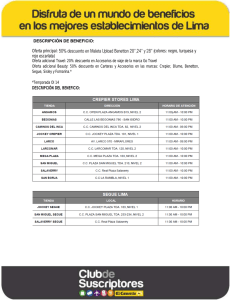
Una introducción a los modelos desagregados de demanda de
Anuncio

245
UNA INTRODUCCION A LOS MODELOS DESAGREGADOS
DE DEMANDA DE TRANS-PORTE
Juan de Dios Ortúzar Salas
Departamento de Ingeniería de Transporte
Pontificia Universidad Católica de Chile
RESUMEN
Los métodos de análisis y predicción de demanda en planificación de sis
temas de transporte, han recurrido tradicionalmente a datos agregados y mode
los con variables dependientes continuas. Debido a una serie de razones teó
ricas y prácticas, los desarrollos más recientes·en este campo se han concen
trado en el uso de modelos desagregados (o a nivel individual) de elección
entre alternativas discretas.
Este trabajo resume los elementos esenciales de estas nuevas metodologías haciendo énfasis en el problema de partición modal de viajes, que ha
sido su campo de aplicación más exitoso.
Acta I Congreso Chileno de Ingeniería de Transporte
246
l.
In t rod uc ción
La utilización de modelos (agregados) de demanda en la planificación de
sistemas de transporte se remonta a l os comienzos de la década del 50 [1, 2, 3],
y ya a principios de la década del 60 existía un cuerpo metodológico aparent~
mente bien entendido y documentado[4J. No obst~nte el trabajo pionero de inve s tigadores como Warner [s]u Oi y Shuldiner L6] , que mostraba la existenci a de serias deficiencias en las metodologías agregadas desarrolladas hasta
ese entonces~ ésta primera generación de modelos siguió siendo utilizada en
forma mayoritaria en proyectos de transporte hasta fines de la década del 70.
De hecho solo hace unos pocos años se empezaron a considerar en forma seria
los modelos desagregados o de la segunda generación [7,8}, que sin duda con~
tituyenun avance metodológico significativo en cuanto a técnicas de estimación
de demanda (Williams ["9] presenta una buena revisión del desarrollo teórico
en es te área) •
"·
El marco conceptual en que se han desar rollado estos nuevos modelos, de
·?.le:;;;c:H},ln:. discreta a nivel individual 7 es el de la Teorí a de la Utilidad Aleatoria [7, lOj ; ésta, que es utilizada en [ ll
para discutir las principa-
J
les características, hipótesis y problemas de una gran variedad de estructuras funcionales,basicamente postule. que~
individuos q~ pertenecient e s a ¡ma. cierta población o segmento de me.E_
Q;C;tÚan .en forma determ~nística y ra ~: ional al e~co?er enue un conjun':o l'l.e alternat1va.s, estando SUJe t os a le :~ m1.smas :restr~cc~ones .-
i) Los
;-:ad~ Q,
i i ) Dado que el modelador, que es un obs e rvador del sistema, no posee inforJD.!
cion perfect a respecto a los atribut<.•s de cada al ternativa Ai e: A={A , A,, •• ,'1i},
1
ni :respecto a las característi cas socio-e conómicas de cada individuo, t1 esta
blece una "utilidad representativau , Ui (para el g:rEpo de individuos y parac:16ól:u "'lternativa Ai t A), y supone que t oda la vari abilidad obse!'Vable en la
pob lación Q se debe a elementos ale a to ri o s~ e:i~ t ale s que:
Ui
= Ui + Ei
La probabilidad de escoger la opción
Pi
= Prob
(1)
Ai~
viene dada por:
{ Ui_:: Uj, vAj
E: .~)
- ~i f(U)dlf.
(2)
a 1t~l q~_:,e f ( U) e s la
:t~ gión
función de dis tribución conj unta de {U , u , • • • ,UN} y Ri es
2
1
de l espacio de utilidad definida por:
Ui~. O
Ri :
Uf2:. Uj
-" lfli&,rtitt d~ estos fundament os, es posible generar distintos modelos hacie!!.
