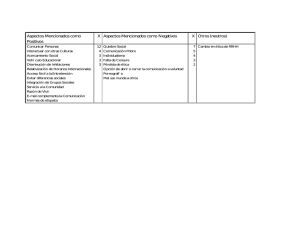
Dise˜no y evaluación de un clúster HPC: Aplicaciones
Anuncio

Diseño y evaluación de un clúster HPC: Aplicaciones Autor: Constantino Gómez Crespo Grado en Ingenierı́a Informática Especialidad en Ingenierı́a de Computadores 26 de Junio de 2014 Director: Agustı́n Fernández Jiménez, Arquitectura de computadores Facultad de Informática de Barcelona Universidad Politécnica de Cataluña (UPC) - BarcelonaTech 2 Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 3 Resumen En este trabajo se presenta un análisis de las aplicaciones utilizadas de manera habitual en el área de la informática conocida como High Performance Computing (HPC). También se hace un inciso en técnicas de optimización para tales aplicaciones mediante el uso de herramientas de profiling, librerı́as y configuración de parámetros. Por último, se realiza la evaluación de rendimiento de un clúster HPC basado en procesadores móviles de bajo consumo. El trabajo tiene como objetivo aprender a construir y optimizar un clúster HPC, acorde con el conjunto de aplicaciones a ejecutar y con la mirada puesta en la eficiencia energética (Energy-to-solution). A destacar, que para la parte final del trabajo se ha montado un clúster con procesadores de bajo consumo, en concreto, System-on-Chip con arquitectura ARMv7 para móviles de Samsung, Exynos 5420. Resum En aquest treball es presenta un anàlisi de les aplicacions utilitzades de manera habitual a l’àrea de l’informàtica coneguda com HPC. També es fa un incı́s en les técniques d’optimització per aquestes aplicacions mitjançant l’ús d’eines de profiling, llibrerı́es i configuració de paràmetres. Per acabar, es realitza la evaluació de rendiment d’un clúster HPC basat en procesadors mòbils de baix consum. Aquest treball té com objectiu aprendre a construir i optimitzar un clúster HPC, concorde amb el conjunt d’aplicacions a executar y amb la mirada posada en la eficiencia energética (Energy-to-solution). Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 4 A destacar, que per la part final del treball s’ha muntat un clúster amb processadors de baix consum, en concret, System-on-Chip amb arquitectura ARMv7 per mòbils de Samsung, Exynos 5420. Abstract This project presents an analysis of the applications commonly used in the area of the computer sciences known as HPC. Also, an introduction in optimization techniques is made for those applications with the use of profiling tools, libraries and parameter configuration. On the last part, a performance evaluation of the HPC cluster based in mobile processors is made. This project has as objective to learn to build and optimize a cluster HPC, according to the set of applications to execute while keeping the energy efficiency in consideration (Energy-to-Solution). As a highlight, for the last part of the project a cluster with low-power mobile processors has been built, in particular, with Samsung’s System-on-Chip with ARMv7 architecture for cellphones Exynos 5420. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 5 Índice general Resumen 4 Prefacio 17 1. Introducción 19 1.1. Orı́genes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 1.2. Problemática . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 1.3. Student Cluster Challenge . . . . . . . . . . . . . . . . . . . . . . . . 20 1.4. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 1.4.1. Objetivos Generales . . . . . . . . . . . . . . . . . . . . . . . 21 1.4.2. Objetivos individuales . . . . . . . . . . . . . . . . . . . . . . 22 2. Planificación y presupuesto 25 2.1. Planificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 2.1.1. Estudio Teórico . . . . . . . . . . . . . . . . . . . . . . . . . . 25 2.1.2. Aplicación Práctica . . . . . . . . . . . . . . . . . . . . . . . . 25 2.2. Estimación temporal . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 2.2.1. Listado de Tareas . . . . . . . . . . . . . . . . . . . . . . . . 28 2.2.2. Diagrama de Gantt . . . . . . . . . . . . . . . . . . . . . . . . 29 2.2.3. Recursos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.3. Presupuesto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.3.1. Recursos humanos . . . . . . . . . . . . . . . . . . . . . . . . 31 2.3.2. Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 2.3.3. Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 2.3.4. Gastos generales . . . . . . . . . . . . . . . . . . . . . . . . . 32 2.3.5. Presupuesto total . . . . . . . . . . . . . . . . . . . . . . . . . 33 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 6 Índice general 3. Sumario del Hardware 35 3.1. Sumario del Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . 35 3.2. Clúster de Arndale Octa . . . . . . . . . . . . . . . . . . . . . . . . . 36 4. Análisis de aplicaciones 39 4.1. Aplicaciones de producción . . . . . . . . . . . . . . . . . . . . . . . 39 4.2. Herramientas de benchmarking . . . . . . . . . . . . . . . . . . . . . 40 4.3. LINPACK Benchmarks . . . . . . . . . . . . . . . . . . . . . . . . . 41 4.3.1. HPL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 4.4. HPCC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 4.4.1. DGEMM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 4.4.2. STREAM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 4.4.3. PTRANS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 4.4.4. RandomAccess . . . . . . . . . . . . . . . . . . . . . . . . . . 46 4.4.5. FTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 4.4.6. Comunications latency and bandwidth . . . . . . . . . . . . . 47 4.5. GROMACS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 4.6. Microkernels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 4.6.1. Patrones de acceso a memoria . . . . . . . . . . . . . . . . . . 49 4.6.2. Float-Point peak performance . . . . . . . . . . . . . . . . . . 49 4.6.3. Overhead al paralelizar . . . . . . . . . . . . . . . . . . . . . 49 4.7. Aplicaciones del SCC’14 . . . . . . . . . . . . . . . . . . . . . . . . . 50 4.8. En resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5. Optimización de aplicaciones 51 5.1. Medidas de rendimiento . . . . . . . . . . . . . . . . . . . . . . . . . 51 5.1.1. Speed Up . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 5.1.2. Eficiencia paralela . . . . . . . . . . . . . . . . . . . . . . . . 51 5.1.3. Ley de amdahl . . . . . . . . . . . . . . . . . . . . . . . . . . 52 5.2. Herramientas de análisis . . . . . . . . . . . . . . . . . . . . . . . . . 52 5.2.1. EXTRAE y Paraver . . . . . . . . . . . . . . . . . . . . . . . 53 5.3. Instalación y configuración de programas . . . . . . . . . . . . . . . . 53 5.4. Optimizando el fichero de configuración de HPL y HPCC . . . . . . 56 Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 6. Evaluación del clúster 7 59 6.1. Benchmarking single node . . . . . . . . . . . . . . . . . . . . . . . . 59 6.1.1. Metodologı́a . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 6.1.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60 6.2. Benchmarking multi nodo . . . . . . . . . . . . . . . . . . . . . . . . 66 6.2.1. Metodologı́a . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 6.2.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68 7. Sostenibilidad 71 7.1. Sostenibilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7.1.1. Viabilidad económica 71 . . . . . . . . . . . . . . . . . . . . . . 71 7.1.2. Impacto Social . . . . . . . . . . . . . . . . . . . . . . . . . . 71 7.1.3. Impacto Ambiental . . . . . . . . . . . . . . . . . . . . . . . . 72 8. Conclusiones individuales 73 8.1. Evaluación global . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73 8.2. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 9. Conclusiones de equipo 75 9.1. Conclusiones de cara a la competición . . . . . . . . . . . . . . . . . 75 9.2. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 Agradecimientos 77 Bibliografı́a 80 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 8 Facultat d’Informàtica de Barcelona Índice general Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 9 Índice de figuras 2.1. Listado de Tareas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 2.2. Diagrama de Gantt . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 2.3. Estado del Laboratorio C6-103 al llegar. . . . . . . . . . . . . . . . . 32 3.1. Vista del clúster (cerveza para comparar la escala) . . . . . . . . . . 36 3.2. Vista del clúster (cerveza para comparar la escala) . . . . . . . . . . 36 3.3. Vista cercana del clúster . . . . . . . . . . . . . . . . . . . . . . . . . 37 3.4. Vista del switch de interconexión . . . . . . . . . . . . . . . . . . . . 37 3.5. Vista general del clúster . . . . . . . . . . . . . . . . . . . . . . . . . 38 4.1. Patrón de acceso a datos según aplicación . . . . . . . . . . . . . . . 44 4.2. Esquema de comunicaciones según la versión de benchmark. . . . . . 44 4.3. Conexiones que realiza MPI en Natural ring . . . . . . . . . . . . . . 47 4.4. Un posible patrón de conexiones que realiza MPI en Random ring . 48 6.1. Ejemplo de fichero de resultados del microkernel N-Body OpenMP . 60 6.2. Speed Up con precisión de 32-bits. . . . . . . . . . . . . . . . . . . . 61 6.3. Speed Up con precisión de 64-bits. . . . . . . . . . . . . . . . . . . . 61 6.4. Comparativa de la eficiencia paralela de simple y doble precisión con 4 threads . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 6.5. Rendimiento y efficiencia paralela con HPL (single node). . . . . . . 63 6.6. Eficiencia respecto al PP de las primeras posiciones del top500. . . . 64 6.7. Eficiencia energética comparada con las primeras posiciones de Green500. 66 6.8. Gráfica de speed up del cluster ejecutando HPL de 1 a 24 procesadores. 68 6.9. Eficiencia paralela del clúster ejecutando HPL de 1 a 24 procesadores. 69 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 10 Facultat d’Informàtica de Barcelona Índice de figuras Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 11 Índice de cuadros 2.1. Distribución de horas de trabajo según rol. . . . . . . . . . . . . . . 27 2.2. Costes asociados a recursos humanos. . . . . . . . . . . . . . . . . . 31 2.3. Costes derivados de la compra de Hardware. . . . . . . . . . . . . . . 31 2.4. Desglose de los gastos generales. . . . . . . . . . . . . . . . . . . . . 33 2.5. Resumen presupuesto total. . . . . . . . . . . . . . . . . . . . . . . . 33 4.1. Operación y medida de rendimiento de los benchmarks de HPCC. . 43 4.2. Versiones disponibles para cada benchmark. . . . . . . . . . . . . . . 45 6.1. Resumen de resultados de HPCC. . . . . . . . . . . . . . . . . . . . . 70 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 12 Facultat d’Informàtica de Barcelona Índice de cuadros Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 13 Abreviaciones BLAS Basic Linear Algebra Subprograms. 42, 49 BSC Barcelona Supercomputing Center. 30, 48 CPU Central Processing Unit. 35, 48 DGEMM Double-precision GEneral Matrix Multiply. 45 eMMC embeded MultiMediaCard. 35 EP Embarrassingly Parallel. 43, 69 FFT Fast Fourier Transformation. 47, 49 GB Gigabyte. 35 GFLOPS Gigaflops. 42, 47, 59, 60 GPU Graphics Processing Unit. 35 GROMACS GROningen MAchine for Chemical Simulations. 39, 40, 48 GUPS Giga UPdates per Second. 46 HPC High Performance Computing. 3, 4, 17, 20, 22, 25, 30, 71, 72 HPCC High Performance Computing Challenge. 39, 41 HPL High-Performance Linpack. 20, 39, 41, 59, 60, 63, 64 ISC International Supercomputing Conference. 17, 19, 20 LU Lower-Upper. 42 Mbps Mega Bits Por Segundo. 35 MHz Gigahercios. 35 MPI Message Passing Interface. 42, 60 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 14 Abreviaciones PP Peak Performance. 42 SCC Student Cluster Challenge. 17, 19, 20, 22, 25, 39 SD Secure Digital. 35 SIMD Single Instruction Multiple Data. 48 SoC System On Chip. 35, 59, 62, 69 W Vatios. 20, 65, 69, 72 Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 15 Glosario Green500 Ránking de los 500 supercomputadores más potentes del mundo ordenados por eficiencia energética. 