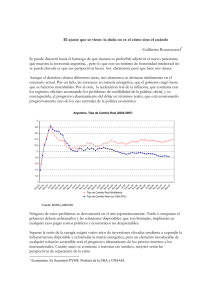
Filtros de Texto UNIX
... y aprenda a manejar vi de una vez.
César A. Cabrera E.
PULPA: Grupo de Usuarios Linux
Universidad Tecnológica de Pereira
¿Qué son los filtros?
Algún texto
de entrada
Filtro
(Procesa texto)
Ejemplos:
tail, head, wc, sort, tr.
Grep, egrep, vgrep, fgrep.
Awk, perl, sed.
Algun texto
de salida
Fuentes de texto
Se sugiere trabajar con who, ps, ls, find y usar
redirección de flujos y/o entubamientos (pipes).
Casi todos permiten especificar un archivo
origen (passwd, shadow, archivos en /etc, etc).
NOTA: He aquí la versatilidad del modelo de los
flujos, yo no tengo que saber de dónde provienen mis
datos, sólo los uso. Cualquier cosa que me arroje datos
es un flujo de entrada (puede ser el hardware mismo).
Los más simples:
Filtricos
sort (Ordenar): Muestra la entrada ordenada por algún campo.
-f :ignorar caso, -n :orden numérico, -nr :numérico descendente, +# :ignorar primeros
# campos (separados por $FS), -o <archivo de salida>, -u :líneas únicas solamente.
wc (Word Count): Cuenta líneas, palabras y caracteres de la entrada.
-l :Líneas, -c :Caracteres
tr (Transliterar): Reemplaza en la entrada los caracteres indicados.
tr <patrón a cambiar> <patron de reemplazo>
tail (Cola) , head (Cabeza): Muestra solamente algunas líneas de la cola o la cabeza de
la entrada (o archivo).
tail -# :mostrar últimas # líneas, +# : mostrar a partir de # líneas
NOTA: Otros filtros curiositos son uniq [-c -d -u], comm, cmp y diff
Ejemplo de filtricos
>$who | sort
>$who | wc -l
>$ls -l | sort +3nr
Como guión de shell:
cat $* | tr -sc A-Za-z '\012' | sort | uniq -c | sort -n|
tail
Meter como guión de shell el anterior contenido lee de su entrada 10
nombres de archivos (máximo) e imprime las 10 más comunes.
tr -s : sustituír repetidos, -c : complementar set de caracteres.
Nuestro viejo amigo 'ed'
Editor de texto orientado a la línea y fué el primer editor de texto
que hubo en Unix. Combinado con el shell es el origen de las
expresiones regulares.
Órdenes para ejecutarlas sobre el contenido. a : adicionar texto (finalizar
entrada de texto con una línea de sólo un . de contenido).
Formato de ordenes:
[indicador de líneas] {a|d|s|p|w|q}: añadir, eliminar, sustituir, imprimir, guardar
y salir respectivamente.
Indicador de líneas:
#ini,#fin lineas comprendidas desde línea #ini hasta línea #fin
#ini y #fin pueden ser . (línea actual), $ (línea final) o una expresión matemática con
ellas (.+1 : línea siguiente a la actual; $-3 : antepenúltima línea).
g/<regular-expresion>/ : Ejecuta la acción sobre las líneas que contengan la expresión
regular.
Nos veremos en el vi!!! (el infierno para muchos legos).
Familia Grep
grep proviene del comando g/regular-expresion/
de nuestro amigo ed.
Imprime las líneas que contengan la expresión o
patrón indicado.
Sintaxis
grep [-v |-n |-y |-b ] <patrón> <archivos>
-v efecto inverso, -n imprimir número de línea, -y acoplar
minúsculas con mayúsculas (mayúsculas siguen acoplando sólo
con mayúsculas).
El resto de la familia
fgrep : Busca en paralelo por varias líneas de texto.
egrep: Busca usando verdaderas expresiones regulares
(con operadores de disjunción, cerradura y
agrupamiento).
La opción -f <nombre_archivo>:
Lee el patrón de un archivo.
NOTA: Debido a que algunos caracteres de las expresiones regulares de
la familia grep se confunden o tienen otros significados para el shell,
los patrones deben ser protegidos con apóstrofes o insertados en un
archivo aparte.
Expresiones regulares
Carácter
Significado
^
inicio de línea
$
fin de línea (debe ir a final de la expresion)
.
cualquier carácter (debe ir al principio de la expresión).
*, + y ?
* = 0 a n ocurrencias del carácter anterior, + = 1 a n
ocurrencias y ? = sólo una ocurrencia. xy* reconocería xyyyy pero no
xyxyxy.
asd | qwe
una ocurrencia de asd o de qwe.
