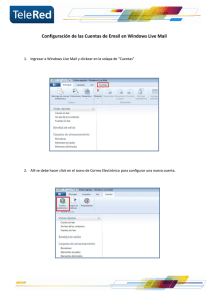
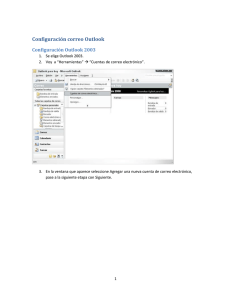
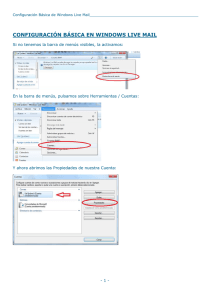
“Diseño de un robot de correo electrónico con funcionalidad MIME “
Anuncio

UNIVERSIDAD AUTONOMA METROPOLITANA UNIDAD AZCAPOTZALCO Tesis para obtener el grado de Maestro en Ciencias de la Computación “Diseño de un robot de correo electrónico con funcionalidad MIME “ Alumno: Ing. Raymundo Juárez Anguiano Asesor: Dr. Rossen Petrov Popnikolov Sinodales: Presidente: Secretario: Vocal: México, D.F. Dr. Juan Carlos Sánchez García M. en C. José Alfredo Estrada Soto Dr. Rossen Petrov Popnikolov Julio 2005 DEDICATORIA A mis padres y mis hermanos: Por su apoyo moral para terminar con este trabajo. A mi hija Andrea Sofía: Por la motivación y empuje extra para llegar hasta el final. A mi asesor, el Dr. Rossen: Por sus palabras siempre alentadoras y motivamentes. A la Universidad Autónoma Metropolitana: Por brindarme la oportunidad de realizar este posgrado. Al CONACYT: Por su apoyo para lograr este objetivo. Julio de 2005 2/165 RESUMEN Se describe el diseño y la operación de un robot de correo electrónico. Un robot de correo electrónico es un conjunto de objetos de software interrelacionados que actúan en coordinación para descargar, procesar y contestar automáticamente mensajes, dirigidos a una cierta dirección de correo electrónico. Para operar correctamente, el robot de correo usa una base de datos que contiene la información, con la que se retroalimenta a los usuarios que envían sus correos al robot. El correo electrónico es una de las aplicaciones más populares de Internet. Por tal motivo, se dedicó parte de este trabajo para mostrar algunos de los aspectos más relevantes de la red de redes. Así también, se hace mención de la pila de protocolos TCP/IP utilizada por Internet. Para la elaboración de los programas fue necesario el estudio y el análisis de los principales protocolos de correo electrónico, tales como: SMTP (rfc821), POP3 (rfc1939), MIME (rfc’s 2045, 2046, 2047, 2048 y 2049), y la estructura de un mensaje de correo (rfc822), entre otros. Para desarrollar el software se utilizó el lenguaje de programación Java, en virtud de que es un lenguaje idóneo para trabajar con Internet. Además, se utilizó una API, llamada JavaMail, la cual contiene diversas clases que modelan los distintos componentes de un sistema de correo electrónico. Para la parte del manejo de la base de datos se empleo otra API conocida como JDBC, la cual permite interactuar con fuentes de datos tabulares desde un programa en Java. 3/165 ABSTRACT A mailbot design and operation is described here. A mailbot is a group of related software objects which act as a whole so as to automaticaly download, process and reply messages intended for a particular mail address. In order to operate in a proper manner, this mailbot uses a database. This database contains useful information, which in turn, it is sent to those users that required it from the mailbot. Electronic mail is one of the most popular Internet applications. That’s why part of this paper is devoted to show some of the most relevant aspects of the Internet. TCP/IP stack is used for Internet, and it is mentioned as well. Studying and analizing main e-mail protocols was necessary during programming stage. E-mail protocols such as SMTP (rfc821), POP3 (rfc1939), MIME (rfc’s 2045, 2046, 2047, 2048 y 2049), and e-mail structure (rfc822) were important issues for this matter. In software development Java lenguage was used. The reason why this programming lenguaje was chosen and no other, it is because Java perfectly fits in an Internet environment. JavaMail API was also employed. JavaMail contains several classes designed for modelling an e-mail system. For database handling purposes we used another API called JDBC, which allows interaction between a Java program and data from tabular sources. 4/165 INDICE Página Resumen Abstract Indice Lista de figuras Lista de tablas Introducción Antecedentes Justificación Objetivo general Objetivos específicos 3 4 5 9 11 12 14 16 17 17 CAPÍTULO 1 FUNDAMENTOS TEORICOS DEL CORREO ELECTRÓNICO 1.1. 1.2. 1.3. Correo electrónico Usos del correo electrónico Cómo funciona el correo electrónico 1.3.1. Front end 1.3.2. Back end El almacén de mensajes (message store) El agente de transporte (transport agent) El agente de directorio (directory agent) 1.4. Estructura de un mensaje de correo electrónico 1.5. Internet Hipertexto 1.6. TCP/IP 1.6.1. Modelo de la arquitectura de TCP/IP Capa de aplicación Capa de transporte Capa de Internet Capa de interfaz de red 1.6.2. Protocolo IP 1.6.3. Protocolo TCP Puertos y sockets TCP 1.7. Resumen capítulo 1 18 18 19 19 19 19 20 21 22 22 23 23 24 24 24 25 26 26 28 29 31 5/165 CAPÍTULO 2 TRANSFERENCIA Y RECUPERACIÓN DEL CORREO ELECTRÓNICO 2.1. 2.2. 2.3. 2.4. 2.5. 2.6. SMTP Comandos y respuestas Razones por las que se eligió SMTP X.400 Comparación entre X.400 y SMTP Tipos de redes sobre las que corre X.400 X.400 y el robot de correo electrónico POP3 Comandos y respuestas IMAP El paradigma cliente-servidor Resumen capítulo 2 CAPÍTULO 3 32 34 36 36 36 37 37 38 38 40 40 41 REPRESENTACIÓN DE DATOS NO TEXTO EN EL CORREO 3.1. MIME 3.1.1. Tipos de datos 3.1.2. Tipos de codificación Codificación Base64 Codificación Quoted-printable 3.1.3. Archivos adjuntos 3.2. Resumen capítulo 3 43 44 45 45 47 48 50 CAPÍTULO 4 HERRAMIENTAS DE CÓMPUTO PARA EL DESARROLLO DEL ROBOT 4.1 Lenguaje Java 4.2 La Interfaz de Programación de Aplicaciones JavaMail 4.2.1 Componentes arquitectónicos 4.2.2 Proceso de manejo de correo 4.2.3 Paquetes de la API JavaMail 4.2.4 Paquetes Sun de Proveedores de protocolo 4.2.5 Componentes principales de la API JavaMail Clase Message Atributo Content-Type Almacenamiento y recuperación de mensajes Composición y transporte de mensajes Clase Session 4.3 La Interfaz de Programación de Aplicaciones JDBC 4.3.1 Controladores (drivers) para JDBC 4.3.2 URL´s para bases de datos 4.3.3 Clase Statement 4.3.4 Clase ResultSet 51 52 53 54 55 57 63 63 63 64 64 64 64 66 70 70 70 6/165 4.3.5 4.3.6 Métodos getter del ResultSet Recuperación de datos utilizando consultas SQL El comando SELECT La cláusula WHERE 4.4 Desempeño de una aplicación en Java Qué se debe medir Medición de tiempos Monitoreo de memoria El desempeño en comunicaciones cliente/servidor 4.5 ACCESS DBMS 4.5.1 Sistema Manejador de Base de Datos Objetivos de un DBMS 4.5.2 Arquitectura de Access Pasos para el diseño de una base de datos Tablas llaves primarias llaves secundarias o foráneas Relaciones Uno a muchos Uno a uno Muchos a muchos Consultas 4.6 Resumen capítulo 4 CAPÍTULO 5 71 72 72 72 72 73 73 74 74 75 75 75 76 77 77 77 77 77 78 78 78 78 79 DISEÑO Y CONSTRUCCIÓN DEL ROBOT DE CORREO 5.1 Descripción general del ambiente de experimentación 5.1.1 Conexión vía marcación (Dial-up) al servidor de correo del ISP 5.1.2 Conexión vía LAN a un servidor de correo local 5.2 Cómo funciona el robot de correo electrónico Establecer el ambiente para que funcione el robot 5.3 Módulo para leer los correos Código fuente para recuperar los correos 5.4 Módulo para recopilación de respuestas Búsqueda de palabras clave Interacción con la base de datos Código fuente para recolectar respuestas para los correos 5.5 Módulo para envío de respuestas a los usuarios Desempeño del robot de correo 5.6 Resumen capítulo 5 80 80 81 82 82 83 84 86 88 89 91 94 98 104 7/165 6 Conclusiones finales y trabajo a futuro Bibliografía Glosario Anexos ¾ Anexo A Solicitudes de Comentarios ¾ Anexo B rfc 1939 POP3 ¾ Anexo C rfc 821 SMTP ¾ Anexo D rfc 822 Estándar para el Formato de Mensajes de Texto Arpa Internet (Standard For The Format Of Arpa Internet Text Messages) ¾ Anexo E rfc 2045 MIME Formatos de Cuerpo de Mensajes Internet (Internet Message Body Formats) ¾ Anexo F rfc 2046 MIME Tipos de Medios (Media Types) ¾ Anexo G rfc 2047 MIME Extensiones de Encabezados de Mensaje para Texto No ASCII (Message Header Extensions for Non ASCII Text) ¾ Anexo H rfc 2048 MIME Procedimientos de Registro (Registration Procedures) ¾ Anexo I rfc 2049 MIME Criterios de Cumplimiento y Ejemplos (Conformance Criteria and Examples) ¾ Anexo J Código fuente del robot de correo y programas complementarios 105 107 110 118 118 119 126 130 137 140 143 145 146 148 8/165 LISTA DE FIGURAS Página Introducción i.1 Sistema de correo electrónico 12 CAPÍTULO 1 FUNDAMENTOS TEORICOS DEL CORREO ELECTRÓNICO 1.1. 1.2. 1.3. 1.4. 1.5. 1.6. 1.7. El almacén de mensajes (Message Store) Componentes de un sistema de correo electrónico Arquitectura de TCP/IP Encapsulamiento de un datagrama IP Trama IP Ubicación de TCP dentro de la arquitectura de la pila TCP/IP Sockets TCP 20 21 24 28 28 29 30 CAPÍTULO 2 TRANSFERENCIA Y RECUPERACIÓN DEL CORREO ELECTRÓNICO 2.1. 2.2. Modelo para el uso de SMTP Modelo Cliente-Servidor 33 38 CAPÍTULO 3 REPRESENTACIÓN DE DATOS NO TEXTO EN EL CORREO 3.1. 3.2. Mapeado de bits en Base64 Codificación Base64 46 46 CAPÍTULO 4 HERRAMIENTAS DE CÓMPUTO PARA EL DESARROLLO DEL ROBOT 4.1 4.2 4.3 4.4 4.5 4.6 4.7 Cómo implementar una aplicación con JavaMail Proceso de manejo de correo de JavaMail Jerarquía de clases de JavaMail Controlador JDBC Tipo 1 Controlador JDBC Tipo 2 Controlador JDBC Tipo 3 Controlador JDBC Tipo 4 CAPÍTULO 5 53 54 65 67 68 69 69 DISEÑO Y CONSTRUCCIÓN DEL ROBOT DE CORREO 5.1 Acceso a un Servidor de correo remoto a través de una conexión por marcación (Dial-up) 5.2 Conexión a un servidor de correo a través de una LAN 81 82 9/165 5.3 Componentes de un sistema de correo electrónico que hace uso de un robot de correo 5.4 Modificando la variable del sistema “Path” 5.5 Pantalla de corrida del programa de robot de correo 5.6 Composición de un mensaje de correo a través de cliente de correo web 5.7 Recuperación de un mensaje de correo 5.8 Tabla de una base de datos creada por medio del manejador de base de datos Access 5.9 Tabla Licenciatura, con algunos registros 5.10 Origen de datos ODBC 5.11 Configurando un origen de datos ODBC para Access 5.12 Escogiendo la base de datos para conectarse 5.13 Origen de datos robot 5.14 Reconocimiento de palabras clave, recolección de respuestas y envío de correo 5.15 Mensaje enviado al usuario que solicitó información al robot 5.16 Archivo adjunto en formato HTML enviado por el robot 5.17 Archivo adjunto en formato PDF 5.18 Correo de aclaración para el usuario 5.19 Archivo adjunto sobre cómo utilizar el robot 5.20 Tiempo de procesamiento del correo 5.21 Uso de memoria del robot durante la revisión del INBOX 5.22 Uso de memoria durante la recuperación y lectura de mensajes 5.23 Uso de memoria durante la búsqueda de palabras clave 5.24 Uso de memoria durante el envío de archivos anexos 83 83 86 87 88 90 90 91 92 92 93 95 96 96 97 97 98 99 100 101 101 102 10/165 LISTA DE TABLAS Página CAPÍTULO 1 FUNDAMENTOS TEORICOS DEL CORREO ELECTRÓNICO 1.1. Puertos TCP “bien conocidos” 30 CAPÍTULO 2 TRANSFERENCIA Y RECUPERACIÓN DEL CORREO ELECTRÓNICO 2.1. 2.2. 2.3. Comandos de SMTP Códigos de respuesta de SMTP Comandos de POP3 CAPÍTULO 3 3.1. 3.2. 3.3. 3.4. 3.5. 35 36 40 REPRESENTACIÓN DE DATOS NO TEXTO EN EL CORREO Tipos de contenido MIME Subtipos Multipart Tipos de codificación MIME Opciones de Codificación para Transmisión Codificación Base64 44 44 45 45 47 CAPÍTULO 4 HERRAMIENTAS DE CÓMPUTO PARA EL DESARROLLO DEL ROBOT 4.1 Propiedades estándar de JavaMail 4.2 Propiedades de System 4.3 Propiedades del proveedor de protocolo IMAP 4.4 Propiedades del proveedor de protocolo POP3 4.5 Propiedades del proveedor de protocolo SMTP 4.6 Resultado del comando SELECT sobre una tabla de una base de datos 4.7 Métodos “getter” 4.8 Herramientas de Access CAPÍTULO 5 56 57 59 60 62 71 71 76 DISEÑO Y CONSTRUCCIÓN DEL ROBOT DE CORREO 5.1 Estadísticas TCP y UDP 5.2 Estadísticas IP e ICMP 102 103 11/165 INTRODUCCIÓN Al comienzo de Internet, el correo electrónico consistía básicamente de mensajes de texto, pero conforme la popularidad del mismo aumentó también lo hicieron sus capacidades, por lo que ahora gran parte de los correos electrónicos se envían tanto en texto como en formato HTML e incluyen una variedad de tipos de contenido [1]. El lenguaje Java, el cual se eligió para desarrollar este proyecto, cuenta con una API especialmente diseñada para manejar las complejidades de este tipo de correo electrónico. Esta API se conoce con el nombre de JavaMail. La red de correo electrónico se compone de servidores SMTP (Protocolo Simple de Transferencia de Correo, Simple Mail Transfer Protocol) interconectados, los cuales almacenan y envían correos (ver figura i.1). Para enviar un correo, el usuario se conecta a su servidor SMTP local y envía el correo, utilizando SMTP. Después, el correo es enviado al servidor del destinatario y se guarda en el folder de correo del mismo. Más tarde, el destinatario recupera el correo utilizando generalmente el protocolo POP3. Conforme aumentó la cantidad de diferentes tipos de contenido del correo, hubo la necesidad de desarrollar una técnica para poder manejarlos y de ello surgieron una serie de Peticiones de Comentarios, RFC’s (Request For Comments), llamadas Extensiones de Correo Internet Multipropósito, MIME (Multipurpose Internet Mail Extensions) [1]. Fig. i.1 Sistema de correo electrónico 12/165 Los bots (contracción de robots) son programas que realizan tareas automáticamente y se clasifican de acuerdo al tipo de actividad a la que están enfocados, por ejemplo: robots de comercio (commerce bots), robots de correo (mail bots), robots de plática (chatter bots), robots de noticias (news bots), robots de búsqueda (search bots), robots de compras (shopping bots), entre otros [10]. Los bots pueden utilizar una variedad de interfaces, desde simple texto hasta voz y animación, para interactuar con los usuarios. En el ambiente de los negocios a los robots de correo se les conoce como “autorrespondedores”. La idea es que si la mayoría de las preguntas de los posibles clientes son repetitivas, entonces se puede elaborar un documento que contenga las respuestas a las Preguntas más Frecuentes, FAQ (Frequently Ask Questions). De esta forma, los prospectos de clientes pueden enviar un correo con la palabra FAQ, y en unos segundos recibirán una lista de preguntas y respuestas con la información más solicitada por la mayoría de la gente. Los robots de correo fueron diseñados para funcionar en forma parecida a la tecnología de fax en demanda, la cual permite a un usuario utilizar un teléfono de tonos para hacer una petición y recibir un documento en un fax. Los robots de correo (mailbots) permiten a los usuarios de correo electrónico recibir documentos, enviando únicamente un correo a una dirección de correo preprogramada que entrega documentos. Un robot de correo es un programa que lee, procesa y contesta todos los mensajes de correo dirigidos a él. Se pueden hacer varias cosas con un robot de correo: ¾ INTERROGAR UNA BASE DE DATOS: El mensaje contiene una consulta (query) en un lenguaje formal y el robot lo responderá después de interrogar, ya sea a una base de datos local, o a una remota, o a ambas. ¾ INGRESAR DATOS: El mensaje contiene datos para ingresar o actualizar en una base de datos. ¾ RESPUESTA AUTOMÁTICA: Cuando un usuario está de viaje se puede dejar que el robot responda automáticamente sus mensajes. ¾ FILTRADO DE MENSAJES: Todos los mensajes se pueden procesar y clasificar en diferentes carpetas, así como desechar los mensajes no deseados. ¾ CONTROL REMOTO: Si se tiene una computadora, controlando la casa o la fábrica, se le puede dirigir un mensaje avisándole que llegará pronto, para que active el mecanismo de calefacción, por ejemplo. 13/165 ANTECEDENTES La palabra “bot” se deriva de “robot” y se refiere a un programa de computadora que recopila información o realiza un servicio. Un bot, también llamado agente, explora Internet, recopila información relativa a los intereses particulares, y se la ofrece al usuario, en términos instantáneos, diarios o periódicos [7 y 8]. El primer bot, Eliza, fue creado en 1966 por el profesor Joseph Weizenbaum del Instituto de Tecnología de Massachusetts (MIT), para estudiar la comunicación, con lenguaje natural, entre el hombre y la computadora. [10] En términos generales, un agente puede realizar ciertas funciones en beneficio de un usuario. Existen básicamente dos tipos de agentes [9]: • Agentes cognitivos: aquellos capaces de efectuar operaciones complejas. Son individualmente inteligentes (son sistemas más o menos expertos, con capacidad de razonamiento sobre su base de conocimiento), pueden comunicarse con los demás agentes y llegar a un acuerdo con todos o algunos de ellos, sobre alguna decisión. • Agentes reactivos: son agentes de bajo nivel y no disponen de un protocolo ni de un lenguaje de comunicación; su única capacidad es responder a estímulos. En la actualidad, existen un sinnúmero de agentes de software que auxilian a los usuarios de diferentes maneras. Existen los robots de búsqueda (searchbots), los robots de correo (mailbots), los robots de programación de citas (schedulingbots), los gusanos (worms), los agentes de interfaz, los agentes www, entre otros. Sin embargo, muchos de estos agentes no son considerados realmente inteligentes [5]. Los agentes de interfaz son programas de cómputo que proporcionan asistencia a un usuario, tratando con una aplicación particular. El agente de interfaz funciona como un asistente personal que está colaborando con el usuario en el mismo ambiente de trabajo. Un ejemplo es el asistente de Office de Microsoft Windows. Los agentes de información tienen acceso a varias fuentes de información y son capaces de cotejar y manipular esa información para responder a las consultas que les hacen los usuarios u otros agentes de información. Existen también los agentes de comercio, los cuales proporcionan servicios comerciales, tales como: ventas, compras, precios o anuncios, para un usuario humano o para otro agente; y los agentes de entretenimiento, que proporcionan diversión al usuario. Algunos ejemplos de robots son los siguientes: • TracerLock. Controla algunos motores de búsqueda y notifica a los usuarios por correo electrónico, cuando aparecen páginas nuevas en Internet que contienen sus palabras clave. http://peacefire.org/tracerlock. 14/165 • • • Reference.com. Busca información en las listas de correo y en los grupos de noticias de Usenet. Manda los resultados diariamente por correo electrónico a múltiples usuarios. http://www.Reference.com ITrack. Este servicio de rastreo de subastas vigila las principales subastas en línea y notifica a los usuarios cuando el objeto que desean está colocado en el bloque de ofrecimientos. http://www.itrack.com RememberIt. Este servicio ayuda a los usuarios a recordar fechas importantes como cumpleaños o aniversarios. Solamente reciben un correo para recordarles el evento en la fecha que especificaron. http://www.rememberit.com • Shopping Bots. Más de 70 robots y agentes inteligentes que le ayudan a encontrar el precio más bajo, visitando docenas de sitios de compras. http://bots.internet.com/search/s-shop.htm Por último, se encontró que aunque existen varios robots de correo en el mercado, no está disponible el código y diseño de los mismos. La complejidad y cantidad de protocolos involucrados en el funcionamiento del correo electrónico, hacen atractivo desde el punto de vista académico, el emprender el diseño y construcción de un robot de correo electrónico. 15/165 JUSTIFICACIÓN • Ejemplificar el diseño y funcionamiento de un robot de correo. Existen varios ejemplos de autorrespondedores o robots de correo comerciales pero no se tiene disponible el código de ellos por obvias razones. Aquí se ha querido mostrar una metodología para el desarrollo de un robot de correo, así como las bases teóricas que fundamentan el correo electrónico. En el capítulo 5 se desglosa el diseño del robot por módulos funcionales y se explica lo que hace el código del programa. • Mostrar una aplicación práctica de los protocolos TCP/IP del nivel de aplicación. La pila de protocolos TCP/IP está dividida en varias capas, similar al modelo OSI de la ISO. Las distintas interacciones que se dan entre las capas, los protocolos y sus pares, tanto en sistema local como remoto, resultan complejas y difíciles de entender en su conjunto. El diseñar una aplicación que se ubica en la capa superior de la pila TCP/IP nos ayuda a entender la importancia de todos los protocolos involucrados en el proceso de comunicación vía red. • Automatizar y agilizar la respuesta a ciertos tipos de correo electrónico, dirigidos a una institución como puede ser la UAM Azcapotzalco. Por lo general el tipo de información que la gente solicita de una institución se repite constantemente. Este patrón y el hecho de que no se puede tener a alguien todo el tiempo revisando y respondiendo a todos los correos, hace factible la implantación de un sistema informático que automatice esta tarea. • Disminuir el tiempo de ocupación de los canales de comunicación por parte de los usuarios que consultan información, contenida en la página web de la UAM Azcapotzalco. En lugar de pasar varios minutos buscando la información dentro del portal de la UAM, un usuario podría simplemente mandar un correo para recibirla automáticamente más tarde, desconectarse de la red, y realizar alguna otra tarea • Permitir a los usuarios de la página web de la UAM Azcapotzalco consultar información “fuera de línea”. Una vez que el usuario recibe la información por correo, se puede desconectar de la red y revisar tranquilamente los archivos con la información requerida, permitiendo que otros usuarios ocupen los recursos de la red. También, por ejemplo, cuando el servidor web está fuera de línea por cuestiones de mantenimiento o alguna otra razón, un usuario que requiriera información no se vería afectado porque el servidor de correo puede ser independiente del servidor web. • Permitir la inclusión de archivos adjuntos multimedia o binarios en la respuesta automática al correo electrónico. Para enriquecer el contenido de las respuestas a los requerimientos de información de los usuarios, se debe permitir el envío de archivos adjuntos en diferentes formatos. Esta funcionalidad requiere que el robot implemente el protocolo MIME. 16/165 OBJETIVO GENERAL: • Diseñar un programa que permita automatizar las tareas de revisar y responder cierto tipo de correos electrónicos, dirigidos a la UAM Azcapotzalco, y que además incluya funcionalidad MIME, utilizando un lenguaje de alto nivel. OBJETIVOS ESPECÍFICOS: • Crear un módulo para la lectura automática de los correos electrónicos por medio de POP3; • Crear un motor de búsqueda automática de “palabras-clave”; • Crear una base de datos de “respuestas”, es decir, de información de retroalimentación para el usuario; • Crear un módulo para la recopilación automática de las respuestas a los correos electrónicos; • Implementar el protocolo MIME en el robot; • Crear un módulo para el envío automático de los correos electrónicos, utilizando SMTP. 17/165 CAPÍTULO 1 CAPÍTULO 1 FUNDAMENTOS TEORICOS DEL CORREO ELECTRÓNICO 1.1 CORREO ELECTRÓNICO El correo electrónico, e-mail (electronic mail), inició a principios de los 60’s y se le llamó Sistema de Mensajería Basado en Computadora, CBMS (Computer Based Messaging System). La compañía norteamericana Western Union registró el nombre de “correo electrónico” en 1974. [20] En aquel entonces, investigadores y programadores quienes usaban terminales tontas conectadas a mainframes, encontraron maneras de escribir “mensajes”. Al principio se trataba de mensajes instantáneos en vivo pero, eventualmente, los investigadores desarrollaron la capacidad de dejar mensajes a la gente que no se encontraba utilizando la computadora en ese momento. Conforme las instituciones se hacían más grandes, con más terminales, se volvía inconveniente tener únicamente un buzón compartido. De tal manera que se desarrolló el software para permitir que cada terminal tuviera su propio buzón personal. Después, los programadores crearon un sistema de cuenta de correo, donde cada persona tenía su propia contraseña. 1.2 USOS DEL CORREO ELECTRÓNICO El correo electrónico combina las ventajas de la escritura con la inmediatez del teléfono. El correo electrónico es útil para compartir notas informales, preguntas u otros comentarios que normalmente se harían por teléfono. El correo electrónico se usa para lo siguiente: • • • Enviar y recibir faxes rápidamente. Compartición de archivos y no sólo de mensajes. Esta opción permite el rápido intercambio de datos, hojas de cálculo, documentos de procesadores de palabras, gráficos, presentaciones animadas, video, música, voz y cualquier cosa que se pueda guardar en una computadora. Los mismos programas de computadora comienzan a utilizar el correo electrónico. Un programa, por ejemplo, podría estar monitoreando algún fenómeno y cuando ocurriera algún cambio en los niveles permitidos, el programa enviaría un mensaje de correo automáticamente a otra computadora para que realizara alguna acción. 18/165 CAPÍTULO 1 1.3 CÓMO FUNCIONA EL CORREO ELECTRÓNICO Tal como otros tipos de software, el correo electrónico tiene una parte que se ve y otra que no. La parte que el usuario ve se llama front end. La parte de la que se encarga el administrador de sistemas se conoce como back end. Debido a la forma en que se configura en la red, el front end del correo electrónico se conoce como cliente. El back end del correo se descompone generalmente en tres partes: el almacén de mensajes (message store), el agente de transporte (transport agent) y el agente de directorio (directory agent). Aunque la mayoría de los paquetes de correo electrónico vienen con un front end y un back end, también se pueden comprar e instalar separadamente. Cada back end tiene su propio nivel de rapidez, confiabilidad y capacidad de tratar con una variedad de formatos de correo, tendencia a tener errores, capacidad de ser escalado y versatilidad [20]. 1.3.1 FRONT END El front end de un cliente de correo comprende la interfaz de usuario (lo que el usuario puede ver y los comandos que el usuario puede ejecutar). El front end es importante ya que determina si el sistema es bien acogido o no, o si es utilizado o no por los usuarios. 1.3.2 BACK END A continuación veremos los tres componentes del back end. EL ALMACÉN DE MENSAJES (MESSAGE STORE) El Almacén de Mensajes (Message Store), también conocido como motor de correo electrónico (E-mail engine), es donde se guardan los mensajes antes de que sean leídos (véase fig. 1.1). Los almacenes de mensajes también guardan los archivos adjuntos que vienen con un mensaje. Debido a que estos archivos pueden quitar mucho espacio, la mayoría de los clientes de correo limitan el número de archivos adjuntos que se pueden enviar. En los viejos dias del correo electrónico, cada usuario tenía su buzón. Cualquier mensaje recibido se guardaba en ese buzón. Sin embargo, este sistema desperdiciaba mucho espacio, ya que si un mensaje grande se enviaba a varios buzones de una misma compañía, se generaban múltiples copias del mismo mensaje. Cualquier paquete de correo electrónico actual, guarda únicamente una copia de cada mensaje en el servidor. Después establece apuntadores, los cuales indican a quién se envió el mensaje. Cuando una persona tiene un nuevo correo, su apuntador se activa, señalando a uno o más mensajes guardados. De hecho, la mayoría de los programas de correo no guardan los mensajes en archivos individuales, sino que se almacenan en un gran paquete de datos, lo que ahorra espacio y facilita respaldar y localizar los mensajes. 19/165 CAPÍTULO 1 Fig. 1.1 El almacén de mensajes (Message Store). EL AGENTE DE TRANSPORTE (TRANSPORT AGENT) El agente de transporte de mensajes, conocido también como “el servicio de ruteo”, determina cómo se mueve el correo electrónico de un buzón a otro. Cuando se trata del envío de correo en una LAN, el mensaje no se mueve, sino que más bien se les da acceso al mensaje, guardado en el buzón del servidor, a los destinatarios del mismo.[20] Los principales estándares de transporte son: • • X.400. Este estándar internacional fue creado por el CCITT. La última versión de X.400 soporta sonido, gráficas y demás multimedia. El Servicio de Manejo de Mensajes, MHS (Message Handling Service), desarrollado originalmente por Action Technologies, lo utiliza Novell como parte de su popular sistema operativo de red Netware. 20/165 CAPÍTULO 1 • • El Protocolo Simple de Transferencia de Correo, SMTP (Simple Mail Transfer Protocol), es utilizado en Internet. Servicios de Distribución de SNA, SNADS (Systems Network Architecture Distribution Services), se utiliza principalmente entre mainframes IBM. El estándar que se utiliza depende del rango y el tipo de correo electrónico que se quiere enviar. EL AGENTE DE DIRECTORIO (DIRECTORY AGENT) Un mensaje de correo electrónico es inútil a menos que se envíe al buzón correcto. Un agente de directorio contiene los nombres de cada usuario en un sistema y permite que el correo sea ruteado a la persona adecuada. Los directorios pueden ser listas de nombres de usuarios de red o algo más complejo, organizando personas en compañías, grupos de trabajo, departamentos, o ubicaciones geográficas. La dirección de un usuario es todo lo que el programa de correo necesita para encontrar ese usuario. Envío del correo del usuario Lectura del correo del usuario SMTP Interfaz de usuario POP3 Área spool de salida de correo Buzones para correo entrante Cliente (transferencia de correos) Conexión TCP para salida de correo SMTP Conexión TCP para correo entrante Servidor (para aceptar correo) SMTP Fig.1.2 Componentes de un sistema de correo electrónico. El usuario invoca una interfaz de usuario para depositar o recuperar correo. En la figura 1.2 se observa que cuando a través de la interfaz de usuario (p. ej. la pantalla de Outlook) se envía un correo, el programa cliente (Outlook) transfiere el correo al servidor de correo local y éste se encarga de enviarlo por medio de SMTP hacia el servidor de correo destino. Por otro lado, cuando se quiere consultar el correo, el programa cliente (Outlook) se comunica por medio de POP3 con el servidor de correo y verifica que existan correos en el buzón, y de ser el caso, los baja a la máquina cliente. [16] 21/165 CAPÍTULO 1 1.4 ESTRUCTURA DE UN MENSAJE DE CORREO ELECTRÓNICO Un mensaje se puede descomponer en dos partes: el encabezado y el cuerpo. El encabezado de un mensaje contiene todo lo que el programa de correo necesita para tomar el mensaje y colocarlo en el buzón apropiado. El encabezado se compone de lo siguiente: • • • • • El número único de identificación del mensaje (Message-ID); Quién envió el mensaje (Sender); A quién se envió el mensaje (incluyendo los destinatarios de copia-al-carbón (carbon-copy) y copia ciegaal-carbón (blind-carbon copy)); El Asunto del mensaje (Subject); La hora y la fecha en la que se envió el mensaje (Date). Algunos encabezados también incluyen toda la información de ruteo, llevando un registro de las redes por las que atravesó el mensaje. [20] 1.5 INTERNET Internet es la colección mundial de computadoras, conectadas entre sí mediante una red de canales de comunicación. La tecnología de comunicaciones consiste en una gran variedad de tecnologías: satélites, microondas, fibra óptica y alambre de cobre. Algunas de las redes que forman parte de Internet son privadas y otras son públicas. Millones de computadoras están conectadas entre sí y pueden intercambiar información. Una de las aplicaciones de mayor uso en Internet es el correo electrónico (e-mail), el cual puede ser utilizado por un individuo para enviar correo a otra persona o a una lista completa de direcciones. A menudo no se necesita saber nada acerca de la tecnología de los vínculos de comunicación para poder utilizar Internet. Desde el punto de vista del usuario inexperto, todo lo que se necesita es utilizar un paquete de software que se ejecuta en la computadora del usuario. Este software, junto con los programas que se ejecutan en las demás computadoras que están en Internet, se encarga de todos los detalles relacionados con la transferencia y el enrutamiento de los mensajes. [13] Una de las aplicaciones de Internet se presenta al crear un archivo de información en un disco (o en un espacio rentado) y permitir que cualquier otra persona en el mundo tenga acceso a la información. Dicho archivo de información se conoce como sitio (site). La información en el archivo puede consistir de texto, gráficos o una combinación de ambos. El proceso de tener acceso a la información de un sitio se conoce como visitar el sitio. La colección de sitios, esparcidos en todo el mundo que ofrecen información de esta manera, se conoce como World Wide Web, WWW o (comúnmente) sólo Web. Para visitar un sitio necesita conocer su dirección. Una dirección en Internet es única, igual que un número telefónico internacional. Una dirección típica tiene la siguiente forma: http://www.google.com/ 22/165 CAPÍTULO 1 Una dirección como la anterior se conoce como URL. Son las siglas de Localizador Uniforme de Recursos (Uniform Resource Locator). Las URL son direcciones únicas e irrepetibles en todo el mundo. Para obtener la información de un sitio Web (para visitar un sitio) necesita una computadora y un programa conocido como navegador Web. Este programa permite escribir la dirección de un sitio: su URL; en ese momento, el navegador envía mensajes, solicitando la información del sitio. Si el sitio lo permite, enviará esa información, la cual será mostrada por el navegador en la pantalla del usuario. La mayoría de los sitios tienen mucha información que ofrecer, por lo que cuando se obtiene acceso a ellos por primera vez, lo que se ve es la página de inicio. Ésta no es otra cosa que una pantalla (o más) que presenta tanto un tapete de bienvenida como un directorio con la información que el sitio ofrece. Si se accesa a un sitio, por lo general se obtendrán diversas opciones de información que se podrán explorar. La Web es una maravillosa enciclopedia internacional que ofrece información de manera gratuita a cualquiera que tenga una computadora, conectada a Internet. HIPERTEXTO La mayoría de las páginas en la Web tienen apuntadores a otras páginas. Al hacer clic con el botón izquierdo del ratón, en una línea de texto que esté resaltada de alguna forma (por lo general subrayada o en azul) o en una imagen gráfica, será transportado a una página distinta. Esta nueva página puede estar en el mismo sitio desde el que fue transportado, o encontrarse en cualquier otra parte del Web. A esto se le conoce como vínculo de hipertexto. Es común seguir estos vínculos para buscar la información que se necesita, o simplemente para explorar. Este proceso se conoce comúnmente como navegar por Internet. [13] En ocasiones un vínculo de hipertexto es sólo un apuntador hacia otro lugar dentro de la misma página Web. Esto muestra que los vínculos de hipertexto son un cambio en la estructura secuencial normal de un documento; por lo general leemos la información empezando desde el principio y leyendo línea por línea hasta llegar al final. En un documento con vínculos de hipertexto los saltos se indican de manera explícita; podemos leer la página en forma secuencial o podemos seguir cualquiera de los vínculos. Se puede crear un documento con vínculos de hipertexto, utilizando un editor con la funcionalidad apropiada. Las partes del texto que permiten que las personas hagan “clic” en los vínculos se escriben en un lenguaje conocido como Lenguaje de Marcación de HiperTexto (HTML). Se puede ver un archivo de ese tipo con un navegador Web. 1.6 TCP/IP El conjunto de protocolos TCP/IP es el estándar a nivel mundial para la interconexión de sistemas abiertos. Ningún otro protocolo ofrece tanta interoperabilidad o abarca tantos fabricantes. Lo que es más importante, ningún otro protocolo se ejecuta sobre tantas tecnologías de red como TCP/IP. TCP/IP es la base de Internet. Además de las conexiones a Internet, muchas organizaciones utilizan TCP/IP para sus redes internas. A una red privada que utiliza TCP/IP se le conoce como intranet. TCP/IP toma su nombre de sus dos protocolos principales: Protocolo de Control de Transmisión, TCP (Transmission Control Protocol) y Protocolo de Internet, IP (Internet Protocol). 