59 Top500 Ránking de los 500 supercomputadores más potentes del mundo ordenados por rendimiento. 41 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 16 Facultat d’Informàtica de Barcelona Glosario Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 17 Prefacio Este trabajo forma parte de un proyecto colaborativo de investigación entre estudiantes que se ubica en el área de la informática conocida como HPC. Comparte tı́tulo y se complementa con el trabajo de tres compañeros de proyecto: David Trilla en el ámbito del hardware, Cristóbal Ortega en el de software de sistema y Constantino Gómez por el apartado de aplicaciones. Por tanto, los siguientes capı́tulos son compartidos a nivel de proyecto: este prefacio, introducción, planificación y presupuestos, sostenibilidad y por último conclusiones de equipo. Estos capı́tulos son compartidos porque aportan información esencial común a todo el proyecto, ası́ como una descripción del trabajo conjunto que ha realizado el equipo. Hoy en dı́a el HPC es una de las herramientas principales para el desarrollo de la ciencia. Por norma general las aplicaciones HPC comparten una caracterı́stica común, se pueden desmenuzar en subtareas para poder ası́ ejecutarse de manera paralela en gran cantidad de procesadores. El principal exponente de este tipo de investigación son los supercomputadores, máquinas con capacidades de cómputo muy por encima de la mayorı́a de ordenadores, y que son imprescindibles para casi cualquier campo cientı́fico e investigación. El HPC se encarga de que estas máquinas sigan evolucionando para permitir que la ciencia siga avanzando a pasos cada vez mayores. Una de las conferencias más importantes en materia HPC es la International Supercomputing Conference (ISC). Los asistentes, mayoritariamente profesionales del sector, participan en charlas técnicas, conferencias y talleres entre otros. Para este trabajo, no es el evento principal el que resulta de interés, sino la competición HPC: Student Cluster Challenge (SCC). En esta competición, que participan universidades de todo el mundo, equipos de estudiantes compiten por conseguir los mejores resultados de rendimiento. La creación del grupo responde a dos necesidades: la de dar cabida a los tres aspectos técnicos más importantes de la tecnologı́a HPC en un proyecto común, y segundo, la de formar un equipo y las opciones que se tendrı́an para ganar una competición como la Student Cluster. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 18 Facultat d’Informàtica de Barcelona Glosario Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 19 Capı́tulo 1 Introducción 1.1. Orı́genes A principios de septiembre de 2013, Álex Ramı́rez reúne a 7 estudiantes de la especialidad de ingenierı́a de computadores, entre ellos los 3 integrantes del grupo, y nos propone formar un equipo con intención de participar en la ISC ‘14 que se celebra en Leipzig del 21 al 25 de Junio en 2014 A lo largo de septiembre y octubre se estudian los requerimientos de la competición y elaboramos el documento de inscripción con información de los participantes y un primer planteamiento del clúster. A principios de diciembre la organización nos comunica que no hemos sido admitidos en la competición sin aportar mayor explicación. En enero de 2014 acordamos seguir con el proyecto a modo de TFG pese a no estar admitido. El grupo se reduce a 3 personas: Constan Gómez, David Trilla y Cristobal Ortega. 1.2. Problemática Por un lado la problemática que se plantea es la siguiente: en caso de querer competir en el futuro en una competición como el SCC, qué competencias de equipo y conocimientos técnicos deberı́amos desarrollar. Por otro lado, nos encontramos otro problema, más general y de más alcance, como es el consumo de los supercomputadores hoy en dı́a. Actualmente, el mantenimiento de los centros de computación tiene un coste muy elevado. Gran parte del coste se debe al consumo eléctrico de sus equipos y la refrigeración necesaria para mantenerlos funcionando. Este problema es atacado de forma indirecta en el SCC por la Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 20 Capı́tulo 1. Introducción limitación de consumo a 3.000 Vatios (W), y en el clúster que construiremos con hardware de bajo consumo. Para ayudarnos a definir los objetivos del trabajo, veamos primero en detalle en que consiste la competición. 1.3. Student Cluster Challenge El SCC es una competición que se celebra en el ámbito del ISC, el escaparate sobre HPC en Europa. El evento ISC ‘14 tiene lugar entre los dı́as 21 y 25 de Junio en Liepzig, Alemania. Esta competición será nuestro marco de referencia, dirigiendo nuestro proyecto como si fuéramos a participar en ella, usando sus directrices y parámetros. El evento consiste en reunir a varios equipos, de hasta 6 estudiantes sin graduar, que junto con un pequeño sistema para supercomputación y a lo largo de 4 dı́as, compitan entre ellos en diferentes categorı́as para determinar el sistema ganador, mediante el montaje y la optimización de los parámetros de las aplicaciones. Existen 3 categorı́as a las cuales se opta a premio, la de mejor resultado con HighPerformance Linpack (HPL), que es la versión para HPC del software de benchmarking LINPACK, la de votación a favorito, y la categorı́a general donde cuenta la puntuación total de todos los benchmarks. La caracterı́stica de la competición de premiar al eficiencia da lugar a la principal restricción que se impone en la competición, que limita el “presupuesto para el consumo”. Esto limita el consumo de cualquier clúster en competición, incluyendo sus elementos para interconexión, a un total de 3.000W. [2] Debido a todas las anteriores normas, nuestra intención es diseñar dos clústeres pensados para presentar al concurso. Un clúster teórico, que cumpla los requisitos anteriores, y que nos permitirá liberarnos de la necesidad de depender del coste de su creación, y posteriormente, con el hardware disponible, crear un clúster que pueda ejecutar eficientemente los benchmarks del concurso, con especial atención en el HPL, y que también cumpla la restricción de consumo. 1.4. Objetivos A continuación se desglosan los objetivos generales del proyecto y los objetivos individuales de cada uno de los tres trabajos. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 1.4.1. 21 Objetivos Generales Basándonos en los requerimientos vistos en la sección anterior se establecen los siguientes objetivos generales y su justificación. Hemos dividido el proyecto en dos fases. Objetivos de la primera fase Estudio del estado del arte HPC Diseñar y montar un clúster con un consumo inferior a los 3kW. Para poder diseñar adecuadamente un clúster necesitamos realizar previamente un estudio del estado del arte. De esta manera podremos extraer cuales son los elementos indispensables para su montaje, y además, adquirir otros conocimientos relacionados que nos ayudarán durante todo el desarrollo del proyecto. El segundo objetivo se aborda de dos maneras diferentes. Por un lado se realiza el diseño teórico de un clúster con procesadores y aceleradores convencionales. Por otro, el diseño y montaje de un prototipo de clúster con procesadores móviles de bajo consumo. Dada la necesidad de asistir con un clúster propio a la competición, es necesario trabajar de primera mano con el hardware y el software de sistema para ser más competitivos. Objetivos de la segunda fase Evaluación del clúster basado en procesadores de bajo consumo. En este momento, mediante benchmarks y aplicaciones, realizaremos las pruebas empı́ricas que demostrarán que nuestra solución al problema está a la altura de la competición. En caso de que no estarlo, se buscará poder señalar de manera precisa la causa de las deficiencias de rendimiento (cuellos de botella) ya sean de diseño, de configuración o de uso incorrecto de las herramientas de evaluación. Dado que ningún integrante del grupo ha participado en algún proyecto similar anteriormente, el proceso de evaluación servirá también para el desarrollo de las habilidades de equipo necesarias en la competición, ya que, gran parte de las técnicas y los test aplicados con el fin de optimizar la máquina y las aplicaciones de este trabajo son extrapolables a otras configuraciones de hardware y otros programas. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 22 Capı́tulo 1. Introducción 1.4.2. Objetivos individuales Objetivos de la sección de hardware Fase 1 Investigación sobre el estado del arte del hardware en el mundo de HPC, cuáles son las tecnologı́as más usadas y los componentes necesarios para construir un clúster. Crear un clúster para HPC de manera conceptual para poder competir en el SCC, sin limitación económica. Evaluar la tecnologı́a usada en el SCC y las capacidades del clúster teórico diseñado. Fase 2 Analizar el hardware a nuestro alcance, disponible para construir un clúster para HPC. Montar y configurar el hardware para tener una plataforma funcional con múltiples nodos sobre la que poder ejecutar software Evaluar el rendimiento del hardware, las diferencias entre los resultados esperados y los reales, y comparar con el clúster conceptual de la primera fase y otros sistemas con tecnologı́as distintas. Objetivos de la sección de software de sistema Fase 1 Investigar que software de sistema es necesario habitualmente para correr aplicaciones del tipo HPC. Estudiar el estado actual en los sistemas de supercomputación para saber que stack de software usan. Seleccionar el software de sistema que necesitemos y elegir el que mejor se nos adapte a nosotros, ya sea por compatibilidad con el hardware o aplicaciones a correr, por documentación existente o requisitos diversos. Fase 2 Basado en la fase 1, instalar y configurar todo el stack de software para crear un clúster totalmente funcional. Es posible que haya que seleccionar otro tipo de software por la plataforma usada. Experimentar con distintas versiones de paso de mensajes MPI para saber realmente cuál se adapta a nuestro sistema Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 23 Objetivos de la sección de aplicaciones Fase 1 Investigar las aplicaciones en el estado del arte actual y analizar las más relevantes para nuestro proyecto. Averiguar que opciones existen de cara a optimizar las aplicaciones que se ejecutarán en el clúster. Fase 2 Evaluar el rendimiento de las aplicaciones descritas a nivel de nodo y a nivel de clúster. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 24 Facultat d’Informàtica de Barcelona Capı́tulo 1. Introducción Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 25 Capı́tulo 2 Planificación y presupuesto 2.1. 2.1.1. Planificación Estudio Teórico La primera fase, es de investigación activa, sobre HPC y el SCC, e información sobre todo lo necesario para la instalación y preparación de un clúster. Esto incluye hardware, software de sistema y aplicaciones. Esta parte del proyecto recabará la información necesaria para elaborar un clúster teórico con el que ir a competir en el SCC. No se esperan grandes contratiempos durante esta fase. Los problemas que puedan surgir serán derivados de la poca información disponible sobre algunos componentes del clúster. 2.1.2. Aplicación Práctica La segunda fase, basada en la experimentación, es en la cual usamos la información recogida en la fase anterior para crear un clúster totalmente funcional. En esta fase es donde es más probable que surjan dificultades técnicas, ya que al ser un mundo casi nuevo, como por ejemplo, que la información recogida en la fase anterior no se ajuste a nuestra arquitectura o software escogido. Los posibles retrasos de ponernos a montar el clúster, instalación de software y benchmarks deberemos tenerlos en cuenta y aplazar el resto de tareas que tengamos, como es la optimización de software y aplicaciones, esto implica que obtendremos peores rendimientos de los que realmente podrı́amos conseguir. Ya que para poder obtener las métricas de rendimiento necesitamos un clúster funcionando. Y aunque no sea un clúster optimizado todo lo posible, el objetivo de tener un clúster de HPC estará conseguido. Los posibles retrasos que aparezcan en esta sección puede aparecer de errores e incompatibilidades en la fase de instalación del clúster, el tiempo Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 26 Capı́tulo 2. Planificación y presupuesto adicional será recortado de las tareas más opcionales dispuestas al final del proyecto, correspondientes a la parte de optimización, lo que implicará que obtendremos peores rendimientos de los que realmente podemos conseguir, ya que la instalación y puesta en marcha del clúster es esencial, sin embargo el proyecto estará finalizado ya que tendremos un clúster totalmente funcional. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 2.2. 27 Estimación temporal La temporización en este proyecto toma especial importancia por dos motivos: hay un gran volumen de tareas a realizar que requieren un esfuerzo conjunto y la alta incertidumbre que albergan algunas de ellas. Debido a las fuertes dependencias entre tareas es imprescindible tener en mente las fechas comprometidas para garantizar que todo el grupo cumple con sus objetivos. Desde el principio se acuerdan unas horas fijas de dedicación semanal en grupo. Por un lado, nos ayudará a empezar con buen ritmo con la parte teórica y a funcionar como un equipo, y por otro, tener margen de reacción de cara al final del proyecto donde se prevén más problemas. Tarea Estudio previo Montaje y configuración Benchmarking Análisis de resultados Dedicación por persona 125h 155h 35h 60h Cuadro 2.1: Distribución de horas de trabajo según rol. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 28 Capı́tulo 2. Planificación y presupuesto 2.2.1. Listado de Tareas Figura 2.1: Listado de Tareas Facultat d’Informàtica de Barcelona Constantino Gómez Crespo 2.2.2. Diagrama de Gantt 29 Figura 2.2: Diagrama de Gantt 30 Capı́tulo 2. Planificación y presupuesto 2.2.3. Recursos Los recursos que tendremos para este proyecto serán principalmente humanos, tendrán un papel importante para el estudio teórico, el montaje y configuración del clúster. Para la parte de estudio, nos apoyaremos en publicaciones cientı́ficas, revistas y papers, además de sitios online especializados de este tipo de hardware y software. También se hará uso de libros que puedan tratar los temas de HPC o clústeres, pese a que estos se prevén en menor medida. Para la parte práctica del montaje del clúster dispondremos principalmente del hardware que nos ofrezca el departamento de computadores y el sitio en el que nos permita colocarlo. Para realizar las medidas de consumo energético se ha dispuesto de un medidor de potencia Yokogawa cedido por el Barcelona Supercomputing Center (BSC). Finalmente, otros recursos utilizados son los ordenadores personales para la redacción de la memoria y conectar en remoto al hardware de desarrollo. 2.3. Presupuesto El proyecto se basa en montar un clúster y configurarlo de manera correcta para poder ejecutar aplicaciones HPC en él. En este documento se hace una estimación del precio de los recursos que se usarán a lo largo del trabajo. Las amortizaciones se calcularán respecto a 6 meses. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 2.3.1. 31 Recursos humanos Se necesitan técnicos que se encarguen de diseñar, instalar y configurar dicho clúster. Siendo 3 personas en este proyecto, repartiremos las mismas horas para todos. Dentro de cada bloque de horas, cada uno se centrará en una de las divisiones lógicas que hemos establecido: hardware, software de sistema y aplicaciones. Para las decisiones de elección de componentes se han considerado horas de Director de proyecto. Para el montaje e instalación del clúster se necesitarán competencias de Administrador de Sistema. Para realizar los benchmarks adecuados e interpretar resultados se han considerado horas de Analista. Los datos que utilizamos están basados en portales online de ofertas laborales. Rol Director de proyecto Administrador de sistema Analista Total Horas estimadas Precio por hora Total por persona Total grupo 125h 155h 95h 375h 50e/h 26e/h 30e/h 6250e 4030e 2850e 18750e 12090e 8550e 39390e Cuadro 2.2: Costes asociados a recursos humanos. 2.3.2. Hardware Para la segunda parte del proyecto será esencial el hardware que adquiramos para poder trabajar con él. Datos obtenidos de tiendas online. Producto Arndale Octa(Exynos 5420) Fuentes de alimentacion Tarjetas SD Power meter Yokogawa Switch Netgear 100-Mbit 1TB Hard Drive Storage 125M cat 5E FTP Total Precio unitario Unidades 150e 5e 7.5e 1830e 89e 70e 68e 6 6 12 1 1 1 1 Vida útil 5 5 5 15 10 7 20 Amortización total años años años años años años años 90e 3e 9e 61e 4.45e 5e 1.7e 174.15e Cuadro 2.3: Costes derivados de la compra de Hardware. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 32 Capı́tulo 2. Planificación y presupuesto Tanto las placas Arndale Octa como las fuentes de alimentación y el medidor de potencia Yokogawa han sido cedidos por el BSC. El resto del material ha sido cedido por el departamento de Arquitectura de Computadores. Al final de la realización del proyecto se espera deshacer el montaje y retornar ı́ntegro todo el material para su posterior reutilización en otras actividades de investigación o proyectos. 2.3.3. Software El software requerido para la instalación, benchmarking y análisis de la máquina es de acceso gratuito. Gran parte de de los programas tienen licencias de Software Libre, y las que no, disponen de versiones gratuitas con propósito no comercial. Necesitaremos distinto software de sistema para gestionar la máquina como aplicaciones para medir su rendimiento. 2.3.4. Gastos generales Necesitaremos un sitio donde instalar el clúster fı́sicamente, para ello necesitaremos un sitio con espacio y una instalación eléctrica adecuada además de Internet para tener acceso a los sistemas desde fuera. El laboratorio C6-103 cedido también por el departamento de AC cuenta con todo lo necesario para la realización del proyecto. Se ha hecho una estimación del coste que supondrı́a disponer de un espacio similar. Figura 2.3: Estado del Laboratorio C6-103 al llegar. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones Concepto Espacio fı́sico Electricidad Internet Total 33 Coste hora Coste total 0.368e 0.083e 0.07e 1590e 358e 300e 2248e Cuadro 2.4: Desglose de los gastos generales. 2.3.5. Presupuesto total Concepto Recursos humanos Hardware Software Gastos generales Total Coste estimado + Impuestos 39390e 174.15e 625e 2248e 42437.15e 51600.9e(31 % S.S.) 210.7e(21 % IVA) 300e(21 % IVA) 2720.08e(21 % IVA) 54831.68e Cuadro 2.5: Resumen presupuesto total. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 34 Facultat d’Informàtica de Barcelona Capı́tulo 2. Planificación y presupuesto Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 35 Capı́tulo 3 Sumario del Hardware 3.1. Sumario del Hardware En resumen el hardware usado que constituye al clúster es el siguiente: Nodo: Arndale Octa (x6) • System On Chip (SoC): Samsung Eynos 5420 ◦ Central Processing Unit (CPU): ARM Cortex-A15 (x4) + ARM Cortex-A7 (x4) ◦ Graphics Processing Unit (GPU): Mali T-628 ◦ Memoria: 2 Gigabyte (GB) 933 Gigahercios (MHz) • 100 Mega Bits Por Segundo (Mbps) Interfaz Ethernet • Almacenamiento: ◦ 4 GB embeded MultiMediaCard (eMMC) ◦ 16 GB Secure Digital (SD) Switch: NetGear FS524 Cables Ethernet Cobre (x6) Transformadores (x6) Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 36 Capı́tulo 3. Sumario del Hardware 3.2. Clúster de Arndale Octa Figura 3.1: Vista del clúster (cerveza para comparar la escala) Figura 3.2: Vista del clúster (cerveza para comparar la escala) Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 37 Figura 3.3: Vista cercana del clúster Figura 3.4: Vista del switch de interconexión Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 38 Capı́tulo 3. Sumario del Hardware Figura 3.5: Vista general del clúster Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 39 Capı́tulo 4 Análisis de aplicaciones En esta sección tiene como propósito presentar y analizar las aplicaciones con las que se trabajará a lo largo del proyecto. Algunas de estas aplicaciones tienen especial relevancia, ya sea por su papel en el estado del arte actual o en la competición SCC. En concreto veremos: Los benchmarks HPL y High Performance Computing Challenge (HPCC), en ellos centraremos la mayor atención, ya que son dos aplicaciones a las que se deben enfrentar cada año los equipos de la SCC, y además son utilizadas para confeccionar los ránkings oficiales de rendimiento de clústers. GROningen MAchine for Chemical Simulations (GROMACS) nos servirá como ejemplo para ver que tipo de aplicaciones cientı́ficas se ejecutan en los supercomputadores. Finalmente listamos y describimos los microkernels que han sido utilizados en la evaluación del clúster final y que implementan algoritmos de uso recurrente en HPC. Se ha decidido dejar fuera del análisis las aplicaciones especı́ficas para esta edición del SCC por el tiempo que llevarı́a trabajar con ellas. Al final veremos una lista y una breve descripción de cuáles son. En el estado del arte actual podemos agrupar entonces en dos grupos, aplicaciones de producción y las de benchmarking. 4.1. Aplicaciones de producción Usaremos el término aplicación de producción para referirnos a aquellas aplicaciones que tienen un uso directo en la investigación o industria. Principalmente, estas Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 40 Capı́tulo 4. Análisis de aplicaciones aplicaciones implementan modelos matemáticos y permiten simular experimentos o fenómenos fı́sicos. Una manera general de determinar la calidad de este tipo de aplicaciones es la relación entre el volumen de datos de entrada, la precisión y el tiempo en obtener los resultados. Generalmente, el volumen de datos a procesar de estas aplicaciones es enorme, ası́ que para poder obtener resultados en un espacio de tiempo razonable, es necesario utilizar ordenadores con gran capacidad de cálculo. Es por tanto que cuando se diseña un clúster HPC el principal objetivo es el de conseguir una configuración de hardware que ofrezca buenos resultados en la aplicación o conjuntos de aplicaciones que queremos ejecutar en él. Las aplicaciones de producción pueden ser usadas, entre otros, en la simulación de dinámica de fluidos, que permite observar el comportamiento fı́sico de materiales o elementos fluidos. Un ejemplo concreto puede ser la simulación de la aerodinámica de un coche dentro de un túnel de viento. Otro uso es en dinámica molecular, permitiendo realizar pruebas con fármacos sin necesidad de usar personas u otros animales. Un ejemplo de este tipo de aplicaciones es GROMACS, explicado un poco más adelante. 4.2. Herramientas de benchmarking Comúnmente, los benchmarks realizan operaciones simples con el fin de estresar partes del hardware y obtener una medida de rendimiento de éstas. Estas medidas de rendimiento las compararemos a su vez con otras obtenidas en otras condiciones, ya sea porque hemos modificado algún parámetro de ejecución o porque han sido obtenidas en otro clúster. Es importante conocer en que consisten dichas operaciones para poder hacer un uso inteligente de estas herramientas. Obtener buen rendimiento al ejecutar una aplicación de producción concreta no implica que el resto de aplicaciones vayan a obtener también buen rendimiento. A bajo nivel esto puede ser debido a muchas causas: diferente patrón de accesos a memoria, número de llamadas a sistema, mal balanceo de carga, etc. En resumen diremos que cada aplicación tiene necesidades computacionales diferentes. Es por eso que nos interesa poder evaluar de manera consistente los recursos hardware del clúster. Por consistente nos referimos a obtener valores que representen las capacidades de la máquina en todos sus niveles. Capacidades de cómputo, comunicaciones, memoria y la escalabilidad al ejecutar aplicaciones. Por ejemplo, supongamos que queremos hacer una estimación del rendimiento que se obtendrá en un tipo de aplicación que hace cálculo intensivo con operaciones de coma flotante, y cuyos accesos a datos son mayoritariamente a vectores en orden secuencial . Podemos prever el rendimiento basándonos en los resultados obtenidos en Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 41 la ejecución en el mismo clúster de un benchmark que tenga caracterı́sticas similares. Hemos seleccionado los benchmark HPL y HPCC, para determinar en qué nos pueden ayudar, y que más tarde nos permitirá hacer una evaluación lo más completa posible del clúster que se ha montado. 