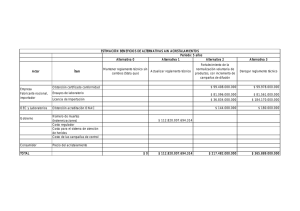
Servicio para la Mejora de Resultados en campañas de Email
Anuncio

UNIVERSIDAD DE CASTILLA-LA MANCHA ESCUELA SUPERIOR DE INFORMÁTICA GRADO EN INGENIERÍA INFORMÁTICA TECNOLOGÍA ESPECÍFICA DE TECNOLOGÍAS DE LA INFORMACIÓN TRABAJO FIN DE GRADO Servicio para la Mejora de Resultados en campañas de Email Marketing Jesús Botella Blanco Septiembre, 2014 S ERVICIO PARA LA M EJORA DE R ESULTADOS EN CAMPAÑAS DE E MAIL M ARKETING UNIVERSIDAD DE CASTILLA-LA MANCHA ESCUELA SUPERIOR DE INFORMÁTICA Tecnologías y Sistemas de Información TECNOLOGÍA ESPECÍFICA DE TECNOLOGÍAS DE LA INFORMACIÓN TRABAJO FIN DE GRADO Servicio para la Mejora de Resultados en campañas de Email Marketing Autor: Jesús Botella Blanco Director: Luis Jiménez Linares Director: Ignacio Arriaga Sánchez Septiembre, 2014 Jesús Botella Blanco Ciudad Real – Spain E-mail: [email protected] Teléfono: 666 690 512 c 2014 Jesús Botella Blanco Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". Se permite la copia, distribución y/o modificación de este documento bajo los términos de la Licencia de Documentación Libre GNU, versión 1.3 o cualquier versión posterior publicada por la Free Software Foundation; sin secciones invariantes. Una copia de esta licencia esta incluida en el apéndice titulado «GNU Free Documentation License». Muchos de los nombres usados por las compañías para diferenciar sus productos y servicios son reclamados como marcas registradas. Allí donde estos nombres aparezcan en este documento, y cuando el autor haya sido informado de esas marcas registradas, los nombres estarán escritos en mayúsculas o como nombres propios. i TRIBUNAL: Presidente: Vocal: Secretario: FECHA DE DEFENSA: CALIFICACIÓN: PRESIDENTE Fdo.: VOCAL SECRETARIO Fdo.: Fdo.: iii Resumen En la actualidad, muchas empresas han descubierto el email marketing como una nueva forma de comunicación y difusión de sus contenidos a sus clientes. Estas empresas utilizan sus propios sistemas de envío de correo o recurren a servicios web de envío de email marketing como Acumbamail para realizar estas campañas. Mediante las plataformas web es posible realizar el seguimiento de resultados pertenecientes a los envíos de las campañas, porcentaje de apertura, número de enlaces visitados, etcétera. Estas estadísticas pueden ser mejoradas mediante sencillas técnicas utilizadas para captar la atención de los usuarios a partir del asunto de las campañas incluyendo o evitando ciertas palabras. Este trabajo fin de grado desarrolla una herramienta para la predicción del porcentaje de apertura en el envío de campañas de email marketing, a partir de las estadísticas de campañas pertenecientes a los usuarios de la plataforma de Acumbamail sin recopilar en ningún momento datos de carácter personal. Estas predicciones pueden ser obtenidas gracias al servicio web desarrollado específicamente para este proyecto, utilizando el árbol de decisión que ha sido entrenado con los datos recopilados de las distintas campañas, permitiendo así mejorar el porcentaje de éxito de las mismas. V Abstract Nowadays, many companies have discovered the email marketing as a new way of communication and spreading their content to their customers. These companies use their own mailing systems or rely on web service for sending email marketing campaigns as Acumbamail. The obtained results in these campaigns can be tracked through web platforms, opening percentage, number of visited links, and so on. These statistics can be improved by simple techniques used to capture the users attention from email subjects, including or avoiding certain words. This project develops a tool for predicting opening rate in email marketing campaigns, from campaign statistics belonging to Acumbamail platform users without collecting any personal data. These predictions can be obtained through the web service developed specifically for this project, using the decision tree that has been trained with the collected data from Acumbamail campaigns, which would improve the success rate. VII Agradecimientos Gracias a todo el mundo que me ha ayudado a llegar a este momento tan importante de mi vida, por pequeña que haya sido la ayuda todo ha de ser agradecido. En primer lugar a mis padres y mi hermano, por quererme, darme todo lo que tengo y la oportunidad de estar donde estoy ahora mismo. Os quiero. A toda mi familia y amigos, por apoyarme y preocuparse en todo momento por mi. A Nuria, gracias por todo y por estar siempre ahí, eres muy buena y genial. No cambies nunca. Te quiero cielo ª. A mis compañeros de carrera, Javi, Cristian, César, Eulalio, David y Rubén, que han sido mi segunda familia estos cuatro años, gracias por ayudarme en todo lo que he necesitado y brindarme vuestra compañía. A Ignacio Arriaga, Rafael Cabanillas y Miguel Gómez por darme la oportunidad de poner mi granito de arena en Acumbamail, aprender multitud de cosas y haber pasado unos meses fantásticos con ellos, gracias y mucha suerte en todo. Y por último, a mi director de proyecto, Luis Jiménez por dirigir este proyecto y enseñarme lo que he tenido que aprender para la realización del mismo. Jesús IX A mis padres, mi hermano y Nuria xi Índice general Resumen V Abstract VII Agradecimientos IX Índice general XIII Índice de cuadros XVII Índice de figuras XIX Índice de listados XXI Listado de acrónimos XXIII 1. Introducción 1 1.1. Estructura del documento . . . . . . . . . . . . . . . . . . . . . . . . . . . 2. Objetivos 2 5 2.1. Objetivo general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.2. Objetivos específicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 2.2.1. Obtención de los datos procedentes de las campañas enviadas por Acumbamail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 2.2.2. Construcción del Árbol de Decisión . . . . . . . . . . . . . . . . . 6 2.2.3. Construcción de la Información . . . . . . . . . . . . . . . . . . . 7 2.2.4. Inferencia de los Supuestos . . . . . . . . . . . . . . . . . . . . . . 7 2.2.5. Selección de la Tecnología Necesaria para el Sistema de Información 8 2.2.6. Implementación del Sistema de Información e Integración de componentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 3. Antecedentes 9 3.1. Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XIII 9 3.2. Árboles de Decisión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 3.3. Email Marketing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 3.4. Servicios web mediante API . . . . . . . . . . . . . . . . . . . . . . . . . 14 3.5. Entorno de Trabajo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 3.5.1. Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 3.5.2. Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 3.5.3. Empresarial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 4. Método 23 4.1. Descripción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 4.2. Roles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 4.3. Documentación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 4.4. Eventos & Reuniones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 4.5. Integración con el Proyecto . . . . . . . . . . . . . . . . . . . . . . . . . . 26 4.5.1. Iteración 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 4.5.2. Iteración 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 4.5.3. Iteración 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 4.5.4. Iteración 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 4.5.5. Iteración 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 4.5.6. Iteración 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 4.5.7. Iteración 7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 4.5.8. Iteración 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 4.5.9. Iteración 9 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 4.5.10. Iteración 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 4.6. Planificación de Tiempos . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 5. Resultados 35 5.1. Visión General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 5.2. Construcción del Sistema de Información . . . . . . . . . . . . . . . . . . 37 5.3. Obtención de la información procedente de Acumbamail . . . . . . . . . . 38 5.4. Construcción del Árbol de Decisión . . . . . . . . . . . . . . . . . . . . . 41 5.4.1. Entrenamiento del Árbol e Inferencia de Supuestos . . . . . . . . . 42 5.5. Servicio Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 5.6. Interfaz Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 5.7. Integración con la plataforma de Acumbamail . . . . . . . . . . . . . . . . 52 5.8. Integración Continua de Cambios . . . . . . . . . . . . . . . . . . . . . . 53 xiv 5.8.1. ¿Cómo se utiliza fabric? . . . . . . . . . . . . . . . . . . . . . . . 6. Conclusiones 55 57 6.1. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 6.2. Problemas Encontrados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 6.3. Propuestas de Mejora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 A. Creación de una aplicación web con Django 63 B. Aspectos Legales 67 Referencias 69 xv Índice de cuadros 5.1. Detalles sobre la agrupación de los porcentajes de la tasa de apertura en las campañas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XVII 45 Índice de figuras 4.1. Línea de Tiempo perteneciente a los hitos del proyecto. . . . . . . . . . . . 33 5.1. Esquema de utilización del servicio . . . . . . . . . . . . . . . . . . . . . 36 5.2. Diagrama de clases del proyecto . . . . . . . . . . . . . . . . . . . . . . . 37 5.3. Árbol de decisión para determinar si es posible jugar al tenis. Pueden ser clasificadas las muestras comparando sus atributos con los del árbol y éste devolverá la clasificación asociada con la muestra elegida. Extraido y traducido desde (M ACHINE L EARNING , T OM M ITCHELL [Mit97]) . . . . 43 5.4. Árbol de decisión creado mediante palabras de ejemplo para ilustrar el funcionamiento del árbol que ha sido creado con las campañas de Acumbamail. Ejemplo en miniatura del árbol real creado con el framework para Python utilizado, scikit-learn . . . . . . . . . . . . . . . . . . . . . . 46 5.5. Diagrama de casos de uso pertenecientes al servicio web . . . . . . . . . . 47 5.6. Captura de pantalla perteneciente al servidor ejecutado manualmente para la muestra del procesamiento de asuntos. Prueba de predicción con la frase "Ten unas vacaciones de película". . . . . . . . . . . . . . . . . . . . . . . 49 5.7. Captura de pantalla perteneciente a la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no tengan cuenta en la plataforma de Acumbamail. Pantalla inicial sin resultados de predicción . . . . . . . . 50 5.8. Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura alta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5.9. Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura media-alta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5.10. Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura media . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5.11. Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura baja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 XIX 5.12. Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Consejos proporcionados a los usuarios . . . . . . . . . . . . 51 5.13. Captura de pantalla perteneciente a la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no tengan cuenta en la plataforma de Acumbamail. Pantalla de resultados de predicción. . . . . . . . . . . . . 52 5.14. Captura de pantalla perteneciente a la interfaz web de Acumbamail. Pantalla de utilización del servicio . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 5.15. Captura de pantalla perteneciente a la interfaz web de Acumbamail. Muestra de errores en la interfaz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 5.16. Captura de pantalla perteneciente a la interfaz web de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura mediaalta. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 xx Índice de listados 3.1. Ejemplo de Array en formato JSON . . . . . . . . . . . . . . . . . . . . . 16 5.1. Modelo de Información perteneciente a las campañas almacenadas . . . . . 38 5.2. Modelo de Información perteneciente a las campañas almacenadas . . . . . 38 5.3. Método para la obtención de la información de las campañas en wrapper de la API en Python . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 5.4. Método encargado de realizar la petición HTTP a la API para la obtención de la información. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 5.5. Código que convierte los asuntos en el formato aceptado por el árbol . . . . 44 5.6. Propiedad de la cabecera que controla el acceso de los servidores web al servicio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 5.7. Respuesta del servicio web en formato JSON, Petición Correcta . . . . . . 48 5.8. Respuesta del servicio web en formato JSON, Petición Errónea . . . . . . . 48 5.9. Modelo de Información perteneciente a las campañas almacenadas . . . . . 55 A.1. Modelo de Información perteneciente a las campañas almacenadas . . . . . 63 A.2. Modelo de Información perteneciente a las campañas almacenadas . . . . . 63 A.3. Modelo de Información perteneciente a las campañas almacenadas . . . . . 63 A.4. Modelo de Información perteneciente a las campañas almacenadas . . . . . 64 A.5. Modelo de Información perteneciente a las campañas almacenadas . . . . . 64 XXI Listado de acrónimos HTML HyperText Markup Language HTTP Hypertext Transfer Protocol JSON JavaScript Object Notation MIME Multipurpose Internet Mail Extensions MVC Modelo Vista Controlador ORM Object-Relational Mapping SOAP Simple Object Access Protocol REST Representational State Transfer RPC Remote Procedure Call URI Uniform Resource Identifier XML Extensible Markup Language CSS Cascading Style Sheets XXIII Capítulo 1 Introducción L nuevos canales de comunicación, como el correo electrónico, permiten transmitir de inmediato a nuestro público objetivo aquellos mensajes que se quieren hacerles llegar. OS La mayoría de los correos electrónicos recibidos en la bandeja de entrada están enviados por servidores automáticos de correo, como por ejemplo, boletines de noticias, emails de comercio electrónico, promociones, y multitud de cosas más. Algunos son abiertos con interés, pero muchos de ellos quedan sin ser leídos porque la información que aportan ha dejado de ser interesante, o el tipo de contenido ha ido cambiando con el tiempo. Un correo electrónico sin leer es una pérdida de recursos utilizados, primero por la persona que ha invertido el tiempo en seleccionar lo que quiere comunicar a los demás y segundo, por los recursos invertidos realizar el envío de ese correo que se va a quedar perdido en la bandeja de entrada. Por ello se tiene que poner todo el esfuerzo necesario en lograr que ese correo electrónico satisfaga al receptor, cumpliendo su cometido, ya sea porque le es útil o porque tiene curiosidad sobre su contenido [WDK11]. En esto se basa el tema de este trabajo fin de grado, en obtener el mayor éxito en la difusión de nuestros contenidos online mediante correo electrónico, como newsletters u ofertas de tiendas online, por ejemplo. También teniendo en cuenta que cada persona realiza una gestión diferente del correo electrónico y las diferencias entre culturas de las personas que puedan recibir nuestro mensaje alrededor del mundo [TMC+ 09]. Uno de los conceptos introducidos recientemente en el mundo de la informática es SaaS (Software as a Service). Basado en el concepto de cloud computing (computación en la nube), SaaS proporciona software que puede ser utilizado como una aplicación web mediante un navegador, o una API dedicada. Todos los datos asociados y el software se encuentran alojados en Internet. Se ha convertido en poco tiempo en un modelo bastante utilizado para aplicaciones de negocio como por ejemplo, Google Drive y Dropbox, entre otras. El trabajo está dirigido a la creación de un servicio para la mejora de los resultados que obtienen los usuarios de la aplicación de envío de email transaccional y boletines de noticias 1 de Acumbamail, analizando variables como el momento más adecuado en el que deben enviarse los correos electrónicos para que la tasa de apertura se maximice, o relacionando la tasa de aperturas de los destinatarios en función del tipo de contenido enviado. Todos estos resultados se obtendrán mediante el análisis de los datos recogidos en tiempo real por la aplicación ya existente, en la que los usuarios pueden realizar el envío de boletines de noticias o email transaccional y pueden ver en todo momento las estadísticas detalladas de los envíos realizados. 