Capítulo 2 Los acidos nucleicos
Anuncio

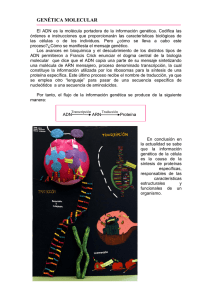
CAPITULO 2.- LOS ÁCIDOS NUCLEICOS
2.1.-INTRODUCCIÓN
La Biología Molecular es una ciencia cuyo objetivo fundamental es la
comprensión de todos aquellos procesos celulares, que contribuyen a que la
información genética se transmita eficientemente de unos seres a otros y se
exprese en los nuevos individuos.
Este conocimiento ha permitido cruzar barreras naturales entre especies y
integrar genes de cualquier organismo, en un organismo hospedador no
relacionado mediante el empleo de técnicas de ingeniería genética. Una de las
consecuencias importantes derivadas de esta tecnología fue la producción de
fragmentos de ácidos nucleicos a gran escala, abriendo las puertas a la
secuenciación de los ácidos nucleicos y por ende a nuevas disciplinas como el
diagnóstico molecular, la terapia génica o la obtención de organismos
superiores recombinantes.
Cronológicamente, podemos citar una serie de hitos que contribuyeron
decisivamente en su desarrollo: La historia de su conocimiento comienza en el
año 1866 cuando Mendel publica sus experimentos que conducen a los
principios de segregación y clasificación independiente de los genes. En 1869
el científico suizo Frederick Miescher descubrió en el núcleo de las células una
sustancia de carácter ácido a la que llamó nucleina. En los años 20, el químico
alemán Robert Feulgen, utilizando una tinción específica, descubrió que el ADN
estaba situado en los cromosomas. A partir de este descubrimiento todo
sucedió muy rápidamente. En 1944 Avery, McCleod y McCarty comprueban
que el ADN es el portador de la información genética. En 1953 Watson y Crick
revelan la estructura del ADN como una doble hélice complementaria que
recuerda la estructura de una escalera de caracol. A partir de entonces y de
manera exponencial, se suceden los descubrimientos (enzimas de restricción,
polimerasas, técnicas de electroforesis, hibridación, secuenciación, reacción en
cadena de la polimerasa etc. ) que conducirán a lo que se conoce como
tecnología del ADN recombinante.
2.2.-LOS ÁCIDOS NUCLEICOS
Podemos considerar el ADN o ácido desoxirribonucleico, como el cerebro
celular que regula el número y naturaleza de cada tipo de estructura y
composición celular, transmitiendo la información hereditaria y determinando la
estructura de las proteínas, y a través de enzimas determinará el resto de
funciones celulares. Las alteraciones en la estructura del ADN forman parte de
la patogenia de numerosas enfermedades, no solo del pequeño grupo de
enfermedades congénitas, sino también para gran parte de los trastornos de
mayor incidencia en la patología humana, como por ejemplo el cáncer.
Pero no solamente el ADN es importante. A finales del siglo diecinueve se
descubrió también la existencia de una segunda clase de ácido nucleico,
denominado ácido ribonucleico (ARN). El ARN se encuentra tanto en el núcleo
(concretamente en el nucleolo) como en el citoplasma de las células de manera
abundante y tiene múltiples funciones que describiremos más adelante
Ambos tipos de ácidos nucleicos, ADN y ARN, se encuentran simultáneamente
en organismos eucariotas (recordemos que son células de núcleo diferenciado,
o sea las de nuestro propio cuerpo) y procariotas (son organismos sin un
núcleo diferenciado como por ejemplo las
bacterias que poseen un
pseudonucleo), y sólo uno de estos ácidos nucleicos se encuentra en los virus.
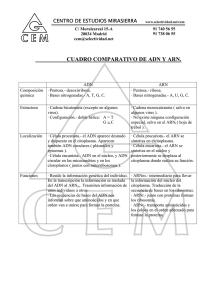
2.3.-COMPOSICIÓN DE LOS ÁCIDOS NUCLEICOS
Los ácidos nucleicos son polímeros de alto peso molecular constituidos por
unidades elementales denominadas "nucleótidos".
¿Qué es un nucleótido?
Los nucleótidos son los componentes elementales de los ácidos nucleicos y
cada uno de ellos está formado a su vez por tres componentes.
