Notas de estadística descriptiva - Dirección General de Planeación
Anuncio

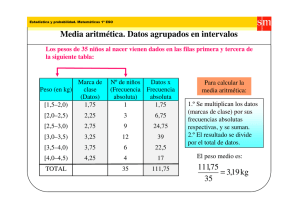
Universidad Nacional Autónoma de México Dirección General de Planeación Notas de estadística descriptiva Mtra. Lilia Elena Sandoval Espinosa Tema 1. Organización de datos 1.1 Introducción 1.2 Algunas definiciones 1.3 Series estadísticas 1.4 Representación gráfica 1.1 Introducción La mayoría de las personas asocian el término estadística con gran cantidad de números, o quizá, con cuadros y gráficas que representan diferentes tipos de información, así como con promedios y medidas semejantes que los resumen. No es de sorprenderse que a las personas que, se dedican a la estadística como campo de estudio, se les relacione con la recolección y presentación de números. En realidad, este punto de vista tan amplio describe en forma muy precisa el interés original de la disciplina. Los primeros estudiosos de la estadística se dedicaron a la recolección de los datos que requería el Estado, de ahí derivó el nombre de estadística. Por ejemplo obtenían información sobre nacimientos y decesos, para auxiliar a los encargados del reclutamiento militar; sobre enfermedades, para ayudar a quienes se ocupaban de la salud pública, por citar algunos ejemplos. La rama de la estadística descriptiva, se enfoca a la tarea de la presentación de datos, de organizarlos y condensarlos, por lo general con ayuda de cuadros, gráficas o medidas numéricas de resumen. este tipo de presentación, a diferencia de grandes cantidades de datos sin elaborar, logra que la información sea comprensible y muchas veces pone al descubierto ciertas características que de otra forma quedarían ocultas. 1.2 Algunas definiciones La rama de la disciplina estadística que se ocupa del desarrollo y utilización de técnicas para la presentación eficaz de información numérica, con el objeto de poner de relieve aspectos que, de otra forma quedarían ocultos en un conjunto de datos, se llama estadística descriptiva. Sin embargo, la estadística descriptiva comprende solo una pequeña parte de la disciplina moderna de la estadística. En la actualidad los estadísticos dirigen la mayor parte de su esfuerzo no hacia la recolección y presentación de información numérica, sino hacia su análisis. Su principal interés esta en hacer deducciones sobre aspectos desconocidos a partir de la información de la que se dispone, por limitada que esta sea. Esta rama de la disciplina estadística que se ocupa del desarrollo y utilización de técnicas para analizar y sacar deducciones de información numérica recibe el nombre de inferencia estadística. En este material nos ocuparemos de la parte de estadística descriptiva Recolección de datos El trabajo estadístico no puede llevarse a cabo en el vacío, requiere de la información pertinente de la materia bajo estudio. Un primer esfuerzo es definir cuáles son las variables que forman parte del fenómeno que se está investigando a las que se les denomina unidades elementales y éstas pueden tener una o varias características de interés para el investigador. Si por ejemplo, nuestro objeto de estudio fuera la población estudiantil de la UNAM, cada estudiante sería una unidad elemental, y de ella podrían interesarnos varias características como serían edad, sexo, lugar de residencia, promedio curricular, ocupación, etc. Población y muestra Por otro lado, la obtención de información cuantitativa puede adquirir dos modalidades. Una de ellas es obtener información de todas las unidades elementales bajo estudio, obteniendo los valores que pueden adquirir todas las variables que nos interesan de ellas. Un ejemplo, puede ser la información recabada por la DGAE, por medio de la cual se obtiene información estadística de cada uno de los estudiantes de nuestra universidad. En este caso el conjunto de datos se refiere a una población. Sin embargo, si la población bajo estudio es muy grande, se tiene como alternativa obtener información de una parte de ésta, conocida como muestra, con la que se logra reducir el costo de la investigación y los resultados pueden obtenerse con mayor rapidez. A partir de la muestra obtenida se pueden extraer conclusiones sobre la población, pero para que estas conclusiones tengan validez, la muestra debe de ser representativa, lo que significa que el comportamiento de los datos muestrales debe ser una imagen del