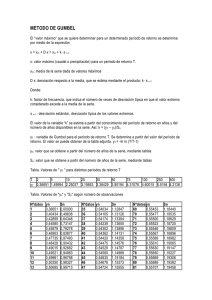
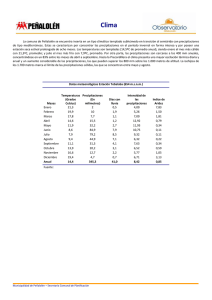
Modelización estocástica de precipitaciones máximas para el
Anuncio

Modelización estocástica de precipitaciones
máximas para el cálculo de eventos extremos a
partir de los periodos de retorno mediante R
Prof. Dr. Antonio José Sáez Castillo
20 de marzo de 2009
Departamento de Estadística e Investigación Operativa, Universidad de Jaén
Resumen
Las precipitaciones máximas en una determinada zona geográfica son
un fenómeno claramente sujeto a incertidumbre. Su modelización mediante distribuciones de probabilidad posibilita la determinación de lo
que puede considerarse un evento extremo en un determinado periodo
de retorno. En este trabajo se describe cómo realizar dicha modelización mediante distribuciones Gumbel, log-normal, log-Pearson Tipo III
y SQRT-ETmax, ajustando sus parámetros mediante el método de máxima verosimilitud, evaluando la bondad de los ajustes mediante el test
de Kolmogorov-Smirnoff y obteniendo los eventos extremos a partir de las
funciones cuantil de las distribuciones ajustadas. Todos los procedimientos
se han implementado en el software estadístico R.
Palabras clave: precipitaciones máximas, eventos extremos, periodos
de retorno, máxima verosimilitud, Gumbel, log-normal, log-Pearson Tipo
III, SQRT-ETmax, Kolmogorov-Smirnoff, R.
1.
Introducción
Aunque la motivación del presente trabajo está en relación con las precipitaciones máximas soportadas por una determinada zona geográfica, en general podemos considerar que el objeto de estudio es una variable aleatoria X
que cuantifica la magnitud de algún evento como tormentas, avenidas, sequías,
subidas del nivel del mar, etc.
Se dice que dicha variable toma como valor un evento extremo si supera un
valor umbral, xT , previamente especificado bajo algún criterio.
El tiempo que transcurre entre la ocurrencia de dos eventos extremos es asimismo una variable aleatoria, t, llamada intervalo de recurrencia, cuya media,
E [t] = T , se denomina periodo de retorno. Teniendo en cuenta que t contabiliza el número de unidades de tiempo hasta la ocurrencia de un nuevo evento
1
Modelización estocástica de precipitaciones máximas
extremo, su distribución de probabilidad de una distribución geométrica de parámetro
p = P [X ≥ xT ] = 1 − F (xT ) ,
(1)
donde F (x) = P [X ≤ x] es la función de distribución de la magnitud del fenómeno. Por tanto su media es
E [t] =
1−p
.
p
Sustituyendo (1) en esta expresión tenemos que
F (xT ) =
1
T −1
=1− .
T
T
Esta expresión permite relacionar el umbral a partir del cual se considera que
un evento es extremo con su frecuencia de ocurrencia, es decir, con el periodo de retorno, a través de la distribución de probabilidad de la variable X.
Concretamente,
1
−1
xT = F
1−
.
(2)
T
Por tanto, y a modo de resumen, si consideramos que un evento extremo es
el que ocurre en promedio una vez cada T años, (2) determina cuál es el evento
extremo.
2.
Modelos probabilísticos para la magnitud del
evento
Queda manifiesto, por tanto, que es necesario conocer la distribución de probabilidad de la magnitud del evento, X, para poner en relación el periodo de
retorno con el evento extremo. En ese sentido vamos a describir a continuación algunos de los modelos probabilísticos más utilizados para tal fin en la
bibliografía consultada.
2.1.
La distribución de Gumbel
La distribudión de Gumbel puede caracterizarse a partir de su función de
distribución, dada por [Wikipedia]
F (x; µ, β) = e−e
(µ−x)/β
.