Molécula de pentosa + Base nitrogenada + ácido fosfórico
Molécula de pentosa
D- Ribosa, en el caso del ARN
D-2- desoxirribosa, en el caso del ADN
Base orgánica nitrogenada
Adenina, Guanina (bases púricas), Citosina y Timina (bases pirimidínicas) en el
caso del ADN. Adenina, Guanina (bases púricas), Citosina y Uracilo (bases
pirimidínicas) en el caso del ARN.
Grupos fosfato
Los nucleótidos se unen formando cadenas cuyo esqueleto está formado por la
unión entre el azúcar de un nucleótido y el fosfato del siguiente, quedando las
bases nitrogenadas en la parte central, unidas cada una al C1 del azúcar.
Estas bases son las que dan especificidad al ácido nucleico.
La unión entre la pentosa y la base nitrogenada se establece por un enlace
glucosídico, llamado N-glucosídico, entre el carbono 1 de la pentosa y el
nitrógeno 1 de una base pirimidínica, o el nitrógeno 9 de una base púrica, lo
que constituye un nucleósido.
La unión del ácido fosfórico y el nucleósido constituye un nucleótido. El enlace
entre ellos es de tipo éster y se establece en el carbono 5 de la pentosa.
Para no complicar la terminología a partir de ahora para representar cada uno
de los nucleótidos presentes en una cadena de ADN o ARN escribiremos las
iniciales de cada una de las bases específicas: A (nucleótido que lleva
adenina); G (nucleótido que lleva guanina); T (nucleótido que lleva timina); C
(nucleótido que lleva citosina) y U (nucleótido que lleve uracilo)
2.4.- ESTRUCTURA DEL ADN
Estructura primaria
La estructura primaria viene dada por la secuencia de nucleótidos. Cuando se
quiere representar la secuencia de un oligonucleótido o de un ácido nucleico,
se representa mediante la terminología de cada una de las bases. Por ejemplo:
5'-ATCCCAGCCCGATTAAAGCC-3'
Esta secuencia representa un oligonucleótido con 20 bases, de las cuales 6
son adeninas (A), 3 son timinas (T), 8 son citosinas (C) y 3 guaninas (G).
El orden de la secuencia es muy importante, ya que en él reside la información
contenida en el ácido nucleico; la orientación viene dada en el sentido 5' 3' ó 3'
5'; el 5' representa el extremo terminal del fosfato y el 3' el extremo final del
átomo de carbono de la desoxirribosa.
Estructura secundaria
Edwin Chargaff analizando las bases del ADN mediante métodos
cromatográficos descubre que éstas no se encuentran en la misma proporción
y que el número de adeninas es igual al de timinas y el de citosinas, al de
guaninas.
En 1953 James Watson y Francis Crick construyeron un modelo tridimensional
del ADN con la configuración más favorable energéticamente combinando los
datos obtenidos hasta entonces, los descubrimientos de Chargaff y la
interpretación tridimensional de los espectros de difracción de Rayos X; ésto
último fue de gran importancia para la consecución de tal modelo, el cual
consiste en una doble hélice antiparalela cuyo esqueleto fundamental está
formado por las cadenas de azúcar (pentosa)-fosfato, quedando en la
parte central las bases puricas y pirimidinicas, enfrentadas las de una
cadena con las de la otra complementaria y formando entre sí puentes de
hidrógeno, factor que da estabilidad a la doble hélice. El enfrentamiento de
bases es constante; la adenina siempre se enfrenta con la timina y entre sí se
forman dos puentes de hidrógeno, y la guanina con la citosina, formándose
entre ambas tres puentes de hidrógeno.
Esta característica provoca que las dos cadenas sean complementarias. Las
dos cadenas de la doble hélice tienen sentidos opuestos, mientras una va en
sentido 5' 3 ', la otra lo hace en sentido 3' 5'. Por eso hablamos del ADN como
una doble hélice antiparalela.
Estructuras terciaria y cuaternaria
Se refiere a cómo almacenar el ADN en un volumen reducido. Teniendo en
cuenta que la longitud de una hebra de ADN humano es de varios metros,
existe la necesidad de adoptar otras estructuras para poder permanecer en el
interior celular. Estas estructuras, terciaria y cuaternaria, permiten el
empaquetamiento del ADN formando los cromosomas. En las células
eucariotas existen varios cromosomas y en los procariotas existe un ADN
empaquetado denominado seudocromosoma.
