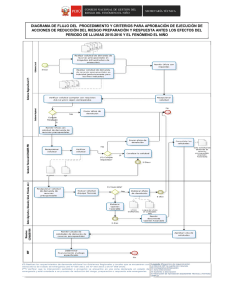
Unidad 4 y 5 - Macrocrespo
Anuncio

UNIDAD Nº4: DISEÑO DE SISTEMAS EN TIEMPO REAL i) El ciclo de vida para software de tiempo real Cumple básicamente las siguientes etapas por las que pasa el producto (sistema); es una visión orientada al producto. El proceso de construcción del sistema pasa por las siguientes etapas: Ciclo de vida del producto Necesidades Identif. de necesidades Especif. de Requerimientos Análisis de Requerim. Diseño Diseño Codificación Codificación Sistema Software Implantación Mantenimiento Etapas 1) Análisis de requerimientos: El propósito de esta fase es asegurar que todo el mundo entienda qué es lo que se quiere construir. Para esto se debe escribir la especificación de los requerimientos del software, el cual probablemente sea el documento más difícil de escribir, debido a la diversidad de personas a la que está destinado. Las siguientes personas están involucradas: a. Los usuarios, clientes: Su objetivo es asegurarse de que el software va a satisfacer sus requerimientos. b. Desarrolladores de software: Su meta es asegurarse de que puedan implementar el software requerido. c. Desarrolladores de hardware: Su objetivo es asegurarse de que el hardware que desarrollen soportará los requerimientos del software. d. Ingenieros de prueba: Deben asegurar que los requerimientos sean entendibles desde el punto de vista de la funcionalidad y deben ser capaces de probar el software y verificar que trabaja como se requiere que trabaje. e. Escritores de la Documentación: Deben asegurarse de entender los requerimientos lo suficientemente bien como para escribir los manuales de los usuarios. f. Administradores de proyectos: Deben asegurarse de que los requerimientos sean especificados de manera que ellos puedan estimar los esfuerzos de desarrollo y controlar los cambios. Las especificaciones de los requerimientos del software deberían ser escritos en 2 partes: La primera destinada a los clientes y usuarios, especificando claramente las limitaciones de lo que se va a construir, y para hacer el primer análisis de factibilidad (es decir, considerando las distintas opiniones de los desarrolladores de software). También se debe especificar lo que se asume como hardware disponible y hardware requerido. La segunda está destinada a los desarrolladores de software y a los organizadores de las pruebas. Se utiliza como base para el diseño y la planificación de las pruebas. Se repasa la primera parte como un requisito esencial, y se escribe el resto del documento. Una vez que el documento pasó una 1ra revisión, se realiza la Revisión Formal del proyecto, en donde se consideran los siguientes asuntos: o La especificación de los requerimientos del software. o El plan de prueba y aceptación del software. o Los recursos. o Los riesgos. o Los beneficios. 2) Fase de Diseño: El propósito de esta fase es desarrollar un esqueleto sólido antes de escribir el código. Al final debería tener la seguridad de que el sistema trabajará y las piezas podrán funcionar juntas. a. Organización del conocimiento: Cuando se desarrollan sistemas en tiempo real embebidos, el diseño será muy influenciado por las interfaces de hardware con las que se debe trabajar. Por lo que la primera parte en la fase de diseño estará destinada a organizar el conocimiento con respecto a las interfaces de hardware, interrupciones, servicios del sistema operativo, etc. Y a asegurar que se entiende la secuencia de eventos requeridos para crear un software que haga lo que se necesita que haga. Los resultados de esta actividad serán notas de ingeniería. Al final de esta actividad se debería realizar otra revisión general apoyada por un ingeniero de hardware que asegure que lo que se propone sea válido. b. Arquitectura de nivel superior: Se determinan los principales componentes del sistema y cómo ellos van a interactuar con cada uno de los otros. Los productos de esta actividad son: una vista concurrente / funcional (con una descripción de los procesos de comunicación), contenido / formato de los comandos y otras interfaces, descripción de los objetos (si se trata de un diseño orientado a objetos). Al final de esta actividad se debería realizar otra revisión general apoyada por un ingeniero de hardware que asegure que lo que se propone sea válido. c. Planificando las tareas y seleccionando el algoritmo de planificación: Tiene en cuenta las tareas del sistema operativo y determina la factibilidad de encontrar un hardware para tiempo real que no sea imposible de construir. No se utiliza en sistemas que no se escriban como aplicaciones multitarea. Se debe determinar el tipo de tareas involucradas, periódicas o manejadas por eventos, cuál algoritmo de planificación se utilizará, el tiempo aproximado de ejecución de cada tarea y el tratamiento de semáforos. La salida de esta actividad es una posible redefinición de las tareas, y el diseño de los algoritmos de planificación para el sistema. 4) Especificación de los componentes: En esta etapa se logra un entendimiento claro de lo que cada componente debe hacer. Después de completar esta etapa, se puede codificar cada componente, con una seguridad razonable de que cada pieza encajará. Lo primero que se debe hacer es describir las responsabilidades de cada componente, para clarificar lo que debe hacer cada uno en relación con los otros. Se debe describir el proceso por el que cada componente maneja cada entrada, describiendo cada componente como una “máquina de estado” si fuera necesario. Luego se determina los servicios adicionales que deben proveer los objetos definidos previamente. Finalmente, se debe actualizar la vista Funcional / Concurrente. Resumen Sistemas de Información 2 3) Análisis del rendimiento: Se deben considerar 3 aspectos (no todos pueden ser aplicables al sistema que se esté desarrollando, pero cada uno provee una perspectiva diferente): a. Analizando escenarios: Esta actividad pone atención en un escenario (secuencia de procesamiento típica del sistema) y evalúa el tiempo que trascurre entre un evento y la respuesta del sistema a ese evento. Se utilizan seudo operaciones (llamada a procedimientos, declaraciones en lenguaje de alto nivel o una operación de entrada / salida sobre un archivo). Cada seudo operación se describe en términos de los recursos primitivos que utiliza (CPU, un dispositivo de salida o un bus). Luego se estima el tiempo de uso de cada recurso por primitiva. Usando toda esta información se calcula el tiempo trascurrido según el escenario que se ha descrito. Los productos de esta actividad son las descripciones de los escenarios y sus resultados, los que son utilizados en el siguiente análisis. b. Analizando el sistema: En esta etapa se utiliza la información derivada de los distintos escenarios y se aplican fórmulas derivadas de la teoría de colas para determinar cuantos eventos diferentes pueden ser manejados en un período de tiempo dado. Aquí se debería: Obtener un juicio de dónde se realizan la mayoría de las tareas de procesamiento. Cuáles son los principales factores que afectan al rendimiento. Determinar dónde ocurren los cuellos de botella. Preocuparse por las tareas que bloquean a otras tareas. El producto de esta actividad también debe ser un reporte, que deberá ser revisado y si no es válido, se debe rediseñar y reanalizar. 2 Los resultados del trabajo en esta etapa son: Diagrama de Comunicación de Tareas. Diagramas de Transición de Estados (DTE). Descripción de componentes. Descripción del manejo de excepciones. Servicios de objetos. 5) Codificación: Se codifican todas las unidades. Si se han revisado los requerimientos y el diseño, no deberían surgir mayores problemas aquí, pero siempre deben existir puntos de revisión. Todo lo que se ha logrado debe traducirse en una forma legible para la computadora. 6) Chequeo del desarrollo: Está constituido por 2 actividades: la Prueba de Unidad y la Prueba de Integración. Prueba de Unidad: Se desarrollan casos de prueba por cada unidad a testear, los cuales se documentan en un Plan de Prueba de Unidad que acompañará al código para hacer la revisión. Prueba de Integración: Comenzará a medida que finaliza el diseño. Se debe desarrollar el software de acuerdo al plan de integración. El producto de esta actividad es el Plan de Prueba de Integración del Software que incluye la matriz de planes de pruebas, también utilizada en la fase de mantenimiento. 7) Chequeo o prueba de aceptación del software: Requiere de un estudio de la especificación de requerimientos y de los manuales de usuario para construir el plan de prueba. También se utiliza en la elaboración de este plan las descripciones de los escenarios desarrolladas para estudiar el rendimiento. La meta del chequeo es encontrar errores. Al final de esta actividad, los administradores deberían comprender el estado del software para que puedan decidir si el software marcha o no marcha. 8) Mantenimiento: Esta actividad tiene lugar una vez que el software ha sido entregado al usuario, ya que indudablemente sufrirá cambios debido a que se hayan encontrado errores, a que deba adaptarse a cambios en el entorno, o debido a que el cliente quiera ampliaciones funcionales o de rendimiento. ii) Problemas a resolver en el diseño de STR 1) 2) 3) 4) 5) 6) 7) 8) Manejo de errores y recuperación de fallas. Flujos y procesos de control. Concurrencia. Representación dinámica del sistema. Sincronización y comunicación entre procesos. Procesamiento asincrónico. Problemas de las representaciones y cambio de contexto. Acoplamiento con el S.O., el hardware y otros elementos externos al sistema. Requisitos que debe reunir un Método de Diseño de STR Debe estructurar el sistema en tareas concurrentes. Debe soportar reusabilidad. Debe definir el comportamiento del sistema por medio del DTE o máquinas de estados finitos. Debe analizar las propiedades de tiempo real del diseño. Clasificación de los Métodos de Diseño Existen 4 diferentes métodos de diseño de STR: Métodos orientados al flujo de datos (Yourdon, Gane y Sarson). Métodos orientados a las estructuras de datos (Yackson, Warnier). Métodos orientados a objetos (Booch, Hrt-Hood, Comet, Mast-RL,UML). Resumen Sistemas de Información 2 El diseño de STR debe incorporar todos los conceptos de alta calidad y se deben resolver un conjunto de problemas tales como: 3 Métodos orientados a los modelos (State-Mate, Ropes, UML) y otros métodos que no tienen una tendencia definida, que utilizan máquinas de estados finitos, Modelo de pasos de mensajes (witt), Modelo de redes de Petri (Vidondo),y otros que utilizan lenguajes especializados (Stewstoff). Métodos de Diseño orientados al Flujo de Datos Metodología Ward - Mellor Propusieron ampliaciones a la notación básica que se emplea en el análisis estructurado (DFD) para poder aplicarlos en los STR. Esta notación se agrega para dos conceptos: control y comportamiento de datos. El comportamiento de datos se expresa en términos de continuidad / discontinuidad. Los objetivos de estas ampliaciones son los siguientes: a) Representar el flujo de información que es recogido o producido de forma continua en el tiempo. b) Representar información de control que pasa por el sistema y el procesamiento de la misma. c) Representar instancias múltiples de una misma tarea que se encuentra a menudo en el sistema multitarea. d) Representar estados del sistema y situaciones que producen cambios de estados. Los símbolos que se agregan son: Flujo de datos continuos Flujo de datos discontinuos Proceso Almacenamiento Entidad Externa Transformación de control, acepta control como entrada y produce control como salida. Flujo o elemento de control, toma un valor lógico o discreto y la flecha indica la dirección del control. Almacenamiento de control, es un depósito de eventos de control que se guardan para ser usados por los procesos. En este método se marca la diferencia entre modelo de diseño y de implementación. Ejemplos: (Flujos de Control Continuos en el tiempo) Entrada Temperatura Supervisada Ajuste de Temperatura Continua Salida Monitorear Continua y ajustar el nivel de Valor temperatura Corregido Resumen Sistemas de Información 2 Instancias múltiples de un mismo proceso. Se usan cuando se crea procesos múltiples en un sistema multitarea. Ej: procesos que controlan semáforos en cada esquina. Los procesos de control se describen cómo máquinas de estado, las acciones se toman cuando ocurre una transición desde un estado a otro. Estas acciones usualmente controlan flujos y tienen nombres como comenzar, controlar, abrir válvula. 