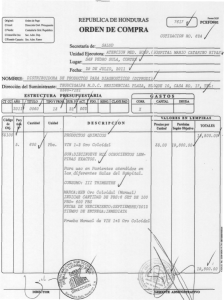
Descargar documento - Instituto Economía Pontificia Universidad
Anuncio

E C O N O M Í A TESIS de MAGÍSTER IInstituto N S T I de T Economía U T O D E DOCUMENTO DE TRABAJO 2011 Impacto de la Pensión Básica Solidaria en la Oferta de Trabajo de las Personas en Edad de Jubilar José Manuel Eguiguren. www.economia.puc.cl PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE INSTITUTO MAGISTER EN DE ECONOMIA ECONOMIA TESIS DE GRADO MAGISTER EN ECONOMIA Eguiguren Cosmelli, José Manuel Julio 2011 PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE INSTITUTO MAGISTER EN DE ECONOMIA ECONOMIA IMPACTO DE LA PENSIÓN BÁSICA SOLIDARIA EN LA OFERTA DE TRABAJO DE LAS PERSONAS EN EDAD DE JUBILAR José Manuel Eguiguren Cosmelli Comisión Juan Pablo Montero Tomás Rau Alejandra Traferri Gert Wagner Santiago, julio 2011 Abstract: This paper presents impact estimations of the creation of a Minimum Pension Benefit (MPB) over the labor supply of the elderly. The MPB is among the most generous subsidies and also is one with highest coverage. Thus, assessing the impact of this benefit over labor market decision is both novel and attractive. Specifically I provide Average Treatment Effects (ATE) estimates of worked hours and labor market participation. First, I use data from the Social Protection Survey (SPS), a panel data set with individual information before and after the implementation of MPB. Here I estimate the ATE using Diferencein-Diference methods. Second, due to sample size issues I also use a cross section survey (CASEN 2009) to estimate the impacts using Matching. The findings are an impact of the MPB over the worked hours and over labor market participation. This effect is coherent with the predictions of economic theory about non labor income variations and is specific to certain groups of the population. Resumen: El objetivo de este trabajo es estimar el Impacto de la Pensión Básica Solidaria (PBS) en la Oferta de Trabajo de las Personas en Edad de Jubilar. La PBS está dentro de los subsidios más generosos y de mayor cobertura que otorga el Estado de Chile a partir de Julio de 2008, y por lo mismo, la observación de su impacto en las decisiones laborales de los beneficiarios resulta atractivo además de novedoso. Específicamente, se estimará el Average Treatment Effect (ATE) o efecto tratamiento promedio de ser beneficiario de la PBS sobre el número de horas trabajadas y la participación laboral de las personas en edad de jubilar. Para estimar el ATE se proponen dos metodologías: la primera es el estimador de diferencias en diferencias, calculado mediante datos de panel y utilizando la Encuesta de Protección Social 20062009; la segunda, consiste en aplicar la metodología de Propensity Score Matchig (PSM) utilizando la Encuesta CASEN 2009. Los resultados indican que efectivamente hay un impacto significativo de la Pensión Básica Solidaria, pues reduce las horas trabajadas y la participación laboral. Este impacto está en línea con la teoría económica sobre ingreso no laboral y es acotado a ciertos grupos de la población. 3 Índice I. II. Introducción ............................................................................................................................... 6 Revisión de la Literatura ............................................................................................................. 9 II.1. Personas en Edad de Jubilar y Oferta Laboral ..................................................................... 9 II.2. Ingreso No Laboral y Oferta Laboral ................................................................................. 10 III. Reforma Previsional.................................................................................................................. 13 III.1. Primer Pilar Pre-Reforma .............................................................................................. 13 III.2. Primer Pilar Post Reforma ............................................................................................. 13 III.3. Implementación de la Reforma ..................................................................................... 14 IV. Marco Teórico .......................................................................................................................... 16 IV.1. Modelo Básico de Ocio – Consumo ............................................................................... 16 IV.2. Impacto del Ingreso No Laboral en el Número de Horas Trabajadas ........................... 17 IV.3. Impacto del Ingreso No Laboral en la Participación Laboral ......................................... 17 V. Estrategia Empírica ................................................................................................................... 19 V.1. Estrategia de Diferencias en Diferencias........................................................................... 23 V.2. Estimación vía Propensity Score Matching ....................................................................... 23 VI. Datos......................................................................................................................................... 24 VI.1. Panel EPS 2006 – 2009 .................................................................................................. 24 VI.2. CASEN 2009 ................................................................................................................... 27 VI.3. Validez Macro y Descripción de Variables .................................................................... 28 VII. Estimaciones y Resultados ....................................................................................................... 29 VII.1. Metodología de Diferencias en Diferencias .................................................................. 29 VII.1.1. Efecto del Tratamiento en las Horas Trabajadas .................................................. 29 VII.1.2. Efecto del Tratamiento en la Participación Laboral .............................................. 30 VII.2. Estimaciones utilizando Propensity Score Matching (PSM) .......................................... 33 VII.2.1. Condición de Independencia ................................................................................. 33 VII.2.2. Efecto del Tratamiento en las Horas Trabajadas .................................................. 34 VII.2.3. Efecto del Tratamiento en la Participación Laboral .............................................. 37 VII.3. Análisis de Resultados ................................................................................................... 39 VIII. Conclusiones ............................................................................................................................. 41 IX. Referencias ............................................................................................................................... 42 X. Anexos ...................................................................................................................................... 44 X.1. Anexo 1: Estrategia de Diferencias en Diferencias............................................................ 44 X.2. Anexo 2: Estrategia de Matching Propensity Score .......................................................... 46 X.3. Anexo 3: Comportamiento Agregado de la Datos ............................................................ 47 X.4. Anexo 4: Descripción de Variables .................................................................................... 49 X.5. Anexo 5: Tablas Modelo Horas Trabajadas (DD)............................................................... 50 X.5.1. Tabla 1: Modelo Horas Trabajadas 100% muestra ................................................... 50 X.5.2. Tabla 2: Modelo Horas Trabajadas 50% más vulnerable .......................................... 51 X.6. Anexo 6: Tablas Modelo de Participación (DD) ................................................................. 52 X.6.1. Tabla 3: Modelo de Participación Laboral ................................................................. 52 4 X.6.2. Tabla 4: Modelo Participación sin Variable donde no hay Diferencias. .................... 53 X.6.3. Tabla 5: Elección del Modelo para el Cálculo del ATE ............................................... 54 X.6.4. Tabla 6: Modelo elegido para diferentes muestras. ................................................. 55 X.6.5. Tabla 7: Estimación MICO de mismos Modelos Alternativos ................................... 56 X.7. Anexo 7: Resultados Estimación de PS del Modelo Horas Trabajadas (PSM) ................... 57 X.8. Anexo 8: Tablas Modelo de Horas Trabajadas (PSM) ....................................................... 59 X.8.1. Tablas Modelo Trabajadores Independientes........................................................... 59 X.8.2. Tablas Modelo Trabajadores Independientes sin Ingreso No Laboral ...................... 62 X.9. Anexo 9: Tablas Modelos de Participación Laboral (PSM) ................................................ 65 X.9.1. Tablas Modelo General de Participación .................................................................. 65 X.9.2. Tablas Modelo de Participación Hombres Jefes de Hogar en Zona Urbana. ............ 67 5 I. Introducción En Julio de 2008 comenzó la implementación de la Reforma Previsional en Chile. A partir de esa fecha, se comenzó a entregar la Pensión Básica Solidaria (PBS), beneficio otorgado a toda persona que al haber cumplido 65 años no tuviera acceso a ningún tipo de pensión autofinanciada y que sea miembro de un hogar que pertenezca al 60% más vulnerable de la población1. La PBS tuvo dos impactos inmediatos y bastante relevantes para las personas pensionadas o en edad de pensionarse. Por una parte, aumentó el ingreso para aquellas personas que eran beneficiarios de la Pensión Asistencial, y en segundo lugar, amplió el universo de personas que tenía derecho a este tipo de pensión solidaria, los que llamaremos efecto monto y efecto cobertura respectivamente. Esta investigación explota la variación exógena en el ingreso no laboral (efecto monto o efecto cobertura de la PBS) para estudiar los efectos que este cambio provoca en las decisiones laborales de las personas con 65 años o más. La investigación se centra en este grupo etario ya que tanto hombres como mujeres pueden postular a este beneficio a partir de los 65 años de edad y no antes. El objetivo fundamental de esta investigación es evaluar el impacto que tuvo la Pensión Básica Solidaria en la oferta laboral de aquellos individuos en edad de jubilar. Así, esta investigación será pionera en evaluar el impacto que tuvo la reforma al pilar solidario en el comportamiento de aquellos agentes que se vieron directamente beneficiados, específicamente observando los impactos sobre el comportamiento laboral de los individuos afectados. Si bien no es un grupo etario representativo de la sociedad en general, esto permitirá de alguna manera extrapolar y concluir sobre los efectos que tienen transferencias no condicionales del estado en el comportamiento de los agentes. La teoría económica subyacente a la evaluación del impacto de la PBS en las decisiones laborales es aquella relacionada con el efecto del ingreso no laboral (PBS) sobre la oferta de trabajo de los individuos. Calcular este efecto no es trivial, debido a que variaciones exógenas del ingreso no laboral son difíciles de encontrar, pero el hecho de contar con un cambio en la legislación previsional que exógenamente aumentó tanto el monto como la cobertura del pilar solidario del Sistema de Pensiones, nos permite, al menos para el grupo etario que está en edad de jubilación, medir el impacto que tiene el ingreso no laboral en la oferta de trabajo. En Chile no existe literatura que mida el impacto del ingreso no laboral (aprovechando una variación exógena) en la oferta laboral de los individuos y aunque este trabajo este acotado a aquellas personas cercanas a su edad de jubilación, aun así constituye un aporte a la literatura en la materia. 1 En un principio fue el 40% más vulnerable y actualmente con la reforma en régimen dicho número llega al 60%. 6 Para reforzar el punto anterior, es necesario tomar en cuenta lo siguiente. Dado que el grupo de estudio son aquellas personas en edad de jubilar, el hecho de tener una medición completamente exógena del ingreso no laboral cobra particular relevancia, pues gran parte de esta clase de ingreso en la vejez está determinado por los ahorros laborales durante la vida activa y que por lo mismo esta medición del ingreso (al no ser completamente exógena) puede estar reflejando preferencias de las personas hacia el trabajo. Dado la disminución que ha existido en la tasa de natalidad del país y el aumento en la esperanza de vida2, el grupo de personas que tiene más de 65 años de edad se ha ido transformando en el grupo etáreo más importante del país y por ende, su disposición al trabajo será relevante a la hora de determinar los niveles de la tasa de dependencia de la economía. Por lo mismo, analizar aspectos del comportamiento laboral de este grupo etáreo es sumamente atractivo. En 1990, según la encuesta CASEN, un 6,7% de la población tenía sobre 65 años, cifra que en 2009 llegaba al 10,8%. En cuanto a su actividad laboral, en 1990, del total de la fuerza laboral, un 2,6% pertenecía a este segmento de la población y un 14,5% de los que pertenecían a dicho segmento participaban en el mercado laboral, cifras que en 2009 llegaban a 3,8% y 15,3% respectivamente. Todo indica que esta tendencia, sumado a las posibilidades físicas que tienen las personas en edad de jubilar de seguir participando en el mercado laboral, seguirá su curso durante las próximas décadas. Luego de esta pequeña introducción, en la segunda parte, se expone una revisión de la literatura relacionada con el tema de la investigación. Por un lado, aquella vinculada a la oferta laboral de las personas en edad de jubilar y por otro, la que guarda relación con el impacto del ingreso no laboral en las decisiones laborales de los agentes. En la tercera parte se presentarán los aspectos centrales de la reforma previsional que se relacionan con la investigación. En una cuarta parte se expone el marco teórico que hay detrás de la pregunta que se quiere responder. A partir de un modelo básico de oferta laboral el cual explota el trade-off que existe entre la decisión de los agentes entre consumo de bienes y consumo de ocio, se llegará a expresar analíticamente cuales son los efectos (y sus signos esperados) que este trabajo pretende medir. En la quinta parte se expondrá las estrategias empíricas que se llevaron a cabo para medir el efecto de la PBS en la Oferta Laboral. Para esto, se disponen de dos fuentes de información que permiten medir el ATE de la PBS sobre horas trabajadas y participación laboral. Dada la naturaleza de ambas fuentes de información -panel de la Encuesta de Protección Social 2006-2009, y corte transversal de la CASEN 2009-, cada una de ellas merece una metodología diferente para estimar el ATE, lo que será explicado en esta sección. 2 En 1990 la esperanza de vida al nacer era de 77 años para las mujeres y de 72 para los hombres, mientras que en 2009 esta llegaba a 82 para las mujeres y a 76 para los hombres. Además la esperanza de vida de las mujeres en 2009 al momento de jubilar (60 años) llegaba a los 84 años y la de los hombres a los 81 años. 7 En la sexta parte se encuentra una descripción de los datos utilizados. En una séptima parte se presentan las estimación y los principales resultados bajos ambas metodologías y luego, en la octava parte, se concluye. 