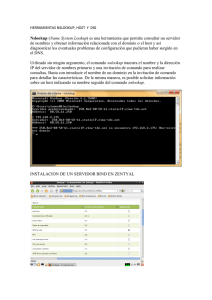
Redes TCP/IP bajo Unix: Conceptos básicos de - UTN
Anuncio

Redes TCP/IP bajo Unix Conceptos básicos de Operación y Administración. por Ing. Fernando A. Cuenca ([email protected]) Laboratorio de Sistemas - UTN Facultad Córdoba Introducción El presente trabajo persigue 2 objetivos: en primer lugar, presentar al lector las posibilidades que ofrece un ambiente de red basado en Unix; en segundo lugar, introducirlo en los conceptos básicos requeridos para administrar una red TCP/IP bajo el citado sistema operativo1. No obstante lo anterior, se hacen dos aclaraciones al lector: • Se asumirá que el lector posee conocimientos básicos de la terminología empleada en tecnología de redes (LAN vs WAN, topologías, medios de transmisión, protocolos, conmutación por paquetes, etc.). • "Lo maravilloso de los estándares es que hay muchos de donde elegir" -- Almirante Grace Murray Hooper2. Uno de los grandes mitos acerca de Unix es su nivel de estandarización. Si bien todas las diversas variantes (o flavors) de Unix comparten una filosofía común muy amplia lo cual hace posible un alto grado de similitud entre todas ellas, en el momento de afinar los detalles de la implementación suelen aparecer discrepancias (en particular, los nombres de los comandos, el formato y nombre de los parámetros, el formato de los resultados que se muestran por pantalla, etc.). Para éste articulo se tomará al sistema operativo Linux (una variante de Unix de distribución gratuita) como plataforma de referencia; será tarea del lector identificar las diferencias con su propia plataforma y realizar las adaptaciones del caso. 1 Cabe aclarar, sin embargo, que la mayoría de los conceptos que se desarrollarán en el capítulo de Administración son aplicables a casi todas las implementaciones de TCP/IP bajo otras plataformas. 2 La Almirante Grace Hooper participó en el diseño del lenguaje COBOL, durante la década del 60. Conectándose a Unix Terminales "bobas", Workstations y PCs El sistema operativo Unix fue concebido en los años 70. En aquellos tiempos, el modelo imperante para los sistemas de computación era el que llegó a conocerse como "de tiempo compartido", en donde un equipo central con capacidad de multiprogramación (conocido como host) atendía simultáneamente a múltiples usuarios conectados al mismo desde terminales remotas ubicadas en el mismo edificio o en otras locaciones conectadas al mismo a través de una red de Figura 1: Computador PDP-8 comunicaciones. Dichas terminales estaban constituidas básicamente por un teclado, una pantalla y un dispositivo de comunicaciones (usualmente de tipo serial, por ejemplo basado en RS-232), y se denominaban "terminales bobas" (dumb terminals) debido a que carecían por completo de capacidad de procesamiento, mas allá de la necesaria para tomar caracteres desde el teclado, enviarlos al equipo central por el vínculo de comunicaciones y recibir desde él nuevos caracteres que desplegar en la pantalla. De esta forma, resultaban meros dispositivos de interface entre el usuario y un proceso en ejecución en la computadora central. Figura 2: Terminal VT100 Luego, durante el transcurso de la década del 80 y conforme los costos de la tecnología de computación disminuían crecientemente, fue creciendo una nueva concepción tendiente a llevar poder de procesamiento más cerca del usuario. Por una parte, las PC (Computadoras Personales) aparecieron en escena y rápidamente empezaron a poblar las oficinas y mas tarde los hogares. Aquellas organizaciones que se vieron en la situación de enfrentar la coexistencia de equipos personales con centralizados encontraron que podían aprovechar lo mejor de ambos mundos permitiendo el acceso desde las PCs a las aplicaciones y datos corporativos corriendo bajo Unix, por medio de conexión de las PCs al host Unix a través de conexiones seriales y la ejecución en la PC de un software emulador de terminal. Dichos programas constituyen básicamente una terminal boba implementada en software, que utiliza el hardware de la PC de manera tal que la misma se comporta como si se tratara de una terminal corriente (es decir, solo procesa entradas y salidas por teclado y pantalla, quedando el procesamiento de la aplicación en manos del equipo central). Por otra parte, en los ambientes de ingeniería e investigación, empezaron a aparecer potentes computadoras personales basadas en Unix y construidas, usualmente, con tecnología RISC, denominadas workstations (estaciones de trabajo). Si bien estos equipos corrían básicamente el mismo Unix que los equipos centralizados, explotaban más sus capacidades de multiprocesamiento que la de atender múltiples usuarios simultáneos; es decir, se trataba de equipos con mucho potencial de cálculo, especialmente pensado para aplicaciones de ingeniería o científicas, operados por un único usuario desde la consola (pantalla y teclado conectado directamente al equipo), siendo muy poco usual que se las conectara a terminales seriales a ser utilizadas por otros usuarios, a pesar de que el sistema operativo soportaba esta modalidad de trabajo. 2 Si bien el pasar de equipos centralizados compartidos a equipos personales individuales trajo como beneficio un mayor poder de procesamiento y flexibilidad para los usuarios, se llevó consigo una de las ventajas de la computación centralizada: la posibilidad de compartir recursos. Es por ello que la década del 80 no sólo es la década de la computación personal, sino también la de la popularización y crecimiento de las redes de área local (denominadas LAN). La idea de interconectar equipos en redes no era nueva; sin embargo, los esfuerzos de investigación y desarrollo en tal sentido se orientaban mas bien a la interconexión de equipos ubicados en locaciones distantes entre sí, formando redes de área amplia (conocidas como WAN), ya que el "área local" estaba dominada por equipos de conexión centralizada. En el caso particular de Unix, la técnica de interconexión que se volvió standard fue la basada en una familia de protocolos de comunicaciones denominada TCP/IP, mediante la cual dos equipos Unix interconectados podían intercambiar datos y permitir a usuarios conectados a uno de ellos iniciar nuevas sesiones de trabajo en el otro. Cuando las workstations aparecieron en la escena a mediados de la década del 803, resultó natural que estuvieran preparadas con capacidades de conectividad en red. No obstante, el tipo de conectividad requerida no era a nivel WAN sino a nivel LAN, a fin de que pudieran interactuar con otras workstations y con equipos centralizados de mayor porte disponibles en la organización. Se volvió entonces practica standard entre los fabricantes de workstations que las mismas contaran con capacidad de conectividad TCP/IP y hardware para conexión a una red LAN, utilizando la norma Ethernet, que finalmente terminó por convertirse en el standard para redes de estas características. De ésta manera, un usuario poseedor de una workstation podría ejecutar localmente sus aplicaciones y al mismo tiempo iniciar sesiones de trabajo remotas Figura 3: en los servidores corporativos (y, por supuesto, en otras Workstation Sun 4 workstations disponibles en la red ). Al mismo tiempo, las PCs fueron ganando terreno en el ámbito de las redes LAN (y, de hecho, resultaron finalmente sus principales impulsores). Sin embargo, no fue hasta mediados de los 90 con la masificación del acceso a servicios Internet (la red TCP/IP por excelencia) que TCP/IP se volvió un componente obligado del software de red de éstas computadoras, desplazando a otros protocolos como IPX y NetBIOS, que dominaron la escena de las LAN entre PCs durante años. Como resultado, hoy puede utilizarse una PC de bajo costo para acceder a servicios de datos y sesión remota sobre servidores Unix, de manera análoga a la que se utilizaría desde una workstation. El Sistema X-Window Cabe mencionar finalmente otro tipo de conexión a sistemas Unix, para el cual hay que analizar previamente el formato con que esas conexiones pueden realizarse. Tradicionalmente, las terminales bobas fueron dispositivos "de caracteres", que permitían conexiones en modo texto. Las primeras terminales eran extremadamente primitivas; denominadas "ttys de vidrio", básicamente eran variaciones de los teletipos (de allí la denominación "tty") y únicamente permitían desplegar líneas de caracteres y producir avances de carro, sin que el programador tuviera control alguno sobre el formateo y ubicación de dichos caracteres en la pantalla. Con el tiempo, fueron evolucionando hasta eliminar esas limitaciones (se transformaron en terminales "de pantalla completa") y agregaron nuevas capacidades como Figura 4: Terminal "de copia dura" o teletipo 3 La primera workstation fue lanzada al mercado por Sun Microsystems en 1983. Esta concepción del trabajo en red llevó a Sun a acuñar el slogan "The network is the computer" ("La computadora es la Red"). 4 3 diferentes estilos (caracteres parpadeantes, remarcados, subrayados, etc.), diferentes juegos de caracteres, caracteres gráficos, etc. Pero continuaron siendo terminales capaces de mostrar solamente texto. Mientras esto ocurría en el ámbito comercial, el MIT (Instituto de Tecnología de Massachusetts) se encontraba trabajando en el Proyecto Athena. Uno de los resultados de ese proyecto fue un "sistema de presentación gráfica distribuida". La idea consistía en permitirle a un programa, llamado cliente, ejecutarse en una computadora y enviar su salida (ya fuera esta texto o gráficos) por medio de enlaces TCP/IP a otro programa, llamado servidor de ventanas (window server), en ejecución en la misma u otra computadora. Las computadoras del cliente y el servidor podrían ser inclusive totalmente diferentes (en hardware y/o sistema operativo), en tanto y en cuanto ambas estuvieran interconectadas de alguna manera por TCP/IP e implementaran un protocolo especial denominado protocolo X. El conjunto resultante se denominó Sistema X-Window, en el cual la funcionalidad de la aplicación se divide entre el Server-X (o servidor de ventanas) que tiene a cargo la administración de los recursos físicos de presentación (es decir, manipula los recursos del hardware de visualización, las entradas por teclado y los eventos del mouse) al cual se conectan múltiples Clientes-X (es decir, las aplicaciones que el usuario ejecuta sobre el equipo central), vinculadas las mismas al Server-X por medio de enlaces TCP/IP. Una de las aplicaciones de X-Window fue permitir la creación de un nuevo tipo de terminales, conocidas como X-Terminals. Una X-Terminal es básicamente una terminal boba en el sentido de que no procesa localmente las aplicaciones del usuario, pero la principal diferencia es que le ofrecen una interfaz gráfica altamente sofisticada. Para ello, una X-Terminal implementa el protocolo X y cuenta con un window server. Cuando el usuario, por medio de una X-Terminal, lanza una aplicación, la misma se ejecuta en el host, excepto las operaciones de dibujo sobre la pantalla y la captura de eventos de teclado y mouse, que son ejecutadas por el Server-X localmente en la XFigura 5: Terminal Terminal. En otras palabras, cuando el Cliente-X requiere X de Tektronics desplegar algún tipo de información por pantalla, le envía una petición al Server-X para que la lleve a cabo; de la misma manera, no es la aplicación la que realiza la lectura de teclado y la captura de eventos del mouse, sino que dicha operación la realiza en Server-X (sobre la X-Terminal) para luego notificar al Cliente-X (en el host) cuando los eventos eventualmente ocurren. Todo ese diálogo entre el Cliente-X y el Server-X se materializa en forma de mensajes TCP/IP. Por otra parte, X-Window se volvió un componente infaltable de las workstations. XWindow es un sistema de ventanas cliente/servidor. Una de las ventajas del modelo cliente/servidor es que puede ser implementado tanto de manera distribuida (es decir, cliente y servidor ejecutándose en computadoras diferentes) como local (cliente y servidor ejecutándose en la misma computadora), debido a que lo único que establece es que deben existir dos procesos (el cliente y el servidor) unidos a través de un canal de comunicaciones. Para el caso de X-Window, esto significa que tanto el Server-X como el Cliente-X podrían eventualmente ejecutarse en la misma computadora, tal como ocurre en una workstation. Finalmente, y dado que ya en el espíritu inicial de los diseñadores de X-Window estaba embebido el concepto de independencia de plataforma entre el Cliente-X y el Server-X, resultó natural la eventual aparición de Servidores-X para plataformas completamente diferentes de Unix, tal como MS-Windows. Ello posibilitó utilizar una máquina Windows como si fuera una X-Terminal, una estrategia análoga a la utilizada anteriormente por medio de emuladores de terminal. 4 En resumen... Se han reseñado varias formas para conectarse a un host Unix: • • • • Por medio de una terminal boba conectada al host a través de un vínculo serial (directo o indirecto -- como por ejemplo, un módem); Por medio de una PC, un programa emulador de terminal y un vínculo serial al host (nuevamente, directo ó indirecto); Por medio de conexiones TCP/IP a través de una red LAN o WAN, desde otro host Unix, una workstation, una PC o cualquier otro tipo de computadora que cuente con software TCP/IP. Desde una X-Terminal o una computadora (PC, workstation, etc.) que implemente el protocolo X5. 5 Este tipo de conexión es estrictamente otra forma de conexión TCP/IP. Se la menciona por separado debido a que su formato es radicalmente diferente al de las conexiones TCP/IP mas conocidas (como por ejemplo, conexiones vía telnet). 