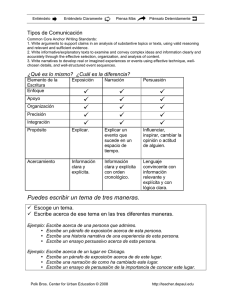
Informatica 1 - Agrupación 15 de Junio – MNR
Anuncio

Informática I Ing. Z. Luna Este apunte es sólo una ayuda o complemento para el estudio de la asignatura. Se ha intentado incorporar muchos ejemplos prácticos y bastantes ejemplos de aplicación a la ingeniería, si bien el curso es del primer año, primer semestre de la carrera, por lo cual los alumnos cuentan con muy pocos conocimientos que tengan que ver con el ciclo profesional. Este apunte no reemplaza a las clases (Teoría, Práctica, Laboratorio), sólo complementa. Las Unidades 1, 2 y 3 son un compendio de varios apuntes de docentes de la cátedra. 1 UNIDAD 1.- FUNDAMENTOS DE LA INFORMÁTICA. ¿Qué es la Informática? Conceptos de algoritmo, procesador, acciones primitivas y no primitivas. Algoritmos y programas. Problemas algorítmicos. Características de los algoritmos: legibilidad, eficiencia y corrección. Datos e Información. Representación interna de la información. Sistemas de numeración. El sistema decimal. El sistema binario o digital. Justificación de su uso. Sistema hexadecimal. Conversiones entre sistemas. Representación interna de números enteros: Técnica de Complemento a 2. Representación interna de números reales: punto flotante. Representación interna de datos alfanuméricos. Código ASCII. Informática: tiene su raíz en el francés informatique y es la designación castellana del inglés Computer Science. Según nuestro diccionario se define como el conjunto de conocimientos científicos y técnicas que hacen posible el tratamiento automático de la información por medio de computadoras. Qué se entiende por información? Datos e información son equivalentes? Datos: como tales se entiende el conjunto de símbolos usados para representar un valor numérico, un hecho, una idea o un objeto. Individualmente los datos tienen un significado puntual. Como ejemplo podemos mencionar el número de CUIL que cada empleado debe tener para sus aportes jubilatorios, un número de teléfono, la edad de unas persona, etc. Información: Por tal se entiende un conjunto de datos procesados, organizados, es decir significativos. La información implica tanto un conjunto de datos como su interrelación. Dependiendo de esta última el mismo conjunto de datos suministra diferente información. Por ejemplo, imaginemos los datos originados en un seguimiento de los alumnos de este curso de su carrera universitaria y profesional: − Nombre − Edad − Carrera universitaria − Promedio académico − Salario profesional Representación de la información Habiendo definido el concepto de información el problema es cómo representarla para poder manejarla en forma automática. Es posible idear muchas formas de hacerlo, pero la clasificación básica nos lleva a una distinción entre técnicas analógicas y digitales. Veamos la diferencia: Representación analógica: Cuando una magnitud física varía continuamente para representar la información tenemos una representación analógica. Por ejemplo, el voltaje en función de la presión producida por la voz en un micrófono. Representación digital: En este caso la información es divida en trozos y cada trozo se representa numéricamente. Lo que se maneja al final es un conjunto de números. La cantidad de trozos en que se divide lo que se quiere representar está relacionado con la calidad de la representación. Un ejemplo actual de esto lo constituyen las cámaras digitales (1, 2, 3.2, 4.1 o más Mega Pixels por foto). En las computadoras modernas toda la información está almacenada digitalmente, desde los números al texto pasando por el audio o el video. Números - sistema binario (conveniencia y simplicidad) - el sistema binario al igual que el decimal es un sistema posicional 2 Decimal 0 1 2 3 Binario 0 1 10 11 Texto - está representado por un código numérico. Cada caracter (letras mayúsculas y minúsculas, signos de puntuación signos especiales como #, @, & etc.) tienen asociado un valor numérico. - Estos valores numéricos son arbitrarios - Código ASCII (American Standard Code for Information Interchange) Caracter / Código Caracter / Código @ 64 $ 36 ……………………………………………………. Conceptos básicos Caracter / Código / 47 Caracter / Código á 160 Un dígito binario se denomina bit (contracción de binary digit). El conjunto de 8 bits se denomina byte. Es interesante saber cuál es el mayor número que se puede representar con un cierto número de bits. Puesto que con un bit se puede representar dos posibilidades, con 2 bits tendremos 4 posibilidades (2x2) y en general tendremos 2N, véase la lista siguiente: Bits Posibilidades 1 21=2 2 22=4 3 23=8 4 24=16 5 25=32 6 26=64 7 27=128 8 (1 byte) 28=256 ... … 2 byte 216=65536 4 byte 232=4294967296 8 byte 264=18446744073709551616 Múltiplos: Kilobyte, MegaByte, Gigabyte, etc. ceptos básicos Definiciones Especificación: se denomina al proceso por el cual se analiza y determina en forma clara y concreta el objetivo que se desea. Abstracción: es proceso por el cual se analiza el mundo real para interpretar los aspectos esenciales de un problema y expresarlo en términos precisos 3 Modelización: se denomina al conjunto que implica abstraer un problema del mundo real y simplificar su expresión, tratando de encontrar los aspectos principales que se pueden resolver (requerimientos), los datos que se han de procesar y el contexto del problema. Lenguaje de programación: es el conjunto de instrucciones permitidas y definidas por sus reglas sintácticas y su valor semántico, para expresar la solución a un problema Programa: es un conjunto de instrucciones ejecutables sobre una computadora, que permite cumplir una función específica. Etapas en la resolución de problemas con computadora − Análisis del problema, se analiza el problema en su contexto del mundo real. Deben obtenerse los requerimientos del usuario. El resultado de este análisis es un modelo preciso del ambiente del problema y del objetivo a resolver. Un componente importante de este modelo son los datos a utilizar y las transformaciones de los mismos que llevan al objetivo. − Diseño de una solución, a partir del modelo se debe definir una estructura de sistema de hardware y software que lo resuelva. El primer paso en el diseño de la solución es la modularización del problema, es decir la descomposición del mismo en partes que tendrán una función bien definida y datos propios (locales). A su vez, debe establecerse la comunicación entre los diferentes módulos del sistema propuesto. − Especificación de algoritmos, la elección del algoritmo adecuado para la función del módulo es muy importante para la eficiencia posterior del sistema en su conjunto. − Escritura del programa, un algoritmo es una especificación simbólica que se debe convertir en un programa real en un lenguaje de programación concreto. El programa escrito en un lenguaje de programación determinado debe traducirse, a su vez, al lenguaje de la máquina. Esta traducción (que es realizada por programas especializados) permite detectar y corregir los errores sintácticos que se comentan en la escritura del programa. − Verificación, de forma de ver si el programa conduce al resultado deseado con los datos representativos del mundo real. Algoritmos Un algoritmo es un conjunto finito, ordenado de reglas o instrucciones bien definidas tal que siguiéndolas paso a paso se obtiene la respuesta a un problema dado. Un algoritmo debe: − Estar compuesto de acciones bien definidas − Constar de una secuencia finita de operaciones − Finalizar en un tiempo finito Por ejemplo se desea calcular la superficie y el perímetro de un círculo en función de su radio. Entrada: radio del círculo Proceso: cálculo de la superficie del círculo y de la longitud de la circunferencia Salida: valor de la superficie y perímetro 4 Entrada: conjunto de información o datos que son necesarios para que el algoritmo lleve a cabo su tarea. Proceso: contiene la descripción de los pasos a seguir para resolver el problema. Programa: Es el algoritmo codificado. Salida: está constituida por los resultados que se obtienen al ejecutar el proceso en función de los datos de entrada. Nuestro procesador: la computadora • su tarea es procesar información • tratamiento de la información en forma automática • sólo puede realizar acciones elementales, tales como − operaciones básicas +, -, /, * . . . . − operaciones relacionales <, >, <=, >= . . . . − almacenar información − repetir grupos de acciones − elegir uno de entre dos o mas caminos El procesador trabaja todo en la memoria. Todo lenguaje de programación contiene CONSTRUCTORES específicos (palabras claves reservadas) las cuales permiten indicarle al procesador las operaciones básicas en dicho lenguaje. Constructores básicos: - tipos de datos - variables - operadores - operador de asignación En una primera parte del curso expondremos todos los conceptos desde un punto de vista genérico. Es decir, los conceptos expuestos son generales y no dependen de un lenguaje determinado y lo llamaremos pseudocódigo (también existe Chapin, …)-. Posteriormente haremos referencia a lenguajes de programación concretos como por ejemplo el Fortran Lenguaje de programación → sentencias → - de declaración: no implica una operación matemática o lógica - Ejecutable: implica una operación matemática o lógica - Comentario: informativa, es ignorada por el procesador 5 UNIDAD 2.- DATOS, OPERACIONES Y EXPRESIONES. Tipos de Datos. Datos simples. Tipo numérico entero y real. Tipo lógico. Tipo alfanumérico. Tipo de dato compuesto String: lectura, escritura y comparación. Constantes y variables. Expresiones. Operadores. Expresiones aritméticas. Jerarquía de los operadores. Expresiones relacionales, lógicas y alfanuméricas. Funciones internas. Tipos de Datos Los lenguajes que aplican una gestión estricta de tipos de datos se denominan lenguajes de tipos fuertes o de tipos estrictos. Por ejemplo, Pascal es un lenguaje de tipo estricto, como lo son Fortran, Java, etc. La programación en MatLab es un ejemplo de programación de tipo no estricto, es decir no hace falta una declaración explícita y estricta de los tipos de datos que se emplean. A nivel de lenguaje de máquina, un dato es un conjunto o secuencia de bits (dígitos 0 y 1). Los lenguajes de alto nivel permiten basarse en abstracciones e ignorar los detalles de la representación interna. Como se mencionó anteriormente los programas manejan datos. Es necesario, por lo tanto, disponer de un mecanismo que permita el almacenamiento y la manipulación de los datos. En un programa esto es llevado a cabo por entidades a las que denominaremos variables y constantes. Variable: es un objeto cuyo valor puede cambiar durante el desarrollo del algoritmo o ejecución del programa. Una variable es un nombre que asignamos para una/s posición/es de memoria usada/s para almacenar un valor de un cierto tipo de dato. Las variables deben declararse antes de usarse, suponiendo un lenguaje de tipo estricto. Cuando se declara una variable estamos reservando una porción de memoria principal para el almacenar los correspondientes valores correspondientes al tipo de variable. La declaración de las variables implica el darles un nombre (identificador de la variable). El valor que almacena una variable se puede modificar (el valor, el tipo NO) a lo largo del programa. Nombres válidos (convenciones): - Todo nombre válido debe comenzar con una letra (obligatorio). - El nombre debe ser representativo (muy recomendable). Constantes: similar al concepto de variable pero con la particularidad de que su valor permanece inalterable en curso de la ejecución del algoritmo. Expresiones: Las expresiones son combinaciones de constantes, variables y símbolos de operación, paréntesis y nombres de funciones. De forma similar a lo que se entiende en notación matemática tradicional. Por ejemplo: a + b * sin(t) * 10^3 Según el tipo de objetos que manipulan las expresiones se califican en : - aritméticas - lógicas - de carácter El resultado de la expresión aritmética es de tipo numérico; el resultado de la expresión relacional y de una expresión lógica es de tipo lógico; el resultado de una expresión de carácter es de tipo carácter. 6 Reglas para evaluar expresiones aritméticas Para evaluar una expresión aritmética hay reglas en cuanto a la “fuerza” de los operadores + y - tienen igual fuerza , pero menos fuerza que * y / (la conocida regla de que “ + y separan y * y / juntan”). Pero acá debemos agregar que si hay una sucesión de operadores de igual fuerza, se van evaluando las operaciones de izquierda a derecha. Las prioridades serían entonces ^ * / + Por ejemplo si tenemos 3 * xx / y + 12 * z * qual * m / 17 / ra / p / s * ty * w + 11 * a / b / c * nu estaríamos representando la siguiente expresión con notación algebraica común 3 . xx 12 . z . qual . m . ty . w 11 . a . nu ---------- + -------------------------------- + ---------------y 17 . ra . p . s b.c las funciones tienen mas fuerza que los operadores y las expresiones entre paréntesis deben ser evaluadas prioritariamente, respetando dentro de ellas las prioridades enunciadas. Expresiones lógicas El resultado de este tipo de expresiones es siempre VERDADERO o FALSO. Las expresiones lógicas se forman combinando constantes lógicas, variables lógicas y otras expresiones lógicas con operadores lógicos (NOT, AND, OR) y con operadores de relación (<, >, <=, >=, =, <>) Genérico: Expresión 1 operador Expresión 2 Operador de Relación Significado > Mayor < Menor = Igual >= Mayor o igual <= Menor o igual <> Distinto Ejemplo: A – 2 < B – 4 es falso si A=4, B=3 Para realizar la comparación de datos tipo carácter se requiere una secuencia de ordenación de los caracteres. Para ello recurrimos al código ASCII (American Standard Code for Information Interchange), donde existe un orden de todos los caracteres. Operadores lógicos Describiremos a continuación los operadores lógicos NOT, AND y OR NOT: es un operador unario, es decir que influye sobre una única expresión del tipo lógica. p F V NOT p V F 7 AND: es la conjunción o multiplicación lógica. Vincula dos expresiones lógicas. Su resultado sólo es verdadero si las dos expresiones son verdaderas. De lo contrario es falso p F F V V p AND q F F F V q F V F V OR: es la disyunción, la suma lógica. Vincula dos expresiones lógicas. Su resultado sólo es falso si las dos expresiones son falsas. De lo contrario es verdadero. p F F V V p OR q F V V V q F V F V (hemos definido el OR inclusivo, hay otro OR, el exclusivo que cuando p y q son verdaderas, su resultado es falso y se identifica EOR y que nosotros no utilizaremos en nuestro curso) Las operaciones que se requieren en los programas exigen en numerosas ocasiones, además de las operaciones aritméticas básicas, ya tratadas, un número determinado de operaciones especiales que se denominan FUNCIONES INTERNAS Función Abs(x) Arctan(x) Cos(x) Exp(x) Ln(x) Log10(x) Redondeo(x) Sin(x) Raiz(x) Trunc(x) Ejemplos: Expresión Raiz(25) Redondeo(6.6) Redondeo(3.1) Redondeo(-3.2) Trunc(5.6) Trunc(3.1) Trunc(-3.8) Abs(9) Abs(-12) Descripción Valor absoluto Arco tangente Coseno Exponencial Logar.neperiano Logar.decimal Redondeo Seno Raiz cuadrada Truncamiento Tipo de argumento Entero o real Entero o real Entero o real Entero o real Entero o real Entero o real Real Entero o real Entero o real Real Resultado Igual al arg. Real Real Real Real Real Entero Real Real Entero Resultado 5.0 (Fortran permite calcular raiz de complejos) 7 3 -3 5 3 -3 9 12 Asignación La operación de asignación es el modo de darle valores a una variable. La operación de asignación la representaremos con el símbolo ← 8 En el desarrollo de nuestros algoritmos nos encontraremos con formas del tipo variable ← expresión esto es lo que llamamos asignación y significa “asignar a la variable el resultado de la expresión” Conversión de tipo: en las asignaciones no se pueden asignar valores a una variable de un tipo diferente del suyo. Por ejemplo, se presentará un error si se trata de asignar valores de tipo carácter a una variable numérica o un valor numérico a una variable tipo carácter. (Fortran permite algunas libertades en este sentido) A una variable de tipo lógico (o booleana), por ej. res se le debe asignar un dato lógico, por lo tanto tiene sentido (suponiendo que a y b sean dos variables reales) una asignación del tipo res ← a = b ¿Cómo interpretamos ésto? a = b es la expresión, lógica en este caso. Si a es igual a b, el resultado de esta expresión será verdadero, y este valor será asignado a la variable lógica res. Como ejemplo, mas adelante, con mayor conocimiento del Fortran se puede probar el siguiente programa. program PruebaFu implicit none logical res real a , b write(*,*)"Ingrese dos reales" read(*,*) a , b res = a == b if (res) then write(*,*) "La variable res quedó con else write(*,*) "La variable res quedó con endif write(*,*)"Ingrese de nuevo dos reales" read(*,*) a , b res = a == b if (res) then write(*,*) "La variable res quedó con else write(*,*) "La variable res quedó con endif end program PruebaFu valor TRUE" valor FALSE" valor TRUE" valor FALSE" Si la primera vez que pide dos reales ingresamos para a y b los valores 3.5 y 3.5 veremos que la salida será La variable res quedó con valor TRUE Si la segunda vez que pide dos reales ingresamos para a y b los valores 2.9 y 7.1 veremos que la salida será La variable res quedó con valor FALSE 9 Entrada y Salida de información Los cálculos que realizan las computadoras requieren para ser útiles la ENTRADA de datos necesarios para la ejecución y que posteriormente definirán la SALIDA. Las operaciones de entrada de datos permiten leer determinados valores y ASIGNARLOS a determinadas VARIABLES. Este proceso se denomina genéricamente LECTURA. Análogamente, la operación de salida se denomina ESCRITURA. Como lo escribimos? leer (lista de variables de entrada) escribir (lista de salida) (en la listade salida puede haber variables, operaciones o constantes) 10 UNIDAD 3.