8 II. Revisión de la Literatura Este apartado consta de dos partes. En primer lugar, se revisa la literatura relacionada a la oferta laboral de las personas en edad de jubilar, concentrándose en su relación con el ingreso no laboral. Segundo, se hace una revisión de la evidencia empírica en cuanto a los determinantes de la oferta laboral de los agentes. II.1. Personas en Edad de Jubilar y Oferta Laboral La literatura económica que estudia la relación existente entre el sistema de bienestar de una sociedad y la estructura de incentivos que determinan la participación laboral de los individuos en edad de jubilar, ha estado centrada en las decisiones de retiro anticipado de los agentes, concentrándose en el impacto del sistema de protección social sobre la modalidad de pensión que eligen y la edad a la cual deciden retirarse (Lumsdaine and Mitchell 1999). En general, como se concluye en Kin y Hurd (1978) y en Borsch-Supan (2003) los mayores beneficios al momento de retirarse inducen a una menor participación laboral de aquellas personas que están en edad de retiro o bien a optar por un retiro anticipado. Lo que se hace en este trabajo es algo distinto. Si bien se está viendo el impacto de un mayor beneficio de jubilación en el número de horas trabajadas y en la participación laboral, ocurre que este beneficio es otorgado a la persona no por el hecho optar por el retiro y dejar de trabajar, sino que por haber cumplido 65 años y pertenecer al grupo más vulnerable de la población. Es decir, la naturaleza del beneficio no obliga a que la persona deje de trabajar y por lo mismo, la pregunta se centra en el impacto en la oferta laboral de las personas en edad de jubilar, ya que la persona puede optar por disminuir el número de horas trabajadas como dejar de participar en el mercado laboral, lo que en muchos casos, pero no en todos significará el retiro. Dentro de la literatura relevante en relación a la oferta laboral de las personas en edad de jubilar, se encuentra un trabajo de Parnes y Sommers (1994), quienes usando la “National Longitudinal Survey” (NLS) encuentran que la probabilidad de trabajar para trabajadores de 68 años o más está fuertemente correlacionada con el buen estado de la salud y con la actitud hacia el trabajo, la cual se midió a través de una proxie con información relativa a la historia de la persona. Encuentran, además, una relación positiva con el nivel educacional y negativa con la edad y el ingreso no laboral. Los autores reconocen el potencial problema de endogeneidad del ingreso no laboral; sin embargo señalan que su signo (y el de las otras variables relevantes bajo análisis) es robusto a diferentes especificación. Haider y Loughran (2001) señalan que 15% de las personas mayores de 65 años trabajan en los Estados Unidos y motivados por la creciente importancia que tendrá este grupo etáreo en la economía norteamericana, analizan el comportamiento laboral de estos individuos. Concluyen que los aspectos que más influyen (positivamente) en la oferta laboral de las personas en edad de jubilar son los altos niveles de educación, la buena salud y la mejor situación económica. Si bien es 9 contraintuitivo que a mayor ingreso no laboral tienda a aumentar la participación en el mercado laboral, lo autores subrayan que el ingreso no laboral en la vejez en gran parte está determinado por los ahorros laborales durante la vida activa y que por lo mismo, esta medición del ingreso (al no ser completamente exógena) puede estar reflejando gustos de las personas hacia el trabajo. Más allá de la incidencia positiva que tiene la riqueza en oferta laboral de las personas de mayor edad, los autores remarcan que son aspectos no pecuniarios (como educación y buena salud) los que tienen mayor importancia a la hora de determinar la oferta laboral. Motivados por el creciente envejecimiento de la población Estadounidense y la importancia creciente que tendrán los trabajadores de mayor edad para la fuerza laboral, Schmidt y Sevak (2008) estudian la respuesta de la oferta laboral de trabajadores mayores a cambios en el sistema impositivo, concentrándose no sólo en las decisiones de participación, sino que también en las horas que trabajan los individuos. Usando un panel de datos a nivel individual a partir de la “Health and RetirementStudy” (HRS), encuentran que un mayor ingreso no laboral impacta positivamente en la propensión a participar en el mercado laboral y negativamente en el número de horas trabajadas. El impacto positivo del ingreso no laboral sobre la decisión de participación contrasta con la teoría de que mayor ingreso no laboral menor es la disposición a ofrecer trabajo de las personas (Cahuc y Zylberberg 2004), pero nuevamente se nombra el punto de que el ingreso no laboral luego de jubilar es algo bastante endógeno a las preferencias por el trabajo. Por otra parte, encuentra un efecto positivo robusto del salario hacia la oferta laboral. Además, cuando el beneficio será dado sólo si es que el trabajador participa en el mercado laboral, es probable que la probabilidad de participar en el mercado laboral aumente. En resumen, la literatura considera como un factor muy preponderante el estado de salud del individuo a la hora de determinar la oferta laboral y en general, no se encuentra el efecto esperado del ingreso no laboral sobre la oferta laboral, lo que se explica en parte por la poca exogeneidad con que se está midiendo la variable. II.2. Ingreso No Laboral y Oferta Laboral Existe una amplia literatura relacionada con la estimación de los efectos del ingreso no laboral en la oferta laboral de los individuos (independiente de su grupo etáreo) y más allá de las diferentes estrategias empíricas utilizadas, en general la dificultad estriba en no tener acceso a medidas exógenas del ingreso no laboral del individuo (Imbens, Ruben y Sacerdote 2000). Una primera medida utilizada frecuentemente en la literatura es utilizar las rentas del capital del individuo, los ingresos del conyugue o ingresos del hogar por subsidios para medir el ingreso no laboral de los individuos. Los resultados de estos estudios se encuentran ampliamente reportados en Blundell y MaCurdy (2000) y en general, usando encuestas de hogares en el tiempo, se encuentran los efectos predichos por la teoría económica (Cahuc y Zylberberg 2004). Es decir, que los ingresos no laborales impactan negativamente en el número de horas trabajadas por los 10 agentes. Sin embargo, uno de los problemas de estos estudios es la exogeneidad de estos ingresos respecto a la oferta laboral de los agentes. Una segunda estrategia que también es ampliamente utilizada es explotar el efecto de cambios que a todas luces son exógenos al comportamiento del individuo y que a su vez impactan en el ingreso no laboral del individuo. Estos se caracterizan por asemejarse a un experimento, en el sentido de que la asignación del tratamiento es hecha por “algún” agente exógeno tal como una ley, un fenómeno natural o cualquier cambio que sea independiente a las preferencias u otros determinantes del comportamiento económico del individuo bajo análisis. Dentro de la literatura sobre esta materia, existen investigaciones que estudian cambios en la legislación que de alguna forma afectan los impuestos o beneficios que debe pagar o recibir un determinado grupo de individuos y aquellas que analizan el efecto laboral de ganar juegos de azar. Eissa y Liebman (1996) examina el impacto de una reforma tributaria hecha en Estados Unidos en 1986, la cual incluyó una expansión del crédito al impuesto al trabajo3 para aquellas personas con hijos y que cumplían cierta condición que las clasificaba como necesitadas. La estrategia de identificación consistió en comparar el cambio en la oferta laboral de las mujeres con hijos versus aquellas que no tenían hijos. El aumento de los beneficios con la reforma consistió en la práctica en una disminución del impuesto al trabajo tanto en términos de tasa como de cobertura (aumento el umbral que daba derecho a beneficiarse con el crédito). Lo novedoso de la reforma es que permitía explotar y testear diferentes comportamientos dependiendo del tramo de ingreso laboral en cual se encontrara el individuo y que además, consistía en un beneficio sólo para aquellas personas que se encontraban trabajando. Por lo mismo, el efecto del aumento del beneficio en la participación fue positivo, mientras que no se encuentra evidencia que permita concluir que el número de horas trabajadas haya disminuido, lo que lleva a los autores a concluir que el programa produce muy pequeñas distorsiones en los incentivos al trabajo. Blundell, Duncan y Meghir (1998) utilizaron una secuencia de reformas tributarias realizadas en el Reino Unido durante los ochentas y principios de los noventas, con el objeto de analizar el efecto de cambios en los salarios y en el ingreso no laboral sobre el número de horas trabajadas. Dentro de sus principales hallazgos se encuentra un efecto positivo y moderado del salario sobre las horas trabajadas y un efecto negativo del ingreso no laboral sólo para aquellas mujeres con hijos, mientras que para aquellas sin hijos, el efecto es nulo. Imbens, Ruben y Sacerdote (2000), llevaron a cabo una encuesta de personas que jugaron lotería en Massachusetts a mediados de los años ochenta, la cual incluyo a personas que ganaron grandes sumas de dineros y aquellos que recibieron bajas sumas de dinero, a los que agruparon en dos grupos: uno de ganadores y otro de perdedores4. Basado en un modelo estático de oferta laboral, estimaron que la propensión marginal a consumir ocio era alrededor de un 10%. La encuesta realizada se cruzó con información administrativa con lo que el trabajo se llevó a cabo con 496 3 EarnedIncomeTaxCredit Los perdedores son aquellos que ganaron bajas sumas de dinero. 4 11 observaciones, de las cuales 259 correspondían a personas calificadas como “perdedoras” y 237 como “ganadoras”. El resultado obtenido no difería entre hombres y mujeres, y era significativamente alto para aquellos individuos que se encontraban cercanos a la edad de jubilar. Además, el estudio veía el impacto sobre las decisiones de ahorro y consumo de los agentes. La investigación para Chile en materia de los determinantes de la oferta laboral es amplia y aunque la mayoría de ellas controla por ingreso no laboral, en ninguna de ellas el impacto de esta variable, es el interés principal de la investigación. Esto se debe, en parte, a la dificultad de contar con una medición verdaderamente exógena del ingreso no laboral. Dentro de la evidencia más reciente esta Medrano (2009), quien mide el impacto del aumento de jardines infantiles en la oferta laboral femenina. Controlando por ingreso no laboral, encuentra que este no tiene un efecto relevante sobre las decisiones laborales de la mujer. Contreras, Sepúlveda y Cabrera (2010) estudian el efecto de la implementación de la jornada escolar completa en la oferta laboral femenina, y al controlar por ingreso no laboral, encuentran un efecto negativo de este sobre el número de horas trabajadas. Además, para Chile, tampoco existe literatura específica relacionada con el comportamiento laboral de personas en edad de jubilar. Estas dos últimas investigaciones tienen las características de estimar la forma reducida de la ecuación que determina el número de horas trabajadas por los individuos, mismo enfoque que se sigue en este trabajo para lidiar con la endogeneidad que existe entre horas trabajadas y salario. 12 III. Reforma Previsional El Sistema Previsional chileno está compuesto por tres pilares. Un primer Pilar Solidario, un segundo Pilar Contributivo y un tercer Pilar Voluntario. Un primer pilar solidario, el cual es no contributivo y se financia con impuestos generales, con lo que se redistribuye cierta riqueza hacia los individuos que no tengan los ingresos suficientes para alcanzar un mínimo establecido que garantice una vejez digna. Un segundo pilar obligatorio y contributivo, el cual tiene como objetivo solucionar el problema de la imprevisión.Este pilar basado en la capitalización individual garantiza que el individuo reciba una pensión de acuerdo a su historia de cotización. Un tercer pilar voluntario, el cual también busca aliviar la imprevisión. Esto se hace necesario dado que con el pilar contributivo no siempre se acumula un monto suficiente para que los individuos obtengan pensiones iguales o cercanas al promedio de los ingresoslaborales que tuvieron durante su época activa. Este pilar posee diferentes tipos de incentivos para que los individuos ahorren más y asípuedan garantizarse un mejor nivel de ingresos en la vejez. La Reforma Previsional genero varios perfeccionamientos al Sistema de Pensiones, de los cuales el más importante y con efectos inmediatos es la re-estructuración completa del llamado Pilar Solidario. III.1. Primer Pilar Pre-Reforma Antes de la reforma el primer pilar incluía a dos programas: 1. Pensiones Asistenciales (PASIS): pensión para las personas de 65 años o más sin derecho a ningún tipo de pensión. Una característica de este programa era su alto grado de focalización, además de que el beneficio otorgado no era lo suficientemente importante como para garantizar una calidad de vida con cierto nivel mínimo de dignidad. En pesos de 2009 este beneficio oscilaba entre $45.000 y $59.000 dependiendo de la edad de los beneficiados. 2. Pensión Mínima Garantizada por el Estado (PMGE): garantizaba un piso mínimo de pensión para aquellos pensionados que hayan acumulado al menos 20 años de cotizaciones y que sus fondos propios no alcanzasen a llegar a ese mínimo (alrededor de $130.000). El mayor problema de este programa era que eran pocas las personas - de más bajos recursos - las que acumulaban en su vida laboral 20 años de cotizaciones y por mismo eran pocos los que podían acceder a la PMGE. III.2. Primer Pilar Post Reforma La reforma creó un nuevo pilar solidario, que incorpora dos cambios sustanciales, uno que viene a reemplazar a las PASIS y otro que viene a hacer las veces de PMGE: 13 1. Pensión Básica Solidaria (PBS): pensión de $75.0005 para las personas de 65 años o más sin derecho a ningún tipo pensión y que pertenezca al 60% de los hogares más vulnerables del país. En comparación a la PASIS, la PBS incrementa en al menos un 25% real el valor de la pensión mínima solidaria y además aumenta notablemente su cobertura, incorporando a muchas personas que antes no recibían PASIS y que ahora por pertenecer al 60% de los hogares más vulnerables si recibirán PBS. 2. Aporte Previsional Solidario (APS): consiste en un aporte extra que recibirá toda persona de 65 años o más que pertenezca al 60% de los hogares más vulnerables del país y que tenga derecho a algún monto de pensión autofinanciada. El objetivo del APS es incrementar –de acuerdo a una regla- la pensión para el individuo en los casos en que su pensión autofinanciada sea menor a los $255.0006. Si una persona recibe “0” pesos de pensión autofinanciada, recibirá $75.000 por concepto de PBS, pero si esa persona tiene derecho a una pensión autofinanciada de $50.000, tendrá derecho a un APS de $60.294, es decir recibirá una pensión total de $110.294. es decir tendrá derecho a un APS de $60.294. El objetivo del APS es que este sea decreciente a medida que aumenta la pensión autofinanciada, así, si una persona recibe una pensión autofinanciada de $200.000, de acuerdo a la regla recibirá un APS de $16.176 y si recibe una pensión autofinanciada de 255.000 recibirá “0” pesos como APS. III.3. Implementación de la Reforma La reforma al sistema previsional se comenzó a implementar gradualmente a partir de julio de 2008 y estará en régimen en julio de 2011. Dentro de los principales impactos inmediatos de la reforma se encuentra: 1. Aumento de la pensión a los que recibían PASIS. Lo que en un principio implicó un aumento exógeno desde lo que recibían por PASIS (entre $45.000 y $59.000) a $60.000 (en régimen serían $75.000). 2. Reciben pensión aquellos que no recibían PASIS y que pertenecían al 40% más vulnerable de la población y que tuviera 65 años o más (en régimen 60%). Para esta población afectada lo relevante es que pasan de recibir “0” pesos por concepto de pensión a recibir $60.000 y luego $75.000. En el siguiente cuadro se observa cómo fue implementada la reforma al pilar solidario del sistema de pensiones. Como se señaló el primer paso fue entregar la PBS por un monto de $60.000 al 40% más vulnerable de la población y luego ir ampliando pausadamente la cobertura como el monto del PBS y le pensión máxima con derecho a aporte solidario. Así, una persona que en Septiembre de 2010 no tenía derecho a ningún tipo de pensión, por el hecho de pertenecer al 55% de los hogares más vulnerables del país tenía derecho a una PBS de $75.000. Si esa persona hubiese 5 6 Todas la cifras monetarias están en pesos 2009. En pesos 2009. 14 tenido derecho a una pensión autofinanciada de $170.000, de acuerdo a la formula hubiese obtenido un APS de $11.250, lo que finalmente le daría derecho a una pensión de $181.250. Por otro lado, si la misma persona hubiese tenido derecho a una pensión autofinanciada de $210.000, por encontrarse sobre el umbral de $200.000 no hubiese tenido derecho a APS y su pensión total hubiese quedado en los mismos $210.000. Fecha Julio de 2008 Julio de 2009 Septiembre de 2009 Julio de 2010 Julio de 2011 Cuadro 1: Implementación Reforma al Pilar Solidario Pensión Básica Pensión Máxima con Cobertura (% de los Solidaria Aporte Solidario hogares más vulnerable) $ 60.000 $ 75.000 $ 75.000 $ 70.000 $ 120.000 $ 150.000 40 45 50 $ 75.000 $ 75.000 $ 200.000 $ 255.000 55 60 Fuente: Ley 20.255 en pesos 2009. De esta forma, la reforma previsional implica un aumento en el monto de pensión inmediato para aquellas personas que eran beneficiarias de la Pensión Asistencial (efecto monto), y el acceso a un beneficio que antes no podía acceder para aquellas personas en el 40% más vulnerable que no calificaban para recibir PBS (efecto cobertura). Ambos efectos aumentan el ingreso no laboral de estas personas modificando su comportamiento, pudiendo cambiar sus decisiones laborales. 15 IV. Marco Teórico Para responder la pregunta de interés si la Pensión Básica Solidaria, mediante el incremento en el ingreso no laboral, cambia las decisiones laborales de los individuos, existe teoría económica documentada (Cahuc y Zylberberg 2004).En esta sección, se presenta el modelo económico básico de oferta laboral, el cual explota el trade-off que existe entre la decisión de los agentes entre consumo de bienes y consumo de ocio, para estudiar desde el punto de vista teórico los dos resultados de interés de esta investigación: 1. El efecto del ingreso no laboral sobre el número de horas trabajadas. 2. El efecto del ingreso no laboral sobre la decisión de participar o no del mercado laboral. IV.1. Modelo Básico de Ocio – Consumo Los supuestos del modelo son: 1. El individuo obtiene utilidad tanto del consumo de bienes (C) como del tiempo dedicado al ocio (O) y suponemos que ambos son bienes normales. Luego la función de utilidad se puede expresar por , . 2. El trabajo se remunera mediante un salario por unidad de tiempo (en este caso horas), el cual se denomina . 3. El precio del los bienes de consumo se normaliza en p=1. 