5 Trabajando en una red Unix Se discutirán a continuación algunas de las actividades más usuales que se realizan al trabajar en el entorno de una red TCP/IP bajo Unix: • • • • Sesiones remotas Transferencia de archivos Ejecución remota Comunicación entre usuarios A los fines de la ejemplificación, se asumirá que el entorno en el que está trabajando un usuario cuyo login name es jperez es el que se muestra en la figura siguiente, y que dicho usuario está actualmente conectado al host Antares, y que dispone de acceso a cuentas de usuario en el host Canopus, ambos corriendo alguna versión de Unix: Canopus Red Local Antares Sesiones remotas Iniciar una sesión remota significa conectarse desde una computadora a otra, a través de una red de comunicaciones, a los fines de ejecutar procesos a la distancia. En otras palabras, por medio de sesiones remotas es posible trabajar en una computadora operándola remotamente desde otra, ubicada quizás a grandes distancias; a los fines prácticos, resulta equivalente a estar sentado en la consola del sistema remoto. En nuestro ejemplo, si el usuario jperez que se encuentra conectado a la computadora Antares inicia una sesión remota en Canopus, a partir de ese momento todo comando que ejecute lo hará en el procesador de Canopus. Cabe aclarar que el acceso a un host Unix desde una terminal serial no se considera una sesión remota, por mas lejana que se encuentre físicamente ubicada la terminal. Las sesiones remotas entre sistemas Unix se realizan por medio de la ejecución de programas basados en TCP/IP, como los descriptos en las secciones siguientes. Arquitectura de una sesión remota Los programas de sesión remota bajo Unix trabajan según un esquema cliente/servidor, en el cual el usuario que desea iniciarla ejecuta localmente en su computadora un programa (el cliente) al cual le indica el nombre del host en el cual se iniciará la sesión. Dicho programa se comunica por medio de TCP/IP con otro ejecutándose en background en la computadora de destino (el servidor), el cual, luego de autenticar la identidad del usuario y verificar que tiene permiso para utilizar el servicio, inicia un shell para interpretar los comandos que envíe el usuario remoto: 6 Shell local Cliente de sesión remota Servidor de sesión remota Shell remoto El servidor de sesión remota asocia el shell remoto con una terminal virtual (o pseudo-tty) cuyas entradas y salidas están asociadas a una conexión de red. Así, todo lo que el usuario teclee en su terminal será capturado por el cliente de sesión remota y enviado a través de la red al shell remoto; de manera similar el shell remoto enviará la salida de los comandos al usuario por la misma conexión de red. Cuando el usuario ejecute el comando para terminar el shell (usualmente, exit o Control-D), el shell remoto finaliza y la sesión remota se cierra. Sesiones remotas utilizando rlogin rlogin es el comando de sesión remota nativo de Unix. Su sintaxis básica es la siguiente: rlogin nombre_de_host Al ser invocado de esa forma, rlogin intenta iniciar una sesión remota en el host indicado, bajo el mismo nombre de usuario actual, previo ingreso de la palabra clave: jperez@antares:$ rlogin canopus Password: Last login: Mon Feb 10 15:30:45 from orion. jperez@canopus:$ _ Si la clave es ingresada correctamente, la sesión remota se inicia, rlogin informa la fecha y origen del último ingreso al sistema y, a partir de ese momento, el usuario puede ejecutar comandos en la máquina remota, obteniendo la salida de los mismos en el host local. Para cerrar la sesión, basta con ingresar el comando normal para finalizar el shell remoto, por ejemplo, exit: jperez@canopus:$ exit Conection closed. jperez@antares:$ _ Si se desea iniciar una sesión remota bajo otra identidad (es decir, entrado como otro usuario), el login name correspondiente puede indicarse utilizando el comando -l: jperez@antares$ rlogin -l plopez canopus Password: plopez@canopus$ _ Como ya se dijo, rlogin pide la contraseña de la cuenta remota antes de permitir el acceso al shell. Sin embargo, es posible configurar rlogin de manera que considere equivalentes dos cuentas y no pida password para iniciar sesiones. Continuando con el ejemplo anterior, si el usuario jperez tiene cuenta tanto en Antares como en Canopus, para evitar que se le pida password al iniciar una sesión remota con rlogin deberá crear en su directorio de login de la máquina remota un archivo llamado .rhosts, y en el mismo listar los nombres de las 7 computadoras desde donde desea entrar sin password. También podría otorgar acceso libre a otros usuarios, listando los nombres de login a continuación del nombre de máquina. Por ejemplo, si el archivo .rhosts ubicado en el directorio de conexión de jperez en Canopus contuviera la siguiente información: antares orion plopez ello indicaría que el usuario jperez puede entrar a Canopus sin password desde Antares, mientras que el usuario plopez podrá hacer lo mismo desde Orión. Cabe destacar que el uso del archivo .rhosts es un serio compromiso a la seguridad de la cuenta y es un recurso que debe ser utilizado con mucha precaución; en el ejemplo anterior, si alguien ganara acceso a la cuenta de jperez en Antares, automáticamente podría entrar a la cuenta de Canopus. Como medida extra de seguridad, rlogin solo prestará atención al archivo .rhosts si el mismo solo puede ser accedido por el usuario (es decir, si su modo es rw------- ó 600 en octal). Sesiones remotas utilizando telnet El comando rlogin fue diseñado teniendo en cuenta que tanto el host local como el remoto son máquinas corriendo Unix6. A fin de permitir sesiones remotas entre equipos con sistemas heterogéneos, fue diseñado otro protocolo denominado TELNET. Bajo Unix, puede establecerse una conexión TELNET con el siguiente comando: telnet nombre_de_host La principal diferencia entre telnet y rlogin es que el primero de estos siempre pide usuario y password para iniciar la sesión: jperez@antares:$ telnet canopus Trying 170.25.1.5 Connected to canopus.galaxia.org.ar Escape character is '^]' Login: jperez Password: Last login: Mon Feb 10 15:30:45 from orion. jperez@canopus:$ _ Aquí puede verse que el usuario jperez inicia una sesión de TELNET hacia Canopus. telnet inicialmente informa que está intentando establecer la conexión con el host remoto (línea Trying....) y luego de unos segundos indicará que la conexión se ha establecido con éxito (línea Connected.....). Seguidamente, telnet informa al usuario cual es el carácter de escape, y pide el nombre de usuario y palabra clave para ingresar al host remoto. El carácter de escape (que usualmente es Control-]) es un carácter que es interceptado por el programa telnet ejecutándose en el host local, y no es enviado al host remoto como el resto de los caracteres tipeados por el usuario. Se utiliza para llamar la atención del programa telnet, el cual responde con un prompt y queda a la espera de comandos: jperez@canopus:$ ^-] telnet> _ 6 Estrictamente, rlogin asume que ambos extremos de la conexión de red ejecutan el demonio identd, que permite identificar el propietario de conexiones TCP. 8 Existen varios comandos que pueden utilizarse aquí, pero el mas usual es el comando exit, utilizado para cortar la conexión, o ! (signo de admiración) que permite iniciar un subshell en el host local. Sesiones remotas utilizando ssh Tanto telnet como rlogin utilizan protocolos de comunicación abiertos, en el sentido de que todos los datos se transmiten sin ningún tipo de protección por encriptado. Esto significa que cualquier otra persona que tenga acceso al medio físico de transmisión podría (con los conocimientos y herramientas apropiadas) interceptar las transmisiones y eventualmente obtener todo aquello que el usuario tipea en su terminal (especialmente, el nombre de usuario y la password) y las respuestas que envía el host remoto. Esto hace que el uso de telnet o rlogin sea inapropiado cuando es necesario un nivel de absoluta seguridad y privacía, especialmente cuando las comunicaciones se realizan a través de largas distancias (por ejemplo, a través de la Internet). Para superar esos inconvenientes, puede utilizarse como alternativa el sistema ssh (por Secure Shell, o Shell Seguro), el cual provee de un esquema de seguridad mucho mas sofisticado y encripta toda el intercambio de datos entre el host local y el remoto. La sintaxis básica7 de ssh es igual a la de rlogin, es decir: ssh [-l nombre_de_usuario] nombre_de_host en donde la indicación del nombre de usuario (a través del parámetro -l) es opcional y se asume el login name actual por defecto. Transferencia de archivos Los protocolos para transferencia de archivos permiten copiar archivos entre dos computadoras, a través de una red. Se verán a continuación tres programas para transferencia de archivos: ftp, rcp y scp. Transferencia de archivos por ftp La principal diferencia entre ftp y los otros comandos radica en el carácter interactivo de éste comando. Esto significa que ftp funciona a la manera de un shell: primeramente establece la conexión con el sistema remoto y luego queda a la espera de que el usuario le indique, por medio de un lenguaje de comandos, las operaciones a realizar. Para iniciar una sesión FTP, debe ejecutarse en comando ftp indicándole como parámetro el nombre de la computadora remota, por ejemplo: jperez@antares:$ ftp canopus Connected to canopus.galaxia.org.ar 220 canopus.galaxia.org.ar FTP server ready. Name(antares:jperez): jperez 331 Password required for jperez. Password: 230 User andres jperez in. Remote system type is UNIX. Using binary mode to transfer files. 7 Ssh ofrece sofisticados mecanismos de seguridad adicionales al tradicional esquema de seguridad basado en palabra clave, como frases clave de acceso, certificados de identidad y varios métodos de autenticación. Para mayores detalles, refiérase a la documentación provista por el software. 9 ftp> _ Aquí, el usuario jperez inicia una conexión FTP a Canopus. Luego de indicar que la conexión se ha establecido y que el servidor FTP se encuentra listo, ftp pide el nombre de usuario con el que se va a ingresar al host remoto, y luego su correspondiente password. Si la misma se ingresa correctamente, el sistema remoto informa su tipo (en este caso, UNIX) y el modo de transferencia de archivos por defecto (en este caso, transferencia binaria) y queda a la espera de comandos del usuario. Adicionalmente de permitir la transferencia de archivos hacia cuentas del sistema remoto (esto es, la conexión se establece indicando una identidad de usuario registrada en el host remoto e ingresando la palabra clave de esa cuenta), ftp fue diseñado para permitir el acceso de usuarios anónimos a grandes repositorios de archivos, de acceso público. Usualmente los servidores FTP utilizan el nombre de usuario anonynmous para los accesos del público en general, quienes deberán utilizar su dirección de correo electrónico como password: jperez@antares:$ ftp canopus Connected to canopus.galaxia.org.ar 220 canopus.galaxia.org.ar FTP server ready. Name(antares:jperez): anonymous 331 Guest login ok, send your complete e-mail address as password. Password: [email protected] 230 Guest login ok, access restrictions apply. Remote system type is UNIX. Using binary mode to transfer files. ftp> _ Los dos comandos básicos de FTP para transferencia de archivos son put (para enviar un archivo al host remoto) y get (para obtener un archivo desde el host remoto). Ambos operan con un único archivo indicado como parámetro, desde y hacia el directorio actual (tanto local como remoto). Por ejemplo, el siguiente comando: ftp> put informe.doc local: informe.doc remote: informe.doc 200 PORT command successful. 150 Opening BINARY mode data connection for informe.doc. 226 Transfer complete. 1908642 bytes sent in 2.34 secs (13.22 Kbytes/sec) ftp> _ transfiere el archivo informe.doc desde el directorio actual local (esto es, el directorio desde el cual se invocó al programa ftp en el host local) al directorio actual en la computadora remota. Luego de la transferencia, ftp informa la cantidad de bytes transmitidos y la velocidad de la transferencia. Por otra parte, el comando: ftp> get informe.doc local: informe.doc remote: informe.doc 200 PORT command successful. 150 Opening BINARY mode data connection for informe.doc. 226 Transfer complete. 1908642 bytes received in 2.34 secs (13.22 Kbytes/sec) ftp> _ 10 El directorio actual en la computadora remota puede averiguarse por medio del comando pwd: ftp> pwd 257 "/home/jperez" is current directory. ftp> _ y puede cambiarse utilizando el comando cd, e indicando una trayectoria absoluta o relativa (de manera totalmente análoga al comando cd del shell): ftp> cd documentos 250 CWD command successful. ftp> pwd 257 "/home/jperez/documentos" is current directory. ftp> _ FTP cuenta con un extenso juego de comandos, cuya lista puede obtenerse tipeando ?. Se ofrece a continuación un resumen de algunos comandos de utilización frecuente: ls binary ascii lcd delete hash mput mget prompt off Lista el contenido del directorio actual Fuerza el modo de transferencia a BINARIO Fuerza el modo de transferencia a ASCII (poco recomendable!) Cambia (o muestra) el directorio actual local Borra un archivo en el host remoto Muestra por pantalla una marca cada cierta cantidad de bytes transmitidos Permiten realizar transferencias múltiples, por medio de la utilización de comodines Deshabilita la confirmación archivo por archivo en las transferencias múltiples La sesión de FTP finaliza cuando el usuario indica el comando bye: ftp> bye 221 Goodbye. jperez@antares:$ _ Transferencia de archivos por rcp y scp Los comandos rcp y scp son utilerías de línea de comandos para transmitir archivos; esto es, no reciben comandos interactivamente desde el usuario, sino que su funcionamiento se indica por medio de parámetros en la línea de comandos del shell. Es esta característica lo que, al contrario que ftp, los hace útiles para la programación de scripts que realicen transferencias automáticas de archivos entre computadoras. rcp pertenece al mismo paquete de comandos que rlogin, mientras que scp pertenece al de ssh. Así la diferencia entre ambos radica en el nivel de seguridad: rcp transfiere los archivos en su formato original, mientras que scp lo hace de manera encriptada. Ambos comandos tienen la misma sintaxis: rcp [-l nombre_de_usuario] origen destino scp [-l nombre_de_usuario] origen destino en donde el parámetro -l es opcional, sirviendo para acceder al host remoto bajo otro nombre de usuario. Los parámetros origen y destino son las especificaciones 11 (expresadas como trayectorias absolutas o relativas) del archivo a transmitir y la ubicación final del mismo respectivamente; uno de ellos deberá hacer referencia a la computadora local, mientras que el otro deberá referirse a la computadora remota. La sintaxis para archivos remotos es la siguiente: nombre_del_host_remoto:[[trayectoria]archivo] Como puede verse, la única parte mandatoria es el nombre del host remoto; si el resto se omite, el archivo transmitido será copiado bajo el mismo nombre en el directorio de login del usuario en la computadora remota. Si el nombre de archivo se omite, la copia se hará en el directorio remoto indicado bajo el mismo nombre; si la trayectoria especificada es relativa, se interpretará como relativa al directorio de login del usuario en la computadora remota. Por ejemplo, los siguientes comandos transfieren archivos de la maquina local al host remoto Canopus: $ scp informe.doc canopus: Copia el archivo informe.doc (ubicado en el directorio actual) al directorio de login en Canopus, con el mismo nombre $ rcp notas/informe.doc canopus:notas/ Copia el archivo informe.doc, bajo el directorio notas al directorio notas bajo el directorio de login de la maquina remota $ scp informe.doc canopus:/usr/informes/info1.doc Copia el archivo informe.doc, al directorio remoto /usr/informes con el nombre info1.doc Para transferir desde el host remoto al host local, los comandos serían los siguientes: $ rcp canopus:informe.doc . $ rcp canopus:notas/informe.doc notas/ $ scp canopus:/usr/informe.doc info1.doc scp siempre pide password antes de realizar la copia; rcp, por su parte, requiere que el usuario haya configurado su cuenta remota para accederla sin solicitar password, por medio del archivo .rhosts (tal como se describe en la sección de rlogin) Ejecución remota Los comandos para ejecución remota permiten ejecutar un único comando en un host remoto, obteniendo su salida en el host local. El comando tradicionalmente utilizado para este tipo de operaciones era rsh. Este comando completa la familia formada por rlogin y rcp, y al igual que este último, requiere de la existencia del archivo .rhosts en el directorio de conexión remoto a fin de poder operar. Su sintaxis es la siguiente: rsh [-l nombre_de_usuario] host comando Por ejemplo, el siguiente comando obtiene un listado del directorio de conexión de un host remoto: jperez@bbs:~$ rsh canopus ls -l total 13 drwxr-xr-x 5 jperez jperez -rw-rw-r-1 jperez jperez drwxrwxr-x 2 jperez jperez drwxrwxr-x 3 jperez jperez drwx-----2 jperez jperez 1024 1376 1024 1024 1024 Sep Sep Oct Oct Sep 26 28 13 29 23 11:58 15:16 16:53 19:48 12:21 GNUstep Xrootenv.0 bin download mail 12 drwxrwxr-x 2 jperez drwxr-xr-x 3 jperez -rw-r--r-1 jperez drwxrwxr-x 6 jperez drwxrwxr-x 9 jperez jperez@bbs:~$ _ jperez jperez jperez jperez jperez 1024 1024 198762 1024 1024 Jul 2 14:34 mnt Jun 30 19:36 ns_imap Nov 1 20:46 informe.doc Oct 22 21:38 temp Oct 29 19:49 trabajo Se aplican a este comando las mismas consideraciones de seguridad que se discutieron para rlogin, por lo que si la seguridad es crítica, puede ser reemplazado por el comando ssh, que ofrece un modo de funcionamiento similar: ssh [-l nombre_de_usuario] host comando con la diferencia que utiliza mecanismos de seguridad avanzada para autenticar al usuario y realiza conexiones encriptadas. Comunicación entre usuarios Unix es un sistema de naturaleza multiusuaria, es decir, soporta múltiples usuarios conectados simultáneamente, ejecutando procesos concurrentemente. En consecuencia, ofrece comandos que permiten a los usuarios comunicarse entre si, ya sea en tiempo real