Presentación
Anuncio

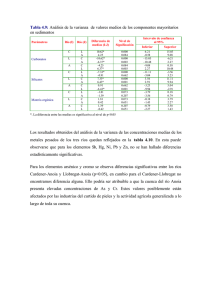
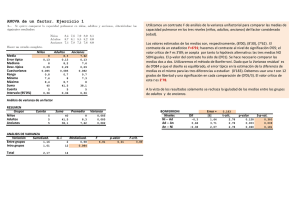
Repaso de Conceptos Estadísticos Básicos CONCEPTOS PREVIOS: PARÁMETROS: Valores que definen la distribución de una o más variables en una población. Se representan con caracteres griegos Ejemplos: Media μ, Varianza σ2, Coeficiente de regresión ρ ESTADÍSTICOS: Valores que definen la distribución de una o más variables en una muestra. Se representan con caracteres latinos. Ejemplos: Media , Varianza s2, Coeficiente de regresión b Se utilizan como estimadores de los parámetros de la distribución poblacional Inferencia: Descripción de características (parámetros, por ejemplo) de una población a partir de una muestra Estimación: De un parámetro poblacional con un estadístico muestral Método de estimación: Procedimiento para obtener un estimador Ejemplos: Mínimos cuadrados Máxima verosimilitud. Distribución muestral de un estimador: Es la distribución que se obtendría con los valores del estimador (estadístico) de un número infinito de muestras extraídas de la población en la que se estima el parámetro. Ejemplo: Distribución muestral de las medias, es la distribución de infinitas medias maestrales Sesgo Diferencia entre el valor medio de la distribución muestral de un determinado estimador y el parámetro que estima Ejemplo: N~ ∞ muestras de tamaño n, extraídas de una población Distribución muestral de las medias: Media= media de todas las medias muestrales = media paramétrica= x x =µ→ Es mador insesgado Distribución muestral de las varianzas: Seudovarianza xs 2 La varianza muestral es: s2 xs 2 2 x x n 2 2 → Estimador 2 Sesgado x x 2 s Seudovarianza n 1 → Insesgado Precisión de una estimación (error típico) Es la desviación típica de la distribución muestral del estimador. Ejemplo: Si la varianza de la distribución muestral de las medias es La precisión de error típico de la media de una muestra (como estimador de µ) es 2 x que se estima con n n s2 s n n s x La precisión de la estima ^ xs X Es s X Estimación por intervalo: Es la estimación de un valor paramétrico obtenida con una probabilidad dada (α) de que dicho valor se encuentre entre un máximo y un mínimo determinados. Ejemplo: El intervalo de confianza del valor paramétrico.de la media con un α=0,05 (95% de probabilidad) es (si el tamaño muestral n es grande): x 1,96 S x , x 1,96 S x Porque en el intervalo comprendido entre 1,96 σ por encima y por debajo de la media μ de una distribución normal se encuentran el 95% de las observaciones. A α se le denomina nivel de significación Muy frecuentemente la inferencia estadística; es decir, la estima de valores paramétricos a partir de una muestra se hace mediante una Prueba o Contraste de Hipótesis Para poder probar las hipótesis hay que realizar varios pasos previos: 1) Lo primero es decidir cual es la variable que puede cuantificar el carácter y poner de manifiesto el factor expresado en la hipótesis, que solo se podrá observar a partir de sus manifestaciones 2) Lo segundo es decidir cual es el modelo que explica la variabilidad de la variable elegida, es decir, cual es la población de esta variable 3) El tercer paso es traducir la hipótesis planteada al lenguaje estadístico, lo que implica la elección del estadístico de prueba 4) El cuarto paso es tomar la muestra y decidir las regiones de aceptación (Ho) y rechazo (Ha) de la hipótesis 5) El quinto paso es establecer la rebla de decisión y la probabilidad de error (nivel de significación) Una hipótesis estadística es una afirmación sobre un modelo probabilístico (población) que una vez asumido, la única o únicas constantes desconocidas son los parámetros de la distribución (población) correspondiente Una prueba de hipótesis es un método para dictaminar sobre la probabilidad de esa afirmación, usando muestras como instrumento Para probar una hipótesis estadística se divide el espacio de valores posibles del parámetro, en el que se esta interesado, en dos subconjuntos; uno de ellos es el espacio definido por la hipótesis nula que constituirá la región de aceptación y el otro espacio es el definido por la hipótesis alternativa que constituirá la región de Rechazo Una vez tomada la muestra se decide que, con ciertas probabilidades de error,el parámetro en cuestión pertenece a uno