modelamiento y diseño de bd
Anuncio

INSTITUTO SUPERIOR
TECNOLÓGICO
NORBERT WIENER
Manual del Alumno
ASIGNATURA: MODELAMIENTO Y
DISEÑO DE BD
PROGRAMA: S3C
LIMA-PERU
2
INDICE GENERAL
1. CAPITULO 1: CONCEPTOS GENERALES
1.1. análisis de datos
2.1.1 Tipo de Entidad
3.1.1 Identificador de un tipo de Entidad
1.2. la realidad y los metadatos
1.3. modelamiento de datos
1.4. modelo de datos
1.5. etapas del diseño de datos
1.5.1 diseño conceptual
1.5.2 diseño lógico
1.5.3 diseño físico
1.6. representación de entidades y relaciones
2. CAPITULO 2:ELEMENTOS DE UN MODELO DE INFORMACIÓN
2.1. entidades
2.2. atributos
2.3. registros
2.4. campos
3.1.1 Tipos de campos
2.5. campo clave
2.6. clave foránea
3. CAPITULO 3: EL MODELO RELACIONAL
3.1. relaciones binarias
3.1.1 Cardinalidad
13.1.1.1 Cardinalidad Mínima
13.1.1.2 Cardinalidad Máxima
3.2. Entidades independientes y dependientes.
3.3. Relaciones 1:1, 1:N, N:M
4. CAPITULO 4: RELACIONES N_ARIAS
4.1. Relación múltiple de entidades independientes.
4.2. Simplificación de relaciones Narias a binarias
4.3. Condiciones.
5. CAPITULO 5: NORMALIZACION I
5.1. Concepto
5.2. Importancia
5.3. FN1: Eliminación de grupos de repetición.
5.4. FN2: Dependencias Funcionales
5.5. FN3: Eliminación de las dependencias transitivas.
6. CAPITULO 6: NORMALIZACION I
6.1. Clave candidata
6.2. Determinante
6.3. Simplificaciones de relaciones
6.4. Descomposición
6.5. Unión
6.6. Transitividad.
6.7. FNBC: la forma normal de Boyce Codd o forma normal óptima
7. CAPITULO 7: NORMALIZACIONES AVANZADAS
7.1. FN4: Eliminación de las dependencias multivaluadas independientes.
7.2. FN5: Eliminación de las dependencias multivaluadas independientes.
8. CAPITULO 8: SUBTIPOS Y SUPERTIPOS
8.1. Modelo Entidad Inter Relación (MER, Entity Relationship Model)
11.3.1 Como modelar en MER
8.2. Modelo entidad relación extendido
8.2.1 Atributos compuestos
8.2.2 Cardinalidad
8.2.3 Cardinalidad de atributo con respecto a un tipo de entidad
8.2.4 Identificador de un tipo de entidad
8.2.5 Clasificación de los tipos de entidad según sus identificadores
3
9.
10.
11.
12.
13.
8.2.6 Estructura de generalización
8.2.7 Cobertura
8.2.8 Agregación de tipos de entidad
8.2.9 Roles de Tipos de Entidad en Tipos de Interrelación
8.2.10 Tipos de Interrelaciones exclusivas con respecto a un tipo de Entidad
8.2.11 Restricciones en MER extendido
8.2.12 Estrategia para modelar en MER
8.3 esquema MER y documentación
DISEÑO FISICO
9.1.
Conversión de un Modelo E-R normalizado a FoxPro
9.2.
Diseño de una BD usando herramientas Case
9.3.
Aplicación de relaciones generadas por computador.
9.4.
Manejo de las relaciones obtenidas del modelado
9.5.
Identificación de las tablas obtenidas del modelado lógico.
MODELO DE BASE DE DATOS
10.1. Concepto de BDD
10.2. Modelo s de BDD
10.2.1 De red
10.2.2 Jerárquico
10.2.3 Relacional
10.3. El sistema administrador de Base de datos (DBMS)
10.4. Componentes del DBMS
COMANDO BÁSICOS DE FOXPRO
11.1. Funciones de Cadena
11.2. Funciones de fecha
11.3. Funciones numéricas
11.3.1 Estadísticos
11.3.2 Matemáticos
11.4. Funciones de conversión de datos.
11.5.1 Ctod
11.4.2 Dtod
11.5.1 Otras Funciones
11.5.1 Deleted
11.5.2 Empty
11.5.3 IIF
11.5.4 Found
11.5.5 Unlist
11.5.6 Seek
ENTRADA / SALIDA EN FOXPRO
12.1. Sentencia: .. Say/Get
17.7.1 Sentencia Get
12.1.2 Sentencia SAY/GET
12.1.3 sentencia TO
12.2. Definición de las principales cláusulas
12.2.1 Picture
12.2.2 Function
12.2.3 When
12.2.4 Valid
12.2.5 Error
PROGRAMACIÓN EN FOXPRO
13.1. Creación de un programa
13.2. Sentencias básicas de programación
13.3. Sentencias condicionales (IF,DO CASE)
13.3.1. sentencias condicionales: if ... end if
13.3.2. sentencias de selección: do case ...endcase
13.4
Sentencias repetitivas (FOR, DO WHILE)
13.4.1 for endfor
13.4.2 do while…enddo
14. CREACIÓN DE MENUS
14.1. Define Menú
4
14.2. Define PopUP
14.3. Define Pad
14.4. Creación automática de Menú (MPR)
15. RELACIONAMIENTO DE BDD
15.1. Relación múltiple de tablas
15.2. Comando SET RELATION TO
16. CREACIÓN DE REPORTES
16.1. Creación de reportes simples
16.2. Creación de reportes con ficheros múltiples
16.3. Creación de pantallas de ingreso
17. GESTION DE BASE DE DATOS
17.1. Archivos Maestros
17.2. Archivos de tablas
17.3. Archivos de transacción
17.4. Archivos indexados simples
17.5. Archivos indexados múltiples
17.6. Operaciones de Modificación.
17.6.1 Modify Estructure
17.7. Operaciones de Añadido
17.7.1
Append From
17.8. Borrado físico y lógico
17.8.1 eliminación temporal: lógico
17.8.2 eliminación definitiva: física
17.9. Update
17.10. Join
17.11. Append Blank
17.12. Insert
17.13. Delete for
17.14. Replace with
5
1. APITULO I: CONCEPTOS GENERALES
1.1. ANÁLISIS DE DATOS
El análisis de datos es el primer paso para obtener un modelo preciso, conciso,
comprensible y concreto del mundo real, antes es preciso entender los requisitos y
el entorno del mundo real en el cual se va a instaurar.
El análisis comienza con la definición de un problema generada por clientes y
posiblemente por los desarrolladores, la definición puede ser incompleta o informal,
el análisis hace que sea más precisa.
1.2. LA REALIDAD Y LOS METADATOS
La realidad única, concreta y objetiva no puede ser captada como tal. Aún cuando
pudiésemos asumir que esta realidad única existe, cada uno de nosotros la modifica
a través del filtro de su percepción. La percepción de cada persona es algo bastante
complejo, que está influido, entre otros posibles factores, por el tiempo, espacio y
estado de ánimo al momento de realizar la percepción, además del impacto de
experiencias previas, factores ambientales, estructura neuronal y el código genético
del individuo.
Lo relevante es que para n observadores de un fenómeno, es posible obtener al
menos n percepciones distintas (aunque posiblemente no “radicalmente” distintas).
1.3. MODELAMIENTO DE DATOS
Es aparente que una interpretación del mundo es necesaria, la que debe ser
suficientemente abstracta para que no sea afectada por la dinámica del mundo (los
pequeños cambios), y debe ser suficientemente robusta para poder representar
como los datos y el mundo se relacionan. Una herramienta como esta es llamada
modelo de datos, el cual permite representar en forma más o menos razonable
alguna realidad. El modelo de datos permite realizar abstracciones del mundo,
permitiendo centrarse en los aspectos macros, sin preocuparse de las
particularidades; así nuestra preocupación se centra en generar un esquema de
representación, y no en los valores de los datos.
Los modelos de datos nos permiten capturar parcialmente el mundo, ya que es
improbable generar un modelo que lo capture totalmente.
Sin embargo, se puede tener un conocimiento relativamente completo de la parte
del mundo que nos interesa. Así, un modelo captura la cantidad de conocimiento tal
que cumpla con los requerimientos que nos hemos impuesto previamente.
DATO: la siguiente tupla: <nombre del objeto, propiedad del objeto, valor, tiempo>
Esta definición es correcta, ya que cada vez que se describe un fenómeno, éste se
refiere a un objeto (nombre del objeto) y ciertas características (propiedades del
objeto) el cual tiene un valor en un momento determinado (tiempo).
Ejemplo.
El precio del pan es S/0.10
nombre: precio del pan
propiedades : (unidad, S/), entero no negativo.
valor: 0.10
tiempo: hoy
En general, el modelar un objeto no se considera el tiempo, sino que éste se
considera implícito en la semántica de él.
Ejemplo.
Consideremos el caso de una matriz:
nombre: matriz _ coeficiente
propiedades: +, -, *, a[i,j] R
valor : [1 2]
[3 4]
6
1.4. MODELO DE DATOS
Un modelo de datos define las reglas por las cuales los datos son estructurados.
Esta estructuración, sin embargo, no da una interpretación completa acerca del
significado de los datos y la forma en que serán usados. Las operaciones que se
permiten efectuar a los datos deben ser definidos.
Ejemplo. Una lista puede ser tratada como pila o fila, dependiendo de las
operaciones que se permitan sobre ella.
Generalmente las operaciones están relacionadas con la estructura de los datos y
tienen validez en el contexto en que fueron definidos.
BASE DE DATOS
Una colección de datos estructurados en una forma particular, según un esquema
particular, se denomina base de datos.
Todo modelo de datos debe poder capturar las propiedades estáticas y dinámicas
de una realidad. Las propiedades estáticas corresponden a lo que es relativamente
invariante en el tiempo, son siempre verdadero y no cambia en el tiempo.
Ejemplo. Que los precios se midan en $ es relativamente invariante.
Las propiedades dinámicas corresponden a la naturaleza evolutiva del mundo. Por
esto, para todo modelo debe ser posible capturar los dos tipos de propiedades.
MODELO DE DATOS
Se define el modelo de datos M consistente de dos partes:
G: un conjunto de reglas que lo generan.
O: un conjunto de operaciones.
El conjunto de reglas G expresan las propiedades estáticas de un modelo de datos y
corresponden a lo que se denomina generalmente Data Definition Language (DDL).
Este define las estructuras permitidas para el modelo de datos M.
El conjunto G se puede dividir en dos:
a)
Gs: las estructuras permitidas.
b)
Gc: las restricciones del modelo.
Así, Gs genera las categorías y estructuras para un modelo, y Gc las restricciones.
Utilizando esta última notación, un esquema S consiste de dos partes: una
estructura Ss y restricciones Sc, donde Sc es una lista explícita de restricciones que
no deben ser violadas.
Por ejemplo, en la definición de la entidad persona, un atributo particular CI (Cédula
de Identidad) puede ser declarado como clave, esto es, en un instante dado no
puede haber dos personas con el mismo valor para CI. Ss no prohíbe dos
ocurrencias, pero Sc sí.
Un modelo de datos también puede tener restricciones que son inherentes a él, las
que generalmente se incorporan en Ss (la estructura).
Ejemplo, sólo se permite relaciones entre objetos mediante una estructura de árbol.
7
Las reglas de generación G son generadoras de un conjunto de esquemas S, en el
que cada uno de ellos define estructuras y restricciones particulares para los datos.
Hoy muchas bases de datos D en términos de la ocurrencia del esquema S, pero
todos tienen la misma estructura genérica y obedecen a las mismas restricciones
definidas en S.
En resumen:
Gs: Su Estructura
G: Reglas Generadoras
M: Modelo de Datos
Gc: Sus Restricciones
O: Operaciones Asociadas
Ss: Estructuras y categorías generadas por Gs
S: Esquema Generado por G
Sc: Restricciones Generadas por Gc
D: Base de Datos
Ocurrencia del esquema S. Las restricciones Sc deben ser
siempre válidas, para toda ocurrencia D del esquema S.
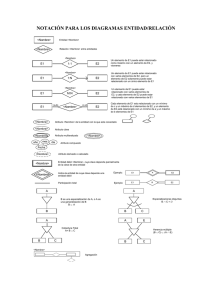
1.5. ETAPAS DEL DISEÑO DE DATOS
Hay tres tipos de diseños en el modelamiento, los cuales tienen directa relación con
los modelos que ocupan: modelos conceptuales, lógicos y físicos.
En la Figura se puede apreciar el proceso de diseño de bases de datos. Los
requisitos de datos constituyen un componente de los requisitos de un producto y
son una entrada al diseño conceptual.
ETAPAS DEL DISEÑO DE DATOS
8
REALIDAD
REQUISITOS
análisis
MODELO
DISEÑO CONCEPTUAL
ESQUEMA
CONCEPTUAL
CONCEPTUAL
MODELO
DISEÑO LOGICO
LOGICO
ESQUEMA LOGICO
MODELO
DISEÑO FISICO
FISICO
ESQUEMA FISICO
diseño
1.5.1 Diseño Conceptual.
Recibe como entrada la especificación de requerimientos y su resultado es
el esquema conceptual de la base de datos, que es una descripción de alto
nivel de la estructura de la base de datos, independiente del software que
se use para manipularla.
Modelos Conceptuales: MER, CCER, HERM, Modelos OO, Formalismo
Individual, Redes Semánticas, Redes de Transición de Estados.
1.5.2 Diseño Lógico.
Recibe como entrada el esquema conceptual y da como resultado un
esquema lógico, que es una descripción de la estructura de la base de
datos que puede procesar el software DBMS.
Modelos Lógicos: Relacional, de Redes, Jerárquico, Redes Semánticas,
Redes de Transición de Estados, Modelos OO.
1.5.3 Diseño Físico.
Recibe como entrada el esquema lógico y da como resultado un esquema
físico, que es una descripción de la implementación de una base de datos
en la memoria secundaria, describe las estructuras de almacenamiento y
los métodos usados para tener un acceso efectivo a los datos.
Modelos Físicos: Modelo Unificador, Memoria de Elementos
1.6
representación de entidades y relaciones
representar modelos generados por la abstracción mediante
diagramas fue un gran avance. En estos diagramas las entidades,
relaciones se representan mediante simbologia asociada la cual lo
encontraras en el capitulo II. Existe software apropiado para tal fin
entre ellos por citar tenemos: Erwin, easy case, Bpwin etc.
Ejemplo simple de una representacion de una entidad relacion.