·'\,:. dtHe:!:e'!:1te s hip5 teds acerca de la distribución conjunta de los Ui, o lo que
'<i' i;1>1! ~ls de los rtli'.:s i duos e stocásticos t::i. Por ejempl o p s i estos se dis tribu'f'G :C,. fle i'b ull ~ son independiente. E y t ienen igual varianza, se obtiene el sencillo
Acta I Congreso Chileno de Ingeniería de Transporte
247
y conyeniente modelo Logit Simple
[12],
dado por:
exp (Üi)
Pi""----
(3)
í: exp(Üj)
j
Si, por otro lado, los Ei tienen una distribución Normal multivariada ~
neral, se obtiene el poderoso (pero computacionalmente difícil de implementar)
modelo Probit Múltiple
que ~o posee una ~xpr~sion analítica sencilla
como (3).y que en la pract1.ca requ1.ere de aprox1.mac1.ones para casos que envuelven más de 3 alternativas.
rl3.J,
En este trabajo discutiremos brevemente algunos aspec to c) l'<;;lac;itmados
con la aplicación de estos modelos de elección discreta, haci~ ndo esp~~ c ial­
mente referencia al uso del sencillo Logit Simple en problemas de predicción
de la partición modal para viajes al trabajo. En la sección 2 nos preocupa
remos de la recolección y medición de datos; la sección 3 estará dedicada al
problema de especificación y la sección 4 al de estimación de modelos . Final
mente, en la sección 5 nos referiremos al problema de agre gación que es nece..,
sarioresolver para la aplicación practica de estas herramientas. No pretendemos cubrir en profundidad todos e stos aspectos, por lo que teferimos a quie
nes estén interesados a buenas discusiones generales de fácil acce so en la ii
t eratura especializada [7, 9, 14, 15, 16 y .. 7] •
.
2.
Recolección y medición de datos.
A pesar de que en teoría suelen existir varios enfoque s alternativos para
atacar un problema determinado, la mera disponibilidad de datos su~le r educir ·
la elección a un sólo método. Históricamente la metodología dominante en pla
nificacion de transporte, ha consistido en recolectar datos para un so lo ina, tante de tiempo (cross-section), típicamente acerca de las preferencias exhibidas por los usuarios del sistema, aunque en ciertas oportunidades se han pre
ferido enfo~ues alternativos basados en información .declarada por los usuarios
.(15, 18, 19J .• El problema de estos métodos es que no es posible (con datos
para un solo instante de tiempo) discriminar entre la gran variedad de fuentes
de dispersión de la información, tales como variación en 'las prefe rencias, res
tricciones operativas o hábitos conductuales 116, 20]. Por otro lado, modelos
basados en paneles, datos de series de tiempo, o simplemente en iu.formacion
del tipo 'antes y después', que podrían permitir testear en forma directa y qui
zas :rechazar hipótesis nulas relativas a la respuesta conduct ual de los usuarios, tienen asociados problemas técnicos propios cuya discusión escapa al ámbito de este trabajo (ver [21} para una interesante aplicación). Un área problema relacionado con la anterior, es la de medición de variables que se esquematiza en la Figura l. Desgraciadamente. se ha avanzado muy poco en este
aspecto y de hecho no ha sido posible cuantificar ninguna de las relaciones o
elementos de la figura. Sin embargo, se pueden encontrar excelentes discusiones del tema en [22
y [ 23].
J
El desarrollo e implementación de modelos de demanda de t ransporte ha estado asociado tradicionalmente a la recolección de gran cant idad de da tos, incluyendo costosas encuestas origen-destino de viajes [3, 4, 7~ 8]. Debido a
que los modelos agregados convencionales utilizaban informaci ón a nivel zonal,
se requerían muest:_ras aleatorias de gran tamaño para la etapa de calibración,
Y es bien sabido 124 ] que en muchas ocasiones los recursos cons umi dos en la
Acta I Congreso Chileno de Ingeniería de Transporte
2"48
recolección y análisis de esto~ datos eran de tal magnitud, que no era posible examinar posteriormente mas que unas pocas alternativas de solución al
problema. En este sentido, debido a que los modelos desagregados de demanda
r equieren observaciones sobre individuos y no sobre grupos definidos geográficamente, pueden en ciertas ocasiones tener la ventaja de reducir sustancial
mente los costos de adquisición de datos.
