aplicación de redes neuronales mlp a la prediccion de un paso en
Anuncio

FUNDACION UNIVERSITARIA KONRAD LORENZ
FACULTAD DE INGENIERIA DE SISTEMAS
APLICACIÓN DE REDES NEURONALES MLP
A LA PREDICCION DE UN PASO EN SERIES DE TIEMPO
DIEGO FERNANDO SOCHA GARZON
GILBERTO ANTONIO ORTIZ HERRADA
BOGOTA D.C., MAYO DE 2.005
Director
Ing. PERVYS RENGIFO RENGIFO
TABLA DE CONTENIDO
1. SERIES DE TIEMPO ________________________________ _______________ 9
1.1. INTRODUCCIÓN ______________________________________________ 9
1.2. DEFINICIÓN________________________________ __________________ 10
1.3. OBJETIVO DEL ANÁLISIS DE UNA SERIE DE TIEMPO _____________ 11
1.4. TERMINOS RELACIONADOS AL ANÁLISIS DE UNA SERIE DE TIEMPO12
1.4.1. VARIABLE ALEATORIA ______________________________________12
1.4.2. PROCESOS ESTOCÁSTICOS ________________________________13
1.4.3. OPERADORES_____________________________________________14
1.4.4. MEDIA____________________________________________________15
1.4.5. VARIANZA ________________________________________________15
1.4.6. COVARIANZA______________________________________________16
1.4.7. FUNCIÓN DE CORRELACIÓN ________________________________16
1.4.8. FUNCIONES DE AUTOCOVARIANZA __________________________17
1.4.9. FUNCIÓN DE AUTOCORRELACIÓN ___________________________17
1.4.10. FUNCIÓN DE AUTOCORRELACIÓN PARCIAL __________________19
1.4.11. ESTACIONARIEDAD ________________________________ _______20
1.4.12. ERGODICIDAD____________________________________________21
1.4.13. CORRELOGRAMA _________________________________________21
1.4.14. RUIDO BLANCO________________________________ ___________23
1.5. COMPONENTES DE UNA SERIE DE TIEMPO______________________ 25
1.6. ANÁLISIS DESCRIPTIVO DE UNA SERIE DE TIEMPO ______________ 25
1.7. MÉTODOS DE PRONÓSTICO ________________________________ __ 28
1.7.1. CONSIDERACIONES PRELIMINARES _________________________28
1.7.2. MÉTODOS CUALITATIVOS O SUBJETIVOS ____________________29
1.7.3. MÉTODOS CUANTITATIVOS_________________________________30
1.7.4. MÉTODOS DE DESCOMPOSICIÓN ___________________________31
1.7.5. MÉTODOS DE SUAVIZAMIENTO _____________________________31
1.8. MODELOS AUTORREGRESIVOS________________________________ 32
1.8.1. AR(1) ____________________________________________________32
1.8.2. AR(P) ____________________________________________________33
1.9. MODELOS DE PROMEDIO MÓVIL _______________________________ 34
1.9.1. MA(Q)____________________________________________________34
1.10. MODELO AUTORREGRESIVO CON PROMEDIO MÓVIL____________ 35
1.11. MODELO ARMA (P,Q) ________________________________________ 36
1.11. CRITERIOS DE EVALUACIÓN DE PREDICCIONES ________________ 36
1.12. OTROS MÉTODOS NO CONVENCIONALES ______________________ 38
1.13. APLICACIONES DE LAS SERIES DE TIEMPO ____________________ 40
2. REDES NEURONALES ____________________________________________ 42
2. 1. INTRODUCCION _____________________________________________ 42
2.2. HISTORIA ___________________________________________________ 43
2.3. NEURONA BIOLÓGICA ________________________________________ 46
2.4. MODELO DE NEURONA ARTIFICIAL _____________________________ 49
2.4.1. MODELO GENERAL ________________________________________50
2.4.2. MODELO ESTANDAR ________________________________ _______54
2.5. REDES NEURONALES Y ARQUITECTURAS ______________________ 55
2.5.1. TIPOS DE ARQUITECTURA __________________________________56
2.6. APRENDIZAJE DE UNA RED NEURONAL ________________________ 58
2.6.1. FASE DE APRENDIZAJE. CONVERGENCIA_____________________59
2.6.2. FASE DE RECUERDO O EJECUCIÓN. ESTABILIDAD _____________61
2.7.
CLASIFICACION DE LOS MODELOS NEURONALES _____________ 63
2.8. COMPUTABILIDAD NEURONAL _________________________________ 64
2.9. REALIZACIÓN Y APLICACIONES DE LAS REDES NEURONALES____ 65
2.10. REDES NEURONALES SUPERVISADAS ________________________ 67
2.10.1. ASOCIADOR LINEAL ________________________________ _______67
2.10.2. PERCEPTRON SIMPLE_____________________________________71
2.10.3. ADALINE _________________________________________________77
2.10.4. EL PERCEPTRON MULTICAPA (MLP)_________________________79
2.11. CAPACIDAD DE GENERALIZACIÓN DE LA RED__________________ 86
2.11.1. VALIDACIÓN CRUZADA (CROSS-VALIDATION) ________________87
2.11.2. NÚMERO DE EJEMPLOS DE ENTRENAMIENTO________________89
2.11.3. REDUCCIÓN DEL TAMAÑO DE LA ARQUITECTURA DE UNA RED 90
3.
MATLAB TOOLBOX ____________________________________________ 92
3.1. INTRODUCCIÓN ________________________________ ______________ 92
3.2. BACKPROPAGATION _________________________________________ 92
3.3. RED FEEDFORWARD _________________________________________ 95
3.4. CREANDO UNA RED (newff) ___________________________________ 96
3.5. SIMULACIÓN (sim) ____________________________________________ 97
3.6. ENTRENAMIENTO ____________________________________________ 98
3.6.1. ENTRENAMIENTO POR LOTE (train)___________________________98
3.6.2. ENTRENAMIENTO POR INCREMENTAL (traingd)________________99
3.7. ENTRENAMIENTO RÁPIDO ___________________________________ 102
3.7.1. TAZA DE APRENDIZAJE (traingda, traingdx) ____________________ 102
3.7.2. REZAGO (TRAINRP) _______________________________________ 104
3.8. ALGORITMOS DE GRADIENTE CONJUGADO ____________________ 105
3.8.1. ACTUALIZACIÓN DE FLETCHER-REEVES (traincgf) _____________ 105
3.8.2. ACTUALIZACIÓN DE POLAK-RIBIÉRE (traincgp)________________ 107
3.8.3. RESTABLECIMIENTO DE POWELL-BEALE (traincgb) ____________ 108
3.8.4. GRADIENTE CONJUGADO ESCALADO (TRAINSCG) ____________ 108
3.9. RUTINAS DE BÚSQUEDA LINEAL ______________________________ 109
3.9.1. BÚSQUEDA DE SECCIÓN DORADA (srchgol) __________________ 110
3.9.2. BÚSQUEDA DE BRENT (srchbre)_____________________________ 110
3.9.3. BÚSQUEDA BISECCIÓN-CÚBICA HÍBRIDA (srchhyb) ____________ 111
3.9.4. BÚSQUEDA DE CARAMBOLA (srchcha)_______________________ 111
3.9.5. BACKTRACKING (srchbac) ________________________________ __ 111
3.10. ALGORITMOS CUASI-NEWTON_______________________________ 112
3.10.1. ALGORITMO DE BFGS (trainbgf) ____________________________ 112
3.10.2. ALGORITMO SECANTE DE UN PASO (trainoss)_______________ 113
3.10.3. LEVENBERG-MARQUARDT (trainlm)_________________________ 114
3.10.4. LEVENBERG-MARQUARDT DE MEMORIA REDUCIDA (trainlm) __ 115
3.11. REGULARIZACIÓN ________________________________ _________ 116
3.11.1. FUNCIÓN DE DESEMPEÑO MODIFICADA ____________________ 116
3.11.2. REGULARIZACIÓN AUTOMATIZADA (trainbr) _________________ 117
3.12. DETENCIÓN TEMPRANA ____________________________________ 119
3.13. PREPROCESO Y POSTPROCESO_____________________________ 121
4. REDES NEURONALES Y SERIES DE TIEMPO _______________________ 124
4.1. REDES NEURONALES EN LA PREDICCION _____________________ 124
4.1.1. ALGUNOS TRABAJOS DE PREDICCIÓN CON REDES NEURONALES
________________________________ ______________________________ 125
4.2. DESARROLLO DE LA INVESTIGACION _________________________ 126
4.3. ANALISIS DE LAS SERIE ________________________________ _____ 127
ANEXOS ________________________________ _________________________ 167
CONCLUSIONES__________________________________________________ 179
INTRODUCCIÓN
La neces idad de explorar parte de las aplicaciones y posibilidades que brindan las
redes neuronales artificiales son múltiples y en diferentes campos, esto debido a
que pueden ser entrenadas mediante algoritmos para hacer una función
determinada. La posibilidad de hacer híbridos con otras técnicas como los
algoritmos genéticos hace que las redes neuronales artificiales multipliquen sus
posibilidades de aplicación y se extiendan a diversos campos. Dentro de este orden
de ideas surge la necesidad de hacer predicciones de datos futuros basados en
datos pasados y presentes,
este fenómeno es importante para saber el
comportamiento aproximado de una variable y sus aplicaciones son infinitas desde
el comportamiento económico de un producto en el mercado hasta la obtenc ión de
la temperatura para un día o una hora precisa.
Estas últimas son el motivo de esta investigación el cual pretende ver la aplicación
de las redes neuronales en este campo de la predicción.
A lo largo de este documento se observaran algunas de las técnicas mas utilizadas
para la predicción de datos tales como las series de tiempo y los métodos que
permiten hacer predicción con ellas, las redes neuronales su historia, estructura,
métodos, arquitecturas y en especial Backpropagation feedforward, una breve
introducción a la utilización del toolbox de matlab para el manejo de redes
neuronales backpropagation y una serie de pruebas que pretende demostrar la
utilidad de las redes neuronales backpropagation tipo feedforward y el potencial de
la herramienta toolbox de matlab para el desarrollo de estas.
MARCO DE REFERENCIA
Una breve introspección al contenido temático de este documento será presentada
a continuación, estos temas serán abordados y complementados dentro del
desarrollo de este.
Series de Tiempo
Gran cantidad de información económica (de los individuos, las empresas, las
economías de los países, etc.) es recopilada con fines de análisis. ¿Qué son las
series de tiempo?: Registro metódico a intervalos de tiempo fijos de las
características de una variable, o su observación numérica.
Herramientas estadísticas: Se usan para describir y analizar series de tiempo.
•
Describir: Resumir en forma concisa,
información.
mediante gráficas y parámetros, la
•
Analizar: inferir de la información
características de (“toda”) la población.
(utilizándola
como
una
muestra),
Para inferir, muchas veces es útil “descomponer” la serie de tiempo por sus
principales componentes:
•
Tendencia y ciclo: representa el movimiento de largo plazo de la serie.
•
Estacionalidad: representa efectos de fenómenos que ocurren o se reproducen
periódicamente (fin de semana, diciembres, los viernes, etc.).
•
Irregularidad: movimientos impredecibles o aleatorios.
Tendencia y ciclo y estacionalidad, conforman la parte determinística de la serie,
mientras que la irregularidad representa la parte no-determinística o estocástica de
la serie.
Muchos usuarios de la información se limitan a desestacionalizar las series
estocásticas (en parte por la generalización de métodos de desestacionalización),
sin intentar un análisis estadístico mas completo.
-Ventajas de aplicar procesos estocásticos a series de tiempo:
•
•
Flexibilidad para representar un amplio número de fenómenos mediante una
sola clase general de modelos.
Facilidad y precisión en pronósticos.
•
Generalizar métodos de análisis de variables individuales a grupos de variables.
Neurona Natural
La neurona es la célula fundamental y básica del sistema nervioso.
Es una célula alargada, especializada en conducir impulsos nerviosos.
En las neuronas se pueden distinguir tres partes fundamentales, que son:
•
•
•
Soma o cuerpo celular: corresponde a la parte más voluminosa de la
neurona. Aquí se puede observar una estructura esférica llamada núcleo.
Éste contiene la información que dirige la actividad de la neurona. Además,
el soma se encuentra el citoplasma. En él se ubican otras estructuras que
son importantes para el funcionamiento de la neurona.
Dendritas: son prolongaciones cortas que se originan del soma neural. Su
función es recibir impulsos de otras neuronas y enviarlas hasta el soma de la
neurona.
Axón: es una prolongación única y larga. En algunas ocasiones, puede medir
hasta un metro de longitud. Su función es sacar el impulso desde el soma
neuronal y conducirlo hasta otro lugar del sistema.
Las neuronas son muy variadas en morfología y tamaño. Pueden ser estrelladas,
fusiformes, piriformes. Pueden medir no más de cuatro micras o alcanzar las 130
micras. También son muy variadas en cuanto a las prolongaciones: las dendritas y
el cilindroeje o axon. Las dendritas, de conducción centrípeta, pueden ser únicas o
múltiples. El axón es siempre único y de conducción centrífuga.
Conociendo la neurona, se explica la estructura básica que permite la actividad
refleja: el arco reflejo.
Todo arco reflejo está formado por varias estructuras. Éstas son: receptor, vía
aferente o vía sensitiva, centro elaborador, vía eferente o vía motora, y efector.
Receptor: es la estructura encargada de captar el estímulo del medio ambiente y
transformarlo en impulso nervioso. En los receptores existen neuronas que están
especializadas según los distintos estímulos.
Se encuentran por ejemplo receptores especializados en:
Ojo
----------------->
Visión
Oído
----------------->
Audición
Nariz
----------------->
Olfato
Lengua
----------------->
Gusto
Piel
----------------->
Tacto, dolor, presión, etc.
El receptor entrega el impulso nervioso a la vía aferente.
•
Vía aferente o vía sensitiva: esta vía tiene como función conducir los
impulsos nerviosos desde el receptor hasta el centro elaborador.
•
•
•
Centro elaborador: es la estructura encargada de elaborar una respuesta
adecuada al impulso nervioso que llegó a través de la vía aferente. La
médula espinal y el cerebro son ejemplos de algunos centros elaboradores.
Vía eferente o motora: esta vía tiene como función conducir el impulso
nervioso que implica una respuesta -acción- hasta el efector.
Efector: estructura encargada de ejecutar la acción frente al estímulo. Los
efectores son generalmente músculos y glándulas. Los músculos efectúan
un movimiento, y las glándulas producen una secreción -sustancias
especiales-. Los efectores están capacitados para hacer efectiva la orden
que proviene del centro elaborador.
Redes Neuronales en la Predicción
La predicción de errores en una red de computadoras, basada en el tráfico que
produce, es una tarea muy difícil. Un buen analista debe contar con muchos
elementos que le permitan conocer la red, además del conocimiento de tráfico
producido por redes semejantes a ésta. Es muy importante que el análisis sea
realizado por un experto en el área.
Las redes neuronales artificiales cuentan con el potencial para realizar este tipo de
análisis, ya que en la mayoría de los casos son muy buenas en el reconocimiento de
patrones complejos, que es básicamente el caso que ocurre con el tráfico producido
por una red de computadoras.
Tipos de Redes Neuronales Artificiales usados para la predicción
El tráfico producido en una red de computadoras no es mas que una serie de
tiempo, es decir un conjunto de valores de un mismo atributo censados en períodos
regulares. Para predecir series de tiempo se han utilizado las redes neuronales
alimentadas hacia adelante (feed-forward) y las redes recurrentes (recurrent).
Dentro de las redes alimentadas hacia adelante existen diferentes algoritmos, como
son: Linear Associator, Backpropagation, Cascade Correlation, Cascade 2, RAN
(resource Allocating Network). En la redes recurrentes tenemos entre otros:
Recurrent Cascade Correlation, Simple Recurrent Networks, Real-Time Recurrent
Learning, Sequential Cascaded Network.
Algunos trabajos de predicción con redes neuronales
En los últimos años se cuenta con muchos trabajos en la predicción de series de
tiempo utilizando redes neuronales artificiales, de los cuales podemos mencionar
los siguientes:
• Predicción de acciones. Consiste en el desarrollo de una red neuronal capaz de
realizar la predicción del precio de las acciones para un número dado de
compañías. Esta predicción se realiza mediante redes alimentadas hacia adelante,
y el objetivo en este particular caso es predecir el siguiente valor en la serie de
tiempo: el próximo precio de la acción.
• Predicción de tráfico vehicular. Se han utilizado redes neuronales recurrentes
para la predicción a corto plazo del tráfico en una carretera, a fin de prevenir
congestiones y tener un control del acceso a la autopista. Para esto se utilizan
datos estimados de otros días con propiedades similares; los mejores resultados e
obtuvieron con una red multi-recurrente, y se pudo comprobar que las redes
neuronales resolvieron este tipo de predicción y obtuvieron mejores resultados que
los métodos estadísticos convencionales (Ulbricht ).
• Predicción del tráfico en una autopista. Dierdre predice el volumen y el nivel de
ocupación de una autopista, los resultados obtenidos fueron mejores que los
obtenidos por técnicas usadas anteriormente. Se demostró que las redes
neuronales con exactitud pueden predecir el volumen y la ocupación 1 minuto por
adelantado, se utiliza una red neuronal multicapa entrenándose mediante
retropropagación, este trabajo se auxilia de una rampa de medición de lógica
• Predicción de la transición mensual del índice de precios de acciones. Usando
recurrencia y retropropagación, la red neuronal es entrenada para aprender
conocimiento experimental y para predecir la transición de precios de acciones,
tomando como entrada principal algunos indicadores económicos y obteniendo la
transición relativa de la composición del índice de precios de acciones, usando
ocho años de datos económicos, la predicción del crecimiento mensual o la caída
del índice del precio de acciones. Los resultados indican que las redes neuronales
son herramientas eficientes para la predicción del precio de las acciones.
1. SERIES DE TIEMPO
1.1.
INTRODUCCIÓN
Toda institución, ya sea la familia, la empresa o el gobierno, tiene que hacer planes
para el futuro si ha de sobrevivir y progresar. Hoy en día diversas instituciones
requieren conocer el comportamiento futuro de ciertos fenómenos con el fin de
planificar, prever o prevenir.
La planificación racional exige prever los sucesos del futuro que probablemente
vayan a ocurrir. La previsión, a su vez, se suele basar en lo que ha ocurrido en el
pasado. Se tiene pues un nuevo tipo de inferencia estadística que se hace acerca
del futuro de alguna variable o compuesto de variables basándose en sucesos
pasados. La técnica más importante para hacer inferencias sobre el futuro con base
en lo ocurrido en el pasado, es el análisis de Series de Tiempo.
Son innumerables las aplicaciones que se pueden citar, en distintas áreas del
conocimiento, tales como, en economía, física, geofísica, química, electricidad, en
demografía, en marketing, en telecomunicaciones, en transporte, etc.
Series de Tiempo
1. Series económicas:
2. Series Físicas:
3. Geofísica:
Ejemplos
- Precios de un artículo
- Tasas de desempleo
- Tasa de inflación
- Índice de precios, etc.
- Meteorología
- Cantidad de agua caída
- Temperatura máxima diaria
- Velocidad del viento (energía eólica)
- Energía solar, etc.
- Series sismologías
4. Series demográficas:
- Tasas de crecimiento de la población
- Tasa de natalidad, mortalidad
- Resultados de censos poblacionales
5. Series de marketing:
- Series de demanda, gastos, ofertas
6. Series de
telecomunicación:
- Análisis de señales
7. Series de transporte:
- Series de tráfico
Uno de los problemas que intenta resolver las Series de Tiempo es el de predicción.
Esto es dado una serie {x(t1),...,x(tn)} nuestros objetivos de interés son describir el
comportamiento de la serie, investigar el mecanismo generador de la serie temporal,
buscar posibles patrones temporales que permitan sobrepasar la incertidumbre del
futuro.
En adelante se estudiará como construir un modelo para explicar la estructura y
prever la evolución de una variable que observamos a lo largo del tiempo. La
variables de interés puede ser macroeconómica (índice de precios al consumo,
demanda de electricidad, series de exportaciones o importaciones, etc.),
microeconómica (ventas de una empresa, existencias en un almacén, gastos en
publicidad de un sector), física (velocidad del viento en una central eólica,
temperatura en un proceso, caudal de un río, concentración en la atmósfera de un
agente contaminante), o social (número de nacimientos, matrimonios, defunciones,
o votos a un partido político). [1]
1.2. DEFINICIÓN
En muchas áreas del conocimiento las observaciones de interés son obtenidas en
instantes sucesivos del tiempo, por ejemplo, a cada hora, durante 24 horas,
mensuales, trimestrales, semestrales o bien registradas por algún equipo en forma
continua.
Se llama Serie de Tiempo a un conjunto de mediciones de cierto fenómeno o
experimento registradas secuencialmente en el tiempo. Estas observaciones serán
denotadas por {x(t1), x(t 2), ..., x(tn)} = {x(t) : t ∈ T ⊆ R} con x(ti) el valor de la variable
x en el instante ti. Si T = Z se dice que la serie de tiempo es discreta y si T = R se
dice que la serie de tiempo es continua. Cuando ti+1 - ti = k para todo i = 1,...,n-1, se
dice que la serie es equiespaciada, en caso contrario será no equiespaciada.
En adelante se trabajará con Series de Tiempo discretas, equiespaciadas en cuyo
caso se asumirá sin perdida de generalidad que: {x(t1), x(t2), ..., x(tn)}= {x(1), x(2),
..., x(n)}. [2]
1.3. OBJETIVO DEL ANÁLISIS DE UNA SERIE DE TIEMPO
Los principales conceptos y características que se tienen en cuenta para el análisis
de una serie de tiempo son:
1. Obtener modelos estadísticos que describen la estructura pasada de las
observaciones que generan la serie; y/o estudiar modelos que explican la
variación de una serie en términos de series (explicativas) conocidas.
2. Suponer que la estructura pasada de la serie de interés o de las series
explicativas se conserva y bajo este supuesto, pronosticar valores futuros de
la serie bajo estudio.
3. Analizar la significancia de los efectos que políticas o intervenciones
pasadas causaron en la estructura de la serie.
4. Simular valores futuros de la serie,
bajo condiciones o restricciones
definidas por políticas o criterios nuevos, para así supervisar y controlar los
cambios que se producen en la serie. [4]
Para una mayor comprensión de la estructura, el comportamiento y el análisis de
una serie de tiempo se debe tener en cuenta como primera medida conocer y
entender algunos términos que se describirán a continuación.
1.4. TERMINOS RELACIONADOS AL ANÁLISIS DE UNA SERIE DE TIEMPO
1.4.1. VARIABLE ALEATORIA
En estadística y teoría de probabilidad una variable aleatoria se define como el
resultado numérico de un experimento aleatorio. Matemáticamente, es una
aplicación
que da un valor numérico a cada suceso en el espacio O de los
resultados posibles del experimento.
Se distinguen entre
•
variables aleatorias discretas
•
variables aleatorias continuas.
Dado una variable aleatoria X se pueden calcular estimadores estadísticos diferentes
como la media (Media aritmética, Media geométrica, Media ponderada) y valor
esperado y varianza de la distribución de probabilidad de X.
Para las variables aleatorias continuas
•
El valor esperado E[X] se calcula así
E[X] = integral {xf(x)dx}
•
La varianza V x (X) es
V x [X] = E[X2] - (E[X])2
Donde
E(X2) = integral {x2f(x)dx}
[6] [7]
1.4.2. PROCESOS ESTOCÁSTICOS
{
}
Un proceso estocástico es una sucesión de variables aleatorias Zt / t ∈ T ⊆ Ζ .
El subíndice que indica como varia t es el índice (puede variar en un subconjunto de
los reales, generando así procesos continuos. Aquí solo se consideran procesos
estocásticos discretos, cuando el índice varía en los enteros.
La relación de un proceso estocástico con una serie de tiempo radica en que una
Serie de Tiempo es una sucesión zt ,
generada
al obtener una y solo una
observación de cada una de las variables aleatorias que definen un proceso
estocástico. Las observaciones son tomadas a intervalos de tiempo o distancia
iguales, según lo indica el índice t que genera la sucesión. En este sentido, la
serie es una realización de un proceso estocástico.
Luego entonces un
pronostico es la predicción de un valor o una variable
aleatoria, Z n + l , en un proceso estocástico. n es el origen del pronostico y l la
posición relativa de la variable a pronosticar con respecto a n.
Cuando se habla de la actualización de un pronóstico se refiere a re-estimar los
parámetros del modelo de predicción, incluyendo las nuevas observaciones, y con
ellas pronosticar los valores futuros estipulados en el horizonte del pronóstico. [3]
1.4.3. OPERADORES
1.4.3.1. OPERADOR DE REZAGO
En el análisis de series de tiempo es una herramienta útil el operador de rezago,
denotado L . Que sirve para expresar ecuaciones en diferencia, que es la forma
típica de las series de tiempo y para encontrar su solución particular (estado
estable). Se define como:
Lτ x1 = xt −τ
Donde τ es el rezago (positivo o negativo) que se desea introducir en la variable
x t por ejemplo:
L3 x t = xt −3
L−2 x t = xt + 2
Lc = c
Donde c es una constante. La propiedad más útil del operador de rezago es:
[
]
1
2
3
= 1 + αL + (αL) + (αL) + .......
1αL
para α < 1
[3]
1.4.3.1. OPERADOR DE DIFERENCIA
Otro operador conveniente y además muy útil para expresar series de tiempo es el
operador de diferencia ∆ xt definido como:
∆ xt = xt − x t −1 = (1 − L ) x t
El cual consiste en tomar una observación y restarle la observación inmediatamente
anterior. También puede aplicarse de manera repetitiva. Por ejemplo
∆2 x t = ∆∆xt = ∆( xt − xt −1 ) = x t − xt −1 − ( xt −1 − x t− 2 )
= x t − x t−1 − x t−1 + x t− 2 = x t − 2 x t−1 + x t− 2 [3]
1.4.4. MEDIA
La media aritmética o promedio de una cantidad finita de números es igual a la
suma de todos ellos dividida entre el número de sumandos.
Así, dados los números a1,a2, ... , an, la media aritmética será igual a:
Por ejemplo, la media aritmética de 8, 5 y -1 es igual a (8 + 5 + (-1)) / 3 = 4.
El símbolo µ (mu) es usado para la media aritmética de una población. Se usa X,
con una barra horizontal sobre el símbolo para medias de una muestra:
.
[6]
1.4.5. VARIANZA
En teoría de probabilidad y estadística la varianza es un estimador de la divergencia
de una variable aleatoria X de su valor esperado1 E[X]. También se utilizan la
desviación estándar, la raíz de la varianza.
La varianza V[X] de una variable aleatoria X para el caso discreto se define como
1
El valor esperado o esperanza matemática de una variable aleatoria es la suma de la probabilidad de
cada suceso multiplicado por su valor.
También se expresa como la diferencia entre el momento de orden 2 y el cuadrado
del valor esperado:
[ ]
V ( x) = E x 2 − E [x ] [6]
1.4.6. COVARIANZA
En teoría de probabilidad y estadística la covarianza es un estimador de la
dependencia lineal de dos variables aleatorias.