o de manera diferida. Averiguando quien está conectado: finger Antes de poder entablar una comunicación, es necesario saber quién está conectado al sistema. Normalmente, el comando para realizar dicha operación era who. Sin embargo, este comando solo informa acerca de los usuarios conectados al sistema local. Si se desea saber quién está conectado a un host remoto debe utilizarse el comando finger: jperez@antares:$ finger @canopus [canopus.galaxia.org.ar] Login Name Tty plopez Pedro Lopez 1 fcuenca Fernando Cuenca p1 arodrig Andrea Rodriguez p2 Idle 20m 20m Login Feb 1 Feb 1 Feb 1 Time 20:36 14:08 20:36 jperez@antares:$ Observar que el nombre del host remoto debe precederse de un signo @. De manera similar, finger permite obtener información sobre un usuario (local o remoto). Por ejemplo, si se quieren conocer los datos del usuario plopez del host local, puede utilizarse el siguiente comando: jperez@bbs:~$ finger plopez Login: plopez Name: Pedro Lopez Directory: /home/plopez Shell: /bin/sh Last login Fri Oct 30 23:16 (ARDT) on tty1 New mail received Sun Nov 1 19:08 1998 (ARDT) Unread since Sun Nov 1 17:45 1998 (ARDT) finger informa el nombre completo del usuario, su directorio de login y shell, la fecha y ubicación de la última conexión al sistema, e información sobre el correo electrónico del usuario. También pueden obtenerse datos de usuarios de otras computadoras, utilizando la sintaxis usuario@computadora: jperez@bbs:~$ finger arodrig@canopus Login: arodrig Name: Andrea Rodriguez Directory: /home/arodrig Shell: /bin/sh 13 Last login Sun Feb 10 15:09 (ARDT) on tty5 New mail received Mon Nov 1 14:33 1998 (ARDT) Unread since Tue Jan 24 11:14 1998 (ARDT) Comunicándose con talk Unix permite realizar charlas en tiempo real con usuarios conectados al sistema local o a sistemas remotos, por medio del comando talk. Por ejemplo, si el usuario jperez, conectado a Antares, quisiera entablar una charla con arodrig, conectada a Canopus, debería ejecutar el siguiente comando: talk arodrig@canopus arodrig recibirá un aviso en su pantalla y, si desea entablar la comunicación, deberá replicar con el siguiente comando: talk jperez@antares tras lo cual la conexión quedará establecida. Ambos verán en sus pantallas lo que el otro escribe, hasta que alguno de ellos finalice la sesión con Control-C. Correo electrónico Talk permite comunicaciones en tiempo real; sin embargo, muchas veces es necesario enviar un mensaje a un usuario que no se encuentra actualmente conectado. Para ello puede utilizarse el correo electrónico. El comando standard para enviar correo electrónico entre sistemas Unix es mail, cuya sintaxis es la siguiente: mail usuario[@computadora] Obsérvese que la especificación del nombre de la computadora es opcional; si se omite, se asumirá que se está enviando correo a otro usuario del sistema local. Al ser ejecutado, el comando mail solicita primeramente al usuario que ingrese el tema del mensaje, y luego lee desde la entrada standard el texto del mensaje, hasta recibir la marca de fin de archivo (Control-D): jperez@antares:$ mail plopez@canopus Subject: Reunion semanal Hola, Le comunico que la reunión semanal tendrá lugar el próximo miércoles a las 15 el la Sala de Reuniones D. Por favor, concurra con el informe de avance. ^D jperez@antares:$ _ Un problema frecuente al trabajar en una red Unix, es que los usuarios normalmente tienen cuenta en mas de un host. Ello puede provocar que su correspondencia se vea diseminada entre sus múltiples casillas de correo (una en cada host en los que se tiene cuenta). Para solucionar esta situación, es posible redirigir el correo desde múltiples cuentas hacia aquella que se usa mas frecuentemente. Para redirigir el correo de una cuenta dada, el usuario deberá crear en el directorio de conexión correspondiente el archivo .forward, conteniendo la dirección de correo electrónico hacia la cual desea que los mensajes sean redirigidos. Por ejemplo, si jperez tiene cuenta tanto en Antares como en Canopus, pero prefiere leer correo en la primera, 14 deberá crear un archivo .forward en su directorio de login de Canopus, conteniendo la siguiente línea: jperez@antares 15 Administración de una red TCP/IP TCP/IP: una familia de protocolos TCP/IP es un conjunto de protocolos de comunicaciones desarrollado para permitir a un conjunto de computadoras cooperar y compartir recursos a través de una red de comunicaciones. De entre sus muchas características, hay dos que lo han transformado en uno de los protocolos de mayor difusión: • Es un standard abierto, diseñado independientemente de plataformas de hardware y software específicas. Así, TCP/IP es ideal para interconectar sistemas mas allá de lo diferentes que éstos sean. • Es independiente de la tecnología física que se utilice para construir la infraestructura de la red. TCP/IP puede montarse sobre Ethernet, Token-Ring, enlaces seriales telefónicos (dial-up links), redes X.25, y virtualmente cualquier otro medio físico de transmisión de datos. Arquitectura de TCP/IP8 La familia TCP/IP está formada por múltiples protocolos de diferentes propósitos. Algunos de ellos, tales como IP, TCP y UDP constituyen el mecanismo básico de transmisión de datos, y serán utilizados por todas las aplicaciones. Otros protocolos permiten realizar tareas mucho más específicas, tales como transferir archivos entre computadoras (FTP), obtener páginas o documentos de la Web (HTTP), o sincronizar la hora desde otro equipo (XNTP). Cualquier aplicación real utilizará varios de esos protocolos. Un caso típico es el envío de correo electrónico. En primer lugar, existe un protocolo para enviar y recibir correo electrónico (denominado SMTP), que define una serie de comandos que una máquina envía a la otra cuando requiere transferirle un mensaje. Esos comandos permiten especificar quien es el autor del mensaje, a quien va dirigido y cual es el texto a enviar. Sin embargo, ese protocolo (como todos los otros protocolos de aplicación) asume que hay alguna manera confiable para comunicar datos entre ambas computadoras, limitándose simplemente a definir a muy alto nivel los comandos necesarios para manejar la transmisión, pero no los detalles acerca de como va a efectivizarse la misma. Dichos detalles son dejados en manos de alguno de los protocolos de menor nivel, llamados protocolo de transporte: TCP o UDP. SMTP utiliza a TCP como protocolo de transporte. TCP es responsable de asegurar que los comandos trasmitidos lleguen al otro extremo de la comunicación, contabilizando qué ha sido transmitido ya y retransmitiendo toda información que no haya llegado exitosamente a destino. Si la información a transmitir es demasiado larga, TCP la segmentará en varios paquetes que se transmitirán individualmente. Obsérvese que esta funcionalidad se requiere para muchas aplicaciones; es por ello que conforma un protocolo independiente en vez de formar parte de la especificación de protocolos como SMTP. Desde el punto de vista del programador, TCP es una libraría de rutinas que las aplicaciones utilizan cuando necesitan comunicaciones confiables con otra computadora a través de la red. De manera similar, TCP utiliza los servicios de IP para efectivamente desplazar los paquetes alrededor de la red. IP constituye un protocolo de red, y es el encargado de determinar que rutas deberán seguir los paquetes para llegar al punto de destino desde el punto de origen. 8 Adaptado principalmente de un articulo de Charles Hedrick (Rutgers Univ., New Brunswick, N.J.) publicado en los newsgroups de Internet el 28 de Junio de 1987, y de otras fuentes mencionadas en la Bibliografía. 16 Nuevamente, IP se presenta como una librería que utilizan protocolos de transporte como TCP al momento de enviar la información. Esta estrategia para construir protocolos en varios niveles se denomina diseño estratificado (o layering). Consiste en considerar a las aplicaciones, a TCP y a IP como diferentes capas, cada una de las cuales hace uso de los servicios ofrecidos por la capa inmediatamente inferior. En general, la arquitectura de las aplicaciones basadas en TCP/IP presentan 4 capas: • Un protocolo de aplicación, para tareas específicas (por ejemplo, correo electrónico) • Un protocolo de transporte, que provee servicios de extremo a extremo (como TCP o UDP) • El protocolo de red IP, que provee el encaminamiento de los paquetes a su destino final • Un protocolo de enlace físico, que provee acceso al medio físico de transmisión (por ejemplo, Ethernet o X.25) Transmitiendo los paquetes A fin de ejemplificar el proceso completo, supongamos que se desea transmitir un archivo de 15000 bytes. El protocolo de aplicación especializado en transferencia de archivos proporciona al protocolo de transporte el contenido del archivo a transmitir. La mayoría de las redes no pueden manejar paquetes de 15000 bytes, por lo que el archivo será segmentado en, digamos, 30 paquetes de 500 bytes cada uno, que entrega al protocolo de red para que sean enviados individualmente al otro extremo de la comunicación. Allí, los paquetes se reunirán para reensamblar el archivo original. Sin embargo, mientras los paquetes estén en tránsito, la red no sabrá que existe algún tipo de relación entre ellos9. Es también posible que el paquete número 15 llegue antes que el 14, o que algunos paquetes se pierdan en el camino y deban ser retransmitidos. Todas estas tareas (segmentación, retransmisión y reensamblaje) son llevadas a cabo por TCP (abreviatura de Transmission Control Protocol, o Protocolo de Control de Transmisión), mientras que el ruteo de paquetes individuales es responsabilidad de IP (abreviatura de Internet Protocol, o Protocolo de Inter-redes). A simple vista podría parecer que TCP es quien hace todo el trabajo, sin embargo, el rutear un paquete desde el origen hacia su destino puede ser una tarea muy compleja. TCP/IP asume que la red está formada por un gran numero de redes independientes, interconectadas entre si por dispositivos denominados gateways10, proporcionando al usuario la capacidad para acceder a recursos ubicados en cualquiera de esas redes, independientemente de su dispersión geográfica11. Los paquetes frecuentemente atravesarán numerosas redes para llegar a su destino, pero el ruteo requerido para ello deberá ser totalmente invisible para el usuario final. Todo lo que el usuario debe conocer es la dirección IP del punto de destino, un número que identifica unívocamente a cada computadora dentro de la inter-red. Así, TCP entrega los paquetes a IP especificándole simplemente la dirección IP de destino hacia donde debe enviarlos. Queda en manos de IP determinar la mejor ruta para que la entrega se haga efectiva. Dicha ruta (continuando con el ejemplo anterior, y en el contexto 9 Más aún, la red ni siquiera sabe que los paquetes conforman un archivo. En la jerga TCP/IP se denomina gateways a dispositivos que están conectados a mas de una red, y ofrecen capacidad para rutear paquetes entre esas redes. Es decir, se trata de ruteadores (dispositivos de nivel OSI 3) y no estrictamente de gateways (dispositivos de nivel OSI superiores, capaces de hacer transformaciones de protocolos, formatos, codificaciones, etc.) 11 De hecho, el término internet (con i minúscula) proviene de internetwork y se refiere a un conjunto de redes interconectadas. No debe confundirse con Internet (con I mayúscula), que se refiere a la red de redes de alcance global. 10 17 de la estructura de la red de la UTN Facultad Córdoba), podría implicar que cada paquete tenga que atravesar varios segmentos de LAN Ethernet dentro de la UTN FC, un enlace de microondas hasta el nodo de conexión a Internet, otro hasta algún telepuerto en Buenos Aires desde donde se establece una conexión satelital hacia los EEUU, y así sucesivamente hasta llegar a la red de destino, en donde deberá ser ruteado internamente hasta la computadora de destino. Finalmente, para transmitir cada paquete, IP utiliza el protocolo de enlace físico que conoce las particularidades para acceder al medio físico de transmisión (por ejemplo, una placa de red Ethernet). Multiplexación: Puertos y Sockets En los párrafos anteriores se ha descripto el proceso para transferir información a lo largo de una conexión TCP/IP. Sin embargo, en un momento dado podrían existir, entre las computadoras de origen y destino, múltiples conexiones ocurriendo simultáneamente; pensemos, por ejemplo, en varios usuarios abriendo sesiones remotas o transfiriendo simultáneamente archivos o correo electrónico entre dos máquinas de la red. Claramente, no es suficiente lograr que los paquetes lleguen al destino correcto; es necesario además poder discriminar a cual conexión pertenecen de las múltiples conexiones simultáneas que pueden existir en un momento dado. Para identificar cada conexión, TCP asigna un número de puerto a cada una. Supongamos que tres personas están transfiriendo archivos entre dos computadoras. TCP asignaría un número de puerto a cada transferencia, por ejemplo, 1000, 1001 y 1002. Todos los paquetes que se envíen como parte de una misma conexión tendrán asignado ese número como puerto de origen. El número de puerto de origen permite también establecer una correspondencia directa entre una conexión de red y el programa de usuario que interviene en uno de los extremos de la conversación. En el otro extremo, habrá otro programa que recibe los datos transmitidos, que también deberá poder asociarse a dicha conexión. Esa asociación se hace por medio del puerto de destino que TCP asigna a cada paquete que transmite. Cuando un programa de usuario (conocido como proceso cliente) abre una conexión de red por medio de TCP, se le asigna (mas o menos al azar) un número de puerto. Ese programa asume que en la otra computadora estará en ejecución otro programa (conocido como proceso servidor o, en la jerga Unix, demonio de red) que espera recibir peticiones desde la red. Cuando ese programa fue iniciado, su capa TCP le asignó también un número de puerto. Obviamente, el número de puerto que se asigne a procesos servidores no puede ser aleatorio, ya que sería imposible para los clientes saber que número especificar como puerto de destino. Los procesos servidores se asocian, entonces, con números de puerto fijos (llamados "números bien conocidos" -- "well-known numbers"), mientras que los procesos cliente obtienen números de puertos aleatorios al iniciar las conexiones12. Obsérvese que una conexión de red puede entonces identificarse unívocamente por medio de un conjunto de 4 números: las direcciones IP de ambos extremos y los números de puerto de origen y destino. Para el caso de las tres transferencias de archivos que se ponían como ejemplo mas arriba, si las direcciones IP de las maquinas de origen y destino son 172.16.10.150 y 172.16.8.123, y la transferencia se hace utilizando el protocolo FTP (que tiene asignado el número de puerto 21), cada conexión se puede identificar de la siguiente manera: 12 No es necesario que un proceso cliente obtenga un "numero bien conocido" ya que nadie está tratando de encontrarlo; por el contrario, es necesario que los servidores tengan esos números a fin de que los clientes puedan conectarse a ellos. 