La mayorf a de las aplicaciones prácticas de modelos de elección discreta
planifica.cion de transporte, se han basado en datos prove nientes de una
muestra aleatoria (ver (25} para una revisionde la experiencia europea). Algunos estudios han utilizado muestras estratificadas, en que la población an~
liza!!!a se d:i.vide en. grupos de acuerdo a alguna carac~erística de especial i.!!,
te rés , que debe ser conocida d(~ antemano (como la tasa de motorización), y
cada sub-población se muestrea en f orma aleatoria [26]. Es necesario hacer
notar que tanto el muestrear en forma aleatoria como estratificada, puede ser
muy costoso cuando una alternativa de i nteré s t iene muy baja probabilidad de
se lección, ya que para lograr una represent ación razonable de ella puede ser
l;!ec:;o.s ario recolectar una muestra muy grande. Una posible solución a este problema consiste en tomar una muestra basada en la elección (esto es, extrayendo
1,;:¡; obser vaciones en base al resultado del proceso de decisión en estudio), di
señada de manera que el número de usuarios que esc:oje la opcion de baja probabilidad este predeterminado. Este tipo de encuestas es bastante común en estu
dios de transporte (encuestas en buses, trenes, estaci onamientos o u la vera
d'iZ1 camino) y es posible obtenerlas con frec uencia a muy bajo costo; sin embargo se han usado en muy raras ocasione3 para calibrar modelos desagregados
d~;nanda , debido a la forma en que debt!i1 es timarse los parámetros de estos
modelos (ver sección 4). De hecho, cada est r ategia de muest r eo resulta en una
dist ri.bución distinta de las elecciones ohse rv~.das y características generales
de la muestra, por lo que tiene· asociada t'~1a función de calibración particular
(po:r ejemplo, la ve rosí.militud). Aun cuando lo s dos primeros métodos de muest:tgc. :no present ..an prob lemas en cuanto a utili zac.:H5n d~l sof tware existente, el
s;:;;tfoque basado ;n ,la ~le cción requiere de algunas modifi cacione a [27] o los pr,2_
gramas produciran parametros sesgados "
·
!í'.~s
A fin de es coger l a estrategia de muestreo más adecuada ( lo que desafortE.
na.dtuneute es un pr oblema muy específico a cada situación parti cular), deben to
cuenta los siguientes aspectos [28J :
i\:J ii!i:Se en
(~~ 1 costo de los distintos métodos de muestreo
e l proceso de elección modelado
l¿¿¡¡; características de la población e s t udiada
~ l cos t o social de aplicar potíticas inadecuadas deb i do a errores de estimad~1Kt~ un interesante ejemplo acerca de la posible magnitud de estos costos se
'fH"(~ sextt.a en
[18] .
embar go~ el problema no posee normalmente una s olución única , por lo que
" '~~<~ml!i~n,lr.1 ~xaminar con cuidado la discusión que se hace en [16} y
[21] •
se
de modelos.
E¡;¡¡ genera l la e st ructura de un modelo , las variab l es explicativas conside<1.d(1 ~ ...,Y . l~t fot·ma de .la s fuucione s de utilidad, son todos aspe. etos susceptibles
u.~! , anBl:un.s Y exper:~..mentacion [29] 11 y a menudo depen.den fu,ertemeute del contexto
i c:J J. '~ "~ ;rw~io Y J os datos dispon.ihl~ s.
Si bi eon ta'!ltn la intuición eomo las consid.<>•"'··~·· p~u -·-· ·~e ""1··~
. .,. • . .
.
1'
: - · -: '"·:"' _ ·"''
.'l;;,t; . y "'
""~vO. r::eonco son muy va. wsas en esta ~t<l'tpa . de ~ úsquada, a menudo
,l,,,,, ~tér'Un: ~l.t~t?,.lll~. t :H~IJ de grau. importaneia es la disponibili dad de; 8oft'í1are
Acta I Congreso Chileno de Ingeniería de Transporte
249
especializado. De hecho, una de las razones que explican l a enorme popularidad del modelo Logit Si mple (LS) e s que pu~~de ser f ácilmente e s timado con
software disponible' mientras que e structuras ma:; gener·ale s presentan enormes dificultades [13] .
Por otro lado, las limitaciones d.: los modelos de ele cción compe nsato·=
ríos, tipificados por la estructura LS, han constituido una de l as motiva-·
ciones básicas para el desarrollo de modelos alterna tivos del proceso de de·u
c isión (como, por ejemplo l os lexicográfico s cuyo representante mas cono cido
es el modelo de 'e liminación por aspecto s' [30] de Tverskí); no ob stante~ se
h a argumentado [2~ que en cierto sent ido el de s a r r o llo de estructuras de uti:
lidad aleatoria mas generales como el mode lo Probít [13] .~ ha elimi nado algun·
nas de las justificacione s originales para const ruir es tos modelos altern ,f.t:i. ~­
vos. Esto no quiere decir, sin embargo, que los mo de los convencionales vay an
a ser a-priori mas adecuados; te:l problema es, como ya mencionamos' que aún
cuando las diferentes estruct ure.;;;; tienden a producir distintos estimadores de
los parámetros y elast ici dades, no es posible discriminar entre ellas con datos de corte transversal.
La búsqueda de la mejo-..: e spe cíficacichn. de un mode lo también esta relaciE.
nada con la forma de las funciones de utilidad. Si b i en hay consenso de que
en el caso de partición moda.l . el qua las funcione s de utilidad sean lineales
en los parámetros (lo que E:-S una. hipótesis muy .:;¡,:rtnl<.m iente) como en (4),
Ui
en que:
Eh~
Xt~ i
= KE
6v::
Y..Ki.