El parámetro µ es conocido como parámetro de localización y el parámetro β
2
como parámetro de escala. Su media es µ + β × γ y su varianza π6 × β.
A partir de estas dos expresiones de la media y la varianza poblacionales,
despejando µ y β en términos de la media y la varianza de los datos, se pueden
obtener las estimaciones de µ y β mediante el método de los momentos, aunque
es conocido que este método no garantiza eficiencia en las estimaciones. Como
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
2
Modelización estocástica de precipitaciones máximas
alternativa al método de los momentos, el método de máxima verosimilitud,
que utilizaremos en este trabajo, se haya implementado en la mayoría de los
paquetes de software estadístico, entre ellos R.
2.2.
La distribución log-normal
La distribución log-normal supone modelizar el logaritmo de los datos mediante una distribución normal. Es decir, consiste en plantear que Y = logX,
sigue una distribución N (µ, σ). La estimación de sus parámetros viene dada por
la estimación de los parámetros de la normal asociada.
2.3.
La distribución log-Pearson Tipo III
De igual forma, la distribución de log-Pearson Tipo III supone modelizar los datos en escala logarítmica, es decir, considerar un modelo para Y =
logX. En este caso, el modelo es la llamada distribución de Pearson Tipo III
[Kotz and Nadarajah, 2000]. Aunque existen distintas parametrizaciones de esta
distribución, una de las más habituales es la dada por la versión biparamétrica
cuya función de densidad es [HydroToolBox],
f (x; k, θ) = xk−1
e−x/θ
para x > 0 y k, θ > 0.
θk Γ(k)
Esta distribución es más conocida como distribución Gamma. El parámetro k
es el llamado parámetro de forma y el parámetro θ, el parámetro de escala. En
otras ocasiones esta densidad se expresa en términos del parámetro de razón
λ = 1/θ.
La estimación de los parámetros puede realizarse mediante el método de
los momentos, aunque el método de máxima verosimilitud suele proporcionar
mejores estimaciones y se encuentra implementado en los paquetes estadíticos
más comunes.
De cara a la implementación en R que veremos después hay que tener en
cuenta que, al contrario que la distrbución log-normal, la distribución de logPearson Tipo III (a partir de ahora, por simplicidad, la llamaremos log-Gamma)
no se encuentra explícitamente implementada en R, sino que debe considerarse a
través de su relación con la distribución Gamma. En este sentido, si Y = logX
y ajustamos una distribución Gamma a Y , dada por la densidad f (y; k, θ),
tendríamos que la densidad de X sería
g (x; k, θ) =
2.4.
f (log (x) ; k, θ)
.
x
La distribución SQRT-ETmax
Esta distribución, originalmente propuesta en el contexto de precipitaciones
máximas en Japón [Etoh et al, 1986], ha venido siendo recomendada por la Dirección General de Carreteras en los último años para la modelización de las
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
3
Modelización estocástica de precipitaciones máximas
precipitaciones máximas [Ferrer y Ardiles, 1994]. Su definición puede hacerse a
partir de su función de distribución, dada por
F (x) = e−k(1+
√
αx)e−
√
αx
para valores positivos de x. Aunque algunos autores han desarrollado una implementación del método de los momentos que permite su evaluación en las hojas
de cálculo más habituales [Zorraquino, 2004]1 , los propios autores que definieron la distribución recomendaban la estimación mediante el método de máxima
verosimilitud [Etoh et al, 1986].
En esta ocasión, ni la distribución SQRT-ETmax ni por supuesto su estimación máximo-verosimil están implementadas en R (ni en ningún paquete
estadístico común), aunque su programación es sencilla, como veremos.
3.
Evaluación de la bondad del ajuste mediante
el test de Kolmogorov-Smirnoff
Acabamos de comentar en la descripción de los modelos la posibilidad de estimar los parámetros de las distintas distribuciones. Eso nos conducirá a obtener
cuatro modelos ajustados a los datos, uno para cada distribución. Inmediatamente surgen dos cuestiones:
1. ¿Son esos modelos ajustados válidos para los datos que modelizan?