El ADN humano contiene 6 mil millones de pares de bases de nucleótidos. Esto
representa por lo menos dos metros de cadenas de ADN. Aquellas cadenas
tienen que ser almacenadas dentro de ± 6 µ en el núcleo. Claramente
demasiado grande para caber en el núcleo. Hace falta pues un mecanismo que
permita almacenar las largas cadenas de ADN. Para ello los eucariotas utilizan
los nucleosomas. Un nucleosoma está constituido por una mezcla entre ADN y
unas proteínas denominadas histonas:
±200pb de ADN
2 moléculas de histona H2a
2 moléculas de histona H2b
2 moléculas de histona H32 moléculas de histona H4
1 molécula de histona H1
La cromatina de núcleos en interfase, cuando se observa mediante técnicas de
microscopia electrónica, se puede describir como un collar de cuentas o un
rosario, en el que cada cuenta es una subunidad esférica o globular que son
los nucleosomas y estos se hallan unidos entre sí mediante fibras de ADN. A
su vez, los nucleosomas se pueden enrollar helicoidalmente para formar un
solenoide (una especie de muelle) que constituye las fibras de cromatina de los
núcleos interfásicos con un diámetro aproximado de 300 Å. Los solenoides
pueden volverse a enrollar para dar lugar a supersolenoides con un diámetro
de 4.000 Å a 6.000 Å que constituirían las fibras de los cromosomas
metafásicos
Eucromatina y Heterocromatina
La cromatina se presenta en dos formas en el núcleo en interfase (que no está
en división) : Eucromatina y Heterocromatina y fueron originalmente llamadas
así por su diferente respuesta a la tinción.
La cromatina mayoritaria, que se tiñe débilmente se denominó eucromatina
(del griego eu, verdadero) y la que se tiñe de forma distinta, de manera más
fuerte, se llamó heterocromatina (del grigo hetero, diferente). El estudio
molecular detallado de ambas cromatinas ha permitido distinguirlas por otras
propiedades: así, la heterocromatina consta de fibras de nucleoproteína
(nucleofilamentos) muy condensadas, casi como los cromosomas en la mitosis
(lo cual impide la transcripción de los genes), se duplica de forma desfasada
(muestra un replicación tardía) con respecto a la eucromatina (que no se
encuentra condensada, y es activa en la expresión génica) y puede contener
secuencias extremadamente repetidas.
2.5.- ARN: ESTRUCTURA Y TIPOS
Está formado por la unión de muchos ribonucleótidos, los cuales se unen entre
ellos mediante enlaces fosfodiester en sentido 5´-3´( igual que en el ADN ).El
ARN generalmente está constituido por una sola cadena de nucleótidos,
aunque existen algunos virus que poseen ARN de doble cadena (reovirus).
2.5.1.- Estructura del ARN
Estructura primaria del ARN
Al igual que el ADN, se refiere a la secuencia de las bases nitrogenadas que
constituyen sus nucleótidos, con la excepción que en lugar de timina existirá
uracilo .
Estructura secundaria
Una misma cadena es capaz de plegarse y aparear
complementarias mediante enlaces de puentes de hidrógeno.
sus
bases
Estructura ternaria del ARN
Es un plegamiento, complicado, sobre la estructura secundaria.
2.5.2.- Tipos de ARNs
Es muy importante que sepamos los distintos tipos de ARNs, ya que cada uno
de ellos tiene una función muy importante en la síntesis de proteínas.
Existen varios tipos de ARN para cuya clasificación se adopta la masa
molecular media de sus cadenas, cuyo valor se deduce de la velocidad de
sedimentación. La masa molecular y por tanto sus dimensiones se miden en
svedberg (S). Según esto tenemos:
ARN mensajero (ARNm)
Sus características son la siguientes:
- Cadenas de largo tamaño con estructura primaria.
- Se le llama mensajero porque transporta la información necesaria para la
síntesis proteica desde el núcleo, donde copia al ADN, hasta el citoplasma.
- Cada ARNm tiene información para sintetizar una proteina determinada.
- Su vida media es corta.
Como en el ADN de donde debe de copiar toda la información, existen exones
(secuencias de bases que codifican proteínas) e intrones (secuencias sin
información). Un ARNm de este tipo ha de madurar (eliminación de intrones)
antes de hacerse funcional. Antes de madurar, el ARNm recibe el nombre de
ARN heterogeneonuclear (ARNhn ).