9
2. CAPITULO II: ELEMENTOS DE UN MODELO DE INFORMACIÓN
2.1 Entidades:
Consideremos un número de conjuntos cada uno orientado a un tipo particular de
objetos. Estos conjuntos están relacionados con dominios y atributos.
10
Si consideramos la relación dada por el producto cartesiano de estos dominios, una
interpretación que se le da a cada una de estas tuplas es que cada una corresponde
a una entidad particular.
Ejemplo.
(Juan , 70,
80,
50)
(Pedro , 90,
50,
70)
2.1.1 Tipo de Entidad.
Los Tipos de Entidad representan clases de objetos de la realidad. Además
se componen de atributos, los cuales representan las características de un
tipo de entidad.
Tipo de
Entidad
En términos de abstracción, un "tipo de entidad" corresponde a la agregación
de atributos.
Ejemplo. El tipo de entidad Persona, corresponde a la agregación de los
atributos (Rut, Nombre, Dirección, Fecha Nacimiento)
Así las entidades son una ocurrencia de un Tipo de Entidad.
2.1.2. Identificador de un tipo de entidad.
Un atributo I, posiblemente compuesto, de un tipo de entidad TE, es un
identificador de TE si y sólo si satisface las siguientes 2 propiedades
independientes del tiempo.
a. Unicidad. En cualquier momento dado, no existen dos elementos en TE
con el mismo valor de I.
b. Minimalidad. Si I es compuesto, no será posible eliminar ningún atributo
componente de I sin destruir la propiedad de unicidad.
Atributo identificador
Tipo de
Entidad
2.2 ATRIBUTOS
Elemento de un Dominio. Aporta mediante su rótulo, la semántica de los valores del
Dominio al que está asociado.
Dominio
Atributo
2.3.Registros
Es un grupo o conjunto de información básica (campos), los cuales se encuentran
relacionados con respecto a un elemento, por ejemplo; los datos de un determinado
11
empleado de la empresa. A cada registro se le asigna un número que representa el
orden en que dicho registro se almacenó en la Base de Datos.
Ejemplo:
CODIGO
342467
345875
342658
254987
AUTOR
DEPECHE MODO
RADIOHEAD
U2
ARIAN I
ALBUM
ULTRA
THE BENDS
POP
ARIAN I LIVE
PRECIO
20
21
21
20
La base de datos es la colección de discos compactos de una empresa comercial.
Registro: Son las filas en este caso hay 4, por ejemplo uno de ellos es:
345875
RADIOHEAD
THE BENDS
21
Los registros son en muchos aspectos parecidos a las entidades del modelo
entidad-relación (E-R). Cada registro es un conjunto de campos (atributos), cada
uno de los cuales sólo contiene un valor de datos. Los enlaces son asociaciones
entre exactamente dos registros. Por tanto, los enlaces pueden considerarse una
forma restringida (binaria) de relación en el sentido del modelo E-R. Una base de
datos en red consiste en un conjunto de registros conectados entre sí mediante
enlaces.
2.4.CAMPOS
Es una unidad básica de información, respecto a un determinado elemento, es decir
es una característica (dato) de una persona u objeto, como por ejemplo: un nombre,
una fecha de nacimiento, un sueldo diario. Como existen diferentes tipos de datos
se usa para diferentes tipos de Campo como son: Carácter, Date, Memo, Logical, y
Numeric. Cada campo se define con un nombre o identificador, un tipo de dato
asociado y una longitud o tamaño.
Del ejercicio anterior:
Nombre del Campo:
Viene a ser: CODIGO AUTOR ALBUM PRECIO
Campo: Es el contenido de cada registro, por ejemplo los campos de AUTOR son 4:
DEPECHE MODE, RADIOHEAD, U2 Y ARIAN .
2.4.1 Tipos de Campos
Carácter (carácter): Estos campos almacenan cadenas de caracteres, los
cuales pueden ser letras, dígitos, caracteres especiales y espacios en blanco.
Como máximo se pueden digitar 254.
Número (Numeric): Estos campos almacenan información de tipo numérica y
su longitud máxima es de 20 posiciones, el punto decimal y los signo positivo
y negativo también ocupan una posición dentro de la longitud del campo.
Lógico (logical): Es un campo definido por el sistema cuya longitud es uno
(byte). Los valores que pueden almacenar son T (verdadero) o F (Falso).
Fecha (date): Es un campo definido por el sistema cuya longitud es ocho. Se
usan para almacenar datos de tipo cronológico. El formato por omisión es
(mm/dd/aa).
Memo (memo): Es un campo definido por el sistema cuya longitud es diez en
el Archivo de Datos. Este tipo de campo crea un archivo FPT donde se
almacenan textos que exceden los 254 caracteres y está limitada por el
dispositivo de almacenamiento disponible.
2.5.CAMPO CLAVE
Campo Clave: Una clave candidata para una relación R es un atributo K
posiblemente compuesto, tal que satisface las siguientes dos propiedades
independientes del tiempo:
12
Unicidad. En cualquier momento dado, no existen dos tuplas en R con el
mismo valor de K.
Minimalidad. Si K es compuesto, no será posible eliminar ningún componente
de K sin destruir la propiedad de unicidad.
De entre las claves candidatas se elige la clave primaria.
Ningún componente de la clave primaria de una relación puede en algún momento
no tener valor (aceptar nulos).
Esto significa que no tiene sentido modelar una entidad que no podemos identificar
ni distinguir unas de otras.
2.6.CLAVE FORÁNEA
Clave foránea: En el modelo relacional se denominan claves ajenas o claves
foráneas a una referencia de una relación a otra, mediante su clave. Este concepto
lo conocemos en el formalismo individual como una relación implícita.
Una Relación (R1) puede poseer como uno de sus atributos (A) una clave primaria
de otra relación (R2). Este atributo (A) constituye una clave foránea en R1 y
referencia a R2.
En este caso las claves foráneas responden al mismo patrón de las relaciones
implícitas del formalismo individual, es decir, existen cuando la cardinalidad de la
relación es uno es a muchos.
La regla de integridad referencial nos indica que ningún atributo A que constituye
una clave foránea en una relación R1 y referencia a la clave primaria de una
relación R2 (no necesariamente distinta) puede tomar un valor que no esté presente
en la relación referenciada R2. Esto significa, que la base de datos no debe
contener valores de clave ajena sin concordancia.
Este modelo fue propuesto pro Codd en 1970 y se divide en tres partes, las cuales
separan la estructura, la integridad y la manipulación de los datos.
3
CAPITULO 3: EL MODELO RELACIONAL
3.1 RELACIONES BINARIAS
Es una correspondencia que se establece entre dos clases. Se puede representar
una agregación binaria entre dos clases mediante la descripción de éstas como
conjuntos y el trazado de una línea entre un elemento de cada conjunto para
representar que están agregados.
a1
a2
a3
a4
a5
Automóviles
Representación para la agregación "POSEE".
p1
p2
p3
Personas
13
Al observar la figura, se puede decir que la persona p1 posee los autos a1 y a2, la
persona p2 posee los autos a2,a4 y a5, mientras que la persona p3 no posee autos.
De esto último se puede observar que no es obligatorio que todas las personas
posean autos, pero al parecer todos los autos deben tener un dueño. Esta última
característica es propia de cada agregación, y se refieren a la cardinalidad de
correspondencia entre las clases.
3.1.1 Cardinalidad.
Caracteriza a los atributos de un tipo de entidad y a los tipos de interrelación.
(Las definición aquí utilizada corresponde a la realizada por Tardieu).
Cardinalidad de atributo con respecto a un tipo de entidad.
Para los atributos, la cardinalidad mínima indica el número mínimo de valores
de un atributo asociado con cada caso (ocurrencia) de una entidad o
interrelación. La cardinalidad máxima indica el número máximo de valores
para un atributo asociado a cada caso de una entidad o interrelación.
Se define la Cardinalidad del Atributo A con respecto al tipo de entidad TE
como:
Card(A,TE)=( mínimo, máximo), con
mínimo, máximo
{0,...,n} y
mínimo máximo.
donde un elemento de A debe participar al menos mínimo veces, y a lo más
máximo veces en cada ocurrencia de TE.
Tipo de
Entidad
Atributo (mínimo, máximo)
3.1.1.1 Cardinalidad mínima.
Consideremos una agregación A entre las clases C y D. La
cardinalidad mínima de C en A, denotada por card-min(C,A), es el
menor número de correspondencias en las que cada elemento de C
puede tomar parte. Análogamente se define card-min(D,A).
Si card-min(A,B)=0, entonces se dice que la clase A tiene una
participación opcional en la agregación B. Si card-min(A,B)>0,
entonces se dice que la clase A tiene una participación obligatoria
en la agregación B.
3.1.1.2 Cardinalidad máxima.
Consideremos una agregación A entre las clases C y D. La
cardinalidad máxima de C en A, denotada por card-máx(C,A), es el
mayor número de correspondencias en las que cada elemento de C
puede tomar parte. Análogamente se define card-máx(D,A).
Si card-max(C,A)=1 y card-max(D,A)=1, se dice que la agregación
es de uno a uno. Si card-max(C,A)=n y card-max(D,A)=1, se dice
que la agregación es de uno a muchos. Si card-max(C,A)=1 y cardmax(D,A)=n, se dice que la agregación es de muchos a uno. Si
card-max(C,A)=n y card-max(D,A)=m, se dice que la agregación es
de muchos a muchos. Nótese que n y m representan valores
mayores que 1.
3.2 ENTIDADES INDEPENDIENTES Y DEPENDIENTES.
14
Toda entidad dependiente tiene un tipo de ligadura denominado dependencia y esta
dada por el conjunto de relaciones como los que a continuación detallamos
3.3 RELACIONES:
a) Relación Uno a Uno.Una entidad en A se asocia con a lo sumo una entidad en B, y una entidad en B
se asocia con a lo sumo una entidad en A.
Agregación Uno a Uno. Card(C,A)=(x,1) y Card(D,A)=(x,1), con x en {0,1}.
b) Relación Uno a Varios.Una entidad en A se asocia con cualquier número de entidades en B. Una
entidad en B, sin embargo, se puede asociar a lo sumo una entidad en A.
Agregación Uno a Muchos. Card(C,A)=(x,n) y Card(D,A)=(y,1), con x en
{0,1,...,n} e y en {0,1}.
c) Relación Varios a Uno.Una entidad en A se asocia con a lo sumo una entidad en B. Una entidad en B,
sin embargo, se puede asociar con cualquier número de entidades en A.
Agregación Muchos a Uno. Card(C,A)=(x,1) y Card(D,A)=(y,n), con x en {0,1} e y en
{0,1,...,n}.
d) Relación Varios a Varios.Una entidad en A se asocia con cualquier número de entidades en B, y una
entidad en B se asocia con cualquier número de entidades en A.
Agregación Muchos a Muchos. Card(C,A)=(x,n) y Card(D,A)=(y,m), con x e y en
{0,1,...,n), n y m valores indefinidos mayores que uno.
a)
b)
c1
d1
c1
c2
c2
d2
d2
c3
c4
d1
c3
d3
c)
c4
d3
d)
c1
d1
c2
c1
c2
d2
c3
c4
d1
d2
c3
d3
c4
d3
15
4
CAPITULO 4: RELACIONES N_ARIAS
4.1 RELACIÓN MÚLTIPLE DE ENTIDADES INDEPENDIENTES.
Es una correspondencia establecida entre tres o más clases. Se mantiene las
definiciones de cardinalidades máxima y mínima.
4.2 SIMPLIFICACIÓN DE RELACIONES N_ARIAS A BINARIAS
Las correspondencias existentes entre clases donde las cardinalidades establecidas
entre las clases son de muchos a muchos pueden ser modelados hasta establecer
una agregación binaria.
Es importante indicar que el tipo de correspondencia N:M conceptualmente es
valido pero lógica y relacionalmente no
4.3 Condiciones.
Cardinalidad Mínima. Consideremos una agregación A entre las clases C1,C2,...,
Cn. La cardinalidad mínima de Ci en A, denotada por card-min(Ci,A), es el menor
número de correspondencias en las que cada elemento de Ci puede tomar parte.
Cardinalidad Máxima. Consideremos una agregación A entre las clases C1,C2,...,
Cn. La cardinalidad máxima de Ci en A, denotada por card-max(Ci,A), es el mayor
número de correspondencias en las que cada elemento de Ci puede tomar parte
16
5
CAPITULO 5: NORMALIZACION I
5.1 CONCEPTO
El diseño de esquemas para generar bases de datos relacionales debe considerar
el objetivo de almacenar información sin redundancia innecesaria, pero que a la
vez nos permitan recuperar información fácilmente. Una técnica consiste en
diseñar esquemas que tengan una forma normal adecuada.
Las propiedades indeseables que trae un mal diseño son básicamente
repetición de información
incapacidad para representar cierta información
pérdida de información.
5.2. IMPORTANCIA
Las formas normales, definidas en la teoría relacional, nos permiten evitar que
estas propiedades indeseables aparezcan en una base de datos basada en un
esquema mal diseñado. Un esquema debe estar a lo menos en tercera forma
normal, para que sea aceptable.
Hay que considerar que las reglas de normalización están dirigidas a la
prevención de anomalías de actualización e inconsistencias en los datos. Ellas no
reflejan ninguna consideración de rendimiento. En cierta forma pueden ser
visualizados como orientadas por el supuesto de que todos los atributos no clave
serán actualizados frecuentemente.
5.3. FN1: ELIMINACIÓN DE GRUPOS DE REPETICIÓN.
PRIMERA FORMA NORMAL
Una relación está en primera forma normal (1FN) si y sólo si todos los dominios
simples subyacentes contienen sólo valores atómicos.
Otra forma de expresar la primera forma normal es decir que todas las
ocurrencias de un tipo de registro deben contener el mismo número de campos.
Ejemplo.
Consideremos el caso de agentes que representan compañías que fabrican
productos. Una relación sin normalizar que indique los productos que venden los
representantes es:
17
AGENTE
COMPAÑÍA
PRODUCTO1
PRODUCTO2
Caro 2
Ford
Auto
camión
GM
Ford
Ford
Auto
Auto
camión
Jeria
Bravo
... 1
Una relación que representa la misma situación y no transgrede la primera forma
normal sería:
AGENTE
Caro
Caro
Caro
Caro
Jeria
Bravo
COMPAÑÍA
Ford
Ford
GM
GM
Ford
Ford
PRODUCTO
Auto
Camión
Auto
Camión
Auto
5.4. FN2: DEPENDENCIAS FUNCIONALES
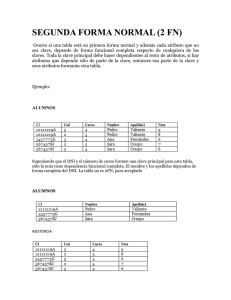
SEGUNDA FORMA NORMAL
Una relación está en segunda forma normal (2FN) si y sólo si está en 1FN y todos
los atributos no clave dependen por completo de la clave primaria.
