mayor información acerca de las diferencias entre la CF y la CO (sustitución, supresión y/o adición). Por lo tanto, su uso directo no es suficiente para los objetivos del presente Proyecto: es necesario saber, no sólo cuantos cambios hay entre cadenas de texto, sino que tipos de cambios han ocurrido. La solución a este problema (saber qué tipo de cambios hay entre CF y CO) se soluciona con el algoritmo de distancia de edición de Brew. 2.2.2 DISTANCIA DE EDICIÓN DE BREW[6] La Distancia de Edición de Brew permite obtener los tipos de cambios necesarios para transformar la Cadena Fuente en la Cadena Objetivo (y no al revés, pues a diferencia de la LD, en este algoritmo adición y supresión se tratan por separado). A continuación presentamos de manera detallada los pasos del algoritmo (que básicamente son los mismos de la LD, con ciertas modificaciones), y un ejemplo de su aplicación: 1. Sean n y m los tamaños de las cadenas de texto CF y CO, respectivamente. Si n = 0, LD = m; si m = 0, LD = n; en otro caso, construimos una matriz D (de distancia) m x n. 2. Inicializamos la primera fila desde 0 hasta n; inicializamos la primera columna desde 0 hasta m. 3. Examinamos cada carácter de CF, con i entre 1 y n. Asimismo, examinamos cada carácter de CO, con j entre 1 y m. 4. Si CF[i] = CO[j], tenemos un costo acierto de valor 0. Caso contrario, tenemos un costo de sustitución, de valor 1. Estos costos, a diferencia de la LD, podrían ser modificables en caso de necesitarlo (para otras aplicaciones). 18 5. En la posición D[i,j] de la matriz, se coloca el valor mínimo de entre los siguientes: - D[i-1, j] + costo de adición - D[i, j-1] + costo de supresión - D[i-1, j-1] + costo acierto o sustitución Los costos de adición y supresión, en este caso, son iguales y de valor 1. También son ajustables, pero para las necesidades del proyecto (saber qué diferencias hay entre las cadenas) basta con utilizar los valores de la LD. El cambio más importante introducido en este algoritmo es el siguiente: en la posición D[i,j] de la matriz se coloca una etiqueta (‘Acierto’, ‘Sustitución’, ‘Adición’ o ‘Supresión’) de acuerdo al valor mínimo obtenido (en la posición D[0,0] se coloca la etiqueta ´Inicio’). Además, se almacena la posición de la matriz donde ocurrió ese mínimo. Esto último permitirá, una vez se complete la matriz, encontrar a partir de la posición D[n, m] todos los cambios ocurridos entre las cadenas de texto. 6. Luego de que la iteración entre los pasos 3 y 5 finalice, el valor LD (dado que los costos se han mantenido iguales) se obtendrá de la posición D[n,m] de la matriz. En la tabla 2.2 se muestra la comparación entre las mismas cadenas de texto que en el ejemplo de la LD, con la finalidad de ilustrar tanto el funcionamiento del algoritmo de Brew como las diferencias con el algoritmo de Levenshtein. 19 Tabla 2.2: Comparación de Cadenas de Texto usando el Algoritmo de Brew. 0 “INICIO” C A R 4 C E 1 “DEL” 0 (0,0) “ACIERTO” 2 3 4 5 6 1 (1,1) “SUPRE” 2 (1,2) “SUPRE” 3 (1,3) “SUPRE” 1 (2,2) “SUPRE” 2 (2,3) “SUPRE” 3 (2,4) “SUPRE” 4 (2,5) “SUPRE” 1 (3,3) “SUPRE” 2 (3,4) “SUPRE” 3 (3,5) “SUPRE” 1 (3,3) “SUST” 2 (3,4) “SUPRE” 3 (4,5) “SUPRE” INCNI 1 “INS” A 2 1 (1,1) “ADICIÓN” 0 (1,1) “ACIERTO” R 3 2 (2,1) “ADICIÓN” 1 (2,2) 0 (2,2) “ADICIÓN” “ACIERTO” A 4 3 (3,1) “ADICIÓN” 2 (3,1) “ACIERTO” 1 (3,3) “INS” C 5 4 (4,1) “ADICIÓN” 3 (4,2) “ADICIÓN” 2 (4,3) “INS” A 6 5 (5,1) “ADICIÓN” 4 (5,1) “ACIERTO” 3 (5,3) “INS” 7 6 (6,1) “ADICIÓN” 5 (6,2) “ADICIÓN” S 4 (0,4) 5 (1,5) “ACIERTO” “SUPRE” 2 (4,3) 1 (4,4) 2 (5,5) ADICIÓN “ACIERTO” “SUPRE” 3 (5,4) “SUST” 2 (5,5) “ADICIÓN” 2 (5,5) “SUST” 4 (6,3) 4 (6,3) 3 (6,5) “ADICIÓN” ADICIÓN “ADICIÓN” 3 (6,6) “INS” En la posición D[n,m] de este ejemplo, tenemos el valor de la LD = 3. A partir de esa posición, si comenzamos a recorrer las posiciones donde ocurrieron los menores costos (valores entre paréntesis) hasta D[0,0], obtendremos los tipos de cambios que hay en CF respecto a la CO (la sustitución y la adición necesarias, pero que no eran indicadas por el algoritmo de Levenshtein). 20 2.3 TÉCNICAS DE SEGMENTACIÓN DE IMÁGENES La Segmentación consiste en dividir una imagen en múltiples regiones (por ejemplo, en píxeles) para ser analizada y/o manipulada de manera más sencilla. Lo ideal para aplicar esta técnica es que cada píxel (en este caso), o grupos de ellos, tengan características y/o propiedades (tales como color, textura, etc.) lo suficientemente diferentes del resto como para ser diferenciados. La característica más utilizada con esta técnica es la amplitud de la luminancia, en el caso de imágenes monocromáticas, y las componentes de color, en el caso de imágenes a colores. Bajo la suposición de que las cadenas de texto de interés en la imagen tenían el mismo color, y de que este era lo suficientemente diferente de los colores de fondo, se procedió a aplicar técnicas de segmentación de imágenes. 2.3.1 UMBRALIZACIÓN La Umbralización es la evaluación, píxel a píxel, de la imagen para hacer algún tipo de discriminación. El objetivo es conservar los pixeles de la imagen que estén dentro de cierto umbral (valores mínimo y máximo), es decir, que sean de determinado color. 2.3.2 ALGORITMOS DE DETECCIÓN DE BORDES: CANNY El algoritmo de detección de bordes utilizado fue el de Canny[7]. Experiencias (satisfactorias) previas en el grupo de trabajo condujeron a su utilización. Asimismo, otras experiencias[8] en detección de bordes de letras, como por ejemplo, matrículas de automóviles[9], donde existen una gran cantidad de imágenes distintas y resultados altamente satisfactorios, sirvieron de referencia a la hora de seleccionarlo. El Algoritmo de Canny se utiliza para detectar los bordes presentes en una imagen. Se basa en el uso de máscaras gaussianas y en el uso de la primera derivada. Las condiciones en las que se basa este algoritmo son las siguientes: 21 - Se deben detectar solamente (todos) los bordes presentes en la imagen. - La distancia entre la posición real del borde y el píxel localizado debe ser la mínima posible. - No deben identificarse varios píxeles como un borde si existe uno solo. Los pasos del algoritmo de Canny se presentan a continuación, con el objetivo de ilustrar el funcionamiento del mismo. 1. Partiendo de una imagen I (figura 2.1), se calcula su gaussiana unidimensional, GU, en las direcciones x e y. Figura 2.1: Imagen original I. [10] 2. Se obtienen la primera derivada (también unidimensional) de las componentes x e y de la gaussiana (GX y GY). 