4. El individuo tiene un ingreso no laboral, el cual se denomina . 5. El individuo elige cuanto tiempo (horas) dedicará al ocio (O) y cuanto a trabajar (L), de un total de tiempo disponible (T). Por lo mismo el ingreso total del individuo pasa a ser una variable endógena y queda representado por la siguiente ecuación . 6. Las preferencias por C y O son racionales, continuas, monotónicas y estrictamente convexas. Luego el problema del consumidor consiste en encontrar los niveles óptimos de consumo y ocio dado las restricciones que enfrentas, es decir: á , Sujeto a: (1) (2) Luego de maximizar (1) sujeto a (2) llegamos a la siguiente condición de primer orden, la cual señala que la tasa marginal de sustitución de ocio por consumo es igual a la razón de precios: ´ ´ (3) 16 De la ecuación (2) y (3) y dada una forma funcional que represente las preferencias descritas se puede ilustrar a partir de una simple derivada parcial cual deberían ser el impacto de un aumento del ingreso no laboral sobre las horas trabajadas y sobre la decisión de participar o no en el mercado laboral. IV.2. Impacto del Ingreso No Laboral en el Número de Horas Trabajadas Utilizando el Teorema de la Función Implícita (TFI) se puede representar la ecuación (3)de la siguiente forma: , (4) y luego introduciendo (4) en (2) se obtiene la siguiente ecuación: , , , , 0 (5) A partir de (5), usando el hecho que , , y el TFI tenemos que esta ecuación se puede re-expresar de la siguiente forma: , , , , , , , , 0 (6) Luego podemos obtener la derivada parcial de la oferta de trabajo con respecto al ingreso no laboral derivando (6) con respecto a 7 : ! "#$ 1/ Tenemos que ' ! ' ! (7) se deriva de la condición de óptimo expresada en (4), por lo cual necesariamente para un mismo nivel de si aumenta O debe aumentar C, luego la derivada expresada en la ecuación (7) es inambiguamente mayor que 0. Dado queL T O, tenemos que + "#$ es necesariamente menor que 0, luego un aumento del ingreso no laboral impacta negativamente en las horas trabajadas del individuo. IV.3. Impacto del Ingreso No Laboral en la Participación Laboral Para ver el impacto del ingreso no laboral sobre la decisión de participar o no en el mercado laboral se debe analizar cómo este ingreso impacta en el salario de reserva del individuo, el cual se define como aquel salario que deja indiferente a la persona entre trabajar y no trabajar, es decir 7 Las derivadas de la ecuación (7) viene de: ! "#$ ,- .,/,"#$ "#$ y ' ! ,0 .,! ! . Estas son las funciones que definen tanto O y C en las decisiones óptimas de los agentes para diferentes valores de las variables exógenas y las derivadas parciales que se calculan son sobre la decisión óptima de L. 17 aquel en el que T = O. Si el salario de reserva se incrementa ante un aumento del ingreso no laboral, tenemos que la participación laboral debería disminuir. De la ecuación (5), asumiendo que T = O y por TFI tenemos que 1 2 , . Luego se puede re-expresar (5) de la siguiente forma: 1 , , 2 , , 0 (8) Luego derivando (8) respecto a obtenemos lo siguiente8: .3 "#$ 1/ ' . (9) Sabemos que ante un aumento del salario el consumo aumenta, luego la expresión .3 "#$ es inambiguamente positiva, lo que significa que a mayor ingreso no laboral, mayor es el salario de reserva y por lo tanto menor es la disposición a trabajar, luego a mayor ingreso no laboral más baja es la participación en el mercado no laboral. 8 Las derivadas de la ecuación (9) viene de: este punto. .3 "#$ ,4 . y ' . = ,0 . . El mismo comentario de la nota número 7 vale para 18 V. Estrategia Empírica El objetivo del trabajo es medir el impacto de recibir el tratamiento (PBS) en la Oferta Laboral del individuo, es decir, tanto en las horas que trabaja el individuo como en su decisión de participar o no el mercado laboral. De esta forma, horas trabajadas y participación laboral serán las variables de resultados, las que por el momento denotaremos indistintamente como 5 , pero notando que en el primer caso la variable de resultado es continua, y en el segundo es binaria, por lo cual las metodologías de estimación serán diferentes y las apropiadas según corresponda. El impacto del tratamiento sobre un individuo i, denotado por 65 , está definido como la diferencia entre el resultado bajo tratamiento y el resultado en ausencia del tratamiento, es decir: 65 5 75 Donde 5 corresponde al resultado del individuo i en la situación con tratamiento e 75 representa el resultado del mismo individuo i en la situación sin tratamiento. Sin embargo, en términos empíricos es imposible observar al mismo individuo en una situación sin tratamiento y a su vez en la situación con tratamiento, es decir, sólo se observa 5 ó 75 . Justamente el desafío para poder realizar la evaluación de impacto está en encontrar un contrafactual apropiado, es decir, lograr medir que hubiese sucedido con el individuo que recibió el tratamiento sino lo hubiese recibido. Este trabajo se concentrará en la medición del impacto promedio del tratamiento o Average Treatment Effect (ATE), el que viene definido por la siguiente expresión: 89 965 9 5 75 Este parámetro puede ser estimado empíricamente a través del siguiente modelo de regresión lineal: 5 : ;<5 =5 Donde <5 es una variable binaria que toma valor 1 si la persona i recibe el tratamiento y 0 si la persona i no recibe el tratamiento. Se tiene que : 9>75 ?, ; 9>5 75 ? y =5 75 9>75 ?. Por lo cual, ; corresponde al ATE. Luego notemos que: 9>5 |<5 1? : ; 9>=5 |<5 1? 9>5 |<5 0? : 9>=5 |<5 0? 19 Entonces, 9>5 |<5 1? 9>5 |<5 0? ; 9>= ABBBBBBBBCBBBBBBBBD 5 |<5 1? 9>=5 |<5 0? EFEGH Así, en la medida de que el tratamiento sea asignado de manera aleatoria el coeficiente β en el modelo de regresión lineal planteado medirá el ATE o la diferencia entre los resultados promedios de los tratados y no tratados, de no ser así se obtendrá una estimación sesgada del ATE. El segundo término en la expresión anterior representa el sesgo de selección presente en la estimación si es que el tratamiento no es asignado de manera aleatoria. Al existir este sesgo, provocado por la correlación entre el error del modelo =5 y la variable de tratamiento <5 , la estimación de ; será inconsistente. En términos generales, podemos hablar de tres metodologías (sin contar realizar un diseño experimental) que permiten abordar este problema: 1. Método de Matching Propensity Score (PSM): asume que el sesgo de selección se basa en un set de características observables, las que permiten construir un grupo de control comparable según estas características como si el tratamiento hubiese sido asignado de manera aleatoria. Para su implementación bastaría tener datos en un momento del tiempo. 2. Método de Diferencias en Diferencias (DD): requiere datos de panel9, asume que el sesgo de selección está presente, pero que es constante en el tiempo. De esta forma, tomando diferenciasen el tiempo del grupo de tratamiento y del grupo de control se elimina el sesgo de selección constante en el tiempo, y luego tomando la diferencia entre las diferencias en el tiempo se obtiene el ATE consistente. 3. Metodología de Variables Instrumentales (IV): puede ser usada con Datos de Panel o Datos de Corte Transversal, y el problema de selección es solucionado a través de la utilización de un instrumento que define la asignación aleatoria del tratamiento. Este método permite que el sesgo de selección varíe en el tiempo10. Un caso particular de este método es el Método de Regresión Discontinua (RDD)11. Para esta investigación se disponen de dos fuentes de información: la Encuesta Longitudinal de Protección Social 2006-2009, y la encuesta de corte transversal CASEN 2009. La primera es una encuesta de aproximadamente 20,000 personas las que fueron entrevistadas por primera vez en el año 2002 y han sido entrevistadas nuevamente en los años 2004, 2006, y 2009, al ser una encuesta longitudinal es posible aplicar la metodología de diferencias en diferencias controlando 9 En estricto rigor no es necesario tener datos de panel, basta con tener los cuatro grupos definidos, lo que se podría obtener con dos cortes transversales. 10 Lo que se mide realmente con IV es un Local AverageTreatmenteEffect (LATE). 11 En la literatura aún existe debate sobre si RDD es IV propiamente tal. Angrist y Pischke, MostlyHarmlessEconometrics. 20 por un sesgo de selección invariante en el tiempo estimando el modelo por la metodología de efecto fijo o efecto aleatorio, testeando cuál de los dos es el más apropiado. La segunda es una encuesta de corte transversal con una cantidad de observaciones significativamente mayor a la EPS, aproximadamente 260 mil observaciones, lo que permite obtener resultados más robustos, pero la metodología de estimación del ATE requiere buscar en la misma base de datos un grupo de control para la eliminación del sesgo de selección, así en estos datos se aplicará la metodología de Propensity Score Matching. El cuadro 2 muestra una comparación entre las ventajas y desventajas de ambas metodologías. Si bien ambas estrategias no son directamente comparables porque tienen supuestos metodológicos y usan bases de datos distintas resulta un aporte desarrollar estas dos alternativas ya que tienen puntos a favor y en contra. Por lo demás es de esperar que de existir el impacto que se busca medir, ambas estrategias deberían dar resultados en la misma dirección o al menos no contradictorios. Los Datos Longitudinales de la EPS 2006- 2009 permiten realizar un estimador de Diferencias en Diferencias, lo que controla por factores individuales no observables o sesgo de selección. De esta forma, este estimador entrega una estimación no sesgada del ATE. Sin embargo, el supuesto clave justamente es que el sesgo de selección no es variable en el tiempo, si existiese alguna razón para pensar que las personas beneficiarias de la PBS toman ex - ante decisiones laborales diferentes a las personas no beneficiarias, este supuesto se invalida y el estimador de Diferencias en Diferencias seguirá siendo sesgado. Sin embargo, las estimaciones presentadas en la siguiente sección son acotadas a las personas con 65 años y más en el 30% de la población más vulnerable12, lo que de alguna forma minimiza la posibilidad de diferencias previas al tratamiento entre ambos grupos. La gran desventaja de estos datos, lo que llevó a buscar una alternativa de estimación utilizando la Encuesta CASEN 2009, es el pequeño tamaño muestral correspondiente a aquellas personas que tenían 65 años o más en 2006 y que pertenecían a la población más vulnerable. La Encuesta CASEN 2009 ofrece una cantidad de observaciones significativamente mayor para hacer un análisis robusto y eficiente de los resultados, sin embargo, al ser un corte transversal sólo nos permite obtener el estimador en primera diferencia, el sesgo de selección se elimina eligiendo un grupo de control mediante la metodología de Propensity Score Matching, la que se basa en que los beneficiarios son elegibles condicional en un conjunto de variables observables, no existiendo sesgo de selección en no observables. De esta forma, y condicional en las fuentes de información disponible, se utilizarán estas dos metodologías para la estimación de ATE. Las metodologías de variables instrumentales y regresión 12 Definido según el puntaje de la Ficha de Protección Social. 21 discontinua no se pueden aplicar para este análisis ya que no se cuenta con un instrumento apropiado (exógeno) que permita discriminar a los beneficiarios de los no beneficiarios.13 Cuadro 2: Comparación Metodologías Estimación Diferencias Diferencias Propensity Matching en Score Datos Panel EPS 2006-2009 Ventajas - Datos longitudinales que permiten controlar por sesgo selección invariante en el tiempo. Metodología - Controla por sesgo de selección en no observables. Por lo mismo no requiere del supuesto de exogeneidad condicional. Datos Casen 2009 - Tamaño muestral grande, muestra de 30,541 personas de 65 años o más, lo que permite obtener resultados eficientes y para diferentes grupos de interés. Metodología - No requiere de Datos longitudinales para su estimación. - Método semi-parámetrico que no requiere de muchos supuestos. Desventajas - Tamaño muestral pequeño, se tienen 1.837 individuos con 65 años o más en la primera ronda (2006), de los cuales 346 trabajaban en 2006 y 222 lo hacían en 2009. Lo que no permite hacer un análisis robusto para diferentes grupos en el caso de medir el ATE sobre el número de horas trabajadas. - Se asume que el sesgo de selección es invariante en el tiempo. - Se asume que los shocks macroeconómicos afectan a ambos grupos por igual. - Corte Transversal lo que no permite controlar por sesgo de selección invariante en el tiempo. Sólo se puede tomar la diferencia entre tratamiento y control en el año 2009 para ver el impacto sobre la variable de resultado. - Se basa en el supuesto, no testeable, de independencia condicional. - El sesgo de selección proviene de variables observables. 13 Si bien se obtuvo de datos administrativos el puntaje de la ficha de protección social, en los primeros años de implementación de la reforma, la asignación no fue 100% definida según este instrumento, es más tampoco se observa un cambio en la probabilidad de recibir el tratamiento en la vecindad del puntaje de corte, lo que ni siquiera permite llevar a cabo una metodología RDD Fuzzy. Además ocurre que en la vecindad del corte el número de observaciones se hace extremadamente pequeño. 22 V.1.Estrategia de Diferencias en Diferencias Cuando la variable de resultado es horas trabajadas (continua), estimador del ATE por Diferencias en Diferencias (ATEDD) está dado el parámetro φ3 en la siguiente ecuación: 9>5I |<5I , 5I ? J7 J KL J <KL J <KL KL 6M5I =5 N5I El que puede ser estimado utilizando datos de panel con efecto individual fijo o aleatorio. En efecto de puede testear cuál de los dos estimadores es apropiado para los datos mediante un Test de Hausman. Cuando la variable de resultado es participación laboral (binaria), el ATE estimado por Diferencias en Diferencias se obtiene de la siguiente manera: ATEQQ Φβ7 β β β β2 X UV Φβ7 β β2 XUV Φβ7 β β2 X UV Φβ7 β2 XUV Lo que requiere previamente estimar el siguiente modelo de probabilidad con datos de panel: E>YUV |DUV , TUV ? Φβ7 β DUV β TUV β DU TUV β2 XUV Dada la no linealidad del modelo de probabilidad sólo se puede utilizar la metodología de efectos aleatorios. Una explicación más detallada de esta estrategia en el anexo 1. V.2.Estimación vía Propensity Score Matching Cuando se utiliza la metodología de Propensity Score Matching el estimador ATE se obtiene de tomar la diferencia entre el resultado promedio de los tratados y el resultado promedio de los no tratados, donde el grupo de los no tratados ha sido elegido como contrafactual a través del propensity score. El efecto promedio del tratamiento se encuentra a partir de la siguiente formula. 89YZ[ ` 1 ]9 1K ^_K \ 5a Donde Y puede ser continua o discreta. Debemos notar dos cosas: la primera es que esta sumatoria se calcula sólo para las observaciones en el soporte común, y lo segundo es que Hb5 corresponde al contrafactual del individuo i, el que puede ser un solo individuo en el caso que el matching sea hace uno a uno, o un ponderado de los “j” individuos. Los algoritmos de matching serán Neighbor(1) y Kernel Normal. Una explicación más detallada de la estrategia en el anexo 2. 23 VI. Datos En esta sección se presentan las dos bases de datos que serán utilizadas en las estimaciones descritas en la sección anterior: Encuesta de Protección Social 2006-2009, y Encuesta CASEN 2009. Adicionalmente en el anexo 3 y 4, se entregarán ciertas estadísticas descriptivas sobre el comportamiento agregado de los datos que se están utilizando además de la descripción de variables utilizadas en las estimaciones. VI.1. Panel EPS 2006 – 2009 Las rondas del año 2006 y la del año 2009 de la Encuesta de Protección Social ofrecen un escenario antes y después de la Reforma Previsional. El Panel 2006-2009 tiene información para un total de 12.600 individuos en dos momentos del tiempo, de las cuales 1.837 representan a todas aquellas personas que en 2006 tenían 65 años o más. En el siguiente cuadro se encuentra información para el total de personas que en 2006 tenía 65 años o más. Se dividió la muestra de acuerdo a veintiles según el puntaje de la Ficha de Protección Social (FPS) quedando un 45% (veintil 12 al 20) de la muestra concentrado en el veintil 12, ya que ellos no tienen un puntaje asignado por la FPS. La importancia de la división de la muestra en veintiles tomara forma al momento de exponer los resultados. En cuanto a los datos, se observa que del total de 1.837, 413 son beneficiarios de PBS, de los cuales 167 eran ex PASIS y 246 nuevos beneficiarios por el aumento de cobertura que se originó en la reforma. Son 1.837 individuos correspondientes a 3.674 observaciones captadas en dos momentos del tiempo. 