La segunda forma normal es transgredida cuando un campo no clave es un dato
sobre un subconjunto de una clave (compuesta).
Ejemplo.
Consideremos el siguiente esquema propuesto para un registro de inventario.
ARTÍCULO BODEGA
CANTIDAD
DIRECCIÓN-BODEGA
Aquí, la clave está formada por (ARTÍCULO, BODEGA).
Se puede observar fácilmente que DIRECCIÓN-BODEGA es un dato acerca de
BODEGA y no de ARTICULO, por lo que no se estaría cumpliendo con la
segunda forma normal.
Los problemas básicos de diseño son:
La dirección de la bodega se repite para cada artículo que se almacena en esa
bodega (redundancia).
Si la dirección de bodega cambia, cada registro que se refiera a un artículo
almacenado en esa bodega debe ser actualizado. Debido a la redundancia, los
datos pueden llegar a ser inconsistentes, con diferentes registros indicando
diferentes direcciones para la misma bodega (integridad).
Si en algún momento no hubiera partes almacenadas en alguna bodega, no
habría un registro para anotar la dirección de la bodega (anomalía).
1Repetición
2Se
variable de atributos, n productos.
forma un grupo.
18
Para satisfacer la segunda forma normal, el esquema anterior debe ser
reemplazado por el siguiente:
5.5. FN3: ELIMINACIÓN DE LAS DEPENDENCIAS TRANSITIVAS.
TERCERA FORMA NORMAL
Una relación está en tercera forma normal (3FN) si y sólo si está en 2FN y todos
atributos no clave dependen de manera no transitiva de la clave primaria.
Para definir formalmente la 3FN necesitamos definir dependencia transitiva: En
una afinidad (tabla bidimensional) que tiene por lo menos 3 atributos (A,B,C) en
donde A determina a B, B determina a C pero no determina a A.
Definición formal:
Una relación R está en 3FN si y solo si esta en 2FN y todos sus atributos no
primos dependen no transitivamente de la llave primaria.
Consiste en eliminar la dependencia transitiva que queda en una segunda
forma normal, en pocas palabras una relación esta en tercera forma normal si está
en segunda forma normal y no existen dependencias transitivas entre los
atributos, nos referimos a dependencias transitivas cuando existe más de una
forma de llegar a referencias a un atributo de una relación.
Por ejemplo, consideremos el siguiente caso:
Tenemos la relación alumno-cursa-materia manejada anteriormente, pero ahora
consideramos al elemento maestro, gráficamente lo podemos representar de la
siguiente manera:
19
Podemos darnos cuenta que se encuentra graficado en segunda forma normal, es
decir que todos los atributos llave están indicados en doble cuadro indicando los
atributos que dependen de dichas llaves, sin embargo en la llave Necono tiene
como dependientes a 3 atributos en el cual el nombre puede ser referenciado por
dos atributos: Necono y RFC (Existe dependencia transitiva), podemos solucionar
esto aplicando la tercera forma normal que consiste en eliminar estas
dependencias separando los atributos, entonces tenemos:
La tercera forma normal es transgredida cuando una propiedad no identificada (no
clave) es un dato acerca de otro campo no clave.
Ejemplo. El esquema siguiente no está en 3FN.
EMPLEADO
PADRE
DIRECCIÓN-PADRE
Ahora, el siguiente esquema no transgrede la 3FN.
EMPLEADO
Padre
PADRE
DIRECCIÓN-Padre
Estas son las tres formas normales básicas, existen además la forma normal de
Boyce/Codd, la cuarta forma normal, quinta forma normal.
20
Ejercicio.
Un hospital mantiene un sistema de control de drogas en el cual las siguientes
características aparecen como las relevantes:
Las drogas están mantenidas en estantes especiales.
Las drogas son provistas por distintos proveedores
Existe un archivo que incorpora datos para permitir la ubicación de los
proveedores usuales o alternativos de las drogas.
Siempre que una droga es usada para una intervención y/o tratamiento, los
registros del archivo indicado anteriormente es actualizado.
Cuando la cantidad de la droga en stock cae bajo un cierto nivel, es puesta
en una lista de re-orden. Se revisan los fabricantes de la droga y se ubican
el proveedor usual o alternativo para ella y se emite una orden de compra
para
ella.
Ocasionalmente pedidos urgentes son hechos por teléfono.
Las drogas recibidas traen adjunto un recibo el cual es chequeado con los
detalles de la droga. El registro de la droga es actualizado y la droga es
ubicada en el estante correspondiente.
Desarrollo.
Supuestos de Diseño.
Los principales supuestos que soportan la normalización del sistema son los que
se indican a continuación.
1. Existen Ubicaciones (por ejemplo casilleros) en donde se almacenan todas las
versiones de una droga.
2. Sólo se almacena a lo más una droga (en todas sus versiones) en una
ubicación.
3. Una droga y sus versiones es almacenada en una y sólo una ubicación.
4. Una droga tiene una o más versiones, las cuales se identifican por un código
(versión).
5. Una versión es única, y pertenece sólo a una droga.
6. No existen dos versiones con el mismo nombre y código para la misma droga.
7. Un laboratorio puede producir una o varias versiones de drogas.
8. Un laboratorio cuenta con uno o más proveedores.
9. Un proveedor representa a uno o más laboratorios.
10. Un proveedor distribuye todas las drogas que produce un laboratorio al cual
representa.
11. Una droga tiene sólo un proveedor usual.
12. Todos los proveedores que proveen una droga y no están catalogados
como su proveedor usual constituyen sus proveedores alternativos.
13. Un proveedor puede ser proveedor usual de ninguna, una o muchas drogas.
14. Dos proveedores pueden tener la misma dirección o teléfono.
21
6.CAPITULO 6: NORMALIZACION I
6.1. CLAVE CANDIDATA
Las claves candidatas son superclaves mínimas. Una superclave es un conjunto
de uno o más atributos que, tomados colectivamente, permiten identificar de
forma única una entidad en el conjunto de entidades. Por ejemplo, el atributo dni
del conjunto de entidades cliente es suficiente para distinguir una entidad cliente
de las otras. Así, dni es una superclave. Análogamente, la combinación de
nombre-cliente y dni es una superclave del conjunto de entidades cliente. Al
atributo nombre-cliente de cliente no es una superclave, porque varias personas
podrían tener el mismo nombre.
El concepto de una superclave no es suficiente para lo que aquí se propone, ya
que, como se ha visto, una superclave puede contener atributos innecesarios. Si
K es una superclave, entonces también lo es cualquier superconjunto de K . A
menudo interesan las superclaves tales que los subconjuntos propios no son
superclave, sino superclaves mínimas.
Se usará el término clave primaria para denotar una clave candidata que es
elegida por el diseñador de una base de datos como elemento principal para
identificar las entidades dentro de un conjunto de entidades. Una clave (primaria,
candidata y superclave) es una propiedad del conjunto de entidades más que de
las entidades individuales. Cualesquiera dos entidades, en el conjunto no pueden
tener el mismo valor en sus atributos clave al mismo tiempo. La designación de
una clave representa una ligadura en el desarrollo del mundo real que se modela.
Relaciones, Atributos y Dominios.
Se constituye el sistema de las siguientes relaciones:
Ubicación (ubicación, estado)
Objetivo: Contener todas las ubicaciones destinadas para el almacenamiento de
las drogas.
ubicación: numérico de largo 4. Varía de 1 a 9999. Único.
estado: caracter de largo 3. Toma valores 'ocu' o 'dis', para indicar ocupado y
disponible respectivamente.
Claves candidatas: ubicación.
Clave primaria: ubicación.
Claves foráneas: no tiene.
Proveedor (proveedor, nombreproveedor, fono, dirección)
Objetivo: contener la información de los proveedores de drogas del hospital.
proveedor: numérico de largo 4. Varía de 1 a 9999. Único.
nombreproveedor: caracter de largo 35. Nombre de los proveedores. Único.
fono: numérico de largo 7. Varía de 1 a 9999999.
dirección: caracter de largo 50. Dirección de los proveedores.
22
Claves Candidatas: proveedor, nombreproveedor.
Clave primaria: proveedor.
Claves foráneas: no tiene.
Laboratorio (laboratorio, nombrelaboratorio)
Objetivo: contener la información de los laboratorios que producen drogas que se
utilizan en el hospital.
laboratorio: numérico de largo 4. Varía de 1 a 9999. Único.
nombrelaboratorio: caracter de largo 15. Nombre de los laboratorios. Único.
Claves candidatas: laboratorio, nombrelaboratorio.
Clave primaria: laboratorio.
Claves foráneas: no tiene.
Droga (droga, nombredroga, stock, stockmin, ubicación, proveedor)
Objetivo: contener la información de las drogas que se utilizan y mantienen en el
hospital.
droga: numérico de largo 4. Varía de 1 a 9999. Único.
nombredroga: caracter de largo 10. Nombre de las drogas. Único.
stock: numérico de largo 4. Mayor que 0. Stock actual de la droga.
stockmin: numérico de largo 4. Mayor que 0. Stock mínimo de la droga.
ubicación: numérico de largo 4. Ubicación de la droga. Único.
proveedor: numérico de largo 4. Proveedor usual de la droga. varía de 1 a 9999.
Claves candidatas: droga, nombredroga, ubicación.
Clave primaria: droga
Claves foráneas:
ubicación, referencia a ubicación en la relación Ubicación.
proveedor, referencia a proveedor en la relación Proveedor.
Versión (droga, versión, nombreversion, laboratorio)
Objetivo: contener la información de las distintas versiones que existen para cada
droga que se utiliza en el hospital.
droga: numérico de largo 4. Varía de 1 a 9999.
versión: numérico de largo 4. Varía de 1 a 9999. .
nombreversión: caracter de largo 35. Nombre de las versiones. Único.
laboratorio: numérico de largo 4. Varía de 1 a 9999.
Claves candidatas: (droga, versión), nombreversion.
Clave primaria: (droga, versión)
Claves foráneas: laboratorio, referencia a laboratorio en la relación Laboratorio.
ProvLab ( proveedor, laboratorio)
Objetivo: contener la información acerca de cuales son los proveedores de un
laboratorio.
proveedor: numérico de largo 4. Varía de 1 a 9999.
laboratorio: numérico de largo 4. Varía de 1 a 9999.
Claves candidatas: (proveedor, laboratorio)
Clave primaria: (proveedor, laboratrorio)
Claves foráneas:
proveedor, referencia a proveedor en la relación Proveedor
laboratorio, referencia a laboratorio en la relación
Laboratorio.
23
a) Restricciones de Integridad.
Además de las restricciones de integridad de las entidades (claves primarias no
nulas), las de integridad referencial para las claves foráneas y las dadas por el
dominio de los atributos, se tienen las que se declaran a continuación.
Si un proveedor es proveedor (usual) para una droga, este proveedor debe
representar a un laboratorio que produzca una versión de esa droga.
Si una droga tiene una ubicación, entonces el estado de esa ubicación debe ser
"ocupado".
Esquema
Ubicación
Key Data
ubicacion [PK1]
Non-Key Data
estado
Droga
Key Data
droga [PK1]
Non-Key Data
nombredroga
stock
stockmin
ubicacion [FK]
proveedor [FK]
Version
Key Data
droga [PK1] [FK]
version [PK2]
Non-Key Data
nombreversion
laboratorio [FK]
Laboratorio
Key Data
laboratorio [PK1]
Non-Key Data
nombrelaboratorio
Proveedor
Key Data
proveedor [PK1]
Non-Key Data
nombreproveedor
fono
direccion
ProvLab
Key Data
proveedor [PK1]
[FK]
laboratorio [PK2]
[FK]
Observación.
El formalismo gráfico utilizado explícita la implementación de interrelaciones (del
MER) entre relaciones(del modelo Relacional) a través de claves foráneas. Las
cardinalidades se representan por la notación pie de gallo, donde
la cardinalidad (1,1) o uno es a uno ,
para la cardinalidad (0,1) o cero o uno,
para la cardinalidad (0,n) o cero es a muchos y
muchos es a uno.
6.2.
Determinante
se utiliza para
para la cardinalidad (n,1) o
24
Uno o más atributos que, de manera funcional, determinan otro atributo o
atributos. En la dependencia funcional (A,B)-->C, (A,B) son los determinantes.
6.3.
SIMPLIFICACIONES DE RELACIONES
Las simplificación de las relaciones entre clases va ha permitir tener la una base
sin redundancias así como es importante indicar que el tipo de correspondencia
mucos a muchos conceptualmente es valido pero lógica y relacionalmente no.
6.4.
DESCOMPOSICIÓN
Consiste en descomponer un esquema de relación que tenga muchos atributos
en varios esquemas con menos atributos.Una descomposición descuidada puede
conducir a otro tipo de diseño incorrecto. Ejm:
Considérese una alternativa de diseño en la cual Esquema-emprestito se
descomponga en los siguientes dos esquemas:
Esquema-sucursal-cliente=(nombre-sucursal, ciudad-sucursal, activo, nombrecliente)
Esquema-préstamo-cliente=(nombre-cliente, número-préstamo, importe)
Usando la relación empréstito se construyen las nuevas relaciones sucursal
cliente (esquema-sucursal-cliente) y préstamo-cliente (Esquema-préstamo-cliente)
si será como sigue:
Sucursal-cliente = Πnombre-sucursal, ciudad- sucursal, activo, nombre-cliente (empréstito)
préstamo-cliente = Πnombre-cliente, número de préstamo, importe (empréstito)
Por supuesto habrá casos en las cuales se necesite reconstruir la relación
empréstito por ejemplo si quisiéramos encontrar todas las sucursales que tienen
empréstitos con importes menores a determinada cantidad.
6.5.
UNIÓN
Consiste en la unión de tuplas de relaciones, las operaciones de unión toman
como entrada dos relaciones y devuelven como resultado otra relación. Cada
variante de las operaciones de unión están formadas por un tipo de unión y una
condición de unión. Las condiciones de unión indican las tuplas pertenecientes a
las dos relaciones que encajan y los atributos que se incluyen en el resultado de
la unión. El tipo de unión definen como se tratan las tuplas de cada relación que
no encajan con ninguna tupla de la otra relación (basado en la condición de
unión).
6.6.
TRANSITIVIDAD.
Se define como la relaciones establecidas entre entidades que nos permiten
establecer cardinalidad con otra entidad :
Si A
ByB
C entonces
A
C
6.7.