18 Conexión 1 Conexión 2 Conexión 3 Dirección IP: Puerto: Dirección IP: Puerto: Dirección IP: Puerto: 172.16.10.150 1000 172.16.10.150 1001 172.16.10.150 1002 Dirección IP: Puerto: Dirección IP: Puerto: Dirección IP: Puerto: 172.16.8.123 21 172.16.8.123 21 172.16.8.123 21 No pueden existir dos conexiones que compartan el mismo conjunto de números, pero es suficiente con que al menos uno sea diferente. En el ejemplo anterior, en donde tres usuarios transfieren archivos entre dos computadoras, dado que las computadoras involucradas en cada transferencia son las mismas, las direcciones IP son iguales para cada conexión y todos realizan transferencias vía FTP, por lo que el puerto de destino para las tres conexiones es el 21. Lo único que difiere es el número de puerto de origen, que permite diferenciar a los tres usuarios. Cada par formado por una dirección IP y un número de puerto se denomina socket (enchufe), por lo que una conexión TCP puede verse como un canal virtual a través de una red, "enchufada" a un socket en cada extremo. Por otra parte, el utilizar un único canal de comunicaciones para combinar múltiples conexiones de datos se denomina multiplexación; la información que arriba desde la red debe ser demultiplexada a fin de que cada módulo de software reciba los paquetes que le corresponden. De hecho, hay varios niveles de multiplexación en TCP/IP. Por una parte, TCP la utiliza para mantener múltiples conexiones, tal como se describió previamente. Por otra parte, sin embargo, existen otros protocolos (como UDP e ICMP) que utilizan IP como un medio para distribuir paquetes a lo largo de la red. Cuando IP recibe paquetes entrantes desde la red, debe poder determinar a cual protocolo de mayor nivel pasar el paquete. Esto constituye también otra forma de demultiplexación, y se realiza por medio de la asignación a cada paquete, por parte del IP de origen, de un numero de protocolo. Dicho número tiene un rol similar al número de puerto, con la diferencia de que no identifica conexión sino el protocolo de transporte que está administrando esa conexión. El proceso de multiplexación y demultiplexación de TCP/IP se esquematiza en la siguiente figura: Aplicaciones (Clientes) Capa de Transporte Capa de Red Capa de Red T C P U D P I C M P Capa de Transporte Aplicaciones (Servidores) T C P I P I P U D P I C M P En resumen... • Una red TCP/IP está formada por múltiples redes interconectadas por medio de gateways. Dichos gateways pueden ser dispositivos físicos especializados (llamados routers) o bien computadoras con múltiples adaptadores de red (llamados multihomed hosts) • Cada una de esas redes estará formada por máquinas individuales (los hosts de la red) o por subredes interconectadas. Cada máquina de la red recibirá un identificador numérico único, llamado dirección IP. 19 • Las computadoras de la red ejecutarán aplicaciones que establecerán comunicaciones entre ellas por medio de protocolos como TCP ó UDP, los cuales utilizarán el protocolo IP para rutear paquetes de información entre el origen y el destino. • Algunas computadoras de la red ofrecerán servicios a las demás, estableciéndose relaciones de tipo cliente/servidor entre ellas. Los roles de cliente y servidor no son excluyentes; una misma maquina puede al mismo tiempo ser cliente y servidor. Mas aun, podría ocurrir que la relación cliente/servidor se dé entre dos procesos ejecutándose en la misma máquina. • Los procesos servidores reciben peticiones desde la red, usualmente "escuchando" en puertos fijos de TCP (llamados números bien conocidos). Los clientes, por otra parte, utilizan puertos TCP asignados mas o menos al azar al iniciar la conexión. • El par formado por una dirección IP y un número de puerto se denomina socket. Una conexión puede identificarse unívocamente por el par de sockets correspondientes al nodo de origen y al de destino. Direcciones IP Clases de direcciones IP Una dirección IP es un número, usualmente expresado por una secuencia de cuatro enteros separados por puntos: a.b.c.d en donde cada uno de esos números asumen valores entre 0 y 255. De esos cuatro números, algunos se utilizan como dirección de red y los restantes como dirección de host. Todos los hosts que pertenezcan a la misma red deberán tener en común la dirección de red y diferir en la dirección de host. La cantidad números que se utilicen para la dirección de red da lugar a tres clases de direcciones IP: Clase A Clase B Clase C a a.b a.b.c b.c.d c.d d 16777214 65534 254 Este esquema de direccionamiento da lugar a la existencia de unas pocas redes clase A, cada una con algo mas de 16 millones de computadoras. En el otro extremo, habrá un número muy grande de redes clase C, de pequeño tamaño. Dada una dirección IP, puede determinarse a que clase pertenece examinando el valor de su primer número: Clase A Clase B Clase C 1 - 126 128 - 191 192 - 224 Así, por ejemplo, una dirección IP como 172.16.4.205 pertenece a la red clase B 172.16, cuyo rango de direcciones va desde 172.16.1.1 hasta 172.16.255.254. Debe hacerse notar que, si bien cada uno de los números de la dirección de host puede variar entre 0 y 255, esos dos valores en particular no pueden asignarse como dirección a ninguna 20 máquina; el cero deberá utilizarse para formar la dirección IP de la red en su conjunto, mientras que el 255 es la dirección de broadcast13 (utilizada para enviar un mismo paquete a todos los hosts de la red). Siguiendo con el ejemplo anterior, para la red 172.16, la dirección IP de la red es 172.16.0.0 y la de broadcast, 172.16.255.255. Observar además que hay ciertos valores faltantes en la tabla expuesta mas arriba: 0, 127 y el rango comprendido entre 225 y 255. En el caso de la red 127.0.0.0, la misma se denomina red de loopback y constituye una red virtual (implementada internamente por el software de TCP/IP y no por dispositivos físicos) que conecta a un host directamente consigo mismo. En la red de loopback se asigna siempre una única dirección IP: 172.0.0.1, que corresponde al host local. Por medio de esa dirección de loopback, las aplicaciones pueden tratar al host local de la misma manera que a cualquier host remoto (esto es, desde el punto de vista de las aplicaciones, el host local es otro host mas de la red y no requiere tratamiento especial). La dirección 0.0.0.0 es utilizada por el software de ruteo como la ruta por defecto, tal como se discutirá más adelante, mientras que las redes que comienzan con números entre 225 y 255 están reservadas para usos especiales14. Obtención de las direcciones IP Como ya se ha dicho, cada dispositivo conectado a una red TCP/IP debe tener asignado una dirección IP, que lo identifique unívocamente en toda la inter-red, es decir, debe ser único no solo en la red a la que ese dispositivo pertenece, sino también en todas las demás redes a las cuales esté indirectamente conectado. Como consecuencia de lo anterior se desprende que a la hora de configurar TCP/IP en una red, su administrador no puede seleccionar arbitrariamente los números IP, especialmente si su red se conecta a otras redes TCP/IP. Si la red en cuestión va a ser conectada a Internet, el juego de direcciones IP a utilizar deberá obtenerse de alguna autoridad centralizadora, usualmente el proveedor de acceso a Internet (conocido como ISP: Internet Service Provider)15. Si la red no tiene vínculos a Internet, se recomienda al administrador que utilice alguna de las direcciones reservadas especialmente para redes desconectadas, o también llamadas direcciones no anunciables: Clase A Clase B Clase C 10.0.0.0 172.16.0.0 192.168.0.0 Subredes Ya sea que las direcciones IP a utilizar en la red se obtengan de una autoridad centralizadora o se utilice una dirección no anunciable, el paso previo es decidir que clase de direcciones se utilizará (A, B o C). Por lo dicho hasta el momento, podría concluirse que el criterio para tomar esa decisión debiera basarse en la cantidad de computadoras (presente y estimada a futuro) que se 13 Estrictamente, la dirección de red es aquella en que todos los bits de la porción de host de la dirección IP son cero, mientras que la dirección de broadcast es aquella en que todos los bits son uno. 14 Actualmente se utilizan para redes multicast (redes que permiten direccionar grupos de computadoras al mismo tiempo). 15 La autoridad centralizadora mundial de direcciones IP es el Internet Network Information Center (o InterNIC). En principio, el InterNIC también recibe solicitudes para la asignación de números de red IP, aunque en los últimos años la tarea se ha delegado casi por completo a los proveedores locales. Para mas datos, consultar la dirección http://www.internic.net. 21 conectarán a la red. Obviamente ese es uno de los parámetros a tener en cuenta, pero no es el único. A los fines del ruteo de los paquetes, la dirección IP debe reflejar además la estructura interna de la red, es decir, sus subredes. Denominaremos subred a una porción de la red tal que todas sus computadoras tienen posibilidad de comunicarse directamente entre sí, sin que sea necesario ningún dispositivo intermediario. Para el caso de redes locales, esto significa usualmente que esas computadoras pertenecen al mismo segmento de Ethernet (esto es, están conectadas todas al mismo tramo de coaxil o al mismo concentrador). Consideremos, por ejemplo, la siguiente red: Antares Rigel Altair Orion Cygni Andromeda Aldebarán Canopus La figura muestra que la red está constituida por cuatro segmentos de Ethernet; todas las máquinas conectadas al mismo segmento (por ejemplo, Antares y Rigel) pertenecen a la misma subred. Por otra parte, algunas computadoras (como Andrómeda, Orión y Cygni) pertenecen a más de una subred (de hecho, conectan subredes entre sí, cumpliendo funciones de gateway). Cuado esta red reciba su dirección de red, el administrador deberá mantener fijos ciertos números de la dirección IP (la parte de red) y tendrá libertad para variar los restantes (la parte de host) para numerar las computadoras individuales de la red. Sin embargo, dado que existen subredes, deberá destinar parte de la dirección de host para numerar también las subredes. Por ejemplo, al usar una dirección clase B, como la 172.16.0.0, es usual utilizar el tercer número para numerar la subred, y el último para numerar la máquina dentro de la subred: 22 Antares Rigel Altair 172.16.1.0 172.16.2.0 Orion 172.16.3.0 Cygni Andromeda Aldebarán 172.16.4.0 Canopus Sin embargo, esta segmentación del espacio de direcciones disponible (ó subnetting) trae como resultado que disminuya la cantidad de direcciones aprovechables para asignar a computadoras. En el caso del ejemplo, si bien una dirección clase B (considerada linealmente) provee de un espacio de mas de 65 mil direcciones, la subdivisión de ese espacio en 4 subredes nos deja con solo cuatro subredes de 254 máquinas cada una, haciendo un total de 1016 direcciones para toda la red. Obviamente, es posible conectar mayor número de estaciones agregando hasta 254 subredes, pero ninguna de ellas podrá superar las 254 computadoras. Estrictamente, utilizar el tercer byte completo para numerar la subred no es la única opción; es posible utilizar solo los primeros bits del tercer byte para la dirección de subred y conformar la dirección de host con los bits restantes sumados al cuarto byte; más aún, esa técnica de segmentación es la única opción cuando se utilizan subredes de una dirección clase C (donde 3 bytes deben permanecer fijos y solo el cuarto puede variarse). Sin embargo, independientemente de las "artimañas" que se utilicen, siempre habrá cierta pérdida en el espacio de direcciones aprovechables (lo cual puede ser especialmente problemático si se usa una dirección clase C). En conclusión, para seleccionar la clase de dirección IP a utilizar, debe tenerse en cuenta no solo la cantidad de máquinas de toda la red, sino también su estructura de subredes y la dimensión de cada una, recordando que será necesario contar con un esquema de subnetting que de cabida a la mayor de ellas. A modo de aclaración, cabe agregar que el subnetting es solo una cuestion administrativa que solo es relevante desde el punto de la administración interna de las direcciones IP y, especialmente, el ruteo interno de paquetes; desde la perspectiva de otras redes, lo único relevante es la dirección de red de la red en su conjunto. En resumen... • Las direcciones IP se forman combinando 4 valores numéricos enteros, y está estructurada en una parte de red y otra de host. • La dirección de red refleja también la estructura interna de subredes en que se encuentra dividida la red. 23 • Al solicitar o seleccionar la dirección de red a utilizar, debe optarse por una dirección clase A, B o C, teniendo en cuenta la cantidad de maquinas de la red y, fundamentalmente, la topología lógica de subredes. • Si van a utilizarse direcciones no anunciables, es recomendable utilizar la clase C 192.168.1.0 si la red es de un solo segmento, o bien la clase B 172.16.0.0 si existen múltiples subredes, utilizando el tercer byte para numerar las subredes. Asignación de direcciones IP Una vez asignada la dirección de red y definido el esquema para numerar las subredes, se puede comenzar a asignar direcciones IP a las computadoras de cada subred, configurando cada interfaz de red con los siguientes parámetros: dirección IP, dirección de broadcast y máscara de subred. Continuando con el ejemplo iniciado mas arriba, la asignación de direcciones IP podría ser la siguiente: Antares 172.16.1.1 Altair 172.16.2.1 Rigel 172.16.1.2 172.16.1.0 172.16.1.254 172.16.2.0 172.16.2.254 172.16.3.254 Orion 172.16.1.253 172.16.3.0 172.16.3.253 172.16.4.253 Cygni 172.16.4.0 Andromeda 172.16.4.254 Aldebarán 172.13.3.1 Canopus 172.16.4.1 Obsérvese que computadoras como Orión y Cygni que estén conectadas a más de una subred, deberán recibir una dirección IP por cada una de las subredes a las que se encuentren conectadas16. Computadoras como éstas, que interconectan subredes, jugarán un importante papel como gateways de la red; el administrador de red está en libertad de asignarles cualquier número de IP dentro del rango válido para cada una de las subredes. Sin embargo, es recomendable adoptar algún tipo de convención al numerar los gateways; de esa forma, dado un número de red cualquiera, resultará más simple identificar la dirección del gateway de la subred. En el ejemplo, la convención adoptada consiste en numerar los hosts con números crecientes a partir de 1, y los gateways con números decrecientes a partir de 254. 16 Esto muestra que en realidad quienes tienen direcciones IP no son las computadoras sino las interfaces de red. 24 La dirección de broadcast y la máscara de subred son iguales para todos los hosts dentro de una subred dada. La dirección de broadcast se forma poniendo en 1 todos los bits correspondientes a la porción de host de la dirección IP. En nuestro ejemplo, la porción de host es el último byte de la dirección; si todos los bits de ese byte se ponen a 1, el valor en decimal es 255, por lo que las direcciones de broadcast serían las siguientes: 172.16.1.0 172.16.2.0 172.16.3.0 172.16.4.0 172.16.1.255 172.16.2.255 172.16.3.255 172.16.4.255 La máscara de subred es un número que se utiliza para obtener la dirección de red partir de una dirección IP. La separación se realiza por medio de una operación lógica AND entre la dirección IP y la máscara de subred, por lo que la máscara de subred deberá tener puestos a 1 aquellos bits que corresponden a la dirección de red (incluyendo la parte de la subred) y a 0 aquellos que formen la dirección de host. Para el caso en que se usen bytes completos para dirección de red y de host, la máscara de subred se formará poniendo un 255 en los bytes que correspondan a la parte de red, y un 0 en los bytes que correspondan a la parte de host. Por ejemplo: A, sin subredes A, con subredes B, sin subredes B, con subredes C, sin subredes 10.0.0.0 10.x.0.0 172.16.0.0 172.16.x.0 192.168.1.0 255.0.0.0 255.255.0.0 255.255.0.0 255.255.255.0 255.255.255.0 Para el caso de la red del ejemplo, se trata de una red con direcciones clase B con subredes, por lo que la máscara de subred a utilizar es 255.255.255.0. Configurando un sistema Unix17 En Unix las interfaces de red se configuran por medio del comando ifconfig, cuya sintaxis básica es la siguiente: ifconfig interfaz dirección_IP netmask máscara broadcast dirección_broadcast en dónde, interfaz dirección_IP máscara broadcast Es el nombre asignado por el sistema operativo al adaptador de red. Es la dirección IP que se le asigna a esta interfaz Máscara de subred. Dirección de broadcast de la subred18. Antes de poder utilizar ifconfig se deben conocer los nombres que el sistema operativo asigna a los adaptadores de red. El administrador puede obtener esa información de la documentación provista por el sistema; en el caso de Red Hat Linux (y de otros sistemas 17 Todos los comandos de configuración deben ejecutarse desde algún usuario con suficientes privilegios; usualmente, solo pueden ser ejecutados por root. 18 El parámetro broadcast es opcional, dado que puede calcularse automáticamente dada la dirección IP y la máscara de subred. 