23/165 CAPÍTULO 1 1.6.1 MODELO DE LA ARQUITECTURA DE TCP/IP TCP/IP fue desarrollado mucho antes de que el modelo OSI de siete capas, propuesto por la ISO, fuera especificado y encaja en su propio modelo de cuatro capas. [18] (véase fig. 1.3) CAPA DE APLICACIÓN Esta capa define los protocolos de aplicación de TCP/IP y proporciona las interfaces entre los programas de aplicación y los servicios de la capa de transporte. La capa de aplicación contiene protocolos y servicios de aplicación tales como HTTP, Telnet, FTP, SNMP, DNS, POP3 y SMTP, entre otros. NIVEL DE APLICACIÓN NIVEL DE TRANSPORTE NIVEL DE INTERNET NIVEL INTERFAZ DE RED FTP, SMTP, TELNET TCP SNMP, X-WINDOWS, RPC, NFS UDP IP, ICMP, 802.2, X.25 ETHERNET, IEEE 802.2, X.25 Fig. 1.3 Arquitectura de TCP/IP. CAPA DE TRANSPORTE Esta capa proporciona sesiones de comunicación entre hosts. Define el nivel de servicio (primera capa o capas inferiores) y el estado de la conexión (con o sin conexión) utilizados al transferir los datos. Entre los protocolos contenidos en la capa están UDP y TCP. Este nivel implementa una comunicación extremo a extremo entre programas de aplicación. La máquina remota recibe exactamente lo mismo que le envió la máquina origen. En este nivel el emisor divide la información que recibe del nivel de aplicación en paquetes, le añade los datos necesarios para el control de flujo y control de errores, y se los pasa al nivel de red junto con la dirección de destino. En el receptor este nivel se encarga de ordenar y unir las tramas para generar de nuevo la información original. Para implementar el nivel de transporte se utilizan dos protocolos: • Protocolo de Datagrama de Usuario, UDP (User Datagram Protocol): proporciona un nivel de transporte no confiable de datagramas, ya que apenas añade información al paquete que envía al nivel inferior, solo la necesaria para la comunicación extremo a extremo. Lo utilizan aplicaciones como NFS y RPC, pero sobre todo, se emplea en tareas de control. • Protocolo de Control de Transmisión, TCP (Transmission Control Protocol): es el protocolo que proporciona un transporte confiable de flujo de bits entre aplicaciones. Está pensado para poder enviar grandes cantidades de información de forma confiable, liberando al programador de aplicaciones de la 24/165 CAPÍTULO 1 dificultad de gestionar la confiabilidad de la conexión (retransmisiones, pérdidas de paquetes, orden en que llegan los paquetes, duplicado de paquetes, ...) que gestiona el propio protocolo. Pero la complejidad de la gestión de la confiabilidad tiene un costo en eficiencia, ya que para llevar a cabo las gestiones anteriores se tiene que añadir bastante información a los paquetes a enviar. Debido a que los paquetes a enviar tienen un tamaño máximo, cuánto más información añada el protocolo para su gestión, menos información que proviene de la aplicación podrá contener ese paquete. Por eso, cuando es más importante la velocidad que la confiabilidad, se utiliza UDP, en cambio TCP asegura la recepción en el destino de la información a transmitir. CAPA DE INTERNET En esta capa los datos se empaquetan en datagramas IP. Éstos contienen la información de origen y destino, utilizada para transmitir los datos entre los hosts y a través de la red. En esta capa se implementa el enrutamiento IP. Entre los protocolos incluidos en la capa están IP, ICMP, IGMP y ARP. Esta etapa coloca la información que le pasa el nivel de transporte en datagramas IP, le añade cabeceras necesarias para su nivel y lo envía al nivel inferior. Es en este nivel donde se emplea el algoritmo de enrutamiento. Al recibir un datagrama del nivel inferior decide, en función de su dirección, si debe procesarlo y pasarlo al nivel superior, o bien enrutarlo hacia otra máquina. Para implementar este nivel se utilizan los siguientes protocolos: • Protocolo de Internet, IP (Internet Protocol): es un protocolo no orientado a la conexión, con mensajes de un tamaño máximo. Cada datagrama se gestiona de forma independiente, por lo que dos datagramas pueden utilizar diferentes caminos para llegar al mismo destino, provocando que lleguen en diferente orden o bien duplicados. Es un protocolo no confiable, eso quiere decir que no corrige los errores, ni tampoco informa de ellos. Este protocolo recibe información del nivel superior y le añade la información necesaria para su gestión (direcciones IP, checksum). • Protocolo de Mensajes de Control de Internet, ICMP (Internet Control Message Protocol): proporciona un mecanismo de comunicación de información de control y de errores, entre máquinas intermedias por las que viajaran los paquetes de datos. A estos datagramas los suelen emplear las máquinas (gateways, hosts, ...) para informarse de condiciones especiales en la red, como la existencia de una congestión, la existencia de errores y las posibles peticiones de cambios de ruta. Los mensajes de ICMP están encapsulados en datagramas IP. • Protocolo de Administración de Grupo de Internet, IGMP (Internet Group Management Protocol): este protocolo esta íntimamente ligado a IP. Se emplea en máquinas que utilizan IP multicast. El IP multicast es una variante de IP que permite emplear datagramas con múltiples destinatarios. También en este nivel, tenemos una serie de protocolos que se encargan de la resolución de direcciones: • Protocolo de Resolución de Dirección, ARP (Address Resolution Protocol): cuando una máquina desea ponerse en contacto con otra y conoce su dirección IP, entonces necesita un mecanismo dinámico que permite conocer su dirección física. Envía una petición ARP por broadcast (o sea, a todas las máquinas). El protocolo establece que una máquina solo contestará a la petición, si ésta lleva su dirección IP. Por lo tanto, sólo contestará la máquina que corresponde a la dirección IP buscada, con un mensaje que incluya la dirección física. El software de comunicaciones debe mantener una cache con los pares IP-dirección 25/165 CAPÍTULO 1 física. De este modo, la siguiente vez que hay que hacer una transmisión a esa dirección IP, ya se conoce la dirección física. • Protocolo de Resolución Inversa de Dirección, RARP (Reverse Address Resolution Protocol): a veces el problema es al revés, o sea, una máquina solo conoce su dirección física, y desea conocer su dirección lógica. Esto ocurre, por ejemplo, cuando se accede a Internet con una dirección diferente, en el caso de PC’s que acceden por módem a Internet, y se le asigna una dirección diferente, de las que tiene el proveedor sin utilizar. Para solucionar esto, se envía por broadcast una petición RARP con su dirección física, para que un servidor pueda darle su correspondencia IP. • Protocolo de Arranque, BOOTP (Bootstrap Protocol): el protocolo RARP resuelve el problema de la resolución inversa de direcciones, pero para que pueda ser más eficiente, enviando más información que meramente la dirección IP, se ha creado el protocolo BOOTP. Éste además de la dirección IP del solicitante, proporciona información adicional, facilitando la movilidad y el mantenimiento de las máquinas. CAPA DE INTERFAZ DE RED Esta capa especifíca los detalles físicos relativos a la forma de transmisión de los datos por una red. Define el medio físico de transmisión de los datos entre los dispositivos de hardware como cable coaxial, fibra óptica o cables de par trenzado. Este nivel se limita a recibir datagramas del nivel superior (nivel de red) y transmitirlo al hardware de la red. Esta capa implementa algunos de los siguientes estándares: Ethernet, Token Ring, FDDI, X.25, Frame Relay, RS-232 y otros similares. 1.6.2 PROTOCOLO IP IP es el protocolo encargado de la clasificación y de la entrega de los paquetes. Cada paquete IP de entrada o de salida se denomina datagrama. IP genera datagramas, encapsulando la carga con la dirección IP de origen del remitente y la dirección IP del destinatario (véase fig. 1.4). A diferencia de las direcciones de Control de Acceso al Medio, MAC (Medium Access Control), las direcciones IP de un datagrama no se modifican durante el trayecto del paquete a través de la red. El datagrama IP suele contener otro paquete de protocolo como carga. La cabecera IP se puede dividir en una serie de campos (véase fig. 1.5): • Versión: Indica la versión de IP. Este campo consta de 4 bits de longitud y contiene el número 4 (que es precisamente la versión en uso de IP) o 6. • Longitud de la cabecera: Indica el número de palabras de 32 bits (4 bytes) de la cabecera IP. Este campo tiene una longitud de 4 bits y contiene un valor de 0x5 (20 bytes) o un valor superior. Opcionalmente, se puede ampliar la longitud de la cabecera de 4 en 4 bits. Si una opción IP no utiliza los 32 bits de una palabra, los restantes se suplen mediante ceros, con el fin de que la longitud de la cabecera sea siempre múltiplo de 32 bits. 26/165 CAPÍTULO 1 • Prioridad y tipo de servicio: Indica los valores de configuración de la Calidad de Servicio (QoS). Este campo consta de 8 bits de longitud y contiene información relativa a la prioridad, retrasos, rendimiento y confiabilidad. • Longitud total: Indica la longitud total del datagrama IP (la cabecera, más la carga). Este campo tiene 16 bits de longitud y contiene una serie de palabras de 32 bits, incluidas en el datagrama. • Identificación: Identifica el datagrama IP específico. Este campo tiene 16 bits de longitud. Si el datagrama se fragmenta durante el proceso de enrutamiento, la información de este campo se utiliza para su reensamblado en el destino. • Resumen de indicadores: Contiene los indicadores de fragmentación. Este campo tiene 3 bits de longitud, pero actualmente, se utilizan únicamente dos de ellos. Uno de los bits sirve para indicar si se trata del fragmento final del datagrama (o si va seguido por otros). El segundo se utiliza para señalar si se puede fragmentar el datagrama, o no. • Desplazamiento de fragmento: Indica la ubicación del fragmento relativa a la carga IP del paquete original. Este campo tiene 13 bits de longitud. • Tiempo de vida (TTL): Indica la cantidad de saltos que hará un datagrama en la red antes de ser desechado. Cada vez que un datagrama pasa por un ruteador, se reduce su TTL en un salto. Este campo consta de 8 bits de longitud. • Protocolo: Indica el protocolo que entregó la carga a IP para su envío. Este campo consta de 8 bits de longitud. La información de este campo es utilizada por las capas superiores del host de destino para procesar la carga. Por ejemplo, el protocolo ICMP se indica con un 1. • Suma de comprobación: Se utiliza únicamente para comprobar la integridad de la cabecera IP, por lo que se suele hacer referencia a este campo como suma de comprobación de cabecera. La carga puede constar de su propia suma de comprobación. Este campo consta de 16 bits de longitud. Dado que el TTL se modifica con cada salto, la suma de comprobación se vuelve a calcular cada vez que el datagrama pasa por un ruteador. • Dirección de destino: Contiene la dirección IP del nodo destino. Este campo contiene 32 bits de longitud en IPv4 y 128 en IPv6. • Opciones y relleno: Especifica las opciones IP. Si existe, su longitud es de 32 bits o de un múltiplo de 32. 27/165 CAPÍTULO 1 Encabezado del datagrama Área de datos del datagrama IP Encabezado de Área de datos de la trama la trama Final de la trama Fig. 1.4 Encapsulamiento de un datagrama IP. 3 0 0 1 2 3 4 5 6 7 8 9 0 1 2 3 3 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 VERS HLEN Tipo de servicio Longitud total Bander Desplazamiento de fragmento Identificación as TTL Protocolo CRC cabecera Dirección IP origen Dirección IP destino Opciones IP (en caso de que existan) Relleno Datos ... 0 10 20 Fig. 1.5. Trama IP. 1.6.3 PROTOCOLO TCP El Protocolo de Control de Transporte , TCP (Transmision Control Protocol), es un estándar TCP/IP definido en la rfc 793, que proporciona un servicio confiable de entrega de paquetes, orientado a la conexión (véase fig. 1.6). TCP segmenta y vuelve a ensamblar los grandes bloques de datos, enviados por los programas y asegura la secuencia correcta y la entrega ordenada de los datos segmentados. Los números de secuencia se utilizan para coordinar la transmisión y la recepción de los datos, y TCP organizará una retransmisión en caso de pérdida de datos. Cada paquete TCP contiene el número de secuencia inicial y final, recibidos del sitio remoto. Utilizando esta información se implementa el protocolo de ventana deslizable. [18] A continuación se enumeran otras características de TCP: • • Opera normalmente en modo full dúplex, lo cual significa que opera en las dos direcciones de manera independiente. Utiliza señales de control para administrar la conexión. 28/165 CAPÍTULO 1 • • • Verifica la integridad de los datos, utilizando el cálculo de suma de comprobación. Si la suma es incorrecta, el datagrama es descartado y se tiene que retransmitir. Asegura una transmisión de datos eficaz a través de la red, mediante el control de flujo. Descubre de una forma dinámica las características de retraso y ajusta sus operaciones para maximizar el flujo de datos sin sobrecargar la red. Cada punto final de TCP tiene un buffer para almacenar los datos transmitidos antes de ser leídos por una aplicación. Esto permite transmitir los datos mientras las aplicaciones están ocupadas, procesando otros datos y así beneficiar el rendimiento. NIVEL DE APLICACIÓN NIVEL DE TRANSPORTE NIVEL DE INTERNET NIVEL INTERFAZ DE RED FTP, SMTP, TELNET TCP SNMP, X-WINDOWS, RPC, NFS UDP IP, ICMP, 802.2, X.25 ETHERNET, IEEE 802.2, X.25 Fig.1.6. Ubicación de TCP dentro de la arquitectura de la pila TCP/IP. PUERTOS Y SOCKETS TCP El TCP reside sobre el IP en el esquema de estratificación por capas de protocolos. El TCP permite que varios programas de aplicación en una máquina se comuniquen de manera concurrente y realiza el demultiplexado del tráfico TCP entrante entre los programas de aplicación. Los puertos TCP utilizan un puerto de programa específico para la entrega de datos (véase tabla 1.1). Un socket corresponde a un extremo de comunicación en la red y se crea especificando la dirección IP de su host, el tipo de servicio (TCP o UDP) y el número de puerto utilizado. Cada socket es asociado con un puerto de conexión del tipo “muchos a uno”. Cada puerto tiene un socket pasivo, que espera las conexiones y varios sockets activos que corresponden a una conexión abierta en el puerto. Cada puerto de un servidor TCP puede ofrecer un acceso compartido a varias conexiones, ya que todas las conexiones TCP se identifican de forma exclusiva mediante dos parejas de direcciones IP y los puertos TCP (una pareja de dirección y un puerto para cada host conectado). Los programas TCP utilizan los números de puerto reservados o bien conocidos. El lado de servidor de cada programa que utiliza puertos TCP, atiende los mensajes que llegan a su número de puerto bien conocido. Todos los números de puerto de servidor TCP inferiores a 1024 (y algunos números superiores) están reservados y registrados por la Autoridad de Números Asignados de Internet, IANA (Internet Assigned Numbers Authority) (véase fig. 1.7). En la siguiente tabla se muestran algunos números de puertos de servidor TCP, bien conocidos. 29/165 CAPÍTULO 1 Número de puerto TCP 20 21 23 25 53 80 110 139 Descripción FTP (canal de datos) FTP (canal de control) Telnet SMTP Transferencias de Zona del Sistema de Nombres de Dominio Web (HTTP) POP3 Servicio de sesiones Netbios Tabla 1.1 Puertos TCP “bien conocidos”. TCP establece las conexiones mediante un mecanismo de saludo, basado en los números de secuencia. Cada conexión requiere el número de secuencia de origen y el número de secuencia de destino. A diferencia del UDP, el TCP es un protocolo orientado a la conexión, el cual requiere que ambos puntos extremos estén de acuerdo en participar. Esto es, antes de que el tráfico TCP pueda pasar a través de una red de redes, los programas de aplicación en ambos extremos de la conexión deben estar de acuerdo en que desean dicha conexión. Para hacerlo, el programa de aplicación en un extremo realiza una función de “apertura pasiva” al contactar a su sistema operativo e indicar que aceptará una conexión entrante. En este momento, el sistema operativo asigna un número de puerto TCP a su extremo de la conexión. El programa de aplicación en el otro extremo, debe contactar a su sistema operativo mediante una solicitud de “apertura activa” para establecer una conexión. Los dos módulos de software TCP se comunican para establecer y llevar a cabo la conexión. Una vez que se crea ésta, los programas de aplicación pueden comenzar a transferir datos; los módulos de software TCP en cada extremo intercambian mensajes que garantizan la entrega confiable. [16] Fig. 1.7 Sockets TCP. 30/165 CAPÍTULO 1 1.7 RESUMEN CAPÍTULO 1 El correo electrónico es por mucho, la aplicación más conocida y utilizada de Internet. Además de intercambiar mensajes, el correo electrónico es utilizado frecuentemente para enviar y recibir todo tipo de archivos, ya sea texto, imágenes, música, entre otros. Un sistema de correo electrónico se compone básicamente de dos partes: un front end, o interfaz con el usuario; y un back end, o lo que es lo mismo, el soporte tecnológico detrás del correo. Este último componente es la parte que maneja un administrador de sistemas y trata todo lo relacionado a las técnicas para almacenar, enviar y entregar los correos. Todo mensaje de correo electrónico está formado por dos secciones: el encabezado y el cuerpo. La primera parte es la que le dice al sistema todo lo relacionado a quién va dirigido el mensaje, quién lo envió, el tipo de codificación que debe usar, y algunas veces lleva un registro de la ruta que sigue el mensaje hasta llegar a su destino, entre otras funciones. La segunda parte es la que le interesa al destinatario, es la información quiere darle a conocer. Internet es la red de redes. Utiliza la pila de protocolos TCP/IP para la interconexión de todas redes que la componen. Es una red a nivel mundial que utiliza múltiples enlaces redundantes, lo que hace posible que siga funcionando aún cuando varios de ellos llegaran a dañarse. La WWW o web es, aparte del correo electrónico, otra de sus aplicaciones más utilizadas. A través de una pieza de software conocida como navegador, es posible consultar todo tipo de información alrededor del mundo. El hipertexto y las URL son algunos de los términos más frecuentes con los que se topa un usuario cuando comienza a utilizar Internet. La pila de protocolos TCP/IP toma su nombre de sus dos protocolos principales: el Protocolo de Control de Transmisión, TCP (Transmisión Control Protocol), y el Protocolo Internet, IP (Internet Protocol). Fue desarrollado mucho antes que ISO definiera su modelo de Interconexión de Sistemas Abiertos, OSI (Open Systems Interconnection). En lugar de definir un sistema de 7 capas, TCP/IP utiliza un modelo de cuatro niveles: aplicación, transporte, internet y de interfaz de red. IP es un protocolo de nivel de red que ofrece entrega de paquetes con el mejor esfuerzo. Esto quiere decir que no provee directamente los mecanismos para asegurar una entrega sin errores, pero sin embargo utilizará todas sus características para hacer posible que los datos lleguen a su destino. TCP es un protocolo de nivel de transporte, el cual proporciona una comunicación full dúplex, extremo a extremo y libre de errores. Para logra esto último se vale del concepto de ventana deslizante, los números de secuencia y los acuses de recibo. Para lograr una conexión utiliza un circuito virtual definido por sus puntos extremos. Estos puntos extremos están definidos a su vez por dos pares de números, dirección IP- número de puerto, es decir un socket por cada punto extremo. 31/165 CAPÍTULO 2 CAPÍTULO 2 TRANSFERENCIA Y RECUPERACIÓN DEL CORREO ELECTRÓNICO 2.1 SMTP El protocolo para transferencia de correo, SMTP, se define en la rfc 821 y está diseñado para transferir el correo electrónico de una manera confiable y eficiente. Es independiente del protocolo de transmisión utilizado pero requiere de un canal de flujo de datos confiable. Esto significa que SMTP sólo funcionará con el servicio de transporte proporcionado por cualquiera de los siguientes protocolos: Protocolo de Control de Red, NCP (Network Control Protocol), Servicio de Transporte Independiente de Redes, NITS (Network Independent Transport Service), o con el Protocolo de Control de Transmisión, TCP (Transmission Control Protocol). Debido a esto, SMTP puede transmitir el correo a través de diferentes entornos de transporte. Como en todo sistema de comunicación, se distinguen dos implicados: el emisor de correo y el receptor de correo. [21] El modelo de SMTP es el siguiente: Como resultado de una petición de envío de correo por parte del usuario, el emisor SMTP, que actúa como cliente, establece una conexión TCP con el receptor SMTP, que hace la función de servidor. Este último puede ser el equipo final (al cual va dirigido el mensaje), o bien un sistema intermedio. El puerto que se utiliza para una conexión SMTP es el 25. Los comandos SMTP son generados por el cliente y son enviados hacia el servidor. Las respuestas viajan del servidor hacia el cliente (véase figura 2.1). Cuando un usuario remite una solicitud de correo electrónico, ocurre lo siguiente: 1. El remitente SMTP establece un canal de transmisión en las dos direcciones hasta el SMTP receptor (comando HELO), que puede ser el punto final o intermediario del destino. 2. El remitente SMTP envía el comando MAIL que indica el emisor del correo. 3. Si el destinatario SMTP puede recibir el correo, responde con 250 OK. 4. El remitente SMTP envía un comando RCPT que identifica el destinatario del correo. 32/165 CAPÍTULO 2 5. Si el receptor SMTP puede aceptar el correo para este destino, responde con 250 OK, en caso contrario responde con una respuesta de rechazo (pero no rechazando la transacción de correo completa, ya que el receptor y el remitente pueden negociar varios destinatarios). 6. Cuando se han negociado los destinatarios, el remitente SMTP envía los datos del correo (comando DATA). 7. Si el receptor SMTP procesa los datos con éxito, responde con una respuesta OK. 8. El canal se cerrará con un QUIT. USUARIO TRANSMISOR SMTP SISTEMA DE ARCHIVOS COMANDOS/ RESPUESTAS SMTP RECEPTOR SMTP Y EL CORREO SISTEMA DE ARCHIVOS Fig. 2.1 Modelo para el uso de SMTP. SMTP proporciona diferentes mecanismos para la transmisión de correo: • Directamente desde el host del usuario emisor hasta el host del usuario receptor, cuando ambos hosts están conectados al mismo servicio de transporte. • A través de uno o más servidores SMTP (que retransmiten el mensaje), cuando el origen y destino no se encuentran en el mismo servicio de transporte. Si los hosts de envío y recepción están conectados al mismo servicio de transporte, SMTP puede transmitir el correo directamente entre ellos. De lo contrario, el mensaje se transmite mediante uno o varios servidores reguladores SMTP. En este último caso, el servidor regulador SMTP tiene que recibir el nombre del último destino al igual que el nombre del buzón de correo. El argumento que admite el comando MAIL especifica el emisor del mensaje. También conocido como camino inverso (reverse-path). Este camino se va modificando a medida que el mensaje atraviesa diferentes servidores de correo y se utiliza para poder obtener el camino de vuelta cuando exista la necesidad de notificar mensajes de error. 33/165 CAPÍTULO 2 El argumento que admite el comando RCPT especifica a quién va dirigido el mensaje (camino–directo, forward-path). Cuando el mensaje va dirigido a varios destinatarios dentro de un mismo host, el servidor SMTP únicamente envía una copia de dicho mensaje. SMTP implementa el servicio de transmisión, utilizado cuando la ruta especificada por el comando RCPT no es correcta, pero el receptor SMTP conoce el destino correcto. En este caso, envía una de las siguientes respuestas dependiendo de las identidades del receptor y del remitente, y si el receptor SMTP puede responsabilizarse de los mensajes: 251 Usuario no local, envío al camino-directo (forward-path) 551 Usuario no local, intente el camino-directo (forward-path) Los comandos SMTP VRFY y EXPN, respectivamente, verifican el nombre de usuario y expanden la lista de correo. Los dos comandos tienen una línea de caracteres como argumento. Para el comando VRFY esta línea es igual al nombre de usuario, y la respuesta tiene que incluir el buzón de correo de usuario y puede incluir el nombre completo de usuario. Para el comando EXPN, esta línea identifica la lista de correo y la respuesta tiene que incluir el buzón de correo de usuario y puede incluir el nombre completo de usuario. La entrega de correo al buzón de correo se denomina como envío de correo y la entrega a la terminal se denomina transmisión. La transmisión y el envío de correo son casi idénticos y normalmente se combinan en SMTP. Los comandos siguientes se pueden utilizar en una transacción de correo en lugar del comando MAIL para soportar la función de envío: • SEND (enviar): Entrega el correo a la terminal del usuario. Si el usuario no está activo en el host (o no acepta los mensajes de la terminal), se envía una respuesta con código igual a 450. • SOML (enviar o entregar correo, send or mail): Entrega el correo a la terminal del usuario, si el usuario está activo en el host y acepta los mensajes de la terminal. De lo contrario, el correo se entrega al buzón de correo del usuario. • SAML (enviar y entregar correo, send and mail): Entrega el correo a la terminal del usuario, si el usuario está activo en el host y acepta los mensajes de la terminal. El correo se entrega al buzón de correo del usuario, independientemente de si se entregó en la terminal. COMANDOS Y RESPUESTAS Los comandos y respuestas pueden ir escritos en letras mayúsculas, minúsculas o una mezcla de ambas (véase tabla 2.1). Sin embargo, los nombres del emisor y receptor deben escribirse en la forma en que fueron definidos cuando se dieron de alta, debido a que muchos servidores realizan una distinción entre letras mayúsculas y minúsculas. 34/165 CAPÍTULO 2 Comando HELO MAIL RCPT DATA RSET SEND SOML SAML VRFY EXPN HELP NOOP QUIT TURN Descripción Inicia la conexión e identifica al receptor SMTP y al remitente SMTP. Inicia la transacción de correo. Identifica a un receptor individual. Identifica a las líneas que siguen al comando como datos de correo del remitente. Aborta la transacción de correo actual. Entrega correo a la terminal. Entrega correo a la terminal. Si esta operación falla, el correo se entrega al buzón de correo. Entrega correo a la terminal. El correo se entrega también al buzón de correo. Verifica el nombre de usuario. Expande la lista de correo. Causa el envío de información de ayuda por remitente. Requiere la respuesta OK del receptor, pero no especifica más acciones. Requiere la respuesta OK del receptor y cierra el canal de transmisión. Requiere que el receptor asuma el papel de remitente. Si recibe una respuesta OK, entonces el receptor se transforma en remitente. Tabla 2.1 Comandos de SMTP. Cada línea que el host envía comienza con un código de respuesta de tres dígitos. Si el cuarto caracter es un “_” existen más líneas relacionadas por venir. Si el caracter es un espacio, se trata de la última línea. Los programas de correo generalmente leen únicamente los primeros cuatro caracteres e ignoran el resto de la línea. Los códigos que empiezan con 2 indican éxito. Los que inician con 3 requieren más información. Los grupos 4XX y 5XX indican falla (siendo las 5XX las fallas más severas). El segundo dígito de la respuesta tiene un significado especial. Un 0 significa que ocurrió un error de sintáxis. Los mensajes de información tienen un 1. Los que tienen un 2 se refieren a la conexión. Finalmente, las respuestas que tienen un 5 se refieren al estado del sistema de correo (véase tabla 2.2). Código de respuesta 211 214 220 221 250 251 354 421 450 451 452 500 Significado Estado de sistema o respuesta de ayuda del sistema. Mensaje de ayuda. Servicio listo. Servicio cerrando el canal de transmisión. El correo solicitado fue aceptado, completado. Usuario no local, envío a camino-directo (forward-path). Iniciando entrada de correo; terminar con <CRLF><CRLF>. Servicio no disponible, cerrando el canal de transmisión. La solicitud de correo no procesada, el buzón de correo no está disponible. La acción solicitada abortada, error local en proceso. La solicitud de correo no fue procesada, insuficiente espacio en el sistema. Error de sintáxis, comando no reconocido. 35/165 CAPÍTULO 2 501 502 504 550 551 552 553 554 Error de sintáxis en el parámetro o en el argumento. Comando no implementado. Parámetro de comando no implementado. La acción solicitada no fue procesada, el buzón de correo no está disponible. Usuario no local, intente camino-directo (forward-path). La solicitud de correo fue abortada, asignación de espacio excedida. La acción solicitada no fue procesada, el nombre de buzón no es permitido. Transacción fallida. Tabla 2.2 Códigos de respuesta de SMTP. RAZONES POR LAS QUE SE ELIGIÓ SMTP SMTP es el protocolo para envío de correo más utilizado a nivel mundial, ya que forma parte de la pila de protocolos TCP/IP, empleada para sustentar la infraestructura de red de Internet. Es un protocolo simple que permite una depuración muy rápida de errores, en virtud de que el intercambio de comandos y respuestas se hace en texto ASCII. Además se pueden reunir fácilmente los elementos necesarios de hardware y software para armar una red de prueba para correo electrónico. 2.2 X.400 X.400 es un nombre corto para nombrar al conjunto de estándares de la ISO y la ITU-T, que describen un servicio de mensajería, donde el correo electrónico es una aplicación (la más utilizada) del servicio. Es un protocolo de capa 7 del modelo OSI. Es el único estándar no propietario para el intercambio de correo electrónico que es avalado por un organismo oficial de estandarización. Actualmente existen dos implementaciones de X.400: • X.400/1984. Esta es la implementación más utilizada. Fue documentada en la serie de “libro rojo” de la ITU-T. • X.400/1988. Está documentada en la serie “libro azul” de la ITU-T. Mucha gente piensa que ésta es una gran mejora sobre la de 84, pero el número de sistemas que la implementan ha disminuido. Es también un estándar de ISO. COMPARACION ENTRE X.400 Y SMTP SMTP ofrece: • Simplicidad. • Amplia aceptación. • Implementaciones de dominio público. • Interfaces de usuario de dominio público. • Muchas características nuevas (aunque opcionales) como MME y reportes de entrega. 36/165 CAPÍTULO 2 • Estándar de facto. X.400 ofrece: • Aceptación en las comunidades de estandarización. • Distribuidores comerciales del servicio. • Formas definidas para transferir datos aparte del texto ASCII (aunque sólo algunas implementaciones lo hacen). • Notificaciones estándares de entrega al buzón del usuario y notificación de que un mensaje está siendo leído por el usuario (estas son frecuentemente implementadas). • Estándar oficial, lo que implica que las implementaciones de X.400 se pueden probar más rigurosamente que los productos con implementaciones SMTP. • Utilizado ampliamente en Europa y Canada. TIPOS DE REDES SOBRE LAS QUE CORRE X.400 X.400’84 se diseñó para correr sobre la pila de protocolos OSI (es decir, X.25, TP0, Sesión BAS), por lo tanto la mayoría de las implementaciones, y todas las que pasan las pruebas de conformidad, pueden correr sobre una red X.25. Estas implementaciones tienen frecuentemente una interfaz X.25 o de nivel de transporte con fabricantes que proporcionan capas inferiores. En el caso del nivel de transporte, X.400 puede correr sobre el Servicio de Red Sin Conexión, CLNS (ConnectionLess Network Service), siempre y cuando éste esté basado en Tli o XTi. Sin embargo, para permitir el uso de una red TCP/IP, muchas implementaciones ofrecen acceso RFC1006 (TP0 sobre TCP/IP). Adicionalmente, algunas implementaciones como PP/ISODE y M.PLUS/UCOM.X vienen con un dispositivo que cumple con la RFC1006 y que actúa como un retransmisor (relay), entre una red X.25 y otra TCP/IP para aplicaciones OSI como X.400 y X.500. Los perfiles MAP/TOP también especifican (y usan) X.400 sobre TP4, para cualquier LAN 802.x (como Ethernet o FDDI). La RFC 1327 especifica un mapeo entre X.400 y el correo Internet. Las RFC’s 1494, 1495 y 1496 especifican mapeos entre X.400 y el correo Internet cuando interviene MIME. X.400 Y EL ROBOT DE CORREO ELECTRÓNICO El diseño de nuestro robot de correo electrónico se hizo tomando en consideración al protocolo SMTP para el envío de correo. La clase de JavaMail para modelar al objeto de transporte de correo está basada en características del protocolo SMTP, tales como el direccionamiento, las cuales son completamente diferentes en X.400. Por tal motivo, este robot de correo no podría operar en ambientes X.400. 37/165 CAPÍTULO 2 2.3 POP3 Para recuperar el correo se usa el protocolo POP3. Éste permite a los usuarios de computadoras que no están permanentemente conectados a Internet consultar sus correos en algún momento posterior al que se reciben en el servidor de correo. POP3 posibilita que un cliente con recursos limitados pueda acceder y recuperar su correo de un servidor que se lo almacena. El protocolo requiere pocos recursos y tiene una funcionalidad limitada. Normalmente, el correo se transfiere y se elimina, pero no se manipula dentro del servidor (véase la figura 2.2). Fig. 2.2 Modelo Cliente-Servidor. Utilizado por los protocolos SMTP y POP3. COMANDOS Y RESPUESTAS POP3 espera comandos en una sola línea terminada con un carácter de retorno de carro y de nueva línea, es decir, el código de la tecla ENTER. El puerto por default es el 110 y se utiliza el protocolo TCP para las conexiones. Los comandos que se envían consisten de tres o cuatro caracteres. Cada comando puede tener parámetros, cada uno separado por un espacio. Cada parámetro debe ser de 40 caracteres de longitud o menos. [22] Cuando la conexión entre cliente y servidor se establece, el servidor POP3 envía un mensaje de bienvenida. El cliente y el servidor intercambian comandos y respuestas hasta que la conexión finalice o se aborte (véase tabla 2.3). El primer caracter de la respuesta puede ser un signo más (+), lo que indica una respuesta exitosa; o un signo menos (-), que indica una falla. Además, el servidor envía un código en mayúsculas que puede ser una respuesta positiva (+OK) o una respuesta negativa (-ERR). La respuesta puede componerse de varias líneas (hasta 512 bytes) que terminan con los caracteres retorno de carro y nueva línea. En el caso de una respuesta de múltiples líneas, la última línea contiene únicamente un punto. 