FNBC: LA FORMA NORMAL DE BOYCE CODD (FORMA NORMAL OPTIMA)
Definición formal:
Una relación R esta en FNBC si y solo si cada determinante es una llave
candidato.
Denominada por sus siglas en ingles como BCNF; Una tabla se considera en esta
forma si y sólo sí cada determinante o atributo es una llave candidato.
Continuando con el ejemplo anterior, si consideramos que en la entidad alumno
sus atributos control y nombre nos puede hacer referencia al atributos esp.,
entonces decimos que dichos atributos pueden ser llaves candidato.
Gráficamente podemos representar la forma normal de Boyce Codd de la
siguiente forma:
25
Obsérvese que a diferencia de la tercera forma normal, agrupamos todas las
llaves candidato para formar una global (representadas en el recuadro) las cuales
hacen referencia a los atributo que no son llaves candidato
7. CAPITULO 7: NORMALIZACIONES AVANZADAS
7.1
Cuarta forma normal.
Eliminación de las dependencias multivaluadas independientes
Definición formal:
Un esquema de relaciones R está en 4FN con respecto a un conjunto D de
dependencias funcionales y de valores múltiples sí, para todas las dependencias
de valores múltiples en D de la forma X->->Y, donde X<=R y Y<=R, se cumple por
lo menos una de estas condiciones:
*
X->->Y
es
una
dependencia
* X es una superllave del esquema R.
de
valores
múltiples
trivial.
Para entender mejor aún esto consideremos una afinidad (tabla) llamada
estudiante que contiene los siguientes atributos: Clave, Especialidad, Curso tal y
como se demuestra en la siguiente figura:
Clave Especialidad Curso
26
S01
S01
S01
B01
C03
Sistemas
Bioquímica
Sistemas
Bioquímica
Civil
Natación
Danza
Natación
Guitarra
Natación
Suponemos que los estudiantes pueden inscribirse en varias especialidades
y en diversos cursos. El estudiante con clave S01 tiene su especialidad en
sistemas y Bioquímica y toma los cursos de Natación y danza, el estudiante B01
tiene la especialidad en Bioquímica y toma el curso de Guitarra, el estudiante con
clave C03 tiene la especialidad de Civil y toma el curso de natación.
En esta tabla o relación no existe dependencia funcional porque los
estudiantes pueden tener distintas especialidades, un valor único de clave puede
poseer muchos valores de especialidades al igual que de valores de cursos. Por
lo tanto existe dependencia de valores múltiples. Este tipo de dependencias
produce redundancia de datos, como se puede apreciar en la tabla anterior, en
donde la clave S01 tiene tres registros para mantener la serie de datos en forma
independiente lo cual ocasiona que al realizarse una actualización se requiera de
demasiadas operaciones para tal fin.
Existe una dependencia de valores múltiples cuando una afinidad tiene por lo
menos tres atributos, dos de los cuales poseen valores múltiples y sus valores
dependen solo del tercer atributo, en otras palabras en la afinidad R (A,B,C) existe
una dependencia de valores múltiples si A determina valores múltiples de B, A
determina valores múltiples de C, y B y C son independientes entre sí.
En la tabla anterior Clave determina valores múltiples de especialidad y clave
determina valores múltiples de curso, pero especialidad y curso son
independientes entre sí.
Las dependencias de valores múltiples se definen de la siguiente manera:
Clave ->->Especialidad y Clave->->Curso; Esto se lee "Clave multidetermina a
Especialidad, y clave multidetermina a Curso"
Para eliminar la redundancia de los datos, se deben eliminar las dependencias
de valores múltiples. Esto se logra construyendo dos tablas, donde cada una
almacena datos para solamente uno de los atributos de valores múltiples.
Para nuestro ejemplo, las tablas correspondientes son:
Tabla EEspecialidad
Clave
Especialidad
S01
Sistemas
B01
Bioquímica
C03
Civil
Tabla ECurso
Clave
S01
S01
B01
C03
Curso
Natación
Danza
Guitarra
Natación
27
7.2 FN5: Eliminación de las dependencias multivaluadas independientes.
Quinta forma normal.
Definición formal:
Un esquema de relaciones R está en 5FN con respecto a un conjunto D de
dependencias funcionales, de valores múltiples y de producto, si para todas
las dependencias de productos en D se cumple por lo menos una de estas
condiciones:
* (R1, R2, R3, ... Rn) es una dependencia de producto trivial.
* Toda Ri es una superllave de R.
La quinta forma normal se refiere a dependencias que son extrañas. Tiene que
ver con tablas que pueden dividirse en subtablas, pero que no pueden
reconstruirse.
8.
CAPITULO 8: SUBTIPOS Y SUPERTIPOS
8.1 Modelo Entidad Inter Relación (MER, Entity Relationship Model)
En 1976, Peter Chen publicó el modelo entidad relación, el cual tuvo gran
aceptación principalmente por su expresividad gráfica. Sobre esta primera
versión han trabajado numerosos autores, generando distintas
extensiones de mayor o menor utilidad y de aceptación variable en el
medio académico y profesional. Muchas de estas extensiones son muy
utiles, pero poco difundidas debido principalmente a la ausencia de
herramientas automatizadas que apoyen su uso.
8.1.1 Cómo Modelar en MER
Para modelar en MER se sigue generalmente el siguiente orden:
a.
b.
c.
d.
e.
Identificar los tipos de entidades.
Identificar los tipos de interrelaciones.
Encontrar las cardinalidades.
Identificar los atributos de cada tipo de entidad.
Identificar las claves de cada tipo de entidad.
La regla básica es distinguir tipos de entidades e interrelaciones de atributos. Así,
los atributos deben ser atómicos y característicos del tipo de entidad o
interrelación que describan.
También los atributos deben pertenecer al tipo de entidad o interrelación que
describen y no a otro tipo.
28
Otra diferencia entre tipo de entidad y atributo es que, por ejemplo, se puede
tener el tipo de entidad Empleado, que tiene como atributo el departamento al que
pertenece. En forma alternativa se pueden tener los tipos de entidades Empleado
y Departamento, y el tipo de interrelación Trabaja_en, que relaciona un empleado
con el departamento donde trabaja.
Esta segunda alternativa es mejor desde el punto de vista del modelamiento
conceptual y presenta una clara diferencia entre atributo y tipos de entidad.
8.2 Modelo Entidad Relación Extendido
El modelo entidad relación ha sido mejorado por varios autores, incorporándole
elementos que aumentan su expresividad y apoyan completitud de la
especificación de la base de datos o realidad modelada.
A continuación se presentan las extensiones más usadas, que enriquesen lo
expuesto en el capítulo anterior.
8.2.1 Atributo Compuesto.
Corresponde a grupos de atributos que tienen afinidad en cuanto a su
significado o a su uso.
Atributo
Compuesto
Atributo Componente 1
Atributo Componente 2
...
Atributo Componente n
8.2.2 Cardinalidad.
Caracteriza a los atributos de un tipo de entidad y a los tipos de
interrelación.
(Las definición aquí utilizada corresponde a la realizada por Tardieu).
8.2.3 Cardinalidad de atributo con respecto a un tipo de entidad.
Para los atributos, la cardinalidad mínima indica el número mínimo de
valores de un atributo asociado con cada caso (ocurrencia) de una entidad
o interrelación. La cardinalidad máxima indica el número máximo de valores
para un atributo asociado a cada caso de una entidad o interrelación.
Se define la Cardinalidad del Atributo A con respecto al tipo de entidad TE
como:
Card(A,TE)=( mínimo, máximo), con mínimo, máximo {0,...,n} y
mínimo máximo.
donde un elemento de A debe participar al menos mínimo veces, y a lo más
máximo veces en cada ocurrencia de TE.
Tipo de
Entidad
Atributo (mínimo, máximo)
8.2.4 identificador de un tipo de entidad.
Sea TE un tipo de entidad, sean A1, A2..., An atributos monovalentes
obligatorios de TE, sean TE1, TE2..., TEm otros tipos de entidad vinculados
a TE por R1, R2..., Rm, tipos de interrelación (binarias) obligatorias.
Considérese un posible identificador I = { a1, a2..., an, TE1, TE2..., TEm}, n
>= 0, m >= 0, n + m >= 1. El valor del identificador para un caso particular te
del tipo de entidad TE se define como el conjunto de todos los valores de
29
los atributos ai (i = 1,2, ..., n) y todos los casos de los tipos de entidad TEj (j
= 1,2, ..., m) vinculadas con te.
Cada entidad puede tener múltiples identificadores alternativos.
Atributo identificador
Tipo de
Entidad
Identificador simple e interno
Atributo
... identificador 1
Atributo identificador n
Tipo de
Entidad
Identificador Compuesto e Interno
Identificador compuesto, mixto y externo
8.2.5 Clasificación de los tipos de entidad según sus identificadores.
Tipo de Entidad Fuerte: Tipo de entidad con identificador interno.
Tipo de Entidad Débil: Tipo de entidad con identificador externo o mixto.
8.2.6 Estructura de Generalización.
Un tipo de entidad TE (tipo de entidad genérica) es una generalización de
un grupo de tipos de entidades STE1 , STE2 , ..., STEn (tipos de entidad
subconjunto) si cada entidad de los tipos de entidad STE1 , STE2 , ..., STEn
es también una entidad del tipo de entidad TE. (Lo opuesto a la
generalización se denomina especialización.)
Además cada atributo, interrelación o generalización definida para un tipo
de entidad genérica, será heredado por todas las entidades subconjunto de
la generalización.
Tipo de
Entidad
Genérica
Tipo de
Entidad
Subconjunto 1
…
Tipo de
Entidad
Subconjunto n-1
Tipo de
Entidad
Subconjunto n
30
8.2.7 Cobertura.
Las jerarquías de generalización presentan la propiedad de cobertura. La
cobertura puede ser parcial o total y exclusiva o superpuesta. La cobertura
parcial o total permite especificar una restricción entre el tipo de entidad
genérica y sus tipos de entidad subconjunto, donde todos los elementos del
tipo de entidad genérico deben pertenecer a alguno de sus tipos de entidad
subconjunto (si es total), o no (si es parcial). La cobertura exclusiva o
superpuesta permite especificar una restricción entre los tipos de entidad
subconjunto, donde los elementos que pertenecen a un tipo de entidad
subconjunto pueden pertenecer también a otro tipo de entidad subconjunto
(si es superpuesto) o no (si es exclusiva).
Tipo de
Entidad
Genérica
(x,y)
Tipo de
Entidad
Subconjunto 1
…
Tipo de
Entidad
Subconjunto n-1
Tipo de
Entidad
Subconjunto n
8.2.8 Agregación de Tipos de Entidad.
Un tipo de interrelación y los tipos de entidad que relaciona, puede ser
manejado como un tipo de entidad en un nivel de abstracción mayor, lo que
posibilita que se pueda interrelacionar con otros tipos de entidad. Este
mecanismo es conocido como Estructura de Agregación o Agregación de
Tipos de Entidad, en aquellas extensiones del MER que la incorporan (por
ejemplo, CCER [Varas98]).
Tipo de
Interrelación
Tipo de
Entidad 1
Tipo de
Entidad n
Agregación de Tipos
de Entidad
8.2.9 Roles de Tipos de Entidad en Tipos de Interrelación.
Un Rol de un Tipo de Entidad en un Tipo de Interrelación es la función que
aquel cumple dentro de ésta. La definición de roles permite atribuirle a un
tipo de entidad su semántica dentro de la agregación, aportándole mayor
expresividad al esquema y permitiendo disminuir ambigüedades en la
definición de cardinalidades (esto cobra mayor importancia en aquellos tipos
de interrelación que involucran a un mismo tipo de entidad más de una vez).
TE 1
Rol TE1 en R
R
Rol TE 2 en R
TE 2
8.2.10 Tipos de Interrelaciones Exclusivas con respecto a un Tipo de
Entidad.
(Esta definición se obtuvo en base a aquella en [deMiguel93]).
31
Sea TE un tipo de entidad y sea un conjunto de tipos de interrelación RE=
{R1,...,Rn} tales que TE Ri, i en {1,...,n}, RE se dice exclusivo, si cada
ocurrencia de TE sólo puede estar presente a lo más en un Ri, i en
{1,...,n}.
Observación: En este caso la cardinalidad mínima de TE con respecto a
Ri, con i en {1,...,n} debe ser 0.
TE1
(a,b)
(c,d)
R1
(e,f)
TE2
(g,h)
R2
8.2.11 Restricciones en MER extendido.
Las restricciones estáticas especifican los estados posibles de la base de
datos modelada en un esquema dado. En un esquema MER la principal
restricción estática está dada por la estructura (pertenencia de un atributo
a un tipo de entidad o interrelación, tipos de entidad que relaciona un tipo
de interrelación), y también se pueden especificar las siguientes.
Dominio.
Cardinalidad de atributo con respecto a un tipo de entidad.
Cardinalidad de un tipo de entidad con respecto a un tipo de
interrelación.
Identificadores.
Cobertura.
Tipos de Interrelación Exclusivas con respecto a un Tipo de Entidad.
Las restricciones dinámicas son aquellas que restringen los cambios de
estado en la base de datos. Estos aspectos, no son soportados por el
modelo entidad relación.
8.2.12 Estrategia para modelar con MER.
Se debe hacer uso de los conceptos de abstracción básicos: clasificación,
agregación y generalización. Para ello se pueden seguir los procesos
siguientes.
1. Identificar Tipos de Entidad y las relaciones que existen entre ellos.
2. Descomponer un tipo de entidad en dos o más tipos de entidad,
relacionados o no, o participando en una estructura de generalización.
3. Descomponer un tipo de interrelación en varias.
4. Identificar atributos para cada elemento.
5. Definir identificadores para los tipos de entidad.
6. Definir restricciones de cardinalidad y cobertura.
7. Verificar que el esquema resultante es correcto con respecto a la
especificación (representa toda la realidad descrita).
8. Verificar que el esquema es correcto con respecto al buen uso del
modelo.
9. Analizar modificaciones al esquema.
8.3 Esquema MER y Documentación.
El esquema conceptual de una base de datos en el modelo entidad relación no es
sólo el diagrama que se genera al utilizar las reglas generadoras del modelo, sino
también la documentación textual asociada.
En este último punto, cobran mayor importancia aquellos aspectos que no quedan
explícitamente especificados en el esquema gráfico, ya sea por un criterio estético
o por falta de expresividad del modelo.
32
Comunmente, los dominios no se incorporan en el esquema gráfico, y su
definición ni siquiera tiene representación, por lo que su documentación fuera del
esquema es obligatoria. También es necesario hacer énfasis en restricciones
estáticas que no fueron modeladas, y, en caso de existir restricciones dinámicas,
estas deben especificarse fuera del esquema, dado que el modelo entidad
relación no las soporta.
