ácidos nucleicos
Anuncio

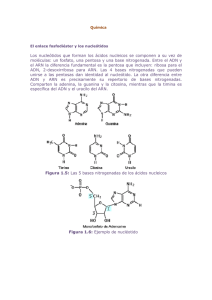
TEMA 10. GUIÓN ÁCIDOS NUCLEICOS. (4 sesiones). 1. CONCEPTO DE ÁC. NUCLEICO COMO PORTADOR DE LA INFORMACIÓN GÉNICA. - Tipos de ácidos nucleicos: DNA y RNA. 2. ESTRUCTURA DE LOS ÁCIDOS NUCLEICOS. - La unidad básica: el nucleótido (molécula compleja formada por base nitrogenada, pentosa y ácido ortofosfórico). - Estructura general de las bases púricas y pirimidínicas. - Concepto de nucleósido. - Concepto de mononucleótido y dinucleótido. 3. ÁCIDO DESOXIRRIBONUCLEICO (DNA). (HIPÓTESIS DE WATSON-CRICK). - Carácter complementario de las bases. - Estructura helicoidal. 4. ÁCIDO RIBONUCLEICO (RNA). - Diferencias con la estructura del DNA. - Tipos de RNA: RNA TRANSFERENTE (RNAt) RNA RIBOSÓMICO (RNAr). RNA MENSAJERO (RNAm). RNA NUCLEOLAR (RNAn). 5. FUNCIÓN DE LOS ÁCIDOS NUCLEICOS. transcripción traducción ADN ───────────────> ARN ───────────────> PROTEÍNAS │ ────────────── │ Transcripción inversa │ │ │duplicación (replicación). │ ADN + ADN - Carácter semiconservativo de la duplicación. Concepto de código genético. 1. CONCEPTO DE ÁC. NUCLEICO COMO PORTADOR DE LA INFORMACIÓN GÉNICA. Los ácidos nucleicos son el material genético de los seres vivos, es decir: ■ Son los agentes moleculares de la herencia, lo que significa que en ellos se almacena la información necesaria para construir y mantener a cada organismo. ■ Se transmite a lo largo de las generaciones, acumulando en su estructura los cambios graduales y útiles que son la base de la evolución. 1 TIPOS DE ÁCIDOS NUCLEICOS. A finales del siglo pasado, se descubre que las piezas elementales del ácido nucleico son el ácido fosfórico, una base nitrogenada y un azúcar y es entonces cuando se percatan de que existen dos tipos de ácidos nucleicos: uno que está constituido por el azúcar ribosa, al que se denomina por esta razón ácido ribonucleico (RNA) y otro, que está formado por desoxirribosa, al que se conoce como ácido desoxirribonucleico (DNA). A mediados de los años 40 de este siglo, a raíz de un sorprendente experimento se conoció que el DNA es el material que imprime las características a los seres vivos. Los hechos ocurrieron del siguiente modo: El médico norteamericano F. Griffith realizó investigaciones acerca de las causas de la neumonía (afección respiratoria grave provocada por la bacteria Streptoccocus pneumoniae). Aisló dos formas bacterianas: una forma S, que en cultivo daba lugar a colonias de aspecto liso (tipo S, de smooth=liso), debido a que poseían una cápsula compuesta de polisacáridos. Esta forma bacteriana es virulenta y produce la enfermedad si infecta a un organismo. y la forma R (tipo R, de rough=rugoso) que daba lugar a colonias de aspecto rugoso debido a que las bacterias no poseían cápsula. Esta forma era no virulenta. Al inyectar bacterias S a ratones, éstos enfermaban y morían, ya que las bacterias, protegidas por su cápsula, podían reproducirse. Si mataba a las bacterias S por medio de calor, y luego las inyectaba a ratones, estos sobrevivían. Si inyectaba a los ratones bacterias de tipo R, los ratones sobrevivían, pues los sistemas de defensa de éstos destruían a las bacterias, por no poseer éstas cápsula protectora. A continuación, Griffith realizó una prueba que resultó decisiva: inyectó una mezcla de bacterias S muertas y de bacterias R vivas y entonces los ratones enfermaban y morían, recuperando de los cadáveres bacterias S vivas ¿Que había ocurrido?. Griffith no pudo explicarlo, pero si que lo hicieron Avery, MacLeod y McCarty. Estos investigadores llegaron a la conclusión que la transformación de las bacterias R era inducida por el ADN de las bacterias S muertas. Al matar mediante el calor a las bacterias S, éstas se destruyen, quedando su ADN libre en el medio. Algunas de estas moléculas de ADN, por simple azar, entraban en contacto con la superficie de las bacterias R y penetraban en su interior. Con la nueva información, las bacterias R vivas podían fabricar el polisacárido de la cápsula, adquiriendo así las características de la forma S. A partir de esto, se tuvo que admitir, que el ADN porta la información que determina las características de las células. 