38/165 CAPÍTULO 2 Los servidores POP3 tienen más de un estado posible. Cuando se conecta por primera vez, el servidor se encuentra en el estado de autorización (AUTHORIZATION). Antes de poder realizar cualquier operación, el cliente se debe autenticar con el servidor, es decir proporcionar el nombre de usuario y la contraseña adecuados. A partir de que se proporcione la información correcta, el servidor entra en el estado de transacción (TRANSACTION). Esto le permite al usuario recuperar el correo y marcar el correo para borrarse. Usualmente, el servidor bloqueará el buzón durante esta etapa. Finalmente, cuando el cliente suministra un comando para terminar la sesión, el servidor entra en el estado de actualización (UPDATE), donde se limpia el buzón entrante, libera el buzón y cierra el socket. El orden en que se ejecutan las operaciones POP3 sería de la siguiente manera: 1) 2) 3) 4) 5) 6) 7) 8) La conexión TCP se abre y el cliente recibe un mensaje de bienvenida. La sesión entra en el estado de autorización (AUTHORIZATION). El cliente se identifica con el servidor, el cual obtiene los recursos asociados con el correo de este cliente. La sesión entra en el estado de transacción (TRANSACTION). El cliente solicita qué acciones debe ejecutar el servidor. El cliente ejecuta el comando terminar (QUIT). La sesión entra en el estado de actualizar (UPDATE). El servidor POP3 libera los recursos adquiridos durante el estado de transacción y envía un mensaje de despedida. 9) La conexión TCP se finaliza. Comando Requerido Estado de validez Respuesta múltiple Descripción USER PASS SI SI AUTHORIZATION AUTHORIZATION NO NO QUIT SI AUTHORIZATION NO STAT SI TRANSACTION NO LIST SI TRANSACTION Posible RETR SI TRANSACTION SI DELE SI TRANSACTION NO NOOP SI TRANSACTION NO Identifica el buzón de correo. Proporciona una contraseña específica servidor/buzón de correo. Termina la sesión sin entrar en el estado de actualización (UPDATE). Proporciona la información sobre la transferencia de correo (por ejemplo, tamaño y número de mensajes). Se denomina “drop listing”. Especifica el número de mensajes y el tamaño de los mensajes. Se denomina “scan listing”. El cliente envía el número del mensaje a recuperar, utilizando este comando. El servidor responde con el contenido del mensaje. El cliente envía el número del mensaje utilizando este comando y el servidor marca el mensaje como eliminado. El mensaje no es eliminado hasta que la transacción no entra en el estado de actualización (UPDATE). Cuando el cliente envía este mensaje, el servidor 39/165 CAPÍTULO 2 RSET SI TRANSACTION NO QUIT SI TRANSACTION NO APOP NO AUTHORIZATION NO TOP NO TRANSACTION SI UIDL NO TRANSACTION Posible da una respuesta positiva sin más información. Desmarca cualquier mensaje que se ha marcado como eliminado en el servidor. Causa la entrada en el estado de actualización (UPDATE). El cliente entonces envía el mensaje de despedida (QUIT) y la conexión se finaliza. Identifica un buzón de correo y una línea de MD5 para la autenticación y la protección de la respuesta. Especifica un número de mensaje y un número n de líneas. El servidor devuelve las primeras n líneas del mensaje. Proporciona un número de mensaje y una identidad única, las cuales forman el listado de identidad única (unique-id listing) del mensaje. Tabla 2.3 Comandos POP3 2.4 IMAP Aunque POP3 es muy popular, algunos servidores también soportan al Protocolo de Acceso a Mensajes de Internet, IMAP (Internet Message Access Protocol), definido en la RFC 2060. La operación de IMAP es similar a POP3, pero tiene funciones especiales que lo hacen adecuado para administrar remotamente un buzón. Tanto POP3 como IMAP trabajan sobre un servidor centralizado que acepta correo a nombre del usuario. POP3 requiere que el usuario descargue su correo en una computadora local. IMAP también puede hacer esto, pero sin embargo está capacitado para administrar el buzón de correo directamente en el servidor. Esto le permite al usuario trabajar con su correo en diferentes máquinas. También es útil para clientes que no tiene mucho espacio en su propia computadora. IMAP es útil en algunas situaciones pero casi todos los servidores soportarán al menos POP3, el cual es más simple de entender porque tiene bastante menos comandos. . 2.5 EL PARADIGMA CLIENTE-SERVIDOR El robot de correo realiza dos funciones automatizadas básicas: descarga del servidor de correo los mensajes correspondientes a la cuenta que tiene asignada, forma los mensajes con las respuestas a esos correos recibidos y contacta nuevamente al servidor de correo para enviarlos. En esta rutina aparece dos veces una interacción cliente-servidor, donde el cliente siempre es el robot de correo y del otro lado tenemos al servidor de correo que actúa como servidor POP3 para entregar los correos al robot, y como servidor SMTP para enviar los correos de respuestas a los usuarios. La figura 2.2 muestra cómo trabaja un modelo cliente-servidor en una red LAN del tipo bus. Para nuestro caso, El cliente A podría ser nuestro robot de correo, el cual intenta comunicarse con el servidor POP3 que está ubicado en el servidor de correo. Éste último está constantemente “escuchando” en el puerto “bien conocido” 110, para establecer una conexión TCP con algún cliente de correo electrónico. Para que este enlace se de, el robot debe intercambiar con el servidor POP3 una serie de comandos y respuestas. Para el caso del servidor SMTP la situación es similar, pero en este caso el puerto “bien conocido” es el 25. (véase la figura 1.7). 40/165 CAPÍTULO 2 2.6 RESUMEN CAPÍTULO 2 El Protocolo Simple de Transferencia de Correo, SMTP (Simple Mail Transfer Protocol) es el que se emplea para la transferencia del Correo Internet. Puede operar sobre diferentes entornos de transporte, y la única condición es que le provean de un canal de flujo confiable. En el caso de Internet, opera sobre el protocolo de transporte TCP, utilizando el puerto bien conocido 25. SMTP está definido en el documento RFC821, aquí se dice que un sistema de transmisión de correo electrónico está conformado por dos entidades principales: un emisor SMTP y un receptor SMTP. Estos se comunican a través de un intercambio de comandos y respuestas, aunque previamente tiene que establecerse una conexión TCP entre ambos para que pueda darse la transmisión de correo. Un servidor SMTP puede establecer varias conexiones SMTP en su puerto 25. El correo electrónico la mayoría de las veces tiene que atravesar varios servidores SMTP para llegar a su destino final. Para asegurar la confiabilidad del sistema, el último servidor SMTP que recibió el correo siempre guarda una copia del mismo, hasta que no recibe confirmación del siguiente receptor SMTP. De esta forma, siempre se puede retransmitir nuevamente la información hacia el próximo servidor SMTP. Existen otros protocolos para la transferencia de correo tales como X.400, MHS, entre otros, pero ninguno tiene un uso tan extendido como el de SMTP. El protocolo X.400, a diferencia de SMTP, es un estándar oficial. Fue aprobado por ISO y está ubicado en el nivel de aplicación o capa 7 del modelo OSI, que trata de la intercomunicación de sistemas abiertos. Como parte de esa pila de protocolos, X.400 corre sobre protocolos OSI de transporte, como TP0, y utiliza la red X.25, a nivel de enlace y red. Sin embargo, existen dispositivos que permiten la convivencia entre redes X.25 y TCP/IP para aplicaciones X.400. El Protocolo de Oficina Postal versión 3, POP3 (Post Office Protocol versión 3) es utilizado para permitir que el correo electrónico se almacene en un servidor, y posteriormente un cliente pueda descargarlo y procesarlo. Dentro del servidor está definido un único fólder (INBOX) para cada usuario. El protocolo proporciona un mecanismo de autenticación basado en un nombre de usuario y una contraseña. Utiliza, al igual que SMTP, el protocolo de transporte TCP para asegurar una transmsión confiable de los correos. Las transacciones se manejan a través de estados. Conforme se suministran diferentes comandos, el servidor de correo transita de un estado a otro. Los comandos que el envía el cliente hacia el servidor están compuestos de 3 o cuatro letras y pueden llevar parámetros separados por un espacio. Las respuestas del servidor pueden ser positivas (+OK) o negativas (-ERR), conteniendo varias líneas hasta 512 bytes. Existe otro protocolo para la recuperación de correo que se conoce como Protocolo de Acceso a Mensajes de Internet, IMAP (Internet Message Access Protocol). Es más complejo pero tiene más opciones que POP3. Permite, a diferencia de POP3, manipular el correo dentro del propio servidor. Se pueden crear jerarquías de carpetas para cada usuario y distribuir los correos de un mismo usuario en diferentes carpetas. Sin embargo, a pesar de todas las características adicionales de funcionalidad que posee este protocolo, su uso no está tan extendido como POP3, y esto quizá se debe a que es más complejo de implementar. 41/165 CAPÍTULO 2 El paradigma cliente-servidor está presente tanto en el protocolo SMTP como en el POP3. Se tiene definido que un servidor SMTP abre una sesión pasiva con el sistema operativo del host donde reside, para “escuchar” sobre el puerto bien conocido 25, cualquier intento de algún cliente por establecer una sesión de correo. Lo propio sucede con un servidor POP3, estableciendo una sesión pasiva con el sistema operativo, y utilizando el puerto 110 para “escuchar”. 42/165 CAPÍTULO 3 CAPÍTULO 3 REPRESENTACIÓN DE DATOS NO TEXTO EN EL CORREO 3.1 MIME La Fuerza de Tarea de Ingeniería Internet, IETF (Internet Engineering Task Force), definió las Extensiones de Correo Internet Multipropósito, MIME (Multipurpose Internet Mail Extensions) para permitir la transmisión de datos no ASCII. MIME permite que datos arbitrarios sigan codificándose en ASCII y luego se envíen por medio de mensajes de correo electrónico (e-mail) estándar. El protocolo MIME permite ampliar la capacidad de representación de mensajes [21]. Algunas de sus principales características son: • • • permite el envío de múltiples “cuerpos” dentro del contenido de un correo. permite añadir contenido de cualquier tipo, no sólo texto. permite utilizar un juego de caracteres diferentes al US-ASCII. Para poder llevar a cabo tal función, es necesario añadir una serie de campos a la cabecera de los mensajes SMTP. Estos campos son: • • • • Versión MIME. Tipo de contenido. Codificación utilizada. Identificación y descripción del contenido. Para adaptarse a tipos y representaciones arbitrarias de datos, cada mensaje MIME incluye datos que informan al receptor sobre el tipo de datos y la codificación utilizada. Cuando un mensaje de correo transporta información, utilizando MIME, la cabecera del protocolo SMTP se ve modificada con la información aportada por MIME [21]. Esta información tiene el aspecto siguiente: From: [email protected] to: [email protected] MIME-Version: 1.0 Content-Type: image/jpeg Content-Transfer-Encoding: base64 43/165 CAPÍTULO 3 Los dos primeros campos son específicos del protocolo SMTP, que definen al emisor y al receptor del mensaje, el tercer campo es la versión del protocolo MIME (actualmente la versión es la 1), el cuarto campo indica el tipo de datos que se está enviando, en este ejemplo es una imagen jpeg. El último campo indica qué tipo de codificación se ha utilizado para convertir la imagen (en este caso) en una representación ASCII de 7 bits, en el ejemplo se utiliza base64. [21] 3.1.1 TIPOS DE DATOS El estándar define siete tipos de contenidos básicos, los subtipos válidos para cada uno y las codificaciones de transferencia (véase tabla 3.1). Tipo de Contenido (ContentType) texto (text) imagen (image) audio (audio) video (video) aplicación (application) mensaje (message) multiparte (multipart) Descripción Permite especificar el conjunto de caracteres, utilizado para el texto Para datos de imagenes estáticas Para grabaciones de sonido Para grabaciones de video Para envío de programas ejecutables Para mensajes de correo completos o referencias externas Para envío de mensajes múltiples Tabla 3.1 Tipos de contenido MIME. El tipo multipart permite 4 subtipos (véase tabla 3.2). Subtipo mezclado (mixed) alternativo (alternative) paralelo (parallel) resumen (digest) Descripción Indica que un mensaje tiene partes independientes, con tipos y codificación diferentes. Indica que el mensaje contiene distintos formatos de representación de la misma información. Indica que el mensaje incluye subpartes que deben ser ejecutadas al mismo tiempo (por ejemplo, audio y video). Indica que el mensaje contiene un conjunto de mensajes. Tabla 3.2 Subtipos Multipart. 44/165 CAPÍTULO 3 3.1.2 TIPOS DE CODIFICACIÓN El tipo de Codificación para Transferencia de Contenido (Content-Transfer-Encoding) puede ser Quotedprintable o Base64 (véase tabla 3.3). Tipo Quoted-printable Descripción Utilizado en secuencias alfanuméricas. Permite representar los caracteres superiores a 127 por una secuencia de caracteres especial “=XX” donde XX es el valor hexadecimal del carácter a representar. Para secuencias de bytes. Permite representar 3 bytes con 4 caracteres ASCII con 6 bits significativos. Base64 Tabla 3.3 Tipos de codificación MIME. La Codificación para Transferencia de Contenido (Content-Transfer-Encoding) describe qué mecanismo se utiliza para convertir datos de 8 bits (No ASCII) a un formato de 7 bits para su transmisión a través de la red. Dependiendo del tipo de datos se tienen tres soluciones recomendadas (ver tabla 3.4). Cantidad de caracteres de 8 bits Ninguna Baja Codificación recomendada Ninguna QuotedPrintable Media o alta Base64 Overhead por la codificación 0% 200% para caracteres de 8 bits 0% para caracteres de 7 bits 33% Tabla 3.4 Opciones de Codificación para Transmisión. Si se está seguro de que el texto no tiene caracteres de 8 bits, tal como texto en inglés, no hay razón para codificarlo. Un texto que tenga una mínima parte de caracteres de 8 bits, como lenguajes del oeste de Europa, utilizará la codificación QuotedPrintable. Cualquier otro tipo de datos, como archivos binarios o muchos lenguajes Asiaticos, serían codificados con Base64. CODIFICACIÓN BASE64 Se le conoce con este nombre porque únicamente usa 64 caracteres (10 dígitos decimales, 26 caracteres en mayúsculas, 26 caracteres en minúsculas, ‘+’, ‘/’). La razón para reducir el conjunto de caracteres a 64 (en lugar de utilizar los 128 posibles con 7 bits) es que todos los caracteres seleccionados se pueden imprimir, y por lo tanto, los puede leer una persona [23]. Los pasos para codificar son (véase figura 3.1): • Convertir los caracteres de 8 bits a 6 bits. • Mapear los valores de 6 bits al conjunto de caracteres Base64. 45/165 CAPÍTULO 3 Bytes Binarios 1 Bits de datos 1 2 3 Caracteres Base64 4 2 5 6 7 8 9 10 1 11 3 12 13 14 15 2 16 17 18 19 20 21 22 3 23 24 4 Fig. 3.1 Mapeado de bits en Base64. La figura 3.2 muestra cómo funciona la reducción de bits. Se aprovecha el hecho de que 24 bits se obtienen tanto con 3x8 bits como por 4x6 bits. Es decir, tres valores de 8 bits pueden transformarse en cuatro valores de 6 bits y viceversa. Tomando esto en cuenta, se subdivide el flujo de entrada en grupos de tres caracteres y se transforma cada tripleta utilizando el mismo procedimiento. Flujo binario de entrada … … 1 1 1 1 1 1 Tripleta n-1 … 9 1 255 1 1 1 1 1 3 1 9 1 1 1 1 1 63 / Flujo Base64 salida … de Tripleta n 66 255 0 0 1 1 Tripleta n+1 170 0 170 1 0 0 … 9 … A O I Tetrapleta n-1 100 … 12 15 1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 40 o J / 6 … … 0 0 58 6 … 99 o Tetrapleta n A 0 0 0 0 0 0 0 A Y 2 Q Tetrapleta n+1 M D … … … … Fig. 3.2 Codificación Base64. En el ejemplo, la tripleta de entrada es (255, 170, 0). A la salida se tienen cuatro nuevas variables, la primera está compuesta de los 6 primeros bits del primer byte; la segunda está formada de los últimos 2 bits del primer bytes y los cuatro primeros bits del segundo byte, y así hasta completarlas. Las cuatro variables resultantes son (63, 58, 40, 0). 46/165 CAPÍTULO 3 El siguiente paso es buscar los valores en la tabla de codificación Base64 (ver tabla 3.5). En ella se encuentran los caracteres codificados (‘/’, ‘6’, ‘o’, ‘A’). Entonces, se concatenan (‘/6oA’), y se agregan al archivo de salida, y se continua con la siguiente tripleta. VALOR 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CODIFICACIÓN VALOR A B C D E F G H I J K L M N O P CODIFICACIÓN 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Q R S T U V W X Y Z a b c d e f VALOR 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 CODIFICACIÓN g h i j k l m n o p q r s t u v VALOR 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 CODIFICACIÓN w x y z 0 1 2 3 4 5 6 7 8 9 + / Tabla 3.5 Codificación Base64. Si el tamaño de byte del archivo es exactamente divisible entre tres, esto es todo lo que se tiene que hacer. En caso contrario, se termina con una tripleta incompleta (uno o dos bytes) al final del archivo. Para completar esta última tripleta, se utiliza un carácter adicional a los 64 que componen el código, y este es “=”. Este carácter sólo puede aparecer al final de un flujo Base64, y puede ser ya sea el último o los últimos dos caracteres, acorde con lo siguiente: • Si el flujo de entrada contiene dos caracteres remanentes, se agrega un cero, se codifica la tripleta y se reemplaza el caracter final de salida con “=.” • Si el flujo de entrada contiene un carácter remanente, se agregan dos ceros, se codifica la tripleta y se reemplazan los dos caracteres finales de salida con “= =.” Por ejemplo, el byte 255 se completaría como (255, 0, 0). Esto se reduciría a (63, 48, 0, 0) y se mapearía a (‘/’, ‘w’, ‘A’, ‘A’), pero se incorporaría al flujo de salida como (‘/w= =)’. Para el caso de dos bytes (255, 255) terminaría como (255, 255, 0), luego (63, 63, 60, 0), enseguida (‘/’, ‘/’, ‘8’, ‘A) y se suma al flujo de salida como (‘//8=’). CODIFICACIÓN QUOTED-PRINTABLE Esta codificación trabaja sobre la premisa de que la mayoría del texto utiliza bytes de 7 bits. Para evitar el overhead de la codificación, así como mantener la legibilidad, el texto de 7 bits se deja como está [23]. Los caracteres de 8 bits se codifican de la siguiente forma: • Se obtiene su índice de la tabla ASCII. 47/165 CAPÍTULO 3 • • El valor se codifica como hexadecimal. Se pone “=” como prefijo al código. Por ejemplo, la letra “ß” es el carácter 223 en el código ASCII. El equivalente hexadecimal del decimal 223 es DF. Por lo tanto, “ß” se codificaría como “=DF.”, y “weiße” como “wei=DFe.” En el otro extremo de la comunicación, el lector detecta el carácter de 8 bits por el “=” y traduce el DF subsecuente a su equivalente ASCII. En el caso de que realmente se deseara mandar la cadena “wei=DFe” en un mensaje, no habría ningún problema ya que para evitar ambigüedades, el carácter “=” también se codifica en la misma forma que los caracteres de 8 bits. Es decir, corresponde a un 61 en decimal y a un 3D en hexadecimal, y por lo tanto se codifica como “=3D.” Esto significa que la cadena “wei=DFe” se codificaría como “we=3DDFe.” Esto significa que el lector sabría que tendría que decodificar el “=3D” pero dejaría intacto el DF ya que no está precedido inmediatamente por un “=”. 3.1.3 ARCHIVOS ADJUNTOS En cuanto a SMTP concierne, todos los mensajes de correo son una sola entidad. Los archivos adjuntos son sólo la interpretación que hace un cliente de correo de un sólo mensaje en múltiples archivos. [22] El tipo de contenido multiparte (Content-Type multipart) se utiliza para los archivos adjuntos. También permite enviar representaciones alternas de un mismo mensaje. El siguiente es un ejemplo de correo MIME: MIME-Version:1.0 Content-Type: multipart/mixed; boundary=”XXXYYYZZZ” Subject: I have atachments --XXXYYYZZZ Content-Type: text/plain this is the main message. --XXXYYYZZZ Content-Type:text/plain Content-Description: test This file is ok --XXXYYYZZZ-Cada parte de un mensaje está separada por dos guiones y el texto limitador, el cual no debe aparecer como parte del mensaje. El último límite tiene dos guiones al frente y otros dos al final. El texto entre los límites es un “mensaje independiente”. Puede tener sus propios encabezados, aunque los encabezados deben comenzar con Content-type (los otros encabezados no significan nada en este contexto). Una línea blanca separa estos subencabezados del resto del mensaje. Como no se necesitan encabezados para el texto ordinario, se permite comenzar el archivo adjunto con una línea blanca, si no se necesitan encabezados 48/165 CAPÍTULO 3 especiales. En este ejemplo, como el encabezado Content-Description del archivo adjunto es test y el encabezado Content-Type es text/plain, el archivo adjunto tendrá el nombre de test.txt. Se pueden agregar más archivos adjuntos simplemente repitiendo el separador --XXXYYYZZZ (utilizando los guiones posteriores únicamente al final de todos los mensajes). La forma en cómo el cliente de correo presentará los archivos adjuntos depende de los siguientes subtipos: • multiparte/mezclado (multipart/mixed). Cada parte está separada y debe aparecer en el orden descrito. El subtipo mixed permite que un solo mensaje contenga submensajes independientes, con tipo independiente y codificación diferente. Los mensajes multipart mezclados hacen posible incluir textos, gráficos y audio en un solo mensaje, o permiten el envío de un memorándum con segmentos de datos adicionales asociados, similares a los adjuntos (enclosures) incluidos en una carta de negocios. • multiparte/alternativo (multipart/alternative). Cada parte es una representación diferente del mismo mensaje (por ejemplo, una parte en texto, otra en HTML y otra en algún formato propietario). Algunas alternativas de los mensajes multipart son útiles cuando se envía un memorándum a muchos destinatarios, de los que no todos utilizan el mismo hardware y software de sistema. • multiparte/resumen (multipart/digest). software de listas de correo). • multiparte/paralelo (multipart/parallel). Cada parte está separada y debería aparecer al mismo tiempo. Esto puede ser de utilidad cuando una parte es una página HTML, y la otra parte es un archivo de sonido que se quiere tocar mientras se observa la página HTML. Pero de hecho, pocos programas hacen esto y en su lugar tratan este tipo como multipart-mixed. Cada parte es otro mensaje de correo (utilizado frecuentemente por 49/165 CAPÍTULO 3 3.2 RESUMEN CAPÍTULO 3 Las Extensiones de Correo Internet Multipropósito, MIME (Multipurpose Internet Mail Extensions) son un conjunto de reglas que permiten incluir en un correo electrónico tanto datos No ASCII (8 bits) como ASCII (7 bits). Define una serie de encabezados que le indican al cliente de correo el tipo de información que se está enviando, así como el tipo de codificación que se utilizó para su transmisión. MIME define siete tipos de contenido básicos: texto (text), imagen (image), audio (audio), video (video), aplicación (application), mensaje (message) y multiparte (multipart). Este último se utiliza para darle al correo la capacidad de incluir múltiples cuerpos dentro del mismo mensaje, entre otras características. Dentro de esta categoría se tienen cuantro subtipos: mezclado (mixed), alternativo (alternative), paralelo (parallel) y resumen (digest). Existen básicamente dos tipos de codificación utilizados: el QuotedPrintable y el Base64. La primera opción se utiliza cuando la cantidad de caracteres de 8 bits es baja con respecto al total. Este tipo de codificación le agrega un overhead de 200 % pero únicamente a los caracteres de 8 bits, pues a los de 7 bits los deja intactos. La codificación Base64 por su parte, se usa cuando la cantidad de caracteres No ASCII se considera mediana o alta. Base64 le agrega un 33 % de overhead al total de los datos. Un archivo adjunto es la interpretación que hace un cliente de correo de un mensaje en múltiples archivos. Para lograr esto se emplea el tipo MIME multiparte. Un cliente de correo utiliza los siguientes subtipos para diferenciar la presentación de archivos adjuntos: • multiparte/mezclado. Permite que cada submensaje tenga un tipo y codificación diferente. Es posible incluir texto, gráficos y audio dentro de un mismo mensaje. • Multiparte/alternativo. Permite representaciones diferentes de un mismo mensaje. • Multiparte/resumen. Permite incluir diferentes mensajes dentro de un mismo correo. • Multiparte/paralelo. Permitiría que las distintas partes dentro de correo aparezcan al mismo tiempo (como por ejemplo una página HTML y un archivo de sonido). Desafortunadamente la mayoría de los clientes de correo tratan este subtipo de la misma forma que un multiparte/mezclado. 50/165 CAPÍTULO 4 CAPÍTULO 4 HERRAMIENTAS DE CÓMPUTO PARA EL DESARROLLO DEL ROBOT 4.1 Lenguaje Java Java fue diseñado por un equipo de la compañía Sun Microsystems en California. Surgió de la necesidad de crear software para la electrónica doméstica (videocaseteras, televisores, teléfonos, radiolocalizadores, entre otros) [13]. Java es uno de los mejores lenguajes de programación que existen y las razones son las siguientes [4]: • Java es ligero y poderoso Los diseñadores omitieron intencionalmente todas las características superficiales de los lenguajes de programación, reduciendo su diseño a lo más esencial. El diseño es ligero, poderoso y fácil de aprender. • Java está orientado a objetos Los lenguajes orientados a objetos son el enfoque más reciente y exitoso de la programación. Java está completamente orientado a objetos: no es un lenguaje al que se le haya agregado esta orientación después de haber sido creado. • Java es compatible con Internet La principal motivación de la creación de Java fue permitir que se desarrollen programas que utilicen Internet y la Web. Los programas en Java pueden invocarse fácilmente desde exploradores Web tales como Netscape Navigator e Internet Explorer; además, pueden transmitirse a través de Internet y ejecutarse en cualquier computadora. • Java es de propósito general Aunque está diseñado para crear aplicaciones para la World Wide Web, Java es verdaderamente un lenguaje de propósito general. Cualquier cosa que pueda hacerse con C++, Ada o cualquier otro lenguaje de programación, también puede hacerse con Java. • Java es independiente de la plataforma Los programas pueden ejecutarse en casi todas las computadoras sin necesidad de modificarlos. • Java es robusto Si un programa de Java falla, no provocará destrozos, daños ni incertidumbre. Como los programas en Java se ejecutan dentro de una “jaula” de protección, los efectos de cualquier error están confinados y controlados; incluso están protegidos contra la filtración de virus. 51/165 CAPÍTULO 4 • Java cuenta con bibliotecas Como Java es un lenguaje pequeño, la mayor parte de su funcionalidad la proporcionan ciertas piezas del lenguaje que están guardadas en bibliotecas. Actualmente existe una gran variedad de software, el cual se puede adquirir comercialmente, con bibliotecas para crear gráficos, tener acceso a Internet y manejar (dar soporte a) las interfaces gráficas de usuario (GUI’s), además de todas las cosas que realizan los lenguajes de programación. 4.2 La Interfaz de Programación de Aplicaciones JavaMail La API JavaMail satisface la necesidad de una estructura para soporte de correo y mensajería para la plataforma del lenguaje Java. JavaMail proporciona un conjunto de clases abstractas que se utilizan para definir los objetos que componen un sistema de correo. Define clases tales como Message, Store y Transport, se pueden extender y obtener subclases para agregar funcionalidad y nuevos protocolos. La API proporciona subclases concretas de las clases abstractas. Estas subclases, incluyendo MimeMessage y Mimebodypart, implementan protocolos de correo Internet ampliamente utilizados y cumplen con el estándar rfc 822 y rfc 2045. JavaMail está diseñada para los siguientes usuarios: ¾ Desarrolladores de cliente, servidor y middleware, interesados en construir aplicaciones de correo y mensajería, utilizando el lenguaje de programación Java. ¾ Desarrolladores de aplicaciones que requieren habilitar la opción de correo en las mismas. ¾ Proveedores de servicio que necesitan implementar protocolos específicos de acceso y transferencia. Por ejemplo, una compañía de telecomunicaciones puede implementar un servicio dónde se envíe un mensaje de correo electrónico a un localizador (pager). JavaMail está pensada para cumplir con los siguientes requerimientos de desarrollo y tiempo de ejecución: ¾ Diseño simple y directo de clases que facilita su aprendizaje e implementación por parte del desarrollador. ¾ La utilización de conceptos y modelos de programación familiares apoyan el desarrollo de código que funciona correctamente con otras API’s de Java. ¾ Utiliza modelos de programación de manejo de excepciones y de manejo de eventos. ¾ Utiliza características del JavaBeans Activation Framework (JAF) para manejar el acceso a datos basado en tipo de datos, y facilita agregar “tipos de datos” y “comandos” sobre esos tipos de datos. ¾ Clases e interfaces sencillas que facilitan el agregar tareas básicas de manejo de correo a cualquier aplicación. ¾ Soporta el desarrollo de aplicaciones robustas, habilitadas para enviar correo, que pueden manejar una compleja variedad de formatos de mensajes de correo, tipos de datos y protocolos de acceso y transporte. JavaMail es fácil de utilizar, ya que aisla las aplicaciones de las complejidades de la implementación a través de su modelo orientado a objetos. JavaMail soporta diferentes implementaciones de sistemas de mensajería, diferentes almacenes de mensajes (message stores), diferentes formatos de mensajes y diferentes transportes de mensajes. Proporciona un conjunto base de clases e interfaces, que define la API para aplicaciones cliente y que será suficiente para la mayoría de las aplicaciones simples de mensajería. 52/165 CAPÍTULO 4 La subclase MimeMessage expone e implementa características comunes de un mensaje de correo Internet, tal como se define en la rfc 822 y en los estándares MIME. Los desarrolladores pueden obtener subclases para proporcionar características de un sistema de mensajería en particular, tal como IMAP4 y POP3. JavaMail proporciona elementos para construir una interfaz para un sistema de mensajería, incluyendo componentes de sistema e interfaces. 4.2.1 COMPONENTES ARQUITECTÓNICOS Los componentes arquitectónicos de JavaMail se estratifican como sigue: ¾ La capa abstracta declara clases, interfaces y métodos abstractos, pensados para manejar funciones de correo que soportan todos los sistemas de correo. Los elementos de la API que comprenden la capa abstracta se utilizan para obtener subclases y heredar para soportar tipos de datos estándar, y para interactuar con protocolos de acceso a mensajes y protocolos de transporte de mensajes. ¾ La capa de implementación de Internet realiza parte de la capa abstracta, utilizando estándares de Internet, rfc 822 y MIME. ¾ JavaMail utiliza los JavaBeans Activation Framework (JAF) para encapsular los datos del mensaje y para manejar comandos para interactuar con dichos datos. La API JavaMail es utilizada por los clientes e implementada por los proveedores de servicio. La arquitectura de diseño estratificado permite a los clientes utilizar las mismas llamadas de la API para enviar, recibir y guardar una variedad de mensajes, utilizando diferentes tipos de datos de diferentes almacenes de mensajes y utilizando diferentes protocolos de transporte de mensajes. Aplicación habilitada para correo JavaBean- utilizado para interactuar y desplegar el contenido de un mensaje JavaMail API JavaMail Capa de Clase Abstracta Correo Internet Capa de Implementación Capa de Implementación IMAP/POP3 Fig.4.1 Cómo implementar una aplicación con JavaMail. 53/165 CAPÍTULO 4 4.2.2 PROCESO DE MANEJO DE CORREO JavaMail está diseñada para realizar las siguientes funciones de manejo de correo, de una aplicación cliente típica (véase la figura 4.2): ¾ Crear un mensaje de correo, que consiste de un conjunto de atributos de encabezados y de un bloque de datos de algún tipo conocido, especificado en el campo de encabezado Tipo de Contenido (Content-Type). JavaMail utiliza la interfaz Part y la clase Message para definir un mensaje de correo. Utiliza el objeto DataHandler definido en la JAF para alojar los datos del mensaje. ¾ Crear un objeto Session, que autentifica al usuario y controla el acceso al almacén de mensajes y al transporte. ¾ Enviar el mensaje a su lista de destinatarios. ¾ Recuperar el mensaje de un almacén de mensajes. ¾ Ejecutar un comando de alto nivel en un mensaje recuperado. Fig. 4.2. Proceso de manejo de correo de JavaMail. 54/165 CAPÍTULO 4 4.2.3 PAQUETES DE LA API JavaMail javax.mail Clases para modelar un sistema de correo. Dentro de este paquete existen interfaces como Part. También se definen clases como Address, Authenticator, BodyPart, Folder, Message, Multipart, Session, Store yTransport. Se manejan excepciones como AuthenticationFailedException, FolderCloseException, MessagingException, NoSuchProviderException, entre otras. javax.mail.event Clases escuchas y clases eventos para la API JavaMail, utilizadas por las clases definidas en javax.mail. Interfases: ConnectionListener, FolderListener, StoreListener, TransportListener, entre otras. Clases: ConnectionEvent, FolderEvent, MailEvent, MessageCountEvent, StoreEvent, entre otras. javax.mail.internet Clases específicas para correo Internet. Soportan características basadas en los estándares MIME, definidas en las rfc’s 2045, 2046 2047. Los protocolos IMAP, SMTP y POP3 utilizan MimeMessages. Interfases: MimePart , entre otras. Clases: ContentType, HeaderTokenizer, InternetAddress, InternetHeaders, MimeBodyPart, MimeMessage, MimeMultipart, entre otras. Excepciones: AddressException, entre otras. javax.mail.search Términos para búsqueda en mensajes para la API JavaMail. Define clases que se pueden usar para construir una expresión, que permita buscar en un fólder mensajes que cumplan con ella. Clases: AddressStringTerm, BodyTerm, DateTerm, FromStringTerm, HeaderTerm, MessageIDTerm, RecipientTerm, entre otras. Excepciones: SearchException. La API JavaMail incluye el paquete javax.mail y algunos subpaquetes. La API soporta las siguientes propiedades estándar (tabla 4.1), las cuales se pueden establecer en el objeto Session, o en el objeto Properties utilizado para crear el objeto Session. Las propiedades se ponen siempre como cadenas; la columna Tipo describe cómo se interpreta la cadena. Nombre Tipo Descripción mail.debug boolean El modo inicial de depuración. El default es falso. mail.from String La dirección de correo electrónico de retorno del usuario actual, utilizada por el método getLocalAddress de InternetAddress. La clase MimeMessage utiliza el método parseHeader de InternetAddress mail.mime.address.strict boolean para analizar los encabezados de los mensajes. Esta propiedad controla la bandera “strict” pasada al método parseHeader. El default es verdadero. mail.host String El nombre de host por default del servidor de correo, tanto para los objetos Stores como para Transports. Se utiliza si la propiedad mail.protocol.host no 55/165 CAPÍTULO 4 se pone. String Especifica el protocolo de acceso a mensajes por default. El método getStore() de Session, regresa un objeto Store que implementa este protocolo. Por default, se regresa el primer Store provider en los archivos de configuración. mail.transport.protocol String Especifica el protocolo de transporte de mensajes por default. El método getTransport de Session, regresa un objeto Transport que implementa este protocolo. Por default, se regresa el primer Transport provider en los archivos de configuración. mail.user String El nombre de usuario que se utiliza por default cuando se conecta al servidor de correo. Se utiliza si no se establece la propiedad mail.protocol.user mail.protocol.class String Especifica el nombre de clase completamente calificado del proveedor para el protocolo especificado. Se utiliza en casos donde existe más de un proveedor para un protocolo dado; esta propiedad puede usarse para especificar cual proveedor utilizar por default. De cualquier forma el proveedor debe estar listado en un archivo de configuración. mail.protocol.host String El nombre de host del servidor de correo para el protocolo especificado. Se antepone a la propiedad mail.host. mail.protocol.port int El número de puerto del servidor de correo para el protocolo especificado. Si no se especifica, se utiliza el número de puerto de protocolo por default mail.protocol.user String El nombre de usuario que se tiene que usar cuando se conecta a servidores de correo utilizando el protocolo especificado. Se antepone a la propiedad mail.user. mail.store.protocol Tabla 4.1 Propiedades estándar de JavaMail. JavaMail soporta las siguientes propiedades de System, las cuales se pueden establecer con el método setProperty de System (ver tabla 4.2). Nombre mail.mime.charset Tipo Descripción String El conjunto de caracteres por default que usará JavaMail. Si no se establece (el caso usual), se utiliza la propiedad estándar de J2SE de System file.encoding. Esto permite a las aplicaciones especificar un conjunto de caracteres por default para enviar mensajes, que es diferente del conjunto de caracteres para guardar archivos en el sistema. Esto es común en sistemas japoneses. La RFC 2047 requiere que el texto codificado empiece al principio de una palabra separada por un espacio en blanco. Algunos programas de correo, mail.mime.decodetext.strict boolean especialmente los japoneses, codifican texto inapropiadamente e incluyen texto codificado en medio de palabras. Esta propiedad controla sí JavaMail intentará decodificar tal texto incorrectamente codificado. El 56/165 CAPÍTULO 4 default es verdadero, lo que significa que JavaMail no intentará decodificar tal texto incorrectamente codificado. Cuando se escoge una codificación para los datos de un mensaje, JavaMail asume que cualquiera de CR, LF o CRLF son terminadores de línea válidos en partes de mensaje que contienen sólo caracteres ASCII imprimibles, aún si la parte no es un tipo de texto MIME. Es común, especialmente en sistemas UNIX, que los datos de tipo MIME application/octet-stream (por ejemplo) sean realmente datos textuales que mail.mime.encodeeol.strict boolean deberían ser transmitidos con las reglas de codificación para texto MIME. En casos raros, tales textos ASCII puros podrían ser de hecho datos binarios en los cuales los caracteres CR y LF deberían ser preservados exactamente. Si esta propiedad se establece a verdadero, JavaMail considerará que en forma individual CR o LF en un cuerpo de mensaje que no es de tipo texto MIME, indicaran que el cuerpo de mensaje necesita ser codificado. El default es falso. Tabla 4.2 Propiedades de System. 