de esos dos subconjuntos. Pero no existe certeza de que no se cometerá un error Ejemplo del examen tipo test con diez preguntas y cinco posibles respuestas. Cada pregunta se puede considerar una repetición del experimento. Se trata de un experimento que se ajusta a una distribución Binomial donde, si se llama éxito (variable X) a un acierto del alumno , el parámetro de la distribución es p, la probabilidad de un acierto. Por lo que se tiene que decidir sobre al magnitud de p, para ello se puede adoptar la hipótesis de que el alumno no conoce la materia, o hipótesis nula (Ho). y simplemente trata de adivinar la respuesta por puro azar. Traducido al lenguaje probabilístico, se tiene una función de probabilidad binomial con p=1/5; mientras que A pretende que su p es mayor de 0.2. Se tiene, entonces, una partición natural del espacio de posibles valores para p. Los valores de p ≤ 0.2, corresponden a la hipótesis H0, mientras que los valores p>0.2 corresponden a la hipótesis alternativa de que el alumno si la conoce (Ha). La distribución de probabilidades de X depende del valor de p. Se rechaza Ho si el alumno acierta más veces que las que acertaría diciendo al azar un número del 1 a 5 Al tomar una decisión se puede estar errando de dos maneras: decidiendo que el alumno conoce la materia cuando no la conoce o decidiendo que no conoce la materia cuando si la conoce. Estadísticamente: se puede rechazar la Ho cuando es cierta y se puede no rechazar la Ho cuando es falsa. α = P(Error Tipo I) = P(rechazar la Ho cuando es cierta) β = P(Error Tipo II) = P(aceptar la Ho cuando es falsa) Si δ(p) = P(rechazar Ho cuando el verdadero valor del parámetro es p), para todos los valores de p en la Ho δ(p) = Probabilidad de Error Tipo II = β y para todos los valores de p en la H1 d(p) = 1 - Probabilidad de Error Tipo II =1- β Puesto que δ(p) es la probabilidad de rechazar una hipótesis dada, dependiendo del verdadero valor del parámetro, se la llama función de potencia de la prueba. Prueba de hipótesis sobre la media de una distribución normal La media de la distribución muestral de las medias es una variable con la siguiente distribución: Si se quiere contrastar una hipótesis Porque la región de rechazo es O bien Siendo Si la muestra es pequeña Este es un contraste de hipótesis relativo a la media para la cola derecha: De forma similar sería para la cola izquierda: Y para las dos colas: En la tabla de valores de t el valor para un contraste de medias de una cola para gl=9 y α =0,05 es 1,8331, por tanto para el contraste de cola izquierda Comparación de las medias de dos grupos de observaciones La media de la distribución muestral de la diferencia de las medias es: Ejemplo de comparación de medias mediante una prueba t de Student y mediante un ANOVA de un factor (Ejemplo1) Datos: G1 6 9 8 7 G2 5 3 4 3 Resultados: t-Student = 4,666 P≤0,003 ANOVA 1 Factor Origen Var. Suma de cuadrados Inter-grupos 28,125 Intra-grupos 7,750 Total 35,875 gl 1 6 7 F=t2 Media cuadrática F P≤ 28,125 21,774 0,003 1,292 Comparación de más de dos medias: ANOVA de 1 Factor (Ejemplo2) Datos: G1 G2 6 5 9 3 8 4 7 3 Cálculos: G3 1 3 2 1 Grupos Gi para i = (1,2,3) Número de grupos g = 3 Número de observaciones por grupo n=4 Número total de observaciones: N = g*n = 12 G1→ x11 = 6 x12 = 5 x13 = 1 G2→ x12 = 9 x22 = 3 x23 = 3 x32 = 4 x33 = 2 G3→ x31 = 8 G4→ x41 = 7 x42 = 3 x43 = 1 Suma de las observaciones de cada grupo: x1 30; x2 15; x3 7 Medias de los grupos: x1 7, 5; x 2 3, 75; x 3 1, 75 Media general: x x .. 4, 333.... Suma de cuadrados: Suma de cuadrados total sin corregir por la media: Es la suma de los cuadrados de todas las observaciones No se puede mostrar la imagen en este momento. Suma de cuadrados total corregida por la media: Es la suma de cuadrados total a la que se le resta el término de corrección (T.C.): No se puede mostrar la imagen en este momento. No se puede mostrar la imagen en este momento. El término de corrección es: No se puede mostrar la imagen en este momento. = Suma de cuadrados de la media Suma de los cuadrados de las medias de los grupos referida a la suma de cuadrados de la media → Es la suma de cuadrados “entre grupos”: 2 SCG x i ( x i )2 g 2 xi2 ( x ..) 