24 Veintiles Cuadro 3: Recepción de PBS por Tramo Ficha de Protección Social No PBS PBS PBS PBS Monto Total Cobertura 1 5% 30 14 14 0 44 2 10% 27 26 16 10 53 3 15% 54 41 19 22 95 4 20% 65 42 29 13 107 5 25% 72 36 19 17 108 6 30% 91 58 33 25 149 7 35% 114 42 19 23 156 8 40% 102 19 10 9 121 9 45% 94 27 18 9 121 10 50% 92 27 17 10 119 11 55% 93 5 3 2 98 12 100% 590 76 49 27 666 1.424 413 246 167 1.837 Total Nota: El universo se encuentra dividido entre receptores de PBS, no receptores de PBS, receptores por monto y receptores por cobertura. El universo es todo el grupo que tenías 65 años o más en 2006. Fuente: Elaboración Propia en Base al Panel EPS 2006 -2009 y datos administrativos IPS sobre FPS. En los siguientes dos cuadros se muestran las principales estadísticas descriptivas. Mientras en el cuadro 4 se observa información para el grupo de tratados (receptores de PBS), en el cuadro 5 se entregan cifras relativas al grupo de no tratados. En el cuadro 4, el número total de observaciones es 413, correspondiente a todas aquellas personas que recibieron PBS y que en 2006 tenían 65 años o más. Se observa que una porción muy baja de ellas trabajaba en alguno de los dos periodos (51 de 413 en 2006 y 32 de 413 en 200914) lo que será un problema al momento de querer medir el impacto de la PBS en el número de horas trabajadas. Además será necesario controlar por edad al momento de realizar las estimaciones, ya que sobre los 65 años cada año extra es más determinante que en otras etapas de la vida.15 14 En las estimaciones donde se ve el impacto sobre las horas trabajadas se considera a aquellas personas que trabajaron en alguno de los dos periodos. Como se verá el número de observaciones no nos permitirá llegar a conclusiones robustas en el tema. 15 La indispensabilidad de controlar por edad se debe a que sobre los 65 años de edad 3 años (años que hay entre encuesta) pueden ser completamente determinante y quizás el principal factor que explica la disminución en horas trabajadas. No controlar por ella podría hacer que se atribuya al tratamiento efectos que son propios de la edad en esa etapa de la vida. 25 Cuadro 4: Grupo de Receptores de PBS por Año Año 2006 Ingreso No Laboral Sin PBS Ingreso Total Resto Hogar Ingreso Por Hora Horas Trabajas Número de Personas Menores Personas en el Hogar Mayores en el Hogar Trabajan en el Hogar Sexo Edad Salud Jefe N 413 413 51 51 413 413 413 413 413 413 413 413 Media $30,572 $115,434 $4,068 38.5 0.8 3.6 1.6 0.6 0.33 72.6 4.1 0.6 Año 2009 D.S. $63,762 $249,994 $9,258 19.07 1.2 2.0 0.5 0.8 0.47 6.3 0.9 0.5 N 413 413 32 32 413 413 413 413 413 413 413 413 Media $30,017 $110,560 $4,277 37.1 0.7 3.4 1.6 0.1 0.33 75.3 4.0 0.6 D.S. $33,170 $142,441 $8,781 17.1 1.2 1.9 0.5 0.2 0.47 6.3 0.9 0.5 Nota: Se encuentran cifras de variables de interés relevantes para todas aquellas personas que tienen 65 años o más al 2006 y que fueron receptores de PBS. El “N” es menor para horas trabajadas e ingreso por hora debido a que un porcentaje menor del universo bajo análisis trabaja. Fuente: Elaboración Propia en Base al Panel EPS 2006 -2009. Cifras monetarias están pesos de 2009. En el cuadro 5 se observan las principales estadísticas descriptivas de los datos a utilizar para llevar a cabo las estimaciones para aquellos que NO recibieron la PBS, es decir aquellas personas que tienen 65 años y más y que no fueron tratados. Se observa diferencia en el nivel de ingreso no laboral, pero la diferencia es mucho mayor en el ingreso no laboral, la cual es la principal variable que se ve afectada por el hecho de recibir el tratamiento. La razón por la cual los “N” para horas trabajadas e Ingreso por hora difieren del total de la muestra es la misma que la explicada en el párrafo anterior al cuadro 5. Adicionalmente el lector podrá observar diferencias no menores entre el grupo de tratados y no tratados en otras variables. Debido a esta diferencia que existe entre el grupo de tratados y el de no tratados, en la sección “Estimaciones y Resultados” se explica los criterios de elección del grupo de control para así darle validez a los resultados obtenidos, lo que básicamente consisten en incluir como regresores aquellas variables donde existe diferencias de medias entre ambos grupos. 26 Cuadro 5: Grupo de NO Receptores de PBS por Año Año 2006 Año 2009 Ingreso No Laboral Sin PBS Ingreso Total Resto Hogar Ingreso Por Hora Horas Trabajas Personas Menores Personas en el Hogar Mayores en el Hogar Trabajan en el Hogar Sexo Edad Salud Jefe N 1424 1424 295 295 1424 1424 1424 1424 1424 1420 1424 1424 Media $145,230 $141,242 $9,088 43.1 0.8 3.6 1.5 0.7 1.1 72.9 3.8 0.8 D.S. $188,365 $294,818 $26,090 15.7 1.2 1.9 0.6 0.8 1.0 6.5 1.0 0.4 N 1424 1424 190 190 1424 1424 1424 1424 1424 1420 1423 1424 Media $161,501 $139,471 $8,035 43.4 0.7 3.4 1.5 0.1 1.1 75.6 3.8 0.8 D.S. $220,051 $367,363 $24,030 17.8 1.1 1.8 0.6 0.2 1.0 6.5 0.9 0.4 Nota: Se encuentran cifras de variables de interés relevantes para todas aquellas personas que tienen 65 años o más al 2006 y que NO fueron receptores de PBS. El “N” es menor para horas trabajadas e ingreso por hora debido a que un porcentaje menor del universo bajo análisis trabaja. Fuente: Elaboración Propia en Base al Panel EPS 2006 -2009 y las cifras monetarias están pesos de 2009. VI.2. CASEN 2009 Para responder a la pregunta de investigación también se usó la CASEN 2009, la cual tiene 30.541 observaciones para personas que se encuentran en edad de jubilar de los cuales 11.545 son beneficiarios de la PBS (Cuadro 6). A diferencia del caso con el Panel EPS aquí no se puede diferenciar entre aquellos que eran ex PASIS y aquellos que no, y además no tenemos como diferencias por nivel de vulnerabilidad (en base al puntaje en la Ficha de Protección Social) y por lo mismo las estratificaciones se hacen en base los deciles de ingresos. Cuadro 6: Grupo Receptores y No Receptores por Deciles de Ingreso Decil 1 2 3 4 5 6 7 8 9 10 Total No PBS PBS Total 1.415 2.197 2.311 2.379 2.619 2.180 1.804 1.677 1.457 957 18.996 4.652 1.823 1.362 951 806 680 515 357 278 121 11.545 6.067 4.020 3.673 3.330 3.425 2.860 2.319 2.034 1.735 1.078 30.541 Nota: Beneficiarios y No Beneficiarios de PBS dentro de todo el universo de personas que declaran tener 65 años o más. Separado por deciles de ingreso per cápita del hogar. Fuente: Elaboración Propia en Base a CASEN 2009 27 En el cuadro 7 se observan las principales estadísticas descriptivas de los datos a utilizar para llevar a cabo las estimaciones vía PSM. Para efectos de las estimaciones se utilizarán los cinco primeros deciles16, de esta forma se observa que el total de NO beneficiarios de la PBS para los 5 primeros deciles es 10.921 y de 18.996 como lo era al momento de considerar a toda la población mayor de 65 años. El número de beneficiarios de la PBS baja de 11.545 a 9.594 al focalizar la atención en 5 primeros deciles. La razón de porque cae más el número de NO beneficiarios que el de beneficiarios es porque los beneficiarios están concentrados en los deciles de menores ingresos. Cuadro 7: Variables para Receptores y No Receptores /5 Primero Deciles. No reciben PBS Ingreso No Laboral Sin PBS Ingreso Total Resto Hogar Ingreso Por Hora Horas Trabajas Número de Personas Menores Personas en el Hogar Mayores en el Hogar Trabajan en el Hogar Sexo Edad Salud Jefe Reciben PBS N Media D.S. N Media D.S. 10921 88757.5 58164.2 9594 4349.3 20073.7 10921 124675.3 164547.6 9594 126913.6 161624.3 965 965 5243.9 40.1 8037.3 17.0 624 624 5289.4 35.3 13129.8 19.4 10921 0.6 0.9 9594 0.4 0.9 10921 10921 10921 10921 10921 10888 10921 3.2 1.5 0.8 0.5 74.3 4.3 0.7 1.9 0.6 1.2 0.5 73.4 1.5 0.4 9594 9594 9594 9594 9594 9565 9594 3.1 1.6 0.7 0.4 74.2 4.2 0.5 1.8 0.6 1.1 0.5 70.7 1.4 0.5 Nota: Se encuentran cifras de variables de interés relevantes para todas aquellas personas que tienen 65 años o más al momento de la encuesta. Se encuentra separado para receptores como para no receptores. Fuente: Elaboración Propia en Base a CASEN 2009 VI.3. Validez Macro y Descripción de Variables En el Anexo 3 se encuentra información sobre comportamiento agregado de los datos y su relación con la encuesta de empleo del INE, mientras que en el Anexo 4 se encuentra la descripción de las variables utilizadas en las estimaciones bajo ambas metodologías. 16 La razón de ello se explica en la sección “Estimaciones y Resultados”. 28 VII. Estimaciones y Resultados En esta sección se exponen los principales resultados de las estimaciones realizadas. La sección se divide en 2. Aquella relativa a la metodología de Diferencias en Diferencias utilizando el Panel EPS 2006-2009, y aquella que utiliza el método de Propensity Score Matching con la Encuesta CASEN 2009. Para la definición de variables ver anexo 4. VII.1. Metodología de Diferencias en Diferencias VII.1.1. Efecto del Tratamiento en las Horas Trabajadas El estimador del ATE usando la metodología de Diferencias en Diferencias se obtiene de estimar el siguiente modelo: 9>5I |<5I , 5I ? J7 J 5I J <5I J <5I 5I 6M5I =5 N5I Utilizando los datos longitudinales de la Encuesta de Protección Social rondas 2006 y 2009, y aplicando las metodologías de efectos fijos y efectos aleatorios. Sabemos que bajo el supuesto de no correlación entre los efectos individuales aleatorios y las variables explicativas del modelo, el estimador de efectos aleatorios es consistente y eficiente, y preferido al de efectos fijos. Para cada uno de los modelos se realizan ambas estimaciones (efecto fijo y aleatorio) y se utiliza el Test de Hausman para decidir si efectos aleatorios es válido. La muestra utilizada para las estimaciones consiste en las personas con 65 años o más de edad en el año 2006, que se encuentran en ambas rondas de la encuesta, y que trabajaron en alguno de los dos años. Esta muestra es de 400 individuos, es decir 800 observaciones. La Tabla 1 (anexo 5) muestra los resultados del estimador de diferencias en diferencias a través de tres modelos diferentes. Las dos primeras columnas muestran los resultados del modelo más sencillo donde no se controla por otras variables explicativas, tanto la estimación de efecto aleatorio (primera columna) como por efecto fijo (segunda columna) muestran un coeficiente φ3 no significativo. Las columnas (3) y (4) incorporan a las estimaciones anteriores características de la personas como sexo, edad, edad al cuadrado, ser jefe de hogar, ingreso no laboral y estado de salud, nuevamente el coeficiente que mide el ATE no resulta significativo, lo que si resulta ser estadísticamente significativo es el estado de salud de las personas, mientras peor es su reporte de salud trabajan en promedio menos horas a la semana, y el ingreso no laboral, donde se observa que a mayor ingreso no laboral menor es la cantidad de horas trabajas en promedio. Las columnas (5) y (6) muestra las estimaciones por efecto fijo y aleatorio incorporando al modelo anterior características del hogar como: ingreso de las otras personas del hogar, número de personas mayores, número de personas menores, y número de personas que trabajan, los resultados anteriores no se ven afectados controlando por estas variables y ninguna de ellas es estadísticamente significativa. En estos tres modelos estimados no se puede rechazar el estimador 29 de efectos aleatorios. Finalmente, las columnas (7) y (8) incorporan una variable binaria que toma valor 1 si la actividad económica donde trabaja la empresa tuvo crecimiento en el empleo en el periodo de tiempo 2006-2009, y cero sino. Esta variable tiene un coeficiente positivo y altamente significativo, sin embargo, no existen cambios con respecto al estimador del ATE y las otras variables del modelo. En este último modelo se rechaza el modelo de efectos aleatorios. La Tabla 2 (anexo 5) muestra las estimaciones de los modelos (1) al (8) de la Tabla 1 pero ahora restringiendo las observaciones a aquellos individuos que se encuentran en el 50% de la población más vulnerable, de forma tal que el grupo de control sea más comparable al de tratamiento. Los resultados son bastante similares a los ya encontrados, el ATE no es significativo, y sólo el estado de salud de las personas tiene un efecto significativo sobre las horas trabajadas. VII.1.2. Efecto del Tratamiento en la Participación Laboral Para medir el ATE sobre participación laboral podemos estimar un modelo similar al utilizado para las horas trabajadas, sin embargo, al ser la variable dependiente binaria estaríamos estimando un modelo de probabilidad lineal el que tendrá problemas de eficiencia debido a la heterocedasticidad, y posibles predicciones fuera de rango. Lo correcto es estimar un modelo no lineal de probabilidad tipo Probit: E>YUV |DUV , TUV ? Φβ7 β DUV β TUV β DU TUV β2 XUV Pero en este modelo β3 no representa el ATE. Este debe ser calculado de la siguiente manera: ATE Φβ7 β β β β2 XUV Φβ7 β β2 XUV Φβ7 β β2 XUV Φβ7 β2 XUV La Tabla 3 (anexo 6) muestra los resultados de estimar, mediante Probit en Panel con efecto aleatorio, un modelo donde además de las variables para medir el efecto del tratamiento se han incorporado otras variables que permiten controlar por características individuales como sexo, edad, edad al cuadrado, si la persona es jefe de hogar, estado de salud e ingreso no laboral, y otras que permiten controlar por características del hogar, como el ingreso de los restantes miembros del hogar, número de personas en el hogar y número de personas que trabajan. La columna (8) de la Tabla 3 muestra los coeficientes estimados para este modelo considerando el total de personas que en el 2006 tenían 65 años o más de edad, se obtiene un coeficiente negativo y estadísticamente significativo para la variable interactiva de tiempo y tratamiento, aunque esta variable no mide exactamente el ATE, nos muestra un efecto negativo del tratamiento en la variable latente. En las restantes columnas de la Tabla 3 lo que se hace es acotar las estimaciones por grados de vulnerabilidad: el 50% más vulnerable, 30% más vulnerable, etc., hasta llegar al 5% más vulnerable. La idea es obtener un mejor grupo de control para las estimaciones. 30 La Tabla 4 (anexo 6) replica las estimaciones de la Tabla 3 pero incluyendo como regresores sólo aquellas variables que tienen diferencia de media significativa17 entre el grupo de control y tratamiento y de esta forma identificar de mejor manera los parámetros de interés. La mayoría de los modelos (con diferentes grupos de control) nos muestran resultados similares: un efecto negativo y significativo de la interacción de tiempo y tratamiento, un efecto negativo y significativo del ingreso no laboral y de estado de salud, y un efecto positivo y significativo de la variable género (hombre). Considerando la muestra de personas que en el año 2006 tenían 65 años y más, y que además están en el 30% más vulnerable, ya que este modelo presenta el mejor equilibrio entre cantidad de observaciones y significancia18, se estimaron diferentes versiones del modelo por Probit en Panel con efectos aleatorios. Los coeficientes estimados son presentados en la Tabla 5 (anexo 6). Utilizando el criterio de información Bayesiano (BIC) se escoge como mejor modelo el presentado en la columna (5). La variable tratamiento en este caso incluye tanto a las personas que vieron incrementado el monto de la pensión (ya que eran beneficiarios de PASIS) como aquellas personas que comenzaron a ser beneficiarios (efecto cobertura). Luego, este modelo es estimado en diferentes muestras (Tabla 6) que permiten visualizar de mejor manera de donde proviene el efecto negativo encontrado. Las primeras dos columnas de la Tabla 6 muestran las estimaciones del modelo seleccionado utilizando el criterio BIC, pero diferenciado por sexo. Se observa claramente que el efecto negativo del tratamiento sobre la variable latente que determina la participación es mayor en las mujeres que en los hombres. Para las estimaciones que se muestran en las columnas (3), (4) y (5) de la Tabla 6 el tratamiento ya no se considera como el hecho de haber recibido PBS, sino como el hecho de haber recibido PBS por concepto de cobertura, es decir se consideran como tratados sólo aquellos individuos que reciben PBS, pero que no eran beneficiarios de la PASIS. Se hace para todos y diferenciado por sexo. Se obtiene que el efecto cobertura tiene un efecto negativo sobre la variable latente que determina participación, tanto para el total de la población como cuando nos concentramos en las mujeres. Finalmente en la columna (6) de la misma tabla el universo del modelo expuesto son todos aquellos que recibieron PBS y que pertenecen al 30% más vulnerable, pero se considera como tratados sólo a aquellos que eran ex beneficiarios PASIS y como grupo de control a aquellos que se 17 El modelo de diferencias en diferencias supone que en T=0 no existen diferencias entre el grupo de control y tratamiento. Por lo mismo además de acotar por grados de vulnerabilidad, igual es necesario incorporar variables observables donde persistan diferencias entre el grupo de tratamiento y de control. 18 La elección de hacer los análisis sobre el universo del 30% más vulnerable de las personas en edad de jubilar se justifica en la medida que la estrategia DD supone que los grupos de control y de tratamiento son comparables. Por lo mismo al elegir un modelo parsimonioso entre cantidad de datos y significancia se está minimizando la posibilidad de que hayan no observables entre ambos grupos que difieran fuertemente. La diferencia en observables no es del todo grave porque al menos se puede contralar por esas variables. 