- RESOL. DE PROBLEMAS ALGORÍTMICOS. Análisis de problemas. Diseño de algoritmos. Representación de algoritmos: Diagramas de flujo. Diagramas de Chapin. Pseudocódigo. Lenguaje natural. Estrategia de resolución: refinamientos sucesivos. Análisis de problemas Del mundo real a la solución por computadora Prob.del mundo real Modelo abstracción análisis y descomposición Módulo/s Programa diseño de algoritmos Etapas en la resolución: − Análisis del problema − Diseño de una solución − Especificación de algoritmos − Escritura del programa. − Verificación. Sintaxis y semántica Diccionario: Semántica es el estudio del significado de las unidades lingüísticas. Sintaxis es la manera de enlazarse y ordenarse las palabras en la oración. Desde el punto de vista del lenguaje de programación: Semántica representa el significado de los distintos constructores sintácticos Sintaxis conocer las reglas sintácticas del lenguaje implica conocer cómo se unen las sentencias, declaraciones y otros constructores del lenguaje − Las reglas de sintaxis de un lenguaje de programación dictan la forma de un programa. Durante la compilación de un programa, se comprueban todas las reglas de sintaxis. La semántica dicta el significado de las sentencias del programa. La semántica define qué sucederá cuando una sentencia se ejecute. − Un programa que sea sintácticamente correcto no tiene por qué serlo semánticamente. Un programa siempre hará lo que le digamos que haga y no lo que queríamos que hiciera. Errores de un programa Errores de compilación: Este tipo de errores son detectados por el compilador. Son errores de compilación los errores de sintaxis o el uso en el programa de tipos de datos incompatibles, tal como pretender almacenar un carácter a una variable de tipo numérica. Errores en tiempo de ejecución: Aunque el programa compile bien puede dar error al ejecutarse, por ejemplo por intentar dividir por cero. En este caso el programa puede que estuviese bien escrito, pero adquirir la variable que realiza el papel de divisor el valor cero, y tratar de realizar la división, es cuando se produce el error y ocasiona que el programa se pare. Los programas tienen que ser “robustos”, es decir que prevengan tantos errores de ejecución como sea posible. Errores lógicos: Se producen cuando el programa compila bien y se ejecuta bien pero el resultado es incorrecto. Esto ocurre porque el programa no está haciendo lo que debería hacer (le hemos dicho en realidad que haga otra cosa). Los errores lógicos por lo general son los más difíciles de descubrir. 11 Localización y corrección de errores (depuración) Eliminación de errores de compilación: Listado de errores. Corrección por orden (muchos errores iniciales determinan la existencia de los siguientes, es decir que al corregir uno, pueden corregirse automáticamente varios otros). Eliminación de errores de ejecución: Se debe localizar el punto del programa en el que se produce el error. Esto se hace siguiendo la traza (flujo lógico del programa) hasta que éste falla. A continuación, se debe analizar la sentencia a fin de identificar la causa del error. Una vez identificado el problema el siguiente paso es su corrección, pasando a continuación al siguiente error hasta que no haya ninguno más. Eliminación de errores de lógica: Es la tarea más difícil. Si el programa funciona pera da un resultado erróneo, lo mejor es tomar un ejemplo conocido e ir contrastando los resultados intermedios del ejemplo con los que da el programa. En este último caso hay que ir, normalmente, consultando los resultados parciales del programa en puntos concretos del mismo, estableciendo lo que se denomina “breakpoints” (punto de ruptura). Ingeniería del software Concepto de ingeniería del software. En la primera época de las computadoras el desarrollo de software tenía mucho de arte, dependiendo su calidad final de la experiencia y habilidad del programador. A mediados de los años sesenta, los sistemas software que se comenzaban a desarrollar eran sistemas donde la complejidad era ya un factor a tener en cuenta. Las técnicas artesanales no servían para tratar el desarrollo de sistemas complejos. El problema desde el punto de vista del desarrollo de software era muy importante, por lo que desató mucho interés y trabajo. La falta de control sobre el desarrollo de software se denominó crisis del software, denominación que se sigue usando hoy en día (Gibbs, 1994). La idea es aplicar al software la filosofía ingenieril que se aplica al desarrollo de cualquier producto. La ingeniería del software pretende el desarrollo de software de manera formal, cumpliendo unos estándares de calidad. El punto de vista de la ingeniería del software trasciende a la mera programación. El software se considera dentro de un ciclo de vida que va desde la concepción del producto, pasando por las etapas de análisis del problema, diseño de una solución, implementación de la misma y mantenimiento del producto, hasta su final retirada por obsolescencia. Ciclo de vida del software Un concepto fundamental en ingeniería del software es la consideración de un producto software en el contexto de un ciclo de vida. Desde un punto de vista general, todo software pasa por tres etapas fundamentales: Desarrollo, Uso y Mantenimiento. Desarrollo: Inicialmente la idea para un programa es concebida por un equipo de desarrollo de software o por un usuario con una necesidad particular. Este programa nuevo se construye en la denominada etapa de desarrollo. En esta etapa tenemos varios pasos a realizar: análisis, diseño, implementación y pruebas. Al final, generamos un programa operativo. Uso: Una vez desarrollado el programa y después de considerar que está completo, que es operativo, se pasa a los usuarios. La versión del programa que van a utilizar los usuarios se denomina “release” o versión del programa. Mantenimiento: Durante el uso, utilizamos el programa en su entorno normal de trabajo y como consecuencia de la aparición de errores, del cambio de algún elemento de entorno (software o hardware) o de la necesidad de mejorar el programa, éste se modifica. Esto es el mantenimiento. Casi siempre los usuarios descubren problemas en el programa. Además, hacen sugerencias de mejoras en el programa o de introducción de nuevas características. Estos defectos y nuevas ideas los recibe el equipo de desarrollo y el programa entra en fase de 12 mantenimiento. Estas dos últimas etapas, uso y mantenimiento, se entremezclan y, de hecho, sólo se habla de etapa de mantenimiento desde el punto de vista de la ingeniería del software. En particular la etapa de desarrollo consta, a su vez, de una serie de etapas bien definidas. Análisis: En la etapa de análisis se especifica el qué queremos. Acá se determinan los requisitos que deberá cumplir el programa de cara al usuario final. También se imponen las condiciones que debe satisfacer el programa, así como las restricciones en el tiempo de desarrollo. Diseño: En esta etapa se determina cómo se consiguen realizar los requisitos recogidos y organizados en la etapa anterior. Codificación: Una vez realizado el diseño hay que implementarlo, generando el código fuente (los programas). Una buena codificación debe constar de la correspondiente documentación. Pruebas: El objetivo de las pruebas es descubrir errores. Mantenimiento: Es la etapa que va desde la obtención de una herramienta operativa, al final de la etapa de desarrollo, hasta la retirada del programa por obsolescencia. Podemos decir que el desarrollo representa sólo el 20 % de todo el esfuerzo. Técnicas de diseño Top down: Esta técnica consiste en establecer una serie de niveles de menor complejidad que den solución al problema. Se trata de reconocer en el problema inicial una serie de subproblemas que se puedan trabajar en forma independiente, y luego tomar a cada una de estas ideas para volver a descomponerlas en acciones cada vez más primitivas. Bottom up: El diseño ascendente se refiere a identificar al problema como la suma de varios subproblemas ya resueltos. Luego tomar éstos y juntarlos para “tratar” de solucionar el problema original. Cuando en la programación se realiza un enfoque bottom-up o ascendente, es difícil (si no se tiene bastante experiencia) llegar a integrar los subsistemas al grado tal de que el desempeño global sea fluido. Tipos de representaciones − Gráficos: Es la representación gráfica de las operaciones que realiza un algoritmo (con dibujos). − No Gráficos: Representa en forma descriptiva las operaciones que debe realizar un algoritmo (texto). Los métodos usuales para representar algoritmos 1. Diagrama de flujo 2. Diagrama de Nassi Schneideerman (Organigrama de Chapin) 3. Pseudocódigo 4. Lenguaje natural 5. Fórmulas El organigrama de Chapin puede verse como un diagrama de flujo donde se omiten las flechas de unión y las acciones se escriben en rectángulos sucesivos. Los métodos de lenguaje natural y fórmulas no suelen ser fáciles de transformar en programas. No es frecuente que un algoritmo sea expresado por medio de una simple fórmula, pues no 13 tiene detalle suficiente para ser traducido a algún lenguaje de programación. Y sabemos lo ambiguo del lenguaje natural (en nuestro caso el español). Diagrama de flujo Es un diagrama que utiliza gráficos (figuras geométricas en su mayoría) y flechas para indicar la secuencia en que deben ejecutarse las acciones. Los símbolos utilizados han sido normalizados por el instituto norteamericano de normalización (ANSI). No se recomienda. Pseudocódigo Este pseudolenguaje está formado por palabras comunes (en el idioma que se elija), dichas palabras tales como VARAIBLES, REAL, ENTERO, INICIO, etc., son reservadas por el lenguaje y no podrán usarse para otra función. No hay que preocuparse de las reglas de un lenguaje específico y además es fácil de modificar si se descubren errores de lógica. Ventajas de utilizar pseudocódigo a un Diagrama de Flujo − Ocupa menos espacio en una hoja de papel. − No se necesita elementos de dibujo para realizarlo. − Permite representar en forma fácil operaciones repetitivas. En el Diagrama de flujo, por ser una técnica de representación antigua no se prevé símbolos para indicar las estructuras de control. − Es muy fácil pasar de pseudocódigo a un programa en algún lenguaje de programación. − Se puede observar claramente los niveles que tiene cada operación. − Es la representación narrativa de los pasos que debe seguir un algoritmo para dar solución a un problema determinado. − El pseudocódigo utiliza palabras comunes que indican el proceso a realizar. − Es muy simple introducir modificaciones. Por todas estas razones nosotros optaremos por el pseudocódigo para escribir los algoritmos. 14 UNIDAD 4.- ESTRUCTURA DE LOS ALGORITMOS. Estructura general de un algoritmo. Declaración de variables. Bloque de acciones. Secciones de encabezamiento, declaración y ejecución. Comentarios. Acción de asignación. Acciones de entrada y salida de información. Programación estructurada. Estructuras de control. Estructuras de selección: Estructura de selección simple. Estructura de selección múltiple. Estructuras de repetición. Anidación de estructuras. Buenos hábitos: Indentación y Comentarios. Codificación, prueba, verificación y documentación. Estructura general de un algoritmo En un algoritmo podemos distinguir tres secciones: encabezamiento, declaración y ejecución. Encabezamiento: En pseudocódigo simplemente pondremos programa NombreDelPrograma. Luego al pasar el algoritmo a un Lenguaje determinado, respetaremos las reglas del mismo. Declaración de variables: Vamos a declarar todas las variables que intervengan en nuestro algoritmo, incluso su estructura si se tratara de variables con una determinada estructura. Esto se considera de utilidad ya que nos obliga a analizar de entrada todas las variables que van a aparecer e incluso, por el hecho de declararlas, no puede haber errores o sorpresas durante la ejecución. Hay Lenguajes que no tienen esta exigencia, incluso algunos permiten que las variables puedan contener datos de diferente tipo a medida que se avanza en la ejecución del programa. Esto no se considera conveniente, por lo menos mientras el alumno esté en los comienzos de su aprendizaje. Bloque de ejecución (o de sentencias): Es la parte donde se detallan las acciones a desarrollar para llegar a la solución del problema. Comentarios: Si bien no son obligatorios, es muy útil indicar en determinados lugares del algoritmo, el objeto de las instrucciones, método utilizado, etc. Acción de asignación: Las variables tienen reservado un lugar en la memoria (enteras 2 bytes, reales 4 bytes, de carácter 1 byte, lógicas 1 byte, …), el programa irá guardando los valores que cada variable vaya tomando a medida que se va ejecutando el algoritmo. La acción de asignación la simbolizamos de la siguiente forma variable ← expresión donde variable es el nombre de una variable de cualquier tipo y expresión es una expresión (un cálculo) que tenga un resultado del mismo tipo que la variable. Funciona de la siguiente manera: Se evalúa la expresión y el resultado se guarda en el domicilio de la variable. Acciones de entrada y salida de información: Entrada: La simbolizaremos así leer ( lista de variables ) donde lista de variables es una sucesión de variables separada por comas. Funciona de la siguiente manera: Se digitan desde la unidad de entrada (supongamos el teclado) los datos que queremos asignar a las variables en el orden en que figuran en la lista, estos datos deben corresponderse en tipo con las variables. Estos datos van a ocupar los domicilios de las variables. Salida: La simbolizaremos así escribir ( lista de variables y/o expresiones ) 15 donde expresiones puede ser una operación o simplemente una constante (generalmente una constante literal o de tipo cadena) y se utiliza para acompañar la salida con textos aclaratorios. Funciona de la siguiente manera: Aparecen por la unidad de salida correspondiente (generalmente la pantalla) el resultado de las expresiones o los contenidos de las variables en el orden en que aparecen la lista. Ejemplo 01: Leer dos valores enteros, sumarlos y mostrar su resultado programa Uno variables a, b, res : enteras comienzo leer ( a , b ) res ← a + b escribir ( ´El resultado es´ , res ) fin programa Uno supongamos que el operador ingresa por teclado en la pantalla aparecerá El resultado es 17 46 <Enter> 63 Este algoritmo, pasado a Fortran sería program Uno integer a , b , res read ( * , *) a , b res = a + b write ( * , * ) “El resultado es ” , res end program Uno Programación estructurada: Cuando se comenzó con la programación, no se seguía ninguna regla, lo importante era que el programa “funcionara”. Como cada programador utilizaba sus propias técnicas, los programas eran muy difíciles de comprender y corregir por otras personas, incluso por el programador mismo, pasado un tiempo. Además fueron apareciendo diferentes campos de aplicación que hicieron necesarias nuevas técnicas para programar. Fueron surgiendo así diferentes técnicas o modelos o paradigmas de programación, como por ejemplo el estructurado, el orientado a objeto, el lógico, el funcional, . . . Nosotros, en el curso, trabajaremos dentro del paradigma estructurado, o sea, con la programación estructurada. Estructuras de control Los Lenguajes tienden a ejecutar sus sentencias secuencialmente, es decir una sentencia, luego la que le sigue, etc. Evidentemente esto no sería eficaz, ya que habría que escribir tantas sentencias como acciones deba efectuar la computadora. Existen las llamadas Estructuras de Control que permiten controlar el flujo de los cálculos o acciones, por ejemplo elegir uno de entre varios caminos, repetir varias veces un grupo de acciones, etc. Dentro de las Estructuras de control tenemos Estructuras de Selección y Estructuras de Repetición Estructuras de Selección Estructura de Selección Simple (o de tipo SI, o IF): Permiten seleccionar uno de entre dos caminos La simbolizaremos así 16 si condición entonces Bloque1 sino Bloque2 finsi donde condición es una expresión booleana, es decir algo que puede ser Verdadero (V) o Falso (F) Bloque1 y Bloque2 son cualquier conjunto de acciones dentro de las cuales puede haber cualquier estructura de las vistas o de las que veremos. Funciona de la siguiente manera: Se ingresa a la estructura (siempre desde arriba), se evalúa la condición, si la condición es Verdadera, se ejecuta el Bloque1 y se sale de la estructura, si la condición es Falsa, se ejecuta el Bloque2 y se sale de la estructura. Puede ocurrir que a veces sólo haya que realizar acciones si la condición es verdadera, en cuyo caso la estructura quedaría así si condición entonces Bloque finsi Ejemplo02: Leer los coeficientes a, b y c (a distinto de cero) de una ecuación de segundo grado y resolverla en el campo real (vamos a distinguir los tres casos: sin solución en el campo real / raíz doble / raíces distintas) (vamos a necesitar poner una estructura SI dentro de otra SI ) programa Dos variables: a, b, c, x1, x2, delta, xd : reales comienzo escribir (“Ingrese los tres coeficientes de la ecuación”) leer (a, b, c) delta ← b2 – 4 . a . c si delta < 0 entonces escribir (“No tiene solución en el campo real”) sino si delta = 0 entonces xd ← - b / ( 2 . a ) escribir (“Raíz doble”, xd) sino x1 ← ( - b – raiz(delta) / ( 2 . a ) ) x2 ← ( - b + raiz(delta) / ( 2 . a ) ) escribir (“Raíces distintas”) escribir (“x1 = ”, x1) escribir (“x2 = ”, x2) finsi finsi fin programa Dos Este algoritmo, pasado a Fortran sería program Dos implicit none esta sentencia nos obliga a declarar todas las variables real a,b,c,x1,x2,delta,xd write(*,*)"Ingrese los tres coeficientes de la ecuacion" read(*,*)a,b,c delta=b*b-4*a*c if (delta<0) then write(*,*)"No tiene solucion en el campo real" 17 else if (delta==0) then xd=-b /(2*a) write(*,*)"Raiz doble : ",xd else x1=(-b-sqrt(delta))/(2*a) x2=(-b+sqrt(delta))/(2*a) write(*,*)"Raices distintas" write(*,*)"x1 = ",x1 write(*,*)"x2 = ",x2 endif endif end program Dos Estructura de Selección Múltiple (o de tipo CASE, o SEGÚN SEA): Permite seleccionar uno de entre varios caminos Esta estructura es la que mas difiere con las implementaciones en un Lenguaje u otro. La explicaremos orientada al Fortran. La simbolizaremos así segun sea selector (s1, s2,… si,): Bloque1 (sj, sk,… sm,): Bloque2 ...... (sn, sp,… st,): BloqueQ fin segun Fortran tiene el CASE DEFAULT que es lo que se ejecutaría en caso de no aparecer el valor del selector entre los s1 , s2 , ... si , … st donde selector es una expresión de cualquier tipo simple (generalmente una variable entera) excepto real s1, s2,… st, son constantes del mismo tipo que el selector Funciona de la siguiente manera: Se ingresa a la estructura, se evalúa el selector, se busca dentro de los si un valor igual al selector y se evalúa ese Bloque, ignorándose los demás. Es usada muchas veces para armar menús de opciones. Ejemplo03: Leer dos números reales (el segundo distinto de cero) y proponer una operación según un menú de opciones programa Tres variables a , b , res : reales opcion : entera comienzo escribir (“Ingrese dos números reales”) leer ( a , b ) escribir (“Indique que operación desea hacer”) escribir (“ 1-Sumarlos”) escribir (“ 2-Restarlos”) escribir (“ 3-Multiplicarlos”) escribir (“ 4-Dividirlos”) escribir (“Ingrese su opcion”) leer ( opcion ) según sea ( opcion) ( 1 ): res ← a + b 18 ( 2 ): res ← a - b ( 3 ): res ← a . b ( 4 ): res ← a / b fin según fin programa Tres Este algoritmo, pasado a Fortran sería program Tres implicit none real a,b,res integer opcion write(*,*)"Ingrese dos numeros reales" read(*,*)a,b write(*,*)"Indique que operacion desea hacer" write(*,*)" 1-Sumarlos" write(*,*)" 2-Restarlos" write(*,*)" 3-Multiplicarlos" write(*,*)" 4-Dividirlos" write(*,*)"Ingrese su opcion:" read(*,*)opcion select case (opcion) case ( 1 ) res=a+b case ( 2 ) res=a-b case ( 3 ) res=a*b case ( 4 ) res=a/b end select write(*,*)"El resultado es : ",res end program Tres El Fortran tiene además el IF LOGICO, que tiene el peligro que puede desestructurar el algoritmo La simbolizaremos así if (condición) sentencia Se evalúa la condición, si es verdadera, se ejecuta la sentencia y se pasa a la sentencia siguiente; si es falsa, se ignora la sentencia y se pasa a la sentencia siguiente al IF lógico. Ya sabemos lo que representa condición, en cuanto a sentencia, si bien hay una amplia gama de sentencias que se pueden usar, casi siempre la usaremos con la sentencia exit cuyo efecto es salir de la estructura de repetición donde se encuentre, es decir se pasa a la sentencia inmediata siguiente al fin de la estructura de repetición. Estructuras de repetición Estructura de Repetición con Contador (o de tipo PARA o FOR) La simbolizaremos así para indi = vi , vf , es Bloque fin para 19 donde indi es llamado índice del para es una variable simple, excepto real (la mayoría de las veces una variable entera) (Fortran acepta tipo real) vi , vf , es son los parámetros del para y se los denomina valor inicial , valor final (sería mejor llamarlo valor de test) y escalón del para y son expresiones (operaciones y/o variables y/o constantes) del mismo tipo que el índice. Si es falta se interpreta que es = 1. Funciona de la siguiente manera: Se ingresa a la estructura, se recorre el Bloque por primera vez con un valor del índice indi = vi, al llegar al final de la estructura se vuelve al principio de la misma y se recorre nuevamente el Bloque con un valor de indi = vi + es, se vuelve al principio de la misma y se recorre nuevamente con un valor de indi = vi + 2 . es, y así sucesivamente hasta recorrerlo por última vez con el mayor (menor) valor de indi que no supere (supere) a vf. Observación: si al ingresar a la estructura vi > (<) vf , el Bloque no se recorre nunca. Si el valor de es fuese negativo, los valores de indi irán descendiendo y en la Observación vale lo que figura entre paréntesis. Ejemplo04: Leer 7 números enteros e informar su suma (DO con contador) programa Cuatro variables nro , tota , i : enteras comienzo tota ← 0 para i = 1 , 7 leer ( nro ) tota ← tota + nro fin para escribir ( “Los 7 números leídos suman ” , tota ) fin programa Cuatro Este algoritmo, pasado a Fortran sería program Cuatro implicit none integer nro,tota,i tota=0 do i = 1,7 read(*,*)nro tota=tota+nro end do write(*,*)"Los 7 numeros leidos suman ",tota end program Cuatro Ejemplo05: Leer los coeficientes a, b y c (a distinto de cero) de diez ecuaciones de segundo grado y resolverlas en el campo real Haremos directamente el programa Fortran program Cinco implicit none real a,b,c,x1,x2,delta,xd 20 integer cont do cont = 1 , 10 write(*,*)"Ingrese los tres coeficientes de la ecuacion" read(*,*)a,b,c delta=b*b-4*a*c if (delta<0) then write(*,*)"No tiene solucion en el campo real" else if (delta==0) then xd=-b/2/a write(*,*)"Raiz doble : ",xd else x1=(-b-sqrt(delta))/(2*a) x2=(-b+sqrt(delta))/(2*a) write(*,*)"Raices distintas" write(*,*)"x1 = ",x1 write(*,*)"x2 = ",x2 endif endif enddo end program Cinco Problema de aplicación P Se sabe que en una “viga simple”, el “momento flector” que produce una carga concentrada P aplicada a una distancia a del apoyo izquierdo vale P. a.(z–a) Mf = --------------------z a z Mf es el momento flector debajo de la propia carga y z la longitud (o luz) de la viga Confeccionar un algoritmo tal que ingresando los valores de la carga P y la luz de la viga z, calcule Mf para valores de a que varíen de 0 a z, con incrementos de a décimos de la luz. (para a = 0 y a = z, el momento es cero). Si por ejemplo a = 6m se informará Mf para a = 0,00 , 0,60 , 1,20….5,40 y 6,00 metros program momflec implicit none real a,z,p,mf integer i write(*,*)"Ingrese la luz de la viga y la carga P" read(*,*)z,p do i=1,11 a=(i-1)*z/10 mf=p*a*(z-a)/z write(*,*)” a=”,a,” Mf=”,mf enddo end program momflec 21 Problema de aplicación Una característica para calcular resistencia de vigas es el llamado “momento resistente” W. En vigas de sección rectangular W se calcula mediante la fórmula b * h2 W = ----------6 este dibujo repre- h senta la sección transversal de la viga Confeccionar un algoritmo tal que ingresando los valores de b y h iniciales, calcule W para valores de b y h que se vayan incrementando ambos de 2 cm en 2 cm hasta llegar a b + 8 cm y h + 16cm (es decir que deben informar 45 valores) b La salida debería tener la forma (suponiendo que se ingresó b = 15 y h = 24) b h ------ -----15 24 15 26 15 …… ……………… ……………… 15 40 17 24 17 26 ……………… ……………… 23 38 23 40 Fin W -----xxxx xxxx xxxx xxxx xxxx xxxx xxxx program dobleve implicit none real bcero,hcero,b,h,w integer i,j write(*,*)”Ingrese b y h iniciales de la sección transversal” read(*,*)bcero,hcero write(*,*)” b h W” write(*,*)” ----------” do i=1,5 b=bcero+(i-1)*2 do j=1,9 h=hcero+(j-1)*2 w=b*h*h/6 write(*,*)b,h,w enddo enddo write(*,*)”Fin” end program dobleve 22 Estructura de Repetición con Condición Mientras (o de tipo MIENTRAS o WHILE) La simbolizaremos así mientras condicion hacer Bloque fin mientras Funciona de la siguiente manera: Se ingresa a la estructura, si la condición es verdadera, se recorre el Bloque hasta el final, se vuelve al principio de la estructura, se evalúa nuevamente la condición, si es verdadera, se vuelve a recorrer el Bloque, y así sucesivamente, mientras la condición sea verdadera. En el momento que la condición se hace falsa, se abandona la estructura. Observación: como el control de la condición se efectúa en la cabecera del Bloque, si al tratar de ingresar a la estructura, la condición es falsa, no se ejecuta el Bloque. Es decir que podría ocurrir que el Bloque no se ejecute nunca. Ejemplo06: Leer una cierta cantidad de números enteros distintos de cero, informar cuantos números fueron leidos y su suma programa Seis variables tota , nro , conta : enteras comienzo conta ← 0 tota ← 0 leer ( nro ) mientras nro <> 0 hacer conta ← conta + 1 tota ← tota + nro leer ( nro ) fin mientras escribir ( “Entraron ”, conta, “ números que suman ”, tota) fin programa Seis Este algoritmo, pasado a Fortran sería program Seis implicit none integer tota,nro,conta conta=0 tota=0 read(*,*)nro do while (nro <> 0) conta=conta+1 tota=tota+nro read(*,*)nro enddo write(*,*)"Entraron ",conta," numeros que suman ",tota end program Seis Ejemplo07: Leer los coeficientes a, b y c (a distinto de cero) de un cierto número (no se sabe cuantas) de ecuaciones de segundo grado y resolverlas en el campo real 23 Haremos directamente el programa Fortran program Siete implicit none real a,b,c,x1,x2,delta,xd write (*,*) “Ingrese el coeficiente a (cero para finalizar)” read (*,*) a do while ( a <> 0 ) write(*,*)"Ingrese los coeficientes b y c" read(*,*)b,c delta=b*b-4*a*c if (delta<0) then write(*,*)"No tiene solucion en el campo real" else if (delta==0) then xd=-b /(2*a) write(*,*)"Raiz doble : ",xd else x1=(-b-sqrt(delta))/(2*a) x2=(-b+sqrt(delta))/(2*a) write(*,*)"Raices distintas" write(*,*)"x1 = ",x1 write(*,*)"x2 = ",x2 endif endif write (*,*) “Ingrese el coeficiente a (cero para finalizar)” read (*,*) a enddo end program Siete Problema de aplicación (el ejercicio siguiente, sólo pretende ser un ejercicio de programación, los conceptos sobre Resistencia de Materiales serán desarrollados con mayor precisión en asignaturas del Ciclo Profesional) Cuando una viga es sometida a flexión simple, en cada sección existe una relación entre el “momento flector” (Mf), el “momento resistente” (W) y la “tensión ” (σ). La misma es la siguiente (donde σ es la tensión en la fibra mas solicitada) Mf σ = ----(en la fibra mas solicitada de la sección ) W y si queremos dimensionar una viga, la presentamos así Mf Wnecesario = ------(σadm es la tensión máxima admisible para el material) σadm y elegimos la sección transversal de la pieza de modo que tenga ese “momento resistente necesario”. Lógicamente, que si por ejemplo la viga fuera un perfil de acero, como no se puede fabricar a medida, se tomará uno que tenga el W mas pequeño que supere al necesario. Si la pieza fuese de madera, tendríamos dos variables para llegar al Wnecesario, es decir, el ancho (b) y la altura (h). Tendríamos infinitas soluciones. Podemos fijar el ancho (b) y calcular la altura (h). Pero acá nos encontramos con que las piezas de madera vienen con medidas que “avanzan” de pulgada (”) en pulgada. Entonces lo que hacemos es fijar el ancho y quedarnos (avanzando de a pulgada) con la primer altura que nos de un W que supere al necesario. 