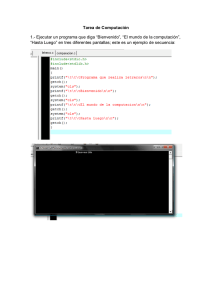
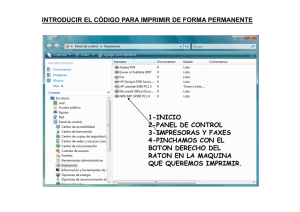
Localización de Información Específica en Internet
Anuncio

Localización de Información Específica en Internet. 1ª Parte. La Web Prólogo de Emilio Ontiveros A pesar de los ya observados, no es fácil anticipar los efectos de distinta naturaleza que la extensión de Internet todavía puede generar. Fue su potencial trascendencia económica la que inicialmente llamó mi atención al poco tiempo de su emergencia y, a decir verdad, lo hizo en los ámbitos más directamente relacionados con la gestión empresarial. La amplia y barata conectividad sobre una base global, abría posibilidades hasta entonces fuera de nuestro alcance. La geografía reducía una parte muy significativa de restricciones, consideradas poco menos que insuperables. La eficiencia económica, por tanto, encontraba, nuevas oportunidades. La primera la derivada de la extensión, de la puesta en común, del conocimiento. No solo de la información. Sino igualmente de los hallazgos y de los trabajos generados en otras latitudes. La posibilidad de conocer, por ejemplo, lo que se enseña en otras universidades y el resultado de las investigaciones en los centros más avanzados en cada una de las disciplinas, es algo cuyas favorables consecuencias son de difícil valoración. En una economía basada cada día de forma más explícita en el conocimiento, en las habilidades de sus ciudadanos y en la calidad de sus instituciones, esa difusión del conocimiento ha aumentado de forma significativa las posibilidades de reducción de las divergencias reales entre las sociedades. La disposición de las posibilidades de la red para aumentar la eficiencia organizativa, no solo en las empresas, es otra de las posibilidades que más frutos están aportando. El trabajo en particular, ha encontrado en la red una flexibilidad sin precedentes. En la medida en que el sector servicios se hace mas dominante, las posibilidades asociadas a ese matrimonio entre el aumento de la capacidad de computación por un lado y la conectividad que propicia la red, por otro, permiten no solo una muy amplia descentralización física de las funciones laborales, sino lo que quizás sea más importante, una flexibilidad horaria. Una menor servidumbre de los horarios, de reglas que se concilian poco con las exigencias económicas y con las preferencias de los ciudadanos. La autonomía individual es perfectamente conciliable con la interrelación, con el trabajo en equipo, de forma cada día más versátil. Esa descentralización ha permitido, lo está haciendo a un ritmo impresionante, una deslocalización de actividades que, aun cuando sus motivaciones estén basadas en el abaratamiento de los costes, posibilita la aceleración en el desarrollo de aquellos países o regiones que han asumido como prioridad esencial de su modelo de crecimiento la inversión en educación. Es el caso de algunas regiones de la India, donde ahora están recogiendo los frutos de una intensa inversión en educación en matemáticas y ciencias de la computación, constituyéndose en una de los centros de producción de software y tecnologías de la información que abastece al resto del mundo, sin excluir la cuna de la revolución tecnológica que protagonizó Internet, Silicon Valley. La fácil difusión de esas tecnologías, su relativamente barata extensión entre amplias capas de la población, permite albergar esperanzas razonables acerca del potencial de transformación de sociedades hasta hace poco condenadas a recorrer fase a fase lo que habían sido las secuencias del proceso de crecimiento tradicional. Hoy los altos son posibles, si al conocimiento se le asigna la importancia estratégica que ya ha puesto de manifiesto en aquellos países que dispusieron de capacidad de anticipación. Es, una vez más, el conocimiento el que con las posibilidades derivadas de la red de redes, se sitúa en el lugar preferente. Y es en este punto en el que España no aporta un balance consecuente con su envergadura económica. Cuando en ocasiones se habla de la brecha digital se piensa en la estrecha relación que existe entre dotación y difusión de las tecnologías de la información y el grado de desarrollo económico. A diferencia de los países norte de Europa, España no captó con la suficiente rapidez el potencial transformador de esas tecnologías, exhibiendo todavía hoy un retraso significativo frente al grado de inserción en la sociedad de la información que presentan las economías más avanzadas e incluso otras que lo son menos, según los indicadores económicos convencionales. Que la prioridad, tanto del sector publico como del privado, debe ser incrementar de forma significativa las inversiones en esas tecnologías la justifica los registros ciertamente pobres de crecimiento de la productividad de nuestra economía durante los últimos años. En ese contexto, es muy saludable que en nuestro país aparezcan trabajos como este libro de David Pla. Una obra ante todo útil, el atributo más escaso en un libro. Un trabajo basado en el trabajo: en experiencias docentes amplias y representativas. Útil, entre otras cosas porque permite explotar inteligentemente las múltiples posibilidades que ofrece la red. Es una excelente guía para la navegación, para no naufragar en ese océano que es hoy Internet. Hay que agradecerle a su autor la generosidad del esfuerzo y la habilidad y buen lenguaje con que ha culminado un empeño merecedor del reconocimiento. Emilio Ontiveros Catedrático de la UAM Autor de “ La Economía en la Red” Acerca del autor Acerca del autor Dr. David Plà Santamaría. David Plà es profesor del área de Economía Financiera en la Escuela Politécnica Superior de Alcoy de la Universidad Politécnica de Valencia. Debido a su afán de conocer, y su curiosidad, llegó al mundo de la búsqueda de Información por Internet mientras finalizaba su licenciatura en la John Moore’s University de Liverpool. Los conocimientos expuestos en este libro son fruto de 10 años de investigación, utilizando la Red como fuente principal de información para sus estudios sobre selección de inversiones. En este, su campo prioritario de trabajo, es autor de varios artículos científicos publicados en revistas internacionales de reconocido prestigio como Omega, International Transactions in Operations Research y Applied Financial Economics. Actualmente vive en Alcoy, su ciudad natal, con su esposa Rosana y su hija Betània y espera que algún día pueda evadirse a un pequeño pueblecito de los Pirineos y continuar su trabajo desde allí… a través de la Red. ¡Ah!, si queréis contactar con él, su email es: [email protected]. Contesta TODOS los correos. Generado con H.A.U.P.A.© 2001-2002 UPA Página 1 de 28 Localización de Información Específica en Internet. 1ª Parte. La Web 1.- Introducción a Internet y antecedentes históricos Esquema Objetivos de la Unidad Pedagógica Después de estudiar esta unidad, el alumno deberá ser capaz de: http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 1. 2. 3. 4. Conocer los orígenes de la Red Saber cómo funciona el protocolo TCP/IP Razonar cómo se desplaza una unidad de información por la Red Comprender que a la información disponible en Internet no hay una sola forma de acceder 5. Distinguir entre direcciones de correo, direcciones de máquinas y direcciones de recursos de información. Introducción Internet se ha convertido en nuestros días en un compañero de trabajo o de clase, un amigo con quien jugar o con quien pasar el rato. Pero la “inocente” Red no nació con esa finalidad precisamente... Veremos por qué Internet es lo que es, también aprenderemos algunos datos IM-PRES-CIN-DIBLES para poder introducirnos en este mundo. “It shouldn't be too much of a surprise that the Internet has evolved into a force strong enough to reflect the greatest hopes and fears of those who use it. After all, it was designed to withstand nuclear war” “No debería sorprender que Internet haya evolucionado hasta convertirse en una fuerza suficientemente grande para reflejar los más grandes miedos y esperanzas de los que lo/la utilizan. Después de todo, no hay que olvidar que fue diseñado para resistir una guerra nuclear” Denise Caruso, (digital commerce columnist, New York Times) ¿Qué es Internet? ¿Qué os parece si iniciamos esta unidad con esta pregunta? Seguro que todos podremos darle una respuesta intuitiva, y lo más probable es que cualquier respuesta que se lance se acercará a la realidad. Internet es una Red de redes, vaya eso por delante, y como tal, contiene una gran cantidad de computadoras que forman estas redes, con información almacenada y en parte, accesible. Esa podría ser una primera visión. También podríamos enfocarlo como un mercado donde se ponen en contacto proveedores y clientes de productos e información. Otra manera de verlo, es la de una nueva forma de comunicación que permite poner en contacto de forma sencilla, barata y a tiempo real, personas situadas en los dos extremos del planeta. En definitiva, cada uno de vosotros puede que haya pensado en una definición aproximada a las anteriores o totalmente diferente, pero que según el enfoque va a ser aplicable. Personalmente, no me atrevo a definir la Red de ningún modo así que prefiero utilizar una definición ya conocida y comentar sobre ella: “Una red de redes basada en los protocolos TCP/IP, una comunidad de gente que usan y desarrollan estos protocolos y un conjunto de recursos accesibles desde esas redes.” (Krol, Hoffman, 1993) Según estos autores, Internet es una red de redes. Cada uno de los ordenadores conectados a Internet, está previamente conectado a una gran red o WAN (Wide Area Network), pero antes de eso está también conectado a una red local o LAN (Local Area Network). Es decir, hasta que http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 la información procedente de Internet es visible en nuestro monitor, ésta ha tenido que viajar por diversas WANs, hasta llegar a la nuestra, para más tarde y cruzando nuestra LAN, llegar a nuestro ordenador que nos la muestra en pantalla (Stallings, 2000, Mathon, 2000). Para que quede más claro pondremos el ejemplo de una universidad como la Politécnica de Valencia (UPV). El ordenador desde donde diseño este curso, está conectado a la LAN de la Escuela Politécnica Superior de Alcoy (EPSA), y ésta a su vez a la LAN de la UPV. Todas las universidades españolas están interconectadas entre ellas y con el Consejo Superior de Investigaciones Científicas (CSIC) a través de la red RedIRIS que ya se puede considerar una WAN. Esta WAN es la que ya da acceso a otras WAN y sirve como puerta de entrada y salida de todo el tráfico de información entre las universidades españolas y la Red. Las WANs y LANs son las redes que físicamente constituyen Internet, pero cuando Krol & Hoffman se refieren a una “red de redes” no creo que únicamente se refieran a las redes físicas. En Internet coexisten paralelamente varias redes que dan acceso a distinto tipo de información. Algunas de ellas muy populares como la world wide web (WWW), otras no tanto como Usenet y otras muy novedosas como Gnutella. Un usuario de Internet puede conectar con la red que más le interese en cada momento en función de lo que quiera encontrar. El siguiente concepto que se nombra en la definición es el protocolo de funcionamiento: el TCP/IP. En realidad se trata de dos protocolos distintos, el protocolo TCP y el protocolo IP. La funcionalidad de estos protocolos prefiero dejarla para un poco más adelante. Más adelante Kroll & Hoffman hacen referencia a una comunidad de gente. Esto es algo que considero muy importante. Cuando entramos por primera vez en la Red no creemos que ésta tenga inteligencia y por tanto que no va a poder responder a nuestras preguntas ... y estamos muy equivocados. Los dos principales enfoques que pueden adaptarse a la hora de localizar información en la Red son: z Trabajar solos. De esta forma podemos utilizar infinidad de técnicas dirigidas a encontrar información que alguien haya colocado online en algún lugar. Este enfoque generalmente da resultado si conocemos las técnicas adecuadas. Pero a veces y por diversas causas como: i) el ordenador no es lo suficientemente potente, ii) nos equivocamos al elegir el sistema de búsqueda, iii) entramos en una red no adecuada para el tipo de información que deseamos localizar, o iv) simplemente la información no se encuentra en la Red, puede que no encontremos lo que queremos. Todo va a depender de la especificidad de la información que se necesita. En estos casos hay que dar otro enfoque a la actividad de búsqueda. z Preguntar a los demás usuarios. Existen personas detrás de las computadoras y tenemos que saber “aprovechar” esta ventaja. Al fin y al cabo, la única utilidad de Internet que supera en usuarios a la búsqueda de información, es la comunicación. Internet es, en primer lugar un sistema de comunicación y en segundo lugar una “gran enciclopedia”. Pues no está mal de vez en cuando cambiar el enfoque y utilizar la comunicación como una herramienta de búsqueda. A lo largo del curso veremos cómo utilizar las herramientas que existen para localizar personas con conocimientos específicos, así como técnicas de obtención de información adicional sobre páginas visitadas utilizando por ejemplo, el clásico correo electrónico. Por último, la definición que estamos revisando hace referencia al conjunto de recursos a los que se puede acceder desde las redes que forman Internet. Este conjunto de recursos hace referencia a todos los archivos que están disponibles en los espacios de memoria de cada una de las máquinas. Una página web es una colección de archivos de varios tipos: .html, .gif, .jpg, etc. A través de la WWW podemos acceder a una gran parte de estos recursos o archivos, pero no a todos. Por ello, tenemos que conocer todas las posibles formas alternativas de acceder a recursos, y no os preocupéis, porque lo haremos... ;-) El nacimiento de Internet http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Existen multitud de páginas web y libros (Tanenbaum, 1997) donde podéis encontrar información más que detallada sobre este tema, pero la explicación a veces se extiende en demasiados detalles y no van a lo práctico. Por mi parte considero que en relación a la historia de la Red, lo importante son las razones que llevaron a sus creadores a darle la estructura interna que tiene en la actualidad. Figura 1.3.1: ARPANET, el inicio de Internet en Septiembre de 1971. Fuente:http://www.cybergeography.org/ Al parecer, la idea de Internet surgió durante la 2ª Guerra Mundial. En el ejército de los Estados Unidos de América (EEUU) se dieron cuenta que las vías de suministro de material bélico como tanques, cañones, tropas, etc. tenían una similitud más que notable con las vías de comunicación de información confidencial o “Top Secret”. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Figura 1.3.2: ARPANET, en Octubre 1980. Fuente: http://www.cybergeography.org/ http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Figura 1.3.3: MILNET en 1989 (EE.UU y Europa), ésta red se separó de ARPANET en 1984. Fuente: http://www.cybergeography.org/ OBJETIVO 1 Conocer los orígenes de la Red Denotaron que las ventajas de un sistema de tráfico descentralizado como puede ser la red de carreteras de un país, era el modelo a seguir a la hora de crear un sistema de comunicaciones secretas. ¿Porqué?, Fijémonos en el mapa de Alemania, en él se pueden ver las autopistas entre las principales ciudades. Si necesitamos enviar material desde la ciudad A hasta la ciudad C podemos hacerlo a través de la ciudad B, con lo que estaríamos utilizando la ruta más corta, o podríamos utilizar cualquier otra ruta, solo que deberíamos dar más vuelta. La ventaja que tiene la red de autopistas es que es muy difícil tomarla toda. Se puede perder una ciudad ante el enemigo, pero entonces lo único que hay que hacer para llegar al destino es rodear la ciudad perdida y alcanzamos nuestro objetivo. Siguiendo este razonamiento, los militares americanos pensaron en crear una red de información que disfrutara de esta ventaja de las autopistas: la inexistencia de un cuartel general. De esta forma, al no haber un cuartel general, es mucho más complicado dejar al enemigo sin capacidad de comunicación con sus tropas únicamente descargando una bomba atómica cerca de donde se estime que está el centro de control. La historia detallada podéis encontrarla en http://www.isoc.org/internet/history/. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Figura 1.3.4: Mapa de ejemplo para el símil entre Internet y autopistas. El símil de las autopistas puede utilizarse también para introducir al lector en una visión en 3D de lo que es la Red. Antes hemos hablado de LANs y WANs y hemos puesto ejemplos de las mismas. Pensad en la red de autopistas españolas, ¿qué equivalente tendrían las LANs y las WANs? Pensadlo un poco............................................................... Desde mi punto de vista, las LANs se verían reflejadas en los suburbios o barrios de las grandes ciudades, las WANs, serían la imagen de las grandes ciudades, y finalmente, las líneas de ONO, Telefónica, Retevisión, Jazztel, etc. que unen las WAN, serían las propias autopistas y autovías del Estado español. La Figura 1.3.5 muestra un gráfico de lo que puede ser la Red en EEUU. Figura 1.3.5: Gráfico de lo que puede ser la Red en EE.UU. El fin último de una estructura como la que hemos comentado es que la información viaje por la Red de forma totalmente independiente, y que cada unidad de información pueda decidir la autovía que va a elegir para llegar a su destino. Un paquete que salga de nuestro ordenador puede perfectamente dar la vuelta al mundo antes de llegar dos manzanas más abajo donde vive el destinatario del mensaje. Generalmente esto no ocurre, porque existen algoritmos para que las unidades de información utilicen el camino más corto. Pero, de todas formas, la Red esté preparada para que esto pueda ocurrir. Las razones de esta funcionalidad fueron en su inicio principalmente dos: z Dificultar al “enemigo” la captura de la información remitida, ya que las unidades de información pueden viajar por cualquier vía, independientemente del lugar de partida y de destino. z Reducir la probabilidad de que una unidad de información no llegue a su destino. Esta segunda razón está relacionada con la posibilidad de que una determinada WAN pueda quedar destruida por un ataque directo. Como las unidades de información son “dueños” de las decisiones del camino a seguir a la hora de alcanzar su destino, cuando detecten que esa WAN ya no da señales de “vida”, decidirán redirigirse por otra vía. Esta capacidad de autodecisión es tan potente que incluso funcionaría en el caso de que una WAN “cayese” (dejara de funcionar) en mitad de la transmisión de un mensaje. El protocolo TCP/IP http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 OBJETIVO 2 Saber cómo funciona el protocolo TCP/IP z Los protocolos TCP e IP, porque en realidad son dos protocolos distintos, son los encargados de organizar físicamente el tráfico por dentro de la Red (Tanenbaum, 1997). Cada uno de ellos desempeña una actividad diferente. Veámoslos: Protocolo IP (Internet Protocol). Es el primero en ponerse a trabajar. En cuanto interactuamos con Internet de alguna forma, como por ejemplo escribir una dirección en el navegador, o enviar un correo electrónico, o simplemente hacer clic sobre algún enlace, el protocolo IP se activa. Su labor consiste en dividir en lo que se llama paquetes IP toda la información que hay que remitir. Los paquetes IP son las unidades de información a las que he estado haciendo referencia hasta ahora. Cada paquete IP puede tener un tamaño diferente, dependiendo de la información que contenga. Un paquete IP puede contener cualquier cosa, desde texto, audio y vídeo, pasando por ejecutables y llegando hasta imágenes y los temidos virus. Figura 1.4.1: Izquierda: cómo el protocolo IP, “trocea” la información y la introduce en un paquete IP. Derecha: ilustración de paquete IP completo, visto de frente. Fuente: http://www.warriorsofthe.net z Protocolo TCP (Transfer Control Protocol). Cuando los paquetes ya se han creado, se pone en marcha este segundo protocolo, cuya labor es la de transmitir los paquetes desde nuestro ordenador hasta su destino. Se podría interpretar como las “reglas universales de la carretera”. Un servidor Web, es el software que se encarga de gestionar la remisión de peticiones de información a través del WWW. Al servidor web, se le alimenta con toda la información que deseemos que pueda ser accesible a través de un navegador como el Internet Explorer y él se encargará de remitir a nuestro browser (navegador), las páginas web que queramos ver. Una vez el paquete IP llega a su destino, se activa de nuevo el protocolo IP para reconstruir a partir de los paquetes IP, la información que hemos enviado. Si estamos navegando, la información que enviamos es básicamente peticiones de visualización de páginas web. Cuando los paquetes IP, con nuestra petición llegan a su destino, el servidor web se encargará de remitirnos con el mismo procedimiento toda la información con texto, multimedia, etc. de la página web que hemos solicitado. Trayecto de los paquetes IP Conocimientos http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Para ilustrar este punto aplicaremos el dicho de que , “una imagen vale más que mil palabras”, así que en vez de intentar explicarlo, os recomiendo que visitéis la página web: http://www.warriorsofthe.net y disfrutéis de la película que desde allí podéis descargar. La película es un cortometraje realizado por Ericsson, a quién hay que felicitar por su excelente labor. El problema con el que nos vamos a encontrar es que a fecha de hoy no hay versión castellana, ni en ninguna otra lengua española. Por tanto he considerado adecuado incluiros en el Caso/Artículo, la trascripción de la película en castellano para que os ayude a entenderla cuando la veáis. Caso/Artículo Story translated by Ernesto Hernández PRESENTA ORGUSOLLAMENTE GUERREROS DE LA RED IP PARA LA PAZ Una película realizada por: Tomas Stephanson Idea Original Y Producción Gunilla Elam Animación y Diseño Niklas Hanberger Música y Sonido Tomas Stephanson y Monte Reid Guión Narración Original Monte Reid PRESENTANDO Paquete TCP Paquete Ping ICMP Paquete UDP El Ruteador El Ping de la Muerte El Switch Ruteador Apoyados por un reparto de millones Por primera vez en la historia... La gente y las máquinas están trabajando juntos, cumpliendo un sueño. Una unión de fuerzas que no conoce límites geográficos. Ni repara en raza, creencia o color. Una nueva era donde la comunicación verdaderamente lleva a unir a la gente. Este es el amanecer de la Red. ¿Quieren conocer como funciona? Haga Clic aquí. Para comenzar su viaje hacia la Red. ¿Sabe que es lo que pasa exactamente cuando hace clic en un enlace? Usted inicia un flujo de información. Esta información viaja hacia su local propio de mensajería personal. Donde el Sr. IP lo empaqueta, etiqueta y pone en camino. Cada paquete es limitado en su tamaño. El local de mensajería debe decidir como dividir la información y como empaquetarla. Cada paquete necesita una etiqueta describiendo información importante, tales como la dirección del remitente, la dirección del destinatario y el tipo de paquete que es. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Debido a que este paquete en particular va dirigido a Internet, también recibe una etiqueta para el servidor Proxy, el cual tiene una función especial como veremos mas tarde. El paquete es lanzado ahora hacia su red de área local o LAN (Por sus siglas en Inglés). Esta Red es usada para conectar a todas las computadoras locales, ruteadores, impresoras, etc. Para el intercambio de información dentro de las paredes físicas del edificio. La LAN es un lugar nada controlado y desafortunadamente pueden ocurrir accidentes. La carretera de la LAN está repleta con toda clase de información. Hay paquetes IP, paquetes Novell, paquetes AppleTalk. Ah, ahí van contra el tráfico como siempre. El Ruteador local lee las direcciones y si es necesario pone los paquetes en otra red. Oh, el Ruteador, un símbolo de control en un mundo desordenado sin par. " Este va aquí, este va allá, este no es de aquí, este no lo quiero". Así es él, sistemático, desinteresado, metódico, conservador y algunas veces no precisamente rápido, pero exacto... en su mayor parte. Cuando los paquetes dejan el ruteador, siguen su camino a través de la Intranet corporativa, adelante hacia el Switch Ruteador. Un poco mas eficiente que el Ruteador, el Switch Ruteador trabaja rápido y suelta los paquetes enrutándolos hábilmente por su camino. Una maquinita de PinBall digital si lo prefieren. "Adentro, vamos, tu por aquí, adentro, adentro, por ahí..." Cuando los paquetes llegan a su destino, son recolectados por la interfase de red; para ser enviados al siguiente nivel, en este caso el Proxy. El Proxy es usado por muchas empresas como un intermediario, con la función de establecer una conexión de Internet y también por razones de seguridad. Como puede verse, todos los paquetes son de diferentes tamaños dependiendo de su contenido. El Proxy abre el paquete y busca la dirección de Internet o URL. Dependiendo de si la dirección es admisible el paquete se enviará hacia Internet. "www.negocios.com" Existen sin embargo algunas direcciones que no cuentan con la aprobación del Proxy, de acuerdo a las llamadas directrices corporativas o de administración. Las cuales son inmediatamente despachadas. Nosotros no tenemos nada de eso. Para aquellos que sí lo logran, es la vuelta al camino de nuevo. Lo que sigue, el "Firewall". El Firewall corporativo sirve a dos propósitos. Previene intromisiones mas bien indeseables provenientes de Internet y evita que información delicada de la empresa sea enviada hacia Internet. Una vez que pasa el "Firewall", un Ruteador recoge cada paquete y lo coloca en un camino o ancho de banda - como es llamado - mucho mas estrecho. Obviamente el camino no es lo suficientemente amplio para llevar todos los paquetes. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Ahora, tal vez se pregunte que pasa con todos esos paquetes que no logran recorrer todo el camino. Bien, cuando el Sr. IP no obtiene un recibo de que el paquete fue recibido a su debido tiempo, simplemente envía un paquete de reemplazo. Ahora estamos listos para entrar al mundo de Internet. Una telaraña de redes interconectadas. La cual se extiende por todo el orbe. Aquí ruteadores y switches establecen ligas entre las redes. Ahora, la red es un ambiente completamente distinto de lo que podemos encontrar dentro de las paredes protectoras de nuestra LAN. Allá afuera es el salvaje oeste. Abundante espacio, abundantes oportunidades, abundantes cosas por explorar, lugares a donde ir. Gracias a un muy reducido control y regulaciones, las nuevas ideas encuentran suelo fértil que empuja el desarrollo de sus posibilidades. Pero a causa de esta libertad, algunos peligros también pueden acechar. Nunca podemos saber cuando encontraremos al terrible Ping de la Muerte. Una versión especial del paquete Ping normal con la que algún Idiota piensa desquiciar servidores insospechados. Las rutas que los paquetes pueden tomar serían satélites, líneas telefónicas, redes inalámbricas o incluso cables transoceánicos; no siempre toman el camino mas corto, mas rápido o mas seguro posible, pero de cualquier modo llegarán allá, eventualmente. Tal vez es por eso que algunas veces es llamada "World, Wide, Wait"; pero cuando todo trabaja sin problemas, podemos circunnavegar el orbe 5 veces en un santiamén, literalmente y todo al costo de una llamada local o menos. Cerca del fin de nuestro viaje, encontraremos otro Firewall. Dependiendo de nuestra perspectiva como paquete de datos, el Firewall puede ser un resguardo de seguridad o un terrible adversario, dependiendo de que lado estemos y cuales sean nuestras intenciones. El Firewall está diseñado para dejar entrar solamente aquellos paquetes que cumplen con el criterio de selección. Este Firewall tiene abiertos los puertos 80 y 25. Todo intento en los demás puertos, está cerrado a las operaciones. El puerto 25 es usado para paquetes de correo. Mientras el puerto 80 es la entrada de los paquetes de Internet hacia el Servidor Web. Dentro del Firewall, los paquetes son filtrados mas concienzudamente. Algunos paquetes pasan fácilmente por la aduana y otros se ven mas bien dudosos. El oficial del Firewall no es fácilmente engañado. Como en el caso de este paquete Ping de la Muerte, que trata de hacerse pasar un paquete Ping normal. "Este está bien, no hay problema, puede pasar, que tenga un buen día, adiós..." Para aquellos paquetes lo suficientemente afortunados para llegar hasta aquí, su jornada casi ha terminado. Están dirigidos hacia la interfase para ser llevados hasta el Servidor Web. Actualmente un Servidor Web puede correr sobre diversas cosas, desde un Mainframe, hasta la Cámara Web en nuestro escritorio o ¿Por qué no en nuestro refrigerador?, con la configuración apropiada, podríamos encontrar si hay los ingredientes para hacer pollo con salsa o si tiene que ir de compras. Recuerde, este es el amanecer de la Red. Casi todo es posible. Uno por uno, los paquetes son recibidos, abiertos y desempacados. La información que contienen, esto es nuestra solicitud de Información - es enviada hacia la aplicación del Servidor Web. El paquete en si mismo es reciclado. Listo para ser usado otra vez, y llenado con la información solicitada; etiquetado y enviado de regreso hacia nosotros. Regresa por el Firewall, ruteadores y a través de todo Internet. De vuelta a nuestro Firewall corporativo y hasta nuestra interfase. Donde es suministrado al Explorador/Navegador de Internet con la información solicitada. Como esta película. Satisfechos con sus esfuerzos y confiando en mundo mejor. Nuestros confiados paquetes se dirigen felizmente hacia el ocaso de otro día mas, sabiendo que han cumplido bien la voluntad de su amo. ¿No es este un final feliz? http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Fuente: http://www.warriorsofthe.net Estructura Cliente-Servidor OBJETIVO 4 Comprender que a la información disponible en Internet, no hay una sola forma de acceder Saber cómo funciona el proceso de transmisión de paquetes no nos sirve de nada si no conocemos la estructura sobre la que se basa el sistema de acceso a la información en la Red (Renaud, 1996). La completa explicación anterior de Warriors of the net, nos explica qué ocurre cuando presionamos sobre un enlace en una página web que estamos visitando con nuestro browser o navegador. Pero, ¿porqué un navegador sirve para poder ver páginas web? La respuesta puede parecer obvia: porque es un programa que se ha creado con ese fin y con ningún otro. De acuerdo, podría aceptar esa respuesta como buena, pero todavía creo interesante el profundizar un poco más en este tema. Como podéis observar en la Figura 1.5.1, aparece un cliente (casa particular) que en primer lugar remite una petición de información al servidor (factoría ¡con su chimenea!) y este le devuelve posteriormente un documento HTML. Figura 1.5.1: Cliente que realiza una petición de información al servidor y éste le devuelve posteriormente un documento HTML. Este sistema de comunicación cliente-servidor es el que predomina en Internet. Cualquier conexión que realicemos con una máquina remota la haremos mediante un programa cliente que rodará en nuestro ordenador, el cual está preparado para conectarse con un programa servidor que estará rodando en el ordenador con el que establecemos comunicación. De este modo es obvio, que el browser o navegador es un cliente, el cual solicitará la información al servidor web. El servidor será el que remita la respuesta de vuelta a nuestro ordenador y de nuevo el browser o navegador interpretará esa información presentándola en nuestra pantalla de forma comprensible. Todo este intercambio de paquetes IP lo habremos establecido entre nuestro cliente web y el servidor web de la máquina con la que conectemos. Ahora bien, la máquina remota no tiene porqué estar ejecutando tan solo un tipo de servidor, el http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 servidor web. Es posible que esa máquina remota tenga en marcha más servidores. Un poco más adelante en este mismo capítulo se introducirá el concepto de “tipo de acceso” y el lector podrá ver las diversas maneras existentes para conectar con un mismo ordenador remoto, cada una de estas formas dará acceso a una clase de información, que puede ser distinta. Un browser o navegador como por ejemplo el Netscape permite el acceso a tres tipos de servidores como mínimo: el servidor web, el servidor ftp y el servidor gopher. Todos ellos son programas ejecutados en la máquina remota. Pero existen otros tipos de servidores especiales, los cuales ofrecen acceso a determinados archivos o servicios a los que a través de un browser o navegador no podemos acceder. En definitiva, para poder ampliar nuestro abanico de posibilidades en el campo de la Localización de Información en Internet, tenemos que saber coordinar el tipo de información que queremos encontrar con el tipo de cliente que vamos a utilizar para conectarnos a una determinada máquina o red de máquinas. Direcciones de Internet Conocimientos OBJETIVO 5 Distinguir entre direcciones de correo, direcciones de máquinas y direcciones de recursos de información Otra de las piedras angulares para poder entrar a navegar por Internet sin perderse, es obviamente saber reconocer los diversos tipos de direcciones que pueden existir. Un determinado ordenador conectado a la Red puede tener desde una sola dirección hasta miles de ellas. Así pues, es necesario que antes de nada, tengamos claro cuántos tipos de direcciones existen y a qué hacen referencia cada uno de ellos. Direcciones de máquinas ¡Ojo!, no confundir protocolo IP, con paquete IP y con dirección IP. Cada una hace referencia a cosas totalmente distintas. Existen dos tipos de direcciones de máquinas, es decir, de las computadoras u ordenadores que componen la Red. Nuestro ordenador, desde el que nos conectamos cada día, tendrá asignada su propia dirección de máquina. Las dos direcciones de máquina que existen se denominan dirección IP y dirección DNS. Ambas son equivalentes, es decir, son dos formas de hacer referencia a una misma máquina, es como si utilizáramos dos lenguajes distintos para hacer referencia a un mismo sitio. Por ejemplo, España es España pero también es Spain, Espagne, Espanya, Espanien, etc. Todas estas formas de la palabra hacen referencia a lo mismo pero en distintas lenguas. Podríamos considerar las direcciones IP y las direcciones DNS como dos idiomas distintos en los que se puede expresar la dirección de una máquina conectada. Direcciones IP El lenguaje que utilizan para expresar la dirección de la computadora son los números. Un ejemplo de dirección IP podría ser: 158.42.65.38. Existen algunas reglas en la estructura de estas direcciones. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 z z z z Cuatro números de un máximo de tres cifras, separados por tres puntos. El valor máximo que pueden alcanzar cada número es 255. Cuando el número es de dos ó una cifra no se incluyen ceros a la izquierda. Generalmente el cero no lo encontraréis como uno de los números de la dirección. Con estas reglas de juego, podemos concluir que las direcciones IP, oscilarán entre 0.0.0.0 hasta 255.255.255.255 con lo que podemos obtener más de 4000 millones de combinaciones, y por tanto, 4000 millones de ordenadores conectados a la Red, como máximo... ¿alcanzaremos alguna vez esa cifra? Parece improbable al menos a medio plazo, pero lo cierto es que se está previendo una falta de direcciones IP para dentro de pocos años por ineficiencias en el sistema de asignación de las direcciones. Para solucionar este problema, se está estudiando la posibilidad de convertir las IP actuales de cuatro números en IP de 6 grupos de números, por ejemplo 255.255.255.255.255.255. con lo que se tendrían hasta 274 billones de direcciones posibles. Este nuevo sistema es lo que se viene denominando IPv6. Para conocer la dirección IP de vuestro ordenador, una de las opciones más seguras es que preguntéis a vuestro ISP (Internet Service Provider, Proveedor de Internet) cuál es o cómo podéis conocer cuál es cada vez que os conectéis, ya que algunos proveedores os asignarán una dirección IP distinta cada vez que accedáis a Internet. Tener clara cuál es nuestra dirección IP, es muy importante, ya que es como nuestro número de teléfono. Para cualquier interconexión entre dos computadoras a través de Internet de tipo multimedia, como por ejemplo a través del programa gratuito de Microsoft Netmeeting, es necesario saber la dirección IP de la otra parte con la que queremos establecer una conexión directa. Existe un servicio gratuito en http://www.yi.org, con el que podemos asignar una dirección DNS fija a una dirección IP aleatoria. Direcciones DNS (Domain Name System, Sistema de Nombres por Dominios) Este tipo de direcciones alternativas, utilizan caracteres alfanuméricos para expresar las direcciones. Esto significa que pueden utilizar tanto números como letras para referirse a una determinada máquina. Este segundo tipo de direcciones apareció cuando la popularidad de la Red empezó a crecer y los creadores se dieron cuenta de que los humanos somos más proclives a recordar letras que números. Este tipo de direcciones no impone demasiadas restricciones en su estructura. z z z Están compuestas por un mínimo de dos cadenas de caracteres alfanuméricos separadas por un punto. Cada cadena debe tener un mínimo de dos caracteres. En general no existe diferencia entre las mayúsculas y las minúsculas. Ejemplos de este tipo de dirección podrían ser por ejemplo: RecerK.com, o google.com, etc. pero también: entorno.epsa.upv.es. Cada una de las direcciones DNS tiene su equivalente en IP. Por ejemplo, entorno.epsa.upv.es corresponde con 158.42.133.101 y google.com corresponde con 64.208.32.101. En la Red existen una serie de computadoras cuyo único trabajo es traducir continuamente direcciones IP en direcciones DNS y a la inversa, de forma que utilizando cualquier tipo de dirección siempre podamos acceder a la máquina que nos interesa. La última cadena de caracteres de una dirección DNS, tiene un nombre propio y se llama dominio. Los dominios son similares a las extensiones de los archivos como .doc, .xls, .html. y nos informan hasta cierto punto del tipo de información que podemos encontrar en esa máquina o en qué país del mundo se encuentra. Existe un dominio por cada país del mundo (excepto EEUU), como se pueden ver en el Caso/Artículo 2. Pero además existen, otros dominios genéricos que hacen referencia al tipo de información que se puede encontrar en el interior de una máquina cuya dirección tiene esa terminación. Los dominios genéricos más comunes son: z z .com, para empresas comerciales. .net, para actividades relacionadas con las nuevas tecnologías o con la Red. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 z .org para otro tipo de organizaciones, como ONGs, etc. En relación a estos dominios genéricos, lo cierto es que existe un gran sesgo hacia la utilización del .com en vez de los otros dos, de hecho casi el 80% de los dominios genéricos son .com . Figura 1.6.1: Distribución de utilización de los dominios .COM, .ORG y .NET A fin de ampliar los conocimientos respecto a este tema, se recomienda observar los documentos expuestos en el Caso/Artículo 1 del presente segmento. Direcciones Personales Como ya dijimos al principio de la unidad, Internet está formado también por las personas que utilizan la Red con distintos fines, no solo por las máquinas. Lógicamente, la mayoría de estas personas dispondrá de una dirección a través de la cual se le pueda hacer llegar información. Estas direcciones son las que se denominan direcciones de e-mail o de correo electrónico. El formato de este tipo de direcciones tiene las siguientes características: z z z Está formada por dos partes bien diferenciadas y separadas por una arroba @ (Alt Gr + número 2 del teclado) La parte anterior a la @ puede contener caracteres alfanuméricos y puntos y se denomina nombre de usuario. Como su nombre indica es la parte de la dirección que hace referencia a la persona dueña de esa cuenta. La parte posterior de la @, es una dirección de máquina DNS o IP, de las que ya hemos hablado. Por tanto, una sola máquina puede tener centenares de direcciones de correo electrónico asignadas a ella. Uniform Resource Locator (URL) ó Direcciones de Recursos de Información Se refieren a direcciones de archivos o directorios específicos en donde hay información almacenada. Estos archivos obviamente estarán almacenados dentro de una máquina conectada, por lo que hacéis bien al pensar que dentro de estas direcciones aparecerá de nuevo una dirección IP o DNS. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 La estructura de una dirección de este tipo es como sigue: Tipo_de_acceso://dirección_de_máquina.dominio/directorio/archivo.extensión Pueden aparecer más directorios si el archivo que buscamos está guardado en un directorio más profundo, pero en esencia la dirección tendrá la estructura indicada. Analicémosla con detalle: z En primer lugar, aparece el Tipo_de_acceso. Hace referencia a la “forma” en la que vamos a visitar la máquina. Cuando conectamos con una computadora remota a través del protocolo TCP/IP, podemos utilizar diversas formas de “visita”. Dependiendo de qué queremos encontrar o qué actividad vamos a realizar en esa computadora remota, utilizaremos un tipo de acceso u otro. Es la eterna pregunta que nos hacen en la aduana cuando entramos en un país remoto: “¿viaje de placer o de negocios?” En el caso de Internet hay más de dos posibilidades. { El conocido http (Hyper Text Transfer Protocol). Se utiliza cuando queremos visitar archivos del tipo .htm, .html, .asp, etc. es decir en general todas las páginas web. El que los archivos que veamos sean de este tipo no quita para que podamos acceder a información dispuesta en otros formatos. Para ello, esta información deberá de estar disponible a través de un enlace en alguna de las páginas web que visitemos. { FTP (File Transfer Protocol). Este tipo de acceso se centra exclusivamente en la transferencia de archivos con una máquina remota. Se utiliza para intercambiar información de cualquier tipo. Utilizando este protocolo podemos “subir” archivos desde nuestro ordenador a otras máquinas o “bajar” archivos desde Internet a nuestra computadora. { Gopher. Protocolo en desuso. Antecesor del http. Servía para acceder a información a través de menús enlazados. Se entraba en lo que se denominaba el “gopherspace” a través de un portal, con un menú. Se seleccionaba en este menú, el tema que más se relacionara con la información que necesitábamos y en seguida, nos dirigía a otro menú en donde se volvía a hacer lo mismo, hasta que finalmente localizábamos archivos relacionados con lo que queríamos. Este tipo de operativa actualmente la podemos encontrar en los directorios tipo http://www.yahoo.com ó http://www.dmoz.com, pero la utilización del protocolo gopher como tal, ha quedado muy restringida a determinado tipo de información como por ejemplo la legal. Podéis ver qué aspecto tiene el acceso con este protocolo en: gopher://gopher.upv.es/ El protocolo gopher tenía sus propios buscadores, que disminuían el tiempo de navegación por menús. Los más conocidos eran VERONICA (Very Easy Rodent Oriented Net Wide Indes to Computer Archives), WAIS (Wide Area Information Services) y Jughead pero actualmente es muy difícil encontrar algún buscador de este tipo que todavía esté operativo. { Telnet. Permite ejecutar programas en ordenadores remotos. El interface con el que nosotros interactuamos es de texto, no soporta ningún tipo de gráfico, ya que este protocolo es de lo más antiguo de la Red, mucho más antiguo que el primitivo Windows 3.11. Anteriormente, en el punto Estructura Cliente-Servidor, ya hemos comentado que es posible conectar con una misma máquina de varias formas distintas. Ahora hemos visto algunas de ellas. La conclusión es que si se puede acceder a una máquina a través de una dirección como http://direccionmaquina.com, es muy posible que también esté activo el acceso ftp://direcciónmáquina.com, gopher://direcciónmáquina.com o telnet://direcciónmáquina.com, lo único que tenemos que hacer para comprobarlo, es escribir el nuevo tipo de acceso. z El siguiente elemento de la estructura de una dirección de recurso de información es: ://. Este símbolo (dos puntos y dos barras) siempre aparecen cuando se trata de una dirección de este tipo, es comparable con la @ en una dirección de correo. En cuanto http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 veamos este símbolo en una dirección sabremos que se trata de un recurso de información, nunca podrá ser una dirección de correo ni una dirección de máquina. Una pregunta frecuente llegados a este punto suele ser la necesidad o no de escribir la parte: Tipo_de_acceso:// cuando queremos visitar una URL. En general, los browsers o navegadores toman como tipo de acceso por defecto el http, por tanto, si queremos vistar una página a través de este acceso no habrá que escribir ni el http ni ://. Para cualquier otro tipo de acceso sí necesitaremos escribir el URL completo. z Llegamos a dirección_de_máquina.dominio. Aquí aparecerá la dirección DNS o IP de la máquina a la que queremos acceder. z /. Las barras se incorporan para indicar la separación entre la dirección de la máquina y el primer directorio, o para separar los nombres de los directorios entre sí y con el archivo final. z Directorio. A partir de la primera barra sencilla (/) aparecerán tantos directorios como haya que profundizar en el ordenador remoto hasta llegar al que almacena el archivo que queremos visualizar. z Archivo.extensión. Finalmente se introduce el nombre del archivo que se quiere abrir con su extensión. Las extensiones más comunes, como ya hemos comentado antes, son .html, .htm y .asp. Con esta pequeña introducción a los conceptos básicos de la Red, creo que uno ya está capacitado para adentrarse en el “ciberespacio” a la caza de la información necesaria para cualquier fin. Caso/Artículo 1 Una multinacional compra el dominio de Internet a un país. La terminación .tv del dominio de Tuvalu, de interés para las empresas audiovisuales. Quién iba a decir al pequeño estado polinesio de Tuvalu, que el sistema de dominios vigente en la Red iba a agraciar al país con una terminación tan apetecible para las grandes compañías de la comunicación audiovisual como es: .tv .Y es que en los orígenes de la red de redes, sus creadores idearon un criterio de designación de los dominios de Internet en base a las características de los mismos, ya fueran estos educativos (con la terminación .edu), militares (.mil), gubernamentales (.gov) o comerciales (com). Por supuesto, teniendo sobre todo en cuenta a los dominios norteamericanos, y dejando para los del resto del mundo un código que hiciera referencia a su país de origen. Según este último criterio geográfico, a las instituciones, empresas y organismos oficiales españoles se les asignaría una terminación .es; a las francesas .fr; o a las portuguesas, por ejemplo, .pt .Estas son las más conocidas, pero hay muchas, tantas como países independientes existen en el mundo. La casualidad ha querido que a Tuvalu, una diminuta isla de la Polinesia, le haya correspondido la terminación .tv , un dominio que ha resultado hasta ahora poco o nada utilizado debido a la escasez de organismos y empresas de ese país que han solicitado un dominio para estar presentes en la red. Si queréis traducir una dirección DNS en una IP o viceversa podéis utilizar el http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 servicio gratuito “nslookup” en : http://swhois.net/. Al contrario que otras terminaciones como .com o las referentes a los países más importantes que, dado el exponencial crecimiento de Internet, empiezan a estar ya saturadas. Precisamente la originalidad de la terminación .tv , su escasa utilización y, sobre todo, unas iniciales que traen a la memoria a uno de los sistemas de comunicación más importantes de la sociedad contemporánea, ha hecho que todas las grandes compañías relacionadas con el sector de la televisión (fabricantes, grandes cadenas, productoras, etc.) piensen en Tuvalu como en un bocado muy apetitoso. En ese sentido, la firma inversora canadiense Information CA, ha decidido adelantarse a la jugada y comprar al estado polinesio su nombre de dominio por la friolera cantidad de 50 millones de dólares para explotarlo comercialmente hasta el año 2048. A partir de ahora, el objetivo de esta compañía es otorgar diferentes nombres de dominio con esta terminación a aquellas empresas o instituciones que se lo soliciten, mediante un alquiler determinado que, a buen seguro, será muy sustancioso. De hecho, parece ser que son ya varias las grandes compañías audiovisuales que se han interesado por la operación. Asimismo, Information CA también se ha comprometido a colaborar en la creación del primer proveedor de servicios de Internet en un lugar con escasa presencia informática, y nulo contacto con la red. En cuanto al estado de Tuvalu, el acuerdo parece haber resultado bastante rentable dada la baja utilización que estaban haciendo de un regalo llovido del cielo de Internet. Según parece, los 50 millones de dólares corresponderían a cinco veces el producto interior bruto anual del país, lo que representa el mejor acuerdo comercial realizado en toda su historia. Algo similar es lo que ha ocurrido con el dominio asignado a la republica, ahora independiente, de Moldavia, que con una terminación .md ha puesto los dientes largos a determinadas empresas relacionadas con la medicina. De hecho, una empresa de Florida ya ha llegado a un acuerdo económico con el pequeño país del este europeo para vender a los médicos de Estados Unidos dicho dominio electrónico. Otros países, como la Federación Micronesia (.fm) han empezado a plantearse hacer algo similar, en este caso con empresas de radiodifusión. Y es que por lo que parece, para algunas empresas de Internet, y según las últimas modas, que una página se apellide .com resulta de lo más vulgar. Fuente: http://www.marketingycomercio.com/numero2/multinac.htm Caso/Artículo 2 .ac – Ascension Island .la – Lao People's Democratic Republic .ad – Andorra .lb – Lebanon .ae – United Arab Emirates .lc – Saint Lucia http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 .af – Afghanistan .ag – Antigua and Barbuda .ai – Anguilla .al – Albania .am – Armenia .an – Netherlands Antilles .ao – Angola .aq – Antartica .ar – Argentina .as – American Samoa .at – Austria .au – Australia .aw – Aruba .az – Azerbaijan .ba – Bosnia and Herzegovina .bb – Barbados .bd – Bangladesh .be – Belgium .bf – Burkina Faso .bg – Bulgaria .bh – Bahrain .bi – Burundi .bj – Benin .bm – Bermuda .bn – Brunei Darussalam .bo – Bolivia .br – Brazil .bs – Bahamas .li – Liechtenstein .lk – Sri Lanka .lr – Liberia .ls – Lesotho .lt – Lithuania .lu – Luxembourg .lv – Latvia .ly – Libyan Arab Jamahiriya .ma – Morocco .mc – Monaco .md – Moldova, Republic of .mg – Madagascar .mh – Marshall Islands .mk – Macedonia, Former Yugoslav Republic .ml – Mali .mm – Myanmar .mn – Mongolia .mo – Macau .mp – Northern Mariana Islands .mq – Martinique .mr – Mauritania .ms – Montserrat .mt – Malta .mu – Mauritius .mv – Maldives .mw – Malawi .mx – Mexico .my – Malaysia http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 .bt – Bhutan .mz – Mozambique .bv – Bouvet Island .na – Namibia .bw – Botswana .nc – New Caledonia .by – Belarus .ne – Niger .bz – Belize .nf – Norfolk Island .ca – Canada .ng – Nigeria .cc – Cocos (Keeling) Islands .ni – Nicaragua .cd – Congo, Democratic People's Republic .nl – Netherlands .cf – Central African Republic .no – Norway .cg – Congo, Republic of .np – Nepal .ch – Switzerland .nr – Nauru .ci – Cote d'Ivoire .nu – Niue .ck – Cook Islands .nz – New Zealand .cl – Chile .om – Oman .cm – Cameroon .pa – Panama .cn – China .pe – Peru .co – Colombia .pf – French Polynesia .cr – Costa Rica .pg – Papua New Guinea .cu – Cuba .ph – Philippines .cv – Cap Verde .pk – Pakistan .cx – Christmas Island .pl – Poland .cy – Cyprus .pm – St. Pierre and Miquelon .cz – Czech Republic .pn – Pitcairn Island .de – Germany .pr – Puerto Rico .dj – Djibouti .ps – Palestinian Territories .dk – Denmark .pt – Portugal .dm – Dominica .pw – Palau .do – Dominican Republic .py – Paraguay http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 .dz – Algeria .ec – Ecuador .ee – Estonia .eg – Egypt .eh – Western Sahara .er – Eritrea .es – Spain .et – Ethiopia .fi – Finland .fj – Fiji .fk – Falkland Islands (Malvina) .fm – Micronesia, Federal State of .fo – Faroe Islands .fr – France .ga – Gabon .gd – Grenada .ge – Georgia .gf – French Guiana .gg – Guernsey .gh – Ghana .gi – Gibraltar .gl – Greenland .gm – Gambia .gn – Guinea .gp – Guadeloupe .gq – Equatorial Guinea .gr – Greece .gs – South Georgia and the South Sandwich Islands .qa – Qatar .re – Reunion Island .ro – Romania .ru – Russian Federation .rw – Rwanda .sa – Saudi Arabia .sb – Solomon Islands .sc – Seychelles .sd – Sudan .se – Sweden .sg – Singapore .sh – St. Helena .si – Slovenia .sj – Svalbard and Jan Mayen Islands .sk – Slovak Republic .sl – Sierra Leone .sm – San Marino .sn – Senegal .so – Somalia .sr – Suriname .st – Sao Tome and Principe .sv – El Salvador .sy – Syrian Arab Republic .sz – Swaziland .tc – Turks and Ciacos Islands .td – Chad .tf – French Southern Territories .tg – Togo http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 .gt – Guatemala .th – Thailand .gu – Guam .tj – Tajikistan .gw – Guinea-Bissau .tk – Tokelau .gy – Guyana .tm – Turkmenistan .hk – Hong Kong .tn – Tunisia .hm – Heard and McDonald Islands .to – Tonga .hn – Honduras .tp – East Timor .hr – Croatia/Hrvatska .tr – Turkey .ht – Haiti .tt – Trinidad and Tobago .hu – Hungary .tv – Tuvalu .id – Indonesia .tw – Taiwan .ie – Ireland .tz – Tanzania .il – Israel .ua – Ukraine .im – Isle of Man .ug – Uganda .in – India .uk – United Kingdom .io – British Indian Ocean Territory .um – US Minor Outlying Islands .iq – Iraq .us – United States .ir – Iran (Islamic Republic of) .uy – Uruguay .is – Iceland .uz – Uzbekistan .it – Italy .va – Holy See (City Vatican State) .je – Jersey .vc – Saint Vincent and the Grenadines .jm – Jamaica .ve – Venezuela .jo – Jordan .vg – Virgin Islands (British) .jp – Japan .vi – Virgin Islands (USA) .ke – Kenya .vn – Vietnam .kg – Kyrgyzstan .vu – Vanuatu .kh – Cambodia .wf – Wallis and Futuna Islands .ki – Kiribati .ws – Western Samoa http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 .km – Comoros .ye – Yemen .kn – Saint Kitts and Nevis .yt – Mayotte .kp – Korea, Democratic People's Republic .yu – Yugoslavia .kr – Korea, Republic of .za – South Africa .kw – Kuwait .zm – Zambia .ky – Cayman Islands .zr – Zaire .kz – Kazakhstan .zw – Zimbabwe Conclusión Video Conclusión de Unidad 1 Recuerda que... •...detrás de las computadoras que forman Internet, hay personas; y éstas, en general, están dispuestas a ayudarte en tus búsquedas. ¡Aprovéchalo! •...el protocolo IP se encarga de dividir la información (archivos de audio, vídeo, texto, etc.) en unidades suficientemente pequeñas como para enviar por la Red. También reconstruye los archivos una vez han llegado a su destino. •...el protocolo TCP se encarga de remitir las unidades de información generadas por su colega IP desde la computadora de origen a la de destino. •... existen 2 direcciones de máquina: dirección IP y dirección DNS. •...las direcciones de recursos de información o URLs, deben contar con el tipo de acceso (por ejemplo: http) y el típico “://” . •...no todas las direcciones web han de tener obligatoriamente el típico “www”. •...las direcciones de personas o correo electrónico siempre han de contener una “@”. •...los dominios de las direcciones son, generalmente, de 2 o 3 letras y si se trata de un país siempre es de 2 letras (.es, .uk, .us, .fr, etc.) Errores más comunes •Creer que TODA la información se encuentra en la Red. O todavía peor: que TODA la información se puede encontrar con Google. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 •Considerar que el pedir ayuda o preguntar a otros sobre cómo encontrar una información o un dato, tan solo se puede dar cuando estamos desesperados. Es decir, no considerarlo como una técnica normal de búsqueda. •Confundir direcciones de máquina con direcciones de persona o de recursos de información (URLs). •Perderse totalmente a la vista de una dirección de máquina en formato IP (255.255.255.255). •Intentar acceder a un servidor FTP iniciando la dirección con el tipo de acceso http:// Taller Ejercicio http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Vamos a acceder a una misma máquina de forma distinta, utilizando dos de los tipos de acceso que hemos visto: http y ftp. De esta forma practicaréis algo que he intentado dejar claro a lo largo de la unidad: existen diversas formas de acceder a una misma máquina. Si esto os queda claro, comprenderéis lo más importante: dependiendo del tipo de información que busquéis, deberéis utilizar un sistema de localización u otro o alternativamente, en caso que utilizando un sistema de localización no encontréis nada, habrá que probar con otro distinto. Para esta práctica, vamos a entrar en la máquina de Microsoft. Y vamos a entrar utilizando su servidor http y su servidor ftp: z z Para entrar utilizando el servidor http, hay que escribir en el browser: http://www.microsoft.com . Inmediatamente veréis toda la información que la empresa pone a disposición de los usuarios de su página, como productos, soporte, etc. Para entrar utilizando el servidor ftp, hay que escribir en el browser: ftp://ftp.microsoft.com . Accederéis a un menú de carpetas con distintos contenidos como services (servicios), products (productos), etc. Podéis navegar en este menú adentrándoos en las carpetas hasta que localicéis el archivo que necesitáis encontrar. El problema del FTP, es que hay que saber con antelación dónde está el archivo, si no pude ser una actividad “time-consuming”. Lo relevante de la práctica es que habéis entrado en una misma máquina: microsoft.com utilizando dos maneras distintas y que la información a la que habéis accedido no se parece, en principio, en absoluto. Es posible que posteriormente, navegado por un servidor y por otro finalmente accedamos a los mismos archivos o a la misma información, pero también es viable que esto no ocurra. Otra máquina en la que podéis probar es kernel.org, http://www.kernel.org y ftp://ftp.kernel.org . Esto mismo ocurre cuando cambiamos el prisma y miramos a la Red de forma global. Podemos acceder a Internet de diversas maneras, utilizando el mismo browser u otros clientes específicos (por ejemplo un cliente de FTP que solo puede entrar en servidores FTP) y localizar mucha más información de la que se puede encontrar en los buscadores o navegando con un browser. Bibliografía Kroll, Ed. y Hoffman E. FYI on `What is the Internet? Network Working Group Request for Comments: 1462; FYI:20. , 1993 Mathon, P Teoría de las Redes Locales Ediciones Software, 2000 Renaud, P Introduction to Client/Server Systems : A Practical Guide for Systems Professionals. 2nd Edition John Wiley and Sons, 1996 Stallings, W Comunicaciones y Redes de Computadores. 6ª Edición Prentice-Hall, 2000 Tanenbaum, A.S Redes de Computadores.3a Edición Prentice-Hall, 1997 Referencias http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 http://www.cybergeography.org/ http://www.isoc.org/internet/history/ http://www.warriorsofthe.net http://www.marketingycomercio.com/numero2/multinac.htm http://www.yahoo.com http://www.dmoz.com http://www.microsoft.com ftp://ftp.microsoft.com http://www.kernel.org ftp://ftp.kernel.org Glosario Antivirus: programa software que detecta y elimina los virus informáticos. Cliente: es una parte del sistema de comunicación utilizado en Internet. Es la parte de este sistema que se pone en contacto con un servidor. (El navegador o browser seria un cliente) Direcciones DNS: es un manera de identificación que se utiliza para las computadoras, equivalente a las direcciones IP pero con algunas especificaciones diferentes y sin tantas restricciones en su estructura. Direcciones IP: forma de identificación de las computadoras equivalente a las direcciones DNS. Dominio: el dominio es la última cadena de caracteres de una dirección DNS. Informan del tipo de información que se puede encontrar en una máquina o en qué país se encuentra. E-mail: dirección personal a través de la cual se les puede hacer llegar la información a las personas. FTP: (file transfer protocol). Es un tipo de acceso para transferir archivos con una máquina remota. Intercambia todo tipo de información. Gopher: es un protocolo que ya esta en desuso. Se accedía a la información a través de menús enlazados. Este protocolo tenia buscadores propios, que disminuyan el tiempo de navegación por los menús. HTTP: (hyper text transfer protocol). Es otro tipo de acceso que se utiliza cuando se quieren visitar archivos del tipo htm, html, asp…. Es el tipo de acceso que por defecto se utiliza (si no especificamos el mismo). Internet: http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 es una red de redes basada en los protocolos TCP/IP, una comunidad de gente que los usan y desarrollan y un conjunto de recursos accesibles desde estas redes. IPS: (Internet service provider) proveedor de Internet. Jughead: era un tipo de buscador específico del protocolo gopher, que disminuya el tiempo de navegación por los menús. Ya no esta operativo. LAN: (local area network) es una red local a la que se conectan los ordenadores contactados a Internet, que a su vez esta conectada a una gran red o WAN. La información procedente de Internet ha de pasar por esta WAN, y después por las LAN necesarias hasta llegar a nuestro ordenador. Paquete IP: son las unidades de información en las que los protocolos IP dividen la información que hay que remitir. Pueden tener un tamaño diferente dependiendo de la información que contenga (texto, audio, video, etc.). Protocolo IP: (Internet protocol). Es el protocolo que se utiliza para interactuar con Internet. Es el primero que se activa. Divide la información remitida en paquetes ip. Protocolo TCP: (transfer control protocol) es el segundo protocolo que se pone en marcha. Cuando los paquetes ya están creados, los trasmite desde nuestro ordenador hasta su destino. Red: sistema de elementos interrelacionados que se conectan mediante un vínculo dedicado o conmutado para proporcionar una comunicación local o remota (de voz, vídeo, datos, etc.) Y facilitar el intercambio de información entre usuarios con intereses comunes. Servidor: en una red, estación host de datos que proporciona servicios a otras estaciones. Telnet: programa de red que ofrece una forma de conectarse y trabajar desde otro equipo. Al conectarse a otro sistema, los usuarios pueden tener acceso a servicios de Internet que quizás no tengan en sus propios equipos. tipo_de_acceso: // es una parte de la dirección de los recursos de información (url), por ejemplo, tipo_de_acceso://dirección_de_máquina.dominio/directorio/archivo.extensión. Hace referencia a la forma de visita que vamos a utilizar para conectarnos a una computadora remota, dependiendo de lo que se quiera encontrar o qué actividad vamos a realizar en esa computadora remota. URL: (Uniform Resource Locators) direcciones de recursos de información. Como su nombre indica, son las direcciones de archivos o directorios en donde hay información almacenada. Verónica: era un tipo de buscador específico del protocolo gopher, que disminuya el tiempo de navegación por los menús. Ya no esta operativo. WAIS: (Wide Area Information Server) potente sistema para buscar grandes cantidades de información muy rápidamente en Internet. WAN: (wide area network). Es una red de area extensa que junto con las LAN, constituyen las redes físicas de Internet. World Wide Web: http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 sistema de Internet que permite vincular, mediante hipertexto, documentos multimedia situados en todo el planeta. Permitiendo así, un fácil acceso, totalmente independiente de la ubicación física, a la información común entre documentos. WWW: significa World Wide Web. Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D1ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 28 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 2.- ¿Qué es un Browser? Esquema http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 2 de 28 Objetivos de la Unidad Pedagógica Después de estudiar esta unidad, el alumno deberá ser capaz de: 1. Distinguir entre un browser y otros clientes de Internet. 2. Listar los protocolos básicos que pueden aparecer en la barra de direcciones de un http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad 3. 4. 5. 6. Página 3 de 28 browser. Personalizar las características básicas de un browser. Utilizar y gestionar los bookmarks. Seleccionar los browsers que prefiera utilizar. Descargarse un buen antivirus gratuito. Introducción OBJETIVO 1 El programa cliente por excelencia en Internet es el Navegador o Distinguir entre un Browser. Su relevancia es grande y merece un capítulo monográfico. Browser y otros clientes El browser suele ser el punto de partida en cualquier búsqueda. de Internet. También es cierto que de vez en cuando hemos de utilizar otro tipo de clientes si queremos profundizar en una temática. “Aquél que abre la puerta a Internet, abandona la ignorancia” Traducción libre de: “He who opens a school door, closes a prison”. Victor Hugo (1802 - 1885) French author, dramatist, In "The Speaker's Electronic Reference Collection," AApex Software, 1994. En efecto, podemos considerar el browser como la puerta principal de Internet. El cliente web es el más desarrollado de todos los clientes software que existen y nos permite acceder a una gran cantidad de información almacenada en la Red. Estudios empíricos (ver http://www.brightplanet.com) aproximan la cantidad de datos accesibles a través de un navegador en un 70% del total de la información disponible. Pero esto no significa que podamos encontrar el 70% de la información, sino que está disponible, siempre y cuando sepamos su dirección. Acceder a ella, sin disponer de su localización exacta es otro problema muy diferente. El primero de los navegadores tal como hoy los conocemos fue creado por Marc Andersen y un equipo de estudiantes del National Center for Supercomputer Applications (NCSA) en el año 1993. Antes de esa fecha ya existía algo parecido a la actual navegación por Internet, pero ésta se estructuraba mediante menús enlazados, a través de los cuales el usuario se adentraba cada vez más en el tema deseado hasta que, finalmente llegaba a una “pantalla” en donde ya no habían más menús, sino que aparecían listados documentos únicamente de texto (sin imágenes, ni contenido multimedia) que tenían relación con todos los menús a través de los cuales había pasado para llegar a esa “pantalla” de contenido. Este medio de navegación de principios e los 90 se denominaba Gopher y había sido desarrollado por la Universidad de Minnesota pocos años antes. En 1993, cuando apareció el primer browser, hay que decir que el protocolo gopher tenía mucho éxito, y la mayoría de los usuarios de Internet de aquella época lo tenían en gran consideración. Pero el “gopherespacio” tenía limitaciones muy severas, en comparación con el “hiperespacio” que apareció con el protocolo http: z z No existían enlaces entre documentos. Así como en el http, podemos hacer clic sobre un determinado término en un texto y pasar a otro documento que nos ofrezca información sobre ese término; en el gopher, no existían enlaces desde el interior de los documentos sino únicamente desde los menús. La información accesible a través del gopher era de tipo solo texto. Los documentos del http, podían dar acceso a otros archivos como imágenes, sonido, vídeo, etc. Estas dos diferencias principales, hicieron que tras la aparición del primer browser, el gopherespacio dejase de ser utilizado por la mayoría de los usuarios en muy pocos meses. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 4 de 28 Pero, es interesante indicar que en la actualidad existen algunas páginas web que han adaptado el sistema de navegación por menús enlazados propio del gopher y le han dotado de una nueva utilidad de gran aceptación entre los usuarios actuales de la Red. Las páginas a las que hago referencia son los directorios de búsqueda, que veremos con detalle en la Unidad 7 del presente curso. Otra característica propia de los browsers es la gran cantidad de “aplicaciones de ayuda” que posee. Como hemos indicado pocas líneas atrás, el browser permite interpretar archivos de texto, sonido, imágenes, vídeos, etc. Para que el navegador pueda abrir todo este abanico de archivos ha de contar, como mínimo, con un visor de documentos de texto, un visor de imágenes, un reproductor de archivos de sonido y un reproductor de archivos de vídeo. Es decir, un conjunto de programas que permitan abrir todos estos archivos y permitir al usuario interpretar su contenido. Todos estos programas son lo que he llamado aplicaciones de ayuda. En realidad, el usuario únicamente instala y trabaja con un solo programa o aplicación, pero ha de ser consciente que ésta aplicación tiene que tener en su interior todos los programas que acabamos de listar para poder presentarnos los diversos tipos de información indicados. Esta es la principal razón del porqué los navegadores ocupan una gran cantidad de espacio en disco duro y son aplicaciones cada vez más grandes. Los Browsers del futuro Siguiendo con el hilo argumental iniciado en la introducción, el futuro de los browsers vendrá marcado por el aumento de tamaño y prestaciones. A mitad de la década de los 90, cuando los navegadores empezaban a evolucionar, eran capaces de interpretar archivos .htm, .html, (que son las extensiones típicas de la Web), algunos formatos de imágenes como .gif y muy poco más. En la actualidad se ha podido ampliar el abanico de posibilidades para acceder a más formatos de información incluyendo archivos multimedia de sonido o vídeo. También se ha creado todo un mundo de lenguajes de programación específicos para la construcción de webs como el java o aplicaciones adaptadas como el Flash. Los formatos gif son: Texto. Imagen. Página web. En el futuro, las diversas empresas líderes en el sector procurarán que su producto sirva de interfaz para acceder a “cuanta más información mejor”. Si actualmente necesitamos un programa para navegar en la Web, otro para entrar en Usenet, otro para visualizar imágenes, otro para capturar páginas, otro para escuchar audio, etcétera; el desarrollo futuro de los browsers vendrá marcado por el objetivo de convertirse en un único programa que lo permita todo. Las ventajas de este enfoque son, por una parte, la comodidad de contar con una sola aplicación para la mayoría de las necesidades básicas de un usuario de Internet. Por otra, el poder acceder a la totalidad de la información disponible en Internet sin tener que ser consciente de que cada subconjunto de la Red requiere un cliente específico o cada formato de información necesita un lector distinto. En definitiva, facilitar la navegación a usuarios noveles y hacer más automática la experiencia de Internet. Las desventajas también se pueden concretar en dos puntos: a) el tamaño de los browsers irá incrementándose paulatinamente; b) los usuarios más expertos verán limitada su libertad de acción y decisión en relación a qué productos utilizar ya que se tenderá a la centralización de las prestaciones en un solo navegador. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 5 de 28 URLs básicos accesibles mediante un browser OBJETIVO 2 En la barra de dirección de un browser podemos Listar los protocolos básicos que pueden encontrarnos con los siguientes protocolos básicos de aparecer en la barra de direcciones de acceso a información: un Browser. z file:///C|/archivo.htm, C:\archivo.htm , file:///C:/archivo.htm o similares. Estos “protocolos” informan al usuario que el archivo que están visualizando está almacenado en su disco duro local C:, por tanto el navegador, en ese momento no está conectando con ningún recurso externo. z http://dirmaq.dom/archivo.htm. Si la barra de dirección indica http en el lugar del protocolo, significará que en ese momento se está visualizando un archivo situado en un servidor web remoto. En el ejemplo estamos entrando en una máquina cuya dirección DNS es "dirmaq.dom" y visualizando la información almacenada en el archivo denominado "archivo.htm". z ftp://dirmaq.dom/. En este caso estamos visualizando el contenido del directorio raíz del servidor ftp de "dirmaq.dom". Ahora estamos conectando con un servidor ftp remoto situado en la misma máquina que antes. La información a la que podemos acceder a través del servidor ftp puede ser la misma que la disponible a través del servidor web o totalmente diferente. De hecho, será el administrador de esos servidores el que los organice para que a través de ellos se acceda al mismo directorio del disco duro o a dos diferentes, por tanto el contenido de esos directorios puede ser completamente distinto. En general y a diferencia del anterior protocolo, cuando accedamos a un servidor a través de ftp, veremos únicamente los iconos correspondientes a los directorios y archivos que se encuentran almacenados en ese disco duro; no veremos el contenido de ninguno de esos archivos. Recuérdese que el protocolo ftp significa “file transfer protocol” y que su utilidad es la de transferir archivos de un lugar a otro, no de interpretarlos. z gopher://dirmaq.dom. El navegador puede entrar en un servidor gopher sin ningún tipo de restricción. A través de un navegador podemos adentrarnos profundamente en el gopherespacio. En este caso, nuestro browser estaría visitando el servidor gopher situado en la máquina "dirmaq.com". La información a la que tengamos acceso va a depender del administrador del servidor. En el caso en que estemos visitando exactamente el mismo directorio que a través del servidor web, únicamente podremos visualizar aquellos archivos que sean de texto. Como ya sabemos, esa es la restricción principal de gopher. z news://dirmaq.dom. Este protocolo es interpretado por cualquier navegador pero en la actualidad no son capaces de acceder a los servidores a los que hace referencia. Este protocolo se utiliza para acceder a servidores Usenet y los browsers no prestan ese servicio. Hace falta un cliente específico de Usenet. La mayoría de los clientes de correo electrónico sirve también como cliente Usenet. Así pues, cuando escribamos el protocolo arriba indicado el navegador lanzará de forma automática el cliente de Usenet que muy probablemente será el mismo que el cliente de correo. z telnet://dirmaq.dom. Por último, el navegador puede interpretar también el protocolo telnet, pero no es capaz de servir como cliente de este tipo. En este caso, el navegador lanzará automáticamente el cliente de telnet que tengamos por defecto. Si no sabéis si existe un cliente telnet en vuestro PC, no os preocupéis, el mismo sistema operativo debe tener incorporado un cliente telnet. Personalización del Browser http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad OBJETIVO 3 Personalizar las características básicas de un Browser Página 6 de 28 Los navegadores permiten ser personalizados al gusto del usuario. Existen multitud de posibilidades dentro de un mismo navegador y todas con un mismo fin: permitir que éste presente la información de la forma más adecuada posible a las preferencias del usuario. En relación a este punto, veremos los ejemplos de los dos navegadores más utilizados: el Netscape Communicator y el Internet Explorer. z Netscape Communicator (NC). Bajo el menú “Editar”, aparece el menú de “Preferencias...” el cual podemos ver en la figura 2.4.1. Entre otras muchas opciones, este menú nos permite alterar el tipo de fuente que queremos que el navegador utilice por defecto, el tamaño de estas fuentes, los colores del texto, enlaces, fondo de páginas, etc. Es recomendable que el lector practique la alteración de alguna de estas propiedades para que observe su efecto sobre la visualización de páginas web. En relación a la opción “Idiomas” que aparece bajo el submenú “Navigator”, indicar que esta opción está haciendo referencia al hecho de que algunas páginas web pueden estar preparadas en varios idiomas (inglés y castellano, por ejemplo) y cuando seleccionamos el idioma castellano en este menú, indicamos al navegador que, si es así, preferimos el castellano al inglés. En ningún momento el navegador va estar capacitado por si solo, para traducir una página web que esté en otro idioma, al castellano o a la inversa. Para ello existen otro tipo de herramientas web, que veremos más adelante. Figura 2.4.1: Cuadro de preferencias del Netscape 7.0. El formato de este menú de preferencias puede variar según las versiones del navegador que el usuario tenga instalado, pero la funcionalidad es exactamente la misma. z Internet Explorer (IE). Bajo el menú “Herramientas” aparece “Opciones de Internet”, tal como se puede ver en la figura 2.4.2. El formato de este apartado de opciones vemos que difiere bastante del observado en la figura 2.4.1, pero en lo sustancial, ambos cuadros de mando tienen la misma utilidad: personalizar a las necesidades del usuario la experiencia de la navegación por la Web. Os recomiendo que le dediquéis unos minutos a explorar estos menús con el fin de conocer todas sus posibilidades. Como ya se sabe, en informática, una gran cantidad de conocimientos se adquieren mediante el sistema de prueba y error. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 7 de 28 Figura 2.4.2: Cuadro de preferencias del Internet Explorer 6.0. Pregunta:Cuáles son los principales browsers? RESPUESTA Los navegadores se pueden personalizar a la medida del usuario: Verdadero. Falso. Ahorra tiempo y esfuerzo: los Bookmarks OBJETIVO 4 Utilizar y gestionar los bookmarks. Estudiaremos su concepto y utilidad utilizando un ejemplo. Supongamos la siguiente situación hipotética. Hemos estado navegando por la Web, en busca de información sobre un tema de interés para nosotros. Después de 30 minutos visitando enlaces, nos topamos con un par de sites? que resultan de interés; las direcciones de estos sites son: http://www.topico1.dom y http://www.topico1bis.dom. Si queremos visitar con tranquilidad las páginas localizadas para sacarles todo el partido, podremos actuar de varias formas: http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 8 de 28 Grabando la página web en nuestro disco duro. Para ello, iremos a “Archivo”, “Guardar como...” y elegiremos el modo que más nos convenga. Entre los diversos modos posibles indicar que, utilizando este sistema, el formato más clásico de almacenamiento de páginas web es el que guarda únicamente el código html ? de la página web. A través de este modo, podremos almacenar, para consultar en otro momento, solamente el texto de la página y su estructura o distribución, no se guardarán las imágenes, ni los efectos multimedia. A esta opción se la denomina “Página Web, solo html”. Una simplificación de este método es guardar solo “Archivo de Texto”. Con el cual únicamente almacena el texto sin formato. z Otro modo seleccionable consiste en almacenar el archivo anterior, junto con una carpeta que contenga los archivos de imagen de la página. A esta opción se la denomina “Página Web, completa”. Por último, el tercer modo seleccionable que vamos a comentar es un “metaarchivo” que aglutina el contenido completo de la página web, con imágenes y multimedia incluidos, todo en uno solo. El archivo creado utilizando esta opción tiene como extensión .mht y es posible que solo pueda interpretarse utilizando el mismo tipo de browser que lo grabó. Cada una de estas opciones estarán disponibles o no, según el navegador que utilicemos. Por ejemplo el IE 6.0, contiene las tres, mientras que el NC (Netscape Communicator) 7.0 solamente contempla las dos primeras. La desventaja principal de este sistema de almacenamiento es que guardará la página que en ese momento estamos contemplando, no almacenará los enlaces que esa página pueda tener y que pueden ser de interés. Por otro lado, su ventaja reside en el tamaño del archivo almacenado, al restringir la captura a una sola página, el espacio ocupado en un sistema de almacenamiento es mínimo. Esta ventaja es importante sobre todo si estamos utilizando un ordenador distinto del nuestro para navegar y tengamos que almacenar los datos obtenidos en disquetes para más tarde analizar la información en nuestra máquina. Captura de páginas web. Existen algunos programas preparados para la captura de sites web completos. Estas aplicaciones están preparadas para reconstruirnos en el disco duro local todas las páginas web que un site contenga, con todos sus enlaces internos y externos (con respecto al site). Estos “capturadores” o “navegadores off-line” permiten guardar toda la información disponible en un site determinado y visitarla en cualquier otro momento sin necesidad de estar conectado a Internet. z La desventaja principal es el tamaño que ocupan las páginas capturadas. Por otro lado, la captura de páginas no es una tarea inmediata, va a depender del tamaño de la captura a realizar, puede que ésta lleve varios minutos o más. Ejemplos de programas de este tipo: SurfSaver (http://www.surfsaver.com), MemoWeb (http://www.memoweb.com) y WebZip (http://www.spidersoft.com) Utilizando los Bookmarks. El archivo de bookmarks, también llamado favoritos o marcadores, es una simple página web que podemos crear con la ayuda de nuestro navegador y que almacena las direcciones URL que nos interesen para, en otro momento, poder conectarnos de nuevo con el site web de interés y volver a visitarlo sin necesidad de recordar la dirección o tener que apuntarla en algún lugar. La ventaja principal de esta tercera opción es el espacio que ocupa el archivo de bookmarks, que es ridículo en comparación con los dos sistemas anteriores. En un disquete de 1.44 Mb, podrían caber más de 5,000 direcciones. Otra ventaja es la actualización, a través de los anteriores métodos tendremos almacenada la información tal como estaba el día de grabación o captura, pero si hay novedades o modificaciones, no las veremos. Utilizando los bookmarks, sí. z Site: “sitio web”. Conjunto de páginas web con la misma URL hasta el dominio. Ejemplo, todas las páginas cuyo URL comience por http://www.upv.es . http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 9 de 28 html: Uno de los más generalizados lenguajes de programación de páginas web. Extensión típica de los archivos base de las páginas web (junto con .htm). ¿ Cómo funcionan los Bookmarks en el NC ? En el NC, los bookmarks se denominan marcadores. El acceso a los marcadores también está indicado en la barra de herramientas personal. Para poder agregar un marcador al archivo de marcadores del NC, tan solo hay que presionar “Marcadores” y después “Marcar esta Página”. Inmediatamente, la dirección y el título de la página que estamos visionando aparecerá en el último lugar de los marcadores que tenemos en nuestro archivo de marcadores. Para poder ver este archivo, tan solo hay que volver a presionar “Marcadores”. Siguiendo este mismo procedimiento podemos ir almacenando las direcciones de todas las páginas que consideramos interesantes. Cuando queramos volver a visionar una página, ya no tendremos que recordar su dirección URL o buscarla, sino que podremos volver a ella, con tan solo hacer clic sobre su título bajo el botón “Marcadores”. Todos los navegadores disponen de las tres formas de grabar páginas web: Verdadero. Falso. Puede que, a medida que vayamos acumulando páginas marcadas en nuestro menú, tengamos necesidad de ordenarlos por temas o de alguna otra forma. Para ello, tan solo hay que volver a presionar “Marcadores” y “Gestionar marcadores”. De esta forma, se nos abre un gestor de marcadores que nos permitirá crear, copiar, borrar páginas marcadas, carpetas temáticas, etc. Además si en algún momento necesitamos extraer el archivo de marcadores de un PC, para pasarlo a otro PC, o llevarlo con nosotros a algún lugar, desde el mismo gestor de marcadores, bajo el menú “Herramientas”, se puede utilizar la herramienta “Exportar…” que nos creará un archivo con el nombre bookmarks.html que puede ser abierto por cualquier browser e incluso puede ser importado por el NC o por el IE de otro PC, para convertirlo en su archivo de marcadores predeterminado. ¿ Cómo funcionan los Bookmarks en el IE ? En el IE, los bookmarks se denominan favoritos y en la barra de menú superior aparece una opción con este nombre. Para agregar la página que estamos visitando al archivo de bookmarks hay que presionar “Favoritos” y “Agregar a Favoritos...”, de esta forma se nos agregará el título de la página y su dirección URL al archivo de favoritos del IE, en el último lugar de toda la lista. Si queremos organizarnos los favoritos en carpetas, iremos a “Favoritos” y “Organizar Favoritos”, automáticamente veremos un interfaz que nos ayudará a organizar los favoritos que tengamos almacenados. Ver Figura 2.7.1. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 10 de 28 Figura 2.7.1: Interfaz para organizar los favoritos. Finalmente, una vez organizados, podemos grabar el archivo en un disquete y así trasladar el archivo creado a otro ordenador y utilizarlo como índice, de igual forma que hemos explicado antes para el NC. Para ello, iremos a “Archivo” “Importar y exportar...” y seleccionaremos “Exportar Favoritos” entre las opciones que se nos indiquen. A través del asistente crearemos un archivo que se denominará bookmark.htm el cual podremos guardar donde nos interese. Este archivo podrá ser abierto por cualquier navegador. ¿ Cuál es mejor, el IE o el NC ? OBJETIVO 5 Descargarse un buen antivirus gratuito. La eterna pregunta. Los dos navegadores más utilizados en la Red, durante los últimos años han sido el IE y el NC, y cuando un nuevo usuario, empieza a trabajar más en serio con la Red, siempre ha de tomar la decisión sobre cuál de los dos elegir. En esta sección incluiremos algunas indicaciones para que el alumno tenga más información a la hora de tomar esta delicada decisión ya que de ella va a depender que su “experiencia Internet” sea más o menos gratificante. Antes de empezar a informar sobre las diferencias más destacadas entre ambos navegadores, hay que aclarar que no solo existen estos dos browsers, sino que en realidad hay centenares de ellos. Ver Figura 2.8.1. Estos han sido tan solo, los más utilizados en los últimos años, pero hay muchos más que, en función de la utilización que se le quiere dar, pueden ser mucho mejores. Pongamos un ejemplo. El navegador Lynx es el más rápido que existe y el IE o NC, nunca podrán acercarse a la velocidad de navegación del Lynx. ¿Por qué? Muy sencillo, en la programación de este browser se ha potenciado la velocidad sobre cualquier otro criterio, por ello solo abre el texto de las páginas, no abre imágenes ni efectos o archivos multimedia. Es un navegador muy específico y útil para aquellos profesionales que no estén interesados en las posibilidades multimedia del Web, sino tan solo en la información textual de las páginas. Así pues un navegador como este que se salta una gran cantidad de información almacenada en los servidores web (léase imágenes, audio, vídeo, banners, etc.) siempre cargará las páginas más rápido que los browsers preparados para proporcionar al usuario una experiencia mucho más atractiva. Otro ejemplo es el navegador Firefox, que desde hace pocos meses está apareciendo realmente como una alternativa al IE. También cabe la posiblidad de que Google lance su propio navegador... No creo que falte mucho tiempo para esto, de hecho, la empresa, durante el 2004 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 11 de 28 ha estado haciendo algún movimiento en ese sentido. Figura 2.8.1: Comparativa entre diferentes navegadores. Fuente: http://browsers.evolt.org/ Entrando en las más marcadas diferencias entre los dos browsers que nos ocupan, podemos agruparlas en tres: z Mayor accesibilidad del IE. El IE es el navegador más utilizado con diferencia, por lo que se han fabricado lenguajes de programación específicos para él, que no puede interpretar ningún navegador más. Esto ha provocado que algunas páginas web, muy avanzadas en efectos multimedia espectaculares, solo puedan visitarse con el IE. Estos desarrollos tan avanzados son pocos y, por tanto, esta característica a favor del IE no es determinante. Lo que sí que hay que tener en cuenta es que el desarrollo del IE, ha avanzado más rápido que el del NC en los últimos años y no hay duda que el NC hoy en día, no puede competir con el IE en espectacularidad de las páginas web que interprete. z Navegador vs. Navegador + Correo. El IE es un navegador únicamente. El NC cuenta con un cliente de correo y Usenet, así como un editor de páginas web. Con el IE, necesitamos a parte estos, otros dos programas. El tener en un mismo programa el navegador y el correo en una misma aplicación o no, es cuestión de gustos. Cada usuario puede elegir la opción que más le convenza. Pero, hay un detalle muy importante con respecto al correo que hay que tener en cuenta necesariamente y que es tan importante que merece comentario a parte. z El Outlook y los virus. No es recomendable utilizar un navegador que tenga el correo adjunto, como el NC, ya que para los virus que entran por el correo o el browser, les será más sencillo infectar ambos programas y a partir de uno u otro saltar al resto de nuestro PC. Ahora bien, la http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 12 de 28 opción de utilizar el IE como navegador y el cliente de correo de Microsoft (Outlook) como correo, en mi opinión, es todavía más arriesgada. Una gran cantidad de virus informáticos están programados para funcionar únicamente con el Outlook, por lo que, podemos evitarnos muchos problemas con el simple hecho de utilizar cualquier otro programa de correo. Ejemplos de programas de correo podrían ser el Eudora (http://www.eudora.com), o el Pegasus Mail (http://www.pmail.com). De todas formas, la mayoría de las veces, un buen antivirus instalado en tu PC evitará que los virus puedan entrar. En esta sección han aparecido por primera vez las palabras virus y antivirus. Estos programas son tan importantes para el usuario de Internet que se hace necesario dedicar esta pequeña sección al respecto. Empecemos por comentar los virus. Definiciones hay tantas como preguntas sin respuesta exacta. Veamos, pues, si cabe la posibilidad de concretar algunos requisitos que cumplen estos agentes víricos: - Son programas de computadora. Su principal cualidad es la de poder autorreplicarse. Intentan ocultar su presencia hasta el momento de la explosión. Producen efectos dañinos en el "huésped". Si exceptuamos el primer punto, los restantes podrían aplicarse también a los virus biológicos. El parecido entre biología y tecnología puede llegar a ser en ocasiones ciertamente abrumador. Como el cuerpo humano, la computadora puede ser atacada por agentes infecciosos capaces de alterar su correcto funcionamiento o incluso provocar daños irreparables en ciertas ocasiones. En este cuadro usaré comúnmente términos biológicos. Esto es debido a que pienso que, realmente, los virus informáticos son auténticas imitaciones de sus hermanos biológicos. Así pues usaré palabras como "explosión", "huésped", "peligrosidad tecnológica o tecnopeligrosidad", "zona caliente", etc. para explicar términos completamente informáticos. Un virus es un agente peligroso que hay que manejar con sumo cuidado. La "contención" es la primera regla de oro. Desarrollemos un poco los puntos expuestos antes: Un virus informático es un programa de computadora, tal y como podría ser un procesador de textos, una hoja de cálculo o un juego. Obviamente ahí termina todo su parecido con estos típicos programas que casi todo el mundo tiene instalados en sus computadoras. Un virus informático ocupa una cantidad mínima de espacio en disco (el tamaño es vital para poder pasar desapercibido), se ejecuta sin conocimiento del usuario y se dedica a