Las reacciones que transforman el ARN primario de transcripción en una
molécula de ARN maduro se conocen colectivamente como "procesamiento del
ARN". En general, los intrones de las moléculas de ARN se eliminan por
"splicing", que consiste en la escisión de las secuencias intrónicas y posterior
unión de las secuencias codificantes, por parte de proteínas y moléculas de
ARN que actúan como enzimas. Algunas de estas moléculas activas de ARN
están localizadas en los propios intrones.
ARN ribosómico (ARNr)
Sus principales características son:
- Cada ARNr presenta cadena de diferente tamaño, con estructura secundaria
y terciaria.
- Forma parte de las subunidades ribosómicas cuando se une con muchas
proteinas.
- Están vinculados con la síntesis de proteinas.
ARN nucleolar (ARNn)
Sus características principales son:
- Se sintetiza en el nucleolo.
- Posee una masa molecular de 45 S, que actúa como precursor de parte del
ARNr, concretamente de los ARNr 28 S (de la subunidad mayor), los ARNr 5,8
S (de la subunidad mayor) y los ARNr 18 S (de la subunidad menor)
ARNu
Sus principales características son:
- Son moléculas de pequeño tamaño
- Se les denomina de esta manera por poseer mucho uracilo en su composición
- Se asocia a proteinas del núcleo y forma ribonucleoproteinas pequeño
nucleares (RNPpn) que intervienen en:
a) Corte y empalme de ARN
b) Maduración en los ARNm de los eucariontes
c) Obtención de ARNr a partir de ARNn 45 S.
ARN transferente (ARNt)
Sus principales características son.
- Son moléculas de pequeño tamaño
- Poseen en algunas zonas estructura secundaria, lo que va hacer que en las
zonas donde no hay bases complementarias adquieran un aspecto de bucles,
como una hoja de trebol.
- Los plegamientos se llegan a hacer tan complejos que adquieren una
estructura terciaria
- Su misión es unir aminoácidos y transportarlos hasta el ARNm para sintetizar
proteinas.
Identifica el lugar exacto para colocarse en el ARNm gracias a tres bases, a
cuyo conjunto se llaman anticodón (las complementarias en el ARN m se
llaman codón).
2.6.- FUNCIONES DE LOS ÁCIDOS NUCLEICOS
Las funciones biológicas del ADN incluyen el almacenamiento de información
(genes y genoma), la codificación de proteínas (transcripción y traducción)
y su autoduplicación (replicación del ADN) para asegurar la transmisión de la
información a las células hijas durante la división celular. En el caso de ARN,
aunque tiene información propia, su función más importante consiste en la
conversión de la información contenida en el ADN en proteínas
específicas.
Replicación del ADN
Como dijimos anteriormente, el ADN está formado por dos hélices
complementarias unidas por enlaces débiles de puentes de hidrógeno. Estos
enlaces pueden romperse y volverse a formar simplemente calentando y
enfriando. A estos procesos se les llama respectivamente desnaturalización y
renaturalización del ADN.
Partiendo de este concepto y de manera muy esquemática, la replicación del
ADN en la naturaleza consiste en:
1.Separación de las dos cadenas que forman la doble hélice, de lo cual se
encargan enzimas y proteínas que se encuentran en la célula eucariótica.
2.Unión de los cebadores ('primers' o iniciadores) de ARN en una de las hebras
separadas.
3.Unión de una polimerasa (proteína con actividad enzimática que se encarga
de copiar ADN mediante la introducción de nucleótidos siguiendo a un molde) a
los lugares donde se encuentra el "primer" para comenzar a copiar de manera
progresiva la hebra de ADN, ya que la polimerasa necesita un cebador o
iniciador que va a formar un dúplex y le va a indicar dónde comenzar, por ser
incapaz de copiar ADN monocatenario. El sentido de la síntesis va siempre de
5' a 3'.
4.Formación de las nuevas copias siempre formadas por una hebra madre y
otra hija, por lo que al proceso se le denomina replicación semiconservativa del
ADN.
De esta forma, de un ADN parental, tras su replicación, se obtienen dos
moléculas hijas exactamente iguales.