Para efectos de documentación, se propone anexar al esquema MER (gráfico),
las tablas siguientes con la informacón que corresponda.
Tipos de Entidad.
Tipo de Entidad
Descripción
Atributo
Dominio
Cardinalidad
Notación para los atributos que son identificadores: Atributo@
Tipos de Interrelación
Tipo de Interrelación
Descripción
Tipos de Entidad
Rol
Relacionados
Atributo
Dominio
Cardinalidad
Cardinalidad
Atributos Compuestos.
Atributo
Descripción
Presente en
Notación para Descripción:
Atributo Componente 1+ Atributo Componente 2+ … + Atributo Componente n : El
atributo se compone de Atributo Componente 1, Atributo Componente 2, … ,
Atributo Componente n. Cada uno de los atributos Atributo Componente i debe
documentarse separadamente.
Atributos.
Atributo
Descripción
Dominio
Presente en
Notación para presente en:
Nombre1(TE) : El objeto donde se usa el atributo se denomina Nombre1 y es un
Tipo de Entidad.
Nombre2(TI): El objeto donde se usa el atributo se denomina Nombre2 y es un
Tipo de Interrelación.
Nombre3(@TE): El objeto donde se usa el atributo se denomina Nombre3 y es un
Tipo de Entidad, siendo este atributo (parte de) el identificador.
Nombre4(A): El objeto donde se usa el atributo se denomina Nombre4 y es un
atributo compuesto.
Dominios.
Dominio
Definición
Atributos
Estructuras de Generalización.
Generalización
Tipo de Entidad Genérica
Cobertura
Tipos de Entidad
Subconjunto
33
Agregación de Tipos de Entidad
Agregación
Nombre Agregación
Tipo de Interrelación
Restricciones Estáticas no modeladas.
Restricciones Estáticas
Id Objetos Involucrados
Res
tricc
ión
Restricción
Restricciones Dinámicas.
Restricciones Dinámicas
Id Objetos Involucrados
Res
tricc
ión
Restricción
9. CAPITULO 9: DISEÑO FISICO
9.1. Conversión de un Modelo E-R normalizado a FoxPro
34
El modelo de datos entidad-relación (E-R) está basado en una percepción del
mundo real que consta de una colección de objetos básicos, llamados entidades,
y de relaciones entre estos objetos. Una entidad es una “cosa” u “objeto” en el
mundo real que es distinguible de otros objetos. Por ejemplo, cada persona es
una entidad, y las cuentas bancarias pueden ser consideradas entidades. Las
entidades se describen en una base de datos mediante un conjunto de atributos.
Una relación es una asociación entre varias entidades. Por ejemplo, una relación
impositor asocia un cliente con cada cuenta que tiene. El conjunto de todas las
entidades del mismo tipo y el conjunto de todas las relaciones del mismo tipo se
denominan conjunto de entidades.
Además de entidades y relaciones, el modelo E-R representa ciertas ligaduras
que los contenidos de la base de datos deben cumplir. Una ligadura importante
es la correspondencia de cardinalidades, que expresa el número de entidades con
las que otra entidad se puede asociar a través de un conjunto de relaciones.
La totalidad de estructuras lógicas de una base de datos se pueden expresar
gráficamente mediante un diagrama E-R, que consta de los siguientes
componentes:
Rectángulos, que representan conjuntos de entidades.
Elipses, que representan atributos.
Rombos, que representan relaciones entre conjuntos de entidades.
Lineas, que unen los atributos con los conjuntos de entidades y los
Conjuntos de entidades con las relaciones.
9.2 diseño de una base de datos usando herramientas case
a) Se crea un nuevo proyecto
b) Sobre un directorio creado previamente con el explorador de windows se
genera el nuevo proyecto (en este caso C:\BASE)
35
Pulse Open
c) Elija el método de modelamiento de datos en este caso se eligió el CHEN
(ERD)
d) Se elige el tipo de carta (Chart Type) en este caso un diagrama de entidad –
relación, haciendo la nominación respectiva (Ejemplo)
36
e) Al hacer la elección y nominación respectiva aparece la siguiente pantalla con
su respectiva caja de herramientas correspondiente a la metodología de
modelamiento.
f) Usando la caja de herramientas dibuje el modelo, comenzando primero por las
entidades independientes (cliente, Factura, Artículo) y luego la entidad de relación
(Pide, De), en caso debe nominar cada entidad como se aprecia en la figura, para
lo cual se pulsa botón derecho luego de seleccionar la entidad y se elige la opción
(Name).
37
g) Se pulsa doble clic sobre cada entidad en el ejemplo se ha efectuado sobre
“Cliente” responda afirmativamente, le pregunta si desea definir el hijo de la
entidad señalada.
h) Al pulsar “Si” aparece la siguiente pantalla, en la cual deberá definir el nombre
del “hijo” y el tipo de entidad como Registro (Record)
38
i) Luego de las definiciones anteriores, llene en el siguiente formato, el nombre de
la tabla “cliente” y sus respectivos campos, note que “Codcli” es campo clave color
“Y” en KEY.
39
40
41
9.3 Aplicación de relaciones generadas por computador.
Las relaciones generadas por el ordenador son aquellas que se utilizaran
para el manejo de la base de datos mediante programas como foxPro u
otros.
9.4 Manejo de las relaciones obtenidas del modelado
Finalmente podemos observar las tablas obtenidas del modelado en este
caso en visual fox pro (diseñador de base de datos)
9.5
Identificación de las tablas obtenidas del modelado lógico.
Create Database ERD00001:
CREATE TABLE Cliente
[CODCLI
NOMCLI
DIRCLI
TELCLI
carácter [5] Unique Not Null.
CARÁCTER [20];
CARÁCTER [20];
CARÁCTER [7]];
CREATE TABLE Factura
[NUMFAC
FEFAC
Date [5] Unique Not Null.
Date [8]];
CREATE TABLE PIDE
[CODCLI
NUMFAC
character [5] Unique Not Null.
Date [5] Unique Not Null]];
PROCESSING RECORD
Cliente
PROCESSING RECORD
Factura
PROCESSING RECORD
Pide
10 CAPITULO 10: MODELO DE BASE DE DATOS
10.3 Concepto de BDD
Una base de datos conceptualmente hablando es un modelo de realidad, es decir
de cómo se percibe. Por lo tanto se puede decir que una Base de Datos es un
modelo de usuario.
42
Técnicamente hablando una Base de Datos es una colección de datos
lógicamente vinculados entre sí, con la finalidad de obtener resultados esperados
como consecuencia de una serie de procesos.
Otra definición puede ser la siguiente: Una Base de Datos es un conjunto de
tablas, las cuales a su vez están constituidas por campos y registros quienes son
finalmente los que alojan a los datos; posteriormente las tablas intervienen en un
proceso de vinculación lógica (relación), la cual permite comunicarse y
organizarse con el objetivo de obtener los resultados esperados por el usuario.
En la actualidad se han incorporado nuevas características a Bases de Datos
como los llamados Procedimientos Almacenados (Store Procedures) y los
Disparadores o Desencadenantes (TRIGERS), los cuales convierten a la Base de
Datos ya no son en un contenedor de datos, sino también en objetos deliberantes
con respecto al tratamiento de sus datos.
10.4 Modelos de BDD
10.4.1 Modelo de red
Los datos en el modelo de red se representan mediante colecciones de
registros (en el sentido de Pascal) y las relaciones entre los datos se
representan mediante enlaces, que se pueden ver como punteros. Los
registros en la base de datos se organizan como colecciones de grafos
dirigidos. Ejemplo:
Gonzalez
19283746
La Granja
C-1001
100,00
0
Gómez
19283746
Cerdera
C-215
140,00
0
López
67789901
Peguerinos
C-102
80,000
Abril
96396396
Valsaín
C-305
70,000
Santos
32112312
Peguerinos
C-201
180,00
0
Rupérez
24466880
León
C-217
150,000
C-222
140,000
10.4.2 Modelo Jerárquico
El modelo jerárquico es similar al modelo de redes, en el sentido en que los
datos y las relaciones entre los datos se representan registros y enlaces,
respectivamente. Este se diferencia del modelo de redes en que los
registros se organizan como colecciones de árboles en lugar de grafos
dirigidos.
10.4.3 Relacional
43
Este modelo fue propuesto pro Codd en 1970 y se divide en tres partes, las
cuales separan la estructura, la integridad y la manipulación de los datos.
a)
Estructura de Datos Relacional.
La estructura de datos relacional tiene como elemento fundamental la
relación. Aquí no existe diferencia entre entidades y relaciones o entre
individuos y relaciones.
Una relación constituye lo que podríamos llamar una tabla. Una Tupla
corresponde a una fila de esta tabla y un atributo a una columna. El número
de tuplas de una relación se denomina cardinalidad y el número de atributos
se denomina grado.
La clave primaria es un identificador único para la tabla, es decir, un atributo
o combinación de atributos tal que nunca existen dos tuplas de la relación
con el mismo valor en ese atributo o combinación de atributos.
Por último, pero no por eso menos importante, un dominio es una colección
de valores, de los cuales uno o más atributos (columnas) obtienen sus
valores reales.
Para efecto de modelación, interesa reconocer relaciones, atributos,
dominios y claves primarias. La cardinalidad de una relación se considera a
un nivel de implementación.
b)
Propiedades de las relaciones.
No existen tuplas repetidas.
Las tuplas no están ordenadas (de arriba hacia abajo).
Los atributos no están ordenados (de izquierda a derecha).
Todos los valores de los atributos son atómicos.
Reglas de Integridad Relacional
i) Claves primarias.
Una clave candidata para una relación R es un atributo K posiblemente
compuesto, tal que satisface las siguientes dos propiedades independientes del
tiempo:
Unicidad. En cualquier momento dado, no existen dos tuplas en R con el
mismo valor de K.
Minimalidad. Si K es compuesto, no será posible eliminar ningún
componente de K sin destruir la propiedad de unicidad.
De entre las claves candidatas se elige la clave primaria.
Ningún componente de la clave primaria de una relación puede en algún
momento no tener valor (aceptar nulos).
Esto significa que no tiene sentido modelar una entidad que no podemos
identificar ni distinguir unas de otras.
44
ii)
Claves Foráneas.
En el modelo relacional se denominan claves ajenas o claves foráneas a una
referencia de una relación a otra, mediante su clave. Este concepto lo conocemos
en el formalismo individual como una relación implícita.
Una Relación (R1) puede poseer como uno de sus atributos (A) una clave
primaria de otra relación (R2). Este atributo (A) constituye una clave foránea en
R1 y referencia a R2.
En este caso las claves foráneas responden al mismo patrón de las relaciones
implícitas del formalismo individual, es decir, existen cuando la cardinalidad de la
relación es uno es a muchos.
La regla de integridad referencial nos indica que ningún atributo A que constituye
una clave foránea en una relación R1 y referencia a la clave primaria de una
relación R2 (no necesariamente distinta) puede tomar un valor que no esté
presente en la relación referenciada R2. Esto significa, que la base de datos no
debe contener valores de clave ajena sin concordancia.
b.
Álgebra Relacional.
Consiste de un conjunto de operadores de alto nivel que operan sobre relaciones.
Cada uno de estos operadores toma una o dos relaciones como entrada y
produce una nueva relación como salida (propiedad de clausura).
Codd definió un conjunto de 8 operadores, los que se describen a continuación.
1.
Restricción. Extrae las tuplas especificadas de una relación dada (o sea,
restringe la relación sólo a las tuplas que satisfagan una condición especificada).
2.
Proyección. Extrae los atributos especificados de una relación dada.
3.
Producto. A partir de dos relaciones especificadas, construye una relación
que contiene todas las combinaciones posibles de tuplas, una de cada una de las
dos relaciones.
4.
Unión. Construye una relación formada por todas las tuplas que aparecen
en cualquiera de las dos relaciones especificadas.
5.
Intersección. Construye una relación formada por todas aquellas tuplas que
aparecen en las dos relaciones especificadas.
6.
Diferencia. Construye una relación formada por todas las tuplas de la
primera relación que no aparezcan en la segunda de las dos relaciones
especificadas.
7.
Reunión. A partir de dos relaciones especificadas, construye una relación
que contiene todas las posibles combinaciones de tuplas, una de cada una
de las dos relaciones, tales que las dos tuplas participantes en una
combinación dada satisfagan alguna condición especificada.
8.
División. Toma dos relaciones, una binaria y otra unaria, y construye una
relación formada por todos los valores de un atributo de la relación binaria
que concuerdan (en el otro atributo) con todos los valores en la relación
unaria.
45
Restricción
Proyección
Producto
a
b
c
z
x
División
=
y
a z
a x
a y
b z
a y
div
a z
b y
c z
b x
c z
c y
c y
Reunión
a1 b1
b1 c1
a2 b2 JOIN
b2 c2
a3 b2
b3 c3
z
y
a
=
c
a1 b1 c1
=
a2 b2 c2
a3 b2 c2
c. Cobertura total o parcial.
La cobertura de una generalización es total (t) si cada elemento de la clase
genérica corresponde al menos a un elemento de las clases subconjunto; es
parcial (p) si existe algún elemento de la clase genérica que no corresponde a
ningún elemento de las clases subconjunto.
d. Cobertura exclusiva o superpuesta.
La cobertura de una generalización es exclusiva (e) si cada elemento de la clase
genérica corresponde, a lo más a un elemento de las clases subconjunto; es
superpuesta (s) si existe algún elemento de la clase genérica que corresponde a
elementos de dos o más clases subconjunto diferentes.
46
Persona
Hombre
Mujer
a) total, exclusiva. Todas las personas son Hombres o Mujeres, pero no ambos.
Empleado
Administrativo
Docente
b) total, superpuesta. Todos los empleados son Administrativos o Docentes,
pudiendo haber empleados desempeñando ambas funciones.
Estudiante
Egresado
Títulado
c) parcial, exclusivo. Algunos estudiantes son egresados, mientras que otros
están titulados, pero no hay ningún estudiante en ambas situaciones.
Estudiante
Ingeniería Postgrado
d) parcial, superpuesta. Algunos estudiantes son de Ingeniería y otros son de
postgrado, y hay algunos estudiantes que son de ingeniería y también participan en
postgrado.