2. Si varios de ellos son válidos, ¿cuál es el mejor ?
Hay que decir, en primer lugar, que ambas preguntas obligan a decidirse por un
criterio de bondad. En el contexto de las distribuciones continuas, uno de los
más habituales es el conocido como test de Kolmogorov-Smirnoff, que se basa
en cuantificar la máxima diferencia entre el modelo teórico y los datos en su
función de distribución.
Recordemos que la función de distribución de un modelo teórico se define
como
F (x) = P [X ≤ x] .
Por su parte, si tenemos la muestra de datos ordenados de menor a mayor,
x(1) , ..., x(N ) , podríamos considerar la proporción de datos inferior a cada uno
de ellos, es decir,
numero de datos ≤ x(i)
i
= .
SN x(i) =
N
N
Lógicamente, el ajuste de los datos dado por F (x) será tanto mejor cuanto
más se parezca a SN (x). Precisamente por ello el test de Kolmogorov-Smirnoff
1 El mismo autor comenta que la función de distribución no tiene primitiva. En realidad
quiere decir que no tiene inversa explícita, pero tampoco algunas de las otras distribuciones
propuestas, como la log-normal, y ello no es un problema, ya que puede aproximarse mediante
métodos numéricos.
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
4
Modelización estocástica de precipitaciones máximas
tiene como estadístico el supremo de las diferencias entre ambas funciones. Este
estadístico es evaluado dentro de la distribución en el muestreo, proporcionando
el p-valor del test.
De forma resumida, el procedimiento en el siguiente:
1. El test se plantea la validez de la hipótesis nula
H0 : el ajuste de F (x) es válido
frente a la alternativa H1 : el ajuste de F (x) no es válido.
2. Se realiza el test, calculando el p-valor, p.
3. Si p < 0,05, rechazaremos H0 en favor de H1 concluyendo que el ajuste es
no válido. Si por el contrario, p ≥ 0,05, aceptaremos el ajuste como válido.
4. Cuanto mayor sea el p-valor, mejor es el ajuste.
5. Si varios ajustes son válidos, el mejor será aquél con mayor p-valor.
Hay que decir, por último, que esta comparación entre distintos modelos a partir
del test de Kolmogorov-Smirnoff puede hacerse ya que nuestros cuatro modelos
tienen todos ellos el mismo número de parámetros, dos.
4.
Determinación del valor de xT dado un periodo
de retorno T
Una vez ajustados los datos por alguno de los modelos y evaluado el modelo
ajustado mediante el test de Kolmogorov-Smirnoff, tendremos una (o varias)
función de distribución ajustada. En ese caso, como se decía en (2), basta considerar la inversa de esta función de distribución para obtener la estimación de
xT .
El único problema viene dado por la inexistencia de expresiones explícitas
para algunas de las distribuciones consideradas. Sin embargo, ese problema no
es tal con el uso de R ya que, o bien el propio R dispone de algoritmos de
aproximación de la inversa o bien podemos implementarlo nosotros mismos (caso
de la SQRT-ETmax).
5.
Implementación en R
R [R Development Team] es un lenguaje de programación especialmente indicado para el análisis estadístico. A diferencia de la mayoría de los programas
que solemos utilizar en nuestros ordenadores, que tienen interfaces tipo ventana,
R es manejado a través de una consola en la que se introduce código propio de
su lenguaje para obtener los resultados deseados.
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
5
Modelización estocástica de precipitaciones máximas
R fue inicialmente diseñado por Robert Gentleman y Ross Ihaka, miembros
del Departamento de Estadística de la Universidad de Auckland, en Nueva Zelanda. Sin embargo, una de las grandes ventajas de R es que hoy en día es, en
realidad, fruto del esfuerzo de miles de personas en todo el mundo que colaboran
en su desarrollo.