24 Se desea dimensionar una viga cargada con una carga concentrada P en el centro de la misma. La viga tiene una longitud z y será construida en madera que tiene una determinada σadm. Construir un programa para dimensionar esa viga. Por cuestiones de proyecto, la viga deberá tener un ancho de cuatro pulgadas (4”) y la altura no puede superar los 40 cm (16”). El programa deberá leer P, z y σadm y deberá prever que bajo estas condiciones no haya solución. La medida mínima disponible es de 4” x 4” (10cm x 10cm) (1” = 2,5 cm). program dimensiona implicit none real p,z,mf,sadm,w,wnece,b,h write(*,*)”Ingrese carga, luz y tension admisible” read(*,*)p,z,sadm mf=p*z/4 wnece=mf/sadm b=10 h=10 notar que en este caso w=b*h*h/6 do while (w<wnece .and. h<40) el valor de salida del DO no es h=h+2.5 un valor leido, sino w=b*h*h/6 valores calculados ( w y h ) enddo if (w >= wnece) then write(*,*)”Medidas b=10cm , h=”,h,” cm” write(*,*)”W=”,w,” (W necesario=”,wnece,”)” else write(*,*)”Imposible dentro de las medidas impuestas” endif end program dimensiona El problema lo pudimos resolver simplemente b . h2 Mf mediante una fórmula, despejando h y luego Wnec= -------- = ------redondeando por exceso a un múltiplo de 2,5 6 σadm (verificar el programa de esta manera) (recordar que habíamos fijado el ancho b en 10cm) h= 6 . Mf --------------10 . σadm Estructura de Repetición con Condición Repetir (o de tipo REPETIR-HASTA QUE o REPEAT-UNTIL) La simbolizaremos así repetir Bloque hasta que condicion Funciona de la siguiente manera: Se ingresa a la estructura (siempre se ingresa), se recorre el Bloque, se llega hasta el pie de la estructura, se analiza la condición, si es falsa, se vuelve a recorrer el Bloque, hasta que la condición se haga verdadera que es el momento en que se abandona la estructura. Debemos hacer varias observaciones: - El Bloque es recorrido por lo menos una vez - Conceptualmente es opuesto al mientras ya que el mientras ejecuta el Bloque cuando la condición es verdadera y el repetir lo abandona cuando la condición es verdadera. - Muchos lenguajes no tienen la estructura repetir, pero la sustituyen con un mientras, en general invirtiendo la condición 25 - En Fortran implementaremos el repetir con un do incondicional y un if lógico con sentencia exit como última sentencia del Bloque. Ejemplo08: Leer una cierta cantidad de números enteros hasta encontrar un -3, informar luego en que posición entró el -3 programa Ocho variables nro , posi : enteras comienzo posi ← 0 repetir posi ← posi + 1 leer ( nro ) hasta que nro = -3 escribir (“El -3 entró en la posición ” , posi) fin programa Ocho Este algoritmo, pasado a Fortran sería program Ocho implicit none integer nro,posi posi=0 do posi=posi+1 read(*,*)nro if (nro==-3) exit enddo write(*,*)"El -3 entro en la posicion ",posi end program Ocho Ejemplo09: Leer los coeficientes a, b y c (a distinto de cero) de un cierto número (no se sabe cuantas, pero por lo menos una) de ecuaciones de segundo grado y resolverlas en el campo real Haremos directamente el programa Fortran program Nueve implicit none real a,b,c,x1,x2,delta,xd write (*,*) “Ingrese el coeficiente a” read (*,*) a do write(*,*)"Ingrese los coeficientes b y c" read(*,*)b,c delta=b*b-4*a*c if (delta<0) then write(*,*)"No tiene solucion en el campo real" else 26 if (delta==0) then xd=-b/2/a write(*,*)"Raiz doble : ",xd else x1=(-b-sqrt(delta))/(2*a) x2=(-b+sqrt(delta))/(2*a) write(*,*)"Raices distintas" write(*,*)"x1 = ",x1 write(*,*)"x2 = ",x2 endif endif write (*,*) “Ingrese el coeficiente a (cero para finalizar)” read (*,*) a if ( a == 0 ) exit enddo end program Nueve Validación de una entrada Tanto el mientras como el repetir pueden usarse para validar entrada de datos. Por ejemplo, supongamos que se desea ingresar un dato de tipo carácter, el cual debe ser una S o una N. Podemos resolverlo de dos maneras. Veamos la porción de algoritmo: ......... ........ escribir (“Ingrese una S o una N”) repetir leer ( letra ) escribir (“Ingrese una S o una N”) mientras letra <> ´S´ y letra <> N´ leer ( letra ) escribir (“Error, ingrese de nuevo”) hasta que letra = ´S´ o letra = ´N´ leer ( letra ) ........ fin mientras .......... Notamos que con el mientras resulta un diálogo mas amigable. Pero lo que vale la pena destacar es que debimos escribir las condiciones una opuesta a la otra. Habíamos dicho al principio del capítulo que Fortran aceptaba como parámetros del do, al tipo real y que a vf era mejor llamarlo “valor de test” en vez de “valor final”. Veamos el siguiente ejemplo: program DoConReales implicit none real i, vi, vf, esca vi=2.75 vf=3.8 esca=0.1 write(*,*)"Valores entre 2,75 y 3,75 con escalon 0,1" write(*,*)"Sin formato" do i=vi, vf, esca write(*,*)i enddo write(*,*)"Con formato" do i=vi, vf, esca write(*,"(F8.2)")i enddo end program DoConReales 27 Este programa produce la siguiente salida Valores entre 2,75 y 3,75 con escalon 0,1 Sin formato 2.750000 2.850000 2.950000 3.050000 3.150000 3.250000 3.349999 3.449999 3.549999 3.649999 3.749999 Con formato 2.75 2.85 2.95 3.05 3.15 3.25 3.35 3.45 3.55 3.65 3.75 Además estamos viendo algo que puede ocurrir a menudo. Al acumular operaciones con reales pueden aparecer “pequeños” (si las operaciones son miles, pueden no ser tan pequeños) errores que harían que un número como por ejemplo 3,35 aparezca con la forma 3.349999. Esto, en una presentación no tiene una forma agradable y puede ser mejor escribirlo con formato (en el ejemplo se usó F8.2) ya que el formato redondea la última cifra y la presentación quedó como esperábamos. Lo que debe quedar bien claro es que escribir con formato no elimina el error, simplemente deja mejor la presentación, pero el “pequeñísimo” error ya existe, en la memoria lo que está guardado es 3.349999 (al escribirlo con formato lo “redondeó”) y este error, aunque pequeño, se manifestó con apenas siete sumas. En problemas de ingeniería frecuentemente se debe trabajar con matrices de grandes dimensiones en donde la cantidad de operaciones pueden contarse de a miles y si bien el tratamiento de errores no es motivo de análisis en este curso, estos comentarios son simplemente de advertencia, Vamos a ver otra posibilidad que nos brinda el Fortran: podemos trabajar con datos complejos. Los complejos son tratados como par de reales. Por ejemplo el complejo 3.25 – 1.789 i en Fortran lo representamos como < 2.25 , - 1.789 >. Como ejemplo vamos a hacer un programa para resolver una ecuación de segundo grado en el campo complejo (si la raiz es real pondrá cero en la parte imaginaria). 28 Resolveremos la ecuación a.x2 + b.x + c = 0, dos veces, la primera vez con a = 1 b =- 5 c = 6 ( x1 = 2 y x2 = 3 ) y la segunda con a = 1 b = 1 c = 1 ( x1 = – 0,5 – 0,866 i y x2 = – 0,5 + 0,866 i ) en vez de leer a , b , c los asignamos directamente en el programa program EcuCompl implicit none real a, b, c complex x1, x2, delta a=1 b=-5 c=6 delta= b**2 - 4*a*c x1=(-b-csqrt(delta)) / x2=(-b+csqrt(delta)) / write(*,*) x1, x2 a=1 b=1 c=1 delta= b**2 - 4*a*c x1=(-b-csqrt(delta)) / x2=(-b+csqrt(delta)) / write(*,*) x1, x2 end program (2*a) (2*a) para raiz cuadrada de números complejos se usa csqrt en vez de sqrt (2*a) (2*a) la salida de este programa es < 2.000000 , 0.0000000E+00 > < -0.500000 , -0.8660254E+00 > < 3.000000 , 0.0000000E+00 > < -0.500000 , 0.8660254E+00 > 29 UNIDAD 5.- SUBALGORITMOS Programación modular. Concepto de subalgoritmo. Declaración y estructura. Subalgoritmo función. Subalgoritmo procedimiento. Cuando tenemos que diseñar un algoritmo de relativa importancia en cuanto a su complejidad, es conveniente dividirlo en partes, o módulos, o subalgoritmos. Si a su vez, a algunos de esos módulos los volvemos a dividir para reducir su complejidad, tenemos un esquema como el siguiente . . . . . . . . . . . . . . . . . . . . . . . . . . . Hemos hecho lo que llamamos refinamientos sucesivos o también análisis top down. (existe otra forma de componer algoritmos y es la bottom up pero no la vamos a utilizar, ya que es necesario tener algo mas de experiencia en algoritmia) (ya mencionado en la Unidad 3). Los subalgoritmos (o subprogramas) son los que permiten aplicar esta idea de los refinamientos sucesivos. Los subalgoritmos tienen otra importante utilidad y es que pueden desarrollarse con parámetros genéricos y luego utilizarse repetidamente con diferentes juegos de datos. Los parámetros de los subalgoritmos pueden ser de cualquier tipo. Presentaremos dos tipos de subalgoritmos: las funciones y los procedimientos. Funciones: Tienen un uso similar a las funciones internas que ya conocemos, pero acá, los cálculos los define el programador. Tienen todas las características de los programas, con la diferencia que no pueden ejecutarse sueltas, sino que se ejecutan cuando son utilizadas (o llamadas) por el programa principal u otro subprograma. Esta utilización puede ser a la derecha en una sentencia de asignación, en una condición (de un if, un while o un repeat) o incluso en una expresión en un write. Las funciones (como las funciones internas) devuelven un único valor a través de su nombre, no devuelven resultados a través de sus parámetros. Veamos un ejemplo: Ejemplo10 Leer dos juegos de 3 números enteros cada juego e informar, en ambos casos, el valor del mínimo 30 programa Diez variables d , e , f , minimo , j : enteras funcion busca (w,x,y) : entera variables w , x , y : enteras si w <= x y w <= y entonces busca ← w sino si x <= w y x <= y entonces busca ← x sino busca ← y finsi finsi fin funcion busca comienzo para j = 1 , 2 escribir (“Ingrese tres enteros”) leer ( d , e , f ) minimo ← busca ( d , e , f ) ( * ) escribir (“El mínimo es ” , minimo) fin para fin programa Diez d, e, f, minimo, j son variables globales w, x, y son parámetros pudimos haber eliminado la variable minimo , también la sentencia ( * ) y cambiar la sentencia escribir por escribir (“El mínimo es ” , busca ( d , e , f )) Este algoritmo, pasado a Fortran sería program Diez implicit none integer d,e,f,busca,minimo,j do j= 1,2 write(*,*)"Ingrese tres enteros" read(*,*)d,e,f minimo=busca(d,e,f) write(*,*)"El minimo es ",minimo enddo end program Diez integer function busca(w,x,y) integer w,x,y if (w <= x .and. w <= y) then busca=w else if (x <= w .and. x <= y) then busca=x else busca=y endif endif end function busca Los parámetros w, x, y que utilizamos en la definición de la función se llaman parámetros formales, ya que sólo sirven para definir el tipo de proceso que sufrirá cada uno. Los parámetros d, e, f que utilizamos en la llamada a la función se llaman parámetros actuales, ya que es con esos valores con los que trabajará la función. Los parámetros formales y los actuales deben coincidir en cantidad, orden y tipo. 31 Antes de terminar con el tema reiteramos un concepto importante: Las funciones no devuelven nada a través de sus parámetros, sino que devuelven un solo dato a través de su nombre. Funciones sentencia: También llamadas sentencias funciones (en inglés “statement function”) Muchas veces las funciones son muy sencillas y pueden escribirse en una sola sentencia y no ameritan la escritura de un subprograma. Fortran permite definirlas en una sola sentencia. Supongamos que en nuestro programa tenemos que usar la función g(x) = x4 + 5x3 - x2 + 9 En nuestro programa podemos tener algo así: . . . real g , x , b , z g(x) = x**4 + 5*x**3 – x**2 + 9 . . . . . . Z = 5.36 + g(b) Hay que tenerla definida antes de usarla y tenemos que definir previamente tanto el tipo de los parámetros formales como el de la función sentencia. La función puede tener mas de un parámetro . . . real juan , x integer i juan(x , i) = x**3 + (2.5+i)*i/3.2 . . . Una función sentencia puede usar otra función sentencia definida anteriormente . . . real a , h , w w(a) = a**4 / 12.5 h(a) = a**3 + a*w(6.0) . . . Lógicamente también puede usar funciones de biblioteca . . . real x , f f(x) = x – sin(x) . . . Problema de aplicación En ingeniería es común encontrarnos con que tenemos que resolver ecuaciones que no tienen una resolvente, por ejemplo f(x) = cos(x) – x = 0 no contamos con una fórmula que nos permita calcular x, tampoco suele interesar la solución exacta (nos conformamos con una solución “bastante” aproximada a la exacta). 32 En general, recurriremos a métodos que se explican en Análisis Numérico, son métodos aproximados (dicotómico, Newton Raphson, …). Haremos un método sencillo, tal vez no tan eficiente como los mencionados, pero que nos permitirá calcular la raíz también de manera aproximada, con tanta precisión como queramos. Sabemos que f(x) es continua y que f(0) = 1 > 0 y f(π/2) = - π/2 < 0. También sabemos que entre 0 y π/2 es decreciente y tiene una sola raiz. Supongamos que queremos aproximar la raiz con un error Є < І 0,00005 І (valor absoluto) Podemos arrancar desde x=0 con “pasos” de 0,0001 calculando la función y avanzando hasta que se haga negativa (o cero por si tenemos la suerte de encontrar la raiz exacta). Si adoptamos como raiz aproximada el promedio entre el último valor de x que hizo a f positiva y el primer valor de x que hizo a f negativa, estaremos asegurando la precisión pedida. program aprox implicit none real f, x, paso, anterior, siguiente, aproxi integer n f(x)=cos(x) - x paso=0.0001 anterior=0. siguiente=0.0001 n=1 do while (f(siguiente)>0. .and. n<30000) n=n+1 anterior=siguiente siguiente=siguiente+paso enddo if (f(siguiente)<=0.) then if (f(siguiente)==0.) then write(*,*)"Raiz exacta ",siguiente else aproxi=(anterior+siguiente)/2. write(*,*)"Raiz aproximada ",aproxi, " calculada en ",n, " pasos" endif else write(*,*)"No se obtuvo la raiz despues de",n,"pasos" endif end program aprox Hemos puesto un contador de pasos de manera que si después de 30.000 pruebas no se encuentra la raíz, el programa se detenga. Esto es importante, ya que si por error tomamos un valor de comienzo equivocado, el programa podría no detenerse nunca. También usamos dos valores para ir avanzando (anterior y siguiente) ya que esto es frecuente en problemas de aproximación. En este caso en particular no hubiesen hecho falta (bastaba avanzar con x) Procedimientos: Los procedimientos tienen un funcionamiento parecido a las funciones, pero no devuelven nada a través de su nombre. Pueden devolver valores (ninguno, uno o varios) a través de sus parámetros. Por lo tanto habrá parámetros de entrada, de salida, o incluso de entrada/salida al procedimiento. A los parámetros que sólo sirven para entrar datos desde el programa (sería mas correcto decir “desde el módulo invocante”) al procedimiento (o sea los de entrada) los llamaremos parámetros por valor, a los parámetros que sirven para devolver datos desde el 33 procedimiento al programa (o sea los de salida, o los de entrada/salida) los llamaremos parámetros por referencia. Veamos su forma de trabajar: Los parámetros por valor, son copiados dentro del procedimiento y el procedimiento trabaja sobre esa copia, por lo tanto las variables (los parámetros actuales) del programa no son modificados, es decir que no se devuelve nada a través de ellos. Cuando los parámetros son por referencia, no son copiados al procedimiento, sino que el procedimiento trabaja sobre el parámetro actual (es decir sobre las variables del programa) pudiendo por lo tanto salir datos del procedimiento hacia fuera. En este punto, debemos hacer una aclaración. En muchos lenguajes, como por ejemplo Pascal, el tipo de parámetro (por valor o por referencia) debe ser declarado en el propio procedimiento. Por lo tanto todas las veces que sea invocado el procedimiento, cada parámetro trabajará de la misma forma, siempre por valor o siempre por referencia. El Fortran permite no definir en el procedimiento la forma de trabajo de cada parámetro, sino que lo deja para el momento de la llamada. Es decir que dentro de un mismo programa, para un procedimiento en particular podría ocurrir que haya parámetros que en una llamada trabajen de una manera y en otra llamada de otra manera. En Fortran si en la llamada, a un parámetro lo encerramos entre paréntesis, trabajará por valor, si no, trabajará por referencia. Ejemplo11: Resolver la ecuación