293, 5 n gn Resto = Suma de cuadrados Residual o del Error → Es la suma de cuadrados “intragrupos”: SC I SC Re sidual SC Error SCTC SCG 10, 5 Las sumas de cuadrados son aditivas: SCT SCG SC I Grados de libertad: Dependen de los tamaños muestrales g.l. “Entre Grupos” = Nº Grupos -1 = 3-1 = 2 g.l. “Intra Grupos” = Nº Grupos * (Tamaño Grupo -1) = g (n-1) = 3*(4-1) = 9 g.l. Totales = Nº Observaciones -1 = 12-1 = 11 Cuadrados medios o medias cuadráticas: -Entre grupos: CM G SCG 97, 833 2 -Intra grupos, residual o error: F CM G 97, 833 83, 857 1,167 CM residual CM I CM Re sidual SC Re sidual 1,167 9 F es un estadístico cuya distribución muestral es una “F de Snedecor” Buscando en la tabla de valores de la F de Snedecor los correspondientes a 2 g.l. (numerador) y 9 g.l. (denominador) α Valores de F Probalidad de 0,1 F=3,01 encontrar un 0,05 F=4,26 azar 0,01 F=8,02 0,005 F=10,11 Todos son menores que F= 29,26, lo que quiere decir que el valor de F encontrado tiene una probabilidad de haber salido por azar y no porque pertenece a la distribución F correspondiente a la hipótesis nula de igualdad de varianzas. Es, por lo tanto, un valor correspondiente a un cociente de varianzas diferente se la unidad y, consecuentemente, entre las medias comparadas EL MODELO LINEAL ADITIVO: Las observaciones del ejemplo anterior se pueden expresar con el siguiente modelo: x ij i ij 2 2 estimado por x x 3, 75 4,33 0,58 2 - 1 1 - estimado por x1 - x 7,5 - 4,33 3,17 3 3 estimado por x 3 x 1, 75 4,33 2, 58 Los ij son xij i Ejemplo, para la primera observación: 11 5 4, 33 ( 0, 58) 1, 25 i 0 Lo que significa que las medias de los distintos grupos son iguales, ya que, por ejemplo: 1 2 2 1 2 0 ALGUNOS MODELOS DE ANOVA A) ANOVA de 1 FACTOR –ModeloI Modelo: (Factores fijos) xij i ij O.V. g.l. Entre grupos a 1 a Intra grupos (error o residual) ni a C.M.E. Estima___ a res no ai2 2 res 2 a Total ni 1 a 2 i n 1 a ni a , siendo a el número de grupos. Si ni igual no a 1 en todos, n0=n i n Si se considera un modelo de efectos fijos, los cuadrados medios estiman: CM I Estima I2 g CM G Estiman n i2 2 I i i son los efectos de los grupos (diferencias entre las medias paramétricas de cada grupo y la media paramétrica general) En este caso, podemos comparar medidas: Para saber si i son diferentes de cero –Contraste de hipótesis-se comparan los dos C.M., ya que: 2 2 CM G I n i F CM I I2 nos permite saber si los valores i son significativamente diferentes de cero DISEÑO EXPERIMENTAL Cuando se quiere contrastar una determinada hipótesis, es necesario plantear un diseño experimental adecuado. El diseño experimental es la manera de elegir las muestras y establecer los grupos que van a servir para realizar el contraste de la hipótesis. El diseño experimental va a permitir generar los resultados experimentales (datos) con los que, siguiendo un determinado modelo, se pueden realizar los contrastes de hipótesis. Cuando se quieren hacer contrastes de hipótesis relativos a la comparación de las medias de varios grupos entre sí, o relativos a la comparación de las varianzas de dichos grupos, recurrimos a los modelos lineales aditivos como el que hemos visto anteriormente. La solución de estos contrastes de hipótesis se obtiene mediante el análisis de varianza. Este análisis de varianza se denomina “unifactorial”, porque solamente existe un factor de clasificación de las observaciones. Existen otros contrastes de hipótesis posibles y, por lo tanto, otros modelos lineales, como los que veremos a continuación. El ANOVA anterior, de efectos fijos, da lugar a una descomposición de la suma de cuadrados total de una variable en dos componentes, intra y entre grupos. Los cuadrados medios correspondientes estiman la varianza residual (varianza de las observaciones) y el efecto debido a la diferencia entre las medias de los grupos, respectivamente. Nos sirve para comparar las medias de más de dos grupos. El ANOVA sirve también para estimar componentes de varianza, cuando el factor de clasificación de los grupos que se está considerando es aleatorio. En este caso el cuadrado medio entre grupos no estima el efecto debido a la diferencia de las medias, si no la varianza entre ellas. La naturaleza fija o aleatoria de un factor de clasificación no es una propiedad intrínseca de dicho factor si no una propiedad asignada a dicho factor en el diseño experimental que, a su vez, es consecuencia