1.1 Estructura del documento A continuación se detalla la estructura restante del documento, los capítulos junto a una breve descripción sobre su contenido para facilitar la lectura dependiendo de la motivación del lector. Los capítulos incluidos a continuación contienen todos los detalles del proyecto, tanto los objetivos a cumplir, como la manera en que han sido llevados a cabo, además de los resultados y las conclusiones obtenidas con la realización del mismo. Capítulo 2: Objetivos En este capítulo se detallan los objetivos que se quieren conseguir con la realización del proyecto. Estos objetivos derivan de los requisitos impuestos al comienzo del proyecto, y de las funcionalidades que se desean obtener. Capítulo 3: Antecedentes En este capítulo se detallan las búsquedas llevadas a cabo previo comienzo del proyecto, para tener conocimiento de posibles proyectos similares que hayan sido ya realizados, o de problemas equivalentes que hayan sido solucionados. Capítulo 4: Método En este capítulo serán detalladas todas las decisiones tomadas para la realización del proyecto, como la elección de las tecnologías que van a ser utilizadas, o las pautas a aplicar para el desarrollo del mismo. También es detallada la planificación seguida a lo largo del proyecto, junto con las distintas etapas en que se ha dividido. Capítulo 5: Resultados En este capítulo se detalla el funcionamiento del sistema completo, además de cómo han sido realizadas todas las propuestas de las funcionalidades expuestas en el capítulo 4. Capítulo 6: Conclusiones En este capítulo se detallan las conclusiones que se han obtenido en el proyecto, sugerencias acerca de posibles mejoras o ideas para futuros proyectos a realizar a partir de este. Anexos Documentos que aportan información adicional sobre temas relacionados con el 2 proyecto. 3 Capítulo 2 Objetivos E este capítulo se describen los objetivos correspondientes al proyecto, el objetivo general y los objetivos específicos pertenecientes a cada parte del proyecto. N 2.1 Objetivo general El objetivo general del proyecto es la construcción de un sistema de ayuda a la toma de decisiones para campañas de comunicación via email. Para la consecución de los objetivos de este proyecto, se ha dividido en dos partes principales, la construccion del sistema de información y la dotación de capacidad de ayuda a la toma de decisiones. Las dos partes son igual de importantes. Sin un sistema de información no podría ser realizada toda la labor de la obtención de datos y su posterior tratamiento antes de la utilización. Igualmente, es fundamental dotar al sistema del componente necesario para realizar esas ayudas a la toma de decisiones. Este proyecto se desarrolla sobre los datos proporcionados por Acumbamail, una empresa cuya actividad principal es el envío de boletines y correos electrónicos transaccionales. Estos datos engloban las estadísticas de las campañas más relevantes enviadas por su sistema, incluyendo: Asunto del correo electrónico enviado en la campaña Número de correos electrónicos enviados en total Número de correos electrónicos de la campaña que han sido abiertos Número de correos electrónicos de la campaña que no han sido abiertos Soft Bounces: Correos Electrónicos no entregados por un problema temporal del servidor del destinatario. Hard Bounces: Correos Electrónicos no entregados porque el dominio no existe o la dirección de email es incorrecta. Número de Quejas en la Campaña: Suscriptores que han marcado la campaña como SPAM. 5 Clicks Únicos: Número de clicks realizados sobre los enlaces de la campaña. Sólo uno por suscriptor en cada enlace. Clicks Totales: Número de clicks realizados sobre los enlaces de la campaña. Tantos como clicks hayan hecho los suscriptores en los enlaces de la campaña. Gracias a estos datos junto a la infraestructura que será desarrollada, se podrá llevar a cabo la construcción de un sistema capaz de realizar predicciones sobre el porcentaje de apertura de las campañas a partir de las palabras claves contenidas en el asunto. Estas predicciones podrán ser consultadas mediante un servicio web, a través de una API, que también será integrado en la plataforma ya existente de Acumbamail. Los posibles usuarios del servicio que no tengan cuenta en Acumbamail también podrán hacer uso del mismo mediante una sencilla plataforma web que cumplirá los estándares de accesibilidad y usabilidad actualmente empleados en el desarrollo web. 2.2 Objetivos específicos 2.2.1 Obtención de los datos procedentes de las campañas enviadas por Acumbamail El primer objetivo del proyecto es la obtención de los datos proporcionados por las estadísticas de las campañas enviadas en Acumbamail. Estos datos, que se encuentran almacenados en la base de datos de la plataforma, tienen que ser extraídos para su posterior análisis y tratamiento. Actualmente, Acumbamail tiene una API con numerosas funciones destinadas a la obtención de los datos de suscriptores a listas entre otras funciones. Esta API permite a sus usuarios, por ejemplo, la obtención de estadísticas de los usuarios suscritos a campañas de email marketing para ser almacenadas, o crear informes destinados a la mejora del contenido de las newsletters. Aprovechando esta circustancia para la consecución del objetivo, se necesita la ampliación de la API existente de Acumbamail para poder obtener los datos relativos a las campañas de los usuarios y realizar el almacenamiento de esos datos. Estas nuevas operaciones de la API creadas como consecuencia de este objetivo devolverán la información deseada en formato JSON para que pueda ser fácilmente almacenada y/o utilizada de la forma preferida por cada usuario de la aplicación. Éstas son privadas y no utilizan datos personales de los usuarios. 2.2.2 Construcción del Árbol de Decisión Una de las partes principales del proyecto es la construcción del árbol clasificador. Éste árbol de decisión va a permitir clasificar los asuntos de las campañas según sus atributos (palabras clave contenidas en él) y la tasa de apertura obtenida, para después poder 6 sacar nuestras propias conclusiones sobre los asuntos que los usuarios quieran evaluar. Los usuarios únicamente tendrán que introducir el contenido de su asunto en la plataforma y/o interfaz web, para que mediante la infraestructura que se construirá posteriormente el árbol evalúe su contenido y pueda predecir, gracias al modelo construido y los datos de entrenamiento, la tasa de apertura que presumiblemente tendrá su campaña enviada vía correo electrónico. Dentro de los árboles de decisión se pueden encontrar algunas variantes, los más conocidos son: ID3, C4.5 y CART. Para la construcción del árbol se puede contar con la utilización de frameworks que faciliten esta tarea, por ejemplo, scikit-learn. 2.2.3 Construcción de la Información Cuando se haya completado el objetivo destinado a la construcción del árbol de decisión, para que éste sea capaz de realizar la inferencia de los supuestos necesita ser entrenado con datos de ejemplo. En nuestro caso estos datos serán los obtenidos de las campañas enviadas desde la plataforma de Acumbamail. Realizar el análisis de los datos obtenidos y encontrar un modelo de datos permitirá conseguir nuestro objetivo lo más eficientemente posible, en términos de espacio y tiempo. La eficiencia es un aspecto bastante importante en este proyecto debido a la gran cantidad de datos disponibles para analizar. Por ello debe realizarse un análisis meticuloso a la hora de efectuar un profiling de nuestro desarrollo, teniendo en cuenta en qué partes se podría obtener una mejora de rendimiento. 2.2.4 Inferencia de los Supuestos Ésta es la parte esencial del proyecto, poder estimar a partir de unos datos de ejemplo previamente analizados qué porcentaje de apertura tendrá una campaña según el contenido encontrado en su asunto. Este objetivo será realizado mediante el framework elegido anteriormente para la construcción de nuestro árbol de decisión, y mediante el modelo que se haya considerado conveniente según la estructura de nuestros datos. La entrada será el asunto proporcionado por el usuario, que el sistema procesará y sobre el que realizará la inferencia. Esta inferencia es el porcentaje estimado de apertura de la campaña que será enviada por el usuario. El usuario solo tendrá que preocuparse de la introducción de datos. Todo el proceso será transparente al usuario. Cuando todo el proceso finalice el usuario será informado del 7 resultado de su consulta. 2.2.5 Selección de la Tecnología Necesaria para el Sistema de Información Todo lo mencionado anteriormente tiene que funcionar por debajo de un sistema de información que facilite todas las tareas que son más complicadas de realizar a mano. El desarrollo estará cubierto mediante una interfaz web que facilitará al usuario la interacción con el servicio, además de una API que permitirá que el servicio sea integrado en la plataforma de Acumbamail. Al tener una API se facilitará la integración del servicio en cualquier dispositivo móvil y/o página web. Es necesario evaluar todas las plataformas y frameworks destinados a la creación de servicios web para tomar la decisión final sobre qué tecnología y lenguaje de programación utilizar para la creación del sistema de información. 2.2.6 Implementación del Sistema de Información e Integración de componentes Cuando se haya elegido la tecnología que va a ser usada para la creación del servicio web éste necesita ser implementado para alcanzar su correcto y completo funcionamiento. Todos los componentes mencionados anteriormente necesitan un punto de salida al usuario, que será nuestro sistema de información encabezado por una interfaz web. Este sistema tiene varios puntos de entrada y salida, la plataforma de Acumbamail, y la interfaz web construida para este propósito. 8 Capítulo 3 Antecedentes 3.1 Data Mining En los últimos tiempos, el aprendizaje automático ha cobrado gran importancia en el campo de la informática. Relacionado con conceptos como el Data Mining, el aprendizaje automático o Machine Learning en inglés, ayuda a descubrir patrones en grandes conjuntos de datos utilizando la inteligencia artificial y la estadística. Este campo permite ayudar a la toma de decisiones en las empresas, ya que el análisis de datos puede descubrir tendencias útiles para la empresa o identificar oportunidades de mejora. Mediante el Data Mining se pueden descubrir patrones que se repiten en nuestros conjuntos de datos para obtener relaciones entre ellos. La información obtenida a partir de las relaciones encontradas es el fundamento de este proyecto, la construcción de un sistema de ayuda a la toma de decisiones para las campañas de Email Marketing. Gracias a la utilización de la informática en conjunto con el Data Mining, la identificación de pautas en los datos analizados permite a los usuarios de las plataformas de envío de campañas que éstas sean mucho más eficaces, mejorando la satisfacción tanto de los clientes de las plataformas porque consiguen mayores tasas de aperturas en sus envíos, como de los usuarios que reciben esos correos porque estarán más enfocados a sus preferencias. El método tradicional para convertir datos en conocimiento consiste en el análisis manual y la interpretación. Por ejemplo, en el área sanitaria es común que los especialistas analicen periódicamente las tendencias y los cambios en los datos provenientes de informes relacionados con la salud de la población. Estos análisis proporcionan un informe detallado que servirá para la toma de decisiones y la planificación para la gestión en el área sanitaria. Para esta y otras muchas aplicaciones, la prueba manual es lenta, cara y altamente subjetiva. De hecho, como el volumen de datos crece muy rápidamente este tipo de análisis se está convirtiendo impracticable en muchos dominios [FPSS96]. El Data Mining es utilizado en campos muy diversos como los videojuegos, los negocios, 9 aplicaciones en la ciencia, ingeniería, medicina y datos geográficos, entre otros. En los videojuegos de los años 60 ya aparecieron aplicaciones del Data Mining, como la extracción de las estrategias utilizadas por humanos para su aplicación a juegos de ajedrez, tres en raya, etcétera. También tiene multitud de aplicaciones en las áreas de marketing de los negocios, tales como proporcionar a los clientes los productos que desean comprar basados en sus preferencias, guardar datos sobre el comportamiento de las personas cada vez que se utiliza una tarjeta de crédito, o una tarjeta de fidelización de un negocio. No sólo está ligado a estos campos, también es utilizado para la clasificación de música en géneros o para la búsqueda de patrones con asociación de reglas en hábitos de consumo, por ejemplo. La exploración de los datos es un proceso de negocio con multiples fases en las cuales las personas utilizan una metodología estructurada para descubrir y evaluar problemas, definir soluciones y estrategias de implementación, y producir resultados medibles. Las etapas del proceso de exploración de los datos son: Explorar el espacio del problema Explorar el espacio de soluciones Especificar el método de implementación Minería de datos Preparación de los datos Inspección de los datos Modelado de los datos El 80 por ciento del éxito está en la búsqueda de un problema asequible, definiendo como es la solucion que se desea encontrar, y lo más crítico de todo, la implementación de la misma. Por otro lado, la minería de datos requiere usualmente la mayoría del tiempo empleado en el proyecto [Pyl99]. Es muy importante la correcta identificación del problema al que se quiere dar solución, ya que en caso contrario se estará abordando el problema equivocado. Identificando correctamente el problema es posible encontrar soluciones apropiadas para los problemas que se están analizando. 