Técnicas de estimación de costo y esfuerzo
Anuncio

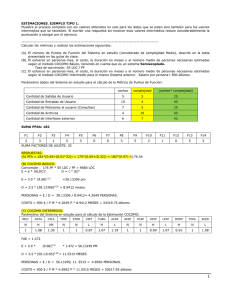
Introducción Cuando se planifica un proyecto se tienen que obtener estimaciones del esfuerzo humano requerido, de la duración cronológica del proyecto y del costo. En la mayoría de los casos las estimaciones se hacen valiéndose de la experiencia pasada como única guía. Aunque en algunos casos puede que la experiencia no sea suficiente. Técnicas de Estimación de Costo y Esfuerzo Estas técnicas de estimación son una forma de resolución de problemas en donde, en la mayoría de los casos, el problema a resolver es demasiado complejo para considerarlo como una sola parte. Por esta razón, descomponemos el problema, recaracterizándolo como un conjunto de pequeños problemas. Líneas de Código y Puntos de Función. Los datos de líneas de código (LDC) y los puntos de función (PF) se emplean de dos formas durante la estimación del proyecto de software: • Variables de estimación, utilizadas para calibrar cada elemento del software. • Métricas de base, recogidas de anteriores proyectos utilizadas junto con las variables de estimación para desarrollar proyecciones de costo y esfuerzo. Estas técnicas son diferentes pero tienen características comunes. El planificador del proyecto comienza con una declaración restringida del ámbito del software y, a partir de esa declaración, intenta descomponer el software en pequeñas subfunciones que pueden ser estimadas individualmente. Entonces, estima las LDC o PF (la variable de estimación) para cada subfunción. Luego, aplica las métricas básicas de productividad a la variable de estimación apropiada y deriva el costo y el esfuerzo para la subfunción. Combinando las estimaciones de las subfunciones se produce la estimación total para el proyecto entero. Difieren en el nivel de detalle que requiere la descomposición. Cuando se utiliza LDC como variable de estimación, la descomposición funcional es absolutamente esencial y, a menudo, se lleva hasta considerables niveles de detalle. Debido a que los datos requeridos para estimar los Puntos de Función son más macroscópicos, en nivel de descomposición al que se llega cuando PF es la variable de estimación es considerablemente menos detallado. También, debe de tenerse en cuenta que mientras que LDC se estima directamente, PF se determina indirectamente mediante la estimación del número de entradas, salidas, archivos de datos, peticiones e interfaces externas, entre otras. Independientemente de la variable de estimación que use, el planificador del proyecto, normalmente, proporciona un rango de valores para cada función descompuesta. A partir de los datos históricos o (cuando todo lo demás falla) usando su intuición, el planificador estima los valores optimista, más probable y pesimista de LDC o de PF para cada función. Cuando lo que se especifica es un rango de valores, implícitamente se proporciona una indicación del grado de incertidumbre. Entonces, se calcula el valor esperado de LDC o de PF. El valor esperado para la variable de estimación, E, se obtiene como una medida ponderada de las estimaciones LDC o PF óptima (a), más probable (m) y pesimista (b). Por ejemplo: 1 E = a + 4m + b 6 da una mayor credibilidad a la estimación más probable y sigue una distribución de probabilidad beta. Técnicas Delfi. Las técnicas delfi fueron desarrolladas en la corporación Rand en el año de 1948, con el fin de obtener el consenso de un grupo de expertos sin contar con los efectos negativos de las reuniones de grupos. La técnica puede adaptarse a la estimación de costos de la siguiente manera: • Un coordinador proporciona a cada experto la documentación con la definición del sistema y una papeleta para que escriba su estimación. • Cada experto estudia la definición y determina su estimación en forma anónima; los expertos pueden consultar con el coordinador, pero no entre ellos. • El coordinador prepara y distribuye un resumen de las estimaciones efectuadas, incluyendo cualquier razonamiento extraño efectuado por alguno de los