Heuristicas
Anuncio

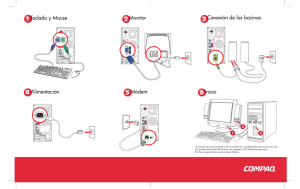
Algoritmos de Búsqueda Informados Tomas Arredondo Vidal 16/6/2010 Algoritmos de Búsqueda Informados Contenidos • Best-first search • Greedy best-first search • A* search • Heurísticas • Búsqueda local Best-first search (i.e. búsqueda del mejor primero) • Idea: usar una función de evaluación f(n) para cada nodo – Estimación de la “deseabilidad" Expandir el nodo no expandido mas deseable • Implementación: Ordenar los nodos en el fringe en orden decreciente de deseabilidad • Casos especiales: – Greedy best-first search (i.e. búsqueda codiciosa del mejor primero) – A* search Rumania con costos de pasos en km Algoritmos de Búsqueda Informados Contenidos • Best-first search • Greedy best-first search • A* search • Heurísticas • Búsqueda local Greedy best-first search • Función de evaluación f(n) = h(n) (heuristic o heuristica) – estimación del costo desde n al objetivo • e.g., hSLD(n) = distancia en línea recta (i.e. straight line distance) desde n a Bucharest • Greedy best-first search expande el nodo que aparece estar mas cercano al objetivo Ejemplo greedy best-first search Ejemplo greedy best-first search Ejemplo greedy best-first search Ejemplo greedy best-first search Propiedades de greedy bestfirst search • Completo? No – se puede quedar pegado en lazos, e.g., Lasi a Fagaras: Lasi Neamt Lasi Neamt ... • Tiempo? O(bm), pero una buena heurística puede dar muchas mejoras • Espacio? O(bm) – mantiene todos los nodos en memoria • Optima? No. e.g., Rimnicu Vilcea Pitesti es mejor que Arad Sibiu Fagaras Algoritmos de Búsqueda Informados Contenidos • Best-first search • Greedy best-first search • A* search • Heurísticas • Búsqueda local Búsqueda A* • Idea: evitar expandir rutas que ya son costosos • Función de evaluación f(n) = g(n) + h(n) • g(n) = costo hasta ahora para llegar a n • h(n) = costo estimado desde n al objetivo • f(n) = costo estimado total de la ruta desde n al objetivo Ejemplo búsqueda A* Ejemplo búsqueda A* Ejemplo búsqueda A* Ejemplo búsqueda A* Ejemplo búsqueda A* Ejemplo búsqueda A* Algoritmos de Búsqueda Informados Contenidos • Best-first search • Greedy best-first search • A* search • Heurísticas • Búsqueda local Heurísticas Admisibles • Una heurística h(n) es admisible si para cada nodo n, h(n) ≤ h*(n), en el cual h*(n) es el costo verdadero para llegar al estado objetivo n. • Una heurística admisible nunca sobreestima el costo para llegar al estado objetivo, i.e., es optimista • Ejemplo: hSLD(n) (nunca sobreestima la distancia real en la carretera) • Teorema: Si h(n) es admisible, A* usando TREESEARCH es optimo Optimalidad de A* • Suponga que algún objetivo subóptimo G2 ha sido generado y esta en el fringe. Deje que n sea un nodo no expandido en el fringe en el cual n esta en la ruta mas corta al objetivo óptimo G. dado que h(G2) = 0 • f(G2) = g(G2) • g(G2) > g(G) dado que G2 es subóptimo • f(G) = g(G) dado que h(G) = 0 • f(G2) > f(G) de lo anterior • h(n) ≤ h*(n) dado que h es admisible • g(n) + h(n) ≤ g(n) + h*(n) • f(n) ≤ f(G) dado que n esta en la ruta a G Entonces f(G2) > f(n), y A* nunca va a elegir a G2 para expansion. Heuristicas Consistentes • Una heurística es consistente si para cada nodo n, cada sucesor n' de n generado por una acción a, h(n) ≤ c(n,a,n') + h(n') • Si h es consistente, tenemos f(n') = g(n') + h(n') = g(n) + c(n,a,n') + h(n') ≥ g(n) + h(n) = f(n) • i.e., f(n) es no-decreciente en cualquier ruta. • Theorema: Si h(n) es consistente, A* usando GRAPHSEARCH es optimo. Optimalidad de A* • A* expande nodos en orden incemental de f value • Gradualmente agrega "f-contornos" de nodos • Contorno i tiene todos los nodos con f = fi, en el cual fi < fi+1 Propertidades de A* • Completo? Si (a menos que hayan infinito nodos con f ≤ f(G) ) • Tiempo? Exponencial • Espacio? Mantiene todos los nodos en memoria • Optimo? Si Heuristicas Admisibles E.g., para el 8-puzzle: • h1(n) = numero de cuadros mal puestos • h2(n) = distancia total Manhattan (i.e., no. de cuadrados de la ubicación deseada para cada cuadro) • h1(S) = ? • h2(S) = ? Heuristicas Admisibles E.g., para el 8-puzzle: • h1(n) = numero de cuadros mal puestos • h2(n) = distancia total Manhattan (i.e., no. de cuadrados de la ubicación deseada para cada cuadro) • h1(S) = ? 8 • h2(S) = ? 3+1+2+2+2+3+3+2 = 18 Dominación • Si h2(n) ≥ h1(n) para todos los n (ambos admisibles) • entonces h2 domina a h1 • h2 es mejor para buscar. • Típicos costos de búsqueda (i.e. numero promedio de nodos expandidos): • d=12 IDS = 3,644,035 nodos A*(h1) = 227 nodos A*(h2) = 73 nodos • d=24 IDS = demasiado numero de nodos A*(h1) = 39,135 nodos A*(h2) = 1,641 nodos Problemas Relajados • Un problema con menos restricciones en sus acciones posibles se llama un problema relajado • El costo de una solución optima para un problema relajado es una heurística admisible para el problema original • Si las reglas del 8-puzzle son relajadas para que un cuadro se pueda mover a cualquier posición, entonces h1(n) da la solución mas corta • Si las reglas se relajan para que un cuadro se pueda mover a cualquier cuadro adyacente, entonces h2(n) entrega la solución mas corta Algoritmos de Búsqueda Informados Contenidos • Best-first search • Greedy best-first search • A* search • Heurísticas • Búsqueda local Algoritmos de búsqueda local • En muchos problemas de optimización, la ruta a un objetivo es irrelevante – el estado final es la solución • Espacio de estados = conjunto de soluciones posibles • Hay que buscar configuraciones que satisfagan sus restricciones • Podemos probar distintos algoritmos: – Búsqueda local: tienen un estado actual, lo tratan de mejorar – Búsqueda global: prueban múltiples estados al mismo tiempo, tratan de encontrar el mejor Algoritmos de búsqueda informados Referencias: [1] S Russell, P Norvig, "Artificial Intelligence A Modern Approach", Prentice Hall, 2003