3.2 Árboles de Decisión Los árboles de decisión clasificadores utilizan las observaciones de los elementos recogidas anteriormente y su valor para determinar cuál puede ser el valor del elemento 10 elegido. En este caso, los elementos son las campañas y el valor corresponde al porcentaje de apertura de los correos electrónicos enviados en esa campaña. Es muy utilizado en estadística, Data Mining y aprendizaje automático. Según Rusell [RN04], la organización de objetos en categorías es una parte vital de la representación del conocimiento. Aunque la interacción con el mundo tiene lugar a nivel de objetos individuales, la mayoría del proceso de razonamiento tiene lugar en el nivel de categorías. Se puede inferir la presencia de ciertos objetos a través de la percepción, inferir la categoría a la que pertenece utilizando las propiedades del objeto percibidas y entonces usar las información sobre categorías para realizar predicciones sobre los objetos. Un árbol de decisión es una forma fácil de categorizar elementos. Se dispone de unos elementos que poseen unas características discretas. Una de ellas se conoce como la clase a la que pertenece el elemento. En los árboles cada nodo interno es una característica. Cada nodo interno tiene arcos salientes nombrados con cada uno de los posibles valores de esa característica. Cada nodo hoja del árbol es nombrado con una de las clases o la probabilidad de distribución de las clases del dominio en el elemento con dichas características. Cada camino desde la raíz de un árbol de decisión a una de sus hojas puede ser transformado en una regla simplemente agrupando las pruebas del árbol para formar la parte de los antecedentes y tomando el valor de la predicción de la clase como el valor que toma el resultado de la regla [RM07]. Para este proyecto se va a utilizar un árbol CART (Classification and Regression Tree) que es un arbol de decisión no paramétrico (la distribución de los datos no se ajusta a los criterios paramétricos y no puede ser definida a priori, ya que la determinan los datos observados) que crea árboles de clasificación o regresión en función de si la variable dependiente es categórica o numérica. Los árboles de decisión están formados a partir de una colección de reglas basadas en el conjunto de datos proporcionado. Estas reglas son: Reglas basadas en los valores de las variables para determinar la mejor separación entre observaciones basadas en la variable dependiente. Una vez que una regla es seleccionada y se realiza la división de un nodo en dos, el mismo proceso se aplica a cada nodo hijo. Es un procedimiento recursivo. La separación acaba cuando CART detecta que no se pueden realizar mejoras adicionales, o bien que se ha cumplido alguna de las reglas de parada configuradas previamente. Alternativamente, los datos son separados tanto como sea posible y después el árbol es podado. Scikit-learn es una biblioteca open source para aprendizaje automático. Contiene algoritmos para la realización de clasificación, regresión y clustering incluyendo máquinas de soporte vectorial, regresión logística, clasificador bayesiano ingenuo, etcétera. Está 11 construido sobre NumPy, SciPy y matplotlib. Tiene licencia BSD, open source y es utilizable comercialmente. Scikit está en desarrollo continuo, entre sus usuarios se encuentran Evernote, el cual usa la biblioteca para distinguir recetas de otras notas mediante un clasificador bayesiano, y Mendeley, que desarrolla sistemas recomendadores mediante el algoritmo de regresión. 3.3 Email Marketing El email marketing se basa en el envío de emails comerciales a un individuo o grupo de usuarios que nos han proporcionado su dirección de correo electrónico. Estos emails pueden ser de contenidos diversos, como la publicidad, información diversa a los usuarios, etcétera. Es posible diferenciar dos tipos de email marketing: Email Transaccional Estos son enviados cuando el cliente realiza una acción con una compañía, como una confirmación de un pedido en una compra, correos de cambio de estado en un pedido, cambio de contraseña, etcétera. El propósito de éstos es informar al usuario de cualquier acción o información relevante. Estos email tienen una tasa de apertura superior a los emails enviados en campañas, por lo que puede ser una buena oportunidad para mejorar la relación con los clientes para proporcionales más información, o recomendarle productos de su interés. Campañas de Envío Las campañas de envío de email están destinadas al envío de un mensaje a un grupo de usuarios por ejemplo anunciando nuestro catálogo de productos, o cualquier anuncio o novedad que pueda interesar a nuestros clientes. Actualmente los objetivos en el aspecto de mejora en el contenido de newsletters de la empresas de email marketing se centran en dar consejos a sus usuarios sobre cómo orientar el contenido de sus campañas o email transaccionales, cómo hacer sus asuntos más atractivos para captar la atención de los suscriptores, que palabras poner o evitar en sus asuntos, etcétera. La gran ventaja del correo electrónico es la capacidad de crear relaciones entre las personas, o relaciones comerciales. El branding es el proceso de hacer y construir una marca con el objetivo de que se asocien los activos de la empresa al nombre y/o logotipo que identifica a la marca proporcionandole valor. Mediante el branding es posible potenciar las relaciones entre empresas y consumidores, ya que no es necesario cada vez que se realiza una comunicación explicar quién está detras de ella, y centrarse en las actividades y conversaciones que fortalecen la relación. 12 Cuatro razones por las que el email es el medio perfecto para el marketing (de [BS07]): El correo electrónico es fácil Hoy en día hay multitud de gestores de correo y plataformas de envío de correos electrónicos y es muy sencillo para las organizaciones realizar el envío de campañas de email marketing efectivas para entablar una relación con sus consumidores. Todas estas herramientas son fáciles de usar, no es necesario poseer grandes conocimientos informáticos para sacar provecho de ellas. No existen barreras de entrada ni obstáculos para realizar una campaña efectiva de email marketing. El correo electrónico es barato Actualmente el medio más economico en actividades de marketing es el correo electrónico. La prensa, la televisión y el teléfono son canales por los cuales también es posible realizar estas acciones, pero el presupuesto requerido para ello sería mucho mayor. El coste del envío de un email es de sólo unos céntimos. Esto permite que empresas de pequeño tamaño sean capaces de lanzar efectivas campañas de marketing que consigan atraer a nuevos usuarios y mantener a los ya existentes. El correo electrónico es interactivo El correo electrónico permite conocer con exactitud el número de usuarios que ha recibido nuestro correo, cuántos lo han abierto, cuándo lo han hecho, cuantos receptores lo han considerado como SPAM, y cuántos han utilizado un vínculo incluido en el correo. Es posible medir y cuantificar el éxito de las campañas, e integrarlo con otros sistemas para evaluar las consecuencias derivadas de la misma (incremento de ventas, etcetera.). Con este medio es posible cuantificar el grado de éxito derivado de las campañas enviadas, cuando con otros medios el grado de éxito obtenido es dificilmente medible. Esta es la parte más novedosa con respecto a la utilización de otros canales de comunicación. El correo electrónico es personalizable Otra de las ventajas del correo electrónico es que los datos proporcionados por el usuario pueden ser utilizados para crear un mensaje único, personalizado. Estos datos son esenciales para crear una buena relación entre la compañía y el cliente mediante el envío de mensajes relevantes para sus intereses. Los responsables de marketing deben centrar sus esfuerzos en la recopilación de datos de consumidores en cada interacción con el consumidor, como el uso de una página web, llamadas, ventas, emails directos, etcétera. Todas estas características hacen del correo electrónico un medio de comunicación único. Todas las empresas pueden hacer un uso exitoso del mismo proporcionando más valor a su compañía. Sólo requiere las herramientas adecuadas y los medios para realizarlo. 13 3.4 Servicios web mediante API La mayoría de los servicios web existentes proporcionan información a sus usuarios mediante una API REST que éstos utilizan con un dispositivo conectado a Internet, bien con un ordenador o bien con un dispositivo móvil gracias a alguna aplicación. En la actualidad, el término REST sirve pare definir cualquier interfaz web que utilice XML/HyperText Markup Language (HTML) y HTTP evitando la utilización de los protocolos basados en el intercambio de mensajes de servicios web basados en Simple Object Access Protocol (SOAP). REST permite la abstración de los elementos arquitecturales que forman un sistema hipermedia distribuido. Ignora los detalles de la implementación de los componentes de la API y la sintaxis de los protocolos para centrarse en el rol que cada componente ocupa en el proceso. Servidor de origen, puerta de enlace, proxy y el navegador del usuario. [FT02] Las características de los servicios REST son (de [ASJH11]): Peticiones sin estado Cada petición contiene todos los datos que son necesarios para su procesamiento. El estado de la sesión es guardado en el cliente. Esta sesión puede ser transferida al servidor y ser guardada en una base de datos por un periodo de tiempo para por ejemplo permitir la autenticación automática de usuarios. El cliente comienza a mandar peticiones cuando está preparado para una transición a un nuevo estado, mientras que si una o más peticiones están pendientes el cliente está en transición. Conjunto de Operaciones definidas Los servicios REST siempre utilizan el mismo conjunto de operaciones, las definidas por HTTP, GET, POST, PUT y DELETE. A diferencia de REST, Remote Procedure Call (RPC) no tiene siempre el mismo conjunto de funciones definidas, ya que las funciones utilizadas son definidas por el programador del servicio. Estas funciones necesitan ser conocidas por las partes que van a utilizar el servicio. es un protocolo que permite ejecutar métodos en otra máquina remota sin ocuparse de las comunicaciones entre ambas. Hay distintos tipos de RPC y no son compatibles entre sí. Actualmente se utiliza XML para la definición de las interfaces y HTTP como protocolo de red, surgiendo lo que se conoce como SOAP RPC Interfaz Uniforme Los recursos en los sistemas REST son identificados en las peticiones utilizando Uniform Resource Identifier (URI). Los recursos enviados son diferentes de los recursos almacenados en el servidor. Por ejemplo, el servidor devuelve recursos en 14 HTML o JSON, pero esta no es la forma en la que se encuentran almacenados en el servidor. Una característica importante de los servicios REST son sus operaciones idempotentes. La idempotencia consiste en que no importa cuantas veces realicemos la misma operación en el servidor web que va a tener siempre el mismo resultado. Si se realiza una petición DELETE una vez, el recurso va a ser eliminado. Si esta petición es realizada de nuevo, lanzará un error 404 pero el estado del recurso no ha cambiado desde la primera petición, está eliminado. Esta característica es útil ya que internet no es una red confiable, nuestra conexión puede tener algún problema y no podríamos saber si la petición ha sido completada. En cambio, podemos lanzar la petición cuantas veces queramos hasta que recibamos una respuesta. [RR13] Si la API que se quiere construir utiliza documentos HTML y/o respuestas en JSON, la semántica del protocolo está limitada a los métodos GET y POST. Si se va a conectar con un servicio de almacenamiento, se necesitará HTTP junto a las extensiones de WebDAV. [RR13] La mecánica de funcionamiento de estos servicios es un «sistema de petición-respuesta». Se recibe una petición HTTP (GET o POST) desde cualquier aplicación invocando a una operación contenida en la API, el servidor ejecuta el código perteneciente a la operación y devuelve al usuario la respuesta por el mismo medio que fue enviada. Esta respuesta suele ser enviada como texto plano en alguno de los formatos más comunes concebidos para el intercambio de datos, como JSON o Extensible Markup Language (XML). Aunque los servicios suelen proporcionar mensajes de estado mediante JSON, éstos también pueden ser vistos mediante los códigos de estado HTTP devueltos en las cabeceras de la respuesta enviada. Algunos de estos códigos comienzan con los dígitos 2, 4 o 5 ( [FGM+ 99]): Los códigos 2XX, que engloban desde el 200 hasta el 207, indican que la petición fue recibida y aceptada correctamente. Los códigos 4XX indican que el cliente ha realizado una petición incorrecta o que la que ha realizado no puede procesarse. El servidor debe incluir una explicación a la situación de error, indicando explicitamente si es temporal o permanente. Algunos de estos códigos indican que la autenticación proporcionada no es correcta (Código 401), que no se tiene permiso para acceder al recurso (Código 403 Prohibido), que el recurso no fue encontrado (Código 404 - No encontrado), etcétera. Cuando un error ha ocurrido en el servidor se lanza un error 5XX. Estos errores se producen cuando el servidor falla al completar una petición que es válida aparentemente. Por ejemplo, el código 500 es enviado cuando ha ocurrido un error interno, emitido por 15 aplicaciones en servidores web cuando se produce algún error al generar el contenido que va a ser enviado. Otros errores son 501, cuando el método por el que se ha realizado la petición (GET, POST, PUT, etc.) no se encuentra implementado. Todos estos códigos son códigos de estado HTTP implementados por múltiples navegadores y servidores web. JSON es un formato ligero para el intercambio de datos. Está hecho para facilitar la lectura y escritura a las personas y a la vez que sea fácil de procesar y generar para los servidores y ordenadores. Está formado por dos estructuras, una colección de elementos clave/valor, tratada como objeto en muchos lenguajes, y una lista de valores, denominada como array, vector o lista por muchos de los lenguajes de programación más comunes. { " Asignaturas " : [ { " Nombre " : { " Nombre " : { " Nombre " : { " Nombre " : } " Sistemas Inteligentes " , " Alumnos " : 25} , " Ingles Tecnico I " , " Alumnos " :15 } , " Tecnologias y Sistemas Web " , " Alumnos " : 18} , " Redes y Servicios Moviles " , " Alumnos " : 20} ] Listado 3.1: Ejemplo de Array en formato JSON Actualmente hay numerosos frameworks con la funcionalidad requerida. Uno de los más utilizados es Node.JS, un entorno de programación que facilita la creación de la capa del servidor basado en Javascript. Otro también muy utilizado escrito en el lenguaje de programación Python es Django. Django es un framework de código abierto que sigue el patrón MVC (Modelo, Vista, Controlador). Django se centra en la reutilización de código, la conectividad, plugins, y el desarrollo ágil de software. 3.5 Entorno de Trabajo 3.5.1 Software El proyecto va a ser completamente desarrollado gracias a los medios proporcionados por Acumbamail. Todo el código e información se encontrará almacenado en un repositorio en uno de los principales servicios de control de versiones online (GitHub, Bitbucket, etc...). Debido al componente web del proyecto, se necesita un servidor web capaz de ejecutar en paralelo todo lo mencionado en los objetivos para poder proporcionar al usuario un servicio confiable y rápido. A continuación se describen las herramientas utilizadas para la realización del proyecto: 16 Lenguajes Python Python [pyt] es un lenguaje de programación interpretado con orientación a objetos, multiplataforma y de código abierto. Posee una licencia Python Software Foundation License, compatible con GNUPG. Está administrado por la Python Software Foundation. Creado por Guido Van Rossum en el Centro para las Matemáticas y la Informática de los Países Bajos. Python sigue una filosofía basada en un desarrollo favorecido por una sintaxis limpia y un código fácilmente legible. Python es un lenguaje de programación versátil que ha permitido realizar varias etapas del proyecto. Desde la extracción de los datos de la API mediante su librería urllib parseando JSON con la clase incluida por defecto. Igualmente la creación y el entrenamiento del árbol de decisión, el servidor web que proporciona el servicio a las plataformas y la sencilla interfaz web que se presenta a los usuarios para la utilización del servicio. Gracias a la utilización de un único lenguaje de programación, la integración entre los componentes ha sido sencilla permitiendo ahorrar tiempo de procesamiento. MySQL MySQL [mys] es el motor de base de datos relacional utilizado en el proyecto. Ha sido empleado por su fácil integración con Django además de ser uno de los más habituales en el mundo de la informática por su rendimiento, perteneciente a la categoría de Software Libre. HTML [HTM] es un lenguaje de marcas para la creación de páginas web. Es un estándar mediante el que se define la estructura de diseño de la página web y sus contenidos multimedia (texto, vídeo, imágenes). HTML Éste estándar es creado por la W3C, un consorcio dedicado a la creación de estándares de las tecnologías que conforman la web. La última revisión de este lenguaje es HTML5, todavía experimental. Entre sus nuevas características, incluye la creación de nuevas etiquetas que reflejan nuevos significados semánticos (como <header>y <footer>), o proporcionan nuevas funcionalidades como las etiquetas para los elementos de audio y vídeo. También se han desechado etiquetas que incluían modificaciones en la presentación, al dejar esta funcionalidad a las hojas de estilos Cascading Style Sheets (CSS). CSS3 CSS [CSS] (u Hoja de Estilos en Cascada) es el lenguaje mediante el cual se proporciona 17 estilo a la estructura de la página web definida en un lenguaje de marcas como HTML. Igual que HTML, CSS fue creado y es mantenido por el W3C. Un documento CSS está compuesto de un conjunto de reglas que aplican los estilos correspondientes a los elementos seleccionados del documento. Javascript Javascript es un lenguaje utilizado mayoritariamente del lado del cliente, interpretado por el navegador, permitiendo realizar cambios en la interfaz de usuario y páginas web dinámicas. Javascript fue creado por Brendan Eich, trabajador de Netscape en 1995. Actualmente, la marca Javascript es propiedad de Oracle Corporation. Actualmente este lenguaje es muy utilizado gracias a frameworks tales como jQuery, biblioteca creada por John Resig que facilita la manera de interactuar con código HTML para modificar su contenido o crear animaciones en las páginas web entre otras utilidades. Gestión y Almacenamiento del Proyecto Repositorio y Control de Versiones Para facilitar la gestión del trabajo se utilizará un sistema de control de versiones. Estos sistemas permiten la gestión de los diversos cambios que se realizan sobre software, o archivos, llevando un control exhaustivo de ellos. Este sistema, además del control de cambios, proporciona un método de almacenamiento de todos los elementos incluidos en el proyecto y un historial con todos los cambios realizados a lo largo de la historia, pudiendo volver a un estado anterior distinto del actual si es necesario. Todos los datos pertenecientes al proyecto se encuentran en el repositorio, el lugar donde se almacenan los mismos y los históricos de cambios. Este repositorio está alojado en un servidor externo. Gracias a ello, no hay que preocuparse de la realización de copias de seguridad. Cada vez que se realizan cambios en el proyecto se genera una revisión nueva, identificada mediante un número o un código de detección de modificaciones (p. ej., SHA1 en GIT). Trello Trello [tre] es una aplicación web orientada a la gestión de proyectos. Utiliza un paradigma para la gestión de proyectos conocido como kanban, un método que fue popularizado por Toyota en los años 80 para las cadenas de suministros. En esta aplicación los proyectos están representados por un "tablón". Éste tablón contiene listas de tareas formadas por tarjetas. Estas listas pueden estar formadas por tarjetas 18 correspondientes a características de nuestro producto en distintas fases de desarrollo. Estas tarjetas van progresando de lista en lista hasta que la idea está completamente desarrollada. Es posible asignar las tareas contenidas en las tarjetas a los distintos integrantes del proyecto. Todos los tablones construidos pueden ser integrados formando una organización. Todo esto puede ser utilizado fácilmente mediante sus aplicaciones móviles para iPhone y Android, con lo que este servicio puede ser utilizado en cualquier sitio y por cualquier persona que esté interesada. Frameworks Django Django [dja] es un framework para aplicaciones web, open source y escrito en python. Está basado en el patron MVC (Modelo, Vista, Controlador). El núcleo del framework consiste en un mapeo objeto relacional (ORM) que permite obtener directamente los datos almacenados en la base de datos como objetos de las clases python definidas en nuestro proyecto. Junto con un sistema de templates para la visualización web, y un despachador de URL mediante expresiones regulares. Django ha evitado la programación de un completo sistema web, proporcionando la conexión con la base de datos y un completo sistema de plantillas que ha sido de gran ayuda para la creación de la interfaz. Django permite omitir la programación de las partes de bajo nivel del sistema, como la conexión a las vistas que muestran los templates cuando un usuario accede a una URL definida en el sistema. jQuery jQuery [jqu] es una biblioteca multiplataforma diseñada para simplificar la creación de scripts para HTML en el lado del servidor. Es usado por más del 60 % de las 10000 páginas web más visitadas del mundo. jQuery está destinado a facilitar la navegación dentro del código HTML, seleccionar elementos del DOM, crear animaciones, eventos y hacer aplicaciones que utilicen AJAX. La arquitectura de jQuery permite a los desarrolladores crear plugins para extender la funcionalidad de jQuery. Actualmente hay miles de plugins para jQuery que permiten utilizar servicios web, tablas de datos, listas dinámicas, herramientas para XML y XSLT, drag and drop en la interfaz web, eventos, manejo de cookies y ventanas modales. jQuery ha facilitado la programación del comportamiento de la interfaz creada para la utilización y la comunicación con el servicio. 19 Bootstrap Bootstrap [boo] es un conjunto de herramientas gratuitas para la creación de páginas y aplicaciones web. Contiene código HTML y plantillas de CSS para tipografías, formularios, botones, navegación y otros componentes de la interfaz. También incluye código JavaScript para dotar de comportamiento a esos elementos. Bootstrap fue desarrollado por dos empleados de Twitter en un intento de crear consistencia en el aspecto de diseño entre las herramientas internas. Fue lanzado como una herramienta open source en Agosto de 2011, y menos de un año después fue el proyecto que más veces ha sido marcado como favorito en GitHub, portal de proyectos muy extendido en el mundo del software libre. El uso es bastante sencillo, sólo se necesita descargar la hoja de estilos CSS de Bootstrap e incluir un enlace al archivo en el HTML. También está disponible en LESS o SASS para la compilación. Es posible utilizar también los scripts de javascript, realizando la misma operación que con el CSS, pero los scripts deben ser utilizados junto a jQuery. La interfaz ha sido realizada mediante Bootstrap, que facilita los elementos de diseño básicos utilizados en la misma y proporciona automáticamente un diseño responsive, destinado para su correcta visualización en cualquier dispositivo tanto de sobremesa como portátil sin requerir la adaptación del diseño a cada dispositivo. Miscelánea Celery Celery [cel] es una cola de tareas asíncrona basada en el paso de mensajes distribuido. Las tareas solicitadas se ejecutan concurrentemente en uno o más servidores (workers). Gracias a la concurrencia, es posible habilitar varios procesos en una misma máquina para que realicen varias tareas a la vez reduciendo los tiempos de espera. Celery está implementado en Python, aunque también puede operar con otros lenguajes mediante WebHooks. Actualmente Celery es usado en los sistemas de producción de empresas conocidas como Instagram, Mozilla y AdRoll. Celery ha proporcionado al proyecto una reducción de tiempos en la obtención de información de la API al permitir obtener la información de varias campañas al mismo tiempo. JSON JSON [jso] es la forma más sencilla para la representación de la información utilizada por la mayoría de los servicios web y APIs actuales. Permite la incorporación de multitud de información en poco espacio para ser transmitida por la red. Ha sido utilizado en este proyecto para realizar todas las comunicaciones entrantes y salientes desde y hacia la 20 API. 3.5.2 Hardware Entorno Local Para el desarrollo del proyecto en un entorno offline se ha llevado a cabo con un ordenador Lenovo con 4GB de RAM y un procesador AMD E2-1800 a 1.7 GHz con 4GB de RAM y 500GB de HDD. Sistema Operativo Linux. Además se ha utilizado un Macbook Pro con un procesador Intel Core i5 a 2,4GHz. 128GB de SSD, y 500GB de HDD. Mac OS X 10.9.4. Entorno Remoto Todo el proyecto necesita ser soportado por un servidor en la nube en el que realizar el despliegue automático de la aplicación. Este servidor es una instancia comprada en Digital Ocean, que cuenta con 1GB de RAM, un procesador de un núcleo, 30GB de disco SSD, y 2GB de transferencia de datos, cortesía de Acumbamail. 3.5.3 Empresarial Este trabajo está desarrollado en el entorno empresarial, gracias a una beca de colaboración proporcionada por Acumbamail. Todos los medios y necesidades a lo largo del proyecto han sido cubiertas por Acumbamail. Acumbamail es una startup de reciente creación dedicada al envío de newsletters y email transaccional, que permite la creación de nuestros propias campañas además de conocer su tasa de apertura y la calidad de los suscriptores. Como modelo de desarrollo, Acumbamail utiliza SCRUM. SCRUM proporciona una metodología ágil. Todo el proceso de desarrollo es documentado mediante el product backlog, en el que se encuentran detallados todos los requisitos y futuras funcionalidades. Esta metodología incluye sprints, periodos definidos por el equipo, en los que se crea un nuevo producto software o se mejora el ya existente. En cada uno de estos periodos, mediante el sprint backlog, se describe cómo el equipo va a implementar las funcionalidades durante el sprint planificado. 21 Capítulo 4 Método E este capítulo se describe la metodología seguida para la realización del proyecto. N Las metodologías mas adecuadas para enfocar este proyecto son las metodologías ágiles, basadas en el desarrollo iterativo e incremental. En 2001, nacieron los métodos ágiles para nombrar al conjunto de las alternativas a las metodologías formales (CMMI y SPICE, por ejemplo). Se definió el manifiesto ágil, soportado por cuatro postulados: Valorar más a los individuos y su interacción que a los procesos y las herramientas. Valorar el software que funciona frente a la documentación exhaustiva. Valorar la colaboración con el cliente más allá de la negociación contractual. Valorar la respuesta al cambio por encima del seguimiento de un plan. La utilización de una metodología perteneciente a este conjunto se justifica por los diversos objetivos a alcanzar, siendo repartidos entre las diversas iteraciones del proyecto, además del seguimiento del proyecto por parte de los directores del mismo. 4.1 Descripción SCRUM [scr] es la metodología elegida para la gestión del proyecto. Fue definida como una estrategia flexible donde el equipo de desarrollo trabaja unido para alcanzar una meta. Un principio clave de Scrum es que los requisitos del proyecto pueden cambiar en cualquier momento durante la realización del mismo, lo que no podría ocurrir con un modelo de desarrollo tradicional. Fue descrito por Hirotaka Takeguchi e Ikujiro Nonaka en el artículo "New New Product Development Game"(Poner Referencia). Sus autores lo describieron como el desarrollo de un producto comercial que hiciera crecer la velocidad y la flexibilidad, basado en casos de estudio de marcas de automoción e impresión. Lo llamaron el método del rugby, ya que todo el proceso es completado por un equipo 23 multifuncional mediante multitud de fases solapadas, donde el equipo «trata de avanzar y se pasa la pelota desde atrás hacia adelante». 4.2 Roles En SCRUM hay tres roles fundamentales junto a otros roles auxiliares. Estos tres roles que forman el equipo SCRUM son los que están construyendo el producto. Propietario del Producto (Product Owner) Responsable del producto en el área de negocio y voz de los usuarios del producto final. Encargado de la escritura de historias de usuario y de su adición al product backlog. Estas historias de usuario son descripciones en lenguaje natural de lo que el usuario necesita hacer como parte de su trabajo. En este caso, el rol de Product Owner es ejercido por los empleados de la empresa de Acumbamail. Scrum Master Responsable de la motivación al equipo destinado a la consecución de los objetivos y resultados del proyecto. No es la persona concebida como el tradicional lider del proyecto o gestor de proyecto. Es el encargado de supervisar la realización de la metodología SCRUM. El rol descrito en este caso es realizado por ambos directores de proyecto. Equipo de Desarrollo Es el encargado de la realización de los incrementos en la funcionalidad del producto al final de cada sprint. Comúnmente, el equipo está formado por un grupo de 3 a 9 personas con conocimientos en campos muy variados relacionados con el proyecto. Realiza el trabajo de análisis, diseño, desarrollo, pruebas, comunicación técnica, documentación, etcétera. El rol es desempeñado por Jesús Botella Blanco. 4.3 Documentación Product Backlog Es un documento con todos los requisitos pertenecientes al proyecto: Características, fallos, requisitos no funcionales, etcétera. En suma, todo aquello necesario para el desarrollo del mismo. Los requisitos son ordenados por el «Product Owner» según el riesgo, valor para el negocio, dependencias, deadline, etcétera. Este documento es utilizado para recopilar las peticiones de modificación de un producto. Incluye nuevas características a implementar, el reemplazo de viejas funcionalidades y los problemas resueltos. Además debe asegurar que el equipo con su trabajo maximiza los beneficios del negocio para el propietario del producto. 24 Normalmente, el Product Owner y el Scrum Team se reunen y organizan todo aquello que necesita ser priorizado y debe ser incluido en los sprints. Sprint Backlog El sprint backlog es una lista del trabajo que el equipo de desarrollo debe realizar durante el siguiente sprint. Esta lista es construida mediante la selección de elementos del product backlog considerados como prioritarios hasta que el equipo de desarrollo confirma que se ha cubierto el cupo de trabajo para el siguiente sprint. Las tareas en el sprint backlog nunca son asignadas a un miembro concreto del equipo de desarrollo, en su lugar se realizan por los distintos componentes según crean oportuno. A menudo se suele encontrar una pizarra dividida por fases de desarrollo, ’por hacer’, ’en progreso’, y ’acabado’. Una vez que el sprint backlog se ha completado no pueden ser añadidas funcionalidades adicionales, excepto si es incorporada por el equipo. Cuando el sprint ha acabado, el product backlog es reanalizado y vuelto a priorizar si es necesario, y se vuelve a empezar el proceso de construcción del product backlog. Burndown Chart El diagrama del trabajo restante del sprint es mostrado públicamente. Se actualiza diariamente y da una visión general del progreso conseguido en cada sprint. Hay varios tipos de estas gráficas dentro de este diagrama. Por ejemplo, el «release burndown chart» muestra la cantidad de trabajo restante para completar el objetivo de una release del producto (distribuido en varias iteraciones). 4.4 Eventos & Reuniones Sprint Es descrito como una iteración en el desarrollo de software. Es un esfuerzo contenido dentro de un rango de tiempo. La duración se fija antes de empezar el sprint. Normalmente se trata de un periodo de tiempo comprendido entre una semana y un mes, aunque lo más normal son dos semanas. Cada sprint comienza con una reunión de planificación donde se eligen las tareas que confirmarán el sprint, y acaba con una reunión de evaluación del progreso para comenzar el nuevo sprint con las lecciones aprendidas. Scrum aboga por que a la finalización del sprint haya un producto que esté completamente a prueba de fallos, documentado y preparado para la salida al mercado. 