4.3. LINPACK Benchmarks LINPACK es una librerı́a de álgebra linear. Originalmente fue escrita en Fortran 66 en 1980 y su propósito era el de ser utilizada en supercomputadores.[22] Basándose en esa librerı́a, se crearon una serie de benchmarks con el propósito de medir la potencia computacional en FLOPS (de doble precisión) de un sistema. Estos benchmarks se conocen como LINPACK Benchmarks. Los LINPACK Benchmarks generan y calculan la solución de un sistema de ecuaciones denso del tipo Ax = b y de tamaño N xN [23]. a1,1 a2,1 .. . a1,2 a2,2 .. . an,1 an,2 . . . a1,n x1 b1 . . . a2,n x2 b2 .. .. = .. .. . . . . . . . an,n xn bn El primero fue LINPACK 100, que como indica el nombre, ofrecı́a medidas de rendimiento resolviendo sistemas de tamaño N = 100. Las siguientes versiones, LINPACK 1000 y HPLinpack, se crean para poder evaluar supercomputadores con más potencia y nuevas arquitecturas (memoria distribuida).[13] 4.3.1. HPL HPL website: http://www.netlib.org/benchmark/hpl/ HPL es la implementación de HPLinpack Benchmark más relevante. Es una versión paralela y escalable preparado para ejecutarse con un modelo de memoria distribuida. Es el benchmark utilizado para elaborar la lista Top500 de supercomputadores www.top500.org. Está implementación es mantenida por la Universidad de Tenesse y actualmente se encuentra en la versión 2.1 de Octubre 2012, está escrita en C para facilitar su portabilidad. Para su ejecución HPL requiere tener instaladas en el sistema librerı́as Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 42 Capı́tulo 4. Análisis de aplicaciones que implementen Message Passing Interface (MPI) y Basic Linear Algebra Subprograms (BLAS).[1] Complejidad y tamaño del problema Para resolver el sistema de ecuaciones, HPL utiliza el método de factorización LowerUpper (LU) y luego resuelve el sistema triangular superior (U) U x = y. La complejidad de este método es 32 n3 + 2n2 , es decir, necesitamos esa cantidad de operaciones de coma flotante (64-bits) para obtener la solución al sistema. De ahı́ extraemos la fórmula que utiliza HPL para medir el rendimiento en Gigaflops (GFLOPS). PHP L = 2 3 3n + 2n2 tsegundos 10−9 (4.1) Cabe decir que en caso de querer optimizar la implementación, queda excluido cualquier método que varie la complejidad del algoritmo (p.ej: algoritmo de Strassen), ya que se deberı́a modificar también la fórmula del rendimiento. Serı́a utilizar un benchmark diferente. El espacio en memoria durante la ejecución depende de la matriz A, siendo la matriz A de tamaño n por n, esta ocupará 8n2 bytes. Los datos que componen la matriz A y el vector b se obtienen a partir de un generador pseudo-aleatorio de números decimales con una media esperada de cero[9]. Eficiencia paralela Con el fin de balancear el volumen de trabajo a realizar en cada nodo, HPL divide en bloques de tamaño BSxBS y los distribuye de manera cı́clica entre procesos[9]. El número de operaciones a realizar es proporcional al tamaño de los datos de entrada. Debido al blocking, el patrón de acceso a memoria explota la localidad espacial y temporal de la cache. Si bien en algún momento se requiere comunicación entre procesos todos-con-todos, el mayor estrés lo sufren las unidades de coma flotante y la conexión de los registros a la caché de cada procesador. Al final de la ejecución se obtiene una medida del rendimiento en GFLOPS. Una ejecución de HPL optimizada suele moverse en el margen de 70-80 % del Peak Performance (PP). Hemos dicho que HPL nos da una medida de rendimiento, sin embargo esta medida solo se puede extrapolar a aplicaciones que hagan un uso similar de los recursos Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 43 de la máquina. ¿Qué pasa con el resto de aplicaciones que usan diferentes de recursos? Hay que seguir haciendo benchmarking. 4.4. HPCC HPCC website: http://icl.cs.utk.edu/hpcc/ HPCC (High Performance Computing Challenge) es una colección de benchmarks confeccionada con el propósito es el de ofrecer medidas de rendimiento de un sistema HPC más completas que las que ofrece HPL, para ello, utiliza variedad de aplicaciones con diferentes tipos de operaciones y patrones de acceso a memoria. HPCC es desarrollado por la Universidad de Tenesse bajo el programa DARPA HPCS[5]. Los desarrolladores de HPCC mantienen además un ránking propio en la sección results de su página web. Anualmente se celebra una competición, que tiene lugar en la Supercomputer Conference, llamada HPC Challenge Awards Competition, y dónde se premia al mejor resultado del ránking y a la mejor implementación de una lista de kernels seleccionados[7]. El listado de benchmarks que componen HPCC, una breve descripción de la operación que realizan y la medida de rendimiento obtenida en cada uno de ellos se puede ver en la tabla 4.2. Benchmark Operación Medida HPL DGEMM STREAM PTRANS RandomAccess FFT b eff Resuelve un sistema de ecuaciones Multiplicación de matrices (64-bit) Conjunto de operaciones con vectores Transposición de matrices Acceso aleatorio a datos enteros Transformada discreta de Fourier Varios patrones de comunicación MPI GFLOPS GFLOPS GB/s GUP/s GUP/s GFLOPS GB/s Cuadro 4.1: Operación y medida de rendimiento de los benchmarks de HPCC. Una representación gráfica del grado y tipo de localidad de los accesos a memoria se puede ver en la figura 4.1. De cada benchmark podemos encontrar hasta tres versiones: Single, Embarrassingly Parallel (EP) y Global. Estas versiones pretenden estresar diferentes partes del hardware suponiendo varios escenarios: uniprocesador, multiprocesador y multinodo. En las versiones single el benchmark se ejecutará utilizando de manera aislada los cores de nuestro clúster, por tanto, no hay comunicación de ningún tipo ni entre procesadores ni entre nodos. Sirve como medida base para evaluar la escalabilidad Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 44 Capı́tulo 4. Análisis de aplicaciones Figura 4.1: Patrón de acceso a datos según aplicación de la aplicación en nuestro sistema. Las versiones Embarrasingly Parallel solo se permiten la comunicación entre cores del procesador de un mismo nodo. Ejecutan el benchmark una vez por nodo y se quedan con la mejor. Permite determinar la eficiencia paralela a nivel de nodo. Las Global apuntan a hacer un uso completo del clúster, durante la ejecución habrá comunicación entre procesadores de diferentes nodos para obtener datos de la memoria. Permite determinar la eficiencia paralela a nivel de clúster y evaluar el rendimiento de la red de comunicación entre nodos. Nota: Los nombres que reciben estas versiones en los informes de resultados son Single, Star y MPI. Una representación gráfica del comportamiento de las versiones descritas puede verse en la figura 4.2 Figura 4.2: Esquema de comunicaciones según la versión de benchmark. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 45 Las versiones disponibles para cada uno de los benchmarks en la tabla ?? Benchmark HPL DGEMM STREAM PTRANS RandomAccess FFT Single EP X X X X X X X X Global X X X X Cuadro 4.2: Versiones disponibles para cada benchmark. A continuación un pequeño análisis individual de las aplicaciones. Se excluye HPL por que ya ha sido explicada anteriormente. 4.4.1. DGEMM Double-precision GEneral Matrix Multiply (DGEMM), se define como una operación de multiplicación de matrices A y B tal que C ← αAB + βC donde A, B, C ∈ Rn×n , α, β ∈ R y n ∈ N. La complejidad de la región a evaluar es de 2n3 operaciones de coma flotante . Como en HPL, no se puede aplicar ninguna optimización que reduzca la complejidad del algoritmo. Por defecto en esta implementación, resuelve la multiplicación con una llamada a la correspondiente rutina CBLAS. El uso de recursos hardware del multiprocesador dependerá de las optimizaciones en la librerı́a instalada(multithreading, vectorización, etc). De todos modos, como HPL, en DGEMM el mayor estrés lo sufre el canal de registros a caché[4]. 4.4.2. STREAM STREAM permite medir el ancho de banda entre el procesador y la memoria principal haciendo operaciones simples con vectores de gran tamaño. Se compone de 4 test u operaciones. Supongamos los vectores a, b, c ∈ Rn y los escalares α, β ∈ R : COPY, c ← a SCALE, b ← αc ADD, c ← a + b TRIAD, a ← b + αc Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 46 Capı́tulo 4. Análisis de aplicaciones En estas operaciones no hay reaprovechamiento de datos, pero los accesos son secuenciales, ası́ que se aprovecha al máximo la localidad espacial. Cada una se mide en regiones de tiempo diferentes pero se repiten almenos 10 veces dentro de cada región para obtener una mejor muestra. El tamaño de datos para vectores de m elementos es 16m bytes para COPY y SCALE, y 24m bytes para ADD y TRIAD, con complejidad 2n y 3n respectivamente. La medida de rendimiento obtenida se expresa en GB/s que representa el ancho de banda sostenido de acceso a la memoria RAM de un nodo[4]. 4.4.3. PTRANS Los benchmarks explicados a partir de ahora están pensados para testear la capacidad de comunicaciones de la red. PTRANS, Parallel TRANSposition, realiza la transposición de una matriz A y le suma una matriz B. Descripción de la operación: A = AT + B donde A, B ∈ Rn×n . Para transponer la matriz se asigna un bloque de datos a cada proceso MPI y entre ellos se comunican por parejas. El rendimiento y el tamaño son O(n2 ), y los datos que contienen las matrices se generan de manera aleatoria. 4.4.4. RandomAccess RandomAccess mide la tasa de actualizaciones aleatorias de memoria con enteros, esta medida se expresa en Giga UPdates per Second (GUPS). Este benchmark tiene implementaciones de las tres versiones. Se crea una tabla T de tamaño 2n y una secuencia Ai de de enteros de 64 bits de longitud 2n+2 generados con la función x2 + x + 1. La secuencia pseudo-aleatoria nos servirá para indicar a que posición de la tabla se deben hacer las actualizaciones de memoria. En la implementación MPI cada procesador genera una parte de la secuencia de ı́ndices y realiza sus propias actualizaciones de memoria, en consecuencia se generan gran cantidad de mensajes de poco tamaño siendo necesario comunicación todos con todos. De este modo se permite analizar el impacto la latencia introducida en el paso de mensajes. La comunicación ser realiza todos-con-todos. Los accesos aleatorios provocan que no exista ningún tipo de localidad y poder evitar el aprovechamiento de la jerarquı́a de memoria (especialmente los niveles de cache) y poder determinar el coste con máxima penalización de acceder a memoria compartida en nuestro sistema [8]. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 4.4.5. 47 FTT Fast Fourier Transformation (FFT), calcula la transformada de fourier de un vector unidimensional de gran tamaño. Este kernel es habitualmente utilizado en aplicaciones reales. Siendo N es el numero de datos (tamaño del vector) y x, z ∈ Cn . Zk = n−1 X xj e−2iπjk/n ; 1≤k≤n (4.2) j=0 Los resultados de este benchmark se expresan en GFLOPS, es calculado en base al tiempo y la complejidad del algoritmo 5n log2 n. Durante la ejecución hay un gran volumen de intercambio de mensajes largos entre procesadores[4]. 