4.2.4 PAQUETES SUN DE PROVEEDORES DE PROTOCOLO La implementación de referencia de JavaMail de Sun incluye proveedores de protocolo en subpaquetes de com.sun.mail. Sin embargo, las API’s de estos proveedores de protocolo no son parte de la API estándar de JavaMail. com.sun.protocol.imap Es un proveedor de protocolo IMAP que proporciona acceso a un almacén de mensajes IMAP. Interfases: IMAPFolder.ProtocolCommand. Clases: IMAPFolder, IMAPStore, entre otras. Están soportados tanto el protocolo IMAP4 como el IMAP4rev1 (rfc2060). El proveedor de protocolo IMAP puede utilizar el mecanismo de autenticación SASL (rfc2222). Un IMAPStore conectado mantiene un pool de objetos de protocolo IMAP para comunicarse con el servidor IMAP. El IMAPStore creará la conexión AUTHENTICATED inicial y sembrará el pool con esta conexión. Conforme se abren los folders y se requieren nuevos objetos de protocolo IMAP, el IMAPStore los tomará del pool, o los creará si no hay ninguno disponible. Cuando se cierra un fólder, su objeto de protocolo IMAP se regresa al pool de conexión si es que aún no está saturado el pool. Se proporciona un mecanismo para desconectar objetos de protocolo IMAP por conexiones ociosas. Las conexiones ociosas se cierran y se quitan del pool de conexiones. El objeto IMAPStore conectado puede o no mantener un objeto de protocolo IMAP por separado, que proporciona al almacén una conexión dedicada al servidor IMAP. El proveedor de protocolo IMAP soporta las siguientes propiedades, las cuales pueden ser establecidas en el objeto Session de JavaMail. Las propiedades se establecen como cadenas; la columna Tipo de la tabla 4.3 describe cómo se interpreta la cadena. 57/165 CAPÍTULO 4 Nombre Tipo Descripción mail.imap.user String Nombre por default para IMAP. mail.imap.host String El servidor IMAP al que se tiene que conectar. mail.imap.port int El puerto del servidor IMAP al que se tiene que conectar. si el método connect() no especifíca explícitamente uno. El default es el 143. mail.imap.connectiontimeout int El valor en milisegundos del tiempo de desconexión del socket. El valor por default es infinito. mail.imap.appendbuffersize int El tamaño máximo de un mensaje para ponerlo en un buffer de memoria cuando se agrega a un folder IMAP. Si no se establece, o se pone a -1, no hay un máximo y todos los mensajes se ponen en el buffer. Si se pone a 0, no se pueden colocar mensajes en el buffer. Si se pone por ejemplo a 8192, los mensajes de 8K bytes o menos se pueden colocar en el buffer, pero los mensajes mayores no. Utilizar el buffer ahorra tiempo de CPU a expensas del uso de memoria de término corto (short term). Si usualmente se agregan mensajes muy grandes a los buzones IMAP, se desearía establecer este parámetro a un valor moderado (1M o menos). mail.imap.connectionpoolsize int Número máximo de conexiones disponibles en el pool de conexión. El default es 1. mail.imap.connectionpooltimeout int Valor del timeout en milisegundos para las conexiones del pool de conexiones. El default es 45000 (45 segundos). mail.imap.separatestoreconnection boolean Bandera que indica si se debe usar una conexión dedicada al almacén para comandos del almacén. El default es falso. mail.imap.allowreadonlyselect Si se pone a falso, los intentos para abrir un folder como lectura/escritura fallaran si el comando SELECT tiene éxito pero indica que el fólder es de sólo lectura (READ-ONLY). Esto algunas veces indica que el contenido del fólder no se puede cambiar, pero las banderas son por usuario y se pueden cambiar, boolean como puede ser el caso de folders públicos compartidos. Si se pone a verdadero, los intentos de apertura tendran éxito, permitiendo que las banderas se puedan cambiar. El método getMode en el objeto Fólder regresará Folder.READ_ONLY en este caso, aunque el método open especificara Folder.READ_WRITE. El default es falso. mail.imap.auth.login.disable boolean Si es verdadero, evita el uso de un comando no estándar AUTHENTICATE LOGIN. El default es falso. String Dirección local (nombre del host) a la que se tiene que ligar cuando se crea un socket IMAP. Por default se liga a la dirección tomada por la clase Socket. Normalmente no se tiene que establecer, pero es útil cuando se trata de hosts multi-homed (es decir, con múltiples mail.imap.localaddress 58/165 CAPÍTULO 4 tarjetas de red) donde es importante escoger una dirección local en particular a la cual ligarse. mail.imap.localport int Numero de puerto local al cual ligarse cuando se crea un socket IMAP. El default es el número de puerto tomado por la clase Socket. mail.imap.socketFactory.class String Si se establece, especifíca el nombre de una clase que implementa la interfaz javax.net.SocketFactory. Esta clase se utilizará para crear sockets IMAP. Tabla 4.3 Propiedades del proveedor de protocolo IMAP. Estas se establecen en un objeto Session. En general, las aplicaciones no necesitan usar directamente las clases en este paquete, más bien utilizan las clases definidas en javax.mail. Las aplicaciones deben usar el objeto Session y a través del método getStore para obtener un objeto Store apropiado y con él obtener objetos Folder. com.sun.mail.pop3 Un proveedor de protocolo POP3 que proporciona acceso a un almacén de mensajes POP3. Clases: POP3Folder, POP3Message, POP3SSLStore y POP3Store. El proveedor POP3 suministra un objeto Store que contiene un único Folder llamado “INBOX”. Debido a las limitaciones del protocolo POP3, muchas de las capacidades de la API JavaMail como notificación de eventos, administración de folders, administración de banderas, entre otras, no están permitidas. Los métodos correspondientes arrojan la excepción MethodNotSupportedException. POP3 no soporta banderas permanentes (Folder.getPermanentFlags()). Por ejemplo, la bandera Flags.Flag.RECENT nunca se establecerá para mensajes POP3. Le toca a la aplicación determinar cuales mensajes son nuevos en un buzón POP3. Existen varias estrategias para lograr esto, dependiendo de las necesidades de la aplicación y del ambiente: • Una forma simple sería llevar un control del mensaje más nuevo visto por la aplicación. • Otra alternativa sería llevar un registro de los UID’s de todos los mensajes que se han visto. • Otra sería descargar todos los mensajes en un buzón local, para que todos los mensajes en el buzón POP3 sean, por definición, nuevos. Todas las alternativas requieren alguna forma de almacenamiento permanente asociado con el cliente. POP3 no soporta el método Folder.expunge(). Para borrar y expurgar mensajes, se establece la bandera Flags.Flag.DELETED en los mensajes y se cierra el folder utilizando el método Folder.close(trae). No se puede expurgar sin cerrar el folder. POP3 no proporciona una “fecha de recepción”, asi es que el método getReceivedDate regresará un valor null. Se pueden examinar otros encabezados del mensaje (como por ejemplo, los encabezados “Received”) para estimar la fecha de llegada, pero estas técnicas son propensas a error, cuando menos. 59/165 CAPÍTULO 4 El proveedor POP3 soporta las siguientes propiedades, las cuales se pueden establecer en el objeto Session. Las propiedades se establecen siempre como cadenas (véase tabla 4.4), la columna Tipo describe cómo se interpretan. Nombre Tipo Descripción mail.pop3.user String Nombre de usuario por default para POP3. mail.pop3.host String El servidor POP3 al que se tiene que conectar. mail.pop3.port int El puerto del servidor POP3 al que se tiene que conectar, si el método connect() no especifíca explícitamente uno. El default es 110. mail.pop3.connectiontimeout int Valor en milisegundos del timeout de la conexión Socket. El default es un timeout infinito. mail.pop3.timeout int Valor en milisegundos del timeout de la E/S del Socket. El default es infinito. mail.pop3.rsetbeforequit Se envía un comando POP3 RSET cuando se cierra el folder, antes de mandar el comando QUIT. Es útil con servidores POP3 que marcan boolean implícitamente como “borrados” a todos los mensajes que se leen. Esto evita que tales mensajes sean borrados y expurgados a menos que el cliente lo requiera. El default es falso. mail.pop3.message.class String Nombre de clase de una subclase de com.sun.mail.pop3.POP3Message. La subclase se puede utilizar para manejar (por ejemplo) encabezados no estándares de Tipo de Contenido. La subclase debe tener un constructor público de la forma MyPOP3Message(Folder f, int msgno) throws MessagingException. mail.pop3.localaddress String La dirección local (nombre de host) a la cual ligarse cuando se crea un socket POP3. El default es ligarse a la dirección tomada por la clase Socket. Normalmente no necesita establecerse, per es útil en hosts multihomed (es decir, cuando tienen múltiples tarjetas de red), donde es importante escoger una dirección local a la cual amarrarse. mail.pop3.localport int Número de puerto local al cual ligarse cuando se crea un socket POP3. El default es el número de puerto tomado por la clase Socket. mail.pop3.apop.enable Si se establece a verdadero, se utiliza APOP en lugar de USER/PASS para “loggearse” al servidor POP3, si el servidor POP3 soporta APOP. boolean APOP envía un resumen de la contraseña (password) en lugar de una contraseña en texto claro. El default es falso. Tabla 4.4 Propiedades del proveedor de protocolo POP3. Estas se establecen en un objeto Session. Al igual que con IMAP, las aplicaciones no utilizan directamente las clases definidas en este paquete. com.sun.mail.smtp 60/165 CAPÍTULO 4 Un proveedor de protocolo SMTP que proporciona acceso a un servidor SMTP. Clases: SMTPMessage, SMTPSSLTransport y SMTPTransport. Excepciones: SMTPAddressFailedException, SMTPAddressSucceededException SMTPSendFailedException. y Cuando se envía un mensaje, se puede encontrar información detallada de cada dirección que falla en una SMTPAddressFailedException, desencadenada por una SendFailedException. Además, si se establece la propiedad mail.smtp.reportsuccess, se incluirá una SMTPAddressSucceededException por cada dirección exitosa. El proveedor SMTP también soporta ESMTP (rfc 1651). Puede utilizar opcionalmente SMTP Authentication (rfc 2554) empleando los mecanismos LOGIN, PLAIN y DIGEST-MD5 (rfc 2592 y rfc 2831). Para usar autenticación SMTP, se necesita proporcionarle al transporte SMTP el nombre de usuario y la contraseña cuando se conecta al servidor SMTP. Esto se puede hacer de alguna de las siguientes maneras: • Suministrar un objeto Authenticator cuando se crea la sesión de correo (Session), y proporcionar el nombre de usuario y la contraseña al objeto Authenticator. Nota: Se puede establecer la propiedad mail.smtp.user para suministrar un nombre de usuario por default durante la llamada, pero de todas formas se tiene que proporcionar la contraseña explícitamente. Esta forma permite utilizar el método estático Transport.send para enviar mensajes. • Llamar al método Transport.connect explícitamente con los argumentos de nombre de usuario y contraseña. Esta alternativa requiere manejar explícitamene un objeto Transport y emplear el método Transport.sendMessage para enviar el mensaje. Cuando se utiliza la autenticación DIGEST-MD5 se necesita suministrar un campo apropiado, información que posee el administrador del servidor SMTP. SMTP puede pedir opcionalmente Notificaciones de Estado de Entrega (rfc 1891). El proveedor de protocolo SMTP soporta las siguientes propiedades, que se pueden establecer en el objeto Session. Las propiedades se ponen como cadenas (véase tabla 4.5); la columna Tipo describe cómo se interpreta la cadena. Nombre Tipo Descripción mail.smtp.user String Nombre de usuario por default para SMTP. mail.smtp.host String El servidor SMTP al que hay que conectarse. mail.smtp.port int El puerto del servidor SMTP al que se tiene que conectar, si el método connect() no especifíca uno explícitamente. El default es 25. mail.smtp.from String La dirección de correo electrónico para usarse con el comando SMTP MAIL. Establece la dirección de retorno del sobre de correo. El default se 61/165 CAPÍTULO 4 obtiene de los métodos msg.getFrom() o InternetAddress.getLocalAddress(). NOTA: Antes se utilizaba mail.smtp.user para este fin. String Nombre de host local utilizado en el comando SMTP HELO o EHLO. El default se obtiene de InetAddress.getLocalHost().getHostName(). Normalmente no es necesario establecerlo si el JDK y el servicio de nombres están configurados apropiadamente. mail.smtp.localaddress String Dirección local (nombre de host) a la cual ligarse cuando se crea un socket SMTP. El default es la dirección que se toma por la clase Socket. Normalmente no es necesario establecerla, pero es útil con los hosts multihomed (múltiples tarjetas de red) donde es importante escoger una dirección local a la cual amarrarse. mail.smtp.localport int Número de puerto local al cual ligarse cuando se crea un socket SMTP. El default es el número de puerto tomado por la clase Socket. mail.smtp.ehlo Si se establece a falso, no debe intentar firmarse con el comando EHLO. El default es verdadero (true). Normalmente cuando falla el comando EHLO boolean entonces se intenta con el comando HELO; esta propiedad sólo existe para servidores que no fallan o no implementan EHLO apropiadamente. mail.smtp.auth boolean mail.smtp.localhost Si es verdadero, intente autenticar al usuario utilizando el comando AUTH. El default es falso. Si se pone a verdadero, y el servidor soporta la extensión 8BITMIME, las partes de texto que utilizan las codificaciones “quoted-printable” o “base64” mail.smtp.allow8bitmime boolean se convierten para usar codificación “8bit” si siguen las reglas de rfc 2045 para texto 8bit. mail.smtp.sasl.realm String El dominio que se usa con la autenticación DIGEST-MD5. mail.smtp.quitwait Si se pone a verdadero, hace que el transporte espere la respuesta al comando QUIT. Si se pone a falso (el default), se envía el comando QUIT y boolean la conexión se cierra inmediatamente. (NOTA: El default puede cambiar en la próxima versión de este software). mail.smtp.reportsuccess Si se pone a verdadero, hace que el transporte incluya una SMTPAddressSucceededException por cada dirección que es exitosa. boolean Nótese que esto también ocasionará que se dispare una SendFailedException por el método sendMessage de SMTPTransport, aún en el caso de que todas las direcciones fueran correctas y el mensaje fuera enviado exitosamente. Tabla 4.5 Propiedades del proveedor de protocolo SMTP. Estas se establecen en un objeto Session. 62/165 CAPÍTULO 4 4.2.5 COMPONENTES PRINCIPALES DE LA API JavaMail CLASE MESSAGE Es una clase abstracta que define un conjunto de atributos y un contenido para un mensaje de correo. Los atributos especifican información de direccionamiento y definen la estructura del contenido, incluyendo el tipo de contenido. El contenido se representa por un objeto DataHandler que envuelve los datos reales. La clase Message implementa la interfaz Part. Ésta establece los atributos requeridos para definir y dar formato al contenido de datos que se llevan en un objeto Message e interactuar exitosamente con un sistema de correo. La clase Message agrega atributos como “De” (From), “A” (To), “Asunto” (Subject), “Contestar-a” (Reply-to), y algunos otros, necesarios para el enrutamiento de mensajes a través de un sistema de transporte de mensajes. Cuando se encuentra dentro de un folder, un mensaje tiene ciertas banderas asociadas. JavaMail no conoce el tipo de datos ni el formato del contenido del mensaje. Un objeto Message interactúa con su contenido a través de la capa intermedia, llamada JAF (JavaBeans Activation Framework) (véase la figura 4.3). JavaMail también soporta objetos Message Multipart, donde cada Cuerpo de Mensaje (Bodypart) define su propio conjunto de atributos y contenido. ATRIBUTO Content-Type Este atributo especifica el tipo de datos del contenido, de acuerdo a la especificación MIME (RFC 2045). Los componentes de la API JavaMail pueden accesar al contenido a través de los siguientes mecanismos: • • • Como un flujo de entrada. La interfaz Part declara el método getInputStream que regresa un flujo de entrada al contenido. Nótese que las implementaciones de Part deben decodificar cualquier codificación de transferencia propia del sistema de correo, antes de proporcionar el flujo de entrada. Como un objeto DataHandler. La interfaz Part declara el método getDataHandler que regresa un objeto javax.activation.DataHandler que envuelve el contenido. El objeto DataHandler permite a los clientes descubrir operaciones disponibles para aplicar al contenido, e instanciar el componente adecuado para realizar esas operaciones. Como un objeto en el lenguaje de programación Java. La interfaz Part declara el método getContent, que regresa el contenido como un objeto en el lenguaje de programación Java. El tipo del objeto depende del tipo de datos del contenido. Si el contenido es multipart, el método getContent regresa un objeto Multipart, o un objeto de una subclase Multipart. El método getContent regresa un flujo de entrada para tipos de contenido desconocidos. Nótese que el método getContent utiliza internamente el DataHandler para obtener la forma nativa. El método setDataHandler(DataHandler) especifica el contenido para un nuevo objeto Part, como parte de la creación de un nuevo mensaje. La interfaz Part también proporciona algunos métodos convenientes para establecer los tipos de contenido más comunes. 63/165 CAPÍTULO 4 La interfaz Part proporciona el método writeTo que escribe su flujo de bytes de forma correo-seguro adecuado para su transmisión. Este flujo de bytes es típicamente un agregado a los atributos de Part y al flujo de bytes de su contenido. ALMACENAMIENTO Y RECUPERACIÓN DE MENSAJES Los mensajes se guardan en objetos Folders, los cuales también pueden contener subfolders, dando lugar a una jerarquía del tipo árbol. La clase Folder declara métodos para traer, agregar, copiar y guardar mensajes. También puede enviar eventos a componentes declarados como escuchas de eventos (event listeners). La clase Store define una base de datos que contiene una jerarquía de folders junto con sus mensajes. También especifica el protocolo de acceso (IMAP4, POP3, entre otros) para entrar en los folders y recuperar los mensajes. COMPOSICIÓN Y TRANSPORTE DE MENSAJES Un cliente crea un mensaje instanciando una subclase Message apropiada. Establece atributos como las direcciones de los destinatarios y el Asunto, e inserta el contenido en un objeto Message. Finalmente, envía el mensaje invocando al método Transport.send. La clase Transport modela al agente de transporte que rutea un mensaje hasta su dirección destino. Proporciona métodos que envían un mensaje a una lista de destinatarios. Cuando se invoca el método Transport.send con un objeto Message, se identifica el transporte adecuado basado en sus direcciones destino. CLASE SESSION Define propiedades de correo, globales o por usuario, que a su vez definen la interfaz entre un cliente con habilidades para enviar correo y la red. Los componentes de sistema de JavaMail utilizan el objeto Session para establecer y obtener propiedades específicas. Esta clase también proporciona, por default, un objeto session autenticado que las aplicaciones de escritorio pueden compartir. 4.3 La Interfaz de Programación de Aplicaciones JDBC La API JDBC (Conectividad a Base de Datos Java, Java DataBase Connectivity) permite accesar virtualmente cualquier fuente de datos tabular desde una aplicación Java. Además de permitir el acceso a bases de datos SQL, con JDBC es posible accesar a otras fuentes de datos tabulares, como hojas de cálculo o archivos planos. La JDBC define una API de bajo nivel, diseñada para soportar funcionalidad SQL básica, independiente de cualquier implementación SQL específica. Esto significa que se enfoca en ejecutar comandos SQL puros y recuperar sus resultados. La API JDBC 2.0 incluye dos paquetes: java.sql, conocido como la JDBC 2.0 core API; y javax.sql, conocido como la JDBC Standard Extension. En conjunto, contienen todas las clases necesarias para desarrollar aplicaciones de bases de datos utilizando Java. JDBC está disponible en cualquier plataforma Java debido a que forma parte del núcleo (core) del lenguaje. 64/165 CAPÍTULO 4 Fig.4.3 Jerarquía de clases de JavaMail. La principal fortaleza de JDBC es que está diseñada para trabajar exactamente en la misma forma con cualquier base de datos relacional. Esto quiere decir que puede escribirse un sólo programa para crear una interfaz SQL, para virtualmente cualquier base de datos relacional. Las tres funciones principales de JDBC son: ¾ Establecer una conexión con una base de datos u otra fuente de datos tabular. ¾ Enviar comandos SQL a la base de datos. ¾ Procesar los resultados. Las interfaces clave en la JDBC Core API son: ¾ java.sql.DriverManager. Además de cargar los controladores (drivers) JDBC, el DriverManager es responsable de regresar una conexión al controlador apropiado. Cuando se llama a getConnection( ), el DriverManager intenta localizar un controlador adecuado para la URL proporcionada en la llamada, interrogando a los controladores registrados. ¾ java.sql.Driver. El objeto Driver implementa el método acceptsURL(String url), confirmando su habilidad para conectar el DriverManager a la URL. 65/165 CAPÍTULO 4 ¾ java.sql.Connection. El objeto Connection proporciona la conexión entre la API JDBC y el sistema manejador de base de datos que especifica la URL. Una conexión representa una sesión con una base de datos específica. ¾ java.sql.Statement. El objeto Statement actúa como un contenedor para ejecutar un enunciado SQL en un objeto Connection dado. ¾ java.sql.ResultSet. El objeto ResultSet controla el acceso a los resultados de un objeto Statement dado, en una estructura que puede recorrerse moviendo el cursor y desde la cual se pueden accesar los datos utilizando una familia de métodos getter. Los principales pasos para accesar una base de datos y recuperar los datos de un objeto ResultSet, utilizando JDBC son: ¾ ¾ ¾ ¾ ¾ Cargar un controlador (driver) JDBC. Obtener una conexión a la base de datos. Crear un objeto statement. Ejecutar una consulta SQL. Recuperar los datos del objeto ResultSet. El objeto ResultSet proporciona los métodos necesarios para navegar a través de los resultados y recuperar los campos individuales de la base de datos, utilizando los métodos apropiados para sus respectivos tipos. 4.3.1 CONTROLADORES (DRIVERS) PARA JDBC JDBC requiere un controlador para cada base de datos, para conectarse con bases de datos individuales. Los controladores para JDBC son de cuatro tipos [24]: ¾ Tipos 1 y 2 son para los programadores de aplicaciones. ¾ Tipos 3 y 4 son utilizados por los fabricantes de middleware o bases de datos. A continuación se analizan los diferentes tipos de controladores: ¾ Tipo 1: bridge JDBC-ODBC, más el controlador ODBC El producto bridge JDBC-ODBC proporciona acceso JDBC a través de controladores ODBC. Requiere que los controladores ODBC estén instalados y configurados en el cliente. Las llamadas a ODBC se realizan fuera del entorno de Java. ODBC (Conectividad Abierta a Base de Datos, Open Database Connectivity) precede a JDBC y es ampliamente utilizado para conectar a bases de datos en ambientes “no Java”. ODBC es probablemente la interfaz de programación más ampliamente utilizada para accesar bases de datos relacionales. Las principales ventajas del bridge JDBC-ODBC son: Ofrece la posibilidad de conectarse a casi todas las bases de datos, en casi todas las plataformas. 66/165 CAPÍTULO 4 Puede ser la única forma de accesar a algunas bases de datos y aplicaciones de bajo nivel. Sus principales desventajas son: Los controladores ODBC deben cargarse también en la máquina destino. La traducción entre JDBC y ODBC afecta el desempeño. ¾ Tipo 2: controlador parcialmente Java API nativa Los controladores tipo 2 utilizan una “API nativa” para comunicarse con un sistema de base de datos. Por ejemplo, la API nativa de Sybase es Open Client, y el de Oracle es OCI. Se utilizan métodos nativos Java para invocar funciones API que realizan operaciones en la base de datos. Una gran ventaja de los controladores tipo 2 es que son generalmente más rápidos que los controladores tipo 1. Las desventajas más notables son: Los controladores tipo 2 requieren código nativo en la máquina destino. La Interfaz Nativa de Java, JNI (Java Native Interface), de la cual dependen, no es implementada consistentemente entre diferentes fabricantes de la Máquina Virtual de Java, JVM (Java Virtual Machine). Máquina cliente Servidor Controlador ODBC Protocolo propietario DBMS Aplicación Java Puente JDBC/ ODBC Fig. 4.4 Controlador JDBC Tipo 1 67/165 CAPÍTULO 4 Máquina cliente Servidor Librería nativa DBMS Protocolo propietario DBMS Aplicación Java Controlador JDBC Fig. 4.5 Controlador JDBC Tipo 2 ¾ Tipo 3: controlador “Java puro” de protocolo de red El controlador tipo 3 traduce llamadas JDBC en un protocolo de red independiente del Sistema Manejador de Base de datos, DBMS (DataBase Management System) que después es traducido por un servidor a un protocolo DBMS. El código cliente se escribe completamente en Java, por lo que se ejecutará en cualquier plataforma de hardware. Las ventajas de los controladores tipo 3 son: No requieren ningún código binario nativo en el cliente. No necesitan instalación de cliente. Soportan varias opciones de red, tales como HTTP tunneling. La mayor desventaja es que pueden ser dificiles de configurar, ya que la arquitectura se complica por la interfaz de red. ¾ Tipo 4: controlador Java puro de protocolo nativo El controlador tipo 4 es un controlador de protocolo nativo, 100% Java. Esto permite llamadas directas de un cliente Java a un servidor DBMS. Debido a que el controlador tipo 4 está escrito 100% en Java, no requiere configuración en la máquina cliente, únicamente hay que indicarle a la aplicación dónde encontrar el controlador. Muchos de estos protocolos son propietarios, es decir que los mismos fabricantes de las bases de datos los proporcionan. 68/165 CAPÍTULO 4 Máquina cliente Servidor Aplicación Java Controlador JDBC Protocolo independiente DBMS Servidor JDBC/ Gateway DBMS Fig. 4.6 Controlador JDBC Tipo 3 Máquina cliente Servidor Aplicación Java DBMS Controlador JDBC Protocolo específico DBMS Fig. 4.7 Controlador JDBC Tipo 4 69/165 CAPÍTULO 4 4.3.2 URL’s PARA BASES DE DATOS Un Localizador Uniforme de Recursos, URL (Uniform Resource Locator) es un identificador para localizar un recurso en Internet. Se puede decir que es como una dirección. Un URL JDBC es una forma flexible de identificar una base de datos, para que el controlador apropiado la reconozca y establezca una conexión con ella. Los URL JDBC permiten a distintos controladores utilizar diferentes esquemas para nombrar a las bases de datos. La sintáxis estándar para los URL’s JDBC es la siguiente: jdbc:<subprotocolo>:<subnombre> dónde: ¾ jdbc- Es el protocolo. El protocolo en un URL JDBC es siempre jdbc. ¾ <subprotocolo>- Es el nombre del controlador o mecanismo de conectividad, el cual puede ser soportado por uno o más controladores. ¾ <subnombre>- Un identificador único para la base de datos. 4.3.3 CLASE STATEMENT Un objeto Statement se utiliza para ejecutar una línea SQL estática y obtener los resultados que produce. El objeto Statement define tres métodos para ejecutar líneas SQL y que producen diferentes tipos de resultados: executeUpdate(String sql):Ejecuta una línea SQL INSERT, UPDATE o DELETE, que regresa ya sea la cantidad de renglones afectados o cero. executeQuery(String sql): Ejecuta una línea SQL que regresa un único objeto ResultSet. execute(String sql): Ejecuta una línea SQL que puede regresar múltiples resultados. 4.3.4 CLASE RESULTSET Un objeto ResultSet es el conjunto de datos que regresa una consulta SQL, y consiste de todos los renglones que satisfacen las condiciones de esa consulta y que son accesados a través de los métodos propios del objeto ResultSet. Un objeto ResultSet está estructurado como una tabla, con los encabezados y datos de columnas en el orden en que se especificaron en el objeto Statement, satisfaciendo las condiciones de la consulta (query). Por ejemplo, si la consulta fuera la siguiente: SELECT Name, Description, Qty, Cost FROM Stock El resultado se vería así (véase tabla 4.6): 70/165 CAPÍTULO 4 Name Precision Windsor Mendoza Description microscopios portaobjetos telescopios Qty 3 50 20 Cost 800.00 50.00 450.00 Tabla 4.6 Resultado del comando SELECT sobre una tabla de una base de datos. Un objeto ResultSet mantiene un cursor, que apunta al renglón de datos accesible a través de los métodos getter del ResultSet. Cada vez que se llama al método ResultSet.next( ), el cursor se mueve un renglón hacia abajo. 4.3.5 Métodos getter del ResultSet Los datos se recuperan del objeto ResultSet, utilizando los métodos getter que hacen referencia a la columna que contiene los datos. Estos métodos proporcionan la obtención de tipos específicos de datos, de los valores de columnas del renglón actual. Dentro de un renglón, se pueden recuperar los valores de columnas en cualquier orden. Cada método getter del objeto ResultSet tiene dos variantes: una hace referencia a la columna por nombre y otra lo hace por número de columna. A continuación se presentan los métodos que utilizan el nombre como referencia (véase tabla 4.7). Tipo de datos BigDecimal boolean byte byte[ ] double float int java.io.InputStream java.io.InputStream java.io.InputStream java.sql.Date java.sql.Time java.sql.Timestamp long Object short String Método getBigDecimal(String columnName, int scale) getBoolean(String columnName) getByte(String columnName) getBytes(String columnName) getDouble(String columnName) getFloat(String columnName) getInt(String columnName) getAsciiStream(String columnName) getUnicodeStream(String columnName) getBinaryStream(String columnName) getDate(String columnName) getTime(String columnName) getTimestamp(String columnName) getLong(String columnName) getObject(String columnName) getShort(String columnName) getString(String columnName) Tabla 4.7 Métodos “getter”. 71/165 CAPÍTULO 4 Los datos se pueden recuperar, utilizando indistintamente el nombre o el número de la columna. 4.3.6 RECUPERACIÓN DE DATOS UTILIZANDO CONSULTAS SQL Una de las funciones más importantes de cualquier aplicación de base de datos, es encontrar los registros en las tablas de una base de datos y regresarlos en la forma deseada. El proceso de encontrar y regresar los registros formateados se conoce como consultar la base de datos. EL COMANDO SELECT El comando SELECT es el corazón de una consulta SQL. Además de utilizarse para regresar datos en una consulta, se puede utilizar en combinación con otros comandos SQL para seleccionar datos para varias operaciones, como modificar registros específicos con el comando UPDATE. Un comando SELECT básico sería asi: SELECT columnName1, columnName2, … FROM tableName; es decir, los nombres de las columnas que se quieren recuperar, seguidas del nombre de la tabla donde se encuentran. LA CLÁUSULA WHERE Esta cláusula permite recuperar registros que cumplen con un criterio. Se utiliza de la siguiente forma: SELECT * FROM nombre_tabla WHERE nombre_campo=’valor’; El resultado de esta consulta sería todos (*, wildcard) los campos de nombre_tabla, en donde nombre_campo sea igual a ‘valor’. 4.4 DESEMPEÑO DE UNA APLICACIÓN EN JAVA Existen tres recursos que limitan todas las aplicaciones: • • • La velocidad y la disponibilidad del CPU La memoria del sistema La E/S del disco (de la red) Cuando la aplicación utiliza demasiados recursos del CPU, puede deberse al código que probablemente esta produciendo cuellos de botella, algoritmos ineficientes, demasiados objetos de corta existencia (la creación de objetos y la recolección de basura son operaciones que consumen mucha potencia de CPU), entre otras razones. 