de la hipótesis que se está contrastando. Así, por ejemplo, se pueden estar contrastando la diferencia entre tres líneas consanguíneas de animales (o tres líneas puras de plantas) concretas, elegidas a propósito (factor línea fijo), para comparar sus medias, o se pueden haber elegido esas tres líneas al azar en un conjunto de líneas para saber si hay una varianza asociada al factor línea (factor aleatorio) y cuantificarla. A) ANOVA de 1 FACTOR –Modelo II Modelo: (Factores aleatorios) x ij i ij C.M.E. estima res 2 no a2 res 2 ^` COMPONENTES DE LA VARIANZA: res 2 sres 2 CMresidual C.M .ERROR C.M .GRUPOS C.M .ERROR sa no ^ 2 a % VARIACIÓN ENTRE GRUPOS: %VARIACIÓN INTRA GRUPOS: 2 sa2 *100 2 2 sres sa sres 2 *100 2 2 sres sa En el ejemplo anterior ^ 2 s2 C.M .ERROR1,167 C.M .GRUPOS C.M.ERROR 97,833 1,167 sa no 4 ^ 2 a 2 24,167 2 Varianza total: 2 2 2 Total a i 24,167 1,167 25,334 % VARIACIÓN ENTRE GRUPOS: sa2 24,167 *100 *100 95,39% 2 2 25,334 s sa %VARIACIÓN INTRA GRUPOS: sres 2 1,167 *100 *100 4,61% 2 2 sres sa 25,334 B) ANOVA MULTIFACTORIAL: Ejemplo de ANOVA de dos factores (diseño equilibrado) COLUMNAS(C) FILAS (F) (factor A) n n n n n n n n n n n n n n n n n n n n (factor B) C= nº filas f= nº columnas n= número de observaciones por casilla o subgrupo ModeloI Yijk i j ij ijk Fijo O.V. g.l. CME f-1 nf c 2 c 1 Entre columnas c-1 nc f 2 f 1 Interacción (f-1) (c-1) Entre filas Error fc(n-1) 2 2 2 2 n c 1 f cf 1 2 ModeloI I Yijk Ai B j AB ij ijk Aleatorio CME Entre filas n AB nf A Entre columnas 2 n AB 2 nc B 2 2 2 Interacción n Error 2 2 2 AB 2 Modelo mixto Yijk Ai j A ij ijk CME Entre filas c nf 2 2 n 2 B c 1 Entre columnas 2 nc 2 B Interacción n Error 2 2 2 B SIGNIFICADO DE LOS EFECTOS Y DE LAS INTERACCIONES: Factor B columnas (C) Niveles B1 B2 A1 Factor A filas (f) Media marginal A1 A2 A2 B1 B2 (B2-B1)1 (B2-B1)2 _______ B2 B1 _______ Media marginal (A2-A1)1 (A2-A1)2 A2 A1 (A2-A1)1 y (A2-A1)2 ________ A2 A1 efectos simples (B2-B1)1 y (B2-B1)2 ________ B2 B1 Tres posibles situaciones: 1.- No hay interacción B1 B2 B2 – B1 A1 2 A2 2 A2 – A1 6 6 efectos principales (B2-B1)1 (B2-B1)2 A1 A2 Lo mismo sería si consideramos las diferencias (A2–A1)1 y (A2–A1)2 2.- Hay interacción debida al cambio de orden de los niveles de un factor según el nivel del otro factor considerado B1 B2 – B1 A1 2 A2 -10 A2 – A1 (B2-B1)2 B2 6 6 (B2-B1)1 A1 A2 3.- Hay interacción debida al cambio de magnitud de la diferencia entre los dos niveles de un factor en función del nivel del otro factor que estemos considerando B1 B2 B2 – B1 A1 2 A2 8 A2 – A1 6 2 (B2-B1)2 (B2-B1)1 A1 A2 Importante: La presencia o ausencia de efectos principales no nos dice nada sobre la posible existencia o no de interacción y viceversa. Tipos de diseños con respecto al número de observaciones en cada casilla (subgrupo) A.- Constante o equilibrado: Número igual de observaciones por subgrupo o casilla n n n n n n n n n n n n B.- Desequilibrado: Número diferente de observaciones por subgrupo 3 6 9 2 4 6 B1.- Proporcional: Números múltiples en filas o columnas B2.- Irregular: Número de observaciones diferentes 6 4 8 3 4 2 5 1 1 5 3 6 4 8 12 El proporcional se resuelve como el equilibrado con pequeñas variantes en el cálculo de la S.C. El irregular exige el ajuste de los valores de los efectos por el método de mínimos cuadrados: → Modelo Lineal General EL DISEÑO DE BLOQUES ALEATORIZADOS Supongamos cinco tratamientos: A,B,C,D,E, y F En cuatro bloques (4 Repeticiones/ Tratamiento) se asignan aleatoriamente los tratamientos en los bloques Bloque 1 A D E B C F E F A B C Bloque 2 D A, B, C,D E, F son los tratamientos (hasta un nº=t) Puede haber bloques (hasta un nº=b) Suponemos 1 observación por tratamiento y bloque Modelo: yij i j ij Variación Bloques g.l. b-1 Tratamientos t-1 Error Total (r-1) (t-1) rt-1 C.M. Esperado 2 t 2 b b t 2 2 i t 1 2 Se debe suponer que no existe interacción → Si hay más de una observación por tratamiento y bloque →Se puede estimar el error independiente de la interacción = Factorial de dos factores. C) ANOVA ANIDADO O JERÁRQUICO Es el análisis de varianza correspondiente a un diseño factorial en el que uno de los factores (el factor subordinado o anidado) es siempre aleatorio (sus categorías han sido elegidas al azar en un universo infinito de posibles categorías) y