comportamiento de la población. Variables continuas y discretas Tal y como se comentó con anterioridad, la estadística se ocupa de datos cuantitativos asignados a determinadas variables, las cuales pueden ser de dos tipos, de acuerdo a los valores que pueden adquirir. Una variable se dice que es continua si puede asumir cualquier valor entre dos valores determinados, es decir en un intervalo. Si solamente puede adquirir determinados valores se dice que es discreta. Por ejemplo la variable número de hijos, solamente puede asumir valores enteros (0,1,2,3…), en tanto que la estatura de determinado grupo de la población puede adquirir cualquier valor entre 0.5m y 2.5m., por lo tanto la variable número de hijos es una variable discreta y la estatura es una variable continua. Características del método estadístico El método estadístico, como técnica para obtener, analizar y presentar datos numéricos, consiste de varias etapas que podemos sintetizar como: Obtención de la información cuantitativa • Clasificación y compactación de la información • Presentación de la información, ya sea en formato de texto, o utilizando cuadros y gráficas. • Si bien el método estadístico es la única vía para manejar conjuntos de gran tamaño de datos numéricos, habría que mencionar que las técnicas estadísticas únicamente pueden aplicarse a datos que estén expresados de forma cuantitativa. Adicionalmente hay que reconocer que a pesar de que la técnica estadística es objetiva, sus resultados pueden verse afectados por interpretaciones subjetivas. 1.3 Series estadísticas Con el propósito de analizar datos numéricos, es necesario ordenarlos sistemáticamente de acuerdo a sus características. Para ejemplificar lo que podría ser una agrupación de datos de acuerdo a su magnitud, consideremos en el siguiente cuadro los aspirantes aceptados mediante concurso de selección a licenciatura, convocatoria febrero de 2009. Para apreciar mejor la información del cuadro anterior, podríamos arreglar los datos en orden descendente: De este cuadro se desprende que la Facultad con más aspirantes asignados en el concurso de Febrero de 2009, es la FES-Aragón, seguida de la Facultad de Derecho, en tanto que la FES-Acatlán es la que tiene la menor cifra. Un cuadro adicional podría ser la distribución relativa del ingreso que permiten esas Facultades, para lo cual se divide cada uno de los datos entre el total y el resultado se multiplica por cien, para llegar a la siguiente presentación: A partir de este cuadro podemos concluir que del total de aspirantes a cursar la licenciatura en Derecho, casi el 40% fue asignado a la Facultad de Estudios Superiores Aragón, y solo un 25% a la Facultad de Estudios Superiores Acatlán. Con la información de los cuadros anteriores podemos construir algunas representaciones gráficas que nos darán todavía mayor claridad sobre el tema. Los datos anteriores se refieren a cifras de una fecha determinada, pero otro tipo de información puede contener valores de una misma variable en el transcurso del tiempo, lo que da lugar a una serie temporal. Tal es el caso del siguiente cuadro en donde se presentan los aspirantes asignados a la Facultad de Derecho y Facultad de Estudios Superiores Aragón para el periodo 2005-2009 1.4 Representación gráfica Como ya habíamos comentado, la información de los cuadros anteriores se puede representar gráficamente. En el caso de los valores absolutos de los asignados podemos utilizar los dos ejes cartesianos ubicando en el de las abscisas las Facultades y en el de las ordenadas, a escala, el valor de los asignados, para llegar a la siguiente gráfica: En cuanto a la información de su participación relativa, podríamos construir una gráfica similar a la anterior, o bien utilizar la de tipo ¨pie¨ que no es mas que un círculo en el que se representa el peso que tiene cada uno de los datos utilizados. En este caso el círculo nos representa el 100%. Finalmente, las series de asignados para la Facultad de Derecho y la Facultad de Estudios Superiores Aragón para el periodo 2005-2009 pueden representarse gráficamente utilizando los ejes cartesianos ubicando los años en el eje de las abscisas y el valor en el de las ordenadas. Para cada facultad tendríamos una línea que nos muestra la trayectoria de asignados. Tema 2. Distribución de Frecuencias 2.1 Rango, número de intervalos, tamaño del intervalo y frecuencia de clase. 