2 2. ESTRUCTURA DE LOS ÁCIDOS NUCLEICOS. Poco después de ser descubiertos los ácidos nucleicos, se averiguó que contenían fósforo, en forma de ácido ortofosfórico (H3PO4). Los enlaces existentes entre el átomo de fósforo y los átomos de oxígeno del ácido fosfórico son fuertes, sin embargo, los átomos de hidrógeno pueden extraerse del compuesto con bastante facilidad, y entonces pueden formarse enlaces con otros átomos o grupos de átomos. O - H │ O ═ P ─ O ─ H │ O ─ H Pronto se descubrió también, que los ácidos nucleicos contenían en su estructura moléculas de azúcar. Este azúcar es la desoxirribosa en el caso del ADN y ribosa en el ARN. Ambos azúcares sólo se diferencian, por la carencia de un átomo de oxígeno en la desoxirribosa (des-oxi-ribosa). Mas tarde se supo que los ácidos nucleicos, además de grupos fosfátidos y azúcares, están compuestos por unas moléculas cíclicas compuestas en parte por nitrógeno. Todos los compuestos que se han lograron extraer con estas características, están construidos o bien con anillos hexagonales o bien a partir de un sistema de 2 anillos, uno hexagonal y otro pentamérico. Estos compuestos, denominados bases nitrogenadas, se clasifican en dos grupos según el tipo de estructura que poseen: si poseen un anillo hexagonal se les llama compuestos pirimidínicos. Ejemplos: Uracilo, Citosina y Timina. si, en cambio, poseen un anillo hexagonal y otro pentagonal, se les llama compuestos púricos. Ejemplos: Adenina y Guanina. A) LA UNIDAD BÁSICA: EL NUCLEÓTIDO. También se averiguó que todos estos componentes estaban organizados formando unas unidades básicas: los nucleótidos. Cada nucleótido está constituido por una base nitrogenada, unida a una pentosa, y ésta, a su vez, unida a una molécula de ácido ortofosfórico. ┌───────────────────────────────────────────┐ │ NUCLEÓTIDO = BASE + PENTOSA + FOSFATO (s) │ │ └──nucleósido──┘ │ └───────────────────────────────────────────┘ Los ácidos nucleicos se forman por la unión de muchas de estas moléculas complejas (nucleótidos), que se enlazan formando largos polímeros (polinucleótidos). Del mismo modo que los aminoácidos son las unidades básicas que forman las proteínas, los nucleótidos son los monómeros a partir de los cuales se forman los ácidos nucleicos; la única diferencia entre unos y otros, es que los aminoácidos constituyen cada uno una especie química definida y los nucleótidos son ya ellos mismos, moléculas complejas que resultan de la unión de otras. Un nucleótido se forma por la unión entre el grupo OH hemiacetálico del C 1´ de una pentosa (ribosa o desoxirribosa) y el hidrógeno del N 1, si se trata de una base pirimidínica, o el N9, si se trata de una base púrica. El enlace es del tipo N-glicosídico y se establece al liberarse una molécula de agua. El grupo 3 fosfato se une a través de uno de sus grupos -OH y el -OH del carbono 5´ de la pentosa. Se trata de un enlace tipo ester. El nombre que reciben componentes del mismo. Grupos P 1 grupo P 1 grupo P los Azúcar ribosa desoxirribosa distintos nucleótidos, Base nitrog. está en NUCLEÓTIDO Adenina Adenosina-5 ´monofosfato Adenina desoxiadenos ina-5´monofosfato función de los Abrev. AMP dAMP 3 grupos P ribosa Adenina Adenosina-5 ´trifosfato ATP 1 grupo P ribosa Citosina Citidina-5´monofosfato CMP 2 grupos P ribosa Uracilo Uridina-5´difosfato UDP En la nomenclatura, a las moléculas formadas por nucleótidos se las conoce añadiéndoles a esta denominación el prefijo, mono, di, tri, tetra....o poli, según sean 1, 2, 3, 4 .....o "n", respectivamente, los nucleótidos que las constituyen. Mononucleótido (1 nucleótido aislado). Dinucleótido (2 nucleótidos unidos) Trinucleótido (3 nucleótidos unidos). Polinucleótidos (muchos nucleótidos). MONONUCLEÓTIDOS. Una de las funciones más importantes de los mononucleótidos es la de actuar como transportadores de energía química. Sobretodo, el adenosin trifosfato (ATP), que participa en la transferencia de energía entre cientos de reacciones celulares distintas. Sus dos fosfatos terminales, reactivos y fácilmente hidrolizables, son obligados a establecer enlaces covalentes entre ellos durante la oxidación de los alimentos; luego, en determinadas reacciones, la hidrólisis de uno o ambos grupos fosfato puede servir para impulsar energéticamente los procesos de biosíntesis desfavorables. Otro mononucleótido importante es el AMP cíclico, cuya estructura es como la del adenosín monofosfato, pero con un puente intramolecular establecido entre un -OH del fosfato y el hidroxilo del carbono 5´ de la pentosa. Esta molécula actúa de segundo mensajero en el interior de la célula, provocando una serie de reacciones por parte de ésta, cuando llegan a ella determinadas hormonas o neurotransmisores. Determinados monucleótidos son coenzimas, por ejemplo: el coenzima A. DINUCLEÓTIDOS.Dinucleótidos que actuan como coenzimas son: el NAD (nicotín adenín dinucleótido), el FAD (flavín adenín dinucleótido). Estas dos moléculas participan en el transporte de electrones en la mitocondria. 