Horquilla replicativa del ADN con todas las enzimas implicadas en la síntesis. Es necesaria la
existencia de un "primer" para que la ADN polimerasa de E. coli inicie cadenas de novo. Este
"primer" es proporcionado por una ARN polimerasa llamada primasa, la cual en asociación con
un complejo de proteínas llamado primosoma sintetiza una cadena corta de ARN. La ADN
polimerasa III puede utilizar este "primer" para continuar la síntesis de ADN. Una proteína
llamada helicasa (originalmente llamada rep) es necesaria para desenlazar y abrir la hélice de
ADN para permitir la replicación. Las proteínas de enlace a ssADN se encargan de estabilizar
las regiones de simple cadena que se forman transitoriamente durante el proceso de
replicación. La ADN polimerasa puede sintetizar ADN en la dirección 5' hacia 3', por lo que una
de las hebras debe ser sintetizada discontinuamente, esto lleva a la formación de cortas
cadenas de ADN con huecos entre ellas que deben ser completados por la acción de la ADN
polimerasa I y unidos por la acción de una ADN ligasa.
Transcripción y traducción en proteínas
¿Cómo hace una molécula de ADN para codificar una proteína?
De una manera resumida lo describiríamos de la siguiente forma: Una
determinada secuencia del ADN que se encuentra en el núcleo (equivaldría a
un gen), es copiada a ARNm (transcripción). Este ARNm se desplazará al
citoplasma para situarse en los ribosomas y convertirse en una proteína
(traducción). Para ello va a necesitar que los diferentes ARNt vayan
transportando aminoácido tras aminoácido (recordemos que los aminoácidos
son los componentes elementales de las proteínas), para anclarlos siguiendo la
secuencia que dicta el ARNm. Cada ARNt transporta un aminoácido y tiene en
su extremo un anticodon (tres nucleótidos específicos) que se va a anclar en un
codón complementario del ARNm de manera secuencial..
Transcripción: La información del ADN es transferida al ARNm, que es
sintetizado utilizando como molde el ADN original y dirigido por la holoenzima
llamada ARN polimerasa. Este ARNm será transportado desde el núcleo a los
ribosomas que se encuentran en el citoplasma.
Traducción: La factoría celular responsable de la síntesis de proteínas es el
ribosoma formado por proteínas y ARN ribosomal. La molécula especifica que
va a trasladar los aminoácidos (componentes elementales de las proteínas)
siguiendo las pautas dictadas por el ARNm es el ARNt. Cada ARNt tiene un
anticodon especifico (formado por tres bases).
Una proteína cargada denominada aminoacil tARN sintetasa es la encargada
de unir el aminoácido correcto correspondiente al anticodon a una posición de
anclaje. De esta manera, a partir de una señal de iniciación en el ARNm (codon
ATG), comienza la síntesis y el primer aminoácido transportado por el ARNt y
correspondiente a este codon es la metionina. Este primer paso se denomina
iniciación de la traducción y tiene lugar en una posición concreta del ribosoma
denominada aminoacil (A). Posteriormente este ARNt junto con su aminoácido
correspondiente salta a una posición contigua denominada peptidil (P) y llega
un nuevo ARNt con el correspondiente aminoácido para anclarse en su codon y
se sitúa en la posición A que ha quedado libre. Entre ambos aminoácidos se
establece una unión peptídica y el ARNt de la posición P es liberado,
comenzando el proceso de nuevo. Este proceso de elongación continua hasta
llegar a un codon de parada.
Una vez sintetizada la proteína puede sufrir modificaciones postranscripcionales (cortes por enzimas proteolíticas, fosforilaciones,
glicosilaciones etc...
2.7.- ALTERACIONES GENETICAS. LAS MUTACIONES
Las mutaciones son simplemente cambios en el ADN. Para comprender el
significado de las mutaciones tenemos que comprender como hace su trabajo
el ADN. El ADN humano contiene instrucciones para formarnos. Estas
instrucciones están inscritas en la estructura de la molecula de ADN a través de
un código genético.
La descripción de su funcionamiento de manera
simplificada es la siguiente:
Como hemos explicado al principio del capítulo, el ADN está formado por una
cadena de pequeñas unidades denominadas nucleotidos y que representamos
por el tipo de la base : A (adenina),G (guanina) , C (citosina) y T (timina).
Según la secuencia de estas bases se codifican instrucciones. Una parte de
nuestro ADN son centros de control para activar o desactivar genes, otra parte
no tienen función o desconocemos cual es esta todavía y finalmente otra parte
son los genes que dan las instrucciones para fabricar proteínas (son cadenas
largas de unidades elementales denominadas aminoácidos). Estas proteínas
ayudan a formar el organismo.
El ADN que codifica proteínas está dividido en codones. Como hemos descrito
anteriormente un codón consiste en tres bases que son específicas para un
aminoácido (hay 20 aminoácidos diferentes) . Los codones son identificados
por las bases que llevan, por ejemplo el codón GCA corresponde al aminoácido
Alanina. La maquinaria celular hará que se vayan ensamblando aminoácidos
siguiendo las instrucciones dictadas por los codones hasta formar una proteína.