2.2. Representación gráfica de una distribución de frecuencias. Histograma, , polígono de frecuencias, frecuencias acumuladas y frecuencias relativas. 2.1 Distribución de frecuencias Una distribución de frecuencias es el arreglo de un conjunto de datos numéricos de acuerdo a su magnitud. Esta distribución de frecuencias se construye definiendo el valor de tres variables: El rango de la serie, esto es el intervalo entre el dato de mayor valor y el de menor valor. • Tomando en cuenta el valor del rango, los datos se dividen en un número determinado de grupos conocidos como intervalos de clase. • En términos generales podemos establecer que el número de intervalos de clase depende en gran medida del número de datos que se manejen, sin embargo se considera que éstos debieran ser entre cinco y quince. Otra alternativa es definirlos a través de la regla de Sturges, la que establece que: c=3.3(log n)+1 donde c es el número de clases y n es el número de observaciones. Existen además otros requisitos para conformar los intervalos de clase: Los intervalos de clase no deben traslaparse, esto es, los intervalos 0-4.99, 5-5.99 deben preferirse a 0-5 y 5-10. ‣ De ser posible los intervalos de clase deben ser del mismo tamaño. ‣ • El tamaño de los intervalos de clase depende tanto del rango como del número de intervalos que se haya definido. Se obtiene dividiendo el valor del rango entre el número de intervalos que se desean, si el resultado es una fracción es conveniente redondearlo. Una vez definidos el rango, el número de intervalos de clase y su tamaño, estos grupos se representan en la primera columna de un cuadro con el propósito de contabilizar cuántas observaciones de nuestro conjunto de datos numéricos pertenecen a cada uno de los intervalos de clase. El número de observaciones en cada intervalo se le conoce como frecuencia de clase. Veamos un ejemplo, el siguiente cuadro nos presenta en número de aciertos que obtuvieron 80 aspirantes a la licenciatura en Administración Pública en el concurso Mayo de 2009 Para construir la tabla de distribución de frecuencias de los aciertos obtenidos, en primer lugar nos fijamos en los datos mayor y menor para calcular el rango de la variable (r), que es la diferencia entre el resultado mayor y menor: r= 97-53=44 A continuación habrá que definir el número de intervalos de clase (c) que tendrá la distribución de frecuencias, recordando que tenemos los aciertos de 80 aspirantes: c=3.3 log (80)+1 c=3.3 (1.9031)+1=7.28 por lo que el número de intervalos de clase para este caso es de 7 . El tamaño de los intervalos (t) lo definimos dividiendo el rango entre el número de intervalos: t= 44 / 7= 6.28 así el tamaño del intervalo deberá ser de 6. Con esta información formamos los intervalos de clase Finalmente habrá que contabilizar cuantas observaciones se ubican en cada uno de los intervalos para así formar la distribución de frecuencias: 2.2 Representación gráfica de una distribución de frecuencias Utilizando los ejes cardinales podemos representar en el eje de las abscisas (o eje de las x) a los intervalos de clase y en el eje de las ordenadas (o eje de las y) la frecuencia correspondiente y el resultado es una gráfica conocida como histograma. Si a cada uno de los intervalos de clase le calculamos el punto medio o marca de clase podemos representar este valor en el histograma. Al unir estos puntos tendremos el polígono de frecuencias. En ocasiones es de utilidad acumular las frecuencias con el propósito de establecer cuantos datos pertenecer a más de una frecuencia, esta información se puede representar, al igual que primer ejemplo, en un histograma, es este caso de frecuencias acumuladas. Otra posibilidad de representar los datos de una distribución de frecuencias es utilizar los valores de las frecuencias relativas, esto es, con que porcentaje del total participa cada uno de los intervalos de clase. La suma de esta nueva columna debe ser el 100%. En este caso se puede utilizar una gráfica conocida como gráfica de ¨pie¨ Tema 3. Descripción de una distribución 3.1 Tasas de crecimiento 3.2 Medidas de tendencia central: media aritmética y moda. 3.3 Medidas de dispersión: desviación media y desviación estándar. 