31 vieron beneficiados sólo por concepto de cobertura. Como el cambio en la pensión es menor para aquellos ex PASIS que para el resto de los recipientes de PBS y que no recibían nada, es de esperar que el coeficiente que acompaña a la variable “time*treat” en este caso sea positiva, lo que efectivamente ocurre. Como se ha dicho a lo largo del trabajo, los coeficiente que se obtienen en la Tabla 6 no representan el ATE y por lo mismo este efecto hay que calcularlo de acuerdo a lo señalado en la sección estrategia empírica. El cuadro 8 muestra las estimaciones del ATE sobre la probabilidad de participar en el mercado del trabajo para los modelos más relevantes estimados. Primero muestra que al ver el efecto de recibir PBS (monto y cobertura de manera simultánea) resulta ser significativo sólo para las mujeres, el impacto es una disminución en 10 puntos de probabilidad. Ahora cuando nos concentramos en el efecto cobertura solamente, se tiene que el impacto del tratamiento es una disminución en 14 puntos de probabilidad de participar, lo que se explica fundamentalmente por las mujeres, ya que en los hombres no existe impacto significativo. Finalmente, cuando nos concentramos en el efecto monto solamente se obtiene un impacto positivo de la PBS sobre la probabilidad de trabajar. Como era de esperar, los signos de los coeficientes se mantienen en relación a lo observado en la tabla 6 (anexo 6), pero ahora si se está estimando el ATE. Cobertura y monto Cuadro 8: ATE sobre Probabilidad de Trabajar N ATE observado ATE estimado Total 551 -0,0621 -0,0577 Mujeres 258 -0,1057 -0,0945 Hombres Cobertura Total Mujeres Hombres Monto Total 293 551 258 293 216 0,0118 -0,1398 -0,1459 -0,0887 0,1578 0,0245 -0,1371 -0,137 -0,0815 0,1597 Modelo MICO Modelo 5 /Tabla 5 -0.0403 Modelo 1 /Tabla 6 -0.132** Modelo 2 /Tabla 6 -0.00884 Modelo 3 /Tabla 6 -0.0969* Modelo 4 /Tabla 6 -0.158*** Modelo 5 /Tabla 6 -0.0832 Modelo 6 95% /Tabla 6 0.126* Intervalo de confianza -0,119 0,0029 90% -0,1302 0,0137 95% -0,1521 -0,0401 90% -0,1551 -0,0317 95% -0,0856 0,1394 90% -0,1024 0,1573 95% -0,2209 -0,0602 90% -0,2313 -0,0507 95% -0,2166 -0,065 90% -0,2282 -0,0482 95% -0,2295 0,0697 90% -0,2599 0,09 95% 0,0655 0,2604 90% 0,0455 0,2813 Nota: Personas con 65 años y más del 30% más vulnerable 19 Nota: Intervalos de Confianza obtenidos mediante Bootstrap en base a 500 repeticiones Nota: Estimación MICO *** 1%, **5% y * 10% de significancia. 19 El tamaño muestral de las estimaciones es reducido, por esta razón se optó por calcular los intervalos de confianza mediante boostrap. 32 Finalmente, y simplemente a modo de comparación se estiman los 7 modelos involucrados en el cuadro 8 por MCO, en el modelo de probabilidad lineal el coeficiente que acompaña a la interacción de tratamiento y tiempo mide directamente el impacto de la PBS sobre la probabilidad de trabajar, los resultados son bastante similares a los obtenidos por la metodología anterior y los coeficientes se pueden ver en la última columna del Cuadro 820. No se encuentra un impacto significativo al analizar cobertura y monto simultáneamente en el total de las personas con 65 años y más y en el 30% más vulnerable, sólo en las mujeres donde el impacto es negativo y de 13.2 puntos de probabilidad. Cuando analizamos de manera separada el efecto cobertura, se obtiene un impacto negativo de 9.7 puntos de probabilidad en el total, y negativo de 15.8 puntos de probabilidad en las mujeres, no se encuentra efecto significativo para los hombres. Finalmente, el efecto monto es positivo de 12.6 puntos de probabilidad. VII.2. Estimaciones utilizando Propensity Score Matching (PSM) En esta sección se exponen los principales resultados de la estimación ATE utilizando los datos de la CASEN 2009 y la metodología de Propensity Score Matching (PSM). En primer lugar se habla del cumplimiento de la condición de independencia, luego se exponen los impactos estimados para el número de horas y finalmente se exponen resultados para el impacto en la participación laboral. VII.2.1. Condición de Independencia El supuesto clave de identificación del ATE a través de esta metodología es la condición de independencia, la que sostiene que luego de controlar por características observables la probabilidad de recibir el tratamiento es aleatoria. A pesar de que esta condición no es testeable empíricamente se tienen los suficientes argumentos para sostener que esta condición se está cumpliendo: 1. Para la estimación del Propensity Score se consideran las variables que son relevantes en determinar la probabilidad de recibir PBS, esperando un alto grado de correlación entre estas variables y la asignación. La PBS se entrega de acuerdo al puntaje en la Ficha de Protección Social (FPS), la cual mide el grado de vulnerabilidad de una familia de acuerdo a características observables del grupo familiar. Por lo mismo como determinantes de recibir el tratamiento se deben incluir características del hogar que determinan el puntaje en la FPS: Ingreso Autónomo del Hogar, Ingreso por Subsidio del Hogar, Número de Personas Mayores, Número de Mujeres, Número de Personas que Trabajan en el Hogar y Escolaridad Promedio del Hogar. A mayor puntaje en FPS menos vulnerable y menos probabilidad de recibir el tratamiento21. 20 Se eligió poner el coeficiente de efecto fijo o aleatorio dependiendo de si se rechazaba o no la existencia de efecto aleatorio. 21 Ver Larrañaga O. y Contreras D., (2010). 33 2. Al ser una política relativamente reciente y sorpresiva para la población, resulta plausible argumentar que no existen conductas adoptadas por los individuos para conseguir la Pensión Básica Solidaria. La reforma en sí, las características de su gradualidad en la implementación y su grado de focalización no pueden haber sido previsto por nadie y por lo mismo no es igual que analizar el impacto de una política que lleva 10 años de funcionamiento. 3. Además de un primer modelo más general, los modelos estimados son acotados a diferentes grupos de interés de manera tal minimizar la probabilidad de sesgo por no observables. VII.2.2. Efecto del Tratamiento en las Horas Trabajadas En primer lugar se estima un modelo bastante general y luego se exponen resultados asociados a modelos más específicos, separados por categoría de ocupación e ingreso no laboral. Para cada uno de ellos lo primero que hay que hacer es estimar el Propensity Score, el cual se realiza tomando en consideración los siguientes tres puntos: 1. Incluir variables que determinan la probabilidad de recibir PBS, es decir variables a nivel de hogar que afecten el grado de vulnerabilidad de este. 2. Incluir variables que además afecten el output objetivo, es decir el número de horas trabajadas como por ejemplo salud del individuo, edad del individuo, ingreso no laboral del individuo y escolaridad del individuo. 3. Se tiene especial cuidado con Ingresos por Subsidios del Hogar (los cuales son determinantes del puntaje de la FPS), ya que hay que excluir el ingreso por concepto de PBS. No se puede meter el ingreso por concepto de PBS si lo que se está determinando es la probabilidad de recibir PBS. Una vez definidas las variables que potencialmente se pueden incorporar en el modelo es necesario hacer las regresiones correspondientes y elegir el modelo que mejor se ajusta a los objetivos, teniendo precaución en que no sea a costa de incluir variables irrelevantes o que puedan ser muy colineales entre ellas, ya que, además de inflar el modelo artificialmente, se afectaran en términos negativos la varianza de los efectos estimados y disminuirán la posibilidad de encontrar un buen soporte común. El primer set de modelos que se estima incluye un modelo general de horas, el cual además se separa entre trabajadores dependientes e independientes, división que se justifica porque los trabajadores dependientes están sujeto a un contrato que en general tienen un número fijo de horas presenciales semanales y por lo mismo pueden estar menos sujetos a cambios en la cantidad de horas a trabajar. Las estimaciones se hacen para aquellos individuos que tienen más 34 de 65 años, que pertenecen a los 5 primeros deciles de ingreso y que obviamente se encuentran trabajando. La razón de escoger los deciles más pobres, se debe a que en el matching el objetivo es elegir un “match” que permita concluir que después de controlar por observables la asignación del tratamiento sea aleatoria. Como es obvio hay potenciales no observables por los cuales no se puede controlar, por lo mismo se acota la muestra, ya que los no observables pueden variar mucho a través de ella y al considerar sólo al 50% más pobre estos problemas se deberían reducir notablemente. La razón de escoger un umbral diferente al elegido para las estimaciones de Diferencias en Diferencias radica en que al momento de la encuesta CASEN 2009 (noviembre) el beneficio tenía una mayor cobertura y era más conocido que al momento de la encuesta EPS 2009 (Abril)22 Sólo para el primer modelo se realiza una descripción más detallada del significado de los determinantes del Propensity Score, la cual se encuentra en el anexo 7. Luego en el anexo 8 el lector podrá ver información relativa a las estimaciones del Propensity Score para el resto de los modelos de horas trabajadas, al cumplimiento de las condiciones de soporte común y aquellos test que nos dan cuenta de la calidad del matching para todos los modelos de horas trabajadas. Para este primer set de modelos (todos los trabajadores, trabajadores dependientes e independientes) los resultados del ATE se encuentran en el cuadro 10. Se observa que la evidencia no es concluyente al incluir a todo tipo de trabajadores en la muestra, ya que bajo el algoritmo Neighbor(1) el efecto es negativo y significativo, mientras que bajo la metodología Kernel el efecto es negativo, pero no significativo. También se observa que para los trabajadores dependientes no hay efecto del tratamiento, lo que en parte se podría explicar porque para ellos las horas semanales de trabajo están reguladas por ley. Para el caso de los trabajadores independientes se obtiene que aquellos que recibieron el tratamiento trabajan en promedio 3.3 horas menos horas a las semana, lo que representa alrededor de un 10% del total de horas trabajadas., lo que indica que el efecto del tratamiento en el número de horas trabajadas estaría dado por efecto sobre los trabajadores independientes. 22 La asignación de la PBS fue implementada gradualmente a partir de julio de 2008, enfocada en el 40% más vulnerable de la población en edad de jubilar y asignando una PBS por un monto de $60.000. En septiembre de 2009 la reforma se extendió al 50% de la población con una PBS por un monto de $75.000. La encuesta CASEN fue recogida fundamentalmente en noviembre de 2009 cuando la reforma ya llevaba más de un año implementada, mientras que la EPS 2009 fue recolectada en abril de 2009, momento en el cual la reforma llevaba casi 10 meses de implementación con una pensión de 60.000. Por lo mismo al momento de la CASEN había una mayor cobertura y un mayor conocimiento por parte de la población de los beneficios de la reforma que en el momento en que se recogió la EPS 2009. 35 Cuadro 10: Primer Set de Modelos Horas Trabajadas Output Estadísticos NearestNeighbor(1) Normal Kernel Hora Trabajadas Media Muestral = 38.2 Total de Trabajadores Hora Trabajadas Media Muestral = 42.3 Trab. Dependientes Hora Trabajadas Media Muestral = 34.6 Trab. Independientes Diferencia -3.15** -1.72 CI por Bootstrap (500) [-6.14; -1.86] [-4.08; 0.002] Diferencia -0.21 -0.15 CI por Bootstrap (500) [-4.11; 4.34] [-3.85; 3.02] Diferencia -3.65** -3.07** CI por Bootstrap (500) [-8.65; -0.413] [-6.05; -0.29] Nota: ** Significancia al 5% y * Significancia al 10%/ Intervalos con 95% de confianza. Un refinamiento del modelo que incluye sólo a los trabajadores independientes, es hacerlo sólo para aquellos que no reciben ingreso por pensión. Como se ha dicho reiteradamente a lo largo del trabajo a la PBS sólo tienen acceso aquellos que no reciben ningún tipo de pensión autofinanciada y por lo mismo al ser esta una variable tan clara en la discriminación entre recibir o no el tratamiento es necesario (Caliendo 2005) analizar el efecto del tratamiento entre aquellos que no tienen ingreso por pensión autofinanciada, lo que se logra incluyendo en las estimaciones sólo a aquellos que tienen ingresos no laborales iguales a 0. Si bien no tener ingresos por pensión no sinónimo de no tener ingresos no laborales, para la muestra (los deciles bajo análisis) es muy similar. Además hay una mayor probabilidad de controlar por aquellos no observables restringiendo la muestra sólo a aquellos que no tienen ingreso no laboral. En el cuadro 11 se observa que el caso de los trabajadores independientes que no tienen ingreso no laboral se obtiene que aquellos que recibieron el tratamiento trabajan alrededor de 3.9 horas menos horas a las semana, lo que representa más de un 10% del total de horas trabajadas. La información que le da validez a las estimaciones se encuentra en el anexo 8. Cuadro 11: Resultados Trabajadores Independientes sin Ingreso no Laboral Outcome Estadísticos NearestNeighbor(1) Normal Kernel Hora Trabajadas Media Muestral = 36.3 Trabajadores por C. Propia Diferencia -3.85** -3.90** CI por Bootstrap (500) [-7.76; -1.04] [-7.93; -1.25] Nota: ** Significancia al 5% y * Significancia al 10% /Intervalos de Confianza con 95% Al separar este último modelo por género se observa que el efecto viene dado por los hombres independientes. Además si este último modelo se replica sólo para trabajadores dependientes se observa que los resultados son altamente no significativos. Estos últimos resultados no se presentan con el objeto de disminuir el uso de cuadro, tablas y gráficos. 36 VII.2.3. Efecto del Tratamiento en la Participación Laboral Para la estimación del Propensity Score se utilizó el modelo expuesto en la Tabla 15 (anexo 9). En este caso se tiene que el universo es mucho mayor ya que lo que se quiere medir es el impacto en la participación y no en las horas trabajadas. El universo se acoto (al igual que el caso anterior) a todos aquellos que tenían más de 65 años y que pertenecen a los 5 primeros deciles de ingreso. En el cuadro 12 se observa que aquellos que reciben el tratamiento participan en promedio -3.3 puntos porcentuales menos que aquellos que no lo reciben, lo que representa un efecto de más de un 30% del promedio de participación nacional (8.5%) para aquellos que tienen más de 65 años y pertenecen a alguno de los 5 primero deciles. Cuadro 12: Efecto Promedio del Tratamiento en La Participación Laboral Output Estadísticos NearestNeighbor(1) Normal Kernel Participación Media Muestral = 0.085 Diferencia -0.033** -0.029** CI por Bootstrap (500) [-0.065; -0.004] [-0.073; -0.0031] Nota: ** Significancia al 5% /Intervalos de Confianza con 95% No obstante que los resultados son acuerdo a lo esperado en materia de participación laboral resulta relevante analizar el cumplimiento de las condiciones básicas para la realización del matching. En la siguiente figura se observa que si bien se cumple la condición de traslape, el “match” realizado entre tratados y no tratados no es bueno y por lo mismo los resultados a los cuales se llega no pueden ser concluyentes. En la tabla 16 (anexo 9) se encuentran los test estadísticos que dan cuenta de cómo en el modelo de participación después de realizar el “match” aún persisten diferencias significativas en algunas variable relevante entre el grupo de tratamiento y el grupo de control. Figura 1: Distribución Propensity Score entre Tratados y No Tratados. 37 Participación Laboral23 Un refinamiento del modelo anterior consiste en analizar el impacto del tratamiento en la participación laboral para aquellas personas que son jefes de hogar hombres y que viven en zona urbana. La única variante a incorporar en este segundo modelo será acotar este mismo modelo aquellas personas que tienen entre 65 y 75 años. No se incluyen resultados para aquellas personas que son mujeres, no jefes de hogar o que viven en zonas rurales porque para estos universos no se cumplen algunos supuestos básicos para la utilización del método de estimación. Con estos grupos ocurre que los modelos de selección tiene un ajuste muy bajo (Pseudo R2 inferior a 0.05 o 0.09 en el mejor de los caso) y la diferencia de medias luego del “match” es estadísticamente significativa entre el grupo de tratados y el grupo de control para varias variables de interés, es decir la calidad del “match” es baja y se observan curvas similares a la expuesta en la figura 1. En el modelo estimado se encuentran resultados negativos y significativos del tratamiento sobre la participación laboral (cuadro 13). Para todos aquellos que tienen más 65 años y que pertenecen al grupo objetivo se encuentra que el hecho de recibir el tratamiento disminuye en 20 puntos porcentuales la probabilidad de participar en el mercado laboral. Si se acota la muestra sólo a los que tienen entre 65 y 75 años de edad dicha cifra se ubica entre 26 y 21 puntos porcentuales dependiendo del algoritmo bajo el cual se haga el análisis. 23 Tanto los test de medias como las figuras mostradas que se presentan son sólo en base a los resultados arrojados por el algoritmo Neighbor(1). 