4 CONCEPTO DE NUCLEÓSIDO. Si un nucleótido pierde el grupo fosfato, se forma un nucleósido. ┌───────────────────────── ─────┐ │ NUCLEÓSIDO = BASE + PENTOSA │ └─────────────────────────── ───┘ Según el tipo de base nitrogenada que constituye el nucleósido, éste recibe distinto nombre: Base nitrogenada NOMBRE NUCLEÓSIDO Abreviatura Adenina ADENOSINA A Guanina GUANOSINA G Citosina CITIDINA C Uracilo URIDINA U Timina TIMIDINA T 3. ÁCIDO DESOXIRRIBONUCLEICO (DNA). (HIPÓTESIS DE WATSON-CRICK) COMPONENTES. El DNA está formado por cuatro tipos de nucleótidos. A su vez, cada nucleótido del ADN están compuestos por: Fosfato la desoxirribosa. una de las siguientes bases nitrogenadas:adenina, guanina,citosina y timina. Cada nucleótido se identifica mediante una inicial que se corresponde con la inicial de la base nitrogenada que lo compone: A, T, G, y C. Un fragmento de DNA puede contener un número cualquiera de estos nucleótidos enlazados en un orden cualquiera. A pesar del tamaño y la aparente complejidad de estas moléculas, resulta muy fácil describir con precisión cualquier trozo; sólo es necesario escribir las iniciales correspondientes a los nucleótidos en el orden correcto. Por ejemplo, "ATGCGGATCC" describe un trozo específico de DNA de 10 nucleótidos de longitud. La molécula de ADN, igual que las proteínas, puede adoptar una configuración espacial en la que pueden describirse hasta cuatro niveles estructurales distintos de complejidad creciente; cada uno de ellos depende del anterior y, a su vez, condiciona al siguiente: son las llamadas estructuras primaria, secundaria, terciaria y cuaternaria. 5 ESTRUCTURA PRIMARIA. Así como en las proteínas se obtenían cadenas polipeptídicas a partir de aminoácidos, también en este caso la estructura primaria del ADN consiste en la formación de largas cadenas de polinucleótidos. Los nucleótidos están unidos por medio de enlaces que se establecen entre el carbono 5´ de una pentosa y el carbono 3´ de la siguiente, mediando entre ambos un grupo fosfato; estos enlaces se denominan enlaces fosfodiéster. En los casos en que los polinucleótidos son polímeros lineales (pueden ser circulares), el último resto nucleotídico de cada uno de los extremos opuestos actúa como término del mismo. Estos dos terminales no son estructuralmente equivalentes, ya que uno de los nucleótidos termina con un grupo -OH libre sobre el C3´, mientras que en el otro extremo, el nucleótido termina con un -OH libre sobre el C5´. Estos extremos de los polinucleótidos se denominan extremo 3´ y 5´, respectivamente. En un polinucleótido se pueden diferenciar dos partes: El esqueleto de polidesoxirribosa-fosfato, que constituye el eje que soporta la estructura de la molécula. Y las diferentes bases de adenina, guanina, citosina y timina, alineadas a lo largo de este esqueleto. De la misma manera que las proteínas se distinguen unas de otras por la composición y el orden de sucesión de los diferentes aminoácidos, igualmente, los polinucleótidos difieren entre sí por la composición y la secuencia de sus bases, es decir, el orden en que se presentan los cuatro tipos de bases (A, G, C y T) a lo largo del esqueleto de polidesoxirribosa fosfato. Cada organismo posee una molécula de ADN diferente, caracterizada por la secuencia concreta de sus bases, y es en la naturaleza misma de esta secuencia en donde reside la información necesaria para la síntesis de las proteínas (Ilustración 3). ESTRUCTURA SECUNDARIA. La mayoría de moléculas de ADN no está formado por cadenas aisladas, sino por dos cadenas de polinucleótidos, unidas una a la otra, formando una doble hélice. Está estructura puede mantenerse gracias a que cada uno de los cuatro nucleótidos puede formar unos enlaces químicos por "puente de H" con un tipo particular de nucleótido de la otra cadena de DNA. Esto fue deducido a partir de los resultados obtenidos por Chargaff, quien, tras analizar numerosas muestras de ADN procedentes de diferentes tipos de células y de numerosas especies animales, demostró que salvo en muy raras excepciones, todos los ADN poseen igual número de moléculas de timina y adenina, y tantas de citosina como de guanina. A partir de esta información se dedujo que el ADN estaba constituido