3. Se hace la convolución de I con GX y GY, obteniendo dos nuevas imágenes: IX e IY IX (figuras 2.2 y 2.3). 4. Se halla la magnitud, ඥIଡ଼ଶ + Iଢ଼ଶ , y se obtiene una nueva imagen N (figura 2.4). 5. En N, se suprimen los píxeles que no sean máximos: se compara la magnitud de cada píxel con sus vecinos en un entorno cercano (figura 2.5). 22 Figuras 2.2 y 2.3: Imágenes IX e IY. [11] Figuras 2.4 y 2.5: Imagen N, antes y después de suprimir los píxeles que no son máximos. [12] 6. Finalmente, se aplica histéresis sobre la imagen N (figura 2.6). Se definen dos umbrales, U1 > U2. Se hace un recorrido por los píxeles de N, y para que alguno pertenezca a un borde debe ser mayor que U1, o mayor que U2 sí y sólo sí al menos uno de sus vecinos sea mayor que U1. Con la histéresis, se logran “encadenar” mejor los píxeles de borde, evitando, de acuerdo a los umbrales, posible ruido presente en la imagen. 23 Figuras 2.6: Imagen final, luego de aplicar histéresis. [13] 2.3.3 CONVERSIÓN A ESCALA DE GRISES La conversión a escala de grises, utilizada en este Proyecto, es la que viene dada por la siguiente ecuación: Y = 0.299*R + 0.587*G + 0.114*B, donde RGB son componentes de color y Y la luminancia o nivel de gris. 2.3.4 CONVERSIÓN A BLANCO Y NEGRO – MÉTODO DE OTSU La conversión a blanco y negro, utilizada en este Proyecto, se hizo aplicando Umbralización Binivel sobre una imagen en escala de grises (resultante de aplicar al conversión del punto 2.3.3), utilizando el método de Otsu para calcular el umbral de luminancia. Entiéndase por Binivel, conversión de cada píxel a blanco o a negro según el umbral obtenido. El método de Otsu[14],[15] consiste en la conversión de una imagen en escala de grises a una imagen en blanco y negro (imagen binaria). Este algoritmo asume que la imagen tiene regiones homogéneas, condición que es inversamente proporcional a la varianza. Asume también que hay dos grandes grupos de píxeles: de objetos y de fondo de imagen. 24 El algoritmo selecciona el umbral minimizando la varianza dentro de cada región de la imagen (un grupo de N cantidad de píxeles, por ejemplo) y maximizándola entre distintas regiones. Este método tiene un gran inconveniente, y es que asume que sólo hay dos tipos de píxeles (objetos y fondo). Esto implica que, cuando estos dos grupos son muy diferentes no funciona correctamente, pues podrían existir una cantidad importante de grupos “intermedios”. Por lo tanto, el método Otsu no funciona bien con iluminación variable. 25 CAPÍTULO III DISEÑO DEL ANALIZADOR DE IMÁGENES 3.1 SELECCIÓN DEL LENGUAJE DE PROGRAMACIÓN Y DEL ENTORNO DE DESARROLLO El lenguaje de programación utilizado en el desarrollo del Proyecto es el C++. Más que una selección, fue una exigencia del proyecto de Telefónica I+D del cual se deriva el Proyecto: Al momento de comenzar este último, los desarrollos se estaban haciendo en C++, por lo cual, por compatibilidad, se decidió dar continuidad a su uso. Como ventaja añadida, en TID se disponía (sin representar un costo adicional para el proyecto) del entorno de desarrollo “Microsoft Visual Studio 2005”, cuyas prestaciones resultaban suficientes para cumplir los objetivos planteados. Adicionalmente, las herramientas utilizadas tanto para el reconocimiento óptico de caracteres como para el análisis de imágenes también estaban desarrolladas en C++ (se verá con mayor detalle más adelante). 3.2 SELECCIÓN DEL OCR Diferentes motores y software OCR fueron considerados antes de la selección de alguno. En la tabla 3.1 se presentan comparaciones entre dichos software de OCR. 26 Tabla 3.1: Comparativas de Motores y Software OCR. Motor / Desarrollador Licencia Software GOCR Ventajas Desventajas Admite diferentes Es fácil de usar No disponible en tipos de fuentes. (para sólo tener español; 5 años de Interfaz poco desarrollo). amigable. El sistema oficial Lee a color o Interfaz poco de OCR de GNU blanco y negro, amigable. Especiales Jörg GNU Schulenburg Ocrad Características Proyecto GNU GNU soporta UTF-8, posee analizador de composición (columnas, filas) Tesseract - Google; Gratuito; Adquirido por Soporta Motor producido OCR Comunidad de Licencia Google. El mejor Windows, Linux hasta el año desarrolladores Apache. software OCR y Mac OS X. 1995. Tiene excelentes Buen manejo El costo (160 algoritmos de del formato euros aprox.). reconocimiento de PDF; texto. actualizaciones gratuito del momento. FineReader ABBYY Comercial OCR periódicas. Readiris IrisLink Comercial Liviano, Rápido, Buen El costo (aunque Simple. funcionamiento existe una con escáner; versión de interfaz prueba de 30 amigable; días). disponibilidad del idioma español. 27 Ms Office Microsoft. Comercial. Patrocinado por Uso intuitivo. El costo. Se Document Microsoft Office; Motor que enfoca en Imaging enlaza con procesa más del documentos de OmniPage PRO de 99%. imagen de ScanSoft. OmniPage Nuance Comercial. Microsoft. El más vendido Automatiza el El costo (100 del mundo proceso de euros aprox.). (actualmente). conversión de texto; trabaja con el formato PDF; precisión del 99%; disponible en múltiples idiomas. El software OCR comercial mejor posicionado en el mercado, para el momento de la escogencia, fue el OmniPage de la compañía Nuance. Sin embargo, su uso de descartó debido a la existencia de motores OCR de uso gratuito. De los motores OCR gratuitos, el que mejor prestaciones presentaba, al momento de la escogencia, era el Tesseract - OCR. El que su código fuente estuviese disponible para Windows en C++ (el lenguaje de programación seleccionado para el desarrollo del proyecto) y el que tuviese la opción de configuración para el idioma español, fueron factores decisivos al momento de seleccionarlo. Adicionalmente, posee un buen soporte, al tener una amplia comunidad de desarrolladores, y el tener la licencia Apache, permite su libre uso en aplicaciones de carácter comercial y/o propietario, como es el caso de la aplicación desarrollada para TID. Una opción adicional de este software es que permite la posibilidad de “entrenamiento”: mediante una aplicación, con interfaz gráfica incluida, puede prepararse a dicho software para reconocer nuevos tipos de fuente. Esta funcionalidad es muy 28 importante, pues permitiría hacer frente a cambios de fuente (imposibles de reconocer por el software) en las imágenes a analizar en este proyecto. 