(4)
"' coce fi.cü ií'!.t:a del atributo K
"" K~é si.mo atd.buto de la alternativa Ai
no presenta problemas, en otros cont exte s comn elección de destino, el cansen·~
s o es que funciones no-lineales acem rM.s Lpr:Jpia da s [25, 31 . 32} . El problema
en este caso es en par te l a f alta de aoft\vare de e st i mación apropiado y ~n par
te e l hecho de que para expresiones . ;;w- line.al>as de uti lidad-t no hay garantía -~
de que la función de vero similitud teng,'i un máximo único [13J. Se han propuesto
tres enfoques para re solver <E f]te p roblema~
la u tilización de
o anál i sis conjunt0;;
y datos de laborat o rio [19 ~
la utilización de t r ans formac i~J~leii e6~ tad:istie:a::; ~ cümo los métodos de Box~ Cox
[ 34]
-
el us o construct ivo de la teoría económica pa r a de rivar la forma funci onal
[35]
Es nece s ario de staca: que formas no-l.ineales de utili~ ad implican difereE,
t es mecanismos de coxrrp:roríüso "''Ue
a.aoc1.a.dos a conceptos ta
l es como el 'va lor del tiempo€ L23] ~ además> se ha dem;)JE~ trado que las elastici:dade s y poder explicativo de un mode lo va·ría.n en forma dramática con la forma
funcional.
El último problema que r esta por cons i derar, en cuanto a especificaciones
de modelo, es que estructura utilizar (por ejemplo, Logi t o Probit) y dada est~
que variables debieran entrar en la función de utilidad y en que fonna. . El pri
mer problema solo puede resolverse examinando la situac ión particular en estu-<di.© , y va a depender de factores talescomo tiempo y r ecurs o s disponibles para
l a modelación (el modelo LS e s mucho mas sendllc y barato que el resto de sus
competidores); grado de exa;;:; t itud de respuesta :r·ey:ue~d do~ existenc i a de correl ación entre alternativas ~ etc. El p roblema es que usar un modelo inadecuado
Acta I Congreso Chileno de Ingeniería de Transporte
(como el LS cuando ttü s e cumplen :Las hipó tesis utilizadas para generarlJ.I)
puede conduc ir a serio s errores [2.0 ~ 36 » · 37].
La deci sión acerca de que variables e.-.trar en. la función de utilidad y en
que f orma (por ejemplo genéric as o esper:Hicas a cad.::;. alternativa), generalmen
te ~ e toma en base a los resultado s de un proceso del tipo 'step wise' (comoei.1 regresión lineal)~ testeando s i la ~1ueva variable o forma considerada, aña
¡poder explicativo al modelo f)6] ,
.
Ea:timadon de ülotie lOi&;; ,,
Esta etapa consiste ¿¿¡, tiet;g:t'rtlKl.l;);l" log vú or.\es de los coeficientes o para
r;1Stl"os 6 de la ecuación (4) '~ a fü11 de :r epr oducir >t'.on el modelo las observaK
ciones en la me jor forma posibl¡¡:; ,, La t écnica de e stimación más adecuada es el
método de máxima verosimilitud , o:¡·_%:! r:c~quiere de una muestra que entregue la si
guiente iílformación p ~r a c::Bld&. ·üno d$.1: sus mi euli:n:'ü s ~
que alternativa. fue !2.8cu g:ida
los atributos relevantes (va~::-ia;bJe:&> d~ <:a ivel d~ s;a r vicia) de todas las alter
que el individuo tie ne disponibles
los atributos relevantes (v«:.:.:d ab les socio·-econornicas) de cada individuo
ü.mthraii
Para ejemplifi c::ar el proceso 2:,:; :i' :Gd u~x:ion, consideremos una muestra de
treJ:> viajeros (observaciot;.es) qu.e deb.c;:l\;. (~e c idir entre dos alternativas. Para
s J rop .l i fi car ~ supongamos qne
<J,.n
E.tt>i rH.d::o ü~) y que estamos utiliza!!