La covarianza C(X,Y) de dos variable aleatorias X y Y se define como
Para dos variables aleatorias independientes 2 la covarianza es cero. La covarianza
de una variable aleatoria consigo misma es su varianza. [6]
1.4.7. FUNCIÓN DE CORRELACIÓN
La c orrelación entre dos variables aleatorias Y y Z mide el grado al cual tienden a
moverse conjuntamente, es una medición sobre el co-movimiento que manifiestan.
y − µ y
Yk = E
σ y
2
Z − µz
,
σ
z
[9]
Dos variables aleatorias son independientes si su probabilidad conjunta es igual al producto de las
marginales
1.4.8. FUNCIONES DE AUTOCOVARIANZA
Sea {Zt / t ∈ Ι ⊂ Ζ}proceso estacionario en covarianza. Como la covarianza entre
dos variables de un proceso estacionario(explicado con detalle más adelante en la
sección de estacionariedad)
solo depende de la distancia que los separa, la
siguiente expresión define la función de autocovarianza.
Y k = C xy (Zt , Zt + k ,) = E [( Zt + k − µ )], k = 0,1, 2,L .
Si C xy (Zt , Zt
+k
) representa
la covarianza entre la variable Zt y la variable futura
Zt + k ⋅ . En cambio, C xy (Z t + k , Z t )representa la covarianza entre la variable Zt + k y la
variable pasada Zt . Estas dos covarianzas son iguales por propiedades de la
covarianza y porque la distancia entre las variables que las definen es k. Luego si
se considera en t un sentido de desplazamiento, la definición puede generalizarse
para k en los enteros, así, cuando k es positivo, Yk mide la covarianza de Zt con
una variable futura, y cuando k es negativo mide la covarianza con respecto a una
variable pasada. Esta generalización queda consignada en la siguiente expresión.
Yk : k → Υk = cov[Zt, Zt + k ] = E [(Zt − µ )(Zt + k − µ )] Z: los enteros R: los reales [10]
Ζ→ℜ
1.4.9. FUNCIÓN DE AUTOCORRELACIÓN
La correlación es la covarianza con los datos centrados y ajustados por la
dispersión. Por lo que ambos conceptos miden el grado de enlace lineal entre Y y Z.
Interesa aplicar esta medida para una variable con su pasado, se estudia el
comportamiento de las observaciones con su historia, esto mide la tendencia de la
serie a comportarse como antes lo hizo, para llevarlo a cabo se toma el par Z t , Z t −k
y se fija en su enlace lineal a k periodos de distancia. Como el valor de k es variable
llegamos a una correspondencia; a cada k le asocia el enlace que presenta el par
( Z t , Z t −k ).
La función de autocorrelación es definida como:
n− k
Yˆk
Pk = =
Yˆo
∑ (Z − Z )(Z
t
t+ k
t =1
− Z)
∑ (Z − Z )
n
, k = 0,1,2, K
2
t
t =1
Para procesos estacionarios de segundo orden la media es constante y por lo tanto
E[ Z t ] = E[ Z t +k ] = Y y
la
varianza
también
es
constante,
esto
es:
σ 2 = V x ( Z t ) = V x ( Z t +k ) para todo valor de k.
El símbolo Y(k) denota a la función de autocorrelación, ya que su labor es medir la
correlación de la serie consigo misma a distancia k, esta función no depende del
punto en el tiempo de referencia solo depende de la distancia que separa a las
observaciones, (no afecta t pero si influye k) ya que si se cambia de t a s queda que:
z − µ z s− k − µ
ρ (k ) = Γ ( Z t , Z t + k ) = E s
,
σ σ
La autocorrelación tiene tres propiedades importantes:
A) ρ (k ) = 1
La autocorrelación de una variable a tiempo presente es igual a uno ya que el grado
de asociación es perfecto.
B) − 1 ≤ ρ (k ) ≤ 1
Indica el grado de tendencia a comportarse similarmente ( Z t , Z t + k ) en el caso de
que sea una autocorrelación positiva, 0 ≤ ρ (k ) ≤ 1 , O a moverse en la dirección
opuesta, bajo autocorrelación negativa − 1 ≤ ρ (k ) ≤ 0 .
C) ρ (k ) = ρ (− k )
Indica que con tabular los valores positivos de k se obtiene toda la información que
es requerida.
Esta última relación se obtiene de observar las igualdades:
ρ (k ) = Γ ( Z t , Z t + k ) = Γ ( Z t − k , Z t ) = ρ (− k )
Su gráfica se obtiene poniendo en el eje horizontal los valores de k, mientras que en
el eje vertical la autocorrelación. [4]
1.4.10. FUNCIÓN DE AUTOCORRELACIÓN PARCIAL
Se puede decir que el último parámetro de la autoregresión (la variable contra su
pasado) nos da el valor de la autocorrelación parcial de orden k.
La autocorrelación parcial de orden k denotada por φ k , mide la correlación que
existe entre Z t y Z t + k después de que ha sido removida la dependencia lineal de las
componentes
intermedias,
Z t +1 , Z t + 2 , Z t +3 ,....., Z t + k − 2 , Z t +k −1
o
sea,
mide
la
contribución que se logra al agregar Z t para explicar Z t + k .
Se define como la correlación condicional:
Pk = Γ[ Zt , Z t+ k | Z t +1, Z t + 2 , Z t +3 ,...., Z t+ k −2 , Z t +k −1 ]
Donde Z t es una serie de media cero E[ Z t ] = 0. Un resultado interesante de la
teoría es hacer ver que es posible obtener la autocorrelación parcial por medio de
una regresión como sigue:
Z t + k = φ k1 Z t + k −1 + φ k 2 Z t +k −2 + φk 3 Z t +k −3 + ..... + φ kk −1 Z t −1 + φkk Z t + ε t + k
Ya que Pk = φ kk es la autocorrelación parcial.
El término Pk se obtienen de la última coordenada de la regresión con k términos sin
constante, (los datos ya han sido centrados). Esta será la ruta a seguir en adelante
para estimar la autocorrelación parcial siempre se tomara el último coeficiente en
una autoregresión. [4]
1.4.11. ESTACIONARIEDAD
Un proceso estocástico (Zt / t ∈ Ι ⊂ Ζ ) es estacionario en covarianza o débilmente
estacionario de orden 2 si:
i. Para
todo
t ∈ Ι , la media y varianza existen y son constantes
E [Z t ] = µ y ,Var [Zt ] = σz 2 ;
ii. Si para cualquier i, j ∈ Ι, Cov(Z 1, Zj ) depende únicamente del número de
períodos que separa las variables, es decir, de j − i , que se denotará k:
número de rezagos.
Sea {Z 1, Z 2, Z 3, L Zn}una serie de tiempo estacionaria. Las siguientes expresiones
definen
estimadores
de
la
función
de
autocovarianza
y
autocorrelación
respectivamente:
1 n− k
Yˆk = ∑ (Zt − Z )(Z t + k − Z ), k = 0,1,2, K
n t =1
n− k
Yˆk
Pˆ k =
=
Yˆo
∑ (Z − Z )(Z
t
t+ k
t =1
∑ (Z − Z )
n
t
− Z)
, k = 0,1,2, K
[3]
2
t =1
Un proceso es estacionario de forma estricta cuando los distintos valores
estadísticos no dependen del instante en que se calculan:
E = [ x(t1 )] = E [ x( t2 )]
f Z t ( Z t ) = f Zt + k ( Z t + k )
1.4.12. ERGODICIDAD
Sea Zt un proceso estocástico estacionario en covarianza.
i. Se dice que el proceso Zt es ergódico con respecto a la media si satisface la
siguiente condición:
lim 1 n −k
∑ Zt = µ
n → ∞ n t =1
ii. Se dice que el proceso Zt es ergódico con respecto a la autocovarianza si
satisface que:
lim ˆ
lim 1 n − k
Yk =
∑ (Zt − Z )(Zt + k − Z ) = Yk
n→∞
n → ∞ n t =1
k=0,1,2,…
Note que si el proceso es ergódico con respecto a la autocovarianza, lo es con
respecto a la varianza y a la autocorrelación pues Y 0 y P k están definidos.
El proceso es ergódico si estos valores coinciden con los de cualquier registro:
E = [ x(ti )] = m( x j ) [3]
1.4.13. CORRELOGRAMA
Como la varianza de la media muestral tiende a cero, para muestras grandes puede
ser ignorado este termino, con lo cual se ve que el primer estimador tiene un mayor
sesgo que el segundo, note que si desea mantener acotado este sesgo se debe
tomar k< T/4
En resumen para la práctica se utiliza la función de autocorrelación muestral a partir
de una muestra de tamaño T, con esta se calculan las covarianzas muéstrales.
La suma va desde 1 hasta T-k, Y se pasa a la función de autocorrelación muestral:
Se debe recordar que se buscan "picos" en la función de autocorrelación muestral,
ya que estos exhiben una alta correlación entre observaciones k periodos aparte; se
define como pico un valor de la autocorrelación que esta afuera de esta banda.
La gráfica de la función de autocorrelación muestral se le llama el correlograma, en
esta a cada valor de k le asocia la correlación revelada en la muestra entre la
variable y su pasado a distancia k. En otras palabras los picos revelan un comovimiento significativo.
Interesa mirar los picos, donde la autocorrelación muestral se sale de la banda,
cuando uno mira el correlograma.
En el dibujo se tienen picos o sea valores elevados para k = 1, 2, 3 y 5, 6 esto
significa
que
las
correlaciones
( Z t yZt −1 ), ( Z t yZt −2 ), ( Z t yZ t − 3 ), ( Z t yZ t −4 ), ( Z t yZ t −5 ), ( Z t yZ t − 6 )
entre
muestran
significativas, mientras que el valor de k = 4, 7, 8, 9,… tienen una correlación baja.
Para localizar los picos en la función de autocorrelación uno puede tomar las
primeras 20 autocorrelaciones.
Note que la función de autocorrelación muestral es también una función simétrica
alrededor del origen:
Ya que la autocovarianza muestral es simétrica:
Tiene una consecuencia práctica importante en lugar de perder las ultimas k
observaciones, tomar los datos desde t = 1, hasta T - k. Es mejor se gastan las
primeras k observaciones en los retrasos y se toman los datos desde t = k + 1, hasta
T. [8]
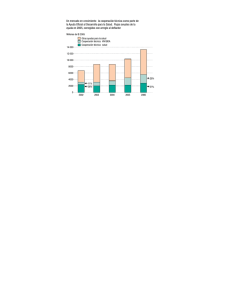
1.4.14. RUIDO BLANCO
Un proceso estocástico
{Zt / t = 1,2, K},
es un Ruido Blanco si la sucesión de
variables aleatorias que lo forman provienen de una misma distribución,
generalmente normal, y cumple:
i.
E [Zt ] = 0
ii.
Var[Zt ] = σ 2
iii.
Yk = [Zt , Z t + k ] = E [Z tZ t + k ] = 0 para todo k ≠ 0
Conclusión: Los errores de un modelo de regresión deben ser ruido blanco. En
series de tiempo los errores se llaman ruido blanco.
Sea Zt un proceso de ruido blanco. Luego reemplazando teniendo en cuenta la
definición de ruido blanco se obtiene: [4]
Yk = E [(Zt − µ )] = E [Zt Zt + k ] luego;
k = 0 Yo = E [Zt Zt ] = Var[Zt ] = σ 2
definición, ii
k ≠ 0 Yk = E [ZtZt + k ] = 0
definición, iii
Función de autocovarianza teórica
Gráfica G1- 1a
Ruido Blanco
= 0
kεΖ
≠ 0
0,75
Ruido Blanco
FAO
σ 2 si k
Yk =
0 si k
Función de autocovarianzas teórica
1
0,5
0,25
0
0
2
4
6
8
10
12
k (rezago)
FAC teórica
Gráfica G1-1b
Ruido blanco
k
= 0
kε Ζ
k ≠ 0
3
FOV
1 si
Pk =
0 si
Función de autocovarianzas teórica
4
Ruido Blanco de
varianza 4
2
1
0
0
2
4
6
k (rezago)
8
10
12
1.5. COMPONENTES DE UNA SERIE DE TIEMPO
Una Serie de Tiempo puede tener las siguientes componentes:
1. Tendencia: Esta componente representa la trayectoria suavizada que define la
serie en el rango de variación del índice y se halla observando la forma funcional
de la grafica de la serie ( zt vs t ) a lo largo del tiempo. La tendencia puede ser:
constante, línea, cuadrática, exponencial, etc.…
2. Componente Estacional: Esta componente se presenta cuando la serie tiene
patrones estaciónales que se repiten con una frecuencia constante, produciendo
en su grafica un efecto periódico.
Los patrones estaciónales se presentan por fenómenos climáticos, recurrencia
en los pagos, costumbres y/o agrupamiento, afectan las observaciones que
generan la serie.
3. Componente Aleatoria: Esta componente se representa los cambios que sufre la
serie ocasionados por fenómenos externos no controlables.
4. Componente Cíclica: Esta componente se presenta en series que son afectadas
por fenómenos físicos o económicos que ocurren con una periodicidad variable.
[1]
1.6. ANÁLISIS DESCRIPTIVO DE UNA SERIE DE TIEMPO
El análisis descriptivo de una serie comprende: la estimación de los estadísticos
básicos de la serie y el análisis en el grafico de zt Vs t (o el índice) de los
siguientes aspectos:
a) Detectar Outlier: se refiere a puntos de la serie que se escapan de lo normal.
Un outliers es una observación de la serie que corresponde a un comportamiento
anormal del fenómeno (sin incidencias futuras) o a un error de medición.
Se debe determinar desde fuera si un punto dado es outlier o no. Si se concluye
que lo es, se debe omitir o reemplazar por otro valor antes de analizar la serie.
Por ejemplo, en un estudio de la producción diaria en una fabrica se presentó la
siguiente situación:
Figura 1.1
Los dos puntos enmarcados en un círculo parecen corresponder a un
comportamiento anormal de la serie. Al investigar estos dos puntos se vio que
correspondían a dos días de paro, lo que naturalmente afectó la producción en esos
días. El problema fue solucionado eliminando las observaciones e interpolando.
b) Permite detectar tendencia: la tendencia representa el comportamiento
predominante de la serie. Esta puede ser definida vagamente como el cambio de la
media a lo largo de un periodo.
Figura 1.2
c) Variación estacional: la variación estacional representa un movimiento periódico
de la serie de tiempo. La duración de la unidad del periodo es generalmente menor
que un año. Puede ser un trimestre, un mes o un día, etc.
Matemáticamente, podemos decir que la serie representa variación estacional si
existe un número s tal que x(t) = x(t + k ⋅s).
Las principales fuerzas que causan una variación estacional son las condiciones del
tiempo, como por ejemplo:
1) en invierno las ventas de helado
2) en verano la venta de lana
3) exportación de fruta en marzo.
Todos estos fenómenos presentan un comportamiento estacional (anual, semanal,
etc.)
Figura 1.3
d) Variaciones irregulares (componente aleatoria): los movimientos irregulares
(al azar) representan todos los tipos de movimientos de una serie de tiempo que no
sea tendencia, variaciones estacionales y fluctuaciones cíclicas. [1]
1.7. MÉTODOS DE PRONÓSTICO
En un pronóstico siempre está latente la incertidumbre causada por el futuro, que
se refleja en un incremento en el error de predicción. Por este motivo, otro de los
objetivos del estudio de las Series de Tiempo es buscar métodos que reduzcan al
máximo el error de predicción.
Se concluye, entonces que un sistema de pronósticos además de predecir un valor
futuro de una variable aleatoria debe estimar su error e idealmente su distribución,
lo cual permitirá cuantificar el riesgo en la toma de las decisiones.
1.7.1. CONSIDERACIONES PRELIMINARES
La siguiente información debe estar claramente definida antes de empezar a
estudiar las diferentes alternativas que brindan los métodos utilizados para
pronosticar una Serie de Tiempo.
1.
Las variables aleatorias a pronosticar, completamente definidas. En este
punto es bueno notar que hay casos en los cuales es más útil pronosticar
los cambios que sufre una variable en su diferencia, que su valor, como
ocurre en procesos de control, donde se predice cuando el sistemas esta
funcionando mal.
2.
Los siguientes tiempos deben especificarse y confrontarse con la
información disponible.
a) Periodo de la serie (o de pronóstico). Es la unidad de tiempo (de
espacio, o del índice)
que indica la frecuencia de lectura de las
observaciones que generan la serie.
Por ejemplo si se desea
pronosticar la demanda semanal de un artículo, el periodo de la serie
es una semana y para estimar las ventas futuras se requiere conocer
las ventas semanales del artículo en algunas semanas anteriores.
b) Horizonte del pronostico (H). Es el número de periodos que debe
cubrir el sistema de pronósticos cada vez que se utiliza, e indica
cuanto se penetra en el futuro; su valor depende de la naturaleza de
lo que se planea.
c) Intervalo de pronostico (IP). Es la frecuencia con la cual se calculan
o actualizan los pronósticos existentes.
3.
Datos históricos además de las observaciones pasadas del proceso o de la
variable de interés, deben precisarse, cuando es posible, los puntos y/o
los intervalos de tiempo o del índice en los cuales la evolución de la variable
fue afectada por factores externos o internos, que se cree modificaron
algunas observaciones o la estructura de correlación de la serie,
para
cuantificar sus efectos o simplemente para eliminar perturbaciones en los
pronósticos.
4.
La precisión requerida de los pronósticos.
5.
Recursos disponibles para implementar el sistema de pronósticos.
Los métodos de pronóstico pueden clasificarse en dos grande bloques:
•
Métodos cualitativos o subjetivos
•
Métodos cuantitativos
1.7.2. MÉTODOS CUALITATIVOS O SUBJETIVOS
Los métodos cualitativos
son procedimientos que estiman los pronósticos
basándose en juicios de expertos, se utilizan la experiencia, intuición, habilidad y
sentido común de personas entrenadas para enfrentar este tipo de problemas. Por
ende, las técnicas estadísticas no juegan papel importante en su implementación.
Los Exploratorios se caracterizan porque partiendo del pasado y del presente se
desplazan hacia el futuro heurísticamente, buscando y analizando las alternativas
factibles.
Los Normativos, en cambio, parten del futuro estableciéndolos objetivos que se
pretenden alcanzar y luego se devuelven hacia el presente para determinar si con
los recursos y tecnología existente pueden alcanzarse los fines inicialmente
planteados.
Estos métodos se utilizan para pronosticar productos nuevos del mercado o
procesos de los cuales se tiene poca información pasad,
por que su
implementación no requiere conocer datos pasados de la serie.
1.7.3. MÉTODOS CUANTITATIVOS
Los métodos cuantitativos son basados en modelos estadísticos o matemáticos y se
caracterizan por que una vez elegido un modelo o una técnica de pronóstico, es
posible obtener nuevos pronósticos automáticamente. Se clasifican en modelos uní
variados y causales.
Los modelos uní variados se basan únicamente en las observaciones pasadas de la
serie para predecir valores futuros.
Los métodos de descomposición,
los de
suavizamiento y los modelos (ARIMA) en el dominio del tiempo o el dominio de la
frecuencia, son considerados métodos uní variados.
Los modelos causales estiman las predicciones futuras de un proceso determinando
la relación existente entre la variable que define la serie y otras variables (otras
series explicativas) que explican su variación. En algunos de estos modelos, para
pronosticar valores futuros de la serie es necesario pronosticar
primero las
variables o series explicativa.
Los modelos de regresión,
de funciones de
transferencia (regresión dinámica) y otros modelos econométricos,
son
considerados modelos causales.
1.7.4. MÉTODOS DE DESCOMPOSICIÓN
Estos métodos para pronosticar valores futuros de una Serie de Tiempo, primero
estiman los componentes d la serie (los parámetros que definen la tendencia y cada
uno de los términos que caracterizan una estación completa) con las observaciones
conocidas, y luego extrapolan o proyectan estas componentes a tiempos futuros.
Además estiman la varianza de la componente aleatoria para calcular los intervalos
de predicción. Su implementación requiere de un buen número de observaciones.
Algunos de estos métodos evalúan la componente cíclica de la serie. Entre estos
métodos de descomposición se encuentran x-11 y el x-11 ARIMA, construidos y
utilizados por la oficina de censos de USA.
1.7.5. MÉTODOS DE SUAVIZAMIENTO
Estos métodos
estiman valores futuros de una serie basándose en la forma
funcional, que el modelador supone, describen las observaciones conocidas de la
serie, y la eliminación de la componente aleatoria mediante ponderaciones que
actuando sobre la las observaciones suavizan la trayectoria (forma funcional) de la
serie,
alterada por la acción de la componente aleatoria.
Las ponderaciones
pueden ser iguales para todas las observaciones o pueden depender de la distancia
de la observación al origen del pronóstico, según el método de suavizamiento
empleado.
En cada actualización de los pronósticos se estiman los paramentos requeridos por
la forma funcional (tendencia y estacionalidad) y con ellos se evalúa la función para
los valores futuros de t que indica el horizonte del pronóstico.
algunos autores los denominan métodos localmente constantes.
Entre los métodos de suavizamiento se encuentran:
Por esta razón
a. Promedios móviles o medias móviles simples: Utilizado con Series de
Tiempo cuya forma funcional es constante, la grafica de la serie oscila
alrededor de un valor medio.
b. Promedios móviles o medias móviles dobles: Empleado con Series de
Tiempo que se supone presentan una tendencia lineal.
c. Suavizamiento exponencial simple (SES): Para modelar series que
presentan tendencia constante y componente aleatoria.
d. Suavizamiento exponencial doble (SED): Para modelar series que
presentan tendencia lineal y componente aleatoria.
e. Suavizamiento exponencial triple (SET): Para modelar series que
presentan tendencia cuadrática y componente aleatoria.
f.
Winter aditivo y Winter multiplicativo: Para modelar series que presentan
tendencia, componente estacional aditiva o multiplicativa según el caso y
componente aleatoria.
g. Mínimos cuadrados descontados: para modelar series que presentan
tendencia, componente estacional aditiva o multiplicativa y componente
aleatoria. [1]
1.8. MODELOS AUTORREGRESIVOS
1.8.1. AR(1)
Veamos primero el más sencillo de los modelos autorregresivos, el AR(1), que tiene
un solo rezago y se escribe,
xt = axt − 1 + εt
O también, empleado el operador de rezago, como (1 − aL)xt = εt
Este modelo podría representar, por ejemplo, los desempleados en el mes como
una proporción fija a de aquellos desempleados en el mes t – i habiendo la otra
proporción 1 – a conseguido empleo, más un nuevo grupo ε que busca trabajo,
donde estas adiciones ε 1 > 0 son ruido blanco.
dx(t )
= (a − 1)x (t ) + ε (1)
dt
En sentido estricto, no puede existir un proceso puramente aleatorio en tiempo
continuo, ε (t ) , ya que los cambios abruptos en períodos infinitesimales de este
proceso requerirían cero inercia o energía infinita.
1.8.2. AR(P)
Este es quizás el modelo más popular para series de tiempo univariadas. Expresa
el valor actual de una serie estacionaria xt en función de su propio pasado, o sea
de sus rezagos x t − 1,K , xt
− p,
.
Un autorregresivo tiene la siguiente expresión
algebráica.
x1 + a1 xt
−1
+ a 2 xt
−2
+ K + ap xt − p = ε t + c
Donde, si se quiere, se puede despejar xt , y donde c es una constante, p es el
número de rezagos, y εt es ruido blanco con media cero y varianza constante σt 2 .
En la literatura de series de tiempo, la secuencia
{εt}se conoce indistintamente
como ruido, error, residuos, innovaciones o shocks.
La expresión del autorregresivo de orden p, omitiendo al constante sin pérdida de
generalidad, se puede escribir en términos del operador de rezago como
(1 + a1L + a 2L 2 + K + apLp )xt
= a( L)xt = εt
xt − µ = a1( xt − 1 − µ ) + a 2( xt − 2 − µ ) + K + ap (xt − p − µ ) + εt
xt = ( µ − a1µ − a 2µ − K − apµ ) + a1xt − 1 + a 2 xt − 2 + K + apxt − p + εt
xt = µ (1 − a1 − a2 K − ap) + a1xt − 1 + a 2 xt − 2 + K + apxt − p + εt
xt = c + a1xt − 1 + a2 xt − 2 + K + apxt − p + εt
Al estimar el modelo se puede incluir una constante si la serie no está en
desviaciones, o se puede restar la media a todas las observaciones y no incluir la
constante. Algunos programas reportan estimativos para la media µ y la constante
c por separado con base en la expresión anterior. [3] [4]
1.9. MODELOS DE PROMEDIO MÓVIL
1.9.1. MA(Q)
El segundo modelo dentro de la metodología Box-Jenkis es el de promedio móvil.
Este expresa la serie x, en función del presente y el pasado de una serie de ruido
blanco {εt } con media cero.
q
xt = c + β 0εt + β 1εt − 1 + β 2εt − 2 + K + βqεt − q = ∑ βsεt − s
0
Donde los coeficientes β no tienen restricciones en cuanto a la estabilidad de la
serie porque una suma finita de términos con varianza finita, como lo son los εt , no
puede ser explosiva. Se ve fácilmente que Εxt = 0 porque Ε εt = 0 .
Como se mencionó antes, en el contexto de series de tiempo, y especialmente en el
caso de los modelos de promedio móvil, la secuencia {εt} también se conoce como
innovaciones, en el sentido de ser información nueve que llega al sistema.
1.9.2. MA(1)
El modelo MA(q) más sencillo es el que tiene un solo rezago de εt . Este se denota
MA(l) y su expresión es
xt = β 0 εt + β 1εt − 1
Es evidente que Ε xt = 0 . La función de
para un MA(l) se encuentra
multiplicando la ecuación anterior por la misma ecuación rezagada, y tomando
expectativas.
De manera que r(l) máximo será
r (l ) max =
β1
±1
1
=
=±
1 + β 12 1 + 1
2
Positivo o negativo dependiendo del signo de β 1 . [3][4]
1.10. MODELO AUTORREGRESIVO CON PROMEDIO MÓVIL
Modelos ARIMA
Estos métodos modelan las Series de Tiempo estudiando la
estructura de la correlación que el tiempo, el índice, o la distancia induce en las
variables aleatorias que originan la serie.
El plan de trabajo de estos modelos es:
I. Por medio de transformaciones y/o diferencias se estabiliza la varianza, y se
eliminan la tendencia y la estacionalidad de la serie; obteniéndose así, una serie
estacionaria.
II. Para la serie estacionaria
obtenida se identifica y se estima un modelo que
explica la estructura de correlación de la serie con el tiempo.
III. Al modelo hallado en II.
Se aplican transformaciones inversas que permitan
reestablecer la variabilidad, la tendencia y la estacionalidad de la serie original.
Este modelo integrado se usa para pronosticar.
Para explicar la estructura de correlación entre las observaciones de una serie
estacionaria se consideran básicamente dos modelos:
∞
Zt = ∑ π j Zt − j + at Modelo auto-regresivo (AR).
j 01
∞
Zt = µ + ∑ψ j at − j Modelo de media móvil (MA).
j 01
Un hecho común a muchos fenómenos es que el comportamiento pasado provee
información sobre el comportamiento futuro; esto es especialmente cierto en series
de tiempo. El pasado de una serie suele incorporar, y de esa manera reemplazar, la
información de otras variables que pudieran intervenir en el proceso.
La
especificación relativamente sencilla, pero efectiva, que resulta de expresar una
variable de función de su propio pasado es conocida como autorregresiva o, en
general, como modelaje Box-Jenkins. Las dos especificaciones principales de esta
metodología son los modelos autorregresivos AR(p) y los modelos de promedio
móvil MA(q), que describiremos a continuación.