4 Metodología Hatley – Pirbhai: Basa su método en el análisis estructurado de Tom de Marco. Ellos, al igual que Ward y Mellor, adicionan notación para diferenciar entre datos y flujo de control, pero esta es diferente. Trabajan con 2 tipos de modelos: uno de Procesamiento y el otro de Control. Modelo de Procesamiento: Está compuesto por 2 componentes, el DFD con sus Especificaciones de Procesos (qué hace cada burbuja del DFD). Modelo de Control: Contiene el DFC (entrada Control y salida Control) con sus Especificaciones de Control. El Modelo de Procesamiento tiene datos de entrada y genera datos de salida, el Modelo de Control sólo genera señales de control. Estos modelos están vinculados; es posible que haya una Condición de Datos como entrada en la especificación de control. Otra vinculación son los Activadores de Procesos (son señales que utilizan los procesos de control para activar una trasformación de datos). Es una evaluación de los eventos que provocan cambios de estado en el sistema y de ese cambio de estado se transforma en llamada de control. Separan dos diagramas: DFD, DFC. Introducen un Modelo de arquitectura para la fase de diseño: en este modelo asumen que al diseñar el hardware y el software, el propósito es proporcionar funcionalidad a los mismos. Muestra mejoras para definir el procesamiento adicional que se requiere en la manipulación de entradas y salidas, interfaces del usuario, mantenimiento y verificación. Se centra menos en la creación de símbolos gráficos adicionales y más en la representación y especificación de aspectos del software orientados a control. Los activadores de procesos son las llamadas E/D (Enable/Disable) y T (trigger); la única simbología que se agrega es: Flujo de control Barra de especificación de control: Describe el comportamiento de un sistema y define como se activan los procesos a consecuencia de los eventos. Entrada de datos Modelo de Procesamiento DFD`S Salida de datos Señales E/D y T Especificaciones de procesos: descripción de cada una de las burbujas PSPEC`S Activadores de Procesos. Un proceso de control activa uno de datos Modelo de Control Condiciones de datos. Ante determinadas condiciones de los datos, se activa un proceso de control. DFC`S Salida de control CSPEC`S Entrada de control Resumen Sistemas de Información 2 Sugieren que se represente por separado todo el manejo de datos en trazo continuo y el manejo de control en trazo discontinuo, creando para cada uno de ellos un modelo. 5 Se define un DFC que tiene los mismos procesos que el DFD, pero muestra el flujo de control en lugar del flujo de datos. Los DFC muestran cómo fluyen los sucesos entre los distintos procesos y muestran cómo los sucesos externos hacen que se activen los procesos. En lugar de representar directamente los procesos de control dentro del modelo, se usa una referencia notacional a una especificación de control (CSPEC). En esencia, se puede considerar a la barra como una “ventana” hacia un “director” (la CSPEC) que controla los procesos representados en el DFD de acuerdo con los sucesos que pasan a través de la ventana. La CSPEC se usa para indicar: 1. Cómo se comporta el software cuando se detecta un suceso o una señal de control. 2. Qué procesos se invocan como consecuencia de la ocurrencia del suceso. Se usa una especificación de procesos (PSPEC) para describir el funcionamiento interno de los procesos representados en el diagrama de flujo. Para representar los datos y los procesos que los manipulan se usan los DFD. El Modelo de Procesamiento está conectado con el Modelo de Control a través de las Condiciones de Datos. El Modelo de control se conecta con el de procesamiento a través de la Activación de Procesos. Ejemplo: Sistema de Control de un tanque Diagrama de Flujo de datos Diagrama de Flujo de Control Presión absoluta del tanque Comprobar y Comprobar y Convertir Convertir Presión Presión Presión Alta Presión Máxima Si presión absoluta del tanque > presión máxima entonces poner presión alta a verdadero sino poner presión alta a falso inicio algoritmo de conversión x - 01a calcular presión convertida fin fin-si Resumen Sistemas de Información 2 PSPEC 6 Métodos de Diseño basado en Modelos: Metodología Súmate - Keller Incorpora muchas ideas del método DARTS; está destinada al diseño de grandes STR utilizando programación ADA. A lo largo de los procesos de análisis, diseño, etc; se van combinando distintos métodos. Aplica Hartley-Pirbhai para el análisis de requerimientos. Transforman los DFD y los DFC obtenidos en este método en un Diagrama Comunicación y Sincronización entre tareas. Encapsulan las tareas en módulos de aplicación y luego desagrega cada una de las tareas. Metodología Statemate Es una herramienta desarrollada en J-Logan basada en un conjunto de lenguajes de modelado entre los que están: DTE (Diagramas de Transición de Estados): sirve para reflejar el comportamiento del sistema; son parte de la herramienta UML. La herramienta asocia a este tipo de diagrama una semántica asociada. DA (Diagrama de Actividad): Permiten hacer una descomposición funcional del sistema.DM (Diagrama de Módulos): Permiten hacer una descomposición estructural del sistema.Metodología UML (Lenguaje de Modelado Unificado) Es el lenguaje de modelado de sistemas de software más conocido y utilizado en la actualidad. Es un lenguaje gráfico para visualizar, especificar, construir y documentar un sistema de software. Se ha convertido en el estándar de facto de la industria, ya que esta notación ha sido ampliamente aceptada debido al prestigio de sus creadores y debido a que incorpora las principales ventajas de cada uno de los métodos particulares en los que se basa (principalmente Booch, OMT y OOSE), que son los tres métodos más usados de orientación a objetos. Tiene las siguientes características: En el caso particular de STR, UML proporciona un conjunto de extensiones de 3 tipos: Cápsulas Puertos Conectores Estos refuerzan las capacidades de UML para la abstracción y modelización de concurrencia. Recientemente se definió una vista de UML que permite hacer una administración de tiempo real. Metodología ROPES (Objetos veloces orientados a procesos para software embebido) Está basado en UML, por lo tanto comparte sus características. Esta basado en un modelo de ciclo de vida iterativo. Está orientado a una generación rápida de prototipos. Resumen Sistemas de Información 2 La estructura del sistema se modela con objetos. Se identifican casos de uso en el sistema en el que se representan salidas en respuestas a determinadas entradas en el sistema. Se usan máquinas de estados finitos para representar el comportamiento del sistema (modelización dinámica). Empaqueta elementos organizados en grupo. Permite representar la comunicación, concurrencia y sincronización entre tareas. Es posible modelar topologías físicas, es decir, pueden llegar a modelos de implementación del sistema. Soporta marcos y formas orientadas a objetos. 7 Hay 4 actividades básicas en el ciclo de prototipos: Análisis Diseño Implementación Testeo Es posible implantarlos también a través de un ciclo de vida estándar o un ciclo de vida en espiral. Abarca etapas tempranas, tiene una visión general de los proyectos de sistema y la implementación de éstos. Aplicación Probada Fases de Desarrollo Pruebas Análisis ROPES Componentes de la Aplicación Modelado de Objetos de Análisis Diseño Modelado de Objetos de Diseño Traducción Análisis: Identifica las características esenciales de todas las posibles soluciones. Diseño: Agrega elementos al análisis que definen una solución particular optimizada. Traducción: Construye una realización ejecutable e implantable del diseño. Pruebas: Verifica que la traducción es equivalente al diseño. Valida que la implementación cumple los criterios de corrección identificados en el análisis. Métodos Orientados a los objetos: Metodología MAST-RT (Modelo y Análisis para STR) Recursos Hardware (Computadoras, redes, equipos, temporizadores, etc.) y Software (Hilos de ejecución, procesos, drivers, etc.) que constituyen la plataforma física del sistema. Componentes Lógicos (clases, métodos, procedimientos, etc.) y mecanismos de sincronización (semáforos, monitores, etc.) Escenarios de tiempo real que definen las situaciones de análisis y que se formulan como conjuntos de transacciones concurrentes, de fuentes externas de eventos que las invocan y de las restricciones temporales que se requieren en ellas. Características de MAST-RT a) Puede usarse para representar el comportamiento de TR en cada fase del ciclo de vida de un sistema. Puede operar en las fases iniciales con modelos poco detallados basados en estimaciones y de igual modo puede describir el comportamiento detallado del sistema en las fases finales en las que el código ya ha sido generado para validar sus prestaciones. Resumen Sistemas de Información 2 MAST-RT (Modeling and Analisis for Real Time Aplications) es una metodología basada en UML. Es un entorno abierto basado en una descripción textual del modelo del sistema de tiempo real. El entorno MAST-RT ofrece componentes conceptuales abstractos para modelar: 8 b) Se ha establecido una modularidad paralela a la modularidad de la vista lógica. Se dispone tanto de un modelo de TR del sistema completo, como también del modelo de cada clase lógica, o incluso el modelo de cada método de su interfaz. Con ello se consigue que los modelos de tiempo real sean reusables. c) Pone a disposición del diseñador de STR herramientas sofisticadas para el análisis cualitativo y cuantitativo de sus diseños. Además, las puede usar sin necesidad de conocer los detalles de los algoritmos en que se basan dichas herramientas. d) Se puede incorporar a una herramienta CASE basada en UML, por ejemplo ROSE-2000. e) En el entorno MAST se han desarrollado los modelos relativos a sistemas monoprocesadores y distribuidos basados en prioridades fijas y con diferentes estrategias de planificación (expulsoras y no expulsoras, servidores esporádicos, polling, etc.). f) Permite el análisis de STR basados en sistemas operativos y lenguajes comerciales de uso frecuente tales como POSIX y Ada. Vista UML de tiempo real La vista UML de tiempo real es una vista adicional que complementa la descripción estándar UML de un sistema durante su fase de diseño; su finalidad es definir un modelo de tiempo real que describa la temporización y los recursos que se asignan a las actividades del sistema y que sirve de base para analizar su planificabilidad mediante herramientas automáticas. La vista UML de tiempo real se compone de tres subvistas complementarias, cada una de ellas describe un aspecto específico