3.3 TESSERACT - OCR El software Tesseract – OCR tiene las siguientes características[16]: - Desarrollado sobre C++. Su código fuente está disponible, lo que lo hace compilable de acuerdo a las necesidades del proyecto. - Soporte de varios idiomas: alemán, español, inglés, italiano, etc. - Admite imágenes en diversos formatos: .bmp, .png, .tiff, etc. (el formato de interés para el proyecto es el .bmp). - Admite imágenes en color, en escala de grises o en blanco y negro, siendo las dos últimas las formas recomendadas para un óptimo funcionamiento. - Las imágenes no necesitan ser de altísima calidad: podrían ser un poco borrosas y/o de bajo contraste. - Generación de los resultados de las lecturas de los caracteres de una imagen en un fichero de texto (.txt) manejable prácticamente por cualquier editor de texto hoy en día. 3.4 ALGORITMO DE SEMEJANZA DE TEXTO El Algoritmo de Semejanza de Texto (AST) es la implementación del Algoritmo de Brew con ciertas modificaciones. Este último permite identificar las diferencias existentes entre dos cadenas de texto; sin embargo, para los objetivos del proyecto, sigue sin ser suficiente. Lo que se necesitaba era obtener una medida que indicase cuán parecida es la CF a la CO. Para ello, considerando que un acierto del 100% ocurre cuando CF = CO, tenemos la siguiente fórmula empírica: 29 Semejanza = 100 - (Penalización / Longitud Máxima) [%] …(i) donde: Penalización: Ponderación de las diferencias ocurridas entre CF y CO. Longitud Máxima: el valor máximo de entre las longitudes de las cadenas, n y m. Utilizando la información obtenida de las diferencias entre las cadenas de texto, se pueden extraer los caracteres involucrados. Es decir, al ocurrir una sustitución, supresión o adición de caracteres, se pueden obtener el par de caracteres envueltos en la acción. La finalidad es ponderar las diferencias ocurridas. Una vez obtenidos los pares de caracteres diferentes, se comprobarían en una tabla de ponderación (ver tabla 3.2) y los valores obtenidos se sumarían a la variable Penalización. En la elaboración de la tabla 3.2, se consideró que: 1. En el caso de ocurrir una sustitución de caracteres, se asumió que la penalización es simétrica, es decir, es igual para una pareja de caracteres ‘ab’ que para una pareja ‘ba’. 2. Al ocurrir una adición o una supresión, el par de caracteres se forma con un caracter presente (en la CF o en la CO, respectivamente) y el caracter “vacío”. Igual que en el caso de la sustitución, se asumió penalización simétrica. Dado que el algoritmo está pensado para usarse con la Cadena Fuente proveniente de la lectura de una imagen con OCR, la tabla 3.2 se elaboró considerando algunos de los fallos más habituales en OCR (ver Apéndice C). 30 Tabla 3.2: Tabla de Confusiones más Comunes. Parejas de Caracteres . , ; : _ * a á b c d e é f g h i í j k l m n ñ o ó p q r s t u ú v w x y z A Á B C D E É F Porcentaje 10 10 20 20 20 20 30 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 40 50 40 40 40 40 40 40 40 40 40 40 50 50 40 40 40 40 40 40 40 40 40 40 Parejas de Caracteres Ii 1I I1 0O O0 0o o0 oO Oo ft tf tl lt tc ct yv vy ao oa gq qg eo oe co oc op po hb bh se es an na fl lf mn nm hn nh bo ob da ad hi ih aá áá Porcentaje 30 30 30 30 30 30 30 30 30 40 40 40 40 50 50 40 40 50 50 40 40 50 50 50 50 40 40 40 40 50 50 50 50 30 30 30 30 30 30 40 40 50 50 50 50 20 20 31 G H I Í J K L M N Ñ O Ó P Q R S T U Ú V W X Y Z .-. ,. ., .: :. ;: :; as sa ae ea ec ce Il lI l1 1l il li it ti iI 40 40 40 40 40 40 40 40 40 50 40 40 40 40 40 40 40 40 40 40 50 50 40 40 20 20 20 20 20 20 20 20 50 50 40 40 40 40 30 30 30 30 30 30 30 30 30 eé ée ií íi oó óo uú úu Ss sS 5S S5 5s s5 4A A4 08 80 MH HM DO OD D0 0D NM MN AÁ ÁA EÉ ÉE IÍ ÍI OÓ ÓO UÚ ÚU UV VU 1] ]1 I] ]I (C C( (c c( ([ [( Otro Caso 20 20 20 20 20 20 20 20 15 15 20 20 20 20 20 20 50 50 50 50 30 30 30 30 30 30 20 20 20 20 20 20 20 20 20 20 20 20 30 30 30 30 20 20 20 20 30 30 50 32 En el caso de que ocurra que una pareja de caracteres no se encuentra en la tabla, se estableció una Penalización = 50, puesto que se asume que si no está en la tabla no ha de ser una ocurrencia habitual. Este valor también es ajustable. Finalmente, al aplicar la fórmula (i) se pueden obtener dos cosas: - Modalidad # 1: El valor porcentual de la semejanza entre las cadenas CF y CO. - Modalidad # 2: De acuerdo a un criterio referencial (con el que se compararía el resultado arrojado por la fórmula mencionada anteriormente), se puede considerar que ha ocurrido un acierto o un fallo de la CF respecto a la CO (esto es, pensando que la Cadena Fuente proviene de la lectura de una imagen con el OCR). Por ejemplo, para el caso de las CF = ‘CAR4CE’ y la CO = ‘CARACAS’, se tendría lo siguiente: - En la sustitución de “4” por “A”, se almacenarían el par de caracteres “4A”. - En la sustitución de “E” por “A”, se almacenarían el par de caracteres “EA”. - En la supresión de “S”, se almacenaría “ S” (el espacio indica vacío, ausencia del caracter). La penalización en este caso sería: 20 correspondiente a la primera sustitución, 50 por la segunda sustitución y 40 por la supresión. Entonces, Penalización = 110. Las longitudes de CF y CO son 6 y 7, respectivamente, siendo la Longitud Máxima = 7. Sustituyendo valores en (i) tenemos: Semejanza = 100 - (110 / 7) = 84,3 % 33 3.5 SELECCIÓN DE LA HERRAMIENTA DE TRATAMIENTO DE IMÁGENES La herramienta utilizada para el tratamiento de imágenes fue OpenCV[17], en su versión de C++. Al igual que en la escogencia del lenguaje de programación, su uso fue una exigencia del proyecto de Telefónica I+D del cual se deriva el Proyecto: al momento de comenzar este último, los desarrollos que involucraban tratamiento de imágenes se estaban haciendo con OpenCV, con lo cual, por compatibilidad, se tuvo que usar. Asimismo, la experiencia del grupo de trabajo con OpenCV representó un valor añadido, pues fueron capaces de proporcionar recomendaciones en el tratamiento de imágenes. OpenCV (en inglés Open Computer Vision) es una librería de visión artificial (o visión por ordenador) orientada al tratamiento de imágenes (capturadas en tiempo real o no). Fue originalmente desarrollada por Intel y está publicada bajo licencia BSD (Berkeley Software Distribution), que permite su libre uso para propósitos de investigación y/o comerciales de manera gratuita. 