1.11. MODELO ARMA (P,Q)
La combinación de los dos modelos anteriores, el AR(p) y el MA(q), junto con el
hecho de que uno se puede convertir en el otro y viceversa, da origen al modelo
ARMA(p,q). Su ventaja es que, al combinar elementos de ambos, puede ofrecer
mayor parsimonia, esto es, usar menos términos. Su expresión será
xt = a1 xt
−1
+ a 2 xt
−2
+ K + a p xt
− p
+ β 0 εt + β 1εt
−1
+ β 2 εt
−2
+ K + β qεt
−q
o también
p
q
j =1
j =0
xt = ∑ ajxt − j + ∑ βjεt −
zt = a 2 z t − 2 + kt
j
[3]
1.11. CRITERIOS DE EVALUACIÓN DE PREDICCIONES
Las medidas de precisión del pronóstico se usan para determinar que tan eficaz es
un pronóstico a través del cálculo de su precisión con respecto a los valores reales,
es decir, buscan obtener una medida de que tan lejos se encuentran los valores
pronosticados de los obtenidos en la realidad. En las siguientes medidas del error,
Xt es el valor de la serie de tiempo en el momento t y Pt es el pronóstico para ese
mismo momento. [11]
Estos son algunos de los indicadores comúnmente utilizados para evaluar
predicciones.
Error
Error Medio
Error Medio Absoluto
Suma de Cuadrados del Error
Suma de Cuadrados del Error Media o Error Cuadrático Medio
Desviación Estándar del Error
Nótese que Pt no es la media de las estimaciones o valores pronosticados como se
podría pensar. Esto significa que la desviación no se mide respecto de la media,
sino que se promedian las desviaciones de las estimaciones respecto a los valores
reales.
Error Porcentual
Error Porcentual Medio
Error Porcentual Medio Absoluto
Error Porcentual Medio Cuadrático
1.12. OTROS MÉTODOS NO CONVENCIONALES
En el afán del hombre por disminuir la inc ertidumbre y aumentar el conocimiento
sobre el comportamiento de las cosas que parecen aleatorias ha desarrollado otros
métodos no convencionales para la predicción y la disminución de esta
incertidumbre. Dichos métodos presentan un nivel mucho más alto de complejidad,
en su mayoría surgieron de la imitación de procesos de la naturaleza. Algunos de
estos métodos no convencionales de predicción son: Redes neuronales Artificiales,
Support vector machine, La Programación genética y filtro kalman.
Redes neuronales Artificiales (RNA) que son dispositivos o software programado de
manera tal que funcionen como las neuronas biológicas de los seres vivos. (Estas
sus características,
usos y funcionamiento serán profundizados en el siguiente
capitulo).
Maquina de soporte vectorial del ingles Support vector machine La SVM fue ideada
originalmente para la resolución de problemas de clasificación binarios en los que
las clases eran linealmente separables (Vapnik y Lerner, 1965). Por este motivo se
conocía también como «hiperplano3 óptimo de decisión» ya que la solución
proporcionada es aquella en la que se clasifican correctamente todas las muestras
disponibles, colocando el hiperplano de separación lo más lejos posible de todas
ellas. Las muestras más próximas al hiperplano óptimo de separación son
conocidas como muestras críticas o «vectores soporte», que es lo que da nombre a
la SVM.
[10]
La Programación genética en cuyos algoritmos hace evolucionar una población
sometiéndola a acciones aleatorias semejantes a las que actúan en la evolución
biológica (mutaciones y recombinación genética), así como también a una selección
de acuerdo con algún criterio, en función del cual se decide cuáles son los
individuos más adaptados, que sobreviven, y cuáles los menos aptos, que son
descartados.
ha tenido gran parte de su utilización para resolver este tipo de
problemas de predicción de eventos.
Filtro kalman (kalman filter) Algoritmo recursivo que se utiliza en ARIMA para
generar valores ajustados y residuos para una serie.
3
Las variedades afines de dimensión 0 en son los subconjuntos de
reducidos a un punto. Las de dimensión 1 se llaman
RECTAS. Las de dimensión 2 se llaman PLANOS. Una variedad afín se llama HIPERPLANO si su dirección
es un
subespacio maximal en
, es decir,
y el único subespacio de
que contiene a
propiamente es
entero .
1.13. APLICACIONES DE LAS SERIES DE TIEMPO
El estudio de las Series de Tiempo tiene como objetivo central desarrollar modelos
estadísticos que expliquen el comportamiento de una variable aleatoria que varia
con el tiempo, o con la distancia, o según un índice; y que permitan estimar
pronósticos futuros de dicha variable aleatoria.
Por ello,
el manejo de las Series de Tiempo es de vital importancia en una
planeación y en mareas del conocimiento donde evaluar el efecto de una política
pasada sobre una variable,
y/o conocer predicciones de sus valores futuros,
aportan criterios que disminuyen el riesgo en la toma de decisiones o en la
implementación de políticas futuras.
En el contexto de las Series de Tiempo,
pronosticar significa predecir valores
futuros de una variable aleatoria basándose en el estudio de la estructura definida
por las observaciones pasadas de la variable, o en el análisis de observaciones
pasadas de variables que explican su variación, suponiendo que la estructura del
pasado se conserva en el futuro.
La existencia del intervalo de tiempo comprendido entre presente y el momento en
el cual ocurrirá el suceso o evento de interés, llamado tiempote previsión oleading
time, origina la necesidad de conocer un pronostico del evento; para así, poder
planear y ejecutar acciones que contrarresten o controlen los efectos que dicho
suceso producirá. La longitud de este intervalo de tiempo da origen a la planeación;
si no existiera o fuera muy pequeño, se estaría enfrentando a situaciones concretas
que deben resolverse mediante acciones inmediatas, más no planearse.
En consecuencia, cuando el tiempo de previsión es apropiado y el resultado final
del evento de interés esta condicionado por factores identificables, la planeación
adquiere sentido y el conocimiento del pronostico del evento permite tomar
decisiones sobre acciones a ejecutar o a controlar para que los resultados finales
estén acordes con la política general de la empresa.
Es importante anotar que existen factores o eventos que influyen en la calidad de un
pronóstico.
Estos factores pueden ser internos o controlables y externos o
incontables. [4]
2. REDES NEURONALES
En este capitulo se abordara el tema de redes neuronales basados en la estructura
del libro Redes Neuronales y Sistemas Difusos de los profesores Martín del Brío y
Sanz Molina [12], debido a su gran énfasis en aplicaciones practicas, su abundancia
de ejemplos y la rigurosidad teórica con que tratan la materia.
2. 1. INTRODUCCION
En el transcurso del capitulo se pretende introducir los conceptos y herramientas
básicas necesarias para el desarrollo de los temas abordados en el capitulo 4,
principal objetivo de este trabajo.
Este capitulo se trabajo basado en referencias e investigaciones sobre los
principales detalles acerca del tema, tal que una persona que no conozca sobre el
tema se relacione con los conceptos de la materia. En primera medida se hará un
recuento cronológico breve de la historia de las redes y su evolución a través de los
años, luego se hará un desarrollo comparativo entre la principal fuente de ideas para
las redes neuronales artificiales, la neurona natural.
Con los conceptos básicos ya desarrollados se entrara en la descripción de la teoría
que fundamenta el desarrollo de las redes neuronales, como son las principales
topologías y el proceso de entrenamiento.
Finalizando el capitulo se definirán topologías especificas que serán usadas
posteriormente en este trabajo
algoritmo del backpropagation.
como el modelo del perceptron multicapa y el
2.2. HISTORIA
Conseguir diseñar y construir máquinas capaces de realizar procesos con cierta
inteligencia ha sido uno de los principales objetivos de los científicos a lo largo de la
historia.
1936 - Alan Turing. Fue el primero en estudiar el cerebro como una forma de ver el
mundo de la computación. Sin embargo, los primeros teóricos que concibieron los
fundamentos de la computación neuronal fueron Warren McCulloch, un
neurofisiólogo, y Walter Pitts, un matemático, quienes, en 1943, lanzaron una teoría
acerca de la forma de trabajar de las neuronas (Un Cálculo Lógico de la Inminente
Idea de la Actividad Nerviosa - Boletín de Matemática Biofísica 5: 115-133). Ellos
modelaron una red neuronal simple mediante circuitos eléctricos. [13]
1943 - Teoría de las Redes Neuronales Artificiales. Walter Pitts junto a Bertran
Russell y Warren McCulloch intentaron explicar el funcionamiento del cerebro
humano, por medio de una red de células conectadas entre sí, para experimentar
ejecutando operaciones lógicas. Partiendo del menor suceso psíquico (estimado por
ellos): el impulso todo/nada, generado por una célula nerviosa.
El bucle "sentidos - cerebro - músculos", mediante la retroalimentación producirían
una reacción positiva si los músculos reducen la diferencia entre una condición
percibida por los sentidos y un estado físico impuesto por el cerebro. También
definieron la memoria como un conjunto de ondas que reverberan en un circuito
cerrado de neuronas. [13]
1949 - Donald Hebb. Escribió un importante libro: La organización del
comportamiento, en el que se establece una conexión entre psicología y fisiología.
Fue el primero en explicar los procesos del aprendizaje (que es el elemento básico
de la inteligencia humana) desde un punto de vista psicológico, desarrollando una
regla de como el aprendizaje ocurría. Aun hoy, este es el fundamento de la mayoría
de las funciones de aprendizaje que pueden hallarse en una red neuronal. Su idea
fue que el aprendizaje ocurría cuando ciertos cambios en una neurona eran
activados. También intentó encontrar semejanzas entre el aprendizaje y la actividad
nerviosa. Los trabajos de Hebb formaron las bases de la Teoría de las Redes
Neuronales. [14]
1950 - Karl Lashley. En sus series de ensayos, encontró que la información no era
almacenada en forma centralizada en el cerebro sino que era distribuida encima de
él. [13]
1956 - Congreso de Dartmouth. Este Congreso frecuentemente se menciona para
indicar el nacimiento de la inteligencia artificial. Durante el congreso se forjó el
término "inteligencia artificial". Asistieron, entre otros, Minsky, Simon y Newell. [13]
1957 - Frank Rosenblatt. Comenzó el desarrollo del Perceptron. Esta es la red
neuronal más antigua; utilizándose hoy en día para aplicación como identificador de
patrones. Este modelo era capaz de generalizar, es decir, después de haber
aprendido una serie de patrones podía reconocer otros similares, aunque no se le
hubiesen presentado en el entrenamiento. Sin embargo, tenía una serie de
limitaciones, por ejemplo, su incapacidad para resolver el problema de la función
OR-exclusiva y, en general, era incapaz de clasificar clases no separables
linealmente, este tema acerca del perceptrón se describe con detalle en la sección
2.10.2. Perceptron Simple. [13]
1959 - Frank Rosenblatt: Principios de Neurodinámica. En este libro confirmó que,
bajo ciertas condiciones, el aprendizaje del Perceptron convergía hacia un estado
finito (Teorema de Convergencia del Perceptron).[14]
1960 - Bernard Widroff/Marcian Hoff. Desarrollaron el modelo Adaline (ADAptative
LINear Elements). Esta fue la primera red neuronal aplicada a un problema real
(filtros adaptativos para eliminar ecos en las líneas telefónicas) que se ha utilizado
comercialmente durante varias décadas. [13]
1961 - Karl Steinbeck: Die Lernmatrix. Red neuronal para simples realizaciones
técnicas (memoria asociativa). [14]
1969 - En este año surgieron críticas que frenaron, hasta 1982, el crecimiento que
estaban experimentando las investigaciones sobre redes neuronales. Minsky y
Papera, del Instituto Tecnológico de Massachussets (MIT), publicaron un libro
Perceptrons. Probaron (matemáticamente) que el Perceptrón no era capaz de
resolver problemas relativamente fáciles, tales como el aprendizaje de una función
linealmente no separable. Esto demostró que el Perceptrón era muy débil, dado que
las funciones linealmente no separable son extensamente empleadas en
computación y en los problemas del mundo real. A pesar del libro, algunos
investigadores continuaron su trabajo. Tal fue el caso de James Anderson, que
desarrolló un modelo lineal, llamado Asociador Lineal, que consistía en unos
elementos integradores lineales (neuronas) que sumaban sus entradas. Este
modelo se basa en el principio de que las conexiones entre neuronas son
reforzadas cada vez que son activadas. Anderson diseñó una potente extensión del
Asociador Lineal, llamada Brain State in a Box (BSB). [14]
1974 - Paul Werbos. Desarrolló la idea básica del algoritmo de aprendizaje de
propagación hacia atrás (backpropagation); cuyo significado quedó definitivamente
aclarado en 1985. [13]
1977 - Stephen Grossberg: Teoría de Resonancia adaptativa (TRA). La Teoría de
Resonancia adaptativa es una arquitectura de red que se diferencia de todas las
demás previamente inventadas. La misma simula otras habilidades del cerebro:
memoria a largo y corto plazo. [14]
1985 - John Hopfield. Provocó el renacimiento de las redes neuronales con su libro:
“Computación neuronal de decisiones en problemas de optimización.” [14]
1986 - David Rumelhart/G. Hinton. Redescubrieron el algoritmo de aprendizaje de
propagación hacia atrás (backpropagation). A partir de 1986, el panorama fue
alentador con respecto a las investigaciones y el desarrollo de las redes neuronales.
En la actualidad, son numerosos los trabajos que se realizan y publican cada año,
las aplicaciones nuevas que surgen (sobretodo en el área de control) y las
empresas que lanzan al mercado productos nuevos, tanto hardware como software
(sobre todo para simulación). [13]
2.3. NEURONA BIOLÓGICA
Se estima que el cerebro humano contiene más de cien mil millones de neuronas y
sinápsis en el sistema nervioso humano. Estudios sobre la anatomía del cerebro
humano concluyen que hay más de 1000 sinápsis a la entrada y a la salida de cada
neurona. Es importante notar que aunque el tiempo de conmutación de la neurona
(unos pocos milisegundos) es casi un millón de veces menor que en las actuales
elementos de las computadoras, ellas tienen una conectividad miles de veces
superior que las actuales supercomputadoras. [13]
El objetivo principal de de las redes neuronales de tipo biológico es desarrollar un
elemento sintético para verificar las hipótesis que conciernen a los sistemas
biológicos. Las neuronas y las conexiones entre ellas (sinápsis) constituyen la clave
para el procesado de la información.
Desde un punto de vista funcional, las neuronas
constituyen procesadores de información sencillos.
Como todo sistema de este tipo, poseen un canal
de entrada de información, las dendritas, un
órgano de cómputo, el soma, y un canal de salida,
el axón. [12]
La neurona es la célula fundamental y básica del
sistema
nervioso.
Es
una
célula
alargada,
especializada en conducir impulsos nerviosos. En
las neuronas se pueden distinguir tres partes
fundamentales, que son:
•
Figura 2.1: Neurona Biológica
Soma o cuerpo celular: corresponde a la parte más voluminosa de la neurona.
Aquí se puede observar una estructura esférica llamada núcleo. Éste contiene la
información que dirige la actividad de la neurona. Además, el soma se encuentra
el citoplasma. En él se ubican otras estructuras que son importantes para el
funcionamiento de la neurona.
•
Dendritas: son prolongaciones cortas que se originan del soma neural. Su
función es recibir impulsos de otras neuronas y enviarlas hasta el soma de la
neurona.
•
Axón: es una prolongación única y larga. En algunas ocasiones, puede medir
hasta un metro de longitud. Su función es sacar el impulso desde el soma
neuronal y conducirlo hasta otro lugar del sistema.
Las neuronas son muy variadas en morfología y tamaño. Pueden ser estrelladas,
fusiformes, piriformes. Pueden medir no más de cuatro micras o alcanzar las 130
micras. También son muy variadas en cuanto a las prolongaciones: las dendritas y
el cilindroeje o axón. Las dendritas, de conducción centrípeta, pueden ser únicas o
múltiples.
La unión entre dos neuronas se denomina sinapsis. En el tipo de sinapsis más
común no existe un contacto físico entre las neuronas, sino que éstas permanecen
separadas por un pequeño vacío de unas 0.2 micras.
En relación a la sinapsis, se habla de neuronas presinápticas (la que envía las
señales) y postsinápticas (la que las recibe). Las sinapsis son direccionales, es
decir, la información fluye siempre en un único sentido.
Las señales nerviosas se pueden transmitir eléctrica o químicamente. La
transmisión química prevalece fuera de la neurona, mientras que la eléctrica lo hace
el interior. La transmisión química se basa en el intercambio de neurotransmisores
mientras que la eléctrica hace uso de descargas que se producen en el cuerpo
celular y que se propagan por el axón.
La forma de comunicación más habitual entre dos neuronas es de tipo químico La
neurona presináptica libera unas sustancias químicas complejas denominadas
neurotransmisores (como el glutamato o la adrenalina), que atraviesan el vació
sináptico. Si la neurona postsináptica posee en las dendritas o en el soma canal
sensibles a los neurotransmisores liberados, los fijarán, y como consecuencia de el
permitirán el paso de determinados iones a través de la membrana.
Las corrientes iónicas que de esta manera se crean provocan pequeños potenciales
postsinápticos excitadores (positivos) o inhibidores (negativos), que se integrarán en
el soma, tanto espacial como temporalmente; éste es el origen de la existencia de
sinapsis excitatoria y de sinapsis inhibitorias.
Si se ha producido un suficiente número de excitaciones, Suma de los potenciales
positivos generados puede elevar el potencial de la neuronas por encima de los -45
mV (umbral de disparo): en ese momento se abren bruscamente los Canales de
sodio, de modo que los iones Na cuya concentración en el exterior es alta, entran
masivamente al interior, provocando la despolarización brusca de neurona, que
pasa de un potencial de reposo de -60 mV a unos +50 mV.
A continuación la neurona vuelve a la situación original de reposo de -6OmV; este
proceso constituye la generación de un potencial de acción (Figura 1.3), que
propagarse a lo largo del axón da lugar a la transmisión eléctrica de la señal
nerviosa. Tras haber sido provocado un potencial de acción, la neurona sufre un
periodo refractario durante el cual no puede generarse uno nuevo.
Un hecho importante es que el pulso así generado es “digital en el sentido que
existe o no existe pulso, y todos ellos s on de la misma magnitud.
Por otra parte ante una estimulación más intensa disminuye el intervalo entre
pulsos, por lo que la neurona se disparará a mayor frecuencia cuanto mayor sea el
nivel de excitación. Es decir ante un estímulo mayor la frecuencia de respuesta
aumenta hasta que se alcanza una saturación conforme se acerca a la frecuencia
máxima
La frecuencia de disparo oscila habitualmente entre 1 y 100 pulsos por segundo,
aunque algunas neuronas pueden llegar a los 500 durante pequeños períodos de
tiempo. Por otra parte, no todas las neuronas se disparan generando un tren de
pulsos de una frecuencia aproximadamente constante, pues la presencia de otras
especies iónicas hace que diferentes tipos de neuronas posean patrones de disparo
distintos, en forma de trenes puros, paquetes de pulsos, o presentando patrones
más complejos.
El mecanismo aquí descrito constituye la forma más común de transmisión de la
señal nerviosa, pero no el único. Cuando la distancia que debe recorrer la señal es
menor de 1 mm la neurona puede no codificarla en frecuencia, sino enviar una señal
puramente analógica. Es decir, la evolución biológica encontró que a distancias
cortas la señal no se degradaba sustancialmente, por lo que podía enviarse tal cual,
mientras que a distancias largas era preciso codificarla para evitar su degradación la
consiguiente pérdida de información. La naturaleza descubrió que la codificación en
forma de frecuencia de pulsos digitales proporcionaba calidad, simplicidad en la
transmisión.1 [12]
2.4. MODELO DE NEURONA ARTIFICIAL
En esta sección se expone el modelo de neurona de los ANS. En primer lugar se
describe la estructura de una neurona artificial muy genérica, para a continuación
mostrar una versión simplificada, de amplio uso en los modelos orientados
aplicaciones prácticas, que posee una estructura más próxima a la neurona tipo
McCulloch-Pitts [1949].
1
Más información sobre el cerebro, las neuronas y la neurotransmision en una pagina denominada el
abc de las neuronas, impulsada por el Instituto de Investigaciones Biológicas Clemente Estable.
http://iibce.edu.uy/uas/neuronas/abc.htm
2.4.1. MODELO GENERAL
Se denomina procesador elemental o neurona a un dispositivo simple de cálculo
que, a partir de un vector de entrada proc edente del exterior o de otras neuronas
proporciona una única respuesta o salida. [12]
Los elementos que constituyen la neurona de etiqueta i son los siguientes (véase la
Figura 2.2):
Figura 2.2: Modelo Genérico Neurona Artificial
•
Conjunto de entradas, xJ (t)
•
Pesos sinápticos de la neurona i, w IJ que representan la intensidad de
interacción entre cada neurona presináptica j y la neurona postsináptica i.
•
Regla de propagación x que proporciona el valor del potencial postsináptico hJ (t)
= s(wIJ , xJ (t)) de la neurona i en función de sus pesos y entradas.
•
Función de desempeño fi(aI (t-1), hI (t)) que proporciona el estado de activación
actual aI (t) = fi(aI (t-1), hI(t)) de la neurona i, en función de su estado anterior aI (t1) y de su potencial postsináptico actual.
•
Función de salida FI (aI (t-1), que proporciona la salida actual yI (t) = FI(aI (t-1) de la
neurona i en función de su estado de activación.
Este modelo de neurona formal se inspira en la operación de la biológica, en el
sentido de integrar una serie de entradas y proporcionar cierta respuesta, que se
propaga por el axón. A continuación se describen cada uno de los elementos. [12]
2.4.1.1. ENTRADAS Y SALIDAS.
Las variables de entrada y salida pueden ser binarias (digitales) o continuas
(analógicas), dependiendo del modelo y aplicación. Por ejemplo, un perceptron
multicapa o MLP (Multilayer Perceptron) admite ambos tipos de señales. Así, para
tareas de clasificación poseería salidas digitales {O, +1}, mientras que para un
problema de ajuste funcional de una aplicación multivariable continua, se utilizarían
salidas continuas pertenecientes a un cierto intervalo.
Dependiendo del tipo de salida, las neuronas suelen recibir nombres específicos.
Así, las neuronas estándar cuya salida sólo puede tomar los valores 0 o 1 se suelen
denominar genéricamente neuronas de tipo McCullochPitts, mientras que aquellas que únicamente pueden tener por salidas -1 o + 1 se
suelen denominar neuronas tipo Ising (debido al paralelismo con los modelos físicos
de partículas con espín que pueden adoptar únicamente dos estados, hacia arriba y
hacia abajo). Si puede adoptar diversos valores discretos en la salida (por ejemplo, 2, + 1, +2), se dice que se trata de una neurona de tipo Potts. En ocasiones, el
rango de los valores que una neurona de salida continua se suele limitar un intervalo
definido, por ejemplo, [ +1] o [ +1]. [12]
2.4.1.2. REGLA DE PROPAGACION
La regla de propagación permite obtener, a partir de las entradas y los pesos el
valor del potencial postsináptico h I de la neurona. La función más habitual es de tipo
lineal, y se basa en la suma ponderada las entradas con los pesos sinápticos
que formalmente también puede interpretarse como producto escalar de los
vectores de entrada y los pesos. [12]
2.4.1.3. FUNCIÓN DE ACTIVACION
La función de desempeño o de transferencia proporciona el estado de actual aI (t) a
partir del potencial postsináptico hI (t) y del propio estado de anterior aI (t-1). Sin
embargo, en muchos modelos se considera que el estado actual de neurona no
depende de su es estado anterior, sino únicamente del actual.
La función de desempeño se suele considerar determinista, y en la mayor parte de
los modelos es monótona creciente y continua, como se observa habitualmente en
las neuronas. Las funciones de activación más empleadas en muestra en la figura
2.3.
En ocasiones los algoritmos de aprendizaje requieren que la función de desempeño
cumpla la Condición de ser derivable. Las más empleadas en este sentido son las
funciones de tipo sigmoideo. [12]
Para explicar porque se utilizan estas funciones de activación se suele emplear la
analogía a la aceleración de un automóvil. Cuando un auto inicia su movimiento
necesita una potencia elevada para comenzar a acelerar. Pero al ir tomando
velocidad, este demanda un menor incremento de dicha potencia para mantener la
aceleración. Al llegar a altas velocidades, nuevamente un amplio incremento en la
potencia es necesario para obtener una pequeña ganancia de velocidad. En
resumen, en ambos extremos del rango de aceleración de un automóvil se demanda
una mayor potencia para la aceleración que en la mitad de dicho rango. [15]
Figura 2.3: Funciones de activación más usuales
2.4.1.4. FUNCIÓN DE SALIDA
Esta función proporciona la salida global de la neurona y en función de su estado de
activación actual aI (t). Muy frecuentemente la función de salida es simplemente la
identidad f(x) = x de modo que el estado de activación de la neurona se considera
como la propia salida. [12]
2.4.2. MODELO ESTANDAR
Figura 2.4: Modelo de Neurona Estándar
El modelo de neurona expuesto en la sección anterior resulta muy general la
práctica suele utilizarse uno más simple, que se denomina neurona estándar, la
neurona estándar consiste en
•
Un conjunto de entradas xI (t) y pesos sinápticos w IJ
•
Una regla de propagación
•
Una función de desempeño que representa simultáneamente la salida de la
es la más común.
neurona y su estado de activación.
Con frecuencia se añade al conjunto de pesos de la neurona un parámetro adicional
? que se denomina umbral, que se resta del potencial postsináptico. En conclusión,
el modelo de neurona estándar queda:
2.5. REDES NEURONALES Y ARQUITECTURAS
Las redes neuronales artificiales (ANN) son sistemas paralelos para el
procesamiento de la información, inspirados en el modo en el que las redes de
neuronas biológicas del cerebro procesan información. [15]
Debido a la inspiración de las ANN en el cerebro, sus aplicaciones principales
estarán centradas en campos donde la inteligencia humana no pueda ser emulada
de forma satisfactoria por algoritmos aritméticos que pueden ser implementados en
ordenadores. Además es de prever que dichas ANN tengan características similares
a las del cerebro:
•
Serán robustas i tolerantes a fallos. En el cerebro mueren todos los días gran
cantidad de neuronas sin afectar sensiblemente a su funcionamiento.
•
Serán flexibles. El cerebro se adapta a nuevas circunstancias mediante el
aprendizaje
•
Podrán trabajar con información borrosa, incompleta, probabilística, con ruido o
inconsistente.
•
Serán altamente paralelas. El cerebro esta formado por muchas neuronas
interconectadas entre si y es precisamente el comportamiento colectivo de todas
ellas lo que caracteriza su forma de procesar la información.
El punto clave de las ANN es la nueva estructura de estos sistemas para el
procesamiento de la información. Estos están compuestos, al igual que el cerebro,
por un número muy elevado de elementos básicos (las neuronas), altamente
interconectados entre ellos y con modelo de respuesta para cada elemento en
función de su entorno muy parecido al comportamiento de las neuronas biológicas.
Estos modelos son simulados en ordenadores convencionales y es el
comportamiento colectivo de todos los elementos lo que le confiere esas
características tan peculiares para la resolución de problemas complejos. Las ANNs,
como las personas, aprenden a partir de ejemplos. Aprender en sistemas biológicos
involucra la modificación de la ínter conectividad entre las neuronas y esto es
también cierto para las ANNs. [13]
Las ANNs han sido aplicadas a un creciente número de problemas reales de
considerable complejidad, por ejemplo reconocimiento de patrones, clasificación de
datos, predicciones, etc. Su ventaja más importante esta en solucionar problemas
que son demasiado complejos para las técnicas convencionales: problemas que no
tienen un algoritmo específico para su solución, o cuyo algoritmo es demasiado
complejo para ser encontrado.