por 2 cadenas de polinucleótidos unidas por medio de sus bases nitrogenadas de una forma semejante a esta: ║ A ■■■ T ║ ║ G ■■■ C ║ Las bases púricas (A y G), que son más grandes, se encuentran enfrentadas a las 6 bases pirimidínicas, más pequeñas, y la unión se realiza por puentes de hidrógeno entre los grupos polares de las bases: dos puentes de hidrógeno en los pares A═T y tres en los pares G░C. Esta relación entre las bases, por la cual cada nucleótido tiene enfrente suyo al nucleótido apropiado se describe como complementariedad. Las bases son complementarias porque cada base de una hebra encaja con una base complementaria en la otra. Tambien se habla de complementariedad de cadenas ya que las dos cadenas posean secuencias complementarias, esto es, si una posee la secuencia ATTCCCC, la otra cadena tendrá la secuencia TAGGGGG. Otra característica estructural importante del ADN de doble hebra es que sus cadenas son antiparalelas. Los polinucleótidos son estructuras que presentan polaridad como puede deducirse tras la inspección de algún esquema de los mismos. Esto hace que las dos hebras estén orientadas en direcciones opuestas, esto es, si dos bases adyacentes en la misma hebra, están conectadas en la dirección 5´--> 3´, sus bases complementarias adenina y guanina lo estarán en la dirección 3 ´---> 5´ (las posiciones se definen uniendo las posiciones 3´y 5´ dentro del mismo nucleótido). (Ilustración 2). Tras las investigaciones realizadas por Franklin y WilKins que indicaban que la molécula de ADN presentaba una estructura helicoidal, Watson y Crick propusieron un modelo para explicar la estructura secundaria del ADN, conocido como modelo de la doble hélice de ADN. Este modelo explica que las dos cadenas polinucleótidas están arrolladas conjuntamente alrededor de un hipotético eje común, conformando cada cadena, una hélice de orientación dextrógira. Este modelo de la doble hélice de Watson y Crick se denomina forma B y durante mucho tiempo se ha considerado como la única estructura del ADN. Sin embargo, otros estudios han revelado que existen otras formas: forma A, forma Z. Todas estas variantes pueden encontrarse juntas dispuestas a lo largo de una misma fibra de ADN, señalizando aquellas secuencias de ADN que tiene que transcribirse. • Esta configuración tridimensional en doble hélice, es la que presenta el ADN de las células eucarióticas y el de ciertos virus bacteriofagos (comedores de bacterias). Aunque es la estructura más general, sin embargo, se han encontrado otras clases de ADN: • En ciertos virus se ha encontrado un tipo de ADN lineal unicatenario. • Virus como el Φ-X-174, presentan un ADN circular unicatenario. • En las bacterias aparece un ADN circular bicatenario. También se encuentra esta forma de ADN en ciertos virus y en las mitocondrias y cloroplastos de eucariotas. 7 4. ÁCIDO COMPONENTES. RIBONUCLEICO (RNA). La composición del RNA es idéntica al DNA, a excepción de 2 diferencias: • la pentosa que constituye los nucleótidos es la ribosa, en cambio en el ADN era la desoxirribosa. • Las bases nitrogenadas púricas son la adenina y la guanina (las mismas que para el ADN); las pirimidínicas son la citosina y el uracilo. A excepción del uracilo que reemplaza a la timina, éstas son las mismas bases que se encuentran en el ADN. ESTRUCTURA PRIMARIA. Los ribonucleótidos están conectados mediante grupos fosfato sencillos que unen el carbono en 3´ de una ribosa con el carbono 5´ de la siguiente ribosa. Este enlace, un fosfodiéster 3´, 5´, forma el armazón esquelético al que se adosan las bases nitrogenadas. Estructuralmente, el RNA sólo suele presentar estructura primaria, aunque en algunos casos existan ciertas regiones en una misma cadena que poseen secuencias complementarias capaces de aparearse y de formar una doble hélice. Esto es lo que ocurre en el RNA transferente. ESTRUCTURA SECUNDARIA y TERCIARIA. Algunos RNA presentan en ciertos tramos una estructura en doble hélice (estructura secundaria). En ocasiones esta doble cadena se pliega sobre si misma dando lugar a estructura terciaria. Hasta ahora todas las formas de RNA que se han descrito son monocatenarias. Sólo hay una excepción: una forma de RNA bicatenario con estructura en doble hélice que se ha encontrado en un tipo de reovirus. TIPOS DE RNA. Tradicionalmente, las especies de RNA se han clasificado como: RNA de transferencia. RNA ribosómico. RNA mensajero. y RNA nucleolar. 