están subordinadas al factor principal, que puede ser fijo o aleatorio. Ejemplo : Experimento para comparar distintos genotipos (estirpes) de gallos de una raza de gallinas. Se tienen las ganancias medias de peso diario en gramos de una muestra de 4 hijas por gallina apareada con un gallo de cada una de las tres estirpes distintas. El factor gallo (estirpe) se considera un factor fijo, porque lo que interesa es conocer si hay diferencia entre las medias de tres estirpes concretas. El factor gallina (anidado a el factor gallo) es aleatorio. Se eligen tres gallinas al azar para aparear con cada gallo. Diseño: Gallos ♂1 Gallinas: ♀1 ♀9 ♀2 111 Id. hijas 112 113 114 121 122 123 124 ♂2 ♀3 131 132 133 134 241 242 243 244 ♂3 ♀4 251 252 253 254 ♀5 261 262 263 264 ♀6 371 372 373 374 ♀7 381 382 383 384 ♀8 391 392 393 394 Tipos de modelo de diseño anidado: Modelo I: Mixto Factor principal: Gallos (efectos medios a comparar) Factor Subordinado: Gallinas (varianza entre gallinas). Siempre aleatorio ijk i Bij ijk B j i Variación G.L. Entre grupos Entre Subgrupos Dentro de Subgrupos Total C.M. Esperado a-1 2 n B nb a(b-1) n ab(n-1) abn-1 2 2 2 i a 1 B 2 Modelo II: Puro Ambos factores son aleatorios. En el ejemplo anterior, los gallos se elegirían al azar, siendo una muestra representativa de un universo de infinitos posibles genotipos. Se estiman las componentes de varianza entre gallos y entre gallinas anidadas a gallos (o entre los grupos de hijas de los distintos gallos y entre los grupos de hijas de las diferentes gallinas apareadas con cada gallo. Se trata de un diseño frecuentemente utilizado para estimar parámetros genéticos. ijn Ai Bij ijk Variación Entre grupos g.l. a-1 C.M. Esperado 2 n 2 B A nb 2 A Entre subgrupos Intra grupos a(b-1) 2 n 2 B A Dentro de subgrupos (Error) ab(n-1) Total abn-1 2 Si el tamaño muestral de los subgrupos no es igual para todos, en lugar de n, se utiliza n0 bi 2 ij n a bi a nij bi nij no g .l .subgrupos Pruebas de significación: Si F = CMsubs es significativo se calcula F= CMerror Si “ CMgrupos CMsubgr no es significativo ver reglas en libro de estadística Descomposición de la varianza: CMError = S2 % Variación entre subgrupos: CM Sub CM Error S2 B A n S2 B A x100 = 2 2 2 S S B A S A CM Grupos CM Subg nb S2 A % variación entre grupos: S2 A = S2 S2 2 S B A A En el ejemplo: Origen Numerador gl Denominador gl Valor F Sig. Intersección 1 24 122157,176 0 ,000 DIETA 2 24 6,882 0,004 FAMILIA(DIETA) 9 24 17,137 0 ,000 Estimación de la varianza: Estimaciones de parámetros de varianza Parámetro Residuos FAMILIA(DIETA) Estimación Error tipico 1,4166667 0,4089564 6,7398990 3,0782787 Procedimiento en el SSPS para estimar las componentes de varianza: ANOVA anidado o jerárquico ANALIZAR – MODELOS MIXTOS – LINEAL – CONTINUAR Establecer VARIABLE DEPENDIENTE Y FACTORES – ALEATORIOS En ventana nueva: CONSTRUIR TÉRMINOS ANIDADOS –Entrar factor principal con flecha hacia la casilla “construir término” y AÑADIR – Entrar factor anidado con flecha hacia la casilla “construir término” DENTRO – factor principal con flecha hacia casilla “construir término” y AÑADIR – CONTINUAR En la ventana anterior: PEGAR: aparece el archivo Sintax. En este archivo cambiar /RANDOM dieta familia(dieta) | COVTYPE(VC) . Por /RANDOM familia(dieta) | COVTYPE(VC) . Quedaría: MIXED crecimie BY dieta familia /CRITERIA = CIN(95) MXITER(100) MXSTEP(5) SCORING(1) SINGULAR(0.000000000001) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE(0.000001, ABSOLUTE) /FIXED = | SSTYPE(3) /METHOD = REML /RANDOM familia(dieta) | COVTYPE(VC) . Comparación de medias Tres planteamientos: 1.- Comparaciones “a priori” Las comparaciones están planificadas al iniciar el experimento, independientemente del resultado del ANOVA. Ejemplo: la comparación de un conjunto de tratamiento con un tratamiento control 2.- Comparaciones múltiples o “a posteriori” Son comparaciones no planificadas al iniciarse el experimento, dependen del resultado del ANOVA; una vez realizado éste y obtenido un valor de F significativo se quiere saber cuales son las medias distintas entre si 3.- Contrastes ortogonales Son contrastes de medias que se realizan cuando los niveles numéricos de un factor cuantitativo están igualmente espaciados y se quieren conocer tendencias. Ejemplo: los tratamientos consisten en dosis proporcionales de un determinado producto Comparación de medias planificada “a priori” Tres planteamientos: 1.