También hay un codón de parada que indica que ya no se debe añadir ningún
aminoácido más ya que la proteína está formada. Una vez sintetizada esta
proteína siguiendo la secuencia de bases dictada por el gen correspondiente,
esta es liberada al medio celular para realizar su función.
Un gen es una entidad estable, pero puede sufrir un cambio en su secuencia. A
ese cambio se le llama mutación.
2.7.1.- Tipos de mutaciones según el mecanismo causal
Hay tres tipos de mutaciones según el mecanismo que ha provocado el cambio
en el material genético: mutaciones cromosómicas; mutaciones génicas o
moleculares y mutaciones cariotípicas o genómicas.
Mutaciones cromosómicas: Producen cambios en la estructura interna del
cromosoma.
· Translocaciones: Implican un intercambio de grandes fragmentos de ADN
entre dos cromosomas diferentes. Las translocaciones se producen cuando
dos cromosomas no homólogos intercambian segmentos cromosómicos.
· Inversiones: Aparecen cuando una región del ADN cambia su orientación
respecto al resto del cromosoma. Para que se produzca este suceso es
necesario una doble rotura y un doble giro de 180º del segmento formado por
las roturas. Hay dos tipos de inversiones según su relación con el centrómero:
Pericéntricas: Incluyen al centrómero. Se detectan fácilmente al microscopio
óptico pues implican un cambio en la forma del cromosoma.
Paracéntricas: No incluyen al centrómero y por tanto tampoco afectan a la
forma del cromosoma.
. Inserción: Un fragmento de uno de los cromosomas se inserta en el otro
cromosoma.
· Delecciones: Perdida de algún fragmento del cromosoma. Un individuo es
portador de una deleción cuando le falta un segmento cromosómico, si este segmento
es un extremo del cromosoma, la alteración se denomina deficiencia. Si la deleción es
muy grande es visible al microscopio óptico ya que el cromosoma presenta menor
tamaño del normal
. Duplicación: Las duplicaciones surgen cuando un segmento cromosómico se replica
más de una vez por error en la duplicación del ADN, como producto de una
reorganización cromosómica de tipo estructural (ver más adelante inversiones y
translocaciones), o relacionado con un proceso de sobrecruzamiento defectuoso.
Mutaciones moleculares o génicas: Son aquéllas que producen
alteraciones en la secuencia de nucleótidos de un gen. Existen varios tipos
Sustituciones de pares de bases:
- Transiciones: Es el cambio en un nucleótido de la secuencia del ADN de una
base púrica por otra púrica o de una base pirimidínica por otra pirimidínica.
Original : AGC CCC CGT
Mutado: AGC CGC CGT
- Transversiones: Es el cambio de una base púrica por una pirimidínica o
viceversa.
Original: AGC CCC CGT
Mutado: AGC CCC TGT
Pérdida o inserción de nucleótidos. Este tipo de mutación produce un
corrimiento en el orden de lectura. Pueden ser:
- Adiciones génicas: Es la inserción de nucleótidos en la secuencia del gen.
Original: AGC CCC CGT
Mutado: AGC GAC CCC GT
- Deleciones génicas: Es la pérdida de nucleótidos en la secuencia del gen.
Original: AGC CCC CGT
Mutado: AGC CC
GT
Las sustituciones provocan la alteración de un único triplete y, por tanto, salvo
que indiquen un triplete de parada, o un aminoácido del centro activo de una
enzima, no suelen tener grandes efectos sobre la proteína codificada, pues
afectan a un único aminoácido y la proteína seguirá pudiendo realizar la misma
función. Sin embargo, las mutaciones que impliquen un corrimiento en el orden
de lectura, adiciones o deleciones, salvo que se compensen entre sí, pueden
alterar la secuencia de aminoácidos de la proteína codificada a partir del punto
donde se produjo la mutación y sus consecuencias suelen ser graves, pues
todos los aminoácidos de la secuencia proteica a partir de dicho punto serán
diferentes.
Veamos un ejemplo
Supongamos la frase inglesa siguiente y supongamos que cada palabra es un
codón.
