Document
Anuncio

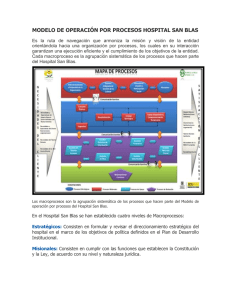
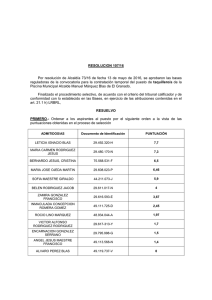
Basic Linear Algebra Subprograms (BLAS) Avances en la Generación de Bibliotecas de Álgebra Lineal Universidad Politécnica de Valencia Marzo, 2006 Índice ¿Qué es la biblioteca BLAS? Organización de BLAS Funcionalidad de BLAS Prestaciones de BLAS BLAS-2 BLAS-3 Optimización del producto de matrices Fuentes de información BLAS ¿Qué es la Biblioteca BLAS? En la base de los problemas de Álgebra lineal pueden identificarse un conjunto de operaciones numéricas básicas como, por ejemplo: Cálculo de la norma de un vector, Resolución de un sistema triangular de ecuaciones, Producto de matrices, etc. BLAS (Basic Linear Algebra Subprograms) es un conjunto de núcleos (rutinas) computacionales escritos en Fortran 77 para operaciones básicas del Álgebra lineal BLAS ¿Qué es la Biblioteca BLAS? Las especificaciones (interfaces y funcionalidad) de los núcleos de BLAS se han convertido en estándares de facto. Ejemplo: Cálculo de la norma de un vector FUNCTION xNRM2( N, X, INCX ) Implementación de referencia http://www.netlib.org/blas BLAS ¿Qué es la Biblioteca BLAS? Si la mayor parte de los cálculos se realizan en forma de las operaciones del BLAS, su optimización redunda en una reducción del tiempo de la resolución de las aplicaciones Existen implementaciones de BLAS optimizadas por los propios fabricantes: ACML de AMD, Velocity Engine de Apple, libsci de Cray, MLIB de HP, ESSL de IBM, MKL de Intel, PDLIB/SX de NEC, SCSL de SGI, Sun Performance Library de SUN, etc. BLAS ¿Qué es la biblioteca BLAS? ...aunque también existen otras implementaciones eficientes Implementación portable: ATLAS GotoBLAS para Intel Pentium/IA-64, Alpha EV, SPARC, IBM PowerPC, AMD Opteron, etc. Además, algunas implementaciones proporcionan paralelismo a nivel de threads para arquitecturas con memoria compartida (espacio de direccionamiento único): MKL de Intel GotoBLAS para Intel ATLAS, etc. BLAS ¿Qué es la biblioteca BLAS? BLAS constituye la interfaz entre las bibliotecas y aplicaciones numéricas de alto nivel y la arquitectura subyacente Aplicaciones Optimizaciones independientes de la arquitectura LAPACK BLAS Proc. BLAS Optimizaciones dependientes de la arquitectura ¿Qué es la biblioteca BLAS? BLAS define la especificación de las rutinas: Interfaz FUNCTION xNRM2( N, X, INCX ) Funcionalidad Cálculo de la norma de un vector Revisaremos la funcionalidad ofrecida por BLAS. Las interfaces de las rutinas se verán en la parte práctica BLAS Organización de BLAS BLAS-1 Operaciones básicas sobre escalares y vectores Caracterización: O(n) cálculos sobre O(n) datos Ejemplo: Cálculo de la norma de un vector BLAS-2 Operaciones básicas de tipo matriz-vector Caracterización: O(n2) cálculos sobre O(n2) datos Ejemplo: Resolución de un sistema triangular de ecuaciones BLAS-3 Operaciones básicas de tipo matriz-matriz Caracterización: O(n3) cálculos sobre O(n2) datos Ejemplo: Producto de matrices BLAS Funcionalidad de BLAS BLAS-1. Operandos: a ∈ℝ , x , y ∈ℝ Operaciones de reducción Producto escalar a ⇐ xT y Suma a ⇐ a ⇐ ∥x∥2 Máximo a ⇐ max∣x i∣ Rotaciones de Givens Operaciones vectoriales x ⇐ ax Escalado de un vector Aplicación de una rotación de Givens AXPY y ⇐ a x y Movimientos de datos BLAS ∑ ∣x i∣ Norma vectorial Generación de transformaciones n Copia x ⇐ y Intercambio x ⇔ y Funcionalidad de BLAS BLAS-2. Operandos: a ∈ℝ , x ∈ℝ n , y∈ℝ m , f A∈ℝ mxn , T ∈ℝnxn triangular , f M =M o M T Producto matriz-vector y ⇐ ya f A x Actualizaciones de rango 1(y 2) A ⇐ Aayx T Resolución de sistemas triangulares lineales x ⇐ f T −1 x BLAS Funcionalidad de BLAS BLAS-3. Operandos: a , b ∈ℝ , f A∈ℝ mxk , f B∈ℝ kxn ,C ∈ℝ mxn T ∈ℝ mxm triangular , f M = M o M T Producto de matrices C ⇐ aC b f A f ' B Actualizaciones de rango k C ⇐ C af A f AT , C=C T , m=n Resolución de sistemas triangulares lineales múltiples B ⇐ f T −1 B , m=k B ⇐ B f T −1 , m=n BLAS Funcionalidad de BLAS Tipos de datos Simple precisión (IEEE 754 – 32 bits) Doble precisión (IEEE 754 – 64 bits) Reales Complejos BLAS Funcionalidad de BLAS Tipos de matrices General Simétrica/ Hermitiana Triangular Densa Formatos empaquetados