- Obtención de una suma de cuadrados y un cuadrado medio para cada comparación y contraste de dicho cuadrado medio con el cuadrado medio del error o el cuadrado medio de contraste que corresponda Ejemplo5: Se quiere saber si hay diferencia en la producción de piezas hechas por cuatro trabajadores diferentes. Los datos son: El ANOVA es: Antes de realizar el análisis se sabía que de los cuatro trabajadores, dos son mujeres (M) y dos hombres (H) y que dos tienen un C.I. Alto (A) y dos bajo (B) y “a priori” se quería saber si existe un efecto del sexo y un efecto del C.I. en la producción y si existe interacción entre ambos efectos Antes de realizar el análisis se sabía que de los cuatro trabajadores, dos son mujeres (M) y dos hombres (H) y que dos tienen un C.I. Alto (A) y dos bajo (B) y “a priori”, antes de hacer el ANOVA, se quería saber si existe un efecto del sexo y un efecto del C.I. en la producción y si existe interacción entre ambos efectos. Es decir, se quiere comparar el número medio de piezas producido por los hombres con el producido por las mujeres (efecto del sexo); la producción de los individuos con C.I. alto con la de los individuos con C.I. bajo (efecto del C.I.) y la producción media de HA y Mb con la media de HB y MA. Para obtener las SC correspondientes a estos contrastes se consideran los siguientes coeficientes : Con los que se calculan: siendo nSc2 = 5x4 = 20 siendo nSc2 = 5x4 = 20 El ANOVA correspondiente a estos contrastes de medias es: Otros posibles contrastes de medias por ejemplo, comparar M de CI alto (MA) con H de CI bajo (CB) y viceversa, HA con MB. Los coeficientes de estos contrastes serían : Y las SC: El ANOVA de estos contrastes: Resolver estos dos últimos contrastes con el SPSS Los contrastes que se han resuelto anteriormente son los relativos a las hipótesis nulas: 1) Ho: - m1 - m2 + m3 + m4 = 0 2) Ho: + m1 + m2 - m3 - m4 = 0 3) Ho: + m1 - m2 - m3 + m4 = 0 4) Ho: + m2 - m3 = 0 5) Ho: + m1 - m4 = 0 Las pruebas planeadas o a priori, se pueden formar con los diferentes niveles de un tratamiento, asignándole a cada nivel un coeficiente de forma que se cumplan las condiciones de ortogonalidad que son: 1) Dentro de una misma comparación, la suma de coeficientes ha de ser cero. 2) Entre los varios contrastes que se puedan formar dentro de un mismo factor, la suma de productos ordenados de los coeficientes ha de ser nula, tomando todas las comparaciones dos a dos De manera que cada comparación o contraste sea independiente de los demás Las reglas para la determinación de los coeficientes son: 1) Si se van a comparar dos grupos de igual tamaño, simplemente se asignan coeficientes +1 a los miembros de un grupo y -1 a los integrantes del otro grupo. No importa a qué grupo se le asigne los coeficientes positivos o negativos. 2) En la comparación de grupos que contienen distintos números de tratamientos, asígnese al primer grupo tantos coeficientes como número de tratamientos tenga el segundo grupo; y a este último, tantos coeficientes, del signo opuesto, como número de tratamientos tenga el primer grupo. Por ejemplo, si entre cinco tratamientos se quiere comparar los dos primeros con los tres últimos, los coeficientes serían +3, +3, -2, -2, -2. 3) Redúzcanse los coeficientes a los enteros más pequeños posibles. Por ejemplo, en la comparación de un grupo de dos tratamientos con un grupo de cuatro se tendrá (regla segunda) los coeficientes +4, +4, -2, -2, 2, -2 pero éstos pueden reducirse, dividiendo por dos, a los coeficientes +2, +2, -1, -1, -1, -1. 