A continuación se puede ver, en la Figura 2.5, un esquema de una red neuronal:
Figura 2.5: Ejemplo de una red neuronal totalmente conectada
La misma está constituida por neuronas interconectadas y arregladas en tres capas
(esto último puede variar). Los datos ingresan por medio de la “capa de entrada”,
pasan a través de la “capa oculta” y salen por la “capa de salida”. Cabe mencionar
que la capa oculta puede estar constituida por varias capas.
2.5.1. TIPOS DE ARQUITECTURA
Se denomina arquitectura a la topología, estructura o patrón de conexionado de una
red neuronal. [12]
Atendiendo a distintos conceptos, pueden establecerse diferentes tipos de
arquitecturas neuronales.
Figura 2.6: Ejemplos de arquitecturas neuronales
Así, en relación a su estructura en capas, se puede hablar de redes monocapa y de
redes multicapa. Las redes monocapa son aquellas compuestas por una única capa
de neuronas. Las redes multicapa (layered networks) son aquellas cuyas neuronas
se organizan en varias capas.
Asimismo, atendiendo al flujo de datos en la red neuronal, se puede hablar de redes
unidireccionales (feedforward) y redes recurrentes (feedback). En las redes
unidireccionales la información circula en un único sentido, desde las neuronas de
entrada hacia las de salida. En las redes recurrentes o realimentadas la información
puede circular entre las capas en cualquier sentido, incluido el de salida-entrada.
Por último, también se habla de redes autoasociativas y heteroasociativas. Con
frecuencia se interpreta la operación de una red neuronal como la de una memoria
asociativa que ante un determinado patrón de entradas responde con un cierto
patrón
Si una red se entrena para que ante la presentación de un patrón A responda otra
diferente B, se dice que la red es heteroasociativa. Si una red es entrenada para
que asocie un patrón A consigo mismo, se dice que es autoasociativa.
2.6. APRENDIZAJE DE UNA RED NEURONAL
El aprendizaje es el proceso por el cual una red neuronal modifica sus pesos en
respuesta a una información de entrada. Los cambios que se producen durante el
mismo se reducen a la destrucción, modificación y creación de conexiones entre las
neuronas. Una red neuronal debe aprender a calcular la salida correcta para cada
constelación (arreglo o vector) de entrada en el conjunto de ejemplos. [15]
Este proceso de aprendizaje se denomina: Proceso de Entrenamiento o
Acondicionamiento. El conjunto de datos (o conjunto de ejemplos) sobre el cual este
proceso se basa es, por ende, llamado: Conjunto de datos de Entrenamiento.
Durante el proceso de aprendizaje, los pesos de las conexiones de la red sufren
modificaciones, por lo tanto, se puede afirmar que este proceso ha terminado (la red
ha aprendido) cuando los valores de los pesos permanecen estables, si los pesos
cambian y sus valores son iguales a 0, se dice que la conexión de la red se ha
destruido. De esta manera, se dice que los pesos se han adaptado, ya que sus
valores son distintos de 0 y su derivada es igual a 0.
En otras palabras el aprendizaje es el proceso por el cual una red neuronal modifica
sus pesos en respuesta a una información de entrada. Los cambios que se
producen durante el mismo se reducen a la destrucción, modificación y creación de
conexiones entre las neuronas.
Un aspecto importante respecto al aprendizaje de las redes neuronales es el
conocer cómo se modifican los valores de los pesos, es decir, cuáles son los
criterios que se siguen para cambiar el valor asignado a las conexiones cuando se
pretende que la red aprenda una nueva información. [13]
Clásicamente se distinguen dos modos de operación en los sistemas neuronales el
modo recuerdo o ejecución, y el modo aprendizaje o entrenamiento.
2.6.1. FASE DE APRENDIZAJE. CONVERGENCIA
Hay dos métodos de aprendizaje importantes que pueden distinguirse:
•
Aprendizaje supervisado.
•
Aprendizaje no supervisado.
2.6.1.1. APRENDIZAJE SUPERVISADO
El aprendizaje supervisado se caracteriza porque el proceso de aprendizaje se
realiza mediante un entrenamiento controlado por un agente externo (supervisor,
maestro) que determina la respuesta que debería generar la red a partir de una
entrada determinada. El supervisor controla la salida de la red y en caso de que ésta
no coincida con la deseada, se procederá a modificar los pesos de las conexiones,
con el fin de conseguir que la salida obtenida se aproxime a la deseada. En este tipo
de aprendizaje se suelen considerar, a su vez, tres formas de llevarlo a cabo, que
dan lugar a los siguientes aprendizajes supervisados:
•
Aprendizaje por corrección de error: Consiste en ajustar los pesos de las
conexiones de la red en función de la diferencia entre los valores deseados y los
obtenidos a la salida de la red, es decir, en función del error cometido en la
salida.
•
Aprendizaje por refuerzo: Se trata de un aprendizaje supervisado, más lento que
el anterior, que se basa en la idea de no disponer de un ejemplo completo del
comportamiento deseado, es decir, de no indicar durante el entrenamiento
exactamente la salida que se desea que proporcione la red ante una
determinada entrada. En el aprendizaje por refuerzo la función del supervisor se
reduce a indicar mediante una señal de refuerzo si la salida obtenida en la red
se ajusta a la deseada (éxito = +1 o fracaso = -1), y en función de ello se ajustan
los pesos basándose en un mecanismo de probabilidades. Se podría decir que
en este tipo de aprendizaje la función del supervisor se asemeja más a la de un
crítico (que opina sobre la respuesta de la red) que a la de un maestro (que
indica a la red la respuesta concreta que debe generar), como ocurría en el caso
de supervisión por corrección del error.
•
Aprendizaje estocástico: Consiste básicamente en realizar cambios aleatorios en
los valores de los pesos de las conexiones de la red y evaluar su efecto a partir
del objetivo deseado y de distribuciones de probabilidad. En pocas palabras el
aprendizaje consistiría en realizar un cambio aleatorio de los valores de los
pesos y determinar la energía de la red. Si la energía es menor después del
cambio, es decir, si el comportamiento de la red se acerca al deseado, se acepta
el cambio; si, por el contrario, la energía no es menor, se aceptaría el cambio en
función de una determinada y preestablecida distribución de probabilidades.
2.6.1.2. APRENDIZAJE NO SUPERVISADO
Las
redes
con
aprendizaje
no
supervisado
(también
conocido
como
autosupervisado) no requieren influencia externa para ajustar los pesos de las
conexiones entre sus neuronas. La red no recibe ninguna información por parte del
entorno que le indique si la salida generada en respuesta a una determinada
entrada es o no correcta. Estas redes deben encontrar las características,
regularidades, correlaciones o categorías que se puedan establecer entre los datos
que se presenten en su entrada.
Existen varias posibilidades en cuanto a la interpretación de la salida de estas
redes, que dependen de su estructura y del algoritmo de aprendizaje empleado. En
cuanto a los algoritmos de aprendizaje no supervisado, en general se suelen
considerar dos tipos, que dan lugar a los siguientes aprendizajes:
•
Aprendizaje hebbiano: Esta regla de aprendizaje es la base de muchas otras, la
cual pretende medir la familiaridad o extraer características de los datos de
entrada. El fundamento es una suposición bastante simple: si dos neuronas Ni y
Nj toman el mismo estado simultáneamente (ambas activas o ambas inactivas),
el peso de la conexión entre ambas se incrementa. Las entradas y salidas
permitidas a la neurona son: {-1, 1} o {0, 1} (neuronas binarias). Esto puede
explicarse porque la regla de aprendizaje de Hebb se originó a partir de la
neurona biológica clásica, que solamente puede tener dos estados: activa o
inactiva.
•
Aprendizaje competitivo y comparativo: Se orienta a la clusterización o
clasificación de los datos de entrada. Como característica principal del
aprendizaje competitivo se puede decir que, si un patrón nuevo se determina
que pertenece a una clase reconocida previamente, entonces la inclusión de
este nuevo patrón a esta clase matizará la representación de la misma. Si el
patrón de entrada se determinó que no pertenece a ninguna de las clases
reconocidas anteriormente, entonces la estructura y los pesos de la red neuronal
serán ajustados para reconocer la nueva clase.
2.6.2. FASE DE RECUERDO O EJECUCIÓN. ESTABILIDAD
Generalmente (aunque no en todos los modelos), una vez que el sistema ha sido
entrenado, el aprendizaje se desconecta por lo que los pesos y la estructura quedan
fijos, estando la red neuronal ya dispuesta para procesar datos. Este modo de
operación se denomina modo recuerdo (recall) o de ejecución. [12]
En las redes unidireccionales, ante un patrón de entrada, las neuronas responden
proporcionando directamente la salida del sistema. Al no existir bucles de
realimentación no existe ningún problema en relación con su estabilidad. Por el
contrario, las redes con realimentación son sistemas dinámicos no lineales, que
requieren ciertas condiciones para que su respuesta acabe convergiendo a un
estado estable o punto fijo. Una serie de teoremas generales como el Teorema de
Cohen – Grossberg – Kosko2, indican las condiciones que aseguran la estabilidad
de la respuesta en una amplia gama de redes neuronales, bajo determinadas
condiciones.
Para demostrar la estabilidad del sistema, estos teoremas se basan en el método de
Lyapunov 3, como alternativa al mucho más tedioso método directo.
El método de Lyapunov constituye una manera asequible de estudiar la estabilidad
de un sistema dinámico. Es interesante observar que con la formulación matemática
planteada en este método simplemente se está expresando que si se es capaz de
encontrar una cierta función energía del sistema, que disminuya siempre en su
operación, entonces el sistema es estable. [12]
Una técnica similar empleó Hopfield para demostrar que su modelo de red
completamente interconectada era estable en de que la matriz de pesos sinápticos
fuese simétrica y de diagonal nula.
Esta técnica es también la que Cohen, Grossberg y Kosko han aplicado en los
teoremas citados para demostrar la estabilidad de una amplia clase de redes
neuronales realimentadas, autoasociativas y heteroasociativas. Así, el teorema de
Cohen-Grossber
determina
las
condiciones
de
estabilidad
para
redes
autoasociativas no adaptativas, el de Cohen-Grossberg-Kosko, establece las
2
El enunciado completo de los teorema así como el desarrollo y la explicación de ellos se pueden ver
en
http://www.nsi.edu/users/izhikevich/publications/arbib.pdf
3
Para mas información sobre el método de Lyapunov, ver el articulo “Sobre el Método de Lyapunov”
en http://www.red -mat.unam.mx/foro/volumenes/vol010/volten_2.html
condiciones de estabilidad para redes autoasociativas adaptativas; y, por último, el
teorema ABAM de Kosko lo hace pata redes adaptativas heteroasociativas.
2.7.
CLASIFICACION DE LOS MODELOS NEURONALES
Dependiendo del modelo concreto de neurona que se utilice, de la arquitectura o
topología de la conexión, y del algoritmo de aprendizaje, surgirán distintos modelos
de redes neuronales.
De la multitud de modelos y variantes que de hecho existen, unos cincuenta son
medianamente conocidos, aunque tan sólo aproximadamente una quincena son
utilizados con asiduidad en las aplicaciones prácticas. Por lo tanto, para llevar a
cabo el estudio sistemático de los modelos se precisa algún tipo de clasificación.
Los dos conceptos que más caracterizan un modelo neuronal son el aprendizaje y la
arquitectura de la red, por ello, se considera que la clasificación debe atender
ambos aspectos.
Figura 2.7 Clasificación de los ANS por el tipo de aprendizaje y arquitectura
De esta manera, en primer lugar, se realiza una distinción en cuanto al tipo de
aprendizaje, por lo que aparece una primera clasificación en modelos supervisados,
no supervisados, de aprendizaje híbrido y modelos de aprendizaje reforzado. A su
vez, y dentro de cada uno de los grandes grupos, tendremos en cuenta el tipo de
topología de la red, por lo que se distinguirá además entre redes realimentadas y
redes unidireccionales (no realimentadas). La clasificación que surge se muestra en
la Figura 2.7. [12]
Se puede apreciar que el conjunto de modelos de redes no realimentadas y de
aprendizaje supervisado es el más numeroso. Esta clase de modelos resulta
especialmente importante por varias razones: por su interés histórico, generalidad,
por ilustrar una amplia clase de aspectos que aparecen con frecuencia en todo el
campo de las redes neuronales (memoria asociativa, clasificación, aproximación
funcional, etc.), y además por ser los sistemas neuronales más empleados en las
aplicaciones prácticas.
2.8. COMPUTABILIDAD NEURONAL
Establecidos los. ANS como un estilo de procesamiento alternativo complementario
al clásico basado en computadores digitales serie (tipo von Neumann), se hace
necesario profundizar en sus características computacionales. Es bien sabido que
un ordenador digital constituye una máquina universal de Turing, por lo que puede
realizar cualquier cómputo. Además, al estar construido en base a funciones lógicas,
se deduce que cualquier problema computacional puede ser resuelto con funciones
booleanas.
Se ha discutido extensamente sobre las características computacionales de los
ANS, demostrándose en particular que, al igual que los computadores digitales
convencionales, las redes neuronales son formalmente capaces de resolver
cualquier problema computacional.[12].
Por lo tanto, los ANS, como los ordenadores convencionales, son máquinas
universales, por lo que para resolver un determinado problema, cualquiera de las
dos aproximaciones sería perfectamente válida, en principio.
La cuestión que entonces surge es, dado un problema, cuál de las dos alternativas,
procesamiento neuronal o convencional, resulta más eficiente en su resolución.
Estudiando en el campo de las redes neuronales los aspectos relacionados con la
complejidad computacional, en varios estudios se deduce que los problemas que
requieren un extenso algoritmo o que precisan almacenar un gran número de datos,
aprovechan mejor la estructura de una red neuronal que aquellos otros que
requieren algoritmos cortos. Así, un ordenador digital resulta más eficiente en la
ejecución de tareas aritméticas y lógicas, mientras que un ANS resolverá mejor
problemas que deban tratar con grandes bases de datos que almacenen ingentes
cantidades de información, y en los que existan muchos casos particulares, como
sucede en los problemas de reconocimiento de patrones en ambiente natural.
De esta manera podemos concluir que un estilo de computación no es mejor que el
otro, simplemente para cada problema particular se deberá elegir el método más
adecuado, y en el caso de problemas muy complejos, éstos deberían ser separados
en partes, para resolver cada una mediante el método más idóneo.[12]
2.9. REALIZACIÓN Y APLICACIONES DE LAS REDES NEURONALES
El modo más habitual de realizar una red neuronal consiste en simularla en un
ordenador convencional, como un PC o una estación de trabajo, haciendo uso de
programas escritos en lenguajes de alto nivel, como C o Pascal. Aunque de esta
manera se pierde su capacidad de cálculo en paralelo, las prestaciones que ofrecen
los ordenadores actuales resultan suficientes para resolver numerosos problemas
prácticos, perm itiendo la simulación de redes de tamaño considerable a una
velocidad razonable. Esta constituye la manera más barata y directa de realizar una
red neuronal. Además, no es necesario que cada diseñador confeccione sus propios
simuladores, pues hay disponible comercialmente software de simulación que
permite el trabajo con multitud de modelos neuronales.
En el resto de las maneras de realizar un ANS se trata de aprovechar, en mayo o
menor medida, su estructura de cálculo paralelo. Un paso adelante en este sentido
consiste en simular la red sobre computadores con capacidad de cálculo paralelo
(sistemas multiprocesador, máquinas vectoriales, masivamente paralelas...). Una
orientación diferente consiste en llevar a cabo la emulación hardware de la red
neuronal, mediante el empleo de sistemas de cálculo expresamente diseñados para
realizar ANS basados, o en microprocesadores de altas prestaciones (RISC DSP...),
o en procesadores especialmente diseñados para el trabajo con redes neuronales.
Estas estructuras se suelen denominar placas aceleradoras neuroemuladores o
neurocomputadores de propósito general. Algunos sistemas de desarrollo de redes
neuronales, además de un software de simulación, incluyen dispositivos de este
tipo, en forma de tarjetas conectables al bus de un PC.
La realización electrónica de redes neuronales es un campo muy activo, abordado
tanto por grupos de investigación universitarios como por empresas de los sectores
de la electrónica e informática. Compañías como Siemens, Philips, Hitachi, AT&T,
IBM o Intel han puesto en marcha desde mediados de los años ochenta programas
de investigación y desarrollo en este campo. Asimismo, se han creado diversas
empresas que tratan de explotar comercialmente (con mejor o peor fortuna) estos
nuevos desarrollos. [12]
Las aplicaciones más habituales de las redes neuronales son las relacionadas con
clasificación, estimación funcional y optimización; en general, el del reconocimiento
de patrones suele considerarse como un denominador común. Se pueden señalar,
entre otras, las siguientes áreas de aplicación de los sistemas neuronales:
reconocimiento del habla, reconocimiento de caracteres, visión, robótica, control,
procesamiento de señal, predicción, economía, defensa, bioingeniería, etc.
Asimismo, se están aplicando ANS para incorporar aprendizaje en los sistemas
borrosos y a la confección de sistemas expertos conexionistas. Un área de intenso
trabajo es el del tratamiento de la información económica, siendo uno de los grupos
punteros el de A.N. Refenes, de la London Businnes School.
Otra de las áreas importantes es la industria. Fujitsu, Kawasaki y Nippon Steel
emplean ANS en el control de procesos industriales, como por ejemplo en plantas
de producción de acero. Siemens aplica redes neuronales y sistemas borrosos en la
fabricación de celulosa en laminadoras y en galvanizadoras. Citróen emplea redes
neuronales en la determinación de la calidad del material utilizado en la confección
de los asientos de los vehículos, Ford en reducción de contaminantes y Renault
para detectar averías en el encendido de los automóviles.4
2.10. REDES NEURONALES SUPERVISADAS
En esta parte del capitulo se trataran los modelos de redes mas populares, así como
sus principales algoritmos, se inicia con los modelos mas sencillos, esto con el fin de
ir introduciendo los conceptos necesarios para describir el perceptron y el algoritmo
denominado backpropagation que servirán de base teórica para la experimentación
hecha en el capitulo 4. No se desarrollaran las redes neuronales no supervisadas
debido a que no son redes diseñadas para la forma en que se predicen series de
tiempo, principal objetivo de este trabajo.
2.10.1. ASOCIADOR LINEAL
Este modelo, mediante una transformación lineal, asocia un conjunto de patrones de
entrada a otros de salida. El asociador lineal consta únicamente de una capa de
neuronas lineales, cuyas entradas las denotamos por x y sus salidas por y, vector
que constituye además la respuesta de la red neuronal.
4
Un índice muy completo de aplicaciones de las RNA se pude encontrar en http://www.ipatlas.com/pub/nap/
Asimismo, denotaremos por W = {w ij} a la matriz de pesos, cada fila de W contiene
los pesos de una neurona wi.
La operación del asociador lineal es simplemente
O bien
Por lo tanto, cada neurona i del asociador lineal lleva a cabo la suma ponderada de
las entradas con sus pesos sinápticos. Es decir esta neurona calcula el potencial
postsináptico por medio de la convencional suma ponderada, cantidad a la que
aplica finalmente una función activación de tipo identidad.
El problema se centra en encontrar la matriz de pesos W óptima en el sentido
descrito anteriormente en este capitulo. Para ello, en el campo de las redes
neuronales normalmente se hace uso de una regla de aprendizaje, que a partir de
las entradas y de las salidas deseadas (en el caso del aprendizaje supervisado),
proporcione el conjunto óptimo de pesos W.5 [12]
5
Algo mas sobre el asociador lineal puede ser consultado en
http://www.comp.nus.edu.sg/~pris/AssociativeMemory/LinearAssociator.html
2.10.1.1. REGLA DE APRENDIZAJE DE HEBB
Uno de los modelos clásicos de aprendizaje de redes neuronales es el propuesto
por Hebb (1949), el cual postulo un mecanismo de aprendizaje para una neurona
biológica, cuya idea básica consiste en que cuando un axón presinaptico causa la
activación de cierta neurona pos-sináptica, la eficacia de la sinapsis que las
relaciona se refuerza.[12]
Si bien este tipo de aprendizaje es simple y local, su importancia radica en que fue
pionero tanto en neurociencias como en neurocomputación, de ahí que otros
algoritmos mas complejos lo tomen como punto de partida.
De manera general se denomina aprendizaje Hebbiano a un aprendizaje que
involucra una modificación en los pesos,
?w ij proporcional al producto de una
entrada xj y de una salida yi de la neurona. Es decir, ?wij = ey ixj, donde a 0<e<1 se
le denomina ritmo de aprendizaje. [12]
Consideremos el caso del asociador lineal. La regla de Hebb se expresa en este
caso particular así
Por lo tanto, el algoritmo de entrenamiento regla de Hebb para el asociador lineal
es:
Si los pesos de partida son nulos, el valor final de W para las p asociaciones será:
2.10.1.2. REGLA DE LA PSEUDOINVERSA
La regla de aprendizaje de Hebb ha sido introducida debido a su plausibilidad
biológica. Sin embargo, en general se tratará de deducir los algoritmos de
aprendizaje a partir de un cierto criterio a optimizar; el aprendizaje usualmente se
planteará como un procedimiento para alcanzar el conjunto de pesos óptimo que
resuelva un problema dado. Para ello se hace necesario definir el significado de
“óptimo” en cada caso concreto, es decir, hay que proponer un criterio que mida el
rendimiento de la red neuronal para encontrar una regla de actualización de pesos
que lo optimice. Una forma habitual de definir el rendimiento es el error cuadrático
medio de las salidas actuales de la red respecto de las deseadas. Para el asociador
lineal se tendría
De este modo, un algoritmo de aprendizaje para el asociador lineal debería obtener
un conjunto de pesos que minimicen esta expresión del error. Si denominamos X a
una matriz nxp que tiene por columnas los vectores de entrada xU, X = (x1, x2,…,x p)
y si llamamos Y a la matriz mxp cuyas columnas son los vectores de salida yU , Y =
(y1, y2,…,yp), la ecuación anterior se transforma en
Con esta nomenclatura, la regla de Hebb se expresa de la forma siguiente:
Una regla de aprendizaje basada en la utilización de la matriz pseudoinversa puede
escribirse como:
Donde X+ denota la pseudoinversa de X. Debido a que ambas reglas son óptimas
según el mismo criterio, la regla de Hebb y la de la pseudoinversa deben estar muy
relacionadas. Esta circunstancia es fácil de apreciar, pues si consideramos un
conjunto de vectores de entrada ortonormales, la regla de la pseudoinversa se
convierte en la de Hebb. Por otra parte, si se realiza la expansión en serie de la
ecuación de la pseudoinversa, el primer término de la serie es Precisamente la
ecuación de la regla de Hebb. Es decir, la regla de Hebb representa en el fondo un
caso particular de la más general regla de la pseudoinversa. [12]
2.10.2. PERCEPTRON SIMPLE
La red tipo Perceptrón fue inventada por el psicólogo Frank Rosenblatt en el año
1957. Su intención era ilustrar algunas propiedades fundamentales de los sistemas
inteligentes en general, sin entrar en mayores detalles con respecto a condiciones
específicas y desconocidas para organismos biológicos concretos. Rosenblatt creía
que la conectividad existente en las redes biológicas tiene un elevado porcentaje de
aleatoriedad, por lo que se oponía al análisis de McCulloch Pitts en el cual se
empleaba lógica simbólica para analizar estructuras bastante idealizadas.
Rosenblatt opinaba que la herramienta de análisis más apropiada era la teoría de
probabilidades, y esto lo llevó a una teoría de separabilidad estadística que utilizaba
para caracterizar las propiedades más visibles de estas redes de interconexión
ligeramente aleatorias.
El primer modelo de Perceptrón fue desarrollado en un ambiente biológico imitando
el funcionamiento del ojo humano, el fotoperceptrón como se le llamo era un
dispositivo que respondía a señales ópticas; como se muestra en el figura 2.9 la luz
incide en los puntos sensibles (S) de la estructura de la retina, cada punto S
responde en forma todo-nada a la luz entrante, los impulsos generados por los
puntos S se transmiten a las unidades de asociación (A) de la capa de asociación;
cada unidad A está conectada a un conjunto aleatorio de puntos S, denominados
conjunto fuente de la unidad A, y las conexiones pueden ser tanto excitatorias como
inhibitorias. [13]
Figura 2.9: Modelo del Fotoperceptrón de Rosenblatt
De forma similar, las unidades A están conectadas a unidades de respuesta (R)
dentro de la capa de respuesta y la conectividad vuelve a ser aleatorio entre capas,
pero se añaden conexiones inhibitorias de realimentación procedentes de la capa de
respuesta y que llegan a la capa de asociación, también hay conexiones inhibitorias
entre las unidades R.
Figura 2.10 : Arquitectura (izquierda) y función de transferencia (derecha) de un perceptrón simple
El perceptrón simple es un modelo unidireccional, compuesto por dos capas de
neuronas, una sensorial o de entradas, y otra de salida (Figura 2.10). La operación
de una red de este tipo, con n neuronas de entrada y m de salida, se puede
expresar como [12]
Las neuronas de entrada no realizan ningún cómputo, únicamente envían la
información (en principio consideraremos señales discretas {O, +1)) a las neuronas
de salida (en el modelo original estas neuronas de entrada representaban
información ya procesada, no datos directamente procedentes del exterior).
La función de desempeño las neuronas de la capa de salida es de tipo escalón. Así,
la operación de un perceptrón simple puede escribirse
con H(.) la función de Heaviside o escalón. El perceptrón puede utilizarse tanto
como clasificador, como para la representación de funciones booleanas, pues su
neurona es esencialmente de tipo MacCulloch-Pitts, de salida binaria. La
importancia teórica del perceptrón radica en su carácter de dispositivo entrenable,
pues el algoritmo de aprendizaje del modelo introducido por Rosenblatt, y que se
describirá mas adelante, permite determinar automáticamente los pesos sinápticos
que clasifican conjunto de patrones a partir de un conjunto de ejemplos etiquetados.
[12]
Se mostrara a continuación que un perceptrón permite realizar tareas de
clasificación. Cada neurona del perceptrón representa una determinada clase, de
modo que dado un vector de entrada, una cierta neurona responde con 0 si no
pertenece a la se que representa, y con un 1 si sí pertenece. Es fácil ver que una
neurona tipo perceptrón solamente permite discriminar entre dos clases linealmente
separables (es decir, cuyas regiones de decisión pueden ser separadas mediante
una única condición lineal o hiperplano Sea una neurona tipo perceptrón de dos
entradas, x1 y x2 con salida y, cuya operación se define por lo tanto
o bien
Si consideramos x y x situadas sobre los ejes de abscisas y ordenadas en el plano,
la condición
representa una recta (hiperplano, si trabajamos con n entradas) que divide el plano
(espacio) en dos regiones, aquellas para las que la neurona proporciona una salida
0 o 1, respectivamente (Figura 2.11). Luego, efectivamente, una neurona tipo
perceptrón representa un discriminador lineal, al implementar una condición lineal
que separa dos regiones en el espacio, que representan dos diferentes clases de
patrones.
Figura 2.11: Región de decisión correspondiente a un perceptrón simple con dos neuronas
de entrada
Consideremos la función lógica NAND, (AND negada de dos entradas), que
representamos sobre el plano (Figura 2.12a). En este caso pueden encontrarse
unos parámetros w 1 y w2 y ? que determinen una recta que separa perfectamente
las regiones correspondientes a los valores lógicos 0 y 1. Por ello, la función lógica
NAND se dice separable linealmente, puesto que hemos podido encontrar una única
condición lineal que divida ambas regiones Por ejemplo, un perceptrón con los
siguientes parámetros implementa la función NAND: w 1 = w 2 = -2 y ? = -3
Figura 2.12: Funciones lógicas NAND (a) y XOR (b)
Sin embargo consideremos la función lógica or - exclusivo o XOR (su salida es el 0
lógico si las variables de entrada son iguales y 1 si son diferentes), se representa en
el plano (Figura 2.12b).