72/165 CAPÍTULO 4 En el caso de aplicaciones que consumen mucha memoria del sistema, puede deberse a secciones de paginación dentro y fuera de la memoria principal. El problema puede ser ocasionado por demasiados objetos, algunos objetos de gran tamaño, que se mantienen erróneamente en memoria; demasiados arrays grandes (utilizados frecuentemente en aplicaciones con buffers); o por el diseño de la aplicación. El acceso a datos externos o escribir en el disco también puede alentar una aplicación. Por ejemplo, existen operaciones que se pueden hacer simultáneamente a través de la característica de multithreading, ahorrando tiempo en la red. El desempeño de una aplicación se debe especificar tomando en cuenta tantos aspectos del sistema como sea posible, por ejemplo: • Los tiempos de respuesta dependiendo del número de usuarios (si es el caso) • La capacidad de procesamiento (throughput) total del sistema (por ejemplo, número de transacciones por minuto del sistema como un todo, o tiempos de respuesta en una red saturada, si es el caso) • El máximo número de usuarios, datos, archivos, tamaño de archivos, objetos, entre otros, que la aplicación soporta • Cualquier degradación aceptable y esperada en el desempeño entre mínima, promedio y valores extremos de recursos soportados. QUÉ SE DEBE MEDIR La medición más importante es la del tiempo real, ya que es la que más aprecia el usuario. Otras mediciones dependen del sistema o de la aplicación. Algunos ejemplos son: • Tiempo de CPU (El tiempo asignado en el CPU para un procedimiento particular). • El número de procesos de ejecución esperando al CPU (esto da una idea de las disputas por recursos del CPU). • Paginación de procesos. • Tamaños de memoria. • Capacidad de procesamiento del disco. • Tiempos de escaneo del disco. • Tráfico, capacidad de procesamiento y latencia en la red. • Tasas de transacción. • Otros valores del sistema. Sin embargo, Java no proporciona mecanismos para medir estos valores directamente, y el medirlos requiere al menos algún conocimiento del sistema, y usualmente algún conocimiento de la aplicación (por ejemplo, qué es una transacción para la aplicación). MEDICIÓN DE TIEMPOS Cuando se trata de tiempos, se tiene que tener en cuenta que las diferentes herramientas para medirlos pueden alterar el desempeño de las aplicaciones de diferentes formas. Cualquier “perfilador” (profiler) desacelera la aplicación que está perfilando. El grado de desaceleración puede variar desde un pequeño porcentaje hasta varios cientos por ciento. La única forma confiable de determinar el tiempo que toma cada parte de la 73/165 CAPÍTULO 4 aplicación es utilizar el método System.currentTimeMillis(). Este método es rápido y no tiene efecto en la temporización de la aplicación (siempre y cuando no se midan demasiados intervalos o intervalos ridículamente cortos). Otra variación en la temporización de una aplicación viene del sistema operativo subyacente. El sistema operativo puede asignar diferentes prioridades para diferentes procesos, y estas prioridades determinan la importancia que el sistema operativo aplica a un proceso en particular. Esto a su vez, afecta la cantidad de tiempo de CPU asignado a un proceso en relación a otros. Aún más, estas prioridades pueden cambiar durante la vida del proceso. Es común que los sistemas operativos de servidor gradualmente decrementen la prioridad de un proceso conforme concluye su ciclo de vida. Esto significa que el proceso tendrá periodos cada vez más cortos de CPU asignados antes de que se regrese a la cola de ejecución. MONITOREO DE MEMORIA El JDK proporciona dos métodos para monitorear la cantidad de memoria utilizada por el sistema de ejecución. Los métodos son freeMemory( ) y totalMemory( ) en la clase java.lang.Runtime totalMemory( ) regresa un dato tipo long, el cual es el número de bytes asignados actualmente al sistema de ejecución para un proceso de la JVM en particular. Dentro de esta asignación de memoria, la JVM administra sus objetos y datos. Algo de esta memoria asignada se mantiene en reserva para crear nuevos objetos. Cuando la memoria actualmente asignada se llena y el colector de basura ya no puede asignar suficiente memoria, la JVM le pide al sistema operativo que le asigne más memoria. Si el sistema no puede asignar más memoria, se envía un error de OutOfMemoryError. La memoria total puede subir y bajar, algunas rutinas de Java pueden regresar secciones de memoria no utilizadas al sistema cuando aún se encuentran corriendo. freeMemory( ) regresa un dato tipo long, el cual es el número de bytes disponibles para que la JVM cree nuevos objetos de la sección de memoria que controla. La memoria libre se incrementa cuando la recolección de basura reclama exitosamente el espacio utilizado por objetos muertos, y también se incrementa cuando el entorno de ejecución de Java pide más memoria al sistema. La memoria libre se reduce cada que vez que se crea un objeto, y también cuando el entorno de ejecución regresa memoria al sistema. Puede ser útil monitorear la utilización de memoria mientras está corriendo una aplicación, puede darse una idea de los puntos críticos de la aplicación. Pueden existir puntos donde disminuye dramáticamente la memoria libre. Esto puede ocurrir cuando se crean continuamente objetos temporales para alguna subrutina o cuando se manipulan frecuentemente elementos gráficos. EL DESEMPEÑO EN COMUNICACIONES CLIENTE/SERVIDOR Los factores más importantes que se tienen que identificar son el número de transferencias de datos de entrada y salida. Estos elementos son los que más afectan el desempeño. Generalmente, si la cantidad de datos que se transfieren es menor a 1 KB, el factor que limita el desempeño es el número de transferencias. Si la cantidad de datos que se transfieren es mayor a una tercera parte de la capacidad de la red, el factor que limita el desempeño es la cantidad de datos. Cualquiera de estos factores puede afectar el desempeño, aunque el más frecuente es el número de transferencias. 74/165 CAPÍTULO 4 Existen varias herramientas genéricas disponibles para monitorear el tráfico en la red, todas dirigidas a administradores de sistemas y de redes (snoop, netstat y ndd de Solaris son algunos ejemplos de herramientas. tcpdump y ethereal son herramientas freeware para monitoreo de comunicaciones). Existen funciones de manejo de bitácoras de nivel de sistema y de red. La más utilizada es netstat, la cual es una utilidad de línea de comandos. Se ejecuta normalmente en un shell de Unix o en una ventana de DOS en Windows. Utilizando netstat con la opción –s obtenemos el conjunto de las estructuras de red más comunes (es un acumulado de las lecturas desde que se inició la máquina). Se puede dar una idea del tráfico de red y la carga extra originada por la aplicación, filtrando, anotando las diferencias y graficando los distintos datos que se obtienen con esta herramienta. 4.5 ACCESS DBMS La información de una organización se guarda en un depósito conocido como Base de Datos, y al programa que manipula dicha información se le denomina Manejador de Base de Datos, DBMS (DataBase Management System) y que en nuestro caso es Access, de la empresa Microsoft [14]. Una base de datos es una colección de datos relacionados que tienen un fin común. Esta colección posee una estructura que permite la manipulación de los datos. Microsoft Access es un manejador de base de datos relacional, esto es, un sistema que extrae información de una base de datos que está construida por tablas relacionadas. Se considera una Base de Datos Relacional porque sus tablas son matrices planas, que están constituidas por campos y registros. 4.5.1 SISTEMA MANEJADOR DE BASE DE DATOS Un Sistema Manejador de Base de Datos, DBMS (DataBase Management System) es un intermediario, puesto que interpreta y procesa las peticiones del usuario para recobrar información de la base. Las preguntas o peticiones del usuario pueden tener distintas formas, pueden teclearse directamente desde la terminal, o codificarse en lenguajes de alto nivel (como Java). En la mayoría de los casos, una petición de consultas tendrá que atravesar varias capas de software en el DBMS y el sistema operativo, antes de que se pueda acceder a la base de datos física. El DBMS responde a una pregunta llamando a los subprogramas apropiados, cada uno de los cuales realizará una función especial para interpretar la petición o localizar los datos deseados en la base y presentarlos en el orden solicitado. Así, el DBMS ayuda a los usuarios a no tener que programar tareas tales como la organización, el almacenamiento y el acceso a los datos. OBJETIVOS DE UN DBMS • • Crear y organizar la base de datos. Establecer y mantener las trayectorias de acceso a la base de datos, de tal manera que los datos en cualquier parte de la base de datos se puedan acceder rápidamente. Evitar la redundancia. Redundancia es cuando la misma información se repite en diferentes archivos de la base de datos. 75/165 CAPÍTULO 4 • Eliminar la inconsistencia de los datos. Surge como resultado de la redundancia, al haber datos duplicados existe el riesgo de no actualizar todos los archivos. • Seguridad de los datos. Protección de los datos contra el acceso accidental o intencional, y contra su indebida destrucción o alteración. • Integridad de los datos. Son las medidas de seguridad usadas para mantener correctos los datos en la base de datos. Hay diferentes maneras de asegurar la integridad de los datos: 1. Validación de los datos. El contenido de cada elemento de entrada debe coincidir con el tipo de datos descrito en el esquema, de otra manera, el DBMS mandará el mensaje apropiado de error. 2. Validación del valor de los datos. El contenido de un campo de entrada puede validarse para cierto rango de valores. 3. Validación de valores de claves primarias y secundarias. o El DBMS debe asegurar que el valor de la clave primaria sea único y no nulo (vacío o no definido). o En el caso de llaves foráneas, el usuario puede especificar si se permiten valores duplicados de tal llave. 4. Integridad referencial. o Controla que no existan registros hijos si no hay un registro padre correspondiente. o La eliminación y actualización de los registros relacionados se efectuará en cascada. 4.5.2 ARQUITECTURA DE ACCESS Cualquier herramienta que forme parte de Access es llamada objeto. Los principales objetos que permiten el manejo integral de la información se presentan en la tabla 4.8. OBJETO Tablas CONCEPTO Se definen y usan para almacenar información. Cada tabla contiene información acerca de un tema en particular. Las tablas están representadas por columnas y registros. Consultas Responden a una serie de preguntas acerca de datos almacenados en tablas. Formas Utilizadas para dar mejor presentación a información proveniente de tablas o consultas. Es un objeto que se usa para ver y editar información de la base de datos, o trabajar registro a registro. Reportes Diseñados para dar formato, calcular, imprimir y agrupar información de la base de datos. Macro Compuesto por un conjunto de acciones usadas para automatizar tareas comunes, como abrir una forma. Módulo de programación Contiene una colección de declaraciones, instrucciones y procedimientos de Access Basic. Tabla 4.8 Herramientas de Access. 76/165 CAPÍTULO 4 PASOS PARA EL DISEÑO DE UNA BASE DE DATOS 1. 2. 3. 4. 5. Determinar el propósito de la base de datos. Precisar las tablas (Entidades). Distinguir los campos (Atributos). Definir las relaciones entre las tablas. Depurar el diseño. TABLAS Una tabla es un objeto que almacena información acerca de un tema en particular. Los datos en una tabla son presentados en un formato matricial, con columnas llamadas campos y renglones llamados registros. Un campo es una categoría de información, esto es, diferentes valores asociados a una cualidad, en tanto que registro es una colección de campos. Cada registro en una tabla, contiene el mismo conjunto de campos y cada campo contiene el mismo tipo de información de cada registro. LLAVES PRIMARIAS Al diseñar las tablas es necesario especificar un identificador exclusivo de registros, mismo que se denomina llave primaria, y consiste en uno o más campos que identifican a cada registro almacenado en la tabla. Las llaves primarias ayudaran en los siguientes casos: • A no repetir registros con el mismo valor de la llave primaria de otros registros ya existentes. • Acelerar las consultas, creando automáticamente un índice para las llaves primarias. • Establecer relaciones entre tablas. LLAVES SECUNDARIAS O FORÁNEAS Se utilizan para establecer relaciones entre entidades. Tienen las siguientes características: • Son llaves primarias de otra entidad. • Aceptan valores nulos. • Pueden modificarse. • Una entidad puede tener múltiples llaves secundarias. • Aceptan valores duplicados. RELACIONES El conjunto de formas en que distintas entidades se relacionan entre sí, se describe como asociaciones o relaciones. Existen tres tipos de relaciones de entidades: uno a muchos, uno a uno y muchos a muchos. 77/165 CAPÍTULO 4 UNO A MUCHOS Se dice que una relación entre entidades es uno a muchos, si una ocurrencia de una entidad está relacionada con diversas ocurrencias de otra entidad. En este tipo de relaciones, la llave primaria de la entidad 1 (entidad padre) pasa como llave foránea en la entidad 2 (entidad hijo), siendo ésta un atributo o campo más. UNO A UNO Con una relación uno a uno, la ocurrencia de un entidad se puede enlazar a sólo una ocurrencia de otra. La relación uno a uno es simétrica, por lo cual la llave primaria de la entidad 1 puede pasar como foránea a la entidad 2 o en sentido contrario, la llave primaria de la entidad 2 pasa como llave foránea a la entidad 1. MUCHOS A MUCHOS Una relación muchos a muchos entre entidades sucede cuando se puede asociar una ocurrencia en una entidad, con muchas ocurrencias en la otra entidad, o viceversa. Aunque la relación muchos a muchos no se puede implantar directamente entre dos grupos de entidades, se puede reducir a dos relaciones uno a muchos, insertando una tabla conectora o asociativa, compuesta por las llaves primarias de las dos tablas que formarán la llave primaria de dicha tabla asociativa. CONSULTAS Una consulta es la respuesta a una serie de preguntas acerca de datos almacenados en una o más tablas. Las consultas sirven para: • Hacer cambios a información contenida en tablas. • Como recurso para elaborar formas, reportes o incluso otras consultas. • Obtener información de diferentes tablas, que a su vez están relacionadas. • Realizar cálculos. 78/165 CAPÍTULO 4 4.5 RESUMEN CAPÍTULO 4 Hoy en día cuando se piensa en un lenguaje para programar aplicaciones para Internet se piensa en Java. Este lenguaje genera un código pequeño pero a la vez robusto, que se puede ejecutar en una variedad de plataformas sin necesidad de modificarlo o recompilarlo. El único requisito para ejecutar estos programas es contar con el intérprete de Java adecuado para cada sistema. Los programas escritos en Java corren dentro de una “jaula de protección” conocida como la Máquina Virtual de Java. El kit de desarrollo de Java 2 se obtiene gratis de la página web de Sun Microsystems: www.sun.com. El lenguaje Java cuenta con diferentes bibliotecas de clases listas para usarse y que sirven para resolver diferentes tipos de problemas. A estas bibliotecas de clases se les conoce como Interfaz de Programación de Aplicaciones (API). Existe una API diseñada para resolver necesidades de mensajería y se conoce como JavaMail. Esta biblioteca tiene soporte únicamente para el protocolo de transporte SMTP y para los protocolos de acceso POP3 e IMAP4. Existen algunos tutoriales para aprender a utilizar las clases, y se dispone de una lista de correo a la que se puede suscribir y estar al tanto de los diversos problemas a los que se enfrentan los programadores. Para resolver la parte de acceso y manipulación de la base de datos del robot de correo, se empleó una API conocida como JDBC (Conectividad a Base de Datos Java). Esta biblioteca viene incluida en el kit de desarrollo de Java (SDK1.4.1_03) y dentro de ella existe un controlador JDBC-ODBC que funciona para interactuar con el manejador de base de datos Microsoft Access. A través de esta biblioteca se emplean sentencias SQL para interrogar a la base de datos y obtener la información requerida por el usuario. Un Sistema Manejador de Base de Datos (DBMS) es un intermediario entre la base de datos física y las peticiones del usuario. Se encarga de crear la base de datos, evitar redundancia, eliminar la inconsistencia de los datos, entre otras cosas. Para nuestro caso, se escogio el DBMS ACCESS de Microsoft. Es un manejador de base de datos relacional y se eligió porque es adecuado para bases de datos de pocos registros y tiene una interfaz de gráfica de usuario (GUI) muy amigable que permite crear las tablas y las relaciones de manera rápida y sencilla. 79/165 CAPÍTULO 5 CAPÍTULO 5 DISEÑO Y CONSTRUCCIÓN DEL ROBOT DE CORREO 5.1 DESCRIPCION GENERAL DEL AMBIENTE DE EXPERIMENTACIÓN Durante la fase de prueba del robot de correo electrónico, se trabajó básicamente sobre dos distintas plataformas: • Conexión vía marcación (Dial-up) al servidor de correo del ISP. • Conexión via Red de Área Local, LAN (Local Area Network) a un servidor de correo local. 5.1.1 CONEXIÓN VÍA MARCACIÓN (DIAL-UP) AL SERVIDOR DE CORREO DEL ISP Para este caso, se contrató una cuenta de acceso a Internet, a través de un Proveedor de Servicio de Internet, ISP (Internet Service Provider), en la modalidad de Marcación por línea telefónica (Dial-Up) (véase figura 5.1). El ISP otorga también una cuenta de correo electrónico, la cual puede consultarse ya sea vía Web, o a través de un agente de correo electrónico, tal como Microsoft Outlook Express. Tanto la cuenta de acceso a Internet, como la cuenta de correo electrónico, requieren de un usuario (user) y una contraseña (password) para poder acceder a ellas. El ISP asignó como USER de las dos cuentas la cadena infouam_azc. HARDWARE UTILIZADO • • • • • • • Laptop Módem interno PCMCIA Línea telefónica Red Telefónica Pública Conmutada Servidor de acceso del ISP Red LAN del ISP Servidor de correo del ISP 80/165 CAPÍTULO 5 Fig. 5.1 Acceso a un Servidor de correo remoto a través de una conexión por marcación (Dial-up). 5.1.2 CONEXIÓN VÍA LAN A UN SERVIDOR DE CORREO LOCAL Esta es una conexión que proporciona un velocidad mucho mayor (10 Mbps) hacia el servidor de correo. Cuando se trata de una transmisión de correo a un usuario de la misma red LAN, la entrega de correo es casi inmediata pues el correo no tiene que viajar fuera de esta red. Cuando el destinatario del correo se encuentra ubicado en otra red, el transmisor SMTP local se conecta con otro receptor SMTP externo a través de algún ruteador de la LAN. Cuando cualquier usuario o el robot de correo desean consultar su correo, lo hacen a través de una trama Ethernet que llega hasta el servidor de correo local y el cual les permite recuperar sus mensajes. Además de los protocolos que se ilustran en la figura 5.2, también tenemos por supuesto a otros protocolos de la pila TCP/IP que intervienen en la entrega de paquetes. Por ejemplo, el protocolo ARP aparece cuando el host donde está ubicado el programa de robot de correo electrónico desea contactar al servidor de correo para consultar su buzón. El host del robot debe enviar una solicitud ARP a toda la red LAN para obtener la dirección física del servidor de correo, y de esta forma hacer posible la entrega de cualquier tipo tramas dirigidas a él. HARDWARE UTILIZADO. • • • • • Hub. PC para el servidor de correo. Laptop donde reside el robot de correo. PC con un cliente de correo. Ruteador para la salida a Internet. 81/165 CAPÍTULO 5 Fig. 5.2 Conexión a un servidor de correo a través de una LAN. 5.2 CÓMO FUNCIONA EL ROBOT DE CORREO ELECTRÓNICO El robot reemplaza la función del (programa) cliente de correo (Outlook), pero en lugar de permitir que un usuario humano introduzca la contestación a través del teclado, el robot toma la información requerida de la base de datos de “respuestas” (véase la figura 5.3). El robot de correo está constantemente monitoreando el folder principal (INBOX) de la cuenta de correo que se le asignó. En cuanto encuentra que ha llegado un nuevo correo, lo abre y revisa el campo “Asunto” y el campo “cuerpo” en busca de palabras clave, definidas previamente en su sistema. Si encuentra la ocurrencia de alguna de estas palabras, entonces toma de su base de datos alguna respuesta adecuada para el correo del usuario y manda el correo de contestación. Con este sistema se tiene respuesta automática a los correos las 24 horas del día, todos los días del año. ESTABLECER EL AMBIENTE PARA QUE FUNCIONE EL ROBOT Después de copiar todos los archivos del robot en una carpeta, se tiene que modificar la variable de ambiente “path” para indicarle al sistema donde están. Para modificar la variable path se ingresa en la carpeta del panel de control, luego en la carpeta de Rendimiento y mantenimiento, opción de variables de entorno (Windows XP) (véase fig. 5.4). 82/165 CAPÍTULO 5 Base de datos de respuestas Envío del correo del robot Interfaz de usuario del robot SMTP Robot de correo Área spool de salida de correo Cliente (transferencia de correos) Lectura del correo del robot POP3 Buzones para correo entrante Servidor (para aceptar correo) Conexión TCP para salida de correo SMTP Conexión TCP para correo entrante SMTP Fig.5.3 Componentes de un sistema de correo electrónico que hace uso de un robot de correo. Fig. 5.4 Modificando la variable del sistema “Path”. 5.3 MÓDULO PARA LEER LOS CORREOS Las clases de JavaMail que se utilizan son las siguientes: • Session Define una sesión de correo básica. 83/165 CAPÍTULO 5 • • • Message Store Folder Para manejar contenido diverso se utiliza la clase javax.mail.internet.MimeMessage. Se conecta al “almacén” de correos para recibir los mensajes. Un almacén de correo contiene folders con mensajes que pueden ser descargados y leídos. El objeto Session utiliza un objeto java.util.Properties para contener información del nivel de aplicación, tal como el nombre del servidor de correo, el usuario y la contraseña. El objeto Message representa el mensaje de correo. Entre las propiedades del objeto se tienen el Asunto (Subject), el Contenido (Content), y las direcciones (Addresses) del remitente y el destinatario. Las direcciones de correo se implementan, utilizando un objeto Address. Normalmente se utiliza la clase javax.mail.internet.InternetAddress. Los pasos necesarios para poder leer un correo son los siguientes: • • • • • • Establecer una sesión de correo electrónico por default. Obtener un objeto POP3 message store. Conectarse al objecto store (almacén) utilizando el nombre del servidor, el usuario y la contraseña. Obtener el folder por default. Obtener el INBOX. Abrir el INBOX y leer los mensajes. CÓDIGO FUENTE PARA RECUPERAR LOS CORREOS Properties props = System.getProperties(); Authenticator auth = new SMTPAuthenticator(); Session session = Session.getDefaultInstance(props, auth); session.setDebug(debug); 1. Se obtiene un objeto Properties para contener las propiedades del sistema, tales como el protocolo de recuperación de mensajes, el protocolo de transporte, el servidor de correo y el nombre de usuario. 2. Se crea un objeto Authenticator que se utiliza para realizar autenticación cuando el servidor de correo lo requiere (generalmente se utiliza con el servidor SMTP). 3. Se obtiene la sesión por default, pasandole como argumentos al constructor los objetos props y auth. 4. Se activa la opción de depuración (debug) para poder observar “paso a paso” la operación de los protocolos de correo. store = session.getStore("pop3"); store.connect(server, username, password); 84/165 CAPÍTULO 5 // -- Obtiene el folder por default -folder = store.getDefaultFolder(); if (folder == null) throw new Exception("No default folder"); // -- Obtiene su "INBOX" -folder = folder.getFolder("INBOX"); if (folder == null) throw new Exception("No POP3 INBOX"); // -- Abre el folder para lectura y escritura-folder.open(Folder.READ_WRITE); 5. Se obtiene el almacén de mensajes para el protocolo POP3 (store) y se conecta a él. 6. Enseguida se obtiene el folder por default. 7. Se obtiene el INBOX (que por tratarse del protocolo POP3 es el único folder). El INBOX es el folder primario para este usuario en este servidor. 8. Se abre el folder para lectura y escritura. Message[] msgs = folder.getMessages(); while(procesaMensaje(msgs[--msgNum],props,auth)); 9. Se obtienen todos los mensajes contenidos en el INBOX. 10. Se procesan uno a uno los mensajes. Para correr el programa, introducimos la siguiente línea de comando: C:\Archivos de programa\robot de correo>java robotCorreo 10000 mail.maxcom.net.mx infouam_azc infouam_azc true Donde: • java es el intérprete del lenguaje Java. • robotCorreo es el nombre del programa. • 10000 es el número de milisegundos, que el programa esperará antes de revisar nuevamente el INBOX, en busca de nuevos mensajes. • mail.maxcom.net.mx es el nombre o la dirección IP del servidor de correo. • infouam_azc es, en este caso, tanto el nombre de usuario como la contraseña. • true indica que el depurador de JavaMail está encendido. En la figura 5.5 podemos observar el intercambio de mensajes cliente-servidor (C-S) para el protocolo POP3. Por ejemplo, para empezar, el programa se conecta al servidor con el nombre mail.maxcom.net.mx (proporcionado, al igual que la dirección de correo para el robot, por el ISP (Internet Service Provider) contratado). Esta conexión se logra a través de un socket, donde el puerto a “escuchar” es el 110, el cual es un estándar para el protocolo POP3. Más adelante, el programa robot (Cliente) ejecuta el comando USER, proporcionando el username del buzón que quiere consultar, a lo que el servidor de correo responde que el usuario tiene un buzón registrado. Después, le pide al servidor que liste los mensajes en el buzón, y al no haber 85/165 CAPÍTULO 5 ninguno simplemente cierra el buzón y espera otros 10,000 milisegundos para volver a establecer una conexión a dicho almacén de mensajes. Fig.5.5 Pantalla de corrida del programa de robot de correo. 5.4 MÓDULO PARA RECOPILACIÓN DE RESPUESTAS Supongamos que un usuario desea información de los posgrados disponibles en CBI, entonces tendría que utilizar un programa cliente de correo, y en el campo “Asunto” debe incluir las palabras “POS” y “CBI” (véase fig. 5.6). Para nuestro caso, la dirección de correo de nuestro robot sería [email protected] Uno de los pasos importantes es obtener el Asunto (Subject) del correo, ya que en él podría estar la palabra clave, que el robot utilizará para seleccionar la respuesta adecuada al mensaje. String subject = message.getSubject(); java.util.Date date=message.getSentDate(); A continuación, se obtiene el Contenido del mensaje. Si el robot no encuentra todas las palabras clave dentro del “Asunto”, entonces continuará buscando dentro del campo “Contenido”. 86/165 CAPÍTULO 5 int msgid =message.getMessageNumber(); Part messagePart=message; Object content=messagePart.getContent(); Fig. 5.6 Composición de un mensaje de correo a través de cliente de correo web. Hay que determinar si el Contenido es Multipart, es decir, si el cuerpo del mensaje se compone de varios segmentos que pueden ser de distintos tipos (texto, html, imagen, entre otros). Enseguida podemos recuperar el correo y comenzar a leerlo (véase fig. 5.7). if (content instanceof Multipart){ for(int i=0;i<((Multipart)content).getCount();i++){ messagePart=((Multipart)content).getBodyPart(i); String contentType=messagePart.getContentType(); if (contentType.startsWith("text/plain") || contentType.startsWith("text/html")){ String emailmsg = leerMensaje(messagePart); System.out.println(msg); System.out.println("El ID de este mensaje es: "+msgid); message.setFlag(Flags.Flag.DELETED, true); // establece la bandera DELETED } } }else{ String contentType=messagePart.getContentType(); if (contentType.startsWith("text/plain") || 87/165 CAPÍTULO 5 contentType.startsWith("text/html")){ String emailmsg = leerMensaje(messagePart); System.out.println(msg); System.out.println("El ID de este mensaje es: "+msgid); message.setFlag(Flags.Flag.DELETED, true); // establece la bandera DELETED } } emailSubjectTxt=subject; Como se puede observar, después de leer el mensaje se le activa la bandera de borrado (DELETED) para que, inmediatamente después de cerrar el INBOX, sea borrado por el servidor. Fig. 5.7 Recuperación de un mensaje de correo. BUSQUEDA DE PALABRAS CLAVE Cuando ya se recuperó tanto el “Asunto” como el “Contenido” del mensaje, entonces podemos comenzar a buscar las palabras clave definidas para el robot. En este caso se escogieron las palabras: CBI, CSH, CAD y todas las que comiencen con: LIC, CARR, POS, MAEST, DOCTOR y ESPECIALI. El código para buscar las palabras es el siguiente: 88/165 CAPÍTULO 5 StringTokenizer s = new StringTokenizer(subject+'\n'+body, " =:.,?!¿¡\t\n\r"); while(s.hasMoreTokens() && (CBI==false || CAD==false || CSH==false || LIC==false || POS==false)){ palabra=s.nextToken().toUpperCase(); System.out.println("el token es: "+palabra); if(palabra.equals("CBI") && CBI==false) { CBI=true; texto=texto+palabra+", "; } else if(palabra.equals("CAD") && CAD==false) { CAD=true; texto=texto+palabra+", "; } else if(palabra.equals("CSH") && CSH==false) { CSH=true; texto=texto+palabra+", "; } else if((palabra.startsWith("LIC") || palabra.startsWith("CARR"))&& LIC==false) { palabra="LICENCIATURAS"; LIC=true; texto2=texto2+palabra+", "; } else if(POS==false && (palabra.startsWith("POS") || palabra.startsWith("MAEST") || palabra.startsWith("DOCTOR") || palabra.startsWith("ESPECIALI")) ) { palabra="POSGRADOS"; POS=true; texto2=texto2+palabra+", "; } } INTERACCIÓN CON LA BASE DE DATOS El objetivo de este sistema es que el usuario obtenga una respuesta automática a su petición de información. Para esto, se hace uso de una base de datos que contiene las posibles respuestas a sus mensajes. Para poder accesar a esta base de datos, el lenguaje Java se vale de la API llamada JDBC. En la siguiente pantalla (fig. 5.8), se observa una tabla de la base de datos, llamada uam01.dbm, que se utilizó. Esta base de datos únicamente contiene 3 tablas: Division, Licenciatura y Posgrado. En la fig. 5.9 se puede ver la tabla Licenciatura ya poblada con registros. 89/165 CAPÍTULO 5 Fig. 5.8 Tabla de una base de datos creada por medio del manejador de base de datos Access. Fig. 5.9 Tabla Licenciatura, con algunos registros. 90/165 CAPÍTULO 5 CÓDIGO FUENTE PARA RECOLECTAR RESPUESTAS PARA LOS CORREOS Del análisis del código, podemos comprobar los pasos requeridos para conectarse a la base de datos y recolectar la información que se incluirá en la respuesta al correo: • • • • • Cargar el controlador JDBC. Obtener una conexión a la base de datos. Crear un objeto Statement. Ejecutar una consulta SQL. Recuperar los datos del objeto ResultSet. Para que el robot pueda interactuar con la base de datos, primero se tiene que establecer un orígen de datos ODBC. Para ello se tiene que acceder la carpeta de Herramientas administrativas dentro de Panel de control. En esta carpeta existe un acceso directo a la aplicación para crear un orígen de datos ODBC (véase la fig. 5.10). Fig. 5.10 Orígen de datos ODBC. 91/165 CAPÍTULO 5 Fig. 5.11 Configurando un orígen de datos ODBC para Access. Una vez que le damos doble clic al ícono, nos aparece una lista con todos los orígenes de datos configurados actualmente. Enseguida le damos clic en opción de agregar. Aquí le dimos el nombre de robot al orígen de datos ODBC para Access. A continuación escogemos la base de datos con la que queremos conectarnos. En este caso se llama uam01.dbm (véanse fig. 5.11 y 5.12). Fig. 5.12 Escogiendo la base de datos para conectarse. 92/165 CAPÍTULO 5 Fig. 5.13 Orígen de datos robot. En la fig. 5.13 estamos viendo cómo queda el orígen de datos ya configurado. El nombre es robot y se utiliza para acceder a una base de datos de Access. A partir de este momento ya podemos interrogar a la base de datos para obtener las respuestas para los correos. Class.forName("sun.jdbc.odbc.JdbcOdbcDriver"); Connection con = DriverManager.getConnection(url); Statement statement = con.createStatement( ); //recuperando información de la base de datos a través de una consulta //con el método executeQuery del objeto statement String SQLQuery11=""; String SQLQuery22=""; String SQLQuery1=""; String SQLQuery2=""; String division=""; if((CBI && CSH && CAD)||(!CBI && !CSH && !CAD)){ SQLQuery1="SELECT nom_Lic, arch_Lic FROM Licenciatura"; SQLQuery2="SELECT nom_Pos, arch_Pos FROM Posgrado"; } if(LIC){ respuesta1="Informacion de licenciaturas: " + '\n'; ResultSet resultsL = statement.executeQuery(SQLQuery1); 93/165 CAPÍTULO 5 String nombre=""; while (resultsL.next()){ nombre=resultsL.getString("nom_Lic"); respuesta1=respuesta1+nombre+'\n'; } System.out.println(respuesta1); MimeBodyPart mbp1 = new MimeBodyPart(); mbp1.setText(respuesta1); mp.addBodyPart(mbp1); } if(POS){ respuesta2="Informacion de Posgrados: " + '\n'; ResultSet resultsP = statement.executeQuery(SQLQuery2); String nombre=""; while (resultsP.next() ){ nombre=resultsP.getString("nom_Pos"); respuesta2=respuesta2+nombre+'\n'; } System.out.println(respuesta2); MimeBodyPart mbp2 = new MimeBodyPart(); mbp2.setText(respuesta2); mp.addBodyPart(mbp2); } statement.close(); con.close(); 5.5 MÓDULO PARA ENVÍO DE RESPUESTAS A LOS USUARIOS Para enviar los correos se utilizan prácticamente las mismas clases que para leerlos, excepto que en lugar de usar la clase Store se utiliza la clase Transport. Esta clase se vale, en este caso, del protocolo SMTP para enviar los correos. Primero, hay que indicarle al robot a qué servidor SMTP se va a conectar y además decirle que necesita usar autenticación. props.put("mail.smtp.host", server); props.put("mail.smtp.auth", "true"); En la figura 5.14 se puede ver el proceso de autenticación y conexión exitosa con el servidor SMTP. Antes de poder enviar el correo, primero hay que construir el mensaje y para ello se utiliza la clase MimeMessage. 94/165 CAPÍTULO 5 Fig. 5.14 Reconocimiento de palabras clave, recolección de respuestas y envío de correo En este caso, el mensaje es de tipo Multipart, es decir, que el cuerpo del mensaje se compone de al menos dos partes: texto y un archivo adjunto tipo MIME. // crea un mensaje Mime Message msg = new MimeMessage(session); // establece la dirección del remitente y destinatario System.out.println("Mensaje de: "+from); InternetAddress addressFrom = new InternetAddress(from); msg.setFrom(addressFrom); System.out.println("Mensaje para: "+recipient); InternetAddress[] addressTo ={ new InternetAddress(recipient)}; msg.setRecipients(Message.RecipientType.TO, addressTo); // Establece el contenido del mensaje a través de las palabras clave // encontradas en el campo Asunto y en el campo Cuerpo del mensaje Multipart mp = consultaBase(subject, body); // Agrega el objeto Multipart al mensaje msg.setContent(mp); subject="RPLY: " +subject; 95/165 CAPÍTULO 5 msg.setSubject(subject); Transport.send(msg); En la siguiente pantalla (fig. 5.15), se observa el mensaje que se enviará al usuario que pide información de posgrados en CBI. Fig. 5.15 Mensaje enviado al usuario que solicitó información al robot. Fig. 5.16 Archivo adjunto en formato HTML enviado por el robot. 96/165 CAPÍTULO 5 Al abrir el mensaje podemos ver que se compone de un texto y archivos adjuntos en formato HTML y PDF (fig. 5.16 y 5.17). Fig. 5.17 Archivo adjunto en formato PDF. Cuando el robot no encuentra alguna palabra clave dentro del correo electrónico, entonces envía al usuario un correo con información sobre qué se puede obtener y cómo pedirselo al robot (véanse fig. 5.18 y 5.19). Fig. 5.18 Correo de aclaración para el usuario. 97/165 CAPÍTULO 5 Fig. 5.19 Archivo adjunto sobre cómo utilizar el robot. DESEMPEÑO DEL ROBOT DE CORREO Para evaluar el desempeño del robot se tomaron algunas muestras de su operación en cuanto al tiempo, memoria y tráfico en la red. A continuación se tienen algunos ejemplos. MEDICIÓN DE TIEMPO Se insertó dentro del código del robot el método System.currentTimeMillis() para medir el tiempo que se tardaba el robot en contestar cada mensaje, el total de mensajes y en simplemente revisar el buzón de entrada. Enseguida se muestran los resultados. 