3.6 TRATAMIENTO DE IMÁGENES En la figura 3.1 se presenta un diagrama que resume el tratamiento de imágenes hecho en este Proyecto. El primer paso consiste en generar las imágenes a ser tratadas, correspondientes a las Páginas Locales de Configuración de los STB de Imagenio, que no son otra cosa que 4 pantallas de configuración de las características de emisión de las señales de audio y video. El objetivo, como fue mencionado anteriormente, es extraer la información presente en las mismas y comprobar su veracidad. Los STB emiten las páginas locales en Video Compuesto. Las imágenes se obtuvieron con la sonda robot Witbe (ver Apéndice A): a partir de la captura de la señal de video en tiempo real, se puede extraer (en cualquier momento) una imagen (frame) en formato .BMP. En las figuras 3.2, 3.3, 3.4 Y 3.5 se muestran imágenes capturadas para el STB (ver Apéndice B) Motorola 1920. 34 Figura 3.1: Resumen del Tratamiento de Imágenes. 35 Figura 3.2: Páginas Locales del STB de Imagenio – Pantalla de Configuración de los Parámetros de Red. 36 Figura 3.3: Páginas Locales del STB de Imagenio – Pantalla de Configuración de los Parámetros de Emisión de Video. 37 Figura 3.4: Páginas Locales del STB de Imagenio – Pantalla de Configuración de los Parámetros de Emisión de Audio. 38 Figura 3.5: Páginas Locales del STB de Imagenio – Pantalla con Información acerca del STB. 39 3.7 PREPARACIÓN DE LAS IMÁGENES PARA EL OCR Antes de aplicarle a cualquiera de las 4 imágenes (figuras 3.2, 3.3, 3.4 y 3.5) OCR, necesitan ser tratadas. Esto se debe a que: - No todas las cadenas de texto presentes en la imagen son de interés. - Lo deseable sería obtener imágenes de cada cadena de texto, y luego leerlas de forma individual. De esta manera se pueden manejar los errores de lectura con mayor facilidad, al tener limitado el origen de los mismos. - El diseño de las imágenes incluye diversos colores y muchos bordes, lo cual podría ser interpretado por el OCR como un carácter o incluso alguna palabra, cuando en realidad no lo son. En síntesis, el objetivo era conseguir “recortar” de la imagen principal cada cadena de texto para posteriormente ser “leídas” con OCR. Para ello, los pasos que había que seguir eran: localización de las cadenas de texto en la imagen, extracción de las mismas y adaptación de los “recortes” de la imagen principal para un funcionamiento óptimo del Tesseract – OCR. A continuación se explica detalladamente el proceso de obtención de las cadenas de texto individualizadas, que luego serán leídas una a una con el Tesseract – OCR. Para ello (y también en explicaciones sucesivas) se utilizará la figura 3.4 como referencia. 3.8 LOCALIZACIÓN DE LAS CADENAS DE TEXTO EN LA IMAGEN Para esta tarea se consideraron 2 alternativas, recomendadas por el grupo de trabajo, pues se habían enfrentado anteriormente al problema de hacer OCR en imágenes: 1. Localización de las cadenas de texto mediante el empleo de Umbralización. 2. Localización de las cadenas de texto mediante el empleo de algoritmos de detección de borde. 40 3.8.1 LOCALIZACIÓN DE LAS CADENAS DE TEXTO MEDIANTE EL EMPLEO DE UMBRALIZACIÓN. La Umbralización se aplicó, sobre la figura 3.4, para las componentes de dos modelos de color, HSV y RGB. Para obtener los umbrales correspondientes, se calcularon histogramas de partes de la imagen original, donde hubiese, al menos, un pedazo de alguna cadena de texto (figuras 3.6a, 3.6b, 3.6c y 3.6d). Lo que se pretendía obtener eran valores suficientemente exactos de las componentes de color (de uno u otro modelo) que permitiesen recorrer la imagen original, píxel a píxel, y hacer una discriminación de los mismos, esperando obtener como resultado una nueva imagen con dichas cadenas de texto. Figuras 3.6a, 3.6b, 3.6c y 3.6d: Imágenes con pedazos de las cadenas de texto de interés, para calcular los histogramas de los modelos de color HSV y RGB. Luego de calcular los histogramas de ambos modelos de color para las figuras 3.6a, 3.6b, 3.6c y 3.6d y de aplicar Umbralización sobre la imagen original, se obtuvieron, respectivamente, las figuras 3.7a, 3.7b, 3.7c y 3.7d para el modelo HSV y las figuras 3.8a, 3.8b, 3.8c y 3.8d para el modelo RGB. Como se observa en las figuras 3.7 y 3.8, la opción de Umbralización no es viable, pues la imagen de la figura 3.4 no es ni uniforme ni homogénea: las componentes de color no presentan valores significativamente diferentes. En consecuencia, esta opción fue descartada. 41 Figura 3.7a: Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6a para obtener el histograma. Figura 3.8a: Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6a para obtener el histograma. 42 Figura 3.7b: Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6b para obtener el histograma. Figura 3.8b.- Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6b para obtener el histograma. 43 Figura 3.7c.- Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6c para obtener el histograma. Figura 3.8c: Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6c para obtener el histograma. 44 Figura 3.7d.- Imagen obtenida luego de aplicar umbralización para el modelo de color HSV, utilizando la figura 3.6d para obtener el histograma. Figura 3.8d.- Imagen obtenida luego de aplicar umbralización para el modelo de color RGB, utilizando la figura 3.6d para obtener el histograma. 45 3.8.2 LOCALIZACIÓN DE LAS CADENAS DE TEXTO MEDIANTE EL EMPLEO DE ALGORITMOS DE DETECCIÓN DE BORDE. En la figura 3.9 se presenta la imagen resultante luego de aplicarle el Algoritmo de Canny a la figura 3.4. Como se puede apreciar, se consiguieron obtener los bordes de las cadenas de texto deseadas y algunos otros que no son de interés. Figura 3.9: Pantalla de Configuración de los Parámetros de Emisión de Audio, luego de la aplicación del Algoritmo de Canny. Luego de ver los resultados de las 2 alternativas propuestas para la localización de las cadenas de texto en la imagen, es evidente que la segunda segunda presenta los resultados más favorables, y por tanto, fue la solución adoptada. Además, dichos resultados serían suficientes para (servir de base a) la obtención de las imágenes individualizadas con las cadenas de texto, como se verá a continuación. 46 3.9 OBTENCIÓN DE LAS CADENAS DE TEXTO EN IMÁGENES INDIVIDUALES A pesar de que el contorno de algunos caracteres no se encuentre perfectamente definido (ver figura 3.9), son lo suficientemente buenos para ayudar a localizar en que parte de la imagen se encuentran las cadenas de texto. Los bordes hallados que no resulten de interés son debidamente filtrados, como se verá posteriormente. Una vez localizadas las cadenas de texto en la imagen, el siguiente paso es su obtención como imágenes individualizadas. P Para ara ello, se procedió a dilatar los bordes de la figura 3.9 hasta convertirlos en “objetos localizables” de la imagen (en otras palabras, convertir en un solo elemento cada cadena de texto). El resultado de la dilatación se muestra en la figura 3.10. Figura 3.10: Imagen resultante luego de dilatar los bordes conseguidos con el Algoritmo de Canny. 