25 Reuniones Reunión de Scrum diaria Cada día dentro del periodo del sprint tiene lugar una reunión del equipo Scrum. En ella cada miembro del equipo contesta a tres cuestiones: ¿Qué han hecho desde ayer?, ¿Qué van a hacer hoy?, ¿Qué impedimentos han encontrado?. La reunión debe empezar puntual aún incluso si falta algún miembro del equipo, debe realizarse siempre en el mismo lugar, y la duración es de 15 minutos como máximo. Reunión de planificación del sprint Reunión que se realiza antes de cada ciclo de sprint. En ella se define el trabajo a realizar, se realiza el sprint backlog con los detalles del tiempo de duración del trabajo, y se identifica y comunica cuanto trabajo será hecho durante el sprint. La duración no puede sobrepasar las ocho horas, las primeras cuatro horas se dedican a priorizar el product backlog, y las segundas cuatro a elaborar el plan para el sprint, que luego determinará el sprint backlog. Reunión de finalización del sprint Cuando acaba un sprint, se realizan dos reuniones: La reunión de evaluación del progreso y la retrospectiva del sprint. En la reunión de evaluación se analiza el trabajo que fue acabado y el trabajo planeado que no se completó. Se presenta el trabajo completado a las partes interesadas del proyecto. Esta reunión tiene un límite de cuatro horas. En la retrospectiva del sprint se plantean dos cuestiones, ¿Qué fue bien durante el sprint? y ¿qué puede ser mejorado en el próximo?. Se realizan continuas mejoras en el proceso. Como límite puede durar tres horas, y es dirigida por el Scrum Master. 4.5 Integración con el Proyecto El proyecto ha sido realizado siguiendo la metodología SCRUM. Las reuniones han sido realizadas periódicamente, según lo requerían las circunstancias, al comienzo y finalización de cada sprint realizado. Los objetivos del proyecto han sido distribuidos a lo largo de las iteraciones realizadas. 4.5.1 Iteración 1 Sprint Backlog Estudio de los datos de las campañas 26 Estudio y creación de Métodos de la API para la obtención de datos procedentes de las campañas Descripción Esta es la iteración inicial del proyecto, en la que se ha realizado el estudio completo de los posibles problemas y soluciones que podían surgir durante el mismo, para confirmar su viabilidad y con el fin de que fuese realizado de la forma más eficaz posible. Se ha llevado a cabo el análisis de los datos que se podían obtener para la realización de la predicción, como el asunto de las campañas, los suscriptores que han abierto la campaña y el contenido del correo electrónico enviado. Una vez completado el estudio y definidos los datos que es necesario es obtener para la realización del proyecto se ha procedido a la obtención de los mismos. Debido a la existencia de la API de Acumbamail se ha considerado la extracción de los datos necesarios mediante este modo, ya que se pueden obtener fácilmente y de forma automatizada mediante peticiones HTTP. Estas funciones han sido creadas en Python, que es el lenguaje en el que se encuentra programada la plataforma de Acumbamail. 4.5.2 Iteración 2 Sprint Backlog Programación Wrapper API en Python Estudio de frameworks para la creación del Sistema de Información Descripción Para la obtención automática de los datos de la plataforma de Acumbamail se necesita un «wrapper» que facilite la tarea, además de proporcionar la información en un formato fácil de tratar para cualquier aplicación o futuro desarrollo que requiera utilizar esta información procedente de Acumbamail. En esta iteración, además de lo mencionado anteriormente, se realizó un estudio de los frameworks para la creación de sistemas de información. Es necesario para el fácil almacenamiento de los datos obtenidos, mediante la utilización de un software ObjectRelational Mapping (ORM). También incluye la búsqueda de un sistema de información para el almacenamiento de los datos obtenidos, además de permitir la creación de una plataforma web. Este sistema de información será el que soporte el servicio web destinado a la predicción de los asuntos proporcionados por los usuarios, mediante un software ORM que facilitará el almacenamiento y la posterior recuperación de los datos. 27 Algunos de los posibles candidatos son Django, un framework web escrito en Python, y Node.JS combinado con Express, un framework web escrito en Javascript. 4.5.3 Iteración 3 Sprint Backlog Construcción del sistema para la obtención de la información de las campañas concurrentemente. Creación del sistema de información encargado del almacenamiento y recuperación de la información de las campañas además de ser el servidor para la interfaz web Descripción La obtención de la información de todas las campañas es un proceso largo, ya que hay que extraer una gran cantidad de información y es un proceso secuencial. Para la reducción de los tiempos empleados en el proceso se ha utilizado un sistema de tareas distribuido, Celery, en el que cada una de las tareas lanzadas consiste en obtener la información de una única campaña para ser almacenada. Este sistema de tareas permite personalizar el apartado de la ejecución, realizando varias tareas en hilos separados, o conectando el número de nodos de ejecución de Celery deseados a la misma cola de mensajes para que realicen tareas concurrentemente. En la pasada iteración se dedicó una parte de la misma a la elección del framework destinado a la creación del sistema de información y una vez elegido se ha construido todo el sistema. La construcción del sistema pasa por la instalación del framework, la definición de los modelos de base de datos, y por la configuración de la capa de presentación y el controlador del sistema. El controlador del sistema es el encargado de la conexión entre las URL(acrónimo) que el usuario introduce en su navegador y el sistema de vistas incluido en Django. La capa de presentación se encarga de procesar las peticiones que llegan al controlador y ejecutar la vista correspondiente con un sistema de templates web. 4.5.4 Iteración 4 Sprint Backlog Estudio de los diferentes frameworks para la creación de árboles de decisión Identificación de la información innecesaria para su limpieza Descripción La creación del árbol de decisión es la parte fundamental del proyecto, por ello se va a dedicar parte de una iteración completa para el estudio de los diversos frameworks que se pueden encontrar con este propósito. 28 Es preciso encontrar un framework adaptado a las necesidades del proyecto para la creación del árbol, y que permita el entrenamiento con los datos almacenados actualmente para mejorar la calidad de las predicciones proporcionadas mediante el asunto introducido. En la información que va a ser obtenida a partir de las campañas existen numerosas palabras que no aportan nada a la determinación del porcentaje de apertura obtenido. Esas palabras que no son utilizadas necesitan ser eliminadas anteriormente a la creación del árbol de decisión para evitar el procesamiento de las mismas, ahorrando tiempo y utilización de memoria al servidor. 4.5.5 Iteración 5 Sprint Backlog Limpieza y almacenamiento de la información obtenida Creación del árbol de decisión Entrenamiento del árbol Descripción Toda la información obtenida será almacenada posteriormente en la base de datos. Ésta requiere ser limpiada y procesada de forma previa a su guardado, eliminando las palabras de los asuntos que han sido identificadas anteriormente y no son necesarias para el entrenamiento. En esta iteración, una vez que se ha escogido el framework que va a ser utilizado, se creará el árbol de decisión que es la base para la inferencia de supuestos que será realizada posteriormente. Utilizando scikit-learn se realizará la construcción del árbol, que será posteriormente entrenado con los datos limpiados de los asuntos de las campañas junto con el porcentaje de apertura calculado. El entrenamiento del árbol se realiza mediante los datos obtenidos y limpiados previamente. Estos datos son convertidos al formato aceptado por el árbol, arrays con las características de cada muestra. Mediante estos datos, el árbol será capaz de estimar las muestras que los usuarios introduzcan por los diversos medios puestos a su disposición. Estos asuntos introducidos serán pasados por el árbol de decisión con el fin de estimar qué rango de porcentaje de apertura se podrá obtener aproximadamente mediante las estadísticas previamente obtenidas. 4.5.6 Iteración 6 Sprint Backlog Inferencia de Supuestos 29 Creación del servicio web Descripción Una vez acabada la iteración anterior y con el árbol de decisión construido, y listo para ser utilizado, es preciso realizar pruebas con la inferencia de supuestos. Estos supuestos pueden ser pasados por el árbol cuando han realizado todo el proceso que ha seguido la información de entrenamiento, es decir, ser eliminadas todas las palabras que no determinan el significado del asunto y sean convertidos al formato de datos que acepta el árbol. Cuando toda la etapa perteneciente a la creación del árbol esté completada se proporciona a los usuarios un punto de entrada para realizar sus estimaciones y utilizar el servicio. Este punto de entrada podrá ser utilizado por la interfaz web creada para este propósito además de la plataforma de Acumbamail. El servicio será construido a partir de un servidor HTTP personalizado. Este servidor aceptará las peticiones de los usuarios que utilicen el servicio, mediante una petición POST que contenga el asunto que quieren analizar. Este servidor sólo podrá ser utilizado por la interfaz web del servicio y por la plataforma de Acumbamail. Cuando recibe una petición la redirige a la instancia del árbol creada cuando se inició el servicio, que éste procesa y devuelve. El servicio será utilizado mediante una interfaz web creada en el proyecto o la interfaz web de la plataforma de Acumbamail. 4.5.7 Iteración 7 Sprint Backlog Despliegue Automático de Aplicaciones Descripción Actualmente una de las partes más importantes en la realización de proyectos es el despliegue de las aplicaciones. Este despliegue consiste en realizar todas las tareas necesarias para que el software esté listo para su utilización. En este caso, existen tres productos software, el árbol de decisión, el servicio web que utiliza al árbol para realizar las predicciones y la plataforma web construida sobre Django. Gracias a la utilización de un sistema de control de versiones con un repositorio situado en la nube, proporcionado por Bitbucket, esta tarea es mucho más sencilla. 30 La tarea consistiría en realizar los cambios sobre la copia local en el ordenador sobre el que se esté trabajando, guardar esos cambios y mandarlos al repositorio para actualizar la copia remota. Luego descargar estos cambios en el servidor y realizar las operaciones necesarias para que sean puestos en marcha. Gracias a algunas herramientas disponibles actualmente se puede detallar todo este proceso y las acciones que es necesario realizar para que sean ejecutadas automáticamente en el ordenador local y en el servidor remoto mediante algúna herramienta de acceso remoto como SSH. Todo este proceso es automático y el desarrollador sólo tiene que estar centrado en la tarea principal, que es el desarrollo de los distintos sistemas que conforman el proyecto. 4.5.8 Iteración 8 Sprint Backlog Creación de plataforma web Integración en Acumbamail Descripción Para facilitar el acceso al servicio de la predicción se ha creado una plataforma independiente de la de Acumbamail para aquellos usuarios que no tengan cuenta en la misma. Esta plataforma está soportada por el sistema construido previamente para el almacenamiento de la información de las campañas en Django. Cuando los usuarios accedan al servidor se les mostrará una página realizada en HTML, en la cual podrán introducir su asunto y realizar la estimación. Esta interfaz web está construida con Bootstrap para que pueda ser utilizada en una gran variedad de dispositivos, como móviles, tablets, etcétera. Además se utiliza jQuery para dotar de comportamiento y animaciones a la misma. Esta interfaz hace una llamada POST al servicio, y este le devuelve la clase encuadrada del asunto introducido. El usuario recibe feedback de su asunto además de algunos consejos básicos sobre Email Marketing para que pueda mejorar sus campañas. El resultado es notificado mediante la misma página donde ha introducido el asunto en la interfaz web, a través de un aviso que será acorde con la respuesta obtenida del servicio. El color será distinto según el rango de porcentajes que devuelva el servicio. El usuario podrá introducir el número de asuntos deseado sin que le sea impuesto ningún limite. 31 4.5.9 Iteración 9 Sprint Backlog Integración en Acumbamail Descripción Este trabajo está diseñado para la integración en la plataforma de Acumbamail, proporcionando consejos sobre los asuntos de las campañas de los usuarios introducidos. Estos consejos serán útiles para la mejora de la tasa de apertura en las campañas de los usuarios de la plataforma. Esta integración se realizará mediante una llamada POST al servicio creado anteriormente. Cuando se realice la llamada y se reciba la respuesta, al usuario se le mostrará mediante una notificación en la misma página donde fue introducido el asunto. Esta notificación incluirá el resultado de la predicción junto a un enlace a consejos relacionados con email marketing para la posible mejora de los resultados. El uso del servicio será transparente al usuario, careciendo de referencias al servicio externo que proporciona la clasificación según la tasa de apertura de los asuntos introducidos. Este servicio estará siempre disponible para los usuarios de la plataforma, corriendo en un servidor dedicado para ello. 4.5.10 Iteración 10 Sprint Backlog Documentación Descripción Esta etapa se irá completando a medida que se vaya realizando el trabajo, pero se reserva una iteración para realizar todo lo restante concerniente a la documentación, posibles funcionalidades no implementadas, etcétera. Toda la documentación será realizada en LATEX, mediante editores con versión para Linux y Mac OS X. Esta documentación incluye todos los aspectos y requisitos del proyecto, objetivos, antecedentes y estado del arte, así como el modo en que ha sido realizado, y los resultados obtenidos con la realización del mismo. Contiene la planificación de los tiempos del proyecto y qué problemas han sido encontrados a lo largo de todo su desarrollo. Además se incluyen las conclusiones obtenidas en la realización del proyecto, los hitos más destacables del trabajo realizado, y las posibles ampliaciones a partir del mismo 32 junto con otros proyectos relacionados que pueden ser explorados. 4.6 Planificación de Tiempos Figura 4.1: Línea de Tiempo perteneciente a los hitos del proyecto. 33 Capítulo 5 Resultados E este capitulo se describen las decisiones adoptadas para la consecución de los objetivos presentados en el capítulo 2. N 5.1 Visión General Este trabajo consta de varias partes bien diferenciadas: Obtención de la información procedente de Acumbamail. Construcción y Entrenamiento del árbol de decisión Creación del servicio web Implementación de la interfaz web Integración del servicio en la plataforma de Acumbamail Para todas ellas ha sido necesaria la investigación sobre la tarea a realizar debido a las numerosas alternativas encontradas a la hora de tratar la solución del problema, y la intención de encontrar la solución más adecuada en términos de eficiencia, eficacia y facilidad en la implementación. Se trata de una tarea compleja que ha requerido de mucho esfuerzo para solucionar los problemas encontrados y realizar un trabajo de calidad, acorde con el conocimiento adquirido durante los años cursados. En la figura 5.1 se ha incluido un diagrama del funcionamiento del sistema para una mejor comprensión. El papel del usuario en el proyecto es el de la utilización del servicio, accediendo bien mediante la página web construida para el proyecto, o bien mediante la plataforma de Acumbamail en la cual también se encuentra integrado. El resultado de su consulta será el mismo independientemente del servicio desde el que la realice. 