38 Cuadro 13: Modelo Refinado de Participación Laboral Output Estadísticos NearestNeighbor(1) Normal Kernel Participación Laboral Media Muestral = 0.28 Todos los Mayores de 65 Participación Laboral Media Muestral = 0.40 Entre 65 y 75 Diferencia -0.21** -0.18** CI por Bootstrap (500) [-0.27; -0.17] [-0.24; -1.13] Diferencia -0.26** -0.21** CI por Bootstrap (500) [-0.41; -0.008] [-0.28; -0.12] ** Significancia al 5% y * Significancia al 10%/Intervalos de Confianza con 95% Respecto a la calidad del “match” para este modelo se observa que para el caso de todos aquellos que están en edad de jubilar hay sólo dos variables de interés en las cual las diferencias persisten luego del “match” no obstante tal como se observa en la figura del anexo correspondientes estas no causan el daño mostrado en la figura 1 recién expuesta24. Al acotar la muestra a aquellos que tienen entre 65 y 75 años de edad la diferencia se mantiene sólo en una variable. El ajuste del modelo de asignación de tratamiento no resulta ser tan bueno para medir el impacto en participación laboral, lo que se puede deber a que en esta decisión existen no observables importantes que no pueden ser capturados a través del modelo, y los que atenta contra el supuesto de independencia condicional, implicando que los resultados sobre participación laboral sean poco robustos. ¿Por qué no se separó por más categorías para el caso en que se analizaron las horas trabajadas como si se hizo para este último modelo de participación laboral? ¿O por qué no se separó por estas mismas categorías en el método de diferencias? Simplemente porque la cantidad de datos no permitía hacerlo. VII.3. Análisis de Resultados En base a la estrategia de Diferencias en Diferencias no es posible concluir sobre el efecto del tratamiento en las horas trabajadas de los individuos, lo que puede estar explicado en gran parte por la poca cantidad de observaciones para la realización de este análisis. Sin embargo, al ver el efecto sobre la participación laboral si se obtienen resultados concluyentes, los cuales además están en línea con lo señalado por la teoría. Se encuentra que para las mujeres existe un efecto negativo del tratamiento (recibir PBS) sobre la probabilidad de participar en el mercado laboral, lo que no ocurre para los hombres. Al utilizar como grupo de tratados sólo a aquellos que recibieron PBS, pero que no eran beneficiarios PASIS, se encuentra que hay un efecto del tratamiento sobre la probabilidad de salir del mercado laboral, 24 En el anexo 9 se puedo observar la figura para todos aquellos mayores de 65 años. La figura para los que tenían entre 65 y 75 años es muy similar. 39 lo que viene explicado por las mujeres tratadas, ya que al separar las estimaciones por sexo, se encuentra que para los hombres el efecto no es significativo. Se encuentra que el efecto es mayor en valor absoluto (-14 v/s -10) para las mujeres que recibieron PBS por concepto de cobertura que para aquellas que la recibieron sólo por monto (ex PASIS), lo que está de acuerdo con la teoría en el sentido que aquellas mujeres que no eran beneficiarias PASIS pasaron de tener una pensión nula a tener un pensión de $60.000, mientras que para aquellas que eran beneficiarias PASIS, el salto fue de menos de $10.000. Este punto se ve reforzado al hacer el análisis sólo para la población beneficiaria de PBS, donde se encuentra que la participación de aquellos que recibieron PBS siendo ex PASIS aumento en comparación a aquellos que recibieron PBS y que antes no recibían nada. En cuanto a la metodología de PSM tenemos que el gran aporte viene dado por la posibilidad de tener un impacto del tratamiento en el número de horas trabajadas, donde se encuentra que para los trabajadores independientes y para los hombres existe una considerable disminución en las horas trabajadas. Esto se explica por la mayor flexibilidad que hay para ajustar horas trabajadas para los independientes. Por otra parte más que concluir que el efecto es sólo para los hombres, ocurre que las mujeres que tienen más de 65 años de edad y que se encuentran trabajando son muy pocas en la muestra, entonces no podemos tener conclusiones para ellas. Además se hacen los ejercicios sólo para aquellos que tienen un ingreso no laboral igual a cero, lo que de alguna forma permitiría alcanzar un mejor match. Los resultados se mueven en la dirección correcta en el sentido que estos se acentúan, es decir para una persona que recibe PBS el efecto contra su clon debería ser mayor si es que este clon tiene ingreso no laboral nulo, a que si tiene algún tipo de ingreso no laboral. Contrario a lo que ocurrió con la estrategia de DD en la estrategia PSM los problemas de identificación se tienen con la medición del impacto sobre la participación laboral. Se observan dificultades para encontrar niveles aceptables de ajuste e la estimación del Propensity Score y cuando se encuentran ocurre que el match realizado es malo. Sólo se pudo encontrar un efecto significativo en el modelo que restringe la estimación a aquellos hombres jefes de hogar y que viven en zonas urbanas. El cuadro 2 se mostró una comparación entre las ventajas y desventajas de ambas metodologías. Como se dijo, las metodologías están cimentadas en diferentes supuestos, las bases de datos no son las mismas y son de naturaleza, fechas y cantidad de observaciones distintas, y por lo mismo el coeficiente medido no puede ser el mismo, pero si se encuentra que ambas estrategias dan resultados en la misma dirección y de acuerdo a lo señalado por la teoría económica. 40 VIII. Conclusiones Este trabajo tiene como objetivo analizar el impacto la Pensión Básica Solidaria (PBS) sobre la oferta laboral de las personas que se encuentran en edad de jubilar. Para las estimaciones realizadas se está frente a dos tipos de resultados. Aquellos en los cuales se cumple lo señalado por la teoría en cuanto a que un mayor ingreso no laboral debería disminuir tanto las horas como la participación en el mercado laboral y aquellos en donde los efectos son no significativos. Es decir bajo ningún análisis los resultados resultan ser contra intuitivos. En primer lugar se realiza una estimación utilizando el Panel de la EPS y se encuentra que no hay evidencia concluyente para aseverar algo sobre el efecto del tratamiento sobre el número de horas. Utilizando el mismo panel, pero estimando el efecto del tratamiento sobre la participación laboral se encuentra que hay un efecto negativo del tratamiento sobre la variable de interés, el cual se acentúa para las mujeres y para aquellos que son beneficiarios de la PBS, pero que no eran beneficiarios de la pensión PASIS. En segundo lugar se realiza una estimación a partir de la CASEN 2009. Utilizando técnicas de matching se concluye que hay un efecto negativo del tratamiento sobre el número de horas trabajadas, el cual se debe al efecto sobre los trabajadores hombres independientes. Al controlar para aquellos trabajadores que no reciben ingreso por pensión autofinanciada también se observa un efecto negativo del tratamiento sobre el promedio de horas trabajadas. Contrario a lo que ocurrió para el caso de la estimación por Panel, se observa que el modelo de participación laboral no puede ser estimado de la forma más idónea debido a que no se cumplían ciertas condiciones necesarias para la utilización del método. En este ámbito sólo se concluye que para aquellos hombres jefes de hogar que viven en zonas urbanas el efecto del tratamiento es negativo. Más allá de los robusto de los resultados, lo cuales muchas vecen los son, pero acotado a pequeños grupos, este trabajo es pionero en analizar el impacto del aspecto más contundente de la reforma previsional que se realizó en 2008. Es positivo además que los efectos encontrados sean de acuerdo a la teoría y no sean contradictorios entre ellos. Resultaría atractivo analizar el impacto de este subsidio sobre otras variables de interés como podría ser gasto en salud, consumo en bienes durables y oferta laboral del resto del hogar. Ocurre que el mercado laboral para aquellas personas que se encuentran en edad de jubilar no es el suficientemente dinámico y por lo mismo podría resultar más factible encontrar efectos sobre variables menos rígidas que las perseguidas en este trabajo. 41 IX. Referencias 1. Borsch-Supan , Incentive Effects of Social Security on Labor Force Participation: Evidence in Germany and Across Europe LABOUR Volume 17, Issue Supplement s1, pages 5–44, August 2003. 2. Blundell, Duncan y Meghir (1998). “Estimating Labor Supply Responses Using Tax Reforms” Econometrica, Vol. 66, No. 4. (Jul., 1998), pp. 827-861. 3. Blundell, Richard and Thomas MaCurdy. 1999. “Labor Supply: A Review of Alternative Approaches.” In Handbook of Labor Economics, Volume 3A, Edited by Orley Ashenfelter and David Card. Amsterdam: North Holland. 4. Cahuc y Zylberberg, “Labor Economics”, MIT Press 2004. 5. Caliendo, M. y Kopeinig, S. (2995): “Some Practical Guidance for the Implementation of Propensity Score Matching”, IZA DP N°1588. 6. Contreras, Sepúlveda y Cabrera (2010); The effects of lengthening the school day on female labor supply: Evidence from a quasi-experiment in Chile. 7. Eissa, N. and J. Liebman (1996). “Labor Supply Response to the Earned Income Tax Credit.” QuarterlyJournal of Economics 61, 605-37. 8. Grau N., (2007) “Dinámica del mercado laboral chileno: Análisis a nivel individual”. Tesis para optar al grado de Ingeniero Comercial mención Economía. Universidad de Chile. 9. Haider yLoughran (2001), “Elderly Labor Supply: Work or Play?”, WP Center for Retirement Research. 10. Heinrich, C., Maffioli, A. y Vázquez, G. (2010): “A Primer for Applying Propensity-Score Matching”, Impact-Evaluation Guidelines, Technical Notes, No. IDB-TN-161. 11. Imbens, G, Rubin D y Sacerdote B. (2001), “Estimating the Effect of Unearned Income on Labor Supply, Earnings, Savings and Consumption: Evidence from a Survey of Lottery Players”, The American Economic Rewiew, volumen 91, 778-794. 12. Larrañaga O. y Contreras D., (2010), “El Sistema de Pensiones Solidarias”, Las Nuevas Políticas de Protección Social en Chile” Capitulo 4. 13. Lechner, M. (2000b): “A Note on the Common Support Problem in Applied Evaluation Studies", Discussion Paper, SIAW. 42 14. Lumsdaine and Mitchell (1999), “New Developments in the Economic Analysis of Retirement”, Capitulo49 en “Handbook of Labor Economics”, 1999, volumen 3, Part C, 3261-3307. 15. Nickell S., (1979) ”Estimating the probability of leaving unemployment”, Econometrica, September 1979, vol. 47(5), 1249-1266. 16. Medrano (2009); Public Day Care and Female Labor Force Participation: Evidence from Chile. 17. Parnes, H. and D. Sommers. 1994. Shunning Retirement: Work Experience of Men in Their Seventies and Eighties. Journal of Gerontology 49(3): S117-S124. 18. Simons y Blume, “Mathematics for Economist” 1994 19. Smith, J. (2000): “A Critical Survey of Empirical Methods for Evaluating ActiveLabor Market Policies," SchweizerischeZeitschriftfrVolkswirtschaft und Statistik, 136(3), 1 – 22. 20. Schmidt y Sevak (2008). “Taxes, Wages, and the Labor Supply of Older Americans” Research on Aging, 2009, 31(2): 207-232. 21. Subsecretaría de Previsión Social, Chile (2006), “Tercera Encuesta de Protección Social", Disponible en www.protecciónsocial.cl. 22. Subsecretaría de Previsión Social, Chile (2009), “Cuarta Encuesta de Protección Social", Disponible en www.protecciónsocial.cl. 43 X. Anexos X.1. Anexo 1: Estrategia de Diferencias en Diferencias Para aplicar la metodología de Diferencias en Diferencias se utiliza la Encuesta de Protección Social (EPS), específicamente se utilizará la ronda del año 2006 y del año 2009, lo que nos ofrece un escenario antes y después de la Reforma Previsional para obtener la estimación del ATE. El estimador de Diferencias en Diferencias estima el impacto promedio del tratamiento (ATE) de la siguiente manera: << 9>/ 7/ |< 1? 9c' 7' |< 0d El estimador DD puede ser obtenido a través de la estimación del siguiente modelo: 9>5I |<5I , 5I ? ;0 ;1 5I ;2 <5I ;3 <5I 5I ;4 MKL (10) La variable <5 toma el valor de 1 si el individuo fue tratado expost y 0 si ocurrió lo contrario, la variable 5 toma el valor de 1 si la información del individuo es posterior al tratamiento y 0 si la información es previa al tratamiento, M5I es un vector de controles y ; es el llamado estimador de Diferencias en Diferencias para el ATE. Notemos que en estricto rigor no es necesario tener datos de panel para estimar el modelo en (10), basta con tener los cuatro grupos definidos. Sin embargo, tener datos de panel da una ventaja adicional, ya que aparte de poder controlar por el sesgo de selección invariante en el tiempo podemos controlar por otras características invariantes en el tiempo. Con datos de panel podemos estimar el siguiente modelo de efecto fijo o efecto aleatorio: 9>5I |<5I , 5I ? J7 J KL J <KL KL 6M5I =5 N5I (11) Donde J es equivalente al estimador de Diferencias en Diferencias (DD). Estimados ambos modelos se debe utilizar un test de hausman para ver cuál de las dos metodologías es la apropiada para estos datos, este test tiene como hipótesis nula que ambos estimadores son consistentes, en tal caso el estimador de efectos aleatorios es preferido al ser más eficiente, por lo contrario si se rechaza la hipótesis nula sólo el estimador de efectos aleatorios es consistentes y este será preferido. Para la estimación del efecto del tratamiento en la participación laboral, el problema es algo más complicado, ya que el estimador DD estimado a partir de la ecuación (10) asume que el modelo que estamos estimando es lineal, sin embargo, cuando la variable dependiente (o de resultado) es 44 binaria este modelo idealmente debe ser modelado como un modelo de probabilidad no lineal, ya sea un modelo Probit o Logit, dependiente de los supuestos del término de error. Cuando la variable de resultado 5 es binaria, podemos estimar el ATE a través de la metodología de Diferencias en Diferencias, estimado el siguiente modelo de probabilidad Probit: E>YUV |DUV , TUV ? Φβ7 β DUV β TUV β DU TUV β2 XUV (12) Lo correcto, en este caso y extendiendo lo expuesto por Angrist y Pischke en MHE25, sería reescribir (12) de la siguiente manera26: E>YU |DUV , TUV ? Φβ7 >Φβ7 β Φβ7 ?DUV >Φβ7 β Φβ7 ?TUV >Φβ7 β β β Φβ7 β Φβ7 β Φβ7 ?DUV TUV (13) A partir de la ecuación (13) se observa que el estimador de DD para el ATE viene dado por el coeficiente que acompaña a la variable DUV TUV, es decir: DD Φβ7 β β β β2 XUV Φβ7 β β2 XUV Φβ7 β β2 XUV Φβ7 β2 XUV (14) Luego el procedimiento sería estimar vía un modelo Probit la ecuación (12) por efectos aleatorios y luego a partir de los coeficientes estimados en ella calcular lo expresado (14) para cada individuo en cada una de las posibles 4 situaciones. Es decir DU 1 y TU 1; DU 1 y TU 0; DU 0 y TU 1; y DU 0 y TU 0. Para obtener la varianza del ATE de la ecuación (14) una alternativa es utilizar el método delta, dado que DD es una función de β, DD(β), se tiene que la varianza de DD(β) está dada por: ij<<;k l<<;m l<<; · i; · l; l; Lo que nos permitiría bajo un supuesto de normalidad del DD calcular el intervalo de confianza de esta estimación. Si el tamaño muestral es pequeño no es claro que se cumpla la normalidad del estimador DD, en este caso el intervalo de confianza puede ser obtenido mediante el método no paramétrico de bootstrap. 25 MostlyHarmlessEconometrics. Es necesario aclarar que por razones gráficas se excluyo el término ;2 M5I de la ecuación (8), el cual debería haber sido incluido en cada uno de los paréntesis redondos puestos en la ecuación anterior. 26 45 X.2. Anexo 2: Estrategia de Matching Propensity Score La aplicación correcta de esta metodología requiere las siguientes consideraciones: 1. Cumplimiento Condición de Independencia Condicional: al no ser una condición testeable (Heinrich 2010) es importante justificar el cumplimiento de la condición. 2. Estimación del Propensity Score: definir el modelo que determina la probabilidad de recibir el tratamiento incorporando variables que afecten tanto la probabilidad de recibir el tratamiento (PBS) como aquellas que afectan el output objetivo. 3. Elección del Algoritmo de Matching: para calcular el efecto del programa 9 5 Hb5 , se debe obtenerHb5 , correspondiente al resultado del individuo contrafactual. Los algoritmos utilizados para decidir quién o quiénes serán los individuos que determinaran Hb5 , serán Nearest Neighbour Matching (NN) y Kernel Matching (KM). También están Caliper y Radius Matching, los cuales son una versión que acota la elección del “match” en el método NN. La forma más apropiada para hacer el “match” con el PS estimado entre tratados y no tratados no es clara (Heinrich 2010). Asintóticamente, cualquiera de estos algoritmos deberían dar resultados similares (Smith 2000) y por los mismo el problema se presenta cuando se dispone de pequeñas muestras, caso en el cual es importante tener en cuenta el trade-off entre sesgo y eficiencia que se presenta en los diferentes métodos. NN tiende a elegir mejores “match” con el riesgo de elegir algunos que no son buenos, mientras que KM al usar mayor cantidad de información tiende a ser más eficiente. Por lo mismo, lo que se hace en este trabajo, es realizar el “match” vía diferentes algoritmos y así mostrar el grado de robustez de los resultados a la elección de diferentes algoritmos. Se reportaran resultados para NN (1) y KM Normal. 4. Traslape o Soporte Común: bajo esta metodología el ATE está definido sólo en aquella región donde existe soporte común, lo que significa que para cada valor de p(X), existe una probabilidad mayor que 0 de ser que hayan individuos que sean tratados y no tratados. 5. Evaluación de la Calidad del Match: un paso fundamental es evaluar la calidad del “match”, lo cual se hace testeando las diferencias de medias entre tratados y no tratados que puede haber en una serie de variables de interés antes y después del matching. Se debe encontrar que si previo al matching hay diferencias de medias relevantes entre tratados y no tratados, y luego de su realización del “match” estas diferencias desaparecen. 