THE FAT CAT SAT (el gato gordo se sentó)
Si nosotros quitamos la primera letra y corremos una posición nos queda
THEF ATC ATS AT
Que no significa absolutamente nada. Igual ocurre en el ADN cualquier adición o
delección provocaría un desplazamiento de los codones y por lo tanto cada uno
de ellos codificaría un aminoácido diferente y por ende una proteína truncada sin
sentido
Mutaciones genómica:
En este grupo englobaríamos a todas aquellas variaciones del número de los
cromosomas como son la aneuploidia (alteración de la cantidad de uno de los
cromosomas homólogos); poliploidia (aumento del número normal de juegos de
cromosomas) y haploidia (mutaciones que provocan la disminución en el número
de juegos de cromosomas).
2.7.2.- Causa de las mutaciones
Las mutaciones son provocadas por varias causas
-
Fallo del ADN al copiarse. Cuando la célula se divide, durante su
proceso de replicación y está copiando su ADN, a veces esa copia no es
lo suficientemente perfecta. Una pequeña diferencia respecto a la
secuencia original es una mutación. Tales errores ocurren con una
probabilidad de 10-7 en células haploides y de 10-14 en células diploides.
-
Influencias externas: Las mutaciones pueden ser causadas por la
exposición a agentes químicos, biológicos o radiaciones. . Estos agentes
causan roturas en el ADN. Estas roturas normalmente son reparadas por
mecanismos de reparación de la propia célula, pero a veces esto no es
posible porque o bien el mecanismo de reparación es defectivo o no es
activado, y esto genera un ADN diferente al original y por lo tanto una
mutación.
Como mutágenos químicos podemos citar los análogos de bases del ADN
(como la 2-aminopurina), que son moléculas que se parecen a las bases
púricas o pirimidinicas pero que muestran propiedades de apareamiento
erróneas). También están los agentes alquilantes (como la
nitrosoguanidina), que reacciona directamente con el ADN originando
cambios químicos en las bases y produciendo también apareamientos
erróneos; y por último están los agentes intercalantes (como las
acridinas), que se intercalan entre dos pares de bases del ADN,
separándolas entre si.
Como mutágenos biológicos podemos considerar determinados virus o la
existencia de pequeños fragmentos de ADN llamados transposones. La
forma que tienen ambos de provocar la mutación consiste en integrase
en puntos concretos del genoma o bien aleatoriamente, cambiando la
información del ADN.
Como agentes que generan mutación a través de la radiación tenemos
los que causan radiaciones ionizantes como los rayos X; los rayos
cósmicos o los rayos gamma y los que causan radiaciones no ionizantes
como la radiación ultravioleta. Las primeras se originan por los radicales
libres que reaccionan con el ADN inactivándolo y las segundas aparecen
como consecuencia de la formación de dímeros de pirimidina en el ADN.
Finalmente están los ROS (Reactive oxygen especies) que se forman a
partir de radiaciones inonizantes o de la actividad enzimática normal.
Como ejemplos podemos citar los radicales hidroxilos, peróxido de
hidrogeno y el radical superoxido, todos ellos muy reactivos y dando lugar
a mutaciones
2.7.3.- Efectos de las mutaciones
Cuando hablamos de mutación siempre pensamos en algo fatal y no siempre
es así. Nuestro medio sufre cambios constantes y nosotros debemos cambiar
con él. Uno de los mecanismos de cambio es a nivel del ADN. Las mutaciones
pueden dar lugar a nuevos genes y funciones que adapten nuestro organismo
a los cambios del medio ambiente en el que vive. La selección natural hará que
sobrevivan solo aquellos seres que hayan sido capaces de adaptarse al nuevo
medio.
Las mutaciones pueden producirse tanto en células somáticas como en células
germinales, en estas últimas tienen mayor transcendencia. Las mutaciones sólo
son heredables cuando afectan a las células germinales. Si afectan a las células
somáticas se extinguen por lo general con el individuo, a menos que se trate de
un organismo con reproducción asexual. Las mutaciones pueden ser: naturales
(espontáneas) o inducidas (provocadas artificialmente con radiaciones,
sustancias químicas u otros agentes mutágenos).
Efectos de las mutaciones en las líneas germinales:
1.- No aparecen cambios en el fenotipo: puede ser porque la mutación tiene
lugar en una zona de ADN que no tiene ninguna funcionalidad; o bien tiene lugar
en una región que codifica a una proteína pero no afecta a la secuencia de
aminoácidos de esa proteína.
2.- Aparición de pequeños cambios en el fenotipo: Por ejemplo mutación que
hace que las orejas de algunos individuos acaben de forma puntiaguda.