4.4.6. Comunications latency and bandwidth Sirve para medir el ancho de banda efectivo y la latencia de la red de interconexión del clúster mediante mensajes punto a punto MPI. No se realizan cálculos de ningún tipo dentro de la región evaluada. Basado en b eff pero con cambios en los patrones de comunicaciones, el número de operaciones que ejecuta es directamente proporcional al numero de procesadores [5]. En concreto, obtiene medidas de latencia y ancho de banda con 3 patrones: Pingpong, Natural Ring y Random ring. 1 2 3 4 5 6 Figura 4.3: Conexiones que realiza MPI en Natural ring Para medir latencia cada nodo intercambia mensajes de 8 bytes de tamaño, para medir el ancho de banda los mensajes son de 2 MB. Se realizan conexiones en los dos sentidos. La latencia se expresa en milisegundos y en ancho de banda en GB/s como es habitual. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 48 Capı́tulo 4. Análisis de aplicaciones 1 4 3 6 2 5 Figura 4.4: Un posible patrón de conexiones que realiza MPI en Random ring 4.5. GROMACS GROMACS es un paquete de software de dinámica molecular que permite hacer simulaciones con sistemas de cientos de millones de partı́culas. Fue desarrollado originalmente por la Universidad de Groningen y hoy en dı́a es mantenido por la comunidad cientı́fica y universidades de todo el mundo. Una de sus particularidades es que implementa gran cantidad de optimizaciones para mejorar su rendimiento. Entre ellas, el uso de librerı́as matemáticas optimizadas, inclusión en el código soporte hasta la última versión Single Instruction Multiple Data (SIMD) x86 y soporte para CUDA 2.0 en adelante[10]. Un caso de uso de esta aplicación es la plataforma de computación distribuida folding@home de la Universidad de Stanford, esta plataforma permite a los usuarios colaborar en proyectos de investigación cientı́fica, principalmente relacionadas con al cura de enfermedades, cediendo tiempo de CPU de sus ordenadores domésticos. El procedimiento es el siguiente: un proveedor central, servidores de la Universidad de Stanford, despacha unidades de tareas a los ordenadores que tienen el cliente de la plataforma instalado. En baja prioridad, para no interferir con las tareas que este realizando el usuario, mediante el uso de la CPU y/o GPU se ejecutan programas como GROMACS. Como entrada de datos se utiliza la unidad de trabajo asignada en ese momento. Al terminar los cálculos, el cliente envı́a los resultados a los servidores centrales y vuelta a empezar[19] [21]. 4.6. Microkernels Usaremos el término microkernel para referirnos a pequeños programas que implementan algoritmos usados habitualmente en software de investigación cientı́fica. Los microkernels aquı́ descritos forman parte de un conjunto de benchmarks desarrollados en el BSC y utilizados en el proyecto Mont-blanc para obtener mediciones de rendimiento de sus plataformas [16] [12]. Cada microkernel pone a prueba diferentes partes de la microarquitectura del SoC/máquina a evaluar; se han agrupado por este criterio. A continuación una breve descripción de cada uno [11]. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 4.6.1. 49 Patrones de acceso a memoria Vector operation. Toma dos vectores de un tamaño N y genera el resultado de un tercero de tamaño N. Realiza sumas uno a uno entre los dos vectores. Permite evaluar el acceso a datos secuencial (localidad espacial). 2D Convolution y 3D stencil. Toman como entrada una matriz 2D de tamaño N xN y una 3D de tamaño N xN xN respectivamente. Ambos generan resultados del mismo tamaño que sus entradas y calculan cada posición de la matriz resultado a partir de la entrada como una combinación lineal del mismo punto y sus adjacentes. Estos benchmarks permiten evaluar el rendimiento de las GPU cuando se realizan accesos a memoria de tipo strided y cuando son intercalados con accesos secuenciales. N-Body. Simula la interacción gravitacional entre una serie de partı́culas con velocidad, masa y posición propias. Evalúa el rendimiento frente a un patrón de accesos a memoria irregular. 4.6.2. Float-Point peak performance FFT y DMMM, son implementaciones de las conocidas rutinas de multiplicación de matrices y transformada de Fourier. Ya han sido explicados en la sección HPCC. Se pueden optimizar mediante el uso de BLAS y FFTW. Atomic Monte-Carlo Dynamics . Su caracterı́stica principal es que al realizar simulaciones independientes, durante su ejecución paralela, no necesita comunicación entre entre threads permitiendo obtener medidas de rendimiento pico. 4.6.3. Overhead al paralelizar La ejecución en paralelo de un programa siempre introduce un overhead respecto a su versión serie. Según el tipo de aplicación el sincronismo entre threads y la serialización al reducir puede suponer una caı́da en el rendimiento importante. Los siguientes tres microkernels nos ayudarán a evaluar el rendimiento que ofrece nuestro multiprocesador en estos casos. Reduction. A partir de un vector de entrada calcula un único valor escalar resultado de la suma por etapas de los elementos del vector. Útil para evaluar como las GPUs pasan progresivamente de el calculo masivo en paralelo a secuencial. Histogram. Calcula el histograma de un vector, como en el caso de reduction evalúa el rendimiento al reducir operaciones con mucho paralelismo. Merge Sort. Evalúa los posibles cuellos de botella derivados del uso de barreras Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 50 Capı́tulo 4. Análisis de aplicaciones de sincronización. 4.7. Aplicaciones del SCC’14 En este apartado mencionamos el conjunto de aplicaciones especificas para la edición de este año del SCC. Quantum ESPRESSO es un paquete de software que integra diversos programas para cálculos eléctrico-estructurales y modelado de materiales. Totalmente Open Source se puede descargar y obtener mucha documentación de su página web. [15] OpenFOAM (Open Field Operation and Manipulation) también Open Source es un paquete de software que permite realizar un gran rango de simulaciones: desde dinámica de fluı́dos hasta transferencia de calor. [14] Por último, GADGET software para simulaciones N-body/SPH (Smoothed-particle Hydrodinamics) [18]. 4.8. En resumen De cara a evaluar de manera completa nuestro clúster serı́a conveniente ejecutar al menos HPL y HPCC. En concreto, la potencia de cálculo la mediremos con HPL, DGEMM y FFT. El ancho de banda a memoria RAM con STREAM. Finalmente las capacidades de la red de interconexión se pueden medir con los test de conectividad de HPCC y el acceso a memoria distribuida de manera más aplicada con PTRANS y RandomAccess. Los microkernels, por la implementación de la que disponemos, solo se usarán para evaluar el rendimiento en modo nodo único (Single Node). Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 51 Capı́tulo 5 Optimización de aplicaciones Una vez se consigue la ejecución correcta de una aplicación, es el momento de analizar el rendimiento obtenido y a partir de ahı́ pensar que optimizaciones se pueden aplicar para mejorar tales resultados. 5.1. Medidas de rendimiento A continuación se comentan las principales medidas de rendimiento utilizadas para evaluar el rendimiento de un clúster y el impacto de las optimizaciones. 5.1.1. Speed Up Speed Up indica la mejora de rendimiento obtenida relativa a una ejecución base. En paralelismo, se toma como base la ejecución secuencial (T1 ) y con ella se relacionan el resto de ejecuciones incrementando el número de procesadores (Tp donde p es el número de procesadores)[6]. SpeedU p = 5.1.2. T1 Tp (5.1) Eficiencia paralela La eficiencia paralela es la relación entre el Speed Up y el número de procesadores utilizados en la aplicación. Ef fp = Sp P (5.2) De manera ideal, el tiempo de ejecución de un programa se reduce de manera proporcional al número de procesadores que utilizamos, es decir, respecto a un procesador, Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 52 Capı́tulo 5. Optimización de aplicaciones si usamos 4 procesadores va 4 veces más rápido (Speed Up 4x). El valor de la eficiencia en estos casos es 1 (el máximo). En la práctica esto no sucede, hay mucha maneras de perder eficiencia: creación de threads (overhead llamadas a sistema), dependencias (barreras de sincronismo), granularidad de tareas o scheduling inadecuado provocando problemas de desbalanceo de carga, uso de un algoritmo con insuficiente grado de paralelismo respecto al número de procesadores, false sharing, mala red de interconexión, etc. Existen dos tipos de escalabilidad: strong scaling se define como la variación de tiempo con en base a un número de procesadores variable y un tamaño de problema fijos, y weak scaling que es el caso inverso, mismo número de procesadores y tamaño de problema variable. 5.1.3. Ley de amdahl La ley de amdahl se utiliza para obtener el valor de mejora máxima alcanzable por un programa cuando únicamente se mejora una parte. La ley de amdahl aplicada a un programa paralelo es la siguiente (γ es la región paralela del programa y p el número de procesadores): Sp = 1 (1 − γ) + γ p (5.3) La metodologı́a para la optimización de rendimiento basada en la ley de amdahl consiste en lo siguiente, se localizan las funciones del programa donde se invierte el mayor tiempo y es ahı́ donde se concentran los esfuerzos de optimización. Esto es exactamente lo que se pretende mediante el uso de HPC, utilizar muchos procesadores para reducir el tiempo de ejecución de la región paralela de la aplicación. Con este propósito usaremos herramientas de análisis de rendimiento paralelo. 5.2. Herramientas de análisis Mediante el uso de herramientas de análisis de rendimiento se pretende obtener la información relevante asociada a la ejecución de una aplicación, de esta manera encontraremos los cuellos de botella causantes del mal rendimiento. Estos análisis sirven para indicar qué optimizaciones darán mayor Speed Up, y es más, tratar de optimizar una aplicación sin realizar análisis puede suponer grandes pérdidas de tiempo. Para hacer mediciones en un clúster multinodo se requieren aplicaciones capaces Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 53 de recopilar información, en forma de trazas, de la ejecución de todos los procesos de la aplicación distribuidos por el clúster. Una de estas herramientas es EXTRAE. 5.2.1. EXTRAE y Paraver EXTRAE es una herramienta software que permite generar trazas de aplicaciones paralelas mediante instrumentación. En estas trazas se recopila información de los contadores de sistema, numero de accesos a funciones y su temporización. Es capaz de instrumentar aplicaciones programadas con MPI, OpenMP, pthreads, OpenCL y StarSS. EXTRAE también ofrece una API que nos permite instrumentar el código manualmente. La herramienta dispone de varios métodos mediante los cuales es capaz de instrumentar y obtener trazas. Ofrece soporte para DynINST, una librerı́a que permite inyectar instrucciones en binarios de manera dinámica y estática. Otra manera de instrumentar es inyectando librerı́as compartidas durante la precarga de un ejecutable. Esto se consigue editando la variable de entorno en Linux LD PRELOAD. Durante la precarga se comprueba si el binario a ejecutar tiene llamadas a sı́mbolos que coinciden con las librerı́as indicadas en la variable de entorno, de darse tal caso, el sistema operativo redirecciona las llamadas hacia la librerı́a compartida. EXTRAE aprovecha esta caracterı́stica para introducir wrappers instrumentados a la funciones. Algunas caracterı́sticas a destacar de la información que recopila. El timestamp de se hace utilizando funciones de baja latencia que permiten precisión de nanosegundos. Utiliza la librerı́a PAPI que además de los contadores de sistema permite obtener información sobre el consumo y la temperatura del procesador. Por último destacar que es capaz de referenciar el código fuente permitiendo encontrar fácilmente las funciones a optimizar. Una vez tengamos las trazas es necesario usar una herramienta que permita visualizar de manera gráfica los datos para un análisis profundos, Paraver es una de ellas. Es flexible y permite guardar vistas de las trazas para retomar o compartir el análisis en cualquier momento. Además de analizar el rendimiento individualmente permite comparar varias trazas a la vez y también establecer nuestras propias métricas. 