En el modelo relacional se usa una colección de tablas para representar tanto los
datos como las relaciones entre esos datos. Cada tabla tiene varias columnas y
cada columna tiene un nombre único. Ejemplo:
Nombre- dni
Calle-cliente Ciudad-cliente Númerocliente
cuenta
Gonzalez 19283746 Arenal
La Granja
C-101
Gómez
19283746 Carretas
Cerceda
C-215
Lopez
67789901 Mayor
Peguerinos
C-102
Abril
96396396 Preciados
Valsaín
C-305
Gonzalez 19283746 Arenal
La Granja
C-201
Santos
32112312 Mayor
Peguerinos
C-217
Ruperéz 24466880 Ramblas
León
C-222
Gómez
19283746 Carretas
Cerceda
C-201
Número-cuenta
C-101
C-215
C-102
saldo
100,000
140,000
80,000
47
C-305
C-201
C-217
C-222
10.5
70,000
180,000
150,000
140,000
El sistema administrador de Base de datos (DBMS)
Un sistema de Administración de Base de Datos (DBMS) es un programa de
computadora para administrar un depósito de datos permanente y autodescriptivo.
Este depósito de datos se denomina base de datos y está almacenado en uno o
más archivos. Los desarrolladores utilizan DBMS por múltiples razones:
a)
Recuperación frente a caídas de sistema. La base de datos queda
protegida frente a fallos de hardware, fallos del medio magnético del disco y
algunos errores del usuario.
b)
Posibilidad de compartir entre usuarios. Pueden acceder a base de datos
muchos usuarios al mismo tiempo.
c)
Posibilidad de compartir entre aplicaciones. Es posible hacer que muchos
programas de aplicación (presumiblemente relacionados) lean y escriban en una
misma Base DE Datos. Una base de datos es un medio neutro que facilita la
comunicación entre programas independientes.
d)
Seguridad, se pueden proteger contra lecturas y escrituras no autorizadas.
e)
Integridad, se pueden especificar reglas que deben de satisfacer los datos.
Un DBMS puede controlar la calidad de sus datos mucho más allá de las
posibilidades ofrecidas por los programas de aplicación.
f)
Extensibilidad, se pueden añadir datos a la base de datos sin perturbar los
programas ya existentes. Los datos se pueden reorganizar para un mejor
rendimiento.
g)
Distribución de datos. La base de datos puede repartir en distintas
ubicaciones, organizaciones y plataformas hardware.
El diseño de Base de datos suele conocerse con el nombre de modelo de datos o
bien esquema.
Esquema:
Para una aplicación particular de un modelo de datos, el modelamiento de la
realidad se llama esquema.
Un esquema es una definición genérica que identifica categorías (ejemplo: libro,
autor, etc.), sus propiedades (nombre, título) y sus relaciones (escrito).
Por ejemplo, un modelo de datos simple es una archivo (tabla). Aplicando este
modelo a una situación particular se puede tener el siguiente esquema:
Persona (Nombre, Edad, Dirección), donde Persona es el nombre genérico de
una entidad, y Nombre, Edad y Dirección son nombres genéricos para los
atributos.
En un diseño típico hay diez veces menos entidades que atributos, así que el
diseño de entidades es mucho más tratable.
48
Un sistema de base de datos proporciona dos tipos de lenguajes diferentes: uno
para especificar el esquema de base de datos y otro para expresar consultas y
actualizaciones de la base de datos.
10.6
Componentes del DBMS
Las aplicaciones de bases de datos incluyen los siguientes pasos:
a)
b)
c)
d)
e)
f)
g)
Diseño de la aplicación
Creación de una arquitectura específica para acoplar la aplicación con la
base de datos.
Selección de un DBMS específico que sirva como plataforma.
Diseño de la base de datos. Escritura del código del DBMS para establecer
las estructuras de base de datos adecuadas.
Escritura de código en un lenguaje de programación para compensar las
deficiencias del DBMS, para proporcionar una interfase de usuario, para
validar los datos y efectuar cálculos. Hay muchos DBMS que ofrecen
herramientas de productividad para simplificar las aplicaciones rutinarias.
Inserción de información en la base de datos.
Ejecución de la aplicación. La base de datos recibe consultas y es
actualizada según sea necesaria.
11 CAPITULO 11: COMANDO BÁSICOS DE FOXPRO
Son ordenes o palabras agrupadas propias del lenguaje, los cuales instruyen al
microordenador para que realice un acción
11.1 Funciones de Cadena
& (Carácter de Sustitución): La sustitución devuelve el valor almacenado
en una variable de tipo carácter.
Formato: &<varmen>[.<expC>]
Alltrim: Esta función devuelve una expresión tipo carácter eliminado los
espacios en blanco tanto a la derecha como a la izquierda.
Formato: ALLTRIM(<exp<C>]
Acs: Esta función devuelve el código ASCII del primer carácter de izquierda
de una expresión de tipo carácter.
Formato: ACS (<ExpC>)
At: Devuelve un valor numérico que indica la posición donde se encuentra
una expresión alfanumérica dentro de otra expresión del mismo tipo. La búsqueda
realizada por AT() distingue mayúsculas de minúsculas.
49
Formato: AT(<ExpC1>,<ExpC2>[,ExpN])
Atc: Realiza la misma función que AT , con la diferencia que no distingue
mayúsculas y minúsculas.
Formato: ATC(<ExpC1>,<ExpC2<[,ExpN>1])
Chr: Devuelve un carácter correspondiente a la expresión numérica que
indique, esta expresión numérica puede tomar cualquiera de los valores de la
tabla ASCII (0-255)
Formato: CHR(ExpN>
Chrtran: Reemplaza cada carácter de un expresión alfanumérica por el
carácter correspondiente de un tercera expresión alfanumérica. Se usa para
traducir una expresión tipo carácter utilizando dos cadenas de caracteres que se
tomaran como tablas para la traducción.
Formato: CHRTRAN(<ExpC1>,<ExpC2>,<ExpC3>
Left: Devuelve n caracteres de una expresión de tipo carácter a partir de la
primera posición de la izquierda de la cadena.
Formato: LEFT(<ExpC>,<ExpN>)
Len: Devuelve la longitud de una expresión de tipo carácter o del campo
memo indicado en el argumento de la función.
Formato: LEN(<ExpC>)
Ltrim: Elimina los espacios en blanco de la izquierda de un expresión de
tipo carácter.
Formato: LTRIM(ExpC>)
Like: Devuelve el valor lógico verdadero (.T.) si al comparara dos
expresiones de tipo carácter estas son iguales o si la primera esta contenida
en la segunda. Diferencia mayúsculas de minúsculas.
Formato: LIKE(ExpC1>,<ExpC2>)
11.2
Funciones de fecha
Date: Devuelve la fecha del sistema
Formato: DATE()
Time: devuelve la hora del sistema
Formato: Time()
Cmont: Devuelve el nombre del mes de la expresión de tipo fecha que se
indique el argumento.
Formato: CMONTH(ExpF>)
11.3 Funciones numéricas
11.3.1 Estadísticos
50
a)SUM: comando que totaliza todos los campos numéricos de una base
de datos en uso
Todos los campos numéricos serán sumados a menos que se
especifique una condición lo mismo sucederá para los registros
Formato: SUM[<lista expr>]
[<alcance>
[FOR<expl1>
[WHILE<expl2>]
[TO<lista varmen>
[TO ARRAY<matriz>]
b) AVERAGE: permite calcular la media aritmética de expresiones
comprendidas en campos numéricos de una base de datos en uso
AVG (expresión)
c) CALCULATE: Ejecuta operaciones financieras de campos o expresiones,
estos valores pueden ser almacenados en variables
CALCULATE <lista de expresiones>
<alcance>
<for<exp1>>
<while<exp2>
to <var>
d) COUNT: determina el numero de registros que tiene el archivo de datos, el
numero de registros que se encuentren en el ámbito especificado, estos
resultados podremos almacenarlos en variables de memoria
Ejemplo:
Contar aquellos registros cuyo stock sea menor a 12
COUNT FOR STOCK<12
11.3.2 MATEMATICAS
a) FLOOR: devuelve el entero mas próximo que sea menor o igual de que
expresión aritmética
formato: floor(<expr>)
ejemplo:
a=20.10
?floor(a)
devuelve 20
b=-20.10
?floor(b)
devuelve
-21
b) int : devuelve el valor entero de la expresion indicada
formato : int(<expr>)
ejemplo:
a=20.10 devuelve 20
c) max: devuelve el valor máximo de una serie de expresiones de tipo numerico
formato:
MAX(expresión)
Max(<lista de expresiones numéricas>)
a=20
b=3
c=54
?max(a,b,c) = 54
51
d) min : devuelve el menor valor de una serie de expresiones de tipo numerico
formato:
ejemplo:
a=20
b=3
c=54
?min(a,b,c) = 3
e) mod permite calcular el resto entero
f) rand:
g) round: devuelve una expresion numerica redondeada a un numero de
especifico de posiciones decimales
formato{<expresion1>,<expresion2>}
ejemplo round(suel_bas,0)
h) sign: devuelve el valor numerico1, -1 ó 0 dependiendo del signo de una
expresión numérica específica
1 positivo
-1 negativo
0 neutro
ejemplo: a=20
?sign(a) devuelve 1
i) sqrt: devuelve la raiza cuadrada de una expresion numerica positiva
ejemplo: sqrt(a)
j)
val devuelve el valor numerico correspondiente a los digitos contenidos en
una expresión de tipo carácter
val(expresión)
11.4 Funciones de conversión de datos.
11.4.1 Ctod: Convierte una expresión de tipo carácter a fecha.
Formato: CTOD(<ExpC>)
11.4.2 Dtoc: Devuelve la fecha del argumento convertida a dato tipo
carácter.
11.5
Formato: DTOC(<ExpF>)
OTRAS FUNCIONES
11.5.1 Deleted: Devuelve el valor lógico verdadero (.T.), si el registro ha sido
marcado para borrar con el mandato DELETE, caso contrario
devuelve el valor lógico falso(.F.).
Formato: DELETE([Alias])
11.5.2 Empty: Determina si la expresión esta vacía, devuelve verdadero (.T.) si la
expresión del argumento no tiene contenido, caso contrario devolverá
falso(.F.)
Formato: EMPTY(<Exp>)
11.5.3 IIF: Devuelve uno de los valores, dependiendo de la condición que se
especifique el argumento.
Formato: IIF(<ExpL>,<Exp1>,<Exp2>)
11.5.4 Found: Devuelve verdadero (.T.) si la ultima operación de búsqueda tuvo
éxito, caso contrario devuelve falso(.F.) .
Formato: FOUND()
11.5.5 Inlist: Devuelve el valor lógico verdadero (.T.) si la expresión esta
contenida en una o mas expresiones.
formato: INLIST(<Exp1>,<lista de expresiones>)
52
11.5.6 Seek: Devuelve un valor lógico verdadero si se encuentra en la base de
datos la expresión indicada en el argumento, sustituye a la combinación del
mandato SEEK con la función found().
Formato: SEEK (<Exp>[.<alias>])
12 CAPITULO 12: ENTRADA / SALIDA EN FOXPRO
12.3 Sentencia: .. Say/Get
Este mandato permite mostrar el contenido de variables de memoria , campos y
expresiones de una determinada posición de la pantalla, pudiendo asignarle una
planilla de formato para los valores numéricos, fecha, y carácter mediante las
cláusulas PICTURE. FUNCION
FORMATO: F,C SAY <valor>
[PICTURE <planilla>]
[FUNTION <planilla>]
[COLOR <par de colores>]
[COLOR SCHEME<esquema>]
donde:
<fil>, <col> Determina la posición de la pantalla, se mostrará el valor
especificando SAY.
COLOR Determina al par de colores (primer plano y segundo plano)
con que se mostrará los colores del SAY
COLOR SCHEME
Determina el esquema de colores que empleará para
Este mandato.
12.1.1. SENTENCIA .. GET
Este mandato permite el ingreso de valores o la edición de variables de memoria
y/o campos de la BD activa. Cuando se emplea este mandato al final de los GET
se debe especificar el mandato READ, para aceptar el ingreso de lops datos de
las variables y/o campos.
FORMATO: < fil>,<col> GET <var o campo>
[PICTURE <planilla>]
[FUNCTION <planilla>]
[DEFAULT <expr>]
[MESSAGE <mensaje>]
[RANGE <desde>, <hasta>]
[VALID <condición>][ERROR <mensage>]
[WHEN <condición>]
[ENABLE I DISABLE]
[COLOR <par de colores>]
[COLOR SCHEME<esquema>]
53
donde:
<fil>, <col> Determina la posición de la pantalla donde se editará los
campos o variables especificando en el mandato.
DEFAULT
Permite definir variable de memoria, sino han sido creadas
anteriormente.
MESSAGE Nos muestra una línea de mensaje al momento de activar
dicho get.
RANGE Solo acepta valores que se encuentren entre el rango
<desde> , <hasta>.
VALID Condiciona el ingreso de un valor aceptándolo sólo si la
condición especificada es verdadera caso contrario nos
muestra el mensaje de ERROR.
WHEN Permite condicionar la edición del GET. Si la condición es
verdadera permite el ingreso de un valor, en caso contrario
ignorará el mandato GET.
ENABLE I DESABLE Activa o desactiva el mandato GET específico.
COLOR Determina al par de colores que se empleará para el ingreso
de datos.
COLOR SCHEME
Determina el esquema de colores que empleará el
mandato GET.
12.1.2. SENTENCIA .. SAY/GET
Estos mandatos se pueden emplear conjuntamente con los anteriores.
Ejemplo:
2,20 SAY „CODIGO‟:‟GET COD VALID SEEK (COD)
14,20 SAY‟ DEXCRIPCION:‟GET DESC PICTURE „!‟
16,20 „COSTP‟:‟GET COST PICTURE „##,###.##‟
18,20 SAY‟ FECHA COMPRA:‟GET FECHA FUNCTION „E‟
20,20 SAY „TIPO DE PROD:‟GET TIPO FUNCTION‟MA,B,C‟
READ
Ejemplos:
CLEAR
STORE SPACE (10) TO XX
5,5 SAY‟ nombre:‟GET XX FUNCTION „!‟
READ
STORE SPACE (10) TO COD
5,5 SAY‟ codigo:‟GET COD FUNCTION „R A-999‟
READ
STORE SPACE (10) TO NOMBRE
5,5 SAY‟ nombres:‟GET NOMBRE FUNCTION „!S10‟
READ
STORE SPACE (5) TO XX1
5,5 SAY‟ INGRESE DATO:‟GET XX1 FUNCTION „!‟VALID
!EMPTY (XX1) ERROR‟CAMPO SIN INFORMACIÓN‟
STORE SPACE (G) TO XCURSO
5,5 SAY‟ LEER CURSO:‟GET XCURSO FUNCTION
„MFOXPRO,QPRO,PASCAL‟
54
VALID!EMPTY (XCURSO)ERROR‟CAMPO SIN INFORMACIÓN‟
MESSAGE;
„Pulse la barra para elegir cursor.