6. Resultados: Los resultados que se expondrán serán los ATE para cada uno de los grupos para los cuales se realicen las estimaciones, además de sus varianzas, las cuales serán calculadas realizando bootstraping. 46 X.3. Anexo 3: Comportamiento Agregado de la Datos El objetivo de esta sección es mostrar el comportamiento agregado de los datos que se utilizarán para las estimaciones y su relación con otras de encuestas relevantes en materia de empleo, específicamente con la Encuesta del INE. La EPS tiene la ventaja de que tienen un porcentaje importante de preguntas relacionadas con el sistema previsional y que además permite construir las historias laborales de los encuestados con una periodicidad mensual. Además es la primera y más antigua encuesta de panel realizada en Chile. Su mayor desventaja frente a otras encuestas de carácter nacional y que son ampliamente reconocidas es que su tamaño maestral es considerablemente menor. En el siguiente cuadro se observa el comportamiento agregado de los datos de empleo para el grupo de personas que se encuentra en edad de jubilar para la Encuesta Nacional de Empleo27 del INE, la encuesta de Caracterización Socioeconómica (CASEN) realizada por MIDEPLAN y para la EPS. Para la encuesta del INE se tomó aquella relativa al trimestre móvil agosto-septiembreoctubre de 2006 y al trimestre móvil marzo-abril-mayo en 2009. Por su parte para la CASEN se tomó las mediciones de 2006 y 2009, las cuales fueron hechas ambas en el mes de noviembre28. En el cuadro 14 vemos que la proporción de personas en edad de jubilar sobre aquella población en edad de trabajar29 muestra una tendencia al alza bajo las tres encuestas recién nombradas, lo que confirma la importancia relativa que ha ido adquiriendo este grupo etáreo a la cual se hacía referencia al principio del trabajo. A su vez vemos que a nivel agregado en materia de ocupados las tres encuestas muestran comportamiento y proporciones observadas comparables, sin embargo al observar las cifras para los desocupados se observa que los datos son marcadamente superiores en la EPS, problema que ha sido advertido en trabajos previos (Grau 2008) y que tiene su raíz en la forma en que la encuesta misma califica a una persona como desempleada o no. Estas diferencias en materia de desempleo hacen que las proporciones en materia de participación laboral también se observen algo distorsionadas. Los datos nos dicen que alrededor de 4% del total de ocupados del país pertenecen al grupo etáreo bajo análisis y que entre un 15% y un 20% del total de personas en edad de jubilar se encuentran trabajando. A su vez se observa que para la persona en edad de jubilar y que trabaja, en general lo hace por cuenta propia, luego como asalariado y después como empleador. Estas proporciones se mantienen para todas las encuestas a excepción de la EPS 2006. 27 Se publican mes a mes con datos relativos al comportamiento del empleo en trimestres móviles y es de carácter nacional. 28 Las fechas con que son hechas las encuestas CASEN y EPS tienen un componente importante de variabilidad, ya que la gran mayoría de la muestra fue tomada en el mes que se menciona, pero es probable que la muestra completa se haya terminado de recoger meses después. 29 Personas que tienen una edad superior o igual a 15 años. 47 Cuadro 14: Comportamiento Agregado de la Datos Año 2006 2009 Encuesta INE CASEN EPS INE CASEN EPS Número de Encuestados 116.305 268.873 16.433 109.733 246.924 14463 Número de Encuestados >= 65 años 11.652 29.038 2.655 12.656 30.553 2.691 Total de >= 65 años sobre el total de la población en edad de trabajar. 12,6% 12,0% 10,8% 14,0% 13,8% 12,6% Participan (%) 15,8% 18,5% 26,1% 16,8% 15,5% 21,5% Ocupados (% del total de Ocupados) 3,9% 4,1% 4,0% 4,5% 4,1% 3,8% Ocupados (% del total de >= 65 años) 15,5% 17,9% 20,6% 16,3% 14,9% 17,8% Tasa de Desempleo (del total de >= 65 años) % Empleadores 1,4% 2,9% 20,9% 3,1% 3,4% 17,1% 10,8% 6,3% 11,1% 8,5% 7,6% 11,3% % Cuenta Propia 52,8% 49,1% 41,3% 49,0% 50,4% 46,5% % Asalariados 28,9% 35,4% 42,3% 36,6% 36,9% 34,4% % Servicio Domestico 2,9% 6,8% 5,1% 3,4% 4,2% 6,4% % Familiar No Remunerado 4,6% 2,4% 0,2% 2,5% 0,8% 1,4% Fuente: Elaboración propia en base bases de datos de las distintas encuestas. Al analizar el grado similitud en los datos agregados (tanto en proporción como en tendencia) hay que tomar en consideración que ellas se hicieron en diferentes fechas (el empleo es altamente dependiente del ciclo) y que los cuestionarios y la forma de preguntar son distintas. A su vez, la mayor similitud que se observa en cuanto al nivel de ocupación no permite tener menos precaución a la hora de realizar las conclusiones en materia de cambio en horas trabajadas que la que se debe tener al momento de concluir en materia del impacto de la reforma en la decisión de participar o no en el mercado laboral, especialmente al usar la Encuesta de Protección Social. Es necesario aclarar que en esta sección se expuso el comportamiento agregado de la EPS 2006 y de la EPS 2009 por separado, es decir cada encuesta se tomó como si fuese una encuesta independiente y no un panel. 48 Anexo 4: Descripción de Variables X.4. En el siguiente cuadro se observa la definición de las principales variables utilizadas en las estimaciones. Variable como edad, jefe de hogar, sexo, escolaridad, zona, además de las variables de interés principal no es necesario describirlas. Cuadro 15: Definición de Variables Variable Panel EPS 2006-09 CASEN 2009 Razón de su Inclusión Está en logaritmo y corresponde a todos aquellos ingresos no laborales del entrevistado. No incluye Ingreso por PBS. Está en logaritmo y corresponde al ingreso total del resto del hogar sin incluir el generado o recibido por el entrevistado. Además de la variable personas en el hogar, esta variable indica el número de personas con más de 65 años que vive en el hogar. Número de personas que tienen menos de 24 años en el hogar. Número de personas que trabajan en el hogar. Como en todos los modelos de Oferta laboral es necesario incluir variables que incorporen mediciones del ingreso base que tendría el individuo si no trabajase. El objetivo de incluir estas variables es que ellas aportan información sobre la tasa de dependencia del hogar. En muchas regresiones se incorpora también la variable Número de Personas del Hogar. Está incluido en la variable Ingreso Resto Hogar. No está incluida en la variable Ingreso Resto Hogar y son todos los Subsidios del Hogar sin PBS. Salud Variable que mide el estado de salud de la persona mediante un autoreporte el cual tiene 6 categorías entre excelente (1) y muy mal (6). Se va de mejor a peor. Actividad Se incluye esta variable, la cual toma valor de 1 si la persona trabaja en una actividad que tuvo crecimiento del empleo entre 2008 y 2009. Variable que mide el estado de salud de la persona mediante un autoreporte el cual tiene 7 categorías entre muy mal (1) y muy bien (7). Se va de peor a mejor. No es necesario incluirla debido a que en este caso hay un solo momento del tiempo. Esta variable se incluye separadamente para el caso de la CASEN 2009, ya que ella influye por si sola en la probabilidad del tratamiento, es decir en la estimación del PSCORE. Los estudio previos señalan que para la personas en edad de jubilar la salud es un determinante relevante en la determinación de la oferta laboral. Ingreso no Laboral Ingreso Resto Hogar Personas Mayores Personas Menores Personas Trabajan Subsidios del Hogar Escolaridad Hogar Es la escolaridad promedio del hogar. La variable se incluye con el objeto de tener una proxie de lo que fue la crisis internacional entre 2008 y 2009. Se espera que hubo crecimiento de la ocupación haya habido un aumento en las horas trabajadas. Se incluye para el caso de la CASEN 2009, ya que ella influye en la probabilidad del tratamiento. 49 X.5. Anexo 5: Tablas Modelo Horas Trabajadas (DD) X.5.1. Tabla 1: Modelo Horas Trabajadas 100% muestra VARIABLES Treat time Time*Treat (1) (2) (3) (4) (5) (6) -4.494 -4.776 -4.449 -1.882 (3.231) (3.277) (3.291) (3.262) -12.79*** -11.31*** -10.10*** -8.997*** (1.785) (1.827) (1.865) (2.188) (2.155) 0.0558 0.0558 -1.814 -2.370 -2.181 -3.056 -2.428 -4.007 (4.570) (4.678) (4.555) (4.854) (4.569) (4.903) (4.483) (4.612) 3.449 1.488 3.671 2.131 4.592 2.697 (2.854) (6.348) (2.939) (6.384) (2.888) (6.003) 1.672 9.893 1.619 10.60 1.387 16.03* (3.320) (9.828) (3.357) (9.950) (3.294) (9.387) -0.0140 -0.101 -0.0138 -0.103 -0.0121 -0.134** (0.0224) (0.0692) (0.0226) (0.0701) (0.0222) (0.0660) Edad Edad2 Sexo Salud Ingreso No Laboral 1.096 1.065 2.688 (2.013) (2.071) (2.053) -2.921*** -5.880*** -2.871*** -5.562*** -2.332** -4.349*** (0.916) (1.750) (0.919) (1.777) (0.906) (1.679) -0.333* -0.364 -0.342* -0.383 -0.241 -0.230 (0.185) (0.324) (0.186) (0.325) (0.183) (0.306) 0.0581 0.105 0.0502 0.118 (0.153) (0.238) (0.150) (0.224) 0.417 1.789 0.773 1.813 (1.481) (3.932) (1.455) (3.697) -0.140 2.913 -0.0666 2.589 (0.782) (2.251) (0.768) (2.117) 2.218 1.759 2.322 2.544 (1.638) (2.355) (1.607) (2.217) 10.70*** 24.49*** (1.912) (3.398) Ingreso Resto Hogar Personas Mayores Personas Menores Personas Trabajan Constante Hausman (Pr>chi2) (8) -12.79*** Jefe Actividad (7) 36.69*** 36.01*** -2.608 -140.3 -2.813 -187.0 -3.834 -428.6 (1.262) (1.189) (122.2) (348.4) (123.4) (353.5) (121.0) (334.1) 0,9987 0,3499 0,5819 0,0006 Observaciones 800 800 800 800 800 800 800 800 Individuos 800 800 800 800 800 800 800 800 Nota: Error Estándar entre Paréntesis y *** p<0.001, ** p<0.05, * p<0.1. La dependiente es horas trabajadas y se considera a aquellos individuos que en trabajaron en alguno de los dos periodos dentro de los que en 2006 tenían 65 años o más. 50 X.5.2. Tabla 2: Modelo Horas Trabajadas 50% más vulnerable VARIABLES Treat time Time*Treat (1) (2) (3) (4) (5) (6) -5.889 -6.421 -5.628 -2.393 (3.850) (4.093) (4.158) (4.170) -14.17*** -13.70*** -13.14*** -11.62*** (2.567) (2.690) (2.766) (3.258) (3.227) 4.631 4.631 3.392 2.479 3.032 2.659 2.244 0.00982 (5.445) (5.707) (5.507) (5.918) (5.572) (6.071) (5.484) (5.758) 1.669 4.652 2.169 5.671 3.184 3.558 (4.174) (9.099) (4.304) (9.176) (4.241) (8.678) 10.91 5.035 10.72 5.243 8.704 12.37 (7.493) (15.43) (7.530) (15.65) (7.424) (14.85) -0.0773 -0.0704 -0.0762 -0.0767 -0.0627 -0.118 (0.0513) (0.109) (0.0516) (0.111) (0.0508) (0.105) Edad Edad2 Sexo Salud Ingreso No Laboral 2.198 1.817 3.753 (2.989) (3.084) (3.073) -2.992** -7.044*** -2.796** -7.298*** -2.014 -5.882*** (1.286) (2.307) (1.298) (2.357) (1.292) (2.243) -0.214 -0.330 -0.213 -0.317 -0.0245 -0.0954 (0.277) (0.488) (0.279) (0.490) (0.278) (0.465) 0.107 0.281 0.135 0.333 (0.231) (0.348) (0.228) (0.329) 1.084 2.163 1.141 2.506 (2.095) (5.295) (2.061) (5.003) 0.597 4.338 0.437 3.863 (1.135) (2.818) (1.118) (2.664) 1.093 -2.831 1.390 -1.843 (2.318) (3.308) (2.281) (3.131) 11.79*** 27.24*** (2.979) (5.249) Ingreso Resto Hogar Personas Mayores Personas Menores Personas Trabajan Constante Hausman(Pr>chi2) (8) -14.17*** Jefe Actividad (7) 36.79*** 35.48*** -337.4 48.03 -333.6 56.99 -270.1 -248.4 (1.815) (1.678) (272.1) (545.4) (273.3) (555.2) (269.3) (527.8) 0,9587 0,5243 0,4289 0,0164 Observaciones 450 450 450 450 450 450 450 450 Grupos 225 225 225 225 225 225 225 225 Nota: Error Estandar entre Parentesis y *** p<0.001, ** p<0.05, * p<0.1. La dependiente es horas trabajadas y se considera a aquellos individuos que en trabajaron en alguno de los dos periodos dentro de los que en 2006 tenían 65 años o más y que pertenecen al 50% de los hogares más vulnerables. 51 X.6. Anexo 6: Tablas Modelo de Participación (DD) X.6.1. Tabla 3: Modelo de Participación Laboral VARIABLES Time Treat Time*Treat Ingreso No Laboral Ingreso Resto Hogar Personas Menores Número de Personas Personas Mayores Sexo Edad Edad2 Salud Jefe Personas Trabajan Constante N 5% 10% 15% 20% 25% 30% 50% 100% Participación Participación Participación Participación Participación Participación Participación Participación 1.407 0.307 0.364 -0.0811 0.0222 -0.0684 -0.273** -0.159* (0.903) (0.400) (0.287) (0.213) (0.185) (0.159) (0.130) (0.0867) 0.709 0.395 -0.0446 0.000199 0.00966 0.0107 -0.0502 -0.123 (0.732) (0.425) (0.318) (0.230) (0.211) (0.186) (0.162) (0.131) -1.696 -1.212** -0.693* -0.403 -0.492* -0.392* -0.142 -0.313** (1.111) (0.572) (0.389) (0.300) (0.269) (0.229) (0.196) (0.158) -0.130** -0.0795** -0.0532** -0.0381** -0.0395** -0.0392** -0.0207 -0.0350*** (0.0638) (0.0329) (0.0243) (0.0180) (0.0165) (0.0147) (0.0127) (0.00919) -0.00596 -0.00285 0.00945 0.0117 0.0111 -0.00374 0.0145 0.0143** (0.0414) (0.0286) (0.0215) (0.0163) (0.0141) (0.0122) (0.00998) (0.00679) 0.446 -0.0675 -0.263 -0.183 -0.132 -0.0377 -0.0742 0.0454 (0.330) (0.222) (0.173) (0.128) (0.114) (0.100) (0.0876) (0.0657) -0.369 0.120 0.113 0.0802 0.0336 -0.0163 -0.000844 -0.0565 (0.0433) (0.265) (0.166) (0.121) (0.0892) (0.0791) (0.0692) (0.0588) 1.188** 0.108 -0.174 -0.0847 -0.0329 0.0187 -0.0116 0.00556 (0.519) (0.280) (0.212) (0.165) (0.148) (0.129) (0.108) (0.0772) 0.266 0.697** 0.741** 0.633** 0.847*** 0.855*** 0.818*** 0.799*** (0.525) (0.355) (0.273) (0.209) (0.200) (0.176) (0.145) (0.102) -1.340* -0.718 -0.914** -0.610** -0.698** -0.561** -0.389** -0.431*** (0.794) (0.537) (0.370) (0.280) (0.250) (0.222) (0.184) (0.129) 0.00830 0.00426 0.00550** 0.00356* 0.00407** 0.00318** 0.00207* 0.00228** (0.00509) (0.00353) (0.00240) (0.00182) (0.00163) (0.00145) (0.00121) (0.000845) -0.288 -0.409** -0.296** -0.211** -0.153** -0.231*** -0.230*** -0.212*** (0.289) (0.178) (0.118) (0.0847) (0.0777) (0.0700) (0.0573) (0.0403) 1.476* 0.690 0.304 0.184 0.0744 0.0663 0.138 0.318** (0.885) (0.460) (0.321) (0.247) (0.225) (0.197) (0.162) (0.114) 0.902* 0.147 0.148 0.0233 0.191 0.225* 0.0701 0.0757 (0.526) (0.284) (0.208) (0.158) (0.134) (0.120) (0.100) (0.0702) 51.06* 29.18 36.95** 25.10** 28.36** 23.63** 16.87** 18.67*** (30.20) (20.18) (14.04) (10.55) (9.448) (8.365) (6.945) (4.870) 88 194 384 598 814 1111 1665 3665 Grupos 44 97 192 299 407 556 833 1833 Wald (9) 10.27 21.8 35.71 51.11 67.48 89.5 122.21 256.75 Nota: Error Estandar entre Parentesis y *** p<0.001, ** p<0.05, * p<0.1. La dependiente es una dummie que toma el valor 1 si la persona participa en el mercado laboral y se considera a aquellos individuos que en trabajaron en alguno de los dos periodos dentro de los que en 2006 tenían 65 años o más. La estimación está hecha para diferentes grupos de vulnerabilidad. 52 X.6.2. Tabla 4: Modelo Participación sin Variable donde no hay Diferencias. VARIABLES Time Treat 5% 10% 15% 20% 25% 30% 50% 100% Participación Participación Participación Participación Participación Participación Participación Participación 1.118 0.162 0.151 -0.260 -0.241 -0.373** -0.460*** -0.379*** (0.852) (0.374) (0.260) (0.198) (0.171) (0.147) (0.118) (0.0779) 0.748 0.431 0.00385 0.0744 0.0782 0.0477 -0.0106 -0.143 (0.858) (0.422) (0.312) (0.230) (0.215) (0.188) (0.164) (0.134) Time*Treat -2.362* -1.365** -0.776** -0.463 -0.518* -0.428* -0.186 -0.374** (1.335) (0.563) (0.380) (0.297) (0.268) (0.229) (0.195) (0.158) Ingreso No Laboral -0.188** -0.0963** -0.0688** -0.0461** -0.0436** -0.0459** -0.0273** -0.0463*** (0.0783) (0.0328) (0.0239) (0.0180) (0.0167) (0.0148) (0.0128) (0.00922) 0.750 0.0267 -0.235 -0.161 -0.156 -0.125 -0.0954 -0.115 (0.528) (0.273) (0.208) (0.160) (0.144) (0.125) (0.105) (0.0740) Personas Mayores Sexo Salud 0.976 0.887** 0.924** 0.759*** 0.992*** 0.935*** 0.913*** 0.898*** (0.660) (0.369) (0.282) (0.213) (0.208) (0.181) (0.149) (0.105) -0.454 -0.447** -0.339** -0.250** -0.206** -0.279*** -0.268*** -0.253*** (0.358) (0.179) (0.117) (0.0849) (0.0787) (0.0706) (0.0580) (0.0407) 1.559 0.667 0.250 0.159 -0.00500 0.0377 0.0775 0.269** (1.044) (0.457) (0.317) (0.248) (0.228) (0.198) (0.164) (0.114) 0.789 0.252 0.225 0.0802 0.169 0.123 0.0675 0.0635 (0.509) (0.232) (0.168) (0.125) (0.108) (0.0958) (0.0801) (0.0567) -1.678 0.332 0.323 0.139 -0.203 0.163 -0.0791 -0.173 (1.936) (0.976) (0.700) (0.528) (0.490) (0.431) (0.355) (0.251) N 88 194 384 598 814 1111 1665 3673 Grupos 44 97 192 299 407 556 833 1837 Wald (9) 7.12 20.54 30.19 39.33 50.93 71.91 96.53 201.54 Jefe Personas Trabajan Constante Nota: Error Estandar entre Parentesis y *** p<0.001, ** p<0.05, * p<0.1. La dependiente es una dummie que toma el valor 1 si la persona participa en el mercado laboral y se considera a aquellos individuos que en trabajaron en alguno de los dos periodos dentro de los que en 2006 tenían 65 años o más. La estimación está hecha para diferentes grupos de vulnerabilidad. Igual a la tabla 3, pero se excluyen aquellas variables en las cuales no hay Diferencias de Media en la medición pre tratamiento. 