4) Los coeficientes de la interacción siempre pueden determinarse mediante la multiplicación de los coeficientes correspondientes de los efectos principales. Modelos con más de un factor Si se tiene un modelo con más de un factor y se quiere hacer pruebas planeadas de uno o mas factores, todo se haría lo mismo teniendo en cuenta que habría que utilizar como término de error el mismo del factor que se esta descomponiendo Ejemplo6.Se han probado cuatro tratamientos en cuatro rebaños elegidos al azar. Los cuatro tratamientos son cuatro piensos que tienen las siguientes características: Se quieren comparar las medias de los piensos con distinto nivel energético , las medias de los piensos con distinto nivel proteico y la interacción entre ambos. Los coeficientes serán: -1 +1 -1 +1 -1 -1 +1 +1 +1 -1 -1 +1 En este caso los contrastes de los cuadrados medios de los dos factores y de la interacción se deben hacer dividiendo dichos cuadrados medios por el cuadrado medio del error, porque la interacción no es significativa A continuación se muestra cuales serían las instrucciones a seguir en el SPSS para realizar los contrastes y para indicar que el término de comparación sea distinto del error: Con el procedimiento MODELO LINEAL GENERAL UNIVARIANTE: 1ª VENTANA: ANALIZAR – MODELO LINEAL GENERAL – UNIVARIANTE 2ª VENTANA: Establecer variable dependiente y factores – MODELO 3ª VENTANA: Establecer modelo (con intersección) y tipo de SC – CONTINUAR Vuelve a la 2ª VENTANA: CONTRASTES 4ª VENTANA: Elegir un modelo y CAMBIAR – CONTINUAR Vuelve a 2ª VENTANA: PEGAR – Aparece un archivo “Sintaxis1” En Sintaxis1: En la fila de CONTRAST poner: /CONTRAST (t)=SPECIAL (1 -1 1 -1) /CONTRAST (t)=SPECIAL (1 1 -1 -1) /CONTRAST (t)=SPECIAL (1 -1 -1 1) /CONTRAST (t)=SPECIAL (0 1 -1 -0) /CONTRAST (t)=SPECIAL (1 0 0 -1) El archivo Sintaxis1 quedaría: UNIANOVA npiezas BY t /CONTRAST (t)=SPECIAL (1 -1 1 -1) /CONTRAST (t)=SPECIAL (1 1 -1 -1) /CONTRAST (t)=SPECIAL (1 -1 -1 1) /CONTRAST (t)=SPECIAL (0 1 -1 -0) /CONTRAST (t)=SPECIAL (1 0 0 -1) /METHOD = SSTYPE(1) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /DESIGN = t . y EJECUTAR – TODO Para realizar el contraste de un cuadrado medio con otro que determinamos: En el archivo “Sintaxis1”: Incluir las filas: /TEST=tratamie VS tratamie*rebaño /TEST=rebaño VS tratamie*rebaño El archivo Sintaxis1 quedaría: UNIANOVA dato BY rebaño tratamie /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /TEST=tratamie VS tratamie*rebaño /TEST=rebaño VS tratamie*rebaño /DESIGN = rebaño tratamie rebaño*tratamie . Con los contrastes sería: UNIANOVA dato BY rebaño tratamie /CONTRAST (tratamie)=SPECIAL (1 -1 1 -1) /CONTRAST (tratamie)=SPECIAL (-1 -1 1 1) /CONTRAST (tratamie)=SPECIAL (1 -1 -1 1) /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /TEST=tratamie VS tratamie*rebaño /TEST=rebaño VS tratamie*rebaño /DESIGN = rebaño tratamie rebaño*tratamie . Si se quieren contrastar los CM de los contrastes con el término de interacción hay que hacerlo a mano Comparación de medias “a posteriori” o comparación múltiple Este tipo de comparación se realiza cuando no existe una idea previa al comienzo del experimento sobre los contrastes entre los diferentes niveles de los tratamientos o cuando el objetivo es comparar todos los posibles pares de medias Los contrastes pueden realizarse en cualquier tipo de diseño para los diferentes niveles de cada uno de los factores, utilizando el CM del error del ANOVA realizado con todos los factores Procedimiento 1) Se ordenan todas las medias de mayor a menor X4 > X3 > X1 > X2 > X5 > X6 2) Se hace un cuadro de doble entrada en el que se ordenan las medias de mayor a menor en vertical y de menor a mayor en horizontal y se realizan las diferencias disponiéndolas en triángulo, de forma que a medida que se desciende en las columnas o se mueve hacia la derecha en las filas el número de medias comprendidas entre las dos que se comparan (ambas inclusive) disminuye de uno en uno, conforme se expresa en la p de cada casilla de la tabla siguiente: Prueba DMS o diferencia mínima significativa (LSD-Least-Significant-Difference) También llamada prueba t múltiple. Se puede usar, también, para pruebas a priori. Para el cálculo de la región crítica se usa la tabla t de la misma forma que se utiliza para contrastar dos medias, comprobando, al nivel a que fijemos, si las diferencias de medias tomadas dos a dos cumplen: Donde es el error típico combinado, es decir, la raíz cuadrada del cuadrado medio del error dividido por el tamaño de submuestra. Esto es: En el caso de que los tamaños de las submuestras sean diferentes (experimento desequilibrado), se utiliza como n el valor de la media armónica de las t submuestras. El contraste sería entonces: Prueba Tukey Es como la anterior solo que no es secuencial y utiliza un solo rango crítico, que es el correspondiente a la p del número total de medias. Para el cálculo de este valor crítico