35 Página Web del Proyecto Página Web de Acumbamail Interfaz Web · Desarrollada para el proyecto Interfaz Web · Plataforma de Acumbamail Servicio Web Árbol de Decisión Figura 5.1: Esquema de utilización del servicio 36 5.2 Construcción del Sistema de Información El proyecto contiene las siguientes clases, pertenecientes al wrapper de la API, el servicio web y el modelo de Django que será exportado a tabla de base de datos. Figura 5.2: Diagrama de clases del proyecto La clase AcumbamailAPI es el wrapper encargado de la obtención de los datos necesarios de la API de Acumbamail mediante los métodos creados para ese fin, obteniendo con cada uno una información distinta. Este wrapper es invocado mediante la clase AcumbamailData, que es la encargada de la extracción de la información y de su posterior procesamiento para que la información almacenada en la base de datos se encuentre ya limpia de información innecesaria. Esta información es guardada por el ORM en la base de datos con el modelo plasmado en la clase DecisionTreeData, que posteriormente es recuperada por el servicio web mediante la clase DecisionTree que realiza la creación del árbol, entrenamiento y la inferencia de supuestos. La clase TreeClasses es una enumeración de las posibles clases en las que campañas introducidas en el árbol pueden ser encuadradas. El árbol de decisión construido y la información proporcionada por Acumbamail requiere un sistema base que permita el almacenamiento y la fácil consulta de la misma. Para ello se ha construido una plataforma web gracias al framework Django. Este framework permite el fácil almacenamiento de la información debido a su ORM que hace posible guardar información mediante objetos en la base de datos. Este framework sigue el patrón Modelo Vista Controlador (MVC), consistente en la separación de los componentes de la representación la información y la interacción con el usuario. Los componentes más importantes de este framework para el sistema son los modelos, que contienen la representación de la información de negocio en el sistema. 37 En este caso la información de negocio es la perteneciente a los datos de las campañas, representada mediante el modelo creado para el almacenamiento. Este modelo necesita tres campos: Número de la campaña a la que pertenece la información por si es necesario realizar alguna comprobación, las palabras incluidas en el asunto una vez que ya hayan sido eliminadas las palabras sobrantes y el porcentaje de apertura que ha obtenido la campaña. Este modelo en Django se construye de la siguiente forma: from django . db import models class DecisionTreeData ( models . Model ) : subject_words = models . TextField () ope ned_pe rcenta ge = models . IntegerField () campaign_number = models . IntegerField () Listado 5.1: Modelo de Información perteneciente a las campañas almacenadas Este modelo es plasmado en la base de datos con estas características: + - - - - - - - - - - - - - - - - - - -+ - - - - - - - - - -+ - - - - - -+ - - - - -+ - - - - - - - - -+ - - - - - - - - - - - - - - - -+ | Field | Type | Null | Key | Default | Extra | + - - - - - - - - - - - - - - - - - - -+ - - - - - - - - - -+ - - - - - -+ - - - - -+ - - - - - - - - -+ - - - - - - - - - - - - - - - -+ | id | int (11) | NO | PRI | NULL | auto_i ncrement | | subject_words | longtext | NO | | NULL | | | o p e n e d _ p e r c e n t a g e | int (11) | NO | | NULL | | | c am pa i gn _n um b er | int (11) | NO | | NULL | | + - - - - - - - - - - - - - - - - - - -+ - - - - - - - - - -+ - - - - - -+ - - - - -+ - - - - - - - - -+ - - - - - - - - - - - - - - - -+ Listado 5.2: Modelo de Información perteneciente a las campañas almacenadas Este modelo será usado posteriormente para guardar la información mediante Celery y para la recuperación de la información utilizada por el servicio web para la creación del árbol de decisión. Directamente se encarga del almacenamiento y de la recuperación de la información de la base de datos sin realizar ninguna consulta en lenguaje SQL. Únicamente hay que configurar el puerto y el servidor donde se encuentre la base de datos, MySQL en este caso, en el archivo de configuración de Django (Settings.py). Este sistema además de lo mencionado anteriormente, será el servidor de la interfaz web que será construida a continuación. 5.3 Obtención de la información procedente de Acumbamail La primera etapa del proyecto es la obtención de los datos de las campañas procedentes de Acumbamail. Estos datos se encuentran almacenados en la base de datos MySQL perteneciente a la plataforma de Acumbamail. Los usuarios pueden consultarlos cuando deseen para obtener 38 toda la información y las estadísticas referentes a las campañas enviadas. Una de las formas más sencillas para la obtención de estos datos es mediante consultas directas al servidor de base de datos, que luego serán almacenadas en el sistema de información para su posterior procesamiento. Acumbamail dispone de una API para sus usuarios, mediante la cual se puede extraer y añadir información concerniente a los suscriptores en las listas de newsletters (crear listas, añadir, obtener y eliminar suscriptores, obtener estadísticas de las listas, etcétera...). Con la finalidad de dar un valor añadido a la API de la plataforma, se ha optado por la última opción, añadiendo los métodos requeridos para obtener toda la información necesaria procedente de las campañas. La mínima información necesaria comprende: Número de emails enviados en total, número de aperturas por parte de los suscriptores de la campaña, y el asunto del correo electrónico enviado en la campaña. Aunque ésta no será la única información que se proporcionará a los usuarios de la plataforma, ya que adicionalmente se incluirán todas las estadísticas pertenecientes a sus envíos (quejas de usuarios, bajas de la newsletter, correos que han dejado de existir, entre otros). Gracias a esta información será posible conocer el porcentaje de aperturas de la campaña enviada, que es el objetivo principal, la predicción del porcentaje de aperturas de un newsletter mediante su asunto. Una vez que es posible adquirir la información, es necesario implementar un método que permita obtenerla para su posterior procesamiento. El wrapper, escrito en Python, hace uso de la librería urllib2 y JSON para la obtención de los datos de la API mediante una llamada POST con los datos de la autenticación, el número identificador de cliente y un token que proporciona la autenticación en la plataforma, y otros parámetros necesarios como el identificador de la campaña de la que se quiere obtener la información. def g e t C a m p a i g n B a s i c I n f o r m a t i o n ( self , campaign_id ) : parameters ={ " campaign_id " : campaign_id } return self . callAPI ( " g e t C a m p a i g n B a s i c I n f o r m a t i o n " , parameters ) Listado 5.3: Método para la obtención de la información de las campañas en wrapper de la API en Python Para la reutilización del código, y seguir con el principio DRY (Don’t repeat yourself, "no te repitas") de las buenas prácticas en programación, se ha construido un único método que es al que todas las funciones llaman para obtener la información. Este método es llamado mediante la función de la API a la que se quiere invocar junto con los parámetros adicionales 39 que sean necesarios. Dichos parámetros son incluidos automáticamente por la función, que los obtiene de los atributos de la clase y fueron introducidos cuando la instancia de la clase fue creada. def callAPI ( self , method , parameters = {}) : url = " https :// acumbamail . com / api /1/ " + method + " / " parameters [ ’ customer_id ’] = self . customer_id parameters [ ’ auth_token ’] = self . auth_token data = urllib . urlencode ( parameters ) req = urllib2 . Request ( url , data ) response = urllib2 . urlopen ( req ) json_response = response . read () return json . loads ( json_response ) Listado 5.4: Método encargado de realizar la petición HTTP a la API para la obtención de la información. Debido a la gran cantidad de datos que proporciona, la mejor opción es la obtención de estos datos de forma asíncrona mediante tareas ejecutadas concurrentemente. Así es posible obtener la información de varias campañas a la vez disminuyendo considerablemente el tiempo de espera hasta que todas las tarea sean completadas. Para ello se utilizará Celery. El script para la obtención de los datos de la API está escrito en Python, y por lo tanto puede ser utilizado por la tarea Celery que es necesario implementar. Este script es capaz de obtener la información directamente de la API con los parámetros necesarios mediante urllib2, una biblioteca que facilita la obtención de datos por medio del protocolo HTTP. ¿Qué cometido va a realizar nuestra tarea? La tarea asíncrona se va a encargar de llamar a los métodos creados para este propósito y obtener la información necesaria de las campañas. Esta información necesita ser procesada y limpiada antes de ser guardada, para evitar tener que desprendernos de la información innecesaria contenida en el asunto cada vez que éste sea utilizado. Éste código es el código escrito para la tarea de Celery, mediante la cual se obtiene la información de cada una de las campañas que después será tratada para eliminar los elementos innecesarios. ¿Qué se puede catalogar como información innecesaria? Información innecesaria es aquella que no es determinante para comprender perfectamente sobre qué trata el correo leyendo únicamente el asunto. 40 @shared_task def getDataAPI ( campaign_id ) : datos_acmb = AcumbamailData () campaign = datos_acmb . getInfo ( campaign_id ) dtd = DecisionTreeData () dtd . subject_words = json . dumps ( campaign [ ’ subject ’ ]) dtd . o pened _perce ntage = campaign [ ’ opened ’] dtd . campaign_number = campaign_id dtd . save () Para la personalización de las campañas de email se utiliza un concepto llamado mergetags. Los mergetags permiten añadir contenido dinámico al correo electrónico enviado en la campaña. Por ejemplo, realizar una personalización de la newsletter incluyendo el nombre del destinatario en el asunto. Este contenido es introducido por el usuario en cadenas envueltas por los caracteres *| y |*. Estos elementos que es posible encontrar en los asuntos no tienen ningún valor semántico para la comprensión del asunto, y por tanto pueden ser eliminados sin ningún problema. En los asuntos de los correos, igual que en el lenguaje escrito, se encuentran abundantes palabras que no son determinantes para el entendimento del contenido. Estas palabras son llamadas palabras vacías (Stopwords en inglés), formadas por artículos, pronombres, preposiciones, etcétera. Todo lo descrito en los párrafos anteriores necesita ser eliminado para comenzar el procesamiento de la información, destinado a la creación de los datos de entrenamiento necesarios para el árbol de decisión utilizado para la resolución del problema. Facilita el procesado de la información, ya que elimina información que no aporta valor para el resultado y alargaría el proceso innecesariamente. Una vez que ya se dispone únicamente del contenido que es útil, éste será guardado en una base de datos para su posterior utilización. Esta información será actualizada cada cierto tiempo con el objetivo de recopilar cada vez más información y mejorar poco a poco los resultados de las predicciones obtenidas. [?] 5.4 Construcción del Árbol de Decisión Una de las partes más importantes del proyecto es la construcción del árbol de decisión, que será el encargado de proporcionar las predicciones de las newsletters gracias a la clasificación de las campañas por palabras similares. Hay diversos frameworks destinados a la creación de este tipo de árboles, el más conocido escrito en Python es scikit-learn, que es el que ha sido utilizado en el proyecto. 41 5.4.1 Entrenamiento del Árbol e Inferencia de Supuestos Una de las acciones fundamentales para el funcionamiento del sistema es el entrenamiento del árbol de decisión. Para esta tarea se utilizan los llamados «training sets» o conjuntos de entrenamiento, conjuntos de datos relevantes extraidos de las observaciones obtenidas. Los árboles de decisión clasifican instancias pasándolas por el árbol desde la raiz hasta algún nodo hoja, el cual proporciona la clasificación de la instancia. Esta clasificación es realizada empezando por la raíz, probando el atributo por todos sus posibles valores y moviéndose a la rama que corresponde por el valor del atributo. Para su mejor comprensión se va a realizar un ejemplo con un árbol de decisión que ayuda a determinar si es posible o no jugar al tenis. (ver Figura 5.3) La primera variable que determina la clasificación es la previsión del tiempo. Ésta previsión puede ser soleada, nublada, o lluviosa. Si en el día de hoy el tiempo está soleado, la siguiente variable es la humedad. Si la humedad es alta, no se puede jugar al tenis. Si por el contrario, la humedad es normal, sí que se puede jugar. Si en el día de hoy el tiempo está nublado, sí se puede jugar al tenis. Si el día de hoy es lluvioso, y el viento es fuerte no se puede jugar al tenis, pero por el contrario si es débil sí que se puede Por lo tanto, si se quiere saber si es posible jugar al tenis en un día soleado con temperaturas altas, humedad alta y fuerte viento, es necesario pasar dicha información por el árbol para que sea categorizada. En este caso, como la previsión es soleada, el avance se realiza por la rama de la izquierda. La siguiente variable que aparece es la humedad. Como la humedad del día de hoy es alta, no se puede jugar al tenis. Este es un ejemplo sencillo de cómo funciona un árbol de decisión ya entrenado. En este punto se describe cómo se realiza el entrenamiento del árbol del proyecto. Para el entrenamiento, el árbol toma como entrada dos arrays: X: array que contiene las características extraidas de las campañas de newsletter. Tiene tantas filas como muestras disponibles, y tantos elementos en cada fila como número de palabras totales de las campañas obtenidas. Y: array que contiene las clases pertenecientes a las muestras del array X. Contiene tantos elementos como muestras haya. Contiene la clase a la que pertenece cada muestra del array X. 42 Sol eado Al t a Nubl ado Nor mal Ll uv i oso Fuer t e Débi l Figura 5.3: Árbol de decisión para determinar si es posible jugar al tenis. Pueden ser clasificadas las muestras comparando sus atributos con los del árbol y éste devolverá la clasificación asociada con la muestra elegida. Extraido y traducido desde (M ACHINE L EARNING , T OM M ITCHELL [Mit97]) Cada uno de los elementos del array X (listas de 1s y 0s) es una de las características pertenecientes a una campaña. Es decir, el numero de elementos de la lista coincide con el número de palabras contenidas en todas las campañas obtenidas de Acumbamail. Estas características se construyen paso a paso, comprobando si cada palabra de las recopiladas se encuentra en el asunto en cuestión. El segundo array, Y, consiste en las clases obtenidas por medio de la agrupación de los porcentajes. Cada una de las clases corresponde a una de las muestras del array X. Éstos porcentajes se han agrupado para conseguir una menor dispersión en los datos introducidos en el árbol. Es posible conocer más detalles sobre estas clases en el cuadro 5.1. Un ejemplo de estos arrays sería: X = [[0, 1, 1, 0, 0, 0, 1], [1, 0, 1, 1, 0, 1, 0], [1, 1, 1, 0, 1, 1, 0], [0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 0, 1, 0, 1], [0, 1, 0, 1, 0, 1, 0], [1, 0, 0, 1, 1, 1, 0]] Y = [0, 1, 2, 3, 4, 5, 6] Estos arrays son construidos mediante 43 def c o n v e r t D a t a T o D a t a T r e e ( self ) : subject = json . loads ( campaign . subject_words ) opened = campaign . op ened_ percen tage if 0 <= opened < 100: appearances =[] for subject_word in self . subject_words : if subject_word in subject : appearances . append (1) else: appearances . append (0) self . data . append ( appearances ) if 0 <= opened <= 7: self . classes . append ( TreeClasses . muy_malo ) elif 8 <= opened <= 13: self . classes . append ( TreeClasses . malo ) elif 14 <= opened <= 19: self . classes . append ( TreeClasses . normal ) elif 20 <= opened <= 30: self . classes . append ( TreeClasses . bueno ) elif 31 <= opened <= 40: self . classes . append ( TreeClasses . mejor_bueno ) elif 41 <= opened <= 60: self . classes . append ( TreeClasses . muy_bueno ) elif 61 <= opened <= 99: self . classes . append ( TreeClasses . excelente ) Listado 5.5: Código que convierte los asuntos en el formato aceptado por el árbol En el listado 5.5 siendo el atributo subject_words de la clase, un conjunto ordenado de las palabras contenidas en todas las campañas obtenidas se añade al array un 0 o un 1 dependiendo de si la palabra está contenida o no, y posteriormente, en función de la tasa de apertura de la campaña, se la encuadra en la clase correspondiente. Si las palabras recopiladas son libro, camisetas, fútbol, ordenador, vacaciones, verano, y oferta, la primera campaña contendría camisetas, fútbol, oferta. Esas serían sus características para nuestro árbol de decisión. Para ilustrar lo descrito anteriormente, se va a exponer un ejemplo como el del juego del tenis en la Figura 5.3. Se parte de la hipótesis de que las palabras recopiladas de las campañas son: «vacaciones», «regalos», «amor», «boda», «película». El árbol puede tener como raíz cualquiera de las palabras mencionadas anteriormente. Colgarían de él todos los posibles atributos, en este caso si la palabra se encuentra en el asunto o por el contrario no está contenida. Después se encontrarían las palabras sucesivas de los asuntos contenidos en todas las campañas como hijos de las ramas dependiendo de si se encuentran enlazados con alguna de las palabras ya existentes en el árbol. 