a.x + b = 0 ( a distinto de cero ) Vamos a resolverlo primero en pseudocódigo: programa Once variables a , b , x : reales procedimiento resuelve ( p , q , r ) variables p , q , r : reales r←-q/p fin procedimiento resuelve comienzo escribir (“Ingrese los coeficientes a y b”) read ( a , b ) resuelve ( a , b , x ) escribir (“La raíz es ” , x) fin programa Once aclaramos que este problema puede resolverse con una función no hace falta armar un procedimiento y pasado a Fortran program Once implicit none real a,b,x write(*,*)"Ingrese los coeficientes read(*,*)a,b call resuelve((a),(b),x) write(*,*)"La raiz es ",x end program Once subroutine resuelve(p,q,r) implicit none real p,q,r r = -q / p end subroutine resuelve a y b" 34 Veamos ahora como se trabaja en la memoria memoria x a programa b se copia a en p procedimiento r “apunta” a x p se copia b en q r q Ejemplo12: Programa que muestra la diferencia entre las llamadas por valor y por referencia a una subrutina program Doce implicit none integer a,b ! Este programa es para probar argumentos por valor y por referencia ! armo una subrutina con dos argumentos formales ( x e y ) a los ! cuales simplemente se les suma 5 ! en las llamadas hago las cuatro combinaciones posibles con los ! argumentos actuales con respecto a valor y referencia a=2 b=2 write(*,*)"Los dos por referencia" write(*,*)a,b call cambia(a,b) write(*,*)a,b a=2 b=2 write(*,*)"El 1ro por referencia y el 2do por valor" write(*,*)a,b call cambia(a,(b)) 35 write(*,*)a,b La pantalla debería quedar así a=2 b=2 write(*,*)"El 1ro por valor y el 2do por referencia" write(*,*)a,b call cambia((a),b) Los dos por referencia write(*,*)a,b 2 2 a=2 7 7 b=2 7 7 write(*,*)"Los dos por valor" El 1ro por referencia y el 2do por valor write(*,*)a,b 2 2 call cambia((a),(b)) 7 7 write(*,*)a,b 7 2 write(*,*)"Fin" El 1ro por valor y el 2do por referencia end program Doce 2 2 subroutine cambia(x,y) 7 7 integer x,y 2 7 x=x+5 Los dos por valor y=y+5 2 2 write(*,*)x,y 7 7 end subroutine 2 2 Fin Tanto las funciones como los procedimientos pueden tener definidas variables. Estas se llaman variables locales, y sólo “se ven” desde el subprograma; del subprograma hacia fuera, “no se ven”, es decir son desconocidas por el programa principal. Las variables definidas en el programa principal se denominan variables globales y “se ven”, y pueden ser usadas en el programa principal y en el subprograma. Si un subprograma tiene una variable local con el mismo nombre de una variable global (hecho que desaconsejamos), dentro del subprograma vale la declaración hecha en él y fuera, vale la declaración global. Cualquier función o procedimiento puede llamar a otra función y/o procedimiento, y así sucesivamente, es decir puede ocurrir una sucesión o cadena de llamadas entre funciones y procedimientos. Noción de recursividad: ¿Qué ocurre, si en vista de lo enunciado en el párrafo anterior una función se llama a si misma? Algunos lenguajes lo permiten y es lo que se conoce como recursividad. Esto es una herramienta poderosa, sobre todo cuando se trata de resolver problemas numéricos. Pero para evitar que la recursión continúe indefinidamente, dentro de la función hay que incluir una condición de terminación. Como ejemplo vamos a resolver en pseudocódigo y en Fortran una función para calcular el factorial de un número entero no-negativo. (recordar que definimos el factorial de cero igual a uno 0! = 1) En pseudocódigo, la función sería algo así: funcion factorial ( n : entero ) : entera comienzo si n = 0 entonces factorial ← 1 sino muchos lenguajes permiten declarar el tipo de sus parámetros en la propia cabecera 36 factorial ← n * factorial ( n – 1 ) finsi fin Vamos a hacer en Fortran un programa que calcule e imprima el factorial de los primeros diez números naturales. Si bien algunos lenguajes no lo exigen, en Fortran debemos aclarar al definir la función que vamos a usar recursividad. Por eso anteponemos la palabra recursive. program recu implicit none integer facto, n, resu, i do i=1,10 resu=facto(i) write(*,*)resu enddo end program recu recursive integer function facto(n) implicit none integer n if (n==0) then facto=1 else facto=n*facto(n-1) endif end function facto La salida de este programa es 1 2 6 24 120 720 5040 40320 362880 3628800 ¿Qué pasó que imprimió enteros mayores a 32767? Si bien muchos lenguajes trabajan con enteros de dos bytes (16 bits) y por lo tanto dentro del rango [-32768 , 32767], Fortran, por defecto trabaja con enteros de cuatro bytes admitiendo valores mucho mayores. No obstante, en Fortran podemos trabajar con integer(1) (ocupan 1 byte) integer(2) (ocupan 2 bytes) integer(8) (ocupan 8 bytes) (sólo disponible en algunas versiones) ¿Qué pasa si en el ejemplo anterior sustituimos por integer facto, n, resu, i integer(2) facto, n, resu, i ? 37 Obtendríamos el siguiente resultado: 1 2 6 24 120 720 5040 -25216 -30336 24320 Lo que ocurrió es que al intentar poner 40320 ( 8 ! ) en 16 bits, la capacidad “rebalsó” por tanto este valor y los dos siguientes dieron resultados inesperados. Pascal, por defecto destina dos bytes a los enteros y si corremos un programa similar en Pascal, también se producirá un rebalse similar y obtendremos exactamente los mismos valores. 38 UNIDAD 6.- ESTRUCTURAS DE DATOS. ARREGLO. Concepto de estructura de datos: datos simples y datos estructurados. Estructuras estáticas y dinámicas. Estructuras homogéneas y heterogéneas. Arreglos unidimensionales. Arreglos multidimensionales. Implantación en memoria. Declaraciones y operaciones. Arreglos como parámetros de subalgoritmos. Todos los datos que hemos visto hasta ahora son datos “sueltos”, datos que no están agrupados de ningún modo, también los llamamos escalares. Hay otros tipos de datos, que están agrupados con ciertas reglas, se llaman datos estructurados, entre los cuales tenemos arreglos, registros . . . . (array, record, . . . .), que son los que pasaremos a ver de aquí en adelante. Arreglo: Es un tipo de dato estructurado cuya principal característica es que todos los elementos que contiene deben ser del mismo tipo. Son estructuras estáticas. Tienen un tamaño fijo y son para trabajarlos en la memoria principal. Pueden tener, una, dos, tres o mas dimensiones. Los elementos del arreglo son referenciados a través de índices de manera unívoca arreglo bidimensional de quince elementos reales, organizado en cinco “filas” y tres “columnas” arreglo unidimensional de seis elementos enteros v= 61 -3 17 12 -3 0 m= v[5] -0.18 17.1 3.46 22.53 10.7 12.0 -14.2539 2.5 14.1 -3.91 2.5 6.44 -9.0 22.12 11.1 m[4,3] hemos adoptado esa forma de visualizarlos, para seguir lo que se realiza en Algebra, pero bien pudimos haberlos dibujado de otra, por ejemplo a v horizontal. Los arreglos de mas de dos dimensiones, resultan algo mas difícil de visualizar, pero es cuestión de práctica. Ejemplo13: Leer dos arreglos unidimensionales a y b de 5 elementos reales cada uno. Calcular la suma del producto de sus elementos de igual posición e informarlo. (acá deberíamos aclarar en el enunciado si se lee primero a y luego b, o si leeremos a1 y b1, luego a2 y b2, etc. Supongamos que leemos primero a y luego b) programa Trece tipo arre5 = arreglo [ 5 ] de reales variables a , b : arre5 suma : real i : entero comienzo para i de 1 a 5 leer ( a [ i ] ) si hubiésemos tenido que leer a1 y b1, luego a2 y b2, etc. tendríamos que finpara cambiar los dos “para” por uno solo para i de 1 a 5 para i de 1 a 5 leer ( b [ i ] ) leer ( a [ i ] , b [ i ] ) finpara finpara suma ← 0 para i de 1 a 5 suma ← suma + a [ i ] . b [ i ] 39 finpara escribir (“El resultado es ”, suma) fin programa Trece pasado a Fortran program Trece implicit none integer i real a,b,suma esta sentencia y la siguiente pueden sustituirse por la única sentencia dimension a(5),b(5) real a(5) , b(5) , suma write(*,*)"Ingrese el arreglo a" read(*,*)(a(i),i=1,5) esta forma de leer la llamamos lectura con formato DO write(*,*)"Ingrese el arreglo b" read(*,*)(b(i),i=1,5) suma=0 do i=1,5 suma=suma+a(i)*b(i) enddo write (*,*)”El resultado es ”,suma end program Trece En Fortran, si uno simplemente nombra el arreglo, se lee o escribe completo. Por lo tanto, las dos sentencias read, simplemente pudieron ponerse read ( * , * ) a y read ( * , * ) b Ejemplo14: Leer por filas un arreglo entero bi-dimensional de cuatro filas y tres columnas y armar un arreglo unidimensional con la suma de los elementos de cada fila y otro con la suma de los elementos de cada columna. (agregamos un ejemplo numérico para comprender el enunciado) -3 9 12 -2 12 0 9 6 0 17 -2 9 f = [ 16 27 24 ] X = c = 9 26 19 13 programa Catorce tipo matri = arreglo [ 4 , 3 ] de enteros vec1 = arreglo [ 4 ] de enteros vec2 = arreglo [ 3 ] de enteros variables x : matri c : vec1 f : vec2 i , j , sc , sf : enteras comienzo para i = 1 , 4 para j = 1 , 3 leer ( x [ i , j ] ) finpara finpara para i = 1 , 4 40 sf ← 0 para j = 1 , 3 sf ← sf + x [ i , j ] finpara c [ i ] ← sf finpara para j = 1 , 3 sc ← 0 para i = 1 , 4 sc ← sc + x [ i , j ] finpara f [ j ] ← sc finpara escribir (“La suma de las filas es”) para i = 1 , 4 escribir ( c [ i ] ) finpara escribir (“La suma de las columnas es”) para j = 1 , 3 escribir ( f [ j ] ) finpara fin programa Catorce Los arreglos son ubicados en memoria en posiciones adyacentes. Con los arreglos unidimensionales no hay problema, se ubica el primer elemento en una posición de la memoria y el resto en posiciones adyacentes consecutivas. En la ubicación en memoria de los arreglos multidimensionales, siempre se colocan sus elementos en posiciones adyacentes, pero depende del lenguaje la forma de ubicarlos. Pascal los ubica por filas y Fortran por columnas. Los arreglos pueden ser parámetros de procedimientos y funciones. Veamos un ejemplo: Ejemplo15: Leer por filas una matriz entera de 3 x 3 calcular su determinante (mediante una función) e informarlo. program Quince implicit none integer i , j , m( 3 , 3 ) , deter, sarrus do i = 1 , 3 read ( * , * ) ( m ( i , j ) , j = 1 , 3 ) enddo deter = sarrus ( m ) write ( * , * ) “Determinante vale”, deter end program Quince integer function sarrus ( x ) integer x ( 3 , 3 ) , suma , resta (suma y resta son variables locales) suma =x(1,1)*x(2,2)*x(3,3)+ x(1,2)*x(2,3)*x(3,1)+ x(1,3)*x(2,1)*x(3,2) resta=x(1,3)*x(2,2)*x(3,1)+ x(1,2)*x(2,1)*x(3,3)+ x(1,1)*x(2,3)*x(3,2) sarrus=suma-resta end function sarrus 41 Vamos a hacer otro problema, donde construiremos la función para calcular por Sarrus un determinante de 3x3 pero sus argumentos serán tres vectores y la usaremos para resolver un sistema no homogéneo de 3x3. Y al sistema en vez de verlo así lo pensaremos así a11 . x 1 + a12 . x2 + a 13 . x3 = b1 p1 . x1 + q1 . x2 + r1 . x3 = b1 a21 . x 1 + a22 . x2 + a 23 . x3 = b2 p2 . x1 + q2 . x2 + r2 . x3 = b2 a31 . x 1 + a32 . x2 + a 33 . x3 = b3 p3 . x1 + q3 . x2 + r3 . x3 = b3 Ejemplo16: Leer por filas la matriz de los coeficientes de un sistema de 3x3, a coeficientes reales. Leer luego el vector de los términos independientes. Calcular la solución e informarla (supondremos que tiene solución única) program Dieciseis implicit none integer i real p(3) , q(3) , r(3) , x1 , x2 , x3 , b(3) , sarrus2, detcoef do i=1,3 read (*,*) p(i) , q(i) , r(i) enddo read (*,*) b detcoef = sarrus2(p,q,r) x1 = sarrus2(b,q,r) / detcoef x2 = sarrus2(p,b,r) / detcoef x3 = sarrus2(p,q,b) / detcoef write (*,*) “Las raíces son ” , x1 , x2 , x3 end program Dieciseis real function sarrus2 (f,g,h) implicit none real suma , resta , f(3) , g(3) , h(3) suma = f(1) * g(2) * h(3) + f(2) * g(3) * h(1) + f(3) * g(1) * h(2) resta = f(3) * g(2) * h(1) + f(2) * g(1) * h(3) + f(1) * g(3) * h(2) sarrus2 = suma – resta end function sarrus2 Problema de aplicación Otra característica que utiliza la resistencia de materiales es el llamado “momento de inercia”, muy importante en el cálculo de vigas, columnas, etc. Si se trata de perfiles de acero, el propio fabricante provee las características geométricas de las secciones entre las cuales se encuentra el mencionado momento x de inercia. Si la pieza tiene como sección transversal una figura geométrica sencilla, el momento de inercia es fácil de calcular y suele ser un ejercicio común en Análisis Matemático para practicar integrales simples o dobles. Se sabe que para una sección rectangular, el momento de inercia con respecto al eje baricéntrico x-x viene dado por la fórmula que figura unos renglones mas arriba. x b h b . h3 Ix = ---------12 42 Construir un programa para armar una tabla con valores del momento de inercia correspondientes a anchos b que varíen desde 10cm hasta 30cm y valores de la altura h que varíen desde 10cm hasta 60cm, ambos valores con escalones de 2,5cm. Los valores del momento de inercia para un mismo b deben ir en una misma columna y los valores del momento de inercia para una misma h deben ir en una misma fila. program TablaInercia implicit none real b, h, iner(9) integer i, j h=7.5 write(*,*)" Tabla de valores del Momento de Inercia de secciones rectangulares" write(*,*)" H y B en centimetros Momentos de Inercia en centimetros a la cuarta" write(*,*)"============================================================================" write(*,*)" B" write(*,*)"============================================================================" write(*,*)" H 10.0 12.5 15.0 17.5 20.0 22.5 25.0 27.5 30.0 " write(*,*)"============================================================================" do i=1,21 h=h+2.5 b=7.5 do j=1,9 b=b+2.5 iner(j)=b*h**3/12. enddo write(*,"(F5.1,9F8.0)")h,iner enddo end program TablaInercia Hemos utilizado salida con formato para que nuestra tabla sea mas fácil de leer. El funcionamiento es muy sencillo. Para escribir un número real (o de punto Flotante) usamos el código F. Fw.d indica que el número debe ocupar w espacios (incluyendo el punto decimal, los decimales y un eventual signo “menos”), el valor d indica la cantidad de decimales que van a aparecer impresos (“redondeando” la última cifra decimal). Para los valores de h, hemos usado F5.1, ya que algunos valores tienen un decimal. Para los valores del momento de inercia hemos usado F8.0 ya que los decimales, trabajando en “centímetros a la cuarta”, en este caso, no tienen importancia desde el punto de vista de un ingeniero. Por ejemplo el número 12.374,766, con el formato F8.0 aparecerá impreso así 1 2 3 7 5 . redondeado (a cero decimales) con dos espacios en blanco a la izquierda. (se aconseja ser “generoso” con el campo d) Problema de aplicación Se tiene una viga de un puente de 15m de longitud. Sobre la P2 P1 misma puede circular una máquina vial que vamos a A representar como dos 3m cargas concentradas P1 y P2 separadas 3m Se pretende hacer circular ese “tren de cargas” x de 10cm en 10cm, desde que P1 toca el apoyo A (P2 todavía no entró) hasta que P2 toca el apoyo B (P1 ya había salido del puente). sentido de avance del “tren de cargas” B 15m 43 Para cada posición del tren de cargas nos interesa conocer el momento que genera en la viga en secciones separadas 30cm es decir que nos interesa conocer 51 valores del momento (ya que incluimos los apoyos A y B, aunque sabemos que debe ser cero) Una carga P que se encuentre a una distancia x del apoyo A, generará un momento en P una sección C que se encuentre a una A C B distancia y del mismo apoyo P.y.(15 - x) M = ---------------15 x ( si y < x ) P.x.