do un modelo LS ~ de modo q~.te ~
l
(5)
Observación
"~1tenc~':'ti;n1
x
x
1
2
<~=·-·~···~·~-=·~=·=~-·=·=,!;s. eo,¡;p.1~..§..~·-,.~·-··~,·~.··~.~. ~·-·~~ ·~-·-·l
;)
1
3
2
1
1
2
3
2
3
4
,~
8 , :ca v;;~ t\J; s imilit i.!d de la muestra, L, esta
(6)
s &Z P~lirtd.!Pl '\Yer éil h. :Figü:C<li: 1 (f.il 'tj'{J,(:; fJé;; h a gra..ficado in L por conveniencia) ,
f ,eYsnt.es valores d~ 8 resultan en d ist i ntos valo res de L. En n uestro ejemplo,
':J<tl in, 8=0p 756 'üKt~dmiz.a e 1 y cot1 re s t~ est i ma ción ~ 1 modelo prediciría las s i
J?:n:;h abi.l id.ades de ~JLau; Lón.;:
Acta I Congreso Chileno de Ingeniería de Transporte
251
Observación
1
2
3
Probabilidades de Elección
, Alternativa 1 Alternativa 2
0,82
0,18
0,32
0,68
0,32
0,68
Por supuesto que en el caso general se tendrían muchos más coeficientes
(normalmente entre 10 y 30), observaciones (500 a 1000) y alternativas (entre
l y 10), por lo que se justifica utilizar paquetes estadísticos especializados
como QUAIL, MLOGIT o BLOGIT (ver [12] y [13] para una discusión de los detalles matemáticos de estos procedimientos).
Las salidas de los programas de estimación se parecen bastante a las de
paquetes estadísticos de regresión tradicionales. Típicamente se incluye una
tabla con los valores d~ los coeficientes estimados, sus errores estándar y
Estadígrafos t (de una aproximación Normal por lo que el valor crítico al 95%
es 1,96). Además, se suelen entregar otros estadígrafos de interés como los
siguientes:
i) El valor del logaritmo de la fun ción de verosimilitud si todos los coeficientes son cero (1(0)).
ii) El mismo valor para el máximo (l(G) )
iii)La :razón de vero s imilitud (2-(1(8) - 1(0)), que para muestras grandes ti~
ne una distribución ~a con grados de l i bertad iguales al número de coeficientes estimados.
2
iv) El índice p2 = l. - 1(8)¡:(0), que es similar en espíritu al estadígrafo R
de regresión lineal múltiple, en el sentido de variar entre O (no hay ajuste)
y 1 (ajuste perfecto). Sin embargo, no tiene una interpretación, intermedia
2
similar a R y se debe tener cuidado al utilizarlo" Buenas discusiones en
cuanto al problema de estimación y los índices de bondad de ajuste utilizados,
se pueden encontrar en [14], [15] , [16} ~ [38] y f39] .
5.
El problema de
agregación~
En una interpretación econometrica de los modelo;> de demanda, la agregasobre características no observables tiene como resultado un modelo de de
cisión probabilístico, y la agregación sobre la distribución de característi-cas observables produce las relaciones macro o agregadas, convencionales [17J.
De esta forma, el problema de agregación depende en gran medida de la descri~
ción del sistema asociada al marco de referencia utilizado por el modelador,
ya ~oo este determina el grado de variabilidad a ser contabilizado en cualquier
rélación causal. Por ejemplo, la explicación de la dispersión estadística de
un conjunto de datos determinado, es muy diferente para un observador que uti
lice como marco de referencia el enfoque de maximización de la entropía[40],que para otro que <se base en la teoría de la utilidad aleatoria, aún cuando
embos arri~en a modelos formalmeute idénticos (Williams [9) discute este fenó
meno conoc~do como, 'equifinalidad ') •
c~on
En nuestro caso el problema de agregación se reduce a la teóricamente sen
ci l la operación de integrar o sumar las relaciones micro, cómo (3), estimadasa nivel individual. En la práctica el proceso solo es sencillo si estamos in
to:&:sados e!'k predicciones da cort o plazo acerca de la partición toodal en el \\l':t~J~ ~~ t :ra.bajo. En ot ros cas cE; ~ particul armente en modelos de distribución
0 _.t~cai.~zaciÓTh~ ~l ;~:ecil-ü<at(;.l! prác ti(;;Ci 'ii.lS muy dif:Lcil de resolver y requiere de
ln.t~~t&;,;;;t;g
t5J~~~t.;¡¡ >a:r{t;t,Bmoa'S y gran cantidad de datos [41].
Acta I Congreso Chileno de Ingeniería de Transporte
ERRORES DE
RECEPCl~ E
INFORMACION
ERRORES DE
'W-----<
'
FIGURA 1
.......
___ ... ""
COt-l.NICACI~
V
APAOXIMACION
/
RELACION ESPECULATIV.i.\1, ENTRE El PROCESO DE ELECCION Y LA
MEOICION DE ATRiBUTOS .
