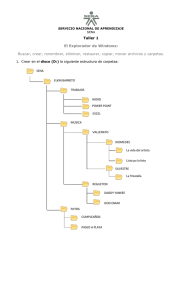
TECNOLOGÍA INFORMÁTICA 3.1 El problema del almacenamiento
Anuncio

UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.1 El problema del almacenamiento de datos. 3.1.1 Ventajas y desventajas del almacenamiento de datos. 3.1.2 Almacenamiento tradicional de datos y archivos. 3.1.3 Problemas comunes en sistemas de almacenamiento tradicional. 3.1.4 Consideraciones empresariales al evaluar medios de almacenamiento. 3.2 Estructura de datos y archivos 3.2.1 Estructura de datos 3.2.2 Estructura de archivos. 3.3 Organización de datos y archivos. 3.3.1 Almacenamiento físico de los archivos. 3.3.2 Administración de recursos de datos. 3.3.3 Conceptos fundamentales de los datos. 3.3.4 Tipos de bases de datos. 3.3.5 Almacén de datos y minería de datos. 3.3.6 Estructuras de base de datos. 3.4 Tecnologías de almacenamiento. 3.4.1 Tecnología de disco magnético y de cinta. 3.4.2 Tecnologías de Disco Óptico. 3.4.3 Almacenamiento de Estado Sólido. 3.4.4 DAS, NAS y SAN 3.5 Herramientas de explotación. 3.5.1 Sistema de Administración de bases de datos (DBMS). 3.5.2 Desarrollo de aplicaciones. 3.5.3 Bases de datos en la Web. 3.5.4 Extracción de datos y análisis en línea. Curso de Microsoft Access SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.1 El problema del almacenamiento de datos. 3.1.1 Ventajas y desventajas del almacenamiento de datos. Los datos y la información deben almacenarse hasta que sean necesarios mediante una variedad de métodos de almacenamiento. Por ejemplo, muchas personas y organizaciones todavía confían en los documentos de papel guardados en gabinetes de archivo, como su forma principal de medio de almacenamiento. Sin embargo, es más probable que usted y otros usuarios de computadoras dependan de los circuitos de memoria y de los dispositivos de almacenamiento secundario de los sistemas informáticos para satisfacer sus requerimientos de almacenamiento. El progreso en la integración, de muy alta escala, que empaqueta millones de elementos de circuitos de memoria en circuitos integrados diminutos de semiconductores, es el responsable del continuo incremento en la capacidad de memoria principal de las computadoras. Las capacidades de almacenamiento secundario también se están incrementando hacia los miles de millones y billones de caracteres, debido a los avances en los medios magnéticos y ópticos. Existen muchos tipos de medios y dispositivos de almacenamiento. Las interrelaciones de costo/velocidad/capacidad según uno se mueve de memoria de semiconductor a discos magnéticos, discos ópticos y cintas magnéticas. Los medios de almacenamiento de alta velocidad cuestan más por byte y proporcionan capacidades menores. Los medios de almacenamiento de gran capacidad cuestan menos por byte, pero son más lentos. Ésta es la razón por la que se tienen diferentes tipos de medios de almacenamiento. Sin embargo, todos los medios de almacenamiento, en especial los circuitos integrados de memoria y los discos magnéticos, continúan aumentando en velocidad y capacidad y disminuyendo en costo. Los desarrollos, como los montajes automatizados de cartucho de alta velocidad, han dado tiempos de acceso más rápidos para las cintas magnéticas, y la velocidad de las unidades de discos ópticos sigue en aumento. Las memorias de semiconductor se utilizan en especial para el almacenamiento primario, aunque a veces se utilizan como dispositivos de almacenamiento secundario de alta velocidad. El disco y la cinta magnética y los dispositivos de discos ópticos, por otra parte, se utilizan como dispositivos de almacenamiento secundario para agrandar de manera significativa la capacidad de almacenamiento de los sistemas informáticos. Además, dado que la mayoría de SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN los circuitos de almacenamiento primario utilizan circuitos integrados RAM o memoria de acceso aleatorio, que pierden su contenido cuando se interrumpe la corriente eléctrica, los dispositivos de almacenamiento secundario proporcionan un tipo más permanente de medio de almacenamiento. 3.1.2 Almacenamiento tradicional de datos y archivos. Sólo imagine qué tan difícil sería obtener cualquier información de un sistema de información si los datos se almacenaran de una manera desorganizada, o si no hubiera alguna forma sistemática para recuperarlos. Por lo tanto, en todos los sistemas de información, los recursos de datos tienen que organizarse y estructurarse de alguna manera lógica, de forma que puedan ser accesados con facilidad, procesados de manera eficiente, recuperados con rapidez y administrados eficazmente. Por eso, se han inventado estructuras y métodos de acceso a los datos, que van desde simples a complejos, para organizar y tener acceso a la información almacenada por los sistemas de información de manera eficaz. ¿Cómo se sentiría si usted fuera ejecutivo de una empresa y le dijeran que la información que usted requiere acerca de sus empleados es demasiado difícil y costosa de obtener? Suponga que el vicepresidente de servicios de información le diera las siguientes razones: La información que usted quiere esta en diversos archivos, cada uno organizado de manera diferente. Cada archivo ha sido organizado para utilizarse con un programa de aplicación diferente, ninguno de los cuales produce la información que desea en la forma que la necesita. No hay disponible ningún programa de aplicación para ayudar a obtener la información que usted requiere de esos archivos. Así como los usuarios finales pueden verse frustrados cuando una organización depende de sistemas de procesamiento de datos y archivos, en los cuales los datos se organizan, almacenan y procesan en archivos independientes de registros de datos. En el enfoque tradicional del procesamiento de archivos que se utilizaba en el procesamiento de información de negocio durante muchos años, cada aplicación de negocio se diseñaba para utilizar uno o más archivos especializados de datos que solo contenían tipos específicos de registros de datos. Por ejemplo, se diseño una aplicación bancaria de procesamiento de cuentas de cheques para accesar y actualizar un archivo de datos que contenía registros especializados de datos de los clientes de cuentas de cheques del SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN banco. De manera similar, la aplicación del procesamiento de créditos revolventes del banco es necesaria para acceder y actualizar un archivo especializado de datos, que contenga los registros de datos acerca de los clientes de los créditos revolventes. El enfoque de almacenamiento y procesamiento de datos y archivos en definitiva llego a ser demasiado engorroso, costoso e inflexible para proporcionar la información necesaria a fin de administrar el negocio moderno y fue remplazado por el enfoque de administración de base de datos. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.1.3 Problemas comunes en sistemas de almacenamiento tradicional. Redundancia de datos. Los archivos independientes de datos incluían muchos datos duplicados; la misma información (tal como el nombre y la dirección de un cliente) se registraban y almacenaban en diversos archivos. Esta redundancia de datos causaba problemas separados cuando la información debía actualizarse, dado que tenían que desarrollarse programas separados de mantenimiento de archivos y coordinarlos para asegurarse de que cada archivo era actualizado de manera adecuada. Por supuesto, esto resulto ser difícil en la práctica, ya que se presentaban muchas inconsistencias entre los datos almacenados en archivos separados. Falta de integración de datos. Tener datos en archivos independientes hizo difícil proporcionar a los usuarios finales información para solicitudes específicas que requerían acceder a datos almacenados en diferentes archivos. Tenían que desarrollarse programas especiales de cómputo para recuperar datos de cada archivo. Independiente. Esto era tan difícil, consumía tanto tiempo y es tan costoso para algunas organizaciones, que les era imposible proporcionar dicha información a los usuarios finales o a la administración. Si era necesario, los usuarios finales tenían que extraer de forma manual la información requerida a partir de diversos reportes producidos por cada aplicación separada y preparar reportes específicos para la administración. Dependencia de datos: en los sistemas de procesamiento de archivos, los componentes principales de un sistema, la organización de los archivos, sus ubicaciones físicas en la hardware de almacenamiento y el software de aplicación utilizado para acceder a esos archivos, dependían unos de otros de manera importante. Por ejemplo, los programas de aplicación contenían, por lo general, referencias al formato específico de los datos almacenados en los archivos que utilizaban. Así, los cambios en el formato y en la estructura de los datos y registros de un archivo requerían que los cambios se hicieran a todos los programas que utilizaran los sistemas de procesamiento de archivos. Demostró ser difícil de llevar a cabo de manera adecuada, lo que produjo una gran inconsistencia en los archivos de datos. Otros problemas. En los sistemas de procesamientos de archivos, era fácil que los diferentes usuarios finales y aplicaciones definieran los elementos de datos, tales como números de inventario y direcciones de clientes, de manera diferente. Esto causó serios problemas de inconsistencia en el desarrollo de los programas para acceder a tales datos. Además se desconfiaba de la integridad de la información (es decir, la precisión y la entereza), porque no había control de su SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN uso y mantenimiento por usuarios finales autorizados. Por lo tanto, la carencia de estándares provocó importantes problemas en el desarrollo y el mantenimiento de los programas de aplicación, y en la seguridad e integridad de los archivos de datos que las organizaciones necesitaban. 3.1.4 Consideraciones empresariales al evaluar medios de almacenamiento. Antes de gastar dinero en dispositivos de almacenamiento, los administradores deben considerar varios factores: el propósito del almacenamiento de los datos, la cantidad de datos que se van a guardar, la velocidad requerida para almacenar y recuperar los datos, cuán portátil necesita ser el dispositivo y el costo. Utilización de los datos almacenados. La primera consideración antes de adoptar un medio de almacenamiento es cómo se utilizarán los datos; sobre todo, si se emplearan para las operaciones actuales o como respaldo. Si sólo se van a utilizar como respaldo y no para procesamiento, una cinta magnética o los Discos Compactos (CD) son una opción adecuada. La cinta magnética cuesta menos y contiene más datos por carrete o cassette que un solo CD; esto también debe ser una consideración. Si los usuarios necesitan acceder con rapidez a los registros individuales, los discos duros magnéticos son la mejor opción. Por lo tanto, una empresa que permite a los clientes recuperar sus registros en línea debe utilizar discos magnéticos rápidos. Si la información es permanente, como las enciclopedias o los mapas utilizados en las bibliotecas, la información debe colocarse en CD o DVD, porque el usuario necesita una recuperación rápida y directa de información específica (registros) y no le conviene una búsqueda secuencial en una cinta. Cantidad de datos almacenados. Cuando el volumen de almacenamiento es el factor más importante, los administradores primero deben considerar el precio por megabyte, es decir, la proporción de dinero entre la capacidad de almacenamiento. Si el medio se va a utilizar solo para respaldo, su bajo costo vuelve ideales las cintas magnéticas y los CD-R. Si el medio se va utilizar para una recuperación rápida, los mejores son los discos magnéticos. Si es necesario guardar muchos datos, sobre todo archivos grandes como imágenes, sonidos y video, pero no es tan importante la velocidad para encontrar un archivo o registro específico, un DVD es una buena opción. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Para algunos propósitos, es importante la capacidad absoluta del dispositivo, no la densidad. Cuando se requiere guardar en un solo dispositivo un conjunto muy grande de aplicaciones de software y/o datos, debe elegirse un dispositivo con capacidad grande. Por ejemplo, si un representante de ventas debe mostrar aplicaciones que representan 4GB, un disco duro portátil pequeño o una unidad flash USB sería una opción más práctica. Velocidad. La velocidad de los discos magnéticos se suele medir en rotaciones por minuto (RPM). Los discos actuales vienen con velocidades de 10 000 y 15 000 RPM. Cuanto mas altas son las RPM, más corto es el tiempo de transferencia de datos y mejor el desempeño general. Aunque son atractivos la gran capacidad y el bajo costo de los CD, la velocidad de transferencia de los discos duros magnéticos todavía es mucho mejor que los CD y DVD. Si se requiere una velocidad muy alta, en la actualidad la mejor opción es un SSD (Disco de Estado Sólido) la cual es una alternativa para los discos magnéticos, se conectan a las computadoras de manera similar a los discos magnéticos y viene con su propia CPU, acelerando el procesamiento de datos. Las organizaciones utilizan los SSD para guardar el software que se utilizan con frecuencia con el fin de evitar “atascos” en el procesamiento de datos. Espacio unitario y portabilidad. A veces el costo de un gigabyte almacenado no es la consideración más importante, sino el tamaño físico del medio de almacenamiento. Un disco duro portátil puede ser económico y rápido, pero para un vendedor puede ser más práctico llevar un CD para sus demostraciones, pero le puede convenir más llevar consigo una unidad flash USB (Bus Serial Universal) de 4 GB en lugar de varios CD, gracias al hecho de que todas las PC tienen puertos USB. Costo. Una vez que los administradores determinan el mejor tipo de dispositivo de almacenamiento de datos para una empresa específica, necesitan considerar el costo. El método sencillo es obtener el mayor tamaño de almacenamiento por la menor cantidad de dinero. Para cada dispositivo propuesto, considere la proporción de pesos por gigabyte de capacidad, cuanto más baja es la proporción, más favorable es el producto. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Confiabilidad y expectativa de vida. Si bien ésta no suele ser la prioridad más alta, las empresas también deben considerar la confiabilidad del medio de almacenamiento y su expectativa de vida. Por ejemplo, los discos ópticos son más confiables y durables que los discos magnéticos. Los datos almacenados en forma magnética permanecen confiables durante unos 10 años, mientras que se espera que los CD y DVD guarden los datos de manera confiable durante 50 o 100 años, siempre y cuando se respeten las condiciones ideales para su conservación física. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.2 Estructura de datos y archivos 3.2.1 Estructura de datos Una estructura de datos es una forma de organizar un conjunto de datos elementales con el objetivo de facilitar su manipulación. Un dato elemental es la mínima información que se tiene en un sistema. Una estructura de datos define la organización e interrelación de éstos y un conjunto de operaciones que se pueden realizar sobre ellos. Las operaciones básicas son: Alta, adicionar un nuevo valor a la estructura. Baja, borrar un valor de la estructura. Búsqueda, encontrar un determinado valor en la estructura para realizar una operación con este valor, en forma secuencial o binario (siempre y cuando los datos estén ordenados). Otras operaciones que se pueden realizar son: Ordenamiento, de los elementos pertenecientes a la estructura. Apareo, dadas dos estructuras originar una nueva ordenada y que contenga a las apareadas. Cada estructura ofrece ventajas y desventajas en relación a la simplicidad y eficiencia para la realización de cada operación. De esta forma, la elección de la estructura de datos apropiada para cada problema depende de factores como la frecuencia y el orden en que se realiza cada operación sobre los datos. Listas. La lista enlazada básica es la lista enlazada simple la cual tiene un enlace por elemento. Este enlace apunta al siguiente elemento en la lista, o al valor nulo a la lista vacía, si es el último elemento. Una lista enlazada simple contiene dos valores: el valor actual del elemento y un enlace al siguiente elemento SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Lista Doblemente Enlazada Un tipo de lista enlazada más sofisticado es la lista doblemente enlazada o lista enlazadas de dos vías. Cada elemento tiene dos enlaces: uno apunta al elemento anterior, o apunta al valor NULO si es el primer elemento; y otro que apunta al elemento siguiente, o apunta al valor NULO si es el último elemento. Una lista doblemente enlazada contiene tres valores: el valor, el link al elemento siguiente, y el link al anterior Matriz. Desde el punto de vista lógico una matriz se puede ver como un conjunto de elementos ordenados en fila (o filas y columnas si tuviera dos dimensiones). En principio, se puede considerar que todas las matrices son de una dimensión, la dimensión principal, pero los elementos de dicha fila pueden ser a su vez matrices, lo que nos permite hablar de la existencia de matrices multidimensionales, aunque las más fáciles de imaginar son los de una, dos y tres dimensiones. Estas estructuras de datos son adecuadas para situaciones en las que el acceso a los datos se realice de forma aleatoria e impredecible. La forma de acceder a los elementos de la matriz es directa; esto significa que el elemento deseado es obtenido a partir de su índice y no hay que ir buscándolo elemento por elemento (en contraposición, en el caso de una lista, para llegar, por ejemplo, al tercer elemento hay que acceder a los dos anteriores. Pilas. Una pila es una lista ordinal o estructura de datos en la que el modo de acceso a sus elementos es último en entrar, primero en salir, que permite almacenar y recuperar datos. Se aplica en multitud de ocasiones en informática debido a su simplicidad y ordenación implícita en la propia estructura. Para el manejo de los datos se cuenta con dos operaciones básicas: apilar, que coloca un objeto en la pila, y su operación inversa, retirar, que retira el último elemento apilado. En cada momento sólo se tiene acceso a la parte superior de la pila, es decir, al último objeto apilado. La operación retirar permite la obtención de este elemento, SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN que es retirado de la pila permitiendo el acceso al siguiente (apilado con anterioridad), que pasa a ser el nuevo último elemento de la pila. Por analogía con objetos cotidianos, una operación apilar equivaldría a colocar un plato sobre una pila de platos, y una operación retirar a retirarlo el que se encuentra hasta arriba. Colas Una cola es una estructura de datos, caracterizada por ser una secuencia de elementos en la que la operación de inserción se realiza por un extremo y la operación de extracción por el otro. El primer elemento en entrar será también el primero en salir. Las colas se utilizan en sistemas informáticos, transportes y operaciones de investigación (entre otros), dónde los objetos, personas o eventos son tomados como datos que se almacenan y se guardan mediante colas para su posterior procesamiento. La particularidad de una estructura de datos de cola es el hecho de que sólo podemos acceder al primer y al último elemento de la estructura. Así mismo, los elementos sólo se pueden eliminar por el principio y sólo se pueden añadir por el final de la cola. Ejemplos de colas en la vida real serían: personas comprando en un supermercado, esperando para entrar a ver un partido de béisbol, esperando en el cine para ver una película, etc. La idea esencial es que son todas líneas de espera. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN En estos casos, el primer elemento de la lista realiza su función (pagar comida, pagar entrada para el partido o para el cine) y deja la cola. Este movimiento está representado en la cola por la función desencolar. Cada vez que otro elemento se añade a la lista de espera se añaden al final de la cola representando la función encolar. Hay otras funciones auxiliares para ver el tamaño de la cola, para ver si está vacía en el caso de que no haya nadie esperando o para ver el primer elemento de la cola. Árbol. Un árbol es una estructura de datos ampliamente usada que imita la forma de un árbol (un conjunto de elementos conectados). Un elemento es la unidad sobre la que se construye el árbol y puede tener cero o más elementos hijos conectados a él. Se dice que un elemento a es padre de un elemento b si existe un enlace desde a hasta b (en ese caso, también decimos que b es hijo de a). Sólo puede haber un único elemento sin padres, que llamaremos raíz. Un elemento que no tiene hijos se conoce como hoja. Los demás elementos (tienen padre y uno o varios hijos) se les conoce como rama. Las operaciones comunes en árboles son: Enumerar todos los elementos. Buscar un elemento. Dado un elemento, listar los hijos (si los hay). Borrar un elemento. Eliminar un subárbol (algunas veces llamada podar). Añadir un subárbol (algunas veces llamada injertar). Encontrar la raíz de cualquier elemento. Usos comunes de los árboles son: Representación de datos jerárquicos. Como ayuda para realizar búsquedas en conjuntos de datos. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.2.2 Estructura de archivos. Un archivo o fichero informático es un conjunto de bits almacenado en un dispositivo periférico. Un archivo es identificado por un nombre y la descripción de la carpeta o directorio que lo contiene. Los archivos informáticos se llaman así porque son los equivalentes digitales de los archivos en tarjetas, papel o microfichas del entorno de oficina tradicional. Los archivos informáticos facilitan una manera de organizar los recursos usados para almacenar permanentemente datos en un sistema informático. El termino archivo fue utilizado para los archiveros y los conjuntos de documentos mucho antes de que se volviera parte del lenguaje de las computadoras personales. Hoy, los archivos de computadora en formato digital ofrecen un modo compacto y conveniente para guardar documentos, fotografías, videos y música. Los archivos de computadora tienen varias características, como nombre, formato, ubicación, tamaño y fecha. Un archivo de computadora o, simplemente, un archivo se define como un conjunto de datos nombrados que existe en un medio de almacenamiento, como un disco, CD, DVD, o cinta. Un archivo puede contener un grupo de registros, un documento, una fotografía, un video, música, un mensaje de correo electrónico o un programa de computadora. Un archivo de datos informático normalmente tiene un tamaño, que generalmente se expresa en bytes; en todos los sistemas operativos modernos, el tamaño puede ser cualquier número entero no negativo de bytes hasta un máximo dependiendo del sistema. Depende del software que se ejecuta en la computadora el interpretar esta estructura básica como por ejemplo un programa, un texto o una imagen, basándose en su nombre y contenido. Los datos de un archivo informático normalmente consisten de paquetes más pequeños de datos (a menudo llamados registros) que son individualmente diferentes pero que comparten algún rasgo en común. Por ejemplo, un archivo de nóminas puede contener datos sobre todos los empleados de una empresa y los detalles de su nómina; cada registro del archivo de nóminas se refiere únicamente a un empleado, y todos los registros tienen la característica común de estar relacionados con las nóminas, esto es muy similar a colocar todos los datos sobre nóminas en un archivador concreto en una oficina que no tenga ninguna computadora. Un archivo de texto puede contener líneas de texto, correspondientes a líneas impresas en una hoja de papel. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN La manera en que se agrupan los datos en un archivo depende completamente de la persona que diseñe el archivo. Esto ha conducido a unas estructuras de archivo más o menos estandarizadas para todos los propósitos imaginables, desde los más simples a los más complejos. La mayoría de los archivos informáticos son usados por programas de computadora. Estos programas crean, modifican y borran archivos para su propio uso bajo demanda. Los programadores que crean los programas deciden qué archivos necesitan, cómo se van a usar, y (a menudo) sus nombres. Cada archivo tiene un nombre y también una extensión. Cuando guarda un archivo, debe proporcionarle un nombre valido que respete las reglas específicas, conocidas como conversiones para nombrar archivos. Cada sistema operativo tiene un conjunto único de conversiones para nombrar archivos. En algunos casos, los programas de computadora manipulan los archivos que se hacen visibles al usuario de la computadora. Por ejemplo, en un programa de procesamiento de texto, el usuario manipula archivos-documento a los que él mismo da nombre. El contenido del archivo-documento está organizado de una manera que el programa de procesamiento de texto entiende, pero el usuario elige el nombre y la ubicación del archivo, y proporciona la información (como palabras y texto) que se almacenará en el archivo. Los archivos de una computadora se pueden crear, mover, modificar, aumentar, reducir y borrar. En la mayoría de los casos, los programas de computadora que se ejecutan en la computadora se encargan de estas operaciones, pero el usuario de una computadora también puede manipular los archivos si es necesario. Por ejemplo, los archivos de Microsoft Office Word son normalmente creados y modificados por el programa Microsoft Word en respuesta a las órdenes del usuario, pero el usuario también puede mover, renombrar o borrar estos archivos directamente usando un programa gestor de archivos como Windows Explorer (en computadoras con sistema operativo Windows). También un archivo es un documento donde uno introduce algún tipo de Dato para almacenar en un objeto que lo pueda leer o modificar una computadora. En los sistemas informáticos modernos, los archivos siempre tienen nombres. Los archivos se ubican en directorios. El nombre de un archivo debe ser único en ese directorio. En otras palabras, no puede haber dos archivos con el mismo nombre en el mismo directorio. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN El nombre de un archivo y la ruta al directorio del archivo lo identifica de manera unívoca entre todos los demás archivos del sistema informático, no puede haber dos archivos con el mismo nombre y ruta. El aspecto del nombre depende del tipo de sistema informático que se use. Las computadoras modernas permiten nombres largos que contengan casi cualquier combinación de letras y dígitos, haciendo más fácil entender el propósito de un archivo de un vistazo. Algunos sistemas informáticos permiten nombres de archivo que contengan espacios; otros no. La distinción entre mayúsculas y minúsculas en los nombres de archivo está determinada por el sistema de archivos. La mayoría de las computadoras organizan los archivos en jerarquías llamadas carpetas, directorios o catálogos. (El concepto es el mismo independientemente de la terminología usada.) Cada carpeta puede contener un número arbitrario de archivos, y también puede contener otras carpetas. Las otras carpetas pueden contener todavía más archivos y carpetas, y así sucesivamente, construyéndose una estructura en árbol en la que una “carpeta raíz” puede contener cualquier número de niveles de otras carpetas y archivos. A las carpetas se les puede dar nombre exactamente igual que a los archivos (excepto para la carpeta raíz, que a menudo no tiene nombre). El uso de carpetas hace más fácil organizar los archivos de una manera lógica. Cuando una computadora permite el uso de carpetas, cada archivo y carpeta no sólo tiene un nombre propio, sino también una ruta, que identifica la carpeta o carpetas en las que reside un archivo o carpeta. En la ruta, se emplea algún tipo de carácter especial (como una barra / ) para separar los nombres de los archivos y carpetas. Por ejemplo, en la ilustración mostrada en este artículo, la ruta /Payroll/Salaries/Managers identifica unívocamente un archivo llamado Managers que está en una carpeta llamada Salaries que a su vez está contenida en una carpeta llamada Payroll. En este ejemplo, los nombres de las carpetas y archivos están separados por barras; la superior o carpeta raíz no tiene nombre, y por ello la ruta comienza con una barra (si la carpeta raíz tuviera nombre, precedería a esta primera barra). Muchos sistemas informáticos usan extensiones en los nombres de archivo para ayudar a identificar qué contienen. En computadoras Windows, las extensiones consisten en un punto al final del nombre del archivo, seguido de unas pocas letras para identificar el tipo de archivo. Una extensión de archivo también conocida como extensión de nombre de archivo) es un identificador de archivo opcional separado del nombre principal del archivo por un punto, como Paint.exe. Cuando se familiarice con las extensiones de archivo, le permitirán suponer qué contiene el archivo. Los archivos con extensiones .exe son los que puede ejecutar la computadora. Por ejemplo, Paint.exe es una utilería de gráficos incluida en el SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN sistema operativo Windows, Los archivos con extensiones .dat suelen ser archivos de datos. Los archivos con extensiones .doc contienen documentos de un procesador de textos. Incluso cuando se utilizan extensiones en un sistema informático, el grado con el que un sistema informático los reconoce y trata puede variar; en algunos sistemas son obligatorios, mientras que en otros sistemas se ignoran completamente si están presentes. Utilerías para la administración de archivos. Casi todos los sistemas operativos ofrecen utilerías para la administración de archivos que presentan una imagen general de los archivos que ha almacenado en sus discos y le ayudan a trabajar con ellos. Por ejemplo, Windows ofrece una utilería para administración de archivos a la que tiene acceso desde el icono Mi PC o Equipo desde la opción en el menú Inicio. En las computadoras Mac OS, las utilerías para administración de archivos se llaman Finder y Spotlight. Estas utilerías, le ayudan a observar una lista de archivos, encontrarlos, mover archivos de un lugar a otro, hacer copias, eliminarlos, descubrir sus propiedades y renombrarlos. Las utilerías para administración de archivos emplean una especie de metáfora de almacenamiento para que visualice y organice dispositivos de almacenamiento. Estas metáforas también se denominan modelos lógicos de almacenamiento, porque se supone que le ayudan a formar una imagen mental (lógica) de la manera en que guarda sus archivos. En esta metáfora cada dispositivo de almacenamiento corresponde a una de las gavetas de un archivero. Las gavetas contienen carpetas y las carpetas contienen archivos. Otra metáfora de almacenamiento se basa en un diagrama jerárquico, que se conoce como estructura de árbol. En esta metáfora un árbol representa un dispositivo de almacenamiento. El tronco del árbol corresponde al directorio raíz. Las ramas del árbol representan las carpetas. Estas ramas se pueden dividir en ramas más pequeñas que representan carpetas dentro de otras La metáfora de la estructura de árbol ofrece una imagen mental útil del modo en que se organizan los archivos y las carpetas. Una utilería para administración de archivos contienen herramientas y procedimientos que le ayudan a rastrear sus programas y archivos de datos, pero estas herramientas son más útiles cuando usted tiene un plan lógico para organizar sus archivos y cuando sigue algunos lineamientos básicos de SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN administración de archivos. Las sugerencias siguientes le ayudarán a administrar los archivos: Emplee nombres descriptivos. Asigne a sus carpetas y archivos nombres descriptivos y evite utilizar abreviaturas innecesarias. Conserve las extensiones de archivos. Al renombrar un archivo, mantenga la extensión original para que pueda abrirlo con facilidad con la aplicación correcta. Agrupe los archivos similares. Separe los archivos en carpetas con base en un tema específico. Por ejemplo, guarde sus tareas de redacción creativa en una carpeta y sus archivos de música MP3 en otra. Organice sus carpetas de lo general a lo particular. Al diseñar una jerarquía de carpetas, piense como quiere consultar y respaldar los archivos. Por ejemplo, es fácil especificar una carpeta y sus carpetas secundarias para hacer un respaldo. Sin embargo, si sus datos importantes están dispersos en diversas carpetas, tardará más tiempo en respaldarlos. Considere emplear el directorio predeterminado Mis documentos. La carpeta predeterminada por el software de Windows para guardar archivos de datos es Mis documentos. Es recomendable utilizar Mis documentos como su carpeta y datos principales y agregar las carpetas secundarias necesarias para organizar sus archivos. No mezcle archivos de datos y archivos de programas. No guarde archivos de datos en las carpetas que contienen su software; en Windows, casi todo el software se guara en carpetas secundarias de la carpeta Archivos de Programas. No guarde archivos en el directorio raíz. Si bien es posible crear carpetas en el directorio raíz, no es una buena práctica guardar programas o archivos de datos en el directorio raíz del disco duro de la computadora. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Consulte los archivos desde el disco duro. Para un mejor desempeño, copie los archivos de los dispositivos flash USB o los CD’s en el disco duro de su computadora antes de consultarlos. Elimine o guarde de manera permanente los archivos que ya no se necesitan. Eliminar los archivos y carpetas que ya no necesita evita que su lista de archivos alcance un tamaño poco manejable. Recuerde las ubicaciones de almacenamiento. Cuando guarde archivos, compruebe que la letra de la unidad y el nombre de la carpeta especifiquen la ubicación de almacenamiento correcta. Haga respaldos. Respalde sus carpetas de regularidad. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.3 Organización de datos y archivos. 3.3.1 Almacenamiento físico de los archivos. A la estructura de archivos y carpetas que observa en el Explorador de Windows se le denomina modelo lógico, porque se supone que le ayuda a crear una imagen mental. El modelo de almacenamiento físico describe lo que en realidad ocurre en los discos y los circuitos. Como puede observar, el modelo físico, es muy diferente al modelo lógico. Antes que una computadora pueda guardar un archivo en un disco, CD o DVD, el medio de almacenamiento debe estar formateado. El proceso de formateado crea el equivalente de recipientes electrónicos para almacenamiento al dividir un disco en pistas y después cada pista en sectores. Las pistas y los sectores se enumeran con el fin de proporcionar direcciones para cada recipiente de almacenamiento de datos. El esquema de numeración depende del dispositivo de almacenamiento del sistema operativo. En los discos flexibles y en el disco duro, las pistas están ordenadas como círculos concéntricos; en los CDs o DVDs, una o más pistas forman una espiral hacia fuera del centro del disco. En la actualidad, casi todos los discos duros se formatean en la fábrica; sin embargo, los sistemas operativos de las computadoras contienen utilería para formatear que usted puede utilizar para volver a formatear algunos dispositivos de almacenamiento: por lo general, discos flexibles y discos duros. Las empresas que fabrican discos duros, unidades grabadoras de CDs o DVDs, y software de grabación también proporcionan utilerías para formatear. Cuando emplea una utilería para formatear, ésta borra cualquier dato que esté en el disco, y después prepara las pistas y los sectores necesarios para contener datos. El sistema operativo emplea un sistema de archivos para rastrear los nombres y las ubicaciones de los archivos que residen en un medio de almacenamiento, como un disco duro. Los distintos sistemas operativos emplean diferentes sistemas de archivos. Casi todas las versiones de Mac OS utilizan el Macintosh Hierarchical File System (HFS). El sistema de archivos nativo para Linux es Ext2fs (extended 2 file system). Windows XP y Vista emplean en un sistema de archivos llamado NTFS (New Technology File System). Para acelerar el proceso de guardar y recuperar datos, el disco duro suele trabajar con un grupo de sectores llamados clúster o “bloque”. El número de sectores que forman un SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN clúster es variable, dependiendo de la capacidad del disco y del modo en que el sistema operativo trabaja con los archivos. La tarea principal de un sistema de archivos es mantener una lista de los clústeres y rastrear cuales están vacíos y cuales contienen datos. Esta información se guarda en un archivo índice especial. Si su computadora emplea NTFS, se llama Tabla Maestra de Archivos (MFT). Cada uno de esos discos contiene su propio archivo índice para tener siempre disponible información acerca de su contenido cuando se emplea. Por desgracia, guardar este archivo crucial en el disco también representa un riesgo, porque si una falla de una cabeza o un virus dañan el archivo índice, ya no puede tener acceso a los datos guardados en el disco. Los archivos índices se dañan con mucha frecuencia, por lo que es importante que respalde sus datos. Cuando guarda un archivo, el sistema operativo de su PC consulta el archivo índice para verificar los clústeres que están vacíos, registran ahí los datos del archivo y después incluye en el archivo índice el nuevo nombre de archivo y su ubicación. Un archivo que no cabe en un solo clúster se aloja en el siguiente clúster adyacente, a menos que este clúster ya contenga datos. Cuando no están disponibles clúster adyacentes, el sistema operativo guarda las partes de un archivo en clústeres no adyacentes. Cuando usted quiere recuperar un archivo, el sistema operativo consulta el índice su nombre y su ubicación. Mueve la cabeza de lectura-escritura del disco duro al primer clúster que contiene los datos del archivo. Con los datos adicionales del archivo índice, el sistema operativo puede mover las cabezas de lectura escritura a cada uno de los clústeres que contiene las partes restantes del archivo. Cuando hace clic en el icono de archivo y después selecciona la opción Eliminar, el sistema operativo simplemente cambia el estado de clústeres del archivo a “vacío” y elimina el nombre del archivo del archivo índice. El nombre del archivo ya no aparece en la lista del directorio, pero los datos permanecen en los clústeres hasta que se guarda ahí un archivo nuevo. Usted puede pensar que estos datos se han borrado, pero es posible adquirir utilerías que recuperan gran parte de estos datos supuestamente eliminados. Para eliminar los datos de un disco de manera que nadie pueda leerlos jamás, es posible utilizar el software especial para triturar archivos, que escribe sobre los sectores supuestamente vacíos con 1’s y 0’s aleatorios. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN La Papelera de reciclaje Windows y utilerías similares en otros sistemas operativos están diseñadas para que cuente con una protección ante el hecho de eliminar por accidente archivos del disco duro que en realidad necesita. En lugar de marcar los clústeres de un archivo como disponibles, el sistema operativo mueve al archivo la carpeta Papelera de reciclaje. El archivo eliminado todavía ocupa espacio en el disco, pero no aparece en la lista de directorios. Es posible recuperar los archivos que están en la Papelera de reciclaje para que vuelvan a aparecer en el directorio. También es posible vaciar la papelera de reciclaje para eliminar de manera permanente los archivos que contiene. Conforme una computadora escribe archivos, las partes de los archivos tienden a dispersarse por todo el disco. Estos archivos fragmentados se guardan en clústeres no adyacentes. El rendimiento de la unidad suele declinar cuando las cabezas de lectura-escritura avanzan y retroceden para localizar los clústeres que contiene las partes de un archivo. Para recuperar un rendimiento optimo, se emplea una utilería de desfragmentación como el Desfragmentador del disco de Windows, para reorganizar los archivos en un disco de modo que se guarde en los clústeres contiguos. 3.3.2 Administración de recursos de datos. La información es un recurso vital de las organizaciones, que tiene que administrarse como cualquier otro activo importante de un negocio. En la actualidad, las empresas no pueden sobrevivir o tener éxito sin información de calidad acerca de sus operaciones internas y de su ambiente externo. Con cada clic del ratón cuando se está en línea, o bien se crea un nuevo bit de datos o bien datos ya almacenados son recuperados a partir de todos esos sitos Web de negocios. Todo eso se presenta junto con la gran demanda por almacenamiento de calidad industrial ya en uso por parte de grandes corporaciones. Lo que está impulsando el crecimiento es un imperativo aplastante para que las corporaciones analicen cada bit de información que puedan extraer de sus enormes almacenes de datos para lograr una ventaja competitiva. Esto ha convertido la función de almacenamiento y administración de datos en una función estratégica clave de la era de la información. Esa es la razón por la cual las organizaciones y sus administradores tiene que practicar la administración de recursos de datos, una actividad administrativa SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN que aplica tecnologías de sistemas de información (como administración de bases de datos, almacenes de datos y otras herramientas de administración de datos) a la tarea de administrar los recursos de datos de una organización, con el fin de satisfacer las necesidades de información de sus participantes de negocio. Se mostrará las implicaciones administrativas de utilizar las tecnologías y los métodos de administración de recursos de datos para administrar los activos de información de una organización, con el fin de satisfacer los requerimientos de información del negocio. 3.3.3 Conceptos fundamentales de los datos. Se ha desarrollado un esquema conceptual de varios niveles de datos, que identifica las diferencias entre diversas agrupaciones, o elementos, de datos. De este modo, los datos pueden organizarse de forma lógica en caracteres, campos, registros, archivos y bases de datos, del mismo modo como la escritura puede organizarse en letras, palabras, oraciones, párrafos y documentos. Caracter. El elemento más básico de los datos lógicos es el caracter, que consiste en un símbolo único alfabético, numérico o de otro tipo. Uno podría argumentar que el bit o el byte es un elemento de dato más básico, pero recuerde que esos términos se refieren a los elementos de almacenamiento físico, proporcionados por el hardware de cómputo. Desde el punto de vista de un usuario ( es decir, desde un punto de vista lógico de los datos en contraposición mal punto de vista físico o de hardware) , un carácter es el elemento más básico de dato que puede ser observado y manipulado. Campo. El siguiente nivel de datos es el campo o elemento de dato. Un campo consiste en una agrupación de caracteres relacionados. Por ejemplo, la agrupación de los caracteres alfabéticos del nombre de una persona puede formar un campo de nombre (o por lo general, campos de primer apellido, segundo apellido y nombre) y la agrupación de números de los montos de ventas forma un campo de monto de ventas. En específico, un campo de información representa un atributo (una característica o cualidad) de alguna entidad (objeto, persona, lugar o evento) por ejemplo, el salario de un empleado es un atributo que es un campo de información típico utilizado para describir una entidad que un empleado de una empresa. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Registro. Los campos relacionados de información se agrupan para formar un registro. Por eso, un registro representa una colección de atributos que describen una entidad. Un ejemplo es el registro de nomina de una persona, el cual consiste en campos de información que describen atributos tales como el nombre de la persona, su número de seguro social y el monto de su paga. Los registros de longitud variable contienen un número variable de campos y de longitudes de campo. Archivo. Un grupo de registros relacionados es un archivo de datos, o tabla. Así un archivo de empleados contendría los registros de los empleados de una empresa. A menudo, los archivos se clasifican según la aplicación para la cual se utilizan principalmente, como por ejemplo, un archivo de nomina o un archivo de inventarios, por el tipo de datos que contienen, como un archivo de documento o un archivo de imágenes graficas. Los archivos también se clasifican según su permanencia, por ejemplo, un archivo maestro de nomina, frente a un archivo de transacción semanal de nomina. Un archivo de transacción, por lo tanto, contendría registros de todas las transacciones que ocurren durante un periodo y que puede utilizarse de forma periódica para actualizar los registros permanentes contenidos en un archivo maestro. Un archivo histórico es un archivo maestro o de transacciones obsoleto retenido para propósitos de respaldo o para un almacenamiento histórico a largo plazo llamado almacenamiento de archivo. Base de datos. Una base de datos es una colección integrada de elementos de datos relacionados de manera lógica. Una base de datos consolida los registros almacenados de antemano en archivos separados dentro de un grupo común de elementos de datos, el cual proporciona información para muchas aplicaciones. Los datos almacenados en una base de datos son independientes de los programas de aplicación que los utilizan, y del tipo de dispositivos de almacenamiento en los que están almacenados. Así, las bases de datos contienen elementos de datos que describen entidades y relaciones entre las entidades, también muestra algunas de las aplicaciones de negocio (facturación, procesamiento de pagos) que dependen del acceso a los elementos de datos de la base de datos. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.3.4 Tipos de bases de datos. Los continuos desarrollos en la tecnología de información y en sus aplicaciones de negocio han dado como resultado la evolución de diversos tipos importantes de bases de datos. Bases de datos operativas. Las bases de datos operativas almacenan datos detallados necesarios para apoyar el proceso y operaciones de negocio de una empresa. También se le llama bases de datos de áreas temáticas (SABD, siglas de termino Subset Área Databases), bases de datos transaccionales o base de datos de producción. Como ejemplos tenemos una base de datos de clientes, base de datos de recursos humanos, base de datos de inventario y otras bases de datos que contienen información generada por las operaciones de negocios. Por ejemplo, una base de datos de recursos humanos incluirá datos que identifican a cada empleado y su tiempo trabajando, compensaciones, beneficios, evaluaciones de desempeño, estatus de capacitación y desarrollo y otros datos relacionados con los recursos humanos. Se señalan algunas de las bases de datos operativas comunes que pueden crearse y administrarse para un negocio pequeño mediante el software de administración de bases de datos Microsoft Access. Bases de datos distribuidas. Muchas organizaciones reproducen y distribuyen copias o partes de bases de datos a servidores de red en una diversidad de sitios. Estas bases de datos distribuidas pueden residir en servidores de red en Internet, en intranets, extranets corporativas, o en otras redes de la empresa. Las bases de datos distribuidas pueden ser copias de bases de datos operativas o analíticas, de bases de hipermedios o de discusión, o cualquier otro tipo de bases de datos. La reproducción en las estaciones de trabajo de los usuarios finales. Asegurar que la información de las bases de datos distribuidas de una organización sea actualizada de manera consistente y concurrente es un desafío importante de la administración de este tipo de bases de datos. Bases de datos externas. El acceso a un acervo de información de bases de datos externas está disponible por una tarifa para servicios comerciales en línea, y con o sin cargo desde muchas fuentes en Internet. Los sitios Web ofrecen una variedad infinita de paginas hipervinculadas de documentos multimedia en bases de datos de SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN hipermedios para un acceso. Los datos están disponibles en forma de estadísticas. O pueden ver o descargar resúmenes o copias completas de cientos de periódicos, revistas, cartas, documentos de investigación y otro material publicado o periódico a partir de bases de datos bibliografía y de textos completos. Bases de datos de hipermedios. El rápido crecimiento de sitios Web en Internet y de intranets y extranets corporativas ha incrementado de manera radical el uso de bases de datos de documentos de hipertexto e hipermedios. Un sitio Web almacena dicha información en una base de datos de hipermedios que consiste en paginas multimedia hipervinculadas (texto, graficas, imágenes fotográficas, segmentos de video, audio, etc.), es decir, desde el punto de vista de la administración una base de datos de elementos interrelacionados de páginas de hipermedios, en lugar de registros de datos interrelacionados. 3.3.5 Almacén de datos y minería de datos. Un almacén de datos guarda datos que se han extraído desde diversas bases de datos operativas, externas y de otro tipo de organización. Es una fuente central de datos que han sido limpiados, transformados y catalogados, de tal manera que los administradores y otros profesionales de negocios puedan utilizarlos para la minería de datos, el procesamiento analítico en línea otras formas de análisis de negocio, investigación de mercados y apoyo a la toma de decisiones. Los almacenes de datos pueden subsidiarse en mercados de datos, que contienen subconjuntos de datos del almacén y que se enfocan en aspectos específicos de una empresa, tales como un departamento o un proceso de negocio. Los datos se capturan a partir de una variedad de bases de datos operativas y externas, y como se limpian y se transforman en datos que pueden ser mejor utilizados para el análisis. Este proceso de adquisición puede incluir actividades como la consolidación de datos de diferentes fuentes, la filtración de datos no deseados, la corrección de datos incorrectos, la conversión de datos en nuevos elementos de datos y la concentración de datos en nuevos subconjuntos de datos. Después, estos datos se almacenan en el almacén de datos de la empresa, desde donde pueden ser trasladados a mercados de datos o a un almacén analítico de datos, que contenga los datos en una forma más útil para ciertos tipos de análisis. Los metadatos (información que define a los datos en el almacén de datos) se almacenan en un depósito de metadatos y se catalogan mediante un directorio de SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN metadatos. Por último, puede proporcionarse una variedad de herramientas analíticas se software para consultar, reportar, realizar minería y analizar los datos para distribuiros mediante Internet y mediante los sistemas de intranet en Web a los usuarios finales de negocio. Minería de datos. La minería de datos es una aplicación principal de las bases de datos de los almacenes de datos. En la minería de datos, los daos de un almacén de datos se analizan para revelar patrones y tendencias ocultos en la actividad histórica del negocio. Esto puede utilizarse para ayudar a los administradores a tomar decisiones acerca de los cambios estratégicos en las operaciones de negocio, con el fin de lograr ventajas competitivas en el mercado. La minería de datos puede descubrir nuevas correlaciones, patrones y tendencias de las grandes cantidades de datos de negocio (con frecuencia varios terabyetes de datos), almacenados en los almacenes de datos. El software de minería de datos utiliza algoritmos avanzados de reconocimiento de patrones, así como una variedad de técnicas matemáticas y estadísticas para filtrar grandes volúmenes de datos y extraer información estratégica de negocio antes ignorada. Por ejemplo, muchas utilizan minería de datos para: Desempeñar “análisis de canasta de mercado” con el fin de identificar nuevos grupos de productos Descubrir las causa de origen de los problemas de calidad o de manufactura. Prevenir el agotamiento de los clientes y adquirir otros nuevos. Vender de forma cruzada a clientes existentes. Realizan la generación de perfiles de los clientes con más precisión. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.3.6 Estructuras de base de datos. Las relaciones entre los muchos elementos de datos individuales almacenados en las bases de datos se basan en una de diversas estructuras lógicas de datos, o modelos. Los paquetes de sistemas de administración de bases de datos se diseñan para utilizar una estructura específica de datos con el fin de proporcionar a los usuarios finales un acceso rápido y fácil a la información almacenada en las bases de datos Estructura jerárquica Los primeros paquetes de sistemas de administración de bases de datos para los grandes sistemas centrales (mainframe) utilizaban la estructura jerárquica, en la cual las relaciones entre los registros forman una jerarquía o estructura de árbol. En el modelo jerárquico tradicional, todos los registros son dependientes y están colocados en estructuras de multiniveles, que consisten en un registro raíz, y un número de niveles subordinados. Así, todas las relaciones entre los registros son de uno a muchos, dado que cada elemento de dato se relaciona con sólo un elemento sobre él. El elemento de dato o registro en el nivel más alto de la jerarquía se denomina el elemento raíz. Cualquier elemento de dato puede ser accesado al moverse de forma progresiva hacia abajo desde una raíz y a largo de las ramas del árbol hasta que se localiza el registro deseado (por ejemplo, el elemento de dato de un empleado). Estructura de red. La estructura de red puede representar relaciones lógicas más complejas, y todavía se utiliza en algunos paquetes de sistemas de administración de bases de datos para grandes sistemas (mainframes). Permite relaciones de muchos a muchos entre los registros, es decir, el modelo de red puede accesar un elemento de dato al seguir uno de diversos caminos, porque se puede relacionar cualquier elemento de datos o registro con cualquier numero de otros elementos de datos. Por ejemplo, los registros departamentales pueden relacionarse con más de un registro de empleado, y los registros de empleados pueden relacionarse con más de un registro de proyecto. Así, uno podría localizar todos los registros de empleados de un departamento en particular, o todos los registros de proyectos relacionados con un empleado determinado. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Estructura relacional. El modelo relacional es el más utilizado de las tres estructuras de base de datos. La mayoría de los paquetes de sistemas de administración de bases de datos y para microcomputadoras lo utilizan, así como la mayoría de los sistemas de rango medio y de grandes sistemas (mainframe). En el modelo relacional, todos los elementos de datos dentro de la base de datos se visualizan como almacenados en forma de tablas simples. Otras tablas, o relaciones, para esta base de datos de una organización pudieran representar las relaciones de los elementos de datos entre proyectos, divisiones, líneas de productos, etc. Los paquetes de sistemas de administración de base de datos en el modelo relacional pueden vincular elementos de datos desde diversas tablas para proporcionar información a los usuarios. Estructura multidimensional. La estructura multidimensional de base de datos es una variación del modelo relacional, que utiliza estructuras multidimensionales para organizar datos y expresar las relaciones entre ellos. Se pueden visualizar las estructuras multidimensionales como cubos de datos y como cubos dentro de los cubos de datos. Cada lado del cubo se considera una dimensión de la información. Cada celda dentro de una estructura multidimensional contiene datos agregados relacionados con elementos a lo largo de cada una de sus dimensiones. Por ejemplo, una única celda puede contener las ventas totales de un producto en una región para un canal de ventas específico de un mes. Un beneficio importante de las bases de datos multidimensionales es que son una forma compacta y fácil de entender para visualizar y manipular los elementos de datos que tienen muchas relaciones entre ellos. Así, se han convertido en la estructura de bases de datos más popular para las bases de datos analíticas que apoyan las aplicaciones de procesamiento analítico en línea (OLAP), en las cuales se esperan respuestas rápidas a consultas complejas de negocio. Estructura orientada a objetos. El modelo de base de datos orientado a objetos se considera como una de las tecnologías clave de una nueva generación de aplicaciones multimedia basada en Web. Un objeto consistente en valores de datos que describen los atributos de una entidad, mas las operaciones que pueden realizarse sobre los datos. Esta capacidad de encapsulación permite al modelo orientado a objetos manejar con SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN más facilidad tipos complejos de datos (graficas, dibujos, voz, texto) que en otras estructuras de base de datos. El modelo orientado a objetos también soporta la herencia; es decir, pueden crearse automáticamente nuevos objetos al replicar algunas o todas las características de uno o más objetos padre. Así, los objetos cuentas de cheques y ahorros pueden heredar los atributos y operaciones comunes del objeto padre cuenta de banco. Dichas capacidades han hecho de los sistemas de administración de bases de datos orientados a objetos (OODBMS, siglas del termino object-oriented database management system) algo popular en un creciente número de aplicaciones. Por ejemplo, la tecnología de objetos permite a los diseñadores desarrollar diseños de productos, almacenarlos como objetos en una base de datos orientada a objetos, y replicarlos y modificarlos para crear nuevos diseños de productos. Además, las aplicaciones multimedia basadas en Web para Internet, intranets y extranets corporativas se han convertido en un área importante de aplicación para la tecnología de objetos. Los defensores de la tecnología de objetos argumentan que un sistema de administración de bases de datos orientado a objetos puede trabajar con tipos de datos complejos, tales como imágenes de documentos y graficas, segmentos de video, segmentos de audio y otros subgrupos de páginas Web, de forma mucho más eficaz que los sistemas de administración de bases de datos relacionales han respondido al añadir módulos orientados a objetos a su software relacional. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.4 Tecnologías de almacenamiento. Un sistema de almacenamiento de datos tiene dos componentes principales: un medio de almacenamiento y un dispositivo de almacenamiento. Un medio de almacenamiento es el disco, la cinta, el CD, el DVD, el papel u otra sustancia que contenga datos. Un dispositivo de almacenamiento es el aparato mecánico que graba y recupera los datos de un medio de almacenamiento. Entre los dispositivos de almacenamiento están las unidades de discos flexibles, las unidades de disco duro, las unidades de cinta, las unidades de CD, las unidades de DVD y las unidades de memoria flash. El término tecnología de almacenamiento se refiere a un dispositivo de almacenamiento y los medios que utiliza. Puede considerar los dispositivos de almacenamiento como tener una conexión directa a la RAM. Los datos se copian del dispositivo de almacenamiento a la RAM, donde esperan ser procesados. Después que se procesan los datos, se mantienen temporalmente en la RAM, pero se suelen copiar en un medio de almacenamiento para ser conservados de manera más permanente. El procesador de una computadora funciona con datos codificados en bits que se representan mediante 1’s y 0’s. Cuando se guardan los datos, estos 1’s y 0’s deben convertirse a algún tipo de señal o marca bastante permanente, pero que se pueda cambiar cuando sea necesario. Es obvio que los datos no se escriben literalmente como "1’s" o "0’s". En lugar de eso, los 1’s y los 0’s deben transformarse en cambios en la superficie de un medio de almacenamiento. Cómo ocurre esta transformación exactamente depende de la tecnología de almacenamiento. Por ejemplo, los discos duros guardan los datos de una manera diferente que los CD-ROM’s. Se suelen usar tres tipos de tecnologías de almacenamiento para las computadoras personales: Magnético, Óptico y De estado sólido. Cada tecnología de almacenamiento tiene ventajas y desventajas. Si un sistema de almacenamiento fuera perfecto, no necesitaríamos tantas unidades de disco y unidades de cinta conectadas a nuestras computadoras. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.4.1 Tecnología de disco magnético y de cinta. Disco Magnético. Las tecnologías de almacenamiento en disco duro, disco flexible y cinta se clasifican como almacenamiento magnético, el cual guarda los datos al magnetizar partículas microscópicas en la superficie de un disco o una cinta. Las partículas conservan su orientación magnética hasta que se modifica la orientación, lo cual hace a los discos y a la cintas medios de almacenamiento bastante permanentes, pero modificables. Un mecanismo de lectura escritura en la unidad de disco magnetiza las partículas para escribir datos y detecta la polaridad de las partículas para leer datos. Antes de guardar los datos, las partículas sobre la superficie del disco se dispersan en esquemas aleatorios. La cabeza de lectura-escritura de la unidad del disco magnetiza las partículas y las orienta en una dirección positiva (norte) o negativa (sur) para representar los bits 0 y 1. Los datos guardados magnéticamente se modifican o eliminan con facilidad con sólo alterar la orientación magnética de las partículas adecuadas en la superficie del disco. Esta característica del medio magnético ofrece mucha flexibilidad para editar datos y reutilizar las áreas del medio de almacenamiento que contienen datos innecesarios. La tecnología de Disco Duro es el tipo preferido de almacenamiento principal para casi todos los equipos de cómputo por tres razones. Primero, ofrece mucha capacidad de almacenamiento. Segundo, aporta un acceso rápido a los archivos. Tercero, un disco duro es económico. El costo de almacenar un megabyte de datos es aproximadamente 1/1700 de dólar. Las unidades de disco duro se encuentran en todo tipo de dispositivos digitales, incluso las computadoras personales, los iPods, etc. Como el principal dispositivo de almacenamiento en casi todas las computadoras, una unidad de disco duro contiene una o más placas y sus cabezas de lecturaescritura asociadas. Una placa de disco duro es un disco plano y rígido hecho de aluminio o vidrio y recubierto con partículas magnéticas de óxido de hierro. Más SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN placas significan más capacidad de almacenamiento de datos. Las placas giran como una unidad sobre un eje a miles de rotaciones por minuto. Cada placa tiene una cabeza de lectura-escritura que se mueve sobre la superficie para leer los datos. La cabeza se desplaza sólo algunas micropulgadas sobre la superficie del disco. Las placas del disco duro de una computadora personal suelen tener 3.5" de diámetro, y su capacidad de almacenamiento va de 40 a 500 GB. Los discos duros en miniatura (también llamados micro discos), como la unidad de 1.8" del reproductor de música digital iPod de Apple, guardan de 30 a 80 GB. Los tiempos de acceso al disco duro de 6 a 11 ms son frecuentes, mientras que un disco flexible o un CD tarda medio segundo para alcanzar su velocidad y encontrar los datos. La velocidad de la unidad de disco duro se suele medir en revoluciones por minuto (rpm). Entre más rápido gira una unidad, más rápido se coloca la cabeza de lectura-escritura sobre los datos específicos. Por ejemplo, una unidad de 7200 rpm accede a los datos más rápido que una unidad de 5400 rpm. Las especificaciones de las computadoras muestran la capacidad, el tiempo de acceso y la velocidad de un disco duro. De modo que "disco duro de 160 GB de 8 ms a 7200 rpm" significa una unidad de disco duro con capacidad de 160 gigabytes, tiempo de acceso de 8 milisegundos y velocidad de 7200 revoluciones por minuto. Estos anuncios rara vez especifican la cantidad de datos que puede transferir un disco duro, pero la velocidad de transferencia de datos promedio es de alrededor de 50 megabytes por segundo. Los discos duros no duran tanto como muchas otras tecnologías dé almacenamiento. Las cabezas lectura-escritura en un disco duro se mueven a una distancia microscópica sobre la superficie del disco. Si una cabeza de lectura-escritura choca contra una partícula de polvo o algún otro contaminante en el disco, puede provocar una falla de la cabeza, la cual daña algunos de los datos en el disco. Para evitar que los contaminantes entren en contacto con las placas y provoquen fallas de la cabeza, un disco duro se sella dentro de su cubierta. Una falla dé la cabeza también ocurre al sacudir el disco duro mientras está en uso. Aunque los discos duros se han vuelto más resistentes en los años recientes, todavía deben manejarse y transportarse con cuidado. También debe hacer una copia de respaldo de los datos guardados en su disco duro en caso de una falla en la cabeza. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Usted aumenta la capacidad de almacenamiento de su computadora al agregar una segunda unidad de disco duro, la cual también sirve de respaldo para su disco duro principal. Los discos duros también se ofrecen como unidades internas o externas. Las unidades internas son económicas y se instalan con facilidad en la unidad de un equipo de cómputo de escritorio. Las unidades externas son más costosas y se conectan a una computadora de escritorio o laptop mediante un cable. Cinta. Proteger la enorme cantidad de datos en el disco duro es de particular interés, porque sería difícil y requeriría mucho tiempo restituirlos. Puede hacerse una copia de respaldo de los datos en un disco duro con diversos dispositivos de almacenamiento, entre ellos las unidades de cinta. Una unidad de cinta es un dispositivo que lee los datos, y los escribe en una extensa variedad de medios para grabar, similar a las cintas utilizadas en el audio cassettes. Las unidades de cinta se usan principalmente en las computadoras de negocios. A diferencia de los CD’s y los DVD’s, un dispositivo de respaldo en cinta no es conveniente para tareas de almacenamiento cotidianas. Una cinta es un medio de almacenamiento secuencial, no de acceso aleatorio. En esencia, los datos se ordenan como una extensa secuencia de bits que comienza en un extremo de la cinta y avanza hacia el otro extremo. El inicio y el fin de cada archivo se marcan con etiquetas especiales. Para localizar un archivo, la unidad de cinta debe comenzar en un extremo de la cinta y leer todos los datos hasta que encuentra la etiqueta correcta. Una cinta puede contener cientos o en el caso de las supercomputadoras miles de metros de cinta. El tiempo de acceso se mide en segundos, no en milisegundos como para las unidades de disco duro. La cinta es muy lenta para ser práctica como dispositivo principal de almacenamiento de una computadora. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.4.2 Tecnologías de Disco Óptico. En la actualidad, casi todas las computadoras vienen equipadas con algún tipo de unidad de CD o unidad de DVD, diseñadas para funcionar con diversos CD’s o DVD’s. Las tecnologías de CD y DVD son similares, pero es diferente la capacidad de almacenamiento. La tecnología de CD (disco compacto) fue diseñada originalmente para contener 74 minutos de música grabada. El estándar original del CD fue adoptado para el almacenamiento de las computadoras con una capacidad para 650 MB de datos. Mejoramientos posteriores en los estándares del CD aumentaron la capacidad a 80 minutos de música o 700 MB de datos. El DVD (disco de video digital o disco versátil digital) es una variación de la tecnología de CD diseñado como una alternativa para las videograbadoras, pero adoptado con rapidez por la industria de las computadoras para guardar datos. El estándar DVD inicial ofrecía 4.7 GB de almacenamiento de datos; unas siete veces la capacidad de un CD. Los mejoramientos posteriores en la tecnología DVD ofrecen todavía más capacidad de almacenamiento. Un DVD de doble capa tiene dos capas para grabar en el mismo lado y puede almacenar 8.5 GB de datos. Un HD-DVD puede guardar 15 GB por capa en un solo lado; un Blue-Ray DVD (BD) tiene una capacidad de 25 GB por capa. Las tecnologías de almacenamiento en CD y en DVD se clasifican como almacenamiento óptico, el cual guarda los datos como puntos microscópicos de luz y oscuridad en Ia superficie del disco. Los puntos oscuros, se llaman huecos. Las áreas del disco más claras que no son huecos se llaman planos. Las unidades de CD y DVD contienen un eje que hace girar el disco sobre un lente láser. El láser dirige un haz de luz hacia la parte inferior del disco. Los huecos oscuros y los planos iluminados de la superficie del disco reflejan la luz de distinta manera. Cuando el lente lee el disco, las diferencias se traducen en los 0’s y 1’s que representan los datos La superficie de un disco óptico está recubierta con un plástico transparente, lo cual hace duradero el disco y menos susceptible al daño ambiental que los datos grabados en los medios magnéticos. Un disco óptico, igual que un CD, no es susceptible a dañarse con la humedad, las huellas digitales, el polvo, los imanes o las bebidas derramadas, Los rasguños en la superficie del disco SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN interfieren con la transferencia de datos, pero una buena pulida con dentífrico puede eliminar el rasguño sin dañar los datos que están debajo. Se calcula que la vida útil de un disco óptico es de más de 30 años. Las unidades de CD originales accedían 150 KB de datos por segundo. La siguiente generación de unidades duplicó la velocidad de transferencia de datos y fue calificada como de unidades de “2X”. Las velocidades de transferencia parecen aumentar sin cesar. Por ejemplo, una unidad de 52X transfiere datos a 80 Mbps, lo cual todavía es relativamente lento en comparación con la velocidad de transferencia de un disco. La velocidad de una unidad de DVD se mide en una escala diferente a la de una unidad de CD. Una unidad de DVD de 1X tiene aproximadamente la misma velocidad que una unidad de CD de 9X. Las unidades de DVD actuales suelen tener velocidades desde 16X para una velocidad de transferencia. Las tecnologías ópticas se agrupan en tres categorías: De sólo lectura, Grabables y Para reescritura. La tecnología de sólo lectura (ROM) guarda los datos de manera permanente en un disco, los cuales después no se pueden agregar o cambiar. Los discos de sólo lectura, como los CD-ROM’s, CD-DA, DVD Video y DVD-ROM’s se graban durante la producción en masa y se usan para distribuir software, música y películas. La tecnología grabable (R) emplea un láser para cambiar el color en una capa de tinta que está bajo la superficie de plástico transparente del disco. El láser crea puntos oscuros en la tinta que se leen como huecos. El cambio en la tinta es permanente, de modo que los datos no pueden cambiarse una vez grabados. La tecnología regrabable (RW) emplea tecnología de cambio de fase para alterar una estructura de cristales en la superficie del disco. La alteración de la estructura de cristales crea esquemas de puntos claros y oscuros similares a los huecos y los planos en un CD. La estructura de cristales puede cambiar de claro a oscuro y viceversa muchas veces, lo cual permite grabar y modificar los datos de una manera similar a un disco duro. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN En la actualidad, varios formatos para CD y DVD son populares para uso en computadoras personales: • CD-DA (audio digital de disco compacto), más conocido como CD de audio es el formato para los CD’s de música comercial. El fabricante graba la música en los CD’s de audio, pero el consumidor no puede modificarlos. • DVD-Video (video disco versátil digital) es el formato para los DVD’s comerciales que contienen películas extensas. • CD-ROM (disco compacto con memoria de sólo lectura) fue el formato original, para guardar datos de computadora. Los datos se graban en el disco en el momento en que se fabrica. No es posible agregar, modificar o eliminar datos de estos discos. • DVD-ROM (disco versátil digital con memoria de sólo lectura) contienen datos grabados en la superficie del disco en el momento de la fabricación. Igual que los CD-ROM’s, los datos en estos discos son permanentes, usted no puede agregarlos o modificarlos. • CD-R (disco compacto grabable), estos discos guardan los datos usando una tecnología regrabable. Los datos en un CD-R no pueden borrarse o eliminarse una vez grabados. Sin embargo, casi todas las unidades CD-R le permiten grabar sus datos en varias secciones. Por ejemplo, puede guardar dos archivos en un disco CD-R hoy, y tiempo después agregar al disco los datos de otros archivos. • DVD+R o DVD-R (disco versátil digital grabable), los discos guardan los datos usando una tecnología grabable similar a un CD-R, pero con una capacidad de almacenamiento de DVD. • CD-RW (disco compacto regrabable), los discos guardan los datos utilizando una tecnología regrabable. Los datos guardados se graban y borran varias veces, lo cual la vuelve una opción de almacenamiento muy flexible. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN • DVD+RW o DVD-RW (disco versátil digital regrabable), los discos guardan los datos mediante una tecnología regrabable similar a un CD-RW, pero con una capacidad de almacenamiento de DVD. Una unidad de CD o DVD regrabable es una buena adición a un equipo de cómputo, pero no es un buen reemplazo para un disco duro. Por desgracia, el proceso de consultar, guardar y modificar los datos en un disco regrabable es relativamente lento en comparación con la velocidad de acceso a un disco duro. Casi todas las unidades de CD pueden leer discos CD-ROM, CD-R y CD-RW, pero no pueden leer DVD’s. Casi todas las unidades DVD pueden leer formatos de CD y DVD. El almacenamiento de datos de computadora y la creación de CD’s de música requieren un dispositivo grabable o regrabable. El dispositivo de almacenamiento óptico más versátil es una combinación DVD-R/RWCD-RW. 3.4.3 Almacenamiento de Estado Sólido. El almacenamiento de estado sólido (también llamado memoria flash) es una tecnología que guarda los datos en circuitos borrables regrabables, y no en discos que giran o en una cinta que se enreda. Se utiliza mucho en dispositivos portátiles como cámaras digitales, reproductoras de música MP3, computadoras laptop, PDAs, y teléfonos celulares. El almacenamiento de estado sólido es portátil y ofrece un acceso bastante rápido a los datos. Es una solución ideal para guardar datos en dispositivos móviles y transportar datos de un dispositivo a otro. El almacenamiento de estado sólido contiene una retícula de circuitos. Cada celda en la retícula contiene dos transistores que funcionan como compuertas. Cuando las compuertas se abren, fluye la corriente y la celda tiene un valor que representa un bit "1". Cuando las compuertas se cierran mediante un proceso llamado canalización de Fowler-Nordheim, la celda tiene un valor que representa un bit "0". Sé requiere muy poca corriente eléctrica para abrir o cerrar las compuertas, lo cual hace ideal el almacenamiento de estado sólido para dispositivos que SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN funcionan con baterías, como las cámaras digitales y los PDA’s. Una vez guardados los datos, se vuelven no volátiles: el chip conserva los datos sin necesidad de una fuente externa de corriente. El almacenamiento de estado sólido aporta un acceso rápido a los datos porque no incluye partes móviles y es muy durable; prácticamente es indiferente a la vibración, los campos magnéticos o las fluctuaciones extremas de temperatura. En la actualidad, la capacidad del almacenamiento de estado sólido ya alcanza la de los discos duros o los DVD’s. El costo por megabyte de almacenamiento alrededor de 0.03 dólares es bastante más alto que el del almacenamiento magnético u óptico. Existen varios tipos de almacenamiento de estado sólido para los consumidores actuales. Los formatos para estas pequeñas tarjetas planas son Compact Flash MultiMedia, SecureDigital (SD) y SmartMedia. Debido a que la fotografía digital es tan popular, algunas PC’s para medios tienen un lector de tarjetas incorporado para simplificar la transferencia de las fotografías de una cámara a su computadora. Al trasladar datos en otra dirección, una computadora puede descargar archivos de música MP3 y guardarlos en una tarjeta de memoria de estado sólido. La tarjeta se puede retirar de la computadora e insertarse en un reproductor MP3 portátil, para que pueda escuchar sus canciones favoritas mientras sale de casa. Aunada a esa versatilidad, las memorias flash USB de estado sólido sirven para guardar archivos de datos de computadora y programas. Una memoria flash USB, como MicroVault de Sony, Cruzer de SanDisk, o Traveler de Kingston, funciona como almacenamiento portátil que se conecta directamente en un puerto USB de una computadora mediante un conector incorporado. También se denominan memorias miniatura, memorias de pluma, memorias USB, y memorias de llavero. Las memorias flash USB tienen el tamaño aproximado de un marca textos y son tan durables que puede traer una como llavero. Los archivos guardados en una memoria flash USB se pueden abrir, modificar, eliminar y ejecutar como si estuvieran almacenados en un medio magnético u óptico. Se puede decir que las memorias flash USB son los nuevos discos flexibles porque no sólo le permiten acceder a los archivos como si estuvieran en discos, sino que también puede ejecutar software desde ellas. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Las memorias flash USB tienen capacidades que van de 16 MB a mas de 8 GB. Tienen velocidades máximas de transferencia de datos de aproximadamente 100 Mbps. Pero es más común que funcionen en el intervalo de 18-28 megabytes por segundo. Cuando quiera retirar una memoria flash USB de una computadora, debe emplear el control de expulsión adecuado en la pantalla. Un dispositivo U3 (también llamado dispositivo inteligente U3) es un tipo especial de memoria flash USB pre-configurado para reproducción automática cuando se inserta en una computadora. Ejecuta una aplicación llamada Launchpad, la cual es similar al menú Inicio de Windows, y enlista los programas a los que se puede acceder desde el dispositivo U3. Existen aplicaciones de software para los dispositivos U3 en el sitio Web de U3. 3.4.4 DAS, NAS y SAN Almacenamiento de Acceso Directo (DAS). Las organizaciones confían cada vez más en sistemas de almacenamiento que permitan a varios usuarios compartir el mismo medio en una red. En el almacenamiento de acceso directo (DAS) el disco o conjunto de discos se conecta directamente a un servidor. Los dispositivos de almacenamiento también pueden ser cintas, sobre todo si son para respaldo. Otras computadoras en la red deben acceder al servidor par utilizar los discos o las cintas. Un DAS es relativamente fácil de desplegar y dirigir y conlleva un costo relativamente bajo. Sin embargo, la velocidad de acceso a los datos se reduce debido a que el servidor también procesa otro software, como el correo electrónico y las bases de datos. Asimismo, si el servidor deja de funcionar, las otras computadoras no pueden acceder a los dispositivos de almacenamiento. Un DAS es conveniente para compartir archivos específicos, lo cual suele ocurrir en la empresas pequeñas. Su escalabilidad es complicada, porque cada servidor adicional y sus dispositivos de almacenamiento deben administrarse por separado. La escalabilidad es la capacidad de agregar más hardware o software con el fin de atender las cambiantes necesidades empresariales. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Otras dos disposiciones ponen a los dispositivos de almacenamiento en la red de una organización para que otras computadoras accedan a ellos directamente. Estos métodos se conocen como almacenamiento conectado a una red (NAS) y red de área de almacenamiento (SAN). Almacenamiento Conectado a una Red (NAS). El almacenamiento conectado a una red (NAS) es un dispositivo especialmente diseñado para almacenamiento en red. Está formado por el medio de almacenamiento, que pueden ser discos duros y el software de administración, el cual se dedica por completo a atender (dar acceso) a los archivos en la red. El NAS alivia al servidor de manejar almacenamiento, con el fin de que pueda procesar otras aplicaciones, como el correo electrónico y las bases de datos. Los discos pueden guardar muchos terabytes de datos en un pequeño espacio central y la administración de un almacenamiento grande en un solo lugar ahora dinero. La escalabilidad del NAS es buena. Aunque en el NAS cada servidor ejecuta su propio sistema operativo, NAS puede comunicarse con otros servidores que ejecuten sistemas operativos diferentes y, por lo tanto, es mucho más flexible al agregar computadoras y otros dispositivos a la red. Red de Área de Almacenamiento (SAN). La red de área de almacenamiento (SAN) es una red completamente dedicada al almacenamiento y la transferencia de datos entre los servidores y los dispositivos de almacenamiento. Los dispositivos de almacenamiento son parte de esta red dedicada, la cual se administra separada de la red de área local de la organización. Una SAN puede combinar dispositivos DAS y NAS. Las líneas de comunicación en esta red son fibras ópticas de alta velocidad. Un NAS identifica los datos mediante archivos. Una SAN identifica cantidades mucho mayores de datos, llamadas bloques de datos y, por lo tanto, puede transferir y respaldar cantidades mucho mayores de datos a la vez. Esto es importante cuando se requiere una transferencia de datos de alta velocidad, como en las transacciones empresariales en línea que contienen una gran cantidad de registros en una base de datos almacenada. Muchos usuarios pueden acceder al mismo tiempo a los datos, sin retrasos. Las SAN tienen una alta escalabilidad. Por estas razones, las SAN son utilizadas por las organizaciones que efectúan negocios en la Web y requieren un procesamiento de transacciones de alto volumen. Si embargo, las SAN son relativamente costosas y su administración es compleja. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN El DAS, el NAS y la SAN suelen incluir RAID (conjunto redundante de discos independientes), en donde los datos se duplican en diferentes discos para mejorar la velocidad de procesamiento y la tolerancia a las fallas. La tolerancia a las fallas es la capacidad del sistema para soportar una falla en un disco, debido a que los mismos datos también aparecen en otro disco. Para de: comparar los dispositivos de almacenamiento, es útil aplicar los criterios Versatilidad, Durabilidad, Velocidad y Capacidad. Algunos dispositivos de almacenamiento acceden a los datos sólo desde un tipo de medio. Los dispositivos más versátiles acceden a los datos desde medios distintos. Por ejemplo, una unidad de discos flexibles sólo tiene acceso a los discos flexibles, mientras que una unidad de DVD tiene acceso a los DVD’s de computadora, las películas en DVD, los CD’s de audio, los CD’s de computadora, y los CD-R’s. Casi todas las tecnologías de almacenamiento son susceptibles a daños por manejo deficiente u otros factores ambientales, como el calor y la humedad. Algunas tecnologías son más susceptibles que otras a sufrir un daño que pueda provocar la pérdida de datos. Por ejemplo, los CD’s y los DVD’s tienden a ser más durables que los discos duros. El acceso rápido a los datos es importante, de modo que se prefieren los dispositivos de almacenamiento más rápidos. El tiempo de acceso es el tiempo promedio que tarda una computadora en localizar los datos en el medio de almacenamiento y leerlos. El tiempo de acceso para un dispositivo de almacenamiento de una computadora personal, como un disco duro, se mide en milisegundos (millonésimas de segundo). Un milisegundo (ms) es la milésima parte de un segundo. Los números más bajos indican tiempos de acceso más rápidos. Por ejemplo, una unidad con un tiempo de acceso de 6 ms es más rápida que una unidad con un tiempo de acceso de 11 ms. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN El tiempo de acceso es mejor para los dispositivos de acceso aleatorio. El acceso aleatorio (también llamado acceso directo) es la capacidad de un dispositivo para "saltar" directamente a los datos solicitados. Las unidades de disco flexible, disco duro, CD, DVD y de estado sólido son dispositivos de acceso aleatorio, al igual que las tarjetas de memoria utilizadas en las cámaras digitales. Por otra parte, una unidad de cinta debe utilizar un acceso secuencial más lento para leer los datos desde el principio de la cinta. La ventaja del acceso aleatorio se vuelve evidente cuando considera que es mucho más rápido y fácil localizar una canción en un CD (acceso aleatorio) que en un cassette (acceso secuencial). La velocidad de transferencia de datos es la cantidad de datos que puede mover un dispositivo de almacenamiento por segundo desde el medio de almacenamiento hacia la computadora. Los números más altos indican velocidades de transferencia más rápidas. Por ejemplo, una unidad de CD-ROM con una velocidad de transferencia de datos de 600 KBps (kilobytes por segundo) es más rápida que una velocidad de transferencia de datos de 300 KBps. En el ambiente de la computación actual, casi siempre se prefiere una mayor capacidad. La capacidad de almacenamiento es la máxima cantidad de datos que se pueden conservar en un medio de almacenamiento, y se mide en kilobytes, megabytes, gigabytes o terabytes. La capacidad de almacenamiento se relaciona directamente con la densidad de almacenamiento, la cantidad de datos que se pueden guardar en un área específica de un medio de almacenamiento, como la superficie de un disco. Entre más alta es la densidad de almacenamiento, se conservan más datos. La densidad de almacenamiento puede aumentar al hacer más pequeñas las partículas que representan los bits, al ponerlas en capas, al guardarlas más cerca entre sí o al apilarlas. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN 3.5 HERRAMIENTAS DE EXPLOTACIÓN. 3.5.1 Sistema de Administración de bases de datos (DBMS). El enfoque de administración de base de datos, como la base de los métodos modernos de administrar datos organizativos. El enfoque de administración de base de datos consolida de manera formal los registros de datos en archivos separados dentro de bases de datos, que pueden ser accesadas por muchos programas de aplicación diferentes. Además, un sistema de administración de bases de datos (DBMS, siglas del término database management system) actúa como una interfase de software entre los usuarios y las bases de datos. Esto ayuda a los usuarios a acceder con facilidad a la información de una base de datos. Por eso, la administración de base de datos implica el uso del software de administración de bases de datos para controlar la forma en que se crean, consultan y se da mantenimiento a las bases de datos y para proporcionar la información necesaria a los usuarios finales. Por ejemplo, los registros de clientes y otros tipos comunes de datos son necesarios para diferentes aplicaciones bancarias, tales como procesamiento de cheques, sistemas de cajeros automáticos, tarjetas de crédito bancarias, cuentas de ahorros y contabilidad de créditos revolventes. Estos datos pueden consolidarse. En una base común de datos de clientes, en lugar de mantenerlos en archivos separados para cada una de esas aplicaciones. Por ejemplo tenemos el caso de la compañía Kingslake que utiliza la conexión de clientes e información en Sri Lanka: Los representantes de ventas viajan en motocicleta en la carretera durante semanas a la vez. La fuerza de ventas de la empresa de servicios públicos recorre largos trayectos que duran días, desde su oficina hasta los medidores. Es un ambiente donde las personas y los negocios están tan dispersos, y la comunicación es tan vital, que algunos elegirían un teléfono celular en lugar de un refrigerador. Es la forma usual de hacer negocios en Sri Lanka. Estos escenarios explican por qué las empresas en Sri Lanka buscan con desesperación formas de mejorar la productividad de sus fuerzas de ventas, y dan la bienvenida a la tecnología como la herramienta para lograrlo. Esto también explica por qué Kingslake International, con base en Sri Lanka, una empresa de consultoría y administración de proyectos para Europa con sede en el Reino Unido, que se enfoca en soluciones innovadoras de TI en el país, ha colocado buena parte de su capital para desarrollar computación móvil y soluciones de administración de datos. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Kingslake se encontró a sí misma limitada en el tipo de aplicaciones móviles para la automatización de la fuerza de ventas que podría desarrollar, porque no existían bases de datos. Sin software de bases de datos, las aplicaciones tenían que depender de funciones básicas y de bajo nivel de administración de datos, no podían sincronizarse y no permitían a los usuarios manipular datos en sus dispositivos de mano. Además, Kingslake exigía cuatro condiciones no negociables: confiabilidad, capacidad de trabajar con baterías, una pequeña superficie y un excelente apoyo del proveedor. Sus condiciones y la oportunidad de ampliar su capacidad de desarrollar soluciones móviles sofisticadas, se cumplieron con el DB2 Everyplace de IBM. Son muchos los ejemplos de los beneficios de la administración móvil de datos. Uno es la solución de automatización de la fuerza de ventas para una empresa que envía a sus representantes de ventas lejos con camionetas cargadas de bienes. Antes, estos representantes pasaban 30 por ciento de su tiempo en trabajos de papelería: escribiendo pedidos para productos que no estaban en la camioneta, emitiendo facturas y regresando luego con dificultades a las oficinas centrales para asegurarse de que el papeleo se procesara. La solución DB2 Everyplace les permitió trabajar con mayor productividad 100 por ciento de su tiempo. Al portar dispositivos móviles, los representantes de ventas podían conectarse con su sistema central para colocar los pedidos directamente desde el lugar donde se encontraran, emitir las facturas y realizar las comprobaciones de crédito en el lugar. Otra aplicación da seguimiento a todo el proceso de una empresa que recoge y renueva llantas de camiones de sus clientes y luego se las regresa. En este caso, la integración entre la aplicación portátil y la aplicación de planeación de recursos empresariales (ERP, siglas del término Enterprise Resource Planning) de la empresa es crítica porque la fuerza de ventas tiene que confirmar los programas de fabricación y las fechas de entrega directamente desde el campo. Incluso otra solución, para una empresa de servicio público de electricidad, permite a los lectores de medidores que viajan lejos, descargar la cuenta del cliente y los códigos de subsidio, introducir y almacenar valiosos datos de semanas, calcular con precisión los costos en sus dispositivos de mano y emitir facturas en el lugar. La ventaja más importante es que los ciudadanos de una economía desafiada por la distancia se han acercado más unos a otros, y a su información. ¡El negocio está prosperando! SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Un sistema de administración de base de datos (DBMS, siglas del término database management system) es la herramienta principal de software del enfoque de la administración de base de datos, dado que controla la creación, el mantenimiento y el uso de las bases de datos de una organización y de sus usuarios finales. Los paquetes de administración de bases de datos para microcomputadoras, tales como Microsoft Access, Lotus Approach o Corel Paradox, permiten configurar y administrar bases de datos en una PC, servidor de red o Internet. En sistemas informáticos de grandes sistemas centrales (mainframe) o de servidores, el sistema de administración de bases de datos es un importante paquete de software que controla el desarrollo, uso y mantenimiento de las bases de datos de las organizaciones que utilizan computadoras. Ejemplos de versiones populares de mainframe y de servidor de software de sistema de administración de base de datos son DB2 Universal Database de IBM, Oracle 10G y MySQL, un popular sistema de administración de bases de datos de código libre. Principales funciones de un DBMS. Las tres principales funciones de un sistema de administración de base de datos son: (1) Crear nuevas bases de datos y aplicaciones para ellas, (2) Mantener la calidad de la información en las bases de datos de una organización y (3) Utilizar las bases de datos de una organización para proporcionar la información necesaria a sus usuarios finales. Si bien una base de datos es un conjunto de varios archivos relacionados, el programa utilizado para desarrollar bases de datos, llenarlas con datos y manipular los datos se llama un sistema de administración de bases de datos (DBMS). Los archivos mismos son la base de datos, pero los DBMS hacen todo el trabajo: estructuran los archivos, guardan los datos y vinculan los registros. Si usted emplea una base de datos, necesita moverse con rapidez de un registro a otro, clasificarlos mediante diversos criterios, crear diferentes tipos de informes y analizar los datos de distintas maneras. Por estas necesidades, las bases de datos se guardan en o se procesan desde dispositivos de almacenamiento con acceso directo, como los discos magnéticos o los CD. Se pueden respaldar en dispositivos de almacenamiento secuencial, como las cintas magnéticas u ópticas, pero no se procesan con eficiencia desde tales medios porque se requiere mucho tiempo para acceder a los registros. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN El desarrollo de base de datos implica definir y organizar el contenido, las relaciones y la estructura de los datos necesarios para construir una base de datos. El desarrollo de la aplicación de base de datos implica utilizar un sistema de administración de bases de datos para desarrollar prototipos de consultas, formularios, reportes y páginas Web para una aplicación de negocio propuesta. Consulta de bases de datos. Se accede a los datos en una base de datos al enviar mensajes conocidos como "consultas", los cuales solicitan los datos de los recursos y/o campos específicos e indican a la computadora que muestre los resultados. También se introducen consultas para manipular los datos. Por lo general el mismo software que sirve para desarrollar y llenar una base de datos, es decir, el DBMS, sirve para presentar consultas. Los DBMS modernos ofrecen medios fáciles para que el usuario consulte una base de datos La capacidad de consulta de una base de datos es un beneficio importante del enfoque de la administración de base de datos. Los usuarios finales pueden utilizar un sistema de administración de base de datos para solicitar información desde una base de datos mediante el uso de una característica de consulta o un generador de reportes. Pueden recibir una respuesta inmediata en forma de pantallas de video o de reportes impresos. No se requiere una programación difícil. La característica de lenguaje de consulta permite obtener con facilidad respuestas inmediatas a solicitudes específicas de datos: usted sólo teclea unas cuantas solicitudes breves. La característica del generador de reportes permite especificar de manera expedita un formato de reporte para la información que se quiera presentar como un reporte. Operaciones relacionales. Los DBMS más populares son los que apoyan el modelo relacional. Por lo tanto, a usted le serviría familiarizarse con una base de datos relacional muy utilizada, como Access, Oracle o SQL Server. Al emplearla, sabrá como funcionan las operaciones relacionales. Una operación relacional crea una tabla temporal que es un subconjunto de la tabla o tablas originales. Le permite crear un informe que contenga registros que satisfagan una condición, crear una lista con solo algunos campos acerca de una entidad o generar un informe de una tabla combinada, la cual incluye datos relevantes de dos o más tablas. Si lo requiere, el usuario puede guardar la tabla recién creada. Casi siempre la tabla temporal solo se necesita para un informe ad hoc y suele desecharse de inmediato. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Las tres operaciones relacionales más importantes son: La selección de los registros que cumplen ciertas condiciones. Por ejemplo, un gerente de recursos humanos necesita un informe que muestre el registro completo de cada empleado cuyo sueldo es mayor de $60 000. Proyección es la selección de ciertas columnas de una tabla, como los sueldos de todos los empleados. Una consulta puede especificar una combinación de selección y proyección. En el ejemplo anterior, el gerente puede requerir solo el número de identificación, el apellido (proyección) y el sueldo de los empleados que superan los $60 000 (selección). Una de las manipulaciones más útiles de una base de datos relacional es la creación de una tabla nueva a partir de dos o más tablas. La combinación de datos de varias tablas se llama una join (combinación). Sin embargo, las consultas combinadas pueden ser mucho más complejas. Por ejemplo, una base de datos relacional empresarial puede tener cuatro tablas: Vendedores, Catalogo, Pedidos y Clientes. Un gerente puede necesitar un informe que muestre, para cada vendedor, una lista de todos los clientes que compraron algo el mes anterior, los artículos que adquirió cada cliente y la cantidad total que gasto cada uno. Se crea una tabla nueva a partir de la operación relacional que extrae datos de las cuatro tablas. La operación de combinación es una manipulación poderosa que puede crear informes muy útiles para tomar decisiones. Una tabla combinada se crea "en un paso" como resultado de una consulta y solo mientras el usuario quiera verla o imprimirla. Las funciones de diseño permiten al usuario cambiar el encabezado de los campos (aunque los nombres de los campos se conservan intactos en la tabla interna), preparar el resultado en diferentes diseños en la pantalla o el papel y agregar imágenes y texto al informe. La tabla nueva puede guardarse como una tabla adicional en la base de datos. El esquema. Al desarrollar una base de datos nueva, los usuarios primero desarrollan un esquema (de la palabra griega que significa "plan"). El esquema describe la estructura de la base de datos que se diseña: los nombres y tipos de los campos en cada tipo de registro y las relaciones generales entre los diferentes conjuntos de registros o archivos. Incluye una descripción de la estructura de la base de datos, los nombres y tamaños de los campos y detalles como cual campo es una SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN llave principal. El número de registros no se especifica nunca porque puede cambiar y la capacidad del medio de almacenamiento determina el número máximo de registros. Los campos pueden contener diferentes tipos de datos: numéricos, alfanuméricos, imágenes o relacionados con el tiempo. Los campos numéricos contienen números que se manipulan mediante suma, multiplicación, promedio y demás. Los campos alfanuméricos contienen valores de texto: palabras, números y símbolos especiales, los cuales forman nombres, direcciones y números de identificación. Los números introducidos en los campos alfanuméricos, como el número del seguro social o el código postal, no se manipulan matemáticamente. El diseñador de una base de datos nueva también debe indicar cuales campos se van a usar como llaves principales, Muchos DBMS también permiten a un diseñador indicar cuando un campo no es único, lo que significa que el valor en ese campo puede ser igual para más de un registro. Una tabla de bases de datos creada con el DBMS Microsoft Access. Se pide al usuario que introduzca los nombres y tipos de los campos. Access permite al usuario nombrar los campos y determinar los tipos de datos. La sección descripción permite al diseñador describir la naturaleza y las funciones de los campos para las personas que conservan la base de datos. La parte inferior de la ventana ofrece al usuario muchas opciones para cada campo, como el tamaño y el formato del campo y demás. En Access, el campo de la llave principal se indica mediante un icono de una llave pequeña a su izquierda. Los metadatos. La descripción de cada estructura de la tabla y tipos de los campos se vuelve parte de un diccionario de datos, el cual es un depósito de información acerca de los datos y su organización. Los diseñadores suelen agregar mas información sobre cada campo, como de donde provienen los datos (de otro sistema o introducidos de manera manual); quien posee los datos originales; a quien se le permite agregar, eliminar o actualizar los datos del campo; y otros detalles que ayudan a los DBA a conservar la base de datos y comprender el significado de los campos y sus relaciones. (Algunas personas prefieren llamar a esto metadatos, lo cual significa "datos acerca de los datos"). Entre los metadatos estan: El origen de los datos, entre ellos información de una persona para comunicarse. Las tablas relacionadas con los datos. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Información del campo y del índice, como el tamaño y tipo del campo (de texto o numérico) y los modos en que se clasifican los datos. Los programas y procesos que emplean los datos. Las reglas de llenado: que se inserta o actualiza y con cuanta frecuencia. Lenguaje de consulta estructurado. SQL (Strutctured Query Language (lenguaje de consultas estructurado) es un lenguaje internacional estándar de consulta, que se encuentra en muchos paquetes de sistemas de administración de bases de datos. La forma básica de una consulta SQL es: SELECT… FROM… WHERE Después de la cláusula SELECT se hace una lista de los campos de datos que se quieren recuperar. Después de la cláusula FROM se hace una lista de los archivos o tablas desde los cuales deben recuperarse los datos. Después de la cláusula WHERE se especifican las condiciones que limitan la búsqueda a sólo aquellos registros de datos en los cuales se está interesado. El lenguaje de consulta estructurado (SQL) se ha convertido en el lenguaje de consulta preferido por muchos desarrolladores de DBMS relacionales. SQL es un estándar internacional y se proporciona con casi todos los programas de administración de una base de datos relacional. Su ventaja son sus comandos intuitivos fáciles de recordar. Por ejemplo suponga que el nombre de la base de datos es DVD_Store, para crear una lista de todos los títulos de DVD de "acción" cuyo precio de venta sea menor que $5.00, la consulta seria: SELECT TITLE, CATEGORY FROM DVD_STORE WHERE CATEGORY = 'Thriller' and RENTPRICE < 5 Se emplean instrucciones como esta para las consultas ad hoc o se integran en un programa que se guarda para uso repetido. Los comandos para actualizar las bases de datos también son fáciles de recordar: INSERT, DELETE y UPDATE (insertar, eliminar y actualizar). Existen varias ventajas de integrar el SQL en un DBMS: Con un lenguaje estándar, los usuarios no tienen que aprender con juntos de comandos diferentes para crear y manipular bases de datos en diferentes DBMS. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Las instrucciones del SQL se incluyen en lenguajes de tercera generación muy utilizados como COBOL o C y en los lenguajes orientados a objetos como C++ o Java, en cuyo caso estos lenguajes se llaman "lenguajes anfitriones". La combinación de instrucciones de 3GL muy adaptadas y eficientes, e instrucciones orientadas a objetos con SQL aumenta la eficiencia y la eficacia de las aplicaciones que consultan las bases de datos relacionales. Debido a que las instrucciones del SQL se pueden trasladar de un sistema operativo a otro, el programador no se ve obligado a redactar de nuevo las instrucciones. Algunos DBMS relacionales como Microsoft Access, proporcionan GUI para crear consultas de SQL, las cuales se preparan al hacer clic en iconos y seleccionar elementos de un menú, los cuales se convierten de manera interna en consultas de SQL y se ejecutan. Esta capacidad permite emplear el SQL a los diseñadores poco experimentados con una base de datos. Consultas gráficas y naturales. Muchos usuarios finales (y profesionales de SI) tienen dificultades para formular de manera correcta estatutos SQL y consultas de otros lenguajes de bases de datos. De modo que la mayoría de los paquetes de administración de bases de datos para usuarios finales ofrecen métodos de interfase gráfica de usuario (GUI, siglas del término graphical user interface) de apuntar y pulsar, que son más fáciles de usar y son traducidos por el software en comandos SQL. Seguridad y privacidad en bases de datos. El uso de las bases de datos plantea problemas de seguridad y privacidad. El hecho de que los datos se guarden solo una vez en una base de datos para varios propósitos diferentes no significa que todos los que consultan esa base de datos tengan acceso a todos los datos que contiene. La limitación del acceso se consigue al personalizar los menús de los diferentes usuarios y al solicitar a los diferentes usuarios que introduzcan códigos que limitan el acceso a ciertos campos o registros. Como resultado, los usuarios tienen vistas diferentes de la base de datos. La posibilidad de limitar las vistas de los usuarios a solo columnas con registros específicos da otra ventaja al administrador de una base de datos (DBA): la posibilidad de implementar medidas de seguridad. Las medidas se implementan una vez para la base de datos, en vez de varias veces para archivos distintos. Por ejemplo, en una base de datos empresarial aunque el gerente de recursos humanos tiene acceso a todos los campos del archivo de los empleados, el personal de nómina solo tiene acceso a cuatro campos y el gerente de SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN proyectos solo tiene acceso a los campos del nombre y las horas trabajadas. En una base de datos, las vistas se pueden limitar a ciertos campos, ciertos registros o una combinación de ambos. Mantenimiento de la base de datos. El proceso de mantenimiento de la base de datos se logra mediante sistemas de procesamiento de transacciones y otras aplicaciones de usuario final, con el apoyo del sistema de administración de bases de datos. Los usuarios finales y los especialistas en información también pueden emplear varias utilerías proporcionadas por un sistema de administración de bases de datos para el mantenimiento de bases de datos. Las bases de datos de una organización necesitar ser actualizadas de continuo para reflejar nuevas transacciones de negocio (tales como ventas realizadas, productos fabricados o inventario distribuido) y otros eventos. Otros cambios diversos también deben actualizarse y los datos corregirse (tales como cambios en el nombre y dirección de clientes o empleados), para asegurar la precisión de los datos en las bases de datos. El mantenimiento de base de datos implica utilizar sistemas de procesamiento de transacciones y otras herramientas para añadir, borrar, actualizar y corregir la información de una base de datos. El uso principal de una base de datos por parte de los usuarios finales implica emplear las capacidades de consulta de base de datos de un sistema de administración de bases de datos para accesar la información de una base de datos, con el fin de recuperar y desplegar información y producir reportes, formularios y otros documentos de manera selectiva. 3.5.2 DESARROLLO DE APLICACIONES. Los paquetes de sistemas de administración de bases de datos también desempeñan una función primordial en el desarrollo de aplicaciones. Los usuarios finales, analistas de sistemas y los desarrolladores de otras aplicaciones pueden utilizar un módulo de un 4GL (lenguaje de programación de cuarta generación). Los programadores emplean este módulo para desarrollar aplicaciones que faciliten las consultas y produzcan informes diseñados con anticipación. y herramientas de desarrollo de software integradas proporcionadas por muchos paquetes de sistemas de administración de bases de datos, para desarrollar programas de aplicación a la medida. Por ejemplo, se puede utilizar un sistema de administración de bases de datos para desarrollar con facilidad las pantallas de captura, formularios, reportes o páginas Web de una aplicación de negocio que SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN tenga acceso a la base de datos de una empresa para encontrar y actualizar los datos que necesita. Un sistema de administración de bases de datos también facilita el trabajo de los desarrolladores de software de aplicación, dado que no tienen que desarrollar procedimientos detallados de manejo de datos mediante el uso de lenguajes de programación convencionales cada vez que escriben un programa. En lugar de eso, pueden incluir características tales como estatutos de lenguaje de manipulación de datos (DML, siglas del término Data Manipulation Language) en su software, que llaman al sistema de administración de bases de datos para realizar las actividades necesarias del manejo de datos. 3.5.3 BASES DE DATOS EN LA WEB. Internet y la fácil de usar Web prácticamente no servirían si las personas no pudieran consultar las bases de datos en línea. La premisa de la Web es que las personas no solo se desplacen por páginas Web atractivas, sino también que busquen y localicen información. Con mucha frecuencia esa información se guarda en bases de datos. Cuando un comprador entra a una tienda en línea, puede buscar información entre miles o cientos de miles de artículos ofrecidos para venta. Por ejemplo, cuando usted entra al sitio de Buy.com, recibe información en línea (como una imagen de un artículo electrónico, el precio, el tiempo de embarque y las evaluaciones de los clientes) de miles de artículos en venta. Los mayoristas ponen sus catálogos en línea. Las aplicaciones en los sitios de subastas reciben consultas por categoría, rango de precios, país u origen, color, fecha y otros atributos y registros de identidad de los artículos que coinciden, entre los cuales están imágenes y descripciones detalladas. Detrás de cada uno de estos sitios esta una base de datos. La única manera para que las organizaciones efectúen estas actividades basadas en la Web es permitir el acceso a sus bases de datos a las personas que están fuera de la organización. En otras palabras, las organizaciones deben vincular sus bases de datos a Internet. Desde un punto de vista técnico, las bases de datos en línea que se usan con los navegadores Web no son diferentes de otras bases de datos. Sin embargo, debe diseñarse una interfaz que funcione con la Web. El usuario debe observar un formulario en el cual introducir consultas o palabras clave para obtener información de la base de datos del sitio. Los diseñadores de la interfaz deben proporcionar un mecanismo para determinar que datos deben insertar los usuarios en los formularios en línea con el fin de colocarlos en los campos adecuados de la base de datos. El sistema también necesita un mecanismo para trasladar las consultas y las palabras clave del usuario a la base de datos. Hay varios SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN programas de interfaz, como CGI (Interfaz Común de Gateway), los servlets de Java, las Páginas Activas del Servidor (ASP) y las API (Interfaz de Programas de Aplicación). Para asegurar que sus bases de datos de producción no sean vulnerables a ataques a través de Internet, las organizaciones evitan vincular sus bases de datos de transacciones a Internet, a menos que estén dedicadas a las transacciones en línea, en cuyo caso la organización debe aplicar software adecuado de seguridad. También deben tener cuidado al vincular un almacén de datos (Data warehouse) con Internet. 