(15 - y) M = ---------------15 ( si y > x ) y ( si y = x vale cualquiera de las dos ) Para cada una de las secciones, interesa conocer el máximo de los valores obtenidos para las diferentes posiciones del tren de carga. Si graficamos estos máximos obtenemos lo que llamamos Diagrama Envolvente de Momento Flector para un tren de dos cargas concentradas P1 y P2 separadas 3m. (si cambiamos el tren de carga, en cuanto a intensidad, cantidad, separación, etc. el diagrama envolvente cambiará). De los 51 valores del diagrama envolvente interesa también conocer el máximo de todos (máximo de todos los máximos o máximo maximorum). Trabajaremos en toneladas y metros. Nuestro programa consistirá en hacer avanzar el tren de carga de a 10cm, desde x=0,10 hasta x=17,90. Distinguiremos 3 casos: x <= 3 (sólo P1 está en el puente), 3 < x <= 15 (ambas cargas están en el puente), 15 < x <= 17,90 (sólo P2 está en el puente). Construiremos una subrutina solouna para calcular los 51 valores del momento cuando una sola carga PE está sobre la viga, a una determinada distancia equis del apoyo izquierdo. Construiremos una subrutina condos para calcular los 51 valores del momento cuando dos cargas (P1 y P2) están sobre la viga, con PUNO a una determinada distancia equis del apoyo izquierdo y PDOS tres metros atrás. Construiremos una subrutina elmayor tal que dados dos vectores de 51 elementos cada uno (v1 y v2), devuelva (en v1) un vector tal que en cada posición se encuentre el máximo de los dos valores que están en esa posición. Nuestro tren de cargas deberá avanzar desde una posición x=10cm y deberá dar 178 pasos de 10cm hasta llegar a 17,9m. program Envolvente implicit none real dista,a,b,c,p,q,r,morum,p1,p2,x,vmax(51),v(51) integer i,idelmax do i=1,51 vmax(i)=0.0 enddo write (*,*)"Ingrese el valor de P1 y P2 (en toneladas)" read (*,*)p1,p2 x=0.10 do i=1,178 if (x <= 3.0) then call solouna ((p1),(x),v) else if (x > 15.0) then 44 call solouna ((p2),(x-3.0),v) else call condos ((p1),(p2),(x),v) endif endif call elmayor (vmax,(v)) x=x+0.1 enddo write(*,*)"Valores del diagrama envolvente" write(*,*)"-------------------------------" do i=1,51 a=0.3*(i-1) p=vmax(i) write(*,*)"Abscisa:",a," Momento:",p enddo morum=vmax(1) idelmax=1 do i=2,51 if (vmax(i) > morum) then idelmax=i morum=vmax(i) endif enddo dista=0.3*(idelmax-1) write(*,"(A20,F4.2,A2,F7.3,A2)")"Maximo maximorum->M(",dista,")=",morum,"tm" end program Envolvente subroutine solouna(pe,equis,ve) implicit none real d,pe,mome,equis,ve(51) integer ka do ka=1,51 d=0.3*(ka-1) if (d < equis) then mome=pe*d*(15.0-equis)/15.0 else mome=pe*equis*(15.0-d)/15.0 endif ve(ka)=mome enddo end subroutine solouna subroutine condos(pe1,pe2,equis,ve) implicit none real d,pe1,pe2,mome,equis,ve(51) integer ka do ka=1,51 d=0.3*(ka-1) if (d < equis) then mome=pe1*d*(15.0-equis)/15.0 else mome=pe1*equis*(15.0-d)/15.0 endif ve(ka)=mome enddo equis=equis-3.0 do ka=1,51 d=0.3*(ka-1) if (d < equis) then mome=pe2*d*(15.0-equis)/15.0 else 45 mome=pe2*equis*(15.0-d)/15.0 endif ve(ka)=ve(ka)+mome enddo end subroutine condos subroutine elmayor(eldelmax,elactual) implicit none real eldelmax(51),elactual(51) integer ka do ka=1,51 if (elactual(ka) > eldelmax(ka)) then eldelmax(ka)= elactual(ka) endif enddo end subroutine elmayor Algunas operaciones con matrices xxxX ( los ejemplos siguientes sólo tienen el objeto se practicar algoritmia, los temas desarrollados serán tratados Se define la multiplicación de matrices de la siguiente manera. con verdadera rigurosidad en las Supongamos que sean asignaturas correspondientes) A = 1 0 -1 A 0 6 1 = -2 1 3 1 0 -1 B 0 6 1 -2 1 3 = 0 1 -1 2 0 3 0 1 -1 2 0 3 -1 3 1 2 5 -2 -4 3 7 -3 19 7 -1 3 1 C = A x B donde el elemento de la segunda fila, tercera columna del producto lo hemos obtenido así 0.(-1) + 6.3 + 1.1 = 19, en general podemos poner …... 3 ci,j = . . ai,k . bk,j (i=1,2,3 / j=1,2,3) k=1 Hemos ejemplificado para dos matrices cuadradas, pero también pudimos hacer la multiplicación para dos matrices no necesariamente cuadradas. El único requisito es que la cantidad de columnas de la que premultiplica sea igual a la cantidad de filas de la que postmultiplica. A m ,n x B n ,q = C m ,q deben ser iguales el producto de matrices no es conmutativo. Mas aún podría existir A x B y no existir B x A Seguiremos trabajando sólo con matrices cuadradas. 46 Definimos la transpuesta de una matriz a otra matriz en donde se han cambiado filas por columnas. (a veces la transposición suele hacerse sobre si misma). Por ejemplo A = 1 0 -1 0 6 1 -2 1 3 AT =T 1 0 -2 0 6 1 -1 1 3 Otra característica que podemos definir es la matriz adjunta de una matriz dada donde el elemento Adj(A) i, j es igual al valor del determinante que se obtiene suprimiendo la fila i y la columna j de la matriz A, con signo + o – según que i+j sea par o impar Recordar que estamos trabajando con matrices cuadradas Veamos un ejemplo A = -2 3 -1 0 2 -3 1 0 4 8 -12 -3 -7 -2 3 Adj(A) = -7 -6 -4 la hemos obtenido de la siguiente manera 2 0 3 0 3 2 - Adj(A) = -3 4 -1 4 0 1 -2 1 - -1 -3 -2 0 -3 4 0 1 -1 4 -1 -3 -2 1 -2 0 3 0 3 2 2 0 Finalmente vamos a definir la inversa de una matriz (la simbolizaremos A-1) a aquella matriz tal que pre o postmultiplicando a la matriz original nos da la matriz identidad, que es una matriz que tiene unos en la diagonal principal y ceros el resto de sus elementos. A-1 x A = A x A-1 = E donde E-1= 1 0 0 0 1 0 1 0 1 a veces a la matriz identidad también se la representa con I. Una manera de calcular la matriz inversa es a través de la adjunta, transpuesta, dividida por el determinante. A-1 = AdjT(A) / det(A) cero. por lo tanto, el determinante de la matriz debe ser distinto de 47 Vamos a hacer un programa Leer por filas una matriz real cuadrada de orden 3, calcular su inversa e informarla. Informar el valor del determinante de la matriz original. Como verificación pre y post multiplicar la matriz por su inversa e informar ambos productos (deben dar como resultado la matriz identidad). Vamos a usar la función sarrus que vimos anteriormente para calcular el determinante y las subrutinas xadju para calcular la adjunta, tra para transponerla sobre si misma y multipli para hacer los dos productos matriciales que se pidieron como verificación. program inversa implicit none integer i, j real m(3,3), invdem(3,3), determi, e(3,3), sarrus write(*,*)"Ingrese por filas la matriz a invertir" do i=1,3 read(*,*)(m(i,j),j=1,3) enddo determi=sarrus (m) write(*,*)"Su determinante vale ", determi call xadju((m),invdem) call tra(invdem) do i=1,3 do j=1,3 invdem(i,j)=invdem(i,j)/determi enddo enddo write(*,*)"Su inversa es" do i=1,3 write(*,"(3F12.3)")(invdem(i,j),j=1,3) enddo call multipli((m),(invdem),e) write(*,*)"El producto de la matriz por su inversa es" do i=1,3 write(*,"(3F12.6)")(e(i,j),j=1,3) enddo call multipli((invdem),(m),e) write(*,*)"El producto de la inversa por la matriz es" do i=1,3 write(*,"(3F12.6)")(e(i,j),j=1,3) enddo end program inversa subroutine multipli(x, y, z) real x(3,3), y(3,3), z(3,3) integer i, j, k do i=1,3 do j=1,3 z(i,j)=0. do k=1,3 z(i,j)=z(i,j)+x(i,k)*y(k,j) enddo enddo enddo end subroutine multipli 48 subroutine xadju(x,axd) real x(3,3), axd(3,3) integer p, q do p=1,3 do q=1,3 if (p==1 .and. q==1) axd(1,1)= x(2,2)*x(3,3)-x(2,3)*x(3,2) if (p==1 .and. q==2) axd(1,2)=(-1.)*(x(2,1)*x(3,3)-x(3,1)*x(2,3)) if (p==1 .and. q==3) axd(1,3)= x(2,1)*x(3,2)-x(3,1)*x(2,2) if (p==2 .and. q==1) axd(2,1)=(-1.)*(x(1,2)*x(3,3)-x(3,2)*x(1,3)) if (p==2 .and. q==2) axd(2,2)= x(1,1)*x(3,3)-x(3,1)*x(1,3) if (p==2 .and. q==3) axd(2,3)=(-1.)*(x(1,1)*x(3,2)-x(3,1)*x(1,2)) if (p==3 .and. q==1) axd(3,1)= x(1,2)*x(2,3)-x(2,2)*x(1,3) if (p==3 .and. q==2) axd(3,2)=(-1.)*(x(1,1)*x(2,3)-x(2,1)*x(1,3)) if (p==3 .and. q==3) axd(3,3)= x(1,1)*x(2,2)-x(2,1)*x(1,2) no es tan fácil el programa para calcular la matriz adjunta enddo enddo si la matriz es de orden superior a 3. end subroutine xadju subroutine tra(x) real x(3,3), aux integer p,q do p=1,3 do q=p+1 , 3 aux = x(p,q) x(p,q)=x(q,p) x(q,p)=aux enddo enddo end subroutine tra real function sarrus ( x ) real x ( 3 , 3 ) , suma , resta suma =x(1,1)*x(2,2)*x(3,3)+ x(1,2)*x(2,3)*x(3,1)+ x(1,3)*x(2,1)*x(3,2) resta=x(1,3)*x(2,2)*x(3,1)+ x(1,2)*x(2,1)*x(3,3)+ x(1,1)*x(2,3)*x(3,2) sarrus=suma-resta end function sarrus 49 UNIDAD 7.- ESTRUCTURA DE DATOS REGISTRO Y ARCHIVO. Conceptos de campo y registro. Campos clave. Declaración formal de registro. Arreglo de registros. Archivo: concepto. Organización secuencial, directa e indexada. Procesamiento de archivos secuenciales: Creación, apertura, cierre, consulta y actualización. (parte de esta Unidad ha sido extraida de apuntes de otros docentes de la Cátedra) Registro: Un registro es un tipo de dato estructurado. Está compuesto por campos que pueden ser de diferente tipo (de cualquier tipo). Es la estructura de datos que se utiliza principalmente para intercambiar datos con los archivos. Por ejemplo, supongamos que estamos tratando con datos de alumnos y que queremos manejar su legajo, apellido, nombre, notas (enteras) de cinco parciales y domicilio. Podríamos agruparlos en un tipo registro ...... tipo alumno = registro legajo: cadena [ 5 ] apeynom : registro apellido: cadena [ 20 ] nombre: cadena [ 25 ] fin notas : arreglo [ 5 ] de enteros domicilio : registro calle : cadena [ 15 ] numero : entero ciudad : cadena [ 20 ] fin fin variables alu1 , alu2 : alumno Podemos imaginar la siguiente representación: alu1 G2015 García Alberto 8 10 6 8 7 Jujuy 1678 Rosario Si en un programa hago referencia a alu1 estoy apuntando a todo el registro con alu1.notas[4] con alu1.domicilio con alu1.domicilio.ciudad Ejemplo17: Leer los datos de dos alumnos de un curso (legajo, apellido nombre, las notas de cinco parciales y domicilio) e informar promedio, legajo, apellido y domicilio del de mayor promedio. programa diecisiete tipo alumno = registro legajo: cadena [ 5 ] apeynom : registro apellido: cadena [ 20 ] nombre: cadena [ 25 ] fin notas : arreglo [ 1 :: 5 ] de enteros domicilio : registro calle : cadena [ 15 ] numero : entero ciudad : cadena [ 20 ] fin 50 fin variables x1 , x2 : alumno i : entera p1 , p2 : reales comienzo leer (x1.legajo, x1. apeynom.apellido, x1. apeynom.nombre) para i de 1 a 5 leer ( x1.notas[i] ) finpara leer (x1.domicilio.calle, x1.domicilio.numero, x1.domicilio.ciudad ) leer (x2.legajo, x2. apeynom.apellido, x2. apeynom.nombre) para i de 1 a 5 leer ( x2.notas[i] ) finpara leer (x2.domicilio.calle, x2.domicilio.numero, x2.domicilio.ciudad ) p1 ← 0 p2 ← 0 para i de 1 a 5 p1 ← p1 + x1.notas[i] p2 ← p2 + x2.notas[i] finpara p1 ← p1 / 5 p2 ← p2 / 5 si p1 > p2 entonces escribir (p1, x1.legajo, x1. apeynom.apellido, x1.domicilio.ciudad) sino escribir (p2, x2.legajo, x2. apeynom.apellido, x2.domicilio.ciudad) finsi escribir ( “ tiene mayor promedio” ) fin programa Diecisiete Se pueden armar arreglos de registros. Por ejemplo si construimos un arreglo unidimensional de registros, tendríamos una especie de “archivo”, pero con los siguientes inconvenientes: tamaño fijo, se lo trabaja en la memoria principal, desaparece al terminar el programa. Tenemos que hacer una aclaración importante: al definir arreglos dijimos que todos los elementos del arreglo tenían que ser del mismo tipo. Podría surgir la siguiente pregunta “¿Al haber dentro del registro, datos de diferente tipo, no se está cometiendo un error?”. NO, ya que desde el punto de vista del arreglo, todos sus elementos son del mismo tipo, es decir registros (por ejemplo de tipo alumno). Ejemplo18: Leer los datos (legajo, apellido, nombre, notas de cinco parciales y domicilio) de un cierto número de alumnos (no mas de 100) e informar el promedio y el apellido del de mayor promedio. Hacemos notar que para resolver este problema no hace falta guardar los datos de todos los alumnos. Podría ir tomando los datos requeridos a medida que se van leyendo los alumnos. Sólo lo hacemos para practicar con arreglos de registros. A nuestro registro le agregaremos un campo mas que llamaremos promedio al que calcularemos ni bien se leen las notas. programa Dieciocho tipo alumno = registro legajo: cadena [ 5 ] apeynom : registro apellido: cadena [ 20 ] nombre: cadena [ 25 ] fin 51 notas : arreglo [ 1. . 5 ] de enteros promedio : real domicilio : registro calle : cadena [ 15 ] numero : entero ciudad : cadena [ 20 ] fin fin variables curso : arreglo [ 1 .. 100 ] de alumno i, idelmax, nroalu : enteros p , pmax : real lega : cadena [ 5 ] comienzo nroalu ← 0 leer ( lega ) mientras lega < > “XXXXX” hacer indico fin de datos con XXXXX nroalu ← nroalu + 1 curso [ nroalu ] . legajo ← lega leer ( curso [ nroalu ] . apeynom . apellido , curso [ nroalu ] . apeynom . nombre ) p←0 para i de 1 a 5 leer (curso [ nroalu ] . notas [ i ] ) p ← p + curso [ nroalu ] . notas [ i ] finpara curso [ nroalu ] . promedio ← p / 5 leer (curso[nroalu].domicilio.calle,curso[nroalu].domicilio.numero) leer(curso[nroalu].domicilio.ciudad) leer ( lega ) fin mientras idelmax ← 1 pmax ← curso [ 1 ] . promedio para i de 2 a nroalu si curso [ i ] . promedio > pmax idelmax ← i pmax ← curso [ i ] . promedio finsi finpara escribir ( “Con ” , pmax , curso [ idelmax ] . apellido, “ tiene el mayor promedio”) fin programa Dieciocho ¿Cómo hacer para guardar, por ejemplo los datos de los alumnos del curso en memoria externa? Supongamos que la memoria externa es un disco. En un dispositivo así se podrá almacenar información (mediante la escritura en disco: de memoria a disco) que luego puede ser recuperada (mediante la lectura desde disco: de disco a memoria) para su procesamiento. Registro lógico: Cuando la información está almacenada en memoria, los datos están agrupados por una lógica impuesta en la declaración de variables del programa, y así a este registro se lo denomina registro lógico. Archivo: Un conjunto de registros con cierto aspecto en común y, organizados para algún propósito particular, se denomina archivo (file). Un archivo es una estructura diseñada para contener datos en un medio externo de almacenamiento. Los datos están organizados de tal modo que puedan ser recuperados 52 fácilmente, actualizados, borrados y almacenados nuevamente en el archivo con todos los cambios realizados. Características de los archivos ♦ Un archivo siempre está en un soporte externo de almacenamiento ( disco, cinta, etc ) ♦ Existe independencia de los datos respecto a los programas ♦ Todo programa intercambia información con un archivo mediante la estructura registro. ♦ La información guardada en un archivo es permanente. ♦ Los archivos permiten una gran capacidad de almacenamiento. Registro físico: En el disco la información está escrita “físicamente”, y la cantidad más pequeña de datos que puede transferirse en una operación de lectura / escritura entre la memoria y el dispositivo periférico se denomina registro físico. Por ejemplo un sector de un disco ( por ejemplo 512 Bytes ), una línea de impresión ( si el dispositivo es la impresora ), etc. Un registro físico puede contener uno o mas registros lógicos, de acuerdo al tamaño del registro lógico. En el ejemplo de buscar el máximo promedio (Ejemplo18) tenemos: Tamaño del registro lógico = 100 bytes legajo : 4 b. / apeynom : (20+25) b. / notas (5x2) b. / promedio : 4 b. / domicilio (15+2+20) b. Tamaño del registro físico = 512 bytes Por lo tanto en la lectura de información desde el disco a la memoria se podrán “bajar” 5 registros de un sola transferencia. Organización de los archivos: Para almacenamiento y para acceder a sus datos, se puede organizar la información dentro de los archivos de tres formas distintas, secuencial, acceso directo y secuencial indexada. El criterio de usar una u otra organización depende del uso posterior de la información. Organización secuencial: En un archivo organizado secuencialmente los registros están ordenados en el orden en el cual fueron originalmente escritos. Todos