-2
_,
.f
T
0,7sti
2
1
-
1
¡
-1,0
-1,5
-2,0
1
ln L
¡;;TGURA 2
FUNCION
LOGARITMO DE LA VEROSIMILITUD
PARA EL EJEMPLO
Acta I Congreso Chileno de Ingeniería de Transporte
253
Los métodos de 'sregacíón propllestos en la literatura [41,42,43,44] ofr~
cen diferentes estrat~gias técnicas para llevar a cabo la integración sobre
relaciones micro, e it;cluyen entre . tras: el enfoque 1 inocente 1 , la enume!."ación muestra! y el método de clasifLación.
El primer e nfoque plantea la su:• ·: itución directa de valores agregados
( o promedio) de las variables explic ;:ivas en las funciones de elección micro
(que son típicamente no-lineales). e:. método, que es extremadamente simple,
puede produc i r enonnes sesgos de agreftción por lo quenoesrecomendado. En el
enfoque de enumeración muestra!, el imflCto de una política dada en la muestra
(que es supuestarnente representativa) E·~ determina a partir de las funciones
individuales , y las predicciones para la población sólo dependen de la estrategia de muestreo ut i lizada. Es te metod·: es muy exacto en el corto plazo,
pero debe ser modific ado cuando l a s caracte rísticas de la población cambian
durante el horizon't e de predicción [45}.
En el método de clasificaciónt la población total se divide en grupos relativamente homogenos y se utilizan los valores promedio de las variables explica!:ivas para determinar la demanda en cada categoría de acuerdo al enfoque
inocente. La exactitud y eficiencia del método dependen tanto del tipo Y número de grupos, como de las características de las variables incluidas.
RRFERENCIAS
l. FRATAR, T . J. (1954) Forecasting d i s t r ibution of ínter zona l vehicular trips
by successive approximations. Highwa_L_R~search Board Proceedin_&!3_, Vol 33, PP·
17- 28.
CARROLL, J . D. (1957) Future traffic predictions for the Detroit area.
way~. Bo~r~LProceedin_gs..'L VE.! 36~ PP~ 71-89 .
2.
3.,
CATS (1959 ) Chi ca~ Area Transport a tion Stu~;2>
High
Final Report, Chicago, EE.UU.
z.
~~TIN~ B .V.~ ~lEMMOT, F.W. y BONE~ A.J. (1961)
I-:-i1ciples and techniques
of predicting future demand for urban area transporta,ion. MIT Research Report
N° ~' Cambridge , EE.UU.
5. WARNER, S.L ., (1962) ~.trategic Choice of l1ode in Urban Travel:
Bin§l.ry Cho ice.. Northwestern University Press, Evanston.
A Study in
6. OI" lCL Y. y SHULDINERs P.W . (1962) An Analysis of Urban Travel Demands.
Northwestern University Press, EvanstoU:
1. OOMENCICH , T .A. y Me FADDEN, D. (1975) Urban Travel Demand: A Behavioural
Analys:i_l!· North Hollru1.d, .Amsterdam.
8 . SPEAR~ B. D. (1917) Applications of new travel demand forecasting techniques
t o t:rcanspoltt<ildon plemning: A study of individual choice models. Federal Highw;;;.y Administr~<!.!:.i2~-!! · S . Departroont of_ Tra,nsportation, Washington, D. C., EE.UU.
íJJILLIAHS~
H.C .tJ ol.oo { 1981) Travel demand forecasting:an overview of theoreEn D..L Bard ster y P .G . Hall (eds.) , !ran!'}~t and Public
~1,;!-CY Pl anni t1.B, e Hi:ir.c&; el l ~ Londr es.
9o
ti c~l develo¡¡;mentsio
Acta I Congreso Chileno de Ingeniería de Transporte
254
10. WILLIAMS, H.C.W.L. (1977) On the formation of travel demand models and
economic evaluation measures of user benefit. Environment and Planning A,
Vol 9, N°3, pp. 285-344.
11. ORTUZAR, J. de D. y WILLIAMS, H.C.W.L. (1982). Una interpretación geo~
trica de los modelos de elección entre alternativas discretas basados en la
teoría de la utilidad aleatoria. Apuntes de Ingeniería 7, pp. 25-50.
12. Me FADDEN, D. (1974) Conditional logit analysis of qualitative choice
"-,ehaviour. En P. Zarembka (ed . ), Frontiers in Econometrics. Academic Press,
Nueva York.
13. DAGANZO, C.F. (1979) Multinomial Probit - The. _Theory and its Applications
to Demand Forecasting. Academic Press, Nueva York.
14. Me FADDEN, D. (1979) Quantitative methods for analysing travel behaviour
of individuals: Sorne re cent developments. En D.A. Hensher y P.R. Stopher
(eds.), Behavioural Travel Model ing. Croom Helm, Londres.