Por otra parte, R se considera la versión libre de otro programa propietario,
llamado S o S-Plus, desarrollado por los Laboratorios Bell. Aunque las diferencias entre R y S son importantes, la mayoría del código escrito para S funciona
en R sin modificaciones.
El código de R está disponible como software libre bajo las condiciones de la
licencia GNU-GPL, y puede ser instalado tanto en el sistema operativo Windows
como en Linux o MacOS X.
La página principal desde la que se puede acceder tanto a los archivos necesarios para su instalación como al resto de recursos del proyecto R es
http://www.r-project.org.
De cara a la puesta en práctica de este trabajo, es necesaria la instalación
de R y de los paquetes adicionales VGAM, MASS y RODBC.
Lo que se describe en esta sección es el uso de un archivo de comandos de R
(en adelante, script) que permite realizar todos los cálculos relativos al objeto
del trabajo, es decir, al ajuste de las distribuciones, a la realización del test de
Kolmogorov-Smirnoff y a la obtención de las estimaciones de las precipitaciones
consideradas extremas dado un periodo de retorno.
5.1.
Importación de los datos
Vamos a suponer que los datos se encuentran en la primera columna de
una hoja de datos de Excel. En el ejemplo desarrollado los datos se refieren al
pantano de Iznájar, de manera que el encabezado de esa columna es iznajar.
Asimismo, el archivo de Excel se llama iznajar.xls.
Los comandos a ejecutar para la importación son los siguientes:
library(RODBC)
chan <- odbcConnectExcel("iznajar.xls")
sqlTables(chan)
Datos <- sqlQuery(chan, "select * from [Hoja1$]")
close(chan)
datos<-Datos$iznajar
5.2.
Ajuste de los datos
En primer lugar es necesario copiar los ficheros de código diseñados para la
distribución SQRT-ETmax en el mismo directorio de trabajo que, en el ejemplo
es "D:/Invest/Marian".
A continuación hay que cargar los paquetes adicionales VGAM y MASS y
los archivos adicionales. Para ello, ejecutamos las siguientes líneas:
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
6
Modelización estocástica de precipitaciones máximas
setwd("D:/Invest/Marian")
library(VGAM)
library(MASS)
source("fit.sqrt.et.max.R")
source("dsqrtetmax.R")
source("psqrtetmax.R")
source("qsqrtetmax.R")
5.2.1.
Ajuste mediante la distribución de Gumbel
Ejecutamos
ajuste.gumbel<-vgam(datos~1,family="gumbel")
location.gumbel<-Coef(ajuste.gumbel)[1]
scale.gumbel<-Coef(ajuste.gumbel)[2]
Coef(ajuste.gumbel)
En el caso del ejemplo la última línea nos dará como resultado que los parámetros ajustados son
location scale
35.917573 8.981163
5.2.2.
Ajuste mediante la distribución log-Gamma
Ejecutamos
ajuste.loggamma<-fitdistr(log(datos),"Gamma")
ajuste.loggamma
shape.loggamma<-ajuste.loggamma$estimate[1]
scale.loggamma<-1/ajuste.loggamma$estimate[2]
Obsérvese en la primera línea que en realidad se está ajustando el logaritmo
de los datos.
El resultado es
shape rate
179.88642 48.82219
5.2.3.
Ajuste mediante la distribución log-normal
Ejecutamos
ajuste.lognormal<-fitdistr(log(datos),"Normal")
mean.lognormal<-ajuste.lognormal$estimate[1]
sd.lognormal<-ajuste.lognormal$estimate[2]
ajuste.lognormal
De nuevo estamos ajustando el logaritmo de los datos. El resultado es
mean sd
3.68452440 0.27610262
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
7
Modelización estocástica de precipitaciones máximas
5.2.4.