autorreplicarse, es decir, hace copias de sí mismo e infecta archivos, tablas de partición o sectores de arranque de los discos duros y disquetes para poder expandirse lo más rápidamente posible. Ya se ha dicho antes que los virus informáticos guardan cierto parecido con los biológicos y es que mientras los segundos infectan células para poder replicarse los primeros usan archivos para la misma función. En ciertos aspectos es una especie de "burla tecnológica" hacia la Naturaleza. Mientras el virus se replica intenta pasar lo más desapercibido que puede, intenta evitar que el "huésped" se dé cuenta de su presencia, hasta que llega el momento de la "explosión". Es el momento culminante que marca el final de la infección y cuando llega suele venir acompañado del formateo del disco duro, borrado de archivos o mensajes de protesta. No obstante el daño se ha estado ejerciendo durante todo el proceso de infección, ya que el virus ha estado ocupando memoria en el computadora, ha ralentizado los procesos y ha "engordado" los archivos que ha infectado. ¿Por que se hace un virus? La gran mayoría de los creadores de virus lo ven como un hobby, aunque también otros usan los virus como un medio de propaganda o difusión de sus quejas o ideas radicales, como por ejemplo el virus Telefónica, que emitía un mensaje de protesta contra las tarifas de esta compañía a la vez que reclamaba un mejor servicio, o el famosísimo Silvia que sacaba por pantalla la dirección de una chica que al parecer no tuvo una buena relación con el programador del virus. En otras ocasiones es el orgullo, o la competitividad entre los programadores de virus lo que les lleva a desarrollar virus cada vez más destructivos y difíciles de controlar. Para evitar que estas aplicaciones víricas puedan infectar nuestro PC, se han desarrollado los programas de antivirus y que son, junto con el navegador y el cliente de correo, las aplicaciones más necesarias cuando uno se dispone a utilizar Internet. Los programas antivirus, contienen una base de datos con los códigos identificativos de todos los virus conocidos y cuando un archivo nuevo entra en nuestro PC, vía correo, descargado de la Web o desde una disquetera o CD, el antivirus lo rastrea para detectar la existencia de ese código vírico. Si localiza el código, el usuario podrá optar por http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 13 de 28 intentar limpiarlo o eliminar el archivo. Lo importante de un antivirus además del programa en sí, son las actualizaciones ya que si no actualizamos la lista de virus conocidos, solo estaremos protegidos el día en que instalemos el programa, el día siguiente seguro que surgen nuevos virus que nuestro sistema de protección no podrá detectar. Vista la definición de virus y la utilidad de los antivirus, espero que el lector haya tomado conciencia de la importancia de contar con un antivirus en su PC. En general, los mejores antivirus son los comerciales, por ejemplo el McAfee (http://www.mcafee.com), el Norton (http://www.symantec.com ) o el Panda (http://www.pandasoftware.com). Pero estos programas suelen tener un coste relativamente importante, y no solo por el programa, sino por el servicio de actualización de virus. Por ello, aquí se ofrecen al lector diversas opciones para seleccionar entre antivirus gratuitos con actualizaciones también gratuitas. Una dirección muy necesaria para encontrar programas antivirus, parches y soluciones de todo tipo para esta lacra es: http://alertaantivirus.red.es/). ANTIVIRUS Valoración Dirección de descarga AVG Uno de los mejores. Ahora gratuito. http://www.grisoft.com AVAST32" (Cuidado con los falsos positivos) http://www.avast.com/ Antivir PE (Cuidado con los falsos positivos) http://www.free-av.com/ F-PROT for DOS El mejor scanner para DOS http://www.f-secure.com/downloadpurchase/tools.shtml VirusScan Integrator ¿Tienes más de un antivirus? Escanea archivos utilizando este integrador http://www.handybits.com/vsi.htm Cuadro 2.8.1: Comparación de diferentes programas antivirus. Fuente: http://www.geocities.com/ogmg.rm/QueSon.html, http://www.wilders.org/free_tools.htm y propia. ¿ Cuál es el mejor Browser ? Independientemente de las diferencias entre IE y NC, ¿hay browsers mejores que éstos dos? La respuesta está siempre en la misma pregunta: define qué entiendes por mejores. De la misma forma que antes hemos hecho referencia al Lynx, otros muchos navegadores están programados para desarrollar mejor un cierto tipo de actividades, por lo que según sean nuestras necesidades, preferiremos un browser a otro. De todas formas, si queremos un browser para navegar en general, y sacar el máximo partido a la Red, en mi opinión, el que hoy en día puede dar una mejor experiencia es el IE. Este navegador es el más utilizado (ver Tabla 2.9.1) y por tanto, sobre el que más se está investigando. Hay aplicaciones que solo funcionan sobre él y páginas que solo se pueden visualizar con él, así como efectos muy atractivos que no pueden ejecutarse en ningún otro browser. Internet ∼66% de los accesos,desde un 74% el año pasado. La http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 14 de 28 Explorer 5.x tendencia es a ir disminuyendo lenta pero progresivamente a medida que se estandariza el IE6. Internet Explorer 6.x ∼22% de los accesos. IE6 será el navegador líder a medida que los usuarios se vayan actualizando; sólo llevó 9 meses a IE5 para convertirse en el navegador líder, por tanto es previsible que el IE6 tenga un comportamiento similar. Internet Explorer 4.x ∼4.7% de los accesos, bajando desde el 12% del año pasado. Seguirá disminuyendo lentamente hasta desaparecer. Netscape 4.x ∼4.4% de los accesos, bajando desde el 10% del año pasado. Este porcentaje irá disminuyendo lentamente hasta que el NN6 se haga más estable, momento en el que su utilización disminuirá rápidamente. AOL ∼5-6% de los accesos. Están incluidos en los accesos de Internet Explorer ya que el navegador de AOL utiliza Internet Explorer. Las previsiones son que siga estable el porcentaje de utilización en los próximos años. Mozilla and Netscape 6.x ∼0.9% de los accesos. Ha aumentado rápidamente desde la puesta en marcha del Netscape 6.1. Opera ∼0.4% de los accesos. Crece muy lentamente. Netscape 3.x ∼0.1% de los accesos. Seguirá disminuyendo hasta desaparecer, a medida que los viejos PCs se vayan retirando del mercado. Internet Explorer 2.x ∼0.1% de los accesos. Seguirá disminuyendo hasta desaparecer, a medida que los viejos PCs se vayan retirando del mercado. Internet Explorer 3.x ∼0.1% de los accesos. Seguirá disminuyendo hasta desaparecer, a medida que los viejos PCs se vayan retirando del mercado. MSN-TV (Web TV) No se han detectado acceso con este navegador, pero puede ser debido a errores en la detección del código del navegador. Nota: ya que MSN TV está disponible sólo en ciertas regiones, el porcentaje va a ser mucho más alto si sus visitantes provienen de esas regiones. Fuentes estadísticas revelan que para USA y Canadá, el número de accesos MSN-TV puede llegar al ∼2%. Navegadores antiguos Muy pocos usuarios utilizan versiones antiguas de Internet Explorer, Opera o Netscape, de modo que los diseñadores web pueden ignorarlos. Tabla 2.9.1: Utilización y otras características de los navegadores más usados. Fuente: http://www.avalonps.com/web/serv_desarrollo_browser.asp Rellene con las palabras adecuadas Un antivirus contiene una base de virus datos conocidos. Cuando un nuevo ordenador por cualquier vía, el antivirus con los códigos identificativos de todos los archivo entra en nuestro lo rastrea para detectar la existencia de ese http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 15 de 28 código actualizar . Han de poderse ya que cada día aparecen nuevos virus. Por otra parte, no hay que olvidar que además del navegador elegido, también tenemos que tener en cuenta qué tipo de conexión a Internet tenemos y con qué PC contamos. Las 3 variables van a tener un papel relevante en la calidad de nuestra navegación por Internet. Es muy complicado medir qué navegador funciona mejor con, por ejemplo, un Pentium 4 a 4, con 512 Mb de RAM y una conexión por cable. ¿Y si cambiamos las condiciones, cuando la conexión es la misma pero el PC es un Celerón a 3.5, con 1 Gb de RAM?? Para poder dar respuesta a estas preguntas, existen servicios gratuitos insertados en páginas web que pueden ofrecernos un informe completo de nuestra conexión, con las características de nuestro PC y de nuestro navegador. Dado que las características de PC y la conexión no son variables a corto plazo, pero sí el navegador, podemos ejecutar este tipo de test con el IE y posteriormente con el NC y ver cuál ofrece un mejor rendimiento o performance. El resultado, nos puede ayudar en la decisión sobre el navegador a utilizar. Uno de los servicios indicados lo podéis encontrar en http://www.browsertune.com/bt2kfast/. Este tipo de test online, son habituales en Internet. Hay muchas páginas web que ofrecen diversos tipos de tests que evalúan cosas tan dispares como por ejemplo el nivel de seguridad de un PC, pasando por evaluar porqué un PC tarda en arrancar, hasta la capacidad de un PC antiguo para ejecutar Windows XP. Este último test detecta incluso, las aplicaciones que ahora están instaladas en el PC y que si actualizamos a Windows XP dejarán de funcionar. Este tipo de servicios a veces son útiles y desde luego es muy interesante saber que existen. Ver por ejemplo: http://www.pcpitstop.com. En este cuadro, se puede observar una lista de servicios comunes de los navegadores. También se indica qué navegador los incorpora y qué navegador no lo hace. Fijaos que a medida que la versión del browser es más moderna, en general, más posibilidades tiene. El que un navegador soporte más servicios supone que va a poder ofrecer más posibilidades de acceso y más efectos multimedia a los usuarios. browsers java frames tables plug- font font java style ITable gif89 dhtml XML ins size color script sheets Frames color Explorer 6.0 S X X X X X X X X X X X X Explorer 5.5 X X X X X X X X X X X X X Explorer 5.0 X X X X X X X X X X X X S Explorer 4.0 X X X X X X X X X X X X Explorer 3.0 X X X X X X X X X X X Explorer 2.0 X X X Explorer 1.0 X X X Netscape 7.0 X X X X X X X X X X X X X Netscape 6.1 X X X X X X X X X X X X X Netscape 6.0 X X X X X X X X X X X X X Navigator 4.7 X X X X X X X X X X X Navigator 4.5 X X X X X X X X X X X http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 16 de 28 Navigator 3.0 X X X X X X X X X Navigator 2.0 X X X X X X S X X Navigator 1.1 Mosaic 3.0 X X X X X Mosaic 1.0 Mozilla 1.1 X X X X X X X X X X X X X Mozilla 1.0 X X X X X X X X X X X X X Opera 6.0 X X X X X X X X X X X X X Opera 5.11 X X X X X X X X X X X X X Opera 4.02 X X X S X X X X X X X X Opera 3.60 X X S X X X X X X Opera 3.5 X X S X X X X X Lynx X X Key Supported X Sort of supported S not supported Tabla 2.9.2: Principales características de los navegadores más utilizados. Fuente: http://hotwired.lycos.com/webmonkey/reference/browser_chart/ La necesidad de tener instalados un número de browsers ≥ 2 OBJETIVO 6 A lo largo de esta unidad hemos dado una visión general sobre los Seleccionar los navegadores, así como diversas características para que los alumnos tengan Browsers que prefiera argumentos suficientes como para seleccionar el browser que prefieran gastar. utilizar. Solo nos queda hacer una última sugerencia con respecto a estas herramientas: siempre va a ser recomendable que en nuestro PC tengamos instalados, por lo menos 2 navegadores. Hay quien prefiere un número superior de ellos, pero consideramos que tampoco son necesarios más de dos. La razón es sencilla. Cuando la conexión con una página web a la que estamos intentando acceder no funciona, las causas de esta conexión defectuosa pueden ser muchas, entre las que podemos destacar: z z z Que el servidor donde está alojada esa página no esté operativo o tenga algún problema. Que a lo largo de todos los routers por los que tiene que pasar la conexión, haya algún problema y no podamos acceder al servidor de destino. Que nuestro PC, tenga algún problema en su conexión a Internet. Que se haya desconfigurado el protocolo TCP-IP o algo similar. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad z Página 17 de 28 Que nuestro browser tenga algún tipo de incompatibilidad con la página objetivo. Si contamos en nuestro PC, con dos navegadores, siempre podremos comprobar si el fallo en la conexión nos lo está dando el navegador o si, por el contrario, es algo más grave. Por ejemplo, en caso de que no podamos conectar con una página con el IE, siempre podremos comprobar que con el NC tampoco funciona. Si es así, y no conecta con ninguno de los dos, podemos concluir que el problema no es nuestro, por tanto, no preocuparnos e intentar la conexión pasado un tiempo. En el caso contrario (que funcione con un navegador, pero no con el segundo) la conclusión es distinta: algo en el código de programación de la página web hace que un determinado browser no pueda interpretarla, pero otro distinto sí. Si se da esta situación, ya sabemos que para esa página en concreto tendremos que utilizar el navegador que funciona y dejar el otro de lado. Lo más probable es que este tipo de problemas no los solucionen, ya que los diseñadores y programadores de páginas, centran su trabajo en el navegador más utilizado (IE) y, en ocasiones, descuidan los demás. Recuerda que... z Con un browser tan solo puedes acceder a la información almacenada en servidores web o compatibles (ftp, gopher). z El navegador o browser tiene un “cuadro de mando” que permite personalizar el modo de navegación. z Tienes diversas opciones a la hora de almacenar la información localizada en una página web. Desde la más rápida y que requiere menos espacio: bookmarks, hasta la más compleja: captura de sitio web. z Es imprescindible que el antivirus que utilices se actualice periódicamente. z Es recomendable que dispongas de 2 browsers en tu PC. Errores más comunes z Creer que con un navegador se puede acceder a toda la información disponible en Internet. z Creer que, sea cual sea la información que buscamos, se puede encontrar navegando por la Web. z Asumir que un browser puede acceder a redes distintas a la Web. z No utilizar los bookmarks y apuntar una dirección url en un papel. z Utilizar el antivirus que os regalan al comprar el PC y creer que con eso vais servidos! (Más que servidos… vais listos!!! ) http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 18 de 28 Aplicación de conocimientos 1. El browser, ¿de qué subred de Internet es un programa cliente? RESPUESTA 2. ¿Conoces algún otro programa cliente que no sea el browser? Nómbralo. ¿Con qué subred trabaja? RESPUESTA 3. ¿Cuáles son los protocolos básicos que puede interpretar un browser? RESPUESTA 4. ¿Cuáles son los protocolos básicos en los que un browser puede servir como cliente? RESPUESTA 5. Indica al menos 5 preferencias de formato de visión de páginas web que puedan ser alteradas por el usuario en el IE o en el NC. RESPUESTA 6. Indica las ventajas y desventajas de almacenar direcciones utilizando el archivo de bookmarks, en comparación con guardar la página a través de la opción “Guardar como…”. RESPUESTA 7. ¿Qué browser has decidido utilizar? Intenta enumerar al menos 3 razones que te hayan llevado a inclinarte por este browser. RESPUESTA 8. ¿Cuál es el segundo browser que vas a tener instalado en tu PC? RESPUESTA 9. ¿Cuál es la característica más importante de un antivirus? RESPUESTA 10. ¿Para qué sirven los test online? RESPUESTA [Imprimir el Cuestrionario Resuelto] Taller En esta sección os voy a proponer el desarrollo del test online de Fred Langa para detectar el browser que mejor se ajusta a las características técnicas del PC y la conexión que utilizáis. Por tanto apuntad vuestro navegador a http://www.browsertune.com/bt2kfast y seguid las instrucciones que allí se indican. ¡Ya se que están en inglés, pero eso no debe desanimaros! El lenguaje es muy sencillo y la verdad es que para ejecutar el test, tan solo hay que saber tener un conocimiento básico del inglés, aunque con algo de vocabulario técnico informático. Por otra parte, indicaros que el test es totalmente seguro y no puede causar ningún tipo de daño al PC. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 19 de 28 El test está indicado para: z z z z z z z z Comparar navegadores. Diagnosticar errores en un navegador inestable y solucionarlos. Comparar el rendimiento de dos proveedores de Internet diferentes. Verificar que la conexión que tenemos contratada, está realmente ofreciéndonos la velocidad que estamos pagando. Asegurarnos que los componentes adicionales (plug-in y add-on) no han mermado la seguridad o estabilidad de nuestro navegador. Descubrir todo lo que el navegador es capaz de hacer. No tan solo lo básico, con lo que seguro ya estamos familiarizados. Aprender acerca de las tecnologías actuales utilizadas por los navegadores. y mucho más… Cuando os pongáis a ello, seguid las instrucciones con tranquilidad. Cuanto más leáis, más aprenderéis. Para los niveles uno y dos, necesitaréis aproximadamente 5-10 minutos. Al finalizar, os remitirán un informe a vuestro correo. El nivel tres es mucho más largo, hablo de más de una o dos horas. Lo que sí es cierto es que se toca prácticamente todo lo que un navegador puede hacer. Si elegís este segundo, os aseguro que aprenderéis muchos detalles del navegador que ni siquiera sabéis que existen. Este tercer nivel no remite ningún informe por correo, el aprendizaje tiene lugar a medida que vamos haciendo las distintas pruebas. No me enrollo más, seguid las instrucciones y ánimo. Revisiones Solución Os adjunto aquí los informes que me han llegado, después de hacer los dos primeros niveles con el IE y con el NC. He remarcado en negrita las diferencias entre los dos tests. Report prepared exclusively for David Plà. You ran BT2K version 5.01. New tests, new versions, and new updates are posted often.Check back Below, you'll find your test results and a multi-part custom analysis. Please also note that this report is simply formatted; this is to ensure compatibility with the widest possible range of browsers. ----------------------------Start Report: You ran the Two Minute Torture Test version of BT2K, and that's agreat place to start. But we strongly recommend you also run the Full Test Suite version of BT2K at least once in order to see moreof your browser's complete capabilities and to ensure Report prepared exclusively for David Plà. You ran BT2K version 5.01. New tests, new versions, and new updates are posted often. Check back! Below, you'll find your test results and a multi-part custom analysis. Please also note that this report is simply formatted; this is to ensure compatibilitywith the widest possible range of browsers. ----------------------------Start Report: You ran the Two Minute Torture Test version of BT2K, and that's agreat place to start. But we strongly recommend you also run theFull Test Suite version of BT2K at least once in order to see moreof your browser's complete capabilities and to ensure that all isworking properly. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad that all is working properly. Página 20 de 28 Although even the quick version of BT2K is thorough,as you scan the test results below, you may be surprised to see just how much more the full BT2K can test for you!Check it out! Although even the quick version of BT2K is thorough,as you scan the test results below, you may be surprised to see just how much more the full BT2K can test for you! Check it out! BASIC TEST RESULTS: BASIC TEST RESULTS: You completed the tests at Wed Feb 12 10:28:30 UTC+0100 2003. You completed the tests at Thu Feb 13 2003 12:08:54 GMT+0100 (MET). Your browser identified itself as Microsoft Internet Explorer,and said it was this version:4.0 (compatible; MSIE 6.0; Windows NT 5.1). Note:Some browsers (Opera, for example) lie about their identity for compatibility purposes. BT2K tries to look past the self-identification to see what the browser really is. Using this method, BT2K identified your browser as 4.0 (compatible; MSIE 6.0; Windows NT 5.1). Your browser identified itself as Netscape, and said it was this version: 5.0 (Windows; es-ES). Note:Some browsers (Opera, for example) lie about their identity for compatibility purposes. BT2K tries to look past the self-identification to see what the browser really is. Using this method, BT2K identified your browser as 5.0 (Windows; es-ES). (More explanation of browser ID? Click: here. ) (More explanation of browser ID? Click: here. ) Your browser also uses this internal code name: Mozilla. (More codename explanation?Click: here. ) Your browser also uses this internal code name: Mozilla. (More codename explanation?Click: here. ) Browsers also use 'user agent' strings to further identify themselves. Your browser's user agent string is: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1). Browsers also use 'user agent' strings to further identify themselves. Your browser's user agentstring is: Mozilla/5.0 (Windows; U; Windows NT 5.1; es-ES; rv:1.0.1) Gecko/20020823 Netscape/7.0. During these tests, your browser's cookie support was Active and Operational. (More cookie explanation?Click: here. ) Your browser's target window support was: Active and Operational. Your browser's popup window support was: Active and Operational. Your browser appears to support JavaScript version 1.2. (More JavaScript explanation?Click: here. ) JavaScript Math Rounding Errors Detected? Yes! (More explanation of math rounding errors?Click: here. ) You ran these tests at a resolution of 1024 x 768 pixels and a color depth of 32 bits. (More resolution and During these tests, your browser's cookie support was Active and Operational. (More cookie explanation?Click: here. ) Your browser's target window support was: Active and Operational. Your browser's popup window support was: Active and Operational. Your browser appears to support JavaScript version 1.4. (More JavaScript explanation?Click: here. ) JavaScript Math Rounding Errors Detected? Yes! (More explanation of math rounding errors?Click: here. ) You ran these tests at a resolution of 1024 x 768 pixels and a color depth of http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad colordepth explanation? Click: here. ) Some browsers---notably Netscape's--have trouble determining what operating system they're running on. When you ran these tests, your browser reported it was running on WindowsNT. (More explanation of OS identification? Click: here. ) FYI: We recommend you run the FULL TEST SUITE version of BrowserTune 2000 at a later date so that you may also test the following items in this category: (66 additional tests in full BASIC section, including:) body text preset sizes= not yet tested heading text preset sizes= not yet tested basic font support= not yet tested basic text formatting= not yet tested support for 16 named colors= not yet tested default page background= not yet tested support for assigned page background= not yet tested support for tiled background= not yet tested support for locked background= not yet tested display area= not yet tested scrolling text box behavior= not yet tested prefilled text box behavior= not yet tested text list handling= not yet tested radio button support= not yet tested check box support= not yet tested list coding error tolerance= not yet tested ampersand (&) support= not yet tested advanced mailto test= not yet tested meta tag support= not yet tested SCRIPTING: Most ad banners, many search engines, some DHTML, and overall many, many elements of web sites are controlled by scripts. In our scripting tests, higher scores are better: your general scripting test score of 651 would have been around 384 if you ran Netscape 4.5x, and around 9 with Opera. Your window-and-text scripting scores Página 21 de 28 32 bits. (More resolution and colordepth explanation? Click: here. ) Some browsers---notably Netscape's--have trouble determining what operating system they're running on. When you ran these tests, your browser reported it was running on WindowsNT. (More explanation of OS identification? Click: here. ) FYI: We recommend you run the FULL TEST SUITE version of BrowserTune 2000 at a later date so that you may also test the following items in this category: (66 additional tests in full BASIC section, including:) body text preset sizes= not yet tested heading text preset sizes= not yet tested basic font support= not yet tested basic text formatting= not yet tested support for 16 named colors= not yet tested default page background= not yet tested support for assigned page background= not yet tested support for tiled background= not yet tested support for locked background= not yet tested display area= not yet tested scrolling text box behavior= not yet tested prefilled text box behavior= not yet tested text list handling= not yet tested radio button support= not yet tested check box support= not yet tested list coding error tolerance= not yet tested ampersand (&) support= not yet tested advanced mailto test= not yet tested meta tag support= not yet tested SCRIPTING: Most ad banners, many search engines, some DHTML, and overall many, many elements of web sites are controlled by scripts. In our scripting tests, higher scores are better: Your general scripting test score of 840 would have been around 1411 if you ran Microsoft IE, and around 24 with Opera. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad of 210 would have been about 2415 if you ran Netscape 4.51, and around 3 with Opera. (More scripting explanation? Click: here. ) FYI: We recommend you run the FULL TEST SUITE version of BrowserTune 2000 at a later date so that you may also test the following items in this category: (4 tests in this section:) Alternate JavaScript Confirmation= not yet tested VBscript support= not yet tested Java Applet support= not yet tested ActiveX (etc.) support= not yet tested Página 22 de 28 Your window-and-text scripting scores of 590 would have been about 50 if you ran Microsoft IE, and around 16 with Opera. (More scripting explanation? Click: here. ) FYI: We recommend you run the FULL TEST SUITE version of BrowserTune 2000 at a later date so that you may also test the following items in this category: (4 tests in this section:) Alternate JavaScript Confirmation= not yet tested VBscript support= not yet tested Java Applet support= not yet tested ActiveX (etc.) support= not yet tested THROUGHPUT: You said you were using a xDSL connection. BT2K ran nine automatic timing tests, using different servers around the USA to help eliminate local or geographic factors. The throughput timing test using Server 1 showed your actual throughput was then averaging about 121Kbps. The second (Server 2) throughput timing test showed your actual throughput was then averaging about 104Kbps. The final (Server 3) throughput timing test showed your actual throughput was then averaging about 163Kbps. The overall average of these tests was 129Kbps. NOTE: BT2K's timing tests measure *everything*--- the result indicates the collective performance of your browser,your system, your connection (e.g. modem), your ISP,the Internet as a whole (including every router or relay along the path your data must travel), and the web server. Each step adds a little delay, or 'latency.' So it's *very* important to realize that throughput involves a *lot* more than just what goes on at your end.It's THROUGHPUT: You said you were using a xDSL connection. BT2K ran nine automatic timing tests, using different servers around the USA to help eliminate local or geographic factors. The throughput timing test using Server 1 showed your actual throughput was then averaging about 68Kbps. The second (Server 2) throughput timing test showed your actual throughput was then averaging about 163Kbps. The final (Server 3) throughput timing test showed your actual throughput was then averaging about 64Kbps. The overall average of these tests was 98Kbps. NOTE: BT2K's timing tests measure *everything*--- the result indicates the collective performance of your browser,your system, your connection (e.g. modem), your ISP,the Internet as a whole (including every router or relay along the path your data must travel), and the web server. Each step adds a little delay, or 'latency'. So it's *very* important to realize that http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad wise to re-run the BT2K tests at different times and dates to help eliminate transient latency problems that clear themselves up. If you rerun the tests and get similar results each time, you can gain increasing confidence in the results. Conversely, you shouldn't place undue import on a single test run. (More throughput test explanation? Click: here. ) Looking at this particular test run: Your three timing test results were inconsistent by more than about ±25%. This suggests that Internet conditions were in flux when you took the test. This is not uncommon but it diminishes the accuracy of the test results. During the tests, your connection's overall latency was good. Your connection's latency isn't a problem. However, your inconsistent throughput numbers (above)suggests that the Internet or your ISP was congested when you ran your test; this may have degraded your test results. You should definitely plan to retest at another time when the Internet or your ISP's conditions are better. Bearing all these caveats in mind, here's our interpretation of the test run reported above, where you obtained an average speed of 129Kbps: xDSL connection speeds are highly variable. Hardware, software,'throttling' or other arbitrary speed limits placed on your connection by the xDSL service provider, plus other factors, all affect final performance. Still, compared to national averages: This is quite slow. The full version of BT2K may help you pinpoint the cause of this problem, but for now, BT2K's Two-Minute Torture Test can make the following suggestions for you: 1) Re-run the BT2K tests, taking care to clear the cache and to follow all other instructions.This will help you Página 23 de 28 throughput involves a *lot* more than just what goes on at your end.It's wise to re-run the BT2K tests at different times and dates to help eliminate transient latency problems that clear themselves up. If you rerun the tests and get similar results each time, you can gain increasing confidence in the results. Conversely, you shouldn't place undue import on a single test run. (More throughput test explanation? Click: here. ) Looking at this particular test run: Your three timing test results were inconsistent by more than about ±25%. This suggests that Internet conditions were in flux when you took the test. This is not uncommon but it diminishes the accuracy of the test results. During the tests, your connection's overall latency was good. Your connection's latency isn't a problem. However, your inconsistent throughput numbers (above)suggests that the Internet or your ISP was congested when you ran your test; this may have degraded your test results. You should definitely plan to retest at another time when the Internet or your ISP's conditions are better. Bearing all these caveats in mind, here's our interpretation of the test run reported above, where you obtained an average speed of 98Kbps xDSL connection speeds are highly variable. Hardware, software,'throttling' or other arbitrary speed limits placed on your connection by the xDSL service provider, plus other factors, all affect final performance. Still, compared to national averages: This is quite slow. The full version of BT2K may help you pinpoint the cause of this problem, but for now, BT2K's Two-Minute Torture Test can make the following suggestions for you: 1) Re-run the BT2K tests, taking care http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 24 de 28 verify if the problem is transient(and therefore not worth fixing) or not. If the problem improve things steps: is real, you can with thefollowing 2)Finish reading the rest of BT2K's report and take whatever other corrective actions it suggests. Then, run the Full Test Suite version of BT2K (we'll give you a direct link to there in a moment)to see what problems remain. This will help you to isolate and more easily correct throughput issues. 3)Consider your connection alternatives.For a complete rundown on connectivity options for faster Internet access, see HIGH-SPEEDSURFING here. 4)Consider potential data bottlenecks inside your PC: For HARDWARE here. Bottlenecks: Click For SOFTWARE Bottlenecks: You may wish to adjust your computer's default networking settings. In Windows (especially) using specific settings optimized for your connection type (rather than the generic default settings)can substantally improve your performance. Click here and here and here. 5)To ensure your PC as a whole is operating properly,run run a free, automated whole-system test, written by the same people who originally wrote WinTune:PC Pitstop. 6)Perhaps your ISP simply isn't up to par. Visit here to see if better/other/faster ISPs existin your area. 7)Finally, after making any changes to your setup, repeat step 1: Re-run the BT2K tests, taking care to clear the cache and to follow all other instructions. FYI: We recommend you run the FULL TEST SUITE version of BrowserTune 2000 at a later date so that you may also test the following items in this category: to clear the cache and to follow all other instructions.This will help you verify if the problem is transient(and therefore not worth fixing) or not. If the problem is real, you can improve things with the following steps: 2) Finish reading the rest of BT2K's report and take whatever other corrective actions it suggests. Then, run the Full Test Suite version of BT2K (we'll give you a direct link to there in a moment)to see what problems remain. This will help you to isolate and more easily correct throughput issues. 3) Consider your connection alternatives.For a complete rundown on connectivity options for faster Internet access, see HIGH-SPEEDSURFING here. 4) Consider potential data bottlenecks inside your PC: For HARDWARE Bottlenecks: Click here. For SOFTWARE Bottlenecks: You may wish to adjust your computer's default networking settings. In Windows (especially) using specific settings optimized for your connection type (rather than the generic default settings)can substantally improve your performance. Click here and here and here. 5) To ensure your PC as a whole is operating properly,run run a free, automated whole-system test, written by the same people who originally wrote WinTune:PC Pitstop. 6) Perhaps your ISP simply isn't up to par. Visit here to see if better/other/faster ISPs existin your area. 7) Finally, after making any changes to your setup, repeat step 1: Re-run the BT2K tests, taking careto clear the cache and to follow all other instructions. FYI: We recommend you run the FULL TEST SUITE version of BrowserTune 2000 at a later date so that you may also test the following items in this http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 25 de 28 (19 additional tests in the Full THROUGHPUT section, including:) cache test= not yet tested automatic ping test= not yet tested manual ping test= not yet tested user-reported ping time= not yet tested trace route test= not yet tested user-reported number of hops= not yet tested obtain traffic jam information= not yet tested automatic throughput test: 1 MB download= N/A Kbps automatic throughput test: 10 MB download= N/A Kbps manual timing tests= not yet tested manually measured throughput= not yet tested Hope you found the Torture Test useful! Two (19 additional tests in the Full THROUGHPUT section, including:) cache test= not yet tested automatic ping test= not yet tested manual ping test= not yet tested user-reported ping time= not yet tested trace route test= not yet tested user-reported number of hops= not yet tested obtain traffic jam information= not yet tested automatic throughput test: 1 MB download= N/A Kbps automatic throughput test: 10 MB download= N/A Kbps manual timing tests= not yet tested manually measured throughput= not yet tested Minute The Full Test Suite goes far deeper, including not only the additional tests you've already been shown, but also extensive testing of your browser's handling of some 250 (!) other browser features and functions,including graphics, tables, multimedia (including streaming media and MP3s), DHTML, XML, XSL, CSS, security issues, integration with other applications and with your OS, channels and other 'push' content, and much more. The Full version also offers more detailed throughput testing, so you can explore this critical issue in detail. Give the Full version a try at http://www.browsertune.com/bt2kfull2/ ! That's it! As promised on the email-signup page, you'll soonget a FREE, spamproof subscription to The LangaList email newsletter that will alert you about new versions of BT2K,plus give you free tips, tricks, and other information to make the most of your browser, your time online and indeed all your hardware and software. That free newsletter is LANGALIST because it's me--Fred Langa, BrowserTune. You'll category: called THE written by author of receive a Hope you found the Two Minute Torture Test useful! The Full Test Suite goes far deeper, including not only the additional tests you've already been shown, but also extensive testing of your browser's handling of some 250 (!) other browser features and functions,including graphics, tables, multimedia (including streaming media and MP3s), DHTML, XML, XSL, CSS, security issues,integration with other applications and with your OS, channels and other 'push' content, and much more. The Full version also offers more detailed throughput testing, so you can explore this critical issue in detail. Give the Full version a try at http://www.browsertune.com/bt2kfull2/ ! That's it! As promised on the email-signup page, you'll soon get a FREE, spamproof subscription to The LangaList email newsletter that will alert you about new versions of BT2K,plus give you free tips, tricks, and other information to make the most of your browser, your time online and indeed all your hardware and software. That free newsletter is called THE LANGALIST because it's written by me--- Fred Langa, author of http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad confirmation email shortly and may unsubscribe instantly or any time, if you wish. Meanwhile, if you have any comments, suggestions,or bug reports (ack!), please send them to [email protected] I'd be especially interested in hearing of any weird or unexpected results you may have gotten so I canensure that BT2K itself is working OK! Thanks again, and happy surfing! Fred Langa author of BrowserTune Página 26 de 28 BrowserTune. You'll receive a confirmation email shortly and may unsubscribe instantly or any time, if you wish. Meanwhile, if you have any comments, suggestions,or bug reports (ack!), please send them to [email protected] I'd be especially interested in hearing of any weird or unexpected results you may have gotten so I can ensure that BT2K itself is working OK! Thanks again, and happy surfing! Fred Langa author of BrowserTune Bibliografía Hay gran cantidad de páginas web, manuales online y tutoriales sobre la información introducida en este capítulo, basta con utilizar cualquier buscador web, con palabras clave como, manual Internet explorer, netscape communicator, etc. A parte de esta abundante información en la Red, os indicaré algo de bibliografía publicada. Andrés-Gay, M. Internet Explorer 6 Anaya. Madrid, 2002 Hernández-Tallada, A. Seguridad informática. Virus, antivirus y protección de datos. Tower Communicationes. Madrid, 1997 Torben R.M. Netscape 6 Marcombo. Barcelona, 2001 Referencias http://www.surfsaver.com http://www.memoweb.com http://www.spidersoft.com http://browsers.evolt.org/ http://www.eudora.com http://www.pmail.com http://www.mcafee.com http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 27 de 28 http://www.symantec.com http://www.pandasoftware.com http://www.grisoft.com http://www.avast.com http://www.free-av.com http://www.f-secure.com http://www.geocities.com/ogmg.rm/QueSon.html http://www.wilders.org/free_tools.htm http://www.avalonps.com/web/serv_desarrollo_browser.asp http://www.browsertune.com/bt2kfast/ http://www.pcpitstop.com http://hotwired.lycos.com/webmonkey/reference/browser_chart/ Glosario Antivirus: programa software que detecta y elimina los virus informáticos. Aplicaciones de ayuda: conjunto de programas que permiten abrir archivos de diversos tipos( texto, imagen, video, sonido..) Bookmark (marcapáginas): señal o recordatorio que los internautas dejan en su aplicación de navegación para marcar un lugar interesante encontrado en la red Internet a fin de poder volver a él posteriormente. Browser (navegador, visor, vusualizador): aplicación para la visualización de todo tipo de información y navegar por Internet. En su forma más básica son aplicaciones de hipertexto que facilitan la navegación por los servidores de información de la Web. Ahora bien, algunos cuentan con funcionalidades plenamente multimedia y permiten indistintamente la navegación por servidores www, ftp y gopher. Capturadores de páginas web: aplicaciones preparadas para reconstruir en el disco duro local todas las páginas web que un site contenga, con todos sus enlaces internos y externos. Permitiendo, a posteriori, visualizar todo el contenido sin necesidad de estar conectado a Internet. Favoritos: (ver Bookmark) Gopher: antiguo servicio de información distribuida, anterior a la aparición del www. Desarrollado por la universidad de Minnesota, ofrecía colecciones jerarquizadas de información en Internet. Gopherespacio: red donde se interconectan todos los sitios del gopher. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Página 28 de 28 Hiperespacio: red donde se interconectan todos los sitios web. html (hypertext markup language): lenguaje de “etiquetas” a través del que se formatean las páginas web y se distribuye la información. Lynx: navegador que se caracteriza por su rapidez, ya que está diseñado para interpretar solo texto, no abre imágenes ni archivos multimedia. Pagina web: fichero que constituye una unidad significativa de información accesible en la Web a través de un programa navegador. Su contenido puede ir desde un texto corto a un voluminoso conjunto de textos, gráficos estáticos o en movimiento, sonido, vídeo, etc. El término página web se utiliza a veces para designar el contenido global de un sitio web. Servidor ftp: son grandes cajones de ficheros distribuidos y organizados en directorios. Contienen programas (normalmente de dominio público o shareware), ficheros de imágenes, sonido y video. El medio de acceso y recuperación de la información es el ftp (file transfer protocol). Servidor gopher: programa que gestionaba el contenido del gopherespacio. Servidor usenet (servidores de noticias): conjunto de cientos de foros electrónicos de discusión llamados "grupos de noticias" ("newsgroups"); los ordenadores que procesan sus protocolos y, finalmente, las personas que leen y envían noticias dentro de esta red. No todos los servidores de noticias están suscritos a la red usenet, ni tampoco todos están accesibles en Internet. Servidor web: servidor de información www. Se utiliza también para definir el universo www en su conjunto. Site (lugar, sitio, website): punto de la red con una dirección única y al que pueden acceder los usuarios para obtener información. Telnet: telnet es el protocolo estándar de Internet para realizar un servicio de conexión desde un terminal remoto; hoy en día ha caído en desuso. Test on line: son test que se realizan en la web y que sirven para evaluar un gran numero de cosas distintas. Son gratuitos. Virus: programa que se duplica a sí mismo en un sistema informático incorporándose a otros programas que son utilizados por varios sistemas. Estos programas pueden causar problemas de diversa gravedad en los sistemas que los almacenan Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D2ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 21 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 3.- Altavista.com Esquema Objetivos de la Unidad Pedagógica Después de cursar el presente modulo o unidad, el alumno deberá ser capaz de: 1. Distinguir entre los distintos formularios de búsqueda que ofrece un motor. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad 2. 3. 4. 5. 6. Página 2 de 21 Definir un mirror y citar alguna diferencia entre ellos. Utilizar, sin problemas, los restrictores del formulario básico de Altavista. Seleccionar los operadores booleanos y restrictores más adecuados y darles uso. Aplicar la herramienta “Traducir” de Altavista cuando sea necesaria. Editar las preferencias de Altavista a su gusto. Introducción Dicen que la experiencia es la mejor herramienta de aprendizaje. Por ello, vamos a introducirnos en las herramientas avanzadas de búsqueda con un ejemplo. Antes de entrar en definiciones y características de los buscadores veremos, en este módulo, cómo trabaja uno de los buscadores más clásicos: Altavista. “La práctica es la mejor de las maestras”. “Practice is the best of all instructors”. Publilius Syrus (≈ 100 AC) Syrius-Roman mimographer. BrainyQuote.com Entramos en materia. Para entrar en contacto con las herramientas de búsqueda, creo que lo mejor es practicar con detalle el funcionamiento de una de ellas. A lo largo de la unidad, aprenderéis a explotar todos los servicios que puede ofrecer, un buscador web de los más grandes? . Para esta primera toma de contacto, creo que la mejor opción es utilizar el buscador Altavista. La elección de Altavista no es casual, y se apoya en el particular sistema de búsqueda avanzada que este motor pone a disposición del usuario. La forma en que Altavista permite utilizar la búsqueda avanzada nos va a ayudar mucho en la asimilación y comprensión de los sistemas para localizar información a través de buscadores. Otra razón es evitar la “Googlerización” que estamos viviendo en estos últimos años. Parece que no existe otro motor de búsqueda que no sea Google y eso no es cierto. Un sesgo así, puede conducirnos a la ineficiencia en la localización de datos. Búsqueda Simple OBJETIVO 1 Distinguir entre los distintos formularios de búsqueda que ofrece un motor. Formulario Empezamos por el formulario? de búsqueda simple que Altavista pone a disposición de los usuarios en su URL http://www.altavista.com. Al escribir esta dirección en el navegador, nos aparecerá la página principal del buscador Altavista. Probablemente, detectará el lenguaje de nuestro PC y nos cargará la página en castellano. Si no lo hace, podemos seleccionar nosotros el idioma que prefiramos, en el enlace de la parte superior derecha de la página “Altavista NombreDeUnPais ▼”. La parte de la página que nos interesa es la que aparece en la figura 3.2.1. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 3 de 21 Figura 3.2.1: Formulario de búsqueda en Altavista. Fuente: http://www.altavista.com Voy a comentar por encima algunas de las herramientas que Altavista nos ofrece en este, su formulario de búsqueda simple. En primer lugar, el lector puede ver que Altavista nos sirve para buscar información (texto) en la Web o también imágenes, audio o vídeo. Además, permite también acceder a un menú a través del enlace denominado “Directorio” que nos permitirá hacer búsquedas temáticas, como una alternativa a la búsqueda por palabra clave. Inmediatamente debajo de este menú, aparece el formulario de introducción de las palabras clave a buscar. Aquí, deberemos introducir las palabras clave acerca del tema sobre el que queremos localizar información. Pero este formulario no solo acepta palabras clave, sino también permite que se le incorporen algunas características restrictivas, que permitirán acotar la búsqueda. También aparece un enlace a la “Búsqueda Avanzada” y a la “Configuración”. Ambas dos determinantes en un buscador. Les dedicaremos secciones enteras más adelante. En la siguiente línea aparece la opción de buscar en “España” o “En todo el mundo”. En esta opción está dando a elegir al usuario entre buscar en la filial española de Altavista o buscar en la central que está situada en Los Ángeles (CA). Altavista tiene varios índices alrededor del mundo. Aunque lo veremos con más detalle en otra unidad, os puedo adelantar que un índice es algo así como el sistema de ordenadores que almacena la información que nosotros buscamos cuando hacemos clic sobre “Encontrar” en un buscador. Uno de estos índices está en Madrid y por tanto su contenido, aunque en gran parte es el mismo que el de su central en EEUU, está sesgado a propósito hacia las páginas hispanas. Es lo que se denomina en inglés un mirror. El problema de los mirrors reside en el tamaño. Es cierto que el mirror de Madrid tendrá más contenido en castellano o más relacionado con temas hispanos, pero es posible que la cantidad de información que contenga no sea comparable a la del mirror de Los Ángeles. Para saber si el seleccionar “En todo el mundo” o elegir “España” es diferente o no, un truco muy útil (es una pena pero a veces nos engañan y no hay distinción), es hacer una búsqueda genérica en ambas opciones y ver si los resultados divergen o no. En mi caso he probado buscar el término “a” (como podéis ver, bastante genérica) y el resultado es que el mirror español es mucho más pequeño que el internacional. Resultados “España”: 21,345,823 Resultados “Internacional”: 159,584,963 OBJETIVO 2 A continuación aparece la posibilidad de elegir el ver los Definir un mirror y citar resultados en “Todos los idiomas” o tan solo los resultados alguna diferencia entre ellos. “español, inglés”. De esta forma estamos limitando la búsqueda a aquellas páginas web que están en castellano e inglés o la ampliamos a todas las páginas que se localicen en cualquier idioma (chino, portugués, catalán, francés etc.). Cuando las palabras clave que estamos introduciendo son suficientemente explícitas, esta restricción es inútil ya que si, por ejemplo, la palabra clave es “contabilidad”, implícitamente estamos indicando que el idioma es el castellano, porque por ejemplo, en inglés, la palabra “contabilidad” no existe (¡y no digamos en chino!), por tanto no se pueden encontrar páginas en inglés que contengan esa palabra (…siempre habrán excepciones que confirmen la regla…). En la última fila, aparecen las herramientas de Altavista: “Traducir”, y “Toolbar”, entre otras. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 4 de 21 Algunas de éstas las comentaremos más adelante, en esta misma unidad. OBJETIVO 3 Utilizar, sin problemas, los restrictores del formulario básico de Altavista. Restrictores Como he comentado antes, el formulario de búsqueda simple permite introducir algo más que sólo palabras clave y las herramientas que podemos utilizar en él, son muy interesantes. Para ver con detalle las instrucciones relacionadas con este formulario debéis ir a http://www.altavista.com/help/search/default#web y si esta dirección no funciona (porque haya cambiado) tenéis que ir al icono de Ayuda de la página http://www.altavista.com y desde allí a “Búsquedas” y después “Web”. Lo que encontraréis es algo muy similar a lo que aparece en la figura 3.2.2. Figura 3.2.2: Sugerencias de búsqueda Web básica en Altavista. Fuente: http://www.altavista.com Este proceso de lectura y autoaprendizaje sobre cómo funciona un determinado buscador web, es muy recomendable y siempre interesante. Seguro que muchos de vosotros, habéis empezado a utilizar Google u otro buscador sin ni siguiera leer las instrucciones. ¿Haríais lo mismo con un aparato de DVD o con vuestro equipo de música? ¡Seguro que no! Cuando adquirimos un electrodoméstico nuevo y en el mando a distancia hay un botón que no sabemos para qué sirve… ¿no os pica la curiosidad y vais al manual de instrucciones a ver qué se puede hacer, para sacarle el máximo partido al aparato? En el caso de un buscador web, la situación no es distinta. El saber cómo funciona un buscador va a ahorrarnos MUCHO tiempo, ya que podremos dirigir las búsquedas mejor y obtener resultados más precisos. De todas las recomendaciones indicadas en la figura 3.2.2, considero que las más importantes a destacar son las que se refieren al restrictor comillas (“”) y a las tildes. z Las comillas. Delimitan una frase. Cuando utilicemos las comillas estaremos indicando al buscador que nos localice una frase en concreto. Nos buscará, por tanto, todas las palabras que le hemos indicado en el mismo orden que las hemos escrito. Si no colocamos las comillas, considerará las palabras como unidades distintas y las buscará en cualquier orden. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad z Página 5 de 21 Las tildes. Si escribimos las tildes, el buscador se limitará a ofrecernos las palabras que contengan la tilde indicada. Si no las escribimos, considerará como éxito, todas aquellas páginas que contengan la palabra indicada con o sin tildes. La recomendación a partir de esta herramienta es: { Si queremos “amplificar” la búsqueda, es decir, si queremos obtener un número más alto de resultados, no escribiríamos las tildes. { Si queremos “restringir” la búsqueda, o sea, disminuir el número de resultados, usaremos las tildes. Marcar las respuestas correctas: Si se quiere realizar una búsqueda de frase exacta deberemos escribirla en el buscador de la siguiente manera: Casas de campo “casas de campo” Respuesta correcta pero incompleta. .Casas de campo. Casas.de/campo Respuesta correcta pero incompleta. La 2 y la 4. La 3 y la 4. La 3 no es una respuesta válida. El Objetivo de Toda Búsqueda Cuando nos ponemos “manos a la obra” a buscar algún tipo de información, no debemos olvidar que somos seres humanos y que no vamos a ser capaces de estudiar todas las páginas que tratan el tema que nos interesa. Por ello, uno de los principales objetivos de la búsqueda es minimizar el número de resultados. A primera vista, esta afirmación puede parecer contradictoria. “¿Por qué minimizar los resultados? Cuantos más, mejor; tendremos más donde elegir…” Razonamiento erróneo. Veamos, una pregunta: ¿Qué es mejor obtener 0 resultados o 200,000? RESPUESTA Búsqueda Avanzada Este formulario incorpora todas las capacidades de restricción que Altavista pone a disposición de sus usuarios. Nos permite limitar los éxitos de una forma mucho más eficiente que los anteriores formularios. Dominar las posibilidades que nos ofrece esta página, insisto, supone una gran ventaja porque, minimizará el tiempo que tardemos en localizar lo que buscamos. Las herramientas que nos ofrece son: z z z Construya una consulta con.... Como podéis ver en la figura 3.3.1, el primer bloque de la búsqueda avanzada coincide exactamente con lo explicado en el epígrafe anterior. Buscar con… (Búsqueda booleana). Este segundo bloque que trata de hacer búsquedas con expresiones booleanas es lo mejor de este formulario de búsqueda avanzada y lo explicaré con detalle al final de este epígrafe. Fecha…. Con esta herramienta podemos restringir los éxitos a aquellos documentos que http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad z Página 6 de 21 se actualizaron por última vez en el rango de fechas indicadas. Si poseemos información relativa a la última vez que se actualizó una página o si sabemos cuándo se publicó en la Web y que desde entonces no se ha modificado, podemos utilizar esta herramienta para encontrarla. Tipo de Archivo…. La web, aunque formado principalmente por páginas web (.html o .htm), también contiene enlaces a muchos otros tipos de archivos de texto, como por ejemplo el Portable Document Format, más conocido por .pdf . También pueden haber documentos de Microsoft Word, (.doc) o de Microsoft Excel (.xls), etc. En definitiva, con esta herramienta podemos limitar el tipo de documentos que queremos encontrar. Si sabemos, por ejemplo que el archivo que buscamos suele estar publicado en formato .pdf, podemos utilizar este servicio para limitar mejor la búsqueda. Los PDF (Portable Document Format) Este tipo de archivo se ha vuelto muy popular en Internet. Mucha de la información susceptible de ser localizada en la Web, está en este formato. Gran cantidad de instituciones han optado por publicar información en .pdf en vez de la clásica página web. ¿Porque? Dos son las causas principales: z z z z Formato. Los documentos .pdf pueden abrirse por cualquier sistema operativo, en cualquier situación, y siempre tienen el mismo aspecto. Este era un problema grave del .html ya que según cómo y cuándo se abriera, muchas veces, el texto o las imágenes estaban cambiadas de lugar. Seguridad. Al contrario que en un .html, el autor de un documento .pdf, puede especificar una serie de opciones de visualización del archivo. El autor puede decidir quién puede abrir el archivo, quién puede imprimirlo, quién puede extraer contenido de él, etc. Ubicación…. Permite restringir los resultados a los servidores web de un determinado país o a un servidor concreto. Así pues, esta herramienta nos sirve para buscar sólo en servidores españoles, o italianos, o japoneses, etc. Para ello, colocaríamos en la celda “por dominio”, “.es”, o “.it”, o “.jp”. En el caso alternativo que quisiéramos buscar algo en la Universidad Politécnica de Valencia (UPV) o en el Ministerio de Educación, Cultura y Deporte, pondríamos en el celda “por URL”, lo siguiente: “www.upv.es” para la UPV o “www.mcu.es”, para el Ministerio. Mostrar…. Por último, esta herramienta se puso en marcha porque algunos webmaster demasiado listos, colocaban muchas copias de una misma página en el un servidor, de forma que cuando se hacía una búsqueda en el motor, podía aparecer 30 ó 40 veces el mismo documento, desorientando a los usuarios noveles. Para evitar esta trampa, los buscadores pueden limitar el número de éxitos que provengan de un mismo sitio o servidor web. Finalmente, el número de resultados por página hace referencia al número de éxitos que queremos que nos liste en una misma página de resultados. Obviamente, cuantos más resultados podamos ver en un golpe de vista, sin necesidad de presionar el botón “Siguiente”, mejor, ya que menos tiempo perderemos pasando páginas. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 7 de 21 Figura 3.3.1: Búsqueda Web avanzada en Altavista. Fuente: http://www.altavista.com/web/adv Analicemos con detalle el segundo bloque: “Búsqueda Booleana”. Como podéis ver, disponemos de una celda más grande que las demás en donde podemos escribir muchos términos. Los términos que incluiremos en esta celda serán las palabras claves y los restrictores que Altavista nos permite gastar. Si os fijáis, a la derecha de la celda aparece un enlace que nos informa sobre todos los términos que se pueden utilizar y cómo funcionan. La página donde lo explica, la he reproducido en el Cuadro 3.3.1: OPERADORES BOOLEANOS Y DE TRUNCACIÓN AND Encuentra documentos que contienen todas las palabras o frases especificadas. Cacahuete AND mantequilla encontrará documentos con ambas palabras, "cacahuete" y "mantequilla". OR Encuentra documentos que contienen al menos una de las palabras o frases especificadas. Cacahuete OR mantequilla encontrará documentos que contienen o "cacahuete" o "mantequilla". Los documentos encontrados pueden contener ambas formas, pero no necesariamente. Excluye los documentos que contienen la palabra o frase especificada. "Cacahuete AND NOT mantequilla" encontrará documentos con "cacahuete" pero que no contienen "mantequilla". NOT debe ser http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 8 de 21 AND NOT utilizado con otro operador, como AND. AltaVista no acepta 'cacahuete NOT mantequilla'; especifique cacahuete AND NOT mantequilla. NEAR Encuentra documentos que contienen ambas palabras o frases especificadas a una distancia máxima de 10 palabras entre sí. Cacahuete NEAR mantequilla encontrará documentos con "mantequilla de cacahuete", pero probablemente ningún otro tipo de "mantequilla". * El asterisco es un comodín; cualquier secuencia de letras puede ser sustituida por el asterisco. Past* encontrará documentos con "pastel", "pastelero" y "pastelería". Debe teclear al menos tres letras antes del *. También puede colocar el * en el medio de una palabra. Esto es útil cuando no está seguro de la ortografía de la palabra. Des*uciar encontrará los documentos que contengan desahuciar, desafuciar o desafiuciar. () Utilice paréntesis para agrupar las expresiones booleanas complejas. Por ejemplo, (cacahuete AND mantequilla) AND (gelatina OR mermelada) encontrará documentos con las palabras "mantequilla de cacahuete y gelatina" o "mantequilla de cacahuete y mermelada" o ambas. RESTRICTORES Anchor:text Encuentra páginas que contienen la palabra o frase especificada en el texto de un hipervínculo. anchor:empleo +programación encontrará páginas con empleo en un vínculo y con la palabra programación en el contenido de la página. No ponga ningún espacio antes ni después de los dos puntos. Debe repetir la palabra clave para buscar más de una palabra o frase; por ejemplo, anchor:empleo OR anchor:carrera encontrará páginas con anclas (anchors) que contienen la palabra "empleo" o la palabra "carrera". applet:class Encuentra páginas que contienen un applet de Java especificado. Utilice applet:morph para encontrar páginas que utilicen applets llamados "morph". object:class Encuentra páginas que contienen un objeto especificado creado por otro programa (ej. un objeto Flash). Utilice object:dinero para encontrar páginas que utilicen objetos llamados dinero. Encuentra páginas dentro del dominio especificado. Utilice domain:uk domain:domainname para encontrar páginas del Reino Unido, o utilice domain:com para encontrar páginas de sitios comerciales. host:hostname Encuentra páginas en un ordenador específico. La búsqueda host:www.shopping.com encontrará páginas que se hallen en el ordenador Shopping.com, y host:dilbert.unitedmedia.com encontrará páginas en el ordenador llamado "dilbert" dentro de unitedmedia.com. image:filename Encuentra páginas con imágenes que tienen un nombre de archivo específico. Utilice image:playas para encontrar páginas con imágenes llamadas "playas". like:URLtext Encuentra páginas similares o relacionadas con una URL especificada. Por ejemplo, like:www.abebooks.com encuentra sitios web que venden libros de viejo, similares al sitio www.abebooks. like:sfpl.lib.ca.us/ encuentra sitios de bibliotecas públicas o universitarias. like:http://www.indiaxs.com/ encuentra sitios sobre cultura en el subcontinente indio. link:URLtext Encuentra páginas con un vínculo a una página con el texto de URL especificado. Utilice link:www.myway.com para encontrar todas las páginas con vínculos a myway.com. text:text Encuentra páginas que contienen el texto especificado en cualquier parte de la página excepto las etiquetas de imagen, los vínculos, o las http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 9 de 21 URL. La búsqueda text:graduación encontrará todas las páginas que contengan el término "graduación". title:text Encuentra páginas que contienen la palabra o frase especificada en el título de la página (que aparece en la barra de título de la mayor parte de los navegadores). La búsqueda title:puesta de sol encontrará las páginas que contienen en el título la frase "puesta de sol". url:text Encuentra páginas con una palabra o frase específicas en la URL. Utilice url:jardín para encontrar todas las páginas de todos los servidores que tengan la palabra jardín en cualquier parte del nombre del host, la ruta, o el nombre del archivo. Cuadro 3.3.1: Operadores booleanos, de truncación y restrictores a emplear en el buscador de Altavista. Fuente: http://www.altavista.com/help/adv_search/syntax Si realizamos una búsqueda uniendo dos palabras con el termino _AND_ , el buscador encuentra documentos que contienen estas dos palabras especificadas. Sí No Si realizamos una búsqueda uniendo dos palabras con el termino _OR_ , el buscador encuentra documentos que contienen al menos una de las palabras especificadas. Sí No OBJETIVO 4 Seleccionar los operadores booleanos y restrictores más adecuados y darles uso. A continuación, comentaré las herramientas que considero más útiles de las listadas en la figura 3.3.2: Como he estado insistiendo a lo largo de la unidad, las herramientas más útiles van a ser casi siempre, las que nos permitan restringir de forma importante el número de éxitos. Por ello, entre los operadores booleanos listados, considero que los más útiles, para este fin, son: z z Operador AND. Este operador, obliga a que todos los términos que une, aparezcan en la página éxito. Por ello, es de los más restrictivos. No es necesario escribirlo en mayúsculas. Operador NEAR. En este caso, no solo obliga a que los términos que une, aparezcan, sino que además han de estar a una distancia máxima de 10 palabras. Sirve para buscar términos, que deban estar relativamente cerca, por ejemplo, dentro de una misma frase. No es necesario escribirlo en mayúsculas. Con el operador AND, se pueden hacer la mayoría de las búsquedas, indicando todas las palabras clave (o frases clave) que queramos buscar. El operador NEAR, es útil tan solo en algunas ocasiones, cuando sabemos que las palabras clave (o frases clave), han de estar en la http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 10 de 21 misma frase. Cuando digo “frase clave”, me refiero a colocar varias palabras clave en un orden determinado utilizando las comillas. Por ejemplo, “david pla santamaria” AND “universidad politecnica de valencia” sería un ejemplo del operador AND, uniendo dos frases clave. Según el motor en el que practiquéis con estos operadores, es posible que sea obligatorio que se escriban en mayusculas. Por ejemplo, en Altavista, mejor escribirlos en mayúsculas. Figura 3.3.2: Elementos de la página de búsqueda en Altavista. Con respecto a los restrictores es más difícil elegir, ya que su especificidad los hace interesantes según qué información estemos buscando. Comentaré algunos: z url:. Localiza palabras clave en la URL de la página? . Es útil cuando conocemos el nombre del archivo o de algún directorio de la ruta de acceso. Ver figura 3.3.2. El restrictor url: es el caso general, pero también existe un restrictor que limita la búsqueda tan solo a una parte del URL, la dirección de la máquina o el servidor: { host:. Con este restrictor podemos indicar que queremos buscar la palabra clave tan solo en la dirección DNS de la máquina, por lo que podemos restringir búsquedas a servidores concretos o a una empresa determinada. z domain: Por último, un caso particular del host:, es limitar la búsqueda al dominio de la máquina, es decir a la última parte de la dirección de máquina. Se utiliza para limitar la búsqueda a un tipo de organización concreta o a un país. title:. Permite limitar la búsqueda tan solo al título de la página. El título es lo que aparece en la barra superior de la ventana del navegador, junto con el icono del navegador y a la misma altura que los botones de minimizar, maximizar y cerrar. Este restrictor permite buscar páginas que se titulen como nosotros queramos. Es mucho más probable que la página que tenga un título relacionado con nuestro interés, contenga información relevante para nosotros. Cuando no colocamos ningún restrictor a la palabra clave, el motor, busca la palabra en cualquier parte de la página: título, URL o cuerpo, por ello puede ofrecer éxitos, pero cuya relevancia sea marginal. No es lo mismo encontrar una página cuyo título sea, por ejemplo, http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 11 de 21 “Bolsa de Madrid” con la sintaxis: “title:bolsa AND title:madrid” o ‘’ title:”bolsa de madrid” ‘’ , que encontrar una página con la sintaxis: “bolsa AND madrid”, que podría referirse a una bolsa de empleo en la comunidad de Madrid. El resto de restrictores, aunque interesantes, son algo técnicos, permiten localizar applets de java (applet:) u objetos de programación específica (object:) en páginas web. No voy a entrar en ellos, aunque recomiendo al alumno que desarrolle alguna prueba con estos restrictores para que conozca su existencia y, en un futuro, pueda utilizarlos, si los necesita. En este cuadro, voy a introducir algunos ejemplos de sintaxis para la búsqueda de información, utilizando las herramientas vistas en este epígrafe. z z z z z z z z z bolsa AND madrid. Ofrecerá los documentos web que tengan la palabra bolsa y la palabra Madrid en cualquier parte (> 200,000 éxitos? ). title:bolsa AND madrid. Ofrecerá los documentos web que contengan la palabra bolsa en el título de la página y la palabra Madrid, en cualquier parte (> 17,000 éxitos). “bolsa de madrid”. Ofrecerá los documentos web que contengan la frase “bolsa de madrid” en cualquier parte de la página (> 17,000 éxitos). title:”bolsa de madrid”. Ofrecerá los documentos web que contengan la frase “bolsa de madrid” en el título (> 20,000 éxitos). host:bolsa AND title:madrid. Ofrecerá los documentos web que contengan la palabra bolsa en la dirección de la máquina y que en el título aparezca la palabra madrid (0 éxitos). host:bolsa* AND title:madrid. Ofrecerá los documentos web que contengan palabras empezadas por bolsa____ en la dirección de la máquina y que en el título aparezca la palabra madrid (453 éxitos). url:bolsa AND domain:es. Ofrecerá los documentos web que contengan la palabra bolsa en alguna parte de la dirección URL y pertenezcan a una máquina española (4,953 éxitos). “bolsa de madrid” AND domain:mx AND url:bolsa. Ofrecerá los documentos web que contengan la frase bolsa de madrid en cualquier parte, estén almacenados en una máquina mexicana y en alguna parte de su dirección URL aparezca la palabra bolsa (1 éxito). “bolsa de madrid” AND enlace AND domain:com. Ofrecerá los documentos web que contengan la frase “bolsa de madrid” en cualquier lugar de la página, tengan la palabra enlace también en cualquier parte y finalmente pertenezcan al servidor de una empresa comercial (154 éxitos). Pistas Utilizar comillas (“”) junto con el restrictor url:, host: o domain:, es un error. No podemos hacer la siguiente búsqueda: host:”bolsa de madrid”. Toda la dirección URL es una sola cadena de caracteres SIN espacios en blanco, por lo que no tiene sentido utilizar comillas, cuyo principal objetivo es el introducir espacios en blanco entre palabras. Plurales (stemming). No utilizar nunca plurales ya que el singular de una palabra está, generalmente, comprendido en su plural. Si utilizamos el singular en lugar del plural, posibilitaremos que todas las páginas donde utilicen uno de los dos términos, aparezcan. De lo contrario, únicamente resultarán éxito los plurales y posiblemente perdamos información potencialmente relevante. Tildes y mayúsculas. Utilizarlos con precaución. Como ya sabéis, los motores, generalmente trabajan en minúsculas y sin tildes. Por tanto si introducís una palabra de esta forma, resultarán como éxitos, esa palabra y todos sus derivados (en mayúsculas, con la inicial en mayúscula, con tilde, etc.). Si la introducís con la inicial en mayúscula o con la tilde, estáis restringiendo a esa palabra concreta, con la tilde o la inicial de esa forma. En este punto hay que tener en cuenta que si la persona que ha escrito la página web que estamos buscando, ha cometido faltas de ortografía al programarla, no la encontremos. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 12 de 21 Unir (*)Introduzca el Orden del Concepto apropiado Orden Concepto Pareja (*) 1 Campo AND casa >>> Ofrecerá documentos web que tengan la palabra “campo” y la palabra “casa” en cualquier parte. 1 2 tittle:campo AND casa >>> Ofrecerá documentos web que contengan la palabra “campo” en el título y “casa” en cualquier parte. 2 Herramienta Traducir OBJETIVO 5 Aplicar la herramienta “Traducir” de Altavista cuando sea necesaria. Cuando Altavista nos ofrece el listado de éxitos, podemos ver hacia el final de cada uno, un enlace que indica “Traducir” o “Translate”. Este enlace nos facilita el acceso a un servicio, el cual permite elegir en qué idioma queremos cargar ese éxito, de entre una lista bastante amplia (chino, francés, alemán, italiano, japonés, coreano, portugués o español). De esta forma, si estamos interesados, podremos traducir cualquier página del inglés, al castellano. Figura 3.4.1: Página de RecerK en español. Figura 3.4.2: Página de RecerK traducida al inglés. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 13 de 21 El servicio no funciona a la inversa desde la página de éxitos, es decir, no ofrece la posibilidad de traducir un éxito del inglés a otro idioma. Pero sí que podemos traducir un documento desde diversos idiomas al inglés (y a la inversa) si vamos a la página principal del servicio de traducción. Tenéis un enlace a este URL en la propia página principal de Altavista (http://www.altavista.com) bajo el menú de herramientas: “Traducir”. Las traducciones que podéis hacer utilizando este servicio se detallen en la figura 3.4.3 Figura 3.4.3: Lista de traducciones posibles en Altavista. Otros sitios web que ofrecen servicios similares son, por ejemplo, http://www.systransoft.com (que es la empresa proveedora del servicio de Altavista) o http://www.freetranslation.com. De estos dos sites, el que ofrece un mayor servicio, en el sentido de trabajar con más idiomas es el primero: Systran. Ver figura 3.4.4. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 14 de 21 Figura 3.4.4: Lista de posibles traducciones en Systransoft. Fuente: http://www.systransoft.com Para concluir este epígrafe, tan solo resaltar que, gracias a este tipo de servicios, vamos a poder leer páginas que están en diferentes idiomas. Idiomas de los que podemos tener alguna noción, o incluso idiomas de los que no sabemos nada. Ahora bien, no se puede ocultar que la traducción instantánea que ofrecen estos servicios no es de gran calidad. Si hacéis alguna prueba, e intentáis traducir entre dos idiomas que dominéis, os daréis cuenta de que la versión traducida no se ajusta a la original. Los errores más comunes son la sintaxis y el vocabulario técnico o específico. Ver figuras 3.4.1 y 3.4.2. Este tipo de servicios, considero que es útil cuando tratamos de leer un documento en un idioma que no dominamos en absoluto, como por ejemplo (en mi caso) el alemán, holandés o ruso. Pero no puede ser sustitutivo del inglés. Aquellos de vosotros que penséis que con esta herramienta, ya no necesitáis aprender inglés, siento daros malas noticias. Como habréis podido observar en las figuras 3.4.1 y 3.4.2, la traducción del castellano al inglés deja mucho que desear y la lectura de la versión traducida de la página puede ser casi tan desconcertante como la lectura del alemán. Además, el utilizar estos servicios supone una inversión en tiempo, que muchas veces no es eficiente. El idioma de Internet es el inglés y no podemos evitarlo. Hay que aprender inglés y cuanto antes se ponga uno a ello, mejor. Ahora bien, tal como he dicho antes, cuando la página que queremos visitar está en un idioma desconocido por completo (y no es inglés), no tenemos otro remedio que traducirla (generalmente al inglés) para poder intentar comprender lo que dice. Otra solución, que es por la que personalmente opto, es dejar esa página y buscar otra que sí que esté en castellano o inglés. Pero cuándo no hay otra salida, cuando no hay otro documento en otro idioma más afín a nosotros, entonces, y solo entonces, es cuando este tipo de servicios son recomendables. Otra situación en la que estas herramientas son interesantes es cuando estamos intentando visualizar una página escrita con otro alfabeto, por ejemplo el japonés o el chino. En un PC de los que normalmente utilizamos en casa o en cualquier lugar de nuestro país, el ordenador trabajará con el alfabeto latino y será incapaz de mostrar una página china o japonesa (todo el documento aparece lleno de cuadraditos y símbolos extraños). Ver, por ejemplo, la figura 3.4.5. No entramos ya en si la podremos leer o no, simplemente, no la podremos ni ver… a menos que… le indiquemos al traductor que nos muestre la página traducida al inglés (o instalemos en el sistema operativo, el paquete alfabético correspondiente). En ese caso sí podremos visualizar su contenido. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 15 de 21 Figura 3.4.5: Arriba página original en chino. Abajo la misma página traducida al español. Configuración OBJETIVO 6 Editar las preferencias de Altavista a su gusto. En la página de configuración se puede seleccionar entre diversidad de opciones para que el trabajo de Altavista se ajuste un poco más a las preferencias del usuario. La práctica totalidad de los motores de búsqueda de prestigio tienen una herramienta similar, algunos con más posibilidades, otros con menos, pero todas útiles. En el caso que nos ocupa, analicémoslas con detalle: z País. Permite provocar un cierto “sesgo” en los resultados de la búsqueda hacia el contenido proveniente de un determinado país. Este servicio puede ser útil cuando, la información que estamos buscando se refiere a un país determinado. Cuando no sea así, cuando estéis buscando información general sobre un tema, sin que tenga relación con ningún país en concreto, la mejor opción es seleccionar EEUU, ya que es el país que más contenidos ofrece. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 16 de 21 z Lengua de los Resultados de la Búsqueda. Nos permite limitar la lengua en la que estarán redactadas las páginas éxito. Siguiendo la línea esbozada anteriormente, utilizando esta opción podéis limitar las páginas a las escritas en castellano o español, pero no filtréis las páginas en inglés. Sino, ya estaréis limitando el 70%-80% del contenido de la Red. Si, en un momento dado, necesitáis buscar información en castellano, siempre podréis utilizar la restricción por idioma que aparece en la misma página de búsqueda avanzada. z Filtro Familiar. Permite limitar contenido ofensivo, pornográfico, etc. en los resultados, de cualquiera de los motores de Altavista. z Presentación de Resultados. Permite seleccionar qué tipo de información queremos ver resumida en el listado de éxitos, entre otros datos relevantes. { Formato de la página de resultados. En este submenú, se nos permite resaltar la palabra clave en el resumen, cosa normalmente muy útil ya que nos facilita la identificación de nuestra palabra clave y no tenemos que leer todo el resumen para ver en qué contexto se está utilizando. También podemos elegir el número de éxitos que queremos ver en cada página de resultados (desde 10 hasta 50). En relación a esta característica, yo siempre opto por la mayor cantidad, pero también es cierto que si la conexión que tenéis es lenta, puede tardar demasiado en cargar los resultados ya que estamos hablando de una página 5 veces más grande que la de 10 resultados. Por tanto, esta decisión también depende de la velocidad de acceso que tengáis contratada con vuestro proveedor. De todas formas siempre defenderé el mayor número de éxitos porque, aunque tarde más en cargar la página, ya no necesitáis cargar 4 páginas más para ver los 50 éxitos. Las demás herramientas que aparecen en el menú de Altavista, que son “Mapas”, “Páginas Amarillas”, “Buscador de Personas”, son servicios subcontratados a MapQuest.com y SmartPages.com por lo que no las vamos a comentar. Tan solo indicar que a través de “Mapas” se accede a una base de datos GPS de Norteamérica y Europa y permite, entre otras cosas, conocer la situación exacta de una dirección postal. Las “Páginas Amarillas” y el “Buscador de Personas” están centrados en contenido estadounidense. Recuerda que ... z Para búsquedas específicas completas y serias, el único formulario válido es el avanzado. z Según qué búsqueda se hace, es interesante cambiar las preferencias de resultados hacia: “España” o “Todo el Mundo”. También hacia “Todos los Idiomas” o “Inglés/Español”. z Tienes que conocer los operadores booleanos básicos y saber cómo introducirlos en el formulario de búsqueda avanzada. Cada motor puede tener sus particularidades. Altavista, por ejemplo exige que se introduzcan en mayúsculas. z Altavista es el único motor que permite el uso del booleano NEAR. Errores más comunes http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 17 de 21 z Utilizar únicamente el formulario de busqueda simple. z No conocer la existencia de booleanos y restrictores. z Buscar cualquier información utilizando tan solo términos en castellano. z No personalizar las preferencias de un buscador al gusto del usuario. z Creer que una búsqueda con 200.000 éxitos es “mejor” que una con 0 éxitos. z Utilizar la herramienta “Traducir” (translate) para idiomas para los que tenemos nociones básicas. Aplicación de conocimientos 1. ¿Cuántos formularios de búsqueda te permite utilizar Altavista? RESPUESTA 2. ¿Cómo se denomina cada uno e ellos? RESPUESTA 3. ¿Qué diferencia existe entre el mirror de Altavista en Los Angeles y el de Madrid? RESPUESTA 4. ¿Cuáles son los restrictores que pueden ser utilizados en el formulario básico de Altavista? RESPUESTA 5. ¿Cuáles son los restrictores del formulario avanzado que más disminuyen el número de resultados o éxitos? RESPUESTA 6. ¿Cuándo es útil la herramienta “Traducir” de Altavista? RESPUESTA 7. ¿Para qué sirven las Preferencias en un motor de búsqueda? RESPUESTA [Imprimir el Cuestrionario Resuelto] Taller El ejercicio para asentar los conocimientos adquiridos durante este capítulo solo puede ser uno: empezar a trabajar con Altavista e ir familiarizándose con su funcionamiento. Os propongo, por tanto, un ejercicio de búsqueda. Localizad cuántas universidades hay en Liverpool (UK) y averiguad cuántos alumnos tiene cada una de ellas. Una vez hecho esto intentad localizar la página web del servicio de intercambio de estudiantes y explorad la posibilidad de organizar por vosotros mismos un intercambio entre la UPV y la universidad que encontréis. Muchos estudiantes universitarios españoles se quejan de que no pueden hacer intercambios http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 18 de 21 con universidades de Gran Bretaña o Irlanda y que han de conformarse con países donde se habla inglés, pero no es la lengua materna. En mi opinión, este problema tiene una solución relativamente fácil: que los propios estudiantes consigan por si mismos una plaza en la universidad de su elección. Hoy en día, esta labor no es algo complicado, utilizando los medios que Internet nos ofrece. Es posible que si nos dirigimos directamente a la oficina de admisiones internacionales nos nieguen el acceso aludiendo a que ellos tratan con sus “iguales” en otras universidades concertadas (cosa que dudo), pero… esa no es la única vía. ¿Porqué no conseguir que un alumno de la universidad donde queramos ir, nos gestione todos los trámites necesarios para obtener una plaza? Actuando de esta forma, es todavía más difícil que la universidad de destino se niegue a aceptarnos ya que es alguien de “dentro” el que está haciendo las gestiones. Este ejercicio tiene como objetivo que exploréis esta posibilidad. Obviamente, lo de Liverpool es un ejemplo, buscad la universidad que más os atraiga. Pensad en ello. ¿Cómo vamos de inglés? … Otra posibilidad de ejercicio para este capítulo es que leáis con detenimiento un informe sobre las bondades y problemas de Altavista, preparado por Greg Notess, uno de los gurús del área que nos ocupa. La URL de este informe: http://www.searchengineshowdown.com/features/av/review.html Bibliografía La mayor parte de los contenidos de este capítulo pueden ampliarse en el propio site de Altavista: http://www.altavista.com. Os indico también un libro relativo a Altavista, aunque es un poco antiguo. Seltzer, R., Ray, E.J., Ray, D.S. (1996) The AltaVista Search Revolution: How to Find Anything on the Internet. McGraw-Hill. Referencias http://www.altavista.com http://www.systransoft.com http://www.freetranslation.com http://www.searchengineshowdown.com/features/av/review.html Glosario () El paréntesis en un buscador se utiliza para agrupar las expresiones booleanas complejas. * El asterisco en un buscador se utiliza como operador booleano. Es un comodín que puede sustituir a cualquier secuencia de letras. Anchor Dentro de la búsqueda booleana de Altavista, anchor es un restrictor. Encuentra páginas que contengan cierta palabra o frase especificada en el texto de un hipervínculo. AND http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 19 de 21 Palabra que significa unión, y que utilizada en Altavista, encuentra documentos que contienen todas las palabras especificadas y unidas por este término. AND NOT Palabra que significa exclusión, y que utilizada en Altavista excluye los documentos que contienen la palabra o frase especificada. Applet Dentro de la búsqueda booleana de Altavista, applet es un restrictor. Encuentra páginas que contienen un applet de Java especificado. Buscador de Personas Servicio subcontratado a otra empresa por Altavista y que puede ser utilizado por el usuario como una herramienta más. Búsqueda Avanzada Opción presente en todos los buscadores. Es un formulario que incorpora todas las capacidades de restricción que Altavista pone a disposición de sus usuarios. Búsqueda booleana Es una de las herramientas que ofrece la búsqueda avanzada, y es lo mejor de ésta búsqueda avanzada, ya que dispone de una gran cantidad de operadores y restrictores. Búsqueda por Dirección Si se quiere buscar directamente en una dirección, en el apartado de búsqueda avanzada , en Ubicación, dentro de la celda URL , se indicaría la dirección. Comillas Las comillas, en un buscador como Altavista se utilizan para delimitar una frase. Indica al buscador que nos ha de localizar esa frase en concreto, con las palabras en el mismo orden en las que se han escrito. Cualquiera de estas palabras Opción de búsqueda que buscará documentos con cualquiera de las palabras especificadas. Domain Dentro de la búsqueda booleana de Altavista, domain es un restrictor. Encuentra páginas dentro del dominio especificado. Esta secuencia exacta Opción de búsqueda que buscará documentos todas las palabras especificadas y en el orden que se ha indicado. Filtro familiar Se puede configurar la página del buscador con este filtro, que permite limitar contenido ofensivo, pornográfico, etc en los resultados de las búsquedas. Formato de la página de resultados Es una forma de configurar la pagina del buscador, que lo que permite es resaltar la palabra clave en el resumen de información que se ha seleccionado anteriormente mediante la opción de “presentación de resultados” Frases clave Aquella frase que se indica al buscador que debe buscar, encerrada entre comillas para que busque las palabras en el orden que le indicamos. Herramienta mostrar herramienta de la búsqueda avanzada que permite limitar el número de éxitos que provengan de un mismo sitio o servidor web. Herramienta traducir herramienta que permite elegir en que idioma queremos cargar un éxito, de entre una lista bastante amplia. Host Dentro de la búsqueda booleana de Altavista, host es un restrictor. Encuentra páginas en un http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 20 de 21 ordenador específico. Image Dentro de la búsqueda booleana de Altavista, image es un restrictor. Encuentra páginas con imágenes que tienen un nombre de archivo específico. Lengua de los resultados de la búsqueda Herramienta que se utiliza para configura el buscador, y que permite limitar la lengua en la que estarán redactadas las páginas éxito. Like Dentro de la búsqueda booleana de Altavista, like es un restrictor. Encuentra páginas similares o relacionadas con una URL especificada. Link Dentro de la búsqueda booleana de Altavista, link es un restrictor. Encuentra páginas con un vínculo a una página con el texto de URL especificado. Mirror Un mirror es un índice que tienen el buscador a parte de la central situada en los Angeles. Su contenido esta sesgado a propósito de páginas del país en el que este situado. Near Al unir varias palabras o frases con este termino, el buscador encuentra documentos que contienen estas palabras o frases a una distancia máxima de 10 palabras. Ninguna de estas palabras Restrictor que se utiliza para realizar una búsqueda, y que excluye de los éxitos aquellos documentos que contengan las palabras aquí especificadas. Object Dentro de la búsqueda booleana de Altavista, object es un restrictor. Encuentra páginas que contienen un objeto especificado creado por otro programa. Objetivo de toda Búsqueda El objetivo de toda búsqueda es minimizar el numero de resultados hasta conseguir una cantidad de éxitos humanamente aceptable, de forma que puedan ser estudiados de forma eficaz. Operadores booleanos son una serie de expresiones que se utilizan para facilitar la búsqueda, y que permiten buscar documentos con dos palabras, con una palabra pero que no contenga alguna otra, buscar documentos donde aparezcan palabras de las que solo conocemos un parte, buscar documentos que contengan palabras muy junta entre si… Or Expresión que se utiliza para unir varias palabras o frases, y que sirve para que el buscador encuentre documentos que contengan al menos una de las palabras o frases especificadas. Paginas Amarillas Es una herramienta de la que dispone altavista y cuyo servicio es subcontratado a otras páginas web. País Al configurar el buscador se puede realizar un sesgo en los resultados de la búsqueda hacia el contenido proveniente de un cierto país. Esto se hace mediante ésta herramienta. Preferencias Es un motor de búsqueda que permite limitar los resultados, seleccionando entre diversas opciones, para que el trabajo del buscador se adapte a lo que el usuario prefiere. Presentación de resultados Permite seleccionar qué tipo de información queremos ver resumida en el listado de éxitos. Restricción por fechas Se pueden restringir los éxitos a aquellos documentos que se actualizaron por ultima vez en el http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Página 21 de 21 rango de fechas indicado. Restrictores Herramientas que permiten limitar los éxitos de las búsquedas realizadas a lo que realmente interesa al usuario. Text Dentro de la búsqueda booleana de Altavista, text es un restrictor. Encuentra páginas que contienen el texto especificado en cualquier parte de la página excepto las etiquetas de imagen, los vínculos… Titles Dentro de la búsqueda booleana de Altavista, title es un restrictor. Encuentra páginas que contienen la palabra o frase especificada en la barra de título de la mayor parte de los navegadores. Tipo de archivo Con esta herramienta se puede limitar el tipo de documento que queremos encontrar: .doc, .xls, .html…. Tildes Al escribir las tildes de las palabras que estamos buscando, la búsqueda se restringe a únicamente los documentos en los que la palabra lleva tilde. En cambio, si no se pone, se busca esa palabra con o sin tilde, con lo que el numero de éxitos es mayor. url Encuentra páginas con una palabra o frase específicas en la URL Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D3ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 22 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 4.- Motores de Búsqueda Web Esquema http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 2 de 22 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 3 de 22 Objetivos de la Unidad Pedagógica Después de estudiar esta unidad, el alumno deberá ser capaz de: 1. Distinguir un motor de búsqueda según su tipología. 2. Saber utilizar y aplicar las tres estrategias básicas de búsqueda. 