3.5.4 EXTRACCIÓN DE DATOS Y ANÁLISIS EN LÍNEA. Por sí solos, los almacenes de datos son inútiles. Para que se vuelvan útiles, las organizaciones deben emplear herramientas de software para convertir el contenido de estas enormes bases de datos en información significativa. Debido a que los ejecutivos obtienen mucha más información acerca de sus clientes, proveedores y de sus propias organizaciones, prefieren llamar a la información extraída con tales herramientas inteligencia de negocios (BI). Siendo sus usos principales para estas bases de datos: la minería de datos y el procesamiento analítico en línea. Minería de datos. Podemos considerar a los almacenes de datos como una especie de mina, en donde los datos son el mineral, y la información útil nueva es un hallazgo precioso. La minería de datos es el proceso de elegir, explorar y modelar grandes cantidades de datos para descubrir relaciones antes desconocidas que apoyen la toma de decisiones. El software de minería de datos busca por enormes cantidades de datos patrones de información significativos. Si bien algunas herramientas ayudan a detectar relaciones y proporciones predefinidas, no responden lo que las herramientas de minería de datos más poderosas pueden contestar: “Cuáles son las relaciones que todavía no conocemos?”. Esto se debe a que, para comenzar, el investigador debe determinar cuál relación debe buscar el software. Para responder esta pregunta, se utilizan otras técnicas en minería de datos, entre ellas las de inteligencia artificial. Para ilustrar la diferencia entre las consultas tradicionales y las consultas en la minería de datos, piense en los ejemplos siguientes. Una consulta tradicional común sería: “ es la relación entre la cantidad del producto X y la cantidad del SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN producto Y que vendimos durante el trimestre anterior?”. Una consulta de minería de datos normal sería: “Descubrir cuáles son los dos productos que es más probable que se vendan juntos un fin de semana”. Esta última consulta permite al software encontrar patrones que no se detectarían mediante la observación. Si bien los datos se han empleado para ver si existe éste o qué patrón, la minería de datos le permite preguntar cuáles patrones existen. Por lo tanto, algunos expertos dicen que la minería de datos permite que la computadora responda las preguntas que usted no sabe formular. La combinación de técnicas de almacenamiento de datos y software de minería de datos facilita predecir los resultados futuros con base en los patrones descubiertos dentro de los datos históricos. La minería de datos tiene cuatro objetivos principales: • Secuencia o análisis de rutas. La detección de patrones donde un evento conduce a otro evento posterior. • Clasificación. La determinación de si ciertos hechos caen dentro de grupos predefinidos. • Agrupamiento. La detección de grupos de hechos relacionados no detectados antes. • Predicción. El descubrimiento de patrones en los datos que conduzcan a predicciones razonables. Estas técnicas se usan en mercadotecnia, detección de fraudes y otras áreas. La minería de datos es muy usada por los gerentes de mercadotecnia, quienes en forma constante analizan patrones de compra para orientarse a los clientes potenciales de manera más eficiente mediante ventas especiales, exhibiciones de productos o campañas de correo directo o electrónico. La minería de datos es un recurso muy poderoso en un ambiente en el que las empresas cambian de comercializar un producto de manera masiva a erigir el cliente individual con diversos productos que quizá lo satisfagan. Algunos observadores llaman a este método “mercadotecnia para uno”. Predicción del comportamiento del cliente. La minería de datos también se emplea en actividades bancarias, en donde sirve para detectar los clientes rentables y los patrones de fraudes. También se usa para predecir las quiebras y el incumplimiento de los préstamos. Por ejemplo, cuando Bank of America buscaba nuevos métodos para conservar clientes, usó técnicas de minería de datos. Combinó diversos patrones de comportamiento en perfiles del cliente bien asignados. Los datos se usaban en grupos más pequeños de personas que utilizaban servicios bancarios que no apoyaban bien sus actividades. Los empleados bancarios se comunicaban con estos clientes y ofrecían sugerencias SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN sobre servicios más satisfactorios. El resultado fue una mayor lealtad de la clientela (medida en menos cuentas canceladas y menos transferencias a otros bancos). Las personas contactadas pensaban que el banco intentaba cuidar bien su dinero. Posibles aplicaciones de la minería de datos. Agrupamiento de clientes: Identificar las características comunes de los clientes que tienden a comprar los mismos productos y servicios de su compañía. Detección de cambio de proveedor: Identificar la razón por la que los clientes se cambian con un competidor; predecir qué clientes es probable que hagan eso. Detección de fraudes: Identificar las características de las transacciones que tengan más probabilidad de ser fraudulentas. Mercadotecnia directa: Identificar qué clientes prospectivos deben incluirse en el correo directo o electrónico para obtener la tasa de respuestas más alta. Mercadotecnia interactiva: Predecir qué es lo más probable que le interese a cada persona que consulta un sitio Web. Análisis de la canasta del mercado: Comprender cuáles productos o servicios se compran juntos y en cuáles días de la semana. Análisis de tendencias: Revelar la diferencia entre un cliente normal en este mes y un cliente normal en el mes anterior. Las empresas que venden servicios de telefonía celular o móvil encaran un creciente desafío de inquietud de los clientes (se cambian con un competidor). Algunas encuestas muestran que más de 50% de los usuarios de teléfonos celulares piensa en cambiarse con un competidor en cierto momento y 15% planean cambiarse con un competidor tan pronto como expire su contrato. Mobilcom GmbH, una empresa alemana con 4.56 millones de clientes y 1100 empleados, emplea la minería de datos para identificar a tales clientes y SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN abordarlos con ofertas para continuar o renovar su contrato antes del cambio. La compañía emplea una aplicación llamada DB Intelligent Miner de IBM. El software busca en forma periódica patrones de inquietud de los clientes y designa a cada cliente una calificación que representa la probabilidad de cancelar el contrato. El software considera muchas variables, entre ellas el número de días que faltan para que venza el contrato y el historial de quejas. La lealtad de los clientes es muy importante porque el costo de obtener un nuevo cliente es muy superior al costo de conservar a quien ya lo es, sobre todo en un mercado muy competitivo como el de los teléfonos celulares. Para asegurar un flujo uniforme de datos de clientes en sus almacenes de datos, las compañías en casi todas las industrias —desde aerolíneas hasta de alojamiento, comida y apuestas— operan programas de clientes leales similares a los programas originales de viajero frecuente. La participación es gratuita y los clientes dejan un registro cada vez que hacen una compra incluso si no emplean una tarjeta de crédito para pagar. En muchos casos la extracción de tales datos aporta la inteligencia de negocios para orientarse a los clientes individuales. Procesamiento analítico en línea (OLAP). Otro tipo de aplicación para aprovechar los almacenes de datos tal vez no sea tan sofisticado en términos del análisis efectuado, pero su respuesta es muy rápida y permite a los ejecutivos tomar decisiones oportunas: el procesamiento analítico en línea (OLAP). Las tablas, incluso si reúnen datos de varias fuentes, limitan la revisión de la información. Los ejecutivos suelen necesitar de la información en varias combinaciones de dos dimensiones. Por ejemplo, una ejecutiva quiere ver un resumen de la cantidad de cada producto vendida en cada región. Después, quiere ver las cantidades totales de cada producto vendidas dentro de cada ciudad de una región. Y es posible que quiera ver las cantidades vendidas de un producto específico en todas las ciudades de todas las regiones. El OLAP está especialmente diseñado para responder consultas como éstas. Las aplicaciones OLAP permiten a un usuario girar “cubos” de información virtuales, en donde cada lado del cubo ofrece otras dos dimensiones de información relevante. La fuerza del OLAP. Las aplicaciones OLAP operan sobre los datos organizados especialmente para tal uso o procesan los datos de bases de datos relacionales. Una aplicación OLAP dinámica responde a los comandos mediante la preparación de tablas “mientras funciona”. Para acelerar la respuesta, las bases de datos se organizan en primer lugar como dimensionales. En las bases de datos dimensionales —también llamadas bases de datos multidimensionales— los datos básicos se organizan en tablas que muestran la información en resúmenes y en proporciones, para que SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN quien consulta no tenga que esperar el procesamiento de los datos básicos. Muchas empresas organizan los datos en bases de datos relacionales y almacenes de datos, pero también emplean aplicaciones que en forma automática resumen esos datos y organizan la información en bases de datos dimensionales para OLAP. Oracle, Cognos, Hyperion y muchas otras compañías venden paquetes de bases de datos multidimensionales y herramientas OLAP para emplearlas. Las aplicaciones OLAP responden con facilidad a preguntas como “ Qué productos se venden bien?” o “ están mis oficinas de ventas con el peor desempeño?”. Observe que, aun que la palabra “cubo” se usa para ilustrar la multidimensionalidad de las tablas OLAP, la cantidad de tablas no se limita a seis, el cual es el número de lados de un cubo real. Es posible producir tablas que muestran las relaciones de dos variables que estén en la bases de datos, siempre y cuando existan los datos. OLAP permite a los administradores ver los resúmenes y las proporciones de la intersección de cualesquiera dos dimensiones. Las aplicaciones OLAP son recursos poderosos para los ejecutivos. Las aplicaciones OLAP se suelen instalar en un servidor especial ubicado entre la computadora del usuario y el servidor o los servidores que contienen un almacén de datos o bases de datos dimensionales (aunque OLAP también puede procesar datos de una base de datos de transacciones). Como las aplicaciones OLAP están diseñadas para procesar grandes cantidades de registros y producir resúmenes, suelen ser mucho más rápidas que las aplicaciones relacionales como las que utilizan consultas de SQL (Lenguaje de Consulta Estructurado). Las aplicaciones OLAP pueden procesar 20 000 registros por segundo. Como ya se mencionó, al emplear tablas dimensionales preorganizadas, el único procesamiento es encontrar la tabla que corresponde a las dimensiones y el modo de presentación (como valores o porcentajes) que especificó el usuario. OLAP y técnicas similares ayudan a los administradores y otros usuarios a analizar con rapidez lo que sucede en los negocios. Los administradores en algunas compañías ahora registran información acerca de sus productos desde la adquisición de materias primas hasta la recepción del pago, no sólo para las operaciones, sino también para aprender más acerca de sus clientes y su propio negocio. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN MICROSOFT OFFICE ACCESS 2007 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CONCEPTOS DE BASE DE DATOS ARCHIVOS DE BASE DE DATOS DE ACCESS TABLAS. CONSULTAS FORMULARIOS INFORMES DISEÑO DE UNA BASE DE DATOS. EL PROCESO DEL DISEÑO DE UNA BASE DE DATOS. ESPECIFICAR CLAVES PRINCIPALES FINALIDAD DE LA BASE DE DATOS BUSCAR Y ORGANIZAR LA INFORMACIÓN DIVIDIR LA INFORMACIÓN EN TABLAS CONVERTIR LOS ELEMENTOS DE INFORMACIÓN EN COLUMNAS ESPECIFICAR CLAVES PRINCIPALES CREAR RELACIONES ENTRE TABLAS INTRODUCCIÓN A MICROSOFT OFFICE ACCESS 2007 CONCEPTOS BÁSICOS. Una base de datos es una colección de información relacionada con un tema u objetivo concreto, como el seguimiento de pedidos de clientes o el mantenimiento de una colección de música. Si la base de datos no está almacenada en un equipo, o sólo lo SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN están partes de la misma, es posible que tenga que hacer el seguimiento de la información en diversos orígenes que tendrá que coordinar y organizar. Por ejemplo, supongamos que los números de teléfono de sus proveedores están almacenados en diversas ubicaciones: en un archivo de tarjetas que contiene los números de teléfono de los proveedores, en archivos de información de los productos, en un archivador y en una hoja de cálculo que contiene información de pedidos. Si cambia el número de teléfono de un proveedor, tendría que actualizar la información en los tres sitios. En una base de datos de Access bien diseñada, el número de teléfono se almacena sólo una vez, de modo que sólo tiene que actualizar esa información en un lugar. Como resultado, al actualizar el número de teléfono de un proveedor, se actualiza automáticamente en cualquier lugar que lo utilice en la base de datos. Archivos de base de datos de Access Puede utilizar Access para administrar todos sus datos en un solo archivo. Dentro de un archivo de base de datos de Access, puede utilizar: Tablas para almacenar los datos. Consultas para buscar y recuperar exactamente los datos que desee. Formularios para ver, agregar y actualizar datos en las tablas. Informes para analizar o imprimir los datos con un diseño específico. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Guardar una vez los datos en una tabla, pero verlos desde varias ubicaciones. Cuando se actualizan los datos, se actualizan automáticamente en cualquier lugar que aparezcan. Recuperar datos mediante una consulta. Ver o introducir datos mediante un formulario. Visualizar o imprimir datos mediante un informe. Todos estos elementos: tablas, consultas, formularios e informes son objetos de Base de Datos. Tablas. Para almacenar los datos, se crea una tabla para cada tipo de información del que se hace un seguimiento. Los tipos de información podrían incluir información de los clientes, productos y otros detalles. Para reunir los datos procedentes de varias tablas en una consulta, formulario o informe, hay que definir las relaciones entre las tablas. La información de los clientes que una vez existió en una lista de direcciones, ahora está ubicada en la tabla Clientes. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN La información de pedidos que una vez estuvo en una hoja de cálculo, ahora está ubicada en la tabla Pedidos. Un identificador exclusivo, como un Id. del cliente, distingue un registro de otro dentro de una tabla. Al agregar un campo de identificador exclusivo de una tabla a otra tabla y definir una relación entre los dos campos, Access puede hacer coincidir los registros relacionados de ambas tablas para que pueda reunirlos en un formulario, informe o consulta. Consultas Una consulta puede ayudarle a recuperar los datos que cumplen las condiciones que especifique, incluidos los datos de varias tablas. También puede utilizar una consulta para actualizar o eliminar varios registros a la vez y realizar cálculos predefinidos o personalizados con los datos. La tabla Clientes tiene información sobre los clientes. La tabla Pedidos tiene información sobre los pedidos de los clientes. Esta consulta recupera el Id. de pedido y los datos de la fecha que se requiere de la tabla Pedidos y el nombre de la compañía y los datos de la ciudad de la tabla Clientes. La consulta sólo devuelve los pedidos que se requerían en abril y sólo para los clientes con sede en Londres. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Formularios Se puede utilizar un formulario para ver, introducir o cambiar los datos de filas de una en una fácilmente. También se puede utilizar un formulario para realizar otras acciones, como enviar datos a otra aplicación. Los formularios contienen normalmente controles que están vinculados a campos subyacentes de las tablas. Al abrir un formulario, Access recupera los datos de una o más tablas y los muestra en el diseño que haya elegido al crear el formulario. Puede crear un formulario mediante uno de los comandos Formulario de la cinta de opciones, el Asistente para formularios, o crear su propio formulario en la vista Diseño. Las tablas muestran muchos registros al mismo tiempo, pero es posible que tenga que desplazarse horizontalmente para ver todos los datos de un solo registro. Asimismo, al visualizar una tabla no puede actualizar los datos de más de una tabla al mismo tiempo. Los formularios se centran en un registro cada vez y pueden mostrar campos de más de una tabla. También pueden mostrar imágenes y otros objetos. Los formularios pueden tener un botón donde hacer clic para imprimir un informe, abrir otros objetos o realizar otras tareas automatizadas. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Informes Los informes se pueden utilizar para analizar rápidamente los datos o presentarlos de una forma concreta, impresos o en otros formatos. Por ejemplo, puede enviar a un colega un informe que clasifique los datos y calcule los totales. O puede crear un informe con los datos de la dirección en un formato para imprimir etiquetas postales. Utilizar un informe para crear etiquetas postales. Utilizar un informe para mostrar los totales en un gráfico. Utilizar un informe para mostrar los totales calculados. Ahora que ya conoce la estructura básica de las bases de datos de Access, siga leyendo para saber cómo utilizar las herramientas integradas para explorar una base de datos de Access concreta. Microsoft Office Access 2007 organiza la información en tablas, que son listas y columnas similares a las de los libros contables o a las de las hojas de cálculo de Microsoft Office Excel 2007. Una base de datos simple puede que sólo contenga una tabla, pero la mayoría de las bases de datos necesitan varias tablas. Por ejemplo, podría tener una tabla con información sobre productos, otra con información sobre pedidos y una tercera con información sobre clientes. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Cada fila recibe también el nombre de registro y cada columna se denomina también campo. Un registro es una forma lógica y coherente de combinar información sobre alguna cosa. Un campo es un elemento único de información: un tipo de elemento que aparece en cada registro. En la tabla Products (Productos), por ejemplo, cada fila o registro contendría información sobre un producto, y cada columna contendría algún dato sobre ese producto, como su nombre o el precio. DISEÑO DE UNA BASE DE DATOS. El proceso de diseño de una base de datos se guía por algunos principios. El primero de ellos es que se debe evitar la información duplicada o, lo que es lo mismo, los datos redundantes, porque malgastan el espacio y aumentan la probabilidad de que se produzcan errores e incoherencias. El segundo principio es que es importante que la información sea correcta y completa. Si la base de datos contiene información incorrecta, los informes que recogen información de la base de datos contendrán también información incorrecta y, por tanto, las decisiones que tome a partir de esos informes estarán mal fundamentadas. Un buen diseño de base de datos es, por tanto, aquél que: Divide la información en tablas basadas en temas para reducir los datos redundantes. Proporciona a Access la información necesaria para reunir la información de las tablas cuando así se precise. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Ayuda a garantizar la exactitud e integridad de la información. Satisface las necesidades de procesamiento de los datos y de generación de informes. EL PROCESO DEL DISEÑO DE UNA BASE DE DATOS. El proceso de diseño consta de los pasos siguientes: Determinar la finalidad de la base de datos Esto le ayudará a estar preparado para los demás pasos. Buscar y organizar la información necesaria Reúna todos los tipos de información que desee registrar en la base de datos, como los nombres de productos o los números de pedidos. Dividir la información en tablas Divida los elementos de información en entidades o temas principales, como Productos o Pedidos. Cada tema pasará a ser una tabla. Convertir los elementos de información en columnas Decida qué información desea almacenar en cada tabla. Cada elemento se convertirá en un campo y se mostrará como una columna en la tabla. Por ejemplo, una tabla Empleados podría incluir campos como Apellido y Fecha de contratación. Especificar claves principales Elija la clave principal de cada tabla. La clave principal es una columna que se utiliza para identificar inequívocamente cada fila, como Id. de producto o Id. de pedido. Definir relaciones entre las tablas Examine cada tabla y decida cómo se relacionan los datos de una tabla con las demás tablas. Agregue campos a las tablas o cree nuevas tablas para clarificar las relaciones según sea necesario. Ajustar el diseño Analice el diseño para detectar errores. Cree las tablas y agregue algunos registros con datos de ejemplo. Compruebe si puede obtener los resultados previstos de las tablas. Realice los ajustes necesarios en el diseño. Aplicar las reglas de normalización Aplique reglas de normalización de los datos para comprobar si las tablas están estructuradas correctamente. Realice los ajustes necesarios en las tablas. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN FINALIDAD DE LA BASE DE DATOS Es conveniente plasmar en papel el propósito de la base de datos: cómo piensa utilizarla y quién va a utilizarla. Para una pequeña base de datos de un negocio particular, por ejemplo, podría escribir algo tan simple como "La base de datos de clientes contiene una lista de información de los clientes para el envío masivo de correo y la generación de informes". Si la base de datos es más compleja o la utilizan muchas personas, como ocurre normalmente en un entorno corporativo, la finalidad podría definirse fácilmente en uno o varios párrafos y debería incluir cuándo y cómo va a utilizar cada persona la base de datos. La idea es desarrollar una declaración de intenciones bien definida que sirva de referencia durante todo el proceso de diseño. Esta declaración de intenciones le permitirá centrarse en los objetivos a la hora de tomar decisiones. BUSCAR Y ORGANIZAR LA INFORMACIÓN Para buscar y organizar la información necesaria, empiece con la información existente. Por ejemplo, si registra los pedidos de compra en un libro contable o guarda la información de los clientes en formularios en papel en un archivador, puede reunir esos documentos y enumerar cada tipo de información que contienen (por ejemplo, cada casilla de un formulario). Si no dispone de formularios, imagine que tiene que diseñar uno para registrar la información de los clientes. ¿Qué información incluiría en el formulario? ¿Qué casillas crearía? Identifique cada uno de estos elementos y cree un listado. Suponga, por ejemplo, que guarda la lista de clientes en fichas. Cada ficha podría contener un nombre de cliente, su dirección, ciudad, provincia, código postal y número de teléfono. Cada uno de estos elementos representa una columna posible de una tabla. Cuando prepare esta lista, no se preocupe si no es perfecta al principio. Simplemente, enumere cada elemento que se le ocurra. Si alguien más va a utilizar la base de datos, pídale también su opinión. Más tarde podrá ajustar la lista. A continuación, considere los tipos de informes o la correspondencia que desea producir con la base de datos. Por ejemplo, tal vez desee crear un informe de ventas de productos que contenga las ventas por región, o un informe de resumen de inventario con los niveles de inventario de los productos. Es posible que también desee generar cartas modelo para enviárselas a los clientes con un anuncio de una actividad de ventas o una oferta. Diseñe el informe en su imaginación y piense cómo le gustaría que fuera. ¿Qué información incluiría en el informe? Cree un listado de cada SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN elemento. Haga lo mismo para la carta modelo y para cualquier otro informe que tenga pensado crear. Detenerse a pensar en los informes y en la correspondencia que desea crear le ayudará a identificar los elementos que necesita incluir en la base de datos. Suponga, por ejemplo, que ofrece a sus clientes la oportunidad de inscribirse o borrarse de las actualizaciones periódicas de correo electrónico y desea imprimir un listado de los que han decidido inscribirse. Para registrar esa información, agrega una columna "Enviar correo electrónico" a la tabla de clientes. Para cada cliente, puede definir el campo en Sí o No. La necesidad de enviar mensajes de correo electrónico a los clientes implica la inclusión de otro elemento. Cuando sepa que un cliente desea recibir mensajes de correo electrónico, tendrá que conocer también la dirección de correo electrónico a la que éstos deben enviarse. Por tanto, tendrá que registrar una dirección de correo electrónico para cada cliente. Parece lógico crear un prototipo de cada informe o listado de salida y considerar qué elementos necesita para crear el informe. Por ejemplo, cuando examine una carta modelo, puede que se le ocurran algunas ideas. Si desea incluir un saludo (por ejemplo, las abreviaturas "Sr." o "Sra." con las que comienza un saludo), tendrá que crear un elemento de saludo. Además, tal vez desee comenzar las cartas con el saludo "Estimado Sr. García", en lugar de "Estimado Sr. Miguel Ángel García". Esto implicaría almacenar el apellido independientemente del nombre. Un punto clave que hay que recordar es que debe descomponer cada pieza de información en sus partes lógicas más pequeñas. En el caso de un nombre, para poder SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN utilizar el apellido, dividirá el nombre en dos partes: el nombre y el apellido. Para ordenar un informe por nombre, por ejemplo, sería útil que el apellido de los clientes estuviera almacenado de forma independiente. En general, si desea ordenar, buscar, calcular o generar informes a partir de un elemento de información, debe incluir ese elemento en su propio campo. Piense en las preguntas que le gustaría que la base de datos contestara. Por ejemplo, ¿cuántas ventas de un determinado producto se cerraron el pasado mes? ¿Dónde viven sus mejores clientes? ¿Quién es el proveedor del producto mejor vendido? Prever esas preguntas le ayudará a determinar los elementos adicionales que necesita registrar. DIVIDIR LA INFORMACIÓN EN TABLAS Para dividir la información en tablas, elija las entidades o los temas principales. Por ejemplo, después de buscar y organizar la información de una base de datos de ventas de productos, la lista preliminar podría ser similar a la siguiente: Las entidades principales mostradas aquí son los productos, los proveedores, los clientes y los pedidos. Por tanto, parece lógico empezar con estas cuatro tablas: una para los datos sobre los productos, otra para los datos sobre los proveedores, otra para los datos sobre los clientes y otra para los datos sobre los pedidos. Aunque esto no complete la lista, es un buen punto de partida. Puede seguir ajustando la lista hasta obtener un diseño correcto. Cuando examine por primera vez la lista preliminar de elementos, podría estar tentado a incluirlos todos ellos en una sola tabla en lugar de en las cuatro tablas SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN mostradas en la ilustración anterior. A continuación le explicaremos por qué eso no es una buena idea. Considere por un momento la tabla que se muestra a continuación: En este caso, cada fila contiene información sobre el producto y su proveedor. Como hay muchos productos del mismo proveedor, la información del nombre y la dirección del proveedor debe repetirse muchas veces, con lo que se malgasta el espacio en disco. Registrar la información del proveedor una sola vez en una tabla Proveedores distinta y luego vincular esa tabla a la tabla Productos es una solución mucho mejor. Otro problema de este diseño surge cuando es necesario modificar la información del proveedor. Suponga, por ejemplo, que necesita cambiar la dirección de un proveedor. Como ésta aparece en muchos lugares, podría sin querer cambiar la dirección en un lugar y olvidarse de cambiarla en los demás lugares. Ese problema se resuelve registrando la información del proveedor en un único lugar. Cuando diseñe la base de datos, intente registrar siempre cada dato una sola vez. Si descubre que está repitiendo la misma información en varios lugares, como la dirección de un determinado proveedor, coloque esa información en una tabla distinta. Por último, suponga que el proveedor Bodega Sol sólo suministra un producto y desea eliminar ese producto pero conservar el nombre del proveedor y la información de dirección. ¿Cómo eliminaría el producto sin perder la información del proveedor? No puede. Como cada registro contiene datos sobre un producto, además de datos sobre un proveedor, no puede eliminar unos sin eliminar los otros. Para mantener estos datos separados, debe dividir la tabla en dos: una tabla para la información sobre los productos y otra tabla para la información sobre los proveedores. Al eliminar un registro de producto sólo se eliminarían los datos del producto y no los datos del proveedor. Una vez seleccionado el tema representado por una tabla, las columnas de esa tabla deben almacenar datos únicamente sobre ese tema. Por ejemplo, la tabla de productos sólo debe contener datos de productos. Como la dirección del proveedor es un dato del proveedor, pertenece a la tabla de proveedores. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN CONVERTIR LOS ELEMENTOS DE INFORMACIÓN EN COLUMNAS Para determinar las columnas de una tabla, decida qué información necesita registrar sobre el tema representado por la tabla. Por ejemplo, para la tabla Clientes, una buena lista de columnas iniciales sería Nombre, Dirección, Ciudad-Provincia-Código postal, Enviar correo electrónico, Saludo y Correo electrónico. Cada registro de la tabla contiene el mismo número de columnas, por lo que puede almacenar información sobre el nombre, dirección, ciudad-provincia-código postal, envío de correo electrónico, saludo y dirección de correo electrónico para cada registro. Por ejemplo, la columna de dirección podría contener las direcciones de los clientes. Cada registro contendrá datos sobre un cliente y el campo de dirección, la dirección de ese cliente. Cuando haya determinado el conjunto inicial de columnas para cada tabla, puede ajustar con mayor precisión las columnas. Por ejemplo, tiene sentido almacenar los nombres de los clientes en dos columnas distintas (el nombre y el apellido) para poder ordenar, buscar e indizar por esas columnas. De igual forma, la dirección consta en realidad de cinco componentes distintos: dirección, ciudad, provincia, código postal y país o región, y parece lógico también almacenarlos en columnas distintas. Si desea realizar, por ejemplo, una búsqueda o una operación de ordenación o filtrado por provincia, necesita que la información de provincia esté almacenada en una columna distinta. Debe considerar también si la base de datos va a contener información sólo de procedencia nacional o internacional. Por ejemplo, si piensa almacenar direcciones internacionales, es preferible tener una columna Región en lugar de Provincia, ya que esa columna puede incluir provincias del propio país y regiones de otros países o regiones. De igual forma, es más lógico incluir una columna Región en lugar de Comunidad Autónoma si va a almacenar direcciones internacionales. En la lista siguiente se incluyen algunas sugerencias para determinar las columnas de la base de datos. No incluya datos calculados En la mayoría de los casos, no debe almacenar el resultado de los cálculos en las tablas. En lugar de ello, puede dejar que Access realice los cálculos cuando desee ver el resultado. Suponga, por ejemplo, que tiene un informe Productos bajo pedido que contiene el subtotal de unidades de un pedido para cada categoría de producto de la base de datos. Sin embargo, no hay ninguna tabla que contenga una columna de subtotal Unidades en pedido. La tabla Productos SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN contiene una columna Unidades en pedido que almacena las unidades incluidas en un pedido de cada producto. Con esos datos, Access calcula el subtotal cada vez que se imprime el informe, pero el subtotal propiamente dicho no debe almacenarse en una tabla. Almacene la información en sus partes lógicas más pequeñas Puede ceder a la tentación de habilitar un único campo para los nombres completos o para los nombres de productos junto con sus descripciones. Si combina varios tipos de información en un campo, será difícil recuperar datos individuales más adelante. Intente dividir la información en partes lógicas. Por ejemplo, cree campos distintos para el nombre y el apellido, o para el nombre del producto, la categoría y la descripción. Una vez ajustadas las columnas de datos de cada tabla, ya puede seleccionar la clave principal de cada tabla. ESPECIFICAR CLAVES PRINCIPALES Cada tabla debe incluir una columna o conjunto de columnas que identifiquen inequívocamente cada fila almacenada en la tabla. Ésta suele ser un número de identificación exclusivo, como un número de identificador de empleado o un número de serie. En la terminología de bases de datos, esta información recibe el nombre de clave principal de la tabla. Access utiliza los campos de clave principal para asociar rápidamente datos de varias tablas y reunir automáticamente esos datos. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Si ya tiene un identificador exclusivo para una tabla, como un número de producto que identifica inequívocamente cada producto del catálogo, puede utilizar ese identificador como clave principal de la tabla, pero sólo si los valores de esa columna son siempre diferentes para cada registro. No puede tener valores duplicados en una clave principal. Por ejemplo, no utilice los nombres de las personas como clave principal, ya que los nombres no son exclusivos. Es muy fácil que dos personas tengan el mismo nombre en la misma tabla. Una clave principal siempre debe tener un valor. Si el valor de una columna puede quedar sin asignar o vacío (porque no se conoce) en algún momento, no puede utilizarlo como componente de una clave principal. Debe elegir siempre una clave principal cuyo valor no cambie. En una base de datos con varias tablas, la clave principal de una tabla se puede utilizar como referencia en las demás tablas. Si la clave principal cambia, el cambio debe aplicarse también a todos los lugares donde se haga referencia a la clave. Usar una clave principal que no cambie reduce la posibilidad de que se pierda su sincronización con las otras tablas en las que se hace referencia a ella. A menudo, se utiliza como clave principal un número único arbitrario. Por ejemplo, puede asignar a cada pedido un número de pedido distinto. La única finalidad de este número de pedido es identificar el pedido. Una vez asignado, nunca cambia. Si piensa que no hay ninguna columna o conjunto de columnas que pueda constituir una buena clave principal, considere la posibilidad de utilizar una columna que tenga el tipo de datos Autonumérico. Cuando se utiliza el tipo de datos Autonumérico, Access asigna automáticamente un valor. Este tipo de identificador no es "fáctico", es decir, no contiene información objetiva sobre la fila que representa. Los identificadores de este tipo son perfectos para usarlos como claves principales, ya que no cambian. Una clave principal que contiene datos sobre una fila, como un número de teléfono o el nombre de un cliente, es más probable que cambie, ya que la propia información "fáctica" podría cambiar. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN Una columna establecida en el tipo de datos Autonumérico suele constituir una buena clave principal. No hay dos identificadores de producto iguales. En algunos casos, tal vez considere conveniente utilizar dos o más campos juntos como clave principal de una tabla. Por ejemplo, una tabla Detalles de pedidos que contenga artículos de línea de pedidos tendría dos columnas en su clave principal: Id. de pedido e Id. de producto. Cuando una clave principal está formada por más de una columna se denomina clave compuesta. Para la base de datos de ventas de productos, puede crear una columna autonumérica para cada una de las tablas que funcione como clave principal: IdProducto para la tabla Productos, IdPedido para la tabla Pedidos, IdCliente para la tabla Clientes e IdProveedores para la tabla Proveedores. CREAR RELACIONES ENTRE TABLAS Ahora que ha dividido la información en tablas necesita un modo de reunir de nuevo la información de forma provechosa. Por ejemplo, el siguiente formulario incluye información de varias tablas. SEMA, GOMA, COAT UNIDAD DE APRENDIZAJE: TECNOLOGÍA INFORMÁTICA UNIDAD III. TECNOLOGÍAS INFORMÁTICAS DE ALMACENAMIENTO ELECTRÓNICO DE INFORMACIÓN La información de este formulario procede de la tabla Clientes... ...la tabla Empleados... ...la tabla Pedidos... ...la tabla Productos... ...y la tabla Detalles de pedidos. Access es un sistema de administración de bases de datos relacionales. En una base de datos relacional, la información se divide en tablas distintas en función del tema. SEMA, GOMA, COAT