[asd]
una ocurrencia de 'a' o de 's' o de 'd'
[^asd]
no ocurrencia de 'a' o de 's' o de 'd'. O lo que es lo mismo
una ocurrencia de cualquier carácter que no sea 'a' o 's' o 'd'.
\c
no interpretar c (buscar $: \$). Es decir escapar c.
Ejemplos de grep
>$ls -l | grep '^d'
>$ls -l | grep '^........rw'
>$grep '^[^:]*::' /etc/passwd
Como un sólo comando
>$echo
'^[^aeiou]*a[^aeiou]*e[^aeiou]*i[^aeiou]*o[^aeiou]*u[^aeiou]*$'
>alphavowels.pat
>$fgrep -f alphavowels.pat /usr/dict/web2
Se supone que /usr/dict/web2 es un diccionario de palabras.
NOTA: El diccionario de palabras de Linux generalmente es
/usr/share/dict/linux.words
El hermanito de ed: sed
sed proviene de 'serial ed'
Sintaxis:
sed [-n] <lista de comandos ed> <archivos+>
La opción -n deshabilita la impresión de línea por defecto.
Sed aplica las órdenes dadas una a una e imprime cada renglón
con los cambios efectuados.
Ejemplo: >$who|sed 's/ .* / /'
... y también acepta la opcion -f <archivo>
No permite expresiones aritmeticas: $-5 es ilegal.
Más sed
/patrón/ es un indicador de línea que acopla con las líneas que
coincidan con el patrón.
/patrón/! Es la negación del patrón, es decir, las líneas que no
coincidan con el patrón.
s/patrón/reemplazo/g busca y reemplaza (sustituye) el patrón en la
línea donde se encuentre. Dado que sólo reemplaza la primera
ocurrencia, la g indica que reemplace todas las que haya en la
línea.
^siempre significa inicio y $ siempre significa fin bien sea fin de
línea o ultima línea, según el contexto.
p. ej.: sed '^$q' muestra todas las líneas hasta llegar a una línea vacía.
r <archivo> inserta un archivo a la salida estandar.
= imprimir número de línea.
AWK: El lenguaje de manejo y
procesamiento de patrones.
El nombre AWK proviene de los creadores:Alho, Al; Weinberger,
Peter y Kernigham, Brian.
Es un filtro que tiene su propio lenguaje y permite la
manipulación de texto de la manera más flexible posible, usando
funciones, condiciones, ciclos y estructuras especiales para
ejecutar al inicio y al final del procesamiento.
Sintaxis:
>$awk 'programa' <archivos>
Donde programa es una serie de líneas con la forma
/patrón/ {comandos}, si /patrón/ no existe la acción se ejecuta para
cada línea y si la acción no existe sólo se imprime la línea.
Acepta la opción -f <archivo>
Variables en awk
Variable
Significado
FS
Separador de campos
NF
línea.
Número de Campos reconocidos en la
NR
Número de registros leídos actualmente.
FILENAME
Adivinen!
RS
Separador de registros (\n por defecto).
OFMT
Output: Formato de números (de salida).
OFS
Output: Separador de campos.
ORS
Output: Separador de registros.
Campos en awk
Campos
Cada parte de la línea que está separada por FS (que por defecto
es tab o espacios). El separador se puede cambiar con la opcion
-F<sep> o asignando un valor a FS en el programa.
Cada campo se referencia anteponiendo $ a su posición en el
renglón: $1 es el primero (contando desde 1). No confundir con
variables, las variables no tienen adornos (como sí lo hacen en
shell).
La cantidad de campos leídos es NF.
Ejemplo:
cat /etc/passwd | awk -F: '{print $1}'
$0 es la línea actual entera.
Funciones en awk
print :
Imprime lo que se desee imprimir para la línea especificada
por el patrón: awk '{print NR, $0}'
printf :
%s”, NR, $0 }'
Usa el formato de printf para imprimir: awk '{printf “%4d,
getline():
Devuelve 0 si es fin de archivo y 1 si no lo es.
index(s1,s2):
Posicion de s2 en s1, 0 si no está.
length(s):
Longitud de la cadena s.
split(s, a, c):
Divide la cadena s usando c como separador y lo almacena
en a. Devuelve la cantidad de partes en que se dividió la cadena.
substr(s,m,n):
Subcadena de s empezando en m y terminando en m+n.
int(expresión):
Parte entera de expresión.
sin(ex), cos(ex), exp(ex) y log(ex): Seno, Coseno, Exponencial y logaritmo
natural respectivamente.
BEGIN y END para awk
BEGIN es un patrón cuyos comandos se ejecutan
antes de leer la primera línea.
END es el patrón cuyos comandos se ejecutan
después de leer la última línea.