3. Elegir o descartar un determinado motor de búsqueda en función de si ofrecen o no algunas herramientas que facilitan las búsquedas. Introducción Visto en la práctica cómo funciona un determinado motor de búsqueda y sus posibilidades, ahora vamos a profundizar en diversas características que definen y diferencian los motores, así como las formas de buscar información. "Aquel que ama la práctica sin teoría es como el navegante que comanda un barco sin timón ni brújula y nunca sabe adónde puede dirigirse." "He who loves practice without theory is like the sailor who boards ship without a rudder and compass and never knows where he may cast." Leonardo Da Vinci, 1452-1519, Artista. BrainyQuote.com Aunque no lo parezca, la búsqueda de información en Internet tiene un componente estratégico muy importante. A medida que uno va adquiriendo más destreza en este campo se va dando cuenta de la importancia de este componente básico. A lo largo de lo que resta de curso, iremos viendo distintas recomendaciones estratégicas que pueden ser utilizadas a la hora de programar una búsqueda. Esta unidad sirve de introducción en este sentido. Además, también mostraremos un conjunto de útiles “herramientas” que algunos motores ofrecen a través de su interfaz para facilitar al usuario la localización de “su” información relevante. Clasificación de los motores de búsqueda en el web Introducción A la hora de ponernos a buscar información en el Web, podemos elegir entre tres tipos de herramientas principales. Veamos las características generales de cada una de ellas: Buscadores Los buscadores son los motores de búsqueda más conocidos. Son enormes bases de datos que pueden alcanzar los 4,000 millones de documentos?. Por otra parte, OBJETIVO 1 Distinguir un motor de búsqueda la selección de estos documentos para ser incluidos en la http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad según su tipología. Página 4 de 22 base de datos o índice del Web, la hacen unos programas que trabajan 24 horas al día, 7 días a la semana. Estos programas denominados crawlers o spiders tienen como misión el ir visitando páginas web y seleccionando aquellas que deben incorporarse a la base de datos del buscador, siempre que cumplan con unos mínimos especificados por el propio spider. Los spiders van saltando de página en página siguiendo los hiperenlaces. Los buscadores se tratarán con detalle en la unidad 6. El spider es un programa que se encarga seleccionar las páginas web que deben ser incluidas en la base de datos del buscador. Verdadero Falso Directorios Estas herramientas, en ocasiones, se confunden con los buscadores. ¿Sabíais que Yahoo no es un buscador, sino un Directorio?(hasta febrero de 2004)? Un directorio es otra base de datos, al igual que un buscador, pero se diferencia de un buscador en tres puntos principalmente: z Sistema de selección de las páginas que entran a indexarse en la base de datos. La selección de los documentos web que se indexan en un directorio no se pone en manos de un spider como en los buscadores. En este caso, la selección la hace un equipo de personas, que trata de crear una base de datos diversificada. El mismo equipo de personas introduce una pequeña descripción del contenido del documento, de forma que el usuario del directorio pueda contar con un pequeño resumen "independiente y objetivo". Debido a este extremo, la calidad de la información disponible a través de un directorio se supone mayor. Hablar de Calidad de Información siempre es abstracto. Cuando decimos que los directorios ofrecen una mayor calidad de información, ¿a qué nos referimos? Los requisitos básicos para definir "buena información" son: { { { Objetividad. Que la información se presente libre de propaganda o desinformación. Completa. Que la información sea total, no una foto parcial del tema. Plural. Que se comuniquen todos los aspectos del tema, que no se restrinjan a un determinado punto de vista (por ejemplo, la censura)?. En general, los resúmenes que los editores hacen de cada una de las páginas que forman el directorio, intentan seguir estos tres principios. Por otra parte, otro tipo de calidad que también tienen en cuenta es la de los enlaces (que funcionen), la velocidad de actualización, etc. z z Tamaño. Es lógico pensar que el equipo de personas que mantienen vivo y en crecimiento un directorio, no puede trabajar al ritmo de un spider (24 horas / 7 días). Esta es la razón por la que el tamaño de la base de datos de un directorio es muy inferior a la de un buscador. Organización. Todo el contenido de un directorio está ordenado y agrupado en lo que se denominan subjects o categorías. Todos y cada uno de los documentos que se incorporan a un directorio, se adscriben a una determinada categoría. Las categorías son subconjuntos del directorio que intentan agrupar páginas en función de su contenido, http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 5 de 22 para facilitar su localización. Los directorios se estudiarán en la unidad 7. Seleccionar aquella ó aquellas características propias de los Directorios: La selección de los documentos se pone en manos de un spider. LA información que se considera buena ha de ser objetiva, completa y plural. Respuesta correcta pero incompleta. La selección de los documentos se pone en manos de un equipo de personas que crea una base de datos diversificada. Respuesta correcta pero incompleta. Su tamaño es superior al de un buscador. La 2 y la 4. Solo la 2 es válida. La 2 y la 3. Buscadores Híbridos Hoy en día, gran cantidad de buscadores y directorios se han convertido en motores híbridos. Es decir, a través de su interfaz, permiten la utilización de un buscador o de un directorio indiferentemente. Este movimiento ha sido, básicamente, una respuesta a la demanda de los usuarios. Ejemplos de motores que actúan de esta forma son: z Google: http://www.google.com / http://directory.google.com z Altavista: http://www.altavista.com / http://www.altavista.com/dir/default z MSN Search: http://search.msn.com / (ambos en la misma página) Metabuscadores Estas herramientas no construyen una base de datos. No cuentan con un spider ni con un equipo de gente que va seleccionando los documentos. Estas herramientas utilizan las bases de datos creadas por otros motores de búsqueda. Así pues, los metabuscadores proporcionan páginas y documentos recopilados por spiders y personas. Otra característica básica de los metabuscadores es que permiten, al usuario, seleccionar qué motores de búsqueda quiere utilizar. Los metabuscadores se analizarán en la unidad 8. Por último, y como una última clasificación marginal, estarían los "motores de búsqueda con operativas especiales". Estos motores se incorporarían en alguno de los anteriores grupos pero, al contar con un procedimiento distinto de lo habitual a la hora de desarrollar las búsquedas, se pueden considerar en un quinto grupo de "operativa especial". Este quinto grupo lo comentaremos también en ella unidad 8. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 6 de 22 Caso Estudio Cómo Funcionan los Motores de Búsqueda Cuando escribimos unas palabras clave en un buscador y apretamos el botón "Buscar" ... ¿qué ocurre? ¿Creéis que las palabras clave "se van por Internet" a buscar páginas que las contengan? ¡Lógicamente no! En realidad, cuando nosotros introducimos una o varias palabras clave en la casilla adecuada de un motor de búsqueda y presionamos el botón "Buscar" las palabras se remiten a una base de datos situada en uno o varios servidores (uno o varios ordenadores) que generalmente están situados en un mismo lugar geográfico. Por ejemplo, las máquinas de Google están situadas en California y las de Alltheweb están en Noruega. Cuando los términos llegan a estos servidores, activan la base de datos para que busque aquellos documentos que los contengan. Esta búsqueda ofrecerá como resultado un número más o menos grande de éxitos, es decir, documentos web que contienen los términos clave especificados, por ejemplo 1,564. El siguiente paso, es su ordenación. El mismo servidor, utilizando algún tipo de algoritmo, decide cuál de los 1,564 resultados es el más relevante, cuál el segundo en importancia y así sucesivamente. Una vez resuelta la ordenación, ese listado se nos remite a nuestro navegador en pequeñas dosis de 10 en 10 éxitos (esta cantidad puede variar). Veamos ahora un pequeño ejercicio que trata de demostrar y aclarar las explicaciones de este punto: z z z z Abrid vuestro navegador y dirigíos a la página principal de Google (http://www.google.com) Buscad el siguiente texto (sin las comillas): "cache:nacion.com". Veréis como lo que Google os abre es la página de un periódico Costarricense, pero ¡fijaos en la fecha! Veréis que es de dos o tres meses atrás. Ahora visitad la página web del propio periódico: http://www.nacion.com. Veréis como la página es la del día que la visitáis, no uno anterior. ¿Qué ha pasado? El restrictor cache: de Google permite ver la página que su spider seleccionó y almacenó en su base de datos. Así pues, la página antigua es la que Google tiene en su base de datos y es la que podremos encontrar si hacemos una búsqueda en su motor. Pero desde que el spider de Google "pasó" por nacion.com ha transcurrido ya un tiempo y, por tanto, la información ha cambiado (página actual de nacion.com), pero Google no lo sabe. Si extraéis una frase clave larga (es decir, copiáis una frase de 8 o 12 palabras y la ponéis entre comillas) de la página actual de nacion.com y las introducimos en una búsqueda en Google, veréis como no encontráis la página de donde lo habéis copiado. La razón, como ya os he comentado, está en que Google no tiene indexada la página actual sino la antigua. Si hacéis la misma operación copiando una frase clave larga de la página antigua, sí que la encontraréis. Esto demuestra, que las palabras clave que introducís en una búsqueda no "se van por Internet" a buscar éxitos, sino que buscan en una base de datos que previamente se ha creado con unos criterios definidos y que tiene un tamaño limitado aunque grande. Estrategias básicas para localizar información en el Web Introducción En este punto se tratarán las tres estrategias básicas que http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad OBJETIVO 2 Saber utilizar y aplicar las tres estrategias básicas de búsqueda. Página 7 de 22 deben utilizarse para buscar información en el Web?. Las tres son complementarias y el inclinarse por una u otra depende, en cada caso, de la información que queramos obtener, así como de los datos de que dispongamos para hacer la búsqueda. Estrategia 1: ¡Adivina! En primer lugar está la "adivinación". Esta estrategia es mucho más efectiva de lo que muchos pueden pensar. Ahora bien, es útil tan solo en unos casos muy concretos. Cuando utilizar esta estrategia: Para encontrar la página principal de una institución o una organización. Las siguientes indicaciones pueden ayudar: 1. Olvidar el http://, ya que los navegadores ya escribirán por defecto esta parte de la dirección URL. { Escribiríamos: http:// 2. Probar el típico www al inicio de la dirección de la máquina. Las tres uves dobles aparecen en muchas ocasiones como inicio de la dirección DNS del servidor web, pero no siempre se utilizan. Por tanto aquí tendríamos dos posibilidades, con www y sin www. { Escribiríamos: http:// ó http://www 3. A continuación, añadiríamos el nombre, acrónimo o nombre abreviado de la institución u organización que queremos localizar como centro de la dirección DNS de la máquina o servidor web. { Escribiríamos (por ejemplo, si quisiéramos ver la web de la Biblioteca Nacional de España): http://bne ó http://www.bne En este punto habría que pensar un poco en cuál puede ser el nombre que la empresa habrá seleccionado para asignar a su sitio web. De todas formas no es en absoluto complicado. Aquí tenéis algunos ejemplos: Universidad Politécnica de Valencia = upv, Honda = honda, Banco Bilbao Vizcaya Argentaria = bbva, Telefónica Móviles = telefonicamoviles. (Recordad que nunca pueden haber espacios en blanco en una URL) 4. Finalmente habría que añadir el dominio de la dirección, como por ejemplo los genéricos: .com, .net, .org; los propios de EEUU: .mil, .gov, .edu, etc.; o el que corresponda con el país donde la institución u organización tenga su sede oficial: .es, .fr, .it, .jp, .uk, etc. La elección del dominio a "probar", indiscutiblemente tiene relación con el tipo de empresa al que se refiere. Como ya vimos en el Capítulo 1, el .com es para empresas comerciales, por lo que en nuestro ejemplo no tendría sentido. Tampoco es una empresa de informática o de Internet, por lo que el .net, tampoco es muy probable. Tan solo habría dos posibilidades: .org ó .es. Así pues, { Escribiríamos: http://bne.es ó http://www.bne.es http://bne.org ó http://www.bne.org http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 8 de 22 Finalmente tendríamos tan solo cuatro posibilidades, las cuales pueden ser testadas en unos pocos segundos. La que sea válida, se reconocerá enseguida, por el contenido de la página que se nos abra. Estrategia 2: Directorios Buscar documentos en una base de datos construida por un equipo de editores mejora la calidad de la información de los documentos que pueden encontrarse ... si se encuentra algo. Ya se han comentado los pros y contras de los directorios, es decir calidad vs. cantidad o tamaño. Por tanto, en función del tipo de información que estemos buscando, es posible que sea recomendable utilizar un directorio. Los directorios son útiles para tópicos como: z z z z z z Tópicos generales Eventos de actualidad Productos comerciales Direcciones de organizaciones Sites que se actualicen periódicamente y/o cuyos enlaces funcionen adecuadamente Páginas principales (home pages) En ellos, el usuario puede elegir cómo lleva a cabo la búsqueda. Puede utilizarlos navegando por las categorías o buscando mediante palabras clave. Algunos incorporan ratings de las páginas web almacenadas. El tamaño que alcanza actualmente uno de los directorios más grandes, supera los 4 millones de documentos. Una de las principales ventajas de los buscadores es precisamente el corto número de documentos. Como sabéis “el Objetivo de Toda Búsqueda? es obtener pocos éxitos relevantes”. Los directorios facilitan la parte de los “pocos éxitos” ya que son mucho más pequeños que los buscadores, pero además, al estar seleccionados por expertos, parten con la “presunción” de mayor calidad. Cuando hablamos de “mayor calidad” también nos estamos refiriendo a la mayor o menor credibilidad de la información que aparece en la página. Hasta cierto punto, la credibilidad puede ser uno de los criterios que pueden utilizar los editores de los directorios. Desde luego, no es una opción a poder tener en cuenta por el spider de un buscador. La tercera ventaja es que están ordenados, cosa que no ocurre con los buscadores. Los documentos, en los directorios, están organizados por categorías y podemos navegar por estas para localizar páginas similares o relacionadas entre ellas. Con los buscadores, esto es más difícil. Estrategia 3: Buscadores La tercera estrategia básica reside en utilizar los índices más grandes: los buscadores. Como ya hemos indicado, estos índices incorporan gran cantidad de documentos, superando los 4,000 millones, pero con un sistema de filtro de mucha menor calidad que los directorios. Incluso en alguna ocasión se han detectado millones de documentos repetidos dentro de la misma base de datos, con lo que se falsea el tamaño y se engaña al usuario?. La búsqueda en una base de datos de tan gran cantidad de documentos no es sencilla. Al ser tan grande, la introducción de palabras clave, en ocasiones, no es suficiente para alcanzar el Objetivo de Toda Búsqueda?: obtener un número de éxitos "humanamente aceptable". Por ello, en los interfaces de los buscadores se ofrecen una gran cantidad de restrictores y operadores para limitar los éxitos al máximo. Ejemplos de estos restrictores se vieron en la unidad 3 Altavista. En general, estos motores son útiles para: http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad z z z z Página 9 de 22 Combinaciones de palabras clave. Limitaciones de palabras claves en campos (restrictores). Páginas enterradas profundamente en un site. Temas muy específicos o concretos. Si se realiza una búsqueda mediante DIRECTORIO, los resultado encontrados serán de un número menor que con un buscador, de mayor calidad y mayor credibilidad y mejor ordenación. Verdadero. Falso. Información NO incluida Sea cual sea la estrategia seguida para localizar información en el Web, hay que ser consciente de que no lo vamos a poder encontrar todo. Hay gran cantidad de datos que no son accesibles a través de ningún motor de búsqueda, ya sean directorios, buscadores o metabuscadores. Veamos con detalle qué tipo de información no podréis encontrar en ningún caso: z z Contenidos de sites que requieran una contraseña. Seguro que durante vuestra navegación por la Web, os habéis encontrado con alguna página web que ofrece información de libre acceso y gratuita, pero que exige que os deis de alta, introduciendo vuestros datos para poder acceder a ella. En muchas ocasiones, los datos que introducimos son falsos, pero de todos modos hay que indicarlos para que el servicio nos dé de alta y nos asigne un nombre de usuario (user name) y una contraseña (password). A partir de ese momento y utilizando estas dos palabras clave, podemos disfrutar de toda la información que el site ofrece gratuitamente a sus usuarios. El problema reside en que el spider, que va indexando el contenido en las bases de datos de los buscadores, no sabe rellenar el formulario de datos y no puede obtener un usuario y una contraseña para acceder a toda esa información disponible y incluirla en su base de datos. Por su parte, los directorios tampoco la incorporan porque no suelen profundizar demasiado en el interior de los sites. Además, si la incorporaran, el usuario no podría acceder a la información si antes no se hubiera dado de alta, por lo que desde la base de datos del directorio tampoco se podría saltar a la página donde estuviera disponible la información, sin antes darse de alta en el site en cuestión. Así pues, en general, de toda esta información públicamente accesible, lo único que podemos encontrar, son las páginas principales; aquellas en las que se informa en términos más genéricos sobre qué podemos encontrar dentro de ese site y cómo darse de alta. Un ejemplo de este tipo de site es el portal: http://www.universia.es Datos obtenidos mediante un formulario. CGI output (.asp). Otro problema reside en los sites que disponen de la información almacenada en una base de datos del tipo asp. Este novedoso sistema de ofrecer información al público, y que está teniendo un crecimiento imparable en los últimos años, sufre del mismo problema que el anterior ítem. En este caso, no existen páginas web sino que hay tan solo un marco vacío que va rellenándose de información en función de las palabras clave que los usuarios van introduciendo en un formulario. Es un sistema de "información por demanda". En el momento en que el usuario rellena el formulario con su petición de información, el site rellena el marco con los datos que ha pedido el usuario y construye una página web ad-hoc. Esta página web desaparecerá en el momento en que el usuario cierre la ventana del navegador. Los spiders no saben qué información pedir a la base de datos, en definitiva no saben rellenar el formulario, por lo que no pueden extraer información desde estas bases de datos. Por ello, todos los datos disponibles en estas bases de datos asp, no se pueden encontrar a través de los motores de búsqueda. Tan solo podríamos encontrar las páginas principales donde se explica y presenta el servicio, pero no el contenido de las bases de datos. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad z z z z Página 10 de 22 Un ejemplo de este tipo de site es la base de datos de los cursos de postgrado ofrecidos por la UPV: http://www.cfp.upv.es/oferta/index.html?z=x Hay una excepción. Una búsqueda en una asp se puede traducir a una dirección URL (aunque muy larga y con una estructura irregular), y esta dirección URL que hace referencia a una búsqueda en una base de datos asp puede colocarse como un hiperenlace en cualquier página web. En caso de que ese hiperenlace se encuentre en alguna página web, el spider sí puede seguirlo e indexar el contenido de esa información. Desgraciadamente este caso es lo dicho: una excepción. Un ejemplo de una base de datos en asp que utiliza direcciones largas como las indicadas en la de http://www.amazon.com. Y dentro de este site, el DVD de Animatrix tiene la siguiente dirección: http://www.amazon.com/exec/obidos/tg/detail//B00008LDPU/qid=1053675938/sr=8-2/ref=sr_8_2/002-2311149-6336855? v=glance&s=dvd&n=507846 Intranets o Páginas sin enlaces desde ningún sitio. Aunque se puede pensar que poco "profesionales" hay un alto número de páginas que, por una razón u otra, no están enlazadas desde ningún lugar. Como los spiders van visitando páginas saltando de enlace en enlace, nunca podrán encontrar e indexar estas páginas. Los directorios, tres cuartos de lo mismo. Si no pueden localizar la página para analizarla, no pueden estudiarla e incluirla, si llegara el caso. Sites que utilizan robots.txt para mantenerse fuera de los índices. Por diversas razones, hay sites que no les interesa que su información pueda localizarse por el público global a través de los motores. Estos sites utilizan unos programas que expulsan a los spiders cuando éstos aparecen. Recursos no web. Los motores tan solo incorporan documentos web. La Web, aunque es la subred más grande de Internet, no es la única. Hay gran cantidad de información y datos disponibles públicamente a través de otro tipo de redes. Toda esta información no está disponible a través de los motores web.Todas estas redes paralelas y cómo encontrar información en ellas, se tratará en cursos posteriores: “Localización de Información Específica en Internet”. Formatos específicos. Hemos dicho que los motores de búsqueda indexan "documentos web". ¿Qué son documentos web? Pocos años atrás, no se hacía referencia a documentos web sino a páginas web, y las bases de datos de los motores de búsqueda incorporaban páginas web (extensiones .htm y .html). Pero poco a poco, al ir creciendo la Web, se han ido incorporando muchos otros formatos muy utilizados por los usuarios de Internet o simplemente de un PC, como por ejemplo .doc (documentos del procesador de textos Word de Microsoft), .xls (archivos de hoja de cálculo de Excel de Microsoft), .ppt (documentos de diapositivas de PowerPoint de Microsoft), .rtf (archivo de texto enriquecido), .ps (archivo de Adobe Postscript) y sobre todo .pdf (documento de Adobe Acrobat). Cuando ahora se habla de documento web, se hace referencia a un archivo de cualquiera de los formatos aludidos en el párrafo anterior. Pero no todos los motores de búsqueda permiten localizar todos estos tipos de documentos. Dependiendo de qué motor de búsqueda utilicemos podremos localizarlos o no. Además el número de documentos de estos tipos que se incorporan es mínimo comparado con el número de páginas web. Toda la información que deseemos obtener, está disponible mediante buscadores o directorios: Verdadero. Falso. ¿Qué hace que un motor de búsqueda sea mejor que otro? Introducción http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad OBJETIVO 3 Elegir o descartar un determinado motor de búsqueda en función de si ofrecen o no algunas herramientas que facilitan las búsquedas. Página 11 de 22 A la hora de diferenciar entre las diversas herramientas de que disponemos para buscar información en la Web, cabe destacar tres características que van a definir la mayor o menor calidad de la respuesta del motor a nuestras búsquedas. A continuación se comenta cada una de ellas. Tamaño del Índice de Referencia Hay una tendencia generalizada a pensar que cuanto más grande sea el motor en el que se lancen las búsquedas, mejores resultados se pueden encontrar. ¡Nada más lejos de la realidad! La única ventaja de un índice grande es que va a incorporar más información sobre más temas y es posible, que de esta forma, incremente la probabilidad de encontrar el tema que nosotros necesitamos, pero en absoluto nos asegura este extremo. La primera desventaja reside en que, cuanta más información hay, más hay que filtrar, por lo que nos vemos obligados a introducir más palabras clave que acoten mejor la búsqueda. En definitiva, un índice grande tiene sus ventajas y sus desventajas. En mi opinión, en general las ventajas superan las desventajas pero no a cualquier precio. Hay que tener en cuenta que es fácil encontrar motores o bases de datos más pequeñas que se ajusten mucho más a nuestras necesidades de información y que pueden proporcionarnos más éxitos relevantes que un motor gigante. Ahora, el alumno debe estar preguntándose: ¿Cómo puede ser que un motor de búsqueda con una base de datos mucho más pequeña pueda contener documentos web más ajustados a mis necesidades? Veamos la segunda característica diferenciadora: Criterios para la construcción del Índice de Referencia Tanto los spiders como los equipos de editores de los directorios siguen unos criterios más o menos flexibles a la hora de decidir la incorporación de un documento web a su base de datos. ¡Ahí es donde está la clave! En esos criterios se puede definir cualquier cosa. Se puede hacer que la base de datos se especialice en un determinado tema o que busque un poco de cada cosa. Se puede hacer que se centre en documentos científicos o de divulgación. Se puede conseguir que incorpore únicamente información con menos de 24 horas de antigüedad. Se puede hacer de todo. De esta forma, si lo que nos interesa es, por ejemplo, la investigación científica, podemos buscar motores, portales verticales o webs especializados que se centren en esta temática. Por lo que no es de extrañar que en ellos encontremos más información científica que la disponible en uno de los grandes motores. Un motor especializado en un tema que sea por ejemplo 40 veces más pequeño que Google, todavía tendría un tamaño de 100 millones de documentos… seguro que ni Google, ni Yahoo, ni ninguno de los grandes motores de búsqueda tiene una base de datos de información financiera de 100 millones de documentos web. ¡Es lógico, los grandes han de "contentar" a todos los usuarios, no solo a los interesados en un determinado tema! Ordenación de los éxitos después de la búsqueda En tercer lugar una característica que muchas veces se pasa por alto. Cuando el motor recibe nuestra petición de información y encuentra, pongamos, 76 documentos que contienen todas nuestras palabras clave, se ve en la imposibilidad de mostrárnoslas todas a la vez, porque no lo http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 12 de 22 entenderíamos. El mismo motor ha de decidir cuál de los 76 documentos es el mejor y cuál el peor, aunque, en principio todos son igual de buenos ya que cumplen con los requisitos que nosotros le habíamos exigido. En este punto, un algoritmo se pone en marcha y, teniendo en cuenta diversos criterios, asigna una puntuación a cada uno de los 76 documentos. Posteriormente, nos presentará los documentos empezando por el que ha obtenido una puntuación más alta, siguiendo por el que haya quedado en segundo lugar y así. El problema es que nosotros no podemos controlar ese algoritmo de ordenación. El criterio de "relevancia" que utiliza cada motor es privado y no elegible por el usuario?. Además, se guarda bastante secreto con respecto a cómo funciona el algoritmo de ordenación. La cuestión aquí es: ¿Puede el motor de búsqueda saber qué es lo que estamos buscando? En realidad, las 76 páginas que ha localizado son óptimas según lo que le hemos indicado, no hay "mejores" ni "peores", todas cumplen nuestros requisitos. El motor no puede saber cuál de las 76 páginas es justo la que nos interesa, él nos hace una ordenación tentativa según sus criterios pero, es muy complicado que esos criterios coincidan con los nuestros, al menos de forma consistente. En definitiva, según sea el algoritmo de ordenación de éxitos, puede que encontremos entre los primeros resultados los que nos interesan o puede que no. Pero no lo podemos saber. Hay motores que tienen algoritmos de ordenación que son más afines a los gustos de unos determinados usuarios y otros motores cuyos algoritmos gustan más a otras personas. En este punto, solo podemos probar distintos motores y ver cuál nos presenta los éxitos relevantes, según nuestro propio punto de vista, más cerca de la primera posición. ¡El tamaño NO es (tan) importante! Con las explicaciones del anterior epígrafe se elimina uno de los mayores bulos o leyendas urbanas que rondan por la Red y fuera de la Red y que está relacionada con que un motor es mejor cuanto más grande es su índice de referencia. Hemos visto que el tamaño es una de las tres grandes características a tener en cuenta, pero si solo tenemos en cuenta el tamaño estamos desestimando 2 de las 3 consideraciones relevantes. La importancia que se le concede al tamaño hoy en día, está relacionado con el secretismo que actualmente existe en relación a las otras dos características. Ningún motor da a conocer los algoritmos de selección de las páginas que aplica su spider. Y los criterios de ordenación de éxitos, aunque no tan secretos, parece que tampoco hay excesivo interés en que el público los conozca. Por ello, los buscadores más grandes: Google y Yahoo, incorporan en su página principal el número actualizado de documentos web que, según ellos, incorporan. A nivel operativo, la relevancia del tamaño se puede interpretar de la siguiente forma: ¿encontraremos más información en una base de datos más grande que en otra más pequeña? Depende: z z z Si lo que buscamos es un tópico general, lo más probable es que lo encontremos en cualquier motor. Todos los motores incorporarán información sobre algo poco específico o de relevancia mundial. Si lo que buscamos es un tópico muy particular, cabe la posibilidad de que no lo encontremos, por muy grande que sea el motor, ya que si su spider no incorpora ese tópico como uno de los que ha de considerar, no lo indexará. No hay que olvidar, que por muy grande que sea el tamaño de motor, estará indexando un porcentaje mínimo de la información disponible. Por ejemplo, el día que estoy escribiendo estas líneas (3 de septiembre de 2004), Google anuncia que su índice contiene 4,285,199,774 documentos web. Si comparamos este valor con el resultado de el estudio de Brightplanet, que vamos a utilizar en varias ocasiones a lo largo del curso, los resultados son preocupantes: Tamaño estimado de la Web en el 2000: 550,000,000,000. 4,285,199,774 / 550,000,000,000 = 0.01 = 1% La conclusión es que, aún con el mayor de los motores estamos buscando en el 1% de la información disponible. Y la cosa todavía es peor si tenemos en cuenta que en el mismo estudio se pronosticaba que la velocidad de incremento del denominador era mayor que la del http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 13 de 22 numerador, por lo que si desde el año 2000 el contenido del mayor motor se ha multiplicado aproximadamente por 4, el del numerador debería haberse multiplicado por un número superior a 4, concretamente por 4.44. ¡¡¡Con lo que estaríamos buscando en el 0.0016 = 0.16% de la información disponible!!! Con todo, aunque los motores de búsqueda indexan miles de millones de documentos y ahí tenemos mucho donde buscar; no hay que olvidar que la información pública y accesible gratuitamente puede ascender a billones de documentos. Otros criterios útiles para seleccionar un motor Introducción A parte del tamaño del índice de referencia, que adolece de los problemas antes indicados, existen diversas herramientas ofrecidas por los distintos motores y que pueden hacer que un usuario se incline por un motor u otro. Vamos a ver algunos: Reconocimiento de Keywords o Palabras Clave Algunos motores resaltan las palabras clave utilizadas en la búsqueda, en la página de éxitos o incluso en la página éxito, una vez abierta. Este servicio nos permite localizar rápidamente el lugar donde se aparece la palabra clave indicada y poder leer alrededor de la misma para decidir si nos interesa o no. No tiene ningún sentido el ponerse a leer todo el documento desde el principio. Es mucho más eficiente leer el contexto en el que se utiliza la palabra clave que hemos introducido y si nos interesa entonces dedicar más tiempo, si no nos interesa, pasar a revisar otro éxito. En caso de que un motor de búsqueda no ofrezca este servicio, podemos utilizar la herramienta "Buscar" del mismo navegador, para localizar la palabra en la página. Es un poco más lento, pero igual de efectivo. La herramienta "Buscar", está en el menú "Edición". También se puede acceder a ella con la tecla rápida: "Ctrl. + F". Revisión de Ortografía Los motores que incorporan este servicio ofrecen palabras clave alternativas en aquellas búsquedas que consideran que tienen errores ortográficos en su formulación. Son muy útiles en lenguajes científicos (por ejemplo en medicina o farmacología). En caso de que se detecte un posible error, el motor no deja de lanzar la búsqueda, pero en la página de éxitos ofrece palabras clave alternativas. Si se quieren utilizar, tan solo hay que hacer clic sobre ellas. Filtros de Contenido El más conocido es el filtro "ofensivo". Trata de filtrar resultados que contengan contenido pornográfico o similar. Estos filtros no acaban de funcionar bien del todo y a veces no filtran documentos ofensivos y sí eliminan algunos que no lo son. Selección del Número de Éxitos por Página http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 14 de 22 Esta herramienta nos permite seleccionar el número de éxitos que queremos que se nos presente en cada una de las páginas. Si seleccionamos un número bajo (10-20) tendremos que ir recargando páginas si entre los primeros éxitos no encontramos el que nos interesa. Si seleccionamos un número alto (75-100, >100) la página puede que tarde unas décimas de segundo más en aparecer, pero ya no tendremos que cargar ninguna página más. Esta selección, por tanto, depende tanto de las preferencias personales como de la velocidad de la conexión que uno tenga. Abrir Resultados en una Nueva Ventana Esta herramienta nos permite tener la página de éxitos siempre abierta y que cuando queramos entrar en una determinada página de éxito que no nos desaparezca el listado de éxitos, sino que se abra en otra ventana. Suele ser muy interesante. Selección de Idioma Permite al usuario elegir el idioma del interfaz. Podemos comunicarnos con el motor de búsqueda en inglés, español, francés, etc. Selección del Formato de la Página de Éxitos Con esta herramienta, el usuario pude elegir hasta qué información quiere que aparezca en la página de éxitos, para cada una de las páginas que han resultado en éxito: z z z z z z El título. La URL. El tamaño. La lengua. Un pequeño resumen. ... o cualquier combinación de los anteriores. También se suele permitir al usuario que decida si quiere que aparezcan algunos vínculos como por ejemplo la posibilidad de traducir la página a un idioma o la posibilidad de encontrar páginas relacionadas. Ranking En general, los motores de búsqueda no ofrecen información sobre cómo ordenan los resultados pero, por lo que he averiguado, los criterios de ordenación suelen ser como los que siguen: z z z z Completo. Cuantos más términos de los solicitados contenga la página, más puntuación. En este punto, los términos se refieren a las palabras clave o a sinónimos o derivados que el propio motor contemple como términos relacionados. Evidencia contextual. Cuantas más veces se repitan los términos, más puntuación. Proximidad. No es lo mismo que los términos estén dentro del mismo párrafo o que aparezcan muy distanciados dentro del documento. Por tanto, cuanto más cerca se encuentren, más puntuación. Alta densidad. Cuanto más alto sea el ratio: términos clave / número total de palabras del documento , más puntuación. Existen más criterios de este estilo, pero el sistema en su conjunto adolece de un problema: el http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 15 de 22 usuario no sabe cuáles de ellos tienen un mayor o menor peso en el algoritmo de ordenación final. Por lo que no va a poder seleccionar un motor u otro según este criterio. Las Palabras Clave o Keywords Este punto es de máxima importancia. Diría que es el más importante de todos los que llevamos en el curso. Por ello, os aviso de antemano para que no os lo saltéis y lo leáis con detenimiento y atención. Lo voy a introducir en un cuadro para resaltarlo aún más. Las Palabras Clave o Keywords Por muchos restrictores que sepamos utilizar, por muy bien que elijamos el motor de búsqueda más adecuado al tipo de información que queremos localizar, por muy expertos que seamos en el filtrado de éxitos sin relevancia real, etc. si no sabemos seleccionar las palabras clave más adecuadas para una búsqueda, estamos perdidos. Ante la problemática de una búsqueda, una vez seleccionado el motor más adecuado, lo siguiente es introducir las palabras clave más ajustadas a lo que necesitamos encontrar. A veces, no le dedicamos el tiempo suficiente a reflexionar sobre qué términos serían los mejores, y esto es un fallo imperdonable de consecuencias desastrosas. Estas fatales consecuencias son claras, dos posibilidades: a) encontrar demasiados resultados no demasiado relevantes para lo que a nosotros nos interesa b) no encontrar ningún resultado, o al menos, ninguno que sea relevante. Las palabras clave son DETERMINANTES. Todos los demás conocimientos referentes a funcionamiento de los motores de búsqueda, restrictores, herramientas, etc. que hemos estado estudiando hasta ahora y que continuaremos viendo con detalle en las siguientes unidades no son tan importantes como la capacidad de acertar con las palabras clave que se deciden utilizar. Existen estrategias que ayudan a la selección de las palabras clave. Veamos algunas: Técnica 1. Tecnicismos. Vamos a ver esta estrategia mediante un ejemplo real que surgió durante un seminario: En este seminario, uno de los alumnos estaba interesado en encontrar información sobre motores hidráulicos para un trabajo de clase. No paraba de introducir las palabras "motores hidráulicos" o +motores +hidráulicos, etc. en distintos motores de búsqueda pero los éxitos que encontraba (miles) no eran, ni mucho menos, relevantes para su objetivo. Mi recomendación aludía a que se planteara qué podía estar haciendo mal. Claramente, la información que necesitaba era suficientemente amplia como para poder encontrarla en un buscador genérico… por lo que el motor no era el problema. Las opciones eran dos: a) utilizar algún restrictor que ajustara la búsqueda y b) reformular la búsqueda con otras palabras clave. En ambos casos, se requería que el alumno pensara en nuevos términos clave que introducir ya junto con restrictores o por si solos. El caso es que no había forma de hacer que el alumno en cuestión pensara en otras palabras clave que motor e hidráulico. Finalmente le hice pensar un poco más allá. ¿Qué términos clave o tecnicismos o vocabulario específico debería aparecer necesariamente en ese trabajo sobre motores hidráulicos? O dicho de otra forma: dime el título de alguna de los capítulos o secciones del trabajo, algo sobre lo que el trabajo tiene que tratar necesariamente. La respuesta del alumno, no se hizo esperar: El Ciclo de Carnot. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 16 de 22 Con este nuevo input, y retocando las palabras claves para no utilizar plurales, ni acentos, permitiendo que el motor encuentre motor y motores, así como hidráulico e hidráulicos; plantemos la búsqueda de la siguiente forma: motor hidraulico "ciclo de carnot" ¡Lanzando estas palabras, el primer documento que apareció ya era el trabajo terminado! Otro ejemplo que surgió también durante un seminario. En este caso el seminario se impartía a profesores de la Universidad Politécnica de Valencia. Uno de los profesores estaba interesado en encontrar bibliografía sobre turismo, en general. El pensamiento lineal al que estamos acostumbrados le dictaba que tenía que introducir búsquedas con las palabras: "bibliografía" o "referencias", etc. y "turismo". ¿Qué ocurría? Lo de siempre, no encontraba nada relevante entre los miles de éxitos. Hay que ser un poco más imaginativos y ponerse en la piel del motor de búsqueda. El caso de la bibliografía hay que enfocarlo de forma distinta al anterior. En este caso hay que ponerse en el lugar del motor de búsqueda e intentar pensar como él, o lo que es lo mismo, pensar cómo podemos pedirle la información que queremos, para que nos ofrezca éxitos relevantes. En el caso de la bibliografía, hemos de ser conscientes de que hay diversas formas generalmente aceptadas de escribir una referencia o cita bibliográfica. Por ejemplo: Apellido, I. (Año) Título del libro o documento. Nombre de la Revista o Editorial. Vol., Núm., pp.8 Cuándo se trata de bibliografía científica (como era el caso) este es el modelo más utilizado. A veces el año se coloca hacia el final, el nombre de la revista o editorial en vez de en cursiva va entre comillas etc. pero en esencia es lo mismo. De hecho, lo que a nosotros nos interesa siempre estará: el vol., el num. el pp. aparecerán siempre. Estos acrónimos aparecerán muchas veces en una bibliografía específica y científica y no aparecerán muy a menudo en ningún otro sitio. Por ello, es recomendable utilizarlos junto con el tipo de bibliografía que se quiera encontrar. Por ejemplo: Turismo gandia vol. num. pp. Por descontado que la aplicación de esta estrategia surtió los efectos deseados en el profesor que formuló la pregunta. Técnica 2. Feedback. Hay que saber aprovechar la información que vamos encontrando a medida que vamos examinando los éxitos. Esta información puede ser de mucha utilidad para restringir la búsqueda a resultados más relevantes. Es relativamente sencillo encontrar determinados términos clave que no conocemos antes de iniciar la búsqueda, pero que cuando empezamos a revisar los éxitos, se nos pueden ocurrir o podemos aprender. Es muy recomendable introducirlos como palabras clave. Por ejemplo: queremos encontrar proveedores o importadores de productos textiles en Polonia. Una primera aproximación a esta búsqueda incluiría una restricción por dominio al país en cuestión: .com.pl ó .pl. También es lógico introducir tecnicismos textiles como por ejemplo: textile, upholstery. Por último, como lo que nos interesa es contactar con esas empresas, lo que estamos buscando es información de contacto: teléfono, dirección, fax, correo electrónico, etc., por ello no está de más introducir una palabra clave que aparecerá en la página donde estén estos datos: contact. Así pues, la búsqueda se podría iniciar con .pl textile contact upholstery Pero a poco que empecemos a ojear los éxitos veremos que la contacto en polaco, se http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 17 de 22 escribe: Kontakt, por lo que podemos introducir esta palabra, que antes desconocíamos como término clave: .pl textile contact upholstery kontakt reduciendo de esta manera en gran medida el número de éxitos. Técnica 3. Sites Verticales. En este caso, vamos a utilizar el mismo ejemplo que en el caso anterior. En vez de plantear la estrategia de búsqueda basada en la localización de las páginas de contacto de las empresas, no es difícil darse cuenta que todas esas direcciones deben estar agrupadas en un mismo site que es el de la Cámara de Comercio de Polonia o el equivalente a esta institución. Por ello, podemos iniciar la búsqueda con: chamber commerce poland que, como se puede ver, es una estrategia totalmente diferente de la anterior, para obtener el mismo objetivo. Concluyendo, esta técnica se basa en que los buscadores genéricos sirven para encontrar bases de datos mucho más específicas y concretas sobre el tópico que nos interesa. A partir de ahí, debemos utilizar los buscadores genéricos para encontrar una base de datos (mucho más pequeña, pero...) específica de los datos que nos interesan, por lo que los éxitos serán mucho más relevantes. En definitiva, hay que plantear la búsqueda en general, y en particular, la elección de las palabras clave como un ejercicio de estrategia. En ocasiones, tenemos que seleccionar cuidadosamente tecnicismos clave, en ocasiones tenemos que intentar "pensar" como lo hacen los motores de búsqueda y otras veces, tenemos que buscar bases de datos específicas más ajustadas a los datos que necesitamos. ¡¡A quien le gusten los juegos de estrategia, desde luego, aquí tiene un filón para disfrutar!! Recuerda que ... z Debes saber distinguir los motores de búsqueda entre todos sus tipos. z Debes entender y saber aplicar cuando corresponda las tres estrategias básicas de búsqueda en Internet. z Debes saber cuándo abandonar un motor de búsqueda si no te facilita tu búsqueda, con las herramientas necesarias, etc... z Existen datos que nunca podrás encontrar en la Web; por ejemplo intranets (acceso con contraseña), formatos específicos, recursos no web, etc... z Los documentos que encontramos en un motor de búsqueda cuando lanzamos una consulta, son todos iguales de buenos, es decir, todos contienen los términos clave solicitados. Por lo tanto, la ordenación que ofrece el motor de los éxitos, no considera nuestras preferencias, es artificial y hay que ser cuidadoso con ella. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 18 de 22 Errores más comunes z Existen 3 tipos básicos de motor de búsqueda: buscadores, directorios y metabuscadores. z Debes seleccionar los motores en función de los servicios que ofrecen y cómo (y cuánto) estos servicios, sirven para facilitarte el proceso de búsqueda. z Recuerda que los spiders “no saben” qué información pedir a una base de datos (por ejemplo en formato asp), “no saben” rellenar el formulario de solicitud de información, por lo que no pueden extraer información desde estas bases de datos e incorporarlas al índice z No te limites a seleccionar y utilizar los buscadores por su tamaño, ya que el tamaño no es tan importante. Lo verdaderamente relevante es la calidad del resultado obtenido. z Los filtros de contenido no acaban de funcionar bien y a veces no filtran documentos “ofensivos” pero sí eliminan algunos que no lo son. Aplicación de conocimientos 1. Enumera los distintos tipo de motores de búsqueda que existen y comenta brevemente sus similitudes y diferencias. RESPUESTA 2. ¿Qué permite ver el restrictor cache: de Google? RESPUESTA 3. ¿Qué es un spider? RESPUESTA 4. ¿Cuál es la información que no podremos encontrar en los motores de búsqueda web? RESPUESTA 5. ¿Cuáles son las 3 diferencias que hacen que un buscador sea distinto de otro? RESPUESTA [Imprimir el Cuestrionario Resuelto] Taller Imaginad que queréis venir a visitarme a Alcoy. Alcoy es una ciudad de la provincia de Alicante, situada en el interior, entre montañas y circundada por dos parques naturales. Pero eso vosotros no lo sabéis. Venís, por ejemplo desde… A Coruña y vuestro destino es Alcoy. Queréis encontrar información sobre esta ciudad. Para ello, vamos a poner en práctica las tres estrategias que hemos visto. 