12.1.3 SENTENCIA ...TO
Este mandato permite diseñar recuadros, en la pantalla o ventana activa.
FORMATO: F1, C1 TO F2,C2
[DOUBLE I PANEOL I<caracter>]
[COLOR>par de color>]
[color scheme<ESQUEMA>]
donde: F1, C1 Determina la esquinma superior izquierda.
F2, C2 Determina la esquina inferior derecha.
[DOUBLE I PANEL]
Determina el tipo de línea, por defecto nos muestra la línea simple, Double,
linea de dobles; panel, líne gruesas.
<carácter>
Se determina una cadena de 8 caracteres con que se
formará el recuadro.
Color
Determina los colores que empleará el recuadro.
Color
Determina el esquema de colores que empleará.
Scheme
el mandato.
Ejemplo: CLEAR
5,5 To 10,50
5,5 To 10,50 DOUBLE
5,5 To 10,50 PANEL
5,5 To 10,50 PANEL COLOR R+/B
5,5 To 10,50 COLOR R+/ W
5,5 To 10,50 *
5,5 To 10,50 COLOR SCHEME 5
12.2 Definición de las principales cláusulas
12.2.1 Picture
Si en lugar de FUNCTION se utiliza PICTURE, se deberá incluir el símbolo
(@) antes del sombrero para lograr los famosos popups que, como ya
sabemos, contienen varias opciones en el interior de un rectángulo
Con el fin de aclara las ideas vamos a ver algunos ejemplos:
PICTURE [@^ASIA;EURO;AFRICA;SALIR]
PICTURE ‟@^ASIA;EURO;AFRICA;SALIR‟
PICTURE ‟@^‟+‟ASIA;EURO;AFRICA;SALIR‟
PICTURE „^ASIA;EURO;AFRICA;SALIR‟
12.2.2 Function
Los POPUP se pueden crear mediante la instrucción FUNCTION o la
palabra clave PICTURE
En el primero, la expc1 debe empezar por un acento circunflejo „^ y a
continuación, dejando un espacio vacío, los nombres de las opciones
separadas por un punto y coma (;).
55
Ejemplo A:
Op=3
@ 4,2 GET op;
FUNCTION [^ASIA;EURO;AFRICA;SALIR]
READ
Ejemplo B:
Op=3
@ 4,2 GET op;
PICTURE [@^ASIA;EURO;AFRICA;SALIR]
READ
12.2.3 When:
Permite condicionar la edición del GET. Si la condición es verdadera
permite el ingreso de un valor, en caso contrario ignorará el mandato GET.
12.2.4 Valid:
Condiciona el ingreso de un valor aceptándolo sólo si la condición
especificada es verdadera caso contrario nos muestra el mensaje de
ERROR.
12.2.5 Error:
devuelve el número de error cometido y activado por la instrucción por la
instrucción on error <mandato>
56
13
CAPITULO 13: PROGRAMACIÓN EN FOXPRO
La programación es un proceso reiterativo, los pasos se repiten numerosas veces,
perfeccionándose el código a medida que se avanza. Entre los pasos básicos de
programación se debe citar los siguientes:
Definición del problema
Desgloce del problema en elementos discretos
Construcción de los elementos
Comprobación y perfeccionamiento de los elementos
Ensamblaje de los elementos
Comprobación del programa en su conjunto
13.1 Creación de un programa
Un programa FoxPro tiene la siguiente estructura básica.
Identificación: Nombre del programador, nombre de la ampliación, objetivo y
fecha de creación.
Entorno: Instrucciones que permiten configurar el ambiente en el que se
desarrollo la ampliación.
Cuerpo del Programa: Son las instrucciones, procedimientos y funciones
que se utilizan en la ampliación.
Salida: Instrucciones que se indican al terminar una ampliación.
13.2 Sentencias básicas de programación
Elementos Básicos de la Programación de FoxPro.
Los Comandos:
SET TALK OFF/ON
CLEAR
SET SAFETY ON/OFF
APPEND BLANK
DELETE
PACK
CLEAR
ETC.
&& Activa/Desactiva la visualización.
&& Activa/Desactiva la presentación
&& Activa/Desactiva confirmación
&& Agrega un registro en blanco en una tabla.
&& Marca un registro de tabla para su eliminación.
&& Elimina el registro marcado con el comando
DELETE.
&& Realiza el limpiado de pantalla.
13.3 Sentencias condicionales (IF ENDIF,DO CASE)
13.3.1. SENTENCIAS CONDICIONALES: IF ... END IF
Evalúa una expresión lógica y ejecuta una instrucción o grupo de
instrucciones dependiendo del resultado. Se ejecuta, <instrl> si el resultado
es verdadero o <instr2> si el resultado es falso.
FORMATO: If <expL.
[ELSE
<instr2>]
ENDIF
Ejemplo: A continuación se muestra el uso de ésta instrucción condicional.
57
Ejemplo:
SET TALK OFF
SET STAT OFF
SET SCOR OFF
NOM=SPACE (1 5)
PF=O
10,20 SAY „NOMBREDELALUMNO:‟GETNOMFUNCTION‟ !‟
!12,20 SAY‟PROMEDIO FINAL‟:GETPFPICTURE‟99‟RANGE 0,20
READ
IF PF>10
MSJ-„DESAPROBADO
ENDIF
14,20 SAY_MSJCOLOR 1*/W
WAIT‟PRESIONE UNA TECLA PARA TERMINAR… „WIND
SET TALK
SET STAT ON
SETSCOR ON
13.3.2. sentencias de selección: do case ...endcase
Esta instrucción también se la conoce como multiselector, puesto que permite
evaluar los diferentes valores que pueden tomar las variables o campos y ejecutar
las instrucciones correspondientes.
FORMATO: DO CASE
CASE <expL1>
<instr1>
CASE <expL2>
.
.
CASE <EXPLN>
<instrN>
OTHERWISE
<instrM>
Donde:
<expL1><expL2>,..
considerar.
Representan a
las
diferentes
expresiones
lógicas
a
OTHERWISE Su uso es opcional y solo se ejecutan sus instrucciones cuando
ninguna expresión lógica considera se satisface.
Ejemplo: A continuación se muestra el uso de la instrucción de selección.
SET TALK OFF
SET STAT OFF
SET SCOR OFF
NOM0SPACE (15)
PF=0
10,20 SAY‟NOMBRE DEL ALUMNO‟:GET NOMFUNCTION‟ !‟
1220 SAY‟PROMEDIO FINAL‟:GET PFPICTURE‟99‟RANGE 0,20
READ
DO CASE
58
CASE PF<6
MSJ=‟PESIMO‟
CASE PF<9
MSJ=‟MUY MALO‟
CASE PF<11
MSJ=‟MALO‟
CASE PF<14
MSJ=‟REGULAR‟
CASE PF<16
MSJ=‟BUENO‟
CASE PF<19
MSJ=‟MUY BUENO‟
CASE PF<20
MSJ=‟EXCELENTE‟
ENDCASE
@14,20 SAY NSJ COLOR 1*/W
WAIT „PRESIONE UNA TECLA PARA CONTINUAR…..‟WIND‟
SET TALK ON
SET STATUS ON
13.4
Sentencias repetitivas (FOR, DO WHILE)
13.4.1 FOR ENDFOR
ejecuta un grupo de instrucciones un determinado numero de veces,
dependiendo del valor inicial y final que toma una variable.
Ejemplo: FOR
SET TALK OFF
SET ECHO OFF
CLEAR
nFila=6
FOR I= 1 TO 12
@ 02,32 SAY "Programa 10" FONT "Arial" ,14
@ 01,03 TO 20,80
@ 04,07 SAY "Tabla de Multiplicar Nº" + STR(I)
@ 05,07 SAY "--------------------------------"
FOR J=1 TO 12
@ nFila+J, 18 SAY STR(I) + "
* " + STR(J) + "
NEXT J
WAIT WINDOW "Pulse una tecla ...."
CLEAR
nFila=6
NEXT I
=" + STR(I*J)
13.4.2 DO WHILE…ENDDO
ejecuta un grupo de instrucciones un determinado numero de veces,
mientras que la <expresión > sea verdadera de lo contrario do while
termina
Ejemplo DO WHILE
SET TALK OFF
SET ECHO OFF
CLEAR
59
@ 01,03 TO 14,80
@ 02,32 SAY "Programa 08" FONT "Arial" ,14
nNumero=0
nSuma=0
DO WHILE nNumero < 10
nNumero=nNumero+1
nSuma=nSuma+nNumero
ENDDO
@ 08,23 SAY "La suma es »" +STR(nSuma,7,2) FONT "Arial" ,18
14 CAPITULO 14: CREACIÓN DE MENUS
14.1
DEFINE MENÚ:
DEFINE MENU es capaz de un menú de tipo BAR; para crear un sistema de
menús, el cual contiene una disposición horizontal o en línea. En el que cada
opción activa un menú tipo popup de opciones en posición vertical.
Para crear un menú es preciso definirlo como DEFINE MENU <nom> ,
posteriormente definir el PAD de las opciones y por ultimo, activar el menú
mediante la instrucción ACTIVATE MENU <nom>
Sintaxis
DEFINE MENÚ <nommenú>
60
[BAR [AT LINE <expN1>]]
[in[WINDOW] <nomwindow> |IN SCREEN]
[KEY <tecla label>]
[MARK <expc1>]
[MESSAGE <expC2>]
[NOMARGIN]
[COLOR <color par list> | COLOR SCHEME <expN2>]
14.2 DEFINE POPUP:
DEFINE POPUP : Crea un POPUP, que contiene una lista de opciones que se
definen mediante una instrucción DEFINE BAR.
Sintaxis
DEFINE POPUP <nomPopup>
[From <fil>, <col>]
[to <fil>, <col>]
[in[WINDOW] <nomwindow> |IN SCREEN]
[FOOTER <expC1>]
[KEY <tecla>]
[MARGIN]
[MARGIN <expc2>]
[MESSAGE <expC3>]
[MOVER]
[MULTI]
[PROPT FIELD <exp>]
| PROMPT FLIES [LIKE <máscara>]
| PROMPT STRUCTURE]
[RELATIVE]
[SCROLL]
[SHADOW]
[TITLE <expC4>]
[COLOR <color par list> | COLOR SCHEME <expN>]
14.3 DEFINE PAD
DEFINE PAD: sirve para crear un PAD en un menú tipo BAR. Se utiliza con
DEFINE MENU para crear un sistema tipo menú.
Sintaxis:
DEFINE PAD <nomPad> OF <nomMenú> PROPT <expC1>
[AT <fil>, <col>]
[BEFPRE <nompad> | AFTER <nompad>]
[KEY <tecla> [. <expC2>]]
[MARKL <expc3>]
[SKIP [FOR <expL>]]
[MESSAGE <expC4>]
[COLOR <color par list> | COLOR SCHEME <expN>]
14.4 Creación automática de Menú (MPR)
Definición de menú
SET SYSMENU TO
SET SYSMENU AUTOMATIC
61
DEFINE PAD _09h12mh30 OF _MSYSMENU PROMPT "MANTENIMIENTO"
COLOR SCHEME 3 ;
KEY ALT+M, ""
DEFINE PAD _09h12mh3a OF _MSYSMENU PROMPT "CONSULTA" COLOR
SCHEME 3 ;
KEY ALT+C, ""
DEFINE PAD _09h12mh3b OF _MSYSMENU PROMPT "KININ" COLOR
SCHEME 3 ;
KEY ALT+K, ""
ON PAD _09h12mh30 OF _MSYSMENU ACTIVATE POPUP mantenimie
ON PAD _09h12mh3a OF _MSYSMENU ACTIVATE POPUP consult
DEFINE POPUP mantenimie MARGIN RELATIVE SHADOW COLOR SCHEME 4
DEFINE BAR 1 OF mantenimie PROMPT "PERSONAL"
DEFINE BAR 2 OF mantenimie PROMPT "SALIR"
ON SELECTION BAR 1 OF mantenimie DO FORM PERSONAL
ON SELECTION BAR 2 OF mantenimie SET SYSMENU TO DEFA
DEFINE POPUP consulta MARGIN RELATIVE SHADOW COLOR SCHEME 4
DEFINE BAR 1 OF consulta PROMPT "CONSULTA 1"
DEFINE BAR 2 OF consulta PROMPT "CONSULTA 2"
ON SELECTION BAR 1 OF consulta DO FORM CONSULTA
ON SELECTION BAR 2 OF consulta DO FORM CONSULTA2
15 CAPITULO 15: RELACIONAMIENTO DE BDD
15.1
15.2
Relación múltiple de tablas
Para usar varias tablas es necesario emplear áreas de trabajo. Un área de
trabajo es una región numerada que identifica una tabla abierta. Las áreas de
trabajo se suelen identificar en las aplicaciones por el alias de la tabla abierta en
ellas. Un alias de tabla es un nombre que se refiere a una tabla abierta en un
área de trabajo.
Comando SET RELATION TO
Puede establecer una relación entre una tabla abierta en el área de trabajo
seleccionada actualmente y otra tabla abierta en otra área.
Uso de SET RELATION TO para establecer una relación entre dos tablas.
-------------------------------------------------------USE customer IN 1
USE orders IN 2
-------------------------------------------------------SELECT orders
SET ORDER TO TAG cust_id
-------------------------------------------------------SELECT customer
SET RELATION TO cust_id INTO orders
62
-------------------------------------------------------SELECT orders
BROWSE NOWAIT
SELECT customer
BROWSE NOWAIT
Permite establecer una relación entre dos Archivos de Datos dando lugar a que se
genere una BASE DE DATOS con información de ambos archivos. Antes de
relacionar dos archivos, el archivo Padre debe estar abierto en el área actual de
trabajo y el archivo hijo en otra área de trabajo. Para utilizar el SET RELATION TO
deberá existir un campo en común entre ambos archivos, además dicho campo
deberá ser la clave de indexación. Luego de relacionar cuando se mueva el puntero
al registro correspondiente del archivo Hijo, de no encontrarse un registro
coincidente en el archivo Hijo el punto se situará en el EOF ().
FORMATO:
SET RELATION TO
[<exp1> INTO <expN1>
|<expC1>
[<exp2> INTO <expN2>
|<expC2>…]
[ADDITIVE]]
16 CAPITULO 16: CREACIÓN DE REPORTES
Muestra o imprime informes bajo el control de un archivo de definición de informe
creado con MODIFY REPORT o CREATE REPORT.
La extensión predeterminada de un archivo de definición de informes es FRX. Si
el archivo de definición está en una unidad distinta de la unidad o el directorio
predeterminados, deberá incluir también la ruta de acceso con el nombre del
archivo.