disponibles Banda Sólo una mitad almacenada BLAS Prestaciones Plataforma: Procesador: Memoria: Biblioteca BLAS: Compilador: S.O.: Intel Xeon 2.4 GHz 512 KB de caché L2 y 1 GB de RAM GotoBLAS 0.96st gcc 3.3.5; optimización -O3 Linux 2.4.27 Parámetro de rendimiento: MFLOPs Velocidad pico teórica: 4800 MFLOPs BLAS Prestaciones: BLAS-2 ¿Qué pasa desde n=220? BLAS Prestaciones: BLAS-2 ¿Qué pasa desde n=220? Una matriz nxn de números en doble precisión, con n=220 ocupa 220x220x8 = 387.200 Bytes... ... y la memoria caché de segundo nivel del procesador es de tamaño 512 Kbytes BLAS Prestaciones: BLAS-3 BLAS Prestaciones: BLAS-3 ¿Por qué 480 Mflops para dgemv y 4000 Mflops para dgemm? La justificación viene de los ratios entre cálculo (flops) y movimientos de datos (memops) dgemv: 2 n2 flops =2 2 memops n ¡Necesitamos una memoria capaz de suministrar datos al procesador a la mitad de velocidad que éste realiza los cálculos! dgemm: 2 n 3 flops n = 2 6 n memops 3 ¡A medida que crece el tamaño del problema, la velocidad de la memoria se vuelve menos importante! BLAS Optimización del Producto de Matrices Consideraremos el producto general C = C + A B con todas las matrices cuadradas de la misma dimensión BLAS Optimización del Producto de Matrices La operación puede implementarse de 3 formas diferentes GEPP BLAS C = C + A B C = C + A B C = C + A B GEMP GEPM Optimización del Producto de Matrices Consideremos la implementación de GEPP B C = C + A Ésta, a su vez, puede implementarse de dos modos diferentes GEPB B C = C + A GEBP B C BLAS = C + A Optimización del Producto de Matrices Por último, consideremos GEBP C = C + A B y supongamos que: C es mc x n, A es mc x kc y B es kc x n Las dimensiones permiten que A y sendas columnas de B y C residan en la caché Disponemos de una implementación capaz de calcular dgemv a la máxima velocidad del procesador si la matriz y los vectores residen en la caché Si A está en la caché, entonces permanece allí hasta que ya no sea necesaria BLAS Optimización del Producto de Matrices Entonces, podemos implementar GEBP como una secuencia de dgemv C = C + A B con los siguientes costes: Cargar A (mc x kc) en la caché: mc kc memops Cargar los pares de columnas de C y B en la caché: (mc+kc)n memops Almacenar las columnas modificadas de C en la memoria: mc n memops Calcular los productos matriz-vector: 2mc kc n flops BLAS Optimización del Producto de Matrices Sea c ≈ mc ≈ kc; entonces el ratio entre cálculo y movimientos de datos es de: 2c 2 n 2 c 3cn Así, si c ≈ n/100, incluso si las¿ operaciones con memoria son 10 veces ¿ más lentas que los cálculos, estas operaciones únicamente añaden un 10% de sobrecoste al total BLAS Fuentes de Información: www, google,... Sitio en netlib: http://www.netlib.org/blas Basic Linear Algebra Subprograms Technical (BLAST) Forum Standard, 2001: http://www.netlib.org/blas/blast-forum BLAS quick reference: http://www.netlib.org/blas/blasqr.pdf BLAS FAQs: http://www.netlib.org/blas/faq.html BLAS de referencia: http://www.netlib.org/blas/blas.tgz BLAS Fuentes de Información: www, google,... Definición de núcleos del Álgebra lineal del BLAS-1 (http://www.acm.org/toms) R.J. Hanson, F.T. Krogh, C.L. Lawson. “A proposal for standard linear algebra subprograms”. ACM Signum Newsletter, 8:16, 1973. C.L. Lawson, R.J. Hanson, D. Kincaid, F.T. Krogh. “Basic Linear Algebra Subprograms for FORTRAN usage”. ACM TOMS, 5:308323, 1979 BLAS Fuentes de Información: www, google,... Definición de núcleos del Álgebra lineal del BLAS-2 y BLAS-3 (http://www.acm.org/toms) J.J. Dongarra, J. Du Croz, S. Hammarling, R.J. Hanson. “An extended set of FORTRAN basic linear algebra subprograms”. ACM TOMS, 14:1-32, 1988 J.J. Dongarra, J. Du Croz, I.S. Duff, S. Hammarling. “A set of level 3 basic linear algebra subprograms”. ACM TOMS, 16:1-28, 1988 BLAS Fuentes de Información: www, google,... Implementaciones optimizadas de BLAS ATLAS: http://math-atlas.sourceforge.net/ GotoBLAS: http://www.tacc.utexas.edu/resources/software MKL de Intel: http://www.intel.com/cd/software/products/asmo-na/eng/perflib/mkl Implementación eficiente del producto de matrices: http://www.cs.utexas.edu/users/flame Laboratorio del curso BLAS