25 Unix que implementen el pseudo-filesystem /proc) pueden conocerse los adaptadores de red detectados por el sistema operativo durante el arranque consultando el archivo /proc/dev/net: # cat /proc/net/dev Inter-| Receive | Transmit face |packets errs drop fifo frame|packets errs drop fifo colls carrier lo: 39 0 0 0 0 39 0 0 0 0 0 eth0: 0 0 0 0 0 0 0 0 0 0 0 El listado anterior muestra que las interfaces detectadas son lo (la interfaz a la red de loopback) y eth0 (una placa de red Ethernet). Así, para configurar la interfaz Ethernet de Antares, se debe ejecutar un comando como el siguiente: # ifconfig eth0 172.16.1.1 netmask 255.255.255.0 broadcast 172.16.1.255 Algunos sistemas configuran la dirección de loopback automáticamente, pero en aquellos en donde debe hacerse explícitamente, puede hacerse corriendo el comando: # ifconfig lo 127.0.0.1 netmask 255.0.0.0 broadcast 127.255.255.255 Comandos como éstos se ejecutan normalmente de manera automática cuando el sistema operativo se inicializa al prender el equipo, usualmente invocados desde algún script de inicialización. El administrador debe modificar directamente esos scripts, o algún archivo de configuración que los mismos utilizan, a fin configurar las interfaces de red. Red Hat Linux inicializa las interfaces desde el script /etc/rc.d/init.d/network, obteniendo los parámetros de configuración desde archivos ubicados en el directorio /etc/sysconfig/network-scripts. Allí existe un archivo por cada interfaz de red (incluida la interfaz de loopback), cuyo nombre es de la forma ifcfg-nombre_de_la_interfaz y que contiene una serie de variables con los parámetros de configuración de la interfaz. Por ejemplo: DEVICE=eth0 IPADDR=172.16.1.1 NETMASK=255.255.255.0 NETWORK=172.16.1.0 BROADCAST=172.16.1.255 ONBOOT=yes BOOTPROTO=none DEVICE=lo IPADDR=127.0.0.1 NETMASK=255.0.0.0 NETWORK=127.0.0.0 BROADCAST=127.255.255.255 ONBOOT=yes BOOTPROTO=none Por otra parte, la mayoría de los Unix modernos proveen al administrador de una interfaz gráfica para la configuración de las interfaces. En Red Hat Linux 5.0 se denomina netcfg, y luce de la siguiente forma: 26 Ruteo de paquetes IP Como se describió previamente, la principal responsabilidad del protocolo IP es determinar qué camino deben tomar los paquetes para llegar al punto de destino. La tarea de determinar ese camino es lo que se conoce como ruteo (o encaminamiento). IP asume que la computadora está directamente conectada a una red local (por ejemplo, una LAN Ethernet) y que puede enviar paquetes directamente a cualquier otra computadora sobre esa misma red; si la dirección de destino es en la red local, IP simplemente accede al medio físico de transmisión y envía el paquete. En la figura siguiente, Antares y Rigel están sobre la misma red, por lo que pueden comunicarse directamente: Antares 170.25.1.1 Altair 170.25.2.1 Rigel 170.25.1.2 170.25.1.0 170.25.1.254 170.25.2.0 170.25.2.254 170.25.3.254 Orion 170.25.1.253 170.25.3.0 170.25.3.253 170.25.4.253 Cygni 170.25.4.254 Andromeda 170.25.4.0 Aldebarán 170.25.3.1 Internet Canopus 170.25.4.1 Centauri 170.25.4.253 27 El problema aparece cuando la dirección de destino queda en otra red, en cuyo caso IP recurrirá a un gateway para enviar indirectamente los paquetes. Como se recordará, se denomina gateway19 a un dispositivo (ya sea otra computadora o un dispositivo específicamente diseñado a tal efecto) que está conectado a más de una red y tiene la capacidad para redirigir (forward) paquetes entre esas redes. En la figura, Orión, Andrómeda, Cygni y Centauri son los gateways de la red. Para determinar a qué gateway deberán enviarse los paquetes, IP extrae la dirección de red del nodo de destino y consulta una tabla, denominada tabla de ruteo, en la cual se listan las redes conocidas y los gateways que pueden utilizarse para alcanzarlas. Por ejemplo, la tabla de ruteo de Aldebarán contiene la siguiente información: 170.25.1.0 170.25.2.0 170.25.3.0 170.25.4.0 170.25.3.254 170.25.3.254 * 170.25.3.253 en donde el asterisco indica que no es necesario ningún gateway para llegar a la red en cuestión dado que la máquina tiene conexión directa a la misma. Obsérvese en primer lugar que el ruteo hacia redes remotas se realiza en base a direcciones de red (esto es, la parte de host de la dirección IP se ignora); además, la tabla de ruteo especifica tanto la red local como las remotas, y que para el caso de éstas últimas, indica la dirección IP de alguna máquina en la red local que puede ser utilizada para alcanzarla. Supongamos, por ejemplo, que Altair requiere enviar datos a Canopus. El módulo IP de Altair determina que la computadora de destino no pertenece a su misma red; consultando su tabla de ruteo, determina que puede llegarse a la red de Canopus a través de Orión, por lo que le envía los paquetes a dicha computadora. El módulo IP residente en Orión, por su parte, sabe que para llegar a Canopus hay dos vías posibles: pasando por Andrómeda o por Cygni. Aplicando algún criterio para evaluar ambas rutas y seleccionar la mejor de ellas, Orión envía cada paquete a, por ejemplo, Andrómeda. Esta última determina que la dirección de destino está en una de las redes a las que se encuentra directamente conectada, por lo que los envía diretamente a Canopus. Es importante observar que la ruta que seguirán los paquetes desde el origen hasta su destino se va decidiendo a medida que los mismos viajan por la red. Cada nodo es responsable de determinar cual es el proximo "salto" en dirección al nodo final, en función del contenido de su tabla de ruteo. Este modelo de ruteo asume que si el nodo de destino no pertenece a la red local, deberá haber una entrada en la tabla de ruteo que especifique el gateway a utilizar. En otras palabras, asume que todos los nodos están al tanto de la estructura de la red. En consecuencia, cada vez que la estructura de la red cambia (por ejemplo, cuando se agrega o elimina una subred), el administrador debería actualizar las tablas de ruteo en todos los nodos. Igualmente, si la red se interconectara a otra red, una nueva entrada debería agregarse en las tablas de ruteo de cada máquina. Siguiendo con este razonamiento, a medida que la red crece y se interconecta a otras redes las tablas de ruteo se hacen mas largas y complejas; inclusive sería posible que fueran virtualmente imposibles de construir o mantener, en especial si la red se conecta a Internet (formada por miles de redes independientes). Por supuesto, existen previsiones para enfrentar estos problemas: el ruteo dinámico o adaptativo y las rutas por defecto. 19 La palabra inglesa gateway podría traducirse como "puerta de salida". 28 Ruteo estático vs. ruteo dinámico La tabla de ruteo de un host puede construirse de dos maneras. Una posibilidad consiste en que el administrador (por medio de scripts que se ejecutan al inicializar el sistema, o por medio de comandos ejecutados interactivamente) introduzca manualmente las entradas de la tabla. Esta técnica se denomina ruteo estático, debido a que la tabla de ruteo se construye cuando la computadora se prende y no varia con el tiempo. La otra posibilidad es ejecutar en cada host un programa que actualice automática y periódicamente la tabla de ruteo. Dichos programas se basan en el hecho de que una computadora siempre tiene acceso a otras computadoras conectadas a la red local; esto se traduce en que las tablas de ruteo contienen inicialmente al menos las direcciones de las redes locales. Si tomamos por caso a Orión, su tabla de ruteo inicialmente contendría la siguiente información: 170.25.1.0 170.25.2.0 170.25.3.0 * * * De manera similar, la tabla de Andrómeda contendrá lo siguiente: 170.25.3.0 170.25.4.0 * * Si Orión y Andrómeda intercambiaran sus tablas de ruteo, cada una podría "aprender" de la otra qué redes son alcanzables por esa vía. Así, Andrómeda podría concluir lo siguiente: 170.25.1.0 170.25.2.0 170.25.3.0 170.25.4.0 170.25.3.254 170.25.3.254 * * Así, si todos los nodos de la red ejecutan un programa de estas características (llamado demonio de ruteo) al cabo de cierto tiempo habrán "descubierto" por si mismas la estructura de la red y construido sus tablas automáticamente. Mas aún, si se produjera algún cambio en la estructura de la red, bastaría con que alguna de las computadoras lo detectara para que en pocos segundos esa nueva información se propagara por toda la red. Esta estrategia se denomina ruteo dinámico o adaptativo y tiene la ventaja de que, al ser automático, permite eliminar las tareas administrativas relacionadas con el mantenimiento de las tablas de ruteo. En ambientes Unix se dispone de dos programas que implementan este tipo de protocolos de ruteo: routed y gated. Rutas por defecto El uso de ruteo dinámico elimina la necesidad de modificar las tablas de ruteo cuando la red cambia. Sin embargo, no resuelve el problema de las abultadas tablas de ruteo resultantes de conectar una red a muchas otras. 29 Consideremos la tabla de ruteo que construiría una máquina como Altair: 170.25.1.0 170.25.2.0 170.25.3.0 170.25.4.0 170.25.2.254 * 170.25.2.254 170.25.2.254 Como puede verse, Altair ha aprendido las rutas a todas las subredes de la red, pero el único gateway que puede utilizar es Orión. De manera similar, si fuera posible que todas las computadoras de la red del ejemplo aprendieran las direcciones de todas las redes que forman la Internet, Altair eventualmente construiría una tabla de ruteo con miles de entradas, en donde todas tendrían a Orión como gateway. En ambos casos, el resultado es una tabla de ruteo con información altamente redundante. Para eliminar este problema, es que puede instalarse en la tabla de ruteo una ruta por defecto (conocida también como default gateway). IP utiliza la ruta por defecto (que se indica con el número 0.0.0.0) cada vez que no se encuentra en la tabla de ruteo una ruta hacia una red específica. Aplicando éste criterio, la tabla de Altair se reduciría a lo siguiente: 170.25.2.0 0.0.0.0 * 170.25.2.254 que sencillamente indica que si la dirección de destino está en la red local, es accesible directamente, y que en caso contrario (independientemente de cual sea el destino), los paquetes deberán enviarse a 170.25.2.254 (es decir, Orión). Configurando los nodos Caso 1: Redes sin segmentación interna En este caso, se tiene una red pequeña, en la que todas las computadoras están ubicadas sobre el mismo segmento físico y no hay ninguna conexión a otras redes TCP/IP: Antares 205.12.9.1 Rigel 205.12.9.2 Altair 205.12.9.3 205.12.9.0 Como se puede ver, todas las computadoras tienen acceso directo a todas las demás. La tabla de ruteo será mínima; solo contendrá una referencia a la red local y a la red de loopback instaladas automáticamente por ifconfig al inicializar las interfaces correspondientes. Puede utilizarse el comando route -n para examinar el contenido de la tabla de ruteo (-n indica a route que utilice formato numérico): # route -n Kernel IP routing table Destination Gateway Iface 127.0.0.0 0.0.0.0 205.12.9.0 0.0.0.0 Genmask Flags Metric Ref 255.0.0.0 255.255.255.0 U U 0 0 1 40 Use 298 lo 1252 eth0 30 En el listado anterior, la primera columna indica dirección de red (que debe interpretarse de acuerdo a la mascara de la tercera columna) y la segunda columna indica el gateway a utilizar (0.0.0.0 se utiliza para indicar que hay conexión directa a la red en cuestión. Route también muestra información adicional sobre cada ruta: Flag: Se compone de una serie de caracteres que indican las características de la ruta. Por ejemplo, U indica que la ruta está operacional (por Up), G que es una ruta a un gateway, H que es una ruta a un host, etc. Metric: Valor utilizado para cuantificar la ruta. IP utiliza este valor para seleccionar la mejor de dos o más rutas alternativas a la misma red. Ref: Cantidad de veces que ésta ruta fue utilizada para establecer una conexión. Use: Cantidad de paquetes trasmitidos a través de esa ruta. Si esta misma red se conectara a otras redes (por ejemplo, la Internet), sería necesario indicar en cada uno de los hosts de la red una ruta estática por defecto hacia el gateway a las otras redes: Antares 205.12.9.1 Rigel 205.12.9.2 Altair 205.12.9.3 205.12.9.0 205.12.9.254 150.104.3.21 Orión Internet Las rutas por defecto puede instalarse en las estaciones por medio del siguiente comando route: # route add -net default 205.12.9.254 Si ahora se reexaminara la tabla de ruteo en dichas estaciones, se obtendría el siguiente resultado: # route -n Kernel IP routing table Destination Gateway Iface 127.0.0.0 0.0.0.0 205.12.9.0 0.0.0.0 0.0.0.0 205.12.9.254 Genmask Flags Metric Ref 255.0.0.0 255.255.255.0 0.0.0.0 U U UG 0 0 0 1 40 0 Use 298 lo 1252 eth0 0 eth0 Obsérvese que Orión interconecta nuestra red con el exterior, por lo que tiene una dirección en la red local (170.25.9.254) y otra en la red del proveedor de acceso a la otra red (en este caso, la Internet). A fin de lograr la conectividad, deberá instalarse en Orión una ruta por 31 defecto hacia el exterior, utilizando como gateway una dirección que el proveedor especifique, por ejemplo: # route add -net default 150.104.3.254 Por otra parte, el proveedor deberá instalar en sus ruteadores alguna ruta que indique que nuestra red es alcanzable a través de la dirección 150.104.3.21, cerrando así el ciclo de entrada y salida a nuestra red. Caso 2: Redes segmentadas En este caso, la red está compuesta por varios segmentos unidos entre sí por gateways. Una primera opción sería ejecutar un demonio de ruteo dinámico en todas las computadoras, y dejar que las tablas se actualicen automáticamente. Sin embargo si tal programa no estuviera disponible (o por alguna razón se decide no emplearlo) bastaría con instalar en las computadoras de cada segmento una ruta estática por defecto hacia el gateway Orión, tal como se muestra en la siguiente figura: Antares 170.25.1.1 Rigel 170.25.1.2 Altair 170.25.2.1 170.25.1.0 Aldebarán 170.25.2.2 170.25.2.0 170.25.1.254 170.25.2.254 Orion Para obtener esta configuración, en Antares y Rigel habría que ejecutar el siguiente comando: # route add -net default gw 170.25.1.254 mientras que en Altair y Aldebarán el comando sería: # route add -net default gw 170.25.2.254 No es necesario instalar manualmente ninguna ruta en Orión, debido a que todas las necesarias serán instaladas automáticamente por ifconfig. Sería diferente si la red tuviera más subredes: 32 Antares 170.25.1.1 Altair 170.25.2.1 Rigel 170.25.1.2 170.25.1.0 170.25.2.0 170.25.1.254 170.25.2.254 170.25.3.254 Orion 170.25.3.0 170.25.3.253 170.25.4.254 Andromeda Aldebarán 170.25.3.1 170.25.4.0 Canopus 170.25.4.1 En éste caso, sería necesario informar a Orión acerca de la existencia de la red 170.25.4.0, y a Andrómeda acerca de las redes 170.25.1.0 y 170.25.2.0. Una vez mas, puede utilizarse el comando route para instalar las rutas, utilizando la siguiente sintaxis: # route add -net red netmask máscara gw gateway Por ejemplo, en Andrómeda habría que ejecutar los siguientes comandos: # route add -net 170.25.1.0 netmask 255.255.255.0 gw 170.25.3.254 # route add -net 170.25.2.0 netmask 255.255.255.0 gw 170.25.3.254 con lo que la tabla de ruteo quedaría conformada de la siguiente manera: # route -n Kernel IP routing table Destination Gateway Iface 127.0.0.0 0.0.0.0 170.25.3.0 0.0.0.0 170.25.4.0 0.0.0.0 170.25.1.0 170.25.3.254 170.25.2.0 170.25.3.254 Genmask Flags Metric Ref 255.0.0.0 255.255.255.0 255.255.255.0 255.255.255.0 255.255.255.0 U U U UG UG 0 0 0 0 0 1 105 55 20 33 Use 298 11252 1976 841 976 lo eth0 eth1 eth0 eth0 Finalmente, si la red tuviera conexión a redes externas, sería necesario instalar en los gateways una ruta por defecto que conduzca hacia el gateway al exterior: 33 Antares 170.25.1.1 Altair 170.25.2.1 Rigel 170.25.1.2 170.25.1.0 170.25.1.254 170.25.2.0 170.25.2.254 170.25.3.254 Orion 170.25.3.0 170.25.3.253 170.25.4.254 Andromeda 170.25.4.0 Aldebarán 170.25.3.1 Internet Canopus 170.25.4.1 Centauri 170.25.4.253 En Orión: # route add -net default gw 170.25.3.253 En Andrómeda: # route add -net default gw 170.25.4.253 Opciones al comando route En todos los ejemplos anteriores se utilizó el comando route para instalar rutas manualmente en la tabla de ruteo. Sin embargo, al igual que ocurre con ifconfig, usualmente el administrador no instala las rutas introduciendo comandos manualmente (o modificando scripts de inicialización del sistema), sino que se limita a modificar archivos de configuración o utilizar alguna herramienta gráfica. En el caso de Red Hat Linux, la utilidad netcfg que se mencionó con anterioridad puede utilizarse para configurar la ruta por defecto e instalar rutas estáticas. También pueden realizarse estas tareas modificando manualmente archivos de configuración network y static-routes respectivamente, ubicados ambos bajo /etc/sysconfig. 