8 RNA TRANSFERENTE (RNAt) Los RNAs de transferencia son ácidos nucleicos relativamente pequeños que tienen una longitud entre 80 y 100 nucleótidos. Todos ellos están constituidos por una sola cadena polinucleotídica, que presenta zonas con estructura primaria y zonas con estructura secundaria. La configuración de estructura secundaria es posible, debido a que en un mismo RNA, hay secuencias de bases complementarias que se aparean, adoptando estos trozos, la configuración en doble hélice, mientras que las zonas que no se aparean adoptan el aspecto de bucles. Esta estructura puede representarse bidimensionalmente, apareciendo un dibujo que recuerda las "hojas del trébol". Sin embargo, la conformación real de los RNAt es mucho más compleja, adoptando estos una forma tortuosa y retorcida, que en nada se parece a una "hoja de trébol"; la estructura terciaria presenta una forma de "L", o de "trébol". (Ilustración 9). En cada RNAt se distinguen los siguientes rasgos estructurales: Existe un brazo aceptor de aminoácidos, en el siempre está la secuencia de bases CCA. Aquí es donde se unen covalentemente los aminoácidos específicos del RNAt. El brazo largo del "bumerán", es la zona que se une al RNA mensajero, durante la síntesis de proteínas. Esta parte contiene una secuencia de 3 bases llamada anticodón. El llamado brazo D, contiene una secuencia de bases que es reconocida de manera específica por una de las 20 enzimas, llamadas aminoacil-ARNt sintetasas, encargadas de unir cada aminoácido con su correspondiente molécula de ARNt. El llamado brazo T, actúa como lugar de reconocimiento del ribosoma. Hasta ahora se han descubierto 56 tipos de RNAt, que se diferencian unos de otros en la combinación de bases que constituyen su anticodón. Estas bases están en correspondencia con el aminoácido que porta el transferente. A menudo, hay varios RNAt diferentes (tienen anticodones distintos) que llevan un mismo tipo de aminoácido, pudiéndose definir estos RNAt como RNAt isoaceptores. 9 RNA RIBOSÓMICO (RNAr). Son moléculas de diferentes tamaños, que presentan estructura secundaria en algunas regiones de la molécula. Para diferenciar unos RNAs ribosómicos de otros, se utiliza como criterio de clasificación el peso molecular medio de cada RNAr, cuyo valor se deduce a partir de la velocidad con que sedimentan dichas moléculas, cuando son sometidas a un campo centrífugo. Así, en los eucariotas, nos encontramos con los siguientes tipos de RNAs ribosómicos: RNAr 28 S RNAr 5´8 S RNAr 5 S RNAr 18 S El peso molecular se expresa en unidades Svedberg (S), nombre del científico sueco que desarrolló esta técnica de análisis. Los RNA ribosómicos de eucariotas, se unen a más de 70 proteínas distintas para constituir a las subunidades que forman los ribosomas. Por ejemplo, los ribosomas citoplasmáticos eucarióticos (80 S), están constituidos por dos subunidades ribosómicas: la subunidad pequeña (40 S) está formada por un RNAr 18 S y alrededor de 30 proteínas distintas. la subunidad grande, (60 S), está formada por un RNAr 28 S, uno 5´8 S y otro 5 S, acoplados con unas 45 proteínas distintas. RNA MENSAJERO (RNAm). Son largas moléculas de polinucleótidos, de aspecto filamentoso, debido a que sólo presentan estructura primaria. El nombre de "mensajero" hace referencia a la función que desempeña en la célula, consistente en trasladar la información genética desde el núcleo a los ribosomas citoplasmáticos. Cada RNAm contiene la información para sintetizar tan sólo, una cadena polipeptídica; sin embargo, con la información de todos los RNAm, se controla el funcionamiento de toda la célula, ya que muchas de las proteínas actúan como enzimas. Las restantes proteínas son estructurales y determinan el fenotipo celular. Estructuralmente, los ARNm poseen en su extremo 5´ una "caperuza" compuesta por un residuo de metil-guanosina unida a un grupo trifosfato. A continuación de la "caperuza", aparece una secuencia que no se traduce llamada "conductora", y al lado de esta, el codón de iniciación (AUG) con el mensaje que se ha de traducir. Al final de la secuencia codificante, se encuentra una secuencia de finalización y por último, una secuencia que no se traduce llamada "remolque" (trailer) que termina con una cola de poli (A). Una característica peculiar de los RNAm es su corta vida, pues transcurren tan sólo unos pocos minutos desde el momento de su síntesis hasta que quedan degradados. 