En este caso podemos apreciar que no se puede encontrar una única condición
lineal que separe las regiones a los valores de salida O y 1, por lo que se dice que la
XOR no es linealmente separable. Como la neurona del perceptron representa en el
fondo un discriminador lineal, esta neurona por sí sola no puede implementar la
función XOR.
Por lo tanto, concluimos con que la clase de funciones no separables linealmente no
puede ser representada por un perceptrón simple. [12]
Minsky (uno de los padres de la IA) y Papert estudiaron en profundidad el
perceptrón, y en 1969 publicaron un exhaustivo trabajo en el que se subrayaba sus
limitaciones, lo que resultó decisivo para que muchos de los recursos que se
estaban invirtiendo en redes neuronales se desviasen hacia otros campos más
prometedores entonces, como era en la época el de la inteligencia artificial. A finales
de los sesenta ya se apuntaba como solución a las limitaciones del perceptrón
introducir capas ocultas, pero el problema residía en que si bien se disponía de un
algoritmo de aprendizaje para el perceptrón simple, el denominado algoritmo del
perceptrón (se explicara el algoritmo en la siguiente sección), no se disponía de
ningún procedimiento que permitiese obtener automáticamente los pesos en uno
multicapa, con neuronas ocultas.
Este problema denominado de ‘asignación de crédito” a las neuronas sin conexión
directa con el exterior (consistente en cómo medir la contribución al error en la
salida de la red neuronal de cada uno de los nodos ocultos que precisamente no
tienen una conexión directa con ella) fue resuelto no mucho más tarde por Paul
Werbos, pero fue preciso esperar hasta mediados de los años ochenta para que el
grupo PDP junto con otros grupos de forma independiente) redescubriera un
algoritmo similar que denominaron back-propagation o BP, y diera a conocer a la
comunidad internacional su gran potencial para la resolución de problemas
prácticos.[12]
2.10.2.1. ALGORITMO DE APRENDIZAJE DEL PERCEPTRON
La importancia del perceptrón radica en su carácter de dispositivo entrenable pues
el algoritmo de aprendizaje introducido por Rosenblatt permite que el perceptrón
determine automáticamente los pesos sinápticos que clasifican un determinado
conjunto de patrones etiquetados. El del perceptrón es un algoritmo de aprendizaje
de los denominados por corrección de errores. Los algoritmos de este tipo (en el
que se incluyen posteriormente también el de la adaline y el BP) ajustan los pesos
en proporción a la diferencia existente entre la salida actual de la red y la salida
deseada, con el objetivo de minimizar el error actual de la red.
Sea un conjunto de p patrones xU , u.=1,…,p, con sus salidas deseadas tU . Tanto las
entradas como las salidas solamente pueden tomar los valores -1 o 1 (o bien, 0 o 1,
según se definan los niveles lógicos). Se tiene una arquitectura de perceptrón
simple, con pesos iniciales aleatorios, y se requiere que clasifique correctamente
todos los patrones del conjunto de aprendizaje (lo cual es posible solamente si son
linealmente separables).
Se decidirá del siguiente modo, ante la presentación del patrón u-ésimo, si la
respuesta que proporciona el perceptrón es correcta, no se actualizaran los pesos;
si es incorrecta, según la regla de Hebb de la sección 2.9.1.1. Se tiene
que se puede reescribir del siguiente modo
que es la forma habitual de expresar la regla del perceptrón. En su utilización
práctica, se debe llegar a un compromiso para el valor del ritmo de aprendizaje ? ,
puesto que un valor pequeño implica un aprendizaje lento, mientras que uno
excesivamente grande puede conducir a oscilaciones en el entrenamiento, al
introducir variaciones en los pesos excesivamente amplias. Al ser las entradas y las
salidas discretas {-1, ÷1}, también lo será la actualización de los pesos, que
únicamente podrá tomar los valores 0 o ±2? .
2.10.3. ADALINE
Al mismo tiempo que Frank Rosenblatt trabajaba en el modelo del Perceptrón
Bernard Widrow y su estudiante Marcian
do introdujeron el modelo de la red
Adaline y su regla de aprendizaje llamada algoritmo LMS (Least Mean Square). El
término Adaline es una sigla, sin embargo su significado cambió ligeramente a
finales de los años sesenta cuando decayó el estudio de las redes neuronales,
inicialmente se llamaba Adaptive Linear Neuron (Neurona Lineal Adaptiva), para
pasar después a ser Adaptive Linear Element (Elemento Lineal
doptivo), este
cambio se debió a que la Adaline es un dispositivo que consta de un único elemento
de procesamiento, como tal no es técnicamente una red neuronal. La estructura
general de la red tipo Adaline puede visualizarse en la figura 2.13. [17]
A diferencia del asociador lineal, la adaline incorpora un parámetro adicional
denominado bias, el cual no debe de ser considerado como un umbral de disparo,
sino como un parámetro que proporciona un grado de libertad adicional al modelo.
Teniendo en cuenta lo anterior, la ecuación de la adaline resulta ser:
con i = 1, …,m.
Otra diferencia fundamental de la adaline con respecto del asociador lineal y el
perceptrón simple radica en la regla de aprendizaje. En la adaline se utiliza la regla
de Widrow – Holf, también conocida como LMS (Least Mean Square) o regla de
mínimos cuadrados. Esta regla permite actualizaciones de los pesos proporcionales
al error cometido por la neurona.
El adaline se viene utilizando desde comienzos de los años sesenta como filtro
adaptativo, por ejemplo en aplicaciones relacionadas con la reducción del ruido en
la transmisión de señales. De este modo, y desde hace años, millones de módems
de todo el mundo incluyen una adaline.
2.10.4. EL PERCEPTRON MULTICAPA (MLP)6
En la sección 2.10.2 se ha visto las limitaciones del perceptrón simple, ya que con él
tan solo se puede discriminar patrones que pueden ser separados por un hiperplano
(una recta en el caso de dos neuronas de entrada). Una manera de solventar estas
limitaciones del perceptrón simple es por medio de la inclusión de capas ocultas,
obteniendo de esta forma una red neuronal que se denomina perceptrón multicapa.
La Figura 2.14 muestra las regiones de decisión que se obtienen para distintas
arquitecturas de redes neuronales considerando dos neuronas en la capa inicial. Así
por ejemplo para una arquitectura de perceptrón simple la región de decisión es una
recta, mientras que el perceptrón multicapa con una única capa de neuronas ocultas
puede discriminar regiones convexas.
Por otra parte el perceptrón multicapa con dos capas de neuronas ocultas es capaz
de discriminar regiones de forma arbitraria.
6
Esta red será el tipo de red central en este trabajo
Figura 2.14: Regiones de decisión obtenida s para el perceptrón simple (arriba), el perceptrón
multicapa con una capa oculta (en medio) y el perceptrón multicapa con dos capas ocultas (abajo)
La estructura del MLP con una única capa oculta se muestra en las Figuras 2.15 y
2.16.
Figura 2.15: Arquitectura (izquierda) y función de desempeño(derecha) para el perceptrón multicapa
Denominaremos xi a las entradas de la red, yj a las salidas de la capa oculta y Zk a
las de la capa final (y globales de la red); tk serán las salidas objetivo (target). Por
otro lado, wij son los pesos de la capa oculta y ?j sus umbrales, w’kj los pesos de la
capa de salida y ?k sus umbrales. La operación de un MLP con una capa oculta y
neuronas de salida lineal (estructura que constituye, como se vera más adelante, un
aproximador universal de funciones) se expresa matemáticamente de la siguiente
manera:
Ésta es la arquitectura más común de MLP, aunque existen numerosas variantes,
como incluir neuronas no lineales en la capa de salida (solución que se adopta
especialmente en problemas de clasificación), introducir más capas ocultas, emplear
otras funciones de activación, limitar el número de conexiones entre una neurona y
las de la capa siguiente, introducir dependencias temporales o arquitecturas
recurrentes, etc.
Figura 2.16: Arquitectura del perceptrón multicapa
2.10.4.1. EL MLP COMO APROXIMADOR UNIVERSAL DE FUNCIONES
El desarrollo del MLP durante los últimos treinta años ha resultado curioso.
Partiendo
de
un
perceptrón
monocapa
y
observando
sus
limitaciones
computacionales, se llegó a la arquitectura perceptrón multicapa, y aplicándolo a
numerosos problemas, se comprobó experimentalmente que éste era capaz de
representar complejos, mappings y de abordar problemas de clasificación de gran
envergadura, de una manera eficaz y relativamente simple. Sin embargo, faltaba
una demostración teórica que permitiese explicar sus aparentemente enormes
capacidades computacionales.
Este proceso histórico comienza con McCulloch y Pitts, quienes mostraron que
mediante su modelo de neurona (esencialmente un dispositivo de umbral) podría
representarse cualquier función booleana; mucho más tarde, Denker y otros,
demostraron que toda función booleana podía ser representada por una red
unidireccional multicapa de una sola capa oculta. Por las mismas fechas, Lippmann
mostró que un perceptrón con dos capas ocultas bastaba para representar regiones
de decisión arbitrariamente complejas. Por otra parte, Lapedes y Farber
demostraron que un perceptrón de dos capas ocultas es suficiente para representar
cualquier función arbitraria (no necesariamente booleana).
Más tarde, Hecht-Nielsen aplicando el teorema de Kolmogorov demostró que una
arquitectura de características similares al MLP, con una única capa oculta,
resultaba ser un aproximador universal de funciones. Por fin, a finales de la década,
diversos grupos propusieron casi a la par teoremas muy similares que demostraban
matemáticamente que un MLP convencional, de una única capa oculta, constituía,
en efecto, un aproximador universal de funciones.
Los teoremas citados resultan de vital importancia, puesto que proporcionan una
sólida base teórica al campo de las redes neuronales, al incidir sobre un aspecto (la
aproximación funcional y un modelo (el MLP) centrales en la teoría de las redes
neuronales artificiales. No obstante, todavía quedan muchos asuntos abiertos. Por
ejemplo estos teoremas no informan sobre el número de nodos ocultos necesarios
para aproximar una función determinada, simplemente se afirma que hay que
colocar los necesarios para lograr el nivel de aproximación requerido.
2.10.4.2. APRENDIZAJE POR RETROPROPAGACIÓN DE ERRORES
Una solución al problema de entrenar los nodos de las capas ocultas pertenecientes
a arquitecturas multicapa la proporciona el algoritmo de retropropagación de errores
o BP (backpropagation).
Sea un MLP de tres capas, cuya arquitectura se presenta en la Figura 2.16, con
[entradas, salidas, pesos y umbrales de las neuronas definidas en la introducción de
la sección 2.9.4. Dado un patrón de entrada xu, (u=1,…,p), se recuerda que la
operación global de esta arquitectura se expresa del siguiente modo:
Las funciones de activación de las neuronas ocultas f (h) son de tipo sigmoideo, con
h el potencial postsináptico o local. La función de costo de la que se parte es el error
cuadrático medio
La minimización se lleva a cabo mediante descenso por el gradiente, pero en esta
ocasión habrá un gradiente respecto de los pesos de la capa de salida y otro
respecto de los de la oculta:
Las expresiones de actualización de los pesos se obtienen sólo con derivar,
teniendo en cuenta las dependencias funcionales y aplicando adecuadamente la
regla de la cadena
La actualización de los umbrales (bias) se realiza haciendo uso de estas mismas
expresiones, considerando que el umbral es un caso particular de peso sináptico,
cuya entrada es una constante igual a -1.
En estas expresiones está implícito el concepto de propagación hacia atrás de los
errores que da nombre al algoritmo. En primer lugar se calcula la expresión
.
que denominaremos señal de error, por s0er proporcional al error de la salida
actual de la red, con el que calculamos la actualización
de los pesos de la capa
de salida. A continuación se propagan hacia atrás los errores
a través de las sinapsis, proporcionando así las señales de error , correspondientes
a las sinapsis de la capa oculta; con éstas se calcula la actualización de las sinapsis
ocultas. El algoritmo puede extenderse fácilmente a arquitecturas con más de una
capa oculta siguiendo el mismo esquema.
En resumen, el procedimiento a seguir para entrenar mediante BP una arquitectura
MLP dada es el siguiente:
Se debe comenzar siempre con pesos iniciales aleatorios (normalmente números
pequeños, positivos y negativos), ya que si se parte de pesos y umbrales iniciales
son nulos el aprendizaje no progresará (puesto que las salidas de las neuronas y el
incremento en los pesos serán siempre serán nulos).
En el esquema presentado, que surge de forma natural del proceso de descenso
por el gradiente, se lleva a cabo una fase de ejecución para todos y cada uno de los
patrones del conjunto de entrenamiento, se calcula la variación en los pesos debida
a cada patrón, se acumulan, y solamente entonces se procede a la actualización de
los pesos. Este esquema se suele denominar aprendizaje por lotes (batch).
Una variación común al algoritmo consiste en actualizar los pesos sinápticos tras la
presentación de cada patrón (en vez de presentarlos todos y luego actualizar),
esquema denominado aprendizaje en serie (on - line). Aunque el verdadero BP es el
que se ejecuta por lotes, el aprendizaje en serie es habitualmente empleado en
aquellos problemas en los que se dispone de un muy numeroso conjunto de
patrones de entrenamiento (compuesto por cientos o miles de patrones), en el que
habrá mucha redundancia en los datos. Si se emplease en este caso el modo por
lotes, el tener que procesar todos los patrones antes de actualizar los pesos
demoraría
considerablemente
el
entrenamiento
(además
de
precisar
el
almacenamiento de numerosos resultados parciales). Por ejemplo, podemos
imaginar un conjunto de entrenamiento compuesto por 10.000 patrones, en el que
cada patrón aparece repetido cien veces, entrenando por lotes el aprendizaje
duraría cien veces más que en modo serie.
En el aprendizaje en serie se debe tener presente que el orden en la presentación
de los patrones debe ser aleatorio, puesto que si siempre se siguiese un mismo
orden el entrenamiento estaría viciado en favor del último patrón del conjunto de
entrenamiento, cuya actualización, por ser la última, siempre predominaría sobre las
anteriores. Además, esta aleatoriedad presenta una importante ventaja, puesto que
puede permitir escapar de mínimos locales en determinadas ocasiones, por lo que
al final del proceso puede alcanzarse un mínimo más profundo.
EL BP tiene como ventaja principal es que se puede aplicar a multitud de problemas
diferentes, proporcionando con frecuencia buenas soluciones con no demasiado
tiempo de desarrollo. No obstante, si se requiere una solución realmente excelente,
habrá que dedicar más tiempo al desarrollo del sistema neuronal, teniendo en
cuenta diferentes cuestiones adicionales.
Como desventaja se encuentra, entre otras, su lentitud de convergencia, uno los
precios que hay que pagar por disponer de un método general de ajuste funcional
que no requiere (en principio) información apriorística.
Sin embargo, se debe tener cuenta que el BP no requiere tanto esfuerzo
computacional como el que sería necesario si se tratasen de obtener los pesos de la
red mediante la evaluación directa de las derivadas; en ese sentido se ha
comparado el BP con la transformada rápida Fourier, que permite calcular la
transformada de Fourier con un muy inferior esfuerzo computac ional. Otro problema
del BP es que puede incurrir en el denominado sobreaprendizaje (o sobreajuste),
fenómeno directamente relacionado con la capacidad de generalización de la red a
partir de los ejemplos presentados. Por otra parte, debe tenerse en cuenta que el
algoritmo BP no garantiza alcanzar el mínimo global de la función error, sólo un
mínimo local, por lo que el proceso de aprendizaje puede quedarse estancado en
uno de estos mínimos locales. 7 [12]
2.11. CAPACIDAD DE GENERALIZACIÓN DE LA RED
Uno de los aspectos fundamentales de los ANS es su capacidad de generalizar a
partir de ejemplos, lo que constituye el problema de la memorización frente a
generalización. Por generalización se entiende la capacidad de la red de dar una
respuesta correcta ante patrones que no han sido empleados en su entrenamiento.
Una red neuronal correctamente entrenada generalizará, lo que significa que ha
7
Mas información sobre pequeñas variaciones al algoritmo de backpropagation en la dirección
http://www.iti.upv.es/~fcn/students/rna/Index.html
aprendido adecuadamente el mapping no sólo los ejemplos concretos presentados,
por lo que responderá correctamente ante patrones nunca vistos con anterioridad.
[12]
2.11.1. VALIDACIÓN CRUZADA (CROSS-VALIDATION)
En un proceso de entrenamiento se debe considerar, por una parte, un error de
aprendizaje, que se suele calcular como el error cuadrático medio de los resultados
proporcionados por la red para el conjunto de patrones de aprendizaje. Con una red
suficientemente grande, puede reducirse tanto como se quiera sólo con llevar a
cabo más iteraciones. Por otra parte, existe un error de generalización, que se
puede medir empleando un conjunto representativo de patrones diferentes a los
utilizados en el entrenamiento. De esta manera, podemos entrenar una red neuronal
haciendo uso de un conjunto de aprendizaje, y comprobar su eficiencia real, o error
de generalización, mediante un conjunto de test.
Un hecho experimental, fácilmente observable con cualquier simulador, es que si se
entrena una red hasta alcanzar un muy pequeño error en aprendizaje (por ejemplo,
inferior a un 1%), la eficacia real del sistema o generalización (medido como error en
test) se degrada.
Si representamos a la vez el error en aprendizaje y el error en test durante el
transcurso del aprendizaje, se obtiene una gráfica como la representada en la
Figura 2.17 (izquierda): tras una fase inicial, en la que pueden aparecer oscilaciones
en el valor del error, el de aprendizaje tiende a disminuir monótonamente, mientras
que el error de generalización a partir de cierto punto comienza a incrementarse, lo
que indica una degradación progresiva del aprendizaje.
Figura 2.17: Evolución del error de aprendizaje y del error de generalización. A la
izquierda, situación idealizada, a la derecha situación real
La explicación de este fenómeno es la siguiente. Al principio la red se adapta
progresivamente al conjunto de aprendizaje, acomodándose al problema y
mejorando la generalización. Sin embargo, en un momento dado el sistema se
ajusta demasiado a las particularidades de los patrones empleados en el
entrenamiento, aprendiendo incluso el ruido en ellos presente, por lo que crece el
error que comete ante patrones diferentes a los empleados en el entrenamiento
(error de generalización). En este momento la red no ajusta correctamente el
mapping, sino que simplemente está memorizando los patrones del conjunto de
aprendizaje, lo que técnicamente se denomina sobreaprendizaje o sobreajuste
(overtraíning o overfitting), pues la red está aprendiendo demasiado (incluso el ruido
presente en los patrones-ejemplo). Idealmente, dada una arquitectura de red
neuronal, ésta debería entrenarse hasta un Punto óptimo (Figura 2.17, izquierda) en
el que el error de generalización es mínimo. El procedimiento consistente en
entrenar y validar a la vez para detenerse en el punto optimo se denomina
validación cruzada (cross validation), y es ampliamente utilizado en la fase de
desarrollo de una red neurona! supervisada (como el MLP).
No obstante, la situación descrita ha sido en cierta medida idealizada; una situación
más realista sería la de la parte derecha de la Figura 2.17: en realidad pueden
presentarse varios mínimos para el conjunto de test, debiendo detener el
aprendizaje en el punto óptimo de mínimo error de generalización, y no quedarnos
en el primer mínimo en test que aparezca.
Muchas veces basta con dejar que el aprendizaje discurra hasta una cota razonable
de error (0.5%, 0.1%, 0.01%..., depende el problema), guardando periódicamente
las distintas configuraciones intermedias de pesos para luego quedarnos con la que
proporcionó un error en test mínimo.
La clave de este asunto está en que las redes neuronales son estimadores no
lineales poderosos, capaces de modelar situaciones muy complejas. En las
herramientas lineales (por ejemplo, en ajuste mediante polinomios) la complejidad
del modelo viene dada simplemente por el número de parámetros libres a ajustar
(coeficientes), mientras que en los sistemas no lineales (como son las redes
neuronales), la complejidad del modelo depende tanto del número de parámetros
como de su valor actual. Los modelos que implementan las redes neuronales son de
elevada complejidad, por lo que pueden aprender (memorizar) casi cualquier cosa,
motivo por el cual incurren fácilmente en sobreaprendizaje.
Cuando se entrena una red unidireccional supervisada debe tenerse muy en cuenta
el tema del sobreaprendizaje, y la técnica de validación cruzada suele ser un buen
remedio (aunque, como se vera a continuación, no es el único disponible);
usualmente, de todo el conjunto de entrenamiento se emplea aproximadamente un
80% de los patrones para entrenar, reservándose un 20% como conjunto de test.
[12]
2.11.2. NÚMERO DE EJEMPLOS DE ENTRENAMIENTO
En definitiva, la capacidad de generalización de la red la determinan en buena
medida las siguientes tres circunstancias: 1) la arquitectura de la red, 2) el número
de ejemplos de entrenamiento y 3) la complejidad del problema. Los tres puntos
están muy relacionados; en términos generales, cuanto más complejo sea el
problema a modelar más grande deberá ser la red (con más parámetros a ajustar) y,
por lo tanto, más ejemplos se necesitarán para entrenarla (ejemplos que deberán
cubrir todo el espacio de entrada, contemplando todas las situaciones posibles).
A menudo el número de patrones -ejemplo disponibles es limitado (y reducido), y en
proporción el número de parámetros efectivos de la red elegida (grados de libertad)
suele ser muy grande. Así, si se quiere que la red alcance un error de
generalización de, por ejemplo,
? = 0.1 (un 10%), el número de patrones de
aprendizaje necesarios p será del orden de p = 10w, expresión que se suele dar
como indicativa del número aproximado de patrones que serán necesarios para
entrenar adecuadamente una red neurona! de w pesos.
Por ejemplo para una red 10-5-1 (10 neuronas de entrada, 5 ocultas y 1 de salida.),
que dispone de 61 parámetros, entre pesos y umbrales, el número de patrones
necesarios para alcanzar un error de! 10% será de unos 610, lo que representa una
cifra de patrones muy alta, no disponible en muchas aplicaciones prácticas. Ello
ilustra de nuevo la facilidad de incurrir en sobreaprendizaje al entrenar una red
neuronal.
2.11.3. REDUCCIÓN DEL TAMAÑO DE LA ARQUITECTURA DE UNA RED
Además, hay que tener presente la llamada maldición de la dimensionalidad (curse
of dimensionality) que consiste en que el número de datos necesarios para
especificar un mapping, en general crece exponencialmente con la dimensión del
espacio de entrada, lo que agrava en los problemas de dimensión de entrada
elevada es el de disponer de un número de patrones para el aprendizaje escaso.
Disminuyendo el número de parámetros de la red (tamaño) se tendrá una relación p
= w/? más favorable. Una forma de reducirlo consiste en limitar el número de las
entradas de la red, pues ello implica la disminución drástica del número de pesos.
Por ejemplo, una red con 200 entradas, 100 neuronas ocultas y 3 salidas, contendrá
del orden de 20.000 pesos, con lo que se necesitarían unos 200.000 patrones para
entrenarla adecuadamente. Si reducimos el número de entradas a 10 (por ejemplo,
realizando un análisis de componentes principales a las variables de entrada,
empleando ratios, etc.), el número de pesos se reduce a 143, con lo que se
precisarían únicamente unos 1400 patrones de aprendizaje.
Otras técnicas empleadas en la reducción del número de parámetros de la red se
relacionan con eliminar algunos de sus pesos; algunas bien conocidas son las de
compartir pesos (weight sharing), podado de la red (pruning) o decaimiento de
pesos (weight decay).
En la primera de las citadas, diversas neuronas comparten sus pesos, de modo que
el número total disminuye. En el proceso de podado la red es entrenada hasta un
cierto nivel, para luego eliminar aquellos pesos que no aportan prácticamente nada
a su operación. El decaimiento es un caso especial del podado; durante el
aprendizaje se deja a los pesos tender poco a poco a cero, para que aquellos que
no sean actualizados periódicamente, se anulen y desaparezcan. [12]
3. MATLAB TOOLBOX
3.1. INTRODUCCIÓN
El objetivo de este capítulo es explicar el uso del toolbox de matlab para entrenar
redes neuronales con el algoritmo backpropagation de tipo feedforward, para
resolver problemas específicos. Generalmente se tienen cuatro pasos en el proceso
de dicho entrenamiento:
1.
2.
3.
4.
Configurar los datos de entrenamiento
Crear la red
Entrenar la red
Simular la respuesta de la red con nuevas entradas
Este capítulo se muestran varias de las funciones de entrenamiento, y para cada
función se deben seguir estos cuatro pasos.
3.2. BACKPROPAGATION
La arquitectura de la red que normalmente es la más usada con el algoritmo del
backpropagation es feedforward de múltiples capas (multilayer).
Una neurona elemental con R entradas se muestra en el grafico 3.1. Cada entrada
es pesada con su w correspondiente. La suma de las entradas y sus pesos forman
la entrada de a la función de transferencia f. las Neuronas pueden usar diferentes
funciones de transferencia f para generar una salida.
Figura 3.1
En una red de múltiples capas (multilayer) a menudo se usa el log-sigmoid o función
de transferencia logarítmica (Figura 3.2).
Figura 3.2
La función logarítmica genera salidas entre 0 y 1 y la entrada de la neurona puede
ir desde infinitamente negativo a infinitamente positivo.
Alternativamente, las redes multicapa pueden usar el tan-sigmoid o función de
transferencia tangencial. (Figura 3.3)
Figura 3.3
De vez en cuando, el purelin o función de traslado lineal se usa en redes
backpropagation. (Figura 3.4)
Figura 3.4
Si la última capa de una red multicapa tiene neuronas sigmoideas
(-sigmoid),
entonces se escalan las salidas de la red en un rango pequeño. Si se usan
neuronas de salida lineal, las salidas de la red pueden tomar cualquier valor.
En backpropagation es importante poder calcular el derivado de cualquier función de
transferencia utilizada. Cada una de las funciones anteriores, tangencial,
logarítmica, y purelin, tienen una función derivativa que les corresponde: dtansig,
dlogsig, y dpurelin. Para obtener el nombre de la función derivativa asociada a cada
función de transferencia se debe llamar la función de transferencia y la función de
matlab 'deriv'.
Ejemplo:
•
tansig('deriv')
•
ans = dtansig
Las tres funciones de transferencia descritas anteriormente son las usadas
normalmente para backpropagation, pero pueden crearse otras funciones diferentes
y usarse con backpropagation si así se desea.
3.3. RED FEEDFORWARD
Una red neuronal de una capa con S neuronas logsig y con R entradas se muestra
en la figura 3.5, se encuentra de forma general en el lado izquierdo y en el lado
derecho un diagrama especifico de la capa.
Figura 3.5
Una red Feedforward a menudo tiene una o más capas ocultas de neuronas de tipo
sigmoideas, seguidas por una capa de salida lineal. Las capas múltiples de
neuronas con funciones de transferencia no lineal permiten a la red aprender
relaciones lineales y no lineales entre la entrada y la salida. La capa del de salida
lineal permite a la red producir el umbral fuera del rango entre -1 y +1.
Por otro lado, si se quiere reprimir las salidas de una red (entre 0 y 1), entonces la
capa de salida debe usar una función de transferencia sigmoidea (como logsig).