del modelo de tiempo real: Modelo de la Plataforma: Modela la capacidad de procesamiento y las restricciones operativas de los recursos de procesamiento hardware y software que constituyen la plataforma sobre la que se ejecuta el sistema. Los componentes básicos que constituyen el modelo de la plataforma son: Servidores de planificación: modelan los procesos, threads y las políticas de planificación de las actividades que se le asignan. La capacidad de operar en tiempo real de un sistema resulta de asignar las actividades que deben llevarse a cabo a threads concurrentes que se priorizan de acuerdo con los requerimientos de tiempo real que deben cumplirse. Recursos de Procesamiento: se utiliza para modelar procesadores, equipos, redes de comunicación, etc. que ejecutan las operaciones requeridas en el sistema. Se han definido dos clases especializadas, los componentes de tipo Processor que representan procesadores, coprocesadores o equipos embarcados que ejecutan actividades formuladas como código de programa, y los componentes de tipo Network que representan redes de comunicación cuya actividad consiste en transferir información entre procesadores. Escenarios de Tiempo Real: Modelan las diferentes configuraciones hardware/software que puede alcanzar el sistema y en las que estén establecidos requerimientos de tiempo real. Cada escenario se modela como un conjunto de transacciones que describen las secuencias de eventos y actividades que deben ser analizados en cuanto a que se satisfagan los requerimientos de tiempo real establecidos en ellas. El análisis de tiempo real se realiza en base a las transacciones, pero para que una transacción de tiempo real pueda ser analizada, se necesita tener definidas todas las transacciones del escenario al que pertenece, o lo que es lo mismo, todas las transacciones de tiempo real que puedan ejecutarse en concurrencia con ella. El conjunto de transacciones de un escenario constituye la carga del sistema en esa configuración y afecta al análisis de cada una de ellas. Componentes del modelo de tiempo real de un escenario: Resumen Sistemas de Información 2 Modelo de los componentes lógicos: Modelan los requerimientos de procesado que exige la ejecución de las operaciones funcionales definidas en los componentes lógicos que se utilizan en el diseño. En este modelo se declaran los recursos que cada operación necesita para poder llevarse a cabo, en especial aquellos que por ser requeridos por varias operaciones con régimen de exclusión mutua, pueden ser origen de retrasos en la ejecución de las operaciones. 9 El modelo de un escenario se compone del conjunto de modelos de sus transacciones. El modelo de cada transacción se compone de su declaración y de su descripción. Modelo de transacciones: Cada escenario de tiempo real se modela como un conjunto de Transacciones. El conjunto de transacciones definidas dentro de un escenario describen la máxima carga posible del sistema de tiempo real en ese escenario. Cada Transacción describe la secuencia no iterativa de actividades que se desencadenan como respuesta a un patrón de eventos externos que sirve de marco para definir los requerimientos temporales. Declaración de Transacción: La declaración de una transacción se realiza mediante un objeto resultante de la instanciación de la clase Transacción del Metamodelo, y que contiene agregadas una lista con la descripción de las fuentes de eventos externos que constituyen su patrón de eventos externos de disparo y una lista con la descripción de los requerimientos temporales definidos en ella. Descripción de una transacción: La descripción de una transacción se realiza mediante un modelo de actividad agregado a su declaración. El modelo de actividad está compuesto de un conjunto de diagramas de actividad que describen las secuencias de actividades, estados y transiciones que se desencadenan como consecuencia de un patrón de eventos externos de entrada. Mast UML Real Time View Subvistas Componentes Servidores de Planificación Recursos de Procesamiento Modelo de los Componentes Lógicos Componentes Diagramas de clases y objetos en los que se declara: Componentes que modelan el comportamiento de clases lógicas relevantes a efecto de su respuesta de TR. Operaciones predefinidas que realizan los coprocesadores, dispositivos o periféricos no programables y que influyen en la respuesta temporal del sistema. Recursos compartidos que requieren ser accedidos por los componentes funcionales en régimen de exclusión mutua, y que soportan la interacción con otros componentes que se ejecutan en concurrencia. Escenarios de Tiempo Real Componentes Modelos de las transacciones del sistema. Cada modelo se compone de: Una declaración. Una descripción. Metodología HRT-HOOD (Diseño Jerárquico Orientado a Objetos p/STR) Esta metodología deriva de H-HOOD (Hierarchical Object-Oriented Design) y en este caso se particularizó para STR y para la construcción de sistemas concurrentes. Resumen Sistemas de Información 2 Modelo de la Plataforma 1 0 HRT-HOOD es un método de diseño estructurado, basado en objetos, para sistemas de tiempo real en general y estrictos en particular. Este método va dirigido u orientado hacia sistemas de tiempo real complejos. Con esta metodología el sistema se diseña como una jerarquía de objetos abstractos, donde, un objeto se caracteriza por sus operaciones y su comportamiento, y cada objeto se puede descomponer en otros de más bajo nivel. Esta metodología se basa en un proceso de desarrollo iterativo centrado en la etapa de diseño. Consiste en validar todos los aspectos que se pueda en la etapa de diseño, prestando especial atención a la validación del comportamiento temporal. Características Los elementos en cada nivel de abstracción adquieren: Compromiso: propiedades que ya no se cambiarán. Obligaciones: que se dejan para niveles inferiores. Durante la fase de diseño se van transformando las obligaciones en compromisos, pero teniendo en cuenta las restricciones impuestas por el entorno de ejecución. Proceso de Desarrollo: El proceso de diseño se concibe como una progresión de compromisos de creciente especificidad, para cada nivel de diseño del software tales compromisos definen propiedades del sistema que el diseñador en etapas siguientes de mayor nivel de detalle no tiene la libertad de cambiar. Aquellos otros aspectos del diseño para los cuales no se establezcan compromisos, permanecen como obligaciones que deberán definirse en sucesivas etapas de refinamiento. Las obligaciones devienen del análisis y especificación de los requisitos (funcionales y no funcionales), y su asentamiento en compromisos, tanto en la definición de la arquitectura como en los niveles de mayor detalle, está en mayor o menor medida influenciado por las restricciones que corresponden a la plataforma (hardware y software) que constituirá su entorno de ejecución. El ciclo de vida que HRT-HOOD propone para el desarrollo de aplicaciones de tiempo real estricto, se orienta a introducir las técnicas de análisis de planificabilidad en las etapas más iniciales que sea posible, empezando en base a estimaciones que luego se van refinando, hasta finalmente aplicarlas sobre valores medidos del tiempo de ejecución de peor caso, tomados del código que es realmente implementado. El tipo de modelos de análisis resultantes se resuelven mediante estrategias de cálculo de planificabilidad basadas en transacciones end-to-end. El diseño de la arquitectura de la aplicación se define en dos fases: Resumen Sistemas de Información 2 Cada objeto se caracteriza por sus Operaciones y su Comportamiento. Operaciones: están vinculadas con la Abstracción y el Ocultamiento de Información. Comportamiento: se puede analizar el comportamiento temporal del sistema siempre que el entorno de ejecución sea conocido y predecible. Para poder representar el Comportamiento Temporal los objetos poseen Atributos Temporales y las relaciones entre objetos están restringidas para asegurar que el diseño se puede analizar. Un Objeto HOOD tiene propiedades Estáticas y Dinámicas que son las siguientes: Estáticas: las interfaces del objeto y los componentes internos que implementan funcionalidad implicada por las interfaces. Dinámicas: el efecto sobre los objetos llamados por la invocación de una operación. Existen 2: Flujo Secuencial: el control se transfiere a la operación y cuando termina regresa al objeto (se activa uno y el otro queda inactivo). Flujo Paralelo: un flujo se activa en la estructura de control de objetos, requerimiento de la operación, la reacción del objeto dependerá del mismo (quedan activos los 2). 1 1 Diseño de la arquitectura lógica: se definen aquellos compromisos para los que no es necesario contemplar las restricciones que impone la plataforma de ejecución. Por lo general se trata de compromisos que implementan requisitos funcionales. Diseño de la arquitectura física: se abordan las obligaciones que devienen de requisitos no funcionales que han quedado pendientes en la fase anterior. En esta fase además se establecen los mecanismos de validación del modelo que permitan asegurar la correcta operación del sistema tanto en el dominio del tiempo como en el funcional y otros requisitos no funcionales, tales como seguridad, fiabilidad, adaptabilidad, control, etc. El método de diseño debe proporcionar: Reconocimiento de actividades / objetos (esporádicos o cíclicos). Integración de la planificación con el diseño de los procesos. Definición de requisitos temporales para cada objeto. Definición de requisitos de fiabilidad para cada objeto. Importancia de cada objeto en el funcionamiento de la aplicación. Soporte para diferentes operaciones y uso de objetos controladores de recursos. Cuando se completan las actividades de diseño arquitectónico, el diseño detallado puede comenzar y producirse el código de la aplicación. Cuando se logra el archivo de ejecución del código debe ser estimado nuevamente para asegurar que el peor caso estimado es adecuado. El diseño detallado debe ser revisado; si la estimación indica que es correcto se procede al test de la aplicación. Esto debe involucrar la medición del tiempo actual en la ejecución del código. Ciclo de Vida Iterativo (Modificado) Ciclo de Vida Iterativo (Modificado) Def. de Requerim. (Requis.) Diseño de la Arquitectura Diseño detallado Test Proceso de desarrollo iterativo de HRT-HOOD Arquitectura Lógica: Objetos y Operaciones En la fase de diseño de la arquitectura lógica se definen los objetos y sus operaciones. Se siguen unas reglas de descomposición jerárquica y uso que posibilitan el análisis del comportamiento temporal. Se tiene en cuenta 2 aspectos: Soporta abstracciones requeridas para el diseño de un STR duro. Tiene en cuenta restricciones para que la arquitectura lógica pueda ser analizada durante el diseño de la arquitectura física. Resumen Sistemas de Información 2 Codificación 1 2 El resultado del diseño de la arquitectura lógica es una colección de objetos terminales con todas sus interacciones totalmente definidas. Tipos de objetos: En HOOD se definen 2 tipos de objetos: Pasivo y activo; HRT-HOOD extiende el número de tipos base e incluye: Protegido, Cíclico y Esporádico. Pasivos: No controlan cuando se ejecutan sus operaciones y no invocan operaciones de otros objetos espontáneamente, por tanto sus operaciones se ejecutan cuando el objeto es invocado. Activos: Pueden controlar cuando se ejecutan invocaciones de sus operaciones y pueden espontáneamente invocar operaciones en otros objetos. Sus operaciones pueden bloquearse por restricciones de operaciones o restricciones funcionales. Protegidos: Pueden controlar cuando se llama a sus operaciones pero ellos no pueden llamar espontáneamente a operaciones de otros objetos. Normalmente las operaciones se ejecutan en exclusión mutua y la invocación puede ser asíncrona o sincrónica. Si es síncrona puede tener temporización. Controlan el acceso a datos compartidos por varios hilos (actividades concurrentes). Cíclicos: Representan actividades periódicas, pueden invocar espontáneamente operaciones de otros objetos; pero solo pueden contener operaciones que demandan atención inmediata, es decir Transferencia de Control Asíncrona (A.T.C.). Esporádicos: Representan actividades esporádicas. Pueden invocar espontáneamente operaciones en otros objetos. Tienen una única operación asíncrona (START). Pueden tener eventualmente operaciones de transferencia de control asíncrona (A.T.C.), es decir de atención inmediata. Transformación de datos Operaciones asociadas a los objetos Respuesta a excepción, puede estar o no. Llamada a Operación Reglas de Descomposición Jerárquica y Uso El diseño de la arquitectura lógica puede comenzar con la producción de objetos Activos y Pasivos, y por un proceso de descomposición se llega a la producción de objetos terminales de un carácter apropiado. Las transacciones están Resumen Sistemas de Información 2 Nombre del objeto Tipo de objeto 1 3 representadas como objetos Cíclicos o Esporádicos dependiendo si está dirigida por el tiempo o por el evento. El objeto es descompuesto en objetos terminales contrastados de precedencia. Restringir Diseño para Análisis Se requiere una serie de restricciones que naturalmente se refieren a la sincronización y comunicación que se permite entre objetos. 