34 Resolución de Nombres Una vez que se han configurado las direcciones IP y el ruteo, una red TCP/IP se encuentra totalmente operativa. Sin embargo, a los fines prácticos hay que cumplimentar un paso adicional: la configuración de la resolución de nombres. Un servicio de resolución de nombres permite a las computadoras de una red transformar nombres en direcciones numéricas y viceversa. Sabemos que, a fin de acceder a servicios a través de la red, es necesario hacer referencia a aquellas computadoras que los ofrecen, las cuales se conectan a una o más redes por medio de interfaces. Como se ha visto, cada interfaz de red conectada a una red TCP/IP se identifica con una dirección IP numérica, por lo que para hacer referencia a la misma, es necesario conocer dicho número. Si bien los protocolos de comunicaciones y las aplicaciones informáticas se sienten a gusto utilizando números, no ocurre lo mismo con las personas, quienes prefieren utilizar nombres para designar a las computadoras de la red, ya que son más fáciles de recordar. Seguramente es más probable que el nombre del sitio web de la UTN Facultad Córdoba (www.frc.utn.edu.ar) esté mas presente en la memoria de sus usuarios que su dirección IP (170.210.248.211). Otra razón para utilizar nombres en lugar de números es el aislar a los usuarios de posibles cambios en la distribución de las direcciones IP. Por ejemplo, si el programa que habitualmente se utiliza para leer correo electrónico está configurado para obtener mensajes a partir de la dirección IP 172.16.4.205, el administrador de red necesitará notificar a todos los usuarios que deberán reconfigurarlo si el servidor de correo se muda a otro equipo, o si la dirección IP del equipo en el que reside se cambia por alguna razón. Por medio de la utilización del servicio de resolución de nombres, el programa de correo electrónico puede configurarse para obtener los mensajes de una máquina llamada, por caso, mailhost, independientemente de dónde se ubique físicamente. La tabla de Hosts Para implementar un servicio de nombres es necesario confeccionar una lista en la que se relacionen nombres con direcciones IP; cuando un programa necesita resolver un nombre (esto es, dado un nombre encontrar la dirección IP), debe consultar dicha lista. En un principio, la resolución de nombres se implementó por medio de un archivo ubicado en cada máquina de la red que contenía dicha lista. En el caso de Unix, ese archivo es el /etc/hosts y tiene el siguiente formato: # # Tabla de resolución de nombres # 127.0.0.1 localhost 170.25.1.1 antares 170.25.1.2 rigel 170.25.1.254 orion 170.25.2.1 altair 170.25.2.254 orion 170.25.3.1 aldebaran 170.25.3.253 andromeda 170.25.3.254 orion 170.25.4.1 canoups 170.25.4.253 centauri 170.25.4.254 andromeda Las líneas que comienzan con # se consideran comentarios y son ignoradas, mientras que las demás asocian un número de IP con el nombre asociado a la computadora. 35 Así, cuando el usuario ejecuta un comando como $ telnet aldebaran el programa telnet antes de iniciar la conexión transforma el nombre aldebaran en la dirección IP 170.25.3.1, según se consigna en la tabla de hosts. Obsérvese además que los gateways de la red figuran varias veces en el listado, según la cantidad de interfaces que posean. También es posible asignar mas de un nombre a una misma interfaz (denominados alias): 170.25.1.254 orion mailhost De esta manera, el comando $ telnet orion resulta totalmente equivalente al comando $ telnet mailhost La tabla de hosts provee de un mecanismo sencillo para implementar la resolución de nombres. Sin embargo, a medida que la red crece y debido a que la información está duplicada en cada host de la red, su mantenimiento se hace cada vez más trabajoso. La situación se complica si varias redes TCP/IP se interconectan, en cuyo caso, a las tareas de sincronización de tablas entre diferentes hosts hay que sumar el control de nombres duplicados para máquinas diferentes. Para solucionar estos problemas de escalabilidad, el mecanismo de resolución de nombres evolucionó hacia uno mucho más sofisticado: el Servicio de Nombres de Dominio, o DNS (Domain Name Service). Sin embargo, aún cuando se utilice DNS, es necesario contar con una tabla de hosts mínima a ser utilizada por el sistema operativo durante el arranque, con información suficiente para resolver el nombre de la máquina y el nombre "localhost" asociado con la dirección de loopback. Por ejemplo, la tabla de hosts de Canopus debiera contener mínimamente lo siguiente: 127.0.0.1 170.25.4.1 localhost canoups Servicio de Nombres de Dominio (DNS) La tabla de hosts fue reemplazada por un esquema mucho más potente y flexible, adecuado para las necesidades de escalabilidad y tolerancia a fallas de grandes redes como la Internet. El DNS es un servicio cliente/servidor, en el cual cuando un proceso necesita resolver un nombre se contacta vía TCP/IP20 con otro proceso, llamado servidor de nombres, quien realiza el proceso de resolución y retorna una respuesta. Como en todo sistema cliente/servidor, ambos procesos pueden ejecutarse sobre la misma maquina o en máquinas completamente diferentes. Un servidor DNS mantiene la lista de direcciones y nombres de una o más agrupaciones de computadoras, llamadas dominios. Dichas agrupaciones se forman de manera conceptual (por área geográfica, motivos organizacionales, por proyectos, etc.) y no tienen necesariamente que tener un correlato con direcciones de red o estructura de subredes. 20 Estrictamente, la comunicación entre el cliente y el server DNS se realiza mediante conexiones UDP. 36 Además de contener computadoras, un dominio puede particionarse en otros subdominios. Este particionamiento se realiza a los fines de permitir la delegación de tareas administrativas. El administrador de un subdominio puede cambiar datos de las computadoras del mismo e incluso crear nuevos subdominios que delegar a terceros. Esto da como resultado una estructura jerárquica, similar a un árbol invertido, en donde para llegar a un dominio en particular, se debe seguir una trayectoria de dominios encadenados a partir de un dominio raíz. Inmediatamente por debajo del dominio raíz, se encuentran los dominios de alto nivel. Inicialmente, los diseñadores de ARPANET (la red predecesora de Internet) concibieron los dominios de alto nivel como dominios organizacionales: • com • edu : • gov: • mil: • net: • org: • int: : organizaciones comerciales; organizaciones educativas; organizaciones gubernamentales; organizaciones militares; organizaciones administradoras de redes globales; organizaciones sin fines de lucro; organizaciones internacionales (como la OTAN, la ONU, etc.). Mas tarde, en vistas a la expansión de la Internet por todo el mundo, se crearon nuevos dominios de alto nivel, uno por cada país: los dominios regionales. Los dominios regionales se designan según un estándar internacional llamado ISO 3166, que asigna a cada país un código de dos letras21. Por ejemplo: • ar: • us: • es: • mx: • uk: Argentina Estados Unidos España México Gran Bretaña22 La administración del DNS a escala global recae en un organismo llamado Internet Network Information Center (o InterNIC), al cual debe recurrirse para solicitar la creación de un subdominio de los dominios de alto nivel. El InterNIC, por su parte, delega la administración de los dominios regionales a las autoridades del país correspondiente; en el caso de la Argentina, es responsabilidad de la Cancillería. Dichas organizaciones son las responsables de decidir la forma en que particionarán el dominio regional. Usualmente, tal como ocurre en Argentina, deciden hacer un paralelo de los dominios organizacionales de alto nivel. Así, por ejemplo, existen los dominios com.ar, org.ar, gov.ar, edu.ar, etc. Sin embargo, algunos países deciden seguir algún otro tipo de esquema; por ejemplo, algunos de los subdominios de Gran Bretaña son co.uk (por "corporations"), ac.uk (por "academic community"), etc. Cuando una organización poseedora de una red desea que se le asigne un dominio, deberá primero decidir bajo que dominio desea ubicarse, para luego solicitar al organismo que lo administre la delegación de un subdominio. Si dicho organismo considera pertinente la 21 A pesar de esto, y por tradición histórica, las organizaciones norteamericanas no se inscriben en el dominio regional de los EE.UU sino directamente en los dominios organizacionales de alto nivel. 22 En "DNS and BIND" de Albitz & Cricket se hace la siguiente aclaración: "La excepción es Gran Bretaña. De acuerdo a ISO 3166 el dominio de la Gran Bretaña debiera ser gb, pero en su lugar, Gran Bretaña e Irlanda del Norte utilizan uk (por United Kingdom). También conducen los automóviles del lado equivocado de la calle" 37 solicitud, creará el dominio solicitado y a partir de ese momento la organización solicitante será la responsable de administrarlo, pudiendo agregar máquinas al dominio o incluso particionarlo en mas subdominios. Por ejemplo, la Universidad Tecnológica Nacional gestionó en Cancillería el dominio utn.edu.ar al cual pertenecen las computadoras del Rectorado (en Buenos Aires); luego decidió crear un subdominio para cada una de sus Facultades Regionales. Así, por ejemplo, existen los dominios frc.utn.edu.ar (Facultad Córdoba), frba.frc.utn.edu.ar (Facultad Buenos Aires), frlp.frc.utn.edu.ar (Facultad La Plata), etc. Dentro de un dominio, sus administradores están en libertad de crear nombres para sus computadoras. El nombre que se asigne a cada máquina se combinará con el nombre del dominio para formar el Nombre de Dominio Totalmente Calificado (conocido como FQDN, por Fully Qualified Domain Name), tal como: khitomer.frc.utn.edu.ar De esta manera, aunque dos dominios tengan máquinas con el mismo nombre, siempre será posible distinguirlas por medio del FQDN23. En síntesis, la estructura del DNS puede reflejarse de la siguiente manera (con el dominio raíz representado por un punto): . com edu org gov mil com net edu ar org gov mil net utn frba frc frlp Resolución de nombres basada en DNS Supongamos que un programa ejecutándose en una máquina en el dominio frc.utn.edu.ar requiere iniciar una conexión con otra computadora. Dado que el primer paso es obtener su dirección IP, dicha aplicación deberá realizar una petición de resolución a algún server de nombres. Como se mencionó anteriormente, un server de nombres posee las tablas de direcciones y nombres referentes a uno o más dominios. Si la petición de resolución hace referencia a una máquina perteneciente a alguno de los dominios administrados localmente (en cuyo caso se dice que el server tiene autoridad sobre ese dominio), el server consulta la tabla respectiva y contesta la petición. En caso contrario deberá realizar una serie de consultas siguiendo la jerarquía de dominios a partir del dominio raíz, hasta encontrar el server que tiene autoridad sobre el dominio al cual pertenece el nombre buscado. Supongamos, por ejemplo, que se intenta resolver el nombre andromeda.galaxia.org.ar. El server de nombres local (frc.utn.edu.ar) redirige la consulta a los servidores de nombres del 23 De hecho, la única forma de referenciar una computadora desde otra red es por medio de su FQDN. 38 dominio raíz, los cuales le contestan con la dirección IP del server DNS del dominio ar. El server local realiza una nueva consulta, esta vez al server de ar, quien responde con la dirección del server que tiene autoridad sobre org.ar. Tras una nueva consulta, el server local recibe la dirección del servidor de nombres de galaxia.org.ar, que al ser consultado retorna la dirección IP de la computadora andrómeda. Esta estrategia de consulta se denomina iterativa, debido a que el server de nombres local recibe como respuesta la dirección de otro server de nombres, por lo que debe repetir la operación (esto es, iterar) hasta que reciba la dirección IP del nombre a resolver. Existe otra posible configuración, llamada recursiva, según la cual un server de nombres puede ser configurado de tal forma que retorne siempre la dirección final buscada; si, por ejemplo, el server de nombres de ar fuera recursivo, en vez de retornar la dirección de org.ar para que luego el server que inició la consulta continúe iterando, realizaría la iteración él mismo. Cualquiera sea la estrategia utilizada, puede observarse que una única resolución implica múltiples consultas a través de la Internet. Para minimizar demoras en las comunicaciones, el diseño del DNS incluye la posibilidad de que los servidores de nombres guarden temporalmente las respuestas a las consultas que se han recibido, es decir, mantienen un cache de consultas previas que pueden ser reutilizadas si la consulta se repite. El Dominio de Reversa Un server DNS permite también realizar operaciones de resolución inversa, esto es, obtener un nombre a partir de una dirección IP. Para ello, existe un dominio especial llamado in-addr.arpa y conocido como dominio de reversa, cuyos subdominios se forman a partir de los valores numéricos de las direcciones IP, tomados en orden inverso. Por ejemplo, la dirección 1.3.25.170.in-addr.arpa. IP 170.25.3.1, pertenece al dominio de reversa Cuando a una red se le asigna un número de red, usualmente también se le delega la administración de su correspondiente dominio de reversa. Por ejemplo, el dominio de reversa correspondiente a 170.25 sería 25.170.in-addr.arpa, quedando en manos de su administrador la decisión de crear subdominios para cada una de sus subredes (por ejemplo, 1.25.170.in-addr.arpa, 2.25.170.in-addr.arpa, etc.) Configuración de un servidor DNS usando BIND La implementación estándar de DNS para Unix es BIND (Berkely Internet Name Domain) y consiste en un módulo cliente llamado "resolver" que se integra a las aplicaciones, y un demonio llamado named, que debe ejecutarse en aquella computadora que se designe como server de nombres del dominio. Si bien el tratamiento completo de la configuración de éste paquete de software escapa al alcance de éste trabajo, se discutirán a continuación los aspectos básicos de su configuración. Tipos de Servidores de Nombres BIND soporta tres modos de configuración para el servidor de nombres: Primario: fuente autorizada de información sobre un determinado dominio, lo cual significa que un servidor de nombres primario es quien tiene la información completa y más actualizada sobre los nombres de computadoras pertenecientes al dominio. Dicha información se obtiene a partir de archivos de datos construidos por el administrador de la red (llamados archivos de zona). Secundario: mantiene una copia de la información sobre un determinado dominio, transfiriéndola periódicamente desde un server de nombres primario (operación llamada transferencia de zona). También se considera fuente autorizada de información sobre ese dominio. 