Para las redes de múltiples capas se acostumbra que el número de las capas
determine el exponente en la matriz de pesos.
Figura 3.6
Esta red puede usarse como un aproximador de una función en general. Puede
aproximar
cualquier
función
con
un
número
finito
de
discontinuidades
arbitrariamente bien, con la cantidad adecuada de neuronas en la capa oculta.
3.4. CREANDO UNA RED (newff)
El primer paso de entrenamiento de una red feedforward es crear la red. La función
newff
crea una red feedforward. Esta función requiere cuatro parámetros de
entrada. La primera es un R que consta de una matriz del mínimo y máximo valor
para cada uno de los elementos de R en el vector de entrada. La segunda entrada
es un arreglo que contiene los tamaños de cada capa (la cantidad de neuronas por
capa). La tercera entrada es un arreglo que contiene los nombres de las funciones
de entrenamiento que serán usadas en cada capa. La última contiene el nombre de
la función de entrenamiento que se usara.
Por ejemplo, lo siguiente crea una red de la dos capas. Hay un vector de la entrada
con dos elementos. Los valores para el primer elemento del vector de entrada son 1 y 2, los valores del segundo elemento del vector de entrada son 0 y 5. Hay tres
neuronas en la primera capa y una neurona en la segunda capa (capa de salida).
La función de transferencia en la primera capa es tan-sigmoid, y en la capa de
salida la función de transferencia es lineal. La función de entrenamiento es traingd
(qué se describirá mas adelante).
•
net=newff([-1 2; 0 5],[3,1],{'tansig','purelin'},'traingd');
Esta orden crea la red y también inicializa los pesos y el umbral de la red; por
consiguiente la red está lista para ser entrenada.
Inicializando pesos (init). Antes de entrenar una red feedforward, los pesos y el
umbral debe inicializarse. El método newff inicializará los pesos automáticamente,
pero si se quieren reinicializar, esto puede hacerse con init. Esta función toma una
red como entrada y reestablece
todos los pesos y el umbral e la red. Así es
inicializa una red (o reinicializada):
•
net = init(net);
3.5. SIMULACIÓN (sim)
La función sim simula una red. sim toma la entrada de la red p, y la red como tal, y
esta retorna las salidas de la red. Así se puede simular la red que se creo
anteriormente para un solo vector de la entrada:
•
p = [1;2];
•
a = sim(net,p)
•
a = -0.1011
(Si prueba estos datos, su resultado puede ser diferente, dependiendo del estado
del generador de números aleatorios que tenga cuando la red fue inicializada.).
3.6. ENTRENAMIENTO
Una vez se han inicializado los pesos de la red y los el umbral, la red está lista para
ser entrenada. La red puede entrenarse para: la aproximación de una función
(regresión no lineal), la asociación del modelo, o la clasificación del modelo. El
proceso de entrenamiento requiere de los patrones de conducta apropiados para la
red, las entradas de la red p y las salidas en blanco t. Durante el entrenamiento los
pesos y el umbral de la red son iterativamente ajustados para minimizar la función
de desempeño de la red net.performFcn. La función de desempeño predefinida
para las redes feedforward es mse,
el promedio cuadrado del error entre los
rendimientos de la red y los rendimientos designados t.
Todos los algoritmos usan la función de desempeño para determinar cómo ajustar
los pesos y minimizar performance.
Hay dos maneras diferentes en las que este algoritmo de descenso de gradiente
puede llevarse a cabo: modo incremental y modo del lote. En el modo de
incremental, el gradiente se computa y los pesos se actualizan después de cada
entrada que se aplica a la red. En el modo del lote todas las entradas se aplican a la
red antes que los pesos se actualicen. A continuación se describe el modo de
entrenamiento por lote.
3.6.1. ENTRENAMIENTO POR LOTE (train)
En modo por lote se actualizan sólo los pesos y el umbral de la red después que el
juego de entrenamiento entero se ha aplicado a la red. Se suman los gradientes
calculados en cada ejemplo de entrenamiento para determinar el cambio en los
pesos y el umbral.
3.6.2. ENTRENAMIENTO POR INCREMENTAL (traingd)
El entrenamiento de disminución de gradiente o por pasos se ejecuta con la función
traingd. En la que se actualizan los pesos y el umbral en dirección negativa del
gradiente de la función de desempeño . Si se quiere entrenar una red que use
incremental por pasos de lote, se debe anteponer trainFcn al traingd, y entonces
llama al entrenamiento de la función.
Hay siete parámetros de entrenamiento asociados con traingd: epochs, show , goal,
time, min_grad, max_fail, y lr. El lr da la proporción de aprendizaje se obtiene
multiplicando tiempos por negativo de el gradiente para determinar los cambios a
los pesos y el umbral. Si la proporción de aprendizaje se hace demasiado grande, el
algoritmo se vuelve inestable. Si la proporción de aprendizaje se fija demasiado
pequeña, el algoritmo toma un largo tiempo para converger.
El estado de entrenamiento se muestra para cada iteración. (Si show se inicializa
NaN, entonces el estado de entrenamiento nunca se muestra.) Los otros parámetros
determinan cuando para el entrenamiento. El entrenamiento se detiene si el número
de iteraciones excede epochs, si los decrementos de la función de desempeño
están por debajo de goal, si la magnitud de el gradiente está en menos del mingrad,
o si el tiempo de entrenamiento es más largo que time. Y max_fail que es asociado
con la técnica de detención temprana.
El siguiente código crea un entrenamiento de entradas p y objetivos t. se entrenara
por lotes, todos los vectores de la entrada se ponen en una matriz.
•
p = [-1 -1 2 2;0 5 0 5];
•
t = [-1 -1 1 1];
Luego, se crea la red feedforward.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'traingd');
Si se quiere modificar algunos de los parámetros de entrenamiento predefinidos se
hace así.
•
net.trainParam.show = 50;
•
net.trainParam.lr = 0.05;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
Si se quiere usar los parámetros de entrenamiento predefinidos,
las órdenes
anteriores no son necesarias.
Ahora entrenar la red.
•
[net,tr]=train(net,p,t);
•
traingd, Performance goal met.
Los entrenamientos graban el tr que contiene la información sobre el progreso de
entrenamiento
Ahora la red especializada puede simularse para obtener su respuesta a las
entradas en el entrenamiento.
•
a = sim(net,p)
3.6.3. DESCENSO DE GRADIENTE POR LOTES CON MOMENTUMN (traingdm).
Además del traingd, hay otro algoritmo de descenso de gradiente de lotes para
redes feedforward que proporciona una convergencia más rápida, el traingdm, que
incluye un descenso con velocidad adquirida. el momentumn permite que la red no
sólo responda a el gradiente local sino también a las tendencias del error. Actuando
como un filtro del bajo-paso, el momentumn permite a la red ignorar rasgos
pequeños en el error. Sin el momentumn una red puede estancarse en un mínimo
local poco profundo.
El momentumn puede agregarse al aprendizaje del backpropagation haciendo
cambios de peso iguales a la suma de un fragmento del último cambio de peso y el
nuevo cambio sugerido por la regla del backpropagation. La magnitud del efecto
que el último cambio de peso se permite tener es mediada por una constante de
velocidad adquirida, mc que puede ser cualquier número entre 0 y 1. Cuando la
constante de momentumn es 0, un el cambio de peso es solamente basado en el
gradiente. Cuando la constante de momentumn es 1, el nuevo cambio de peso se
pone para igualar el último cambio de peso y el gradiente simplemente se ignora. El
gradiente es computada sumando los gradientes calculadas a cada dato de
entrenamiento y sólo se actualizan los pesos y el umbral después de todos los datos
del entrenamiento que se ha presentado.
Si la nueva función de desempeño en una iteración dada excede la función de
desempeño en una iteración anterior por más de un max_perf_inc de proporción de
predefinida (típicamente 1.04), se desechan los nuevos pesos, el umbral, y el mc
coeficiente de momentumn se pone en cero.
La forma de entrenamiento de descenso de gradiente con momentumn se invoca
con la función traingdm. Esta función usa los mismos pasos mostrados que el
traingd sólo que el mc, lr y max_perf_inc aprenden todos parámetros.
En el código siguiente se utilizara la red creada anteriormente pero será entrenada
con la función traingd. Los parámetros serán iguales con la inclusión del mc factor
de momentumn y el máximo perfonmance aumento max_perf_inc. (Los parámetros
de entrenamiento se restablecen a los valores predefinidos siempre que net.trainFcn
se ponga al traingdm.).
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'traingdm');
•
net.trainParam.show = 50;
•
net.trainParam.lr = 0.05;
•
net.trainParam.mc = 0.9;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
•
a=
-1.0026 -1.0044
0.9969
0.9992
3.7. ENTRENAMIENTO RÁPIDO
Los dos algoritmos de entrenamiento backpropagation: descenso de gradiente, y
descenso de gradiente con velocidad adquirida. Son métodos son lentos y para
resolver problemas prácticos. Existen algoritmos que pueden converger de diez a
cien veces más rápidamente que estos.
Estos algoritmos más rápidos entran en dos categorías principales. La primera
categoría usa técnicas heurísticas que se desarrollaron de un análisis para la
optimización del algoritmo de descenso de gradiente normal. Una de estas
modificaciones heurísticas es la técnica de velocidad adquirida. Dos de estas
técnicas heurísticas son: el de variable de taza de aprendizaje traingda; y el de
rezago trainrp.
3.7.1. TAZA DE APRENDIZAJE (traingda, traingdx)
Con el algoritmo de descenso normal, la proporción de aprendizaje se mantiene
constante a lo largo del entrenamiento. La activación del algoritmo es muy sensible
a la taza de aprendizaje. Si la esta se fija demasiado alta, el algoritmo puede oscilar
y volverse inestable. Si la taza de aprendizaje es demasiado pequeña, el algoritmo
tardara en converger. No es práctico determinar el valor óptimo para la taza de
aprendizaje antes de entrenar. El rendimiento del algoritmo de descenso puede
mejorarse si se permite que la taza de aprendizaje pueda cambiar durante el
proceso de entrenamiento.
Además requiere algunos cambios en el procedimiento de entrenamiento usado por
traingd. Primero, se calculan el rendimiento de la red inicial y el error. A cada epochs
se le calculan nuevos pesos, el umbral usando y la taza aprendizaje actual. Se
calculan las nuevas salidas y los errores.
Como con velocidad adquirida, si el nuevo error excede el error viejo por más de un
max_perf_inc predefinido (típicamente 1.04), se desechan los nuevos pesos y el
umbral. Además, la proporción de aprendizaje se disminuye (típicamente
multiplicando por lr_dec = 0.7). Por otra parte, se guardan los nuevos pesos, etc. Si
el nuevo error es menor del error anterior, la taza de aprendizaje se aumenta
(típicamente multiplicando por lr_inc = 1.05).
Este procedimiento aumenta la taza de aprendizaje, pero sólo a la magnitud que la
red puede aprender sin aumentos grandes de error. Así, se obtiene una taza de
aprendizaje aproximada a la óptima. Cuando la taza de aprendizaje es muy alta el
aprendizaje es estable, la taza de aprendizaje se aumenta. Para garantizar una
disminución en el error.
El entrenamiento con taza de aprendizaje adaptable se ejecuta con la función
traingda, se invoca como el traingd, salvo el max_perf_inc, lr_dec, y lr_inc se deben
incluir en los parámetros así.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'traingda');
•
net.trainParam.show = 50;
•
net.trainParam.lr = 0.05;
•
net.trainParam.lr_inc = 1.05;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
La función traingdx combina taza de aprendizaje adaptable con el entrenamiento de
velocidad adquirida. Se invoca de la misma manera como traingda, sólo que tiene el
mc de coeficiente de momentumn como un parámetro de entrenamiento adicional.
3.7.2. REZAGO (TRAINRP)
En las redes multicapa se usan funciones de transferencia sigmoideas en la capa
oculta. Estas funciones comprimen un rango de la entrada infinito en uno finito. Las
funciones sigmoideas son caracterizadas por que tienden a acercarse a ceros
cuando la entrada es más grande. Esto es un problema cuando se usan algoritmos
de descenso para entrenar una red multicapa con funciones sigmoideas, por que el
gradiente puede tener una magnitud muy pequeña y por consiguiente, causar
cambios pequeños en los pesos y el umbral, aunque los pesos y el umbral están
lejos de sus valores óptimos.
El propósito del algoritmo de entrenamiento de rezago (Rprop) es eliminar los
efectos de las magnitudes de los derivados parciales. La señal del derivado se usa
para determinar la dirección de la actualización del peso; la magnitud del derivado
no tiene efecto en la actualización del peso. El tamaño del cambio de peso es
determinado por un valor de actualización aparte. El valor de actualización para
cada peso y el umbral es aumentado por un factor delt_inc siempre que el derivado
de la función de desempeño con respecto a ese peso tenga la misma señal para
dos iteraciones sucesivas. El valor de actualización es disminuido por un factor
delt_dec siempre que el derivado con respeto que el peso cambie la señal de la
iteración anterior.
Si el derivado es cero, entonces los restos de valor de
actualización son los
mismos.
Siempre que los pesos estén oscilando que el
cambio de peso se reducirá. Si el peso continúa cambiando en la misma dirección
para varias iteraciones, entonces la magnitud del cambio de peso se aumentará.
Los parámetros de entrenamiento para el trainrp son epochs, show, goal, time,
min_grad, max_fail, delt_inc, delt_dec, delta0, deltamax. Los últimos dos son el
tamaño del paso inicial y el máximo tamaño, respectivamente. El algoritmo Rprop
generalmente converge más rápido que los algoritmos anteriores.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainrp');
Rprop generalmente es más rápido que el algoritmo de descenso normal. También
requiere sólo un espacio modesto en memoria.
3.8. ALGORITMOS DE GRADIENTE CONJUGADO
El algoritmo del backpropagation básico ajusta los pesos en la dirección de
descenso (negativo del gradiente). Ésta es la dirección en la que la función de
desempeño disminuye rápidamente. Aunque la función disminuya rápidamente a lo
largo del negativo del gradiente, esto necesariamente no produce una convergencia
más rápida. En los algoritmos de gradiente conjugado una búsqueda se realiza a lo
largo de direcciones conjugadas que producen generalmente una convergencia más
rápida que las direcciones de descenso.
En la mayoría de los algoritmos de gradiente conjugado, el tamaño del paso se
ajusta en cada iteración. Una búsqueda se hace a lo largo de la dirección de
gradiente conjugado para determinar el tamaño del paso que minimiza la función de
desempeño. Hay cinco funciones de la búsqueda diferentes incluidas en el toolbox y
cuatro variaciones diferentes de algoritmos de este tipo.
3.8.1. ACTUALIZACIÓN DE FLETCHER-REEVES (traincgf)
Todos los algoritmos de gradiente conjugado empiezan investigando en la dirección
de descenso (negativo de gradiente) en la primera iteración.
Se realiza una búsqueda de la línea para determinar la distancia óptima para
determinar la dirección de la búsqueda actual entonces:
Entonces la próxima dirección de búsqueda es determinada para que sea conjugada
a las direcciones de la búsqueda anteriores. El procedimiento determina la nueva
dirección de la búsqueda al combinar la nueva dirección de descenso con la
dirección de la búsqueda anterior:
Las diferentes versiones de gradiente conjugado son distinguidas por la manera en
la que la constante
se computa. Para el Fletcher-Reeves el procedimiento es:
En el siguiente código se incluyen los parámetros de entrenamiento para el traincgf
son epochs, epochs, show, goal, time, min_grad, max_fail, srchFcn, scal_tol, alfa,
beta, delta, gama, low_lim, up_lim, maxstep, minstep, bmax.. El parámetro srchFcn
es el nombre de la función de búsqueda lineal. Puede ser cualquiera de las
funciones que existen (o una función usuario). Los parámetros restantes son
asociados con rutinas de búsqueda lineal específicas. La búsqueda lineal
predefinida el srchcha se usa en este ejemplo. El traincgf generalmente converge en
menos iteraciones que el trainrp (aunque hay más cómputo requerido en cada
iteración).
•
net=newff(minm ax(p),[3,1],{'tansig','purelin'},'traincgf');
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
3.8.2. ACTUALIZACIÓN DE POLAK-RIBIÉRE (traincgp)
Otra versión del algoritmo de pendiente conjugado fue propuesta por Polak y
Ribiére. Como con el algoritmo de Fletcher-Reeves, la dirección de la búsqueda a
cada iteración es determinada por:
Para Polak-Ribiére la constante
se calcula con:
En el siguiente código, se tomara el mismo ejemplo anterior y se entrenara con
versión del algoritmo de Polak-Ribiére. Los parámetros de entrenamiento para el
traincgp son iguales que para el traincgf. La búsqueda lineal predefinida el srchcha
se usa en este ejemplo. Los parámetros show y epochs tienen a los mismos valores.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'traincgp');
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
3.8.3. RESTABLECIMIENTO DE POWELL-BEALE (traincgb)
Para todos los algoritmos de gradiente conjugado, la dirección de la búsqueda se
restablecerá periódicamente al negativo del gradiente. La norma de restablecer
ocurre cuando el número de iteraciones es igual al número de parámetros de la red
(pesos y el umbral), pero hay otros métodos de restablecimiento que pueden
mejorar la eficacia de entrenamiento. Esto se prueba con la siguiente desigualdad:
Si esta condición está satisfecha, la dirección de la búsqueda se restablece al
negativo de la pendiente.
En el siguiente código, se crea nuevamente la red anterior y se entrena con la
versión del algoritmo de Powell-Beal. Los parámetros de entrenamiento para el
traincgb son los mismos que para el traincgf. La búsqueda lineal predefinida el
srchcha se usa en este ejemplo. Los parámetros show y epochs tienen los mismos
valores.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'traincgb');
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);.
•
a = sim(net,p)
3.8.4. GRADIENTE CONJUGADO ESCALADO (TRAINSCG)
Hasta ahora cada uno de los algoritmos de gradiente conjugado requiere una
búsqueda lineal en cada iteración.
Esta búsqueda lineal requiere un alto nivel
computacional, ya que requiere que la respuesta de la red a todas las entradas de
entrenamiento sea computada en varios tiempos por cada búsqueda. El algoritmo
de gradiente conjugado escalado (SCG) fue diseñado para evitar la búsqueda lineal.
Este algoritmo es demasiado complejo para explicar en unas líneas, pero la idea
básica es combinar el la aproximación de región de modelo-confianza con el
gradiente conjugado.
En el siguiente código, se crea nuevamente la red anterior pero ahora utilizando el
algoritmo de entrenamiento de gradiente escalado.
Los parámetros de
entrenamiento para el trainscg son epochs, epochs, show, goal, time, min_grad,
max_fail, sigma, lambda. El parámetro sigma determina el cambio en el peso para la
segunda aproximación derivativa. El parámetro lambda regula la indecisión. Los
parámetros show y epchs son 10 y 300, respectivamente.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainscg');
•
net.trainParam.show = 10;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);.
•
a = sim(net,p)
3.9. RUTINAS DE BÚSQUEDA LINEAL
Algunos de los algoritmos de entrenamiento de gradiente conjugado y cuasi-Newton
requieren una búsqueda lineal. Toolbox ofrece cinco búsquedas lineales diferentes
que se puede usar con el parámetro srchFcn de la función entrenamiento y dando a
este el valor de la función de búsqueda deseada.
3.9.1. BÚSQUEDA DE SECCIÓN DORADA (srchgol)
La búsqueda de sección dorada srchgol, es una búsqueda lineal que no requiere el
cálculo de la pendiente. Esta rutina empieza localizando un intervalo en el que el
mínimo de la activación ocurre. Esto se hace evaluando la activación a una sucesión
de puntos, empezando a una distancia de delta y doblando en esta distancia cada
paso, a lo largo de la dirección de la búsqueda. Cuando la activación aumenta entre
dos iteraciones sucesivas, un mínimo se une. El próximo paso es reducir el tamaño
del intervalo que contiene el mínimo. Se localizan dos nuevos puntos dentro del
intervalo inicial. Los valores de la activación a estos dos puntos determinan una
sección del intervalo que puede desecharse y un nuevo punto interior se pone
dentro del nuevo intervalo. Este procedimiento es seguido hasta que el intervalo de
incertidumbre se reduzca al tamaño que es igual al delta/scale_tol.
3.9.2. BÚSQUEDA DE BRENT (srchbre)
La búsqueda de Brent es una búsqueda lineal y una combinación híbrida de la
búsqueda de la sección dorada y una interpolación cuadrática. Los métodos de
comparación de función, como la búsqueda de la sección dorada, tienen una
proporción del primer orden de convergencia, mientras los métodos como el de
interpolación polinómica tienen una proporción que es más rápida que la súper
lineal.
Por otro lado, la proporción de convergencia para las salidas de búsqueda
de sección doradas cuando el algoritmo se inicializa es considerando que la
conducta proporcional para los métodos de la interpolación polinómica puede tomar
muchas iteraciones para soluc ionarse. La búsqueda de Brent intenta combinar los
mejores atributos de ambos acercamientos.
Para la búsqueda de Brent se empieza con el mismo intervalo de incertidumbre que
se uso con la búsqueda de la sección dorada, pero algunos puntos adicionales se
computan. Una función cuadrática se ajusta entonces a estos puntos y el mínimo
de la función cuadrática se computa.
Si este mínimo está dentro del intervalo
apropiado de incertidumbre, se usa en la próxima fase de la búsqueda y una nueva
aproximación cuadrática se realiza. Si las caídas mínimas están fuera del intervalo
conocido de incertidumbre, entonces un paso de la búsqueda de la sección dorada
se realizara.
3.9.3. BÚSQUEDA BISECCIÓN-CÚBICA HÍBRIDA (srchhyb)
La búsqueda de Brent, srchhyb son un algoritmo híbrido. Es una combinación de
bisección y la interpolación cúbica. Para el algoritmo de la bisección, un punto se
localiza en el intervalo de incertidumbre, la activación y su derivado se computan.
Basados en esta información, la mitad del intervalo de incertidumbre se desecha. En
el algoritmo híbrido, una interpolación cúbica de la función es obtenida usando el
valor de la activación y su derivado a los dos puntos del extremo. Si el mínimo de la
interpolación cúbica cae dentro del intervalo conocido de incertidumbre, entonces se
usa para reducir el intervalo de incertidumbre. De lo contrario un paso del algoritmo
de bisección se usa.
3.9.4. BÚSQUEDA DE CARAMBOLA (srchcha)
El método de Carambola srchcha fue diseñado para ser usado en combinación con
un algoritmo de gradiente conjugado para el entrenamiento de red neuronal. Como
los dos métodos anteriores, es una búsqueda híbrida. Usa una interpolación cúbica,
junto con un tipo de seccionamiento.
3.9.5. BACKTRACKING (srchbac)
La búsqueda backtracking srchbac se satisface mejor para usar con los algoritmos
de optimización cuasi-Newton.
Empieza con un multiplicador del paso de 1 y
entonces se reduce hasta un valor aceptable en la activación. En el primer paso
usa el valor de activación al punto actual y a un multiplicador del paso de 1.
También usa el valor del derivado de activación al punto actual, obtener una
aproximación cuadrática a la función de la activación a lo largo de la dirección de la
búsqueda. El mínimo de la aproximación cuadrática se vuelve un punto óptimo
provisional (bajo ciertas condiciones) y la activación se prueba. Si la activación no
se reduce suficientemente, una interpolación cúbica se obtiene y el mínimo de la
interpolación cúbica se vuelve el nuevo punto óptimo provisional. Este proceso es
continuado hasta lograr reducción suficiente en la activación.
3.10. ALGORITMOS CUASI-NEWTON
3.10.1. ALGORITMO DE BFGS (trainbgf)
El método de Newton es una alternativa a los métodos de gradiente conjugado para
la optimización rápida. El paso básico del método de Newton es:
Donde
es la matriz de Hesianos de la segunda derivada del índice de la
activación, los valores actuales de los pesos y el umbral. El método de Newton
converge a menudo más rápidamente que los métodos de gradiente conjugado.
Desgraciadamente, es complejo y requiere alta computabilidad. Hay una clase de
algoritmos que son basados en el método de Newton, pero que no requiere el
cálculo de la segunda derivada. Éstos se llaman cuasi-Newton (o secantes). Ellos
actualizan una matriz de Hesianos aproximada a cada iteración del algoritmo. La
actualización se computa como una función de gradiente. El método cuasi-Newton
más exitoso en estudios publicados es el Broyden, Fletcher, Goldfarb, y Shanno
(BFGS) la actualización. Este algoritmo se logra con la función trainbfg.
Ahora en el ejemplo se reiniciara la red pero ahora entrenándola con el algoritmo
BFGS cuasi-Newton. Los parámetros de entrenamiento para el trainbfg serán igual
que aquéllos para el traincgf. La búsqueda lineal predefinida es el srchbac. Los
parámetros show y epochs corresponden a 5 y 300, respectivamente.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainbfg');
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
3.10.2. ALGORITMO SECANTE DE UN PASO (trainoss)
Desde que el algoritmo BFGS requiere más almacenamiento y cómputo en cada
iteración que los algoritmos de gradiente conjugado, surge la necesidad de una
aproximación secante con almacenamiento más pequeño y menos requisitos del
cómputo. El método secante de un paso (OSS) es un esfuerzo cubrir el espacio
entre los algoritmos de gradiente conjugado y
los algoritmos cuasi-Newton
(secante). Este algoritmo no guarda la matriz de Hesianos completa; asume en
cada iteración que el Hesiano anterior era la matriz de identidad. Esto tiene la
ventaja adicional que la nueva dirección de la búsqueda puede calcularse sin
computar el inverso de la matriz.
Nuevamente es creado nuestro habitual ejemplo reemplazando la red y
entrenándola mediante el algoritmo de secante de un paso. Los parámetros de
entrenamiento para el trainoss son iguales que para el traincgf. La búsqueda de la
línea predefinida es srchbac. Los parámetros show y epochs son ajustados a 5 y
300, respectivamente.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainoss');
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
3.10.3. LEVENBERG-MARQUARDT (trainlm)
Como los métodos cuasi-Newton, el algoritmo de Levenberg-Marquardt fue
diseñado para acercarse en segundo orden que entrena a gran velocidad sin tener
que computar la matriz de Hesianos. Cuando la función de la activación tiene la
forma de una suma de cuadrados (como es típico entrenando feedforward),
entonces la matriz de Hesianos puede aproximarse como:
Y el gradiente puede computarse como:
Donde
es la matriz de Jacobianos que contiene la derivada de los errores de la
red primero con respecto a los pesos y el umbral y
red.
es el vector de errores de la
La matriz de Jacobianos puede computarse a través de backpropagation
normal que es mucho menos complejo de computar que la matriz de Hesianos.
El algoritmo de Levenberg-Marquardt hace esta aproximación de la matriz de
Hesianos como la siguiente actualización Newton:
Cuando el escalar µ es cero, se comporta como el método de Newton usando la
matriz de Hesianos aproximada. Cuando µ es alto, se comporta de descenso de
gradiente pero con un paso pequeño. El método de Newton es más rápido y más
exacto cerca de un mínimo del error, así que el objetivo es cambiar hacia el método
de Newton tan rápidamente como sea posible. Así, µ se disminuye después de cada
paso exitoso (reducción en función de la activación) y sólo se aumenta en un paso
provisional. De esta manera, la función de desempeño se reducirá siempre a cada
iteración del algoritmo.