los tipos de almacenamiento externos ( discos, cinta, etc. ) permiten este tipo de organización. Algunos dispositivos, por su naturaleza física, sólo soportan archivos secuenciales, por ejemplo, acceder a la información almacenada en un registro particular de una cinta magnética, requiere el acceso a los registros desde el primero hasta el buscado en ese momento ( Es análogo a la búsqueda de un tema musical en un cassette ). Otros dispositivos estrictamente secuenciales son las impresoras. Para el manejo de este tipo de archivo existen instrucciones especiales, tales como: abrir un archivo: abrir (nombre del archivo, referencia) o abrir (nombre del archivo, variable de tipo archivo) En un programa se le da una referencia a ese archivo. Esta es una variable de tipo “archivo” (file) que se usa para cada vez que se quiera nombrar a ese archivo. Se pueden tener varios archivos abiertos al mismo tiempo en un programa. leer el registro siguiente desde el dispositivo de almacenamiento externo: leer ( registro, referencia al archivo ) o leer ( variable de tipo registro, variable de tipo archivo ) escribir o grabar un registro en dispositivo de almacenamiento externo: grabar(registro,referencia al archivo) o grabar(variable de tipo registro, variable de tipo archivo) cerrar un archivo abierto: cerrar ( referencia ) o cerrar ( variable de tipo archivo) 53 Para acceder a los datos de un archivo, primero debemos abrirlo, como si se tratara de un libro. En esta operación el procesador coloca un “puntero” que "apunta" al primer registro del archivo. Luego de leer este registro, dicho puntero se ubica en el registro siguiente. Si continuamos leyendo, llegará un momento en que hemos leído todos los registros, llegando al final del mismo. Una vez que el procesador lee la marca de fin del archivo (eof: End Of File) este no se puede seguir leyendo pues da error. Sólo se puede leer el archivo mientras no sea el final del mismo. En general en nuestros programas tendremos algo así: mientras no eof (referencia) hacer Ejemplos de algoritmos para este tipo de archivos: Altas Hacer un algoritmo que permita agregar ( ALTAS ) registros al archivo DATOS.DAT, cuyos registros tienen los campos que vimos en el Ejemplo18 (sin el campo promedio) programa Altas tipo alumno = registro legajo: cadena [ 5 ] apeynom : registro apellido: cadena [ 20 ] nombre: cadena [ 25 ] fin notas : arreglo [ 1 .. 5 ] de enteros domicilio : registro calle : cadena [ 15 ] numero : entero ciudad : cadena [ 20 ] fin fin variables a : alumno c: archivo de alumno rta , esta : char lega: string [ 5 ] comienzo abrir (DATOS.DAT , c) ! DATOS. DAT es el nombre del archivo en disco y ! c es la referencia al archivo en el programa. rta ← "S" mientras rta = "S" hacer ! Este mientras es para permitir hacer varias altas esta ← "N" escribir ( "Legajo : " ) leer ( lega ) ! ahora busca si este registro ya esta grabado leer ( a , c ) mientras no ( eof(c) ) y esta = "N" hacer si a.legajo = lega entonces escribir ( " Ya esta este Legajo " ) esta ← "S" sino leer ( a , c ) fin si fin mientras si esta = "N" entonces escribir ( "Apellido: " ) leer ( a . apeynom . apellido ) 54 escribir ( "Nombre: " ) leer ( a . apeynom . nombre ) escribir (“Ingrese las cinco notas”) para i de 1 a 5 leer ( a . notas [ i ] ) fin para escribir (“Ingrese Calle Nro. Ciudad”) leer ( a . domicilio. calle , a . domicilio . numero , a . domicilio . ciudad ) a . legajo ← lega grabar ( a, c ) fin si escribir ( " Quiere ingresar otro registro ? " ) leer ( rta ) fin mientras cerrar ( c ) fin programa Altas Bajas Hacer un algoritmo que permita eliminar ( BAJAS ) registros del archivo DATOS.DAT, cuyos registros fueron descriptos en el ejemplo anterior. Hacemos el algoritmo para una sola baja. programa Bajas tipo alumno = registro legajo: cadena [ 5 ] apeynom : registro apellido: cadena [ 20 ] nombre: cadena [ 25 ] fin notas : arreglo [ 1 .. 5 ] de enteros domicilio : registro calle : cadena [ 15 ] numero : entero ciudad : cadena [ 20 ] fin fin variables a : alumno c , b: archivo de alumno esta : char lega: string [ 5 ] comienzo abrir (DATOS.DAT , c) la idea es copiar uno a uno los registros DATOS.DAT abrir (AUX.DAT , b ) en AUX.DAT con excepción del que queremos dar está ←"N" de baja, luego eliminamos DATOS.DAT y renomescribir ( "Legajo a eliminar : " ) bramos AUX.DAT como DATOS.DAT leer ( lega ) leer ( a , c ) ahora busca si este legajo está en el archivo mientras no( EOF( c ) hacer si lega = a.legajo entonces escribir ( " Este Legajo corresponde a ", a . apeynom . apellido , “ y se borrará” esta ← "S" sino grabar ( a , b ) graba el registro en AUX fin si leer ( a , c ) siguiente registro de DATOS.DAT fin mientras 55 si esta = "N" entonces escribir (" No se encontró ese Legajo ", lega ) fin si cerrar ( c ) cerrar ( b ) borrar DATOS.DAT renombrar AUX.DAT como DATOS.DAT fin. Modificaciones Hacer un algoritmo que permita modificar ( MODIFICACIONES ) registros del archivo DATOS.DAT, cuyos registros fueron descriptos en el ejemplo anterior. Hacemos el algoritmo para una sola modificación. programa Modificar tipo alumno = registro legajo: cadena [ 5 ] apeynom : registro apellido: cadena [ 20 ] nombre: cadena [ 25 ] fin notas : arreglo [ 1 .. 5 ] de enteros domicilio : registro calle : cadena [ 15 ] numero : entero ciudad : cadena [ 20 ] fin fin variables a : alumno c, b : archivo de alumno esta : char i : entera lega: string [ 5 ] comienzo abrir (DATOS.DAT , c) abrir (AUX.DAT , b ) esta = "N" escribir ( "Legajo : " ) leer ( lega ) ahora busco si este registro ya está grabado leer ( a , c ) mientras no eof(c) y esta = "N" hacer si a . legajo = lega entonces mostrar ( a ) cambios ( a ) esta ← "S" sino grabar (a , b) fin si leer ( a , c ) fin mientras si esta = "N" entonces escribir ( " El Legajo ", lega ," no existe" ) fin si cerrar ( c ) cerrar ( b ) 56 borrar DATOS.DAT renombrar AUX.DAT como DATOS.DAT fin . procedimiento mostrar ( a: alumno ) comienzo escribir ( "Legajo : " , a . legajo) escribir ( "Apellido : ", a . apeynom . apellido) escribir ( "Nombre : ", a . apeynom . nombre) escribir ( "Calle : ", a . domicilio . calle , a . domicilio . numero) escribir ( "Localidad : " , a . domicilio . ciudad) escribir ( “Notas :”) para i de 1 a 5 escribir ( a . notas[ i ] ) finpara fin procedimiento mostrar procedimiento cambios ( a: alumno ) comienzo escribir (“Ingrese, en el mismo orden todos los datos correctos”) leer (a . legajo) leer (a . apeynom . apellido) leer (a . apeynom . nombre) leer (a . domicilio . calle , a . domicilio . numero) leer (a . domicilio . ciudad) para i de 1 a 5 leer ( a . notas[ i ] ) finpara grabar ( a, b ) fin del procedimiento cambios Organización de acceso directo: En este tipo de organización se accede al registro sin necesidad de leer los registros que le anteceden. Cuando se graban los registros que componen el archivo, en los soportes físicos (discos o CD), el procesador junto a su sistema operativo, ubica cada registro en direcciones del disco que las obtiene a través de una fórmula. Suponiendo que todos los registros tienen el mismo tamaño, y sabiendo cuanto lugar ocupa cada uno en el disco, le es simple al procesador ubicar el registro número N , sin necesidad de leer todos los registros. Organización secuencial indexada: Los registros están grabados consecutivamente, pero el acceso puede hacerse mediante un camino muy corto, casi directo. Los diccionarios con pestañas, son un buen ejemplo de este tipo de organización: si buscamos la palabra " Saber ", primero buscaremos la pestaña S , y luego buscaremos la palabra " Saber ". En esta organización los índices se encuentran en una tabla e indican la localización de un grupo de registros. Un archivo con organización secuencial indexada, o simplemente indexado consta de : - un archivo de datos: los registros con información propiamente dicha - uno o varios archivos de índices ordenados según un campo clave. Cada registro de este archivo contiene la clave del último registro de cada grupo, y la dirección relativa del primer registro del grupo. Por ejemplo en que hoja comienza la letra a y cual es la ultima palabra que empieza con dicha letra. Cuando deseamos localizar un registro por su clave, primero realiza una búsqueda en el archivo de índices, hasta encontrar la primera clave superior a la dada. Junto a esta clave, se encuentra la dirección inicial del grupo de registros que debe contener el registro a localizar. El 57 procesador se posiciona directamente en esa dirección, efectuando una búsqueda secuencial del registro por su clave. Archivos en Fortran Trabajaremos sólo con archivos de acceso secuencial. En Fortran (en otros lenguajes también) no hace falta trabajar con registros para comunicarnos con los archivos (si bien en ejemplos anteriores vimos que se puede hacer), podemos leer y o escribir las variables directamente. Cada write deja una marca como de “fin de registro”.Vamos a hacer un ejemplo muy simple. Armamos un archivo que contenga los siguientes datos: 1er. registro: 1.01 11.11 21.21 1 2do. registro: 101.01 111.11 121.21 101 3er. registro: 201.01 211.11 221.21 201 4to. registro: 301.01 311.11 321.21 301 Volvemos al 1er. registro (con REWIND) y leemos los registros y los vamos mostrando por pantalla. program ArConReg implicit none type unregi real a, c, d integer b end type unregi type (unregi) z integer i open(17, file="c:\ArConReg.dat") z.a= 1.01 z.c= 11.11 z.d= 21.21 z.b= 1 do i=1, 3 write(17,*)z z.a= z.a + 100. z.c= z.c + 100. z.d= z.d + 100. z.b= z.b + 100 enddo write(17,*)z REWIND(17) do i=1,4 read(17,*)z write(*,*)z.a, z.b, z.c, z.d enddo close(17) end program ArConReg Al abrir el archivo queda preparado para leer y/o escribir en el primer “registro”. Cada vez que se lee y/o escribe un “registro”, se avanza al “registro” siguiente (aunque no se hayan leído todas las variables del “registro”). Vamos a hecer un programa que haga exactamente lo mismo que el anterior, pero, además, que luego vuelva a leer y escribir el archivo, pero al leer el segundo “registro”, que sólo lea una variable y verificamos que aunque no lo lea completo salta al siguiente (al tercero). 58 program ArSinReg implicit none real a, c, d, w, y, z integer b, x, i open(17, file="c:\ArSinReg.dat") a= 1.01 c= 11.11 d= 21.21 b= 1 write(17,*)a, c, d, b a= a + 100. c= c + 100. d= d + 100. b= b + 100 write(17,*) a, c, d, b a= a + 100. c= c + 100. d= d + 100. b= b + 100 write(17,*) a, c, d, b a= a + 100. c= c + 100. d= d + 100. b= b + 100 write(17,*) a, c, d, b REWIND(17) do i=1,4 read(17,*)w, y, z, x esto es para hacer notar que los nombres de las variables con que write(*,*)w, y, z, x se lee el archivo no tienen por que ser iguales a los nombres de las enddo variables con que fue escrito write(*,*)"Ahora voy a leerlo de nuevo con 4 read, pero en el segundo" write(*,*)"solo voy a leer una variable, pero vemos que a pesar de no" write(*,*)"leer completo los cuatro datos grabados, lo mismo salta al" write(*,*)"""registro"" siguiente" rewind(17) read(17,*)w, y, z, x write(*,*)w, y, z, x read(17,*)w write(*,*)w read(17,*)w, y, z, x write(*,*)w, y, z, x read(17,*)w, y, z, x write(*,*)w, y, z, x close(17) end program ArSinReg Veamos un tercer programa: Un grupo de amigos decide organizar un Quini4, las apuestas consisten en elegir cuatro números distintos entre 0 y 9 (ambos incluidos). Luego se sortearán 4 números distintos entre 0 y 9 (ambos incluidos). Se considera apuesta ganadora aquella cuyos cuatro números coincidan con los cuatro sorteados (no interesa el orden). Construir un programa Fortran para: 1) Leer nombre de cada apostador (seis caracteres) y los cuatro números de su apuesta y grabarlos en el archivo c: \ apuestas.dat. No se sabe cuantos apostadores hubo. 59 2) Leer los cuatro números sorteados 3) Grabar las apuestas ganadoras en c: \ ganaron.dat. 4) Informar cuantas apuestas hubo, y si hubo o no ganadores y en caso de haberlos, cuantos fueron y sus nombres y cual fue su apuesta. program Quini4 implicit none integer i, apuesta(4), cantapu, cantgana, sorteo(4), aciertos character*6 nombre open (32,file="c:\apuestas.dat") open (10,file="c:\ganaron.dat") cantapu=0 write(*,*)"Ingrese nombre (xxxxxx termina)" read(*,*)nombre do while (nombre <> "xxxxxx") cantapu=cantapu+1 write(*,*)"y los cuatro numeros de la apuesta" read(*,*)apuesta write(32,*)nombre, apuesta write(*,*)"Ingrese nombre (xxxxxx termina)" read(*,*)nombre enddo write(*,*)"Ahora los cuatro numeros del sorteo" read(*,*)sorteo rewind(32) cantgana=0 do i=1, cantapu read(32,*)nombre, apuesta if (aciertos(sorteo, apuesta)==4) then cantgana=cantgana+1 write(10,*)nombre, apuesta endif enddo write(*,*)"Total de apuestas:", cantapu rewind(10) if (cantgana>0) then write(*,*)"hubo ", cantgana, " ganadores y son los siguientes" do i=1, cantgana read(10,*) nombre, apuesta write(*,*) nombre, apuesta enddo else write(*,*)"No hubo ganadores" endif close(10) close(32) end program Quini4 integer function aciertos(a,b) integer p, q, a(4), b(4) aciertos=0 do p=1,4 do q=1,4 if (a(p)==b(q)) then pudo ponerse un IF lógico aciertos=aciertos+1 if(a(p)==b(q)) aciertos=aciertos+1 60 endif enddo enddo end function aciertos 61 UNIDAD 8.- ORDENAMIENTO, BUSQUEDA E INTERCALACION. Ordenamiento por selección del mínimo, por inserción y por intercambio. Estimación de la cantidad de operaciones a efectuar. Idea de eficiencia de un algoritmo. Búsqueda secuencial y binaria. Intercalación. Trabajando con arreglos unidimensionales, surgen inmediatamente tres tareas típicas: ordenamiento (clasificación), búsqueda e intercalación. ordenamiento: Dado un arreglo, reordenar sus elementos de modo que queden en orden creciente (o decreciente). búsqueda: Dado un arreglo, determinar si un cierto dato se encuentra o no dentro de él. intercalación: Dados dos arreglos que contengan elementos del mismo tipo, ambos ordenados con el mismo criterio, no necesariamente ambos con la misma cantidad de elementos. Armar un tercer arreglo que contenga los elementos de ambos y que esté ordenado con el mismo criterio. Observación: Si bien el resultado sería el pedido, en intercalación no consideraremos correcto armar un arreglo con los elementos de ambos y luego ordenarlo, ya que esto implicaría un número mucho mayor de operaciones. Ordenamiento: Si bien hay capítulos de libros dedicados a este tema, sólo veremos tres métodos: por intercambio (burbuja), por selección del mínimo y por inserción. Por intercambio: Consiste en comparar el último elemento del arreglo con el penúltimo, si están en el orden buscado, se los deja así, si no, se los intercambia. Lugo se compara el penúltimo con el antepenúltimo, si están en el orden buscado, se los deja así, si no, se los intercambia. Y así sucesivamente hasta repetir lo mismo, comparando el primer elemento con el segundo. De esta manera, aseguramos que en la primer posición quedó el menor o el mas liviano, elemento que se comportó como una burbuja. Repetimos lo mismo, siempre comenzando desde el fondo del arreglo, pero esta vez llegamos hasta la segunda posición del arreglo. Estamos seguro que los dos mas pequeños quedaron en las dos primeras posiciones y en orden. Repetimos siempre lo mismo hasta la penúltima posición con lo que garantizamos que hasta la penúltima posición quedaron en orden, y por lo tanto la última también. Veamos un ejemplo numérico. Tratemos de ordenar el arreglo ( 8 2 0 5 1 8 8 8 8 8 0 0 0 0 0 0 0 0 0 0 0 2 2 2 2 0 8 8 8 8 1 1 1 1 1 1 1 0 0 0 0 2 2 2 2 1 8 8 8 2 2 2 2 5 5 1 1 1 1 1 1 2 2 2 2 8 8 4 4 1 1 5 5 5 5 4 4 4 4 4 4 4 4 8 5 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 8 1er. paso 3er. paso 2do. paso 4) 5to. paso 4to. paso 62 Ejemplo19: Leer un arreglo de 10 elementos reales, ordenarlo por el método de intercambio. Imprimirlo ordenado. program Diecinueve integer i,j real v(10), aux write(*,*)"Ingrese el arreglo" read(*,*)(v(i),i=1,10) do i = 1 ,9 do j = 9 , i , -1 if ( v(j) > v(j+1) ) then aux = v(j) podría incorporarse una verificación v(j) = v(j+1) tal que si antes de completar el DO v(j+1) = aux de mas afuera nos damos cuenta que el endif arreglo YA quedó ordenado, abandoneenddo mos el proceso. enddo write(*,*)"El mismo arreglo ordenado" write(*,*)(v(i),i=1,10) end program Diecinueve Por selección del mínimo: En un primer paso, se busca el mínimo de todos los elementos del arreglo (memorizando valor y posición) y se lo intercambia con el que está en la primera posición. Luego se vuelve a buscar el mínimo, pero buscando desde la segunda posición en adelante y se lo intercambia con el segundo. Así sucesivamente hasta llegar al penúltimo elemento. Ejemplifiquemos sobre el mismo arreglo anterior 8 0 0 0 0 0 2 2 1 1 1 1 0 8 8 2 2 2 5 5 5 5 4 4 1 1 2 8 8 5 4 4 4 4 5 8 1er. paso 2do. paso 3er. paso 4to. paso 5to. paso Ejemplo20: Leer un arreglo de 10 elementos reales, ordenarlo por el método de selección del mínimo. Imprimirlo ordenado. program Veinte implicit none integer i ,j , posmin real v(10) , mini write(*,*)"Ingrese el arreglo" read(*,*) v do i=1,9 posmin=i mini=v(i) do j=i+1,10 63 if (v(j) < mini) then posmin=j mini=v(j) endif enddo v(posmin) = v(i) v(i) = mini enddo write(*,*)"El arreglo quedo asi" write(*,*)v end program Veinte Por inserción: Este método es muy similar a la operación que se efectúa con los naipes cuando se quiere dejarlos ordenados. En medio del proceso, se elige un elemento del arreglo (un naipe), se lo reserva, y se van corriendo los anteriores una posición hasta encontrar uno que sea menor, o llegar al principio del arreglo. (el proceso empieza desde la posición 2) Supongamos que estoy en medio del proceso y deseo acomodar el quinto de ocho elementos. 