3.- Grandes cambios en el genotipo: Un ejemplo seria la aparición de insectos
resistentes a insecticidas como el DDT. También hay mutaciones de este tipo
que pueden causar la muerte del organismo.
2.8.- Mecanismos de reparación del ADN
Las células poseen múltiples mecanismos para reparar los genes dañados por
las mutaciones y restaurar la información perdida. Las células utilizan la cadena
de ADN complementaria (si no ha sido modificada) o la cromátida hermana
como "plantilla" para restaurar la información original. Si no hay ninguna
plantilla disponible, las células utilizan como último recurso un sistema de
recuperación propenso a los errores conocido como síntesis de translesión.
Las células tienen distintos sistemas de detectar los daños provocados por las
mutaciones, uno de ellos está basado en la alteración, tras la mutación, de la
configuración espacial de la doble hélice de ADN. Este cambio topológico
implica la adherencia de moléculas reparadoras específicas del ADN, que se
adhieren al punto dañado o cerca de él, induciendo a su vez a otras moléculas
a adherirse y formar un complejo que permite la reparación. Los tipos de
moléculas implicados y el mecanismo de reparación que se utiliza depende del
tipo de daños que haya sufrido el ADN y de la fase del ciclo celular en que se
encuentre la célula.
2.8.1.- Inversión directa
Eliminan los daños en el ADN provocados en una sola base invirtiéndolos
químicamente, por lo que estos mecanismos no requieren una plantilla de ADN,
Uno de las mutaciones más conocidas es la de dímeros de timina (unión de
dos timinas adyacentes ) después de irradiación con luz ultravioleta. La
reparación se realiza mediante el proceso de fotorreactivación, el cual
invierte directamente este daño mediante la acción de la enzima fotoliasa, la
activación depende necesariamente de la energía absorbida de la luz azul/UVA
(longitud de onda de 300-500Nm) para promover la catálisis. Otro tipo de daño
es la metilación de bases de guanina (unión de un grupo –CH3) haciéndolas
irreconocibles. Este proceso es directamente revertido por la proteína
metilguanina metil transferasa (MGMT). Se trata de un proceso exigente en
recursos, pues cada molécula de MGMT sólo se puede utilizar una vez.
También existen mecanismos de reparación para las metilaciones de las bases
citosina y adenina.
2.8.2.- Daños en una de las cadenas
Cuando sólo una de las dos cadenas de la doble hélice tiene un defecto, la otra
puede ser utilizada como plantilla para dirigir la corrección de la cadena
dañada. Para reparar daños a una de las moléculas pareadas de ADN, existen
varios mecanismos de reparación de escisiones, que eliminan el nucleótido
dañado y lo sustituyen con un nucleótido intacto complementario al que se
encuentra en la cadena de ADN no dañada. Entre los métodos de reparación
existen:
Reparación por escisión de base; Se elimina el nucleótido con la base mutada y
se introduce el nucleótido correcto uniéndolo con los nucleótidos adyacentes.
Este proceso repara daños por alquilación o por radiación ionizante. Esta
reparación es compleja y en el proceso intervienen ADN glicosilasas específicas
para cada una de las bases alteradas, AP endonucleasas (APE1 específica de
humanos), fosfodiesterasas, la ADN polimerasa beta y la ADN ligasa.
Reparación por escisión de nucleótido: Este proceso repara el ADN que se
encuentra distorsionado espacialmente debido a la presencia de bases
modificadas con grandes grupos químicos, dímeros de pirimidina o uniones
intracadena. Este tipo de daño suele producirse por agentes químicos o por
radiación ultravioleta
Reparación de mal apareamiento: En este caso las diferencias en la metilación
de una cadena con respecto a la otra sirven para detectar fallos de replicación.
Intervienen proteínas que cuando detectan cadenas hemimetiladas, retiran el
nucleótido incorrecto e introducen el correcto. Este tipo de proceso de reparación
del ADN puede ir acoplado a la replicación del ADN
2.8.3.- Daños a cadena doble
Las roturas de cadena doble, en el que ambas cadenas de la doble hélice
quedan rotas, son especialmente peligrosos para la célula, ya que pueden
provocar problemas en el genoma. Existen dos mecanismos que reparan estas
roturas: la unión de extremos no homólogos (NHEJ del inglés Non-homologous
DNA End Joining) y la reparación recombinativa (también conocida como
reparación asistida por plantilla o reparación de recombinación homóloga).