Si se emite REPORT sin ningún argumento adicional, aparecerá el cuadro de
diálogo Abrir, mostrando una lista de los archivos de informes existentes para que
elija.
FORMATO: REPORT [FORM<archivo>]| ?]
[ENVIROMENT]
[<ámbito>]
[FOR <expL1>]
[WHILE <expL2>]
[HEADING <expC>]
[NOEJECT]
[NOCONSOLE]
[NOOPTIMIZE]
[PDSETUP]
[PLAIN]
[PREVIEW]
63
[TO PRINTER [PROMPT]
[TO FILE <archivo>]
[SUMARI]
16.1 Creación de reportes simples (rápido)
Reportes en los cuales se pueden emitir listados simple a diferencia de los
reportes personalizados en los cuales se muestran datos agrupados, cálculos
,etc.
Primeramente activemos el Archivo de datos (tabla):
USE (Tabla)
Luego en la ventana de comandos ingresamos:
Por ejemplo: CREATE REPORT GG
Haga clic
aquí
del menú desplegado seleccionar informe simple y observará la siguiente
ventana
al aceptar observará:
64
si desea visualizar el reporte antes de la impresión teclee en la ventana
de comando report form gg preview finalmente podrá observar:
16.2
Creación de reportes con ficheros múltiples
Son reportes en los cuales se muestran encabezados personalizados con
datos agrupados donde se podrán mostrar datos con un ordenamiento
diferente mostrando información mas detallada de manera tal que pueda
mostrase los datos al usuario en un formato mas personalizado; usualmente
se requieren obtener resúmenes a partir de los datos del informe.
Para lo cual deberá seguir los siguientes pasos:
Se activar el Archivo de datos (tabla) y luego proceda a indexar
USE (tabla)
INDEX ON SECCION + NOMBRE TO SN
Luego ingresamos:
CREATE REPORT INFOGRUP
Agrupamos los datos por SECCIÓN, activando el menú informe y luego la
agrupación [agrupar datos...]:
65
primero deberá definir el titulo ,agrupar datos ( por mes, año, categorías,
etc)
bien como requerimos obtener resúmenes o cálculos utilizaremos variables
tal como se puede observar en la figura anterior
finalmente defina el formato.
16.3 Creación de pantallas de ingreso
PROGRAMA DE INGRESO DE DATOS:
SET ECHO OFF
SET TALK OFF
SET STATUS OFF
SET BELL OFF
USE productos
SET ORDER TO xidartic
rpta="S"
sw="S"
DO WHILE sw="S"
CLEAR
xcod=SPACE(6)
xcat=SPACE(8)
xdescri=SPACE(27)
xpuni=0
xpcos=0
xsto=0
@01,21 SAY "control" FONT "courier", 12 STYLE "B"
@02,01,24,78 BOX
@03,28 SAY "INGRESODATOS"
@04,28 SAY "--------------------------------"
@22,55 SAY "Pulse[Esc] para Salir"
@5,60 SAY "Código" GET mcod PICT " 999999"
READ
IF xcod=SPACE(6) or LASTKEY()=27
EXIT
ENDIF
SEEK xcod
IF FOUND()
DO ventana
DO datos
66
CLEAR GETS
@20,5 SAY "Pulse Una tecla Para Continuar..."
WAIT WINDOW "Código Ya Registrado"
@20,5
@02,01,24,78 BOX
ELSE
DO ventana
DO datos
READ
@18,20 SAY "Desea Grabar los Datos (S/N) " COLOR GB*/W
@18,50 GET rpta PICT "@!"VALID rpta $ "SN" ERROR "Respuesta
Incorrecta"
READ
IF rpta="S"
APPEND BLANK
REPLACE idartic WITH xcod
REPLACE idcateg WITH xcat
REPLACE nombre WITH xdescri
REPLACE pcosto WITH xpcos
REPLACE stock WITH xsto
ENDIF
@ 18,20 CLEAR TO 18,79
ENDIF
@18,15 SAY "Desea Continuar Con el Ingreso (S/N) " COLOR GB*/W
@18,55 GET sw PICT "!" VALID sw $"SN" ERROR "Respuesta Incorrecta"
READ
CLEAR
ENDDO
*******************************
PROCEDURE ventana
*******************************
@07,8 SAY "Categoría"
@07,23 SAY "»"
@08,8 SAY "Descripción"
@08,23 SAY "»"
@10,8 SAY "Precio unitario"
@10,23 SAY "»"
@11,8 SAY "Precio costo"
@11,23 SAY "»"
@12,8 SAY "Stock"
@12,23 SAY "»"
******************************
PROCEDURE datos
******************************
@07,25 GET idcateg FONT "Arial, 8"
@08,25 GET descri
@10,25 GET punitario
@11,25 GET pcosto
@12,25 GET stock
67
17 CAPITULO 17: GESTION DE BASE DE DATOS
17.1 Archivos Maestros
Son aquellos archivos que contienen la información principal en los cuales se
almacenan los datos mas importante (no en detalle) los archivos donde se
almacenan con mas detalles son los llamados de transacción.
17.2 Archivos de tablas:
Una tabla es un archivo que posee una estructura bien definida de datos. Sus
elementos principales que lo conforman son:
Los campos( es la definición mínima de datos que puede contener una tabla), los
registros (es el conjunto de campos los cuales guardan una relación lógica con
respecto a una entidad ó sus transacciones), los procedimientos almacenados y los
desencadenantes. Los archivos de tabla se reconocen por que tiene por extensión
las letras. DBF
17.3 Archivos de transacción
La transacción se procesa como una sola unidad, es decir o se graban todos los
cambios de todas las tablas involucradas en la transacción o se descartan todos a
la vez. Se pueden anidar transacciones hasta 5 niveles de profundidad y se pueden
usar en actualización de Buffer.
Nota: Solamente tablas de una Base de datos, se puede aprovechar de las
transacciones.
Para guardar las modificaciones realizadas y finalizar la transacción, emita END
TRANSACTION. Si la transacción falla (el servidor se estropea, la estación de
trabajo falla o sale de FoxPro sin ejecutar la transacción) o si emite ROLLBACK, los
archivos de la transacción se restaurarán a su estado original.
Cuando modifique registros de una base de datos que forman parte de una
transacción, otros usuarios de la red no tendrán acceso (lectura o escritura) a los
registros hasta que usted finalice la transacción
Cuando otros usuarios de la red intenten acceder a registros que usted ha
modificado, deberán esperar hasta que usted finalice su transacción. Recibirán el
mensaje “Registro no disponible”
17.4 Archivos indexados simples
INDEX ON TO
Crea un archivo índice (IDX) para mostrar los registros del Archivo de datos activo
en orden lógico según la expresión de indexación empleada. Un archivo índica no
cambia el orden físico de los registros en el Archivo de datos.
FORMATO:
INDEX ON <expr> TO <archivo.idx>
[FOR <expL>]
[COMPACT]
[UNIQUE]
[ADDITIVE]
Ejemplo: Indexar el Archivo de Datos PLANILLA.DBF, por ApelPat y Apelmat sin
repeticiones.
USE PLANILLA
INDEX ON APELPAT+APELPAT UNIQUE TO INDAPE
LIST CODIGO APELPAT, APELMAT, NOMBRE.
68
17.5 Archivos indexados múltiples
INDEX –ON-TAG
Indexa el Archivo de Datos activo, creando etiquetas (TAG) dentro de un archivo
compuesto con extensión CDX. Por omisión el archivo compuesto toma el mismo
nombre que el Archivo de Datos, pero se puede asignar un nombre diferente para
estos archivos, a través de la cláusula OF. A diferencia de los archivos
compuestos pueden almacenar varias etiquetas índice (cada una corresponde a
una indexación diferente). Estos archivos compuestos se activan automáticamente
al abrir el Archivo de Datos, siempre que tenga el mismo nombre.
FORMATO:
INDEX ON < expr> TAG <etiqueta>
[OF <archivo.cdx>
[FOR<expL.]
[ASCENDING|DESCENDING]
[UNIQUE]
Ejemplo:
Indexar el Archivo de Datos PLANILLA.DBF en forma descendente por el Sueldo
Neto.
USE PLANILLAS
INDEX ON SUELDO_NET TAG ETISUE DESCENDING
LISTCODIGFO,SUELDO_NET.
17.6
Operaciones de Modificación.
modificación de la estructura de un archivo de datos
17.6.1 MODIFY STRUCTURE
Permite modificar la estructura del archivo de datos en uso, si no hay ningún
archivo se le pedirá que seleccione un archivo para modificarlo.
Los cambios que se pueden hacer en la estructura de un archivo de datos incluye
la edición y eliminación de campos así como la modificación de los hombres,
tamaños, y tipos. Etc.
Luego de realizar las modificaciones necesarias pulse [CTRL.] – [w] para grabar la
nueva estructura del disco.
Utilice [CTRL.] – [I] para insertar un nuevo campo si desea eliminarlo pulse
[CTRL.] – [D].
FORMATO: MODIFY STRUCTURE.
Ejemplo: Modifique la estructura del archivo de datos PLANILLA.DBF agregando
los siguientes campos según se indica.
MODIFY STRUCTURE
Estructura: C:\FPPD26\PLANILLA.DBF
Nombre:
Tipo
Ancho
Dec. Campo
CATEGORÍA
FECHA_ING
Numérico
Fecha 8
1 0
Campo
<insertar>
69
SUELDO_BAS
BONIFICAC
SUELDO_BRU
DSCTS
SUELD_NET
REFERENCIA
Campos: 15
Numérico
Numérico
5 2
Numérico
Numérico
Numérico
7 0
Memo
Longitud: 101
7 2
<elimiar>
7 2
5 2
<Aceptar>
10
<cancelar>
Disponible: 65399
Pulse [CTRL.] – [w] para grabar la estructura modificada del archivo.
Nota: Debe tener en cuenta de que la caja de diálogo anterior se aprecia
parcialmente la estructura del archivo de datos.
A continuación responda en forma afirmativa al parecer la siguiente caja de
diálogo.
¿Desea hacer permanentes los cambios de la estructura?
<<Si>>
<<No>>
17.7
Operaciones de Añadido
17.7.1 APPEND FROM
Comando que permite agregar registros al final de una Base de Datos
desde otro archivo. Si la estructura es igual, copiará el contenido de todos
los campos, de lo contrario lo hará sólo con los campos comunes o iguales.
FORMATO:
APPEND FROM, <archivop> |?FIELDS<lista de
campos>][FOR<expL>][TYPE]
[DELIMITED [UIT TAB|UIT <Delimiter> |WITH BLANK]| DIF | FW2|MOD|
PDOX| RPD| SDF|SYLK|WK1| WK3| WKS | WR1|XLS]]
PROCEDIMIENTO
Seleccione la secuencia de DATABASE, APPEND FROM (Alt,D,s) o bien
escriba el comando APPEND FROM en la ventana Command.
Aparecerá una ventana de diálogo que le permitirá definir todos los
parámetros necesarios para ejecutar el comando.
Haga clic con el mouse en el botón OK después de ejecutar los cambios
necesarios.
17.8 Borrado físico y lógico
Para eliminar registro de una DB debe seguir los siguientes pasos:
* Marcar los registros a ser eliminados.
* Decidir si la eliminación será temporal o definitiva.
17.8.1 Eliminación temporal: lógico
Es aquella que ignora los registros marcados para los subsiguientes comandos del
FoxPro para Windows a ejecutarse, pero físicamente permanecen en la Base de
Datos.
17.8.2 eliminación definitiva: física
Es aquella que elimina física y definitivamente los registros marcados de una Base
de Datos.
Posicionarse con el registro y luego escribir el comando delete ahora el registro
quedara marcado para ser borrado.
70
Bien si desea visualizar el registro escriba la siguiente instrucción: SET DELETE ON
se mostrara los registros incluso los marcados para ser borrados finalmente si
desea eliminarlo físicamente Utilicé el comando PACK para eliminarlo
ZAP para borrar todos los registros de la base de datos
17.9
17.10
Update:
Actualiza el fichero en activo mediante otro fichero ordenando también por un
campo índice común
Formato:
Update ON campoindx FROM nomarchi replace WITH valor1 campo2 WITH valor2
Ejemplo:
SELECT 2
&& ARTICULO.DBF
USE ARTICULOS INDEX CODIGO1 ALIAS ART
SELECT 1
USE INGRESO INDEX CODIGO2 ALIAS ING
&& INGRESO.DBF
UPDATE ON CODIGO FROM ARTICULO REPLACE CANTIDAD WITH CANTIDAD
+ ART->CANTIDAD
Join
Crea un nuevo Archivo de Datos uniendo otros dos existentes, el archivo actual y
un segundo archivo identificado por su área de trabajo o su alias.
JOIN coloca el puntero de registro del archivo actual y busca a través de los
registros del segundo archivo.
FORMATO:
JOIN UIT <expN> | WITH <expcC>
TO <archivo>
FOR <expL>
[FIELD <lista de campos>
Ejemplo:
Se tiene los siguientes Archivos de Base de Datos: TRABAJ.DBF
17.11
Append Blank
Permite añadir uno o más registros al final de un archivo de datos activo. APPEND
abre una ventana de edición para que se introduzca datos en los nuevos registros.
Al ejecutar APPEND BLANK se adiciona un registro blanco en forma automática,
este registro podrá se editado posteriormente utilizando el mandato BROWSE.
FORMATO: APPEND [BLANK]
Añadir registros desde un archivo de datos almacenado en un disco
17.12 insercion de registros (INSERT)
Inserta registros en el Archivo de Datos activo, la ubicación de los registros
insertados
Dependerá de la posición del puntero de registros y de la cláusula utilizada.
Si ejecutamos INSERT sin la cláusula BLANK, se mostrará una ventan de edición
para que pueda introducir datos en el nuevo registro.
17.13
FORMATO: INSERT[BEFORE][BLANK]
Delete for
Este mandato permite eliminar en forma lógica uno o mas registros de archivos de
datos , colocando una marca “*” en estos registros
71
El ámbito por omisión es next1
Formato: delete [<ámbito>]
for[<expL1>]
while[<expL2>]
ejemplo: consideremos el archivo de datos planilla.dbf se encuentra activo, elimine
en forma lógica los registros que comiencen con la letra R en el nombre
delete for nombre = [R]
list nombre
17.14
Replace with
Permite actualizar un archivo de datos en los campos especificado, con las
expresiones consideradas dentro de la orden.
El ambito por omisión es next1
Formarto
replace [<campo.with <expr1>]
replace [<campo1.with <expr2>]
[<ámbito>]
for[<expL1>]
while[<expL2>]