47 Al localizar todos los objetos de la imagen, es posible calcular su área y su perímetro. Estos dos criterios, junto con las coordenadas x,y de cada uno, sirvieron para discriminar las cadenas de texto de interés de los objetos no deseados. Como fue mencionado el apartado 3.3, el funcionamiento óptimo del Tesseract – OCR es con imágenes en escala de grises y/o blanco y negro. En las figuras 3.11 y 3.12 se presentan ambas conversiones. La mejor imagen es la figura 3.11, pues no presenta deterioros drásticos como la imagen de la figura 3.12. Con sólo aplicarla a esta imagen es descartable la conversión a blanco y negro, puesto que en la parte afectada todas las imágenes tienen texto de interés (figuras 3.2, 3.3, 3.4 y 3.5). Figura 3.11: Pantalla de Configuración Configuración de los Parámetros de Emisión de Audio, en escala de grises. 48 Figura 3.12: Pantalla de Configuración de los Parámetros de Emisión de Audio, en blanco y negro. Finalmente, se utilizaron las coordenadas x,y de los objetos deseados y se procedió a “recortar” de la figura 3.11 las cadenas de texto respectivas (ver figura 3.13). Figura 3.13: Cadenas de texto individualizadas. 49 3.10 MEJORAS DE LAS IMÁGENES CONTENEDORAS DE LAS CADENAS DE TEXTO PARA EL TESSERACT – OCR. Una mejora adicional sobre las imágenes de la figura 3.13, antes de utilizarlas con Tesseract – OCR, es hacerles una ampliación. El desempeño del Tesseract – OCR mejora cuanto más grandes son los caracteres a reconocer. De manera experimental se consiguió que, aumentando por un factor de 4, las cadenas de texto individualizadas se leían mucho mejor respecto a su tamaño original. Factores mayores a ese no mejoraban más la lectura, e incluso para factores superiores a 5-6 la lectura comenzaba de degradarse. Para hacer la ampliación de las imágenes, se utilizaron los métodos de interpolación vecino más próximo (figura 3.14), bilineal (figura 3.15) y bicúbico (figura 3.16). El primero puede perder algunos valores, pues sólo usa la información del píxel más cercano. Los dos últimos utilizan información de los 4 y 16 píxeles más cercanos, respectivamente. El método bicúbico es, por lo tanto, el que añade menor distorsión a la imagen, es decir, el que arroja imágenes más parecidas a la original. En las figuras 3.14 y 3.15 se puede ver como el método vecino más próximo parece haber eliminado píxeles y el método bilineal desdibujado un poco las letras. En la figura 3.16 se muestra una imagen, si bien no perfecta, bastante fidedigna respecto a la original y mejor que las otras 2, por lo cual, fue el método seleccionado para la ampliación de las imágenes. Figura 3.14: Ejemplos de cadenas de texto individualizadas, aumentadas por un factor de 4 utilizando interpolación vecino más próximo. 50 Figura 3.15: Ejemplos de cadenas de texto individualizadas, aumentadas por un factor de 4 utilizando interpolación bilineal. Figura 3.16: Ejemplos de cadenas de texto individualizadas, aumentadas por un factor de 4 utilizando interpolación bicúbica. 3.11 PROCESAMIENTO DE LA INFORMACIÓN CONTENIDA EN LAS IMÁGENES Una vez listas las imágenes individuales contenedoras de las cadenas de texto, se procede a “leerlas” con el Tesseract – OCR. En otras palabras, se procede a obtener la información de dichas imáge imágenes. nes. Para comprobar cuan acertada es la lectura, se dispone del Algoritmo de Semejanza de Texto, expuesto en el apartado 3.4. 51 3.11.1 CLASIFICACIÓN DE LAS DE CADENAS DE TEXTO. Las cadenas de texto fueron clasificadas en Títulos, Campos Estáticos o Campos Variables, de acuerdo tanto al tipo de información brindada, como a su variabilidad. Entiéndase por esto último, la posibilidad de una cadena de texto de ser modificada. En la figura 3.17 se muestran indicadores con la clasificación de las cadenas de texto presentes en las Páginas Locales de los STB de Imagenio. 1. Títulos: Los Títulos sirven para clasificar los parámetros (campos estáticos y variables) de cada pantalla de configuración de los STB. Pueden o no existir. Para el momento de realización de este Proyecto, sólo la pantalla de configuración de los parámetros de audio contenía títulos (figura 3.4). Sin embargo, el desarrollo hecho admite la aparición y/o supresión de títulos en cualquiera de las páginas locales. 2. Campos Estáticos: Los campos estáticos son las cadenas de texto que no pueden ser modificadas por el usuario. Situados al lado izquierdo de cada página local, definen los parámetros de configuración de los STB. Pueden ser agregados o removidos campos estáticos en las páginas locales, según varíen los parámetros de configuración de los STB. 3. Campos Variables: Los campos variables, situados a la derecha de cada página local, son aquellas cadenas de texto modificables por el usuario, por el propio STB (por ejemplo, el campo estático “Fecha” de la figura 3.5) o desde la planta de producción de Imagenio (por ejemplo, los campos variables asociados a los estáticos “Versión Software” y “Versión Firmware” de la figura 3.5, que varían según sean actualizados vía ADSL) en cualquier momento. 52 Figura 3.17: Identificación de las Cadenas de Texto en la Pantalla de Configuración de los Parámetros de Emisión de Audio. 3.11.2 ALMACENAMIENTO DE LA INFORMACIÓN La información extraída de las imágenes de Páginas Locales se almacenará de la siguiente forma: se guardará cada Campo Estático con su respectivo Campo Variable asociado. En el caso de existir algún Título, pasa a formar parte de cada Campo Estático asociado, y en consecuencia, estará asociado indirectamente al Campo Variable. El objetivo es que, consultando un Campo Estático (o Título + Campo Estático) se pueda conocer el valor del Campo Variable, y con ello, verificar la correcta configuración de los parámetros de una determinada Página Local. 53 La veracidad de los Campos Estáticos, como se verá en el apartado 3.12.3, se debe comprobar antes de almacenarse la información, pues este será el “Identificador” a consultar por parte de los usuarios del Analizador de Texto (ver Apéndice D). Los Campos Variables serán, por lo tanto, cadenas de texto cuya veracidad se comprobará utilizando los valores introducidos por dichos usuarios. 