1. Probad http://www.alcoy.com, http://www.alcoy.org, etc. a ver si van… http://alcoy.com, http://www.alcoy.net, http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 19 de 22 2. Buscad en un directorio (http://www.dmoz.org) la palabra “alcoy” a ver que tal funciona. Nota: Veréis que cuando el directorio os ofrece los resultados, podéis ver las categorías en donde se encuentran los mismos, por lo que si, en vez de ir directamente a la página, os dirigís primero a la categoría podéis ver un conjunto de páginas estrechamente relacionadas. Este conjunto de posibilidades, probablemente os oriente bastante. 3. Buscad la palabra “alcoy” en algún buscador. A ver qué os ofrece. Las conclusiones más profundas os las dejo a vosotros. Pero, a primera vista, podéis ver que a través del directorio, se nos da una visión general tanto de la Comunidad Valenciana, como de la provincia de Alicante, como de la comarca de L’Alcoià. Con acceso a distintos documentos de interés no solo de Alcoy, sino de su entorno. El buscador nos ofrece otro tipo de datos, como accesos a empresas o entidades alcoyanas. En definitiva, en función de cuál sea nuestro objetivo, habrá que elegir una herramienta u otra. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 20 de 22 SOLUCIÓN AL TALLER Bibliografía No hay mucha bibliografía en castellano que entre en profundidad en este tema en concreto. De todas formas, estos libros puede que ayuden. Mudry, R.J. (1997) Domine la Web. Thomson Paraninfo SA. Peters, T. (2002) La Inevitable Revolución de Internet: Estamos en el Mundo Web. Ediciones Nowtilus S.L. Referencias http://www.google.com http://www.nacion.com http://directory.google.com http://search.msn.com http://www.bne.es http://www.universia.eshttp://www.cfp.upv.es/oferta/index.html?z=x http://www.amazon.com http://www.amazon.com/exec/obidos/tg/detail/-/B00008LDPU/qid=1053675938/sr=8- http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 21 de 22 2/ref=sr_8_2/002-2311149-6336855?v=glance&s=dvd&n=507846 http://www.alcoy.com http://www.dmoz.org Glosario Alta densidad Gran cantidad de información en poco espacio. Asp Microsoft Active Server Pages. Buscador/-es Sitio web donde mediante podemos introducir palabras o frases y encontrar enlaces a nuestra búsqueda en toda la red de redes… Buscador Híbrido permite la utilización de un buscador o de un directorio indiferentemente. Directorio Sitio web que lista otros sitios web organizados por temas. Estratégias Básicas Son los diferentes métodos para poder encontrar información específica en Internet. Evidencia contextual criterios de ordenación; cuantas más veces se repitan los términos, más puntuación. Keywords Son las palabras que introducimos en los motores de búsqueda. Metabuscadores motores de búsqueda en la red que funcionan, por una parte de forma automatizada, pero posteriormente su información es indexada y ordenada con intervención de criterios establecidos por un moderador u organización. Motores Híbridos permiten la utilización de un buscador o de un directorio indiferentemente. Objetividad Describir información o hechos acaecidos tal y cómo han sucedido, sin apoyarse en ninguna postura determinada. Caché Copia que mantiene un ordenador de las páginas web visitadas últimamente de forma que si el usuario vuelve a solicitarlas, las mismas son leídas desde el disco duro sin necesidad de tener que conectarse de nuevo a la red; consiguiéndose así una mejora muy apreciable del tiempo de respuesta. Calidad de la información Consiste en la valoración óptima de los resultados obtenidos en una búsqueda. Categorías Subconjuntos del directorio que intentan agrupar páginas en función de su contenido, para facilitar su localización. CGI output Common Gateway Interface. Programa para generar contenido en tiempo real. Sus lenguajes de programación son, entre otros, Perl y C. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Página 22 de 22 Clasificación Ver ránking. Contraseña Clave secreta que da acceso a un sitio web. Crawlers Robot que indexará varias páginas de una web, siguiendo los enlaces que en ésta aparezcan. Palabras clave Ver keywords. Password Ver Contraseña. Ranking Mera clasificación de resultados determinado. de una búsqueda ordenados siguiendo algún patrón Robots.txt Programas que expulsan a los spiders cuando éstos aparecen. Spider Consiste en un software y miles de servidores que rastrean toda la Internet bajando y guardando todas las páginas que encuentran. Subjects Ver categorías. Tamaño Es la medida de la cantidad de webs que puede encontrar un buscador. Término clave Ver keywords. Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D4ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 12 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 5.- Estrategias de Búsqueda en Web Esquema http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 2 de 12 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 3 de 12 Objetivos de la Unidad Pedagógica Después de estudiar esta unidad, el alumno deberá ser capaz de: 1. Seleccionar la mejor estrategia para cada necesidad de información. 2. Evitar la mayoría de los problemas de los usuarios noveles. 3. Utilizar eficaz y eficientemente las distintas herramientas que los motores ponen a disposición de los usuarios. Introducción La búsqueda en el Web es como una partida de ajedrez: una actividad para estrategas. Los motores nos proporcionan muchas herramientas útiles (piezas) que nos permiten plantear infinitos enfoques para localizar la información que necesitamos (rey). Pero sin una estrategia clara para explotar las herramientas (mover las piezas por el tablero) es fácil NO alcanzar nuestro objetivo. Tienes que adaptarte rápidamente a las circunstancias de tu entorno sino, incluso la mejor estrategia, es inútil” “You have to be fast on your feet and adaptive or else a strategy is useless”. Charles De Gaulle , 1890-1970, Político. BrainyQuote.com A medida que fui aprendiendo a utilizar todas las herramientas disponibles que hay en la Web y, de las cuales, ya tenéis una idea; me di cuenta que la evolución natural del aprendizaje se dirigía a plantear mejores técnicas o estrategias para la limitación de los éxitos a aquellos verdaderamente relevantes. La combinación de herramientas avanzadas de búsqueda y técnicas adecuadas para la selección de términos clave es lo que verdaderamente produce la página de resultados que estamos buscando: un listado corto de documentos altamente relevantes. Los Términos Clave o Keywords [Aquí se ha insertado una animación/vídeo/anexo] Por muchos restrictores que sepamos utilizar; por muy bien que elijamos el motor de búsqueda adecuado al tipo de información que queremos localizar; por muy expertos que seamos en el filtrado de éxitos sin relevancia; etc. si no sabemos seleccionar los términos clave para una búsqueda… estamos perdidos. Ante la problemática de una búsqueda, una vez seleccionado el motor más adecuado, lo siguiente es introducir los términos clave más ajustados a lo que necesitamos encontrar. A veces, no le dedicamos el tiempo suficiente a reflexionar sobre cuáles serían los mejores, y esto http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 4 de 12 es un fallo imperdonable de consecuencias desastrosas. Estas fatales consecuencias son claras. Dos posibilidades: a. encontrar demasiados resultados no demasiado relevantes para lo que nos interesa b. no encontrar ningún resultado o, lo que es peor, ninguno que sea relevante. El efecto negativo más directo de estas dos situaciones, por lo demás muy comunes, es la enorme pérdida de tiempo, pero no es el único: desmoralización del usuario y abandono, serían otros efectos. Los términos clave son DETERMINANTES. Todos los demás conocimientos referentes a funcionamiento de los motores de búsqueda, restrictores, herramientas, etc. que hemos estado estudiando hasta ahora, y que continuaremos viendo con detalle en las siguientes unidades, no son tan importantes como la capacidad de acertar con los términos clave que se deciden utilizar. Existen estrategias que ayudan a la selección de los términos clave. Veamos algunas. Técnica 1. Tecnicismos. OBJETIVO 1 Seleccionar la mejor estrategia para cada necesidad de información. Vamos a ver esta estrategia mediante ejemplos reales surgidos durante los seminarios. Ejemplo 1. En este seminario, uno de los alumnos estaba interesado en encontrar información sobre motores hidráulicos para un trabajo de clase de mecánica. No paraba de introducir las términos “motores hidráulicos” o +motores +hidráulicos, etc. en distintos motores de búsqueda pero los éxitos que encontraba (miles) no eran, ni mucho menos, relevantes para su objetivo. Mi recomendación aludió a que se planteara qué podía estar haciendo mal. Claramente, la información que necesitaba era suficientemente amplia como para poder encontrarla en un buscador genérico… por lo que el motor no era el problema. Las opciones eran dos: a) utilizar algún restrictor que ajustara la búsqueda y b) reformular la búsqueda con otros términos clave. En ambos casos, se requería que el alumno pensara en nuevos términos clave que introducir ya junto con restrictores o por si solos. El caso es que no había forma de hacer que el alumno en cuestión pensara en otros términos clave que motor e hidráulico. Finalmente le hice pensar un poco más. “¿Qué términos clave o tecnicismos o vocabulario específico debería aparecer necesariamente en ese trabajo sobre motores hidráulicos? O dicho de otra forma: dime el título de alguno de los capítulos o secciones del trabajo, algo sobre lo que el trabajo tiene que tratar necesariamente”. La respuesta del alumno, no se hizo esperar: “El Ciclo de Carnot”. Con este nuevo input, y retocando los términos claves para no utilizar plurales (stemming)? , ni tildes, permitiendo que el buscador encuentre motor y motores, así como hidráulico e hidráulicos; planteamos la búsqueda de la siguiente forma: motor hidraulico “ciclo de carnot” ¡Lanzando estas palabras, el primer documento que apareció ya era el trabajo terminado! Ejemplo 2. En este caso el seminario se impartía a profesores de la Universidad Politécnica de Valencia. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 5 de 12 Uno de los participantes estaba interesado en encontrar bibliografía sobre turismo, en general. El pensamiento lineal al que estamos acostumbrados le dictaba que tenía que introducir búsquedas con las palabras: “bibliografía” o “referencias”, etc. y “turismo”. ¿Qué ocurría? Lo de siempre, no encontraba nada relevante entre los miles de éxitos. Hay que ser un poco más imaginativos y ponerse en la piel del motor de búsqueda. El caso de la bibliografía hay que enfocarlo de forma distinta al anterior. En este caso hay que ponerse en el lugar del motor de búsqueda e intentar pensar como él, o lo que es lo mismo, pensar cómo podemos pedirle la información que queremos, para que nos ofrezca éxitos relevantes. En definitiva: pensar qué datos habrá en el documento que estamos buscando e introducírselo al motor para que lo encuentre. En el caso de la bibliografía, tenemos que ser conscientes de que hay diversas formas generalmente aceptadas de escribir una referencia o cita bibliográfica. Por ejemplo: Apellido, I. (Año) Título del libro o documento. Nombre de la Revista o Editorial. Vol., Núm., pp.? Cuándo se trata de bibliografía científica (como era el caso) este es el modelo más utilizado. A veces el año se coloca hacia el final, el nombre de la revista o editorial en vez de en cursiva va entre comillas etc. pero en esencia es lo mismo. De hecho, lo que a nosotros nos interesa es que siempre estarán: el vol., el num. el pp. Estos acrónimos aparecerán muchas veces en una bibliografía específica y científica, y lo que es aún mejor: no aparecerán en ningún otro sitio. Por ello, es recomendable utilizarlos junto con el tipo de bibliografía que se quiera encontrar. Por ejemplo: turismo gandia vol. num. pp. Por descontado que la aplicación de esta estrategia surtió los efectos deseados en el profesor que formuló la pregunta. Técnica 2. Retroalimentación o Feedback Hay que saber aprovechar la información que vamos encontrando a medida que vamos examinando los éxitos. Esta información puede ser de mucha utilidad para restringir la búsqueda a resultados más relevantes. Es relativamente sencillo encontrar determinados términos clave que no conocemos antes de iniciar la búsqueda, pero que cuando empezamos a revisar los éxitos, se nos pueden ocurrir o podemos aprender. Es muy recomendable introducirlos como términos clave. En definitiva: utiliza lo que vas aprendiendo sobre la marcha. Y recordad, cuanto más específico o “raro” sea el nuevo término, más restringirá los resultados y más relevantes serán los éxitos. Por ejemplo: queremos encontrar proveedores o importadores de productos textiles en Polonia. Una primera aproximación a esta búsqueda incluiría una restricción por dominio al país en cuestión: .com.pl ó .pl. También es lógico introducir tecnicismos textiles como por ejemplo: textile, upholstery. Por último, como lo que nos interesa es contactar con esas empresas, lo que estamos buscando es información de contacto: teléfono, dirección, fax, correo electrónico, etc., por ello no está de más introducir una palabra clave que aparecerá en la página donde estén estos datos: contact. Así pues, la búsqueda se podría iniciar con: .pl textile contact upholstery Pero a poco que empecemos a ojear los éxitos veremos que la palabra contacto en polaco, se escribe: Kontakt, por lo que podemos introducir esta palabra, que antes desconocíamos como término clave: .pl textile contact upholstery kontakt http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 6 de 12 reduciendo de esta manera en gran medida el número de éxitos. Técnica 3. Sites Verticales. En este caso, vamos a utilizar el mismo ejemplo que en el caso anterior. En vez de plantear la estrategia de búsqueda basada en la localización de las páginas de contacto de las empresas, no es difícil darse cuenta que todas esas direcciones deben estar agrupadas en un mismo site que es el de la Cámara de Comercio de Polonia o el equivalente a esta institución. Por ello, podemos iniciar la búsqueda con: chamber commerce poland que, como se puede ver, es una estrategia totalmente diferente de la anterior, para obtener el mismo objetivo. Concluyendo, esta técnica se basa en que los buscadores genéricos sirven para encontrar bases de datos mucho más específicas y concretas sobre el tópico que nos interesa. Así pues, según esta técnica, deberíamos utilizar los buscadores genéricos para encontrar una base de datos (mucho más pequeña, pero…) específica de la información que queremos. Y buscar en este “site vertical”. Técnica 4. Los Prismáticos . Como ya sabéis, el objetivo inicial de toda estrategia de búsqueda es encontrar pocos resultados y relevantes. En este sentido, algunos especialistas defienden la técnica de los prismáticos?, es decir, colocar el zoom al máximo y posteriormente, poco a poco, ir reduciéndolo hasta que podemos enfocar y ver bien lo que sea que estamos intentando ver. El mismo enfoque, pero aplicado a la búsqueda en la Web sería: plantear primero una búsqueda muy concreta que ofrezca 0 resultados, y poco a poco ir eliminando términos clave de forma que vayamos obteniendo algún resultado. Según los defensores de esta técnica, “es más sencillo ampliar desde 0 éxitos que reducir desde 96.000 éxitos”. En relación a esta técnica, también es recomendable el utilizar cuantos más términos clave conozcamos, desde un primer momento. Por ejemplo, si estamos buscado un listado de la obra de Picasso, no escirbamos solo “cuadros de picasso”, sino incluid también todos los nombres de las obras que conozcáis, así pues: picasso guernica “el guitarrista ciego” “los tres musicos” cadaques sería una forma mejor de enfocar la búsqueda. La técnica de los prismáticos se basa en plantear primero una búsqueda sin términos clave, e ir introduciéndolos conforme avancemos en la búsqueda: Verdadero. Falso. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 7 de 12 Técnica 5. Reenfoca. Cuando una búsqueda no consigue los resultados esperados, párate a pensar un poco y reenfócala. Cambia los términos clave y utiliza otra estrategia. No confíes siempre en que la primera manera de enfocar una búsqueda va a funcionar. Un ejemplo claro de que esto a veces no funciona lo tenéis en la forma en que trabajan los bibliotecarios. Estos profesionales de la información no buscan una sola vez “perfecta”. Buscan una y otra vez, cercando la “víctima”. Eliminando una restricción cada vez. Primero tratan de ser más restrictivos aquí y menos allí, después intentan lo contrario. No existe “la búsqueda perfecta” pero sí se puede encontrar una buena combinación de búsquedas. Técnica 6. No Utilices la Barra de Desplazamiento. OBJETIVO 2 Evitar la mayoría de los problemas de los usuarios noveles. El objetivo de toda búsqueda es encontrar pocos éxitos, por lo que no es recomendable utilizar la barra de desplazamiento para ver los resultados de una búsqueda, si estos son muchos. Es mucho mejor, refinar la búsqueda introduciendo más términos clave, para que los éxitos sean más relevantes. Una vez elegida una página interesante y que queremos ojear, otra vez lo mismo: no utilizar la barra de desplazamiento para leerla… hay que buscar dónde están nuestros términos clave y leer su contexto para ver si nos interesa o no. Para esto hay diversas posibilidades en función del motor de búsqueda utilizado o software instalado en nuestro PC, pero siempre tendremos la opción de utilizar la herramienta de búsqueda del propio navegador. A esta herramienta se accede con la tecla de acceso directo: “Ctrl.+F”, o desde el menú Edición. Técnica 7. Utiliza SOLO Aquello que Sepas Seguro pero Utiliza TODO lo que Sepas Seguro. Cuando los términos clave de lo que estás buscando se pueden escribir de varias formas, utiliza tan solo los términos clave comunes. Por ejemplo, si queremos un listado de las comunidades autónomas que tienen reconocido el derecho para crear una policía autonómica, podemos asumir que el término “policía autonómica” aparecerá en la página, pero puede que lo que aparezca sea “policía autónoma”. Por lo que únicamente deberíamos utilizar la palabra “policía” y buscar otros términos que necesariamente estén en la página. Por ejemplo añadir aquellas comunidades que sabemos positivamente que sí tienen esta competencia o la palabra “estatuto” que será donde se dotará a la comunidad autónoma de este “derecho”. Por tanto, el enfoque de esta búsqueda sería: estatuto derecho competencia policía cataluña “pais vasco” navarra (No incluyo la “Comunidad Valenciana”, por si acaso lo que aparece es “Valencia”) Anteriormente en este mismo capítulo (Técnica 1.) hemos comentado el stemming. Una de las ventajas del stemming es el poder escribir las palabras en singular y que el motor automáticamente busque tanto los singulares como los plurales. Esto no hay que olvidarlo porque es muy útil, pero antes de ponerse a utilizarlo en un determinado motor hay que averiguar si ese motor dispone del servicio o no. No todos los motores lo tienen. Por ejemplo, recuerdo que durante el verano de 2003, Google todavía no ofrecía este servicio. Actualmente sí lo ofrece. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 8 de 12 Técnica 8. La Utilidad del Restrictor Comillas (“”). OBJETIVO 3 Utilizar eficaz y eficientemente las distintas herramientas que los motores ponen a disposición de los usuarios. Cuando lo que se quiere averiguar es si un determinado texto publicado puede o no estar disponible gratuitamente a través de la Web, la mejor opción es utilizar las comillas. En ocasiones los propios autores u otros usuarios cuelgan el texto completo de un libro o de un artículo científico o de un discurso, etc. en la Web. No hay nada más fácil de encontrar… si está en algún motor. Lo único que hay que hacer es escribir una frase completa, “tal cual” aparece en el texto a localizar. Con puntos, comas y tildes. Esta frase ha de tener, alrededor de 10 palabras. Con esto estaremos limitando el termino de búsqueda a una frase suficientemente larga como para que no haya ningún otro documento en la Web, a parte del libro o artículo buscado, que la tenga. Es muy útil. Personalmente, utilizo esta técnica muy a menudo, debido a mi trabajo como profesor universitario y la necesidad de localizar artículos científicos que generalmente son de pago. Lo que hago es buscar en la Web of Science (http://www.isiwebofknowledge) a la que mi universidad está suscrita, los abstract o resúmenes de los artículos que me interesan y posteriormente, extraigo una larga frase del mismo abstract y la utilizo en los motores genéricos a ver si alguien ha puesto ese artículo online de forma gratuita. El éxito va a depender del área de conocimiento a la que cada especialista pertenezca, en mi caso, diría que funciona al 60%. Técnica 9. Tildes, Mayúsculas, Minúsculas, etc. Ya se ha comentado, pero cabe recalcar que la mayoría de los motores, permiten que se les introduzcan los términos en minúsculas y sin tildes. De esta forma, buscarán estos términos y sus posibles variaciones. Es decir, si escribimos “gandia”, considerarán como éxito todo esto: z z z z z z gandia Gandia Gandía GANDIA gANDÍA GaNdÍa, etc. De la misma forma, en cuanto utilizamos alguna mayúscula o tilde, restringe los resultados a esa única palabra. Así pues, si escribimos “Gandía”, tan solo encontrará “Gandía”. En este sentido, podéis optar por escribir el término clave tal como debe ser o podéis eliminar mayúsculas y tildes para ampliar la búsqueda, en caso de necesitarlo. También es importante comentar que si escribimos el término adecuadamente con tilde, pero el autor del documento web que estamos buscando, no ha sido tan cuidadoso con el lenguaje como nosotros, el documento no nos aparecerá como éxito. Rellene con las palabras adecuadas Una forma de reducir los resultados de la búsqueda introduciendo términos clave adecuados es utilizando la retroalimentación , que utiliza palabras que antes no teníamos en cuenta y que hemos ido observando en los éxitos encontrados, como palabras clave. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 9 de 12 Antes de reenfocar una búsqueda, siempre se debe ver todos los resultados obtenidos por ver si alguno de los encontrados es adecuado a lo que estábamos buscando. Verdadero. Falso. Si escribimos la palabra patín, los resultados que ofrecerá el motor son: patín Respuesta correcta pero incompleta. Patín Respuesta correcta pero incompleta. patin pAtin La 1 y la 2. La 3 y la 4. Conclusión Hay que tener una estrategia para el planteamiento de la búsqueda, y más concretamente, para la elección de los términos clave. En algunas ocasiones, tenemos que seleccionar cuidadosamente “tecnicismos” clave, o tenemos que intentar “pensar” como lo hacen los motores de búsqueda, otras veces tenemos que buscar bases de datos específicas más ajustadas a los datos que necesitamos, etc. En definitiva, ¡¡a quien le gusten los juegos de estrategia, desde luego, aquí tiene un filón para disfrutar!! Recuerda que... z Debes saber seleccionar qué estrategia de búsqueda es la mejor para cada información. z Debes evitar los fallos típicos de los usuarios noveles a la hora de utilizar los buscadores. z Debes saber aplicar las herramientas que nos proporciona cada buscador, de manera que obtengamos como resultado de la búsqueda, la información deseada eficientemente. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 10 de 12 z Si no sabemos seleccionar los términos clave con la mayor exactitud para una búsqueda, por mucho que refinemos con los motores de búsqueda…no encontraremos la información de calidad que esperamos obtener. z El objetivo inicial de toda estrategia de búsqueda es encontrar pocos resultados y relevantes. z La combinación de herramientas avanzadas de búsqueda y técnicas adecuadas para la selección de términos clave es lo que verdaderamente produce la página de resultados que estamos buscando: un listado corto de documentos altamente relevantes. z Cuanto más específico o “raro” sea el nuevo término, más restringirá los resultados y más relevantes serán los éxitos. z Cuando no encuentres los resultados esperados en tu búsqueda, debes saber reenfocar; cambia los términos clave, utiliza otra estrategia, etc. z No es recomendable utilizar la barra de desplazamiento para ver los resultados de una búsqueda, si estos son muchos. Es mucho mejor, refinar la búsqueda introduciendo más términos clave, para que los éxitos sean más relevantes. z Los motores ofrecen muchas y diversas herramientas de búsqueda y selección de éxitos que facilitan nuestra labor. Errores más comunes z Dar siempre los mismos pasos cuando buscamos información diferente. z No invertir el suficiente tiempo a la hora de seleccionar los términos clave más adecuados. z No tener ni siquiera una ligera noción sobre las herramientas que ofrece un motor de búsqueda para facilitar la labor al usuario. Taller Ahora vamos unidad hasta Polonia para venderles los de partida. a llevar una de las búsquedas que hemos utilizado como ejemplo a lo largo de la el final. Queremos encontrar direcciones de contacto de empresas textiles en tantear la posibilidad de importar sus productos a España o, si es posible, nuestros. ¡A ver qué encontráis! Podéis utilizar los ejemplos del texto como punto El resultado que he hallado es un listado de 96 empresas textiles polonesas, con su nombre, dirección, teléfono, fax, teléfono móvil y telex. A ver si encontráis esta página… ¡u otro/s resultado/s mejor/es! Pista: la página que yo he encontrado acaba en .asp (es una base de datos dinámica) por lo que, lo más probable, es que no lo podáis encontrar si solamente utilizáis motores de búsqueda genéricos. Bibliografía http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 11 de 12 Sobre estrategias de búsqueda, no hay demasiado material en castellano, pero sí en inglés. Un listado actualizado lo podéis encontrar en: http://www.searchengineshowdown.com/bib/ Bates, M.E. (1999) Super Searchers Do Business: The Online Secrets of Top Business Researchers. CyberAge Books. Halvorson, T. R. (1999) Law of the Super Searchers: The Online Secrets of Top Legal Researchers. Cyberage Books. Hock. R (2001) Extreme Searcher's Guide to Web Search Engines: A Handbook for the Serious Searcher. Information Today. Paul, N. et. al. (1999) Great Scouts!: CyberGuides for Subject Searching on the Web. Cyberage Books. Schlein, A. M. (1999) Find It Online: The Complete Guide to Online Research. Tempe: Facts on Demand Press. Referencias http://www.isiwebofknowledge http://www.searchengineshowdown.com/bib/ Glosario Barra de desplazamiento Es el elemento de la derecha de la ventana del navegador web; que sirve para desplazarse por toda la página con mayor rapidez que con el cursor. Reenfoca Estrategia de búsqueda de información en Internet. Restrictor comillas Utilidad que sirve para averiguar si un determinado texto publicado puede o no estar disponible gratuitamente a través de la Web. Restrictores Palabras que delimitan una búsqueda por una línea determinada en la red. Retroalimentación ver Feedback. Feedback Estrategia de búsqueda de información en Internet. Stemming buscar singulares o plurales, sinónimos o variantes gramaticales del mismo término clave que nosotros escribimos… sin avisar. Tecnicismos Palabras específicas de un tema determinado. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Página 12 de 12 Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D5ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 24 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 6.- Buscadores Esquema http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 2 de 24 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 3 de 24 Objetivos de la Unidad Pedagógica Después de estudiar esta unidad, el alumno deberá ser capaz de: 1. Distinguir los requisitos que tiene que cumplir un buen buscador. 2. Revisar las principales ventajas e inconvenientes que presentan los buscadores de mayor tamaño. 3. Conocer estudios que muestran la popularidad de los motores. 4. Acceder a un cuadro resumen de Search Engine ShowDown que expone las diferencias más relevantes entre los distintos motores. Introducción Conocida la estrategia de búsqueda, solo nos queda ponerla en práctica sobre el “tablero”. Pero, al contrario de lo que ocurre en el ajedrez, hay muchos tableros distintos. ¿Cómo seleccionar el buscador o tablero sobre el que ejecutar nuestra estrategia? ¿Cuál es el mejor? “Obsessed by a fairy tale, we spend our lives searching for a magic door and a lost kingdom of peace.” “Como obsesionados por un cuento de hadas, pasamos la vida buscando la puerta mágica que nos conduzca al reino de la paz” Eugene O'Neill, 1888-1953, Escritor. OBJETIVO 1 Distinguir los requisitos que tiene que cumplir un buen buscador. ¿Y qué tiene que ver la cita del inicio de esta unidad con la búsqueda de información? Pues bastante. Los alumnos de los seminarios de Localización de Información Específica en Internet, siempre me hacen la misma pregunta: “¿Cuál es el mejor buscador?” Desgraciadamente, esta pregunta no tiene respuesta, porque no es algo objetivo. Si la pregunta fuera “¿cuál es el más grande? o ¿cuál es el más rápido? es posible que sí hubiera una única respuesta, pero “el mejor”… no está claro. Alguien dijo que el mejor buscador es aquél que sabemos manejar con más maestría; en definitiva, es una decisión subjetiva y nuestro “mejor” motor va a ser distinto según quienes seamos, cómo seamos, e incluso según qué busquemos y cómo lo busquemos. Con todo esto en cuenta, sólo puedo “presentaros” los principales buscadores y explicaros una técnica que os permite probar su efectividad, con el objetivo de que seáis vosotros mismos los que elijáis cuáles de ellos os gustan más y cuáles menos. El siguiente punto va a tratar las bases teóricas de esta técnica. A continuación iré revisando cada uno de los principales motores, ordenados de mayor a menor tamaño. Después, mostraré un conjunto de estadísticas relativas a los buscadores: tamaño, velocidad de actualización, utilización, etc. Por último, comentaremos un cuadro resumen que permite comparar las principales herramientas que ofrecen los buscadores analizados. Finalizaremos la unidad con las pertinentes conclusiones. Es necesario recalcar que la mayor parte de la información relativa a los buscadores listados en esta unidad, siempre la podéis encontrar actualizada en http://www.searchengineshowdown.com. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 4 de 24 Técnica para seleccionar los “mejores” Buscadores Introducción Ya he demostrado en una unidad anterior, que el tamaño de un buscador no es determinante para que sea mejor que los demás, aunque es en lo que más se basan los grandes motores para promocionarse?. Entonces, ¿en qué podemos basar la elección de un buscador? Considero que esta decisión ha de centrarse en las herramientas que el propio buscador nos ofrece. Una visión mucho más útil y cercana al usuario. Así pues, esta técnica se basa en estudiar cuatro puntos básicos: 1. Tutorial de Ayuda (Help) En primer lugar, hay que dirigirse a las páginas de ayuda del buscador y ver aspectos como: z z z z Facilidad de acceso a las mismas. Claridad en la exposición. Profundidad de la explicación. Relevancia de los ejemplos. En definitiva, en lo que hay que fijarse es en la calidad del servicio de ayuda. Tenemos que repasar las distintas páginas de este servicio y estudiar en detalle, cómo funciona el buscador. Por ejemplo, qué restrictores y operadores booleanos nos permite utilizar y cómo. El cómo es importante, porque distintos buscadores pueden ofrecer los mismos restrictores y operadores, pero para que funcionen hay que introducirlos de una determinada forma que puede ser distinta en cada motor. Pero, por otra parte, hay restrictores exclusivos de determinados motores. Hay que saber que existen, para poder utilizarlos, si los necesitásemos alguna vez. En otros casos, en lugar de escribir un restrictor, hay que rellenar términos clave en una determinada celda y es el motor, el que se encargará de interpretar que esos términos se quieren buscar en el titulo (title:) o en la dirección del recurso (url:), etc. Cuando veáis el formulario de búsqueda avanzada de cada motor, estos detalles, os quedarán más claros. Cuando os compráis un reproductor de DVD o un equipo estéreo para el coche… ¿no os leéis las instrucciones? Pues esto es igual. Hay que mirar la ayuda porque es el manual de manejo de un motor. 2. Formulario de Búsqueda Avanzada (Advanced Search) En segundo lugar, nos dirigimos a analizar la página de búsqueda avanzada y tenemos que ver qué servicios nos ofrece este formulario. Aspectos a tener en cuenta en este estudio podrían ser: z z z z z z ¿De cuántas formas podemos restringir las búsquedas? ¿Se trata de un cuadro amplio, en donde introducimos términos clave, restrictores y operadores, o por el contrario, es un formulario, en el que vamos rellenando celdas? ¿Permite restricción por: lenguaje, fechas, tipo de archivo (cuáles), lugar del documento, dominio, máquina, etc.? ¿Permite elegir los éxitos que queremos por página? ¿Tiene un filtro de contenido explícito? ¿Permite encontrar páginas relacionadas? http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad z Página 5 de 24 ¿Permite encontrar páginas con enlaces a una en concreto (link:)? z z z ¿Permite limitar a un rango de direcciones IP? ¿Qué otras opciones de restricción ofrece? Y lo que es más importante que todo el listado anterior: z ¿Nos interesan estos servicios o, para la forma en que nosotros vamos a utilizar el motor, son irrelevantes? 3. Capacidades de Personalización (Customize) En tercer lugar, tenemos que averiguar si el motor ofrece opciones de personalización de funcionamiento. Un buen motor de búsqueda ofrece a sus usuarios distintas opciones respecto a su forma de trabajar. Estas opciones suelen estar tras un enlace denominado: personalizar, preferencias, configuración, preferences, custimize, custom, etc. En esta página, el usuario puede decidir algunas o muchas características de funcionamiento del motor. Por ejemplo: z z z z z z z z z El lenguaje del interfaz. El remarcado de las palabras clave (on-off). Las celdas que aparecerán en el formulario de búsqueda avanzada. El tamaño de la letra. Dónde prefieres que se abra la página de éxitos (en la misma ventana, en una nueva, etc.) El catálogo (o base de datos) en el que se va a buscar por defecto. El lenguaje en el que estarán escritas las páginas que se ofrezcan como éxito. Cambiar el color de fondo o aplicar una “piel” al motor. Seleccionar teclas de acceso directo, etc. Dependiendo qué buscador visites, éste ofrecerá un mayor o menor número de opciones de personalización. Como siempre, cuanto más control nos ceda, mejor. Pero también hay que fijarse en si esas opciones nos son relevantes o no. Por último, indicar que las tres páginas visitadas hasta ahora, pueden estar “mezcladas”. Es decir, las opciones que un motor nos ofrece en la personalización, otro nos las ofrece en la búsqueda avanzada. También suele ocurrir que un posible restrictor a utilizar solo se nombre en la ayuda y si no la leemos, no podremos utilizarlo, porque el formulario de búsqueda avanzada no da información sobre él. 4. Búsqueda Específica En cuarto lugar, como ya habréis visto las posibilidades que ofrecen los distintos motores (…si seguís las instrucciones en los tres puntos anteriores…) solo queda probarlos. El objetivo de esta cuarta prueba es comparar los resultados que ofrecen los distintos motores y decidir cuál de ellos ofrece éxitos más relevantes para cada uno de nosotros. Así pues, en este punto lo que tenéis que hacer es plantear una búsqueda específica, concreta, que os interese. Del tema sobre el que trabajáis o sobre el que estudiáis, o algún trabajo o informe que tengáis que presentar en un futuro próximo. Algo que dominéis, de forma que podáis discriminar entre éxitos relevantes e irrelevantes. Pensad en los términos clave, restrictores y operadores que vais a utilizar para esta búsqueda y planteadla exactamente igual en todos y cada uno de los motores que vayamos visitando. Es http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 6 de 24 posible que, al utilizar restrictores, la forma de plantear la búsqueda haya que adaptarla a cada motor. Pero cercioraos que siempre sea la misma búsqueda. En este caso, como el tema lo ponéis vosotros y la relevancia es subjetiva, no puedo orientaros sobre qué es lo que tiene que tener un resultado para ser más interesante o de mayor calidad, en definitiva: mejor que otro. Revisión de Buscadores Introducción En este epígrafe voy a presentaros un listado con los principales buscadores a nivel mundial, ordenados según tamaño. Os daré algunos datos puntuales sobre ellos y vosotros tendréis que dedicarle algún tiempo a cada uno para poder formaros una idea sobre su utilidad aplicada al tema de vuestro interés. Para más información, visitar los reviews en: http://searchengineshowdown.com/features/ Google (http://www.google.com) OBJETIVO 2 Revisar las principales ventajas e inconvenientes que presentan los buscadores de mayor tamaño. Ventajas: z z z Tamaño. Es el más grande e incluye archivos .pdf, .doc, .xls, .ppt, .ps y otros muchos. Liderazgo. Ha sido el referente de innovación en el sector durante los últimos años y continúa mejorando continuamente sus servicios y prestaciones. Relevancia u ordenación. Su sistema de establecer un ranking entre los éxitos está basado en los propios enlaces entre las páginas así como de la autoridad de la página que enlaza. Este es un punto determinante. Creo que este sistema de ordenación ha sido el que ha colocado a Google donde está, como líder indiscutible del sector y, por tanto, requiere de una explicación más detallada: Un documento que resulta éxito en una búsqueda en Google aparecerá más cerca del número 1 en el listado de éxitos cuanto: 1. Más páginas la “recomienden”, es decir, más páginas tengan enlaces a ella. 2. Más importante sea la página que “recomienda”. La página que tiene un enlace a otra (es decir, que está recomendando a otra) puede ser la principal de Microsoft o de Ford. Pero también podría ser la de la panadería de la esquina. Por ello no se da la misma importancia a todos los enlaces o “recomendaciones”. z A partir de estas simples reglas de ordenación, Google se hizo con el mercado de búsquedas en muy poco tiempo, desbancando a los mastodónticos Altavista o Yahoo, hacia finales de los 90. Por aquel entonces Google no era, ni de cerca, el más grande, pero su sistema de ordenación supuso una revolución. Actualmente, todos los motores han imitado este sistema. Caché. El motor da acceso a los documentos que tiene en su base de datos. Cuando el spider llega a un documento, hace una copia del mismo y la remite al buscador. Cuando nosotros hacemos una búsqueda en el motor, éste lo que hace es analizar las copias de documentos remitidas por el spider y nos dice cuántas de esas copias cumplen nuestros requisitos de búsqueda. A partir de ahí, nosotros pinchamos en uno de esos éxitos y http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad z Página 7 de 24 somos remitidos hacia la dirección original del documento, saliendo por completo del site del buscador. Pero también podríamos acceder a la copia que, en este caso Google, tiene del documento, es decir, la copia que remitió el spider y que Google guarda en su base de datos o caché. La utilidad de esta herramienta es diversa: i) acceder a un documento que ya no existe en su ubicación original; ii) acceder a un documento que ha cambiado de dirección o que ha sido modificado en su ubicación original; iii) acceder a un documento que temporalmente es inaccesible en su ubicación original, por cualquier causa (fallo del servidor, no hay luz, no llega la red… etc.). Bases de datos adicionales. Grupos, noticias, directorio, etc. El directorio de Google está basado principalmente sobre el ODP (http://www.dmoz.org), que es un directorio abierto mantenido por voluntarios. Lo estudiaremos en el próximo capítulo. En relación a los grupos y a las noticias, se analizarán con detalle en el segundo volumen de este libro. Inconvenientes: z z z z Restrictores limitados. No permite el anidado (los paréntesis) ni la truncación (el asterisco), además tampoco dispone de todos los booleanos (por ejemplo el NEAR, y el OR funciona solo parcialmente). Restrictor link. Las búsquedas tienen que ser exactas. Indexación parcial. Tan solo indexa los 101Kb primeros de cada página web y los 120Kb primeros de cada .pdf. Stemming. Según se mire este servicio puede ser una ventaja o un inconveniente. Como sabéis, lo que hace es buscar singulares o plurales, sinónimos o variantes gramaticales del mismo término clave que nosotros escribimos… sin avisar. En mi opinión, el que busque el plural del término es una ventaja, pero sinónimos u otras variantes es delicado y puede ser contraproducente en algunos casos. Yahoo (http://search.yahoo.com) Ventajas: z z z z z Tamaño. Es una de los índices más grandes. Novedad. Además es uno de los índices más nuevos. Nació en febrero de 2004. Caché. Permite el acceso al caché de las páginas. Directorio. Incluye entre sus éxitos, los provenientes del directorio de Yahoo. Booleanos. Incorpora la totalidad de los operadores booleanos. Inconvenientes z z z z Truncación. No dispone de truncación. Indexación parcial. Tan solo indexa los primeros 500Kb de una página web. De todas formas, ya es más que Google que indexa tan solo 101Kb. Restrictor link. Requiere la inclusión del “http://” Acepta sites que pagan por aparecen en el listado de éxitos. Teoma (http://www.teoma.com) Ventajas: z z Identifica metasites. Son páginas que contienen gran cantidad de enlaces a otras páginas, generalmente sobre un tema concreto. Normalmente están mantenidas por usuarios independientes. Son como pequeños directorios. Web communities. Dispone de una herramienta de “refinado” (refine) que facilita el filtrado de información. Agrupa documentos y páginas con contenidos similares para http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 8 de 24 facilitar el acceso. Inconvenientes: z z z z Tamaño. Base de datos pequeña, comparada con los dos gigantes. Remisión de URLs. No se puede remitir la dirección de una web para su inclusión en la base de datos, de forma gratuita. Clustering. No permite ver más de dos resultados por site. Normalmente los motores limitan el número de éxitos que ofrecen desde un mismo site. La razón, como ya os expliqué en un capítulo anterior, es que los webmasters o administradores de un site, para que sus páginas aparecieran más en los listados de éxitos de los motores, colocaban varias páginas iguales en el servidor. De esta forma cuando un usuario hacía una búsqueda en un motor, en algunas ocasiones lo que obtenía era un listado de éxitos en donde todas las páginas eran la misma. Esto se solucionó con el límite de dos éxitos por site, de forma que si el administrador hace ese truco, el usuario no se vea perjudicado o piense que ese es el único o mejor documento que existe en relación al tema buscado. Lo que ocurre es que esta limitación de resultados a un solo site, normalmente puede ser eliminada si el usuario quiere ver más documentos de un mismo sitio. Google y Yahoo lo permiten, pero Teoma no. Sin acceso al caché. MSN (http://search.msn.com) Ventajas: z z Limitación de la profundidad de la página. Permite indicar hasta qué nivel de profundidad se quiere buscar el documento: páginas principales, páginas secundarias, páginas a 6 niveles de profundidad, etc. Búsqueda avanzada detallada. Cuenta con todos los operadores y restrictores booleanos comunes. Inconvenientes: z z z Restrictor link. Las búsquedas de este tipo han de ser exactas. Truncación. Su disponibilidad es inconsistente. Caché. No ofrece acceso a caché. Unir (*)Introduzca el Orden del Concepto apropiado Orden Concepto 1 Google 2 3 4 Pareja (*) >>> No ofrece acceso a caché 4 Yahoo >>> Indexa los primeros 500 Kb de una página web 2 Teoma >>> El buscador más grande 1 >>> Dispone de una herramienta de refinado que facilita el filtrado de información 3 Msn http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 9 de 24 Wisenut (http://www.wisenut.com) Ventajas z z Novedad. Es uno de los índices más nuevos y con la política de diferenciar su contenido del resto de los motores. Más adelante, en el epígrafe de estadísticas veremos cómo afecta esta política a nuestras búsquedas. Agrupación de resultados?. Reúne los éxitos en subconjuntos para facilitar la localización de información más relacionada con lo que se busca y el refinamiento de las búsquedas. Inconvenientes z z Caché. No ofrece acceso al caché. Búsqueda avanzada. No dispone de la mayoría de opciones de la búsqueda avanzada de los buscadores. Gigablast (http://www.gigablast.com) Ventajas z z z z z Caché. Ofrece acceso al caché. Información sobre fechas. Indica cuándo se indexó la página y cuándo se modificó por última vez. WayBack Machine(http://www.archive.org). Ofrece enlaces a este servidor de “historia” de páginas web?. Tipos de archivos. Permite la búsqueda de .pdf, .doc y otros tipos de archivos. Web communities. Dispone de una herramienta de “refinado” (refine) que facilita el filtrado de información. Agrupa documentos y páginas con contenidos similares para facilitar el acceso. Inconvenientes z z Tamaño. Base de datos pequeña y lenta en actualizarse. Herramientas. No dispone de truncación, proximidad, y otros servicios de búsqueda avanzada. Rellene con las palabras adecuadas El buscador Hotbot solo muestra pocos éxitos de cada site, sin posibilidad de acceder al resto de documentos del mismo site que han resultado un éxito. Exalead (http://www.exalead.com) Ventajas: z z z Operadores de truncación, proximidad y otros muy avanzados. Incluye “thumbnails” o instantáneas de las páginas. Provee diversas opciones de filtrado en la barra lateral izquierda. Inconvenientes: z La compleja composición de la página puede confundir al usuario. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad z z Página 10 de 24 Base de datos pequeña. Software en versión beta todavía. Cuadro Comparativo A continuación os presento un cuadro comparativo que puede servir para ir fijando las valoraciones subjetivas que consideráis para cada motor. Una tabla similar a esta se utiliza en los seminarios para que los asistentes puedan sistematizar la comparativa. El resultado se puede obtener multiplicando la valoración subjetiva de cada aspecto en cada buscador por la importancia asignada a cada uno (última fila) y posteriormente, sumar el resultado obtenido para cada motor. Eso os dará un “valor resumen” en cada buscador y que podréis comparar unos con otros. La tabla incorpora también los directorios y metabuscadores, que estudiaremos con detalle en los próximos capítulos, pero que se analizan de forma prácticamente idéntica. La tabla de evaluación considera los siguientes aspectos: z z z z z Prueba de Tamaño. Trata de hacer una búsqueda genérica simple para comprar el número de resultados obtenidos. El ejemplo que se propone es buscar la letra “a”. El número de éxitos de esta búsqueda es un indicador válido del tamaño absoluto del índice (o por lo menos relativo, a efectos compartativos). Para el caso de los directorios, hay dos pruebas de tamaño relevantes. La primera es la misma que para los buscadores. La segunda nos sirve para comparar el tamaño de una categoría. En este segundo caso, hay que navegar hasta una categoría de segundo nivel (atravesando dos menús, por ejemplo entrar en “Computers” y después entrar en “Internet” y contar el número de categorías que se encuentran allí). Valoración de relevancia (1). Para rellenar esta columna, primero hay que seguir varios pasos: i) seleccionar un tema que dominemos, que conozcamos; ii) decidir un número máximo de éxitos que queramos revisar; iii) lanzar una búsqueda suficientemente específica, añadiendo tantos términos clave como sean necesarios, hasta obtener un número de éxitos inferior al máximo decidido; iv) revisarlos todos y cada uno de ellos; v) valorar, según vuestro criterio, la calidad o relevancia de los documentos encontrados. Valoración de relevancia (2). En esta ocasión, se trata de hacer lo mismo que en el punto anterior pero utilizando siempre los MISMOS TÉRMINOS CLAVE. Haciendo la misma búsqueda. En este caso es posible que el número de éxitos localizados supere el máximo fijado en el punto anterior. Ahora esto es secundario. Lo importante es utilizar siempre la misma sintaxis exactamente. Obviamente habrá que ajustar la búsqueda a lo que cada motor acepta. Por ejemplo si utilizáis el restrictor “host:” en Altavista, tendréis que rellenar la casilla correspondiente en Google o utilizar el restrictor “site:” que sería lo equivalente. Valoración del ranking. En este caso la búsqueda desarrollada en los dos puntos anteriores es válida. Ahora lo que tenéis que valorar es hasta qué punto los documentos más relevantes están cerca del éxito número 1 o, al contrario, el motor los ha listado más hacia el final. Valoración del menú de preferencias, Búsqueda avanzada y Ayuda. En este punto la existencia o no y la calidad de cada uno de estos servicios que algunos motores ofrecen y otros no, así como a distinto nivel de detalle. Cuadro Comparativo Algunos Estudios Empíricos sobre Buscadores Introducción OBJETIVO 3 Conocer estudios que muestran la popularidad de los motores. Toda la información que a continuación se ofrece está basada en estudios de Greg Notess. Los estudios, sus conclusiones, así como información detallada, se puede encontrar en: http://searchengineshowdown.com/stats/ Tamaño Relativo Este estudio trata de contrastar el tamaño relativo de los motores de búsqueda con el objetivo de poder http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 11 de 24 comparar los tamaños de las distintas bases de datos. El estudio lanza 25 búsquedas simples de una sola palabra. Google se coloca en primera posición ya que ofrece más éxitos que cualquier otro buscador. Además obtuvo más éxitos en 25 de las 25 búsquedas. AllTheWeb y Altavista son los que ahora forman Yahoo, con lo que se puede intuir que Yahoo se colocaría en segundo lugar, aunque a la fecha en que estoy escribiendo estas líneas, el estudio no se ha desarrollado desde que Yahoo lanzó su nuevo motor (de hecho, el estudio que os presento data del 31 de diciembre de 2002). En tercer lugar se afianza Wisenut, por encima del nivel marcado por los motores basados en el índice de Inktomi, es decir, Hotbot y MSN. A continuación, pero muy de cerca, se sitúa Teoma y finalmente, mucho más reducido es el tamaño de Gigablast. Figura 6.4.1: Estudio del tamaño relativo de los diferentes motores de búsqueda. Tamaño Absoluto Basado en el mismo estudio que el anterior ítem, este análisis trata de verificar si el tamaño “anunciado” por los distintos departamentos comerciales de los buscadores es creíble. Se puede observar que, en la fecha del estudio, los motores que parecen anunciar datos realistas son Google, AllTheWeb y WiseNut. En segundo lugar están los motores que parecen reclamar el tener un tamaño que en realidad no parece que exista: los basados en Inktomi: Hotbot y MSN. Por último hay algunos motores que parecen tener más tamaño del que anuncian: Altavista y Gigablast. En mi opinión, este último caso se produce por un error en la política de comunicación de la compañía. Es decir, la empresa mejora su base de datos y la amplía, pero no lanza ninguna noticia a la prensa, comunicando estas mejoras. Buscador Estimación de Showdown (millones) Anunciado (millones) Google 3,033 3,083 AlltheWeb 2,106 2,112 AltaVista 1,689 1,000 WiseNut 1,453 1,500 Hotbot 1,147 3,000 MSN Search 1,018 3,000 Teoma 1,015 500 Gigablast 275 150 Tabla 6.4.1: Veracidad del tamaño anunciado por los distintos motores de búsqueda. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 12 de 24 Actualización Este estudio es algo posterior a los anteriores, data del 17 de mayo de 2003 y nos muestra la velocidad de actualización de las bases de datos de los distintos buscadores. Lo que uno desea es que un buscador se actualice lo antes posible para poder incorporar todos los nuevos documentos que van apareciendo en la Web. También es deseable que los índices mantengan los documentos el máximo tiempo posible, pero este estudio está hecho sobre páginas que requieren actualización diaria por lo que no nos sirve para evaluar este segundo aspecto. Como se observa en la figura 6.4.2, los motores que menos tiempo tardan en actualizar la totalidad de su base de datos son los de Inktomi, Google y AllTheWeb (ahora Yahoo). También es interesante remarcar que Gigablast es el que mantiene más tiempo los documentos, ya que el dato de Altavista está afectado por ruido estadístico al contar con datos atípicos?. Figura 6.4.2: Tiempo que tardan los distintos motores de búsqueda en actualizar la totalidad de sus bases de datos. Las principales conclusiones de este estudio podrían resumirse en tres: z z z La mayoría de los resultados se han indexado en los últimos días. La mayor parte de las bases de datos tienen como mínimo un mes de antigüedad. Algunas páginas no se han re-indexado (actualizado) en mucho más tiempo. Superposición de Bases de Datos Este análisis compara el resultado de cuatro búsquedas simples sobre diez buscadores diferentes. Las cuatro búsquedas localizaron 334 éxitos, 141 de los mismos eran únicos y el resto eran repeticiones de los anteriores. De esos 141 resultados específicos, 71 los encontró un solo motor de entre los diez (no siempre el mismo), mientras que 30 de ellos los encontraron 2 motores. El resto del gráfico se lee en los mismos términos. Así, tan solo hay 2 páginas que están en las 10 bases de datos. Y de todo esto, ¿se puede extraer alguna conclusión interesante y útil? Pues lo cierto es que SÍ, y muy importante: Actualmente NO existe una superposción relevante entre los índices de los distintos buscadores, que haría que la utilización de un solo motor fuese suficiente, ya que en el resto encontraríamos más o menos lo mismo. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 13 de 24 Como se puede ver en la figura 6.4.3, la utilización de un segundo motor de búsqueda para complementar el número de resultados relevantes incrementa el número de éxitos DISTINTOS, hasta un 50%. El utilizar un tercer motor para complementar más éxitos tan solo incrementa los resultados en un 10%. Así pues, a partir de este estudio, la recomendación es clara: cuando utilicéis los buscadores para investigar sobre un tema, tenéis que utilizar DOS herramientas que os ayudarán a complementar los éxitos. Si tan solo utilizáis un buscador, os estaréis dejando el 50% de la Web por explorar. Con dos buscadores ya solo os dejaréis el 25%. Con tres, el incremento marginal es ya muy pequeño como para recomendaros su utilización, de todas formas, es decisión vuestra. Figura 6.4.3: Relación entre número de motores de búsqueda empleados y tanto por ciento de web explorado. Por otro lado, surge la pregunta: y de los 71 éxitos que ha dado un solo motor, ¿cuál ha sido el buscador que más resultados distintos ha ofrecido? Observad la figura 6.4.4. Figura 6.4.4: Resultados distintos ofrecidos por un mismo motor. Se puede ver, claramente, que el motor que más resultados únicos ofrece es Google con 57%. Entre otras razones, esta primera posición de Google viene dada por su mayor tamaño. Es lógico que si la base de datos es más grande, contenga documentos que no estén en las demás bases de datos. Pero sí sorprende que el segundo sea Wisenut y no AllTheWeb o Altavista ya que son los siguientes en tamaño. La explicación a este dato reside en que Wisenut, al ser un motor de más reciente creación (al igual que Teoma) ya nace bajo el predominio de Google y una de sus (pocas) posibilidades de competir, es diferenciar su base de datos, de forma que pueda ser utilizado como complemento a Google. Si su política fuera replicar al líder del sector, ¿quién los utilizaría? Los usuarios no lo gastarían si saben que su índice es un subconjunto de la http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 14 de 24 de Google, así que intentan indexar contenido distinto. Utilización de Buscadores En la dirección http://searchenginewatch.com/reports/index.php, podéis encontrar un amplio listado de estadísticas relacionadas con diversos aspectos de los motores de búsqueda. En este punto voy a resaltar algunos de los contenidos más relevantes. Cuota de Búsquedas Figura 6.4.5: Porcentaje de búsquedas hechas por usuarios estadounidenses en Mayo de 2004. Los datos mostrados en esta figura se refieren a cualquier búsqueda hecha en un buscador del dominio, por ejemplo, en Google están consideradas tanto las búsquedas en el índice web como en el de imágenes. Proveedores de Resultados La figura 6.4.6, muestra las peticiones de búsqueda recibidas por cada motor. Como ya se ha explicado, no todos los motores utilizan su propio índice o base de datos. Algunos subcontratan las búsquedas a otras empresas y muestran los resultados. En esta figura se muestra la distribución según este criterio. Figura 6.4.6: Porcentaje de peticiones de búsqueda recibidas por cada motor. Popularidad de los Motores http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 15 de 24 Tabla 6.4.2: Porcentaje de las visitas a un motor de búsqueda por usuarios estadounidenses durante el mes de abril del 2004. Se puede observar que Google es el motor más popular en EEUU, pero que Yahoo no está a una distancia excesivamente grande. En tercer lugar y tampoco tan alejado se encuentra MSN con la base de datos de Inktomi. Es remarcable que a parte de la búsqueda básica en web, tanto Google como Yahoo, aparecen más veces en el listado con sus buscadores específicos: Google Image Search, Yahoo Directory, Yahoo Yellow Pages, Yahoo Image Search. Nielsen Net Ratings Nielsen Net Ratings es uno de los servicios de análisis de audiencia de Internet más prestigioso. Provee ratings a nivel mundial sobre sitios web basándose en una muestra de 225,000 usuarios en 26 países. Estos usuarios tienen instalados cronómetros en sus computadoras que monitorizan los sites que visitan. Esta información sirve de base para las estadísticas. En la figura 6.4.7 se puede observar el motor utilizado en cada búsqueda por usuarios norteamericanos en Junio de 2004, tanto en casa como en el trabajo. Debido a que un usuario puede utilizar más de un motor para desarrollar su investigación, el resultado combinado supera el 100%. Figura 6.4.7: Motor utilizado en cada búsqueda por usuarios norteamericanos en Junio de 200 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 16 de 24 KEY: GG=Google, YH=Yahoo, MSN=MSN, AOL=AOL, AJ=Ask Jeeves. OVR=Overture, MY=MyWay INF=Information.com, LY=Lycos Networks, WS=WebSearch.com, IS=InfoSpace Networks, NS=Netsca AV=AltaVista, MS=Microsoft.com, HB=HighBeam.com. Para más información, ver http://searchenginewatch.com/links/article.php/2156221 Otra forma de medir la popularidad es computar la cantidad de tiempo que un usuario ha dedicado determinado motor en un periodo dado. La tabla 6.4.3 muestra el tiempo medio por persona invertido por de un determinado motor en junio de 2004. Motor Minutos Google 0:29:57 AOL Search 0:28:28 Netscape 0:13:09 InfoSpace 0:11:41 Yahoo 0:11:04 Web Search 0:08:06 MSN Search 0:07:39 Ask Jeeves 0:06:29 Altavista 0:06:27 My Way Search 0:05:11 Overture 0:03:25 Lycos Network 0:02:53 Microsoft Search 0:02:22 HighBeamResearch 0:01:36 Information.com 0:00:50 Tabla 6.4.3: Tiempo medio por persona invertido por los visitantes de un determinado motor en junio Estadísticas para España Las estadísticas para España, provenientes de la misma fuente que los datos anteriores, son algo sorpr solo no aparece Google en primer lugar, cosa que llama poderosamente la atención, sino que surge un llamado “i Internacional” del que no había oído hablar nunca. El que MSN aparezca en primera posición tiene su explicación. En la mayoría de los sistemas operativ basados en Windows, cuando nos equivocamos al escribir una URL en la barra de direcciones del navega browser nos redirige automáticamente a MSN a buscar el texto que hemos escrito mal. Esto hace que búsquedas en MSN se disparen. Aunque en realidad no hemos hecho una búsqueda voluntariamente e cuenta para las estadísticas. Creo que considerando esas dos puntualizaciones, las estadísticas son creíbles. Motor o Portal Porcentaje MSN 35.6% Google 30.2% Terra Network 20.7% Yahoo! 20.5% Wanadoo 17.9% Ya.com 13.5% http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 17 de 24 Lycos Europe 10.6% eresMas 10.5% i Intenational 9.9% HispaVista 6.3% Tabla 6.4.4: Motor utilizado en cada búsqueda por usuarios españoles en Junio de 2004. Rellene con las palabras adecuadas El buscador que más a menudo se actualiza es el MSN Rellene con las palabras adecuadas El segundo buscador más utilizado es YAHOO Cuadro Resumen OBJETIVO 4 Acceder a un cuadro resumen de Search Engine ShowDown que expone las diferencias más relevantes Este cuadro resumen de buscadores está actualizado a 16 de abril de 2004 y ta obtenido de la página web de Search Engine (http://www.searchengineshowdown.com). Os recomiendo encarecidamente q ya que en ella vais a poder encontrar mucha más información de la que os pued este libro y además, es muy probable que se haya actualizado. La tabla 6.4.5 es completamente interactiva y podéis pinchar sobre cualquier parte de la misma para información sobre ese aspecto. Cuenta con la siguiente información para cada buscador: z z z z z z z z z z Columna 1. Motores. Cuenta con enlaces a las páginas principales de los distintos motores así com detallado y actualizado sobre cada uno de ellos. En este informe se puede ver qué bases de dato motor, qué otros buscadores utilizan las bases de datos del motor analizado, qué información se página de resultados, etc. También cuenta con enlaces a artículos que comentan especificaciones d Incluso podéis encontrar referencias a herramientas ofrecidas por los buscadores, pero que al est pruebas, todavía no se anuncian en la página de “ayuda” del propio motor. Columna 2. Booleanos. Informa sobre cómo pueden conectarse los distintos términos clave que búsqueda. Columna 3. PorDefecto. Informa sobre qué operador booleano se considera cuando el usuario intro términos clave sin escribir ningún nexo entre ellos. Columna 4. Proximidad. Se refiere a la posibilidad de especificar cuán cerca tienen que estar unos t de otros. Columna 5. Truncación. Se refiere a la posibilidad de buscar tan solo una porción de una palabra cla Columna 6. May/Min (Case). Informa sobre la relevancia de escribir los términos clave en m minúsculas. ¿Existe alguna diferencia entre escribir Alcoy, alcoy, ALCOY o aLcoY? Columna 7. Campos. Se refiere a la posibilidad de que el usuario indique dónde quiere que un término clave aparezca, en vez de buscarlo en cualquier parte de la página. Columna 8. Limites. Informa sobre la posibilidad de reducir el número de éxitos, añadiendo algu específica a la búsqueda, como por ejemplo el idioma o la fecha de actualización. Columna 9. Stop. Indica si existen palabras comunes y muy frecuentes que son filtradas de automáticamente. Ejemplos claros son artículos o conjunciones (el, un, de, y, etc.). Columna 10. Ordenación. Informa sobre la manera de ordenar que se puede seleccionar en cada m http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Motores Google Review Página 18 de 24 Booleanos -, OR Por May/ Proximidad Truncación Campos Limites Min Defecto and Frase No, pero sí stemming, palabra en frase No No intitle, inurl, link, site, y más Stop Idioma, Varios, tipo de con + archivo, obligas fecha, a dominio buscar intitle, Idioma, url, site, tipo, inurl, fecha, link, y dominio más Yahoo! Review AND, OR, NOT, ( ), - and Frase No, pero sí palabra en frase Teoma Review -, OR and Frase No No MSNSearch AND, OR, Review NOT, ( ), - and Frase No, pero sí stemming No title, link Idioma, tipo, Algunas fecha HotBot AND, OR, (Inktomi) NOT, ( ), Review and Frase No No title, y más Idioma, Algunas fecha No WiseNut Review - only and Frase No No Gigablast Review AND, OR, AND NOT, ( ),+, - and Frase No No O Si, en frases Idioma, intitle, Si, con dominio, inurl +… fecha Idioma Si, con +… title, Dominio, site, ip, Varios, type y más Tabla 6.4.5: Resumen de características de los diferentes motores de búsqueda. Conclusiones Otro punto importante a la hora de enfocar las búsquedas es la selección del motor. En esta unidad se h un sistema que permite la comparación subjetiva entre las distintas herramientas. NO existe el “mej búsqueda. Cada uno de nosotros va a asignar ese “título” a la herramienta que más le satisfaga en f preferencias respecto a qué servicios ofrece cada motor y cómo los ofrece. Lo que sí podemos hacer es s comparativa siguiendo un mismo método para evaluar los distintos buscadores. Al final de todo el pro seleccionar como mínimo dos motores ya que, como se ha demostrado en los estudios empíricos utilización de un solo motor, nos está limitando el conjunto de oportunidad a un reducido 50%. Mie utilización de 2 motores nos lo incrementa hasta el 75%. Por otra parte, también se observa claramente que el motor más popular es Google seguido de Yaho Altavista y AllTheWeb han sido fusionados en éste). El tercero en esta pugna, MSN, a fecha de hoy preparando su “lanzamiento comercial a lo grande”. En cuanto lo haga, y se supone que ha de ser dura 2004, veremos qué ocurre. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 19 de 24 Recuerda que ... z Escribir el tipo de acceso a una máquina (http://, ) cuando se trata de un servidor web, no es necesario. Si lo es cuando es otro tipo de servidor (ftp://) z No debemos confundir entre tamaño relativo y tamaño absoluto de los buscadores; ya que el tamaño relativo trata de comparar las distintas bases de datos y el tamaño absoluto trata de verificar si el tamaño “anunciado” por los distintos departamentos comerciales de los buscadores es creíble. z No existe el “mejor” motor de búsqueda. Cada uno de nosotros va a asignar ese “título” a la herramienta que más le satisfaga en función de las preferencias respecto a qué servicios ofrece cada motor y cómo los ofrece. z Considerar que en cualquier buscador se va a encontrar la misma información. z Considerar que en un buscador se puede encontrar todo. Errores más comunes z Es muy útil reconocer qué motores de búsqueda, aparte de Google, gozan de popularidad en Internet. z Acceder a Search Engine ShowDown, eventualmente te va a permitir mantenerte actualizado sobre las principales diferencias existentes entre los motores más importantes. z Debes conocer qué ventajas e inconvenientes muestran los buscadores de información en la Web. z Hay que averiguar si el motor de búsqueda ofrece opciones de personalización de funcionamiento. Un buen motor de búsqueda ofrece a sus usuarios distintas opciones respecto a su forma de trabajar, de manera que trabajaremos más cómodamente y obtengamos búsquedas de mayor calidad. Aplicación de conocimientos 1. ¿Cuántos aspectos han de tenerse en cuenta a la hora de seleccionar el motor con el que vamos a trabajar (y por tanto vamos a pasar muchas y muchas horas con él)? ¿Qué aspectos son estos? RESPUESTA 2. ¿Porqué es tan importante el echar un vistazo al documento de “Ayuda” de un motor? RESPUESTA 3. ¿Qué otros términos podemos encontrar en los motores de búsqueda cuando estamos intentando acceder a la página de “ayuda”, a la página de “búsqueda avanzada”, o a la página de “personalización”? RESPUESTA 4. Los motores de búsqueda, cuando indexan una página, ¿la indexan en su totalidad? RESPUESTA http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 20 de 24 5. ¿Para qué puede servir el caché de un motor? RESPUESTA 6. ¿Y el stemming? RESPUESTA 7. ¿Qué son las metasites? RESPUESTA 8. ¿Y el clustering, para qué sirve? RESPUESTA 9. ¿Y qué me puedes decir de la truncación? RESPUESTA 10. ¿En qué motores podría buscar un archivo de Microsoft Word, en castellano y que contuviera una palabra que rimara con Antonio? RESPUESTA 11. ¿En qué motores podría buscar un archivo de Microsoft Word, en castellano y que contuviera la frase “Comunidad Valenciana”? RESPUESTA 12. ¿En qué motor puedo localizar listados de directorios publicados por los propios usuarios de la Red con direcciones sobre la temática buscada? RESPUESTA [Imprimir el Cuestrionario Resuelto] Taller El ejercicio de esta unidad es aplicar los cuatro puntos indicados en la sección “Técnica para Seleccionar los Mejores Buscadores”, en cada uno de los motores listados. Es un trabajo un poco pesado, pero que os va a servir para asimilar las marcadas diferencias entre los distintos motores que, por no usarlos, no las conocemos. Además, os obliga a utilizar herramientas de búsqueda que, si no fuera así, jamás utilizaríais y, ser conscientes así, de lo que os podéis estar perdiendo. Podéis utilizar el Cuadro Comparativo si os facilita el trabajo de síntesis. Cuadro Comparativo Cuadro Comparativo Solución Bibliografía Una vez más, no existe ningún libro que tenga como objetivo prioritario el exponer las diferencias existentes entre los distintos motores de búsqueda y cómo seleccionar el “mejor”. El mejor contenido en este campo está en la web que os he recomendado en varias ocasiones a lo largo del capítulo: http://www.searchengineshowdown.com. De todas formas, voy a listaros un par de libros que comentan diferencias entre motores, aunque no con la misma profundidad: Farb, D. et al (2003) Internet Searches Manual and CD: Computer Skills Development Program on the Use of the Internet for Optimal Searching, With an Emphasis on Healthcare, Pharmaceuticals, and Sales. University of Health Care. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 21 de 24 <>Hock. R (2001) Extreme Searcher's Guide to Web Search Engines: A Handbook for the Serious Searcher. Information Today. (ya recomendado en capítulos anteriores) Tomaiuolo NG. (2004) The Web Library: Building a World Class Personal Library With Free Web Resources. Cyberage Books. (Muy recomendable) También os introduzco algunos libros que se centran en la utilización de Google. Timesaver Books (2003) Google in 30 Pages or Less. Timesaver Books. Referencias http://www.searchengineshowdown.com http://searchengineshowdown.com/features/ http://www.google.com http://www.dmoz.org http://search.yahoo.com http://www.teoma.com http://search.msn.com http://www.hotbot.com http://www.wisenut.com http://www.gigablast.com http://www.archive.org http://searchengineshowdown.com/stats/ http://searchenginewatch.com/reports/index.php http://www.searchengineshowdown.com Glosario Advanced Search Búsqueda avanzada mediante palabras clave o keywords. Son las herramientas que dispone el buscador para hacer una búsqueda más concreta. Agrupación Conjunto (Ver clústering). Altavista AltaVista (motor de búsqueda). Anidado http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 22 de 24 restrictor que se utiliza para dar preferencias a unos operadores o restrictores sobre otros. Normalmente son los paréntesis: () AOL Search America Online (Portal y Motor de búsqueda). Poco popular en Europa. Ask Jeeves Ask Jeeves (motor de búsqueda). Booleanos búsquedas más potentes mediante las herramientas denominadas operadores booleanos que influyen en la forma en el software evalúa tu consulta. Búsqueda avanzada Ver Advanced Search. Caché Copia que mantiene un ordenador de las páginas web visitadas últimamente de forma que si el usuario vuelve a solicitarlas, las mismas son leídas desde el disco duro sin necesidad de tener que conectarse de nuevo a la red; consiguiéndose así una mejora muy apreciable del tiempo de respuesta. Campos Espacio donde se pueden introducir carácteres. Clustering Es la agrupación que realizan los buscadores para no mostar más de un cierto número de páginas de un sitio web para una determinada búsqueda. Custimize ver Personalización. Custom ver Personalización. Directorios Las páginas que se incluyen en la base de datos del directorio son previamente revisadas por una persona, quien observa que se encuadre en la temática y en la política del sitio. No se agrega la página completa, sino únicamente algunos datos tales como el título, la URL y un breve comentario redactado especialmente que explique el contenido, y se la ubica en una categoría. Las consultas se realizan entrando en el árbol de las categorías o mediante palabras clave. En este último caso, el programa busca en la base de datos que la palabra clave anotada por el navegante se encuentre en la URL, en el título o en el comentario. Lycos motor de búsqueda. Metasites Son páginas que contienen gran cantidad de enlaces a otras páginas, generalmente sobre un tema concreto. MSN Microsoft Network (motor de búsqueda y portal) My Way Search Motor de búsqueda. Nielsen Net ratings es uno de los servicios de análisis de audiencia de Internet más prestigioso. Ordenación La “clasificación” que mediante unos patrones toma un buscador al evaluar los resultados tras una búsqueda. Overture Motor de búsqueda. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 23 de 24 Personalización Consiste en la posibilidad de “moldear” un buscador con herramientas que solemos gastar nosotros habitualmente, opciones ya configuradas por nosotros mismos, etc… Personalizar Ver Personalización. Popularidad Propiedad que adquieren los buscadores al ser cuanto más conocidos. Por defecto Se refiere a opciones o supuestos que entiende el ordenador o programa deben estar activadas o no desde un principio. Preferences Ver Personalización. Preferencias Ver Personalización. Profundidad Es la distancia que hay entre una superficie y su fondo. Referido a las webs, consiste en lo “alejada” (cantidad de enlaces a seguir) que se encuentran determinadas webs de la principal. Proveedor Entidad que proporciona y gestiona un enlace físico a Internet. Enlaces Hipervínculo que al hacer clic sobre él, nos lleva a otra dirección web. EresMas Portal de Internet. Actualmente de Wanadoo. Gigablast Motor de búsqueda. Google Google - Motor de búsqueda creado en la universidad de Stanford por Sergey Brin y Larry Page. Actualmente, quien maneja el mayor porcentaje de búsquedas del mercado. Hotbot Motor de búsqueda. Sus resultados son provistos por Inktomi y también funciona como metabuscador. Indexación parcial acción por la que se da de alta un documento en los buscadores pero no de forma completa, sino que tan solo se incorporan los primeros X Kb de información. Information.com Motor de búsqueda. InfoSpace Motor de búsqueda. Inktomi Motor de búsqueda. Refine herramienta que facilita el filtrado de información. Restrictor Link Permite localizar documentos o sites que tengan un enlace a otro determinado por el usuario Restrictores limitados No permite el anidado (los paréntesis) ni la truncación (el asterisco), además tampoco dispone http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Página 24 de 24 de todos los booleanos (por ejemplo el NEAR, y el OR funciona solo parcialmente). Spider Consiste en un software y miles de servidores que rastrean toda la Internet bajando y guardando todas las páginas que encuentran. Stemming buscar singulares o plurales, sinónimos o variantes gramaticales del mismo término clave que nosotros escribimos. Todo automáticamente. Superposición estudio de comparación entre motores de búsqueda que analiza la similitud de sus bases de datos. Tamaño absoluto este análisis trata de verificar si el tamaño “anunciado” por los distintos departamentos comerciales de los buscadores es creíble. Tamaño Relativo contrastar el tamaño relativo de los motores de búsqueda con el objetivo de poder comparar los tamaños de las distintas bases de datos. Teoma Motor de búsqueda. Terra Portal de Internet. Tipos de Archivos Diferentes extensiones de archivos. Truncación El uso de la truncación a la izquierda y a la derecha es útil para obtener resultados generales a partir de los que se puede limitar la búsqueda. La truncación se hace utilizando un signo de asterisco antes y/o después del término o fracción del término, así recuperará los títulos que contengan términos con cualquier carácter o caracteres antes y después que lo que hemos escrito. Wanadoo Wanadoo (motor de búsqueda). Wayback Servidor de “historia” de páginas web. Web Communities Agrupa documentos y páginas con contenidos similares para facilitar el acceso. Wisenut Motor de búsqueda. Ya.com Motor de búsqueda. Yahoo Motor de búsqueda, directorio y portal. Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D6ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 10 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 7.- Directorios Esquema Objetivos de la Unidad Pedagógica Después de estudiar esta unidad, el alumno deberá ser capaz de: 1. Distinguir claramente entre directorio y buscador. 2. Decidir qué tipo de información es factible localizar en un directorio. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 2 de 10 3. Recordar cuáles son los principales directorios y sus URLs. 4. Utilizar detalladamente cada uno de los principales directorios. Introducción Por mucho que nos empeñemos, no podemos olvidar que los buscadores son grandes cantidades de documentos seleccionados por una máquina y sin ordenar. ¿Qué preferís, poco y bueno o mucho y malo? Queramos o no, los directorios son una buena alternativa. “Science is organized knowledge. Wisdom is organized life”. “La ciencia es el conocimiento organizado. La sabiduría es la vida organizada”. Immanuel Kant, 1888-1953, Filósofo. OBJETIVO 1 Distinguir claramente entre directorio y buscador. Llegamos (¡por fin!) a un recurso de información previamente organizado, para facilitar nuestras búsquedas Los directorios son índices organizados del contenido de la Web. Son bases de datos en donde cada una de sus entradas está clasificada e incluso valorada por un equipo de editores. En ocasiones estos editores son voluntarios, como en el caso del ODP (Open Directory Project) y otras veces es el departamento de una corporación, como por ejemplo en Yahoo. Como ya se introdujo en la unidad 4, los directorios son bases de datos con tres puntos diferenciadores respecto a los buscadores: z z z Sistema de selección de páginas. A través de editores en vez de automáticamente mediante un spider. Esto, en teoría, debe dar mayor calidad a la base de datos ya que un equipo de trabajo formado por profesionales es más difícil de “engañar” que un spider. La información que los editores decidan incorporar al índice tiene que ser de calidad, ya que en ello va la “marca de la casa”. Tamaño. Mucho menor que un buscador, los más grandes alcanzan los 4,500.000 de documentos (en verano de 2004). Una de las consecuencias de este punto es que los directorios suelen limitarse a indexar las páginas principales de los sites; dejando fuera cualquier documento que se localice a varios niveles de profundidad. Por ejemplo: http://www.imsersomayores.csic.es/SENIINV/BASIS/seniinv/web/docu2/SF es una página web situada a 7 niveles de profundidad (el número de barras indicadoras de directorios +1), mientras que http://www.upv.es es una página principal o a nivel de profundidad 1. Organización. Todas las páginas están clasificadas en alguna categoría que ordena los documentos según su temática. Al igual que en la unidad anterior, éste va a estar dedicado a presentar los principales directorios con sus ventajas e inconvenientes para que cada uno de vosotros podáis probar su “usabilidad” en las búsquedas que os interesan. La técnica recomendada en la unidad anterior para los buscadores, es de completa aplicación para los directorios. De hecho, en el Cuadro Comparativo al final del punto Revisión de Buscadores de la unidad 6, se incorporan también los directorios de forma que se puedan evaluar junto con los buscadores. A grandes rasgos os percataréis que, en general, los directorios no van a ofrecer una búsqueda avanzada con tanto detalle como los buscadores ya que al contar con bases de datos mucho más reducidas, no requieren de grades despliegues tecnológicos para poder reducir el número de éxitos a un valor “humanamente aceptable”. Los epígrafes de esta unidad van a seguir la línea marcada por los buscadores. A continuación os presentaré cada uno de los principales directorios ordenados de mayor a menor tamaño. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 3 de 10 También os presentaré algunas estadísticas referentes a estos motores. Posteriormente, comentaremos el cuadro resumen de Greg Notess referente a los directorios y que podéis encontrar siempre actualizado en http://www.searchengineshowdown.com. Acabaremos la unidad con algunas conclusiones. Revisión de Directorios Introducción OBJETIVO 2 Decidir qué tipo de información es factible localizar en un directorio. A continuación se listan los principales directorios Web. Al igual que en la anterior unidad, os daré algunos datos sobre ellos y tendréis que dedicar un poco de tiempo a cada uno para familiarizaros con ellos y ver si os pueden ser útiles. Si queréis más información, leeros los reviews disponibles en: http://searchengineshowdown.com/dir/ ODP, Open Directory Project (http://www.dmoz.org) OBJETIVO 3 Recordar cuáles son los principales directorios y sus URLs. Ventajas: z z Actualidad. Es más nuevo que el de Yahoo y parece que se actualiza con mayor rapidez. Gestión. Administrado y mantenido por un amplio número de voluntarios (más de 64,000 en verano de 2004) Inconvenientes: z Calidad Inconsistente. Al estar rodado por voluntarios, éstos parece que suelen alimentar al directorio más de unas secciones o categorías que de otras. Esto es lógico. El perfil del voluntario para colaborar en este directorio es mucho más probable que sea el de un ingeniero técnico en telemática que el de un ingeniero agrónomo, por lo que algunos temas (como el de redes) están mucho más desarrollados que otros (como el de tecnología alimentaria). Yahoo! (http://directory.yahoo.com) Ventajas: z z Popularidad. Uno de los sites más conocidos de la Web con amplio contenido adicional. Portal. Contenido adicional de portal que permite acceso a mucha información general sobre servicios y productos. Inconvenientes: z Actualización. Debido probablemente a que ya no es el buscador por defecto de Yahoo, se ha descuidado la actualización del directorio y, en ocasiones, se encuentra contenido http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad z Página 4 de 10 obsoleto o enlaces muertos?. Comercial. El énfasis de este directorio es comercial ya que se ha desarrollado dentro de una corporación con ánimo de lucro. LookSmart (http://search.looksmart.com) Ventajas: z Partners. Uno de sus partners es Zeal.com, que tiene el mismo objetivo que ODP, pero que cuenta con el mayor número de voluntarios en una plataforma de este tipo (188,000 en verano de 2004) Inconvenientes: z z Búsqueda Avanzada. No ofrece ningún interfaz de búsqueda avanzada. Calidad inconsistente. Por las mismas razones que el ODP. Otros Directorios Adicionalmente a estos tres líderes del sector, también se podrían listar otros que podrían ser considerados como aproximaciones a directorios y que vale la pena conocer: z z z z z z z Librarians Index to the Internet (http://www.lii.org/) InfoMine (http://infomine.ucr.edu/) RDN (http://www.rdn.ac.uk/) About.com (http://www.about.com) World Wide Web Virtual Library (http://vlib.org/Overview.html) Go Guides (http://www.goguides.org/) JoeAnt (http://joeant.com/) El directorio con más popularidad que existe es el ODP, ya que es uno de los más conocidos en la red. Verdadero. Falso. Estadísticas sobre Directorios OBJETIVO 4 Utilizar detalladamente cada uno de los principales directorios En los últimos años, los directorios han ido perdiendo popularidad poco a poco. La irrupción de Google con su sistema de ordenación han apartado a la mayoría de los usuarios de la calidad de los datos almacenados en estas bases. De la misma forma, no parecen haber muchos estudios empíricos sobre utilización de directorios, popularidad, actualización, superposición, etc. La única comparativa que parece que se ha actualizado en los últimos años es la disponible en http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 5 de 10 http://www.geniac.net/odp/, la cual compara la evolución histórica entre Yahoo y el ODP. A continuación os presento dos de los estudios desarrollados por Geniac y presentados en esta URL. En la figura 7.3.1, podéis observar la evolución de ambos directorios desde junio de 1998 hasta junio de 2000. Aunque Yahoo fue creado en febrero de 1994, el primer dato relativo a su tamaño que se conoció está fechado en noviembre de 1997 y en ese momento Yahoo contaba con 730,000 páginas. Por su parte, el ODP se creó el 5 de junio de 1998 y por aquel entonces se llamaba GnuHoo. Poco después pasó a llamarse NewHoo y finalmente el 17 de noviembre de 1998, Netscape adquirió NewHoo y lo bautizó como lo conocemos ahora. El tamaño del ODP en ese momento era de 100,000 documentos y el de Yahoo, de 1,077,709?. A partir de este momento, Yahoo frena su velocidad de crecimiento, y ODP acelera, de tal forma que el 4 de abril de 2000, ODP iguala y supera a Yahoo. En ese momento ambos tenían 1,636,000 documentos. El último estudio que se ha hecho data del 6 de enero de 2004, y podéis ver sus conclusiones en la figura 7.3.2. La escala de tiempos no está clara pero abarca desde la misma fecha que la figura 7.3.1(junio 1998), hasta septiembre de 2005. Se puede observar que el gap existente entre el ODP y Yahoo va a continuar ampliándose con el tiempo aunque a una menor velocidad. Y esto tiene dos causas: Yahoo ha aumentado su velocidad de crecimiento y a la vez, ODP ha ralentizado la suya. Según el mismo estudio, se prevé que ODP alcance los 5 millones de documentos el 28 de abril de 2005 y Yahoo los 3 millones el 17 de septiembre de 2005. Figura 7.3.1: Evolución de los directorios de Yahoo y ODP desde junio de 1998 hasta junio de 2000. Fuente: http://www.geniac.net/odp/ http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 6 de 10 Figura 7.3.2: Evolución de los directorios de Yahoo y ODP desde junio de 1998 hasta enero de 2004. Fuente: http://www.geniac.net/odp/ Cuadro Resumen Este cuadro se ha obtenido, como los anteriores, de la web de Search Engine ShowDown (http://www.searchengineshowdown.com) y os vuelvo a recomendar que la visitéis para obtener una versión actualizada del mismo. Esta versión está fechada a 30 de octubre de 2003 y, como ya os habréis dado cuenta, los tamaños de los directorios están desfasados respecto a la fecha en la que escribo estas líneas (verano 2004). Una vez más, el cuadro es interactivo en lo relacionado a los principales directorios y podéis pinchar en cualquier parte para obtener más información sobre sus detalles?. También cuenta con tres reviews que ofrecen un análisis exhaustivo de cada motor. Además da acceso a los demás motores citados. Cuenta con la siguiente información para cada directorio: z z z z z z z Columna 1. Directorios. En esta columna aparecen los nombres de los principales directorios. Tiene enlaces tanto a sus respectivos sites como a informes de los mismos. En estos informes se pueden ver las bases de datos que son alimentadas en su totalidad o en parte por los resultados de cada directorio, las opciones de búsqueda que permite cada motor, estudios comparativos, sistemas de ordenación, etc. Columna 2. Selección. Indica quién y cómo son seleccionadas las sites para su inclusión. Columna 3. Tamaño. Se refiere al número de entradas únicas en la base de datos. Columna 4. Booleanos. Informa sobre cómo pueden conectarse los distintos términos clave que forman una búsqueda. Columna 5. Truncación. Se refiere a la posibilidad de buscar tan solo una porción de una palabra clave. Columna 6. Campos. Se refiere a la posibilidad de que el usuario indique dónde quiere que un determinado término clave aparezca, en vez de buscarlo en cualquier parte de la página. Columna 7. Ordenación. Informa sobre la manera de ordenar que se pueden seleccionar en cada motor. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 7 de 10 Selección Tamaño Booleanos Truncación Campos Ordenación >59,000 editores >3,800,000 and, or, andnot, +, - Yes, * Ninguno Categorias y sites +, - Automatico, excepto en frase t:title u:url Categorias y Google Stemming automatico Ninguno Sites aleatorios e Inktomi Yes, * Subject, title, author, y más Relevancia, título No Ninguno Relevancia Yes, * Subject, title, author, y más Relevancia Open Directory Review Yahoo Review Remitidas por >3,000,000 los editores LookSmart Automatico Seleccionadas >2,300,000 Review AND InfoMine Académico Bibliotecarios 120,000 and, or, and not, ( ), near4 RDN Selecciones Académicas 30,000? and, OR, - 10,000 and, or, not, ( ) "phrase" Librarians' Bibliotecarios Publicos Index (LII) Tabla 7.4.1: Características de los distintos directorios. http://searchengineshowdown.com/ Conclusiones Cuando uno tiene que utilizar un determinado programa o aplicación en un PC, ya sea un procesador de textos o una hoja de cálculo, la mayoría de las veces nos dejamos llevar por la costumbre más que por la eficiencia. Si uno ya sabe manejar el Microsoft Office, ¿para qué probar con otro Office, por ejemplo el StarOffice, aunque sea una buena alternativa? Esto suele ocurrir para cualquier tarea que llevemos adelante con un ordenador… y la búsqueda de información no es una excepción. La utilización o no de los directorios es una opción personal de cada uno. A algunos les serán útiles y a otros no les gustarán. De todas formas, como ya he comentado en varias ocasiones, hay que ser conscientes de que este tipo de motores tiene algunas características diferenciadoras de los buscadores, sobre todo relacionadas con la calidad de la información y la ordenación de los datos. Por poco que os agraden los directorios, no hay que olvidarlos. En mi caso, puedo aseguraros que según qué búsquedas, son muy útiles ya que eliminan gran cantidad de resultados no relevantes cuando el tema objetivo es adaptable. Pensad que antes de que vosotros buscarais los datos, ya ha habido un equipo de profesionales ordenado el índice. Ahora, cuando el tópico buscado es muy específico, generalmente no son una opción. Recuerda que ... z Debemos saber distinguir entre lo que es un buscador y un directorio. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 8 de 10 z Hay que saber decidir si utilizar un directorio o un buscador para iniciar una búsqueda. z Es útil tener en mente diversos motores de búsqueda para alternar y complementar resultados… z Tienes que practicar para conocer todo lo posible el funcionamiento y relevancia de los distintos directorios y buscadores. Errores más comunes z Confundir buscadores con directorios. z Considerar que tanto los buscadores como los directorios sirven indistintamente para encontrar cualquier tipo de información. z No ser conscientes que según qué se esté buscando, en ocasiones es mejor iniciar la investigación por un directorio y otras veces es mejor empezar por un buscador. z Creer que por que un directorio tan solo contiene una milésima parte de documentos de los que contiene un buscador… ya va a ser peor. Aplicación de conocimientos 1. ¿Cuántos directorios de primera línea existen? RESPUESTA 2. ¿En qué se diferencian las bases de datos de un directorio y de un buscador? RESPUESTA 3. ¿Cuál es el directorio de mayor tamaño? RESPUESTA 4. ¿Qué tipo de búsquedas lanzarías a un directorio antes que a un buscador? RESPUESTA 5. Si quisieras buscar un documento que se titulara: “Hedge Funds”, ¿qué directorio podrías utilizar? RESPUESTA 6. Si lo que quieres es lanzar esta búsqueda: victor OR victoria, ¿qué directorio tendrías que seleccionar? RESPUESTA [Imprimir el Cuestrionario Resuelto] Taller El ejercicio de esta unidad es continuar aplicando los cuatro puntos indicados en la sección “Técnica para Seleccionar los Mejores Buscadores” de la unidad 6. Buscadores. Pero en este http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 9 de 10 caso, utilizando los Directorios. Si seguís el Cuadro 20 dela unidad 6, dispondréis de información relevante no solo para comparar los directorios entre sí, sino para poder comparar éstos con los buscadores y ver hasta qué punto un buscador es mejor o peor que un directorio para cada uno de vosotros. Bibliografía Existen diversidad de libros que explican como utilizar Yahoo. Al ser una potente empresa listada en el SP500, puede permitirse publicar libros de autobombo. De todas formas, son buenos libros relacionados con los directorios y por ello os los indico: Newquist, HP (2002) Yahoo!: The Ultimate Guide to the Internet. I Books. Hill, B (2000) Yahoo! for Dummies. For Dummies. (Este libro no solo trata el directorio de Yahoo, sino que contempla Yahoo como portal de servicios) Referencias http://www.imsersomayores.csic.es/SENIINV/BASIS/seniinv/web/docu2/SF http://www.upv.es http://www.searchengineshowdown.com http://searchengineshowdown.com/dir/ http://www.dmoz.org http://directory.yahoo.com http://search.looksmart.com http://www.lii.org/ http://infomine.ucr.edu/ http://www.rdn.ac.uk/ http://www.about.com http://vlib.org/Overview.html http://www.goguides.org/ http://joeant.com/ http://www.geniac.net/odp/ Glosario http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Página 10 de 10 Calidad Consiste en la valoración óptima de los resultados obtenidos en una búsqueda. Gnuhoo Nombre que recibió ODP a partir del 5 de junio de 1998. Looksmart Directorio web. Newhoo Gnuhoo que pasó a llamarse después Newhoo. Niveles de profundidad Se refiere a la distancia que existe entre un enlace web y su web principal; si está muy escondida, difícil de encontrar, etc… ODP Open Directory Project (directorio). Partners “Compañeros”; se refiere a convenios entre buscadores, empresas colaboradoras entre sí, etc… Tamaño Es la medida de la cantidad de documentos que puede encontrar un motor de búsqueda. Truncación sistema de búsquqeda que permite lanzar consultas indicando tan solo una parte de la palabra clave. Por ejemplo: candid* ofrecería como éxito: candidato, cándido, candidatura candidata, etc. Yahoo Yahoo! (directorio, portal y motor de búsqueda). Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D7ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 21 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 8.- Metabuscadores y Otros Esquema http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 2 de 21 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 3 de 21 Objetivos de la Unidad Pedagógica Después de estudiar esta uinidad, el alumno deberá ser capaz de: 1. 2. 3. 4. Distinguir claramente entre directorio, buscador y ahora, metabuscador. Decidir qué búsquedas de información son más adecuadas para los metabuscadores. Recordar las mejores direcciones de metabuscadores. Distinguir nuevas y/o distintas herramientas de búsqueda que incorporan diferencias en el interfaz de presentación de éxitos. 5. Encontrar diversas bases de datos específicas a través de buscadores de buscadores. 6. Mantenerse actualizado con todas las novedades que vayan aconteciendo el campo de la localización de información. Introducción Si el documento que estamos buscando está en algún motor pero no sabemos en cual… ¿qué hacemos? ¿Revisarlos todos, uno por uno? ¡¡Algo tiene que haber que solucione este problema!! En efecto, los metabuscadores son la respuesta adecuada. “From their experience or from the recorded experience of others (history), men learn only what their passions and their metaphysical prejudices allow them to learn” “De la propia experiencia o de la experiencia adquirida de terceros, el hombre tan solo aprende lo que sus pasiones y sus prejuicios metafísicos le permiten aprender”. Aldous Huxley, 1894-1963, Escritor. OBJETIVO 1 Distinguir claramente entre directorio, buscador y ahora, metabuscador Los metabuscadores son motores de búsqueda sin base de datos propia. Utilizan la de los demás motores ya sean directorios o buscadores. Así pues, a través de estos motores podemos obtener de una sola vez, los éxitos de los que dispone por ejemplo: MSN, LookSmart, Wisenut y ODP. En general, estos motores lanzan la búsqueda a los distintos índices y obtienen los X primeros resultados de cada uno. El valor X, suele ser una variable que el usuario selecciona. Una vez obtenidos, el metabuscador filtra los resultados repetidos en las diferentes bases de datos y aplica un algoritmo propio de ordenación. Con esto, el usuario obtiene un conjunto de resultados más completo que utilizando cada uno de los motores por separado (para esos primeros X éxitos?). Y además utilizando mucho menos tiempo. De hecho, es la única forma eficiente de comparar los resultados de los motores ya que la primera parte, la de hacer la misma búsqueda en varias bases es relativamente sencilla, aunque un poco lenta. Pero la parte de filtrado de éxitos repetidos, es prácticamente inviable “a mano”. OBJETIVO 2 Decidir qué búsquedas de información son más adecuadas para los metabuscadores Uno de los principales problemas de estas herramientas es que normalmente no incorporan las principales bases de datos, por ejemplo las de Google y Yahoo ya que estas compañías no están interesadas en que se acceda a su información sin pasar por su interfaz. Por lo que los metabuscadores pierden efectividad al no poder trabajar con las bases de datos líderes. Selecciona la característica o características de los metabuscadores. Tienen base de datos propia. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 4 de 21 Obtienen resultados más completos y más rápidamente que con los buscadores y directorios. Respuesta correcta pero incompleta. Pueden trabajar con las bases de datos líderes. Realiza un filtrado de resultados. Respuesta correcta pero incompleta. La 1, la 2 y la 3. La respuesta 2 es correcta pero la 1 y la 3 no. La 2 y la 4. Revisión de Metabuscadores Introducción OBJETIVO 3 Recordar las mejores direcciones de metabuscadores. De nuevo voy a listaros los principales metabuscadores que existen, en esta ocasión no hay un cuadro comparativo, pero os daré un pequeño comentario sobre cada uno. Dogpile (http://www.dogpile.com) Este metabuscador es uno de los más antiguos y actualmente es propiedad de InfoSpace como Metacrawler o Excite. Si hacéis una búsqueda en Dogpile, Metacrawler (http://www.metacrawler.com) o Excite (http://www.excite.com) veréis que todos son prácticamente iguales. Actualmente no permite la selección de motores sobre los que lanzar la búsqueda y creo que esto es una desventaja. Utiliza, por tanto, siempre los mismos motores y ofrece los resultados ordenados según de qué motor provienen o por relevancia. Desde hace poco tiempo ofrece también la opción de “refinar” los resultados a través del clustering. Mamma (http://www.mamma.com) También uno de los motores con más años. Aquí sí podemos seleccionar los motores con los que trabajar. Permite refinar el resultado, pero con un sistema menos sofisticado que el de clustering. Tan solo ofrece términos relacionados con los clave y hace la búsqueda con ellos, ni siquiera los añade al ya introducido… en definitiva: manifiestamente mejorable. Por otra parte, informa sobre qué motores han ofrecido cada éxito. Surfwax (http://www.surfwax.com) Este motor es algo distinto de lo habitual. Dispone de algunas mejoras exclusivas que permiten ver las estadísticas de la búsqueda. También se puede acceder a una previsualización de la página elegida en donde se muestra el contexto en el que se encuentran las palabras clave introducidas. Además, y esto sí es una novedad, cuenta con un servicio denominado http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 5 de 21 “FocusWords” en el que se proporcionan sinónimos e ideas para los términos clave introducidos, de forma que se puede consultar en caso de que no se nos ocurra algún sinónimo de los términos utilizados. En la página previsualizada, se ofrece un listado de las palabras que aparecen en el documento y que también están dentro de la base de datos de FocusWords. Toda esta innovación tiene un problema: hace al motor un poco lento. Fazzle (http://www.fazzle.com) Este motor es relativamente nuevo, cuenta con un interfaz de búsqueda avanzada curioso ya que permite elegir entre diversas bases de datos desde locales de Francia o Alemania hasta directorios o buscadores. Ordena los resultados según su propio criterio de relevancia pero informa sobre qué posición ha obtenido cada resultado en las distintas bases de datos consultadas. Cuenta con la posibilidad de abrir las páginas en una pequeña ventana dentro de cada listado de éxitos (lo que en Wisenut se denominaba “Sneek-a-Peek”) y también permite añadir cada éxito a los favoritos. Además informa sobre cuántos documentos se han encontrado en total, cuántos han sido únicos (eliminando los que se han encontrado repetidos en más de un motor) y cuántos se han seleccionado para listar como éxitos. Infonetware (http://www.infonetware.com) Este motor incorpora una tecnología propia de la empresa que lo ha desarrollado. Es interesante ya que facilita el filtrado de resultados en función de los términos clave que seleccionemos. A través de su interfaz, ofrece dos estrategias de búsqueda complementarias (quick view y drill down) que tienen como objetivo la localización de los documentos verdaderamente relevantes para el usuario, superando el problema de la ordenación por relevancia que aplican todos los motores. En la página http://www.infonetware.com/realterm/inw/powerhelp.html explica cómo aplicar estrategias sobre los resultados. En general, las estrategias se basan en un filtrado de los éxitos obtenidos a partir de nuevos términos propuestos por el motor y que se ha detectado que se repiten en los documentos encontrados en la primera batida. El usuario, selecciona cuáles de esos términos adicionales quiere que aparezcan y cuáles quiere que no aparezcan. A partir de ahí reordena los resultados de forma que los que cumplen los requisitos indicados tienen un mejor ranking. El interfaz permite también seleccionar los éxitos interesantes y listarlos posteriormente todos juntos (shortlist), además este listado puede ser remitido por correo. Por último, este motor también informa sobre qué índices han localizado cada éxito y qué ranking obtuvieron en cada uno?. Ithaki (http://www.ithaki.net) Lo más interesante de este motor es que permite búsquedas específicas en países utilizando motores domésticos de cada país. Por ejemplo, cuando seleccionamos España, incorpora Ozú y Sol a los genéricos como Google. Esta es una de las razones del porqué este metabuscador anuncia que busca sus resultados en más de 450 motores. Ixquick (http://www.ixquick.com) Este motor cuenta con diversos motores hispanos como Hispanista o Terra. Además es el único (junto con Ithaki) que incorpora a Google como fuente de resultados. Su sistema de ordenar los éxitos se basa en el ranking de los primeros 10 resultados que ofrece cada motor. Indica con estrellas el número de motores que han clasificado cada documento entre los 10 mejores. También informa qué motor ofrece el éxito y en qué orden. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 6 de 21 Metaeureka (http://www.metaeureka.com) Este metabuscador cuenta con el servicio de refine que ya se ha nombrado anteriormente. Este servicio propone un listado de términos que se han detectado en las páginas de resultados y si se selecciona uno de esos términos, éste se añade al anterior y se hace una búsqueda con ambos o simplemente se repite la búsqueda tan solo con el nuevo término. Es un paso menos que el clustering. El listado de éxitos incorpora un enlace para cada éxito en el que se puede acceder a información relativa al site de donde procede el éxito: servidor, fecha del servidor, ultima modificación, tamaño de la página, título, autor, con qué aplicación se ha programado, descripción, términos clave y número de enlaces a esta página desde Google y desde Altavista. Además también ofrece la información de la base de datos de Alexa sobre la página: enlaces relacionados, estadísticas de la página (ranking de tráfico y enlaces a ella) e información de contacto. Por último, también da acceso a la base de datos de archive.org en donde podemos ver las distintas versiones por las que ha pasado este documento desde el inicio de la Web. Indicar también que este motor dispone de una barra de herramientas? muy completa y que ofrece gran cantidad de herramientas. Vivísimo (http://www.vivisimo.com) Este metabuscador fue uno de los primeros en poner en marcha un servicio de refine basado en el clustering?. La búsqueda avanzada es la más completa. Permite lanzar búsquedas complejas utilizando gran cantidad de restrictotes y/o booleanos. El problema es que aunque vivísimo lo permite, algunos de los motores a los que remite la búsqueda no lo soportan por lo que si nos excedemos en la programación de la búsqueda puede que nos resulten 0 resultados y la explicación que nos dará es: “Open Directory - not queried, query syntax not supported.”; o sea, que la búsqueda remitida al ODP no ha dado ningún resultado porque el ODP no la ha entendido, debido a que se habrán introducido restrictores no utilizados por ese motor. Los éxitos incorporan distintas opciones para abrirlos: nueva ventana, en el mismo frame, preview (como el Sneek-a-Peak). Informa de qué motor ha ofrecido el resultado y en qué orden. Tiene la opción de remarcar en el menú de los clusters aquellos que contienen un determinado éxito, lo cual facilita el encontrar documentos relacionados. Esta posibilidad parece ser un servicio exclusivo de este motor. Además, permite hacer búsquedas de términos clave en los propios nombres de los clusters, y remarca las agrupaciones que contienen el término, así como el lugar donde aparece en cada uno de los éxitos. En definitiva, muchos motores donde elegir, el ejercicio de este capítulo será el probar cada uno de ellos, como hemos estado haciendo hasta ahora con las distintas herramientas de búsqueda. De todas formas, si tenéis poco tiempo os recomendaría que, por lo menos no dejéis de probar Vivísimo e Infonetware. Unir (*)Introduzca el Orden del Concepto apropiado Orden Concepto Pareja (*) 1 Dogpile >>> Facilita el filtrado de resultados en función de los términos clave seleccionados 3 2 Mamma >>> Informa sobre los motores que ofrecen cada éxito, 2 http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 7 de 21 pero es manifiestamente mejorable 3 Infonetware >>> es uno de los metabuscadores más antiguos. Permite seleccionar los motores sobre los que realizar la búsqueda 4 Vivísimo >>> Realiza la búsqueda avanzada más completa 1 4 Rellene con las palabras adecuadas El metabuscacor IXQUICK cuenta con motores hispanos como Terra o Hispania. Barras de Herramientas A lo largo de vuestras pruebas en los distintos motores, necesariamente tenéis que haber “chocado” con algún comentario sobre las barras de herramientas que cada uno de los índices ponen a disposición del usuario. Estas barras de herramientas permiten que podamos lanzar búsquedas simples desde nuestro navegador sin necesidad de visitar la página de motor. Son muy útiles y es recomendable que probéis las barras de los motores que hayáis decidido utilizar. En la figura 8.3.1 podéis ver la barra de Google y la de Yahoo instaladas en un mismo navegador. Como podéis ver, no ocupan demasiado espacio y ahorran mucho tiempo. Decir que incorporan opciones que facilitan la el acceso a la información relevante. Figura 8.3.1: Barras de herramientas de Google y Yahoo instaladas en un mismo navegador. A continuación os listo unas cuantas direcciones de barras de herramientas de motores de búsqueda: z z z z z z z z z z z http://www.altavista.com/toolbar/default. La de Altavista. http://sp.ask.com/docs/toolbar/. La de Ask Jeeves. http://www.dogpile.com/info.dogpl/tbar/. La de Dogpile. http://toolbar.google.com/deskbar/. La de Google que funciona en el propio escritorio, en vez de en el navegador. No necesitas abrir el navegador para buscar información. http://toolbar.google.com/. La de Google normal, del navegador. http://www.hotbot.com/tools/. La de Hotbot. http://sp.ask.com/docs/teoma/toolbar/. La de Teoma. http://companion.yahoo.com/. La de Yahoo. http://www.advancedsearchbar.com/. Da acceso a diversos motores y cuenta con varias aplicaciones incluidas como calculadora, traducción de páginas, etc. http://download.alexa.com/. Ofrece resultados de Google y a la vez busca páginas relacionadas con las que estamos visitando de forma automática. http://www.copernic.com/en/products/meta/. La de Copernic. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad z z z z z z z z z z z Página 8 de 21 http://www.dqsd.net/. Da acceso a varios motores y cuenta con varias aplicaciones incluidas. Además se instala en el escritorio de nuestro ordenador en vez de en el navegador. http://www.frysianfools.com/ggsearch/. Da acceso a varios tipos de búsquedas ofertadas por Google. Incluso más que la barra oficial de Google. http://www.groowe.com/. Da acceso a varios motores además de distintos tipos: web, imágenes, etc. http://googlebar.mozdev.org/. Es la versión de la barra de Google para Netscape. http://www.gophoria.com/. Permite remarcar palabras en la página web que estemos visitando y buscarlas en Google o obtener definiciones o sinónimos. http://gu.st/proj/SearchGoogle.service/. Permite que seleccionando un texto desde cualquier programa, podamos lanzar una búsqueda en Google con esos términos. http://www.metaeureka.com/download.shtml. Gran cantidad de aplicaciones en una sola barra de herramientas. Incluso da acceso a correo. http://www.trellian.com/toolbar/. Es una barra-metabuscador. Permite lanzar búsquedas a distintos motores y obtener 9 resultados de cada uno. http://www.ultrabar.com/. Tiene casi todas las herramientas de la barra de Google pero da acceso a más motores. Además permite que nosotros podamos indicarle cuáles. http://vivisimo.com/toolbar/toolbar-download.html. La barra de vivísimo. http://vivisimo.com/toolbar/minibar-download.html. Una versión reducida de la barra de vivísimo para que pueda caber incluso si tenemos ya varias instaladas y no nos quite espacio. Otros Tipos de Motores de Búsqueda Conocimientos OBJETIVO 4 Distinguir nuevas y/o distintas herramientas de búsqueda que incorporan diferencias en el interfaz de presentación de éxitos. Todas las herramientas de búsqueda en la Red que encontréis a lo largo de vuestra “navegación” han de pertenecer a alguno de los tipos estudiados: buscadores, directorios o metabuscadores. Es posible que encontréis algún motor que, a primera vista no esté claro lo que puede ser. Pero a poco que lo utilicéis os daréis cuenta, por ejemplo, haciendo una búsqueda genérica, si el numero de resultados está más cerca de un directorio que de un buscador, pues… ya lo sabéis. Ahora bien, no todos los motores son tan “cuadrados” como los que hemos visto hasta ahora. Algunos incorporan sistemas distintos no ya en cómo buscar la información, sino en cómo presentarla al usuario o en cómo interactuar con el usuario. Estos motores suelen basarse en alguno de los índices que ya hemos visto, pero el interfaz funciona de una forma completamente distinta y es útil para poder sacar algunas conclusiones que con el clásico listado de éxitos, con su título, resumen, url, etc. no son extraíbles. A continuación os presento algunos proyectos que tratan de ofrecer nuevos puntos de vista al usuario y así, ser complementarios a los motores clásicos. Kartoo (http://www.kartoo.com) Kartoo es un metabuscador… aunque a primera vista no lo parezca. Su principal diferencia con los clásicos reside en el mapa que utiliza para presentar la página de éxitos. A cada uno de los resultados, en función de diversos aspectos les asigna un icono que tiene un significado. Además, sitúa términos clave entre los éxitos y si colocamos el ratón sobre estos términos, nos relaciona en qué documentos aparecen. Estos términos es una derivación del renombrado refine que se utiliza en otros motores, aunque presentado a través del interfaz de Kartoo que nos da nuevas posibilidades. Para ver el clásico resumen de la página, tan solo hay que colocar el ratón sobre el icono correspondiente y aparecerá. También informa sobre los motores que han ofrecido cada http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 9 de 21 resultado aunque no el puesto en el que aparecía. Kartoo no incorpora a Google, pero sí a Yahoo. El mapa puede ser guardado, remitido por correo, etc. Touchgraph (http://www.touchgraph.com/tggooglebrowser.html) Este proyecto permite graficar las páginas relacionadas a partir de una URL por ejemplo “www.upv.es”. Ver figura 8.4.1. Figura 8.4.1: Formas de representar los resultados de una búsqueda. Izq. Touchgraph, Dcha. Clásica. En la figura 8.4.1 se puede apreciar la gran diferencia que existe entre la forma clásica de presentar los resultados de una búsqueda y la alternativa propuesta, en este caso, por TouchGraph. Como es de suponer, la opción alternativa no será siempre la más útil, pero algunos usuarios, para ciertas búsquedas o para cierto punto de vista, preferirán el modo esquemático que el listado. Amazon, la gran librería, ya está probando esta tecnología para incorporarla a su Web y permite hacer búsquedas de libros, DVDs y música. Podéis ver este servicio en:http://www.pmbrowser.info/amazon.html. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 10 de 21 Figura 8.4.2: Representación de resultados de búsqueda en Amazon empleando la técnica de TouchGraph. Existen muchos otros motores que tratan de crear nuevos interfaces para facilitar al usuario la localización de los documentos relevantes entre los éxitos encontrados?. Además esta área está creciendo rápidamente y en el medio plazo puede que además de seleccionar motor de búsqueda podamos seleccionar incluso el tipo de interfaz que prefiramos. Motores Específicos Espero que, a estas alturas, tengáis claro que el buscar información en los motores genéricos es recomendable, si uno dedica un poco de tiempo a investigar cómo funciona. A partir de ahí, tan solo tenemos que seleccionar los que más nos gusten y utilizar alguno de ellos en función de la información que queramos encontrar. Lo que no es recomendable en absoluto es buscar información TAN SOLO en los motores genéricos. Hay que tener siempre en cuenta la Técnica 3: “Sites Verticales” que vimos en la unidad 5: “Estrategias de Búsqueda en Web”. Para refrescaros un poco la memoria y como es muy importante os la voy a repetir aquí: a modo de introducción os recuerdo que el ejercicio trataba de encontrar direcciones, teléfonos, emails de contacto con empresas textiles polacas que estuvieran interesadas en importar o exportar material a o desde España. Técnica 3. Sites Verticales. En este caso, vamos a utilizar el mismo ejemplo que en el caso anterior. En vez de plantear la estrategia de búsqueda basada en la localización de las páginas de contacto de las empresas, no es difícil darse cuenta que todas esas direcciones deben estar agrupadas en un mismo site que es el de la Cámara de Comercio de Polonia o el equivalente a esta institución. Por ello, podemos iniciar la búsqueda con: chamber commerce poland http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 11 de 21 que, como se puede ver, es una estrategia totalmente diferente de la anterior, para obtener el mismo objetivo. Concluyendo, esta técnica se basa en que los buscadores genéricos sirven para encontrar bases de datos mucho más específicas y concretas sobre el tópico que nos interesa. Así pues, según esta técnica, deberíamos utilizar los buscadores genéricos para encontrar una base de datos (mucho más pequeña, pero…) específica de la información que queremos. Y buscar en este “site vertical”. Con esta técnica estaremos ampliando el abanico de documentos que podemos encontrar desde un 0.16% (utilizando tan solo un buscador genérico) hasta un 54% (buscando una base de datos específica y utilizándola). Estas cifras se refieren a un estudio desarrollado en el año 2003 y que concluye que el 54% del tamaño de la Web está formado por bases de datos específicas o sites verticales… frente al 0.18% que supone el contenido de Google. De ahí la gran importancia, en muchos casos de que uno no se ponga a buscar la información que requiere, sino que busque el PROVEEDOR de esa información (en nuestro ejemplo, la cámara de comercio) ya que siguiendo este sistema, podemos encontrar mucho más contenido. Es por esto que a continuación os voy a listar ejemplos de bases de datos específicas que existen, no para que vengáis a estas páginas cuando necesitéis algo… ¡¡sino para que veáis que hay motores específicos de prácticamente casi todo!! Por ello, os voy a listar un conjunto de bases de datos no convencionales. Así pues, si necesitáis algún dato, no desistáis si no lo encontráis en los motores genéricos, pensad quién puede tener ese dato y buscadlo a él. Una vez encontréis el proveedor, buscad directamente en su Web. ¡No falla! Lo dicho, ejemplos de motores específicos: De artículos científicos. http://www.findarticles.com, http://www.scirus.com, http://repec.org. De citas literarias. http://www.quotationspage.com (el que he utilizado para las citas que aparecen al principio de cada capítulo). De subastas. http://www.ebay.com, http://www.eurobid.com. En estos sites es donde habitualmente se venden los objetos personales de personalidades conocidas que saltan a la palestra por alguna razón. Cuando en el “Telediario” comentan que… “en Internet ya se están vendiendo…” pues se refieren a estos sites. De productos. http://www.pricegrabber.com, http://www.shopping.com, http://www.addall.com. Estas páginas permiten comparar precios de distintas tiendas para el mismo producto. Interesante cuando tenemos que comprar algo. Addall es de libros y os lo recomiendo. De series estadísticas. http://www.ine.es, http://www.ssb.no/english/links/main.shtml. De empleo. http://www.monster.com, http://www.global-work.com. http://www.statistics.gov.uk, http://www.infojobs.net, http://www.jobline.es, De extensiones de archivos. http://www.filext.com, http://www.techadvice.com/specs/searchfile-ext.asp. De tipos de letra. http://www.smackbomb.com/famousfonts, http://www.1001freefonts.com. De Audio. http://www.lib.berkeley.edu/MRC/audiofiles.html, http://speechbot.research.compaq.com. De Imágenes. http://www.corbis.com, http://www.maptech.com/mapserver/index.cfm. http://www.CEOlive.com, http://www.desktopia.com, http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 12 de 21 De vídeo. http://www.movieflix.com, http://www.studentreel.com, http://www.recordtv.com. Generalmente los grandes buscadores incorporan su propio motor de imágenes, noticias, productos, etc. Y la verdad es que funcionan bastante bien, de todas formas, lo que aquí os enlazo, no tiene desperdicio. De Webcams. http://www.comfm.fr/webcam, http://www.earthcam.com. ¿Queréis poder ver a tiempo real (o con muy poco retraso) lo que está ocurriendo en distintos puntos del mundo? Pues para eso están las webcams. Aquí tenéis índices de ellas que os permiten ver instantáneas desde la Plaza del Obradoiro hasta la Zona 0 de Nueva York, pasando por la Plaza Roja de Moscú. De shareware y freeware. http://tucows.ua.es, http://www.shareware.com, http://www.windrivers.com. http://www.download.com, ¿Alguna vez habéis tenido que hacer alguna labor repetitiva y habéis pensado… “ojalá hubiera un programita que hiciera esto”? O, necesitabais una aplicación para abrir un determinado archivo (como un .zip o un .rar), o queríais buscar un programa que gestionase mejor la tarjeta gráfica, etc. Pues bien, existen bases de datos de programas en donde podéis buscar la aplicación que mejor cumpla vuestras necesidades. Estos programas pueden ser de tres tipos diferentes: z z z Shareware. Este tipo de aplicaciones funcionan en nuestro equipo, normalmente durante 30 días, al cabo de los cuales, nos indican que si queremos continuar utilizándolas, debemos registrar nuestra copia pagando alrededor de 20-30€. En otras ocasiones, la aplicación funciona solo parcialmente hasta que la registremos (es lo que se llama un programa “capado”). Adware. Este tipo de programas funciona perfectamente pero nos muestra banners con publicidad de forma continuada. Si queremos evitar este bombardeo tenemos que registrarnos. Otra vez 20-30€. Freeware. En este caso las aplicaciones sí que son gratuitas desde el primer día y para siempre. Además los programas funcionan al 100%. Es posible que el autor nos indique que acepta donaciones por su trabajo, pero no nos obliga a pagar. De parches. http://astalavista.box.sk. De la misma forma que hay buscadores de software, también existen buscadores de parches que rompen la seguridad de esos programas shareware y adware. Utilizando estos parches o cracks, se puede utilizar el programa descargado sin tener que pagar la licencia. Obviamente esto está prohibido en la mayoría de los países desarrollados, pero algunos no opinan igual. Ver Cuadro 33. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 13 de 21 Figura 8.5.1: Página de Cracks.am en la que se pueden encontrar parches o cracks. Fuente: http://www.cracks.am Existen programas específicos que para realizar labores repetitivas, o aplicaciones para abrir un determinado archivo… Cuál o cuales: maphtech findarticles shareware Respuesta correcta pero incompleta. adware Respuesta correcta pero incompleta. techadvice freeware Respuesta correcta pero incompleta. La 3, 4 y 6. Todas las anteriores. Buscadores de Buscadores http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad OBJETIVO 5 Encontrar diversas bases de datos específicas a través de buscadores de buscadores. Página 14 de 21 ¡¡Pues sí!! Hasta buscadores de buscadores existen. En caso de que practicando la técnica comentada anteriormente no localicéis al proveedor de la información, tenéis otra posibilidad utilizando bases de datos en las que se concentran la direcciones de miles de portales verticales, directorios o buscadores temáticos. Algunos de estos índices son: z z z http://www.buscopio.net (en castellano y muy interesante) http://www.infobuscadores.com http://www.finderseeker.com A modo de ejemplo os listo algunos de los buscadores que os podéis encontrar aquí: z z z z z http://www.shoppingplace.com/cgi-bin/search/hyperseek.cgi ¡que es un motor de búsqueda para devotos del chocolate y del café! http://www.hivaidssearch.com que aborda la problemática del sida desde distintos aspectos: sanitario, laboral, legal, etc. http://www.buscacine.comque trata del cine español. http://www.ivillage.com que es un directorio de recursos relacionados con la mujer (según los administradores de la página) y cuenta con más de 1.5 millones de usuarias. Y así, hasta 3073 solo en Buscopio (a fecha de 01/09/2004). Existen bases de datos en las que se concentran las direcciones de miles de portales verticales, directorios o buscadores temáticos: Verdadero. Falso. Conclusiones Los metabuscadores son útiles, por ejemplo, cuando queremos hacer un “barrido” para conocer el contenido de las distintas bases de datos sobre un tópico concreto. Los metabuscadores gráficos, tipo Kartoo, nos sirven además para revisar las relaciones existentes entre los documentos y los sites localizados. Ahora bien, este tipo de motores, no son una opción cuando queremos hacer una búsqueda minuciosa de todos y cada uno de los éxitos relacionados con un tópico. ¿Por qué? Recordad que todos los metabuscadores trabajan con los “mejores” éxitos de cada uno de los motores que consultan. Un metabuscador lanza su query, y recoge los primeros X resultados que le ofrece cada uno de los índices consultados. El problema es que esos resultados ya han sido filtrados por el algoritmo de ordenación del motor. ¿Cómo podemos saber que esos primeros resultados que estamos recogiendo son los más relevantes para nosotros? Simplemente no podemos. Cabe la posibilidad de que el éxito más interesante desde nuestro punto de vista esté en la posición X+1, y quede fuera del rango seleccionado por el metabuscador. Por ello, cuando estemos desarrollando una búsqueda concienzuda, estas herramientas no son recomendables. Rellene con las palabras adecuadas http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad kartoo Los metabuscadores como documentos y sites encontrados. Página 15 de 21 sirven para revisar las relaciones entre Recuerda que ... z Buscadores, directorios y metabuscadores son herramientas distintas y válidas para distintos tipos de búsquedas. z Es interesante saber de memoria las direcciones de distintos motores. Tanto buscadores como directorios y metabuscadores. z Una de las mejores estrategias es buscar bases de datos específicas sobre las que poder encontrar la información que necesitas. z No debes olvidar los buscadores de buscadores. z Es útil e interesante mantenerse al día de cómo van acontenciendo las novedades en el campo de localización de la información: mejoras en los motores o motores nuevos, nuevas herramientas o restrictores, etc. z Todavía existen muchas herramientas de búsqueda en Internet diferentes a las vistas aquí, como motores de la Web invisible, Redes P2P, Usenet, etc... z No puedes limitarte al uso de los motores genéricos y menos a uno solo de ellos (Google??) ya que este paso supone solo el inicio de la investigación. Si actuamos de esta forma estaremos descartando nada menos que el >99% de la información disponible. Errores más comunes z Confundir metabuscador con buscador o directorio. z Creer que los metabuscadores pueden encontrar más información relevante que un buscador, independientemente del tópico a encontrar. z Limitarse al uso de los motores genéricos. Aplicación de conocimientos 1. ¿Para qué son útiles los metabuscadores? RESPUESTA 2. ¿Cuáles son los principales problemas de los metabuscadores? RESPUESTA 3. ¿Qué similitudes y diferencias existen entre los servicios de refine y clustering que http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 16 de 21 incorporan gran cantidad de motores? RESPUESTA 4. ¿Para qué sirve una barra de herramientas y cuál es el motor sobre el que trabajan la mayoría? RESPUESTA 5. ¿Cuál es la utilidad de los motores con interfaz gráfico? RESPUESTA 6. ¿Es importante considerar bases de datos específicas a la hora de buscar información? RESPUESTA 7. ¿Cómo podemos encontrar bases de datos específicas? RESPUESTA 8. ¿Cómo podéis manteneros actualizados sobre las novedades en el campo de la localización de información en Internet? RESPUESTA [Imprimir el Cuestrionario Resuelto] Taller El ejercicio de esta unidad es volver a aplicar los cuatro puntos indicados en la sección “Técnica para Seleccionar los Mejores Buscadores” de la unidad 6. Buscadores. Pero en este caso, utilizando los Metabuscadores. Se trata de repetir el ejercicio que ya venís desarrollando desde la unidad 6. Podéis utilizar de nuevo el cuadro comparativo de esa misma unidad (punto "Revisión de buscadores"). Bibliografía Una vez más, los libros relacionados con buscadores y directorios son los que tratan, en alguno de sus capítulos los metabuscadores, por lo que bibliografía específica de metabuscadores no hay. Lo que sí hay es bibliografía de la Web invisible y es la que os adjunto. Ackermann, E.C., Hartman, K. (2002) Searching and Researching on the Internet and the World Wide Web. Franklin Beedle & Associates. Bergman, M.K. (2001) The Deep Web: Surfacing Hidden Value. BrightPlanet.com. Pedley, P., Webb S.P. (2001) The Invisible Web (Aslib Know How Guides). Europa Publications. Sherman, C. Price, G. (2001) The Invisible Web: Uncovering Information Sources Search Engines Can't See. Independent Publishers Group. Referencias http://www.dogpile.com http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 17 de 21 http://www.metacrawler.com http://www.excite.com http://www.mamma.com http://www.surfwax.com http://www.fazzle.com http://www.infonetware.com http://www.infonetware.com/realterm/inw/powerhelp.html http://www.ithaki.net http://www.ixquick.com http://www.metaeureka.com http://www.vivisimo.com http://www.altavista.com/toolbar/default http://sp.ask.com/docs/toolbar/ http://www.dogpile.com/info.dogpl/tbar/ http://toolbar.google.com/deskbar/ http://toolbar.google.com/ http://www.hotbot.com/tools/ http://sp.ask.com/docs/teoma/toolbar/ http://companion.yahoo.com/ http://www.advancedsearchbar.com/ http://download.alexa.com/ http://www.copernic.com/en/products/meta/ http://www.dqsd.net/ http://www.frysianfools.com/ggsearch/ http://www.groowe.com/ http://googlebar.mozdev.org/ http://www.gophoria.com/ http://gu.st/proj/SearchGoogle.service/ http://www.metaeureka.com/download.shtml http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 18 de 21 http://www.trellian.com/toolbar/ http://www.ultrabar.com/ http://vivisimo.com/toolbar/toolbar-download.html http://vivisimo.com/toolbar/minibar-download.html http://www.kartoo.com http://www.touchgraph.com/TGGoogleBrowser.html http://www.pmbrowser.info/amazon.html http://www.findarticles.com http://www.scirus.com http://repec.org http://www.quotationspage.com http://www.ebay.com http://www.eurobid.com http://www.pricegrabber.com http://www.shopping.com http://www.addall.com http://www.ine.es http://www.statistics.gov.uk http://www.ssb.no/english/links/main.shtml http://www.monster.com http://www.infojobs.net http://www.jobline.es http://www.global-work.com http://www.filext.com http://www.techadvice.com/specs/search-file-ext.asp http://www.smackbomb.com/famousfonts http://www.1001freefonts.com http://www.lib.berkeley.edu/MRC/audiofiles.html http://www.CEOlive.com http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 19 de 21 http://speechbot.research.compaq.com http://www.corbis.com http://www.desktopia.com http://www.maptech.com/mapserver/index.cfm http://www.movieflix.com http://www.studentreel.com http://www.recordtv.com http://www.comfm.fr/webcam http://www.earthcam.com http://tucows.ua.es http://www.download.com http://www.shareware.com http://www.windrivers.com http://astalavista.box.sk http://www.buscopio.net http://www.infobuscadores.com http://www.finderseeker.com http://www.shoppingplace.com/cgi-bin/search/hyperseek.cgi http://www.hivaidssearch.com http://www.buscacine.com http://www.ivillage.com http://www.recerk.blogspot.com http://es.groups.yahoo.com/group/recerk/ http://www.brightplanet.com/technology/deepweb.asp http://www.sims.berkeley.edu/research/projects/how-much-info-2003 Glosario Adware software que durante su funcionamiento despliega publicidad de distintos productos o servicios. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 20 de 21 Buscadores de buscadores bases de datos en las que se concentran la direcciones de miles de portales verticales, directorios o buscadores temáticos. Clustering Es la agrupación que realizan los buscadores para no mostar más de un cierto número de páginas de una web para una determinada búsqueda. Cracks Son archivos que “engañan” un programa para que no ejecute una determinada acción. Deep web Ver Web Invisible Dogpile Meta-buscador Fazzle Motor de búsqueda. Refine “refinado” ; facilita el filtrado de información. Shareware Programas que pueden ser obtenidos por Internet en computadoras de acceso público. Se pueden utilizar libremente durante un periodo determinado (generalmente 30 dias), a partir del cual solicitan un pago (aproximadamente 30 US$) para poder continuar utilizándolos. Sneek-a-Peek Sistema de abrir las páginas en una pequeña ventana dentro de cada listado de éxitos. FocusWords tipo de búsqueda basada en el significado con descriptores, sinónimos e ideas para los términos clave introducidos. Frame (Marcos) Una página que contiene otras, creando un efecto en el cual el visitante entonces visualiza varias páginas a la vez. No son recomendables para los buscadores ya que son difíciles de indexar. No obstante, realizando los cambios pertinentes (modificando la etiqueta "noframes" y mejorando el linkeo interno entre otros) pueden sobrepasarse la mayoría de inconvenientes. Freeware Progarma informático gratuito. Infonetware Metabuscador. InfoSpace Directorio Web. Ithaki Metabuscador. Ixquick Metabuscador. Kartoo Metabuscador gráfico. Mamma Metabuscador. Metacrawler o Metabuscador difiere de los demás buscadores en que no posee una base de datos en la cual buscar sino que usa las de los demás buscadores. Este buscador trabaja preguntando a los demás buscadores y http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Página 21 de 21 organizando los resultados en un formato único. Metaeureka Metabuscador. Parches Modificación llevada a cabo en un programa informático al objeto de sustituir una parte del código con el fin de eliminar un error en su programación. Preview Vista previa. Surfwax Metabuscador. Vivísimo Metabuscador. Web invisible Información que no puede recuperarse en los motores de búsqueda genéricos. Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D8ale... 26/10/2005 Imprimir Unidad Imprimir Página 1 de 3 Volver Localización de Información Específica en Internet. 1ª Parte. La Web 9.- Conclusiones Finales Conclusión Quiero recalcar una vez más la necesidad de aplicar estrategias válidas de localización de información. La utilización o no de una estrategia adecuada a la información que se desea encontrar es la clave para localizar rápidamente los documentos relevantes. En un segundo nivel de importancia colocaría las herramientas utilizadas. A lo largo de todo este manual habéis podido probar detalladamente todos los motores más grandes o más conocidos de la Web y, necesariamente, habréis llegado a alguna conclusión sobre qué sites son los que más os convencen. Espero que hayáis elegido, cuando menos, 2 buscadores, 1 directorio y 1 metabuscador sobre los que desarrollar vuestras estrategias de búsqueda y podáis elegir un punto de partida u otro en función del tipo de información solicitada. No olvidéis leer las “instrucciones de manejo” para poder extraer el máximo partido a cada motor. Imaginaos que os compráis un coche y el anterior que teníais era de los antiguos con solo 4 marchas. ¿No sería una imprudencia el no ser conscientes de que los coches actualmente vienen con 5 marchas? Desde luego no sacaríais todo el provecho a vuestra nueva adquisición. Pues lo mismo, leed la ayuda o el help antes de empezar a utilizar un motor y eventualmente revisadlas porque se van incorporando nuevos servicios y herramientas. Otra forma de mantenerse actualizado es visitar de vez en cuando: http://www.recerk.blogspot.com. En esta dirección, el Proyecto RecerK.com trata de mantener un listado de noticias actualizado con todas las novedades que acontecen en el mundo de la búsqueda de información en Internet. Si el visitar esta página eventualmente es demasiado trabajo, podéis suscribiros (gratuitamente, por supuesto) a una lista de correo en la que se publica aproximadamente la misma información y que tenéis disponible en: http://es.groups.yahoo.com/group/recerk/; de esta forma, recibiréis un correo mensual en el que se resumen las novedades acaecidas durante cada mes. Para acabar con este primer curso quisiera hacer hincapié una vez más en los dos estudios que se han citado a lo largo del texto y que hacen referencia a la cantidad de información disponible a través de la Red: el de Brightplanet (http://www.brightplanet.com/technology/deepweb.asp) y el de la Universidad de Berkeley (http://www.sims.berkeley.edu/research/projects/how-muchinfo-2003). La conclusión principal que se extrae de estos estudios es que NO podemos limitarnos a utilizar los motores genéricos. La elección de los 2 buscadores, el directorio y el metabuscador que como mínimo tenéis que haber hecho a lo largo de la lectura de este curso es solo el punto de partida. Cuando la información buscada es simple no hay problema. Pero cuando la cosa se complica, el uso de los motores genéricos ha de suponer solo el inicio de la investigación. A través de estas herramientas tenemos que llegar a encontrar las bases de datos específicas para, una vez allí, localizar la información. Si no actuamos de esta forma estaremos descartando nada menos que el >99% de la información disponible. Ver figura 9.1.1. En ella se muestra esquemáticamente y utilizando el símil de la pesca, qué documentos podemos encontrar si nos limitamos a buscar en los motores genéricos, o sea, en la Web de superficie y qué documentos podemos encontrar si utilizamos estrategias adecuadas o directamente entramos en motores que exploren el Deep Web o Web invisible. http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D10al... 26/10/2005 Imprimir Unidad Página 2 de 3 Figura 9.1.1: Símil de pesca en relación a la Web. Si nos fijamos en la figura 9.1.2, se puede observar la abismal diferencia que existe entre la información contenida en formato papel, en la Web de superficie y en la Web invisible. Como se puede observar la digitalización de TODA la información que existe en el mundo en formato papel ocuparía aproximadamente 500-600 terabytes de espacio en disco duro. Como es fácil imaginar, este volumen de información está estancado desde 1994. El crecimiento de la Web en este periodo ha sido impresionante. Desde el año 1997 hasta el 2003, la Web ha incrementado su tamaño de forma exponencial y la Web invisible incluso a una mayor velocidad que la Web de superficie. Ver figura 9.1.2. Notar que la escala es logarítmica. Figura 9.1.2: Evolución de la información contenida en formato papel, en la Web de superficie y en la Web invisible. Y os preguntaréis, ¿porqué remarcas o•t•r•a v•e•z estos datos al final del libro? Pues, para comunicaros que con lo que hemos visto hasta ahora podemos hacer muchas cosas, pero todavía existen gran cantidad de herramientas de búsqueda en Internet, la mayoría de las cuales ya se salen de la Web, pero que es imprescindible dominar para poder contestar a la http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D10al... 26/10/2005 Imprimir Unidad Página 3 de 3 pregunta: “¿Qué herramienta utilizo para esta búsqueda?”. Todas estas herramientas entre las que se encuentran: z z z z z z z z z Motores de la Web invisible, Redes P2P, Usenet, Weblogs, Listservs, Motores de noticias de actualidad, IRC, Mensajería Instantánea, Etc. …se tratarán en el segundo volumen de este manual: Localización de Información Específica en Internet. Si habéis leído hasta aquí, seguro que os gustará. Generado con H.A.U.P.A.© 2001-2002 UPA Cursos on-line Universidad Politécnica Abierta http://www.upvabierta.net/upa/cursos/c390/visualdavidpla/imprimir.asp@iu%3D10al... 26/10/2005