44 Clase Porcentajes que comprende Etiqueta Porcentaje de Campañas Cubierto 0 0≤x≥7 Muy malo 1 8 ≤ x ≥ 13 Malo 2 14 ≤ x ≥ 19 Normal 3 20 ≤ x ≥ 30 Bueno 4 31 ≤ x ≥ 40 Mejor que Bueno 5 41 ≤ x ≥ 60 Muy bueno 6 61 ≤ x ≥ 99 Excelente 9.25 % Acumulado: 9.25 % 17 % Acumulado: 26.25 % 18.69 % Acumulado: 44.94 % 18.16 % Acumulado: 63.1 % 9.98 Acumulado: 73.08 % 14.17 % Acumulado: 87.25 % 12.75 % Acumulado: 100 % Cuadro 5.1: Detalles sobre la agrupación de los porcentajes de la tasa de apertura en las campañas. Detalles sobre que porcentaje engloba cada clase, la etiqueta que se asigna a cada clase y el porcentaje de campañas qué cubre cada una Se va a tomar como ejemplo la frase "Ten unas vacaciones de película". A esta frase sería necesario eliminarle las stopwords y las palabras sin significado, como «unas» o «de» para evitar palabras innecesarias. El asunto que sería pasado por el árbol contendría las palabras ”ten”, ”vacaciones” y ”película”. Siguiendo el árbol de ejemplo en la figura 5.4, la primera palabra que se encuentra es vacaciones. Como en nuestro asunto está contenida se avanza por la rama de la izquierda (sí). Ahora la siguiente palabra que es encontrada es película. Como también está contenida se avanza por la rama izquierda (sí). El árbol, gracias a los datos de entrenamiento, estima que los asuntos que contienen las palabras vacaciones y película pertenecen a la clase 3. Esta clase engloba los porcentajes desde el 20 % hasta el 30 %, ambos inclusive. Como se puede observar, es una tarea costosa cuando es posible encontrar varias decenas de miles de palabras contenidas en todas las campañas extraídas, si bien permite realizar estimaciones precisas sobre los datos que se han proporcionado al árbol para realizar la inferencia del supuesto. 5.5 Servicio Web Para la utilización del árbol de decisión se ha construido un servicio web mediante el cual es posible obtener fácilmente la inferencia de los supuestos introducidos por los usuarios. Este servidor está creado con la clase BaseHTTPServer en Python. Mediante un handler se implementan las operaciones necesarias para la funcionalidad 45 Vacaciones sí no Película sí Clase: 3 Amor no no Clase: 2 Boda sí Clase: 1 sí Clase: 6 Figura 5.4: Árbol de decisión creado mediante palabras de ejemplo para ilustrar el funcionamiento del árbol que ha sido creado con las campañas de Acumbamail. Ejemplo en miniatura del árbol real creado con el framework para Python utilizado, scikit-learn planteada anteriormente. Estas funcionalidades comprenden la recepción de las peticiones POST desde los distintos puntos de entrada al servicio, y la respuesta a las peticiones HEAD que se requieran. Mediante las cabeceras están deshabilitados los demás dominios que puedan realizar una petición, dejando solo hábiles los dominios que sean de nuestra propiedad. Access−Control−Allow−Origin : http :// sandbox . acumbamail . com Listado 5.6: Propiedad de la cabecera que controla el acceso de los servidores web al servicio A continuación se detalla el funcionamiento del servicio: Los casos de uso de todos los actores con respecto a la utilización del servicio web están detallados en la figura 5.5. 46 Figura 5.5: Diagrama de casos de uso pertenecientes al servicio web El servicio se encuentra permanentemente ejecutado en un servidor web respondiendo y parseando las peticiones POST que le llegan por el puerto en el que se encuentra escuchando. Cuando llega una petición al servicio este llama a la función implementada en el handler encargada de parsear la petición. Ésta función está encargada de parsear los argumentos contenidos en la petición y de mandar el resultado a través de HTTP. Estos argumentos pueden llegar al servidor de varias formas, según indique el campo «content-type» en las cabeceras de la petición POST. Se pueden encontrar dos valores, «application/x-www-form-urlencoded» o «multipart/form-data». Mediante «application/x-www-form-urlencoded», lo que el servidor recibe es una cadena con todos los atributos enviados mediante POST, separando los pares de nombre y valor con un ampersand (&) y los nombres son separados de los valores por el símbolo de igual (=). variable1 = valor1&variable2 = valor2&variable3 = valor3 Cuando los payloads son muy grandes y contienen muchos caracteres alfanuméricos, este método se vuelve muy ineficiente ya que por cada byte no alfanumérico en cada valor utiliza tres bytes para representarlo, multiplicando el tamaño por tres. La otra opción es «multipart/form-data». Con este método cada par está representado por una parte en un mensaje Multipurpose Internet Mail Extensions (MIME), separando estas partes por un caracter especial que no aparece en ninguno de los valores del payload. Una vez que ya han sido extraidas todas estas variables contenidas en la petición, el asunto que el usuario ha introducido es procesado para dejar únicamente solo las palabras válidas, es decir, aquellas que pueden determinar el resultado. Este proceso se realiza mediante una función creada para este propósito, que es utilizada 47 también cuando se obtienen los datos procedentes de las campañas. Posteriormente el árbol realiza la estimación del asunto mediante los datos que ya han sido proporcionados con anterioridad. La respuesta que proporciona el árbol de decisión es devuelta al servicio web desde el que ha sido llamado mediante JSON, junto a un mensaje para poder determinar si la petición ha sido correcta (Ver Listado 5.7) o se ha producido algún fallo (Ver Listado 5.8). { " status " : " ok " , " subject_class " : " 3 " } Listado 5.7: Respuesta del servicio web en formato JSON, Petición Correcta { " status " : " error " , " error_msg " : " The service is temporarily unavailable . " } Listado 5.8: Respuesta del servicio web en formato JSON, Petición Errónea Una vez que la respuesta es construida es enviada de vuelta al usuario. Ésta es procesada por su navegador y muestra el resultado a través de la interfaz web. Aunque en la figura 5.6 esté ejecutado manualmente, en el entorno de producción este servidor es ejecutado mediante un servicio en Linux, dejando el mando de la ejecución al sistema y recopilando todos los errores un log situado en una carpeta creada al efecto en la unidad de almacenamiento. 5.6 Interfaz Web Para la fácil interacción de los usuarios con el servicio se ha creado una interfaz web minimalista, que está dedicada a la introducción del asunto por parte de los usuarios y a mostrar, de una forma simple y que favorezca la usabilidad, la respuesta obtenida desde el servicio web, ejecutado en el mismo servidor. En la Figura 5.7 se puede ver el diseño de la interfaz. Esta interfaz está construida con la finalidad de centrar al usuario en la tarea principal, realizar la predicción de los asuntos. Se encuentra únicamente una barra de navegación con enlaces a las distintas partes de la interfaz. Como contenido principal se dispone de un campo destinado a la introducción del texto del asunto. Con el fin de recordar la utilidad del mismo se encuentra marcado a la izquierda con el icono del sobre de una carta. Cuando el usuario introduce el asunto únicamente es preciso pulsar el botón enviar para que se realice la predicción. 48 Figura 5.6: Captura de pantalla perteneciente al servidor ejecutado manualmente para la muestra del procesamiento de asuntos. Prueba de predicción con la frase "Ten unas vacaciones de película". Esta interfaz está construida mediante Bootstrap y jQuery como frameworks principales. Estos frameworks permiten crear una interfaz de una forma fácil, sin necesidad de consumir recursos en aspectos estéticos o de diseño. Bootstrap dispone de todos los elementos necesarios para la construcción de nuestra interfaz. Para la representación del resultado se utiliza una asociación de colores a cada rango de tasa de apertura. El color rojo se asocia a una tasa de apertura baja, el color amarillo a una tasa de apertura media, el color azul a una tasa de apertura media alta y el color verde a una tasa de apertura alta. Como se puede observar en las figuras 5.8, 5.9, 5.10, 5.12, correspondientes a las notificaciones que aparecen en la interfaz, se puede diferenciar perfectamente a qué clase (clases en las que se dividen el rango total de porcentajes de apertura) pertenece el asunto analizado. Además en la notificación se encuentra de forma escrita el rango de porcentajes al que la tasa de apertura del asunto investigado. Junto a estas notificaciones de la tasa de apertura se proporcionan consejos para la mejora 49 Figura 5.7: Captura de pantalla perteneciente a la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no tengan cuenta en la plataforma de Acumbamail. Pantalla inicial sin resultados de predicción Figura 5.8: Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura alta Figura 5.9: Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura media-alta Figura 5.10: Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura media 50 Figura 5.11: Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura baja de las campañas enviadas por email marketing. Figura 5.12: Captura de pantalla de la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no disponen de cuenta en la plataforma de Acumbamail. Consejos proporcionados a los usuarios Estos consejos son ideas esenciales para que las campañas sean más exitosas. Es necesario llamar la atención del receptor para que sienta curiosidad acerca del contenido de la campaña. Para ello es preciso evitar las palabras habitualmente utilizadas en campañas de publicidad, emplear un asunto que no tenga demasiada longitud, y renovarlo si se envía varias veces la misma campaña. La estructura descrita anteriormente es la que forma la interfaz web que los usuarios utilizarán cuando accedan al servicio que se proporciona. Como se aprecia en la figura 5.13, se dispone de una interfaz minimalista centrada en la acción principal, consistente en mostrar el resultado de la predicción realizada mediante el asunto proporcionado. En el desarrollo de la interfaz se han seguido principios de usabilidad dictados por Jakob 51 Nielsen. Se ha intentado minimizar la longitud vertical de la página para que no sea necesario hacer scroll. Otra de las características importantes es el tamaño de la caja de búsqueda, con un tamaño adecuado para la introducción del asunto. Igualmente se ha diseñado la página con los elementos imprescindibles para su funcionamiento, evitando la sobrecarga y reduciendo las incertidumples que se pudieran producir en el uso de la misma. Figura 5.13: Captura de pantalla perteneciente a la interfaz web creada para el acceso al servicio perteneciente a los usuarios que no tengan cuenta en la plataforma de Acumbamail. Pantalla de resultados de predicción. 5.7 Integración con la plataforma de Acumbamail Este proyecto está concebido con el objetivo de proporcionar el servicio creado a los usuarios de la plataforma de Acumbamail. Este servicio es útil para ampliar información acerca de los temas que han sido anteriormente enviados en las campañas y han tenido éxito, o por el contrario no han sido exitosos y es necesario revisar el tema del asunto. Esta integración se ha realizado de forma sencilla, mediante un botón en la interfaz web actual. La función de este botón es la activación del servicio. Cuando es pulsado se envía el contenido de la caja de texto al servidor que alberga el servicio web mediante una petición POST. Éste obtiene las variables incluidas en la petición, las procesa y las convierte al formato necesario para realizar la predicción. Esto es pasado al árbol que proporciona la predicción y es devuelta mediante JSON al cliente. 52 El navegador del cliente procesa la respuesta y dependiendo de la información obtenida muestra unos elementos u otros. Los elementos mostrados en la plataforma son los mismos que son mostrados en la interfaz web propia del servicio. La integración se ha realizado con el fin de facilitar al máximo la utilización por parte de los usuarios. La utilización del servicio en la plataforma se reduce a la inclusión de un botón junto al campo de entrada de los asuntos en las creaciones de las campañas. Por tanto, los usuarios sólo tienen que introducir el contenido del asunto cuando se encuentren creando la campaña y para comprobar la estimación que proporciona el servicio web únicamente es preciso pulsar el botón situado en la parte derecha. El botón está asociado a un icono que de forma intuitiva proporciona información sobre la función que realiza. El icono asociado es el de un tacómetro, un dispositivo para realizar una medida. Para clarificar la utilización del botón se ha incluido una burbuja que aparece al mover el ratón sobre el icono y da una explicación de la acción que dicho botón ejecuta. Como se puede observar en la figura 5.15, se ha realizado un control de errores para que el usuario esté informado en todo momento del estado del proceso, y en su caso de la ocurrencia del motivo del fallo, tanto si es un fallo del usuario como un fallo del servicio web. Aunque la plataforma de Acumbamail incorpora su propia gestión de fallos como se puede ver en la figura mencionada anteriormente, se ha incluido una gestión propia para que el usuario reciba feedback en caso de que no se produzca ninguna acción cuando pulsa el botón. Para minimizar el impacto de la inclusión del servicio en la plataforma, además de evitar el agrandamiento del contenido verticalmente en la página, se ha optado por la incorporación de un enlace al contenido de los consejos proporcionados para la mejora de las campañas, siendo los mismos que son ofrecidos en la interfaz web del servicio. 5.8 Integración Continua de Cambios Uno de los aspectos claves del proyecto es la integración de los cambios realizados en el ordenador local. Estos son enviados al repositorio y tienen que ser descargados del mismo en el servidor remoto en el que el servicio está alojado. Existen multitud de herramientas que permiten la automatización del despliegue de estos cambios, denominados como “Integración Contínua”. La herramienta elegida en el proyecto para la realización de esta tarea ha sido fabric. Fabric es una biblioteca de Python y un ejecutable por línea de comandos para el despliegue 53 Figura 5.14: Captura de pantalla perteneciente a la interfaz web de Acumbamail. Pantalla de utilización del servicio Figura 5.15: Captura de pantalla perteneciente a la interfaz web de Acumbamail. Muestra de errores en la interfaz. Figura 5.16: Captura de pantalla perteneciente a la interfaz web de Acumbamail. Notificaciones de resultados correspondientes a las tasas de apertura media-alta. de aplicaciones o de tareas para la administración de servidores. Proporciona un conjunto de operaciones para ejecutar en una máquina local o para la ejecución de comandos en terminales remotas. 