98/165 CAPÍTULO 5 Fig. 5.20 Tiempo de procesamiento del correo. De la fig. 5.20 podemos observar que el robot se toma menos de dos segundos en abrir, revisar y cerrar el buzón. Le tomaron poco menos de dos minutos y medio en recuperar y leer un correo de más o menos 20 palabras, y luego enviar un correo con seis archivos adjuntos con aproximadamente 300 KB en total. MONITOREO DE MEMORIA Para tener una idea del gasto de memoria se empleó una pequeña aplicación gráfica. MemoryMonitor lo que hace es utilizar tres hilos o threads de ejecución que permiten que simultáneamente se muestre una gráfica con la memoria total asignada al entorno de ejecución de la JVM, tomar muestras del uso de la memoria por parte del robot, y correr el robot. 99/165 CAPÍTULO 5 Fig. 5.21 Uso de memoria del robot durante la revisión del INBOX. La línea azul de la gráfica de memoria en la figura 5.21 representa la memoria asignada al sistema de ejecución para este proceso particular de la Máquina Virtual de Java. Podemos ver que son aproximadamente 2 MB. La línea roja representa la memoria libre, es decir, los bytes disponibles para la VM pueda crear objetos. La memoria libre se incrementa cuando la recolección de basura libera memoria o cuando el sistema operativo asigna más memoria al entorno de ejecución. La memoria libre se decrementa cuando se crean objetos o cuando se le regresa memoria al sistema operativo. De la gráfica observamos que la memoria libre disminuye paulatinamente mientras se crean nuevos objetos para recuperar y leer los mensajes en el INBOX. En la fig. 5.22 se observa que el momento en el que se ocupa más memoria es en el proceso de recuperación y lectura de los mensajes por parte del robot. Se ve claramente que en este momento la línea roja desaparece en el fondo de la gráfica. De la fig. 5.23 podemos concluir que el momento en que se utiliza menos memoria es al final de la búsqueda de palabras clave. Se observa claramente un escalon pronunciado en la gráfica lo que indica que se liberó bastante memoria. Por último, de la fig. 5.24 observamos que durante la fase de envío de archivos anexos, la utilización de memoria se estabiliza al mínimo. 100/165 CAPÍTULO 5 Fig. 5.22 Uso de memoria durante la recuperación y lectura de mensajes. Fig. 5.23 Uso de memoria durante la búsqueda de palabras clave 101/165 CAPÍTULO 5 Fig. 5.24 Uso de memoria durante el envío de archivos anexos. TRAFICO EN LA RED Utilizando la herramienta del sistema, netstat –s, se tomaron tres muestras del tráfico de red desde el punto de vista de la computadora en donde se está corriendo el robot de correo. Estas fotografías del tráfico las podemos ver en las tablas 5.1 y 5.2. Podemos concluir que tráfico consiste fundamentalmente de segmentos TCP, y lo cual ya intuiamos por tratarse de transacciones de correo electrónico. Estadísticas de TCP para IPv4 Activos abiertos Pasivos abiertos Intentos de conexión erróneos Conexiones restablecidas Conexiones actuales Segmentos recibidos Segmentos enviados Segmentos retransmitidos Estadísticas UDP para IPv4 =0 =0 =0 =0 =0 =0 =0 =0 Datagramas recibidos =4 Sin puerto =0 Errores de recepción =0 Datagramas enviados =4 Tabla 5.1 Estadísticas TCP y UDP. Al conectarse Al procesar un correo =1 =0 =0 =0 =0 =5 =6 =0 Al conectarse =9 =0 =0 =0 =0 = 562 = 564 =0 Al procesar un correo = 11 =2 =0 = 42 = 12 =2 =0 = 43 102/165 CAPÍTULO 5 Estadísticas de IPv4 al encender la computadora Paquetes recibidos Errores de encabezado recibidos Errores de dirección recibidos Datagramas reenviados Protocolos desconocidos recibidos Paquetes recibidos descartados Paquetes recibidos procesados Solicitudes de salida Descartes de ruta Paquetes de salida descartados Paquetes de salida sin ruta Reensambles requeridos Reensambles correctos Reensambles err¢neos Datagramas correctamente fragmentados Datagramas mal fragmentados Fragmentos creados =4 =0 =3 =0 =0 =0 =4 =4 =0 =0 =0 =0 =0 =0 =0 =0 =0 Estadísticas ICMPv4 Recibidos Enviados Mensajes 0 0 Errores 0 0 Destino inaccesible 0 0 Tiempo agotado 0 0 Problemas de parámetros 0 0 Paquetes de control de flujo 0 0 Redirecciones 0 0 Echos 0 0 Respuestas de eco 0 0 Fechas 0 0 Respuestas de fecha 0 0 Máscaras de direcciones 0 0 Máscaras de direcciones respondidas 0 0 Tabla 5.2 Estadísticas IP e ICMP. Al conectarse a la Al procesar un correo red = 18 = 576 =0 =0 =6 =6 =0 =0 =0 =0 =0 =0 = 18 = 576 = 51 = 610 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 =0 Al conectarse Al procesar un correo R 1 0 1 0 0 0 0 0 0 0 0 0 0 R 1 0 1 0 0 0 0 0 0 0 0 0 0 E 1 0 1 0 0 0 0 0 0 0 0 0 0 E 1 0 1 0 0 0 0 0 0 0 0 0 0 103/165 CAPÍTULO 5 5.6 RESUMEN CAPÍTULO 5 Existen dos posibles escenarios cuando se utiliza el servicio de correo electrónico. El primero de ellos, y en el cual encaja la mayoría de los usuarios residenciales, es el de la conexión por marcación a un Proveedor de Servicios de Internet con servidor de correo. Para lograr esta conexión remota a un servidor de correo, primero se tiene que suscribir a un ISP, el cual le proporciona al cliente un nombre de usuario y una contraseña, además, claro, de un número telefónico y un DNS con los cuales tiene que configurar la conexión a Internet en su computadora. La mayor parte del tiempo se hicieron las pruebas con el robot de correo utilizando esta conexión. La razón fue que se podían realizar pruebas en cualquier lugar donde hubiera disponible una línea telefónica, y llevando consigo una laptop. En lo que respecta a la conexión vía LAN se tuvieron problemas con la parte del envío de correos por parte del robot, ya que al parecer el servidor de correo local tenía algún tipo de restricción a este respecto. Se habló con el administrador de sistemas pero no pudo dar una respuesta satisfactoria. Sin embargo, la lectura de los correos de entrada por parte del robot no tuvo ningún problema. Esta clase de problemas surgen por la necesidad de las organizaciones de prevenir el spam a través de la negación del servicio del servidor SMTP a posibles usuarios maliciosos. Es importante apuntar que para la operación formal de un robot de correo, el encargado de administrar el servidor de correo debe proporcionar los permisos y contraseñas necesarias para permitir la correcta configuración del robot. El primer problema fuerte que se enfrentó fue la autenticación con el servidor de correo. Para lograrla fue necesario hacer uso de una clase del lenguaje Java llamada AUTHENTICATOR, y a la cual se le pasan como parámetros el nombre de usuario y la contraseña del ISP. Otro asunto importante fue el diseño de la base de datos. Para nuestro caso, lo esencial era conjuntar todos los elementos del robot para que funcionaran correctamente. Por ello se decidió que la base de datos fuera lo más sencilla posible para no introducir más complicaciones y no desviar la atención de la parte esencial que es la operación de los protocolos de comunicaciones SMTP y POP3. Cuando se decidió incluir gráficos o archivos en los registros de la base de datos se tuvieron algunas complicaciones a la hora de recuperar dichos datos a través de una consulta SQL. Se tuvo un periodo largo de pruebas para lograr el objetivo. 104/165 CONCLUSIONES FINALES Y TRABAJO A FUTURO El correo electrónico es una de las aplicaciones más populares de Internet. La ubicuidad de Internet hace posible que se pueda recibir el correo en casi cualquier parte del mundo. Sin embargo, es tal la cantidad de los correos electrónicos que se reciben por parte de algunas grandes instituciones, que el procesarlos consume cada vez más tiempo y esfuerzo. Se ha vuelto necesario encontrar una manera de automatizar la lectura y la respuesta a la gran mayoría de estos correos. Una forma práctica de hacerlo es a través de los robots de correo electrónico. Los robots de correo son programas de software, diseñados para automatizar el procesamiento del correo electrónico. Para el diseño y la elaboración de un programa de esta naturaleza se deben conocer los fundamentos de las redes de computadoras, de Internet, y más específicamente del correo electrónico. La pila de los protocolos TCP/IP es la base para el funcionamiento de Internet. El protocolo IP se encarga de rutear los paquetes de la aplicación (en este caso los paquetes del correo electrónico) y el protocolo TCP asegura que los paquetes lleguen libres de errores a su destino. El protocolo SMTP trata de la transmisión del correo entre los servidores, a través de los servicios de transporte. El protocolo POP3 permite recuperar el correo de un servidor y hace posible que la máquina del usuario no tenga que estar permanentemente conectada a la red para recibir todos sus correos. Para el envío de datos “No-ASCII” a través del correo electrónico es necesario implementar el protocolo MIME, el cual hace posible adjuntar archivos multimedia al cuerpo del mensaje de correo. Se utilizó el lenguaje Java, y sus interfaces de programación de aplicaciones JavaMail y JDBC, para programar el robot, además del manejador de base de datos Access para crear la base de datos de las posibles “respuestas” a los correos de los clientes. El uso de Java implicó el reto de aprender a programar con un enfoque orientado a objetos, dejando de lado la programación estructurada y procedural de epocas anteriores. Se encontró que para poder llevar a cabo del desarrollo e implementación de estos sistemas de robot de correo, es necesario establecer una comunicación directa con el departamento de sistemas, o con el encargado de administrar el servidor de correo en la institución donde se pretende implantar esta solución. De esta forma, se obtiene más fácilmente la cooperación del encargado en caso de presentarse problemas de autenticación con el servidor. Se presentó el problema de cómo almacenar archivos dentro de un campo de la base de datos, de forma tal que permitiera su correcta recuperación para el envío hacia el usuario. Nos encontramos que no se puede simplemente copiar y pegar dentro del campo, sino más bien se tiene que utilizar una rutina de programación que serialice el objeto para almacenarlo como tipo Objetos Binarios Grandes, BLOB (Binary Large OBjects). Cuando el robot necesita enviar esta información al usuario, lo deserializa y lo convierte nuevamente en un archivo antes de enviarlo como archivo anexo en el mensaje de correo. También se concluye que aunque el robot contesta inmediatamente los correos electrónicos, existen algunos factores que pueden hacer que el usuario que requiere información perciba lentitud en la respuesta. Estos factores pueden ser el retraso del servidor de correo local del 105/165 usuario en enviar su correo, el tiempo de tránsito del correo en la red de servidores SMTP, tanto desde el usuario hasta el robot de correo como viceversa. El objetivo de la tesis se cumplió ampliamente, ya que se creó un conjunto de programas que procesan automáticamente el correo electrónico, dirigido a una cuenta, y además envían las respectivas respuestas con un contenido multimedia. Una posible mejora, a futuro, a este trabajo consistiría en darle seguimiento automático a los correos de los usuarios por medio del robot de correo. Es decir, utilizando el campo de identificación de cada correo, que viene definido en el encabezado, se podría llevar un registro de las peticiones que hiciera un usuario, y de esta forma se podrían dar respuestas más concisas conforme se siguieran recibiendo correos de la misma fuente. También se podría trabajar sobre una Interfaz Gráfica de Usuario para el robot, haciendolo de esta forma más amigable y con más opciones de configuración. También se podría mejorar el diseño de la base datos para adaptarla a una situación real. 106/165 BIBLIOGRAFÍA ARTÍCULOS [1] Venditto, Gus . “E-mail face-off” Internet World, pags. 87-106, dic. 1996 [2]Savetz, Kevin. “E-mail Tricks” Internet World, pags. 39-42, jun. 1994 [3]Khare, Rohit. “the spec’s in the mail” Internet Computing, pags. 82-86, sept. 1998 [4]Adida, Ben. “Java: more than a revolution” Internet Computing, pags. 70-72, may. 1997 [5]Petrie, Charles J. “What’s an agent … and what’s so intelligent about it” IEEE Internet Computing, pags. 4-5, jul-ago 1997 [6]Huhns, M. N. “Agent teams: building and implementing software” IEEE Internet Computing, pags. 93-95, ene-feb, 2000 [7]Wooldridge, M. Deckerk, K. “Agents on the net: Infraestructure, technology, applications” IEEE Internet Computing, pags. 46-48, mar-abr, 2000 [8]Smith, J. “The best of bots” “Web agents that work for you” Smart Computing, pags. 214-217, feb. 2001 [9]Maruri, Eduardo, “Agentes Inteligentes: ¿máquinas pensantes aplicadas a la vida cotidiana del hombre” Revista RED, pags. 44-49, AÑO X, número 114, mar. 2000 DIRECCIONES ELECTRÓNICAS [10]http://www.botspot.com [11] http://www.alvestrand.no//x400/ LIBROS [12]Meyers, Nathan. “Java programming on linux” Waite Group Press 2000 107/165 [13]Bell, Douglas and Parr, Mike. “Java for students “ Pearson Education Limited 1999 [14]Valiente, Angélica. “Manejador de bases de datos Access” Guias y textos de cómputo, DGSCA-UNAM [15]Date, C. J. “An Introduction to database systems” Addison Wesley 2000 [16]Commer, Douglas. “Internetworking with TCP/IP, Vol. I: Principles, Protocols, and Architecture” Prentice-Hall 1996 [17]O’Donahue, John. “Java Database Programming Bible” Wiley Publishing 2002 [18]McLean, Ian, “Windows 2000 TCP/IP” Coriolis Group 2000 [19]”Cisco Networking Academy Program: Second Year Companion Guide” Cisco Press, Second Edition 2001 [20]Williams, Ernest, ”Using e-mail” Addisson-Wesley 2001 [21]Owens, Richard, ”Protocolos de Internet” Editorial RA-MA 2000 [22]Rice, Edward, ”Java 2” Prentice Hall 2000 [23]Rothon, John, ”Programmer’s guide to Internet Mail” Digital Press 2000 [24]Melton, Jim y colaboradores, ”Understanding SQL and Java Together: A Guide to SQLJ, JDBC, and Related Technologies ” Academic Press 2002 [25]Thomas, Todd M., ”Java Data Access: JDBC, JNDI, and JAXP” M&T Books 2002 [26]Reese, George, ”Database Programming with JDBC and Java” O’Reilly 2000, Second Edition [27]Shirazi, Jack, “Java Performance Tuning” 108/165 O’Reilly 2000 MANUALES [28]Varios “Documentación del J2SDK ver. 1.4.1_03” Sun Microsystems [29]Mani, John y colaboradores “Documentación de JavaMail ver. 1.2” Sun Microsystems RFC’s PARA CORREO ELECTRÓNICO • • • • • rfc 821: SMTP (Simple Mail Transfer Protocol) rfc 2045-2049: MIME(Multipurpose Internet Mail Extensions) rfc 1939: POP3 (Post Office Protocol ver. 3) rfc 2060: IMAP (Interactive Message Access Protocol) ver. 4 rev. 1 rfc 822 Definición de la estructura de los mensajes de correo. 109/165 GLOSARIO A API (Interfaz de Programación de Aplicaciones, Application Programming Interface). Especificación de las convenciones para llamar funciones, que define una interfaz hacia un servicio. En el caso del lenguaje Java se refiere al conjunto de librerias de clases que vienen incluidas con el kit de desarrollo. Aplicación. Un programa que realiza una función directamente para un usuario. Los clientes FTP y Telnet constituyen ejemplos de aplicaciones de red. Aplicación cliente/servidor. Una aplicación que está almacenada en un servidor y a la que acceden las estaciones de trabajo, haciendo que su mantenimiento y protección sea más fácil. Applet. Un subprograma, o aplicación pequeña, invocada por un navegador Web desde una página en Internet, escrita ya sea en Java o en algún otro lenguaje de programación. Este tipo de aplicación comúnmente muestra gráficos, animaciones, emite sonidos y/o reproduce videos, e interactúa con el usuario. En Java, a los subprogramas se les conoce como applets, término que se deriva de los vocablos ingleses application (aplicación) y let (pequeña). ARPA (Agencia de Proyectos de Investigación Avanzada, Advanced Research Projects Agency). Una organización de investigación y desarrollo que forma parte del Departamento de Defensa de los E.U. ARPA está detrás de muchos de los avances tecnológicos en las comunicaciones y las redes. ARPA se convirtió en DARPA, y después volvió a ser nuevamente ARPA en 1994. ASCII (Código Normalizado Americano para el Intercambio de Información, American Standard Code for Information Interchange). Un código de 8 bits (7 bits de datos más uno de paridad) para la representación de caracteres. B Backbone. El núcleo estructural de la red, que conecta todos los componentes de la red, de forma que tenga lugar la comunicación. Binario. Un sistema de numeración caracterizado por unos y ceros (1=activado; 0=desactivado). Bit. Un dígito binario que se usa en el sistema de numeración binario. Puede ser un cero o un uno. BLOB (Binary Large Objects). Tipo de datos en SQL3 que permite representar datos binarios de gran longitud, como sonidos, gráficos, archivos binarios,videos, entre otros. Una característica importante es que con este tipo de datos no se trabaja directamente con los datos en el lado cliente. Se tiene acceso a los datos originales en el servidor a través de un apuntador lógico en el cliente, llamado Localizador (LOCATOR ). Como resultado, los clientes no tienen que materializar los datos en sus estaciones de trabajo cuando se utiliza el tipo BLOB. 110/165 Tratandose de datos tan grandes esto es una ventaja en términos de tiempo de descarga y de manejo de memoria. Sin embargo, cuando se requiere materializar los datos en el cliente se puede utilizar el método ResultSet.getXXX(). Los datos permanecen en la base de datos a menos que se materializen explícitamente. Byte. Una serie de dígitos binarios consecutivos que se operan como unidad (por ejemplo, un byte de 8 bits). C Cabecera. Información de control que se coloca delante de los datos, cuando éstos son encapsulados para la transmisión por la red. CCITT (Comité de Consultoría Internacional para Telefonía y Telegrafía, Consultative Committee for International Telegraph and Telephone). Una organización internacional encargada del desarrollo de los estándares de comunicación. Ahora se le llama ITU-T. Clase. Unidad de programación en un lenguaje orientado a objetos como Java. Representa un conjunto de objetos similares (o idénticos). Describe los datos (variables) y métodos (funciones) que contiene un objeto. Cliente. Un nodo o programa de software (dispositivo frontal, front end) que solicita servicios de un servidor. Cliente/Servidor. La arquitectura de la relación que hay entre una estación de trabajo y un servidor en una red. Codificación. El proceso en virtud del cual los bits están representados por voltajes. Técnicas eléctricas que se usan para transportar señales binarias. Cola. 1) Por regla general, una lista ordenada de elementos que esperan a ser procesados. 2) En lo que respecta al enrutamiento, un conjunto de paquetes retrasados que esperan a ser reenviados sobre una interfaz de un router. Colisión. En Ethernet, el resultado de dos nodos transmitiendo a la vez. Las tramas de cada dispositivo colisionan y quedan dañadas cuando confluyen en el medio físico. Confiabilidad. El índice de mensajes de actividad recibidos desde un enlace. Si el índice es alto, la línea será confiable. Congestión. El exceso de tráfico que supera la capacidad de la red. Control de flujo. Una técnica que sirve para garantizar que una entidad de transmisión, no satura de datos a una entidad receptora. Cuando los búferes del dispositivo receptor están llenos, se envía un mensaje al dispositivo emisor para suspender la transmisión, hasta que se procesen los datos de los búferes. Control de flujo de ventana deslizante. Un método de control de flujo, en el que un receptor da permiso a un transmisor para transmitir datos hasta que la ventana esté llena. Cuando lo esté, el transmisor deberá dejar de transmitir hasta que el receptor publique una ventana más grande. TCP, otros protocolos de transporte y varios protocolos de capa de enlace de datos utilizan este método de control de flujo. 111/165 Correo electrónico (electronic mail). Aplicación de red muy popular, en la que se transmiten electronicamente mensajes de correo entre usuarios terminales a través de varios tipos de redes, mediante varios protocolos de red. Se le suele llamar e-mail. D Datagrama. Un agrupamiento lógico de información, enviado como unidad de la capa de red sobre un medio de transmisión, sin el establecimiento previo de un circuito virtual. Los términos celda, trama, mensaje, paquete y segmento también se emplean para describir información lógica, de las distintas capas del modelo de referencia OSI y de los distintos círculos tecnológicos. Datagrama IP. Una unidad de información fundamental que pasa por Internet. Contiene direcciones de origen y de destino junto con datos y un número de campos, que definen cuestiones como la longitud del datagrama, la suma de comprobación de la cabecera e indicadores que señalan si se puede o no, fragmentar el datagrama. Dirección de red. Una dirección de capa de red que hace referencia a un dispositivo de red lógico (en vez de físico). También llamada dirección de protocolo. Dirección IP. Una dirección de 32 bits que se asigna a los hosts por medio de TCP/IP. Una dirección IP pertenece a una de cinco clases (A, B, C, D o E) y está escrita como cuatro octetos separados por puntos (es decir, en formato decimal con puntos). Cada dirección consta de un número de red, un número de subred opcional y un número de host. Los números de red y subred se usan para el enrutamiento, y el número de host se utiliza para dirigirse a un host individual de la red o subred. Una máscara de subred se usa para extraer información de red y subred de la dirección IP. También se llama dirección de Internet. E Encapsulación. Envolver datos en una determinada cabecera de protocolo. Por ejemplo, los datos de Ethernet están envueltos en una determinada cabecera Ethernet antes de que se produzca el tránsito por la red. Enrutamiento. El proceso de localizar una ruta a un host de destino. El enrutamiento es muy complejo en redes muy grandes, debido a los numerosos destinos intermedios potenciales que podría atravesar un paquete antes de llegar a su host de destino. Ethernet. Una especificación LAN de banda base inventada por Xerox Corporation y desarrollada conjuntamente por Xerox, Intel y Digital Equipment Corporation. Las redes Ethernet utilizan CSMA/CD y se ejecutan sobre una serie de tipos de cable a 10 Mbps. Extender. Declarar una nueva clase que hereda el comportamiento de otra. F 112/165 Fragmentación. El proceso de división de un paquete en unidades más pequeñas, cuando se transmite sobre un medio de red que no puede soportar el tamaño original del paquete. G Gateway. En la comunidad IP, un término que se refiere a un dispositivo de enrutamiento. Actualmente, el término router se usa para describir los nodos que llevan a cabo esta función, mientras que gateway hace referencia a un dispositivo de propósito especial, que realiza una conversión de la información de capa de aplicación, de una pila de protocolo a la otra. Gateway de último recurso. Un ruteador (router) al que se envian todos los paquetes no enrutables. H Herencia. La manera en la que una nueva clase puede incorporar las características de una clase existente. Host. Un sistema computacional de una red. Parecido al nodo, exceptuando que host suele aludir a un sistema computacional, mientras que nodo suele aplicarse a cualquier sistema de red, incluyendo el acceso a los servidores y los routers. HTML (Lenguaje de Marcado de Hipertexto, Hipertext Markup Language). Un lenguaje sencillo de formateo de documentos de hipertexto, que utiliza etiquetas para indicar cómo debe interpretar una determinada parte de un documento, una aplicación de visualización como un navegador web. HTTP (Protocolo de Transferencia de Hipertexto, Hipertext Transfer Protocol). El protocolo que utilizan los navegadores web y los servidores web para transferir archivos, tales como archivos de texto y archivos gráficos. I IAB (Comité de Arquitectura de Internet, Internet Architecture Board). Un comité de investigadores de internetwork que tratan temas relacionados con la arquitectura de Internet. Es el encargado de nombrar a una serie de grupos relacionados con Internet, como IANA, IESG e IRSG. El IAB es nombrado por los fideicomisarios de la ISOC. IANA (Agencia de Asignación de Números de Internet, Internet Assigned Numbers Authority). Una organización que funciona bajo los auspicios de la ISOC, como parte del IAB. La IANA delega su competencia en lo relativo a asignación de espacio de direcciones, y asignación de nombres de dominio a InterNIC y otras organizaciones. La IANA también mantiene una base de datos de identificadores de protocolo asignados, que se usan en la pila TCP/IP, entre los que se incluyen los nombres de sistema autónomo. 113/165 IEEE (Instituto de Ingenieros Eléctricos y Electrónicos, Institute of Electrical and Electronic Engineers). Una organización profesional, cuyas actividades incluyen el desarrollo de comunicaciones y los estándares de redes. Actualmente, los estándares LAN IEEE son los más extendidos. Instancia. Un objeto creado a partir de una clase. Internet. La red global más grande, basada en la pila de protocolos TCP/IP, que conecta decenas de miles de redes a nivel mundial, y que se centra en la investigación y en la normalización en base al uso en la vida real. Muchas de las tecnologías de redes más avanzadas proceden de la comunidad Internet. Internet se desarrolló a partir de ARPANET. Se le llamó DARPA Internet, término que no hay que confundir con el término general internet. Internetwork. Una colección de redes interconectadas mediante routers y otros dispositivos que funciona (por regla general) como una sola red. Internetworking. La industria dedicada a la interconexión de redes. El término puede hacer referencia a los productos, los procedimientos y las tecnologías. InterNIC. Una organización que presta sus servicios a la comunidad Internet proporcionando asistencia al usuario, documentación, aprendizaje, servicios de registro para los nombres de dominio de Internet, direcciones de red y otros servicios. Antiguamente llamada Centro de Información de la red, NIC (Network Information Center). Intranet. Una red interna a la que acceden los usuarios que tengan acceso a la LAN interna de una organización. IP (Protocolo Internet, Internet Protocol). Un protocolo de capa de red de la pila TCP/IP que ofrece un servicio de internetwork sin conexión. IP proporciona funciones para el direccionamiento, la especificación de tipo de servicio, la fragmentación y el reensamblado y la seguridad. Se define en la rfc 791. IPv4 (Protocolo Internet, versión 4) es un protocolo de conmutación de paquetes sin conexión y de máximo esfuerzo de entrega. ISO (Organización Internacional para la Normalización, International Organization for Standardization). Una organización internacional encargada de una amplia gama de estandares, entre los cuales se incluyen los que son importantes para el networking. ISO desarrolló el modelo de referencia OSI, que es un modelo de referencia de networking muy conocido. ISOC (Sociedad de Internet, Internet SOCiety). Una organización internacional sin fines de lucro, fundada en 1992, que coordina la evolución y el uso de Internet. Además, la ISOC delega la autoridad a otros grupos relacionados con Internet, como el IAB. La ISOC tiene su cuartel general en Reston, Virginia, E.U. J Java. Lenguaje de programación de propósito general, diseñado originalmente para crear aplicaciones para electrodomésticos y después para Internet. 114/165 M Mail bridge (puente de correo). Término empleado informalmente como sinónimo de compuerta de correo. Mail exchanger (intercambiador de correo). Computadora que acepta correo electrónico; algunas máquinas que intercambian correo lo envían hacia otras computadoras. Un DNS tiene un tipo de dirección separado para las máquinas que intercambian correo. Mail exploder (distribuidor de correo). Parte de un sistema de correo electrónico que acepta correo y una lista de direcciones como entrada, y envía una copia del mensaje a cada dirección de la lista. La mayor parte de los sistemas de correo electrónico, incorpora un distribuidor de correo para permitir que los usuarios definan listas de correo locales. Mail gateway (compuerta de correo). Máquina que se conecta a dos o más sistemas de correo electrónico (en especial a sistemas de correo diferentes o de dos redes distintas) y transfiere mensajes de correo entre ellas. Las compuertas de correo generalmente capturan un mensaje de correo completo, lo reformatean siguiendo las reglas del sistema de correo de destino y luego envían el mensaje. Máquina Virtual de Java, JVM (Java Virtual Machine). Pieza de software que permite que Java se ejecute en un equipo específico. La JVM interpreta el código de bytes producido por el compilador de Java. Método. Una de las acciones asociadas con un objeto (en otros lenguajes de programación se le conoce como función, procedimiento o subrutina). Un método tiene un nombre y puede tener uno o más parámetros. El nombre “método” se deriva de la idea de tener un método para hacer algo. MIME (Extensiones de Correo Internet Multipropósito, Multipurpose Internet Mail Extensions). Estándar utilizado para codificar datos, tales como imágenes, en texto ASCII para su transmisión a través del correo electrónico. N Navegador Web. Pieza de software que permite que un usuario en una computadora, obtenga acceso a los archivos ubicados en otros lugares dentro de Internet. Un navegador interpreta la información incrustrada en el archivo, la cual describe la manera en que ésta debe mostrarse en pantalla. Los navegadores más populares son Netscape Navigator e Internet Explorer. Nodo. Un punto final de una conexión de red o una confluencia común a dos o más líneas de una red. Los nodos pueden ser procesadores, controladores o estaciones de trabajo. Los nodos, que varían en el enrutamiento y otras opciones de funcionalidad, pueden estar interconectados por enlaces, y sirven como puntos de control de la red. 115/165 O Objeto. Componente de un programa en un lenguaje orientado a objetos. Un objeto incorpora algunos datos (variables) y las acciones (métodos) asociadas a esos datos. OSI (Interconexión de Sistemas Abiertos, Open Systems Interconnection). Un programa de normalización internacional creado por la ISO y la ITU-T, para desarrollar estándares para networking de datos, que facilita la interoperabilidad de equipamiento de múltiples fabricantes. P . Páginas Web. Un archivo de información ubicado en una computadora, que puede verse mediante el uso de un navegador en cualquier computadora, utilizando World Wide Web. El archivo se divide en páginas para su mejor exploración. Paquete. Una manera en Java de agrupar un número de clases relacionadas. Todos los nombres dentro de la clase son privados, a menos que un usuario haga referencia en forma explícita al paquete y a la clase mediante el uso de una instrucción import. El uso de paquetes ayuda a evitar que surja el problema potencial de los nombres duplicados, especialmente en piezas extensas de software. Pila de protocolo. Una serie de protocolos de comunicación relacionados que funcionan conjuntamente y que, como grupo, dirigen la comunicación a alguna de (o a todas) las siete capas del modelo de referencia OSI. No todas las pilas de protocolo cubren cada una de las capas del modelo y, generalmente, un solo protocolo de la pila se dirige a una serie de capas a la vez. TCP/IP es una pila de protocolo típica. POP3 (Protocolo de Oficina Postal Versión 3, Post Office Protocol ver. 3). Protocolo que permite la recuperación de mensajes y que hace posible que un usuario reciba correos electrónicos, aunque no esté conectado permanentemente a una red. Protocolo. Una descripción formal de una serie de reglas y convenciones, que rigen cómo los dispositivos de una red intercambian información. Puerto. 1) Una interfaz de un dispositivo de internetworking (como un router). 2) Un conector hembra de un patch panel que acepta el mismo tamaño de conector que un RJ-45. Estos puertos se usan para conectar computadoras, que están a su vez conectadas con el patch panel. 3) En terminología IP, un proceso de capa superior que recibe información de las capas inferiores. Los puertos están numerados, y muchos están asociados con un proceso específico. Por ejemplo, SMTP está asociado con el puerto 25. Un número de puerto de este tipo se llama dirección o puerto bien conocido. R Red. Una colección de computadoras, impresoras, routers, switches y otros dispositivos que son capaces de comunicarse entre sí a través de un medio de transmisión. 116/165 Router (ruteador). Un dispositivo de capa de red que utiliza una o más métricas para determinar la ruta óptima por la que hay que reenviar el tráfico de red. Los routers reenvían paquetes desde una red a otra en base a la información de la capa de red. A veces se le llama gateway. S Sitio Web. Archivo ubicado en una computadora, a la cual se puede tener acceso a través de Internet. SMTP (Protocolo Simple de Transferencia de Correo, Simple Mail Transfer Protocol). Protocolo estándar del TCP/IP para transferir mensajes de correo electrónico de una máquina a otra. SMTP especifica cómo interactúan dos sistemas de correo y el formato de los mensajes de control, que intercambian para transferir el correo. T TCP (Protocolo de Control de Transmisión, Transmission Control Protocol). Protocolo de nivel de transporte TCP/IP estándar, que proporciona el servicio de flujo confiable full dúplex y del cual dependen muchas aplicaciones. El TCP/IP permite que el proceso en una máquina, envíe un flujo de datos hacia el proceso de otra. El TCP está orientado a la conexión en el sentido de que, antes de transmitir datos, los participantes deben establecer la conexión. Todos los datos viajan en segmentos TCP, en donde cada viaje se realiza a través de Internet en un datagrama IP. El conjunto de protocolos completo se conoce frecuentemente como TCP/IP debido a que el TCP y el IP son los dos protocolos más importantes. Topología. Una organización física de nodos de red y medios en una estructura de networking empresarial. U URL (Localizador Universal de Recursos, Uniform Resource Locator). Un esquema de direccionamiento estandarizado que sirve para acceder a documentos de hipertexto y a otros servicios por medio de un navegador. W WAN (Red de Área Amplia, Wide Area Network). Una red de comunicación de datos, que presta servicios a los usuarios en una zona geográfica amplia, y que suele utilizar dispositivos de transmisión suministrados por proveedores de servicios comunes. World Wide Web (WWW) o Web. El principal medio de acceso a la información en Internet. La Web define un estándar para la representación de archivos (incluyendo HTML), para las direcciones de archivos en cualquier parte del mundo (URL’s) y el protocolo de comunicación entre computadoras. 117/165 ANEXO A SOLICITUDES DE COMENTARIOS Los estándares de TCP/IP están publicados en varios documentos denominados Solicitud de Comentarios, rfc’s (Request For Comments). Las rfc’s son un conjunto de informes, propuestas de protocolos y estándares de protocolos que describen el funcionamiento interno de TCP/IP e Internet. [18] No todas las rfc’s son especificaciones de estándares. Las rfc’s son redactadas por individuos que voluntariamente preparan y presentan una propuesta para el Grupo de Trabajo de Ingeniería de Internet, IETF (Internet Engineering Task Force) y otros grupos de trabajo similares. Los borradores que se presentan, en primer lugar son revisados y, a continuación, se les asigna un estado. Si un borrador pasa esta primera etapa de revisión, se pone en circulación en la amplia comunidad de Internet para otra etapa de comentarios y revisión adicionales, y se le asigna un número de rfc. Si se realizan cambios en la especificación propuesta, los borradores revisados o actualizados se ponen en circulación con una nueva rfc. Consecuentemente, las rfc’s con número más alto son las más recientes. Existen cinco estados que se asignan a las rfc´s en el proceso de estándares como se muestra en la siguiente tabla. Estado Protocolo estándar Protocolo estándar en borrador Protocolo estándar propuesto Protocolo experimental Protocolo informativo Protocolo histórico Descripción Protocolo estándar oficial de Internet. En fase de consideración y revisión activas para llegar al protocolo estándar. Protocolo que en el futuro puede llegar a protocolo estándar. Protocolo diseñado para propósitos experimentales y no destinados al uso. Protocolo desarrollado por otras organizaciones de estándares. Protocolos sustituidos por otros protocolos. 