3.11.3 EXTRACCIÓN Y VALIDACIÓN DE LA INFORMACIÓN Al momento de extraer la información de las imágenes, hay que tener en cuenta que cada campo estático tiene asociado un campo variable, y que ambos estarán asociados a un título en el caso de existir. Las imágenes serán leídas con el Tesseract OCR en el siguiente orden: Títulos, Campo Estático, Campo Variable, Campo Estático, Campo Variable, etc. Cada cadena de texto obtenida (de las imágenes individualizadas) con Tesseract – OCR debe ser comprobada. Es decir, debe verificarse si la cadena de texto conseguida era la esperada, o al menos si es suficientemente parecida como para darse por válida. Existen dos tipos de comprobación, una para Títulos y Campos Estáticos, y otra para Campos Variables. Comprobación de Títulos y Campos Estáticos Estas cadenas de texto son del tipo no modificables. Por lo tanto, siempre tendrán valores fijos y conocidos. A continuación se enumeran los pasos para hacer la comprobación, utilizando un Campo Estático como ejemplo: 1. Se lee la imagen correspondiente, obteniendo así la CF (figura 3.18) Røtardo Audlo SPDIF Figura 3.18: Resultado de la lectura de un Campo Estático con Tesseract – OCR. 54 2. La cadena de texto obtenida (CF) se compara con cada uno de los posibles campos estáticos, conocidos previamente, para la Pantalla de Configuración que se está analizando. Al conjunto de estos últimos se les llama “Diccionario”. La comparación se hace utilizando la modalidad 1 del AST (ver tabla 3.3). Tabla 3.3: 3.3: Resultados del AST, en modalidad # 1. Cadena Fuente (CF) Røtardo Audlo SPDIF Cadena Objetivo (CO) Semejanza [%] Configuración SPDIF 33.00 Configuración HDMI 16.00 Conversión AC3 a estéreo 11.25 Retardo Audio SPDIF 88.50 3. Se escoge como CO aquella que presente el mayor parecido con la CF. En este caso, CO = ‘Retardo Audio SPDIF’. 4. Se hace una comparación de la CF con la CO utilizando la modalidad 2 del AST. En el caso de ocurrir “Acierto” (figura 3.19), se almacena el campo estático correspondiente y se procede a leer y comprobar su campo variable asociado. En el caso de ocurrir “Fallo” no se almacena nada y se asume que el campo estático no existe, y por lo tanto, tampoco existe un campo variable asociado. Retardo Audio SPDIF Figura 3.19: Campo Estático obtenido. En la figura 3.20 se presenta un diagrama con los pasos para la comprobación de Títulos y Campos Estáticos. 55 Figura 3.20: 3.20: Comprobación de Título / Campo Estático. Comprobación de Campos Variables Estas cadenas de texto son del tipo modificable. Las modificaciones pueden ser de dos tipos: - Modificaciones “Conocidas”: Son las modificaciones que pueden hacerse de manera limitada y conocida, es decir, cuando el parámetro puede tomar solamente ciertos valores predefinidos. Por ejemplo, el parámetro ‘Conversión AC3 a estéreo’ puede tomar los valores ‘Sí’ y ‘No’ (figura 3.4). Para este tipo de campo variable puede usarse un Diccionario. - Modificaciones “Desconocidas”: Son las modificaciones que pueden hacerse de manera ilimitada y/o desconocida, por lo que está descartado el uso de Diccionario alguno. Por ejemplo, el parámetro ‘Versión Software’ de la figura 3.5. A continuación se enumeran los pasos para hacer la comprobación de un Campo Variable: 1. Se lee la imagen correspondiente, obteniendo así la CF (figura 3.21). desactivado Figura 3.21: Resultado de la lectura de un Campo Variable con Tesseract – OCR. 56 2. En el caso de existir Diccionario (caso contrario, saltar al paso 4): La cadena de texto obtenida (CF) se compara con cada uno de los posibles campos variables conocidos previamente. La comparación se hace utilizando la modalidad 1 del AST (ver tabla 3.4). 3. Se escoge como nueva CF aquella que presente el mayor parecido con la CF inicial. En este caso, la nueva CF = ‘desactivado’. Tabla 3.4: Resultados del AST, en modalidad # 1. Cadena Fuente (CF) desactivado Cadena Objetivo (CO) Semejanza [%] desactivado 100 100 ms 27.27 200 ms 27.27 300 ms 27.27 4. Se hace una comparación de la CF con la CO utilizando la modalidad 2 del AST. La cadena CO es el valor que desea comprobarse (ver Apéndice D). En el caso de ocurrir “Acierto”, se almacena el campo variable asociado al campo estático correspondiente. En el caso de ocurrir “Fallo”, se deja el campo variable vacío. En la figura 3.22 se presenta un diagrama con los pasos para la comprobación de los Campos Variables. 57 Figura 3.22: Comprobación de Campo Variable. 3.12 CONSULTA DE LA INFORMACIÓN La información obtenida de las imágenes, y luego de su correspondiente validación, se almacena en una tabla, y puede ser consultada utilizando como identificador/localizador al Título + Campo Estático, como se mencionó en el apartado 3.12. De existir, se devuelve el identificador acompañado del Campo Variable asociado, que a su vez puede contener información o estar vacío. Si no existe, se devuelven ambos campos vacíos. 3.13 IMPLEMENTACIÓN DEL ANALIZADOR DE IMÁGENES Como se mencionó en el punto 3.1, el desarrollo del Analizador de Imágenes fue hecho en el lenguaje C++. Una vez culminado, fue incluido en una librería dinámica, llamada “OCR.DLL”, que incluía otras aplicaciones del proyecto de TID. No obstante, el desarrollo software de la sonda robot WITBE fue hecho en el lenguaje Python. Por cuestiones de compatibilidad, fue necesario el uso de un “puente” entre ambos lenguajes, que permitiesen ejecutar las funcionalidades incluidas en la “OCR.DLL” desde Python (ver figura 3.23). 58 La sonda ejecuta una serie de funciones, llamadas “Tareas”. Por ejemplo, hace mediciones de la calidad del audio y video emitido por los STB, verifica el correcto funcionamiento de los STB, verifica la correcta configuración de los STB, etc. Esta última funcionalidad utiliza el Analizador de Imágenes desarrollado en este Proyecto. El nombre de la Tarea asociada es “Páginas Locales”, y tiene como parámetros de entrada una imagen para analizar y las cadenas de texto que se deseen comprobar. Figura 3.23: Esquema de la implementación del Analizador de Imágenes en la sonda robot WITBE. 59 CAPÍTULO IV PRUEBAS REALIZADAS Y ANÁLISIS DE LOS RESULTADOS En este apartado se presentarán una serie de resultados obtenidos al utilizar el Tesseract – OCR, sobre imágenes preparadas para ello, tal y como fue expuesto en los puntos 3.8 al 3.11. 