expertos. • Los expertos realizan una segunda ronda de estimaciones, otra vez anónimamente, utilizando los resultados de la estimación anterior. En los casos que una estimación difiera mucho de las demás, se podrá solicitar que también en forma anónima el experto justifique su estimación. • El proceso se repite varias veces como se juzgue necesario, impidiendo una discusión grupal durante el proceso. El siguiente enfoque es una variación de la técnica Delfi tradicional que aumenta la comunicación conservando el anonimato. • El coordinador proporciona a cada experto la documentación con la definición del sistema y una papeleta para que escriba su estimación. • Cada experto estudia su definición, y el coordinador llama a una reunión del grupo con el fin de que los expertos puedan analizar los aspectos de la estimación con él y entre ellos. • Los expertos terminan su estimación en forma anónima. • El coordinador prepara un resumen de las estimaciones efectuadas sin incluir los razonamientos realizados por algunos de los expertos. • El coordinador solicita una reunión del grupo para discutir los puntos donde las estimaciones varíen más. • Los expertos efectúan una segunda ronda de estimaciones, otra vez en forma anónima. El proceso se repite tantas veces como se juzgue necesario. COCOMO. El Modelo Constructivo de Costos (COnstructive COst Model) es una jerarquía de modelos de estimación para el software. Esta jerarquía está constituida por los siguientes modelos: 2 • El modelo COCOMO básico es un modelo univariable estático que calcula el esfuerzo (y el costo) del desarrollo de software en función del tamaño del programa expresando en líneas de código (LDC) estimadas. • El modelo COCOMO intermedio calcula el esfuerzo del desarrollo de software en función del tamaño del programa y de un conjunto de conductores de costo, que incluyen la evaluación subjetiva del producto, del hardware, del personal y de los atributos del proyecto. • El modelo COCOMO avanzado incorpora todas las características de la versión intermedia y lleva a cabo una evaluación de impacto de los conductores de costo en cada fase (análisis, diseño, etc.) del proceso de ingeniería de software. Los modelos COCOMO están definidos para tres tipos de proyecto de software. Modelo Orgánico. Proyectos de software relativamente pequeños y sencillos en los que trabajan pequeños equipos, con buena experiencia en la aplicación, sobre el conjunto de requisitos poco rígidos (por ejemplo, un programa de análisis termal desarrollado para un grupo calórico). Modelo Semiacoplado. Proyectos de software intermedios (en tamaño y complejidad) en los que los equipos, con variados niveles de experiencia, deben satisfacer requisitos poco o medio rígidos (por ejemplo, un sistema de procesamiento de transacciones con requisitos fijos para un hardware de terminal o un software de gestión de base de datos). Modelo Empotrado. Proyectos de software que deben ser desarrollados en un conjunto de hardware, software y restricciones operativas muy restringidas (por ejemplo, software de control de navegación para un avión). Las ecuaciones del modelo COCOMO básico tienen la siguiente forma: E = ab (KLDC) exp (bb) D = cb (E) exp (db) donde E es el esfuerzo aplicado en personas−mes, D es el tiempo de desarrollo en meses cronológicos y KLDC es el número estimado de Líneas de Código distribuídas (en miles) para el proyecto. Las ecuaciones del modelo COCOMO intermedio toma la forma: E = ai (KLDC) exp (bi) x FAE donde E es el esfuerzo aplicado en personas−mes, KLDC es el número estimado de Líneas de Código distribuídas para el proyecto. Conclusiones Se han desarrollado varias técnicas de estimación para el desarrollo de software como establecer de antemano el ámbito del proyecto, usar las métricas del software (mediciones del pasado) como base para la realización de estimaciones y desglosar el proyecto en partes mas pequeñas que se estiman individualmente. Esto ayuda al programador, ya que le permite dedicar más tiempo a otras partes del proyecto. 3