15. HENSHER, D.A. y JOHNSON, L.W. (1981) Applíed Discrete Choice Modelling.
Croom Helm, Londres .
16. ORTUZAR, J. de D. (1982) Fundamentals of disctete multimodal choice model
ling. Transport Reviews, Vol 2, N°l~ J:lp, 1.}7-7 8.
17. WILLIAMS, H.C .W.L y ORTUZAR, J. de D. (1982a)Travel demand and response
analysis-some integrating themes. Transportati.?n Research, Vol 16 A, N°5/6 ,
pp. 345-362.
18. GENSCH, D.H. (1980) Choice model calibrated on current behaviour predicts
public response t o new policies. Tra~s.J2ortation_Re _s earch, Vol 14 A, N°2, pp.
137=142.
19. HENSHER, D.A. y LOUVIERE, J.J. (1~79) Behavi oural intentions as- predictors
of very specific behaviour . Transpo~~ ation.z Vol 8_, N°2, pp. 167-182
20 . WILLIAMS, H.C.W.L. y ORTUZAR, J . de D. (1982 b) Behavioural theories of
d.ispe rsion and the mis-specification of travel demand models. Transportation
Research 2 Vol 16B, N°3, pp. 167-219.
·
21. JOHNSON, L.W. y HENSHER, D.A. (1982) Application of multínomial probit to
a t wo-period panel data set. Transeortation Research 2 Vol 16 A, N°5/6, pp •. 457-
464.
22. DALY, A.J. (1978) Issues in the estimation of journey attribute values.
En D.A. Hensher y M.Q. Dalvi (eds), Determinants of Travel Choice~ Saxon House,
i3u6i sex.
~J" BRUZELIUS, N. (1979) The Value of Travel Time - Theory and Measurement.
Croom Helm, Londres.
BOYCE, D.E . , DAY, N.~. y Me ~ONALD, C. (1970) Metropolitan Plan Making.
k•io:::t·vgraph Series N°4 s Reg1.onal Sc1ence Research Institute, Philadelphia.
Acta I Congreso Chileno de Ingeniería de Transporte
255
26. COSSLETT, S. (1980) Efficient esti.matürn of disc:rete choiee JHrl :kds . En
C.F. Manski y D. Mac Fadden (eds.); ~.tr2._ct ~3:2..l An_a1ypj._!~C?.L"!l~gs!J:..t.s:...1?.9-_t..~.:
With Economctri~ Applicat:i.ons.. MIT Press, Cambridge, H.;w::;,
27.
LERHAN, S, R. y
M.A.J.iSKI~
C. F. (1976) Alternaf::ive sr:;mp l:i ng procedu:res for
'l'r<:!_E!:.~O..E.~~~:.:~ ot_i_I~:.:!.~! 3:~..l::.SJL__!~~;:._r:yr:~.-?.92 ~
calibrating disaggrc-:gate choice models.
pp. 24-28 .
28. LERMAN~ S .R. y HANSKI~ C.F. (1979) Sampling de;-dgn for di screte choice
analysis of travel behaviour: the state of the art. I!.:!i:'!!:'.ES:!J::!~J ot."L!ü::~:!_,
Vo1__l3A , No 1, pp. 29-44
I.EAMER, E. ( 19 7 8) Spe e i f i ca t ion S eaEsl~e S..:.._..•~~!_ lio s_..Ln f.~E~.!!.~!7.."'~gll.k!~2!1?.~~·
rímental Data... Wiley t Nueva York.
'
29 .
30 . TVERSKI, A. (1972) Elimination by a 13 pect: s; a th eory of cho:í.ee.
ll.;gical Revie~~!_-'79_, N°4, pp. 281-299.
_Psyr:-ho_-
31. FOERSTERt J, F. ( 19 8 1) Nonl inear and n.cmcompc:.nsat ory perceptua J funct:íons
o:E f!Valuati.on and. ehoica. En P .R, Stoph er) .A.H. Meyburg y ~J. l:lrog (eds.),
~~~~-ll~ns ir~!:.:;"i.Ve_l-~ehav:i.ou~- 1:1.~-..s~ayd!.• D.G. Reat.h and Co., Lexington.
32. LOUVIERE, J. J . (1981) On t he i dent:i fication of the functional form of
the ut:ility expression an.d its relatiom;hip to discrete choice. Apendice B
de Hensher p D.A. y Johnson~ L.W. (19 81) (op. cit), pp, 385-415.
33. I.ERM..o\N, S.R. y LOUVIERE, .J.J. (1978) 1'he use of funetion.al measurement
t:o i.de ntify th;;c; form of utility functions :Ln t l 'itvt:1 dewand models.