39 Cache: responde consultas haciendo peticiones a otros servidores de nombres, y las almacena localmente para agilizar futuras consultas por la misma información. Sin embargo, no mantiene la base de datos de ningún dominio (esto es, no tiene autoridad sobre ningún dominio en particular). Archivos de configuración named requiere un archivo de configuración llamado /etc/named.boot y varios archivos de zona, según los dominios que se vayan a administrar. El archivo /etc/named.boot define parámetros generales para la configuración del servidor, en especial el modo de operación (primario, secundario o cache) y la ubicación y nombres de los archivos de zona. El archivo /etc/named.boot típico para configurar el server de nombres primario de una red como la del dominio galaxia.org.ar contendrá la siguiente información: ; ; Server de nombres primario de galaxia.org.ar ; directory /etc primary galaxia.org.ar named.hosts primary 25.170.in-addr.arpa named.rev primary 0.0.127.in-addr.arpa named.local cache . named.cache Cada línea del archivo /etc/named.boot especifica una directiva de configuración, excepto aquellas que comiencen con punto y coma (;), que se consideran comentarios y son ignoradas. La directiva directory indica el directorio donde named podrá encontrar los archivos de datos que se mencionen a continuación. La directiva primary configura el server de nombres para ser servidor primario del dominio que se indica a continuación, obteniendo la lista de nombres y direcciones desde el archivo que figura como último parámetro. En ejemplo anterior, puede verse que el server de nombres será server primario de los dominios galaxia.org.ar (el dominio asignado a la organización), 25.170.in-addr.arpa (el dominio de reversa correspondiente a la dirección asignada a la red) y 0.0.127.in-addr.arpa (el dominio de reversa de la red de loopback). Finalmente, con la directiva cache se indica a named el archivo a utilizar como contenido inicial del cache de direcciones y nombres. Es en este archivo donde se indican las direcciones IP de los servidores de nombres del dominio raíz. La configuración de un server secundario resulta similar: ; ; Server de nombres secundario de galaxia.org.ar ; directory secondary galaxia.org.ar 170.25.4.254 secondary 25.170.in-addr.arpa 170.25.4.254 primary 0.0.127.in-addr.arpa cache . /etc named.hosts named.rev named.local named.cache En lugar de la directiva primary se utiliza la directiva secondary, cuyos argumentos son el nombre del dominio, la dirección IP del server primario desde donde transferir los archivos de datos y el nombre del archivo local donde almacenarlos. Dichos archivos serán 40 creados automáticamente la primera vez que el server se inicie, y serán actualizados periódicamente. Archivos de Zona Al definir un server primario, utilizando la directiva primary, el administrador indica el nombre del archivo de zona desde donde obtener los datos. La diferencia entre zona y dominio es sutil: una zona contiene la información sobre un dominio y todos aquellos subdominios que no han sido delegados a otro server. La partición en subdominios se realiza fundamentalmente para agrupar conceptualmente computadoras relacionadas, idealmente con el objetivo de delegar en sus usuarios la administración de la información sobre las mismas. Sin embargo, puede ocurrir que los mismos no estén en condiciones de hacerse cargo de esas tareas (por falta de equipamiento, capacitación, etc.), en cuyo caso el administrador de la red puede optar por crear los subdominios, pero no delegarlos. Obviamente, en un dominio cuyos subdominios han sido todos delegados, la zona y el dominio coinciden. Un archivo de zona está compuesto por registros, cuya sintaxis es la siguiente (los campos entre corchetes son opcionales): [nombre] [ttl] IN tipo datos en donde: nombre: es el nombre de la entidad que el registro define (direcciones, nombres, etc.). Dicho nombre es relativo al dominio actual y si se omite, se considera igual al valor del campo nombre del registro anterior. ttl: es un valor numérico (en segundos) que indica cuanto tiempo ese registro debe conservarse en el cache antes de ser refrescado (es la abreviatura de Time To Live). Si se omite, se considera igual al ttl por defecto de la zona (ver registro SOA, mas adelante). tipo: identifica el tipo de registro: Tipo SOA NS A PTR MX CNAME datos: Función Start Of Authority. Indica el inicio de la zona, y define parámetros generales para la misma Name Server. Define el nombre del server de nombres del dominio. Address. Define la dirección IP asociada a un nombre. Pointer. Define el nombre asociado a una dirección IP. Mailer Exchange. Define el nombre del host que recibe el correo electrónico para un determinado nombre del dominio. Canonical Name. Define un alias para un host. información específica, dependiente del tipo de registro. El archivo de zona para un dominio como galaxia.gov.ar, llamado named.hosts como se indicó en named.boot, tendrá el siguiente contenido: 41 ; ; ; @ ( server de nombres primario de galaxia.org.ar IN SOA cygni.galaxia.org.ar. 1998062202 43200 3600 3600000 360000 ) galaxia.org.ar. IN galaxia.org.ar. IN ; ; ; ; ; root.cigni.galaxia.org.ar. nro de serie refresco cada 12 horas reintentar despues de 1 hora expirar despues de 1000 horas ttl por defecto en 100 horas NS MX 10 cygni.galaxia.ar. andromeda.galaxia.ar. localhost IN A 127.0.0.1 antares rigel cygni orion altair orion aldebaran orion andromeda canopus cygni centauri andromeda IN IN IN IN IN IN IN IN IN IN IN IN IN 170.25.1.1 170.25.1.2 170.25.1.253 170.25.1.254 170.25.2.1 170.25.2.254 170.25.3.1 170.25.3.254 170.25.3.253 170.25.4.1 170.25.4.252 170.25.4.253 170.25.4.254 mailhost www IN CNAME andromeda.galaxia.org.ar. IN CNAME orion.galaxia.org.ar A A A A A A A A A A A A A Como puede verse, el archivo comienza con un registro SOA que declara el inicio de una zona. El símbolo @ en el registro SOA hace referencia al dominio actual, esto es, el que se indica en la directiva primary del archivo named.boot. El primer nombre que figura continuación es el nombre de la computadora que contiene este archivo, seguido de la dirección de correo del administrador del DNS (obsérvese que no contiene un @ sino un punto luego del nombre del usuario). Seguidamente aparecen entre paréntesis valores de configuración generales de la zona, como el ttl por defecto y el período de refresco de los datos (esto es, cada cuanto named deberá releer el archivo de zona para verificar si ha habido cambios en el mismo). Particularmente importante es el número de serie del archivo de zona (primer parámetro numérico del registro SOA). Este número deberá ser incrementado por el administrador cada vez que introduzca un cambio en los datos de la zona. Por medio de ese valor, un servidor secundario sabrá que debe pedir una transferencia de zona a fin de actualizar su copia local del archivo. Es práctica común escribir ese número como una codificación de la fecha en que se realizo el cambio (en formato Año/Mes/Día), seguida de un numero de versión, por si se realiza más de un cambio en la misma fecha. Obsérvese que ninguno de los registros posteriores especifica un valor de ttl; todos ellos toman el valor por defecto especificado en el registro SOA. Además los registros NS y MX no especifican el campo nombre. A continuación del registro SOA aparece el registro NS, que define que el nombre del servidor de nombres de galaxia.org.ar es la computadora llamada cygni. Lo sigue un registro MX, que indica que el correo electrónico destinado a éste domino deberá ser 42 enviado a la computadora andrómeda (obsérvese que el nombre que se especifica debe terminar con punto; si no fuera así, se asumiría que ese nombre debe completarse con el nombre del dominio actual). Finalmente, se listan los registros A, que establecen la relación entre un nombre y una dirección IP y un par de registros CNAME, que definen aliases para ciertas computadoras (por ejemplo, especifican que www.galaxia.org.ar es equivalente a orion.galaxia.org.ar). Archivos de zona para dominios de reversa El archivo named.boot indicaba que se administrarían dos dominios de reversa: uno para las direcciones correspondientes a la dirección de red y otro para la red de loopback. Los archivos de zona de un dominio de reversa contienen registros de tipo PTR. En dichos registros se utilizan los bytes de la parte de host de la dirección IP para el campo nombre, tomándolos en orden inverso. El dato asociado a cada registro es el nombre correspondiente a esa dirección IP. El archivo de zona para la red de loopback es virtualmente idéntico en todas las configuraciones: @ ( IN SOA cygni.galaxia.org.ar. 1 43200 3600 3600000 360000 ) ; ; ; ; ; root.cigni.galaxia.org.ar. nro de serie refresco cada 12 horas reintentar despues de 1 hora expirar despues de 1000 horas ttl por defecto en 100 horas galaxia.org.ar. IN NS cygni.galaxia.ar. 1 IN PTR localhost El contenido del archivo named.rev es similar: @ ( IN SOA cygni.galaxia.org.ar. 1998102305 43200 3600 3600000 360000 ) galaxia.org.ar. IN 1.1 2.1 253.1 254.1 1.2 254.2 1.3 254.3 253.3 1.4 252.4 253.4 254.4 IN IN IN IN IN IN IN IN IN IN IN IN IN PTR PTR PTR PTR PTR PTR PTR PTR PTR PTR PTR PTR PTR ; ; ; ; ; NS root.cigni.galaxia.org.ar. nro de serie refresco cada 12 horas reintentar despues de 1 hora expirar despues de 1000 horas ttl por defecto en 100 horas cygni.galaxia.ar. antares rigel cygni orion altair orion aldebaran orion andromeda canopus cygni centauri andromeda 43 Archivo de inicialización del cache Como se mencionó anteriormente, el archivo named.cache contendrá las direcciones IP de los servidores de nombres del dominio raíz, y se utilizará como el contenido inicial del cache. El archivo tendrá el siguiente aspecto: ; ; Nombres de los servidores del dominio raiz ; . 99999999 IN NS A.ROOT-SERVERS.NET. 99999999 IN NS B.ROOT-SERVERS.NET. 99999999 IN NS C.ROOT-SERVERS.NET. 99999999 IN NS D.ROOT-SERVERS.NET. 99999999 IN NS E.ROOT-SERVERS.NET. 99999999 IN NS F.ROOT-SERVERS.NET. 99999999 IN NS G.ROOT-SERVERS.NET. 99999999 IN NS H.ROOT-SERVERS.NET. 99999999 IN NS I.ROOT-SERVERS.NET. ; ; Direcciones de los servidores del dominio raiz ; A.ROOT-SERVERS.NET. 99999999 IN A 198.41.0.4 B.ROOT-SERVERS.NET. 99999999 IN A 128.9.0.107 C.ROOT-SERVERS.NET. 99999999 IN A 192.33.4.12 D.ROOT-SERVERS.NET. 99999999 IN A 128.8.10.90 E.ROOT-SERVERS.NET. 99999999 IN A 192.203.230.10 F.ROOT-SERVERS.NET. 99999999 IN A 192.5.5.241 G.ROOT-SERVERS.NET. 99999999 IN A 192.112.36.4 H.ROOT-SERVERS.NET. 99999999 IN A 128.63.2.53 I.ROOT-SERVERS.NET. 99999999 IN A 192.36.148.17 Como se puede apreciar, el archivo contiene registros NS que definen los nombres de los servidores de nombre del dominio raíz, y registros A con sus direcciones IP. Una lista completa y actualizada de estos servidores puede obtenerse por FTP anónimo, desde ftp://nic.ddn.mil/netinfo/root-servers.txt. Configuración del "resolver" Como ya se dijo, las aplicaciones que utilizan los servicios de un server DNS lo hacen por medio de un módulo del sistema operativo llamado resolver. En Unix, el resolver se configura por medio del archivo /etc/resolv.conf, cuyo contenido mínimo consta de las siguientes directivas: domain galaxia.org.ar nameserver 170.25.1.253 La directiva domain indica cual es el dominio por defecto, mientras que la directiva nameserver especifica la dirección IP del servidor de nombres a utilizar para peticiones de resolución. Pueden indicarse varias de estas directivas, para utilizar servidores de nombres alternativos. 44 Consultando interactivamente un servidor de nombres El paquete BIND provee una herramienta de depuración llamada nslookup que puede utilizarse para hacer consultas interactivamente a un servidor de nombres. Al ser ejecutada desde la línea de comandos, nslookup informa cual es el server de nombres que se utilizará y queda a la espera de comandos del usuario: $ nslookup Default server: cygni.galaxia.org.ar Address: 170.25.1.253 > _ Si se escribe el nombre de una computadora, nslookup realizará la consulta al server de nombres y nos mostrará el resultado: $ nslookup Default server: cygni.galaxia.org.ar Address: 170.25.1.253 > rigel Server: cygni.galaxia.org.ar Address: 170.25.1.253 Name: andromeda.galaxia.org.ar Address: 170.25.1.2 De manera similar, es posible utilizar nslookup para hacer consultas sobre otro dominio: $ nslookup Default server: cygni.galaxia.org.ar Address: 170.25.1.253 > bbs.frc.utn.edu.ar Server: cygni.galaxia.org.ar Address: 170.25.1.253 Name: bbs.frc.utn.edu.ar Address: 170.210.248.214 45 Diagnóstico de una red TCP/IP Una vez que la red ha sido diseñada y configurada, sus usuarios comienzan a trabajar sobre ella y a utilizar sus servicios. Es un hecho que, tarde o temprano, alguno de ellos tendrá alguna dificultad para acceder a algún servicio y recurrirá al administrador de la red a fin de obtener una solución. Sin embargo, antes de poder ofrecer alguna, el administrador deberá diagnosticar el problema, esto es, hallar sus causas. Mensajes de error usuales Hay ciertas condiciones de error que son usuales en una red TCP/IP. Si bien los mensajes de error con que las aplicaciones informan al usuario acerca de las mismas son altamente dependientes de la plataforma, la mayoría de las veces son similares a los siguientes: Unknown host: El nombre de host utilizado por el usuario no pudo resolverse; es decir, no pudo obtenerse su dirección IP. Puede ser indicativo de un error en el acceso al servidor de nombres: quizás es errónea la dirección IP indicada en el archivo /etc/resolv.conf, o el demonio named no se encuenta activo en esa computadora, o el módulo TCP/IP de la misma no se encuentra funcionando correctamente. Sin embargo, también puede deberse a un error en el tipeo del nombre (esto es, podría no existir una computadora con el nombre indicado). Network unreachable: El sistema local no tiene una ruta que conduzca a la red a la que corresponde la dirección IP de la máquina remota. Puede deberse a un error en la configuración de la tabla de ruteo, a que la ruta se haya vuelto inalcanzable (por ejemplo, porque el gateway o los vínculos de comunicación que conectan con ella están fuera de línea) o a que la dirección IP utilizada es errónea. No answer from host: El sistema remoto no contesta las peticiones realizadas desde el host local. En este caso, usualmente la dirección IP es correcta y existen rutas a la red a la cual pertenece, pero el host no puede ser contactado debido a que, por ejemplo, se encuentra apagado o desconectado de la red. Connection refused by peer: Este error indica que, si bien pudo contactarse al host remoto, el mismo denegó la conexión. Puede deberse a medidas de seguridad (es decir, la computadora remota por alguna razón de seguridad no permite el acceso desde la computadora local al servicio que se le requiere) o a que no hay un servicio "escuchando" en el puerto TCP indicado desde la computadora local (por ejemplo, se desea acceder al demonio named en la computadora remota, y el mismo no se encuentra ejecutándose allí). Herramientas de diagnóstico Algunas de las herramientas ofrecidas por Unix para diagnosticar problemas de red (y usualmente disponibles también en otras plataformas) son las siguientes: ping: Es la herramienta básica para verificar la conectividad de la red. Permite determinar si un host es alcanzable y proporciona estadísticas sobre los tiempos de respuesta de la red. traceroute24: Muestra la ruta que los paquetes seguirán desde un host de origen hasta otro host de destino. Permite, entonces, diagnosticar problemas de ruteo. 24 Bajo Windows NT, este comando está disponible bajo el nombre de tracert. 