Ajuste mediante la distribución SQRT-ETmax
Ejecutamos
ajuste.sqrtetmax<-fit.sqrt.et.max(y=datos,metodo=3)
k.sqrtetmax<-exp(ajuste.sqrtetmax$coefficients[1])
alfa.sqrtetmax<-exp(ajuste.sqrtetmax$coefficients[2])
ajuste.sqrtetmax
En este caso el resultado es más amplio, ya que es necesario controlar algunos
aspectos relativos al método de máxima verosimilitud. De todas formas, lo más
relevante es el valor de las estimaciones de los parámetros, que en el ejemplo
son
c(k.sqrtetmax,alfa.sqrtetmax)
[1] 1004.781812 2.409086
5.3.
Evaluación de las bondades de ajuste
El test de Kolmogorov-Smirnoff nos va a permitir contrastar si los ajustes
son válidos y cuál es el más preciso.
Ejecutamos
ks.test(datos,"pgumbel",location.gumbel,scale.gumbel)
ks.test(datos,"plnorm",mean.lognormal,sd.lognormal)
ks.test(log(datos),"pgamma",shape.loggamma,1/scale.loggamma)
ks.test(datos,"psqrtetmax",k.sqrtetmax,alfa.sqrtetmax)
Los p-valores para los cuatro ajustes son, respectivamente, 0.6416, 0.7353,
0.746 y 0.6618. Ponen de manifiesto que los ajustes son bastante precisos y que
el mejor de ellos es el de la log-Gamma.
Una forma gráfica de plasmar la bondad de los ajustes es comparar la función
de densidad ajustada con el histograma de los datos. Para hacerlo en nuestro
caso debemos ejecutar
hist(datos,freq=FALSE)
lines(sort(datos),dsqrtetmax(sort(datos),k.sqrtetmax,alfa.sqrtetmax),col="red")
lines(sort(datos),dgumbel(sort(datos),location.gumbel,scale.gumbel),col="blue")
lines(sort(datos),dlnorm(sort(datos),mean.lognormal,sd.lognormal),col="green")
lines(sort(datos),dgamma(log(sort(datos)),shape=shape.loggamma,
scale=scale.loggamma)/sort(datos),col="grey")
El resultado es la Figura 1.
5.4.
Estimación del valor de xT
Una vez realizados los ajustes es trivial aplicar la expresión dada en (2) para
obtener la estimación del valor de xT para un valor de T dado. Como ejemplo,
hemos considerado T = 100 años.
Ejecutamos
T<-100
p.max.gumbel<-qgumbel(1-1/T,location.gumbel,scale.gumbel)
p.max.gumbel
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
8
Modelización estocástica de precipitaciones máximas
Figura 1: Histograma de los datos y densidades ajustadas. En rojo la SQRTETmax, en azul la Gumbel, en verde la lognormal y en gris la Log-Gamma
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
9
Modelización estocástica de precipitaciones máximas
p.max.lognormal<-qlnorm(1-1/T,mean.lognormal,sd.lognormal)
p.max.lognormal
p.max.loggamma<-exp(qgamma(1-1/T,shape=shape.loggamma,scale=scale.loggamma))
p.max.loggamma
p.max.sqrtetmax<-qsqrtetmax(1-1/T,k.sqrtetmax,alfa.sqrtetmax)
p.max.sqrtetmax
El resultado nos dice que las estimaciones según los cuatro ajustes son
77.23226 (Gumbel), 75.70431 (log-normal), 77.75436 (log-Gamma) y 84.129
(SQRT-ETmax) años.