1. Objetos cíclicos y esporádicos no pueden llamar arbitrariamente a operaciones bloqueantes de otros objetos de este tipo. 2. Objetos cíclicos y esporádicos pueden llamar operaciones con el objeto ATC en otros objetos de este tipo. 3. Objetos protegidos no pueden llamar a operaciones bloqueantes en otro objeto. 4. Las operaciones pasivas contienen solo código potencial que no necesitan ser sincronizadas con otras operaciones u objetos. Arquitectura física El objetivo de esta fase es relacionar la arquitectura lógica con recursos de ejecución y asegurar el cumplimiento de los requisitos no funcionales. Para ello se realiza: Asignar objetos a procesadores: asegurarse que todos los objetos que controlan los dispositivos que están situados en el lugar en que reside el dispositivo. Planificar la red de comunicaciones: para que el retrazo de los mensajes sea limitado. Planificar el procesador: Determinar la política de planificación (estática o dinámica) de forma que se asegure de que todas las tareas dentro de los objetos residentes en los procesadores cumplan sus plazos. Análisis de fiabilidad: Determinar si un objeto debe ser reproducido para tolerar fallos de hardware y estimar técnicas de tolerancia según la complejidad del objeto. Como resultado de esta fase se obtiene un sistema de objetos con atributos temporales y de otros tipos, además de un análisis temporal y otros tipos de análisis. Diseño detallado y codificación Una vez planteada la arquitectura se continúa con las fases de diseño detallado, generación del código y estimación de sus tiempos de ejecución (incluida la plataforma) a fin de verificar los presupuestos previstos. Metodología DARTS (Design Approach for Real Time Systems) Autor: Hassan Gomaa. Es un método basado en la notación y el enfoque del Diseño Orientado al Flujo de Datos adaptado a las necesidades especiales de los STR. El método tiene una serie de extensiones respecto a los que tienen el diseño orientado al flujo de datos, las que le permiten: 1. Representar la Comunicación y Sincronización entre tareas. 2. Suministrar una notación especial para representar la dependencia entre estados. 3. Suministrar una notación adicional para representar todas las características de los STR Puede verse como una extensión de diseño o análisis estructurado, dando un método para estructurar al sistema en tareas y un mecanismo para definir las interfaces entre tareas. Se intenta que sea iterativo. La mayoría de los STR soportan algún mecanismo de sincronización y comunicación entre tareas, debido a que estos son esenciales en las Resumen Sistemas de Información 2 Prueba y medida de tiempos Finalmente durante la fase de pruebas se miden los tiempos de ejecución y se verifica que se cumplen las restricciones temporales. 1 4 operaciones entre tareas, a que hay múltiples tareas para compartir el procesador y debido a que éstas se ejecutan simultáneamente en procesadores distribuidos. En lo que hace a la sincronización, los tipos provistos son: Exclusión mutua: Se aplica cuando 2 tareas quieren acceder a un área de datos compartida al mismo tiempo. Estimulación Cruzada: Se aplica cuando una tarea señala a la otra que está esperando que haya terminado alguna actividad, entonces la tarea señalada puede proceder. Los tipos de comunicación provistos en este método son: Uso común de Memoria por intercambio de mensajes: Fuertemente acoplada. Débilmente acoplada Las Etapas del método son las siguientes: 1. Análisis del flujo de datos: Los DFD´s son usados como una herramienta de análisis. Comenzando con los requerimientos funcionales del sistema, son analizados los DFD´s del sistema y determinadas las funciones principales. Se realiza la representación general del sistema a través del Diagrama de Contexto. Construcción de la Lista de Eventos. Construcción de los DFD`s y DFC’s con sus correspondientes especificaciones de procesos mediante (Ward-Mellor / Hatley Pirbhai). Realizar la documentación en el Diccionario de Datos. Identificación de tareas de TR. 2. Descomposición en Tareas: Una vez creados los DFD y el DC, el sistema debe analizarse desde un punto de vista diferente para identificar las tareas de tiempo real. Nos basamos en el análisis de los DFD`s para ver si las transformaciones de datos que allí aparecen constituyen en sí mismas una tarea en tiempo real o agruparlas en otras trasformaciones para que en conjunto constituyan una tarea en TR. Hassam Gomaa propone una serie de criterios para analizar si conviene agruparlas a las tareas. Dependencia de Entrada-Salida: Aquellas trasformaciones de datos que lleven a cabo operaciones de E/S deben mantenerse como una tarea del tiempo real; no se deben agrupar con otras porque la tarea debe trabajar a la velocidad del dispositivo con el que interactúa y conviene dejarlos como tareas independientes. Funciones de Tiempo Crítico: Una función de tiempo crítico es aquella que necesita ejecutarse a una alta prioridad. Tampoco conviene agruparlas con otras porque transformaríamos en crítica a otra tarea que no lo es. Requisitos Computacionales: Hay tareas o conjuntos de tareas que realizan mucho cálculo, por lo que pueden ejecutarse con prioridad baja aprovechando tiempo sobrante de procesador. También en ese caso conviene tenerla como una tarea aparte. Cohesión Funcional: Las transformaciones que ejecuten un conjunto de funciones fuertemente relacionadas, conviene agruparse juntas en una sola tarea puesto que el tráfico de datos entre ellas puede ser alto y si se las toma como tareas separadas se incrementaría la sobrecarga del sistema desde el punto de vista de las interfaces. No deberíamos colocar juntas funciones que realicen distintas tareas. Cohesión Temporal: Ciertas transformaciones ejecutan funciones que se realizan en el mismo tiempo. Si en un sistema tenemos más de una función activada por el mismo evento temporal, es conveniente agruparlas en una sola tarea. Resumen Sistemas de Información 2 Criterios: 1 5 Ejecución Periódica: Una trasformación que necesita ejecutarse periódicamente puede estructurarse como una tarea separada que se activa a intervalos regulares. 3. Modelización de la Comunicación y Sincronización entre Tareas: Después de agrupar las tareas, hay que considerar las interfaces entre ellas. En DARTS las interfaces entre las tareas son manejadas definiendo dos clases de módulos de interfaces entre tareas: Módulos de Comunicación entre tareas y Módulos de Sincronización entre Tareas. Módulo de Comunicación entre Tareas (MCT): Es producido por una tarea de comunicación y utiliza las primitivas de sincronización del S.O. para asegurar el adecuado acceso a los datos. Dos Diferentes tipos de de MCT son soportados en DARTS: Módulo de Comunicación de Mensajes (MCM): Soporta mecanismos de comunicación e implementa los mecanismos adecuados para gestionar una Cola de Mensajes en el caso en el que la comunicación sea Débilmente Acoplada y Primitivas de Sincronización cuando la comunicación es Fuertemente Acoplada. MCM Fuertemente Acoplado MCM Débilmente Acoplado Mensaje (M) P P C Productor P envía mensaje (C,M) Cola de Mensajes. C Consumidor C recibe Productor P envía el mensaje (P,M) y mensaje (C,M) y queda Respuesta (R) genera la respuesta suspendido a la espera (P,R) de la respuesta (C,R) Consumidor C recibe el mensaje (P,M) P queda bloqueado a la espera de la respuesta P no queda bloqueado. Módulo de Ocultamiento de la Información (MOI): Utiliza área de memoria compartida, la cual es accesible para dos o más tareas para propósitos de lectura y de lectura/escritura. MCM Débilmente Acoplado Almacén de datos T1 Datos Leídos No hay mensajes, la comunicación se da por un área común de memoria. Datos Escritos T2 Módulo de Sincronización entre Tareas (MST): Se usa cuando en lugar de transferir datos se transfiere control. Una tarea destino puede esperar por la ocurrencia de un evento, o una tarea origen puede mandar como señal un evento que activa la tarea destino. El mecanismo de sincronización se extiende para permitir que una tarea espere por cualquiera de varios eventos que sean señalados. Si cualquier evento es señalado, la tarea es activada. Las primitivas para señalar un evento y esperar por un evento son provistas por el sistema operativo. Esperar por un número de eventos puede llegar a ser una situación de sincronización más complicada, y, por esta razón, es introducido el concepto de MST. Suceso S F D (Señal) Fuente F señala a D el suceso S (Emisora de la señal) No hay intercambio de datos sino de control entre tareas. Destino D espera el Suceso S (Receptora de la Señal) Un MST es típicamente el módulo principal o el módulo supervisor de una tarea. Hay usualmente un solo MST por tarea, y este es requerido únicamente por aquellas tareas que hacen una cantidad significativa de tareas de sincronización. En este módulo, la tarea espera la ocurrencia de uno o más eventos; estos pueden ser eventos sincronizados o eventos de colas de mensajes. Dependiendo de las circunstancias, la tarea puede esperar por eventos diferentes en tiempos diferentes. Resumen Sistemas de Información 2 Datos Escritos 1 6 Ejemplo de la aplicación del Método: Consideremos un Sistema de Control de Tráfico Aéreo (SCTA). Debe adquirir información de los equipos transmisores de un avión dentro de un área de control. Los datos se colocan en una BD desde la que se crean visualizaciones para los controladores de tráfico aéreo. Los controladores pueden pedir a la BD determinadas informaciones. Avión con transmisor Radar Interacción con Controlador y Visualización Controlador de Tráfico Aéreo Base de Datos Adquisición y Análisis de Datos El sistema debe operar bajo un rendimiento rígido y ligaduras de fiabilidad. La adquisición de datos debe ser conducida a intervalos pre-especificados. El análisis debe ejecutarse dentro de las ligaduras de tiempo de ejecución especificado. La BD debe ser actualizada a