4.1 PRIMERA PRUEBA: PARA LAS CUATRO PANTALLAS DE CONFIGURACIÓN, EMITIDAS POR UN STB. En las tablas 4.1, 4.2, 4.3 y 4.4 se presentan resultados obtenidos para las cuatro Pantallas de Configuración de los STB: Red, Video, Audio y Otros (figuras 3.2, 3.3, 3.4 y 3.5), capturadas con la sonda robot WITBE y emitidas por el STB Motorola 1920. Por cada pantalla se capturó una muestra de 20 imágenes. Se presentan resultados promediados en cada una de las cuatro tablas. Se considera que ocurre un “Acierto” cuando se obtiene con el Tesseract – OCR el caracter esperado de la imagen. Se considera que ocurre un “Fallo” cuando se obtiene un caracter incorrecto (uno diferente al original), cuando se añaden caracteres en la lectura o cuando se suprimen caracteres de la cadena de texto original. 60 Tabla 4.1: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Red. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Modo de Red 11 7,2 3,9 estático 8 8,0 0,0 Dirección IP 12 12,0 0,0 10.42.4.250 11 9,85 1,15 Máscara de Subred 17 16,0 1,0 255.255.255.248 15 13,1 2,0 Pasarela 8 7,2 0,9 10.42.4.249 11 9,85 1,3 Dirección del OPCH 21 21,0 0,0 239.0.2.10:22222 16 15,9 0,4 DNS Primario 12 12,0 0,0 172.26.23.3 11 10,15 1,15 Tabla 4.2: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Video. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Modo de vídeo 13 11,5 1,8 Euroconector 12 10,0 2,0 Modo de salida (Eurocon) 24 23,3 0,8 S-Video 7 6,0 1,0 Frecuencia RF 13 13,0 0,0 36 2 2,0 0,0 61 Tabla 4.3: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Audio. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Configuración SPDIF 19 9,9 9,3 Conversión AC3 a estéreo 24 20,1 4,0 Sí 2 2,0 0,0 Retardo Audio SPDIF 19 17,8 1,2 Desactivado 11 11,0 0,0 Configuración HDMI 18 16,0 2,0 Conversión AC3 a estéreo 24 21,6 2,4 Sí 2 2,0 0,0 Tabla 4.4: Resultados obtenidos con las imágenes emitidas por el STB Motorola 1920, para la Pantalla de Configuración de Otros Parámetros. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Fabricante 10 8,0 2,1 motorola - vip1920-9t 21 16,4 5,8 Fecha 5 5,0 0,0 06/08/2008 - 11:09 18 17,6 2,0 Versión Software 16 16,0 0,0 2008.05.28.15.12.35 19 15,8 6,3 Versión Hardware 16 16,0 0,0 535636-008-00 13 10,2 2,8 Versión Firmware 16 14,4 1,7 2.21 (4.15.3 - 1.2.3.9) 23 21,6 3,4 62 4.2. SEGUNDA PRUEBA: SOBRE UNA MISMA PANTALLA DE CONFIGURACIÓN, EMITIDA POR DIFERENTES STB. En las tablas 4.5, 4.6 y 4.7 se presentan resultados obtenidos para la Pantalla de Configuración de Red de los STB (figura 3.4), capturada con la sonda robot WITBE y emitida por 3 STB diferentes. De dicha pantalla se utilizaron únicamente las cadenas de texto comunes para los 3 STB. Para cada uno de ellos, se capturó una muestra de 20 imágenes. Se presentan resultados promediados en cada una de las tres tablas. Tabla 4.5: Resultados obtenidos para las imágenes emitidas por el STB Philips 5750. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Modo de Red 11 6,7 5,2 Estático 8 7,9 0,1 Dirección IP 12 11,3 0,7 Máscara de Subred 17 16,5 0,5 255.255.255.248 15 9,9 5,1 Pasarela 8 7,7 0,3 Dirección IP del OPCH 21 20,7 0,9 239.0.2.10:22222 16 13,9 3,0 DNS Primario 12 12,0 0 63 Tabla 4.6: Resultados obtenidos para las imágenes emitidas por el STB ADB 5810. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Modo de Red 11 8,8 2,2 Estático 8 8,0 0 Dirección IP 12 8,8 3,2 Máscara de Subred 17 14,8 2,2 255.255.255.248 15 9,2 5,8 Pasarela 8 5,7 2,3 Dirección IP del OPCH 21 17,2 3,8 239.0.2.10:22222 16 15,8 0,5 DNS Primario 12 12,0 0 Tabla 4.7: Resultados obtenidos para las imágenes emitidas por el STB Motorola 1920. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Modo de Red 11 7,2 3,9 estático 8 8,0 0 Dirección IP 12 12,0 0 Máscara de Subred 17 16,0 1,0 255.255.255.248 15 13,1 2,0 Pasarela 8 7,2 0,9 Dirección IP del OPCH 21 21,0 0 239.0.2.10:22222 16 15,9 0,4 DNS Primario 12 12,0 0 En la tabla 4.8 se presentan los resultados promediados para los 3 STB. En otras palabras, resultados conjuntos para las 60 capturas de imagen de la Pantalla de Configuración de Audio de los STB. 64 Tabla 4.8: Resultados obtenidos para las imágenes emitidas por los 3 STB. Cadena de Texto Objetivo (CO) N° caracteres <Aciertos> <Fallos> Modo de Red 11 7,6 3,8 estático 8 8,0 0,0 Dirección IP 12 10,7 1,3 Máscara de Subred 17 15,8 1,2 255.255.255.248 15 10,7 4,3 Pasarela 8 6,9 1,2 Dirección IP del OPCH 21 19,6 1,6 239.0.2.10:22222 16 15,2 1,3 4.3. CONCLUSIONES SOBRE LAS PRUEBAS Luego de realizar las dos pruebas anteriores, se obtuvieron las siguientes conclusiones: - Las lecturas con Tesseract – OCR de las imágenes correspondientes a las primeras cadenas de texto (parte superior de la imagen) son las menos efectivas, especialmente las ubicadas en la parte superior izquierda. Esto se debe a que en esa área hay una mayor cantidad de brillo, que afecta el contraste de la imagen en escala de grises. - Unas cadenas de texto se leen mejor que otras, es decir, el OCR no es 100% acertado. De allí que se justifique el uso del AST para comprobar los resultados, y que este permita la posibilidad de hacerlo con diferentes criterios numéricos, que irán en función de lo acertado de la lectura en cada parte de la imagen. - Los resultados de OCR no varían significativamente entre diferentes STB (Segunda Prueba). 65 CONCLUSIONES Y RECOMENDACIONES El Analizador de Imágenes basado en OCR que ha sido desarrollado durante este Proyecto ha cumplido con los objetivos inicialmente planteados: extracción del texto de las Pantallas de Configuración de los STB de Imagenio, y su respectiva validación. Asimismo, luego de su finalización, fue implementado (ver Apéndice D) satisfactoriamente en las Sondas Robot Witbe, y ha pasado, por tanto, a formar parte de las Pruebas de Validación de los STB que Telefónica S.A. tiene en su Planta de Producción. Es importante saber que el Analizador funciona tal y como está bajo una serie de condiciones: - Es dependiente del Look and Feel de Imagenio. Es decir, depende de la apariencia de la interfaz de usuario del servicio, en este caso, de las Páginas Locales. Modificaciones en el tipo de fuente y los colores, por ejemplo, afectarían el desempeño del Analizador hecho. - El Algoritmo de Semejanza de Texto no admite como confusiones más probables el que un caracter sea leído como un par de caracteres. Por ejemplo, que el OCR en lugar de leer “m” lea “rn”,”tn”, etc. La inclusión de estos casos mejoraría el desempeño del mismo. - En el caso de modificaciones de fuente en las cadenas de texto de las Páginas Locales, será necesario ajustar el Algoritmo de Semejanza de Texto, pues es posible que ocurran y/o desaparezcan confusiones comunes del Tesseract – OCR. - Los Diccionarios, explicados en el apartado 3.12.3, sirven para comprobar los parámetros de Red, Audio y Vídeo existentes a día de hoy. Modificaciones en los mismos, requerirán la actualización de los Diccionarios. El funcionamiento del Analizador de Imágenes está garantizado siempre y cuando se respeten las condiciones mencionadas anteriormente. De no cumplirse alguna de ellas, es 66 posible que funcione, pero no perfectamente, y los resultados obtenidos en esos casos no tendrán completa fiabilidad. 