En el ejemplo se reinicia la red y se entrena usando el algoritmo de LevenbergMarquardt. Los parámetros de entrenamiento para trainlm son epochs, show, goal,
time, min_grad, max_fail, mu, mu_dec, mu_inc, mu_max, mem_reduc,. El parámetro
mu es el valor inicial de µ. Este valor es multiplicado por mu_dec siempre que la
función de desempeño se reduzca un paso. Es multiplicado por mu_inc siempre que
aumentara la función de desempeño en un paso. Si mu se vuelve mayor que el
mu_max, el algoritmo se detiene. El parámetro mem_reduc se usa para controlar la
cantidad de memoria usada por el algoritmo. Los parámetros show y epochs se
inicializan en 5 y 300, respectivamente.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainlm');
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
•
a = sim(net,p)
3.10.4. LEVENBERG-MARQUARDT DE MEMORIA REDUCIDA (trainlm)
El inconveniente principal del algoritmo de Levenberg-Marquardt es que requiere
hacer el almacenamiento de las matrices que con toda seguridad es bastante
grande. El tamaño de la matriz de Jacobianos es
, donde Q es que el número
de juegos de entrenamiento y n es el número de pesos y el umbral en la red.
Resulta que esta matriz no tiene que ser computada y guarda en conjunto. Por
ejemplo, si se quiere dividir el Jacobiano en dos submatrices iguales que se pueden
computar como la matriz aproximada de Hesianos así:
El Hesiano aproximado puede ser computado sumando una serie de subterminos.
Una vez un subtermino se ha computado pueden aclararse las submatrices
correspondientes del Jacobiano.
Cuando se usa la función de entrenamiento trainlm, el parámetro mem_reduc se usa
para determinar cuántas filas del Jacobiano serán computadas en cada submatriz.
Si el mem_reduc toma el valor 1, entonces el Jacobiano lleno se computa y ninguna
reducción de memoria se logra. Si el mem_reduc se pone a 2, entonces sólo la
mitad del Jacobiano se computará. Esto ahorra es la mitad de la memoria usada por
el cálculo del Jacobiano lleno.
3.11. REGULARIZACIÓN
El primer método para mejorar la generalización se llama regularización. Donde se
va modificando la función de desempeño que normalmente se es la suma de
cuadrados de los errores de la red en entrenamiento.
3.11.1. FUNCIÓN DE DESEMPEÑO MODIFICADA
La función de desempeño típica que se usa para entrenar las redes feedforward es
la suma de cuadrados de los errores de la red.
Es posible mejorar generalización si se modifica la función de desempeño
agregando un término que consiste en la suma de cuadrados de los pesos de la red
y el umbral.
Donde
es la proporción de activación, y
Usando esta función de desempeño causarán la red tenga pesos y umbrales más
pequeños y esto obligará a que las salidas la red sea más plana.
En el siguiente ejemplo se reinicializara la red y se volverá a entrenar usando el
algoritmo de BFGS con la función de desempeño regularizada. La proporción de
actuación será 0.5 y el peso igual a los errores cuadrados de los pesos. pesos
cuadrados malos.
•
net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainbfg');
•
net.performFcn = 'msereg';
•
net.performParam.ratio = 0.5;
•
net.trainParam.show = 5;
•
net.trainParam.epochs = 300;
•
net.trainParam.goal = 1e-5;
•
[net,tr]=train(net,p,t);
El problema con regularización es que es difícil de determinar el valor óptimo por el
parámetro de proporción de activación. Si se hace este parámetro demasiado
grande, nosotros podemos conseguir más aproximado. Si la proporción es
demasiado pequeña,
la red no encajará los datos de entrenamiento de forma
adecuada.
3.11.2. REGULARIZACIÓN AUTOMATIZADA (trainbr)
Es deseable determinar los parámetros de regularización óptimos en una moda
automatizada. Un acercamiento a este proceso Bayesiano de David MacKay. En
este armazón, los pesos y el umbral de la red se asumen como variables al azar con
distribuciones especifica. Los parámetros de regularización se relacionan a las
variaciones desconocidas y asociadas con estas distribuciones.
La regularización Bayesiana se hace con la función trainbr. El siguiente código
muestra cómo se puede entrenar una 1-20-1 red que usa esta función para
aproximar.
•
p = [-1:.05:1];
•
t = sin(2*pi*p)+0.1*randn(size(p));
•
net=newff(minmax(p),[20,1],{'tansig','purelin'},'trainbr');
•
net.trainParam.show = 10;
•
net.trainParam.epochs = 50;
•
randn('seed',192736547);
•
net = init(net);
•
[net,tr]=train(net,p,t);
Un rasgo de este algoritmo proporciona una medida de cuántos parámetros de la
red (pesos y umbral) es usando eficazmente por esta. En este caso, la red
especializada final usa aproximadamente 12 parámetros (indicado por #Par) fuera
del total de 61 pesos y umbral en la red 1-20-1. Este número eficaz de parámetros
debe permanecer aproximadamente igual, no importa que tan grande sea el número
total de parámetros en la red. (Esto asume que la red ha estado especializada para
un número suficiente de iteraciones y asegura su convergencia.)
El algoritmo del trainbr generalmente trabaja mejor cuando se descascaran las
entradas de la red y objetivos para que ellos se escalen aproximadamente [-1,1].
Ése es el caso para el problema de la prueba que se ha usado. Si sus entradas y
objetivos no se escalan en este rango, se puede usar la función premnmx, o prestd.
La figura siguiente muestra la salida de la red especializada. Se ve que la respuesta
de la red esta muy cerca de la función seno subyacente (línea punteada), y por
consiguiente, la red generalizará bien a las nuevas entradas.
Al usar trainbr, es importante dejar correr el algoritmo hasta el número justo de
parámetros que han convergido. Los entrenamientos se detienen con el mensaje
"Maximum MU reached.". Esto indica que el algoritmo ha convergido de verdad.
También puede decirse que el algoritmo ha convergido si la suma cuadrada del
error (SSE) y la suma cuadrada de los pesos (SSW) son relativamente constantes
en varias iteraciones.
Figura 3.7
3.12. DETENCIÓN TEMPRANA
Otro método para mejorar la generalización es el de detención temprana. En esta
técnica los datos disponibles
son divididos tres subconjuntos.
El primer
subconjunto es el entrenamiento puesto que se usa para computar el gradiente y
actualizar los pesos de la red y el umbral. El segundo subconjunto es el juego de
aprobación. El error en el juego de aprobación se supervisa durante el proceso de
entrenamiento. El error de aprobación normalmente disminuirá durante la fase inicial
de entrenamiento. Sin embargo, cuando la red empieza validar los datos, el error en
el juego de aprobación empezará a subir típicamente. Cuando el error de
aprobación aumenta para un número especificado de iteraciones, el entrenamiento
se detiene y se vuelven los pesos y el umbral al mínimo del error de aprobación.
Primero se crea un problema de una prueba simple. Para este entrenamiento
generando una ola de la función seno que oscila entre -1 a 1 con pasos de 0.05.
•
p = [-1:0.05:1];
•
t = sin(2*pi*p)+0.1*randn(size(p));
Luego se genera el juego de aprobación. Las entradas van de -1 a 1, como en la
prueba puesta. Para hacer el problema más realista, se agrega también una
sucesión del ruido diferente a la función seno subyacente.
•
val.P = [-0.975:.05:0.975];
•
val.T = sin(2*pi*v.P)+0.1*randn(size(v.P));
Para este ejemplo se usa la función de entrenamiento traingdx.
•
net=newff([-1 1],[20,1],{'tansig','purelin'},'traingdx');
•
net.trainParam.show = 25;
•
net.trainParam.epochs = 300;
•
net = init(net);
•
[net,tr]=train(net,p,t,[],[],val); 6
•
TRAINGDX, Validation stop.
La figura siguiente muestra un gráfico de la respuesta de la red.
Figura 3.8
3.13. PREPROCESO Y POSTPROCESO
Puede hacerse una red neuronal más eficaz si se realizan ciertos pasos en el
preprocesando las entradas y los objetivos de la red.
Min y Max (premnmx, postmnmx, tramnmx)
Antes de entrenar, es útil escalar las entradas y objetivos para que siempre caigan
dentro de un rango específico. La función premnmx puede usarse para escalar las
entradas y objetivos para que queden en el rango [-1,1]. El código siguiente ilustra el
uso de esta función.
•
•
[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t);
net=train(net,pn,tn);
Se dan las entradas y objetivos originales de la red en matrices p y t. pn y tn que
devuelven todos a caer en el intervalo [-1,1]. El minp de los vectores y maxp que
contienen el mínimo y el máximo valor de las entradas originales y los vectores, los
maxt que contienen el mínimo y el máximo valor de los objetivos originales.
Después que la red ha estado especializada, estos vectores deben usarse para
transformar cualquier entrada futura que se aplica a la red. Ellos se vuelven una
parte de la red.
Si el premnmx se usa para escalar las entradas y objetivos, entonces la salida de la
red se entrenará para produc ir respuestas en el rango [-1,1]. Si se quiere convertir
estos resultados en las mismas unidades que se usaron para los objetivos
originales, entonces se debe usar el postmnmx. En el código siguiente, simula la
red, y convierte las salidas de la red a las unidades originales.
•
an = sim(net,pn);
•
a = postmnmx(an,mint,maxt);
El rendimiento de la red corresponde al tn de los objetivos normalizados. El
rendimiento de la red in-normalizado está en las mismas unidades como los
objetivos originales t.
Siempre que la red especializada se use con nuevas entradas estas deben ser
preprocesadas con el mínimo y máximo que se computaron para el juego de
entrenamiento. Esto puede lograrse con el tramnmxo. En el código siguiente, se
aplica un nuevo juego de entradas a la red que ya se ha entrenado.
•
pnewn = tramnmx(pnew,minp,maxp);
•
anewn = sim(net,pnewn);
•
anew = postmnmx(anewn,mint,maxt);
Normalización Estándar Dev.(prestd, poststd, trastd)
Otro procedimiento para las entradas y los objetivos de la red es la normalización,
la desviación estándar y normal del juego de entrenamiento. Este procedimiento se
lleva a cabo con la función prestd. Normaliza las entradas y objetivos. El código
siguiente ilustra el uso de prestd.
•
[pn,meanp,stdp,tn,meant,stdt] = prestd(p,t);
Se dan las entradas y objetivos de la red originales en matrices p y t. Las entradas
normalizadas y objetivos, pn y tn que tendrán ceros intermedios y la unidad de
desviación normal. El meanp de los vectores y stdp que contienen las desviaciones
estándar y normales de las entradas originales, y los vectores significativos y los
stdt contienen los medios y las desviaciones normales de los objetivos originales.
Después que la red ha estado especializada, estos vectores deben usarse para
transformar cualquier entrada futura que se aplica a la red.
En el siguiente código se simula la red especializada en el código anterior
y
convierte las salidas de la red atrás en las unidades originales.
•
an = sim(net,pn);
•
a = poststd(an,meant,stdt);
Las salidas de la red corresponden al tn de los objetivos normalizados. La salida de
la red in-normalizada está en las mismas unidades como los objetivos originales t.
Esto puede lograrse con el trastd. En el siguiente código, se aplica un nuevo juego
de entradas a la red ya hemos entrenado.
•
pnewn = trastd(pnew,meanp,stdp);
•
anewn = sim(net,pnewn);
•
anew = poststd(anewn,meant,stdt);
4. REDES NEURONALES Y SERIES DE TIEMPO
4.1. REDES NEURONALES EN LA PREDICCION
En la actualidad, las Redes Neuronales Artificiales, se reconocen como una de las
herramientas matemáticas de uso computacional que mejores resultados presenta a
la hora de modelar un problema, ya sea de aproximación de funciones: como el
diagnostico y control de maquinaria, en el control del piloto automático de un avión,
o en el control de un robot. En problemas de clasificación: como el diagnostico
medico, reconocimiento de caracteres, detección de fraude o clasificación de riesgo
crediticio. En el procesamiento de datos: como en el filtrado de ruido o en el
encriptamiento de información,
La predicción de series de tiempo, es algo que ha ocupado mucho a investigadores
de distintas disciplinas debido al interés que producen, en parte debido a la alta nolinealidad de su comportamiento fluctuante y a veces “caprichoso”. Varios modelos
matemáticos han sido diseñados para el tratamiento de la predicción en las series
de tiempo, el más conocido es el Proceso Autorregresivo Integrado de Media Móvil
(ARIMA), comúnmente conocido como la metodología de Box-Jenkins (1976). Este
método de predicción, que se utiliza muy frecuentemente se fundamenta en el su
puesto implícito de la linealidad del sistema que generan la trayectoria de las
variables, mas información sobre este y otros modelos de predicción pude ser
encontrada en el capitulo 1.
Sin embargo, las RNA han tenido aquí un éxito que otras técnicas no han logrado.
Diferentes modelos de redes neuronales han sido desarrollados para la predicción
de mercados, algunos se enfocan en la predicción del precio futuro de un valor o en
modelar la rentabilidad de una acción, otros son aplicados para reconocer ciertos
patrones de precios del mercado.
4.1.1. ALGUNOS TRABAJOS DE PREDICCIÓN CON REDES NEURONALES
En los últimos años se cuenta con muchos trabajos en la predicción de series de
tiempo utilizando redes neuronales artificiales, de los cuales podemos mencionar los
siguientes:
•
Predicción de acciones. Consiste en el desarrollo de una red neuronal capaz de
realizar la predicción del precio de las acciones para un número dado de
compañías. Esta predicción se realiza mediante redes alimentadas hacia
adelante, y el objetivo en este particular caso es predecir el siguiente valor en la
serie de tiempo: el próximo precio de la acción. 11
•
Predicción de tráfico vehicular. Se han utilizado redes neuronales recurrentes
para la predicción a corto plazo del tráfico en una carretera, a fin de prevenir
congestiones y tener un control del acceso a la autopista. Para esto se utilizan
datos estimados de otros días con propiedades similares; los mejores resultados
se obtuvieron con una red multi - recurrente, y se pudo comprobar que las redes
neuronales resolvieron este tipo de predicción y obtuvieron mejores resultados
que los métodos estadísticos convencionales. 12
•
Predicción de Tornado. Basada en atributos obtenidos de un radar Doppler, el
cual observa diferentes fenómenos que a la larga llegan a producir tornados. Las
tormentas eléctricas algunas veces llegan a producirlos, pero no siempre son
antecedente de ello. Una red neuronal alimentada hacia adelante es usada para
diagnosticar cuales fenómenos detectados por el radar llegarán a producir un
tornado. La red neuronal es diseñada para la identificación de tornados, con ese
fin, se desarrollaron procedimientos para determinar el tamaño del conjunto de
11
Se puede encontrar más información en un trabajo enfocado a la predicción financiera.
UNIVERSIDAD DE VIGO. Negative Feedback Network For Financial Prediction (pdf), Marzo de
2004, http://ann7.ei.uvigo.es/~fdiaz/doc/1999sci-isas.pdf.
12
Un interesante modelo para la predicción del tráfico. TAO, Yang, A Neural Network Model for
Traffic Prediction in the Presence of Incidents via Data Fusion, Universidad de Wisconsin, Julio de
2004, http://homepages.cae.wisc.edu/~yang/incident%20impact_final.pdf.
entrenamiento y el número de nodos ocultos necesarios para el funcionamiento
óptimo. Se mostró que la red neuronal encontrada de este modo supera un
algoritmo basado en reglas.13
4.2. DESARROLLO DE LA INVESTIGACION
Utilizando un método de pronóstico no tradicional, como las redes neuronales, se
intentara establecer mediante resultados comparativos la efectividad de la
predicción para una serie de tiempo de tipo común.
La serie elegida es el consumo mensual de ACPM, los datos de esta serie fueron
tomados desde el mes de enero de 1998 hasta el mes diciembre de 2003. 72 datos
en total. Estos datos fueron actualizados en marzo 19 de 2004 por personal del
departamento de planeación nacional. El consumo de ACPM presenta variaciones
importantes mes a mes debido a factores como el precio de la gasolina, importación
de petróleo y al observar la serie se podría pensar a priori que las épocas del año
afectan el consumo.
La metodología propuesta para realizar esta investigación es:
1. Presentación de la serie.
2. Preprocesamiento de los datos: Es decir una preparación de los datos, una
transformación de los datos si es necesario (escalamiento, logaritmización,
normalización, etc.)
3. Analizar mediante métodos estadísticos básicos el estado de la serie y basados
en ellos hacer una selección de los parámetros óptimos iniciales.
4. Analizar la serie con la ayuda del Neural Network Toolbox de Matlab.
13
MARZABAN, C. and Stumpf, G.J. (1996), A Neural Network for Tornado Prediction Based on
Doppler Radar-Derived Attributes, Journal of Applied Meteorology Ed 35, 1996. Pag. 617-626.
5. Comparar los datos obtenidos con los datos reales mediante graficas.
6. Concluir con base en los resultados y comparaciones en el posible modelo para
predecir.
4.3. ANALISIS DE LAS SERIE
Los datos de la serie se muestran en el anexo 1, el grafico del consumo de gasolina
ACPM por mes y año se muestra en la figura 4.1.
Figura 4.1: Consumo de Gasolina ACPM (1998 – 2003)
Se toma para el desarrollo del presenta análisis, se toman topologías de 3 capas, en
el capitulo 2 (El MLP como aproximador universal de funciones) se asocia este
hecho a algunos teoremas como los de Kolmogorov y Funahashi, los cuales
demuestran que con solo 3 capas se puede aproximar cualquier función.
Para el desarrollo del análisis de la serie se deben escalan los datos, esto se debe a
las funciones de transferencia que se pretenden usar en el entrenamiento de las
redes, las funciones utilizadas requieren entradas en el rango [-1, 1]. Para este fin
se utilizan las herramientas de Preprocesamiento de datos que ofrece matlab en el
toolbox, más precisamente la función premnmx14.
Se organizan los datos en 2 columnas (Anexo 2), 3 columnas (Anexo 3)
y 4
columnas (Anexo 4). Esta organización se realiza con el fin de manejar topologías
con 1, 2 y 3 neuronas en la capa de entrada y variar de 2 a 3 en la capa oculta y
hasta 2 capas ocultas, esto ultimo tomando en cuenta el numero de ejemplos de
entrenamiento que se tiene disponible de la forma que se escalo y el numero optimo
definido en el capitulo 2 (Número de ejemplos de entrenamiento).
En los anexos se define como Xi las entradas a la red y como D la salida deseada.
Si se observa con un poco más detalle se observa que para predecir la salida
deseada se están usando los datos inmediatamente anteriores.
Se realiza una regresión de los datos de los anexos (2 al 4) y arrogan los siguientes
resultados:
Para 3 entradas y una salida deseada (anexo 4) se tiene un coeficiente de
correlación múltiple del 0,67217, es decir que las 3 entradas explican en un 65% la
salida deseada. Según la prueba f el modelo tiene poder explicativo,
pero
solamente una de las variables explica la serie.
Para 2 entradas y una salida deseada (anexo 3) se tiene un coeficiente de
correlación múltiple del 0,66385, es decir que las 2 entradas explican en un 66% la
salida deseada. Según la prueba f el modelo tiene poder explicativo,
explicado por cada una de las variables.
14
Mas información sobre la función premnmx en la dirección
http://www.mathworks.com/access/helpdesk/help/toolbox/nnet/premnmx.html
se ve
Para 1 entradas y una salida deseada (anexo 2) se tiene un coeficiente de
correlación múltiple del 0,66385, es decir que las 2 entradas explican en un 52% la
salida deseada. Según la prueba f el modelo tiene poder explicativo, pero no es
explicado por la variable dependiente.
Analizando en forma rápida estos resultados vemos que el modelo de 2 entradas y
una salida deseada servirá un poco más que los otros, debido a que sus variables
inciden en el modelo. Por lo tanto, se realiza una división en 2 grupos de los datos
del anexo 2. Basando en ejemplos encontrados en las referencias bibliograficas del
capitulo 2 [1, 6, 7], se formara el primer conjunto con el 75% de los datos, este
conjunto será el conjunto de entrenamiento de la red, los datos restantes se dejaran
como datos de verificación.
Se toman 4 topologías para desarrollar las pruebas a través de matlab, la primera
será 2-2-1 (3 neuronas en la capa de entrada, 2 en la capa oculta y 1 en la capa de
salida), 2-3-1 (3 neuronas en la capa de entrada, 3 en la capa oculta y 1 en la capa
de salida) y 2-2-2-1 (3 neuronas en la capa de entrada, 4 en dos capas ocultas y 1
en la capa de salida). Los resultados arrojados a través del toolbox de matlab
fueron:
TOPOLOGÍA 2-2-1
Traingd
Numero de capas: 3
Neuronas por capa 2 - 2 - 1
Error de entrenamiento 0.101245 de 0.05
Gradiente final 0.000180352 de 1e-010
Numero de iteraciones 60000
Funciones por capa: Purelin – Tansig – Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingd
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
traingd
1,0000
0,5000
0,0000
traingd
1
3
5
7
9
11
13
-0,5000
-1,0000
Traingdm
Numero de capas: 3
Neuronas por capa: 2 - 2 - 1
Error de entrenamiento: 0.101258 de 0.05
Gradiente final: 0.000306383 de 1e-010
Numero de iteraciones: 60000
Funciones por capa: Purelin – Tansig - Tansig
15
17
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingd
m
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
traingdm
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
traingdm
-0,4000
-0,6000
-0,8000
-1,0000
Traingda
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.101299 de 0.05
•
Gradiente final: 0.0484528 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingda
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
traingda
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
traingda
-0,4000
-0,6000
-0,8000
-1,0000
Traingdx
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.101959 de 0.05
•
Gradiente final: 0.0747351 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingdx
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
traingdx
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
1
3
5
7
9
11
13
15
17
traingdx
-0,6000
-0,8000
-1,0000
Trainrp
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.101182 de 0.05
•
Gradiente final: 2.88016e-005 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainrp
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
13
15
17
-0,4000
Grafica del error (datos de validación)
trainrp
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
trainrp
-0,4000
-0,6000
-0,8000
-1,0000
Traincgf
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.100747 de 0.05
•
Gradiente final: 0.000142827 de 1e-010
•
Numero de iteraciones: 170
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traincgf
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
traincgf
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
traincgf
-0,4000
-0,6000
-0,8000
-1,0000
Traincgb
•
Numero de capas : 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.101014 de 0.05
•
Gradiente final: 0.000841213 de 1e-010
•
Numero de iteraciones: 144
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traincgb
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
traincgb
1,0000
0,5000
0,0000
traincgb
1
3
5
7
9
11
13
15
17
-0,5000
-1,0000
Trainscg
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.0956961 de 0.05
•
Gradiente final: 8.98431e-007 de 1e-010
•
Numero de iteraciones: 10655
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainscg
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
trainscg
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
trainscg
-0,4000
-0,6000
-0,8000
-1,0000
Trainbfg
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.101227 de 0.05
•
Gradiente final: 5.83355e-007 de 1e-010
•
Numero de iteraciones: 240
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainbfg
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
trainbfg
1,5000
1,0000
0,5000
trainbfg
0,0000
1
3
5
7
9
11
13
15
17
-0,5000
-1,0000
Trainoss
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.0956943 de 0.05
•
Gradiente final: 9.62612e-007 de 1e-010
•
Numero de iteraciones: 31991
•
Funciones por capa: Purelin – Tansig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainoss
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
trainoss
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
-0,4000
-0,6000
-0,8000
-1,0000
Trainml
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.0956813 de 0.05
•
Gradiente final: 6.93512e-006 de 1e-010
•
Numero de iteraciones: 12209
•
Funciones por capa: Purelin – Tansig - Tansig
17
trainoss
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainlm
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
-0,4000
Grafica del error (datos de validación)
trainlm
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7
9
11
13
15
17
trainlm
-0,4000
-0,6000
-0,8000
-1,0000
d
traingd
traingdm
traingda
traingdx
trainrp
traincgf
traincgb
trainscg
trainbfg
trainoss
trainlm
Respuestas obtenidas con la simulación de la red:
-0,20
-0,29
-0,30
-0,31
-0,27
-0,30
-0,30
-0,30
-0,29
-0,29
-0,29
-0,29
0,25
-0,19
-0,19
-0,19
-0,17
-0,20
-0,18
-0,19
-0,16
-0,19
-0,16
-0,16
-0,14
-0,24
-0,25
-0,25
-0,22
-0,25
-0,24
-0,25
-0,22
-0,25
-0,22
-0,22
0,30
0,00
0,00
-0,02
0,04
0,01
0,00
0,00
-0,01
0,00
-0,01
-0,01
0,04
-0,22
-0,22
-0,22
-0,20
-0,23
-0,21
-0,22
-0,19
-0,22
-0,19
-0,19
-0,03
0,04
0,04
0,00
0,07
0,05
0,03
0,04
0,01
0,04
0,01
0,01
0,45
-0,13
-0,13
-0,12
-0,10
-0,13
-0,12
-0,13
-0,10
-0,13
-0,10
-0,10
0,15
-0,16
-0,16
-0,16
-0,14
-0,17
-0,15
-0,16
-0,13
-0,16
-0,13
-0,13
0,48
0,14
0,13
0,06
0,16
0,17
0,11
0,14
0,07
0,14
0,07
0,07
0,01
-0,06
-0,06
-0,07
-0,03
-0,06
-0,06
-0,06
-0,05
-0,06
-0,05
-0,05
0,60
0,17
0,14
0,07
0,18
0,19
0,13
0,16
0,08
0,16
0,08
0,08
0,58
-0,14
-0,14
-0,14
-0,11
-0,14
-0,13
-0,14
-0,11
-0,14
-0,11
-0,11
0,56
0,26
0,21
0,10
0,25
0,10
0,20
0,25
0,12
0,24
0,12
0,12
0,49
0,24
0,20
0,10
0,24
0,14
0,19
0,23
0,11
0,23
0,11
0,11
0,32
0,23
0,19
0,09
0,23
0,18
0,18
0,22
0,11
0,22
0,11
0,11
1,00
0,18
0,15
0,07
0,19
0,20
0,14
0,17
0,08
0,17
0,08
0,08
-0,10
0,05
0,05
0,01
0,08
0,07
0,04
0,05
0,02
0,05
0,02
0,02
-0,30
0,53
0,36
0,18
0,39
0,15
0,41
0,51
0,22
1,00
0,22
0,22
Al hacer un análisis se del error cuadrático generado por matlab y de las graficas de
aproximación, se ven en la figura 4.2 la salida deseada con las 2 funciones que mas
se acercaron al modelo.