intervalos definidos. La interacción del controlador no debe impedir cualquier otra función del sistema. El método DARTS: comienza con la derivación de los niveles 01 y 02 de los DFD. Además el analista debe crear el Diccionario de Datos para todos los elementos de datos. Estos no hacen referencia a la naturaleza del TR del SCTA, sino a las diferentes tareas que se requieren para implementar el SCTA. DFD Nivel 01 Señal transmisor Avión Visualización SCTA Controlador de Tráfico Aéreo Consultas y órdenes DFD Nivel 02 1 2 3 tare as BD 5 4 6 Informes Resumen Sistemas de Información 2 Estación de control Avisos 1 7 Examinando el DFD del Nivel 02 y aplicando criterios de definición de tareas puede definirse el conjunto de tareas del sistema: Tarea de Adquisición de Datos. Tarea de Análisis de Datos. Tarea de E/S de la BD. Tarea de Visualización. Tarea de Interacción del Controlador de Tráfico Aéreo. Cada una de estas tareas puede ser subdividida posteriormente en otras tareas concurrentes. Puede crearse un DTE para ilustrar la comunicación y los sucesos que hacen que un sistema pase de un estado al siguiente. Volviendo al Nivel 02 del DFD para SCTA, las tareas de TR están superpuestas sobre el flujo de datos usando los límites en líneas discontinuas para delinear las tareas. Finalmente, se crea la representación del control y comunicación entre tareas. Interrupción del temporizador DFD Nivel 03 Adquisición de la Señal Interrupción del controlador Análisis de la Señal Cualquiera puede tomar la información; en una cola solo una tarea Interacción con el Controlador Cola de Mensajes Procesador de E/S Proceso de Visualización El método DARTS extiende la notación de flujo de datos facilitando al diseñador la representación de transiciones de estado, comunicación entre tareas y concurrencia. Además el uso de módulos de interfaces de tareas (MCT y MST) da un medio de implementar las actividades de comunicación y sincronización. Metodología COMET DISEÑO DE SISTEMAS EMBEBIDOS Y DE TIEMPO REAL CON EL METODO COMET/UML La mayoría de los métodos de análisis y diseño orientados a objetos solamente dirigen el diseño de sistemas secuenciales u omiten problemas importantes de diseño que necesitan ser dirigidos cuando se diseñan aplicaciones en tiempo real y distribuidas [Bacon97, Douglas99, Selic94]. Es esencial combinar conceptos orientados a objetos con los conceptos de procesamiento con concurrente [MageeKramer99] para diseñar exitosamente estas aplicaciones. Este artículo describe algunos de los aspectos claves del método COMET para diseñar sistemas embebidos y de tiempo real Resumen Sistemas de Información 2 Los DFD's de Nivel 03 pueden crearse para cada tarea. Estas pueden transformarse en estructura de programa usando conversión por transformación o transacción. Los módulos de dentro de la estructura de programa para cada tarea pueden diseñarse usando métodos convencionales. 1 8 [Gomaa00], el cual integra conceptos orientados a objetos y de procesamiento concurrente utilizando la notación UML [Booch98, Rumbaugh99]. Se proporcionan ejemplos para un Sistema de Control de un Elevador (Ascensor) [Gomma00]. METODO COMET COMET es un Método de Diseño de Arquitectura y Modelado de Objetos Concurrente basado en UML para el desarrollo de aplicaciones concurrentes, en particular aplicaciones de tiempo de tiempo real y distribuidas [Gomma00]. El Ciclo de Vida del Software Orientado a Objetos COMET es altamente iterativo. En la fase Modelo de Requisitos se desarrolla un modelo de caso de uso, en el cual se definen los requerimientos funcionales del sistema en términos de actores y casos de uso. En la fase Modelo de Análisis, se desarrollan modelos estáticos y dinámicos del sistema. El modelo estático define las relaciones estructurales entre las clases del dominio del problema. Se utilizan criterios de estructuración de objetos para determinar los objetos a ser considerados para el modelo de análisis. El modelo dinámico se desarrolla luego, en éste los casos de uso del modelo de requisitos se redefinen para mostrar los objetos que participan en cada caso de uso y como interactúan unos con otros. En el modelo dinámico se definen objetos dependientes utilizando cartas de estados. En la fase de Modelo de Diseño, se desarrolla un Modelo de Diseño de Arquitectura. Se proveen criterios de estructuración de subsistemas para la arquitectura de software en conjunto. Para aplicaciones distribuidas se toma un enfoque de desarrollo basado en componentes, en el cual cada subsistema se diseña como un componente en si mismo distribuido. El énfasis está puesto en la división de responsabilidades entre clientes y servidores, incluyendo problemas concernientes a la descentralización vs. distribución de datos y control., y el diseño de interfases de comunicación de mensajes que incluyen comunicación sincrónica, asincrónica, de agente y de grupo. Cada subsistema concurrente se diseña en términos de objetos activos (tareas) y objetos pasivos. Se definen interfases de comunicación y sincronización entre tareas. El rendimiento de la planificación del tiempo real se estima usando una aproximación en base a un análisis monotónico [SEI93]. Fig. 1 Modelo de casos de uso /con casos de uso abstractos Resumen Sistemas de Información 2 MODELADO DE REQUERIEMINTOS CON UML En el modelo de requerimientos, el sistema se considera como una caja negra. Se desarrolla el Modelo de Casos de Uso (Fig. 1) , en el cual los requerimientos funcionales del sistema se definen en términos de casos y actores. Un actor es frecuentemente un usuario humano. En sistemas en tiempo real y embebidos, un actor que son dispositivos externos de E/S y relojes son particularmente prevalentes en sistemas embebidos de tiempo real, donde el sistema interactúa con el entorno externo a través de sensores y actuadores. 1 9 MODELO DE ANALISIS CON UML Modelo Estático Para los sistemas embebidos y en tiempo real, es particularmente importante comprender la interfase entre el sistema y el entorno externo (contexto del sistema). En UML, el contexto del sistema pude describirse usando ya sea un modelo estático o un modelo colaborativo [Douglass99]. El diagrama de clases del contexto del sistema provee una vista más detallada del límite del sistema para un sistema en tiempo real que un diagrama de casos de uso. Usando la notación de UML para el modelo estático, el contexto del sistema se describe mostrando el sistema como una clase agregada con el estereotipo de “sistema”, y el entorno externo se describe como una clase externa para el cual el sistema tiene una interfase. Las clases externas se categorizar usando estereotipos. Una clase externa puede ser un “dispositivo de entrada externo”, un “dispositivo de salida externo”, un “dispositivo externo de E/S”, un “usuario externo”, un “sistema externo”, o un reloj externo. Para un sistema en tiempo real es deseable identificar clases externas de bajo nivel que se correspondan con dispositivos físicos de E/S para los cuales el sistema tiene una interfase. Estas clases externas se describen con el estereotipo “dispositivo externo de E/S”. Los nombres utilizados en los diagramas de clases del contexto del sistema son (Fig. 2): “dispositivo de entrada externo”, entradas al “sistema” “dispositivo de salida externo”, salidas del “sistema” “usuario externo” interactúa con el sistema “interfases de un sistema externo” con el “sistema” “reloj externo” alerta (despierta) al sistema. Fig. 2 Diagrama de contexto de clases de un sistema de control de un elevador Modelo Dinámico Para aplicaciones concurrentes, distribuidas y de tiempo real, el modelo dinámico es particularmente importante. UML no enfatiza chequeo de consistencia entre las múltiples vistas de varios modelos. Durante el modelado dinámico es importante comprender como el modelo de máquina de estado finito se describe usando un diagrama de estados que Resumen Sistemas de Información 2 2 0 se ejecuta mediante un estado que depende de un objeto de control relacionado al modelo de interacción de estos objetos con otros objetos. El análisis dinámico dependiente del estado dirige la interacción entre los objetos que participan en el caso de uso dependiente del estado. El caso de uso estado dependiente del estado tiene un objeto de control dependiente del estado, el cual ejecuta un diagrama de estados, que provee el control y la secuencia del caso de uso. La interacción entre los objetos que participan en el caso de uso se describe sobre un diagrama de colaboración o un diagrama de secuencia. La carta de estado (Fig. 3) necesita ser considerada en conjunción con el diagrama de colaboración. En particular, esto es necesario para considerar los mensajes que se reciben y envían mediante el objeto de control, el cual ejecuta la carta de estados. Un evento de entrada en el objeto de control sobre el diagrama de colaboración debe ser consistente con el mismo evento descripto en la carta de estados. El evento de salida (quien causa una acción, habilita o deshabilita una actividad) en la carta de estados debe ser consistente con el evento de salida mostrado en el diagrama de colaboración. Cuando el análisis dinámico dependiente del estado se ha completado para la secuencia principal del caso de uso, la secuencia alternativa descripta en el caso de uso necesita ser considerada. Por ejemplo, ramas alternativas son necesarias para manejar un error. MODELO DE DISEÑO Arquitectura del Software Para la transición del análisis al diseño, es necesario sintetizar un diseño inicial del software desde el análisis realizado hasta ahora. En el modelo del análisis se desarrolla un diagrama colaborativo para cada caso de uso. El diagrama de colaboración consolidado es una síntesis de todos los diagramas de colaboración desarrollados para soportar los casos de uso. La consolidación realizada en esta etapa es análoga en robustez al análisis realizado en otros métodos [Jacobson92, Rosenberg99]. Estos otros métodos usan el modelo estático para el análisis robusto, mientras que COMET enfatiza el modelo dinámico, como así también direcciona la interfaz de comunicación de mensajes, lo cual es crucial en el diseño de aplicaciones de tiempo real y distribuidas. El diagrama de colaboración consolidado describe los objetos y mensajes de todos los casos de uso basados en diagramas de colaboración. Las interacciones entre objetos y mensajes que aparecen en más de un diagrama de colaboración se muestran solamente una vez. En el diagrama de colaboración consolidado es necesario mostrar los mensajes que son enviados tanto como los resultados de la ejecución de secuencias alternativas además de la Resumen Sistemas de Información 2 Fig. 3 Carta jerárquica de estados para control del elevador 2 1 secuencia principal a través de cada caso de uso. El diagrama de colaboración consolidado intenta así ser una descripción completa de la comunicación de todos los mensajes. El diagrama de colaboración consolidado puede ser muy grande para un sistema grande, y puede no ser práctico para mostrar todos los objetos en un diagrama. Una aproximación para manejar problemas de gran escala es desarrollar diagramas de colaboración consolidados para cada subsistema, y desarrollar un diagrama de colaboración para un subsistema de alto nivel para mostrar las interacciones dinámicas entre subsistemas, el cual describe la arquitectura global (total) del software (Fig. 4). Fig. 4 Ejemplo de un Sistema de Control de un Elevador Distribuido DISEÑO DE LA ARQUITECTURA DE SISTEMAS DE TIEMPO REAL DISTRIBUIDOS Estructuración de tareas Durante la fase de estructuración de tareas (objetos