Ejemplos:
>$awk 'BEGIN {FS=”:”}
>$2==”” '
>$awk 'END {print NR}'
Ejemplos
Programa para contar frecuencia de palabras
>$cat <<FIN >contar.awk
{ for (i=1; i<NF ; i++) num[$i]++ }
END { for (word in num) print word, num[word] }
FIN
>$awk -f contar.txt <archivo de texto>
Programa para identificar palabras repetidas
>$cat <<FIN >repetidas.awk
FILENAME != prevfile { NR=1
prevfile=FILENAME
}
NF>0 { if ($1==lastword)
printf “Duplicada %s en %s, línea %d\n”, $1, FILENAME, NR
for ( i=2; i<NF; i++)
if( $i==$(i-1))
if(NF>0)
printf “Duplicada %s en %s, línea %d, $i\n”, FILENAME, NR
lastword=$NF
}
FIN
>$awk -f repetidas.awk <archivo de texto>
Más detalles
AWK es un programa muy potente y complejo, explorarlo no es de sólo recibir una
charlita y ya, hay que explorarlo ensayando y leyendo el manual(es) que haya a la
mano.
Print y printf aceptan redireccionamientos como si estuvieran en shell (print >, >> y |).
Patrón, patrón como selector: si se usa patrón, patrón como selector esto equivale a las
líneas donde ocurra el primer patrón hasta la línea donde aparezca el segundo patrón.
Ejemplo NR==10, NR==20 equivale a las líneas de 10 a 20.
Diseño de programas en Unix:
Todos los programas de utilidad de Unix comparten un diseño común,
todos leen por defecto de la entrada estandar y escriben a la salida
estandar (lo que permite el uso de redireccionamientos e
interconexiones) generalmente (y por defecto) sin encabezados ni
adornos (para que cada línea sea un objeto de interés).
Los parámetros opcionales van siempre antes de los nombres de
archivo a los cuales se aplica el comando y finalmente, escriben los
errores en el error estandar lo cual hace que estos no se pierdan en las
interconexiones ni en los redireccionamientos.
Y el vi?
Vi es sucesor de ed.
Tiene dos formas de trabajar: modo de edición y
modo de comandos.
Al modo de edición se entra con 'i', 'a'.
Al modo de comandos se entra por defecto y con
la tecla 'esc'.
Para poder escribir hay que estar en modo de
edición, para poder ejecutar acciones (buscar,
reemplazar, numerar, etc.) hay que estar en modo
comandos.
Escribir en vi
Entrar a modo edición
Escribir 'a' en modo comandos: permite adicionar texto después de la letra en la que se
encuentra el cursor. 'A' adiciona al final de la línea.
Escribir 'i' en modo comandos: permite insertar texto justo donde se encuentra el
cursor. 'I' inserta al comienzo de la línea.
'o' agrega una línea debajo de la actual. 'O' la agrega encima de la actual.
'c' cambia el carácter en el que se encuentra el cursor.
Otros comandos útiles
'u' deshace el último comando dado.
'.' repite la última acción
'd' elimina el carácter en el que se encuentra el cursor. Igual que 'x'.
'dd' elimina la línea entera
<número>comando: hace el comando las veces que diga número: 10x
elimina 10 caracteres desde donde está el cursor.
Movimiento vi
Movimiento del cursor
Fin de línea
$
Inicio de línea
0
Palabra siguiente
e|w
Palabra anterior
b
Copiar línea
yy
Pegar línea
p
Salir
:q
Guardar
:w <nombre>
Salir y guardar
:x
Lo interesante
Buscar palabras: escribir '/patrón/' en modo comandos. Ensayar
con los patrones.
Reemplazar en la línea actual: escribir
':s /pat_busqueda/reemplazo/'
Se le pueden poner modificadores después del último '/' (Probar
con g, y, m).
Qué pasa con el selector de líneas: puede ser . (línea actual), $
(última línea) o un número.
P.ej.: 1,. d elimina las líneas desde la primera hasta la actual!
Más vi
:set number : Numera las líneas
:set nonumber : Quita la numeración de líneas
:r <archivo> : Inserta el archivo donde esté el
cursor.
:<número> : Pone el cursor en la línea que diga
<número>
n : Muestra la siguiente ocurrencia de la
última búsqueda realizada. N busca la anterior.
Ctrl-g: Muestra el nombre del archivo, línea,
columna, etc. en el que se está trabajando.
Referencias
Esta presentación se encuentra disponible públicamente en el
sitio del grupo de usuarios Linux de Pereira (Universidad
Tecnológica de Pereira):
???
El tema ha sido seleccionado del libro “El entorno de
programación Unix”, Brian Kernighan, Rob Pike, editorial
Prentice Hall 1987.
Alguna ayuda fué tomada del e-book Mandrake 8.2 Reerence
Guide.
RTFM : Read The Fucking Manual.
 0
0