46 nslookup: Permite hacer consultas interactivas a un servidor DNS, tal como se discutió en el capítulo anterior. netstat: Despliega información sobre la tabla de ruteo, las interfaces y los sockets activos. ifconfig: Si bien es básicamente una herramienta de configuración, puede utilizarse también como herramienta de diagnóstico, para detectar errores en la dirección IP, mascara de subred o dirección de broadcast (ver capítulo sobre asignación de direcciones IP). Testeo de alcanzabilidad El primer paso para diagnosticar un problema en una red TCP/IP es verificar la alcanzabilidad de un host, esto es, si es posible enviar paquetes al mismo a través de la red. La herramienta primordial para testear alcanzabilidad es ping, cuya sintaxis básica es la siguiente: ping nombre_de_host_o_dirección_IP Por ejemplo, para verificar si el host Rigel es alcanzable, habría que ejecutar el siguiente comando: $ ping rigel PING rigel.galaxia.org.ar (170.25.1.2): 56 data bytes 64 bytes from 170.25.1.2: icmp_seq=0 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=1 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=2 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=3 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=4 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=5 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=6 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=7 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=8 ttl=64 time=0.1 ms 64 bytes from 170.25.1.2: icmp_seq=9 ttl=64 time=0.1 ms ^C --- rigel.galaxia.org.ar ping statistics --10 packets transmitted, 10 packets received, 0% packet loss round-trip min/avg/max = 0.1/0.1/0.1 ms ping envía paquetes al host remoto utilizando el protocolo ICMP, los cuales, de ser recibidos por dicho host, generan un paquete similar de respuesta para el host local. Cuando el host local los recibe, muestra una línea de información por pantalla, y el ciclo continúa hasta que el usuario lo cancele con Control-C. Al terminar, ping muestra un reporte estadístico, en el que informa la cantidad de paquetes transmitidos y recibidos, y el porcentaje de pérdida de paquetes. También se informa sobre los tiempos mínimo, promedio y máximo que toma el recorrido de ida y vuelta entre ambos hosts. Como puede verse, ping permite además determinar el nivel de carga de la red: si el porcentaje de perdida de paquetes o los tiempos de ida y vuelta es muy alto, podría ser un indicio de sobrecarga de tráfico, interferencias en el medio de comunicación, o inclusive problemas de hardware. Verificación del estado de las interfaces Como se recordará el comando ifconfig, al ser invocado sin argumentos, muestra el estado actual de las interfaces de red configuradas: 47 $ ifconfig lo Link encap:Local Loopback inet addr:127.0.0.1 Bcast:127.255.255.255 Mask:255.0.0.0 UP BROADCAST LOOPBACK RUNNING MTU:3584 Metric:1 RX packets:331036 errors:0 dropped:0 overruns:0 TX packets:331036 errors:0 dropped:0 overruns:0 eth0 Link encap:Ethernet HWaddr 00:10:4B:38:27:BA inet addr:170.25.2.254.216 Bcast:170.25.2.244 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:4563766 errors:1 dropped:0 overruns:1 TX packets:5864531 errors:0 dropped:0 overruns:0 Interrupt:11 Base address:0x6100 eth1 Link encap:Ethernet HWaddr 00:10:4B:62:45:81 inet addr:170.25.3.254 Bcast:170.25.3.254 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:4279043 errors:3 dropped:0 overruns:1 TX packets:2940848 errors:0 dropped:0 overruns:0 Interrupt:10 Base address:0x6200 En el listado anterior, se muestran 3 interfaces (dos placas Ethernet y la interfaz lógica de loopback). En todos los casos, se muestra la dirección de IP asignada, así también como la dirección de broadcast y la máscara de subred. En el caso de las placas Ethernet, se informa también la dirección física del adaptador (o MAC Address), y características de configuración del adaptador (número de interrupción y dirección base de I/O). Las líneas que comienzan con RX y TX presentan un informe del funcionamiento de la interfaz en términos de cantidad de paquetes recibidos y transmitidos, respectivamente. También se informa en cada caso la cantidad de paquetes erróneos detectados por la interfaz. Información similar en un formato mas compacto puede obtenerse con el comando netstat -i: $ netstat -i Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR lo 3584 0 331036 0 0 0 eth0 1500 0 4563766 1 0 0 eth1 1500 0 4279043 3 0 0 TX-OK TX-ERR TX-DRP TX-OVR Flag 331036 0 0 0 BLRU 5864531 0 0 0 BRU 2940848 0 0 0 BRU Verificación de las rutas Por medio de los comandos ifconfig y netstat -i podemos determinar el estado de las interfaces locales, a fin de determinar si son capaces de enviar y recibir paquetes. Usando ping podemos verificar si el host remoto "es visible" desde el host local a través de la red. Si la comprobación de las interfaces muestra que su estado es el correcto, pero ping no da resultados positivos, el siguiente paso en el diagnóstico de un problema de conectividad con un host remoto es determinar que tan lejos llegan los paquetes. El comando traceroute permite verificar cual es la ruta que los paquetes siguen para llegar a un host remoto, y de esa manera detectar errores en la configuración de las tablas de ruteo: $ traceroute canopus 48 tracing to canopus.galaxia.org.ar (170.25.4.1), 30 hops max, 40 bytes packets 1 orion (170.225.1.254) 0.361 ms 0.302 ms 0.296 ms 2 andromeda (170.25.3.253) 44.366 ms 38.533 ms 13.282 ms 3 canopus (170.25.4.1) 28.743 ms 50.976 ms 39.28 ms Como puede verse, traceroute se invoca con el nombre de un host remoto, y muestra como resultado todos los gateways intermedios que se atraviesan hasta llegar a destino. La información se recaba por medio del envío de paquetes ICMP; si alguno de ellos se perdiera en el camino, traceroute mostrará una serie de asteriscos. Por ejemplo, supongamos que el usuario de la computadora Antares reporta la imposibilidad para conectarse a Canopus. El primer paso en el diagnóstico sería revisar la configuración de las interfaces con ifconfig y luego verificar si realmente no hay conectividad, utilizando ping. Si ese fuera el caso, puede deberse tanto a que Canopus esté fuera de línea como a que exista algún problema en algún punto intermedio de la red. Por medio de traceroute puede determinarse cual es el caso. Supongamos que la salida de traceroute es la siguiente: $ traceroute canopus tracing to canopus.galaxia.org.ar (170.25.4.1), 30 hops max, 40 bytes packets 1 orion (170.225.1.254) 0.361 ms 0.302 ms 0.296 ms 2 andromeda (170.25.3.253) 44.366 ms 38.533 ms 13.282 ms 3 * * * 4 * * * 5 * * * traceroute continuará mostrando asteriscos hasta llegar a los 30 intentos o hasta que el usuario lo cancele con Ctrl-C. La conclusión aquí es que la falta de conectividad se debe a que Canopus está fuera de línea o bien los enlaces desde Andrómeda estan fallando. Podría probarse, por ejemplo, el utilizar ping para intentar llegar a otra computadora sobre la misma subred de Canopus (por ejemplo, ping centauri); si la respuesta es negativa se trataría de un problema de red, mientras que si es positiva, la respuesta es que Canopus está fuera de línea. Si el resultado de traceroute fuera el siguiente: $ traceroute canopus tracing to canopus.galaxia.org.ar (170.25.4.1), 30 hops max, 40 bytes packets 1 orion (170.225.1.254) 0.361 ms 0.302 ms 0.296 ms 2 * * * 3 * * * 4 * * * 5 * * * entonces o bien hay un problema en el gateway o en las líneas de comunicación hacia él. La cuestión puede zanjarse procediendo de manera similar al caso anterior. 49 Compartiendo archivos: NFS NFS (Network File System) permite el acceso transparente a archivos y directorios ubicados en computadoras remotas, es decir, permite que usuarios y programas traten archivos remotos como si fueran locales. La computadora remota (llamada server NFS) pone ciertos directorios de su propio sistema de archivos a disposición de otras computadoras exportándolos hacia la red. Para acceder a los archivos remotos, las computadoras que los utilizan (los clientes NFS) previamente deben montar alguno de los directorios exportados por el servidor en algún punto de su sistema de archivos (de la misma forma que los sistemas de archivos residentes en discos duros locales deben ser montados antes de poder ser utilizados). Andrómeda (server NFS) / bin usr Altair (cliente NFS) / etc tmp net bin etc bin usr etc tmp apps bin local A modo de ejemplo, en el gráfico anterior se muestra que Andrómeda, actuando como servidor NFS, exporta a la red el directorio /net, y que un cliente NFS, en éste caso Altair, lo monta en /usr/local. Esto significa que para los usuarios de Altair existen los directorios /usr/local/bin, /usr/local/etc y /usr/local/apps, pero en realidad dichos directorios están ubicados en Andrómeda. NFS fue desarrollado originariamente por Sun Microsystems, y se transformó en el standard para compartir archivos bajo plataforma Unix; también existen actualmente implementaciones de NFS para otros sistemas operativos. Los demonios de NFS Para ofrecer servicios NFS, una computadora debe ejecutar los siguientes demonios: rpc.nfsd: Es el demonio principal de NFS, responsable de manejar las peticiones de los clientes para acceder a archivos remotos. rpc.mountd: Procesa las peticiones de montura de los clientes NFS. Algunas implementaciones de NFS requieren demonios auxiliares adicionales como los siguientes: biod: Demonio de E/S por bloques. Gestiona el lado del cliente de las peticiones de Entrada/Salida vía NFS. Este demonio solo es necesario en el cliente NFS. rpc.lockd: Demonio de bloqueo. Este demonio se ejecuta tanto en el cliente como en el server, y gestiona las peticiones de acceso en modo exclusivo. rpc.statd: Demonio de control de estado. Este demonio es requerido por rpc.lockd para monitorear las operaciones de E/S por NFS. 50 Exportando directorios Para exportar directorios desde un server NFS, el administrador debe listarlos en el archivo /etc/exports, teniendo en cuenta las siguientes consideraciones: • No se pueden exportar subdirectorios de un directorio exportado, a menos que el subdirectorio se encuentre en otro dispositivo físico; tampoco se pueden exportar directorios ubicados por arriba de un directorio exportado, a menos que pertenezcan a diferentes dispositivos físicos. • Solo es posible exportar directorios locales. El archivo /etc/exports contendrá una línea por cada directorio exportado, en la que se indicará la ruta completa al mismo, seguida por ciertos parámetros que configurarán el modo en que se exporta el directorio, los cuales permiten especificar cuales computadoras tienen derecho a montar remotamente el directorio exportado, y de que manera: /net /home/jperez /datos/ftp/public *.galaxia.org.ar(rw) canopus.galaxia.org.ar(rw) (ro) En el ejemplo anterior, el server NFS exporta tres directorios: /net Accesible desde cualquier computadora del dominio galaxia.org.ar, en modo de lectura/escritura (rw = read/write). /home/jperez Accesible sólo desde la computadora Canopus, también en modo de lectura/escritura. /datos/ftp/public Accesible desde cualquier computadora (de cualquier dominio), pero en modo de sólo lectura (ro = read only). Montando directorios Los directorios remotos se montan localmente de la misma manera que otro sistema de archivos: manualmente por medio del comando mount, o listándolos en /etc/fstab para que se monten automáticamente al inicializar el sistema operativo. En ambos casos, la sintaxis para especificar un directorio remoto es la siguiente: nombre_del_host:directorio_remoto Por ejemplo, para montar manualmente el directorio /net de Andrómeda en /usr/local de Altair, se debe ejecutar el siguiente comando: # mount andromeda:/net /usr/local Alternativamente, se podría agregar la siguiente línea en /etc/fstab: andromeda:/net /usr/local nfs rw,bg 0 0 Obsérvese que al montar un directorio remoto pude indicarse la opción bg a fin de realizar la operación de montura en background. Si al momento de solicitar la montura el server NFS no se encuentra disponible, el cliente permanecerá reintentando hasta que el server lo esté. La opción bg premite que esos reintentos continúen en background y así no detener las demás operaciones del cliente que no dependen del acceso a ese recurso compartido. Cuanto tiempo el cliente permanecerá reintentando depende de si la montura es dura (hard mounts) o blanda (soft mounts). 51 Por defecto, las monturas de directorios NFS son duras, lo cual significa que el cliente permanecerá reintentando indefinidamente hasta recibir respuesta del server. Si la montura es blanda (en cuyo caso deberá utilizarse la opción soft en /etc/fstab o al montar manualmente con mount), al cabo de cierto número de reintentos la operación fallará y retornará un mensaje de error al usuario, indicando que el server es inaccesible. Administración centralizada de hosts: NIS Uno de los aspectos que puede volverse mas problemático en la administración de una red Unix es el mantenimiento de la consistencia en ciertos archivos de configuración. Supóngase que en una red como la de galaxia.org.ar se desea que todos los usuarios puedan utilizar cualquier computadora de la red, utilizando en todas ellas el mismo nombre de login y password. Ello implica que la base de datos de usuarios (esto es, el archivo /etc/passwd) deberá ser igual en todas las computadoras de la red y que ante cada cambio (por ejemplo, al agregar un nuevo usuario o cuando un usuario cambia su password), dicho cambio deberá ser propagado a todas las demás computadoras de la red. Si la red tiene pocas computadoras, la consistencia de los archivos replicados puede mantenerse manualmente, pero, a medida que la red crece, el trabajo y la probabilidad de cometer errores crece desmedidamente. NIS (sigla de Network Information Service, o Servicio de Información de Red) fue diseñado para solucionar este problema, proveyendo los medios para administrar centralizadamente archivos de datos y diseminarlos luego en un grupo de computadoras que forman parte de un dominio NIS25. NIS es también un sistema cliente/servidor, en donde ciertas computadoras (denominadas servidores NIS) mantienen los archivos de datos (llamados mapas NIS) y responden consultas de otras computadoras (los clientes NIS) acerca de información contenida en esos archivos. Un dominio NIS puede contar con varios servidores NIS. Uno de ellos, el servidor NIS maestro, contiene la copia original de los archivos de datos y es responsable de mantener actualizado un grupo de servidores NIS esclavos, los cuales responden peticiones de los clientes, pero no modifican sus archivos de datos directamente. La arquitectura general de un dominio NIS se esquematiza en la siguiente figura: Server NIS Maestro Server NIS Esclavo Cliente NIS Cliente NIS Transferencia de Mapa Server NIS Esclavo Cliente NIS Cliente NIS Petición NIS 25 Un dominio NIS no tiene ninguna relación con un dominio DNS, aunque muchas veces el administrador decide que ambos coindan. 52 Ejecutando NIS Los detalles de configuración de un dominio NIS varían según la implementación y están mas allá de los alcances del presente trabajo. No obstante, y a manera de referencia, cabe mencionar que hay tres piezas de software esenciales para ejecutar NIS: domainname, ypserv e ypbind26. El comando domainname permite asignar el nombre de dominio NIS a las computadoras que lo forman. ypserv, por otra parte, es el demonio que se ejecutará en el servidor NIS, mientras que ypbind deberá ejecutarse tanto en el servidor como en los clientes. 26 El prefijo yp se debe a que anteriormente NIS se conocía bajo el nombre Yellow Pages (Paginas Amarillas) 53 Bibliografía recomendada • "Essential System Administration", por Aeleen Frisch • "TCP/IP Network Administration", por Craig Hunt • "DNS and BIND", por Paul Albitz & Cricket Liu • "Managing NFS and NIS", por Hal Stern • "Sistemas Operativos: diseño e implementación" , por Andrew S. Tanenbaum • "The Unix-Haters Handbook", por Simson Garfinkel, Daniel Weise & Steven Strassman 54