activos), cada subsistema se estructura dentro de una tarea concurrente y se definen las interfases entre tareas. Los criterios de estructuración de tareas son provistos para asistir en el mapeo de un modelo de de análisis del sistema orientado a objetos a una arquitectura de tareas concurrentes (Fig. 5). Siguiendo la aproximación usada para estructurar objetos, se utilizan estereotipos para describir las diferentes clases de tareas. Los estereotipos son también usados para describir diferentes clases de dispositivos que vinculan las tareas. Durante la tarea de estructuración, si se determina en el modelo de análisis un objeto como activo, entonces es categorizado más tarde para mostrar sus tareas características. Por ejemplo, un objeto activo “interfase de dispositivo de E/S” es considerado una tarea y categorizado como: una “tarea de interfase de dispositivo E/S asíncrono”, una “tarea de interfase de dispositivo E/S periódica”, una “tarea de interfase de dispositivo E/S pasiva”, o una tarea de “monitor de recurso”. Similarmente un dispositivo de entrada externo se clasifica, dependiendo de sus características en, “dispositivo de entrada asíncrono” o “dispositivo de entrada pasivo”. Resumen Sistemas de Información 2 Los sistemas en tiempo real distribuidos se ejecutan sobre nodos distribuidos geográficamente mediante una red de área local o área extensa. Con COMET, un sistema en tiempo real distribuido se estructura dentro de subsistemas distribuidos, donde un subsistema se diseña como un componente configurable y corresponde a un nodo lógico. Un subsistema componente se define como un conjunto de tareas concurrentes que se ejecutan sobre un nodo lógico. Un subsistema componente potencialmente reside sobre diferentes nodos, toda comunicación entre subsistemas componentes debe restringirse a comunicación de mensajes. Las tareas en diferentes subsistemas pueden comunicarse entre ellas usando varios tipos diferentes de comunicación mensajes (Fig. 4) que incluyen comunicación asíncrona y comunicación síncrona, comunicación cliente/servidor, comunicación grupal, agentes de comunicación, y comunicación negociada. 2 2 Fig. 5 Arquitectura de tareas e interfases de tareas del subsistema Elevador Diseño Detallado del Software En esta etapa, se diseña la composición interna de las tareas que contienen objetos anidados, se detallan los problemas de sincronización de tareas, se diseñan las clases conectoras que encapsulan el detalle de la comunicación entre tareas, y se define la secuencia lógica de eventos internos de cada tarea. Las clases conectoras encapsulan los detalles de comunicación entre tareas, tales como comunicación de mensajes débil y fuertemente acopladas. Algunos lenguajes de programación concurrentes, tales como Ada y Java proveen mecanismos para comunicación y sincronización entre tareas. Ninguno de estos lenguajes soporta comunicación de mensajes débilmente acoplada. Para proveer esta capacidad es necesario diseñar una clase conector Cola de mensajes, la cual encapsula una cola de mensajes y provee operaciones para acceder a la cola. Un conector se diseña usando un monitor, el cual combina los conceptos de ocultamiento de información y sincronización de tareas [Bacon97, MageeKramer99]. Estos monitores son usados en sistemas de un solo procesador o múltiples procesadores con memoria compartida. Los conectores pueden ser diseñados para manejar comunicación de mensajes débilmente acoplada, comunicación de mensajes fuertemente acoplada sin respuesta, y comunicación fuertemente acoplada con respuesta. ANALISIS DE PERFOMANCE DE DISEÑOS DE TIEMPO REAL El análisis de perfomance del diseño del software es particularmente importante para sistemas de tiempo real. Las consecuencias de una falla del sistema de tiempo real para lograr una meta pueden ser catastróficas. El análisis cuantitativo del diseño de un sistema de tiempo real permite la detección temprana de un problema potencial de perfomance. El análisis se realiza para el diseño conceptual del software que se ejecuta sobre una Resumen Sistemas de Información 2 Si una clase pasiva es accedida por más de una tarea, entonces las operaciones de clases deben sincronizar el acceso a los datos encapsulados. La sincronización se logra usando la exclusión mutua o algoritmos de múltiples lectores y escritores [Bacon97]. 2 3 configuración de hardware dada con un trabajo externo dado aplicado a el. La detección temprana de problemas potenciales de perfomance permite diseñar software alternativo e investigar configuraciones de hardware. En COMET el análisis de perfomance del diseño del software se logra mediante la aplicación de teoría de planificación de tiempo real. La planificación de tiempo real es una aproximación particularmente apropiada para sistemas de tiempo real duro que tienen plazos que deben ser cumplidos [SEI93]. Con esta aproximación el diseño en tiempo real se analiza para determinar si se pueden lograr sus plazos. Una segunda aproximación para analizar la perfomance de un diseño es usar un análisis de la secuencia de eventos e integrar esto con la teoría de planificación de tiempo real. El análisis de la secuencia de eventos considera escenarios de colaboración de tareas (objetos activos) y las anota con parámetros de tiempo para cada uno de los objetos activos que participan en cada colaboración (Fig. 6), además del sistema superior para la comunicación entre objetos y el cambio de contexto. El período equivalente para los objetos activos en la colaboración es el mínimo tiempo entre arribos de eventos externos que inicializan la colaboración. Fig. 6 Sistema de Control de Elevador no distribuido, diagrama de secuencia de tiempo Cuando se diseña sistemas de tiempo real embebidos, es esencial combinar conceptos orientados a objetos con los conceptos de procesamiento concurrente. En este trabajo se han descripto algunos de los aspectos claves del método COMET para diseñar sistemas de tiempo real embebidos, el cual integra conceptos orientados a objetos y de procesamiento concurrente, y utiliza la notación UML. Resumen Sistemas de Información 2 CONCLUSIONES 2 4 Unidad 5: Modelización de la Implementación. i) Investigación de las restricciones de implementación Modelo de implementación La idea fundamental con la que el Modelo Esencial es concebido es la de Tecnología Perfecta en la cual no hay restricciones de cantidad de memoria, tamaño del disco o velocidad del procesador. Con el Modelo de Implementación se describe la tecnología sobre la cual se implementa y que se empleará para que el sistema pueda operar de una manera óptima. Se debe considerar ahora, las imperfecciones de la tecnología y determinar: la cantidad de procesadores necesarios, las cualidades de estos procesadores, el tamaño de disco necesario de acuerdo al volumen de la información a ser almacenada, etc. Luego se diseña la solución sobre la base de esas restricciones tecnológicas. La creación de un modelo de implementación es fundamentalmente una actividad de derivación, en la cual se traza el contenido del modelo esencial en un entorno de implementación. Es el diseño lógico de cómo se va a implementar físicamente un sistema a partir del modelo esencial. Restricciones de Implementación: Puede definirse como el límite de la performance del sistema, como resultado de la elección de la tecnología de implementación. Ejemplo: velocidad de procesamiento, capacidad de memoria, etc. Lo que implica que la determinación de estas restricciones debe ir mano a mano con el modelado de la implementación. Restricciones ambientales: Son aquellas restricciones cuantitativas que no dependen de la tecnología de implementación y que están asociadas al modelo esencial. Restricciones de Implementación Vs. Disponibilidad de recursos Las restricciones de implementación hacen diferencia entre la cantidad de recursos que se quiere utilizar O(u); y la máxima cantidad de recursos que se pueden adquirir O(s). Si O(u)>O(s) => La implementación no es factible y se debe explorar una nueva estrategia. Si O(u)<O(s) => Existen recursos potencialmente en exceso que deben ser redistribuidos. Solamente Si O(u)=O(s) => es una restricción bien justificada y prudente. Información del ambiente para determinar restricciones Las restricciones de implementación frecuentemente deben derivarse de la información del ambiente del sistema. Una fuente útil de información es el DC y los flujos de entrada y salida del DC cuyas características deben ser consideradas en la implementación. Para examinar tales características se las separa en discretas y continuas. Flujos discretos Tamaño del flujo (Nº de bits x flujo) Tasa promedio de ocurrencia Resumen Sistemas de Información 2 Las restricciones de implementación dependen de la disponibilidad de recursos de implementación física tales como: el tamaño de memoria, tasa de comunicación, etc. Es necesario identificar cuánto de estos recursos se necesita y cuánto es lo que se puede adquirir. 2 5 Máxima tasa de ocurrencia Tiempo requerido de retención (si el sistema debe almacenar internamente el flujo). Flujos continuos Rango (o máxima amplitud) Tasa de señal/ruido Perfil de frecuencia (identificación del componente más importante de frecuencia máxima de variación). El Modelo Esencial como fuente de restricciones de implementación La parte del Modelo Esencial relacionada con las transformaciones, tanto de datos como de control, puede servir como esqueleto para identificar las necesidades o restricciones de implementación. Aquí se debe tener en cuenta los elementos del modelo esencial cuya duración es independiente de la implementación como: transformaciones de datos habilitadas y deshabilitadas, estados transitorios Y aquellos elementos del modelo esencial cuya duración depende de la implementación: transiciones entre estados, intervalos entre entradas y salidas discretas de la transformaciones de datos, intervalo entre el cambio en el valor de una entrada continua y la salida correspondiente de la transformación de datos. La porción del modelo esencial que se refiere a los datos almacenados (almacenes) también puede generar restricciones de implementación que pueden referirse a la disponibilidad de memoria primaria y secundaria. Para determinar la cantidad de almacenamiento requerido es necesario conocer: Tamaño de los flujos de entrada. Tasa de arribo de estos flujos de entrada. Tiempo que se deben retener los flujos de entrada. Las relaciones en un DER también generan necesidades de volumen de almacenamiento de datos ya que una relación debe ser implementada como un puntero o como datos embebidos. MODELO DE PROCESADORES El Modelo de Ambiente de Procesadores cubre tres áreas de desarrollo: 1) Selección de procesadores físicos sobre los cuales implementar el desarrollo. 2) Asignación del Modelo Esencial a estos procesadores físicos. Esto considera los requerimientos definidos por el Modelo Esencial, examinando el procesador disponible para realizar el trabajo y decidiendo que partes del trabajo se debe realizar sobre el procesador. 3) Definición de la Interfaz Hombre-Maquina. CRITERIOS DE ASIGNACION Se comparan los rasgos distintivos del procesador candidato y los datos distintivos del Modelo Esencial. Único Procesador: es el caso más simple de reorganización. El procesador candidato es capaz de llevar acabo todo el trabajo descripto en el Modelo Esencial. Si hay más de un procesador adecuado, la selección se basa en factores secundarios como el costo. Resumen Sistemas de Información 2 Muestra las decisiones que tomamos sobre las asignaciones a procesadores y las interfaces entre ellos. Cada procesador es responsable de una porción del Modelo Esencial. 