3.1 Tasas de crecimiento Para conocer la variación que ha tenido nuestra serie a lo largo del tiempo podemos hacer uso de las tasas de crecimiento, estas pueden ser anuales o considerar un periodo. Anual: [(VF/VI)-1]*100 Promedio: [(VF/VI)1/n-1]*100 3.2 Medidas de tendencia central. Las medidas de tendencia central corresponden a valores que generalmente se ubican en la parte central de un conjunto de datos, nos permiten analizar los datos en torno a un valor central. La tendencia central se refiere al punto medio de una distribución. Entre éstas están la media aritmética, la moda y la mediana. Media aritmética. La media aritmética de un conjunto de observaciones es una medida de posición que se conoce comúnmente como promedio. Es la medida de posición central más utilizada, la más conocida y la más sencilla de calcular, debido principalmente a que sus ecuaciones se prestan para el manejo algebraico, lo cual la hace de gran utilidad. Su principal desventaja radica en su sensibilidad al cambio de uno de sus valores o a los valores extremos demasiado grandes o pequeños. La media se define como la suma de todos los valores observados, dividido por el número total de observaciones. Esta fórmula únicamente es aplicable si los datos se encuentran desagrupados; en caso contrario debemos calcular la media mediante la multiplicación de los diferentes valores por la frecuencia con que se encuentren dentro de la información. Ejemplo Tomemos la de los números de aciertos de un examen aplicado a 80 estudiantes de la unidad anterior. La suma de los 80 resultados de los exámenes es 6020. y si este numero lo dividimos entre el número de observaciones tenemos, 6020/80=75 Lo que nos indica este valor es que el promedio de aciertos que tuvieron los alumnos es de 75 aciertos. Moda. La moda nos indica el valor que más veces se repite dentro de los datos; es decir, si tenemos la serie ordenada (2, 2, 5 y 7), el valor que más veces se repite es el número 2 quien sería la moda de los datos. Es posible que en algunas ocasiones se presente dos valores con la mayor frecuencia, lo cual se denomina bimodal o en otros casos más de dos valores, lo que se conoce como multimodal. Ejemplo. Si observamos los datos de la serie que hemos venido trabajando, encontramos que el número que mas se repite es el 75, por lo que la moda para los datos no agrupados es 75. 3.2 Medidas de dispersión En el análisis estadístico es importante conocer que tanto varían las observaciones alrededor de un valor central. Esta variabilidad puede medirse de dos maneras: como distancia entre observaciones seleccionadas o bien como desviaciones promedio de las observaciones individuales respecto a un valor central. La dispersión es importante porque: • Proporciona información adicional que permite juzgar la confiabilidad de la medida de tendencia central. Si los datos se encuentran ampliamente dispersos, la posición central es menos representativa de los datos. • Ya que existen problemas característicos para datos ampliamente dispersos, debemos ser capaces de distinguir que presentan esa dispersión antes de abordar esos problemas. • Quizá se desee comparar las dispersiones de diferentes muestras. Si no se desea tener una amplia dispersión de valores con respecto al centro de distribución o esto presenta riesgos inaceptables, necesitamos tener habilidad de reconocerlo y evitar escoger distribuciones que tengan las dispersiones más grandes. Pero si hay dispersión en la mayoría de los datos, y debemos estar en capacidad de describirla. Ya que la dispersión ocurre frecuentemente y su grado de variabilidad es importante, ¿cómo medimos la variabilidad de una distribución empírica? Desviación media. Equivale a la división de la sumatoria del valor absoluto de las distancias existentes entre cada dato y su media aritmética y el número total de datos. Ejemplo. En el caso de los datos no agrupados, tomamos el valor ya calculado de la media aritmética de nuestro ejemplo, obtenemos las diferencias absolutas y dividimos entre le número de observaciones: Desviación estándar La desviación estándar es una medida del grado de dispersión de los datos del valor promedio. Dicho de otra manera, la desviación estándar es simplemente el "promedio" o variación esperada con respecto de la media aritmética. Ejemplo. En los datos de las calificaciones, la desviación estándar de datos no agrupados, elevamos las diferencias con respecto a la media. La serie anterior se divide entre el número de observaciones y finalmente se obtiene la raíz cuadrada.