1,20
1,00
0,80
0,60
d
0,40
traingd
0,20
traincgb
0,00
-0,20
1
3
5
7
9
11
13
15
17
-0,40
Figura 4.2: Grafica de respuestas obtenidas topología 2 - 2 - 1
TOPOLOGÍA 2-3-1
Traingd
•
Numero de capas:3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.101723 de 0.05
•
Gradiente final: 0.00114838 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Logsig – Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingd
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15
17
-0,4000
Grafica del error (datos de validación)
traingd
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000 1
-0,4000
-0,6000
-0,8000
-1,0000
Traingdm
3
5
7
9
11
13
15
17
traingd
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.101244 de 0.05
•
Gradiente final: 0.000149962 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingdm
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15
17
-0,4000
Grafica del error (datos de validación)
traingdm
1,0000
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000 1
-0,4000
-0,6000
-0,8000
-1,0000
Traingda
traingdm
3
5
7
9
11 13 15 17
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.101299 de 0.05
•
Gradiente final: 0.0484528 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
0,4000
d
0,2000
traingda
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
-0,6000
-0,8000
Grafica del error (datos de validación)
traingda
0,2000
0,0000
1
3
5
7
9
11
13 15
17
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Traingdx
traingda
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.0985181 de 0.05
•
Gradiente final: 0.0912678 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traingdx
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
traingdx
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
-1,2000
Trainrp
1
3
5
7
9
11
13
15
17
traingdx
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.0831358 de 0.05
•
Gradiente final: 9.93196e-007 de 1e-010
•
Numero de iteraciones: 28202
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainrp
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
trainrp
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Traincgf
1
3
5
7
9
11
13
15
17
trainrp
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.0879971 de 0.05
•
Gradiente final: 0.000294713 de 1e-010
•
Numero de iteraciones: 1038
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traincgf
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
traincgf
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Traincgb
1
3
5
7
9
11
13
15
17
traincgf
•
Numero de capas: 3
•
Neuronas por capa: 2 - 2 - 1
•
Error de entrenamiento: 0.101227 de 0.05
•
Gradiente final: 6.56347e-006 de 1e-010
•
Numero de iteraciones: 77
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
traincgb
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
traincgb
1,0000
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Trainscg
traincgb
1
3
5
7
9
11
13
15
17
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.0879377 de 0.05
•
Gradiente final: 9.64971e-007 de 1e-010
•
Numero de iteraciones: 4211
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainscg
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
trainscg
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Trainbfg
1
3
5
7
9
11
13
15
17
trainscg
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.101227 de 0.05
•
Gradiente final: 4.09674e-007 de 1e-010
•
Numero de iteraciones: 67
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainbgf
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
trainbfg
1,0000
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Trainoss
trainbfg
1
3
5
7
9
11
13
15
17
•
Numero de capas: 3
•
Neuronas por capa: 2 -3 - 1
•
Error de entrenamiento: 0.101227 de 0.05
•
Gradiente final: 8.12267e-007 de 1e-010
•
Numero de iteraciones: 546
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainoss
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15 17
-0,4000
Grafica del error (datos de validación)
trainoss
1,0000
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000
-0,4000
-0,6000
-0,8000
-1,0000
Trainml
trainoss
1
3
5
7
9
11
13
15
17
•
Numero de capas: 3
•
Neuronas por capa: 2 - 3 - 1
•
Error de entrenamiento: 0.0874688 de 0.05
•
Gradiente final: 0.000846157 de 1e-010
•
Numero de iteraciones: 3377
•
Funciones por capa: Purelin – Logsig - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,2000
1,0000
0,8000
0,6000
d
0,4000
trainlm
0,2000
0,0000
-0,2000
1
3
5
7
9
11 13 15
17
-0,4000
Grafica del error (datos de validación)
trainlm
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9
11 13
15
17
-0,4000
-0,6000
-0,8000
-1,0000
Respuestas obtenidas con la simulación de la red:
trainlm
trainlm
-0,2
-0,2
-0,2
-0,1
-0,2
-0,2
-0,3
-0,1
-0,2
-0,2
-0,2
-0,2
-0,2
-0,2
-0,2
0,3
0,0
0,0
-0,1
0,0
0,1
0,1
0,0
0,1
0,0
0,0
0,1
0,0
-0,2
-0,2
-0,3
-0,1
-0,2
-0,2
-0,2
-0,2
-0,2
-0,2
-0,2
0,0
0,0
0,0
0,0
0,0
0,1
0,1
0,0
0,1
0,0
0,0
0,1
0,4
-0,1
-0,1
-0,2
0,0
-0,2
-0,2
-0,1
-0,2
-0,1
-0,1
-0,2
0,1
-0,1
-0,2
-0,2
-0,1
-0,2
-0,2
-0,2
-0,2
-0,2
-0,2
-0,2
0,5
0,1
0,1
0,1
0,1
0,1
0,1
0,1
0,1
0,1
0,1
0,1
0,0
-0,1
-0,1
-0,1
0,0
-0,1
-0,1
-0,1
-0,1
-0,1
-0,1
0,1
0,6
0,1
0,2
0,1
0,1
0,1
0,1
0,2
0,1
0,2
0,2
0,1
0,6
-0,1
-0,1
-0,2
0,0
-0,2
-0,2
-0,1
-0,2
-0,1
-0,1
-0,2
0,6
0,2
0,2
0,1
0,1
0,1
0,1
0,2
0,1
0,2
0,2
0,1
0,5
0,2
0,2
0,1
0,1
0,1
0,1
0,2
0,1
0,2
0,2
0,1
0,3
0,1
0,2
0,1
0,1
0,1
0,1
0,2
0,1
0,2
0,2
0,1
1,0
0,1
0,2
0,1
0,1
0,1
0,1
0,2
0,1
0,2
0,2
0,1
-0,1
0,0
0,1
0,0
0,0
0,1
0,1
0,1
0,1
0,1
0,1
0,1
-0,3
0,4
0,5
-0,6
0,1
0,1
0,1
0,5
0,1
0,5
0,5
0,1
s
-0,3
-0,2
trainos
-0,3
-0,2
f
trainbg
-0,2
-0,2
g
-0,3
-0,2
trainsc
-0,2
-0,2
b
-0,2
-0,1
traincg
traincg
-0,2
-0,3
f
trainrp
-0,4
-0,2
x
-0,3
-0,2
a
traingd
traingd
traingd
traingd
-0,3
0,2
m
d
-0,2
Al hacer un análisis se del error cuadrático generado por matlab, se ven en la figura
4.3 la salida deseada con las 2 funciones que mas se acercaron al modelo.
1,2
1,0
0,8
0,6
d
0,4
0,2
traingda
0,0
-0,2
1
3
5
7
9
11
13
15
17
traingdx
-0,4
-0,6
-0,8
Figura 4.3: Grafica de valores resultantes de iterar la serie 2-3-1
TOPOLOGÍA 2 - 2 - 2 -1
Traingd
•
Numero de capas: 4
•
Neuronas por capa: 2 – 2 - 2 - 1
•
Error de entrenamiento: 0.083368 de 0.05
•
Gradiente final: 0.00075513 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
traingd
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
traingd
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
traingd
-0,4000
-0,6000
-0,8000
-1,0000
Traingdm
•
Numero de capas: 4
•
Neuronas por capa: 2 – 2 - 2 - 1
•
Error de entrenamiento: 0.0835231 de 0.05
•
Gradiente final: 0.000282096 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
traingdm
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
traingdm
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7 9 11 13 15 17
traingdm
-0,4000
-0,6000
-0,8000
-1,0000
Traingda
•
Numero de capas: 4
•
Neuronas por capa: 2 - 2 - 2 - 1
•
Error de entrenamiento: 0.0891906 de 0.05
•
Gradiente final: 0.173402 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
traingda
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
traingda
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
traingda
-0,4000
-0,6000
-0,8000
-1,0000
Traingdx
•
Numero de capas: 4
•
Neuronas por capa: 2 – 2 - 2 - 1
•
Error de entrenamiento: 0.0850742 de 0.05
•
Gradiente final: 0.127728 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig – Purelin – Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
traingdx
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
traingdx
0,6000
0,4000
0,2000
0,0000
-0,2000
1
3
5
7 9 11 13 15 17
traingdx
-0,4000
-0,6000
-0,8000
-1,0000
Trainrp
•
Numero de capas: 4
•
Neuronas por capa: 2 - 2 - 2 - 1
•
Error de entrenamiento: 0.0789043 de 0.05
•
Gradiente final: 0.00281069 de 1e-010
•
Numero de iteraciones: 60000
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
trainrp
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
trainrp
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
trainrp
-0,4000
-0,6000
-0,8000
-1,0000
Traincgf
•
Numero de capas : 4
•
Neuronas por capa: 2 - 2 - 2 - 1
•
Error de entrenamiento: 0.0847961 de 0.05
•
Gradiente final: 0.00064192 de 1e-010
•
Numero de iteraciones: 185
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
traincgf
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
traincgf
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
traincgf
-0,4000
-0,6000
-0,8000
-1,0000
Traincgb
•
Numero de capas: 4
•
Neuronas por capa: 2 - 2 - 2 - 1
•
Error de entrenamiento: 0.083838 de 0.05
•
Gradiente final: 0.00119069 de 1e-010
•
Numero de iteraciones: 135
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
traincgb
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
traincgb
1,2000
1,0000
0,8000
0,6000
0,4000
0,2000
0,0000
-0,2000 1
-0,4000
-0,6000
-0,8000
-1,0000
traincgb
3
5
7
9 11 13 15 17
Trainscg
Numero de capas: 4
Neuronas por capa: 2 - 2 - 2 - 1
Error de entrenamiento: 0.0803516 de 0.05
Gradiente final: 8.18243e-007 de 1e-010
Numero de iteraciones: 1290
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
trainscg
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
trainscg
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
trainscg
-0,4000
-0,6000
-0,8000
-1,0000
Trainbfg
•
Numero de capas: 4
•
Neuronas por capa: 2 - 2 - 2 - 1
•
Error de entrenamiento: 0.0803511 de 0.05
•
Gradiente final: 5.01321e-007 de 1e-010
•
Numero de iteraciones: 380
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
trainbgf
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
trainbfg
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
trainbfg
-0,4000
-0,6000
-0,8000
-1,0000
Trainoss
Numero de capas: 4
Neuronas por capa: 2 -2 - 2 - 1
Error de entrenamiento: 0.0835118 de 0.05
Gradiente final: 7.71694e-007 de 1e-010
Numero de iteraciones: 2355
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
trainoss
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
trainoss
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
trainoss
-0,4000
-0,6000
-0,8000
-1,0000
Trainml
•
Numero de capas: 4
•
Neuronas por capa: 2 - 2 - 2 - 1
•
Error de entrenamiento: 0.0788702 de 0.05
•
Gradiente final: 2.05572e-006 de 1e-010
•
Numero de iteraciones: 5503
•
Funciones por capa: Purelin – Tansig – Purelin - Tansig
Grafica de salida deseada & salida obtenida (datos de validación)
1,20
1,00
0,80
0,60
d
0,40
trainlm
0,20
0,00
-0,20
1
3
5
7
9
11 13 15 17
-0,40
Grafica del error (datos de validación)
trainlm
0,6000
0,4000
0,2000
0,0000
-0,2000 1
3
5
7
9 11 13 15 17
trainlm
-0,4000
-0,6000
-0,8000
-1,0000
d
traingd
traingdm
traingda
traingdx
trainrp
traincgf
traincgb
trainscg
trainbgf
trainoss
trainlm
Respuestas obtenidas con la simulación de la red:
-0,20
-0,25
-0,25
-0,14
-0,31
-0,22
-0,25
-0,26
-0,23
-0,23
-0,25
-0,22
0,25
-0,16
-0,16
-0,06
-0,21
-0,14
-0,17
-0,18
-0,13
-0,13
-0,15
-0,14
-0,14
-0,06
-0,06
0,05
-0,11
-0,06
-0,10
-0,12
-0,07
-0,08
-0,06
-0,06
0,30
0,02
0,02
0,12
-0,14
0,01
0,00
-0,01
-0,06
-0,06
0,03
0,01
0,04
-0,02
-0,02
0,09
0,07
-0,03
-0,06
-0,07
0,15
0,15
-0,02
-0,03
-0,03
0,07
0,07
0,15
-0,14
0,07
0,08
0,06
-0,06
-0,06
0,07
0,07
0,45
-0,03
-0,03
0,07
-0,15
-0,04
-0,07
-0,08
-0,07
-0,07
-0,03
-0,04
0,15
0,06
0,06
0,15
0,07
0,05
0,04
0,11
0,15
0,15
0,06
0,05
0,48
0,11
0,11
0,18
0,07
0,13
0,18
0,17
0,16
0,16
0,11
0,13
0,01
0,10
0,10
0,17
0,07
0,10
0,14
0,27
0,16
0,16
0,09
0,11
0,60
0,10
0,11
0,17
-0,08
0,11
0,16
0,14
0,15
0,05
0,10
0,11
0,58
0,09
0,09
0,17
0,07
0,09
0,10
0,43
0,1 6
0,16
0,09
0,09
0,56
0,14
0,14
0,19
0,07
0,21
0,38
0,70
0,16
0,16
0,13
0,22
0,49
0,14
0,14
0,19
0,07
0,21
0,37
0,67
0,16
0,16
0,13
0,21
0,32
0,13
0,14
0,19
0,07
0,19
0,34
0,54
0,16
0,16
0,13
0,20
1,00
0,13
0,13
0,18
0,07
0,16
0,26
0,28
0,16
0,16
0,12
0,16
-0,1
0,14
0,14
0,19
0,07
0,21
0,37
0,85
0,16
0,16
0,13
0,22
-0,3
0,14
0,14
0,19
0,07
0,20
0,38
0,35
0,16
0,16
0,13
0,21
Al hacer un análisis se del error cuadrático generado por matlab y de las graficas de
aproximación, se ven en la figura 4.2 la salida deseada con las 2 funciones que mas
se acercaron al modelo.
1,20
1,00
0,80
0,60
d
0,40
traincgf
0,20
traincgb
0,00
1
-0,20
3
5
7
9
11
13
15
17
-0,40
Figura 4.4: Grafica de valores resultantes de iterar la serie 2 - 2 - 2 - 1
Se pude observar que los modelos con mayor numero de capas parecen ajustar
mejor la curva del conjunto de validación debido que no describe totalmente el
comportamiento de la serie pero si encuentra puntos en los cuales coincide la serie,
eso da a suponer que en un momento dado y con muchos mas datos de
entrenamiento se puede ajustar un modelo que sin estar sobrentrenado halle el
modelo que se ajuste con mucho menor error a la serie.
ANEXOS
ANEXO 1: CONSUMO DE GASOLINA ACPM (1998 – 2003)
ACPM
BPM*
98 E
1.801.100
F
1.716.876
M
1.835.944
A
1.908.060
M
1.851.072
J
1.749.090
JL
1.952.132
A
1.807.238
S
1.838.280
O
1.895.929
N
1.507.920
D
1.795.737
99 E
1.561.129
F
1.522.108
M
1.787.832
A
1.541.850
M
1.615.100
J
1.411.800
Jl
1.700.505
A
1.706.674
S
1.646.100
O
1.613.798
N
1.758.090
D
1.692.259
00 E
1.744.773
F
1.633.716
M
1.859.008
A
1.687.050
M
1.686.307
J
1.917.930
JL
1.816.042
A
1.949.931
S
1.945.260
O
1.937.314
N
1.942.890
D
1.962.362
01 E
1.950.861
F
1.768.200
M
2.087.385
A
1.928.220
M
1.869.021
J
1.897.830
Jl
1.534.810
A
1.721.244
S
1.619.910
O
1.964.346
N
1.733.430
D
1.793.784
02 E
1.563.196
F
1.544.717
M
1.568.947
A
1.654.625
M
1.600.368
J
1.548.217
Jl
1.705.590
A
1.808.208
S
1.759.327
O
1.953.194
N
1.783.266
D
1.975.678
03 E
1.861.458
F
1.833.307
M
2.039.511
A
1.910.577
M
2.052.503
J
1.851.952
Jl
2.104.383
A
2.097.689
S
2.089.104
O
2.059.732
N
1.984.912
D
2.280.121
04 E
ANEXO 2: SERIE ESCALADA EN EL RANGO [-1,1] CON UNA ENTRADA Y UNA
SALIDA.
x1
d
0,1033
0,2973
0,0231
0,1430
0,2973
0,0231
0,1430
0,0118
0,0118 0,2231
0,2231 0,2445
0,2445 0,0892
0,0892 0,0177
0,0177 0,1151
0,1151 0,7786
0,7786 0,1157
0,1157 0,6561
0,6561 0,7459
0,7459 0,1339
0,1339 0,7005
0,7005 0,5317
0,5317 1,0000
1,0000 0,3350
0,3350 0,3208
0,3208 0,4603
0,4603 0,5347
0,5347 0,2024
-
0,2024
0,3540
0,2331
0,4889
0,3540
0,2331
0,4889
0,0301
0,3660
0,0301
0,3660 0,3677
0,3677 0,1658
0,1658 0,0689
0,0689 0,2395
0,2395 0,2287
0,2287 0,2104
0,2104 0,2233
0,2233 0,2681
0,2681 0,2416
0,2416 0,1791
0,1791 0,5561
0,5561 0,1895
0,1895 0,0531
0,0531 0,1195
0,1195 0,7167
0,7167 0,2873
0,2873 0,5207
0,5207 0,2727
0,2727 0,2592
0,2592 0,1202
0,1202 0,6513
0,6513 0,6939
0,6939 0,6380
0,6380
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,2470
0,2470 0,1444
0,1444 0,2988
0,2988 0,0357
0,0357 0,0291
0,0291 0,4458
0,4458 0,1488
0,1488 0,4757
0,4757 0,0138
0,0138 0,5952
0,5952 0,5798
0,5798 0,5600
0,5600 0,4924
0,4924 0,3200
0,3200 1,0000
1,0000 0,1033
ANEXO 3: SERIE ESCALADA EN EL RANGO [-1,1] CON DOS ENTRADAS Y
UNA SALIDA.
x1
x2
d
0,1033 0,2973 0,0231
0,2973 0,0231 0,1430
0,0231 0,1430 0,0118
0,1430 0,0118 0,2231
0,0118 0,2231 0,2445
0,2231 0,2445 0,0892
0,2445 0,0892 0,0177
0,0892 0,0177 0,1151
0,0177 0,1151 0,7786
0,1151 0,7786 0,1157
0,7786 0,1157 0,6561
0,1157 0,6561 0,7459
0,6561 0,7459 0,1339
0,7459 0,1339 0,7005
0,1339 0,7005 0,5317
0,7005 0,5317 1,0000
0,5317 1,0000 0,3350
1,0000 0,3350 0,3208
0,3350 0,3208 0,4603
0,3208 0,4603 0,5347
0,4603 0,5347 0,2024
0,5347 0,2024 0,3540
-
0,2024
0,3540
0,2331
0,4889
0,0301
0,3660
0,3677
0,1658
0,0689
0,2395
0,2287
0,2104
0,2233
0,3540 0,2331
0,2331 0,4889
0,4889 0,0301
0,0301 0,3660
0,3660 0,3677
0,3677 0,1658
0,1658 0,0689
0,0689 0,2395
0,2395
0,2287
0,2104
0,2233
0,2681
0,2287
0,2104
0,2233
0,2681
0,2416
0,2681 0,2416 0,1791
0,2416 0,1791 0,5561
0,1791 0,5561 0,1895
0,5561 0,1895 0,0531
0,1895 0,0531 0,1195
0,0531 0,1195 0,7167
0,1195 0,7167 0,2873
0,7167 0,2873 0,5207
0,2873 0,5207 0,2727
0,5207 0,2727 0,2592
0,2727 0,2592 0,1202
0,2592 0,1202 0,6513
0,1202 0,6513 0,6939
0,6513 0,6939 0,6380
-
0,6939
0,6380
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,6380
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,2470
0,2470 0,1444
0,2470 0,1444 0,2988
0,1444 0,2988 0,0357
0,2988 0,0357 0,0291
0,0357 0,0291 0,4458
0,0291 0,4458 0,1488
0,4458 0,1488 0,4757
0,1488 0,4757 0,0138
0,4757 0,0138 0,5952
0,0138 0,5952 0,5798
0,5952 0,5798 0,5600
0,5798 0,5600 0,4924
0,5600 0,4924 0,3200
0,4924 0,3200 1,0000
0,3200 1,0000 0,1033
1,0000 0,1033 0,2973
ANEXO 4: SERIE ESCALADA EN EL RANGO [-1,1] CON TRES ENTRADAS Y
UNA SALIDA.
x1
x2
x3
d
0,1033 0,2973 0,0231 0,1430
0,2973 0,0231 0,1430 0,0118
0,0231 0,1430 0,0118 0,2231
0,1430 0,0118 0,2231 0,2445
0,2231
0,0892
0,0118
0,2445
0,2231 0,2445 0,0892 0,0177
0,2445 0,0892 0,0177 0,1151
0,0892 0,0177 0,1151 0,7786
0,0177 0,1151 0,7786 0,1157
0,1151 0,7786 0,1157 0,6561
0,7786 0,1157 0,6561 0,7459
0,1157 0,6561 0,7459 0,1339
0,6561 0,7459 0,1339 0,7005
0,7459 0,1339 0,7005 0,5317
0,1339 0,7005 0,5317 1,0000
0,7005 0,5317 1,0000 0,3350
0,5317 1,0000 0,3350 0,3208
1,0000 0,3350 0,3208 0,4603
0,3350 0,3208 0,4603 0,5347
0,3208 0,4603 0,5347 0,2024
0,4603 0,5347 0,2024 0,3540
0,5347 0,2024 0,3540 0,2331
0,2024
0,3540
0,2331
0,4889
0,0301
0,3660
0,3677
0,1658
0,0689
0,2395
0,2287
0,2104
0,3540 0,2331 0,4889
0,2331 0,4889 0,0301
0,4889 0,0301 0,3660
0,0301 0,3660 0,3677
0,3660 0,3677 0,1658
0,3677 0,1658 0,0689
0,1658 0,0689 0,2395
0,0689 0,2395 0,2287
0,2395
0,2287
0,2104
0,2233
0,2287
0,2104
0,2233
0,2681
0,2104
0,2233
0,2681
0,2416
0,2233 0,2681 0,2416 0,1791
0,2681 0,2416 0,1791 0,5561
0,2416 0,1791 0,5561 0,1895
0,1791 0,5561 0,1895 0,0531
0,5561 0,1895 0,0531 0,1195
0,1895 0,0531 0,1195 0,7167
0,0531 0,1195 0,7167 0,2873
0,1195 0,7167 0,2873 0,5207
0,7167 0,2873 0,5207 0,2727
0,2873 0,5207 0,2727 0,2592
0,5207 0,2727 0,2592 0,1202
0,2727 0,2592 0,1202 0,6513
0,2592 0,1202 0,6513 0,6939
0,1202 0,6513 0,6939 0,6380
0,6513
0,6939
0,6380
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,2470
0,1444
0,2988
0,0357
0,0291
0,4458
0,1488
0,4757
0,0138
0,5952
0,5798
0,5600
0,6939
0,6380
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,6380
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,4407
0,5657
0,6858
0,3233
0,0870
0,1995
0,4458
0,1488
0,4757
0,0138
0,5952
0,5798
0,5600
0,4924
0,1488
0,4757
0,0138
0,5952
0,5798
0,5600
0,4924
0,3200
0,4757
0,0138
0,5952
0,5798
0,5600
0,4924
0,3200
1,0000
0,1033
0,2973
0,0231
0,2470
0,2470 0,1444
0,2470 0,1444 0,2988
0,1444 0,2988 0,0357
0,2988 0,0357 0,0291
0,0357 0,0291 0,4458
0,0291 0,4458 0,1488
0,4924 0,3200 1,0000
0,3200 1,0000 0,1033
1,0000 0,1033 0,2973
CONCLUSIONES
1. Gracias a las características de flexibilidad y adaptabilidad las Redes
Neuronales Artificiales nos presentan una alternativa, no lineal, para analizar y
predecir las series de tiempo.
2. El problema de la predicción es un tema que ha abarcado muchos escenarios de
la vida diaria, como se vio, las redes neuronales son una herramienta poderosa
para el análisis de estos fenómenos, la aparente fiabilidad que tiene debido a los
muchos ejemplos de predicción en los cuáles se aplica, da seguridad suficiente
para creer en los resultados, en algunos casos se puede llegar a tener mas
fiabilidad en las RNA que en los métodos clásicos de predicción.
3. La predicción través de redes neuronales al parecer es un método totalmente
paralelo a los métodos estadísticos clásicos para la predicción, pero ha sido
mediante la estadística que las redes neuronales se han fortalecido como
métodos estándar, en este trabajo se expone el modelo del aproximador general
de funciones, esto se demuestra a través de métodos y teoremas estadísticos.
4. El numero de datos de entrenamiento y de datos de validación condiciona en
gran forma los resultados que se obtienen cuando se entrena una red neuronal,
si se tiene un gran número de datos se debe controlar que no haya sobre
entrenamiento, pero al tener pocos, no se sabe claramente lo que se pude llegar
a obtener, la reglas expuestas en el capitulo 2 sobre como escoger un optimo
número de datos de validación intenta solucionar este problema, pero aun así
este problema es resuelto mas basado en la experiencia de éxito de otros
modelos en problema similares, por lo tanto las redes neuronales siempre van a
tener una parte aleatoria que pude llegar a condicionar a la parte teórica.
BIBLIOGRAFIA
[1] Chao, Lincoln L. (1975) Estadística para ciencias sociales y administrativas.
Bogota: McGraw-Hill.
[2] George C. Canavos. (1988) Probabilidad y Estadística Aplicaciones y Métodos.
Mexico: Mc Graw Hill
[3] Álvaro M. García. (2000) Series de Tiempo. Bogota: Pontificia Universidad
Javeriana, Facultades Economía y Administración.
[4] Emilia Correa Moreno. (2000) Series de Tiempo Conceptos Básicos. Medellín:
Universidad Nacional de Colombia Facultad Ciencias Departamento Matemáticas
[5] Iglesias Z. Pilar. (1988). Elementos de series de tiempo.
[6] Enciclopedia Libre Wikipedia (Online). España 2005.
http://es.wikipedia.org/wiki/Categor%C3%ADa:Estad%C3%ADstica
[7] Hospital Ramón y Cajal (Online). Estadistica. Madrid España. 1996
http://www.hrc.es/bioest/M_docente.html#tema2
[8] Jorge Ludlow Wiechers. Desarrollo Latino. Instrumentos de trabajo, Procesos
Estacionarios.
http://www.desarrollolatino.org/index.htm
[9] Carlos E. Mendoza Durán. Cursos (Online). Probabilidad y Estadística.
http://www.mor.itesm.mx/~cmendoza/ma835/ma83511.html
[10] Raúl Sánchez Vítores . Fac - Mac.
Revista (Online).
Sistemas de
Reconocimiento Facial. Julio, 2004.
http://www.faq-mac.com/mt/archives/009001.php
[11] Cursos (Online). Ingenierías. Pronósticos.
http://www.prodigyweb.net.mx/lmfs/ingenierias/pronósticos/pronósticos.html
[12] DEL BRIO, Martín. Redes Neuronales y Sistemas Difusos. Universidad de
Zaragoza. España: Alfaomega 2002, 399p.
[13] GIARDINA, Daniel. Redes Neuronales: Conceptos Básicos y Aplicaciones.
Rosario, Argentina, 2001, 55 p. Trabajo de Grado (Ingeniero Electrónico).
Universidad Nacional de Rosario. Facultad de Ciencias Exactas, Ingeniería y
Agrimensura.
[14] ANDINA, Diego. Tutorial de Redes Neuronales (Online). Universidad Politécnica
de Madrid. España. Noviembre de 2001.
http://www.gc.ssr.upm.es/inves/neural/ann2/anntutorial.html
[15] KASABOV, Nikola. Foundations of Neural Networks, Fuzzy Systems, and
Knowledge Engineering. Massachusetts Institute of Technology, 1996. 570p.
[16] KROSE, Ben. An Introduction to Neural Networks. The University of Amsterdam.
1996.
[17] CAVUTO, David. An Exploration And Development Of Current Artificial Neural
Network Theory And Applications With Emphasis On Artificial Life. Albert Nerken
School Of Engineering, 1997. 126p.
[18] UNIVERSIDAD TECNOLOGICA DE PEREIRA. Tutorial de Redes Neuronales
(Online). Colombia. 2000. http://ohm.utp.edu.co/neuronales/
[19] Toolbox Matlab v. 6.5. Neural Network Toolbox. Backpropagation. Junio 2002