TransE.~?.Et'!..~i on R~-~-!E.~LB·e'-?_9J.· d J:I~.~ pp, 78~·85.
3th GAUDRY, N, J . I. y WILLS; H,J . (1978) Estimat.ing the. functiona1 form of
travel demand modds. :,er.?J.!.!!I~.Or.~~~~or:..J<.c¡;¡ears:J.!.~-V2l.l2 .• N"' 4 ~ pp. 25 7-289.
35~
TR-4.IN~ I<~ y M~c f"i. t\DDEN~
.
IJ~ (1978) Tt1.e. go c.H1 é:;/ le.isltre trade-o:ff and disaggregat.e work trip mod.e choice mod<üt::. !E§.E;~ EE.E!~!::iE!.~~-}~§:!=:.~~c.h 2 _,Yol.)2~ N°5,
pp. 349-353.
36 .
ORTUZAR, .J. de D. (1980) H:i.xf:.d·~mode demand forecasting techniques.
J?.~t~.on,_Plam;.ti~~g__a!!...<!.1.i.:ehi!0~0._&1.~.. Vo:J.:..i., N"2, pp, 81 --95.
37,. HOROl.JITZ, J . L (1981) Sources of error and uncertainty in behavioral
l; rtwel dernand modelsi o En P.R. Stoph er, A.IL Mayb ur g y '(,.], B:r.og (eds.), Ne.w
lt~?:f:h~~~!ls il'!,.].~1.J?_ehaviour Re ~earch. D. C. H;;at:b and Co .. , Lexington .- ·
38. TARDIF'F, 'f .J. (1976) A note on gocdm;ss··of- fit sta.tis ties for probit aud
l a;; gl t mod,ús ... 'I' 1~an!!..!.!.2!~!:.~ti~lf!:~-Yot_l , N" 1-t ~ p·p . .377···388 .
39. GUNN, H.F'. y BATES, .J ..L (1982) Statü:>tical .aspe e ts cf travel demand m.o delling. T r.§!;rts p_o·~:t¿¡tiSJ.E:..~.!SJ!.a.. .Y.~l._j.6~~ N" 5i6, pp, 371-382.
40..
tHI.SON ~ A. G.. (1970) E!J.J:.E..~Lin Urb an
a,r.1u _}{egion~l ,!i_()d~l_+_!..E;_&.
dre:s~
Acta I Congreso Chileno de Ingeniería de Transporte
Pion~ Loo~·
256
t¡l.
Me FADDEN, D. 'y REID~ F. (1975) Aggregate t ravel i.'kmand fora cast:.ing from
.!.1::.~n~;r ~~~!Lg_<;.~eaTE:!':~. ,.I~:.E9L'L.5 3~-' pp. 24-
di s aggregate behaviour al -mode 1 s.
37.
42 . KOPPELMAN, F.S. (1976) Guidelines for aggn~gate r :r;-lV!~ l prediction md.ng
disaggregate choice models. T.fans,p~rta t ion .P~::-~f.O<!._~-:_!}__E.~:::~E.fL010.~ pp. 19~ 24. ·
BOUTHELIER, F. y DAGANZO, C.F. (1979) Aggregat:ion vith multinomial probit
and estimation of disaggregate models ·with a.ggrcg<J.t~.· data~ a new:·tnet:hodolo.gical approach. Trat;ls?ortation ~ar~h,á__y_g ::t J .~!!?. , N"2, pp. 133 ... JA6.
43.
REID, F .A. ( 1978) . Sysi:ematic a.nd eff.id.c;·cit TllfJ tbodD f\.Yr mi.nintizing errot·s
in aggregate predictions f:¡:-om dis.aggregatc niDdels • .~-if9_:~~~i:!!~•.d?.,ap f{'¡,t¡; }~la Ins- ·
titute vfl'ransport~ti.on,Stl;!die !!_, Un~ver¡>:i_ty of Cal:LCorni a '.at. Berk~l~Y•
:
44.
.
45. BEN-AKIVA, M.E. y ATHERTON, T.J. (1977) ~kothodo1ogy fm:· ahort;j;ía..nge tra..
vel demand prediction: analysis of ea.rpoc;lip.g inct':nd.ves . Jcurn.4l."of
_,_ -'t<ransJ?._Ort.,~conomics and. !'.Q!icj[.....__ yo+..., .; !.l, N°3, pp. 224,...261.
-,· ,.e·
_....~'
~
.. .
¡:~ ~~
... ,
~··
.
'
Acta I Congreso Chileno de Ingeniería de Transporte