Apéndices
Vamos a detallar el código relativo a la implementacón de los cálculos correspondientes a la distribución SQRT-ETmax
Densidad de la SQRT-ETmax
dsqrtetmax<-function(x,k,alfa){
k*alfa/2*exp(-k*(1+sqrt((alfa*x)))*exp(-sqrt(alfa*x))-sqrt(alfa*x))
}
Función de distribución de la SQRT-ETmax
psqrtetmax<-function(x,k,alfa){
exp(-k*(1+sqrt((alfa*x)))*exp(-sqrt(alfa*x)))
}
Método de máxima verosimilitud para la estimación de los
parámetros de la SQRT-ETmax
fit.sqrt.et.max<-function(y=NULL,p0k=0.5,p0alfa=1,iters=10000,metodo=2){
logver<-function(p){
k<-exp(p[1])
alfa<-exp(p[2])
n<-length(y)
-(-n*log(1-exp(-k))+n*log(k)+n*log(alfa)-n*log(2)-sum(sqrt(alfa*y))
-k*sum((1+sqrt(alfa*y))*exp(-sqrt(alfa*y))))
}
p0<-c(p0k,p0alfa)
if (metodo==1){
#nlm
ajuste<-nlm(logver,p=p0,hessian= TRUE,iterlim=iters)
ajuste$value<-ajuste$minimum
ajuste$par<-ajuste$estimate
ajuste$convergence<-ajuste$code
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
10
Modelización estocástica de precipitaciones máximas
metodo="nlm con hessiano"
}
if (metodo==2){
#optim (Nelder-Mead con hessiano)
ajuste<-optim(p0,logver,hessian=TRUE,control=list(maxit=iters))
metodo<-"optim Nelder-Mead con hessiano"
}
if (metodo==3){
#optim (BFGS)
ajuste<-optim(p0,logver,method="BFGS",hessian=TRUE,control=list(maxit=iters))
metodo<-"optim BFGS con hessiano"
}
if (metodo==4){
#optim (CG)
ajuste<-optim(p0,logver,method="CG",hessian=TRUE,control=list(maxit=iters))
metodo<-"optim CG con hessiano"
}
if (metodo==5){
#optim (L-BFGS-B)
ajuste<-optim(p0,logver,method="L-BFGS-B",hessian=TRUE,control=list(maxit=iters))
metodo<-"optim L-BFGS-B con hessiano"
}
if (metodo==6){
#optim (SANN)
ajuste<-optim(p0,logver,method="SANN",hessian=TRUE,control=list(maxit=iters))
metodo<-"optim SANN con hessiano"
}
#Resultados
resultados<-list(
optimum=ajuste$value,
aic=2*(ajuste$value+2),
coefficients=ajuste$par,
hessian=ajuste$hessian,
cov=solve(ajuste$hessian),
se=sqrt(diag(solve(ajuste$hessian))),
code=ajuste$convergence,#VER AYUDA DE nlm
metodo=metodo
)
return(resultados)
}
Inversa de la función de distribución (función cuantil) de la
SQRT-ETmax
qsqrtetmax<-function(p,k,alfa){
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
11
Modelización estocástica de precipitaciones máximas
source("psqrtetmax.R")
x<-rep(0,length(p))
for (i in 1:length(p)){
while (psqrtetmax(x[i],k,alfa)<p[i]) x[i]<-x[i]+0.01
}
x
}
Referencias
[Wikipedia]
http://en.wikipedia.org/wiki/Gumbel_distribution
[Kotz and Nadarajah, 2000] Kotz, S. and Nadarajah, S. (2000) Extreme Value
Distributions: Theory and Applications, London: Imperial College Press.
[HydroToolBox]
http://www.dartmouth.edu/~renshaw/hydrotoolbox/
[Zorraquino, 2004]
Zorraquino Junquera, C. (2004) El modelo SQRTETmax: Revista de Obras Públicas: Organo profesional de los ingenieros de caminos, canales y puertos, Nº.
3447, 2004 , pags. 33-37.
[Etoh et al, 1986]
Etoh T, Murota A, Nakanishi M (1986)
SQRT—Exponential type distribution of maximum.
In: Proceedings of international symposium on flood
frequency and risk analysis. Louisiana, pp 235–265.
[Ferrer y Ardiles, 1994] Ferrer, F. J., y Ardiles, L. (1994): “Análisis estadístico de las series anuales de máximas lluvias diarias en
España”. Ingeniería Civil/95, pp 87-100.
[R Development Team] R Development Core Team. R: A Language and
Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2008.
http://www.R-project.org.
Prof. Dr. Antonio José Sáez Castillo. Universidad de Jaén
12