10 RNA NUCLEOLAR (RNAn). Es un tipo de RNA, de elevado peso molecular, que se sintetiza en el nucléolo. En realidad no es más que el precursor de los diferentes tipos de ARN ribosómico. El ARNn es una larga cadena compuesta por nucleótidos, que en un determinado momento, se rompe por lugares específicos y da lugar a tres fragmentos de ARNr: el ARNr 28 S y el ARNr 5´8 S (constituyentes de la subunidad grande de los ribosomas) y el ARNr 18 S (componente de la subunidad pequeña). El fragmento de ARNr 5 S no se obtiene a partir del ARN nucleolar. 5. FUNCIÓN DE LOS ÁCIDOS NUCLEICOS. El ÁCIDO DESOXIRRIBONUCLEICO es una macromolécula funciones trascendentales para todos los seres vivos: 1) Es el material que contiene la información síntesis de todas las proteínas de un organismo. que desempeña necesaria para dos la Hemos visto que toda la información necesaria para construir una molécula proteica tridimensional se encuentra en la secuencia lineal de los aminoácidos de la proteína. Una vez que los aminoácidos apropiados se unen en la secuencia correcta, las fuerzas elementales de la termodinámica hacen el resto, asegurándose de que la proteína se pliega en la conformación precisa para realizar su trabajo. Por tanto, para contener la información necesaria para producir proteínas lo único que debe hacer un ácido nucleico es especificar la secuencia en la que deben disponerse los aminoácidos de la proteína que se va a formar. Los ácidos nucleicos transportan la información en forma de variaciones en la secuencia de nucleótidos, de manera que cada grupo de 3 nucleótidos puede especificar la incorporación de un cierto aminoácido a una cadena proteica en crecimiento. Cómo el ADN se encuentra en el nucleo celular y las proteínas se sintetizan en el citosol, las células necesitan un mecanismo para transmitir la información necesaria desde el núcleo hasta el citoplasma. A un fragmento de DNA que contiene la información necesaria para producir una proteína especifica se le suele denominar "gen". Primero se produce una copia del gen que es necesario para la célula; copia que en todos los organismos consiste en un RNA de cadena sencilla, al que se conoce por "RNA mensajero" (mRNA). La producción de la copia de mRNA se realiza mediante la separación de las hebras hermanas de la doble hélice de DNA seguida por la copia de una de ellas a mRNA. El proceso de formación de este mRNA réplica se denomina TRANSCRIPCIÓN. Este término establece una analogía con la escritura ya que la información genética se transcribe desde el DNA original a un mRNA que contiene la misma información pero escrita en otro tipo de caracteres (es decir, RNA en lugar de DNA). 11 En realidad, la producción de las proteínas se da cuando el mRNA se une a los ribosomas en el citoplasma. Un ribosoma se desplaza a lo largo de la molécula de mRNA y, a medida que lo hace, los grupos de 3 nucleótidos ("codones") que codifican cada uno de ellos un cierto aminoácido, van pasando por un lugar especial del ribosoma. Cada vez que un codón de 3 nucleótidos se encuentra en este sitio, el aminoácido correspondiente se transporta al ribosoma y se une a la cadena de proteína naciente. Una vez que el ribosoma ha recorrido la molécula de mRNA en toda su longitud habrá producido la proteína completa cuya secuencia de aminoácidos está total y precisamente determinada en la secuencia de nucleótidos que forma el mRNA. La proteína ya acabada se liberará del ribosoma y esto permitirá que se pliegue y empiece a realizar la función para la que su secuencia de aminoácidos la hace idónea. La conversión de la información genética que lleva el mRNA a moléculas de proteína se conoce como TRADUCCIÓN, ya que la información se traduce del lenguaje de los ácidos nucleicos al lenguaje de las proteínas. (Ilustración 17). En los años 60, el concepto de que el ADN se transcribe en ARN y éste se traduce en proteínas, se conocio como DOGMA CENTRAL DE LA BIOLOGIA MOLECULAR.Esta idea recibió un duro golpe, cuando se descubrieron una serie de virus cuyo material génico era ARN. Algunos de estos virus (como el del SIDA), una vez en el interior de las células a las que parasitan, son capaces de sintetizar ADN a partir del ARN que los compone, por medio de una enzima llamada transcriptasa inversa. A estos virus se les conoce como retrovirus. Actualmente se ha encontrado retrotranscripción, en otros organismos más complejos como las levaduras, insectos e incluso los mamiferos. transcripción traducción ADN ───────────────> ARN ───────────────> PROTEÍNAS │ ────────────── │ Transcripción inversa │ │ │Duplicación (replicación). │ ADN + ADN 2) Además de regular la expresión celular, el DNA juega un papel exclusivo en la herencia. El DNA puede hacer copias de sí mismo , al mismo tiempo que se divide la célula, de manera que cada copia se dona a una célula hija. Así, las células descendientes, heredan todas y cada una de las propiedades y características de la célula original. A) DUPLICACIÓN. (Carácter semiconservador de la duplicación) Desde el mismo momento en que se propuso el modelo de doble hebra del DNA quedó claro que con esta estructura era fácil imaginar un mecanismo para la replicación del DNA: las dos hebras del DNA son separables y cada una de ellas puede servir como molde para la síntesis de una nueva hebra, de manera que, una vez formadas las nuevas cadenas, se tendrían 2 moléculas de ADN de doble hebra. Al principio, se plantearon 3 tres posibles mecanismos para la replicación: Según una hipótesis, conocida como replicación conservadora, las 2 moléculas de ADN que se obtendrían tras la duplicación serían diferentes: una de ellas estaría formada por las dos hebras originales y la otra molécula estaría constituida por las dos cadenas sintetizadas de nuevo. Una segunda hipótesis, denominada dispersiva, postulaba que no existirían cadenas originales ni cadenas nuevas. Los nucleótidos del DNA original se 12 entremezclarían entre las secuencias sintetizadas de nuevo, siendo cada una de las hebras resultantes, una combinación de secuencias originales, dispersadas al azar entre las secuencias nuevas. Se comprobó finalmente que la síntesis de ADN es un proceso semiconservador. Después de cada ciclo de replicación, los DNA obtenidos están formados por una de las hebras originales acoplada a un polinucleótido complementario sintetizado de nuevo. Se demostró que la replicación del DNA era un proceso semiconservador, a través de un elegante experimento que consistió en lo siguiente: 1) Se cultivó "E. coli" en un medio que contenía cloruro amónico con N 15 como única fuente de nitrógeno. Se permitió que tuviesen lugar varias divisiones celulares durante las que el N15 fue incorporado para formar los nucleótidos y los nuevos ADNs. El N15 también se conoce como nitrógeno pesado, porque cuando se incorporara al DNA y este se centrífuga, el DNA se comporta como si fuera más pesado y se sitúa más al fondo en la centrífuga que el DNA normal (producido con N14). 2) Se cambió a las bacterias a un nuevo medio de cultivo, que contenía cloruro amónico con N14. Se mantuvieron durante media hora en este medio, que es el tiempo necesario para que se duplique el ADN bacteriano, y estas incorporaron en sus DNAs el N14. 3) Se comprobó que estos DNAs eran híbridos ya que ocupaban en el tubo de centrifugación una posición intermedia entre la que ocupaba el DNA con N15 yla del DNA con N14. Se separaron las hebras que constituían los DNAs y mediante centrifugación se demostró que las moléculas hijas de DNA contenían dos hebras de densidades diferentes: una hebra estaba constituida por nucleótidos que contenían exclusivamente N14 y la otra hebra contenía nucleótidos con N15. Con estos resultados, quedó claro que las nuevas hebras se sintetizan por completo, utilizando como molde la hebra original. Quedó demostrado que la replicación se hace exclusivamente según el modelo semiconservador, esto es, en cada ciclo de replicación se mantiene intacta una de las hebras paternas que se combina con una de las hebras recién sintetizadas. B) EL CÓDIGO GENÉTICO. El ADN no controla directamente los procesos funcionales y aspectos fenotípicos de un organismo, sino que a través de determinadas proteínas, cuya síntesis dirige, el DNA puede controlar cualquier propiedad tanto física como química de las células. Y son éstas, las que determinan las características de los organismos pluricelulares. Por ejemplo, el ADN es incapaz de transportar oxígeno, en cambio, puede sintetizar la proteína hemoglobina, y a través de ésta, realizar la función. Cada segmento de ADN que contiene la información necesaria para la síntesis de una proteína se denomina GEN. Debido a que el ADN de una célula eucariótica está localizado dentro del núcleo celular y que la síntesis proteica se realiza en el citoplasma, las células requieren transferir la información codificada en un gen desde el núcleo hasta el citoplasma. Para ello, sintetizan una macromolécula denominada ácido ribonucleico mensajero (ARNm), cuya secuencia es complementaria a la del gen. Este ARNm es el que actúa como molde para la fabricación de la proteína. Para la síntesis proteica, además del ARNm, se necesitan otros dos tipos de ácidos ribonucleicos: los ARN de transferencia que portan los aminoácidos que constituirán la proteína y el RNA ribosómico, formador de los ribosomas. 