2 4 11 12 7 reservo el 5o. 9 13 8 (en la variable x en el programa) 7 corro un lugar los anteriores mayores hasta donde estaba el seleccionado 1er. elem. 2 4 11 12 9 13 8 y ubico el reservado en el “hueco” que quedó 2 4 7 11 12 9 13 8 y repito el proceso hasta el final Ejemplo21: Leer un arreglo de 10 elementos reales, ordenarlo por el método de inserción. Imprimirlo ordenado. program Veintiuno implicit none integer i,j real a(10), x write(*,*)"Ingrese el arreglo" read(*,*)a do i=2,10 64 x=a(i) reservo el i-ésimo elemento j=i-1 do while (x<a(j).and.j>0) corro un lugar los anteriores a(j+1)=a(j) mayores hasta encontrar el j=j-1 primer elemento que sea endddo menor al i-ésimo reservado a(j+1)=x y ubico el elemento reservado en el “hueco” que quedó enddo write(*,*)" El arreglo quedo asi " write(*,*)a end program Veintiuno Búsqueda: Consiste en lo siguiente, dado un arreglo averiguar si dentro del arreglo está, o no un determinado elemento (que podemos llamar k). Existen muchos métodos de búsqueda, cada uno con diferentes variaciones. Veremos sólo dos, búsqueda secuencial y búsqueda binaria (o dicotómica). El uso de uno u otro método, depende de que el arreglo esté ordenado o no. La búsqueda binaria o dicotómica sirve si el arreglo está ordenado. Si no tenemos garantía de que el arreglo esté ordenado, no hay que usarla. La búsqueda secuencial sirve en ambos casos, pero en arreglos de muchos elementos si bien funciona, es ineficiente y no deberíamos usarla. Podemos hacer el siguiente cuadro. Arreglo NO ordenado Secuencial Binaria USAR NO USAR (no sirve) Arreglo ordenado NO USAR (ineficiente) USAR También en cada uno de los métodos podemos distinguir dos posibilidades. Que, en caso de estar el elemento buscado tenga la posibilidad de estar mas de una vez, y debamos decidir si nos conformamos con encontrar una ocurrencia, o queremos encontrar todas. Vale la pena hacer notar que en un arreglo ordenado, si puede haber elementos repetidos, los repetidos deben estar todos juntos. Búsqueda secuencial: Consiste en recorrer uno a uno los elementos del arreglo (desordenado) y compararlos con k hasta encontrarlo o no Para ejemplificar, supongamos que tenemos el arreglo a de 7 elementos enteros y deseamos saber si un cierto entero k está o no dentro del arreglo, y si está, en que posición está su primer ocurrencia. Supongamos a= 16 -39 0 25 5 25 17 y supongamos que k sea -4 la respuesta del algoritmo debería ser no está si suponemos que k es 25 la respuesta del algoritmo debería ser está en la posición 4 65 Si nos interesa conocer todas las ocurrencias. a= 25 -39 22 25 5 22 17 y supongamos que k sea -4 la respuesta del algoritmo debería ser no está si suponemos que k es 22 la respuesta del algoritmo debería ser está en la posición 3 está en la posición 6 Veamos los algoritmos Para el caso que interese una sola ocurrencia Ejemplo22: Leer un arreglo de 7 elementos enteros. Leer luego un entero. Informar si ese entero está o no. Si está, informar la posición de su primera ocurrencia. programa Veintidos tipo v7 = arreglo [ 7 ] de entero variables a : v7 i , k , pos : entero comienzo escribir ( ´Ingrese el arreglo´ ) para i de 1 a 7 leer ( a [ i ] ) finpara escribir ( ´Ingrese el dato a buscar´ ) leer ( k ) pos ← 0 repetir pos ← pos + 1 hasta que a [ pos ] = k ó pos = 7 si a [ pos ] = k entonces escribir ( ´está en la posición´ , pos ) sino escribir ( ´no está´ ) finsi fin programa Veintidos recorro el arreglo hasta encontrarlo o agotarlo pregunto si salí porque lo encontré o porque no lo encontré program Veintidós implicit none integer i , k , pos , a(7) write (*,*) “Ingrese el arreglo” read (*,*) a write (*,*) “Ingrese el dato a buscar” read (*,*) k pos = 0 do pos = pos + 1 if ( a(pos)==k .or. pos==7 ) exit enddo if ( a(pos)==k ) then write (*,*) “Está en la posición” , pos 66 else write (*,*) “No está” endif end program Veintidós Para el caso que interesen todas las ocurrencias Ejemplo23: Leer un arreglo de 7 elementos enteros. Leer luego un entero. Informar si ese entero está o no. Si está, informar la posición de todas sus ocurrencias. programa Veintitres tipo v7 = arreglo [ 7 ] de entero variables a : v7 i , k : entero hay : boolean comienzo escribir ( ´Ingrese el arreglo´ ) para i de 1 a 7 leer ( a [ i ] ) finpara escribir ( ´Ingrese el dato a buscar´ ) leer ( k ) pongo esa “bandera” en falso (no encontrado todavía) hay ← falso para i de 1 a 7 si a [ i ] = k entonces escribir ( ´está en la posición´ , i ) pongo la “bandera” en verdadero (hay uno por lo menos) hay ← verdadero finsi finpara si no hay entonces escribir ( ´no está´ ) finsi fin programa Veintitres program Veintitres implicit none integer i , k , a(7) logical hay write (*,*) “Ingrese el arreglo” read (*,*) a write (*,*) “Ingrese el dato a buscar” read (*,*) k hay = .false. do i=1,7 if ( a(i)==k ) then write (*,*) “Está en la posición” , i hay = .true. endif enddo if .not. hay then write (*,*) “No está” endif end program Veintitres 67 Búsqueda dicotómica: Consiste en tener dos indicadores, uno de la posición de menor orden (min) y otro de la posición de mayor orden (max). Al principio uno valdrá 1 y el otro N, suponiendo que la cantidad de elementos sea N. (N=11 en los dos ejemplos que siguen). Probamos si el elemento que está en el “medio” del arreglo es igual al buscado. Si es el buscado, lo encontramos y finaliza el algoritmo (suponemos que nos conformamos con una sola ocurrencia). Si no es el buscado, nos fijamos si es mayor o menor al buscado, y como el arreglo está ordenado, si el elemento del “medio” es menor, si el buscado está, está en la parte de “abajo”, y nos quedamos con esa parte bajando min hasta medio, pero como ya sabíamos que el del “medio” no era, lo bajamos una posición mas, es decir hacemos medio ← medio + 1 Análogo razonamiento si el elemento del “medio” es mayor. En nuestro algoritmo si max y min son de distinta paridad, su promedio dará “coma cinco” lo que está prohibido como índice, entonces tomamos la división entera, es decir hacemos medio ← ( min + max ) div 2 (donde con div simbolizamos la división entera) Vamos a ejemplificar para el caso de búsqueda exitosa (el elemento buscado se encuentra en el arreglo). Supongamos que el elemento que busco es 9 ( k = 9 ) Los elementos sombreados es porque están descartados min -22 min -16 0 medio medio max -22 -22 -16 -16 -16 0 3 9 -22 max 0 0 3 min medio 3 3 9 max 9 min/max/medio y se encuentra el valor buscado 9 17 17 17 17 25 25 25 25 40 40 40 40 63 63 63 63 82 82 82 82 94 94 94 94 Vamos a ejemplificar para el caso de búsqueda fallida (el elemento buscado NO se encuentra en el arreglo). Supongamos que el elemento que busco es 36 ( k = 36 ) min medio -22 -22 -22 -22 -22 -16 -16 -16 -16 -16 0 0 0 0 0 3 3 3 3 3 9 9 9 9 9 17 17 17 17 25 min 40 63 medio 82 max 94 max 17 25 min medio 25 40 max min/medio/max 25 max 25 40 40 min 40 63 63 63 63 82 82 82 82 94 94 94 94 68 y al quedar el máximo por encima del mínimo, se deduce que el elemento buscado no está Ejemplo24: Leer un arreglo de 11 elementos enteros, se sabe que está ordenado en forma creciente. Leer luego un entero. Informar si ese entero está o no. Si está, informar su posición. programa Veinticuatro tipo v11 = arreglo [ 11 ] de entero variables a : v11 min , k, max , medio : entero comienzo escribir ( ´Ingrese el arreglo´ ) para i de 1 a 11 leer ( a [ i ] ) finpara escribir ( ´Ingrese el dato a buscar´ ) leer ( k ) min ← 1 max ← 11 medio ← ( min + max ) div 2 mientras min <= max y k <> a [ medio ] hacer si k < a [ medio ] entonces max ←medio - 1 sino min ←medio + 1 finsi medio ← ( min + max ) div 2 finmientras si k = a [ medio ] entonces escribir ( “El valor se encontró en” , medio ) sino escribir ( “No se encontró” ) finsi fin programa Veinticuatro program Veinticuatro implicit none integer min , max , medio , k , a(11) write (*,*) “Ingrese el arreglo” read (*,*) a write (*,*) “Ingrese el dato a buscar” read (*,*) k min = 1 max = 11 medio = ( min + max ) / 2 do while ( min <= max .and. k <> a ( medio ) ) if ( k < a ( medio ) ) then max = medio – 1 else min = medio + 1 endif medio = ( min + max ) / 2 enddo 69 if ( k == a write else write endif end program ( medio ) ) then (*,*) “El valor se encontró en” , medio (*,*) “No se encontró” Veinticuatro No vamos a tratar el caso de búsqueda dicotómica de todas las ocurrencias cuando hay elementos repetidos, simplemente damos una idea. Si un arreglo ordenado tiene elementos repetidos, estarán en posiciones adyacentes. Aplicando el algoritmo de búsqueda dicotómica, que es mucho mas rápido que el secuencial, encontraremos uno, pero no sabemos si es el “primero”, el “último”, o uno cualquiera del grupo, hacemos lo siguiente: vamos “hacia arriba” hasta llegar a un elemento distinto y luego “bajamos” listando las posiciones mientras los elementos sean iguales al buscado. Intercalación: Tenemos dos arreglos, ambos del mismo tipo de elementos. Ambos ordenados con el mismo criterio (ambos en forma creciente o ambos en forma decreciente). No necesariamente ambos con la misma cantidad de elementos. Llamemos a y b a ambos arreglos. Sea N la cantidad de elementos de a, y sea M la cantidad de elementos de b. Queremos armar un nuevo arreglo c que contenga todos los elementos de a y todos los elementos de b (es decir que tenga N+M elementos) y que esté también ordenado con el mismo criterio. Veamos un ejemplo a(N=3) 9 35 47 b(M=7) 7 20 25 43 50 73 92 c ( 7 + 3 = 10 elementos) 7 9 20 25 35 43 47 50 73 92 (podría surgir la idea de armar un nuevo arreglo que contenga al principio los elementos de a y colocar a continuación los de b y luego a este nuevo arreglo ordenarlo. Pero esto es muy ineficiente comparado con el método que veremos a continuación) Vamos a llamar i al índice con que vamos a recorrer a, j al índice con que vamos a recorrer b y k al índice con que vamos a recorrer c. La idea es recorrer desde el principio los arreglos a y b, comenzamos con los índices i, j, k en 1 comparamos ai con bj y al elemento menor lo copiamos en ck, incrementamos en 1 a k y al índice del arreglo del que hayamos copiado, y así hasta agotar uno de los dos arreglos (a o b), luego ponemos los elementos que quedaban sin colocar del otro, “al final” de c. Vamos directamente al algoritmo Ejemplo25: Leer un arreglo de 10 elementos reales (se sabe que ingresa ordenado en forma creciente), leer luego un arreglo de 8 elementos reales (se sabe que ingresa ordenado en 70 forma creciente). Formar un arreglo que contenga todos los elementos del primero y todos los elementos del segundo y que también esté ordenado en forma creciente. Escribirlo programa Veinticinco variables a [ 10 ] , b [ 8 ] , c [ 18 ] de reales i , j , k , q : enteras comienzo escribir (“Ingrese el primer arreglo”) para i de 1 a 10 leer ( a [ i ] ) finpara escribir (“Ingrese el segundo arreglo”) para i de 1 a 8 leer ( b [ i ] ) finpara i←1 j←1 k←1 mientras i <= 10 y j <= 8 hacer si a [ i ] <= b [ j ] entonces c[k]←a[i] i ←i + 1 sino c[k]←b[j] j←j+1 finsi k ← k +1 finmientras si i > 10 entonces para q de j a 8 hacer c[k]← b[q] k ← k +1 finpara sino para q de i a 10 hacer c[k]← a[q] k ← k +1 finpara finsi escribir (“El resultado es”) para i de 1 a 18 hacer escribir ( c [ i ] ) finpara fin programa Veinticinco program Veinticinco implicit none real a(10) , b(8) , c(18) integer i , j , k , q write (*,*) “Ingrese el primer arreglo” read (*,*) a write (*,*) “Ingrese el segundo arreglo” read (*,*) b 71 i = 1 j = 1 k = 1 do while ( i <= 10 .and. j <= 8 ) if ( a(i) <= b(j) ) then c(k) = a(i) i = i + 1 else c(k) = b(j) j = j + 1 endif k = k + 1 enddo if ( i > 10 ) then do q = j , 8 c(k) = b(q) k = k + 1 enddo else do q = i , 10 c(k) = a(q) k = k + 1 enddo endif write (*,*) “El resultado es” write (*,*) c end program Veinticinco Eficiencia del algoritmo: ¿ Por que decimos que el algoritmo que acabamos de presentar es mas eficiente que copiar a en c y a partir de ahí copiar b en c, para luego ordenar c ? En nuestro algoritmo no tenemos ningún anidamiento de estructuras de repetición. En cambio en los métodos de ordenamiento tenemos anidadas dos estructuras de repetición. Supongamos que tenemos dos para anidados. El de mas afuera que se repita 200 veces y el interior 400 veces para i de 1 a 200 para j de 1 a 400 sentencia finpara finpara esta sentencia se ejecutará 80.000 veces ¿Qué pasa, por ejemplo con el método por intercambio? Supongamos que queremos ordenar por intercambio un arreglo de 200 elementos 72 Analicemos cuantas veces se ejecuta el IF que está dentro de esos dos DOs anidados. Usemos el ejemplo ya hecho, pero para 200 elementos program Diecinueve integer i,j real v(200), aux write(*,*)"Ingrese el arreglo" read(*,*)(v(i),i=1,200) do i = 1 , 199 do j = 199 , i , -1 if ( v(j) > v(j+1) ) then queremos ver cuantas veces se ejecuta este IF aux = v(j) v(j) = v(j+1) v(j+1) = aux endif enddo enddo write(*,*)"El mismo arreglo ordenado" write(*,*)(v(i),i=1,10) end program Diecinueve El de DO de mas afuera se ejecutará 199 veces. y el de mas adentro se ejecutará: la 1ra. vez, 1 vez la 2da. vez, 2 veces ........ ........ la última vez, 199 veces es decir que el de mas adentro (y por lo tanto el IF) se ejecutará 199 + 198 + 197 + . . . . 3 + 2 + 1 = (199 x 200) / 2 = 19.900 veces o sea que el IF se ejecutará 19.900 veces n n.(n+1) i = ---------------2 Zzzzz i=1 Otra manera, aproximada de pensarlo es decir: si el de mas adentro se ejecuta tal cual lo explicamos, podemos pensar que en promedio funciona como un DO que va de 1 a (1+199)/2=100 veces, Y como el DO de mas afuera se ejecutaba 199 veces, el IF se ejecutará 199 x 100 = 19.900 73