53 X.6.3. Tabla 5: Elección del Modelo para el Cálculo del ATE VARIABLES Treat Time Time*Treat (1) (2) (3) (4) (5) (6) (7) part1 part1 part1 part1 part1 part1 part1 -0.0582 -0.233 -0.237 -0.0474 -0.00132 0.00223 0.0187 (0.184) (0.198) (0.197) (0.194) (0.188) (0.189) (0.190) -0.522*** -0.472*** -0.463*** -0.444*** -0.431*** -0.432*** -0.367** (0.138) (0.139) (0.139) (0.139) (0.137) (0.137) (0.148) -0.127 -0.291 -0.296 -0.352 -0.401* -0.402* -0.427* (0.219) (0.229) (0.229) (0.229) (0.228) (0.228) (0.230) -0.0370** -0.0380** -0.0460*** -0.0469*** -0.0472*** -0.0481*** (0.0153) (0.0153) (0.0151) (0.0148) (0.0148) (0.0149) -0.106 -0.137 -0.140 -0.130 -0.130 (0.130) (0.125) (0.121) (0.125) (0.126) 1.021*** 0.944*** 0.920*** 0.932*** (0.169) (0.162) (0.180) (0.182) -0.285*** -0.284*** -0.278*** (0.0705) (0.0705) (0.0710) 0.0579 0.0606 (0.199) (0.200) Ingreso No Laboral Personas Mayores Hombre Estado de Salud Jefe 0.114 Personas que trabajan Constante BIC criterio Número de observaciones Número de individuos (0.0961) -0.858*** -0.516*** -0.351 -0.860*** 0.328 0.281 0.169 (0.130) (0.185) (0.272) (0.286) (0.387) (0.419) (0.432) 1149,99 1151,07 1157,41 1120,35 1110,70 1117,62 1123,20 1,102 1,102 1,102 1,102 1,102 1,102 1,102 551 551 551 551 551 551 551 Nota: Error Estandar entre Parentesis y *** p<0.001, ** p<0.05, * p<0.1. La dependiente es una dummie que toma el valor 1 si la persona participa en el mercado laboral y se considera a aquellos individuos que en trabajaron en alguno de los dos periodos dentro de los que en 2006 tenían 65 años o más. La estimación está hecha para diferentes grupos de vulnerabilidad. Igual a la tabla 3, pero se excluyen aquellas variables en las cuales no hay Diferencias de Media en la medición pre tratamiento. A través del BIC Criterio se elige el modelo (5). 54 X.6.4. Tabla 6: Modelo elegido para diferentes muestras. VARIABLES Time Treat Time*Treat Ingreso No Laboral Personas Mayores Cobertura y Monto Cobertura y Monto Cobertura Cobertura Cobertura Monto Mujeres Hombres Total Mujeres Hombres Total (1) (2) (3) (4) (5) (6) part1 part1 part1 part1 part1 part1 -0.0239 -0.616*** -0.448*** -0.156 -0.607*** -0.996*** (0.252) (0.171) (0.124) (0.216) (0.156) (0.257) 0.451 -0.329 0.385* 0.696** 0.131 -0.685** (0.295) (0.265) (0.204) (0.297) (0.304) (0.290) -0.934** -0.130 -0.598** -1.010** -0.330 0.565 (0.388) (0.302) (0.264) (0.414) (0.369) (0.357) -0.0197 -0.0711*** -0.0392*** -0.0168 -0.0574*** -0.0396* (0.0232) (0.0203) (0.0130) (0.0205) (0.0177) (0.0229) -0.188 -0.0686 -0.137 -0.219 -0.0386 -0.512** (0.198) (0.163) (0.122) (0.200) (0.164) (0.203) Hombre 0.993*** 0.826*** (0.166) (0.235) Estado de salud -0.271** -0.302*** -0.295*** -0.276** -0.309*** -0.313*** (0.108) (0.0971) (0.0712) (0.108) (0.0982) (0.112) Constante -0.136 1.554*** 0.180 -0.0945 1.305*** 1.308** (0.576) (0.515) (0.375) (0.553) (0.497) (0.599) Número de Observaciones 515 586 1,101 515 586 432 Número de Individuos 258 293 551 258 293 216 Error Estandar entre Parentesis y *** p<0.001, ** p<0.05, * p<0.1 55 H a us m a n ( P r>c hi2 ) N úm e ro de o bs e rv a c io ne s N úm e ro de indiv iduo s C o ns t a nt e E s t a do de S a lud H o m bre P e rs o na s M a yo re s Ingre s o N o La bo ra l T im e *T re a t T im e T re a t V A R IA B LE S Modelos -0.00421 (0.00397) 0.0220 (0.0518) -0.00956*** (0.00298) -0.0287 (0.0240) (0.113) 1,101 551 1,101 551 0,0054 (0.0754) 258 515 258 515 (0.149) 0.354** 0,8006 (0.0871) 0.361*** 293 586 293 586 (0.166) 0.312* (0.0300) 0,0004 (0.116) 0.850*** (0.0217) 551 1,101 FE 551 1,101 (0.113) 0.360*** (0.0192) -0.0145 (0.0517) 0.0222 (0.00399) -0.00587 (0.0530) -0.0969* (0.0234) -0.0908*** 0,0231 (0.0722) 0.496*** (0.0135) 0.339*** (0.0232) 0.526*** (0.0160) (0.0192) (0.0136) 0.192*** (0.0240) -0.0290 (0.00255) -0.00788*** (0.0501) -0.117** (0.0233) -0.0565*** 0.00471 (0.0727) 0.110 (0.00644) -0.0111* (0.0740) -0.00884 (0.0372) -0.0880*** (0.0414) 0.0754* RE -0.0124 -0.0669*** (0.0373) -0.0143 (0.00477) -0.0181*** (0.0715) -0.0510 (0.0369) -0.159*** FE -0.0549*** -0.0244 (0.0738) -0.0534 (0.00471) -0.000537 (0.0570) -0.117** (0.0382) -0.140*** (0.0625) -0.0817 RE (4 ) Modelo 3 /Tabla 6 (0.0289) -0.0409** (0.0298) -0.0290 (0.00355) -0.00257 (0.0543) -0.132** (0.0372) -0.0124 FE (3 ) Modelo 2 /Tabla 6 (0.0289) 0.185*** (0.0457) -0.0403 -0.0713 (0.0441) (0.0267) (0.0265) -0.00687 -0.0881*** 0.0756* RE (0.0449) -0.0968*** FE (2) Modelo 1 /Tabla 6 (0.0384) -0.00559 RE (1) Modelo 5 /Tabla 5 258 515 FE 258 515 (0.149) 0.368** (0.0232) -0.0265 (0.0735) -0.0545 (0.00470) -0.00121 (0.0612) -0.145** (0.0318) -0.0261 0,8859 (0.0838) 0.370*** (0.0159) -0.0415*** (0.0300) -0.0343 (0.00308) -0.00243 (0.0575) -0.158*** (0.0311) -0.0243 (0.0461) 0.121*** RE (5) Modelo 4 /Tabla 6 293 586 (0.111) FE 293 586 (0.167) 0.339** (0.0300) 0.00351 (0.0725) 0.108 (0.00650) -0.0135** (0.0920) -0.0832 (0.0339) -0.149*** 0,0014 0.785*** (0.0217) -0.0688*** (0.0373) -0.00710 (0.00406) -0.0142*** (0.0867) -0.101 (0.0336) -0.137*** (0.0717) 0.0337 RE (6) Modelo 5 /Tabla 6 216 432 (0.117) FE 216 432 (0.173) 0.554*** (0.0307) -0.0322 (0.0851) -0.0849 (0.00591) -0.00305 (0.0697) 0.102 (0.0512) -0.173*** 0,2631 0.721*** (0.0213) -0.0627*** (0.0440) 0.169*** (0.0393) -0.104*** (0.00453) -0.00800* (0.0682) 0.126* (0.0474) -0.203*** (0.0579) -0.146** RE (7) Modelo 6 /Tabla 6 X.6.5. Tabla 7: Estimación MICO de mismos Modelos Alternativos 56 X.7. Anexo 7: Resultados Estimación de PS del Modelo Horas Trabajadas (PSM) En este anexo, se expone y se explica más detalladamente los determinantes del Propensity Score para un modelo general de horas trabajadas. Tabla 9: Estimación de Probabilidad de Tratamiento Total Trabajadores Coef. P-Value Ingreso No Laboral -0.11 0.00 Ingreso Resto Hogar 0.01 0.11 Subsidios del Hogar 0.00 0.65 Categoría 0.89 0.00 Zona -0.21 0.04 Sexo -0.21 0.01 Jefe 0.08 0.48 Menores Hogar 0.16 0.02 Trabajan Hogar 0.09 0.04 Salud Entrevistado -0.03 0.23 Edad 1.02 0.00 Edad -0.01 0.00 Escolaridad Hogar -0.04 0.00 Escolaridad Individuo -0.03 0.03 Persona en el Hogar -0.17 0.00 Decil 2 -0.17 0.19 Decil 3 -0.26 0.05 Decil 4 -0.46 0.00 Decil 5 -0.59 0.00 Constante -37.46 0.00 Pseudo R2 0.37 Observaciones 1553 Como era de esperar la variable ingreso no laboral30 tiene un impacto negativo sobre la probabilidad de recibir PBS, lo que se explica porque esta variable contiene información sobre la pensión autónoma recibida por la persona y un requisito para tener PBS es no ser beneficiario de pensión autónoma. Además esta variable tiene otras rentas no laborales. 30 Todas las variables de ingreso se expresan en logaritmos. 57 La variable Ingreso del Hogar tiene un impacto positivo (pero pequeño) en la probabilidad de recibir PBS, lo que es extraño ya que esta política está orientada hacia los hogares más vulnerables, lo que debería estar asociado a un hogar con menores ingresos. Esta variable incluye todos los ingresos autónomos del hogar, excluyendo aquellos generados por el entrevistado. La variable Ingreso por Subsidio del Hogar (la que excluye PBS) tiene el signo esperado, ya que los hogares con más subsidios en teoría deberían ser más vulnerables y por lo mismo tener una mayor probabilidad de recibir la PBS. Ambas no son significativas en el caso de la ecuación realizada para estimar las horas trabajadas. Las variables sexo disminuye la probabilidad de recibir PBS; mientras que si la persona vive en zona rural también ve disminuidas sus posibilidades. El hecho de que haya más menores en el hogar aumenta la probabilidad de recibir PBS. La variable menor contabiliza al número total de personas que tienen menos de 24 años de edad. Esto se asocia inequívocamente a una mayor tasa de dependencia en el hogar, lo que de alguna forma aumento su vulnerabilidad y su probabilidad de recibir PBS. Por otra parte se esperaría que mientras más personas trabajen en el hogar menor sea el nivel de vulnerabilidad del hogar, no obstante no es lo que ocurre con el signo de la variable. Correctamente se observa que a menor escolaridad promedio del resto del hogar (no incluye al entrevistado), menor probabilidad de recibir PBS, como también a mayor decil de ingreso. También se incluyen una variable que contabiliza a todas a aquellas personas que viven en el hogar. Se podría haber incluido el número total de mujeres del hogar o el número total de personas en edad de jubilar, pero se da un alto problema de colinealidad al incluir muchas variables que están muy relacionadas entre ellas como lo son personas que trabajan, menores, mayores, etc. Variables como edad, edad2, salud del entrevistado y escolaridad se incluyen como parte de aquellas variables que inciden en la oferta no laboral de las personas en edad de jubilar. 58 X.8. Anexo 8: Tablas Modelo de Horas Trabajadas (PSM) En esta sección se encuentran todas las tablas relativas a las estimaciones realizadas y que resultaron ser significativas31, tanto aquellas que indican resultados como aquellas que muestran el cumplimiento de algunos supuestos básicos para la utilización del método. X.8.1. Tablas Modelo Trabajadores Independientes. El modelo es el explicado en el texto principal y se encuentra información relativa al modelo de Horas Trabajadas para todos los trabajadores independientes que fue el que arrojo resultados significativos. En el tabla 10 se observan las observaciones que son botadas de la muestra por no cumplir con la condición de soporte común conocida como la Comparación de la Mínima y la Máxima, es decir si en el grupo de tratamiento el PS se ubica en el intervalos [0.06; 0.95] y en el grupo de control el PS se ubica en el intervalo [0.04; 0.88], tenemos que de acuerdo a este criterio la región de soporte común viene determinada por el intervalo [0.07; 0.88]. Tabla 10: Condición de Soporte Min-Max Neighbor(1) y Normal Kernel Off Support On Support Total Untreated 20 362 382 Treated 25 446 471 Total 45 808 853 Concluir sólo a partir de la tabla 10 puede tener el problema que la condición de soporte común (0 o p< 1 o 1 ) no se cumpla en algún intervalo al interior de la región seleccionada para lo cual basta mirar la siguiente figura y concluir que existe un traslape claro y amplio entre el PS estimado para los tratados y para los no tratados. 31 No se muestran las no significativas sólo por razones de espacio y de aclarar la exposición del trabajo en su conjunto. 59 Figura 2: Distribución Propensity Score entre Tratados y No Tratados. Antes y Después del Matching / Modelo 1 Horas Trabajadas Además de poder observar la condición de traslape mediante el análisis gráfico, la figura 2 resulta bastante útil para tener una idea de la calidad del matching. En la imagen de la derecha se observa que la distribución del PS entre tratados y no tratados luego de realizar el matching es muy similar. A pesar de ellos es necesario realizar ciertos test estadísticos que nos muestren el grado de similitud entre ambas muestras que se logró con el matching. En la siguiente tabla se observa la diferencia en valor promedio de diferentes variables de interés entre el grupo de tratados y el grupo de control. Se observa que para el caso previo al matching, las diferencias entre las variables son notorias y estadísticamente significativas, lo que se observa que para casi todas ellas el valor del P-Value es 0, es decir se rechaza la nula de que las medias son iguales. Lo contrario ocurre para los tests posterior al matching realizados entre las mismas variables. 60 Tabla 11: Calidad del Match Modelo Total de Trabajadores Independientes Variable Matching Tratados Control Diferencia P- Value Ingreso No Laboral Ingreso Resto Hogar Subsidios del Hogar Zona Sexo Jefe Menores Hogar Trabajan Hogar Salud Entrevistado Edad Escolaridad Hogar Escolaridad Individuo Persona en el Hogar Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después 0.72 0.76 5.38 5.58 4.30 4.38 0.37 0.39 0.69 0.70 0.81 0.81 0.52 0.55 0.82 0.85 4.44 4.46 71.32 71.09 4.98 5.22 4.01 4.16 3.04 3.11 5.42 0.59 6.17 5.16 4.89 4.37 0.52 0.39 0.74 0.70 0.86 0.81 0.80 0.58 0.99 0.78 4.64 4.57 69.79 70.63 6.90 5.25 5.12 4.22 3.70 3.02 -4.70 0.17 -0.79 0.43 -0.59 0.00 -0.14 0.00 -0.05 0.00 -0.05 0.00 -0.28 -0.03 -0.17 0.07 -0.20 -0.10 1.53 0.46 -1.92 -0.03 -1.11 -0.06 -0.66 0.09 0.00 0.34 0.05 0.27 0.07 0.99 0.00 0.89 0.11 0.88 0.06 0.87 0.00 0.63 0.04 0.36 0.04 0.27 0.00 0.21 0.00 0.92 0.00 0.78 0.00 0.41 61 X.8.2. Tablas Modelo Trabajadores Independientes sin Ingreso No Laboral Tabla 12: Estimación de Probabilidad de Tratamiento Trabajadores Independientes Coeficiente P-Value Ingreso Resto Hogar 0.01 0.48 Subsidios del Hogar 0.00 0.91 Zona -0.11 0.39 Sexo -0.37 0.00 Jefe -0.13 0.35 Menores Hogar 0.18 0.06 Trabajan Hogar 0.13 0.04 Salud Entrevistado 0.00 0.95 Edad 0.85 0.00 Edad -0.01 0.00 Escolaridad Hogar -0.04 0.02 Escolaridad Individuo -0.02 0.12 Persona en el Hogar -0.23 0.00 Decil 2 -0.19 0.27 Decil 3 -0.19 0.30 Decil 4 -0.46 0.01 Decil 5 -0.57 -0.42 -30.19 0.00 0.02 0.00 Decil 6 Constante Pseudo R2 Observaciones 0.12 796 Tabla 13: Condición de Soporte Min-Max Neighbor(1) y Kernel /Trab. Indepen. Off Support On Support Total 4 270 274 Treated 29 493 522 Total 33 763 796 Untreated 62 Figura 3: Distribución Propensity Score entre Tratados y No Tratados. Antes y Después del Matching Modelo 4 63 Tabla 14: Calidad del Match Modelo Trabajadores Independientes sin Ingreso No Laboral Tratados Ingreso Resto Hogar Control Diferencia P- Value Antes Después Antes Después Antes Después Antes Después Antes Después Antes 5.90 6.11 4.03 4.13 0.70 0.70 0.36 0.38 0.80 0.80 0.48 7.21 6.55 4.65 4.48 0.76 0.70 0.54 0.37 0.81 0.77 0.77 -1.32 -0.44 -0.62 -0.35 -0.06 0.00 -0.18 0.01 -0.01 0.03 -0.29 0.00 0.24 0.07 0.24 0.09 0.95 0.00 0.74 0.75 0.22 0.00 Después 0.51 0.51 0.00 0.97 Antes 0.84 1.02 -0.18 0.04 Después 0.86 0.84 0.02 0.80 Salud Entrevistado Antes 4.50 4.62 -0.11 0.26 Después Edad Antes Después Antes Después Antes Después Antes Después 4.53 71.27 70.99 5.17 5.43 4.02 4.18 3.04 3.11 4.53 69.10 70.68 7.03 5.49 5.20 3.95 3.77 3.08 0.00 2.17 0.32 -1.86 -0.06 -1.18 0.23 -0.73 0.03 0.98 0.00 0.36 0.00 0.82 0.00 0.26 0.00 0.79 Subsidios del Hogar Sexo Zona Jefe Menores Hogar Trabajan Hogar Escolaridad Hogar Escolaridad Individuo Persona en el Hogar 64 X.9. Anexo 9: Tablas Modelos de Participación Laboral (PSM) X.9.1. Tablas Modelo General de Participación Tabla 15: Estimación de Probabilidad de Tratamiento Output Participación Laboral Ingreso No Laboral Ingreso Resto Hogar Subsidios del Hogar Zona Sexo Jefe Menores Hogar Trabajan Hogar Salud Entrevistado Edad Edad2 Escolaridad Hogar Escolaridad Individuo Persona en el Hogar Decil 2 Decil 3 Decil 4 Decil 5 Constante Pseudo R2 Observaciones Coeficiente P-Value -0.20 0.00 0.02 0.00 0.01 0.03 -0.24 0.00 -0.23 0.00 0.03 0.34 0.04 0.06 0.05 0.00 -0.01 0.30 0.27 0.00 0.00 0.00 -0.03 0.00 -0.02 0.00 -0.11 0.00 -0.33 0.00 -0.44 0.00 -0.67 0.00 -0.76 0.00 -9.29 0.00 0.5012 20.453 65 Tabla 16: Calidad del Match Modelo Universo Total Modelo Participación Tratados Control Diferencia P- Value Ingreso No Laboral Ingreso Resto Hogar Subsidios del Hogar Zona Sexo Jefe Menores Hogar Trabajan Hogar Salud Entrevistado Edad Escolaridad Hogar Escolaridad Individuo Persona en el Hogar Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después 0.76 0.76 7.22 7.22 4.05 4.05 0.45 0.45 0.38 0.38 0.53 0.53 0.45 0.45 0.72 0.72 4.23 4.23 74.22 74.22 5.16 5.17 3.49 3.49 3.06 3.06 9.24 0.70 6.78 7.19 4.04 4.39 0.64 0.50 0.53 0.35 0.73 0.52 0.56 0.46 0.79 0.69 4.31 4.19 74.30 73.50 6.22 5.16 4.57 3.84 3.22 3.03 -8.48 0.06 0.44 0.03 0.01 -0.34 -0.19 -0.06 -0.15 0.03 -0.20 0.01 -0.11 -0.01 -0.07 0.03 -0.08 0.04 -0.08 0.71 -1.05 0.00 -1.08 -0.35 -0.16 0.03 0.00 0.14 0.00 0.75 0.82 0.00 0.00 0.00 0.00 0.00 0.00 0.11 0.00 0.37 0.00 0.03 0.00 0.05 0.46 0.00 0.00 0.94 0.00 0.00 0.00 0.22 66 X.9.2. Tablas Modelo de Participación Hombres Jefes de Hogar en Zona Urbana. Tabla 17: Estimación de Probabilidad de Tratamiento Todos los Mayores de 65 Entre 65 y 75 Años Coeficiente P-Value Coeficiente P-Value Ingreso Resto Hogar Subsidios del Hogar Menores Hogar 0.042 -0.004 0.094 0.000 0.656 0.205 0.032 0.002 0.097 0.004 0.856 0.271 Trabajan Hogar 0.069 0.173 0.062 0.320 Salud Entrevistado 0.022 0.433 -0.018 0.585 Edad 0.536 0.000 1.862 0.013 Edad -0.003 0.000 -0.013 0.019 Escolaridad Hogar -0.019 0.149 -0.029 0.066 -0.052 0.000 -0.044 0.002 -0.210 -0.398 -0.578 -0.959 -0.923 -20.417 0.000 0.002 0.000 0.000 0.000 0.000 -0.180 -0.336 -0.592 -0.945 -0.993 -66.876 0.005 0.028 0.000 0.000 0.000 0.010 Escolaridad Individuo Persona en el Hogar Decil 2 Decil 3 Decil 4 Decil 5 Constante Pseudo R2 Observaciones 0.2 1337 0.2 855 Tabla 18: Condición de Soporte Min-Max Neighbor(1) y Kernel Off Support On Support 7 421 Treated 10 Total 17 Untreated Neighbor(1) Y Kernel Total Off Support On Support Total 428 3 343 346 899 909 3 506 509 1.320 1.337 6 849 855 67 Figura 4: Distribución Propensity Score entre Tratados y No Tratados. Antes y Después del Matching / Todos Mayores de 65 Tabla 18: Calidad del Match /Mayores de 65 años Ingreso Resto Hogar Subsidios del Hogar Menores Hogar Trabajan Hogar Salud Entrevistado Edad Escolaridad Hogar Escolaridad Individuo Persona en el Hogar Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Tratados 5.13 5.15 4.02 4.04 0.40 0.40 0.60 0.60 4.40 4.40 74.99 74.91 5.16 5.21 4.24 4.28 2.88 2.90 Control 6.65 5.20 4.84 4.42 0.74 0.36 0.95 0.63 4.60 4.56 70.34 74.64 7.47 5.14 5.96 4.14 3.77 2.88 Diferencia -1.53 -0.05 -0.83 -0.38 -0.34 0.04 -0.35 -0.03 -0.20 -0.16 4.65 0.27 -2.31 0.07 -1.72 0.14 -0.89 0.02 P- Value 0.00 0.85 0.00 0.09 0.00 0.25 0.00 0.53 0.02 0.02 0.00 0.39 0.00 0.70 0.00 0.42 0.00 0.85 68 Tabla 19: Calidad del Match Modelo 5/Entre 65 y 75 Años Ingreso Resto Hogar Subsidios del Hogar Menores Hogar Trabajan Hogar Salud Entrevistado Edad Escolaridad Hogar Escolaridad Individuo Persona en el Hogar Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Antes Después Tratados Control Diferencia P- Value 5.20 5.23 4.37 4.37 0.48 0.48 0.62 0.62 4.51 4.52 70.20 70.19 5.35 5.39 4.52 4.54 3.01 3.02 6.80 6.20 4.90 4.28 0.78 0.54 0.97 0.66 4.73 4.54 67.96 70.11 7.74 5.42 6.15 4.39 3.81 3.19 -1.60 -0.97 -0.53 0.10 -0.30 -0.06 -0.34 -0.03 -0.22 -0.02 2.24 0.08 -2.38 -0.03 -1.63 0.16 -0.80 -0.17 0.00 0.01 0.10 0.74 0.00 0.33 0.00 0.60 0.03 0.83 0.00 0.65 0.00 0.90 0.00 0.49 0.00 0.11 69