13 Las moléculas de ARN son sintetizadas a través de un proceso conocido como transcripción del ADN, que se parece en muchos aspectos a la replicación del ADN. Los enzimas que catalizan esta reacción se denominan RNA polimerasas (Ilustración 10). La transcripción se inicia, desenrollandose aquella secuencia de ADN que se tiene que transcribir y separándose las dos hebras que la constituyen. Al mismo tiempo, el complejo enzimático que participa en este proceso reconoce un punto de inicio de transcripción y pone en marcha el proceso de síntesis. A continuación, sobre la hebra que actúa de patrón, la RNA polimerasa va examinando las posibilidades de apareamiento, entre los ribonucleótidos que están libres por el entorno y las bases nitrogenadas del ADN. Cuando se consigue un buen ajuste con el ADN patrón, el ribonucleótido es incorporado a la cadena de ARN en crecimiento. La información necesaria para la síntesis de las proteínas reside en los ARN mensajeros. Es una información similar a la que utilizamos los humanos en el lenguaje escrito, basada en una serie de letras que forman palabras y frases. Las palabras de estos apuntes, por ejemplo, están formadas a partir de un juego de 28 símbolos que se pueden disponer en muchos miles de palabras. Pero estas señales en las páginas no significarían nada, a menos que se las pueda descodificar de manera que se sepa qué señales corresponden a cada una de las ideas y cosas de las que se está tratando. No obstante, en el lenguaje genético sólo hay 4 letras: son las cuatro bases A, G, U y C que se repiten, aunque en distintas ordenaciones, dentro de la secuencia del RNAm. Cada "palabra" del RNAm, tiene que hacer referencia a un aminoácido. El orden de las diferentes "palabras" en la secuencia del ARNm, indica el orden en que deben situarse los aminoácidos en la nueva proteína. Como las proteínas sólo están formadas por 20 aminoácidos, el lenguaje del RNAm debe tener, al menos, 20 palabras (Esquema 14). La pregunta clave que resuelve el código genético y que fue descifrada entre los años 50 y 60 es la siguiente: "¿cuál es la relación entre la secuencia de nucleótidos de un fragmento de ácido nucleico y la secuencia de aminoácidos de la proteína para la que codifica?". La respuesta también se puede resolver con sencillez: CADA UNA DE LAS SECUENCIAS DE TRES NUCLEÓTIDOS PUEDE ESPECIFICAR LA INCORPORACIÓN DE UN CIERTO AMINOÁCIDO A UNA CADENA PROTEICA EN CRECIMIENTO. (Ilustración 15). Las combinaciones posibles son 64 (43 = 64 permutaciones). Con este numero de palabras hay más que suficientes para designar a los 20 aminoácidos. Estas palabras de 3 letras se denominan TRIPLETES o CODONES. Deducido esto, el siguiente paso en la investigación científica, fue establecer la relación entre cada codón y cada aminoácido. Esta clave genética, que permite establecer la correspondencia entre una secuencia de nucleótidos en un ARNm y la secuencia de aminoácidos que podrá sintetizarse a partir de él, es a lo que se conoce como CÓDIGO GENÉTICO. + 14 El examen atento CARACTERÍSTICAS: del código genético revela que TIENE LAS SIGUIENTES algunos aminoácidos pueden ser especificados por varios codones. Por ejemplo, los aminoácidos arginina, la leucina y la serina están relacionados con 6 codones cada uno. La existencia de varios codones para un mismo aminoácido se conoce como "degeneración del código genético". el codón AUG constituye una señal de iniciación que indica el lugar por donde tiene que empezar la síntesis proteica. Este codón, también especifica el aminoácido metionina. hay 3 codones que especifican señales de terminación. Estos tripletes no especifican aminoácidos, por lo que también se les conoce como codones sin sentido. EL CÓDIGO GENÉTICO ES UNIVERSAL, excepto para las mitocondrias. Este diccionario genético es utilizado de la misma forma por todos los seres vivos (virus, bacterias, plantas, animales, etc); esto llevó a considerarlo como universal. Sin embargo, recientemente se ha descubierto que las mitocondrias poseen su propio DNA y tienen una maquinaria exclusiva de síntesis proteica que utiliza un código genético ligeramente diferente. 15