118/165 ANEXO B rfc 1939 Protocolo de Oficina Postal, Post Office Protocol – Version 3 (POP3) El POP3 permite a una estación de trabajo accesar dinámicamente a un repositorio de correo en un servidor. Sin embargo, no está diseñado para permitir la manipulación del correo dentro del propio servidor, sino que más bien se descarga el correo y se borra del servidor. OPERACIÓN BÁSICA El host servidor comienza el servicio POP3, “escuchando” en el puerto TCP 110. Cuando un host cliente desea utilizar el servicio establece una conexión TCP con el servidor. Cuando se ha realizado la conexión, el servidor POP3 envía un saludo. A partir de este momento, el cliente y el servidor intercambian comandos y respuestas hasta que se cierra o se aborta la conexión. Los comandos en POP3 consisten en palabras cortas, seguidas algunas veces de uno o más argumentos. Todos los comandos se terminan con un par CRLF. Los comandos y argumentos consisten de caracteres ASCII imprimibles, separados por un espacio. Los comandos consisten de 3 o 4 caracteres y los argumentos pueden ser de hasta 40 caracteres. Las respuestas en POP3 consisten de un indicador de estado y de un código, seguido probablemente por más información. Todas las respuestas se terminan con un par CRLF. Las respuestas pueden ser de hasta 512 caracteres de longitud, incluyendo el par CRLF. Actualmente existen dos indicadores de estado: positivo (“+OK”) y negativo (“-ERR”) (los servidores deben enviarlos en mayúsculas, tal como están escritos). Una sesión POP3 pasa por diferentes estados durante su vida. Una vez que se abre la conexión TCP y el servidor POP3 envió su saludo, la sesión entra en el estado AUTORIZACIÓN (AUTHORIZATION). En este estado, el cliente debe indentificarse con el servidor POP3. Cuando el cliente se identifica exitosamente, el servidor adquiere los recursos asociados al buzón de este cliente y la sesión entra en el estado TRANSACCIÓN (TRANSACTION). En este estado, el cliente hace peticiones al servidor. Cuando el cliente envía el comando SALIR (QUIT), la sesión entra en el estado ACTUALIZAR (UPDATE). En este estado, el servidor libera los recursos adquiridos durante el estado TRANSACCIÓN (TRANSACTION) y se despide. En este instante se cierra la conexión TCP. Un servidor POP3 puede tener un temporizador de autodesconexión (autologout) por inactividad. Tal temporizador debe ser de al menos 10 minutos. Si se recibe cualquier comando por parte del cliente, debe ser suficiente para resetear el temporizador. Cuando el temporizador expira, la sesión no entra en estado ACTUALIZAR (UPDATE) y el servidor debe cerrar la conexión TCP, pero sin borrar ningún mensaje ni enviar ninguna respuesta al cliente. 119/165 El ESTADO AUTORIZACIÓN (AUTHORIZATION) Una vez que el cliente POP3 abre la conexión TCP, el servidor responde con un saludo positivo, compuesto por una línea como la siguiente: S: +OK POP3 SERVER READY En este momento, la sesión entra en el estado AUTORIZACIÓN (AUTHORIZATION). El cliente debe identificarse y autenticarse con el servidor POP3, lo cual puede hacer, valiendose de cualquiera de dos mecanismos: la combinación de los comandos USER y PASS, y el comando APOP. Una vez que el servidor ha determinado, a través de algún medio de autenticación, que se le debe dar acceso al cliente al buzón requerido, el servidor adquiere un seguro de acceso exclusivo al buzón para prevenir que los mensajes sean modificados o borrados antes de entrar en estado ACTUALIZAR (UPDATE). Si se adquiere dicho seguro, el servidor responde con un indicador de estado positivo. En este momento, se entra en el estado de TRANSACCIÓN (TRANSACTION) con ningún mensaje marcado para borrar. Si el buzón no se puede abrir, el servidor POP3 responde con un indicador de estado negativo. Después de regresar un indicador de estado negativo el servidor puede cerrar la conexión. Si el servidor no cierra la conexión, el cliente puede suministrar un nuevo comando de autenticación y comenzar de nuevo o puede mandar un comando QUIT. Después de que el servidor abre el buzón, asigna un número a cada mensaje y marca el tamaño del mensaje en octetos. El primer número asignado es el “1”, y así sucesivamente. Resumen del comando QUIT utilizado en el estado AUTORIZACIÓN (AUTHORIZATION) QUIT Argumentos: ninguno Restricciones: ninguna Respuestas: +OK Ejemplos: C: QUIT S: +OK prodigy POP3 server signing off EL ESTADO TRANSACCIÓN (TRANSACTION) Cuando la sesión entra en este estado, el cliente puede enviar cualquiera de los siguientes comandos al servidor POP3, mientras que el servidor emite una respuesta después de cada comando. Eventualmente, el cliente envía el comando QUIT y la sesión entra en el estado ACTUALIZAR (UPDATE). 120/165 STAT Argumentos: Restricciones: Respuestas: Ejemplos: ninguno sólo se puede dar en el estado TRANSACCIÓN (TRANSACTION) +OK nn mm C: STAT S: +OK 2 320 LIST [msg] Argumentos: Restricciones: Respuestas: Ejemplos: un número de mensaje (opcional), el cual no debe referirse a un mensaje marcado para borrar. sólo se puede dar en el estado TRANSACCIÓN (TRANSACTION) +OK scan listing follows -ERR no such message C: LIST S: +OK 2 messages (320 octets) S: 1 120 S: 2 200 S: . … C: LIST 2 S:+OK 2 200 … C: LIST 3 S:-ERR no such message, only 2 messages in maildrop RETR msg Argumentos: un número de mensaje (requerido) que no está marcado como borrado. Restricciones: sólo puede darse en el estado TRANSACCIÓN (TRANSACTION). Respuestas: +OK message follows -ERR no such message Ejemplos: C: RETR 1 S: +OK 120 octets S: (el servidor POP3 envía el mensaje aqui) S: . DELE msg Argumentos: un número de mensaje (requerido) que no está marcado como borrado. Restricciones: sólo puede darse en el estado TRANSACCIÓN (TRANSACTION). 121/165 Respuestas: +OK message deleted -ERR no such message Ejemplos: C: DELE 1 S: +OK message 1 deleted … C: DELE 2 S: -ERR message 2 already deleted NOOP Argumentos: ninguno Restricciones: sólo puede darse en el estado TRANSACCIÓN (TRANSACTION) Respuestas: +OK Ejemplos: C: NOOP S: +OK RSET Argumentos: ninguno Restricciones: sólo puede darse en el estado TRANSACCIÓN (TRANSACTION) Respuestas: +OK Ejemplos: C: RSET S: +OK maildrop has 2 messages (320 octets) EL ESTADO ACTUALIZAR (UPDATE) Cuando el cliente envía el comando QUIT desde el estado TRANSACCIÓN (TRANSACTION), la sesión entra en el estado ACTUALIZAR (UPDATE). QUIT Argumentos: ninguno Restricciones: ninguna Respuestas: +OK -ERR some deleted messages not removed Ejemplos: C: QUIT S: +OK prodigy POP3 server signing off (maildrop empty) … C: QUIT 122/165 S: +OK prodigy POP3 server signing off (2 messages left) … COMANDOS POP3 OPCIONALES TOP msg n Argumentos: un número de mensaje (requerido) que no se refiere a un mensaje marcado como borrado y un número no negativo de líneas (requerido). Restricciones: sólo puede darse en el estado TRANSACCIÓN (TRANSACTION) Respuestas: +OK top of message follows -ERR no such message Ejemplos: C: TOP 1 10 S: +OK S: <el servidor POP3 envía los encabezados del mensaje, una línea en blanco, y las primeras 10 líneas del cuerpo del mensaje. S: . … C: TOP 100 3 S: -ERR no such message USER name Argumentos: una cadena identificando un buzón (requerida), la cual tiene significado sólo para el servidor. Restricciones: sólo puede darse en el estado AUTORIZACIÓN (AUTHORIZATION) después del saludo del servidor o después de un comando USER o PASS no exitoso. Respuestas: +OK name is a valid mailbox -ERR never heard of mailbox name Ejemplos: C: USER juan S: -ERR sorry, no mailbox for juan here … C: USER pedro S: +OK pedro is a real hoopy frood PASS string Argumentos: una contraseña servidor/buzón-específico. Restricciones: sólo puede darse en el estado AUTORIZACIÓN (AUTHORIZATION) inmediatamente después de un comando USER exitoso. 123/165 Respuestas: +OK maildrop locked and ready -ERR invalid password -ERR unable to lock maildrop Ejemplos: C: USER juan S: -OK juan is a frIiend C: PASS secret S: -ERR maildrop already locked … C: USER juan S: -OK juan is a real friend C: PASS secret S: +OK juan´s maildrop has 2 messages (320 octets) RESUMEN DE COMANDOS POP3 COMANDOS POP3 MíNIMOS USER name PASS string QUIT Válidos en el estado AUTORIZACIÓN (AUTHORIZATION) STAT LIST [msg] RET msg DELE msg NOOP RSET QUIT Válidos en el estado TRANSACCIÓN (TRANSACTION) COMANDOS POP3 OPCIONALES APOP name digest Válido en el estado AUTORIZACIÓN (AUTHORIZATION) TOP msg n UIDL [msg] Válidos en el estado TRANSACCIÓN (TRANSACTION) RESPUESTAS POP3 +OK 124/165 -ERR Nótese que a excepción de los comandos STAT, LIST y UIDL, la respuesta dada por el servidor POP3 a cualquier comando sólo es significativa a “+OK” y “-ERR”. Cualquier texto que siga puede ser ignorado por el cliente. FORMATO DE LOS MENSAJES Todos los mensajes transmitidos durante una sesión POP3 se asume que se apegan al formato de los mensajes de texto Internet (rfc822). 125/165 ANEXO C rfc 821 Protocolo Simple de Transferencia de Correo, Simple Mail Transfer Protocol (SMTP) INTRODUCCIÓN El objetivo del Protocolo Simple de Transferencia de Correo, SMTP (Simple Mail Transfer Protocol) es transferir correo confiable y eficientemente. Una característica importante de SMTP es su capacidad de retransmitir correo a través de diferentes ambientes de servicios de transporte. EL MODELO SMTP Como resultado de una petición de correo de un usuario, el emisor-SMTP establece un canal de transmisión dúplex con un receptor-SMTP. Este último puede ser el destino final o uno intermedio. El emisor-SMTP genera comandos SMTP y se envían al receptor SMTP. Este envía respuestas SMTP al emisor-SMTP como contestación a los comandos. Una vez que se establece el canal de transmisión, el transmisor SMTP envía un comando MAIL indicando el remitente del correo. Si el receptor SMTP puede aceptar correo contesta con una respuesta OK. Entonces, el emisor-SMTP envía un comando RCPT identificando un destinatario del correo. Si el receptor SMTP puede aceptar el correo para ese destinatario contesta con una respuesta OK; en caso contrario, contesta con una respuesta rechazando ese destinatario (pero no la transacción completa). Tanto el emisor como el receptor SMTP pueden negociar varios destinatarios. Cuando se han negociado los destinatarios, el emisor envía los datos del correo, terminando con una secuencia especial. Si el receptor SMTP procesa exitosamente los datos del correo, contesta con una respuesta OK. El argumento del comando MAIL es una trayectoria (path) invertida, que especifica de quién es el correo. El argumento del comando RCPT es una trayectoria, que especifica para quién es el correo. La trayectoria invertida es una ruta de regreso (que puede ser usada para regresar un correo a un emisor, cuando ocurre un error con un mensaje retransmitido). Cuando se envía correo a múltiples destinatarios, SMTP recomienda sólo una copia de los datos para todos los destinatarios en un mismo host. Los comandos y respuestas de correo tienen una sintáxis rígida. Las respuestas tienen únicamente código numérico. Los comandos y las respuestas no son sensibles a mayúsculas y minúsculas. Esto no aplica para nombres de usuario de buzones de correo. 126/165 Los comandos y respuestas se componen de caracteres del código ASCII. Cuando el servicio de transporte proporciona un canal de transmisión de 8 bits, cada caracter de 7 bits se envía justificado hacia la derecha y el bit de más alto orden del octeto se pone a cero. PROCEDIMIENTOS SMTP MAIL Hay tres pasos en las transacciones de correo SMTP. La transacción comienza con un comando MAIL que contiene la identificación del emisor. Continúa con uno o más comandos RCPT con la información de los destinatarios. Sigue el comando DATA con los datos del correo y finalmente el indicador de fin del mensaje termina la transacción. La sintaxis del comando MAIL es la siguiente: MAIL <SP> FROM :<reverse-path> <CRLF> El camino inverso (reverse-path) contiene el buzón origen. Este comando le dice al receptor SMTP que ha comenzado una transacción de correo y que restablezca sus tablas de estado y bufferes, incluyendo cualquier destinatario y datos de correo. Si el receptor SMTP lo acepta contesta con una respuesta 250 OK. El camino inverso (reverse-path) tiene más que un buzón, es una lista de enrutamiento fuente inverso de hosts y buzón origen. El primer host en la lista debe ser el host que envía el comando. El segundo paso en el procedimiento es el comando RCPT. RCPT <SP> TO: <forward-path> <CRLF> Este comando da un camino directo (forward-path) que identifica un destinatario. Si el receptor SMTP lo acepta contesta con un 250 OK, y guarda el camino directo (forward-path). Si el destinatario es desconocido, el receptor SMTP regresa un 550 Failure. El camino directo (forward-path) tiene más que un buzón, es una lista de enrutamiento fuente directo de hosts y buzón destino. El primer host en la lista debe ser el host que recibe el comando. El tercer paso en el procedimiento es el comando DATA. DATA <CRLF> Si el receptor SMTP lo acepta, responde con un 354 Intermediate y toma todas las líneas subsecuentes como el texto del mensaje. Cuando se recibe y se guarda el final del texto, el receptor SMTP responde con un 250 OK. Para indicar el fin del mensaje SMTP envía una línea conteniendo únicamente un punto. El indicador del final del mensaje, también confirma la transacción de correo y le dice al receptor SMTP que procese los destinatarios y los mensajes. Si lo acepta, el receptor responde con un 250 OK. El comando DATA 127/165 falla únicamente si la transacción fue incompleta (por ejemplo, sin destinatario (s)) o si los recursos no están disponibles. Ejemplo: el usuario Smith ubicado en el host Alpha.ARPA envía un correo a Jones, Green y Brown ubicados supuestamente en el host Beta.ARPA. Se asume que el host Alpha.ARPA contacta directamente al host Beta.ARPA. S: MAIL FROM:<[email protected]> R: 250 OK S: RCPT TO:<[email protected]> R: 250 OK S: RCPT TO:<[email protected]> R: 550 No such user here S: RCPT TO:<[email protected]> R: 250 OK S: DATA R: 354 Start mail input; end with <CRLF>.<CRLF> S: Blah blah blah... S: ...etc. etc. etc. S: <CRLF>.<CRLF> R: 250 OK El correo fue aceptado por Jones y Brown. Green no tenía un buzón en el host Beta. APERTURA Y CIERRE En el momento que el canal de transmisión se abre, hay un intercambio para asegurar que los hosts se están comunicando con los hosts que ellos creen. La sintáxis es como sigue: HELO <SP> <domain> <CRLF> QUIT <CRLF> En el comando HELO, el host que lo envía se identifica a si mismo. El comando se puede interpretar como “Hola, yo soy <domain>”. Ejemplo de apertura de conexión: 128/165 R: 220 BBN-UNIX.ARPA Simple Mail Transfer Service Ready S: HELO USC-ISIF.ARPA R: 250 BBN-UNIX.ARPA Ejemplo de cierre de conexión: S: QUIT R: 221 BBN-UNIX.ARPA Service closing transmission channel RESTABLECER, RESET (RSET) Este comando indica que la transacción actual de correo debe abortarse. Cualquier emisor, destinatarios o datos de correo guardados deben ser descartados y se deben limpiar todos los bufferes y tablas de estado. El receptor debe enviar una respuesta OK. NINGUNA OPERACIÓN, NOOP (NOOP) Este comando no afecta ningún parámetro o parametros ingresados anteriormente. Únicamente especifica que el receptor debe enviar una respuesta OK. SALIR (QUIT) Este comando especifica que el receptor debe enviar una respuesta OK y entonces cerrar el canal de transmisión. El receptor no debe cerrar el canal de transmisión (aún si hay errores) a menos que reciba un comando QUIT y envíe una respuesta OK. A su vez, el emisor no debe cerrar el canal de transmisión hasta que envíe un comando QUIT y reciba una respuesta OK. Si el canal de transmisión se cierra prematuramente, el receptor debe actuar como si hubiera recibido un comando RSET (cancelando cualquier transacción pendiente, pero sin deshacer ninguna transacción debidamente terminada). El emisor debe actuar como si el comando o transacción en progreso hubiera recibido un error temporal. IMPLEMENTACIÓN MÍNIMA Para que el protocolo SMTP sea funcional, se deben implementar los siguientes comandos en todos los receptores: HELO, MAIL, RCPT, DATA, RSET, NOOP y QUIT. 129/165 ANEXO D rfc 822 Estándar para el Formato de Mensajes de Texto de Arpa Internet, Standard For The Format Of Arpa Internet Text Messages INTRODUCCIÓN Este estándar define la sintáxis de mensajes de texto, que se envían entre computadoras, dentro de la estructura de mensajes de correo electrónico. No prevee transmisión de audio, video u otros tipos de datos estructurados en el correo electrónico. Se han publicado varias extensiones, tales como las series de documentos MIME (rfc’s 2045, 2046 y 2049), las cuales describen mecanismos que extienden la sintáxis de este estándar o que estructuran tales mensajes para que se ajusten a la sintáxis aquí explicada. En el contexto del correo electrónico, los mensajes se componen de un sobre y contenido. El sobre contiene cualquier información necesaria para lograr la transmisión y entrega. El contenido comprende el objeto que se entrega al destinatario. Este estándar se aplica sólo al formato y a algo de la semántica del contenido del mensaje, pero no especifica la información en el sobre. Sin embargo, algunos sistemas pueden utilizar la información del contenido para construir el sobre. ANALISIS LÉXICO DE LOS MENSAJES Un mensaje consiste de campos de encabezado y, opcionalmente, un cuerpo. Éste es una secuencia de líneas de caracteres US-ASCII en el rango 1 a 127 y está separado del encabezado por una línea nula (es decir, una línea que contiene únicamente los caracteres Retorno de Carro/Línea Nueva, Carriage Return/Line Feed, (CRLF)). Cada línea no DEBE ser mayor de 998 caracteres y no DEBERÍA (recomendación) exceder los 78 caracteres, excluyendo los caracteres CRLF. ENCABEZADOS Cada campo de encabezado, se puede ver como una sola línea lógica de caracteres ASCII compuesta por un nombre y un cuerpo. Por conveniencia, la porción del cuerpo se puede dividir en múltiples líneas. Al nombre del campo encabezado le sigue el caracter “:”, enseguida el cuerpo y por último los caracteres CRLF. Un nombre de campo DEBE estar formado por caracteres US-ASCII imprimibles (33-126). El cuerpo del encabezado puede estar compuesto por cualquier caracter US-ASCII excepto CR y LF. 130/165 CUERPOS DE ENCABEZADO NO ESTRUCTURADOS Son aquellos mencionados anteriormente, compuestos de cualquier caracter US-ASCII excepto CR y LF, sin más restricciones. Se les trata como una única línea de caracteres. CUERPOS DE ENCABEZADO ESTRUCTURADOS Son secuencias de tokens léxicos específicos. A muchos de estos tokens se les permite que comiencen o terminen con comentarios, así como los caracteres espacio (ASCII 32, SP) y tabulador horizontal (ASCII 9, HTAB) (conocidos en su conjunto como los caracteres white space, WSP). CUERPO Se imponen las dos limitaciones siguientes: • CR y LF DEBEN ocurrir juntos en una línea como CRLF; no deben aparecer independientemente en el cuerpo. • Las líneas de caracteres DEBEN limitarse a 998 caracteres y DEBERÍAN limitarse a 78, excluyendo CRLF. ESPECIFICACIÓN DE FECHA Y HORA La fecha y la hora aparecen en varios campos del encabezado y a continuación se muestra la sintáxis de los mismos: date-time = day-of-week = [ day-of-week "," ] date FWS time [CFWS] ([FWS] day-name) / obs-day-of-week day-name = "Mon" / "Tue" / "Wed" / "Thu" / "Fri" / "Sat" / "Sun" date = day month year year = 4*DIGIT / obs-year month = (FWS month-name FWS) / obs-month month-name = "Jan" / "Feb" / "Mar" / "Apr" / "May" / "Jun" / "Jul" / "Aug" / "Sep" / "Oct" / "Nov" / "Dec" day = ([FWS] 1*2DIGIT) / obs-day 131/165 time = time-of-day FWS zone time-of-day = hour ":" minute [ ":" second ] hour = 2DIGIT / obs-hour minute = 2DIGIT / obs-minute second = 2DIGIT / obs-second zone = (( "+" / "-" ) 4DIGIT) / obs-zone El día se representa como el número de día del mes y el año es cualquier número a partir del 1900. La hora-del-día (time-of-day) especifÍca el número de horas, minutos y opcionalmente segundos a partir de la medianoche del día indicado. La fecha y hora-del-día (time-of-day) DEBERÍA expresar el tiempo local. La zona representa la desviación del Tiempo Universal Coordinado (UTC, conocido anteriormente como Tiempo del Meridiano de Greenwich) que la fecha y la hora –del-día (time-of-day) representan. El “+” o el “-“, indican si la hora del día está adelantada (al este de) o atrasada (al oeste de) con respecto al Tiempo Universal. ESPECIFICACIÓN DE DIRECCIONES Las direcciones indican los remitentes y destinatarios de los mensajes. Una dirección puede representar un buzón individual o un conjunto de los mismos. address = mailbox / group mailbox = name-addr / addr-spec name-addr = [display-name] angle-addr angle-addr = [CFWS] "<" addr-spec ">" [CFWS] / obs-angle-addr group = display-name ":" [mailbox-list / CFWS] ";" [CFWS] display-name = phrase mailbox-list = (mailbox *("," mailbox)) / obs-mbox-list address-list = (address *("," address)) / obs-addr-list Normalmente, un buzón (mailbox) se compone de dos partes: 132/165 • • un nombre de despliegue opcional, que indica el nombre del destinatario (el cual puede ser una persona o un sistema) que puede ser desplegado al usuario de una aplicación de correo. una dirección (addr-spec) encerrada entre paréntesis angulares (“<” y “>”). Existe una forma simple de buzón donde la dirección (addr-spec) aparece sola sin el nombre del destinatario o los paréntesis. ESPECIFICACIÓN addr-spec Es un identificador específico de Internet que contiene una cadena interpretada localmente, seguida de un caracter at-sign (“@”, valor ASCII 64) seguido de un dominio de Internet. addr-spec = local-part "@" domain local-part = dot-atom / quoted-string / obs-local-part domain = dot-atom / domain-literal / obs-domain domain-literal = [CFWS] "[" *([FWS] dcontent) [FWS] "]" [CFWS] dcontent = dtext / quoted-pair dtext = NO-WS-CTL / ; Non white space controls %d33-90 / ; The rest of the US-ASCII %d94-126 ; characters not including "[", ; "]", or "\" La parte del dominio identifica el punto en el cual se entrega el correo. La porción local es una cadena dependiente del dominio. Se interpreta simplemente como el nombre de un buzón en particular en un host. DEFINICIONES DE CAMPOS Todos los campos de encabezado tiene la misma estructura sintáctica general: un nombre de campo, seguido de una coma, seguida por el cuerpo del campo. Es importante destacar que los campos no siguen un orden específico y que a veces se reordenan cuando viajan a través de Internet. Los únicos campos de encabezado requeridos son la fecha de origen y la dirección del origen. Todos los demás son sintácticamente opcionales. campos = *(trace 133/165 *(resent-date / resent-from / resent-sender / resent-to / resent-cc / resent-bcc / resent-msg-id)) *(orig-date / from / sender / reply-to / to / cc / bcc / message-id / in-reply-to / references / subject / comments / keywords / campos opcionales) EL CAMPO FECHA DE ORIGEN (ORIGINATION DATE) Consiste del nombre de campo “Fecha” (Date) seguida de una especificación fecha-hora. orig-date = “Date:” date-time CRLF Especifica la fecha y hora, en la que el creador del mensaje indicó que el mensaje estaba completo y listo para entrar al sistema de entrega de correo. LOS CAMPOS PROCEDENCIA (ORIGINATOR) Los campos procedencia (originator) de un mensaje son “de” (from), “remitente” (sender) (cuando aplique), y opcionalmente el campo “contestar-a” (reply-to). El campo de (from) consiste de un nombre de campo “From” y una lista separada por comas de uno o más buzones. Si el campo de (from) contiene más de un buzón en la lista de buzones, entonces el campo remitente (sender), que contiene el nombre de campo “Sender” y un sólo buzón, DEBEN aparecer en el mensaje. from = "From:" mailbox-list CRLF sender = "Sender:" mailbox CRLF reply-to = "Reply-To:" address-list CRLF 134/165 El campo “From:” especifica el (los) autor(es) del mensaje, es decir, el (los) buzón(es) de la(s) persona(s) o sistema(s) responsable(s) de la escritura del mensaje. El campo “Sender:” especifica el buzón del agente responsable de la transmisión real del mensaje. Por ejemplo, si una secretaria enviara un correo de otra persona, el buzón de la secretaria aparecería en el campo “Sender:” y el buzón del autor del mensaje aparecería en el campo “From:”. Si el originador del mensaje se puede indicar por un sólo buzón y el transmisor y el autor son idénticos, el campo “Sender:” NO DEBERÍA usarse. Los campos procedencia (originator) también proporcionan la información necesaria para contestar un mensaje. Cuando está presente el campo “Contestar-a” (Reply-to) indica el (los) buzón(es) al (los) que el autor del mensaje sugiere que se envíe la respuesta. CAMPOS DE DIRECCIÓN DESTINO Consisten de tres campos posibles, cada uno con la misma forma: el nombre del campo, el cual es ya sea “To”, “Cc” o “Bcc”, seguido de una lista de una o más direcciones separadas por coma. to = "To:" address-list CRLF cc = "Cc:" address-list CRLF bcc = "Bcc:" (address-list / [CFWS]) CRLF Estos campos especifican los destinatarios del mensaje. Cada campo puede tener una o más direcciones y la única diferencia entre estos campos es la forma en que se usan. El campo “To:” contiene la(s) dirección(es) del (de los) destinatario(s) primario(s) del mensaje. El campo “Cc” (copia al carbón) contiene las direcciones de otros usuarios que recibirán el mensaje, aunque el contenido del mensaje no esté dirigido a ellos. El campo “Bcc” (copia ciega al carbón) contiene las direcciones de destinatarios del mensaje cuyas direcciones no serán reveladas a otros destinatarios del mensaje. CAMPOS DE IDENTIFICACIÓN Aunque es opcional, cada mensaje DEBERÍA tener un campo “Message-ID:”. El campo “Message-ID:” contiene un identificador único de mensaje. Los campos “Referencias:” (References) y “en-respuesta-a” (inreply-to) contienen uno o más identificadores, opcionalmente separados por CFWS. message-id = "Message-ID:" msg-id CRLF in-reply-to = "In-Reply-To:" 1*msg-id CRLF references = "References:" 1*msg-id CRLF 135/165 El campo “Message-ID:” proporciona un identificador único de mensaje, que se refiere a una versión particular de un mensaje en especial. La unicidad del identificador del mensaje está asegurada por el host que lo genera. Este identificador tiene significado para la máquina y no necesariamente para el humano. Los campos “En-respuesta-a” (In-reply-to) y “Referencias” (References) se usan cuando se responden mensajes. Contienen el identificador del mensaje original y los identificadores de otros mensajes. Cuando se crea una respuesta a un mensaje, los campos “In-reply-to” y “References” del mensaje resultante se utilizan de la siguiente forma: el campo “In-reply-to” tiene el contenido del campo “Message-ID:” del mensaje que se está respondiendo (el “mensaje padre”). Si existe más de un mensaje padre, el campo “In-reply-to:” contendrá el contenido de todos los campos “Message-ID:” padres. CAMPOS DE INFORMACIÓN Estos campos son opcionales. El campo “keywords:” contiene una lista de una o más palabras o cadenas acotadas, separadas por comas. Los campos “Asunto” (Subject:) y “Comentarios” (Comments) son no estructurados y por lo tanto pueden contener texto o FWS. subject = "Subject:" unstructured CRLF comments = "Comments:" unstructured CRLF keywords = "Keywords:" phrase *("," phrase) CRLF Estos tres campos contienen información acerca del mensaje, de interés para el humano. El campo “Subject:” es el más común y contiene una cadena corta que identifica el tópico del mensaje. Cuando se utiliza para responder un mensaje, el cuerpo del campo puede empezar con “Res:”, seguida del contenido del campo “Subject:” del mensaje original. El campo “Comments:” contiene cualquier comentario adicional sobre el texto del mensaje. El campo “Keywords:” contiene una lista de palabras y frases importantes, separadas por comas, que podrían ser útiles para el destinatario. 136/165 ANEXO E rfc 2045 Extensiones de Correo Internet Multipropósito, Multipurpose Internet Mail Extensions (MIME) Parte Uno: Formatos de Cuerpos de Mensajes Internet, Internet Message Body Formats Este conjunto de documentos, conocido como Extensiones de Correo Internet Multipropósito, MIME (Multipurpose Internet Mail Extensions), redefine el formato de los mensajes considerados en la rfc 822 para permitir lo siguiente: • • • • Cuerpos de mensaje textual en conjuntos de caracteres diferentes al US-ASCII. Un conjunto extensible de diferentes formatos para cuerpos de mensaje de no texto. Cuerpos de mensaje multiparte. Información de encabezado en texto en conjuntos de caracteres diferentes al US-ASCII. Este primer documento especifica los distintos encabezados utilizados para describir la estructura de los mensajes MIME. El segundo documento, rfc 2046, define la estructura general del sistema de tipos de medios MIME y define un conjunto general de tipos de medios. El tercer documento, rfc 2047, define extensiones de rfc 822 para permitir datos de texto no US-ASCII en los campos de encabezado de correo Internet. El cuarto documento, rfc 2048, especifica diferentes procedimientos de registro IANA para opciones relacionadas con MIME. El quinto y último documento, rfc 2049, describe los criterios para apegarse a MIME. Asimismo, proporciona algunos ejemplos ilustrativos de formatos de mensaje MIME, reconocimientos y bibliografía. Este documento describe varios mecanismos que se combinan para cubrir las deficiencias de la rfc 822, y estos son: • • • Un campo de encabezado Versión-MIME (MIME-Version), que utiliza un número de versión para declarar que un mensaje se apega a MIME y que permite que los agentes de procesamiento de correo puedan distinguir entre estos mensajes y aquellos generados por software antiguo o que no cumple, y que presumiblemente carecen de este campo. Un campo de encabezado Tipo-Contenido (Content-Type), que se puede utilizar para especificar el tipo y subtipo de medios de datos en el cuerpo del mensaje, y para especificar completamente la representación nativa (forma canónica) de tales datos. Un campo de encabezado Codificación-Transferencia-Contenido (Content-Transfer-Encoding), que se puede utilizar para especificar tanto la transformación de codificación que se aplicó al cuerpo, como el dominio del resultado. Las transformaciones de código se aplican normalmente a los datos para permitirles 137/165 • que pasen a través de sistemas de transporte de correo que podrían tener limitaciones de datos o de conjuntos de caracteres. Dos campos de encabezado adicionales que se pueden usar para describir más ampliamente los datos en el cuerpo, el Identificador-Contenido (Content-ID) y la Descripción-Contenido (Content-Description). CAMPOS DE ENCABEZADO MIME MIME define varios nuevos campos de encabezado rfc 822, que se utilizan para describir el contenido de una entidad MIME. Estos campos de encabezado ocurren en los siguientes dos contextos: 1. Como parte de un encabezado regular de un mensaje rfc 822. 2. En un encabezado de parte de cuerpo MIME dentro de una estructura multiparte. La definición formal de estos campos de encabezado es la siguiente: entity-headers := [ content CRLF ] [ encoding CRLF ] [ id CRLF ] [ description CRLF ] *( MIME-extension-field CRLF ) MIME-message-headers := entity-headers fields version CRLF ; The ordering of the header ; fields implied by this BNF ; definition should be ignored. MIME-part-headers := entity-headers [ fields ] ; Any field not beginning with ; "content-" can have no defined ; meaning and may be ignored. ; The ordering of the header ; fields implied by this BNF ; definition should be ignored. CAMPO DE ENCABEZADO Versión-MIME (MIME-Version) Este campo se utiliza para declarar la versión del estándar del formato del cuerpo de mensaje de Internet en uso. Los mensajes que se compongan utilizando este estándar, deben de tener tal campo de encabezado con el siguiente texto: 138/165 MIME-Version: 1.0 La presencia de este campo de encabezado es una afirmación de que el mensaje está compuesto utilizando este estándar. Cuando no existe un campo MIME-Version, un agente de usuario de correo receptor, MUA (receiving Mail User Agent) opcionalmente puede escoger interpretar el cuerpo del mensaje de acuerdo a convenciones locales. CAMPO DE ENCABEZADO Tipo-Contenido (Content-Type) El propósito de este campo, es describir completamente los datos contenidos en el cuerpo para que el agente de usuario receptor, pueda escoger un agente o mecanismo apropiado para presentar los datos al usuario, o manejar adecuadamente los datos de otra forma. El valor en este campo se conoce como tipo de medio (media type). Este campo especifica la naturaleza de los datos en el cuerpo de una entidad, dando los identificadores de tipo de medio (media type) y subtipo (subtype), y proveyendo información auxiliar que puede ser requerida por ciertos tipos de medios. Después de los nombres de tipos y subtipos de medios, lo que resta del campo de encabezado es simplemente un conjunto de parámetros, especificado en una notación atributo = valor. El orden de los parámetros no importa. En general, el tipo de medio (media type) de alto nivel se utiliza para declarar el tipo general de datos, mientras que el subtipo especifica un formato específico para ese tipo de datos. En la rfc 2046 se define un conjunto de siete tipos de medios de alto nivel. CAMPO DE ENCABEZADO DE CODIFICACIÓN DE TRANSFERENCIA DE CONTENIDO Muchos tipos de medios, que podrian ser transportados útilmente vía correo electrónico, se representan en forma natural en palabras de 8 bits, pero tal formato no lo soportan algunos protocolos de transporte. Por ejemplo, SMTP restringe el tamaño de los datos a 7 bits del código US-ASCII, con líneas de no más de 1000 caracteres incluyendo los caracteres de separación de línea CRLF. Por lo tanto, es necesario definir un mecanismo para codificar tales datos en un formato de 7 bits. El valor de este campo es un sólo token que especifica el tipo de codificación, tal como se indica a continuación: codificación := “Content-Transfer-Encoding” “:” mecanismo mecanismo := “7bit” /“8bit” /“binary”/“quoted-printable” /“base64”/ ietf-token/x-token El valor por default es 7bit. 139/165 ANEXO F rfc 2046 Extensiones de Correo Internet Multipropósito, Multipurpose Internet Mail Extensions (MIME) Parte dos: Tipos de Medios, Media Types Definición de un tipo de medio de alto nivel. La definición consiste de: 1. Un nombre y una descripción del tipo, incluyendo el criterio por el cual un tipo particular calificaría dentro de dicho tipo. 2. Los nombres y definiciones de los parámetros, si existen, que están definidos para todos los subtipos de ese tipo (incluyendo si dichos parámetros son requeridos u opcionales). 3. Cómo un agente de usuario y/o un gateway deberían manejar los subtipos desconocidos de este tipo. 4. Consideraciones generales de entidades que realizan funciones de gateway de este tipo de alto nivel, si existen. 