5.3. Instalación y configuración de programas Se ha decidido incluir esta sección en este capı́tulo porque en él se muestra como habilitar el uso de librerı́as de álgebra optimizadas como ATLAS. En ella se detallan los pasos de instalación y configuración de los 3 paquetes de aplicaciones que se han Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 54 Capı́tulo 5. Optimización de aplicaciones ejecutado en el clúster. HPL Para instalar este programa hemos instalado previamente ATLAS y OpenMPI. HPL se puede descargar de la página oficial: http://www.netlib.org/benchmark/hpl/ Una vez descargado ejecutaremos: //Descomprimimos el paquete $ tar xf hpl-2.1.tar.gz $ cd hpl-2.1 //Copiamos un makefile predefinido $ cp Make.ubuntuARM setup/Make.PII_CBLAS Entonces editaremos diferentes regiones del fichero Make.ubuntuARM de la siguiente manera. A destacar la configuración de la última región donde hemos habilitado el uso de la versión optimizada de CBLAS del paquete ATLAS. #Platform identifier ARCH = ubuntuARM [...] #HPL Directory Structure / HPL library TOPdir = /media/ancient/benchmarks/hpl [...] #Message Passing library (MPI) MPdir = /usr/local/openmpi1.8.1 MPinc = MPlib = [...] #Linear Algebra library (BLAS or VSIPL) LAdir = /usr/local/atlas LAinc = LAlib = $(LAdir)/lib/libatlas.a $(LAdir)/lib/libcblas.a [...] #Compilers /linkers CC = $(OPENMPI)/bin/mpicc LINKER = $(OPENMPI)/bin/mpif77 Ahora, HPL ya está listo para compilar. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 55 $ make arch=ubuntuARM // El anterior comando crea la carpeta bin/ubuntuARM con el ejecutable $ cd bin/ubuntuARM/ Antes de ejecutar hará falta configurar HPL.dat de manera adecuada y crear el hostfile con las direcciones IP de los nodos donde queremos ejecutar el benchmark. Una vez tengamos eso estamos listos para lanzar la aplicación mediante los siguientes comandos. $ mpirun -np <#procesadores> -hostfile <hostfile> xhpl HPCC Por suerte para nosotros el benchmark HPCC requiere exactamente los mismos pasos a excepción de uno. Durante la configuración del fichero Make.ubuntuARM antes de compilar el benchmark habrá que editar el parámetro TOPdir. #HPL Directory Structure / HPL library TOPdir = ../../.. También encontramos que el fichero de configuración para ejecutar los benchmarks HPL.dat tiene otro nombre: hpccinf.txt. Microkernels Para la instalación y configuración de los microkernels hemos seguido estos pasos: $ ./setup.sh $ mkdir build $ cd build //Indicamos el path de la libreria ATLAS en los flags de compilacion $ CPPFLAGS=-I/usr/local/atlas/include LDFLAGS=-L/usr/local/atlas/lib ./configure --prefix=‘pwd‘/../ //Si lo hemos configurado correctamente al finalizar del script configure obtendremos un mensaje indicando que se hara uso de CBLAS. $ make $ make install Ahora ya podemos elegir entre ejecutar uno por uno los diferentes microkernels o lanzar una ejecución de todos ellos con los comandos: $ cd .. $ ./benchmark.py En caso de querer editar el número de iteraciones a ejecutar o el tamaño del problema deberemos editar el fichero benchmark.py. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 56 Capı́tulo 5. Optimización de aplicaciones 5.4. Optimizando el fichero de configuración de HPL y HPCC Como hemos mencionado, el benchmark HPL dispone de un fichero de configuración HPL.dat que permite definir más de 20 parámetros que hacen referencia a aspectos de la ejecución. Veamos cuales son: A cada parámetro le corresponde una lı́nea del fichero. Lı́neas 1-2: sin utilizar, permiten al usuario escribir comentarios Lı́nea 3: Permite especificar el nombre del fichero de salida Lı́nea 4: Permite especificar hacia donde redireccionar la salida. Lı́nea 5: Número de tamaños de problema a ejecutar. Lı́nea 6: Tamaños de problema, es decir, dimensiones de la matriz del sistema de ecuaciones. Lı́nea 7: Numero de tamaños de bloque a ejecutar. Lı́nea 8: Tamaños de bloque en los que se dividirá la matriz Lı́nea 9: Como se distribuyen los procesos MPI entre nodos. Lı́nea 10: Número de grids (PxQ) de procesos a ejecutar. Lı́nea 11: Valores de P Lı́nea 12: Valores de Q Lı́nea 13: Threshold Lı́neas 14-21: Tipo de subdivisión en paneles de la matriz. Lı́nea 22: Número de tipos de broadcast a ejecutar. Lı́nea 23: Permite elegir diferentes patrones de comunicación de mensajes MPI. Lı́nea 24: Profundidad lookahead. Lı́nea 25: Valor de la profundidad. Lı́nea 26: SWAP. Lı́nea 27: Umbral de SWAP. Lı́nea 28: Permite transponer o no la matriz L1. Lı́nea 29: Permite transponer o no la matriz U. Lı́nea 30: Equilibrado Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 57 Lı́nea 31: Alineamiento de memoria para doble precisión Con la información conocida sobre los parámetros y una serie de pruebas empı́ricas se ha optimizado el fichero de configuración para obtener los mejores resultados en la medida de lo posible. A continuación veremos la justificación de los valores que más impacto han tenido sobre el rendimiento de HPL. Tamaño de problema. La documentación de HPL recomienda utilizar alrededor de un 80 % de la memoria fı́sica disponible. En nuestras pruebas sobre un único nodo a partir de 12K elementos (51 % del total de memoria) la mejora es inapreciable. En multinodo el impacto del tamaño de problema es mucho mayor y si se recomiendo ocupar el máximo (en nuestro caso 32K elementos, casi 8 GB). Tamaño de bloque. Utilizar blocking aumenta el rendimiento debido a que se explota la localidad espacial y temporal de datos. En las pruebas hemos obtenido 64 ya que se ajusta al tamaño de la caché L1 (32KB). Factorización y recursividad de paneles Estos parámetros varı́an la manera en que HPL resuelve el sistema de ecuaciones. No se ha podido analizar en detalle por el coste y la complejidad del algoritmo. Lo que si se ha podido observar que combinaciones de valores ofrecı́an los mejores resultados. Estos son: R2R2, C2C2 y R2C2. Alineamiento, equilibrado y transposición. En alineamiento debemos especificar 8, ya que es el tamaño de bytes de una palabra en doble precisión, activaremos el equilibrado con valor 1 y habilitaremos la transposición de las matrices L1 y U dejando el valor a 0. La transposición de matrices permite explotar la temporalidad local de los accesos a memoria durante las operaciones entre matrices donde la segunda matriz se recorre por columnas. Nota: HPCC utiliza el mismo tipo de fichero de configuración con algunas opciones más que no hemos precisado describir. Únicamente tener en cuenta que el tamaño de problema de los diferentes test dentro de HPCC se calcula en base al valor especificado en la lı́nea 6. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 58 Facultat d’Informàtica de Barcelona Capı́tulo 5. Optimización de aplicaciones Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 59 Capı́tulo 6 Evaluación del clúster 6.1. Benchmarking single node Inicialmente, se han realizado una serie de pruebas para conocer la potencia de la unidad básica de nuestro clúster, el nodo. Para evaluar el SoC Exynos 5 Octa se han seleccionado el conjunto de microkernels descritos en el capı́tulo de análisis de aplicaciones y HPL. El conjuntos de pruebas que se llevará a cabo es el siguiente: Primero, se ejecutará la versión OpenMP de los microkernels con 1, 2 y 4 threads en simple y doble precisión con el propósito de evaluar la eficiencia paralela del SoC en variedad de situaciones. Segundo, se ejecutará el benchmark HPL con 1, 2 y 4 procesos MPI. Compararemos la eficiencia computacional conseguida en HPL con la de los 9 primeros supercomputadores más MareNostrum del Top500. La eficiencia computacional se obtiene de la relación entre GFLOPS obtenidos en HPL y pico teórico de GFLOPS del SoC. Finalmente, de las mediciones de consumo eléctrico con un medidor de potencia, se hace una comparación en este caso con los primeros 9 primeros supercomputadores más MareNostrum del ránking Green500. Los benchmarks con peores resultados en escalabilidad indicarán los puntos débiles (cuellos de botella) de nuestro SoC. Además podremos estudiar el comportamiento frente a diferentes patrones de acceso a memoria. 6.1.1. Metodologı́a Los microkernels se ejecutan con el script Python subministrado con el paquete: Benchmark.py. En él se pueden especificar parámetros para configurar la ejecución Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 60 Capı́tulo 6. Evaluación del clúster de los diferentes test: volumen de datos, número de iteraciones, versiones, tipos de datos (single, double), etc. Para conseguir muestras fiables se han especificado un números de iteraciones suficiente para conseguir tiempos de ejecución serie superiores a los 40 segundos en cada benchmark. Los resultados obtenidos se vuelcan en ficheros de texto; un fichero por cada versión y microkernel. dataType,numIterations,numThreads,n,totalTime,avgTime,stdDev,gflops,validated float,25,1,8192,195.82830200,7.83313208,0.00576846,0.17134618,n/a Figura 6.1: Ejemplo de fichero de resultados del microkernel N-Body OpenMP En la figura 6.1.1 vemos un ejemplo de fichero CSV de resultados. En los resultados se especifica los parámetros usados durante la ejecución, medidas de tiempo medias y totales con su desviación estándar y la una medida de rendimiento (GFLOPS) en base al tiempo de ejecución medio. Los resultados de la ejecución de HPL se han obtenido con el set de parámetros optimizado descrito en el capı́tulo anterior, y aparte del uso de ATLAS no se han hecho más optimizaciones. El comando utilizado ha sido: $ > sudompirun − np < 1, 2, 4 > −hostf ile < HF SingleN ode > ./xhpl donde < 1, 2, 4 > corresponde al número de procesos MPI para cada una de las 3 muestras y < HF SingleN ode > es un fichero de Hosts MPI con una única lı́nea con la dirección de la tarjeta de loopback. La metodologı́a para la medición de consumo eléctrico y resultados está detallada en la sección del trabajo de hardware ??. 6.1.2. Resultados Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 61 Figura 6.2: Speed Up con precisión de 32-bits. Figura 6.3: Speed Up con precisión de 64-bits. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 62 Capı́tulo 6. Evaluación del clúster Figura 6.4: Comparativa de la eficiencia paralela de simple y doble precisión con 4 threads . Los resultados de escalabilidad vistos en las figuras 6.2 y 6.3 son bastante buenos. En precisión simple, la eficiencia paralela con 4 threads ronda el 90 %+ excepto en VecOP. Montecarlo demuestra que en caso de no compartir datos entre threads se alcanza una eficiencia del 99 %. Sobre el detrimento de eficiencia de doble precisión frente a simple observado en la figura 6.4, se debe a que cada procesador tiene más tiempo ocupado el bus de memoria para traerse datos de 64 bits, y siendo la memoria un recurso compartido entre procesadores, implica que el resto de threads deben esperar hasta que el bus esté disponible. Los benchmarks que hacen un uso importante del ancho de banda a memoria como VecOP y 3D stencil son los más afectados. Como nota, sorprende la mejora de N-body en doble respecto a simple precisión, harı́a falta estudiar en detalle que operaciones se realizan para obtener esos resultados. HPL En la figura 6.5 vemos la eficiencia computacional obtenida con 1, 2 y 4 procesos MPI en un mismo SoC. A partir del rendimiento pico de un núcleo Cortex-A15 @ 800MHz (1.6 GFLOPS) calculamos el rendimiento pico del SoC, en total 6.4 GFLOPS. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 63 Figura 6.5: Rendimiento y efficiencia paralela con HPL (single node). Con el resultado de ejecutar HPL con 4 procesos MPI en un mismo nodo 4,27 GF LOP S (precisión doble) calculamos la eficiencia computacional. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 64 Capı́tulo 6. Evaluación del clúster Ef f.comp. = 4,27 = 0,667187 6,4 (6.1) Tomamos un 67 % de eficiencia. Veamos como de bueno es este resultado respecto a máquinas del TOP 500. En la figura 6.6 se aprecia como la eficiencia conseguida (linea horizontal) hasta el momento entra en unos márgenes aceptables. A nuestro favor decir que los cálculos en HPL son de doble precisión, la operación en coma flotante tarda lo mismo pero los accesos a memoria requieren más tiempo. En nuestra contra, los valores obtenidos no se ven afectados por el overhead introducido por la red de interconexión para realizar el paso de mensajes. En la siguiente sección ’Evaluación multinodo’ se verá el impacto que tiene el uso de la red. Figura 6.6: Eficiencia respecto al PP de las primeras posiciones del top500. Como nota, destacar que Supercomputadores como el Tiahne, Titan y Stampede muestran peor eficiencia siendo 3 de los 4 supercomputadores, entre las 10 primeras posiciones, que hacen uso de aceleradores (Xeon Phi y NVidia K20). Sabiendo que hay una máquina con aceleradores que ofrece un 80 % de eficiencia como es el Piz Daint, se entiende que se pueden desarrollar implementaciones de HPL que saquen un mejor partido a estos componentes. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 65 Al final de la evaluación de rendimiento paralelo y de cálculo quedan varios puntos claros. Primero, pese a disponer de unidad de coma flotante capaz de hacer operaciones de 64-bits, en las versiones de doble precisión existe una pérdida de rendimiento relativa a la versión de simple precisión que va de un 3 a un 30 %. Segundo, la escalabilidad del SoC a nivel de nodo es buena, en muchos de los benchmarks se observa un >90 %. Por último, los valores obtenidos en DGEMM Single Precisión, demuestran que el SoC Exynos 5 es capaz de ofrecer un rendimiento bueno del 80 % respecto a su máximo teórico en aplicaciones reales. Eficiencia energética Hemos hecho mediciones de consumo energético con los nuestros dos test mejor optimizados, HPL y DGEMM precisión simple. Durante la ejecución de HPL con 4 threads hemos obtenido un consumo medio de 7.73W, mientras que en DGEMM-SP observamos 6.59W. Dividiendo el rendimiento obtenido en los anteriores apartados con el consumo nos da como resultado una eficiencia energética de 552.2 MFLOPS/W en HPL, y 792.5 en DGEMM-SP. En la figura 6.7 hemos indicado la supuesta posición que ocuparı́amos en la tabla Green500, la linea horizontal marca nuestro récord (DGEMM-SP) conseguido en los test. Teniendo en cuenta el estado del arte actual, y a simple vista, los resultados resultan un tanto flojos. Sin embargo hay muchos factores jugando en contra como la baja frecuencia de la CPU y el consumo de componentes como la tarjeta gráfica y de red que podrı́an estar apagados. Con esto damos por finalizado el estudio Single node, de nuestra máquina. Los datos obtenidos en esta sección nos permiten establecer el valor de rendimiento base a partir del cual estudiaremos la escalabilidad multinodo de la siguiente sección. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 66 Capı́tulo 6. Evaluación del clúster Figura 6.7: Eficiencia energética comparada con las primeras posiciones de Green500. 6.2. Benchmarking multi nodo En esta sección se muestran los resultados obtenidos al evaluar el clúster al completo, es decir, hasta 24 procesadores en paralelo. El propósito de estos test es obtener, ahora sı́, una medida realista del rendimiento que ofrece la configuración que hemos montado. En cualquier clúster HPC la red de comunicación entre nodos para acceder a la memoria distribuida es el nivel que ofrece mayor latencia con diferencia, si a eso sumamos las bajas prestaciones que ofrece el puerto de comunicaciones Ethernet presente en las placas Arndale Octa, cabe anticipar una caı́da de rendimiento considerable respecto a los resultados del apartado anterior. Para comparar con los resultados anteriores se ejecutará HPL con hasta 24 procesadores. Esto nos permitirá evaluar dos cosas: la pérdida de eficiencia paralela al introducir la red de interconexión y una idea del máximo rendimiento que podemos conseguir con el clúster funcionando al máximo de sus capacidades. Seguidamente, volveremos a evaluar la relación GFLOPS/W con la nueva medida de rendimiento obtenida con HPL y el consumo total del cluster. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 67 Por último mostraremos los resultados que obtenemos con HPCC. 6.2.1. Metodologı́a Empezando con HPL, introducimos varios cambios en los parámetros de ejecución. Primero aumentamos el tamaño de problema a 20K elementos. Esto hace un tamaño de problema de: P roblemSize = 200002 × 8 = 3051,87M Bytes 220 (6.2) Es necesario este incremento en el tamaño de problema para intentar disminuir en la medida de lo posible el impacto de paso de mensajes. Con un mayor tamaño de problema, cada procesador deberá realizar más cálculos antes propagar los resultados en la memoria compartida. El máximo tamaño de problema que soporta nuestro clúster ronda los 32K elementos, pero por problemas de inestabilidad y sobrecalentamiento de las placas solo disponemos datos para hacer las gráficas de hasta 20K. Ha sido necesario ajustar el tamaño del problema a medida que se aumentaba el tamaño de problema para tratar de que sea proporcional. El tipo de broadcast de mensajes, que hasta el momento no importaba, será de tipo mixed ring. El grid de procesos que mejor resultados ofrece en las pruebas se obtiene fijando P = 2 e incrementando Q = 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12. El fichero hostfile utilizado en este caso contiene las direcciones IP de cada una de las placas en la red. Y se utiliza el mismo comando que en el apartado anterior, pero ahora con el parámetro −np 24 para indicar al runtime de MPI que cree tantos procesos como procesadores Cortex A-15. Se muestra a continuación el contenido del hostfile usado para la evaluación multinodo. [email protected] slots=4 [email protected] slots=4 [email protected] slots=4 [email protected] slots=4 [email protected] slots=4 [email protected] slots=4 Para HPCC hemos utilizado un fichero de configuración con parámetros similares, y para ejecutar, el mismo fichero hostfile y un comando equivalente mpirun también con 24 procesos MPI. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 68 Capı́tulo 6. Evaluación del clúster 6.2.2. Resultados HPL Figura 6.8: Gráfica de speed up del cluster ejecutando HPL de 1 a 24 procesadores. En la gráfica 6.8 se aprecia como HPL escala con un factor mucho menor que 1, siendo 1 el factor de escala lineal ideal. La deceleración de crecimiento que se observa en el paso de Single Node (1-4 procesadores) a Multinode (4-24 procesadores) muestra el impacto negativo de la red de interconexión en el rendimiento de la máquina. Por tanto, si continuáramos añadiendo nodos en nuestro clúster, esperamos seguir perdiendo eficiencia paralela como se puede ver en la figura 6.9. En esta última figura podemos ver que con 10 procesadores (3 nodos) se irrumpe por debajo del 50 % de eficiencia, a partir de este punto ya se pueden considerar ’malos’ los resultados. Como ya hemos dicho, debido a lo inestable del sistema y el tiempo disponible para hacer las pruebas, no se ha podido obtener una muestra de datos muy grande, pero en este caso, las suficiente para poder sacar conclusiones (que es al fin y al cabo lo que buscamos) ya que las variaciones son muy acentuadas. En cuanto al valor máximo de rendimiento se ha obtenido con un test de 32K elementos que duró alrededor de 20 minutos, este test se ha repetido 3 veces. El resultado medio fue de 14.38 GFLOPS una eficiencia computacional del 37 % resFacultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 69 Figura 6.9: Eficiencia paralela del clúster ejecutando HPL de 1 a 24 procesadores. pecto al PP teórico de 38.4 GFLOPS. Ası́ mismo también se tomaron mediciones de consumo durante las pruebas donde obtuvimos una media 62.58W, ofreciendo una eficiencia energética de 229.78 MFLOPS/W. En el Green500 caerı́amos a la posición 317. HPCC Resumen de los resultados obtenidos en el benchmark HPCC con parámetro N = 20000 y 24 procesadores. Hemos tomado los resultados del supercomputador Jaguar y hemos podido observar valores de rendimiento reales más allá de la potencia de coma flotante. Su red de interconexión tiene 15.98 µs de latencia, casi 20 veces menos que la nuestra y su ancho de banda es de 1.52 GB/s en el peor caso, al menos 140 veces mejor. Lo único que no parece estar como mı́nimo un orden de magnitud por detrás es el ancho de banda de la memoria donde Jaguar puntúa 3.31 GB/s en su versión EP, en este test nuestro SoC ofrece 1.48 GB/s [20]. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 70 Capı́tulo 6. Evaluación del clúster Benchmark MPIRandomAccess StarRandomAccess PTRANS WALL PTRANS CPU StarDGEMM StarSTREAM (Scale) SingleSTREAM (Scale) MPIFFT StarFFT Net Latency ping-pong Net Bandwidth ping-pong Resultado 0.0004309 GUP/s 0.006904 GUP/s 15.59 s. @ 0.051 GB/s 2.34 s. @ 0.343 GB/s 1.23 GFLOP/s 1.48 GB/s 2.85 GB/s 0.11 GFLOP/s 0.22 GFLOP/s 315.68 µs 11.657 MB/s Cuadro 6.1: Resumen de resultados de HPCC. No es posible comparar directamente otros test como MPIRandomAcces o MPIFFT ya que los resultados varian en base al número de nodos. Si podemos comparar StarRandomAccess donde Jaguar ofrece un poco menos del doble de ancho de banda. StarFFT en este caso ha sido fuertemente optimizado y el rendimiento es hasta 50 veces mejor que el nuestro. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 71 Capı́tulo 7 Sostenibilidad 7.1. Sostenibilidad Los aspectos sobre la sostenibilidad del proyecto se tratarán en tres categorı́as distintas: viabilidad económica, impacto social e impacto ambiental. 7.1.1. Viabilidad económica La viabilidad económica de un supercomputador que obtenga un buen rendimiento con un consumo muy reducido está prácticamente asegurada. La necesidad que existe actualmente de procesar grandes cantidades de datos hace imprescindible disponer de máquinas de este tipo, sin embargo, su alto consumo, añadido a la gran inversión inicial necesaria, hace que el mantenimiento de dichas infraestructuras resulte un esfuerzo muy costoso. Un clúster con buen rendimiento, no solo tiene salida en el sector de HPC, actualmente algunos de los supercomputadores más potentes del mundo se usan para dar otro tipo de servicios, como granjas de máquinas virtuales, o servidores web muy potentes, la ventaja que supone reducir el consumo en este tipo de máquinas puede interesar a estos sectores también. 7.1.2. Impacto Social A pesar de que la sociedad no percibe de manera directa los beneficios derivados del uso de la supercomputación. Si que de manera indirecta tiene un impacto muy importante en el dı́a a dı́a de cualquier sociedad moderna. En general, los usos de los computadores actuales para HPC tienen un impacto positivo, indirecto en la sociedad. Son las máquinas que ayudan a liderar proyectos de investigación importantes, como en medicina, mediante simulaciones sobre enfermedades o de fármacos. La gran capacidad de cálculo de estos dispositivos permite Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 72 Capı́tulo 7. Sostenibilidad acortar tiempos de investigación y ahorrar recursos mediante aproximaciones de los modelos reales. También pueden ayudar en otros campos de investigación, como fı́sica o la quı́mica, por ejemplo: la simulación de fluidos. Todos estos resultados ayudan a la sociedad a hacer progresos. A parte de investigación y desarrollo, los supercomputadores tienen mucha utilidad en proveer cálculos para ciertos servicios que necesita una sociedad, como por ejemplo la aproximación del clima, que es fundamental para sectores como el transporte. Otro campo al cual proveer potencia de cálculo mediante un supercomputador, es en la prospección de recursos naturales, como por ejemplo el petróleo, donde el uso de algoritmos para detectar dónde se encuentran los recursos naturales puede ser vital para ahorrar los cuantiosos costes que requieren hacer exploraciones de este tipo. [17] 7.1.3. Impacto Ambiental Al ser un clúster basado en procesadores de bajo consumo con uno de los objetivos principales fijado en la eficiencia energética, no solo tiene un impacto ambiental relativamente bajo, sino que pretende mejorar el paradigma de la sostenibilidad en HPC, debido a la regla impuesta de consumir menos de 3.000 W . Por ejemplo, si basada en esta tecnologı́a se desarrollara un clúster con buen rendimiento por W consumido, un grupo de investigación con necesidad de un clúster HPC podrı́a montar una réplica de éste con el ahorro energético que supondrı́a. Además, en Cataluña el consumo de energı́a primaria en cuanto a renovables es muy bajo, un 4,1 %. Esto implica que más del 90 % de la energı́a primaria que se consume en Cataluña sale de energı́a no renovable como el carbón, petróleo... Esto es un punto más a favor para tener en cuenta el consumo de un clúster de supercomputación como este.