se necesita el valor de q que se encuentra en la Tabla 8 (ver el archivo) según la expresión: Siendo: el error típico combinado, es decir, la raíz cuadrada del cuadrado medio del error dividido por el tamaño de submuestra q el valor que se encuentra en la tabla 8 para p=número total de medias y gl del error -No se incluye el término porque va incluido en los valores de q de la tabla En el caso de tamaños de submuestras diferentes se utilizaría como n el valor de la media armónica de las dos submuestras, siendo la prueba: Prueba de Student-Newmans-Keuls o SNK Se basa en el valor q (tabla 8), de recorrido Studentizado, pero en lugar de tomar un solo valor para la región crítica, correspondiente a la p del número total de medias que se van a comparar, la región crítica cambiará, dentro de la misma prueba, con arreglo a la distancia, en número de medias, entre las dos medias que se comparan. Por tanto, los valores de p dentro de una misma prueba cambiaran de un mínimo de p=2, correspondiente a dos medias contiguas, hasta un valor máximo de p=t-1, correspondiente a las dos medias de valor más alejado. Por lo que para cada valor de q se calcula su región crítica multiplicando el valor q de la tabla por el error típico combinado de las medias, quedando la prueba de la siguiente manera: Siendo el error típico combinado, es decir, la raíz cuadrada del cuadrado medio del error dividido por el tamaño de submuestra y q los valores de la tabla 8 para p=número de medias entre las dos que se están contrastando y los gl del error En el caso de tamaños de submuestras diferentes se utilizaría como n el valor de la media armónica de las dos submuestras, siendo la prueba: Prueba de Duncan o de amplitudes múltiples Se parece a la prueba SNK en que usa amplitudes múltiples y regiones críticas variables que dependen del número de medias que entran en cada etapa. Se usa la tabla r (Tabla 7) para los rangos críticos. Para efectuar las comparaciones múltiples entre t medias, se necesita, como en las anteriores pruebas, el cuadrado medio del error sus grados de libertad y el número de observaciones (n) en cada nivel del factor El contraste consiste en: Siendo: el error típico combinado, es decir, la raíz cuadrada del cuadrado medio del error dividido por el tamaño de submuestra y r los valores de la tabla 7 para p=número de medias entre las dos que se están contrastando y los gl del error. En el caso de tamaños de submuestras diferentes se utilizaría como n el valor de la media armónica de las dos submuestras, siendo la prueba: Prueba de Scheffe Es muy general en el sentido de que todas las posibles comparaciones pueden probarse en cuanto a significación, es decir que no solamente se pueden establecer contrastes entre dos medias sino entre ciertas combinaciones lineales de ellas, no siendo necesario que el número de elementos por tratamiento sea igual para todos ellos. El contraste consiste en: Siendo: En el caso de tamaños de submuestras diferentes se utilizaría como n el valor de la media armónica de las dos submuestras, siendo la prueba Contrastes ortogonales con factores cuantitativos Son comparaciones planeadas de los tratamientos cuando éstos tienen niveles numéricos igualmente espaciados. Se estudia la tendencia que presenta la variable analizada al aumentar progresivamente los niveles del tratamiento. Esta tendencia puede ser lineal, cuadrática, cúbica, etc., y una vez establecida servirá para interpretar los resultados El cálculo de los coeficientes para estos contrastes se puede realizar teniendo en cuenta el tipo de función a la que se quiere ajustar los puntos obtenidos. Los coeficientes para las sumas cuadrados para las funciones lineal, cuadrática y cúbica se encuentran en la Tabla 6 y no hay más que aplicarlos directamente para la obtención de las SC Ejemplo Se han aplicado cuatro dosis,15, 20, 25 y 30 de un determinado producto a un cultivo celular, habiéndose obtenido las siguientes respuestas: El resultado del ANOVA es: Como F(3,12; 0.05) = 4.49 los tratamientos son significativos. Para saber si el efecto de la dosis es lineal cuadrático o cúbico se toman los coeficientes dados en la Tabla 6 para dichas funciones y 3 gl (nº de tratamientos -1): Las SC son: El ANOVA correspondiente será: La respuesta es, por tanto, lineal Se Se Se