2 6 Conjunto de Procesadores: la elección de procesadores se basa en: Distinciones Cualitativas Disponibilidad de un procesador en particular de un conjunto extendido de operaciones aritméticas. Capacidad para procesar arreglos. Facilidades de interfaz con un dispositivo periférico particular. Distinciones Cuantitativas Velocidad Capacidad de memoria principal Capacidad de memoria secundaria Característica del Ambiente del Sistema. El conflicto más serio que se puede presentar es Dividir una Transformación de Datos (representa una única respuesta a un evento) entre dos o más procesadores, pues se debe tener en cuenta detalles de sincronización entre procesadores. Además, es más difícil de implementar un cambio en la respuesta a un evento cuando la lógica está dispersa en dos procesadores IDENTIFICACION DE PROCESADORES Para identificar los procesadores necesarios se debe tener suficientes conocimientos técnicos y comprender los requerimientos del usuario o cliente en cuanto a tiempo de respuestas, costos de sus sistema, etc. Luego de identificar el procesador o los procesadores requeridos se los debe etiquetar con un nombre. Para hacer esto, se debe tener en cuenta el rol que el procesador juega en el sistema más que el nombre del fabricante o cualquier otra característica física. EVALUACION DE PROCESADORES La evaluación de un procesador implica considerar la capacidad del mismo para realizar un determinado tipo de trabajo, la capacidad en cuanto a poder de procesamiento, y el costo del mismo contra los beneficios que proporcionan. 1. El Modelo de Comportamiento Esencial: Se lo examina para cuantificar los recursos que se requieren. Primero se trabaja con los flujos de datos en el nivel más bajo del Modelo de Comportamiento y se evalúa cada una de las transformaciones. En cuanto a Transformaciones de Datos se puede analizar: el Tamaño de Código, el uso de CPU y la Clase de función. En cuanto Almacén de Datos se debe analizar el Tamaño de los Datos, y el Medio de Almacenamiento preferido. En cuanto a Flujo de Datos se debe evaluar la Tasa de Datos. Las estimaciones para las transformaciones del nivel más bajo de un DFD pueden unirse para dar una estimación de las trasformaciones de datos de más alto nivel. 2. Restricciones de Implementación y Ambientales: son requerimientos extras que no afectan el trabajo fundamental hecho por el sistema, pero afecta la forma en que se implementa. 3. Conocimiento de las Restricciones de Diseño Posteriores: estas pueden verse de dos formas: a) Se tiene que usar una arquitectura de software especial, necesitándose para ello un procesador que lo soporte. b) Presentir que algo que está en el diseño de más bajo nivel es probable que de problemas sobre cierto procesador; se debe ir entonces hacia niveles más bajos de diseño para identificar las áreas de problemas para confirmar que elección del procesador dará una solución que pueda ser implementada. Resumen Sistemas de Información 2 Aspectos a evaluar para determinar la capacidad de procesador requerido 2 7 4. Comportamiento Concurrente: se debe examinar el sistema en busca de áreas de potencial comportamiento concurrente. Puede ser no deseable tener demasiadas áreas de Comportamiento Concurrente. MECANISMOS DE ASIGNACION La asignación de procesadores es una reorganización del Modelo Esencial. Esto permite ver lo siguiente: 1) Requerimientos esenciales que serán soportados por el procesador. 2) Comportamiento extra que será agregado al procesador para soportar la asignación. 3) Interfaces que serán necesarias entre los procesadores. Para llevar a cabo este trabajo se necesita lo siguiente: El Modelo Esencial Las Restricciones de Implementación Ambiente y Conocimiento de Tecnologías disponibles. Al asignar comportamientos a procesadores siempre debe buscarse minimizar las interfaces creadas entre ellas. Cuando un sistema simple es dividido entre dos procesadores, una interfaz es creada. Esta interfaz debe ser considerada desde el punto de vista fisco y conceptual (software). Razones por las cuales se pueden requerir más de un procesador. I. Existen muchas actividades concurrentes en el sistema. II. Razones ambientales pueden imponer que el sistema no puede ser colocado en un solo lugar. III. No puede encontrarse un procesador que no tenga la capacidad de cómputo y desempeño para soportar la aplicación. En caso de alojar el Modelo Esencial en más de un procesador siempre se debe empezar por las transformaciones de alto nivel. MODELO DE INTERFAZ HOMBRE-MAQUINA (IHM) Es la parte visible del sistema, lo que ve el usuario y con lo que interactúa. Allí se representan entradas, ventanas, botones y salidas del mismo. Para evitar desperdiciar dinero en desarrollar una IHM que el cliente luego modifique se considera la construcción previa de prototipos. Para el cliente la IHM es la parte más importante del sistema. Es un área donde el cliente tiene una idea de lo que el sistema debería hacer. Cuando la IHM es realizada, el cliente comienza a discutirla y surgen nuevas áreas de funcionabilidad. Lo que le interesa al cliente es que el sistema se vea, se use y funcione bien para que cause buena impresión. Una mayor amigabilidad no implica funcionabilidad superior. Se debe diferenciar al cliente del operador. Para evitar errores hay que hablar con el operador. LA VISION DEL DESARROLLADOR Es la interfaz que involucra el mayor trabajo y mayor dificultad para hacerlo bien. El sistema debe pedir la información de la manera más detallada posible porque es mucho mas probable que una persona cometa errores a que lo haga la maquina. El sistema debe chequear la entrada de datos al mismo y tratar de guiar al usuario cuando este cometa algún error. Además, la interfaz entre el sistema y una persona es mas subjetiva; no siempre el diseño agradará a todas las personas, pero debe hacerse acorde a la mayoría de estas, la mayor parte del tiempo. La interfaz hacia una persona suele ser más grande que la de una pieza de equipo. Cuando el sistema “habla” con una persona: Resumen Sistemas de Información 2 LA VISION DEL USUARIO 2 8 1. Debe ser agradable a la persona. 2. No es lo mismo que la persona entienda lo que hace el sistema en primera instancia a que entienda el funcionamiento completo. 3. Es mucho más probable que una persona cometa errores a lo que lo cometa una maquina. Existe una gran diferencia entre el simple diagrama, el Modelo Esencial y la mucha más complicada realización de la IHM en la implementación. ESTRATEGIAS PARA LA MODELIZACION DE LA IHM Una vez que tenemos idea de la IHM requeridas podemos modelar el comportamiento para ayudarnos a verificar la IHM con el cliente y el operador y también desarrollar la interfaz completa a través del código. Los detalles deben ser recogidos desde el usuario del sistema. Existen tres estrategias, la selección depende de la complejidad y tipo de IHM requerida: 1. Descomposición Funcional Descendente (Top-Down): se descompone una función y se realiza la secuencia con que se efectuara el dialogo. Este método se usa cuando la IHM no es muy complicada y se confía en la descomposición realizada, sin separar el sistema en unidades de implementación. En esta etapa modelamos requerimientos de la IHM; Ej. Lo que hará y no como haremos que lo haga. Este método da como resultado el DFD y su correspondiente DTE. 2. Partición de Eventos: se crea un nuevo DC describiendo la IHM, desde el cual se puede construir la LE. El DC y la LE forman el Modelo Ambiental de la IHM. Este modelo posee tres ventajas: a. Existe un bajo acoplamiento entre el sistema y la interfaz, o sea el código es independiente (no esta mezclado). Por lo tanto es fácil cambiar el código de la interfaz sin cambiar el de las funciones. b. Modelar el sistema y la interfaz de usuario como sistemas paralelos permite que el desarrollo de cada uno de estos sea mucho más fácil. Un grupo puede trabajar sobre la funcionalidad esencial del sistema mientras que otra trabaja con la IHM. Los estados del DTE son análogos a las pantallas de la IHM. Las condiciones son análogas a las entradas del usuario y las acciones análogas a las respuestas del sistema a las entradas del usuario. Por lo tanto, debe ser fácil modelar una secuencia de pantalla usando un DTE. MODELO DEL AMBIENTE SOFTWARE El MAS permite considerar el SO, las rutinas de E/S y otras facilidades que se tienen disponibles en los procesadores. La Arquitectura del Software (AS): es una capa entre la aplicación y el procesador, la cual permite a la aplicación usar el procesador. Las Unidades de Ejecución: son las unidades de procesamiento en la AS elegida. Las Unidades de Almacenamientos de Datos: son unidades de datos en la AS elegida. Hay tres etapas en la MAS: 1) Elegir y evaluar la AS: consiste en describir que puede hacer la aplicación con la AS. Resumen Sistemas de Información 2 c. Debido al bajo acoplamiento entre la IHM y el sistema, es mucho más fácil generar el mismo sistema con diferentes interfaces acorde al requerimiento de los clientes. 3. Estructura de Menú: la estrategia final de comenzar con una estructura de menú y transformarla en una jerarquía de un DTE y un DFD. Sólo es aplicable si la IHM involucra ya sea una estructura de menú o secuencia de pantallas. En un DTE el sistema entra en un estado y espera que ocurra una condición con lo que lleva a cabo unas acciones que lo llevan al siguiente estado. 2 9 2) Remover toda la Tecnología Perfecta: consiste en descubrir todo lo que se necesita conocer acerca de cómo el procesador puede ser usado una vez que se haya elegido la AS del procesador. 3) Alojar el Modelo de Procesamiento, al Modelo de Ejecución y a las Unidades de Almacenamiento de Datos. El MAS producirá una jerarquía de DFDs para cada procesador. Las Transformaciones de Datos sobre el nivel superior del DFD en cada jerarquía representan ya sea Unidades de Ejecución o partes de la AS. Estos diagramas muestran como las Unidades de Ejecución utilizaran la AS. Las piezas de la AS son vistas como Terminadores Internos. Como desarrolladores solo nos interesamos en comprender la interfaz del sistema con estas piezas. Las Transformaciones de Datos las cuales representan la AS normalmente no se explotan en un DFD de más bajo nivel. EVALUACION DE LA ARQUITECTURA DEL SOFTWARE Los factores a considerar en la AS son: Adecuación Funcional de la AS: consiste en encontrar una AS que permita hacer lo que se necesita en el sistema. Ej. Elección de un paquete para graficar, elección del SO. Flexibilidad de la AS: es la capacidad de la AS para acomodarse a cambios en los requerimientos del sistema. Al elegir una AS se debe pensar no solo en lo que el sistema necesita en la actualidad, sino también en lo que podría necesitar en el futuro. Ej. Áreas concurrentes. Costo de la AS: existen muchos costos involucrados en la AS pero no todos son relevantes. Los costos que siempre deben ser considerados son: los Costos Financieros; los Costos relacionados con Tiempo y Esfuerzo para usar la Arquitectura y finalmente considera la Cantidad de Espacio y Tiempo de Procesador que usará la Arquitectura. “La elección de la AS tiene un gran impacto en el Tiempo de Desarrollo y por lo tanto en el Costo del Sistema. En el mundo real siempre antes de desarrollar el sistema se debe conocer la AS para no gastar tiempo diseñando problemas que no existen, escribiendo facilidades que ya estén disponibles o produciendo diseños imposibles de implementar en la AS elegida.” ADECUACION DE LOS ASPECTOS TECNOLOGICOS Esta etapa consiste en reemplazar la Tecnología Perfecta por la Tecnología Real. Como consecuencia de este cambio cinco áreas de problemas deben ser tratadas: Arribo de Datos Discretos Enable/Desable Simula llamada a procedimientos con parámetros Simula llamadas a procedimientos de E/S 2. Procesamiento de Datos Continuos: la tasa de instrucción cero y la capacidad de procesamiento infinito hicieron que fuera factible aceptar y procesar datos continuamente. En tecnología real una Transferencia de Datos Continua podría procesar toda la potencia de procesamiento dejándolo sin tiempo para otras cosas (consume el tiempo del procesador). Se propone el uso de intervalos de muestreo. El intervalo de muestreo depende de la capacidad del procesador y de la tasa de cambio de la información muestreada. 