[3] Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 73 Capı́tulo 8 Conclusiones individuales 8.1. Evaluación global Tras finalizar el trabajo, señalar los puntos más importantes que hemos aprendido a nivel de aplicaciones. El SoC Exynos 5420, efectivamente, es capaz de ejecutar las aplicaciones del estado del arte HPC actual y funcionar como un clúster. Todas las aplicaciones del estado del arte trabajan en doble precisión. Los test con microkernels demuestran que con un procesador de 32-bit partimos en desventaja. Los ficheros de configuración de HPL y HPCC, son útiles para optimizar en la medida de lo posible las ejecuciones, pero si se quiere solventar los fuertes problemas de escalabilidad que aparecen en los resultados debemos pasar al siguiente nivel, usar herramientas de análisis. La red de interconexión tiene un impacto negativo enorme en el rendimiento y la escalabilidad de las aplicaciones. El rendimiento de las aplicaciones es muy sensible a las tareas que hay ejecutándose en background del sistema operativo. Nuestro clúster y las aplicaciones out-of-the-box no obtiene un rendimiento como para ser competitivo en una competición como el SCC, pero hay mucho margen para optimizar. En muchos casos, no podemos evitar los accesos a memoria entre nodos, pero si podemos minimizarlos: optimizar el código de la aplicación para hacer blocking, ajustar el tamaño de problema al máximo de la memoria fı́sica, etc. Es importante disponer de un buen surtido de librerı́as con funciones optimizadas para HPC. Las mejoras de rendimiento que ofrecen son muy grandes y son relativamente poco costosas de incluir en el sistema. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 74 Capı́tulo 8. Conclusiones individuales Es importante estudiar los resultados de los benchmarks cuidadosamente, sin lanzarse a conclusiones precipitadas. Un mal resultado puede tener su causa en muchos factores. Los benchmarks son una manera simple de detectar cuellos de botella. Son herramientas clave para la mejora del trabajo de todo el equipo. 8.2. Trabajo futuro De cara al trabajo futuro, lo primero serı́a abordar el uso de herramientas de análisis que en este trabajo solo han podido mostrarse de manera teórica por problemas técnicos. Instalar correctamente y ganar experiencia con ellas, asunto de gran importancia de cara a optimizar aplicaciones mediante análisis. En los futuros análisis, se deberı́a dar prioridad a estudiar el rendimiento de la red para ası́ poder ofrecer feedback al resto del equipo y ası́ poder tomar mejores decisiones. Por otro lado serı́a interesante instalar y configurar individualmente los benchmarks dentro de HPCC para poder lanzar únicamente los test que nos interesan con parámetros independientes. Esto permitirı́a al grupo trabajar mejor y más rápido. En el momento en el que esté disponible el soporte para OpenCL, se deberı́an obtener o desarrollar versiones de las aplicaciones para la tarjeta gráfica. Esto se extiende a otros recursos hardware de la máquina que puedan estar en desuso como las unidades vectoriales. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 75 Capı́tulo 9 Conclusiones de equipo 9.1. Conclusiones de cara a la competición En el estado actual de nuestro proyecto resulta inviable participar en la competición por varios motivos. No reboot - Always Up. La normativa de la competición establece que las máquinas no se pueden reiniciar ni apagar durante toda la competición (excepto por motivos de seguridad). Nuestro sistema es todavı́a inestable, hasta el punto que resulta improbable sobrevivir cinco dı́as sin reiniciar o que alguno de los nodos falle, de hecho serı́a improbable aguantar uno. Además se prevé tener que instalar nuevo software e incluso alguna librerı́a dado que hay un set de aplicaciones a ejecutar que se darán a conocer durante la competición. Sin duda, este serı́a un objetivo prioritario y una manera de abordar este problema serı́a abandonar el uso de tarjetas SD hacı́a un sistema de inicio y ficheros en red mediante NFS. Rendimiento. El rendimiento no es bueno, al menos no suficiente. En ediciones pasadas de la competición se alcanzaron los 8.5 TFLOPS en HPL que, en el peor caso, suponen 2.8 GFLOPS/W, 12 veces más que nuestros 0.229 GFLOPS/W actuales. No serı́a realista esperar asistir por primera vez con una máquina preparada para competir por los primeros puestos, pero si que podamos competir por no quedar últimos. Consideramos que una primera meta serı́a desarrollar un prototipo con unas previsiones de rendimiento mı́nimas de 6 TFLOPS en HPL para plantear el seriamente el asistir. Preparación, tanto de los componentes del equipo como del clúster. Aún teniendo la formación adecuada, tomar decisiones de diseño, montar una máquina y prepararla a nivel de software de sistema y aplicaciones requiere mucho tiempo. Contar que además el equipo deberı́a ser de seis personas, por un lado agiliza el desarrollo pero por otro lado requiere mayor nivel de coordinación. Además entendemos que, para formar un equipo estable, se requerirı́a una persona vinculada a la FIB con conocimiento de primera mano del estado del arte HPC. Asumirı́a el rol de director Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 76 Capı́tulo 9. Conclusiones de equipo equipo y además de coordinar deberı́a garantizar la continuidad de la representación de la facultad en sucesivas ediciones. Recursos. Este proyecto ha podido llevarse a cabo únicamente con recursos cedidos por el departamento de AC y por el BSC. Creemos que el desarrollo de un prototipo competitivo a pequeña escala podrı́a hacerse con un coste no mucho mayor, pero en el caso de asistir a la competición, harı́a falta un desembolso de dinero considerable. Es en este punto en el que entran en juego los sponsors. Todos los equipos que asisten a la competición están esponsorizados por grandes fabricantes de hardware que aprovechan la competición a modo de escaparate. Nuestro plan serı́a conseguir uno o varios sponsors que financiaran como mı́nimo, el coste total de los componentes del clúster y el desplazamiento y alojamiento durante el evento. 9.2. Trabajo futuro Este trabajo, pese a demostrar no estar preparados para la competición, ha servido para sentar las bases a partir de las cuales poder seguir trabajando y mejorar los puntos débiles de nuestro prototipo. De cara al futuro, la primera acción a realizar serı́a valorar todas las opciones y decidir si continuamos desarrollando un clúster basado en tecnologı́a móvil, si se decide abandonar en favor de tecnologı́a HPC más habitual (p.ej: Intel Xeon y aceleradores Nvidia) o valorar otras opciones menos estudiadas y no mencionadas como por ejemplo: procesadores móviles con aceleradores externos Nvidia. Personalmente creemos que en el ámbito de procesadores móviles queda mucho trabajo por hacer y que lo mejor está por venir. En esta lı́nea, por tanto, tenemos mucho trabajo futuro sobre la mesa. A corto plazo empezarı́amos por abordar el problema de la red de interconexión de nodos, y a la vez, tratarı́amos de hacer un mejor uso del hardware disponible: aceleradores, ocho núcleos y máxima frecuencia de procesador entre otros. A medio plazo se buscarı́a obtener nuevas placas de desarrollo con arquitectura ARMv8 de 64-bits y profundizar en el análisis y optimización profunda de las aplicaciones. Facultat d’Informàtica de Barcelona Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 77 Agradecimientos En este espacio quiero aprovechar para dar las gracias a aquellas personas que han colaborado de una manera u otra con este proyecto. A Álex Ramı́rez, por darnos la oportunidad y las ideas para desarrollar el proyecto. A Nikola Rajovic, por el trato cordial y proporcionar información y material para usar el medidor de potencia Yokogawa y los benchmarks de Montblanc. A Agustı́n Fernández que como director de este trabajo ha ofrecido soporte y seguimiento durante todo el trabajo. Al departamento de Arquitectura de Computadores y el BSC por la cesión de todo el material y recursos necesarios para realizar el montaje del clúster. A Dani y Uri por compartir conocimiento y experiencia que ha resultado de gran utilidad. A Enric Agüera por su curso acelerado de LateX. A mis padres y mi hermano por su apoyo incondicional. Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 78 Facultat d’Informàtica de Barcelona Capı́tulo 9. Conclusiones de equipo Constantino Gómez Crespo Diseño y evaluación de un clúster HPC: aplicaciones 79 Bibliografı́a [1] J. Dongarra A. Cleary A. Petitet, R. C. Whaley. Hpl - a portable implementation of the high-performance linpack benchmark for distributed-memory computers, 2008. [Online; accedido 30-Abril-2014]. 42 [2] HPC Advisory Council. Hpc advisory council - isc’14 student cluster competition - home, 2014. [Online; accedido 10-Abril-2014]. 20 [3] Generalitat de Catalunya. Balanç energètic de catalunya - institut català d’energia, 2009. [Online; accedido 2-Junio-2014]. 72 [4] J. J. Dongarra and P. Luszczek. Hpc challenge: Design, history, and implementation highlights. 45, 46, 47 [5] J. J. Dongarra and P. Luszczek. Introduction to the hpcchallenge benchmark suite. December 2004. 43, 47 [6] D. Jiménez E. Ayguadé. Parallelism, analysis of parallel applications. 2012. 51 [7] hpcc.org. The hpcchallenge award competition, 2014. [Online; accedido 5-Mayo2014]. 43 [8] hpcc.org. Randomaccess rules, 2014. [Online; accedido 5-Mayo-2014]. 46 [9] P. Luszczek J. J. Dongarra and A. Petitet. The linpack benchmark: Past, present, and future. August 2003. 42 [10] mabraham. About gromacs – gromacs, 2013. [Online; accedido 17-Mayo-2014]. 48 [11] A. Rico et al. N. Rajovic. Experiences with mobile processors for energy efficient hpc. March 2013. 48 [12] P. Carpenter et al. N. Rajovic. Supercomputing with commodity cpus: Are mobile socs ready for hpc. November 2013. 48 [13] University of Tenesse. High performance linpack benchmark poster at sc2010, 2010. [Online; accedido 30-Abril-2014]. 41 [14] openfoam.org. Features of openfoam, 2014. [Online; accedido 20-Mayo-2014]. 50 Constantino Gómez Crespo Facultat d’Informàtica de Barcelona 80 Bibliografı́a [15] quantum espresso.org. Manifesto – quantumespresso, 2014. [Online; accedido 20-Mayo-2014]. 50 [16] Nikola Rajovic, Alejandro Rico, Nikola Puzovic, Chris Adeniyi-Jones, and Alex Ramirez. Tibidabo: Making the case for an arm-based {HPC} system. Future Generation Computer Systems, 2013. DOI: http://dx.doi.org/10.1016/j.future.2013.07.013. 48 [17] SINC. La supercomputación ayuda a repsol a descubrir nuevos yacimientos, 2013. [Online; accedido 2-Junio-2014]. 72 [18] V. Springel. Cosmological simulations with gadget, 2005. [Online; accedido 20-Mayo-2014]. 50 [19] Stanford University. The software — folding@home, 2014. [Online; accedido 10-Junio-2014]. 48 [20] university of tennesse. Hpcc record: Cray xt5 196608 amd opteron 2.6 ghz, 2009. [Online; accedido 15-Junio-2014]. 69 [21] Wikipedia. Folding@home — Wikipedia, the free encyclopedia, 2014. [Online; accedido 10-Junio-2014]. 48 [22] Wikipedia. Linpack — Wikipedia, the free encyclopedia, 2014. [Online; accedido 10-Junio-2014]. 41 [23] Wikipedia. Linpack benchmarks — Wikipedia, the free encyclopedia, 2014. [Online; accedido 30-Abril-2014]. 41 Facultat d’Informàtica de Barcelona Constantino Gómez Crespo