54 5.8.1 ¿Cómo se utiliza fabric? La utilización de fabric es bastante sencilla. Únicamente es preciso escribir un script en Python con las acciones que se desean realizar en la máquina local y en la remota. En este caso, las acciones serían enviar los cambios locales al repositorio alojado en Bitbucket en el que se encuentra la copia principal y descargar esos cambios en la máquina remota mediante GIT. Las acciones deseadas son definidas mediante tareas. Estas tareas son funciones comunes a las que se le agrega un decorador que de forma transparente al usuario envuelve a la función como una subclase de la clase Task de Fabric. Fabric permite realizar todos los comandos deseados en las máquinas locales o remotas mediante SSH. import sys from fabric . api from fabric . api from fabric . api from fabric . api import import import import sudo cd local , run settings HOST _MAPP ING_DI CT = { ’ master ’: ’ testplugins . acumbamail . com ’ } B RA N C H _M A P PI N G _D I C T = { ’ master ’: ’ master ’ } def pull ( env = ’ master ’) : with settings ( user = ’ django ’ , password = ’ XXXXXXXXXX ’) , with cd ( ’/ home / django / tfg ’) : run ( ’ git pull origin master ’) def push ( env = ’ master ’) : host = HO ST_MAP PING_D ICT [ env ] local ( ’ git push origin %s ’ % B R A NC H _ M AP P I NG _ D IC T [ env ]) local ( ’ fab −H %s pull : env = %s ’ % ( host , env ) ) Listado 5.9: Modelo de Información perteneciente a las campañas almacenadas Mediante el código del listado 5.9 se realizan las acciones deseadas para el despliegue de los cambios que se hayan realizado en la máquina local. Estas acciones consisten en realizar mediante el comando «git push» perteneciente a GIT el envío de los cambios en los que previamente se ha realizado la acción commit (confirmar que los cambios realizados pueden ser enviados) al repositorio en Bitbucket. Posteriormente, mediante SSH, se ejecuta el comando «git pull» para descargar los cambios del repositorio que se hayan subido desde la última vez que fueron descargados. 55 Capítulo 6 Conclusiones Ahora se van a detallar las conclusiones obtenidas a la finalización del proyecto. El campo de la inteligencia de negocio, como es conocido actualmente, es una materia a explotar todavía por las empresas tecnológicas o no tecnológicas. Ésta permite obtener información útil para el negocio gracias a los datos recopilados. Ésto extrapolado a las campañas de email marketing que mandan estas empresas es lo que se ha tratado de mejorar gracias a la realización de este proyecto. Todas las estadísticas recogidas por Acumbamail procedentes de las campañas enviadas mediante su servicio es lo que ha sido analizado, incluido en un árbol de decisión para realizar las predicciones, y mostrado gracias a la creación de un servicio web que utiliza el mismo a través de la plataforma de Acumbamail o la interfaz web creada para este propósito. 6.1 Objetivos Todos los objetivos han sido alcanzados satisfactoriamente. Obtención de los datos procedentes de las campañas enviadas por Acumbamail Estos datos son obtenidos gracias a los nuevos métodos de la API construidos para este propósito, y mediante el wrapper en Python elaborado para facilitar su extracción y almacenaje en la base de datos existente. Construcción de la Información Los datos extraídos se encuentran moldeados y en el formato que el árbol de decisión acepta en su entrenamiento. Los datos originales han sido filtrados para eliminar lo innecesario y conocer su porcentaje de apertura. Construcción del Árbol de Decisión El árbol de decisión está construido mediante el framework scikit-learn, y es entrenado correctamente para mejorar los resultados de la inferencia de supuestos. Éste árbol es el que da soporte al servicio web destinado a sus usuarios. Inferencia de los Supuestos El árbol de decisión realiza correctamente la inferencia de supuestos. Estos supuestos 57 son obtenidos mediante el servicio web que ha sido construido en Python. Igual que los datos originales, son filtrados y convertidos al formato necesario para realizar la inferencia. Implementación del Sistema de Información e Integración de componentes Se ha realizado una sencilla interfaz web en la que los usuarios pueden introducir sus asuntos y conocer el resultado de la predicción, además de la integración del mismo servicio en la plataforma de Acumbamail. Ambas soluciones utilizan el servicio web creado para tal fin, que proporciona mediante una respuesta JSON la predicción del asunto deseado. Correcto Funcionamiento de todos los elementos del sistema El sistema ha sido probado con éxito, y todos los elementos funcionan correctamente. Hay una integración eficiente entre ellos. 6.2 Problemas Encontrados Uno de las principales dificultades es la gran cantidad de información a manejar. Las campañas que actualmente dispone Acumbamail en su base de datos tienen que ser extraídas mediante la API, procesadas y almacenadas por el sistema construido. Después el árbol de decisión ha de ser entrenado con esos datos. La gran cantidad de datos almacenada hace que todo este proceso se alargue en el tiempo, llevando múltiples horas hasta que es completado. Otro de los factores determinantes es la construcción de la informacion. Debido a la gran cantidad de palabras que se encuentran en todas las campañas, el árbol emplea mucho tiempo en su construcción. 6.3 Propuestas de Mejora Este proyecto es un comienzo básico de todo un sistema de mejora de campañas de email marketing. El primer parámetro analizado es el asunto, que puede permitir aumentar el porcentaje de apertura en una campaña. También hay multitud de parámetros que pueden permitir que nuestro correo no llegue a la carpeta de SPAM del cliente de correo, o que los usuarios abran más enlaces del contenido de la campaña. Para que nuestra campaña no llegue a SPAM es preciso evitar palabras incluidas en correos de publicidad como oferta, promoción, descuento, o no incluir demasiadas imágenes en relación con el texto incluido en el correo electrónico. Igualmente podría ser analizado el código de la plantilla de la campaña para determinar si 58 el contenido del correo podrá ser visualizado correctamente en los principales proveedores de correo, como GMail, Hotmail, etcétera, además de en los clientes de correo desarrollados para plataformas de escritorio y/o móviles. Cada una de las campañas es enviada a distintas listas de suscriptores, y dependiendo de las preferencias de cada usuario puede aumentar o disminuir el porcentaje de apertura. Para mejorar las predicciones se podría segmentar los datos por los diferentes proveedores de correo. La interfaz web para la utilización del servicio es sencilla. Se podrían incluir más funcionalidades con el fin de hacerla más completa, como el registro de usuarios para llevar control de todas las acciones realizadas y guardar un histórico de las peticiones realizadas. Actualmente los datos analizados son proporcionados únicamente por Acumbamail, si bien podrían ser incluidas fácilmente otras fuentes de datos utilizando la tarea creada en Celery y creando otro wrapper para API para el servicio del que se van a incluir los datos. 59 ANEXOS 61 Anexo A Creación de una aplicación web con Django La creación de una aplicación web en Django es un proceso rápido y fácil, y en poco tiempo se puede empezar a escribir la aplicación. Todo el conocimiento necesario sobre Django, se encuentra en The Django Book [HKM07]. El primer paso es la instalación de Django. Esto puede ser realizado de varias formas, descargándolo desde la página web oficial (http://www.djangoproject.com/download/) o, lo más recomendado, mediante pip, un instalador de paquetes Python. Para instalar pip se necesita descargar su archivo get-pip.py, que se puede descargar mediante el comando wget en GNU/Linux. wget https :// bootstrap . pypa . io / get−pip . py Listado A.1: Modelo de Información perteneciente a las campañas almacenadas Después es instalado con Python, mediante el comando (desde la misma carpeta donde se encuentra el archivo): sudo python get−pip . py Listado A.2: Modelo de Información perteneciente a las campañas almacenadas Una vez acabada la instalación de pip, ya se puede proceder a la instalación de Django. Gracias a pip, es posible instalar paquetes python en la versión deseada, que no tiene que ser necesariamente la última. El comando de instalación de Django en pip es: sudo pip install Django Listado A.3: Modelo de Información perteneciente a las campañas almacenadas También se permite instalar una versión concreta, distinta a la última versión disponible. 63 sudo pip install Django ==1.4 a Listado A.4: Modelo de Información perteneciente a las campañas almacenadas Una vez finalizada la instalación de Django, si se va a utilizar una base de datos MySQL es necesario instalar el controlador para Python, que es instalado así: sudo pip install mysql−python Listado A.5: Modelo de Información perteneciente a las campañas almacenadas Ahora ya es posible empezar la creación de la aplicación en Django. El primer paso es crear una carpeta que albergue el proyecto en la carpeta del usuario correspondiente. Si se requiere tener varias instalaciones de Django independientes e instalar diferentes paquetes es posible usar entornos virtuales (virtualenvs). Una vez creada la carpeta y estando dentro de ella, se ejecuta el comando: django−admin . py startproject ∗ mysite ∗ Donde mysite es el nombre dado al proyecto de la aplicación web. Esto creará la estructura de directorios básica para el comienzo del proyecto, el archivo manage.py, que es una utilidad para interactuar con el sistema mediante línea de comandos. Dentro de la carpeta principal existe otra carpeta con el mismo nombre que contiene los archivos, init.py, settings.py, urls.py y wsgi.py. Estos archivos contienen los ajustes, las URL definidas para el servidor y el punto de entrada WSGI para el servidor web en el proyecto. Una vez creado el directorio principal es posible arrancar el servidor aunque no haya nada que mostrar, simplemente para comprobar su funcionamiento. El comando es: python manage . py runserver El comando tendrá una salida parecida a esta: Validating models ... 0 errors found . Django version 1.4.2 , using settings ’ mysite . settings ’ Development server is running at http :/ /1 27 .0 .0 .1: 80 00 / Quit the server with CONTROL−C . 64 Si se accede a esa URL aparecerá un mensaje con el contenido «Welcome to Django» en color azul. Para la construcción de la aplicación se dispone de tres puntos clave, los modelos, las vistas y las URL. La configuración de las URL es la parte clave, puesto que indicará al sistema que métodos tiene que ejecutar cuando se acceda a cualquiera de las URLs definidas. Para ello se accede al archivo urls.py. Si se desea añadir más URLs es preciso incluirlas en la variable urlpatterns. Un ejemplo podría ser este: from django . conf . urls . defaults import patterns , include , url from tfg . views import inicio , info urlpatterns = patterns ( ’ ’ , url ( r ’^ $ ’ , inicio ) , url ( r ’^ suma / $ ’ , info ) , ) En este ejemplo se encuentran configuradas dos URLs, la principal, y un subdirectorio llamado suma. Estas URL cuando son invocadas llaman a las vistas correspondientes, en este caso, inicio para la URL principal y suma para la segunda URL. Para la creación de estas vistas se necesita crear un nuevo archivo llamado views.py. En este archivo, se incluirán dos funciones denominadas inicio y suma. from django . http import HttpResponse def inicio ( request ) : return HttpResponse ( " Hello world " ) def suma ( request , one , two ) : try: one = int( one ) two = int( two ) except ValueError : raise Http404 () sum = one + two html = " < html > < body > La suma de %d mas %d es %d </ body > </ html > " % ( one , two , sum) return HttpResponse ( html ) Estas funciones serán invocadas cuando se acceda a las URLs mediante el navegador. 65 Esta es la configuración básica de Django. Posteriormente, mediante los modelos es posible incorporar la lógica de negocio a la aplicación web. Conforme a lo descrito anteriormente, Django está dispuesto para comenzar la escritura de la aplicación web. 66 Anexo B Aspectos Legales La titularidad de los derechos de propiedad intelectual del trabajo será compartida entre Jesús Botella y Acumbamail S.L. Jesús Botella renuncia a cualquier tipo de reclamación que pueda realizar a Acumbamail S.L. por la utilización de cualquier material derivado de la realización de este trabajo. No ha sido recopilado ni se ha trabajado con ningún tipo de dato personal, por tanto la LOPD no es de aplicación en este proyecto. 67 Referencias [ASJH11] Paul Adamczyk, Patrick H. Smith, Ralph E. Johnson, and Munawar Hafiz. Rest and web services: In theory and in practice. In Erik Wilde and Cesare Pautasso, editors, REST: From Research to Practice, pages 35–57. Springer, 2011. ISBN 978-1-4419-8302-2. URL http://dblp.uni-trier.de/db/ books/collections/Wilde2011.html#AdamczykSJH11. [boo] Bootstrap framework. URL http://getbootstrap.com/. [BS07] Chris Baggott and Ali Sales. Email Marketing By the Numbers. Wiley, 1st edition, Jul 2007. ISBN 9780470148280. [cel] Celery. URL http://www.celeryproject.org/. [CSS] Css. URL http://www.w3.org/standards/techs/css. [dja] Django. URL https://www.djangoproject.com/. [FGM+ 99] R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, and T. Berners-Lee. Rfc 2616, hypertext transfer protocol – http/1.1, 1999. URL http://www.rfc.net/rfc2616.html. [FPSS96] Usama M. Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. Advances in knowledge discovery and data mining. chapter From Data Mining to Knowledge Discovery: An Overview, pages 1–34. American Association for Artificial Intelligence, Menlo Park, CA, USA, 1996. ISBN 0-262-56097-6. URL http://dl.acm.org/citation.cfm?id=257938.257942. [FT02] Roy T. Fielding and Richard N. Taylor. Principled design of the modern web architecture. ACM Trans. Internet Technol., 2(2):115–150, May 2002. ISSN 1533-5399. URL http://doi.acm.org/10.1145/514183.514185. [HKM07] Adrian Holovaty and Jacob Kaplan-Moss. The Definitive Guide to Django: Web Development Done Right. Apress, 2007. [HTM] Html. URL http://www.w3.org/standards/techs/html. [jqu] jquery. URL http://jquery.com/. 69 [jso] Json. URL http://json.org/. [Mit97] Tom Mitchell. Machine Learning. McGraw Hill, 1997. ISBN 0070428077. [mys] Mysql. URL http://www.mysql.com/. [Pyl99] Dorian Pyle. Data Preparation for Data Mining. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1999. ISBN 1-55860-529-0. [pyt] Python. URL https://www.python.org/. [RM07] L. Rokach and O. Maimon. Data Mining with Decision Trees - Theory and Applications. World Scientific Publishing Co. Pte. Ltd., 2007. ISBN 978-981277-171-1. [RN04] S. J. Rusell and P. Norvig. Inteligencia Artificial. Un enfoque moderno. Segunda Edición. PEARSON EDUCACIÓN S.A., 2004. ISBN 978-842-054-003-0. [RR13] Leonard Richardson and Sam Ruby. Restful Web APIs. O’Reilly, first edition, 2013. ISBN 978-1-4493-5806-8. [scr] Scrum. URL https://www.scrum.org/. [TMC+ 09] John C. Tang, Tara Matthews, Julian Cerruti, Stephen Dill, Eric Wilcox, Jerald Schoudt, and Hernan Badenes. Global differences in attributes of email usage. In Proceedings of the 2009 International Workshop on Intercultural Collaboration, IWIC ’09, pages 185–194. ACM, New York, NY, USA, 2009. ISBN 978-160558-502-4. URL http://doi.acm.org/10.1145/1499224.1499252. [tre] Trello. URL https://trello.com/. [WDK11] Jaclyn Wainer, Laura Dabbish, and Robert Kraut. Should i open this email?: Inbox-level cues, curiosity and attention to email. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’11, pages 3439– 3448. ACM, New York, NY, USA, 2011. ISBN 978-1-4503-0228-9. URL http://doi.acm.org/10.1145/1978942.1979456. 70 Este documento fue editado y tipografiado con LATEX empleando la clase esi-tfg que se puede encontrar en: https://bitbucket.org/arco group/esi-tfg 71