67 REFERENCIAS BIBLIOGRÁFICAS • Chen, C.H.; Wang, P. S. Handbook of Pattern Recognition and Computer Vision. 3ERA edición. World Scientific, 2004. Referencia [4] • De la Escalera, A. Visión por Computador, Fundamentos y Métodos. Prentice Hall, 2001. Referencias [7], [14] • Hamey, L.; Priest, C. Automatic Number Plate Recognition for Australian Conditions. Digital Image Computing: Techniqiues and Applications, IEEE Proceedings, Diciembre 2005. Referencia [9] • Jain, A. K.; Jung, K.; Kim, K. I. Text Information Extraction in Images and Video: A Survey. Pattern Recognition, Volumen 37, Capítulo 5, Mayo 2004, Págs. 977-997. • Kanai, J.; Nartker, T.; Rice, S.V. An Evaluation of OCR Accuracy. Technical Report 93-01, Information Science Research Institute, University of Nevada, Las Vegas, Abril 1993. Referencia [15] • Optichal Character Recognition (OCR). The Association for Automatic Identification and Data Capture Technologies, Septiembre 2000. Referencia [3] • Pratt, W. K. Digital Image Processing, 4TA edición. Wiley, 2007. Referencia [19] • Ringlstetter, C. OCR correction and determination of Levenshtein weights. Master's Degree Course Work in Computational Linguistics, Information and Language Center, Ludwig-Maximilians University of Munich, Septiembre 2003. Referencia [20] • S.A. Tesseract – OCR. Disponible en Internet: http://code.google.com/p/tesseract-ocr/, consultado el 17 de Diciembre de 2008. Referencia • S.A. Algoritmo de [16] Levenshtein. Disponible en Internet: http://www.levenshtein.net/index.html, consultado el 17 de Diciembre de 2008. Referencia • S.A. [5] Algoritmo de Brew. Disponible en Internet: http://www.ling.ohio- state.edu/~cbrew/795M/string-distance.html, consultado el 17 de Diciembre de 2008. Referencia [6] • S.A. Intranet de Telefónica I+D. Consultado el 17 de Diciembre de 2008. Referencias [2] [1], 68 • S.A. OpenCV. Disponible en Internet: http://opencv.willowgarage.com/wiki/, consultado el 17 de Diciembre de 2008. Referencia • S.A. Sondas Robot [17] Witbe. Disponible en Internet: http://www.witbe.net/qoe/index.php/english/Monitoring/video-tv.html, consultado el 17 de Diciembre de 2008. Referencia [18] 69 APÉNDICES APÉNDICE A: SONDA ROBOT WITBE La Sonda Robot Witbe S4000[18] (figura A.1) permite el monitoreo de servicios de TV, IPTV y VoD. Posee la capacidad de capturar señales de audio y video en definición estándar (S-Video o Video Compuesto) y en alta definición, y realizar mediciones sobre las mismas: tiempo de cambio entre canales, calidad de audio y de video percibidos (Quality of Experience, QoE), análisis de red (para el servicio IPTV y VoD), entre otras. Para realizar mediciones, como las mencionadas anteriormente, la sonda ejecuta una serie de “Tareas”, que no son otra cosa que aplicaciones específicas para cada una. Son ajustables mediante la modificación de sus de parámetros. A partir de las capacidades y/o funcionamiento básico de la sonda robot, es posible diseñar nuevas Tareas. Gracias a esto, fue posible diseñar las Tareas necesarias para el proyecto de TID “Sistema para la validación automática de descodificadores y aplicaciones de Imagenio”. Figura A.1: Sonda Video Robot WITBE S4000 (imagen referencial). 70 APÉNDICE B: STB Al momento de culminar el Analizador de Imágenes, existían 5 tipos diferentes de STB: 1. PHILIPS DIT - 5750 2. ADB 3800 3. ADB - 5810TWX 4. MOTOROLA IP - STB - 1720 5. MOTOROLA VIP 1920 - 9t. Todos estos STB emiten las Páginas Locales en definición estándar con el Modo de Video Compuesto. 71 APÉNDICE C: CONFUSIONES MÁS COMUNES EN OCR. En la elaboración de la tabla 3.2 se utilizaron como base los resultados de dos estudios distintos. El primero[19], elaborado en “The Information Science Research Institute University of Nevada” y el segundo[20] hecho en la “Ludwig Maximilians Universität München”. En las figuras C.1 y C.2 se presentan, a modo de referencia, los datos empleados de ambos estudios. Figura C.1: Tablas de confusiones más comunes, pertenecientes al primer estudio. 72 Figura C.2: Tablas de confusiones más comunes, pertenecientes al segundo estudio. 73 APÉNDICE D: TAREA DE PÁGINAS LOCALES. Para ejecutar las Tareas en la sonda robot WITBE, se dispone de una interfaz web. Desde allí son configurables todos los parámetros de las diversas Tareas disponibles. A continuación se muestra, de manera simplificada, la configuración y ejecución de una Tarea de Páginas Locales. Lo primero que hay que hacer es autenticarse en el sistema (figura D.1). Seguidamente, entramos en el menú principal, donde clicamos en “Definición casos de prueba” (figura D.2) y posteriormente en “Prueba de Páginas Locales” (figura D.4). Se desplegará una nueva pantalla donde se define la imagen a analizar (figura D.3) y los parámetros que se desean comprobar. Figura D.1: Tarea de Páginas Locales – Paso 1. 74 Figura D.2: Tarea de Páginas Locales – Paso 2. Figura D.3: Pantalla de Configuración de los Parámetros de Video, correspondiente al STB Motorola 1720. 75 Figura D.4: Tarea de Páginas Locales – Paso 3. Después de definir los parámetros de la Tarea de Páginas Locales, la guardamos y procedemos a ejecutarla. En “Planes de Prueba” (figura D.5) se encuentran disponibles todas las Tareas configuradas hasta el momento y susceptibles de ser ejecutadas. Como se puede ver en la figura anterior, la Tarea con nombre “Parámetros Video” fue debidamente almacenada. Figura D.5: Tarea de Páginas Locales – Paso 4. 76 Clicando en la opción “Ejecuciones” (figura D.6) escogemos la Tarea y la sonda robot donde queremos ejecutarla. Al clicar en la opción “Guardar” la tarea comienza su ejecución en la sonda escogida. Figura D.6: Tarea de Páginas Locales – Paso 5. Finalmente, accediendo a la opción “Resultados” (figura D.7), se puede buscar la Tarea de interés y verificar los resultados obtenidos (figura D.8). Figura D.7: Tarea de Páginas Locales – Paso 6 (y último) . 77 Figura D.8: Tarea de Páginas Locales – Resultados.