3. Procesamiento de Datos Discretos: se debe tener en cuenta que los datos discretos están sujetos a arribos asincrónicos, puesto que en Tecnología Perfecta siempre se asumió que se podría ser capaz de aceptar y procesar los datos en el momento que estos arriben. Resumen Sistemas de Información 2 1. Proceso de Activación: consideramos los mecanismos actuales de activación disponibles en el SO y como logramos que cada Unidad de Ejecución corra en el momento (tiempo) requerido. El mecanismo mas común soportado por el SO son los Mecanismos de Interrupciones y Reanulación. Este tipo de mecanismos solo debe ser reflejado en el nivel superior del DFD. En los niveles más bajos del DFD, se utiliza los Mecanismos de Activación disponibles en el lenguaje de programación. Trigger Simula llamada a procedimientos sin parámetros. 3 0 Sin tener Tecnología Perfecta de los datos discretos pueden causar dos tipos de problemas: a. Los sistemas pueden no estar siempre disponibles para procesar los datos a medida que arriban. Existen dos alternativas de solución: I. Implementar un sistema para almacenar los datos que arriban para su posterior procesamiento. II. Comprarse un procesador más potente. b. En el Modelo Esencial las Transformaciones de Datos siempre tiene que esperar por datos discretos que no saben cuando arribaran. La única manera que el sistema no pierda el arribo asincrónico es que lo este esperando todo el tiempo. En un sistema de un solo procesador esto debe ser implementado a través de dos transformaciones, una que se encargue del envío y la otra que chequee la recepción. 4. Comportamiento Concurrente: se debe tener en cuenta que la concurrencia debe ser simulada porque solo se puede hacer una sola cosa a la vez en un procesador. La concurrencia puede ser necesaria ya sea porque es un requerimiento del usuario o para hacer un mejor uso del procesador cuando se tenga que trabajar con E/S. 5. Seguridad de los Datos: en Tecnología Perfecta el acceso a los datos es tan rápido que no existen problemas de contención (coordinación) entre transformaciones de datos que leen y escriben en áreas de datos compartidas. Se define una capa de acceso de datos. ASIGNACION DEL SOFTWARE Es una reorganización del MAP la cual muestra lo siguiente: a. Para cada requerimiento del MAP, como aquel requerimiento será implementado dentro de una AS o una Unidad de Ejecución. b. Comportamiento agregado al MAP para implementar el comportamiento requerido por la AS. c. Como las Unidades de Ejecución usaran la AS. Para llevar acabo la Asignación del Software se necesita lo siguiente: El MAP que muestre los requerimientos esenciales de cada procesador junto a cualquier información de implementación relevante. Un conocimiento de la AS disponible en cada procesador. 1. Asignar el Comportamiento de la MAP a la AS: consiste en colocar cada componente de la MAP ya sea dentro de una AS o dentro de las Unidades de Ejecución o Unidades de Almacenamiento de Datos. Cada componente del modelo MAP que sea dividido en más de una Unidad de Ejecución provoca la creación de una Interfaz, la implementación de la misma depende de las facilidades provistas por el SO. Siempre se debe buscar minimizar la cantidad de interfaces. En esta etapa se analiza como la AS implementara el comportamiento requerido de cada procesador. 2. Quitar áreas comunes de procesamiento desde la MAP 3. Asignación de Procesamiento (Transformación de Datos y Procesos de Control) a las Unidades de Ejecución: consiste en dividir el procesamiento en las Unidades de Ejecución, tomando como base la Concurrencia. Posibles Áreas de Concurrencia: Áreas de comportamiento conectadas por un único almacén de datos. Transformaciones de Datos que procesan secuencialmente flujos de datos. Transformaciones de Datos conectas por DTEs. Transformaciones de Datos habilitadas al mismo tiempo o cuando una transformación de datos es habilitada mediante el Enable/Desable y otra mediante Trigger. 4. Asignación de Datos a Unidades de Almacenamiento de Datos: se analiza como se implementaran físicamente los Almacenes de Datos del Modelo Esencial; Ej. la estructura de datos que se usaran, si se usaran un Sistema de Administración de BD; etc. Resumen Sistemas de Información 2 Pasos para la Asignación del Software 3 1 MODELO DE LA ORGANIZACIÓN DEL CODIGO (COM) Los aspectos que abarca la COM son los siguientes: 1. Traducir cada Unidad de Ejecución producida por el MAS en una Carta de Estructura (CE) preliminar. 2. Refinar la CE preliminar de modo tal que pueda escribirse con ella un programa implementable y bien estructurado. Un DFD no puede ser mapeado directo en un programa porque le falta la jerarquía de la mayoría de los lenguajes de programación. En la COM se introduce una jerarquía sobre los modelos existentes, usando la CE como documentación. En esta etapa nos concentramos sobre los DFDs y los DTEs. CARTA DE ESTRUCTURA (CE) O DIAGRAMA DE ESTRUCTURA (DE) Es un diagrama usado para mostrar la organización del código en un programa. Muestra en forma jerárquica los módulos de un programa y las interacciones entre ellos. COMPONENTES DE LA CE Modulo: es una colección de instrucciones tratadas como una unidad por el lenguaje de programación que se use (puede ser procedimiento, subrutina o función); se muestra como una caja con un nombre. Cada modulo tiene una especificación de apoyo que explica lo que pasa dentro de él. Llamada a Módulos: conectan a los módulos. El control de la CE siempre devolverá el modulo de arriba. Los flujos de control y de datos a través de una CE son a menudo diferentes, considerando que en los DFDs los flujos de control y de datos son los mismos. Acoples: el de los datos con vinculo al final de la flecha sin llenar, muestran que pasan datos; el de control que tiene un circulo lleno al final de la flecha, muestra que pasa información de estado. Centro de Selección: los módulos conectados a él son llamados en exclusión mutua. Inclusión: se coloca en la parte superior de un modulo, significa que su lógica se implementará en el modulo superior. Acople de Dialogo: un parámetro pasado al modulo inferior es modificado y devuelto al modulo superior. CONSTRUCCION La CE se construye a partir de la inspección de los DFDs y los DTEs. El proceso de control (DTE) se convierte en modulo principal, el cual describe la función del programa completo. Todo el trabajo del DTE es hecho por los niveles mas bajos de la CE, por lo tanto toda acción en el DTE se vuelve modulo. TRADUCCION DE LAS UNIDADES DE EJECUCION EN CARTAS DE ESTRUCTURA Traducción de los DTEs a CE Existen dos métodos para pasar de un DTE a una CE: 1. Tabla de Transición de Estados (TTE): son convenientes cuando la lógica dentro del DTE no es trivial. Para formar la TTE nos concentramos en los estados que poseen el sistema, y los eventos que pueden ocurrir. Para cada estado, designamos en una fila; y para cada evento, destinamos una columna. En las celdas de las tablas son divididas en dos partes: I. En la primera parte se definen las acciones que se han de llevar a cabo cuando ocurre el evento correspondiente a la columna, mientras el sistema se encuentra en el estado correspondiente a la fila. II. En el segundo fragmento se escribe el estado al cual pasa el sistema ante la ocurrencia del evento durante el estado correspondiente a la fila. Resumen Sistemas de Información 2 La información sobre acoplamiento es tomada desde los DFDs. Finalmente las especificaciones de los módulos se genera a partir de la Especificaciones de las Transformaciones de Datos. 3 2 Con esa matriz, surgen dos arreglos: la Tabla de Acción y la Tabla de Estados, ambos embebidos en el Modulo Principal del programa. La Tabla de Acción recibe un estado y una condición o evento, y devuelve las acciones a llevar a cabo estas circunstancias. La Tabla de Estados acepta un estado y un evento, y devuelve el estado al cual se pasa en esa transición. Por ultimo, se traduce a una instrucción CASE, donde los casos a evaluar son las acciones. 2. Codificación Directa: se usa cuando la lógica es muy simple, de manera que podrá ser codificado de manera manual. Los problemas relacionados con este método es que es mucho más difícil seguir entre éste código y el DTE, que entre las TTE y el DTE. Las condiciones inesperadas no son explícitamente consideradas. Traducción de DFD a CE Para poder aplicar este método lo primero que se debe hacerse identificar el Proceso de Control en el DFD, porque este será el programa principal y la jerarquía del programa de estructura se construye en base a este. Para identificar el proceso se conviene determinar si el DFD esta centrado en las Transformaciones o Transacciones. Se dice que un DFD esta centrado en las Transformaciones cuando existe un centro de proceso que transforma datos de entrada en salidas esenciales, en tanto que, en que en un DFD centrado en Transacciones existe un centro de proceso que en función de la entrada determina que camino seguirá en el DFD. Para traducir un DFD en un DE se debe seguir los siguientes pasos: Introducir Jerarquía Si el DFD es centrado en Transacción debemos identificar las transformaciones de datos controladora. Si el DFD es centrado en Transformación, la transformación de datos controladora es aquella que lleva a cabo la toma de decisiones y el procesamiento esencial. Una forma de facilitar el reconocimiento de esta transformación, es eliminando todas las transformaciones de datos vinculadas con la conversión de entradas de bajo nivel en entradas de alto nivel y salidas de alto nivel en salidas de bajo nivel. Si luego de este proceso queda más de una transformación de datos, se debe elegir la de más alto nivel. REFINAMIENTO DE LA CE En el Refinamiento de la CE se busca principalmente: Asegurar que le modulo no sea demasiado grande, demasiado pequeño o demasiado complejo. Asegurar que los módulos no realicen las mismas funciones. De ser necesario, se debe agrupar algunos módulos. Los pasos que se siguen en esta etapa son los siguientes: I. Factorear los Módulos del DE: a través de la factorizacion se expondrán las áreas de trabajo de más bajo nivel, las cuales pueden ser compartidas con módulos de más alto nivel. II. Módulos Pequeños absorbidos por los Módulos Convocantes: la división y la unión en el DE puede resultar en la obstrucción de la buena estructura inicial. III. Chequear Cohesión y Acoplamiento en el Diagrama de los Módulos, y el Balanceo del DE, reestructurando donde sea necesario. Resumen Sistemas de Información 2 Conversión del DFD Situar la Transformación de Datos controladora en el tope del DFD y hacer que el resto quede hacia abajo. Esto nos permite obtener una idea básica de cómo esta configurado el DE. Para determinar la conversión se debe traducir las Transformaciones de Datos en Módulos y los Flujos de Datos en Llamadas a Módulos con los datos asociados. 3 3