5. Cualquier restricción en codificaciones de transferencia de contenido para entidades de este tipo de contenido. GENERALIDADES DE LOS TIPOS DE MEDIO DE ALTO NIVEL INICIALES Los cinco tipos de medios de alto nivel discretos son: 1. texto (text) – información textual. El subtipo “plano” (plain) en particular, indica texto plano sin comandos de formato o directivas de ningún tipo. El texto plano está pensado para ser desplegado “como es”. No se requiere software especial para obtener el significado total del texto, aparte del soporte para el conjunto de caracteres indicado. Se puede utilizar el parámetro “conjunto de caracteres” (charset) para indicar el conjunto de caracteres que se utiliza en el cuerpo, acompañado del subtipo “texto/plano” (text/plain) utilizado comúnmente para texto plano. El texto plano es visto como una secuencia lineal de caracteres, interrumpida algunas veces por saltos de línea o de página. Aparte del texto plano existe lo que se conoce con el nombre de texto enriquecido, que aún sin el software apropiado se puede mostrar al usuario como “texto” (text), ya que es legible. El parámetro charset puede estar especificado en el campo Content-Type para datos “text/plain”. Se vería como sigue: Content-type: text/plain; charset=iso-8859-1 El parámetro charset por default es “US-ASCII” 2. imagen (image) – datos de imagen. “image” requiere un dispositivo de despliegue (tal como una pantalla gráfica, una impresora gráfica, o un fax) para ver la información. Se define un subtipo inicial para el 140/165 formato de imagen JPEG ampliamente utilizado. Están definidos subtipos para los dos formatos de imagen más utilizados, gif y jpeg. Los subtipos no reconocidos de “imagen” (image) se deben tratar como “application/octet-stream”. Algunas implementaciones pueden escoger pasar los subtipos no reconocibles a una aplicación segura y robusta de propósito general para ver imagenes, en caso de que esté disponible alguna. 3. audio – datos de audio. “audio” requiere de un dispositivo de salida de audio (tal como una bocina o un teléfono) para “desplegar” el contenido. Está definido un subtipo inicial “basico” (basic) en este documento. El contenido del subtipo “audio/basic” es un canal de audio codificado en 8 bits ISDN ley Mu (PCM), a una frecuencia de muestreo de 8 kHz. Los subtipos no recocidos de audio deben ser tratados como “application/octet-stream”. Algunas implementaciones pueden escoger pasar los subtipos no reconocibles a una aplicación segura y robusta de propósito general para tocar audio, en caso de que esté disponible alguna. 4. video – datos de video. “video” requiere de capacidad de desplegar imagenes móviles, e incluye típicamente hardware y software especializado. Se define un subtipo inicial “mpeg” en este documento. El tipo de medio “video”, indica que el cuerpo contiene una imagen variable en el tiempo, posiblemente con color y sonido coordinado. Subtipos no reconocidos de video deben ser tratados como “application/octet-stream”. Algunas implementaciones pueden escoger pasar los subtipos no reconocibles, a una aplicación segura y robusta de propósito general para tocar video, en caso de que esté disponible alguna. 5. aplicación (application) – otro tipo de datos, ya sea datos binarios sin interpretar o información a ser procesada por una aplicación. El subtipo “octet-stream” se utiliza en el caso de datos binarios sin interpretar, en cuyo caso la acción más simple recomendada es ofrecer escribir la información en un archivo para el usuario. Otros usos esperados para “aplicación” (application) incluyen hojas de cálculo, lenguajes para mensajería “activa”, y formatos de procesamiento de palabras que no son legibles directamente. Se utiliza para datos discretos que no encajan en otra categoría y que generalmente serán procesados por algún tipo de programa de aplicación. Tiene dos subtipos: octet-stream y PostScript. El subtipo octet-stream se utiliza para indicar que el cuerpo contiene datos binarios arbitrarios. La acción recomendada para una implementación que reciba datos tipo “application/octet-stream” es poner los datos en un archivo. Un tipo de medios “application/postscript” indica un programa postscript. La definición del lenguaje Postscript, proporciona herramientas para el etiquetado interno de los recursos del lenguaje específico, que utiliza un programa dado. Los dos tipos de medios compuestos de alto nivel, los cuales se manejan por mecanismos MIME, son: 1. multiparte (multipart) – datos que consisten de múltiples entidades de tipos de datos independientes. Se definen cuatro subtipos iniciales, incluyendo el subtipo básico “mezclado” (mixed) que especifica un conjunto genérico mezclado de partes; “alternativo” (alternative) para representar los mismos datos en 141/165 múltiples formatos; “paralelo” (parallel) para partes que se ven simultáneamente; y “resumen” (digest) para entidades multiparte en las que cada parte tiene un tipo default de “message/rfc822”. Los cuerpos van precedidos de una línea delimitadora y terminan también con una línea delimitadora. Después de la línea delimitadora, sigue un encabezado, una línea en blanco, y un cuerpo del mensaje. Un cuerpo que carece de encabezado se asume que tiene valores por default. La ausencia de un encabezado de Content-Type indica que se tienen los siguientes valores: Content-Type="text/plain; charset=US-ASCII". 2. mensaje (message) – un mensaje encapsulado. Un cuerpo de tipo de medios “message” es en sí mismo todo o parte de algún tipo de objeto mensaje. Tales objetos pueden o no contener otras entidades. Se utiliza el subtipo “rfc822” cuando el contenido encapsulado es un mensaje rfc 822. El subtipo “parcial” (partial) se usa para mensajes rfc 822 parciales, para permitir la transmisión fragmentada de cuerpos que son demasiado grandes para pasar enteros a través de servicios de transporte. 142/165 ANEXO G rfc 2047 Extensiones de Correo Internet Multipropósito, Multipurpose Internet Mail Extensions (MIME) Parte tres: Extensiones de Encabezado de Mensaje para Texto No ASCII, Message Header Extensions for Non-ASCII Text La rfc 2045 describe un mecanismo para denotar partes de cuerpos textuales que están codificados en diferentes conjuntos de caracteres, así como métodos para codificar tales partes como secuencias de caracteres US-ASCII imprimibles. Este documento describe técnicas similares para permitir la codificación de texto no ASCII, en varias partes de un encabezado de mensaje tipo rfc 822, de tal forma que sea improbable confundir al software manejador de mensajes existente. Algunos programas de reenvío de correo se sabe que hacen lo siguiente: • borran algunos campos de encabezado de mensaje mientras que retienen otros, • reordenan las direcciones en los campos To o Cc, • reordenan (verticalmente) los campos de encabezado, • y/o “envuelven” los encabezados de mensaje en lugares diferentes a los del mensaje original. Además, algunos programas de correo tienen dificultad para interpretar correctamente los encabezados de mensaje que, aunque se apegan al estándar rfc 822, utilizan el caracter diagonal invertida (backslash) para esconder caracteres especiales como “<”, “,” o “:”, o que explotan otras características poco frecuentes de rfc 822. Un programa de composición de correo que implemente este estándar proveerá medios para introducir texto no ASCII en los campos de encabezado, pero traducirá dichos campos en palabras codificadas antes de insertarlos en el encabezado del mensaje. Un lector de correo que implementa esta especificación, reconocerá las palabras codificadas y las traducirá en el texto original, antes de mostrarlas al usuario. SINTAXIS DE LAS PALABRAS CODIFICADAS Una “palabra codificada“ (encoded-word) se define por la siguiente gramática, utilizando la notación rfc822 excepto que los espacios en blanco NO DEBEN aparecer entre los componentes de una palabra codificada. encoded-word = "=?" charset "?" encoding "?" encoded-text "?=" charset = token ; encoding = token ; 143/165 token = 1*<cualquier CHAR excepto SPACE, CTLs, y especials> especials = "(" / ")" / "<" / ">" / "@" / "," / ";" / ":" / " <"> / "/" / "[" / "]" / "?" / "." / "=" encoded-text = 1*<Cualquier caracter ASCII imprimible a parte de "?" o SPACE> ; Una palabra codificada no puede tener más de 75 caracteres de longitud, incluyendo “charset”, “encoding”, “encoding-text” y los delimitadores. Si se desea codificar más caracteres se puede hacer con múltiples “encoded-words” (separadas por caracteres de CRLF y SPACE). Si bien no existe límite para la longitud de un campo de encabezado de múltiples líneas, cada línea de un campo de encabezado que contiene una o más “palabras codificadas” está limitada a 76 caracteres. Las restricciones de longitud sirven tanto para facilitar la interoperabilidad entre mail gateways, como para imponer un límite a la cantidad de tiempo que un analizador de encabezado debe emplear, para decidir si un token es una “palabra codificada” (encoded-word) o alguna otra cosa. CONJUNTOS DE CARACTERES La parte de “charset” de una “palabra codificada” (encoded-word) especifica el conjunto de caracteres asociado con el texto sin codificar. Un “charset” puede ser cualquiera de los nombres de conjuntos de caracteres permitidos, en un parámetro “charset” de MIME de un cuerpo de mensaje “text/plain”, o cualquier nombre de conjuntos de caracteres registrados con IANA para utilizarse con un tipo de contenido MIME “text/plain”. CODIFICACIONES Inicialmente, los valores legales para la parte de “codificación” (encoding) son “Q” y “B”. La codificación “Q” se utiliza cuando la mayoría de los caracteres que se quieren codificar pertenecen al código ASCII; en caso contrario se utiliza la codificación “B”. 144/165 ANEXO H rfc 2048 Extensiones de Correo Internet Multipropósito, Multipurpose Internet Mail Extensions (MIME) Parte cuatro: Procedimientos de Registro, Registration Procedures Especifica varios procedimientos de registro IANA (Autoridad de Internet de Números Asignados, Internet Assigned Numbers Authority) para las siguientes opciones MIME: 1. tipos de medios, 2. tipos externos de acceso a cuerpos de mensajes, 3. codificaciones de transferencia de contenido. Se han desarrollado cuidadosamente protocolos de Internet recientes, para ser extendibles fácilmente en ciertas áreas. Por ejemplo, rfc 2045 es una plataforma abierta y puede dar cabida a tipos de objetos adicionales, conjuntos de caracteres y métodos de acceso sin necesidad de modificar el protocolo básico. Sin embargo, se requiere de un proceso de registro para asegurar que el conjunto de tales valores sea desarrollado en una forma ordenada, detallada y pública. Este documento define procedimientos de registro, que utilizan la IANA como un registro central para tales valores. REGISTRO DE TIPOS DE MEDIOS El registro de un nuevo(s) tipo(s) de medio empieza con la construcción de una propuesta de registro. El registro puede ocurrir en diferentes arboles de registro, los cuales tienen diversos requerimientos. 145/165 ANEXO I rfc 2049 Extensiones de Correo Internet Multipropósito, Multipurpose Internet Mail Extensions (MIME) Parte cinco: Criterios de Cumplimiento y Ejemplos, Conformance Criteria and Examples Describe qué porciones de MIME debe soportar una aplicación MIME. También describe varios errores de sistemas contemporáneos de mensajería, así como el modelo de codificación canónico sobre el que está basado MIME. Un agente de usuario de correo compatible con MIME DEBE: 1. Generar siempre un campo de encabezado de “MIME-version:1.0” en cualquier mensaje que crea. 2. Reconocer el campo de encabezado Content-Transfer-Encoding y decodificar todos los datos recibidos, codificados en implementaciones ya sea quoted-printable o Base64. También deben ser reconocidas las transformaciones de identidad de 7 bits, 8 bits y binarias. Cualesquiera datos de no 7 bits sin codificar deben ser etiquetados con un Content-Transfer-Encoding de 8 bits o binario, según corresponda. Si el transporte no soporta 8 bits o binario (tal como SMTP rfc822), se requiere que el emisor codifique y etiquete los datos utilizando un content-transfer-encoding apropiado, tal como quoted-printable o base64. 3. Tratar cualquier content-transfer-encoding desconocido como si tuviera un content-type de “application/octet-stream”, sin importar si el Content-Type real es reconocido o no. 4. Reconocer e interpretar el campo de encabezado Content-Type, y evitar mostrar a los usuarios datos crudos con un Content-Type diferente de texto. Las implementaciones deben de ser capaces de enviar al menos mensajes text/plain, con el conjunto de caracteres especificado con el parámetro charset si no es US-ASCII. 5. Ignorar cualesquiera parámetros de tipo de contenido cuyos nombres no reconocen. 6. Manejar explícitamente los siguientes valores de tipos de medios, Texto, Text: • Reconoce y despliega correo de “texto” con el conjunto de caracteres US-ASCII. • Reconoce algunos otros conjuntos de caracteres, para al menos ser capaz de informar al usuario acerca del conjunto de caracteres que utiliza el mensaje. • Trata material de conjuntos de caracteres desconocidos como si fuera "application/octet-stream". Imagen (Image), audio y video: • provee opciones mínimas para tratar subtipos desconocidos como si fueran "application/octet-stream". Aplicación (Application): • ofrece la opción de remover la codificación quoted-printable o base64 y poner la información resultante en un archivo de usuario. 146/165 Multiparte (Multipart): • reconoce el subtipo mezclado (mixed). Despliega toda la información relevante a nivel de mensaje, al nivel de encabezado de cuerpo y entonces despliega u ofrece desplegar cada parte de cuerpo de mensaje individualmente. • trata cualesquiera subtipos desconocidos como si fueran “mixed”. Mensaje (Message): • reconoce y despliega al menos la encapsulación de mensaje rfc 822 de forma tal de preservar cualquier estructura recursiva, es decir, despliega u ofrece desplegar los datos encapsulados de acuerdo a su tipo de medio. 147/165 ANEXO J Código fuente del robot de correo y programas complementarios El archivo que contiene el código fuente del robot de correo electrónico se llama robotCorreo.java. Además de este programa principal, se incluyen dos programas complementarios: carga_planes.java y carga_archivos, que sirven para subir los archivos binarios [24 y 25] que corresponden a los planes de estudio y de información general, en formato PDF y HTML respectivamente, en la base de datos de respuestas. Antes de subir los archivos a la base de datos, es necesario dar de alta manualmente cada clave de licenciatura o posgrado dentro de sus respectivas tablas. Antes de poder utilizar los programas se tuvieron que compilar por única vez mediante la siguiente instrucción: c:\Archivos de programa\robot de correo\javac nombre_programa.java Con esto obtuvimos los archivos en bytecodes del tipo nombre_programa.class, los cuales ya se pueden correr utilizando el intérprete de Java adecuado. La forma de ejecutar los programas es la siguiente: c:\Archivos de programa\robot de correo\java carga_planes clave archivo.pdf estudios donde, clave archivo.pdf estudios es el código asignado a cada licenciatura o posgrado es el nombre completo del archivo pdf, incluyendo su ruta relativa al directorio actual es LIC para licenciaturas y POS para posgrados c:\Archivos de programa\robot de correo\java carga_archivos clave archivo.html estudios donde, clave archivo.html estudios es el código asignado a cada licenciatura o posgrado es el nombre completo del archivo html, incluyendo su ruta relativa al directorio actual es LIC para licenciaturas y POS para posgrados c:\Archivos de programa\robot de correo\java robotCorreo freq server user pass false|trae donde, freq server user pass false|true es la cantidad de milisegundos entre cada revisión del INBOX es el nombre o la dirección IP del servidor de correo es el nombre de usuario de la cuenta de correo es la contraseña de la cuenta de correo desactiva o activa la visualización del depurador de JavaMail Para detener la ejecución del programa hay que oprimir las teclas CTRL+C 148/165 /* robotCorreo es un robot de correo que sirve para monitorear una cuenta de correo y ** responder automáticamente los mensajes dirigidos a ésta, valiendose de una base ** de datos */ /*uso:java robotCorreo freq server username password true|false **donde freq es el número de milisegundos que espera el robot **antes de volver a revisar el buzón; server es la dirección IP o el nombre **del servidor SMTP; username y password son el nombre de usuario **y la contraseña, respectivamente, de la cuenta de correo que **revisa el robot; el último parámetro enciende o apaga el depurador */ import javax.mail.*; import javax.mail.internet.*; import java.util.*; import java.io.*; import java.sql.*; import javax.sql.*; import javax.activation.*; //Definición de la clase robotCorreo public class robotCorreo{ static String server=""; static String username=""; static String password=""; static String emailSubjectTxt=""; static String emailFromAddress = "[email protected]"; static String email=""; //Comienza el método main public static void main(String args[]){ if (args.length != 5) { System.out.println("uso: java robotCorreo <freq> <server> <username> <password>"+ " true|false"); return; } server= args[1]; 149/165 username= args[2]; password= args[3]; boolean debug = Boolean.valueOf(args[4]).booleanValue(); try { int freq = Integer.parseInt(args[0]); long time=0; for (; ;) { time=System.currentTimeMillis(); revisaInbox(server, username, password, debug); System.out.println("El revisar el buzon y procesar todos los mensajes "+ "tomo: " + (System.currentTimeMillis()-time) + " milisegundos"); Thread.sleep(freq); // Después de revisar el INBOX y procesar los // mensajes, el robot espera unos milisegundos // para volver a empezar } }catch (Exception e){ System.err.println(e); } System.exit(0); } //Termina el método main //Comienza método revisaInbox //revisaInbox se encarga de conectarse al servidor POP3 //obtener los encabezados de los mensajes y procesarlos public static void revisaInbox(String server,String username,String password, boolean debug){ Store store=null; Folder folder=null; //Comienza bloque try-catch 1 try{ // -- Obtiene la sesión por default -Properties props = System.getProperties(); Authenticator auth = new SMTPAuthenticator(); Session session = Session.getDefaultInstance(props, auth); 150/165 session.setDebug(debug); // -- Obtiene un almacén de mensajes POP3, y se conecta a él -store = session.getStore("pop3"); store.connect(server, username, password); // -- Obtiene el folder por default -folder = store.getDefaultFolder(); if (folder == null) throw new Exception("No existe default folder"); // -- Obtiene su "INBOX" -folder = folder.getFolder("INBOX"); if (folder == null) throw new Exception("No existe POP3 INBOX"); // -- Abre el folder para lectura y escritura-folder.open(Folder.READ_WRITE); //Comienza bloque try-catch 2 try{ Message[] msgs = folder.getMessages(); int msgNum = msgs.length; if(msgNum==0){ System.out.println("No hay mensajes: "+msgNum); return;} System.out.println("num de mensajes: "+msgNum); // -- Obtiene y procesa cada uno de los mensajes -long time2=0; while(msgNum>0){ time2=System.currentTimeMillis(); procesaMensaje(msgs[--msgNum],props,auth); System.out.println("El procesar el mensaje "+(msgNum+1) +" tomo: " + (System.currentTimeMillis()-time2) + " milisegundos"); } }catch (ArrayIndexOutOfBoundsException iex){ iex.printStackTrace(); } //Termina bloque try-catch 2 }catch (Exception e){ e.printStackTrace(); }//Termina bloque try-catch 1 finally{ //Comienza bloque try-catch 3 try{ if (folder!=null) folder.close(true); 151/165 if (store!=null) store.close(); }catch (Exception e) { e.printStackTrace(); }//Termina bloque try-catch 3 }//Termina bloque finally } // Termina el método revisaInbox //Comienza el método procesaMensaje public static boolean procesaMensaje(Message message, Properties props, Authenticator auth ){ Calendar today = Calendar.getInstance(); String emailmsg=""; try{ // Obtiene información del encabezado String subject = message.getSubject(); String dateString = ""; String to = ((InternetAddress)message.getAllRecipients()[0]).getPersonal(); String toEmail = ((InternetAddress)message.getAllRecipients()[0]).getAddress(); String from = ((InternetAddress)message.getFrom()[0]).getPersonal(); email = ((InternetAddress)message.getFrom()[0]).getAddress(); if (to==null) to = toEmail; if (from==null) from = email; java.util.Date date=message.getSentDate(); Calendar mDate = Calendar.getInstance(); // Verifica la fecha de envío de los mensajes y procesa únicamente los // del dia de hoy y de hasta 3 dias de antiguedad. if(date!=null){ dateString = date.toString(); mDate.setTime(date); 152/165 if(mDate.get(Calendar.DAY_OF_MONTH)< today.get(Calendar.DAY_OF_MONTH)-3) return false; } System.out.println("DATE: "+dateString); System.out.println("TO: "+to+" <"+toEmail +">"); System.out.println("FROM: "+from+" <"+email +">"); System.out.println("SUBJECT: "+subject); // -- Obtiene el mensaje -int msgid =message.getMessageNumber(); Part messagePart=message; Object content=messagePart.getContent(); if (content instanceof Multipart){ for(int i=0;i<((Multipart)content).getCount();i++){ messagePart=((Multipart)content).getBodyPart(i); String contentType=messagePart.getContentType(); if (contentType.startsWith("text/plain") || contentType.startsWith("text/html")){ emailmsg = leerMensaje(messagePart); System.out.println(emailmsg); System.out.println("El ID de este mensaje es: "+msgid); message.setFlag(Flags.Flag.DELETED, true); // establece la bandera DELETED } } }else{ String contentType=messagePart.getContentType(); if (contentType.startsWith("text/plain") || contentType.startsWith("text/html")){ emailmsg = leerMensaje(messagePart); System.out.println(emailmsg); System.out.println("El ID de este mensaje es: "+msgid); message.setFlag(Flags.Flag.DELETED, true); // establece la bandera DELETED } } emailSubjectTxt=subject; }catch (Exception ex){ ex.printStackTrace(); } enviarCorreo(props, auth, email, emailSubjectTxt, emailmsg, emailFromAddress); 153/165 return true; } //Termina el método procesaMensaje //Comienza el método leerMensaje //leerMensaje lee línea por línea el mensaje public static String leerMensaje(Part messagePart){ String message = ""; //inicia bloque try-catch try{ String contentType=messagePart.getContentType(); if (contentType.startsWith("text/plain")|| contentType.startsWith("text/html")){ InputStream is = messagePart.getInputStream(); BufferedReader reader = new BufferedReader(new InputStreamReader(is)); String line = reader.readLine(); while(line!=null){ message = message + line+'\n'; line = reader.readLine(); } } }catch(Exception e){ System.err.println(e); } //termina bloque try-catch return message; } //termina el método leerMensaje //Comienza el método enviarCorreo public static void enviarCorreo(Properties props, Authenticator auth, String recipient, String subject, String body, String from){ try{ //Establece la dirección IP del host y habilita la autenticación props.put("mail.smtp.host", server); props.put("mail.smtp.auth", "true"); 154/165 Session session = Session.getDefaultInstance(props, auth); // crea un mensaje Mime Message msg = new MimeMessage(session); // establece la dirección de remitente y destinatario System.out.println("Mensaje de: "+from); InternetAddress addressFrom = new InternetAddress(from); msg.setFrom(addressFrom); System.out.println("Mensaje para: "+recipient); InternetAddress[] addressTo ={ new InternetAddress(recipient)}; msg.setRecipients(Message.RecipientType.TO, addressTo); // Establece el contenido del mensaje a través de las palabras clave // encontradas en el campo Asunto y en el campo Cuerpo del mensaje Multipart mp = consultaBase(subject, body); // Agrega el objeto Multipart al mensaje msg.setContent(mp); subject="RPLY: " +subject; msg.setSubject(subject); Transport.send(msg); }catch(MessagingException e){ e.printStackTrace(); } } // Fin del método enviarCorreo /** * consultaBase se utiliza para seleccionar la respuesta al correo * dentro de la base de datos de acuerdo al contenido de los campos * "Asunto" y "cuerpo" */ public static Multipart consultaBase(String subject, String body){ String url = "jdbc:odbc:robot"; boolean CBI=false; boolean CSH=false; boolean CAD=false; boolean LIC=false; 155/165 boolean POS=false; String palabra=""; String texto="Pidio informacion de las siguientes areas: "; String texto2="Nivel de estudios: "; Multipart mp= new MimeMultipart(); StringTokenizer s = new StringTokenizer(subject+'\n'+body, " =:.,?!¿¡\t\n\r"); while(s.hasMoreTokens() && (CBI==false || CAD==false || CSH==false || LIC==false || POS==false)){ palabra=s.nextToken().toUpperCase(); System.out.println("el token es: "+palabra); if(palabra.equals("CBI") && CBI==false) { CBI=true; texto=texto+palabra+", "; } else if(palabra.equals("CAD") && CAD==false) { CAD=true; texto=texto+palabra+", "; } else if(palabra.equals("CSH") && CSH==false) { CSH=true; texto=texto+palabra+", "; } else if((palabra.startsWith("LIC") || palabra.startsWith("CARR"))&& LIC==false) { palabra="LICENCIATURAS"; LIC=true; texto2=texto2+palabra+", "; } else if(POS==false && (palabra.startsWith("POS") || palabra.startsWith("MAEST") || palabra.startsWith("DOCTOR") || palabra.startsWith("ESPECIALI")) ) { palabra="POSGRADOS"; POS=true; texto2=texto2+palabra+", "; } } if((!CBI && !CSH && !CAD && !LIC && !POS) || (!LIC && !POS)){ try { // Crea y llena la primera parte del mensaje texto ="Al parecer no tenemos la informacion que busca."+'\n'+ "Por favor, revise el archivo anexo para conocer la informacion "+ "disponible y/o como enviar un correo para solicitarla."; MimeBodyPart mbp1 = new MimeBodyPart(); mbp1.setText(texto); 156/165 // Crea la segunda parte del mensaje MimeBodyPart mbp2 = new MimeBodyPart(); // Agrega el archivo al mensaje String filename="leame.html"; FileDataSource fds = new FileDataSource(filename); mbp2.setDataHandler(new DataHandler(fds)); mbp2.setFileName(fds.getName()); // Le agrega las partes al objeto Multipart mp.addBodyPart(mbp1); mp.addBodyPart(mbp2); return(mp); }catch(MessagingException e){ e.printStackTrace(); } } texto=texto.substring(0, (texto.length()-2) ); texto2=texto2.substring(0, (texto2.length()-2) ); System.out.println(texto); System.out.println(texto2); String respuesta1=""; String respuesta2=""; try{ //se carga el driver JDBC Class.forName("sun.jdbc.odbc.JdbcOdbcDriver"); //se conecta a la fuente de datos(la base de datos) Connection con = DriverManager.getConnection(url); Statement statement = con.createStatement( ); //recuperando información de la base de datos a través de una consulta //con el método executeQuery del objeto statement String SQLQuery11=""; String SQLQuery22=""; String SQLQuery1=""; String SQLQuery2=""; String division=""; if((CBI && CSH && CAD)||(!CBI && !CSH && !CAD)){ 157/165 SQLQuery1="SELECT nom_Lic, arch_Lic FROM Licenciatura"; SQLQuery2="SELECT nom_Pos, arch_Pos FROM Posgrado"; } if(CBI && !CSH && CAD){ SQLQuery1="SELECT nom_Lic, arch_Lic FROM Licenciatura WHERE"+ "(cve_Div = 'CBI' OR cve_Div = 'CAD')"; SQLQuery2="SELECT nom_Pos, arch_Pos FROM Posgrado WHERE"+ " (cve_Div = 'CBI' OR cve_Div = 'CAD')"; } if(CBI && CSH && !CAD){ SQLQuery1="SELECT nom_Lic, arch_Lic FROM Licenciatura WHERE"+ " (cve_Div = 'CBI' OR cve_Div='CSH')"; SQLQuery2="SELECT nom_Pos, arch_Pos FROM Posgrado WHERE"+ " (cve_Div = 'CBI' OR cve_Div='CSH')"; } if(!CBI && CSH && CAD){ SQLQuery1="SELECT nom_Lic, arch_Lic FROM Licenciatura WHERE"+ " (cve_Div = 'CSH' OR cve_Div='CAD')"; SQLQuery2="SELECT nom_Pos, arch_Pos FROM Posgrado WHERE"+ " (cve_Div = 'CSH' OR cve_Div='CAD')"; } if(CBI && !CSH && !CAD){ division="CBI"; if(LIC){ SQLQuery1="SELECT nom_Lic FROM Licenciatura WHERE"+ " cve_Div = '"+division+"';"; SQLQuery11="SELECT cve_Lic, nom_Lic, arch_Lic, plan_Lic FROM"+ " Licenciatura WHERE cve_Div = '"+division+"';"; mp=cargaAnexos("CBI",SQLQuery11,statement,mp); } if(POS){ SQLQuery2="SELECT nom_Pos, arch_Pos, plan_Pos FROM Posgrado"+ " WHERE cve_Div = '"+division+"';"; SQLQuery22="SELECT cve_Pos, nom_Pos, arch_Pos, plan_Pos FROM"+ " Posgrado WHERE cve_Div = '"+division+"';"; mp=cargaAnexos("CBI",SQLQuery22,statement,mp); } } if(!CBI && CSH && !CAD){ division="CSH"; if(LIC){ SQLQuery1="SELECT nom_Lic FROM Licenciatura WHERE"+ " cve_Div = '"+division+"';"; SQLQuery11="SELECT cve_Lic, nom_Lic, arch_Lic, plan_Lic FROM"+ 158/165 " Licenciatura WHERE cve_Div = '"+division+"';"; mp=cargaAnexos(division,SQLQuery11,statement,mp); } if(POS){ SQLQuery2="SELECT nom_Pos, arch_Pos, plan_Pos FROM Posgrado"+ " WHERE cve_Div = '"+division+"';"; SQLQuery22="SELECT cve_Pos, nom_Pos, arch_Pos, plan_Pos FROM"+ " Posgrado WHERE cve_Div = '"+division+"';"; mp=cargaAnexos(division,SQLQuery22,statement,mp); } } if(!CBI && !CSH && CAD){ division="CAD"; if(LIC){ SQLQuery1="SELECT nom_Lic FROM Licenciatura WHERE"+ " cve_Div = '"+division+"';"; SQLQuery11="SELECT cve_Lic, nom_Lic, arch_Lic, plan_Lic FROM"+ " Licenciatura WHERE cve_Div = '"+division+"';"; mp=cargaAnexos("CBI",SQLQuery11,statement,mp); } if(POS){ SQLQuery2="SELECT nom_Pos, arch_Pos, plan_Pos FROM Posgrado"+ " WHERE cve_Div = '"+division+"';"; SQLQuery22="SELECT cve_Pos, nom_Pos, arch_Pos, plan_Pos FROM"+ " Posgrado WHERE cve_Div = '"+division+"';"; mp=cargaAnexos("CBI",SQLQuery22,statement,mp); } } if(LIC){ respuesta1="Informacion de licenciaturas: " + '\n'; ResultSet resultsL = statement.executeQuery(SQLQuery1); String nombre=""; while (resultsL.next()){ nombre=resultsL.getString("nom_Lic"); respuesta1=respuesta1+nombre+'\n'; } System.out.println(respuesta1); MimeBodyPart mbp1 = new MimeBodyPart(); mbp1.setText(respuesta1); mp.addBodyPart(mbp1); } if(POS){ 159/165 respuesta2="Informacion de Posgrados: " + '\n'; ResultSet resultsP = statement.executeQuery(SQLQuery2); String nombre=""; while (resultsP.next() ){ nombre=resultsP.getString("nom_Pos"); respuesta2=respuesta2+nombre+'\n'; } System.out.println(respuesta2); MimeBodyPart mbp2 = new MimeBodyPart(); mbp2.setText(respuesta2); mp.addBodyPart(mbp2); } statement.close(); con.close(); }catch (Exception e){ System.out.println(e.getMessage() ); e.printStackTrace(); } return(mp); } //Fin del método consultaBase /** * cargaAnexos se utiliza para armar el contenido multiparte * a través de agregar cada archivo de la base de datos que * cumple con los requerimientos del usuario a un objeto Multipart */ public static Multipart cargaAnexos(String division, String SQLQuery, Statement statement, Multipart mp){ try{ ResultSet results = statement.executeQuery(SQLQuery); System.out.println("se obtuvo el resultset en cargaAnexos" ); java.io.InputStream fin=null; java.io.InputStream fin2=null; String clave=""; while (results.next() ){ clave=results.getString(1); fin= results.getBinaryStream(3); fin2= results.getBinaryStream(4); javax.activation.DataSource ds = new ByteArrayDataSource(fin, 160/165 "text/html"); javax.activation.DataSource ds2 = new ByteArrayDataSource(fin2, "application/pdf"); System.out.println("se obtuvo la respuesta"); // create and fill the first message part MimeBodyPart mbp1 = new MimeBodyPart(); mbp1.setDataHandler(new DataHandler(ds)); mbp1.setFileName(clave+".html"); mp.addBodyPart(mbp1); MimeBodyPart mbp2 = new MimeBodyPart(); mbp2.setDataHandler(new DataHandler(ds2)); mbp2.setFileName(clave+".pdf"); mp.addBodyPart(mbp2); } }catch (Exception e){ System.out.println(e.getMessage() ); e.printStackTrace(); } return(mp); } // fin del método cargaAnexos /** * SimpleAuthenticator es una clase que se utiliza para hacer una autenticación * cuando el servidor SMTP lo requiere. */ private static class SMTPAuthenticator extends javax.mail.Authenticator { public PasswordAuthentication getPasswordAuthentication() { String username_AUTH = username; String password_AUTH = password; return new PasswordAuthentication(username_AUTH, password_AUTH); } } } //termina clase robotCorreo 161/165 //carga_planes es un programa para cargar //un archivo con el plan de estudio en formato pdf //a la base de datos de respuestas. import java.util.*; import java.io.*; import java.sql.*; import javax.sql.*; import javax.activation.*; //Definición de la clase public class carga_planes{ //Comienza el método main public static void main(String args[]){ String nomcarrera=args[0]; String nomarch=args[1]; String base=args[2]; try { cargaArchivo(nomcarrera, nomarch, base); }catch (Exception e){ System.err.println(e); } System.exit(0); } //Termina el método main public static void cargaArchivo(String lic, String arch, String base) { String url = "jdbc:odbc:robot2"; PreparedStatement pstmt= null; Connection con=null; long time=System.currentTimeMillis(); try{ 162/165 //se carga el driver JDBC Class.forName("sun.jdbc.odbc.JdbcOdbcDriver"); //se conecta a la fuente de datos(la base de datos) con = DriverManager.getConnection(url); //recuperando información de la base de datos a través de una consulta //con el método executeQuery del objeto statement base=base.toUpperCase(); String sqlActual; if(base.equals("LIC")) sqlActual="UPDATE Licenciatura SET plan_Lic=? WHERE cve_Lic=?"; else sqlActual="UPDATE Posgrado SET plan_Pos=? WHERE cve_Pos=?"; pstmt = con.prepareStatement(sqlActual); File file = new File(arch); FileInputStream fis = new FileInputStream(file); pstmt.setBinaryStream(1, fis, (int)file.length()); pstmt.setString(2, lic); pstmt.execute(); System.out.println("El cargar el archivo tomó: " + (System.currentTimeMillis()-time) + " milisegundos"); }catch(SQLException se){ se.printStackTrace(); } catch (Exception e){ System.out.println(e.getMessage()); e.printStackTrace(); }finally { try{ if (con != null) con.close(); }catch(SQLException se){ se.printStackTrace(); } }//FIN DE FINALLY }// fin de cargaArchivo }//termina clase carga_planes 163/165 //carga_archivos es un programa para cargar //un archivo con información general en formato html //a la base de datos de respuestas. import java.util.*; import java.io.*; import java.sql.*; import javax.sql.*; import javax.activation.*; //Definición de la clase public class carga_archivos{ //Comienza el método main public static void main(String args[]){ String nomcarrera=args[0]; String nomarch=args[1]; String base=args[2]; try { cargaArchivo(nomcarrera, nomarch, base); }catch (Exception e){ System.err.println(e); } System.exit(0); } //Termina el método main public static void cargaArchivo(String lic, String arch, String base) { String url = "jdbc:odbc:robot2"; PreparedStatement pstmt= null; Connection con=null; long time=System.currentTimeMillis(); try{ //se carga el driver JDBC 164/165 Class.forName("sun.jdbc.odbc.JdbcOdbcDriver"); //se conecta a la fuente de datos(la base de datos) con = DriverManager.getConnection(url); //recuperando información de la base de datos a través de una consulta //con el método executeQuery del objeto statement base=base.toUpperCase(); String sqlActual; if(base.equals("LIC")) sqlActual="UPDATE Licenciatura SET arch_Lic=? WHERE cve_Lic=?"; else sqlActual="UPDATE Posgrado SET arch_Pos=? WHERE cve_Pos=?"; pstmt = con.prepareStatement(sqlActual); File file = new File(arch); FileInputStream fis = new FileInputStream(file); pstmt.setBinaryStream(1, fis, (int)file.length()); pstmt.setString(2, lic); pstmt.execute(); System.out.println("El cargar el archivo tomó: " + (System.currentTimeMillis()-time) + " milisegundos"); }catch(SQLException se){ se.printStackTrace(); } catch (Exception e){ System.out.println(e.getMessage()); e.printStackTrace(); }finally { try{ if (con != null) con.close(); }catch(SQLException se){ se.printStackTrace(); } }//FIN DE FINALLY }// fin de cargaArchivo } //termina clase carga_archivos 165/165